
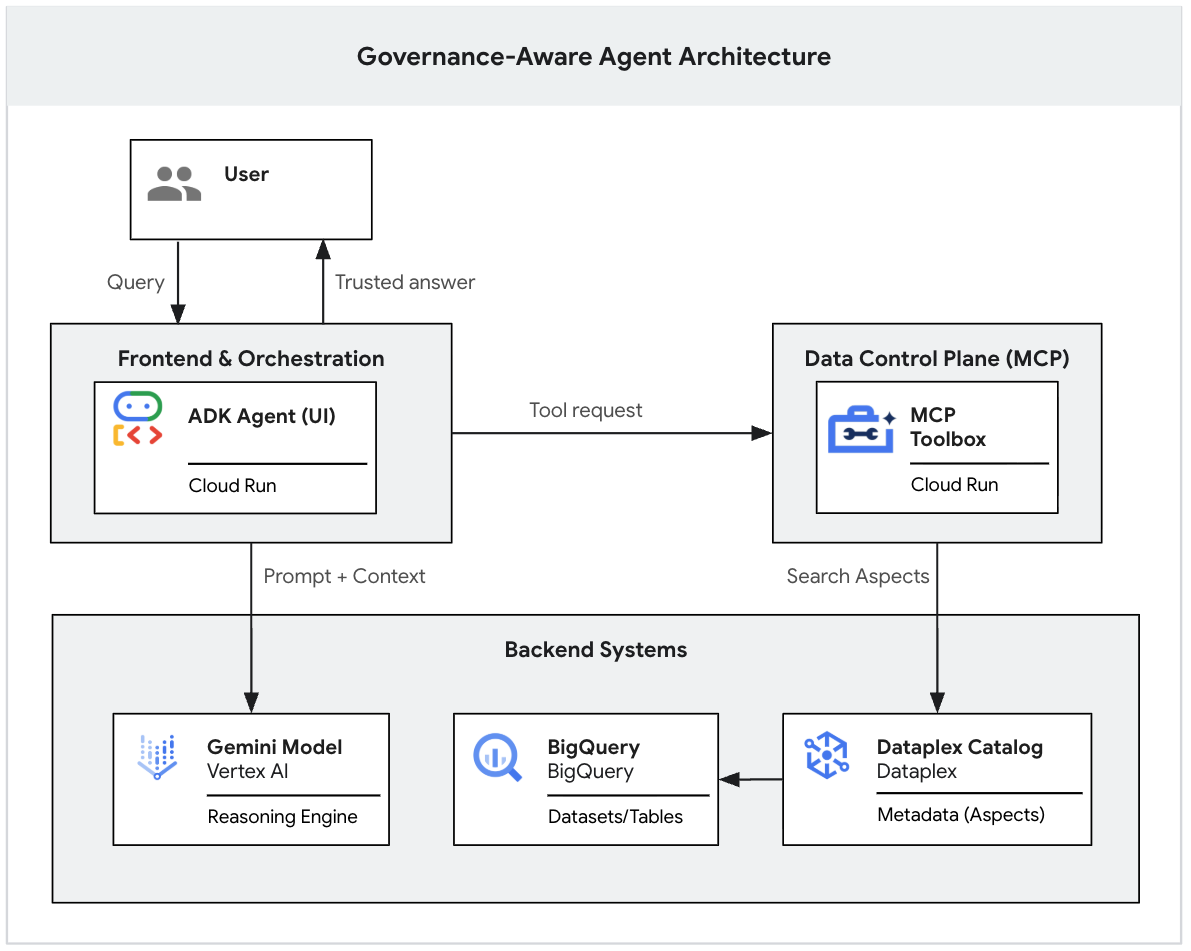
1. 簡介
生成式 AI 模型擅長推理,但缺乏機構脈絡。如果高階主管詢問 AI 代理「我們第一季的收益是多少?」,代理可能會在資料湖中找到數十個名為「收益」的表格。有些是嚴謹的財務報表,有些是即時行銷估算值,許多可能是已淘汰的沙箱。
如果沒有明確的基準,AI 代理程式會根據簡單的名稱相似度選取資料表,導致從未經確認的資料得出「令人信服的錯誤」答案。
本程式碼研究室是兩部分系列的第一部分,探討如何建構具備治理意識的生成式 AI 代理程式。
在第一部分中,您將建構資料基礎。您將在 BigQuery 中設定實際的「雜亂」資料湖、套用嚴格的中繼資料標記 (Dataplex 方面),區分有效資料和雜訊,並使用 Gemini CLI 在本機測試 LLM 是否嚴格遵守管理規則。
(您可以閱讀本系列的第二部分,瞭解如何使用 Model Context Protocol (MCP) 和 Cloud Run,將這個本機原型部署至安全無虞的企業級網路應用程式。👉 閱讀第 2 部分)
必要條件
- 已啟用計費功能的 Google Cloud 專案。
- 對 BigQuery、Dataplex Universal Catalog 和 Terraform 有基本瞭解。
- 存取 Google Cloud Shell。
課程內容
- 使用 Terraform 部署多層式資料湖,模擬真實環境。
- 在 Dataplex 中設計嚴格的中繼資料範本 (切面類型),以區分正式資料產品和原始沙箱資料表。
- 在編寫任何應用程式碼之前,請先使用 Gemini CLI 在本機驗證控管規則。
軟硬體需求
- 存取 Google Cloud Shell
- Terraform (已預先安裝於 Cloud Shell)。
- Gemini CLI (已預先安裝在 Cloud Shell 中)。
重要概念
- Dataplex Universal Catalog:整合式中繼資料管理服務。我們使用這項功能,以業務背景資訊 (治理) 充實技術中繼資料 (結構定義)。
- 切面類型:結構化中繼資料範本。與任意文字標記不同,層面會強制執行嚴格型別 (列舉、布林值),因此機器評估時可信度較高。
2. 設定和需求條件
啟動 Cloud Shell
雖然可以透過筆電遠端操作 Google Cloud,但在本程式碼研究室中,您將使用 Google Cloud Shell,這是可在雲端執行的指令列環境。
在 Google Cloud 控制台中,點選右上工具列的 Cloud Shell 圖示:
佈建並連線至環境的作業需要一些時間才能完成。完成後,您應該會看到如下的內容:

這部虛擬機器搭載各種您需要的開發工具,並提供永久的 5GB 主目錄,而且可在 Google Cloud 運作,大幅提升網路效能並強化驗證功能。您可以在瀏覽器中完成本程式碼研究室的所有作業。您不需要安裝任何軟體。
初始化環境
開啟 Cloud Shell 並設定專案變數,確保所有指令都以正確的基礎架構為目標。
export PROJECT_ID=$(gcloud config get-value project)
gcloud config set project $PROJECT_ID
export REGION="us-central1"
啟用 API
啟用必要的 Google Cloud 服務,即可執行下列操作。
gcloud services enable \
artifactregistry.googleapis.com \
bigqueryunified.googleapis.com \
cloudaicompanion.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com \
datacatalog.googleapis.com \
run.googleapis.com
複製存放區
從 GitHub 存放區取得基礎架構程式碼和自動化指令碼。為節省 Cloud Shell 的磁碟空間,我們只會下載本實驗室所需的特定資料夾。
# Perform a shallow clone to get only the latest repository structure without the full history
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
# Specify and download only the folder we need for this lab
git sparse-checkout set data-analytics/governance-context
cd data-analytics/governance-context
建立「雜亂」的資料湖泊
現實世界中的資料環境很少是乾淨的。為了模擬現實情況,我們需要混合使用「官方」資料市集和不受信任的「沙箱」資料表。
我們將使用 Terraform 部署這個環境。這項設定會處理兩項工作:
- 基礎架構:建立 Dataplex Aspect 類型和 BigQuery 資料集/資料表。
- 資料載入:執行 BigQuery INSERT 工作,在建立資料表後立即填入範例資料。
- 前往
terraform目錄並初始化。
cd terraform
terraform init
- 套用設定。這項作業最多可能需要一分鐘。
terraform apply -var="project_id=${PROJECT_ID}" -var="region=${REGION}" -auto-approve
檢查點:您現在擁有完整填入資料的資料湖,但完全不受管理。對 AI 來說,每個表格看起來都完全相同。
3. 套用管理規則
這是重要的工程步驟。目前,finance_mart.fin_monthly_closing_internal 和 analyst_sandbox.tmp_data_dump_v2_final_real 這兩個表格對 LLM 來說完全相同。這些只是含有資料欄的物件。
身為控管工程師,您必須將「Aspect」 (經過認證的中繼資料標籤) 附加至這些資料表,以區分兩者。在實際企業中,您會透過 CI/CD 管道自動執行這項操作。我們將使用指令碼模擬自動化作業。
產生控管酬載
Dataplex 構面鍵在全域內不得重複 (前置字元為專案 ID)。./generate_payloads.sh 指令碼會動態產生 YAML 中繼資料檔案。
cd ..
chmod +x ./generate_payloads.sh
./generate_payloads.sh
輸出內容:
這會建立「./aspect_payloads」資料夾,內含 4 個 YAML 檔案,定義控管情境 (Gold/Internal、Gold/Public、Silver/Realtime、Bronze/Sandbox)。
透過 CLI 套用 Aspect
執行指令碼前,先來看看我們實際套用的內容,瞭解這個程序。執行下列指令,查看內部財務酬載的結構:
cat aspect_payloads/fin_internal.yaml
並顯示下列內容。
your-project-id.us-central1.official-data-product-spec:
data:
product_tier: GOLD_CRITICAL
data_domain: FINANCE
usage_scope: INTERNAL_ONLY
update_frequency: DAILY_BATCH
is_certified: true
請注意,這個 YAML 會明確定義業務背景資訊,例如設定 is_certified: true 旗標,以及指派 GOLD_CRITICAL 層級。為 AI 提供明確的結構化評估規則,而不是僅根據表格名稱進行猜測。
現在,請執行應用程式指令碼。這會逐一檢查 BigQuery 資料表,並執行 gcloud dataplex entries update 指令來附加這項嚴格的中繼資料。
chmod +x ./apply_governance.sh
./apply_governance.sh
驗證 (選用)
繼續操作前,請先確認中繼資料已在控制台中正確套用。
- 在 Google Cloud 控制台中開啟 Dataplex Universal Catalog 頁面。如果左側導覽選單中沒有「Dataplex Universal Catalog」,請使用 Google Cloud 控制台視窗頂端的搜尋列,輸入 Dataplex,然後選取「熱門結果」或「產品與頁面」下方的結果。
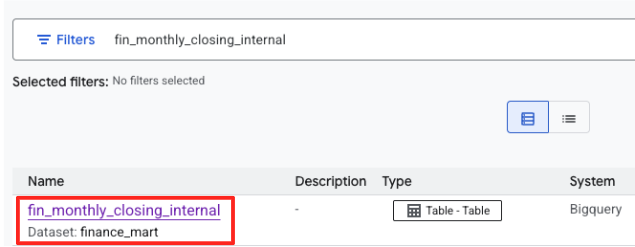
- 搜尋
fin_monthly_closing_internal。結果中應該會列出 BigQuery 資料表。按一下表格名稱,進入詳細資料頁面。
- 在資料表的詳細資料頁面中,找出底部的「選用標記和面向」部分。
- 你會看到
official-data-product-spec方面。確認值與我們套用的「Gold Internal」情境相符。
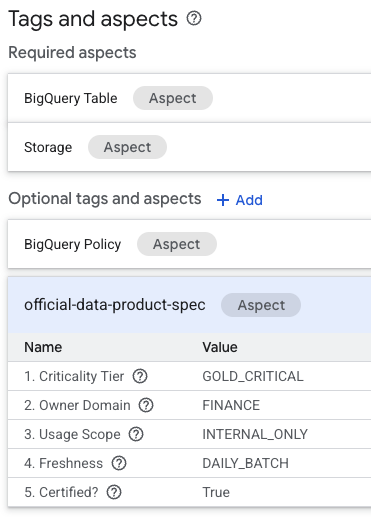
您現在已確認,技術上相同的 BigQuery 資料表 (fin_monthly_closing_internal 和 tmp_data_dump_v2_final_real) 在邏輯上可透過機器可讀取的中繼資料區分。
4. 設定及製作代理程式原型
在建構網頁應用程式之前 (我們將在第 2 部分進行),我們會先在本機驗證控管邏輯。我們需要安裝 Dataplex 擴充功能,並設定系統提示。
安裝擴充功能
在 Cloud Shell 中安裝 Dataplex 擴充功能。系統會要求你確認設定詳細資料。
export DATAPLEX_PROJECT="${PROJECT_ID}"
gemini extensions install https://github.com/gemini-cli-extensions/dataplex
(輸入 Y 接受安裝,並在系統提示時輸入專案 ID)。
定義政策檔案
GEMINI.md 檔案包含可轉換抽象人類規則 (例如「「我需要安全資料」) 轉換為嚴格的技術查詢。
這個檔案目前為一般檔案。為避免代理程式從公開網際網路或其他情境產生幻覺表格,代理程式必須確切知道要搜尋哪個 Google Cloud 專案。
- 將
PROJECT_ID插入政策檔案。
envsubst < GEMINI.md > GEMINI.md.tmp && mv GEMINI.md.tmp GEMINI.md
- 檢查檔案,瞭解我們教導 AI 的演算法。
cat GEMINI.md
請注意這個檔案中的兩件事:
- 專案範圍:檢查第 2 階段。請確認 projectid:
${PROJECT_ID}已替換為實際專案 ID(e.g., projectid:my-lab-project)。如果未替換這個變數,代理程式會在您有權存取的所有專案中搜尋,導致答案不正確。 - 演算法:請注意第 1 階段 / 第 2 階段的邏輯。我們明確指示模型「不要」猜測 SQL。必須先搜尋正確的標記定義 (第 1 階段),然後才能搜尋資料 (第 2 階段)。
啟動代理程式並測試各種情況
啟動 Gemini CLI 工作階段,這次載入控管政策做為系統脈絡。
gemini
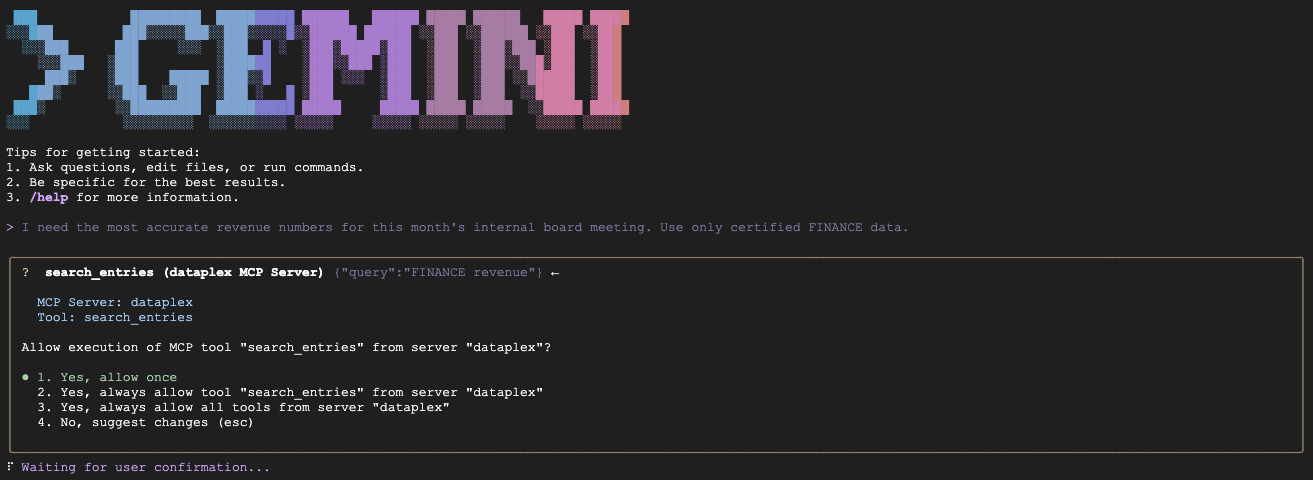
注意:系統可能會載入多個內容檔案 (例如 GEMINI.md 等)。這是正常的狀況。CLI 會載入這個專案的本機 GEMINI.md,瞭解特定規則,以及 Dataplex 擴充功能的預設指令。
驗證安裝
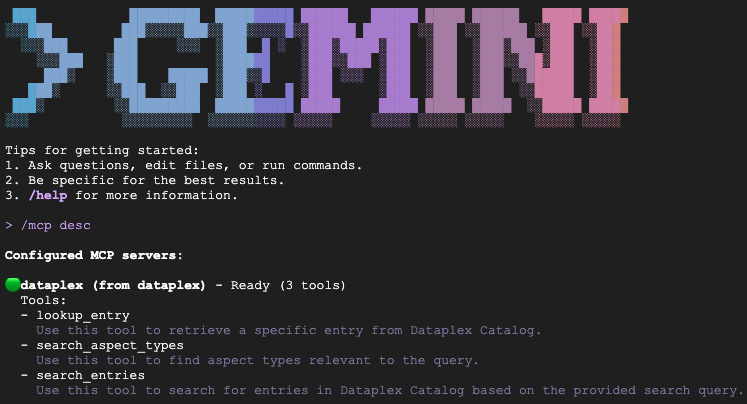
輸入 /mcp desc,確認 Dataplex 擴充功能已啟用。您應該會看到 dataplex 列為已設定的 MCP 伺服器,並顯示可用的工具。
測試情境 (原型設計)
將下列提示逐一貼到執行中的代理程式工作階段,確認代理程式遵守規則。
- 情境 A (認證財務長資料):
"We are preparing the deck for an internal Board of Directors meeting next week. I need the numbers to be absolutely finalized, trustworthy, and kept strictly confidential. Which table is safe to use?"
預期結果:查詢 fin_monthly_closing_internal,因為在「方面」中,這項查詢與 GOLD_CRITICAL (準確) 和 INTERNAL_ONLY (董事會會議) 在語意上相符。
- 情境 B (公開揭露):
"I need to share our quarterly financial summary with an external consulting firm. It is critical that we do not leak any raw or internal metrics. Which dataset is officially scrubbed and explicitly approved for external sharing?"
預期結果:代理程式必須略過每月內部表格,並嚴格選取 fin_quarterly_public_report,因為這是唯一標記 EXTERNAL_READY 的資產。
- 情境 C (營運需求):
"My dashboard needs to show what's happening right now with our ad spend. I can't wait for the overnight load. What do you recommend?"
預期:代理程式會選取 mkt_realtime_campaign_performance,因為代理程式會識別 REALTIME_STREAMING 更新頻率,並優先處理該頻率,而非財務資料的 GOLD_CRITICAL 層級。
- 情境 D (沙箱實驗):
"I'm just playing around with some new ML models and need a lot of raw data. It doesn't need to be perfect, just a sandbox environment."
預期結果:代理程式會選取 tmp_data_dump_v2_final_real,因為在該代理程式的 Aspect 中,tmp_data_dump_v2_final_real 在語意上與 BRONZE_ADHOC (原始資料) 和 is_certified: false (沙箱環境) 相符。
(如要結束 Gemini 工作階段,請輸入 /quit)
5. 恭喜!接下來要做什麼?
您已成功建構受控資料基礎,並透過本機 CLI 原型證明 AI 可以嚴格遵守中繼資料規則!
您現在已完成查核點。請選擇後續行動:
方法 A:我想立即繼續第 2 部分!
如要使用 Model Context Protocol (MCP) 和 Cloud Run,將這個本機原型變成安全無虞的正式版網路應用程式,請按照下列步驟操作:
選項 B:我稍後會完成第 2 部分,或我只想完成第 1 部分。
如要暫時停止作業並避免產生雲端費用,請清除資源。
別擔心!在第 2 部分,我們會提供「快速腳本」,讓您在短短 2 分鐘內完全重建第 1 部分的環境,並從上次中斷的地方繼續。
👉 前往「清除」部分。
6. 清除 (僅適用於選項 B)
如果您的課程就此停住,請銷毀資源,以免產生費用。
刪除 Datalake (Terraform)
如果目前在 Gemini CLI 環境中,請按兩次 Ctrl+C 或輸入 /quit,結束工作階段。然後執行下列指令:
cd ~/devrel-demos/data-analytics/governance-context/terraform
terraform destroy -var="project_id=${PROJECT_ID}" -var="region=${REGION}" -auto-approve
解除安裝 Gemini CLI 擴充功能並移除本機檔案
gemini extensions uninstall dataplex
cd ~
rm -rf ~/devrel-demos