
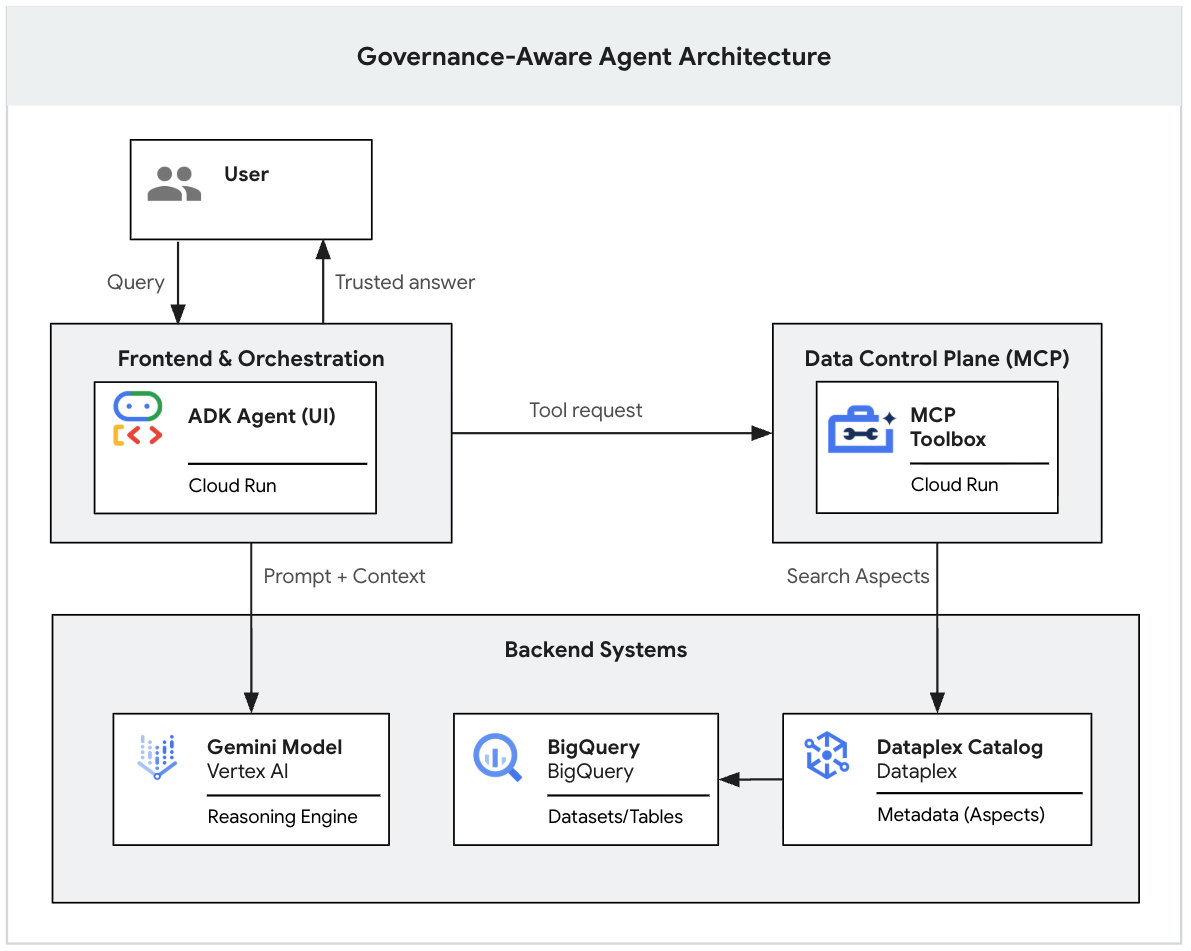
1. מבוא
מודלים של AI גנרטיבי הם כלי רב עוצמה לניתוח מידע, אבל חסר להם הקשר מוסדי. אם מנהל ישאל סוכן AI, 'מה ההכנסות שלנו ברבעון הראשון?', הסוכן עשוי למצוא עשרות טבלאות בשם 'הכנסות' במאגר הנתונים שלכם. חלק מהדוחות הם דוחות פיננסיים מדויקים, חלקם הם אומדנים שיווקיים בזמן אמת, ויש גם הרבה ארגזי חול שסביר להניח שהוצאו משימוש.
בלי ביסוס מפורש, סוכן AI יבחר טבלה על סמך דמיון פשוט בשם, וכך יספק תשובות שנראות נכונות אבל הן שגויות שמבוססות על נתונים לא מאומתים.
ה-Codelab הזה הוא חלק מסדרה בת שני חלקים שבה נסביר איך ליצור סוכן GenAI שמודע לניהול.
בחלק הראשון הזה, תבנו את בסיס הנתונים. תגדירו אגם נתונים ריאליסטי ו'מבולגן' ב-BigQuery, תחילות תגי מטא-נתונים נוקשים (היבטים של Knowledge Catalog) כדי להבחין בין נתונים תקפים לבין רעשי רקע, ותשתמשו ב-Gemini CLI כדי לבדוק באופן מקומי אם מודל ה-LLM פועל בהתאם לכללי הממשל שהגדרתם.
(אפשר לקרוא את החלק השני בסדרה, שבו מוסבר איך לפרוס את אב הטיפוס המקומי הזה לאפליקציית אינטרנט מאובטחת ברמה ארגונית באמצעות Model Context Protocol (MCP) ו-Cloud Run. 👉 לקריאת חלק 2)
דרישות מוקדמות
- פרויקט ב-Google Cloud שהחיוב בו מופעל.
- הבנה בסיסית של BigQuery, Knowledge Catalog Universal Catalog ו-Terraform.
- גישה ל-Google Cloud Shell.
מה תלמדו
- פריסה של אגם נתונים (data lake) מציאותי עם כמה רמות באמצעות Terraform.
- כדאי לעצב תבניות מחמירות של מטא נתונים (סוגי היבטים) ב-Knowledge Catalog כדי להבחין בין מוצרי נתונים רשמיים לבין טבלאות גולמיות בארגז חול.
- לפני שכותבים קוד לאפליקציה, כדאי לאמת את כללי השליטה באופן מקומי באמצעות Gemini CLI.
מה תצטרכו
- גישה ל-Google Cloud Shell
- Terraform (מותקן מראש ב-Cloud Shell).
- Gemini CLI (מותקן מראש ב-Cloud Shell).
מושגים מרכזיים
- קטלוג אוניברסלי של Knowledge Catalog: שירות מאוחד לניהול מטא-נתונים. אנחנו משתמשים בו כדי להעשיר מטא-נתונים טכניים (סכימות) בהקשר עסקי (ניהול).
- סוג מאפיין: תבנית של מטא-נתונים מובְנים. בניגוד לתגי טקסט חופשי, מאפיינים מחייבים הקלדה חזקה (ספירות, ערכים בוליאניים), ולכן המכונות יכולות להסתמך עליהם לצורך הערכה.
2. הגדרה ודרישות
מפעילים את Cloud Shell
אפשר להפעיל את Google Cloud מרחוק מהמחשב הנייד, אבל ב-Codelab הזה נשתמש ב-Google Cloud Shell, סביבת שורת פקודה שפועלת בענן.
ב-מסוף Google Cloud, לוחצים על סמל Cloud Shell בסרגל הכלים שבפינה הימנית העליונה:
יחלפו כמה רגעים עד שההקצאה והחיבור לסביבת העבודה יושלמו. בסיום התהליך, יופיע משהו כזה:

המכונה הווירטואלית הזו כוללת את כל הכלים שדרושים למפתחים. יש בה ספריית בית בנפח מתמיד של 5GB והיא פועלת ב-Google Cloud, מה שמשפר מאוד את הביצועים והאימות ברשת. אפשר לבצע את כל העבודה ב-codelab הזה בדפדפן. לא צריך להתקין שום דבר.
אתחול הסביבה
פותחים את Cloud Shell ומגדירים את משתני הפרויקט כדי לוודא שכל הפקודות מכוונות לתשתית הנכונה.
export PROJECT_ID=$(gcloud config get-value project)
gcloud config set project $PROJECT_ID
export REGION="us-central1"
הפעלת ממשקי API
מפעילים את שירותי Google Cloud הנדרשים כדי לבצע את ההוראה הבאה.
gcloud services enable \
artifactregistry.googleapis.com \
bigqueryunified.googleapis.com \
cloudaicompanion.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com \
datacatalog.googleapis.com \
run.googleapis.com
שכפול המאגר
מקבלים את קוד התשתית ואת סקריפטים האוטומציה ממאגר GitHub. כדי לחסוך במקום בדיסק ב-Cloud Shell, נוריד רק את התיקייה הספציפית שדרושה למעבדה הזו.
# Perform a shallow clone to get only the latest repository structure without the full history
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
# Specify and download only the folder we need for this lab
git sparse-checkout set data-analytics/governance-context
cd data-analytics/governance-context
בניית אגם נתונים 'מבולגן'
בדרך כלל, סביבות נתונים בעולם האמיתי לא נקיות. כדי לדמות את המציאות, אנחנו צריכים שילוב של מרכזי נתונים 'רשמיים' וטבלאות 'ארגז חול' לא מהימנות.
נשתמש ב-Terraform כדי לפרוס את הסביבה הזו. ההגדרה מטפלת בשתי משימות:
- תשתית: יצירת סוגי היבטים של Knowledge Catalog וטבלאות או מערכי נתונים של BigQuery.
- טעינת נתונים: מריץ משימות INSERT ב-BigQuery כדי לאכלס את הטבלאות בנתונים לדוגמה מיד אחרי שהן נוצרות.
- מנווטים לספרייה
terraformומפעילים אותה.
cd terraform
terraform init
- מחילים את ההגדרה. יכול להיות שהפעולה תימשך עד כדקה.
terraform apply -var="project_id=${PROJECT_ID}" -var="region=${REGION}" -auto-approve
נקודת עצירה: עכשיו יש לכם אגם נתונים מלא, אבל לא מנוהל. ל-AI, כל הטבלאות נראות בדיוק אותו דבר.
3. החלת ניהול נתונים
זהו שלב הנדסי קריטי. בשלב הזה, הטבלאות finance_mart.fin_monthly_closing_internal ו-analyst_sandbox.tmp_data_dump_v2_final_real נראות זהות למודל שפה גדול (LLM). הן פשוט אובייקטים עם עמודות.
כמהנדסי ניהול, אתם צריכים לצרף מאפיין (תווית מטא-נתונים מאושרת) לטבלאות האלה כדי להבדיל ביניהן. בארגון אמיתי, הייתם מבצעים אוטומציה של הפעולה הזו באמצעות צינורות עיבוד נתונים של CI/CD. אנחנו נדמה את האוטומציה הזו באמצעות סקריפטים.
יצירת מטען ייעודי (payload) של ניהול
מפתחות ההיבטים ב-Knowledge Catalog חייבים להיות ייחודיים באופן גלובלי (עם קידומת של מזהה הפרויקט). הסקריפט ./generate_payloads.sh ייצור באופן דינמי את קובצי המטא-נתונים של YAML.
cd ..
chmod +x ./generate_payloads.sh
./generate_payloads.sh
פלט:
הפעולה הזו יוצרת תיקייה בשם './aspect_payloads' שמכילה 4 קובצי YAML, שמגדירים את תרחישי השליטה (Gold/Internal, Gold/Public, Silver/Realtime, Bronze/Sandbox).
החלת היבטים באמצעות CLI
לפני שמריצים את הסקריפט, כדאי להבין מה אנחנו עושים בפועל כדי להסביר את התהליך. מריצים את הפקודה הבאה כדי לראות את המבנה של מטען הייעודי (payload) של הכספים הפנימיים:
cat aspect_payloads/fin_internal.yaml
יוצג לכם התוכן הבא.
your-project-id.us-central1.official-data-product-spec:
data:
product_tier: GOLD_CRITICAL
data_domain: FINANCE
usage_scope: INTERNAL_ONLY
update_frequency: DAILY_BATCH
is_certified: true
שימו לב איך קובץ ה-YAML הזה מגדיר באופן מפורש את ההקשר העסקי, למשל על ידי הגדרת הדגל is_certified כ-true והקצאת הרמה GOLD_CRITICAL. כך ה-AI מקבל כללים ברורים ומובנים להערכה במקום לנחש על סמך שמות הטבלאות.
עכשיו מריצים את סקריפט האפליקציה. הסקריפט מבצע איטרציה בטבלאות BigQuery ומריץ את הפקודה gcloud dataplex entries update כדי לצרף את המטא-נתונים הקשיחים האלה.
chmod +x ./apply_governance.sh
./apply_governance.sh
אימות (אופציונלי)
לפני שממשיכים, צריך לוודא שהמטא-נתונים הוחלו בצורה נכונה במסוף.
- פותחים את הדף Knowledge Catalog Universal Catalog במסוף Google Cloud. אם האפשרות Knowledge Catalog Universal Catalog (קטלוג אוניברסלי של Knowledge Catalog) לא מופיעה בתפריט הניווט הימני, משתמשים בסרגל החיפוש בחלק העליון של חלון מסוף Google Cloud, מקלידים Knowledge Catalog ובוחרים את התוצאה בקטע Top results (התוצאות המובילות) או Products & Pages (מוצרים ודפים).
- חיפוש של
fin_monthly_closing_internal. הטבלה ב-BigQuery אמורה להופיע ברשימת התוצאות. לוחצים על שם הטבלה כדי להיכנס לדף הפרטים שלה.
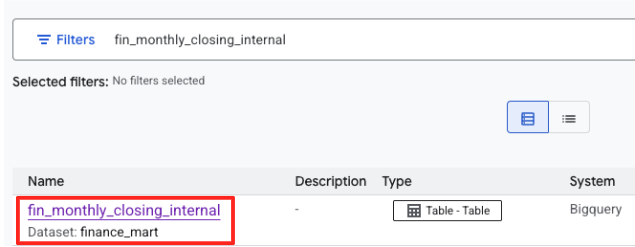
- בדף הפרטים של הטבלה, מחפשים את הקטע תגים והיבטים אופציונליים בתחתית הדף.
- תראו את ההיבט
official-data-product-spec. מוודאים שהערכים תואמים לתרחיש Gold Internal שהגדרנו.
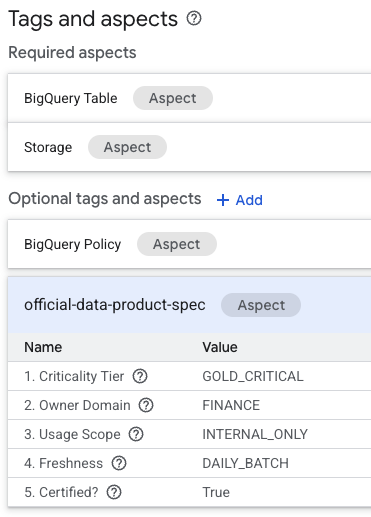
עכשיו אישרתם שטבלאות BigQuery זהות מבחינה טכנית (fin_monthly_closing_internal ו-tmp_data_dump_v2_final_real), אבל הן שונות מבחינה לוגית בגלל מטא-נתונים שניתנים לקריאה על ידי מכונה.
4. הגדרה ויצירת אב-טיפוס של הסוכן
לפני שנבנה אפליקציית אינטרנט (בשלב השני), נאמת את לוגיקת השליטה שלנו באופן מקומי. צריך להתקין את התוסף Knowledge Catalog ולהגדיר את ההנחיה למערכת.
התקנת התוסף
ב-Cloud Shell, מתקינים את התוסף Knowledge Catalog. תתבקשו לאשר את הפעולה ולספק את פרטי ההגדרה.
export DATAPLEX_PROJECT="${PROJECT_ID}"
gemini extensions install https://github.com/gemini-cli-extensions/dataplex
(מזינים Y כדי לאשר את ההתקנה, ומזינים את מזהה הפרויקט כשמוצגת בקשה).
הגדרת קובץ המדיניות
קובץ GEMINI.md מכיל את הלוגיקה שמתרגמת כללים אנושיים מופשטים (לדוגמה, "אני צריך נתונים בטוחים") לחיפושים טכניים מדויקים.
הקובץ הזה הוא כרגע כללי. הסוכן צריך לדעת בדיוק באיזה פרויקט בענן של Google לחפש כדי למנוע ממנו להזות טבלאות מהאינטרנט הציבורי או מהקשרים אחרים.
- מזריקים את
PROJECT_IDלקובץ המדיניות.
envsubst < GEMINI.md > GEMINI.md.tmp && mv GEMINI.md.tmp GEMINI.md
- בודקים את הקובץ כדי להבין את האלגוריתם שאנחנו מלמדים את ה-AI.
cat GEMINI.md
כמה דברים שכדאי לשים לב אליהם בקובץ הזה:
- היקף הפרויקט: בודקים את שלב 2. מוודאים שהמחרוזת projectid:
${PROJECT_ID}הוחלפה במזהה הפרויקט בפועל(e.g., projectid:my-lab-project). אם המשתנה הזה לא יוחלף, הסוכן יחפש בכל הפרויקטים שיש לכם גישה אליהם, והתשובות יהיו שגויות. - האלגוריתם: שימו לב ללוגיקה של שלב 1 / שלב 2. אנחנו מנחים את המודל באופן מפורש לא לנחש SQL. קודם צריך לחפש את הגדרת התג הנכונה (שלב 1) ורק אחר כך לחפש נתונים (שלב 2).
הפעלת הסוכן ובדיקת תרחישים
מתחילים את הסשן ב-Gemini CLI, והפעם טוענים את מדיניות השליטה כהקשר של המערכת.
gemini
הערה: יכול להיות שייטענו כמה קובצי הקשר (למשל, GEMINI.md ואחרים). זהו נוהל רגיל. ממשק ה-CLI טוען את הקובץ GEMINI.md המקומי בשביל הכללים הספציפיים של הפרויקט הזה, בנוסף להוראות ברירת המחדל של התוסף Knowledge Catalog עצמו.
אימות ההתקנה
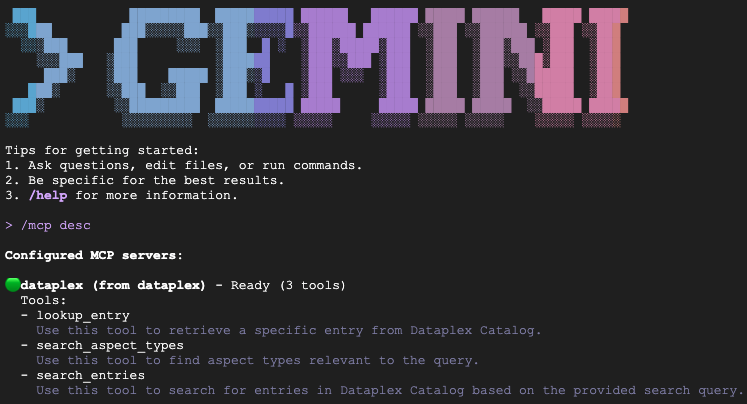
מקלידים /mcp desc כדי לאשר שהתוסף של Knowledge Catalog פעיל. הכתובת dataplex צריכה להופיע כשרת MCP מוגדר עם כלים זמינים.
תרחישי בדיקה (אבות טיפוס)
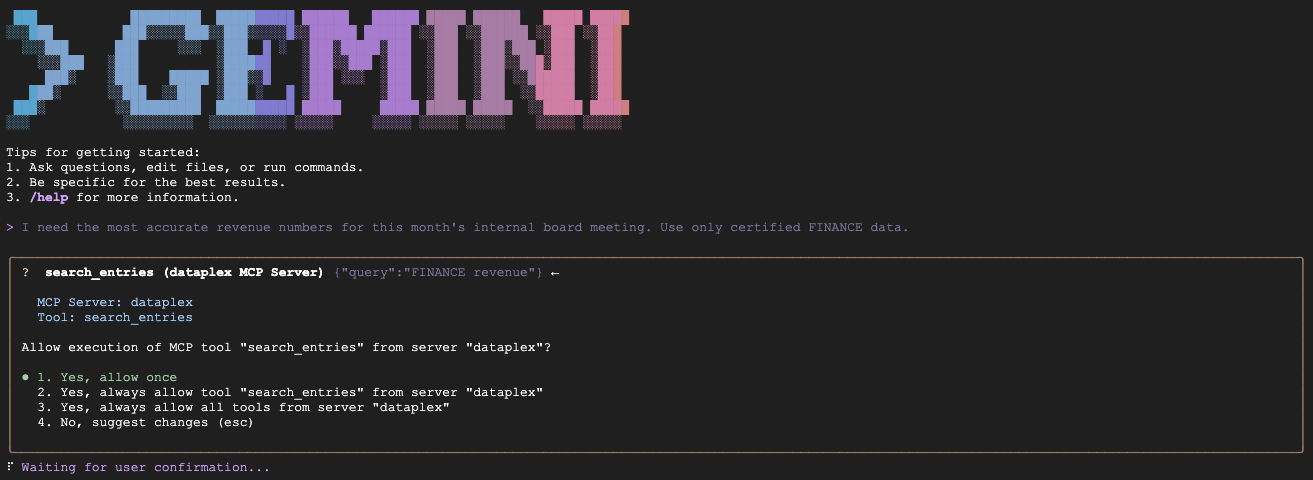
כדי לוודא שהסוכן פועל בהתאם לכללים, מדביקים את ההנחיות הבאות אחת אחרי השנייה בסשן הפעיל של הסוכן.
- תרחיש א' (אישור הנתונים של סמנכ"ל הכספים):
"We are preparing the deck for an internal Board of Directors meeting next week. I need the numbers to be absolutely finalized, trustworthy, and kept strictly confidential. Which table is safe to use?"
התוצאה הצפויה: שאילתות fin_monthly_closing_internal כי יש התאמה סמנטית ל-GOLD_CRITICAL (מדויק) ול-INTERNAL_ONLY (ישיבת דירקטוריון) בהיבט שלה.
- תרחיש ב' (גילוי נאות לציבור):
"I need to share our quarterly financial summary with an external consulting firm. It is critical that we do not leak any raw or internal metrics. Which dataset is officially scrubbed and explicitly approved for external sharing?"
מה שצריך לקרות: הסוכן צריך לדלג על הטבלה הפנימית החודשית ולבחור רק את fin_quarterly_public_report כי הוא הנכס היחיד שתויג EXTERNAL_READY.
- תרחיש ג' (צרכים תפעוליים):
"My dashboard needs to show what's happening right now with our ad spend. I can't wait for the overnight load. What do you recommend?"
התשובה הצפויה: הסוכן בוחר באפשרות mkt_realtime_campaign_performance כי הוא מזהה את תדירות העדכון REALTIME_STREAMING, ונותן לה עדיפות על פני רמת המידע GOLD_CRITICAL של נתוני הכספים.
- תרחיש ד' (ניסוי בארגז חול):
"I'm just playing around with some new ML models and need a lot of raw data. It doesn't need to be perfect, just a sandbox environment."
מה שקורה בפועל: הסוכן בוחר ב-tmp_data_dump_v2_final_real כי הוא תואם סמנטית ל-BRONZE_ADHOC (נתונים גולמיים) ול-is_certified: false (סביבת ארגז חול) בהיבט שלו.
(כדי לצאת מהסשן ב-Gemini, מקלידים /quit)
5. מעולה! מה השלב הבא?
יצרתם בהצלחה בסיס נתונים מנוהל והוכחתם ש-AI יכול לפעול בהתאם לכללי המטא-נתונים שלכם באמצעות אב טיפוס מקומי של CLI.
הגעתם לנקודת ביקורת. בחירת השלב הבא:
אפשרות א': אני רוצה להמשיך לחלק 2 עכשיו!
אם אתם רוצים להפוך את אב הטיפוס המקומי הזה לאפליקציית אינטרנט מאובטחת ברמת ייצור באמצעות Model Context Protocol (MCP) ו-Cloud Run:
אפשרות ב': אשלים את חלק 2 מאוחר יותר או שרציתי להשלים רק את חלק 1.
אם רוצים להפסיק את השימוש היום כדי להימנע מעלויות בענן, צריך לנקות את המשאבים.
אל דאגה! בחלק 2, נספק 'סקריפט להפעלה מהירה' שיבנה מחדש את סביבת חלק 1 תוך 2 דקות בלבד, כדי שתוכלו להמשיך בדיוק מהמקום שבו הפסקתם.
👉 עוברים לקטע 'ניקוי'.
6. ניקוי (רק לאפשרות ב')
אם אתם מפסיקים כאן, צריך להרוס את המשאבים כדי להימנע מחיובים.
כיבוי סופי של אגם הנתונים (Terraform)
אם אתם נמצאים כרגע בסביבת Gemini CLI, יוצאים מהסשן על ידי הקשה על Ctrl+C פעמיים או הקלדה של /quit. לאחר מכן, מריצים את הפקודות הבאות:
cd ~/devrel-demos/data-analytics/governance-context/terraform
terraform destroy -var="project_id=${PROJECT_ID}" -var="region=${REGION}" -auto-approve
הסרת התוסף ל-Gemini CLI ומחיקת קבצים מקומיים
gemini extensions uninstall dataplex
cd ~
rm -rf ~/devrel-demos