
1. Introdução
Os modelos de IA generativa são ótimos para raciocínio, mas não têm contexto institucional. Se um executivo perguntar a um agente de IA: "Qual é nossa receita do primeiro trimestre?", o agente poderá encontrar dezenas de tabelas chamadas "receita" no data lake. Alguns são relatórios financeiros rigorosos, outros são estimativas de marketing em tempo real, e muitos provavelmente são sandboxes descontinuados.
Sem embasamento explícito, um agente de IA seleciona uma tabela com base em uma simples semelhança de nome, o que leva a respostas "convencionalmente erradas" derivadas de dados não verificados.
Este codelab faz parte de uma série de duas partes que mostra como criar um agente de IA com reconhecimento de governança.
Nesta primeira parte, você vai criar uma base de dados. Você vai configurar um data lake realista e "bagunçado" no BigQuery, aplicar tags de metadados rígidas (aspectos do Knowledge Catalog) para diferenciar dados válidos de ruídos e usar a CLI do Antigravity (AGY) para testar localmente se o agente segue estritamente suas regras de governança de dados.
Leia a segunda parte desta série, que aborda como implantar o protótipo de agente local em um aplicativo da Web seguro e de nível empresarial usando o Protocolo de Contexto de Modelo (MCP) e o Cloud Run. 👉 Leia a Parte 2
O que você vai aprender
- Implante um data lake realista de várias camadas usando um script de configuração.
- Projete e registre modelos de metadados personalizados (tipos de aspectos) no Knowledge Catalog para distinguir produtos de dados oficiais de tabelas de sandbox brutas.
- Verifique as regras de governança de dados localmente usando a CLI do AGY antes de gravar qualquer código de aplicativo.
O que é necessário
- Ter um projeto do Google Cloud com o faturamento ativado.
- Acesso ao Google Cloud Shell (a CLI do AGY já está pré-instalada no Cloud Shell).
- Entendimento básico e familiaridade com o BigQuery e o Knowledge Catalog.
Principais conceitos
- Knowledge Catalog:o serviço unificado de gerenciamento de metadados. Usamos isso para enriquecer metadados técnicos (esquemas) com contexto comercial (governança).
- Tipo de aspecto:um modelo de metadados estruturados. Ao contrário das tags de texto livre, os aspectos aplicam tipagem forte (enums, booleanos), o que os torna confiáveis para avaliação por máquinas.
2. Configuração e requisitos
Iniciar o Cloud Shell
Embora o Google Cloud e o Spanner possam ser operados remotamente do seu laptop, neste codelab usaremos o Google Cloud Shell, um ambiente de linha de comando executado no Cloud.
No Console do Google Cloud, clique no ícone do Cloud Shell na barra de ferramentas superior à direita:
O provisionamento e a conexão com o ambiente levarão apenas alguns instantes para serem concluídos: Quando o processamento for concluído, você verá algo como:

Essa máquina virtual contém todas as ferramentas de desenvolvimento necessárias. Ela oferece um diretório principal persistente de 5 GB, além de ser executada no Google Cloud. Isso aprimora o desempenho e a autenticação da rede. Neste codelab, todo o trabalho pode ser feito com um navegador. Você não precisa instalar nada.
Inicializar o ambiente
Abra o Cloud Shell e defina as variáveis do projeto para garantir que todos os comandos sejam direcionados à infraestrutura correta.
export PROJECT_ID=$(gcloud config get-value project)
gcloud config set project $PROJECT_ID
export REGION="us-central1"
Ativar APIs
Ative os serviços necessários do Google Cloud para executar a instrução a seguir.
gcloud services enable \
bigquery.googleapis.com \
dataplex.googleapis.com
Clonar o repositório
Acesse o código de infraestrutura e os scripts de automação no repositório do GitHub. Para economizar espaço em disco no Cloud Shell, vamos baixar apenas a pasta específica necessária para este laboratório.
# Perform a shallow clone to get only the latest repository structure without the full history
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
# Specify and download only the folder we need for this lab
git sparse-checkout set data-analytics/governance-context
cd data-analytics/governance-context
Criar o data lake "bagunçado"
Os ambientes de dados do mundo real raramente são limpos. Para simular a realidade, precisamos de uma combinação de data marts "oficiais" e tabelas de "sandbox" não confiáveis.
Vamos usar um script de configuração para implantar os conjuntos de dados e as tabelas do BigQuery.
- Torne o script de configuração executável e execute-o. Isso vai criar três conjuntos de dados do BigQuery (
finance_mart,marketing_prod,analyst_sandbox) e preencher as tabelas deles com dados de exemplo.
chmod +x ./setup_bq_tables.sh
./setup_bq_tables.sh
Checkpoint: agora você tem um data lake totalmente preenchido, mas sem governança. Para uma IA, todas as tabelas são exatamente iguais.
3. Como criar o modelo de governança de dados (tipo de aspecto)
Agora vamos definir algumas regras de governança de dados. No Knowledge Catalog, isso é feito criando um tipo de aspecto, que é um modelo de metadados reutilizável e fortemente tipado.
Vamos registrar esse modelo usando a CLI gcloud para que você veja como ele é definido.
Inspecionar o esquema de aspecto
Mostre o conteúdo de aspect_template.json para ver a definição do esquema.
cat aspect_template.json
Ela vai mostrar a seguinte estrutura JSON:
{
"name": "OfficialDataProductSpec",
"type": "record",
"recordFields": [
{
"name": "product_tier",
"type": "enum",
"enumValues": [
{ "name": "GOLD_CRITICAL", "index": 1 },
{ "name": "SILVER_STANDARD", "index": 2 },
{ "name": "BRONZE_ADHOC", "index": 3 }
],
...
},
{
"name": "is_certified",
"type": "bool",
...
}
]
}
Observe como esse esquema impõe tipos de dados estritos, como enum para o nível de gravidade (GOLD_CRITICAL, SILVER_STANDARD, BRONZE_ADHOC) e um bool para is_certified. Isso garante que os metadados permaneçam estruturados e legíveis por máquina.
Registrar o tipo de aspecto
Execute o seguinte comando gcloud para registrar esse modelo no seu registro do Knowledge Catalog.
gcloud dataplex aspect-types create official-data-product-spec \
--location="${REGION}" \
--project="${PROJECT_ID}" \
--description="Defines the comprehensive profile of a data product for governance agents." \
--display-name="Official Data Product Spec" \
--metadata-template-file-name="aspect_template.json"
4. Aplicar governança
Essa é a etapa de engenharia crítica. No momento, as tabelas finance_mart.fin_monthly_closing_internal e analyst_sandbox.tmp_data_dump_v2_final_real parecem idênticas para um LLM. São apenas objetos com colunas.
Como engenheiro de governança, você precisa anexar um aspecto (um rótulo de metadados certificado) a essas tabelas para diferenciá-las. Em uma empresa real, você automatizaria isso usando pipelines de CI/CD. Vamos simular essa automação com scripts.
Gerar payloads de governança
As chaves de aspecto do Knowledge Catalog precisam ser globalmente exclusivas (prefixadas com o ID do projeto). O script ./generate_payloads.sh vai gerar dinamicamente os arquivos de metadados YAML.
chmod +x ./generate_payloads.sh
./generate_payloads.sh
Saída:
Isso cria uma pasta "./aspect_payloads" com quatro arquivos YAML, definindo os cenários de governança (Gold/Internal, Gold/Public, Silver/Realtime, Bronze/Sandbox).
Aplicar aspectos com a CLI
Antes de executar o script, vamos analisar o que estamos aplicando para simplificar o processo. Execute o comando a seguir para conferir a estrutura da carga útil financeira interna:
cat aspect_payloads/fin_internal.yaml
Ele vai mostrar o seguinte conteúdo.
your-project-id.us-central1.official-data-product-spec:
data:
product_tier: GOLD_CRITICAL
data_domain: FINANCE
usage_scope: INTERNAL_ONLY
update_frequency: DAILY_BATCH
is_certified: true
Observe como esse YAML define explicitamente o contexto comercial, como definir a flag is_certified: true e atribuir o nível GOLD_CRITICAL. Fornecer ao LLM regras claras e estruturadas para avaliação, em vez de simplesmente adivinhar com base nos nomes das tabelas.
Agora, execute o script do aplicativo. Isso itera pelas tabelas do BigQuery e executa o comando gcloud dataplex entries update para anexar esses metadados rígidos.
chmod +x ./apply_governance.sh
./apply_governance.sh
Verificação (opcional)
Antes de continuar, verifique se os metadados foram aplicados corretamente no console.
- Abra a página Knowledge Catalog no console do Google Cloud. Se "Knowledge Catalog" não aparecer no menu de navegação à esquerda, use a barra de pesquisa na parte de cima da janela do console do Google Cloud, digite "Knowledge Catalog" e selecione o resultado em "Principais resultados" ou "Produtos e páginas".
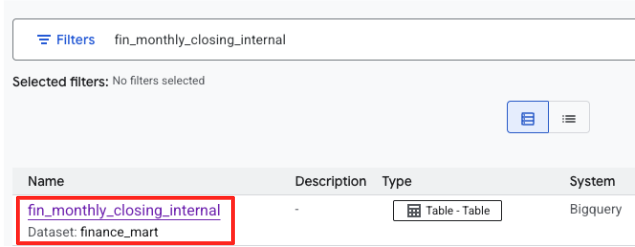
- Pesquisar por
fin_monthly_closing_internal. A tabela do BigQuery vai aparecer nos resultados. Clique no nome da tabela para acessar a página de detalhes.
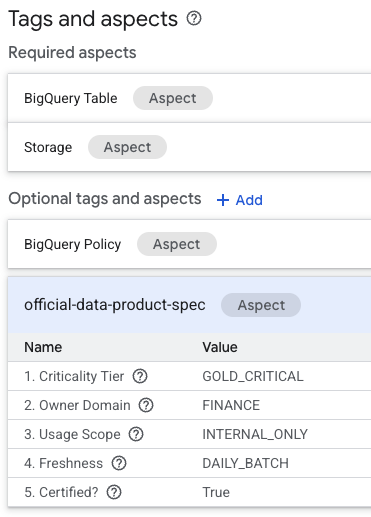
- Na página de detalhes da tabela, procure a seção Tags e aspectos opcionais na parte de baixo.
- Você vai encontrar o aspecto
official-data-product-spec. Confirme se os valores correspondem ao cenário "Gold Internal" que aplicamos.
Agora você confirmou que tabelas do BigQuery tecnicamente idênticas (fin_monthly_closing_internal e tmp_data_dump_v2_final_real) são diferenciadas logicamente por metadados legíveis por máquina.
5. Configurar e criar um protótipo do agente
Antes de criar um aplicativo (o que faremos na Parte 2), vamos verificar nossa lógica de governança de dados localmente. Precisamos instalar o plug-in do Knowledge Catalog e configurar a habilidade do agente.
Instalar a extensão
No Cloud Shell, instale o plug-in do Knowledge Catalog. Ele vai pedir confirmação e os detalhes da configuração.
export DATAPLEX_PROJECT="${PROJECT_ID}"
agy plugin install https://github.com/gemini-cli-extensions/dataplex
Inspecionar a habilidade do agente
A habilidade do agente é um arquivo de definição estático e reutilizável localizado em .agents/skills/knowledge_catalog_governance/SKILL.md. Ele contém a lógica que traduz regras humanas abstratas (por exemplo, "Preciso de dados seguros") em pesquisas técnicas rigorosas.
Inspecione o arquivo para entender o algoritmo que estamos ensinando à IA:
cat .agents/skills/knowledge_catalog_governance/SKILL.md
Ele instrui explicitamente o modelo a seguir um loop estrito de Fase 1 (verificação de metadados) e Fase 2 (execução de consultas). O modelo precisa descobrir e verificar os metadados antes de criar qualquer SQL.
Iniciar o agente e testar cenários
Inicie a sessão da CLI do AGY. Ele vai descobrir e carregar automaticamente a habilidade do diretório .agents/skills.
agy
Observação: vários arquivos de contexto podem ser carregados. Isso é normal. A CLI carrega a habilidade local para as regras específicas deste projeto, além das instruções padrão para o próprio plug-in do Knowledge Catalog.
Confirme a instalação
Digite /mcp para confirmar se o plug-in do Knowledge Catalog está ativo. O knowledge-catalog vai aparecer como um plug-in ativo com as ferramentas disponíveis.
/mcp
Resposta esperada:
MCP Servers
...
> ✓ knowledge-catalog Tools: search_entries, lookup_context, lookup_entry
Cenários de teste (prototipagem)
Cole os comandos a seguir na sessão do agente em execução um por um para verificar se ele obedece às suas regras.
- Cenário A (certificar os dados do CFO):
"We are preparing the deck for an internal Board of Directors meeting next week. I need the numbers to be absolutely finalized, trustworthy, and kept strictly confidential. Which table is safe to use?"
Esperado:o agente descobre automaticamente seu projeto e região ativos nas ferramentas dele, consulta fin_monthly_closing_internal porque corresponde semanticamente a GOLD_CRITICAL (preciso) e INTERNAL_ONLY (reunião do conselho) no Aspecto e recomenda.
- Cenário B (divulgação pública):
"I need to share our quarterly financial summary with an external consulting firm. It is critical that we do not leak any raw or internal metrics. Which dataset is officially scrubbed and explicitly approved for external sharing?"
Esperado:o agente precisa ignorar a tabela interna mensal e selecionar estritamente fin_quarterly_public_report porque é o único recurso marcado como EXTERNAL_READY.
- Cenário C (necessidades operacionais):
"My dashboard needs to show what's happening right now with our ad spend. I can't wait for the overnight load. What do you recommend?"
Esperado:o agente seleciona mkt_realtime_campaign_performance porque identifica a frequência de atualização REALTIME_STREAMING, priorizando-a em vez do nível GOLD_CRITICAL dos dados financeiros.
- Cenário D (experiência no sandbox):
"I'm just playing around with some new ML models and need a lot of raw data. It doesn't need to be perfect, just a sandbox environment."
Esperado:o agente seleciona tmp_data_dump_v2_final_real porque ele corresponde semanticamente a BRONZE_ADHOC (dados brutos) e is_certified: false (ambiente de sandbox) no aspecto.
(Para sair da sessão do AGY, digite /exit ou /quit)
6. Parabéns! A seguir
Você criou uma base de dados gerenciada e provou que uma IA pode seguir estritamente suas regras de metadados usando um protótipo de CLI local.
Agora você chegou a um ponto de verificação. Escolha a próxima etapa:
Opção A: quero continuar para a Parte 2 agora mesmo!
Se você quiser transformar esse protótipo local em um aplicativo da Web seguro e de nível de produção usando o Protocolo de Contexto de Modelo (MCP) e o Cloud Run:
👉 Link para o Codelab da Parte 2
Opção B: vou fazer a Parte 2 depois ou só queria concluir a Parte 1.
Se você quiser parar por hoje e evitar custos na nuvem, limpe seus recursos.
Não se preocupe! Na Parte 2, vamos fornecer um "Script de faixa rápida" que vai reconstruir completamente o ambiente da Parte 1 em apenas 2 minutos para que você possa continuar exatamente de onde parou.
👉 Acesse a seção de limpeza.
7. Limpeza (somente para a opção B)
Se você vai parar por aqui, destrua os recursos para evitar cobranças.
Destruir o data lake
Se você estiver na sessão da CLI do AGY, saia dela pressionando Ctrl+C duas vezes ou digitando /quit. Em seguida, execute os comandos abaixo:
chmod +x ./cleanup_data_lake.sh
./cleanup_data_lake.sh
Desinstalar o plug-in da CLI do AGY e remover arquivos locais
agy plugin uninstall dataplex
cd ~
rm -rf ~/devrel-demos