
1. مقدمة
في هذا الدرس التطبيقي حول الترميز، ستتعرّف على كيفية تسريع سير عمل تحليلات البيانات على مجموعات البيانات الكبيرة باستخدام وحدات معالجة الرسومات من NVIDIA ومكتبات مفتوحة المصدر على Google Cloud. ستبدأ بتحسين البنية الأساسية، ثم ستستكشف كيفية تطبيق تسريع وحدة معالجة الرسومات بدون إجراء أي تغييرات على الرموز البرمجية.
ستركّز على pandas، وهي مكتبة شائعة لمعالجة البيانات، وستتعرّف على كيفية تسريعها باستخدام مكتبة cuDF من NVIDIA. والأفضل من ذلك هو أنّه يمكنك الاستفادة من تسريع وحدة معالجة الرسومات بدون تغيير رمز pandas الحالي.
أهداف الدورة التعليمية
- التعرّف على Colab Enterprise على Google Cloud
- تخصيص بيئة وقت تشغيل Colab باستخدام إعدادات محدّدة لوحدة معالجة الرسومات ووحدة المعالجة المركزية والذاكرة
- تسريع
pandasبدون إجراء أي تغييرات على الرمز باستخدامcuDFمن NVIDIA - إنشاء ملف تعريف للرمز البرمجي لتحديد المؤثّرات السلبية في الأداء وتحسينها
تتضمّن الصفحة التالية أرصدة يمكنك استخدامها لإكمال الدرس التطبيقي.
2. لماذا يجب تسريع معالجة البيانات؟
قاعدة 80/20: لماذا يستغرق إعداد البيانات وقتًا طويلاً؟
غالبًا ما تكون مرحلة إعداد البيانات هي المرحلة الأكثر استهلاكًا للوقت في مشروع التحليلات. يقضي علماء البيانات والمحللون جزءًا كبيرًا من وقتهم في تنظيف البيانات وتحويلها وتنظيمها قبل بدء أي تحليل.
لحسن الحظ، يمكنك تسريع المكتبات الشائعة مفتوحة المصدر، مثل pandas وApache Spark وPolars، على وحدات معالجة الرسومات من NVIDIA باستخدام cuDF. على الرغم من هذا التسريع، يظلّ إعداد البيانات يستغرق وقتًا طويلاً للأسباب التالية:
- بيانات المصدر نادرًا ما تكون جاهزة للتحليل: غالبًا ما تتضمّن البيانات الواقعية تناقضات وقيمًا ناقصة ومشاكل في التنسيق.
- تؤثّر الجودة في أداء النموذج: يمكن أن تؤدي جودة البيانات الضعيفة إلى إبطال فعالية أكثر الخوارزميات تطورًا.
- تتفاقم المشاكل مع زيادة الحجم: تتحوّل مشاكل البيانات التي تبدو بسيطة إلى اختناقات حرجة عند التعامل مع ملايين السجلات.
3- اختيار بيئة دفتر ملاحظات
مع أنّ العديد من علماء البيانات على دراية بخدمة Colab للمشاريع الشخصية، يوفّر Colab Enterprise تجربة آمنة وتعاونية ومتكاملة للمفكرات مصمَّمة خصيصًا للأنشطة التجارية.
على Google Cloud، لديك خياران أساسيان لبيئات دفاتر الملاحظات المُدارة: Colab Enterprise وGemini Enterprise Agent Platform Workbench. يعتمد الاختيار الصحيح على أولويات مشروعك.
حالات استخدام "منصة Agent Platform Workbench"
اختَر Agent Platform Workbench عندما تكون أولويتك هي التحكّم والتخصيص المتقدّم. هذا الخيار مثالي إذا كنت بحاجة إلى:
- إدارة البنية التحتية الأساسية ودورة حياة الآلات
- استخدام حاويات مخصّصة وإعدادات شبكة
- يمكنك الدمج مع مسارات MLOps وأدوات مخصّصة لدورة الحياة.
حالات استخدام Colab Enterprise
اختَر Colab Enterprise عندما تكون أولويتك هي الإعداد السريع وسهولة الاستخدام والتعاون الآمن. وهو حلّ مُدار بالكامل يتيح لفريقك التركيز على التحليل بدلاً من البنية الأساسية.
تساعدك Colab Enterprise في ما يلي:
- تطوير مهام سير عمل علم البيانات المرتبطة بشكل وثيق بمستودع البيانات يمكنك فتح دفاتر الملاحظات وإدارتها مباشرةً في BigQuery Studio.
- تدريب نماذج تعلُّم الآلة ودمجها مع أدوات MLOps في "منصّة الوكلاء"
- استمتِع بتجربة مرنة وموحّدة. يمكن فتح دفتر ملاحظات Colab Enterprise تم إنشاؤه في BigQuery وتشغيله في Agent Platform، والعكس صحيح.
الميزة الاختبارية اليوم
يستخدم هذا الدرس التطبيقي حول الترميز Colab Enterprise لإجراء تحليلات البيانات بشكل أسرع.
لمزيد من المعلومات حول الاختلافات، راجِع المستندات الرسمية حول اختيار حلّ دفتر الملاحظات المناسب.
4. ضبط نموذج وقت التشغيل
في Colab Enterprise، اتّصِل ببيئة تشغيل تستند إلى نموذج بيئة تشغيل تم إعداده مسبقًا.
نموذج وقت التشغيل هو إعداد قابل لإعادة الاستخدام يحدّد البيئة بأكملها لدفتر الملاحظات، بما في ذلك:
- نوع الجهاز (وحدة المعالجة المركزية والذاكرة)
- المسرِّع (نوع وحدة معالجة الرسومات وعددها)
- حجم القرص ونوعه
- إعدادات الشبكة وسياسات الأمان
- قواعد الإيقاف التلقائي في وضع الخمول
أهمية نماذج وقت التشغيل
- الحصول على بيئة متسقة: يمكنك أنت وزملاؤك في الفريق الحصول على البيئة نفسها الجاهزة للاستخدام في كل مرة لضمان إمكانية تكرار عملك.
- العمل بأمان من خلال التصميم: تفرض النماذج تلقائيًا سياسات الأمان في مؤسستك.
- إدارة التكاليف بفعالية: يتم تحديد حجم الموارد مسبقًا، مثل وحدات معالجة الرسومات ووحدات المعالجة المركزية، في النموذج، ما يساعد في تجنُّب تجاوز التكاليف عن طريق الخطأ.
إنشاء نموذج وقت تشغيل
إعداد نموذج وقت تشغيل قابل لإعادة الاستخدام للمختبر
- في Google Cloud Console، انتقِل إلى قائمة التنقّل > منصة Agent > دفاتر الملاحظات.
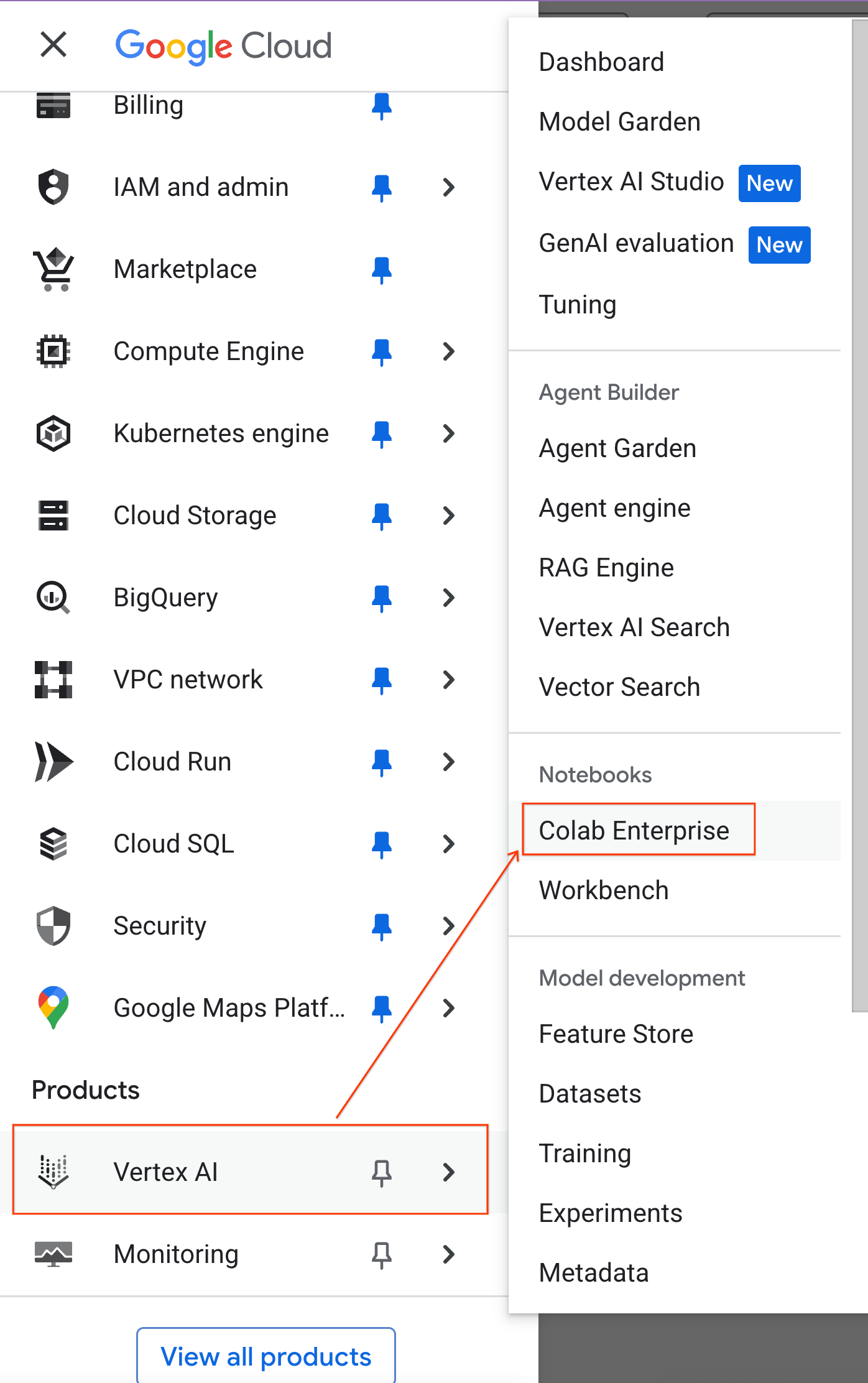
- في Colab Enterprise، انقر على نماذج وقت التشغيل، ثم اختَر نموذج جديد.
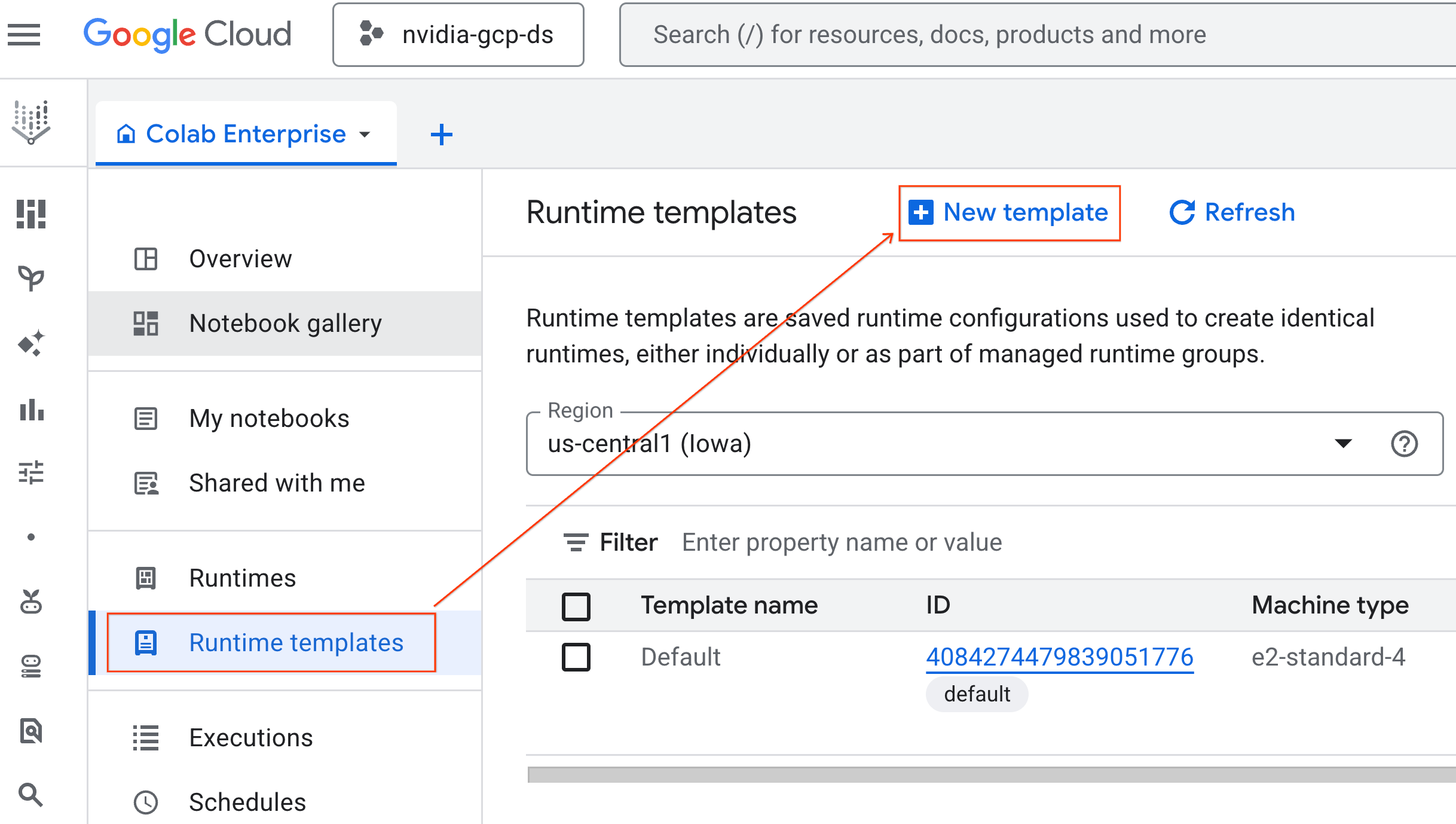
- ضمن أساسيات وقت التشغيل:
- اضبط الاسم المعروض على
gpu-template. - اضبط المنطقة المفضّلة.
- اضبط الاسم المعروض على
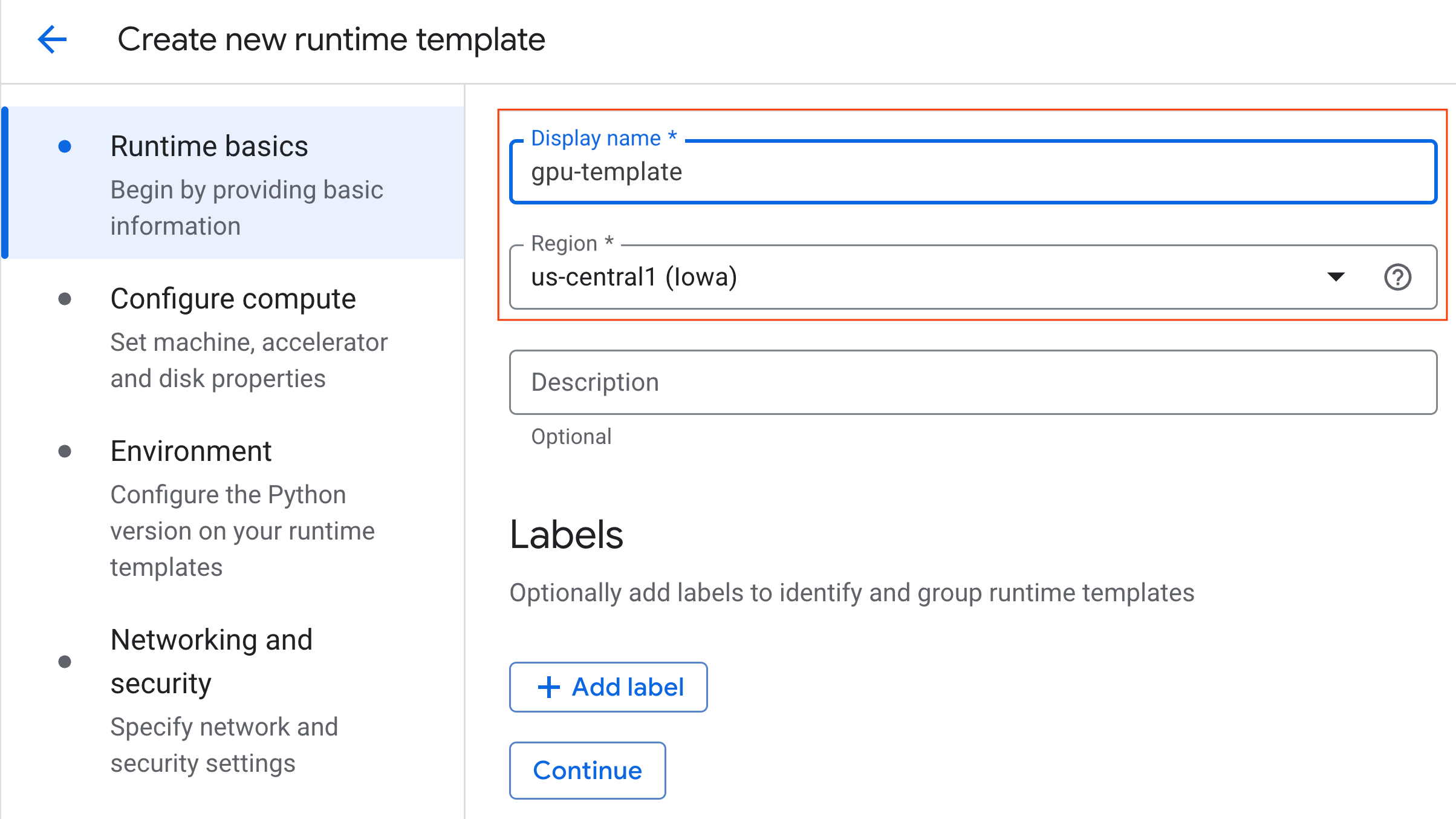
- ضمن ضبط الحساب:
- اضبط نوع الجهاز على
g2-standard-4. - احتفِظ بالإعداد التلقائي نوع أداة التسريع على
NVIDIA L4مع عدد أدوات التسريع بقيمة 1. - غيِّر الإيقاف التلقائي في حال عدم النشاط إلى 60 دقيقة.
- انقر على متابعة.
- اضبط نوع الجهاز على
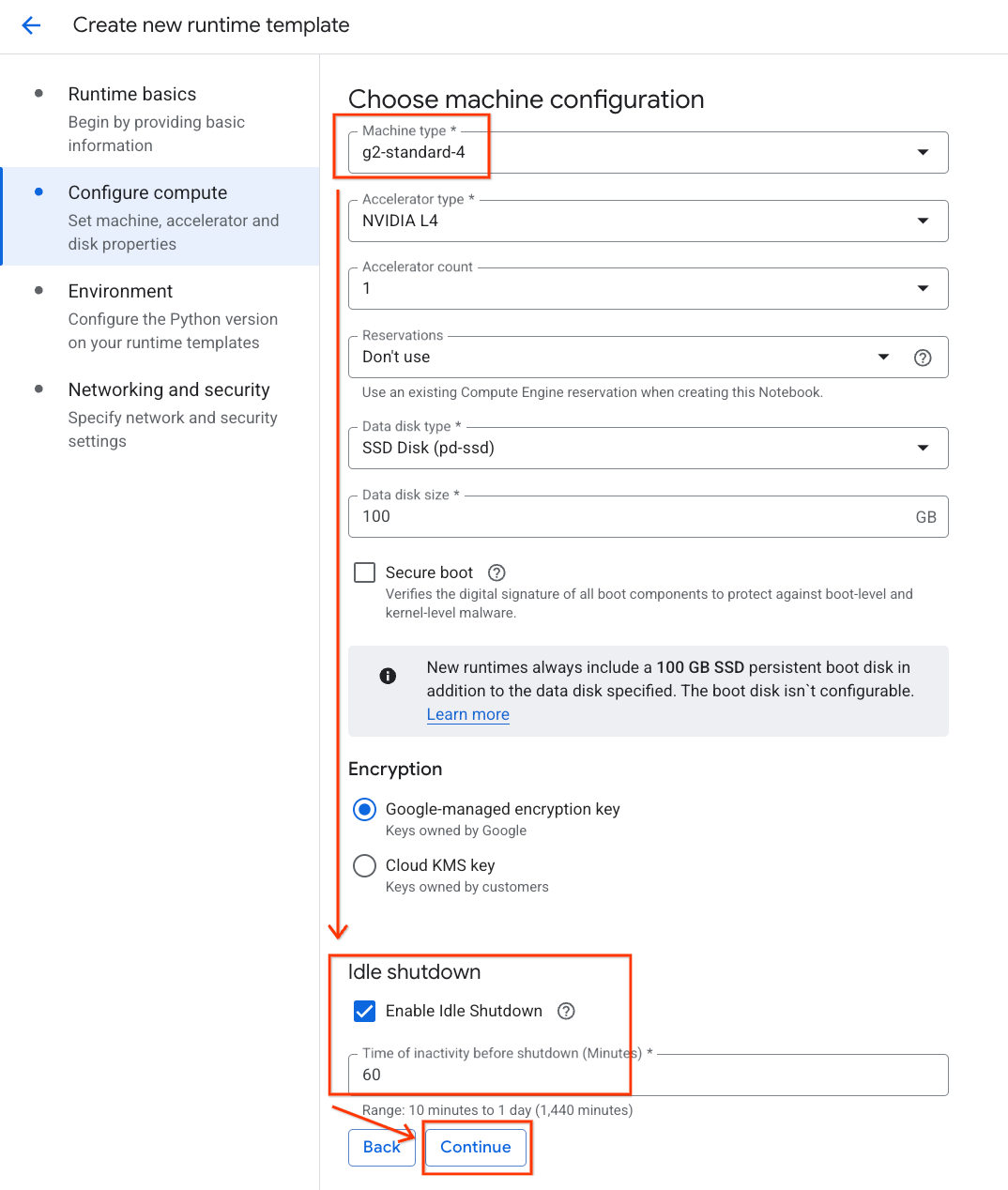
- ضمن البيئة:
- اضبط البيئة على
Python 3.11
- اضبط البيئة على
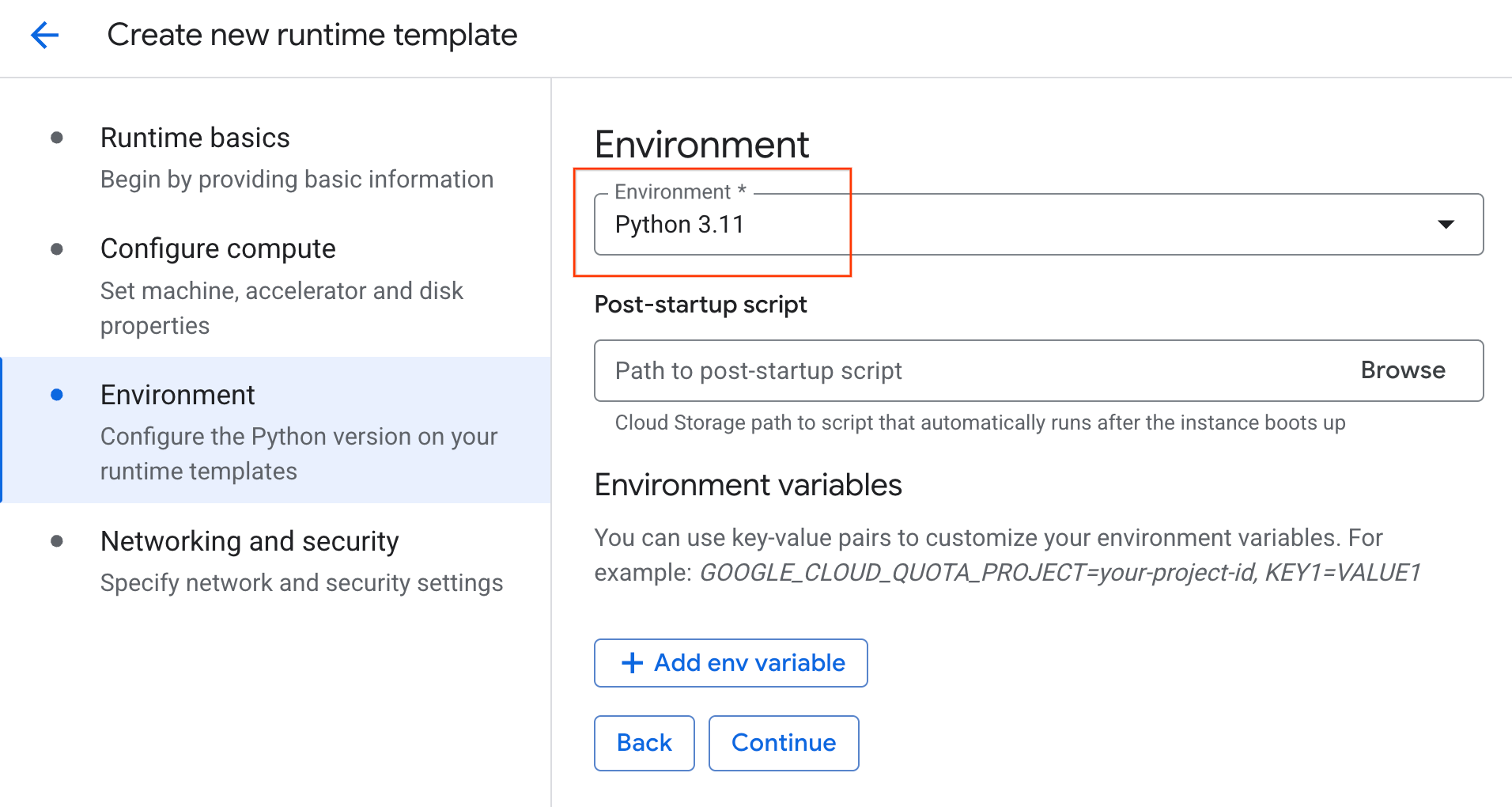
- انقر على إنشاء لحفظ نموذج وقت التشغيل. من المفترض أن تعرض صفحة "نماذج وقت التشغيل" النموذج الجديد الآن.
5- بدء وقت التشغيل
بعد إعداد النموذج، يمكنك إنشاء وقت تشغيل جديد.
- من Colab Enterprise، انقر على وقت التشغيل ثم اختَر إنشاء.
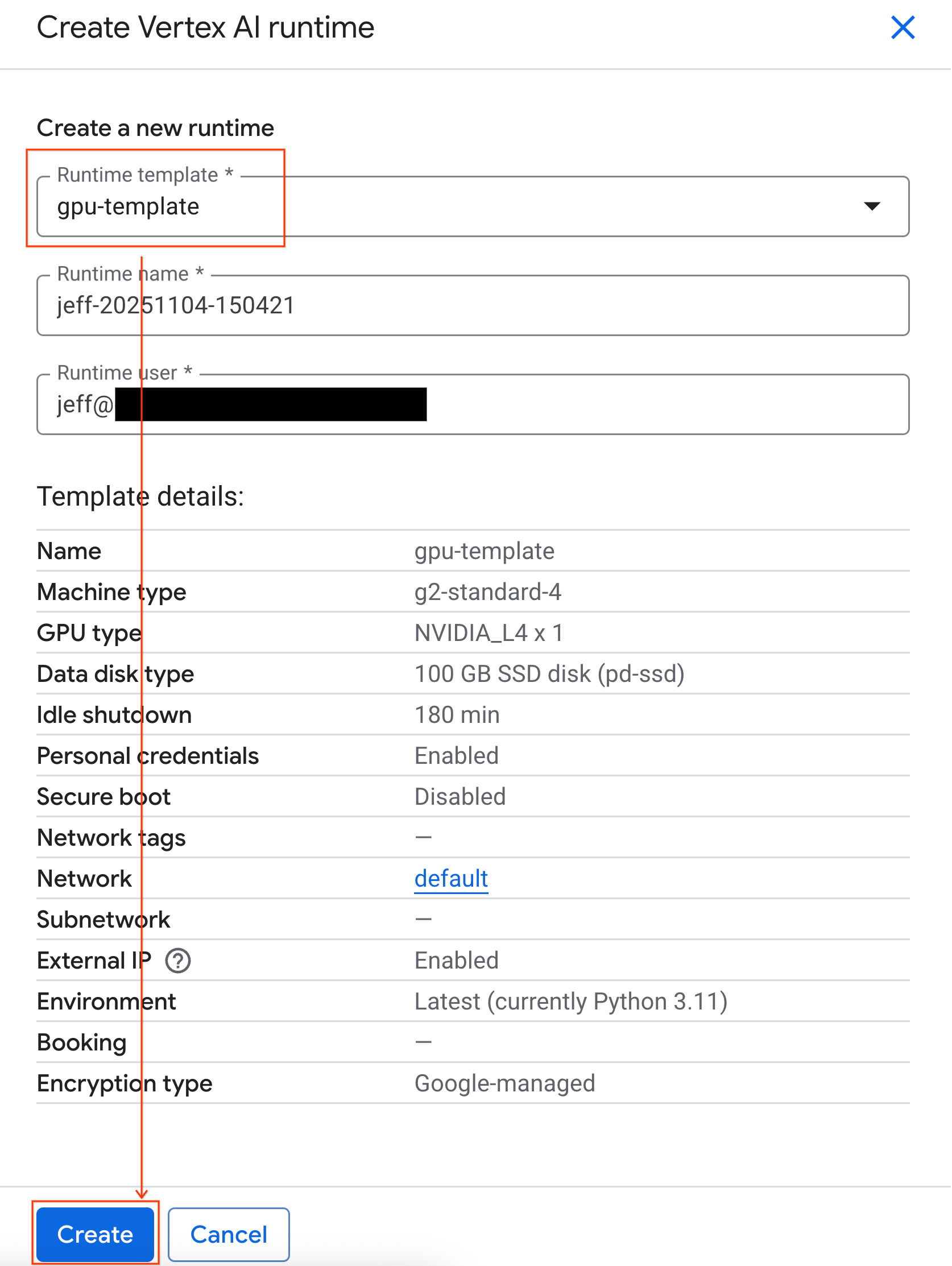
- ضمن نموذج وقت التشغيل، اختَر الخيار
gpu-template. انقر على إنشاء وانتظر حتى يتم تشغيل وقت التشغيل.
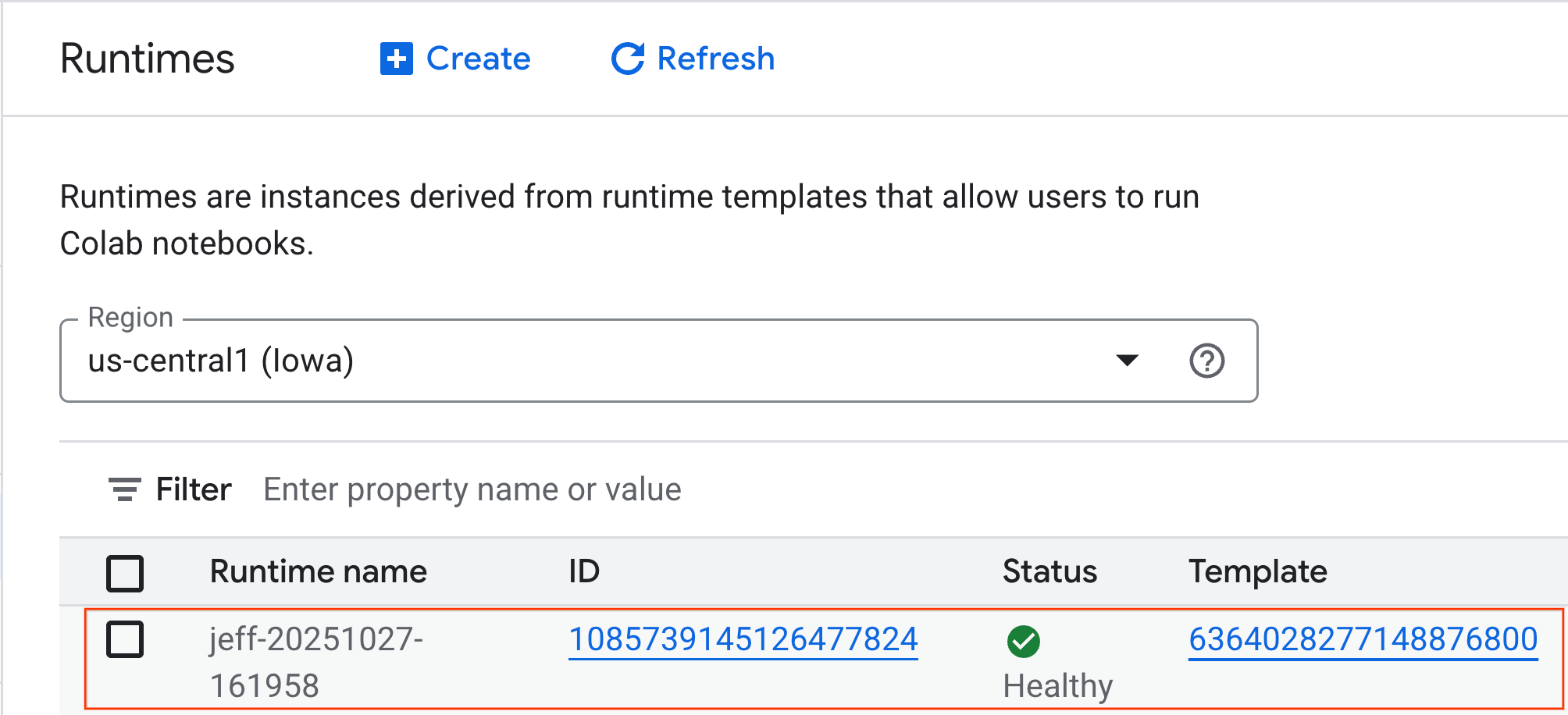
- بعد بضع دقائق، ستظهر مدة التشغيل المتاحة.
6. إعداد دفتر الملاحظات
بعد تشغيل البنية الأساسية، عليك استيراد دفتر الملاحظات الخاص بالتجربة وربطه بوقت التشغيل.
استيراد دفتر الملاحظات
- من Colab Enterprise، انقر على دفاتري ثم على استيراد.
- انقر على زر الاختيار عنوان URL وأدخِل عنوان URL التالي:
https://github.com/GoogleCloudPlatform/ai-ml-recipes/blob/main/notebooks/analytics/gpu_accelerated_analytics.ipynb
- انقر على استيراد. ستنسخ Colab Enterprise دفتر الملاحظات من GitHub إلى بيئتك.
الاتصال ببيئة التشغيل
- افتح دفتر الملاحظات الذي تم استيراده حديثًا.
- انقر على السهم المتّجه للأسفل بجانب ربط.
- انقر على الاتصال ببيئة تشغيل.

- استخدِم القائمة المنسدلة واختَر وقت التشغيل الذي أنشأته سابقًا.
- انقر على ربط.
تم ربط ورقة الملاحظات الآن ببيئة تشغيل متوافقة مع وحدة معالجة الرسومات. يمكنك الآن البدء في تنفيذ طلبات البحث.
7. إعداد مجموعة بيانات سيارات الأجرة في نيويورك
يستخدم هذا الدرس التطبيقي حول الترميز بيانات سجلّ الرحلات الصادر عن هيئة سيارات الأجرة والليموزين في نيويورك (TLC).
تحتوي مجموعة البيانات على سجلات رحلات فردية من سيارات الأجرة الصفراء في مدينة نيويورك، وتشمل حقولاً مثل:
- تواريخ وأوقات ومواقع الاستلام والتسليم
- مسافات الرحلات
- مبالغ الأجرة المفصّلة
- عدد الركاب
تنزيل البيانات
بعد ذلك، نزِّل بيانات الرحلات لعام 2024 بأكمله. يتم تخزين البيانات بتنسيق ملف Parquet.
تنفّذ مجموعة الرموز البرمجية التالية هذه الخطوات:
- تحدّد هذه السمة نطاق السنوات والأشهر المطلوب تنزيلها.
- يتم إنشاء دليل محلي باسم
nyc_taxi_dataلتخزين الملفات. - تتكرّر هذه العملية لكل شهر، ويتم تنزيل ملف Parquet ذي الصلة إذا لم يكن متوفّرًا من قبل، ثم يتم حفظه في الدليل.
نفِّذ الرمز البرمجي التالي في ورقة الملاحظات لجمع البيانات وتخزينها في وقت التشغيل:
from tqdm import tqdm
import requests
import time
import os
YEAR = 2024
DATA_DIR = "nyc_taxi_data"
os.makedirs(DATA_DIR, exist_ok=True)
print(f"Checking/Downloading files for {YEAR}...")
for month in tqdm(range(1, 13), unit="file"):
# Define standardized filename for both local path and URL
file_name = f"yellow_tripdata_{YEAR}-{month:02d}.parquet"
local_path = os.path.join(DATA_DIR, file_name)
url = f"https://d37ci6vzurychx.cloudfront.net/trip-data/{file_name}"
if not os.path.exists(local_path):
try:
with requests.get(url, stream=True) as response:
response.raise_for_status()
with open(local_path, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
time.sleep(1)
except requests.exceptions.HTTPError as e:
print(f"\nSkipping {file_name}: {e}")
if os.path.exists(local_path):
os.remove(local_path)
print("\nDownload complete.")
8. استكشاف بيانات رحلات سيارات الأجرة
بعد تنزيل مجموعة البيانات، حان الوقت لإجراء تحليل استكشافي أولي للبيانات (EDA). الهدف من الاستكشاف هو فهم بنية البيانات والعثور على القيم الشاذة والكشف عن الأنماط المحتملة.
تحميل بيانات شهر واحد
ابدأ بتحميل بيانات شهر واحد. يوفّر ذلك عيّنة كبيرة بما يكفي (أكثر من 3 ملايين صف) لتكون مفيدة مع الحفاظ على إمكانية إدارة استخدام الذاكرة لإجراء التحليل التفاعلي.
import pandas as pd
import glob
# Load the last month of the downloaded data
df = pd.read_parquet("nyc_taxi_data/yellow_tripdata_2024-12.parquet")
df.head()
الحصول على إحصاءات موجزة
استخدِم طريقة .describe() لإنشاء إحصاءات موجزة عالية المستوى للأعمدة الرقمية. هذه خطوة أولى رائعة لتحديد المشاكل المحتملة في جودة البيانات، مثل القيم الدنيا أو القصوى غير المتوقّعة.
df.describe().round(2)
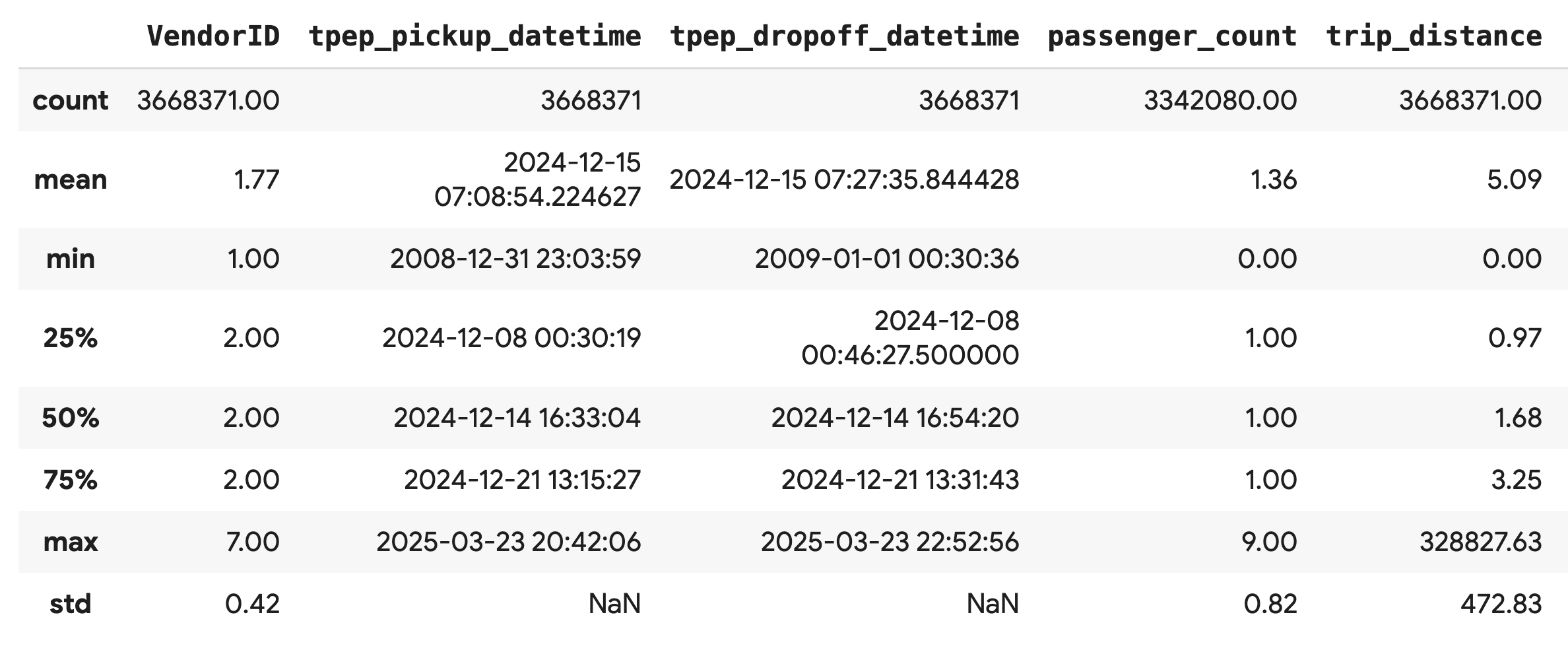
التحقّق من جودة البيانات
يكشف الناتج من .describe() عن مشكلة على الفور. لاحظ أنّ قيمة min لكل من tpep_pickup_datetime وtpep_dropoff_datetime هي 2008، وهو أمر غير منطقي لمجموعة بيانات تعود إلى عام 2024.
هذا مثال على أهمية فحص بياناتك دائمًا. يمكنك التحقّق من ذلك بشكل أكبر من خلال فرز DataFrame للعثور على الصفوف الدقيقة التي تحتوي على هذه التواريخ الشاذة.
# Sort by the dropoff datetime to see the oldest records
df.sort_values("tpep_pickup_datetime").head()
تمثيل توزيعات البيانات بيانيًا
بعد ذلك، يمكنك إنشاء مدرّجات تكرارية للأعمدة الرقمية لتمثيل توزيعاتها بشكل مرئي. يساعدك ذلك في فهم مدى انتشار وتوزيع ميزات، مثل trip_distance وfare_amount. الدالة .hist() هي طريقة سريعة لرسم المدرّجات التكرارية لجميع الأعمدة الرقمية في DataFrame.
_ = df.hist(figsize=(20, 20))
أخيرًا، أنشئ مصفوفة مبعثرة لتمثيل العلاقات بين بعض الأعمدة الرئيسية. بما أنّ رسم ملايين النقاط يستغرق وقتًا طويلاً ويمكن أن يحجب الأنماط، استخدِم .sample() لإنشاء الرسم البياني من عيّنة عشوائية تضم 100,000 صف.
_ = pd.plotting.scatter_matrix(
df[['passenger_count', 'trip_distance', 'tip_amount', 'total_amount']].sample(100_000),
diagonal="kde",
figsize=(15, 15)
)
9- لماذا يُنصح باستخدام تنسيق ملف Parquet؟
يتم توفير مجموعة بيانات سيارات الأجرة في مدينة نيويورك بتنسيق Apache Parquet. هذا خيار متعمّد تم اتخاذه لإجراء إحصاءات على نطاق واسع. توفّر Parquet العديد من المزايا مقارنةً بأنواع الملفات الأخرى، مثل CSV:
- الكفاءة والسرعة: بما أنّ Parquet هو تنسيق عمودي، فهو فعّال للغاية في التخزين والقراءة. يتوافق هذا التنسيق مع طرق الضغط الحديثة التي تؤدي إلى تصغير أحجام الملفات وتسريع عمليات الإدخال والإخراج بشكل كبير، خاصةً على وحدات معالجة الرسومات.
- الحفاظ على المخطط: يخزِّن Parquet أنواع البيانات في البيانات الوصفية للملف. لن تحتاج أبدًا إلى تخمين أنواع البيانات عند قراءة الملف.
- تفعيل القراءة الانتقائية: يتيح لك البناء العمودي قراءة الأعمدة المحدّدة التي تحتاج إليها لإجراء تحليل فقط. يمكن أن يؤدي ذلك إلى تقليل كمية البيانات التي عليك تحميلها في الذاكرة بشكل كبير.
استكشاف ميزات Parquet
لنستكشف اثنتين من هذه الميزات الفعّالة باستخدام أحد الملفات التي نزّلتها.
فحص البيانات الوصفية بدون تحميل مجموعة البيانات الكاملة
على الرغم من أنّه لا يمكنك عرض ملف Parquet في محرّر نصوص عادي، يمكنك بسهولة فحص المخطط والبيانات الوصفية بدون تحميل أي بيانات في الذاكرة. وهذا مفيد لفهم بنية الملف بسرعة.
from pyarrow.parquet import ParquetFile
import pyarrow as pa
# Open one of the downloaded files
pf = ParquetFile('nyc_taxi_data/yellow_tripdata_2024-12.parquet')
# Print the schema
print("File Schema:")
print(pf.schema)
# Print the file metadata
print("\nFile Metadata:")
print(pf.metadata)
قراءة الأعمدة التي تحتاج إليها فقط
لنفترض أنّك تحتاج فقط إلى تحليل مسافة الرحلة ومبالغ الأجرة. باستخدام Parquet، يمكنك تحميل هذه الأعمدة فقط، ما يجعله أسرع وأكثر فعالية من حيث استخدام الذاكرة مقارنةً بتحميل DataFrame بالكامل.
import pandas as pd
# Read only four specific columns from the Parquet file
df_subset = pd.read_parquet(
'nyc_taxi_data/yellow_tripdata_2024-12.parquet',
columns=['passenger_count', 'trip_distance', 'tip_amount', 'total_amount']
)
df_subset.head()
10. تسريع pandas باستخدام NVIDIA cuDF
NVIDIA CUDA for DataFrames (cuDF) هي مكتبة مفتوحة المصدر ومسرَّعة بواسطة وحدة معالجة الرسومات تتيح لك التفاعل مع DataFrames. تتيح لك cuDF إجراء عمليات البيانات الشائعة، مثل الفلترة والدمج والتجميع على وحدة معالجة الرسومات مع التوازي الهائل.
الميزة الأساسية التي تستخدمها في هذا الدرس العملي هي وضع cudf.pandas المسرَّع. عند تفعيل هذه الميزة، تتم إعادة توجيه رمز pandas العادي تلقائيًا لاستخدام نواة cuDF المستندة إلى وحدة معالجة الرسومات، وكل ذلك بدون الحاجة إلى تغيير الرمز.
تفعيل ميزة "تسريع وحدة معالجة الرسومات"
لاستخدام NVIDIA cuDF في دفتر ملاحظات Colab Enterprise، عليك تحميل إضافة Magic الخاصة به قبل استيراد pandas.
أولاً، افحص مكتبة pandas العادية. لاحظ أنّ الناتج يعرض المسار إلى عملية التثبيت التلقائية pandas.
import pandas as pd
pd # Note the output for the standard pandas library
الآن، حمِّل الإضافة cudf.pandas واستورِد pandas مرة أخرى. شاهِد كيف تتغيّر النتيجة للوحدة pd، فهذا يؤكّد أنّ الإصدار المتوافق مع وحدة معالجة الرسومات نشط الآن.
%load_ext cudf.pandas
import pandas as pd
pd # Note the new output, indicating cudf.pandas is active
طُرق أخرى لتفعيل cudf.pandas
على الرغم من أنّ الأمر السحري (%load_ext) هو أسهل طريقة في دفتر ملاحظات، يمكنك أيضًا تفعيل المسرِّع في بيئات أخرى:
- في نصوص Python البرمجية: استدعِ
import cudf.pandasوcudf.pandas.install()قبل استيرادpandas. - من بيئات غير دفترية: شغِّل النص البرمجي باستخدام
python -m cudf.pandas your_script.py.
11. مقارنة أداء وحدة المعالجة المركزية (CPU) بوحدة معالجة الرسومات (GPU)
والآن، ننتقل إلى الجزء الأكثر أهمية: مقارنة أداء pandas العادي على وحدة معالجة مركزية (CPU) بأداء cudf.pandas على وحدة معالجة الرسومات (GPU).
لضمان الحصول على خط أساس عادل تمامًا لوحدة المعالجة المركزية، يجب أولاً إعادة ضبط وقت تشغيل Colab. يؤدي ذلك إلى محو أي أدوات تسريع لوحدة معالجة الرسومات ربما فعّلتها في الأقسام السابقة. يمكنك إعادة تشغيل وقت التشغيل من خلال تنفيذ الخلية التالية أو اختيار إعادة تشغيل الجلسة من قائمة وقت التشغيل.
import IPython
IPython.Application.instance().kernel.do_shutdown(True)
تحديد مسار الإحصاءات
بعد أن أصبحت البيئة نظيفة، ستحدّد دالة قياس الأداء. تتيح لك هذه الدالة تشغيل مسار المعالجة نفسه تمامًا، أي التحميل والترتيب والتلخيص، باستخدام أي وحدة pandas تمرّرها إليها.
import time
import glob
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
def run_analytics_pipeline(pd_module):
"""Loads, sorts, and summarizes data using the provided pandas module."""
timings = {}
# 1. Load all 2024 Parquet files from the directory
t0 = time.time()
df = pd_module.concat(
[pd_module.read_parquet(f) for f in glob.glob("nyc_taxi_data/*_2024*.parquet")],
ignore_index=True
)
timings["load"] = time.time() - t0
# 2. Sort the data by multiple columns
t0 = time.time()
df = df.sort_values(
['tpep_pickup_datetime', 'trip_distance', 'passenger_count'],
ascending=[False, True, False]
)
timings["sort"] = time.time() - t0
# 3. Perform a groupby and aggregation
t0 = time.time()
df['tpep_pickup_datetime'] = pd_module.to_datetime(df['tpep_pickup_datetime'])
_ = (
df.loc[df.tpep_pickup_datetime > '2024-11-01']
.groupby(['VendorID', 'tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
timings["summarize"] = time.time() - t0
return timings
تشغيل المقارنة
أولاً، ستشغّل مسار العرض باستخدام pandas العادي على وحدة المعالجة المركزية. بعد ذلك، فعِّل cudf.pandas وشغِّله مرة أخرى على وحدة معالجة الرسومات.
# --- Run on CPU ---
print("Running analytics pipeline on CPU...")
# Ensure we are using standard pandas
import pandas as pd
assert "cudf" not in str(pd), "Error: cuDF is still active. Please restart the kernel."
cpu_times = run_analytics_pipeline(pd)
print(f"CPU times: {cpu_times}")
# --- Run on GPU ---
print("\nEnabling cudf.pandas and running on GPU...")
# Load the extension
%load_ext cudf.pandas
import pandas as gpu_pd
gpu_times = run_analytics_pipeline(gpu_pd)
print(f"GPU times: {gpu_times}")
عرض النتائج
أخيرًا، يمكنك عرض الفرق بشكل مرئي. يحسب الرمز التالي تسريع كل عملية ويرسمها جنبًا إلى جنب.
# Create a DataFrame for plotting
results_df = pd.DataFrame([cpu_times, gpu_times], index=["CPU", "GPU"]).T
total_cpu_time = results_df['CPU'].sum()
total_gpu_time = results_df['GPU'].sum()
speedup = total_cpu_time / total_gpu_time
print("--- Performance Results ---")
print(results_df)
print(f"\nTotal CPU Time: {total_cpu_time:.2f} seconds")
print(f"Total GPU Time: {total_gpu_time:.2f} seconds")
print(f"Overall Speedup: {speedup:.2f}x")
# Plot the results
fig, ax = plt.subplots(figsize=(10, 6))
results_df.plot(kind='bar', ax=ax, color={"CPU": "tab:blue", "GPU": "tab:green"})
ax.set_ylabel("Time (seconds)")
ax.set_title(f"CPU vs. GPU Runtimes (Overall Speedup: {speedup:.2f}x)", fontsize=14)
ax.tick_params(axis='x', rotation=0)
# Add numerical labels to the bars
for container in ax.containers:
ax.bar_label(container, fmt="%.2f", padding=3)
plt.tight_layout()
plt.show()
مثال على النتائج:
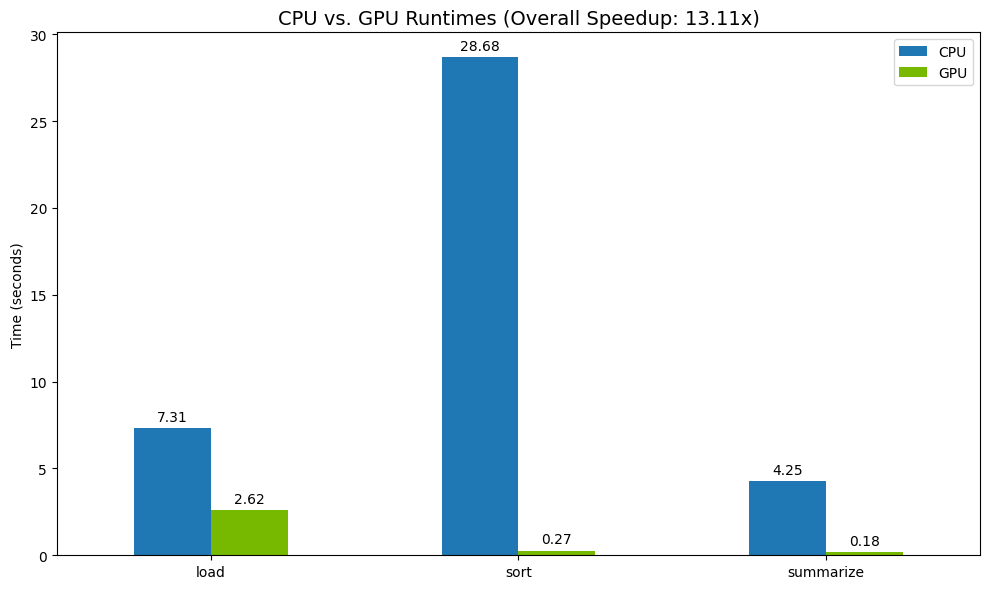
توفّر وحدة معالجة الرسومات زيادة واضحة في السرعة مقارنةً بوحدة المعالجة المركزية.
12. تحديد المشاكل في أداء الرمز البرمجي
حتى مع تسريع وحدة معالجة الرسومات، قد تعود بعض عمليات pandas إلى وحدة المعالجة المركزية إذا لم تكن cuDF تتيحها بعد. ويمكن أن تصبح هذه "الخيارات الاحتياطية لوحدة المعالجة المركزية" من العوامل التي تعيق الأداء.
لمساعدتك في تحديد هذه المجالات، يتضمّن cudf.pandas أداتَي تحليل مضمّنتَين. يمكنك استخدامها لمعرفة الأجزاء المحدّدة من الرمز البرمجي التي يتم تنفيذها على وحدة معالجة الرسومات والأجزاء التي يتم تنفيذها على وحدة المعالجة المركزية.
%%cudf.pandas.profile: استخدِم هذه السمة للحصول على ملخّص عام لكل وظيفة من وظائف الرمز. وهي الأفضل للحصول على نظرة عامة سريعة على العمليات التي يتم تنفيذها على أي جهاز.%%cudf.pandas.line_profile: استخدِم هذا الخيار للحصول على تحليل مفصّل سطرًا بسطر. وهي الأداة الأفضل لتحديد الأسطر الدقيقة في الرمز التي تؤدي إلى الرجوع إلى وحدة المعالجة المركزية.
استخدِم أدوات تحليل الأداء هذه كـ "أوامر سحرية للخلايا" في أعلى خلية دفتر ملاحظات.
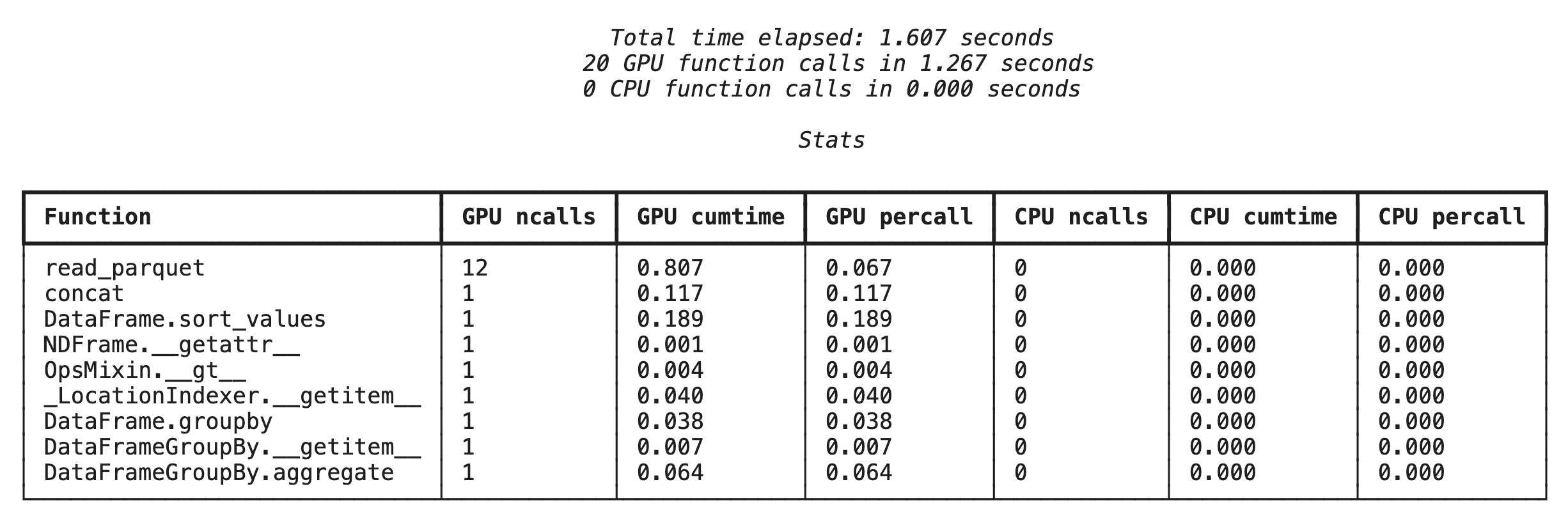
إنشاء ملفات تعريف على مستوى الدوال باستخدام %%cudf.pandas.profile
أولاً، شغِّل أداة قياس الأداء على مستوى الوظيفة على مسار الإحصاءات نفسه من القسم السابق. يعرض الناتج جدولاً يتضمّن كل دالة تم استدعاؤها والجهاز الذي تم تشغيلها عليه (وحدة معالجة الرسومات أو وحدة المعالجة المركزية) وعدد مرات استدعائها.
%load_ext cudf.pandas
import pandas as pd
import glob
pd.DataFrame({"a": [1]})
بعد التأكّد من تفعيل cudf.pandas، يمكنك تشغيل ملف شخصي.
%%cudf.pandas.profile
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*2024*.parquet")], ignore_index=True)
df = df.sort_values(['tpep_pickup_datetime', 'trip_distance', 'passenger_count'], ascending=[False, True, False])
summary = (
df
.loc[(df.tpep_pickup_datetime > '2024-11-01')]
.groupby(['VendorID','tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
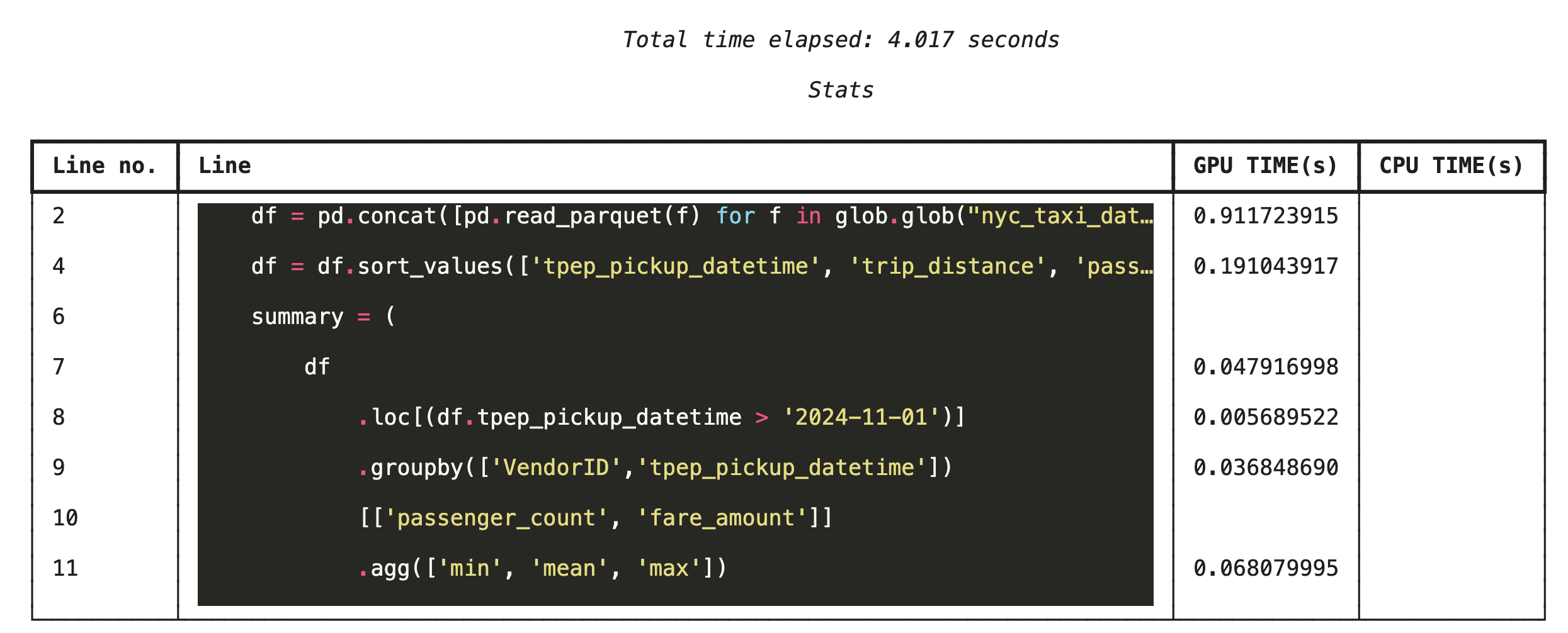
إنشاء ملفات تعريف الأداء سطرًا بسطر باستخدام %%cudf.pandas.line_profile
بعد ذلك، شغِّل أداة تحليل الأداء على مستوى الأسطر. يمنحك ذلك عرضًا أكثر تفصيلاً، حيث يعرض جزء الوقت الذي استغرقه كل سطر من الرموز البرمجية في التنفيذ على وحدة معالجة الرسومات مقارنةً بوحدة المعالجة المركزية. هذه هي الطريقة الأكثر فعالية للعثور على المشاكل المحدّدة التي يجب تحسينها.
%%cudf.pandas.line_profile
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*2024*.parquet")], ignore_index=True)
df = df.sort_values(['tpep_pickup_datetime', 'trip_distance', 'passenger_count'], ascending=[False, True, False])
summary = (
df
.loc[(df.tpep_pickup_datetime > '2024-11-01')]
.groupby(['VendorID','tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
إنشاء ملفات تعريف من سطر الأوامر
تتوفّر أدوات تحليل الأداء هذه أيضًا من سطر الأوامر، ما يفيد في الاختبار التلقائي وتحليل أداء نصوص Python البرمجية.
يمكنك استخدام ما يلي في واجهة سطر الأوامر:
python -m cudf.pandas --profile your_script.pypython -m cudf.pandas --line_profile your_script.py
13. الدمج مع Google Cloud Storage
Google Cloud Storage (GCS) هي خدمة تخزين عناصر تتميّز بالمتانة والقدرة العالية على التكيّف. عند استخدام Colab Enterprise، يمكنك تخزين مجموعات البيانات ونقاط التحقّق من النماذج وغيرها من العناصر في GCS.
يملك وقت تشغيل Colab Enterprise الأذونات اللازمة لقراءة البيانات وكتابتها مباشرةً في حِزم GCS، ويتم تسريع هذه العمليات باستخدام وحدة معالجة الرسومات لتحقيق أعلى مستوى من الأداء.
إنشاء حزمة GCS
أولاً، أنشئ حزمة جديدة في "خدمة التخزين السحابي من Google". تكون أسماء حِزم GCS فريدة على مستوى العالم، لذا أضِف معرّف UUID إلى الاسم.
from google.cloud import storage
import uuid
unique_suffix = uuid.uuid4().hex[:12]
bucket_name = f'nyc-taxi-codelab-{unique_suffix}'
project_id = storage.Client().project
client = storage.Client()
try:
bucket = client.create_bucket(bucket_name)
print(f"Successfully created bucket: gs://{bucket.name}")
except Exception as e:
print(f"Bucket creation failed. You may already own it or the name is taken: {e}")
كتابة البيانات مباشرةً في GCS
الآن، احفظ إطار بيانات مباشرةً في حزمة GCS الجديدة. إذا لم يكن المتغيّر df متاحًا من الأقسام السابقة، سيحمّل الرمز أولاً بيانات شهر واحد.
%%cudf.pandas.line_profile
# Ensure the DataFrame exists before saving to GCS
if 'df' not in locals():
print("DataFrame not found, loading a sample file...")
df = pd.read_parquet('nyc_taxi_data/yellow_tripdata_2024-12.parquet')
print(f"Writing data to gs://{bucket_name}/nyc_taxi_data.parquet...")
df.to_parquet(f"gs://{bucket_name}/nyc_taxi_data.parquet", index=False)
print("Write operation complete.")
التحقّق من الملف في GCS
يمكنك التأكّد من أنّ البيانات متوفّرة في GCS من خلال الانتقال إلى الحزمة. تنشئ التعليمة البرمجية التالية رابطًا قابلاً للنقر.
from IPython.display import Markdown
gcs_url = f"https://console.cloud.google.com/storage/browser/{bucket_name}?project={project_id}"
Markdown(f'**[Click here to view your GCS bucket in the Google Cloud Console]({gcs_url})**')
قراءة البيانات مباشرةً من GCS
أخيرًا، اقرأ البيانات مباشرةً من مسار GCS إلى DataFrame. تتم هذه العملية أيضًا باستخدام وحدة معالجة الرسومات، ما يتيح لك تحميل مجموعات البيانات الكبيرة من مساحة التخزين السحابية بسرعة عالية.
%%cudf.pandas.line_profile
print(f"Reading data from gs://{bucket_name}/nyc_taxi_data.parquet...")
df_from_gcs = pd.read_parquet(f"gs://{bucket_name}/nyc_taxi_data.parquet")
df_from_gcs.head()
14. تنظيف
لتجنُّب تحمّل رسوم غير متوقّعة في حسابك على Google Cloud، عليك تنظيف الموارد التي أنشأتها.
لحذف البيانات التي نزّلتها، اتّبِع الخطوات التالية:
# Permanately delete the GCS bucket
print(f"Deleting GCS bucket: gs://{bucket_name}...")
!gsutil rm -r -f gs://{bucket_name}
print("Bucket deleted.")
# Remove NYC taxi dataset on the Colab runtime
print("Deleting local 'nyc_taxi_data' directory...")
!rm -rf nyc_taxi_data
print("Local files deleted.")
إيقاف بيئة تشغيل Colab
- في Google Cloud Console، انتقِل إلى صفحة أوقات التشغيل في Colab Enterprise.
- في قائمة المنطقة، اختَر المنطقة التي تحتوي على وقت التشغيل.
- اختَر وقت التشغيل الذي تريد حذفه.
- انقر على حذف.
- انقر على تأكيد.
حذف دفتر الملاحظات
- في Google Cloud Console، انتقِل إلى صفحة دفاتري في Colab Enterprise.
- في قائمة المنطقة، اختَر المنطقة التي يتضمّنها دفتر الملاحظات.
- اختَر دفتر الملاحظات الذي تريد حذفه.
- انقر على حذف.
- انقر على تأكيد.
15. تهانينا
تهانينا! لقد تمكّنت بنجاح من تسريع سير عمل تحليلات pandas باستخدام NVIDIA cuDF على Colab Enterprise. تعرّفت على كيفية ضبط بيئات التشغيل المتوافقة مع وحدات معالجة الرسومات، وتفعيل cudf.pandas لتسريع الأداء بدون تغيير الرمز، وتحديد المشاكل في الرمز، والدمج مع Google Cloud Storage.