
১. ভূমিকা
এই কোডল্যাবে, আপনি শিখবেন কীভাবে গুগল ক্লাউডে এনভিডিয়া জিপিইউ এবং ওপেন-সোর্স লাইব্রেরি ব্যবহার করে বড় ডেটাসেটের উপর আপনার ডেটা অ্যানালিটিক্স ওয়ার্কফ্লোকে ত্বরান্বিত করা যায়। আপনি প্রথমে আপনার ইনফ্রাস্ট্রাকচার অপ্টিমাইজ করে শুরু করবেন এবং তারপর দেখবেন কীভাবে কোনো কোড পরিবর্তন ছাড়াই জিপিইউ অ্যাক্সিলারেশন প্রয়োগ করা যায়।
আপনি একটি জনপ্রিয় ডেটা ম্যানিপুলেশন লাইব্রেরি, pandas )-এর উপর মনোযোগ দেবেন এবং শিখবেন কীভাবে এনভিডিয়ার (NVIDIA) cuDF লাইব্রেরি ব্যবহার করে এর গতি বাড়ানো যায়। সবচেয়ে ভালো দিকটি হলো, আপনি আপনার বিদ্যমান pandas কোডে কোনো পরিবর্তন না করেই এই জিপিইউ (GPU) অ্যাক্সিলারেশন পেতে পারেন।
আপনি যা শিখবেন
- গুগল ক্লাউডে কোলাব এন্টারপ্রাইজ সম্পর্কে জানুন।
- নির্দিষ্ট GPU, CPU, এবং মেমরি কনফিগারেশন দিয়ে একটি কোলাব রানটাইম এনভায়রনমেন্ট কাস্টমাইজ করুন।
- NVIDIA
cuDFব্যবহার করে কোডে কোনো পরিবর্তন ছাড়াইpandasগতি বাড়ান। - পারফরম্যান্সের প্রতিবন্ধকতাগুলো শনাক্ত ও অপ্টিমাইজ করতে আপনার কোড প্রোফাইল করুন।
পরবর্তী পৃষ্ঠায় সেই ক্রেডিটগুলো রয়েছে যা আপনি ল্যাবটি সম্পন্ন করতে ব্যবহার করতে পারেন।
২. ডেটা প্রসেসিং ত্বরান্বিত করার প্রয়োজন কেন?
৮০/২০ নিয়ম: কেন ডেটা প্রস্তুতিতে এত সময় লাগে
একটি অ্যানালিটিক্স প্রকল্পের সবচেয়ে সময়সাপেক্ষ পর্যায় হলো ডেটা প্রস্তুতি। যেকোনো বিশ্লেষণ শুরু করার আগে, ডেটা বিজ্ঞানী ও বিশ্লেষকরা তাদের সময়ের একটি বড় অংশ ডেটা পরিষ্কার, রূপান্তর এবং কাঠামোবদ্ধ করতে ব্যয় করেন।
সৌভাগ্যবশত, আপনি cuDF ব্যবহার করে NVIDIA GPU-তে pandas, Apache Spark, এবং Polars-এর মতো জনপ্রিয় ওপেন-সোর্স লাইব্রেরিগুলোর গতি বাড়াতে পারেন। এই গতিবৃদ্ধি সত্ত্বেও, ডেটা প্রস্তুতি সময়সাপেক্ষই থেকে যায়, কারণ:
- উৎস ডেটা খুব কমই বিশ্লেষণের জন্য প্রস্তুত থাকে: বাস্তব ডেটাতে প্রায়শই অসঙ্গতি, অনুপস্থিত মান এবং বিন্যাসগত সমস্যা থাকে।
- ডেটার গুণমান মডেলের কর্মক্ষমতাকে প্রভাবিত করে: নিম্নমানের ডেটা এমনকি সবচেয়ে অত্যাধুনিক অ্যালগরিদমকেও অকেজো করে দিতে পারে।
- পরিধি সমস্যাকে বাড়িয়ে তোলে: লক্ষ লক্ষ রেকর্ড নিয়ে কাজ করার সময় আপাতদৃষ্টিতে ছোটখাটো ডেটা সমস্যাও গুরুতর প্রতিবন্ধকতায় পরিণত হয়।
৩. নোটবুক পরিবেশ নির্বাচন করা
যদিও অনেক ডেটা সায়েন্টিস্ট ব্যক্তিগত প্রোজেক্টের জন্য কোলাবের সাথে পরিচিত, কোলাব এন্টারপ্রাইজ ব্যবসার জন্য ডিজাইন করা একটি নিরাপদ, সহযোগিতামূলক এবং সমন্বিত নোটবুক অভিজ্ঞতা প্রদান করে।
গুগল ক্লাউডে, পরিচালিত নোটবুক পরিবেশের জন্য আপনার কাছে দুটি প্রধান বিকল্প রয়েছে: কোলাব এন্টারপ্রাইজ এবং জেমিনি এন্টারপ্রাইজ এজেন্ট প্ল্যাটফর্ম ওয়ার্কবেঞ্চ । সঠিক বিকল্পটি আপনার প্রকল্পের অগ্রাধিকারের উপর নির্ভর করে।
এজেন্ট প্ল্যাটফর্ম ওয়ার্কবেঞ্চ কখন ব্যবহার করবেন
নিয়ন্ত্রণ এবং গভীর কাস্টমাইজেশন যখন আপনার অগ্রাধিকার, তখন এজেন্ট প্ল্যাটফর্ম ওয়ার্কবেঞ্চ বেছে নিন। আপনার যদি নিম্নলিখিত বিষয়গুলোর প্রয়োজন হয়, তবে এটিই আদর্শ পছন্দ:
- অন্তর্নিহিত অবকাঠামো এবং মেশিনের জীবনচক্র পরিচালনা করুন।
- কাস্টম কন্টেইনার এবং নেটওয়ার্ক কনফিগারেশন ব্যবহার করুন।
- MLOps পাইপলাইন এবং কাস্টম লাইফসাইকেল টুলিংয়ের সাথে একীভূত করুন।
কখন কোলাব এন্টারপ্রাইজ ব্যবহার করবেন
দ্রুত সেটআপ, ব্যবহারের সহজতা এবং নিরাপদ সহযোগিতা যখন আপনার অগ্রাধিকার, তখন কোলাব এন্টারপ্রাইজ বেছে নিন। এটি একটি সম্পূর্ণ পরিচালিত সমাধান যা আপনার দলকে পরিকাঠামোর পরিবর্তে বিশ্লেষণের উপর মনোযোগ দিতে সাহায্য করে।
কোলাব এন্টারপ্রাইজ আপনাকে সাহায্য করে:
- আপনার ডেটা ওয়্যারহাউসের সাথে ঘনিষ্ঠভাবে সংযুক্ত ডেটা সায়েন্স ওয়ার্কফ্লো তৈরি করুন। আপনি সরাসরি BigQuery Studio- তে আপনার নোটবুকগুলো খুলতে ও পরিচালনা করতে পারবেন।
- এজেন্ট প্ল্যাটফর্মে মেশিন লার্নিং মডেলগুলোকে প্রশিক্ষণ দিন এবং MLOps টুলগুলোর সাথে একীভূত করুন।
- একটি নমনীয় ও সমন্বিত অভিজ্ঞতা উপভোগ করুন। BigQuery-তে তৈরি করা একটি Colab Enterprise নোটবুক Agent Platform-এ খোলা ও চালানো যায় এবং এর বিপরীতটিও সম্ভব।
আজকের ল্যাব
এই কোডল্যাবটি দ্রুত ডেটা অ্যানালিটিক্সের জন্য কোলাব এন্টারপ্রাইজ ব্যবহার করে।
পার্থক্যগুলো সম্পর্কে আরও জানতে, সঠিক নোটবুক সলিউশন বেছে নেওয়ার বিষয়ে অফিসিয়াল ডকুমেন্টেশন দেখুন।
৪. একটি রানটাইম টেমপ্লেট কনফিগার করুন
কোলাব এন্টারপ্রাইজে, একটি পূর্ব-কনফিগার করা রানটাইম টেমপ্লেটের উপর ভিত্তি করে তৈরি রানটাইমের সাথে সংযোগ স্থাপন করুন।
একটি রানটাইম টেমপ্লেট হলো একটি পুনঃব্যবহারযোগ্য কনফিগারেশন যা আপনার নোটবুকের জন্য সম্পূর্ণ পরিবেশ নির্দিষ্ট করে, যার মধ্যে অন্তর্ভুক্ত রয়েছে:
- মেশিনের ধরণ (সিপিইউ, মেমরি)
- অ্যাক্সিলারেটর (GPU-এর ধরন এবং সংখ্যা)
- ডিস্কের আকার এবং প্রকার
- নেটওয়ার্ক সেটিংস এবং নিরাপত্তা নীতি
- স্বয়ংক্রিয় নিষ্ক্রিয় শাটডাউন নিয়ম
কেন রানটাইম টেমপ্লেটগুলি দরকারী
- একটি সামঞ্জস্যপূর্ণ পরিবেশ পান: আপনার এবং আপনার দলের সদস্যদের জন্য প্রতিবার একই রকম ব্যবহারের জন্য প্রস্তুত পরিবেশ নিশ্চিত করা হয়, যা আপনাদের কাজের পুনরাবৃত্তিযোগ্যতা নিশ্চিত করে।
- ডিজাইন অনুযায়ীই সুরক্ষিতভাবে কাজ করুন: টেমপ্লেটগুলো স্বয়ংক্রিয়ভাবে আপনার প্রতিষ্ঠানের নিরাপত্তা নীতিমালা প্রয়োগ করে।
- কার্যকরভাবে খরচ পরিচালনা করুন: টেমপ্লেটে GPU এবং CPU-এর মতো রিসোর্সগুলোর আকার আগে থেকেই নির্ধারণ করা থাকে, যা অপ্রত্যাশিত অতিরিক্ত খরচ হওয়া প্রতিরোধ করতে সাহায্য করে।
একটি রানটাইম টেমপ্লেট তৈরি করুন
ল্যাবের জন্য একটি পুনঃব্যবহারযোগ্য রানটাইম টেমপ্লেট তৈরি করুন।
- গুগল ক্লাউড কনসোলে, নেভিগেশন মেনু > এজেন্ট প্ল্যাটফর্ম > নোটবুকস- এ যান।
- Colab Enterprise থেকে, Runtime templates-এ ক্লিক করুন এবং তারপর New Template নির্বাচন করুন।
- রানটাইমের মৌলিক বিষয়াবলীর অধীনে :
- ডিসপ্লে নাম হিসেবে
gpu-templateসেট করুন। - আপনার পছন্দের অঞ্চল নির্ধারণ করুন।
- ডিসপ্লে নাম হিসেবে
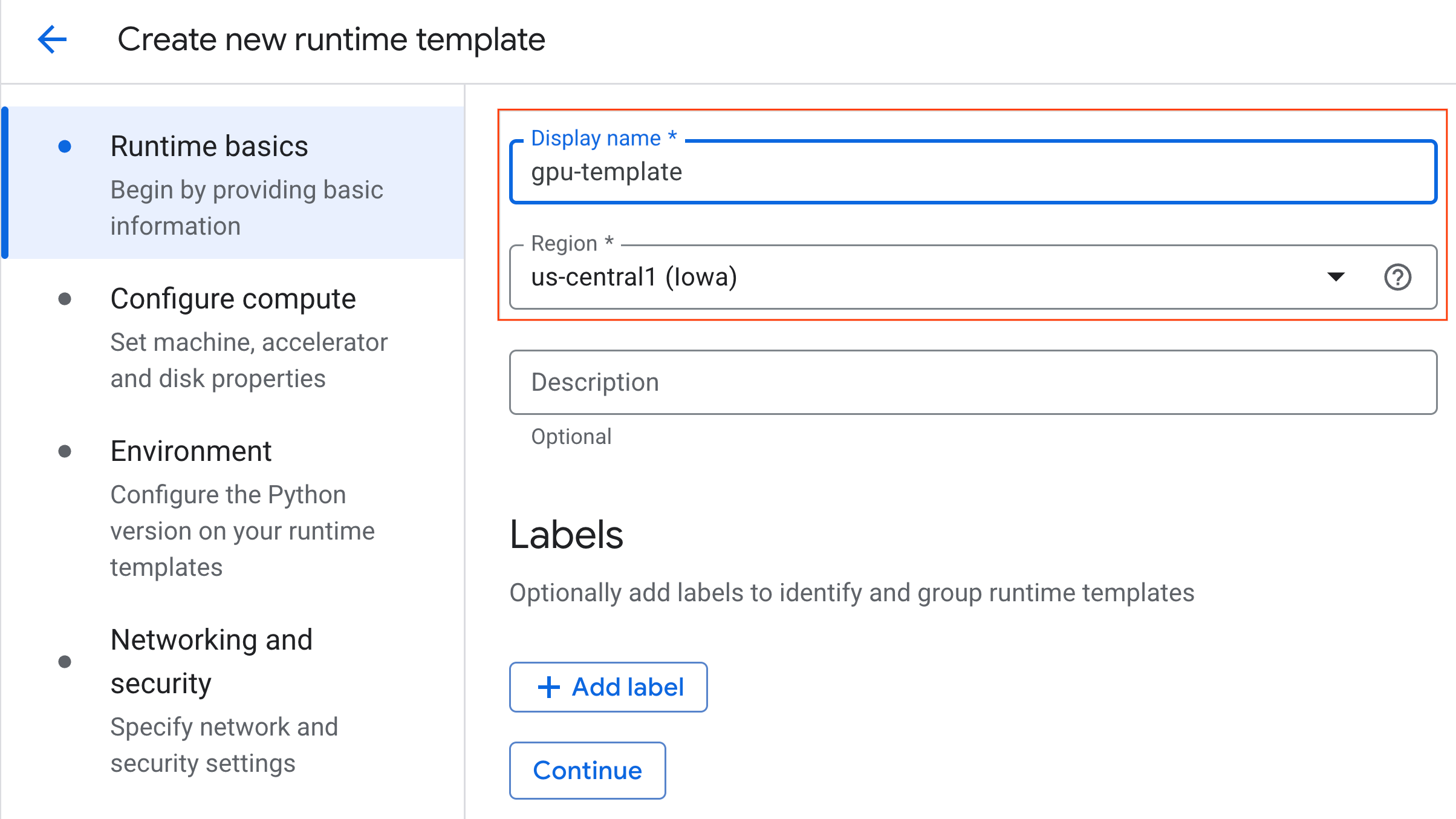
- কম্পিউট কনফিগার করার অধীনে :
- মেশিনের ধরণ
g2-standard-4এ সেট করুন। - ডিফল্ট অ্যাক্সিলারেটর টাইপ হিসেবে
NVIDIA L4এবং অ্যাক্সিলারেটর কাউন্ট ১ রাখুন। - নিষ্ক্রিয় শাটডাউন ৬০ মিনিটে পরিবর্তন করুন।
- চালিয়ে যান-এ ক্লিক করুন।
- মেশিনের ধরণ
- পরিবেশের অধীনে :
- পরিবেশটি
Python 3.11এ সেট করুন।
- পরিবেশটি
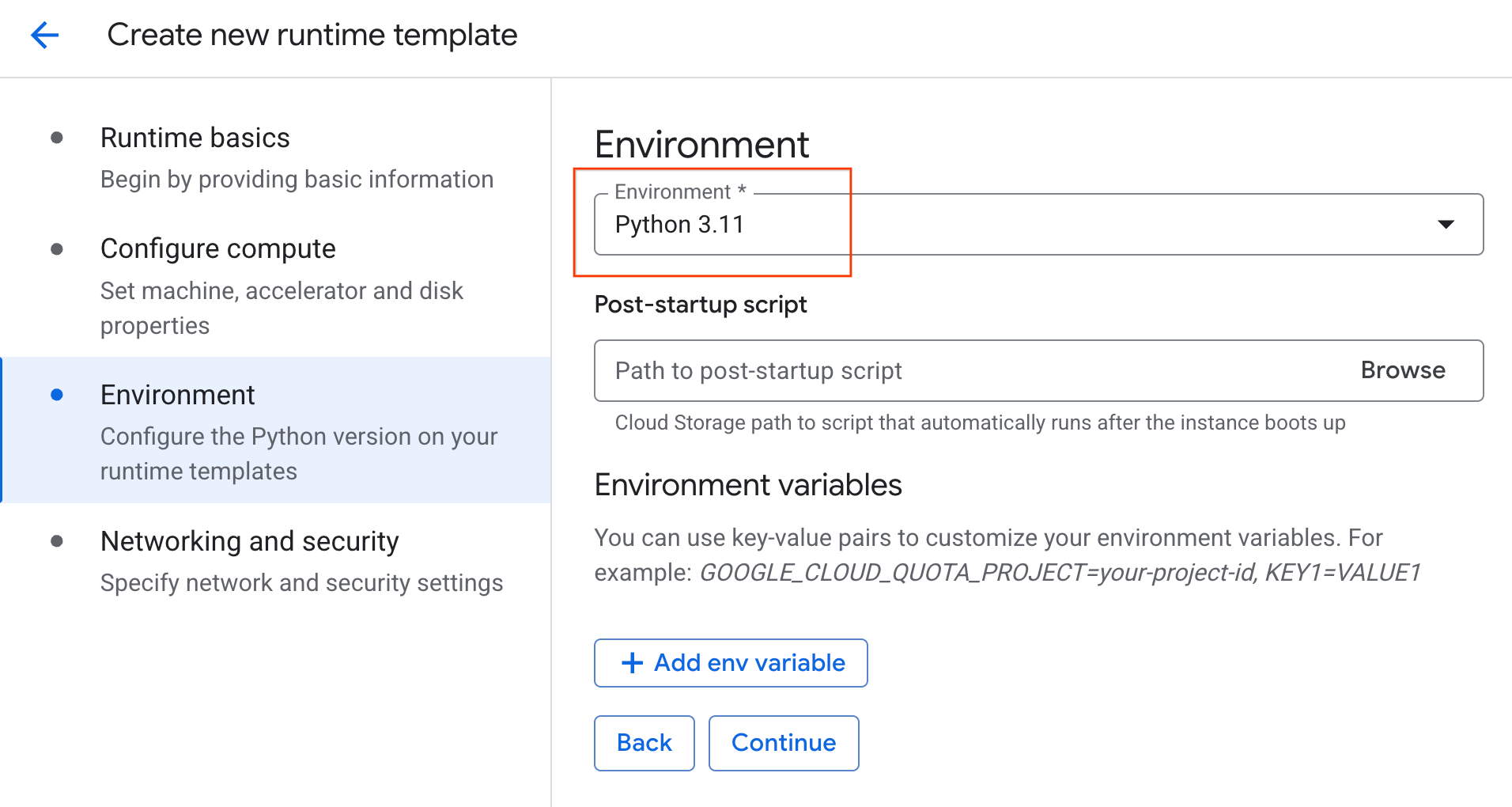
- রানটাইম টেমপ্লেটটি সংরক্ষণ করতে Create- এ ক্লিক করুন। এখন আপনার রানটাইম টেমপ্লেট পেজে নতুন টেমপ্লেটটি প্রদর্শিত হবে।
৫. একটি রানটাইম শুরু করুন
আপনার টেমপ্লেট প্রস্তুত হয়ে গেলে, আপনি একটি নতুন রানটাইম তৈরি করতে পারেন।
- Colab Enterprise থেকে, Runtimes-এ ক্লিক করুন এবং তারপর Create নির্বাচন করুন।
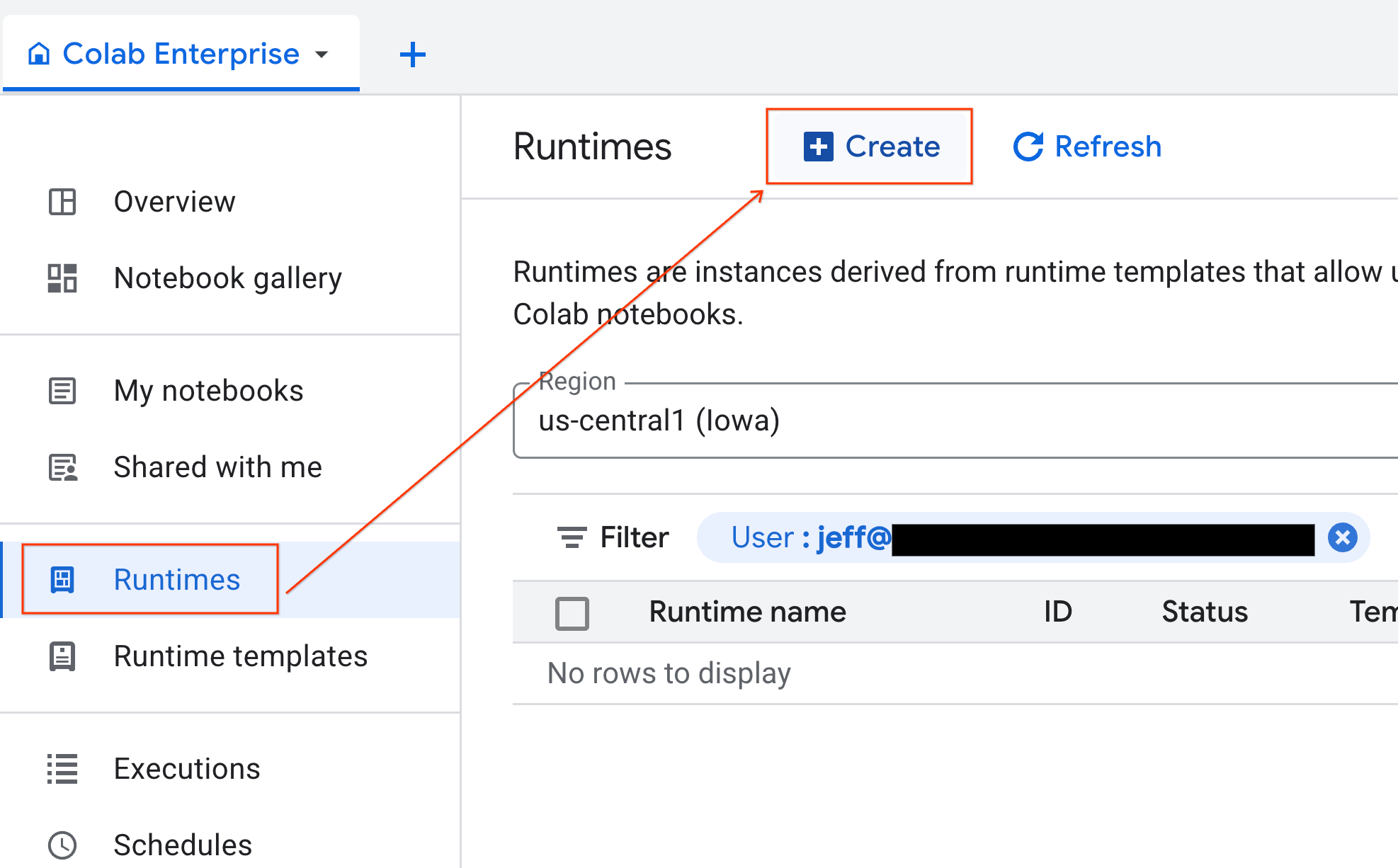
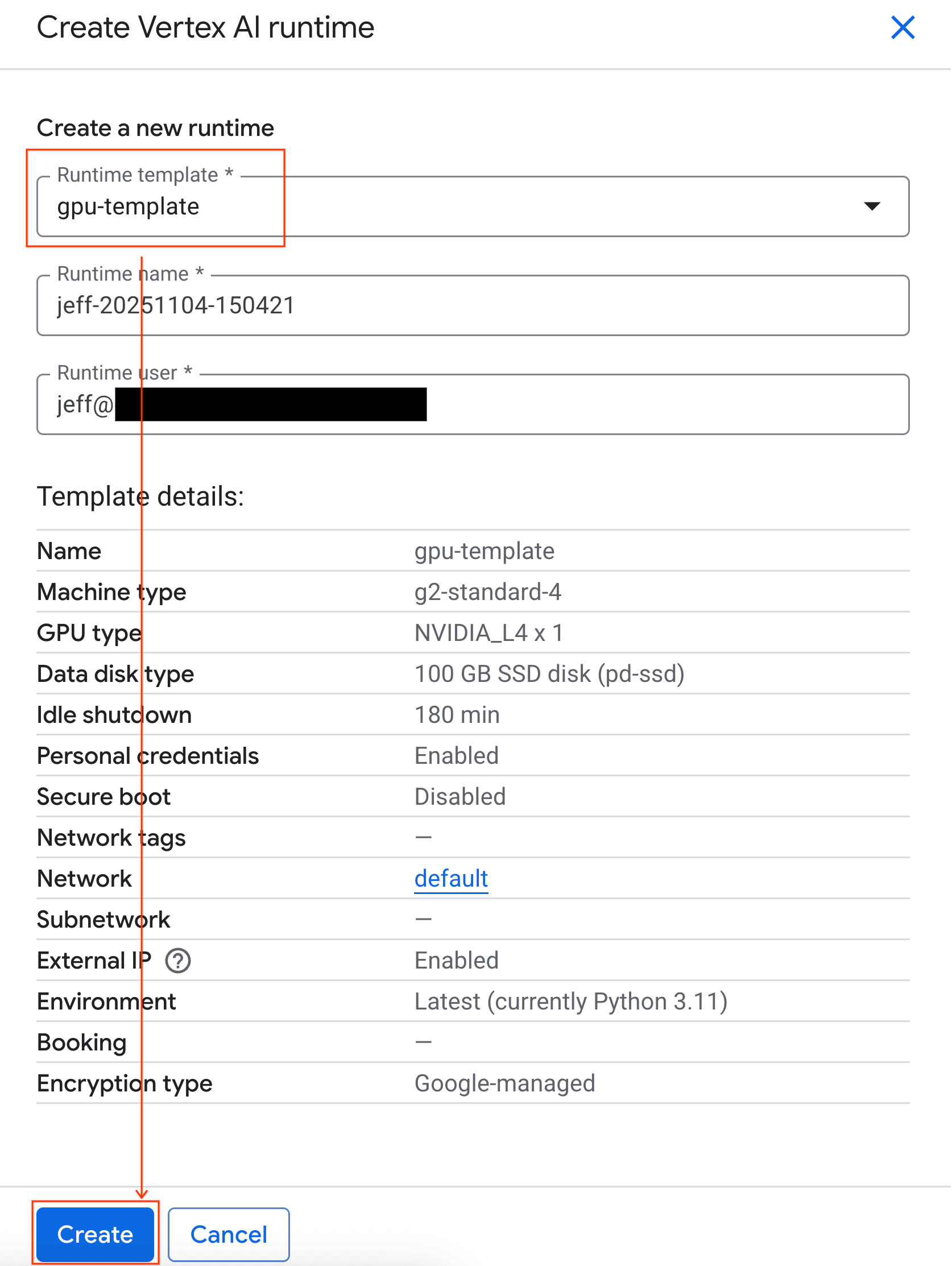
- রানটাইম টেমপ্লেটের অধীনে,
gpu-templateঅপশনটি নির্বাচন করুন। Create-এ ক্লিক করুন এবং রানটাইম বুট আপ হওয়া পর্যন্ত অপেক্ষা করুন।
- কয়েক মিনিট পর আপনি রানটাইম দেখতে পাবেন।
৬. নোটবুকটি সেট আপ করুন।
এখন যেহেতু আপনার পরিকাঠামো চালু হয়ে গেছে, আপনাকে ল্যাব নোটবুকটি ইম্পোর্ট করে আপনার রানটাইমের সাথে সংযুক্ত করতে হবে।
নোটবুকটি আমদানি করুন
- Colab Enterprise থেকে, My notebooks-এ ক্লিক করুন এবং তারপর Import-এ ক্লিক করুন।
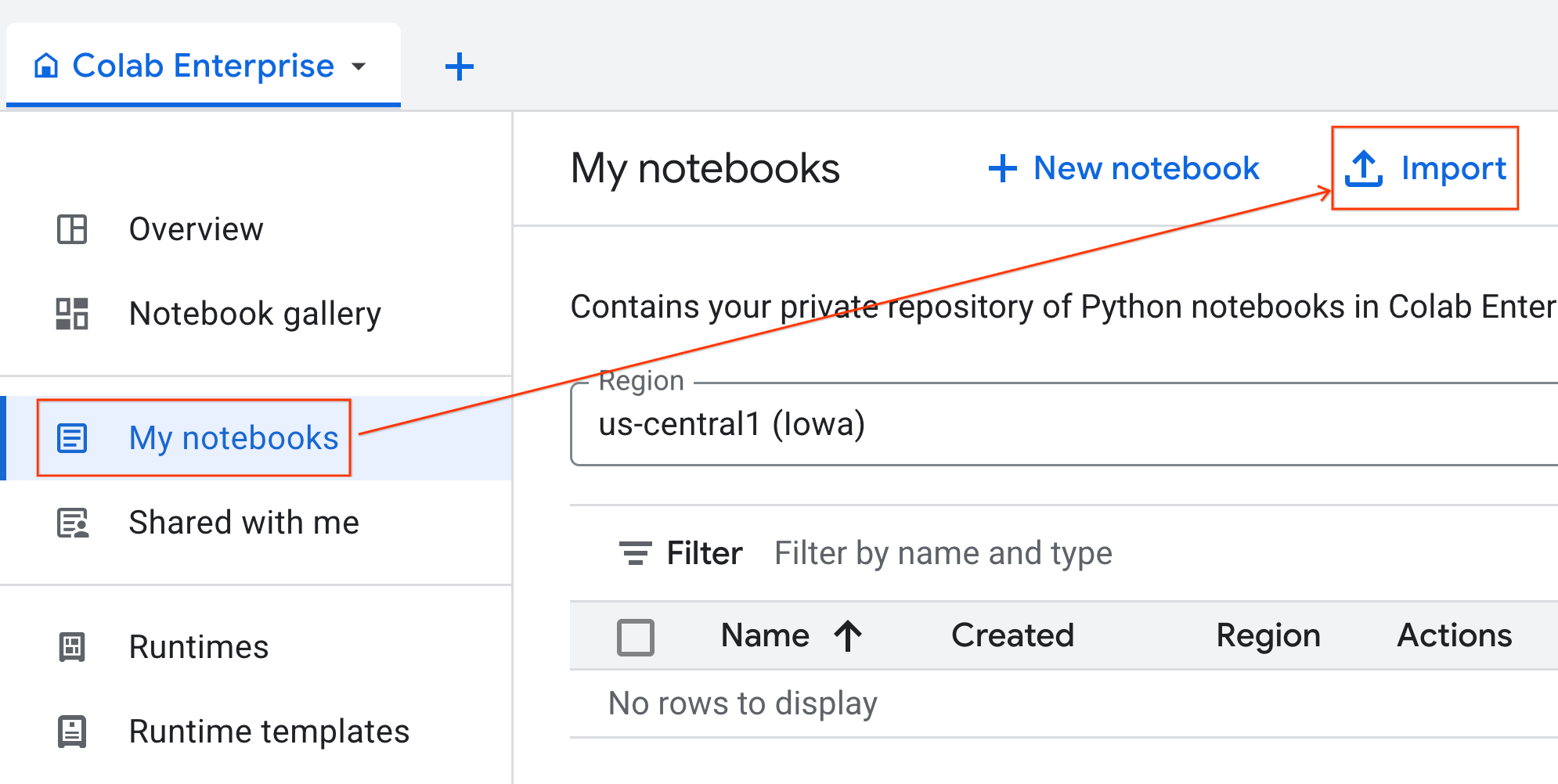
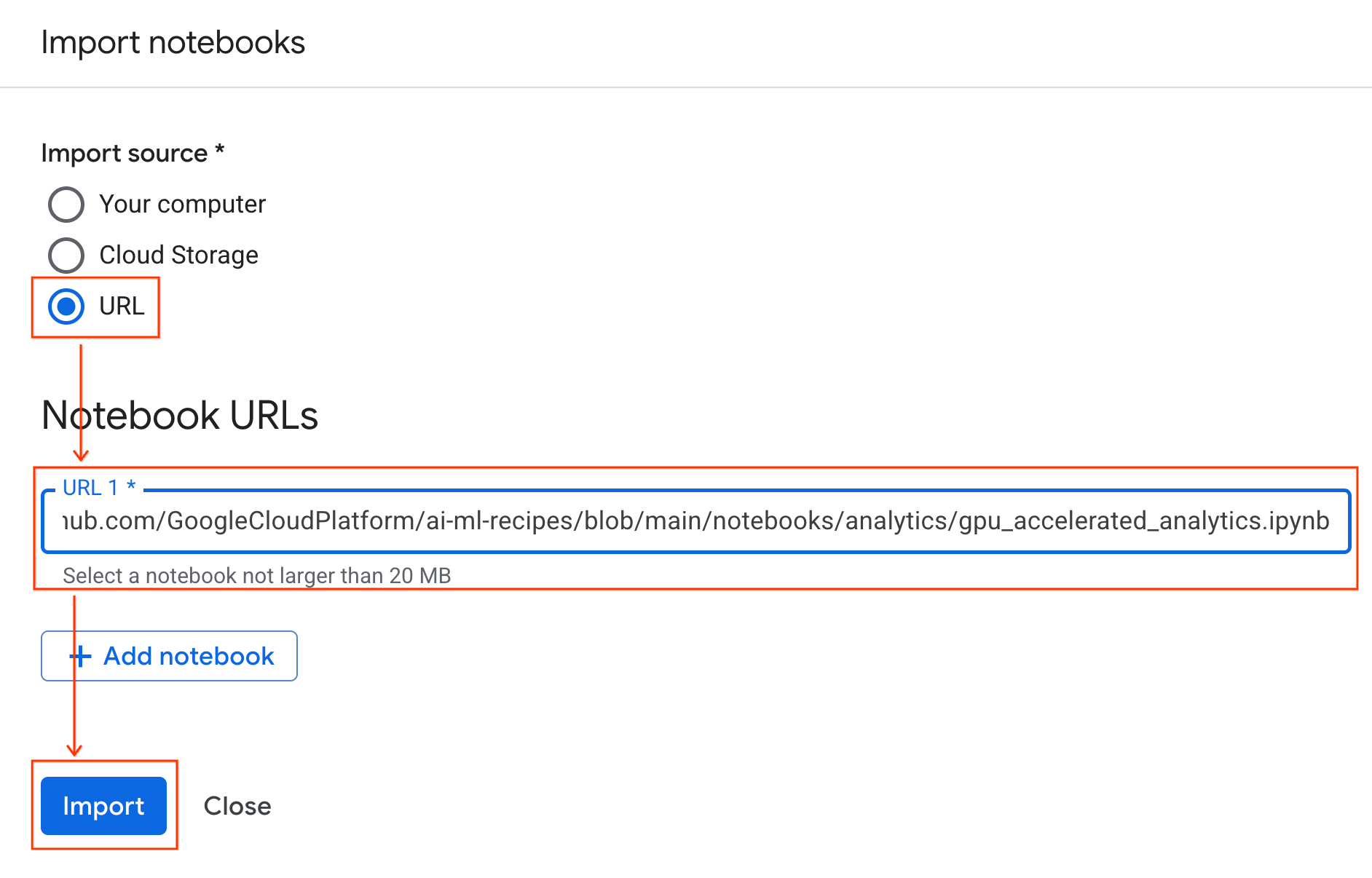
- URL রেডিও বাটনটি সিলেক্ট করুন এবং নিম্নলিখিত URL-টি ইনপুট করুন:
https://github.com/GoogleCloudPlatform/ai-ml-recipes/blob/main/notebooks/analytics/gpu_accelerated_analytics.ipynb
- ইমপোর্ট-এ ক্লিক করুন। কোলাব এন্টারপ্রাইজ গিটহাব থেকে নোটবুকটি আপনার এনভায়রনমেন্টে কপি করে দেবে।
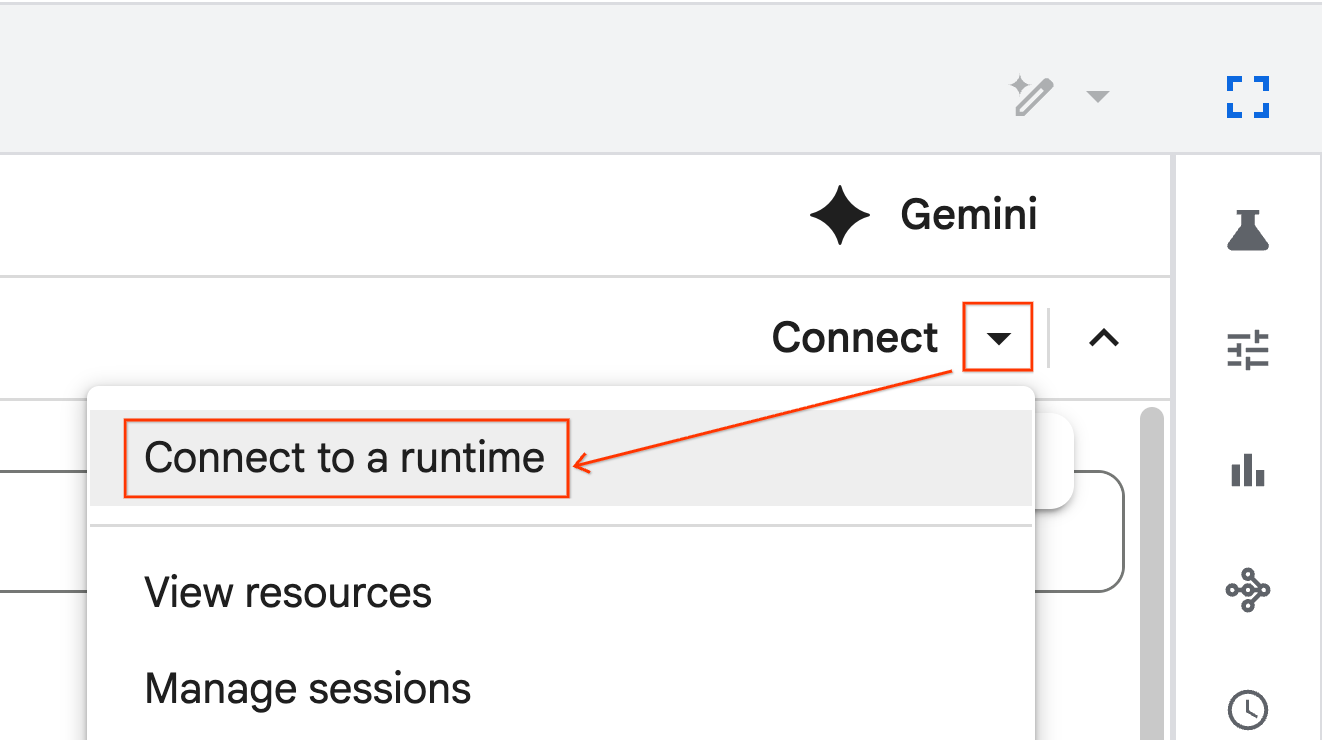
রানটাইমের সাথে সংযোগ করুন
- নতুন ইম্পোর্ট করা নোটবুকটি খুলুন।
- Connect-এর পাশের নিচের দিকে মুখ করা তীরচিহ্নটিতে ক্লিক করুন।
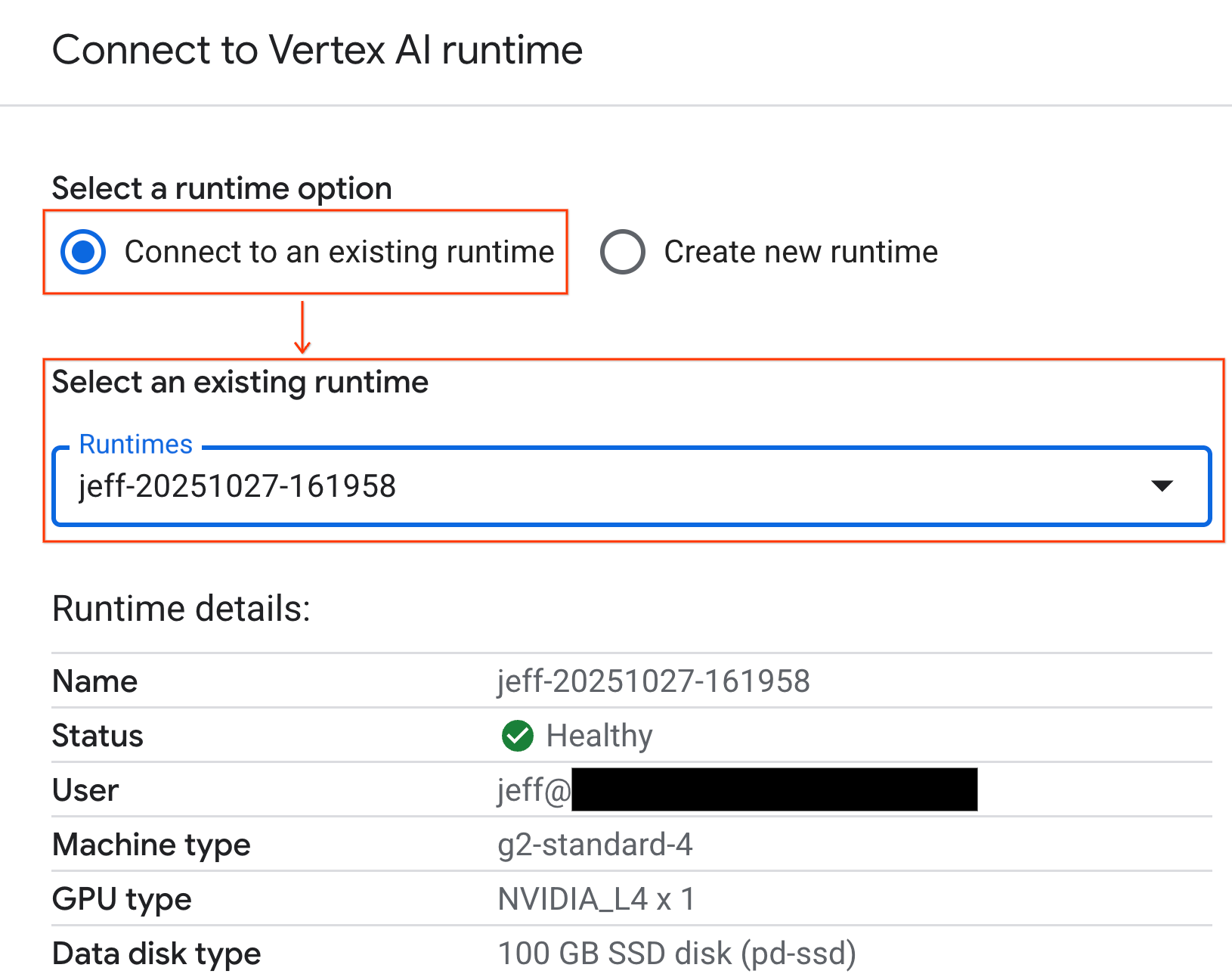
- রানটাইমের সাথে সংযোগ নির্বাচন করুন।
- ড্রপডাউন ব্যবহার করে আপনার পূর্বে তৈরি করা রানটাইমটি নির্বাচন করুন।
- সংযোগ করুন- এ ক্লিক করুন।
আপনার নোটবুকটি এখন একটি GPU-সক্ষম রানটাইমের সাথে সংযুক্ত। এখন আপনি কোয়েরি চালানো শুরু করতে পারেন!
৭. এনওয়াইসি ট্যাক্সি ডেটাসেট প্রস্তুত করুন।
এই কোডল্যাবটি নিউ ইয়র্ক সিটি ট্যাক্সি ও লিমুজিন কমিশন (TLC)-এর ট্রিপ রেকর্ড ডেটা ব্যবহার করে।
ডেটাসেটটিতে নিউ ইয়র্ক সিটির হলুদ ট্যাক্সিগুলোর স্বতন্ত্র ট্রিপ রেকর্ড রয়েছে এবং এতে নিম্নলিখিত ফিল্ডগুলো অন্তর্ভুক্ত আছে:
- পিক-আপ এবং ড্রপ-অফের তারিখ, সময় এবং স্থান
- ভ্রমণের দূরত্ব
- বিস্তারিত ভাড়ার পরিমাণ
- যাত্রী সংখ্যা
ডেটা ডাউনলোড করুন
এরপর, ২০২৪ সালের পুরো বছরের ভ্রমণের ডেটা ডাউনলোড করুন। ডেটাটি Parquet ফাইল ফরম্যাটে সংরক্ষিত আছে।
নিম্নলিখিত কোড ব্লকটি এই ধাপগুলো সম্পাদন করে:
- ডাউনলোড করার জন্য বছর ও মাসের পরিসীমা নির্ধারণ করে।
- ফাইলগুলো সংরক্ষণের জন্য
nyc_taxi_dataনামের একটি স্থানীয় ডিরেক্টরি তৈরি করে। - প্রতিটি মাসের মধ্য দিয়ে চক্রাকারে চলে, সংশ্লিষ্ট Parquet ফাইলটি আগে থেকে বিদ্যমান না থাকলে তা ডাউনলোড করে এবং ডিরেক্টরিতে সংরক্ষণ করে।
ডেটা সংগ্রহ করতে এবং রানটাইমে তা সংরক্ষণ করতে আপনার নোটবুকে এই কোডটি চালান:
from tqdm import tqdm
import requests
import time
import os
YEAR = 2024
DATA_DIR = "nyc_taxi_data"
os.makedirs(DATA_DIR, exist_ok=True)
print(f"Checking/Downloading files for {YEAR}...")
for month in tqdm(range(1, 13), unit="file"):
# Define standardized filename for both local path and URL
file_name = f"yellow_tripdata_{YEAR}-{month:02d}.parquet"
local_path = os.path.join(DATA_DIR, file_name)
url = f"https://d37ci6vzurychx.cloudfront.net/trip-data/{file_name}"
if not os.path.exists(local_path):
try:
with requests.get(url, stream=True) as response:
response.raise_for_status()
with open(local_path, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
time.sleep(1)
except requests.exceptions.HTTPError as e:
print(f"\nSkipping {file_name}: {e}")
if os.path.exists(local_path):
os.remove(local_path)
print("\nDownload complete.")
৮. ট্যাক্সি ট্রিপের ডেটা অন্বেষণ করুন
এখন যেহেতু আপনি ডেটাসেটটি ডাউনলোড করে ফেলেছেন, তাই প্রাথমিক অনুসন্ধানমূলক ডেটা বিশ্লেষণ (EDA) করার সময় এসেছে। EDA-এর লক্ষ্য হলো ডেটার গঠন বোঝা, অসঙ্গতি খুঁজে বের করা এবং সম্ভাব্য প্যাটার্ন উন্মোচন করা।
এক মাসের ডেটা লোড করুন
প্রথমে এক মাসের ডেটা লোড করে শুরু করুন। এটি অর্থবহ হওয়ার জন্য যথেষ্ট বড় একটি নমুনা (৩০ লক্ষেরও বেশি সারি) প্রদান করে এবং একই সাথে ইন্টারেক্টিভ বিশ্লেষণের জন্য মেমরির ব্যবহারও সহনীয় পর্যায়ে রাখে।
import pandas as pd
import glob
# Load the last month of the downloaded data
df = pd.read_parquet("nyc_taxi_data/yellow_tripdata_2024-12.parquet")
df.head()
সারসংক্ষেপ পরিসংখ্যান পান
সংখ্যাসূচক কলামগুলোর জন্য উচ্চ-স্তরের সারসংক্ষেপ পরিসংখ্যান তৈরি করতে .describe() মেথডটি ব্যবহার করুন। অপ্রত্যাশিত সর্বনিম্ন বা সর্বোচ্চ মানের মতো ডেটার গুণগত মানের সম্ভাব্য সমস্যাগুলো চিহ্নিত করার জন্য এটি একটি চমৎকার প্রথম পদক্ষেপ।
df.describe().round(2)

ডেটার গুণমান তদন্ত করুন
.describe() থেকে প্রাপ্ত আউটপুটে তাৎক্ষণিকভাবে একটি সমস্যা প্রকাশ পায়। লক্ষ্য করুন যে tpep_pickup_datetime এবং tpep_dropoff_datetime এর min মান ২০০৮ সালে রয়েছে, যা ২০২৪ সালের একটি ডেটাসেটের জন্য অযৌক্তিক।
আপনার ডেটা কেন সবসময় পরীক্ষা করা উচিত, এটি তার একটি উদাহরণ। এই ব্যতিক্রমী তারিখগুলো ধারণকারী সুনির্দিষ্ট সারিগুলো খুঁজে বের করার জন্য আপনি ডেটাফ্রেমটি সর্ট করে বিষয়টি আরও খতিয়ে দেখতে পারেন।
# Sort by the dropoff datetime to see the oldest records
df.sort_values("tpep_pickup_datetime").head()
ডেটা বিতরণ কল্পনা করুন
এরপর, সংখ্যাসূচক কলামগুলোর বিন্যাস দেখার জন্য আপনি হিস্টোগ্রাম তৈরি করতে পারেন। এটি আপনাকে trip_distance এবং fare_amount মতো ফিচারগুলোর বিস্তার ও বৈষম্য বুঝতে সাহায্য করে। একটি ডেটাফ্রেমের সমস্ত সংখ্যাসূচক কলামের জন্য হিস্টোগ্রাম তৈরি করার একটি দ্রুত উপায় হলো .hist() ফাংশন।
_ = df.hist(figsize=(20, 20))
অবশেষে, কয়েকটি মূল কলামের মধ্যকার সম্পর্ক দৃশ্যমান করার জন্য একটি স্ক্যাটার ম্যাট্রিক্স তৈরি করুন। যেহেতু লক্ষ লক্ষ পয়েন্ট প্লট করা ধীরগতির এবং এতে প্যাটার্ন অস্পষ্ট হয়ে যেতে পারে, তাই দৈবচয়নের ভিত্তিতে ১,০০,০০০টি সারির নমুনা থেকে প্লটটি তৈরি করতে .sample() ব্যবহার করুন।
_ = pd.plotting.scatter_matrix(
df[['passenger_count', 'trip_distance', 'tip_amount', 'total_amount']].sample(100_000),
diagonal="kde",
figsize=(15, 15)
)
৯. পার্কেট ফাইল ফরম্যাট কেন ব্যবহার করা হয়?
NYC ট্যাক্সি ডেটাসেটটি অ্যাপাচি পার্কেট ফরম্যাটে প্রদান করা হয়েছে। বৃহৎ পরিসরের বিশ্লেষণের জন্য এটি একটি সচেতন সিদ্ধান্ত। CSV-এর মতো ফাইল টাইপের তুলনায় পার্কেটের বেশ কিছু সুবিধা রয়েছে:
- দক্ষ ও দ্রুত: একটি কলামভিত্তিক ফরম্যাট হওয়ায়, Parquet সংরক্ষণ ও পাঠের জন্য অত্যন্ত দক্ষ। এটি আধুনিক কম্প্রেশন পদ্ধতি সমর্থন করে, যার ফলে ফাইলের আকার ছোট হয় এবং I/O উল্লেখযোগ্যভাবে দ্রুততর হয়, বিশেষ করে GPU-তে।
- স্কিমা সংরক্ষণ করে: Parquet ফাইলের মেটাডেটাতে ডেটা টাইপ সংরক্ষণ করে। ফাইলটি পড়ার সময় আপনাকে ডেটা টাইপ নিয়ে কখনও অনুমান করতে হয় না।
- নির্বাচিত পঠন সক্ষম করে: কলামভিত্তিক কাঠামো আপনাকে বিশ্লেষণের জন্য শুধুমাত্র প্রয়োজনীয় নির্দিষ্ট কলামগুলো পড়ার সুযোগ দেয়। এর ফলে মেমোরিতে লোড করতে হয় এমন ডেটার পরিমাণ উল্লেখযোগ্যভাবে কমে যেতে পারে।
পার্কেটের বৈশিষ্ট্যগুলি অন্বেষণ করুন
চলুন, আপনার ডাউনলোড করা ফাইলগুলোর মধ্যে একটি ব্যবহার করে এই শক্তিশালী বৈশিষ্ট্যগুলোর মধ্যে দুটি অন্বেষণ করা যাক।
সম্পূর্ণ ডেটাসেট লোড না করেই মেটাডেটা পরিদর্শন করুন
যদিও একটি Parquet ফাইল সাধারণ টেক্সট এডিটরে দেখা যায় না, তবে মেমরিতে কোনো ডেটা লোড না করেই এর স্কিমা এবং মেটাডেটা সহজেই পরীক্ষা করা যায়। ফাইলের গঠন দ্রুত বোঝার জন্য এটি বেশ কার্যকর।
from pyarrow.parquet import ParquetFile
import pyarrow as pa
# Open one of the downloaded files
pf = ParquetFile('nyc_taxi_data/yellow_tripdata_2024-12.parquet')
# Print the schema
print("File Schema:")
print(pf.schema)
# Print the file metadata
print("\nFile Metadata:")
print(pf.metadata)
শুধুমাত্র আপনার প্রয়োজনীয় কলামগুলো পড়ুন।
ধরুন, আপনাকে শুধু ভ্রমণের দূরত্ব এবং ভাড়ার পরিমাণ বিশ্লেষণ করতে হবে। Parquet-এর সাহায্যে আপনি শুধু ওই কলামগুলো লোড করতে পারেন, যা পুরো ডেটাফ্রেমটি লোড করার চেয়ে অনেক দ্রুত এবং মেমরির দিক থেকে বেশি সাশ্রয়ী।
import pandas as pd
# Read only four specific columns from the Parquet file
df_subset = pd.read_parquet(
'nyc_taxi_data/yellow_tripdata_2024-12.parquet',
columns=['passenger_count', 'trip_distance', 'tip_amount', 'total_amount']
)
df_subset.head()
১০. এনভিডিয়া cuDF ব্যবহার করে পান্ডাস-এর গতি বাড়ান।
এনভিডিয়া কুডা ফর ডেটাফ্রেমস (cuDF) হলো একটি ওপেন-সোর্স, জিপিইউ-ত্বরিত লাইব্রেরি যা আপনাকে ডেটাফ্রেমের সাথে কাজ করতে দেয়। cuDF আপনাকে জিপিইউ-তে ব্যাপক সমান্তরালতার সাথে ফিল্টারিং, জয়েনিং এবং গ্রুপিং-এর মতো সাধারণ ডেটা অপারেশনগুলো সম্পাদন করতে দেয়।
এই কোডল্যাবে ব্যবহৃত মূল ফিচারটি হলো cudf.pandas অ্যাক্সিলারেটর মোড। যখন আপনি এটি সক্রিয় করেন, আপনার কোডে কোনো পরিবর্তন না করেই, আপনার সাধারণ pandas কোড স্বয়ংক্রিয়ভাবে অভ্যন্তরীণভাবে GPU-চালিত cuDF কার্নেল ব্যবহার করার জন্য পুনঃনির্দেশিত হয়।
GPU ত্বরণ সক্ষম করুন
Colab Enterprise নোটবুকে NVIDIA cuDF ব্যবহার করতে হলে, pandas ইম্পোর্ট করার আগে এর ম্যাজিক এক্সটেনশনটি লোড করতে হয়।
প্রথমে, স্ট্যান্ডার্ড pandas লাইব্রেরিটি পরীক্ষা করুন। লক্ষ্য করুন, আউটপুটে ডিফল্ট pandas ইনস্টলেশনের পাথটি দেখানো হচ্ছে।
import pandas as pd
pd # Note the output for the standard pandas library
এখন, cudf.pandas এক্সটেনশনটি লোড করুন এবং আবার pandas ইম্পোর্ট করুন। লক্ষ্য করুন pd মডিউলের আউটপুট কীভাবে পরিবর্তিত হয় - এটি নিশ্চিত করে যে GPU-ত্বরিত সংস্করণটি এখন সক্রিয় হয়েছে।
%load_ext cudf.pandas
import pandas as pd
pd # Note the new output, indicating cudf.pandas is active
cudf.pandas সক্রিয় করার অন্যান্য উপায়
যদিও নোটবুকে ম্যাজিক কমান্ড ( %load_ext ) সবচেয়ে সহজ পদ্ধতি, আপনি অন্যান্য পরিবেশেও অ্যাক্সিলারেটরটি সক্রিয় করতে পারেন:
- পাইথন স্ক্রিপ্টে:
pandasইম্পোর্ট করার আগেimport cudf.pandasএবংcudf.pandas.install()কল করুন। - নোটবুক ছাড়া অন্য পরিবেশে: আপনার স্ক্রিপ্টটি
python -m cudf.pandas your_script.py. ব্যবহার করে চালান।
১১. সিপিইউ বনাম জিপিইউ পারফরম্যান্সের তুলনা করুন
এবার সবচেয়ে গুরুত্বপূর্ণ অংশ: সিপিইউ-তে স্ট্যান্ডার্ড pandas এবং জিপিইউ-তে cudf.pandas এর পারফরম্যান্সের তুলনা করা।
সিপিইউ-এর জন্য একটি সম্পূর্ণ ন্যায্য বেসলাইন নিশ্চিত করতে, আপনাকে প্রথমে কোলাব রানটাইম রিসেট করতে হবে। এটি পূর্ববর্তী বিভাগগুলিতে আপনার সক্রিয় করা যেকোনো জিপিইউ অ্যাক্সিলারেটর মুছে দেয়। আপনি নিম্নলিখিত সেলটি চালিয়ে, অথবা রানটাইম মেনু থেকে 'রিস্টার্ট সেশন' নির্বাচন করে রানটাইম পুনরায় চালু করতে পারেন।
import IPython
IPython.Application.instance().kernel.do_shutdown(True)
অ্যানালিটিক্স পাইপলাইন সংজ্ঞায়িত করুন
এখন যেহেতু পরিবেশটি পরিষ্কার, আপনি বেঞ্চমার্কিং ফাংশনটি সংজ্ঞায়িত করবেন। এই ফাংশনটি আপনাকে আপনার দেওয়া যেকোনো pandas মডিউল ব্যবহার করে হুবহু একই পাইপলাইন—লোডিং, সর্টিং এবং সামারাইজিং—চালানোর সুযোগ দেয়।
import time
import glob
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
def run_analytics_pipeline(pd_module):
"""Loads, sorts, and summarizes data using the provided pandas module."""
timings = {}
# 1. Load all 2024 Parquet files from the directory
t0 = time.time()
df = pd_module.concat(
[pd_module.read_parquet(f) for f in glob.glob("nyc_taxi_data/*_2024*.parquet")],
ignore_index=True
)
timings["load"] = time.time() - t0
# 2. Sort the data by multiple columns
t0 = time.time()
df = df.sort_values(
['tpep_pickup_datetime', 'trip_distance', 'passenger_count'],
ascending=[False, True, False]
)
timings["sort"] = time.time() - t0
# 3. Perform a groupby and aggregation
t0 = time.time()
df['tpep_pickup_datetime'] = pd_module.to_datetime(df['tpep_pickup_datetime'])
_ = (
df.loc[df.tpep_pickup_datetime > '2024-11-01']
.groupby(['VendorID', 'tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
timings["summarize"] = time.time() - t0
return timings
তুলনাটি চালান
প্রথমে, আপনি সিপিইউ-তে স্ট্যান্ডার্ড pandas ব্যবহার করে পাইপলাইনটি চালাবেন। তারপর, আপনি cudf.pandas সক্রিয় করে এটি জিপিইউ-তে আবার চালাবেন।
# --- Run on CPU ---
print("Running analytics pipeline on CPU...")
# Ensure we are using standard pandas
import pandas as pd
assert "cudf" not in str(pd), "Error: cuDF is still active. Please restart the kernel."
cpu_times = run_analytics_pipeline(pd)
print(f"CPU times: {cpu_times}")
# --- Run on GPU ---
print("\nEnabling cudf.pandas and running on GPU...")
# Load the extension
%load_ext cudf.pandas
import pandas as gpu_pd
gpu_times = run_analytics_pipeline(gpu_pd)
print(f"GPU times: {gpu_times}")
ফলাফলগুলো কল্পনা করুন
অবশেষে, পার্থক্যটি দৃশ্যমান করুন। নিচের কোডটি প্রতিটি অপারেশনের গতিবৃদ্ধি গণনা করে এবং সেগুলোকে পাশাপাশি প্লট করে।
# Create a DataFrame for plotting
results_df = pd.DataFrame([cpu_times, gpu_times], index=["CPU", "GPU"]).T
total_cpu_time = results_df['CPU'].sum()
total_gpu_time = results_df['GPU'].sum()
speedup = total_cpu_time / total_gpu_time
print("--- Performance Results ---")
print(results_df)
print(f"\nTotal CPU Time: {total_cpu_time:.2f} seconds")
print(f"Total GPU Time: {total_gpu_time:.2f} seconds")
print(f"Overall Speedup: {speedup:.2f}x")
# Plot the results
fig, ax = plt.subplots(figsize=(10, 6))
results_df.plot(kind='bar', ax=ax, color={"CPU": "tab:blue", "GPU": "tab:green"})
ax.set_ylabel("Time (seconds)")
ax.set_title(f"CPU vs. GPU Runtimes (Overall Speedup: {speedup:.2f}x)", fontsize=14)
ax.tick_params(axis='x', rotation=0)
# Add numerical labels to the bars
for container in ax.containers:
ax.bar_label(container, fmt="%.2f", padding=3)
plt.tight_layout()
plt.show()
নমুনা ফলাফল:
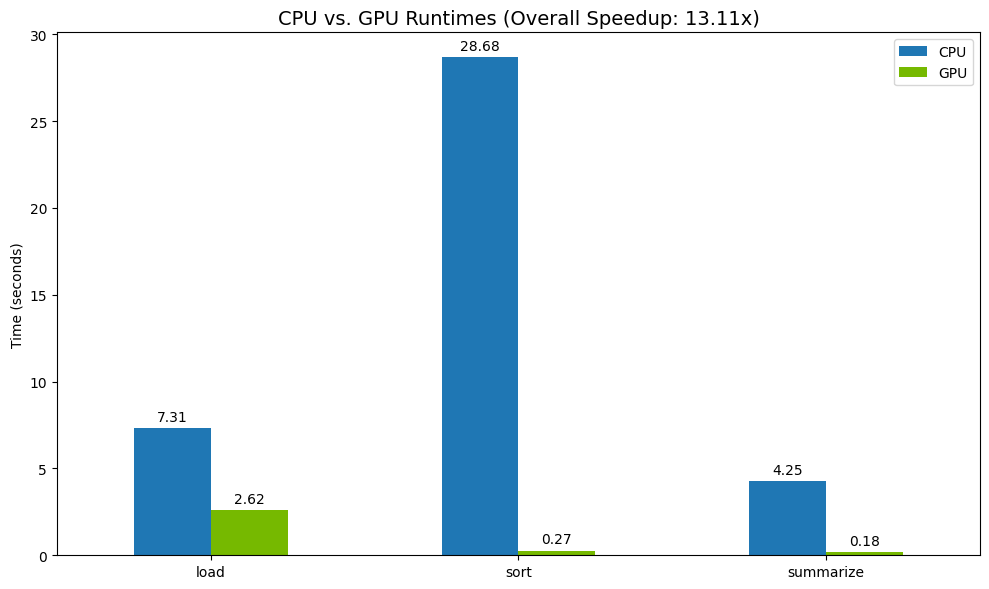
সিপিইউ-এর তুলনায় জিপিইউ সুস্পষ্ট গতি বৃদ্ধি করে।
১২. কোডের প্রতিবন্ধকতা খুঁজে বের করতে সেটির প্রোফাইল তৈরি করুন।
GPU অ্যাক্সিলারেশন থাকা সত্ত্বেও, কিছু pandas অপারেশন CPU-তে ফিরে যেতে পারে যদি সেগুলি cuDF দ্বারা এখনও সমর্থিত না হয়। এই "CPU ফলব্যাকগুলি" পারফরম্যান্সের বাধা হয়ে দাঁড়াতে পারে।
এই এলাকাগুলো শনাক্ত করতে আপনাকে সাহায্য করার জন্য, cudf.pandas দুটি বিল্ট-ইন প্রোফাইলার রয়েছে। আপনার কোডের ঠিক কোন অংশগুলো GPU-তে চলছে এবং কোনগুলো CPU-তে ফিরে যাচ্ছে, তা দেখতে আপনি এগুলো ব্যবহার করতে পারেন।
-
%%cudf.pandas.profile: আপনার কোডের একটি উচ্চ-স্তরের, ফাংশন-ভিত্তিক সারাংশের জন্য এটি ব্যবহার করুন। কোন ডিভাইসে কোন অপারেশনগুলো চলছে তার একটি দ্রুত ধারণা পাওয়ার জন্য এটি সবচেয়ে ভালো। -
%%cudf.pandas.line_profile: বিস্তারিত, লাইন-বাই-লাইন বিশ্লেষণের জন্য এটি ব্যবহার করুন। আপনার কোডের যে লাইনগুলো সিপিইউ-তে ফলব্যাক ঘটাচ্ছে, সেগুলোকে সুনির্দিষ্টভাবে চিহ্নিত করার জন্য এটিই সেরা টুল।
এই প্রোফাইলারগুলোকে নোটবুক সেলের শীর্ষে 'সেল ম্যাজিক' হিসেবে ব্যবহার করুন।
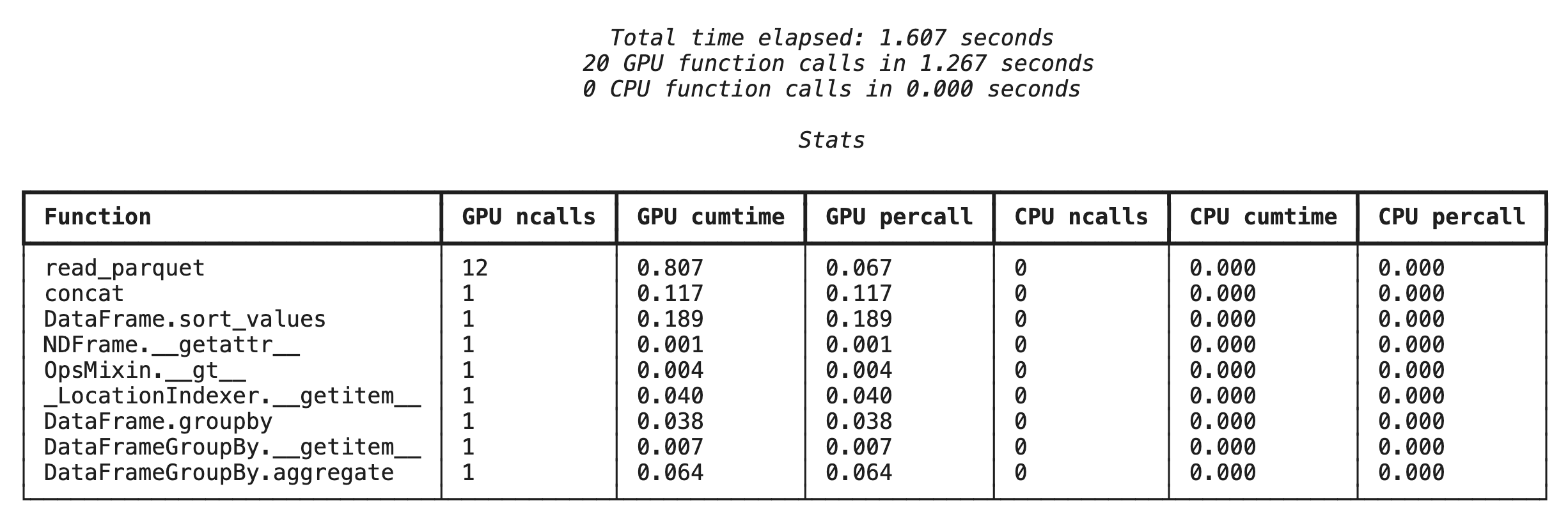
%%cudf.pandas.profile ব্যবহার করে ফাংশন-স্তরের প্রোফাইলিং
প্রথমে, পূর্ববর্তী বিভাগের অ্যানালিটিক্স পাইপলাইনটিতে ফাংশন-লেভেল প্রোফাইলারটি চালান। এর আউটপুটে একটি সারণিতে প্রতিটি কল করা ফাংশন, সেটি কোন ডিভাইসে (GPU বা CPU) চলেছে এবং কতবার কল করা হয়েছে, তা দেখানো হবে।
%load_ext cudf.pandas
import pandas as pd
import glob
pd.DataFrame({"a": [1]})
cudf.pandas সক্রিয় আছে কিনা তা নিশ্চিত করার পর, আপনি একটি প্রোফাইল চালাতে পারেন।
%%cudf.pandas.profile
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*2024*.parquet")], ignore_index=True)
df = df.sort_values(['tpep_pickup_datetime', 'trip_distance', 'passenger_count'], ascending=[False, True, False])
summary = (
df
.loc[(df.tpep_pickup_datetime > '2024-11-01')]
.groupby(['VendorID','tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
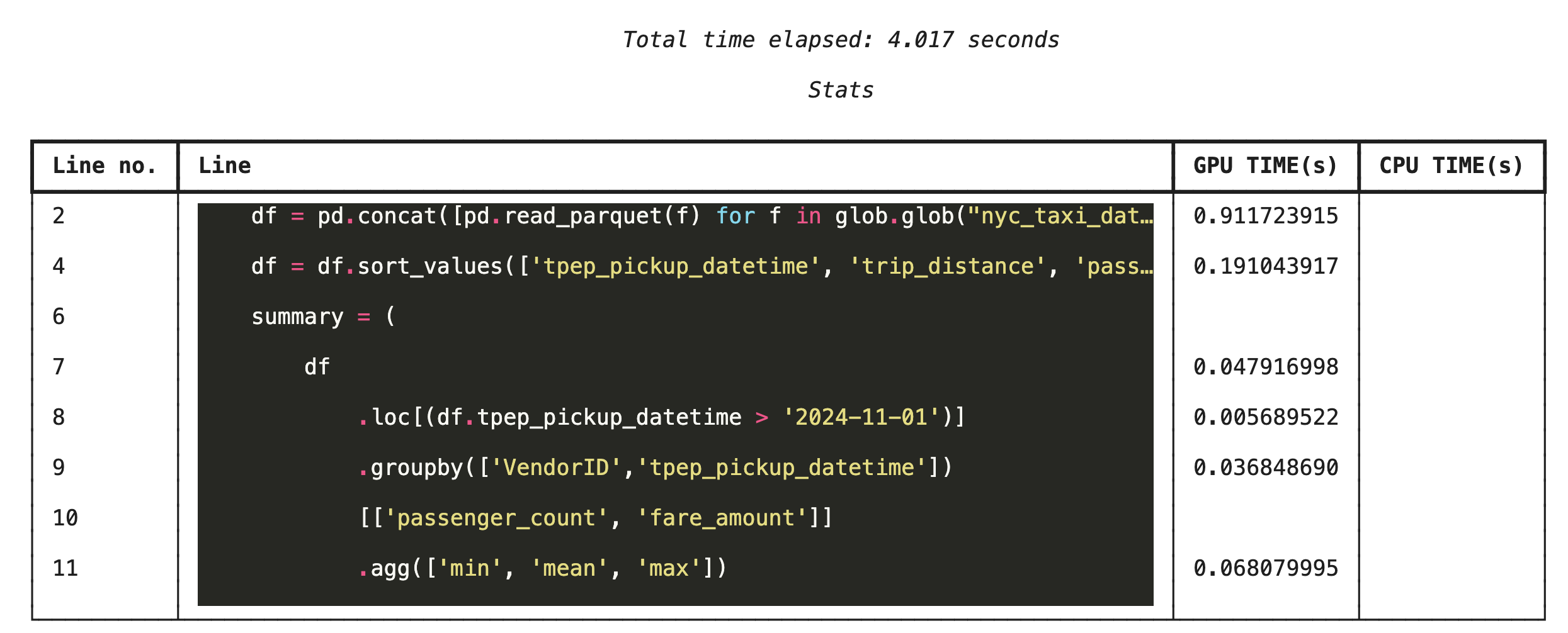
%%cudf.pandas.line_profile ব্যবহার করে লাইন-বাই-লাইন প্রোফাইলিং
এরপর, লাইন-লেভেল প্রোফাইলারটি চালান। এটি আপনাকে আরও বিশদ চিত্র দেবে, যেখানে দেখানো হবে কোডের প্রতিটি লাইন সিপিইউ-এর তুলনায় জিপিইউ-তে কতটুকু সময় ব্যয় করেছে। অপটিমাইজ করার জন্য নির্দিষ্ট বাধাগুলো খুঁজে বের করার এটিই সবচেয়ে কার্যকর উপায়।
%%cudf.pandas.line_profile
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*2024*.parquet")], ignore_index=True)
df = df.sort_values(['tpep_pickup_datetime', 'trip_distance', 'passenger_count'], ascending=[False, True, False])
summary = (
df
.loc[(df.tpep_pickup_datetime > '2024-11-01')]
.groupby(['VendorID','tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
কমান্ড লাইন থেকে প্রোফাইলিং
এই প্রোফাইলারগুলো কমান্ড লাইন থেকেও ব্যবহার করা যায়, যা পাইথন স্ক্রিপ্টের স্বয়ংক্রিয় টেস্টিং ও প্রোফাইলিংয়ের জন্য উপযোগী।
আপনি কমান্ড লাইন ইন্টারফেসে নিম্নলিখিতগুলি ব্যবহার করতে পারেন:
-
python -m cudf.pandas --profile your_script.py -
python -m cudf.pandas --line_profile your_script.py
১৩. গুগল ক্লাউড স্টোরেজের সাথে সংযুক্ত করুন
গুগল ক্লাউড স্টোরেজ (GCS) একটি স্কেলেবল এবং টেকসই অবজেক্ট স্টোরেজ পরিষেবা। আপনি যখন কোলাব এন্টারপ্রাইজ ব্যবহার করেন, তখন আপনার ডেটাসেট, মডেল চেকপয়েন্ট এবং অন্যান্য আর্টিফ্যাক্ট সংরক্ষণের জন্য GCS একটি চমৎকার জায়গা।
আপনার Colab Enterprise রানটাইমের সরাসরি GCS বাকেটগুলিতে ডেটা পড়া এবং লেখার জন্য প্রয়োজনীয় অনুমতি রয়েছে, এবং সর্বোচ্চ পারফরম্যান্সের জন্য এই অপারেশনগুলি GPU-অ্যাক্সিলারেটেড।
একটি GCS বাকেট তৈরি করুন
প্রথমে, একটি নতুন GCS বাকেট তৈরি করুন। GCS বাকেটের নামগুলো বিশ্বব্যাপী অনন্য, তাই এর নামের সাথে একটি UUID যুক্ত করুন।
from google.cloud import storage
import uuid
unique_suffix = uuid.uuid4().hex[:12]
bucket_name = f'nyc-taxi-codelab-{unique_suffix}'
project_id = storage.Client().project
client = storage.Client()
try:
bucket = client.create_bucket(bucket_name)
print(f"Successfully created bucket: gs://{bucket.name}")
except Exception as e:
print(f"Bucket creation failed. You may already own it or the name is taken: {e}")
সরাসরি GCS-এ ডেটা লিখুন
এখন, সরাসরি আপনার নতুন GCS বাকেটে একটি ডেটাফ্রেম সেভ করুন। যদি আগের সেকশনগুলো থেকে df ভ্যারিয়েবলটি পাওয়া না যায়, তাহলে কোডটি প্রথমে এক মাসের ডেটা লোড করে।
%%cudf.pandas.line_profile
# Ensure the DataFrame exists before saving to GCS
if 'df' not in locals():
print("DataFrame not found, loading a sample file...")
df = pd.read_parquet('nyc_taxi_data/yellow_tripdata_2024-12.parquet')
print(f"Writing data to gs://{bucket_name}/nyc_taxi_data.parquet...")
df.to_parquet(f"gs://{bucket_name}/nyc_taxi_data.parquet", index=False)
print("Write operation complete.")
GCS-এ ফাইলটি যাচাই করুন
বাকেটটি ভিজিট করে আপনি ডেটা GCS-এ আছে কিনা তা যাচাই করতে পারেন। নিম্নলিখিত কোডটি একটি ক্লিকযোগ্য লিঙ্ক তৈরি করে।
from IPython.display import Markdown
gcs_url = f"https://console.cloud.google.com/storage/browser/{bucket_name}?project={project_id}"
Markdown(f'**[Click here to view your GCS bucket in the Google Cloud Console]({gcs_url})**')
সরাসরি GCS থেকে ডেটা পড়ুন
অবশেষে, সরাসরি একটি GCS পাথ থেকে ডেটা পড়ে একটি ডেটাফ্রেমে নিন। এই অপারেশনটিও GPU-ত্বরিত, যা আপনাকে ক্লাউড স্টোরেজ থেকে উচ্চ গতিতে বিশাল ডেটাসেট লোড করার সুযোগ দেয়।
%%cudf.pandas.line_profile
print(f"Reading data from gs://{bucket_name}/nyc_taxi_data.parquet...")
df_from_gcs = pd.read_parquet(f"gs://{bucket_name}/nyc_taxi_data.parquet")
df_from_gcs.head()
১৪. পরিষ্কার করা
আপনার গুগল ক্লাউড অ্যাকাউন্টে অপ্রত্যাশিত চার্জ এড়ানোর জন্য, আপনার তৈরি করা রিসোর্সগুলো পরিষ্কার করতে হবে।
আপনার ডাউনলোড করা ডেটা মুছে ফেলুন:
# Permanately delete the GCS bucket
print(f"Deleting GCS bucket: gs://{bucket_name}...")
!gsutil rm -r -f gs://{bucket_name}
print("Bucket deleted.")
# Remove NYC taxi dataset on the Colab runtime
print("Deleting local 'nyc_taxi_data' directory...")
!rm -rf nyc_taxi_data
print("Local files deleted.")
আপনার কোলাব রানটাইম বন্ধ করুন
- গুগল ক্লাউড কনসোলে, কোলাব এন্টারপ্রাইজ রানটাইমস পৃষ্ঠায় যান।
- রিজিয়ন মেনু থেকে, আপনার রানটাইম ধারণকারী রিজিয়নটি নির্বাচন করুন।
- যে রানটাইমটি আপনি মুছতে চান, সেটি নির্বাচন করুন।
- ডিলিট-এ ক্লিক করুন।
- নিশ্চিত করুন -এ ক্লিক করুন।
আপনার নোটবুকটি মুছে ফেলুন
- Google Cloud কনসোলে, Colab Enterprise My Notebooks পৃষ্ঠায় যান।
- রিজিয়ন মেনু থেকে, আপনার নোটবুকটি যে রিজিয়নে অবস্থিত, সেটি নির্বাচন করুন।
- যে নোটবুকটি মুছতে চান, সেটি নির্বাচন করুন।
- ডিলিট-এ ক্লিক করুন।
- নিশ্চিত করুন -এ ক্লিক করুন।
১৫. অভিনন্দন
অভিনন্দন! আপনি সফলভাবে কোলাব এন্টারপ্রাইজে এনভিডিয়া cuDF ব্যবহার করে একটি পান্ডাস অ্যানালিটিক্স ওয়ার্কফ্লোকে ত্বরান্বিত করেছেন। আপনি শিখেছেন কীভাবে GPU-সক্ষম রানটাইম কনফিগার করতে হয়, কোডে কোনো পরিবর্তন ছাড়াই গতি বাড়ানোর জন্য cudf.pandas সক্রিয় করতে হয়, কোডের প্রতিবন্ধকতা চিহ্নিত করতে প্রোফাইলিং করতে হয় এবং গুগল ক্লাউড স্টোরেজের সাথে ইন্টিগ্রেট করতে হয়।