
1. Einführung
In diesem Codelab erfahren Sie, wie Sie Ihre Datenanalyse-Workflows für große Datasets mit NVIDIA-GPUs und Open-Source-Bibliotheken in Google Cloud beschleunigen können. Sie beginnen mit der Optimierung Ihrer Infrastruktur und erfahren dann, wie Sie die GPU-Beschleunigung ohne Codeänderungen anwenden können.
Sie konzentrieren sich auf pandas, eine beliebte Bibliothek zur Datenbearbeitung, und erfahren, wie Sie sie mit der cuDF-Bibliothek von NVIDIA beschleunigen können. Das Beste daran ist, dass Sie diese GPU-Beschleunigung erhalten, ohne Ihren vorhandenen pandas-Code ändern zu müssen.
Lerninhalte
- Colab Enterprise in Google Cloud kennenlernen
- Sie können eine Colab-Laufzeitumgebung mit bestimmten GPU-, CPU- und Arbeitsspeicherkonfigurationen anpassen.
pandasohne Codeänderungen mit NVIDIAcuDFbeschleunigen.- Profilieren Sie Ihren Code, um Leistungsengpässe zu identifizieren und zu optimieren.
Auf der nächsten Seite finden Sie das Guthaben, das Sie zum Abschließen des Labs verwenden können.
2. Warum die Datenverarbeitung beschleunigen?
Die 80/20-Regel: Warum die Datenaufbereitung so viel Zeit in Anspruch nimmt
Die Datenaufbereitung ist oft die zeitaufwendigste Phase eines Analyseprojekts. Data Scientists und Analysten verbringen einen Großteil ihrer Zeit damit, Daten zu bereinigen, zu transformieren und zu strukturieren, bevor sie mit der Analyse beginnen können.
Glücklicherweise können Sie beliebte Open-Source-Bibliotheken wie pandas, Apache Spark und Polars auf NVIDIA-GPUs mit cuDF beschleunigen. Auch wenn die Datenvorbereitung beschleunigt wird, ist sie weiterhin zeitaufwendig, weil:
- Quelldaten sind selten bereit für die Analyse:Daten aus der Praxis weisen oft Inkonsistenzen, fehlende Werte und Formatierungsprobleme auf.
- Qualität wirkt sich auf die Modellleistung aus:Bei schlechter Datenqualität sind selbst die ausgefeiltesten Algorithmen nutzlos.
- Skalierung verstärkt Probleme:Scheinbar geringfügige Datenprobleme werden zu kritischen Engpässen, wenn Sie mit Millionen von Datensätzen arbeiten.
3. Notebook-Umgebung auswählen
Viele Data Scientists kennen Colab für private Projekte. Colab Enterprise bietet jedoch eine sichere, auf Zusammenarbeit ausgelegte und integrierte Notebook-Umgebung, die für Unternehmen entwickelt wurde.
In Google Cloud haben Sie zwei primäre Optionen für verwaltete Notebook-Umgebungen: Colab Enterprise und die Gemini Enterprise Agent Platform Workbench. Die richtige Wahl hängt von den Prioritäten Ihres Projekts ab.
Wann sollte die Agent Platform Workbench verwendet werden?
Wählen Sie Agent Platform Workbench aus, wenn Kontrolle und umfassende Anpassung für Sie Priorität haben. Diese Option ist ideal, wenn Sie Folgendes benötigen:
- Verwaltung der zugrunde liegenden Infrastruktur und des Maschinenlebenszyklus
- Benutzerdefinierte Container und Netzwerkkonfigurationen verwenden
- Einbindung in MLOps-Pipelines und benutzerdefinierte Tools für den Lebenszyklus.
Wann wird Colab Enterprise verwendet?
Wählen Sie Colab Enterprise, wenn schnelle Einrichtung, Nutzerfreundlichkeit und sichere Zusammenarbeit für Sie Priorität haben. Es handelt sich um eine vollständig verwaltete Lösung, mit der sich Ihr Team auf die Analyse statt auf die Infrastruktur konzentrieren kann.
Colab Enterprise bietet folgende Vorteile:
- Data-Science-Workflows entwickeln, die eng mit Ihrem Data Warehouse verknüpft sind Sie können Ihre Notebooks direkt in BigQuery Studio öffnen und verwalten.
- Modelle für maschinelles Lernen trainieren und in MLOps-Tools in der Agent Platform einbinden.
- Sie profitieren von einer flexiblen und einheitlichen Umgebung. Ein in BigQuery erstelltes Colab Enterprise-Notebook kann in der Agent Platform geöffnet und ausgeführt werden und umgekehrt.
Heutiges Lab
In diesem Codelab wird Colab Enterprise für die beschleunigte Datenanalyse verwendet.
Weitere Informationen zu den Unterschieden finden Sie in der offiziellen Dokumentation unter Die richtige Notebooklösung auswählen.
4. Laufzeitvorlage konfigurieren
Stellen Sie in Colab Enterprise eine Verbindung zu einer Laufzeit her, die auf einer vorkonfigurierten Laufzeitvorlage basiert.
Eine Laufzeitvorlage ist eine wiederverwendbare Konfiguration, die die gesamte Umgebung für Ihr Notebook angibt, einschließlich:
- Maschinentyp (CPU, Arbeitsspeicher)
- Beschleuniger (GPU-Typ und -Anzahl)
- Laufwerkgröße und -typ
- Netzwerkeinstellungen und Sicherheitsrichtlinien
- Regeln für das automatische Herunterfahren bei Inaktivität
Vorteile von Laufzeitvorlagen
- Konsistente Umgebung:Sie und Ihre Teammitglieder erhalten jedes Mal dieselbe sofort einsatzbereite Umgebung, damit Ihre Arbeit reproduzierbar ist.
- Sicheres Arbeiten durch Design:Vorlagen erzwingen automatisch die Sicherheitsrichtlinien Ihrer Organisation.
- Kosten effektiv verwalten:Ressourcen wie GPUs und CPUs sind in der Vorlage vordimensioniert, was hilft, versehentliche Kostenüberschreitungen zu vermeiden.
Laufzeitvorlage erstellen.
Richten Sie eine wiederverwendbare Laufzeitvorlage für das Lab ein.
- Rufen Sie in der Google Cloud Console das Navigationsmenü > Agent Platform > Notebooks auf.
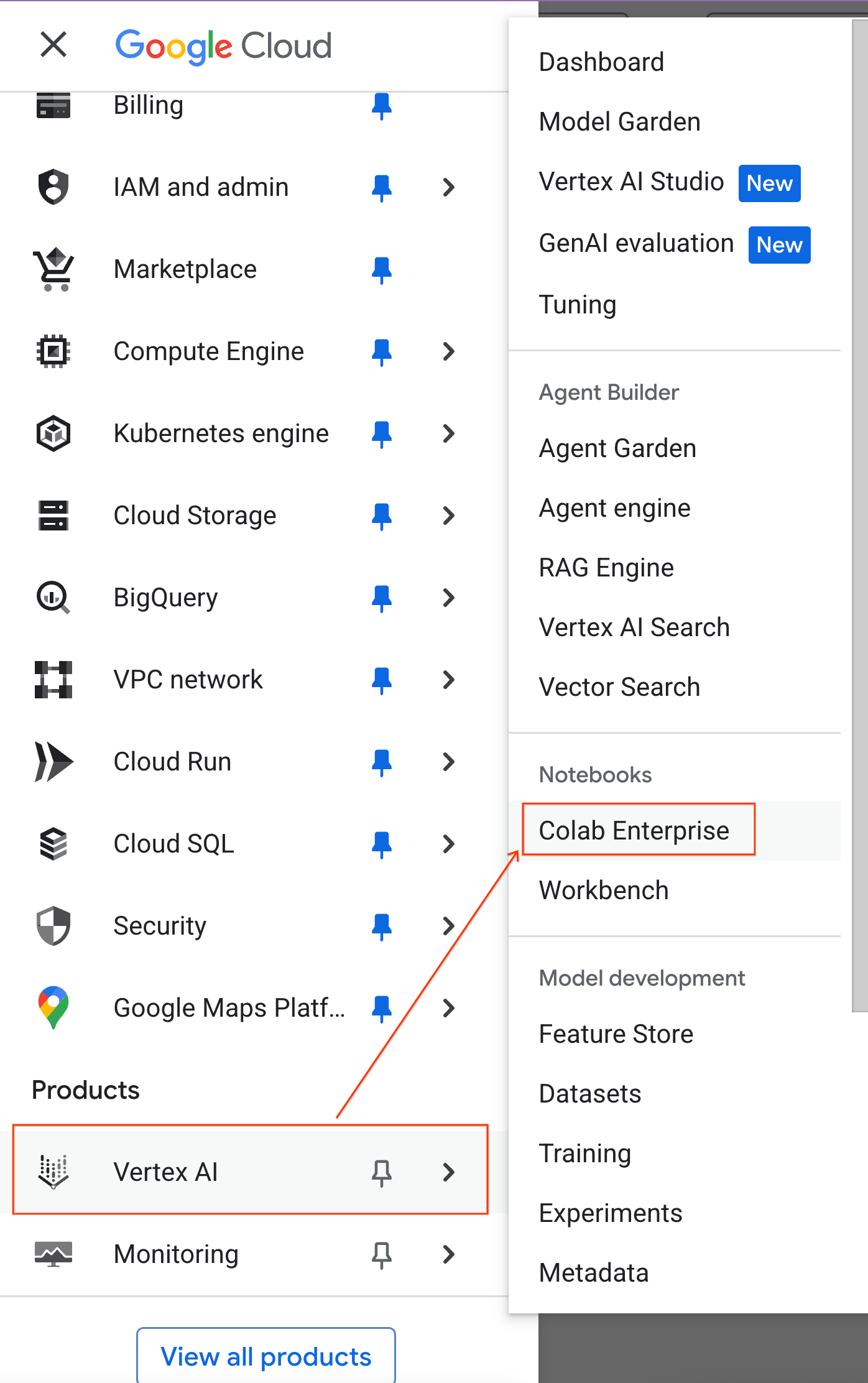
- Klicken Sie in Colab Enterprise auf Laufzeitvorlagen und wählen Sie dann Neue Vorlage aus.
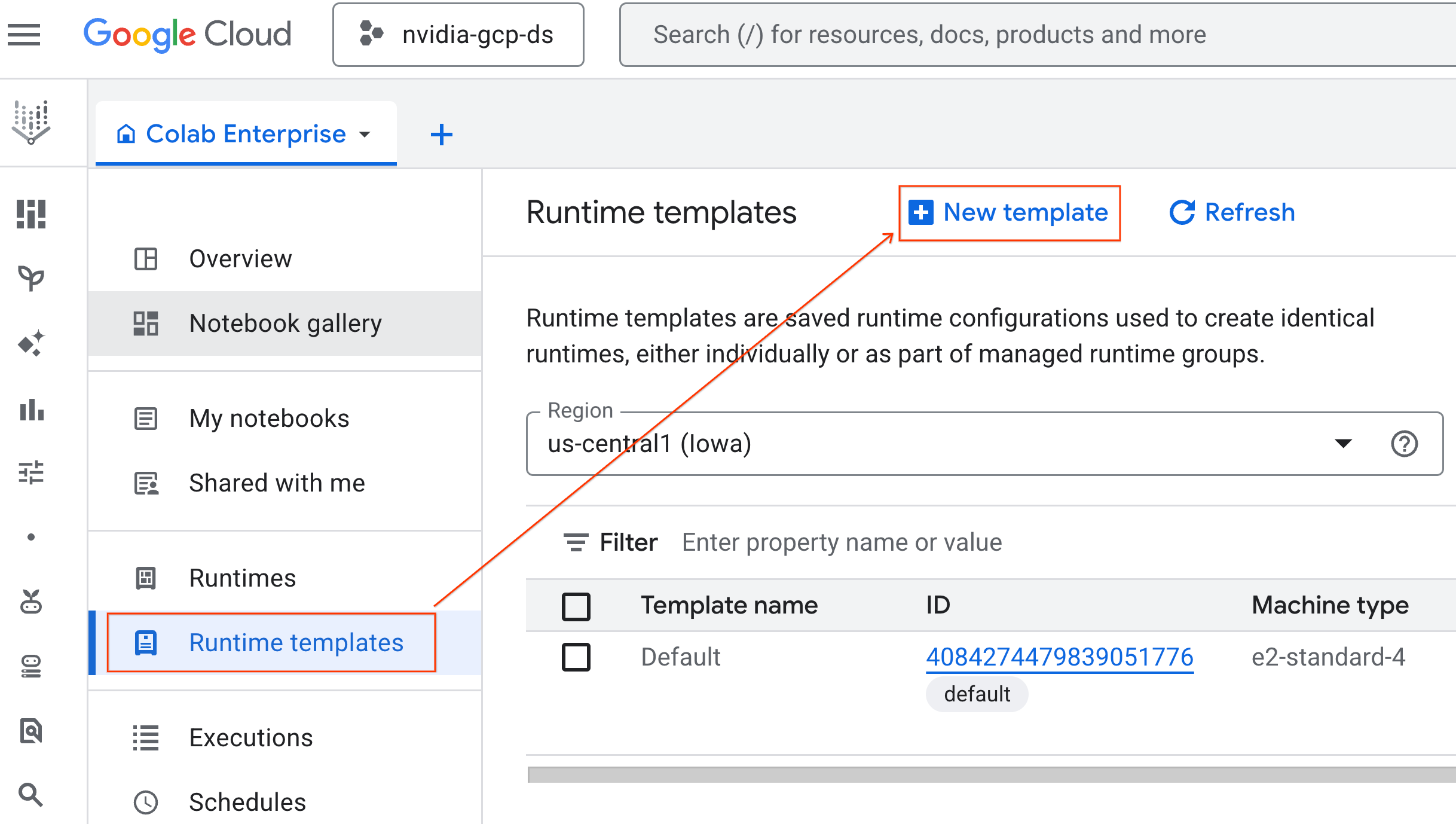
- Unter Laufzeitgrundlagen:
- Legen Sie als Anzeigename
gpu-templatefest. - Legen Sie Ihre bevorzugte Region fest.
- Legen Sie als Anzeigename
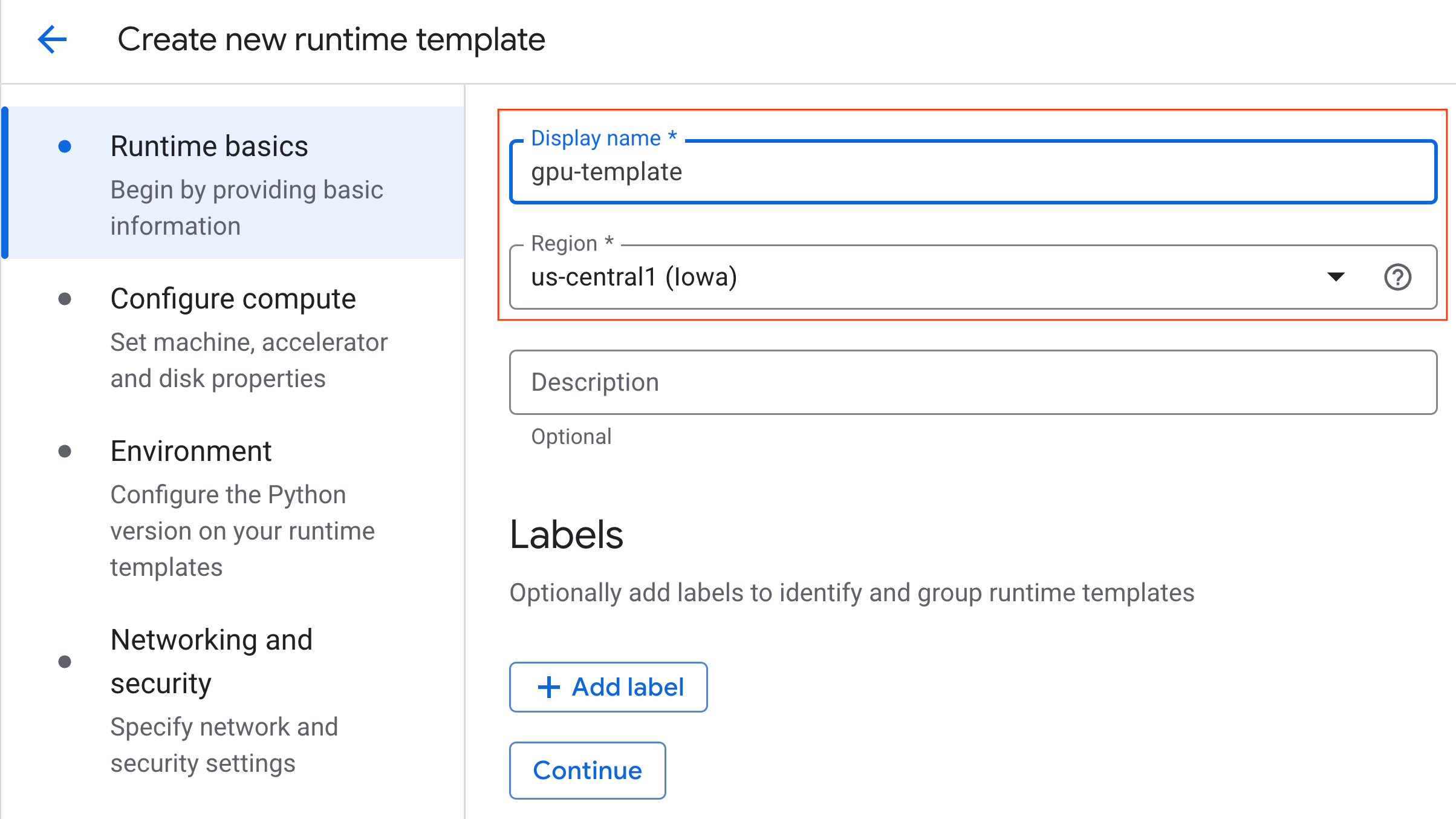
- Unter Compute konfigurieren:
- Legen Sie den Maschinentyp auf
g2-standard-4fest. - Behalten Sie den Standardwert
NVIDIA L4für Beschleunigertyp mit einer Anzahl der Beschleuniger von 1 bei. - Ändern Sie die Option Herunterfahren bei Inaktivität auf 60 Minuten.
- Klicken Sie auf Weiter.
- Legen Sie den Maschinentyp auf
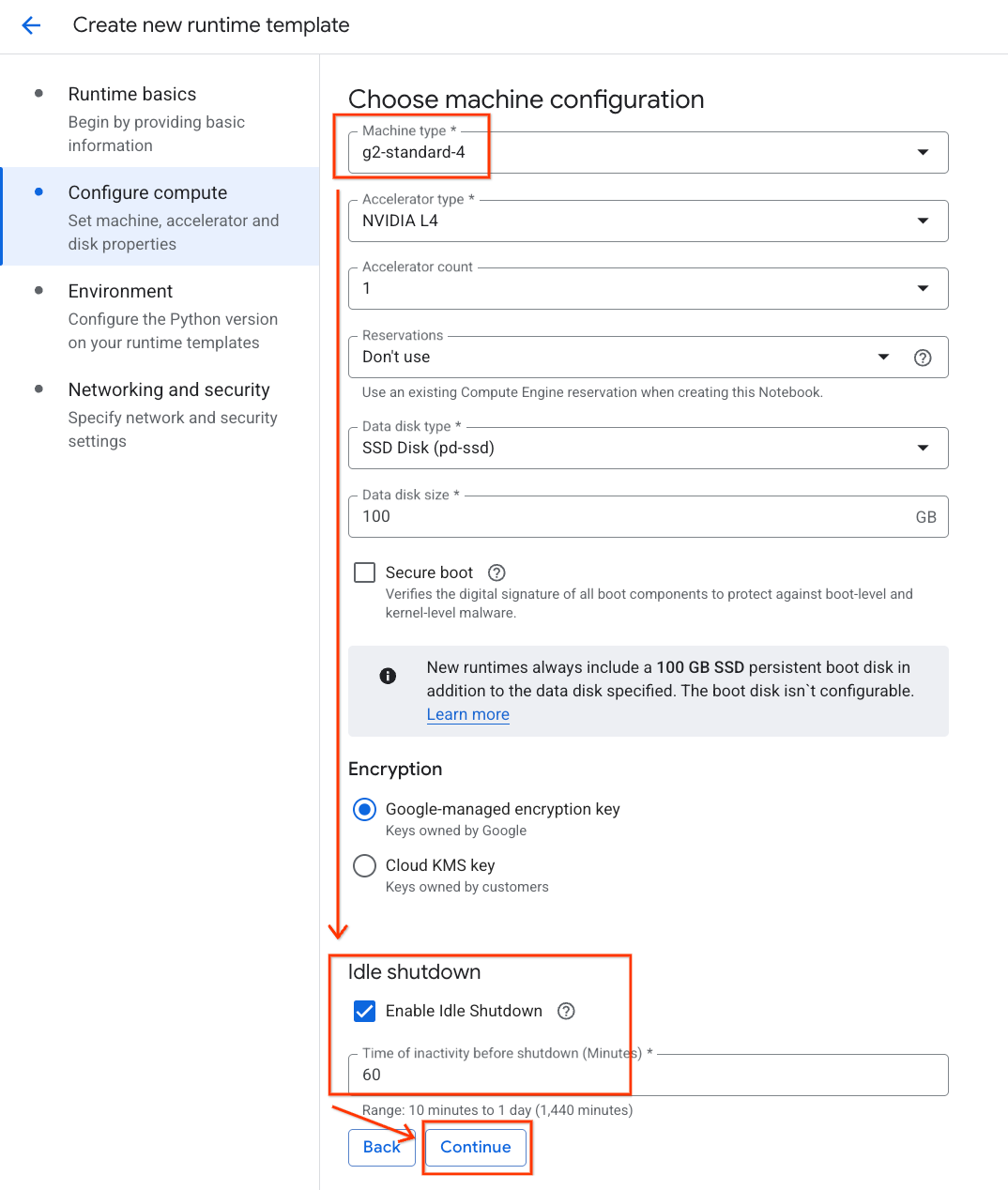
- Unter Umgebung:
- Legen Sie die Umgebung auf
Python 3.11fest.
- Legen Sie die Umgebung auf
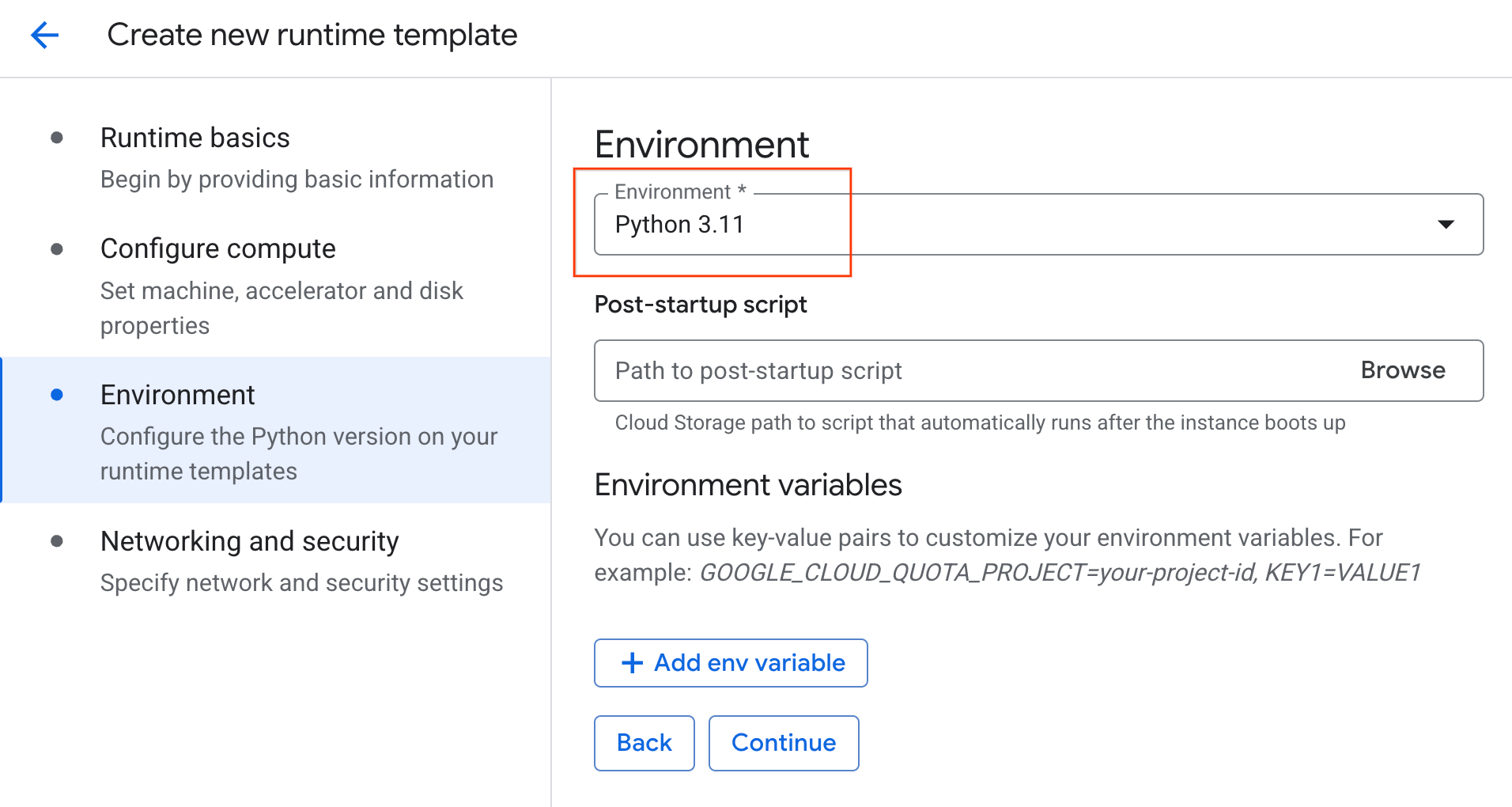
- Klicken Sie auf Erstellen, um die Laufzeitvorlage zu speichern. Die neue Vorlage sollte jetzt auf der Seite „Laufzeitvorlagen“ angezeigt werden.
5. Laufzeit starten
Nachdem Sie die Vorlage erstellt haben, können Sie eine neue Laufzeit erstellen.
- Klicken Sie in Colab Enterprise auf Laufzeiten und wählen Sie dann Erstellen aus.
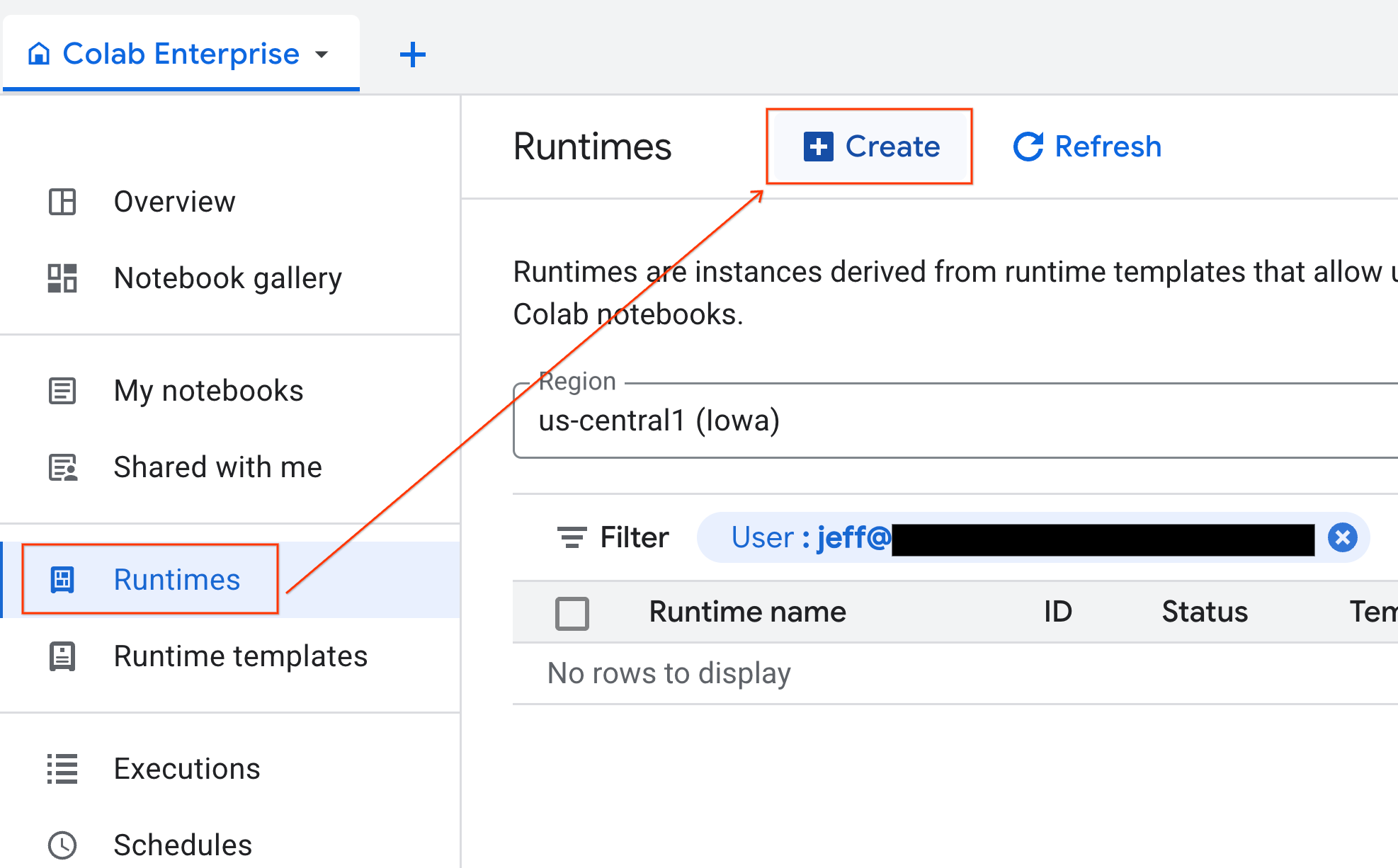
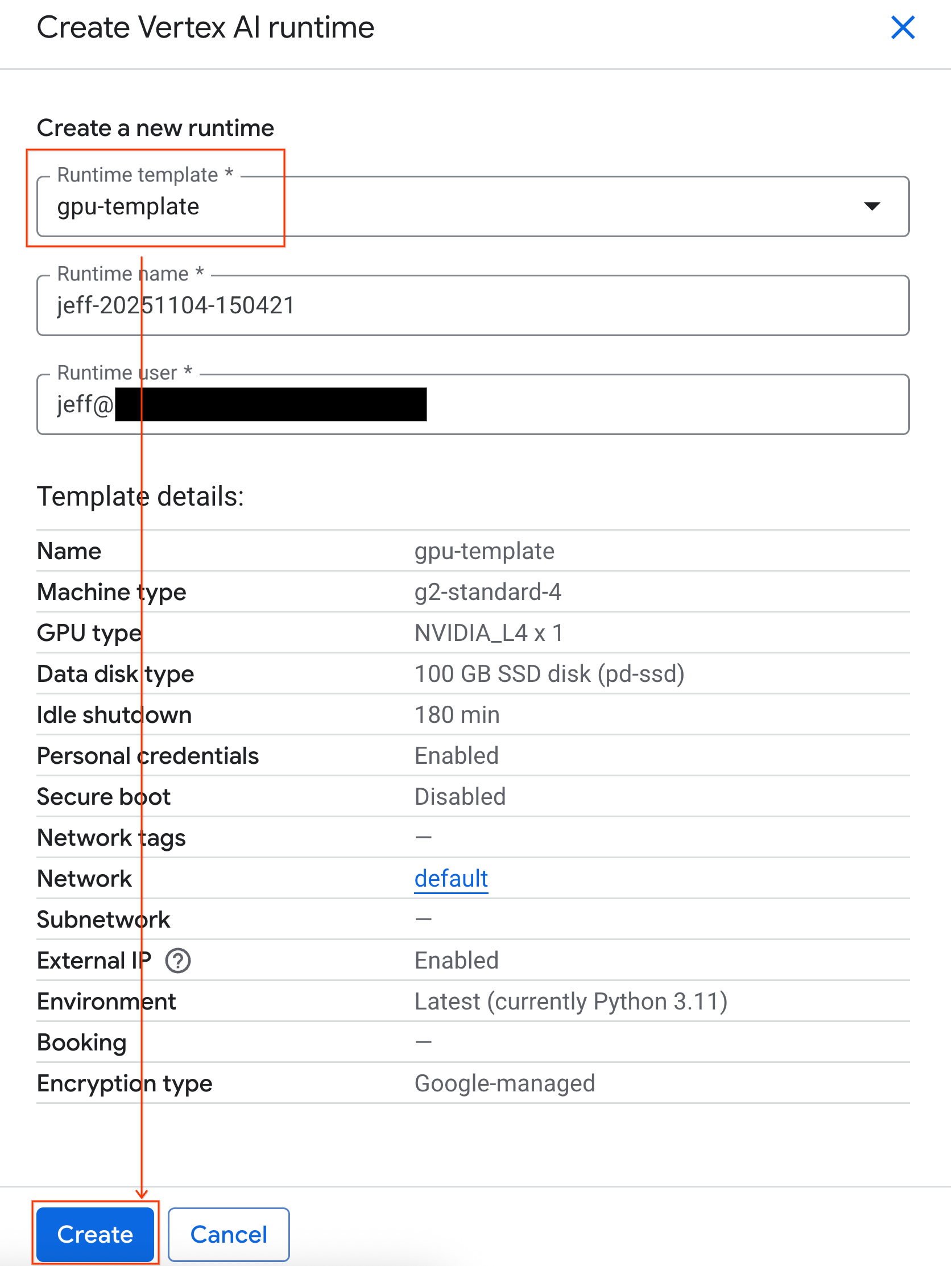
- Wählen Sie unter Laufzeitvorlage die Option
gpu-templateaus. Klicken Sie auf Erstellen und warten Sie, bis die Laufzeitumgebung gestartet wurde.
- Nach einigen Minuten wird die Laufzeit angezeigt.
6. Notebook einrichten
Nachdem Ihre Infrastruktur nun ausgeführt wird, müssen Sie das Lab-Notebook importieren und mit Ihrer Laufzeit verbinden.
Notebook importieren
- Klicken Sie in Colab Enterprise auf Meine Notebooks und dann auf Importieren.
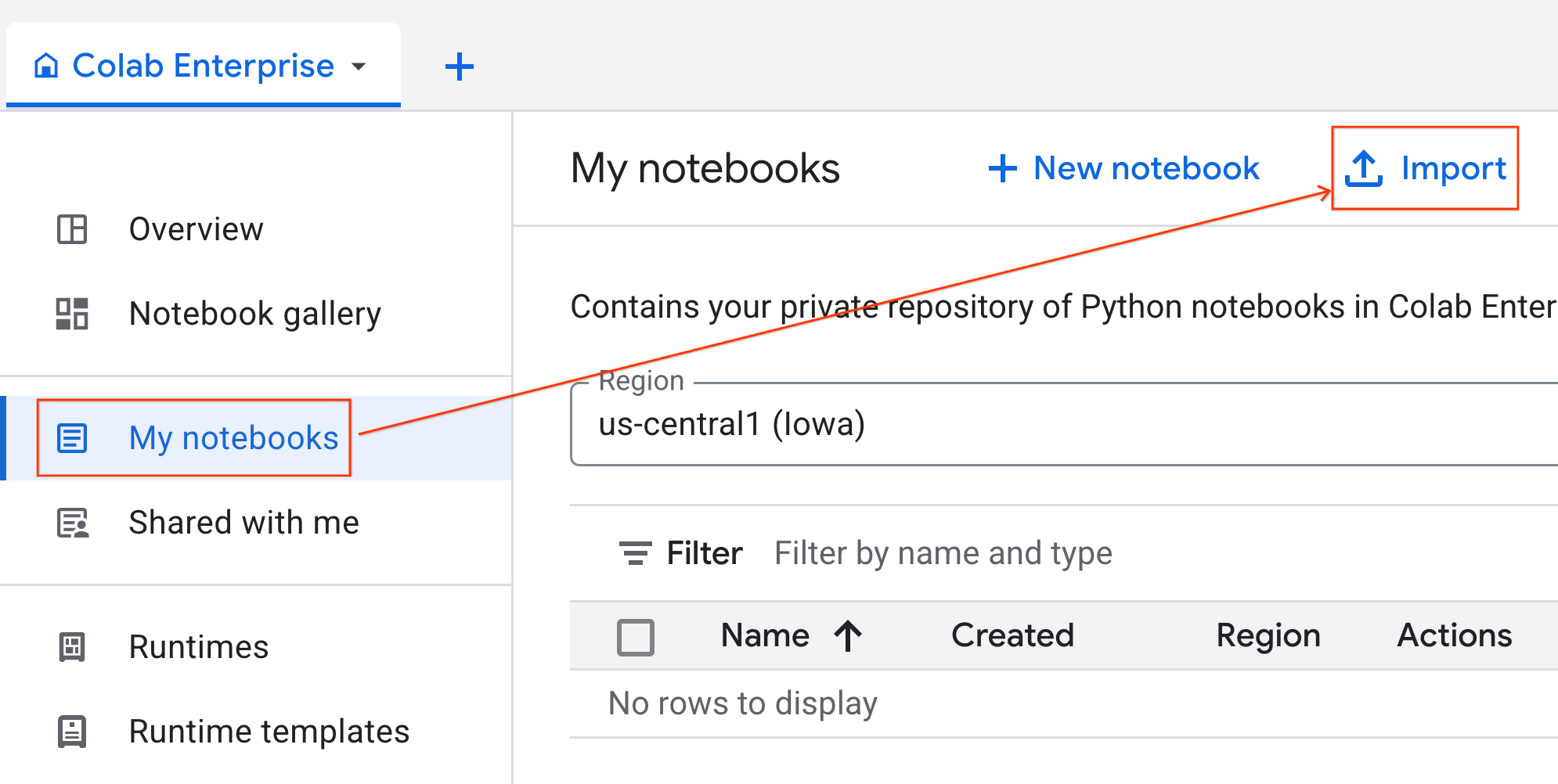
- Wählen Sie das Optionsfeld URL aus und geben Sie die folgende URL ein:
https://github.com/GoogleCloudPlatform/ai-ml-recipes/blob/main/notebooks/analytics/gpu_accelerated_analytics.ipynb
- Klicken Sie auf Importieren. Colab Enterprise kopiert das Notebook aus GitHub in Ihre Umgebung.
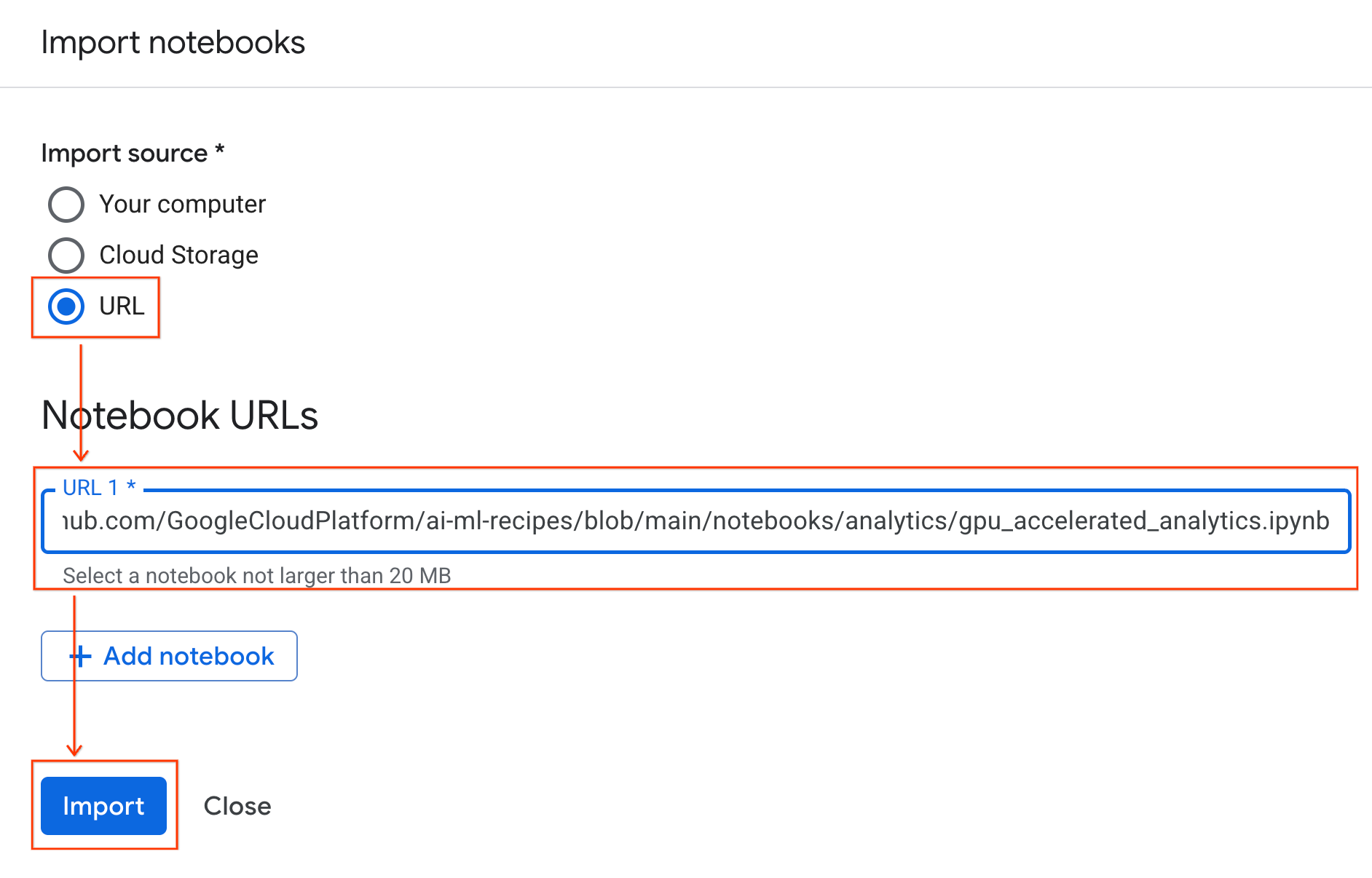
Mit der Laufzeit verbinden
- Öffnen Sie das neu importierte Notebook.
- Klicken Sie neben Verbinden auf den Drop-down-Pfeil.
- Wählen Sie Mit einer Laufzeit verbinden aus.
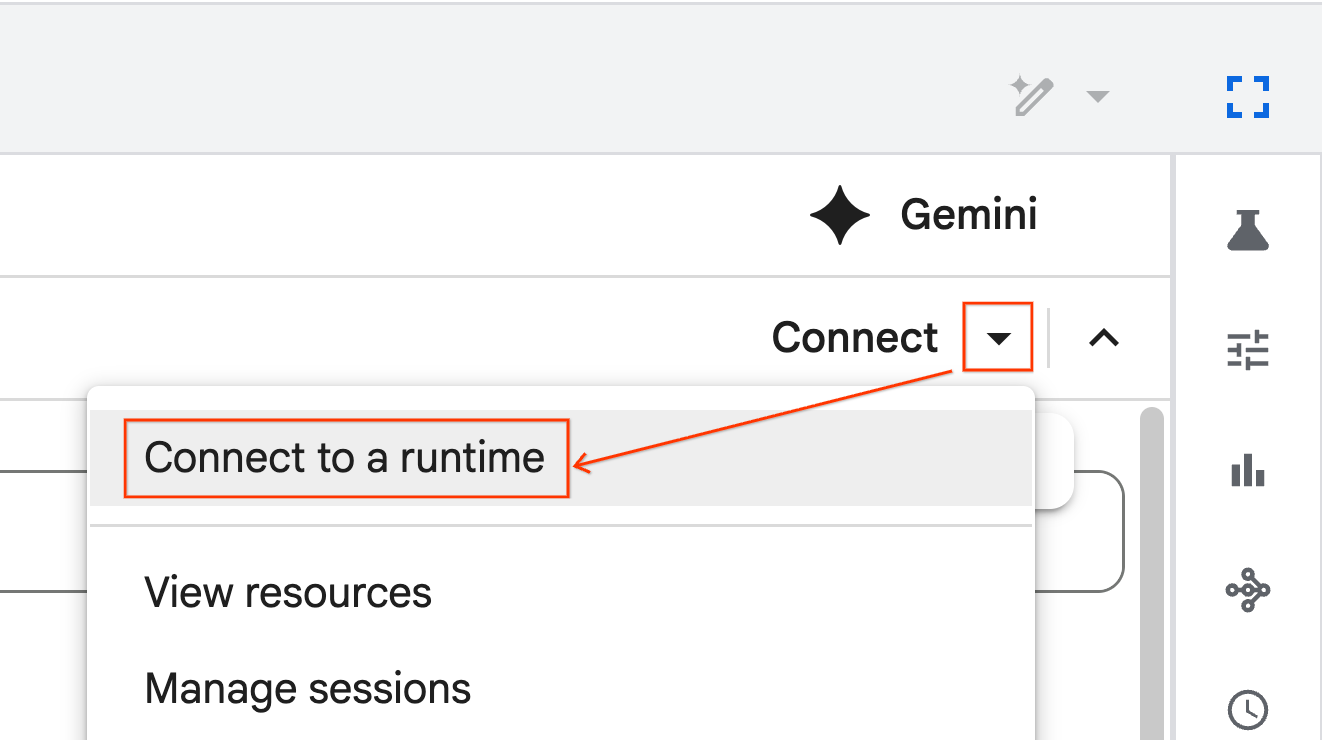
- Wählen Sie im Drop-down-Menü die Laufzeit aus, die Sie zuvor erstellt haben.
- Klicken Sie auf Verbinden.
Ihr Notebook ist jetzt mit einer GPU-fähigen Laufzeit verbunden. Sie können jetzt mit dem Ausführen von Abfragen beginnen.
7. NYC-Taxidataset vorbereiten
In diesem Codelab werden die Fahrtenaufzeichnungen der NYC Taxi & Limousine Commission (TLC) verwendet.
Der Datensatz enthält einzelne Fahrtdatensätze von gelben Taxis in New York City und umfasst Felder wie:
- Abhol- und Abgabedatum, ‑uhrzeit und ‑ort
- Fahrtentfernungen
- Aufgeschlüsselte Fahrpreisbeträge
- Anzahl der Passagiere
Daten herunterladen
Laden Sie als Nächstes die Fahrtdaten für das gesamte Jahr 2024 herunter. Die Daten werden im Parquet-Dateiformat gespeichert.
Der folgende Codeblock führt diese Schritte aus:
- Definiert den Zeitraum (Jahre und Monate), der heruntergeladen werden soll.
- Erstellt ein lokales Verzeichnis mit dem Namen
nyc_taxi_datazum Speichern der Dateien. - Die Funktion durchläuft jeden Monat, lädt die entsprechende Parquet-Datei herunter, falls sie noch nicht vorhanden ist, und speichert sie im Verzeichnis.
Führen Sie diesen Code in Ihrem Notebook aus, um die Daten zu erfassen und in der Laufzeit zu speichern:
from tqdm import tqdm
import requests
import time
import os
YEAR = 2024
DATA_DIR = "nyc_taxi_data"
os.makedirs(DATA_DIR, exist_ok=True)
print(f"Checking/Downloading files for {YEAR}...")
for month in tqdm(range(1, 13), unit="file"):
# Define standardized filename for both local path and URL
file_name = f"yellow_tripdata_{YEAR}-{month:02d}.parquet"
local_path = os.path.join(DATA_DIR, file_name)
url = f"https://d37ci6vzurychx.cloudfront.net/trip-data/{file_name}"
if not os.path.exists(local_path):
try:
with requests.get(url, stream=True) as response:
response.raise_for_status()
with open(local_path, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
time.sleep(1)
except requests.exceptions.HTTPError as e:
print(f"\nSkipping {file_name}: {e}")
if os.path.exists(local_path):
os.remove(local_path)
print("\nDownload complete.")
8. Taxifahrtdaten ansehen
Nachdem Sie das Dataset heruntergeladen haben, können Sie mit einer ersten explorativen Datenanalyse (Exploratory Data Analysis, EDA) beginnen. Ziel der explorativen Datenanalyse ist es, die Struktur der Daten zu verstehen, Anomalien zu finden und potenzielle Muster aufzudecken.
Daten für einen einzelnen Monat laden
Laden Sie zuerst die Daten für einen Monat. So erhalten Sie eine ausreichend große Stichprobe (über 3 Millionen Zeilen), die aussagekräftig ist, und gleichzeitig bleibt die Arbeitsspeichernutzung für interaktive Analysen überschaubar.
import pandas as pd
import glob
# Load the last month of the downloaded data
df = pd.read_parquet("nyc_taxi_data/yellow_tripdata_2024-12.parquet")
df.head()
Zusammenfassende Statistiken abrufen
Verwenden Sie die Methode .describe(), um allgemeine zusammenfassende Statistiken für die numerischen Spalten zu generieren. Das ist ein guter erster Schritt, um potenzielle Probleme mit der Datenqualität zu erkennen, z. B. unerwartete Mindest- oder Höchstwerte.
df.describe().round(2)
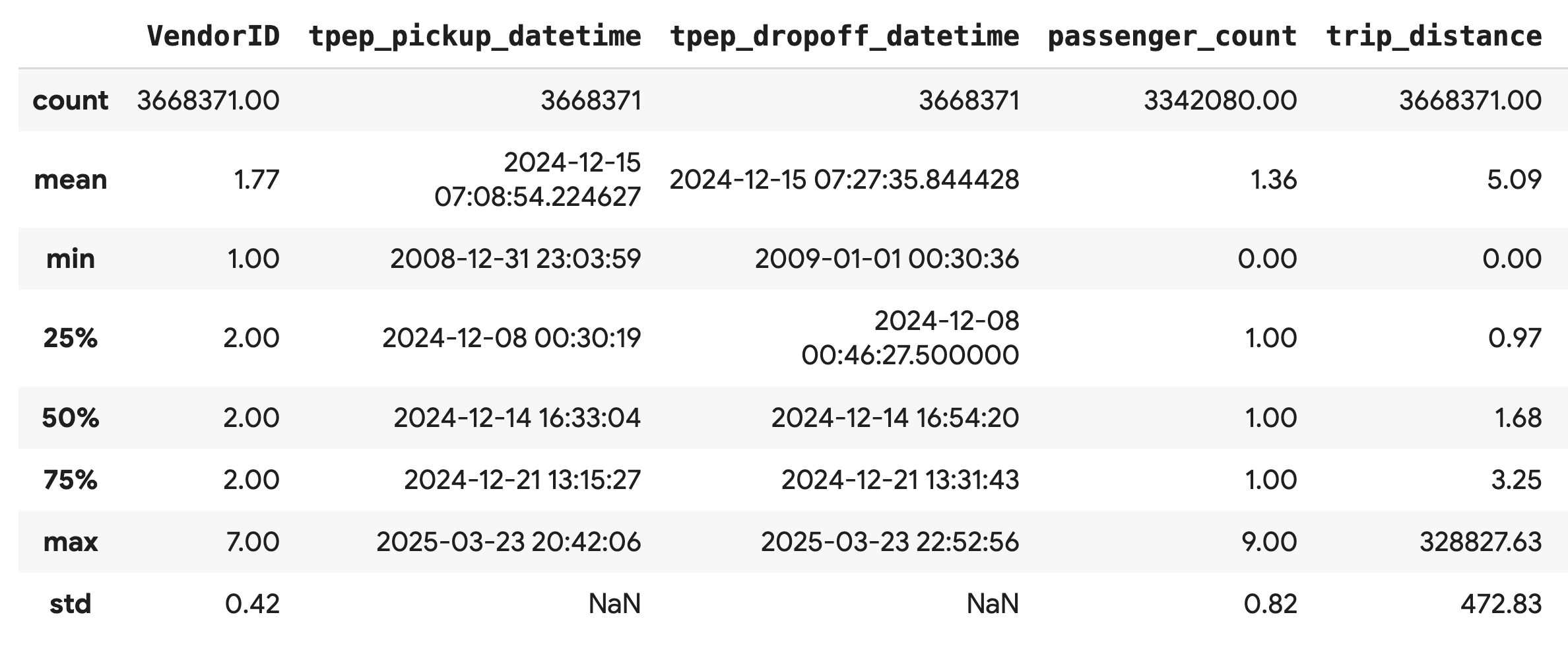
Datenqualität untersuchen
Die Ausgabe von .describe() weist sofort auf ein Problem hin. Der min-Wert für tpep_pickup_datetime und tpep_dropoff_datetime stammt aus dem Jahr 2008, was für ein Dataset aus dem Jahr 2024 nicht sinnvoll ist.
Dies ist ein Beispiel dafür, warum Sie Ihre Daten immer prüfen sollten. Sie können dies weiter untersuchen, indem Sie den DataFrame sortieren, um die genauen Zeilen zu finden, die diese Ausreißerdaten enthalten.
# Sort by the dropoff datetime to see the oldest records
df.sort_values("tpep_pickup_datetime").head()
Datenverteilungen visualisieren
Als Nächstes können Sie Histogramme der numerischen Spalten erstellen, um ihre Verteilungen zu visualisieren. So können Sie die Verteilung und Abweichung von Merkmalen wie trip_distance und fare_amount besser nachvollziehen. Mit der Funktion .hist() lassen sich schnell Histogramme für alle numerischen Spalten in einem DataFrame erstellen.
_ = df.hist(figsize=(20, 20))
Erstellen Sie zum Schluss eine Streumatrix, um die Beziehungen zwischen einigen wichtigen Spalten zu visualisieren. Da das Darstellen von Millionen von Punkten langsam ist und Muster verdecken kann, verwenden Sie .sample(),um das Diagramm aus einer zufälligen Stichprobe von 100.000 Zeilen zu erstellen.
_ = pd.plotting.scatter_matrix(
df[['passenger_count', 'trip_distance', 'tip_amount', 'total_amount']].sample(100_000),
diagonal="kde",
figsize=(15, 15)
)
9. Vorteile des Parquet-Dateiformats
Der NYC-Taxidatensatz wird im Apache Parquet-Format bereitgestellt. Dies ist eine bewusste Entscheidung, die für die Analyse großer Datenmengen getroffen wurde. Parquet bietet gegenüber Dateitypen wie CSV mehrere Vorteile:
- Effizient und schnell:Als spaltenorientiertes Format ist Parquet sehr effizient zu speichern und zu lesen. Es unterstützt moderne Komprimierungsmethoden, die zu kleineren Dateigrößen und deutlich schnelleren E/A-Vorgängen führen, insbesondere auf GPUs.
- Schema wird beibehalten:In Parquet werden Datentypen in den Metadaten der Datei gespeichert. Sie müssen beim Lesen der Datei nie Datentypen erraten.
- Selektives Lesen möglich:Dank der spaltenorientierten Struktur können Sie nur die Spalten lesen, die Sie für eine Analyse benötigen. Dadurch kann die Menge der Daten, die in den Arbeitsspeicher geladen werden müssen, erheblich reduziert werden.
Parquet-Funktionen
Sehen wir uns zwei dieser leistungsstarken Funktionen anhand einer der heruntergeladenen Dateien an.
Metadaten ansehen, ohne das gesamte Dataset zu laden
Sie können eine Parquet-Datei zwar nicht in einem Standardtexteditor ansehen, aber ihr Schema und ihre Metadaten lassen sich ganz einfach prüfen, ohne dass Daten in den Arbeitsspeicher geladen werden müssen. Das ist nützlich, um die Struktur einer Datei schnell zu erfassen.
from pyarrow.parquet import ParquetFile
import pyarrow as pa
# Open one of the downloaded files
pf = ParquetFile('nyc_taxi_data/yellow_tripdata_2024-12.parquet')
# Print the schema
print("File Schema:")
print(pf.schema)
# Print the file metadata
print("\nFile Metadata:")
print(pf.metadata)
Nur die benötigten Spalten lesen
Angenommen, Sie müssen nur die Entfernung und die Fahrpreise analysieren. Mit Parquet können Sie nur die Spalten laden, die Sie benötigen. Das ist viel schneller und speichereffizienter als das Laden des gesamten DataFrames.
import pandas as pd
# Read only four specific columns from the Parquet file
df_subset = pd.read_parquet(
'nyc_taxi_data/yellow_tripdata_2024-12.parquet',
columns=['passenger_count', 'trip_distance', 'tip_amount', 'total_amount']
)
df_subset.head()
10. Pandas mit NVIDIA cuDF beschleunigen
NVIDIA CUDA for DataFrames (cuDF) ist eine Open-Source-Bibliothek, die GPU-beschleunigt ist und mit der Sie mit DataFrames interagieren können. Mit cuDF können Sie gängige Datenvorgänge wie Filtern, Verknüpfen und Gruppieren auf der GPU mit massiver Parallelität ausführen.
Die wichtigste Funktion, die Sie in diesem Codelab verwenden, ist der cudf.pandas-Beschleunigermodus. Wenn Sie die Funktion aktivieren, wird Ihr Standardcode für pandas automatisch so umgeleitet, dass im Hintergrund GPU-basierte cuDF-Kernels verwendet werden. Dazu müssen Sie Ihren Code nicht ändern.
GPU-Beschleunigung aktivieren
Wenn Sie NVIDIA cuDF in einem Colab Enterprise-Notebook verwenden möchten, laden Sie die zugehörige Magic-Erweiterung, bevor Sie pandas importieren.
Sehen Sie sich zuerst die Standardbibliothek pandas an. In der Ausgabe wird der Pfad zur Standardinstallation von pandas angezeigt.
import pandas as pd
pd # Note the output for the standard pandas library
Laden Sie nun die cudf.pandas-Erweiterung und importieren Sie pandas noch einmal. Sehen Sie sich an, wie sich die Ausgabe für das Modul pd ändert. Das bestätigt, dass die GPU-beschleunigte Version jetzt aktiv ist.
%load_ext cudf.pandas
import pandas as pd
pd # Note the new output, indicating cudf.pandas is active
Weitere Möglichkeiten zum Aktivieren von cudf.pandas
Der Magic-Befehl (%load_ext) ist die einfachste Methode in einem Notebook. Sie können den Beschleuniger aber auch in anderen Umgebungen aktivieren:
- In Python-Scripts:Rufen Sie
import cudf.pandasundcudf.pandas.install()vor dem Import vonpandasauf. - In Umgebungen, die keine Notebooks sind:Führen Sie Ihr Script mit
python -m cudf.pandas your_script.pyaus.
11. CPU- und GPU-Leistung vergleichen
Nun zum wichtigsten Teil: dem Vergleich der Leistung von Standard-pandas auf einer CPU mit cudf.pandas auf einer GPU.
Damit die CPU-Baseline wirklich fair ist, müssen Sie zuerst die Colab-Laufzeit zurücksetzen. Dadurch werden alle GPU-Beschleuniger entfernt, die Sie in den vorherigen Abschnitten aktiviert haben. Sie können die Laufzeit neu starten, indem Sie die folgende Zelle ausführen oder im Menü Laufzeit die Option Sitzung neu starten auswählen.
import IPython
IPython.Application.instance().kernel.do_shutdown(True)
Analysepipeline definieren
Nachdem die Umgebung bereinigt wurde, definieren Sie die Benchmarking-Funktion. Mit dieser Funktion können Sie dieselbe Pipeline ausführen – Laden, Sortieren und Zusammenfassen – unabhängig davon, welches pandas-Modul Sie übergeben.
import time
import glob
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
def run_analytics_pipeline(pd_module):
"""Loads, sorts, and summarizes data using the provided pandas module."""
timings = {}
# 1. Load all 2024 Parquet files from the directory
t0 = time.time()
df = pd_module.concat(
[pd_module.read_parquet(f) for f in glob.glob("nyc_taxi_data/*_2024*.parquet")],
ignore_index=True
)
timings["load"] = time.time() - t0
# 2. Sort the data by multiple columns
t0 = time.time()
df = df.sort_values(
['tpep_pickup_datetime', 'trip_distance', 'passenger_count'],
ascending=[False, True, False]
)
timings["sort"] = time.time() - t0
# 3. Perform a groupby and aggregation
t0 = time.time()
df['tpep_pickup_datetime'] = pd_module.to_datetime(df['tpep_pickup_datetime'])
_ = (
df.loc[df.tpep_pickup_datetime > '2024-11-01']
.groupby(['VendorID', 'tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
timings["summarize"] = time.time() - t0
return timings
Vergleich ausführen
Zuerst führen Sie die Pipeline mit dem Standard-pandas auf der CPU aus. Aktivieren Sie dann cudf.pandas und führen Sie es noch einmal auf der GPU aus.
# --- Run on CPU ---
print("Running analytics pipeline on CPU...")
# Ensure we are using standard pandas
import pandas as pd
assert "cudf" not in str(pd), "Error: cuDF is still active. Please restart the kernel."
cpu_times = run_analytics_pipeline(pd)
print(f"CPU times: {cpu_times}")
# --- Run on GPU ---
print("\nEnabling cudf.pandas and running on GPU...")
# Load the extension
%load_ext cudf.pandas
import pandas as gpu_pd
gpu_times = run_analytics_pipeline(gpu_pd)
print(f"GPU times: {gpu_times}")
Ergebnisse visualisieren
Stellen Sie den Unterschied schließlich visuell dar. Im folgenden Code wird die Beschleunigung für jede Operation berechnet und nebeneinander dargestellt.
# Create a DataFrame for plotting
results_df = pd.DataFrame([cpu_times, gpu_times], index=["CPU", "GPU"]).T
total_cpu_time = results_df['CPU'].sum()
total_gpu_time = results_df['GPU'].sum()
speedup = total_cpu_time / total_gpu_time
print("--- Performance Results ---")
print(results_df)
print(f"\nTotal CPU Time: {total_cpu_time:.2f} seconds")
print(f"Total GPU Time: {total_gpu_time:.2f} seconds")
print(f"Overall Speedup: {speedup:.2f}x")
# Plot the results
fig, ax = plt.subplots(figsize=(10, 6))
results_df.plot(kind='bar', ax=ax, color={"CPU": "tab:blue", "GPU": "tab:green"})
ax.set_ylabel("Time (seconds)")
ax.set_title(f"CPU vs. GPU Runtimes (Overall Speedup: {speedup:.2f}x)", fontsize=14)
ax.tick_params(axis='x', rotation=0)
# Add numerical labels to the bars
for container in ax.containers:
ax.bar_label(container, fmt="%.2f", padding=3)
plt.tight_layout()
plt.show()
Beispielergebnisse:
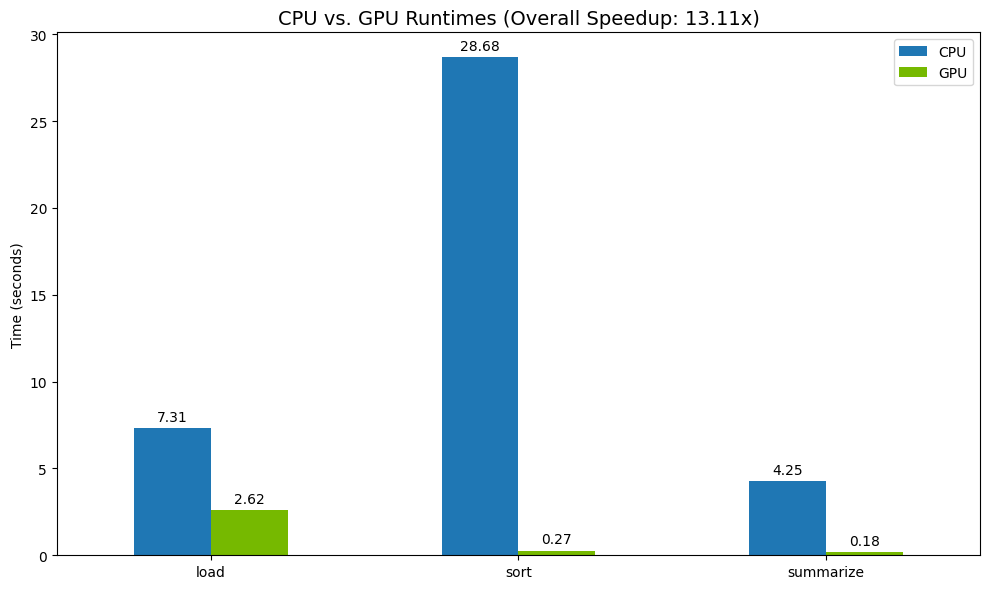
Die GPU bietet eine deutliche Geschwindigkeitssteigerung im Vergleich zur CPU.
12. Code profilieren, um Engpässe zu finden
Auch bei GPU-Beschleunigung kann es sein, dass einige pandas-Vorgänge auf die CPU zurückgreifen, wenn sie noch nicht von cuDF unterstützt werden. Diese „CPU-Fallbacks“ können zu Leistungsengpässen führen.
cudf.pandas enthält zwei integrierte Profiler, die Ihnen helfen, diese Bereiche zu identifizieren. Damit können Sie genau sehen, welche Teile Ihres Codes auf der GPU ausgeführt werden und welche auf die CPU zurückgreifen.
%%cudf.pandas.profile: Verwenden Sie diese Option für eine allgemeine Zusammenfassung Ihres Codes nach Funktion. So erhalten Sie einen schnellen Überblick darüber, welche Vorgänge auf welchem Gerät ausgeführt werden.%%cudf.pandas.line_profile: Verwenden Sie diese Option für eine detaillierte Analyse Zeile für Zeile. Es ist das beste Tool, um die genauen Zeilen in Ihrem Code zu ermitteln, die einen Fallback zur CPU verursachen.
Verwenden Sie diese Profiler als „Zellen-Magics“ oben in einer Notebook-Zelle.
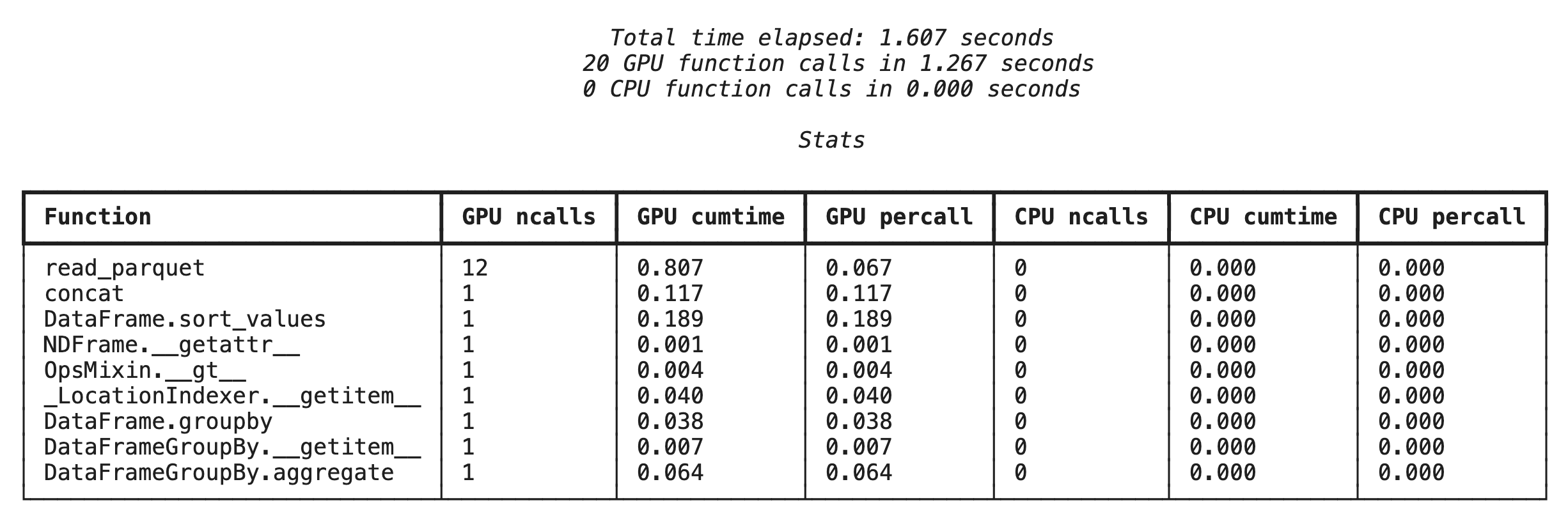
Profilierung auf Funktionsebene mit %%cudf.pandas.profile
Führen Sie zuerst den Profiler auf Funktionsebene für dieselbe Analyse-Pipeline aus dem vorherigen Abschnitt aus. Die Ausgabe enthält eine Tabelle mit jeder aufgerufenen Funktion, dem Gerät, auf dem sie ausgeführt wurde (GPU oder CPU), und der Häufigkeit des Aufrufs.
%load_ext cudf.pandas
import pandas as pd
import glob
pd.DataFrame({"a": [1]})
Nachdem Sie sichergestellt haben, dass „cudf.pandas“ aktiv ist, können Sie ein Profil ausführen.
%%cudf.pandas.profile
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*2024*.parquet")], ignore_index=True)
df = df.sort_values(['tpep_pickup_datetime', 'trip_distance', 'passenger_count'], ascending=[False, True, False])
summary = (
df
.loc[(df.tpep_pickup_datetime > '2024-11-01')]
.groupby(['VendorID','tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
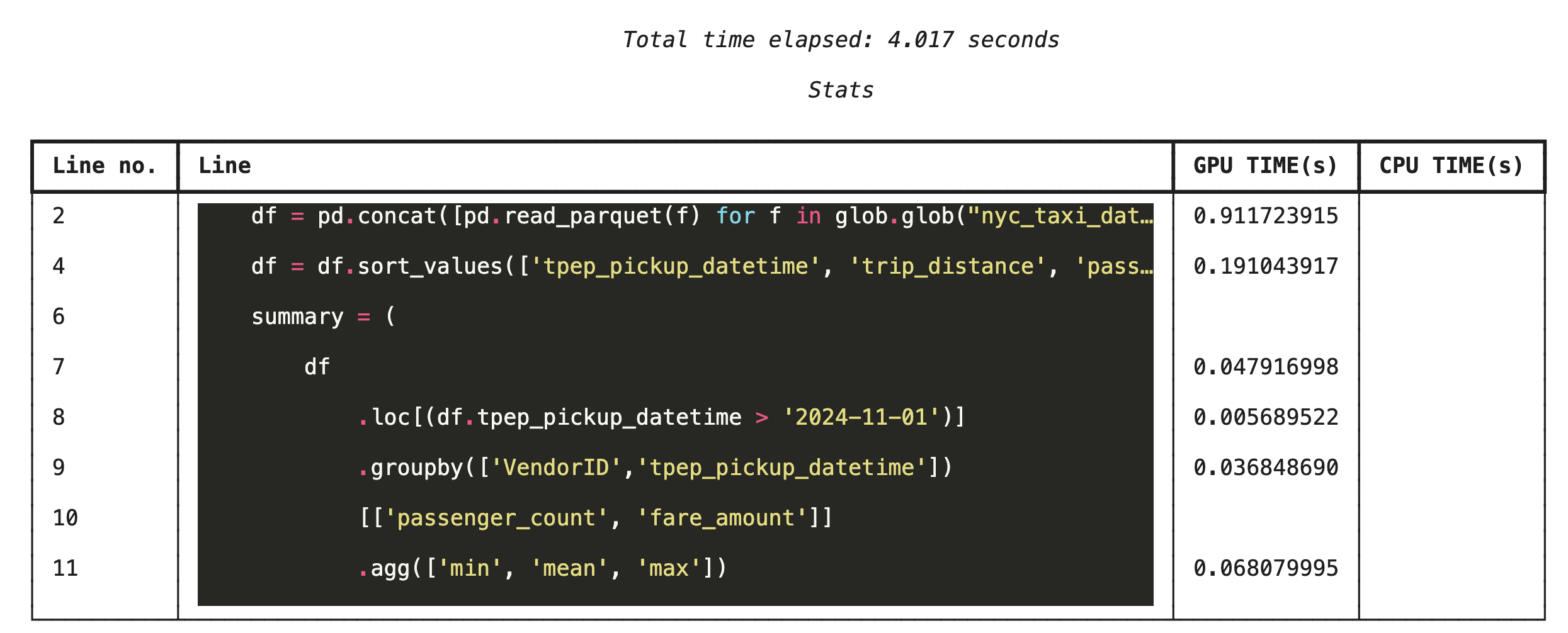
Zeilenweises Profiling mit %%cudf.pandas.line_profile
Führen Sie als Nächstes das Profiler-Tool auf Zeilenebene aus. So erhalten Sie einen viel detaillierteren Überblick und sehen, wie viel Zeit jede Codezeile für die Ausführung auf der GPU im Vergleich zur CPU benötigt hat. So lassen sich bestimmte Engpässe am effektivsten finden, um sie zu optimieren.
%%cudf.pandas.line_profile
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*2024*.parquet")], ignore_index=True)
df = df.sort_values(['tpep_pickup_datetime', 'trip_distance', 'passenger_count'], ascending=[False, True, False])
summary = (
df
.loc[(df.tpep_pickup_datetime > '2024-11-01')]
.groupby(['VendorID','tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
Profiling über die Befehlszeile
Diese Profiler sind auch über die Befehlszeile verfügbar, was für automatisierte Tests und das Profiling von Python-Skripts nützlich ist.
Sie können Folgendes in einer Befehlszeilenschnittstelle verwenden:
python -m cudf.pandas --profile your_script.pypython -m cudf.pandas --line_profile your_script.py
13. Einbindung in Google Cloud Storage
Google Cloud Storage (GCS) ist ein skalierbarer und langlebiger Objektspeicherdienst. Wenn Sie Colab Enterprise verwenden, ist GCS ein guter Ort zum Speichern Ihrer Datasets, Modell-Checkpoints und anderer Artefakte.
Ihre Colab Enterprise-Laufzeit hat die erforderlichen Berechtigungen, um Daten direkt in GCS-Buckets zu lesen und zu schreiben. Diese Vorgänge sind für maximale Leistung GPU-beschleunigt.
GCS-Bucket erstellen
Erstellen Sie zuerst einen neuen GCS-Bucket. GCS-Bucket-Namen sind global eindeutig. Hängen Sie daher eine UUID an den Namen an.
from google.cloud import storage
import uuid
unique_suffix = uuid.uuid4().hex[:12]
bucket_name = f'nyc-taxi-codelab-{unique_suffix}'
project_id = storage.Client().project
client = storage.Client()
try:
bucket = client.create_bucket(bucket_name)
print(f"Successfully created bucket: gs://{bucket.name}")
except Exception as e:
print(f"Bucket creation failed. You may already own it or the name is taken: {e}")
Daten direkt in GCS schreiben
Speichern Sie nun einen DataFrame direkt in Ihrem neuen GCS-Bucket. Wenn die Variable df aus den vorherigen Abschnitten nicht verfügbar ist, werden zuerst Daten für einen einzelnen Monat geladen.
%%cudf.pandas.line_profile
# Ensure the DataFrame exists before saving to GCS
if 'df' not in locals():
print("DataFrame not found, loading a sample file...")
df = pd.read_parquet('nyc_taxi_data/yellow_tripdata_2024-12.parquet')
print(f"Writing data to gs://{bucket_name}/nyc_taxi_data.parquet...")
df.to_parquet(f"gs://{bucket_name}/nyc_taxi_data.parquet", index=False)
print("Write operation complete.")
Datei in GCS überprüfen
Sie können prüfen, ob die Daten in GCS vorhanden sind, indem Sie den Bucket aufrufen. Mit dem folgenden Code wird ein anklickbarer Link erstellt.
from IPython.display import Markdown
gcs_url = f"https://console.cloud.google.com/storage/browser/{bucket_name}?project={project_id}"
Markdown(f'**[Click here to view your GCS bucket in the Google Cloud Console]({gcs_url})**')
Daten direkt aus GCS lesen
Schließlich lesen Sie Daten direkt aus einem GCS-Pfad in ein DataFrame. Dieser Vorgang ist auch GPU-beschleunigt, sodass Sie große Datasets schnell aus dem Cloud-Speicher laden können.
%%cudf.pandas.line_profile
print(f"Reading data from gs://{bucket_name}/nyc_taxi_data.parquet...")
df_from_gcs = pd.read_parquet(f"gs://{bucket_name}/nyc_taxi_data.parquet")
df_from_gcs.head()
14. Bereinigen
Um unerwartete Kosten für Ihr Google Cloud-Konto zu vermeiden, müssen Sie die von Ihnen erstellten Ressourcen bereinigen.
Löschen Sie die heruntergeladenen Daten:
# Permanately delete the GCS bucket
print(f"Deleting GCS bucket: gs://{bucket_name}...")
!gsutil rm -r -f gs://{bucket_name}
print("Bucket deleted.")
# Remove NYC taxi dataset on the Colab runtime
print("Deleting local 'nyc_taxi_data' directory...")
!rm -rf nyc_taxi_data
print("Local files deleted.")
Colab-Laufzeit herunterfahren
- Rufen Sie in der Google Cloud Console die Colab Enterprise-Seite Laufzeiten auf.
- Wählen Sie im Menü Region die Region aus, in der sich Ihre Laufzeit befindet.
- Wählen Sie die Laufzeit aus, die Sie löschen möchten.
- Klicken Sie auf Löschen.
- Klicken Sie auf Bestätigen.
Notebook löschen
- Rufen Sie in der Google Cloud Console die Colab Enterprise-Seite Meine Notebooks auf.
- Wählen Sie im Menü Region die Region aus, in der sich Ihr Notebook befindet.
- Wählen Sie das Notebook aus, das Sie löschen möchten.
- Klicken Sie auf Löschen.
- Klicken Sie auf Bestätigen.
15. Glückwunsch
Glückwunsch! Sie haben einen Pandas-Analyse-Workflow mit NVIDIA cuDF in Colab Enterprise beschleunigt. Sie haben gelernt, wie Sie GPU-fähige Runtimes konfigurieren, cudf.pandas für die Beschleunigung ohne Codeänderung aktivieren, Code auf Engpässe hin analysieren und in Google Cloud Storage einbinden.