
1. Introducción
En este codelab, aprenderás a acelerar tus flujos de trabajo de análisis de datos en conjuntos de datos grandes con las GPU de NVIDIA y las bibliotecas de código abierto en Google Cloud. Comenzarás por optimizar tu infraestructura y, luego, explorarás cómo aplicar la aceleración de GPU sin realizar cambios en el código.
Te enfocarás en pandas, una biblioteca popular de manipulación de datos, y aprenderás a acelerarla con la biblioteca cuDF de NVIDIA. Lo mejor es que puedes obtener esta aceleración por GPU sin cambiar tu código pandas existente.
Qué aprenderás
- Comprende Colab Enterprise en Google Cloud.
- Personaliza un entorno de ejecución de Colab con configuraciones específicas de GPU, CPU y memoria.
- Acelera
pandassin cambiar el código concuDFde NVIDIA. - Crea perfiles de tu código para identificar y optimizar los cuellos de botella en el rendimiento.
En la página siguiente, se incluyen los créditos que puedes usar para completar el lab.
2. ¿Por qué acelerar el procesamiento de datos?
La regla de 80/20: Por qué la preparación de datos consume tanto tiempo
La preparación de los datos suele ser la fase más larga de un proyecto de análisis. Los científicos y analistas de datos dedican gran parte de su tiempo a limpiar, transformar y estructurar los datos antes de que pueda comenzar cualquier análisis.
Afortunadamente, puedes acelerar bibliotecas populares de código abierto, como pandas, Apache Spark y Polars, en las GPUs de NVIDIA con cuDF. Incluso con esta aceleración, la preparación de datos sigue siendo un proceso que requiere mucho tiempo por los siguientes motivos:
- Los datos de origen rara vez están listos para el análisis: Los datos del mundo real suelen tener inconsistencias, valores faltantes y problemas de formato.
- La calidad afecta el rendimiento del modelo: La mala calidad de los datos puede hacer que incluso los algoritmos más sofisticados sean inútiles.
- La escala amplifica los problemas: Los problemas de datos que parecen menores se convierten en cuellos de botella críticos cuando se trabaja con millones de registros.
3. Cómo elegir un entorno de notebook
Si bien muchos científicos de datos conocen Colab para proyectos personales, Colab Enterprise proporciona una experiencia de notebook segura, colaborativa e integrada diseñada para empresas.
En Google Cloud, tienes dos opciones principales para los entornos de notebooks administrados: Colab Enterprise y Gemini Enterprise Agent Platform Workbench. La elección correcta depende de las prioridades de tu proyecto.
Cuándo usar Agent Platform Workbench
Elige Agent Platform Workbench cuando tu prioridad sea el control y la personalización profunda. Es la opción ideal si necesitas hacer lo siguiente:
- Administrar la infraestructura subyacente y el ciclo de vida de la máquina
- Usar contenedores personalizados y configuraciones de red
- Integración con canalizaciones de MLOps y herramientas personalizadas del ciclo de vida
Cuándo usar Colab Enterprise
Elige Colab Enterprise cuando tu prioridad sea la configuración rápida, la facilidad de uso y la colaboración segura. Es una solución completamente administrada que permite que tu equipo se enfoque en el análisis en lugar de la infraestructura.
Colab Enterprise te ayuda a hacer lo siguiente:
- Desarrolla flujos de trabajo de ciencia de datos que estén estrechamente vinculados a tu almacén de datos. Puedes abrir y administrar tus notebooks directamente en BigQuery Studio.
- Entrena modelos de aprendizaje automático y realiza integraciones con herramientas de MLOps en Agent Platform.
- Disfruta de una experiencia flexible y unificada. Un notebook de Colab Enterprise creado en BigQuery se puede abrir y ejecutar en Agent Platform, y viceversa.
Laboratorio de hoy
En este codelab, se usa Colab Enterprise para el análisis de datos acelerado.
Para obtener más información sobre las diferencias, consulta la documentación oficial sobre cómo elegir la solución de notebook adecuada.
4. Configura una plantilla de entorno de ejecución
En Colab Enterprise, conéctate a un entorno de ejecución basado en una plantilla de entorno de ejecución preconfigurada.
Una plantilla de entorno de ejecución es una configuración reutilizable que especifica todo el entorno de tu notebook, lo que incluye lo siguiente:
- Tipo de máquina (CPU, memoria)
- Acelerador (tipo y recuento de GPU)
- Tamaño y tipo de disco
- Configuración de red y políticas de seguridad
- Reglas de cierre automático por inactividad
Por qué son útiles las plantillas de tiempo de ejecución
- Obtén un entorno coherente: Tú y tus compañeros de equipo obtienen el mismo entorno listo para usar cada vez para garantizar que tu trabajo sea repetible.
- Trabaja de forma segura por diseño: Las plantillas aplican automáticamente las políticas de seguridad de tu organización.
- Administra los costos de manera eficaz: Los recursos, como las GPUs y las CPUs, tienen un tamaño predeterminado en la plantilla, lo que ayuda a evitar sobrecostos accidentales.
Crea una plantilla de entorno de ejecución
Configura una plantilla de entorno de ejecución reutilizable para el lab.
- En la consola de Google Cloud, ve al menú de navegación > Agent Platform > Notebooks.
- En Colab Enterprise, haz clic en Plantillas de entorno de ejecución y, luego, selecciona Plantilla nueva.
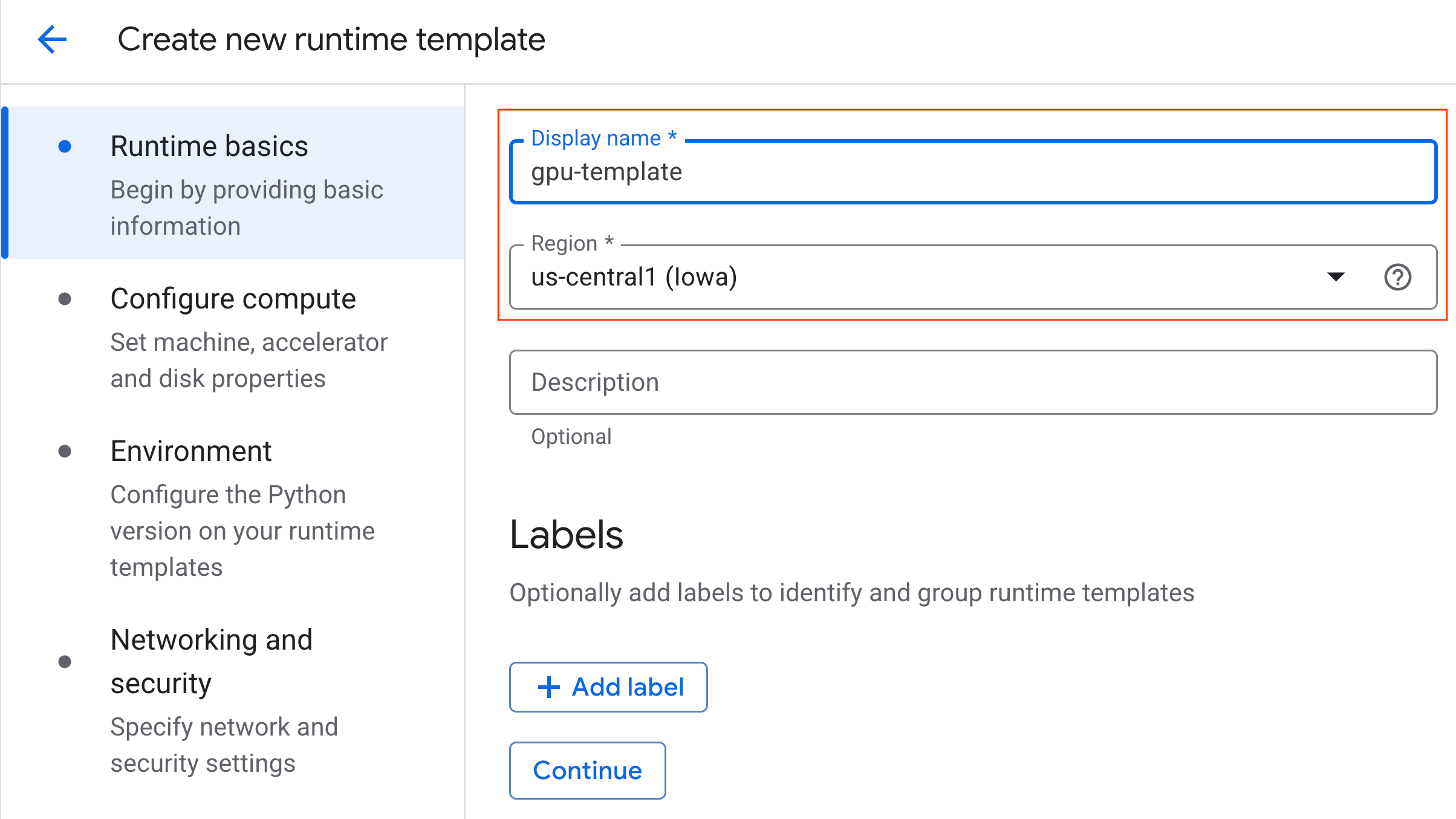
- En Conceptos básicos del entorno de ejecución, haz lo siguiente:
- Establece el Nombre visible como
gpu-template. - Establece tu región preferida.
- Establece el Nombre visible como
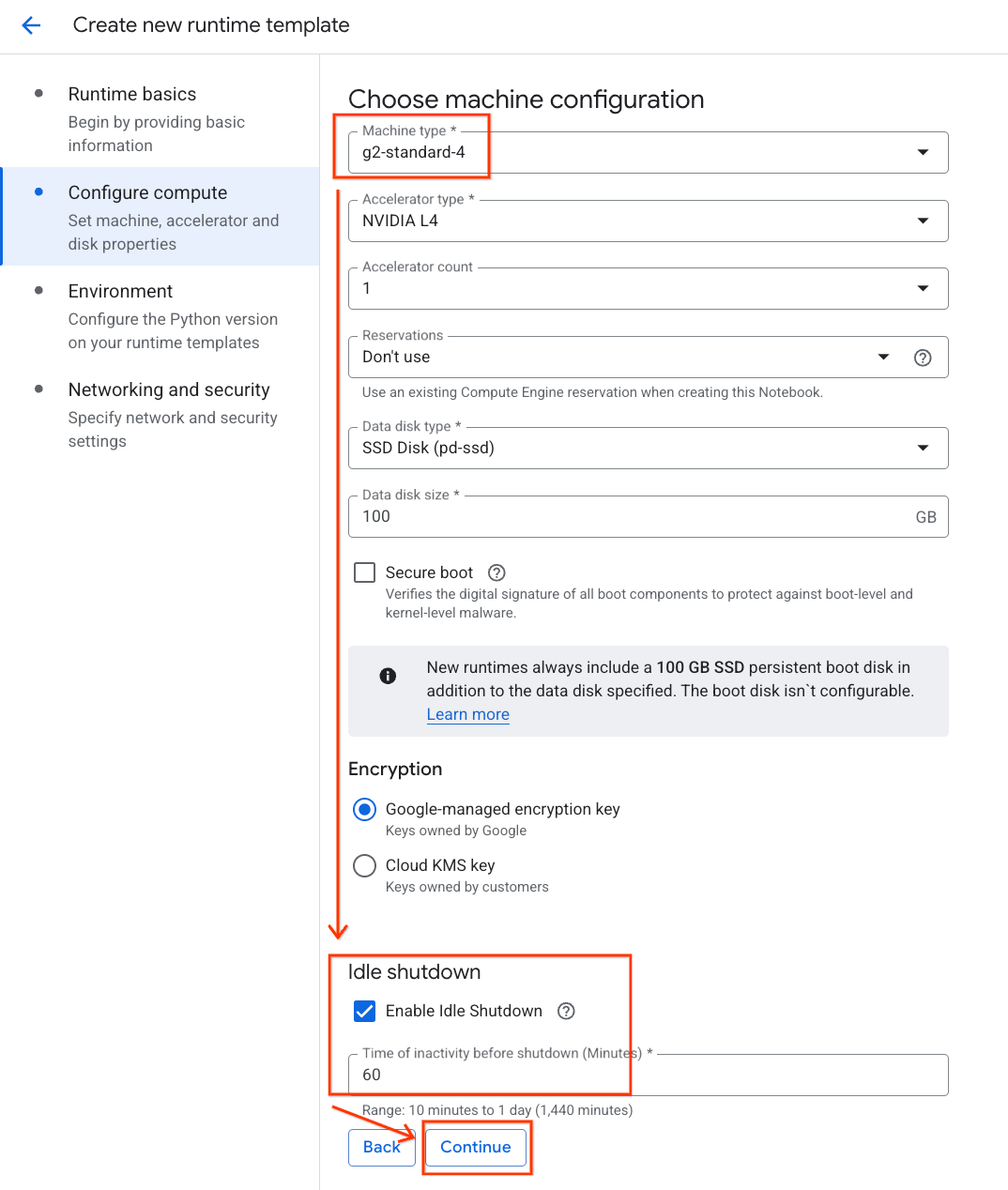
- En Configurar recursos de procesamiento, haz lo siguiente:
- Establece el Tipo de máquina en
g2-standard-4. - Mantén el Tipo de acelerador predeterminado como
NVIDIA L4con un Recuento de aceleradores de 1. - Cambia la opción Cierre inactivo a 60 minutos.
- Haz clic en Continuar.
- Establece el Tipo de máquina en
- En Environment, haz lo siguiente:
- Configura Environment como
Python 3.11.
- Configura Environment como
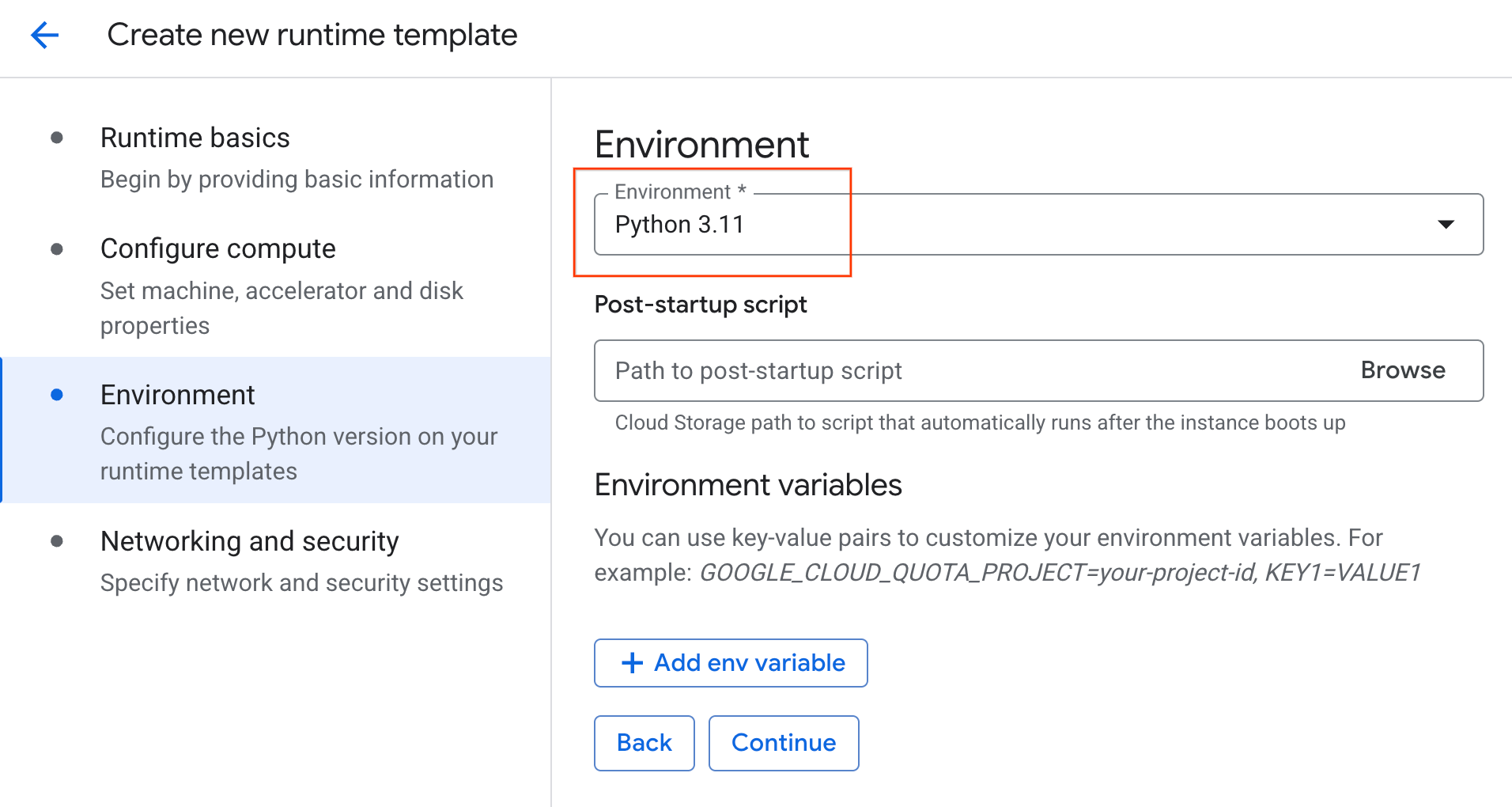
- Haz clic en Crear para guardar la plantilla de entorno de ejecución. En la página Plantillas de entorno de ejecución, ahora debería aparecer la plantilla nueva.
5. Inicia un entorno de ejecución
Cuando la plantilla esté lista, podrás crear un nuevo tiempo de ejecución.
- En Colab Enterprise, haz clic en Tiempos de ejecución y, luego, selecciona Crear.
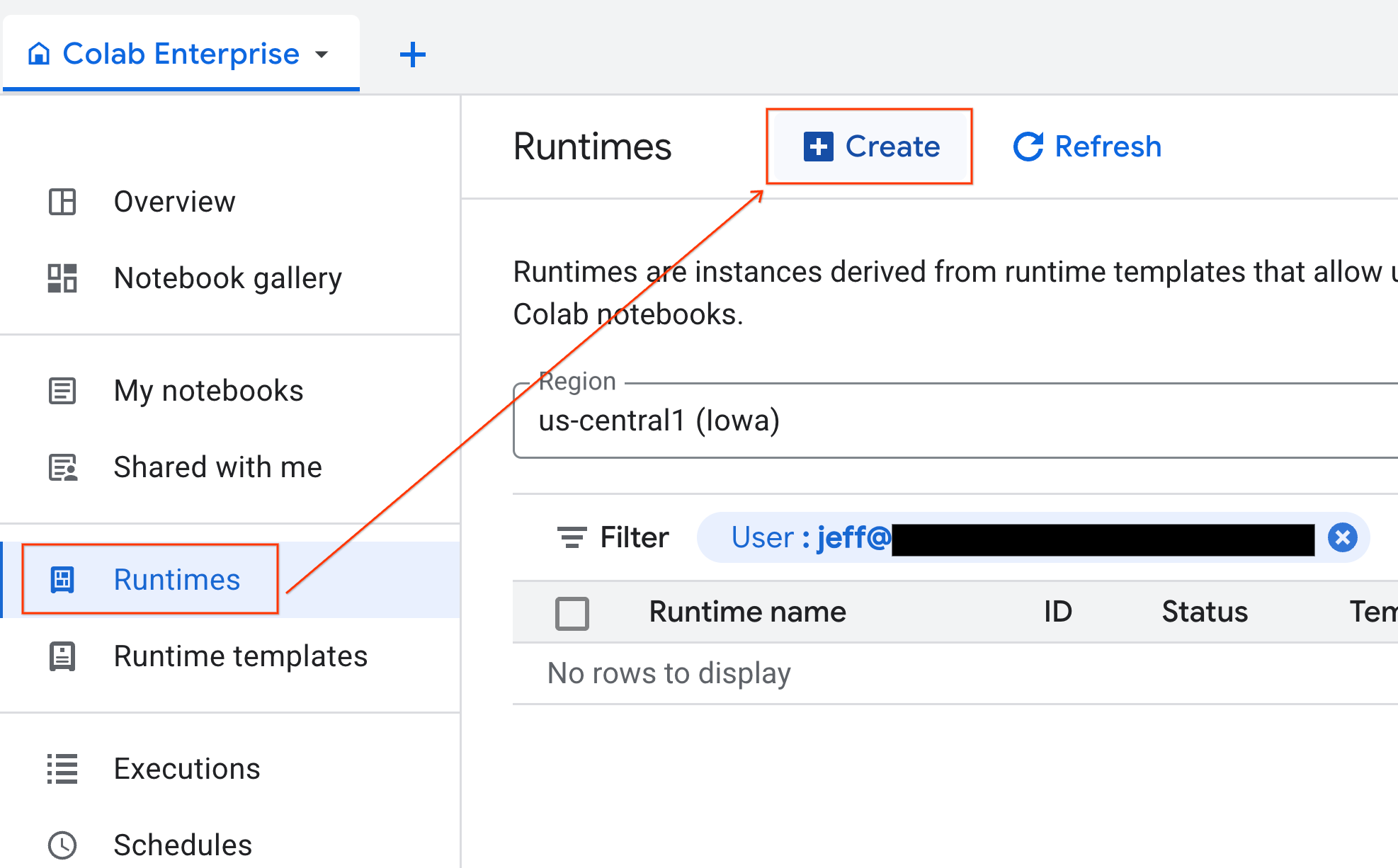
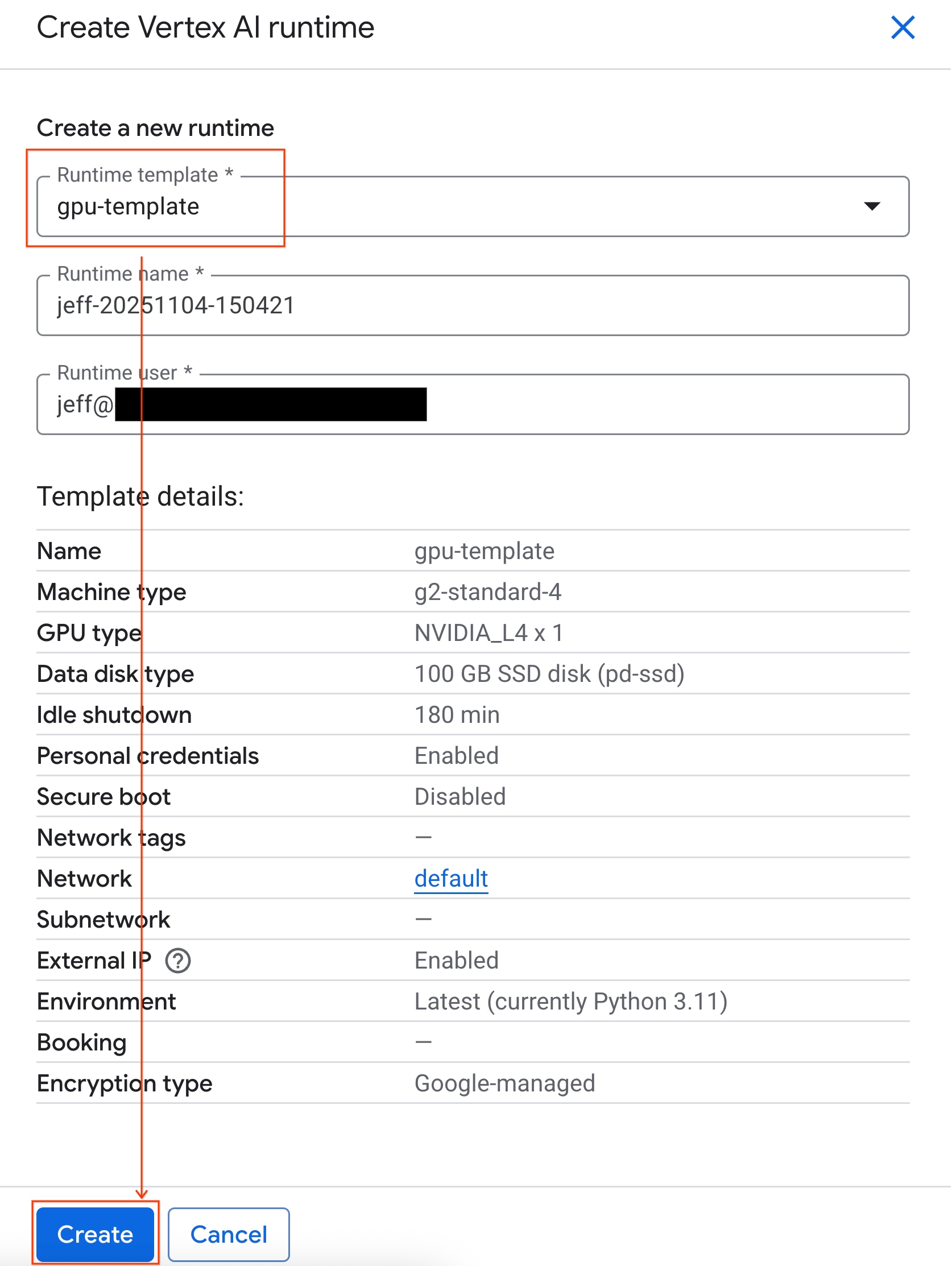
- En Plantilla de entorno de ejecución, selecciona la opción
gpu-template. Haz clic en Crear y espera a que se inicie el entorno de ejecución.
- Después de unos minutos, verás el tiempo de ejecución disponible.
6. Configura el notebook
Ahora que tu infraestructura está en funcionamiento, debes importar el notebook del lab y conectarlo a tu entorno de ejecución.
Importa el notebook
- En Colab Enterprise, haz clic en Mis notebooks y, luego, en Importar.
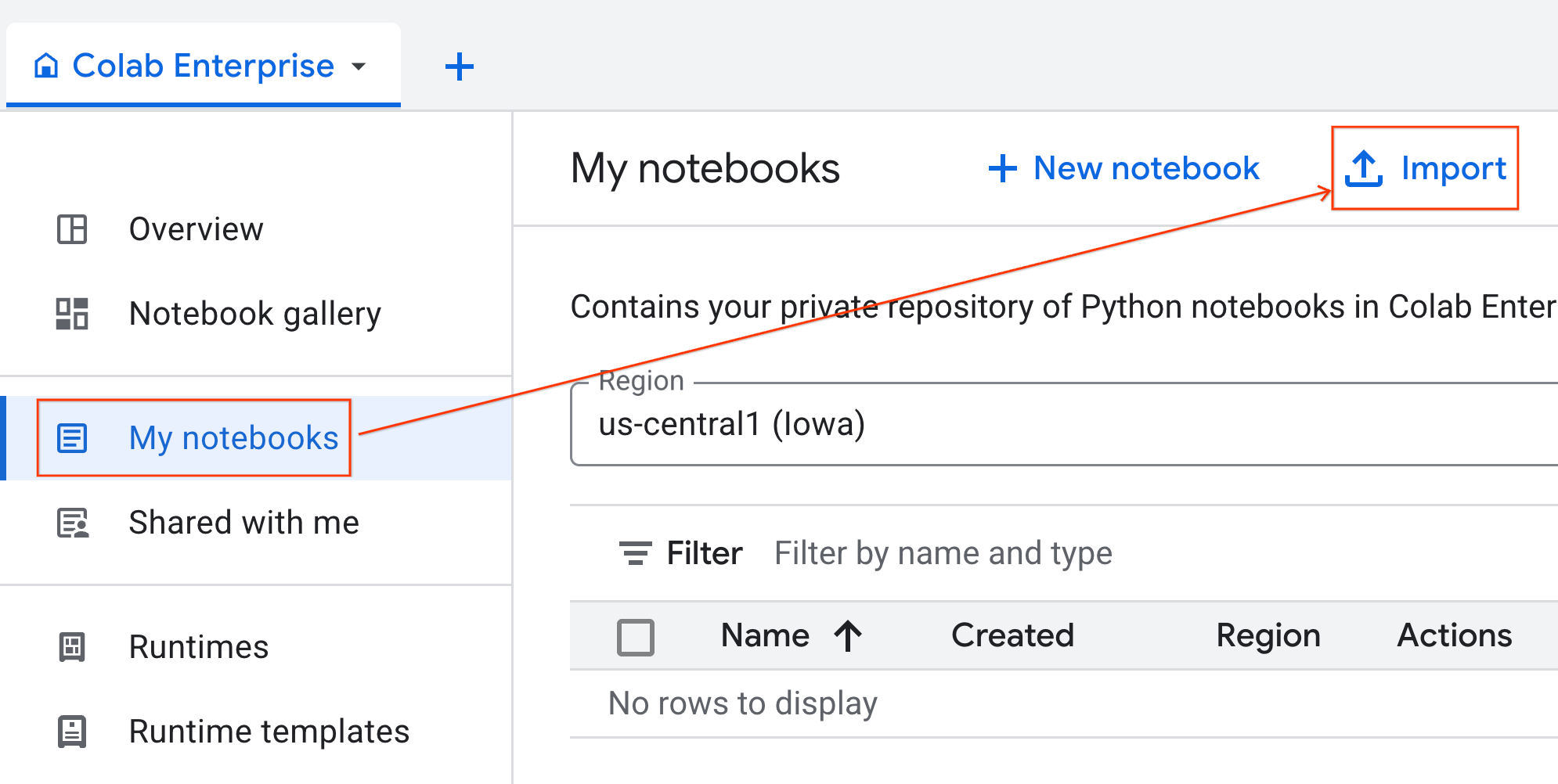
- Selecciona el botón de selección URL y, luego, ingresa la siguiente URL:
https://github.com/GoogleCloudPlatform/ai-ml-recipes/blob/main/notebooks/analytics/gpu_accelerated_analytics.ipynb
- Haz clic en Importar. Colab Enterprise copiará el notebook de GitHub a tu entorno.
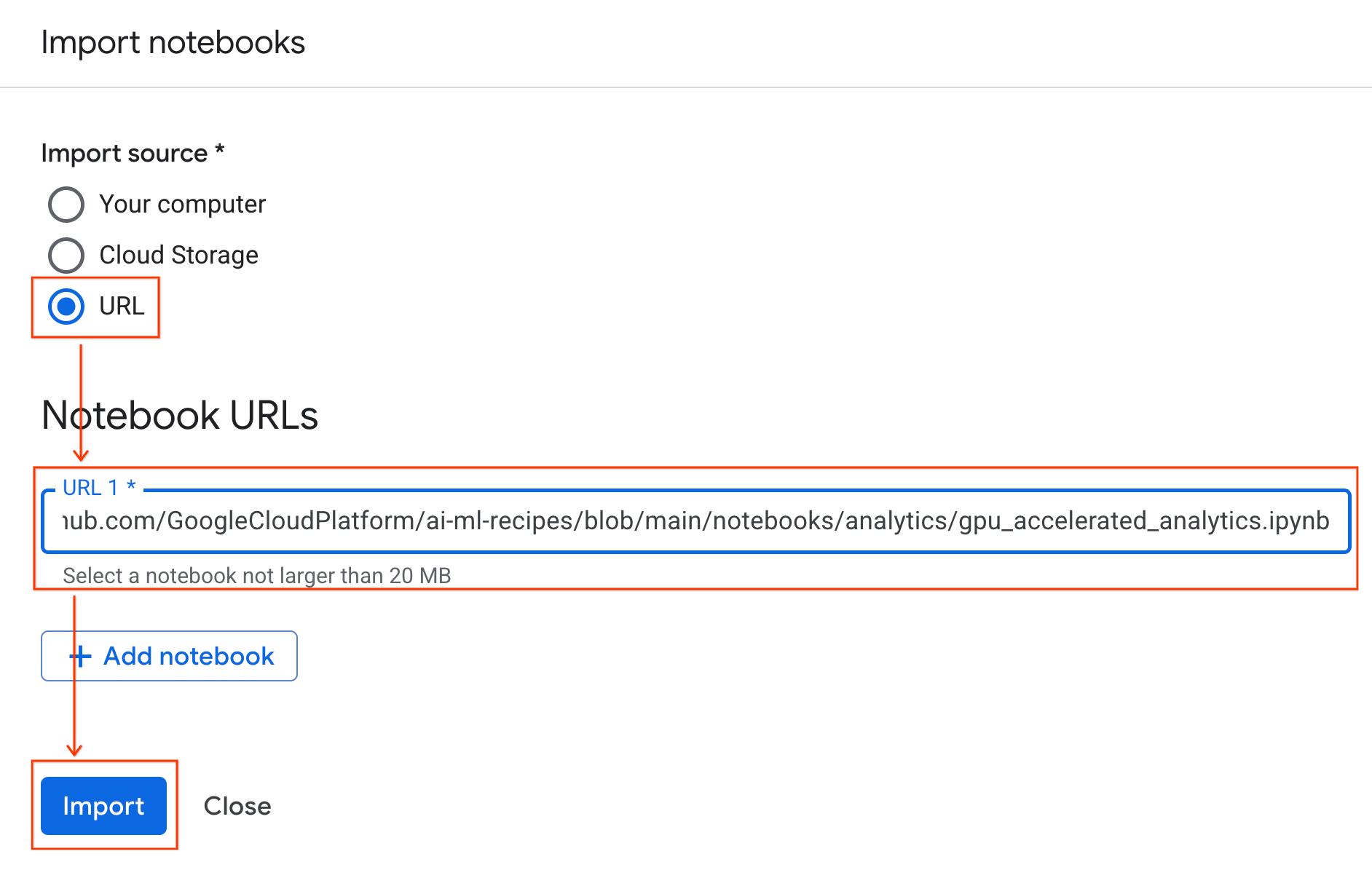
Conéctate al entorno de ejecución
- Abre el notebook que acabas de importar.
- Haz clic en la flecha hacia abajo junto a Conectar.
- Selecciona Conectar a un entorno de ejecución.
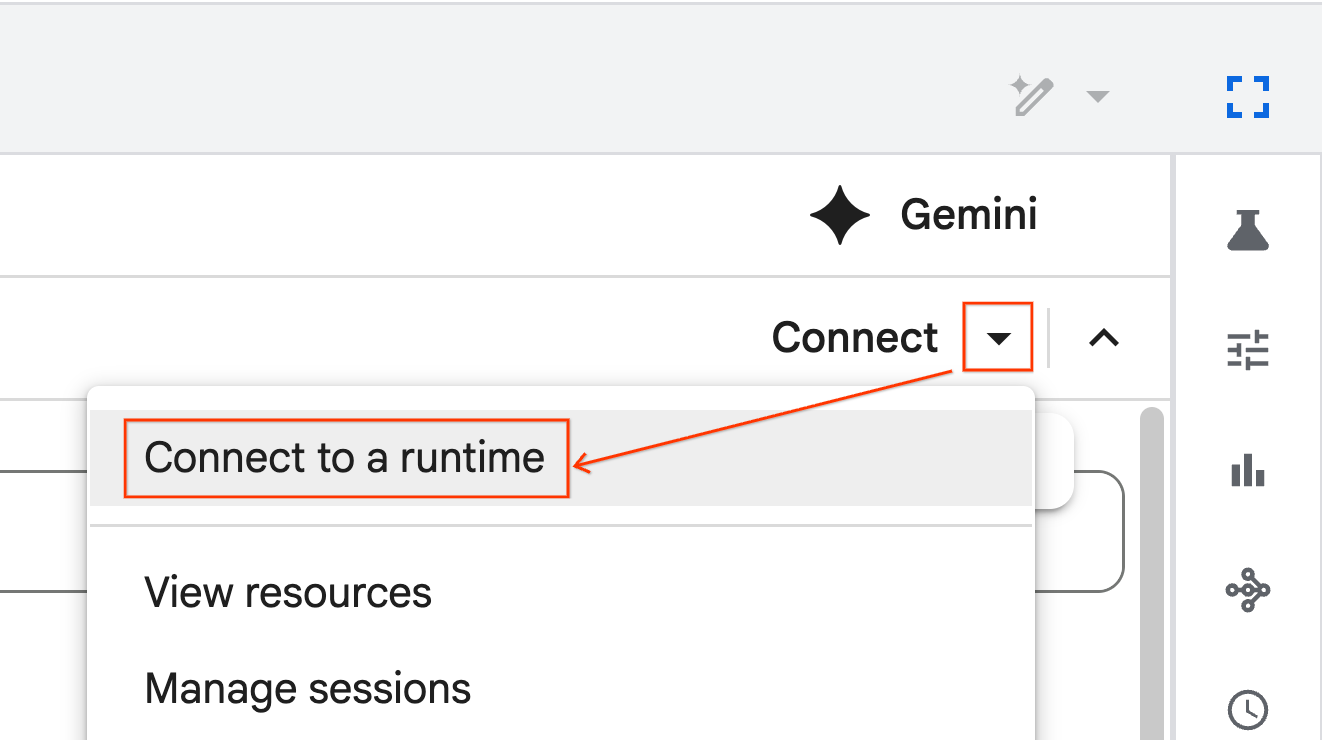
- Usa el menú desplegable y selecciona el tiempo de ejecución que creaste antes.
- Haz clic en Conectar.
Tu notebook ahora está conectado a un entorno de ejecución habilitado para GPU. Ahora puedes comenzar a ejecutar consultas.
7. Prepara el conjunto de datos de taxis de la ciudad de Nueva York
En este codelab, se usan los datos de registros de viajes de la Comisión de Taxis y Limusinas (TLC) de la Ciudad de Nueva York.
El conjunto de datos contiene registros de viajes individuales de taxis amarillos en la ciudad de Nueva York y contiene campos como los siguientes:
- Fechas, horarios y ubicaciones de partida y llegada
- Distancias de los viajes
- Importes de la tarifa desglosados
- Recuentos de pasajeros
Descarga los datos
A continuación, descarga los datos de viajes de todo el 2024. Los datos se almacenan en el formato de archivo Parquet.
El siguiente bloque de código realiza estos pasos:
- Define el período de años y meses que se descargará.
- Crea un directorio local llamado
nyc_taxi_datapara almacenar los archivos. - Itera cada mes, descarga el archivo Parquet correspondiente si aún no existe y lo guarda en el directorio.
Ejecuta este código en tu notebook para recopilar los datos y almacenarlos en el entorno de ejecución:
from tqdm import tqdm
import requests
import time
import os
YEAR = 2024
DATA_DIR = "nyc_taxi_data"
os.makedirs(DATA_DIR, exist_ok=True)
print(f"Checking/Downloading files for {YEAR}...")
for month in tqdm(range(1, 13), unit="file"):
# Define standardized filename for both local path and URL
file_name = f"yellow_tripdata_{YEAR}-{month:02d}.parquet"
local_path = os.path.join(DATA_DIR, file_name)
url = f"https://d37ci6vzurychx.cloudfront.net/trip-data/{file_name}"
if not os.path.exists(local_path):
try:
with requests.get(url, stream=True) as response:
response.raise_for_status()
with open(local_path, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
time.sleep(1)
except requests.exceptions.HTTPError as e:
print(f"\nSkipping {file_name}: {e}")
if os.path.exists(local_path):
os.remove(local_path)
print("\nDownload complete.")
8. Explora los datos de viajes en taxi
Ahora que descargaste el conjunto de datos, es hora de realizar un análisis de datos exploratorio (EDA) inicial. El objetivo del EDA es comprender la estructura de los datos, encontrar anomalías y descubrir posibles patrones.
Carga los datos de un solo mes
Comienza por cargar los datos de un solo mes. Esto proporciona una muestra lo suficientemente grande (más de 3 millones de filas) para que sea significativa y, al mismo tiempo, mantiene el uso de memoria manejable para el análisis interactivo.
import pandas as pd
import glob
# Load the last month of the downloaded data
df = pd.read_parquet("nyc_taxi_data/yellow_tripdata_2024-12.parquet")
df.head()
Cómo obtener estadísticas de resumen
Usa el método .describe() para generar estadísticas de resumen de alto nivel para las columnas numéricas. Este es un excelente primer paso para detectar posibles problemas de calidad de los datos, como valores mínimos o máximos inesperados.
df.describe().round(2)
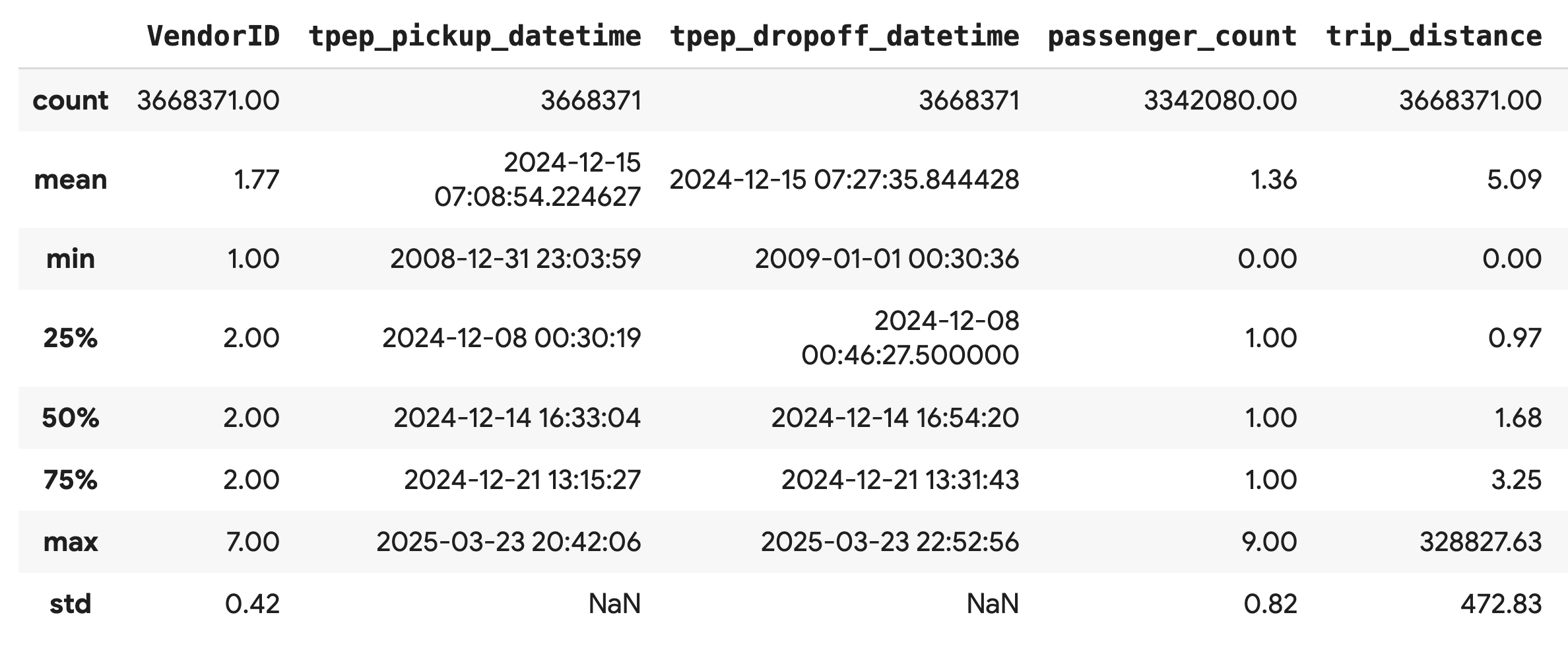
Investiga la calidad de los datos
El resultado de .describe() revela un problema de inmediato. Ten en cuenta que el valor de min para tpep_pickup_datetime y tpep_dropoff_datetime es el año 2008, lo que no tiene sentido para un conjunto de datos de 2024.
Este es un ejemplo de por qué siempre debes inspeccionar tus datos. Puedes investigar esto más a fondo ordenando el DataFrame para encontrar las filas exactas que contienen estas fechas atípicas.
# Sort by the dropoff datetime to see the oldest records
df.sort_values("tpep_pickup_datetime").head()
Visualiza las distribuciones de datos
A continuación, puedes crear histogramas de las columnas numéricas para visualizar sus distribuciones. Esto te ayuda a comprender la distribución y la asimetría de las características, como trip_distance y fare_amount. La función .hist() es una forma rápida de generar histogramas para todas las columnas numéricas de un DataFrame.
_ = df.hist(figsize=(20, 20))
Por último, genera una matriz de dispersión para visualizar las relaciones entre algunas columnas clave. Debido a que trazar millones de puntos es lento y puede ocultar patrones, usa .sample() para crear el gráfico a partir de una muestra aleatoria de 100,000 filas.
_ = pd.plotting.scatter_matrix(
df[['passenger_count', 'trip_distance', 'tip_amount', 'total_amount']].sample(100_000),
diagonal="kde",
figsize=(15, 15)
)
9. ¿Por qué usar el formato de archivo Parquet?
El conjunto de datos de taxis de NYC se proporciona en formato Apache Parquet. Esta es una elección deliberada para el análisis a gran escala. Parquet ofrece varias ventajas sobre los tipos de archivos como CSV:
- Eficiente y rápido: Como formato en columnas, Parquet es muy eficiente para almacenar y leer. Admite métodos de compresión modernos que generan tamaños de archivo más pequeños y E/S significativamente más rápidas, especialmente en las GPUs.
- Conserva el esquema: Parquet almacena los tipos de datos en los metadatos del archivo. Nunca tendrás que adivinar los tipos de datos cuando leas el archivo.
- Permite la lectura selectiva: La estructura de columnas te permite leer solo las columnas específicas que necesitas para un análisis. Esto puede reducir drásticamente la cantidad de datos que debes cargar en la memoria.
Explora las funciones de Parquet
Exploremos dos de estas poderosas funciones con uno de los archivos que descargaste.
Inspecciona los metadatos sin cargar el conjunto de datos completo
Si bien no puedes ver un archivo Parquet en un editor de texto estándar, puedes inspeccionar fácilmente su esquema y metadatos sin cargar ningún dato en la memoria. Esto es útil para comprender rápidamente la estructura de un archivo.
from pyarrow.parquet import ParquetFile
import pyarrow as pa
# Open one of the downloaded files
pf = ParquetFile('nyc_taxi_data/yellow_tripdata_2024-12.parquet')
# Print the schema
print("File Schema:")
print(pf.schema)
# Print the file metadata
print("\nFile Metadata:")
print(pf.metadata)
Lee solo las columnas que necesitas
Imagina que solo necesitas analizar la distancia del viaje y los importes de las tarifas. Con Parquet, puedes cargar solo esas columnas, lo que es mucho más rápido y eficiente en cuanto a la memoria que cargar todo el DataFrame.
import pandas as pd
# Read only four specific columns from the Parquet file
df_subset = pd.read_parquet(
'nyc_taxi_data/yellow_tripdata_2024-12.parquet',
columns=['passenger_count', 'trip_distance', 'tip_amount', 'total_amount']
)
df_subset.head()
10. Acelera Pandas con NVIDIA cuDF
NVIDIA CUDA para DataFrames (cuDF) es una biblioteca de código abierto acelerada por GPU que te permite interactuar con DataFrames. cuDF te permite realizar operaciones de datos comunes, como filtrar, unir y agrupar en la GPU con un paralelismo masivo.
La función clave que usarás en este codelab es el modo de aceleración cudf.pandas. Cuando lo habilitas, tu código pandas estándar se redirecciona automáticamente para usar kernels cuDF potenciados por GPU de forma interna, todo sin necesidad de que cambies tu código.
Habilita la aceleración por GPU
Para usar NVIDIA cuDF en un notebook de Colab Enterprise, debes cargar su extensión mágica antes de importar pandas.
Primero, inspecciona la biblioteca pandas estándar. Observa que el resultado muestra la ruta de acceso a la instalación predeterminada de pandas.
import pandas as pd
pd # Note the output for the standard pandas library
Ahora, carga la extensión cudf.pandas y vuelve a importar pandas. Observa cómo cambia el resultado del módulo pd. Esto confirma que la versión acelerada por GPU ahora está activa.
%load_ext cudf.pandas
import pandas as pd
pd # Note the new output, indicating cudf.pandas is active
Otras formas de habilitar cudf.pandas
Si bien el comando mágico (%load_ext) es el método más sencillo en un notebook, también puedes habilitar el acelerador en otros entornos:
- En secuencias de comandos de Python: Llama a
import cudf.pandasycudf.pandas.install()antes de importarpandas. - Desde entornos que no son de notebook: Ejecuta tu secuencia de comandos con
python -m cudf.pandas your_script.py.
11. Comparar el rendimiento de la CPU y la GPU
Ahora, la parte más importante: comparar el rendimiento de pandas estándar en una CPU con cudf.pandas en una GPU.
Para garantizar un modelo de referencia completamente justo para la CPU, primero debes restablecer el tiempo de ejecución de Colab. Esto borrará cualquier acelerador de GPU que hayas habilitado en las secciones anteriores. Para reiniciar el entorno de ejecución, ejecuta la siguiente celda o selecciona Reiniciar sesión en el menú Entorno de ejecución.
import IPython
IPython.Application.instance().kernel.do_shutdown(True)
Define la canalización de análisis
Ahora que el entorno está limpio, definirás la función de comparativas. Esta función te permite ejecutar exactamente la misma canalización (carga, ordenamiento y resumen) con el módulo pandas que le pases.
import time
import glob
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
def run_analytics_pipeline(pd_module):
"""Loads, sorts, and summarizes data using the provided pandas module."""
timings = {}
# 1. Load all 2024 Parquet files from the directory
t0 = time.time()
df = pd_module.concat(
[pd_module.read_parquet(f) for f in glob.glob("nyc_taxi_data/*_2024*.parquet")],
ignore_index=True
)
timings["load"] = time.time() - t0
# 2. Sort the data by multiple columns
t0 = time.time()
df = df.sort_values(
['tpep_pickup_datetime', 'trip_distance', 'passenger_count'],
ascending=[False, True, False]
)
timings["sort"] = time.time() - t0
# 3. Perform a groupby and aggregation
t0 = time.time()
df['tpep_pickup_datetime'] = pd_module.to_datetime(df['tpep_pickup_datetime'])
_ = (
df.loc[df.tpep_pickup_datetime > '2024-11-01']
.groupby(['VendorID', 'tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
timings["summarize"] = time.time() - t0
return timings
Ejecuta la comparación
Primero, ejecutarás la canalización con pandas estándar en la CPU. Luego, habilita cudf.pandas y vuelve a ejecutarlo en la GPU.
# --- Run on CPU ---
print("Running analytics pipeline on CPU...")
# Ensure we are using standard pandas
import pandas as pd
assert "cudf" not in str(pd), "Error: cuDF is still active. Please restart the kernel."
cpu_times = run_analytics_pipeline(pd)
print(f"CPU times: {cpu_times}")
# --- Run on GPU ---
print("\nEnabling cudf.pandas and running on GPU...")
# Load the extension
%load_ext cudf.pandas
import pandas as gpu_pd
gpu_times = run_analytics_pipeline(gpu_pd)
print(f"GPU times: {gpu_times}")
Visualización de resultados
Por último, visualiza la diferencia. El siguiente código calcula la aceleración para cada operación y las grafica una al lado de la otra.
# Create a DataFrame for plotting
results_df = pd.DataFrame([cpu_times, gpu_times], index=["CPU", "GPU"]).T
total_cpu_time = results_df['CPU'].sum()
total_gpu_time = results_df['GPU'].sum()
speedup = total_cpu_time / total_gpu_time
print("--- Performance Results ---")
print(results_df)
print(f"\nTotal CPU Time: {total_cpu_time:.2f} seconds")
print(f"Total GPU Time: {total_gpu_time:.2f} seconds")
print(f"Overall Speedup: {speedup:.2f}x")
# Plot the results
fig, ax = plt.subplots(figsize=(10, 6))
results_df.plot(kind='bar', ax=ax, color={"CPU": "tab:blue", "GPU": "tab:green"})
ax.set_ylabel("Time (seconds)")
ax.set_title(f"CPU vs. GPU Runtimes (Overall Speedup: {speedup:.2f}x)", fontsize=14)
ax.tick_params(axis='x', rotation=0)
# Add numerical labels to the bars
for container in ax.containers:
ax.bar_label(container, fmt="%.2f", padding=3)
plt.tight_layout()
plt.show()
Resultados de muestra:
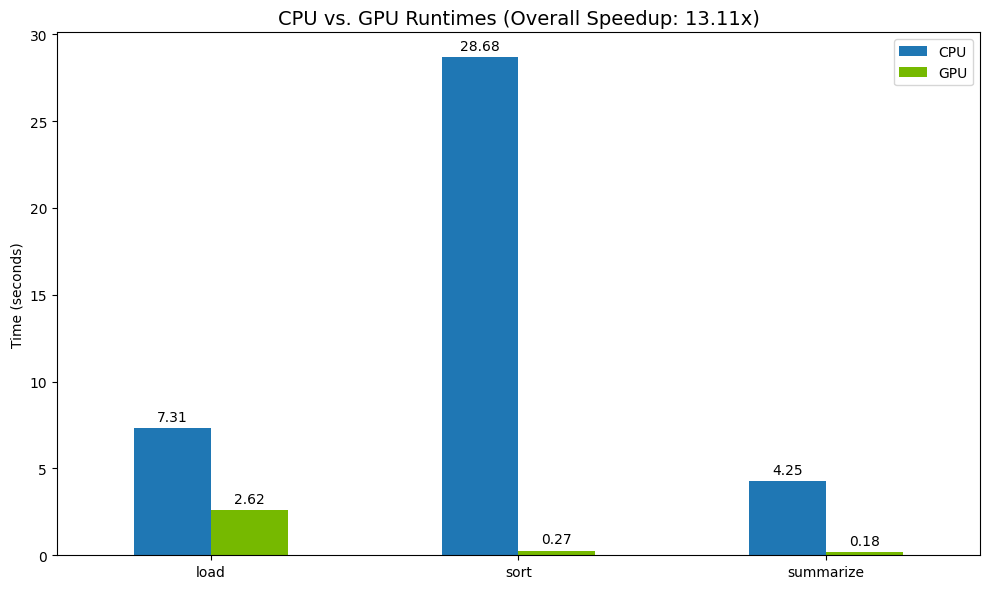
La GPU proporciona un aumento de velocidad claro en relación con la CPU.
12. Genera un perfil de tu código para encontrar cuellos de botella
Incluso con la aceleración de la GPU, algunas operaciones de pandas podrían recurrir a la CPU si cuDF aún no las admite. Estos "recursos alternativos de CPU" pueden convertirse en cuellos de botella de rendimiento.
Para ayudarte a identificar estas áreas, cudf.pandas incluye dos generadores de perfiles integrados. Puedes usarlos para ver exactamente qué partes de tu código se ejecutan en la GPU y cuáles recurren a la CPU.
%%cudf.pandas.profile: Usa este resumen para obtener una descripción general de tu código, función por función. Es ideal para obtener una descripción general rápida de qué operaciones se ejecutan en qué dispositivo.%%cudf.pandas.line_profile: Usa esta opción para obtener un análisis detallado línea por línea. Es la mejor herramienta para identificar las líneas exactas de tu código que provocan una reversión a la CPU.
Usa estos generadores de perfiles como "comandos mágicos de celda" en la parte superior de una celda del notebook.
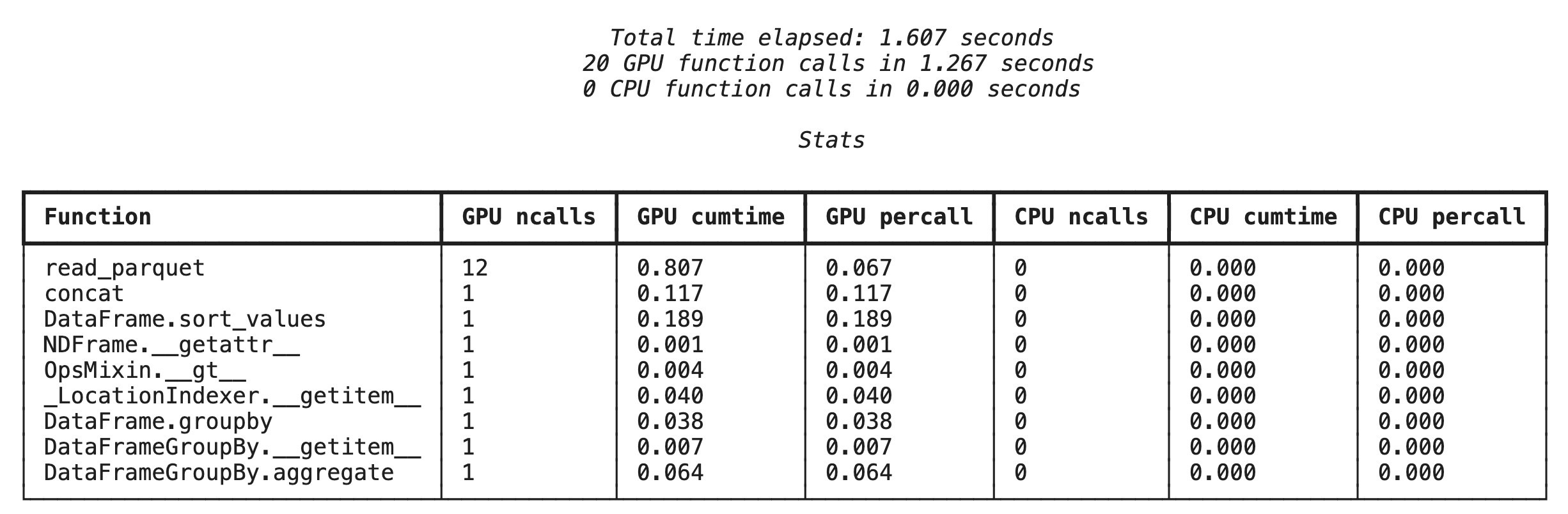
Generación de perfiles a nivel de la función con %%cudf.pandas.profile
Primero, ejecuta el generador de perfiles a nivel de la función en la misma canalización de análisis de la sección anterior. El resultado muestra una tabla de cada función llamada, el dispositivo en el que se ejecutó (GPU o CPU) y la cantidad de veces que se llamó.
%load_ext cudf.pandas
import pandas as pd
import glob
pd.DataFrame({"a": [1]})
Después de asegurarte de que cudf.pandas esté activo, puedes ejecutar un perfil.
%%cudf.pandas.profile
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*2024*.parquet")], ignore_index=True)
df = df.sort_values(['tpep_pickup_datetime', 'trip_distance', 'passenger_count'], ascending=[False, True, False])
summary = (
df
.loc[(df.tpep_pickup_datetime > '2024-11-01')]
.groupby(['VendorID','tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
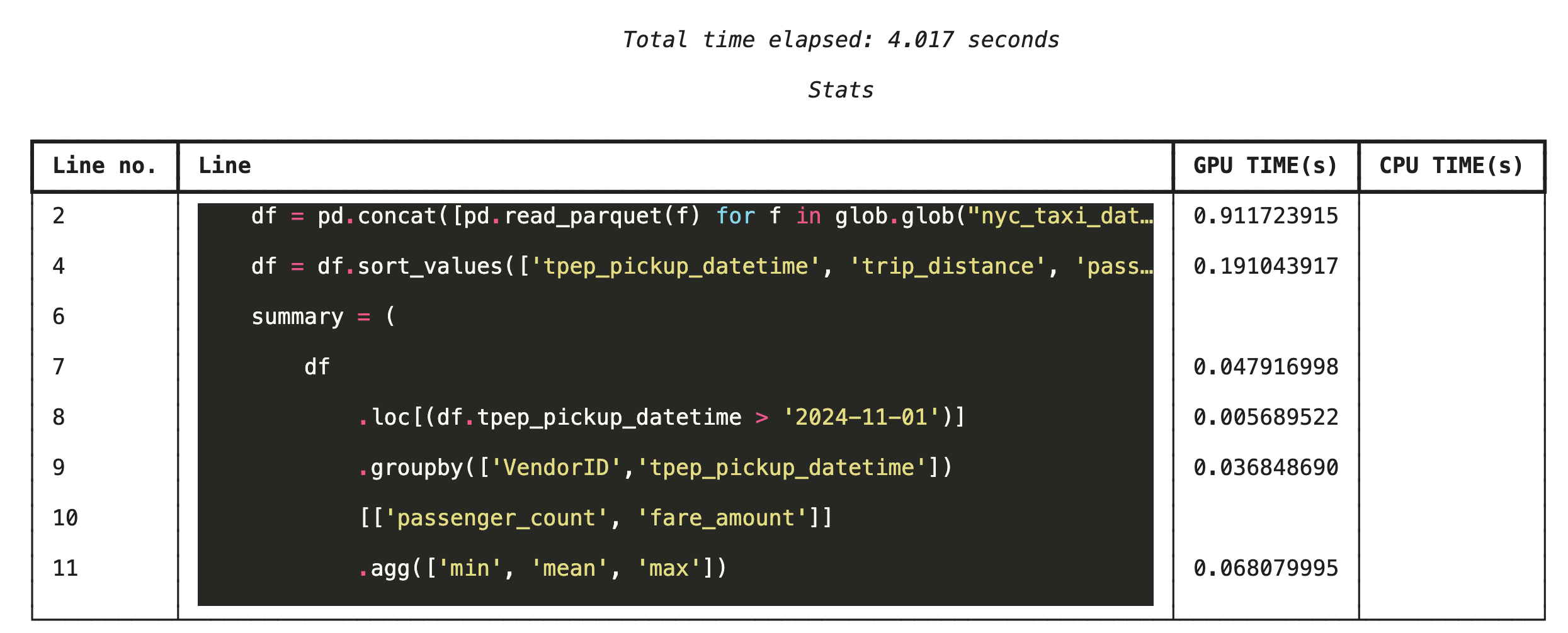
Perfilamiento línea por línea con %%cudf.pandas.line_profile
A continuación, ejecuta el generador de perfiles a nivel de la línea. Esto te brinda una vista mucho más detallada, ya que muestra la proporción de tiempo que cada línea de código dedicó a ejecutarse en la GPU en comparación con la CPU. Esta es la forma más eficaz de encontrar cuellos de botella específicos para optimizar.
%%cudf.pandas.line_profile
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*2024*.parquet")], ignore_index=True)
df = df.sort_values(['tpep_pickup_datetime', 'trip_distance', 'passenger_count'], ascending=[False, True, False])
summary = (
df
.loc[(df.tpep_pickup_datetime > '2024-11-01')]
.groupby(['VendorID','tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
Cómo generar perfiles desde la línea de comandos
Estos analizadores también están disponibles desde la línea de comandos, lo que resulta útil para las pruebas automatizadas y la generación de perfiles de secuencias de comandos de Python.
Puedes usar lo siguiente en una interfaz de línea de comandos:
python -m cudf.pandas --profile your_script.pypython -m cudf.pandas --line_profile your_script.py
13. Integración con Google Cloud Storage
Google Cloud Storage (GCS) es un servicio de almacenamiento de objetos escalable y duradero. Cuando usas Colab Enterprise, GCS es un excelente lugar para almacenar tus conjuntos de datos, puntos de control del modelo y otros artefactos.
Tu entorno de ejecución de Colab Enterprise tiene los permisos necesarios para leer y escribir datos directamente en los buckets de GCS, y estas operaciones se aceleran con GPU para obtener el máximo rendimiento.
Crear un bucket de GCS
Primero, crea un bucket de GCS nuevo. Los nombres de los buckets de GCS son únicos a nivel global, por lo que debes agregar un UUID a su nombre.
from google.cloud import storage
import uuid
unique_suffix = uuid.uuid4().hex[:12]
bucket_name = f'nyc-taxi-codelab-{unique_suffix}'
project_id = storage.Client().project
client = storage.Client()
try:
bucket = client.create_bucket(bucket_name)
print(f"Successfully created bucket: gs://{bucket.name}")
except Exception as e:
print(f"Bucket creation failed. You may already own it or the name is taken: {e}")
Escribe datos directamente en GCS
Ahora, guarda un DataFrame directamente en tu nuevo bucket de GCS. Si la variable df no está disponible en las secciones anteriores, el código primero carga los datos de un solo mes.
%%cudf.pandas.line_profile
# Ensure the DataFrame exists before saving to GCS
if 'df' not in locals():
print("DataFrame not found, loading a sample file...")
df = pd.read_parquet('nyc_taxi_data/yellow_tripdata_2024-12.parquet')
print(f"Writing data to gs://{bucket_name}/nyc_taxi_data.parquet...")
df.to_parquet(f"gs://{bucket_name}/nyc_taxi_data.parquet", index=False)
print("Write operation complete.")
Verifica el archivo en GCS
Para verificar que los datos estén en GCS, visita el bucket. El siguiente código crea un vínculo en el que se puede hacer clic.
from IPython.display import Markdown
gcs_url = f"https://console.cloud.google.com/storage/browser/{bucket_name}?project={project_id}"
Markdown(f'**[Click here to view your GCS bucket in the Google Cloud Console]({gcs_url})**')
Leer datos directamente desde GCS
Por último, lee los datos directamente desde una ruta de acceso de GCS en un DataFrame. Esta operación también se acelera con la GPU, lo que te permite cargar grandes conjuntos de datos desde el almacenamiento en la nube a alta velocidad.
%%cudf.pandas.line_profile
print(f"Reading data from gs://{bucket_name}/nyc_taxi_data.parquet...")
df_from_gcs = pd.read_parquet(f"gs://{bucket_name}/nyc_taxi_data.parquet")
df_from_gcs.head()
14. Limpieza
Para evitar que se apliquen cargos inesperados a tu cuenta de Google Cloud, debes limpiar los recursos que creaste.
Borra los datos que descargaste:
# Permanately delete the GCS bucket
print(f"Deleting GCS bucket: gs://{bucket_name}...")
!gsutil rm -r -f gs://{bucket_name}
print("Bucket deleted.")
# Remove NYC taxi dataset on the Colab runtime
print("Deleting local 'nyc_taxi_data' directory...")
!rm -rf nyc_taxi_data
print("Local files deleted.")
Cierra el entorno de ejecución de Colab
- En la consola de Google Cloud, ve a la página Entornos de ejecución de Colab Enterprise.
- En el menú Región, selecciona la región que contiene el entorno de ejecución.
- Selecciona el tiempo de ejecución que deseas borrar.
- Haz clic en Borrar.
- Haz clic en Confirmar.
Borra tu notebook
- En la consola de Google Cloud, ve a la página Mis notebooks de Colab Enterprise.
- En el menú Región, selecciona la región que contiene el notebook.
- Selecciona el notebook que quieres borrar.
- Haz clic en Borrar.
- Haz clic en Confirmar.
15. Felicitaciones
¡Felicitaciones! Aceleraste correctamente un flujo de trabajo de análisis de pandas con NVIDIA cuDF en Colab Enterprise. Aprendiste a configurar tiempos de ejecución habilitados para GPU, habilitar cudf.pandas para la aceleración sin cambios en el código, crear perfiles de código para identificar cuellos de botella y realizar la integración con Google Cloud Storage.