
۱. مقدمه
در این Codelab، شما یاد خواهید گرفت که چگونه با استفاده از پردازندههای گرافیکی NVIDIA و کتابخانههای متنباز در Google Cloud، گردشهای کاری تجزیه و تحلیل دادههای خود را در مجموعه دادههای بزرگ تسریع کنید. شما با بهینهسازی زیرساخت خود شروع خواهید کرد و سپس نحوه اعمال شتابدهی GPU را بدون تغییر کد بررسی خواهید کرد.
شما بر روی pandas ، یک کتابخانه محبوب دستکاری دادهها، تمرکز خواهید کرد و یاد خواهید گرفت که چگونه با استفاده از کتابخانه cuDF انویدیا، آن را تسریع کنید. بهترین بخش این است که میتوانید این شتاب GPU را بدون تغییر کد pandas موجود خود دریافت کنید.
آنچه یاد خواهید گرفت
- آشنایی با Colab Enterprise در فضای ابری گوگل
- یک محیط زمان اجرای Colab را با تنظیمات خاص GPU، CPU و حافظه سفارشی کنید.
- با استفاده از NVIDIA
cuDFpandasبدون تغییر کد سرعت بخشید. - کد خود را برای شناسایی و بهینهسازی گلوگاههای عملکرد، نمایهسازی کنید.
صفحه بعدی شامل واحدهایی است که میتوانید برای تکمیل آزمایشگاه از آنها استفاده کنید.
۲. چرا پردازش دادهها را تسریع کنیم؟
قانون ۸۰/۲۰: چرا آمادهسازی دادهها اینقدر زمانبر است
آمادهسازی دادهها اغلب زمانبرترین مرحله از یک پروژه تحلیلی است. دانشمندان و تحلیلگران داده بخش زیادی از وقت خود را صرف پاکسازی، تبدیل و ساختاردهی دادهها قبل از شروع هرگونه تجزیه و تحلیل میکنند.
خوشبختانه، شما میتوانید با استفاده از cuDF کتابخانههای متنباز محبوبی مانند pandas، Apache Spark و Polars را روی پردازندههای گرافیکی NVIDIA شتاب دهید. حتی با وجود این شتاب، آمادهسازی دادهها همچنان زمانبر است زیرا:
- دادههای منبع به ندرت برای تجزیه و تحلیل آماده هستند: دادههای دنیای واقعی اغلب دارای ناسازگاریها، مقادیر از دست رفته و مشکلات قالببندی هستند.
- کیفیت بر عملکرد مدل تأثیر میگذارد: کیفیت پایین دادهها میتواند حتی پیچیدهترین الگوریتمها را نیز بیفایده کند.
- مقیاس، مشکلات را تشدید میکند: مشکلات به ظاهر جزئی دادهها، هنگام کار با میلیونها رکورد، به تنگناهای حیاتی تبدیل میشوند.
۳. انتخاب محیط نوتبوک
در حالی که بسیاری از دانشمندان داده با Colab برای پروژههای شخصی آشنا هستند، Colab Enterprise یک تجربه نوتبوک امن، مشارکتی و یکپارچه را برای کسبوکارها ارائه میدهد.
در گوگل کلود، شما دو انتخاب اصلی برای محیطهای مدیریتشدهی نوتبوک دارید: Colab Enterprise و Gemini Enterprise Agent Platform Workbench . انتخاب درست به اولویتهای پروژه شما بستگی دارد.
چه زمانی از میز کار پلتفرم عامل استفاده کنیم
اگر اولویت شما کنترل و سفارشیسازی عمیق است، Agent Platform Workbench را انتخاب کنید. اگر به موارد زیر نیاز دارید، این انتخاب ایدهآلی است:
- مدیریت زیرساختهای زیربنایی و چرخه عمر ماشینآلات.
- از کانتینرها و پیکربندیهای شبکه سفارشی استفاده کنید.
- با خطوط لوله MLOps و ابزارهای چرخه عمر سفارشی ادغام شوید.
چه زمانی از Colab Enterprise استفاده کنیم؟
وقتی اولویت شما راهاندازی سریع، سهولت استفاده و همکاری امن است، Colab Enterprise را انتخاب کنید. این یک راهکار کاملاً مدیریتشده است که به تیم شما اجازه میدهد به جای زیرساخت، روی تجزیه و تحلیل تمرکز کند.
شرکت کولب به شما کمک میکند:
- گردشهای کاری علوم داده را که ارتباط نزدیکی با انبار داده شما دارند، توسعه دهید. میتوانید دفترچههای یادداشت خود را مستقیماً در BigQuery Studio باز و مدیریت کنید.
- مدلهای یادگیری ماشین را آموزش دهید و با ابزارهای MLOps در Agent Platform ادغام کنید.
- از یک تجربه انعطافپذیر و یکپارچه لذت ببرید. یک نوتبوک Colab Enterprise که در BigQuery ایجاد شده است، میتواند در Agent Platform باز و اجرا شود و برعکس.
آزمایشگاه امروز
این Codelab از Colab Enterprise برای تجزیه و تحلیل دادههای شتابیافته استفاده میکند.
برای کسب اطلاعات بیشتر در مورد تفاوتها، به مستندات رسمی در مورد انتخاب راهکار مناسب برای نوتبوک مراجعه کنید.
۴. پیکربندی یک الگوی زمان اجرا
در Colab Enterprise، به یک محیط اجرایی متصل شوید که بر اساس یک الگوی زمان اجرای از پیش پیکربندی شده است.
یک الگوی زمان اجرا، یک پیکربندی قابل استفاده مجدد است که کل محیط نوتبوک شما را مشخص میکند، از جمله:
- نوع دستگاه (پردازنده، حافظه)
- شتابدهنده (نوع و تعداد پردازنده گرافیکی)
- اندازه و نوع دیسک
- تنظیمات شبکه و سیاستهای امنیتی
- قوانین خاموش شدن خودکار در حالت بیکار
چرا قالبهای زمان اجرا مفید هستند؟
- یک محیط ثابت داشته باشید: شما و همتیمیهایتان هر بار یک محیط آماده برای استفاده یکسان دریافت میکنید تا از تکرارپذیری کار خود اطمینان حاصل کنید.
- با طراحی ایمن کار کنید: قالبها به طور خودکار سیاستهای امنیتی سازمان شما را اجرا میکنند.
- مدیریت موثر هزینهها: منابعی مانند پردازندههای گرافیکی (GPU) و پردازندههای مرکزی (CPU) از قبل در قالب تعیین شدهاند که به جلوگیری از افزایش تصادفی هزینهها کمک میکند.
ایجاد یک الگوی زمان اجرا
یک الگوی زمان اجرای قابل استفاده مجدد برای آزمایشگاه تنظیم کنید.
- در کنسول گوگل کلود، به منوی ناوبری > پلتفرم عامل > نوتبوکها بروید.
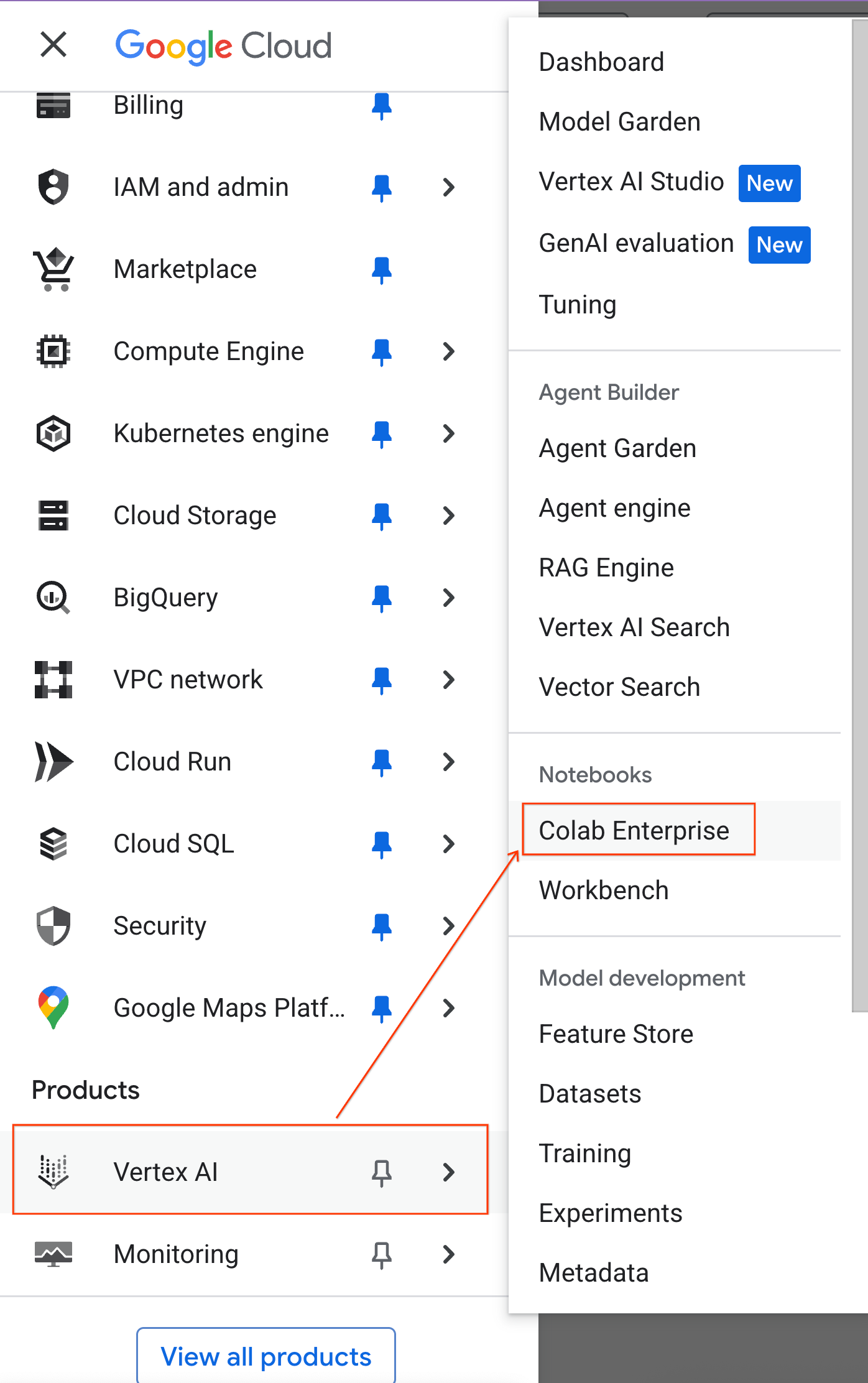
- از Colab Enterprise، روی Runtime templates کلیک کنید و سپس New Template را انتخاب کنید.
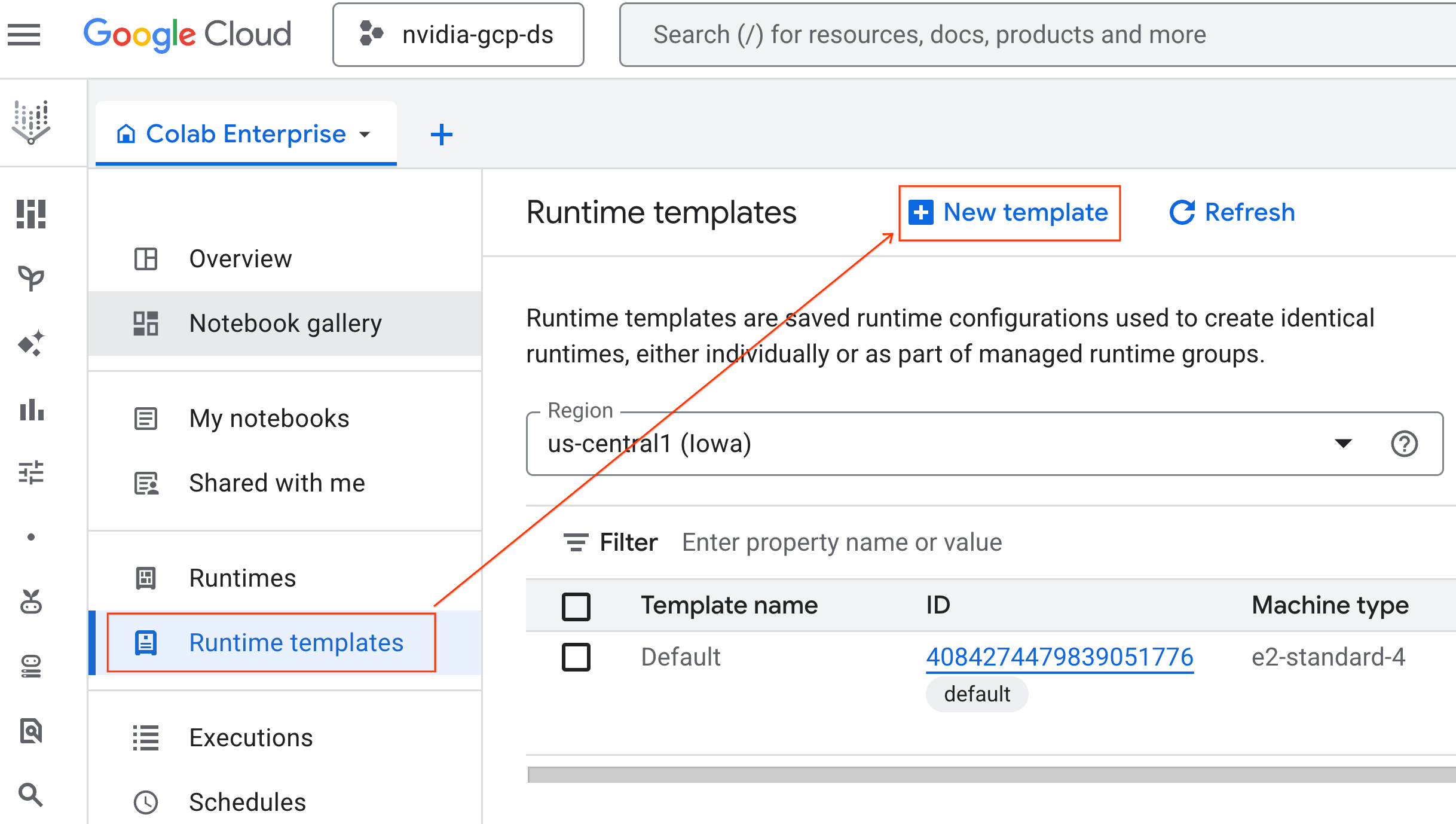
- در بخش اصول اولیهی زمان اجرا :
- نام نمایش را روی
gpu-templateتنظیم کنید. - منطقه مورد نظر خود را تنظیم کنید.
- نام نمایش را روی
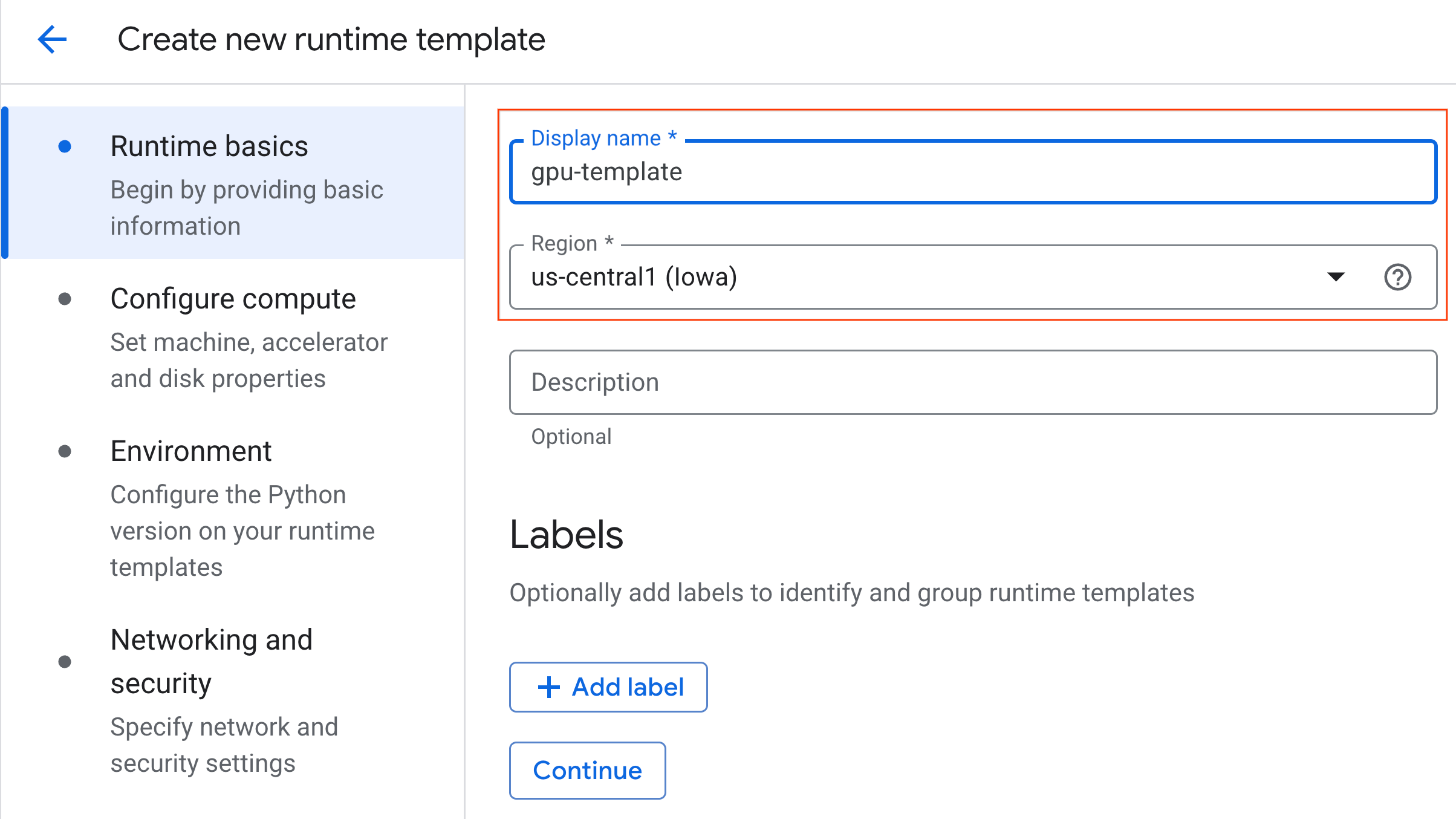
- در قسمت پیکربندی محاسبات :
- نوع ماشین (Machine type) را روی
g2-standard-4تنظیم کنید. - نوع شتابدهنده پیشفرض را
NVIDIA L4با تعداد شتابدهنده ۱ نگه دارید. - خاموش شدن در حالت آماده به کار را به ۶۰ دقیقه تغییر دهید.
- روی ادامه کلیک کنید.
- نوع ماشین (Machine type) را روی
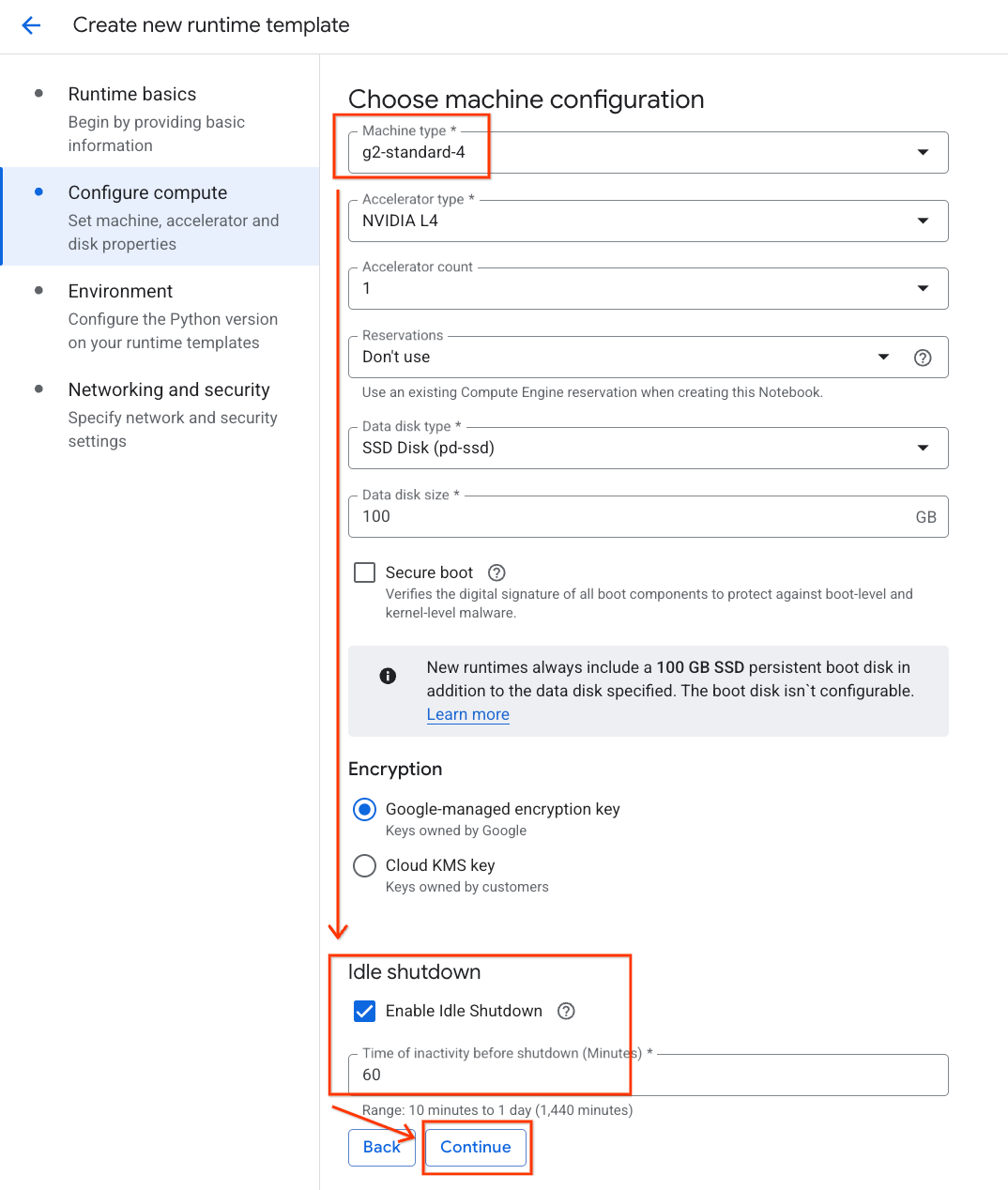
- تحت محیط :
- محیط را روی
Python 3.11تنظیم کنید
- محیط را روی
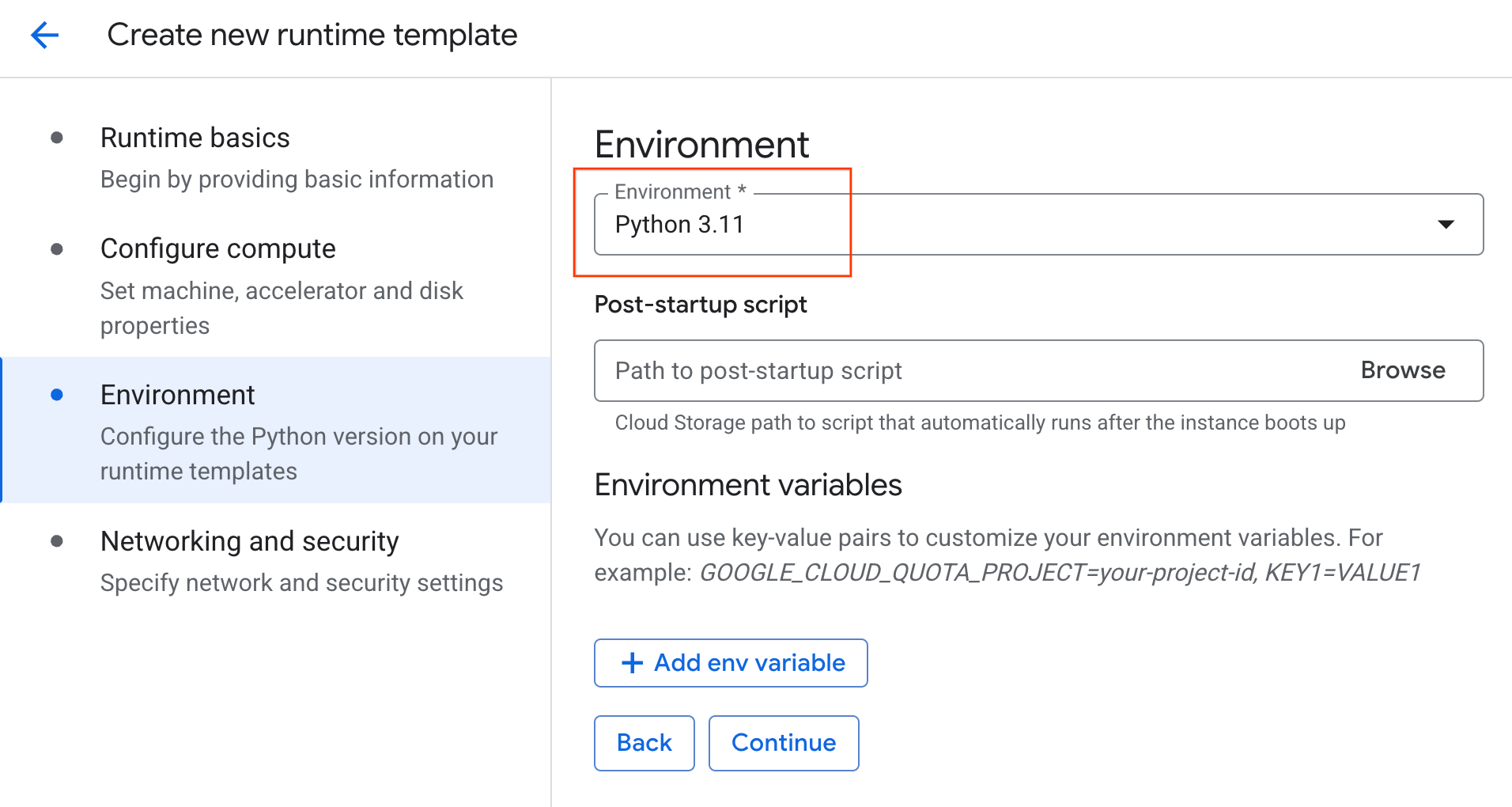
- برای ذخیره الگوی زمان اجرا، روی ایجاد کلیک کنید. صفحه الگوهای زمان اجرا شما اکنون باید الگوی جدید را نمایش دهد.
۵. شروع یک رانتایم
با آماده شدن قالب، میتوانید یک runtime جدید ایجاد کنید.
- از Colab Enterprise، روی Runtimes کلیک کنید و سپس Create را انتخاب کنید.
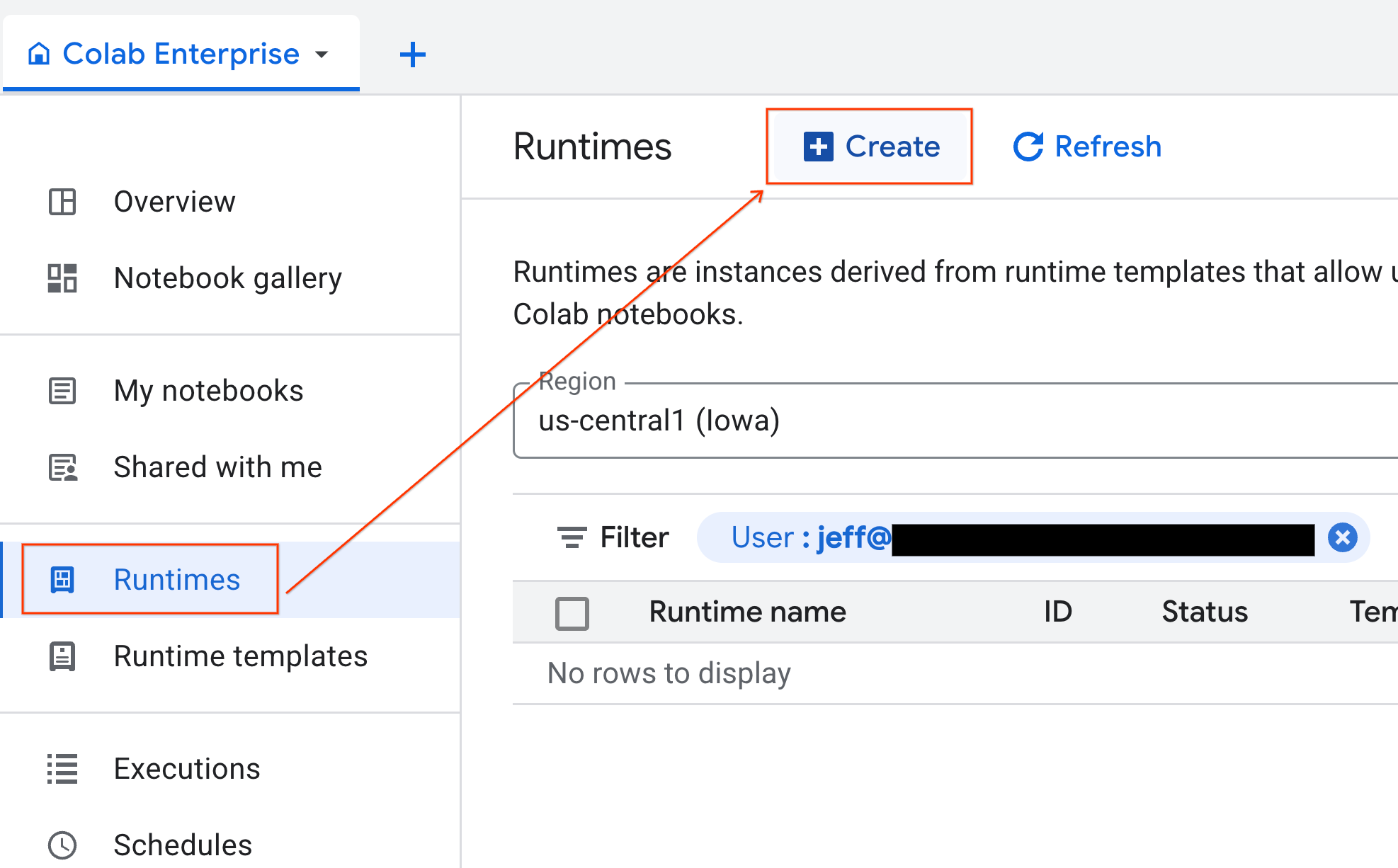
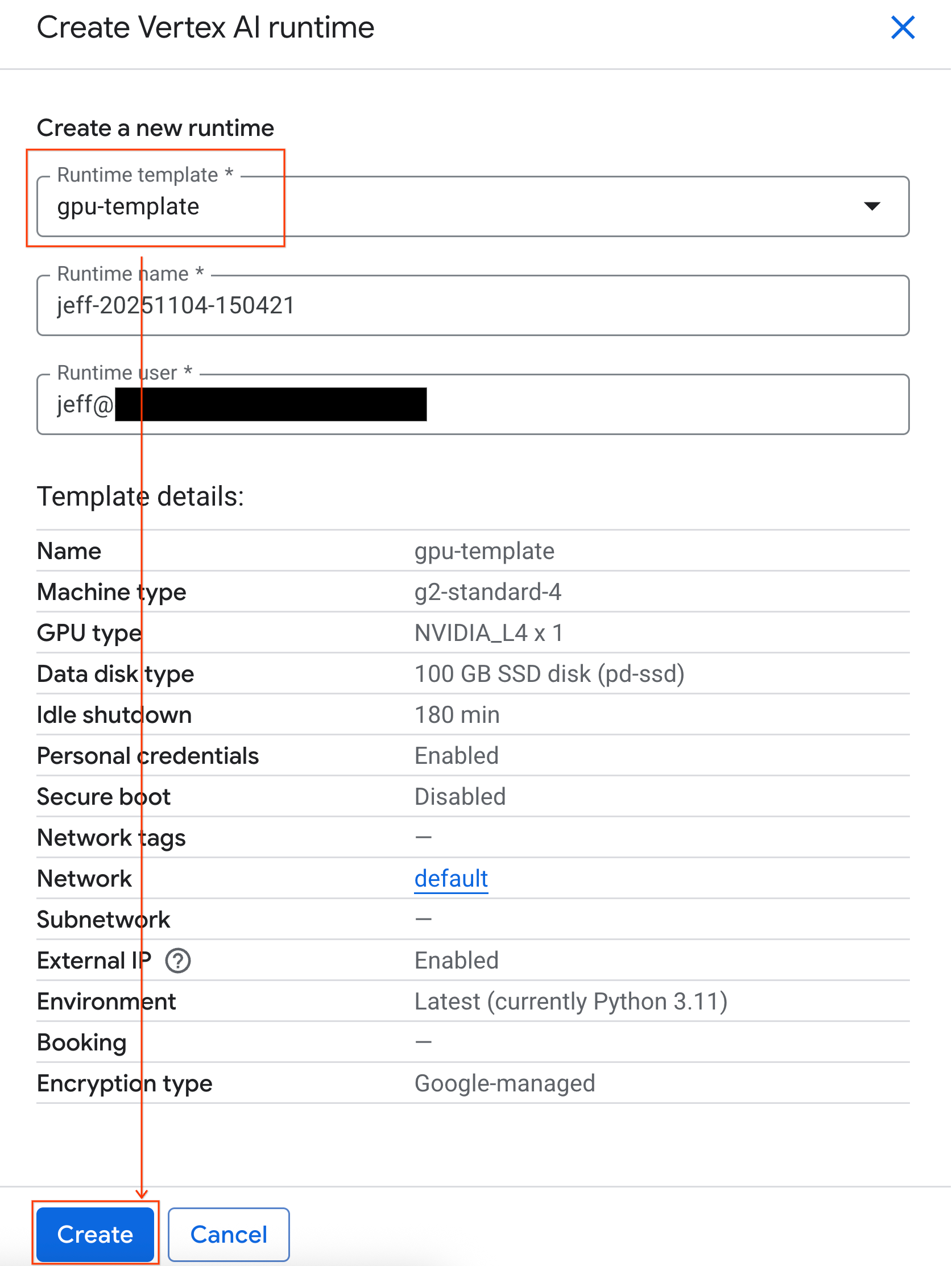
- در قسمت Runtime template ، گزینه
gpu-templateرا انتخاب کنید. روی Create کلیک کنید و منتظر بمانید تا runtime بوت شود.
- بعد از چند دقیقه، زمان اجرا موجود را مشاهده خواهید کرد.
۶. دفترچه یادداشت را تنظیم کنید
اکنون که زیرساخت شما در حال اجرا است، باید دفترچه آزمایشگاه را وارد کرده و آن را به محیط زمان اجرا متصل کنید.
وارد کردن دفترچه یادداشت
- از Colab Enterprise، روی My notebooks کلیک کنید و سپس روی Import کلیک کنید.
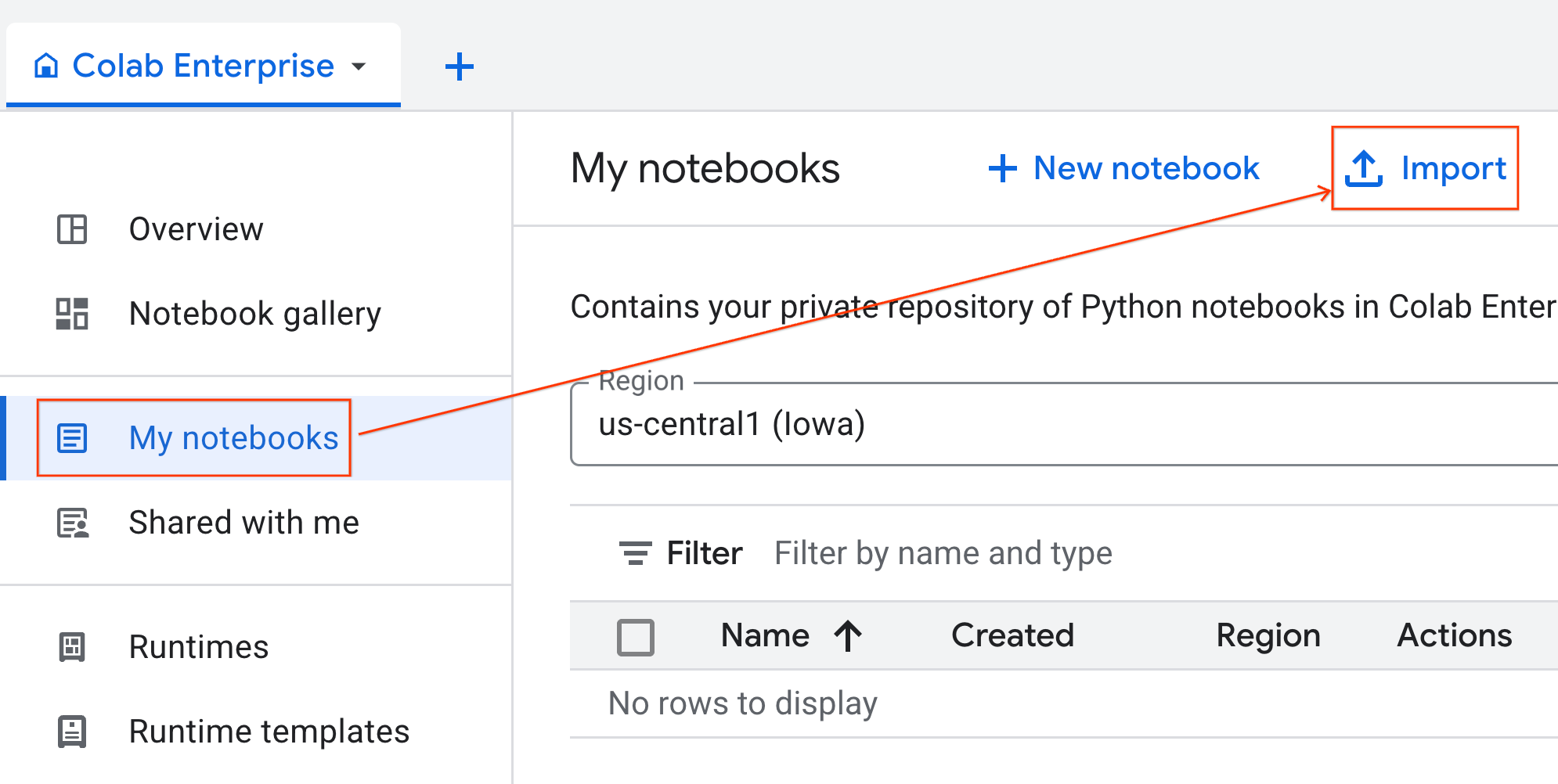
- دکمه رادیویی URL را انتخاب کنید و URL زیر را وارد کنید:
https://github.com/GoogleCloudPlatform/ai-ml-recipes/blob/main/notebooks/analytics/gpu_accelerated_analytics.ipynb
- روی «وارد کردن» کلیک کنید. Colab Enterprise دفترچه یادداشت را از GitHub در محیط شما کپی خواهد کرد.
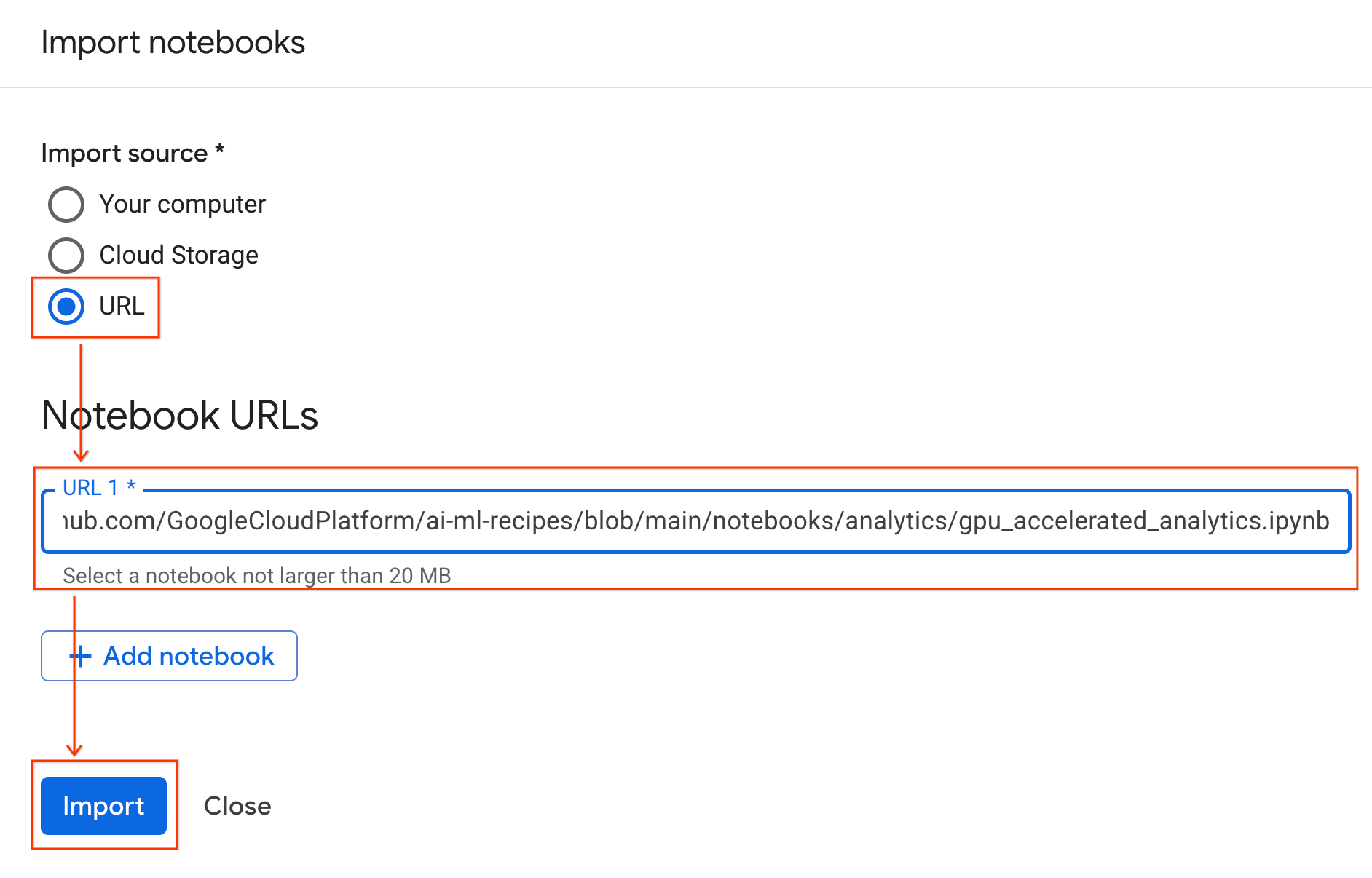
اتصال به زمان اجرا
- دفترچه یادداشت تازه وارد شده را باز کنید.
- روی فلش رو به پایین کنار گزینه Connect کلیک کنید.
- اتصال به یک زمان اجرا را انتخاب کنید.
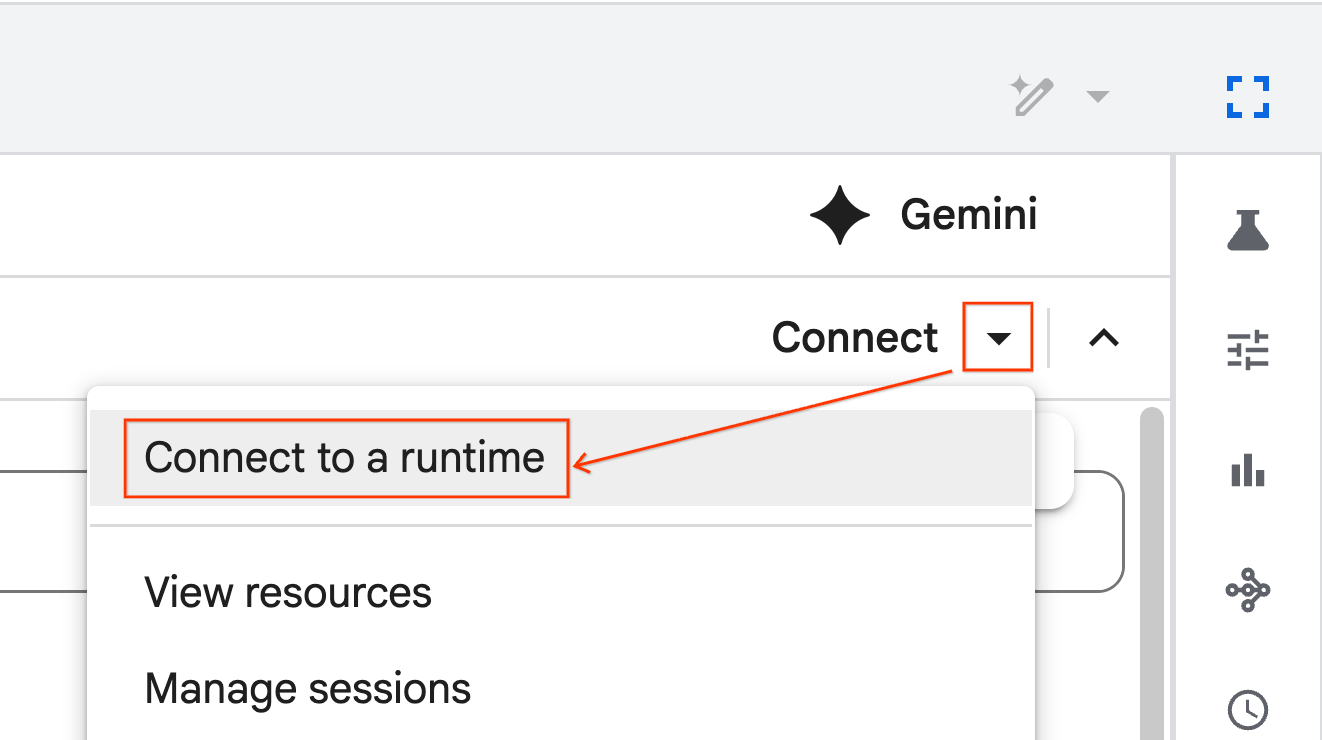
- از منوی کشویی استفاده کنید و زمان اجرایی که قبلاً ایجاد کردهاید را انتخاب کنید.
- روی اتصال کلیک کنید.
نوتبوک شما اکنون به یک محیط اجرای مبتنی بر GPU متصل شده است. اکنون میتوانید اجرای کوئریها را شروع کنید!
۷. مجموعه دادههای تاکسی نیویورک را آماده کنید
این Codelab از دادههای ثبت سفر کمیسیون تاکسی و لیموزین نیویورک (TLC) استفاده میکند.
این مجموعه دادهها شامل سوابق سفرهای انفرادی از تاکسیهای زرد در شهر نیویورک است و شامل فیلدهایی مانند موارد زیر میشود:
- تاریخها، زمانها و مکانهای سوار و پیاده شدن
- مسافت سفر
- مبالغ کرایه به تفکیک
- تعداد مسافران
دانلود دادهها
در مرحله بعد، دادههای سفر را برای کل سال ۲۰۲۴ دانلود کنید. دادهها در قالب فایل پارکت ذخیره میشوند.
بلوک کد زیر این مراحل را انجام میدهد:
- محدوده سالها و ماهها را برای دانلود تعریف میکند.
- یک دایرکتوری محلی به نام
nyc_taxi_dataبرای ذخیره فایلها ایجاد میکند. - هر ماه را مرور میکند، اگر فایل Parquet مربوطه از قبل وجود نداشته باشد، آن را دانلود میکند و در دایرکتوری ذخیره میکند.
این کد را در نوتبوک خود اجرا کنید تا دادهها را جمعآوری کرده و در زمان اجرا ذخیره کند:
from tqdm import tqdm
import requests
import time
import os
YEAR = 2024
DATA_DIR = "nyc_taxi_data"
os.makedirs(DATA_DIR, exist_ok=True)
print(f"Checking/Downloading files for {YEAR}...")
for month in tqdm(range(1, 13), unit="file"):
# Define standardized filename for both local path and URL
file_name = f"yellow_tripdata_{YEAR}-{month:02d}.parquet"
local_path = os.path.join(DATA_DIR, file_name)
url = f"https://d37ci6vzurychx.cloudfront.net/trip-data/{file_name}"
if not os.path.exists(local_path):
try:
with requests.get(url, stream=True) as response:
response.raise_for_status()
with open(local_path, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
time.sleep(1)
except requests.exceptions.HTTPError as e:
print(f"\nSkipping {file_name}: {e}")
if os.path.exists(local_path):
os.remove(local_path)
print("\nDownload complete.")
۸. دادههای سفر تاکسی را بررسی کنید
اکنون که مجموعه دادهها را دانلود کردهاید، زمان آن رسیده است که یک تحلیل اکتشافی اولیه دادهها (EDA) انجام دهید. هدف EDA درک ساختار دادهها، یافتن ناهنجاریها و کشف الگوهای بالقوه است.
بارگذاری دادههای یک ماه
با بارگذاری دادههای یک ماه شروع کنید. این کار نمونهای به اندازه کافی بزرگ (بیش از ۳ میلیون ردیف) فراهم میکند که معنادار باشد و در عین حال، میزان استفاده از حافظه را برای تجزیه و تحلیل تعاملی قابل مدیریت نگه دارد.
import pandas as pd
import glob
# Load the last month of the downloaded data
df = pd.read_parquet("nyc_taxi_data/yellow_tripdata_2024-12.parquet")
df.head()
دریافت آمار خلاصه
از متد .describe() برای تولید آمار خلاصه سطح بالا برای ستونهای عددی استفاده کنید. این اولین قدم عالی برای تشخیص مشکلات بالقوه کیفیت دادهها، مانند مقادیر حداقل یا حداکثر غیرمنتظره است.
df.describe().round(2)
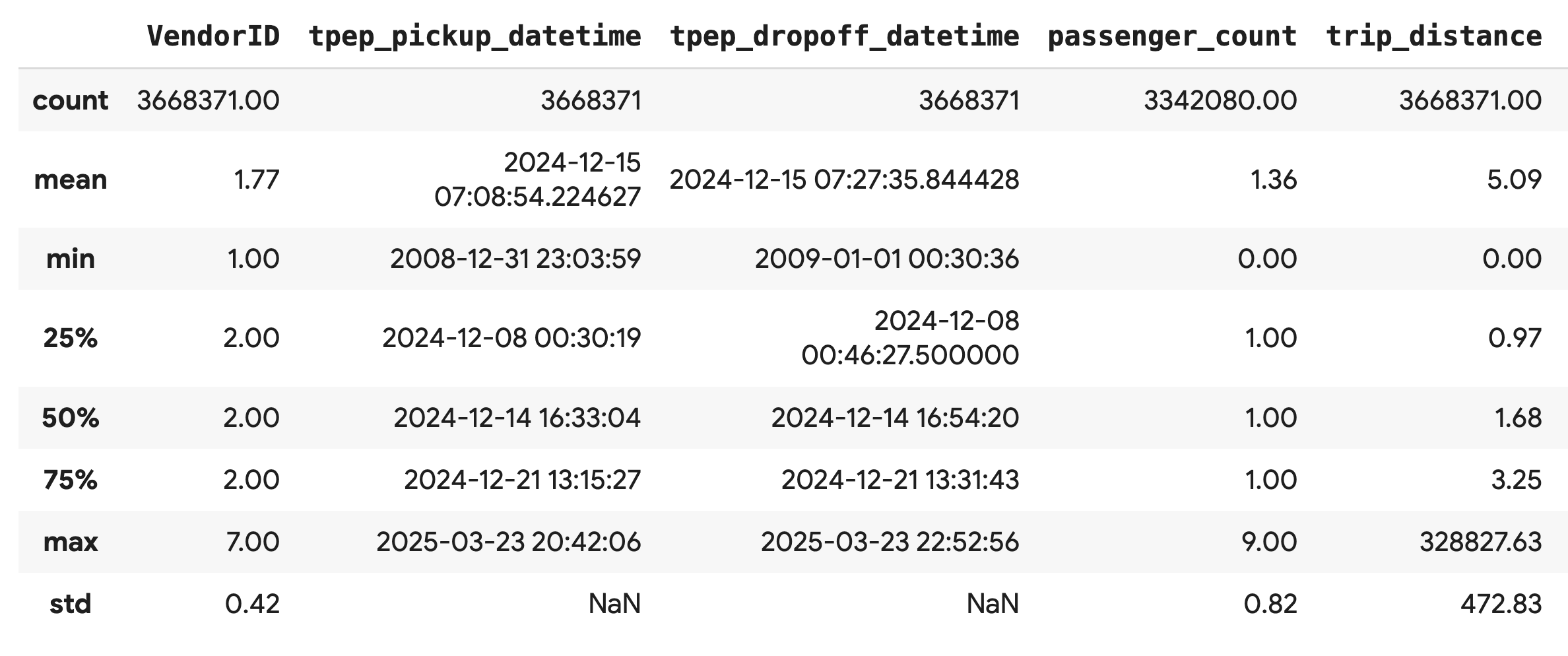
بررسی کیفیت دادهها
خروجی تابع .describe() بلافاصله یک مشکل را آشکار میکند. توجه داشته باشید که min مقدار برای tpep_pickup_datetime و tpep_dropoff_datetime در سال ۲۰۰۸ است که برای مجموعه داده ۲۰۲۴ منطقی نیست.
این مثالی است که چرا همیشه باید دادههای خود را بررسی کنید. میتوانید با مرتبسازی DataFrame، این موضوع را بیشتر بررسی کنید تا ردیفهای دقیقی را که حاوی این تاریخهای پرت هستند، پیدا کنید.
# Sort by the dropoff datetime to see the oldest records
df.sort_values("tpep_pickup_datetime").head()
تجسم توزیع دادهها
در مرحله بعد، میتوانید هیستوگرامهایی از ستونهای عددی ایجاد کنید تا توزیع آنها را تجسم کنید. این به شما کمک میکند تا پراکندگی و چولگی ویژگیهایی مانند trip_distance و fare_amount را درک کنید. تابع .hist() راهی سریع برای رسم هیستوگرام برای همه ستونهای عددی در یک DataFrame است.
_ = df.hist(figsize=(20, 20))
در نهایت، یک ماتریس پراکندگی ایجاد کنید تا روابط بین چند ستون کلیدی را تجسم کنید. از آنجا که رسم میلیونها نقطه کند است و میتواند الگوها را مبهم کند، از .sample() برای ایجاد نمودار از یک نمونه تصادفی از ۱۰۰۰۰۰ ردیف استفاده کنید.
_ = pd.plotting.scatter_matrix(
df[['passenger_count', 'trip_distance', 'tip_amount', 'total_amount']].sample(100_000),
diagonal="kde",
figsize=(15, 15)
)
۹. چرا از فرمت فایل پارکت استفاده کنیم؟
مجموعه دادههای تاکسیهای نیویورک در قالب آپاچی پارکت ارائه شده است. این یک انتخاب آگاهانه برای تجزیه و تحلیل در مقیاس بزرگ است. پارکت مزایای متعددی نسبت به انواع فایل مانند CSV ارائه میدهد:
- کارآمد و سریع: به عنوان یک فرمت ستونی، پارکت برای ذخیره و خواندن بسیار کارآمد است. این فرمت از روشهای فشردهسازی مدرن پشتیبانی میکند که منجر به کاهش حجم فایلها و سرعت قابل توجه ورودی/خروجی، به خصوص در پردازندههای گرافیکی، میشود.
- حفظ طرحواره: پارکت انواع دادهها را در فرادادههای فایل ذخیره میکند. شما هرگز مجبور نیستید هنگام خواندن فایل، انواع دادهها را حدس بزنید.
- خواندن انتخابی را فعال میکند: ساختار ستونی به شما این امکان را میدهد که فقط ستونهای خاصی را که برای تجزیه و تحلیل نیاز دارید، بخوانید. این میتواند به طور چشمگیری میزان دادههایی را که باید در حافظه بارگذاری کنید، کاهش دهد.
ویژگیهای پارکت را بررسی کنید
بیایید دو مورد از این ویژگیهای قدرتمند را با استفاده از یکی از فایلهایی که دانلود کردهاید، بررسی کنیم.
بررسی متادیتا بدون بارگذاری کل مجموعه داده
اگرچه نمیتوانید یک فایل پارکت را در یک ویرایشگر متن استاندارد مشاهده کنید، اما میتوانید به راحتی طرحواره و فرادادههای آن را بدون بارگذاری هیچ دادهای در حافظه بررسی کنید. این برای درک سریع ساختار یک فایل مفید است.
from pyarrow.parquet import ParquetFile
import pyarrow as pa
# Open one of the downloaded files
pf = ParquetFile('nyc_taxi_data/yellow_tripdata_2024-12.parquet')
# Print the schema
print("File Schema:")
print(pf.schema)
# Print the file metadata
print("\nFile Metadata:")
print(pf.metadata)
فقط ستونهایی را که نیاز دارید بخوانید
تصور کنید که فقط نیاز به تجزیه و تحلیل مسافت سفر و مبلغ کرایه دارید. با Parquet، میتوانید فقط آن ستونها را بارگذاری کنید، که بسیار سریعتر و از نظر حافظه کارآمدتر از بارگذاری کل DataFrame است.
import pandas as pd
# Read only four specific columns from the Parquet file
df_subset = pd.read_parquet(
'nyc_taxi_data/yellow_tripdata_2024-12.parquet',
columns=['passenger_count', 'trip_distance', 'tip_amount', 'total_amount']
)
df_subset.head()
۱۰. افزایش سرعت پانداها با NVIDIA cuDF
NVIDIA CUDA برای DataFrames (cuDF) یک کتابخانه متنباز و شتابیافته توسط GPU است که به شما امکان تعامل با DataFrames را میدهد. cuDF به شما امکان میدهد عملیات دادهای رایج مانند فیلتر کردن، اتصال و گروهبندی را روی GPU با موازیسازی گسترده انجام دهید.
ویژگی کلیدی که در این Codelab استفاده میکنید، حالت شتابدهنده cudf.pandas است. وقتی آن را فعال میکنید، کد استاندارد pandas شما به طور خودکار به سمت استفاده از هستههای cuDF مبتنی بر GPU در زیر کاپوت هدایت میشود، بدون اینکه نیازی به تغییر کد شما باشد.
فعال کردن شتابدهنده گرافیکی (GPU)
برای استفاده از NVIDIA cuDF در یک نوتبوک Colab Enterprise، قبل از وارد کردن pandas ، باید افزونهی magic آن را بارگذاری کنید.
ابتدا، کتابخانه استاندارد pandas را بررسی کنید. توجه داشته باشید که خروجی، مسیر نصب پیشفرض pandas را نشان میدهد.
import pandas as pd
pd # Note the output for the standard pandas library
حالا، افزونهی cudf.pandas را بارگذاری کنید و دوباره pandas را وارد کنید. ببینید خروجی ماژول pd چگونه تغییر میکند - این تأیید میکند که نسخه شتابیافته با GPU اکنون فعال است.
%load_ext cudf.pandas
import pandas as pd
pd # Note the new output, indicating cudf.pandas is active
راههای دیگر برای فعال کردن cudf.pandas
اگرچه دستور جادویی ( %load_ext ) سادهترین روش در یک نوتبوک است، اما میتوانید شتابدهنده را در محیطهای دیگر نیز فعال کنید:
- در اسکریپتهای پایتون: قبل از وارد کردن
pandas، تابعهایimport cudf.pandasوcudf.pandas.install()را فراخوانی کنید. - از محیطهای غیر نوتبوک: اسکریپت خود را با استفاده از
python -m cudf.pandas your_script.pyاجرا کنید.
۱۱. عملکرد CPU را در مقابل GPU مقایسه کنید
حالا به مهمترین بخش میرسیم: مقایسه عملکرد pandas استاندارد روی CPU با cudf.pandas روی GPU.
برای اطمینان از یک خط مبنای کاملاً منصفانه برای CPU، ابتدا باید زمان اجرای Colab را مجدداً تنظیم کنید. این کار هرگونه شتابدهنده GPU را که ممکن است در بخشهای قبلی فعال کرده باشید، پاک میکند. میتوانید با اجرای سلول زیر یا انتخاب Restart session از منوی Runtime ، زمان اجرا را مجدداً راهاندازی کنید.
import IPython
IPython.Application.instance().kernel.do_shutdown(True)
تعریف خط لوله تجزیه و تحلیل
حالا که محیط پاک شده است، تابع بنچمارک را تعریف خواهید کرد. این تابع به شما امکان میدهد دقیقاً همان خط لوله - بارگیری، مرتبسازی و خلاصهسازی - را با استفاده از هر ماژول pandas که به آن منتقل میکنید، اجرا کنید.
import time
import glob
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
def run_analytics_pipeline(pd_module):
"""Loads, sorts, and summarizes data using the provided pandas module."""
timings = {}
# 1. Load all 2024 Parquet files from the directory
t0 = time.time()
df = pd_module.concat(
[pd_module.read_parquet(f) for f in glob.glob("nyc_taxi_data/*_2024*.parquet")],
ignore_index=True
)
timings["load"] = time.time() - t0
# 2. Sort the data by multiple columns
t0 = time.time()
df = df.sort_values(
['tpep_pickup_datetime', 'trip_distance', 'passenger_count'],
ascending=[False, True, False]
)
timings["sort"] = time.time() - t0
# 3. Perform a groupby and aggregation
t0 = time.time()
df['tpep_pickup_datetime'] = pd_module.to_datetime(df['tpep_pickup_datetime'])
_ = (
df.loc[df.tpep_pickup_datetime > '2024-11-01']
.groupby(['VendorID', 'tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
timings["summarize"] = time.time() - t0
return timings
مقایسه را اجرا کنید
ابتدا، شما خط لوله را با استفاده از pandas استاندارد روی CPU اجرا خواهید کرد. سپس، cudf.pandas فعال کرده و دوباره آن را روی GPU اجرا میکنید.
# --- Run on CPU ---
print("Running analytics pipeline on CPU...")
# Ensure we are using standard pandas
import pandas as pd
assert "cudf" not in str(pd), "Error: cuDF is still active. Please restart the kernel."
cpu_times = run_analytics_pipeline(pd)
print(f"CPU times: {cpu_times}")
# --- Run on GPU ---
print("\nEnabling cudf.pandas and running on GPU...")
# Load the extension
%load_ext cudf.pandas
import pandas as gpu_pd
gpu_times = run_analytics_pipeline(gpu_pd)
print(f"GPU times: {gpu_times}")
نتایج را تجسم کنید
در نهایت، تفاوت را تجسم کنید. کد زیر افزایش سرعت را برای هر عملیات محاسبه کرده و آنها را در کنار هم رسم میکند.
# Create a DataFrame for plotting
results_df = pd.DataFrame([cpu_times, gpu_times], index=["CPU", "GPU"]).T
total_cpu_time = results_df['CPU'].sum()
total_gpu_time = results_df['GPU'].sum()
speedup = total_cpu_time / total_gpu_time
print("--- Performance Results ---")
print(results_df)
print(f"\nTotal CPU Time: {total_cpu_time:.2f} seconds")
print(f"Total GPU Time: {total_gpu_time:.2f} seconds")
print(f"Overall Speedup: {speedup:.2f}x")
# Plot the results
fig, ax = plt.subplots(figsize=(10, 6))
results_df.plot(kind='bar', ax=ax, color={"CPU": "tab:blue", "GPU": "tab:green"})
ax.set_ylabel("Time (seconds)")
ax.set_title(f"CPU vs. GPU Runtimes (Overall Speedup: {speedup:.2f}x)", fontsize=14)
ax.tick_params(axis='x', rotation=0)
# Add numerical labels to the bars
for container in ax.containers:
ax.bar_label(container, fmt="%.2f", padding=3)
plt.tight_layout()
plt.show()
نتایج نمونه:
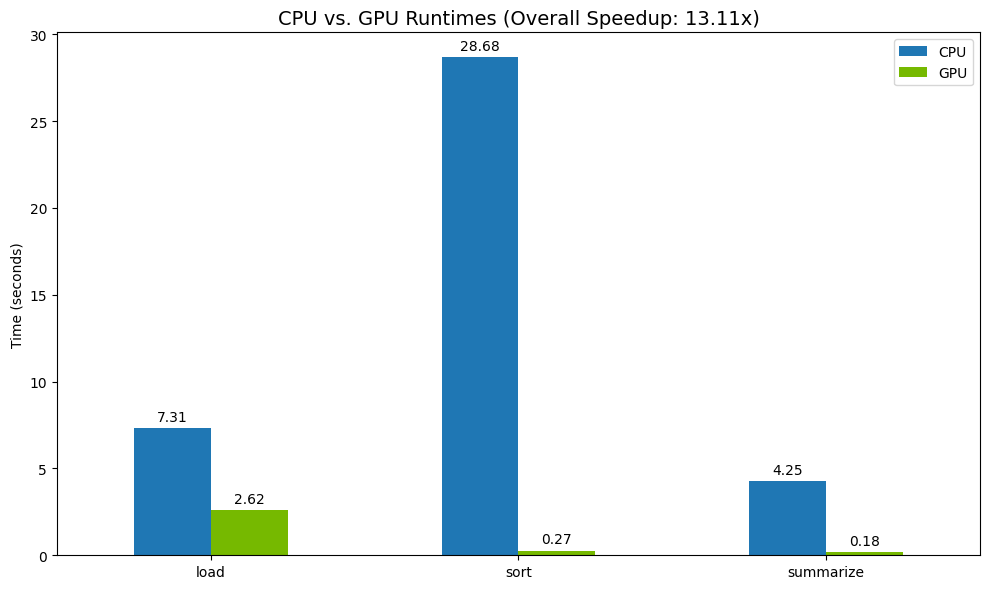
پردازنده گرافیکی (GPU) افزایش سرعت قابل توجهی نسبت به پردازنده مرکزی (CPU) ارائه میدهد.
۱۲. کد خود را برای یافتن گلوگاهها (bottlenecks) پروفایل کنید
حتی با شتابدهی با GPU، برخی از عملیات pandas اگر هنوز توسط cuDF پشتیبانی نشوند، ممکن است به CPU منتقل شوند. این «فرایندهای جایگزین CPU» میتوانند به گلوگاههای عملکرد تبدیل شوند.
برای کمک به شما در شناسایی این نواحی، cudf.pandas شامل دو پروفایلر داخلی است. میتوانید از آنها استفاده کنید تا دقیقاً ببینید کدام بخشهای کد شما روی GPU اجرا میشوند و کدامها به CPU برمیگردند.
-
%%cudf.pandas.profile: از این برای خلاصهای سطح بالا و تابع به تابع از کد خود استفاده کنید. این گزینه برای دریافت یک مرور سریع از اینکه کدام عملیات روی کدام دستگاه اجرا میشوند، بهترین گزینه است. -
%%cudf.pandas.line_profile: از این برای تجزیه و تحلیل دقیق و خط به خط استفاده کنید. این بهترین ابزار برای مشخص کردن دقیق خطوطی در کد شماست که باعث ایجاد خطای fallback در CPU میشوند.
از این پروفایلرها به عنوان "جادوی سلولی" در بالای سلول نوت بوک استفاده کنید.
پروفایلسازی در سطح تابع با %%cudf.pandas.profile
ابتدا، پروفایلر سطح تابع را روی همان خط لوله تحلیلی از بخش قبل اجرا کنید. خروجی، جدولی از هر تابع فراخوانی شده، دستگاهی که روی آن اجرا شده (GPU یا CPU) و تعداد دفعات فراخوانی آن را نشان میدهد.
%load_ext cudf.pandas
import pandas as pd
import glob
pd.DataFrame({"a": [1]})
پس از اطمینان از فعال بودن cudf.pandas، میتوانید یک پروفایل اجرا کنید.
%%cudf.pandas.profile
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*2024*.parquet")], ignore_index=True)
df = df.sort_values(['tpep_pickup_datetime', 'trip_distance', 'passenger_count'], ascending=[False, True, False])
summary = (
df
.loc[(df.tpep_pickup_datetime > '2024-11-01')]
.groupby(['VendorID','tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
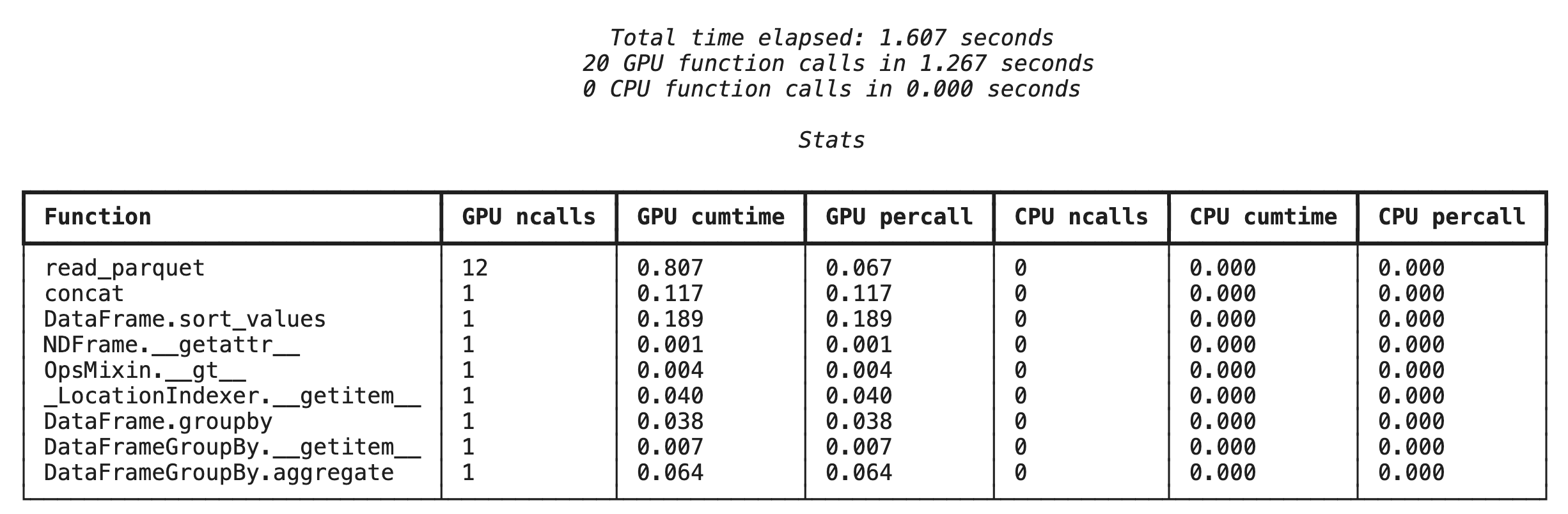
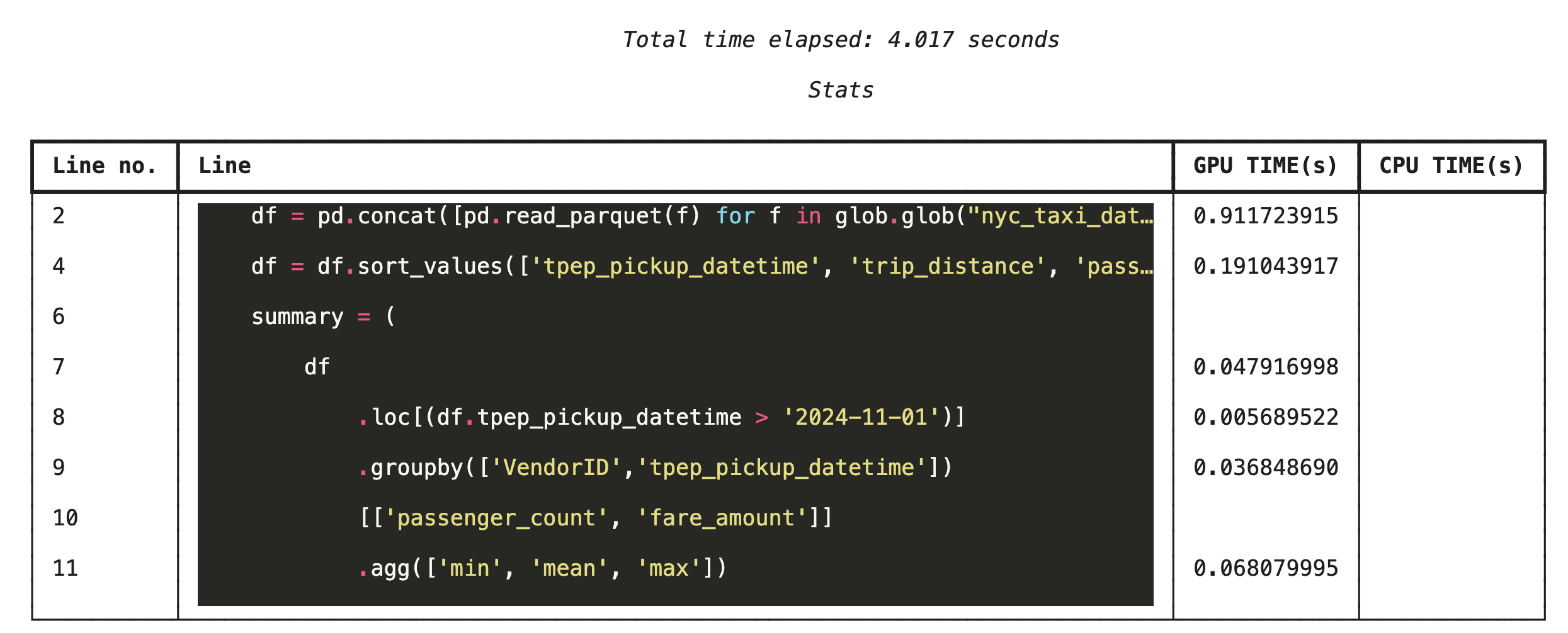
پروفایلسازی خط به خط با %%cudf.pandas.line_profile
در مرحله بعد، ابزار پروفایل سطح خط را اجرا کنید. این ابزار، نمای بسیار جزئیتری به شما میدهد و نسبت زمانی که هر خط کد صرف اجرای آن روی پردازنده گرافیکی (GPU) در مقایسه با پردازنده مرکزی (CPU) میکند را نشان میدهد. این مؤثرترین روش برای یافتن گلوگاههای خاص و بهینهسازی آنهاست.
%%cudf.pandas.line_profile
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*2024*.parquet")], ignore_index=True)
df = df.sort_values(['tpep_pickup_datetime', 'trip_distance', 'passenger_count'], ascending=[False, True, False])
summary = (
df
.loc[(df.tpep_pickup_datetime > '2024-11-01')]
.groupby(['VendorID','tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
پروفایلینگ از خط فرمان
این پروفایلرها از طریق خط فرمان نیز در دسترس هستند که برای تست خودکار و پروفایلبندی اسکریپتهای پایتون مفید است.
میتوانید از موارد زیر در رابط خط فرمان استفاده کنید:
-
python -m cudf.pandas --profile your_script.py -
python -m cudf.pandas --line_profile your_script.py
۱۳. با فضای ذخیرهسازی ابری گوگل ادغام شوید
فضای ذخیرهسازی ابری گوگل (GCS) یک سرویس ذخیرهسازی اشیاء مقیاسپذیر و بادوام است. وقتی از Colab Enterprise استفاده میکنید، GCS مکان بسیار خوبی برای ذخیره مجموعه دادهها، نقاط بررسی مدل و سایر مصنوعات شما خواهد بود.
محیط اجرایی Colab Enterprise شما مجوزهای لازم برای خواندن و نوشتن مستقیم دادهها در باکتهای GCS را دارد و این عملیات برای حداکثر عملکرد توسط GPU شتابدهی میشوند.
یک سطل GCS ایجاد کنید
ابتدا، یک سطل GCS جدید ایجاد کنید. نام سطل GCS به صورت سراسری منحصر به فرد است، بنابراین یک UUID به نام آن اضافه کنید.
from google.cloud import storage
import uuid
unique_suffix = uuid.uuid4().hex[:12]
bucket_name = f'nyc-taxi-codelab-{unique_suffix}'
project_id = storage.Client().project
client = storage.Client()
try:
bucket = client.create_bucket(bucket_name)
print(f"Successfully created bucket: gs://{bucket.name}")
except Exception as e:
print(f"Bucket creation failed. You may already own it or the name is taken: {e}")
نوشتن دادهها مستقیماً در GCS
حالا، یک DataFrame را مستقیماً در باکت GCS جدید خود ذخیره کنید. اگر متغیر df از بخشهای قبلی در دسترس نباشد، کد ابتدا دادههای یک ماه را بارگذاری میکند.
%%cudf.pandas.line_profile
# Ensure the DataFrame exists before saving to GCS
if 'df' not in locals():
print("DataFrame not found, loading a sample file...")
df = pd.read_parquet('nyc_taxi_data/yellow_tripdata_2024-12.parquet')
print(f"Writing data to gs://{bucket_name}/nyc_taxi_data.parquet...")
df.to_parquet(f"gs://{bucket_name}/nyc_taxi_data.parquet", index=False)
print("Write operation complete.")
فایل را در GCS تأیید کنید
شما میتوانید با مراجعه به سطل دادهها، از وجود آنها در GCS اطمینان حاصل کنید. کد زیر یک لینک قابل کلیک ایجاد میکند.
from IPython.display import Markdown
gcs_url = f"https://console.cloud.google.com/storage/browser/{bucket_name}?project={project_id}"
Markdown(f'**[Click here to view your GCS bucket in the Google Cloud Console]({gcs_url})**')
خواندن دادهها مستقیماً از GCS
در نهایت، دادهها را مستقیماً از مسیر GCS به یک DataFrame بخوانید. این عملیات همچنین توسط GPU شتاب داده میشود و به شما امکان میدهد مجموعه دادههای بزرگ را از فضای ذخیرهسازی ابری با سرعت بالا بارگیری کنید.
%%cudf.pandas.line_profile
print(f"Reading data from gs://{bucket_name}/nyc_taxi_data.parquet...")
df_from_gcs = pd.read_parquet(f"gs://{bucket_name}/nyc_taxi_data.parquet")
df_from_gcs.head()
۱۴. تمیز کردن
برای جلوگیری از هزینههای غیرمنتظره برای حساب Google Cloud خود، باید منابعی را که ایجاد کردهاید، پاکسازی کنید.
دادههایی که دانلود کردهاید را حذف کنید:
# Permanately delete the GCS bucket
print(f"Deleting GCS bucket: gs://{bucket_name}...")
!gsutil rm -r -f gs://{bucket_name}
print("Bucket deleted.")
# Remove NYC taxi dataset on the Colab runtime
print("Deleting local 'nyc_taxi_data' directory...")
!rm -rf nyc_taxi_data
print("Local files deleted.")
زمان اجرای Colab خود را خاموش کنید
- در کنسول Google Cloud، به صفحه Colab Enterprise Runtimes بروید.
- در منوی Region ، منطقهای را که شامل زمان اجرای شماست، انتخاب کنید.
- زمان اجرایی که میخواهید حذف کنید را انتخاب کنید.
- روی حذف کلیک کنید.
- روی تأیید کلیک کنید.
دفترچه یادداشت خود را حذف کنید
- در کنسول گوگل کلود، به صفحه دفترچههای من در Colab Enterprise بروید.
- در منوی منطقه ، منطقهای را که دفترچه یادداشت شما در آن قرار دارد، انتخاب کنید.
- دفترچه یادداشتی را که میخواهید حذف کنید، انتخاب کنید.
- روی حذف کلیک کنید.
- روی تأیید کلیک کنید.
۱۵. تبریک
تبریک! شما با موفقیت گردش کار تحلیلی پانداس را با استفاده از NVIDIA cuDF در Colab Enterprise تسریع بخشیدید. شما یاد گرفتید که چگونه زمانهای اجرای فعالشده با GPU را پیکربندی کنید، cudf.pandas برای شتابدهی بدون تغییر کد فعال کنید، کد را برای تنگناها نمایه کنید و با Google Cloud Storage ادغام کنید.