
1. Introduction
Dans cet atelier de programmation, vous allez apprendre à accélérer vos workflows d'analyse de données sur de grands ensembles de données à l'aide de GPU NVIDIA et de bibliothèques Open Source sur Google Cloud. Vous commencerez par optimiser votre infrastructure, puis vous découvrirez comment appliquer l'accélération GPU sans modifier le code.
Vous vous concentrerez sur pandas, une bibliothèque de manipulation de données populaire, et apprendrez à l'accélérer à l'aide de la bibliothèque cuDF de NVIDIA. La bonne nouvelle, c'est que vous pouvez bénéficier de cette accélération GPU sans modifier votre code pandas existant.
Points abordés
- Comprendre Colab Enterprise sur Google Cloud
- Personnalisez un environnement d'exécution Colab avec des configurations spécifiques de GPU, de processeur et de mémoire.
- Accélérez
pandassans modifier le code à l'aide decuDFNVIDIA. - Profilez votre code pour identifier et optimiser les goulots d'étranglement.
La page suivante indique les crédits que vous pouvez utiliser pour réaliser l'atelier.
2. Pourquoi accélérer le traitement des données ?
La règle des 80/20 : pourquoi la préparation des données prend-elle autant de temps ?
La préparation des données est souvent la phase la plus longue d'un projet d'analyse. Les data scientists et les analystes consacrent une grande partie de leur temps à nettoyer, transformer et structurer les données avant de pouvoir commencer toute analyse.
Heureusement, vous pouvez accélérer les bibliothèques Open Source populaires telles que pandas, Apache Spark et Polars sur les GPU NVIDIA à l'aide de cuDF. Même avec cette accélération, la préparation des données reste chronophage, car :
- Les données sources sont rarement prêtes à être analysées : les données réelles présentent souvent des incohérences, des valeurs manquantes et des problèmes de mise en forme.
- La qualité a un impact sur les performances du modèle : une mauvaise qualité des données peut rendre inutiles même les algorithmes les plus sophistiqués.
- L'échelle amplifie les problèmes : des problèmes de données apparemment mineurs deviennent des goulots d'étranglement critiques lorsque vous travaillez avec des millions d'enregistrements.
3. Choisir un environnement de notebook
Alors que de nombreux data scientists connaissent Colab pour leurs projets personnels, Colab Enterprise offre une expérience de notebook sécurisée, collaborative et intégrée, conçue pour les entreprises.
Sur Google Cloud, vous avez deux options principales pour les environnements de notebooks gérés : Colab Enterprise et Gemini Enterprise Agent Platform Workbench. Le bon choix dépend des priorités de votre projet.
Quand utiliser Agent Platform Workbench
Choisissez Agent Platform Workbench lorsque votre priorité est le contrôle et la personnalisation avancée. C'est le choix idéal si vous devez :
- Gérez l'infrastructure sous-jacente et le cycle de vie des machines.
- Utiliser des conteneurs et des configurations réseau personnalisés.
- Intégrez-vous aux pipelines MLOps et aux outils de cycle de vie personnalisés.
Quand utiliser Colab Enterprise
Choisissez Colab Enterprise si votre priorité est la rapidité de configuration, la facilité d'utilisation et la collaboration sécurisée. Il s'agit d'une solution entièrement gérée qui permet à votre équipe de se concentrer sur l'analyse plutôt que sur l'infrastructure.
Colab Enterprise vous aide à :
- Développez des workflows de data science étroitement liés à votre entrepôt de données. Vous pouvez ouvrir et gérer vos notebooks directement dans BigQuery Studio.
- Entraînez des modèles de machine learning et intégrez-les aux outils MLOps dans Agent Platform.
- Profitez d'une expérience flexible et unifiée. Un notebook Colab Enterprise créé dans BigQuery peut être ouvert et exécuté dans Agent Platform, et inversement.
Atelier d'aujourd'hui
Cet atelier de programmation utilise Colab Enterprise pour accélérer l'analyse des données.
Pour en savoir plus sur les différences, consultez la documentation officielle sur le choix de la solution de notebook appropriée.
4. Configurer un modèle d'exécution
Dans Colab Enterprise, connectez-vous à un environnement d'exécution basé sur un modèle d'exécution préconfiguré.
Un modèle d'exécution est une configuration réutilisable qui spécifie l'ensemble de l'environnement de votre notebook, y compris :
- Type de machine (processeur, mémoire)
- Accélérateur (type et nombre de GPU)
- Taille et type de disque
- Paramètres réseau et règles de sécurité
- Règles d'arrêt automatique en cas d'inactivité
Pourquoi les modèles d'exécution sont-ils utiles ?
- Obtenez un environnement cohérent : vous et vos coéquipiers bénéficiez du même environnement prêt à l'emploi à chaque fois pour garantir la reproductibilité de votre travail.
- Travaillez en toute sécurité grâce à la conception : les modèles appliquent automatiquement les règles de sécurité de votre organisation.
- Gérez efficacement les coûts : les ressources telles que les GPU et les processeurs sont prédimensionnées dans le modèle, ce qui permet d'éviter les dépassements de coûts accidentels.
Créer un modèle d'environnement d'exécution
Configurez un modèle d'exécution réutilisable pour l'atelier.
- Dans la console Google Cloud, accédez au menu de navigation > Plate-forme de l'agent > Notebooks.
- Dans Colab Enterprise, cliquez sur Modèles d'exécution, puis sélectionnez Nouveau modèle.
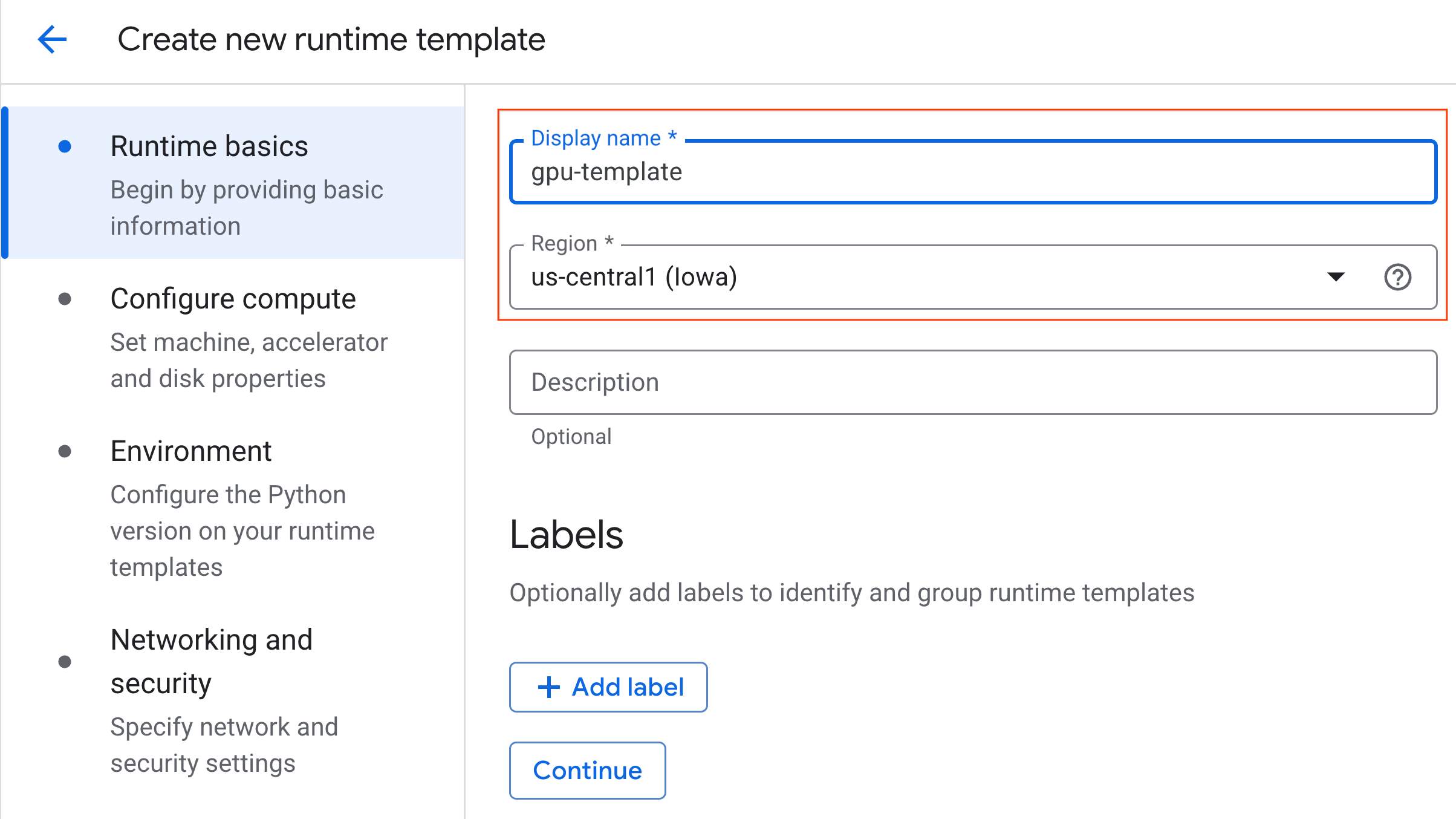
- Sous Principes de base de l'exécution :
- Définissez le nom à afficher sur
gpu-template. - Définissez la région de votre choix.
- Définissez le nom à afficher sur
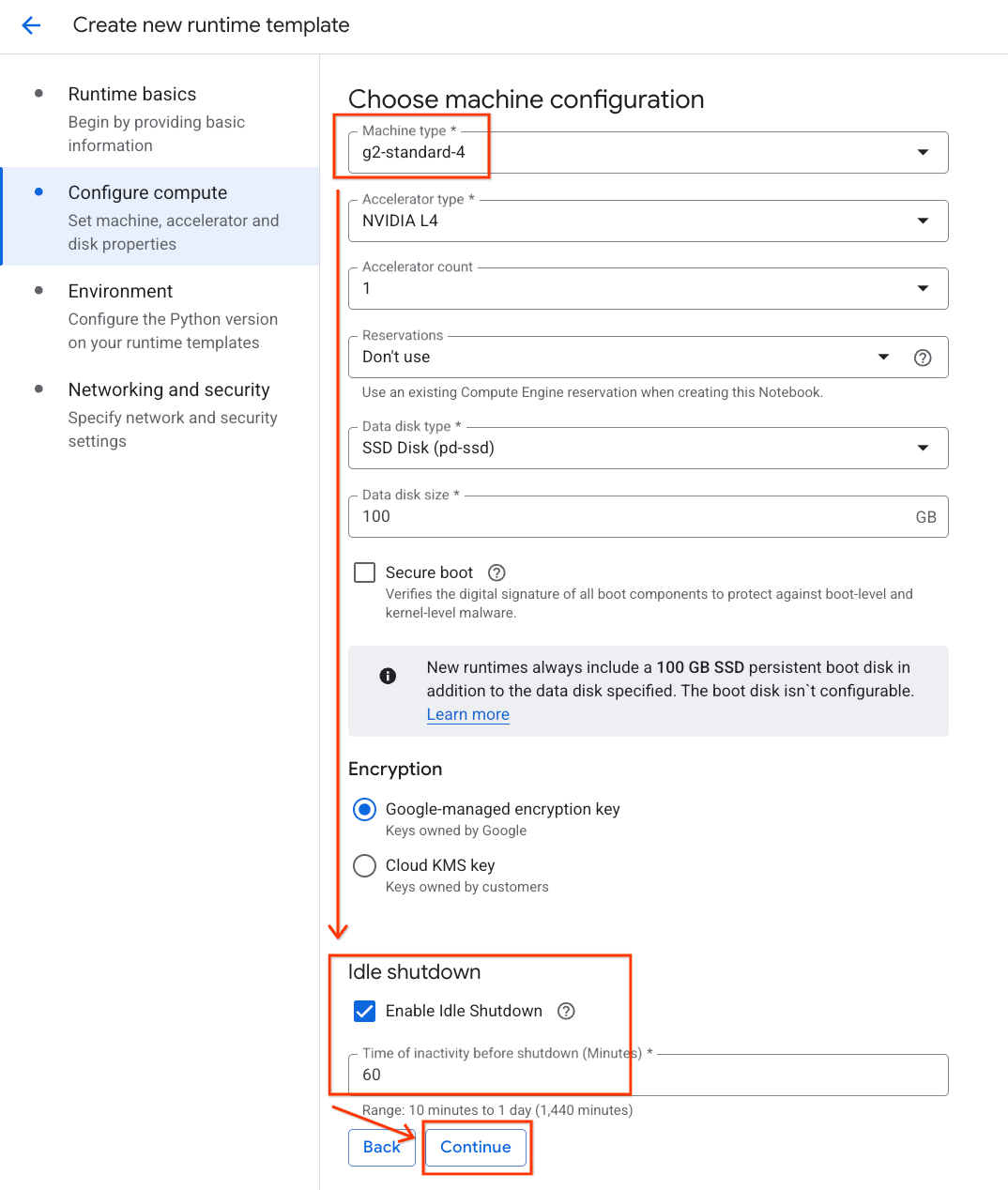
- Sous Configurer le calcul :
- Définissez le type de machine sur
g2-standard-4. - Conservez le type d'accélérateur par défaut (
NVIDIA L4) et définissez le nombre d'accélérateurs sur 1. - Définissez l'arrêt en cas d'inactivité sur 60 minutes.
- Cliquez sur Continuer.
- Définissez le type de machine sur
- Sous Environnement :
- Définissez l'environnement sur
Python 3.11.
- Définissez l'environnement sur
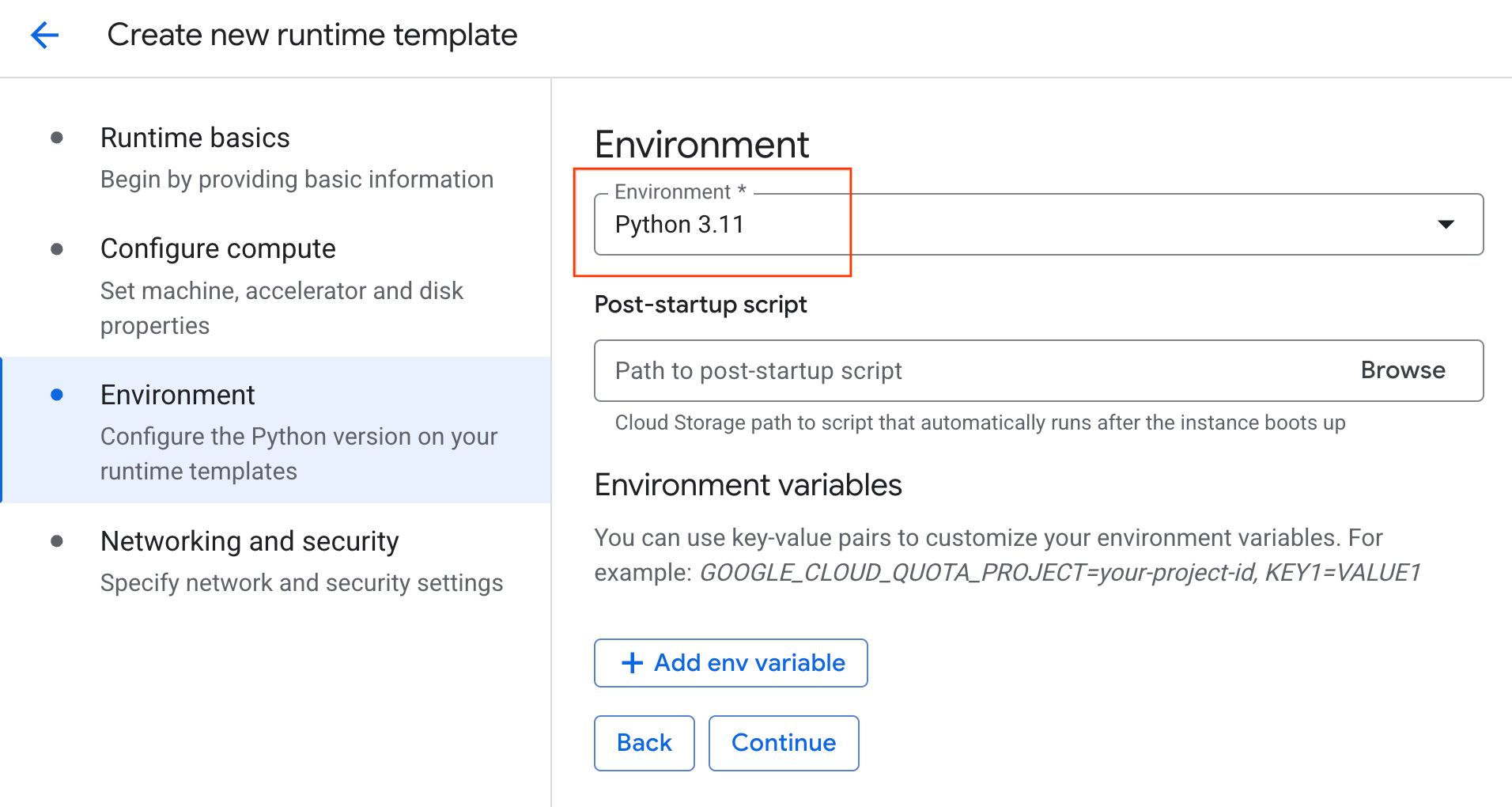
- Cliquez sur Créer pour enregistrer le modèle d'exécution. La nouvelle page "Modèles d'exécution" devrait désormais afficher le nouveau modèle.
5. Démarrer un environnement d'exécution
Une fois votre modèle prêt, vous pouvez créer un environnement d'exécution.
- Dans Colab Enterprise, cliquez sur Exécutions, puis sélectionnez Créer.
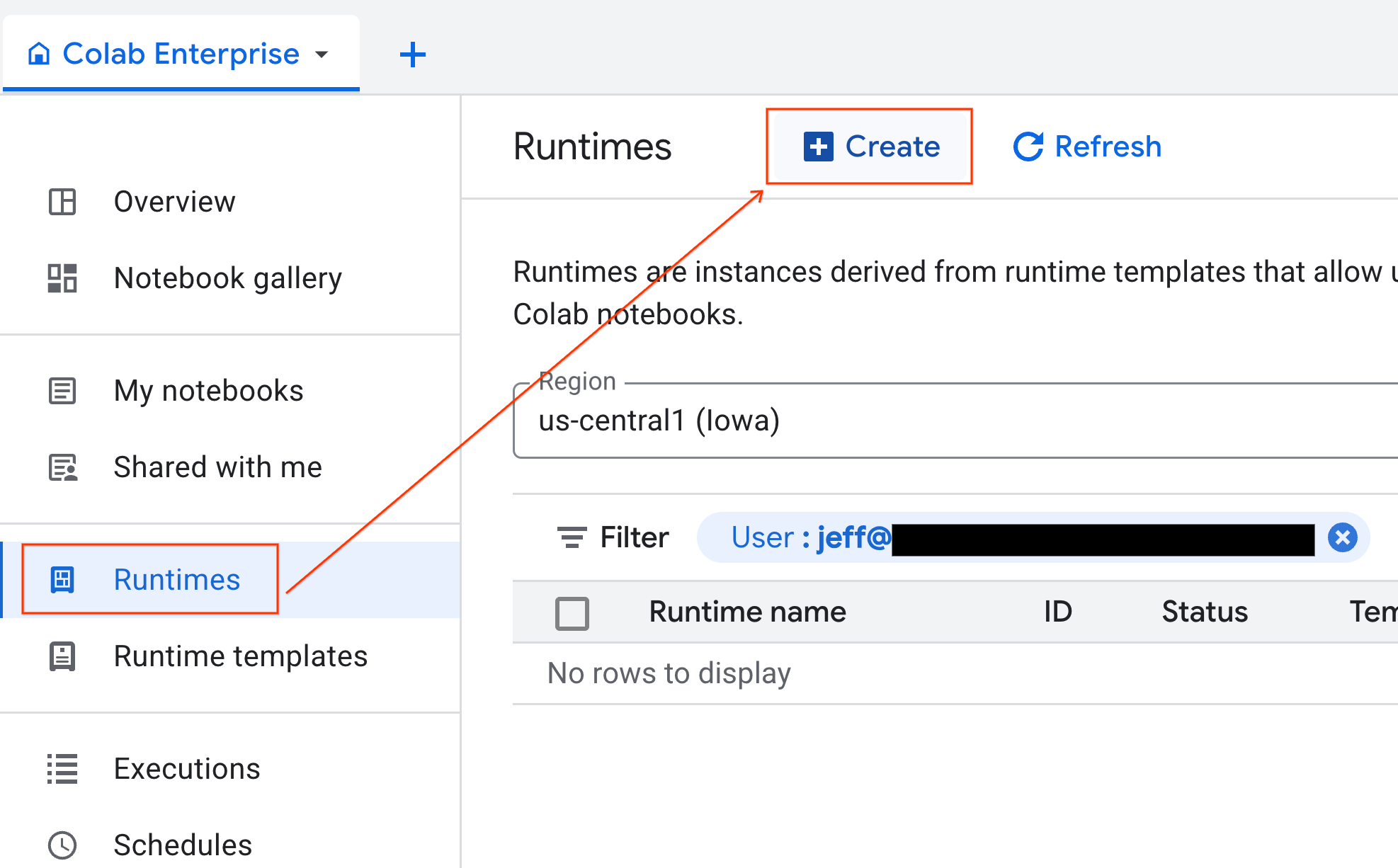
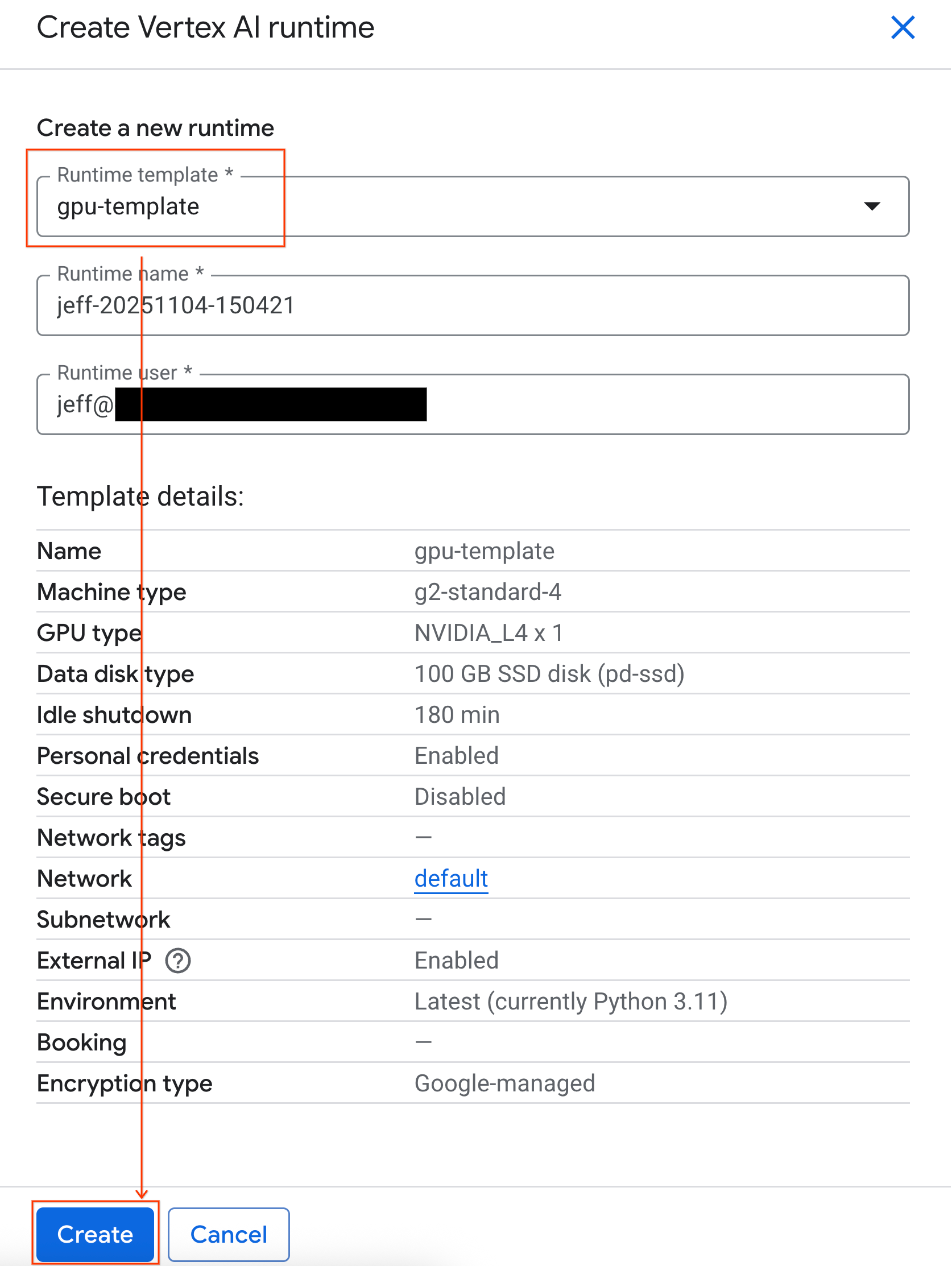
- Sous Modèle d'environnement d'exécution, sélectionnez l'option
gpu-template. Cliquez sur Créer et attendez que l'environnement d'exécution démarre.
- Au bout de quelques minutes, le temps d'exécution disponible s'affiche.
6. Configurer le notebook
Maintenant que votre infrastructure est en cours d'exécution, vous devez importer le notebook de l'atelier et le connecter à votre environnement d'exécution.
Importer le notebook
- Dans Colab Enterprise, cliquez sur Mes notebooks, puis sur Importer.
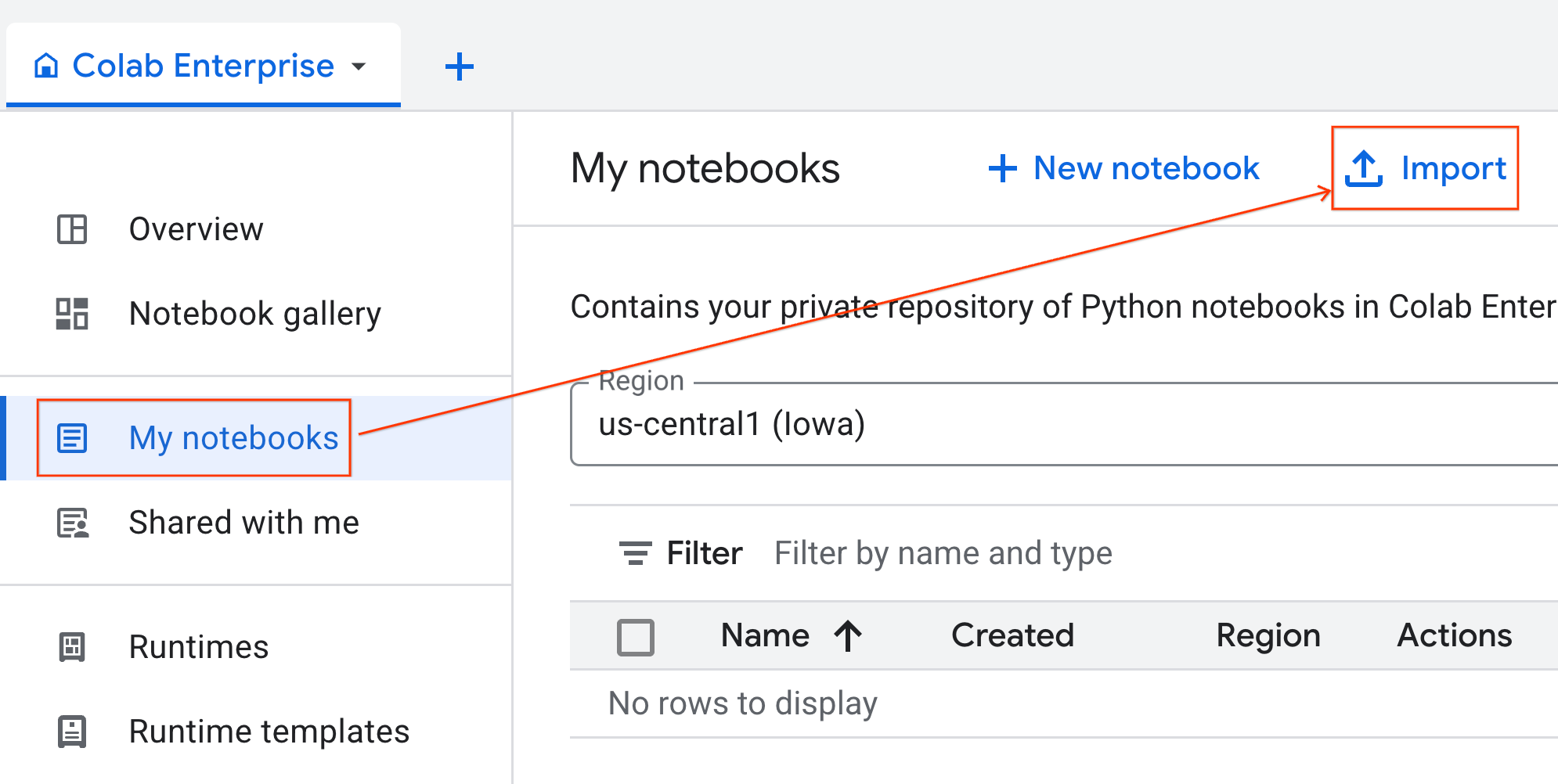
- Sélectionnez la case d'option URL et saisissez l'URL suivante :
https://github.com/GoogleCloudPlatform/ai-ml-recipes/blob/main/notebooks/analytics/gpu_accelerated_analytics.ipynb
- Cliquez sur Importer. Colab Enterprise copie le notebook depuis GitHub dans votre environnement.
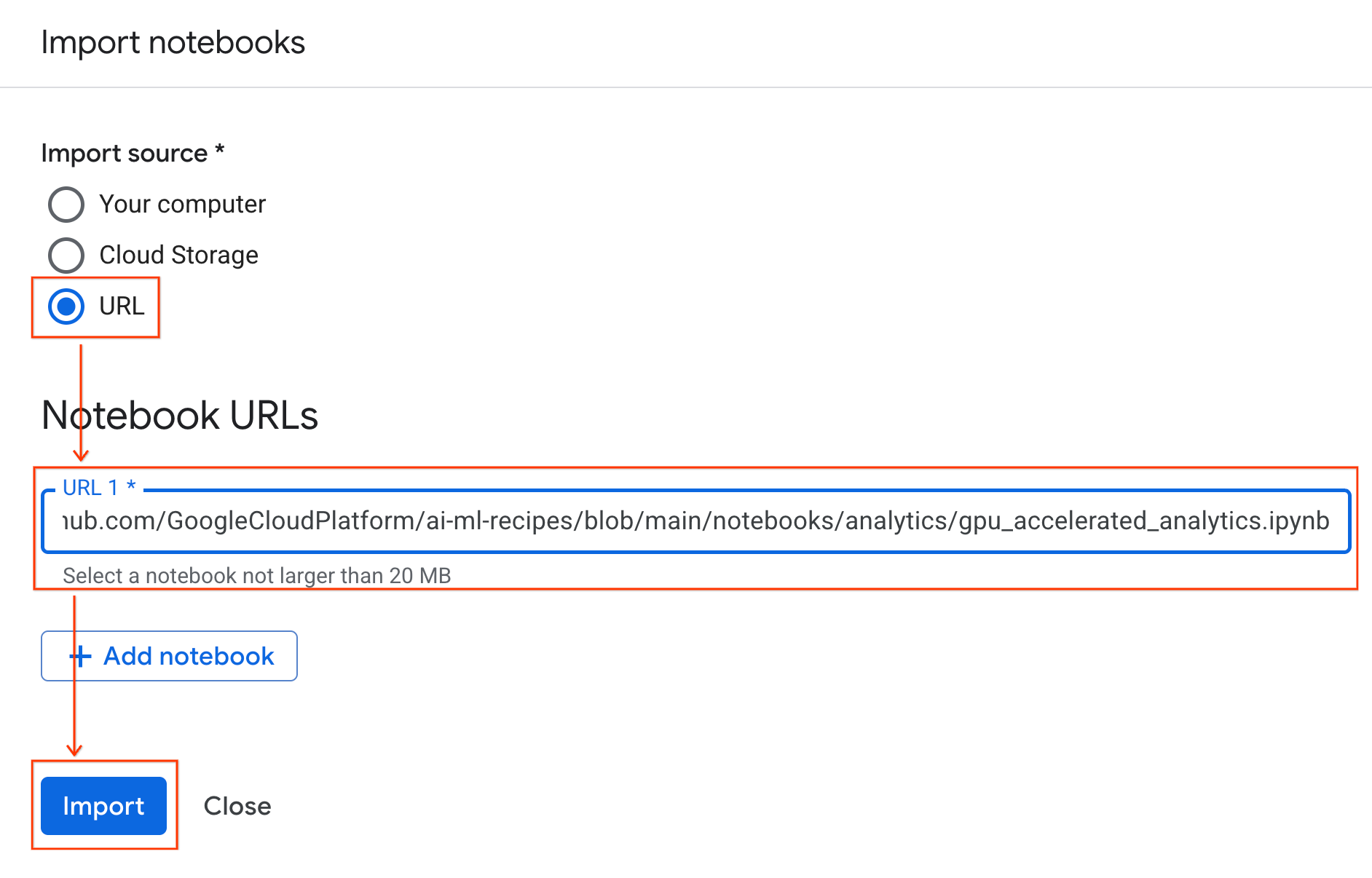
Se connecter à l'environnement d'exécution
- Ouvrez le notebook que vous venez d'importer.
- Cliquez sur la flèche vers le bas à côté de Connecter.
- Sélectionnez Se connecter à un environnement d'exécution.
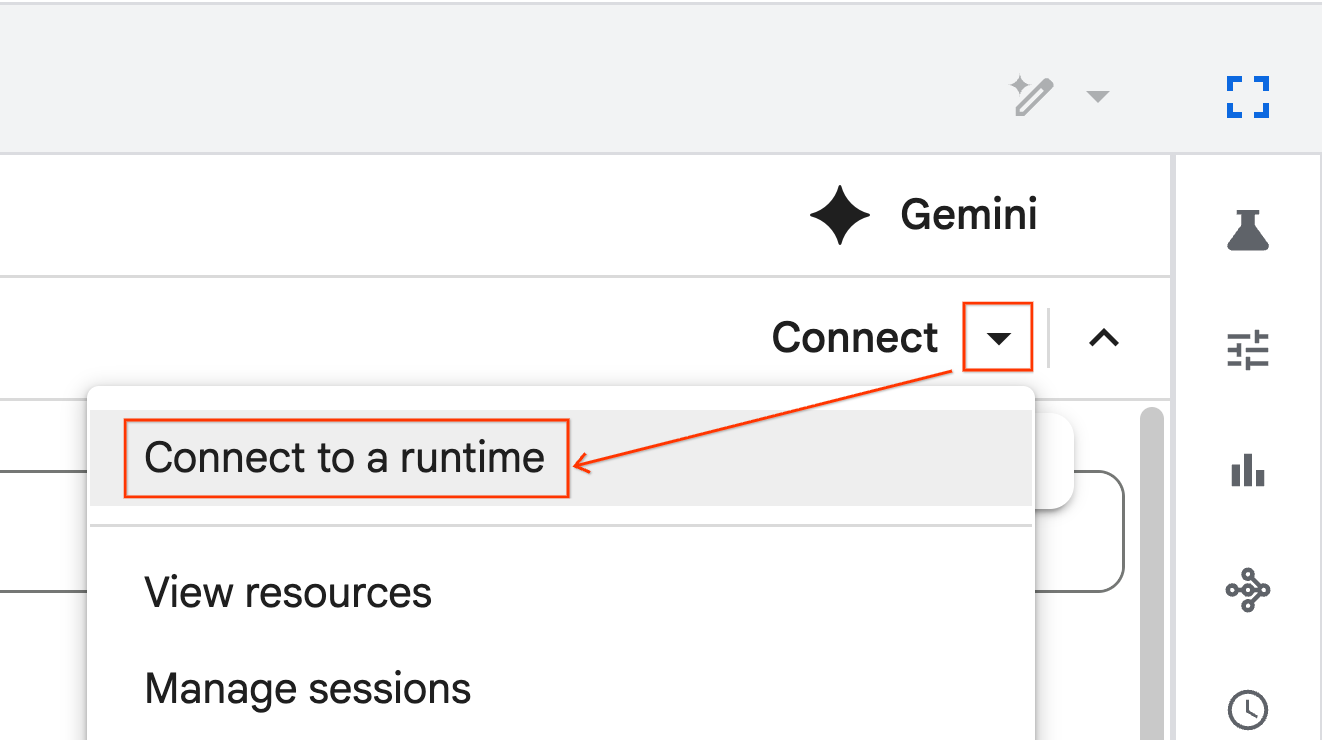
- Dans le menu déroulant, sélectionnez le runtime que vous avez créé précédemment.
- Cliquez sur Se connecter.
Votre notebook est désormais connecté à un environnement d'exécution compatible avec les GPU. Vous pouvez maintenant commencer à exécuter des requêtes.
7. Préparer l'ensemble de données sur les taxis new-yorkais
Cet atelier de programmation utilise les données d'enregistrement des courses de la NYC Taxi & Limousine Commission (TLC).
L'ensemble de données contient des enregistrements de trajets individuels de taxis jaunes à New York, et inclut des champs tels que :
- Dates, heures et lieux de prise en charge et de dépose
- Distances des trajets
- Montants détaillés des tarifs
- Nombre de passagers
Télécharger les données
Ensuite, téléchargez les données de trajet pour toute l'année 2024. Les données sont stockées au format de fichier Parquet.
Le bloc de code suivant effectue ces étapes :
- Définit la plage d'années et de mois à télécharger.
- Crée un répertoire local nommé
nyc_taxi_datapour stocker les fichiers. - Parcourt chaque mois, télécharge le fichier Parquet correspondant s'il n'existe pas déjà et l'enregistre dans le répertoire.
Exécutez ce code dans votre notebook pour collecter les données et les stocker dans l'environnement d'exécution :
from tqdm import tqdm
import requests
import time
import os
YEAR = 2024
DATA_DIR = "nyc_taxi_data"
os.makedirs(DATA_DIR, exist_ok=True)
print(f"Checking/Downloading files for {YEAR}...")
for month in tqdm(range(1, 13), unit="file"):
# Define standardized filename for both local path and URL
file_name = f"yellow_tripdata_{YEAR}-{month:02d}.parquet"
local_path = os.path.join(DATA_DIR, file_name)
url = f"https://d37ci6vzurychx.cloudfront.net/trip-data/{file_name}"
if not os.path.exists(local_path):
try:
with requests.get(url, stream=True) as response:
response.raise_for_status()
with open(local_path, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
time.sleep(1)
except requests.exceptions.HTTPError as e:
print(f"\nSkipping {file_name}: {e}")
if os.path.exists(local_path):
os.remove(local_path)
print("\nDownload complete.")
8. Explorer les données de trajet en taxi
Maintenant que vous avez téléchargé l'ensemble de données, il est temps d'effectuer une première analyse exploratoire des données (EDA). L'objectif de l'EDA est de comprendre la structure des données, de trouver des anomalies et de découvrir des schémas potentiels.
Charger les données d'un seul mois
Commencez par charger les données d'un seul mois. Cela fournit un échantillon suffisamment grand (plus de 3 millions de lignes) pour être significatif, tout en maintenant une utilisation de la mémoire gérable pour l'analyse interactive.
import pandas as pd
import glob
# Load the last month of the downloaded data
df = pd.read_parquet("nyc_taxi_data/yellow_tripdata_2024-12.parquet")
df.head()
Obtenir des statistiques récapitulatives
Utilisez la méthode .describe() pour générer des statistiques récapitulatives de haut niveau pour les colonnes numériques. Il s'agit d'une excellente première étape pour identifier les problèmes potentiels de qualité des données, tels que des valeurs minimales ou maximales inattendues.
df.describe().round(2)

Examiner la qualité des données
La sortie de .describe() révèle immédiatement un problème. Notez que la valeur min pour tpep_pickup_datetime et tpep_dropoff_datetime est en 2008, ce qui n'a pas de sens pour un ensemble de données de 2024.
Voici un exemple qui montre pourquoi il est important d'inspecter vos données. Pour en savoir plus, vous pouvez trier le DataFrame afin de trouver les lignes exactes contenant ces dates aberrantes.
# Sort by the dropoff datetime to see the oldest records
df.sort_values("tpep_pickup_datetime").head()
Visualiser les distributions de données
Ensuite, vous pouvez créer des histogrammes des colonnes numériques pour visualiser leurs distributions. Cela vous aide à comprendre la répartition et l'asymétrie de caractéristiques telles que trip_distance et fare_amount. La fonction .hist() est un moyen rapide de représenter des histogrammes pour toutes les colonnes numériques d'un DataFrame.
_ = df.hist(figsize=(20, 20))
Enfin, générez une matrice de dispersion pour visualiser les relations entre quelques colonnes clés. Étant donné que le tracé de millions de points est lent et peut masquer des tendances, utilisez .sample() pour créer le graphique à partir d'un échantillon aléatoire de 100 000 lignes.
_ = pd.plotting.scatter_matrix(
df[['passenger_count', 'trip_distance', 'tip_amount', 'total_amount']].sample(100_000),
diagonal="kde",
figsize=(15, 15)
)
9. Pourquoi utiliser le format de fichier Parquet ?
L'ensemble de données sur les taxis de New York est fourni au format Apache Parquet. Il s'agit d'un choix délibéré pour l'analyse à grande échelle. Parquet offre plusieurs avantages par rapport aux types de fichiers tels que CSV :
- Efficace et rapide : en tant que format en colonnes, Parquet est très efficace pour le stockage et la lecture. Il est compatible avec les méthodes de compression modernes qui permettent de réduire la taille des fichiers et d'accélérer considérablement les E/S, en particulier sur les GPU.
- Conserve le schéma : Parquet stocke les types de données dans les métadonnées du fichier. Vous n'avez jamais à deviner les types de données lorsque vous lisez le fichier.
- Lecture sélective : la structure en colonnes vous permet de lire uniquement les colonnes spécifiques dont vous avez besoin pour une analyse. Cela peut réduire considérablement la quantité de données que vous devez charger en mémoire.
Explorer les fonctionnalités Parquet
Explorons deux de ces puissantes fonctionnalités à l'aide de l'un des fichiers que vous avez téléchargés.
Inspecter les métadonnées sans charger l'ensemble de données complet
Bien que vous ne puissiez pas afficher un fichier Parquet dans un éditeur de texte standard, vous pouvez facilement inspecter son schéma et ses métadonnées sans charger de données en mémoire. Cela permet de comprendre rapidement la structure d'un fichier.
from pyarrow.parquet import ParquetFile
import pyarrow as pa
# Open one of the downloaded files
pf = ParquetFile('nyc_taxi_data/yellow_tripdata_2024-12.parquet')
# Print the schema
print("File Schema:")
print(pf.schema)
# Print the file metadata
print("\nFile Metadata:")
print(pf.metadata)
Lire uniquement les colonnes dont vous avez besoin
Imaginez que vous n'ayez besoin d'analyser que la distance des trajets et les montants des courses. Avec Parquet, vous pouvez charger uniquement ces colonnes, ce qui est beaucoup plus rapide et plus efficace en termes de mémoire que de charger l'ensemble du DataFrame.
import pandas as pd
# Read only four specific columns from the Parquet file
df_subset = pd.read_parquet(
'nyc_taxi_data/yellow_tripdata_2024-12.parquet',
columns=['passenger_count', 'trip_distance', 'tip_amount', 'total_amount']
)
df_subset.head()
10. Accélérer pandas avec NVIDIA cuDF
NVIDIA CUDA pour DataFrames (cuDF) est une bibliothèque Open Source accélérée par GPU qui vous permet d'interagir avec les DataFrames. cuDF vous permet d'effectuer des opérations de données courantes telles que le filtrage, la jointure et le regroupement sur le GPU avec un parallélisme massif.
La fonctionnalité clé que vous utiliserez dans cet atelier de programmation est le mode accélérateur cudf.pandas. Lorsque vous l'activez, votre code pandas standard est automatiquement redirigé pour utiliser des kernels cuDF optimisés par GPU en arrière-plan, sans que vous ayez à modifier votre code.
Activer l'accélération GPU
Pour utiliser NVIDIA cuDF dans un notebook Colab Enterprise, vous devez charger son extension magique avant d'importer pandas.
Commencez par inspecter la bibliothèque pandas standard. Notez que le résultat indique le chemin d'accès à l'installation pandas par défaut.
import pandas as pd
pd # Note the output for the standard pandas library
Maintenant, chargez l'extension cudf.pandas et importez à nouveau pandas. Observez comment la sortie du module pd change. Cela confirme que la version accélérée par GPU est désormais active.
%load_ext cudf.pandas
import pandas as pd
pd # Note the new output, indicating cudf.pandas is active
Autres façons d'activer cudf.pandas
Bien que la commande magique (%load_ext) soit la méthode la plus simple dans un notebook, vous pouvez également activer l'accélérateur dans d'autres environnements :
- Dans les scripts Python : appelez
import cudf.pandasetcudf.pandas.install()avant votre importationpandas. - Depuis des environnements autres que les notebooks : exécutez votre script à l'aide de
python -m cudf.pandas your_script.py.
11. Comparer les performances du CPU et du GPU
Passons maintenant à la partie la plus importante : comparer les performances de pandas standard sur un processeur avec cudf.pandas sur un GPU.
Pour garantir une base de référence totalement équitable pour le processeur, vous devez d'abord réinitialiser l'exécution Colab. Cela efface tous les accélérateurs GPU que vous avez peut-être activés dans les sections précédentes. Vous pouvez redémarrer l'environnement d'exécution en exécutant la cellule suivante ou en sélectionnant Redémarrer la session dans le menu Environnement d'exécution.
import IPython
IPython.Application.instance().kernel.do_shutdown(True)
Définir le pipeline d'analyse
Maintenant que l'environnement est propre, vous allez définir la fonction de benchmarking. Cette fonction vous permet d'exécuter exactement le même pipeline (chargement, tri et résumé) en utilisant le module pandas que vous lui transmettez.
import time
import glob
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
def run_analytics_pipeline(pd_module):
"""Loads, sorts, and summarizes data using the provided pandas module."""
timings = {}
# 1. Load all 2024 Parquet files from the directory
t0 = time.time()
df = pd_module.concat(
[pd_module.read_parquet(f) for f in glob.glob("nyc_taxi_data/*_2024*.parquet")],
ignore_index=True
)
timings["load"] = time.time() - t0
# 2. Sort the data by multiple columns
t0 = time.time()
df = df.sort_values(
['tpep_pickup_datetime', 'trip_distance', 'passenger_count'],
ascending=[False, True, False]
)
timings["sort"] = time.time() - t0
# 3. Perform a groupby and aggregation
t0 = time.time()
df['tpep_pickup_datetime'] = pd_module.to_datetime(df['tpep_pickup_datetime'])
_ = (
df.loc[df.tpep_pickup_datetime > '2024-11-01']
.groupby(['VendorID', 'tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
timings["summarize"] = time.time() - t0
return timings
Exécuter la comparaison
Tout d'abord, vous allez exécuter le pipeline à l'aide de pandas standard sur le processeur. Ensuite, activez cudf.pandas et exécutez-le à nouveau sur le GPU.
# --- Run on CPU ---
print("Running analytics pipeline on CPU...")
# Ensure we are using standard pandas
import pandas as pd
assert "cudf" not in str(pd), "Error: cuDF is still active. Please restart the kernel."
cpu_times = run_analytics_pipeline(pd)
print(f"CPU times: {cpu_times}")
# --- Run on GPU ---
print("\nEnabling cudf.pandas and running on GPU...")
# Load the extension
%load_ext cudf.pandas
import pandas as gpu_pd
gpu_times = run_analytics_pipeline(gpu_pd)
print(f"GPU times: {gpu_times}")
Visualiser les résultats
Enfin, visualisez la différence. Le code suivant calcule l'accélération pour chaque opération et les représente côte à côte.
# Create a DataFrame for plotting
results_df = pd.DataFrame([cpu_times, gpu_times], index=["CPU", "GPU"]).T
total_cpu_time = results_df['CPU'].sum()
total_gpu_time = results_df['GPU'].sum()
speedup = total_cpu_time / total_gpu_time
print("--- Performance Results ---")
print(results_df)
print(f"\nTotal CPU Time: {total_cpu_time:.2f} seconds")
print(f"Total GPU Time: {total_gpu_time:.2f} seconds")
print(f"Overall Speedup: {speedup:.2f}x")
# Plot the results
fig, ax = plt.subplots(figsize=(10, 6))
results_df.plot(kind='bar', ax=ax, color={"CPU": "tab:blue", "GPU": "tab:green"})
ax.set_ylabel("Time (seconds)")
ax.set_title(f"CPU vs. GPU Runtimes (Overall Speedup: {speedup:.2f}x)", fontsize=14)
ax.tick_params(axis='x', rotation=0)
# Add numerical labels to the bars
for container in ax.containers:
ax.bar_label(container, fmt="%.2f", padding=3)
plt.tight_layout()
plt.show()
Exemple de résultats :
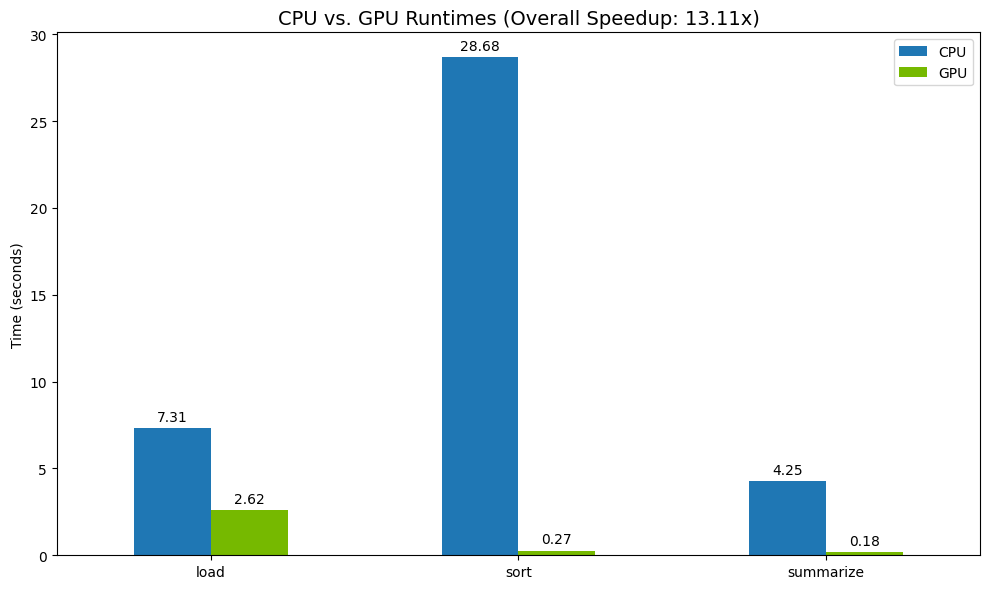
Le GPU offre une nette augmentation de la vitesse par rapport au CPU.
12. Profiler votre code pour identifier les goulots d'étranglement
Même avec l'accélération GPU, certaines opérations pandas peuvent revenir au processeur si elles ne sont pas encore compatibles avec cuDF. Ces "replis sur le processeur" peuvent devenir des goulots d'étranglement au niveau des performances.
Pour vous aider à identifier ces zones, cudf.pandas inclut deux profileurs intégrés. Vous pouvez les utiliser pour voir exactement quelles parties de votre code s'exécutent sur le GPU et lesquelles reviennent au CPU.
%%cudf.pandas.profile: utilisez cette option pour obtenir un résumé général de votre code, fonction par fonction. Elle est idéale pour obtenir un aperçu rapide des opérations en cours sur chaque appareil.%%cudf.pandas.line_profile: utilisez cette option pour obtenir une analyse détaillée, ligne par ligne. Il s'agit du meilleur outil pour identifier précisément les lignes de code qui entraînent un retour au processeur.
Utilisez ces profileurs comme "cellules magiques" en haut d'une cellule de notebook.
Profilage au niveau des fonctions avec %%cudf.pandas.profile
Commencez par exécuter le profileur au niveau de la fonction sur le même pipeline d'analyse que dans la section précédente. Le résultat affiche un tableau de chaque fonction appelée, de l'appareil sur lequel elle s'est exécutée (GPU ou CPU) et du nombre de fois où elle a été appelée.
%load_ext cudf.pandas
import pandas as pd
import glob
pd.DataFrame({"a": [1]})
Après vous être assuré que cudf.pandas est actif, vous pouvez exécuter un profil.
%%cudf.pandas.profile
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*2024*.parquet")], ignore_index=True)
df = df.sort_values(['tpep_pickup_datetime', 'trip_distance', 'passenger_count'], ascending=[False, True, False])
summary = (
df
.loc[(df.tpep_pickup_datetime > '2024-11-01')]
.groupby(['VendorID','tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
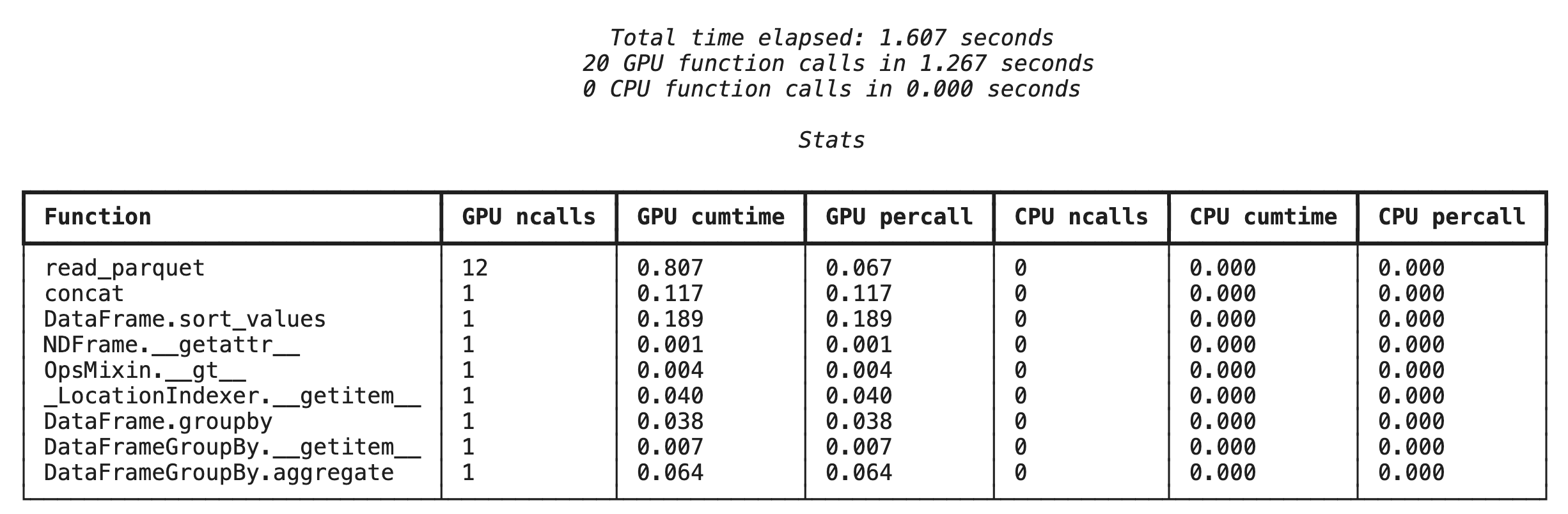
Profilage ligne par ligne avec %%cudf.pandas.line_profile
Exécutez ensuite le profileur au niveau de la ligne. Vous obtenez ainsi une vue beaucoup plus précise, qui indique la part de temps que chaque ligne de code a passé à s'exécuter sur le GPU par rapport au CPU. C'est le moyen le plus efficace d'identifier les goulots d'étranglement spécifiques à optimiser.
%%cudf.pandas.line_profile
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*2024*.parquet")], ignore_index=True)
df = df.sort_values(['tpep_pickup_datetime', 'trip_distance', 'passenger_count'], ascending=[False, True, False])
summary = (
df
.loc[(df.tpep_pickup_datetime > '2024-11-01')]
.groupby(['VendorID','tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
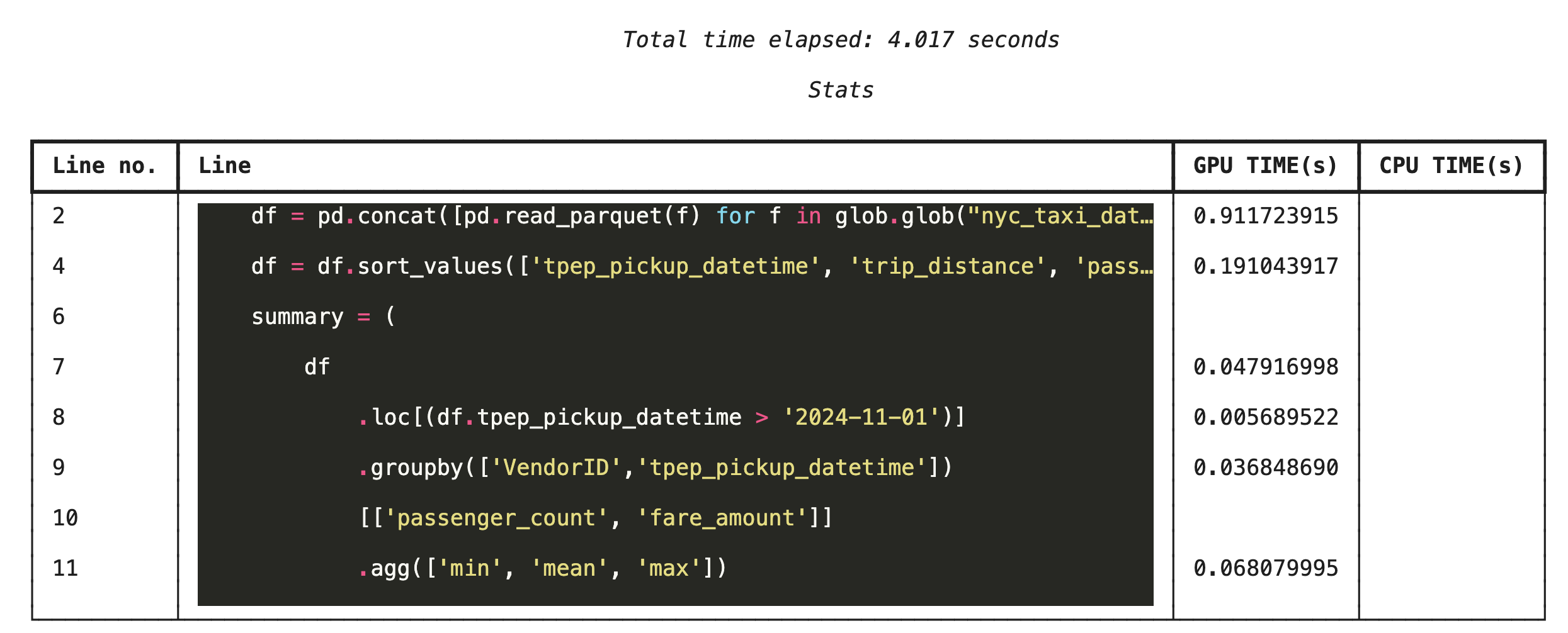
Profiler à partir de la ligne de commande
Ces profileurs sont également disponibles à partir de la ligne de commande, ce qui est utile pour les tests automatisés et le profilage des scripts Python.
Vous pouvez utiliser les éléments suivants dans une interface de ligne de commande :
python -m cudf.pandas --profile your_script.pypython -m cudf.pandas --line_profile your_script.py
13. S'intégrer à Google Cloud Storage
Google Cloud Storage (GCS) est un service de stockage d'objets évolutif et durable. Lorsque vous utilisez Colab Enterprise, GCS est un excellent endroit pour stocker vos ensembles de données, vos points de contrôle de modèle et d'autres artefacts.
Votre environnement d'exécution Colab Enterprise dispose des autorisations nécessaires pour lire et écrire des données directement dans les buckets GCS. Ces opérations sont accélérées par GPU pour des performances maximales.
Créer un bucket GCS
Commencez par créer un bucket GCS. Les noms de buckets GCS sont uniques. Ajoutez donc un UUID à son nom.
from google.cloud import storage
import uuid
unique_suffix = uuid.uuid4().hex[:12]
bucket_name = f'nyc-taxi-codelab-{unique_suffix}'
project_id = storage.Client().project
client = storage.Client()
try:
bucket = client.create_bucket(bucket_name)
print(f"Successfully created bucket: gs://{bucket.name}")
except Exception as e:
print(f"Bucket creation failed. You may already own it or the name is taken: {e}")
Écrire des données directement dans GCS
Enregistrez maintenant un DataFrame directement dans votre nouveau bucket GCS. Si la variable df n'est pas disponible dans les sections précédentes, le code charge d'abord un seul mois de données.
%%cudf.pandas.line_profile
# Ensure the DataFrame exists before saving to GCS
if 'df' not in locals():
print("DataFrame not found, loading a sample file...")
df = pd.read_parquet('nyc_taxi_data/yellow_tripdata_2024-12.parquet')
print(f"Writing data to gs://{bucket_name}/nyc_taxi_data.parquet...")
df.to_parquet(f"gs://{bucket_name}/nyc_taxi_data.parquet", index=False)
print("Write operation complete.")
Vérifier le fichier dans GCS
Vous pouvez vérifier que les données se trouvent dans GCS en accédant au bucket. Le code suivant crée un lien cliquable.
from IPython.display import Markdown
gcs_url = f"https://console.cloud.google.com/storage/browser/{bucket_name}?project={project_id}"
Markdown(f'**[Click here to view your GCS bucket in the Google Cloud Console]({gcs_url})**')
Lire les données directement depuis GCS
Enfin, lisez les données directement à partir d'un chemin GCS dans un DataFrame. Cette opération est également accélérée par GPU, ce qui vous permet de charger de grands ensembles de données depuis le stockage cloud à grande vitesse.
%%cudf.pandas.line_profile
print(f"Reading data from gs://{bucket_name}/nyc_taxi_data.parquet...")
df_from_gcs = pd.read_parquet(f"gs://{bucket_name}/nyc_taxi_data.parquet")
df_from_gcs.head()
14. Effectuer un nettoyage
Pour éviter que des frais inattendus ne soient facturés sur votre compte Google Cloud, vous devez nettoyer les ressources que vous avez créées.
Supprimez les données que vous avez téléchargées :
# Permanately delete the GCS bucket
print(f"Deleting GCS bucket: gs://{bucket_name}...")
!gsutil rm -r -f gs://{bucket_name}
print("Bucket deleted.")
# Remove NYC taxi dataset on the Colab runtime
print("Deleting local 'nyc_taxi_data' directory...")
!rm -rf nyc_taxi_data
print("Local files deleted.")
Arrêter votre environnement d'exécution Colab
- Dans la console Google Cloud, accédez à la page Environnements d'exécution de Colab Enterprise.
- Dans le menu Région, sélectionnez la région qui contient votre environnement d'exécution.
- Sélectionnez l'environnement d'exécution que vous souhaitez supprimer.
- Cliquez sur Supprimer.
- Cliquez sur Confirmer.
Supprimer votre notebook
- Dans la console Google Cloud, accédez à la page Mes notebooks de Colab Enterprise.
- Dans le menu Région, sélectionnez la région qui contient votre notebook.
- Sélectionnez le notebook que vous souhaitez supprimer.
- Cliquez sur Supprimer.
- Cliquez sur Confirmer.
15. Félicitations
Félicitations ! Vous avez réussi à accélérer un workflow d'analyse pandas à l'aide de NVIDIA cuDF sur Colab Enterprise. Vous avez appris à configurer des environnements d'exécution compatibles avec les GPU, à activer cudf.pandas pour l'accélération sans modification du code, à profiler le code pour identifier les goulots d'étranglement et à l'intégrer à Google Cloud Storage.