
1. מבוא
ב-Codelab הזה תלמדו איך להאיץ את תהליכי העבודה של ניתוח נתונים במערכי נתונים גדולים באמצעות מעבדי GPU של NVIDIA וספריות קוד פתוח ב-Google Cloud. תתחילו באופטימיזציה של התשתית, ואז תלמדו איך להשתמש בהאצת GPU בלי לבצע שינויים בקוד.
התמקדות תהיה ב-pandas, ספרייה פופולרית למניפולציה של נתונים, ותלמדו איך להאיץ אותה באמצעות הספרייה cuDF של NVIDIA. היתרון הכי גדול הוא שאפשר להשתמש בהאצת ה-GPU הזו בלי לשנות את קוד pandas הקיים.
מה תלמדו
- הסבר על Colab Enterprise ב-Google Cloud.
- אפשר להתאים אישית סביבת זמן ריצה של Colab עם הגדרות ספציפיות של GPU, CPU וזיכרון.
- אפשר להאיץ את
pandasבלי לשנות את הקוד באמצעות NVIDIAcuDF. - יצירת פרופיל של הקוד כדי לזהות צווארי בקבוק בביצועים ולבצע אופטימיזציה שלהם.
בדף הבא מופיעים הקרדיטים שבהם אפשר להשתמש כדי להשלים את ה-Lab.
2. למה כדאי להאיץ את עיבוד הנתונים?
כלל 80/20: למה הכנת הנתונים צורכת כל כך הרבה זמן
הכנת הנתונים היא לרוב השלב שלוקח הכי הרבה זמן בפרויקט ניתוח נתונים. מדעני נתונים ואנליסטים מקדישים חלק גדול מהזמן שלהם לניקוי, לשינוי ולסידור של נתונים לפני שהם מתחילים בניתוח נתונים.
למזלכם, אתם יכולים להאיץ ספריות פופולריות בקוד פתוח כמו pandas, Apache Spark ו-Polars ב-GPUs של NVIDIA באמצעות cuDF. גם עם ההאצה הזו, הכנת הנתונים עדיין אורכת זמן רב כי:
- נתוני המקור לא תמיד מוכנים לניתוח: לרוב, בנתונים מהעולם האמיתי יש חוסר עקביות, ערכים חסרים ובעיות בפורמט.
- האיכות משפיעה על ביצועי המודל: איכות נתונים נמוכה עלולה להפוך גם את האלגוריתמים המתוחכמים ביותר ללא שימושיים.
- היקף הנתונים מגדיל את הבעיות: בעיות נתונים שנראות קטנות הופכות לצווארי בקבוק קריטיים כשעובדים עם מיליוני רשומות.
3. בחירת סביבת Notebook
מדעני נתונים רבים מכירים את Colab לשימוש בפרויקטים אישיים, אבל Colab Enterprise מספק חוויית מחברת מאובטחת, משולבת ושיתופית שמיועדת לעסקים.
ב-Google Cloud יש שתי אפשרויות עיקריות לסביבות מחברות מנוהלות: Colab Enterprise ו-Gemini Enterprise Agent Platform Workbench. הבחירה הנכונה תלויה בסדרי העדיפויות של הפרויקט.
מתי כדאי להשתמש ב-Agent Platform Workbench
בוחרים ב-Agent Platform Workbench אם העדיפות היא שליטה והתאמה אישית מתקדמת. האפשרות הזו מתאימה במקרים הבאים:
- לנהל את התשתית הבסיסית ואת מחזור החיים של המכונות.
- שימוש במאגרי תגים מותאמים אישית ובהגדרות רשת.
- שילוב עם צינורות MLOps וכלים מותאמים אישית למחזור החיים.
מתי כדאי להשתמש ב-Colab Enterprise
כדאי לבחור ב-Colab Enterprise אם העדיפות שלכם היא הגדרה מהירה, קלות שימוש ושיתוף פעולה מאובטח. זהו פתרון מנוהל שמאפשר לצוות שלכם להתמקד בניתוח במקום בתשתית.
Colab Enterprise מאפשר לכם:
- פיתוח תהליכי עבודה של מדעי הנתונים שקשורים קשר הדוק למחסן הנתונים. אפשר לפתוח ולנהל את מחברות ה-Notebook ישירות ב-BigQuery Studio.
- אימון מודלים של למידת מכונה ושילוב עם כלי MLOps בפלטפורמת הסוכנים.
- ליהנות מחוויה גמישה ומאוחדת. אפשר לפתוח ולהריץ ב-Agent Platform מחברת Colab Enterprise שנוצרה ב-BigQuery, ולהיפך.
התכונה של היום מ-Labs
ב-Codelab הזה נשתמש ב-Colab Enterprise לניתוח נתונים מואץ.
לקבלת מידע נוסף על ההבדלים, אפשר לעיין בתיעוד הרשמי בנושא בחירת פתרון המחברת הנכון.
4. הגדרת תבנית בזמן ריצה
ב-Colab Enterprise, מתחברים לסביבת זמן ריצה שמבוססת על תבנית מוגדרת מראש של סביבת זמן ריצה.
תבנית של זמן ריצה היא הגדרה לשימוש חוזר שמציינת את כל הסביבה של מחברת, כולל:
- סוג המכונה (מעבד, זיכרון)
- מאיץ (סוג ה-GPU ומספר המאיצים)
- גודל וסוג הדיסק
- הגדרות רשת ומדיניות אבטחה
- כללים אוטומטיים לכיבוי במצב המתנה
למה כדאי להשתמש בתבניות בזמן ריצה
- סביבה עקבית: אתם והצוות שלכם מקבלים בכל פעם את אותה סביבה מוכנה לשימוש, כדי להבטיח שהעבודה שלכם תהיה עקבית.
- עבודה מאובטחת משלב התכנון: התבניות אוכפות באופן אוטומטי את מדיניות האבטחה של הארגון.
- ניהול עלויות יעיל: משאבים כמו מעבדי GPU ומעבדי CPU מוגדרים מראש בתבנית, מה שעוזר למנוע חריגות לא מכוונות מהתקציב.
יצירת תבנית בזמן ריצה
מגדירים תבנית זמן ריצה לשימוש חוזר לשיעור ה-Lab.
- במסוף Google Cloud, עוברים אל תפריט הניווט > Agent Platform > Notebooks.
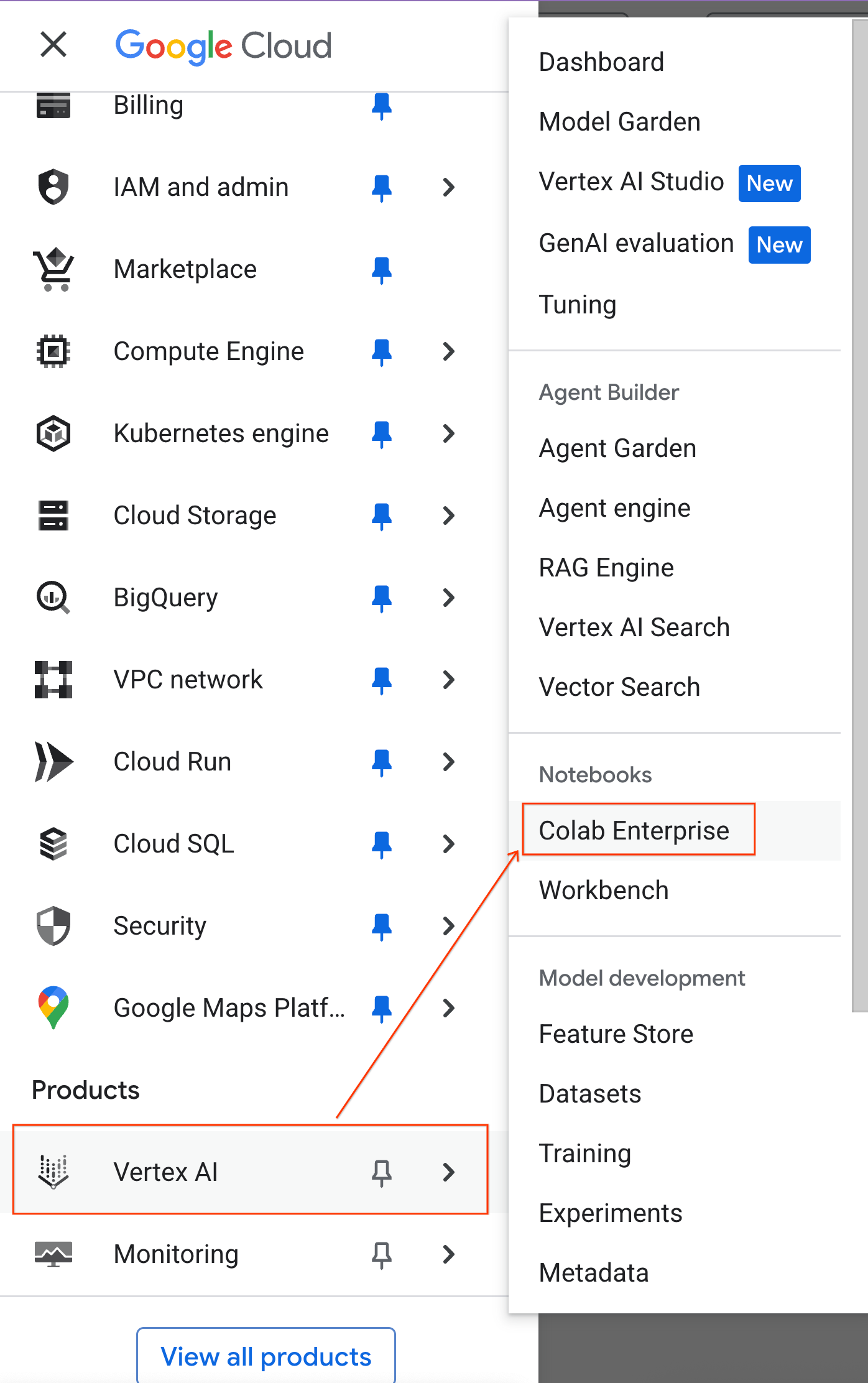
- ב-Colab Enterprise, לוחצים על תבניות של סביבת ריצה ואז על תבנית חדשה.
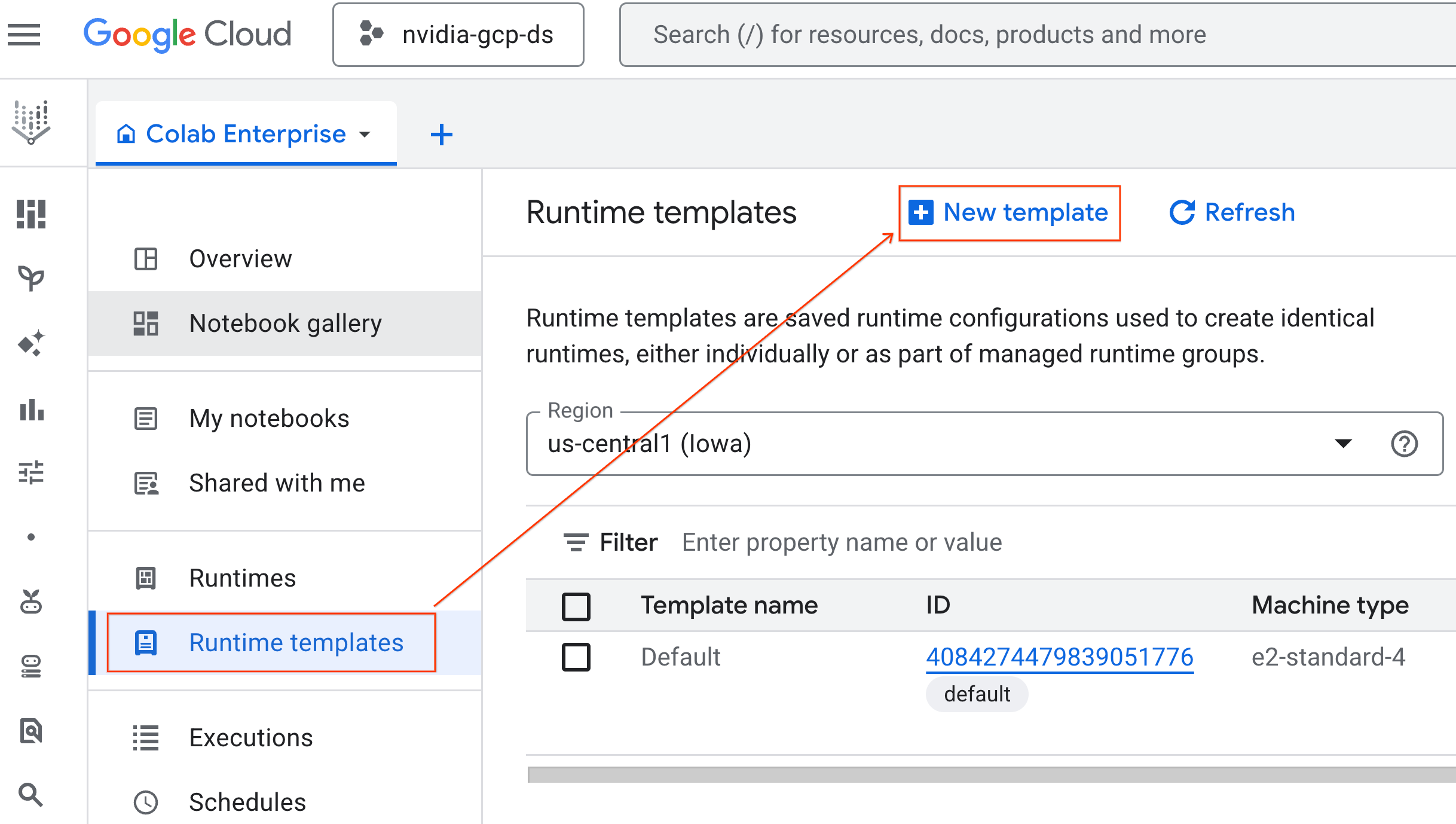
- בקטע יסודות של זמן ריצה:
- מגדירים את השם המוצג כ-
gpu-template. - מגדירים את האזור המועדף.
- מגדירים את השם המוצג כ-
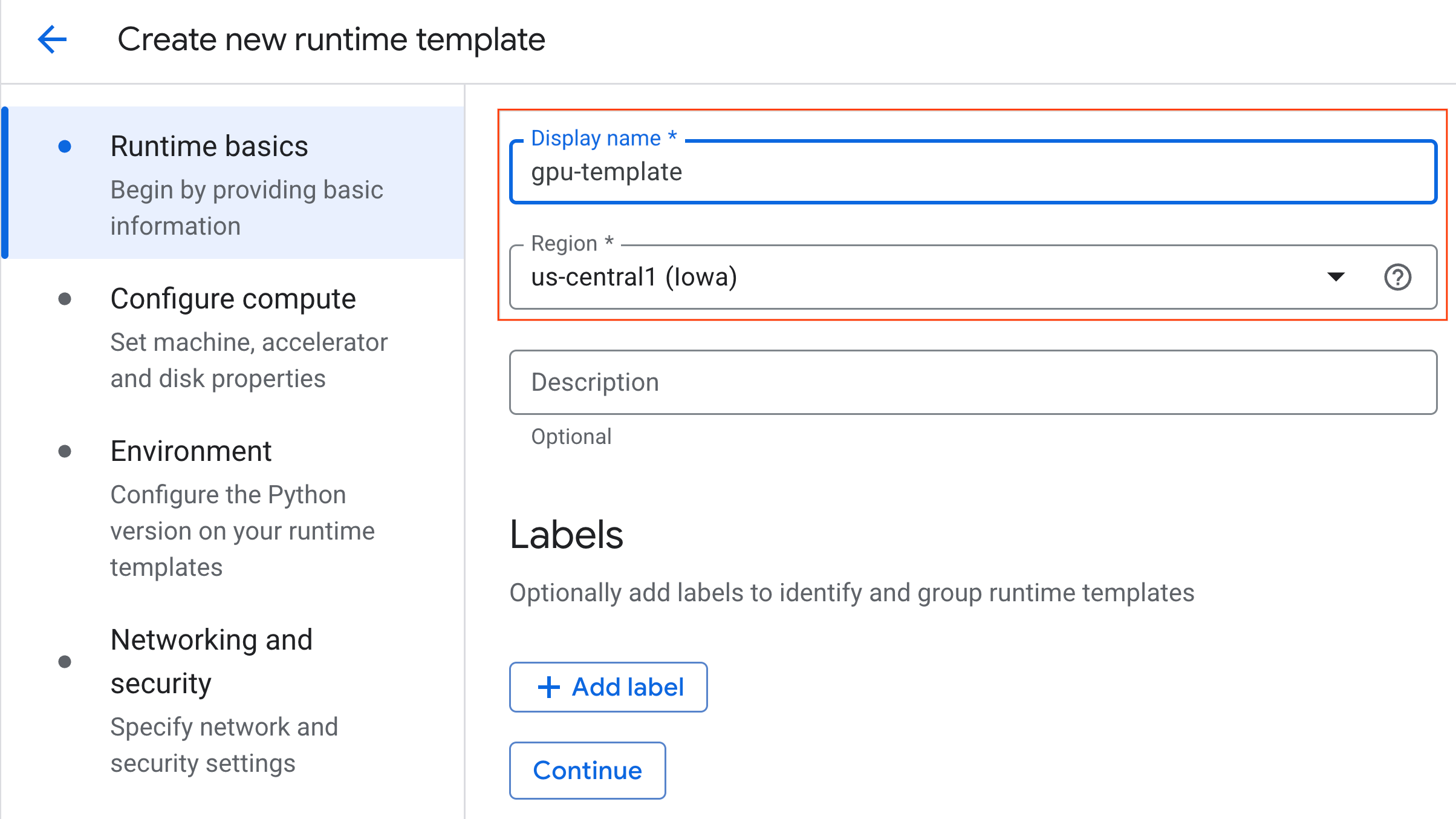
- בקטע Configure compute (הגדרת משאבי מחשוב):
- מגדירים את סוג המכונה לערך
g2-standard-4. - משאירים את הגדרת ברירת המחדל סוג המאיץ כ-
NVIDIA L4עם מספר מאיצים של 1. - משנים את ההגדרה כיבוי במצב לא פעיל ל-60 דקות.
- לוחצים על המשך.
- מגדירים את סוג המכונה לערך
- בקטע סביבה:
- מגדירים את הסביבה לערך
Python 3.11
- מגדירים את הסביבה לערך
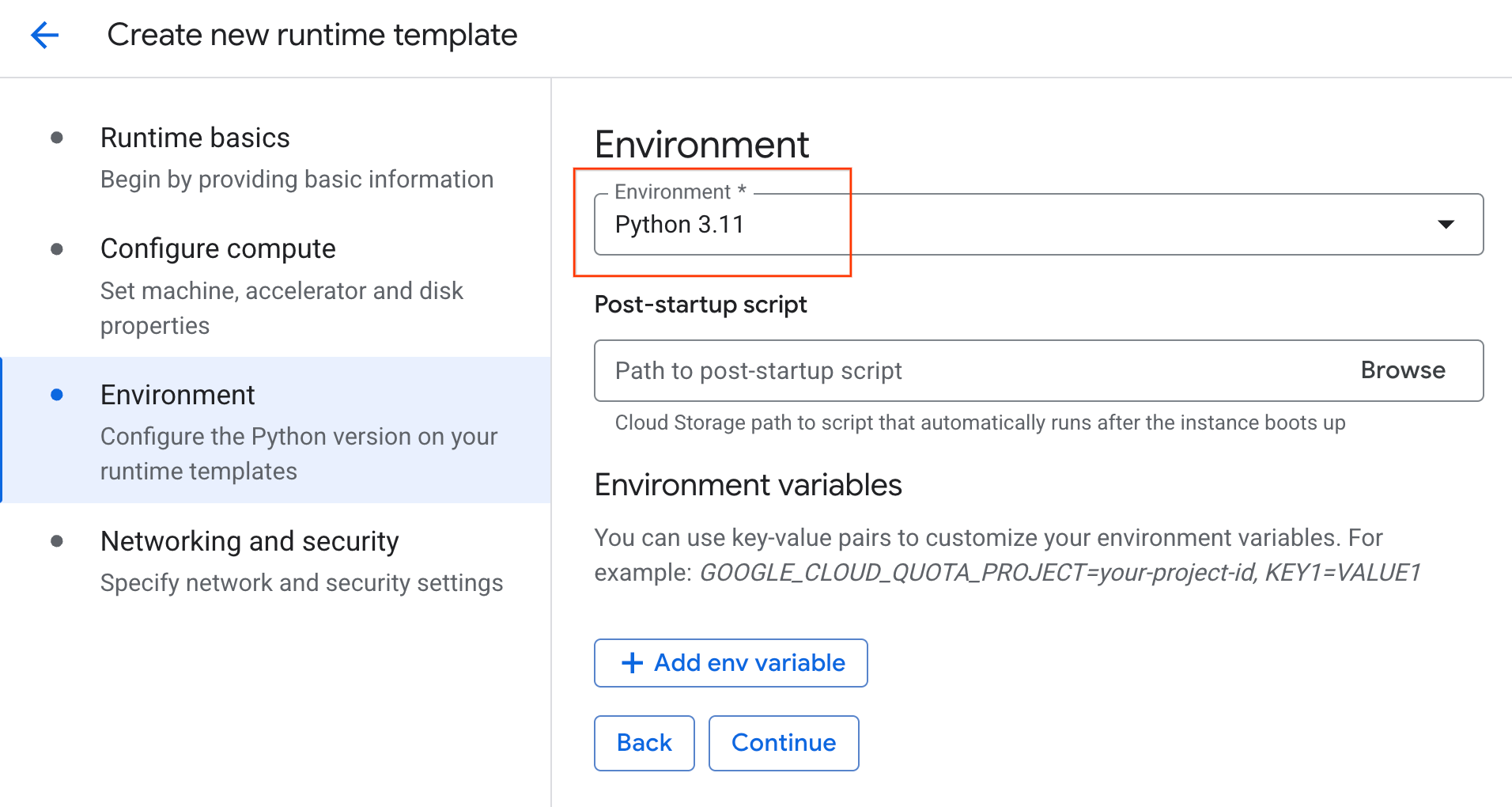
- לוחצים על יצירה כדי לשמור את תבנית זמן הריצה. התבנית החדשה אמורה להופיע בדף 'תבניות בזמן ריצה'.
5. הפעלת סביבת זמן ריצה
אחרי שהתבנית מוכנה, אפשר ליצור סביבת ריצה חדשה.
- ב-Colab Enterprise, לוחצים על Runtimes ואז על Create.
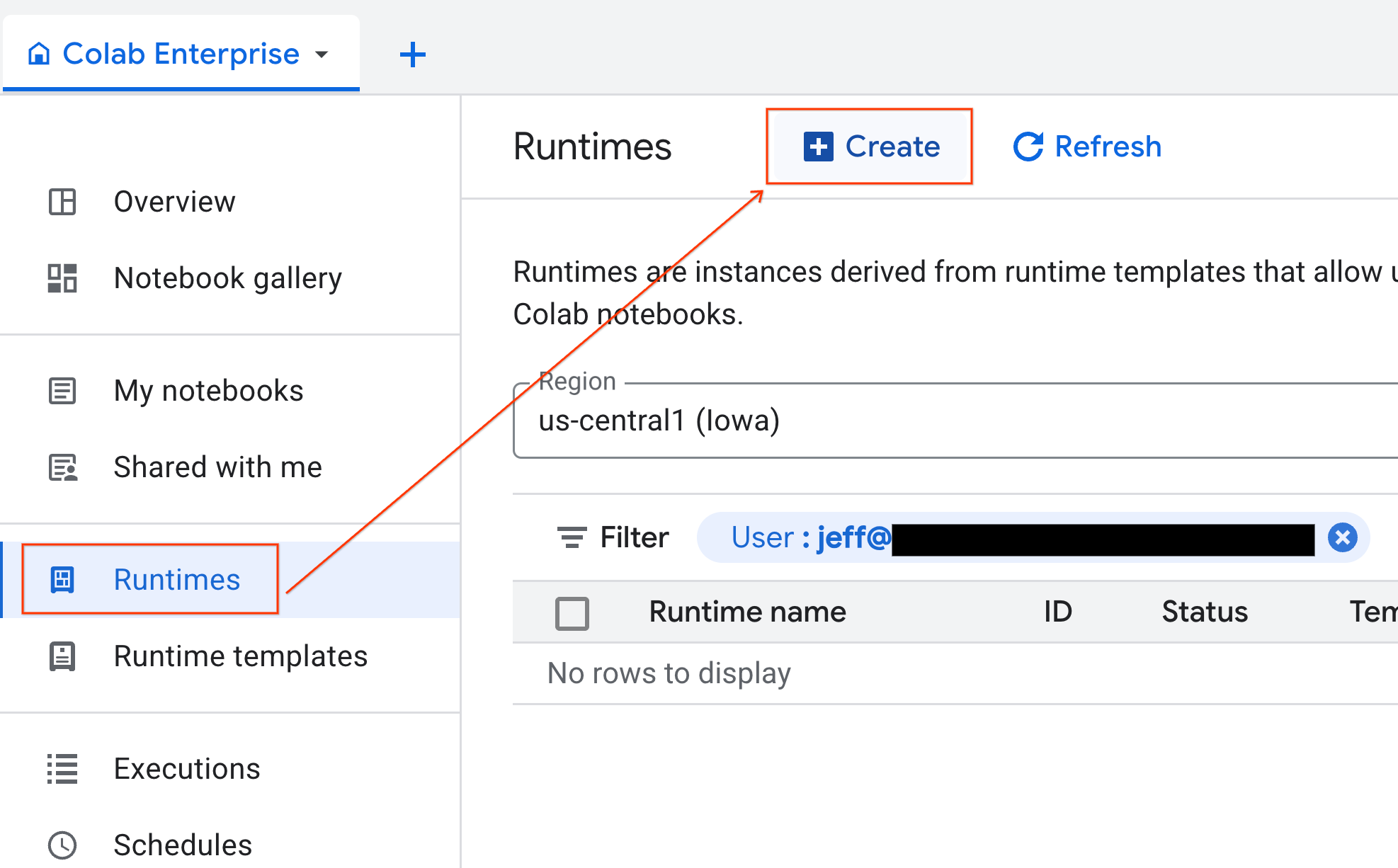
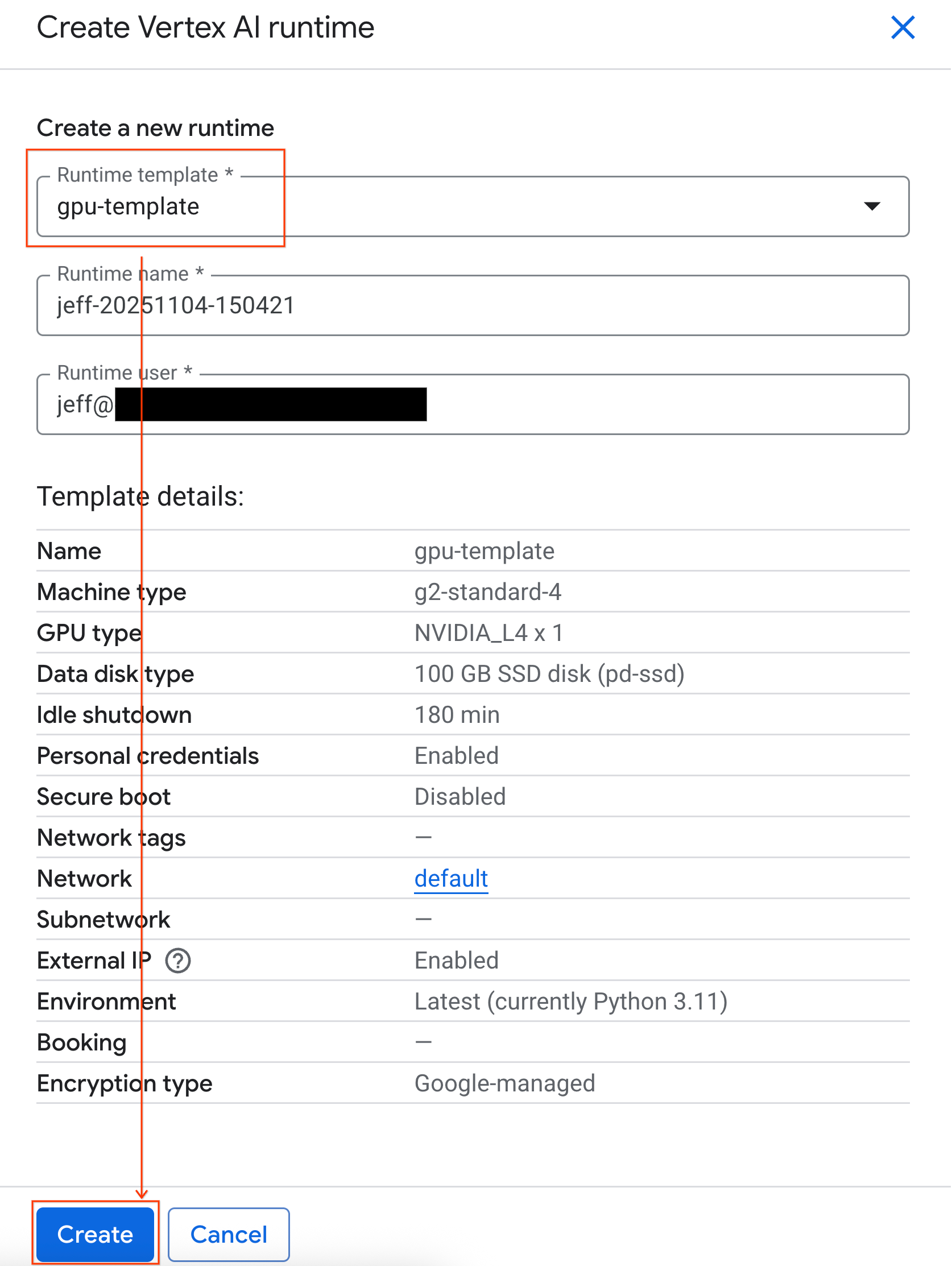
- בקטע Runtime template, בוחרים באפשרות
gpu-template. לוחצים על Create ומחכים עד שהסביבה תופעל.
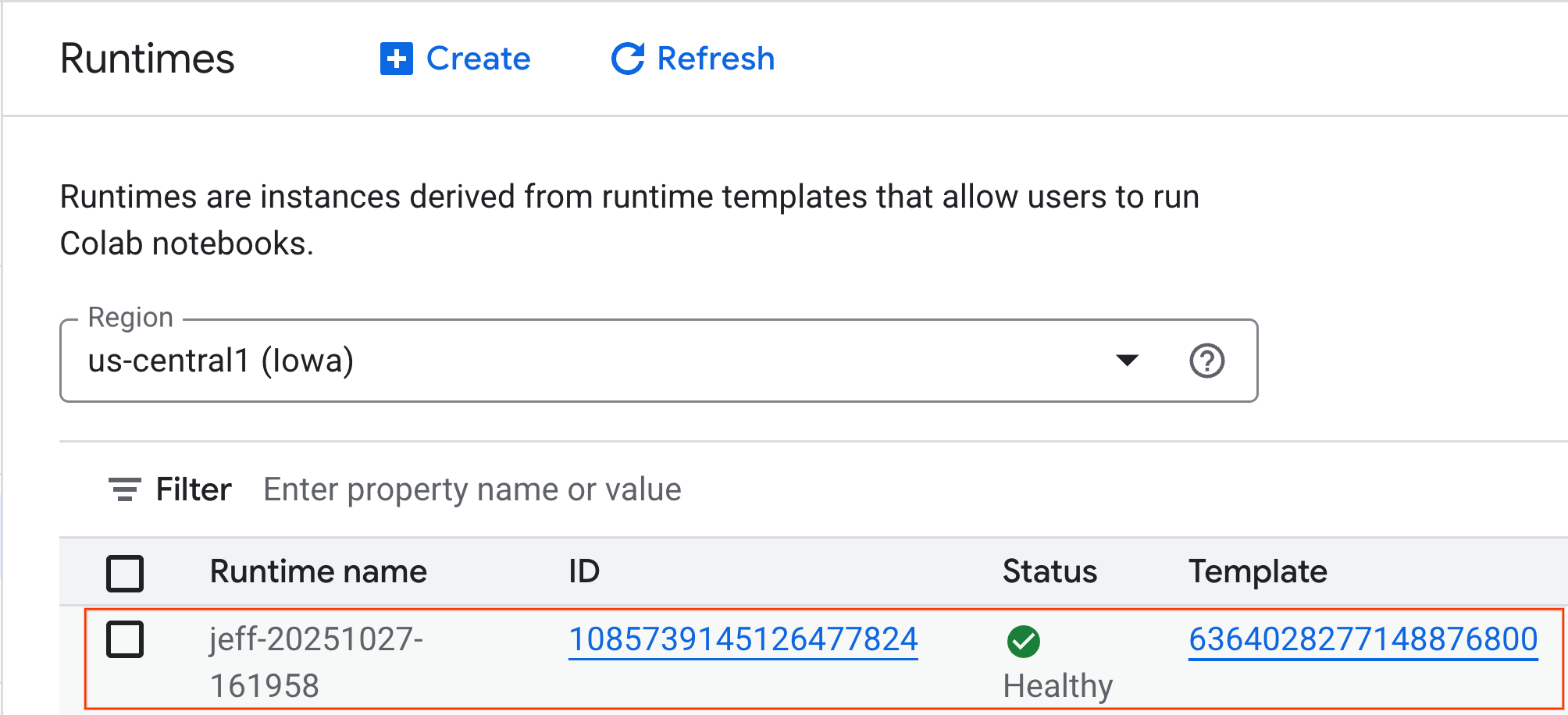
- אחרי כמה דקות, זמן הריצה יהיה זמין.
6. הגדרת ה-Notebook
עכשיו, כשהתשתית פועלת, צריך לייבא את מחברת ה-Lab ולחבר אותה לזמן הריצה.
ייבוא המחברת
- ב-Colab Enterprise, לוחצים על המחברות שלי ואז על ייבוא.
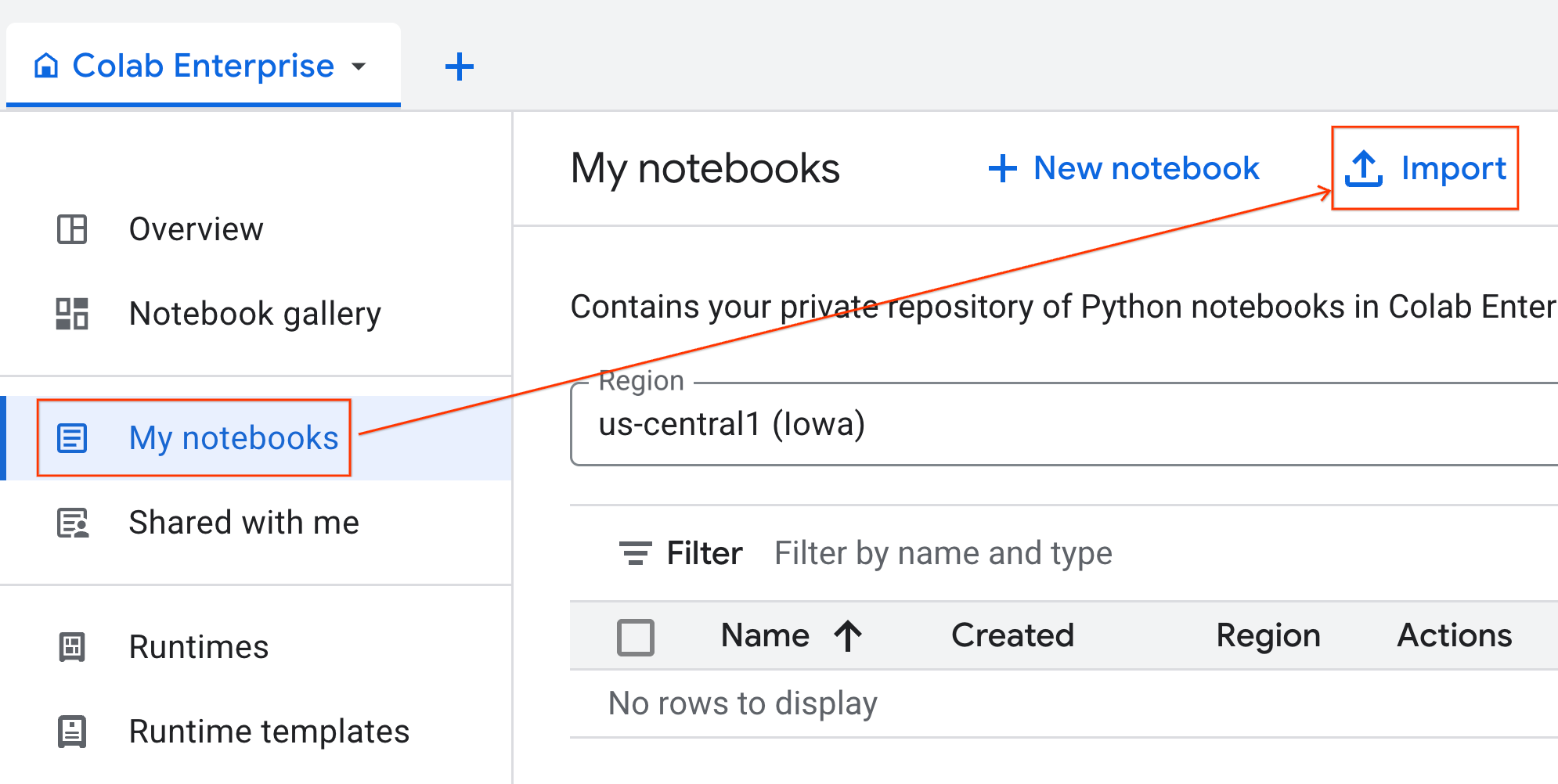
- בוחרים בלחצן האפשרויות כתובת URL ומזינים את כתובת ה-URL הבאה:
https://github.com/GoogleCloudPlatform/ai-ml-recipes/blob/main/notebooks/analytics/gpu_accelerated_analytics.ipynb
- לוחצים על ייבוא. מערכת Colab Enterprise תעתיק את ה-notebook מ-GitHub לסביבה שלכם.
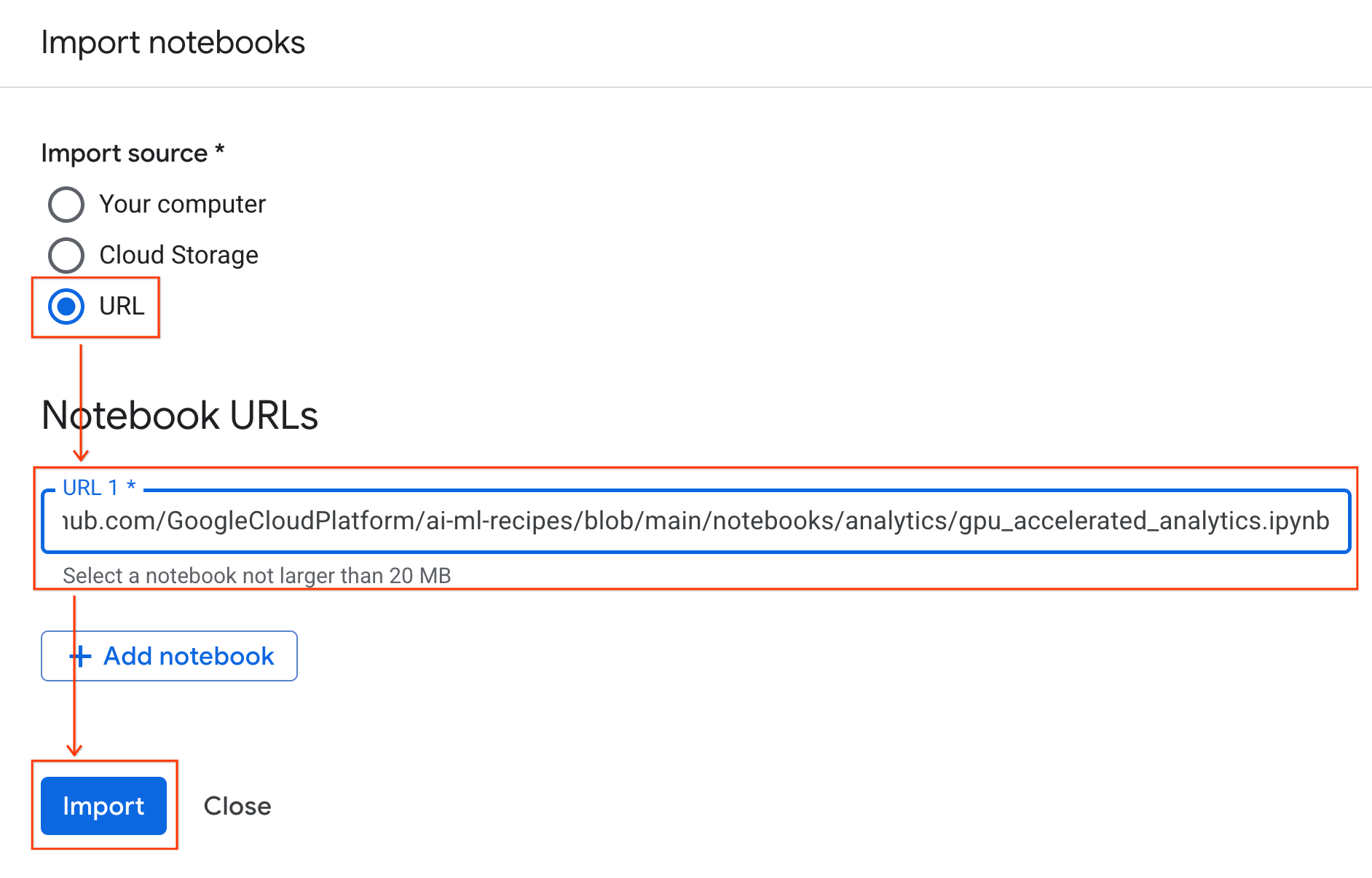
התחברות לסביבת זמן ריצה
- פותחים את ה-notebook החדש שיובא.
- לוחצים על החץ למטה לצד קישור.
- בוחרים באפשרות התחברות לסביבת זמן ריצה.
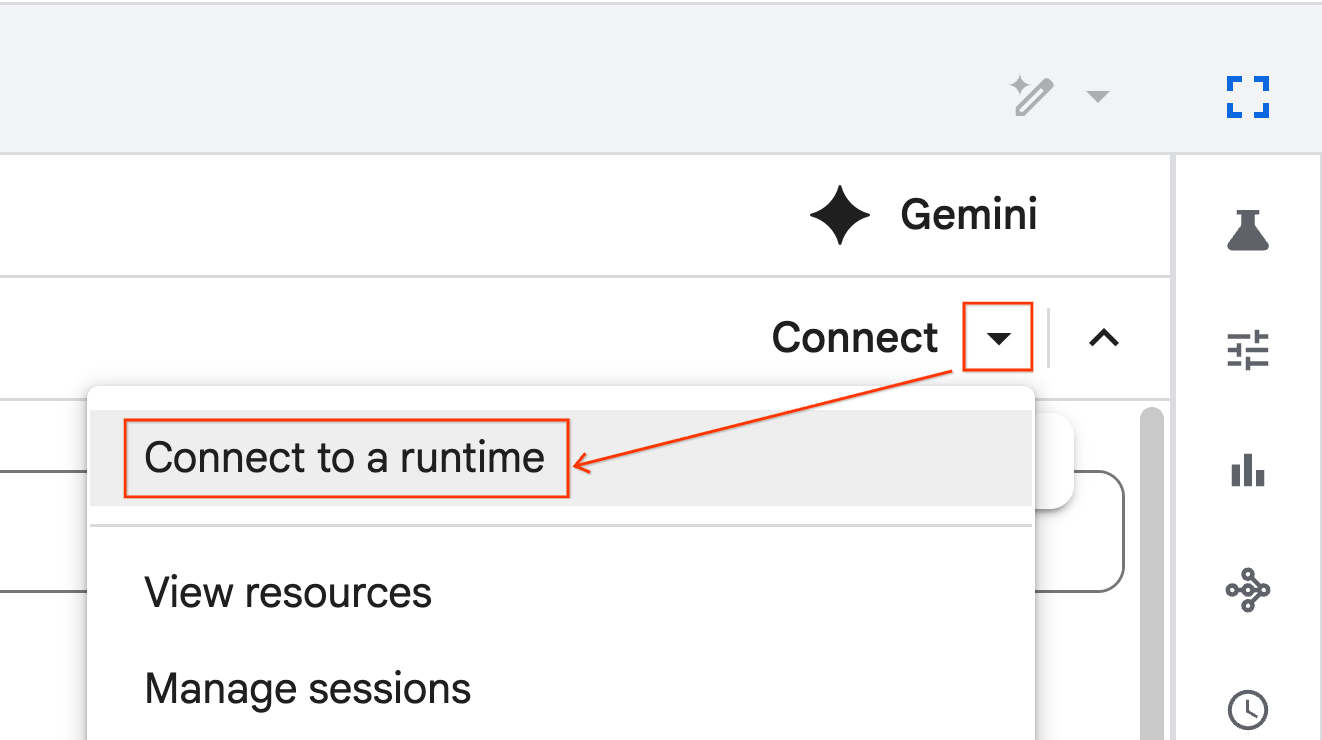
- משתמשים בתפריט הנפתח ובוחרים את זמן הריצה שיצרתם קודם.
- לוחצים על חיבור.
ה-notebook שלכם מחובר עכשיו לסביבת זמן ריצה עם GPU. עכשיו אפשר להתחיל להריץ שאילתות.
7. הכנת מערך הנתונים של מוניות בניו יורק
ב-Codelab הזה נעשה שימוש בנתוני רשומות נסיעה של NYC Taxi & Limousine Commission (ועדת המוניות והלימוזינות של ניו יורק, TLC).
מערך הנתונים מכיל רשומות של נסיעות במוניות צהובות בניו יורק, וכולל שדות כמו:
- תאריכים, שעות ומיקומים של איסוף והורדה
- מרחקי נסיעה
- סכומי התעריפים המפורטים
- מספר הנוסעים
הורדת הנתונים
לאחר מכן, מורידים את נתוני הנסיעות לכל שנת 2024. הנתונים מאוחסנים בפורמט הקובץ Parquet.
בלוק הקוד הבא מבצע את השלבים האלה:
- ההגדרה קובעת את טווח השנים והחודשים להורדה.
- יוצר ספרייה מקומית בשם
nyc_taxi_dataלאחסון הקבצים. - הסקריפט עובר על כל חודש, מוריד את קובץ ה-Parquet המתאים אם הוא עדיין לא קיים ושומר אותו בספרייה.
מריצים את הקוד הזה ב-notebook כדי לאסוף את הנתונים ולאחסן אותם בזמן הריצה:
from tqdm import tqdm
import requests
import time
import os
YEAR = 2024
DATA_DIR = "nyc_taxi_data"
os.makedirs(DATA_DIR, exist_ok=True)
print(f"Checking/Downloading files for {YEAR}...")
for month in tqdm(range(1, 13), unit="file"):
# Define standardized filename for both local path and URL
file_name = f"yellow_tripdata_{YEAR}-{month:02d}.parquet"
local_path = os.path.join(DATA_DIR, file_name)
url = f"https://d37ci6vzurychx.cloudfront.net/trip-data/{file_name}"
if not os.path.exists(local_path):
try:
with requests.get(url, stream=True) as response:
response.raise_for_status()
with open(local_path, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
time.sleep(1)
except requests.exceptions.HTTPError as e:
print(f"\nSkipping {file_name}: {e}")
if os.path.exists(local_path):
os.remove(local_path)
print("\nDownload complete.")
8. עיון בנתוני הנסיעות במוניות
אחרי שהורדתם את מערך הנתונים, הגיע הזמן לבצע ניתוח ראשוני של הנתונים (EDA). המטרה של EDA היא להבין את מבנה הנתונים, למצוא חריגות ולגלות דפוסים פוטנציאליים.
טעינה של נתונים מחודש אחד
מתחילים בטעינת נתונים של חודש אחד. כך מתקבל מדגם גדול מספיק (מעל 3 מיליון שורות) כדי להיות משמעותי, ועדיין השימוש בזיכרון נשאר ברמה שמאפשרת ניתוח אינטראקטיבי.
import pandas as pd
import glob
# Load the last month of the downloaded data
df = pd.read_parquet("nyc_taxi_data/yellow_tripdata_2024-12.parquet")
df.head()
קבלת נתונים סטטיסטיים מסכמים
משתמשים בשיטה .describe() כדי ליצור נתונים סטטיסטיים של סיכום ברמה גבוהה לעמודות המספריות. זהו שלב ראשון מצוין לזיהוי בעיות פוטנציאליות באיכות הנתונים, כמו ערכי מינימום או מקסימום לא צפויים.
df.describe().round(2)
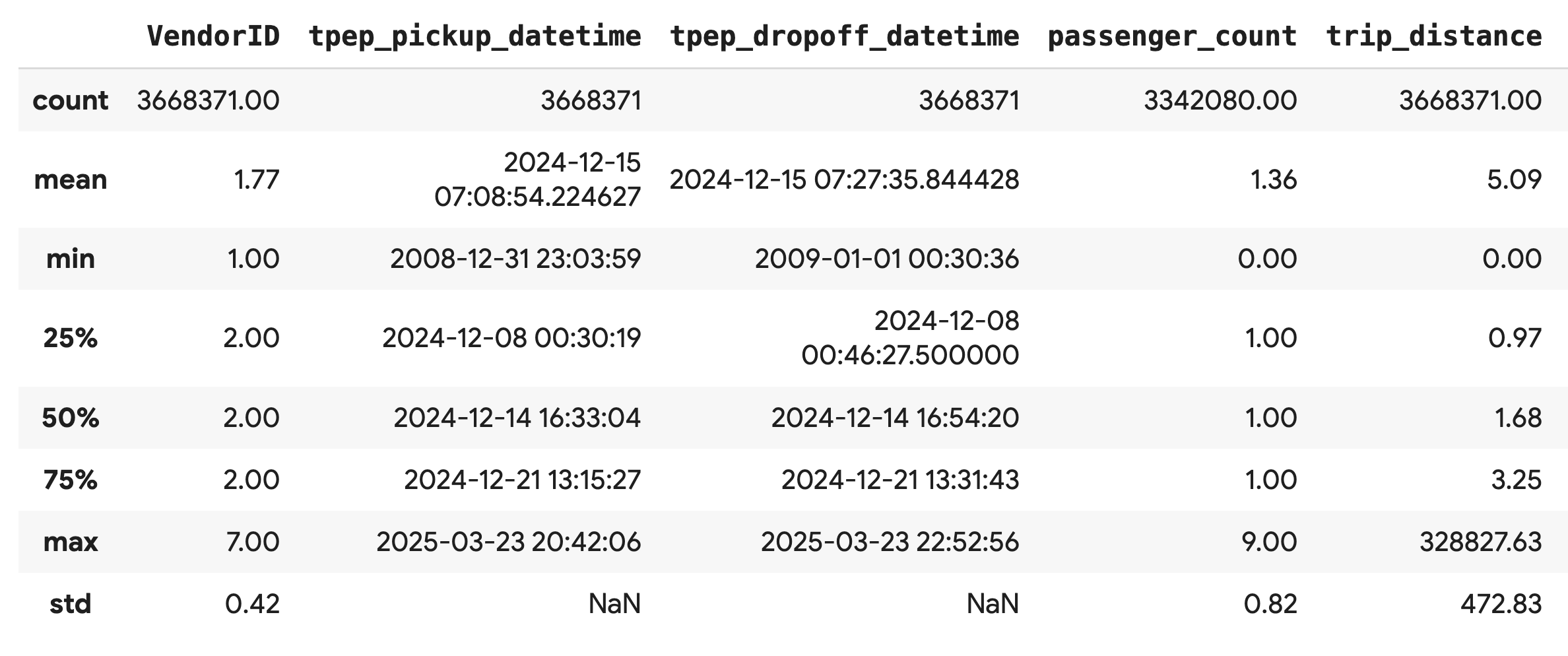
בדיקת איכות הנתונים
הפלט מ-.describe() חושף בעיה באופן מיידי. שימו לב שהערך min של tpep_pickup_datetime ושל tpep_dropoff_datetime הוא משנת 2008, וזה לא הגיוני למערך נתונים משנת 2024.
זו דוגמה שממחישה למה חשוב תמיד לבדוק את הנתונים. כדי לבדוק את זה לעומק, אפשר למיין את ה-DataFrame כדי למצוא את השורות המדויקות שמכילות את התאריכים החריגים האלה.
# Sort by the dropoff datetime to see the oldest records
df.sort_values("tpep_pickup_datetime").head()
המחשה חזותית של התפלגויות נתונים
לאחר מכן, אפשר ליצור היסטוגרמות של העמודות המספריות כדי להציג את ההתפלגויות שלהן באופן ויזואלי. כך תוכלו להבין את הפיזור וההטיה של תכונות כמו trip_distance ו-fare_amount. הפונקציה .hist() היא דרך מהירה לשרטוט היסטוגרמות לכל העמודות המספריות ב-DataFrame.
_ = df.hist(figsize=(20, 20))
לבסוף, יוצרים מטריצת פיזור כדי להמחיש את הקשרים בין כמה עמודות מרכזיות. שרטוט של מיליוני נקודות הוא תהליך איטי, והוא עלול להסתיר דפוסים. לכן, כדאי להשתמש ב-.sample() כדי ליצור את התרשים מדגימה אקראית של 100,000 שורות.
_ = pd.plotting.scatter_matrix(
df[['passenger_count', 'trip_distance', 'tip_amount', 'total_amount']].sample(100_000),
diagonal="kde",
figsize=(15, 15)
)
9. למה כדאי להשתמש בפורמט הקובץ Parquet?
מערך הנתונים של מוניות בניו יורק מסופק בפורמט Apache Parquet. זו בחירה מכוונת שנעשתה לצורך ניתוח נתונים בקנה מידה גדול. ל-Parquet יש כמה יתרונות על פני סוגי קבצים כמו CSV:
- יעיל ומהיר: פורמט Parquet הוא פורמט עמודתי, ולכן הוא יעיל מאוד לאחסון ולקריאה. הוא תומך בשיטות דחיסה מודרניות שמניבות קבצים קטנים יותר וקלט/פלט מהיר משמעותית, במיוחד ב-GPU.
- שומר על הסכימה: Parquet מאחסן את סוגי הנתונים במטא-נתונים של הקובץ. אתם לא צריכים לנחש את סוגי הנתונים כשאתם קוראים את הקובץ.
- מאפשר קריאה סלקטיבית: המבנה העמודתי מאפשר לכם לקרוא רק את העמודות הספציפיות שאתם צריכים לניתוח. כך אפשר לצמצם באופן משמעותי את כמות הנתונים שצריך לטעון לזיכרון.
תכונות של Parquet
בואו נבדוק שתיים מהתכונות המתקדמות האלה באמצעות אחד מהקבצים שהורדתם.
בדיקת מטא-נתונים בלי לטעון את מערך הנתונים המלא
אי אפשר לראות קובץ Parquet בעורך טקסט רגיל, אבל אפשר לבדוק בקלות את הסכימה והמטא-נתונים שלו בלי לטעון נתונים לזיכרון. האפשרות הזו שימושית להבנת המבנה של קובץ במהירות.
from pyarrow.parquet import ParquetFile
import pyarrow as pa
# Open one of the downloaded files
pf = ParquetFile('nyc_taxi_data/yellow_tripdata_2024-12.parquet')
# Print the schema
print("File Schema:")
print(pf.schema)
# Print the file metadata
print("\nFile Metadata:")
print(pf.metadata)
קריאה רק של העמודות שצריך
נניח שאתם צריכים לנתח רק את מרחק הנסיעה ואת סכומי התשלום. עם Parquet, אפשר לטעון רק את העמודות האלה, וזה הרבה יותר מהיר ויעיל מבחינת זיכרון מאשר טעינה של כל ה-DataFrame.
import pandas as pd
# Read only four specific columns from the Parquet file
df_subset = pd.read_parquet(
'nyc_taxi_data/yellow_tripdata_2024-12.parquet',
columns=['passenger_count', 'trip_distance', 'tip_amount', 'total_amount']
)
df_subset.head()
10. האצת pandas באמצעות NVIDIA cuDF
NVIDIA CUDA for DataFrames (cuDF) היא ספרייה בקוד פתוח עם האצת GPU שמאפשרת לכם לקיים אינטראקציה עם DataFrames. בעזרת cuDF תוכלו לבצע פעולות נפוצות על נתונים כמו סינון, צירוף וקיבוץ ב-GPU עם מקביליות מסיבית.
התכונה העיקרית שבה משתמשים ב-Codelab הזה היא מצב ההאצה cudf.pandas. כשמפעילים את האפשרות הזו, קוד pandas הרגיל מופנה אוטומטית לשימוש בגרעיני cuDF שמבוססים על GPU, בלי שצריך לשנות את הקוד.
הפעלת האצת GPU
כדי להשתמש ב-NVIDIA cuDF במחברת Colab Enterprise, צריך לטעון את תוסף הקסם שלו לפני שמייבאים את pandas.
קודם כל, בודקים את ספריית pandas הרגילה. שימו לב שהפלט מציג את הנתיב להתקנת ברירת המחדל של pandas.
import pandas as pd
pd # Note the output for the standard pandas library
עכשיו, טוענים את התוסף cudf.pandas ומייבאים שוב את pandas. צופים בשינוי בפלט של מודול pd – כך אפשר לוודא שהגרסה עם האצת GPU פעילה עכשיו.
%load_ext cudf.pandas
import pandas as pd
pd # Note the new output, indicating cudf.pandas is active
דרכים אחרות להפעלה של cudf.pandas
פקודת הקסם (%load_ext) היא השיטה הכי פשוטה במחברת, אבל אפשר להפעיל את ההאצה גם בסביבות אחרות:
- בתסריטי Python: קוראים ל-
import cudf.pandasול-cudf.pandas.install()לפני הייבוא שלpandas. - מסביבות שאינן מחברות: מריצים את הסקריפט באמצעות
python -m cudf.pandas your_script.py.
11. השוואה בין ביצועי המעבד (CPU) לבין ביצועי המעבד הגרפי (GPU)
עכשיו לחלק הכי חשוב: השוואה בין הביצועים של pandas רגיל במעבד לבין cudf.pandas במעבד גרפי.
כדי לוודא שנקודת הבסיס של המעבד הוגנת לחלוטין, צריך קודם לאפס את זמן הריצה של Colab. הפעולה הזו תנקה את כל מאיצי ה-GPU שאולי הפעלתם בקטעים הקודמים. כדי להפעיל מחדש את זמן הריצה, מריצים את התא הבא או בוחרים באפשרות הפעלה מחדש של הסשן בתפריט זמן ריצה.
import IPython
IPython.Application.instance().kernel.do_shutdown(True)
הגדרת צינור עיבוד הנתונים לניתוח
אחרי שהסביבה נקייה, מגדירים את פונקציית ההשוואה. הפונקציה הזו מאפשרת להריץ בדיוק את אותו פייפליין – טעינה, מיון וסיכום – באמצעות כל מודול pandas שמעבירים אליה.
import time
import glob
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
def run_analytics_pipeline(pd_module):
"""Loads, sorts, and summarizes data using the provided pandas module."""
timings = {}
# 1. Load all 2024 Parquet files from the directory
t0 = time.time()
df = pd_module.concat(
[pd_module.read_parquet(f) for f in glob.glob("nyc_taxi_data/*_2024*.parquet")],
ignore_index=True
)
timings["load"] = time.time() - t0
# 2. Sort the data by multiple columns
t0 = time.time()
df = df.sort_values(
['tpep_pickup_datetime', 'trip_distance', 'passenger_count'],
ascending=[False, True, False]
)
timings["sort"] = time.time() - t0
# 3. Perform a groupby and aggregation
t0 = time.time()
df['tpep_pickup_datetime'] = pd_module.to_datetime(df['tpep_pickup_datetime'])
_ = (
df.loc[df.tpep_pickup_datetime > '2024-11-01']
.groupby(['VendorID', 'tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
timings["summarize"] = time.time() - t0
return timings
הפעלת ההשוואה
קודם מריצים את צינור העיבוד באמצעות pandas רגיל במעבד. לאחר מכן מפעילים את cudf.pandas ומפעילים פתרונות חכמים שוב ב-GPU.
# --- Run on CPU ---
print("Running analytics pipeline on CPU...")
# Ensure we are using standard pandas
import pandas as pd
assert "cudf" not in str(pd), "Error: cuDF is still active. Please restart the kernel."
cpu_times = run_analytics_pipeline(pd)
print(f"CPU times: {cpu_times}")
# --- Run on GPU ---
print("\nEnabling cudf.pandas and running on GPU...")
# Load the extension
%load_ext cudf.pandas
import pandas as gpu_pd
gpu_times = run_analytics_pipeline(gpu_pd)
print(f"GPU times: {gpu_times}")
הצגה חזותית של התוצאות
לבסוף, מציגים את ההבדל באופן חזותי. הקוד הבא מחשב את ההאצה לכל פעולה ומציג אותן זו לצד זו.
# Create a DataFrame for plotting
results_df = pd.DataFrame([cpu_times, gpu_times], index=["CPU", "GPU"]).T
total_cpu_time = results_df['CPU'].sum()
total_gpu_time = results_df['GPU'].sum()
speedup = total_cpu_time / total_gpu_time
print("--- Performance Results ---")
print(results_df)
print(f"\nTotal CPU Time: {total_cpu_time:.2f} seconds")
print(f"Total GPU Time: {total_gpu_time:.2f} seconds")
print(f"Overall Speedup: {speedup:.2f}x")
# Plot the results
fig, ax = plt.subplots(figsize=(10, 6))
results_df.plot(kind='bar', ax=ax, color={"CPU": "tab:blue", "GPU": "tab:green"})
ax.set_ylabel("Time (seconds)")
ax.set_title(f"CPU vs. GPU Runtimes (Overall Speedup: {speedup:.2f}x)", fontsize=14)
ax.tick_params(axis='x', rotation=0)
# Add numerical labels to the bars
for container in ax.containers:
ax.bar_label(container, fmt="%.2f", padding=3)
plt.tight_layout()
plt.show()
תוצאות לדוגמה:
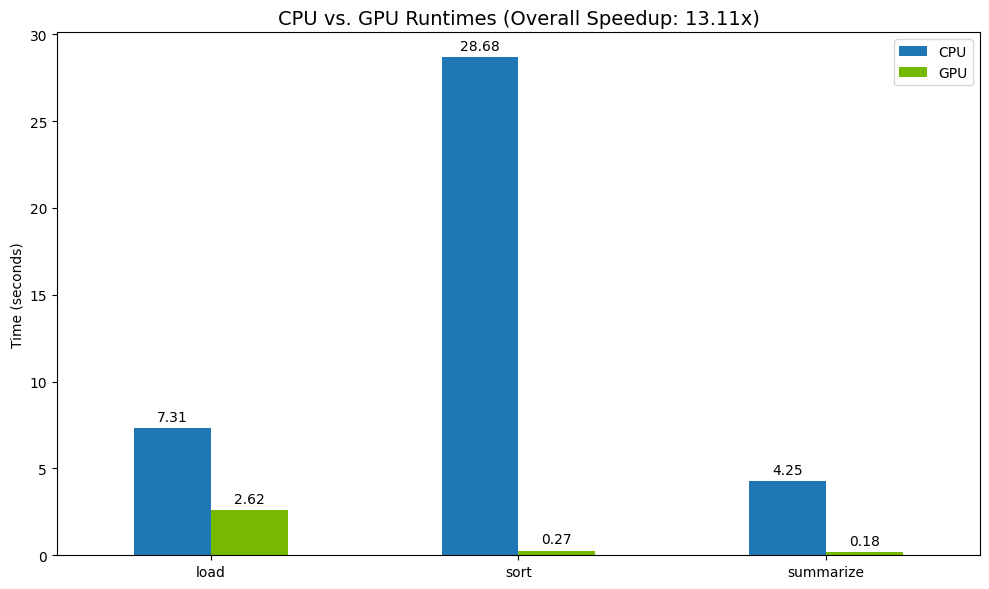
ה-GPU מספק עלייה ברורה במהירות ביחס למעבד.
12. ניתוח הפרופיל של הקוד כדי למצוא צווארי בקבוק
גם עם האצת GPU, יכול להיות שחלק מהפעולות של pandas יחזרו ל-CPU אם הן עדיין לא נתמכות על ידי cuDF. המעברים האלה ל-CPU עלולים להפוך לצווארי בקבוק בביצועים.
כדי לעזור לכם לזהות את התחומים האלה, cudf.pandas כולל שני פרופילים מובנים. אפשר להשתמש בהם כדי לראות בדיוק אילו חלקים בקוד פועלים ב-GPU ואילו חלקים פועלים ב-CPU.
-
%%cudf.pandas.profile: משתמשים באפשרות הזו כדי לקבל סיכום כללי של הקוד, לפי פונקציות. האפשרות הזו מתאימה במיוחד לקבלת סקירה מהירה של הפעולות שפועלות בכל מכשיר. -
%%cudf.pandas.line_profile: משתמשים באפשרות הזו לניתוח מפורט של כל שורה. זהו הכלי הטוב ביותר לזיהוי מדויק של השורות בקוד שגורמות לחזרה ל-CPU.
אפשר להשתמש בפרופילים האלה כ-cell magics בחלק העליון של תא ב-notebook.
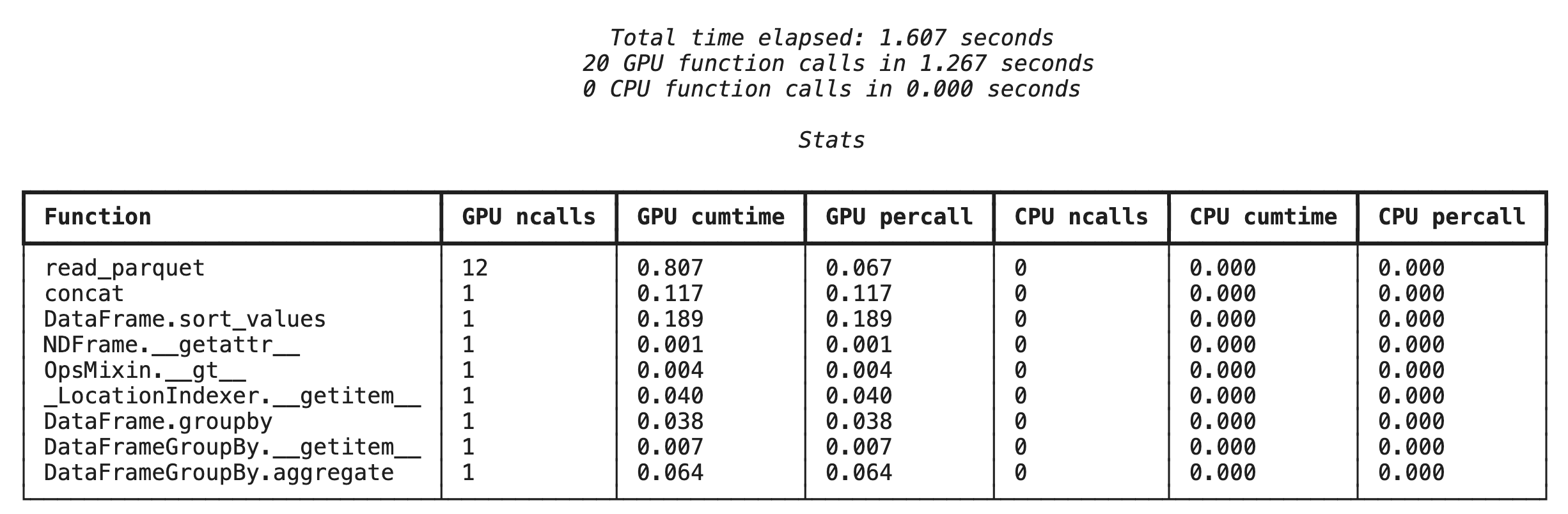
פרופיל ברמת הפונקציה באמצעות %%cudf.pandas.profile
קודם מריצים את כלי לניתוח ביצועים (profiler) ברמת הפונקציה באותו פייפליין ניתוח נתונים מהקטע הקודם. הפלט מציג טבלה של כל פונקציה שהופעלה, המכשיר שהיא פעלה בו (GPU או CPU) ומספר הפעמים שהיא הופעלה.
%load_ext cudf.pandas
import pandas as pd
import glob
pd.DataFrame({"a": [1]})
אחרי שמוודאים ש-cudf.pandas פעיל, אפשר להריץ פרופיל.
%%cudf.pandas.profile
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*2024*.parquet")], ignore_index=True)
df = df.sort_values(['tpep_pickup_datetime', 'trip_distance', 'passenger_count'], ascending=[False, True, False])
summary = (
df
.loc[(df.tpep_pickup_datetime > '2024-11-01')]
.groupby(['VendorID','tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
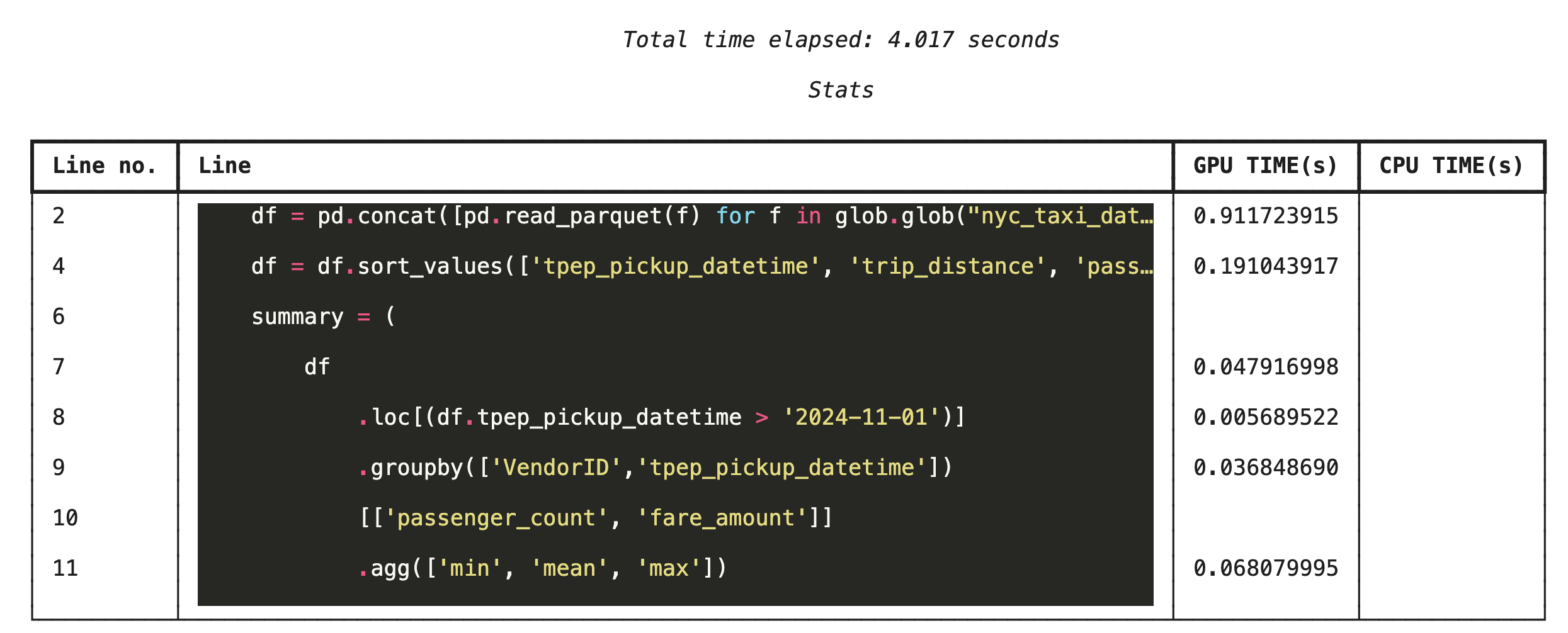
יצירת פרופיל שורה אחר שורה באמצעות %%cudf.pandas.line_profile
לאחר מכן, מריצים את פרופילר ברמת השורה. כך מקבלים תצוגה מפורטת הרבה יותר, שבה אפשר לראות את משך הזמן שכל שורת קוד השקיעה בהרצה ב-GPU לעומת ב-CPU. זו הדרך הכי יעילה למצוא צווארי בקבוק ספציפיים כדי לבצע אופטימיזציה.
%%cudf.pandas.line_profile
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*2024*.parquet")], ignore_index=True)
df = df.sort_values(['tpep_pickup_datetime', 'trip_distance', 'passenger_count'], ascending=[False, True, False])
summary = (
df
.loc[(df.tpep_pickup_datetime > '2024-11-01')]
.groupby(['VendorID','tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
יצירת פרופיל משורת הפקודה
הפרופילים האלה זמינים גם משורת הפקודה, וזה שימושי לבדיקות אוטומטיות ולפרופילים של סקריפטים ב-Python.
אפשר להשתמש בפקודות הבאות בממשק שורת הפקודה:
python -m cudf.pandas --profile your_script.pypython -m cudf.pandas --line_profile your_script.py
13. שילוב עם Google Cloud Storage
Google Cloud Storage (GCS) הוא שירות אחסון אובייקטים עמיד וניתן להרחבה. כשמשתמשים ב-Colab Enterprise, GCS הוא מקום מצוין לאחסון של מערכי נתונים, נקודות ביקורת של מודלים וארטיפקטים אחרים.
לזמן הריצה של Colab Enterprise יש את ההרשאות הנדרשות לקריאה ולכתיבה של נתונים ישירות בקטגוריות של GCS, והפעולות האלה מואצות על ידי GPU כדי להשיג ביצועים מקסימליים.
יצירת קטגוריה ב-GCS
קודם יוצרים קטגוריית GCS חדשה. שמות של קטגוריות GCS הם ייחודיים גלובלית, לכן מוסיפים לשם UUID.
from google.cloud import storage
import uuid
unique_suffix = uuid.uuid4().hex[:12]
bucket_name = f'nyc-taxi-codelab-{unique_suffix}'
project_id = storage.Client().project
client = storage.Client()
try:
bucket = client.create_bucket(bucket_name)
print(f"Successfully created bucket: gs://{bucket.name}")
except Exception as e:
print(f"Bucket creation failed. You may already own it or the name is taken: {e}")
כתיבת נתונים ישירות ל-GCS
עכשיו שומרים את DataFrame ישירות בקטגוריה החדשה של GCS. אם המשתנה df לא זמין מהקטעים הקודמים, הקוד טוען קודם נתונים של חודש אחד.
%%cudf.pandas.line_profile
# Ensure the DataFrame exists before saving to GCS
if 'df' not in locals():
print("DataFrame not found, loading a sample file...")
df = pd.read_parquet('nyc_taxi_data/yellow_tripdata_2024-12.parquet')
print(f"Writing data to gs://{bucket_name}/nyc_taxi_data.parquet...")
df.to_parquet(f"gs://{bucket_name}/nyc_taxi_data.parquet", index=False)
print("Write operation complete.")
אימות הקובץ ב-GCS
כדי לוודא שהנתונים נמצאים ב-GCS, אפשר להיכנס לדלי. הקוד הבא יוצר קישור שאפשר ללחוץ עליו.
from IPython.display import Markdown
gcs_url = f"https://console.cloud.google.com/storage/browser/{bucket_name}?project={project_id}"
Markdown(f'**[Click here to view your GCS bucket in the Google Cloud Console]({gcs_url})**')
קריאת נתונים ישירות מ-GCS
לבסוף, קוראים נתונים ישירות מנתיב GCS לתוך DataFrame. הפעולה הזו מואצת באמצעות GPU, ולכן אפשר לטעון מערכי נתונים גדולים מאחסון בענן במהירות גבוהה.
%%cudf.pandas.line_profile
print(f"Reading data from gs://{bucket_name}/nyc_taxi_data.parquet...")
df_from_gcs = pd.read_parquet(f"gs://{bucket_name}/nyc_taxi_data.parquet")
df_from_gcs.head()
14. הסרת המשאבים
כדי למנוע חיובים לא צפויים בחשבון Google Cloud, צריך למחוק את המשאבים שיצרתם.
מחיקת הנתונים שהורדתם:
# Permanately delete the GCS bucket
print(f"Deleting GCS bucket: gs://{bucket_name}...")
!gsutil rm -r -f gs://{bucket_name}
print("Bucket deleted.")
# Remove NYC taxi dataset on the Colab runtime
print("Deleting local 'nyc_taxi_data' directory...")
!rm -rf nyc_taxi_data
print("Local files deleted.")
כיבוי של סביבת זמן הריצה ב-Colab
- במסוף Google Cloud, עוברים לדף Runtimes של Colab Enterprise.
- בתפריט Region (אזור), בוחרים את האזור שבו נמצא זמן הריצה.
- בוחרים את זמן הריצה שרוצים למחוק.
- לוחצים על מחיקה.
- לוחצים על אישור.
מחיקת ה-Notebook
- במסוף Google Cloud, נכנסים לדף My Notebooks של Colab Enterprise.
- בתפריט Region (אזור), בוחרים את האזור שבו נמצא ה-Notebook.
- בוחרים את המחברת שרוצים למחוק.
- לוחצים על מחיקה.
- לוחצים על אישור.
15. מזל טוב
מעולה! הצלחתם להאיץ תהליך עבודה של ניתוח נתונים ב-pandas באמצעות NVIDIA cuDF ב-Colab Enterprise. למדתם איך להגדיר סביבות זמן ריצה עם GPU, להפעיל את cudf.pandas להאצה ללא שינוי קוד, ליצור פרופיל קוד לזיהוי צווארי בקבוק ולבצע שילוב עם Google Cloud Storage.