
1. परिचय
इस कोडलैब में, आपको Google Cloud पर NVIDIA GPU और ओपन-सोर्स लाइब्रेरी का इस्तेमाल करके, बड़े डेटासेट पर डेटा विश्लेषण के वर्कफ़्लो को तेज़ करने का तरीका बताया जाएगा. सबसे पहले, आपको अपने इंफ़्रास्ट्रक्चर को ऑप्टिमाइज़ करना होगा. इसके बाद, आपको यह पता लगाना होगा कि कोड में कोई बदलाव किए बिना, जीपीयू ऐक्सेलरेटेड प्रोसेस को कैसे लागू किया जाए.
इस कोर्स में, आपको डेटा में बदलाव करने के लिए इस्तेमाल की जाने वाली लोकप्रिय लाइब्रेरी pandas के बारे में बताया जाएगा. साथ ही, NVIDIA की cuDF लाइब्रेरी का इस्तेमाल करके, इसकी परफ़ॉर्मेंस को बेहतर बनाने का तरीका सिखाया जाएगा. सबसे अच्छी बात यह है कि आपको अपने मौजूदा pandas कोड में बदलाव किए बिना, जीपीयू ऐक्सेलरेटर की सुविधा मिल सकती है.
आपको क्या सीखने को मिलेगा
- Google Cloud पर Colab Enterprise के बारे में जानें.
- किसी खास जीपीयू, सीपीयू, और मेमोरी कॉन्फ़िगरेशन की मदद से, Colab के रनटाइम एनवायरमेंट को पसंद के मुताबिक बनाएं.
- NVIDIA
cuDFका इस्तेमाल करके, कोड में कोई बदलाव किए बिनाpandasकी प्रोसेस को तेज़ करें. - अपने कोड की प्रोफ़ाइल बनाएं, ताकि परफ़ॉर्मेंस से जुड़ी समस्याओं का पता लगाया जा सके और उन्हें ऑप्टिमाइज़ किया जा सके.
इसके बाद वाले पेज पर, आपको क्रेडिट मिलेंगे. इनका इस्तेमाल करके, इस लैब को पूरा किया जा सकता है.
2. डेटा प्रोसेसिंग की स्पीड क्यों बढ़ानी चाहिए?
80/20 का नियम: डेटा तैयार करने में इतना समय क्यों लगता है
डेटा तैयार करना, अक्सर किसी विश्लेषण प्रोजेक्ट का सबसे ज़्यादा समय लेने वाला चरण होता है. डेटा साइंटिस्ट और विश्लेषक, विश्लेषण शुरू करने से पहले डेटा को क्लीन करने, बदलने, और स्ट्रक्चर करने में ज़्यादा समय बिताते हैं.
खुशी की बात यह है कि cuDF का इस्तेमाल करके, NVIDIA के जीपीयू पर pandas, Apache Spark, और Polars जैसी लोकप्रिय ओपन-सोर्स लाइब्रेरी को तेज़ किया जा सकता है. डेटा को तेज़ी से प्रोसेस करने की सुविधा के बावजूद, डेटा तैयार करने में समय लगता है. इसकी वजह यह है कि:
- सोर्स डेटा का विश्लेषण करना मुश्किल होता है: असल दुनिया के डेटा में अक्सर गड़बड़ियां होती हैं, वैल्यू मौजूद नहीं होती हैं, और फ़ॉर्मैटिंग से जुड़ी समस्याएं होती हैं.
- डेटा क्वालिटी से मॉडल की परफ़ॉर्मेंस पर असर पड़ता है: खराब डेटा क्वालिटी की वजह से, सबसे बेहतर एल्गोरिदम भी काम नहीं करते.
- स्केल बढ़ाने पर समस्याएं बढ़ जाती हैं: लाखों रिकॉर्ड के साथ काम करते समय, डेटा से जुड़ी छोटी समस्याएं भी गंभीर अड़चनें बन जाती हैं.
3. नोटबुक एनवायरमेंट चुनना
कई डेटा साइंटिस्ट, निजी प्रोजेक्ट के लिए Colab का इस्तेमाल करते हैं. हालांकि, Colab Enterprise को कारोबारों के लिए डिज़ाइन किया गया है. यह सुरक्षित, सहयोगी, और इंटिग्रेटेड नोटबुक का अनुभव देता है.
Google Cloud पर, मैनेज किए गए नोटबुक एनवायरमेंट के लिए आपके पास दो मुख्य विकल्प हैं: Colab Enterprise और Gemini Enterprise Agent Platform Workbench. सही विकल्प चुनने के लिए, यह देखना ज़रूरी है कि आपके प्रोजेक्ट की प्राथमिकताएं क्या हैं.
Agent Platform Workbench का इस्तेमाल कब करना चाहिए
अगर आपकी प्राथमिकता कंट्रोल और बेहतर तरीके से पसंद के मुताबिक बनाना है, तो Agent Platform Workbench चुनें. अगर आपको ये काम करने हैं, तो यह विकल्प आपके लिए सबसे सही है:
- बुनियादी इंफ़्रास्ट्रक्चर और मशीन के लाइफ़साइकल को मैनेज करना.
- कस्टम कंटेनर और नेटवर्क कॉन्फ़िगरेशन का इस्तेमाल करें.
- MLOps पाइपलाइन और कस्टम लाइफ़साइकल टूलिंग के साथ इंटिग्रेट करें.
Colab Enterprise का इस्तेमाल कब करना चाहिए
अगर आपकी प्राथमिकता तेज़ी से सेटअप करना, इस्तेमाल में आसानी, और सुरक्षित तरीके से साथ मिलकर काम करना है, तो Colab Enterprise चुनें. यह पूरी तरह से मैनेज किया गया समाधान है. इससे आपकी टीम, इन्फ़्रास्ट्रक्चर के बजाय विश्लेषण पर ध्यान दे पाती है.
Colab Enterprise से आपको इन कामों में मदद मिलती है:
- डेटा साइंस के ऐसे वर्कफ़्लो बनाएं जो आपके डेटा वेयरहाउस से जुड़े हों. BigQuery Studio में जाकर, सीधे तौर पर अपनी नोटबुक खोली और मैनेज की जा सकती हैं.
- मशीन लर्निंग मॉडल को ट्रेन करें और उन्हें Agent Platform में MLOps टूल के साथ इंटिग्रेट करें.
- एक जैसा और बेहतर अनुभव पाएं. BigQuery में बनाया गया Colab Enterprise नोटबुक, Agent Platform में खोला और चलाया जा सकता है. इसके उलट, Agent Platform में बनाया गया Colab Enterprise नोटबुक, BigQuery में खोला और चलाया जा सकता है.
आज की लैब
इस कोडलैब में, डेटा के तेज़ी से विश्लेषण के लिए Colab Enterprise का इस्तेमाल किया गया है.
इनके बीच के अंतर के बारे में ज़्यादा जानने के लिए, सही नोटबुक समाधान चुनने से जुड़ा आधिकारिक दस्तावेज़ देखें.
4. रनटाइम टेंप्लेट को कॉन्फ़िगर करना
Colab Enterprise में, पहले से कॉन्फ़िगर किए गए रनटाइम टेंप्लेट पर आधारित रनटाइम से कनेक्ट करें.
रनटाइम टेंप्लेट, फिर से इस्तेमाल किया जा सकने वाला कॉन्फ़िगरेशन होता है. यह आपके नोटबुक के पूरे एनवायरमेंट के बारे में बताता है. इसमें ये शामिल हैं:
- मशीन टाइप (सीपीयू, मेमोरी)
- ऐक्सेलरेटर (जीपीयू का टाइप और संख्या)
- डिस्क का साइज़ और टाइप
- नेटवर्क सेटिंग और सुरक्षा नीतियां
- निष्क्रियता की वजह से अपने-आप बंद होने के नियम
रनटाइम टेंप्लेट क्यों काम के होते हैं
- एक जैसा एनवायरमेंट पाएं: आपको और आपकी टीम के सदस्यों को हर बार इस्तेमाल के लिए तैयार एक जैसा एनवायरमेंट मिलता है. इससे यह पक्का किया जा सकता है कि आपका काम दोहराया जा सके.
- सुरक्षित तरीके से काम करना: टेंप्लेट, आपके संगठन की सुरक्षा नीतियों को अपने-आप लागू करते हैं.
- लागत को असरदार तरीके से मैनेज करें: जीपीयू और सीपीयू जैसे संसाधन, टेंप्लेट में पहले से तय किए गए साइज़ के हिसाब से होते हैं. इससे, गलती से लागत बढ़ने से रोकने में मदद मिलती है.
रनटाइम टेंप्लेट बनाना
लैब के लिए, रीयूज़ किया जा सकने वाला रनटाइम टेंप्लेट सेट अप करें.
- Google Cloud Console में, नेविगेशन मेन्यू > एजेंट प्लैटफ़ॉर्म > नोटबुक पर जाएं.
- Colab Enterprise में, रनटाइम टेंप्लेट पर क्लिक करें. इसके बाद, नया टेंप्लेट चुनें.
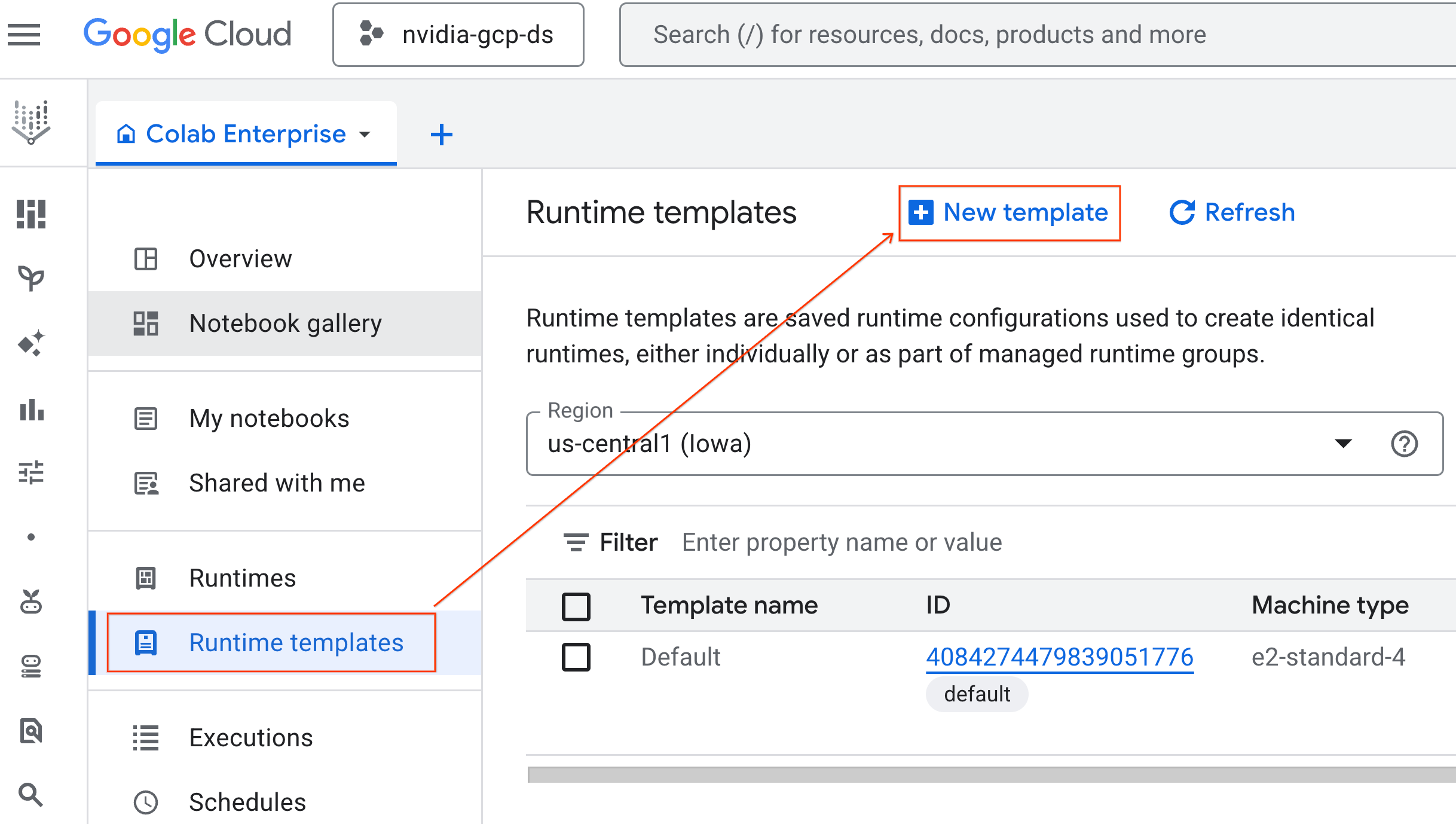
- रनटाइम की बुनियादी बातें में जाकर:
- डिसप्ले नेम को
gpu-templateके तौर पर सेट करें. - अपनी पसंद का देश/इलाका चुनें.
- डिसप्ले नेम को
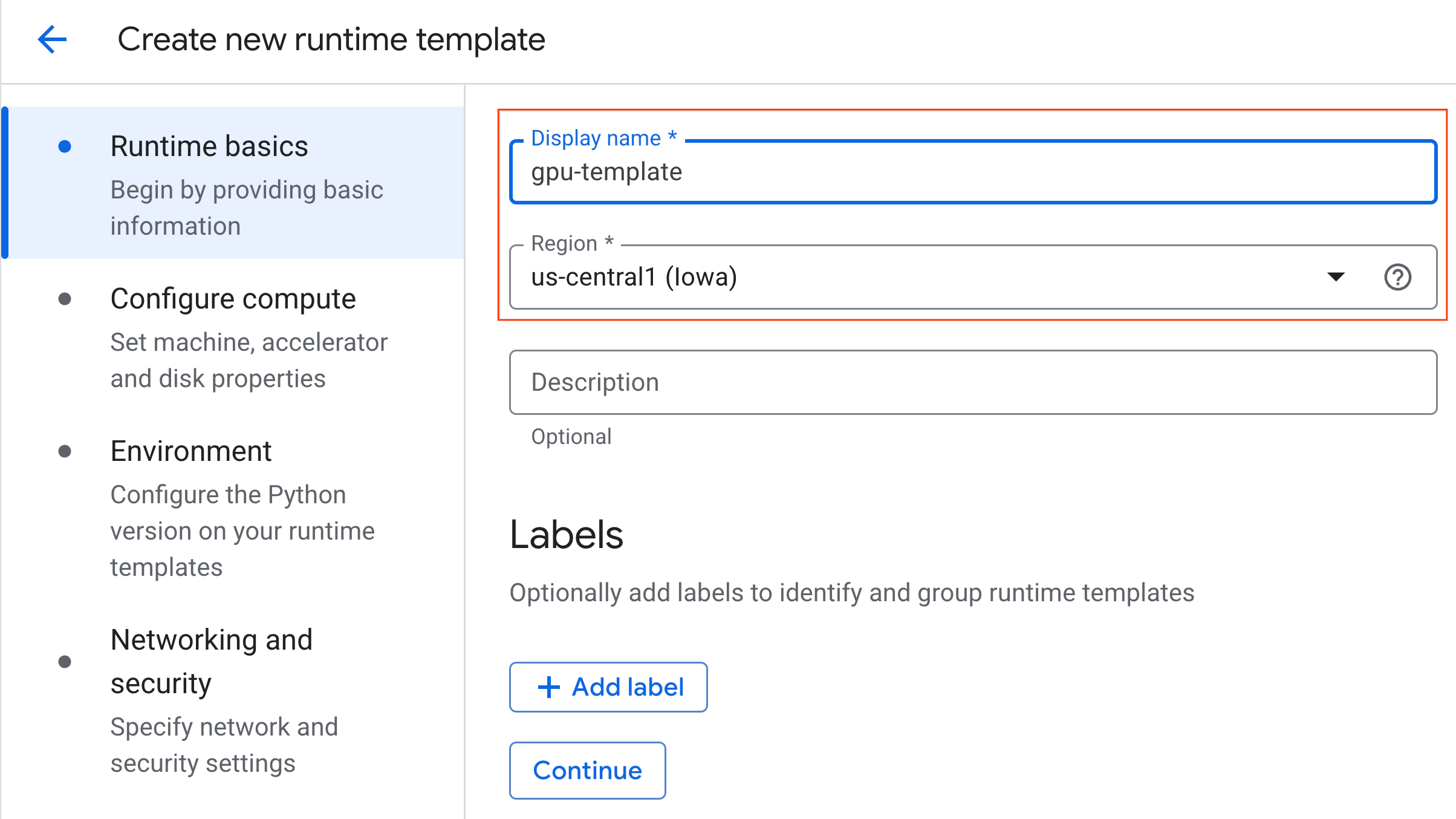
- कंप्यूट कॉन्फ़िगर करें में जाकर:
- मशीन टाइप को
g2-standard-4पर सेट करें. - डिफ़ॉल्ट ऐक्सलरेटर टाइप को
NVIDIA L4पर सेट रखें. साथ ही, ऐक्सलरेटर की संख्या को 1 पर सेट रखें. - निष्क्रिय होने पर बंद होने की सुविधा को 60 मिनट पर सेट करें.
- जारी रखें पर क्लिक करें.
- मशीन टाइप को
- परिवेश में जाकर:
- Environment को
Python 3.11पर सेट करें
- Environment को
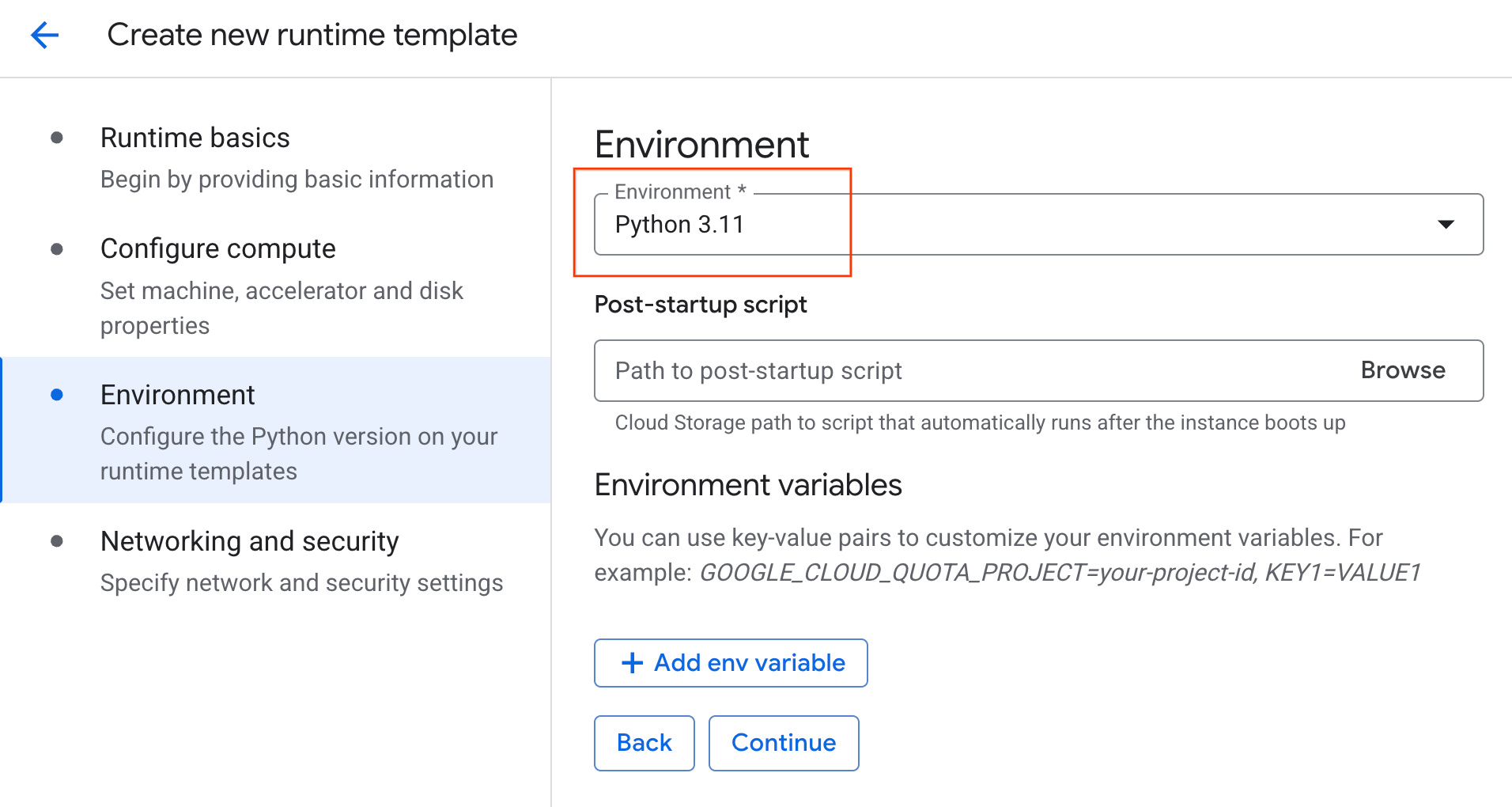
- रनटाइम टेंप्लेट को सेव करने के लिए, बनाएं पर क्लिक करें. अब आपको रनटाइम टेंप्लेट वाले पेज पर नया टेंप्लेट दिखेगा.
5. रनटाइम शुरू करना
टेंप्लेट तैयार होने के बाद, नया रनटाइम बनाया जा सकता है.
- Colab Enterprise में, Runtimes पर क्लिक करें. इसके बाद, Create को चुनें.
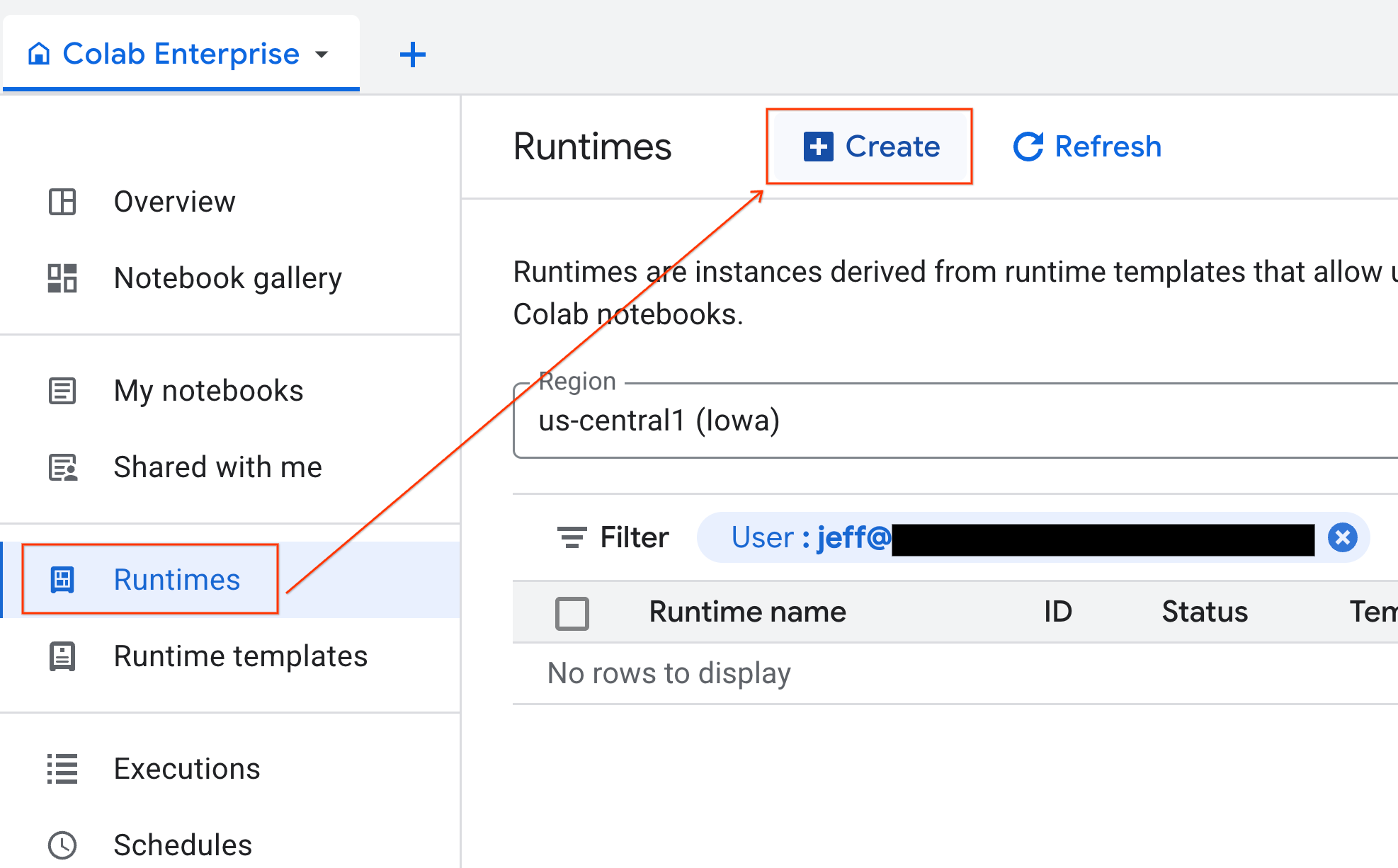
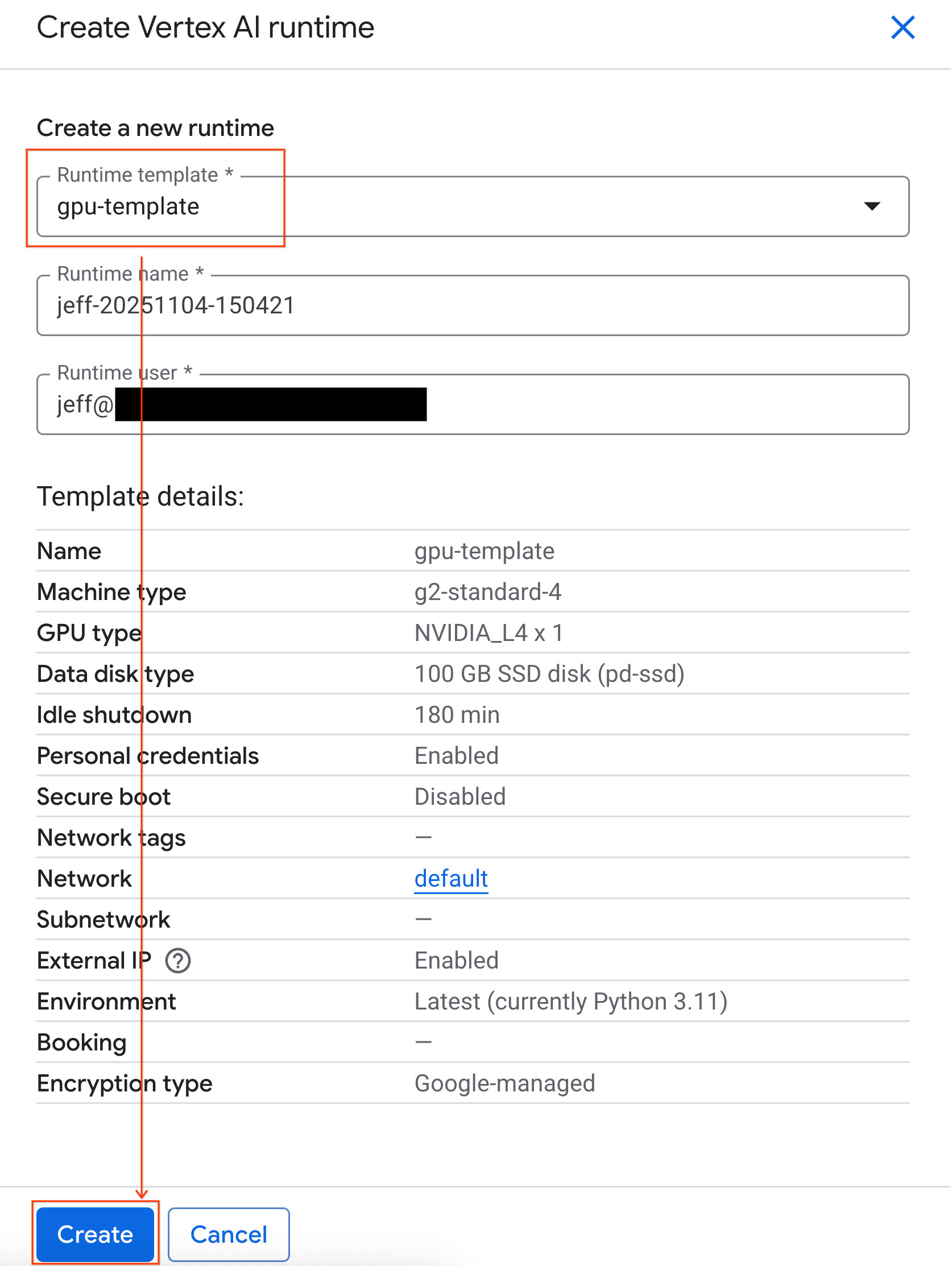
- रनटाइम टेंप्लेट में जाकर,
gpu-templateविकल्प चुनें. बनाएं पर क्लिक करें और रनटाइम के बूट अप होने का इंतज़ार करें.
- कुछ मिनट बाद, आपको रनटाइम दिखेगा.
6. नोटबुक सेट अप करना
अब आपका इन्फ़्रास्ट्रक्चर चालू हो गया है. आपको लैब नोटबुक इंपोर्ट करनी होगी और उसे अपने रनटाइम से कनेक्ट करना होगा.
नोटबुक इंपोर्ट करना
- Colab Enterprise में, मेरी नोटबुक पर क्लिक करें. इसके बाद, इंपोर्ट करें पर क्लिक करें.
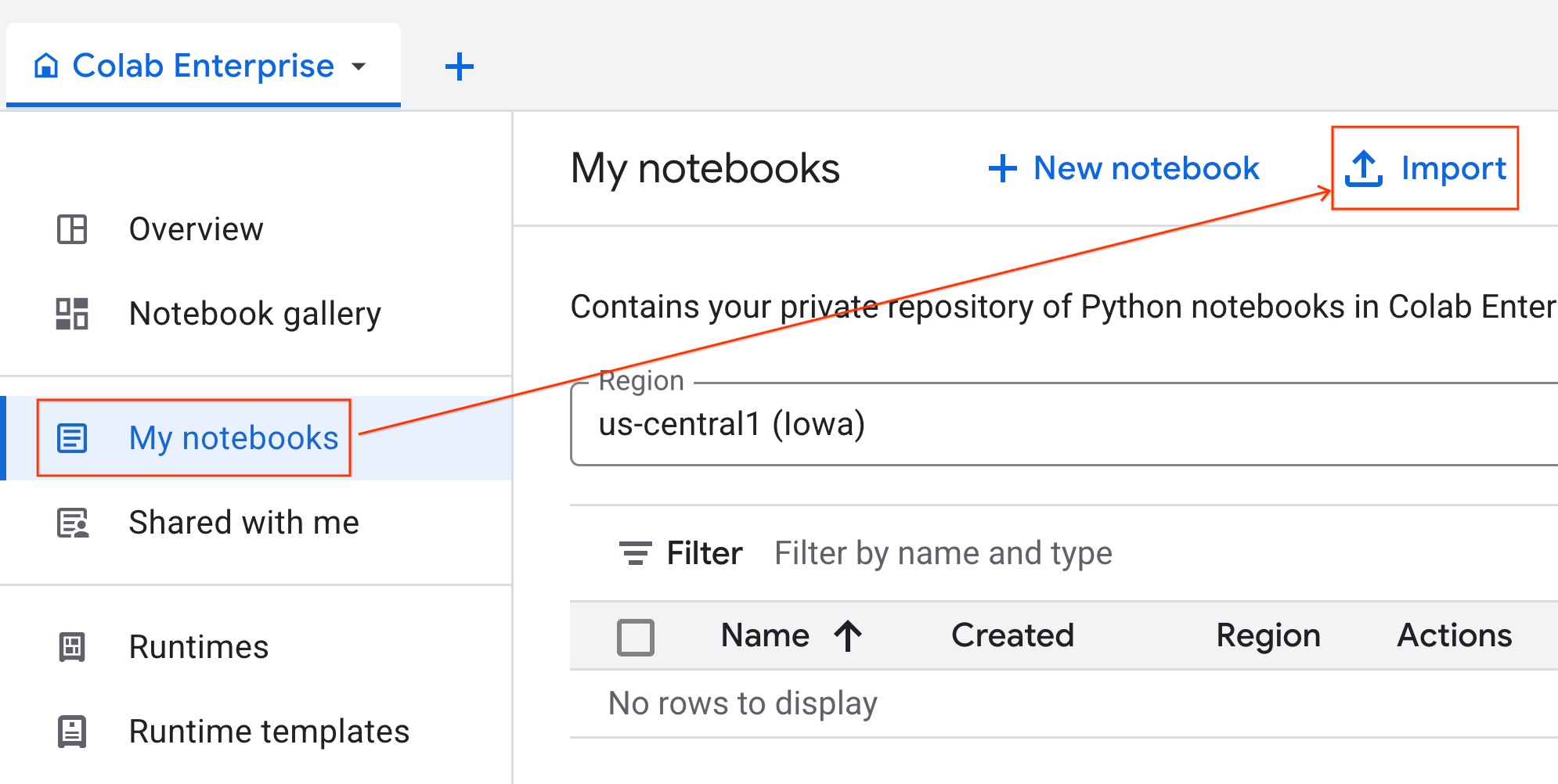
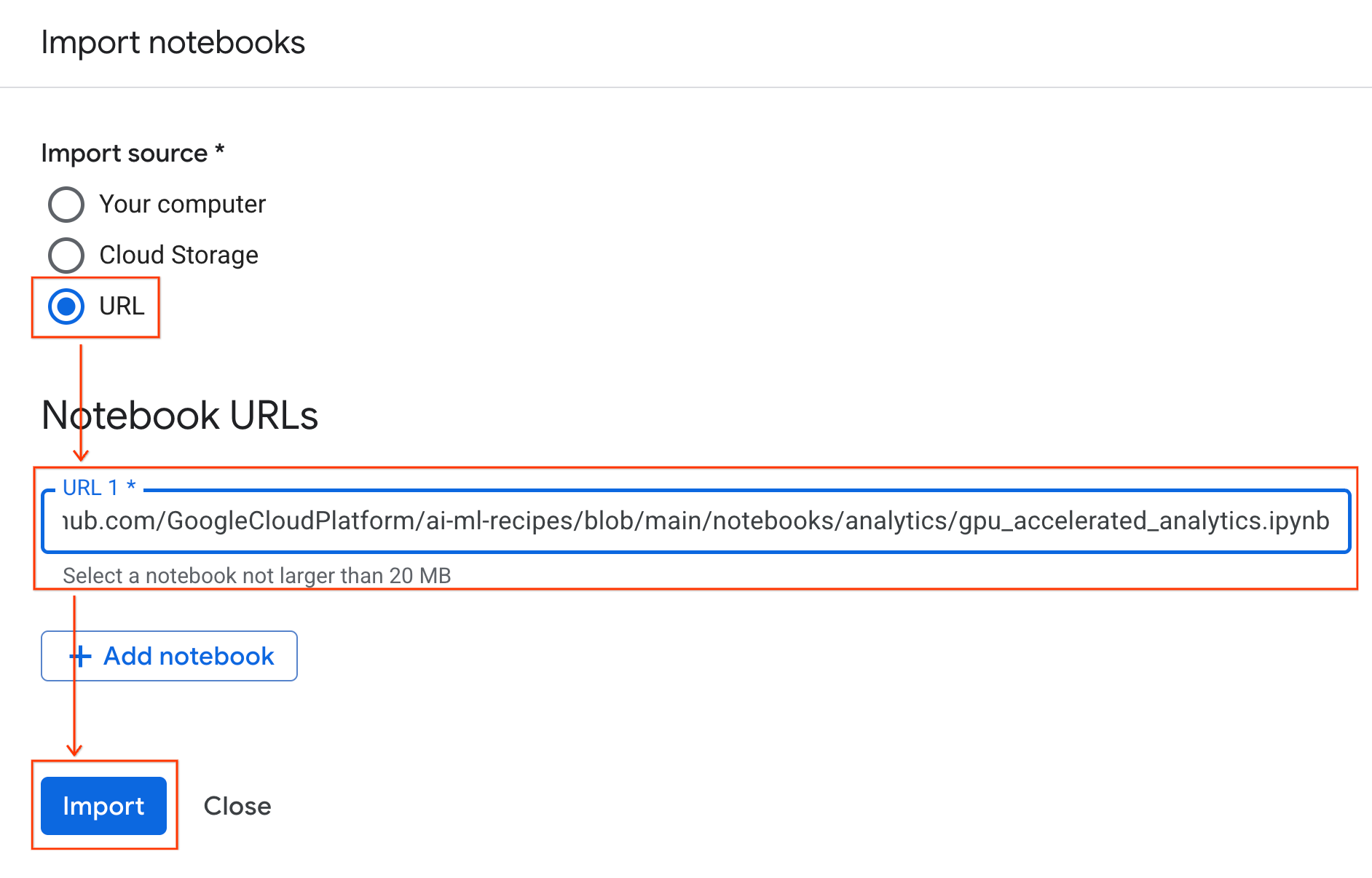
- यूआरएल रेडियो बटन चुनें और यह यूआरएल डालें:
https://github.com/GoogleCloudPlatform/ai-ml-recipes/blob/main/notebooks/analytics/gpu_accelerated_analytics.ipynb
- इंपोर्ट करें पर क्लिक करें. Colab Enterprise, GitHub से notebook को आपके एनवायरमेंट में कॉपी कर देगा.
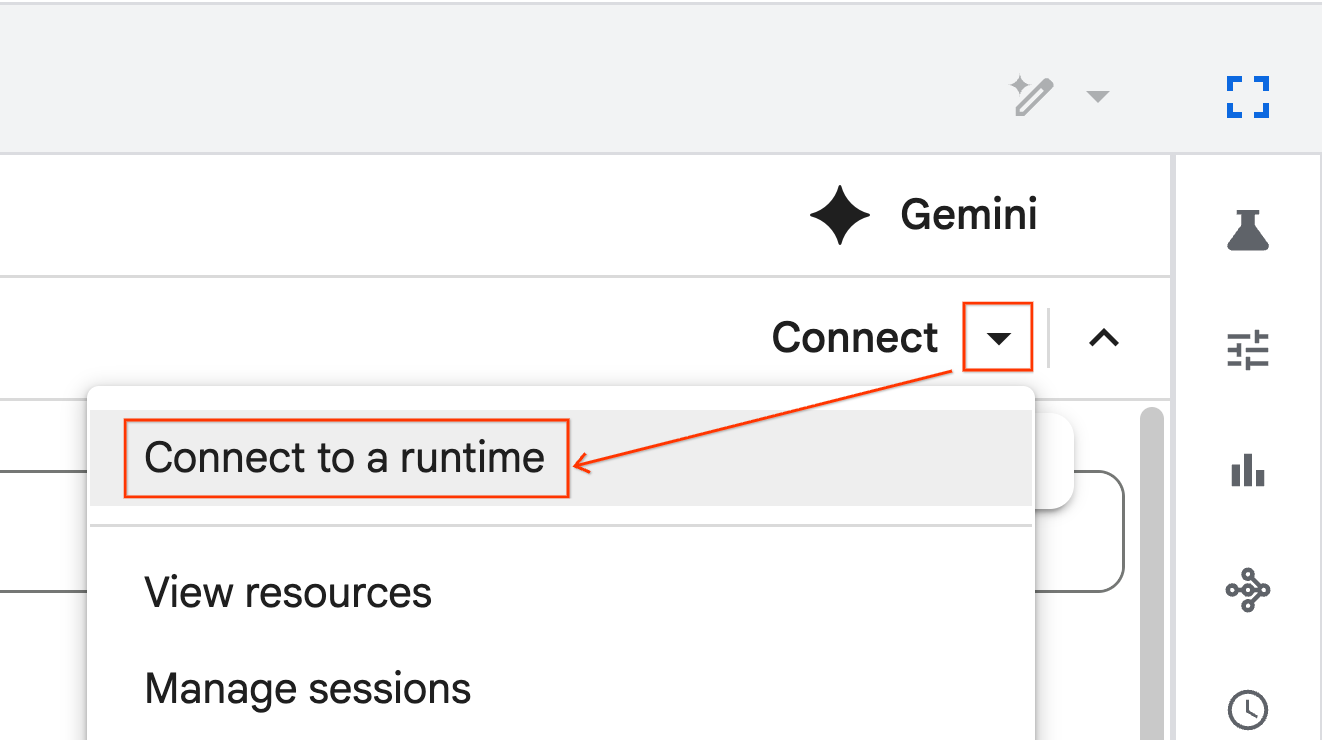
रनटाइम से कनेक्ट करना
- अभी इंपोर्ट की गई नोटबुक खोलें.
- कनेक्ट करें के बगल में मौजूद, डाउन ऐरो पर क्लिक करें.
- किसी रनटाइम से कनेक्ट करें को चुनें.
- ड्रॉपडाउन का इस्तेमाल करें और पहले से बनाया गया रनटाइम चुनें.
- कनेक्ट करें पर क्लिक करें.
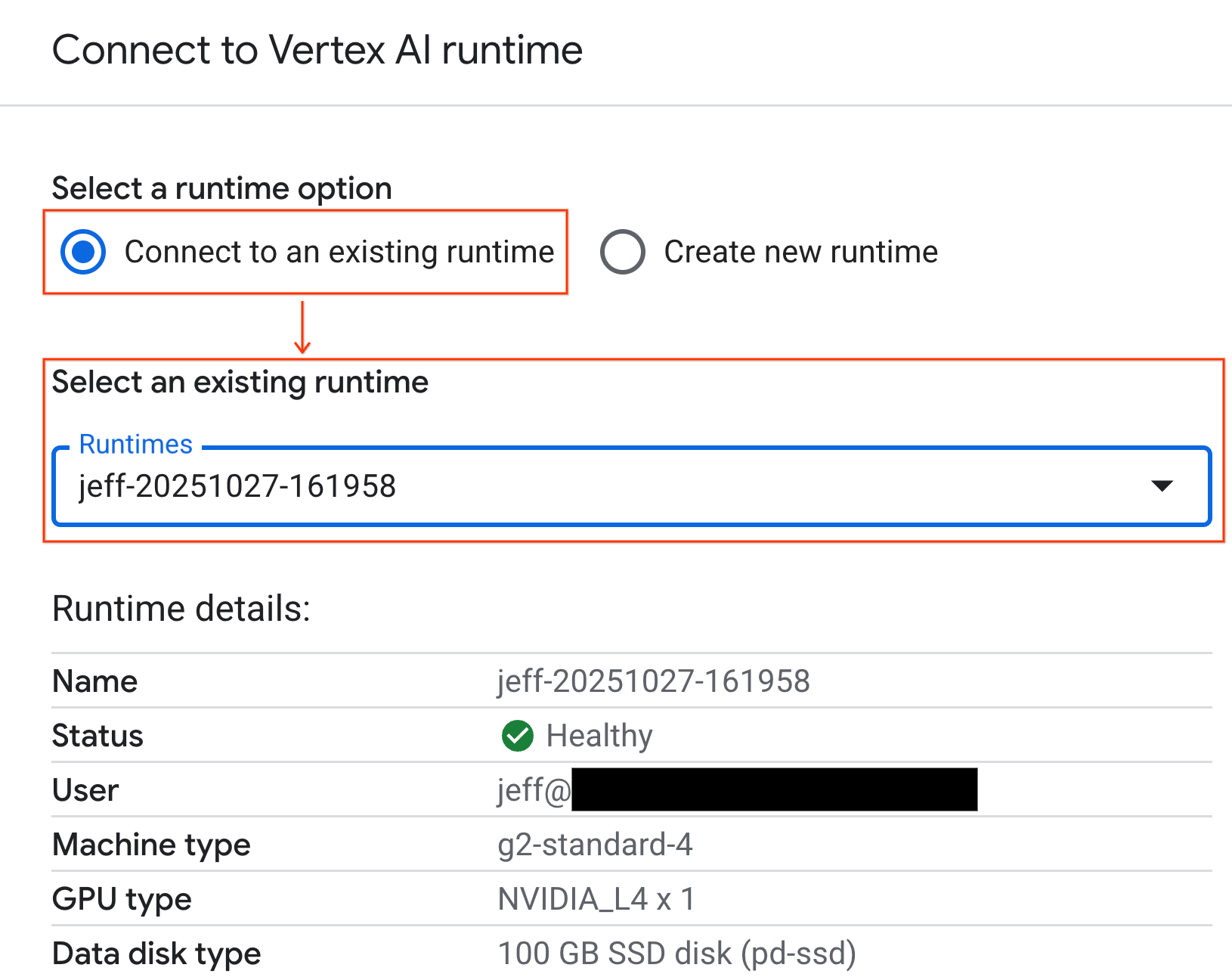
आपकी नोटबुक अब GPU की सुविधा वाले रनटाइम से कनेक्ट हो गई है. अब क्वेरी की जा सकती हैं!
7. NYC टैक्सी का डेटासेट तैयार करना
इस कोडलैब में, NYC Taxi & Limousine Commission (TLC) के ट्रिप रिकॉर्ड डेटा का इस्तेमाल किया गया है.
इस डेटासेट में, न्यूयॉर्क शहर में चलने वाली येलो टैक्सी की हर यात्रा का रिकॉर्ड शामिल है. इसमें ये फ़ील्ड शामिल हैं:
- पिक-अप और ड्रॉप-ऑफ़ की तारीखें, समय, और जगहें
- यात्रा की दूरी
- किराये की रकम की जानकारी
- यात्रियों की संख्या
डेटा डाउनलोड करें
इसके बाद, साल 2024 के लिए यात्रा का डेटा डाउनलोड करें. डेटा को Parquet फ़ाइल फ़ॉर्मैट में सेव किया जाता है.
नीचे दिए गए कोड ब्लॉक में, यह तरीका बताया गया है:
- इससे डाउनलोड करने के लिए, सालों और महीनों की रेंज तय की जाती है.
- यह फ़ाइलों को सेव करने के लिए,
nyc_taxi_dataनाम की एक लोकल डायरेक्ट्री बनाता है. - यह हर महीने के हिसाब से लूप करता है. अगर Parquet फ़ाइल पहले से मौजूद नहीं है, तो उसे डाउनलोड करता है और डायरेक्ट्री में सेव करता है.
डेटा इकट्ठा करने और उसे रनटाइम पर सेव करने के लिए, अपनी नोटबुक में यह कोड चलाएं:
from tqdm import tqdm
import requests
import time
import os
YEAR = 2024
DATA_DIR = "nyc_taxi_data"
os.makedirs(DATA_DIR, exist_ok=True)
print(f"Checking/Downloading files for {YEAR}...")
for month in tqdm(range(1, 13), unit="file"):
# Define standardized filename for both local path and URL
file_name = f"yellow_tripdata_{YEAR}-{month:02d}.parquet"
local_path = os.path.join(DATA_DIR, file_name)
url = f"https://d37ci6vzurychx.cloudfront.net/trip-data/{file_name}"
if not os.path.exists(local_path):
try:
with requests.get(url, stream=True) as response:
response.raise_for_status()
with open(local_path, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
time.sleep(1)
except requests.exceptions.HTTPError as e:
print(f"\nSkipping {file_name}: {e}")
if os.path.exists(local_path):
os.remove(local_path)
print("\nDownload complete.")
8. टैक्सी की यात्रा का डेटा एक्सप्लोर करना
डेटासेट डाउनलोड करने के बाद, अब समय है कि डेटा का शुरुआती विश्लेषण (ईडीए) किया जाए. ईडीए का मकसद, डेटा के स्ट्रक्चर को समझना, गड़बड़ियों का पता लगाना, और संभावित पैटर्न का पता लगाना है.
एक महीने का डेटा लोड करना
शुरुआत में, एक महीने का डेटा लोड करें. इससे इंटरैक्टिव विश्लेषण के लिए, मेमोरी का इस्तेमाल मैनेज किया जा सकता है. साथ ही, यह काफ़ी बड़ा सैंपल (30 लाख से ज़्यादा लाइनें) उपलब्ध कराता है, ताकि विश्लेषण को बेहतर बनाया जा सके.
import pandas as pd
import glob
# Load the last month of the downloaded data
df = pd.read_parquet("nyc_taxi_data/yellow_tripdata_2024-12.parquet")
df.head()
खास जानकारी के आंकड़े पाना
संख्या वाले कॉलम के लिए, खास जानकारी देने वाले आंकड़े जनरेट करने के लिए, .describe() तरीके का इस्तेमाल करें. यह डेटा क्वालिटी से जुड़ी संभावित समस्याओं का पता लगाने का एक बेहतरीन तरीका है. जैसे, कम से कम या ज़्यादा से ज़्यादा वैल्यू का अनुमान न लगाया जा पाना.
df.describe().round(2)

डेटा क्वालिटी की जांच करना
.describe() से मिले आउटपुट में, समस्या के बारे में तुरंत पता चल जाता है. ध्यान दें कि tpep_pickup_datetime और tpep_dropoff_datetime के लिए min की वैल्यू 2008 में है, जो 2024 के डेटासेट के लिए सही नहीं है.
इस उदाहरण में बताया गया है कि आपको अपने डेटा की जांच क्यों करनी चाहिए. डेटाफ़्रेम को क्रम से लगाकर, इस बारे में ज़्यादा जानकारी पाई जा सकती है. इससे, उन लाइनों का पता लगाया जा सकता है जिनमें तारीखें आउटलायर हैं.
# Sort by the dropoff datetime to see the oldest records
df.sort_values("tpep_pickup_datetime").head()
डेटा डिस्ट्रिब्यूशन को विज़ुअलाइज़ करना
इसके बाद, संख्या वाले कॉलम के हिस्टोग्राम बनाए जा सकते हैं, ताकि उनके डिस्ट्रिब्यूशन को विज़ुअलाइज़ किया जा सके. इससे आपको trip_distance और fare_amount जैसी सुविधाओं के स्प्रेड और स्क्यू को समझने में मदद मिलती है. .hist() फ़ंक्शन, DataFrame में मौजूद सभी संख्यात्मक कॉलम के लिए हिस्टोग्राम प्लॉट करने का एक आसान तरीका है.
_ = df.hist(figsize=(20, 20))
आखिर में, कुछ मुख्य कॉलम के बीच के संबंध दिखाने के लिए स्कैटर मैट्रिक्स जनरेट करें. लाखों पॉइंट प्लॉट करने में समय लगता है और इससे पैटर्न छिप सकते हैं. इसलिए, .sample() का इस्तेमाल करके, 1,00,000 लाइनों के रैंडम सैंपल से प्लॉट बनाएं.
_ = pd.plotting.scatter_matrix(
df[['passenger_count', 'trip_distance', 'tip_amount', 'total_amount']].sample(100_000),
diagonal="kde",
figsize=(15, 15)
)
9. Parquet फ़ाइल फ़ॉर्मैट का इस्तेमाल क्यों करें?
NYC टैक्सी डेटासेट, Apache Parquet फ़ॉर्मैट में उपलब्ध है. यह फ़ैसला, बड़े पैमाने पर आंकड़ों के विश्लेषण के लिए लिया गया है. Parquet फ़ाइल फ़ॉर्मैट, CSV जैसे फ़ाइल फ़ॉर्मैट की तुलना में कई फ़ायदे देता है:
- बेहतर और तेज़: Parquet, कॉलम के हिसाब से फ़ॉर्मैट किया गया डेटा होता है. इसलिए, इसे सेव करना और पढ़ना बहुत आसान होता है. यह आधुनिक कंप्रेशन के तरीकों के साथ काम करता है. इससे फ़ाइल का साइज़ कम हो जाता है और I/O की स्पीड काफ़ी बढ़ जाती है. खास तौर पर, जीपीयू पर.
- स्कीमा को सुरक्षित रखता है: Parquet, फ़ाइल के मेटाडेटा में डेटा टाइप सेव करता है. फ़ाइल को पढ़ते समय, आपको डेटा टाइप का अनुमान लगाने की ज़रूरत नहीं होती.
- चुनिंदा डेटा पढ़ने की सुविधा चालू करता है: कॉलम के हिसाब से डेटा व्यवस्थित होने की वजह से, आपको सिर्फ़ वे कॉलम पढ़ने की सुविधा मिलती है जिनकी ज़रूरत आपको विश्लेषण के लिए होती है. इससे, मेमोरी में लोड किए जाने वाले डेटा की मात्रा में काफ़ी कमी आ सकती है.
Parquet फ़ाइल फ़ॉर्मैट की सुविधाओं के बारे में जानें
आइए, डाउनलोड की गई किसी फ़ाइल का इस्तेमाल करके, इन दो शानदार सुविधाओं के बारे में जानें.
पूरे डेटासेट को लोड किए बिना मेटाडेटा की जांच करना
Parquet फ़ाइल को स्टैंडर्ड टेक्स्ट एडिटर में नहीं देखा जा सकता. हालांकि, मेमोरी में कोई डेटा लोड किए बिना, इसके स्कीमा और मेटाडेटा की आसानी से जांच की जा सकती है. इससे किसी फ़ाइल के स्ट्रक्चर को तुरंत समझने में मदद मिलती है.
from pyarrow.parquet import ParquetFile
import pyarrow as pa
# Open one of the downloaded files
pf = ParquetFile('nyc_taxi_data/yellow_tripdata_2024-12.parquet')
# Print the schema
print("File Schema:")
print(pf.schema)
# Print the file metadata
print("\nFile Metadata:")
print(pf.metadata)
सिर्फ़ उन कॉलम को पढ़ें जिनकी आपको ज़रूरत है
मान लें कि आपको सिर्फ़ यात्रा की दूरी और किराये का विश्लेषण करना है. Parquet की मदद से, सिर्फ़ उन कॉलम को लोड किया जा सकता है जिनकी ज़रूरत है. यह पूरे DataFrame को लोड करने की तुलना में, ज़्यादा तेज़ और मेमोरी के लिए बेहतर होता है.
import pandas as pd
# Read only four specific columns from the Parquet file
df_subset = pd.read_parquet(
'nyc_taxi_data/yellow_tripdata_2024-12.parquet',
columns=['passenger_count', 'trip_distance', 'tip_amount', 'total_amount']
)
df_subset.head()
10. NVIDIA cuDF की मदद से pandas को तेज़ करना
NVIDIA CUDA for DataFrames (cuDF) एक ओपन-सोर्स लाइब्रेरी है. यह जीपीयू की मदद से काम करती है. इसकी मदद से, DataFrames के साथ इंटरैक्ट किया जा सकता है. cuDF की मदद से, जीपीयू पर डेटा से जुड़ी सामान्य कार्रवाइयां की जा सकती हैं. जैसे, फ़िल्टर करना, जोड़ना, और ग्रुप करना. इसके लिए, बड़े पैमाने पर पैरललिज़्म का इस्तेमाल किया जाता है.
इस कोडलैब में, cudf.pandas ऐक्सेलरेटर मोड का इस्तेमाल किया जाता है. इसे चालू करने पर, आपका स्टैंडर्ड pandas कोड अपने-आप रीडायरेक्ट हो जाता है. इससे, बैकग्राउंड में GPU की मदद से काम करने वाले cuDF कर्नल का इस्तेमाल किया जा सकता है. इसके लिए, आपको अपने कोड में बदलाव करने की ज़रूरत नहीं होती.
जीपीयू ऐक्सेलरेटर की सुविधा चालू करना
Colab Enterprise notebook में NVIDIA cuDF का इस्तेमाल करने के लिए, pandas को इंपोर्ट करने से पहले, इसके मैजिक एक्सटेंशन को लोड करें.
सबसे पहले, स्टैंडर्ड pandas लाइब्रेरी की जांच करें. ध्यान दें कि आउटपुट में, डिफ़ॉल्ट pandas इंस्टॉलेशन का पाथ दिखता है.
import pandas as pd
pd # Note the output for the standard pandas library
अब cudf.pandas एक्सटेंशन लोड करें और pandas को फिर से इंपोर्ट करें. देखें कि pd मॉड्यूल के लिए आउटपुट कैसे बदलता है. इससे पुष्टि होती है कि जीपीयू की मदद से काम करने वाला वर्शन अब चालू हो गया है.
%load_ext cudf.pandas
import pandas as pd
pd # Note the new output, indicating cudf.pandas is active
cudf.pandas को चालू करने के अन्य तरीके
नोटबुक में मैजिक कमांड (%load_ext) का इस्तेमाल करना सबसे आसान तरीका है. हालांकि, अन्य एनवायरमेंट में भी ऐक्सेलरेटर को चालू किया जा सकता है:
- Python स्क्रिप्ट में:
pandasइंपोर्ट करने से पहले,import cudf.pandasऔरcudf.pandas.install()को कॉल करें. - नॉन-नोटबुक एनवायरमेंट से:
python -m cudf.pandas your_script.pyका इस्तेमाल करके अपनी स्क्रिप्ट चलाएं.
11. सीपीयू और जीपीयू की परफ़ॉर्मेंस की तुलना करना
अब सबसे अहम बात: सीपीयू पर स्टैंडर्ड pandas की परफ़ॉर्मेंस की तुलना, जीपीयू पर cudf.pandas की परफ़ॉर्मेंस से करना.
सीपीयू के लिए पूरी तरह से सही बेसलाइन तय करने के लिए, आपको सबसे पहले Colab रनटाइम को रीसेट करना होगा. इससे, पिछले सेक्शन में चालू किए गए सभी जीपीयू ऐक्सलरेटर बंद हो जाते हैं. रनटाइम को फिर से शुरू करने के लिए, नीचे दी गई सेल को चलाएं. इसके अलावा, रनटाइम मेन्यू में जाकर, सेशन फिर से शुरू करें को चुनें.
import IPython
IPython.Application.instance().kernel.do_shutdown(True)
Analytics पाइपलाइन तय करना
अब जब एनवायरमेंट साफ़ हो गया है, तब बेंचमार्किंग फ़ंक्शन तय किया जाएगा. इस फ़ंक्शन की मदद से, एक ही पाइपलाइन को चलाया जा सकता है. जैसे, डेटा लोड करना, उसे क्रम से लगाना, और खास जानकारी तैयार करना. इसके लिए, आपको सिर्फ़ pandas मॉड्यूल पास करना होगा.
import time
import glob
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
def run_analytics_pipeline(pd_module):
"""Loads, sorts, and summarizes data using the provided pandas module."""
timings = {}
# 1. Load all 2024 Parquet files from the directory
t0 = time.time()
df = pd_module.concat(
[pd_module.read_parquet(f) for f in glob.glob("nyc_taxi_data/*_2024*.parquet")],
ignore_index=True
)
timings["load"] = time.time() - t0
# 2. Sort the data by multiple columns
t0 = time.time()
df = df.sort_values(
['tpep_pickup_datetime', 'trip_distance', 'passenger_count'],
ascending=[False, True, False]
)
timings["sort"] = time.time() - t0
# 3. Perform a groupby and aggregation
t0 = time.time()
df['tpep_pickup_datetime'] = pd_module.to_datetime(df['tpep_pickup_datetime'])
_ = (
df.loc[df.tpep_pickup_datetime > '2024-11-01']
.groupby(['VendorID', 'tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
timings["summarize"] = time.time() - t0
return timings
तुलना करना
सबसे पहले, आपको सीपीयू पर स्टैंडर्ड pandas का इस्तेमाल करके पाइपलाइन को चलाना होगा. इसके बाद, cudf.pandas को चालू करें और इसे जीपीयू पर फिर से चलाएं.
# --- Run on CPU ---
print("Running analytics pipeline on CPU...")
# Ensure we are using standard pandas
import pandas as pd
assert "cudf" not in str(pd), "Error: cuDF is still active. Please restart the kernel."
cpu_times = run_analytics_pipeline(pd)
print(f"CPU times: {cpu_times}")
# --- Run on GPU ---
print("\nEnabling cudf.pandas and running on GPU...")
# Load the extension
%load_ext cudf.pandas
import pandas as gpu_pd
gpu_times = run_analytics_pipeline(gpu_pd)
print(f"GPU times: {gpu_times}")
नतीजों को विज़ुअलाइज़ करना
आखिर में, अंतर को विज़ुअलाइज़ करें. यहां दिए गए कोड से, हर ऑपरेशन के लिए स्पीडअप का हिसाब लगाया जाता है. साथ ही, उन्हें एक साथ प्लॉट किया जाता है.
# Create a DataFrame for plotting
results_df = pd.DataFrame([cpu_times, gpu_times], index=["CPU", "GPU"]).T
total_cpu_time = results_df['CPU'].sum()
total_gpu_time = results_df['GPU'].sum()
speedup = total_cpu_time / total_gpu_time
print("--- Performance Results ---")
print(results_df)
print(f"\nTotal CPU Time: {total_cpu_time:.2f} seconds")
print(f"Total GPU Time: {total_gpu_time:.2f} seconds")
print(f"Overall Speedup: {speedup:.2f}x")
# Plot the results
fig, ax = plt.subplots(figsize=(10, 6))
results_df.plot(kind='bar', ax=ax, color={"CPU": "tab:blue", "GPU": "tab:green"})
ax.set_ylabel("Time (seconds)")
ax.set_title(f"CPU vs. GPU Runtimes (Overall Speedup: {speedup:.2f}x)", fontsize=14)
ax.tick_params(axis='x', rotation=0)
# Add numerical labels to the bars
for container in ax.containers:
ax.bar_label(container, fmt="%.2f", padding=3)
plt.tight_layout()
plt.show()
नतीजों के उदाहरण:
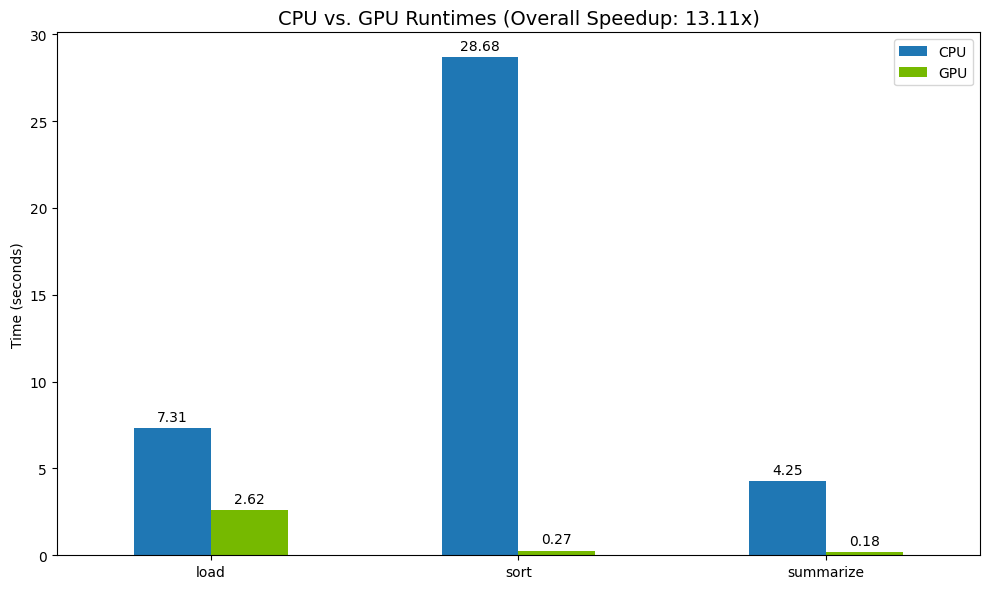
सीपीयू की तुलना में जीपीयू की स्पीड काफ़ी ज़्यादा होती है.
12. बॉटलनैक ढूंढने के लिए, अपने कोड की प्रोफ़ाइल बनाना
जीपीयू की मदद से तेज़ी लाने की सुविधा चालू होने पर भी, हो सकता है कि कुछ pandas कार्रवाइयाँ सीपीयू पर वापस आ जाएँ. ऐसा तब होता है, जब cuDF में अब तक उन कार्रवाइयों के लिए सहायता उपलब्ध न हो. ये "सीपीयू फ़ॉलबैक", परफ़ॉर्मेंस में रुकावटें पैदा कर सकते हैं.
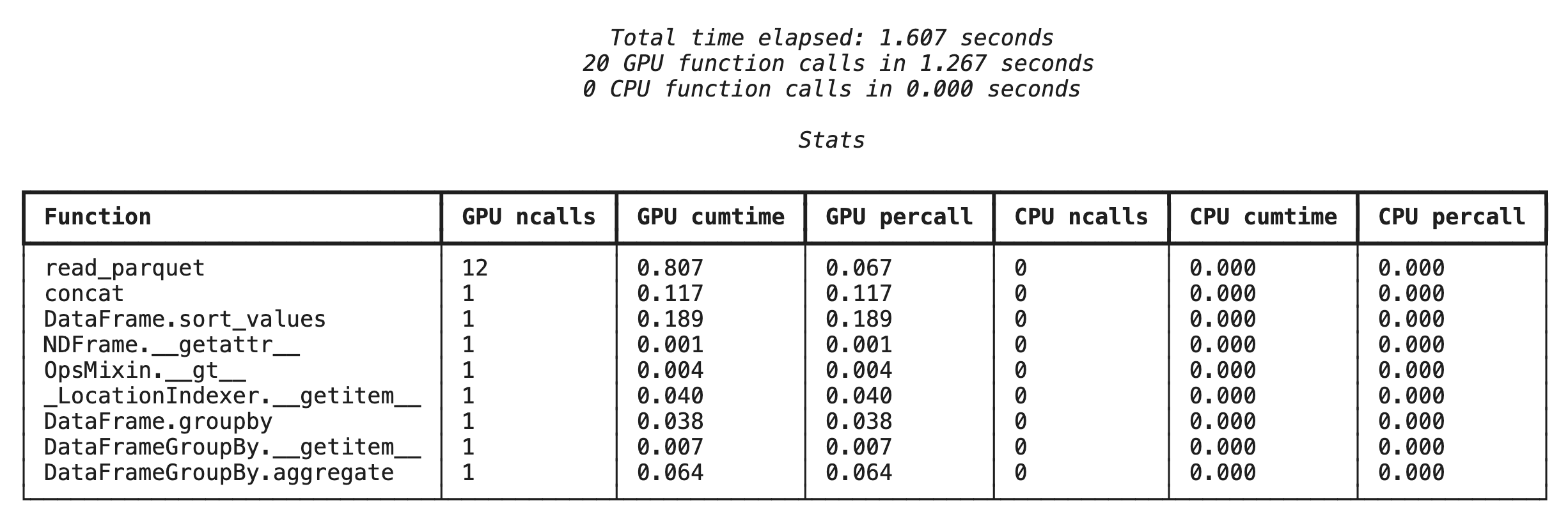
इन क्षेत्रों की पहचान करने में आपकी मदद करने के लिए, cudf.pandas में दो बिल्ट-इन प्रोफ़ाइलर शामिल हैं. इनका इस्तेमाल करके, यह देखा जा सकता है कि आपके कोड के कौनसे हिस्से GPU पर चल रहे हैं और कौनसे CPU पर वापस आ रहे हैं.
%%cudf.pandas.profile: इसका इस्तेमाल, अपने कोड की फ़ंक्शन के हिसाब से खास जानकारी पाने के लिए करें. इससे यह पता चलता है कि कौनसी कार्रवाइयां किस डिवाइस पर चल रही हैं.%%cudf.pandas.line_profile: इसका इस्तेमाल, लाइन-बाय-लाइन विश्लेषण के लिए करें. यह टूल, आपके कोड की उन लाइनों का पता लगाने के लिए सबसे अच्छा है जिनकी वजह से सीपीयू का इस्तेमाल किया जा रहा है.
इन प्रोफ़ाइलर का इस्तेमाल, नोटबुक सेल में सबसे ऊपर "सेल मैजिक" के तौर पर करें.
%%cudf.pandas.profile की मदद से फ़ंक्शन-लेवल की प्रोफ़ाइलिंग
सबसे पहले, पिछले सेक्शन में दी गई उसी Analytics पाइपलाइन पर फ़ंक्शन-लेवल का प्रोफ़ाइलर चलाएं. आउटपुट में, कॉल किए गए हर फ़ंक्शन की टेबल दिखती है. साथ ही, यह भी दिखता है कि फ़ंक्शन किस डिवाइस (जीपीयू या सीपीयू) पर चला और उसे कितनी बार कॉल किया गया.
%load_ext cudf.pandas
import pandas as pd
import glob
pd.DataFrame({"a": [1]})
cudf.pandas के चालू होने के बाद, प्रोफ़ाइल को चलाया जा सकता है.
%%cudf.pandas.profile
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*2024*.parquet")], ignore_index=True)
df = df.sort_values(['tpep_pickup_datetime', 'trip_distance', 'passenger_count'], ascending=[False, True, False])
summary = (
df
.loc[(df.tpep_pickup_datetime > '2024-11-01')]
.groupby(['VendorID','tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
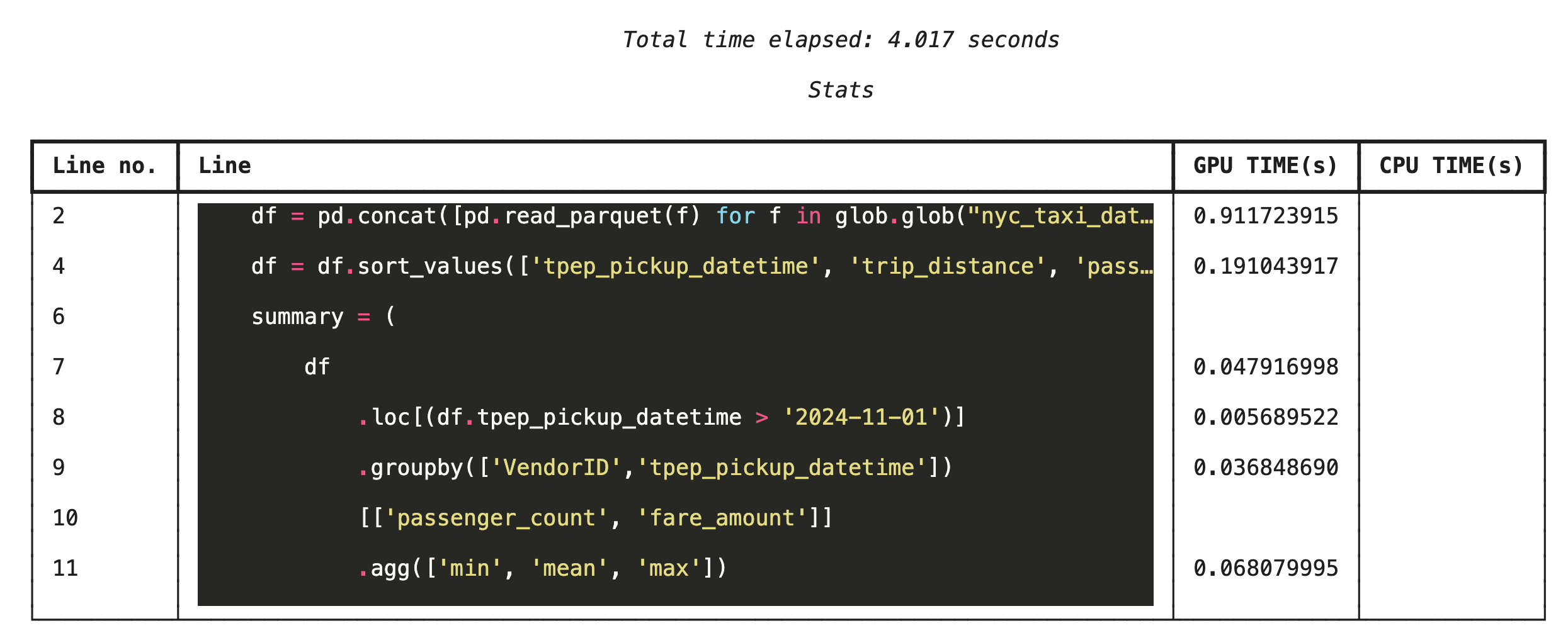
%%cudf.pandas.line_profile की मदद से, लाइन-बाय-लाइन प्रोफ़ाइलिंग
इसके बाद, लाइन-लेवल प्रोफ़ाइलर चलाएं. इससे आपको ज़्यादा जानकारी मिलती है. इसमें यह दिखाया जाता है कि कोड की हर लाइन को GPU पर एक्ज़ीक्यूट होने में कितना समय लगा और CPU पर एक्ज़ीक्यूट होने में कितना समय लगा. यह ऑप्टिमाइज़ेशन के लिए, खास समस्याओं का पता लगाने का सबसे असरदार तरीका है.
%%cudf.pandas.line_profile
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*2024*.parquet")], ignore_index=True)
df = df.sort_values(['tpep_pickup_datetime', 'trip_distance', 'passenger_count'], ascending=[False, True, False])
summary = (
df
.loc[(df.tpep_pickup_datetime > '2024-11-01')]
.groupby(['VendorID','tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
कमांड लाइन से प्रोफ़ाइलिंग करना
ये प्रोफ़ाइलर, कमांड लाइन से भी उपलब्ध होते हैं. यह Python स्क्रिप्ट की ऑटोमेटेड टेस्टिंग और प्रोफ़ाइलिंग के लिए फ़ायदेमंद है.
कमांड लाइन इंटरफ़ेस पर इनका इस्तेमाल किया जा सकता है:
python -m cudf.pandas --profile your_script.pypython -m cudf.pandas --line_profile your_script.py
13. Google Cloud Storage के साथ इंटिग्रेट करना
Google Cloud Storage (GCS), ऑब्जेक्ट स्टोरेज की एक ऐसी सेवा है जिसे बड़े पैमाने पर इस्तेमाल किया जा सकता है और जो टिकाऊ है. Colab Enterprise का इस्तेमाल करते समय, GCS आपके डेटासेट, मॉडल चेकपॉइंट, और अन्य आर्टफ़ैक्ट सेव करने के लिए एक बेहतरीन जगह है.
आपके Colab Enterprise रनटाइम के पास, GCS बकेट में मौजूद डेटा को सीधे तौर पर पढ़ने और लिखने की ज़रूरी अनुमतियां होती हैं. साथ ही, बेहतर परफ़ॉर्मेंस के लिए इन कार्रवाइयों को जीपीयू की मदद से तेज़ किया जाता है.
GCS बकेट बनाना
सबसे पहले, एक नया GCS बकेट बनाएं. GCS बकेट के नाम दुनिया भर में यूनीक होते हैं. इसलिए, इसके नाम में UUID जोड़ें.
from google.cloud import storage
import uuid
unique_suffix = uuid.uuid4().hex[:12]
bucket_name = f'nyc-taxi-codelab-{unique_suffix}'
project_id = storage.Client().project
client = storage.Client()
try:
bucket = client.create_bucket(bucket_name)
print(f"Successfully created bucket: gs://{bucket.name}")
except Exception as e:
print(f"Bucket creation failed. You may already own it or the name is taken: {e}")
GCS में सीधे तौर पर डेटा लिखना
अब DataFrame को सीधे अपने नए GCS बकेट में सेव करें. अगर पिछले सेक्शन से df वैरिएबल उपलब्ध नहीं है, तो कोड सबसे पहले एक महीने का डेटा लोड करता है.
%%cudf.pandas.line_profile
# Ensure the DataFrame exists before saving to GCS
if 'df' not in locals():
print("DataFrame not found, loading a sample file...")
df = pd.read_parquet('nyc_taxi_data/yellow_tripdata_2024-12.parquet')
print(f"Writing data to gs://{bucket_name}/nyc_taxi_data.parquet...")
df.to_parquet(f"gs://{bucket_name}/nyc_taxi_data.parquet", index=False)
print("Write operation complete.")
GCS में फ़ाइल की पुष्टि करना
बकेट में जाकर, यह पुष्टि की जा सकती है कि डेटा GCS में है. नीचे दिया गया कोड, क्लिक किए जा सकने वाला लिंक बनाता है.
from IPython.display import Markdown
gcs_url = f"https://console.cloud.google.com/storage/browser/{bucket_name}?project={project_id}"
Markdown(f'**[Click here to view your GCS bucket in the Google Cloud Console]({gcs_url})**')
जीसीएस से सीधे डेटा पढ़ना
आखिर में, GCS पाथ से सीधे DataFrame में डेटा पढ़ें. इस ऑपरेशन को जीपीयू की मदद से भी तेज़ी से किया जा सकता है. इससे, क्लाउड स्टोरेज से बड़े डेटासेट को तेज़ी से लोड किया जा सकता है.
%%cudf.pandas.line_profile
print(f"Reading data from gs://{bucket_name}/nyc_taxi_data.parquet...")
df_from_gcs = pd.read_parquet(f"gs://{bucket_name}/nyc_taxi_data.parquet")
df_from_gcs.head()
14. क्लीन अप करें
अपने Google Cloud खाते पर अनचाहे शुल्क से बचने के लिए, आपको बनाए गए संसाधनों को हटाना होगा.
डाउनलोड किया गया डेटा मिटाने के लिए:
# Permanately delete the GCS bucket
print(f"Deleting GCS bucket: gs://{bucket_name}...")
!gsutil rm -r -f gs://{bucket_name}
print("Bucket deleted.")
# Remove NYC taxi dataset on the Colab runtime
print("Deleting local 'nyc_taxi_data' directory...")
!rm -rf nyc_taxi_data
print("Local files deleted.")
Colab रनटाइम बंद करना
- Google Cloud Console में, Colab Enterprise के रंटाइम पेज पर जाएं.
- रीजन मेन्यू में जाकर, वह रीजन चुनें जिसमें आपका रनटाइम मौजूद है.
- वह रनटाइम चुनें जिसे आपको मिटाना है.
- मिटाएं पर क्लिक करें.
- पुष्टि करें पर क्लिक करें.
अपनी नोटबुक मिटाना
- Google Cloud Console में, Colab Enterprise के My Notebooks पेज पर जाएं.
- रीजन मेन्यू में जाकर, वह रीजन चुनें जिसमें आपकी नोटबुक मौजूद है.
- वह नोटबुक चुनें जिसे मिटाना है.
- मिटाएं पर क्लिक करें.
- पुष्टि करें पर क्लिक करें.
15. बधाई हो
बधाई हो! आपने Colab Enterprise पर NVIDIA cuDF का इस्तेमाल करके, pandas के ऐनलिटिक्स वर्कफ़्लो की रफ़्तार बढ़ा दी है. आपने जीपीयू की सुविधा वाले रनटाइम को कॉन्फ़िगर करने, कोड में कोई बदलाव किए बिना प्रोसेस को तेज़ करने के लिए cudf.pandas को चालू करने, परफ़ॉर्मेंस से जुड़ी समस्याओं का पता लगाने के लिए कोड को प्रोफ़ाइल करने, और Google Cloud Storage के साथ इंटिग्रेट करने का तरीका सीखा.