
1. Pengantar
Dalam Codelab ini, Anda akan mempelajari cara mempercepat alur kerja analisis data pada set data besar menggunakan GPU NVIDIA dan library open source di Google Cloud. Anda akan memulai dengan mengoptimalkan infrastruktur, lalu mempelajari cara menerapkan akselerasi GPU tanpa perubahan kode.
Anda akan berfokus pada pandas, library manipulasi data populer, dan mempelajari cara mempercepatnya menggunakan library cuDF NVIDIA. Yang terbaik adalah Anda bisa mendapatkan akselerasi GPU ini tanpa mengubah kode pandas yang ada.
Yang akan Anda pelajari
- Memahami Colab Enterprise di Google Cloud.
- Sesuaikan lingkungan runtime Colab dengan konfigurasi GPU, CPU, dan memori tertentu.
- Percepat
pandastanpa perubahan kode menggunakancuDFNVIDIA. - Buat profil kode Anda untuk mengidentifikasi dan mengoptimalkan bottleneck performa.
Halaman berikutnya berisi kredit yang dapat Anda gunakan untuk menyelesaikan lab.
2. Mengapa perlu mempercepat pemrosesan data?
Aturan 80/20: Mengapa penyiapan data menghabiskan banyak waktu
Persiapan data sering kali menjadi fase yang paling memakan waktu dalam project analisis. Data scientist dan analis menghabiskan sebagian besar waktu mereka untuk membersihkan, mentransformasi, dan menyusun data sebelum analisis dapat dimulai.
Untungnya, Anda dapat mempercepat library open source populer seperti pandas, Apache Spark, dan Polars di GPU NVIDIA menggunakan cuDF. Meskipun dengan akselerasi ini, persiapan data tetap memakan waktu karena:
- Data sumber jarang siap untuk dianalisis: Data dunia nyata sering kali memiliki inkonsistensi, nilai yang tidak ada, dan masalah pemformatan.
- Kualitas memengaruhi performa model: Kualitas data yang buruk dapat membuat algoritma yang paling canggih sekalipun menjadi tidak berguna.
- Skala memperbesar masalah: Masalah data yang tampaknya kecil menjadi hambatan kritis saat bekerja dengan jutaan data.
3. Memilih lingkungan notebook
Meskipun banyak ilmuwan data sudah familiar dengan Colab untuk project pribadi, Colab Enterprise memberikan pengalaman notebook yang aman, kolaboratif, dan terintegrasi yang dirancang untuk bisnis.
Di Google Cloud, Anda memiliki dua pilihan utama untuk lingkungan notebook terkelola: Colab Enterprise dan Gemini Enterprise Agent Platform Workbench. Pilihan yang tepat bergantung pada prioritas proyek Anda.
Kapan harus menggunakan Workbench Platform Agen
Pilih Agent Platform Workbench jika prioritas Anda adalah kontrol dan penyesuaian mendalam. Opsi ini adalah pilihan ideal jika Anda perlu:
- Mengelola infrastruktur dan siklus proses mesin yang mendasarinya.
- Menggunakan konfigurasi jaringan dan container kustom.
- Terintegrasi dengan pipeline MLOps dan alat siklus proses kustom.
Kapan harus menggunakan Colab Enterprise
Pilih Colab Enterprise jika prioritas Anda adalah penyiapan cepat, kemudahan penggunaan, dan kolaborasi yang aman. Layanan ini adalah solusi terkelola sepenuhnya yang memungkinkan tim Anda berfokus pada analisis, bukan infrastruktur.
Colab Enterprise membantu Anda:
- Kembangkan alur kerja data science yang terkait erat dengan data warehouse Anda. Anda dapat membuka dan mengelola notebook secara langsung di BigQuery Studio.
- Latih model machine learning dan integrasikan dengan alat MLOps di Agent Platform.
- Nikmati pengalaman yang fleksibel dan terpadu. Notebook Colab Enterprise yang dibuat di BigQuery dapat dibuka dan dijalankan di Agent Platform, dan sebaliknya.
Lab hari ini
Codelab ini menggunakan Colab Enterprise untuk analisis data yang dipercepat.
Untuk mempelajari lebih lanjut perbedaannya, lihat dokumentasi resmi tentang memilih solusi notebook yang tepat.
4. Mengonfigurasi template runtime
Di Colab Enterprise, hubungkan ke runtime yang didasarkan pada template runtime yang telah dikonfigurasi sebelumnya.
Template runtime adalah konfigurasi yang dapat digunakan kembali yang menentukan seluruh lingkungan untuk notebook Anda, termasuk:
- Jenis mesin (CPU, memori)
- Akselerator (jenis dan jumlah GPU)
- Ukuran dan jenis disk
- Setelan jaringan dan kebijakan keamanan
- Aturan penonaktifan otomatis saat tidak ada aktivitas
Alasan pentingnya template runtime
- Dapatkan lingkungan yang konsisten: Anda dan rekan tim Anda mendapatkan lingkungan siap pakai yang sama setiap saat untuk memastikan pekerjaan Anda dapat diulang.
- Bekerja dengan aman berdasarkan desain: Template secara otomatis menerapkan kebijakan keamanan organisasi Anda.
- Mengelola biaya secara efektif: Resource seperti GPU dan CPU telah ditentukan ukurannya dalam template, yang membantu mencegah pembengkakan biaya yang tidak disengaja.
Membuat template runtime
Siapkan template runtime yang dapat digunakan kembali untuk lab.
- Di Konsol Google Cloud, buka Navigation Menu > Agent Platform > Notebooks.
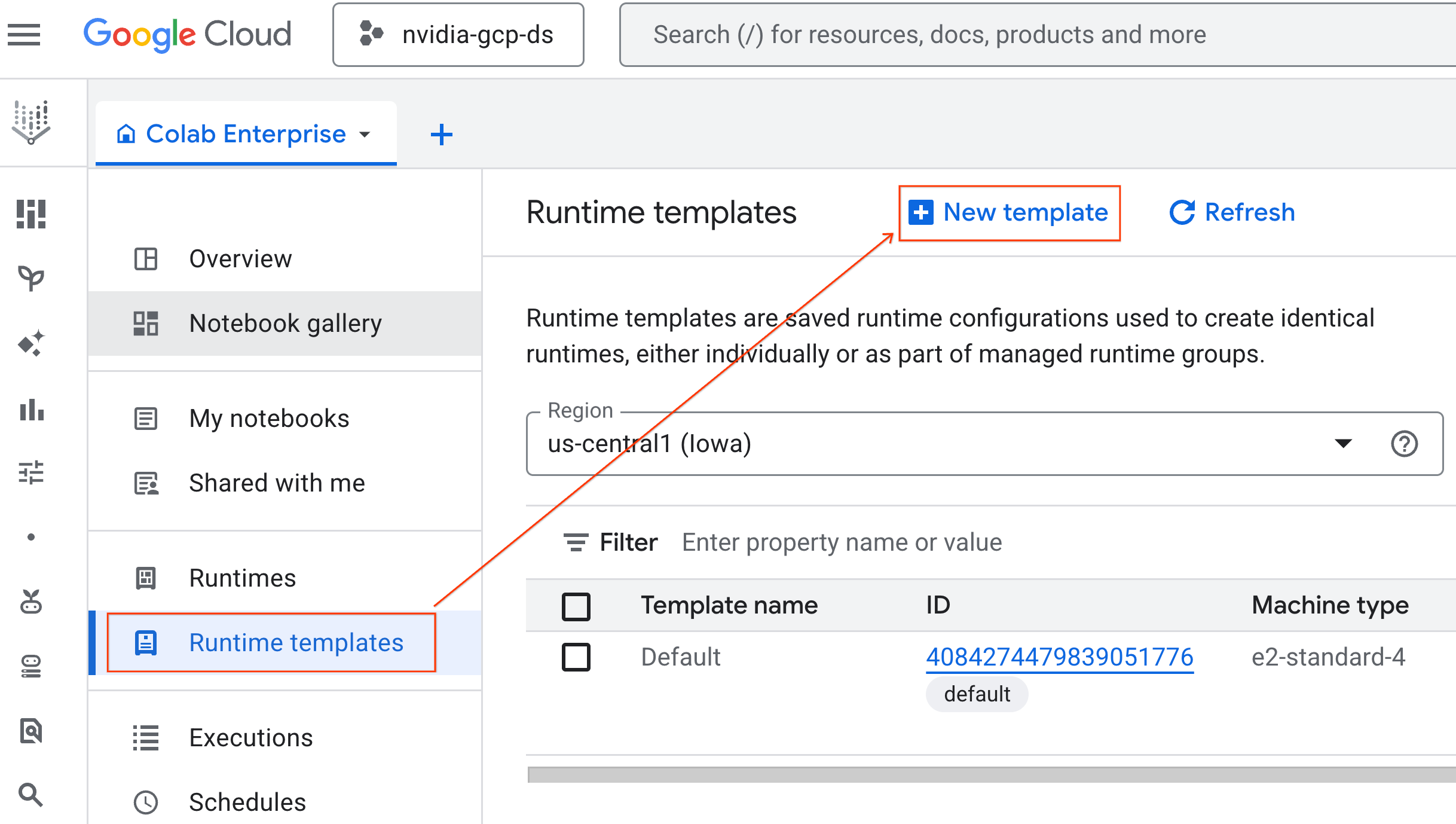
- Dari Colab Enterprise, klik Runtime templates, lalu pilih New Template.
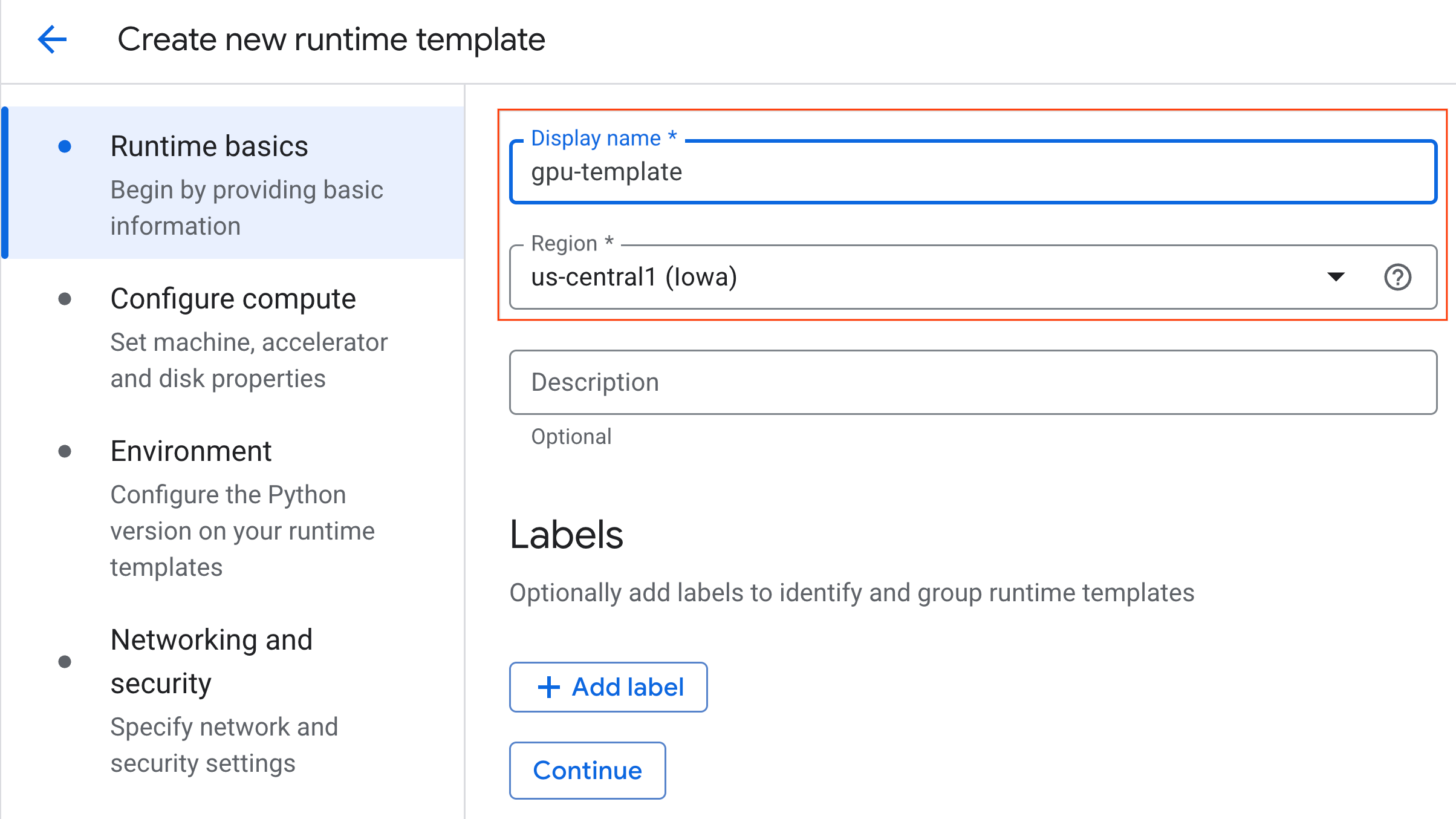
- Di bagian Dasar-dasar runtime:
- Tetapkan Display name sebagai
gpu-template. - Tetapkan Wilayah pilihan Anda.
- Tetapkan Display name sebagai
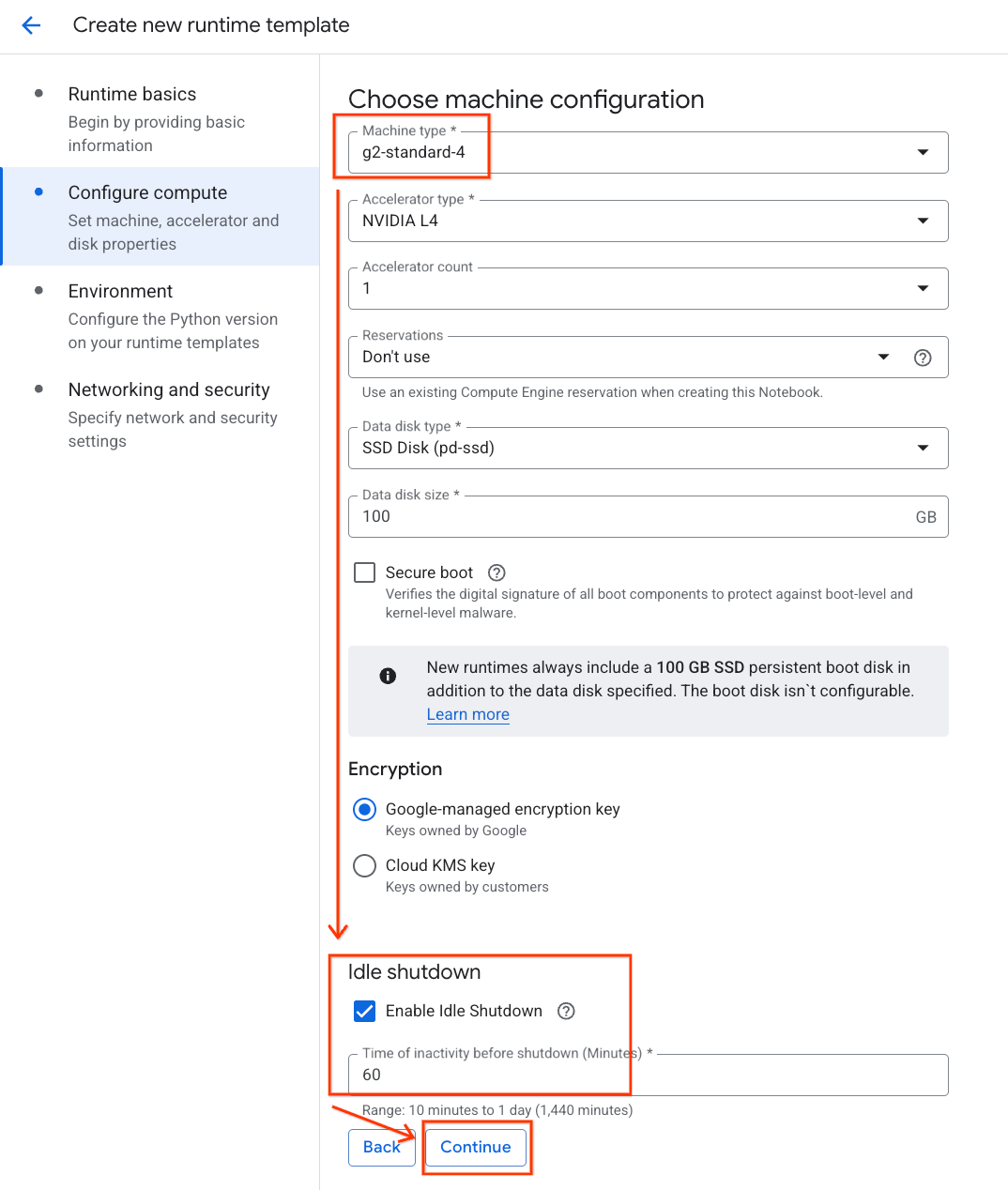
- Di bagian Konfigurasi komputasi:
- Tetapkan Jenis mesin ke
g2-standard-4. - Biarkan Jenis Akselerator default sebagai
NVIDIA L4dengan Jumlah akselerator 1. - Ubah Penonaktifan tidak ada aktivitas menjadi 60 menit.
- Klik Lanjutkan.
- Tetapkan Jenis mesin ke
- Di bagian Lingkungan:
- Tetapkan Environment ke
Python 3.11
- Tetapkan Environment ke
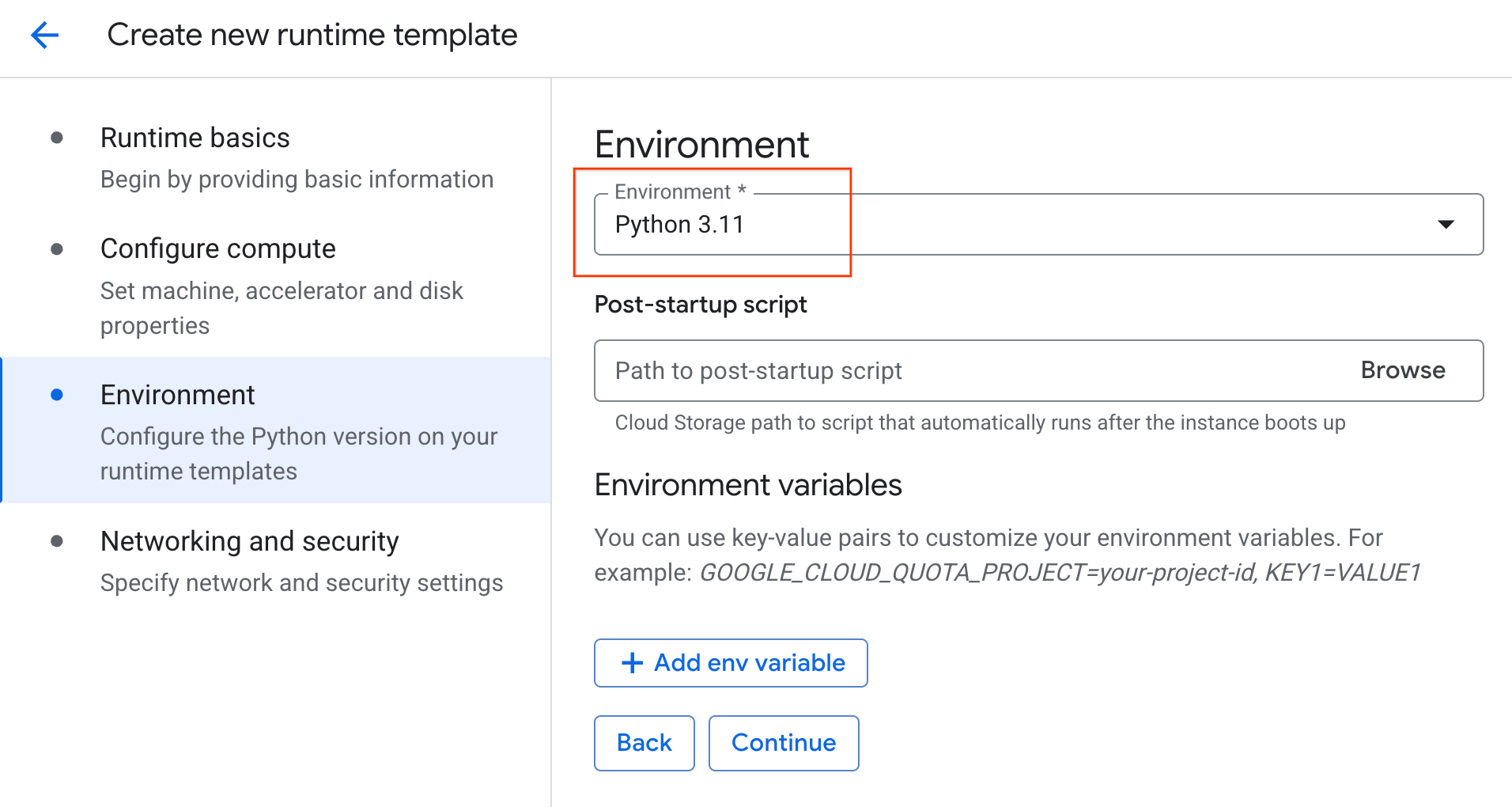
- Klik Buat untuk menyimpan template runtime. Halaman Template runtime Anda kini akan menampilkan template baru.
5. Mulai runtime
Setelah template siap, Anda dapat membuat runtime baru.
- Dari Colab Enterprise, klik Runtimes, lalu pilih Create.
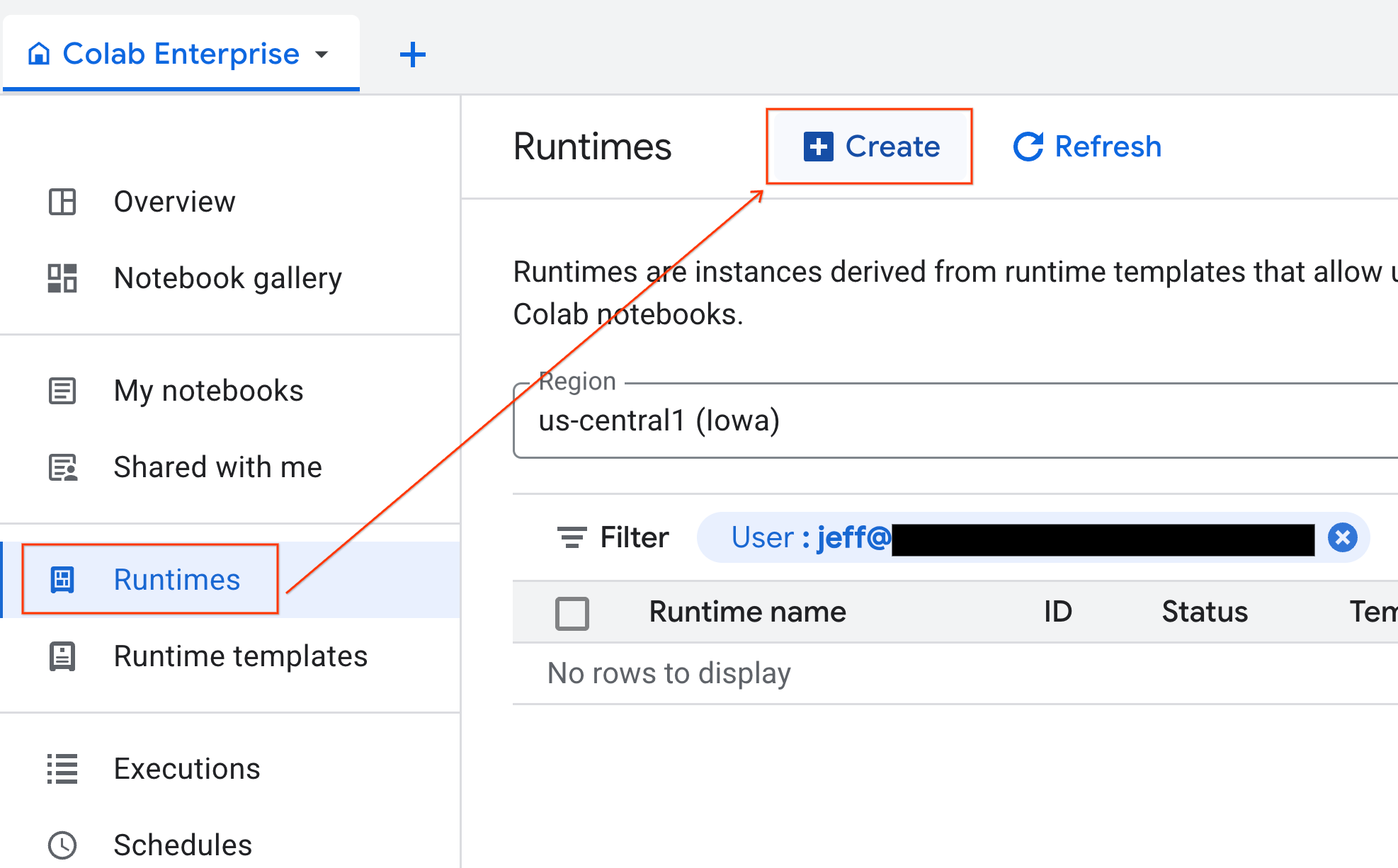
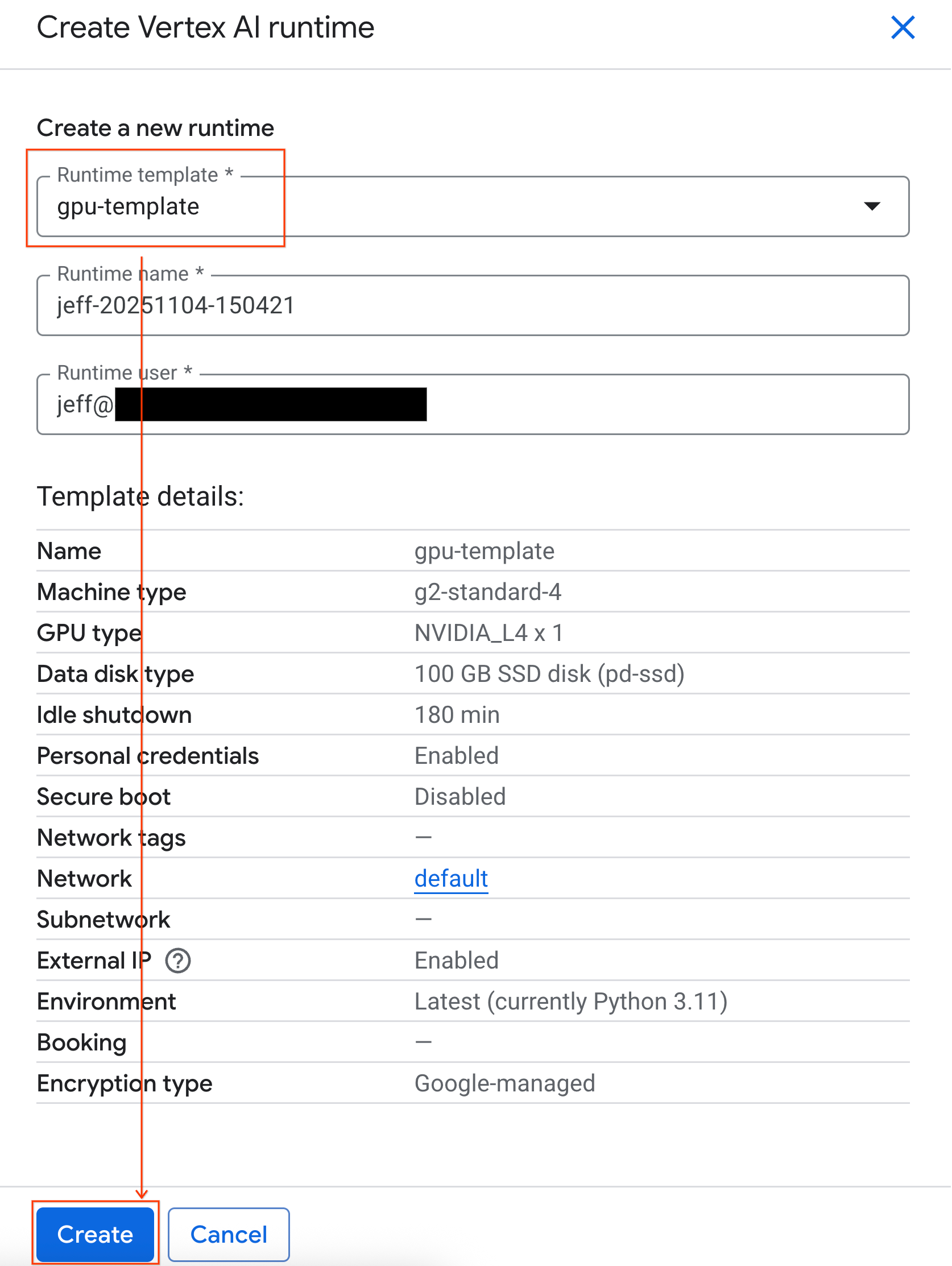
- Di bagian Runtime template, pilih opsi
gpu-template. Klik Create dan tunggu hingga runtime di-boot.
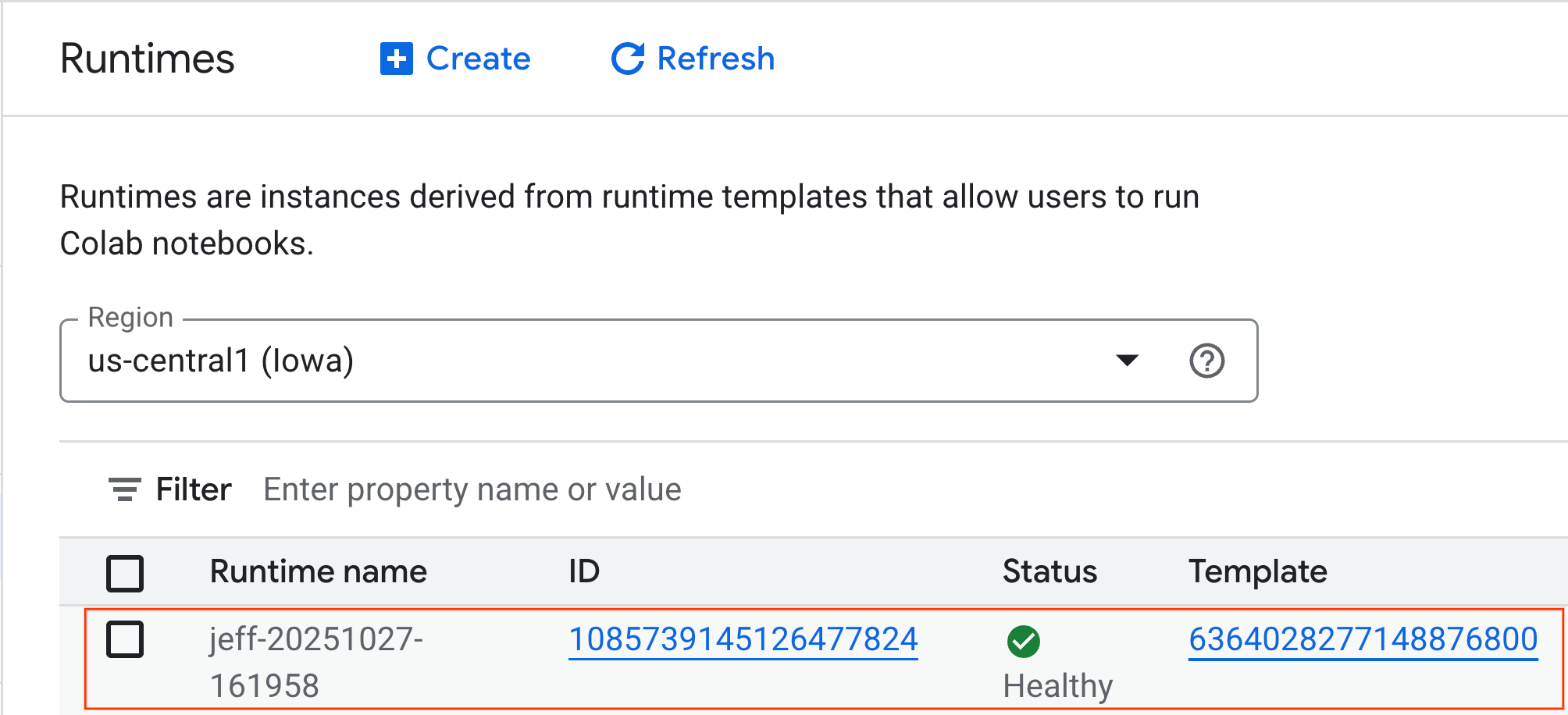
- Setelah beberapa menit, Anda akan melihat runtime tersedia.
6. Menyiapkan notebook
Setelah infrastruktur Anda berjalan, Anda perlu mengimpor notebook lab dan menghubungkannya ke runtime Anda.
Mengimpor notebook
- Dari Colab Enterprise, klik Notebook saya, lalu klik Impor.
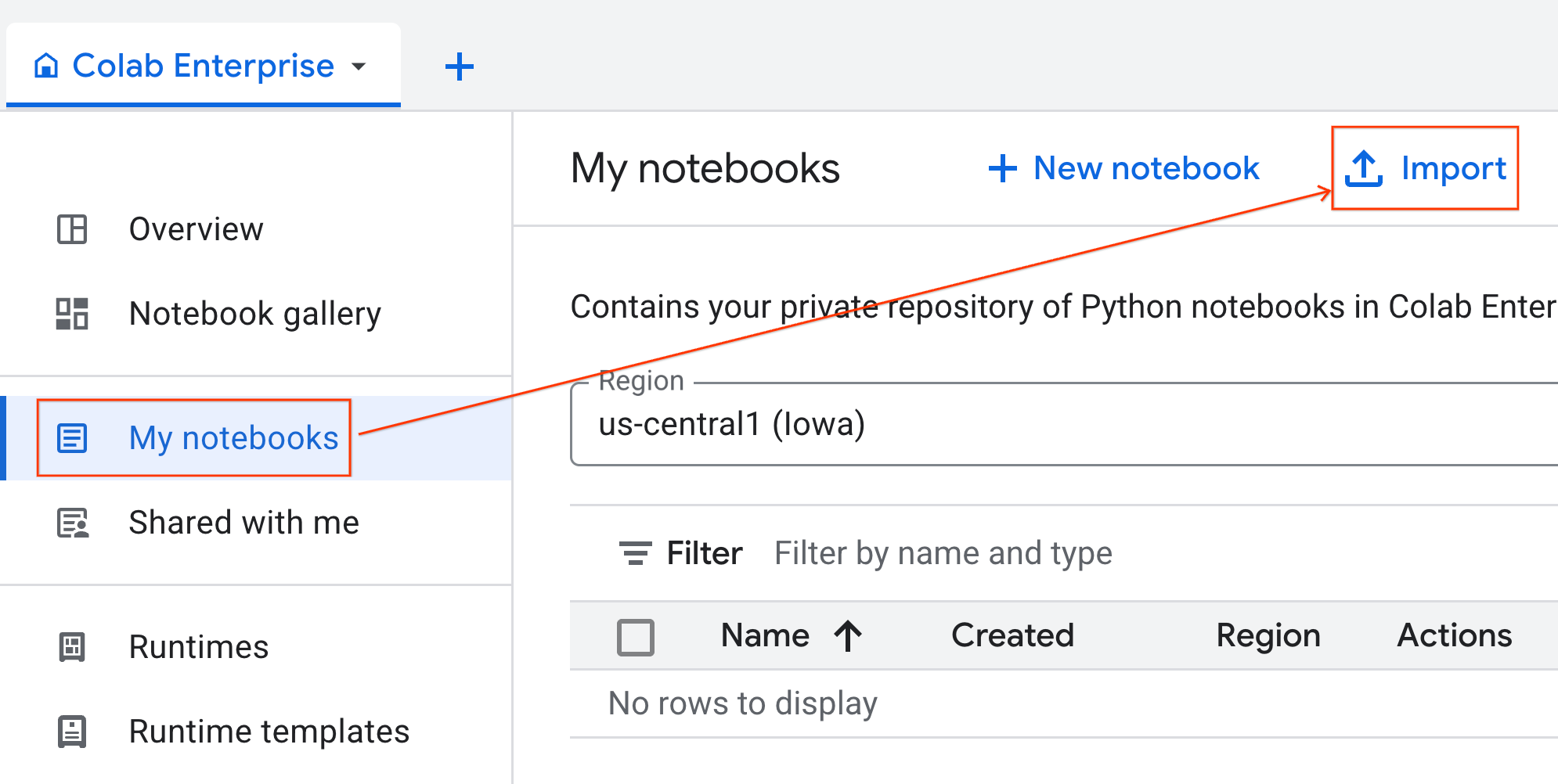
- Pilih tombol pilihan URL, lalu masukkan URL berikut:
https://github.com/GoogleCloudPlatform/ai-ml-recipes/blob/main/notebooks/analytics/gpu_accelerated_analytics.ipynb
- Klik Impor. Colab Enterprise akan menyalin notebook dari GitHub ke lingkungan Anda.
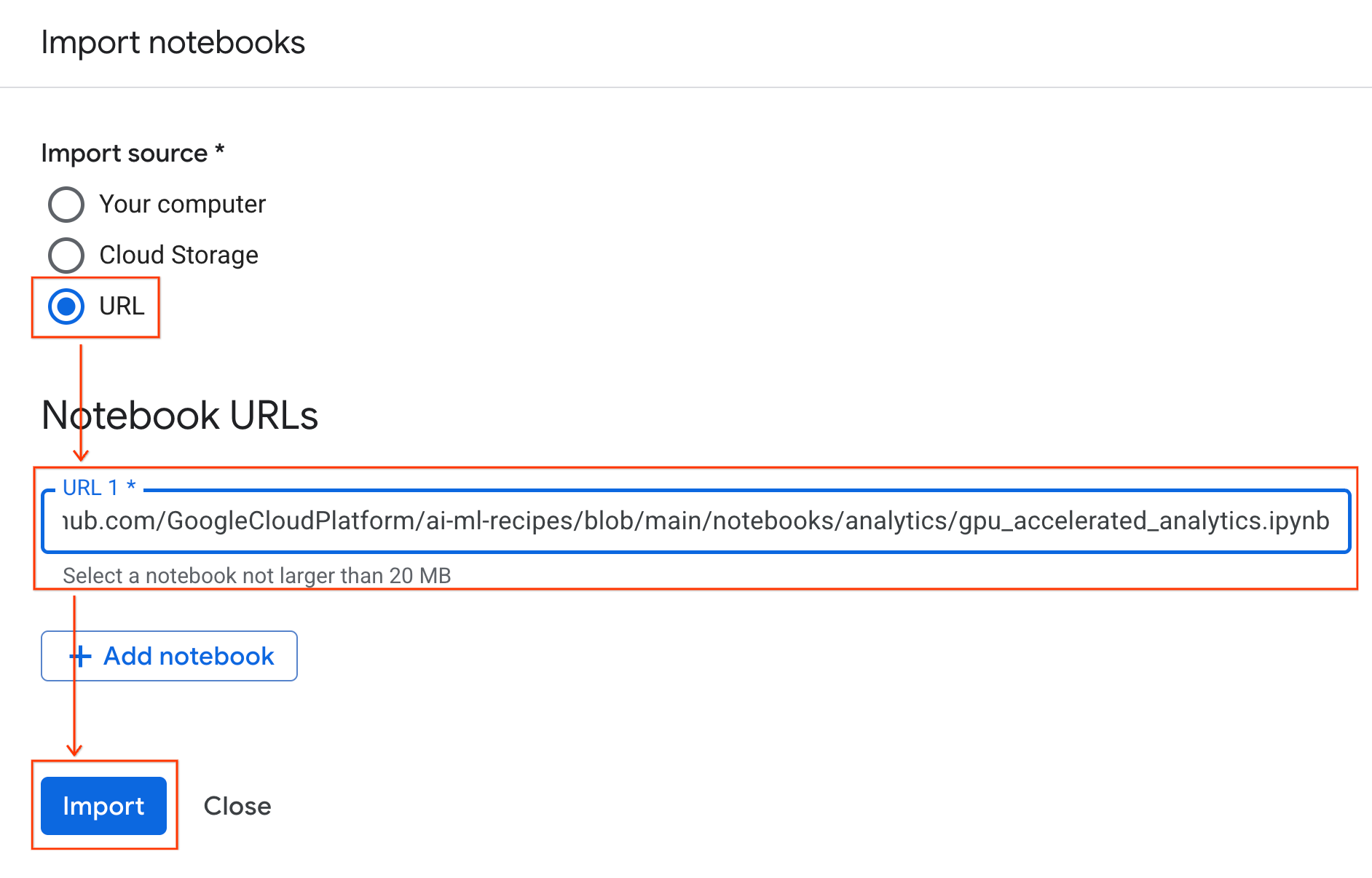
Menghubungkan notebook ke runtime
- Buka notebook yang baru diimpor.
- Klik panah drop-down di samping Connect.
- Pilih Connect to a Runtime.
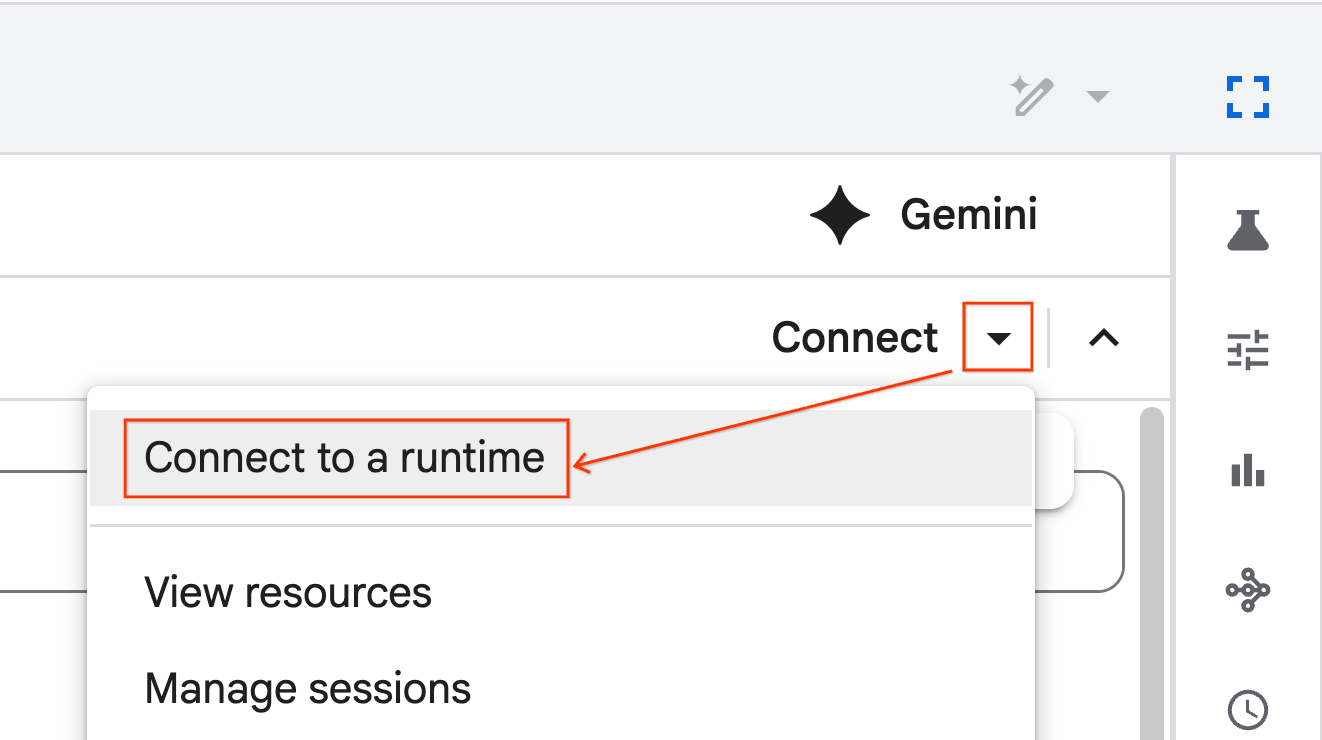
- Gunakan dropdown dan pilih runtime yang Anda buat sebelumnya.
- Klik Hubungkan.
Notebook Anda kini terhubung ke runtime yang mendukung GPU. Sekarang Anda dapat mulai menjalankan kueri.
7. Menyiapkan set data taksi NYC
Codelab ini menggunakan Data Catatan Perjalanan NYC Taxi & Limousine Commission (TLC).
Set data berisi catatan perjalanan individual dari taksi kuning di New York City, dan mencakup kolom seperti:
- Tanggal, waktu, dan lokasi penjemputan dan pengantaran
- Jarak perjalanan
- Jumlah tarif yang dikelompokkan per item
- Jumlah penumpang
Mendownload data
Selanjutnya, download data perjalanan untuk sepanjang tahun 2024. Data disimpan dalam format file Parquet.
Blok kode berikut melakukan langkah-langkah ini:
- Menentukan rentang tahun dan bulan yang akan didownload.
- Membuat direktori lokal bernama
nyc_taxi_datauntuk menyimpan file. - Melakukan loop di setiap bulan, mendownload file Parquet yang sesuai jika belum ada, dan menyimpannya ke direktori.
Jalankan kode ini di notebook Anda untuk mengumpulkan data dan menyimpannya di runtime:
from tqdm import tqdm
import requests
import time
import os
YEAR = 2024
DATA_DIR = "nyc_taxi_data"
os.makedirs(DATA_DIR, exist_ok=True)
print(f"Checking/Downloading files for {YEAR}...")
for month in tqdm(range(1, 13), unit="file"):
# Define standardized filename for both local path and URL
file_name = f"yellow_tripdata_{YEAR}-{month:02d}.parquet"
local_path = os.path.join(DATA_DIR, file_name)
url = f"https://d37ci6vzurychx.cloudfront.net/trip-data/{file_name}"
if not os.path.exists(local_path):
try:
with requests.get(url, stream=True) as response:
response.raise_for_status()
with open(local_path, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
time.sleep(1)
except requests.exceptions.HTTPError as e:
print(f"\nSkipping {file_name}: {e}")
if os.path.exists(local_path):
os.remove(local_path)
print("\nDownload complete.")
8. Menjelajahi data perjalanan taksi
Setelah mendownload set data, sekarang saatnya melakukan analisis data eksploratif (EDA) awal. Tujuan EDA adalah memahami struktur data, menemukan anomali, dan mengungkap potensi pola.
Memuat data satu bulan
Mulailah dengan memuat data selama satu bulan. Hal ini memberikan sampel yang cukup besar (lebih dari 3 juta baris) agar bermakna sekaligus menjaga penggunaan memori tetap dapat dikelola untuk analisis interaktif.
import pandas as pd
import glob
# Load the last month of the downloaded data
df = pd.read_parquet("nyc_taxi_data/yellow_tripdata_2024-12.parquet")
df.head()
Mendapatkan statistik ringkasan
Gunakan metode .describe() untuk membuat statistik ringkasan tingkat tinggi untuk kolom numerik. Ini adalah langkah pertama yang bagus untuk menemukan potensi masalah kualitas data, seperti nilai minimum atau maksimum yang tidak terduga.
df.describe().round(2)

Menyelidiki kualitas data
Output dari .describe() akan langsung mengungkapkan masalah. Perhatikan bahwa nilai min untuk tpep_pickup_datetime dan tpep_dropoff_datetime adalah tahun 2008, yang tidak masuk akal untuk set data tahun 2024.
Berikut contoh alasan mengapa Anda harus selalu memeriksa data. Anda dapat menyelidikinya lebih lanjut dengan mengurutkan DataFrame untuk menemukan baris persis yang berisi tanggal pencilan ini.
# Sort by the dropoff datetime to see the oldest records
df.sort_values("tpep_pickup_datetime").head()
Memvisualisasikan distribusi data
Selanjutnya, Anda dapat membuat histogram kolom numerik untuk memvisualisasikan distribusinya. Hal ini membantu Anda memahami penyebaran dan kemiringan fitur seperti trip_distance dan fare_amount. Fungsi .hist() adalah cara cepat untuk memplot histogram untuk semua kolom numerik dalam DataFrame.
_ = df.hist(figsize=(20, 20))
Terakhir, buat matriks sebaran untuk memvisualisasikan hubungan antara beberapa kolom utama. Karena memetakan jutaan titik itu lambat dan dapat mengaburkan pola, gunakan .sample() untuk membuat plot dari sampel acak 100.000 baris.
_ = pd.plotting.scatter_matrix(
df[['passenger_count', 'trip_distance', 'tip_amount', 'total_amount']].sample(100_000),
diagonal="kde",
figsize=(15, 15)
)
9. Mengapa menggunakan format file Parquet?
Set data taksi NYC disediakan dalam format Apache Parquet. Ini adalah pilihan yang disengaja untuk analisis berskala besar. Parquet menawarkan beberapa keunggulan dibandingkan jenis file seperti CSV:
- Efisien dan Cepat: Sebagai format kolom, Parquet sangat efisien untuk disimpan dan dibaca. Format ini mendukung metode kompresi modern yang menghasilkan ukuran file yang lebih kecil dan I/O yang jauh lebih cepat, terutama pada GPU.
- Mempertahankan Skema: Parquet menyimpan jenis data dalam metadata file. Anda tidak perlu menebak jenis data saat membaca file.
- Memungkinkan Pembacaan Selektif: Struktur kolom memungkinkan Anda membaca hanya kolom tertentu yang diperlukan untuk analisis. Hal ini dapat mengurangi jumlah data yang harus Anda muat ke dalam memori secara drastis.
Menjelajahi fitur Parquet
Mari kita pelajari dua fitur canggih ini menggunakan salah satu file yang Anda download.
Memeriksa metadata tanpa memuat set data lengkap
Meskipun Anda tidak dapat melihat file Parquet di editor teks standar, Anda dapat dengan mudah memeriksa skema dan metadatanya tanpa memuat data apa pun ke dalam memori. Hal ini berguna untuk memahami struktur file dengan cepat.
from pyarrow.parquet import ParquetFile
import pyarrow as pa
# Open one of the downloaded files
pf = ParquetFile('nyc_taxi_data/yellow_tripdata_2024-12.parquet')
# Print the schema
print("File Schema:")
print(pf.schema)
# Print the file metadata
print("\nFile Metadata:")
print(pf.metadata)
Hanya baca kolom yang diperlukan
Bayangkan Anda hanya perlu menganalisis jarak perjalanan dan jumlah tarif. Dengan Parquet, Anda dapat memuat hanya kolom tersebut, yang jauh lebih cepat dan lebih hemat memori daripada memuat seluruh DataFrame.
import pandas as pd
# Read only four specific columns from the Parquet file
df_subset = pd.read_parquet(
'nyc_taxi_data/yellow_tripdata_2024-12.parquet',
columns=['passenger_count', 'trip_distance', 'tip_amount', 'total_amount']
)
df_subset.head()
10. Mempercepat pandas dengan NVIDIA cuDF
NVIDIA CUDA for DataFrames (cuDF) adalah library open source yang dipercepat GPU yang memungkinkan Anda berinteraksi dengan DataFrame. cuDF memungkinkan Anda melakukan operasi data umum seperti pemfilteran, penggabungan, dan pengelompokan di GPU dengan paralelisme besar-besaran.
Fitur utama yang Anda gunakan dalam Codelab ini adalah mode akselerator cudf.pandas. Saat Anda mengaktifkannya, kode pandas standar Anda akan otomatis dialihkan untuk menggunakan kernel cuDF yang didukung GPU di balik layar, tanpa mengharuskan Anda mengubah kode.
Mengaktifkan akselerasi GPU
Untuk menggunakan NVIDIA cuDF di notebook Colab Enterprise, Anda memuat ekstensi ajaibnya sebelum mengimpor pandas.
Pertama, periksa library pandas standar. Perhatikan bahwa output menampilkan jalur ke penginstalan pandas default.
import pandas as pd
pd # Note the output for the standard pandas library
Sekarang, muat ekstensi cudf.pandas dan impor pandas lagi. Perhatikan perubahan output untuk modul pd - ini mengonfirmasi bahwa versi yang dipercepat GPU kini aktif.
%load_ext cudf.pandas
import pandas as pd
pd # Note the new output, indicating cudf.pandas is active
Cara lain untuk mengaktifkan cudf.pandas
Meskipun perintah ajaib (%load_ext) adalah metode termudah di notebook, Anda juga dapat mengaktifkan akselerator di lingkungan lain:
- Dalam skrip Python: Panggil
import cudf.pandasdancudf.pandas.install()sebelum imporpandasAnda. - Dari lingkungan non-notebook: Jalankan skrip Anda menggunakan
python -m cudf.pandas your_script.py.
11. Membandingkan performa CPU vs. GPU
Sekarang untuk bagian yang paling penting: membandingkan performa pandas standar di CPU dengan cudf.pandas di GPU.
Untuk memastikan dasar yang sepenuhnya adil untuk CPU, Anda harus mereset runtime Colab terlebih dahulu. Tindakan ini akan menghapus akselerator GPU yang mungkin telah Anda aktifkan di bagian sebelumnya. Anda dapat memulai ulang runtime dengan menjalankan sel berikut, atau memilih Mulai ulang sesi dari menu Runtime.
import IPython
IPython.Application.instance().kernel.do_shutdown(True)
Menentukan pipeline analisis
Setelah lingkungan bersih, Anda akan menentukan fungsi tolok ukur. Dengan fungsi ini, Anda dapat menjalankan pipeline yang sama persis - memuat, mengurutkan, dan meringkas - menggunakan modul pandas apa pun yang Anda teruskan ke dalamnya.
import time
import glob
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
def run_analytics_pipeline(pd_module):
"""Loads, sorts, and summarizes data using the provided pandas module."""
timings = {}
# 1. Load all 2024 Parquet files from the directory
t0 = time.time()
df = pd_module.concat(
[pd_module.read_parquet(f) for f in glob.glob("nyc_taxi_data/*_2024*.parquet")],
ignore_index=True
)
timings["load"] = time.time() - t0
# 2. Sort the data by multiple columns
t0 = time.time()
df = df.sort_values(
['tpep_pickup_datetime', 'trip_distance', 'passenger_count'],
ascending=[False, True, False]
)
timings["sort"] = time.time() - t0
# 3. Perform a groupby and aggregation
t0 = time.time()
df['tpep_pickup_datetime'] = pd_module.to_datetime(df['tpep_pickup_datetime'])
_ = (
df.loc[df.tpep_pickup_datetime > '2024-11-01']
.groupby(['VendorID', 'tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
timings["summarize"] = time.time() - t0
return timings
Jalankan perbandingan
Pertama, Anda akan menjalankan pipeline menggunakan pandas standar di CPU. Kemudian, Anda mengaktifkan cudf.pandas dan menjalankannya lagi di GPU.
# --- Run on CPU ---
print("Running analytics pipeline on CPU...")
# Ensure we are using standard pandas
import pandas as pd
assert "cudf" not in str(pd), "Error: cuDF is still active. Please restart the kernel."
cpu_times = run_analytics_pipeline(pd)
print(f"CPU times: {cpu_times}")
# --- Run on GPU ---
print("\nEnabling cudf.pandas and running on GPU...")
# Load the extension
%load_ext cudf.pandas
import pandas as gpu_pd
gpu_times = run_analytics_pipeline(gpu_pd)
print(f"GPU times: {gpu_times}")
Memvisualisasikan hasil
Terakhir, visualisasikan perbedaannya. Kode berikut menghitung peningkatan kecepatan untuk setiap operasi dan memplotnya secara berdampingan.
# Create a DataFrame for plotting
results_df = pd.DataFrame([cpu_times, gpu_times], index=["CPU", "GPU"]).T
total_cpu_time = results_df['CPU'].sum()
total_gpu_time = results_df['GPU'].sum()
speedup = total_cpu_time / total_gpu_time
print("--- Performance Results ---")
print(results_df)
print(f"\nTotal CPU Time: {total_cpu_time:.2f} seconds")
print(f"Total GPU Time: {total_gpu_time:.2f} seconds")
print(f"Overall Speedup: {speedup:.2f}x")
# Plot the results
fig, ax = plt.subplots(figsize=(10, 6))
results_df.plot(kind='bar', ax=ax, color={"CPU": "tab:blue", "GPU": "tab:green"})
ax.set_ylabel("Time (seconds)")
ax.set_title(f"CPU vs. GPU Runtimes (Overall Speedup: {speedup:.2f}x)", fontsize=14)
ax.tick_params(axis='x', rotation=0)
# Add numerical labels to the bars
for container in ax.containers:
ax.bar_label(container, fmt="%.2f", padding=3)
plt.tight_layout()
plt.show()
Hasil sampel:
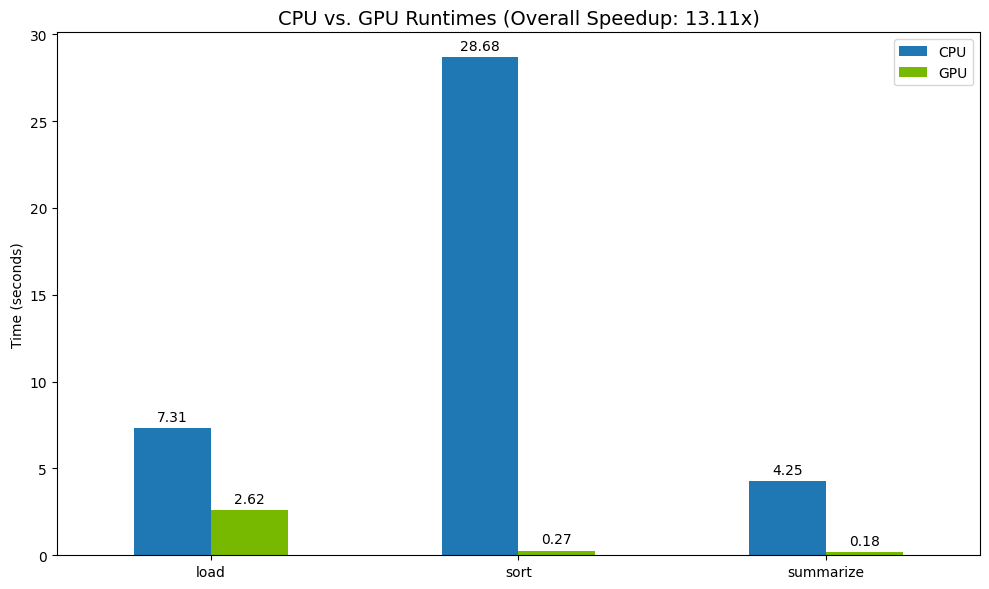
GPU memberikan peningkatan kecepatan yang jelas dibandingkan dengan CPU.
12. Membuat profil kode untuk menemukan bottleneck
Meskipun dengan akselerasi GPU, beberapa operasi pandas mungkin beralih kembali ke CPU jika belum didukung oleh cuDF. "Penggantian CPU" ini dapat menjadi hambatan performa.
Untuk membantu Anda mengidentifikasi area ini, cudf.pandas menyertakan dua profiler bawaan. Anda dapat menggunakannya untuk melihat secara persis bagian kode mana yang berjalan di GPU dan bagian mana yang kembali ke CPU.
%%cudf.pandas.profile: Gunakan ini untuk ringkasan tingkat tinggi, fungsi demi fungsi dari kode Anda. Opsi ini paling baik untuk mendapatkan ringkasan cepat tentang operasi mana yang berjalan di perangkat mana.%%cudf.pandas.line_profile: Gunakan ini untuk analisis mendetail baris demi baris. Ini adalah alat terbaik untuk menunjukkan baris yang tepat dalam kode Anda yang menyebabkan penggantian ke CPU.
Gunakan profiler ini sebagai "cell magic" di bagian atas sel notebook.
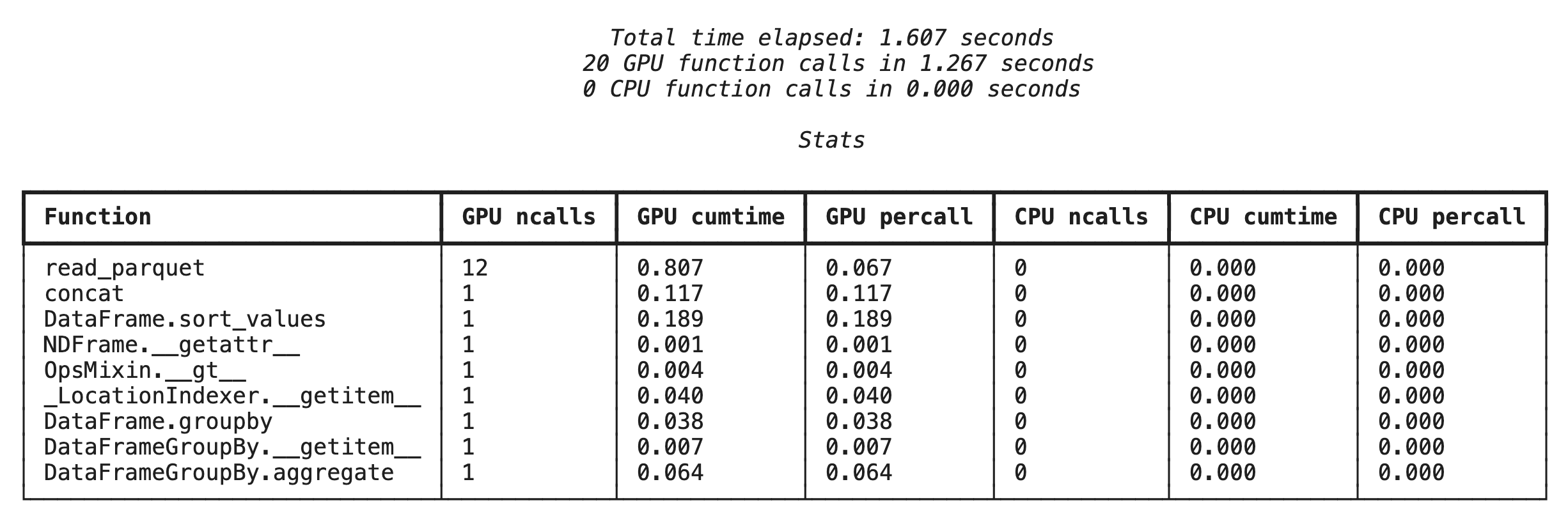
Pembuatan profil tingkat fungsi dengan %%cudf.pandas.profile
Pertama, jalankan profiler tingkat fungsi pada pipeline analisis yang sama dari bagian sebelumnya. Output menampilkan tabel setiap fungsi yang dipanggil, perangkat tempat fungsi tersebut berjalan (GPU atau CPU), dan berapa kali fungsi tersebut dipanggil.
%load_ext cudf.pandas
import pandas as pd
import glob
pd.DataFrame({"a": [1]})
Setelah memastikan cudf.pandas aktif, Anda dapat menjalankan profil.
%%cudf.pandas.profile
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*2024*.parquet")], ignore_index=True)
df = df.sort_values(['tpep_pickup_datetime', 'trip_distance', 'passenger_count'], ascending=[False, True, False])
summary = (
df
.loc[(df.tpep_pickup_datetime > '2024-11-01')]
.groupby(['VendorID','tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
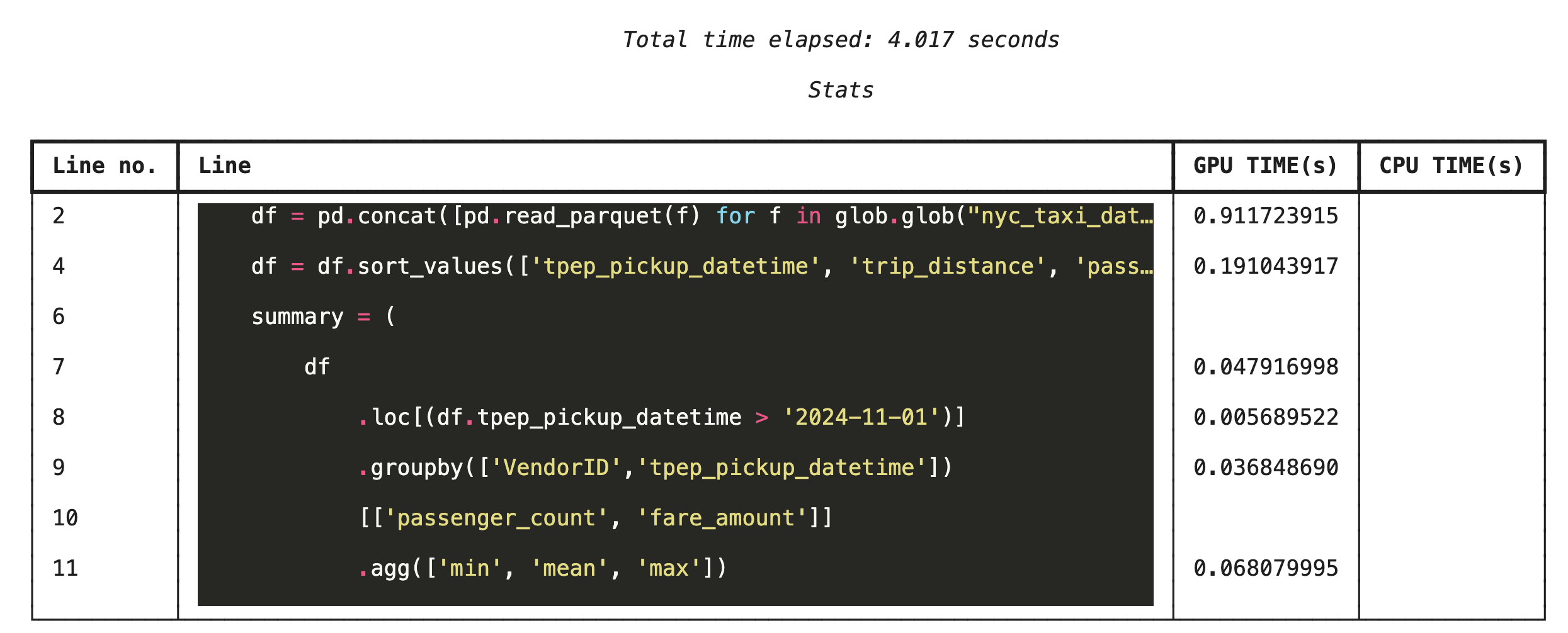
Pembuatan profil baris demi baris dengan %%cudf.pandas.line_profile
Selanjutnya, jalankan profiler tingkat baris. Hal ini memberi Anda tampilan yang jauh lebih terperinci, yang menunjukkan porsi waktu yang dihabiskan setiap baris kode untuk dieksekusi di GPU versus CPU. Cara ini adalah cara paling efektif untuk menemukan hambatan tertentu yang perlu dioptimalkan.
%%cudf.pandas.line_profile
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*2024*.parquet")], ignore_index=True)
df = df.sort_values(['tpep_pickup_datetime', 'trip_distance', 'passenger_count'], ascending=[False, True, False])
summary = (
df
.loc[(df.tpep_pickup_datetime > '2024-11-01')]
.groupby(['VendorID','tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
Membuat profil dari command line
Profiler ini juga tersedia dari command line, yang berguna untuk pengujian dan pembuatan profil skrip Python secara otomatis.
Anda dapat menggunakan perintah berikut di antarmuka command line:
python -m cudf.pandas --profile your_script.pypython -m cudf.pandas --line_profile your_script.py
13. Berintegrasi dengan Google Cloud Storage
Google Cloud Storage (GCS) adalah layanan penyimpanan objek yang skalabel dan tahan lama. Saat Anda menggunakan Colab Enterprise, GCS adalah tempat yang tepat untuk menyimpan set data, titik pemeriksaan model, dan artefak lainnya.
Runtime Colab Enterprise Anda memiliki izin yang diperlukan untuk membaca dan menulis data langsung ke bucket GCS, dan operasi ini dipercepat GPU untuk performa maksimum.
Buat bucket GCS
Pertama, buat bucket GCS baru. Nama bucket GCS unik secara global, jadi tambahkan UUID ke namanya.
from google.cloud import storage
import uuid
unique_suffix = uuid.uuid4().hex[:12]
bucket_name = f'nyc-taxi-codelab-{unique_suffix}'
project_id = storage.Client().project
client = storage.Client()
try:
bucket = client.create_bucket(bucket_name)
print(f"Successfully created bucket: gs://{bucket.name}")
except Exception as e:
print(f"Bucket creation failed. You may already own it or the name is taken: {e}")
Menulis data langsung ke GCS
Sekarang, simpan DataFrame langsung ke bucket GCS baru Anda. Jika variabel df tidak tersedia dari bagian sebelumnya, kode akan memuat data satu bulan terlebih dahulu.
%%cudf.pandas.line_profile
# Ensure the DataFrame exists before saving to GCS
if 'df' not in locals():
print("DataFrame not found, loading a sample file...")
df = pd.read_parquet('nyc_taxi_data/yellow_tripdata_2024-12.parquet')
print(f"Writing data to gs://{bucket_name}/nyc_taxi_data.parquet...")
df.to_parquet(f"gs://{bucket_name}/nyc_taxi_data.parquet", index=False)
print("Write operation complete.")
Verifikasi file di GCS
Anda dapat memverifikasi bahwa data ada di GCS dengan membuka bucket. Kode berikut akan membuat link yang dapat diklik.
from IPython.display import Markdown
gcs_url = f"https://console.cloud.google.com/storage/browser/{bucket_name}?project={project_id}"
Markdown(f'**[Click here to view your GCS bucket in the Google Cloud Console]({gcs_url})**')
Membaca data langsung dari GCS
Terakhir, baca data langsung dari jalur GCS ke dalam DataFrame. Operasi ini juga dipercepat dengan GPU, sehingga Anda dapat memuat set data besar dari penyimpanan cloud dengan kecepatan tinggi.
%%cudf.pandas.line_profile
print(f"Reading data from gs://{bucket_name}/nyc_taxi_data.parquet...")
df_from_gcs = pd.read_parquet(f"gs://{bucket_name}/nyc_taxi_data.parquet")
df_from_gcs.head()
14. Pembersihan
Agar tidak menimbulkan biaya yang tidak terduga pada akun Google Cloud Anda, Anda harus membersihkan resource yang Anda buat.
Hapus data yang Anda download:
# Permanately delete the GCS bucket
print(f"Deleting GCS bucket: gs://{bucket_name}...")
!gsutil rm -r -f gs://{bucket_name}
print("Bucket deleted.")
# Remove NYC taxi dataset on the Colab runtime
print("Deleting local 'nyc_taxi_data' directory...")
!rm -rf nyc_taxi_data
print("Local files deleted.")
Menutup runtime Colab
- Di konsol Google Cloud, buka halaman Runtimes Colab Enterprise.
- Di menu Region, pilih region yang berisi runtime Anda.
- Pilih runtime yang ingin Anda hapus.
- Klik Hapus.
- Klik Konfirmasi.
Menghapus Notebook Anda
- Di konsol Google Cloud, buka halaman Notebook Saya Colab Enterprise.
- Di menu Region, pilih region yang berisi notebook Anda.
- Pilih notebook yang ingin Anda hapus.
- Klik Hapus.
- Klik Konfirmasi.
15. Selamat
Selamat! Anda telah berhasil mempercepat alur kerja analisis pandas menggunakan NVIDIA cuDF di Colab Enterprise. Anda telah mempelajari cara mengonfigurasi runtime yang mendukung GPU, mengaktifkan cudf.pandas untuk akselerasi tanpa perubahan kode, memprofilkan kode untuk menemukan hambatan, dan berintegrasi dengan Google Cloud Storage.