
1. Introduzione
In questo codelab imparerai ad accelerare i flussi di lavoro di analisi dei dati su set di dati di grandi dimensioni utilizzando GPU NVIDIA e librerie open source su Google Cloud. Inizierai ottimizzando l'infrastruttura e poi scoprirai come applicare l'accelerazione GPU senza modificare il codice.
Ti concentrerai su pandas, una libreria di manipolazione dei dati molto diffusa, e imparerai ad accelerarla utilizzando la libreria cuDF di NVIDIA. La cosa migliore è che puoi ottenere questa accelerazione della GPU senza modificare il codice pandas esistente.
Obiettivi didattici
- Comprendere Colab Enterprise su Google Cloud.
- Personalizza un ambiente di runtime Colab con configurazioni specifiche di GPU, CPU e memoria.
- Accelera
pandassenza modifiche al codice utilizzando NVIDIAcuDF. - Esegui la profilazione del codice per identificare e ottimizzare i colli di bottiglia delle prestazioni.
La pagina successiva include i crediti che puoi utilizzare per completare il lab.
2. Perché accelerare l'elaborazione dei dati?
La regola 80/20: perché la preparazione dei dati richiede così tanto tempo
La preparazione dei dati è spesso la fase più dispendiosa in termini di tempo di un progetto di analisi. I data scientist e gli analisti dedicano gran parte del loro tempo alla pulizia, alla trasformazione e alla strutturazione dei dati prima di poter iniziare qualsiasi analisi.
Fortunatamente, puoi accelerare le librerie open source più utilizzate come pandas, Apache Spark e Polars sulle GPU NVIDIA utilizzando cuDF. Anche con questa accelerazione, la preparazione dei dati rimane un'attività che richiede molto tempo perché:
- I dati di origine sono raramente pronti per l'analisi:i dati del mondo reale spesso presentano incoerenze, valori mancanti e problemi di formattazione.
- La qualità influisce sulle prestazioni del modello:una scarsa qualità dei dati può rendere inutili anche gli algoritmi più sofisticati.
- La scalabilità amplifica i problemi:problemi di dati apparentemente minori diventano colli di bottiglia critici quando si lavora con milioni di record.
3. Scegliere un ambiente notebook
Molti data scientist conoscono Colab per i progetti personali, ma Colab Enterprise offre un'esperienza di notebook sicura, collaborativa e integrata progettata per le aziende.
Su Google Cloud, hai due scelte principali per gli ambienti notebook gestiti: Colab Enterprise e Gemini Enterprise Agent Platform Workbench. La scelta giusta dipende dalle priorità del tuo progetto.
Quando utilizzare Agent Platform Workbench
Scegli Agent Platform Workbench quando la tua priorità è il controllo e la personalizzazione avanzata. È la scelta ideale se devi:
- Gestisci l'infrastruttura sottostante e il ciclo di vita delle macchine.
- Utilizza container personalizzati e configurazioni di rete.
- Esegui l'integrazione con le pipeline MLOps e gli strumenti personalizzati del ciclo di vita.
Quando utilizzare Colab Enterprise
Scegli Colab Enterprise se la tua priorità è configurazione rapida, facilità d'uso e collaborazione sicura. È una soluzione completamente gestita che consente al tuo team di concentrarsi sull'analisi anziché sull'infrastruttura.
Colab Enterprise ti aiuta a:
- Sviluppa flussi di lavoro di data science strettamente correlati al tuo data warehouse. Puoi aprire e gestire i notebook direttamente in BigQuery Studio.
- Addestra modelli di machine learning e integrali con gli strumenti MLOps in Agent Platform.
- Goditi un'esperienza flessibile e unificata. Un notebook Colab Enterprise creato in BigQuery può essere aperto ed eseguito in Agent Platform e viceversa.
Laboratorio di oggi
Questo codelab utilizza Colab Enterprise per l'analisi dei dati accelerata.
Per scoprire di più sulle differenze, consulta la documentazione ufficiale sulla scelta della soluzione di blocco note giusta.
4. Configurare un template di runtime
In Colab Enterprise, connettiti a un runtime basato su un template di runtime preconfigurato.
Un modello di runtime è una configurazione riutilizzabile che specifica l'intero ambiente per il notebook, tra cui:
- Tipo di macchina (CPU, memoria)
- Acceleratore (tipo e numero di GPU)
- Dimensioni e tipo di disco
- Impostazioni della rete e policy di sicurezza
- Regole di spegnimento automatico inattivo
Perché i modelli di runtime sono utili
- Ottieni un ambiente coerente:tu e i tuoi colleghi ottenete ogni volta lo stesso ambiente pronto all'uso per garantire che il vostro lavoro sia ripetibile.
- Lavora in modo sicuro by design:i modelli applicano automaticamente le norme di sicurezza della tua organizzazione.
- Gestisci i costi in modo efficace:risorse come GPU e CPU sono predimensionate nel modello, il che aiuta a evitare superamenti accidentali dei costi.
Crea un template di runtime
Configura un modello di runtime riutilizzabile per il lab.
- Nella console Google Cloud, vai al menu di navigazione > Agent Platform > Notebook.
- In Colab Enterprise, fai clic su Modelli di runtime e poi seleziona Nuovo modello.
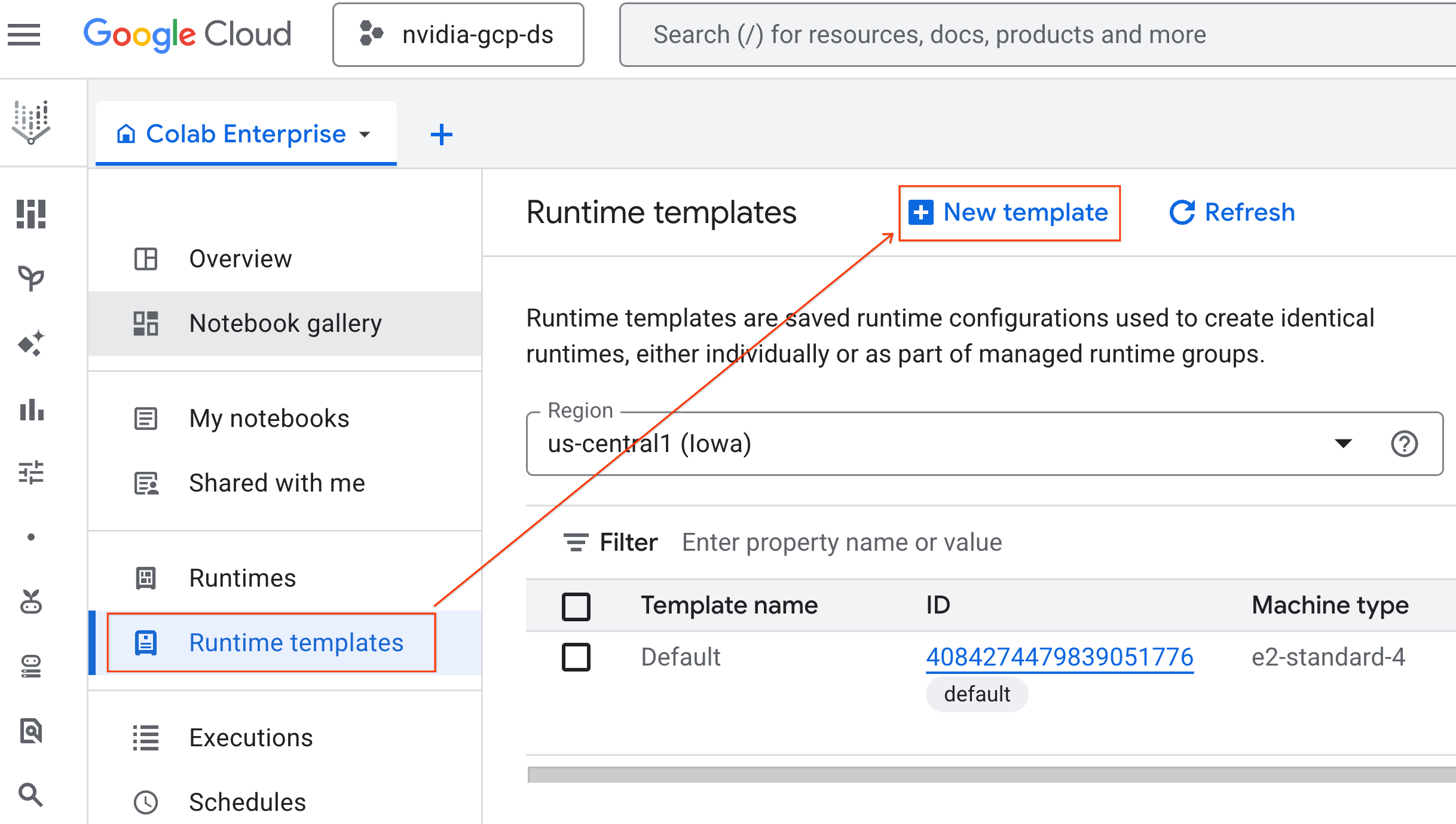
- In Nozioni di base sul runtime:
- Imposta il Nome visualizzato su
gpu-template. - Imposta la regione che preferisci.
- Imposta il Nome visualizzato su
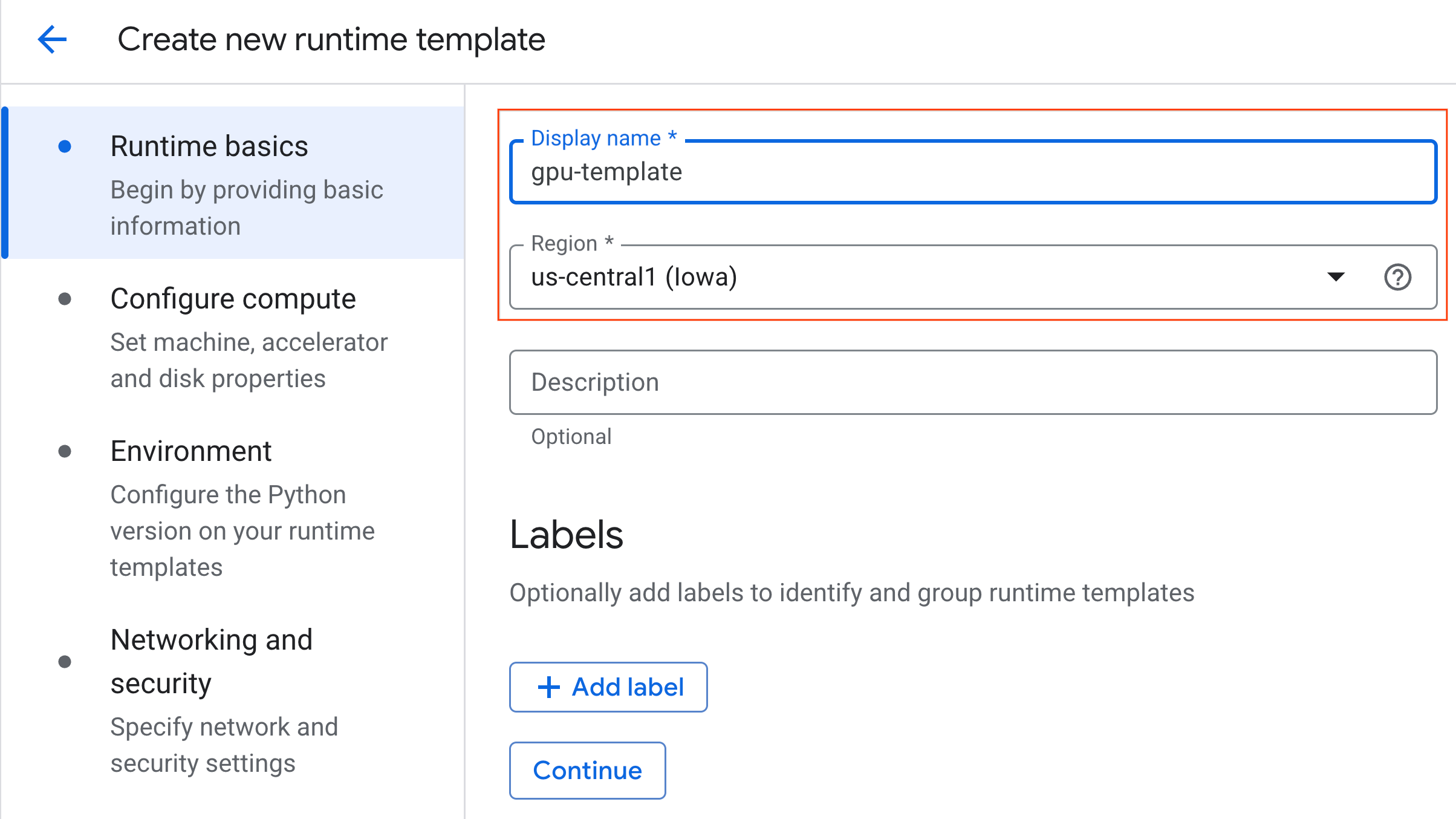
- In Configura calcolo:
- Imposta Tipo di macchina su
g2-standard-4. - Mantieni il Tipo di acceleratore predefinito
NVIDIA L4con un Conteggio acceleratori pari a 1. - Imposta Arresto inattività su 60 minuti.
- Fai clic su Continua.
- Imposta Tipo di macchina su
- In Ambiente:
- Imposta Ambiente su
Python 3.11.
- Imposta Ambiente su
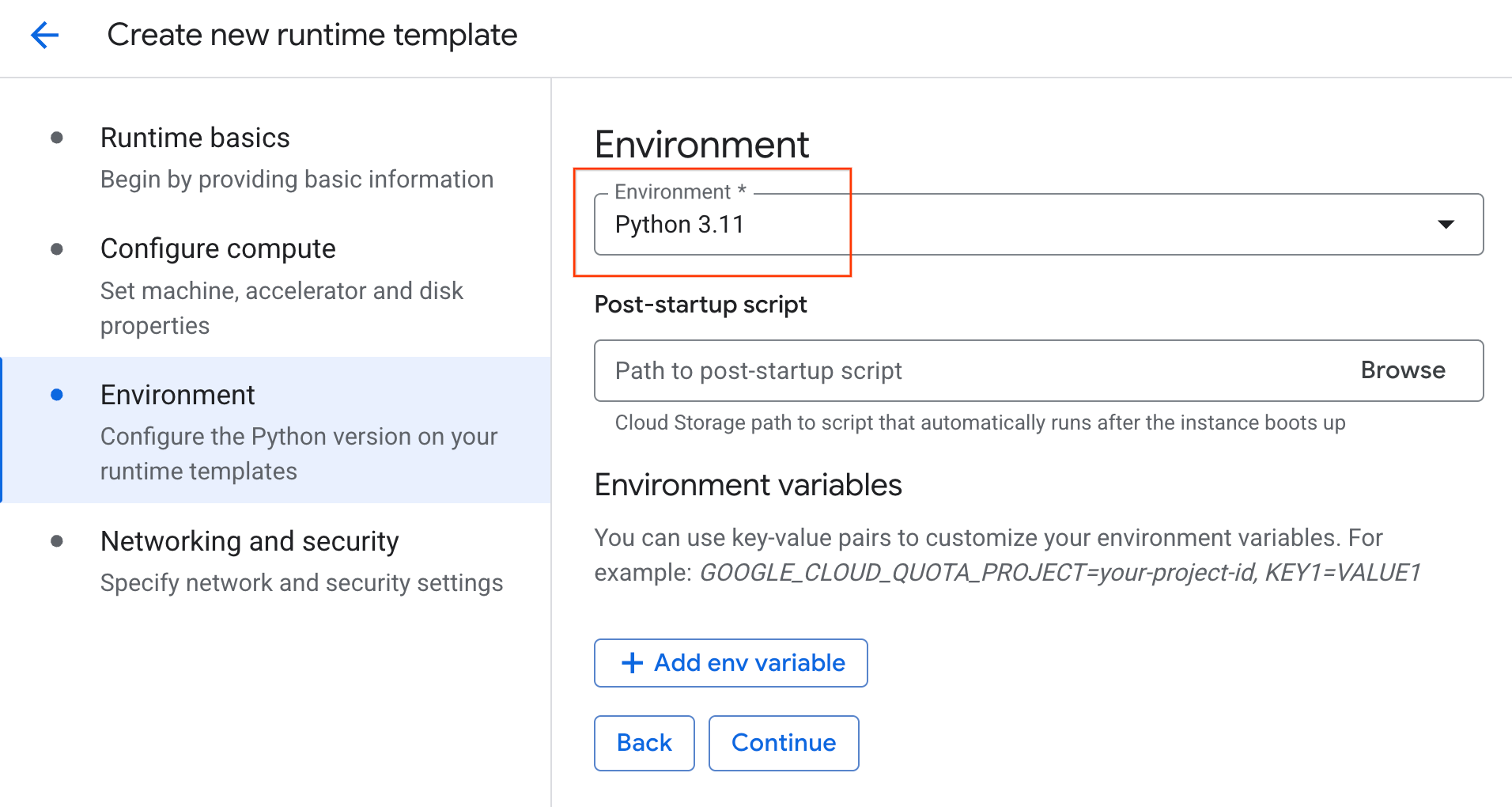
- Fai clic su Crea per salvare il modello di runtime. La pagina dei modelli di runtime ora dovrebbe mostrare il nuovo modello.
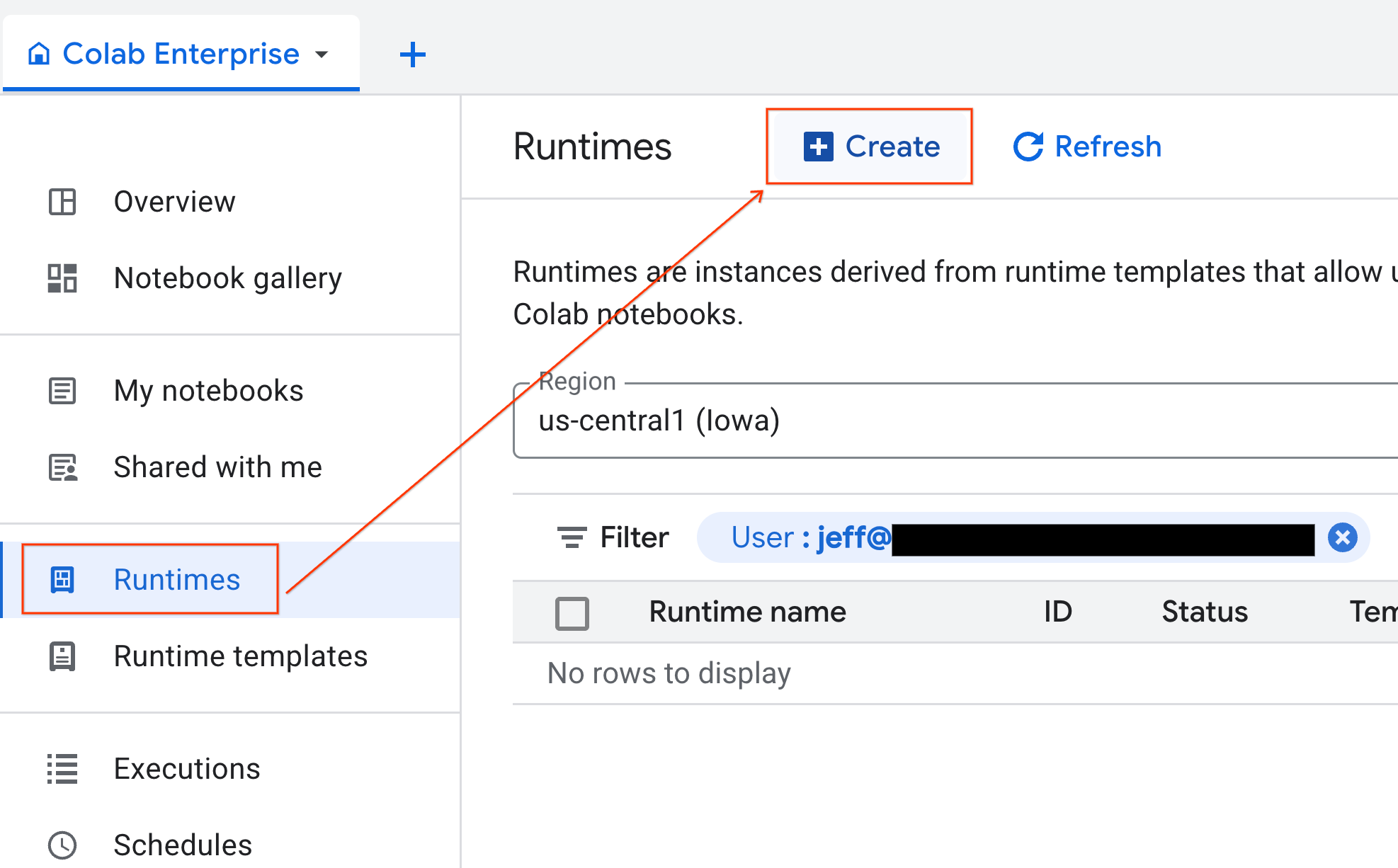
5. Avvia un runtime
Una volta pronto il modello, puoi creare un nuovo runtime.
- In Colab Enterprise, fai clic su Runtime e poi seleziona Crea.
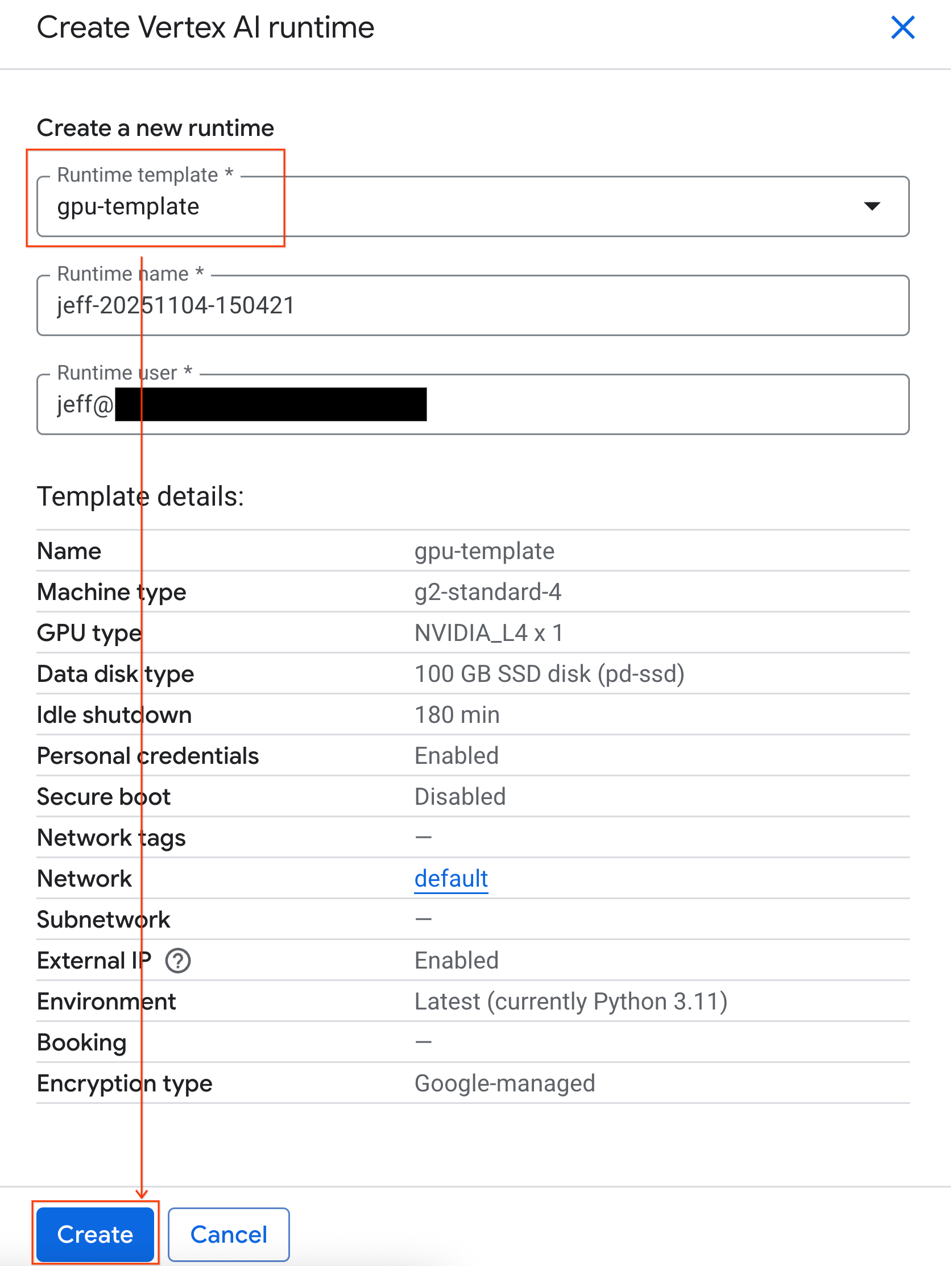
- In Modello di runtime, seleziona l'opzione
gpu-template. Fai clic su Crea e attendi l'avvio del runtime.
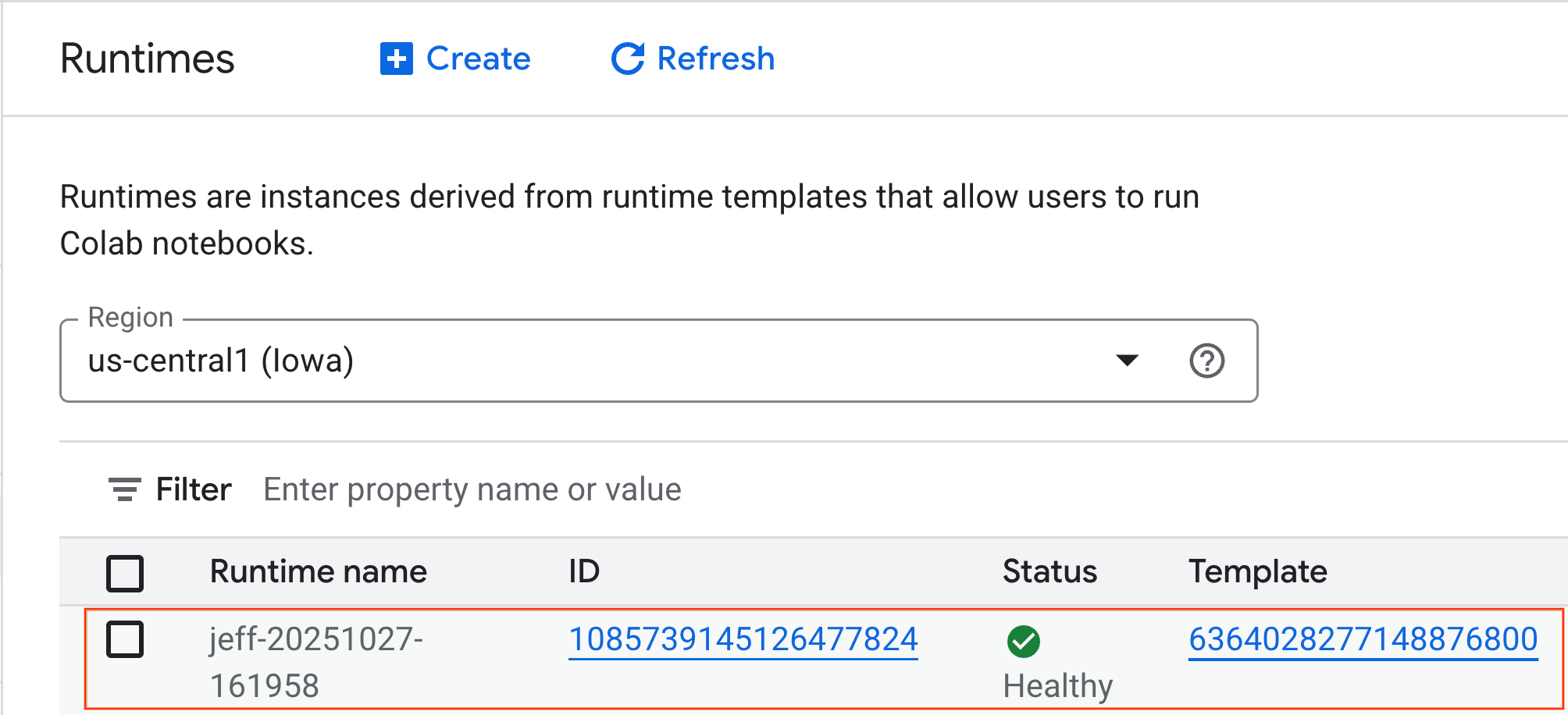
- Dopo qualche minuto, vedrai il runtime disponibile.
6. configura il notebook
Ora che l'infrastruttura è in esecuzione, devi importare il notebook del lab e connetterlo al runtime.
Importa il notebook
- In Colab Enterprise, fai clic su I miei blocchi note e poi su Importa.
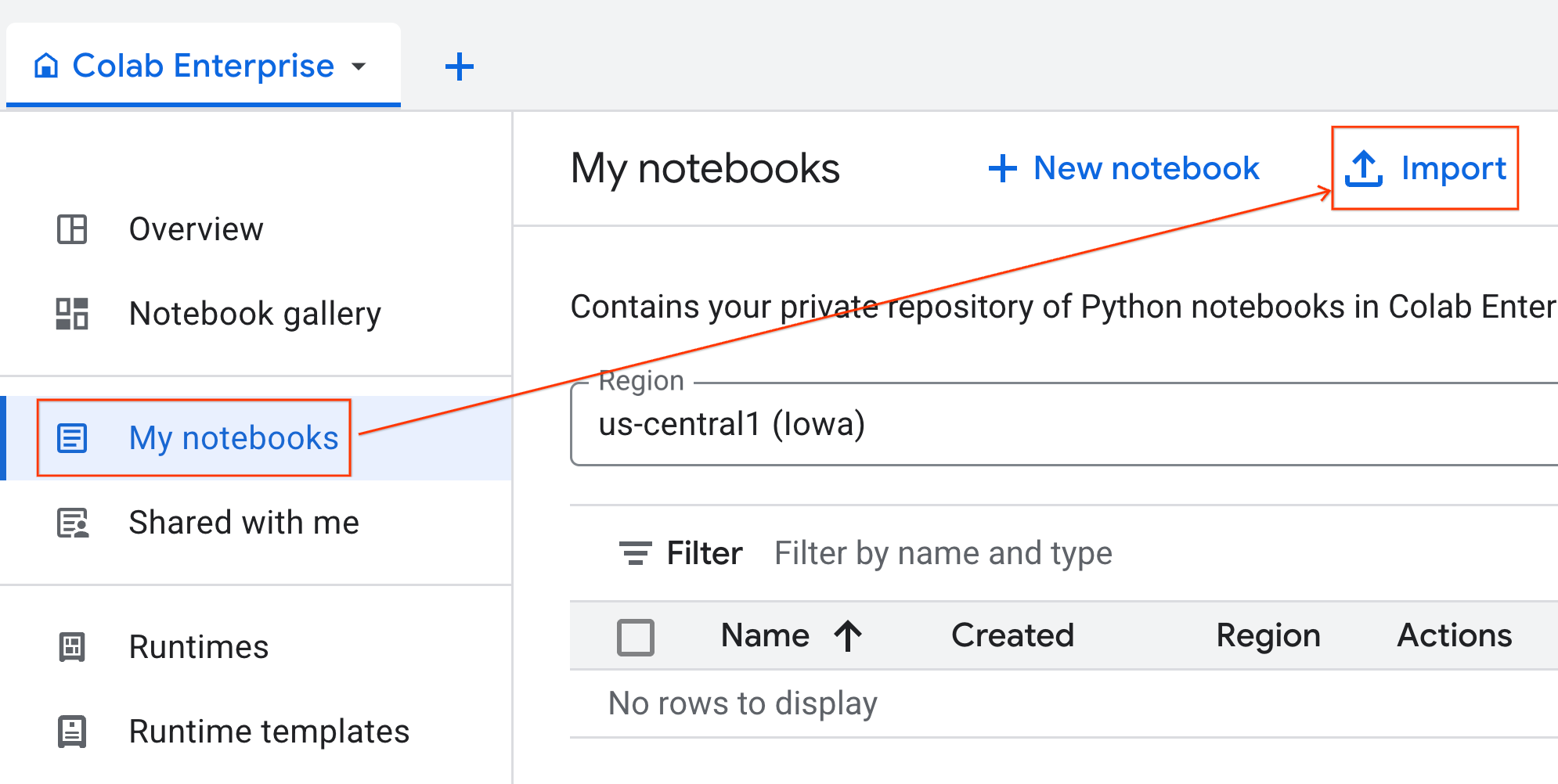
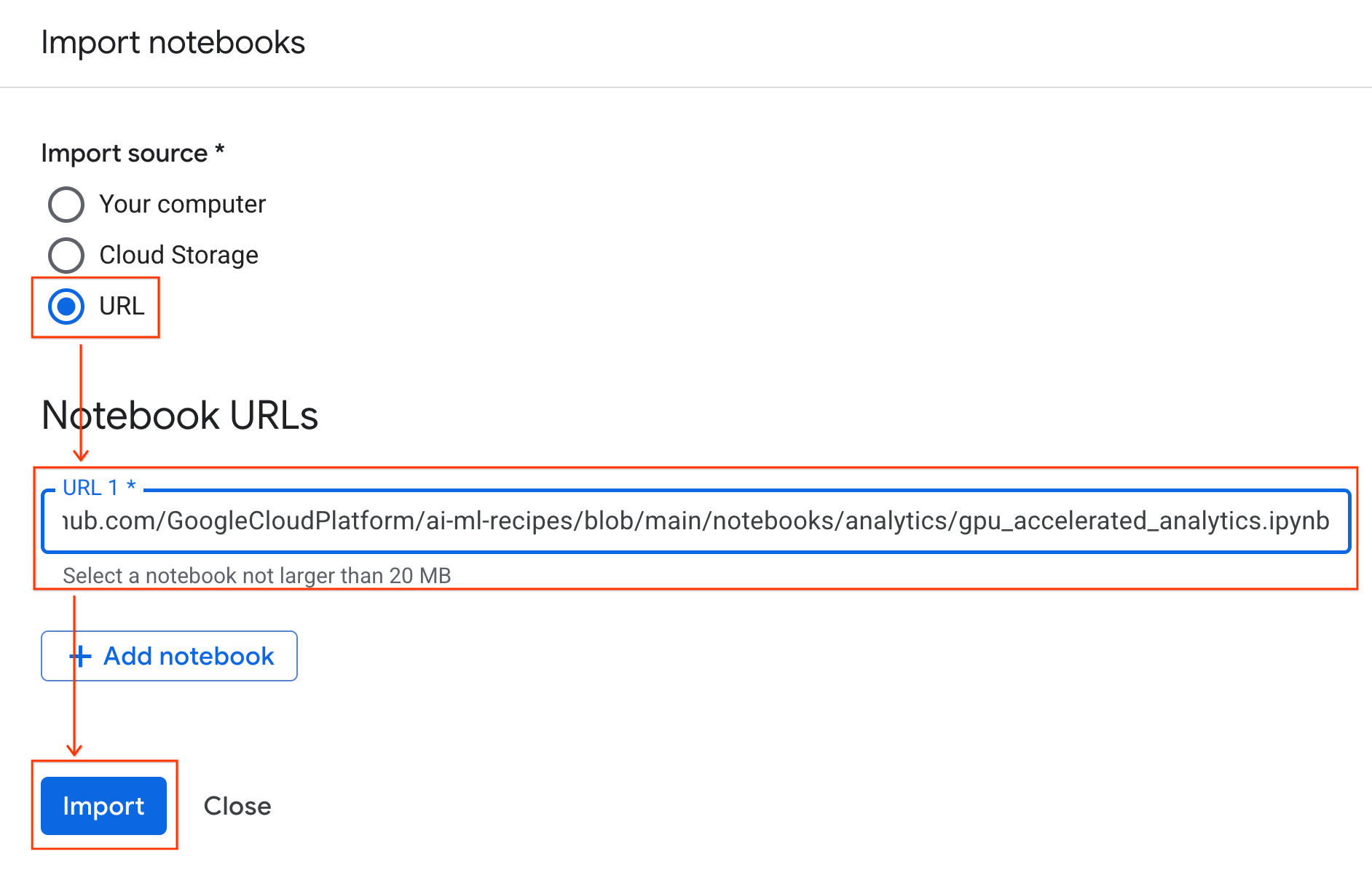
- Seleziona il pulsante di opzione URL e inserisci il seguente URL:
https://github.com/GoogleCloudPlatform/ai-ml-recipes/blob/main/notebooks/analytics/gpu_accelerated_analytics.ipynb
- Fai clic su Importa. Colab Enterprise copierà il notebook da GitHub nel tuo ambiente.
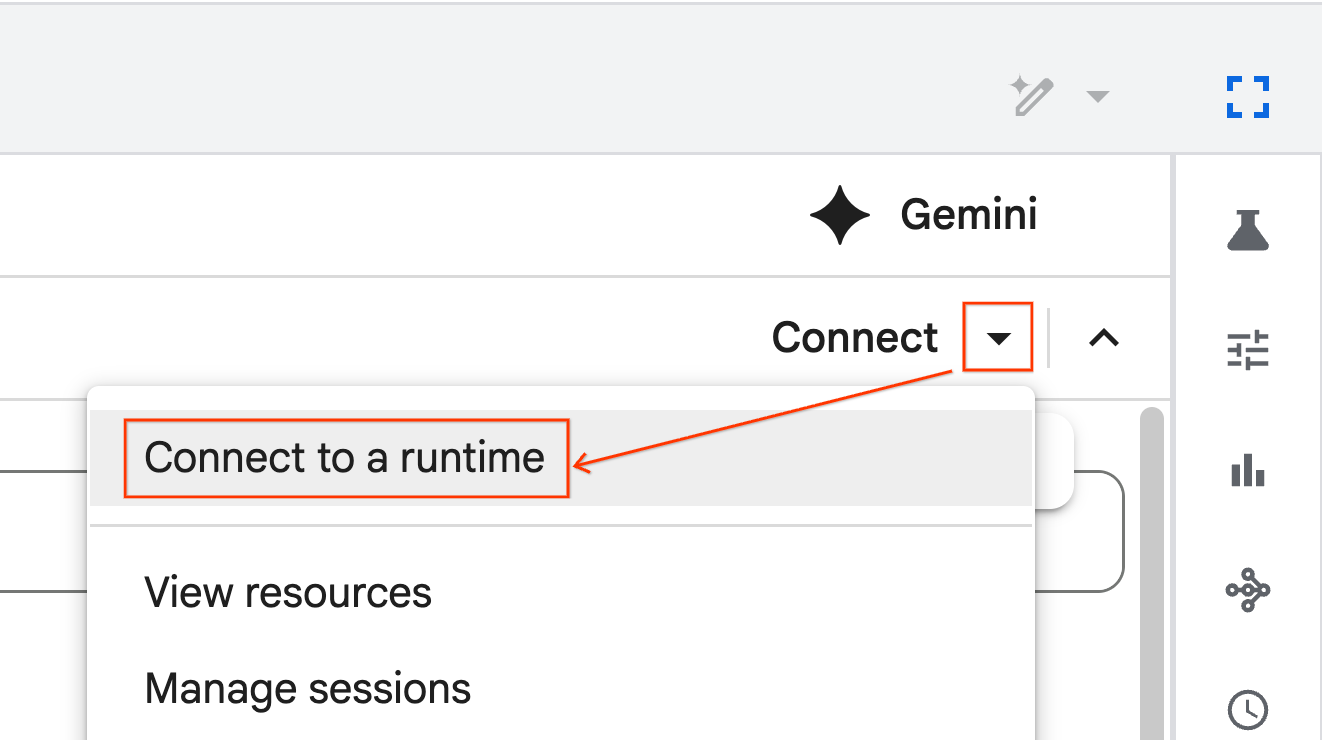
Connettiti al runtime
- Apri il notebook appena importato.
- Fai clic sulla Freccia giù accanto a Collega.
- Seleziona Connetti a un runtime.
- Utilizza il menu a discesa e seleziona il runtime che hai creato in precedenza.
- Fai clic su Connetti.
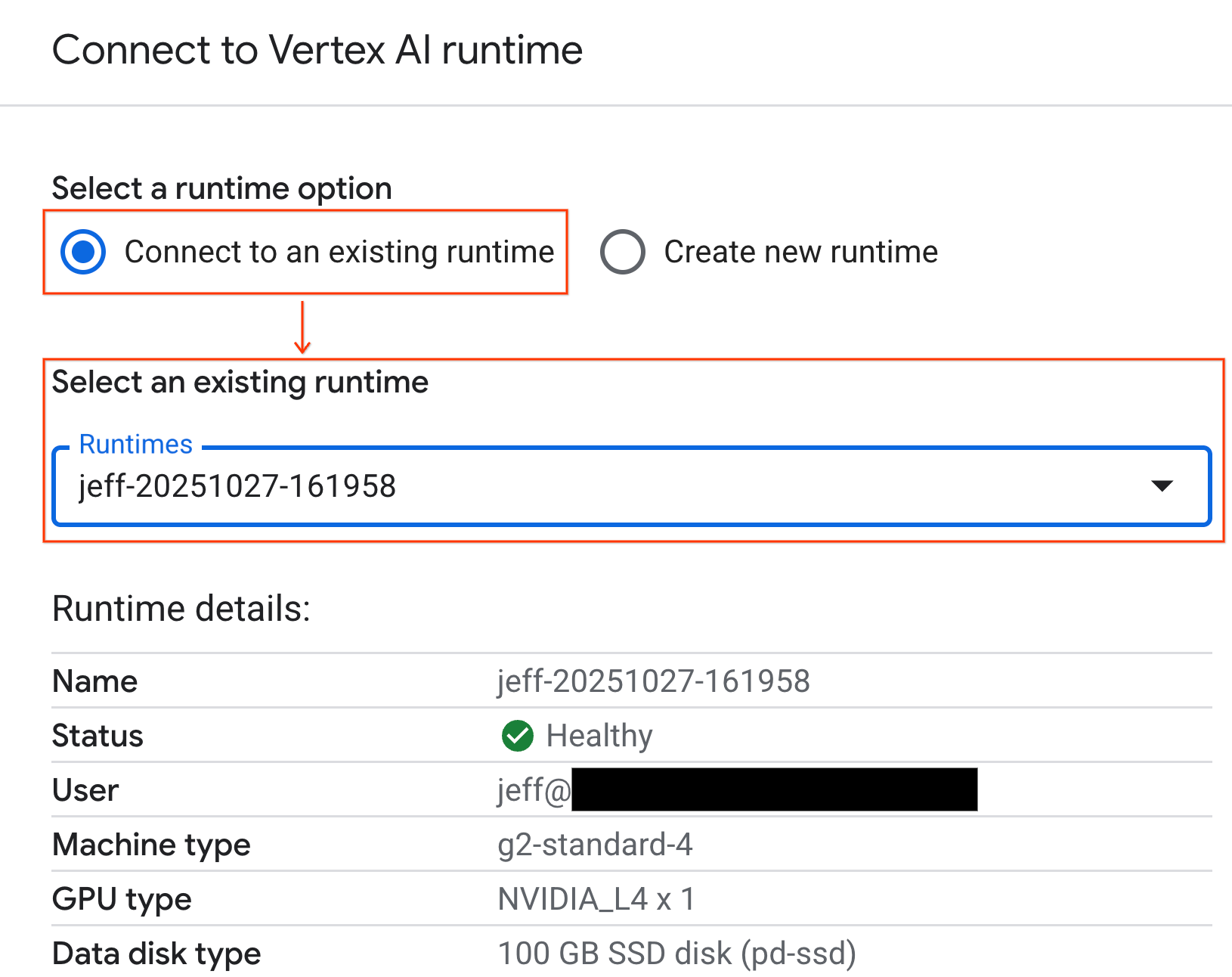
Il tuo notebook è ora connesso a un runtime abilitato per la GPU. Ora puoi iniziare a eseguire query.
7. Prepara il set di dati sui taxi di New York
Questo codelab utilizza i dati di registrazione delle corse della NYC Taxi & Limousine Commission (TLC).
Il set di dati contiene i singoli record di viaggio dei taxi gialli di New York City e include campi come:
- Date, orari e località di partenza e arrivo
- Distanze dei viaggi
- Importi delle tariffe dettagliate
- Numero di passeggeri
Scarica i dati
A questo punto, scarica i dati sul percorso per tutto il 2024. I dati vengono archiviati nel formato di file Parquet.
Il seguente blocco di codice esegue questi passaggi:
- Definisce l'intervallo di anni e mesi da scaricare.
- Crea una directory locale denominata
nyc_taxi_dataper archiviare i file. - Esegue un ciclo per ogni mese, scarica il file Parquet corrispondente se non esiste già e lo salva nella directory.
Esegui questo codice nel notebook per raccogliere i dati e memorizzarli nel runtime:
from tqdm import tqdm
import requests
import time
import os
YEAR = 2024
DATA_DIR = "nyc_taxi_data"
os.makedirs(DATA_DIR, exist_ok=True)
print(f"Checking/Downloading files for {YEAR}...")
for month in tqdm(range(1, 13), unit="file"):
# Define standardized filename for both local path and URL
file_name = f"yellow_tripdata_{YEAR}-{month:02d}.parquet"
local_path = os.path.join(DATA_DIR, file_name)
url = f"https://d37ci6vzurychx.cloudfront.net/trip-data/{file_name}"
if not os.path.exists(local_path):
try:
with requests.get(url, stream=True) as response:
response.raise_for_status()
with open(local_path, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
time.sleep(1)
except requests.exceptions.HTTPError as e:
print(f"\nSkipping {file_name}: {e}")
if os.path.exists(local_path):
os.remove(local_path)
print("\nDownload complete.")
8. Esplora i dati sul percorso in taxi
Ora che hai scaricato il set di dati, è il momento di eseguire un'analisi esplorativa iniziale dei dati (EDA). L'obiettivo dell'EDA è comprendere la struttura dei dati, trovare anomalie e scoprire potenziali pattern.
Caricare i dati di un solo mese
Inizia caricando i dati di un solo mese. In questo modo, viene fornito un campione sufficientemente grande (oltre 3 milioni di righe) per essere significativo, mantenendo al contempo la memoria utilizzata gestibile per l'analisi interattiva.
import pandas as pd
import glob
# Load the last month of the downloaded data
df = pd.read_parquet("nyc_taxi_data/yellow_tripdata_2024-12.parquet")
df.head()
Visualizzare le statistiche riepilogative
Utilizza il metodo .describe() per generare statistiche di riepilogo di alto livello per le colonne numeriche. Questo è un ottimo primo passo per individuare potenziali problemi di qualità dei dati, come valori minimi o massimi imprevisti.
df.describe().round(2)
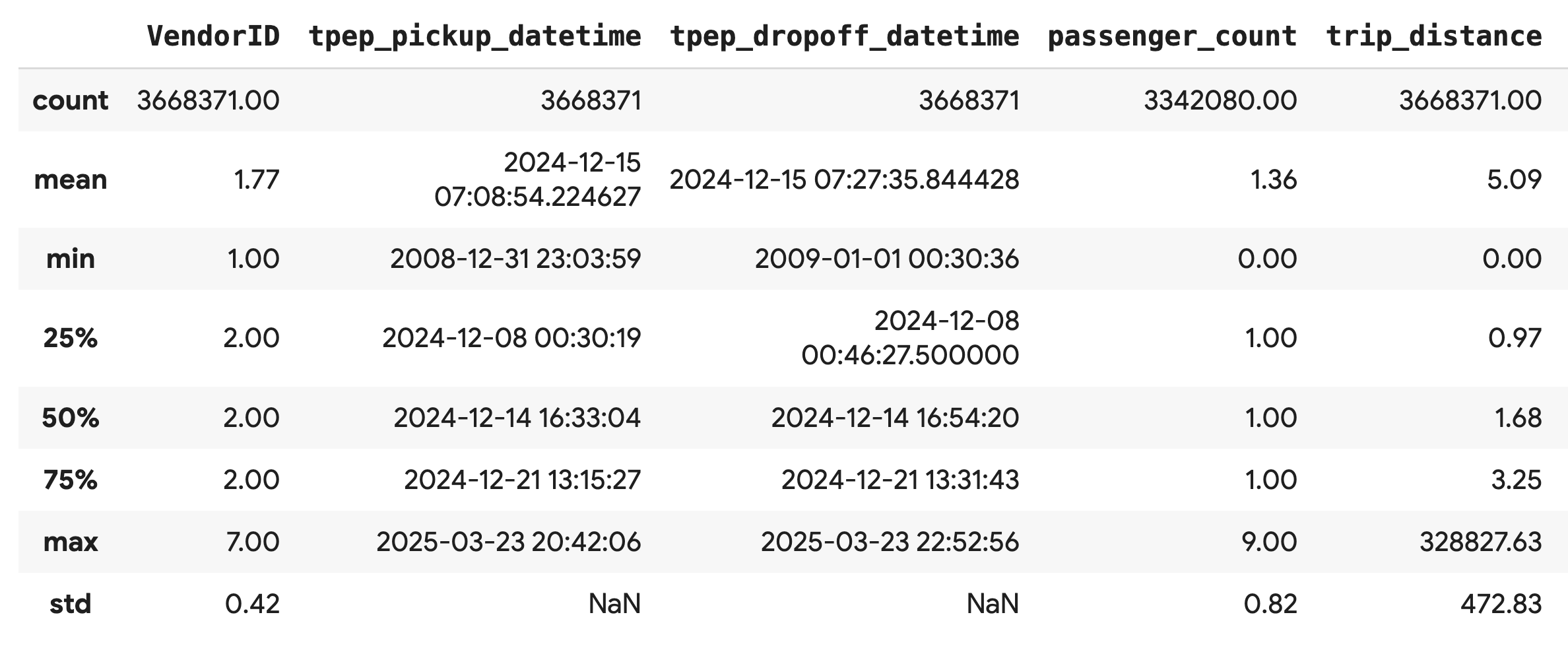
Esaminare la qualità dei dati
L'output di .describe() rivela immediatamente un problema. Nota che il valore min per tpep_pickup_datetime e tpep_dropoff_datetime è l'anno 2008, il che non ha senso per un set di dati del 2024.
Questo è un esempio del motivo per cui è sempre necessario esaminare i dati. Puoi approfondire la questione ordinando il DataFrame per trovare le righe esatte che contengono queste date anomale.
# Sort by the dropoff datetime to see the oldest records
df.sort_values("tpep_pickup_datetime").head()
Visualizzare le distribuzioni dei dati
Successivamente, puoi creare istogrammi delle colonne numeriche per visualizzarne le distribuzioni. In questo modo puoi comprendere la distribuzione e l'asimmetria di funzionalità come trip_distance e fare_amount. La funzione .hist() è un modo rapido per tracciare istogrammi per tutte le colonne numeriche di un DataFrame.
_ = df.hist(figsize=(20, 20))
Infine, genera una matrice di dispersione per visualizzare le relazioni tra alcune colonne chiave. Poiché tracciare milioni di punti è lento e può oscurare i pattern, utilizza .sample() per creare il grafico da un campione casuale di 100.000 righe.
_ = pd.plotting.scatter_matrix(
df[['passenger_count', 'trip_distance', 'tip_amount', 'total_amount']].sample(100_000),
diagonal="kde",
figsize=(15, 15)
)
9. Perché utilizzare il formato file Parquet?
Il set di dati sui taxi di New York viene fornito in formato Apache Parquet. Si tratta di una scelta deliberata fatta per l'analisi su larga scala. Parquet offre diversi vantaggi rispetto a tipi di file come CSV:
- Efficiente e veloce:in quanto formato colonnare, Parquet è molto efficiente da archiviare e leggere. Supporta metodi di compressione moderni che comportano dimensioni dei file più piccole e I/O significativamente più veloci, soprattutto sulle GPU.
- Conserva lo schema:Parquet archivia i tipi di dati nei metadati del file. Non dovrai mai indovinare i tipi di dati quando leggi il file.
- Consente la lettura selettiva:la struttura colonnare ti consente di leggere solo le colonne specifiche di cui hai bisogno per un'analisi. In questo modo, puoi ridurre drasticamente la quantità di dati da caricare in memoria.
Esplorare le funzionalità di Parquet
Esploriamo due di queste potenti funzionalità utilizzando uno dei file che hai scaricato.
Controllare i metadati senza caricare l'intero set di dati
Anche se non puoi visualizzare un file Parquet in un editor di testo standard, puoi ispezionare facilmente lo schema e i metadati senza caricare dati in memoria. Questo è utile per comprendere rapidamente la struttura di un file.
from pyarrow.parquet import ParquetFile
import pyarrow as pa
# Open one of the downloaded files
pf = ParquetFile('nyc_taxi_data/yellow_tripdata_2024-12.parquet')
# Print the schema
print("File Schema:")
print(pf.schema)
# Print the file metadata
print("\nFile Metadata:")
print(pf.metadata)
Leggere solo le colonne necessarie
Immagina di dover analizzare solo la distanza del viaggio e gli importi delle tariffe. Con Parquet, puoi caricare solo queste colonne, il che è molto più veloce ed efficiente in termini di memoria rispetto al caricamento dell'intero DataFrame.
import pandas as pd
# Read only four specific columns from the Parquet file
df_subset = pd.read_parquet(
'nyc_taxi_data/yellow_tripdata_2024-12.parquet',
columns=['passenger_count', 'trip_distance', 'tip_amount', 'total_amount']
)
df_subset.head()
10. Accelerare Pandas con NVIDIA cuDF
NVIDIA CUDA for DataFrames (cuDF) è una libreria open source con accelerazione GPU che ti consente di interagire con i DataFrame. cuDF ti consente di eseguire operazioni comuni sui dati come il filtraggio, l'unione e il raggruppamento sulla GPU con un parallelismo massiccio.
La funzionalità principale che utilizzi in questo codelab è la modalità di accelerazione cudf.pandas. Quando lo abiliti, il codice pandas standard viene reindirizzato automaticamente per utilizzare i kernel cuDF basati su GPU in background, senza richiedere modifiche al codice.
Attivare l'accelerazione GPU
Per utilizzare NVIDIA cuDF in un notebook Colab Enterprise, devi caricare la relativa estensione magica prima di importare pandas.
Innanzitutto, esamina la libreria standard pandas. Nota che l'output mostra il percorso dell'installazione predefinita di pandas.
import pandas as pd
pd # Note the output for the standard pandas library
Ora carica l'estensione cudf.pandas e importa di nuovo pandas. Osserva come cambia l'output del modulo pd. In questo modo, confermi che la versione con accelerazione GPU è ora attiva.
%load_ext cudf.pandas
import pandas as pd
pd # Note the new output, indicating cudf.pandas is active
Altri modi per attivare cudf.pandas
Anche se il comando magico (%load_ext) è il metodo più semplice in un notebook, puoi abilitare l'acceleratore anche in altri ambienti:
- Negli script Python:chiama
import cudf.pandasecudf.pandas.install()prima dell'importazione dipandas. - Da ambienti non notebook: esegui lo script utilizzando
python -m cudf.pandas your_script.py.
11. Confrontare le prestazioni della CPU e della GPU
Ora passiamo alla parte più importante: confrontare le prestazioni di pandas standard su una CPU con cudf.pandas su una GPU.
Per garantire una baseline completamente equa per la CPU, devi prima reimpostare il runtime di Colab. In questo modo vengono cancellati tutti gli acceleratori GPU che potresti aver attivato nelle sezioni precedenti. Puoi riavviare il runtime eseguendo la cella seguente o selezionando Riavvia sessione dal menu Runtime.
import IPython
IPython.Application.instance().kernel.do_shutdown(True)
Definisci la pipeline di analisi
Ora che l'ambiente è pulito, definirai la funzione di benchmarking. Questa funzione ti consente di eseguire esattamente la stessa pipeline (caricamento, ordinamento e riepilogo) utilizzando il modulo pandas che le trasmetti.
import time
import glob
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
def run_analytics_pipeline(pd_module):
"""Loads, sorts, and summarizes data using the provided pandas module."""
timings = {}
# 1. Load all 2024 Parquet files from the directory
t0 = time.time()
df = pd_module.concat(
[pd_module.read_parquet(f) for f in glob.glob("nyc_taxi_data/*_2024*.parquet")],
ignore_index=True
)
timings["load"] = time.time() - t0
# 2. Sort the data by multiple columns
t0 = time.time()
df = df.sort_values(
['tpep_pickup_datetime', 'trip_distance', 'passenger_count'],
ascending=[False, True, False]
)
timings["sort"] = time.time() - t0
# 3. Perform a groupby and aggregation
t0 = time.time()
df['tpep_pickup_datetime'] = pd_module.to_datetime(df['tpep_pickup_datetime'])
_ = (
df.loc[df.tpep_pickup_datetime > '2024-11-01']
.groupby(['VendorID', 'tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
timings["summarize"] = time.time() - t0
return timings
Esegui il confronto
Innanzitutto, esegui la pipeline utilizzando pandas standard sulla CPU. Poi, attiva cudf.pandas ed eseguilo di nuovo sulla GPU.
# --- Run on CPU ---
print("Running analytics pipeline on CPU...")
# Ensure we are using standard pandas
import pandas as pd
assert "cudf" not in str(pd), "Error: cuDF is still active. Please restart the kernel."
cpu_times = run_analytics_pipeline(pd)
print(f"CPU times: {cpu_times}")
# --- Run on GPU ---
print("\nEnabling cudf.pandas and running on GPU...")
# Load the extension
%load_ext cudf.pandas
import pandas as gpu_pd
gpu_times = run_analytics_pipeline(gpu_pd)
print(f"GPU times: {gpu_times}")
Visualizza i risultati
Infine, visualizza la differenza. Il seguente codice calcola l'accelerazione per ogni operazione e le traccia una accanto all'altra.
# Create a DataFrame for plotting
results_df = pd.DataFrame([cpu_times, gpu_times], index=["CPU", "GPU"]).T
total_cpu_time = results_df['CPU'].sum()
total_gpu_time = results_df['GPU'].sum()
speedup = total_cpu_time / total_gpu_time
print("--- Performance Results ---")
print(results_df)
print(f"\nTotal CPU Time: {total_cpu_time:.2f} seconds")
print(f"Total GPU Time: {total_gpu_time:.2f} seconds")
print(f"Overall Speedup: {speedup:.2f}x")
# Plot the results
fig, ax = plt.subplots(figsize=(10, 6))
results_df.plot(kind='bar', ax=ax, color={"CPU": "tab:blue", "GPU": "tab:green"})
ax.set_ylabel("Time (seconds)")
ax.set_title(f"CPU vs. GPU Runtimes (Overall Speedup: {speedup:.2f}x)", fontsize=14)
ax.tick_params(axis='x', rotation=0)
# Add numerical labels to the bars
for container in ax.containers:
ax.bar_label(container, fmt="%.2f", padding=3)
plt.tight_layout()
plt.show()
Risultati di esempio:
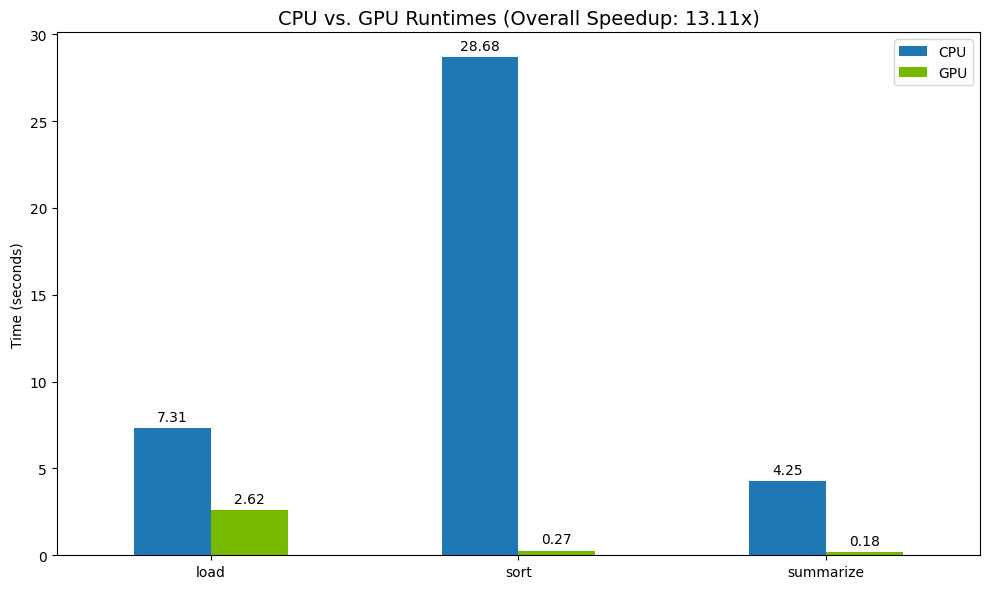
La GPU offre un chiaro aumento di velocità rispetto alla CPU.
12. Profilare il codice per trovare i colli di bottiglia
Anche con l'accelerazione GPU, alcune operazioni pandas potrebbero tornare alla CPU se non sono ancora supportate da cuDF. Questi "fallback della CPU" possono diventare colli di bottiglia delle prestazioni.
Per aiutarti a identificare queste aree, cudf.pandas include due profiler integrati. Puoi utilizzarli per vedere esattamente quali parti del codice vengono eseguite sulla GPU e quali tornano alla CPU.
%%cudf.pandas.profile: utilizza questo campo per un riepilogo generale del codice, funzione per funzione. È ideale per avere una rapida panoramica delle operazioni in esecuzione su ciascun dispositivo.%%cudf.pandas.line_profile: utilizza questa opzione per un'analisi dettagliata riga per riga. È lo strumento migliore per individuare le righe esatte del codice che causano un fallback alla CPU.
Utilizza questi profiler come "magie delle celle" nella parte superiore di una cella del blocco note.
Profilazione a livello di funzione con %%cudf.pandas.profile
Innanzitutto, esegui il profiler a livello di funzione sulla stessa pipeline di analisi della sezione precedente. L'output mostra una tabella di ogni funzione chiamata, il dispositivo su cui è stata eseguita (GPU o CPU) e il numero di volte in cui è stata chiamata.
%load_ext cudf.pandas
import pandas as pd
import glob
pd.DataFrame({"a": [1]})
Dopo aver verificato che cudf.pandas sia attivo, puoi eseguire un profilo.
%%cudf.pandas.profile
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*2024*.parquet")], ignore_index=True)
df = df.sort_values(['tpep_pickup_datetime', 'trip_distance', 'passenger_count'], ascending=[False, True, False])
summary = (
df
.loc[(df.tpep_pickup_datetime > '2024-11-01')]
.groupby(['VendorID','tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
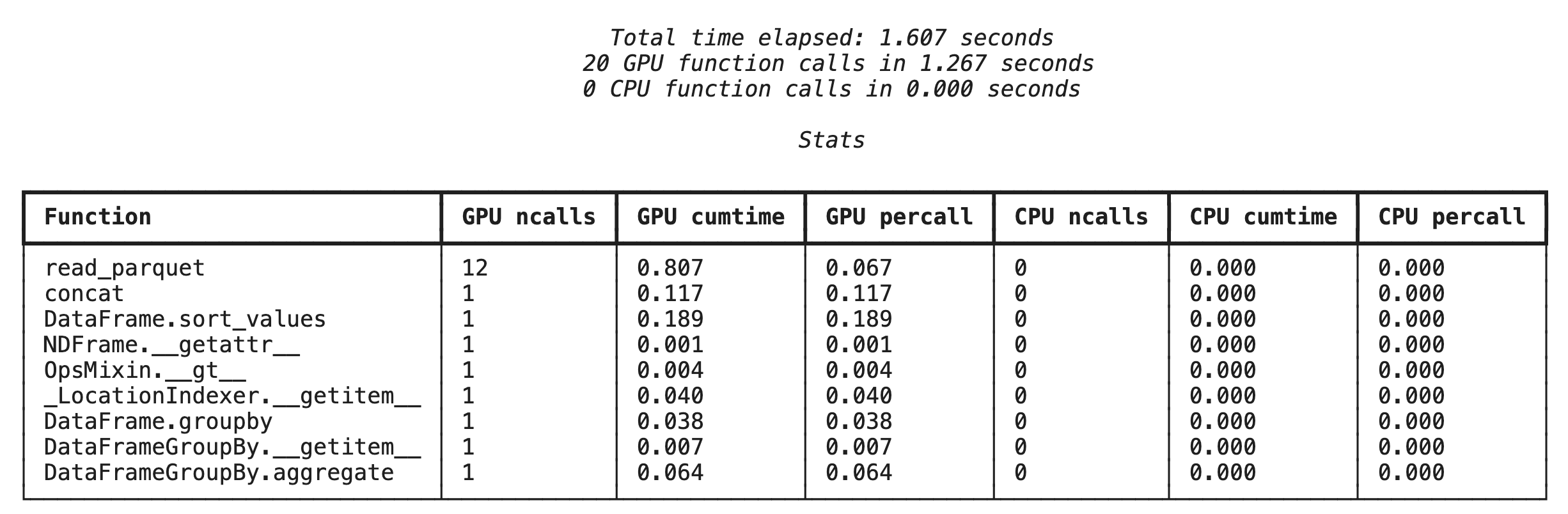
Profilazione riga per riga con %%cudf.pandas.line_profile
Successivamente, esegui il profiler a livello di riga. In questo modo, avrai una visualizzazione molto più granulare, che mostra la porzione di tempo che ogni riga di codice ha trascorso eseguendo sulla GPU rispetto alla CPU. Questo è il modo più efficace per trovare colli di bottiglia specifici da ottimizzare.
%%cudf.pandas.line_profile
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*2024*.parquet")], ignore_index=True)
df = df.sort_values(['tpep_pickup_datetime', 'trip_distance', 'passenger_count'], ascending=[False, True, False])
summary = (
df
.loc[(df.tpep_pickup_datetime > '2024-11-01')]
.groupby(['VendorID','tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
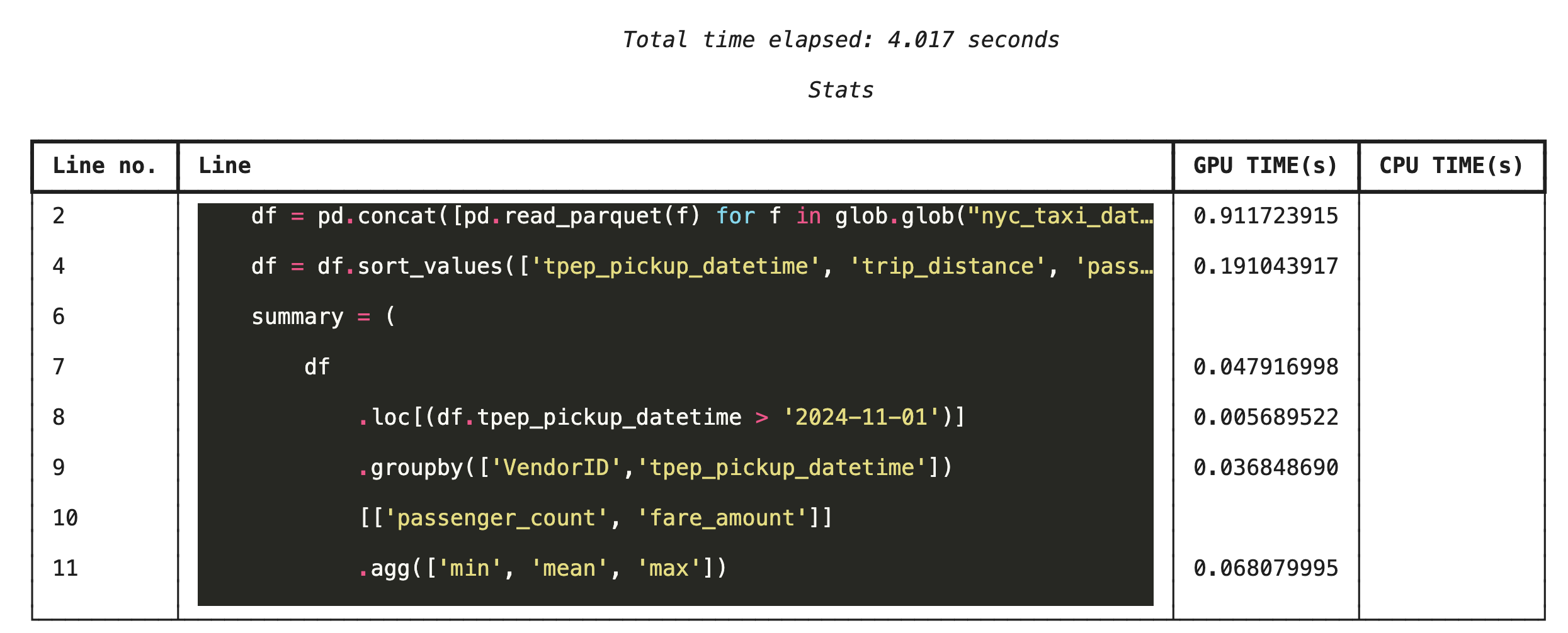
Profilazione dalla riga di comando
Questi profiler sono disponibili anche dalla riga di comando, il che è utile per i test automatizzati e la profilazione degli script Python.
Puoi utilizzare quanto segue in un'interfaccia a riga di comando:
python -m cudf.pandas --profile your_script.pypython -m cudf.pandas --line_profile your_script.py
13. Eseguire l'integrazione con Google Cloud Storage
Google Cloud Storage (GCS) è un servizio di archiviazione di oggetti scalabile e durevole. Quando utilizzi Colab Enterprise, GCS è un ottimo posto per archiviare i set di dati, i checkpoint del modello e altri artefatti.
Il runtime di Colab Enterprise dispone delle autorizzazioni necessarie per leggere e scrivere dati direttamente nei bucket GCS e queste operazioni sono accelerate dalla GPU per ottenere le massime prestazioni.
Crea un bucket GCS
Innanzitutto, crea un nuovo bucket GCS. I nomi dei bucket GCS sono univoci a livello globale, quindi aggiungi un UUID al nome.
from google.cloud import storage
import uuid
unique_suffix = uuid.uuid4().hex[:12]
bucket_name = f'nyc-taxi-codelab-{unique_suffix}'
project_id = storage.Client().project
client = storage.Client()
try:
bucket = client.create_bucket(bucket_name)
print(f"Successfully created bucket: gs://{bucket.name}")
except Exception as e:
print(f"Bucket creation failed. You may already own it or the name is taken: {e}")
Scrivere i dati direttamente in GCS
Ora salva un DataFrame direttamente nel nuovo bucket GCS. Se la variabile df non è disponibile nelle sezioni precedenti, il codice carica prima i dati di un solo mese.
%%cudf.pandas.line_profile
# Ensure the DataFrame exists before saving to GCS
if 'df' not in locals():
print("DataFrame not found, loading a sample file...")
df = pd.read_parquet('nyc_taxi_data/yellow_tripdata_2024-12.parquet')
print(f"Writing data to gs://{bucket_name}/nyc_taxi_data.parquet...")
df.to_parquet(f"gs://{bucket_name}/nyc_taxi_data.parquet", index=False)
print("Write operation complete.")
Verifica il file in GCS
Puoi verificare che i dati si trovino in GCS visitando il bucket. Il seguente codice crea un link cliccabile.
from IPython.display import Markdown
gcs_url = f"https://console.cloud.google.com/storage/browser/{bucket_name}?project={project_id}"
Markdown(f'**[Click here to view your GCS bucket in the Google Cloud Console]({gcs_url})**')
Leggi i dati direttamente da GCS
Infine, leggi i dati direttamente da un percorso GCS in un DataFrame. Questa operazione è anche accelerata dalla GPU, il che ti consente di caricare grandi set di dati dallo spazio di archiviazione cloud ad alta velocità.
%%cudf.pandas.line_profile
print(f"Reading data from gs://{bucket_name}/nyc_taxi_data.parquet...")
df_from_gcs = pd.read_parquet(f"gs://{bucket_name}/nyc_taxi_data.parquet")
df_from_gcs.head()
14. Elimina
Per evitare addebiti imprevisti al tuo account Google Cloud, devi liberare spazio dalle risorse che hai creato.
Elimina i dati che hai scaricato:
# Permanately delete the GCS bucket
print(f"Deleting GCS bucket: gs://{bucket_name}...")
!gsutil rm -r -f gs://{bucket_name}
print("Bucket deleted.")
# Remove NYC taxi dataset on the Colab runtime
print("Deleting local 'nyc_taxi_data' directory...")
!rm -rf nyc_taxi_data
print("Local files deleted.")
Arrestare il runtime di Colab
- Nella console Google Cloud, vai alla pagina Runtime di Colab Enterprise.
- Nel menu Regione, seleziona la regione che contiene il runtime.
- Seleziona il runtime che vuoi eliminare.
- Fai clic su Elimina.
- Fai clic su Conferma.
Eliminare il notebook
- Nella console Google Cloud, vai alla pagina I miei blocchi note di Colab Enterprise.
- Nel menu Regione, seleziona la regione che contiene il notebook.
- Seleziona il blocco note da eliminare.
- Fai clic su Elimina.
- Fai clic su Conferma.
15. Complimenti
Complimenti! Hai accelerato correttamente un flusso di lavoro di analisi pandas utilizzando NVIDIA cuDF su Colab Enterprise. Hai imparato a configurare i runtime abilitati alla GPU, ad attivare cudf.pandas per l'accelerazione senza modifiche al codice, a profilare il codice per i colli di bottiglia e a eseguire l'integrazione con Google Cloud Storage.