
1. はじめに
この Codelab では、Google Cloud で NVIDIA GPU とオープンソース ライブラリを使用して、大規模なデータセットのデータ分析ワークフローを高速化する方法について学習します。まず、インフラストラクチャを最適化し、コードを変更せずに GPU アクセラレーションを適用する方法について説明します。
このコースでは、一般的なデータ操作ライブラリである pandas に焦点を当て、NVIDIA の cuDF ライブラリを使用して高速化する方法を学びます。最大のメリットは、既存の pandas コードを変更せずにこの GPU アクセラレーションを利用できることです。
学習内容
- Google Cloud の Colab Enterprise について理解する。
- 特定の GPU、CPU、メモリ構成で Colab ランタイム環境をカスタマイズします。
- NVIDIA
cuDFを使用して、コードを変更することなくpandasを高速化します。 - コードをプロファイリングして、パフォーマンスのボトルネックを特定し、最適化します。
次のページには、ラボの完了に使用できるクレジットが表示されます。
2. データ処理を高速化する理由
80/20 ルール: データ準備に時間がかかる理由
多くの場合、データ準備は分析プロジェクトで最も時間がかかるフェーズです。データ サイエンティストやアナリストは、分析を開始する前に、データのクリーンアップ、変換、構造化に多くの時間を費やしています。
幸いなことに、cuDF を使用すると、pandas、Apache Spark、Polars などの一般的なオープンソース ライブラリを NVIDIA GPU で高速化できます。この高速化を行っても、データ準備には時間がかかります。
- 元データが分析に適していることはほとんどない: 実際のデータには、不整合、欠損値、形式の問題がよくあります。
- 品質がモデルのパフォーマンスに影響する: データの品質が低いと、最も高度なアルゴリズムでも役に立たなくなります。
- スケールによって問題が拡大する: 数百万件のレコードを処理する場合、一見すると軽微なデータの問題が重大なボトルネックになります。
3. ノートブック環境の選択
多くのデータ サイエンティストは個人プロジェクトで Colab を使用していますが、Colab Enterprise は企業向けに設計された安全で共同作業が可能な統合ノートブック エクスペリエンスを提供します。
Google Cloud には、マネージド ノートブック環境として Colab Enterprise と Gemini Enterprise Agent Platform Workbench の 2 つの主な選択肢があります。適切な選択は、プロジェクトの優先度によって異なります。
Agent Platform Workbench を使用するタイミング
制御と詳細なカスタマイズが優先される場合は、Agent Platform Workbench を選択します。この方法は、次のような場合に最適です。
- 基盤となるインフラストラクチャとマシンのライフサイクルを管理します。
- カスタム コンテナとネットワーク構成を使用する。
- MLOps パイプラインとカスタム ライフサイクル ツールと統合します。
Colab Enterprise を使用するタイミング
迅速な設定、使いやすさ、安全なコラボレーションを重視する場合は、Colab Enterprise を選択します。これは、チームがインフラストラクチャではなく分析に集中できるフルマネージド ソリューションです。
Colab Enterprise は、次のことを支援します。
- データ ウェアハウスに密接に関連するデータ サイエンス ワークフローを開発します。ノートブックは BigQuery Studio で直接開いて管理できます。
- Agent Platform で ML モデルをトレーニングし、MLOps ツールと統合します。
- 柔軟で統一されたエクスペリエンスをお楽しみください。BigQuery で作成された Colab Enterprise ノートブックは、Agent Platform で開いて実行できます。その逆も可能です。
今日のラボ
この Codelab では、高速データ分析に Colab Enterprise を使用します。
違いの詳細については、適切なノートブック ソリューションの選択に関する公式ドキュメントをご覧ください。
4. ランタイム テンプレートを構成する
Colab Enterprise で、事前構成されたランタイム テンプレートに基づくランタイムに接続します。
ランタイム テンプレートは、ノートブックの環境全体を指定する再利用可能な構成です。これには次のものが含まれます。
- マシンタイプ(CPU、メモリ)
- アクセラレータ(GPU のタイプと数)
- ディスクのサイズとタイプ
- 掲載ネットワークの設定とセキュリティ ポリシー
- 自動アイドル シャットダウン ルール
ランタイム テンプレートが有用な理由
- 一貫した環境を取得する: チームメンバーと自分自身が、毎回同じすぐに使用できる環境を取得して、作業の再現性を確保します。
- 設計段階から安全に作業: テンプレートにより、組織のセキュリティ ポリシーが自動的に適用されます。
- 費用を効果的に管理する: GPU や CPU などのリソースはテンプレートで事前にサイズ設定されているため、想定外の費用超過を防ぐことができます。
ランタイム テンプレートを作成する
ラボ用に再利用可能なランタイム テンプレートを設定します。
- Google Cloud コンソールで、ナビゲーション メニュー > [エージェント プラットフォーム] > [ノートブック] に移動します。
- Colab Enterprise で、[ランタイム テンプレート] をクリックし、[新しいテンプレート] を選択します。
- [ランタイムの基本] で、次の操作を行います。
- [表示名] を
gpu-templateに設定します。 - 優先するリージョンを設定します。
- [表示名] を
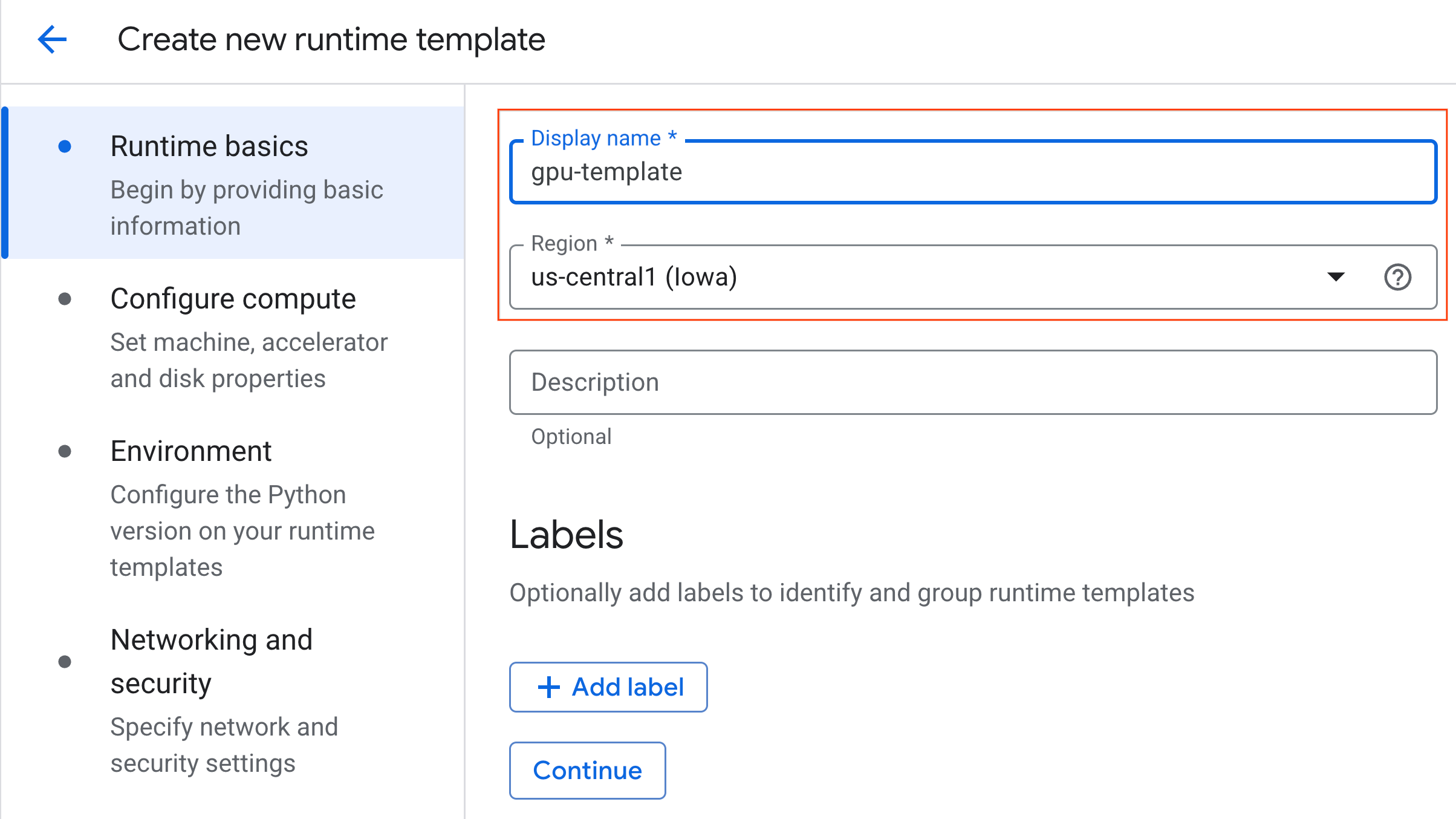
- [コンピューティングを構成] で、次の操作を行います。
- [マシンタイプ] を
g2-standard-4に設定します。 - デフォルトの [アクセラレータ タイプ] は
NVIDIA L4のままで、[アクセラレータ数] は 1 にします。 - [アイドル状態のシャットダウン] を 60 分に変更します。
- [続行] をクリックします。
- [マシンタイプ] を
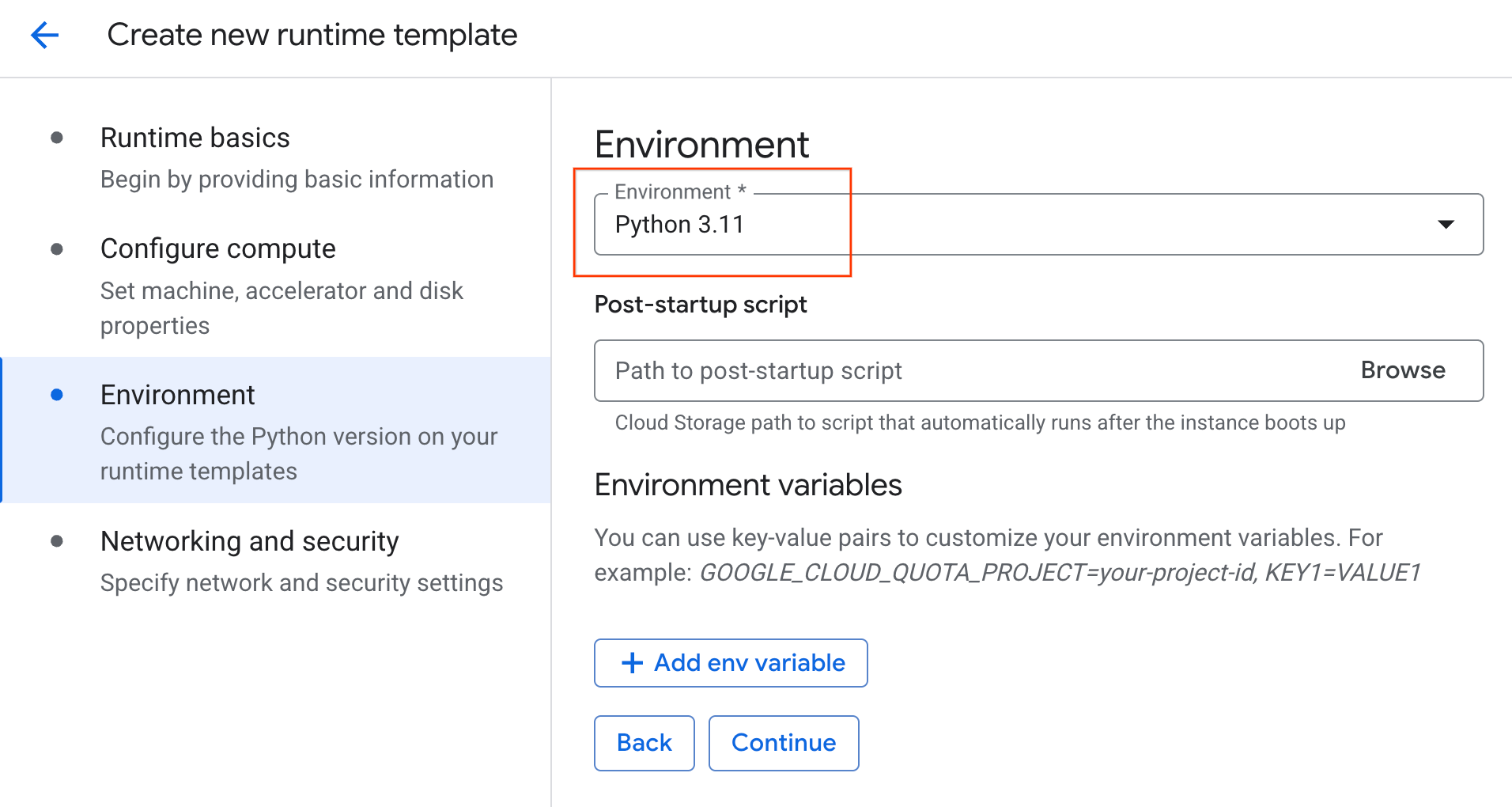
- [環境] で、次の操作を行います。
- [環境] を
Python 3.11に設定します。
- [環境] を
- [作成] をクリックして、ランタイム テンプレートを保存します。[ランタイム テンプレート] ページに新しいテンプレートが表示されます。
5. ランタイムを開始する
テンプレートの準備ができたら、新しいランタイムを作成できます。
- Colab Enterprise で、[ランタイム] をクリックし、[作成] を選択します。
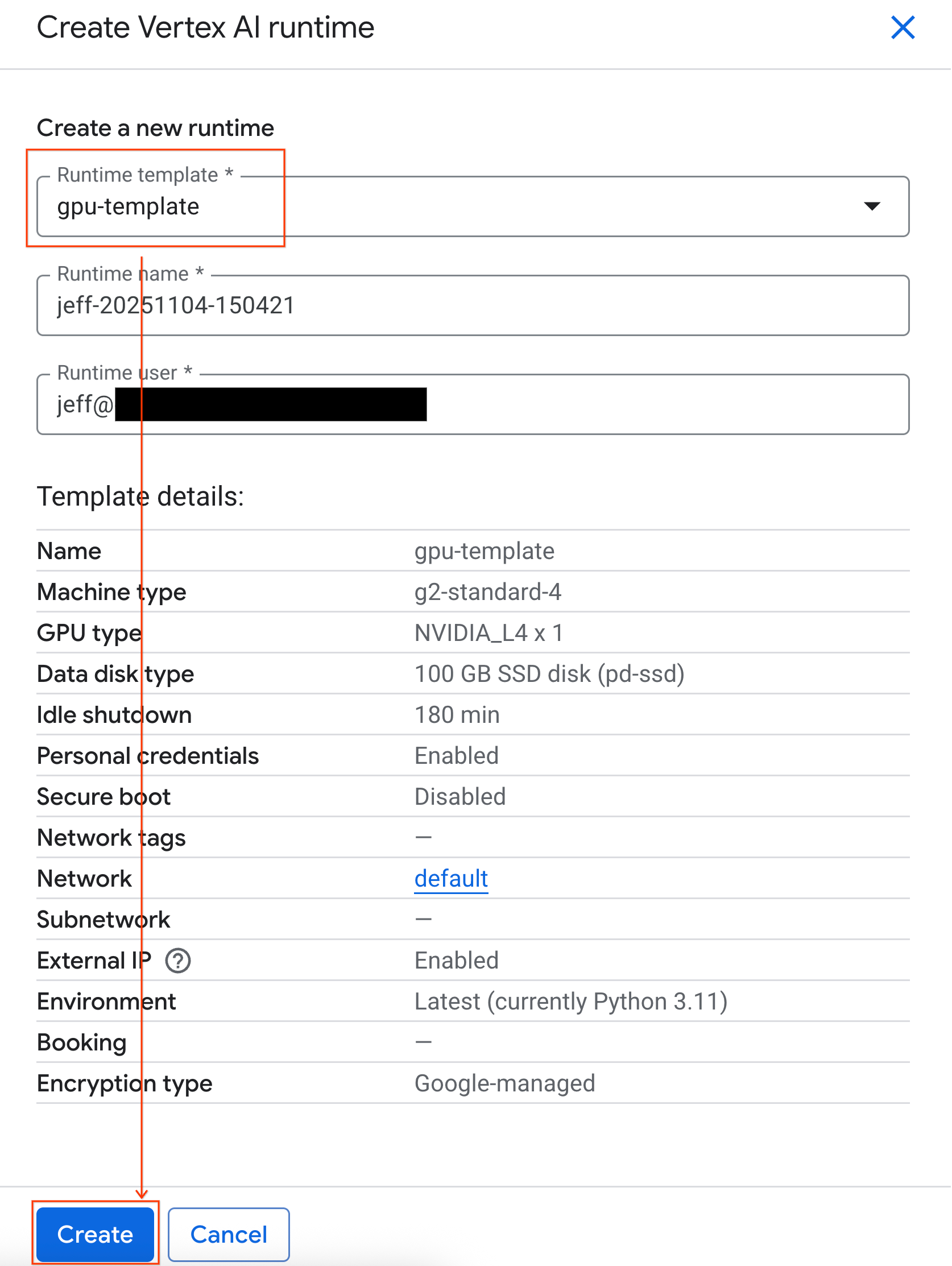
- [ランタイム テンプレート] で、[
gpu-template] オプションを選択します。[作成] をクリックし、ランタイムが起動するまで待ちます。
- 数分後、ランタイムが利用可能になります。
6. ノートブックを設定する
インフラストラクチャが実行されたので、ラボのノートブックをインポートしてランタイムに接続する必要があります。
ノートブックをインポートする
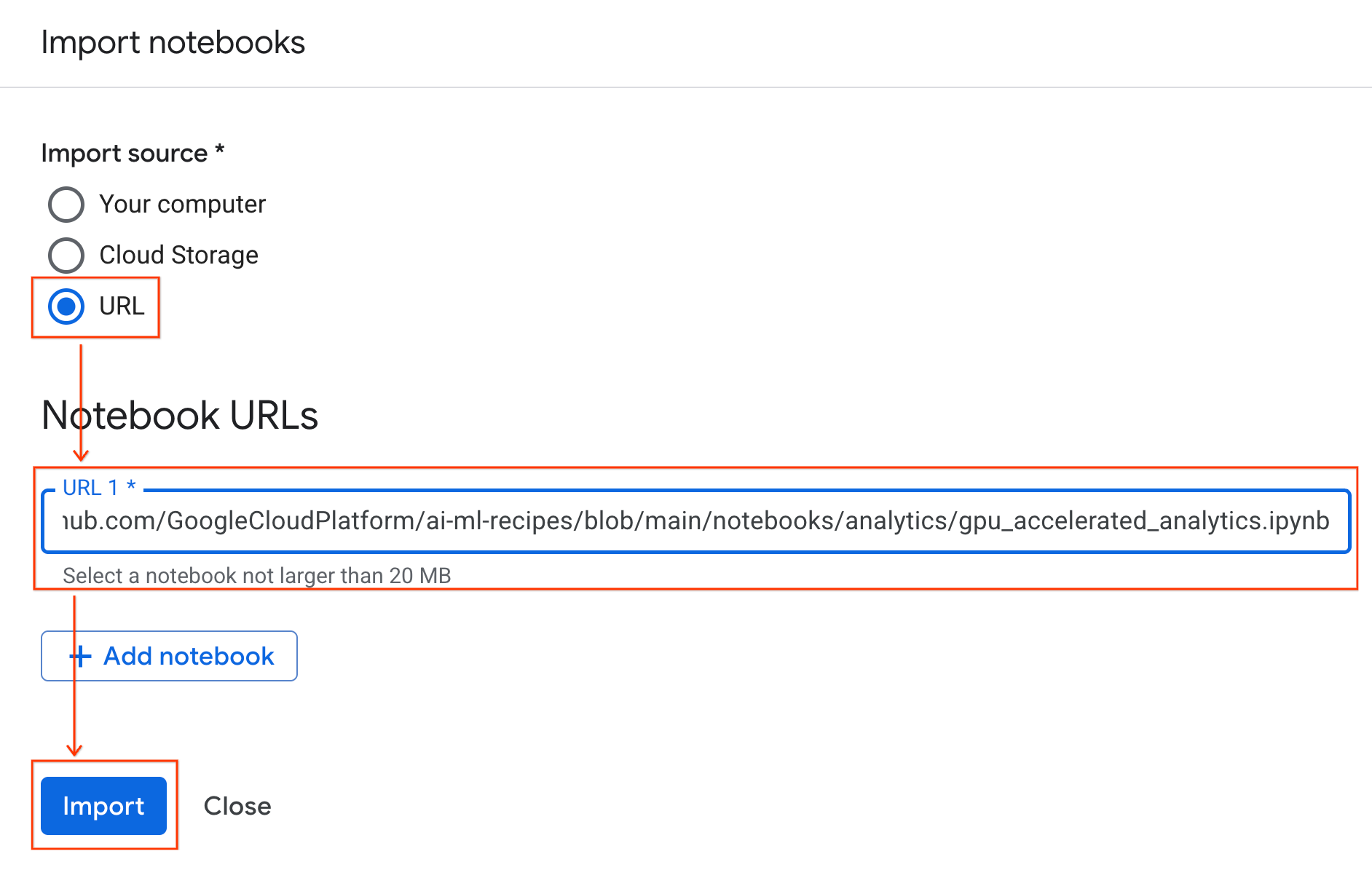
- Colab Enterprise で、[マイ ノートブック] をクリックし、[インポート] をクリックします。
![[ノートブックのインポート] ペインを開きます](https://codelabs.developers.google.com/static/accelerated-analytics-with-gpus/img/notebook/1_import.png?hl=ja)
- [URL] ラジオボタンを選択し、次の URL を入力します。
https://github.com/GoogleCloudPlatform/ai-ml-recipes/blob/main/notebooks/analytics/gpu_accelerated_analytics.ipynb
- [インポート] をクリックすると、Colab Enterprise は、GitHub から環境にノートブックをコピーします。
ランタイムに接続する
- 新しくインポートしたノートブックを開きます。
- [接続] の横にある下矢印をクリックします。
- [ランタイムに接続] を選択します。
![[ノートブックのインポート] ペインを開きます](https://codelabs.developers.google.com/static/accelerated-analytics-with-gpus/img/notebook/2_start_connection.png?hl=ja)
- プルダウンを使用して、以前に作成したランタイムを選択します。
- [接続] をクリックします。
![[ノートブックのインポート] ペインを開きます](https://codelabs.developers.google.com/static/accelerated-analytics-with-gpus/img/notebook/3_final_connection.png?hl=ja)
これで、ノートブックが GPU 対応ランタイムに接続されました。これでクエリの実行を開始できます。
7. ニューヨーク市のタクシー データセットを準備する
この Codelab では、NYC Taxi & Limousine Commission(TLC)の乗車記録データを使用します。
このデータセットには、ニューヨーク市のイエローキャブの個々の乗車記録が含まれており、次のようなフィールドがあります。
- 乗車と降車の日時と場所
- 移動距離
- 運賃の明細金額
- 乗客数
データをダウンロード
次に、2024 年のすべてのルートデータをダウンロードします。データは Parquet ファイル形式で保存されます。
次のコードブロックは、これらの手順を実行します。
- ダウンロードする年と月の範囲を定義します。
- ファイルを保存する
nyc_taxi_dataという名前のローカル ディレクトリを作成します。 - 各月をループ処理し、対応する Parquet ファイルが存在しない場合はダウンロードして、ディレクトリに保存します。
ノートブックで次のコードを実行して、データを収集し、ランタイムに保存します。
from tqdm import tqdm
import requests
import time
import os
YEAR = 2024
DATA_DIR = "nyc_taxi_data"
os.makedirs(DATA_DIR, exist_ok=True)
print(f"Checking/Downloading files for {YEAR}...")
for month in tqdm(range(1, 13), unit="file"):
# Define standardized filename for both local path and URL
file_name = f"yellow_tripdata_{YEAR}-{month:02d}.parquet"
local_path = os.path.join(DATA_DIR, file_name)
url = f"https://d37ci6vzurychx.cloudfront.net/trip-data/{file_name}"
if not os.path.exists(local_path):
try:
with requests.get(url, stream=True) as response:
response.raise_for_status()
with open(local_path, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
time.sleep(1)
except requests.exceptions.HTTPError as e:
print(f"\nSkipping {file_name}: {e}")
if os.path.exists(local_path):
os.remove(local_path)
print("\nDownload complete.")
8. タクシーのルートデータを調べる
データセットをダウンロードしたら、初期の探索的データ分析(EDA)を実行します。EDA の目的は、データの構造を理解し、異常を見つけ、潜在的なパターンを発見することです。
1 か月分のデータを読み込む
まず、1 か月分のデータを読み込みます。これにより、インタラクティブ分析でメモリ使用量を管理可能な状態に保ちながら、有意義なサンプル(300 万行以上)を確保できます。
import pandas as pd
import glob
# Load the last month of the downloaded data
df = pd.read_parquet("nyc_taxi_data/yellow_tripdata_2024-12.parquet")
df.head()
統計情報の概要を取得する
.describe() メソッドを使用して、数値列の概要統計情報を生成します。これは、予期しない最小値や最大値など、データ品質に関する潜在的な問題を特定するための最初のステップとして最適です。
df.describe().round(2)
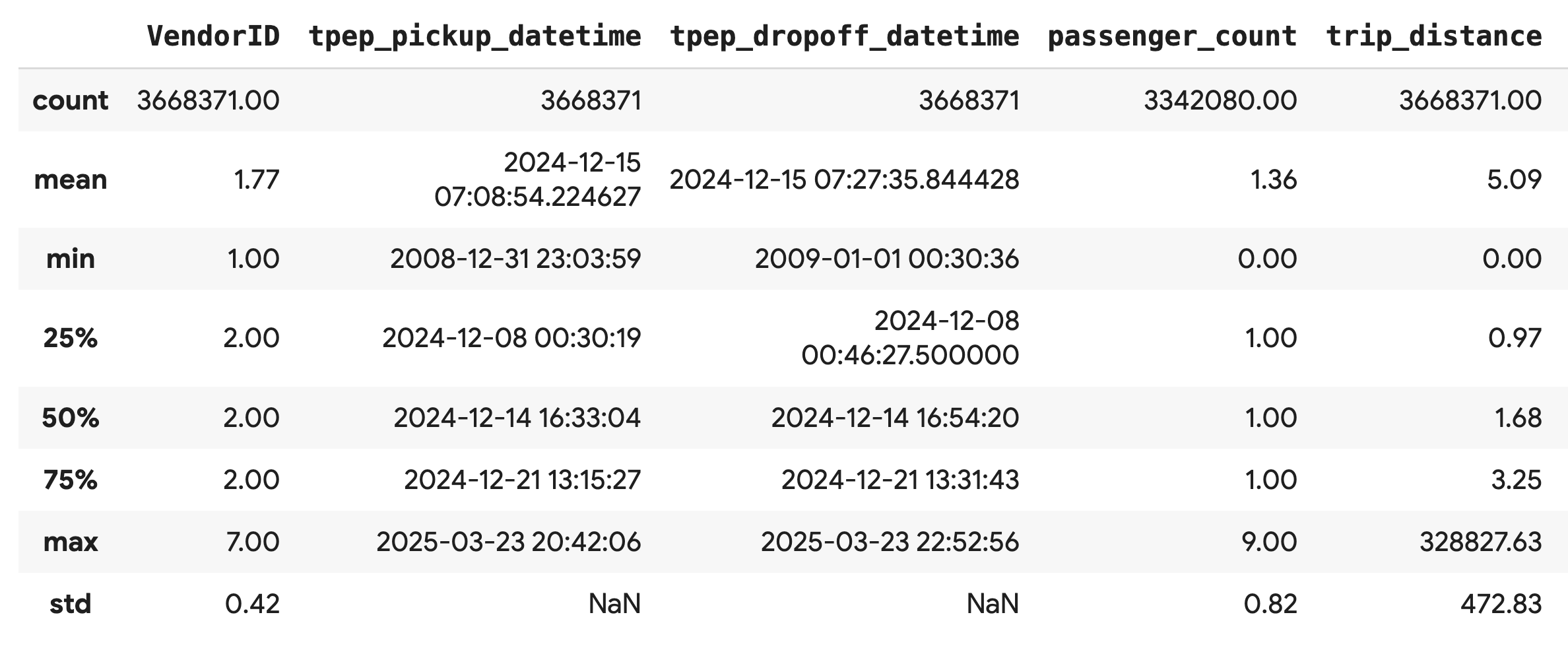
データ品質を調査する
.describe() の出力から、すぐに問題が明らかになります。tpep_pickup_datetime と tpep_dropoff_datetime の min 値は 2008 年になっています。これは 2024 年のデータセットとしては不自然です。
これは、常にデータを検査する理由の例です。DataFrame を並べ替えて、外れ値の日付を含む行を特定することで、さらに詳しく調べることができます。
# Sort by the dropoff datetime to see the oldest records
df.sort_values("tpep_pickup_datetime").head()
データ分布を可視化する
次に、数値列のヒストグラムを作成して、分布を可視化できます。これにより、trip_distance や fare_amount などの特徴の分布と歪度を把握できます。.hist() 関数は、DataFrame 内のすべての数値列のヒストグラムをすばやくプロットする方法です。
_ = df.hist(figsize=(20, 20))
最後に、散布図行列を生成して、いくつかのキー列間の関係を可視化します。数百万のポイントをプロットすると処理が遅くなり、パターンがわかりにくくなる可能性があるため、.sample() を使用して 100,000 行のランダム サンプルからプロットを作成します。
_ = pd.plotting.scatter_matrix(
df[['passenger_count', 'trip_distance', 'tip_amount', 'total_amount']].sample(100_000),
diagonal="kde",
figsize=(15, 15)
)
9. Parquet ファイル形式を使用する理由
NYC タクシー データセットは Apache Parquet 形式で提供されます。これは、大規模な分析のために意図的に選択されたものです。Parquet には、CSV などのファイル形式に比べて次のような利点があります。
- 効率的で高速: カラム形式である Parquet は、保存と読み取りが非常に効率的です。最新の圧縮方式をサポートしており、ファイルサイズを縮小し、特に GPU で I/O を大幅に高速化できます。
- スキーマを保持する: Parquet は、データ型をファイルのメタデータに保存します。ファイルを読み取るときにデータ型を推測する必要はありません。
- 選択的読み取りが可能: 列構造により、分析に必要な特定の列のみを読み取ることができます。これにより、メモリに読み込む必要のあるデータ量を大幅に削減できます。
Parquet の機能を調べる
ダウンロードしたファイルの 1 つを使用して、これらの強力な機能のうち 2 つを見てみましょう。
完全なデータセットを読み込まずにメタデータを検査する
標準のテキスト エディタで Parquet ファイルを表示することはできませんが、メモリにデータを読み込むことなく、スキーマとメタデータを簡単に検査できます。これは、ファイルの構造をすばやく理解するのに役立ちます。
from pyarrow.parquet import ParquetFile
import pyarrow as pa
# Open one of the downloaded files
pf = ParquetFile('nyc_taxi_data/yellow_tripdata_2024-12.parquet')
# Print the schema
print("File Schema:")
print(pf.schema)
# Print the file metadata
print("\nFile Metadata:")
print(pf.metadata)
必要な列のみを読み取る
移動距離と運賃のみを分析する必要があるとします。Parquet を使用すると、これらの列のみを読み込むことができます。これは、DataFrame 全体を読み込むよりもはるかに高速で、メモリ効率も優れています。
import pandas as pd
# Read only four specific columns from the Parquet file
df_subset = pd.read_parquet(
'nyc_taxi_data/yellow_tripdata_2024-12.parquet',
columns=['passenger_count', 'trip_distance', 'tip_amount', 'total_amount']
)
df_subset.head()
10. NVIDIA cuDF で pandas を高速化する
NVIDIA CUDA for DataFrames(cuDF)は、DataFrame を操作できるオープンソースの GPU アクセラレーション ライブラリです。cuDF を使用すると、フィルタリング、結合、グループ化などの一般的なデータ オペレーションを GPU で大規模な並列処理で実行できます。
この Codelab で使用する主な機能は、cudf.pandas アクセラレータ モードです。有効にすると、標準の pandas コードは、コードを変更することなく、GPU を搭載した cuDF カーネルを使用するように自動的にリダイレクトされます。
GPU アクセラレーションを有効にする
Colab Enterprise ノートブックで NVIDIA cuDF を使用するには、pandas をインポートする前にマジック拡張機能を読み込みます。
まず、標準の pandas ライブラリを調べます。出力にデフォルトの pandas インストールのパスが表示されていることに注意してください。
import pandas as pd
pd # Note the output for the standard pandas library
次に、cudf.pandas 拡張機能を読み込み、pandas を再度インポートします。pd モジュールの出力がどのように変化するかを確認します。これにより、GPU アクセラレーション バージョンが有効になったことを確認できます。
%load_ext cudf.pandas
import pandas as pd
pd # Note the new output, indicating cudf.pandas is active
cudf.pandas を有効にするその他の方法
マジック コマンド(%load_ext)はノートブックで最も簡単な方法ですが、他の環境でアクセラレータを有効にすることもできます。
- Python スクリプトの場合:
pandasインポートの前にimport cudf.pandasとcudf.pandas.install()を呼び出します。 - ノートブック以外の環境の場合:
python -m cudf.pandas your_script.pyを使用してスクリプトを実行します。
11. CPU と GPU のパフォーマンスを比較する
ここからは、最も重要な部分である、CPU の標準 pandas と GPU の cudf.pandas のパフォーマンスを比較します。
CPU の完全に公平なベースラインを確保するには、まず Colab ランタイムをリセットする必要があります。これにより、前のセクションで有効にした GPU アクセラレータがクリアされます。ランタイムを再起動するには、次のセルを実行するか、[ランタイム] メニューから [セッションを再起動] を選択します。
import IPython
IPython.Application.instance().kernel.do_shutdown(True)
分析パイプラインを定義する
環境がクリーンになったので、ベンチマーク関数を定義します。この関数を使用すると、渡された pandas モジュールを使用して、同じパイプライン(読み込み、並べ替え、要約)を実行できます。
import time
import glob
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
def run_analytics_pipeline(pd_module):
"""Loads, sorts, and summarizes data using the provided pandas module."""
timings = {}
# 1. Load all 2024 Parquet files from the directory
t0 = time.time()
df = pd_module.concat(
[pd_module.read_parquet(f) for f in glob.glob("nyc_taxi_data/*_2024*.parquet")],
ignore_index=True
)
timings["load"] = time.time() - t0
# 2. Sort the data by multiple columns
t0 = time.time()
df = df.sort_values(
['tpep_pickup_datetime', 'trip_distance', 'passenger_count'],
ascending=[False, True, False]
)
timings["sort"] = time.time() - t0
# 3. Perform a groupby and aggregation
t0 = time.time()
df['tpep_pickup_datetime'] = pd_module.to_datetime(df['tpep_pickup_datetime'])
_ = (
df.loc[df.tpep_pickup_datetime > '2024-11-01']
.groupby(['VendorID', 'tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
timings["summarize"] = time.time() - t0
return timings
比較を実行する
まず、CPU で標準の pandas を使用してパイプラインを実行します。次に、cudf.pandas を有効にして、GPU で再度実行します。
# --- Run on CPU ---
print("Running analytics pipeline on CPU...")
# Ensure we are using standard pandas
import pandas as pd
assert "cudf" not in str(pd), "Error: cuDF is still active. Please restart the kernel."
cpu_times = run_analytics_pipeline(pd)
print(f"CPU times: {cpu_times}")
# --- Run on GPU ---
print("\nEnabling cudf.pandas and running on GPU...")
# Load the extension
%load_ext cudf.pandas
import pandas as gpu_pd
gpu_times = run_analytics_pipeline(gpu_pd)
print(f"GPU times: {gpu_times}")
結果の可視化
最後に、差分を可視化します。次のコードは、オペレーションごとにスピードアップを計算し、それらを並べてプロットします。
# Create a DataFrame for plotting
results_df = pd.DataFrame([cpu_times, gpu_times], index=["CPU", "GPU"]).T
total_cpu_time = results_df['CPU'].sum()
total_gpu_time = results_df['GPU'].sum()
speedup = total_cpu_time / total_gpu_time
print("--- Performance Results ---")
print(results_df)
print(f"\nTotal CPU Time: {total_cpu_time:.2f} seconds")
print(f"Total GPU Time: {total_gpu_time:.2f} seconds")
print(f"Overall Speedup: {speedup:.2f}x")
# Plot the results
fig, ax = plt.subplots(figsize=(10, 6))
results_df.plot(kind='bar', ax=ax, color={"CPU": "tab:blue", "GPU": "tab:green"})
ax.set_ylabel("Time (seconds)")
ax.set_title(f"CPU vs. GPU Runtimes (Overall Speedup: {speedup:.2f}x)", fontsize=14)
ax.tick_params(axis='x', rotation=0)
# Add numerical labels to the bars
for container in ax.containers:
ax.bar_label(container, fmt="%.2f", padding=3)
plt.tight_layout()
plt.show()
結果の例を以下に示します。
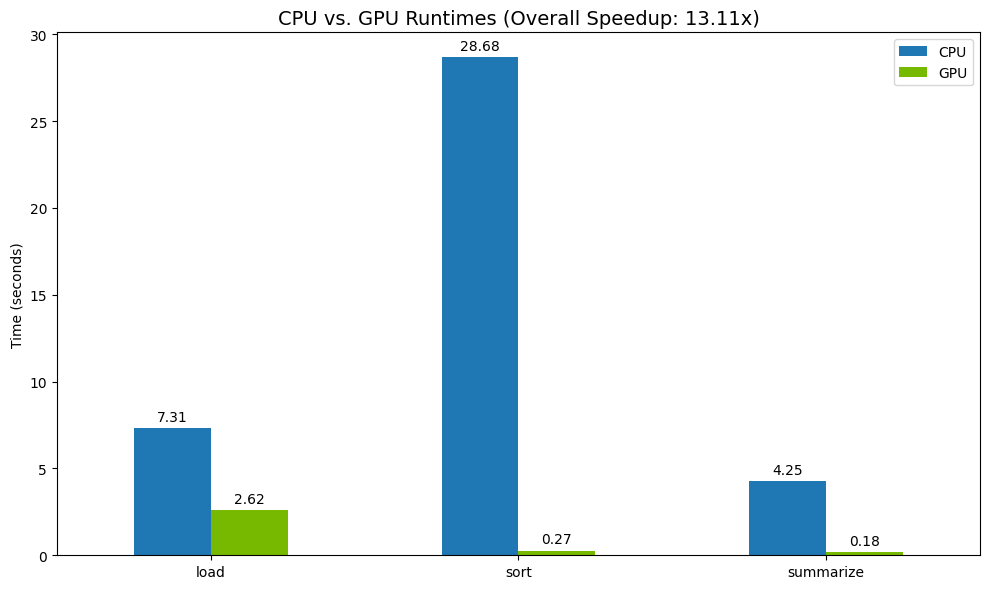
GPU は CPU と比較して明らかに速度が向上します。
12. コードをプロファイリングしてボトルネックを検出する
GPU アクセラレーションを使用しても、cuDF でまだサポートされていない pandas オペレーションは CPU にフォールバックされることがあります。このような「CPU フォールバック」は、パフォーマンスのボトルネックになる可能性があります。
これらの領域を特定するために、cudf.pandas には 2 つの組み込みプロファイラが含まれています。これらを使用すると、コードのどの部分が GPU で実行され、どの部分が CPU にフォールバックしているかを正確に確認できます。
%%cudf.pandas.profile: コードの概要を関数ごとに確認する場合に使用します。どのオペレーションがどのデバイスで実行されているかを簡単に把握するのに最適です。%%cudf.pandas.line_profile: 詳細な行ごとの分析に使用します。これは、CPU へのフォールバックの原因となっているコードの正確な行を特定するのに最適なツールです。
これらのプロファイラは、ノートブック セルの上部で「セルマジック」として使用します。
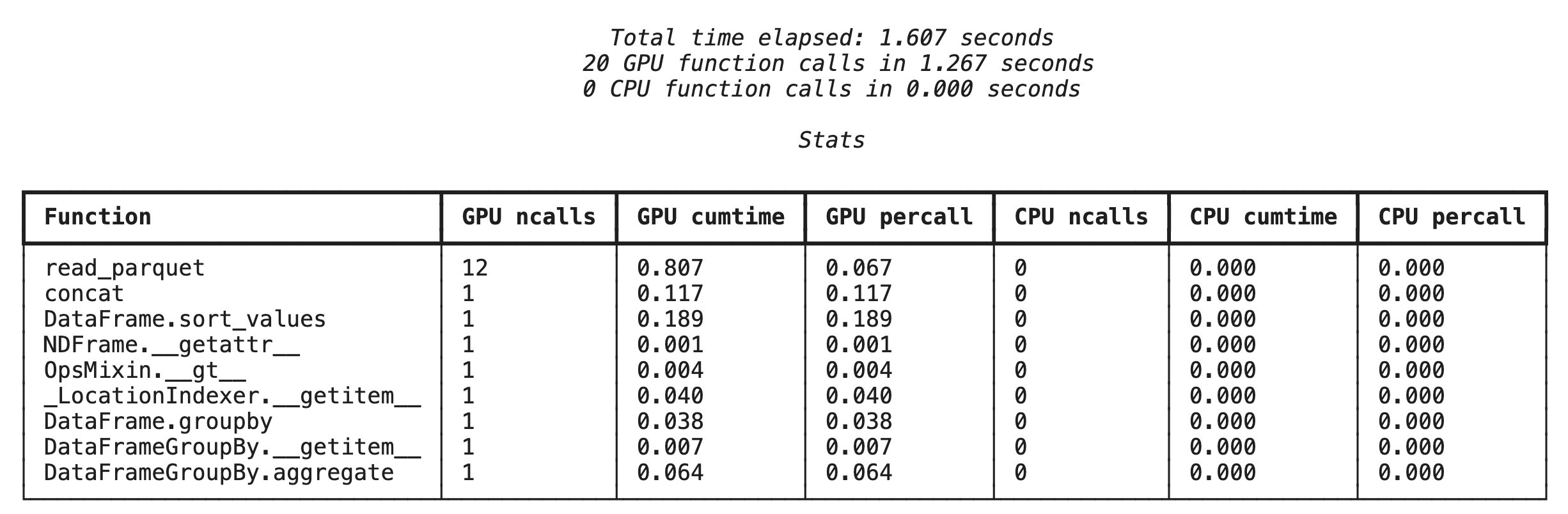
%%cudf.pandas.profile を使用した関数レベルのプロファイリング
まず、前のセクションと同じ分析パイプラインで関数レベルのプロファイラを実行します。出力には、呼び出されたすべての関数、実行されたデバイス(GPU または CPU)、呼び出された回数の表が表示されます。
%load_ext cudf.pandas
import pandas as pd
import glob
pd.DataFrame({"a": [1]})
cudf.pandas がアクティブであることを確認したら、プロファイルを実行できます。
%%cudf.pandas.profile
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*2024*.parquet")], ignore_index=True)
df = df.sort_values(['tpep_pickup_datetime', 'trip_distance', 'passenger_count'], ascending=[False, True, False])
summary = (
df
.loc[(df.tpep_pickup_datetime > '2024-11-01')]
.groupby(['VendorID','tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
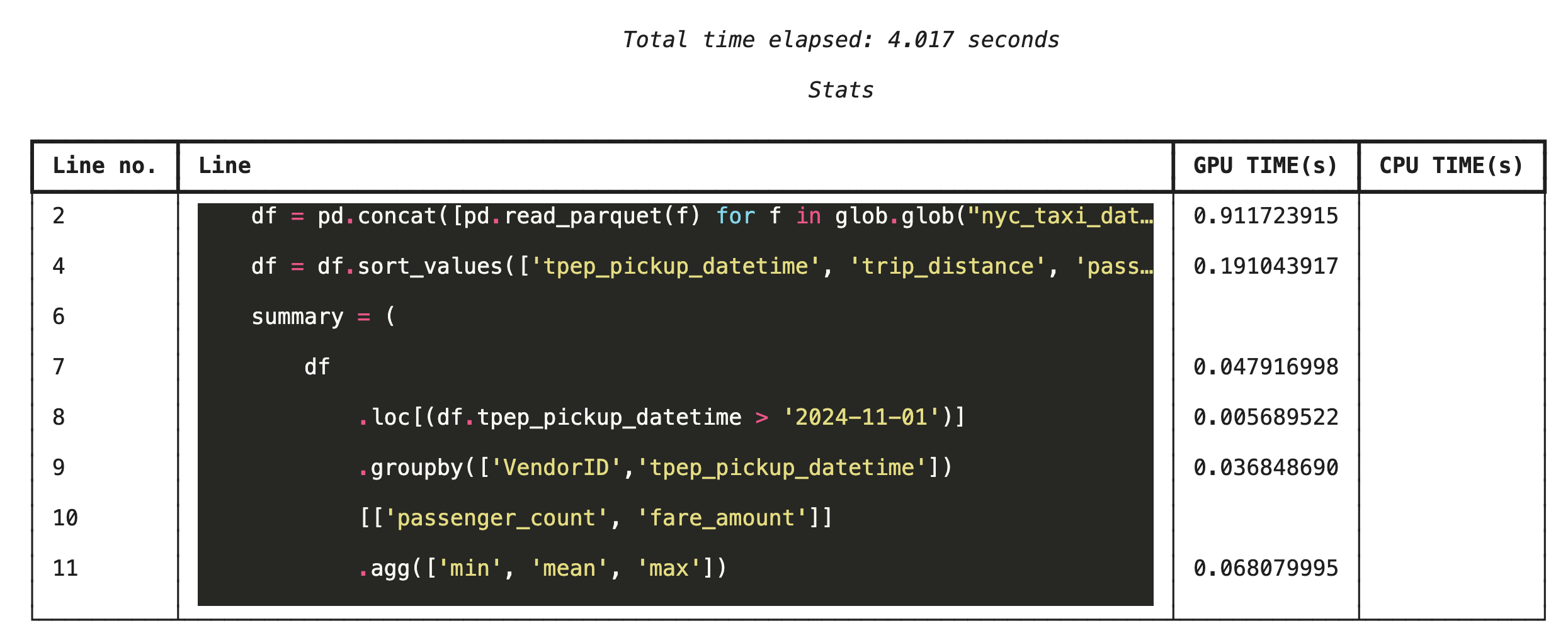
%%cudf.pandas.line_profile を使用した行ごとのプロファイリング
次に、行レベルのプロファイラを実行します。これにより、各コード行が GPU と CPU で実行された時間の割合を示す、より詳細なビューが表示されます。これは、最適化する特定のボトルネックを見つける最も効果的な方法です。
%%cudf.pandas.line_profile
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*2024*.parquet")], ignore_index=True)
df = df.sort_values(['tpep_pickup_datetime', 'trip_distance', 'passenger_count'], ascending=[False, True, False])
summary = (
df
.loc[(df.tpep_pickup_datetime > '2024-11-01')]
.groupby(['VendorID','tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
コマンドラインからのプロファイリング
これらのプロファイラはコマンドラインからも使用できます。これは、Python スクリプトの自動テストとプロファイリングに役立ちます。
コマンドライン インターフェースで次のコマンドを使用できます。
python -m cudf.pandas --profile your_script.pypython -m cudf.pandas --line_profile your_script.py
13. Google Cloud Storage と統合する
Google Cloud Storage(GCS)は、スケーラビリティと耐久性に優れたオブジェクト ストレージ サービスです。Colab Enterprise を使用する場合、GCS はデータセット、モデル チェックポイント、その他のアーティファクトを保存するのに最適な場所です。
Colab Enterprise ランタイムには、データを GCS バケットに直接読み書きするために必要な権限が付与されています。これらのオペレーションは GPU で高速化され、パフォーマンスが最大化されます。
GCS バケットを作成する
まず、新しい GCS バケットを作成します。GCS バケット名はグローバルに一意であるため、名前に UUID を追加します。
from google.cloud import storage
import uuid
unique_suffix = uuid.uuid4().hex[:12]
bucket_name = f'nyc-taxi-codelab-{unique_suffix}'
project_id = storage.Client().project
client = storage.Client()
try:
bucket = client.create_bucket(bucket_name)
print(f"Successfully created bucket: gs://{bucket.name}")
except Exception as e:
print(f"Bucket creation failed. You may already own it or the name is taken: {e}")
データを GCS に直接書き込む
次に、DataFrame を新しい GCS バケットに直接保存します。df 変数が前のセクションで使用できない場合、コードは最初に 1 か月分のデータを読み込みます。
%%cudf.pandas.line_profile
# Ensure the DataFrame exists before saving to GCS
if 'df' not in locals():
print("DataFrame not found, loading a sample file...")
df = pd.read_parquet('nyc_taxi_data/yellow_tripdata_2024-12.parquet')
print(f"Writing data to gs://{bucket_name}/nyc_taxi_data.parquet...")
df.to_parquet(f"gs://{bucket_name}/nyc_taxi_data.parquet", index=False)
print("Write operation complete.")
GCS でファイルを確認する
バケットにアクセスして、データが GCS に存在することを確認できます。次のコードは、クリック可能なリンクを作成します。
from IPython.display import Markdown
gcs_url = f"https://console.cloud.google.com/storage/browser/{bucket_name}?project={project_id}"
Markdown(f'**[Click here to view your GCS bucket in the Google Cloud Console]({gcs_url})**')
GCS からデータを直接読み取る
最後に、GCS パスから DataFrame にデータを直接読み取ります。このオペレーションも GPU で高速化されているため、クラウド ストレージから大規模なデータセットを高速で読み込むことができます。
%%cudf.pandas.line_profile
print(f"Reading data from gs://{bucket_name}/nyc_taxi_data.parquet...")
df_from_gcs = pd.read_parquet(f"gs://{bucket_name}/nyc_taxi_data.parquet")
df_from_gcs.head()
14. クリーンアップ
Google Cloud アカウントに予期しない料金が発生しないようにするには、作成したリソースをクリーンアップする必要があります。
ダウンロードしたデータを削除します。
# Permanately delete the GCS bucket
print(f"Deleting GCS bucket: gs://{bucket_name}...")
!gsutil rm -r -f gs://{bucket_name}
print("Bucket deleted.")
# Remove NYC taxi dataset on the Colab runtime
print("Deleting local 'nyc_taxi_data' directory...")
!rm -rf nyc_taxi_data
print("Local files deleted.")
Colab ランタイムをシャットダウンする
- Google Cloud コンソールで、Colab Enterprise の [ランタイム] ページに移動します。
- [リージョン] メニューで、ランタイムを含むリージョンを選択します。
- 削除するランタイムを選択します。
- [削除] をクリックします。
- [確認] をクリックします。
ノートブックを削除する
- Google Cloud コンソールで、Colab Enterprise の [マイ ノートブック] ページに移動します。
- [リージョン] メニューで、ノートブックを含むリージョンを選択します。
- 削除するノートブックを選択します。
- [削除] をクリックします。
- [確認] をクリックします。
15. 完了
おめでとうございます!Colab Enterprise で NVIDIA cuDF を使用して、pandas 分析ワークフローを高速化できました。GPU 対応のランタイムの構成、コード変更なしの高速化のための cudf.pandas の有効化、ボトルネックのコードのプロファイリング、Google Cloud Storage との統合について学習しました。