
1. Wprowadzenie
Z tego ćwiczenia dowiesz się, jak przyspieszyć przepływy pracy związane z analizą danych w przypadku dużych zbiorów danych za pomocą procesorów graficznych NVIDIA i bibliotek open source w Google Cloud. Zaczniesz od optymalizacji infrastruktury, a następnie dowiesz się, jak zastosować akcelerację GPU bez wprowadzania zmian w kodzie.
Skupisz się na pandas, popularnej bibliotece do manipulowania danymi, i dowiesz się, jak ją przyspieszyć za pomocą biblioteki cuDF firmy NVIDIA. Najlepsze jest to, że możesz uzyskać to przyspieszenie GPU bez zmiany istniejącego kodu pandas.
Czego się nauczysz
- Poznaj Colab Enterprise w Google Cloud.
- Dostosowywanie środowiska wykonawczego Colab za pomocą określonych konfiguracji procesora graficznego, procesora i pamięci.
- Przyspiesz
pandasbez wprowadzania zmian w kodzie, korzystając zcuDFNVIDIA. - Profiluj kod, aby identyfikować i optymalizować wąskie gardła wydajności.
Na kolejnej stronie znajdziesz środki, których możesz użyć do ukończenia ćwiczenia.
2. Dlaczego warto przyspieszyć przetwarzanie danych?
Zasada 80/20: dlaczego przygotowanie danych zajmuje tak dużo czasu
Przygotowywanie danych jest często najbardziej czasochłonnym etapem projektu analitycznego. Badacze i analitycy danych poświęcają dużo czasu na oczyszczanie, przekształcanie i strukturyzowanie danych, zanim będą mogli rozpocząć analizę.
Na szczęście możesz przyspieszyć działanie popularnych bibliotek open source, takich jak pandas, Apache Spark i Polars, na procesorach graficznych NVIDIA za pomocą cuDF. Nawet przy tym przyspieszeniu przygotowanie danych nadal jest czasochłonne, ponieważ:
- Dane źródłowe rzadko są gotowe do analizy: dane z rzeczywistego świata często zawierają niespójności, brakujące wartości i problemy z formatowaniem.
- Jakość wpływa na wydajność modelu: niska jakość danych może sprawić, że nawet najbardziej zaawansowane algorytmy będą bezużyteczne.
- Skala potęguje problemy: pozornie drobne problemy z danymi stają się krytycznymi wąskimi gardłami podczas pracy z milionami rekordów.
3. Wybór środowiska notatnika
Wielu specjalistów ds. danych zna Colab z projektów osobistych, ale Colab Enterprise zapewnia bezpieczne, oparte na współpracy i zintegrowane środowisko notatników zaprojektowane z myślą o firmach.
W Google Cloud masz 2 główne opcje zarządzanych środowisk notatników: Colab Enterprise i Gemini Enterprise Agent Platform Workbench. Wybór zależy od priorytetów projektu.
Kiedy używać Agent Platform Workbench
Wybierz Agent Platform Workbench, jeśli priorytetem jest kontrola i zaawansowane dostosowywanie. Jest to idealne rozwiązanie, jeśli chcesz:
- zarządzać bazową infrastrukturą i cyklem życia maszyny;
- używać kontenerów niestandardowych i konfiguracji sieci;
- Integracja z potokami MLOps i niestandardowymi narzędziami do zarządzania cyklem życia.
Kiedy używać Colab Enterprise
Wybierz Colab Enterprise, jeśli zależy Ci na szybkiej konfiguracji, łatwości obsługi i bezpiecznej współpracy. Jest to usługa w pełni zarządzana, która pozwala zespołowi skupić się na analizie zamiast na infrastrukturze.
Colab Enterprise ułatwia:
- Tworzenie przepływów pracy związanych z badaniem danych, które są ściśle powiązane z hurtownią danych. Notatniki możesz otwierać i nimi zarządzać bezpośrednio w BigQuery Studio.
- Trenuj modele uczenia maszynowego i integruj je z narzędziami MLOps na platformie Agent Platform.
- Korzystaj z elastycznego i ujednoliconego środowiska. Notatnik Colab Enterprise utworzony w BigQuery można otworzyć i uruchomić na platformie Agent Platform i odwrotnie.
Dzisiejsze laboratorium
W tym ćwiczeniu wykorzystujemy Colab Enterprise do przyspieszonej analizy danych.
Więcej informacji o różnicach między nimi znajdziesz w oficjalnej dokumentacji na temat wybierania odpowiedniego rozwiązania do obsługi notatników.
4. Konfigurowanie szablonu środowiska wykonawczego
W Colab Enterprise połącz się ze środowiskiem wykonawczym opartym na wstępnie skonfigurowanym szablonie środowiska wykonawczego.
Szablon środowiska wykonawczego to konfiguracja wielokrotnego użytku, która określa całe środowisko notatnika, w tym:
- Typ maszyny (procesor, pamięć)
- Akcelerator (typ i liczba GPU)
- Rozmiar i typ dysku
- Ustawienia sieci i zasady zabezpieczeń
- Reguły automatycznego wyłączania w przypadku braku aktywności
Dlaczego szablony środowiska wykonawczego są przydatne
- Spójne środowisko: Ty i Twoi współpracownicy za każdym razem otrzymujecie to samo gotowe do użycia środowisko, co zapewnia powtarzalność pracy.
- Bezpieczna praca dzięki odpowiedniej konstrukcji: szablony automatycznie egzekwują zasady bezpieczeństwa obowiązujące w Twojej organizacji.
- Skuteczne zarządzanie kosztami: zasoby takie jak GPU i CPU są wstępnie określane w szablonie, co pomaga zapobiegać przypadkowym przekroczeniom kosztów.
Tworzenie szablonu środowiska wykonawczego
Skonfiguruj szablon środowiska wykonawczego do wielokrotnego użytku na potrzeby laboratorium.
- W konsoli Google Cloud otwórz Menu nawigacyjne > Platforma agentów > Notatniki.
- W Colab Enterprise kliknij Szablony środowiska wykonawczego, a następnie wybierz Nowy szablon.
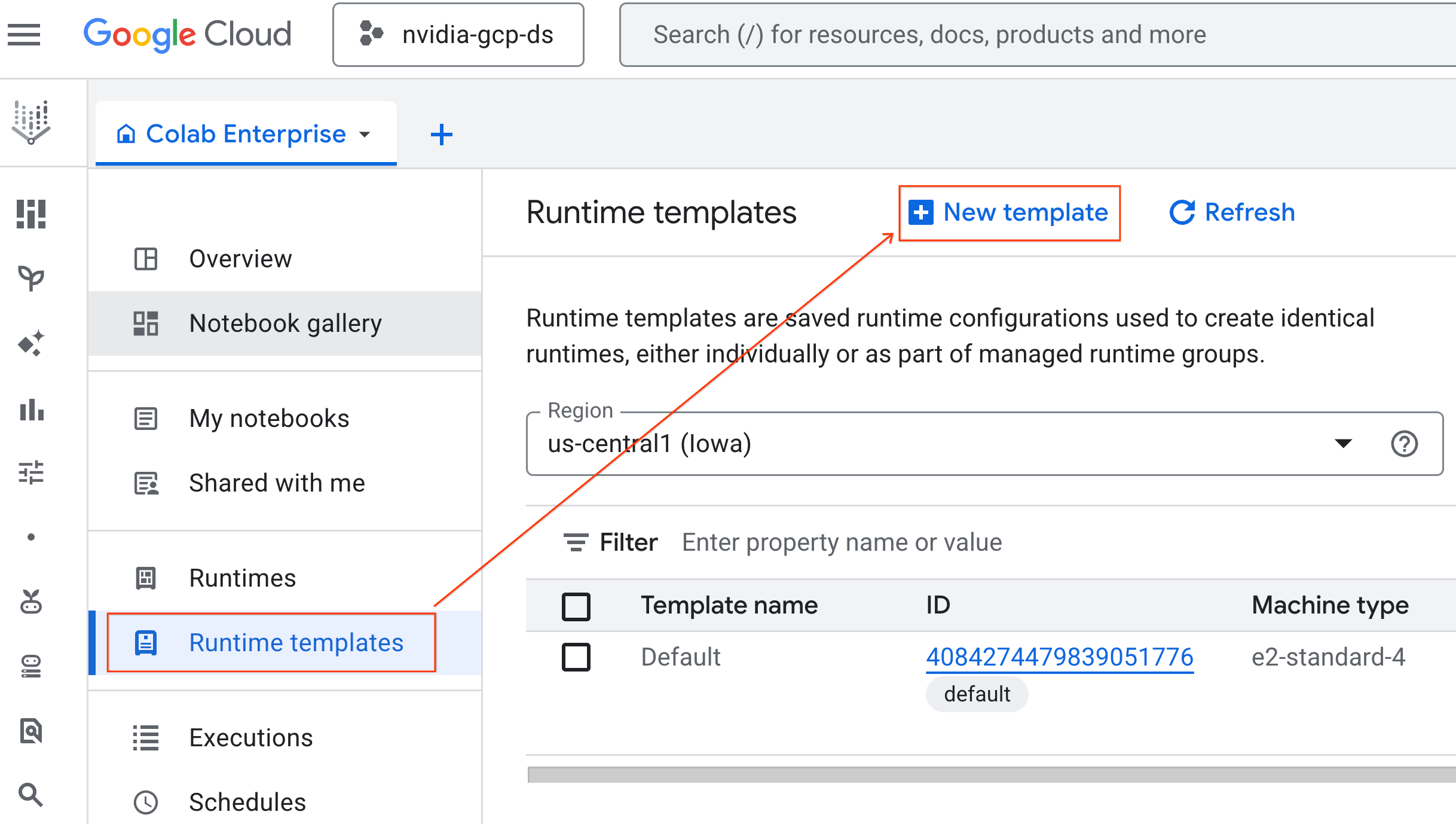
- W sekcji Podstawy środowiska wykonawczego:
- Ustaw wyświetlaną nazwę na
gpu-template. - Ustaw preferowany Region.
- Ustaw wyświetlaną nazwę na
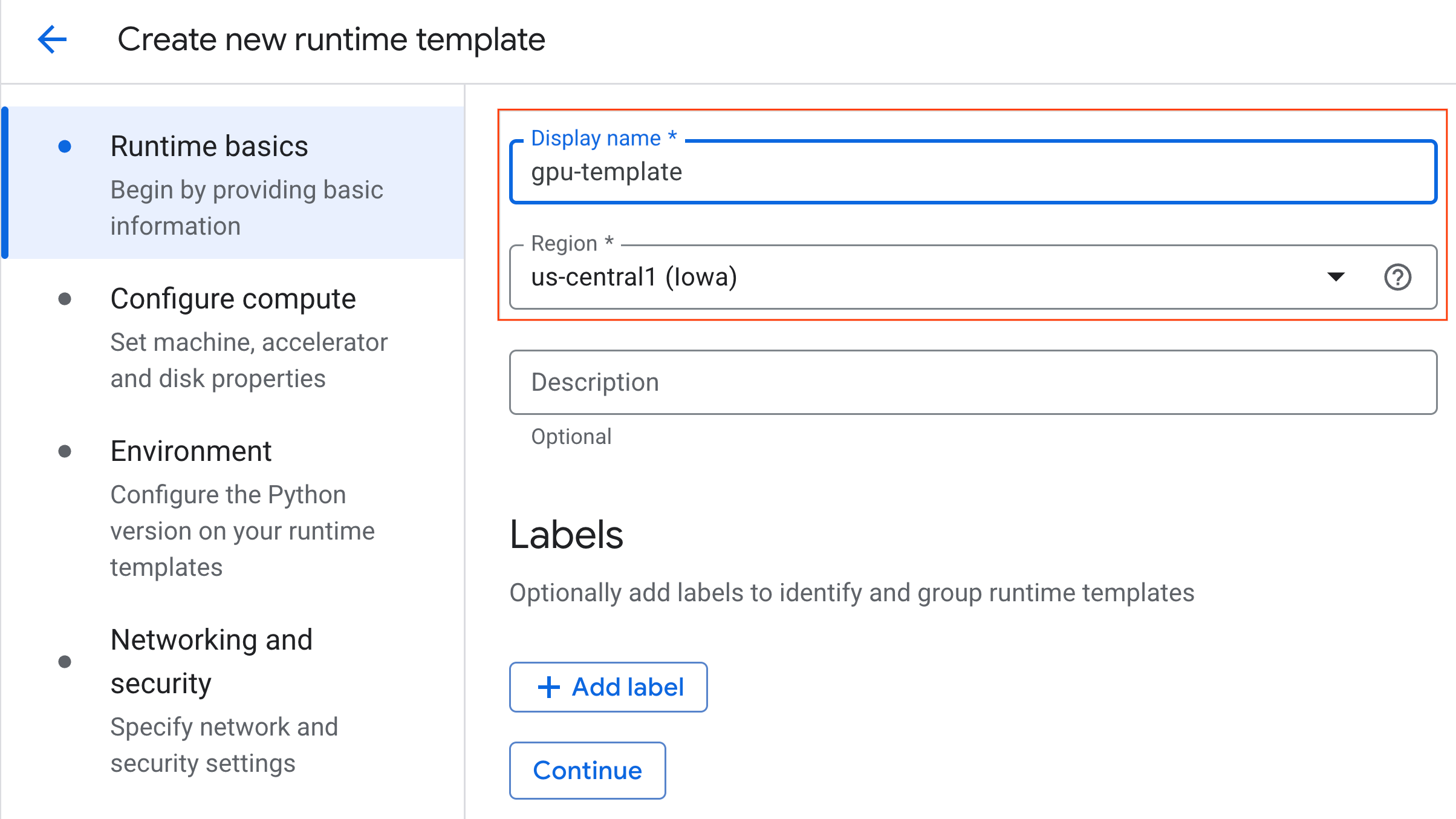
- W sekcji Skonfiguruj zasoby obliczeniowe:
- Ustaw Typ maszyny na
g2-standard-4. - Pozostaw domyślny typ akceleratora jako
NVIDIA L4z liczbą akceleratorów równą 1. - Zmień ustawienie Wyłączanie w przypadku braku aktywności na 60 minut.
- Kliknij Dalej.
- Ustaw Typ maszyny na
- W sekcji Środowisko:
- Ustaw Środowisko na
Python 3.11.
- Ustaw Środowisko na
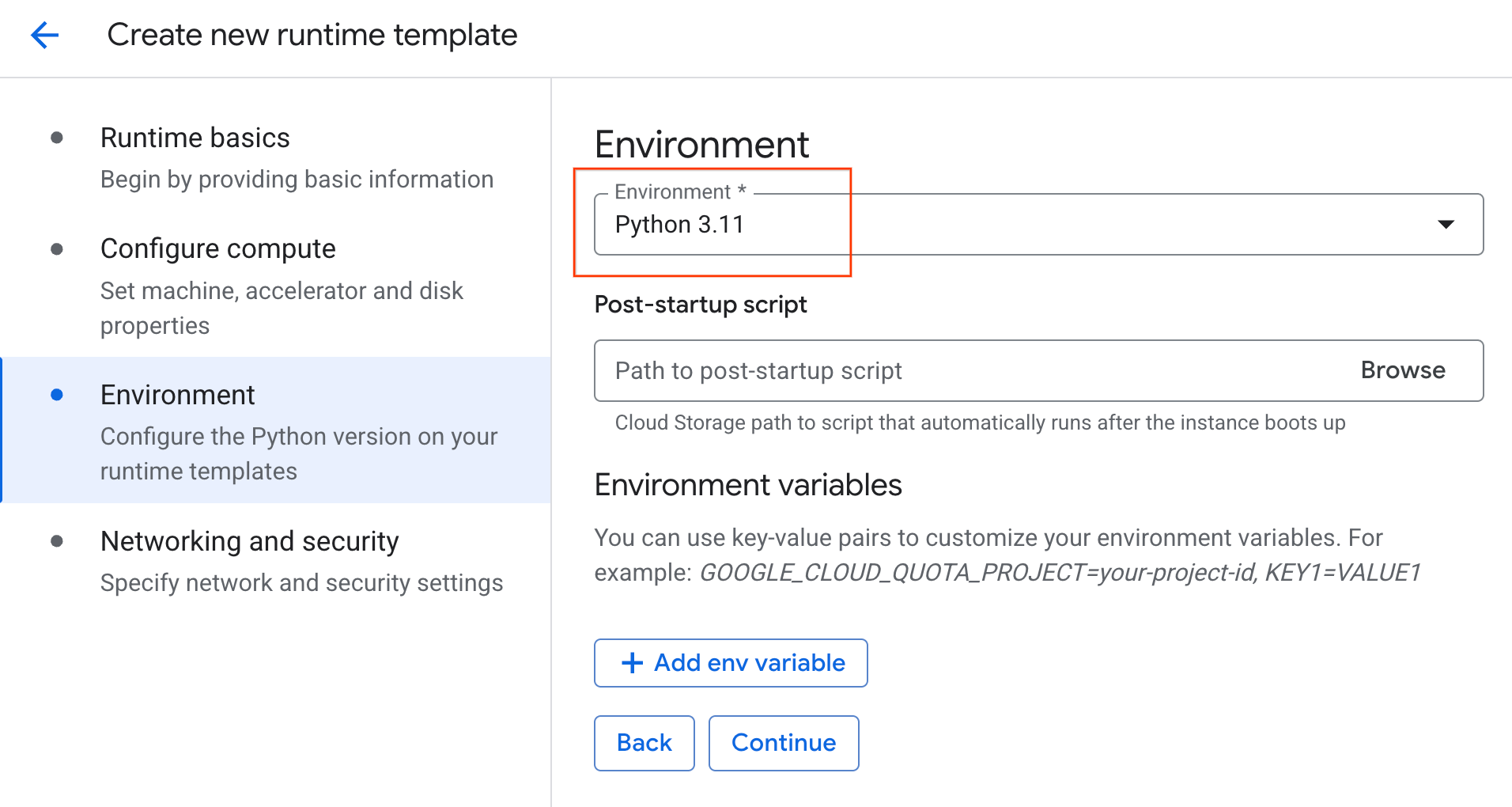
- Kliknij Utwórz, aby zapisać szablon środowiska wykonawczego. Na stronie Szablony środowiska wykonawczego powinien być teraz widoczny nowy szablon.
5. Uruchamianie środowiska wykonawczego
Gdy szablon będzie gotowy, możesz utworzyć nowe środowisko wykonawcze.
- W Colab Enterprise kliknij Środowiska wykonawcze, a następnie wybierz Utwórz.
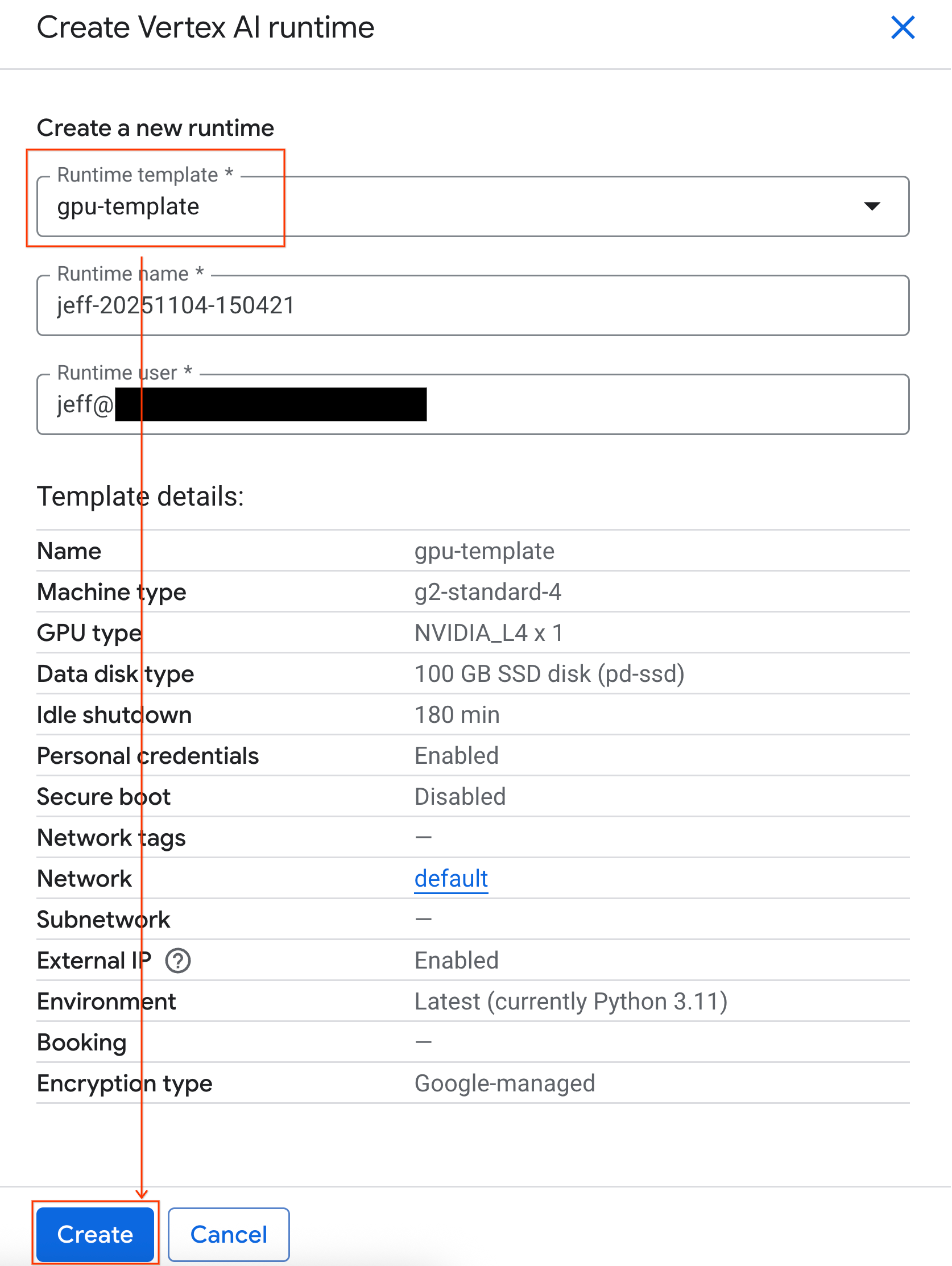
- W sekcji Szablon środowiska wykonawczego wybierz opcję
gpu-template. Kliknij Utwórz i poczekaj na uruchomienie środowiska wykonawczego.
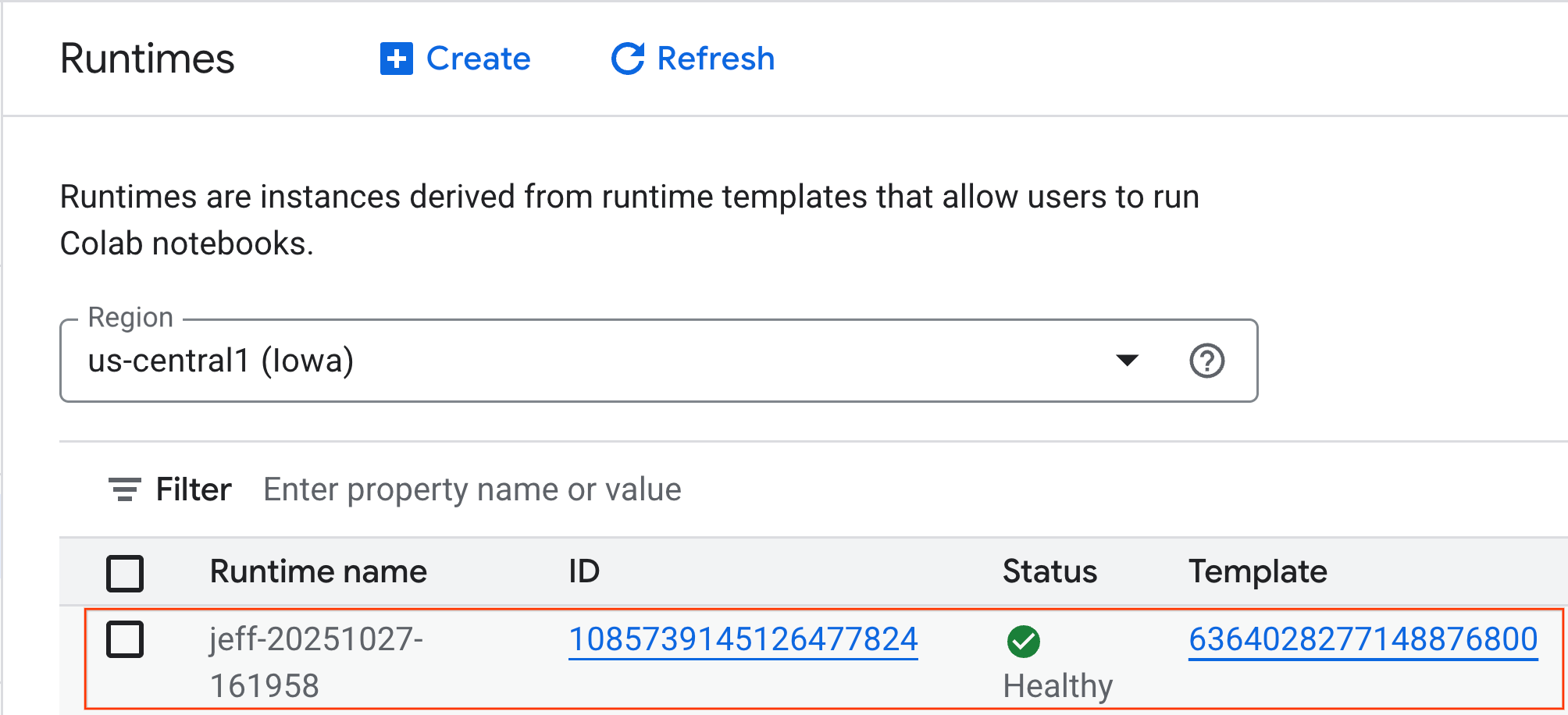
- Po kilku minutach zobaczysz dostępny czas działania.
6. Konfigurowanie notatnika
Infrastruktura już działa, więc musisz zaimportować notatnik modułu i połączyć go ze środowiskiem wykonawczym.
Importowanie notatnika
- W Colab Enterprise kliknij Moje notatniki, a następnie Importuj.
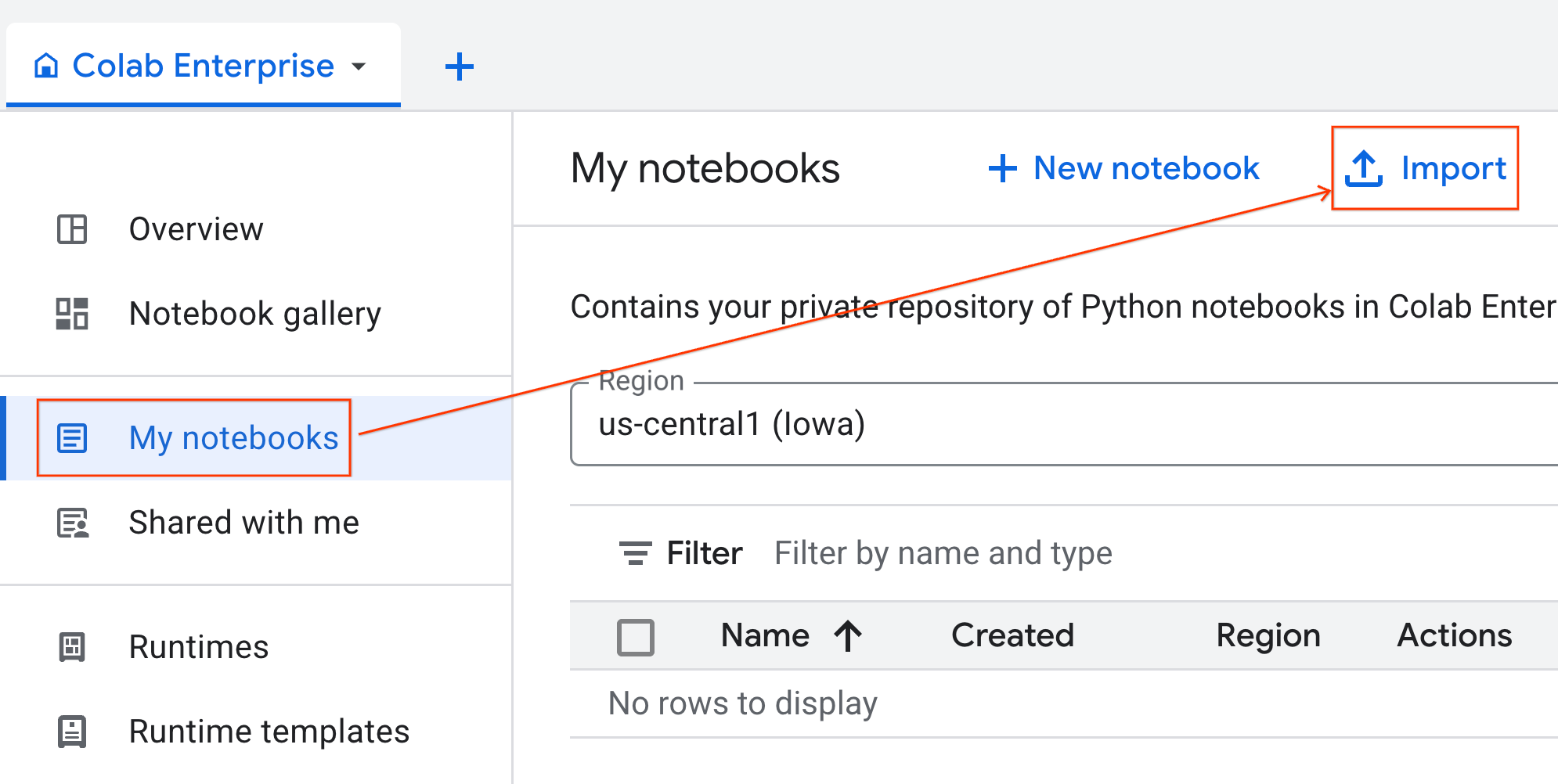
- Zaznacz opcję URL i wpisz ten adres URL:
https://github.com/GoogleCloudPlatform/ai-ml-recipes/blob/main/notebooks/analytics/gpu_accelerated_analytics.ipynb
- Kliknij Importuj. Colab Enterprise skopiuje notatnik z GitHuba do Twojego środowiska.
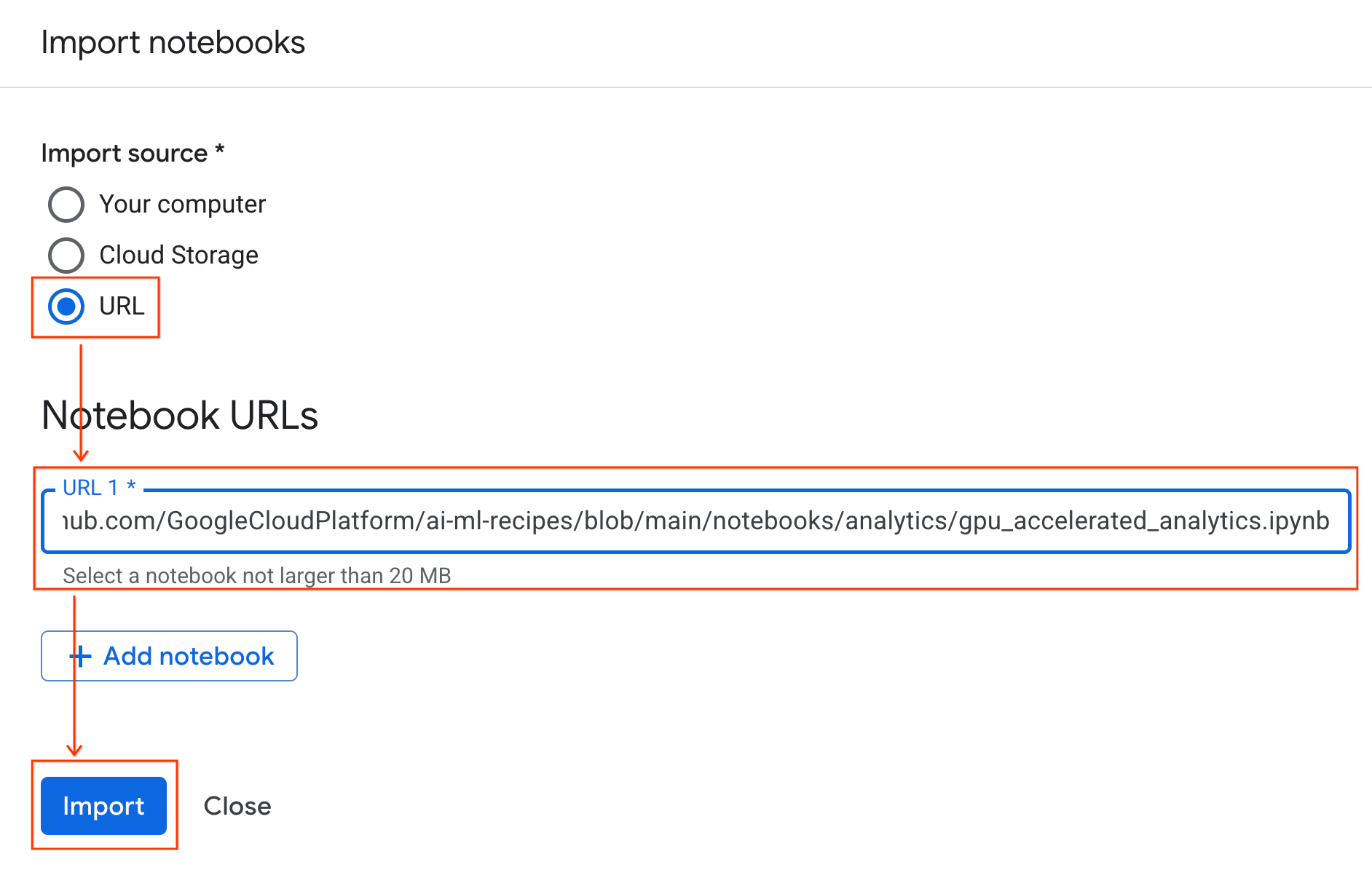
Połącz się ze środowiskiem wykonawczym
- Otwórz nowo zaimportowany notatnik.
- Kliknij strzałkę w dół obok opcji Połącz.
- Kliknij Połącz ze środowiskiem wykonawczym.
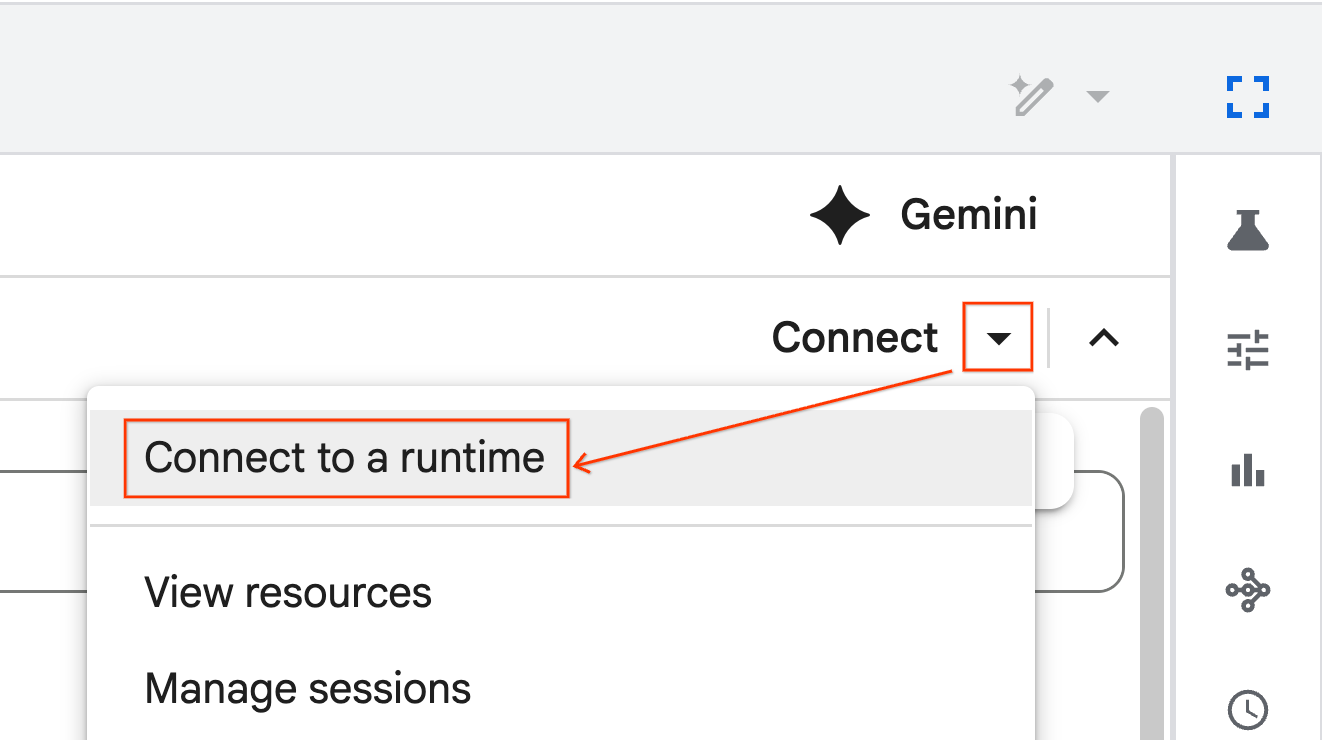
- Użyj menu i wybierz utworzone wcześniej środowisko wykonawcze.
- Kliknij Połącz.
Notatnik jest teraz połączony ze środowiskiem wykonawczym z obsługą GPU. Teraz możesz zacząć wykonywać zapytania.
7. Przygotowywanie zbioru danych o taksówkach w Nowym Jorku
W tym ćwiczeniu użyjemy danych o przejazdach taksówkami i limuzynami z komisji NYC Taxi & Limousine Commission (TLC).
Zbiór danych zawiera poszczególne rekordy przejazdów żółtymi taksówkami w Nowym Jorku i obejmuje takie pola jak:
- daty, godziny i miejsca odbioru i zwrotu;
- Dystans podróży
- Szczegółowe kwoty opłat
- Liczba pasażerów
Pobierz dane
Następnie pobierz dane o podróży za cały 2024 r. Dane są przechowywane w formacie plików Parquet.
Ten blok kodu wykonuje te czynności:
- Określa zakres lat i miesięcy do pobrania.
- Tworzy lokalny katalog o nazwie
nyc_taxi_data, w którym będą przechowywane pliki. - Przechodzi przez każdy miesiąc, pobiera odpowiedni plik Parquet, jeśli jeszcze nie istnieje, i zapisuje go w katalogu.
Aby zebrać dane i zapisać je w środowisku wykonawczym, uruchom w notatniku ten kod:
from tqdm import tqdm
import requests
import time
import os
YEAR = 2024
DATA_DIR = "nyc_taxi_data"
os.makedirs(DATA_DIR, exist_ok=True)
print(f"Checking/Downloading files for {YEAR}...")
for month in tqdm(range(1, 13), unit="file"):
# Define standardized filename for both local path and URL
file_name = f"yellow_tripdata_{YEAR}-{month:02d}.parquet"
local_path = os.path.join(DATA_DIR, file_name)
url = f"https://d37ci6vzurychx.cloudfront.net/trip-data/{file_name}"
if not os.path.exists(local_path):
try:
with requests.get(url, stream=True) as response:
response.raise_for_status()
with open(local_path, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
time.sleep(1)
except requests.exceptions.HTTPError as e:
print(f"\nSkipping {file_name}: {e}")
if os.path.exists(local_path):
os.remove(local_path)
print("\nDownload complete.")
8. Przeglądanie danych o przejazdach taksówką
Po pobraniu zbioru danych możesz przeprowadzić wstępną eksploracyjną analizę danych (EDA). Celem EDA jest zrozumienie struktury danych, znalezienie anomalii i odkrycie potencjalnych wzorców.
Wczytywanie danych z jednego miesiąca
Zacznij od wczytania danych z jednego miesiąca. Zapewnia to wystarczająco dużą próbę (ponad 3 miliony wierszy), aby była miarodajna, a jednocześnie utrzymuje wykorzystanie pamięci na poziomie umożliwiającym interaktywną analizę.
import pandas as pd
import glob
# Load the last month of the downloaded data
df = pd.read_parquet("nyc_taxi_data/yellow_tripdata_2024-12.parquet")
df.head()
Pobieranie statystyk podsumowujących
Użyj metody .describe(), aby wygenerować ogólne statystyki podsumowujące dla kolumn numerycznych. To świetny pierwszy krok do wykrywania potencjalnych problemów z jakością danych, takich jak nieoczekiwane wartości minimalne lub maksymalne.
df.describe().round(2)

Sprawdzanie jakości danych
Dane wyjściowe z .describe() natychmiast ujawniają problem. Zwróć uwagę, że wartość min w przypadku tpep_pickup_datetime i tpep_dropoff_datetime jest w roku 2008, co nie ma sensu w przypadku zbioru danych z 2024 r.
To przykład, dlaczego zawsze warto sprawdzać dane. Możesz to dokładniej sprawdzić, sortując ramkę danych, aby znaleźć dokładne wiersze zawierające te daty odstające.
# Sort by the dropoff datetime to see the oldest records
df.sort_values("tpep_pickup_datetime").head()
Wizualizacja rozkładów danych
Następnie możesz utworzyć histogramy kolumn numerycznych, aby wizualizować ich rozkłady. Pomaga to zrozumieć rozkład i asymetrię cech takich jak trip_distance i fare_amount. Funkcja .hist() to szybki sposób na wykreślenie histogramów dla wszystkich kolumn numerycznych w obiekcie DataFrame.
_ = df.hist(figsize=(20, 20))
Na koniec wygeneruj macierz punktową, aby wizualizować relacje między kilkoma kluczowymi kolumnami. Wykreślanie milionów punktów jest powolne i może zaciemniać wzorce, dlatego użyj funkcji .sample(),aby utworzyć wykres na podstawie losowej próbki 100 000 wierszy.
_ = pd.plotting.scatter_matrix(
df[['passenger_count', 'trip_distance', 'tip_amount', 'total_amount']].sample(100_000),
diagonal="kde",
figsize=(15, 15)
)
9. Dlaczego warto używać formatu pliku Parquet?
Zbiór danych o taksówkach w Nowym Jorku jest udostępniany w formacie Apache Parquet. Jest to celowy wybór dokonany z myślą o analizach na dużą skalę. Format Parquet ma kilka zalet w porównaniu z innymi typami plików, np. CSV:
- Wydajny i szybki: format kolumnowy Parquet jest bardzo wydajny w zakresie przechowywania i odczytywania danych. Obsługuje nowoczesne metody kompresji, które zmniejszają rozmiar plików i znacznie przyspieszają operacje wejścia/wyjścia, zwłaszcza na procesorach graficznych.
- Zachowuje schemat: Parquet przechowuje typy danych w metadanych pliku. Podczas odczytywania pliku nie musisz zgadywać typów danych.
- Umożliwia selektywne odczytywanie: struktura kolumnowa pozwala odczytywać tylko te kolumny, które są potrzebne do analizy. Może to znacznie zmniejszyć ilość danych, które musisz wczytać do pamięci.
Poznaj funkcje Parquet
Przyjrzyjmy się 2 z tych zaawansowanych funkcji na przykładzie jednego z pobranych plików.
Sprawdzanie metadanych bez wczytywania pełnego zbioru danych
Pliku Parquet nie można wyświetlić w standardowym edytorze tekstu, ale możesz łatwo sprawdzić jego schemat i metadane bez wczytywania danych do pamięci. Jest to przydatne, gdy chcesz szybko poznać strukturę pliku.
from pyarrow.parquet import ParquetFile
import pyarrow as pa
# Open one of the downloaded files
pf = ParquetFile('nyc_taxi_data/yellow_tripdata_2024-12.parquet')
# Print the schema
print("File Schema:")
print(pf.schema)
# Print the file metadata
print("\nFile Metadata:")
print(pf.metadata)
Odczytywanie tylko potrzebnych kolumn
Załóżmy, że musisz przeanalizować tylko odległość podróży i kwoty opłat. W przypadku formatu Parquet możesz wczytać tylko te kolumny, co jest znacznie szybsze i bardziej efektywne pod względem pamięci niż wczytywanie całego obiektu DataFrame.
import pandas as pd
# Read only four specific columns from the Parquet file
df_subset = pd.read_parquet(
'nyc_taxi_data/yellow_tripdata_2024-12.parquet',
columns=['passenger_count', 'trip_distance', 'tip_amount', 'total_amount']
)
df_subset.head()
10. Przyspieszanie biblioteki pandas za pomocą NVIDIA cuDF
NVIDIA CUDA for DataFrames (cuDF) to biblioteka open source z akceleracją GPU, która umożliwia interakcję z ramkami danych. cuDF pozwala wykonywać typowe operacje na danych, takie jak filtrowanie, łączenie i grupowanie, na procesorze graficznym z wykorzystaniem równoległości na dużą skalę.
Kluczową funkcją, której użyjesz w tym laboratorium, jest tryb akceleratora cudf.pandas. Gdy włączysz tę opcję, Twój standardowy kod pandas zostanie automatycznie przekierowany do korzystania z jąder cuDF opartych na GPU, a Ty nie będziesz musiał(a) wprowadzać żadnych zmian w kodzie.
Włączanie akceleracji GPU
Aby używać NVIDIA cuDF w notatniku Colab Enterprise, przed zaimportowaniem pandas musisz wczytać jego magiczne rozszerzenie.
Najpierw sprawdź standardową bibliotekę pandas. Zwróć uwagę, że dane wyjściowe pokazują ścieżkę do domyślnej instalacji pandas.
import pandas as pd
pd # Note the output for the standard pandas library
Teraz wczytaj rozszerzenie cudf.pandas i ponownie zaimportuj pandas. Obserwuj, jak zmienia się wynik działania modułu pd. Potwierdza to, że wersja przyspieszana przez GPU jest już aktywna.
%load_ext cudf.pandas
import pandas as pd
pd # Note the new output, indicating cudf.pandas is active
Inne sposoby włączania cudf.pandas
Polecenie magiczne (%load_ext) to najprostsza metoda w przypadku notatnika, ale akcelerator możesz też włączyć w innych środowiskach:
- W skryptach Pythona: przed importem
pandaswywołaj funkcjeimport cudf.pandasicudf.pandas.install(). - W środowiskach innych niż notatniki: uruchom skrypt za pomocą
python -m cudf.pandas your_script.py.
11. Porównywanie wydajności procesora i procesora graficznego
Teraz najważniejsza część: porównanie wydajności standardowego pandas na procesorze z cudf.pandas na procesorze graficznym.
Aby zapewnić całkowicie sprawiedliwą wartość bazową dla procesora, musisz najpierw zresetować środowisko wykonawcze Colab. Spowoduje to usunięcie wszystkich akceleratorów GPU, które mogły być włączone w poprzednich sekcjach. Możesz ponownie uruchomić środowisko wykonawcze, uruchamiając poniższą komórkę lub wybierając Uruchom ponownie sesję w menu Środowisko wykonawcze.
import IPython
IPython.Application.instance().kernel.do_shutdown(True)
Zdefiniuj potok analityczny
Teraz, gdy środowisko jest czyste, zdefiniujesz funkcję testu porównawczego. Ta funkcja umożliwia uruchomienie dokładnie tego samego potoku – wczytywania, sortowania i podsumowywania – przy użyciu dowolnego modułu pandas, który do niej przekażesz.
import time
import glob
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
def run_analytics_pipeline(pd_module):
"""Loads, sorts, and summarizes data using the provided pandas module."""
timings = {}
# 1. Load all 2024 Parquet files from the directory
t0 = time.time()
df = pd_module.concat(
[pd_module.read_parquet(f) for f in glob.glob("nyc_taxi_data/*_2024*.parquet")],
ignore_index=True
)
timings["load"] = time.time() - t0
# 2. Sort the data by multiple columns
t0 = time.time()
df = df.sort_values(
['tpep_pickup_datetime', 'trip_distance', 'passenger_count'],
ascending=[False, True, False]
)
timings["sort"] = time.time() - t0
# 3. Perform a groupby and aggregation
t0 = time.time()
df['tpep_pickup_datetime'] = pd_module.to_datetime(df['tpep_pickup_datetime'])
_ = (
df.loc[df.tpep_pickup_datetime > '2024-11-01']
.groupby(['VendorID', 'tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
timings["summarize"] = time.time() - t0
return timings
Przeprowadź porównanie
Najpierw uruchom potok za pomocą standardowego pandas na procesorze. Następnie włącz cudf.pandas i uruchom go ponownie na procesorze graficznym.
# --- Run on CPU ---
print("Running analytics pipeline on CPU...")
# Ensure we are using standard pandas
import pandas as pd
assert "cudf" not in str(pd), "Error: cuDF is still active. Please restart the kernel."
cpu_times = run_analytics_pipeline(pd)
print(f"CPU times: {cpu_times}")
# --- Run on GPU ---
print("\nEnabling cudf.pandas and running on GPU...")
# Load the extension
%load_ext cudf.pandas
import pandas as gpu_pd
gpu_times = run_analytics_pipeline(gpu_pd)
print(f"GPU times: {gpu_times}")
Zwizualizuj wyniki
Na koniec wizualizuj różnicę. Poniższy kod oblicza przyspieszenie dla każdej operacji i wykreśla je obok siebie.
# Create a DataFrame for plotting
results_df = pd.DataFrame([cpu_times, gpu_times], index=["CPU", "GPU"]).T
total_cpu_time = results_df['CPU'].sum()
total_gpu_time = results_df['GPU'].sum()
speedup = total_cpu_time / total_gpu_time
print("--- Performance Results ---")
print(results_df)
print(f"\nTotal CPU Time: {total_cpu_time:.2f} seconds")
print(f"Total GPU Time: {total_gpu_time:.2f} seconds")
print(f"Overall Speedup: {speedup:.2f}x")
# Plot the results
fig, ax = plt.subplots(figsize=(10, 6))
results_df.plot(kind='bar', ax=ax, color={"CPU": "tab:blue", "GPU": "tab:green"})
ax.set_ylabel("Time (seconds)")
ax.set_title(f"CPU vs. GPU Runtimes (Overall Speedup: {speedup:.2f}x)", fontsize=14)
ax.tick_params(axis='x', rotation=0)
# Add numerical labels to the bars
for container in ax.containers:
ax.bar_label(container, fmt="%.2f", padding=3)
plt.tight_layout()
plt.show()
Przykładowe wyniki:
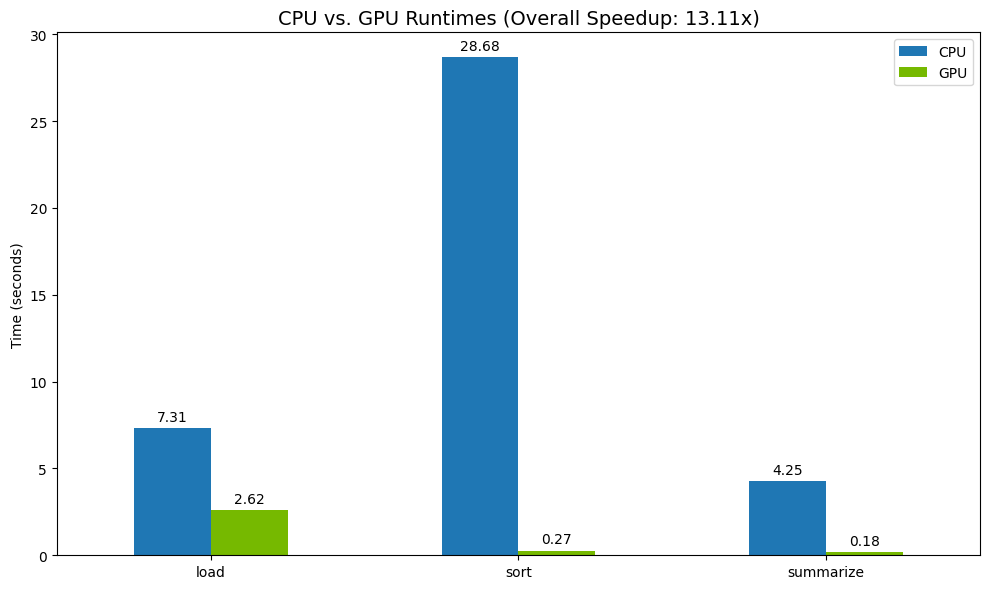
GPU zapewnia wyraźny wzrost szybkości w porównaniu z CPU.
12. Profilowanie kodu w celu znalezienia wąskich gardeł
Nawet przy akceleracji GPU niektóre operacje pandas mogą być wykonywane na procesorze, jeśli nie są jeszcze obsługiwane przez cuDF. Te „rezerwy procesora” mogą stać się wąskim gardłem wydajności.
Aby pomóc Ci w identyfikacji tych obszarów, cudf.pandas zawiera 2 wbudowane profilery. Dzięki nim możesz dokładnie sprawdzić, które części kodu są uruchamiane na procesorze graficznym, a które na procesorze.
%%cudf.pandas.profile: użyj tego podsumowania, aby przedstawić ogólny opis kodu z podziałem na funkcje. To najlepszy sposób na szybkie sprawdzenie, które operacje są wykonywane na którym urządzeniu.%%cudf.pandas.line_profile: Użyj tej opcji, aby uzyskać szczegółową analizę wiersz po wierszu. To najlepsze narzędzie do wskazywania dokładnych wierszy kodu, które powodują powrót do procesora.
Używaj tych profilerów jako „magicznych komórek” u góry komórki notatnika.
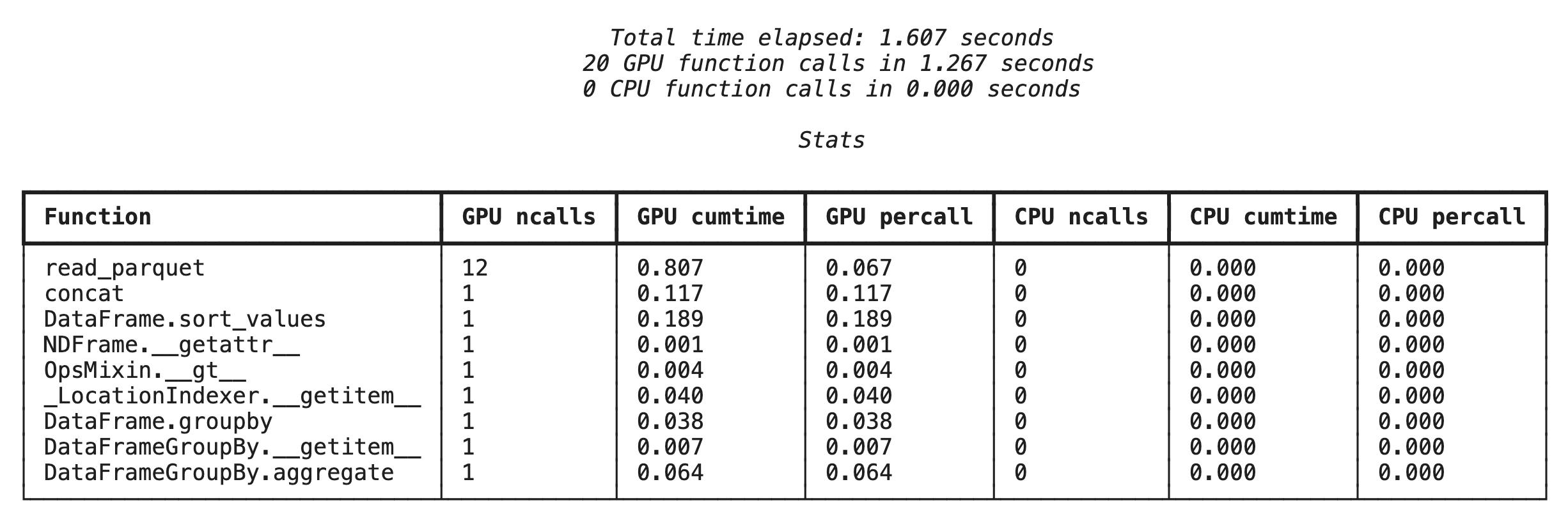
Profilowanie na poziomie funkcji za pomocą %%cudf.pandas.profile
Najpierw uruchom profiler na poziomie funkcji w tej samej ścieżce analitycznej co w poprzedniej sekcji. Dane wyjściowe zawierają tabelę z każdą wywołaną funkcją, urządzeniem, na którym została uruchomiona (GPU lub CPU), oraz liczbą wywołań.
%load_ext cudf.pandas
import pandas as pd
import glob
pd.DataFrame({"a": [1]})
Po upewnieniu się, że cudf.pandas jest aktywny, możesz uruchomić profil.
%%cudf.pandas.profile
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*2024*.parquet")], ignore_index=True)
df = df.sort_values(['tpep_pickup_datetime', 'trip_distance', 'passenger_count'], ascending=[False, True, False])
summary = (
df
.loc[(df.tpep_pickup_datetime > '2024-11-01')]
.groupby(['VendorID','tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
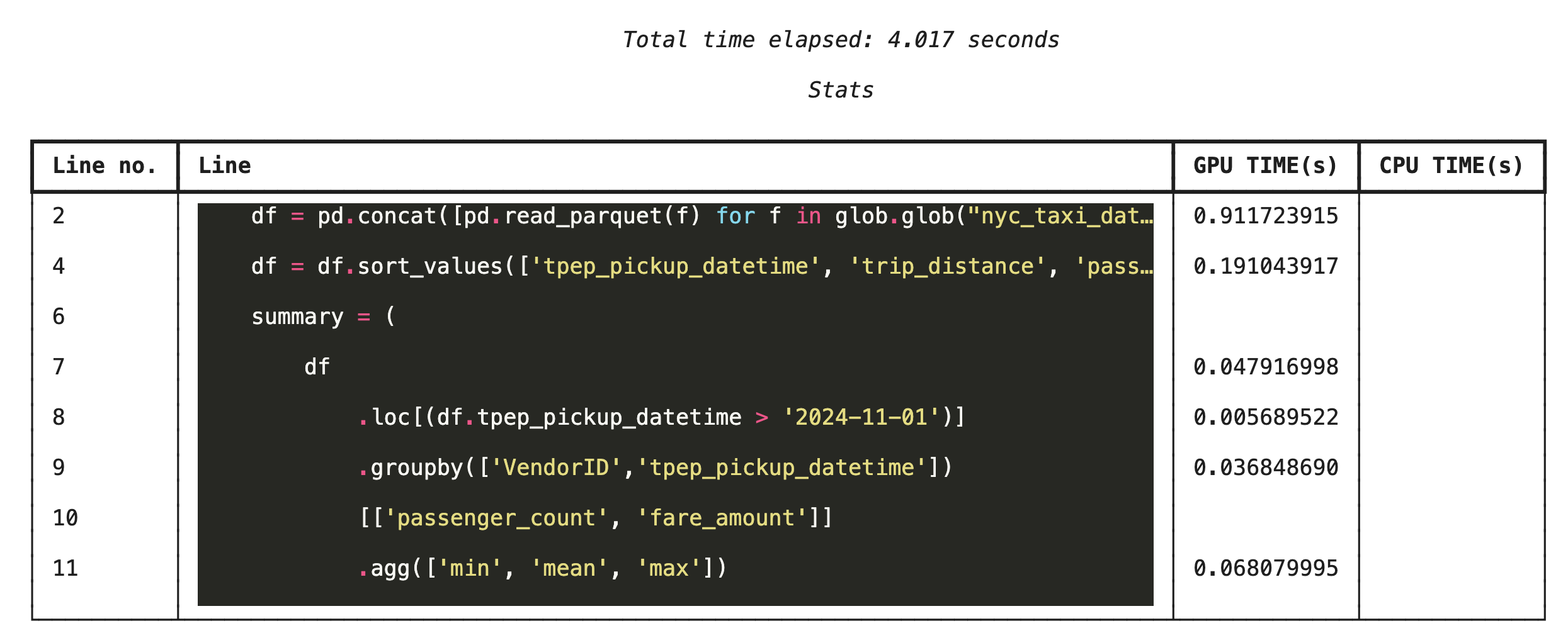
Profilowanie wiersz po wierszu za pomocą %%cudf.pandas.line_profile
Następnie uruchom profiler na poziomie wiersza. Dzięki temu uzyskasz znacznie bardziej szczegółowy widok, który pokazuje, ile czasu każda linia kodu spędziła na wykonywaniu obliczeń na GPU w porównaniu z CPU. To najskuteczniejszy sposób na znalezienie konkretnych wąskich gardeł, które można zoptymalizować.
%%cudf.pandas.line_profile
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*2024*.parquet")], ignore_index=True)
df = df.sort_values(['tpep_pickup_datetime', 'trip_distance', 'passenger_count'], ascending=[False, True, False])
summary = (
df
.loc[(df.tpep_pickup_datetime > '2024-11-01')]
.groupby(['VendorID','tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
Profilowanie z wiersza poleceń
Te profilerzy są też dostępne w wierszu poleceń, co jest przydatne w przypadku testów automatycznych i profilowania skryptów w Pythonie.
W interfejsie wiersza poleceń możesz użyć tych elementów:
python -m cudf.pandas --profile your_script.pypython -m cudf.pandas --line_profile your_script.py
13. Integracja z Google Cloud Storage
Google Cloud Storage (GCS) to skalowalna i trwała usługa obiektowej pamięci masowej. Gdy korzystasz z Colab Enterprise, GCS to świetne miejsce do przechowywania zbiorów danych, punktów kontrolnych modelu i innych artefaktów.
Środowisko wykonawcze Colab Enterprise ma uprawnienia niezbędne do odczytywania i zapisywania danych bezpośrednio w zasobnikach GCS, a te operacje są przyspieszane przez GPU, co zapewnia maksymalną wydajność.
Tworzenie zasobnika GCS
Najpierw utwórz nowy zasobnik GCS. Nazwy zasobników GCS są globalnie niepowtarzalne, więc dołącz do nazwy identyfikator UUID.
from google.cloud import storage
import uuid
unique_suffix = uuid.uuid4().hex[:12]
bucket_name = f'nyc-taxi-codelab-{unique_suffix}'
project_id = storage.Client().project
client = storage.Client()
try:
bucket = client.create_bucket(bucket_name)
print(f"Successfully created bucket: gs://{bucket.name}")
except Exception as e:
print(f"Bucket creation failed. You may already own it or the name is taken: {e}")
Zapisywanie danych bezpośrednio w GCS
Teraz zapisz ramkę danych bezpośrednio w nowym zasobniku GCS. Jeśli zmienna df nie jest dostępna w poprzednich sekcjach, kod najpierw wczytuje dane z jednego miesiąca.
%%cudf.pandas.line_profile
# Ensure the DataFrame exists before saving to GCS
if 'df' not in locals():
print("DataFrame not found, loading a sample file...")
df = pd.read_parquet('nyc_taxi_data/yellow_tripdata_2024-12.parquet')
print(f"Writing data to gs://{bucket_name}/nyc_taxi_data.parquet...")
df.to_parquet(f"gs://{bucket_name}/nyc_taxi_data.parquet", index=False)
print("Write operation complete.")
Sprawdź plik w GCS
Aby sprawdzić, czy dane znajdują się w GCS, otwórz zasobnik. Ten kod tworzy klikalny link.
from IPython.display import Markdown
gcs_url = f"https://console.cloud.google.com/storage/browser/{bucket_name}?project={project_id}"
Markdown(f'**[Click here to view your GCS bucket in the Google Cloud Console]({gcs_url})**')
Odczytywanie danych bezpośrednio z GCS
Na koniec odczytaj dane bezpośrednio ze ścieżki GCS do struktury DataFrame. Ta operacja jest też akcelerowana przez GPU, co pozwala szybko wczytywać duże zbiory danych z pamięci w chmurze.
%%cudf.pandas.line_profile
print(f"Reading data from gs://{bucket_name}/nyc_taxi_data.parquet...")
df_from_gcs = pd.read_parquet(f"gs://{bucket_name}/nyc_taxi_data.parquet")
df_from_gcs.head()
14. Czyszczenie
Aby uniknąć nieoczekiwanych opłat na koncie Google Cloud, musisz wyczyścić utworzone zasoby.
Usuń pobrane dane:
# Permanately delete the GCS bucket
print(f"Deleting GCS bucket: gs://{bucket_name}...")
!gsutil rm -r -f gs://{bucket_name}
print("Bucket deleted.")
# Remove NYC taxi dataset on the Colab runtime
print("Deleting local 'nyc_taxi_data' directory...")
!rm -rf nyc_taxi_data
print("Local files deleted.")
Wyłączanie środowiska wykonawczego Colab
- W konsoli Google Cloud otwórz stronę Colab Enterprise Runtimes (Środowiska wykonawcze).
- W menu Region wybierz region, w którym znajduje się środowisko wykonawcze.
- Wybierz czas działania, który chcesz usunąć.
- Kliknij Usuń.
- Kliknij Potwierdź.
Usuwanie notatnika
- W konsoli Google Cloud otwórz stronę Colab Enterprise Moje notatniki.
- W menu Region wybierz region, w którym znajduje się Twój notatnik.
- Wybierz notatnik, który chcesz usunąć.
- Kliknij Usuń.
- Kliknij Potwierdź.
15. Gratulacje
Gratulacje! Udało Ci się przyspieszyć przepływ pracy analitycznej w pandas za pomocą NVIDIA cuDF w Colab Enterprise. Dowiedzieliśmy się, jak konfigurować środowiska wykonawcze z obsługą GPU, włączać cudf.pandas w celu przyspieszenia bez zmiany kodu, profilować kod pod kątem wąskich gardeł i integrować się z Google Cloud Storage.