
1. Introdução
Neste codelab, você vai aprender a acelerar seus fluxos de trabalho de análise de dados em grandes conjuntos de dados usando GPUs NVIDIA e bibliotecas de código aberto no Google Cloud. Você vai começar otimizando sua infraestrutura e depois aprender a aplicar a aceleração de GPU sem mudar o código.
Você vai se concentrar no pandas, uma biblioteca de manipulação de dados conhecida, e aprender a acelerar o processo usando a biblioteca cuDF da NVIDIA. A melhor parte é que você pode aproveitar essa aceleração de GPU sem mudar o código pandas atual.
O que você vai aprender
- Entenda o Colab Enterprise no Google Cloud.
- Personalize um ambiente de execução do Colab com configurações específicas de GPU, CPU e memória.
- Acelere o
pandassem alterar o código usando ocuDFda NVIDIA. - Crie um perfil do seu código para identificar e otimizar gargalos de desempenho.
A página seguinte inclui créditos que você pode usar para concluir o laboratório.
2. Por que acelerar o tratamento de dados?
A regra 80/20: por que a preparação de dados consome tanto tempo
A preparação de dados costuma ser a fase mais demorada de um projeto de análise. Os cientistas e analistas de dados gastam uma grande parte do tempo limpando, transformando e estruturando dados antes de iniciar qualquer análise.
Felizmente, é possível acelerar bibliotecas de código aberto conhecidas, como pandas, Apache Spark e Polars em GPUs NVIDIA usando cuDF. Mesmo com essa aceleração, a preparação de dados continua demorada porque:
- Os dados de origem raramente estão prontos para análise:os dados do mundo real costumam ter inconsistências, valores ausentes e problemas de formatação.
- A qualidade de dados afeta o desempenho do modelo:dados de baixa qualidade podem tornar inúteis até mesmo os algoritmos mais sofisticados.
- A escala amplifica os problemas:problemas de dados aparentemente pequenos se tornam gargalos críticos ao trabalhar com milhões de registros.
3. Como escolher um ambiente de notebook
Embora muitos cientistas de dados estejam familiarizados com o Colab para projetos pessoais, o Colab Enterprise oferece uma experiência de notebook segura, colaborativa e integrada projetada para empresas.
No Google Cloud, você tem duas opções principais de ambientes de notebook gerenciados: o Colab Enterprise e o Gemini Enterprise Agent Platform Workbench. A escolha certa depende das prioridades do seu projeto.
Quando usar o Workbench da plataforma de agentes
Escolha o Agent Platform Workbench quando sua prioridade for controle e personalização avançada. É a opção ideal se você precisa:
- Gerenciar a infraestrutura e o ciclo de vida da máquina.
- Usar contêineres personalizados e configurações de rede.
- Integração com pipelines de MLOps e ferramentas personalizadas de ciclo de vida.
Quando usar o Colab Enterprise
Escolha o Colab Enterprise quando sua prioridade for configuração rápida, facilidade de uso e colaboração segura. É uma solução totalmente gerenciada que permite que sua equipe se concentre na análise em vez da infraestrutura.
O Colab Enterprise ajuda você a:
- Desenvolva fluxos de trabalho de ciência de dados que estejam intimamente ligados ao seu data warehouse. É possível abrir e gerenciar seus notebooks diretamente no BigQuery Studio.
- Treine modelos de machine learning e faça a integração com ferramentas de MLOps na plataforma de agentes.
- Aproveite uma experiência flexível e unificada. Um notebook do Colab Enterprise criado no BigQuery pode ser aberto e executado na plataforma de agentes e vice-versa.
Laboratório de hoje
Este codelab usa o Colab Enterprise para análise de dados acelerada.
Para saber mais sobre as diferenças, consulte a documentação oficial sobre como escolher a solução de notebook certa.
4. Configurar um modelo de ambiente de execução
No Colab Enterprise, conecte-se a um ambiente de execução com base em um modelo de ambiente de execução pré-configurado.
Um modelo de ambiente de execução é uma configuração reutilizável que especifica todo o ambiente do notebook, incluindo:
- Tipo de máquina (CPU, memória)
- Acelerador (tipo e contagem de GPU)
- Tamanho e tipo do disco
- Configurações de rede e políticas de segurança
- Regras de encerramento automático por inatividade
Por que os modelos de ambiente de execução são úteis
- Tenha um ambiente consistente:você e seus colegas de equipe têm o mesmo ambiente pronto para uso sempre que necessário, garantindo que seu trabalho seja repetível.
- Trabalhe com segurança por design:os modelos aplicam automaticamente as políticas de segurança da sua organização.
- Gerenciar custos com eficiência:recursos como GPUs e CPUs são pré-dimensionados no modelo, o que ajuda a evitar estouros de custos acidentais.
Criar um modelo de ambiente de execução
Configure um modelo de ambiente de execução reutilizável para o laboratório.
- No console do Google Cloud, acesse o Menu de navegação > Plataforma de agentes > Notebooks.
- No Colab Enterprise, clique em Modelos de ambiente de execução e selecione Novo modelo.
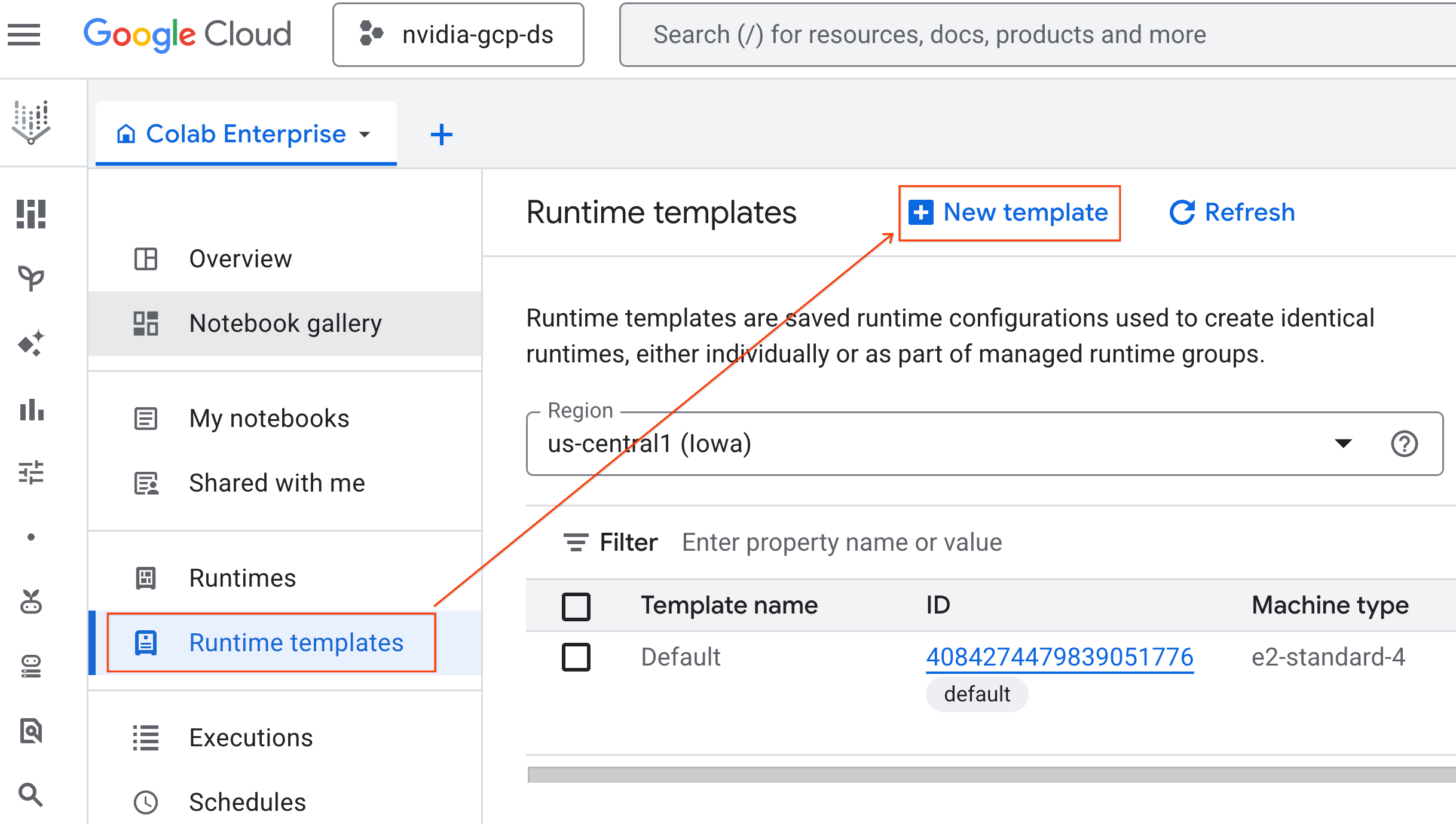
- Em Fundamentos do ambiente de execução:
- Defina o Nome de exibição como
gpu-template. - Defina a região de sua preferência.
- Defina o Nome de exibição como
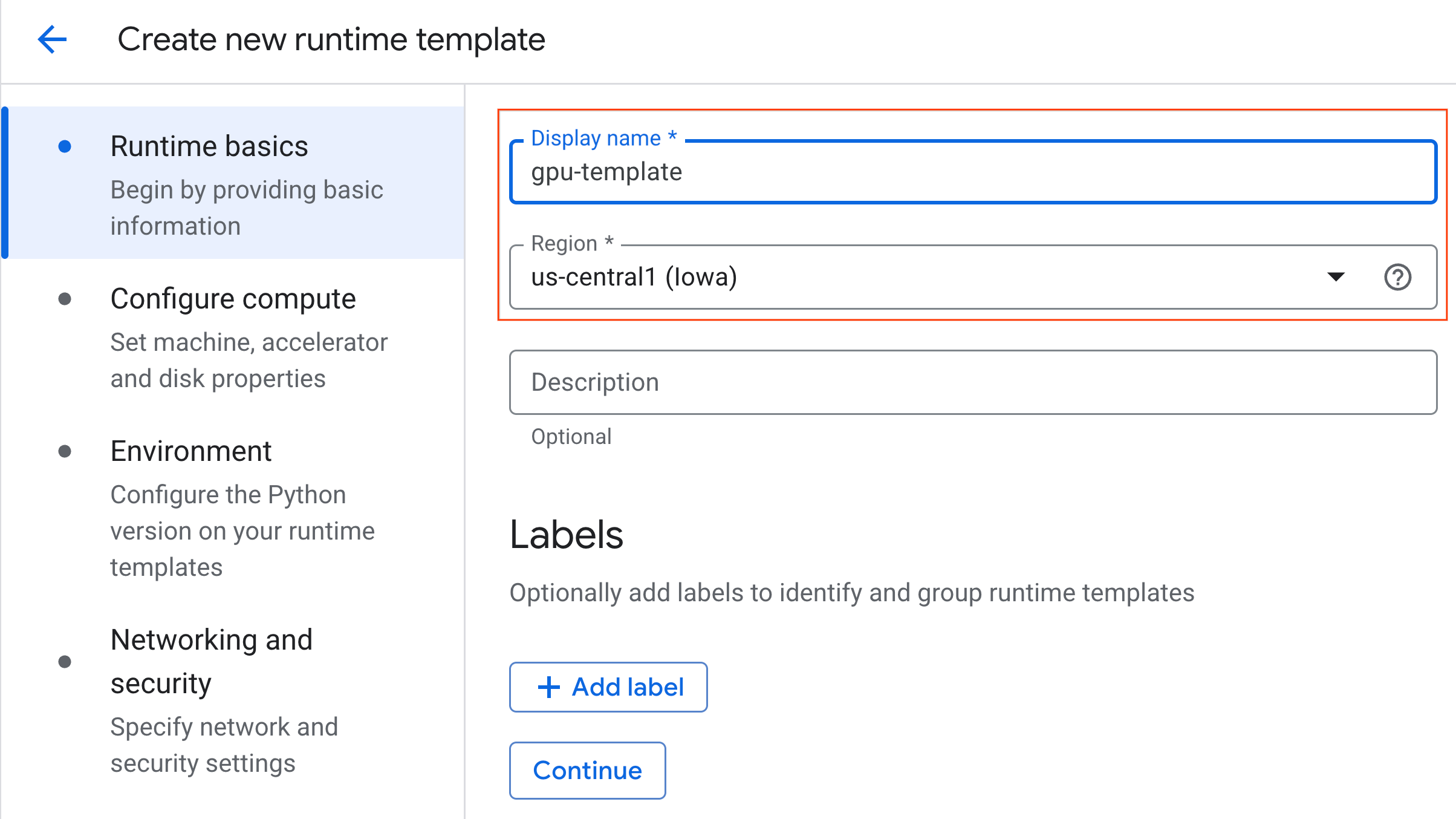
- Em Configurar computação:
- Defina o Tipo de máquina como
g2-standard-4. - Mantenha o Tipo de acelerador padrão como
NVIDIA L4com uma Contagem de aceleradores de 1. - Mude o Encerramento inativo para 60 minutos.
- Clique em Continuar.
- Defina o Tipo de máquina como
- Em Ambiente:
- Defina o ambiente como
Python 3.11
- Defina o ambiente como
- Clique em Criar para salvar o modelo de ambiente de execução. A página "Modelos de ambiente de execução" agora vai mostrar o novo modelo.
5. Iniciar um ambiente de execução
Com o modelo pronto, você pode criar um novo ambiente de execução.
- No Colab Enterprise, clique em Tempos de execução e selecione Criar.
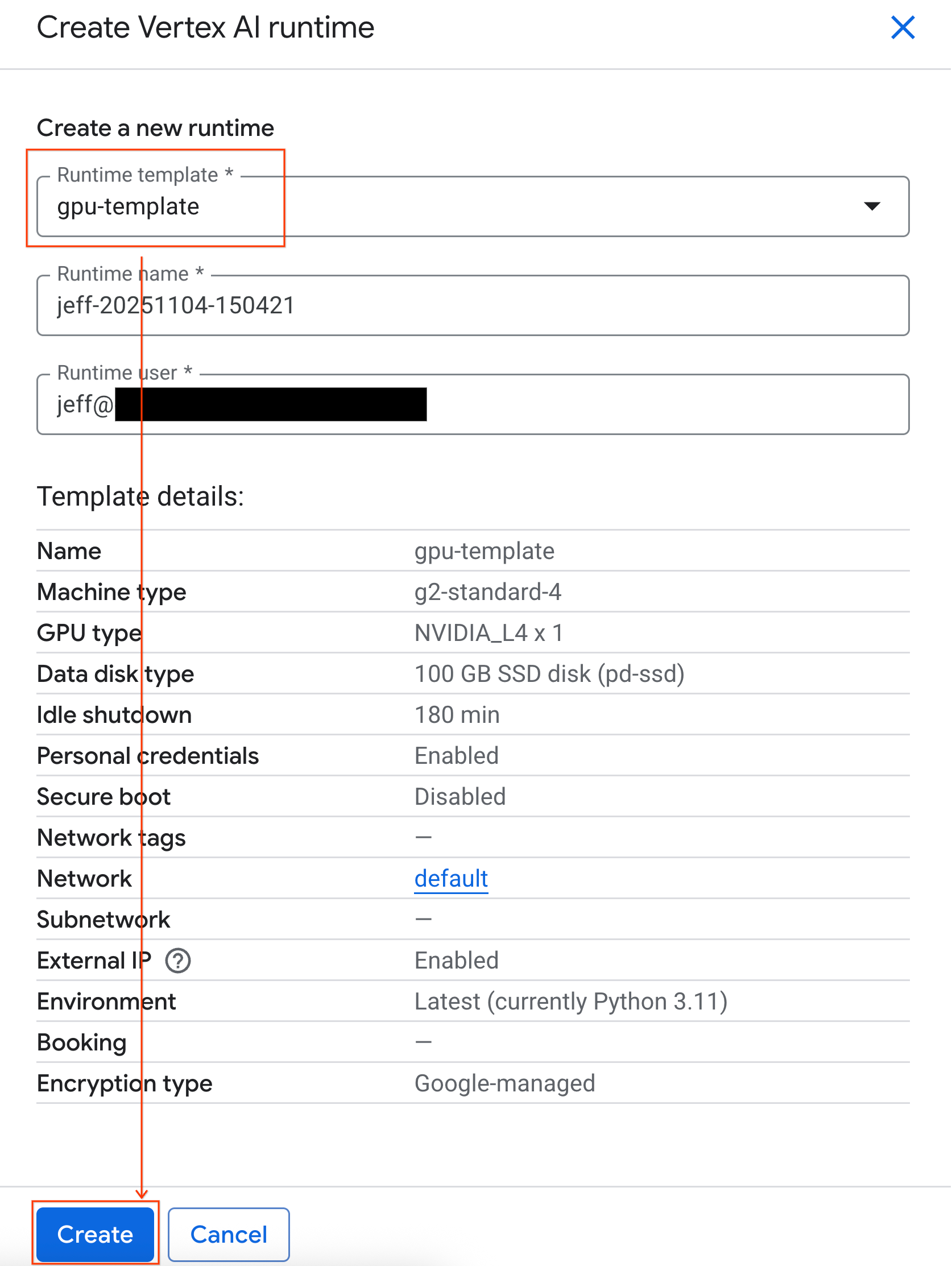
- Em Modelo de execução, selecione a opção
gpu-template. Clique em Criar e aguarde a inicialização do ambiente de execução.
- Depois de alguns minutos, o tempo de execução vai aparecer.
6. configurar o notebook
Agora que sua infraestrutura está em execução, importe o notebook do laboratório e conecte-o ao ambiente de execução.
Importar o notebook
- No Colab Enterprise, clique em Meus notebooks e em Importar.
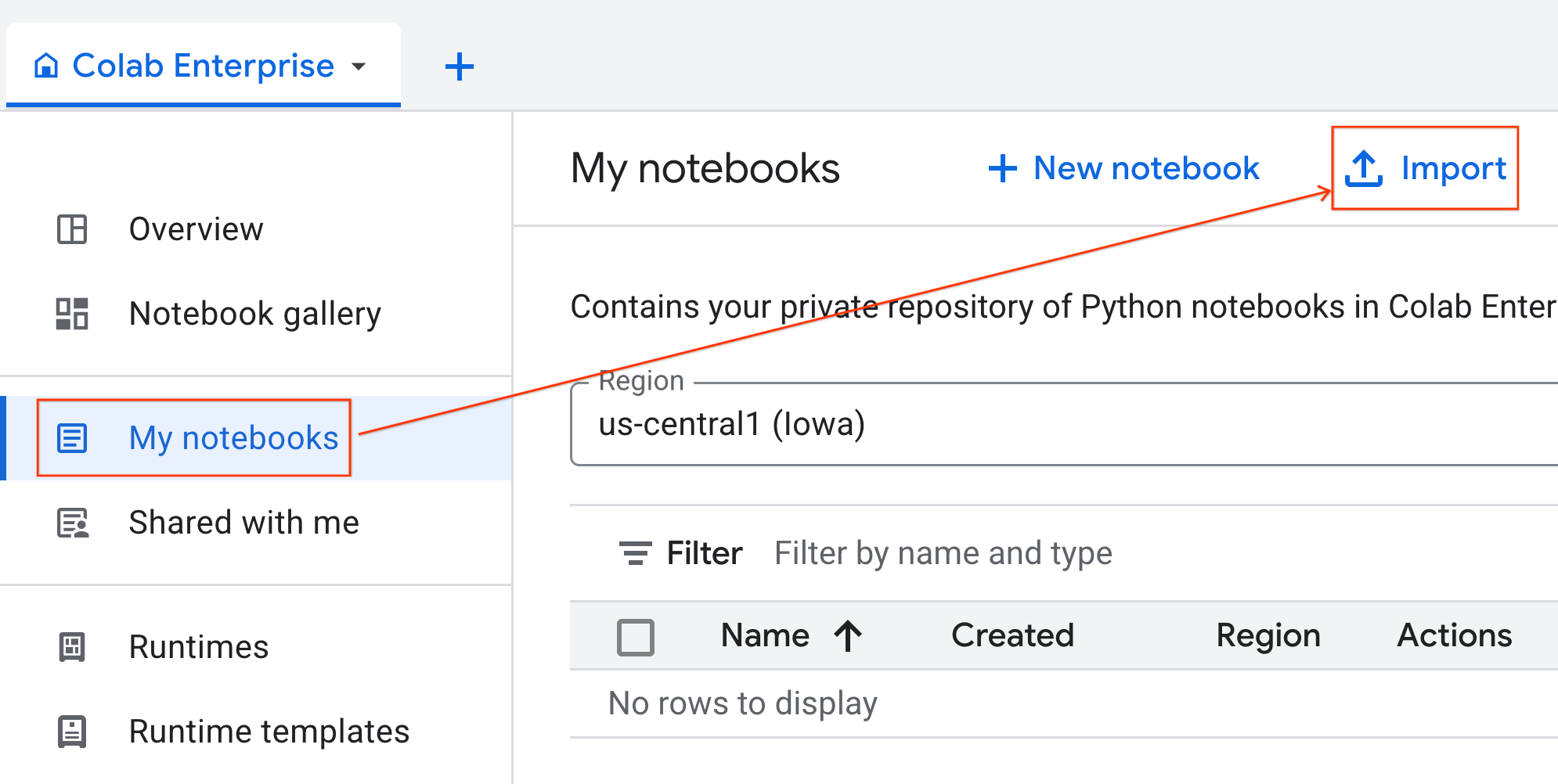
- Selecione o botão de opção URL e insira o seguinte URL:
https://github.com/GoogleCloudPlatform/ai-ml-recipes/blob/main/notebooks/analytics/gpu_accelerated_analytics.ipynb
- Clique em Importar. O Colab Enterprise vai copiar o notebook do GitHub para seu ambiente.
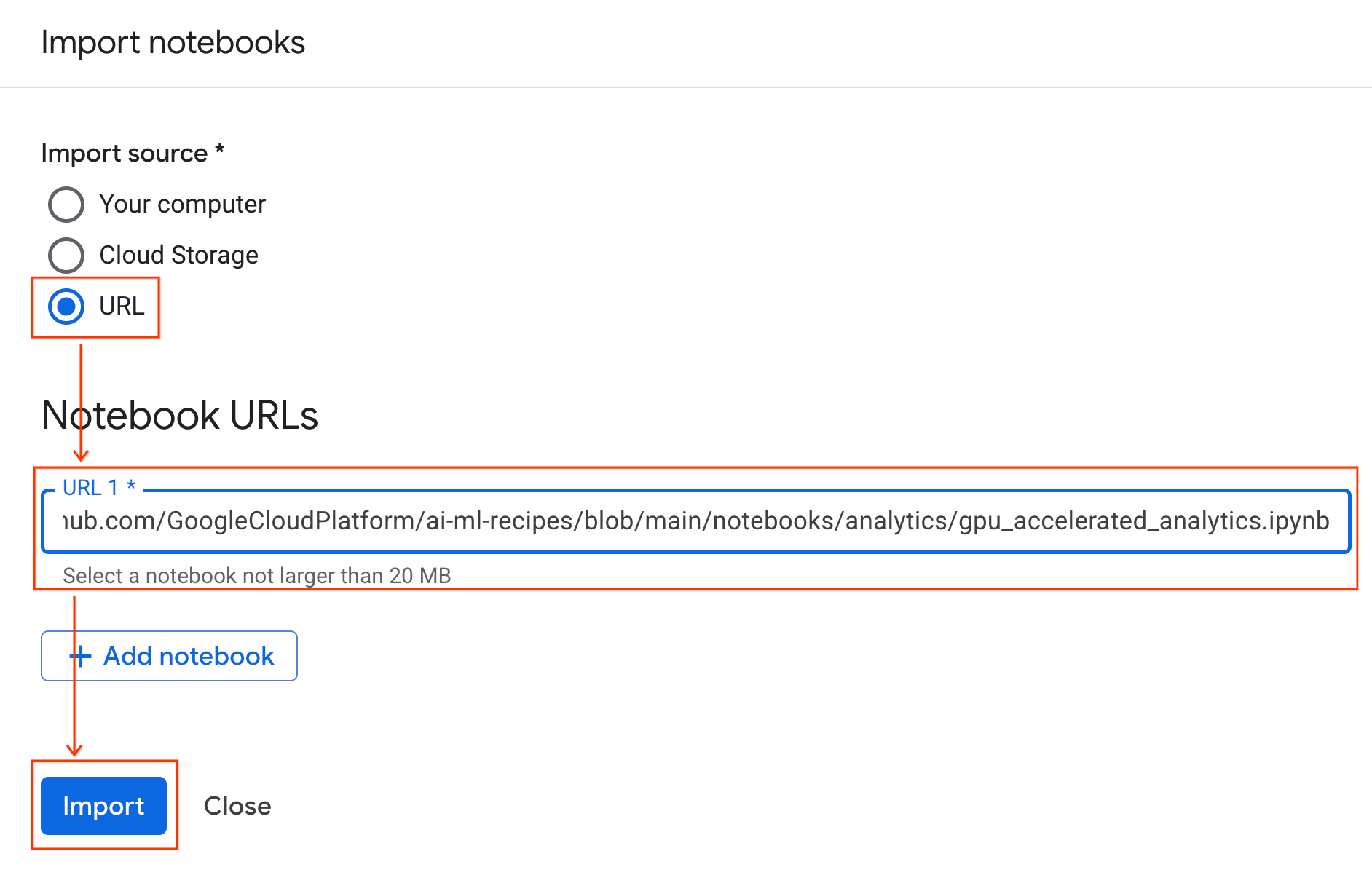
Conectar ao ambiente de execução
- Abra o notebook recém-importado.
- Clique na seta para baixo ao lado de Conectar.
- Selecione Conectar a um ambiente de execução.
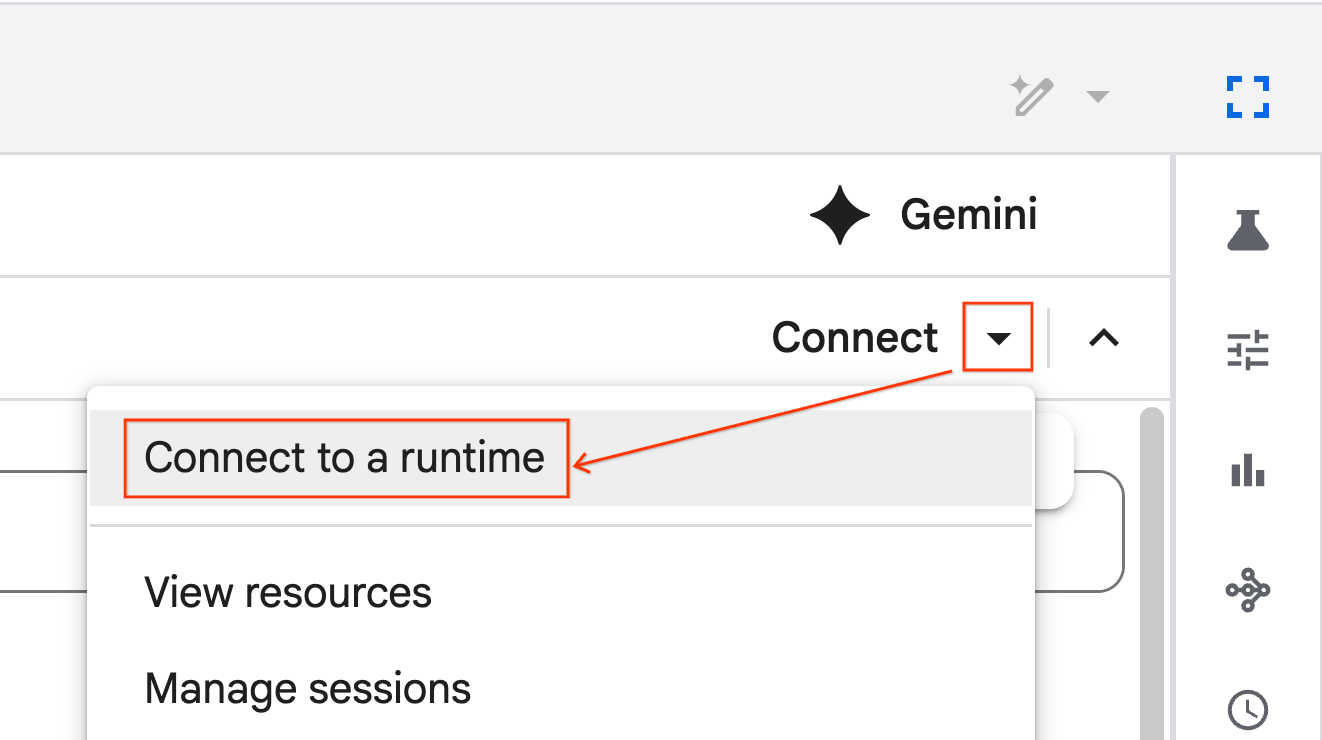
- Use o menu suspenso e selecione o ambiente de execução que você criou anteriormente.
- Clique em Conectar.
Seu notebook agora está conectado a um ambiente de execução ativado para GPU. Agora você pode começar a executar consultas.
7. Preparar o conjunto de dados de táxis de Nova York
Este codelab usa os dados de registro de viagens da Comissão de Táxis e Limusines (TLC, na sigla em inglês) de Nova York.
O conjunto de dados contém registros de viagens individuais de táxis amarelos na cidade de Nova York e inclui campos como:
- Datas, horários e locais de embarque e desembarque
- Distâncias da viagem
- Valores detalhados da tarifa
- Número de passageiros
Fazer download dos dados
Em seguida, baixe os dados de viagens de todo o ano de 2024. Os dados são armazenados no formato de arquivo Parquet.
O bloco de código a seguir executa estas etapas:
- Define o período de anos e meses para download.
- Cria um diretório local chamado
nyc_taxi_datapara armazenar os arquivos. - Faz um loop em cada mês, baixa o arquivo Parquet correspondente se ele ainda não existir e o salva no diretório.
Execute este código no notebook para coletar os dados e armazená-los no ambiente de execução:
from tqdm import tqdm
import requests
import time
import os
YEAR = 2024
DATA_DIR = "nyc_taxi_data"
os.makedirs(DATA_DIR, exist_ok=True)
print(f"Checking/Downloading files for {YEAR}...")
for month in tqdm(range(1, 13), unit="file"):
# Define standardized filename for both local path and URL
file_name = f"yellow_tripdata_{YEAR}-{month:02d}.parquet"
local_path = os.path.join(DATA_DIR, file_name)
url = f"https://d37ci6vzurychx.cloudfront.net/trip-data/{file_name}"
if not os.path.exists(local_path):
try:
with requests.get(url, stream=True) as response:
response.raise_for_status()
with open(local_path, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
time.sleep(1)
except requests.exceptions.HTTPError as e:
print(f"\nSkipping {file_name}: {e}")
if os.path.exists(local_path):
os.remove(local_path)
print("\nDownload complete.")
8. Analisar os dados de viagens de táxi
Agora que você baixou o conjunto de dados, é hora de realizar uma análise exploratória de dados (EDA) inicial. O objetivo da EDA é entender a estrutura dos dados, encontrar anomalias e descobrir possíveis padrões.
Carregar um único mês de dados
Comece carregando os dados de um único mês. Isso fornece uma amostra grande o suficiente (mais de 3 milhões de linhas) para ser significativa, mantendo o uso da memória gerenciável para análise interativa.
import pandas as pd
import glob
# Load the last month of the downloaded data
df = pd.read_parquet("nyc_taxi_data/yellow_tripdata_2024-12.parquet")
df.head()
Receber estatísticas de resumo
Use o método .describe() para gerar estatísticas de resumo de alto nível para as colunas numéricas. Essa é uma ótima primeira etapa para identificar possíveis problemas de qualidade de dados, como valores mínimos ou máximos inesperados.
df.describe().round(2)

Investigar a qualidade de dados
A saída de .describe() revela um problema imediatamente. O valor min para tpep_pickup_datetime e tpep_dropoff_datetime é de 2008, o que não faz sentido para um conjunto de dados de 2024.
Este é um exemplo de por que é importante sempre inspecionar seus dados. Para investigar mais a fundo, classifique o DataFrame e encontre as linhas exatas que contêm essas datas discrepantes.
# Sort by the dropoff datetime to see the oldest records
df.sort_values("tpep_pickup_datetime").head()
Visualizar distribuições de dados
Em seguida, crie histogramas das colunas numéricas para visualizar as distribuições. Isso ajuda você a entender a dispersão e o viés de recursos como trip_distance e fare_amount. A função .hist() é uma maneira rápida de criar histogramas para todas as colunas numéricas em um DataFrame.
_ = df.hist(figsize=(20, 20))
Por fim, gere uma matriz de dispersão para visualizar as relações entre algumas colunas principais. Como representar milhões de pontos é lento e pode ocultar padrões, use .sample() para criar o gráfico com uma amostra aleatória de 100.000 linhas.
_ = pd.plotting.scatter_matrix(
df[['passenger_count', 'trip_distance', 'tip_amount', 'total_amount']].sample(100_000),
diagonal="kde",
figsize=(15, 15)
)
9. Por que usar o formato de arquivo Parquet?
O conjunto de dados de táxi de Nova York é fornecido no formato Apache Parquet. Essa é uma escolha deliberada feita para análises em grande escala. O Parquet oferece várias vantagens em relação a tipos de arquivo como CSV:
- Eficiente e rápido:como um formato colunar, o Parquet é altamente eficiente para armazenar e ler. Ele é compatível com métodos de compactação modernos que resultam em tamanhos de arquivo menores e E/S significativamente mais rápida, especialmente em GPUs.
- Preserva o esquema:o Parquet armazena tipos de dados nos metadados do arquivo. Você nunca precisa adivinhar os tipos de dados ao ler o arquivo.
- Permite a leitura seletiva:a estrutura colunar permite ler apenas as colunas específicas necessárias para uma análise. Isso pode reduzir drasticamente a quantidade de dados que você precisa carregar na memória.
Conheça os recursos do Parquet
Vamos conhecer dois desses recursos eficientes usando um dos arquivos que você baixou.
Inspecionar metadados sem carregar o conjunto de dados completo
Não é possível visualizar um arquivo Parquet em um editor de texto padrão, mas é fácil inspecionar o esquema e os metadados dele sem carregar dados na memória. Isso é útil para entender rapidamente a estrutura de um arquivo.
from pyarrow.parquet import ParquetFile
import pyarrow as pa
# Open one of the downloaded files
pf = ParquetFile('nyc_taxi_data/yellow_tripdata_2024-12.parquet')
# Print the schema
print("File Schema:")
print(pf.schema)
# Print the file metadata
print("\nFile Metadata:")
print(pf.metadata)
Ler somente as colunas necessárias
Imagine que você só precisa analisar a distância da viagem e os valores das tarifas. Com o Parquet, é possível carregar apenas essas colunas, o que é muito mais rápido e eficiente em termos de memória do que carregar todo o DataFrame.
import pandas as pd
# Read only four specific columns from the Parquet file
df_subset = pd.read_parquet(
'nyc_taxi_data/yellow_tripdata_2024-12.parquet',
columns=['passenger_count', 'trip_distance', 'tip_amount', 'total_amount']
)
df_subset.head()
10. Acelere o pandas com o cuDF da NVIDIA
O NVIDIA CUDA para DataFrames (cuDF) é uma biblioteca de código aberto acelerada por GPU que permite interagir com DataFrames. Com o cuDF, é possível realizar operações comuns de dados, como filtragem, junção e agrupamento na GPU com paralelismo massivo.
O principal recurso usado neste codelab é o modo de acelerador cudf.pandas. Quando você ativa esse recurso, seu código pandas padrão é redirecionado automaticamente para usar kernels cuDF com tecnologia de GPU, sem precisar mudar o código.
Ativar aceleração de GPU
Para usar o cuDF da NVIDIA em um bloco do Colab Enterprise, carregue a extensão mágica antes de importar pandas.
Primeiro, inspecione a biblioteca padrão pandas. Observe que a saída mostra o caminho para a instalação padrão do pandas.
import pandas as pd
pd # Note the output for the standard pandas library
Agora, carregue a extensão cudf.pandas e importe pandas novamente. Observe como a saída do módulo pd muda. Isso confirma que a versão acelerada por GPU agora está ativa.
%load_ext cudf.pandas
import pandas as pd
pd # Note the new output, indicating cudf.pandas is active
Outras formas de ativar o cudf.pandas
Embora o comando mágico (%load_ext) seja o método mais fácil em um notebook, você também pode ativar o acelerador em outros ambientes:
- Em scripts Python:chame
import cudf.pandasecudf.pandas.install()antes da importação depandas. - Em ambientes que não são de notebook:execute o script usando
python -m cudf.pandas your_script.py.
11. Comparar o desempenho da CPU e da GPU
Agora, a parte mais importante: comparar o desempenho do pandas padrão em uma CPU com o cudf.pandas em uma GPU.
Para garantir uma linha de base completamente justa para a CPU, primeiro redefina o ambiente de execução do Colab. Isso limpa todos os aceleradores de GPU que você pode ter ativado nas seções anteriores. Para reiniciar o ambiente de execução, execute a célula a seguir ou selecione Reiniciar sessão no menu Ambiente de execução.
import IPython
IPython.Application.instance().kernel.do_shutdown(True)
Definir o pipeline de análise
Agora que o ambiente está limpo, você vai definir a função de comparativo de mercado. Essa função permite executar exatamente o mesmo pipeline (carregamento, classificação e resumo) usando qualquer módulo pandas que você transmita a ela.
import time
import glob
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
def run_analytics_pipeline(pd_module):
"""Loads, sorts, and summarizes data using the provided pandas module."""
timings = {}
# 1. Load all 2024 Parquet files from the directory
t0 = time.time()
df = pd_module.concat(
[pd_module.read_parquet(f) for f in glob.glob("nyc_taxi_data/*_2024*.parquet")],
ignore_index=True
)
timings["load"] = time.time() - t0
# 2. Sort the data by multiple columns
t0 = time.time()
df = df.sort_values(
['tpep_pickup_datetime', 'trip_distance', 'passenger_count'],
ascending=[False, True, False]
)
timings["sort"] = time.time() - t0
# 3. Perform a groupby and aggregation
t0 = time.time()
df['tpep_pickup_datetime'] = pd_module.to_datetime(df['tpep_pickup_datetime'])
_ = (
df.loc[df.tpep_pickup_datetime > '2024-11-01']
.groupby(['VendorID', 'tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
timings["summarize"] = time.time() - t0
return timings
Fazer a comparação
Primeiro, execute o pipeline usando o pandas padrão na CPU. Em seguida, ative e execute cudf.pandas novamente na GPU.
# --- Run on CPU ---
print("Running analytics pipeline on CPU...")
# Ensure we are using standard pandas
import pandas as pd
assert "cudf" not in str(pd), "Error: cuDF is still active. Please restart the kernel."
cpu_times = run_analytics_pipeline(pd)
print(f"CPU times: {cpu_times}")
# --- Run on GPU ---
print("\nEnabling cudf.pandas and running on GPU...")
# Load the extension
%load_ext cudf.pandas
import pandas as gpu_pd
gpu_times = run_analytics_pipeline(gpu_pd)
print(f"GPU times: {gpu_times}")
Visualizar os resultados
Por fim, visualize a diferença. O código a seguir calcula o speedup de cada operação e os mostra lado a lado.
# Create a DataFrame for plotting
results_df = pd.DataFrame([cpu_times, gpu_times], index=["CPU", "GPU"]).T
total_cpu_time = results_df['CPU'].sum()
total_gpu_time = results_df['GPU'].sum()
speedup = total_cpu_time / total_gpu_time
print("--- Performance Results ---")
print(results_df)
print(f"\nTotal CPU Time: {total_cpu_time:.2f} seconds")
print(f"Total GPU Time: {total_gpu_time:.2f} seconds")
print(f"Overall Speedup: {speedup:.2f}x")
# Plot the results
fig, ax = plt.subplots(figsize=(10, 6))
results_df.plot(kind='bar', ax=ax, color={"CPU": "tab:blue", "GPU": "tab:green"})
ax.set_ylabel("Time (seconds)")
ax.set_title(f"CPU vs. GPU Runtimes (Overall Speedup: {speedup:.2f}x)", fontsize=14)
ax.tick_params(axis='x', rotation=0)
# Add numerical labels to the bars
for container in ax.containers:
ax.bar_label(container, fmt="%.2f", padding=3)
plt.tight_layout()
plt.show()
Veja um exemplo de como os resultados aparecem:
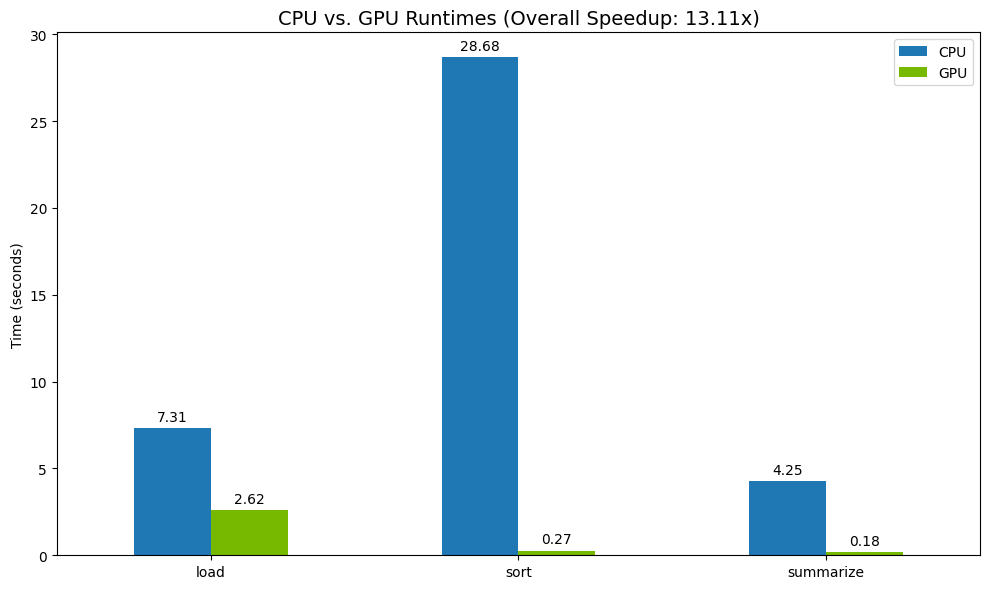
A GPU oferece um aumento claro de velocidade em relação à CPU.
12. Criar perfil do código para encontrar gargalos
Mesmo com a aceleração da GPU, algumas operações de pandas podem voltar para a CPU se ainda não forem compatíveis com cuDF. Esses "fallbacks de CPU" podem se tornar gargalos de desempenho.
Para ajudar você a identificar essas áreas, o cudf.pandas inclui dois criadores de perfil integrados. Você pode usá-los para ver exatamente quais partes do código estão sendo executadas na GPU e quais estão voltando para a CPU.
%%cudf.pandas.profile: use isso para um resumo de alto nível, função por função, do seu código. É ideal para ter uma visão geral rápida de quais operações estão sendo executadas em qual dispositivo.%%cudf.pandas.line_profile: use isso para uma análise detalhada, linha por linha. É a melhor ferramenta para identificar as linhas exatas do código que estão causando um fallback para a CPU.
Use esses criadores de perfil como "mágicas de célula" na parte de cima de uma célula do notebook.
Criação de perfil no nível da função com %%cudf.pandas.profile
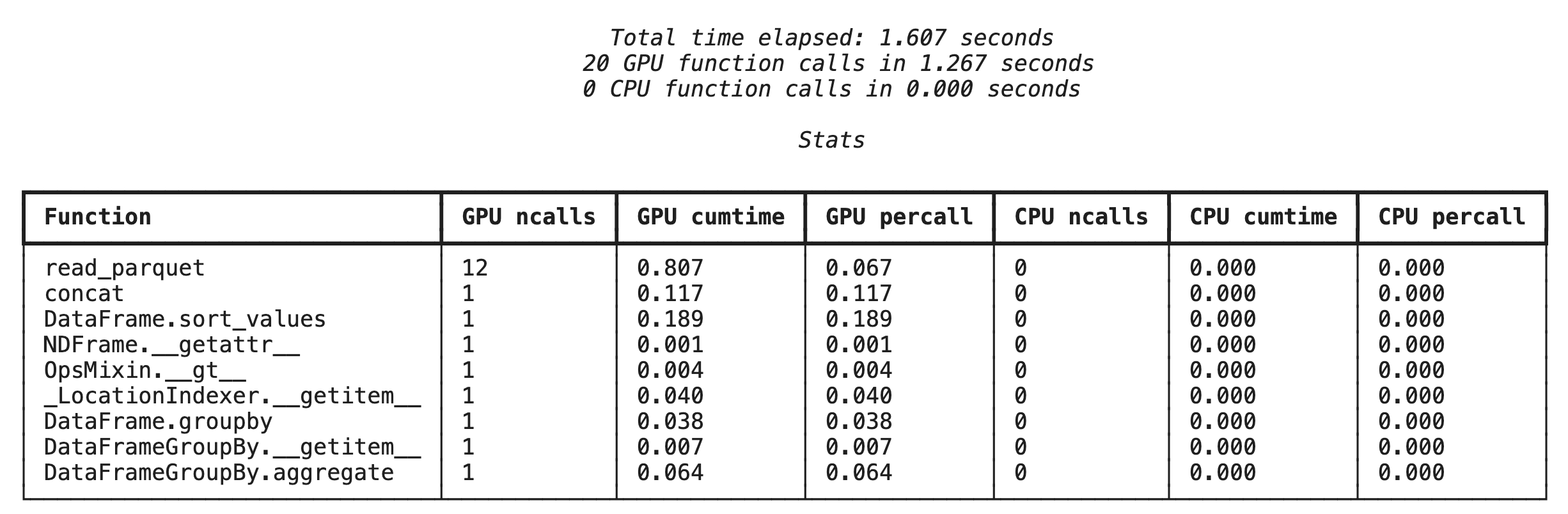
Primeiro, execute o criador de perfis no nível da função no mesmo pipeline de análise da seção anterior. A saída mostra uma tabela de todas as funções chamadas, o dispositivo em que elas foram executadas (GPU ou CPU) e quantas vezes foram chamadas.
%load_ext cudf.pandas
import pandas as pd
import glob
pd.DataFrame({"a": [1]})
Depois de garantir que cudf.pandas esteja ativo, você pode executar um perfil.
%%cudf.pandas.profile
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*2024*.parquet")], ignore_index=True)
df = df.sort_values(['tpep_pickup_datetime', 'trip_distance', 'passenger_count'], ascending=[False, True, False])
summary = (
df
.loc[(df.tpep_pickup_datetime > '2024-11-01')]
.groupby(['VendorID','tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
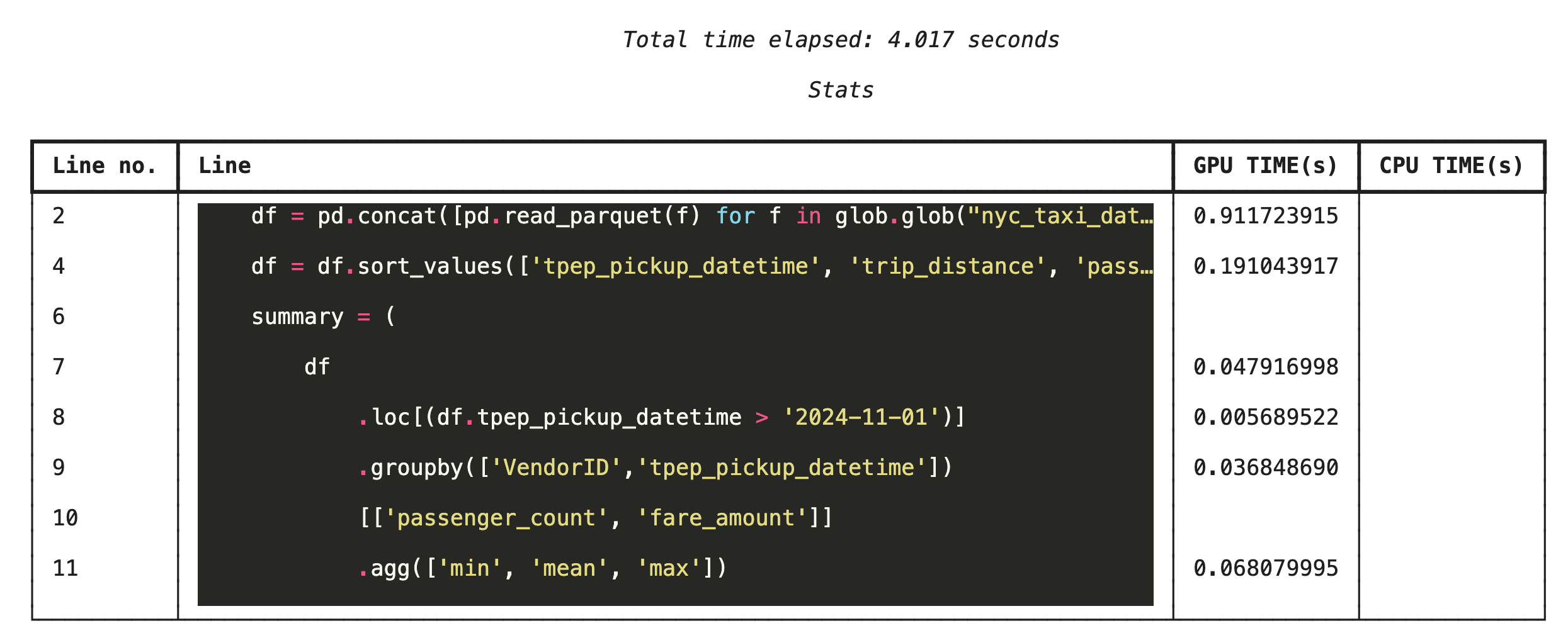
Perfil linha por linha com %%cudf.pandas.line_profile
Em seguida, execute o criador de perfil no nível da linha. Isso oferece uma visão muito mais granular, mostrando a parte do tempo que cada linha de código passou sendo executada na GPU em comparação com a CPU. Essa é a maneira mais eficaz de encontrar gargalos específicos para otimizar.
%%cudf.pandas.line_profile
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*2024*.parquet")], ignore_index=True)
df = df.sort_values(['tpep_pickup_datetime', 'trip_distance', 'passenger_count'], ascending=[False, True, False])
summary = (
df
.loc[(df.tpep_pickup_datetime > '2024-11-01')]
.groupby(['VendorID','tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
Como criar perfil na linha de comando
Esses criadores de perfil também estão disponíveis na linha de comando, o que é útil para testes automatizados e criação de perfil de scripts Python.
É possível usar o seguinte em uma interface de linha de comando:
python -m cudf.pandas --profile your_script.pypython -m cudf.pandas --line_profile your_script.py
13. Integrar com o Google Cloud Storage
O Google Cloud Storage (GCS) é um serviço de armazenamento de objetos escalonável e durável. Ao usar o Colab Enterprise, o GCS é um ótimo lugar para armazenar seus conjuntos de dados, checkpoints de modelos e outros artefatos.
O ambiente de execução do Colab Enterprise tem as permissões necessárias para ler e gravar dados diretamente em buckets do GCS, e essas operações são aceleradas por GPU para oferecer o máximo de desempenho.
Criar um bucket do GCS
Primeiro, crie um bucket do GCS. Os nomes dos buckets do GCS são exclusivos globalmente. Portanto, adicione um UUID ao nome.
from google.cloud import storage
import uuid
unique_suffix = uuid.uuid4().hex[:12]
bucket_name = f'nyc-taxi-codelab-{unique_suffix}'
project_id = storage.Client().project
client = storage.Client()
try:
bucket = client.create_bucket(bucket_name)
print(f"Successfully created bucket: gs://{bucket.name}")
except Exception as e:
print(f"Bucket creation failed. You may already own it or the name is taken: {e}")
Gravar dados diretamente no GCS
Agora, salve um DataFrame diretamente no novo bucket do GCS. Se a variável df não estiver disponível nas seções anteriores, o código vai carregar primeiro um único mês de dados.
%%cudf.pandas.line_profile
# Ensure the DataFrame exists before saving to GCS
if 'df' not in locals():
print("DataFrame not found, loading a sample file...")
df = pd.read_parquet('nyc_taxi_data/yellow_tripdata_2024-12.parquet')
print(f"Writing data to gs://{bucket_name}/nyc_taxi_data.parquet...")
df.to_parquet(f"gs://{bucket_name}/nyc_taxi_data.parquet", index=False)
print("Write operation complete.")
Verificar o arquivo no GCS
Para verificar se os dados estão no GCS, acesse o bucket. O código a seguir cria um link clicável.
from IPython.display import Markdown
gcs_url = f"https://console.cloud.google.com/storage/browser/{bucket_name}?project={project_id}"
Markdown(f'**[Click here to view your GCS bucket in the Google Cloud Console]({gcs_url})**')
Ler dados diretamente do GCS
Por fim, leia dados diretamente de um caminho do GCS para um DataFrame. Essa operação também é acelerada por GPU, permitindo carregar grandes conjuntos de dados do armazenamento em nuvem em alta velocidade.
%%cudf.pandas.line_profile
print(f"Reading data from gs://{bucket_name}/nyc_taxi_data.parquet...")
df_from_gcs = pd.read_parquet(f"gs://{bucket_name}/nyc_taxi_data.parquet")
df_from_gcs.head()
14. Limpeza
Para evitar cobranças inesperadas na sua conta do Google Cloud, limpe os recursos criados.
Exclua os dados baixados:
# Permanately delete the GCS bucket
print(f"Deleting GCS bucket: gs://{bucket_name}...")
!gsutil rm -r -f gs://{bucket_name}
print("Bucket deleted.")
# Remove NYC taxi dataset on the Colab runtime
print("Deleting local 'nyc_taxi_data' directory...")
!rm -rf nyc_taxi_data
print("Local files deleted.")
Desligar o ambiente de execução do Colab
- No console do Google Cloud, acesse a página Ambientes de execução do Colab Enterprise.
- No menu Região, selecione a região que contém o ambiente de execução.
- Selecione o tempo de execução que você quer excluir.
- Clique em Excluir.
- Clique em Confirmar.
Excluir o notebook
- No console do Google Cloud, acesse a página Meus notebooks do Colab Enterprise.
- No menu Região, selecione a região que contém o notebook.
- Selecione o notebook que você quer excluir.
- Clique em Excluir.
- Clique em Confirmar.
15. Parabéns
Parabéns! Você acelerou um fluxo de trabalho de análise do pandas usando o NVIDIA cuDF no Colab Enterprise. Você aprendeu a configurar tempos de execução com GPU, ativar o cudf.pandas para aceleração sem mudança de código, criar perfil de código para gargalos e fazer a integração com o Google Cloud Storage.