
1. บทนำ
ใน Codelab นี้ คุณจะได้เรียนรู้วิธีเร่งเวิร์กโฟลว์การวิเคราะห์ข้อมูลในชุดข้อมูลขนาดใหญ่โดยใช้ GPU ของ NVIDIA และไลบรารีโอเพนซอร์สใน Google Cloud คุณจะเริ่มต้นด้วยการเพิ่มประสิทธิภาพโครงสร้างพื้นฐาน จากนั้นจะดูวิธีใช้การเร่งด้วย GPU โดยไม่ต้องเปลี่ยนโค้ด
คุณจะมุ่งเน้นไปที่ pandas ซึ่งเป็นไลบรารีการจัดการข้อมูลยอดนิยม และเรียนรู้วิธีเร่งความเร็วโดยใช้ไลบรารี cuDF ของ NVIDIA และที่สำคัญที่สุดคือคุณสามารถใช้การเร่งความเร็ว GPU นี้ได้โดยไม่ต้องเปลี่ยนpandasโค้ดที่มีอยู่
สิ่งที่คุณจะได้เรียนรู้
- ทำความเข้าใจ Colab Enterprise ใน Google Cloud
- ปรับแต่งสภาพแวดล้อมรันไทม์ของ Colab ด้วยการกำหนดค่า GPU, CPU และหน่วยความจำที่เฉพาะเจาะจง
- เร่งความเร็ว
pandasโดยไม่ต้องเปลี่ยนแปลงโค้ดด้วย NVIDIAcuDF - สร้างโปรไฟล์โค้ดเพื่อระบุและเพิ่มประสิทธิภาพจุดคอขวดด้านประสิทธิภาพ
หน้าถัดไปจะมีเครดิตที่คุณใช้เพื่อทำ Lab ให้เสร็จสมบูรณ์
2. เหตุผลที่ควรเร่งการประมวลผลข้อมูล
กฎ 80/20: เหตุใดการเตรียมข้อมูลจึงใช้เวลานานมาก
การเตรียมข้อมูลมักเป็นระยะที่ใช้เวลานานที่สุดในโปรเจ็กต์การวิเคราะห์ นักวิทยาศาสตร์ข้อมูลและนักวิเคราะห์ใช้เวลาส่วนใหญ่ไปกับการล้างข้อมูล การเปลี่ยนรูปแบบ และการจัดโครงสร้างข้อมูลก่อนที่จะเริ่มการวิเคราะห์ได้
โชคดีที่คุณสามารถเร่งความเร็วไลบรารีโอเพนซอร์สยอดนิยม เช่น pandas, Apache Spark และ Polars บน NVIDIA GPU ได้โดยใช้ cuDF แม้จะมีการเร่งความเร็วนี้ แต่การเตรียมข้อมูลก็ยังคงใช้เวลานานเนื่องจากสาเหตุต่อไปนี้
- ข้อมูลต้นทางมักจะไม่พร้อมสำหรับการวิเคราะห์: ข้อมูลในโลกแห่งความเป็นจริงมักจะมีความไม่สอดคล้องกัน ค่าที่ขาดหายไป และปัญหาการจัดรูปแบบ
- คุณภาพส่งผลต่อประสิทธิภาพของโมเดล: คุณภาพของข้อมูลที่ไม่ดีอาจทําให้อัลกอริทึมที่ซับซ้อนที่สุดใช้ไม่ได้
- การปรับขนาดจะขยายปัญหา: ปัญหาข้อมูลที่ดูเหมือนเล็กน้อยจะกลายเป็นอุปสรรคร้ายแรงเมื่อทำงานกับระเบียนหลายล้านรายการ
3. การเลือกสภาพแวดล้อม Notebook
แม้ว่านักวิทยาศาสตร์ข้อมูลหลายคนจะคุ้นเคยกับ Colab สำหรับโปรเจ็กต์ส่วนตัว แต่ Colab Enterprise มอบประสบการณ์การใช้งาน Notebook ที่ปลอดภัย ทำงานร่วมกันได้ และผสานรวม ซึ่งออกแบบมาสำหรับธุรกิจ
ใน Google Cloud คุณมีตัวเลือกหลัก 2 อย่างสำหรับสภาพแวดล้อม Notebook ที่มีการจัดการ ได้แก่ Colab Enterprise และ Gemini Enterprise Agent Platform Workbench ตัวเลือกที่เหมาะสมจะขึ้นอยู่กับลำดับความสำคัญของโปรเจ็กต์
กรณีที่ควรใช้ Agent Platform Workbench
เลือก Agent Platform Workbench เมื่อคุณให้ความสำคัญกับการควบคุมและการปรับแต่งอย่างละเอียด ตัวเลือกนี้เหมาะสำหรับคุณในกรณีต่อไปนี้
- จัดการโครงสร้างพื้นฐานและวงจรของเครื่อง
- ใช้คอนเทนเนอร์และการกำหนดค่าเครือข่ายที่กำหนดเอง
- ผสานรวมกับไปป์ไลน์ MLOps และเครื่องมือวงจรที่กำหนดเอง
กรณีที่ควรใช้ Colab Enterprise
เลือก Colab Enterprise เมื่อคุณให้ความสำคัญกับการตั้งค่าที่รวดเร็ว ความสะดวกในการใช้งาน และการทำงานร่วมกันที่ปลอดภัย ซึ่งเป็นโซลูชันที่มีการจัดการครบวงจรที่ช่วยให้ทีมของคุณมุ่งเน้นที่การวิเคราะห์แทนที่จะเป็นโครงสร้างพื้นฐาน
Colab Enterprise ช่วยให้คุณทำสิ่งต่อไปนี้ได้
- พัฒนาเวิร์กโฟลว์วิทยาศาสตร์ข้อมูลที่เชื่อมโยงกับคลังข้อมูลอย่างใกล้ชิด คุณสามารถเปิดและจัดการ Notebook ได้โดยตรงใน BigQuery Studio
- ฝึกโมเดลแมชชีนเลิร์นนิงและผสานรวมกับเครื่องมือ MLOps ใน Agent Platform
- เพลิดเพลินกับประสบการณ์การใช้งานที่ยืดหยุ่นและเป็นหนึ่งเดียว สมุดบันทึก Colab Enterprise ที่สร้างใน BigQuery สามารถเปิดและเรียกใช้ใน Agent Platform ได้ และในทางกลับกัน
ห้องทดลองวันนี้
Codelab นี้ใช้ Colab Enterprise เพื่อการวิเคราะห์ข้อมูลที่รวดเร็วขึ้น
ดูข้อมูลเพิ่มเติมเกี่ยวกับความแตกต่างได้ในเอกสารอย่างเป็นทางการเกี่ยวกับการเลือกโซลูชัน Notebook ที่เหมาะสม
4. กำหนดค่าเทมเพลตรันไทม์
ใน Colab Enterprise ให้เชื่อมต่อกับรันไทม์ที่อิงตามเทมเพลตรันไทม์ที่กำหนดค่าไว้ล่วงหน้า
เทมเพลตรันไทม์เป็นการกำหนดค่าที่นำมาใช้ใหม่ได้ซึ่งระบุสภาพแวดล้อมทั้งหมดสำหรับ Notebook รวมถึงสิ่งต่อไปนี้
- ประเภทเครื่อง (CPU, หน่วยความจำ)
- Accelerator (ประเภทและจำนวน GPU)
- ขนาดและประเภทดิสก์
- การตั้งค่าเครือข่ายและนโยบายความปลอดภัย
- กฎการปิดเครื่องอัตโนมัติเมื่อไม่มีการใช้งาน
เหตุผลที่เทมเพลตรันไทม์มีประโยชน์
- รับสภาพแวดล้อมที่สอดคล้องกัน: คุณและเพื่อนร่วมทีมจะได้รับสภาพแวดล้อมที่พร้อมใช้งานเหมือนกันทุกครั้งเพื่อให้มั่นใจว่างานของคุณจะทำซ้ำได้
- ทำงานอย่างปลอดภัยตั้งแต่การออกแบบ: เทมเพลตจะบังคับใช้นโยบายความปลอดภัยขององค์กรโดยอัตโนมัติ
- จัดการค่าใช้จ่ายอย่างมีประสิทธิภาพ: ทรัพยากร เช่น GPU และ CPU จะมีขนาดที่กำหนดไว้ล่วงหน้าในเทมเพลต ซึ่งช่วยป้องกันไม่ให้ค่าใช้จ่ายเกินงบประมาณโดยไม่ตั้งใจ
สร้างเทมเพลตรันไทม์
ตั้งค่าเทมเพลตรันไทม์ที่นำกลับมาใช้ใหม่ได้สำหรับแล็บ
- ในคอนโซล Google Cloud ให้ไปที่เมนูการนำทาง > แพลตฟอร์มเอเจนต์ > Notebook
- จาก Colab Enterprise ให้คลิกเทมเพลตรันไทม์ แล้วเลือกเทมเพลตใหม่
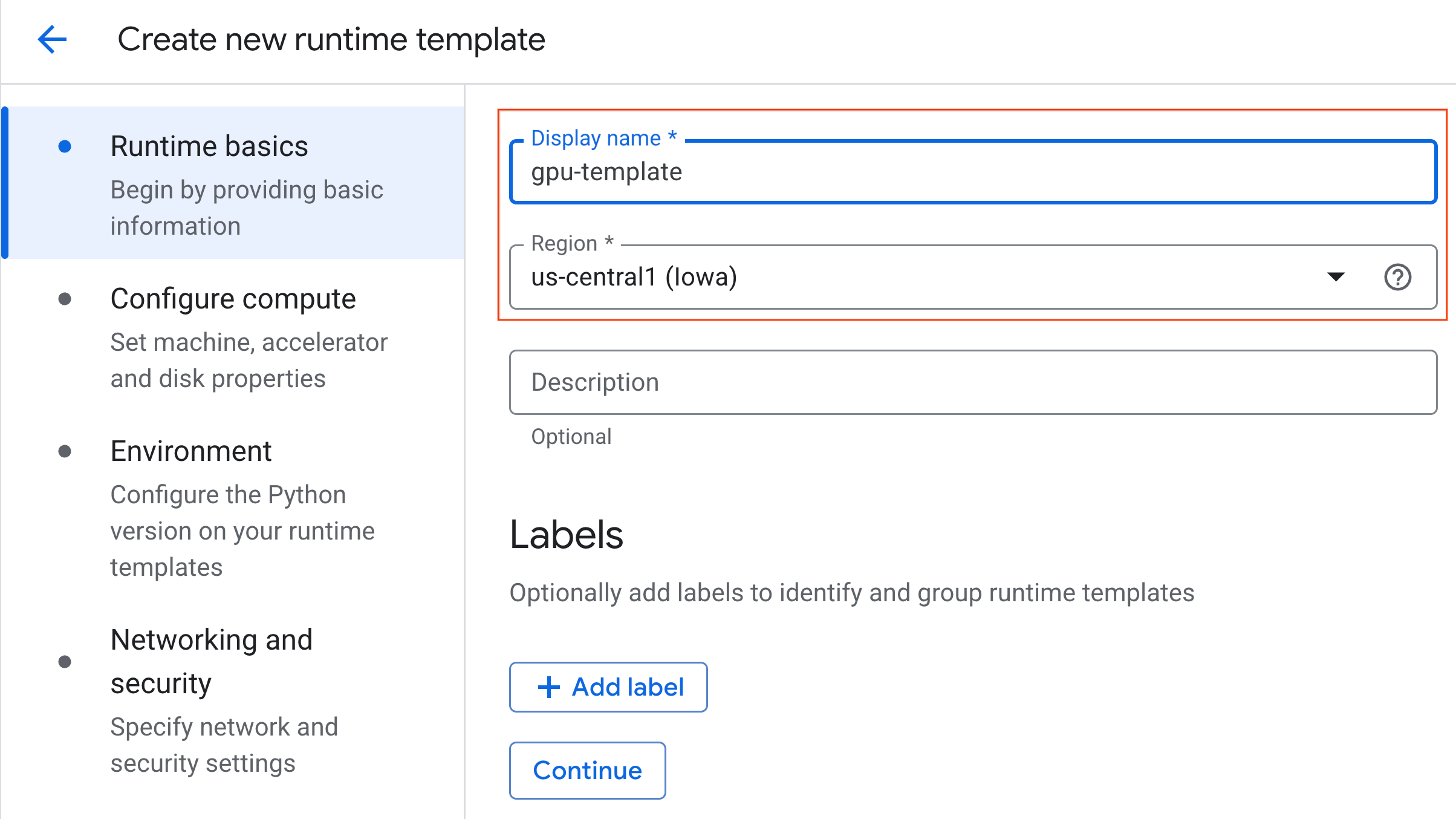
- ในส่วนข้อมูลพื้นฐานเกี่ยวกับรันไทม์ ให้ทำดังนี้
- ตั้งค่าชื่อที่แสดงเป็น
gpu-template - ตั้งค่าภูมิภาคที่ต้องการ
- ตั้งค่าชื่อที่แสดงเป็น
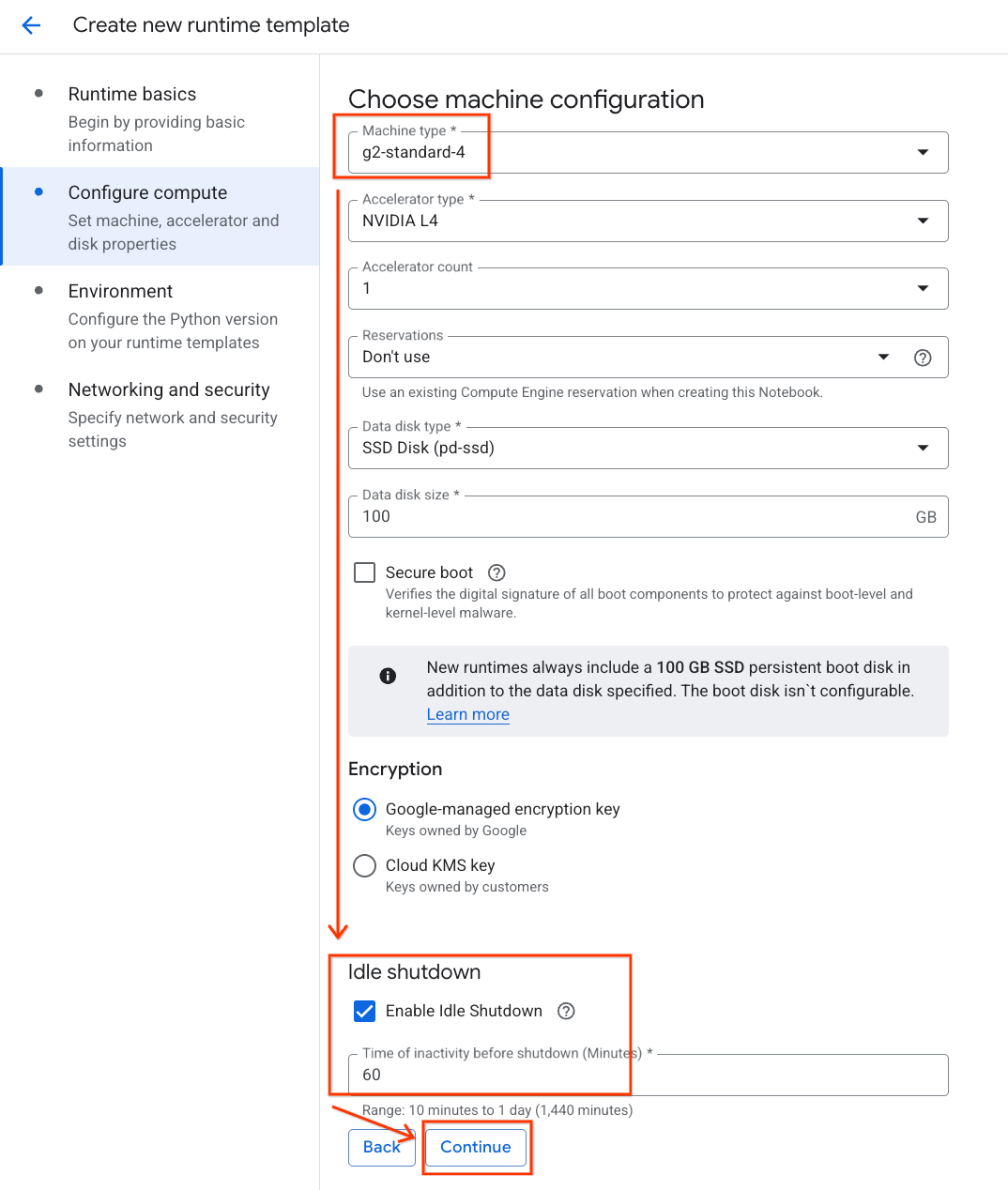
- ในส่วนกำหนดค่าการประมวลผล ให้ทำดังนี้
- ตั้งค่าประเภทเครื่องเป็น
g2-standard-4 - ใช้ประเภท Accelerator เป็น
NVIDIA L4ที่มีจำนวน Accelerator เป็น 1 ตามค่าเริ่มต้น - เปลี่ยนการปิดเครื่องเมื่อไม่มีการใช้งานเป็น 60 นาที
- คลิกต่อไป
- ตั้งค่าประเภทเครื่องเป็น
- ในส่วนสภาพแวดล้อม ให้ทำดังนี้
- ตั้งค่าสภาพแวดล้อมเป็น
Python 3.11
- ตั้งค่าสภาพแวดล้อมเป็น
- คลิกสร้างเพื่อบันทึกเทมเพลตรันไทม์ ตอนนี้หน้าเทมเพลตรันไทม์ควรแสดงเทมเพลตใหม่แล้ว
5. เริ่มรันไทม์
เมื่อเทมเพลตพร้อมแล้ว คุณจะสร้างรันไทม์ใหม่ได้
- จาก Colab Enterprise ให้คลิกรันไทม์ แล้วเลือกสร้าง
- ในส่วนเทมเพลตรันไทม์ ให้เลือกตัวเลือก
gpu-templateคลิกสร้าง แล้วรอให้รันไทม์บูตขึ้น
- หลังจากนั้นไม่กี่นาที คุณจะเห็นรันไทม์ที่พร้อมใช้งาน
6. ตั้งค่า Notebook
เมื่อโครงสร้างพื้นฐานทำงานแล้ว คุณต้องนำเข้า Notebook ของ Lab และเชื่อมต่อกับรันไทม์
นำเข้า Notebook
- จาก Colab Enterprise ให้คลิกสมุดบันทึกของฉัน แล้วคลิกนำเข้า
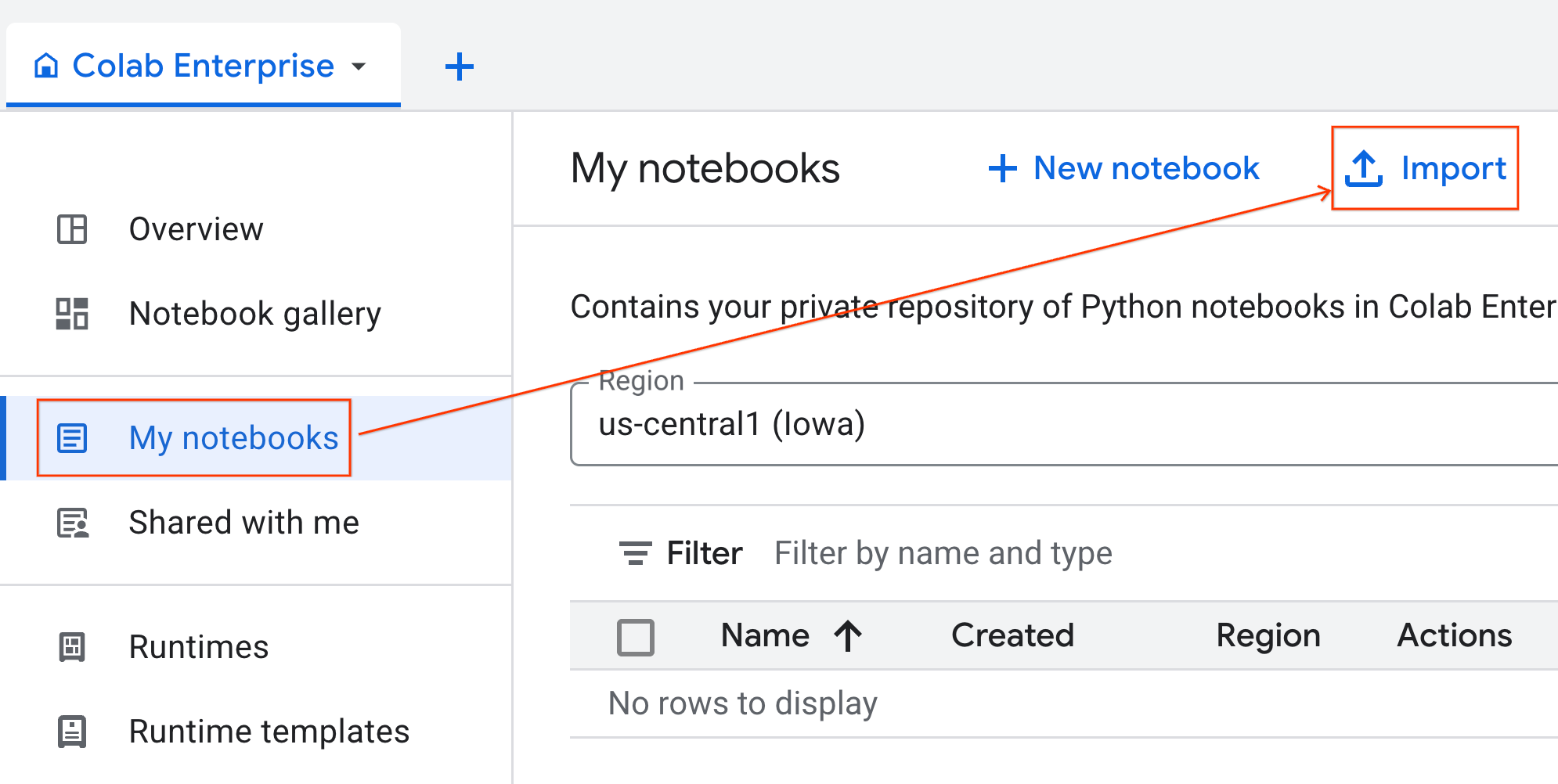
- เลือกปุ่มตัวเลือก URL แล้วป้อน URL ต่อไปนี้
https://github.com/GoogleCloudPlatform/ai-ml-recipes/blob/main/notebooks/analytics/gpu_accelerated_analytics.ipynb
- คลิกนำเข้า Colab Enterprise จะคัดลอกสมุดบันทึกจาก GitHub ไปยังสภาพแวดล้อมของคุณ
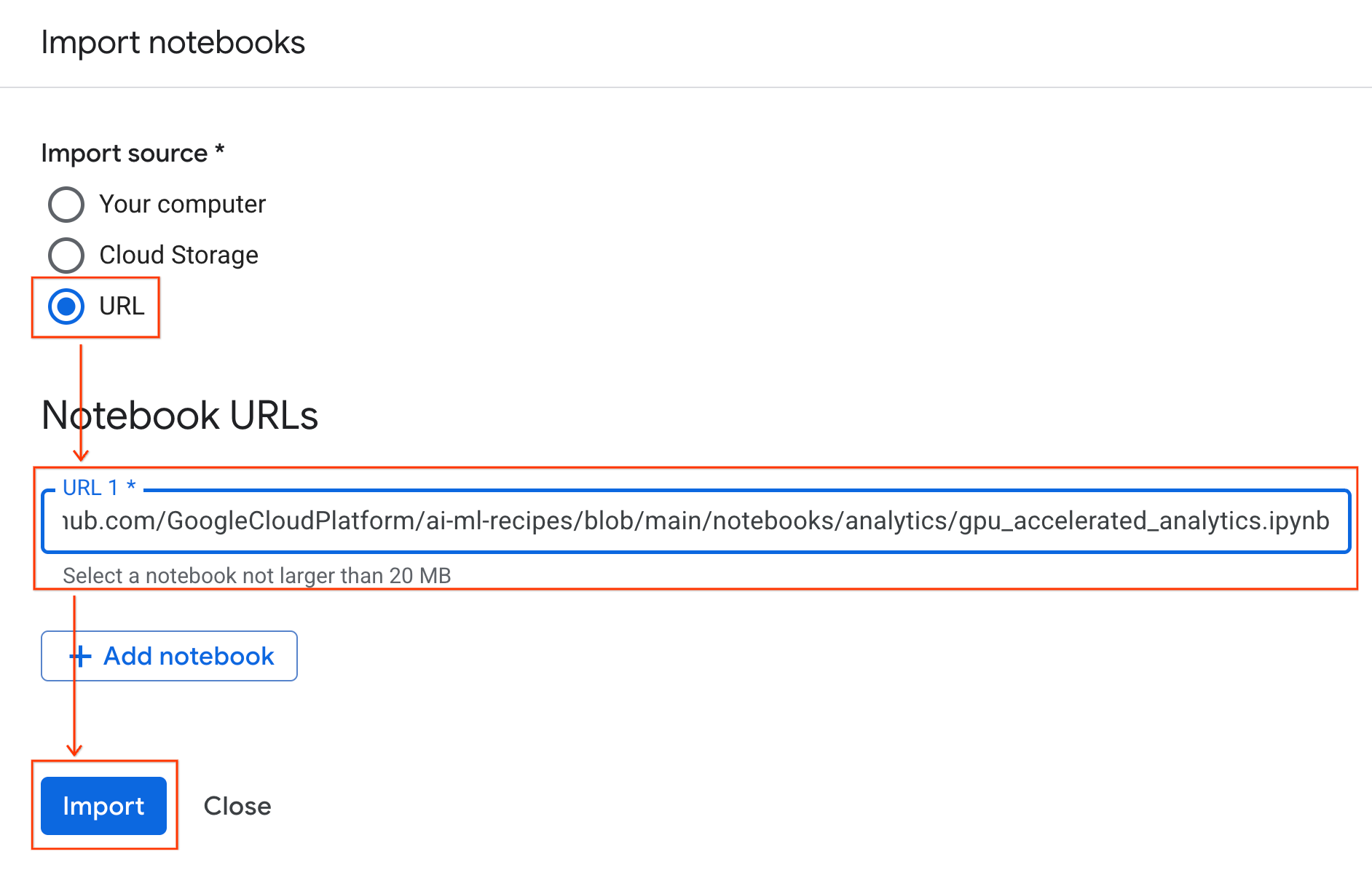
เชื่อมต่อกับรันไทม์
- เปิด Notebook ที่เพิ่งนำเข้า
- คลิกลูกศรลงข้างเชื่อมต่อ
- เลือกเชื่อมต่อกับรันไทม์
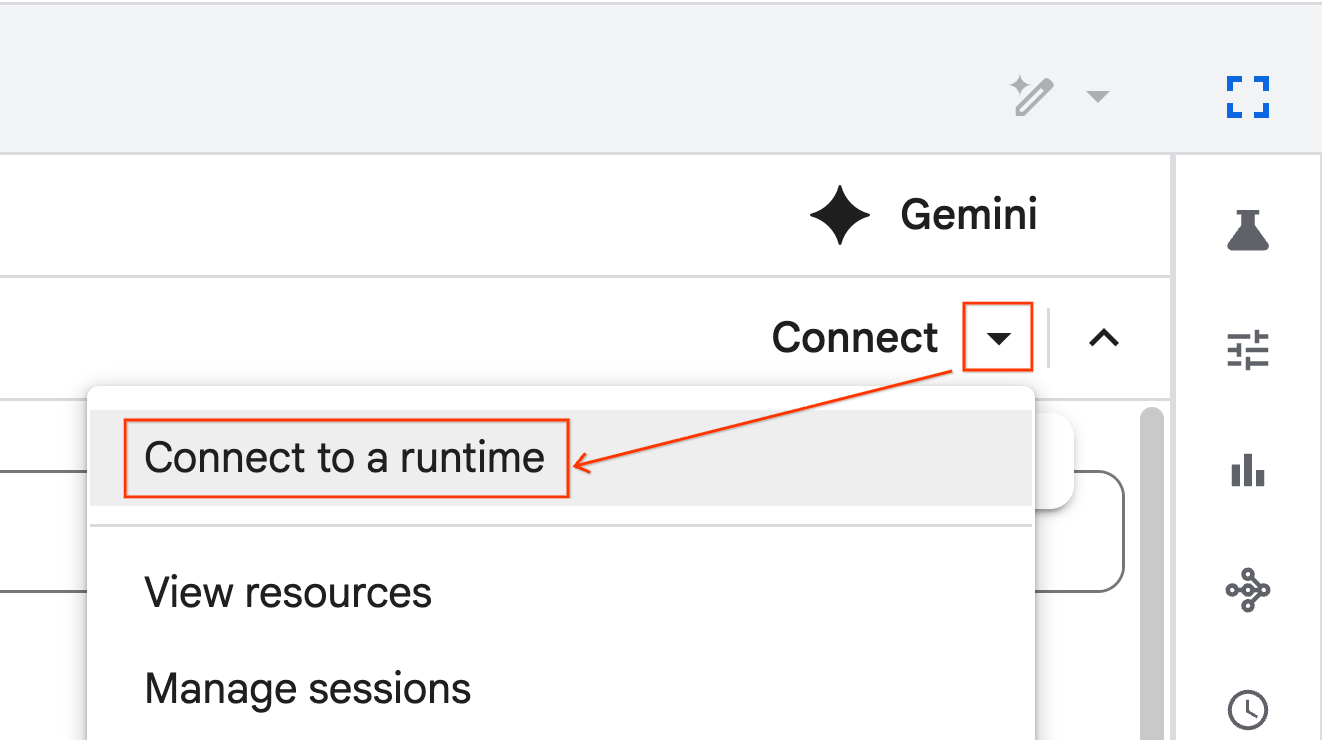
- ใช้เมนูแบบเลื่อนลงแล้วเลือกรุ่นรันไทม์ที่คุณสร้างไว้ก่อนหน้านี้
- คลิกเชื่อมต่อ
ตอนนี้สมุดบันทึกของคุณเชื่อมต่อกับรันไทม์ที่เปิดใช้ GPU แล้ว ตอนนี้คุณก็เริ่มเรียกใช้การค้นหาได้แล้ว
7. เตรียมชุดข้อมูลแท็กซี่ในนิวยอร์ก
Codelab นี้ใช้ข้อมูลบันทึกการเดินทางของคณะกรรมการแท็กซี่และรถลีมูซีน (TLC) ของนิวยอร์ก
ชุดข้อมูลประกอบด้วยบันทึกการเดินทางแต่ละรายการจากแท็กซี่สีเหลืองในนิวยอร์กซิตี้ และมีฟิลด์ต่างๆ เช่น
- วันที่ เวลา และสถานที่รับและส่ง
- ระยะทางการเดินทาง
- จำนวนค่าโดยสารแบบแยกรายการ
- จำนวนผู้โดยสาร
ดาวน์โหลดข้อมูล
จากนั้นให้ดาวน์โหลดข้อมูลการเดินทางของปี 2024 ทั้งหมด ระบบจะจัดเก็บข้อมูลในรูปแบบไฟล์ Parquet
โค้ดบล็อกต่อไปนี้จะดำเนินการตามขั้นตอนเหล่านี้
- กำหนดช่วงปีและเดือนที่จะดาวน์โหลด
- สร้างไดเรกทอรีในเครื่องชื่อ
nyc_taxi_dataเพื่อจัดเก็บไฟล์ - วนซ้ำในแต่ละเดือน ดาวน์โหลดไฟล์ Parquet ที่เกี่ยวข้องหากยังไม่มี และบันทึกลงในไดเรกทอรี
เรียกใช้โค้ดนี้ในสมุดบันทึกเพื่อรวบรวมข้อมูลและจัดเก็บไว้ในรันไทม์
from tqdm import tqdm
import requests
import time
import os
YEAR = 2024
DATA_DIR = "nyc_taxi_data"
os.makedirs(DATA_DIR, exist_ok=True)
print(f"Checking/Downloading files for {YEAR}...")
for month in tqdm(range(1, 13), unit="file"):
# Define standardized filename for both local path and URL
file_name = f"yellow_tripdata_{YEAR}-{month:02d}.parquet"
local_path = os.path.join(DATA_DIR, file_name)
url = f"https://d37ci6vzurychx.cloudfront.net/trip-data/{file_name}"
if not os.path.exists(local_path):
try:
with requests.get(url, stream=True) as response:
response.raise_for_status()
with open(local_path, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
time.sleep(1)
except requests.exceptions.HTTPError as e:
print(f"\nSkipping {file_name}: {e}")
if os.path.exists(local_path):
os.remove(local_path)
print("\nDownload complete.")
8. สำรวจข้อมูลการเดินทางด้วยแท็กซี่
เมื่อดาวน์โหลดชุดข้อมูลแล้ว ก็ถึงเวลาทําการวิเคราะห์ข้อมูลเบื้องต้น (EDA) เป้าหมายของ EDA คือการทำความเข้าใจโครงสร้างของข้อมูล ค้นหาความผิดปกติ และค้นพบรูปแบบที่อาจเกิดขึ้น
โหลดข้อมูล 1 เดือน
เริ่มต้นด้วยการโหลดข้อมูล 1 เดือน ซึ่งจะให้ตัวอย่างที่ใหญ่พอ (กว่า 3 ล้านแถว) ที่มีความหมายในขณะที่ยังคงควบคุมการใช้งานหน่วยความจำให้จัดการได้สำหรับการวิเคราะห์แบบอินเทอร์แอกทีฟ
import pandas as pd
import glob
# Load the last month of the downloaded data
df = pd.read_parquet("nyc_taxi_data/yellow_tripdata_2024-12.parquet")
df.head()
ดูสถิติสรุป
ใช้เมธอด .describe() เพื่อสร้างสถิติสรุประดับสูงสำหรับคอลัมน์ตัวเลข นี่เป็นขั้นตอนแรกที่ยอดเยี่ยมในการระบุปัญหาด้านคุณภาพของข้อมูลที่อาจเกิดขึ้น เช่น ค่าต่ำสุดหรือสูงสุดที่ไม่คาดคิด
df.describe().round(2)
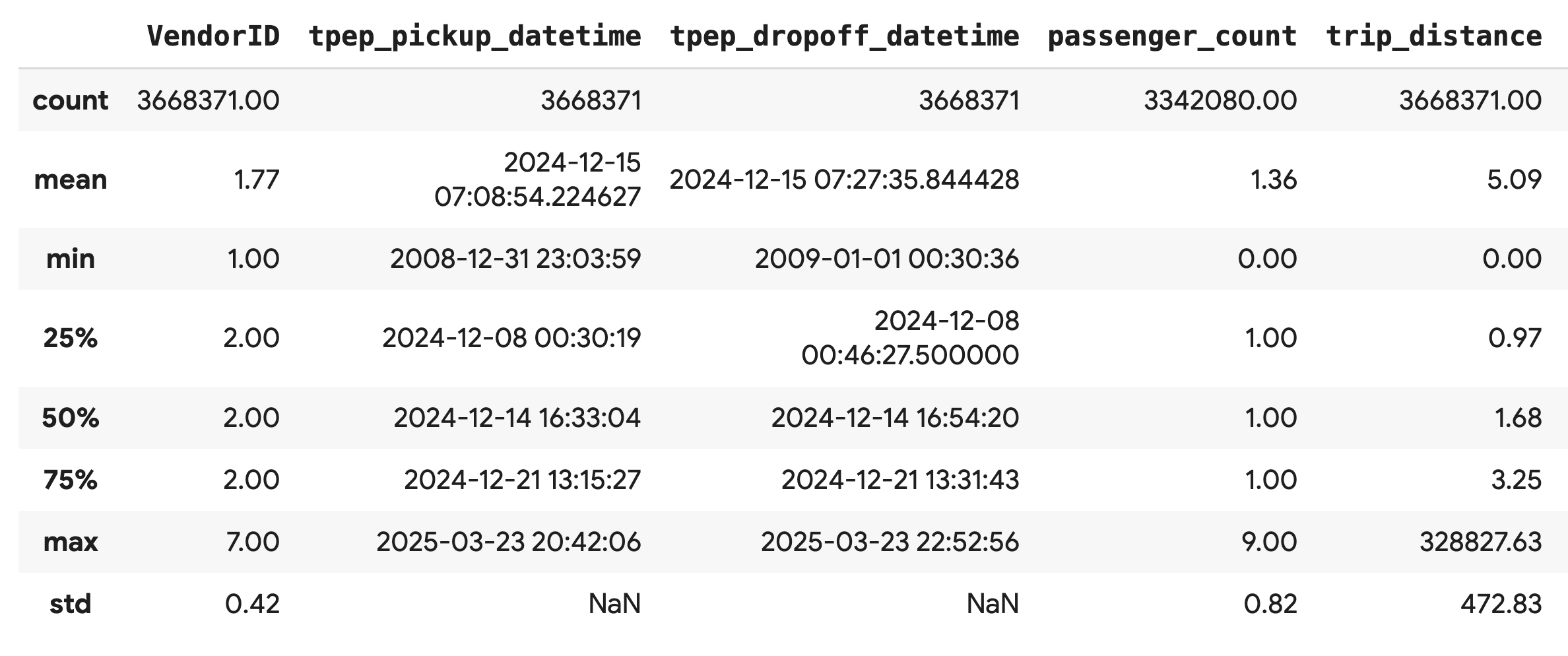
ตรวจสอบคุณภาพของข้อมูล
เอาต์พุตจาก .describe() จะแสดงปัญหาทันที โปรดสังเกตว่าค่า min สำหรับ tpep_pickup_datetime และ tpep_dropoff_datetime อยู่ในปี 2008 ซึ่งไม่สมเหตุสมผลสำหรับชุดข้อมูลปี 2024
นี่คือตัวอย่างเหตุผลที่ควรตรวจสอบข้อมูลเสมอ คุณสามารถตรวจสอบเพิ่มเติมได้โดยการจัดเรียง DataFrame เพื่อค้นหาแถวที่แน่นอนซึ่งมีวันที่ผิดปกติเหล่านี้
# Sort by the dropoff datetime to see the oldest records
df.sort_values("tpep_pickup_datetime").head()
แสดงภาพการกระจายข้อมูล
จากนั้นคุณสามารถสร้างฮิสโทแกรมของคอลัมน์ตัวเลขเพื่อแสดงภาพการกระจายได้ ซึ่งจะช่วยให้คุณเข้าใจการกระจายและความเบ้ของฟีเจอร์ต่างๆ เช่น trip_distance และ fare_amount .hist() ฟังก์ชันเป็นวิธีที่รวดเร็วในการสร้างฮิสโทแกรมสำหรับคอลัมน์ตัวเลขทั้งหมดใน DataFrame
_ = df.hist(figsize=(20, 20))
สุดท้าย ให้สร้างเมทริกซ์แบบกระจายเพื่อแสดงภาพความสัมพันธ์ระหว่างคอลัมน์สําคัญ 2-3 คอลัมน์ เนื่องจากการพล็อตจุดหลายล้านจุดนั้นช้าและอาจบดบังรูปแบบต่างๆ ให้ใช้ .sample() เพื่อสร้างพล็อตจากตัวอย่างแบบสุ่ม 100,000 แถว
_ = pd.plotting.scatter_matrix(
df[['passenger_count', 'trip_distance', 'tip_amount', 'total_amount']].sample(100_000),
diagonal="kde",
figsize=(15, 15)
)
9. เหตุผลที่ควรใช้รูปแบบไฟล์ Parquet
ชุดข้อมูลแท็กซี่ในนิวยอร์กมีให้ในรูปแบบ Apache Parquet นี่เป็นการเลือกที่ตั้งใจทำเพื่อการวิเคราะห์ขนาดใหญ่ Parquet มีข้อดีหลายประการเหนือกว่าประเภทไฟล์อย่าง CSV ดังนี้
- มีประสิทธิภาพและรวดเร็ว: Parquet เป็นรูปแบบคอลัมน์ จึงมีประสิทธิภาพสูงในการจัดเก็บและอ่าน โดยรองรับวิธีการบีบอัดที่ทันสมัยซึ่งส่งผลให้ไฟล์มีขนาดเล็กลงและ I/O เร็วขึ้นอย่างมาก โดยเฉพาะใน GPU
- รักษา Schema: Parquet จัดเก็บประเภทข้อมูลในข้อมูลเมตาของไฟล์ คุณไม่ต้องคาดเดาประเภทข้อมูลเมื่ออ่านไฟล์
- ช่วยให้อ่านข้อมูลที่เลือกได้: โครงสร้างแบบคอลัมน์ช่วยให้อ่านได้เฉพาะคอลัมน์ที่ต้องการสำหรับการวิเคราะห์ ซึ่งจะช่วยลดปริมาณข้อมูลที่คุณต้องโหลดลงในหน่วยความจำได้อย่างมาก
สำรวจฟีเจอร์ของ Parquet
มาดูฟีเจอร์ที่มีประสิทธิภาพ 2 อย่างนี้โดยใช้ไฟล์ที่คุณดาวน์โหลดกัน
ตรวจสอบข้อมูลเมตาโดยไม่ต้องโหลดชุดข้อมูลทั้งหมด
แม้ว่าจะดูไฟล์ Parquet ในโปรแกรมแก้ไขข้อความมาตรฐานไม่ได้ แต่คุณก็สามารถตรวจสอบสคีมาและข้อมูลเมตาได้อย่างง่ายดายโดยไม่ต้องโหลดข้อมูลใดๆ ลงในหน่วยความจำ ซึ่งมีประโยชน์ในการทำความเข้าใจโครงสร้างของไฟล์อย่างรวดเร็ว
from pyarrow.parquet import ParquetFile
import pyarrow as pa
# Open one of the downloaded files
pf = ParquetFile('nyc_taxi_data/yellow_tripdata_2024-12.parquet')
# Print the schema
print("File Schema:")
print(pf.schema)
# Print the file metadata
print("\nFile Metadata:")
print(pf.metadata)
อ่านเฉพาะคอลัมน์ที่คุณต้องการ
ลองนึกภาพว่าคุณต้องการวิเคราะห์เฉพาะระยะทางการเดินทางและจำนวนค่าโดยสาร Parquet ช่วยให้คุณโหลดได้เฉพาะคอลัมน์เหล่านั้น ซึ่งเร็วกว่าและประหยัดหน่วยความจำมากกว่าการโหลด DataFrame ทั้งหมด
import pandas as pd
# Read only four specific columns from the Parquet file
df_subset = pd.read_parquet(
'nyc_taxi_data/yellow_tripdata_2024-12.parquet',
columns=['passenger_count', 'trip_distance', 'tip_amount', 'total_amount']
)
df_subset.head()
10. เร่งความเร็ว pandas ด้วย NVIDIA cuDF
NVIDIA CUDA สำหรับ DataFrames (cuDF) เป็นไลบรารีโอเพนซอร์สที่เร่งความเร็วด้วย GPU ซึ่งช่วยให้คุณโต้ตอบกับ DataFrames ได้ cuDF ช่วยให้คุณดำเนินการกับข้อมูลทั่วไป เช่น การกรอง การรวม และการจัดกลุ่มใน GPU ด้วยการทำงานแบบคู่ขนานจำนวนมาก
ฟีเจอร์หลักที่คุณใช้ใน Codelab นี้คือcudf.pandasโหมดเร่งความเร็ว เมื่อเปิดใช้ ระบบจะเปลี่ยนเส้นทางโค้ด pandas มาตรฐานโดยอัตโนมัติเพื่อใช้เคอร์เนล cuDF ที่ทำงานด้วย GPU เบื้องหลังโดยที่คุณไม่ต้องเปลี่ยนโค้ด
เปิดใช้การเร่ง GPU
หากต้องการใช้ NVIDIA cuDF ในสมุดบันทึก Colab Enterprise คุณจะต้องโหลดส่วนขยาย Magic ก่อนที่จะนำเข้า pandas
ก่อนอื่น ให้ตรวจสอบไลบรารี pandas มาตรฐาน โปรดสังเกตว่าเอาต์พุตแสดงเส้นทางไปยังการติดตั้ง pandas เริ่มต้น
import pandas as pd
pd # Note the output for the standard pandas library
ตอนนี้ ให้โหลดส่วนขยาย cudf.pandas แล้วนำเข้า pandas อีกครั้ง ดูว่าเอาต์พุตของโมดูล pd เปลี่ยนแปลงอย่างไร ซึ่งจะยืนยันว่าตอนนี้เวอร์ชันที่เร่งด้วย GPU ใช้งานได้แล้ว
%load_ext cudf.pandas
import pandas as pd
pd # Note the new output, indicating cudf.pandas is active
วิธีอื่นๆ ในการเปิดใช้ cudf.pandas
แม้ว่าคำสั่ง Magic (%load_ext) จะเป็นวิธีที่ง่ายที่สุดใน Notebook แต่คุณก็เปิดใช้ตัวเร่งในสภาพแวดล้อมอื่นๆ ได้เช่นกัน โดยทำดังนี้
- ในสคริปต์ Python: เรียกใช้
import cudf.pandasและcudf.pandas.install()ก่อนที่จะนำเข้าpandas - จากสภาพแวดล้อมที่ไม่ใช่ Notebook: เรียกใช้สคริปต์โดยใช้
python -m cudf.pandas your_script.py
11. เปรียบเทียบประสิทธิภาพของ CPU กับ GPU
มาถึงส่วนที่สำคัญที่สุดกันแล้ว นั่นคือการเปรียบเทียบประสิทธิภาพของ pandas มาตรฐานใน CPU กับ cudf.pandas ใน GPU
หากต้องการให้ค่าพื้นฐานของ CPU มีความยุติธรรมอย่างสมบูรณ์ คุณต้องรีเซ็ตรันไทม์ Colab ก่อน ซึ่งจะเป็นการล้างตัวเร่ง GPU ที่คุณอาจเปิดใช้ไว้ในส่วนก่อนหน้า คุณรีสตาร์ทรันไทม์ได้โดยเรียกใช้เซลล์ต่อไปนี้ หรือเลือกรีสตาร์ทเซสชันจากเมนูรันไทม์
import IPython
IPython.Application.instance().kernel.do_shutdown(True)
กำหนดไปป์ไลน์การวิเคราะห์
ตอนนี้สภาพแวดล้อมสะอาดแล้ว คุณจะกำหนดฟังก์ชันการเปรียบเทียบ ฟังก์ชันนี้ช่วยให้คุณเรียกใช้ไปป์ไลน์เดียวกันทุกประการได้ ไม่ว่าจะเป็นการโหลด การจัดเรียง และการสรุป โดยใช้โมดูล pandas ที่คุณส่งไปยังฟังก์ชัน
import time
import glob
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
def run_analytics_pipeline(pd_module):
"""Loads, sorts, and summarizes data using the provided pandas module."""
timings = {}
# 1. Load all 2024 Parquet files from the directory
t0 = time.time()
df = pd_module.concat(
[pd_module.read_parquet(f) for f in glob.glob("nyc_taxi_data/*_2024*.parquet")],
ignore_index=True
)
timings["load"] = time.time() - t0
# 2. Sort the data by multiple columns
t0 = time.time()
df = df.sort_values(
['tpep_pickup_datetime', 'trip_distance', 'passenger_count'],
ascending=[False, True, False]
)
timings["sort"] = time.time() - t0
# 3. Perform a groupby and aggregation
t0 = time.time()
df['tpep_pickup_datetime'] = pd_module.to_datetime(df['tpep_pickup_datetime'])
_ = (
df.loc[df.tpep_pickup_datetime > '2024-11-01']
.groupby(['VendorID', 'tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
timings["summarize"] = time.time() - t0
return timings
เรียกใช้การเปรียบเทียบ
ก่อนอื่น คุณจะเรียกใช้ไปป์ไลน์โดยใช้ pandas มาตรฐานใน CPU จากนั้นเปิดใช้ cudf.pandas แล้วเรียกใช้บน GPU อีกครั้ง
# --- Run on CPU ---
print("Running analytics pipeline on CPU...")
# Ensure we are using standard pandas
import pandas as pd
assert "cudf" not in str(pd), "Error: cuDF is still active. Please restart the kernel."
cpu_times = run_analytics_pipeline(pd)
print(f"CPU times: {cpu_times}")
# --- Run on GPU ---
print("\nEnabling cudf.pandas and running on GPU...")
# Load the extension
%load_ext cudf.pandas
import pandas as gpu_pd
gpu_times = run_analytics_pipeline(gpu_pd)
print(f"GPU times: {gpu_times}")
แสดงภาพผลลัพธ์
สุดท้ายนี้ ให้เห็นภาพความแตกต่าง โค้ดต่อไปนี้จะคำนวณการเพิ่มความเร็วสำหรับการดำเนินการแต่ละอย่างและพล็อตไว้ข้างกัน
# Create a DataFrame for plotting
results_df = pd.DataFrame([cpu_times, gpu_times], index=["CPU", "GPU"]).T
total_cpu_time = results_df['CPU'].sum()
total_gpu_time = results_df['GPU'].sum()
speedup = total_cpu_time / total_gpu_time
print("--- Performance Results ---")
print(results_df)
print(f"\nTotal CPU Time: {total_cpu_time:.2f} seconds")
print(f"Total GPU Time: {total_gpu_time:.2f} seconds")
print(f"Overall Speedup: {speedup:.2f}x")
# Plot the results
fig, ax = plt.subplots(figsize=(10, 6))
results_df.plot(kind='bar', ax=ax, color={"CPU": "tab:blue", "GPU": "tab:green"})
ax.set_ylabel("Time (seconds)")
ax.set_title(f"CPU vs. GPU Runtimes (Overall Speedup: {speedup:.2f}x)", fontsize=14)
ax.tick_params(axis='x', rotation=0)
# Add numerical labels to the bars
for container in ax.containers:
ax.bar_label(container, fmt="%.2f", padding=3)
plt.tight_layout()
plt.show()
ตัวอย่างผลลัพธ์
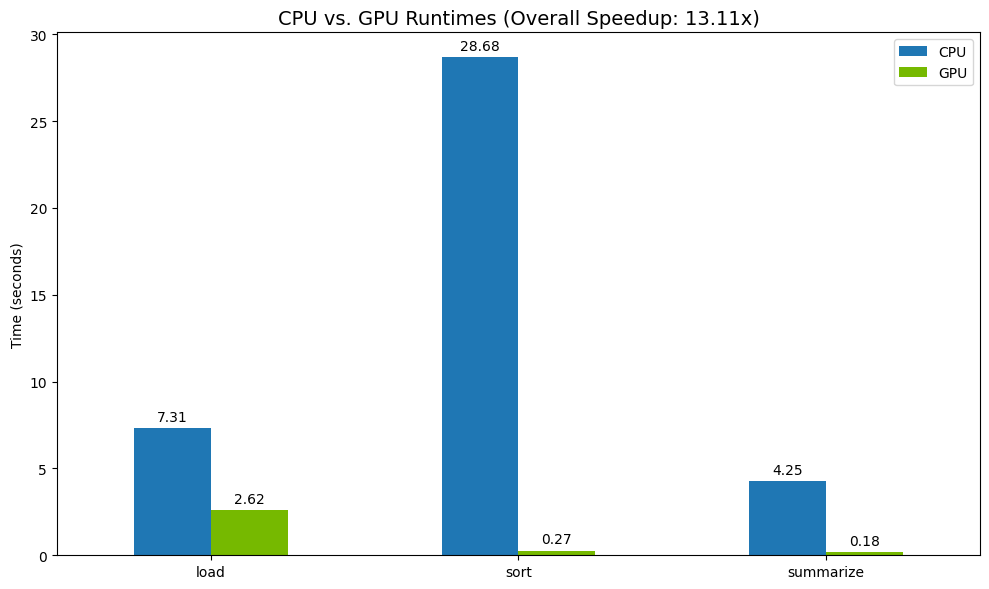
GPU ช่วยเพิ่มความเร็วได้อย่างชัดเจนเมื่อเทียบกับ CPU
12. ทำโปรไฟล์โค้ดเพื่อหาคอขวด
แม้จะมีการเร่งด้วย GPU แต่pandasการดำเนินการบางอย่างอาจกลับไปใช้ CPU หาก cuDF ยังไม่รองรับ "การสำรองข้อมูล CPU" เหล่านี้อาจกลายเป็นคอขวดด้านประสิทธิภาพ
cudf.pandas มีโปรไฟล์เลอร์ในตัว 2 รายการเพื่อช่วยคุณระบุพื้นที่เหล่านี้ คุณสามารถใช้เครื่องมือเหล่านี้เพื่อดูว่าส่วนใดของโค้ดที่ทำงานบน GPU และส่วนใดที่กลับไปใช้ CPU
%%cudf.pandas.profile: ใช้เพื่อสรุปโค้ดของคุณในระดับสูงแบบฟังก์ชันต่อฟังก์ชัน เหมาะที่สุดสำหรับการดูภาพรวมอย่างรวดเร็วว่าการดำเนินการใดทำงานบนอุปกรณ์ใด%%cudf.pandas.line_profile: ใช้ตัวเลือกนี้เพื่อการวิเคราะห์แบบละเอียดทีละบรรทัด ซึ่งเป็นเครื่องมือที่ดีที่สุดในการระบุบรรทัดที่แน่นอนในโค้ดที่ทำให้เกิดการเปลี่ยนไปใช้ CPU
ใช้โปรไฟล์เลอร์เหล่านี้เป็น "Cell Magics" ที่ด้านบนของเซลล์ Notebook
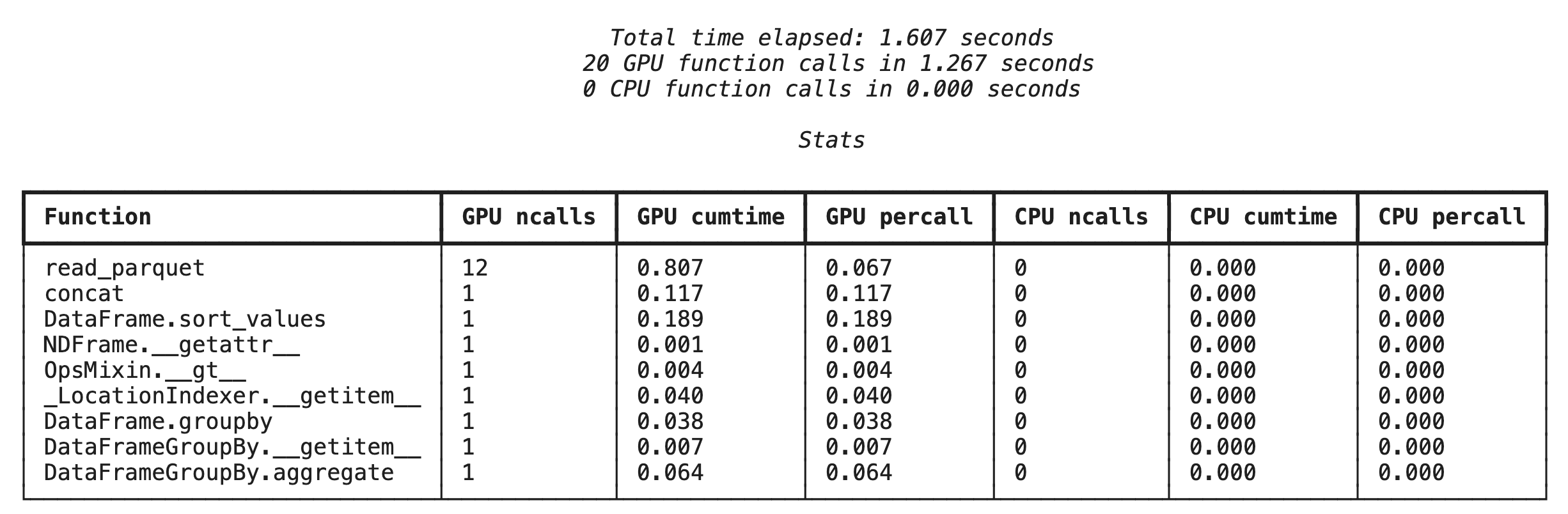
การสร้างโปรไฟล์ระดับฟังก์ชันด้วย %%cudf.pandas.profile
ก่อนอื่น ให้เรียกใช้โปรไฟล์เลเวลฟังก์ชันในไปป์ไลน์การวิเคราะห์เดียวกันจากส่วนก่อนหน้า เอาต์พุตจะแสดงตารางของทุกฟังก์ชันที่เรียกใช้ อุปกรณ์ที่เรียกใช้ (GPU หรือ CPU) และจำนวนครั้งที่เรียกใช้
%load_ext cudf.pandas
import pandas as pd
import glob
pd.DataFrame({"a": [1]})
หลังจากตรวจสอบว่า cudf.pandas ทำงานอยู่ คุณจะเรียกใช้โปรไฟล์ได้
%%cudf.pandas.profile
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*2024*.parquet")], ignore_index=True)
df = df.sort_values(['tpep_pickup_datetime', 'trip_distance', 'passenger_count'], ascending=[False, True, False])
summary = (
df
.loc[(df.tpep_pickup_datetime > '2024-11-01')]
.groupby(['VendorID','tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
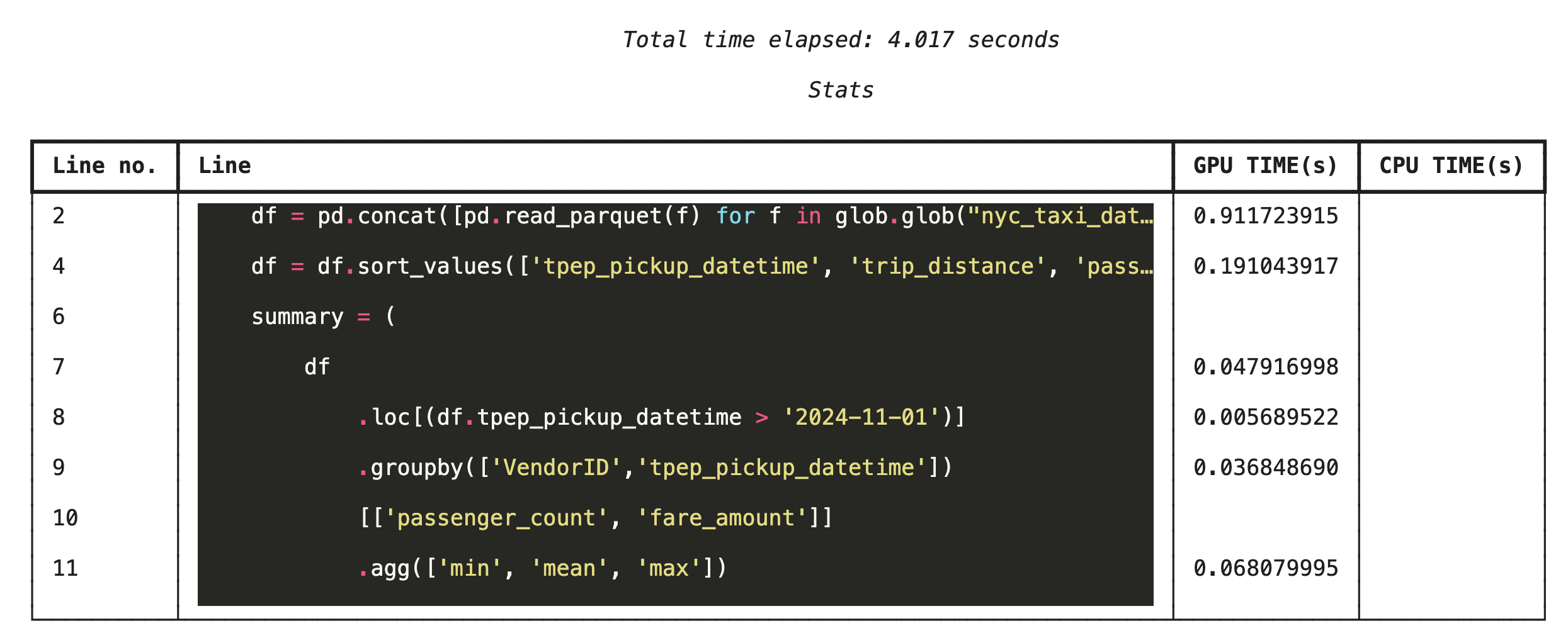
การสร้างโปรไฟล์ทีละบรรทัดด้วย %%cudf.pandas.line_profile
จากนั้นเรียกใช้โปรไฟล์เลเยอร์บรรทัด ซึ่งจะช่วยให้คุณเห็นมุมมองที่ละเอียดยิ่งขึ้น โดยแสดงสัดส่วนเวลาที่โค้ดแต่ละบรรทัดใช้ในการดำเนินการบน GPU เทียบกับ CPU ซึ่งเป็นวิธีที่มีประสิทธิภาพมากที่สุดในการค้นหาคอขวดที่เฉพาะเจาะจงเพื่อเพิ่มประสิทธิภาพ
%%cudf.pandas.line_profile
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*2024*.parquet")], ignore_index=True)
df = df.sort_values(['tpep_pickup_datetime', 'trip_distance', 'passenger_count'], ascending=[False, True, False])
summary = (
df
.loc[(df.tpep_pickup_datetime > '2024-11-01')]
.groupby(['VendorID','tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
การสร้างโปรไฟล์จากบรรทัดคำสั่ง
Profiler เหล่านี้ยังพร้อมใช้งานจากบรรทัดคำสั่ง ซึ่งมีประโยชน์สำหรับการทดสอบอัตโนมัติและการสร้างโปรไฟล์ของสคริปต์ Python
คุณใช้สิ่งต่อไปนี้ในอินเทอร์เฟซบรรทัดคำสั่งได้
python -m cudf.pandas --profile your_script.pypython -m cudf.pandas --line_profile your_script.py
13. ผสานรวมกับ Google Cloud Storage
Google Cloud Storage (GCS) คือบริการพื้นที่เก็บข้อมูลออบเจ็กต์ที่ปรับขนาดได้และมีความคงทน เมื่อใช้ Colab Enterprise คุณจะใช้ GCS เป็นที่จัดเก็บชุดข้อมูล จุดตรวจสอบโมเดล และอาร์ติแฟกต์อื่นๆ ได้
รันไทม์ Colab Enterprise มีสิทธิ์ที่จำเป็นในการอ่านและเขียนข้อมูลไปยัง Bucket ของ GCS โดยตรง และการดำเนินการเหล่านี้จะได้รับการเร่งความเร็วด้วย GPU เพื่อให้มีประสิทธิภาพสูงสุด
สร้างที่เก็บข้อมูล GCS
ก่อนอื่นให้สร้างที่เก็บข้อมูล GCS ใหม่ ชื่อที่เก็บข้อมูล GCS จะไม่ซ้ำกันทั่วโลก ดังนั้นให้ต่อท้าย UUID กับชื่อ
from google.cloud import storage
import uuid
unique_suffix = uuid.uuid4().hex[:12]
bucket_name = f'nyc-taxi-codelab-{unique_suffix}'
project_id = storage.Client().project
client = storage.Client()
try:
bucket = client.create_bucket(bucket_name)
print(f"Successfully created bucket: gs://{bucket.name}")
except Exception as e:
print(f"Bucket creation failed. You may already own it or the name is taken: {e}")
เขียนข้อมูลลงใน GCS โดยตรง
ตอนนี้คุณบันทึก DataFrame ลงใน Bucket ของ GCS ใหม่ได้โดยตรงแล้ว หากตัวแปร df ไม่พร้อมใช้งานจากส่วนก่อนหน้า โค้ดจะโหลดข้อมูล 1 เดือนก่อน
%%cudf.pandas.line_profile
# Ensure the DataFrame exists before saving to GCS
if 'df' not in locals():
print("DataFrame not found, loading a sample file...")
df = pd.read_parquet('nyc_taxi_data/yellow_tripdata_2024-12.parquet')
print(f"Writing data to gs://{bucket_name}/nyc_taxi_data.parquet...")
df.to_parquet(f"gs://{bucket_name}/nyc_taxi_data.parquet", index=False)
print("Write operation complete.")
ยืนยันไฟล์ใน GCS
คุณยืนยันได้ว่าข้อมูลอยู่ใน GCS โดยไปที่ที่เก็บข้อมูล โค้ดต่อไปนี้สร้างลิงก์ที่คลิกได้
from IPython.display import Markdown
gcs_url = f"https://console.cloud.google.com/storage/browser/{bucket_name}?project={project_id}"
Markdown(f'**[Click here to view your GCS bucket in the Google Cloud Console]({gcs_url})**')
อ่านข้อมูลจาก GCS โดยตรง
สุดท้าย ให้อ่านข้อมูลจากเส้นทาง GCS ลงใน DataFrame โดยตรง การดำเนินการนี้ยังเร่งความเร็วด้วย GPU ด้วย ซึ่งช่วยให้คุณโหลดชุดข้อมูลขนาดใหญ่จาก Cloud Storage ได้ด้วยความเร็วสูง
%%cudf.pandas.line_profile
print(f"Reading data from gs://{bucket_name}/nyc_taxi_data.parquet...")
df_from_gcs = pd.read_parquet(f"gs://{bucket_name}/nyc_taxi_data.parquet")
df_from_gcs.head()
14. ล้าง
คุณต้องล้างข้อมูลทรัพยากรที่สร้างขึ้นเพื่อหลีกเลี่ยงการเรียกเก็บเงินที่ไม่คาดคิดกับบัญชี Google Cloud
วิธีลบข้อมูลที่ดาวน์โหลด
# Permanately delete the GCS bucket
print(f"Deleting GCS bucket: gs://{bucket_name}...")
!gsutil rm -r -f gs://{bucket_name}
print("Bucket deleted.")
# Remove NYC taxi dataset on the Colab runtime
print("Deleting local 'nyc_taxi_data' directory...")
!rm -rf nyc_taxi_data
print("Local files deleted.")
ปิดรันไทม์ Colab
- ในคอนโซล Google Cloud ให้ไปที่หน้ารันไทม์ของ Colab Enterprise
- ในเมนูภูมิภาค ให้เลือกภูมิภาคที่มีรันไทม์
- เลือกรันไทม์ที่ต้องการลบ
- คลิกลบ
- คลิกยืนยัน
ลบ Notebook
- ในคอนโซล Google Cloud ให้ไปที่หน้าสมุดบันทึกของฉันใน Colab Enterprise
- ในเมนูภูมิภาค ให้เลือกภูมิภาคที่มี Notebook
- เลือกสมุดบันทึกที่ต้องการลบ
- คลิกลบ
- คลิกยืนยัน
15. ขอแสดงความยินดี
ยินดีด้วย คุณเร่งเวิร์กโฟลว์การวิเคราะห์ pandas โดยใช้ NVIDIA cuDF ใน Colab Enterprise ได้สำเร็จแล้ว คุณได้เรียนรู้วิธีกำหนดค่ารันไทม์ที่เปิดใช้ GPU, เปิดใช้ cudf.pandas เพื่อเพิ่มความเร็วโดยไม่ต้องเปลี่ยนโค้ด, โปรไฟล์โค้ดเพื่อหาคอขวด และผสานรวมกับ Google Cloud Storage