
1. Giriş
Bu Codelab'de, Google Cloud'da NVIDIA GPU'ları ve açık kaynak kitaplıklarını kullanarak büyük veri kümelerindeki veri analizi iş akışlarınızı hızlandırmayı öğreneceksiniz. Önce altyapınızı optimize edecek, ardından GPU hızlandırmayı kod değişikliği yapmadan nasıl uygulayacağınızı öğreneceksiniz.
Popüler bir veri işleme kitaplığı olan pandas üzerinde duracak ve NVIDIA'nın cuDF kitaplığını kullanarak bu kitaplığı nasıl hızlandıracağınızı öğreneceksiniz. En iyi yanı, mevcut pandas kodunuzu değiştirmeden bu GPU hızlandırmasını elde edebilmenizdir.
Neler öğreneceksiniz?
- Google Cloud'da Colab Enterprise'ı anlama
- Belirli GPU, CPU ve bellek yapılandırmalarıyla Colab çalışma zamanı ortamını özelleştirin.
- NVIDIA
cuDFkullanarak tek bir kod değişikliği yapmadanpandashızlandırın. - Performans sorunlarını belirlemek ve optimize etmek için kodunuzun profilini oluşturun.
Sonraki sayfada, laboratuvarı tamamlamak için kullanabileceğiniz krediler yer alır.
2. Veri işleme neden hızlandırılmalıdır?
80/20 kuralı: Veri hazırlama neden bu kadar çok zaman alır?
Veri hazırlama, genellikle bir analiz projesinin en çok zaman alan aşamasıdır. Veri bilimciler ve analistler, herhangi bir analize başlamadan önce zamanlarının büyük bir bölümünü verileri temizlemek, dönüştürmek ve yapılandırmakla geçirir.
Neyse ki cuDF kullanarak pandas, Apache Spark ve Polars gibi popüler açık kaynak kitaplıklarını NVIDIA GPU'larda hızlandırabilirsiniz. Bu hızlandırmaya rağmen veri hazırlama işlemi zaman alıcı olmaya devam eder. Bunun nedenleri:
- Kaynak veriler nadiren analize hazır olur: Gerçek dünyadaki verilerde genellikle tutarsızlıklar, eksik değerler ve biçimlendirme sorunları bulunur.
- Kalite, model performansını etkiler: Veri kalitesinin düşük olması, en gelişmiş algoritmaları bile işe yaramaz hale getirebilir.
- Ölçek, sorunları büyütür: Görünüşte küçük olan veri sorunları, milyonlarca kayıtla çalışırken kritik darboğazlar haline gelir.
3. Not defteri ortamı seçme
Birçok veri bilimci kişisel projeler için Colab'i kullanır. Colab Enterprise ise işletmeler için tasarlanmış güvenli, ortak çalışmaya uygun ve entegre bir not defteri deneyimi sunar.
Google Cloud'da yönetilen not defteri ortamları için iki temel seçeneğiniz vardır: Colab Enterprise ve Gemini Enterprise Agent Platform Workbench. Doğru seçim, projenizin önceliklerine bağlıdır.
Agent Platform Workbench ne zaman kullanılır?
Önceliğiniz kontrol ve derin özelleştirme ise Agent Platform Workbench'i seçin. Aşağıdaki durumlarda bu seçeneği kullanabilirsiniz:
- Temel altyapıyı ve makine yaşam döngüsünü yönetin.
- Özel container'lar ve ağ yapılandırmaları kullanın.
- MLOps işlem hatları ve özel yaşam döngüsü araçlarıyla entegrasyon.
Colab Enterprise'ı ne zaman kullanmalısınız?
Önceliğiniz hızlı kurulum, kullanım kolaylığı ve güvenli ortak çalışma olduğunda Colab Enterprise'ı seçin. Bu çözüm, ekibinizin altyapı yerine analize odaklanmasını sağlayan, tümüyle yönetilen bir çözümdür.
Colab Enterprise ile şunları yapabilirsiniz:
- Veri ambarınızla yakından ilişkili veri bilimi iş akışları geliştirin. Not defterlerinizi doğrudan BigQuery Studio'da açıp yönetebilirsiniz.
- Makine öğrenimi modellerini eğitin ve Agent Platform'daki MLOps araçlarıyla entegre edin.
- Esnek ve birleşik bir deneyimin keyfini çıkarın. BigQuery'de oluşturulan bir Colab Enterprise not defteri, Agent Platform'da açılıp çalıştırılabilir ve bunun tersi de geçerlidir.
Bugünün laboratuvarı
Bu Codelab'de, hızlandırılmış veri analizi için Colab Enterprise kullanılmaktadır.
Farklılıklar hakkında daha fazla bilgi edinmek için doğru not defteri çözümünü seçme ile ilgili resmi belgelere bakın.
4. Çalışma zamanı şablonunu yapılandırma
Colab Enterprise'da, önceden yapılandırılmış bir çalışma zamanı şablonuna dayalı bir çalışma zamanına bağlanın.
Çalışma zamanı şablonu, aşağıdakiler de dahil olmak üzere not defterinizin tüm ortamını belirten, yeniden kullanılabilir bir yapılandırmadır:
- Makine türü (CPU, bellek)
- Hızlandırıcı (GPU türü ve sayısı)
- Disk boyutu ve türü
- Ağ ayarları ve güvenlik politikaları
- Otomatik boşta kalma kapatma kuralları
Çalışma zamanı şablonları neden yararlıdır?
- Tutarlı bir ortam elde edin: Çalışmanızın tekrarlanabilir olmasını sağlamak için siz ve ekip arkadaşlarınız her seferinde aynı kullanıma hazır ortamı elde edersiniz.
- Tasarım gereği güvenli çalışma: Şablonlar, kuruluşunuzun güvenlik politikalarını otomatik olarak uygular.
- Maliyetleri etkili bir şekilde yönetin: GPU'lar ve CPU'lar gibi kaynaklar şablonda önceden boyutlandırılır. Bu sayede, yanlışlıkla maliyet aşımı yaşanması önlenir.
Çalışma zamanı şablonu oluşturma
Laboratuvar için yeniden kullanılabilir bir çalışma zamanı şablonu oluşturun.
- Google Cloud Console'da Gezinme Menüsü > Agent Platform > Notebooks'a (Not Defterleri) gidin.
- Colab Enterprise'da Çalışma zamanı şablonları'nı tıklayın ve Yeni Şablon'u seçin.
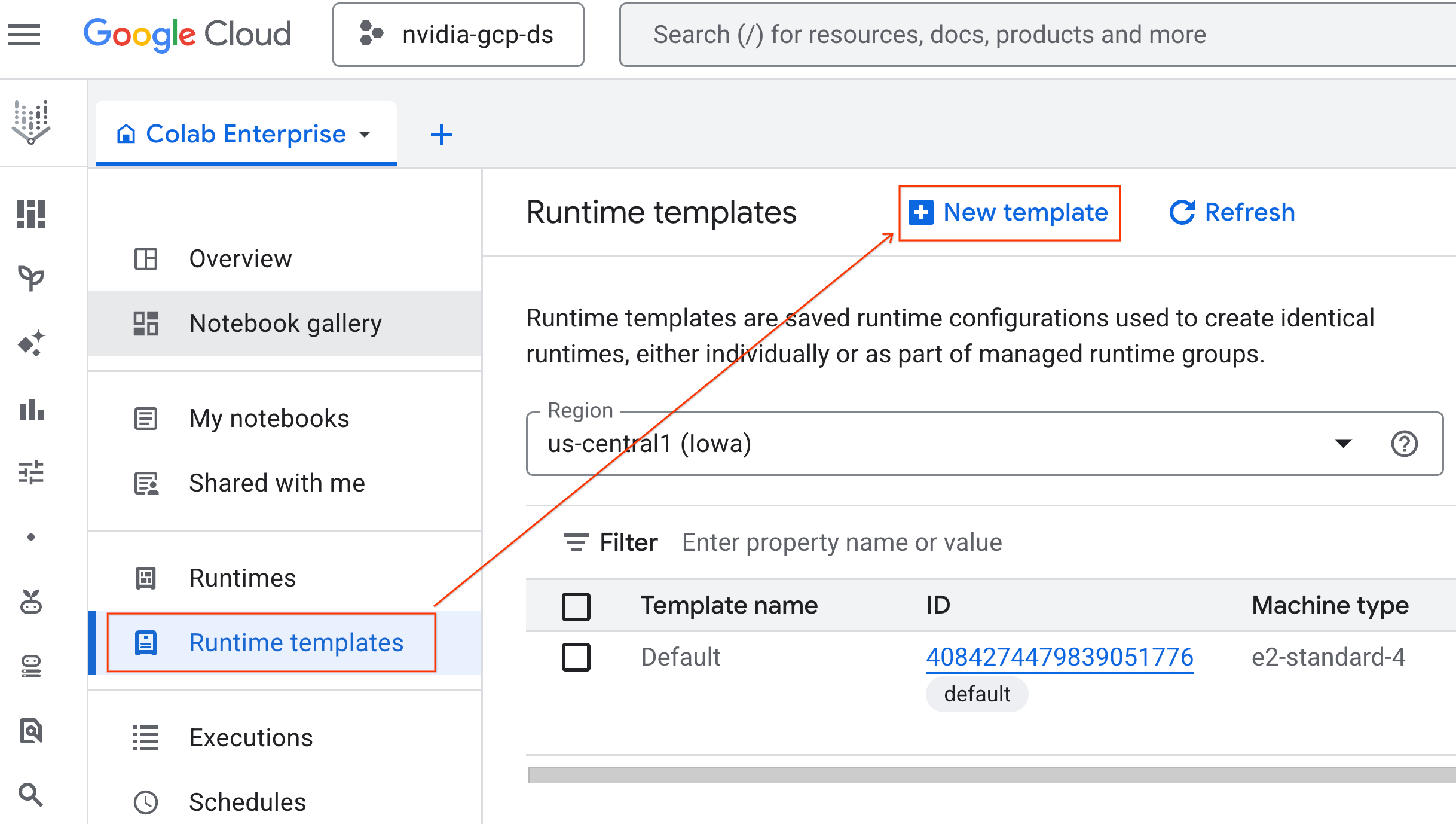
- Çalışma zamanıyla ilgili temel bilgiler bölümünde:
- Görünen adı
gpu-templateolarak ayarlayın. - Tercih ettiğiniz bölgeyi ayarlayın.
- Görünen adı
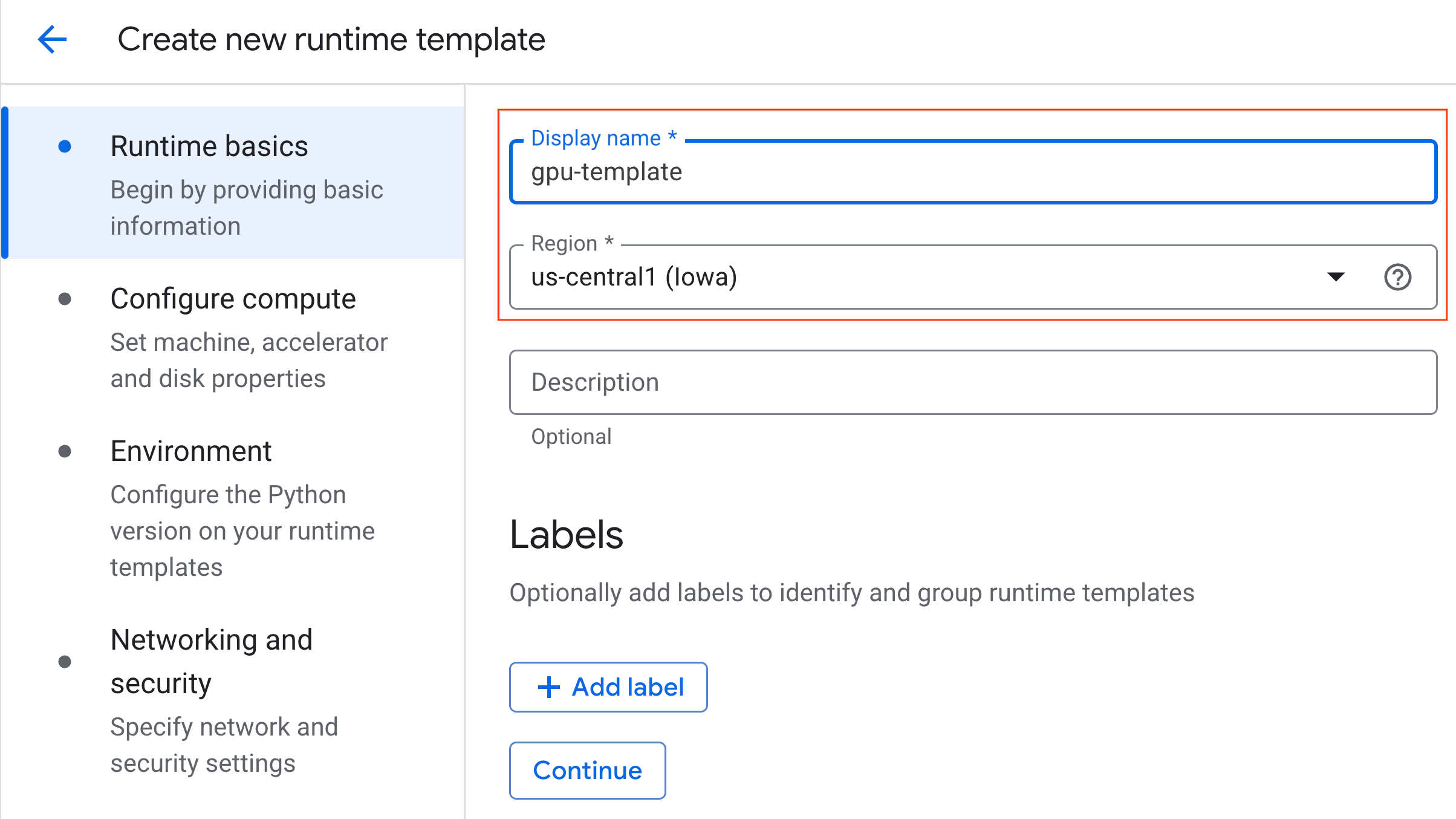
- Bilgi işlem yapılandırma bölümünde:
- Makine türü'nü
g2-standard-4olarak ayarlayın. - Varsayılan Hızlandırıcı Türü'nü
NVIDIA L4olarak ve Hızlandırıcı sayısı'nı 1 olarak bırakın. - Boşta kalma nedeniyle kapatma süresini 60 dakika olarak değiştirin.
- Devam'ı tıklayın.
- Makine türü'nü
- Ortam bölümünde:
- Ortam'ı
Python 3.11olarak ayarlayın.
- Ortam'ı
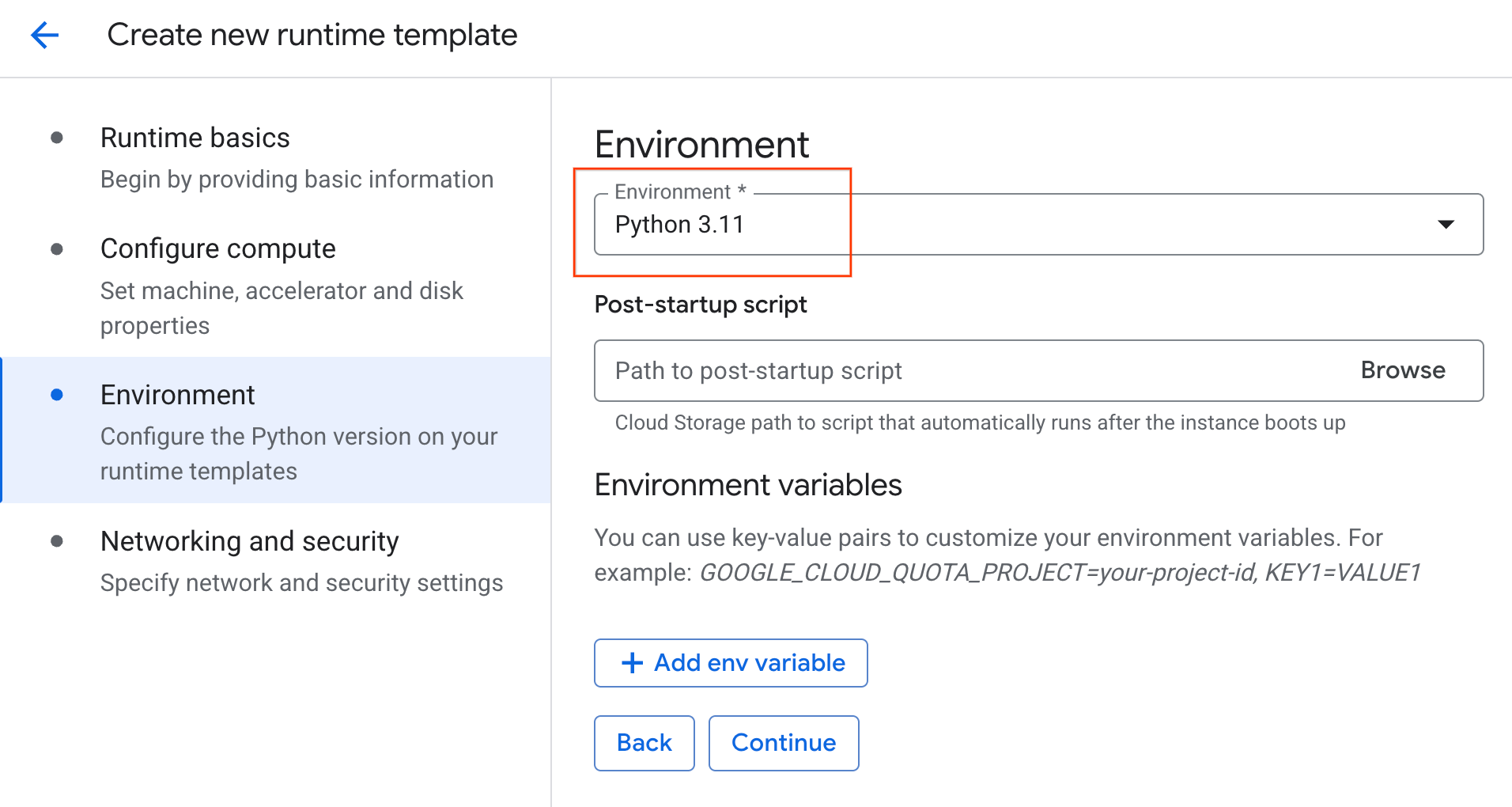
- Çalışma zamanı şablonunu kaydetmek için Oluştur'u tıklayın. Çalışma zamanı şablonları sayfanızda artık yeni şablon gösteriliyor olmalıdır.
5. Çalışma zamanı başlatma
Şablonunuz hazır olduğunda yeni bir çalışma zamanı oluşturabilirsiniz.
- Colab Enterprise'da Çalışma zamanları'nı tıklayın ve Oluştur'u seçin.
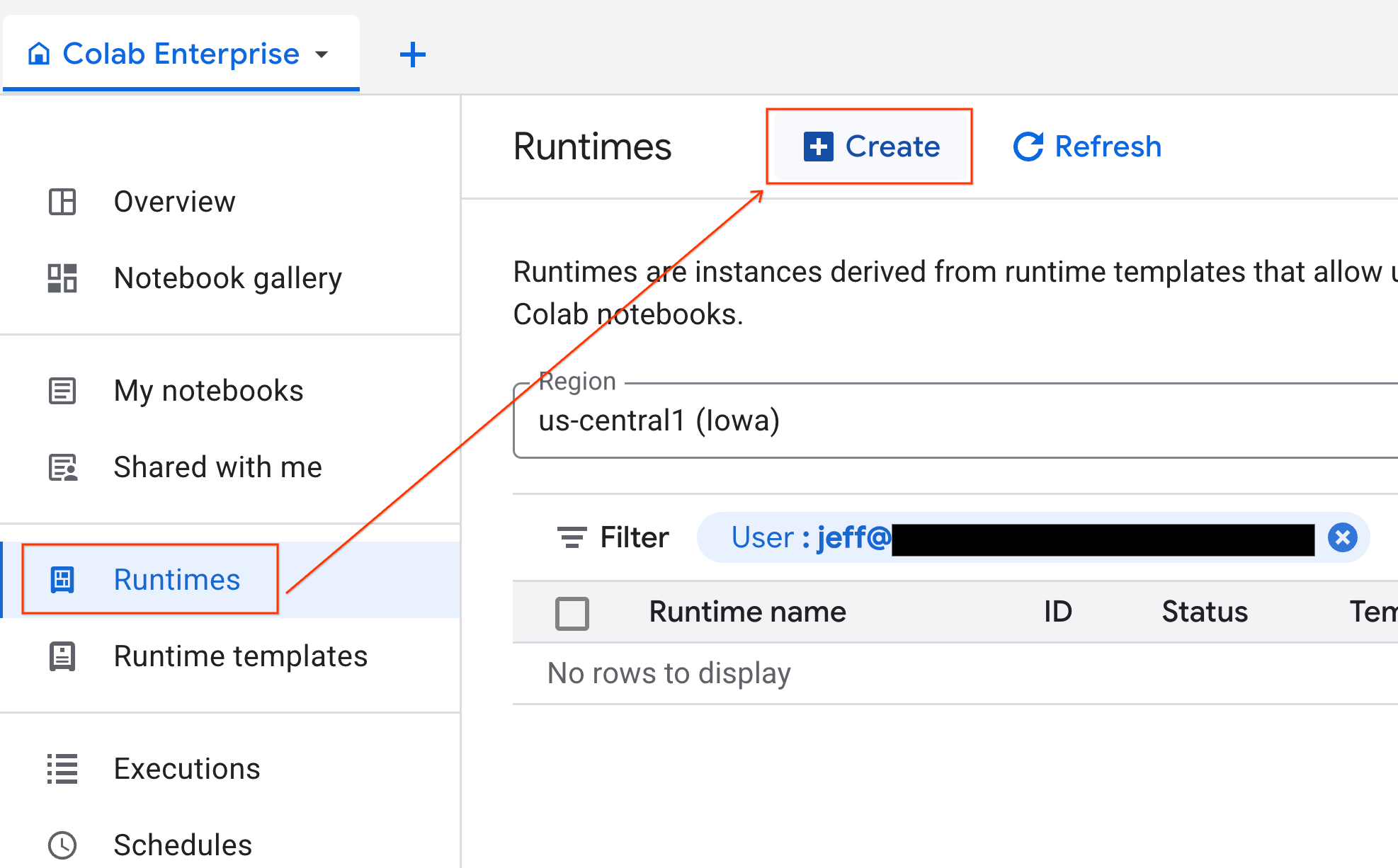
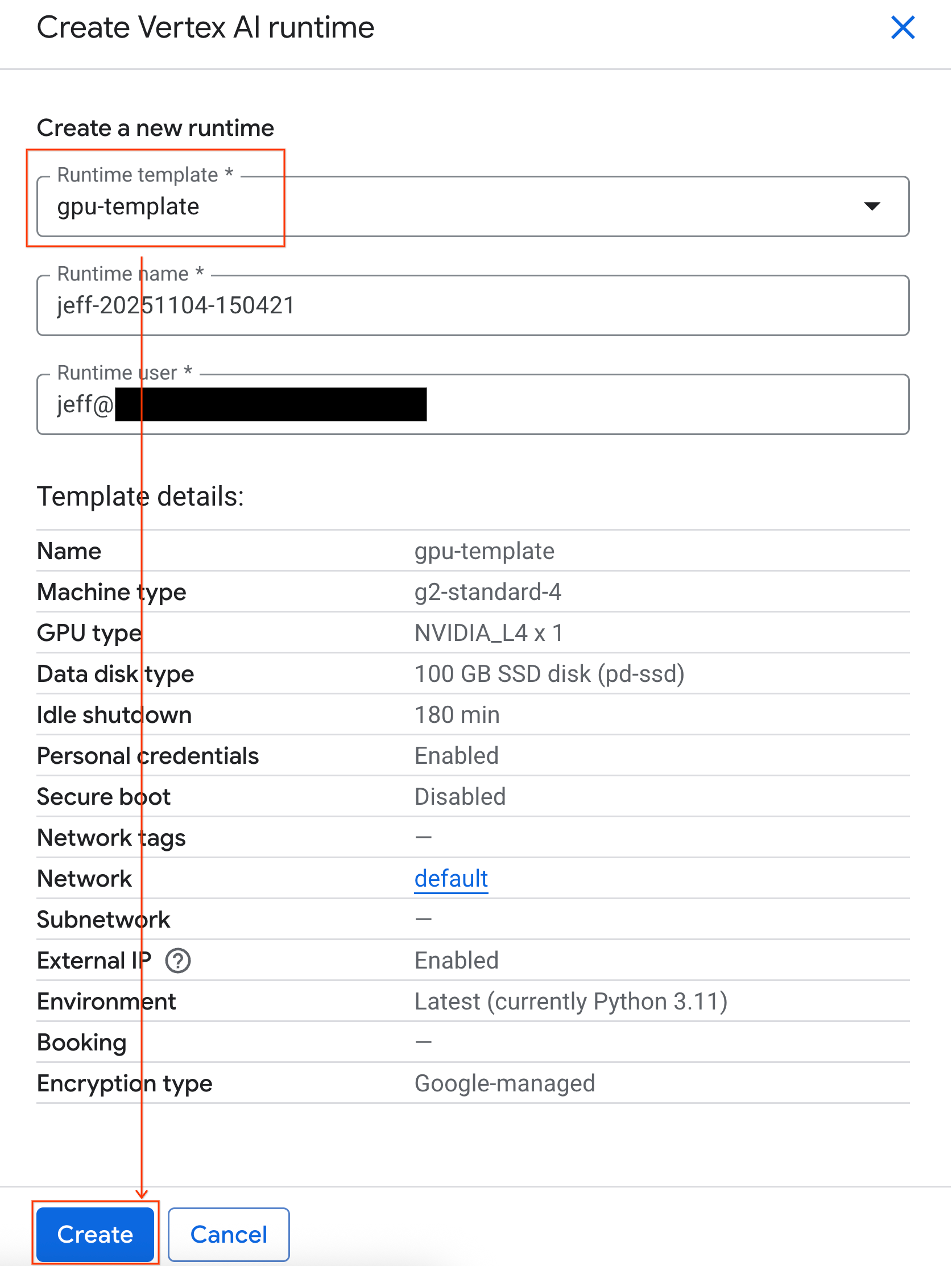
- Çalışma zamanı şablonu bölümünde
gpu-templateseçeneğini belirleyin. Oluştur'u tıklayın ve çalışma zamanının başlatılmasını bekleyin.
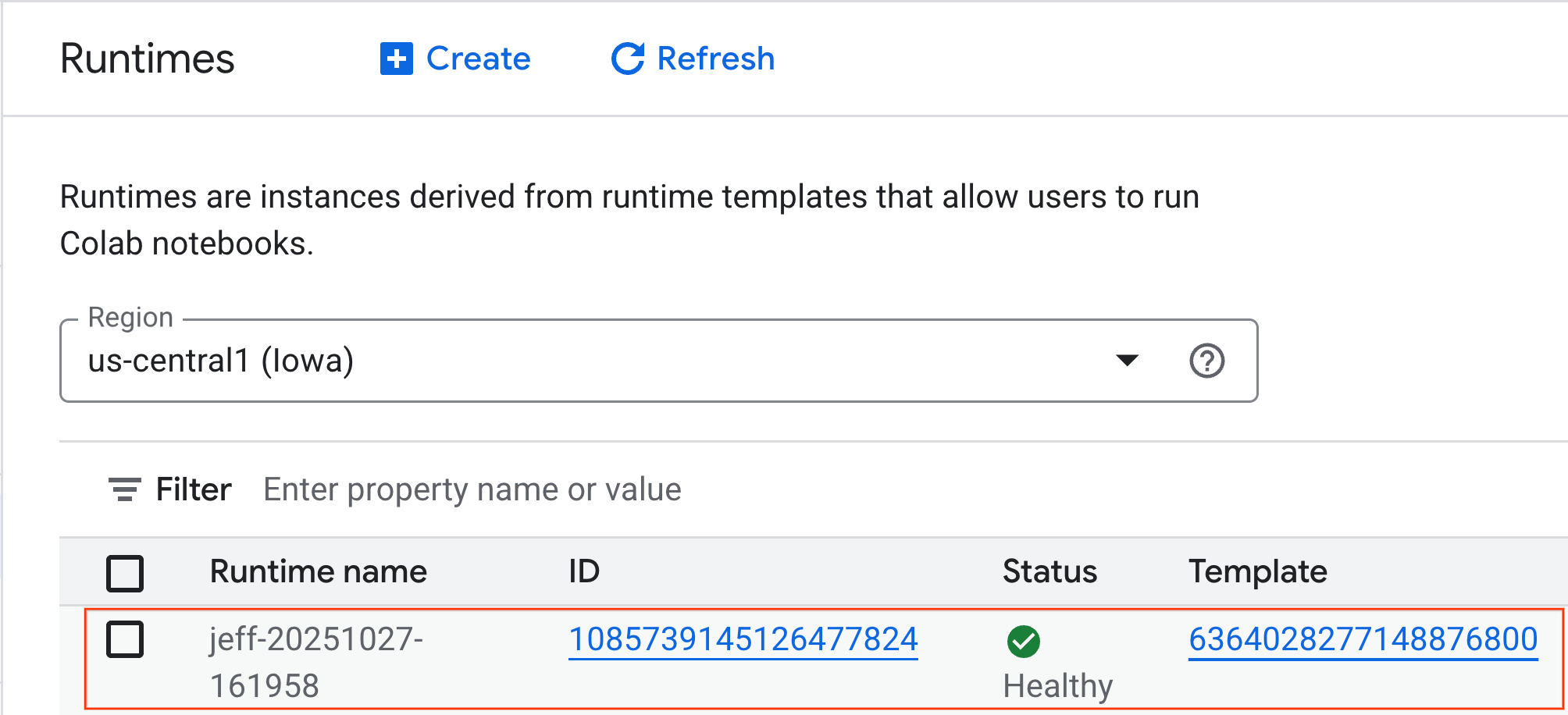
- Birkaç dakika sonra çalışma süresini görebilirsiniz.
6. Not defterini ayarlayın
Altyapınız çalışır duruma geldiğine göre artık laboratuvar not defterini içe aktarmanız ve çalışma zamanınıza bağlamanız gerekir.
Not defterini içe aktarma
- Colab Enterprise'da Not defterlerim'i ve ardından İçe aktar'ı tıklayın.
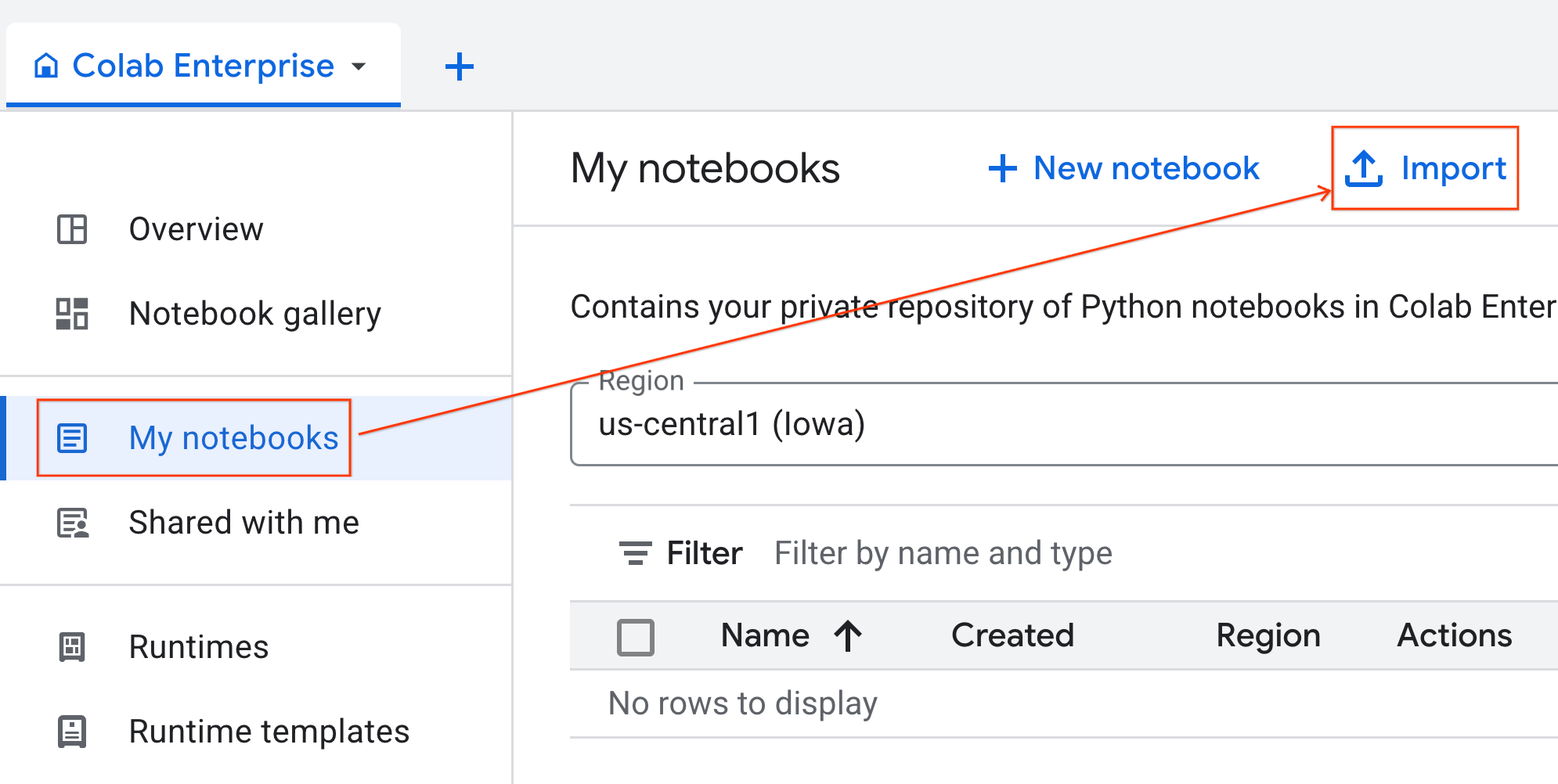
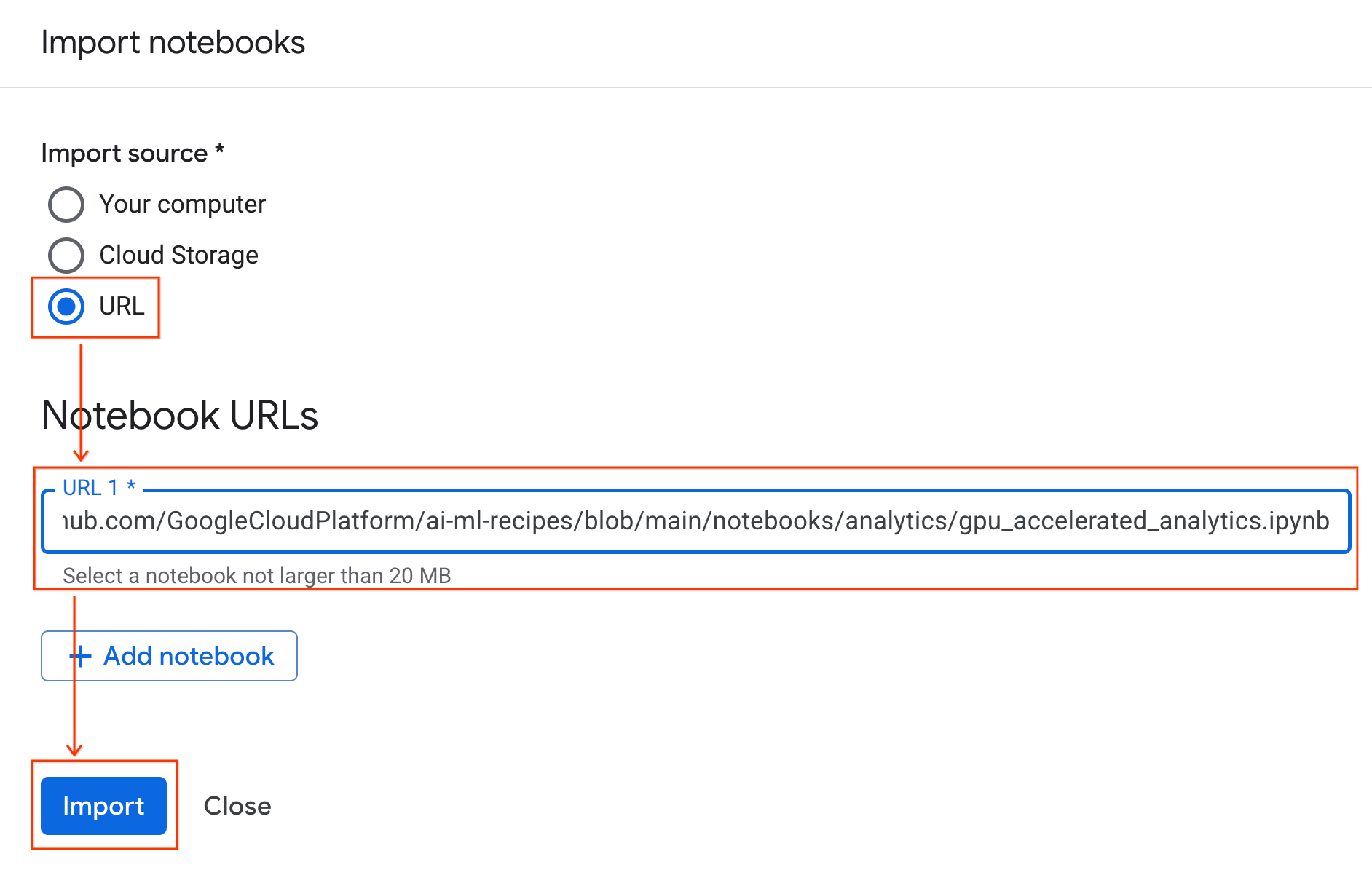
- URL radyo düğmesini seçin ve aşağıdaki URL'yi girin:
https://github.com/GoogleCloudPlatform/ai-ml-recipes/blob/main/notebooks/analytics/gpu_accelerated_analytics.ipynb
- İçe Aktar'ı tıklayın. Colab Enterprise, not defterini GitHub'dan ortamınıza kopyalar.
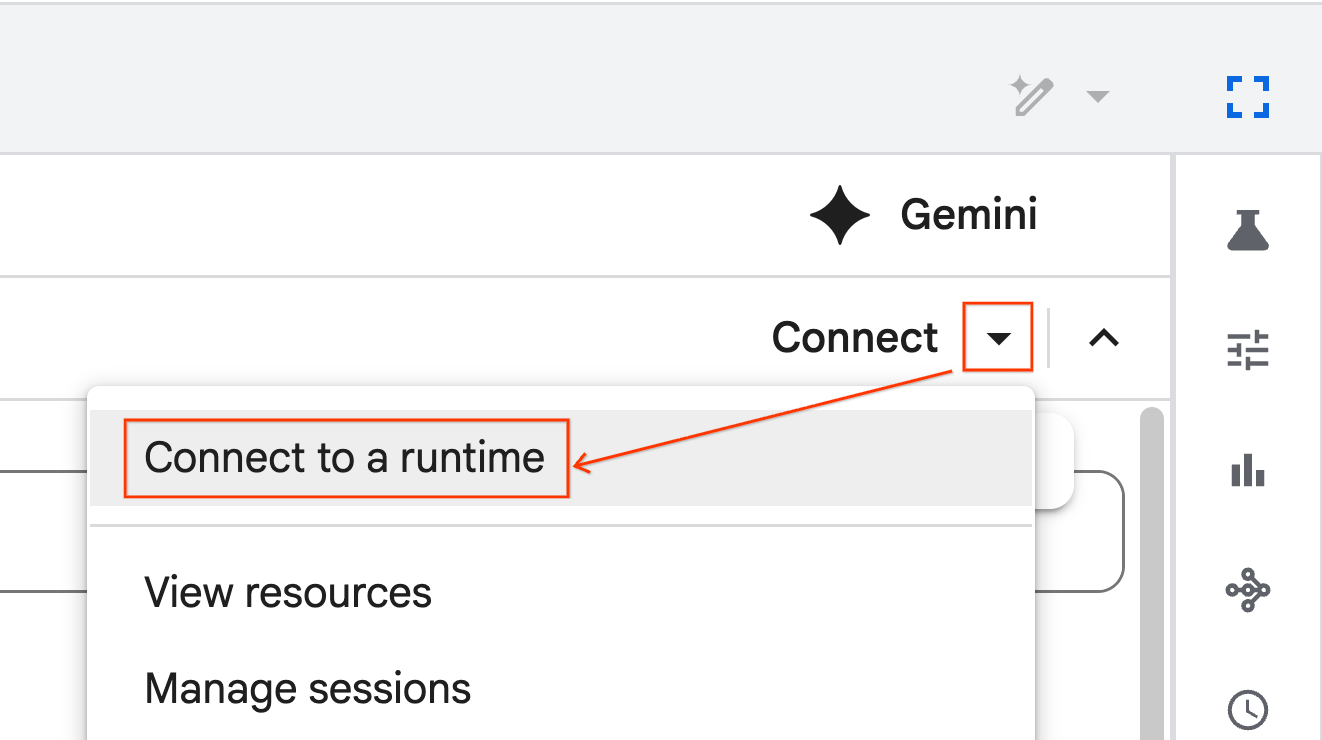
Çalışma zamanına bağlanma
- Yeni içe aktarılan not defterini açın.
- Bağlan'ın yanındaki aşağı oku tıklayın.
- Çalışma zamanına bağlan'ı seçin.
- Açılır listeyi kullanarak daha önce oluşturduğunuz çalışma zamanını seçin.
- Bağlan'ı tıklayın.
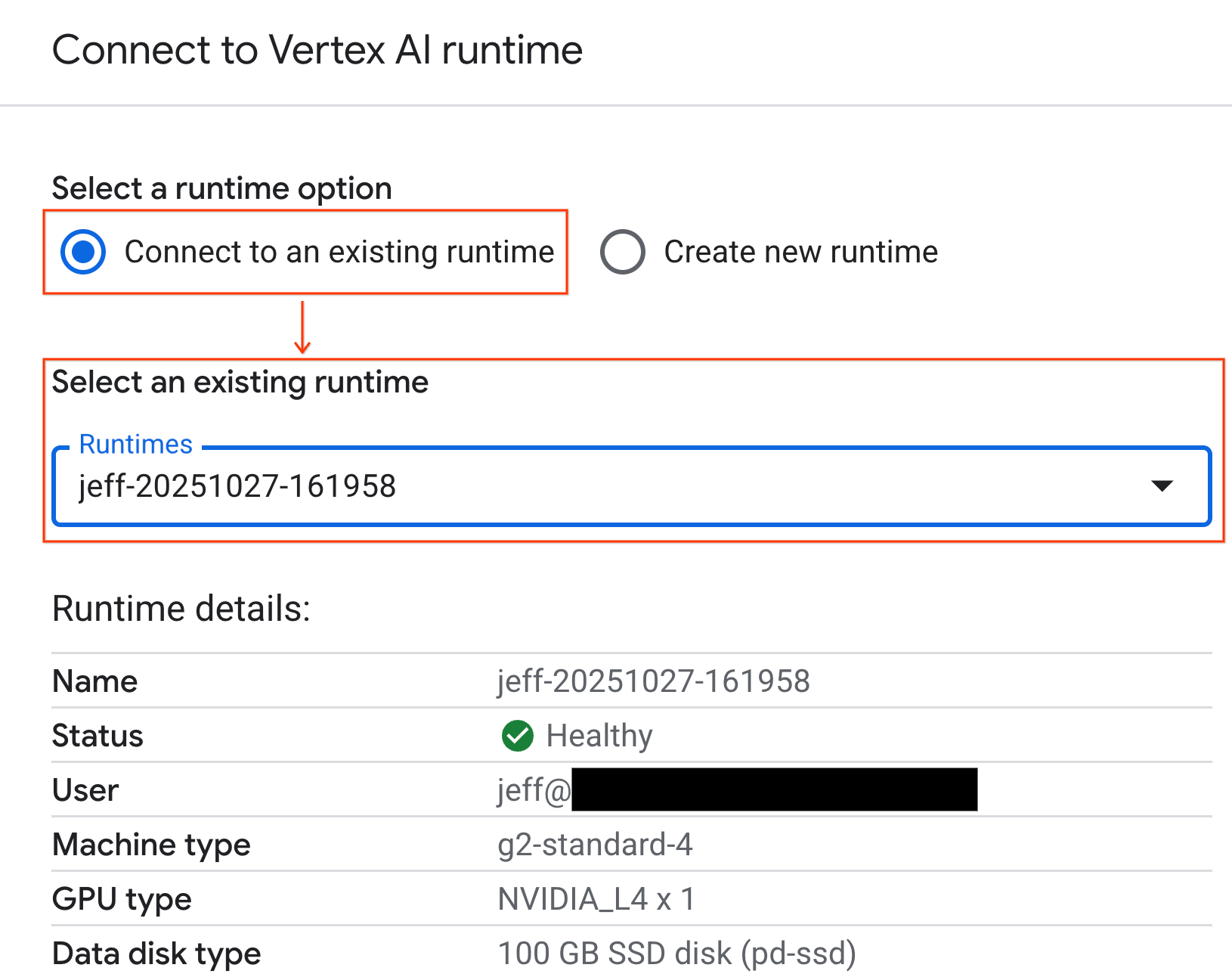
Not defteriniz artık GPU özellikli bir çalışma zamanına bağlı. Artık sorgu çalıştırmaya başlayabilirsiniz.
7. NYC taksi veri kümesini hazırlama
Bu Codelab'de NYC Taxi & Limousine Commission (TLC) Trip Record Data kullanılır.
Veri kümesi, New York City'deki sarı taksilerin ayrı ayrı yolculuk kayıtlarını içerir ve aşağıdaki gibi alanları kapsar:
- Teslim alma ve teslim etme tarihleri, saatleri ve konumları
- Gezi mesafeleri
- Ayrıntılı ücret tutarları
- Yolcu sayıları
Verileri indirin
Ardından, 2024'ün tamamına ait gezi verilerini indirin. Veriler Parquet dosya biçiminde depolanır.
Aşağıdaki kod bloğu bu adımları gerçekleştirir:
- İndirilecek yıl ve ay aralığını tanımlar.
- Dosyaları depolamak için
nyc_taxi_dataadlı bir yerel dizin oluşturur. - Her ay için döngü oluşturur, henüz mevcut değilse ilgili Parquet dosyasını indirir ve dizine kaydeder.
Verileri toplamak ve çalışma zamanında depolamak için bu kodu not defterinizde çalıştırın:
from tqdm import tqdm
import requests
import time
import os
YEAR = 2024
DATA_DIR = "nyc_taxi_data"
os.makedirs(DATA_DIR, exist_ok=True)
print(f"Checking/Downloading files for {YEAR}...")
for month in tqdm(range(1, 13), unit="file"):
# Define standardized filename for both local path and URL
file_name = f"yellow_tripdata_{YEAR}-{month:02d}.parquet"
local_path = os.path.join(DATA_DIR, file_name)
url = f"https://d37ci6vzurychx.cloudfront.net/trip-data/{file_name}"
if not os.path.exists(local_path):
try:
with requests.get(url, stream=True) as response:
response.raise_for_status()
with open(local_path, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
time.sleep(1)
except requests.exceptions.HTTPError as e:
print(f"\nSkipping {file_name}: {e}")
if os.path.exists(local_path):
os.remove(local_path)
print("\nDownload complete.")
8. Taksi yolculuğu verilerini keşfetme
Veri kümesini indirdiğinize göre artık ilk keşifsel veri analizini (EDA) yapabilirsiniz. EDA'nın amacı, verilerin yapısını anlamak, anormallikleri bulmak ve olası kalıpları ortaya çıkarmaktır.
Tek bir aylık verileri yükleme
Öncelikle bir aylık verileri yükleyerek başlayın. Bu sayede, etkileşimli analiz için bellek kullanımı yönetilebilir düzeyde tutulurken anlamlı olacak kadar büyük bir örnek (3 milyondan fazla satır) sağlanır.
import pandas as pd
import glob
# Load the last month of the downloaded data
df = pd.read_parquet("nyc_taxi_data/yellow_tripdata_2024-12.parquet")
df.head()
Özet istatistikleri alma
Sayısal sütunlar için üst düzey özet istatistikleri oluşturmak üzere .describe() yöntemini kullanın. Bu, beklenmeyen minimum veya maksimum değerler gibi olası veri kalitesi sorunlarını tespit etmek için harika bir ilk adımdır.
df.describe().round(2)

Veri kalitesini inceleme
.describe() çıkışı hemen bir sorunu ortaya çıkarıyor. tpep_pickup_datetime ve tpep_dropoff_datetime için min değerinin 2008 yılında olduğunu fark edebilirsiniz. Bu, 2024 veri kümesi için mantıklı değildir.
Bu, verilerinizi neden her zaman incelemeniz gerektiğine dair bir örnektir. Bu durumu daha ayrıntılı olarak incelemek için DataFrame'i sıralayarak bu aykırı tarihleri içeren satırları bulabilirsiniz.
# Sort by the dropoff datetime to see the oldest records
df.sort_values("tpep_pickup_datetime").head()
Veri dağılımlarını görselleştirme
Ardından, dağılımlarını görselleştirmek için sayısal sütunların histogramlarını oluşturabilirsiniz. Bu sayede, trip_distance ve fare_amount gibi özelliklerin dağılımını ve çarpıklığını anlayabilirsiniz. .hist() işlevi, bir DataFrame'deki tüm sayısal sütunlar için histogramlar oluşturmanın hızlı bir yoludur.
_ = df.hist(figsize=(20, 20))
Son olarak, birkaç temel sütun arasındaki ilişkileri görselleştirmek için bir dağılım matrisi oluşturun. Milyonlarca noktayı çizmek yavaş olduğundan ve desenleri gizleyebileceğinden, 100.000 satırlık rastgele bir örnekten grafiği oluşturmak için .sample() kullanın.
_ = pd.plotting.scatter_matrix(
df[['passenger_count', 'trip_distance', 'tip_amount', 'total_amount']].sample(100_000),
diagonal="kde",
figsize=(15, 15)
)
9. Parquet dosya biçimini neden kullanmalısınız?
NYC taksi veri kümesi, Apache Parquet biçiminde sağlanır. Bu, büyük ölçekli analizler için bilinçli olarak yapılmış bir seçimdir. Parquet, CSV gibi dosya türlerine kıyasla çeşitli avantajlar sunar:
- Verimli ve hızlı: Parquet, sütun biçimli bir format olduğundan depolama ve okuma açısından son derece verimlidir. Bu, özellikle GPU'larda daha küçük dosya boyutları ve önemli ölçüde daha hızlı G/Ç sağlayan modern sıkıştırma yöntemlerini destekler.
- Şemayı korur: Parquet, veri türlerini dosyanın meta verilerinde depolar. Dosyayı okurken veri türlerini tahmin etmeniz gerekmez.
- Seçerek okuma olanağı sunar: Sütun yapısı, analiz için yalnızca ihtiyacınız olan sütunları okumanıza olanak tanır. Bu, belleğe yüklemeniz gereken veri miktarını önemli ölçüde azaltabilir.
Parquet özelliklerini keşfedin
İndirdiğiniz dosyalardan birini kullanarak bu güçlü özelliklerden ikisini inceleyelim.
Meta verileri, veri kümesinin tamamını yüklemeden inceleme
Parquet dosyalarını standart bir metin düzenleyicide görüntüleyemezsiniz ancak herhangi bir veriyi belleğe yüklemeden şemasını ve meta verilerini kolayca inceleyebilirsiniz. Bu özellik, bir dosyanın yapısını hızlıca anlamak için kullanışlıdır.
from pyarrow.parquet import ParquetFile
import pyarrow as pa
# Open one of the downloaded files
pf = ParquetFile('nyc_taxi_data/yellow_tripdata_2024-12.parquet')
# Print the schema
print("File Schema:")
print(pf.schema)
# Print the file metadata
print("\nFile Metadata:")
print(pf.metadata)
Yalnızca ihtiyacınız olan sütunları okuma
Yalnızca seyahat mesafesini ve ücret tutarlarını analiz etmeniz gerektiğini düşünün. Parquet ile yalnızca bu sütunları yükleyebilirsiniz. Bu, tüm DataFrame'i yüklemekten çok daha hızlıdır ve daha az bellek kullanır.
import pandas as pd
# Read only four specific columns from the Parquet file
df_subset = pd.read_parquet(
'nyc_taxi_data/yellow_tripdata_2024-12.parquet',
columns=['passenger_count', 'trip_distance', 'tip_amount', 'total_amount']
)
df_subset.head()
10. NVIDIA cuDF ile pandas'ı hızlandırma
NVIDIA CUDA for DataFrames (cuDF), DataFrame'lerle etkileşim kurmanıza olanak tanıyan açık kaynaklı, GPU hızlandırmalı bir kitaplıktır. cuDF, GPU'da büyük paralellik ile filtreleme, birleştirme ve gruplandırma gibi yaygın veri işlemlerini gerçekleştirmenize olanak tanır.
Bu Codelab'de kullandığınız temel özellik cudf.pandas hızlandırıcı modudur. Bu özelliği etkinleştirdiğinizde, standart pandas kodunuz arka planda GPU destekli cuDF çekirdekleri kullanmak üzere otomatik olarak yönlendirilir. Bu işlem için kodunuzda herhangi bir değişiklik yapmanız gerekmez.
GPU hızlandırmayı etkinleştirme
NVIDIA cuDF'yi Colab Enterprise not defterinde kullanmak için pandas öğesini içe aktarmadan önce sihirli uzantısını yüklersiniz.
Öncelikle standart pandas kitaplığını inceleyin. Çıkışın, varsayılan pandas yüklemesinin yolunu gösterdiğini fark edin.
import pandas as pd
pd # Note the output for the standard pandas library
Şimdi cudf.pandas uzantısını yükleyin ve pandas öğesini tekrar içe aktarın. pd modülünün çıkışının nasıl değiştiğini izleyin. Bu, GPU hızlandırmalı sürümün artık etkin olduğunu onaylar.
%load_ext cudf.pandas
import pandas as pd
pd # Note the new output, indicating cudf.pandas is active
cudf.pandas özelliğini etkinleştirmenin diğer yolları
Not defterinde en kolay yöntem sihirli komut (%load_ext) olsa da hızlandırıcıyı diğer ortamlarda da etkinleştirebilirsiniz:
- Python komut dosyalarında:
pandasiçe aktarma işleminizden önceimport cudf.pandasvecudf.pandas.install()işlevlerini çağırın. - Not defteri olmayan ortamlarda: Komut dosyanızı
python -m cudf.pandas your_script.pykullanarak çalıştırın.
11. CPU ve GPU performansını karşılaştırma
Şimdi en önemli kısma geçelim: CPU'da standart pandas ile GPU'da cudf.pandas performansını karşılaştırma.
CPU için tamamen adil bir temel oluşturmak istiyorsanız önce Colab çalışma zamanını sıfırlamanız gerekir. Bu işlem, önceki bölümlerde etkinleştirmiş olabileceğiniz tüm GPU hızlandırıcılarını temizler. Aşağıdaki hücreyi çalıştırarak veya Çalışma zamanı menüsünden Oturumu yeniden başlat'ı seçerek çalışma zamanını yeniden başlatabilirsiniz.
import IPython
IPython.Application.instance().kernel.do_shutdown(True)
Analiz ardışık düzenini tanımlama
Ortam temizlendiğine göre artık karşılaştırma işlevini tanımlayabilirsiniz. Bu işlev, hangi pandas modülünü geçirirseniz geçirin yükleme, sıralama ve özetleme gibi aynı ardışık düzeni çalıştırmanıza olanak tanır.
import time
import glob
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
def run_analytics_pipeline(pd_module):
"""Loads, sorts, and summarizes data using the provided pandas module."""
timings = {}
# 1. Load all 2024 Parquet files from the directory
t0 = time.time()
df = pd_module.concat(
[pd_module.read_parquet(f) for f in glob.glob("nyc_taxi_data/*_2024*.parquet")],
ignore_index=True
)
timings["load"] = time.time() - t0
# 2. Sort the data by multiple columns
t0 = time.time()
df = df.sort_values(
['tpep_pickup_datetime', 'trip_distance', 'passenger_count'],
ascending=[False, True, False]
)
timings["sort"] = time.time() - t0
# 3. Perform a groupby and aggregation
t0 = time.time()
df['tpep_pickup_datetime'] = pd_module.to_datetime(df['tpep_pickup_datetime'])
_ = (
df.loc[df.tpep_pickup_datetime > '2024-11-01']
.groupby(['VendorID', 'tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
timings["summarize"] = time.time() - t0
return timings
Karşılaştırmayı çalıştırma
Öncelikle, işlemci üzerinde standart pandas kullanarak işlem hattını çalıştıracaksınız. Ardından cudf.pandas'yı etkinleştirip GPU'da tekrar çalıştırırsınız.
# --- Run on CPU ---
print("Running analytics pipeline on CPU...")
# Ensure we are using standard pandas
import pandas as pd
assert "cudf" not in str(pd), "Error: cuDF is still active. Please restart the kernel."
cpu_times = run_analytics_pipeline(pd)
print(f"CPU times: {cpu_times}")
# --- Run on GPU ---
print("\nEnabling cudf.pandas and running on GPU...")
# Load the extension
%load_ext cudf.pandas
import pandas as gpu_pd
gpu_times = run_analytics_pipeline(gpu_pd)
print(f"GPU times: {gpu_times}")
Sonuçları görselleştirme
Son olarak, farkı görselleştirin. Aşağıdaki kod, her işlem için hızlanmayı hesaplar ve bunları yan yana çizer.
# Create a DataFrame for plotting
results_df = pd.DataFrame([cpu_times, gpu_times], index=["CPU", "GPU"]).T
total_cpu_time = results_df['CPU'].sum()
total_gpu_time = results_df['GPU'].sum()
speedup = total_cpu_time / total_gpu_time
print("--- Performance Results ---")
print(results_df)
print(f"\nTotal CPU Time: {total_cpu_time:.2f} seconds")
print(f"Total GPU Time: {total_gpu_time:.2f} seconds")
print(f"Overall Speedup: {speedup:.2f}x")
# Plot the results
fig, ax = plt.subplots(figsize=(10, 6))
results_df.plot(kind='bar', ax=ax, color={"CPU": "tab:blue", "GPU": "tab:green"})
ax.set_ylabel("Time (seconds)")
ax.set_title(f"CPU vs. GPU Runtimes (Overall Speedup: {speedup:.2f}x)", fontsize=14)
ax.tick_params(axis='x', rotation=0)
# Add numerical labels to the bars
for container in ax.containers:
ax.bar_label(container, fmt="%.2f", padding=3)
plt.tight_layout()
plt.show()
Örnek sonuçlar:
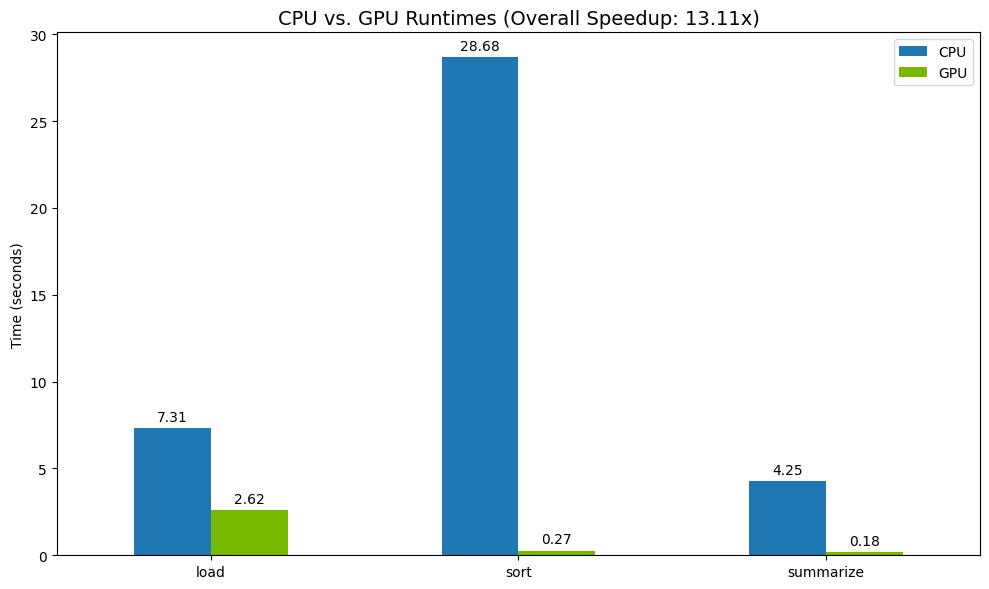
GPU, CPU'ya kıyasla belirgin bir hız artışı sağlar.
12. Darboğazları bulmak için kodunuzun profilini oluşturma
GPU hızlandırma etkin olsa bile, pandas işlemlerinden bazıları cuDF tarafından henüz desteklenmiyorsa CPU'ya geri dönebilir. Bu "CPU yedekleri" performans darboğazlarına neden olabilir.
Bu alanları belirlemenize yardımcı olmak için cudf.pandas iki yerleşik profil oluşturucu içerir. Kodunuzun hangi bölümlerinin GPU'da çalıştığını, hangilerinin ise CPU'ya geri döndüğünü tam olarak görmek için bu araçları kullanabilirsiniz.
%%cudf.pandas.profile: Kodunuzun işlev bazında üst düzey bir özetini almak için bu özelliği kullanın. Hangi işlemlerin hangi cihazda çalıştığına dair hızlı bir genel bakış elde etmek için en iyi yöntemdir.%%cudf.pandas.line_profile: Ayrıntılı, satır satır analiz için bunu kullanın. Bu araç, kodunuzda CPU'ya geri dönüşe neden olan satırları tam olarak belirlemek için en iyi araçtır.
Bu profiller, not defteri hücresinin üst kısmında "hücre sihirleri" olarak kullanılır.
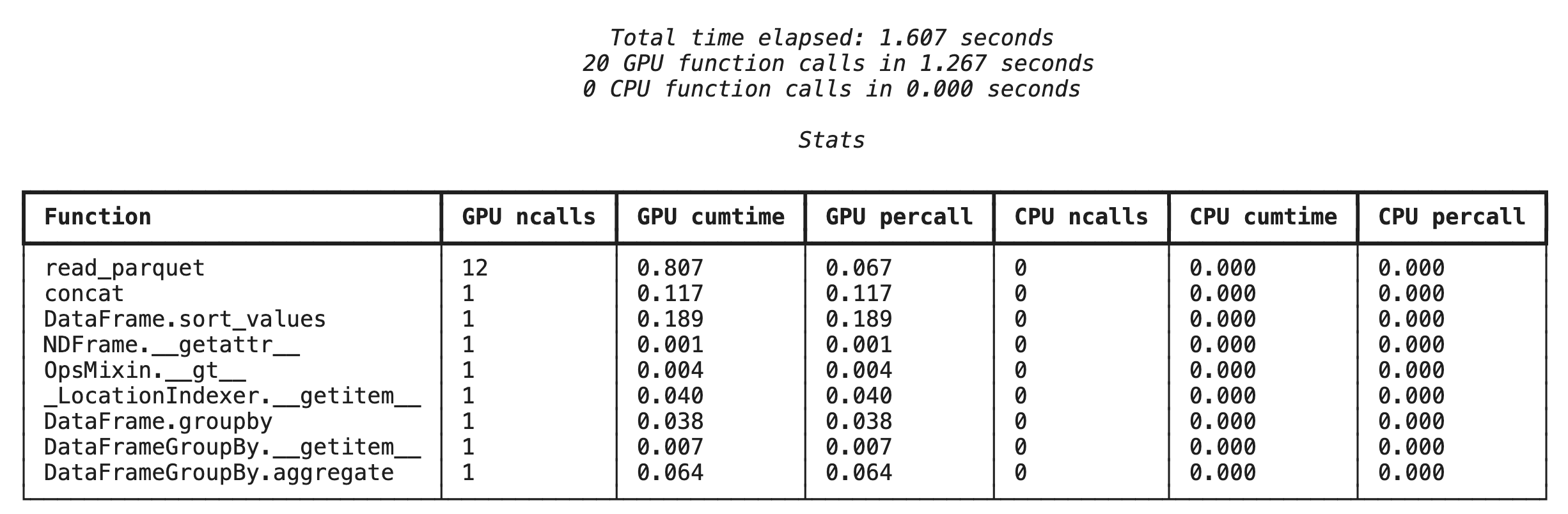
%%cudf.pandas.profile ile işlev düzeyinde profil oluşturma
Öncelikle, önceki bölümdekiyle aynı analiz ardışık düzeninde işlev düzeyinde profil aracı çalıştırın. Çıktıda, çağrılan her işlevin, üzerinde çalıştırıldığı cihazın (GPU veya CPU) ve kaç kez çağrıldığının yer aldığı bir tablo gösterilir.
%load_ext cudf.pandas
import pandas as pd
import glob
pd.DataFrame({"a": [1]})
cudf.pandas'ın etkin olduğundan emin olduktan sonra profil oluşturabilirsiniz.
%%cudf.pandas.profile
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*2024*.parquet")], ignore_index=True)
df = df.sort_values(['tpep_pickup_datetime', 'trip_distance', 'passenger_count'], ascending=[False, True, False])
summary = (
df
.loc[(df.tpep_pickup_datetime > '2024-11-01')]
.groupby(['VendorID','tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
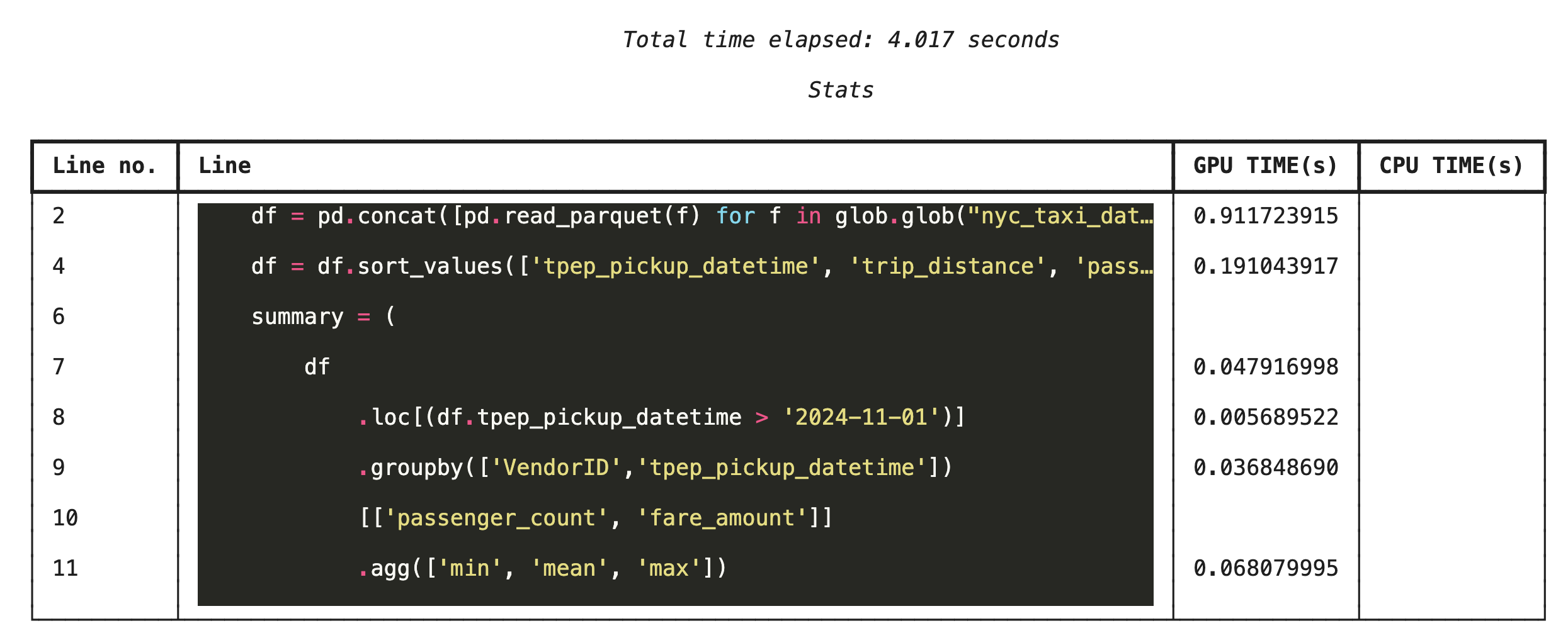
%%cudf.pandas.line_profile ile satır satır profilleme
Ardından, satır düzeyinde profil oluşturucuyu çalıştırın. Bu sayede, her bir kod satırının GPU'da ve CPU'da yürütülürken harcadığı sürenin oranını gösteren çok daha ayrıntılı bir görünüm elde edersiniz. Bu, optimize edilecek belirli darboğazları bulmanın en etkili yoludur.
%%cudf.pandas.line_profile
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*2024*.parquet")], ignore_index=True)
df = df.sort_values(['tpep_pickup_datetime', 'trip_distance', 'passenger_count'], ascending=[False, True, False])
summary = (
df
.loc[(df.tpep_pickup_datetime > '2024-11-01')]
.groupby(['VendorID','tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
Komut satırından profil oluşturma
Bu profiller, komut satırından da kullanılabilir. Bu özellik, Python komut dosyalarının otomatik olarak test edilmesi ve profillendirilmesi için yararlıdır.
Komut satırı arayüzünde aşağıdakileri kullanabilirsiniz:
python -m cudf.pandas --profile your_script.pypython -m cudf.pandas --line_profile your_script.py
13. Google Cloud Storage ile entegrasyon
Google Cloud Storage (GCS), ölçeklenebilir ve dayanıklı bir nesne depolama hizmetidir. Colab Enterprise'ı kullandığınızda GCS, veri kümelerinizi, model kontrol noktalarınızı ve diğer yapılarınızı depolamak için ideal bir yerdir.
Colab Enterprise çalışma zamanınızın, verileri doğrudan GCS paketlerine okuma ve yazma için gerekli izinleri vardır. Bu işlemler, maksimum performans için GPU ile hızlandırılır.
GCS paketi oluşturma
Öncelikle yeni bir GCS paketi oluşturun. GCS paketi adları genel olarak benzersizdir. Bu nedenle, adının sonuna bir UUID ekleyin.
from google.cloud import storage
import uuid
unique_suffix = uuid.uuid4().hex[:12]
bucket_name = f'nyc-taxi-codelab-{unique_suffix}'
project_id = storage.Client().project
client = storage.Client()
try:
bucket = client.create_bucket(bucket_name)
print(f"Successfully created bucket: gs://{bucket.name}")
except Exception as e:
print(f"Bucket creation failed. You may already own it or the name is taken: {e}")
Verileri doğrudan GCS'ye yazma
Şimdi bir DataFrame'i doğrudan yeni GCS paketinize kaydedin. df değişkeni önceki bölümlerde kullanılamıyorsa kod önce bir aylık veriyi yükler.
%%cudf.pandas.line_profile
# Ensure the DataFrame exists before saving to GCS
if 'df' not in locals():
print("DataFrame not found, loading a sample file...")
df = pd.read_parquet('nyc_taxi_data/yellow_tripdata_2024-12.parquet')
print(f"Writing data to gs://{bucket_name}/nyc_taxi_data.parquet...")
df.to_parquet(f"gs://{bucket_name}/nyc_taxi_data.parquet", index=False)
print("Write operation complete.")
GCS'deki dosyayı doğrulama
Paketi ziyaret ederek verilerin GCS'de olduğunu doğrulayabilirsiniz. Aşağıdaki kod, tıklanabilir bir bağlantı oluşturur.
from IPython.display import Markdown
gcs_url = f"https://console.cloud.google.com/storage/browser/{bucket_name}?project={project_id}"
Markdown(f'**[Click here to view your GCS bucket in the Google Cloud Console]({gcs_url})**')
Verileri doğrudan GCS'den okuma
Son olarak, verileri doğrudan bir GCS yolundan DataFrame'e okuyun. Bu işlem GPU ile de hızlandırılır. Böylece, bulut depolama alanından büyük veri kümelerini yüksek hızda yükleyebilirsiniz.
%%cudf.pandas.line_profile
print(f"Reading data from gs://{bucket_name}/nyc_taxi_data.parquet...")
df_from_gcs = pd.read_parquet(f"gs://{bucket_name}/nyc_taxi_data.parquet")
df_from_gcs.head()
14. Temizleme
Google Cloud hesabınızın beklenmedik şekilde ücretlendirilmesini önlemek için oluşturduğunuz kaynakları temizlemeniz gerekir.
İndirdiğiniz verileri silme:
# Permanately delete the GCS bucket
print(f"Deleting GCS bucket: gs://{bucket_name}...")
!gsutil rm -r -f gs://{bucket_name}
print("Bucket deleted.")
# Remove NYC taxi dataset on the Colab runtime
print("Deleting local 'nyc_taxi_data' directory...")
!rm -rf nyc_taxi_data
print("Local files deleted.")
Colab çalışma zamanınızı kapatma
- Google Cloud Console'da Colab Enterprise Çalışma Zamanları sayfasına gidin.
- Bölge menüsünde, çalışma zamanınızı içeren bölgeyi seçin.
- Silmek istediğiniz çalışma zamanını seçin.
- Sil'i tıklayın.
- Onayla'yı tıklayın.
Not defterinizi silme
- Google Cloud Console'da Colab Enterprise Not Defterlerim sayfasına gidin.
- Bölge menüsünde, not defterinizin bulunduğu bölgeyi seçin.
- Silmek istediğiniz not defterini seçin.
- Sil'i tıklayın.
- Onayla'yı tıklayın.
15. Tebrikler
Tebrikler! Colab Enterprise'da NVIDIA cuDF kullanarak bir pandas analiz iş akışını başarıyla hızlandırdınız. GPU özellikli çalışma zamanlarını yapılandırmayı, sıfır kod değişikliğiyle hızlandırma için cudf.pandas'yı etkinleştirmeyi, darboğazlar için kodu profillemeyi ve Google Cloud Storage ile entegrasyonu öğrendiniz.