
1. Giới thiệu
Trong Lớp học lập trình này, bạn sẽ tìm hiểu cách tăng tốc quy trình phân tích dữ liệu trên các tập dữ liệu lớn bằng GPU NVIDIA và các thư viện nguồn mở trên Google Cloud. Bạn sẽ bắt đầu bằng cách tối ưu hoá cơ sở hạ tầng, sau đó tìm hiểu cách áp dụng tính năng tăng tốc GPU mà không cần thay đổi mã.
Bạn sẽ tập trung vào pandas, một thư viện thao tác dữ liệu phổ biến, đồng thời tìm hiểu cách tăng tốc thư viện này bằng thư viện cuDF của NVIDIA. Điều tuyệt vời nhất là bạn có thể sử dụng tính năng tăng tốc GPU này mà không cần thay đổi mã pandas hiện có.
Kiến thức bạn sẽ học được
- Tìm hiểu về Colab Enterprise trên Google Cloud.
- Tuỳ chỉnh môi trường thời gian chạy Colab bằng các cấu hình GPU, CPU và bộ nhớ cụ thể.
- Tăng tốc
pandasmà không cần thay đổi mã bằngcuDFcủa NVIDIA. - Phân tích mã của bạn để xác định và tối ưu hoá các điểm tắc nghẽn về hiệu suất.
Trang tiếp theo có tín dụng mà bạn có thể dùng để hoàn thành bài tập thực hành.
2. Tại sao nên tăng tốc quá trình xử lý dữ liệu?
Quy tắc 80/20: Tại sao việc chuẩn bị dữ liệu lại tốn nhiều thời gian đến vậy
Chuẩn bị dữ liệu thường là giai đoạn tốn nhiều thời gian nhất của một dự án phân tích. Nhà khoa học dữ liệu và chuyên viên phân tích dành phần lớn thời gian để làm sạch, chuyển đổi và cấu trúc dữ liệu trước khi bắt đầu phân tích.
Rất may là bạn có thể tăng tốc các thư viện nguồn mở phổ biến như pandas, Apache Spark và Polars trên GPU NVIDIA bằng cách sử dụng cuDF. Ngay cả khi có sự tăng tốc này, việc chuẩn bị dữ liệu vẫn tốn nhiều thời gian vì:
- Dữ liệu nguồn hiếm khi sẵn sàng để phân tích: Dữ liệu trong thế giới thực thường có sự không nhất quán, thiếu giá trị và gặp vấn đề về định dạng.
- Chất lượng ảnh hưởng đến hiệu suất của mô hình: Chất lượng dữ liệu kém có thể khiến ngay cả những thuật toán phức tạp nhất cũng trở nên vô dụng.
- Quy mô làm tăng các vấn đề: Các vấn đề nhỏ về dữ liệu có vẻ như không quan trọng sẽ trở thành những điểm tắc nghẽn nghiêm trọng khi bạn làm việc với hàng triệu bản ghi.
3. Chọn môi trường sổ tay
Mặc dù nhiều nhà khoa học dữ liệu đã quen thuộc với Colab cho các dự án cá nhân, nhưng Colab Enterprise mang đến trải nghiệm sổ tay bảo mật, cộng tác và tích hợp được thiết kế cho doanh nghiệp.
Trên Google Cloud, bạn có 2 lựa chọn chính cho môi trường sổ tay được quản lý: Colab Enterprise và Gemini Enterprise Agent Platform Workbench. Lựa chọn phù hợp phụ thuộc vào các ưu tiên của dự án.
Trường hợp sử dụng Agent Platform Workbench
Chọn Agent Platform Workbench khi bạn ưu tiên khả năng kiểm soát và tuỳ chỉnh chuyên sâu. Đây là lựa chọn lý tưởng nếu bạn cần:
- Quản lý cơ sở hạ tầng cơ bản và vòng đời của máy.
- Sử dụng vùng chứa tuỳ chỉnh và cấu hình mạng.
- Tích hợp với các quy trình MLOps và công cụ vòng đời tuỳ chỉnh.
Trường hợp nên sử dụng Colab Enterprise
Chọn Colab Enterprise khi bạn ưu tiên thiết lập nhanh chóng, dễ sử dụng và cộng tác an toàn. Đây là một giải pháp được quản lý hoàn toàn, cho phép nhóm của bạn tập trung vào việc phân tích thay vì cơ sở hạ tầng.
Colab Enterprise giúp bạn:
- Phát triển quy trình khoa học dữ liệu gắn liền với kho dữ liệu của bạn. Bạn có thể mở và quản lý sổ tay ngay trong BigQuery Studio.
- Huấn luyện các mô hình học máy và tích hợp với các công cụ MLOps trong Nền tảng Agent.
- Tận hưởng trải nghiệm linh hoạt và đồng nhất. Bạn có thể mở và chạy một sổ tay Colab Enterprise được tạo trong BigQuery trong Nền tảng tác nhân và ngược lại.
Today's lab
Lớp học lập trình này sử dụng Colab Enterprise để tăng tốc quá trình phân tích dữ liệu.
Để tìm hiểu thêm về những điểm khác biệt này, hãy xem tài liệu chính thức về cách chọn giải pháp sổ tay phù hợp.
4. Định cấu hình mẫu thời gian chạy
Trong Colab Enterprise, hãy kết nối với một môi trường thời gian chạy dựa trên một mẫu môi trường thời gian chạy được định cấu hình sẵn.
Mẫu thời gian chạy là một cấu hình có thể dùng lại, chỉ định toàn bộ môi trường cho sổ tay của bạn, bao gồm:
- Loại máy (CPU, bộ nhớ)
- Trình tăng tốc (loại và số lượng GPU)
- Dung lượng và loại ổ đĩa
- Chế độ cài đặt mạng và chính sách bảo mật
- Quy tắc tự động tắt khi không hoạt động
Lý do mẫu thời gian chạy hữu ích
- Có được một môi trường nhất quán: Bạn và đồng đội sẽ có cùng một môi trường sẵn sàng sử dụng mỗi khi cần để đảm bảo công việc của bạn có thể lặp lại.
- Làm việc an toàn ngay từ đầu: Mẫu tự động thực thi các chính sách bảo mật của tổ chức bạn.
- Quản lý chi phí hiệu quả: Các tài nguyên như GPU và CPU được định cỡ trước trong mẫu, giúp ngăn chặn tình trạng vượt quá chi phí do nhầm lẫn.
Tạo mẫu thời gian chạy
Thiết lập một mẫu thời gian chạy có thể sử dụng lại cho phòng thí nghiệm.
- Trong Bảng điều khiển Google Cloud, hãy chuyển đến Trình đơn điều hướng > Nền tảng tác nhân > Sổ tay.
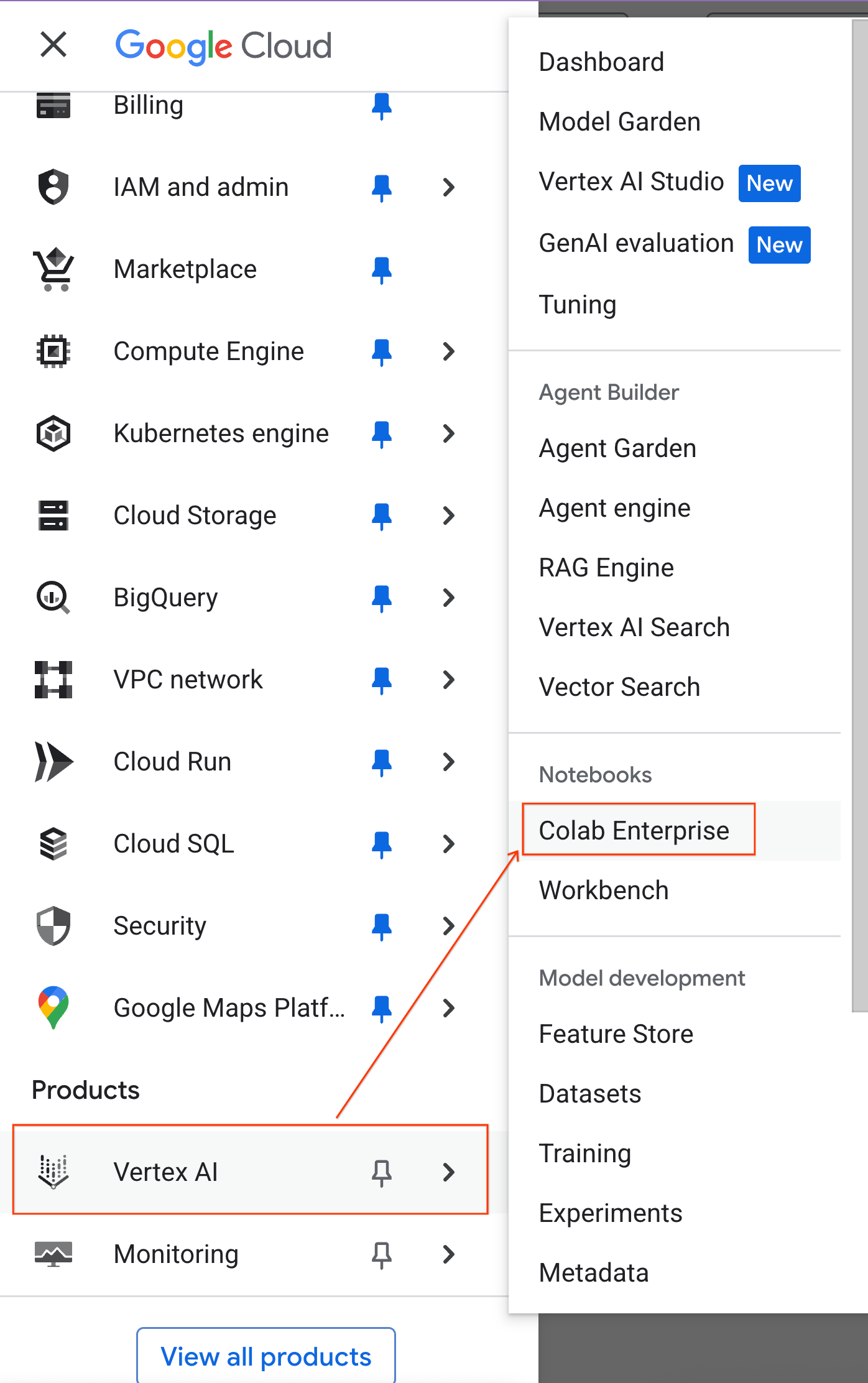
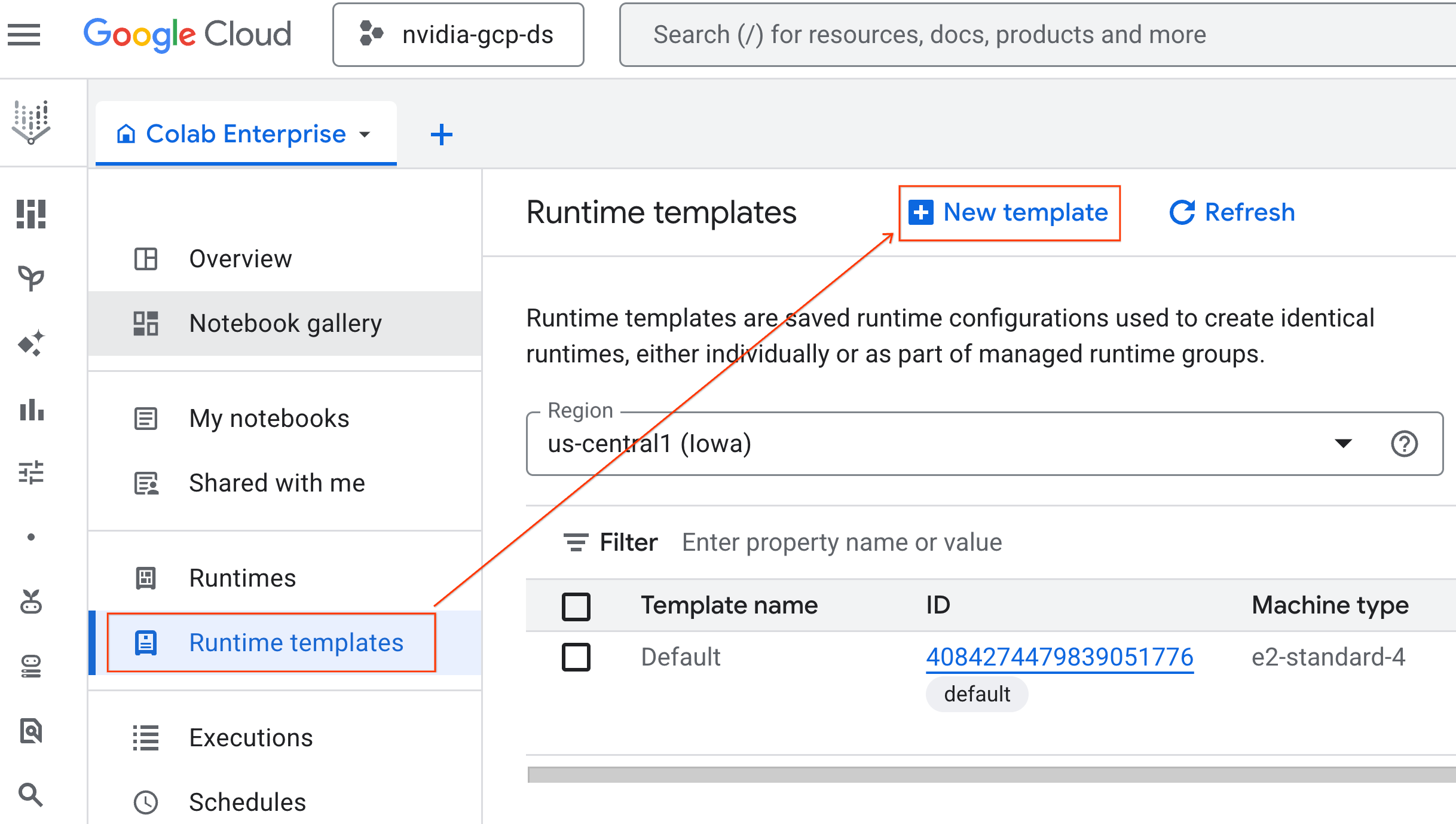
- Trong Colab Enterprise, hãy nhấp vào Mẫu thời gian chạy rồi chọn Mẫu mới.
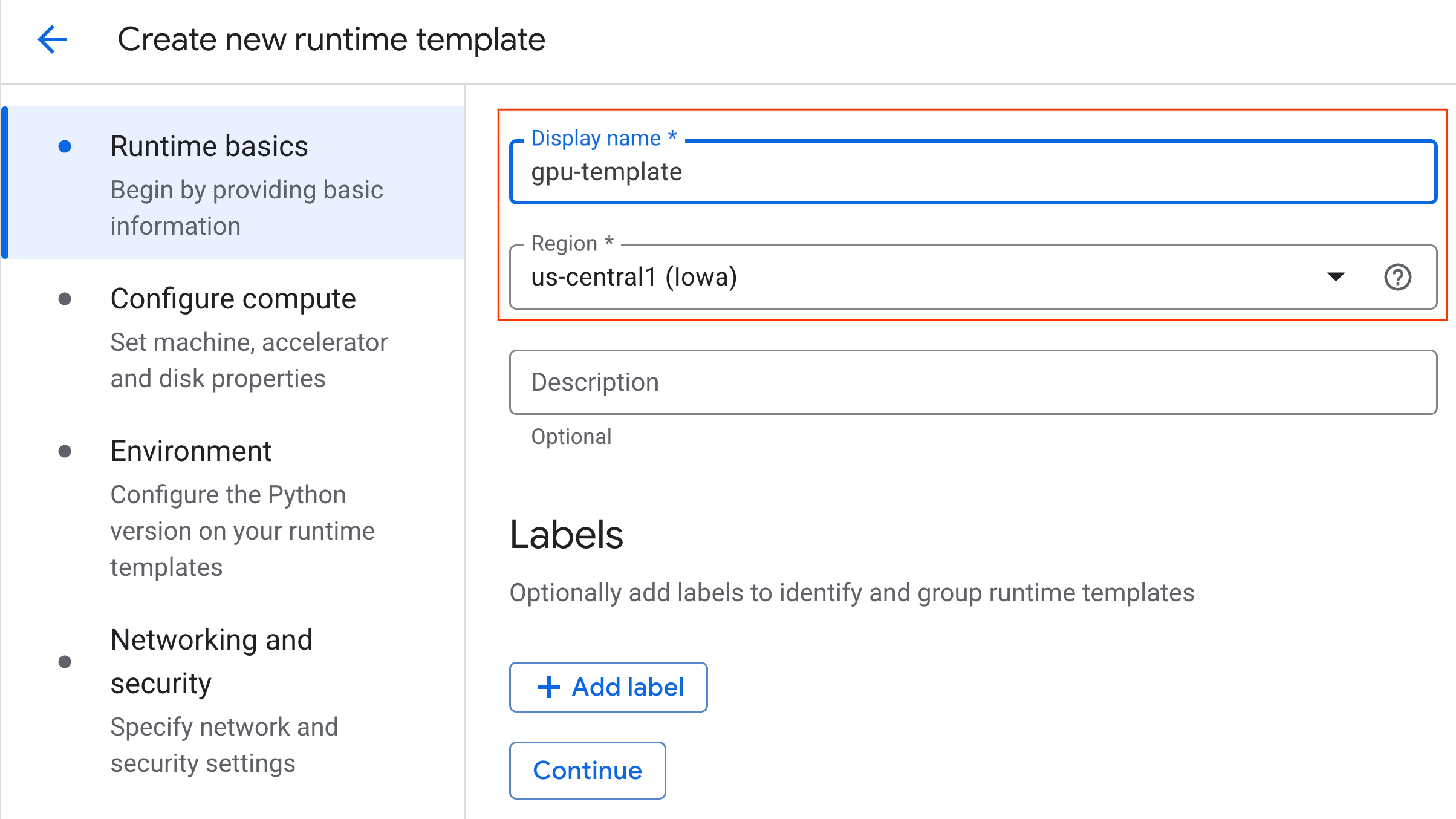
- Trong phần Kiến thức cơ bản về thời gian chạy:
- Đặt Tên hiển thị thành
gpu-template. - Đặt Khu vực mà bạn muốn.
- Đặt Tên hiển thị thành
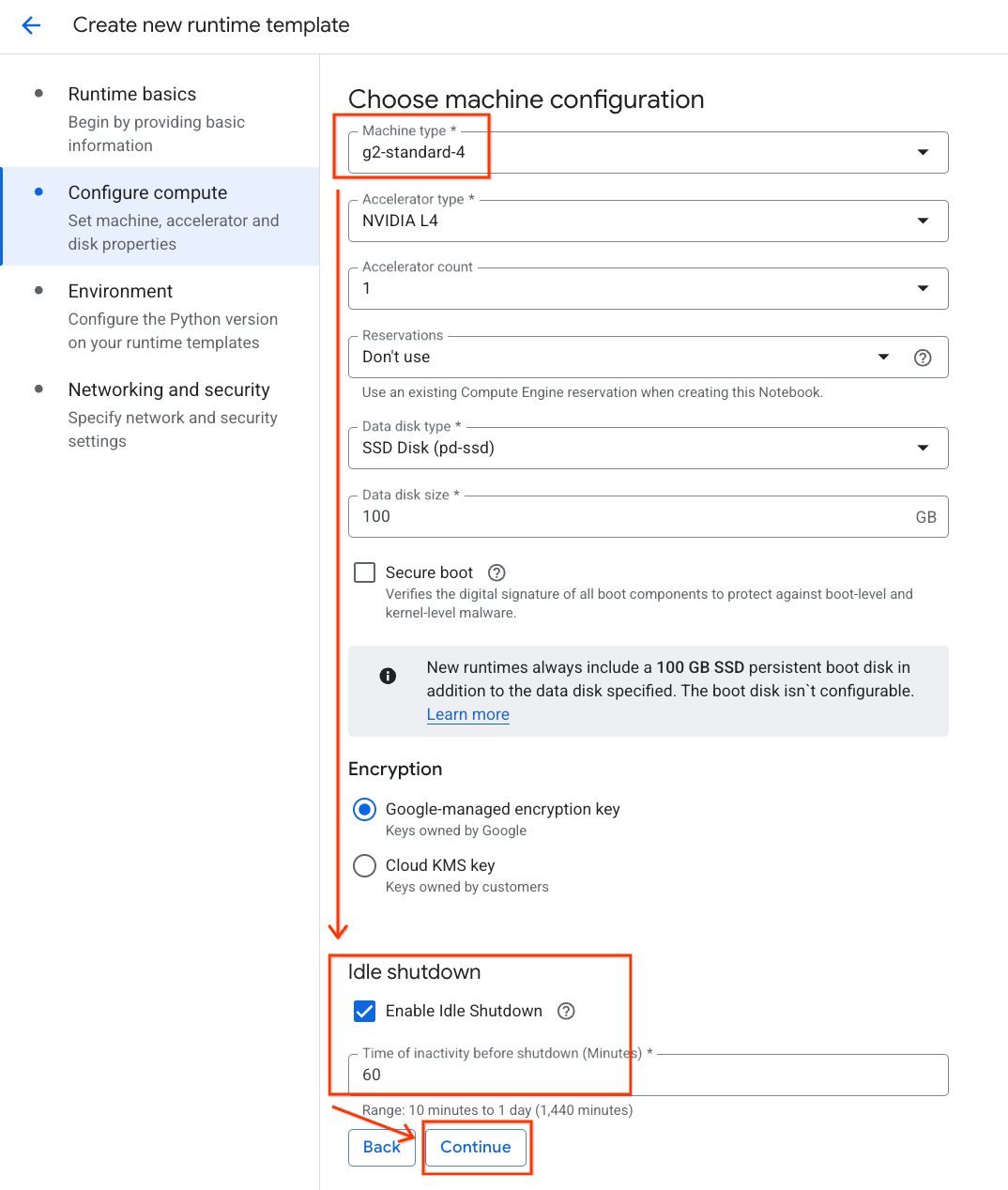
- Trong phần Định cấu hình tài nguyên điện toán:
- Đặt Loại máy thành
g2-standard-4. - Giữ nguyên Loại bộ tăng tốc mặc định là
NVIDIA L4với Số lượng bộ tăng tốc là 1. - Thay đổi chế độ Tắt khi không hoạt động thành 60 phút.
- Nhấp vào Tiếp tục.
- Đặt Loại máy thành
- Trong phần Môi trường:
- Đặt Environment (Môi trường) thành
Python 3.11
- Đặt Environment (Môi trường) thành
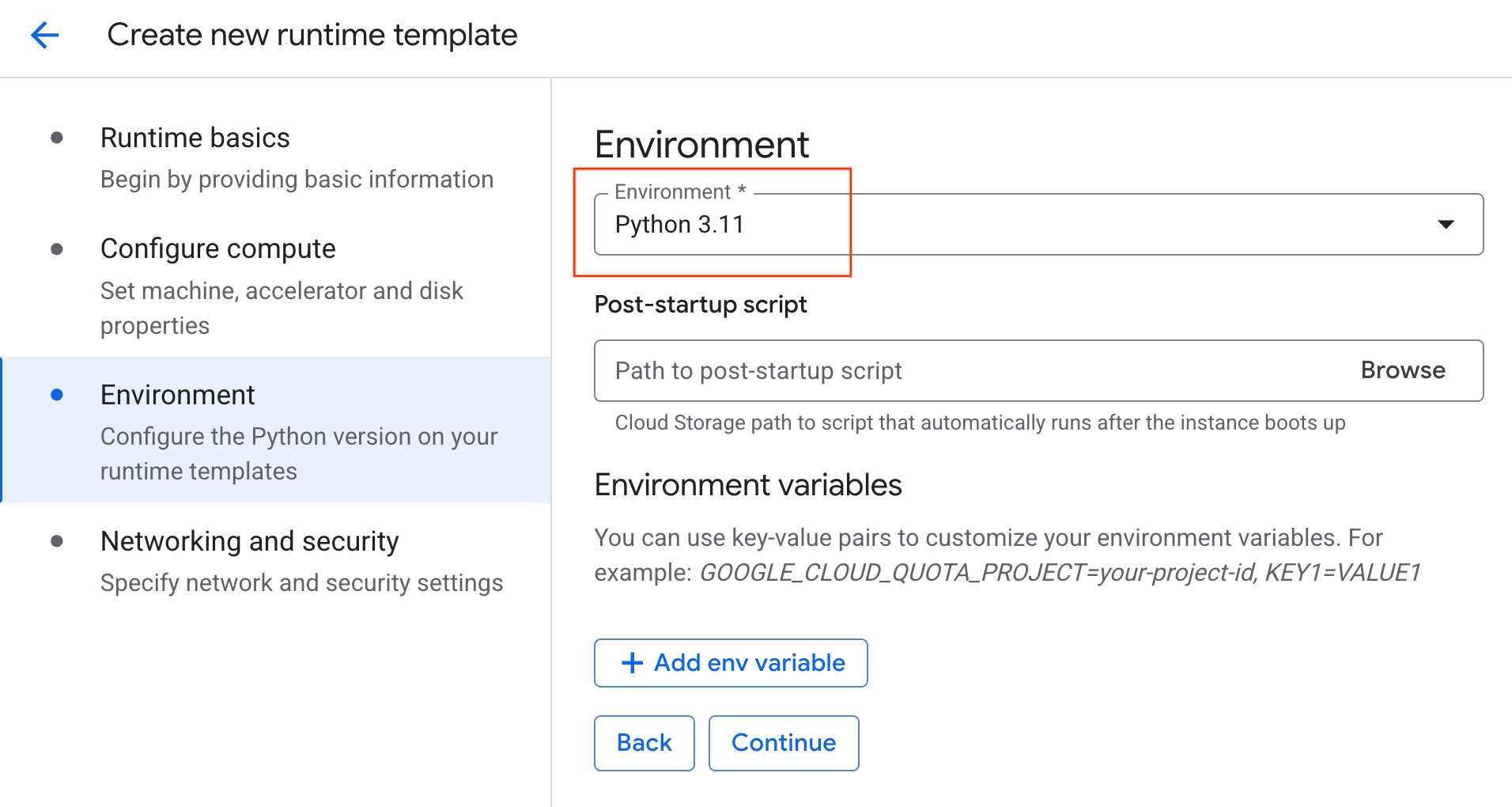
- Nhấp vào Tạo để lưu mẫu thời gian chạy. Trang Mẫu thời gian chạy của bạn giờ đây sẽ hiển thị mẫu mới.
5. Khởi động một môi trường thời gian chạy
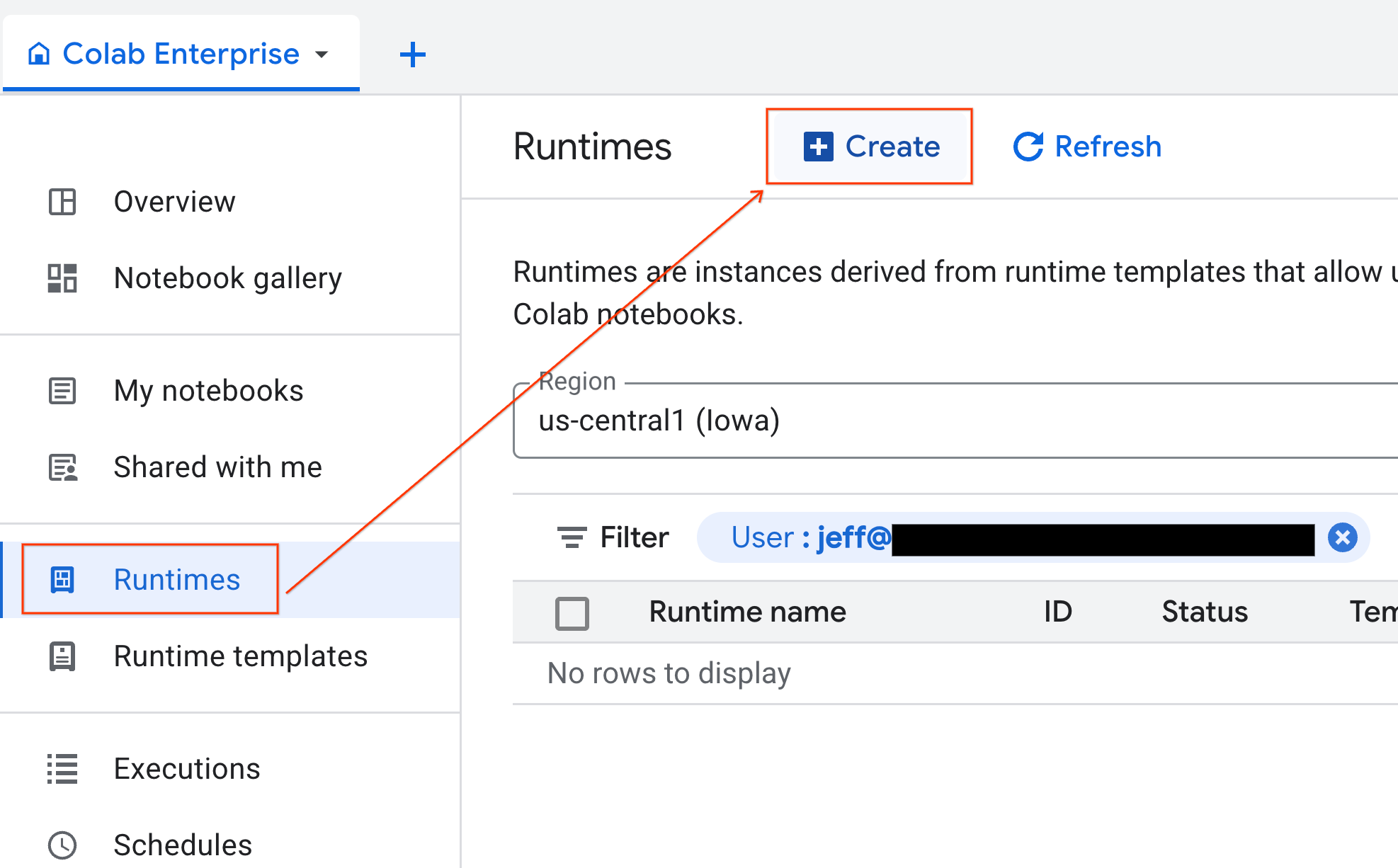
Khi đã chuẩn bị xong mẫu, bạn có thể tạo một thời gian chạy mới.
- Trong Colab Enterprise, hãy nhấp vào Thời gian chạy rồi chọn Tạo.
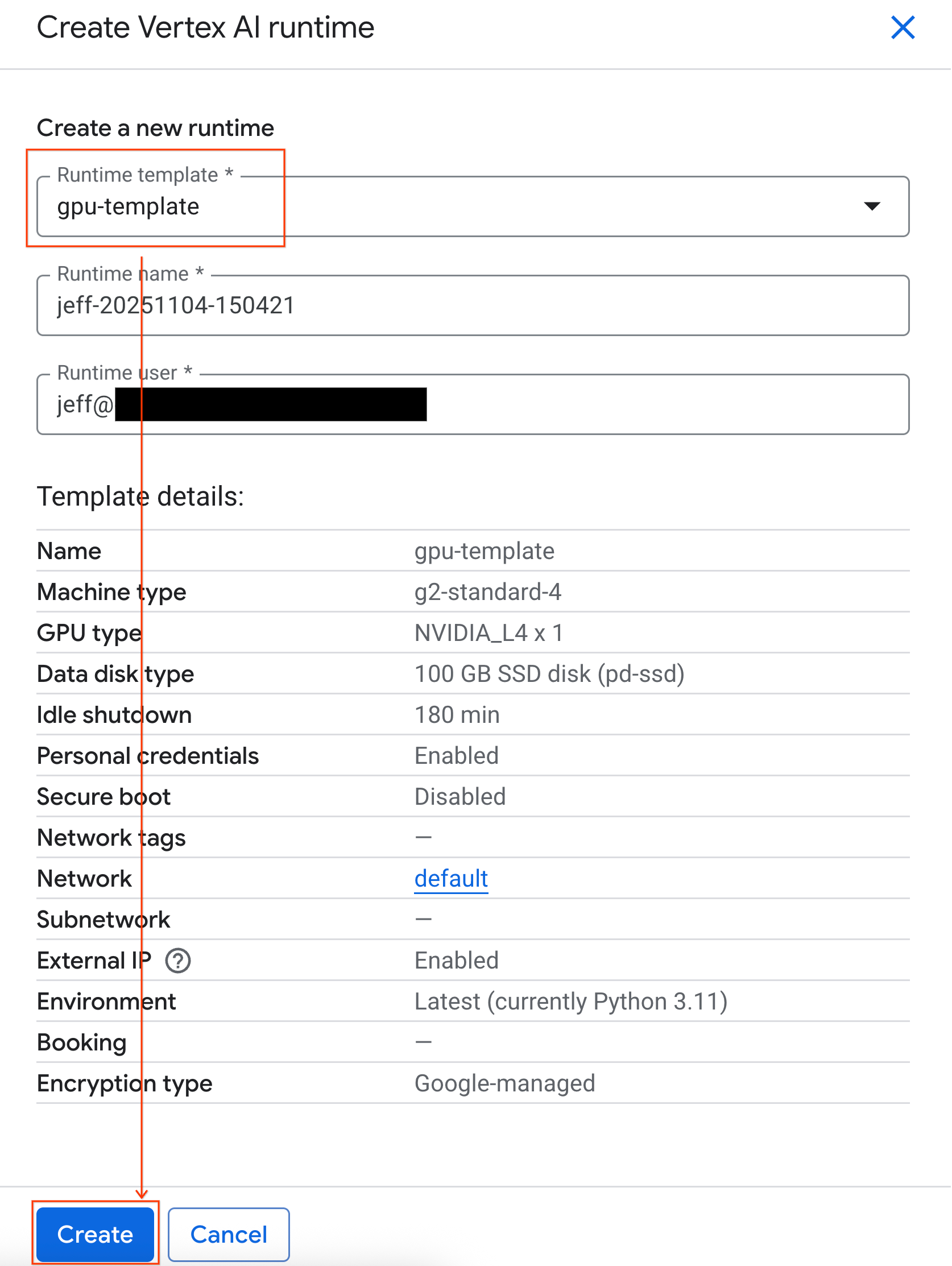
- Trong phần Runtime template (Mẫu thời gian chạy), hãy chọn lựa chọn
gpu-template. Nhấp vào Create (Tạo) rồi đợi cho đến khi thời gian chạy khởi động.
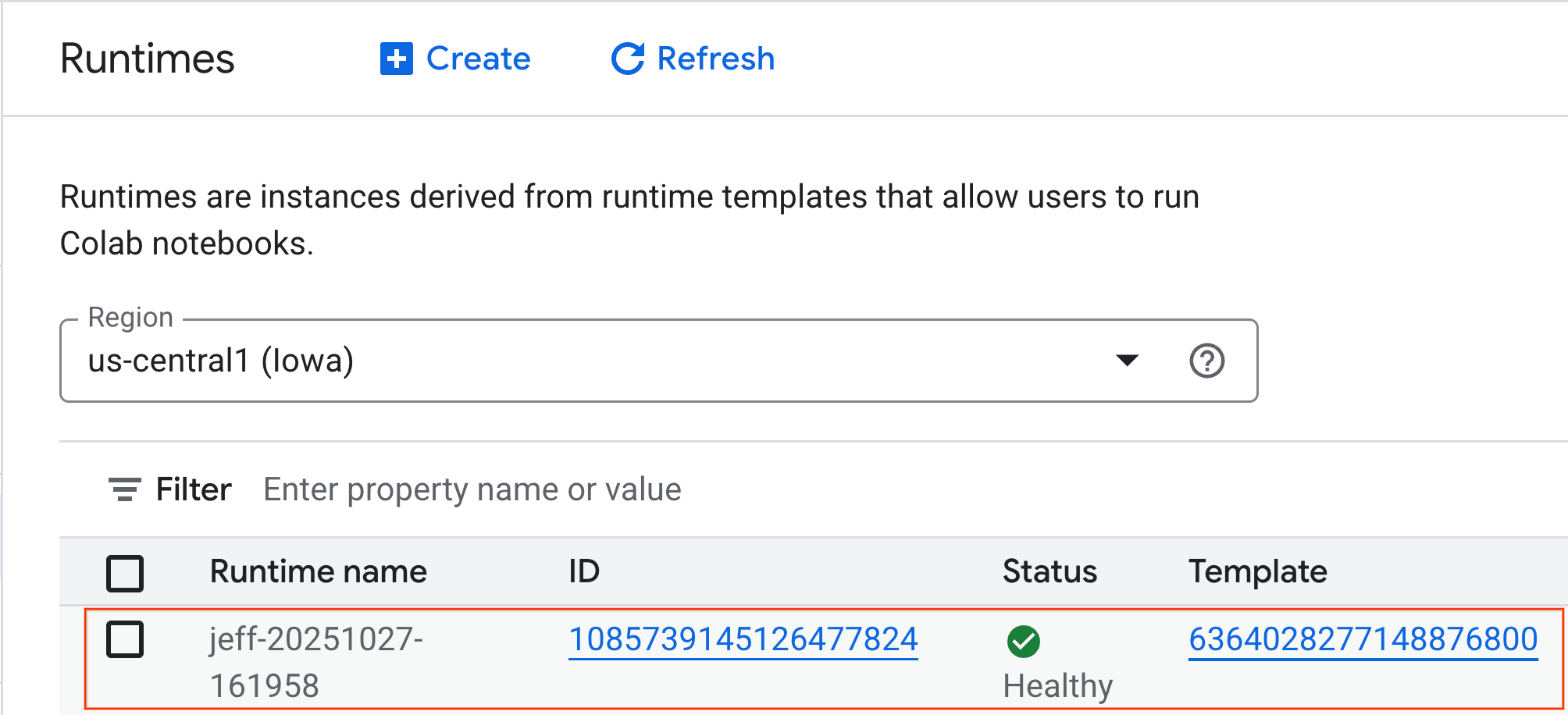
- Sau vài phút, bạn sẽ thấy thời gian chạy có sẵn.
6. Thiết lập sổ tay
Giờ đây, khi cơ sở hạ tầng của bạn đang chạy, bạn cần nhập sổ tay phòng thí nghiệm và kết nối sổ tay đó với thời gian chạy.
Nhập sổ tay
- Trong Colab Enterprise, hãy nhấp vào Sổ tay của tôi rồi nhấp vào Nhập.
- Chọn nút chọn URL rồi nhập URL sau:
https://github.com/GoogleCloudPlatform/ai-ml-recipes/blob/main/notebooks/analytics/gpu_accelerated_analytics.ipynb
- Nhấp vào Nhập. Colab Enterprise sẽ sao chép sổ tay từ GitHub vào môi trường của bạn.
Kết nối với môi trường thời gian chạy
- Mở sổ tay vừa nhập.
- Nhấp vào mũi tên xuống bên cạnh Kết nối.
- Chọn Kết nối với một thời gian chạy.
- Sử dụng trình đơn thả xuống và chọn thời gian chạy mà bạn đã tạo trước đó.
- Nhấp vào Kết nối.
Sổ tay của bạn hiện đã kết nối với một môi trường thời gian chạy có GPU. Giờ đây, bạn có thể bắt đầu chạy các truy vấn!
7. Chuẩn bị tập dữ liệu taxi ở Thành phố New York
Lớp học lập trình này sử dụng Dữ liệu bản ghi chuyến đi của Uỷ ban Taxi và xe limousine của Thành phố New York (TLC).
Tập dữ liệu này chứa các bản ghi chuyến đi riêng lẻ của taxi màu vàng ở Thành phố New York và bao gồm các trường như:
- Ngày, giờ và địa điểm đón và trả khách
- Khoảng cách của chuyến đi
- Số tiền giá vé được phân chia
- Số lượng hành khách
Tải dữ liệu xuống
Tiếp theo, hãy tải dữ liệu chuyến đi cho toàn bộ năm 2024 xuống. Dữ liệu được lưu trữ ở định dạng tệp Parquet.
Khối mã sau đây thực hiện các bước này:
- Xác định phạm vi năm và tháng cần tải xuống.
- Tạo một thư mục cục bộ có tên
nyc_taxi_datađể lưu trữ các tệp. - Lặp lại qua từng tháng, tải tệp Parquet tương ứng xuống nếu tệp đó chưa tồn tại và lưu tệp đó vào thư mục.
Chạy mã này trong sổ tay của bạn để thu thập dữ liệu và lưu trữ dữ liệu đó trên thời gian chạy:
from tqdm import tqdm
import requests
import time
import os
YEAR = 2024
DATA_DIR = "nyc_taxi_data"
os.makedirs(DATA_DIR, exist_ok=True)
print(f"Checking/Downloading files for {YEAR}...")
for month in tqdm(range(1, 13), unit="file"):
# Define standardized filename for both local path and URL
file_name = f"yellow_tripdata_{YEAR}-{month:02d}.parquet"
local_path = os.path.join(DATA_DIR, file_name)
url = f"https://d37ci6vzurychx.cloudfront.net/trip-data/{file_name}"
if not os.path.exists(local_path):
try:
with requests.get(url, stream=True) as response:
response.raise_for_status()
with open(local_path, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
time.sleep(1)
except requests.exceptions.HTTPError as e:
print(f"\nSkipping {file_name}: {e}")
if os.path.exists(local_path):
os.remove(local_path)
print("\nDownload complete.")
8. Khám phá dữ liệu chuyến đi bằng taxi
Sau khi tải tập dữ liệu xuống, bạn có thể tiến hành phân tích dữ liệu khám phá (EDA) ban đầu. Mục tiêu của EDA là hiểu cấu trúc dữ liệu, tìm ra điểm bất thường và khám phá các mẫu hình tiềm ẩn.
Tải dữ liệu của một tháng
Bắt đầu bằng cách tải dữ liệu của một tháng. Điều này cung cấp một mẫu đủ lớn (hơn 3 triệu hàng) để có ý nghĩa trong khi vẫn duy trì mức sử dụng bộ nhớ có thể quản lý được cho hoạt động phân tích tương tác.
import pandas as pd
import glob
# Load the last month of the downloaded data
df = pd.read_parquet("nyc_taxi_data/yellow_tripdata_2024-12.parquet")
df.head()
Nhận số liệu thống kê tóm tắt
Sử dụng phương thức .describe() để tạo số liệu thống kê tóm tắt cấp cao cho các cột số. Đây là bước đầu tiên hiệu quả để phát hiện các vấn đề tiềm ẩn về chất lượng dữ liệu, chẳng hạn như giá trị tối thiểu hoặc tối đa không mong muốn.
df.describe().round(2)
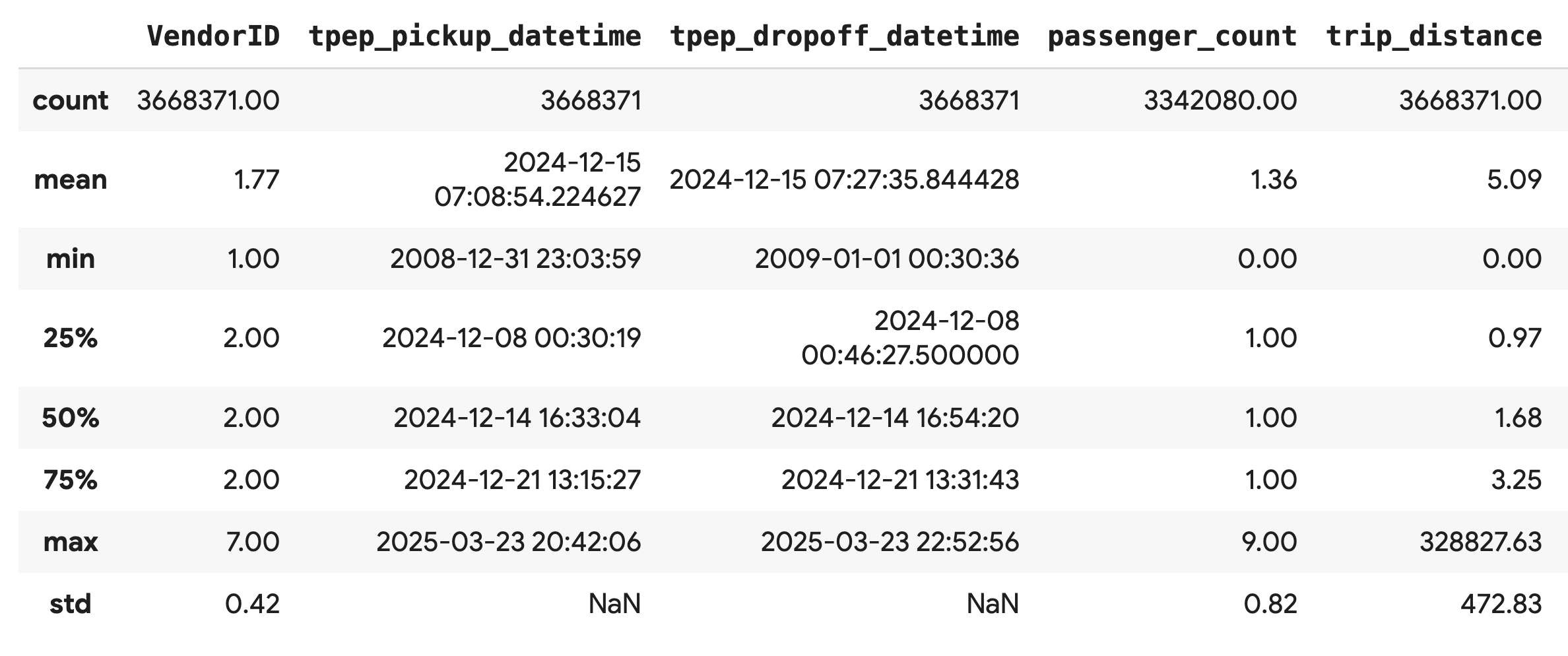
Điều tra chất lượng dữ liệu
Đầu ra từ .describe() sẽ cho thấy ngay một vấn đề. Lưu ý rằng giá trị min cho tpep_pickup_datetime và tpep_dropoff_datetime là năm 2008, điều này không hợp lý đối với một tập dữ liệu năm 2024.
Đây là một ví dụ về lý do bạn nên luôn kiểm tra dữ liệu của mình. Bạn có thể điều tra thêm bằng cách sắp xếp DataFrame để tìm chính xác những hàng chứa các ngày ngoại lệ này.
# Sort by the dropoff datetime to see the oldest records
df.sort_values("tpep_pickup_datetime").head()
Trực quan hoá các bản phân phối dữ liệu
Tiếp theo, bạn có thể tạo biểu đồ tần suất của các cột số để trực quan hoá phân phối của chúng. Điều này giúp bạn hiểu được mức độ phân tán và độ lệch của các đặc điểm như trip_distance và fare_amount. Hàm .hist() là một cách nhanh chóng để vẽ biểu đồ cho tất cả các cột số trong DataFrame.
_ = df.hist(figsize=(20, 20))
Cuối cùng, hãy tạo một ma trận phân tán để hình dung mối quan hệ giữa một số cột chính. Vì việc vẽ hàng triệu điểm sẽ diễn ra chậm và có thể che khuất các mẫu, hãy sử dụng .sample() để tạo biểu đồ từ một mẫu ngẫu nhiên gồm 100.000 hàng.
_ = pd.plotting.scatter_matrix(
df[['passenger_count', 'trip_distance', 'tip_amount', 'total_amount']].sample(100_000),
diagonal="kde",
figsize=(15, 15)
)
9. Tại sao nên sử dụng định dạng tệp Parquet?
Tập dữ liệu taxi ở Thành phố New York được cung cấp ở định dạng Apache Parquet. Đây là lựa chọn có chủ ý được đưa ra cho hoạt động phân tích quy mô lớn. Parquet mang lại một số lợi ích so với các loại tệp như CSV:
- Hiệu quả và nhanh chóng: Là một định dạng dạng cột, Parquet có hiệu quả cao trong việc lưu trữ và đọc. Định dạng này hỗ trợ các phương pháp nén hiện đại giúp giảm kích thước tệp và tăng tốc độ I/O đáng kể, đặc biệt là trên GPU.
- Duy trì giản đồ: Parquet lưu trữ các kiểu dữ liệu trong siêu dữ liệu của tệp. Bạn không bao giờ phải đoán các loại dữ liệu khi đọc tệp.
- Cho phép đọc có chọn lọc: Cấu trúc dạng cột cho phép bạn chỉ đọc những cột cụ thể cần thiết cho một hoạt động phân tích. Điều này có thể giảm đáng kể lượng dữ liệu bạn phải tải vào bộ nhớ.
Khám phá các tính năng của Parquet
Hãy khám phá 2 trong số những tính năng mạnh mẽ này bằng cách sử dụng một trong các tệp bạn đã tải xuống.
Kiểm tra siêu dữ liệu mà không cần tải toàn bộ tập dữ liệu
Mặc dù không thể xem tệp Parquet trong trình chỉnh sửa văn bản tiêu chuẩn, nhưng bạn có thể dễ dàng kiểm tra giản đồ và siêu dữ liệu của tệp đó mà không cần tải bất kỳ dữ liệu nào vào bộ nhớ. Điều này hữu ích khi bạn muốn nhanh chóng nắm được cấu trúc của một tệp.
from pyarrow.parquet import ParquetFile
import pyarrow as pa
# Open one of the downloaded files
pf = ParquetFile('nyc_taxi_data/yellow_tripdata_2024-12.parquet')
# Print the schema
print("File Schema:")
print(pf.schema)
# Print the file metadata
print("\nFile Metadata:")
print(pf.metadata)
Chỉ đọc những cột cần thiết
Hãy tưởng tượng bạn chỉ cần phân tích khoảng cách của chuyến đi và số tiền vé. Với Parquet, bạn chỉ có thể tải những cột đó, nhanh hơn và tiết kiệm bộ nhớ hơn nhiều so với việc tải toàn bộ DataFrame.
import pandas as pd
# Read only four specific columns from the Parquet file
df_subset = pd.read_parquet(
'nyc_taxi_data/yellow_tripdata_2024-12.parquet',
columns=['passenger_count', 'trip_distance', 'tip_amount', 'total_amount']
)
df_subset.head()
10. Tăng tốc pandas bằng NVIDIA cuDF
NVIDIA CUDA cho DataFrame (cuDF) là một thư viện mã nguồn mở, được tăng tốc bằng GPU, cho phép bạn tương tác với DataFrame. cuDF cho phép bạn thực hiện các thao tác dữ liệu phổ biến như lọc, kết hợp và nhóm trên GPU với khả năng song song hoá quy mô lớn.
Tính năng chính mà bạn sử dụng trong Lớp học lập trình này là chế độ tăng tốc cudf.pandas. Khi bạn bật tính năng này, mã pandas tiêu chuẩn của bạn sẽ tự động được chuyển hướng để sử dụng các nhân cuDF dựa trên GPU, mà bạn không cần phải thay đổi mã.
Bật tính năng tăng tốc GPU
Để sử dụng NVIDIA cuDF trong sổ tay Colab Enterprise, bạn cần tải tiện ích mở rộng đặc biệt của tiện ích này trước khi nhập pandas.
Trước tiên, hãy kiểm tra thư viện pandas tiêu chuẩn. Lưu ý rằng đầu ra cho thấy đường dẫn đến quá trình cài đặt pandas mặc định.
import pandas as pd
pd # Note the output for the standard pandas library
Bây giờ, hãy tải tiện ích cudf.pandas và nhập lại pandas. Quan sát cách thay đổi đầu ra cho mô-đun pd – điều này xác nhận rằng phiên bản tăng tốc bằng GPU hiện đang hoạt động.
%load_ext cudf.pandas
import pandas as pd
pd # Note the new output, indicating cudf.pandas is active
Những cách khác để bật cudf.pandas
Mặc dù lệnh đặc biệt (%load_ext) là phương thức dễ nhất trong sổ tay, nhưng bạn cũng có thể bật trình tăng tốc trong các môi trường khác:
- Trong tập lệnh Python: Gọi
import cudf.pandasvàcudf.pandas.install()trước khi nhậppandas. - Từ các môi trường không phải sổ tay: Chạy tập lệnh bằng cách sử dụng
python -m cudf.pandas your_script.py.
11. So sánh hiệu suất của CPU và GPU
Giờ đây, đến phần quan trọng nhất: so sánh hiệu suất của pandas tiêu chuẩn trên CPU với cudf.pandas trên GPU.
Để đảm bảo có một đường cơ sở hoàn toàn công bằng cho CPU, trước tiên, bạn phải đặt lại thời gian chạy Colab. Thao tác này sẽ xoá mọi bộ tăng tốc GPU mà bạn có thể đã bật trong các phần trước. Bạn có thể khởi động lại thời gian chạy bằng cách chạy ô sau hoặc chọn Khởi động lại phiên trong trình đơn Thời gian chạy.
import IPython
IPython.Application.instance().kernel.do_shutdown(True)
Xác định quy trình phân tích
Giờ đây, khi môi trường đã sạch, bạn sẽ xác định hàm đo điểm chuẩn. Hàm này cho phép bạn chạy chính xác cùng một quy trình (tải, sắp xếp và tóm tắt) bằng cách sử dụng bất kỳ mô-đun pandas nào mà bạn truyền vào.
import time
import glob
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
def run_analytics_pipeline(pd_module):
"""Loads, sorts, and summarizes data using the provided pandas module."""
timings = {}
# 1. Load all 2024 Parquet files from the directory
t0 = time.time()
df = pd_module.concat(
[pd_module.read_parquet(f) for f in glob.glob("nyc_taxi_data/*_2024*.parquet")],
ignore_index=True
)
timings["load"] = time.time() - t0
# 2. Sort the data by multiple columns
t0 = time.time()
df = df.sort_values(
['tpep_pickup_datetime', 'trip_distance', 'passenger_count'],
ascending=[False, True, False]
)
timings["sort"] = time.time() - t0
# 3. Perform a groupby and aggregation
t0 = time.time()
df['tpep_pickup_datetime'] = pd_module.to_datetime(df['tpep_pickup_datetime'])
_ = (
df.loc[df.tpep_pickup_datetime > '2024-11-01']
.groupby(['VendorID', 'tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
timings["summarize"] = time.time() - t0
return timings
Chạy phép so sánh
Trước tiên, bạn sẽ chạy quy trình bằng pandas tiêu chuẩn trên CPU. Sau đó, bạn bật cudf.pandas và chạy lại trên GPU.
# --- Run on CPU ---
print("Running analytics pipeline on CPU...")
# Ensure we are using standard pandas
import pandas as pd
assert "cudf" not in str(pd), "Error: cuDF is still active. Please restart the kernel."
cpu_times = run_analytics_pipeline(pd)
print(f"CPU times: {cpu_times}")
# --- Run on GPU ---
print("\nEnabling cudf.pandas and running on GPU...")
# Load the extension
%load_ext cudf.pandas
import pandas as gpu_pd
gpu_times = run_analytics_pipeline(gpu_pd)
print(f"GPU times: {gpu_times}")
Hình dung kết quả
Cuối cùng, hãy hình dung sự khác biệt. Đoạn mã sau đây tính toán mức tăng tốc cho từng thao tác và vẽ đồ thị cho các thao tác đó cạnh nhau.
# Create a DataFrame for plotting
results_df = pd.DataFrame([cpu_times, gpu_times], index=["CPU", "GPU"]).T
total_cpu_time = results_df['CPU'].sum()
total_gpu_time = results_df['GPU'].sum()
speedup = total_cpu_time / total_gpu_time
print("--- Performance Results ---")
print(results_df)
print(f"\nTotal CPU Time: {total_cpu_time:.2f} seconds")
print(f"Total GPU Time: {total_gpu_time:.2f} seconds")
print(f"Overall Speedup: {speedup:.2f}x")
# Plot the results
fig, ax = plt.subplots(figsize=(10, 6))
results_df.plot(kind='bar', ax=ax, color={"CPU": "tab:blue", "GPU": "tab:green"})
ax.set_ylabel("Time (seconds)")
ax.set_title(f"CPU vs. GPU Runtimes (Overall Speedup: {speedup:.2f}x)", fontsize=14)
ax.tick_params(axis='x', rotation=0)
# Add numerical labels to the bars
for container in ax.containers:
ax.bar_label(container, fmt="%.2f", padding=3)
plt.tight_layout()
plt.show()
Kết quả mẫu:
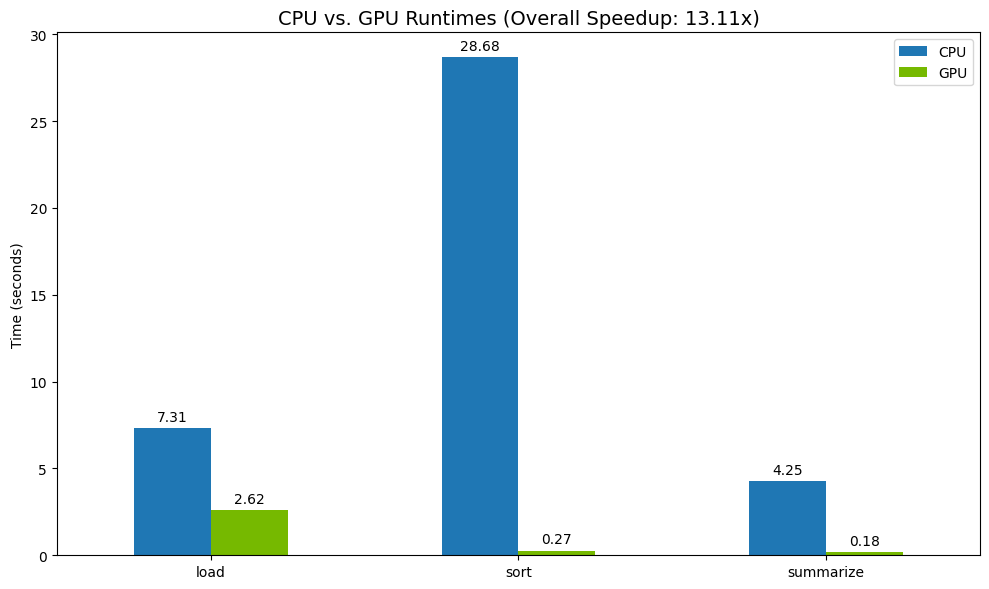
GPU giúp tăng tốc độ rõ rệt so với CPU.
12. Lập hồ sơ mã của bạn để tìm ra các điểm tắc nghẽn
Ngay cả khi có tính năng tăng tốc GPU, một số thao tác pandas có thể quay lại CPU nếu cuDF chưa hỗ trợ các thao tác đó. Những "CPU dự phòng" này có thể trở thành điểm tắc nghẽn về hiệu suất.
Để giúp bạn xác định những khu vực này, cudf.pandas có 2 trình phân tích tài nguyên tích hợp. Bạn có thể sử dụng các công cụ này để biết chính xác những phần nào trong mã của bạn đang chạy trên GPU và những phần nào đang quay lại CPU.
%%cudf.pandas.profile: Sử dụng tính năng này để có được bản tóm tắt tổng quan về từng chức năng trong mã của bạn. Đây là cách tốt nhất để xem nhanh thông tin tổng quan về những thao tác đang chạy trên thiết bị nào.%%cudf.pandas.line_profile: Sử dụng tính năng này để phân tích chi tiết từng dòng. Đây là công cụ tốt nhất để xác định chính xác những dòng trong mã của bạn đang gây ra tình trạng dự phòng cho CPU.
Sử dụng các trình phân tích tài nguyên này làm "cell magics" ở đầu một ô sổ tay.
Hồ sơ ở cấp hàm bằng %%cudf.pandas.profile
Trước tiên, hãy chạy trình phân tích hiệu suất ở cấp hàm trên cùng một quy trình phân tích như trong phần trước. Kết quả cho thấy một bảng gồm mọi hàm đã gọi, thiết bị mà hàm đó chạy (GPU hoặc CPU) và số lần hàm đó được gọi.
%load_ext cudf.pandas
import pandas as pd
import glob
pd.DataFrame({"a": [1]})
Sau khi đảm bảo cudf.pandas đang hoạt động, bạn có thể chạy một hồ sơ.
%%cudf.pandas.profile
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*2024*.parquet")], ignore_index=True)
df = df.sort_values(['tpep_pickup_datetime', 'trip_distance', 'passenger_count'], ascending=[False, True, False])
summary = (
df
.loc[(df.tpep_pickup_datetime > '2024-11-01')]
.groupby(['VendorID','tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
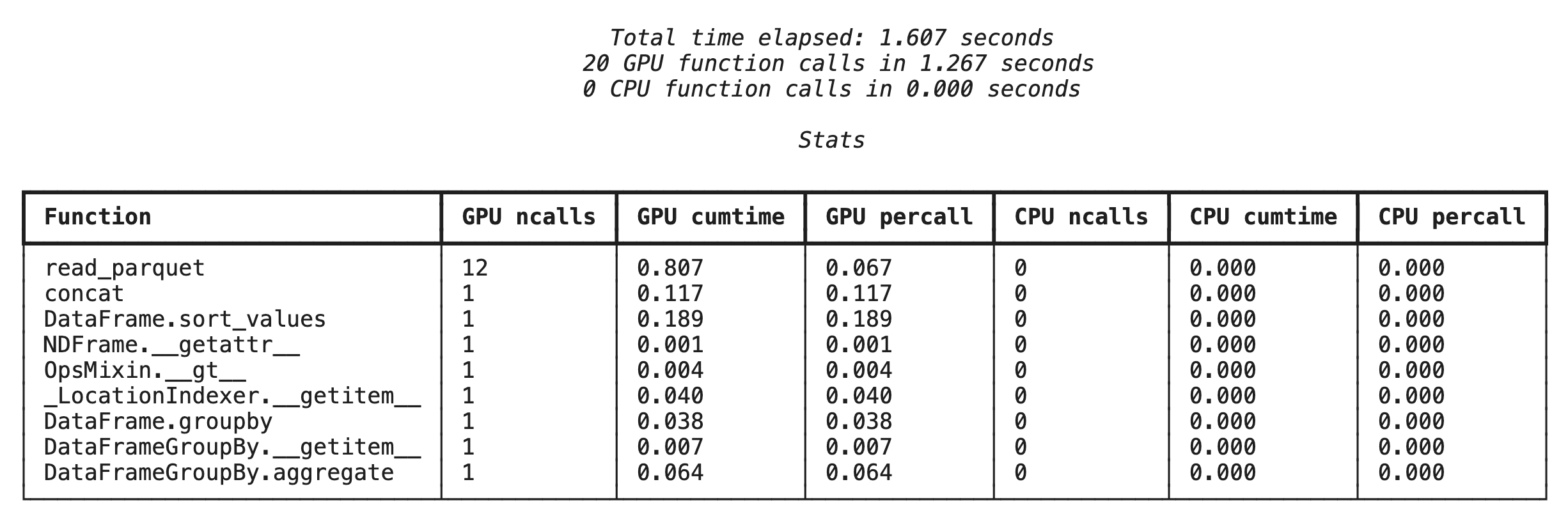
Lập hồ sơ từng dòng bằng %%cudf.pandas.line_profile
Tiếp theo, hãy chạy trình phân tích tài nguyên ở cấp dòng. Nhờ đó, bạn sẽ có được thông tin chi tiết hơn nhiều, cho biết khoảng thời gian mà mỗi dòng mã đã dành để thực thi trên GPU so với CPU. Đây là cách hiệu quả nhất để tìm ra những điểm tắc nghẽn cụ thể cần tối ưu hoá.
%%cudf.pandas.line_profile
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*2024*.parquet")], ignore_index=True)
df = df.sort_values(['tpep_pickup_datetime', 'trip_distance', 'passenger_count'], ascending=[False, True, False])
summary = (
df
.loc[(df.tpep_pickup_datetime > '2024-11-01')]
.groupby(['VendorID','tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
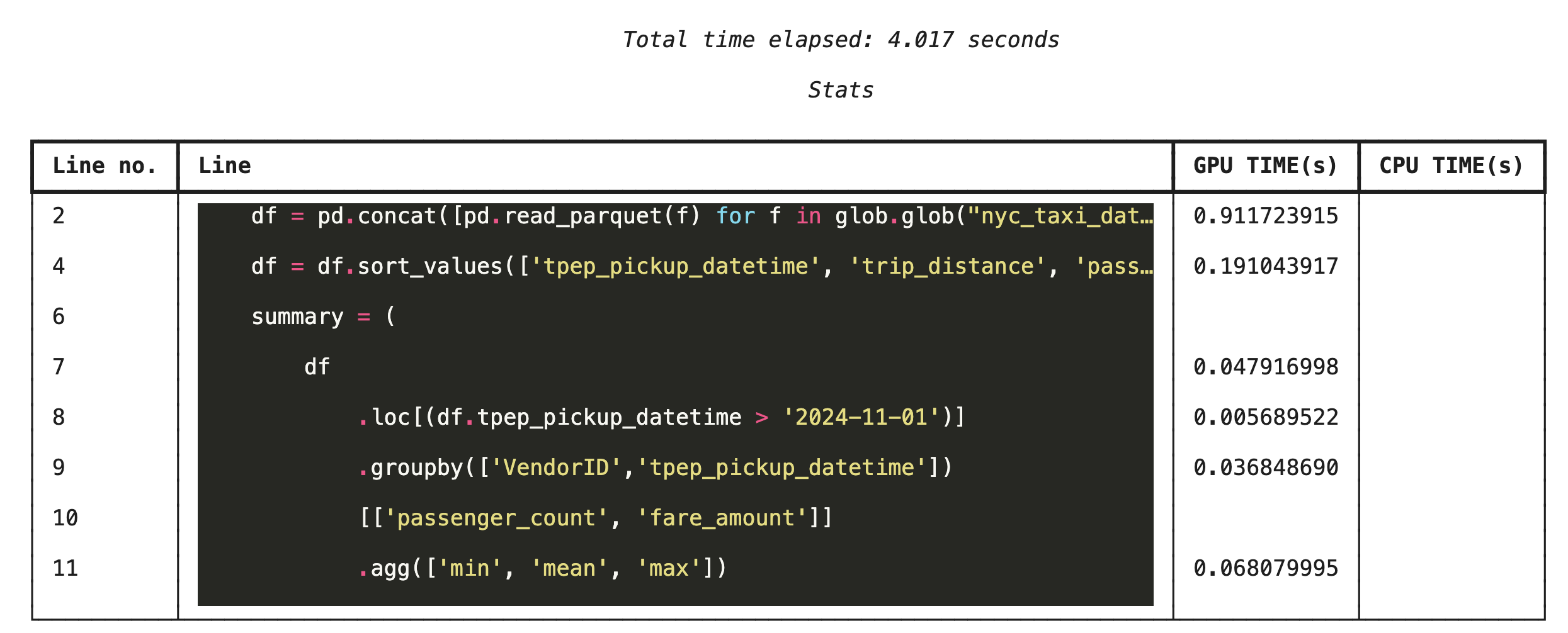
Hồ sơ từ dòng lệnh
Các trình phân tích tài nguyên này cũng có sẵn trên dòng lệnh, rất hữu ích cho việc kiểm thử tự động và lập hồ sơ các tập lệnh Python.
Bạn có thể sử dụng những lệnh sau trên giao diện dòng lệnh:
python -m cudf.pandas --profile your_script.pypython -m cudf.pandas --line_profile your_script.py
13. Tích hợp với Google Cloud Storage
Google Cloud Storage (GCS) là một dịch vụ lưu trữ đối tượng có khả năng mở rộng và bền bỉ. Khi bạn sử dụng Colab Enterprise, GCS là nơi lý tưởng để lưu trữ các tập dữ liệu, điểm kiểm tra mô hình và các cấu phần phần mềm khác.
Thời gian chạy Colab Enterprise có các quyền cần thiết để đọc và ghi dữ liệu trực tiếp vào các bộ chứa GCS, đồng thời các thao tác này được tăng tốc bằng GPU để đạt hiệu suất tối đa.
Tạo một vùng lưu trữ GCS
Trước tiên, hãy tạo một vùng chứa GCS mới. Tên bộ chứa GCS là duy nhất trên toàn cầu, vì vậy hãy thêm một UUID vào tên của bộ chứa.
from google.cloud import storage
import uuid
unique_suffix = uuid.uuid4().hex[:12]
bucket_name = f'nyc-taxi-codelab-{unique_suffix}'
project_id = storage.Client().project
client = storage.Client()
try:
bucket = client.create_bucket(bucket_name)
print(f"Successfully created bucket: gs://{bucket.name}")
except Exception as e:
print(f"Bucket creation failed. You may already own it or the name is taken: {e}")
Ghi dữ liệu trực tiếp vào GCS
Giờ đây, hãy lưu DataFrame trực tiếp vào vùng lưu trữ GCS mới của bạn. Nếu biến df không có trong các phần trước, thì mã này sẽ tải dữ liệu của một tháng trước.
%%cudf.pandas.line_profile
# Ensure the DataFrame exists before saving to GCS
if 'df' not in locals():
print("DataFrame not found, loading a sample file...")
df = pd.read_parquet('nyc_taxi_data/yellow_tripdata_2024-12.parquet')
print(f"Writing data to gs://{bucket_name}/nyc_taxi_data.parquet...")
df.to_parquet(f"gs://{bucket_name}/nyc_taxi_data.parquet", index=False)
print("Write operation complete.")
Xác minh tệp trong GCS
Bạn có thể xác minh dữ liệu trong GCS bằng cách truy cập vào nhóm. Đoạn mã sau đây tạo một đường liên kết có thể nhấp.
from IPython.display import Markdown
gcs_url = f"https://console.cloud.google.com/storage/browser/{bucket_name}?project={project_id}"
Markdown(f'**[Click here to view your GCS bucket in the Google Cloud Console]({gcs_url})**')
Đọc dữ liệu trực tiếp từ GCS
Cuối cùng, hãy đọc dữ liệu trực tiếp từ một đường dẫn GCS vào DataFrame. Thao tác này cũng được tăng tốc bằng GPU, cho phép bạn tải các tập dữ liệu lớn từ bộ nhớ đám mây với tốc độ cao.
%%cudf.pandas.line_profile
print(f"Reading data from gs://{bucket_name}/nyc_taxi_data.parquet...")
df_from_gcs = pd.read_parquet(f"gs://{bucket_name}/nyc_taxi_data.parquet")
df_from_gcs.head()
14. Dọn dẹp
Để tránh bị tính phí không mong muốn vào tài khoản Google Cloud, bạn cần dọn dẹp các tài nguyên mà bạn đã tạo.
Xoá dữ liệu bạn đã tải xuống:
# Permanately delete the GCS bucket
print(f"Deleting GCS bucket: gs://{bucket_name}...")
!gsutil rm -r -f gs://{bucket_name}
print("Bucket deleted.")
# Remove NYC taxi dataset on the Colab runtime
print("Deleting local 'nyc_taxi_data' directory...")
!rm -rf nyc_taxi_data
print("Local files deleted.")
Tắt thời gian chạy Colab
- Trong bảng điều khiển Cloud của Google, hãy chuyển đến trang Thời gian chạy của Colab Enterprise.
- Trong trình đơn Khu vực, hãy chọn khu vực chứa thời gian chạy của bạn.
- Chọn thời gian chạy mà bạn muốn xoá.
- Nhấp vào Xóa.
- Nhấp vào Xác nhận.
Xoá sổ ghi chú
- Trong bảng điều khiển Cloud của Google, hãy chuyển đến trang My Notebooks (Sổ tay của tôi) của Colab Enterprise.
- Trong trình đơn Khu vực, hãy chọn khu vực chứa sổ tay của bạn.
- Chọn sổ tay bạn muốn xoá.
- Nhấp vào Xóa.
- Nhấp vào Xác nhận.
15. Xin chúc mừng
Xin chúc mừng! Bạn đã tăng tốc thành công quy trình phân tích pandas bằng NVIDIA cuDF trên Colab Enterprise. Bạn đã tìm hiểu cách định cấu hình thời gian chạy có hỗ trợ GPU, bật cudf.pandas để tăng tốc mà không thay đổi mã, phân tích mã để tìm ra các điểm tắc nghẽn và tích hợp với Google Cloud Storage.