
1. 简介
在此 Codelab 中,您将学习如何在 Google Cloud 上使用 NVIDIA GPU 和开源库来加速处理大型数据集的数据分析工作流。您将首先优化基础设施,然后探索如何在不更改任何代码的情况下应用 GPU 加速。
您将重点学习热门数据处理库 pandas,并了解如何使用 NVIDIA 的 cuDF 库来加速该库。最棒的是,您无需更改现有的 pandas 代码即可获得这种 GPU 加速功能。
学习内容
- 了解 Google Cloud 上的 Colab Enterprise。
- 自定义具有特定 GPU、CPU 和内存配置的 Colab 运行时环境。
- 使用 NVIDIA
cuDF加速pandas,无需更改任何代码。 - 分析代码以找出并优化性能瓶颈。
后续页面包含可用于完成实验的点数。
2. 为什么要加快数据处理速度?
80/20 法则:为什么数据准备会占用这么多时间
数据准备通常是分析项目中最耗时的阶段。数据科学家和分析师在开始任何分析之前,都需要花费大量时间来清理、转换和构建数据。
幸运的是,您可以使用 cuDF 在 NVIDIA GPU 上加速 pandas、Apache Spark 和 Polars 等热门开源库。即使有了这种加速,数据准备仍然很耗时,因为:
- 源数据很少能直接用于分析:现实世界中的数据通常存在不一致、缺失值和格式问题。
- 数据质量会影响模型性能:糟糕的数据质量可能会使最复杂的算法也变得毫无用处。
- 规模会放大问题:在处理数百万条记录时,看似微小的数据问题会成为严重的瓶颈。
3. 选择笔记本环境
虽然许多数据科学家都熟悉 Colab,并将其用于个人项目,但 Colab Enterprise 提供安全、协作且集成的笔记本体验,专为企业而设计。
在 Google Cloud 上,您可以选择两种主要的受管笔记本环境:Colab Enterprise 和 Gemini Enterprise Agent Platform Workbench。具体选择哪种方案取决于您项目的优先事项。
何时使用 Agent Platform Workbench
如果您的首要任务是控制和深度自定义,请选择 Agent Platform Workbench。如果您需要执行以下操作,那么此选项是理想之选:
- 管理底层基础设施和机器生命周期。
- 使用自定义容器和网络配置。
- 与 MLOps 流水线和自定义生命周期工具集成。
Colab Enterprise 的适用场景
如果您优先考虑快速设置、易用性和安全协作,请选择 Colab Enterprise。它是一种全托管式解决方案,可让您的团队专注于分析,而不是基础架构。
Colab Enterprise 可帮助您:
- 开发与数据仓库紧密相关的数据科学工作流。您可以直接在 BigQuery Studio 中打开和管理笔记本。
- 在 Agent Platform 中训练机器学习模型并与 MLOps 工具集成。
- 享受灵活统一的体验。在 BigQuery 中创建的 Colab Enterprise 笔记本可以在 Agent Platform 中打开和运行,反之亦然。
今天的实验
此 Codelab 使用 Colab Enterprise 加速数据分析。
如需详细了解这些区别,请参阅有关选择合适的笔记本解决方案的官方文档。
4. 配置运行时模板
在 Colab Enterprise 中,连接到基于预配置的运行时模板的运行时。
运行时模板是一种可重复使用的配置,用于指定笔记本的整个环境,包括:
- 机器类型(CPU、内存)
- 加速器(GPU 类型和数量)
- 磁盘大小和类型
- 投放网络设置和安全政策
- 自动空闲关停规则
运行时模板的用途
- 获得一致的环境:您和您的团队成员每次都能获得相同的即用型环境,确保您的工作可重复。
- 从设计上保证安全地工作:模板会自动强制执行组织的安全政策。
- 有效管理费用:模板中预先确定了 GPU 和 CPU 等资源的大小,有助于防止意外的费用超支。
创建运行时模板
为实验设置可重复使用的运行时模板。
- 在 Google Cloud 控制台中,依次前往导航菜单 > Agent Platform > Notebooks。
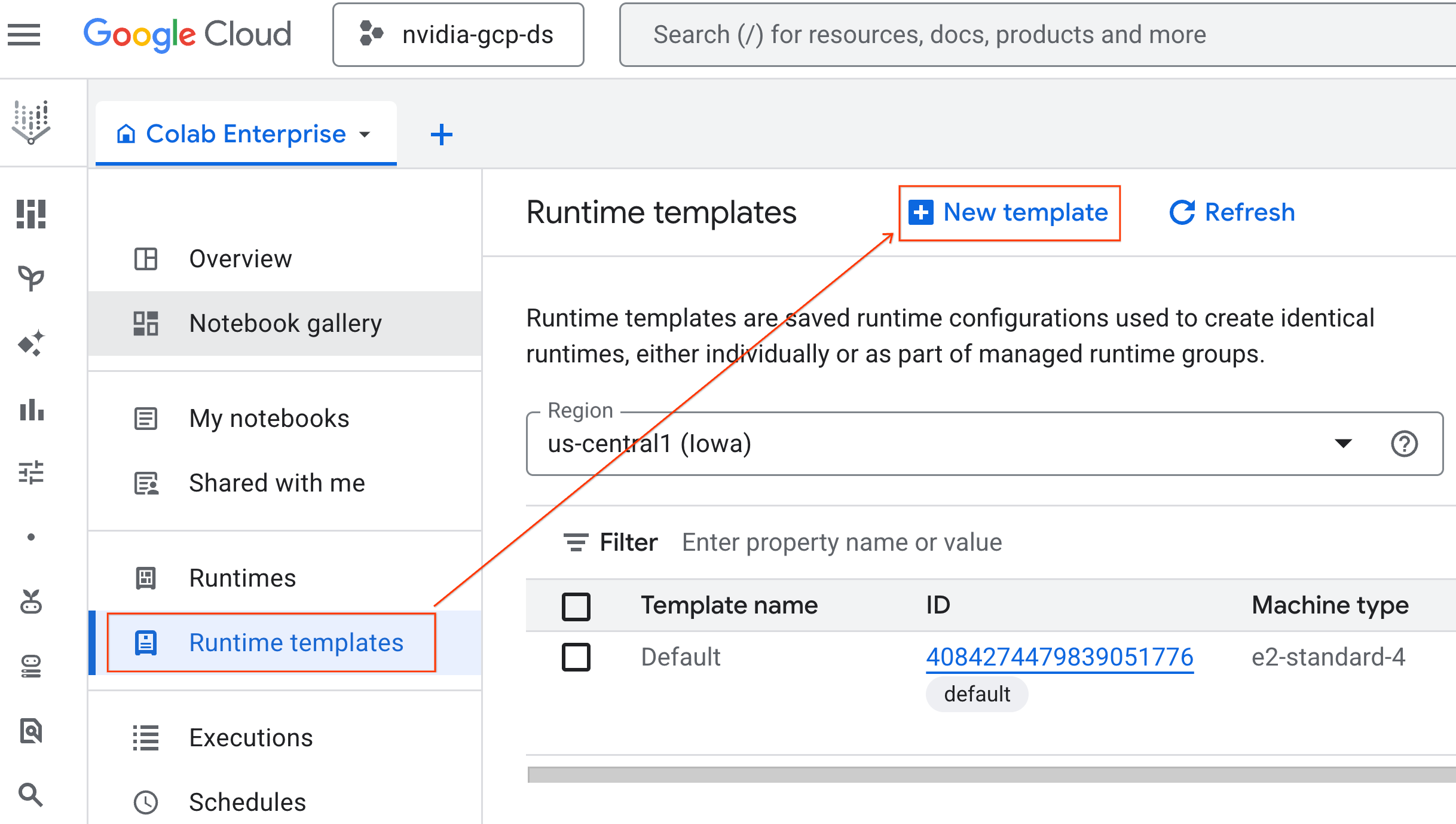
- 在 Colab Enterprise 中,点击运行时模板,然后选择新建模板。
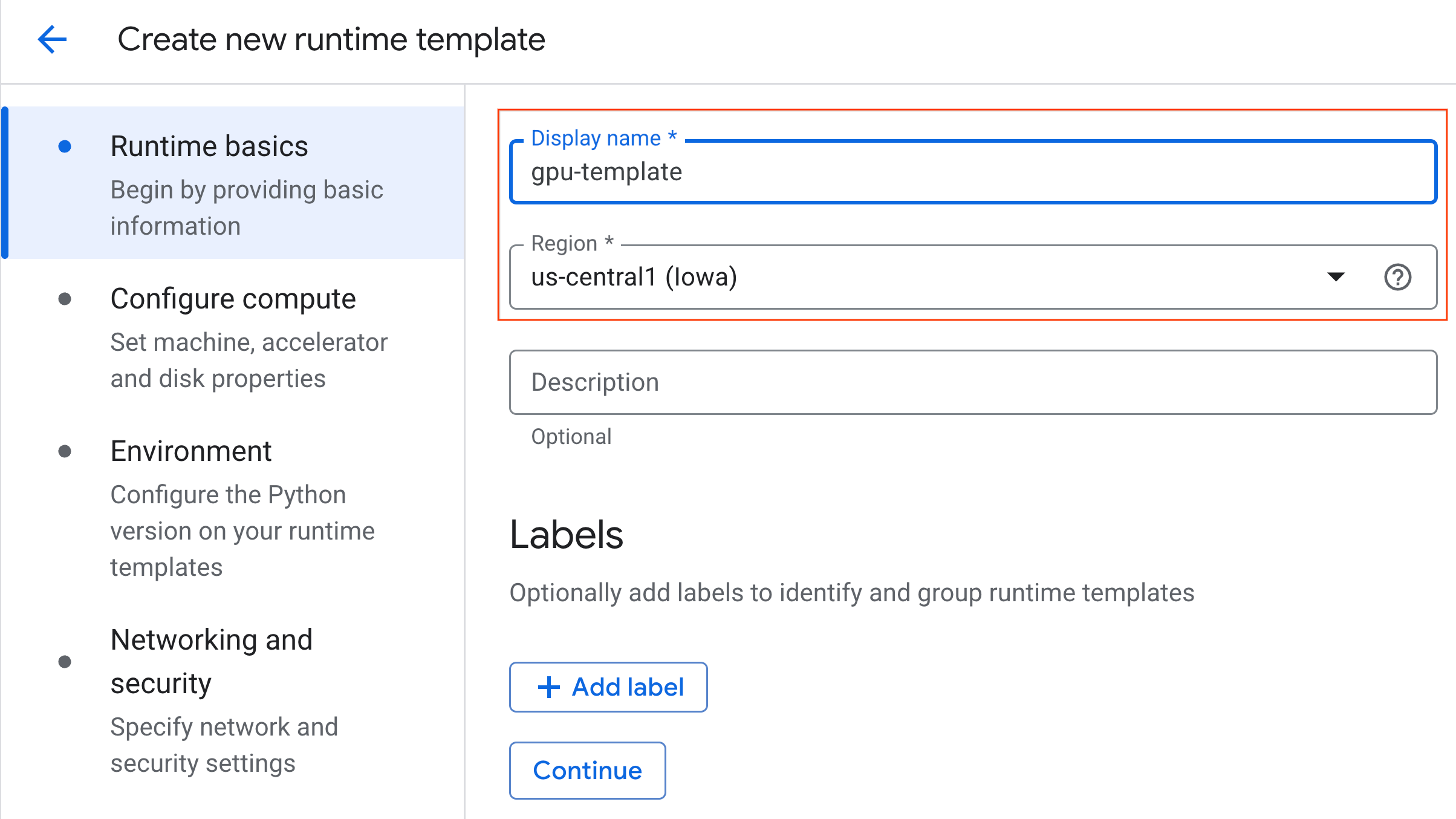
- 在运行时基本信息下:
- 将显示名称设置为
gpu-template。 - 设置您的首选区域。
- 将显示名称设置为
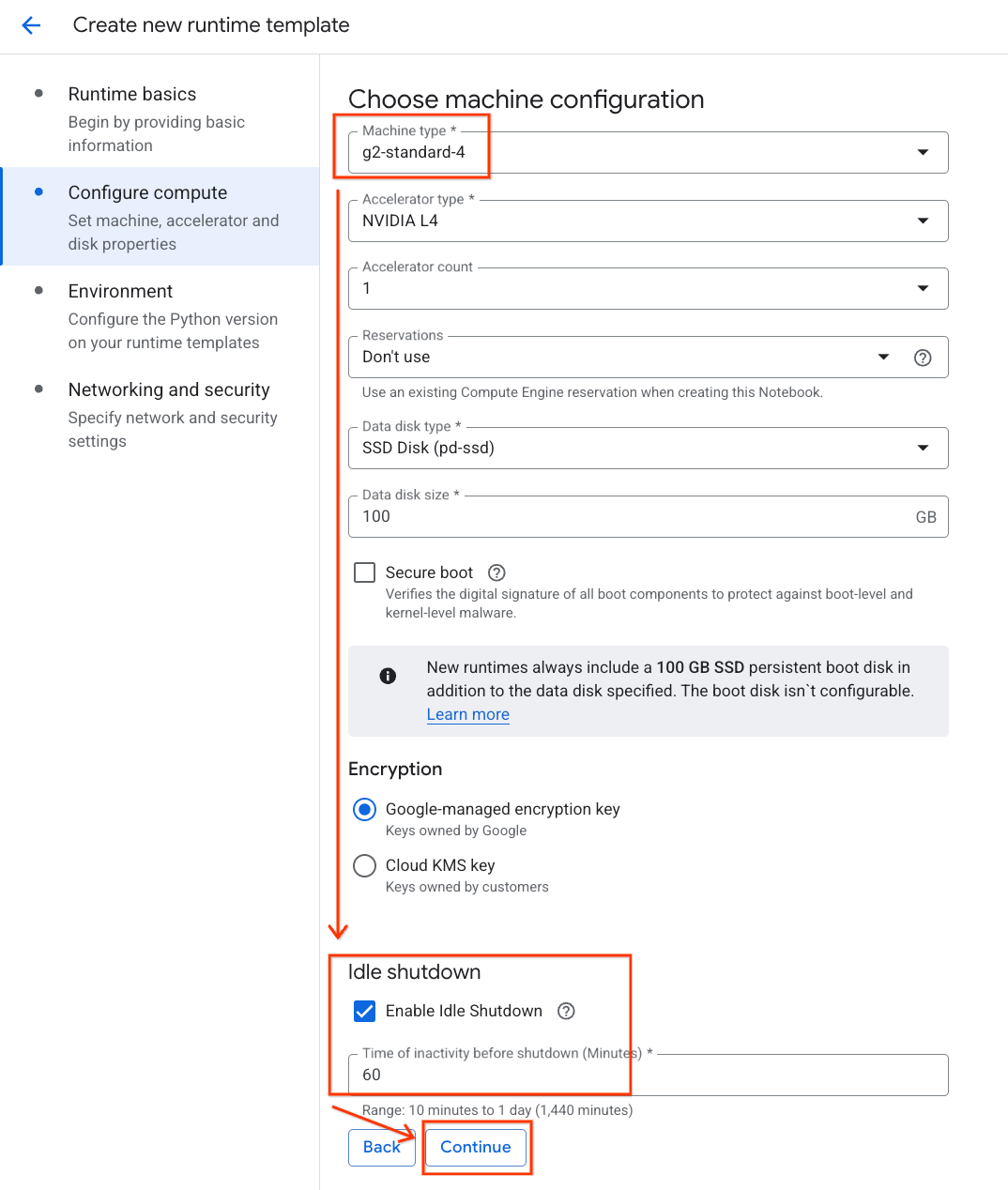
- 在配置计算下:
- 将机器类型设置为
g2-standard-4。 - 将默认加速器类型保留为
NVIDIA L4,并将加速器数量设置为 1。 - 将空闲关闭时间更改为 60 分钟。
- 点击继续。
- 将机器类型设置为
- 在环境下:
- 将环境设置为
Python 3.11
- 将环境设置为
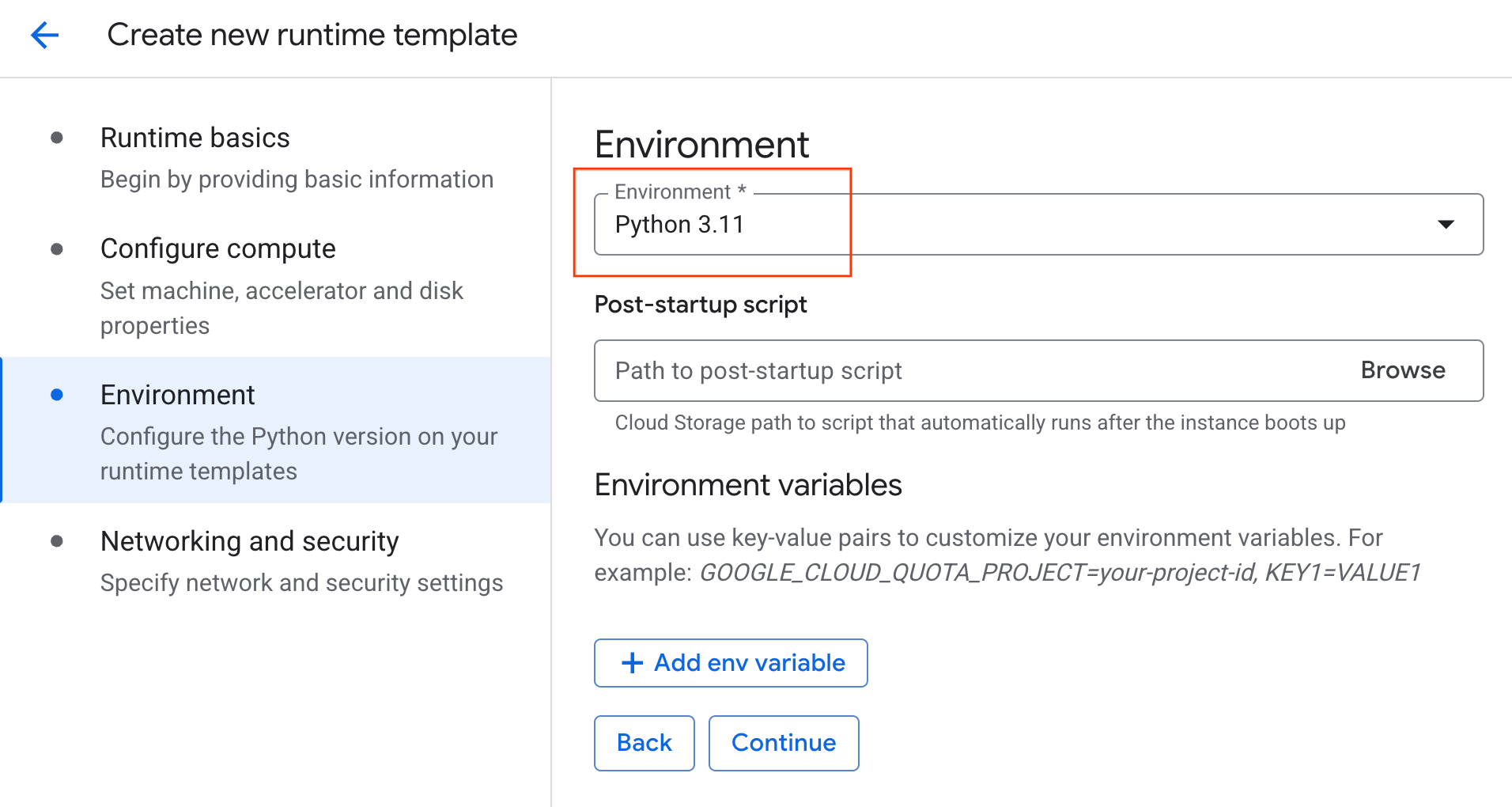
- 点击创建以保存运行时模板。您的“运行时模板”页面现在应会显示新模板。
5. 启动运行时
准备好模板后,您就可以创建新的运行时了。
- 在 Colab Enterprise 中,点击运行时,然后选择创建。
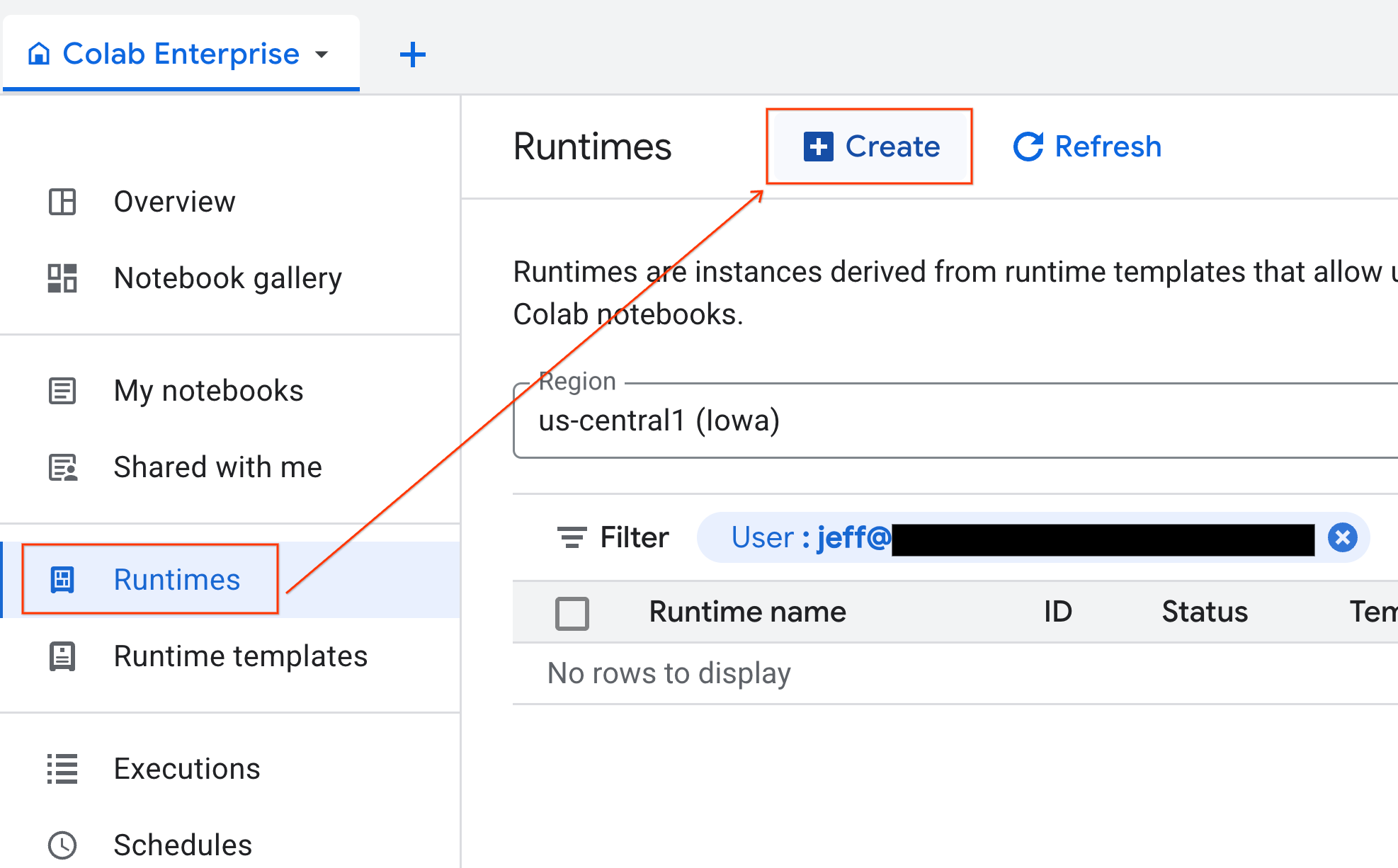
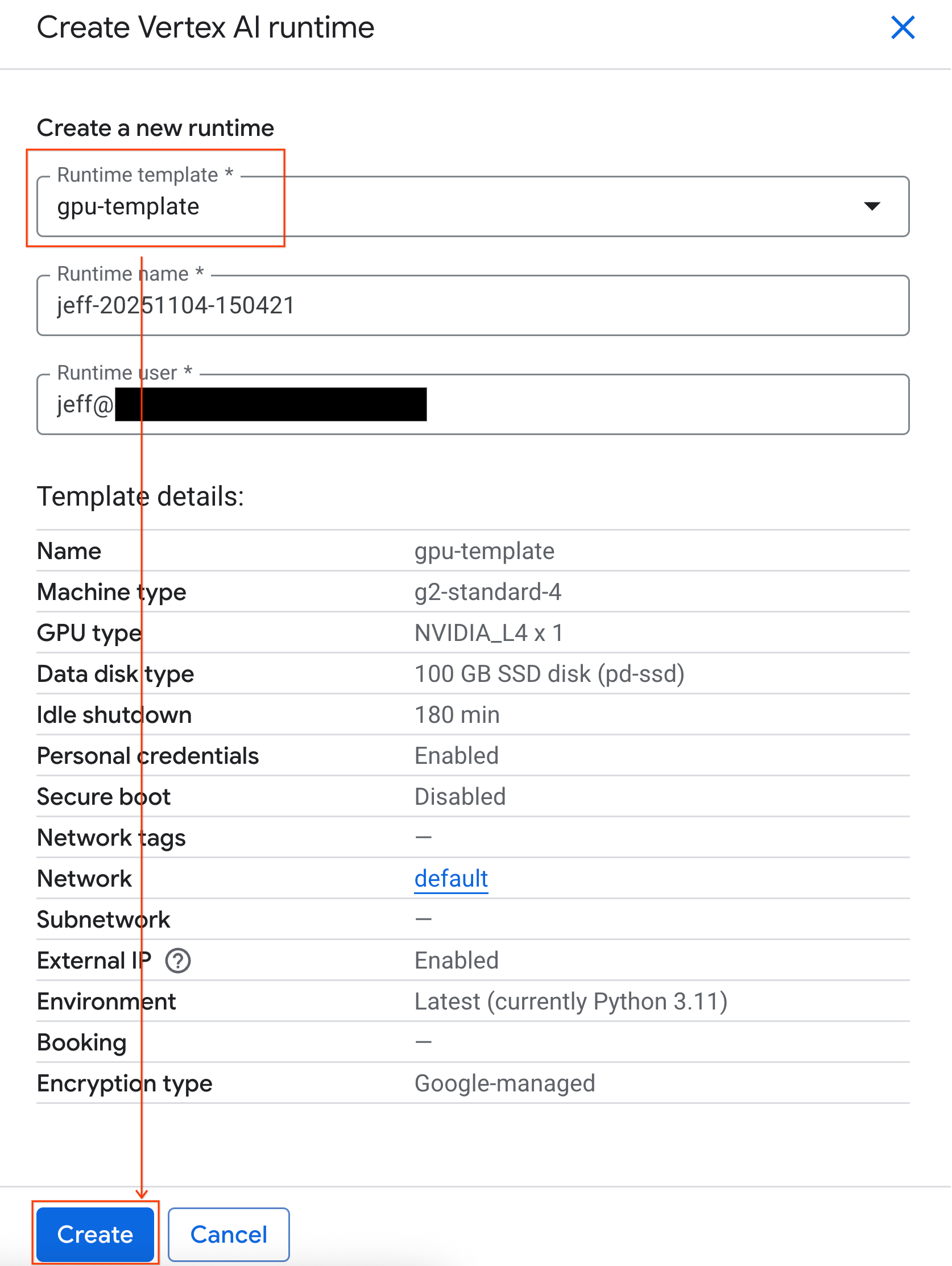
- 在运行时模板下方,选择
gpu-template选项。点击创建,然后等待运行时启动。
- 几分钟后,您会看到运行时可用。
6. 设置笔记本
现在,您的基础架构已在运行,您需要导入实验笔记本并将其连接到运行时。
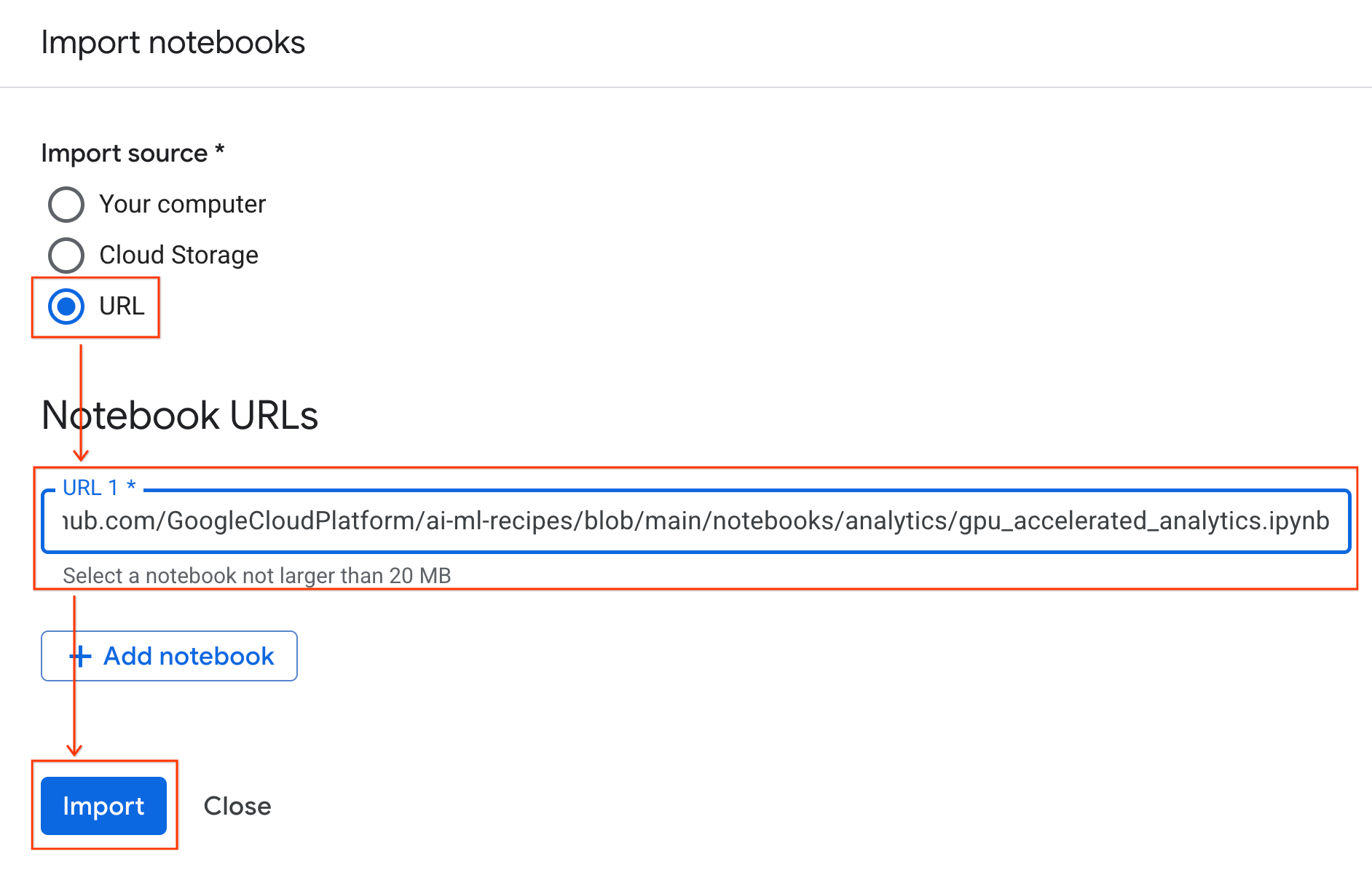
导入笔记本
- 在 Colab Enterprise 中,点击我的笔记本,然后点击导入。

- 选择网址单选按钮,然后输入以下网址:
https://github.com/GoogleCloudPlatform/ai-ml-recipes/blob/main/notebooks/analytics/gpu_accelerated_analytics.ipynb
- 点击导入。Colab Enterprise 会将笔记本从 GitHub 复制到您的环境中。
连接到运行时
- 打开新导入的笔记本。
- 点击连接旁边的下拉箭头。
- 选择连接到运行时。

- 使用下拉菜单选择您之前创建的运行时。
- 点击连接。
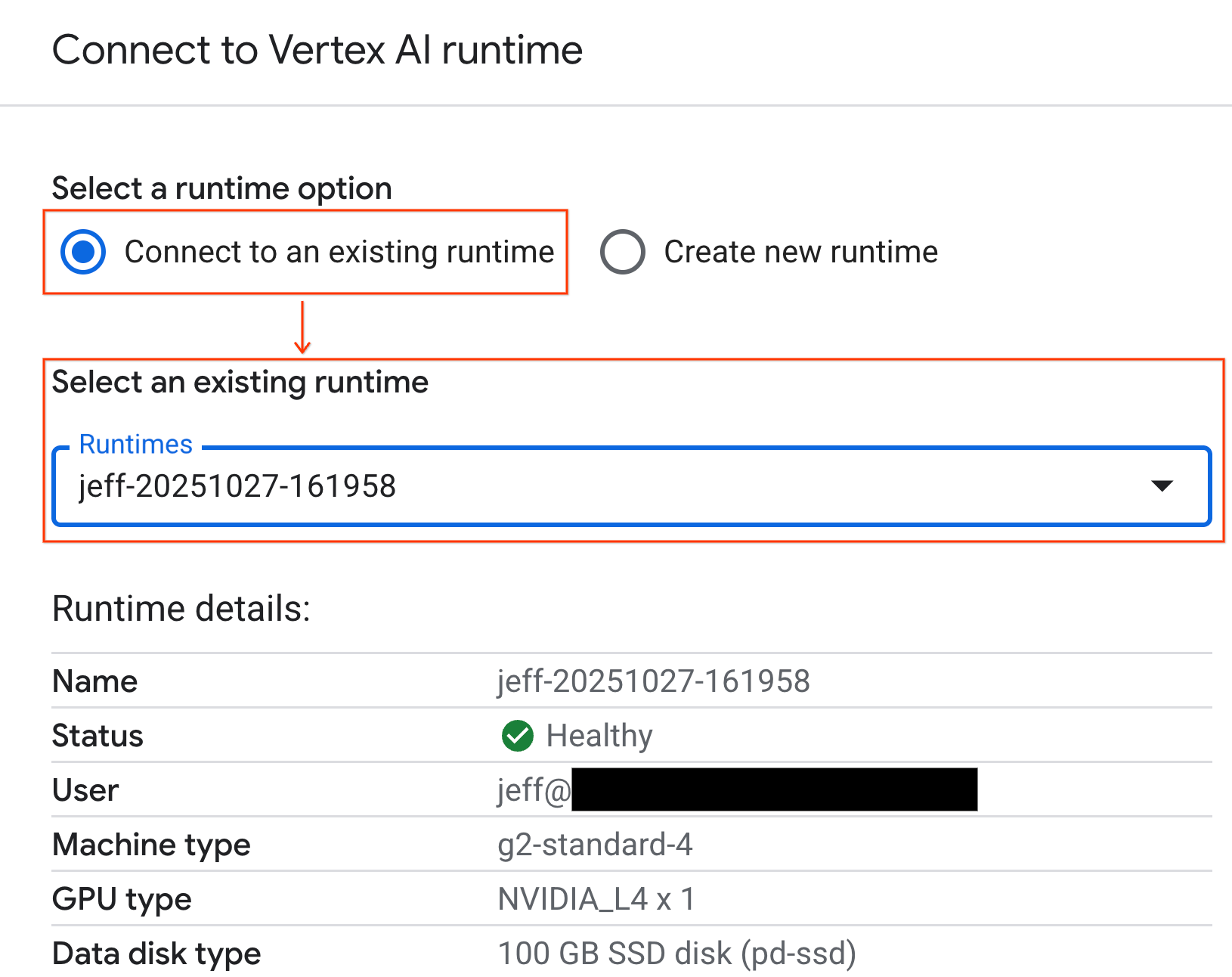
您的笔记本现已连接到启用 GPU 的运行时。现在,您可以开始运行查询了!
7. 准备纽约市出租车数据集
本 Codelab 使用了纽约市出租车和豪华轿车委员会 (TLC) 的行程记录数据。
该数据集包含纽约市黄色出租车的各个行程记录,其中包括以下字段:
- 上车和下车日期、时间及地点
- 行程距离
- 分项车费金额
- 乘客人数
下载数据
接下来,下载 2024 年全年的行程数据。数据以 Parquet 文件格式存储。
以下代码块执行这些步骤:
- 定义要下载的年份和月份范围。
- 创建一个名为
nyc_taxi_data的本地目录来存储文件。 - 循环遍历每个月,下载相应的 Parquet 文件(如果尚不存在),并将其保存到目录中。
在笔记本中运行此代码,以收集数据并将其存储在运行时中:
from tqdm import tqdm
import requests
import time
import os
YEAR = 2024
DATA_DIR = "nyc_taxi_data"
os.makedirs(DATA_DIR, exist_ok=True)
print(f"Checking/Downloading files for {YEAR}...")
for month in tqdm(range(1, 13), unit="file"):
# Define standardized filename for both local path and URL
file_name = f"yellow_tripdata_{YEAR}-{month:02d}.parquet"
local_path = os.path.join(DATA_DIR, file_name)
url = f"https://d37ci6vzurychx.cloudfront.net/trip-data/{file_name}"
if not os.path.exists(local_path):
try:
with requests.get(url, stream=True) as response:
response.raise_for_status()
with open(local_path, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
time.sleep(1)
except requests.exceptions.HTTPError as e:
print(f"\nSkipping {file_name}: {e}")
if os.path.exists(local_path):
os.remove(local_path)
print("\nDownload complete.")
8. 探索出租车行程数据
现在,您已下载数据集,接下来可以执行初始探索性数据分析 (EDA)。EDA 的目标是了解数据的结构、发现异常情况并揭示潜在的模式。
加载单个月的数据
首先,加载一个月的数据。这样可以提供足够大的样本(超过 300 万行),从而确保分析有意义,同时使内存用量保持在可管理的范围内,以便进行交互式分析。
import pandas as pd
import glob
# Load the last month of the downloaded data
df = pd.read_parquet("nyc_taxi_data/yellow_tripdata_2024-12.parquet")
df.head()
获取汇总统计信息
使用 .describe() 方法可为数值列生成高级汇总统计信息。这是发现潜在数据质量问题(例如意外的最小值或最大值)的绝佳第一步。
df.describe().round(2)
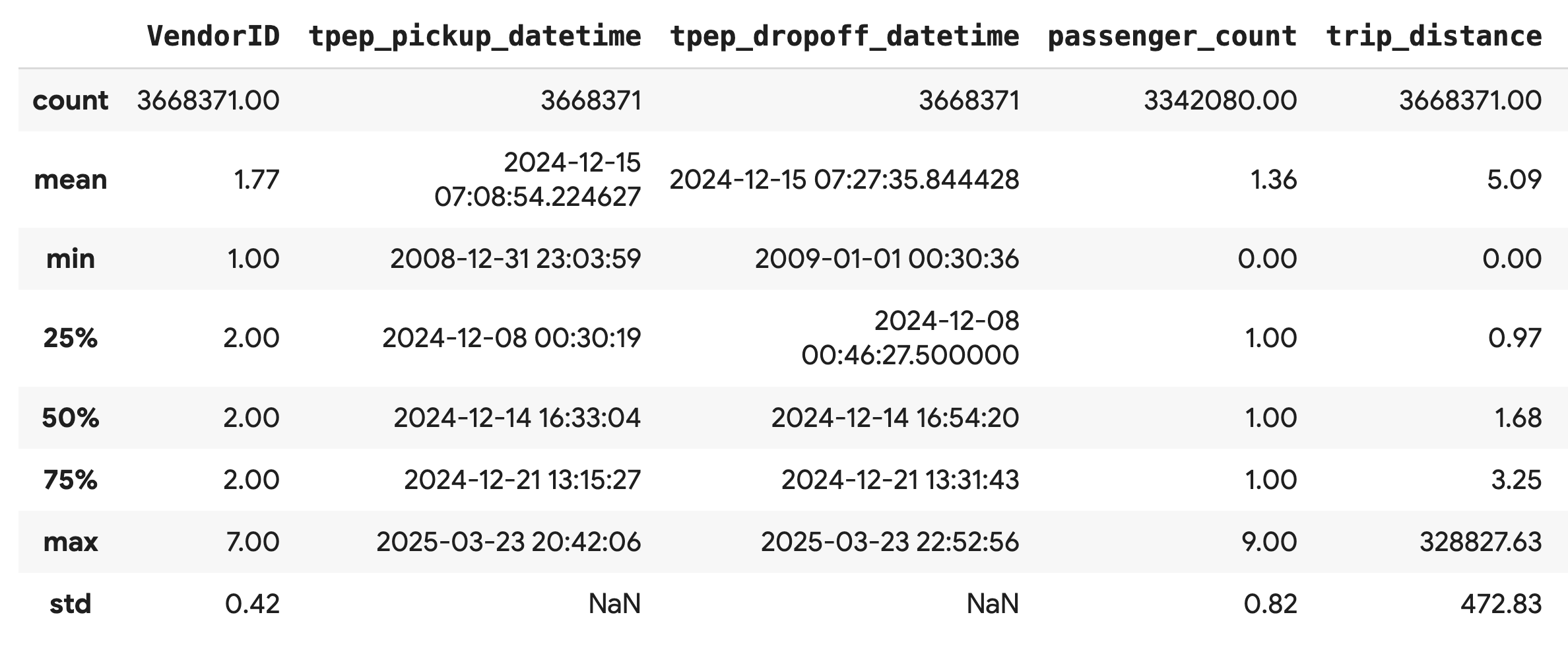
调查数据质量
.describe() 的输出会立即显示问题。请注意,tpep_pickup_datetime 和 tpep_dropoff_datetime 的 min 值是 2008 年,这对于 2024 年的数据集来说是不合理的。
此示例旨在说明为何应始终检查数据。您可以对 DataFrame 进行排序,以查找包含这些异常日期的确切行,从而进一步调查此问题。
# Sort by the dropoff datetime to see the oldest records
df.sort_values("tpep_pickup_datetime").head()
直观呈现数据分布
接下来,您可以创建数值列的直方图,以直观呈现其分布情况。这有助于您了解 trip_distance 和 fare_amount 等特征的分布和偏度。.hist() 函数可用于快速绘制 DataFrame 中所有数值列的直方图。
_ = df.hist(figsize=(20, 20))
最后,生成散点矩阵,直观呈现几个关键列之间的关系。由于绘制数百万个点速度较慢,并且可能会掩盖模式,因此请使用 .sample() 从 10 万行的随机样本中创建图表。
_ = pd.plotting.scatter_matrix(
df[['passenger_count', 'trip_distance', 'tip_amount', 'total_amount']].sample(100_000),
diagonal="kde",
figsize=(15, 15)
)
9. 为何使用 Parquet 文件格式?
纽约市出租车数据集以 Apache Parquet 格式提供。这是为了大规模分析而做出的有意选择。与 CSV 等文件类型相比,Parquet 具有以下优势:
- 高效快速:作为一种列式格式,Parquet 在存储和读取方面非常高效。它支持现代压缩方法,可减小文件大小并显著加快 I/O 速度,尤其是在 GPU 上。
- 保留架构:Parquet 将数据类型存储在文件的元数据中。读取文件时,您无需猜测数据类型。
- 实现选择性读取:列式结构可让您仅读取分析所需的特定列。这可以大幅减少您必须加载到内存中的数据量。
探索 Parquet 功能
接下来,我们将使用您下载的其中一个文件来探索这两项强大的功能。
检查元数据,而不加载完整的数据集
虽然您无法在标准文本编辑器中查看 Parquet 文件,但可以轻松检查其架构和元数据,而无需将任何数据加载到内存中。这有助于快速了解文件的结构。
from pyarrow.parquet import ParquetFile
import pyarrow as pa
# Open one of the downloaded files
pf = ParquetFile('nyc_taxi_data/yellow_tripdata_2024-12.parquet')
# Print the schema
print("File Schema:")
print(pf.schema)
# Print the file metadata
print("\nFile Metadata:")
print(pf.metadata)
只读取您需要的列
假设您只需要分析行程距离和车费金额。借助 Parquet,您只需加载这些列,这比加载整个 DataFrame 快得多,也更节省内存。
import pandas as pd
# Read only four specific columns from the Parquet file
df_subset = pd.read_parquet(
'nyc_taxi_data/yellow_tripdata_2024-12.parquet',
columns=['passenger_count', 'trip_distance', 'tip_amount', 'total_amount']
)
df_subset.head()
10. 使用 NVIDIA cuDF 加速 Pandas
NVIDIA CUDA for DataFrames (cuDF) 是一个开源的 GPU 加速库,可让您与 DataFrame 进行交互。借助 cuDF,您可以在 GPU 上以大规模并行方式执行常见的数据操作,例如过滤、联接和分组。
在此 Codelab 中,您将使用 cudf.pandas 加速器模式。启用后,您的标准 pandas 代码会自动重定向为在后台使用 GPU 驱动的 cuDF 内核,而无需您更改代码。
启用 GPU 加速
如需在 Colab Enterprise 笔记本中使用 NVIDIA cuDF,请在导入 pandas 之前加载其 magic 扩展程序。
首先,检查标准 pandas 库。请注意,输出显示了默认 pandas 安装的路径。
import pandas as pd
pd # Note the output for the standard pandas library
现在,加载 cudf.pandas 扩展程序并再次导入 pandas。观察 pd 模块的输出如何变化 - 这可确认 GPU 加速版本现已处于活跃状态。
%load_ext cudf.pandas
import pandas as pd
pd # Note the new output, indicating cudf.pandas is active
启用 cudf.pandas 的其他方式
虽然 magic 命令 (%load_ext) 是笔记本中最简单的方法,但您也可以在其他环境中启用加速器:
- 在 Python 脚本中:在导入
pandas之前调用import cudf.pandas和cudf.pandas.install()。 - 在非笔记本环境中:使用
python -m cudf.pandas your_script.py运行脚本。
11. 比较 CPU 与 GPU 的性能
现在到了最重要的部分:比较 CPU 上标准 pandas 的性能与 GPU 上 cudf.pandas 的性能。
为了确保 CPU 基准完全公平,您必须先重置 Colab 运行时。这会清除您可能在之前部分中启用的所有 GPU 加速器。您可以运行以下单元格来重启运行时,也可以从运行时菜单中选择重启会话。
import IPython
IPython.Application.instance().kernel.do_shutdown(True)
定义分析流水线
现在环境已清理完毕,接下来您将定义基准比较函数。此函数可让您使用传递给它的任何 pandas 模块运行完全相同的流水线(加载、排序和总结)。
import time
import glob
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
def run_analytics_pipeline(pd_module):
"""Loads, sorts, and summarizes data using the provided pandas module."""
timings = {}
# 1. Load all 2024 Parquet files from the directory
t0 = time.time()
df = pd_module.concat(
[pd_module.read_parquet(f) for f in glob.glob("nyc_taxi_data/*_2024*.parquet")],
ignore_index=True
)
timings["load"] = time.time() - t0
# 2. Sort the data by multiple columns
t0 = time.time()
df = df.sort_values(
['tpep_pickup_datetime', 'trip_distance', 'passenger_count'],
ascending=[False, True, False]
)
timings["sort"] = time.time() - t0
# 3. Perform a groupby and aggregation
t0 = time.time()
df['tpep_pickup_datetime'] = pd_module.to_datetime(df['tpep_pickup_datetime'])
_ = (
df.loc[df.tpep_pickup_datetime > '2024-11-01']
.groupby(['VendorID', 'tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
timings["summarize"] = time.time() - t0
return timings
运行比较
首先,您将使用标准 pandas 在 CPU 上运行流水线。然后,启用 cudf.pandas 并再次在 GPU 上运行。
# --- Run on CPU ---
print("Running analytics pipeline on CPU...")
# Ensure we are using standard pandas
import pandas as pd
assert "cudf" not in str(pd), "Error: cuDF is still active. Please restart the kernel."
cpu_times = run_analytics_pipeline(pd)
print(f"CPU times: {cpu_times}")
# --- Run on GPU ---
print("\nEnabling cudf.pandas and running on GPU...")
# Load the extension
%load_ext cudf.pandas
import pandas as gpu_pd
gpu_times = run_analytics_pipeline(gpu_pd)
print(f"GPU times: {gpu_times}")
直观呈现结果
最后,直观呈现差异。以下代码计算了每项操作的加速比,并将其并排绘制。
# Create a DataFrame for plotting
results_df = pd.DataFrame([cpu_times, gpu_times], index=["CPU", "GPU"]).T
total_cpu_time = results_df['CPU'].sum()
total_gpu_time = results_df['GPU'].sum()
speedup = total_cpu_time / total_gpu_time
print("--- Performance Results ---")
print(results_df)
print(f"\nTotal CPU Time: {total_cpu_time:.2f} seconds")
print(f"Total GPU Time: {total_gpu_time:.2f} seconds")
print(f"Overall Speedup: {speedup:.2f}x")
# Plot the results
fig, ax = plt.subplots(figsize=(10, 6))
results_df.plot(kind='bar', ax=ax, color={"CPU": "tab:blue", "GPU": "tab:green"})
ax.set_ylabel("Time (seconds)")
ax.set_title(f"CPU vs. GPU Runtimes (Overall Speedup: {speedup:.2f}x)", fontsize=14)
ax.tick_params(axis='x', rotation=0)
# Add numerical labels to the bars
for container in ax.containers:
ax.bar_label(container, fmt="%.2f", padding=3)
plt.tight_layout()
plt.show()
示例结果如下:
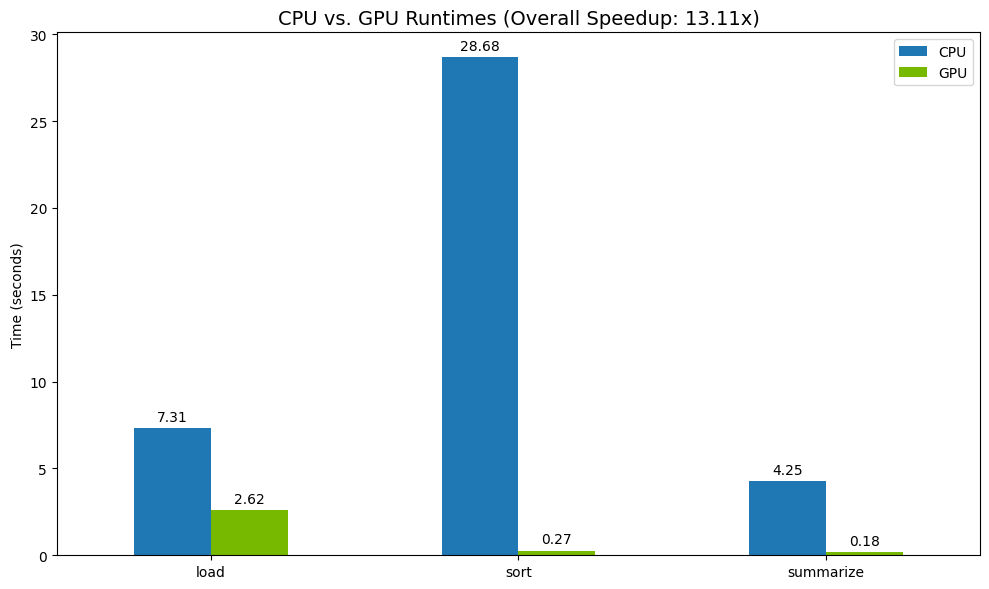
与 CPU 相比,GPU 可显著提高速度。
12. 分析代码以查找瓶颈
即使使用 GPU 加速,如果某些 pandas 操作尚不受 cuDF 支持,也可能会回退到 CPU。这些“CPU 回退”可能会成为性能瓶颈。
为了帮助您确定这些区域,cudf.pandas 包含两个内置的分析器。您可以使用它们来准确了解代码的哪些部分在 GPU 上运行,哪些部分回退到 CPU。
%%cudf.pandas.profile:使用此功能可获取代码的高级函数级摘要。最适合快速了解哪些操作正在哪些设备上运行。%%cudf.pandas.line_profile:使用此参数可进行详细的逐行分析。这是用于精确定位代码中导致回退到 CPU 的确切行的最佳工具。
在笔记本单元格顶部使用这些分析器作为“单元格 magic”。
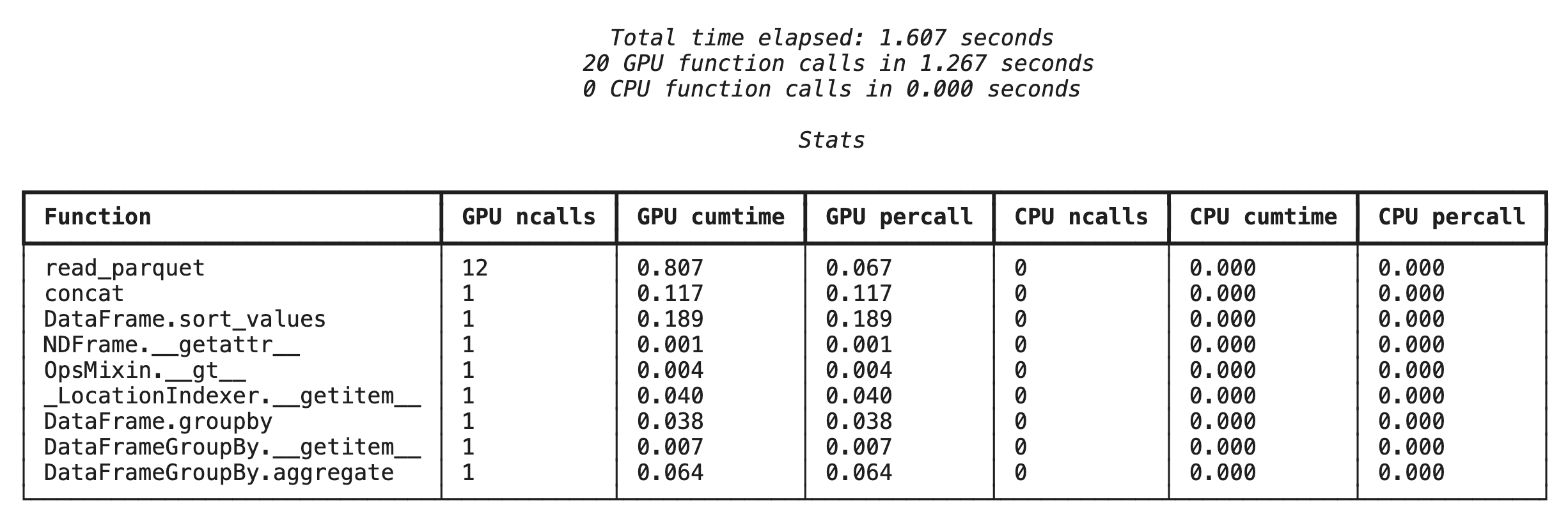
使用 %%cudf.pandas.profile 进行函数级分析
首先,对上一部分中的同一分析流水线运行函数级分析器。输出会显示一个表格,其中包含每个被调用的函数、运行该函数的设备(GPU 或 CPU)以及该函数被调用的次数。
%load_ext cudf.pandas
import pandas as pd
import glob
pd.DataFrame({"a": [1]})
确保 cudf.pandas 处于有效状态后,您就可以运行分析了。
%%cudf.pandas.profile
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*2024*.parquet")], ignore_index=True)
df = df.sort_values(['tpep_pickup_datetime', 'trip_distance', 'passenger_count'], ascending=[False, True, False])
summary = (
df
.loc[(df.tpep_pickup_datetime > '2024-11-01')]
.groupby(['VendorID','tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
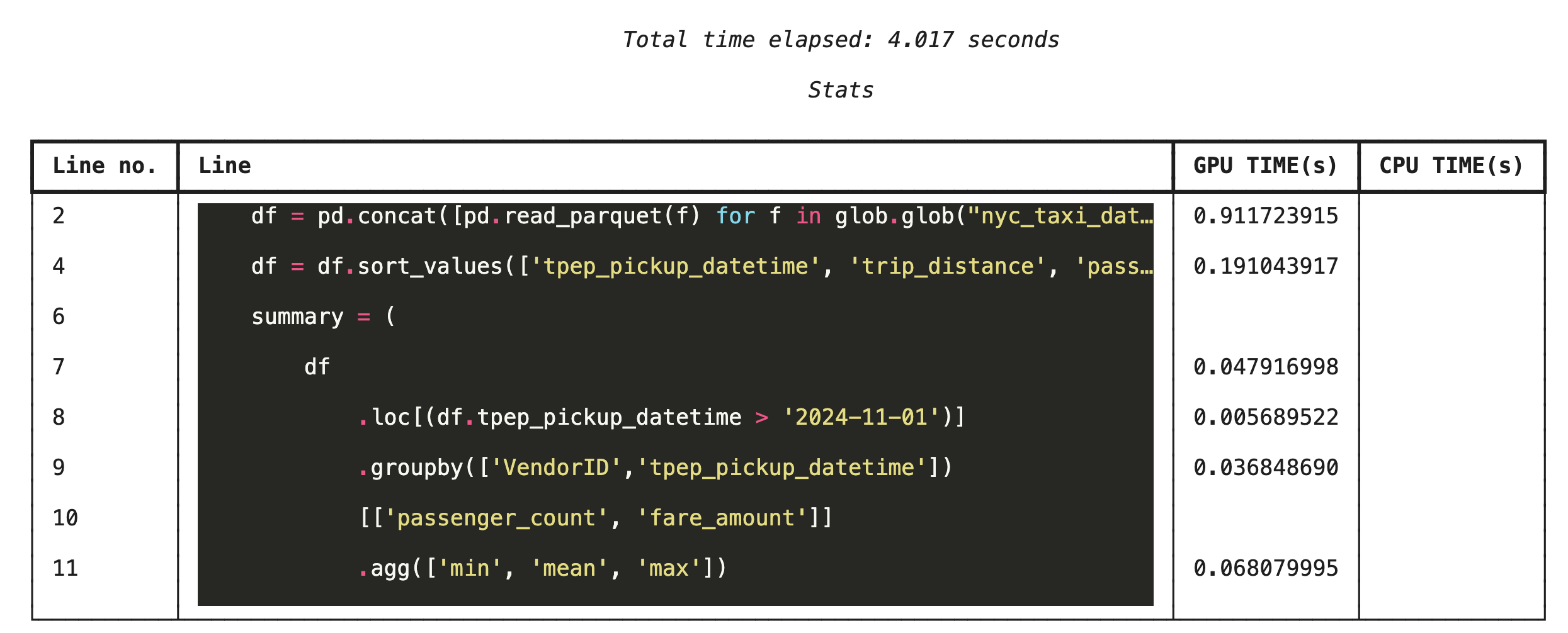
使用 %%cudf.pandas.line_profile 进行逐行分析
接下来,运行行级分析器。这样一来,您就可以获得更精细的视图,其中显示了每行代码在 GPU 上执行所花费的时间与在 CPU 上执行所花费的时间之比。这是查找要优化的特定瓶颈的最有效方法。
%%cudf.pandas.line_profile
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*2024*.parquet")], ignore_index=True)
df = df.sort_values(['tpep_pickup_datetime', 'trip_distance', 'passenger_count'], ascending=[False, True, False])
summary = (
df
.loc[(df.tpep_pickup_datetime > '2024-11-01')]
.groupby(['VendorID','tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
从命令行进行性能剖析
这些分析器也可通过命令行使用,这对于自动测试和分析 Python 脚本非常有用。
您可以在命令行界面中使用以下命令:
python -m cudf.pandas --profile your_script.pypython -m cudf.pandas --line_profile your_script.py
13. 与 Google Cloud Storage 集成
Google Cloud Storage (GCS) 是一项可伸缩且耐用的对象存储服务。使用 Colab Enterprise 时,GCS 是存储数据集、模型检查点和其他制品的好去处。
您的 Colab Enterprise 运行时拥有直接读取和写入 GCS 存储分区中数据的必要权限,并且这些操作经过 GPU 加速,可实现最佳性能。
创建 GCS 存储分区
首先,创建一个新的 GCS 存储分区。GCS 存储分区名称是全局唯一的,因此请在其名称后附加一个 UUID。
from google.cloud import storage
import uuid
unique_suffix = uuid.uuid4().hex[:12]
bucket_name = f'nyc-taxi-codelab-{unique_suffix}'
project_id = storage.Client().project
client = storage.Client()
try:
bucket = client.create_bucket(bucket_name)
print(f"Successfully created bucket: gs://{bucket.name}")
except Exception as e:
print(f"Bucket creation failed. You may already own it or the name is taken: {e}")
直接将数据写入 GCS
现在,将 DataFrame 直接保存到新的 GCS 存储分区。如果前面的部分中没有 df 变量,代码会先加载一个月的数据。
%%cudf.pandas.line_profile
# Ensure the DataFrame exists before saving to GCS
if 'df' not in locals():
print("DataFrame not found, loading a sample file...")
df = pd.read_parquet('nyc_taxi_data/yellow_tripdata_2024-12.parquet')
print(f"Writing data to gs://{bucket_name}/nyc_taxi_data.parquet...")
df.to_parquet(f"gs://{bucket_name}/nyc_taxi_data.parquet", index=False)
print("Write operation complete.")
验证 GCS 中的文件
您可以访问存储分区,验证数据是否已存储在 GCS 中。以下代码会创建一个可点击的链接。
from IPython.display import Markdown
gcs_url = f"https://console.cloud.google.com/storage/browser/{bucket_name}?project={project_id}"
Markdown(f'**[Click here to view your GCS bucket in the Google Cloud Console]({gcs_url})**')
直接从 GCS 读取数据
最后,直接从 GCS 路径将数据读取到 DataFrame 中。此操作还支持 GPU 加速,让您能够高速从云存储空间加载大型数据集。
%%cudf.pandas.line_profile
print(f"Reading data from gs://{bucket_name}/nyc_taxi_data.parquet...")
df_from_gcs = pd.read_parquet(f"gs://{bucket_name}/nyc_taxi_data.parquet")
df_from_gcs.head()
14. 清理
为避免系统向您的 Google Cloud 账号收取意外费用,您需要清理您创建的资源。
删除您下载的数据:
# Permanately delete the GCS bucket
print(f"Deleting GCS bucket: gs://{bucket_name}...")
!gsutil rm -r -f gs://{bucket_name}
print("Bucket deleted.")
# Remove NYC taxi dataset on the Colab runtime
print("Deleting local 'nyc_taxi_data' directory...")
!rm -rf nyc_taxi_data
print("Local files deleted.")
关闭 Colab 运行时
- 在 Google Cloud 控制台中,前往 Colab Enterprise 运行时页面。
- 在区域菜单中,选择包含运行时的区域。
- 选择要删除的运行时。
- 点击删除。
- 点击确认。
删除笔记本
- 在 Google Cloud 控制台中,前往 Colab Enterprise 我的笔记本页面。
- 在区域菜单中,选择包含笔记本的区域。
- 选择要删除的笔记本。
- 点击删除。
- 点击确认。
15. 恭喜
恭喜!您已成功在 Colab Enterprise 上使用 NVIDIA cuDF 加速了 Pandas 分析工作流。您已了解如何配置启用 GPU 的运行时、启用 cudf.pandas 以实现零代码更改加速、分析代码以找出瓶颈,以及与 Google Cloud Storage 集成。