
1. مقدمة
في هذا الدرس التطبيقي حول الترميز، ستتعرّف على كيفية تسريع سير عمل عِلم البيانات وتعلُّم الآلة على مجموعات البيانات الكبيرة باستخدام وحدات معالجة الرسومات من NVIDIA ومكتبات مفتوحة المصدر على Google Cloud. ستبدأ بإعداد البنية الأساسية، ثم ستتعرّف على كيفية تطبيق تسريع وحدة معالجة الرسومات.
ستركّز على دورة حياة علم البيانات، بدءًا من إعداد البيانات باستخدام pandas إلى تدريب النموذج باستخدام scikit-learn وXGBoost. ستتعرّف على كيفية تسريع هذه المهام باستخدام مكتبتَي cuDF وcuML من NVIDIA. والأفضل من ذلك، يمكنك الاستفادة من تسريع وحدة معالجة الرسومات بدون تغيير رمز pandas أو scikit-learn الحالي.
أهداف الدورة التعليمية
- التعرّف على Colab Enterprise على Google Cloud
- تخصيص بيئة وقت تشغيل Colab باستخدام إعدادات محدّدة لوحدة معالجة الرسومات والذاكرة
- تطبيق تسريع وحدة معالجة الرسومات للتنبؤ بمبالغ الإكراميات باستخدام ملايين السجلات من مجموعة بيانات سيارات الأجرة في نيويورك
- يمكنك تسريع
pandasبدون إجراء أي تغييرات على الرمز باستخدام مكتبةcuDFمن NVIDIA. - يمكنك تسريع
scikit-learnبدون إجراء أي تغييرات على الرمز باستخدام مكتبةcuMLووحدات معالجة الرسومات من NVIDIA. - إنشاء ملف تعريف للرمز لتحديد قيود الأداء وتحسينها
تتضمّن الصفحة التالية أرصدة يمكنك استخدامها لإكمال الدرس التطبيقي.
2. لماذا يجب تسريع عملية تعلُّم الآلة؟
الحاجة إلى تكرار أسرع في تعلُّم الآلة
تستغرق عملية إعداد البيانات وقتًا طويلاً، وقد يستغرق تدريب النموذج أو تقييمه وقتًا أطول مع زيادة حجم مجموعات البيانات. قد يستغرق تدريب نماذج مثل الغابات العشوائية أو XGBoost على ملايين الصفوف باستخدام وحدة معالجة مركزية ساعات أو أيام.
يؤدي استخدام وحدات معالجة الرسومات إلى تسريع عمليات التدريب هذه باستخدام مكتبات مثل cuML وXGBoost المسرَّعة بواسطة وحدة معالجة الرسومات. تتيح لك هذه السرعة ما يلي:
- التكرار بشكل أسرع: يمكنك اختبار الميزات الجديدة والمعلَمات الفائقة بسرعة.
- التدريب على مجموعات البيانات الكاملة: استخدِم بياناتك الكاملة بدلاً من تقليل عدد العيّنات للحصول على دقة أفضل.
- تقليل التكاليف: يمكنك إكمال أحمال العمل الكبيرة في وقت أقل لخفض تكاليف الحوسبة.
3- الإعداد والمتطلبات
التكاليف المحتملة
يستخدم هذا الدرس التطبيقي حول الترميز موارد Google Cloud، بما في ذلك بيئات تشغيل Colab Enterprise مع وحدات معالجة الرسومات NVIDIA L4. يُرجى الانتباه إلى الرسوم المحتملة واتّباع قسم التنظيف في نهاية الدرس العملي لإيقاف الموارد وتجنُّب الفوترة المستمرة. للحصول على معلومات تفصيلية حول الأسعار، يُرجى الرجوع إلى أسعار Colab Enterprise وأسعار وحدة معالجة الرسومات.
قبل البدء
يُفترض أن يكون لديك معرفة متوسطة بلغة Python وpandas وscikit-learn وممارسات تعلُّم الآلة العادية (مثل التحقّق من الصحة المتبادلة/التجميع).
- في Google Cloud Console، في صفحة اختيار المشروع، اختَر مشروعًا على Google Cloud أو أنشِئ مشروعًا.
- تأكَّد من تفعيل الفوترة لمشروعك على Google Cloud.
تفعيل واجهات برمجة التطبيقات
لاستخدام Colab Enterprise، عليك أولاً تفعيل واجهات برمجة التطبيقات اللازمة.
- افتح Google Cloud Shell من خلال النقر على رمز Cloud Shell في أعلى يسار Google Cloud Console.

- في Cloud Shell، اضبط رقم تعريف مشروعك من خلال استبدال
PROJECT_IDبرقم تعريف مشروعك:
gcloud config set project <PROJECT_ID>
- نفِّذ الأمر التالي لتفعيل واجهات برمجة التطبيقات اللازمة:
gcloud services enable \
compute.googleapis.com \
dataform.googleapis.com \
notebooks.googleapis.com \
aiplatform.googleapis.com
عند التنفيذ بنجاح، من المفترض أن تظهر لك رسالة مشابهة للرسالة الموضّحة أدناه:
Operation "operations/..." finished successfully.
4. اختيار بيئة دفتر ملاحظات
مع أنّ العديد من علماء البيانات على دراية بخدمة Colab للمشاريع الشخصية، يوفّر Colab Enterprise تجربة آمنة وتعاونية ومتكاملة للمفكرات مصمَّمة خصيصًا للأنشطة التجارية.
على Google Cloud، لديك خياران أساسيان لبيئات دفاتر الملاحظات المُدارة: Colab Enterprise وGemini Enterprise Agent Platform Workbench. يعتمد الاختيار الصحيح على أولويات مشروعك.
حالات استخدام "منصة Agent Platform Workbench"
اختَر Agent Platform Workbench عندما تكون أولويتك هي التحكّم والتخصيص المتقدّم. هذا الخيار مثالي إذا كنت بحاجة إلى:
- إدارة البنية التحتية الأساسية ودورة حياة الآلات
- استخدام حاويات مخصّصة وإعدادات شبكة
- يمكنك الدمج مع مسارات MLOps وأدوات مخصّصة لدورة الحياة.
حالات استخدام Colab Enterprise
اختَر Colab Enterprise عندما تكون أولويتك هي الإعداد السريع وسهولة الاستخدام والتعاون الآمن. وهو حلّ مُدار بالكامل يتيح لفريقك التركيز على التحليل بدلاً من البنية الأساسية.
تساعدك Colab Enterprise في ما يلي:
- تطوير مهام سير عمل علم البيانات المرتبطة بشكل وثيق بمستودع البيانات يمكنك فتح دفاتر الملاحظات وإدارتها مباشرةً في BigQuery Studio.
- تدريب نماذج تعلُّم الآلة ودمجها مع أدوات MLOps في "منصّة الوكلاء"
- استمتِع بتجربة مرنة وموحّدة. يمكن فتح دفتر ملاحظات Colab Enterprise تم إنشاؤه في BigQuery وتشغيله في Agent Platform، والعكس صحيح.
الميزة الاختبارية اليوم
يستخدم هذا الدرس التطبيقي حول الترميز Colab Enterprise لتسريع عملية تعلُّم الآلة.
لمزيد من المعلومات حول الاختلافات، راجِع المستندات الرسمية حول اختيار حلّ دفتر الملاحظات المناسب.
5- ضبط نموذج وقت التشغيل
في Colab Enterprise، اتّصِل ببيئة تشغيل استنادًا إلى نموذج بيئة تشغيل مُعدّ مسبقًا.
نموذج وقت التشغيل هو إعداد قابل لإعادة الاستخدام يحدّد بيئة دفتر الملاحظات، بما في ذلك:
- نوع الجهاز (وحدة المعالجة المركزية والذاكرة)
- المسرِّع (نوع وحدة معالجة الرسومات وعددها)
- حجم القرص ونوعه
- إعدادات الشبكة وسياسات الأمان
- قواعد الإيقاف التلقائي في وضع الخمول
أهمية نماذج وقت التشغيل
- الاتساق: يمكنك أنت وفريقك الحصول على البيئة نفسها لضمان إمكانية تكرار العمل.
- الأمان: تفرض النماذج سياسات أمان المؤسسة.
- إدارة التكاليف: يتم تحديد حجم الموارد مسبقًا في النموذج للمساعدة في تجنُّب التكاليف غير المقصودة.
إنشاء نموذج وقت تشغيل
إعداد نموذج وقت تشغيل قابل لإعادة الاستخدام للمختبر
- في Google Cloud Console، انتقِل إلى قائمة التنقّل > منصة Agent > دفاتر الملاحظات.
- في Colab Enterprise، انقر على نماذج وقت التشغيل، ثم اختَر نموذج جديد.
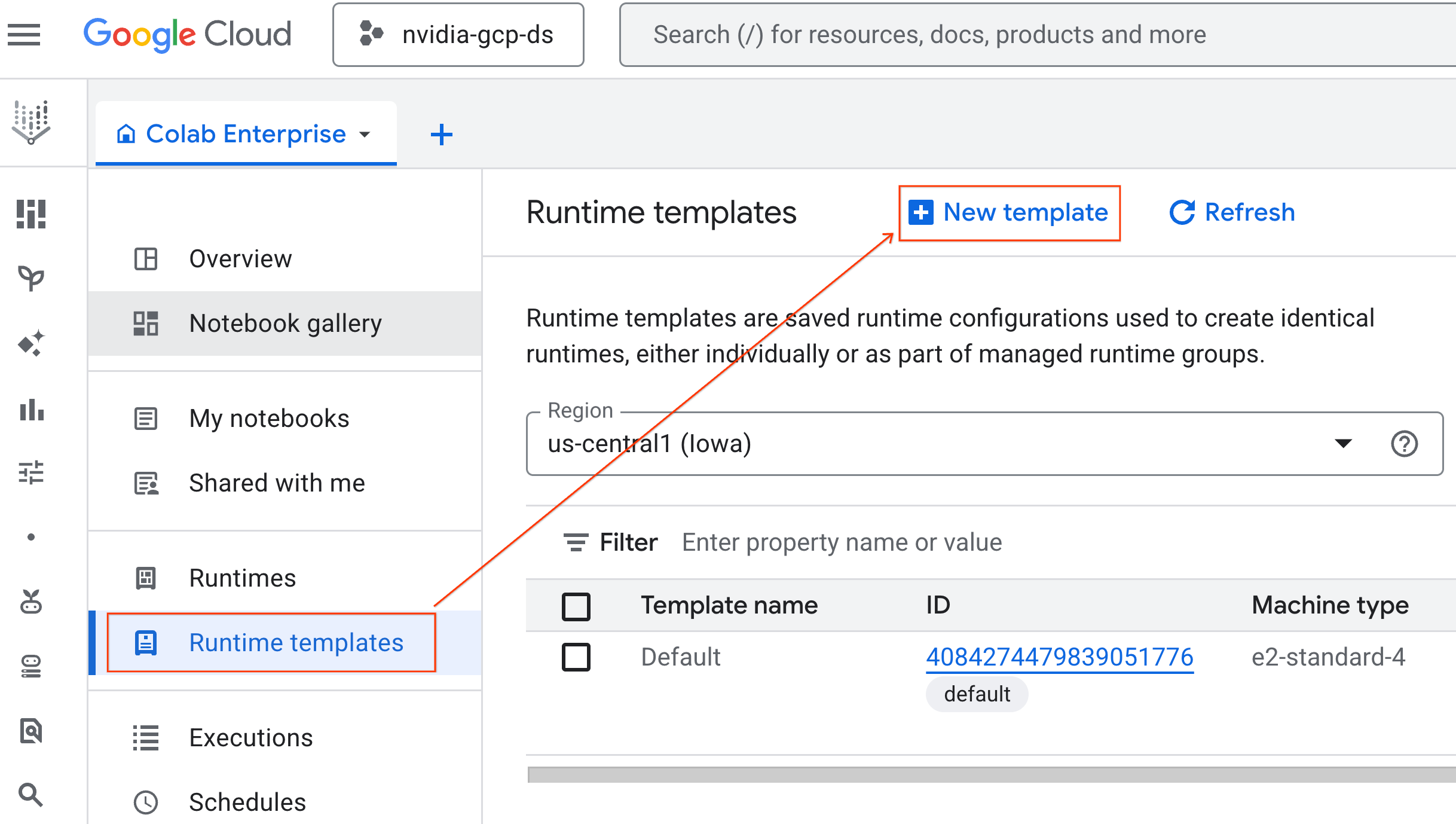
- ضمن أساسيات وقت التشغيل:
- اضبط الاسم المعروض على
gpu-template. - اضبط المنطقة المفضّلة.
- اضبط الاسم المعروض على
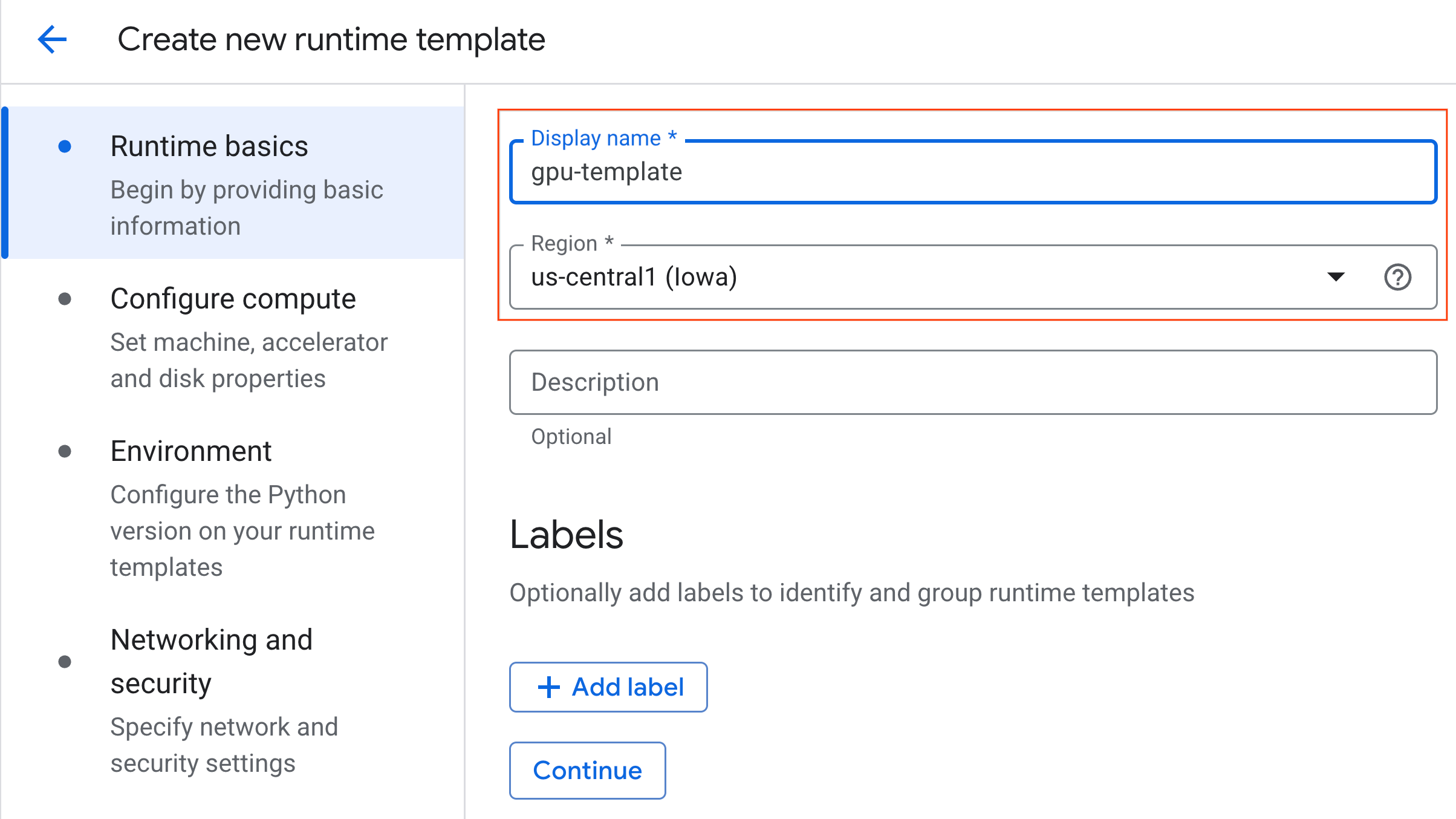
- ضمن ضبط الحساب:
- اضبط نوع الجهاز على
g2-standard-4. - احتفِظ بالإعداد التلقائي نوع أداة التسريع على
NVIDIA L4مع عدد أدوات التسريع بقيمة 1. - غيِّر الإيقاف التلقائي في حال عدم النشاط إلى 60 دقيقة.
- انقر على متابعة.
- اضبط نوع الجهاز على
- ضمن البيئة:
- اضبط البيئة على
Python 3.11
- اضبط البيئة على
- انقر على إنشاء لحفظ نموذج وقت التشغيل. من المفترض أن تعرض صفحة "نماذج وقت التشغيل" النموذج الجديد الآن.
6. بدء وقت التشغيل
بعد إعداد النموذج، يمكنك إنشاء وقت تشغيل جديد.
- من Colab Enterprise، انقر على وقت التشغيل ثم اختَر إنشاء.
- ضمن نموذج وقت التشغيل، اختَر الخيار
gpu-template. انقر على إنشاء وانتظر حتى يتم تشغيل وقت التشغيل.
- بعد بضع دقائق، ستظهر مدة التشغيل المتاحة.
7. إعداد دفتر الملاحظات
بعد تشغيل البنية الأساسية، عليك استيراد دفتر الملاحظات الخاص بالتجربة وربطه بوقت التشغيل.
استيراد دفتر الملاحظات
- من Colab Enterprise، انقر على دفاتري ثم على استيراد.
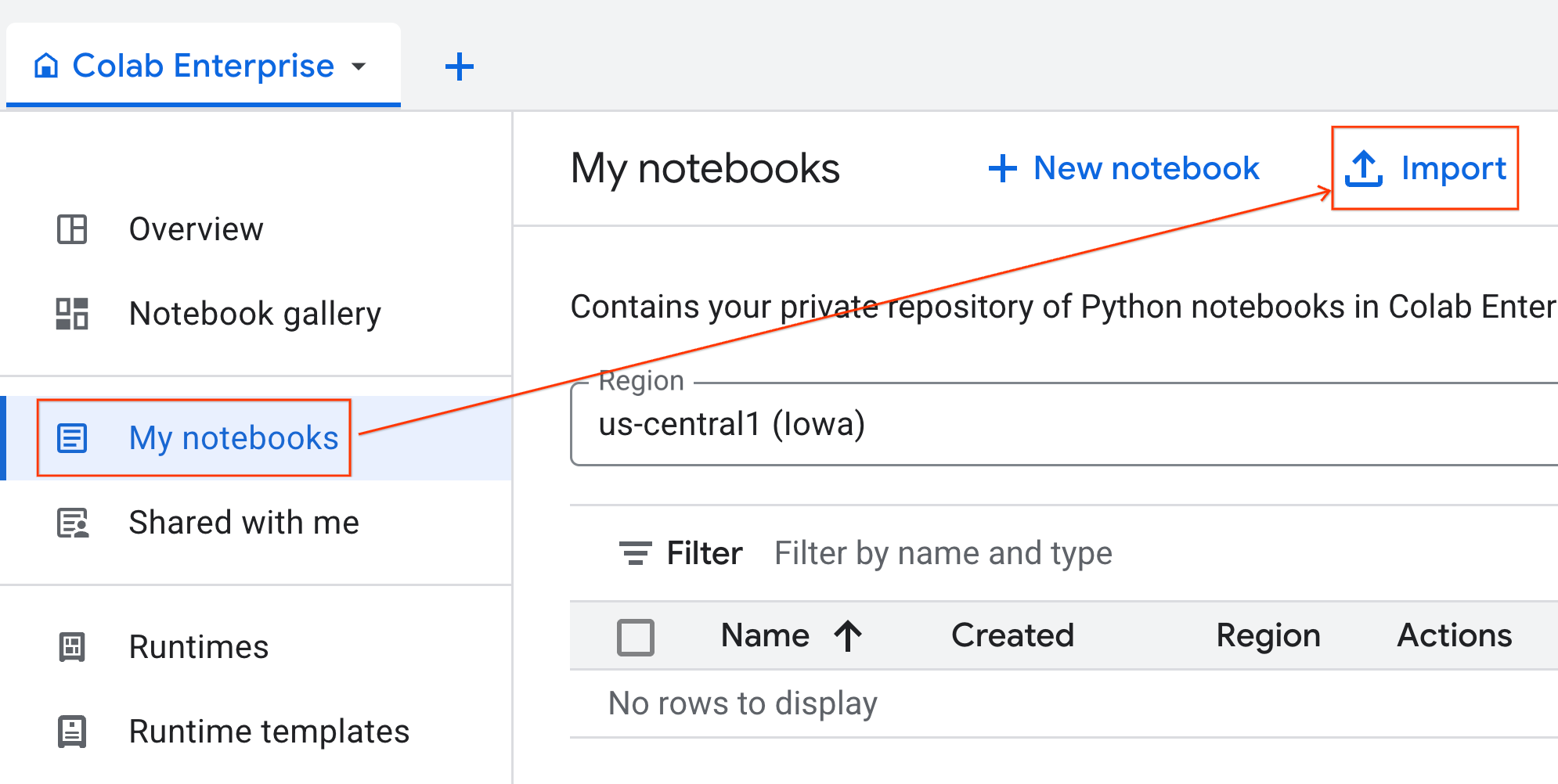
- انقر على زر الاختيار عنوان URL وأدخِل عنوان URL التالي:
https://github.com/GoogleCloudPlatform/ai-ml-recipes/blob/main/notebooks/regression/gpu_accelerated_regression/gpu_accelerated_regression.ipynb
- انقر على استيراد. ستنسخ Colab Enterprise دفتر الملاحظات من GitHub إلى بيئتك.
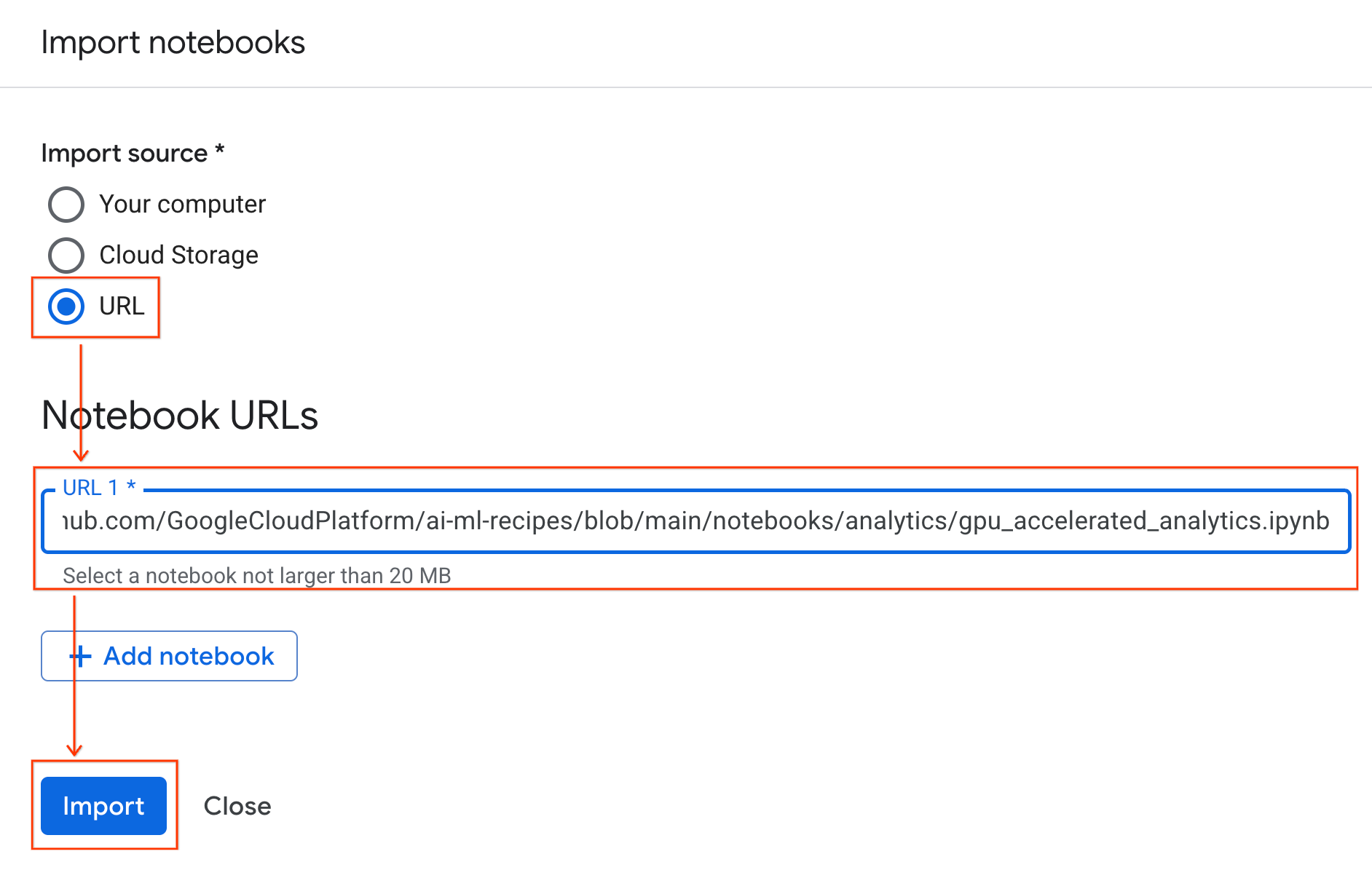
الاتصال ببيئة التشغيل
- افتح دفتر الملاحظات الذي تم استيراده حديثًا.
- انقر على السهم المتّجه للأسفل بجانب ربط.
- انقر على الاتصال ببيئة تشغيل.
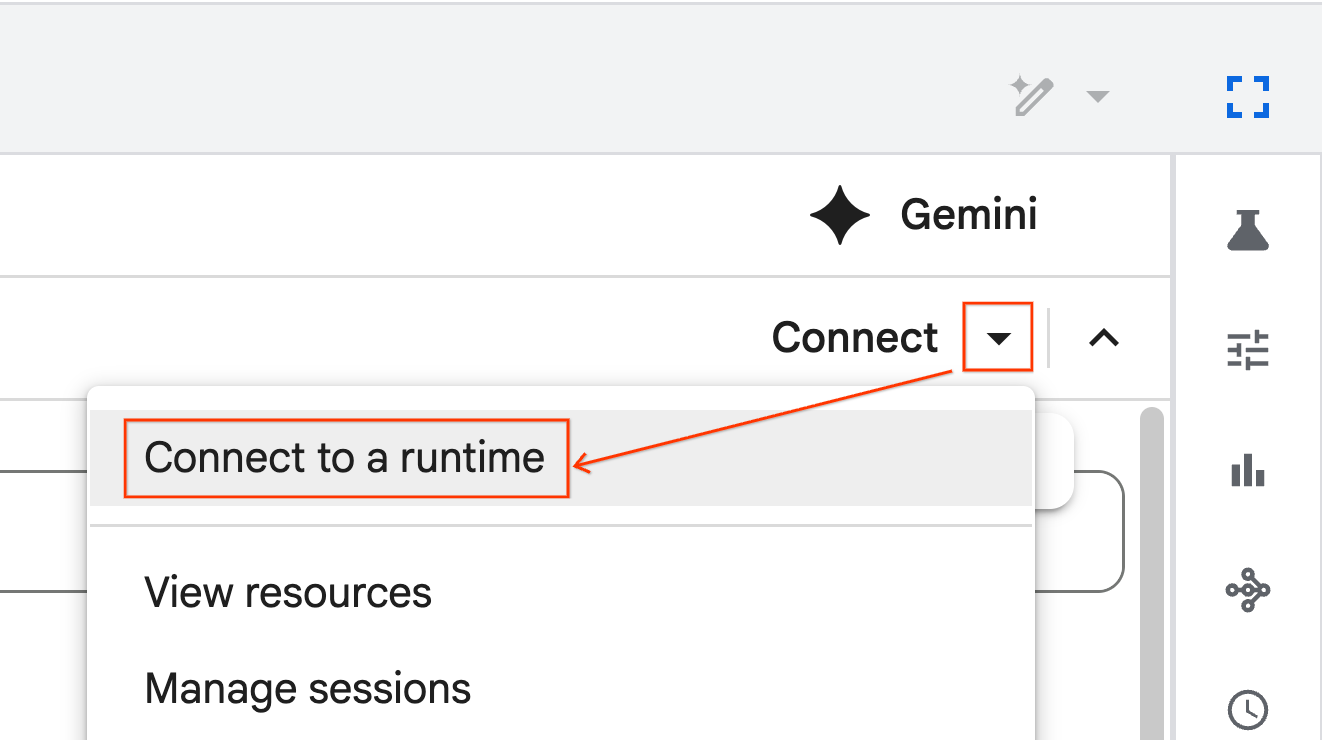
- استخدِم القائمة المنسدلة واختَر وقت التشغيل الذي أنشأته سابقًا.
- انقر على ربط.
تم ربط ورقة الملاحظات الآن ببيئة تشغيل متوافقة مع وحدة معالجة الرسومات.
المهام التابعة المُضمَّنة
إحدى مزايا استخدام Colab Enterprise هي أنّها تأتي مثبَّتة مسبقًا مع المكتبات التي تحتاج إليها. لا تحتاج إلى تثبيت التبعيات أو إدارتها يدويًا، مثل cuDF أو cuML أو XGBoost، في هذا المختبر.
8. إعداد مجموعة بيانات سيارات الأجرة في نيويورك
يستخدم هذا الدرس التطبيقي حول الترميز بيانات سجلّ الرحلات الصادر عن هيئة سيارات الأجرة والليموزين في نيويورك. تحتوي مجموعة البيانات على سجلّات الرحلات من سيارات الأجرة الصفراء في مدينة نيويورك، بما في ذلك:
- تواريخ وأوقات ومواقع الاستلام والتسليم
- مسافات الرحلات
- مبالغ الأجرة المفصّلة
- عدد الركاب
- مبالغ البقشيش (هذا ما سنتوقّعه!)
ضبط وحدة معالجة الرسومات وتأكيد التوفّر
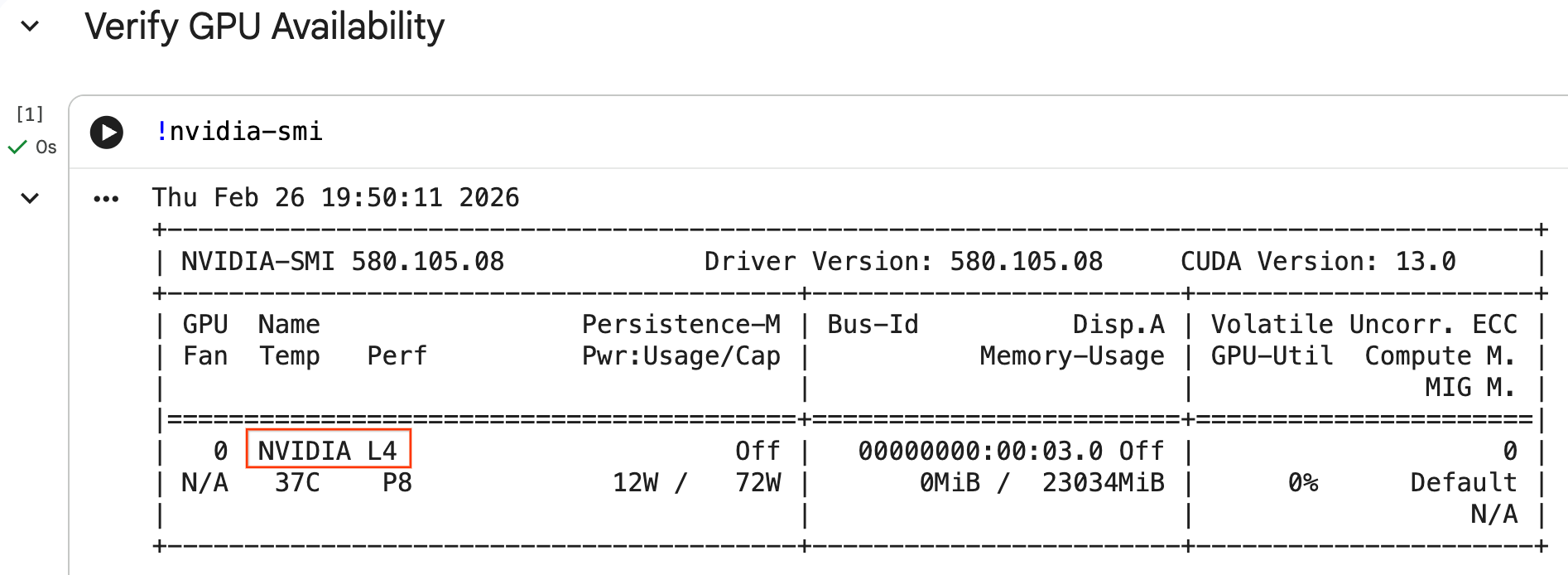
يمكنك التأكّد من التعرّف على وحدة معالجة الرسومات من خلال تنفيذ الأمر nvidia-smi. تعرض هذه الأداة إصدار برنامج التشغيل وتفاصيل وحدة معالجة الرسومات (مثل NVIDIA L4).
nvidia-smi
يجب أن تعرض الخلية وحدة معالجة الرسومات المرفقة ببيئة التشغيل، على النحو التالي:
تنزيل البيانات
نزِّل بيانات الرحلات لعام 2024.
from tqdm import tqdm
import requests
import time
import os
YEAR = 2024
DATA_DIR = "nyc_taxi_data"
os.makedirs(DATA_DIR, exist_ok=True)
print(f"Checking/Downloading files for {YEAR}...")
for month in tqdm(range(1, 13), unit="file"):
file_name = f"yellow_tripdata_{YEAR}-{month:02d}.parquet"
local_path = os.path.join(DATA_DIR, file_name)
url = f"https://d37ci6vzurychx.cloudfront.net/trip-data/{file_name}"
if not os.path.exists(local_path):
try:
with requests.get(url, stream=True) as response:
response.raise_for_status()
with open(local_path, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
time.sleep(1)
except requests.exceptions.HTTPError as e:
print(f"\nSkipping {file_name}: {e}")
if os.path.exists(local_path):
os.remove(local_path)
print("\nDownload complete.")
تسريع pandas باستخدام cuDF من NVIDIA
تعمل مكتبة pandas على وحدة المعالجة المركزية (CPU) وقد تكون بطيئة مع مجموعات البيانات الكبيرة. يعدّل الأمر السحري %load_ext cudf.pandas من NVIDIA مكتبة pandas ديناميكيًا لاستخدام تسريع وحدة معالجة الرسومات، مع إمكانية الرجوع إلى وحدة المعالجة المركزية عند الحاجة.
نستخدم هذا الأمر السحري بدلاً من عملية الاستيراد العادية لأنّه يوفّر تسريعًا "بدون تغيير في الرمز". ولست بحاجة إلى إعادة كتابة أي من الرموز الحالية. يؤدي الأمر المشابه %load_ext cuml.accel الوظيفة نفسها تمامًا للنطاق scikit-learn models. يمكنك استخدام هذه الميزة في أي بيئة Jupyter تتضمّن وحدة معالجة رسومات NVIDIA متوافقة، وليس فقط في Colab Enterprise.
%load_ext cudf.pandas
للتأكّد من أنّه نشط، استورِد pandas وتحقّق من نوعه:
import pandas as pd
pd
سيؤكّد لك الناتج أنّك تستخدم الآن الوحدة cudf.pandas.
تحميل البيانات وتنظيفها
مع تفعيل cudf.pandas، حمِّل ملفات Parquet ونفِّذ عملية تنظيف البيانات. يتم تشغيل هذه العملية تلقائيًا على وحدة معالجة الرسومات.
import glob
# Load data into memory
df = pd.concat(
[pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")],
ignore_index=True
)
# Filter for valid trips. We filter for payment_type=1 (credit card)
# because tip amounts are only reliably recorded for credit card transactions.
df = df[
(df['fare_amount'] > 0) & (df['fare_amount'] < 500) &
(df['trip_distance'] > 0) & (df['trip_distance'] < 100) &
(df['tip_amount'] >= 0) & (df['tip_amount'] < 100) &
(df['payment_type'] == 1)
].copy()
# Downcast numeric columns to save memory
float_cols = df.select_dtypes(include=['float64']).columns
df[float_cols] = df[float_cols].astype('float32')
int_cols = df.select_dtypes(include=['int64']).columns
df[int_cols] = df[int_cols].astype('int32')
هندسة الميزات
إنشاء ميزات مشتقة من تاريخ ووقت الاستلام يحتوي دفتر الملاحظات على ميزات أخرى مستخدَمة في الخطوات اللاحقة.
import numpy as np
# Time Features
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['dow'] = df['tpep_pickup_datetime'].dt.dayofweek
df['is_weekend'] = (df['dow'] >= 5).astype(int)
df['is_rush_hour'] = (
((df['hour'] >= 7) & (df['hour'] <= 9)) |
((df['hour'] >= 17) & (df['hour'] <= 19))
).astype(int)
...
# Other features
...
9- تدريب النماذج الفردية باستخدام التصديق المتقاطع
لتوضيح كيف يمكن لوحدة معالجة الرسومات تسريع عملية تعلُّم الآلة، ستدرّب ثلاثة أنواع مختلفة من نماذج الانحدار لتوقُّع tip_amount لرحلة بسيارة أجرة.
تسريع scikit-learn باستخدام cuML من NVIDIA
تشغيل خوارزميات scikit-learn على وحدة معالجة الرسومات باستخدام cuML من NVIDIA بدون تغيير طلبات البيانات من واجهة برمجة التطبيقات أولاً، حمِّل إضافة cuml.accel.
%load_ext cuml.accel
ميزات الإعداد والاستهداف
حدِّد الميزات التي تريد أن يتعلّم منها النموذج وقسِّم عمود الاستهداف (tip_amount).
feature_cols = [
'trip_distance', 'fare_amount', 'passenger_count',
'hour', 'dow', 'is_weekend', 'is_rush_hour',
'fare_log', 'fare_decimal', 'is_round_fare',
'route_frequency', 'pu_tip_mean', 'pu_tip_std',
'PULocationID', 'DOLocationID'
]
X = df[feature_cols].fillna(df[feature_cols].median())
y = df['tip_amount'].copy()
إعداد تقسيمات التحقّق المتبادل لتقييم أداء النموذج بشكلٍ فعّال
from sklearn.model_selection import KFold
import numpy as np
import time
from sklearn.metrics import mean_squared_error
from tqdm.notebook import tqdm
n_splits = 3
kf = KFold(n_splits=n_splits, shuffle=True, random_state=42)
1. XGBoost
XGBoost هي خوارزمية مسرَّعة بواسطة وحدة معالجة الرسومات. مرِّر tree_method='hist' وdevice='cuda' لاستخدام وحدة معالجة الرسومات أثناء التدريب.
import xgboost as xgb
start_time = time.perf_counter()
def train_xgb_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# XGBoost handles GPU natively when tree_method='hist' and device='cuda'
model = xgb.XGBRegressor(
objective='reg:squarederror',
max_depth=5,
learning_rate=0.1,
n_estimators=100,
tree_method='hist',
device='cuda',
random_state=42
)
model.fit(X_train, y_train)
preds = model.predict(X_val)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
xgb_rmse, xgb_preds = train_xgb_cv(X, y)
print(f"\n{'XGBoost RMSE:':<20} ${xgb_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
2. الانحدار الخطي
تدريب نموذج انحدار خطي عندما يكون %load_ext cuml.accel نشطًا، يتم تلقائيًا ربط LinearRegression بما يعادله من وحدات معالجة الرسومات.
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
start_time = time.perf_counter()
def train_linreg_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# Scale features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_val_scaled = scaler.transform(X_val)
# Automatically accelerated by cuML
model = LinearRegression()
model.fit(X_train_scaled, y_train)
preds = model.predict(X_val_scaled)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
linreg_rmse, linreg_preds = train_linreg_cv(X, y)
print(f"\n{'Linear Reg RMSE:':<20} ${linreg_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
3- الغابة العشوائية
درِّب نموذجًا مجمّعًا باستخدام RandomForestRegressor. غالبًا ما يستغرق تدريب النماذج المستندة إلى الشجرة وقتًا طويلاً على وحدة المعالجة المركزية، ولكن يمكن لوحدة معالجة الرسومات تسريع معالجة ملايين الصفوف.
from sklearn.ensemble import RandomForestRegressor
start_time = time.perf_counter()
def train_rf_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# Automatically accelerated by cuML
model = RandomForestRegressor(
n_estimators=100,
max_depth=10,
n_jobs=-1,
max_features='sqrt',
random_state=42
)
model.fit(X_train, y_train)
preds = model.predict(X_val)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
rf_rmse, rf_preds = train_rf_cv(X, y)
print(f"\n{'Random Forest RMSE:':<20} ${rf_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
10. تقييم مسار التعلّم الكامل
اجمع التوقعات من النماذج الثلاثة باستخدام مجموعة موحدة خطية بسيطة. يؤدي ذلك عادةً إلى تحسُّن طفيف في الدقة مقارنةً بالنماذج الفردية.
تطبيق انحدار خطّي على التوقّعات للعثور على الأوزان المثالية:
ensemble_weights = LinearRegression(positive=True, fit_intercept=False).fit(
np.c_[xgb_preds, rf_preds, linreg_preds], y
).coef_
# Normalize weights
ensemble_weights = ensemble_weights / ensemble_weights.sum()
ensemble_preds = np.c_[xgb_preds, rf_preds, linreg_preds] @ ensemble_weights
ensemble_rmse = np.sqrt(mean_squared_error(y, ensemble_preds))
قارِن النتائج للاطّلاع على التحسُّن في أداء المجموعة:
print(f"\n{'Model':<20} {'RMSE':>10}")
print("-" * 32)
print(f"{'Linear Regression':<20} ${linreg_rmse:>9.4f}")
print(f"{'Random Forest':<20} ${rf_rmse:>9.4f}")
print(f"{'XGBoost':<20} ${xgb_rmse:>9.4f}")
print("-" * 32)
print(f"{'Ensemble':<20} ${ensemble_rmse:>9.4f}")
print(f"\nEnsemble lift: ${xgb_rmse - ensemble_rmse:.4f}")
11. مقارنة أداء وحدة المعالجة المركزية (CPU) بوحدة معالجة الرسومات (GPU)
لإجراء مقارنة صحيحة بين الأداء، عليك إعادة تشغيل النواة لضمان حالة تنفيذ نظيفة، وتشغيل مسار معالجة علوم البيانات بالكامل على وحدة المعالجة المركزية، ثم إعادة تشغيله على وحدة معالجة الرسومات.
إعادة تشغيل النواة
نفِّذ الأمر IPython.Application.instance().kernel.do_shutdown(True) لإعادة تشغيل النواة وإخلاء الذاكرة.
import IPython
IPython.Application.instance().kernel.do_shutdown(True)
تحديد مسار علم البيانات
ضمِّن سير العمل الأساسي (تحميل البيانات وتنظيفها وهندسة الخصائص وتدريب النموذج) في دالة واحدة. تقبل هذه الدالة وحدة pandas pd_module ووسيطة use_gpu للتبديل بين البيئات.
def run_ml_pipeline(pd_module, use_gpu=False):
import time
import glob
import numpy as np
from sklearn.ensemble import RandomForestRegressor
import xgboost as xgb
timings = {}
# 1. Load Data
t0 = time.perf_counter()
df = pd_module.concat(
[pd_module.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")],
ignore_index=True
)
timings['Load Data'] = time.perf_counter() - t0
# 2. Clean Data
t0 = time.perf_counter()
# Filter for payment_type=1 (credit card) because tip amounts
# are only reliably recorded for credit card transactions.
df = df[
(df['fare_amount'] > 0) & (df['fare_amount'] < 500) &
(df['trip_distance'] > 0) & (df['trip_distance'] < 100) &
(df['tip_amount'] >= 0) & (df['tip_amount'] < 100) &
(df['payment_type'] == 1)
].copy()
# Downcast numeric columns to save memory
float_cols = df.select_dtypes(include=['float64']).columns
df[float_cols] = df[float_cols].astype('float32')
int_cols = df.select_dtypes(include=['int64']).columns
df[int_cols] = df[int_cols].astype('int32')
timings['Clean Data'] = time.perf_counter() - t0
# 3. Feature Engineering
t0 = time.perf_counter()
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['dow'] = df['tpep_pickup_datetime'].dt.dayofweek
df['is_weekend'] = (df['dow'] >= 5).astype(int)
df['fare_log'] = np.log1p(df['fare_amount'])
timings['Feature Engineering'] = time.perf_counter() - t0
# 4. Modeling Prep
feature_cols = ['trip_distance', 'fare_amount', 'passenger_count', 'hour', 'dow', 'is_weekend', 'fare_log']
X = df[feature_cols].fillna(df[feature_cols].median())
y = df['tip_amount'].copy()
# Free memory
del df
import gc
gc.collect()
# 5. Train Random Forest
t0 = time.perf_counter()
rf_model = RandomForestRegressor(
n_estimators=100,
max_depth=10,
n_jobs=-1,
max_features='sqrt',
random_state=42
).fit(X, y)
timings['Train Random Forest'] = time.perf_counter() - t0
# 6. Train XGBoost
t0 = time.perf_counter()
params = {
'objective': 'reg:squarederror',
'max_depth': 5,
'n_estimators': 100,
'random_state': 42
}
if use_gpu:
params['device'] = 'cuda'
params['tree_method'] = 'hist'
xgb_model = xgb.XGBRegressor(**params).fit(X, y)
timings['Train XGBoost'] = time.perf_counter() - t0
del X
del y
gc.collect()
return timings
التشغيل على وحدة المعالجة المركزية
استدعاء مسار العرض باستخدام وحدة معالجة مركزية عادية pandas
import pandas as pd
print("Running pipeline on CPU...")
cpu_times = run_ml_pipeline(pd, use_gpu=False)
print("CPU Execution Finished.")
التشغيل على وحدة معالجة الرسومات
حمِّل إضافات مكتبة NVIDIA، ومرِّر الوحدة cudf.pandas المسرَّعة إلى مسار التعلّم، واضبط جهاز XGBoost على cuda داخليًا.
import IPython.core.magic
if not hasattr(IPython.core.magic, 'output_can_be_silenced'):
IPython.core.magic.output_can_be_silenced = lambda x: x
%load_ext cudf.pandas
%load_ext cuml.accel
import pandas as pd
print("Running pipeline on GPU...")
gpu_times = run_ml_pipeline(pd, use_gpu=True)
print("GPU Execution Finished.")
تصوُّر تحسُّن الأداء
يمكنك عرض التوقيتات بشكل مرئي باستخدام matplotlib. تعرض النتائج الوقت الذي تم توفيره أثناء معالجة البيانات وتدريب النموذج عند استخدام وحدات معالجة الرسومات.
import matplotlib.pyplot as plt
import numpy as np
labels = list(cpu_times.keys())
cpu_values = list(cpu_times.values())
gpu_values = list(gpu_times.values())
x = np.arange(len(labels))
width = 0.35
fig, ax = plt.subplots(figsize=(10, 6))
rects1 = ax.bar(x - width/2, cpu_values, width, label='CPU', color='#4285F4')
rects2 = ax.bar(x + width/2, gpu_values, width, label='GPU', color='#76B900')
ax.set_ylabel('Execution Time (seconds)')
ax.set_title('NYC Taxi ML Pipeline: CPU vs. GPU Performance')
ax.set_xticks(x)
ax.set_xticklabels(labels, rotation=45, ha="right")
ax.legend()
# Add data labels
def autolabel(rects):
for rect in rects:
height = rect.get_height()
ax.annotate(f'{height:.2f}s',
xy=(rect.get_x() + rect.get_width() / 2, height),
xytext=(0, 3), # 3 points vertical offset
textcoords="offset points",
ha='center', va='bottom', fontsize=9)
autolabel(rects1)
autolabel(rects2)
plt.tight_layout()
plt.show()
# Calculate overall speedup
total_cpu_time = sum(cpu_values)
total_gpu_time = sum(gpu_values)
overall_speedup = total_cpu_time / total_gpu_time
print(f"\nOverall Pipeline Speedup: {overall_speedup:.2f}x faster on GPU!")
من المفترض أن يظهر لك محتوى مثل:
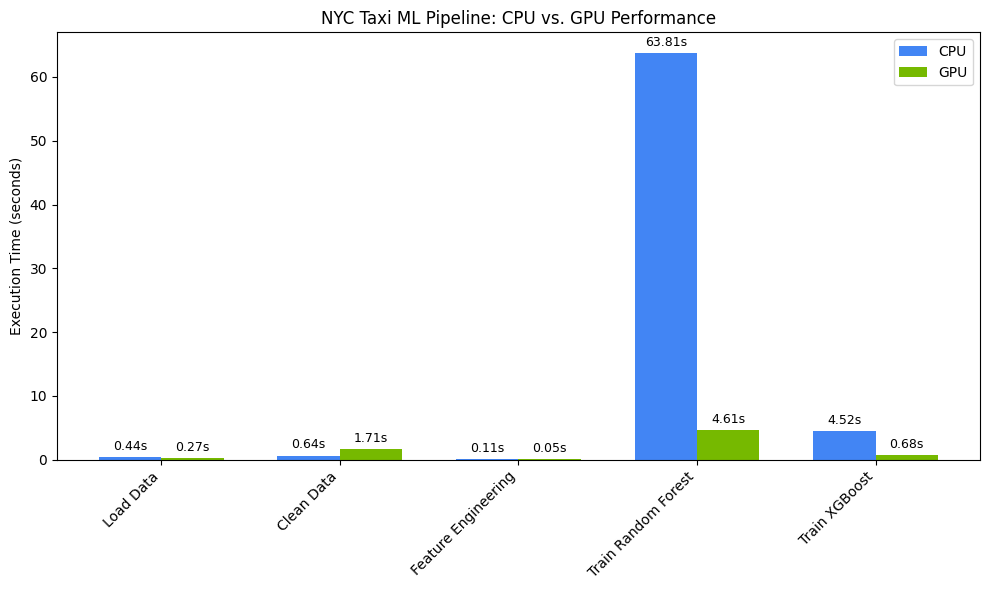
يوضّح هذا الرسم البياني الميزة الكبيرة التي توفّرها وحدة معالجة الرسومات (GPU) في الأداء على مستوى سير عمل علم البيانات بالكامل. من المتوقّع أن تلاحظ أكبر توفير في الوقت خلال مراحل تدريب النماذج التي تتطلّب قدرًا كبيرًا من الحوسبة للخوارزميات، مثل Random Forest وXGBoost.
12. تحديد المشاكل في الرمز البرمجي للعثور على قيود الأداء
عند استخدام cudf.pandas، يتم تشغيل معظم الدوال على وحدة معالجة الرسومات. إذا كانت عملية معيّنة غير متاحة بعد في cuDF، سيتم تنفيذها مؤقتًا باستخدام وحدة المعالجة المركزية. توفّر NVIDIA أمرَين سحريَين مضمّنَين في Jupyter لتحديد عمليات الرجوع الاحتياطي هذه.
التحليل عالي المستوى باستخدام %%cudf.pandas.profile
يقدّم الأمر السحري %%cudf.pandas.profile ملخّصًا للوظائف التي تم تنفيذها على وحدة معالجة الرسومات أو وحدة المعالجة المركزية.
%%cudf.pandas.profile
import glob
import pandas as pd
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")], ignore_index=True)
summary = (
df
.groupby(['PULocationID', 'payment_type'])
[['passenger_count', 'fare_amount', 'tip_amount']]
.agg(['min', 'mean', 'max'])
)
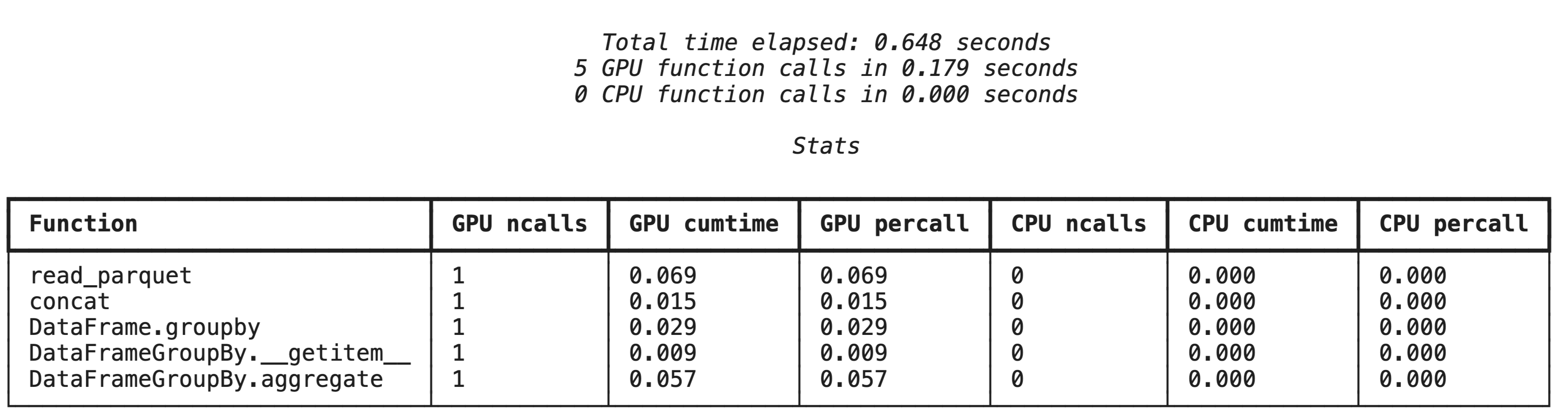
إنشاء ملفات تعريف الأداء سطرًا بسطر باستخدام %%cudf.pandas.line_profile
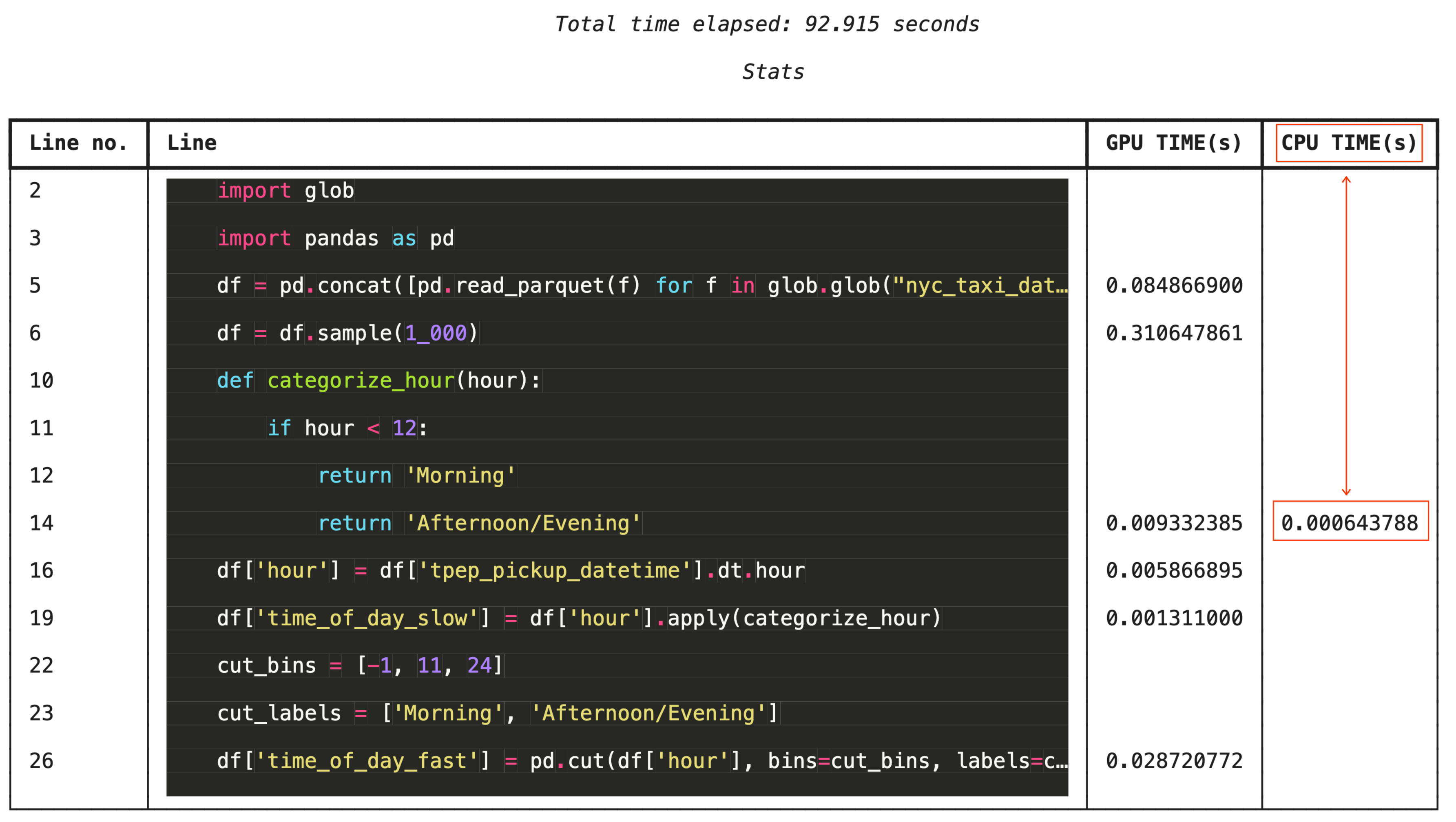
لتحديد المشاكل بدقة، يضيف %%cudf.pandas.line_profile تعليقًا توضيحيًا إلى كل سطر من الرمز البرمجي يتضمّن عدد المرات التي تم فيها تنفيذه على وحدة معالجة الرسومات مقارنةً بوحدة المعالجة المركزية.
%%cudf.pandas.line_profile
import glob
import pandas as pd
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")], ignore_index=True)
df = df.sample(1_000)
# Iterating row-by-row or using custom python apply functions often falls back to the CPU
def categorize_hour(hour):
if hour < 12:
return 'Morning'
else:
return 'Afternoon/Evening'
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['time_of_day_slow'] = df['hour'].apply(categorize_hour)
# Using vectorized pandas operations (like pd.cut) stays entirely on the GPU
cut_bins = [-1, 11, 24]
cut_labels = ['Morning', 'Afternoon/Evening']
df['time_of_day_fast'] = pd.cut(df['hour'], bins=cut_bins, labels=cut_labels)
13. تنظيف
لتجنُّب تكبّد رسوم غير متوقّعة في حسابك على Google Cloud، عليك تنظيف الموارد التي أنشأتها أثناء استخدام هذا الدرس التعليمي البرمجي.
حذف المراجع
احذف مجموعة البيانات المحلية في بيئة التشغيل باستخدام الأمر !rm -rf في خلية ورقة ملاحظات.
print("Deleting local 'nyc_taxi_data' directory...")
!rm -rf nyc_taxi_data
print("Local files deleted.")
إيقاف بيئة تشغيل Colab
- في Google Cloud Console، انتقِل إلى صفحة أوقات التشغيل في Colab Enterprise.
- في قائمة المنطقة، اختَر المنطقة التي تحتوي على وقت التشغيل.
- اختَر وقت التشغيل الذي تريد حذفه.
- انقر على حذف.
- انقر على تأكيد.
حذف دفتر الملاحظات
- في Google Cloud Console، انتقِل إلى صفحة دفاتري في Colab Enterprise.
- في قائمة المنطقة، اختَر المنطقة التي يتضمّنها دفتر الملاحظات.
- اختَر دفتر الملاحظات الذي تريد حذفه.
- انقر على حذف.
- انقر على تأكيد.
14. تهانينا
تهانينا! لقد تمكّنت من تسريع سير عمل pandas وscikit-learn لتعلُّم الآلة باستخدام مكتبتَي NVIDIA cuDF وcuML على Colab Enterprise. من خلال إضافة بعض الأوامر السحرية (%load_ext cudf.pandas و%load_ext cuml.accel) ببساطة، يتم تشغيل الرمز العادي على وحدة معالجة الرسومات، ومعالجة السجلات، وتطابق النماذج المعقدة محليًا في جزء من الوقت.
لمزيد من المعلومات عن تسريع تحليل البيانات باستخدام وحدات معالجة الرسومات، اطّلِع على الدرس التطبيقي تسريع تحليل البيانات باستخدام وحدات معالجة الرسومات.
المواضيع التي تناولناها
- التعرّف على Colab Enterprise على Google Cloud
- تخصيص بيئة وقت تشغيل Colab باستخدام إعدادات محدّدة لوحدة معالجة الرسومات والذاكرة
- تطبيق تسريع وحدة معالجة الرسومات لتوقّع مبالغ الإكراميات باستخدام ملايين السجلات من مجموعة بيانات سيارات الأجرة في مدينة نيويورك
- تسريع
pandasبدون إجراء أي تغييرات على الرمز باستخدام مكتبةcuDFمن NVIDIA - تسريع
scikit-learnبدون إجراء أي تغييرات على الرمز باستخدام مكتبةcuMLووحدات معالجة الرسومات من NVIDIA - تحديد خصائص الرمز البرمجي لتحديد قيود الأداء وتحسينها