
১. ভূমিকা
এই কোডল্যাবে, আপনি শিখবেন কীভাবে গুগল ক্লাউডে এনভিডিয়া জিপিইউ এবং ওপেন-সোর্স লাইব্রেরি ব্যবহার করে বড় ডেটাসেটের উপর আপনার ডেটা সায়েন্স এবং মেশিন লার্নিং ওয়ার্কফ্লোকে ত্বরান্বিত করা যায়। আপনি প্রথমে আপনার পরিকাঠামো সেট আপ করার মাধ্যমে শুরু করবেন, তারপর জিপিইউ অ্যাক্সিলারেশন কীভাবে প্রয়োগ করতে হয় তা জানবেন।
আপনি ডেটা সায়েন্স লাইফসাইকেলের উপর মনোযোগ দেবেন, যার মধ্যে রয়েছে pandas দিয়ে ডেটা প্রস্তুতি থেকে শুরু করে scikit-learn এবং XGBoost দিয়ে মডেল প্রশিক্ষণ পর্যন্ত। আপনি শিখবেন কীভাবে এনভিডিয়ার (NVIDIA) cuDF এবং cuML লাইব্রেরি ব্যবহার করে এই কাজগুলোকে ত্বরান্বিত করা যায়। সবচেয়ে ভালো দিকটি হলো, আপনি আপনার বিদ্যমান pandas বা scikit-learn কোড পরিবর্তন না করেই এই জিপিইউ (GPU) অ্যাক্সিলারেশন পেতে পারেন।
আপনি যা শিখবেন
- গুগল ক্লাউডে কোলাব এন্টারপ্রাইজ সম্পর্কে জানুন।
- নির্দিষ্ট জিপিইউ এবং মেমরি কনফিগারেশন দিয়ে কোলাব রানটাইম এনভায়রনমেন্ট কাস্টমাইজ করুন।
- NYC ট্যাক্সি ডেটাসেটের লক্ষ লক্ষ রেকর্ড ব্যবহার করে টিপের পরিমাণ অনুমান করতে GPU অ্যাক্সিলারেশন প্রয়োগ করুন।
- এনভিডিয়ার
cuDFলাইব্রেরি ব্যবহার করে কোডে কোনো পরিবর্তন ছাড়াইpandasগতি বাড়ান। - এনভিডিয়ার
cuMLলাইব্রেরি এবং জিপিইউ ব্যবহার করে কোডে কোনো পরিবর্তন ছাড়াইscikit-learnগতি বাড়ান। - পারফরম্যান্সের সীমাবদ্ধতা শনাক্ত ও অপ্টিমাইজ করতে আপনার কোড প্রোফাইল করুন।
পরবর্তী পৃষ্ঠায় সেই ক্রেডিটগুলো রয়েছে যা আপনি ল্যাবটি সম্পন্ন করতে ব্যবহার করতে পারেন।
২. মেশিন লার্নিংকে ত্বরান্বিত করা কেন প্রয়োজন?
এমএল-এ দ্রুততর পুনরাবৃত্তির প্রয়োজনীয়তা
ডেটা প্রস্তুতি একটি সময়সাপেক্ষ কাজ, এবং ডেটাসেট বড় হওয়ার সাথে সাথে মডেলের প্রশিক্ষণ বা মূল্যায়নে আরও বেশি সময় লাগতে পারে। একটি সিপিইউ ব্যবহার করে লক্ষ লক্ষ সারির উপর র্যান্ডম ফরেস্ট বা এক্সজিবিউস্টের মতো মডেল প্রশিক্ষণ দিতে কয়েক ঘন্টা বা দিন লেগে যেতে পারে।
cuML এবং GPU-accelerated XGBoost মতো লাইব্রেরি ব্যবহার করে GPU-এর মাধ্যমে এই প্রশিক্ষণ প্রক্রিয়া দ্রুততর করা যায়। এই ত্বরণের ফলে আপনি যা করতে পারবেন:
- দ্রুততর পুনরাবৃত্তি করুন: নতুন বৈশিষ্ট্য এবং হাইপারপ্যারামিটারগুলি দ্রুত পরীক্ষা করুন।
- সম্পূর্ণ ডেটাসেটে প্রশিক্ষণ দিন: আরও ভালো নির্ভুলতার জন্য ডাউনস্যাম্পলিং না করে আপনার সম্পূর্ণ ডেটা ব্যবহার করুন।
- খরচ কমান: কম সময়ে ভারী কাজ সম্পন্ন করে কম্পিউটিং খরচ হ্রাস করুন।
৩. সেটআপ এবং প্রয়োজনীয়তা
সম্ভাব্য খরচ
এই কোডল্যাবটিতে গুগল ক্লাউড রিসোর্স ব্যবহার করা হয়েছে, যার মধ্যে NVIDIA L4 GPU সহ Colab Enterprise রানটাইম অন্তর্ভুক্ত। অনুগ্রহ করে সম্ভাব্য চার্জ সম্পর্কে সচেতন থাকুন এবং রিসোর্স বন্ধ করতে ও চলমান বিলিং এড়াতে কোডল্যাবের শেষে থাকা ক্লিন আপ (Clean Up) বিভাগটি অনুসরণ করুন। বিস্তারিত মূল্য সংক্রান্ত তথ্যের জন্য, Colab Enterprise pricing এবং GPU pricing দেখুন।
শুরু করার আগে
পাইথন, pandas , scikit-learn এবং প্রচলিত মেশিন লার্নিং পদ্ধতি (যেমন ক্রস-ভ্যালিডেশন/এনসেম্বলিং) সম্পর্কে মধ্যম মানের জ্ঞান থাকা আবশ্যক।
- গুগল ক্লাউড কনসোলের প্রজেক্ট সিলেক্টর পেজে, একটি গুগল ক্লাউড প্রজেক্ট নির্বাচন করুন বা তৈরি করুন।
- আপনার গুগল ক্লাউড প্রোজেক্টের জন্য বিলিং চালু আছে কিনা, তা নিশ্চিত করুন।
এপিআইগুলি সক্রিয় করুন
Colab Enterprise ব্যবহার করার জন্য, আপনাকে প্রথমে প্রয়োজনীয় API-গুলো সক্রিয় করতে হবে।
- Google Cloud Console- এর উপরের ডানদিকে থাকা Cloud Shell আইকনে ক্লিক করে Google Cloud Shell খুলুন।

- ক্লাউড শেলে,
PROJECT_IDএর জায়গায় আপনার প্রজেক্ট আইডি বসিয়ে আপনার প্রজেক্ট আইডি সেট করুন:
gcloud config set project <PROJECT_ID>
- প্রয়োজনীয় API-গুলো সক্রিয় করতে নিম্নলিখিত কমান্ডটি চালান:
gcloud services enable \
compute.googleapis.com \
dataform.googleapis.com \
notebooks.googleapis.com \
aiplatform.googleapis.com
সফলভাবে কার্যকর হলে, আপনি নীচে দেখানো বার্তার মতো একটি বার্তা দেখতে পাবেন:
Operation "operations/..." finished successfully.
৪. নোটবুক পরিবেশ নির্বাচন করা
যদিও অনেক ডেটা সায়েন্টিস্ট ব্যক্তিগত প্রোজেক্টের জন্য কোলাবের সাথে পরিচিত, কোলাব এন্টারপ্রাইজ ব্যবসার জন্য ডিজাইন করা একটি নিরাপদ, সহযোগিতামূলক এবং সমন্বিত নোটবুক অভিজ্ঞতা প্রদান করে।
গুগল ক্লাউডে, পরিচালিত নোটবুক পরিবেশের জন্য আপনার কাছে দুটি প্রধান বিকল্প রয়েছে: কোলাব এন্টারপ্রাইজ এবং জেমিনি এন্টারপ্রাইজ এজেন্ট প্ল্যাটফর্ম ওয়ার্কবেঞ্চ । সঠিক বিকল্পটি আপনার প্রকল্পের অগ্রাধিকারের উপর নির্ভর করে।
এজেন্ট প্ল্যাটফর্ম ওয়ার্কবেঞ্চ কখন ব্যবহার করবেন
নিয়ন্ত্রণ এবং গভীর কাস্টমাইজেশন যখন আপনার অগ্রাধিকার, তখন এজেন্ট প্ল্যাটফর্ম ওয়ার্কবেঞ্চ বেছে নিন। আপনার যদি নিম্নলিখিত বিষয়গুলোর প্রয়োজন হয়, তবে এটিই আদর্শ পছন্দ:
- অন্তর্নিহিত অবকাঠামো এবং মেশিনের জীবনচক্র পরিচালনা করুন।
- কাস্টম কন্টেইনার এবং নেটওয়ার্ক কনফিগারেশন ব্যবহার করুন।
- MLOps পাইপলাইন এবং কাস্টম লাইফসাইকেল টুলিংয়ের সাথে একীভূত করুন।
কখন কোলাব এন্টারপ্রাইজ ব্যবহার করবেন
দ্রুত সেটআপ, ব্যবহারের সহজতা এবং নিরাপদ সহযোগিতা যখন আপনার অগ্রাধিকার, তখন কোলাব এন্টারপ্রাইজ বেছে নিন। এটি একটি সম্পূর্ণ পরিচালিত সমাধান যা আপনার দলকে পরিকাঠামোর পরিবর্তে বিশ্লেষণের উপর মনোযোগ দিতে সাহায্য করে।
কোলাব এন্টারপ্রাইজ আপনাকে সাহায্য করে:
- আপনার ডেটা ওয়্যারহাউসের সাথে ঘনিষ্ঠভাবে সংযুক্ত ডেটা সায়েন্স ওয়ার্কফ্লো তৈরি করুন। আপনি সরাসরি BigQuery Studio- তে আপনার নোটবুকগুলো খুলতে ও পরিচালনা করতে পারবেন।
- এজেন্ট প্ল্যাটফর্মে মেশিন লার্নিং মডেলগুলোকে প্রশিক্ষণ দিন এবং MLOps টুলগুলোর সাথে একীভূত করুন।
- একটি নমনীয় ও সমন্বিত অভিজ্ঞতা উপভোগ করুন। BigQuery-তে তৈরি করা একটি Colab Enterprise নোটবুক Agent Platform-এ খোলা ও চালানো যায় এবং এর বিপরীতটিও সম্ভব।
আজকের ল্যাব
এই কোডল্যাবটি দ্রুত মেশিন লার্নিংয়ের জন্য কোলাব এন্টারপ্রাইজ ব্যবহার করে।
পার্থক্যগুলো সম্পর্কে আরও জানতে, সঠিক নোটবুক সলিউশন বেছে নেওয়ার বিষয়ে অফিসিয়াল ডকুমেন্টেশন দেখুন।
৫. একটি রানটাইম টেমপ্লেট কনফিগার করুন
কোলাব এন্টারপ্রাইজে, আগে থেকে কনফিগার করা রানটাইম টেমপ্লেটের উপর ভিত্তি করে একটি রানটাইমের সাথে সংযোগ স্থাপন করুন।
একটি রানটাইম টেমপ্লেট হলো একটি পুনঃব্যবহারযোগ্য কনফিগারেশন যা আপনার নোটবুকের জন্য পরিবেশ নির্দিষ্ট করে, যার মধ্যে অন্তর্ভুক্ত রয়েছে:
- মেশিনের ধরণ (সিপিইউ, মেমরি)
- অ্যাক্সিলারেটর (GPU-এর ধরন এবং সংখ্যা)
- ডিস্কের আকার এবং প্রকার
- নেটওয়ার্ক সেটিংস এবং নিরাপত্তা নীতি
- স্বয়ংক্রিয় নিষ্ক্রিয় শাটডাউন নিয়ম
কেন রানটাইম টেমপ্লেটগুলি দরকারী
- সামঞ্জস্য: আপনি এবং আপনার দল একই পরিবেশ পান, যা কাজের পুনরাবৃত্তি নিশ্চিত করে।
- নিরাপত্তা: টেমপ্লেটগুলো প্রতিষ্ঠানের নিরাপত্তা নীতিমালা প্রয়োগ করে।
- ব্যয় ব্যবস্থাপনা: অনিচ্ছাকৃত খরচ এড়াতে টেমপ্লেটে রিসোর্সগুলোর আকার আগে থেকেই নির্ধারণ করা থাকে।
একটি রানটাইম টেমপ্লেট তৈরি করুন
ল্যাবের জন্য একটি পুনঃব্যবহারযোগ্য রানটাইম টেমপ্লেট তৈরি করুন।
- গুগল ক্লাউড কনসোলে, নেভিগেশন মেনু > এজেন্ট প্ল্যাটফর্ম > নোটবুকস- এ যান।
- Colab Enterprise থেকে, Runtime templates-এ ক্লিক করুন এবং তারপর New Template নির্বাচন করুন।
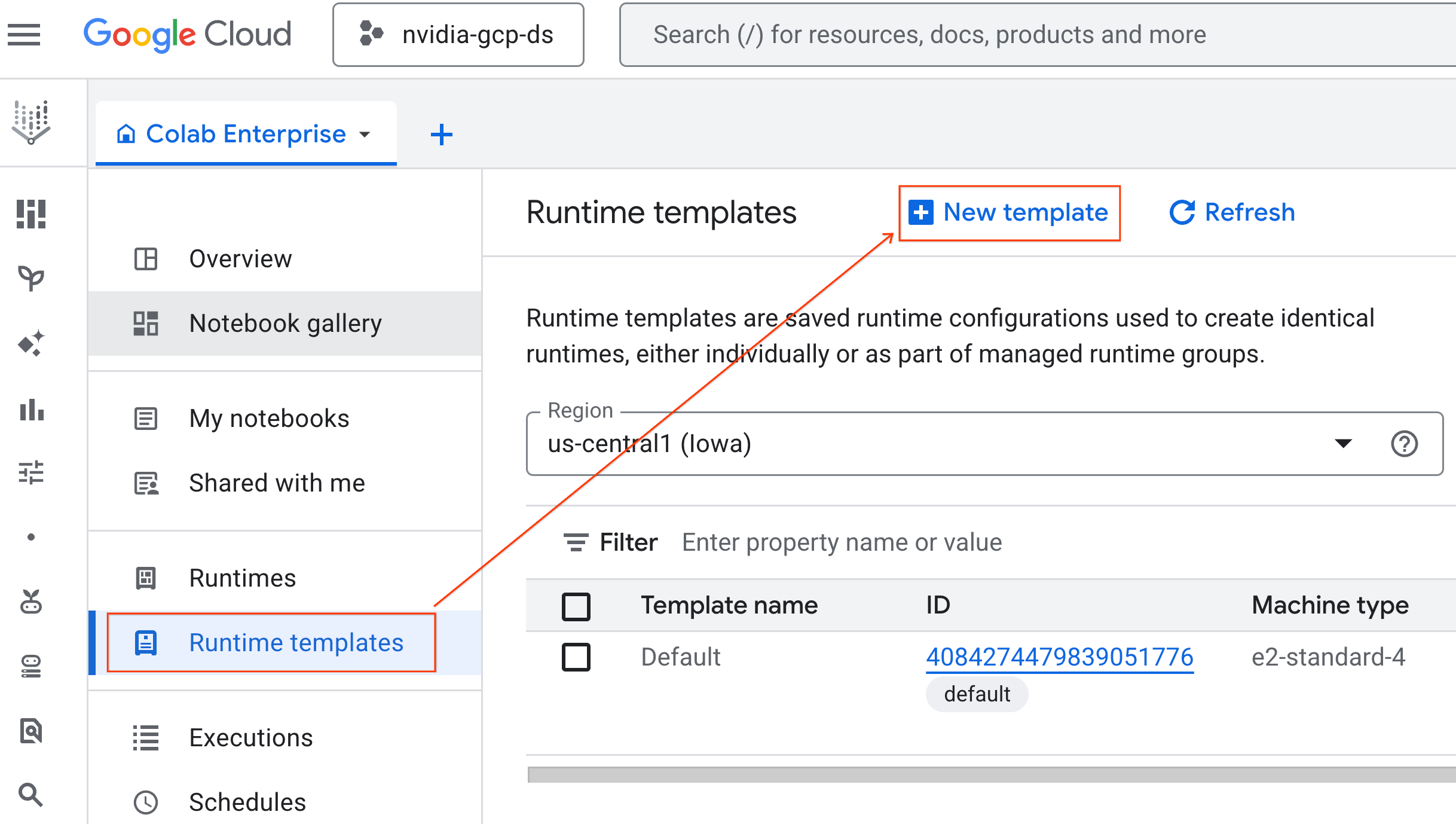
- রানটাইমের মৌলিক বিষয়াবলীর অধীনে :
- ডিসপ্লে নাম হিসেবে
gpu-templateসেট করুন। - আপনার পছন্দের অঞ্চল নির্ধারণ করুন।
- ডিসপ্লে নাম হিসেবে
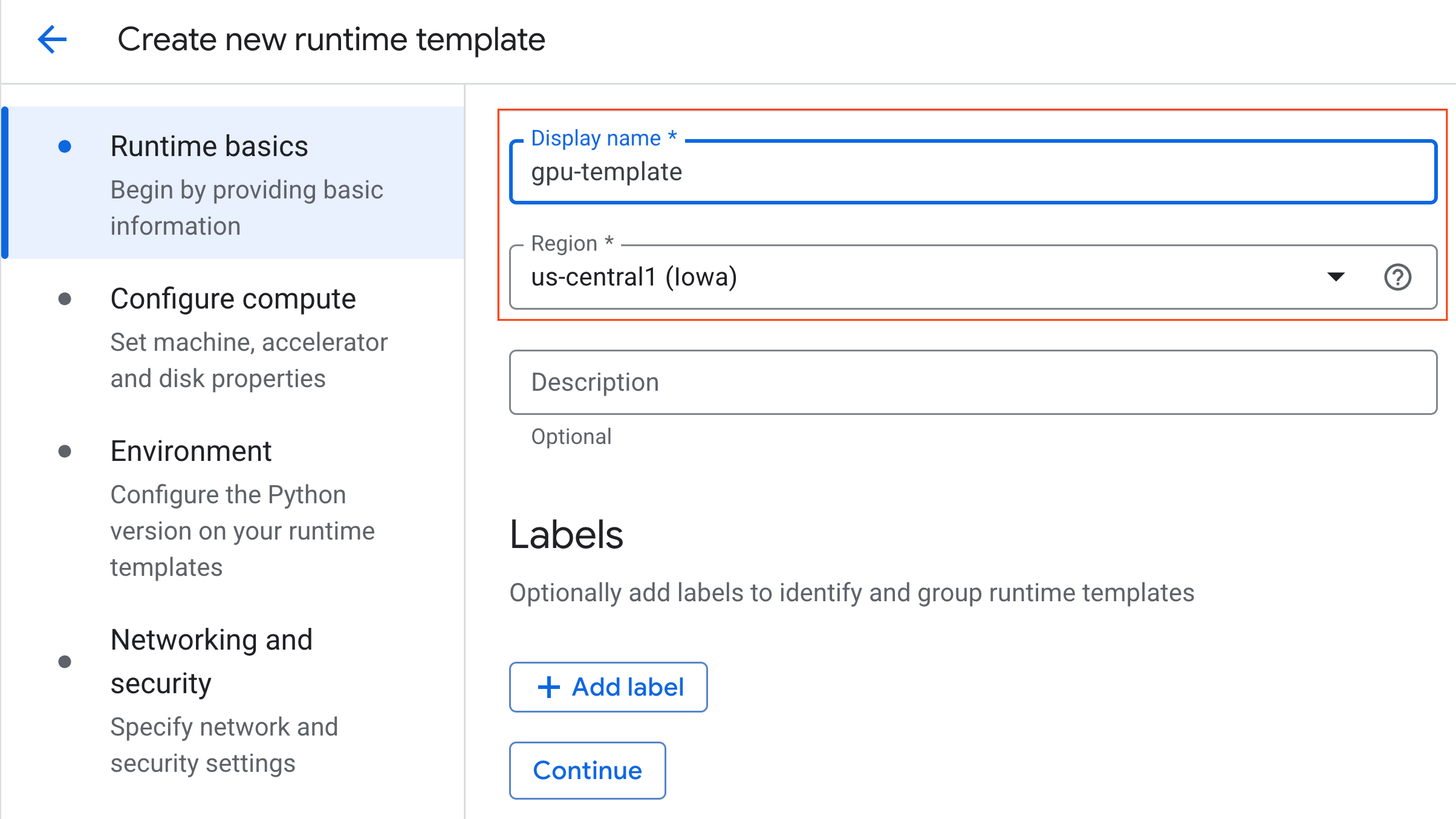
- কম্পিউট কনফিগার করার অধীনে :
- মেশিনের ধরণ
g2-standard-4এ সেট করুন। - ডিফল্ট অ্যাক্সিলারেটর টাইপ হিসেবে
NVIDIA L4এবং অ্যাক্সিলারেটর কাউন্ট ১ রাখুন। - নিষ্ক্রিয় শাটডাউন ৬০ মিনিটে পরিবর্তন করুন।
- চালিয়ে যান-এ ক্লিক করুন।
- মেশিনের ধরণ
- পরিবেশের অধীনে :
- পরিবেশটি
Python 3.11এ সেট করুন।
- পরিবেশটি
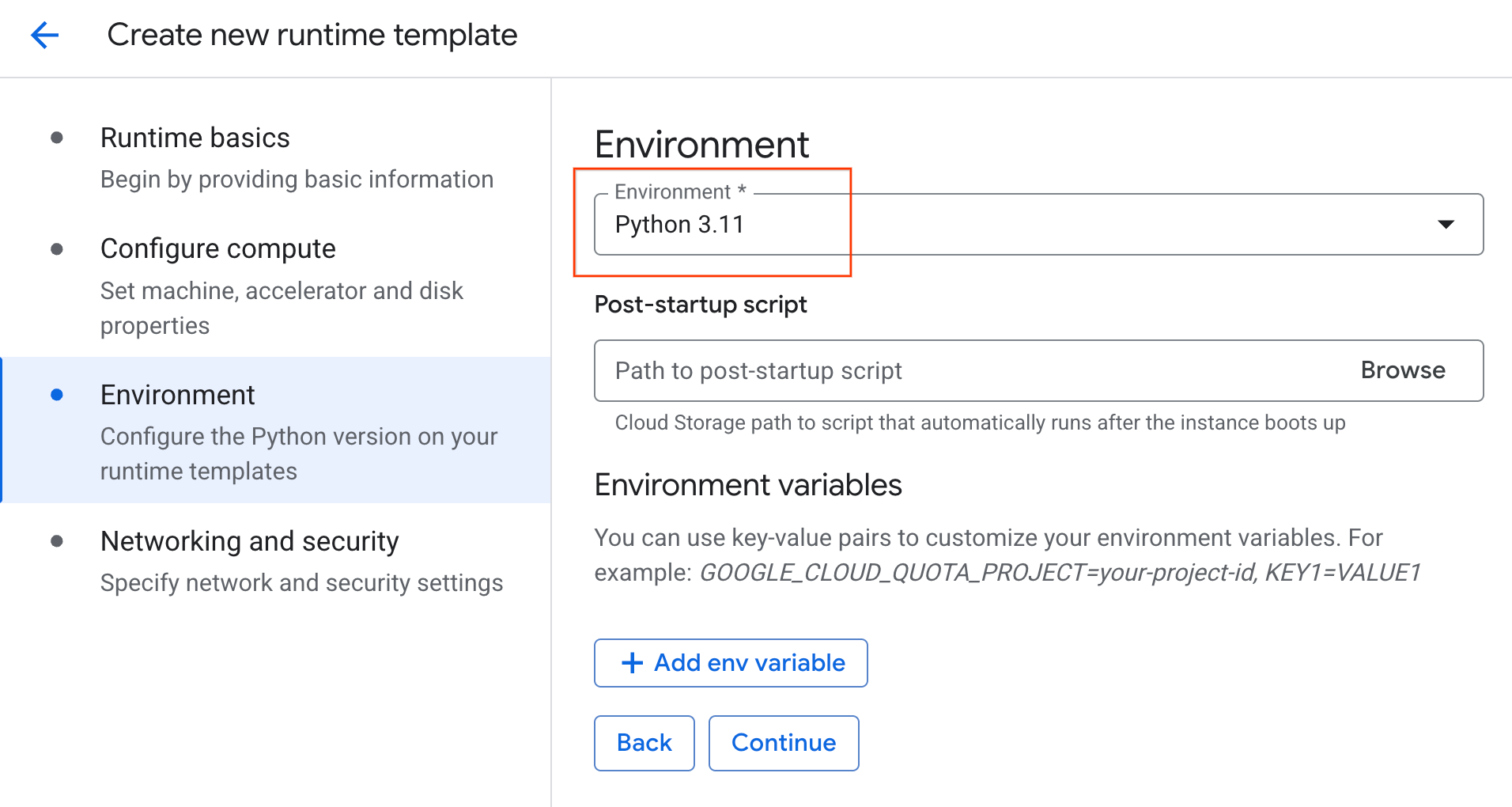
- রানটাইম টেমপ্লেটটি সংরক্ষণ করতে Create- এ ক্লিক করুন। এখন আপনার রানটাইম টেমপ্লেট পেজে নতুন টেমপ্লেটটি প্রদর্শিত হবে।
৬. একটি রানটাইম শুরু করুন
আপনার টেমপ্লেট প্রস্তুত হয়ে গেলে, আপনি একটি নতুন রানটাইম তৈরি করতে পারেন।
- Colab Enterprise থেকে, Runtimes-এ ক্লিক করুন এবং তারপর Create নির্বাচন করুন।
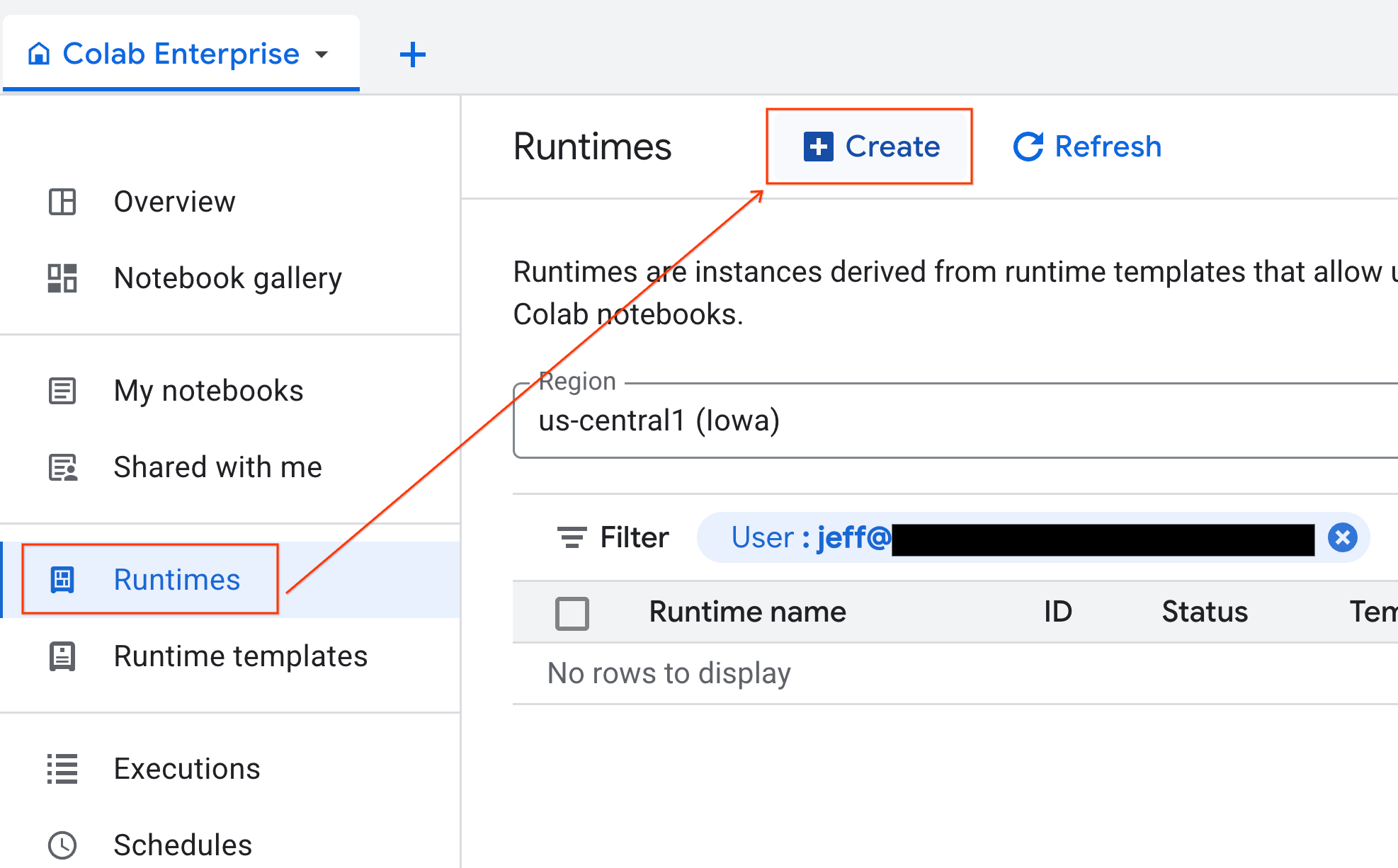
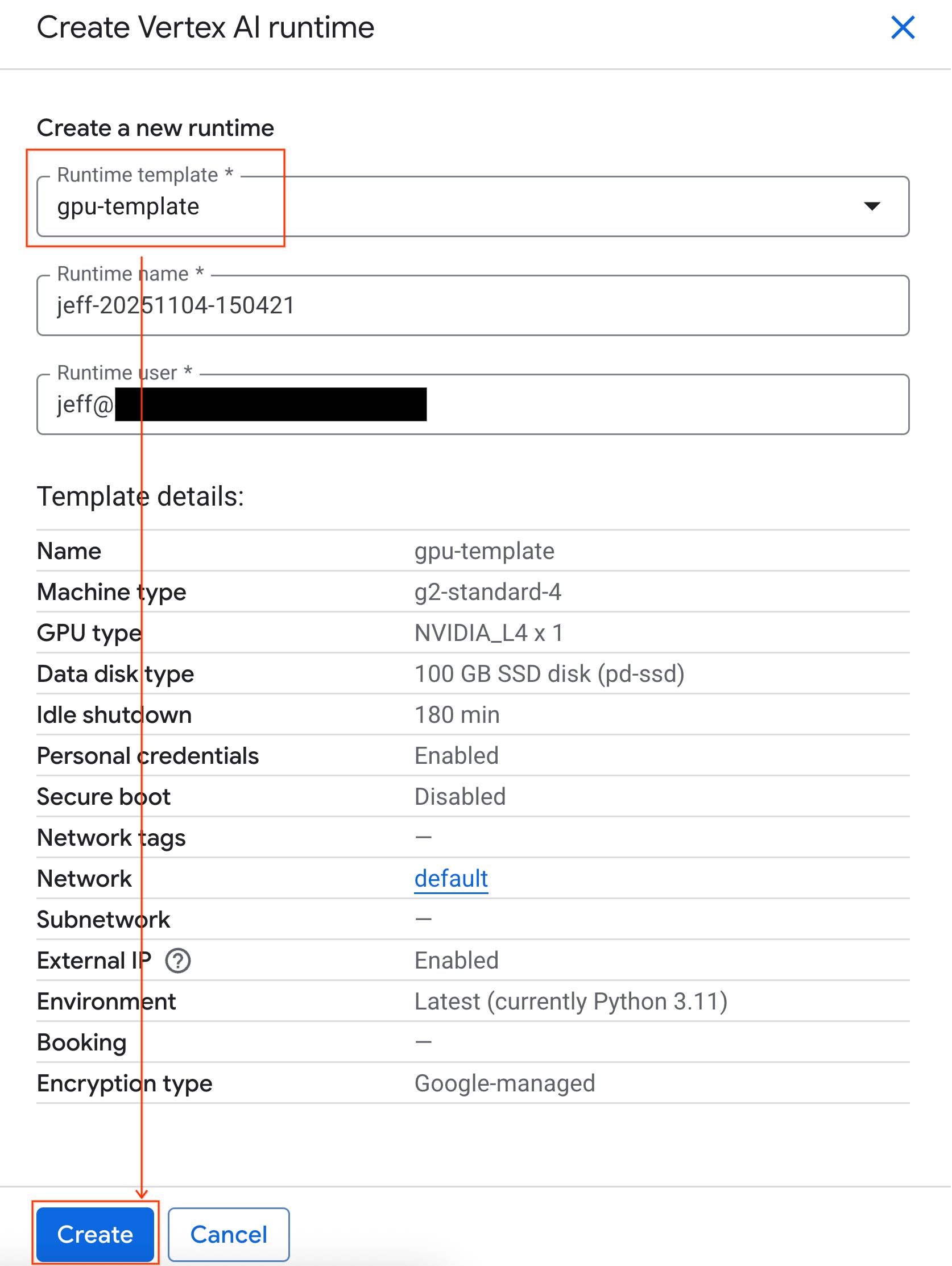
- রানটাইম টেমপ্লেটের অধীনে,
gpu-templateঅপশনটি নির্বাচন করুন। Create-এ ক্লিক করুন এবং রানটাইম বুট আপ হওয়া পর্যন্ত অপেক্ষা করুন।
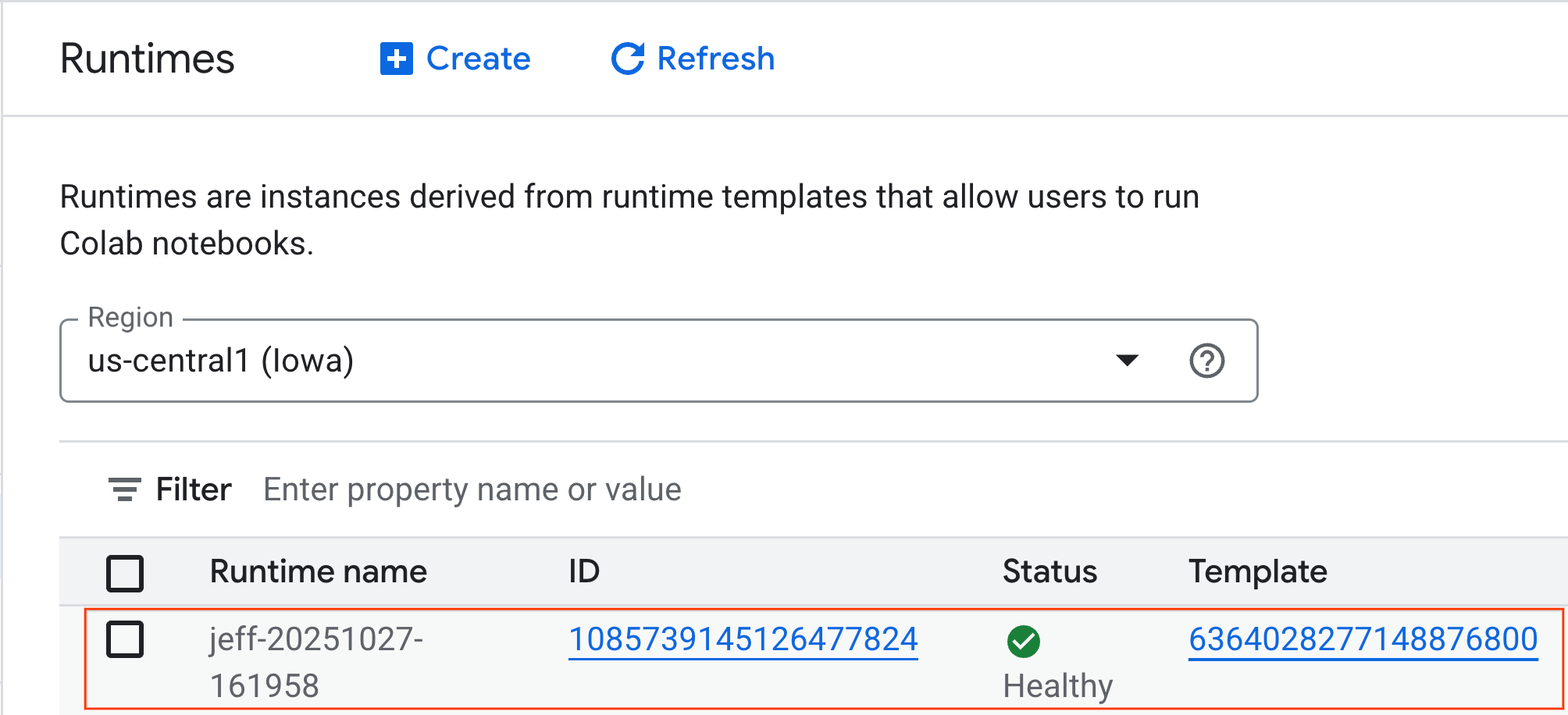
- কয়েক মিনিট পর আপনি রানটাইম দেখতে পাবেন।
৭. নোটবুকটি সেট আপ করুন।
এখন যেহেতু আপনার পরিকাঠামো চালু হয়ে গেছে, আপনাকে ল্যাব নোটবুকটি ইম্পোর্ট করে আপনার রানটাইমের সাথে সংযুক্ত করতে হবে।
নোটবুকটি আমদানি করুন
- Colab Enterprise থেকে, My notebooks-এ ক্লিক করুন এবং তারপর Import-এ ক্লিক করুন।
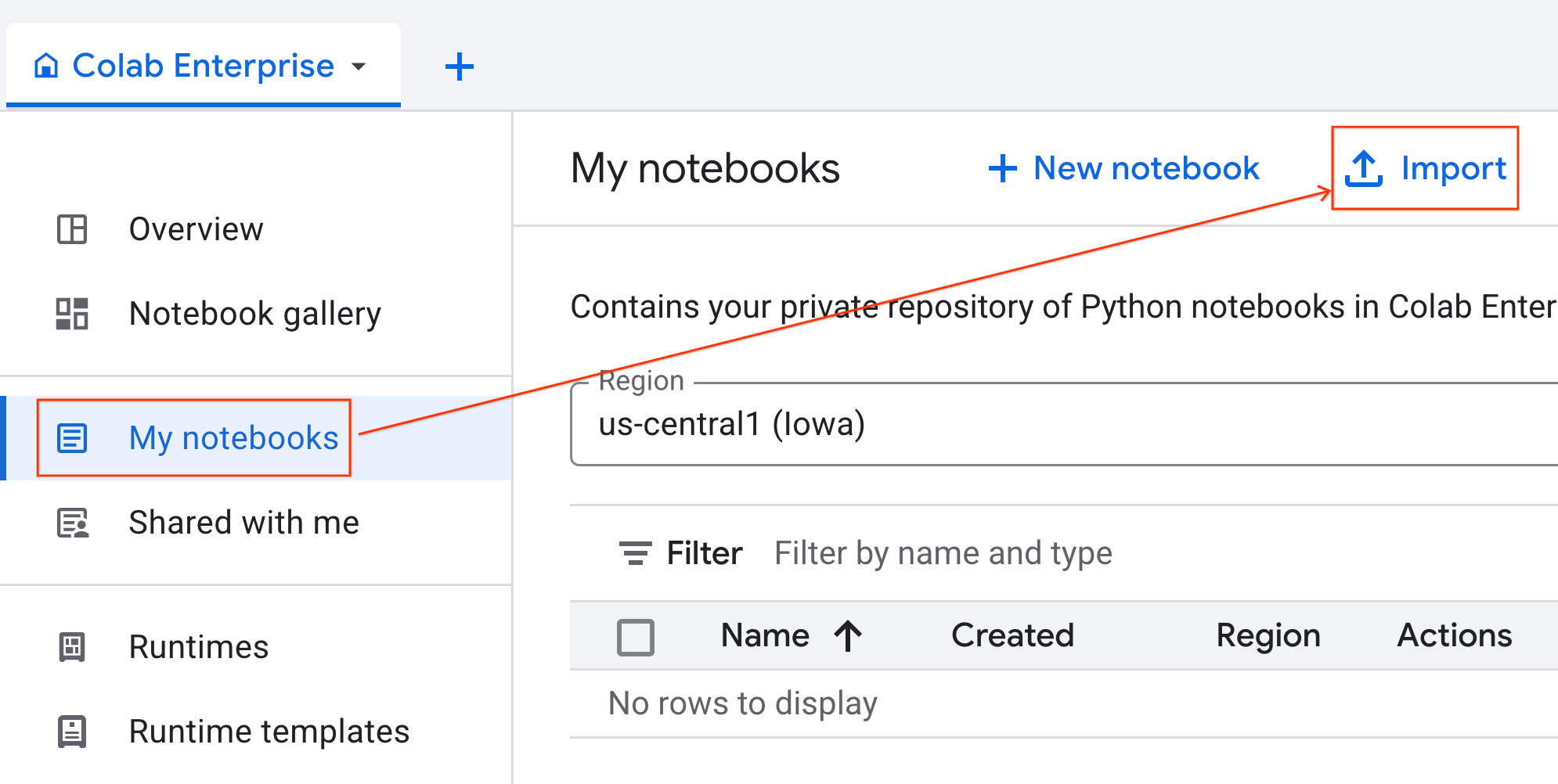
- URL রেডিও বাটনটি সিলেক্ট করুন এবং নিম্নলিখিত URL-টি ইনপুট করুন:
https://github.com/GoogleCloudPlatform/ai-ml-recipes/blob/main/notebooks/regression/gpu_accelerated_regression/gpu_accelerated_regression.ipynb
- ইমপোর্ট-এ ক্লিক করুন। কোলাব এন্টারপ্রাইজ গিটহাব থেকে নোটবুকটি আপনার এনভায়রনমেন্টে কপি করে দেবে।
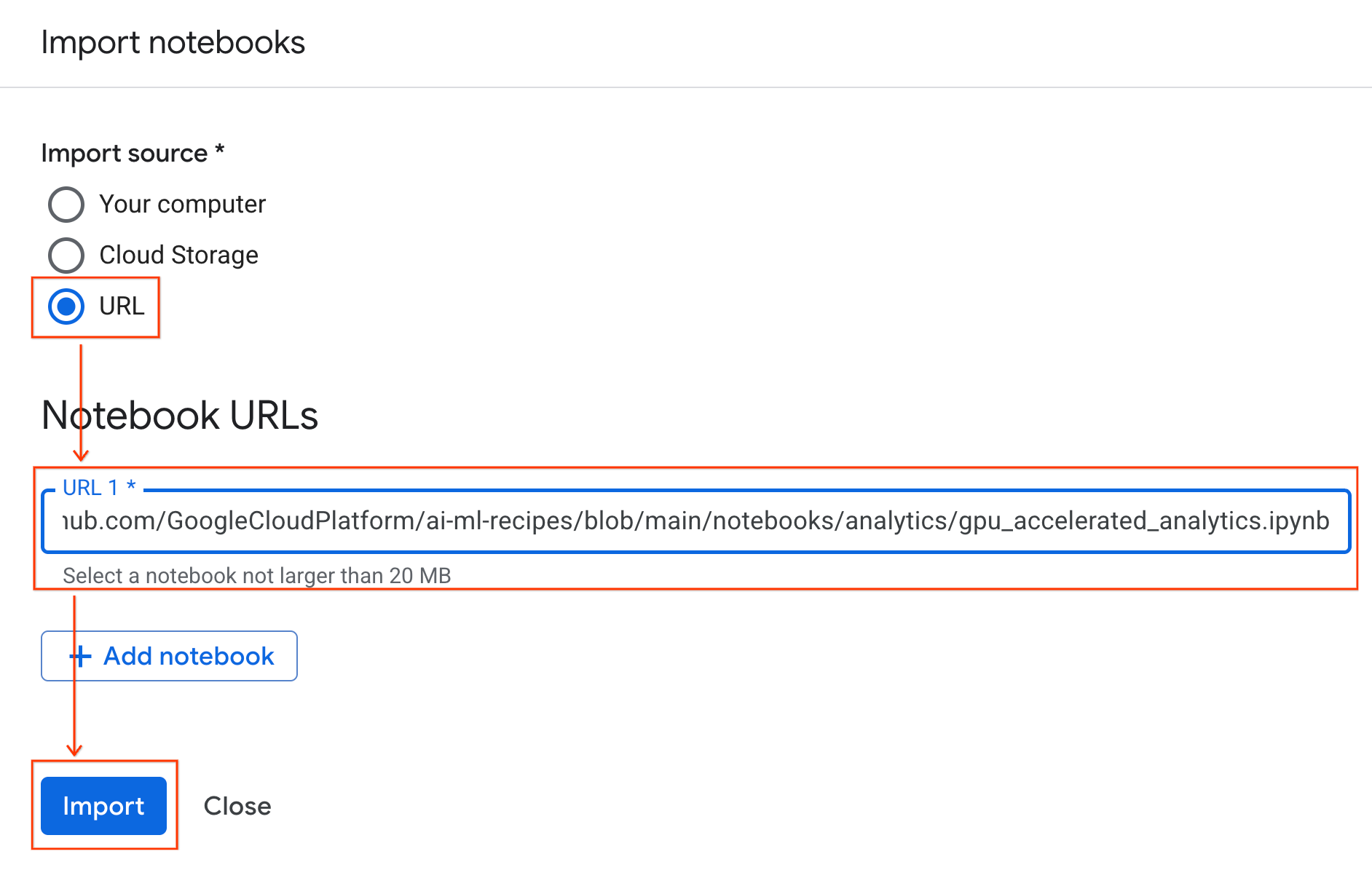
রানটাইমের সাথে সংযোগ করুন
- নতুন ইম্পোর্ট করা নোটবুকটি খুলুন।
- Connect-এর পাশের নিচের দিকে মুখ করা তীরচিহ্নটিতে ক্লিক করুন।
- রানটাইমের সাথে সংযোগ নির্বাচন করুন।
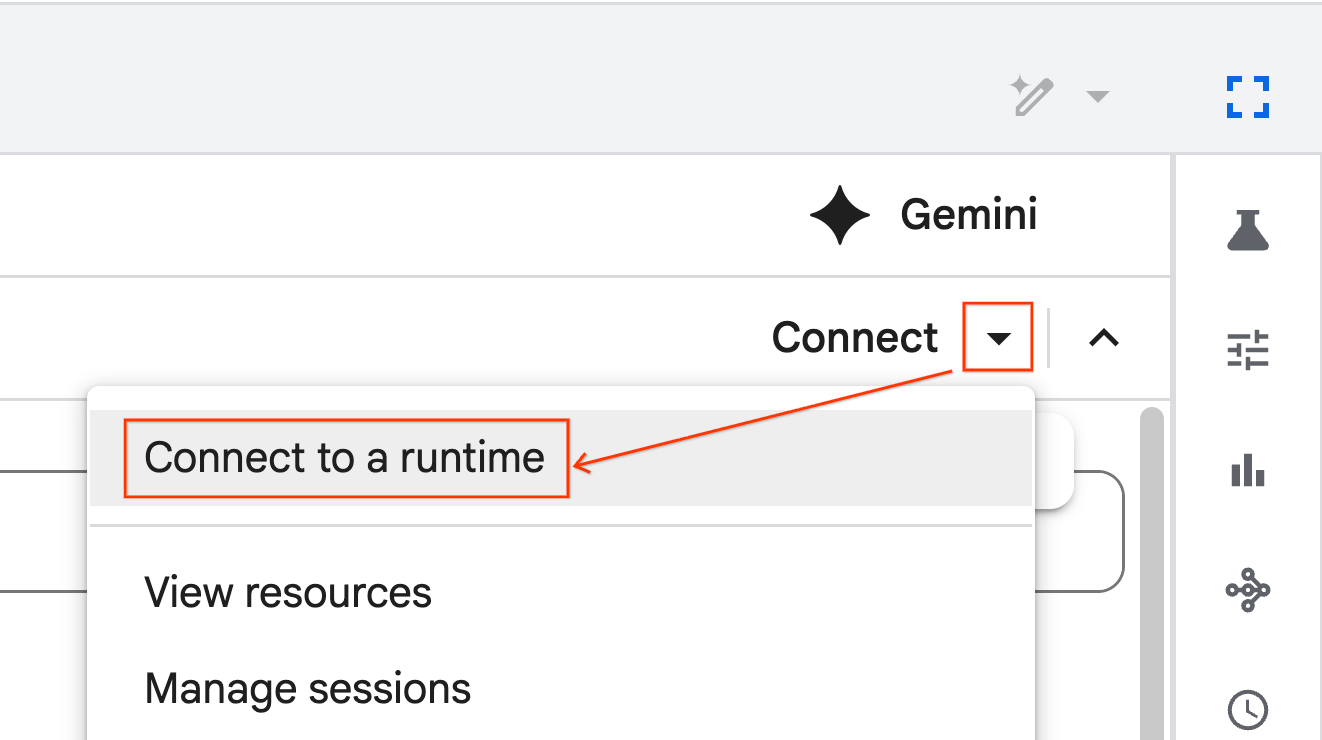
- ড্রপডাউন ব্যবহার করে আপনার পূর্বে তৈরি করা রানটাইমটি নির্বাচন করুন।
- সংযোগ করুন- এ ক্লিক করুন।
আপনার নোটবুকটি এখন একটি জিপিইউ-সক্ষম রানটাইমের সাথে সংযুক্ত।
অন্তর্নির্মিত নির্ভরতা
কোলাব এন্টারপ্রাইজ ব্যবহারের একটি সুবিধা হলো, এতে আপনার প্রয়োজনীয় লাইব্রেরিগুলো আগে থেকেই ইনস্টল করা থাকে। এই ল্যাবের জন্য আপনাকে cuDF , cuML বা XGBoost মতো ডিপেন্ডেন্সিগুলো ম্যানুয়ালি ইনস্টল বা পরিচালনা করতে হবে না।
৮. এনওয়াইসি ট্যাক্সি ডেটাসেট প্রস্তুত করুন।
এই কোডল্যাবটি নিউ ইয়র্ক সিটি ট্যাক্সি অ্যান্ড লিমুজিন কমিশন (TLC)-এর ট্রিপ রেকর্ড ডেটা ব্যবহার করে। ডেটাসেটটিতে নিউ ইয়র্ক সিটির হলুদ ট্যাক্সিগুলোর ট্রিপ রেকর্ড রয়েছে, যার মধ্যে অন্তর্ভুক্ত:
- পিক-আপ এবং ড্রপ-অফের তারিখ, সময় এবং স্থান
- ভ্রমণের দূরত্ব
- বিস্তারিত ভাড়ার পরিমাণ
- যাত্রী সংখ্যা
- টিপের পরিমাণ ( এটাই আমরা অনুমান করব! )
জিপিইউ কনফিগার করুন এবং প্রাপ্যতা নিশ্চিত করুন
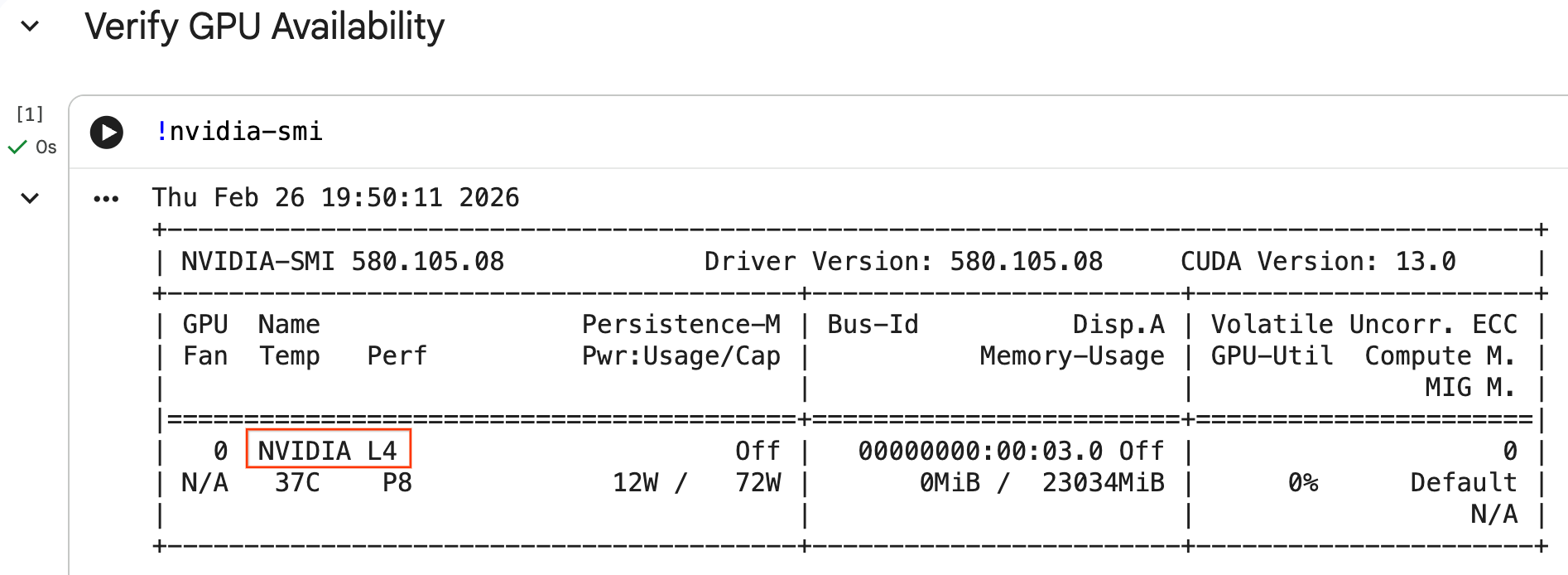
আপনি nvidia-smi কমান্ডটি চালিয়ে জিপিইউটি শনাক্ত হয়েছে কিনা তা নিশ্চিত করতে পারেন। এটি ড্রাইভার সংস্করণ এবং জিপিইউ-এর বিবরণ (যেমন এনভিডিয়া এল৪) প্রদর্শন করে।
nvidia-smi
সেলটি আপনার রানটাইমের সাথে সংযুক্ত GPU-টি ফেরত দেবে, যা নিম্নলিখিতের অনুরূপ হবে:
ডেটা ডাউনলোড করুন
২০২৪ সালের ভ্রমণ তথ্য ডাউনলোড করুন।
from tqdm import tqdm
import requests
import time
import os
YEAR = 2024
DATA_DIR = "nyc_taxi_data"
os.makedirs(DATA_DIR, exist_ok=True)
print(f"Checking/Downloading files for {YEAR}...")
for month in tqdm(range(1, 13), unit="file"):
file_name = f"yellow_tripdata_{YEAR}-{month:02d}.parquet"
local_path = os.path.join(DATA_DIR, file_name)
url = f"https://d37ci6vzurychx.cloudfront.net/trip-data/{file_name}"
if not os.path.exists(local_path):
try:
with requests.get(url, stream=True) as response:
response.raise_for_status()
with open(local_path, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
time.sleep(1)
except requests.exceptions.HTTPError as e:
print(f"\nSkipping {file_name}: {e}")
if os.path.exists(local_path):
os.remove(local_path)
print("\nDownload complete.")
NVIDIA cuDF ব্যবহার করে pandas গতি বাড়ান।
pandas লাইব্রেরি সিপিইউ-তে চলে এবং বড় ডেটাসেটের ক্ষেত্রে এটি ধীরগতির হতে পারে। এনভিডিয়ার %load_ext cudf.pandas ম্যাজিক কমান্ডটি ডাইনামিকভাবে পান্ডাসকে জিপিইউ অ্যাক্সিলারেশন ব্যবহার করার জন্য প্যাচ করে এবং প্রয়োজনে সিপিইউ-তে ফিরে যায়।
আমরা স্ট্যান্ডার্ড ইম্পোর্টের পরিবর্তে এই বিশেষ কমান্ডটি ব্যবহার করি, কারণ এটি কোডে কোনো পরিবর্তন ছাড়াই অ্যাক্সিলারেশন প্রদান করে। আপনাকে আপনার বিদ্যমান কোনো কোড নতুন করে লিখতে হবে না। %load_ext cuml.accel এর মতো একটি কমান্ড scikit-learn models জন্য হুবহু একই কাজ করে! এটি শুধুমাত্র Colab Enterprise-এই নয়, একটি সামঞ্জস্যপূর্ণ NVIDIA GPU সহ যেকোনো Jupyter এনভায়রনমেন্টে কাজ করে।
%load_ext cudf.pandas
এটি সক্রিয় কিনা তা যাচাই করতে, pandas ইম্পোর্ট করুন এবং এর টাইপ পরীক্ষা করুন:
import pandas as pd
pd
আউটপুটটি নিশ্চিত করবে যে আপনি এখন cudf.pandas মডিউলটি ব্যবহার করছেন।
ডেটা লোড এবং পরিষ্কার করুন
cudf.pandas সক্রিয় থাকা অবস্থায়, Parquet ফাইলগুলো লোড করুন এবং ডেটা ক্লিনিং সম্পাদন করুন। এই প্রক্রিয়াটি স্বয়ংক্রিয়ভাবে GPU-তে চলে।
import glob
# Load data into memory
df = pd.concat(
[pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")],
ignore_index=True
)
# Filter for valid trips. We filter for payment_type=1 (credit card)
# because tip amounts are only reliably recorded for credit card transactions.
df = df[
(df['fare_amount'] > 0) & (df['fare_amount'] < 500) &
(df['trip_distance'] > 0) & (df['trip_distance'] < 100) &
(df['tip_amount'] >= 0) & (df['tip_amount'] < 100) &
(df['payment_type'] == 1)
].copy()
# Downcast numeric columns to save memory
float_cols = df.select_dtypes(include=['float64']).columns
df[float_cols] = df[float_cols].astype('float32')
int_cols = df.select_dtypes(include=['int64']).columns
df[int_cols] = df[int_cols].astype('int32')
ফিচার ইঞ্জিনিয়ারিং
পিকআপ ডেটটাইম থেকে ডিরাইভড ফিচার তৈরি করুন। নোটবুকটিতে অন্যান্য ফিচার রয়েছে যা পরবর্তী ধাপগুলিতে ব্যবহৃত হয়।
import numpy as np
# Time Features
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['dow'] = df['tpep_pickup_datetime'].dt.dayofweek
df['is_weekend'] = (df['dow'] >= 5).astype(int)
df['is_rush_hour'] = (
((df['hour'] >= 7) & (df['hour'] <= 9)) |
((df['hour'] >= 17) & (df['hour'] <= 19))
).astype(int)
...
# Other features
...
৯. ক্রস-ভ্যালিডেশনের মাধ্যমে স্বতন্ত্র মডেলগুলোকে প্রশিক্ষণ দিন
জিপিইউ কীভাবে মেশিন লার্নিংকে ত্বরান্বিত করতে পারে তা দেখানোর জন্য, আপনি একটি ট্যাক্সি ট্রিপের tip_amount অনুমান করতে তিন ধরনের রিগ্রেশন মডেলকে প্রশিক্ষণ দেবেন।
NVIDIA cuML সাহায্যে scikit-learn গতি বাড়ান।
এপিআই কল পরিবর্তন না করেই এনভিডিয়া cuML ব্যবহার করে জিপিইউ-তে scikit-learn অ্যালগরিদম চালান। প্রথমে, cuml.accel এক্সটেনশনটি লোড করুন।
%load_ext cuml.accel
সেটআপ বৈশিষ্ট্য এবং লক্ষ্য
মডেলটি যে বৈশিষ্ট্যগুলো থেকে শিখবে তা শনাক্ত করুন এবং টার্গেট কলামটি ( tip_amount ) আলাদা করে নিন।
feature_cols = [
'trip_distance', 'fare_amount', 'passenger_count',
'hour', 'dow', 'is_weekend', 'is_rush_hour',
'fare_log', 'fare_decimal', 'is_round_fare',
'route_frequency', 'pu_tip_mean', 'pu_tip_std',
'PULocationID', 'DOLocationID'
]
X = df[feature_cols].fillna(df[feature_cols].median())
y = df['tip_amount'].copy()
মডেলের কর্মক্ষমতা নির্ভরযোগ্যভাবে মূল্যায়ন করার জন্য ক্রস-ভ্যালিডেশন স্প্লিট সেট আপ করুন।
from sklearn.model_selection import KFold
import numpy as np
import time
from sklearn.metrics import mean_squared_error
from tqdm.notebook import tqdm
n_splits = 3
kf = KFold(n_splits=n_splits, shuffle=True, random_state=42)
১. এক্সজিবিউস্ট
XGBoost স্বাভাবিকভাবেই GPU দ্বারা ত্বরান্বিত। প্রশিক্ষণের সময় GPU ব্যবহার করতে tree_method='hist' এবং device='cuda' পাস করুন।
import xgboost as xgb
start_time = time.perf_counter()
def train_xgb_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# XGBoost handles GPU natively when tree_method='hist' and device='cuda'
model = xgb.XGBRegressor(
objective='reg:squarederror',
max_depth=5,
learning_rate=0.1,
n_estimators=100,
tree_method='hist',
device='cuda',
random_state=42
)
model.fit(X_train, y_train)
preds = model.predict(X_val)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
xgb_rmse, xgb_preds = train_xgb_cv(X, y)
print(f"\n{'XGBoost RMSE:':<20} ${xgb_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
২. রৈখিক রিগ্রেশন
একটি লিনিয়ার রিগ্রেশন মডেলকে প্রশিক্ষণ দিন। %load_ext cuml.accel সক্রিয় থাকলে, LinearRegression স্বয়ংক্রিয়ভাবে এর GPU সমতুল্যে ম্যাপ হয়ে যায়।
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
start_time = time.perf_counter()
def train_linreg_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# Scale features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_val_scaled = scaler.transform(X_val)
# Automatically accelerated by cuML
model = LinearRegression()
model.fit(X_train_scaled, y_train)
preds = model.predict(X_val_scaled)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
linreg_rmse, linreg_preds = train_linreg_cv(X, y)
print(f"\n{'Linear Reg RMSE:':<20} ${linreg_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
৩. র্যান্ডম ফরেস্ট
RandomForestRegressor ব্যবহার করে একটি এনসেম্বল মডেলকে প্রশিক্ষণ দিন। ট্রি-ভিত্তিক মডেলগুলো সিপিইউ-তে প্রশিক্ষণ দিতে প্রায়শই ধীরগতির হয়, কিন্তু জিপিইউ অ্যাক্সিলারেশন লক্ষ লক্ষ সারি দ্রুত প্রসেস করে।
from sklearn.ensemble import RandomForestRegressor
start_time = time.perf_counter()
def train_rf_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# Automatically accelerated by cuML
model = RandomForestRegressor(
n_estimators=100,
max_depth=10,
n_jobs=-1,
max_features='sqrt',
random_state=42
)
model.fit(X_train, y_train)
preds = model.predict(X_val)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
rf_rmse, rf_preds = train_rf_cv(X, y)
print(f"\n{'Random Forest RMSE:':<20} ${rf_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
১০. এন্ড-টু-এন্ড পাইপলাইন মূল্যায়ন করুন
একটি সরল রৈখিক এনসেম্বল ব্যবহার করে তিনটি মডেলের পূর্বাভাসগুলিকে একত্রিত করুন। এটি সাধারণত স্বতন্ত্র মডেলগুলির তুলনায় নির্ভুলতায় সামান্য বৃদ্ধি ঘটায়।
সর্বোত্তম ওয়েটগুলো খুঁজে বের করার জন্য প্রেডিকশনগুলোর উপর একটি লিনিয়ার রিগ্রেশন ফিট করুন:
ensemble_weights = LinearRegression(positive=True, fit_intercept=False).fit(
np.c_[xgb_preds, rf_preds, linreg_preds], y
).coef_
# Normalize weights
ensemble_weights = ensemble_weights / ensemble_weights.sum()
ensemble_preds = np.c_[xgb_preds, rf_preds, linreg_preds] @ ensemble_weights
ensemble_rmse = np.sqrt(mean_squared_error(y, ensemble_preds))
সামগ্রিক উন্নতি দেখতে ফলাফলগুলো তুলনা করুন:
print(f"\n{'Model':<20} {'RMSE':>10}")
print("-" * 32)
print(f"{'Linear Regression':<20} ${linreg_rmse:>9.4f}")
print(f"{'Random Forest':<20} ${rf_rmse:>9.4f}")
print(f"{'XGBoost':<20} ${xgb_rmse:>9.4f}")
print("-" * 32)
print(f"{'Ensemble':<20} ${ensemble_rmse:>9.4f}")
print(f"\nEnsemble lift: ${xgb_rmse - ensemble_rmse:.4f}")
১১. সিপিইউ বনাম জিপিইউ পারফরম্যান্সের তুলনা করুন
পারফরম্যান্সের পার্থক্য সঠিকভাবে বেঞ্চমার্ক করার জন্য, আপনি কার্নেলটি রিস্টার্ট করে একটি পরিষ্কার এক্সিকিউশন স্টেট নিশ্চিত করবেন, সম্পূর্ণ ডেটা সায়েন্স পাইপলাইনটি সিপিইউ-তে চালাবেন এবং তারপরে এটি আবার জিপিইউ-তে চালাবেন।
কার্নেল পুনরায় চালু করুন
কার্নেল পুনরায় চালু করতে এবং মেমরি মুক্ত করতে IPython.Application.instance().kernel.do_shutdown(True) কমান্ডটি চালান।
import IPython
IPython.Application.instance().kernel.do_shutdown(True)
ডেটা সায়েন্স পাইপলাইন সংজ্ঞায়িত করুন
মূল কার্যপ্রবাহকে (ডেটা লোড করা, পরিষ্করণ, ফিচার ইঞ্জিনিয়ারিং এবং মডেল প্রশিক্ষণ) একটিমাত্র ফাংশনের মধ্যে আবদ্ধ করুন। এই ফাংশনটি একটি পান্ডাস মডিউল ' pd_module এবং বিভিন্ন এনভায়রনমেন্টের মধ্যে পরিবর্তন করার জন্য একটি use_gpu আর্গুমেন্ট গ্রহণ করে।
def run_ml_pipeline(pd_module, use_gpu=False):
import time
import glob
import numpy as np
from sklearn.ensemble import RandomForestRegressor
import xgboost as xgb
timings = {}
# 1. Load Data
t0 = time.perf_counter()
df = pd_module.concat(
[pd_module.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")],
ignore_index=True
)
timings['Load Data'] = time.perf_counter() - t0
# 2. Clean Data
t0 = time.perf_counter()
# Filter for payment_type=1 (credit card) because tip amounts
# are only reliably recorded for credit card transactions.
df = df[
(df['fare_amount'] > 0) & (df['fare_amount'] < 500) &
(df['trip_distance'] > 0) & (df['trip_distance'] < 100) &
(df['tip_amount'] >= 0) & (df['tip_amount'] < 100) &
(df['payment_type'] == 1)
].copy()
# Downcast numeric columns to save memory
float_cols = df.select_dtypes(include=['float64']).columns
df[float_cols] = df[float_cols].astype('float32')
int_cols = df.select_dtypes(include=['int64']).columns
df[int_cols] = df[int_cols].astype('int32')
timings['Clean Data'] = time.perf_counter() - t0
# 3. Feature Engineering
t0 = time.perf_counter()
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['dow'] = df['tpep_pickup_datetime'].dt.dayofweek
df['is_weekend'] = (df['dow'] >= 5).astype(int)
df['fare_log'] = np.log1p(df['fare_amount'])
timings['Feature Engineering'] = time.perf_counter() - t0
# 4. Modeling Prep
feature_cols = ['trip_distance', 'fare_amount', 'passenger_count', 'hour', 'dow', 'is_weekend', 'fare_log']
X = df[feature_cols].fillna(df[feature_cols].median())
y = df['tip_amount'].copy()
# Free memory
del df
import gc
gc.collect()
# 5. Train Random Forest
t0 = time.perf_counter()
rf_model = RandomForestRegressor(
n_estimators=100,
max_depth=10,
n_jobs=-1,
max_features='sqrt',
random_state=42
).fit(X, y)
timings['Train Random Forest'] = time.perf_counter() - t0
# 6. Train XGBoost
t0 = time.perf_counter()
params = {
'objective': 'reg:squarederror',
'max_depth': 5,
'n_estimators': 100,
'random_state': 42
}
if use_gpu:
params['device'] = 'cuda'
params['tree_method'] = 'hist'
xgb_model = xgb.XGBRegressor(**params).fit(X, y)
timings['Train XGBoost'] = time.perf_counter() - t0
del X
del y
gc.collect()
return timings
আপনার সিপিইউতে চালান
স্ট্যান্ডার্ড সিপিইউ pandas ব্যবহার করে পাইপলাইনটি কল করুন।
import pandas as pd
print("Running pipeline on CPU...")
cpu_times = run_ml_pipeline(pd, use_gpu=False)
print("CPU Execution Finished.")
আপনার জিপিইউ-তে চালান
NVIDIA লাইব্রেরি এক্সটেনশনগুলো লোড করুন, পাইপলাইনে অ্যাক্সিলারেটেড cudf.pandas মডিউলটি পাস করুন, এবং অভ্যন্তরীণভাবে আপনার XGBoost ডিভাইসটিকে cuda তে সেট করুন।
import IPython.core.magic
if not hasattr(IPython.core.magic, 'output_can_be_silenced'):
IPython.core.magic.output_can_be_silenced = lambda x: x
%load_ext cudf.pandas
%load_ext cuml.accel
import pandas as pd
print("Running pipeline on GPU...")
gpu_times = run_ml_pipeline(pd, use_gpu=True)
print("GPU Execution Finished.")
পারফরম্যান্সের গতিবৃদ্ধি কল্পনা করুন
matplotlib ব্যবহার করে সময়গুলো দৃশ্যমান করুন। ফলাফল থেকে দেখা যায়, জিপিইউ ব্যবহারের ফলে ডেটা প্রসেসিং এবং মডেল প্রশিক্ষণের সময় সাশ্রয় হয়।
import matplotlib.pyplot as plt
import numpy as np
labels = list(cpu_times.keys())
cpu_values = list(cpu_times.values())
gpu_values = list(gpu_times.values())
x = np.arange(len(labels))
width = 0.35
fig, ax = plt.subplots(figsize=(10, 6))
rects1 = ax.bar(x - width/2, cpu_values, width, label='CPU', color='#4285F4')
rects2 = ax.bar(x + width/2, gpu_values, width, label='GPU', color='#76B900')
ax.set_ylabel('Execution Time (seconds)')
ax.set_title('NYC Taxi ML Pipeline: CPU vs. GPU Performance')
ax.set_xticks(x)
ax.set_xticklabels(labels, rotation=45, ha="right")
ax.legend()
# Add data labels
def autolabel(rects):
for rect in rects:
height = rect.get_height()
ax.annotate(f'{height:.2f}s',
xy=(rect.get_x() + rect.get_width() / 2, height),
xytext=(0, 3), # 3 points vertical offset
textcoords="offset points",
ha='center', va='bottom', fontsize=9)
autolabel(rects1)
autolabel(rects2)
plt.tight_layout()
plt.show()
# Calculate overall speedup
total_cpu_time = sum(cpu_values)
total_gpu_time = sum(gpu_values)
overall_speedup = total_cpu_time / total_gpu_time
print(f"\nOverall Pipeline Speedup: {overall_speedup:.2f}x faster on GPU!")
আপনি এইরকম কিছু দেখতে পাবেন:
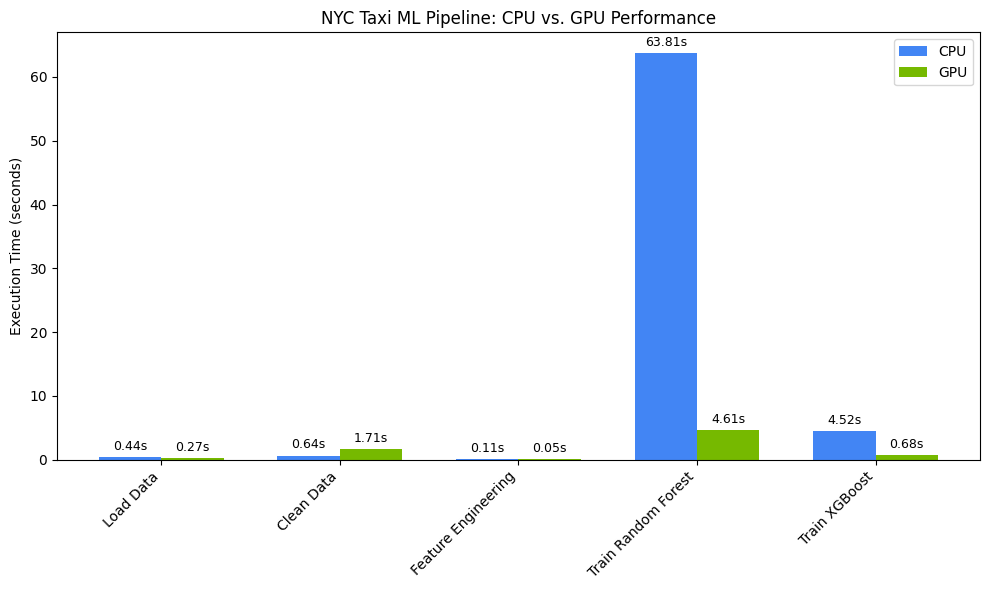
এই চার্টটি সম্পূর্ণ ডেটা সায়েন্স ওয়ার্কফ্লো জুড়ে GPU-এর উল্লেখযোগ্য পারফরম্যান্স সুবিধা তুলে ধরে। Random Forest এবং XGBoost-এর মতো অ্যালগরিদমগুলির জন্য গণনা-নিবিড় মডেল প্রশিক্ষণের পর্যায়গুলিতে সবচেয়ে নাটকীয় সময় সাশ্রয় দেখতে পাওয়ার সম্ভাবনা রয়েছে।
১২. পারফরম্যান্সের সীমাবদ্ধতা খুঁজে বের করতে আপনার কোডের প্রোফাইল তৈরি করুন।
cudf.pandas ব্যবহার করার সময়, বেশিরভাগ ফাংশন GPU-তে চলে। যদি কোনো নির্দিষ্ট অপারেশন cuDF দ্বারা এখনও সমর্থিত না হয়, তবে এক্সিকিউশন সাময়িকভাবে CPU-তে ফিরে যায়। এই ফলব্যাকগুলো শনাক্ত করার জন্য NVIDIA দুটি বিল্ট-ইন Jupyter ম্যাজিক কমান্ড প্রদান করে।
%%cudf.pandas.profile ব্যবহার করে উচ্চ-স্তরের প্রোফাইলিং
%%cudf.pandas.profile ম্যাজিক কমান্ডটি GPU বা CPU-তে কোন ফাংশনগুলো চলেছে তার একটি সারাংশ প্রদান করে।
%%cudf.pandas.profile
import glob
import pandas as pd
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")], ignore_index=True)
summary = (
df
.groupby(['PULocationID', 'payment_type'])
[['passenger_count', 'fare_amount', 'tip_amount']]
.agg(['min', 'mean', 'max'])
)
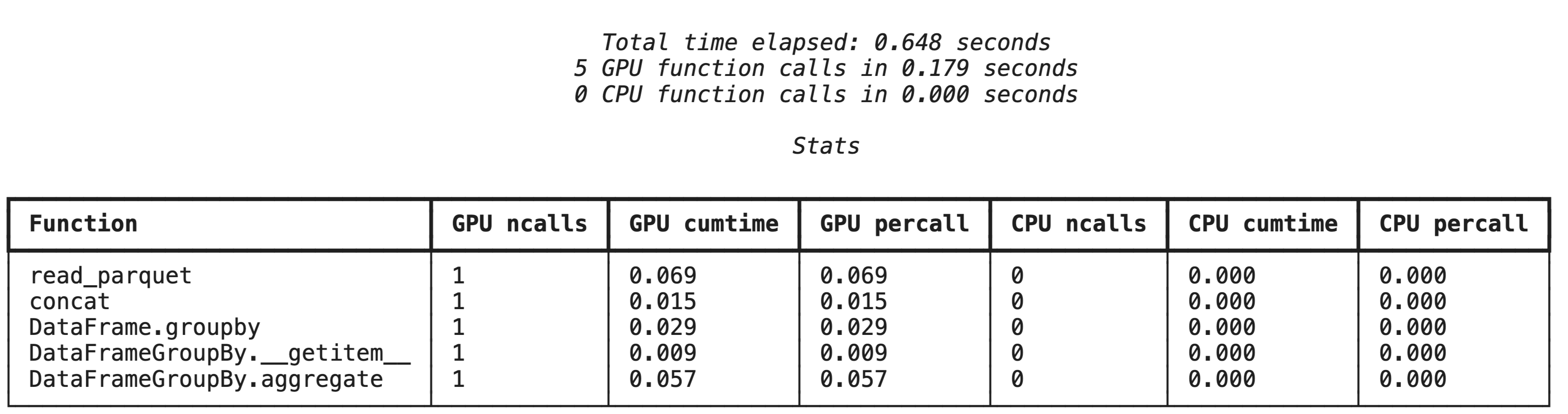
%%cudf.pandas.line_profile ব্যবহার করে লাইন-বাই-লাইন প্রোফাইলিং
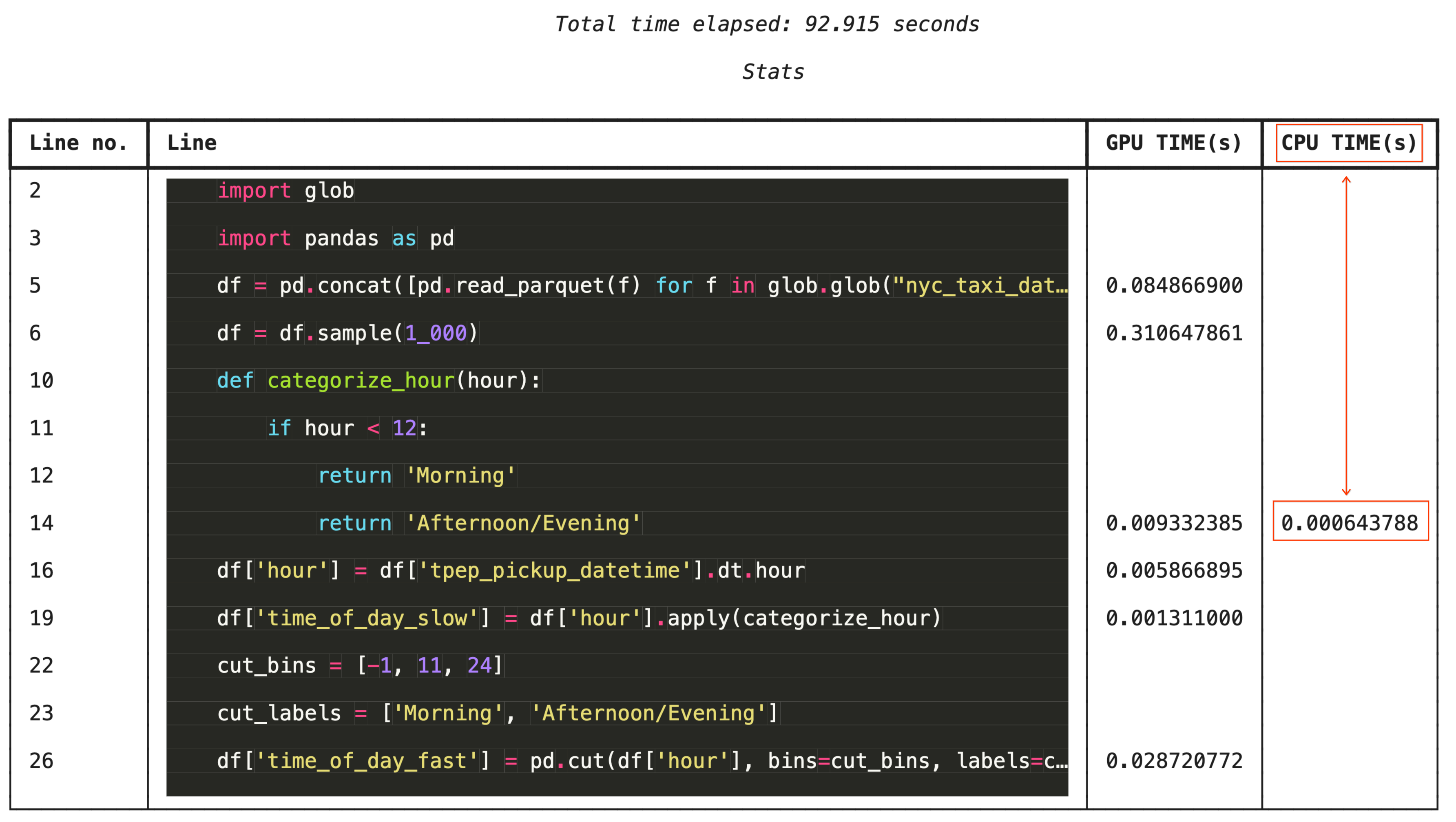
সূক্ষ্মভাবে সমস্যা সমাধানের জন্য, %%cudf.pandas.line_profile প্রতিটি কোড লাইনকে GPU এবং CPU-তে কতবার এক্সিকিউট হয়েছে, তা দিয়ে টীকাযুক্ত করে।
%%cudf.pandas.line_profile
import glob
import pandas as pd
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")], ignore_index=True)
df = df.sample(1_000)
# Iterating row-by-row or using custom python apply functions often falls back to the CPU
def categorize_hour(hour):
if hour < 12:
return 'Morning'
else:
return 'Afternoon/Evening'
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['time_of_day_slow'] = df['hour'].apply(categorize_hour)
# Using vectorized pandas operations (like pd.cut) stays entirely on the GPU
cut_bins = [-1, 11, 24]
cut_labels = ['Morning', 'Afternoon/Evening']
df['time_of_day_fast'] = pd.cut(df['hour'], bins=cut_bins, labels=cut_labels)
১৩. পরিষ্কার করা
আপনার গুগল ক্লাউড অ্যাকাউন্টে অপ্রত্যাশিত চার্জ এড়াতে, এই কোডল্যাব চলাকালীন আপনার তৈরি করা রিসোর্সগুলো পরিষ্কার করুন।
সম্পদ মুছে ফেলুন
নোটবুকের একটি সেলে !rm -rf কমান্ড ব্যবহার করে রানটাইমে স্থানীয় ডেটাসেটটি মুছে ফেলুন।
print("Deleting local 'nyc_taxi_data' directory...")
!rm -rf nyc_taxi_data
print("Local files deleted.")
আপনার কোলাব রানটাইম বন্ধ করুন
- গুগল ক্লাউড কনসোলে, কোলাব এন্টারপ্রাইজ রানটাইমস পৃষ্ঠায় যান।
- রিজিয়ন মেনু থেকে, আপনার রানটাইম ধারণকারী রিজিয়নটি নির্বাচন করুন।
- যে রানটাইমটি আপনি মুছতে চান, সেটি নির্বাচন করুন।
- ডিলিট-এ ক্লিক করুন।
- নিশ্চিত করুন -এ ক্লিক করুন।
আপনার নোটবুকটি মুছে ফেলুন
- Google Cloud কনসোলে, Colab Enterprise My Notebooks পৃষ্ঠায় যান।
- রিজিয়ন মেনু থেকে, আপনার নোটবুকটি যে রিজিয়নে অবস্থিত, সেটি নির্বাচন করুন।
- যে নোটবুকটি মুছতে চান, সেটি নির্বাচন করুন।
- ডিলিট-এ ক্লিক করুন।
- নিশ্চিত করুন -এ ক্লিক করুন।
১৪. অভিনন্দন
অভিনন্দন! আপনি সফলভাবে কোলাব এন্টারপ্রাইজে এনভিডিয়া cuDF এবং cuML লাইব্রেরি ব্যবহার করে একটি pandas এবং scikit-learn মেশিন লার্নিং ওয়ার্কফ্লোকে ত্বরান্বিত করেছেন। শুধুমাত্র কয়েকটি বিশেষ কমান্ড ( %load_ext cudf.pandas এবং %load_ext cuml.accel ) যোগ করার মাধ্যমে, আপনার সাধারণ কোড GPU-তে চলে এবং রেকর্ড প্রসেস করার পাশাপাশি জটিল মডেলগুলোকে স্থানীয়ভাবে অনেক কম সময়ে ফিট করে।
ডেটা অ্যানালিটিক্সে জিপিইউ-অ্যাক্সিলারেশন সম্পর্কে আরও তথ্যের জন্য, “ Accelerated Data Analytics with GPUs” কোডল্যাবটি দেখুন।
আমরা যা আলোচনা করেছি
- গুগল ক্লাউডে কোলাব এন্টারপ্রাইজ বোঝা।
- নির্দিষ্ট জিপিইউ এবং মেমরি কনফিগারেশন ব্যবহার করে কোলাব রানটাইম এনভায়রনমেন্ট কাস্টমাইজ করা।
- NYC ট্যাক্সি ডেটাসেটের লক্ষ লক্ষ রেকর্ড ব্যবহার করে টিপের পরিমাণ অনুমান করতে GPU অ্যাক্সিলারেশন প্রয়োগ করা হচ্ছে।
- এনভিডিয়ার
cuDFলাইব্রেরি ব্যবহার করে কোডে কোনো পরিবর্তন ছাড়াইpandasগতি বৃদ্ধি করা। - এনভিডিয়ার
cuMLলাইব্রেরি এবং জিপিইউ ব্যবহার করে কোডে কোনো পরিবর্তন ছাড়াইscikit-learnলার্নের গতি বৃদ্ধি করা। - পারফরম্যান্সের সীমাবদ্ধতা শনাক্ত ও অপ্টিমাইজ করার জন্য আপনার কোডের প্রোফাইলিং করা।