
1. Einführung
In diesem Codelab erfahren Sie, wie Sie Ihre Data Science- und Machine-Learning-Workflows für große Datasets mit NVIDIA-GPUs und Open-Source-Bibliotheken in Google Cloud beschleunigen können. Sie beginnen mit der Einrichtung Ihrer Infrastruktur und sehen sich dann an, wie Sie die GPU-Beschleunigung anwenden.
Sie konzentrieren sich auf den Data-Science-Lebenszyklus, von der Datenvorbereitung mit pandas bis zum Modelltraining mit scikit-learn und XGBoost. Sie erfahren, wie Sie diese Aufgaben mit den Bibliotheken cuDF und cuML von NVIDIA beschleunigen können. Das Beste daran ist, dass Sie diese GPU-Beschleunigung erhalten können, ohne Ihren vorhandenen pandas- oder scikit-learn-Code zu ändern.
Lerninhalte
- Colab Enterprise in Google Cloud kennenlernen
- Sie können eine Colab-Laufzeitumgebung mit bestimmten GPU- und Arbeitsspeicherkonfigurationen anpassen.
- GPU-Beschleunigung anwenden, um Trinkgeldbeträge anhand von Millionen von Datensätzen aus einem NYC-Taxi-Dataset vorherzusagen.
- Beschleunigen Sie
pandasohne Codeänderungen mit dercuDF-Bibliothek von NVIDIA. - Beschleunigen Sie
scikit-learnohne Codeänderungen mit dercuML-Bibliothek und den GPUs von NVIDIA. - Profilieren Sie Ihren Code, um Leistungsbeschränkungen zu identifizieren und zu optimieren.
Auf der nächsten Seite finden Sie Guthabenpunkte, die Sie für das Lab verwenden können.
2. Warum sollte man maschinelles Lernen beschleunigen?
Schnellere Iteration bei ML erforderlich
Die Datenvorbereitung ist zeitaufwendig und das Trainieren oder Bewerten von Modellen kann noch länger dauern, wenn Datasets größer werden. Das Training von Modellen wie Random Forests oder XGBoost mit Millionen von Zeilen auf einer CPU kann Stunden oder Tage dauern.
Durch die Verwendung von GPUs werden diese Trainingsläufe mit Bibliotheken wie cuML und GPU-beschleunigtem XGBoost beschleunigt. Durch diese Beschleunigung können Sie:
- Schnellere Iterationen:Neue Funktionen und Hyperparameter schnell testen.
- Mit vollständigen Datasets trainieren:Verwenden Sie Ihre vollständigen Daten anstelle von Downsampling, um die Genauigkeit zu verbessern.
- Kosten senken:Rechenintensive Arbeitslasten in kürzerer Zeit erledigen, um die Computing-Kosten zu senken.
3. Einrichtung und Anforderungen
Potenzielle Kosten
In diesem Codelab werden Google Cloud-Ressourcen verwendet, darunter Colab Enterprise-Runtimes mit NVIDIA L4-GPUs. Achten Sie auf mögliche Gebühren und folgen Sie dem Abschnitt Bereinigen am Ende des Codelabs, um Ressourcen zu beenden und laufende Abrechnungen zu vermeiden. Detaillierte Preisinformationen finden Sie unter Colab Enterprise-Preise und GPU-Preise.
Hinweis
Es wird davon ausgegangen, dass Sie über fortgeschrittene Kenntnisse in Python, pandas, scikit-learn und Standardverfahren für maschinelles Lernen (z. B. Kreuzvalidierung/Ensembling) verfügen.
- Wählen Sie in der Google Cloud Console auf der Seite zur Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie ein Google Cloud-Projekt.
- Die Abrechnung für das Google Cloud-Projekt muss aktiviert sein.
APIs aktivieren
Damit Sie Colab Enterprise verwenden können, müssen Sie zuerst die erforderlichen APIs aktivieren.
- Öffnen Sie Google Cloud Shell, indem Sie rechts oben in der Google Cloud Console auf das Cloud Shell-Symbol klicken.

- Legen Sie in Cloud Shell Ihre Projekt-ID fest. Ersetzen Sie dazu
PROJECT_IDdurch Ihre Projekt-ID:
gcloud config set project <PROJECT_ID>
- Führen Sie den folgenden Befehl aus, um die erforderlichen APIs zu aktivieren:
gcloud services enable \
compute.googleapis.com \
dataform.googleapis.com \
notebooks.googleapis.com \
aiplatform.googleapis.com
Bei erfolgreicher Ausführung sollte eine Meldung ähnlich der folgenden angezeigt werden:
Operation "operations/..." finished successfully.
4. Notebook-Umgebung auswählen
Viele Data Scientists kennen Colab für private Projekte. Colab Enterprise bietet jedoch eine sichere, auf Zusammenarbeit ausgelegte und integrierte Notebook-Umgebung, die für Unternehmen entwickelt wurde.
In Google Cloud haben Sie zwei primäre Optionen für verwaltete Notebook-Umgebungen: Colab Enterprise und die Gemini Enterprise Agent Platform Workbench. Die richtige Wahl hängt von den Prioritäten Ihres Projekts ab.
Wann sollte die Agent Platform Workbench verwendet werden?
Wählen Sie Agent Platform Workbench aus, wenn Kontrolle und umfassende Anpassung für Sie Priorität haben. Diese Option ist ideal, wenn Sie Folgendes benötigen:
- Verwaltung der zugrunde liegenden Infrastruktur und des Maschinenlebenszyklus
- Benutzerdefinierte Container und Netzwerkkonfigurationen verwenden
- Einbindung in MLOps-Pipelines und benutzerdefinierte Tools für den Lebenszyklus.
Wann wird Colab Enterprise verwendet?
Wählen Sie Colab Enterprise, wenn schnelle Einrichtung, Nutzerfreundlichkeit und sichere Zusammenarbeit für Sie Priorität haben. Es handelt sich um eine vollständig verwaltete Lösung, mit der sich Ihr Team auf die Analyse statt auf die Infrastruktur konzentrieren kann.
Colab Enterprise bietet folgende Vorteile:
- Data-Science-Workflows entwickeln, die eng mit Ihrem Data Warehouse verknüpft sind Sie können Ihre Notebooks direkt in BigQuery Studio öffnen und verwalten.
- Modelle für maschinelles Lernen trainieren und in MLOps-Tools in der Agent Platform einbinden.
- Sie profitieren von einer flexiblen und einheitlichen Umgebung. Ein in BigQuery erstelltes Colab Enterprise-Notebook kann in der Agent Platform geöffnet und ausgeführt werden und umgekehrt.
Heutiges Lab
In diesem Codelab wird Colab Enterprise für beschleunigtes maschinelles Lernen verwendet.
Weitere Informationen zu den Unterschieden finden Sie in der offiziellen Dokumentation unter Die richtige Notebooklösung auswählen.
5. Laufzeitvorlage konfigurieren
In Colab Enterprise stellen Sie eine Verbindung zu einer Laufzeit her, die auf einer vorkonfigurierten Laufzeitvorlage basiert.
Eine Laufzeitvorlage ist eine wiederverwendbare Konfiguration, die die Umgebung für Ihr Notebook angibt, einschließlich:
- Maschinentyp (CPU, Arbeitsspeicher)
- Beschleuniger (GPU-Typ und -Anzahl)
- Laufwerkgröße und -typ
- Netzwerkeinstellungen und Sicherheitsrichtlinien
- Regeln für das automatische Herunterfahren bei Inaktivität
Vorteile von Laufzeitvorlagen
- Konsistenz:Sie und Ihr Team erhalten dieselbe Umgebung, damit die Arbeit wiederholbar ist.
- Sicherheit:Mit Vorlagen werden die Sicherheitsrichtlinien der Organisation erzwungen.
- Kostenmanagement:Die Ressourcen in der Vorlage sind so dimensioniert, dass versehentliche Kosten vermieden werden.
Laufzeitvorlage erstellen.
Richten Sie eine wiederverwendbare Laufzeitvorlage für das Lab ein.
- Rufen Sie in der Google Cloud Console das Navigationsmenü > Agent Platform > Notebooks auf.
- Klicken Sie in Colab Enterprise auf Laufzeitvorlagen und wählen Sie dann Neue Vorlage aus.
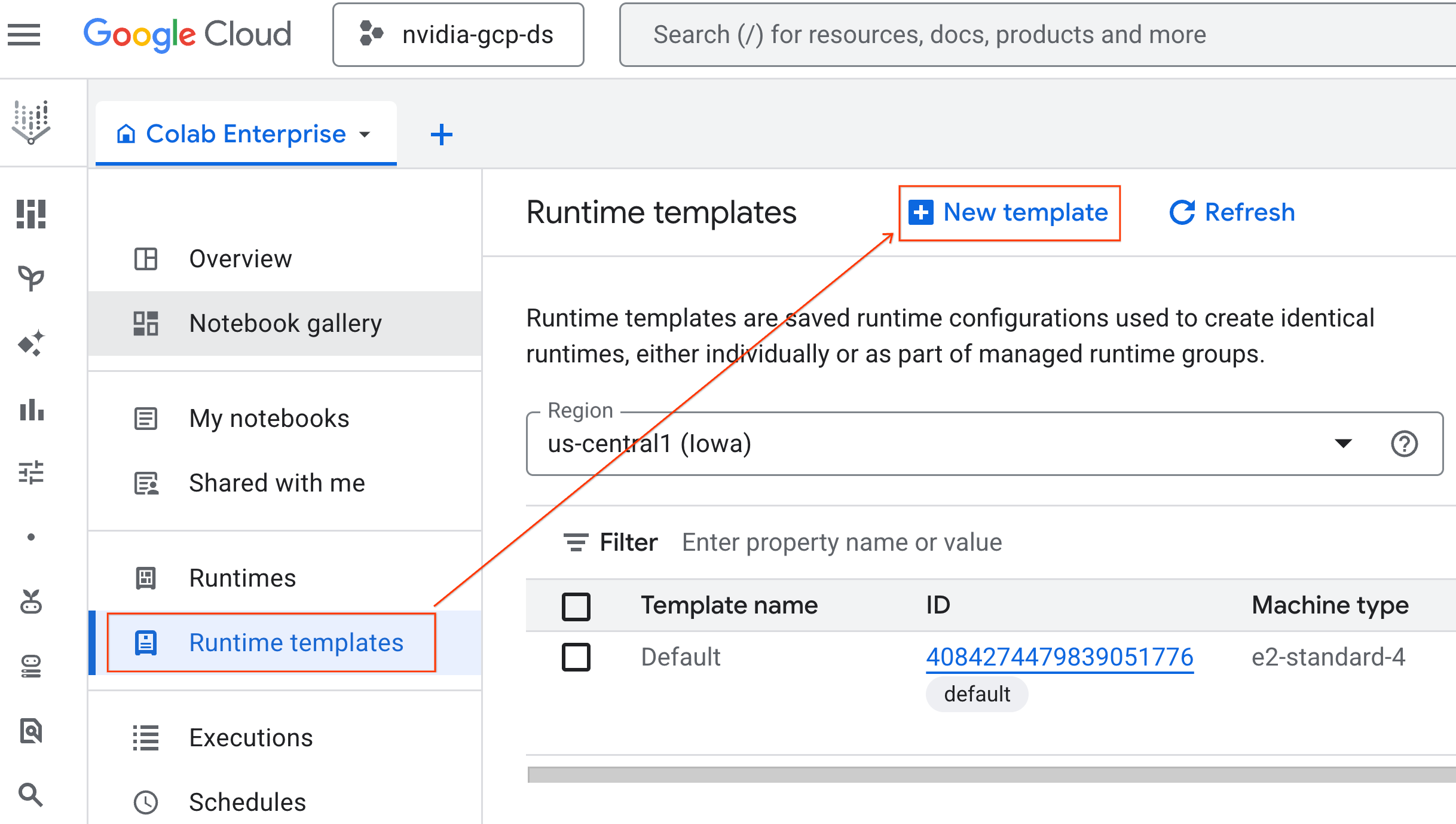
- Unter Laufzeitgrundlagen:
- Legen Sie als Anzeigename
gpu-templatefest. - Legen Sie Ihre bevorzugte Region fest.
- Legen Sie als Anzeigename
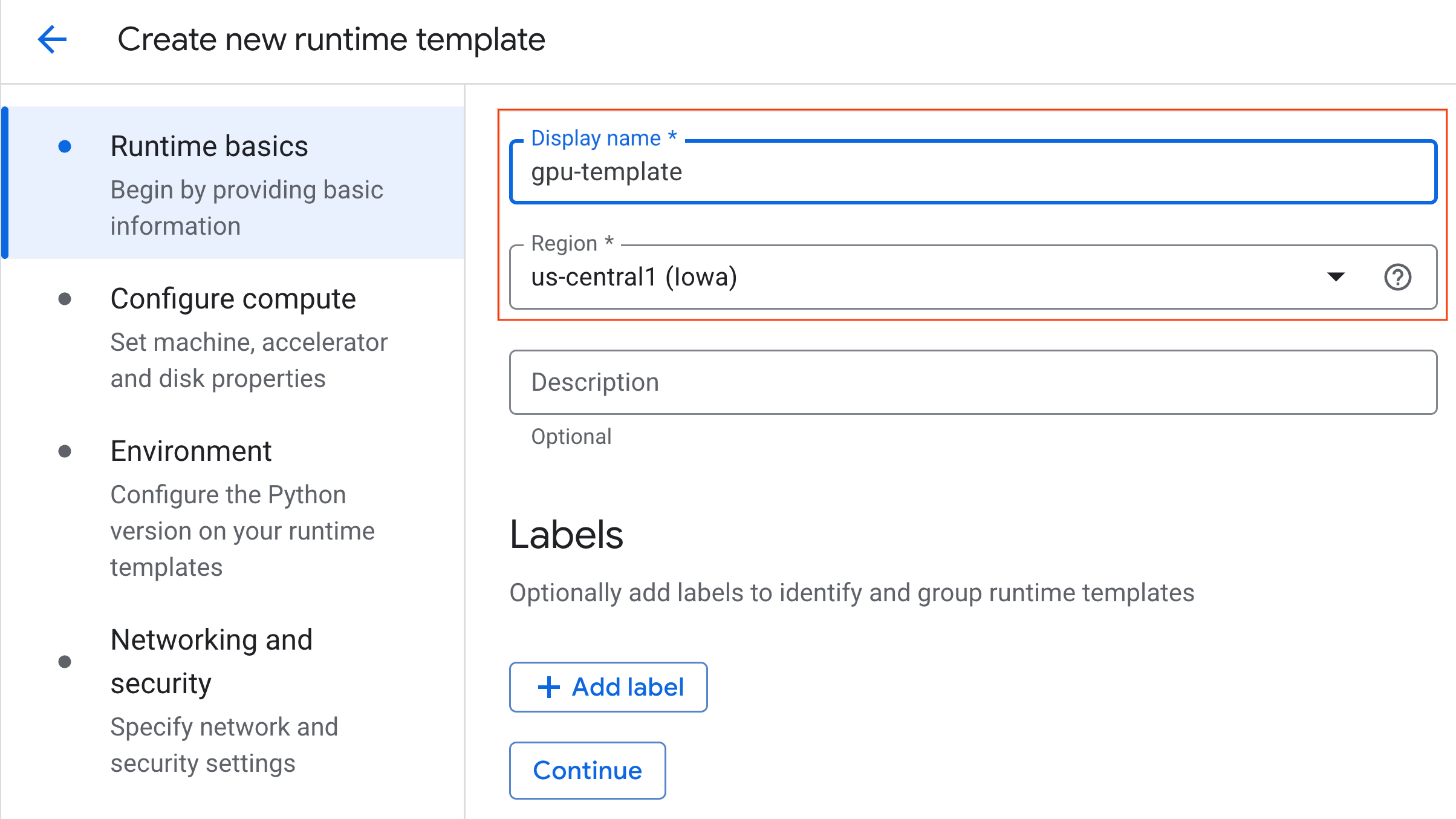
- Unter Compute konfigurieren:
- Legen Sie den Maschinentyp auf
g2-standard-4fest. - Behalten Sie den Standardwert
NVIDIA L4für Beschleunigertyp mit einer Anzahl der Beschleuniger von 1 bei. - Ändern Sie die Option Herunterfahren bei Inaktivität auf 60 Minuten.
- Klicken Sie auf Weiter.
- Legen Sie den Maschinentyp auf
- Unter Umgebung:
- Legen Sie die Umgebung auf
Python 3.11fest.
- Legen Sie die Umgebung auf
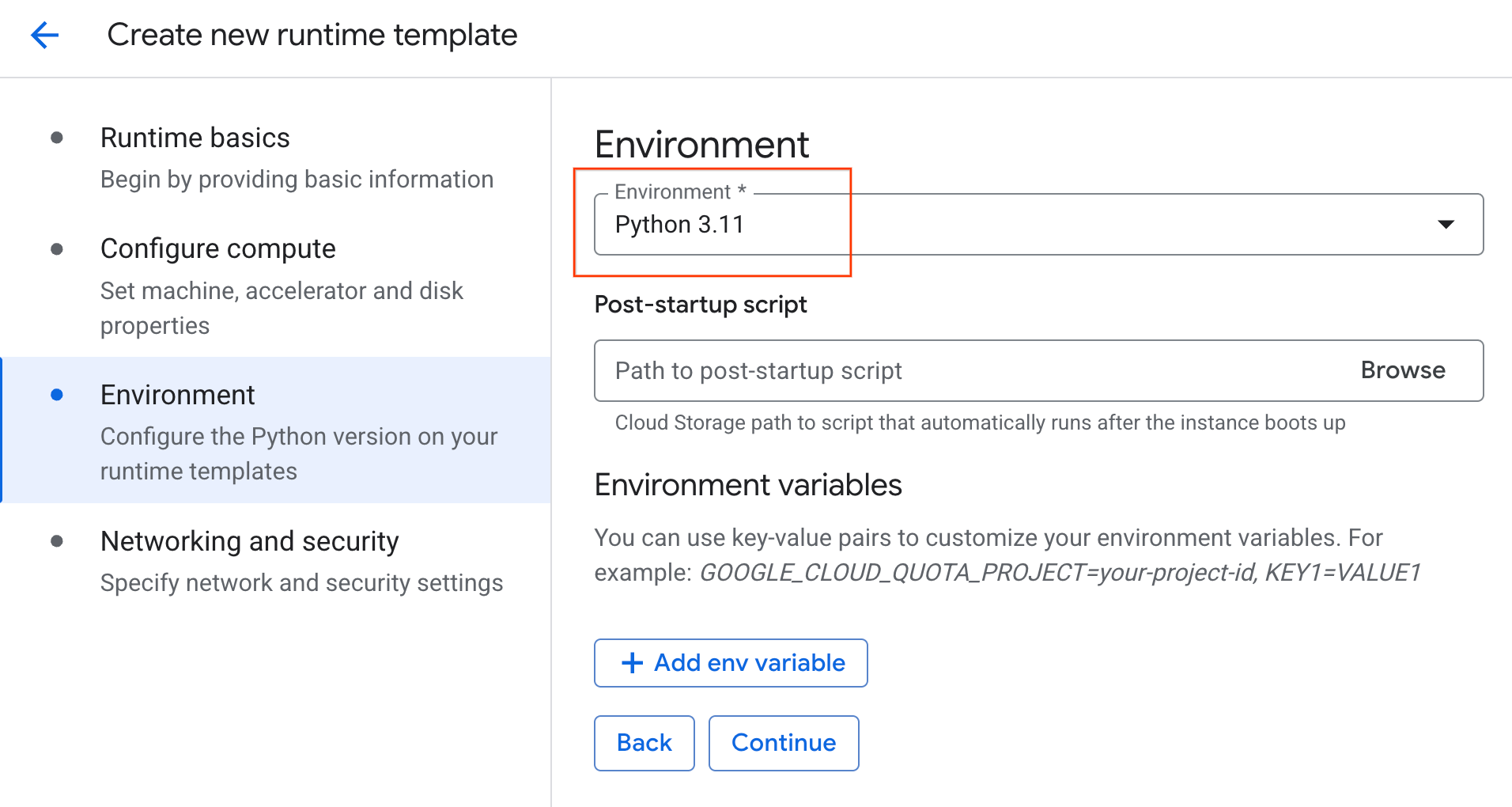
- Klicken Sie auf Erstellen, um die Laufzeitvorlage zu speichern. Die neue Vorlage sollte jetzt auf der Seite „Laufzeitvorlagen“ angezeigt werden.
6. Laufzeit starten
Nachdem Sie die Vorlage erstellt haben, können Sie eine neue Laufzeit erstellen.
- Klicken Sie in Colab Enterprise auf Laufzeiten und wählen Sie dann Erstellen aus.
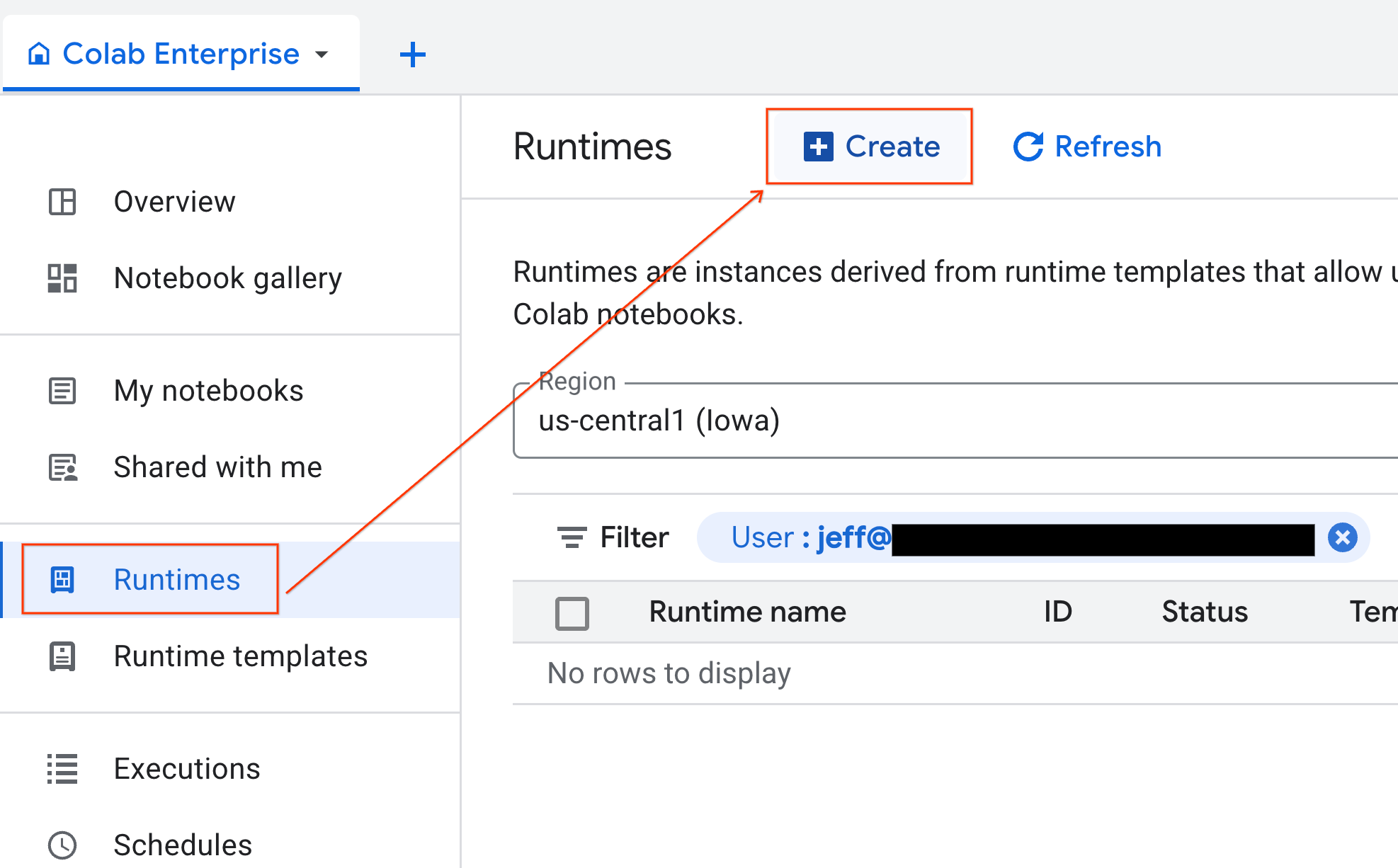
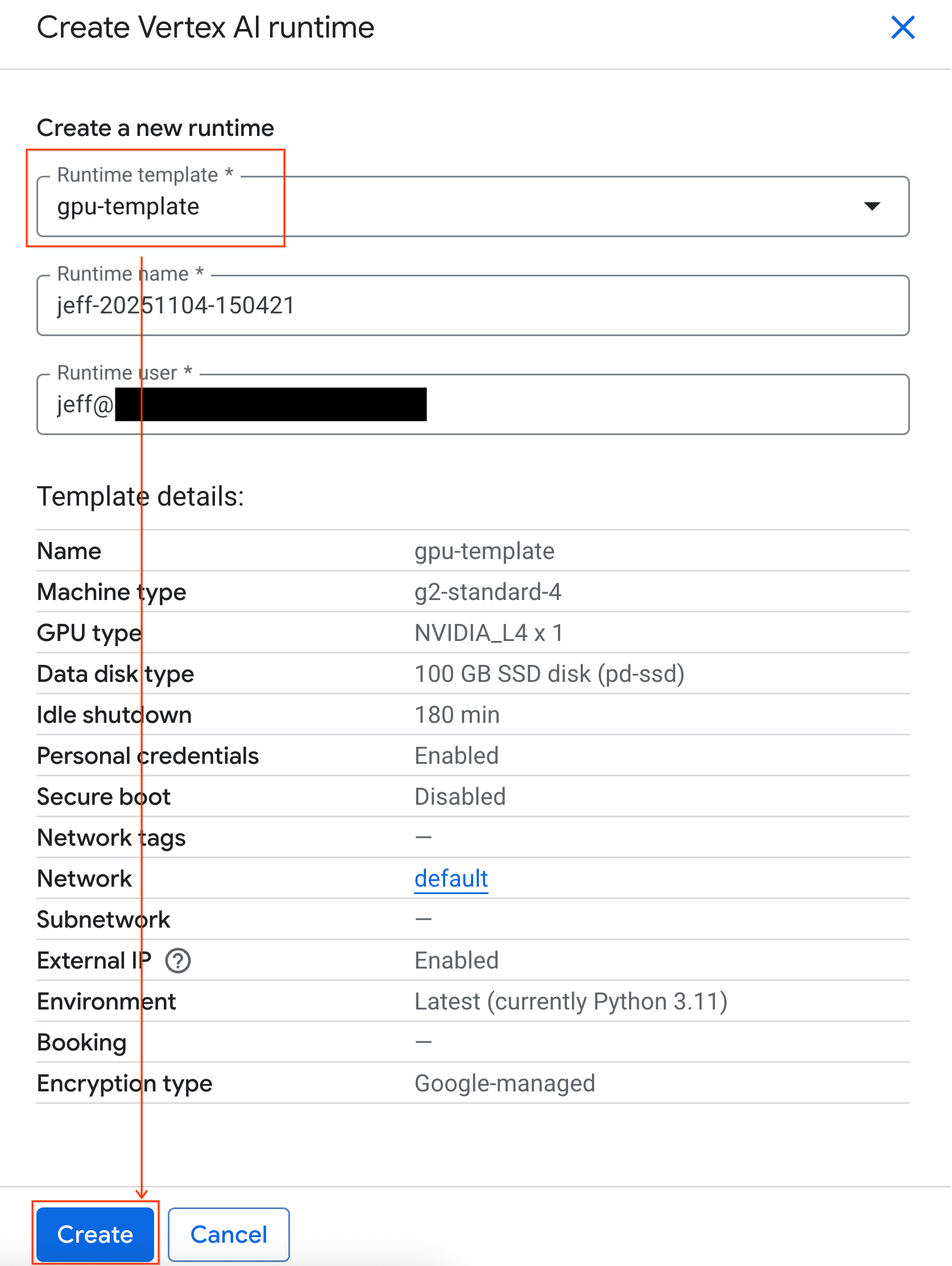
- Wählen Sie unter Laufzeitvorlage die Option
gpu-templateaus. Klicken Sie auf Erstellen und warten Sie, bis die Laufzeitumgebung gestartet wurde.
- Nach einigen Minuten wird die Laufzeit angezeigt.
7. Notebook einrichten
Nachdem Ihre Infrastruktur nun ausgeführt wird, müssen Sie das Lab-Notebook importieren und mit Ihrer Laufzeit verbinden.
Notebook importieren
- Klicken Sie in Colab Enterprise auf Meine Notebooks und dann auf Importieren.
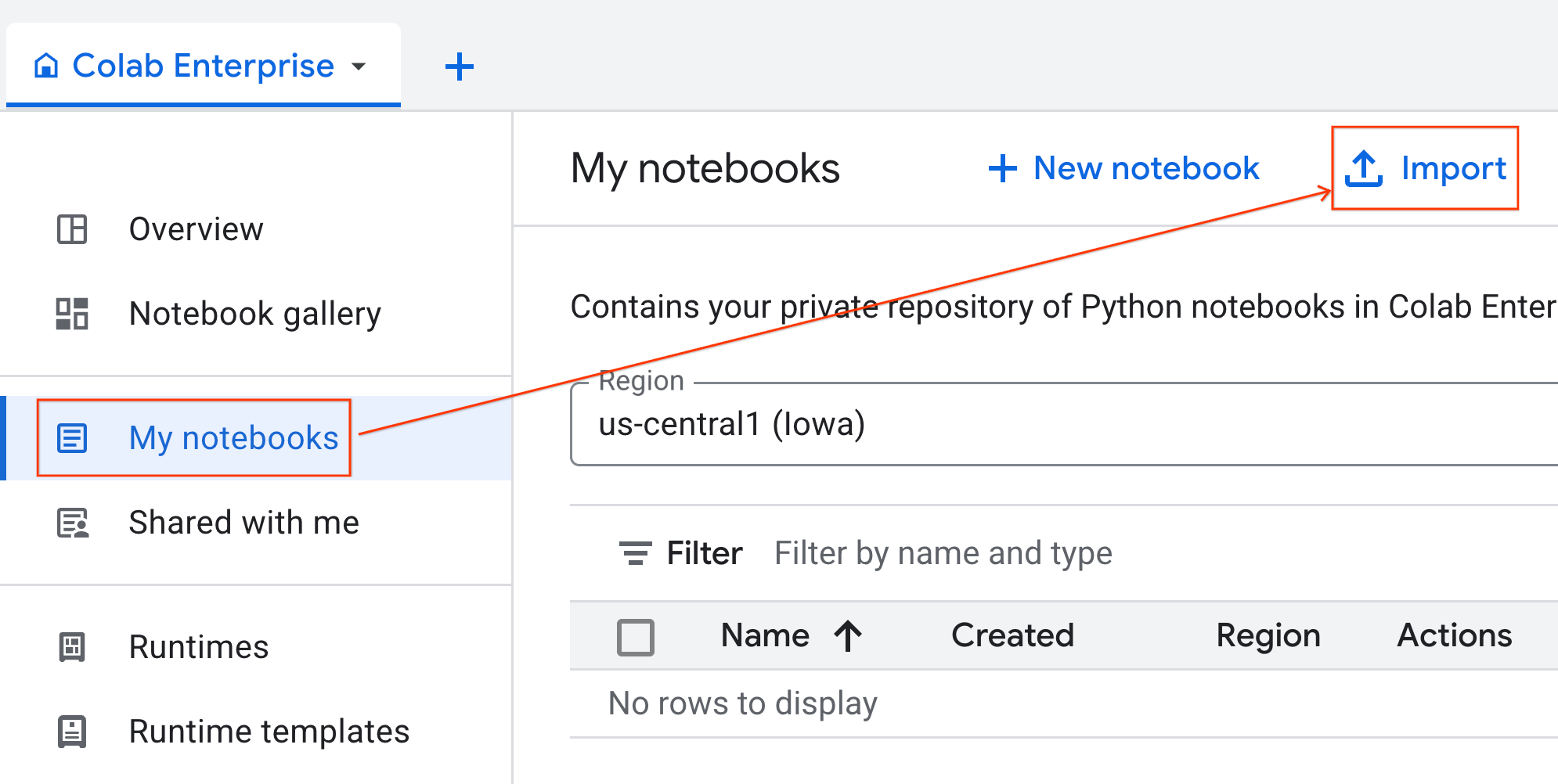
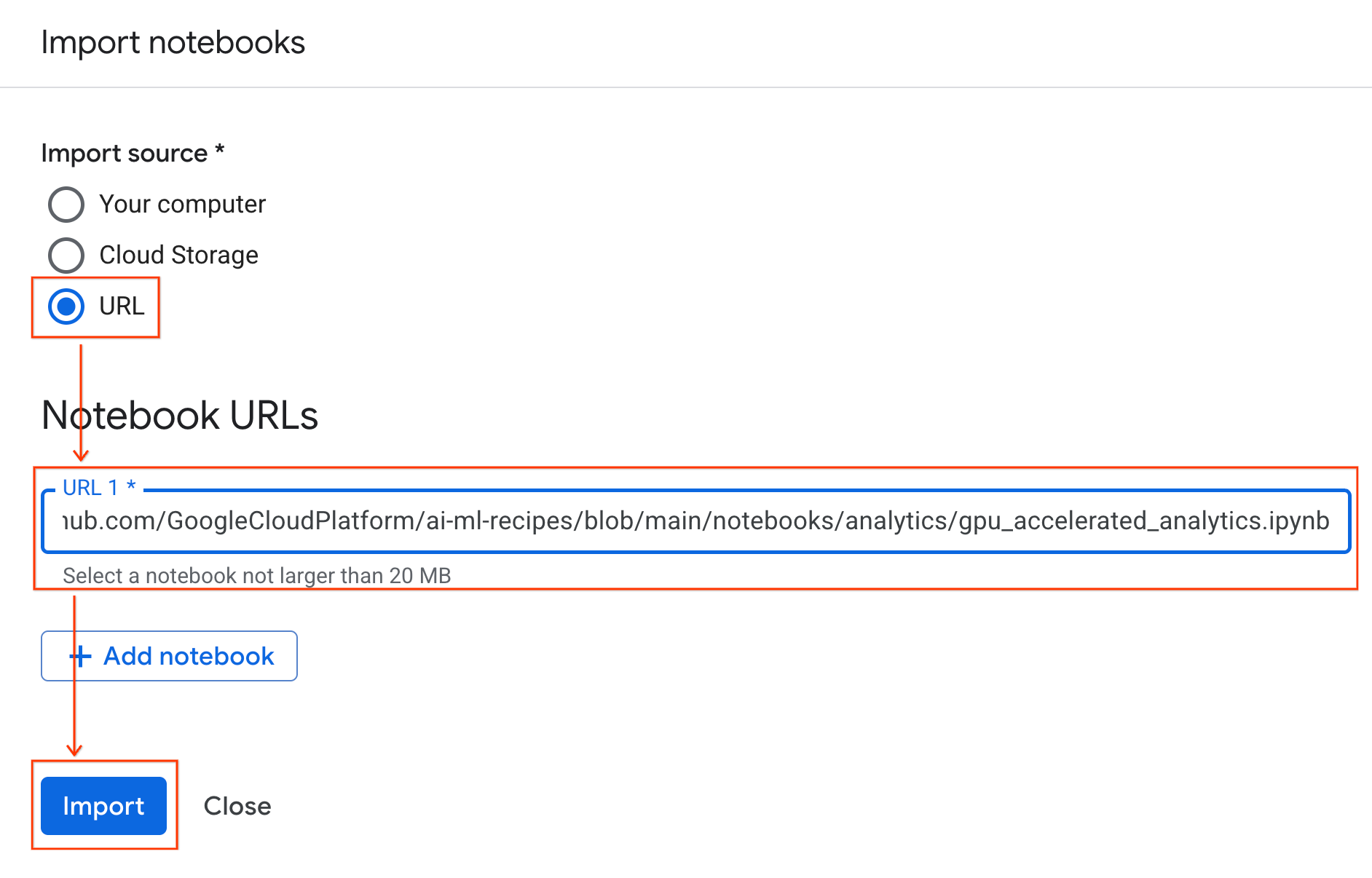
- Wählen Sie das Optionsfeld URL aus und geben Sie die folgende URL ein:
https://github.com/GoogleCloudPlatform/ai-ml-recipes/blob/main/notebooks/regression/gpu_accelerated_regression/gpu_accelerated_regression.ipynb
- Klicken Sie auf Importieren. Colab Enterprise kopiert das Notebook aus GitHub in Ihre Umgebung.
Mit der Laufzeit verbinden
- Öffnen Sie das neu importierte Notebook.
- Klicken Sie neben Verbinden auf den Drop-down-Pfeil.
- Wählen Sie Mit einer Laufzeit verbinden aus.
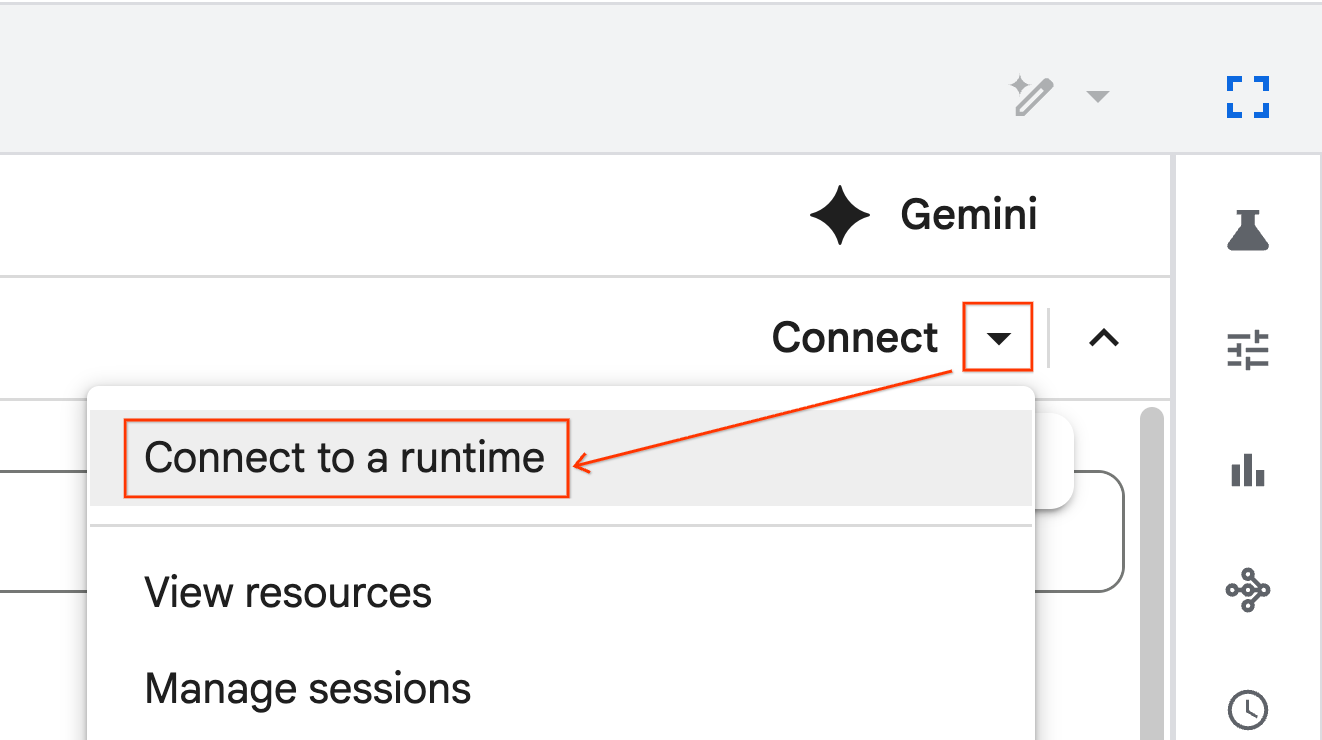
- Wählen Sie im Drop-down-Menü die Laufzeit aus, die Sie zuvor erstellt haben.
- Klicken Sie auf Verbinden.
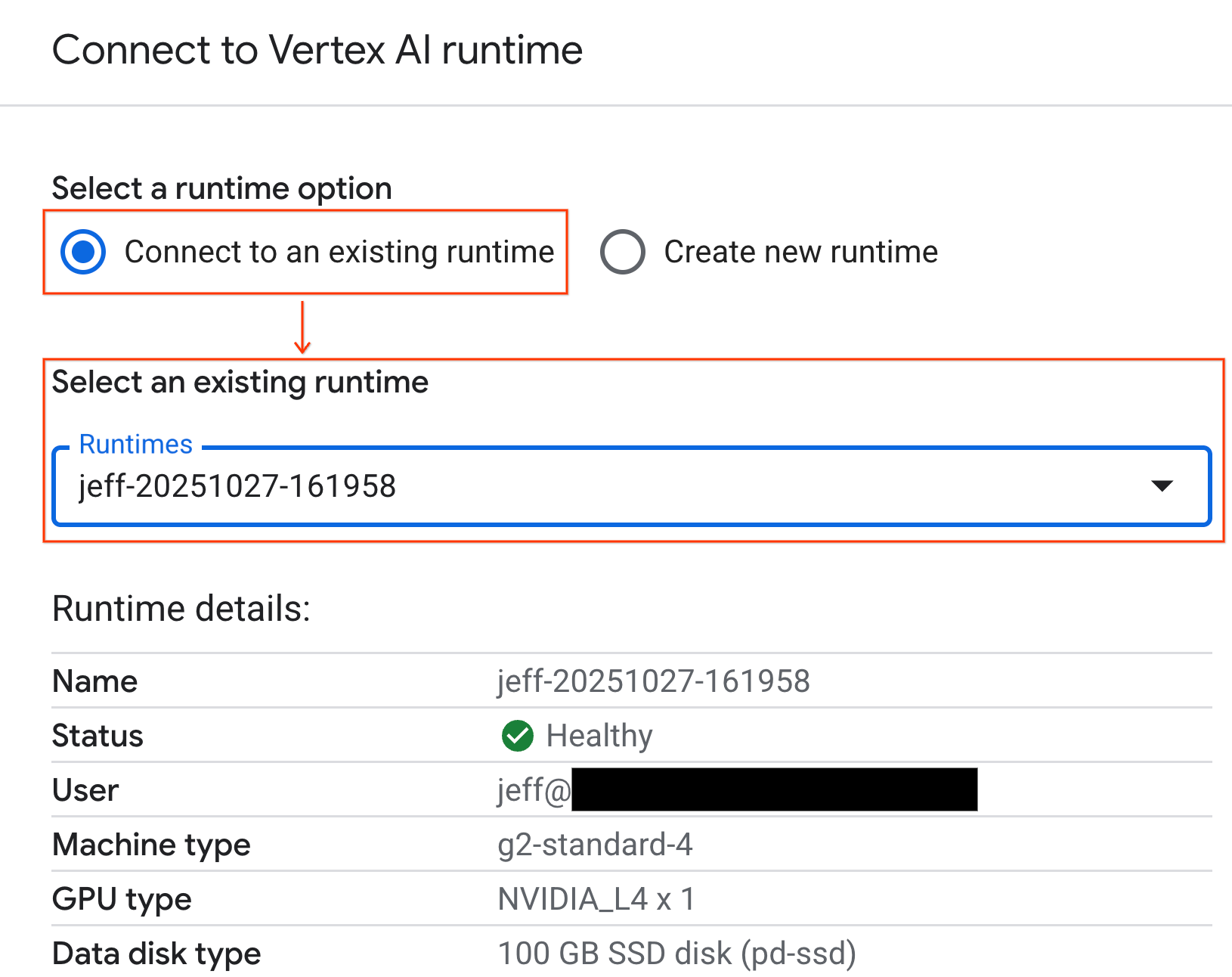
Ihr Notebook ist jetzt mit einer GPU-fähigen Laufzeit verbunden.
Integrierte Abhängigkeiten
Ein Vorteil von Colab Enterprise ist, dass die benötigten Bibliotheken vorinstalliert sind. Für dieses Lab müssen Sie Abhängigkeiten wie cuDF, cuML oder XGBoost nicht manuell installieren oder verwalten.
8. NYC-Taxidataset vorbereiten
In diesem Codelab werden Fahrtenaufzeichnungen der NYC Taxi & Limousine Commission (TLC) verwendet. Der Datensatz enthält Fahrten mit gelben Taxis in New York City, darunter:
- Abhol- und Abgabedatum, ‑uhrzeit und ‑ort
- Fahrtentfernungen
- Aufgeschlüsselte Fahrpreisbeträge
- Anzahl der Passagiere
- Trinkgeldbeträge (das ist das, was wir vorhersagen werden)
GPU konfigurieren und Verfügbarkeit bestätigen
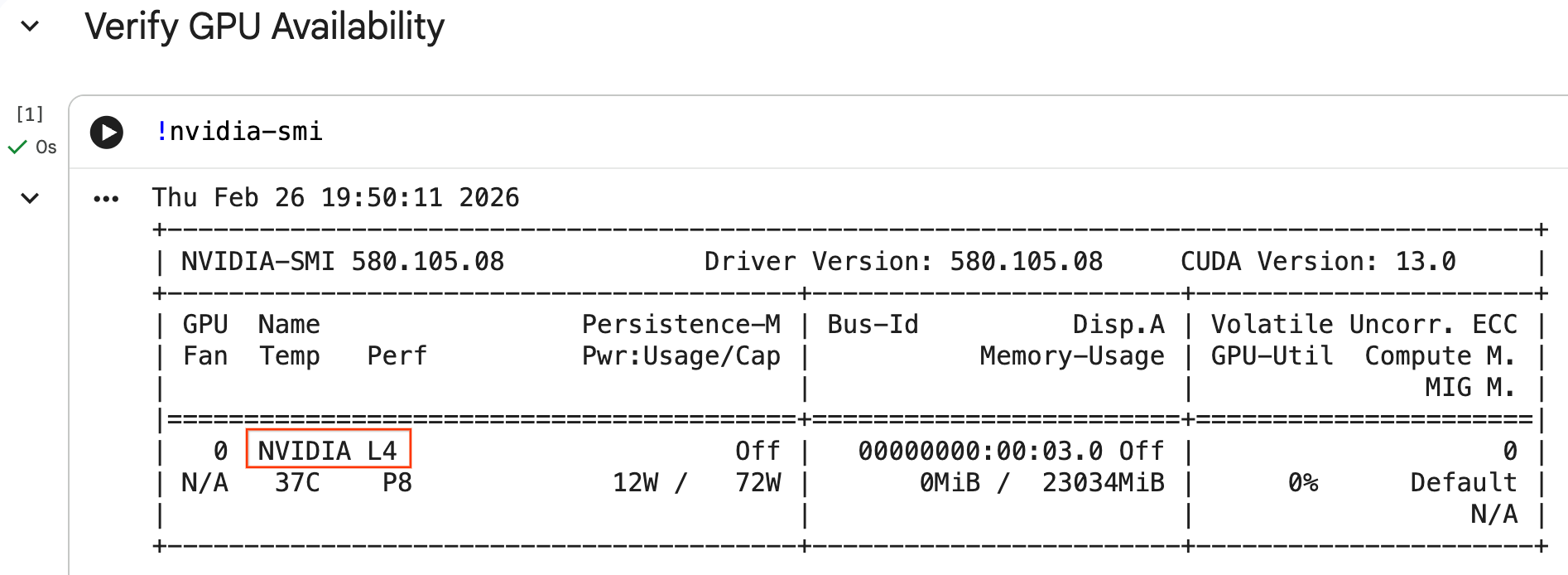
Mit dem Befehl nvidia-smi können Sie prüfen, ob die GPU erkannt wurde. Dort werden die Treiberversion und GPU-Details (z. B. NVIDIA L4) angezeigt.
nvidia-smi
Die Zelle sollte die GPU zurückgeben, die mit Ihrer Laufzeit verbunden ist, ähnlich dem Folgenden:
Daten herunterladen
Laden Sie die Fahrtdaten für 2024 herunter.
from tqdm import tqdm
import requests
import time
import os
YEAR = 2024
DATA_DIR = "nyc_taxi_data"
os.makedirs(DATA_DIR, exist_ok=True)
print(f"Checking/Downloading files for {YEAR}...")
for month in tqdm(range(1, 13), unit="file"):
file_name = f"yellow_tripdata_{YEAR}-{month:02d}.parquet"
local_path = os.path.join(DATA_DIR, file_name)
url = f"https://d37ci6vzurychx.cloudfront.net/trip-data/{file_name}"
if not os.path.exists(local_path):
try:
with requests.get(url, stream=True) as response:
response.raise_for_status()
with open(local_path, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
time.sleep(1)
except requests.exceptions.HTTPError as e:
print(f"\nSkipping {file_name}: {e}")
if os.path.exists(local_path):
os.remove(local_path)
print("\nDownload complete.")
pandas mit NVIDIA cuDF beschleunigen
Die pandas-Bibliothek wird auf der CPU ausgeführt und kann bei großen Datasets langsam sein. Mit dem NVIDIA-Magic-Befehl %load_ext cudf.pandas wird Pandas dynamisch gepatcht, um die GPU-Beschleunigung zu verwenden. Bei Bedarf wird auf die CPU zurückgegriffen.
Wir verwenden diesen Magic-Befehl anstelle eines Standardimports, da er eine Beschleunigung ohne Codeänderung ermöglicht. Sie müssen keinen vorhandenen Code neu schreiben. Ein ähnlicher Befehl, %load_ext cuml.accel, führt genau dasselbe für scikit-learn models aus. Das funktioniert in jeder Jupyter-Umgebung mit einer kompatiblen NVIDIA-GPU, nicht nur in Colab Enterprise.
%load_ext cudf.pandas
So prüfen Sie, ob sie aktiv ist: Importieren Sie pandas und prüfen Sie den Typ:
import pandas as pd
pd
Die Ausgabe bestätigt, dass Sie jetzt das Modul cudf.pandas verwenden.
Daten laden und bereinigen
Laden Sie die Parquet-Dateien und führen Sie die Datenbereinigung aus, während cudf.pandas aktiv ist. Dieser Vorgang wird automatisch auf der GPU ausgeführt.
import glob
# Load data into memory
df = pd.concat(
[pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")],
ignore_index=True
)
# Filter for valid trips. We filter for payment_type=1 (credit card)
# because tip amounts are only reliably recorded for credit card transactions.
df = df[
(df['fare_amount'] > 0) & (df['fare_amount'] < 500) &
(df['trip_distance'] > 0) & (df['trip_distance'] < 100) &
(df['tip_amount'] >= 0) & (df['tip_amount'] < 100) &
(df['payment_type'] == 1)
].copy()
# Downcast numeric columns to save memory
float_cols = df.select_dtypes(include=['float64']).columns
df[float_cols] = df[float_cols].astype('float32')
int_cols = df.select_dtypes(include=['int64']).columns
df[int_cols] = df[int_cols].astype('int32')
Feature Engineering
Abgeleitete Features aus dem Abholdatum und der Abholzeit erstellen Das Notebook enthält weitere Funktionen, die in späteren Schritten verwendet werden.
import numpy as np
# Time Features
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['dow'] = df['tpep_pickup_datetime'].dt.dayofweek
df['is_weekend'] = (df['dow'] >= 5).astype(int)
df['is_rush_hour'] = (
((df['hour'] >= 7) & (df['hour'] <= 9)) |
((df['hour'] >= 17) & (df['hour'] <= 19))
).astype(int)
...
# Other features
...
9. Einzelne Modelle mit Kreuzvalidierung trainieren
Um zu zeigen, wie die GPU das maschinelle Lernen beschleunigen kann, trainieren Sie drei verschiedene Arten von Regressionsmodellen, um die tip_amount einer Taxifahrt vorherzusagen.
scikit-learn mit NVIDIA cuML beschleunigen
scikit-learn-Algorithmen mit NVIDIA cuML auf der GPU ausführen, ohne API-Aufrufe zu ändern. Laden Sie zuerst die cuml.accel-Erweiterung.
%load_ext cuml.accel
Funktionen und Ziele einrichten
Legen Sie die Features fest, aus denen das Modell lernen soll, und trennen Sie die Zielspalte (tip_amount).
feature_cols = [
'trip_distance', 'fare_amount', 'passenger_count',
'hour', 'dow', 'is_weekend', 'is_rush_hour',
'fare_log', 'fare_decimal', 'is_round_fare',
'route_frequency', 'pu_tip_mean', 'pu_tip_std',
'PULocationID', 'DOLocationID'
]
X = df[feature_cols].fillna(df[feature_cols].median())
y = df['tip_amount'].copy()
Richten Sie Kreuzvalidierungsaufteilungen ein, um die Modellleistung zuverlässig zu bewerten.
from sklearn.model_selection import KFold
import numpy as np
import time
from sklearn.metrics import mean_squared_error
from tqdm.notebook import tqdm
n_splits = 3
kf = KFold(n_splits=n_splits, shuffle=True, random_state=42)
1. XGBoost
XGBoost ist nativ GPU-beschleunigt. Übergeben Sie tree_method='hist' und device='cuda', um die GPU während des Trainings zu verwenden.
import xgboost as xgb
start_time = time.perf_counter()
def train_xgb_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# XGBoost handles GPU natively when tree_method='hist' and device='cuda'
model = xgb.XGBRegressor(
objective='reg:squarederror',
max_depth=5,
learning_rate=0.1,
n_estimators=100,
tree_method='hist',
device='cuda',
random_state=42
)
model.fit(X_train, y_train)
preds = model.predict(X_val)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
xgb_rmse, xgb_preds = train_xgb_cv(X, y)
print(f"\n{'XGBoost RMSE:':<20} ${xgb_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
2. Lineare Regression
Lineares Regressionsmodell trainieren Wenn %load_ext cuml.accel aktiv ist, wird LinearRegression automatisch der entsprechenden GPU zugeordnet.
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
start_time = time.perf_counter()
def train_linreg_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# Scale features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_val_scaled = scaler.transform(X_val)
# Automatically accelerated by cuML
model = LinearRegression()
model.fit(X_train_scaled, y_train)
preds = model.predict(X_val_scaled)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
linreg_rmse, linreg_preds = train_linreg_cv(X, y)
print(f"\n{'Linear Reg RMSE:':<20} ${linreg_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
3. Random Forest
Ensemble-Modell mit RandomForestRegressor trainieren. Das Training von baumbasierten Modellen auf der CPU dauert oft lange. Durch die GPU-Beschleunigung werden Millionen von Zeilen jedoch schneller verarbeitet.
from sklearn.ensemble import RandomForestRegressor
start_time = time.perf_counter()
def train_rf_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# Automatically accelerated by cuML
model = RandomForestRegressor(
n_estimators=100,
max_depth=10,
n_jobs=-1,
max_features='sqrt',
random_state=42
)
model.fit(X_train, y_train)
preds = model.predict(X_val)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
rf_rmse, rf_preds = train_rf_cv(X, y)
print(f"\n{'Random Forest RMSE:':<20} ${rf_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
10. End-to-End-Pipeline bewerten
Kombinieren Sie die Vorhersagen der drei Modelle mit einem einfachen linearen Ensemble. Dies führt in der Regel zu einer leichten Steigerung der Genauigkeit im Vergleich zu einzelnen Modellen.
Passen Sie eine lineare Regression an die Vorhersagen an, um die optimalen Gewichte zu ermitteln:
ensemble_weights = LinearRegression(positive=True, fit_intercept=False).fit(
np.c_[xgb_preds, rf_preds, linreg_preds], y
).coef_
# Normalize weights
ensemble_weights = ensemble_weights / ensemble_weights.sum()
ensemble_preds = np.c_[xgb_preds, rf_preds, linreg_preds] @ ensemble_weights
ensemble_rmse = np.sqrt(mean_squared_error(y, ensemble_preds))
Vergleichen Sie die Ergebnisse, um den Ensemble-Lift zu sehen:
print(f"\n{'Model':<20} {'RMSE':>10}")
print("-" * 32)
print(f"{'Linear Regression':<20} ${linreg_rmse:>9.4f}")
print(f"{'Random Forest':<20} ${rf_rmse:>9.4f}")
print(f"{'XGBoost':<20} ${xgb_rmse:>9.4f}")
print("-" * 32)
print(f"{'Ensemble':<20} ${ensemble_rmse:>9.4f}")
print(f"\nEnsemble lift: ${xgb_rmse - ensemble_rmse:.4f}")
11. CPU- und GPU-Leistung vergleichen
Um den Leistungsunterschied richtig zu messen, starten Sie den Kernel neu, um einen sauberen Ausführungsstatus zu gewährleisten, führen Sie die gesamte Data-Science-Pipeline auf der CPU aus und dann noch einmal auf der GPU.
Kernel neu starten
Führen Sie den Befehl IPython.Application.instance().kernel.do_shutdown(True) aus, um den Kernel neu zu starten und Speicher freizugeben.
import IPython
IPython.Application.instance().kernel.do_shutdown(True)
Data-Science-Pipeline definieren
Fassen Sie den Kern-Workflow (Daten laden, Datenbereinigung, Feature Engineering und Modelltraining) in einer einzigen Funktion zusammen. Diese Funktion akzeptiert ein Pandas-Modul pd_module und ein use_gpu-Argument, um zwischen Umgebungen zu wechseln.
def run_ml_pipeline(pd_module, use_gpu=False):
import time
import glob
import numpy as np
from sklearn.ensemble import RandomForestRegressor
import xgboost as xgb
timings = {}
# 1. Load Data
t0 = time.perf_counter()
df = pd_module.concat(
[pd_module.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")],
ignore_index=True
)
timings['Load Data'] = time.perf_counter() - t0
# 2. Clean Data
t0 = time.perf_counter()
# Filter for payment_type=1 (credit card) because tip amounts
# are only reliably recorded for credit card transactions.
df = df[
(df['fare_amount'] > 0) & (df['fare_amount'] < 500) &
(df['trip_distance'] > 0) & (df['trip_distance'] < 100) &
(df['tip_amount'] >= 0) & (df['tip_amount'] < 100) &
(df['payment_type'] == 1)
].copy()
# Downcast numeric columns to save memory
float_cols = df.select_dtypes(include=['float64']).columns
df[float_cols] = df[float_cols].astype('float32')
int_cols = df.select_dtypes(include=['int64']).columns
df[int_cols] = df[int_cols].astype('int32')
timings['Clean Data'] = time.perf_counter() - t0
# 3. Feature Engineering
t0 = time.perf_counter()
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['dow'] = df['tpep_pickup_datetime'].dt.dayofweek
df['is_weekend'] = (df['dow'] >= 5).astype(int)
df['fare_log'] = np.log1p(df['fare_amount'])
timings['Feature Engineering'] = time.perf_counter() - t0
# 4. Modeling Prep
feature_cols = ['trip_distance', 'fare_amount', 'passenger_count', 'hour', 'dow', 'is_weekend', 'fare_log']
X = df[feature_cols].fillna(df[feature_cols].median())
y = df['tip_amount'].copy()
# Free memory
del df
import gc
gc.collect()
# 5. Train Random Forest
t0 = time.perf_counter()
rf_model = RandomForestRegressor(
n_estimators=100,
max_depth=10,
n_jobs=-1,
max_features='sqrt',
random_state=42
).fit(X, y)
timings['Train Random Forest'] = time.perf_counter() - t0
# 6. Train XGBoost
t0 = time.perf_counter()
params = {
'objective': 'reg:squarederror',
'max_depth': 5,
'n_estimators': 100,
'random_state': 42
}
if use_gpu:
params['device'] = 'cuda'
params['tree_method'] = 'hist'
xgb_model = xgb.XGBRegressor(**params).fit(X, y)
timings['Train XGBoost'] = time.perf_counter() - t0
del X
del y
gc.collect()
return timings
Auf der CPU ausführen
Rufen Sie die Pipeline mit der Standard-CPU pandas auf.
import pandas as pd
print("Running pipeline on CPU...")
cpu_times = run_ml_pipeline(pd, use_gpu=False)
print("CPU Execution Finished.")
Auf Ihrer GPU ausführen
Laden Sie die NVIDIA-Bibliotheks-Erweiterungen, übergeben Sie das beschleunigte cudf.pandas-Modul an die Pipeline und legen Sie das XGBoost-Gerät intern auf cuda fest.
import IPython.core.magic
if not hasattr(IPython.core.magic, 'output_can_be_silenced'):
IPython.core.magic.output_can_be_silenced = lambda x: x
%load_ext cudf.pandas
%load_ext cuml.accel
import pandas as pd
print("Running pipeline on GPU...")
gpu_times = run_ml_pipeline(pd, use_gpu=True)
print("GPU Execution Finished.")
Leistungssteigerung visualisieren
Zeiten mit matplotlib visualisieren Die Ergebnisse zeigen, wie viel Zeit bei der Datenverarbeitung und beim Modelltraining durch die Verwendung von GPUs eingespart wurde.
import matplotlib.pyplot as plt
import numpy as np
labels = list(cpu_times.keys())
cpu_values = list(cpu_times.values())
gpu_values = list(gpu_times.values())
x = np.arange(len(labels))
width = 0.35
fig, ax = plt.subplots(figsize=(10, 6))
rects1 = ax.bar(x - width/2, cpu_values, width, label='CPU', color='#4285F4')
rects2 = ax.bar(x + width/2, gpu_values, width, label='GPU', color='#76B900')
ax.set_ylabel('Execution Time (seconds)')
ax.set_title('NYC Taxi ML Pipeline: CPU vs. GPU Performance')
ax.set_xticks(x)
ax.set_xticklabels(labels, rotation=45, ha="right")
ax.legend()
# Add data labels
def autolabel(rects):
for rect in rects:
height = rect.get_height()
ax.annotate(f'{height:.2f}s',
xy=(rect.get_x() + rect.get_width() / 2, height),
xytext=(0, 3), # 3 points vertical offset
textcoords="offset points",
ha='center', va='bottom', fontsize=9)
autolabel(rects1)
autolabel(rects2)
plt.tight_layout()
plt.show()
# Calculate overall speedup
total_cpu_time = sum(cpu_values)
total_gpu_time = sum(gpu_values)
overall_speedup = total_cpu_time / total_gpu_time
print(f"\nOverall Pipeline Speedup: {overall_speedup:.2f}x faster on GPU!")
Sie sollte etwa so aussehen:
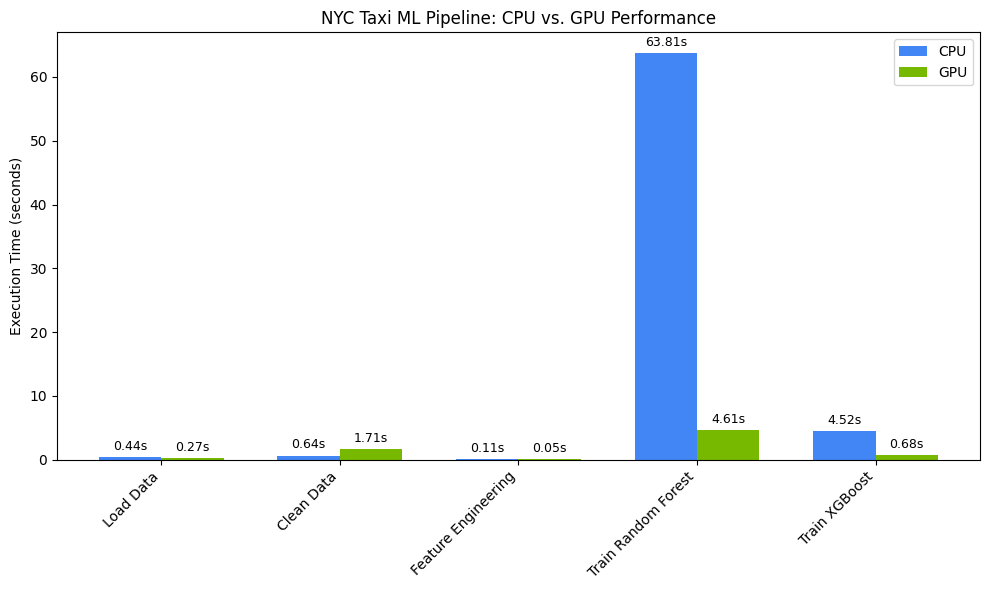
Dieses Diagramm veranschaulicht den erheblichen Leistungsvorteil der GPU über den gesamten Data-Science-Workflow hinweg. Die größten Zeitersparnisse sind während der rechenintensiven Modelltrainingsphasen für Algorithmen wie Random Forest und XGBoost zu erwarten.
12. Code profilieren, um Leistungsbeschränkungen zu finden
Bei Verwendung von cudf.pandas werden die meisten Funktionen auf der GPU ausgeführt. Wenn ein bestimmter Vorgang von cuDF noch nicht unterstützt wird, wird die Ausführung vorübergehend auf die CPU zurückgesetzt. NVIDIA bietet zwei integrierte Jupyter-Magic-Befehle, um diese Fallbacks zu identifizieren.
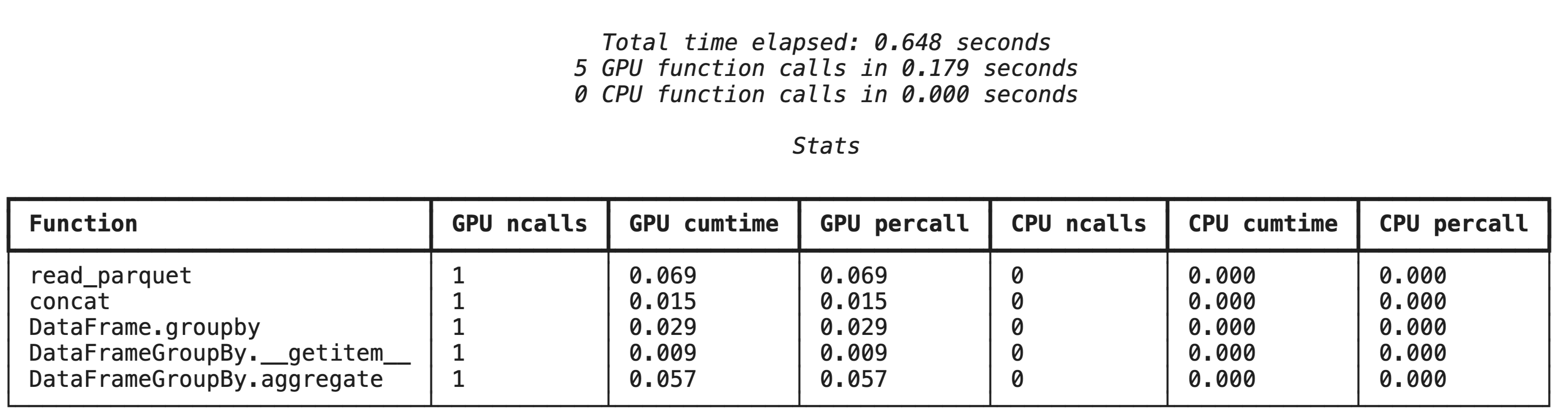
Profilübersicht mit %%cudf.pandas.profile
Der Magic-Befehl %%cudf.pandas.profile bietet eine Zusammenfassung der Funktionen, die auf der GPU oder CPU ausgeführt wurden.
%%cudf.pandas.profile
import glob
import pandas as pd
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")], ignore_index=True)
summary = (
df
.groupby(['PULocationID', 'payment_type'])
[['passenger_count', 'fare_amount', 'tip_amount']]
.agg(['min', 'mean', 'max'])
)
Zeilenweises Profiling mit %%cudf.pandas.line_profile
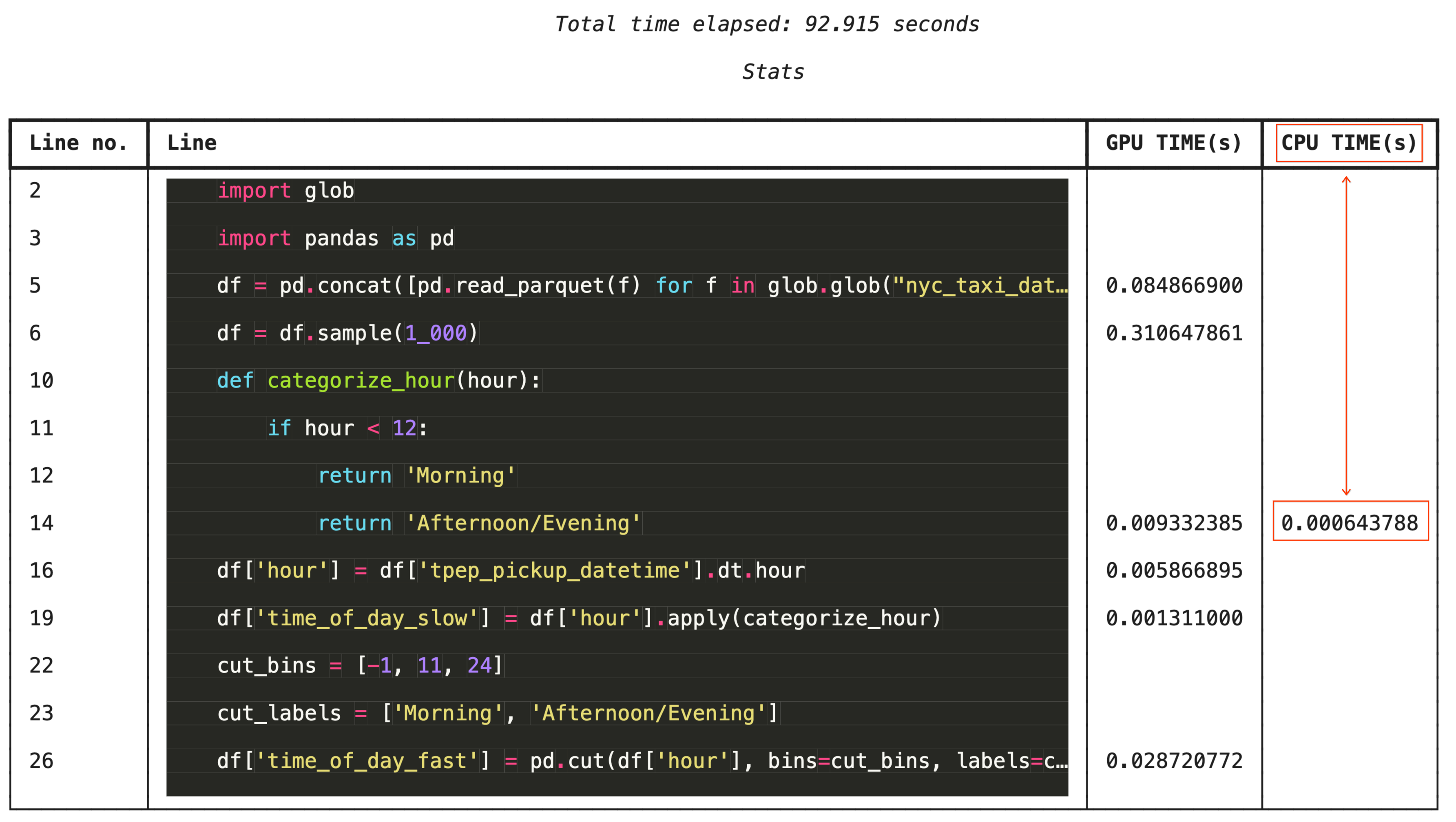
Für eine detaillierte Fehlerbehebung wird in %%cudf.pandas.line_profile jede Codezeile mit der Anzahl der Ausführungen auf der GPU im Vergleich zur CPU versehen.
%%cudf.pandas.line_profile
import glob
import pandas as pd
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")], ignore_index=True)
df = df.sample(1_000)
# Iterating row-by-row or using custom python apply functions often falls back to the CPU
def categorize_hour(hour):
if hour < 12:
return 'Morning'
else:
return 'Afternoon/Evening'
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['time_of_day_slow'] = df['hour'].apply(categorize_hour)
# Using vectorized pandas operations (like pd.cut) stays entirely on the GPU
cut_bins = [-1, 11, 24]
cut_labels = ['Morning', 'Afternoon/Evening']
df['time_of_day_fast'] = pd.cut(df['hour'], bins=cut_bins, labels=cut_labels)
13. Bereinigen
Um unerwartete Kosten für Ihr Google Cloud-Konto zu vermeiden, bereinigen Sie die Ressourcen, die Sie in diesem Codelab erstellt haben.
Ressourcen löschen
Löschen Sie das lokale Dataset in der Laufzeit mit dem Befehl !rm -rf in einer Notebookzelle.
print("Deleting local 'nyc_taxi_data' directory...")
!rm -rf nyc_taxi_data
print("Local files deleted.")
Colab-Laufzeit herunterfahren
- Rufen Sie in der Google Cloud Console die Colab Enterprise-Seite Laufzeiten auf.
- Wählen Sie im Menü Region die Region aus, in der sich Ihre Laufzeit befindet.
- Wählen Sie die Laufzeit aus, die Sie löschen möchten.
- Klicken Sie auf Löschen.
- Klicken Sie auf Bestätigen.
Notebook löschen
- Rufen Sie in der Google Cloud Console die Colab Enterprise-Seite Meine Notebooks auf.
- Wählen Sie im Menü Region die Region aus, in der sich Ihr Notebook befindet.
- Wählen Sie das Notebook aus, das Sie löschen möchten.
- Klicken Sie auf Löschen.
- Klicken Sie auf Bestätigen.
14. Glückwunsch
Glückwunsch! Sie haben einen pandas- und scikit-learn-Workflow für maschinelles Lernen mit den NVIDIA-Bibliotheken cuDF und cuML in Colab Enterprise beschleunigt. Wenn Sie einfach ein paar Magic-Befehle (%load_ext cudf.pandas und %load_ext cuml.accel) hinzufügen, wird Ihr Standardcode auf der GPU ausgeführt, wobei Datensätze verarbeitet und komplexe Modelle lokal in einem Bruchteil der Zeit angepasst werden.
Weitere Informationen zur GPU-Beschleunigung für die Datenanalyse finden Sie im Codelab Accelerated Data Analytics with GPUs.
Behandelte Themen
- Colab Enterprise in Google Cloud
- Anpassen einer Colab-Laufzeitumgebung mit bestimmten GPU- und Arbeitsspeicherkonfigurationen.
- GPU-Beschleunigung anwenden, um Trinkgeldbeträge anhand von Millionen von Datensätzen aus einem NYC-Taxi-Dataset vorherzusagen.
pandasmit dercuDF-Bibliothek von NVIDIA ohne Codeänderungen beschleunigen.scikit-learnmit dercuML-Bibliothek und GPUs von NVIDIA beschleunigen, ohne dass Codeänderungen erforderlich sind.- Erstellen von Profilen für Ihren Code, um Leistungsbeschränkungen zu identifizieren und zu optimieren.