
1. Introducción
En este codelab, aprenderás a acelerar tus flujos de trabajo de ciencia de datos y aprendizaje automático en conjuntos de datos grandes con las GPU de NVIDIA y las bibliotecas de código abierto en Google Cloud. Comenzarás por configurar tu infraestructura y, luego, explorarás cómo aplicar la aceleración por GPU.
Te enfocarás en el ciclo de vida de la ciencia de datos, desde la preparación de datos con pandas hasta el entrenamiento de modelos con scikit-learn y XGBoost. Aprenderás a acelerar estas tareas con las bibliotecas cuDF y cuML de NVIDIA. Lo mejor es que puedes obtener esta aceleración de GPU sin cambiar tu código existente de pandas o scikit-learn.
Qué aprenderás
- Comprende Colab Enterprise en Google Cloud.
- Personaliza un entorno de ejecución de Colab con configuraciones específicas de GPU y memoria.
- Aplicar la aceleración por GPU para predecir los importes de las propinas con millones de registros de un conjunto de datos de taxis de NYC
- Acelera
pandassin cambiar el código con la bibliotecacuDFde NVIDIA. - Acelera
scikit-learnsin cambiar el código con la bibliotecacuMLy las GPUs de NVIDIA. - Crea perfiles de tu código para identificar y optimizar las restricciones de rendimiento.
En la siguiente página, se incluyen los créditos que puedes usar para completar el lab.
2. ¿Por qué acelerar el aprendizaje automático?
La necesidad de iterar más rápido en el AA
La preparación de datos lleva mucho tiempo, y el entrenamiento o la evaluación de modelos pueden llevar aún más tiempo a medida que crecen los conjuntos de datos. Entrenar modelos como los de bosque aleatorio o XGBoost en millones de filas con una CPU puede tardar horas o días.
El uso de GPUs acelera estas ejecuciones de entrenamiento con bibliotecas como cuML y XGBoost acelerado por GPU. Esta aceleración te permite hacer lo siguiente:
- Itera más rápido: Prueba rápidamente nuevas funciones e hiperparámetros.
- Entrena con conjuntos de datos completos: Usa tus datos completos en lugar de reducir la cantidad de muestras para obtener una mejor precisión.
- Reduce los costos: Completa cargas de trabajo pesadas en menos tiempo para reducir los costos de procesamiento.
3. Configuración y requisitos
Costos potenciales
En este codelab, se usan recursos de Google Cloud, incluidos los tiempos de ejecución de Colab Enterprise con GPUs NVIDIA L4. Ten en cuenta los posibles cargos y sigue la sección Realiza una limpieza al final del codelab para cerrar los recursos y evitar la facturación continua. Para obtener información detallada sobre los precios, consulta Precios de Colab Enterprise y Precios de GPU.
Antes de comenzar
Se supone que tienes un conocimiento intermedio de Python, pandas, scikit-learn y prácticas estándar de aprendizaje automático (como la validación cruzada o el ensamblado).
- En la página del selector de proyectos de Google Cloud Console, selecciona o crea un proyecto de Google Cloud.
- Asegúrate de que la facturación esté habilitada para tu proyecto de Google Cloud.
Habilita las APIs
Para usar Colab Enterprise, primero debes habilitar las APIs necesarias.
- Para abrir Google Cloud Shell, haz clic en el ícono de Cloud Shell en la parte superior derecha de la consola de Google Cloud.

- En Cloud Shell, reemplaza
PROJECT_IDpor tu ID del proyecto para establecerlo:
gcloud config set project <PROJECT_ID>
- Ejecuta el siguiente comando para habilitar las APIs necesarias:
gcloud services enable \
compute.googleapis.com \
dataform.googleapis.com \
notebooks.googleapis.com \
aiplatform.googleapis.com
Si la ejecución se realiza correctamente, deberías ver un mensaje similar al que se muestra a continuación:
Operation "operations/..." finished successfully.
4. Cómo elegir un entorno de notebook
Si bien muchos científicos de datos conocen Colab para proyectos personales, Colab Enterprise proporciona una experiencia de notebook segura, colaborativa e integrada diseñada para empresas.
En Google Cloud, tienes dos opciones principales para los entornos de notebooks administrados: Colab Enterprise y Gemini Enterprise Agent Platform Workbench. La elección correcta depende de las prioridades de tu proyecto.
Cuándo usar Agent Platform Workbench
Elige Agent Platform Workbench cuando tu prioridad sea el control y la personalización profunda. Es la opción ideal si necesitas hacer lo siguiente:
- Administrar la infraestructura subyacente y el ciclo de vida de la máquina
- Usar contenedores personalizados y configuraciones de red
- Integración con canalizaciones de MLOps y herramientas personalizadas del ciclo de vida
Cuándo usar Colab Enterprise
Elige Colab Enterprise cuando tu prioridad sea la configuración rápida, la facilidad de uso y la colaboración segura. Es una solución completamente administrada que permite que tu equipo se enfoque en el análisis en lugar de la infraestructura.
Colab Enterprise te ayuda a hacer lo siguiente:
- Desarrolla flujos de trabajo de ciencia de datos que estén estrechamente vinculados a tu almacén de datos. Puedes abrir y administrar tus notebooks directamente en BigQuery Studio.
- Entrena modelos de aprendizaje automático y realiza integraciones con herramientas de MLOps en Agent Platform.
- Disfruta de una experiencia flexible y unificada. Un notebook de Colab Enterprise creado en BigQuery se puede abrir y ejecutar en Agent Platform, y viceversa.
Laboratorio de hoy
En este codelab, se usa Colab Enterprise para acelerar el aprendizaje automático.
Para obtener más información sobre las diferencias, consulta la documentación oficial sobre cómo elegir la solución de notebook adecuada.
5. Configura una plantilla de entorno de ejecución
En Colab Enterprise, conéctate a un entorno de ejecución basado en una plantilla de entorno de ejecución preconfigurada.
Una plantilla de tiempo de ejecución es una configuración reutilizable que especifica el entorno de tu notebook, lo que incluye lo siguiente:
- Tipo de máquina (CPU, memoria)
- Acelerador (tipo y recuento de GPU)
- Tamaño y tipo de disco
- Configuración de red y políticas de seguridad
- Reglas de cierre automático por inactividad
Por qué son útiles las plantillas de tiempo de ejecución
- Coherencia: Tú y tu equipo obtienen el mismo entorno para garantizar que el trabajo sea repetible.
- Seguridad: Las plantillas aplican las políticas de seguridad de la organización.
- Administración de costos: Los recursos tienen un tamaño predeterminado en la plantilla para ayudar a evitar costos accidentales.
Crea una plantilla de entorno de ejecución
Configura una plantilla de entorno de ejecución reutilizable para el lab.
- En la consola de Google Cloud, ve al menú de navegación > Agent Platform > Notebooks.
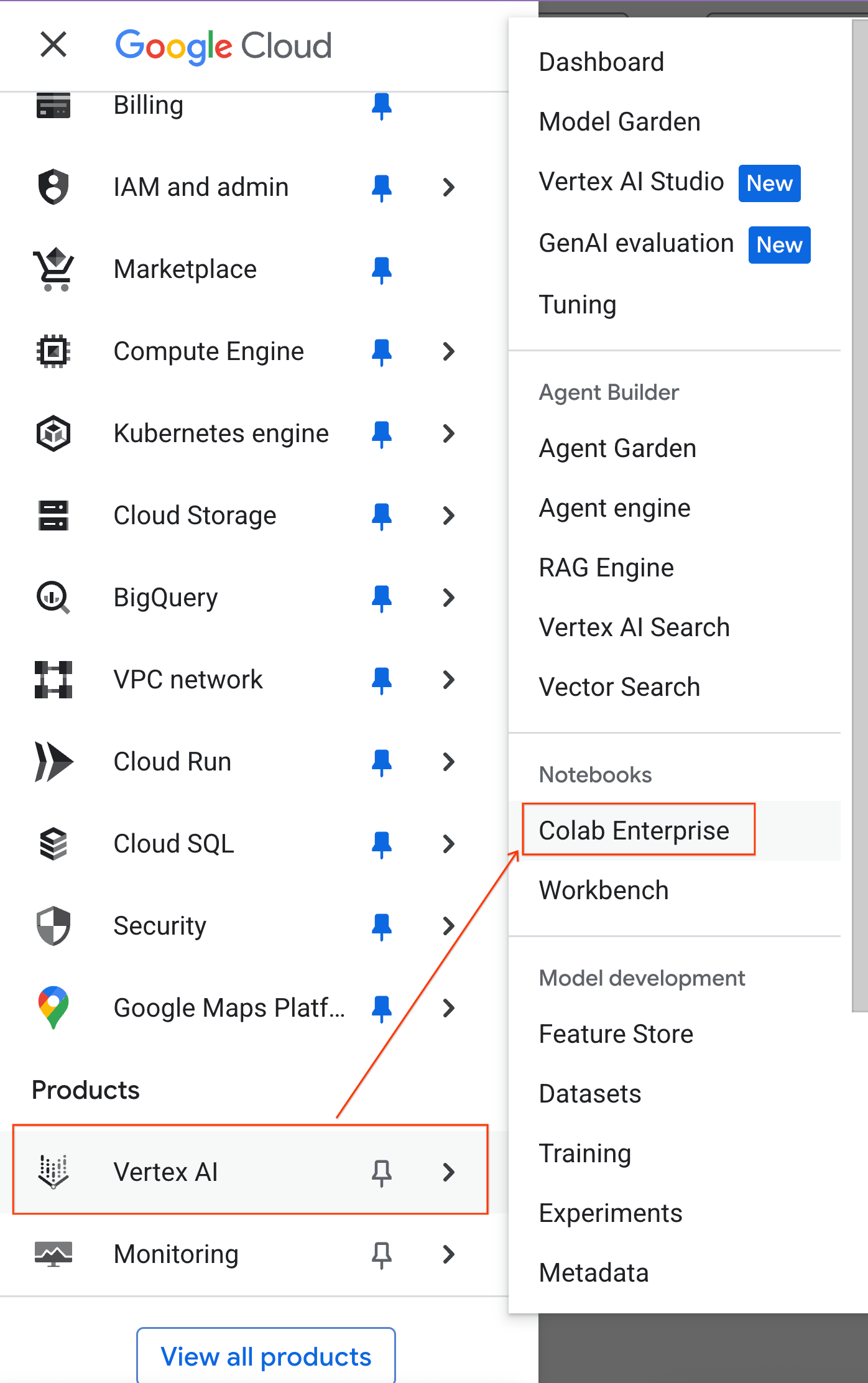
- En Colab Enterprise, haz clic en Plantillas de entorno de ejecución y, luego, selecciona Plantilla nueva.
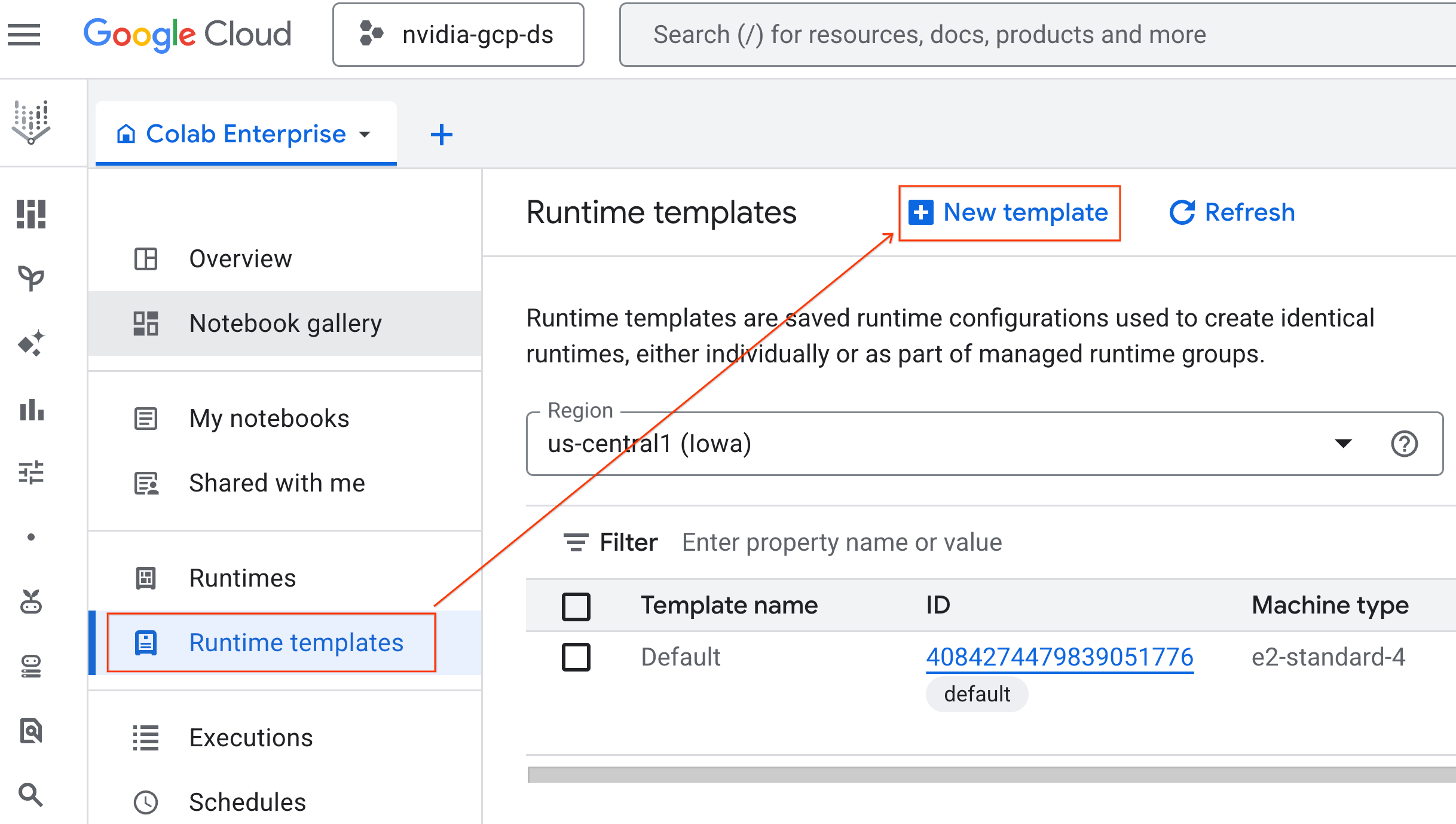
- En Conceptos básicos del entorno de ejecución, haz lo siguiente:
- Establece el Nombre visible como
gpu-template. - Establece tu región preferida.
- Establece el Nombre visible como
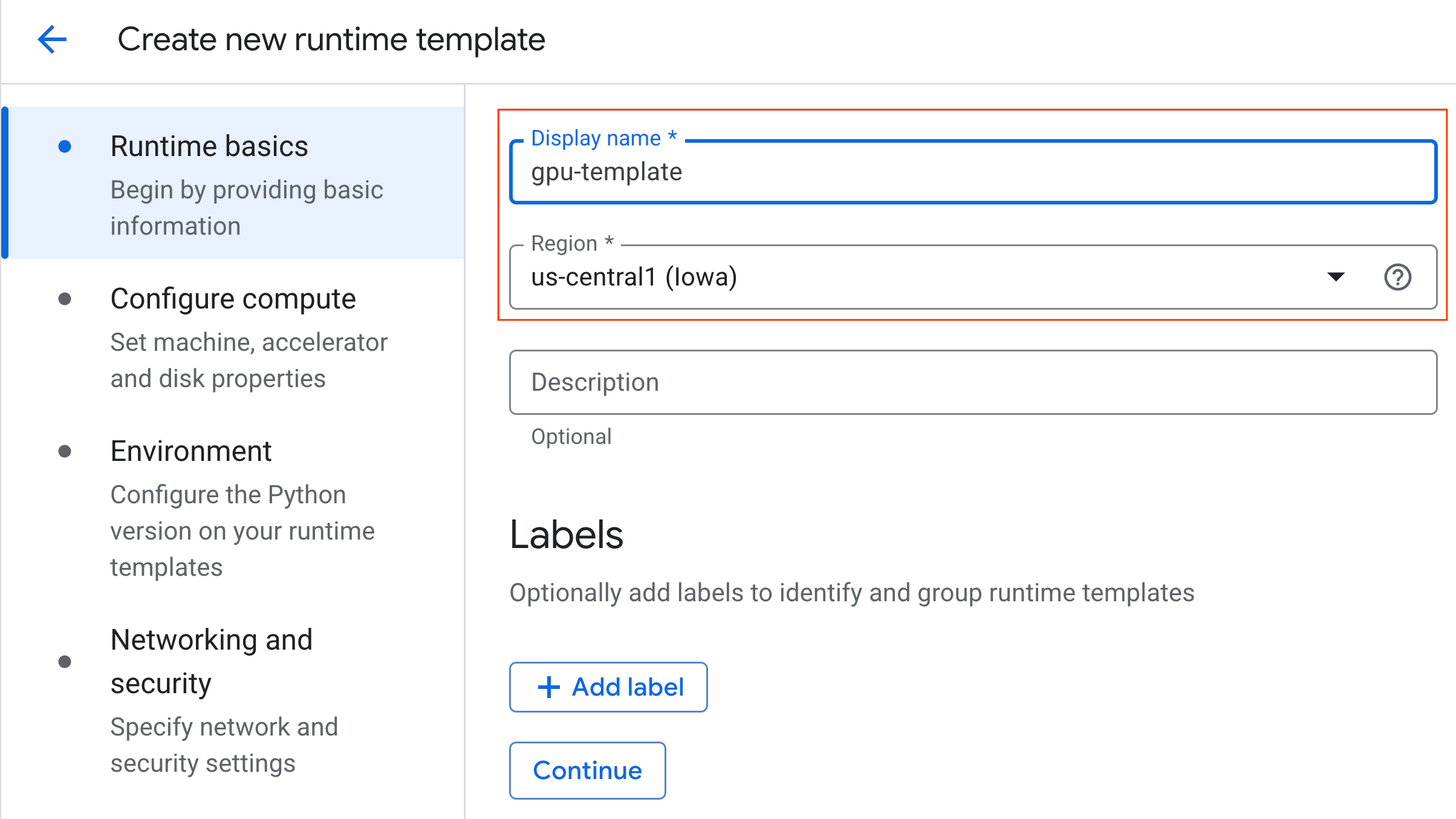
- En Configurar recursos de procesamiento, haz lo siguiente:
- Establece el Tipo de máquina en
g2-standard-4. - Mantén el Tipo de acelerador predeterminado como
NVIDIA L4con un Recuento de aceleradores de 1. - Cambia la opción Cierre inactivo a 60 minutos.
- Haz clic en Continuar.
- Establece el Tipo de máquina en
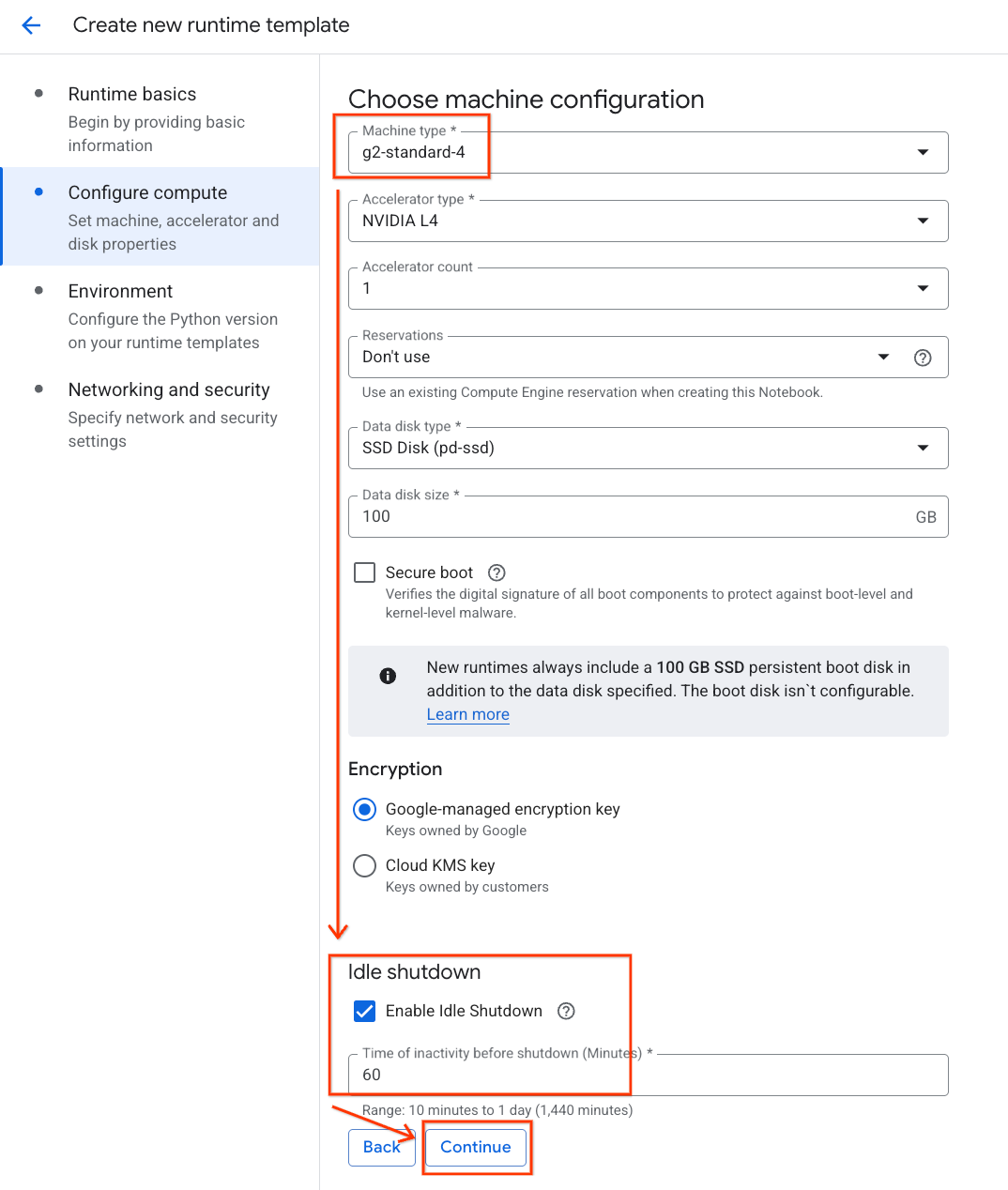
- En Environment, haz lo siguiente:
- Configura Environment como
Python 3.11.
- Configura Environment como
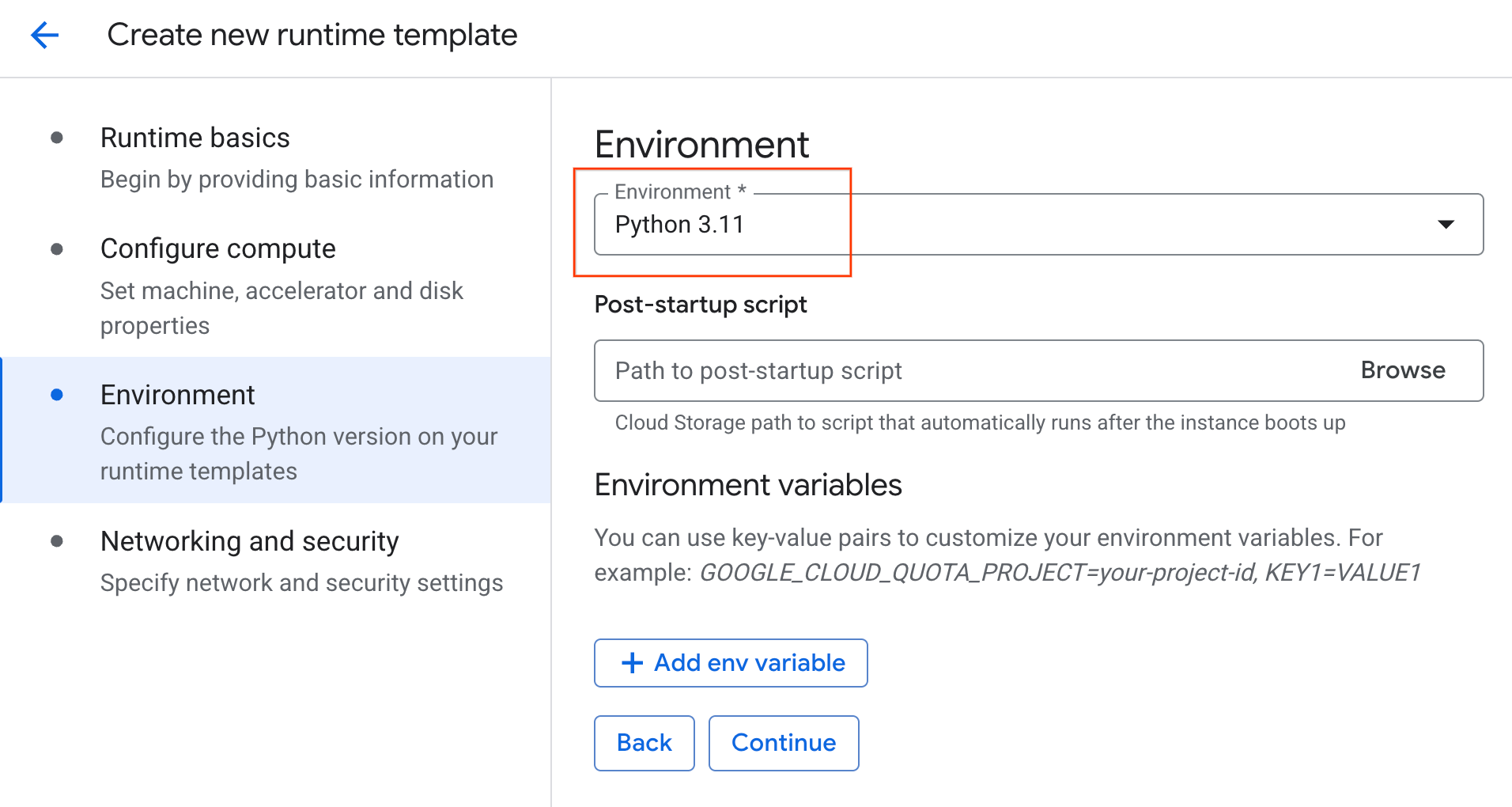
- Haz clic en Crear para guardar la plantilla de entorno de ejecución. En la página Plantillas de entorno de ejecución, ahora debería aparecer la plantilla nueva.
6. Inicia un entorno de ejecución
Cuando la plantilla esté lista, podrás crear un nuevo tiempo de ejecución.
- En Colab Enterprise, haz clic en Tiempos de ejecución y, luego, selecciona Crear.
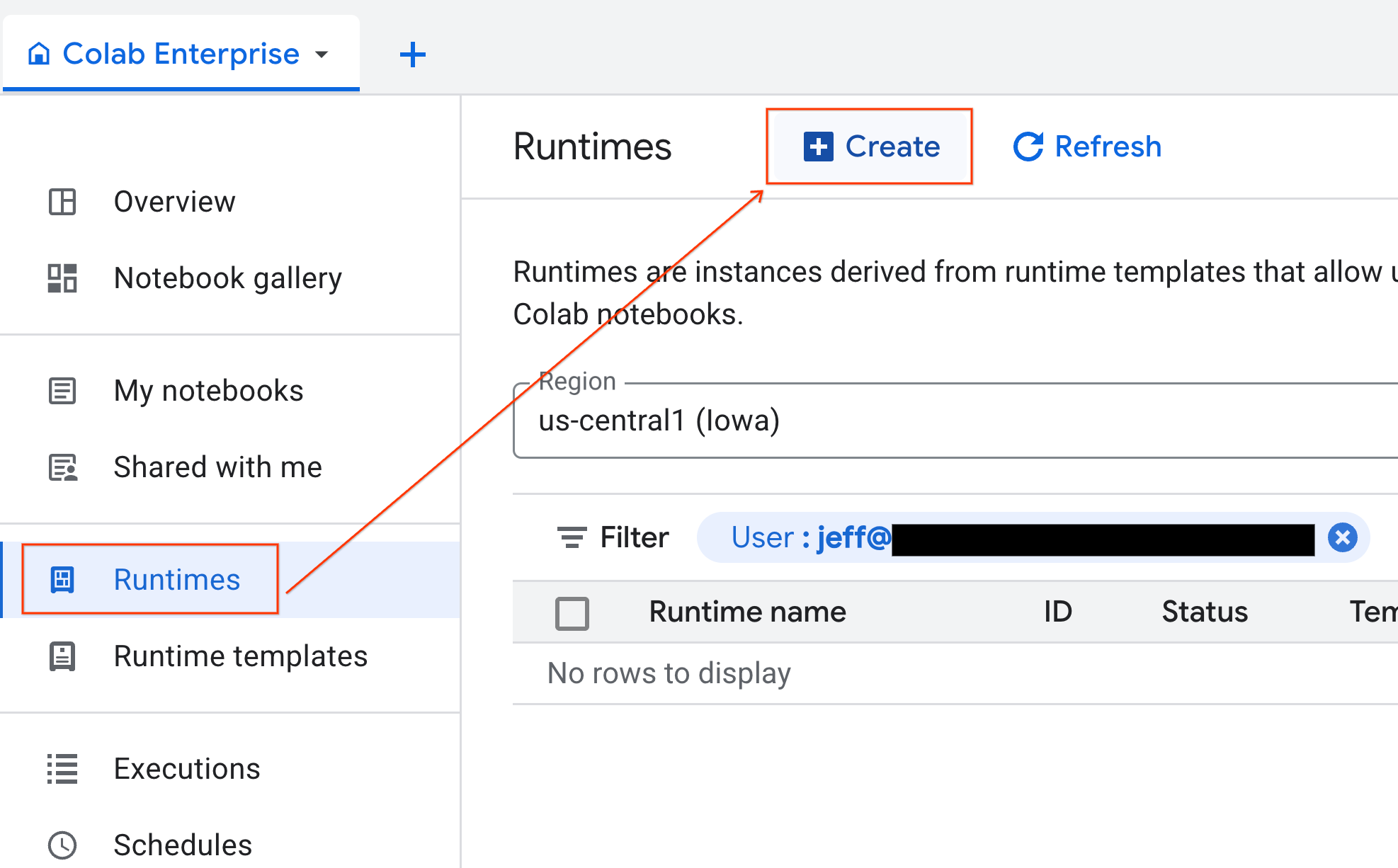
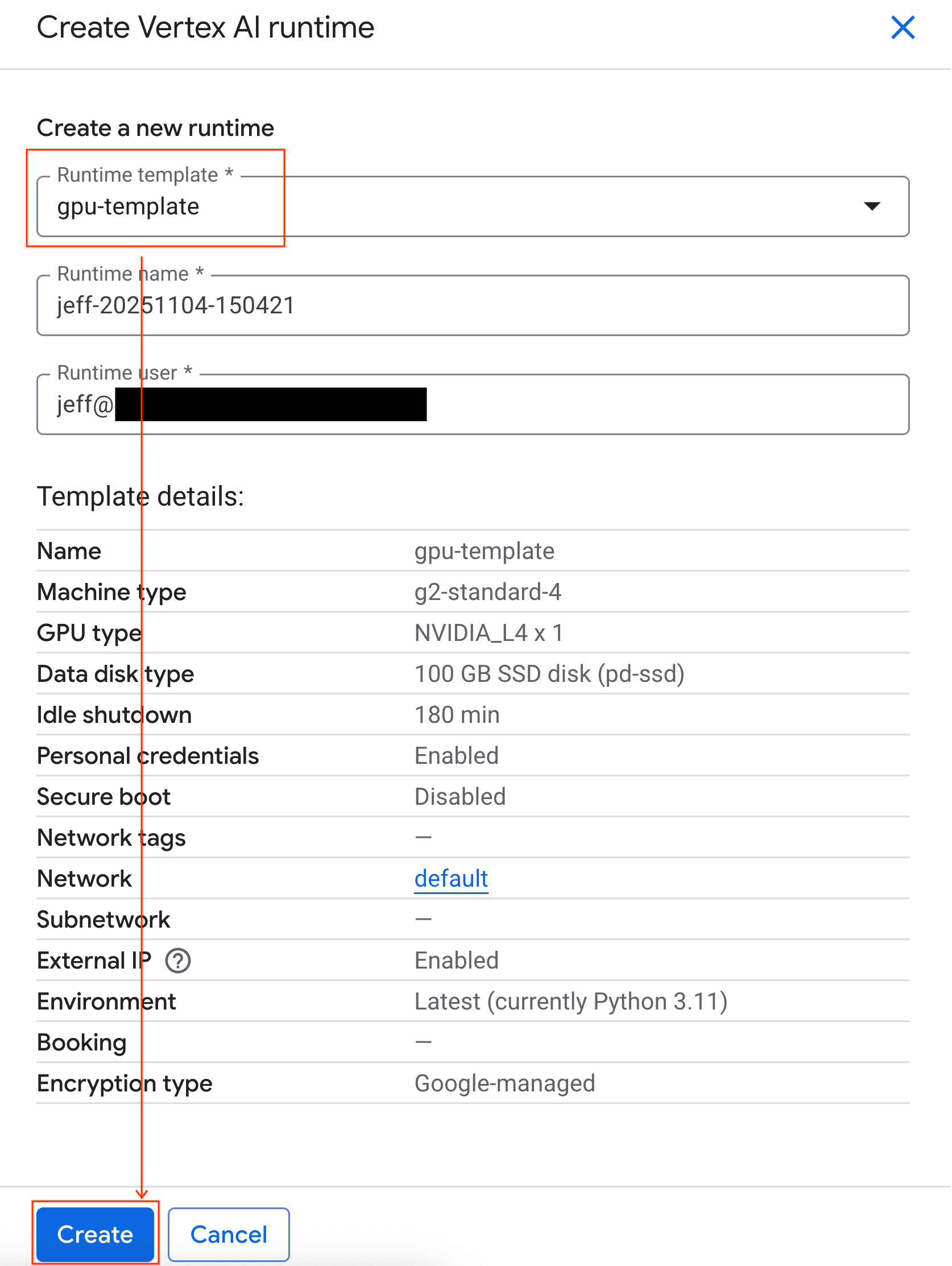
- En Plantilla de entorno de ejecución, selecciona la opción
gpu-template. Haz clic en Crear y espera a que se inicie el entorno de ejecución.
- Después de unos minutos, verás el tiempo de ejecución disponible.
7. Configura el notebook
Ahora que tu infraestructura está en funcionamiento, debes importar el notebook del lab y conectarlo a tu entorno de ejecución.
Importa el notebook
- En Colab Enterprise, haz clic en Mis notebooks y, luego, en Importar.
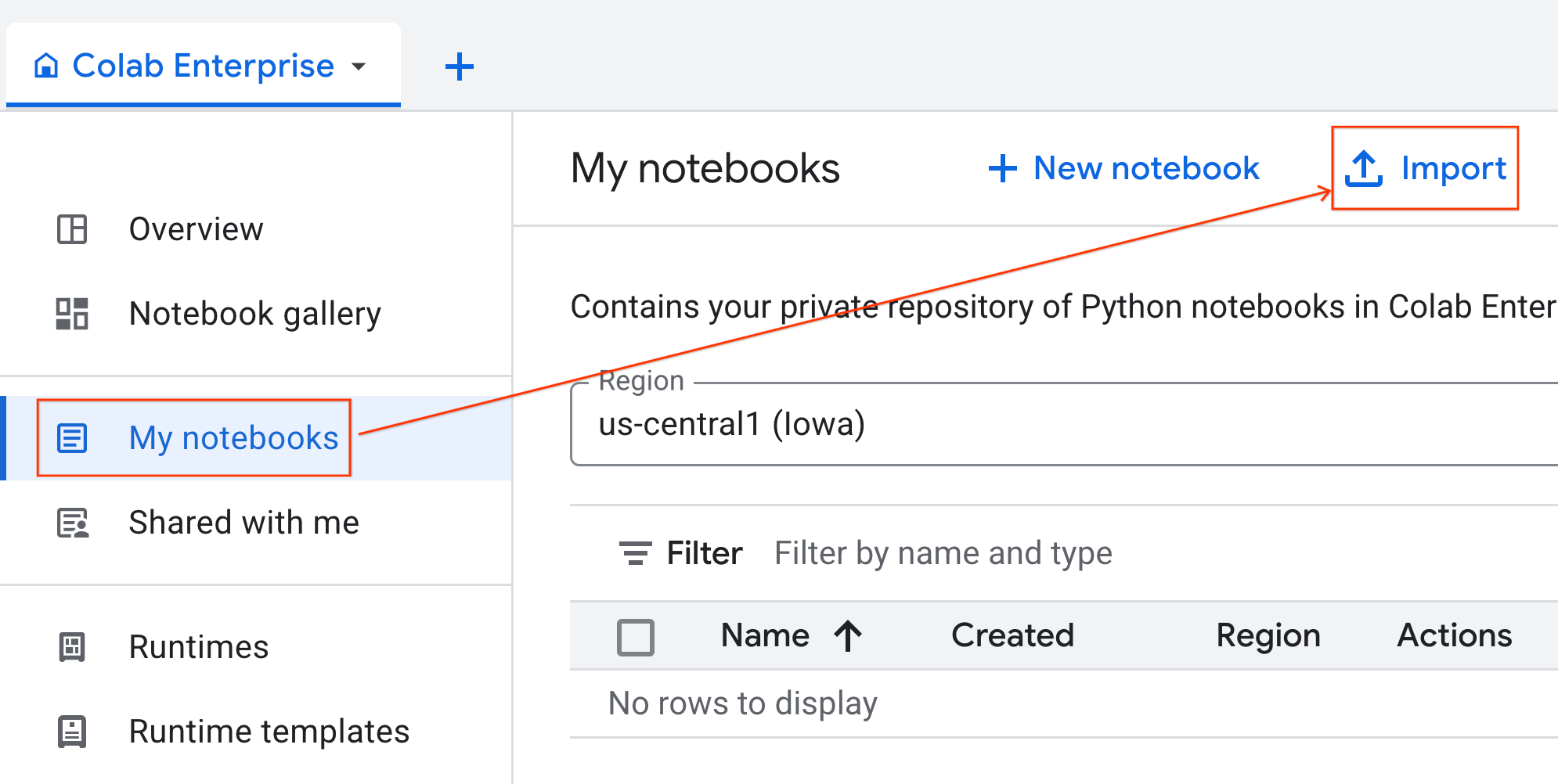
- Selecciona el botón de selección URL y, luego, ingresa la siguiente URL:
https://github.com/GoogleCloudPlatform/ai-ml-recipes/blob/main/notebooks/regression/gpu_accelerated_regression/gpu_accelerated_regression.ipynb
- Haz clic en Importar. Colab Enterprise copiará el notebook de GitHub a tu entorno.
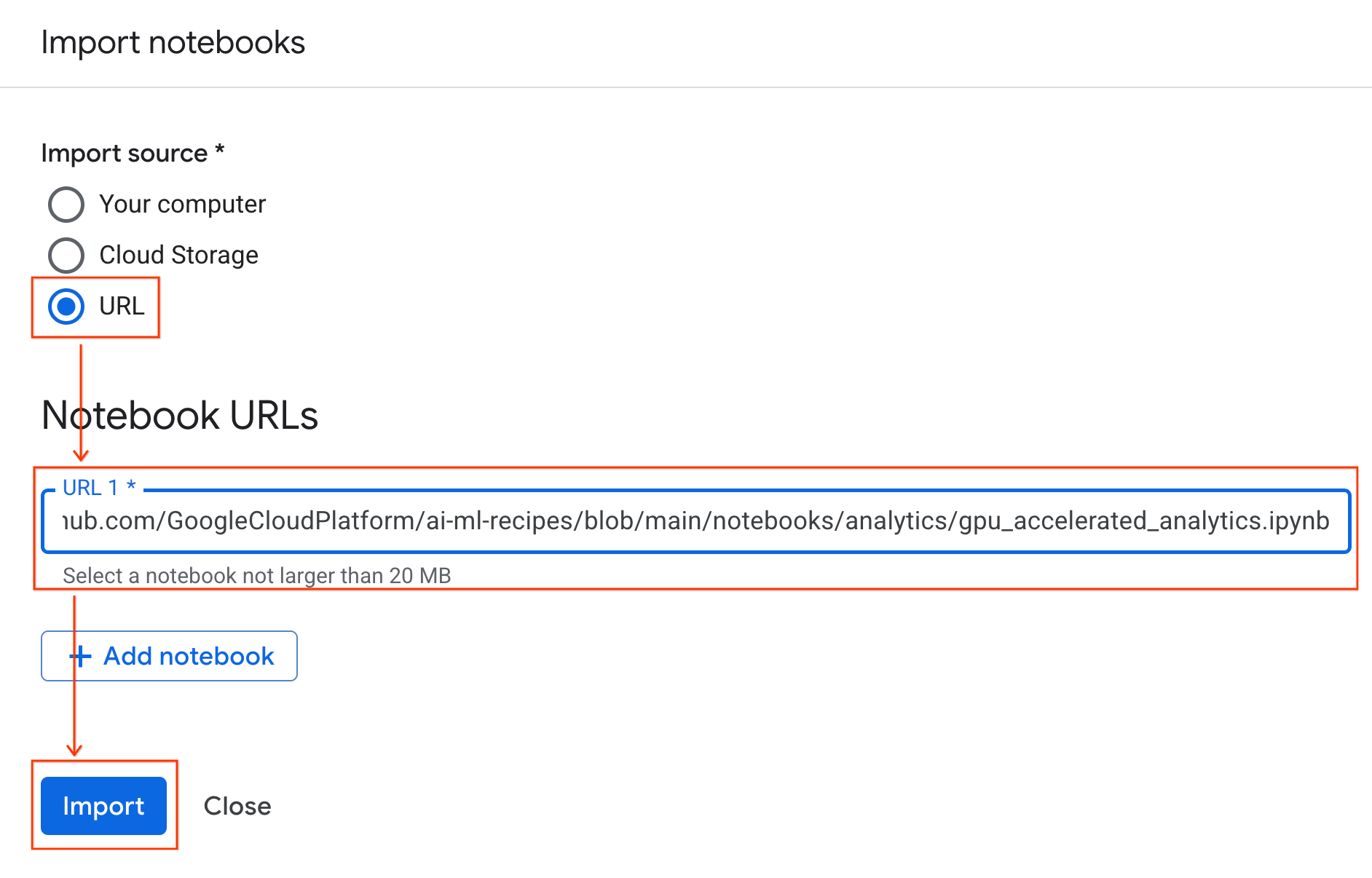
Conéctate al entorno de ejecución
- Abre el notebook que acabas de importar.
- Haz clic en la flecha hacia abajo junto a Conectar.
- Selecciona Conectar a un entorno de ejecución.
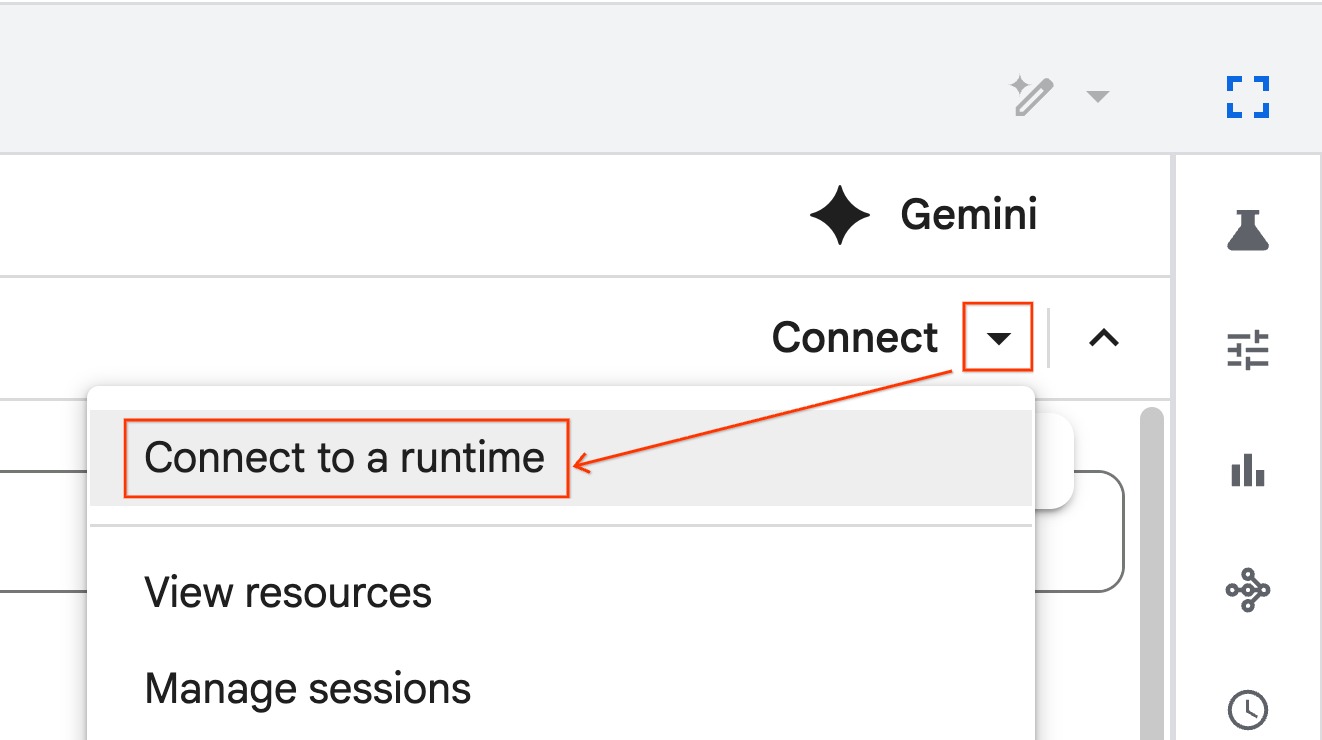
- Usa el menú desplegable y selecciona el tiempo de ejecución que creaste antes.
- Haz clic en Conectar.
Tu notebook ahora está conectado a un entorno de ejecución habilitado para GPU.
Dependencias integradas
Un beneficio de usar Colab Enterprise es que viene preinstalado con las bibliotecas que necesitas. No es necesario que instales ni administres manualmente dependencias como cuDF, cuML o XGBoost para este lab.
8. Prepara el conjunto de datos de taxis de la ciudad de Nueva York
En este codelab, se utilizan los datos de registros de viajes de la Comisión de Taxis y Limusinas (TLC) de la Ciudad de Nueva York. El conjunto de datos contiene registros de viajes en taxis amarillos en la ciudad de Nueva York, incluidos los siguientes:
- Fechas, horarios y ubicaciones de partida y llegada
- Distancias de los viajes
- Importes de la tarifa desglosados
- Recuentos de pasajeros
- Importes de propinas (esto es lo que predeciremos)
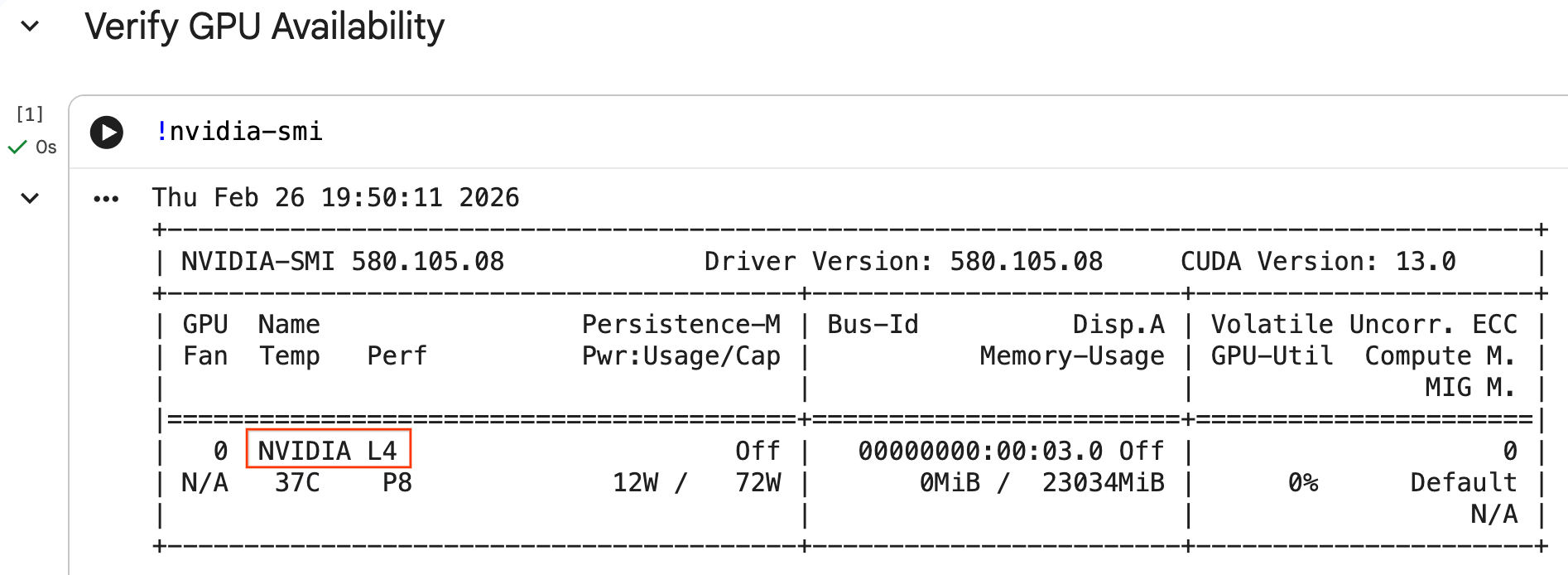
Configura la GPU y confirma su disponibilidad
Para confirmar que se reconoce la GPU, ejecuta el comando nvidia-smi. Se muestran la versión del controlador y los detalles de la GPU (como la NVIDIA L4).
nvidia-smi
La celda debería devolver la GPU adjunta a tu entorno de ejecución, similar a lo siguiente:
Descarga los datos
Descarga los datos de viajes del 2024.
from tqdm import tqdm
import requests
import time
import os
YEAR = 2024
DATA_DIR = "nyc_taxi_data"
os.makedirs(DATA_DIR, exist_ok=True)
print(f"Checking/Downloading files for {YEAR}...")
for month in tqdm(range(1, 13), unit="file"):
file_name = f"yellow_tripdata_{YEAR}-{month:02d}.parquet"
local_path = os.path.join(DATA_DIR, file_name)
url = f"https://d37ci6vzurychx.cloudfront.net/trip-data/{file_name}"
if not os.path.exists(local_path):
try:
with requests.get(url, stream=True) as response:
response.raise_for_status()
with open(local_path, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
time.sleep(1)
except requests.exceptions.HTTPError as e:
print(f"\nSkipping {file_name}: {e}")
if os.path.exists(local_path):
os.remove(local_path)
print("\nDownload complete.")
Acelera pandas con NVIDIA cuDF
La biblioteca pandas se ejecuta en la CPU y puede ser lenta con grandes conjuntos de datos. El comando mágico %load_ext cudf.pandas de NVIDIA aplica parches de forma dinámica a pandas para usar la aceleración por GPU y recurre a la CPU si es necesario.
Usamos este comando mágico en lugar de una importación estándar porque proporciona una aceleración de "cero cambios en el código". No tienes que volver a escribir el código existente. Un comando similar, %load_ext cuml.accel, hace exactamente lo mismo para scikit-learn models. Esto funciona en cualquier entorno de Jupyter con una GPU de NVIDIA compatible, no solo en Colab Enterprise.
%load_ext cudf.pandas
Para verificar que esté activo, importa pandas y verifica su tipo:
import pandas as pd
pd
El resultado confirmará que ahora usas el módulo cudf.pandas.
Carga y limpia los datos
Con cudf.pandas activo, carga los archivos Parquet y ejecuta la limpieza de datos. Este proceso se ejecuta automáticamente en la GPU.
import glob
# Load data into memory
df = pd.concat(
[pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")],
ignore_index=True
)
# Filter for valid trips. We filter for payment_type=1 (credit card)
# because tip amounts are only reliably recorded for credit card transactions.
df = df[
(df['fare_amount'] > 0) & (df['fare_amount'] < 500) &
(df['trip_distance'] > 0) & (df['trip_distance'] < 100) &
(df['tip_amount'] >= 0) & (df['tip_amount'] < 100) &
(df['payment_type'] == 1)
].copy()
# Downcast numeric columns to save memory
float_cols = df.select_dtypes(include=['float64']).columns
df[float_cols] = df[float_cols].astype('float32')
int_cols = df.select_dtypes(include=['int64']).columns
df[int_cols] = df[int_cols].astype('int32')
Ingeniería de atributos
Crea atributos derivados a partir de la fecha y hora de retiro. El notebook contiene otras funciones que se usan en pasos posteriores.
import numpy as np
# Time Features
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['dow'] = df['tpep_pickup_datetime'].dt.dayofweek
df['is_weekend'] = (df['dow'] >= 5).astype(int)
df['is_rush_hour'] = (
((df['hour'] >= 7) & (df['hour'] <= 9)) |
((df['hour'] >= 17) & (df['hour'] <= 19))
).astype(int)
...
# Other features
...
9. Entrena modelos individuales con validación cruzada
Para mostrar cómo la GPU puede acelerar el aprendizaje automático, entrenarás tres tipos diferentes de modelos de regresión para predecir el tip_amount de un viaje en taxi.
Acelera scikit-learn con NVIDIA cuML
Ejecuta algoritmos de scikit-learn en la GPU con cuML de NVIDIA sin cambiar las llamadas a la API. Primero, carga la extensión cuml.accel.
%load_ext cuml.accel
Configura funciones y objetivos
Identifica las características de las que deseas que aprenda el modelo y divide la columna de destino (tip_amount).
feature_cols = [
'trip_distance', 'fare_amount', 'passenger_count',
'hour', 'dow', 'is_weekend', 'is_rush_hour',
'fare_log', 'fare_decimal', 'is_round_fare',
'route_frequency', 'pu_tip_mean', 'pu_tip_std',
'PULocationID', 'DOLocationID'
]
X = df[feature_cols].fillna(df[feature_cols].median())
y = df['tip_amount'].copy()
Configura divisiones de validación cruzada para evaluar de forma sólida el rendimiento del modelo.
from sklearn.model_selection import KFold
import numpy as np
import time
from sklearn.metrics import mean_squared_error
from tqdm.notebook import tqdm
n_splits = 3
kf = KFold(n_splits=n_splits, shuffle=True, random_state=42)
1. XGBoost
XGBoost se acelera de forma nativa con la GPU. Pasa tree_method='hist' y device='cuda' para usar la GPU durante el entrenamiento.
import xgboost as xgb
start_time = time.perf_counter()
def train_xgb_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# XGBoost handles GPU natively when tree_method='hist' and device='cuda'
model = xgb.XGBRegressor(
objective='reg:squarederror',
max_depth=5,
learning_rate=0.1,
n_estimators=100,
tree_method='hist',
device='cuda',
random_state=42
)
model.fit(X_train, y_train)
preds = model.predict(X_val)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
xgb_rmse, xgb_preds = train_xgb_cv(X, y)
print(f"\n{'XGBoost RMSE:':<20} ${xgb_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
2. Regresión lineal
Entrena un modelo de regresión lineal. Con %load_ext cuml.accel activo, LinearRegression se asigna automáticamente a su equivalente de GPU.
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
start_time = time.perf_counter()
def train_linreg_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# Scale features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_val_scaled = scaler.transform(X_val)
# Automatically accelerated by cuML
model = LinearRegression()
model.fit(X_train_scaled, y_train)
preds = model.predict(X_val_scaled)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
linreg_rmse, linreg_preds = train_linreg_cv(X, y)
print(f"\n{'Linear Reg RMSE:':<20} ${linreg_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
3. Bosque aleatorio
Entrena un modelo de ensamble con RandomForestRegressor. Los modelos basados en árboles suelen tardar en entrenarse en la CPU, pero la aceleración de la GPU procesa millones de filas más rápido.
from sklearn.ensemble import RandomForestRegressor
start_time = time.perf_counter()
def train_rf_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# Automatically accelerated by cuML
model = RandomForestRegressor(
n_estimators=100,
max_depth=10,
n_jobs=-1,
max_features='sqrt',
random_state=42
)
model.fit(X_train, y_train)
preds = model.predict(X_val)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
rf_rmse, rf_preds = train_rf_cv(X, y)
print(f"\n{'Random Forest RMSE:':<20} ${rf_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
10. Evalúa la canalización de extremo a extremo
Combina las predicciones de los tres modelos con un ensamble lineal simple. Por lo general, esto proporciona un ligero aumento de la precisión en comparación con los modelos individuales.
Ajusta una regresión lineal en las predicciones para encontrar los pesos óptimos:
ensemble_weights = LinearRegression(positive=True, fit_intercept=False).fit(
np.c_[xgb_preds, rf_preds, linreg_preds], y
).coef_
# Normalize weights
ensemble_weights = ensemble_weights / ensemble_weights.sum()
ensemble_preds = np.c_[xgb_preds, rf_preds, linreg_preds] @ ensemble_weights
ensemble_rmse = np.sqrt(mean_squared_error(y, ensemble_preds))
Compara los resultados para ver la efectividad del conjunto:
print(f"\n{'Model':<20} {'RMSE':>10}")
print("-" * 32)
print(f"{'Linear Regression':<20} ${linreg_rmse:>9.4f}")
print(f"{'Random Forest':<20} ${rf_rmse:>9.4f}")
print(f"{'XGBoost':<20} ${xgb_rmse:>9.4f}")
print("-" * 32)
print(f"{'Ensemble':<20} ${ensemble_rmse:>9.4f}")
print(f"\nEnsemble lift: ${xgb_rmse - ensemble_rmse:.4f}")
11. Comparar el rendimiento de la CPU y la GPU
Para comparar correctamente la diferencia de rendimiento, reiniciarás el kernel para garantizar un estado de ejecución limpio, ejecutarás toda la canalización de ciencia de datos en la CPU y, luego, la volverás a ejecutar en la GPU.
Reinicia el kernel
Ejecuta el comando IPython.Application.instance().kernel.do_shutdown(True) para reiniciar el kernel y liberar memoria.
import IPython
IPython.Application.instance().kernel.do_shutdown(True)
Define la canalización de ciencia de datos
Encapsula el flujo de trabajo principal (carga de datos, limpieza, ingeniería de atributos y entrenamiento del modelo) en una sola función. Esta función acepta un módulo de pandas pd_module y un argumento use_gpu para cambiar entre entornos.
def run_ml_pipeline(pd_module, use_gpu=False):
import time
import glob
import numpy as np
from sklearn.ensemble import RandomForestRegressor
import xgboost as xgb
timings = {}
# 1. Load Data
t0 = time.perf_counter()
df = pd_module.concat(
[pd_module.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")],
ignore_index=True
)
timings['Load Data'] = time.perf_counter() - t0
# 2. Clean Data
t0 = time.perf_counter()
# Filter for payment_type=1 (credit card) because tip amounts
# are only reliably recorded for credit card transactions.
df = df[
(df['fare_amount'] > 0) & (df['fare_amount'] < 500) &
(df['trip_distance'] > 0) & (df['trip_distance'] < 100) &
(df['tip_amount'] >= 0) & (df['tip_amount'] < 100) &
(df['payment_type'] == 1)
].copy()
# Downcast numeric columns to save memory
float_cols = df.select_dtypes(include=['float64']).columns
df[float_cols] = df[float_cols].astype('float32')
int_cols = df.select_dtypes(include=['int64']).columns
df[int_cols] = df[int_cols].astype('int32')
timings['Clean Data'] = time.perf_counter() - t0
# 3. Feature Engineering
t0 = time.perf_counter()
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['dow'] = df['tpep_pickup_datetime'].dt.dayofweek
df['is_weekend'] = (df['dow'] >= 5).astype(int)
df['fare_log'] = np.log1p(df['fare_amount'])
timings['Feature Engineering'] = time.perf_counter() - t0
# 4. Modeling Prep
feature_cols = ['trip_distance', 'fare_amount', 'passenger_count', 'hour', 'dow', 'is_weekend', 'fare_log']
X = df[feature_cols].fillna(df[feature_cols].median())
y = df['tip_amount'].copy()
# Free memory
del df
import gc
gc.collect()
# 5. Train Random Forest
t0 = time.perf_counter()
rf_model = RandomForestRegressor(
n_estimators=100,
max_depth=10,
n_jobs=-1,
max_features='sqrt',
random_state=42
).fit(X, y)
timings['Train Random Forest'] = time.perf_counter() - t0
# 6. Train XGBoost
t0 = time.perf_counter()
params = {
'objective': 'reg:squarederror',
'max_depth': 5,
'n_estimators': 100,
'random_state': 42
}
if use_gpu:
params['device'] = 'cuda'
params['tree_method'] = 'hist'
xgb_model = xgb.XGBRegressor(**params).fit(X, y)
timings['Train XGBoost'] = time.perf_counter() - t0
del X
del y
gc.collect()
return timings
Ejecutar en tu CPU
Llama a la canalización con la CPU estándar pandas.
import pandas as pd
print("Running pipeline on CPU...")
cpu_times = run_ml_pipeline(pd, use_gpu=False)
print("CPU Execution Finished.")
Ejecuta en tu GPU
Carga las extensiones de la biblioteca de NVIDIA, pasa el módulo cudf.pandas acelerado a la canalización y configura tu dispositivo XGBoost como cuda de forma interna.
import IPython.core.magic
if not hasattr(IPython.core.magic, 'output_can_be_silenced'):
IPython.core.magic.output_can_be_silenced = lambda x: x
%load_ext cudf.pandas
%load_ext cuml.accel
import pandas as pd
print("Running pipeline on GPU...")
gpu_times = run_ml_pipeline(pd, use_gpu=True)
print("GPU Execution Finished.")
Visualiza la aceleración del rendimiento
Visualiza los tiempos con matplotlib. Los resultados muestran el tiempo ahorrado durante el procesamiento de datos y el entrenamiento del modelo cuando se usan GPUs.
import matplotlib.pyplot as plt
import numpy as np
labels = list(cpu_times.keys())
cpu_values = list(cpu_times.values())
gpu_values = list(gpu_times.values())
x = np.arange(len(labels))
width = 0.35
fig, ax = plt.subplots(figsize=(10, 6))
rects1 = ax.bar(x - width/2, cpu_values, width, label='CPU', color='#4285F4')
rects2 = ax.bar(x + width/2, gpu_values, width, label='GPU', color='#76B900')
ax.set_ylabel('Execution Time (seconds)')
ax.set_title('NYC Taxi ML Pipeline: CPU vs. GPU Performance')
ax.set_xticks(x)
ax.set_xticklabels(labels, rotation=45, ha="right")
ax.legend()
# Add data labels
def autolabel(rects):
for rect in rects:
height = rect.get_height()
ax.annotate(f'{height:.2f}s',
xy=(rect.get_x() + rect.get_width() / 2, height),
xytext=(0, 3), # 3 points vertical offset
textcoords="offset points",
ha='center', va='bottom', fontsize=9)
autolabel(rects1)
autolabel(rects2)
plt.tight_layout()
plt.show()
# Calculate overall speedup
total_cpu_time = sum(cpu_values)
total_gpu_time = sum(gpu_values)
overall_speedup = total_cpu_time / total_gpu_time
print(f"\nOverall Pipeline Speedup: {overall_speedup:.2f}x faster on GPU!")
Deberías ver algo como lo siguiente:
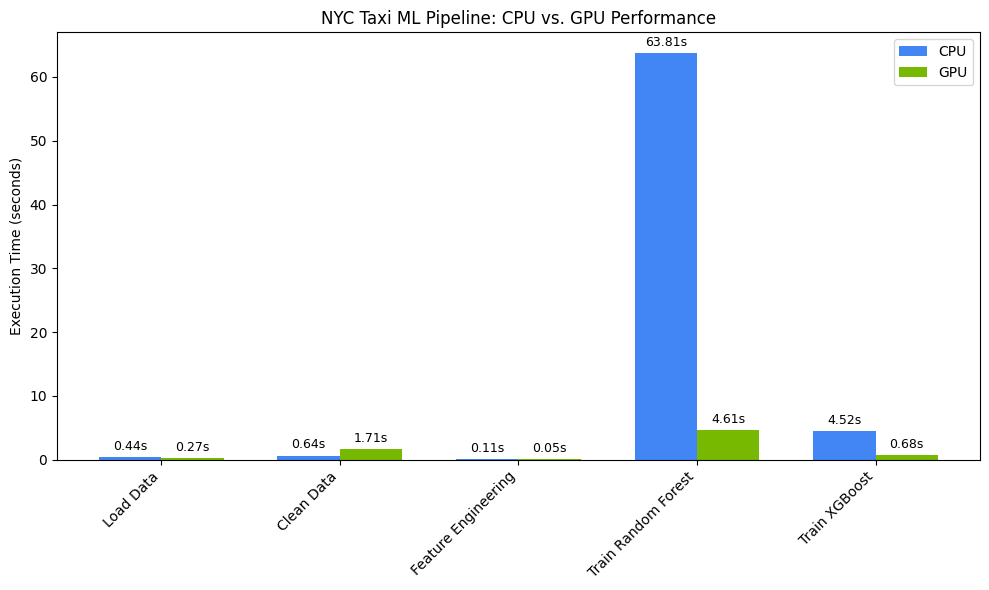
En este gráfico, se ilustra la ventaja significativa de rendimiento de la GPU en todo el flujo de trabajo de ciencia de datos. Deberías ver los ahorros de tiempo más significativos durante las fases de entrenamiento del modelo que requieren una gran cantidad de procesamiento para algoritmos como Random Forest y XGBoost.
12. Genera un perfil de tu código para encontrar restricciones de rendimiento
Cuando se usa cudf.pandas, la mayoría de las funciones se ejecutan en la GPU. Si cuDF aún no admite una operación específica, la ejecución vuelve temporalmente a la CPU. NVIDIA proporciona dos comandos mágicos integrados de Jupyter para identificar estos mecanismos de resguardo.
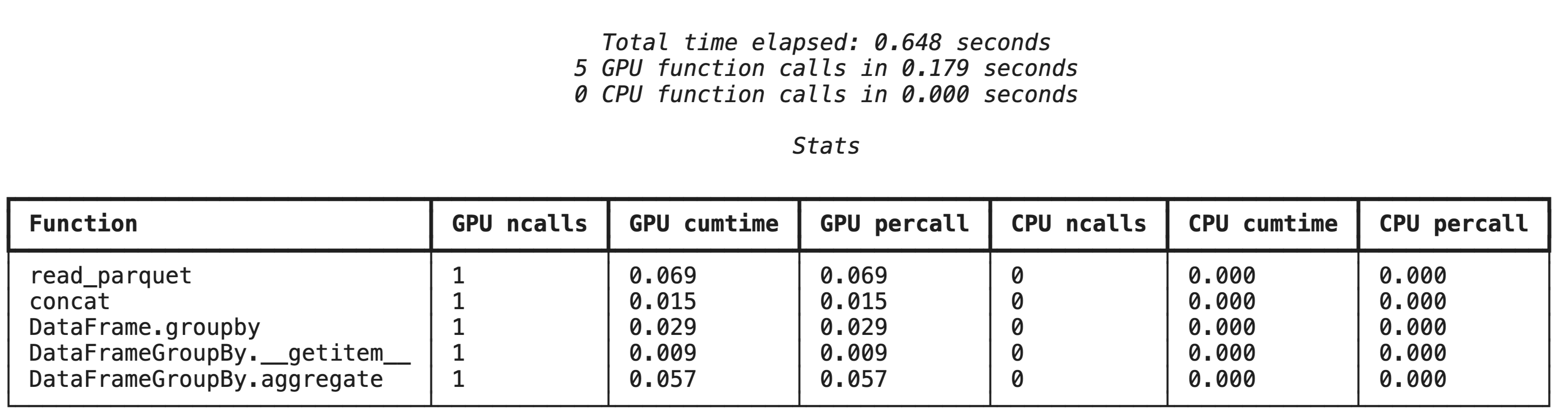
Generación de perfiles de alto nivel con %%cudf.pandas.profile
El comando mágico %%cudf.pandas.profile proporciona un resumen de las funciones que se ejecutaron en la GPU o la CPU.
%%cudf.pandas.profile
import glob
import pandas as pd
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")], ignore_index=True)
summary = (
df
.groupby(['PULocationID', 'payment_type'])
[['passenger_count', 'fare_amount', 'tip_amount']]
.agg(['min', 'mean', 'max'])
)
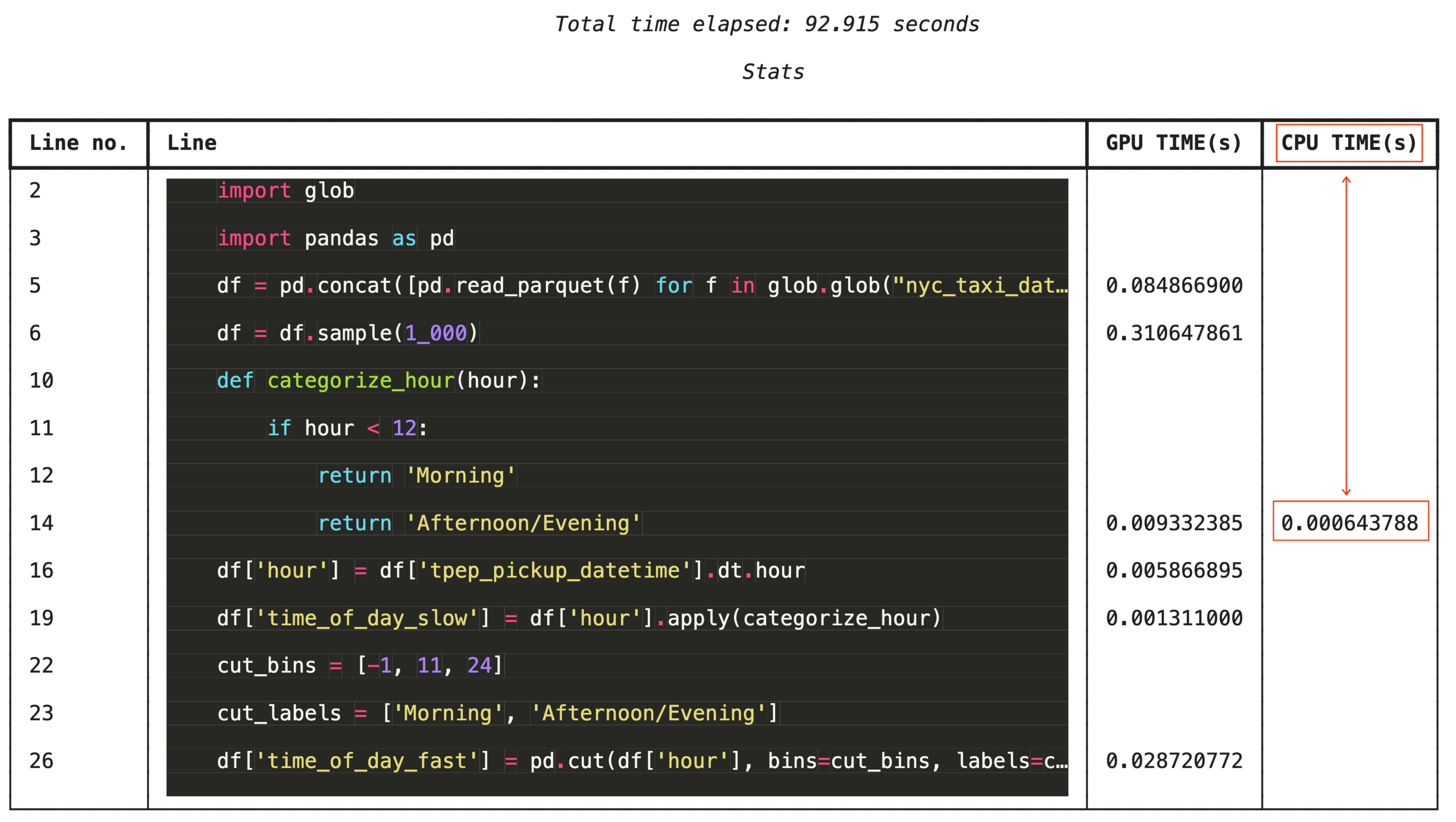
Perfilamiento línea por línea con %%cudf.pandas.line_profile
Para solucionar problemas de forma detallada, %%cudf.pandas.line_profile anota cada línea de código con la cantidad de veces que se ejecutó en la GPU en comparación con la CPU.
%%cudf.pandas.line_profile
import glob
import pandas as pd
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")], ignore_index=True)
df = df.sample(1_000)
# Iterating row-by-row or using custom python apply functions often falls back to the CPU
def categorize_hour(hour):
if hour < 12:
return 'Morning'
else:
return 'Afternoon/Evening'
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['time_of_day_slow'] = df['hour'].apply(categorize_hour)
# Using vectorized pandas operations (like pd.cut) stays entirely on the GPU
cut_bins = [-1, 11, 24]
cut_labels = ['Morning', 'Afternoon/Evening']
df['time_of_day_fast'] = pd.cut(df['hour'], bins=cut_bins, labels=cut_labels)
13. Limpieza
Para evitar que se apliquen cargos inesperados a tu cuenta de Google Cloud, limpia los recursos que creaste durante este codelab.
Borrar los recursos
Borra el conjunto de datos local en el tiempo de ejecución con el comando !rm -rf en una celda del notebook.
print("Deleting local 'nyc_taxi_data' directory...")
!rm -rf nyc_taxi_data
print("Local files deleted.")
Cierra el entorno de ejecución de Colab
- En la consola de Google Cloud, ve a la página Entornos de ejecución de Colab Enterprise.
- En el menú Región, selecciona la región que contiene el entorno de ejecución.
- Selecciona el tiempo de ejecución que deseas borrar.
- Haz clic en Borrar.
- Haz clic en Confirmar.
Borra tu notebook
- En la consola de Google Cloud, ve a la página Mis notebooks de Colab Enterprise.
- En el menú Región, selecciona la región que contiene el notebook.
- Selecciona el notebook que quieres borrar.
- Haz clic en Borrar.
- Haz clic en Confirmar.
14. Felicitaciones
¡Felicitaciones! Aceleraste correctamente un flujo de trabajo de aprendizaje automático de pandas y scikit-learn con las bibliotecas cuDF y cuML de NVIDIA en Colab Enterprise. Con solo agregar algunos comandos mágicos (%load_ext cudf.pandas y %load_ext cuml.accel), tu código estándar se ejecuta en la GPU, procesa registros y ajusta modelos complejos de forma local en una fracción del tiempo.
Para obtener más información sobre la aceleración por GPU para el análisis de datos, consulta el codelab Accelerated Data Analytics with GPUs.
Temas abordados
- Comprende Colab Enterprise en Google Cloud.
- Personalizar un entorno de ejecución de Colab con configuraciones específicas de GPU y memoria
- Aplicar la aceleración por GPU para predecir los importes de las propinas con millones de registros de un conjunto de datos de taxis de NYC
- Aceleración de
pandassin cambiar el código con la bibliotecacuDFde NVIDIA. - Aceleración de
scikit-learnsin cambios de código con la bibliotecacuMLy las GPUs de NVIDIA - Crear perfiles de tu código para identificar y optimizar las restricciones de rendimiento