
۱. مقدمه
در این آزمایشگاه کد، شما یاد خواهید گرفت که چگونه با استفاده از پردازندههای گرافیکی NVIDIA و کتابخانههای متنباز در Google Cloud، گردشهای کاری علوم داده و یادگیری ماشین خود را در مجموعه دادههای بزرگ تسریع کنید. شما با راهاندازی زیرساخت خود شروع خواهید کرد، سپس نحوه اعمال شتابدهی GPU را بررسی خواهید کرد.
شما بر چرخه حیات علم داده، از آمادهسازی دادهها با pandas تا آموزش مدل با scikit-learn و XGBoost تمرکز خواهید کرد. یاد خواهید گرفت که چگونه با استفاده از کتابخانههای cuDF و cuML انویدیا، این وظایف را تسریع کنید. بهترین بخش این است که میتوانید این شتابدهی GPU را بدون تغییر کد pandas یا scikit-learn موجود خود دریافت کنید.
آنچه یاد خواهید گرفت
- آشنایی با Colab Enterprise در فضای ابری گوگل
- یک محیط زمان اجرای Colab را با تنظیمات خاص GPU و حافظه سفارشی کنید.
- با استفاده از میلیونها رکورد از مجموعه دادههای تاکسی نیویورک، از شتابدهی GPU برای پیشبینی میزان انعام استفاده کنید.
- با استفاده از کتابخانه
cuDFانویدیا،pandasبدون تغییر کد، سرعت بخشید. - با استفاده از کتابخانه
cuMLانویدیا و پردازندههای گرافیکی، سرعتscikit-learnرا بدون هیچ تغییری در کد افزایش دهید. - کد خود را برای شناسایی و بهینهسازی محدودیتهای عملکرد، نمایهسازی کنید.
صفحه بعد شامل واحدهایی است که میتوانید برای تکمیل آزمایشگاه از آنها استفاده کنید.
۲. چرا باید یادگیری ماشینی را تسریع کرد؟
نیاز به تکرار سریعتر در یادگیری ماشینی
آمادهسازی دادهها زمانبر است و آموزش یا ارزیابی مدل با افزایش مجموعه دادهها میتواند حتی بیشتر طول بکشد. آموزش مدلهایی مانند جنگلهای تصادفی یا XGBoost روی میلیونها ردیف با یک CPU میتواند ساعتها یا روزها طول بکشد.
استفاده از پردازندههای گرافیکی (GPU) این اجرای آموزش را با کتابخانههایی مانند cuML و XGBoost شتابیافته با پردازنده گرافیکی تسریع میکند. این شتاب به شما امکان میدهد:
- سریعتر تکرار کنید: ویژگیها و هایپرپارامترهای جدید را به سرعت آزمایش کنید.
- آموزش روی مجموعه دادههای کامل: برای دقت بهتر، به جای نمونهبرداری کاهشی، از دادههای کامل خود استفاده کنید.
- کاهش هزینهها: انجام حجمهای کاری سنگین در زمان کمتر برای کاهش هزینههای محاسباتی.
۳. تنظیمات و الزامات
هزینههای بالقوه
این آزمایشگاه کد از منابع Google Cloud، از جمله زمانهای اجرای Colab Enterprise با پردازندههای گرافیکی NVIDIA L4 استفاده میکند. لطفاً از هزینههای احتمالی آگاه باشید و بخش پاکسازی را در انتهای آزمایشگاه کد دنبال کنید تا منابع را خاموش کنید و از پرداخت صورتحساب مداوم جلوگیری کنید. برای اطلاعات دقیق در مورد قیمتگذاری، به قیمتگذاری Colab Enterprise و قیمتگذاری GPU مراجعه کنید.
قبل از اینکه شروع کنی
آشنایی متوسط با پایتون، pandas ، scikit-learn و شیوههای استاندارد یادگیری ماشین (مانند اعتبارسنجی متقابل/ترکیب) فرض میشود.
- در کنسول گوگل کلود، در صفحه انتخاب پروژه، یک پروژه گوگل کلود را انتخاب یا ایجاد کنید.
- مطمئن شوید که پرداخت برای پروژه Google Cloud شما فعال است.
فعال کردن APIها
برای استفاده از Colab Enterprise، ابتدا باید APIهای لازم را فعال کنید.
- با کلیک روی آیکون Cloud Shell در سمت راست بالای کنسول Google Cloud، Google Cloud Shell را باز کنید.

- در Cloud Shell، شناسه پروژه خود را با جایگزینی
PROJECT_IDبا شناسه پروژه خود تنظیم کنید:
gcloud config set project <PROJECT_ID>
- برای فعال کردن API های لازم، دستور زیر را اجرا کنید:
gcloud services enable \
compute.googleapis.com \
dataform.googleapis.com \
notebooks.googleapis.com \
aiplatform.googleapis.com
در صورت اجرای موفقیتآمیز، باید پیامی مشابه آنچه در زیر نشان داده شده است را مشاهده کنید:
Operation "operations/..." finished successfully.
۴. انتخاب محیط نوتبوک
در حالی که بسیاری از دانشمندان داده با Colab برای پروژههای شخصی آشنا هستند، Colab Enterprise یک تجربه نوتبوک امن، مشارکتی و یکپارچه را برای کسبوکارها ارائه میدهد.
در گوگل کلود، شما دو انتخاب اصلی برای محیطهای مدیریتشدهی نوتبوک دارید: Colab Enterprise و Gemini Enterprise Agent Platform Workbench . انتخاب درست به اولویتهای پروژه شما بستگی دارد.
چه زمانی از میز کار پلتفرم عامل استفاده کنیم
اگر اولویت شما کنترل و سفارشیسازی عمیق است، Agent Platform Workbench را انتخاب کنید. اگر به موارد زیر نیاز دارید، این انتخاب ایدهآلی است:
- مدیریت زیرساختهای زیربنایی و چرخه عمر ماشینآلات.
- از کانتینرها و پیکربندیهای شبکه سفارشی استفاده کنید.
- با خطوط لوله MLOps و ابزارهای چرخه عمر سفارشی ادغام شوید.
چه زمانی از Colab Enterprise استفاده کنیم؟
وقتی اولویت شما راهاندازی سریع، سهولت استفاده و همکاری امن است، Colab Enterprise را انتخاب کنید. این یک راهکار کاملاً مدیریتشده است که به تیم شما اجازه میدهد به جای زیرساخت، روی تجزیه و تحلیل تمرکز کند.
شرکت کولب به شما کمک میکند:
- گردشهای کاری علوم داده را که ارتباط نزدیکی با انبار داده شما دارند، توسعه دهید. میتوانید دفترچههای یادداشت خود را مستقیماً در BigQuery Studio باز و مدیریت کنید.
- مدلهای یادگیری ماشین را آموزش دهید و با ابزارهای MLOps در Agent Platform ادغام کنید.
- از یک تجربه انعطافپذیر و یکپارچه لذت ببرید. یک نوتبوک Colab Enterprise که در BigQuery ایجاد شده است، میتواند در Agent Platform باز و اجرا شود و برعکس.
آزمایشگاه امروز
این Codelab از Colab Enterprise برای یادگیری ماشینی شتابیافته استفاده میکند.
برای کسب اطلاعات بیشتر در مورد تفاوتها، به مستندات رسمی در مورد انتخاب راهکار مناسب برای نوتبوک مراجعه کنید.
۵. پیکربندی یک الگوی زمان اجرا
در Colab Enterprise، بر اساس یک الگوی زمان اجرای از پیش تنظیم شده، به یک زمان اجرا متصل شوید.
یک الگوی زمان اجرا، یک پیکربندی قابل استفاده مجدد است که محیط نوتبوک شما را مشخص میکند، از جمله:
- نوع دستگاه (پردازنده، حافظه)
- شتابدهنده (نوع و تعداد پردازنده گرافیکی)
- اندازه و نوع دیسک
- تنظیمات شبکه و سیاستهای امنیتی
- قوانین خاموش شدن خودکار در حالت بیکار
چرا قالبهای زمان اجرا مفید هستند؟
- ثبات: شما و تیمتان محیط یکسانی را در اختیار دارید تا از تکرارپذیری کار اطمینان حاصل شود.
- امنیت: قالبها سیاستهای امنیتی سازمان را اجرا میکنند.
- مدیریت هزینه: منابع در قالب از پیش تعیین شدهاند تا از هزینههای تصادفی جلوگیری شود.
ایجاد یک الگوی زمان اجرا
یک الگوی زمان اجرای قابل استفاده مجدد برای آزمایشگاه تنظیم کنید.
- در کنسول گوگل کلود، به منوی ناوبری > پلتفرم عامل > نوتبوکها بروید.
- از Colab Enterprise، روی Runtime templates کلیک کنید و سپس New Template را انتخاب کنید.
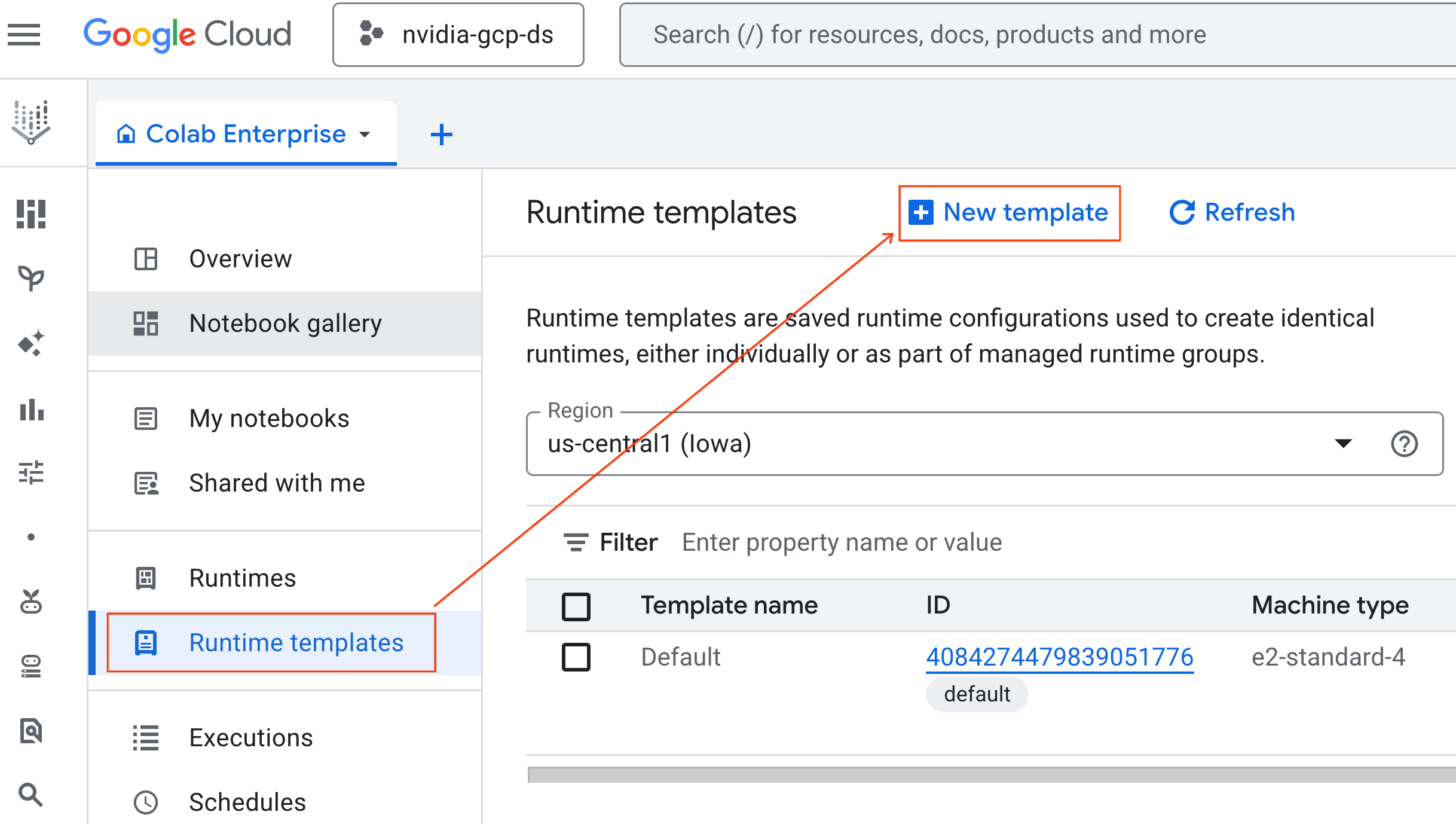
- در بخش اصول اولیهی زمان اجرا :
- نام نمایش را روی
gpu-templateتنظیم کنید. - منطقه مورد نظر خود را تنظیم کنید.
- نام نمایش را روی
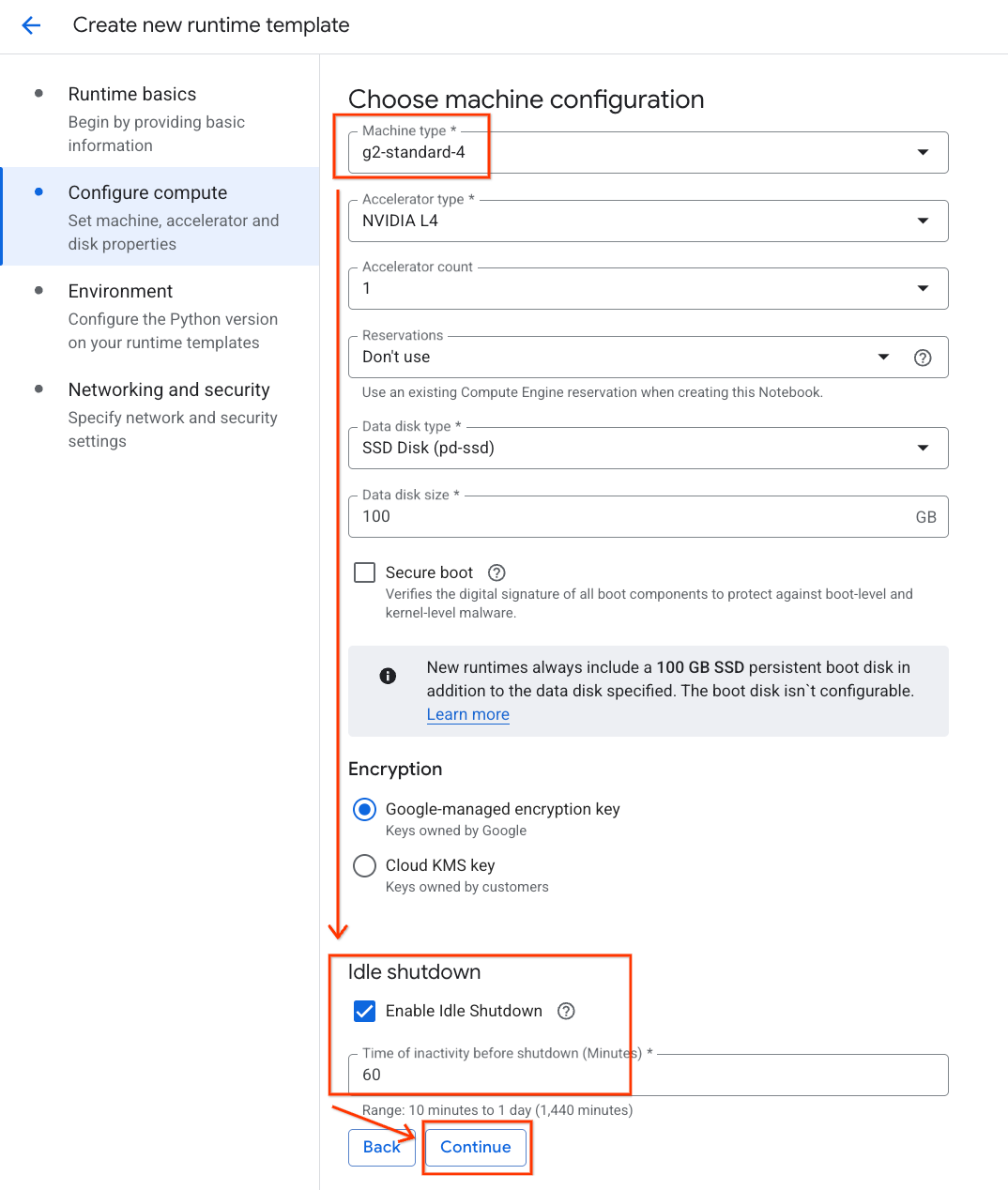
- در قسمت پیکربندی محاسبات :
- نوع ماشین (Machine type) را روی
g2-standard-4تنظیم کنید. - نوع شتابدهنده پیشفرض را
NVIDIA L4با تعداد شتابدهنده ۱ نگه دارید. - خاموش شدن در حالت آماده به کار را به ۶۰ دقیقه تغییر دهید.
- روی ادامه کلیک کنید.
- نوع ماشین (Machine type) را روی
- تحت محیط :
- محیط را روی
Python 3.11تنظیم کنید
- محیط را روی
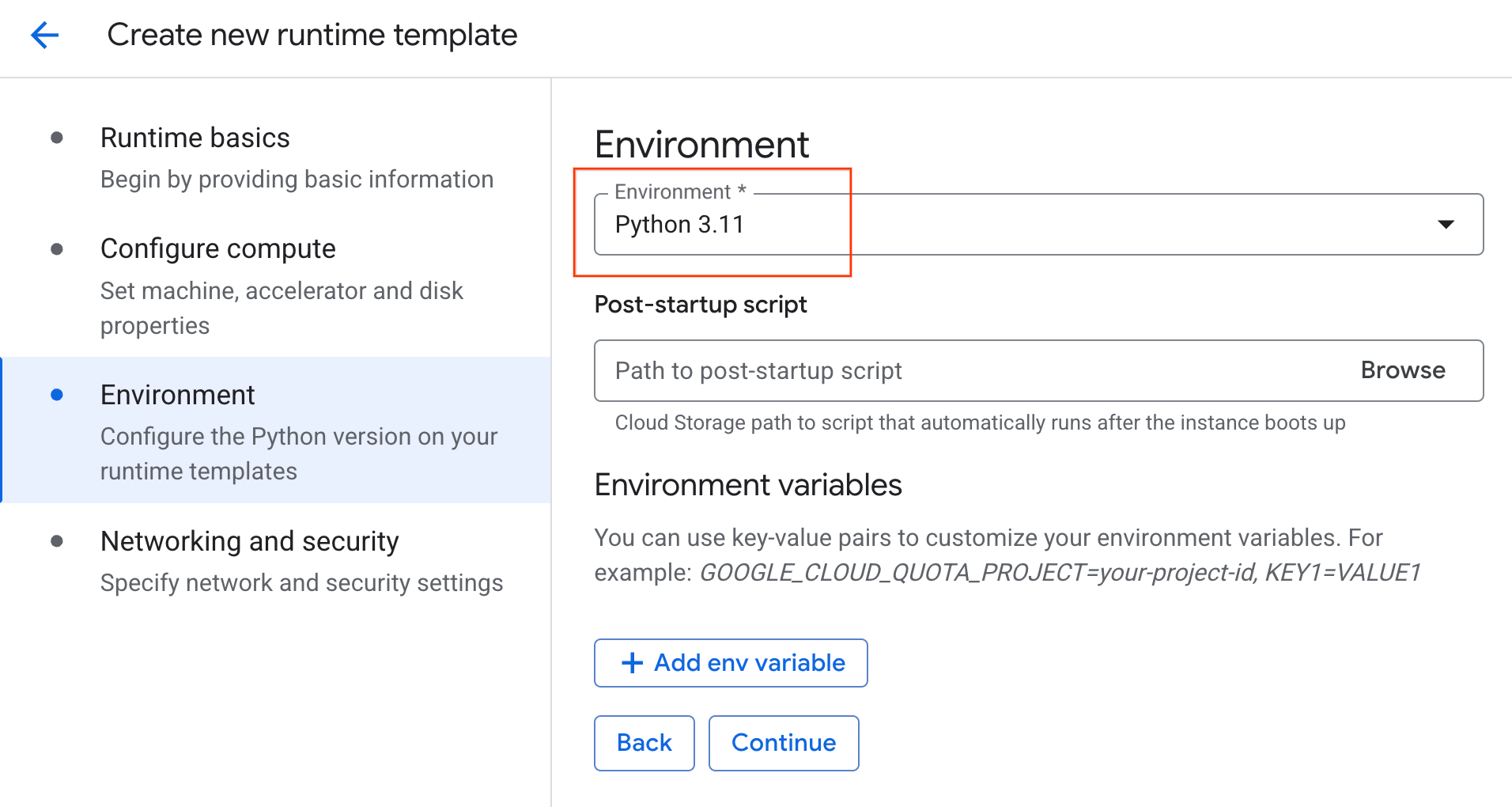
- برای ذخیره الگوی زمان اجرا، روی ایجاد کلیک کنید. صفحه الگوهای زمان اجرا شما اکنون باید الگوی جدید را نمایش دهد.
۶. شروع یک رانتایم
با آماده شدن قالب، میتوانید یک runtime جدید ایجاد کنید.
- از Colab Enterprise، روی Runtimes کلیک کنید و سپس Create را انتخاب کنید.
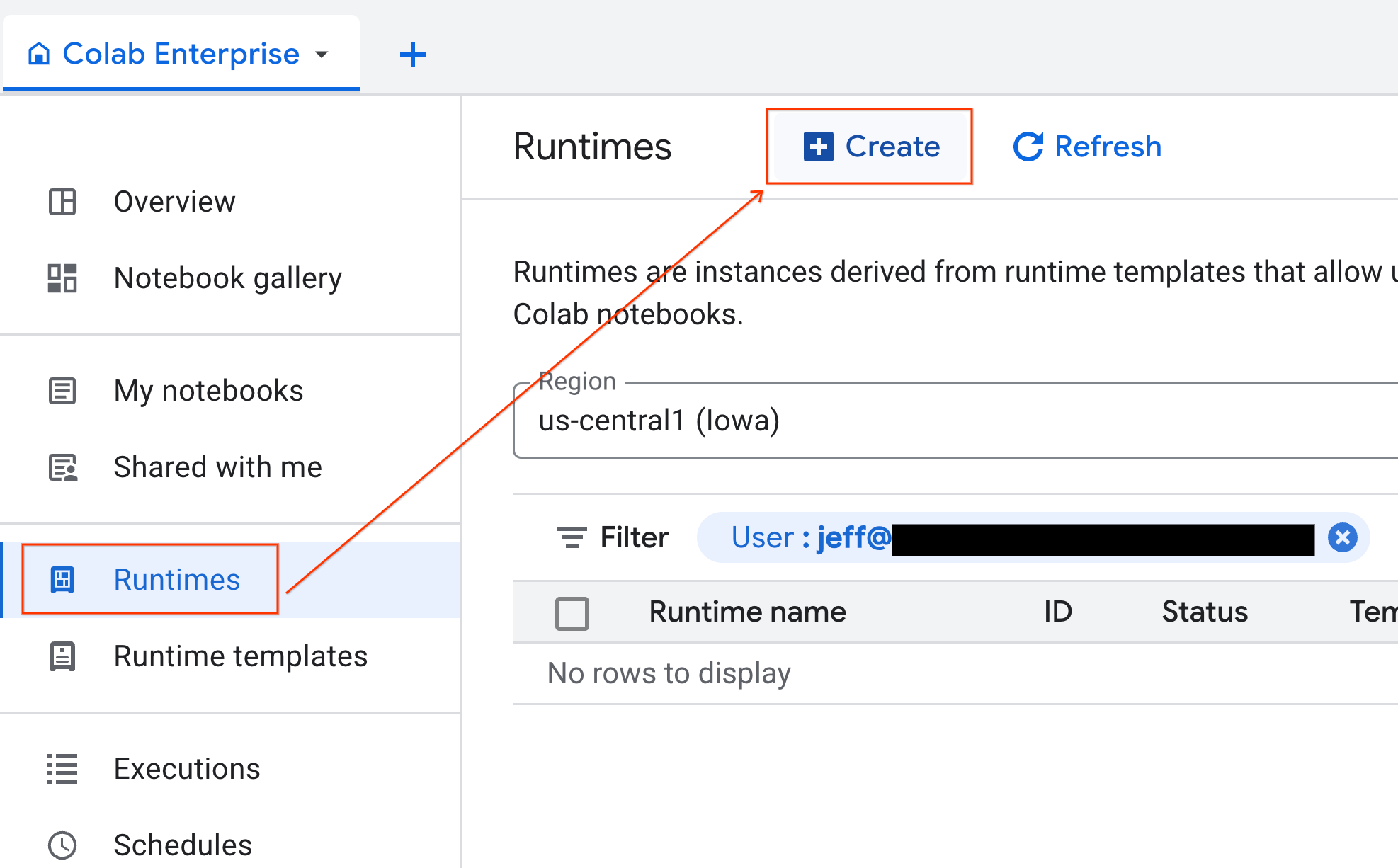
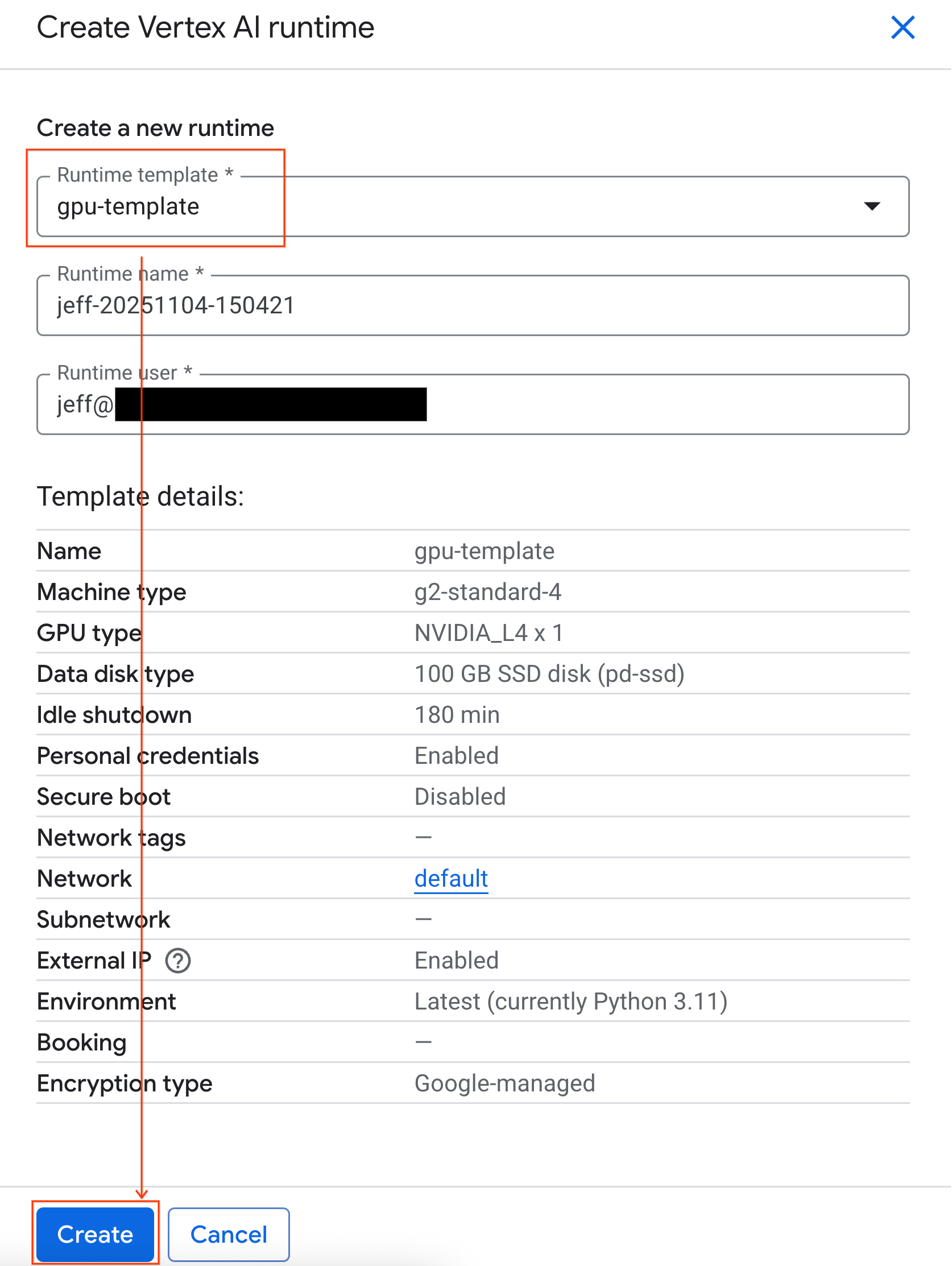
- در قسمت Runtime template ، گزینه
gpu-templateرا انتخاب کنید. روی Create کلیک کنید و منتظر بمانید تا runtime بوت شود.
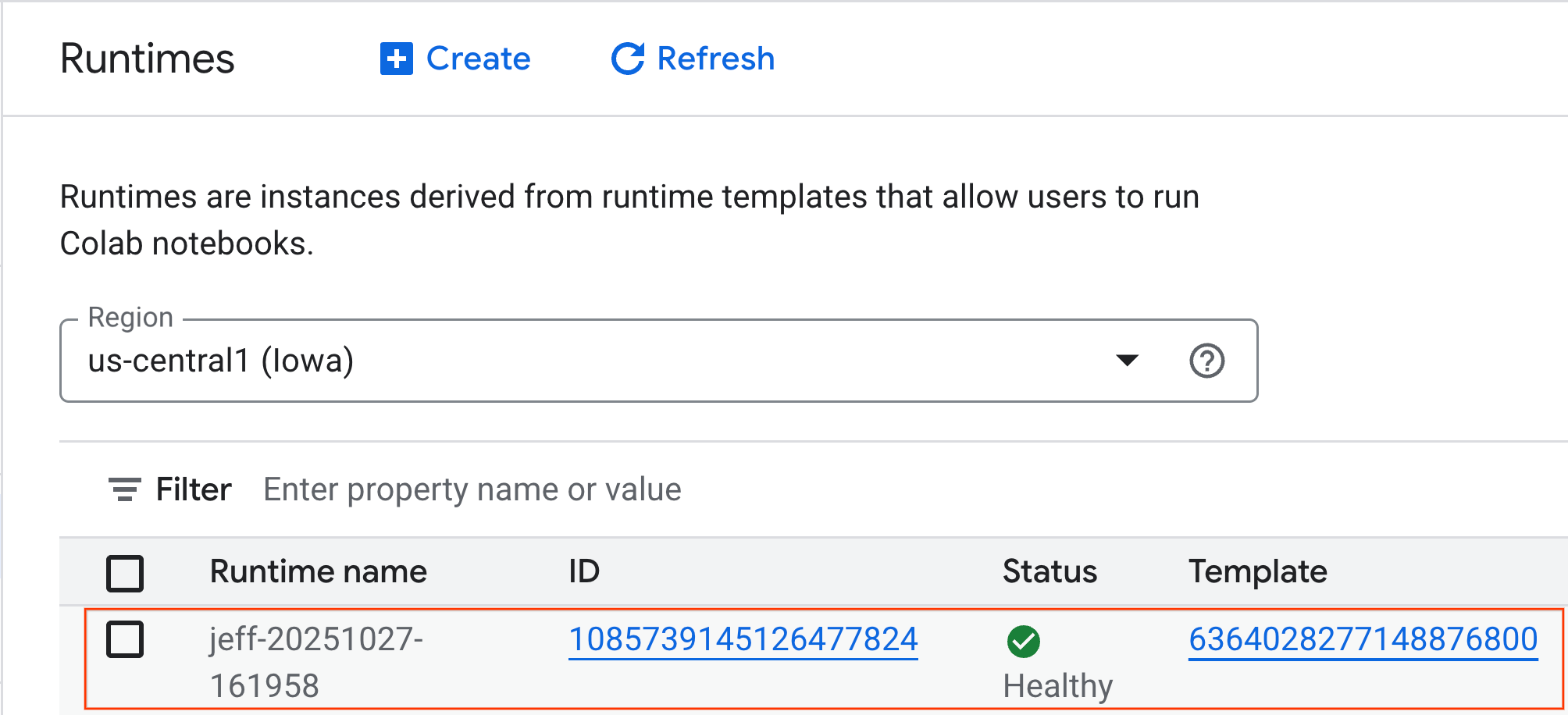
- بعد از چند دقیقه، زمان اجرا موجود را مشاهده خواهید کرد.
۷. دفترچه یادداشت را تنظیم کنید
اکنون که زیرساخت شما در حال اجرا است، باید دفترچه آزمایشگاه را وارد کرده و آن را به محیط زمان اجرا متصل کنید.
وارد کردن دفترچه یادداشت
- از Colab Enterprise، روی My notebooks کلیک کنید و سپس روی Import کلیک کنید.
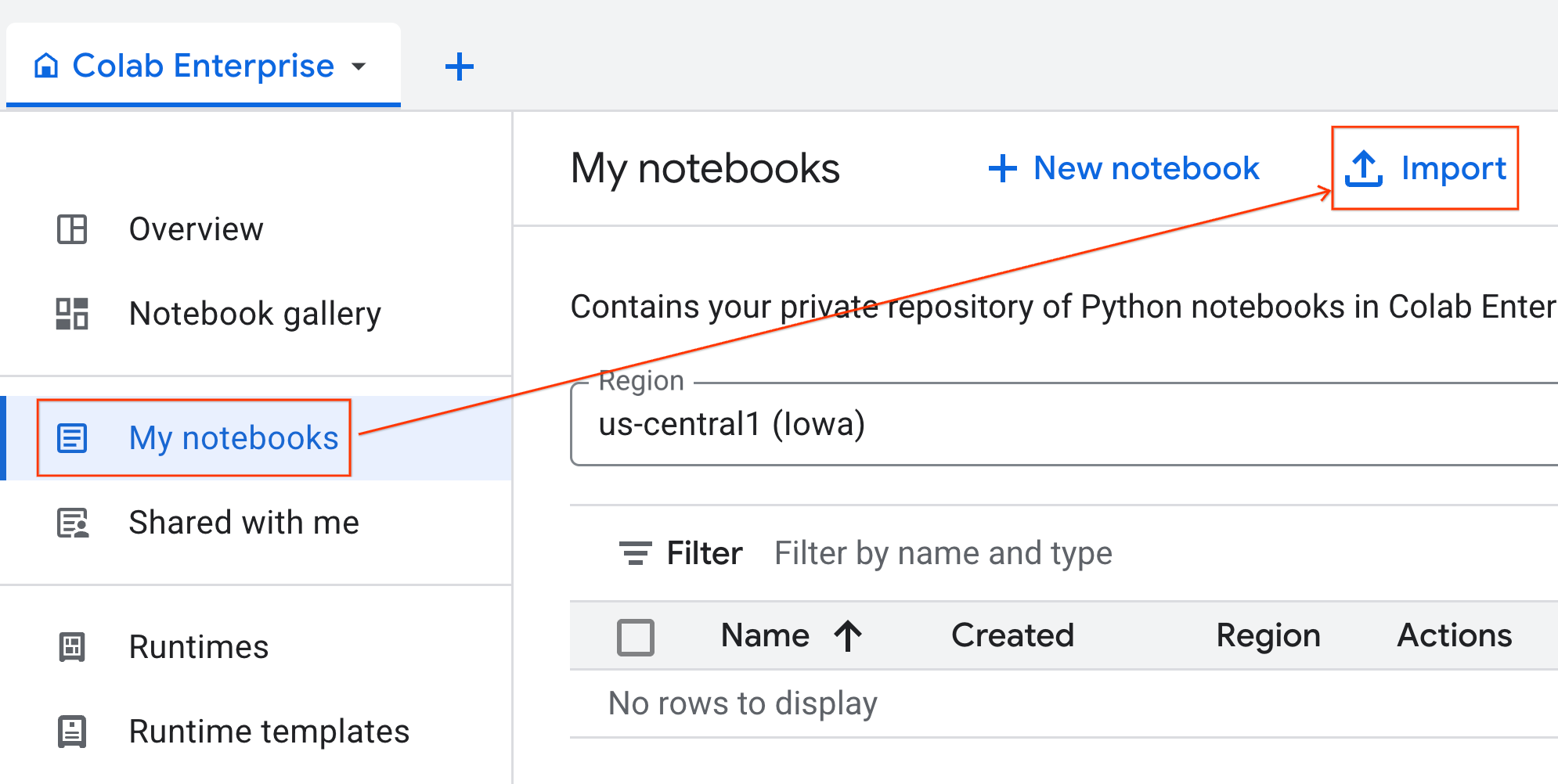
- دکمه رادیویی URL را انتخاب کنید و URL زیر را وارد کنید:
https://github.com/GoogleCloudPlatform/ai-ml-recipes/blob/main/notebooks/regression/gpu_accelerated_regression/gpu_accelerated_regression.ipynb
- روی «وارد کردن» کلیک کنید. Colab Enterprise دفترچه یادداشت را از GitHub در محیط شما کپی خواهد کرد.
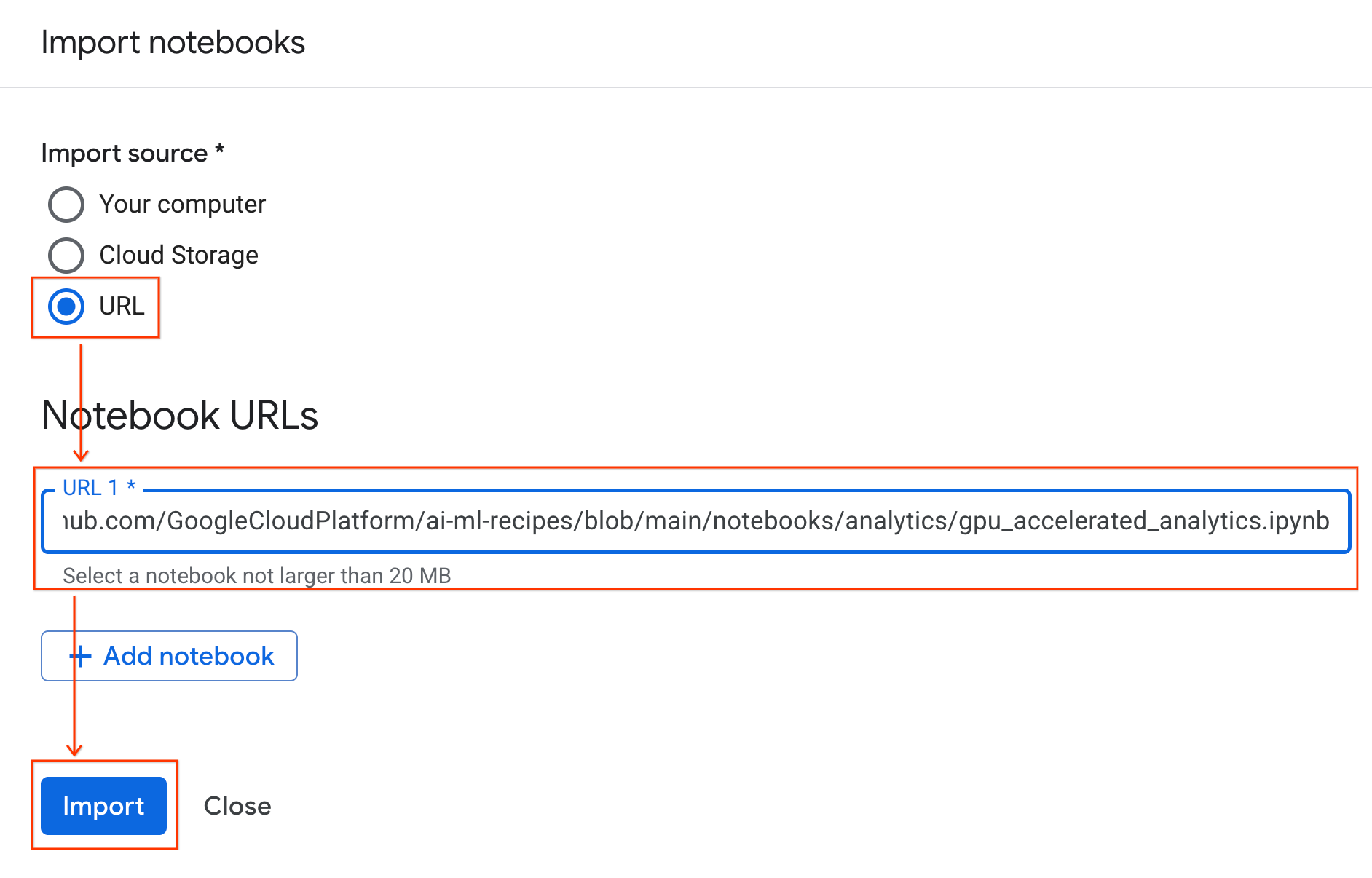
اتصال به زمان اجرا
- دفترچه یادداشت تازه وارد شده را باز کنید.
- روی فلش رو به پایین کنار گزینه Connect کلیک کنید.
- اتصال به یک زمان اجرا را انتخاب کنید.
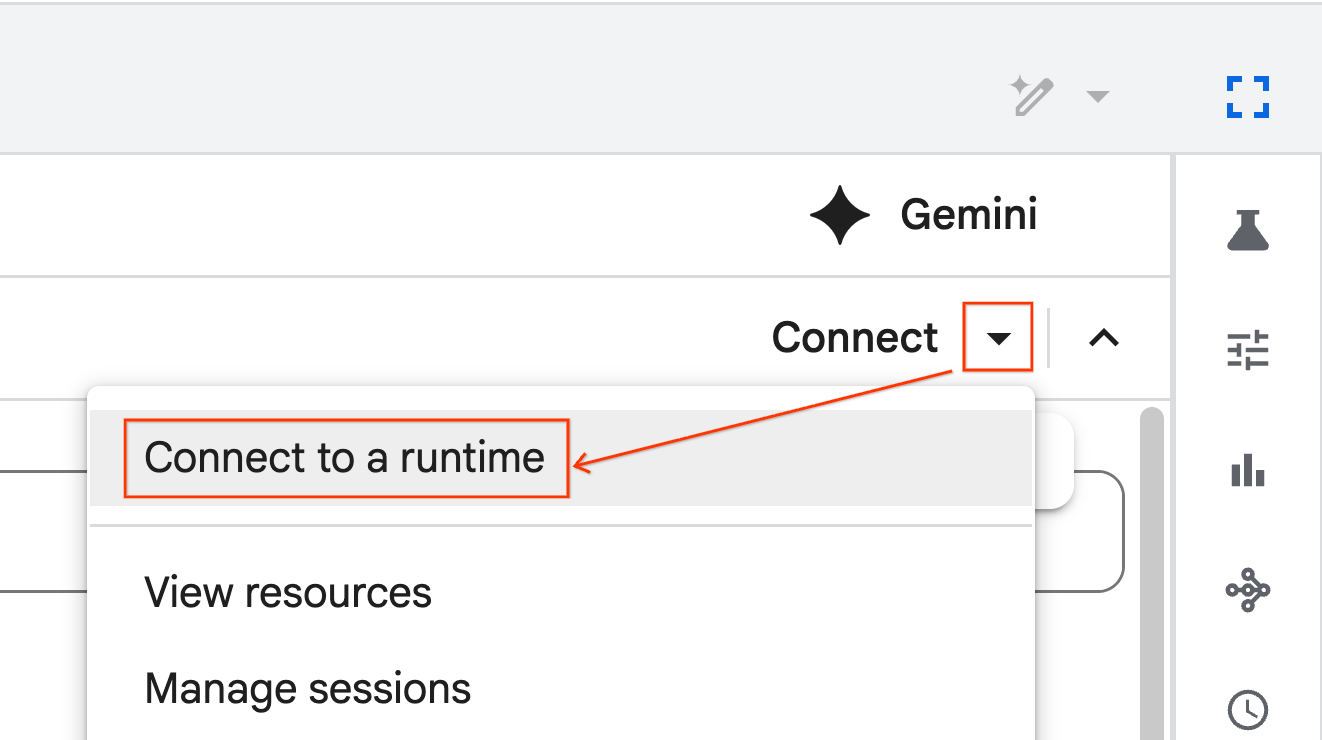
- از منوی کشویی استفاده کنید و زمان اجرایی که قبلاً ایجاد کردهاید را انتخاب کنید.
- روی اتصال کلیک کنید.
اکنون نوتبوک شما به یک سیستم زمان اجرای مجهز به پردازنده گرافیکی (GPU) متصل شده است.
وابستگیهای داخلی
یکی از مزایای استفاده از Colab Enterprise این است که کتابخانههای مورد نیاز شما از قبل نصب شدهاند. نیازی نیست که وابستگیهایی مانند cuDF ، cuML یا XGBoost را برای این آزمایشگاه به صورت دستی نصب یا مدیریت کنید.
۸. مجموعه دادههای تاکسی نیویورک را آماده کنید
این آزمایشگاه کد از دادههای ثبت سفر کمیسیون تاکسی و لیموزین نیویورک (TLC) استفاده میکند. این مجموعه داده شامل سوابق سفر تاکسیهای زرد در شهر نیویورک است، از جمله:
- تاریخها، زمانها و مکانهای سوار و پیاده شدن
- مسافت سفر
- مبالغ کرایه به تفکیک
- تعداد مسافران
- مبلغ انعام ( این چیزی است که ما پیشبینی خواهیم کرد! )
پیکربندی GPU و تأیید در دسترس بودن
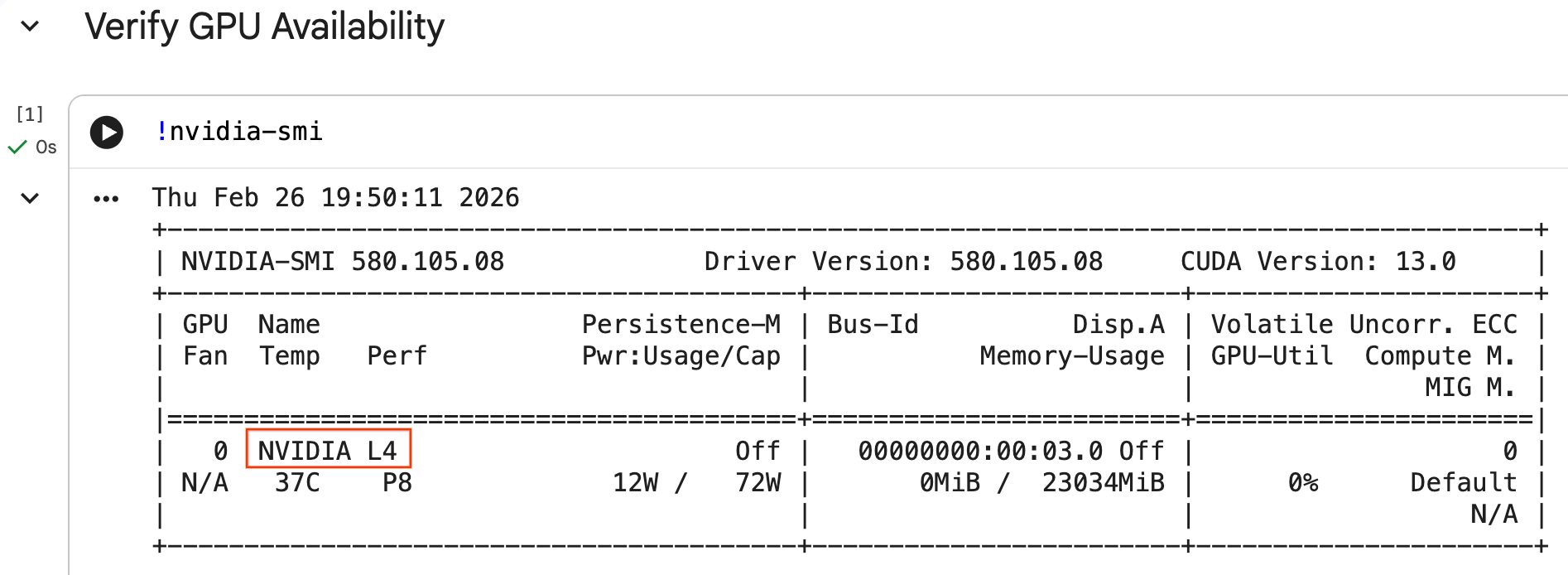
میتوانید با اجرای دستور nvidia-smi از شناسایی شدن پردازنده گرافیکی (GPU) مطمئن شوید. این دستور نسخه درایور و جزئیات پردازنده گرافیکی (مانند NVIDIA L4) را نمایش میدهد.
nvidia-smi
سلول باید GPU متصل به زمان اجرا را، مشابه زیر، برگرداند:
دانلود دادهها
دادههای سفر مربوط به سال ۲۰۲۴ را دانلود کنید.
from tqdm import tqdm
import requests
import time
import os
YEAR = 2024
DATA_DIR = "nyc_taxi_data"
os.makedirs(DATA_DIR, exist_ok=True)
print(f"Checking/Downloading files for {YEAR}...")
for month in tqdm(range(1, 13), unit="file"):
file_name = f"yellow_tripdata_{YEAR}-{month:02d}.parquet"
local_path = os.path.join(DATA_DIR, file_name)
url = f"https://d37ci6vzurychx.cloudfront.net/trip-data/{file_name}"
if not os.path.exists(local_path):
try:
with requests.get(url, stream=True) as response:
response.raise_for_status()
with open(local_path, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
time.sleep(1)
except requests.exceptions.HTTPError as e:
print(f"\nSkipping {file_name}: {e}")
if os.path.exists(local_path):
os.remove(local_path)
print("\nDownload complete.")
pandas با NVIDIA cuDF تسریع کنید
کتابخانه pandas روی CPU اجرا میشود و میتواند با مجموعه دادههای بزرگ کند باشد. دستور جادویی NVIDIA %load_ext cudf.pandas به صورت پویا pandas را برای استفاده از شتاب GPU وصله میکند و در صورت نیاز به CPU بازمیگردد.
ما از این دستور جادویی به جای یک دستور استاندارد import استفاده میکنیم زیرا شتاب «بدون تغییر کد» را فراهم میکند. لازم نیست هیچ یک از کدهای موجود خود را بازنویسی کنید. دستور مشابه %load_ext cuml.accel دقیقاً همین کار را برای scikit-learn models انجام میدهد! این دستور در هر محیط Jupyter با یک پردازنده گرافیکی NVIDIA سازگار، و نه فقط Colab Enterprise، کار میکند.
%load_ext cudf.pandas
برای تأیید فعال بودن آن، pandas را وارد کنید و نوع آن را بررسی کنید:
import pandas as pd
pd
خروجی تأیید میکند که اکنون از ماژول cudf.pandas استفاده میکنید.
بارگذاری و پاکسازی دادهها
با فعال بودن cudf.pandas ، فایلهای Parquet را بارگذاری کرده و عملیات پاکسازی دادهها را اجرا کنید. این فرآیند به طور خودکار روی GPU اجرا میشود.
import glob
# Load data into memory
df = pd.concat(
[pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")],
ignore_index=True
)
# Filter for valid trips. We filter for payment_type=1 (credit card)
# because tip amounts are only reliably recorded for credit card transactions.
df = df[
(df['fare_amount'] > 0) & (df['fare_amount'] < 500) &
(df['trip_distance'] > 0) & (df['trip_distance'] < 100) &
(df['tip_amount'] >= 0) & (df['tip_amount'] < 100) &
(df['payment_type'] == 1)
].copy()
# Downcast numeric columns to save memory
float_cols = df.select_dtypes(include=['float64']).columns
df[float_cols] = df[float_cols].astype('float32')
int_cols = df.select_dtypes(include=['int64']).columns
df[int_cols] = df[int_cols].astype('int32')
مهندسی ویژگی
ویژگیهای مشتقشده از تاریخ و زمان دریافت را ایجاد کنید. این دفترچه شامل ویژگیهای دیگری است که در مراحل بعدی استفاده میشوند.
import numpy as np
# Time Features
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['dow'] = df['tpep_pickup_datetime'].dt.dayofweek
df['is_weekend'] = (df['dow'] >= 5).astype(int)
df['is_rush_hour'] = (
((df['hour'] >= 7) & (df['hour'] <= 9)) |
((df['hour'] >= 17) & (df['hour'] <= 19))
).astype(int)
...
# Other features
...
۹. آموزش مدلهای منفرد با اعتبارسنجی متقابل
برای نشان دادن اینکه چگونه GPU میتواند یادگیری ماشین را تسریع کند، شما سه نوع مختلف از مدلهای رگرسیون را برای پیشبینی tip_amount یک سفر تاکسی آموزش خواهید داد.
افزایش سرعت scikit-learn با NVIDIA cuML
الگوریتمهای scikit-learn را با استفاده از NVIDIA cuML بدون تغییر فراخوانیهای API روی GPU اجرا کنید. ابتدا، افزونه cuml.accel را بارگذاری کنید.
%load_ext cuml.accel
ویژگیها و اهداف راهاندازی
ویژگیهایی را که میخواهید مدل از آنها یاد بگیرد شناسایی کنید و ستون هدف ( tip_amount ) را جدا کنید.
feature_cols = [
'trip_distance', 'fare_amount', 'passenger_count',
'hour', 'dow', 'is_weekend', 'is_rush_hour',
'fare_log', 'fare_decimal', 'is_round_fare',
'route_frequency', 'pu_tip_mean', 'pu_tip_std',
'PULocationID', 'DOLocationID'
]
X = df[feature_cols].fillna(df[feature_cols].median())
y = df['tip_amount'].copy()
برای ارزیابی دقیق عملکرد مدل، تقسیمبندیهای اعتبارسنجی متقابل را تنظیم کنید.
from sklearn.model_selection import KFold
import numpy as np
import time
from sklearn.metrics import mean_squared_error
from tqdm.notebook import tqdm
n_splits = 3
kf = KFold(n_splits=n_splits, shuffle=True, random_state=42)
۱. ایکسجیبوست
XGBoost به صورت ذاتی توسط GPU شتابدهی میشود. برای استفاده از GPU در طول آموزش، tree_method='hist' و device='cuda' را وارد کنید.
import xgboost as xgb
start_time = time.perf_counter()
def train_xgb_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# XGBoost handles GPU natively when tree_method='hist' and device='cuda'
model = xgb.XGBRegressor(
objective='reg:squarederror',
max_depth=5,
learning_rate=0.1,
n_estimators=100,
tree_method='hist',
device='cuda',
random_state=42
)
model.fit(X_train, y_train)
preds = model.predict(X_val)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
xgb_rmse, xgb_preds = train_xgb_cv(X, y)
print(f"\n{'XGBoost RMSE:':<20} ${xgb_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
۲. رگرسیون خطی
یک مدل رگرسیون خطی آموزش دهید. با فعال بودن %load_ext cuml.accel ، LinearRegression به طور خودکار به معادل GPU خود نگاشت میشود.
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
start_time = time.perf_counter()
def train_linreg_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# Scale features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_val_scaled = scaler.transform(X_val)
# Automatically accelerated by cuML
model = LinearRegression()
model.fit(X_train_scaled, y_train)
preds = model.predict(X_val_scaled)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
linreg_rmse, linreg_preds = train_linreg_cv(X, y)
print(f"\n{'Linear Reg RMSE:':<20} ${linreg_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
۳. جنگل تصادفی
آموزش یک مدل گروهی با استفاده از RandomForestRegressor . مدلهای مبتنی بر درخت اغلب در آموزش روی CPU کند هستند، اما شتابدهنده GPU میلیونها ردیف را سریعتر پردازش میکند.
from sklearn.ensemble import RandomForestRegressor
start_time = time.perf_counter()
def train_rf_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# Automatically accelerated by cuML
model = RandomForestRegressor(
n_estimators=100,
max_depth=10,
n_jobs=-1,
max_features='sqrt',
random_state=42
)
model.fit(X_train, y_train)
preds = model.predict(X_val)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
rf_rmse, rf_preds = train_rf_cv(X, y)
print(f"\n{'Random Forest RMSE:':<20} ${rf_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
۱۰. ارزیابی خط لوله سرتاسری
پیشبینیهای سه مدل را با استفاده از یک مجموعه خطی ساده ترکیب کنید. این کار معمولاً افزایش جزئی دقت را نسبت به مدلهای منفرد فراهم میکند.
برای یافتن وزنهای بهینه، یک رگرسیون خطی روی پیشبینیها برازش دهید:
ensemble_weights = LinearRegression(positive=True, fit_intercept=False).fit(
np.c_[xgb_preds, rf_preds, linreg_preds], y
).coef_
# Normalize weights
ensemble_weights = ensemble_weights / ensemble_weights.sum()
ensemble_preds = np.c_[xgb_preds, rf_preds, linreg_preds] @ ensemble_weights
ensemble_rmse = np.sqrt(mean_squared_error(y, ensemble_preds))
نتایج را مقایسه کنید تا میزان افزایش قدرت را ببینید:
print(f"\n{'Model':<20} {'RMSE':>10}")
print("-" * 32)
print(f"{'Linear Regression':<20} ${linreg_rmse:>9.4f}")
print(f"{'Random Forest':<20} ${rf_rmse:>9.4f}")
print(f"{'XGBoost':<20} ${xgb_rmse:>9.4f}")
print("-" * 32)
print(f"{'Ensemble':<20} ${ensemble_rmse:>9.4f}")
print(f"\nEnsemble lift: ${xgb_rmse - ensemble_rmse:.4f}")
۱۱. عملکرد CPU را در مقابل GPU مقایسه کنید
برای سنجش صحیح تفاوت عملکرد، هسته را مجدداً راهاندازی میکنید تا از وضعیت اجرای بینقص اطمینان حاصل شود، کل خط لوله علوم داده را روی CPU اجرا میکنید و سپس دوباره آن را روی GPU اجرا میکنید.
کرنل را دوباره راه اندازی کنید
دستور IPython.Application.instance().kernel.do_shutdown(True) را اجرا کنید تا هسته مجدداً راهاندازی شود و حافظه آزاد شود.
import IPython
IPython.Application.instance().kernel.do_shutdown(True)
تعریف خط لوله علم داده
گردش کار اصلی (بارگذاری دادهها، پاکسازی، مهندسی ویژگیها و آموزش مدل) را در یک تابع واحد قرار دهید. این تابع یک ماژول pandas pd_module و یک آرگومان use_gpu برای جابجایی بین محیطها میپذیرد.
def run_ml_pipeline(pd_module, use_gpu=False):
import time
import glob
import numpy as np
from sklearn.ensemble import RandomForestRegressor
import xgboost as xgb
timings = {}
# 1. Load Data
t0 = time.perf_counter()
df = pd_module.concat(
[pd_module.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")],
ignore_index=True
)
timings['Load Data'] = time.perf_counter() - t0
# 2. Clean Data
t0 = time.perf_counter()
# Filter for payment_type=1 (credit card) because tip amounts
# are only reliably recorded for credit card transactions.
df = df[
(df['fare_amount'] > 0) & (df['fare_amount'] < 500) &
(df['trip_distance'] > 0) & (df['trip_distance'] < 100) &
(df['tip_amount'] >= 0) & (df['tip_amount'] < 100) &
(df['payment_type'] == 1)
].copy()
# Downcast numeric columns to save memory
float_cols = df.select_dtypes(include=['float64']).columns
df[float_cols] = df[float_cols].astype('float32')
int_cols = df.select_dtypes(include=['int64']).columns
df[int_cols] = df[int_cols].astype('int32')
timings['Clean Data'] = time.perf_counter() - t0
# 3. Feature Engineering
t0 = time.perf_counter()
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['dow'] = df['tpep_pickup_datetime'].dt.dayofweek
df['is_weekend'] = (df['dow'] >= 5).astype(int)
df['fare_log'] = np.log1p(df['fare_amount'])
timings['Feature Engineering'] = time.perf_counter() - t0
# 4. Modeling Prep
feature_cols = ['trip_distance', 'fare_amount', 'passenger_count', 'hour', 'dow', 'is_weekend', 'fare_log']
X = df[feature_cols].fillna(df[feature_cols].median())
y = df['tip_amount'].copy()
# Free memory
del df
import gc
gc.collect()
# 5. Train Random Forest
t0 = time.perf_counter()
rf_model = RandomForestRegressor(
n_estimators=100,
max_depth=10,
n_jobs=-1,
max_features='sqrt',
random_state=42
).fit(X, y)
timings['Train Random Forest'] = time.perf_counter() - t0
# 6. Train XGBoost
t0 = time.perf_counter()
params = {
'objective': 'reg:squarederror',
'max_depth': 5,
'n_estimators': 100,
'random_state': 42
}
if use_gpu:
params['device'] = 'cuda'
params['tree_method'] = 'hist'
xgb_model = xgb.XGBRegressor(**params).fit(X, y)
timings['Train XGBoost'] = time.perf_counter() - t0
del X
del y
gc.collect()
return timings
روی CPU خود اجرا کنید
با استفاده از CPU pandas استاندارد، خط لوله را فراخوانی کنید.
import pandas as pd
print("Running pipeline on CPU...")
cpu_times = run_ml_pipeline(pd, use_gpu=False)
print("CPU Execution Finished.")
روی پردازنده گرافیکی خود اجرا کنید
افزونههای کتابخانه NVIDIA را بارگذاری کنید، ماژول cudf.pandas شتابیافته را به خط لوله منتقل کنید و دستگاه XGBoost خود را به صورت داخلی روی cuda تنظیم کنید.
import IPython.core.magic
if not hasattr(IPython.core.magic, 'output_can_be_silenced'):
IPython.core.magic.output_can_be_silenced = lambda x: x
%load_ext cudf.pandas
%load_ext cuml.accel
import pandas as pd
print("Running pipeline on GPU...")
gpu_times = run_ml_pipeline(pd, use_gpu=True)
print("GPU Execution Finished.")
افزایش سرعت عملکرد را تجسم کنید
زمانبندیها را با استفاده از matplotlib تجسم کنید. نتایج، زمان صرفهجویی شده در طول پردازش دادهها و آموزش مدل هنگام استفاده از GPUها را نشان میدهد.
import matplotlib.pyplot as plt
import numpy as np
labels = list(cpu_times.keys())
cpu_values = list(cpu_times.values())
gpu_values = list(gpu_times.values())
x = np.arange(len(labels))
width = 0.35
fig, ax = plt.subplots(figsize=(10, 6))
rects1 = ax.bar(x - width/2, cpu_values, width, label='CPU', color='#4285F4')
rects2 = ax.bar(x + width/2, gpu_values, width, label='GPU', color='#76B900')
ax.set_ylabel('Execution Time (seconds)')
ax.set_title('NYC Taxi ML Pipeline: CPU vs. GPU Performance')
ax.set_xticks(x)
ax.set_xticklabels(labels, rotation=45, ha="right")
ax.legend()
# Add data labels
def autolabel(rects):
for rect in rects:
height = rect.get_height()
ax.annotate(f'{height:.2f}s',
xy=(rect.get_x() + rect.get_width() / 2, height),
xytext=(0, 3), # 3 points vertical offset
textcoords="offset points",
ha='center', va='bottom', fontsize=9)
autolabel(rects1)
autolabel(rects2)
plt.tight_layout()
plt.show()
# Calculate overall speedup
total_cpu_time = sum(cpu_values)
total_gpu_time = sum(gpu_values)
overall_speedup = total_cpu_time / total_gpu_time
print(f"\nOverall Pipeline Speedup: {overall_speedup:.2f}x faster on GPU!")
شما باید چیزی شبیه به این را ببینید:
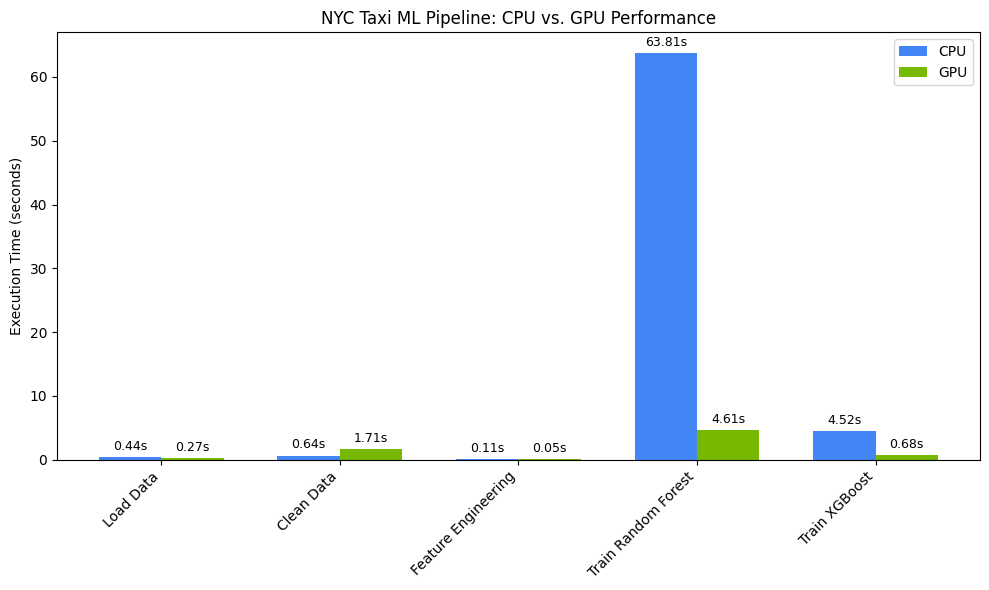
این نمودار، مزیت عملکرد قابل توجه GPU را در کل گردش کار علم داده نشان میدهد. شما باید انتظار داشته باشید که در طول مراحل آموزش مدل که محاسبات فشردهای دارند، برای الگوریتمهایی مانند جنگل تصادفی و XGBoost، شاهد بیشترین صرفهجویی در زمان باشید.
۱۲. کد خود را برای یافتن محدودیتهای عملکرد، پروفایل کنید
هنگام استفاده از cudf.pandas ، اکثر توابع روی GPU اجرا میشوند. اگر یک عملیات خاص هنوز توسط cuDF پشتیبانی نشود، اجرا به طور موقت به CPU برمیگردد. NVIDIA دو دستور جادویی Jupyter داخلی برای شناسایی این fallbackها ارائه میدهد.
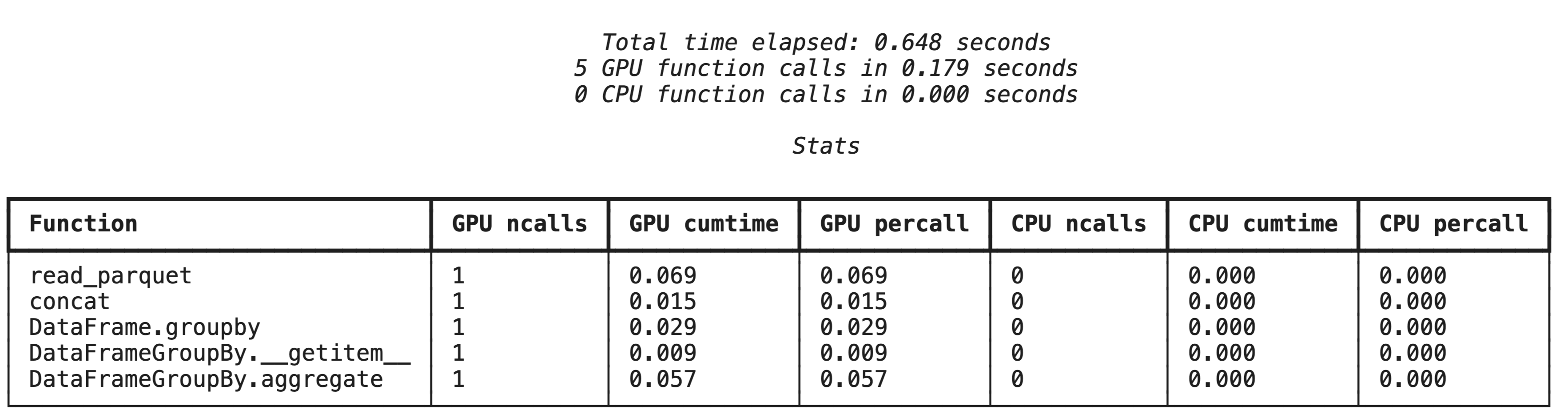
پروفایلسازی سطح بالا با %%cudf.pandas.profile
دستور جادویی %%cudf.pandas.profile خلاصهای از توابع اجرا شده روی GPU یا CPU را ارائه میدهد.
%%cudf.pandas.profile
import glob
import pandas as pd
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")], ignore_index=True)
summary = (
df
.groupby(['PULocationID', 'payment_type'])
[['passenger_count', 'fare_amount', 'tip_amount']]
.agg(['min', 'mean', 'max'])
)
پروفایلسازی خط به خط با %%cudf.pandas.line_profile
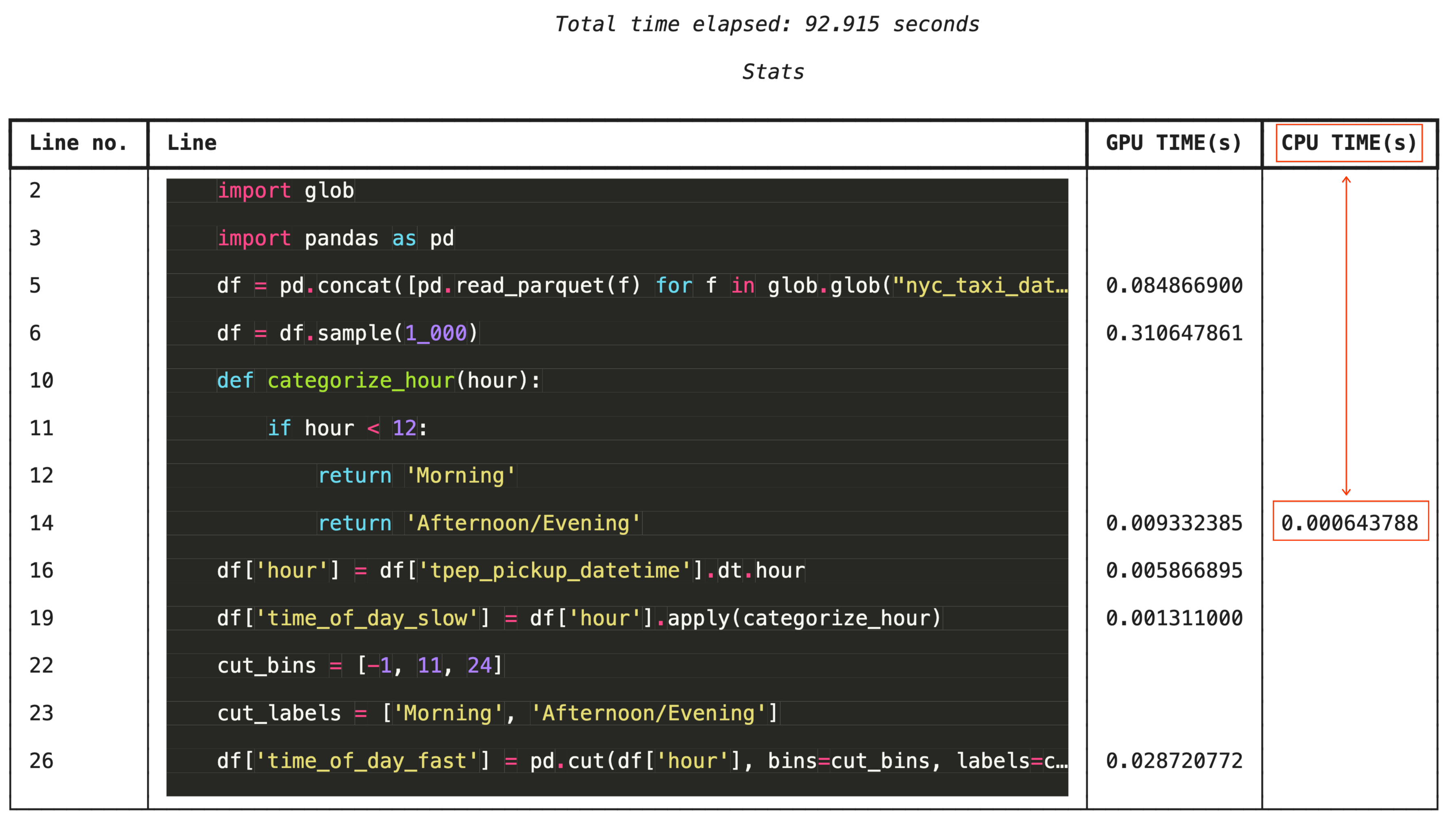
برای عیبیابی جزئیتر، %%cudf.pandas.line_profile هر خط کد را با تعداد دفعاتی که روی GPU در مقابل CPU اجرا شده است، حاشیهنویسی میکند.
%%cudf.pandas.line_profile
import glob
import pandas as pd
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")], ignore_index=True)
df = df.sample(1_000)
# Iterating row-by-row or using custom python apply functions often falls back to the CPU
def categorize_hour(hour):
if hour < 12:
return 'Morning'
else:
return 'Afternoon/Evening'
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['time_of_day_slow'] = df['hour'].apply(categorize_hour)
# Using vectorized pandas operations (like pd.cut) stays entirely on the GPU
cut_bins = [-1, 11, 24]
cut_labels = ['Morning', 'Afternoon/Evening']
df['time_of_day_fast'] = pd.cut(df['hour'], bins=cut_bins, labels=cut_labels)
۱۳. تمیز کردن
برای جلوگیری از هزینههای غیرمنتظره در حساب Google Cloud خود، منابعی را که در طول این آزمایش کد ایجاد کردهاید، پاک کنید.
حذف منابع
مجموعه دادههای محلی را در زمان اجرا با استفاده از دستور !rm -rf در یک سلول نوتبوک حذف کنید.
print("Deleting local 'nyc_taxi_data' directory...")
!rm -rf nyc_taxi_data
print("Local files deleted.")
زمان اجرای Colab خود را خاموش کنید
- در کنسول Google Cloud، به صفحه Colab Enterprise Runtimes بروید.
- در منوی Region ، منطقهای را که شامل زمان اجرای شماست، انتخاب کنید.
- زمان اجرایی که میخواهید حذف کنید را انتخاب کنید.
- روی حذف کلیک کنید.
- روی تأیید کلیک کنید.
دفترچه یادداشت خود را حذف کنید
- در کنسول گوگل کلود، به صفحه دفترچههای من در Colab Enterprise بروید.
- در منوی منطقه ، منطقهای را که دفترچه یادداشت شما در آن قرار دارد، انتخاب کنید.
- دفترچه یادداشتی را که میخواهید حذف کنید، انتخاب کنید.
- روی حذف کلیک کنید.
- روی تأیید کلیک کنید.
۱۴. تبریک
تبریک! شما با موفقیت گردش کار یادگیری ماشین pandas و scikit-learn را با استفاده از کتابخانههای NVIDIA cuDF و cuML در Colab Enterprise تسریع کردهاید. تنها با اضافه کردن چند دستور جادویی ( %load_ext cudf.pandas و %load_ext cuml.accel )، کد استاندارد شما روی GPU اجرا میشود، رکوردها را پردازش میکند و مدلهای پیچیده را به صورت محلی در کسری از زمان برازش میدهد.
برای اطلاعات بیشتر در مورد شتابدهی GPU برای تجزیه و تحلیل دادهها، به Accelerated Data Analytics with GPUs codelab مراجعه کنید.
آنچه ما پوشش دادهایم
- درک Colab Enterprise در Google Cloud.
- سفارشیسازی محیط زمان اجرای Colab با پیکربندیهای خاص GPU و حافظه.
- اعمال شتابدهی GPU برای پیشبینی میزان انعام با استفاده از میلیونها رکورد از مجموعه دادههای تاکسی نیویورک.
- افزایش سرعت
pandasبدون تغییر کد با استفاده از کتابخانهcuDFانویدیا. - تسریع
scikit-learnبدون نیاز به تغییر کد با استفاده از کتابخانهcuMLانویدیا و پردازندههای گرافیکی. - پروفایل کردن کد شما برای شناسایی و بهینهسازی محدودیتهای عملکرد.