
1. Introduction
Dans cet atelier de programmation, vous allez apprendre à accélérer vos workflows de data science et de machine learning sur de grands ensembles de données à l'aide de GPU NVIDIA et de bibliothèques Open Source sur Google Cloud. Vous commencerez par configurer votre infrastructure, puis vous découvrirez comment appliquer l'accélération GPU.
Vous vous concentrerez sur le cycle de vie de la data science, de la préparation des données avec pandas à l'entraînement de modèle avec scikit-learn et XGBoost. Vous apprendrez à accélérer ces tâches à l'aide des bibliothèques cuDF et cuML de NVIDIA. Le meilleur, c'est que vous pouvez bénéficier de cette accélération GPU sans modifier votre code pandas ou scikit-learn existant.
Points abordés
- Comprendre Colab Enterprise sur Google Cloud
- Personnalisez un environnement d'exécution Colab avec des configurations de GPU et de mémoire spécifiques.
- Appliquez l'accélération GPU pour prédire les montants des pourboires à l'aide de millions d'enregistrements provenant d'un ensemble de données sur les taxis à New York.
- Accélérez
pandassans modifier le code à l'aide de la bibliothèquecuDFde NVIDIA. - Accélérez
scikit-learnsans modifier le code en utilisant la bibliothèquecuMLet les GPU de NVIDIA. - Profilez votre code pour identifier et optimiser les contraintes de performances.
La page suivante inclut les crédits que vous pouvez utiliser pour terminer l'atelier.
2. Pourquoi accélérer le machine learning ?
Nécessité d'une itération plus rapide dans le ML
La préparation des données prend du temps, et l'entraînement ou l'évaluation des modèles peuvent prendre encore plus de temps à mesure que les ensembles de données augmentent. L'entraînement de modèles tels que les forêts aléatoires ou XGBoost sur des millions de lignes avec un processeur peut prendre des heures, voire des jours.
L'utilisation de GPU accélère ces entraînements avec des bibliothèques telles que cuML et XGBoost accéléré par GPU. Cette accélération vous permet :
- Itérer plus rapidement : testez rapidement de nouvelles fonctionnalités et de nouveaux hyperparamètres.
- Entraînez vos modèles sur des ensembles de données complets : utilisez vos données complètes au lieu de les sous-échantillonner pour améliorer la précision.
- Réduisez les coûts : effectuez des charges de travail importantes en moins de temps pour réduire les coûts de calcul.
3. Préparation
Coûts potentiels
Cet atelier de programmation utilise des ressources Google Cloud, y compris des runtimes Colab Enterprise avec des GPU NVIDIA L4. Veuillez noter que des frais peuvent s'appliquer. Suivez les instructions de la section Nettoyer à la fin de l'atelier de programmation pour éteindre les ressources et éviter toute facturation continue. Pour en savoir plus sur les tarifs, consultez les pages Tarifs de Colab Enterprise et Tarifs des GPU.
Avant de commencer
Nous partons du principe que vous avez un niveau intermédiaire de connaissances sur Python, pandas, scikit-learn et les pratiques standards de machine learning (comme la validation croisée/l'ensemble).
- Dans Google Cloud Console, sur la page de sélection du projet, sélectionnez ou créez un projet Google Cloud.
- Vérifiez que la facturation est activée pour votre projet Google Cloud.
Activer les API
Pour utiliser Colab Enterprise, vous devez d'abord activer les API nécessaires.
- Ouvrez Google Cloud Shell en cliquant sur l'icône Cloud Shell en haut à droite de la console Google Cloud.

- Dans Cloud Shell, définissez l'ID de votre projet en remplaçant
PROJECT_IDpar l'ID de votre projet :
gcloud config set project <PROJECT_ID>
- Exécutez la commande suivante pour activer les API nécessaires :
gcloud services enable \
compute.googleapis.com \
dataform.googleapis.com \
notebooks.googleapis.com \
aiplatform.googleapis.com
Si l'exécution réussit, un message semblable à celui ci-dessous s'affiche :
Operation "operations/..." finished successfully.
4. Choisir un environnement de notebook
Alors que de nombreux data scientists connaissent Colab pour leurs projets personnels, Colab Enterprise offre une expérience de notebook sécurisée, collaborative et intégrée, conçue pour les entreprises.
Sur Google Cloud, vous avez deux options principales pour les environnements de notebooks gérés : Colab Enterprise et Gemini Enterprise Agent Platform Workbench. Le bon choix dépend des priorités de votre projet.
Quand utiliser Agent Platform Workbench
Choisissez Agent Platform Workbench lorsque votre priorité est le contrôle et la personnalisation avancée. C'est le choix idéal si vous devez :
- Gérez l'infrastructure sous-jacente et le cycle de vie des machines.
- Utiliser des conteneurs et des configurations réseau personnalisés.
- Intégrez-vous aux pipelines MLOps et aux outils de cycle de vie personnalisés.
Quand utiliser Colab Enterprise
Choisissez Colab Enterprise si votre priorité est la rapidité de configuration, la facilité d'utilisation et la collaboration sécurisée. Il s'agit d'une solution entièrement gérée qui permet à votre équipe de se concentrer sur l'analyse plutôt que sur l'infrastructure.
Colab Enterprise vous aide à :
- Développez des workflows de data science étroitement liés à votre entrepôt de données. Vous pouvez ouvrir et gérer vos notebooks directement dans BigQuery Studio.
- Entraînez des modèles de machine learning et intégrez-les aux outils MLOps dans Agent Platform.
- Profitez d'une expérience flexible et unifiée. Un notebook Colab Enterprise créé dans BigQuery peut être ouvert et exécuté dans Agent Platform, et inversement.
Atelier d'aujourd'hui
Cet atelier de programmation utilise Colab Enterprise pour accélérer le machine learning.
Pour en savoir plus sur les différences, consultez la documentation officielle sur le choix de la solution de notebook appropriée.
5. Configurer un modèle d'exécution
Dans Colab Enterprise, connectez-vous à un environnement d'exécution basé sur un modèle d'exécution préconfiguré.
Un modèle d'exécution est une configuration réutilisable qui spécifie l'environnement de votre notebook, y compris :
- Type de machine (processeur, mémoire)
- Accélérateur (type et nombre de GPU)
- Taille et type de disque
- Paramètres réseau et règles de sécurité
- Règles d'arrêt automatique en cas d'inactivité
Pourquoi les modèles d'exécution sont-ils utiles ?
- Cohérence : vous et votre équipe bénéficiez du même environnement pour garantir la répétabilité du travail.
- Sécurité : les modèles appliquent les règles de sécurité de l'organisation.
- Gestion des coûts : les ressources sont prédimensionnées dans le modèle pour éviter les coûts accidentels.
Créer un modèle d'environnement d'exécution
Configurez un modèle d'exécution réutilisable pour l'atelier.
- Dans la console Google Cloud, accédez au menu de navigation > Plate-forme de l'agent > Notebooks.
- Dans Colab Enterprise, cliquez sur Modèles d'exécution, puis sélectionnez Nouveau modèle.
- Sous Principes de base de l'exécution :
- Définissez le nom à afficher sur
gpu-template. - Définissez la région de votre choix.
- Définissez le nom à afficher sur
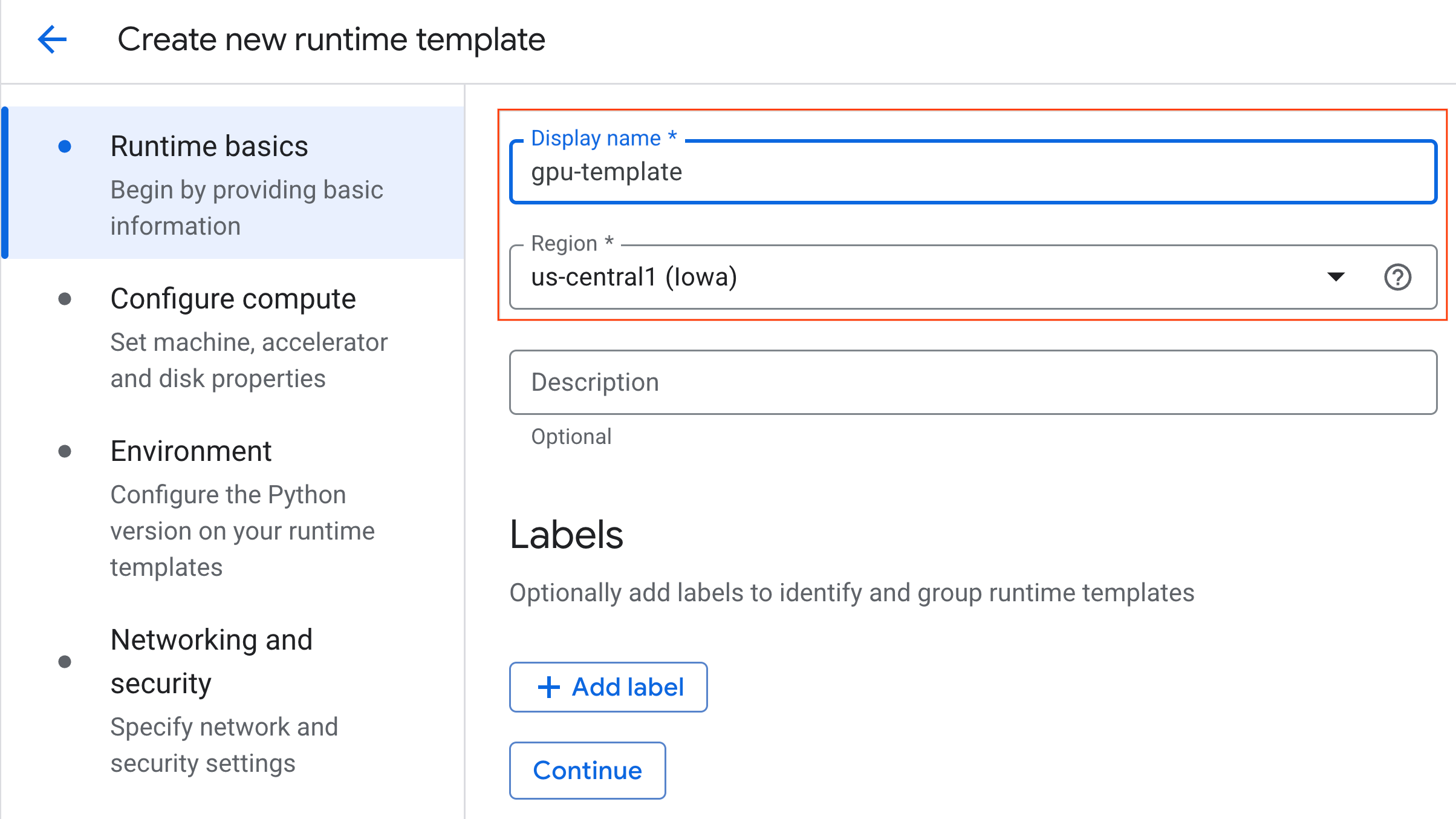
- Sous Configurer le calcul :
- Définissez le type de machine sur
g2-standard-4. - Conservez le type d'accélérateur par défaut (
NVIDIA L4) et définissez le nombre d'accélérateurs sur 1. - Définissez Arrêt en cas d'inactivité sur 60 minutes.
- Cliquez sur Continuer.
- Définissez le type de machine sur
- Sous Environnement :
- Définissez l'environnement sur
Python 3.11.
- Définissez l'environnement sur
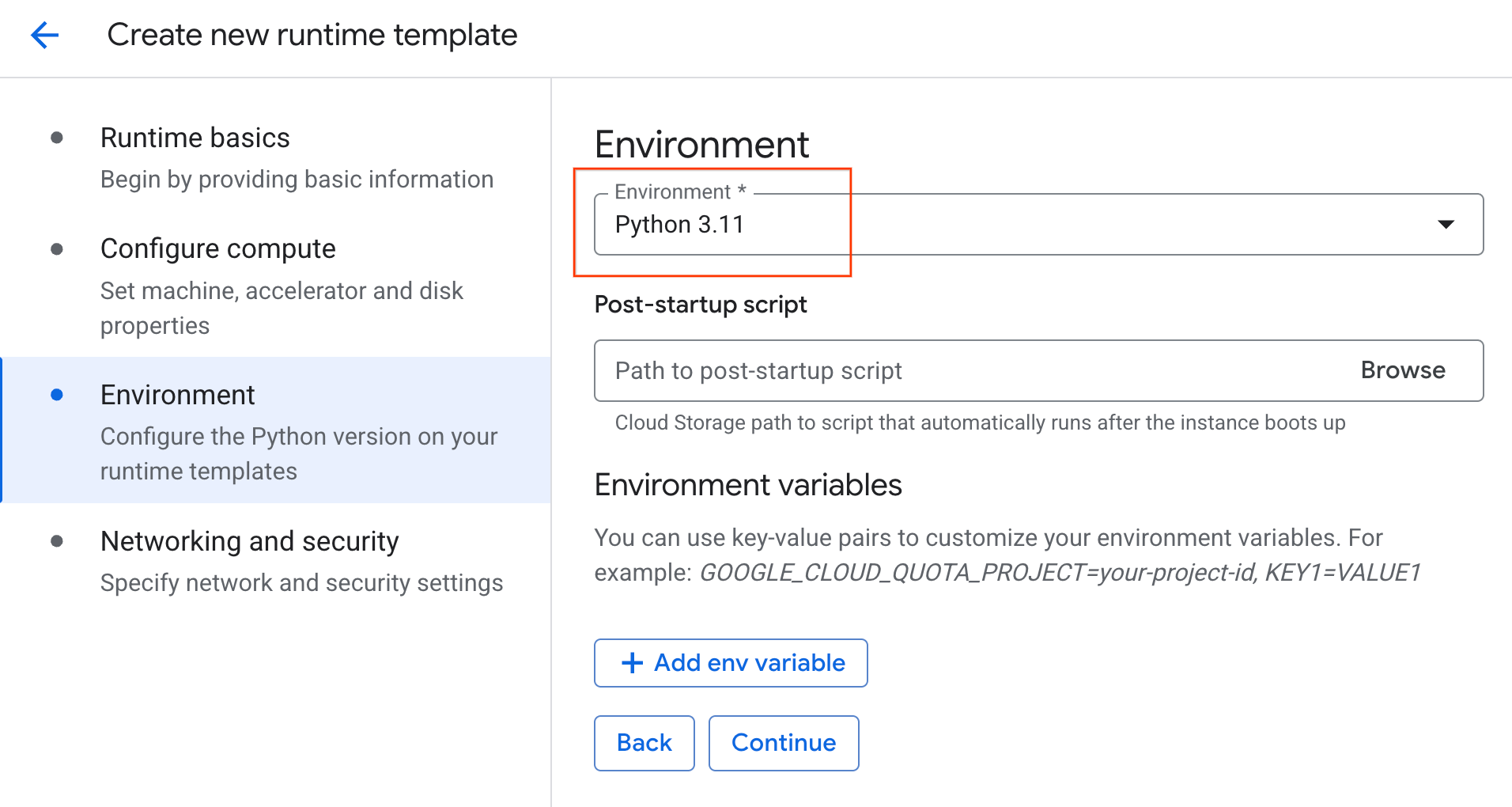
- Cliquez sur Créer pour enregistrer le modèle d'exécution. La nouvelle page "Modèles d'exécution" devrait désormais afficher le nouveau modèle.
6. Démarrer un environnement d'exécution
Une fois votre modèle prêt, vous pouvez créer un environnement d'exécution.
- Dans Colab Enterprise, cliquez sur Exécutions, puis sélectionnez Créer.
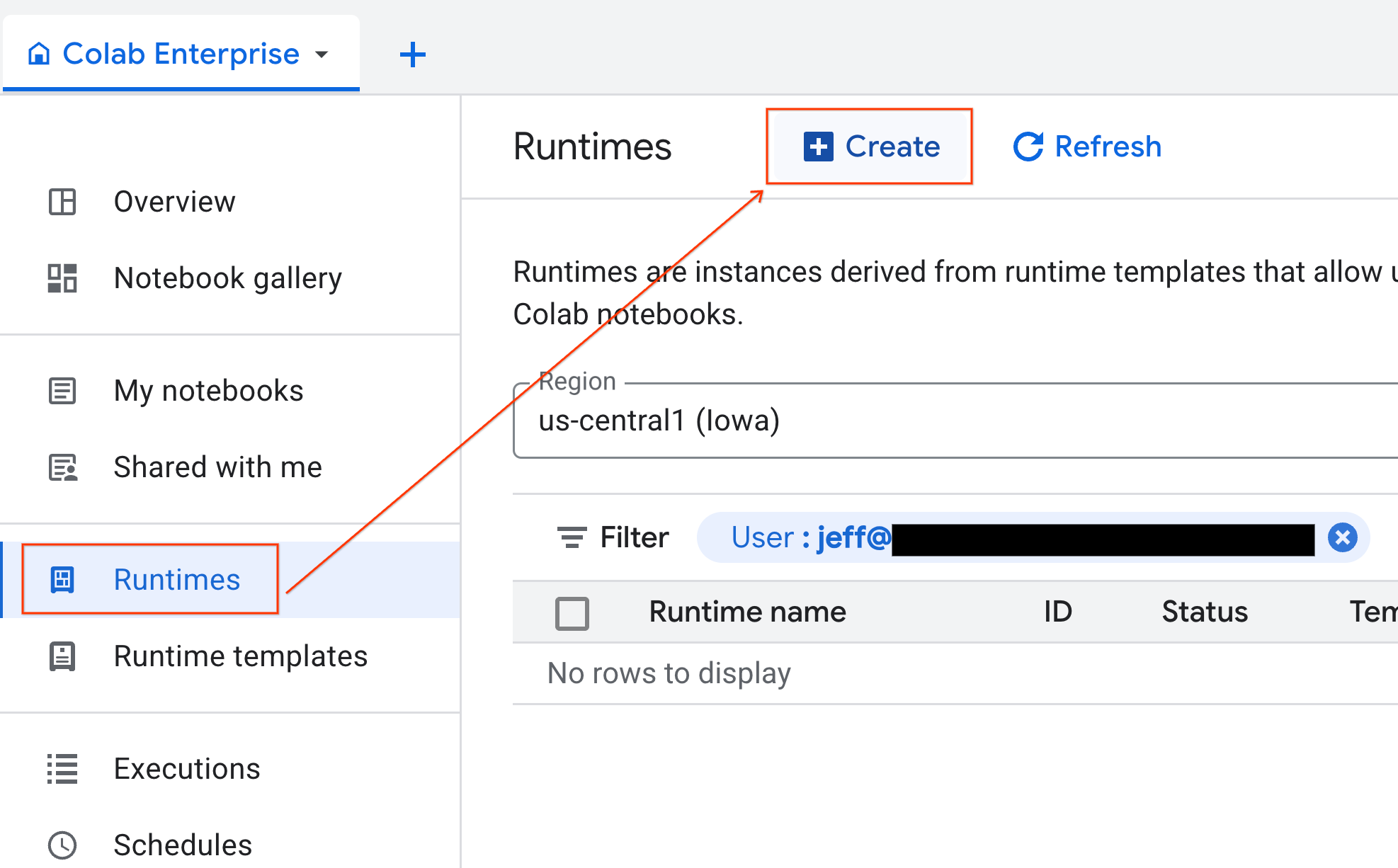
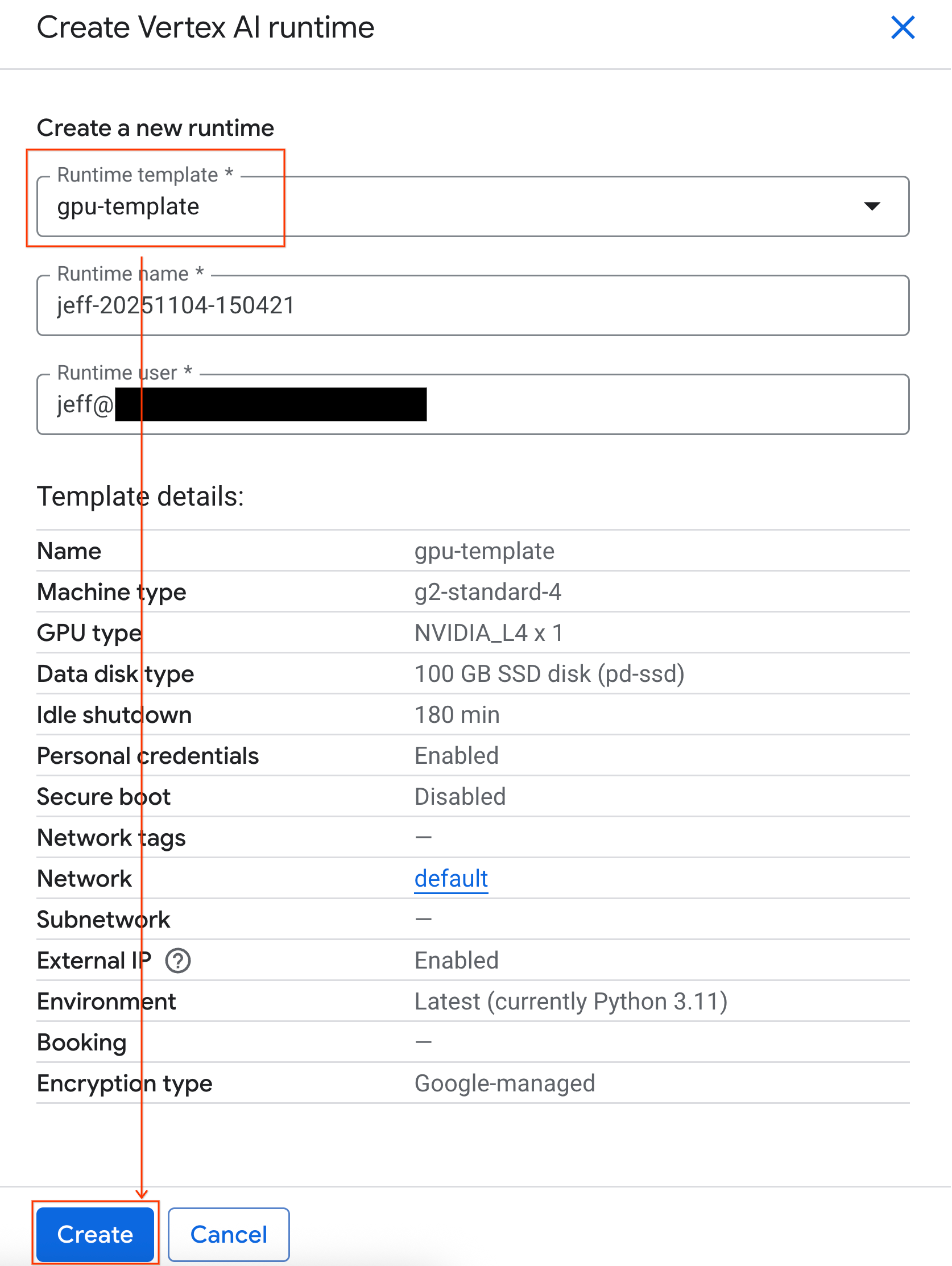
- Sous Modèle d'environnement d'exécution, sélectionnez l'option
gpu-template. Cliquez sur Créer et attendez que l'environnement d'exécution démarre.
- Au bout de quelques minutes, le temps d'exécution disponible s'affiche.
7. Configurer le notebook
Maintenant que votre infrastructure est en cours d'exécution, vous devez importer le notebook de l'atelier et le connecter à votre environnement d'exécution.
Importer le notebook
- Dans Colab Enterprise, cliquez sur Mes notebooks, puis sur Importer.
- Sélectionnez la case d'option URL et saisissez l'URL suivante :
https://github.com/GoogleCloudPlatform/ai-ml-recipes/blob/main/notebooks/regression/gpu_accelerated_regression/gpu_accelerated_regression.ipynb
- Cliquez sur Importer. Colab Enterprise copie le notebook depuis GitHub dans votre environnement.
Se connecter à l'environnement d'exécution
- Ouvrez le notebook que vous venez d'importer.
- Cliquez sur la flèche vers le bas à côté de Connecter.
- Sélectionnez Se connecter à un environnement d'exécution.
- Dans le menu déroulant, sélectionnez le runtime que vous avez créé précédemment.
- Cliquez sur Se connecter.
Votre notebook est désormais connecté à un environnement d'exécution compatible avec les GPU.
Dépendances intégrées
L'un des avantages de Colab Enterprise est qu'il est préinstallé avec les bibliothèques dont vous avez besoin. Vous n'avez pas besoin d'installer ni de gérer manuellement les dépendances telles que cuDF, cuML ou XGBoost pour cet atelier.
8. Préparer l'ensemble de données sur les taxis new-yorkais
Cet atelier de programmation utilise les données d'enregistrement des courses de la NYC Taxi & Limousine Commission (TLC). L'ensemble de données contient des enregistrements de courses de taxis jaunes à New York, y compris :
- Dates, heures et lieux de prise en charge et de dépose
- Distances des trajets
- Montants détaillés des tarifs
- Nombre de passagers
- Montants des pourboires (c'est ce que nous allons prédire !)
Configurer le GPU et confirmer sa disponibilité
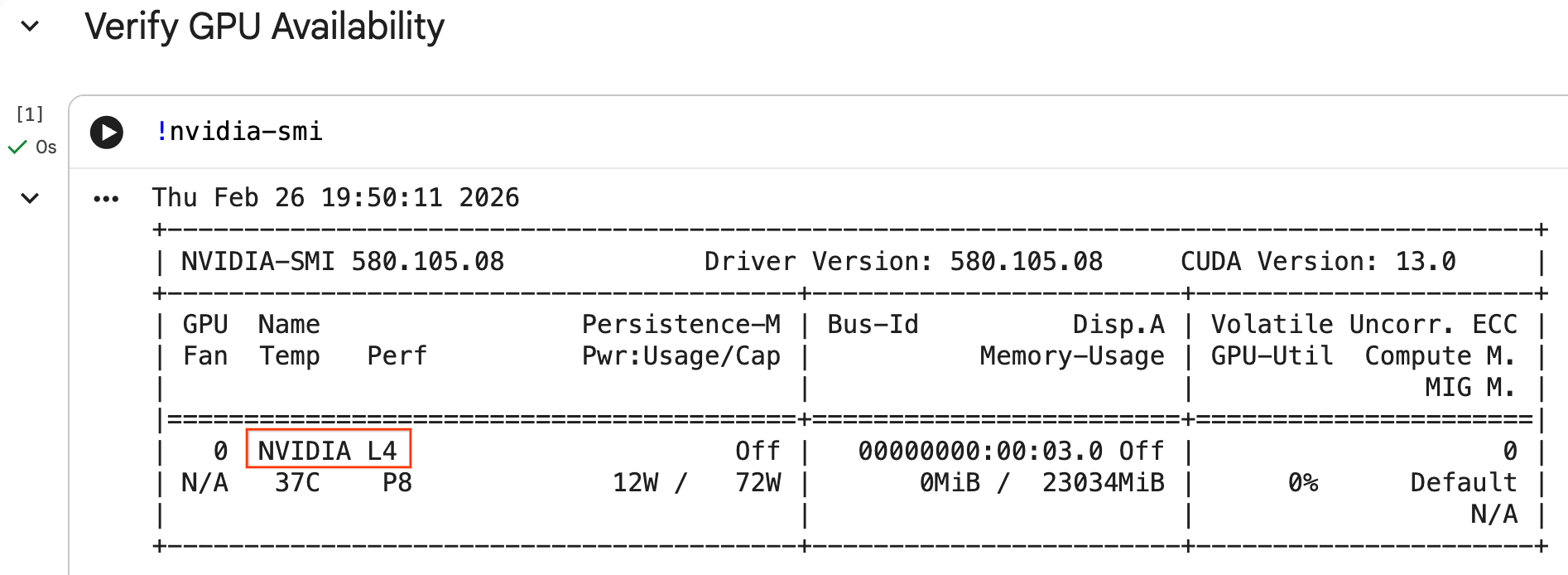
Vous pouvez vérifier que le GPU est reconnu en exécutant la commande nvidia-smi. Il affiche la version du pilote et les détails du GPU (comme le NVIDIA L4).
nvidia-smi
La cellule doit renvoyer le GPU associé à votre environnement d'exécution, comme suit :
Télécharger les données
Téléchargez les données de trajet pour 2024.
from tqdm import tqdm
import requests
import time
import os
YEAR = 2024
DATA_DIR = "nyc_taxi_data"
os.makedirs(DATA_DIR, exist_ok=True)
print(f"Checking/Downloading files for {YEAR}...")
for month in tqdm(range(1, 13), unit="file"):
file_name = f"yellow_tripdata_{YEAR}-{month:02d}.parquet"
local_path = os.path.join(DATA_DIR, file_name)
url = f"https://d37ci6vzurychx.cloudfront.net/trip-data/{file_name}"
if not os.path.exists(local_path):
try:
with requests.get(url, stream=True) as response:
response.raise_for_status()
with open(local_path, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
time.sleep(1)
except requests.exceptions.HTTPError as e:
print(f"\nSkipping {file_name}: {e}")
if os.path.exists(local_path):
os.remove(local_path)
print("\nDownload complete.")
Accélérer pandas avec NVIDIA cuDF
La bibliothèque pandas s'exécute sur le processeur et peut être lente avec de grands ensembles de données. La commande magique NVIDIA %load_ext cudf.pandas corrige dynamiquement pandas pour utiliser l'accélération GPU, en revenant au CPU si nécessaire.
Nous utilisons cette commande magique au lieu d'une importation standard, car elle permet une accélération "sans modification du code". Vous n'avez pas besoin de réécrire votre code existant. Une commande similaire, %load_ext cuml.accel, fait exactement la même chose pour scikit-learn models. Cette méthode fonctionne dans n'importe quel environnement Jupyter avec un GPU NVIDIA compatible, et pas seulement dans Colab Enterprise.
%load_ext cudf.pandas
Pour vérifier qu'il est actif, importez pandas et vérifiez son type :
import pandas as pd
pd
Le résultat confirmera que vous utilisez désormais le module cudf.pandas.
Charger et nettoyer les données
Avec cudf.pandas actif, chargez les fichiers Parquet et exécutez le nettoyage des données. Ce processus s'exécute automatiquement sur le GPU.
import glob
# Load data into memory
df = pd.concat(
[pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")],
ignore_index=True
)
# Filter for valid trips. We filter for payment_type=1 (credit card)
# because tip amounts are only reliably recorded for credit card transactions.
df = df[
(df['fare_amount'] > 0) & (df['fare_amount'] < 500) &
(df['trip_distance'] > 0) & (df['trip_distance'] < 100) &
(df['tip_amount'] >= 0) & (df['tip_amount'] < 100) &
(df['payment_type'] == 1)
].copy()
# Downcast numeric columns to save memory
float_cols = df.select_dtypes(include=['float64']).columns
df[float_cols] = df[float_cols].astype('float32')
int_cols = df.select_dtypes(include=['int64']).columns
df[int_cols] = df[int_cols].astype('int32')
Ingénierie des caractéristiques
Créez des caractéristiques dérivées à partir de la date et de l'heure de prise en charge. Le notebook contient d'autres fonctionnalités utilisées dans les étapes suivantes.
import numpy as np
# Time Features
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['dow'] = df['tpep_pickup_datetime'].dt.dayofweek
df['is_weekend'] = (df['dow'] >= 5).astype(int)
df['is_rush_hour'] = (
((df['hour'] >= 7) & (df['hour'] <= 9)) |
((df['hour'] >= 17) & (df['hour'] <= 19))
).astype(int)
...
# Other features
...
9. Entraîner des modèles individuels avec validation croisée
Pour montrer comment le GPU peut accélérer le machine learning, vous allez entraîner trois types différents de modèles de régression pour prédire le tip_amount d'un trajet en taxi.
Accélérer scikit-learn avec NVIDIA cuML
Exécutez des algorithmes scikit-learn sur le GPU à l'aide de cuML de NVIDIA sans modifier les appels d'API. Commencez par charger l'extension cuml.accel.
%load_ext cuml.accel
Configurer les caractéristiques et les cibles
Identifiez les caractéristiques à partir desquelles vous souhaitez que le modèle apprenne et divisez la colonne cible (tip_amount).
feature_cols = [
'trip_distance', 'fare_amount', 'passenger_count',
'hour', 'dow', 'is_weekend', 'is_rush_hour',
'fare_log', 'fare_decimal', 'is_round_fare',
'route_frequency', 'pu_tip_mean', 'pu_tip_std',
'PULocationID', 'DOLocationID'
]
X = df[feature_cols].fillna(df[feature_cols].median())
y = df['tip_amount'].copy()
Configurez des fractionnements de validation croisée pour évaluer de manière robuste les performances du modèle.
from sklearn.model_selection import KFold
import numpy as np
import time
from sklearn.metrics import mean_squared_error
from tqdm.notebook import tqdm
n_splits = 3
kf = KFold(n_splits=n_splits, shuffle=True, random_state=42)
1. XGBoost
XGBoost est accéléré par GPU de manière native. Transmettez tree_method='hist' et device='cuda' pour utiliser le GPU pendant l'entraînement.
import xgboost as xgb
start_time = time.perf_counter()
def train_xgb_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# XGBoost handles GPU natively when tree_method='hist' and device='cuda'
model = xgb.XGBRegressor(
objective='reg:squarederror',
max_depth=5,
learning_rate=0.1,
n_estimators=100,
tree_method='hist',
device='cuda',
random_state=42
)
model.fit(X_train, y_train)
preds = model.predict(X_val)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
xgb_rmse, xgb_preds = train_xgb_cv(X, y)
print(f"\n{'XGBoost RMSE:':<20} ${xgb_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
2. Régression linéaire
Entraînez un modèle de régression linéaire. Lorsque %load_ext cuml.accel est actif, LinearRegression est automatiquement mappé à son équivalent GPU.
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
start_time = time.perf_counter()
def train_linreg_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# Scale features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_val_scaled = scaler.transform(X_val)
# Automatically accelerated by cuML
model = LinearRegression()
model.fit(X_train_scaled, y_train)
preds = model.predict(X_val_scaled)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
linreg_rmse, linreg_preds = train_linreg_cv(X, y)
print(f"\n{'Linear Reg RMSE:':<20} ${linreg_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
3. Random Forest
Entraînez un modèle d'ensemble à l'aide de RandomForestRegressor. Les modèles basés sur des arbres sont souvent lents à entraîner sur le CPU, mais l'accélération par GPU traite des millions de lignes plus rapidement.
from sklearn.ensemble import RandomForestRegressor
start_time = time.perf_counter()
def train_rf_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# Automatically accelerated by cuML
model = RandomForestRegressor(
n_estimators=100,
max_depth=10,
n_jobs=-1,
max_features='sqrt',
random_state=42
)
model.fit(X_train, y_train)
preds = model.predict(X_val)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
rf_rmse, rf_preds = train_rf_cv(X, y)
print(f"\n{'Random Forest RMSE:':<20} ${rf_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
10. Évaluer le pipeline de bout en bout
Combinez les prédictions des trois modèles à l'aide d'un simple ensemble linéaire. Cela permet généralement d'améliorer légèrement la précision par rapport aux modèles individuels.
Ajustez une régression linéaire sur les prédictions pour trouver les pondérations optimales :
ensemble_weights = LinearRegression(positive=True, fit_intercept=False).fit(
np.c_[xgb_preds, rf_preds, linreg_preds], y
).coef_
# Normalize weights
ensemble_weights = ensemble_weights / ensemble_weights.sum()
ensemble_preds = np.c_[xgb_preds, rf_preds, linreg_preds] @ ensemble_weights
ensemble_rmse = np.sqrt(mean_squared_error(y, ensemble_preds))
Comparez les résultats pour voir l'impact de l'ensemble :
print(f"\n{'Model':<20} {'RMSE':>10}")
print("-" * 32)
print(f"{'Linear Regression':<20} ${linreg_rmse:>9.4f}")
print(f"{'Random Forest':<20} ${rf_rmse:>9.4f}")
print(f"{'XGBoost':<20} ${xgb_rmse:>9.4f}")
print("-" * 32)
print(f"{'Ensemble':<20} ${ensemble_rmse:>9.4f}")
print(f"\nEnsemble lift: ${xgb_rmse - ensemble_rmse:.4f}")
11. Comparer les performances du CPU et du GPU
Pour comparer correctement les performances, vous allez redémarrer le noyau afin de garantir un état d'exécution propre, exécuter l'intégralité du pipeline de science des données sur le processeur, puis l'exécuter à nouveau sur le GPU.
Redémarrer le noyau
Exécutez la commande IPython.Application.instance().kernel.do_shutdown(True) pour redémarrer le noyau et libérer de la mémoire.
import IPython
IPython.Application.instance().kernel.do_shutdown(True)
Définir le pipeline de science des données
Encapsulez le workflow principal (chargement, nettoyage des données, ingénierie des caractéristiques et entraînement de modèle) dans une seule fonction. Cette fonction accepte un module pandas pd_module et un argument use_gpu pour basculer entre les environnements.
def run_ml_pipeline(pd_module, use_gpu=False):
import time
import glob
import numpy as np
from sklearn.ensemble import RandomForestRegressor
import xgboost as xgb
timings = {}
# 1. Load Data
t0 = time.perf_counter()
df = pd_module.concat(
[pd_module.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")],
ignore_index=True
)
timings['Load Data'] = time.perf_counter() - t0
# 2. Clean Data
t0 = time.perf_counter()
# Filter for payment_type=1 (credit card) because tip amounts
# are only reliably recorded for credit card transactions.
df = df[
(df['fare_amount'] > 0) & (df['fare_amount'] < 500) &
(df['trip_distance'] > 0) & (df['trip_distance'] < 100) &
(df['tip_amount'] >= 0) & (df['tip_amount'] < 100) &
(df['payment_type'] == 1)
].copy()
# Downcast numeric columns to save memory
float_cols = df.select_dtypes(include=['float64']).columns
df[float_cols] = df[float_cols].astype('float32')
int_cols = df.select_dtypes(include=['int64']).columns
df[int_cols] = df[int_cols].astype('int32')
timings['Clean Data'] = time.perf_counter() - t0
# 3. Feature Engineering
t0 = time.perf_counter()
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['dow'] = df['tpep_pickup_datetime'].dt.dayofweek
df['is_weekend'] = (df['dow'] >= 5).astype(int)
df['fare_log'] = np.log1p(df['fare_amount'])
timings['Feature Engineering'] = time.perf_counter() - t0
# 4. Modeling Prep
feature_cols = ['trip_distance', 'fare_amount', 'passenger_count', 'hour', 'dow', 'is_weekend', 'fare_log']
X = df[feature_cols].fillna(df[feature_cols].median())
y = df['tip_amount'].copy()
# Free memory
del df
import gc
gc.collect()
# 5. Train Random Forest
t0 = time.perf_counter()
rf_model = RandomForestRegressor(
n_estimators=100,
max_depth=10,
n_jobs=-1,
max_features='sqrt',
random_state=42
).fit(X, y)
timings['Train Random Forest'] = time.perf_counter() - t0
# 6. Train XGBoost
t0 = time.perf_counter()
params = {
'objective': 'reg:squarederror',
'max_depth': 5,
'n_estimators': 100,
'random_state': 42
}
if use_gpu:
params['device'] = 'cuda'
params['tree_method'] = 'hist'
xgb_model = xgb.XGBRegressor(**params).fit(X, y)
timings['Train XGBoost'] = time.perf_counter() - t0
del X
del y
gc.collect()
return timings
Exécuter sur votre CPU
Appelez le pipeline à l'aide du processeur standard pandas.
import pandas as pd
print("Running pipeline on CPU...")
cpu_times = run_ml_pipeline(pd, use_gpu=False)
print("CPU Execution Finished.")
Exécuter sur votre GPU
Chargez les extensions de bibliothèque NVIDIA, transmettez le module cudf.pandas accéléré au pipeline et définissez votre appareil XGBoost sur cuda en interne.
import IPython.core.magic
if not hasattr(IPython.core.magic, 'output_can_be_silenced'):
IPython.core.magic.output_can_be_silenced = lambda x: x
%load_ext cudf.pandas
%load_ext cuml.accel
import pandas as pd
print("Running pipeline on GPU...")
gpu_times = run_ml_pipeline(pd, use_gpu=True)
print("GPU Execution Finished.")
Visualiser l'amélioration des performances
Visualisez les timings à l'aide de matplotlib. Les résultats indiquent le temps gagné lors du traitement des données et de l'entraînement du modèle lorsque des GPU sont utilisés.
import matplotlib.pyplot as plt
import numpy as np
labels = list(cpu_times.keys())
cpu_values = list(cpu_times.values())
gpu_values = list(gpu_times.values())
x = np.arange(len(labels))
width = 0.35
fig, ax = plt.subplots(figsize=(10, 6))
rects1 = ax.bar(x - width/2, cpu_values, width, label='CPU', color='#4285F4')
rects2 = ax.bar(x + width/2, gpu_values, width, label='GPU', color='#76B900')
ax.set_ylabel('Execution Time (seconds)')
ax.set_title('NYC Taxi ML Pipeline: CPU vs. GPU Performance')
ax.set_xticks(x)
ax.set_xticklabels(labels, rotation=45, ha="right")
ax.legend()
# Add data labels
def autolabel(rects):
for rect in rects:
height = rect.get_height()
ax.annotate(f'{height:.2f}s',
xy=(rect.get_x() + rect.get_width() / 2, height),
xytext=(0, 3), # 3 points vertical offset
textcoords="offset points",
ha='center', va='bottom', fontsize=9)
autolabel(rects1)
autolabel(rects2)
plt.tight_layout()
plt.show()
# Calculate overall speedup
total_cpu_time = sum(cpu_values)
total_gpu_time = sum(gpu_values)
overall_speedup = total_cpu_time / total_gpu_time
print(f"\nOverall Pipeline Speedup: {overall_speedup:.2f}x faster on GPU!")
Vous devez obtenir un résultat semblable au suivant :
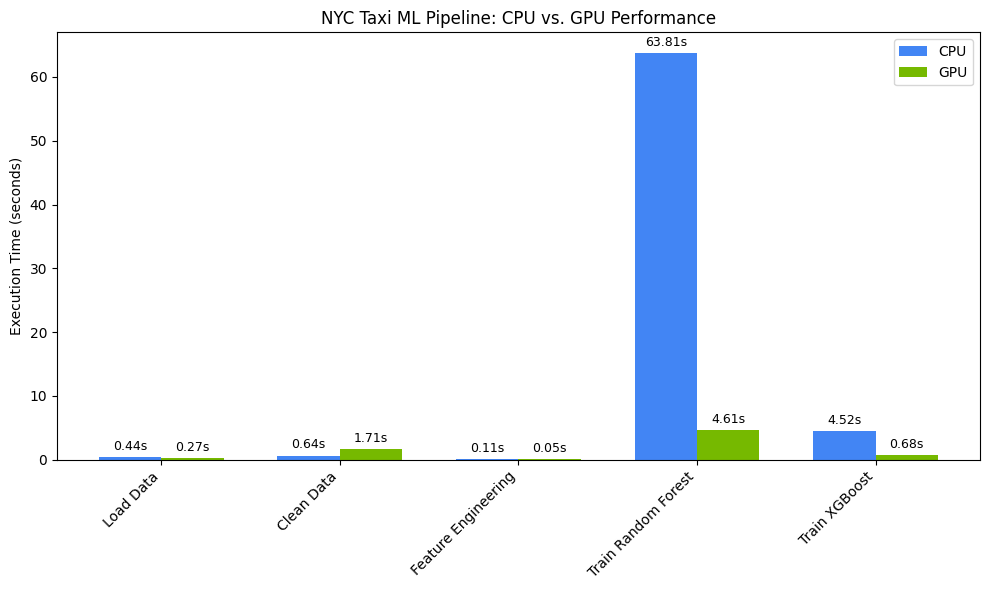
Ce graphique illustre l'avantage de performances significatif du GPU sur l'ensemble du workflow de data science. Vous devriez constater les gains de temps les plus spectaculaires lors des phases d'entraînement de modèles gourmandes en calculs pour des algorithmes tels que Random Forest et XGBoost.
12. Profiler votre code pour identifier les contraintes de performances
Lorsque vous utilisez cudf.pandas, la plupart des fonctions s'exécutent sur le GPU. Si une opération spécifique n'est pas encore prise en charge par cuDF, l'exécution est temporairement transférée au processeur. NVIDIA fournit deux commandes magiques Jupyter intégrées pour identifier ces solutions de secours.
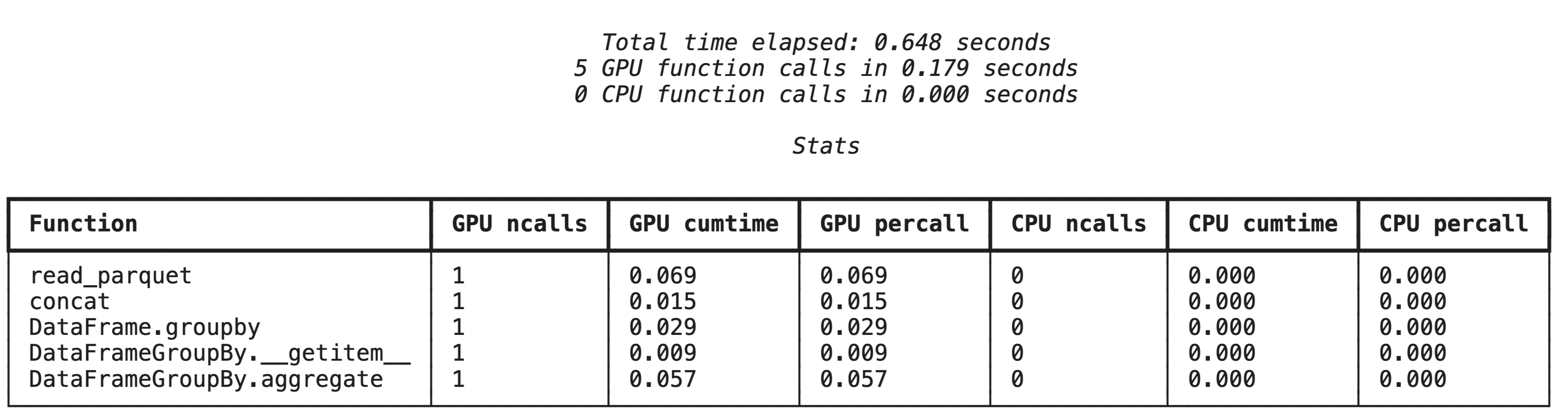
Profilage de haut niveau avec %%cudf.pandas.profile
La commande magique %%cudf.pandas.profile fournit un récapitulatif des fonctions exécutées sur le GPU ou le CPU.
%%cudf.pandas.profile
import glob
import pandas as pd
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")], ignore_index=True)
summary = (
df
.groupby(['PULocationID', 'payment_type'])
[['passenger_count', 'fare_amount', 'tip_amount']]
.agg(['min', 'mean', 'max'])
)
Profilage ligne par ligne avec %%cudf.pandas.line_profile
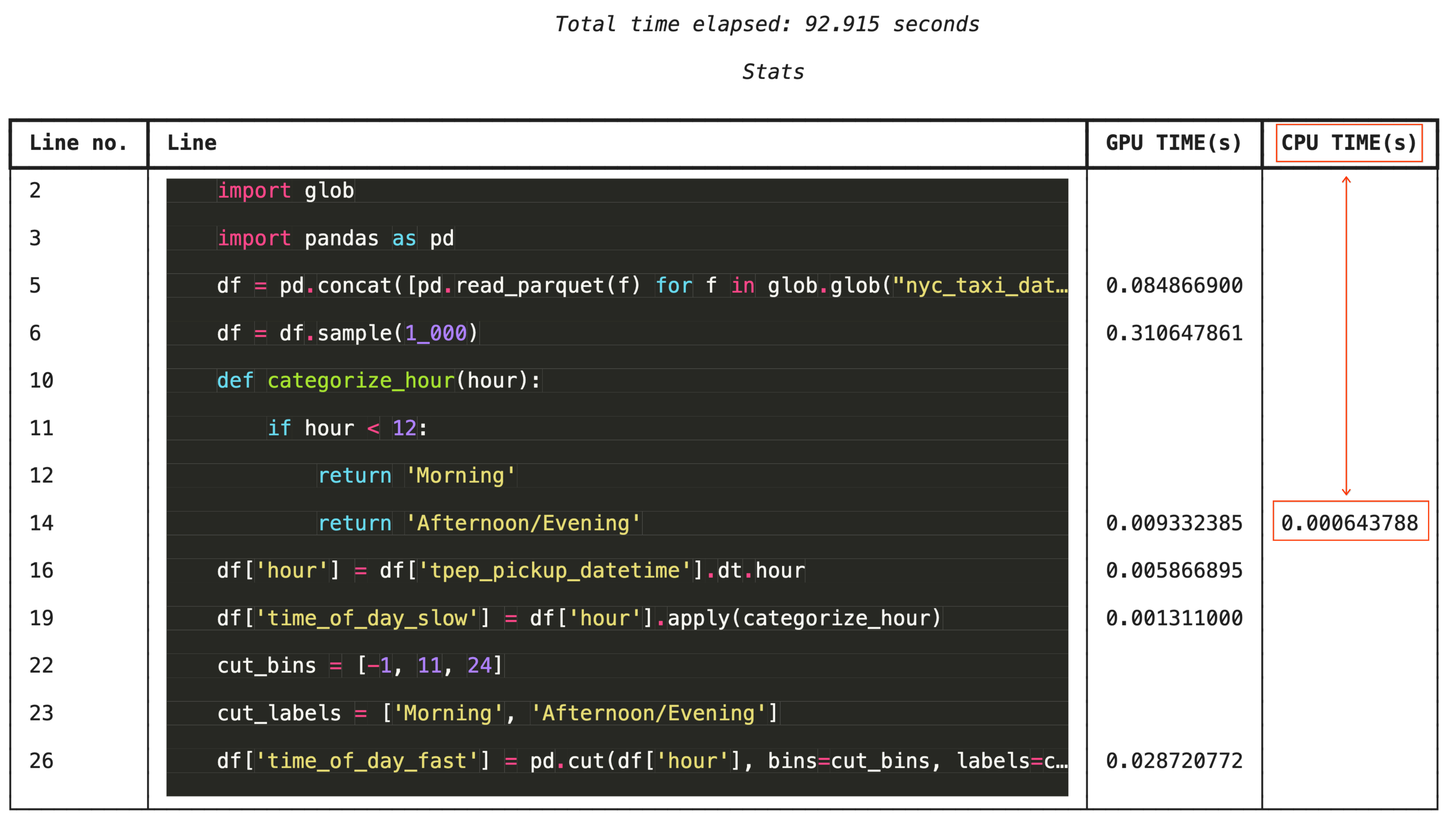
Pour un dépannage précis, %%cudf.pandas.line_profile annote chaque ligne de code avec le nombre de fois où elle a été exécutée sur le GPU par rapport au CPU.
%%cudf.pandas.line_profile
import glob
import pandas as pd
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")], ignore_index=True)
df = df.sample(1_000)
# Iterating row-by-row or using custom python apply functions often falls back to the CPU
def categorize_hour(hour):
if hour < 12:
return 'Morning'
else:
return 'Afternoon/Evening'
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['time_of_day_slow'] = df['hour'].apply(categorize_hour)
# Using vectorized pandas operations (like pd.cut) stays entirely on the GPU
cut_bins = [-1, 11, 24]
cut_labels = ['Morning', 'Afternoon/Evening']
df['time_of_day_fast'] = pd.cut(df['hour'], bins=cut_bins, labels=cut_labels)
13. Effectuer un nettoyage
Pour éviter des frais inattendus sur votre compte Google Cloud, nettoyez les ressources que vous avez créées lors de cet atelier de programmation.
Delete resources
Supprimez l'ensemble de données local sur le runtime à l'aide de la commande !rm -rf dans une cellule de notebook.
print("Deleting local 'nyc_taxi_data' directory...")
!rm -rf nyc_taxi_data
print("Local files deleted.")
Arrêter votre environnement d'exécution Colab
- Dans la console Google Cloud, accédez à la page Environnements d'exécution de Colab Enterprise.
- Dans le menu Région, sélectionnez la région qui contient votre environnement d'exécution.
- Sélectionnez l'environnement d'exécution que vous souhaitez supprimer.
- Cliquez sur Supprimer.
- Cliquez sur Confirmer.
Supprimer votre notebook
- Dans la console Google Cloud, accédez à la page Mes notebooks de Colab Enterprise.
- Dans le menu Région, sélectionnez la région qui contient votre notebook.
- Sélectionnez le notebook que vous souhaitez supprimer.
- Cliquez sur Supprimer.
- Cliquez sur Confirmer.
14. Félicitations
Félicitations ! Vous avez accéléré un workflow de machine learning pandas et scikit-learn à l'aide des bibliothèques NVIDIA cuDF et cuML sur Colab Enterprise. En ajoutant simplement quelques commandes magiques (%load_ext cudf.pandas et %load_ext cuml.accel), votre code standard s'exécute sur le GPU, ce qui permet de traiter les enregistrements et d'ajuster les modèles complexes localement en une fraction du temps.
Pour en savoir plus sur l'accélération GPU pour l'analyse de données, consultez l'atelier de programmation Accelerated Data Analytics with GPUs.
Points abordés
- Comprendre Colab Enterprise sur Google Cloud.
- Personnaliser un environnement d'exécution Colab avec des configurations de GPU et de mémoire spécifiques.
- Application de l'accélération GPU pour prédire les montants des pourboires à l'aide de millions d'enregistrements d'un ensemble de données sur les taxis à New York.
- Accélération de
pandassans modification du code à l'aide de la bibliothèquecuDFde NVIDIA. - Accélérer
scikit-learnsans modifier le code à l'aide de la bibliothèquecuMLet des GPU de NVIDIA. - Profilage de votre code pour identifier et optimiser les contraintes de performances.