
1. מבוא
ב-Codelab הזה תלמדו איך להאיץ את תהליכי העבודה של מדעי הנתונים ולמידת מכונה במערכי נתונים גדולים באמצעות מעבדי GPU של NVIDIA וספריות קוד פתוח ב-Google Cloud. תתחילו בהגדרת התשתית, ואז תלמדו איך להשתמש בהאצת GPU.
התכנים יתמקדו במחזור החיים של מדעי הנתונים, מהכנת נתונים באמצעות pandas ועד לאימון מודלים באמצעות scikit-learn ו-XGBoost. תלמדו איך להאיץ את המשימות האלה באמצעות הספריות cuDF ו-cuML של NVIDIA. היתרון הכי גדול הוא שאפשר להשתמש בהאצת ה-GPU בלי לשנות את הקוד הקיים של pandas או scikit-learn.
מה תלמדו
- הסבר על Colab Enterprise ב-Google Cloud.
- התאמה אישית של סביבת זמן ריצה ב-Colab עם הגדרות ספציפיות של GPU וזיכרון.
- החלת האצת GPU כדי לחזות את סכומי הטיפים באמצעות מיליוני רשומות ממערך נתונים של מוניות בניו יורק.
- אפשר להאיץ את
pandasללא שינויים בקוד באמצעות ספרייתcuDFשל NVIDIA. - האצת
scikit-learnללא שינויים בקוד באמצעות ספרייתcuMLומעבדי GPU של NVIDIA. - יוצרים פרופיל של הקוד כדי לזהות אילוצים שמשפיעים על הביצועים ולבצע אופטימיזציה שלהם.
בדף הבא מופיעים הקרדיטים שבהם אפשר להשתמש כדי להשלים את ה-Lab.
2. למה כדאי להאיץ את למידת המכונה?
הצורך באיטרציה מהירה יותר ב-ML
הכנת הנתונים היא תהליך שלוקח זמן, ואימון המודל או ההערכה שלו יכולים לקחת עוד יותר זמן ככל שמערכי הנתונים גדלים. אימון מודלים כמו יערות אקראיים או XGBoost על מיליוני שורות באמצעות מעבד (CPU) יכול להימשך שעות או ימים.
השימוש ב-GPU מאיץ את ההרצות האלה של האימון באמצעות ספריות כמו cuML ו-XGBoost מבוסס-GPU. התאוצה הזו מאפשרת לכם:
- חזרה מהירה על תהליך העבודה: בדיקה מהירה של תכונות חדשות ושל היפרפרמטרים.
- אימון על מערכי נתונים מלאים: כדי לשפר את הדיוק, כדאי להשתמש בנתונים המלאים במקום בדגימה.
- הפחתת עלויות: אפשר להשלים עומסי עבודה כבדים בפחות זמן כדי להפחית את עלויות המחשוב.
3. הגדרה ודרישות
עלויות פוטנציאליות
ב-Codelab הזה נעשה שימוש במשאבי Google Cloud, כולל סביבות זמן ריצה של Colab Enterprise עם מעבדי GPU מסוג NVIDIA L4. חשוב לשים לב לחיובים פוטנציאליים ולפעול לפי ההוראות שבקטע ניקוי בסוף ה-codelab כדי להשבית משאבים ולמנוע חיובים שוטפים. למידע מפורט על תמחור, אפשר לעיין במאמרים בנושא תמחור של Colab Enterprise ותמחור של GPU.
לפני שמתחילים
ההנחה היא שיש לכם היכרות ברמה בינונית עם Python, pandas, scikit-learn ושיטות סטנדרטיות של למידת מכונה (כמו אימות צולב או שילוב של מודלים).
- במסוף Google Cloud, בדף לבחירת הפרויקט בענן, בוחרים פרויקט בענן או יוצרים פרויקט בענן חדש.
- הקפידו לוודא שהחיוב מופעל בפרויקט בענן שלכם ב-Google Cloud.
הפעלת ממשקי ה-API
כדי להשתמש ב-Colab Enterprise, צריך קודם להפעיל את ממשקי ה-API הנדרשים.
- פותחים את Google Cloud Shell בלחיצה על הסמל של Cloud Shell בפינה הימנית העליונה של מסוף Google Cloud.

- ב-Cloud Shell, מחליפים את
PROJECT_IDבמזהה הפרויקט כדי להגדיר אותו:
gcloud config set project <PROJECT_ID>
- מריצים את הפקודה הבאה כדי להפעיל את ממשקי ה-API הנדרשים:
gcloud services enable \
compute.googleapis.com \
dataform.googleapis.com \
notebooks.googleapis.com \
aiplatform.googleapis.com
אם הפעולה בוצעה בהצלחה, תוצג הודעה שדומה לזו שמופיעה בהמשך:
Operation "operations/..." finished successfully.
4. בחירת סביבת Notebook
מדעני נתונים רבים מכירים את Colab לשימוש בפרויקטים אישיים, אבל Colab Enterprise מספק חוויית מחברת מאובטחת, משולבת ושיתופית שמיועדת לעסקים.
ב-Google Cloud יש שתי אפשרויות עיקריות לסביבות מחברות מנוהלות: Colab Enterprise ו-Gemini Enterprise Agent Platform Workbench. הבחירה הנכונה תלויה בסדרי העדיפויות של הפרויקט.
מתי כדאי להשתמש ב-Agent Platform Workbench
בוחרים ב-Agent Platform Workbench אם העדיפות היא שליטה והתאמה אישית מתקדמת. האפשרות הזו מתאימה במקרים הבאים:
- לנהל את התשתית הבסיסית ואת מחזור החיים של המכונות.
- שימוש במאגרי תגים מותאמים אישית ובהגדרות רשת.
- שילוב עם צינורות MLOps וכלים מותאמים אישית למחזור החיים.
מתי כדאי להשתמש ב-Colab Enterprise
כדאי לבחור ב-Colab Enterprise אם העדיפות שלכם היא הגדרה מהירה, קלות שימוש ושיתוף פעולה מאובטח. זהו פתרון מנוהל שמאפשר לצוות שלכם להתמקד בניתוח במקום בתשתית.
Colab Enterprise מאפשר לכם:
- פיתוח תהליכי עבודה של מדעי הנתונים שקשורים קשר הדוק למחסן הנתונים. אפשר לפתוח ולנהל את מחברות ה-Notebook ישירות ב-BigQuery Studio.
- אימון מודלים של למידת מכונה ושילוב עם כלי MLOps בפלטפורמת הסוכנים.
- ליהנות מחוויה גמישה ומאוחדת. אפשר לפתוח ולהריץ ב-Agent Platform מחברת Colab Enterprise שנוצרה ב-BigQuery, ולהיפך.
התכונה של היום מ-Labs
ב-Codelab הזה נעשה שימוש ב-Colab Enterprise כדי להאיץ את למידת המכונה.
לקבלת מידע נוסף על ההבדלים, אפשר לעיין בתיעוד הרשמי בנושא בחירת פתרון המחברת הנכון.
5. הגדרת תבנית בזמן ריצה
ב-Colab Enterprise, מתחברים לסביבת זמן ריצה שמבוססת על תבנית מוגדרת מראש של סביבת זמן ריצה.
תבנית בזמן ריצה היא הגדרה לשימוש חוזר שמציינת את הסביבה של המחברת, כולל:
- סוג המכונה (מעבד, זיכרון)
- מאיץ (סוג ה-GPU ומספר המאיצים)
- גודל וסוג הדיסק
- הגדרות רשת ומדיניות אבטחה
- כללים אוטומטיים לכיבוי במצב המתנה
למה כדאי להשתמש בתבניות בזמן ריצה
- עקביות: אתם והצוות שלכם מקבלים את אותה סביבה כדי להבטיח שאפשר יהיה לחזור על העבודה.
- אבטחה: התבניות אוכפות את מדיניות האבטחה של הארגון.
- ניהול עלויות: המשאבים מוגדרים מראש בתבנית כדי למנוע עלויות לא מכוונות.
יצירת תבנית בזמן ריצה
מגדירים תבנית זמן ריצה לשימוש חוזר לשיעור ה-Lab.
- במסוף Google Cloud, עוברים אל תפריט הניווט > Agent Platform > Notebooks.
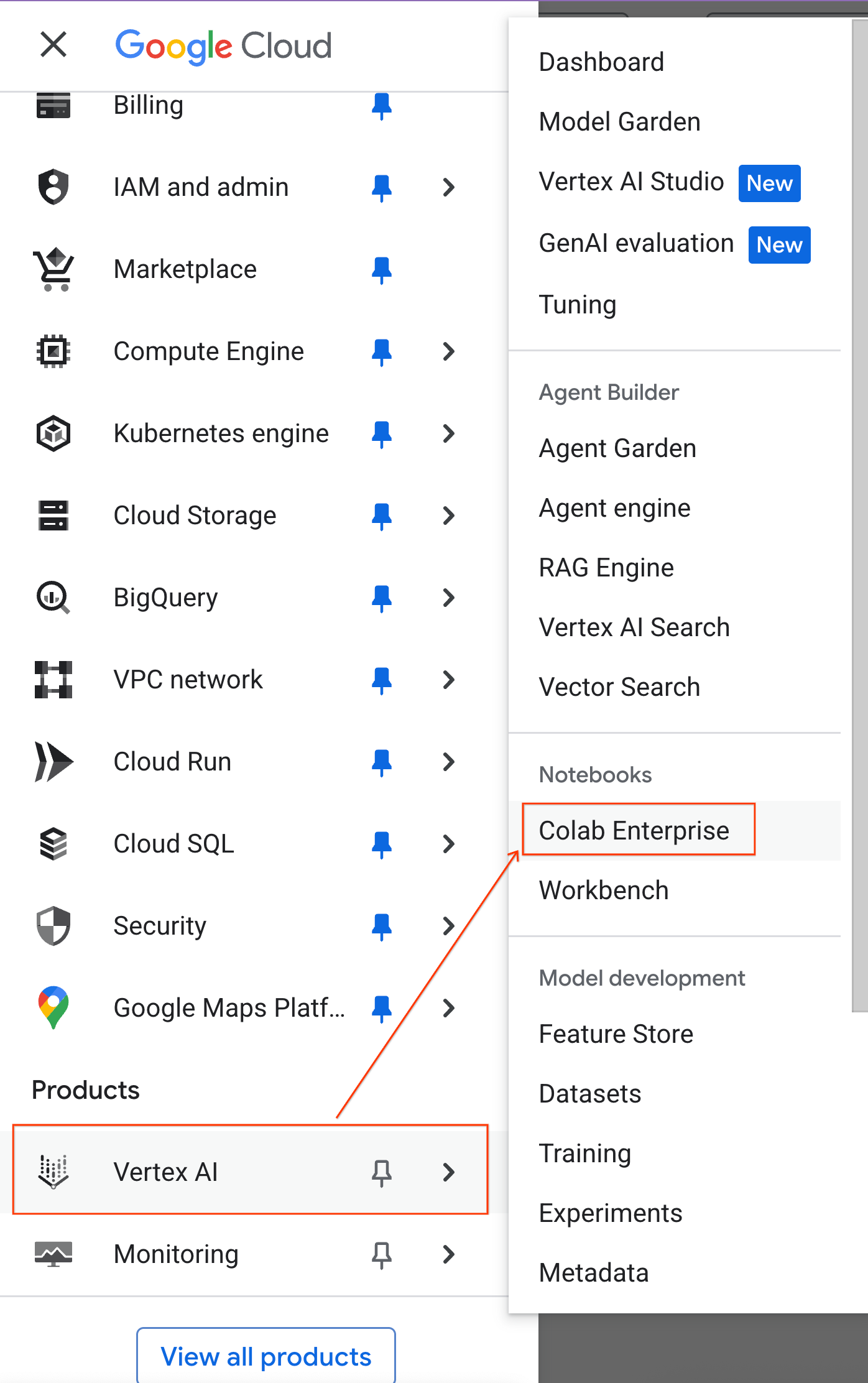
- ב-Colab Enterprise, לוחצים על תבניות של סביבת ריצה ואז על תבנית חדשה.
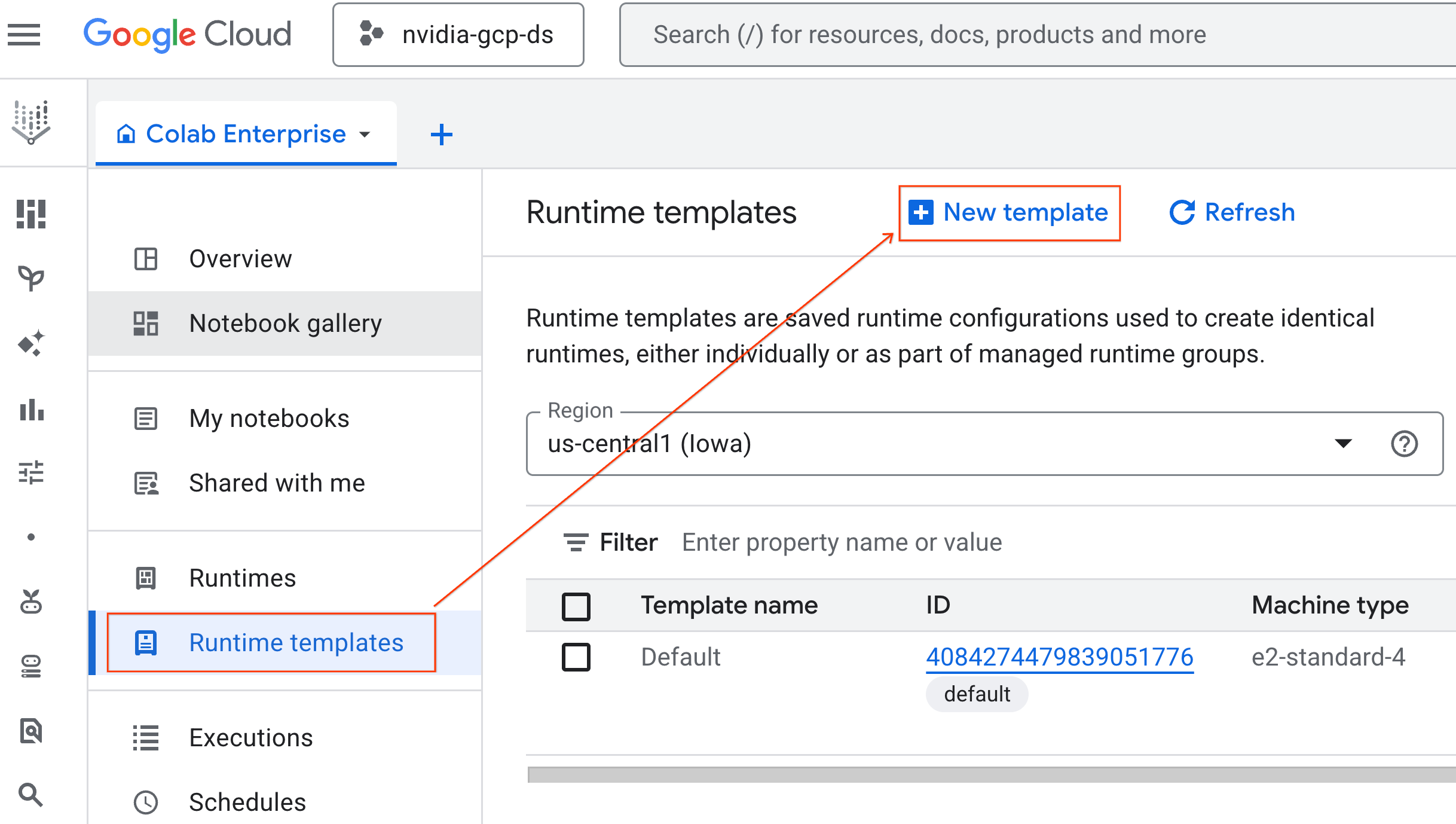
- בקטע יסודות של זמן ריצה:
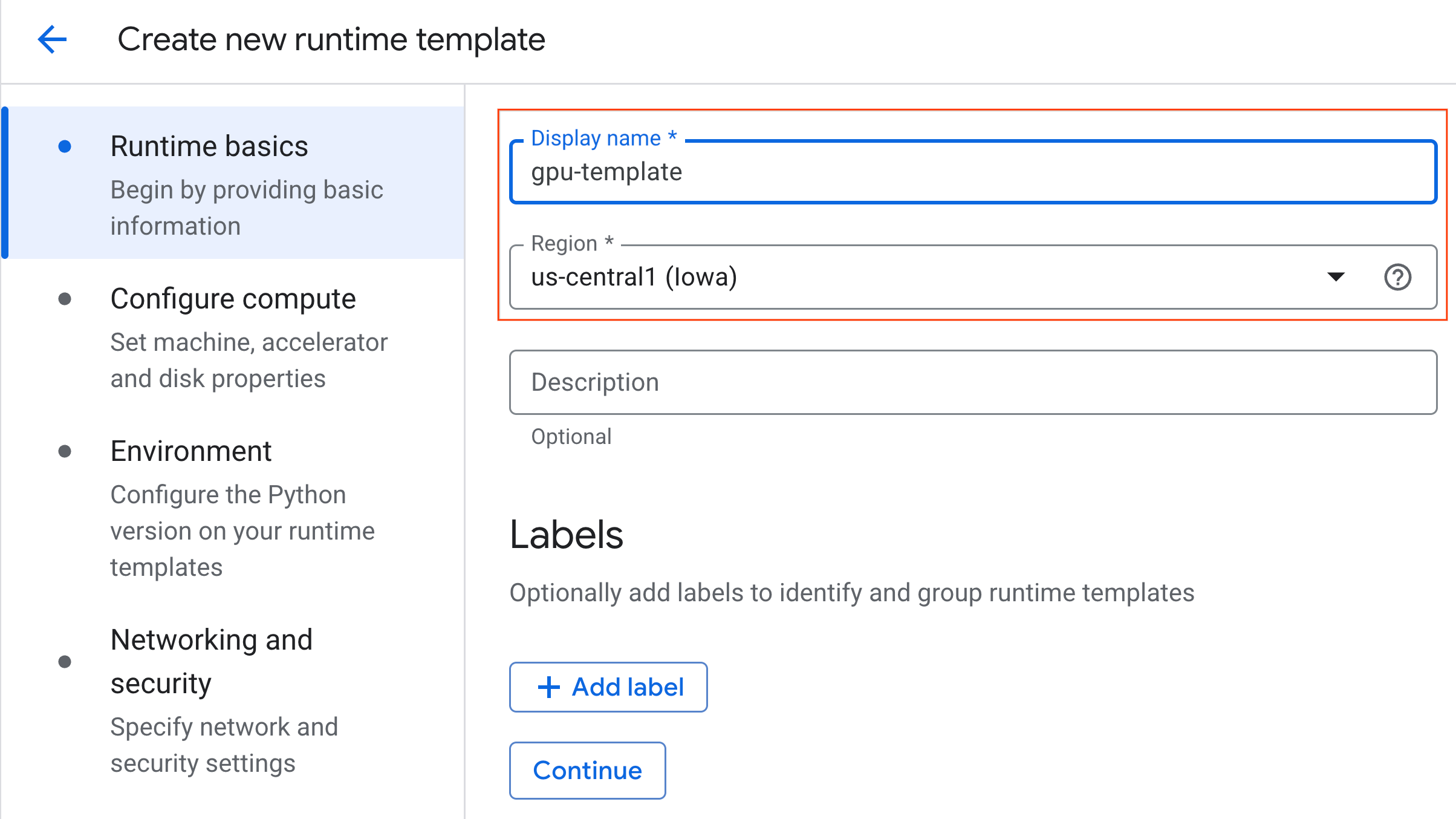
- מגדירים את השם המוצג כ-
gpu-template. - מגדירים את האזור המועדף.
- מגדירים את השם המוצג כ-
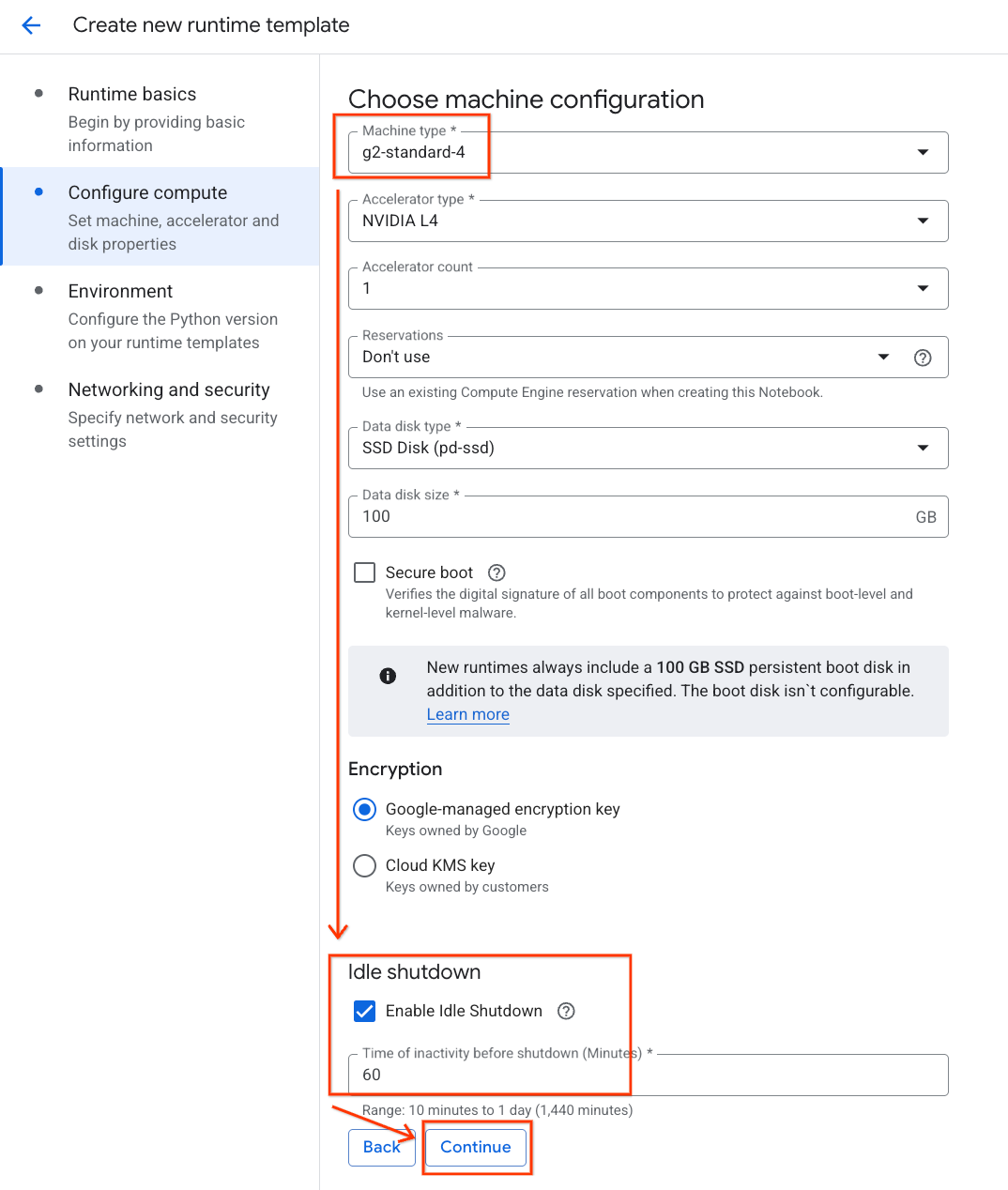
- בקטע Configure compute (הגדרת משאבי מחשוב):
- מגדירים את סוג המכונה לערך
g2-standard-4. - משאירים את הגדרת ברירת המחדל סוג המאיץ כ-
NVIDIA L4עם מספר מאיצים של 1. - משנים את ההגדרה כיבוי במצב לא פעיל ל-60 דקות.
- לוחצים על המשך.
- מגדירים את סוג המכונה לערך
- בקטע סביבה:
- מגדירים את הסביבה לערך
Python 3.11
- מגדירים את הסביבה לערך
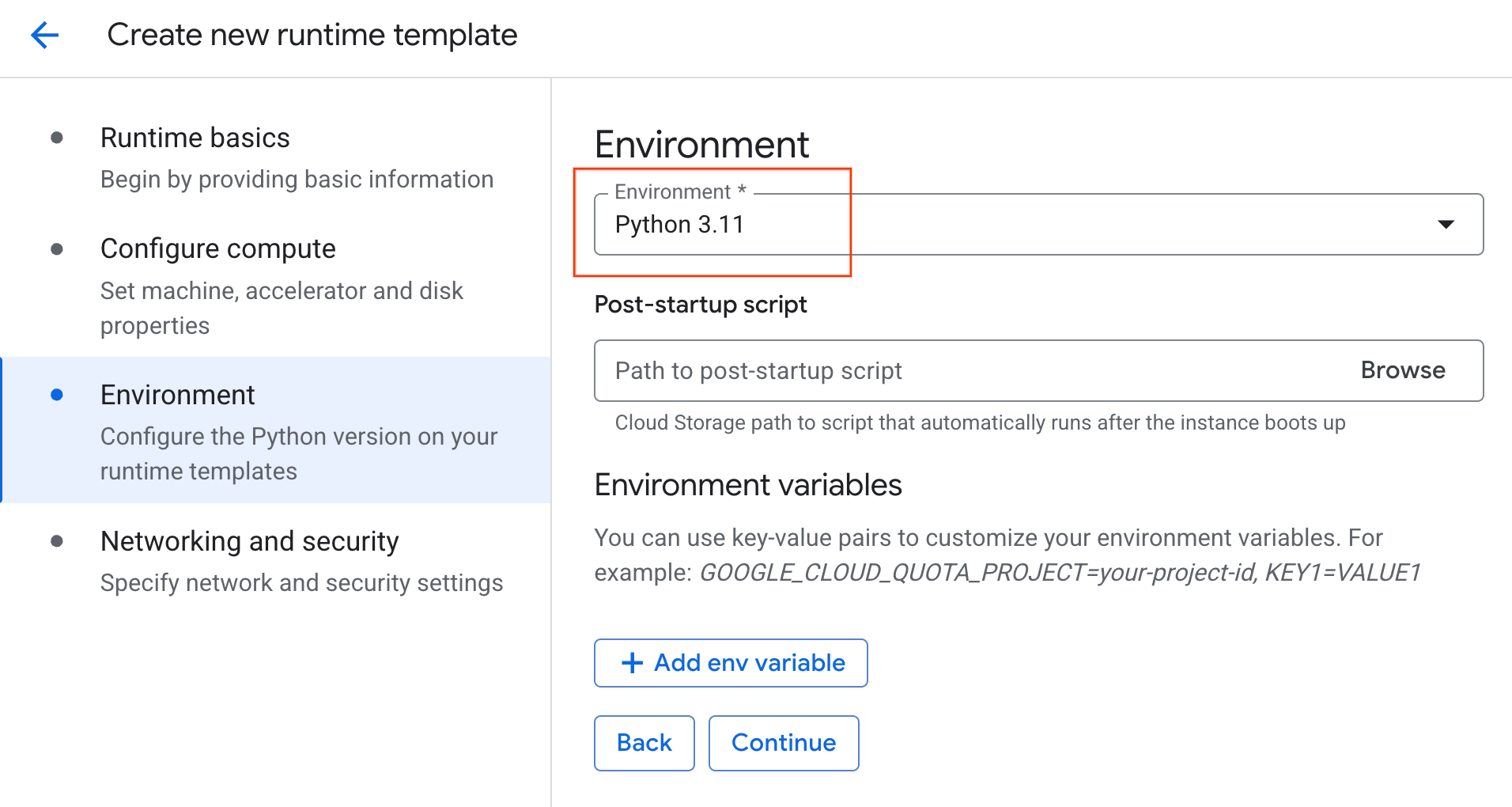
- לוחצים על יצירה כדי לשמור את תבנית זמן הריצה. התבנית החדשה אמורה להופיע בדף 'תבניות בזמן ריצה'.
6. הפעלת סביבת זמן ריצה
אחרי שהתבנית מוכנה, אפשר ליצור סביבת ריצה חדשה.
- ב-Colab Enterprise, לוחצים על Runtimes ואז על Create.
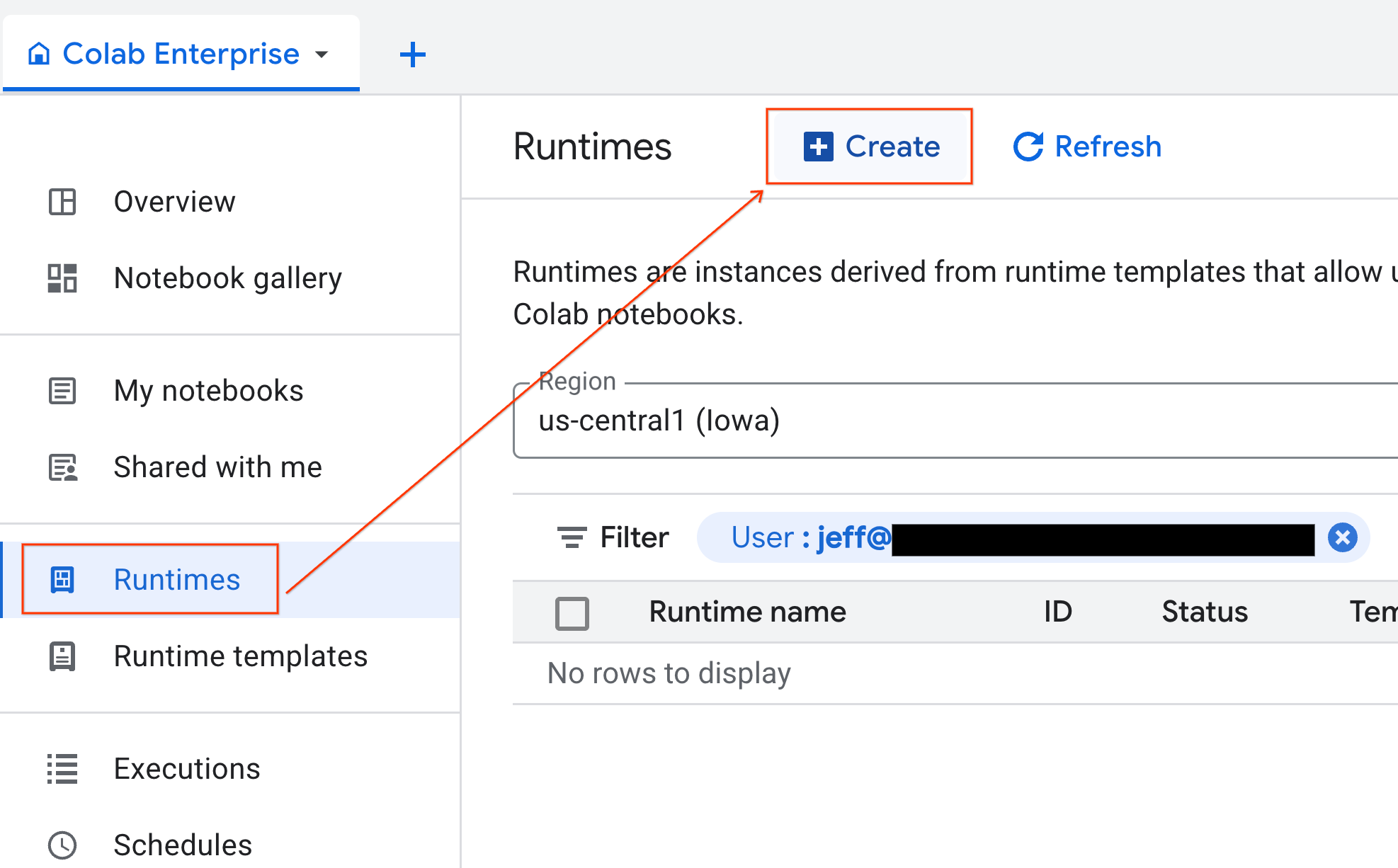
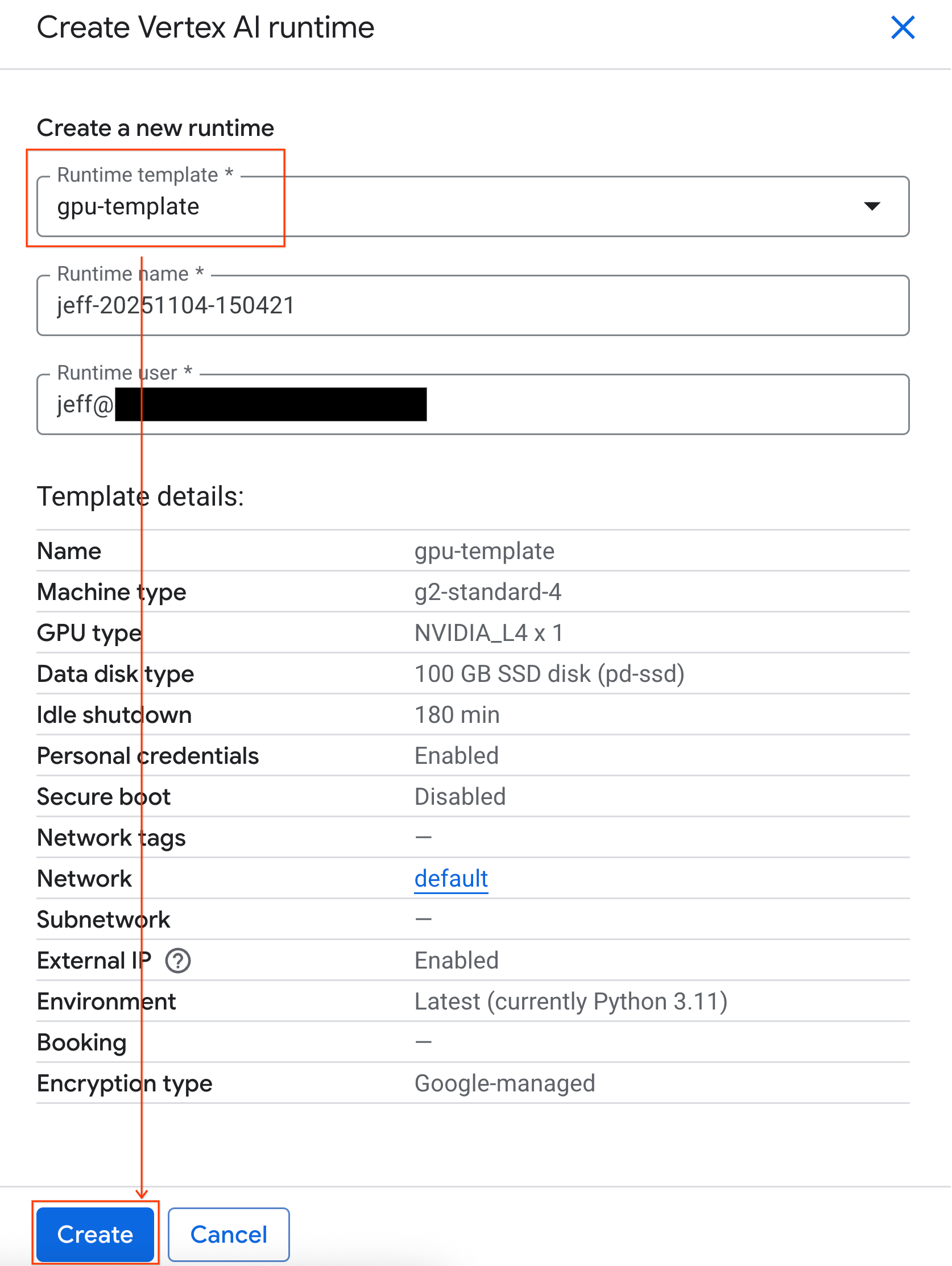
- בקטע Runtime template, בוחרים באפשרות
gpu-template. לוחצים על Create ומחכים עד שהסביבה תופעל.
- אחרי כמה דקות, זמן הריצה יהיה זמין.
7. הגדרת ה-Notebook
עכשיו, כשהתשתית פועלת, צריך לייבא את מחברת ה-Lab ולחבר אותה לזמן הריצה.
ייבוא המחברת
- ב-Colab Enterprise, לוחצים על המחברות שלי ואז על ייבוא.
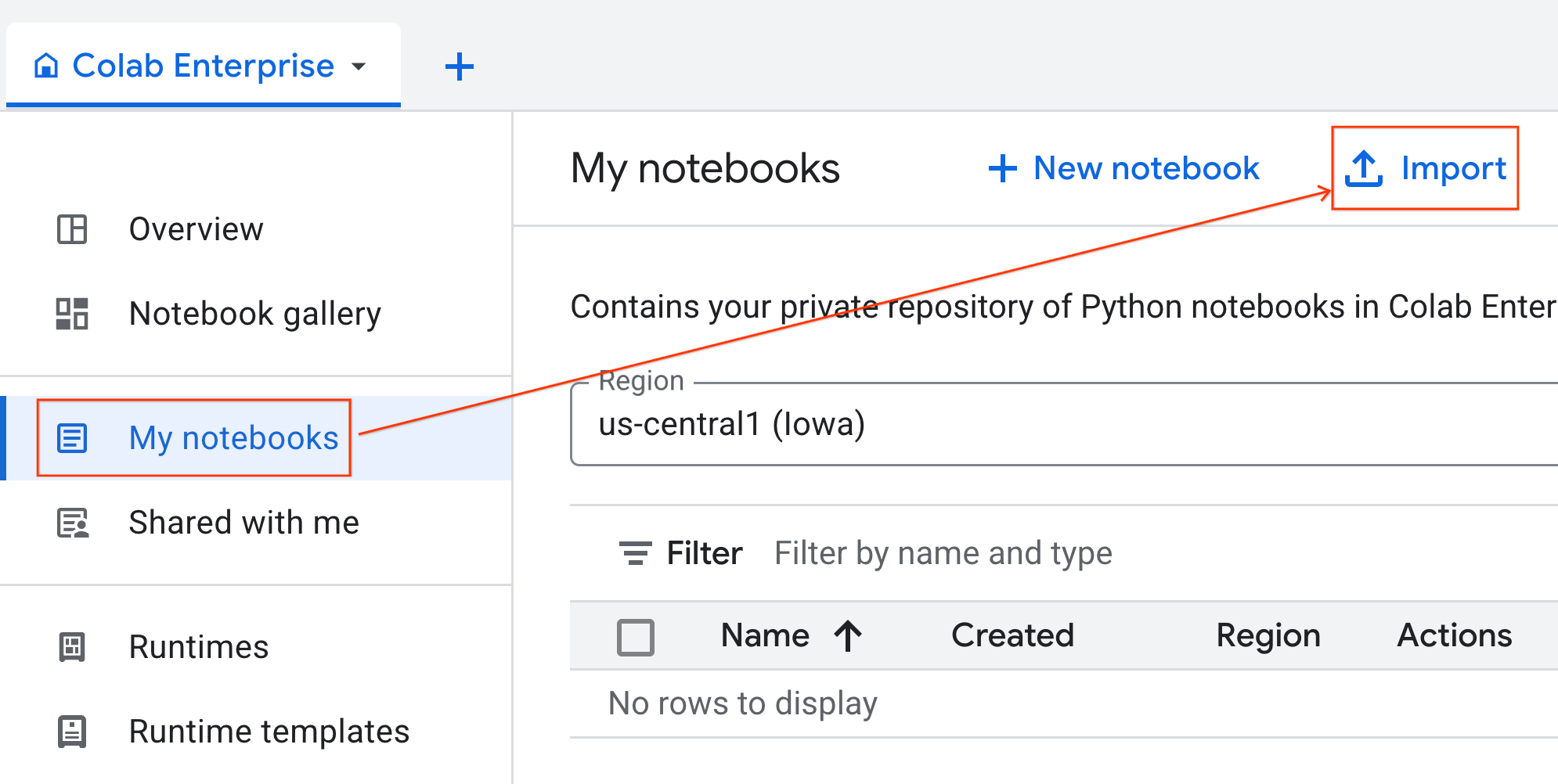
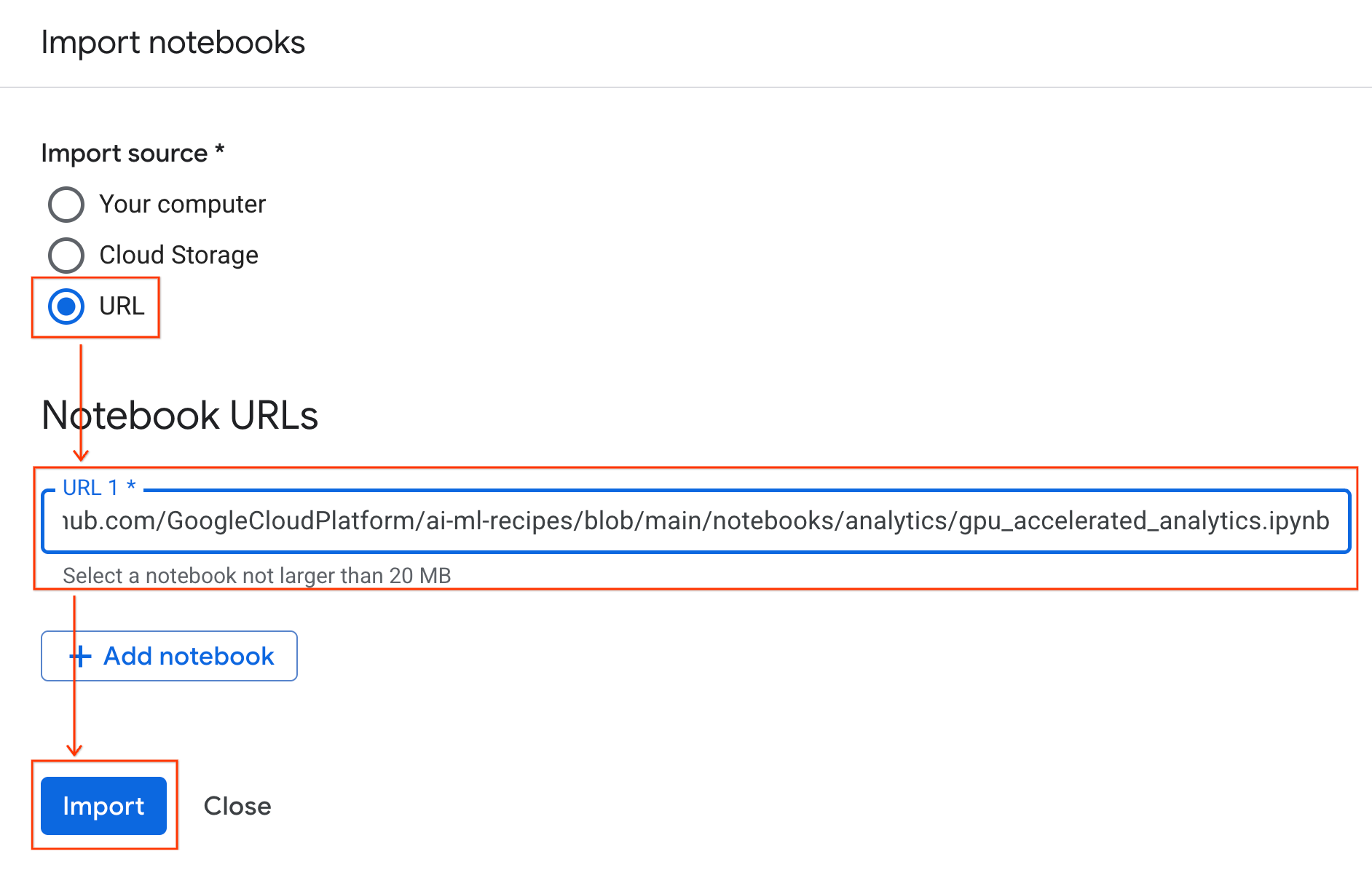
- בוחרים בלחצן האפשרויות כתובת URL ומזינים את כתובת ה-URL הבאה:
https://github.com/GoogleCloudPlatform/ai-ml-recipes/blob/main/notebooks/regression/gpu_accelerated_regression/gpu_accelerated_regression.ipynb
- לוחצים על ייבוא. מערכת Colab Enterprise תעתיק את ה-notebook מ-GitHub לסביבה שלכם.
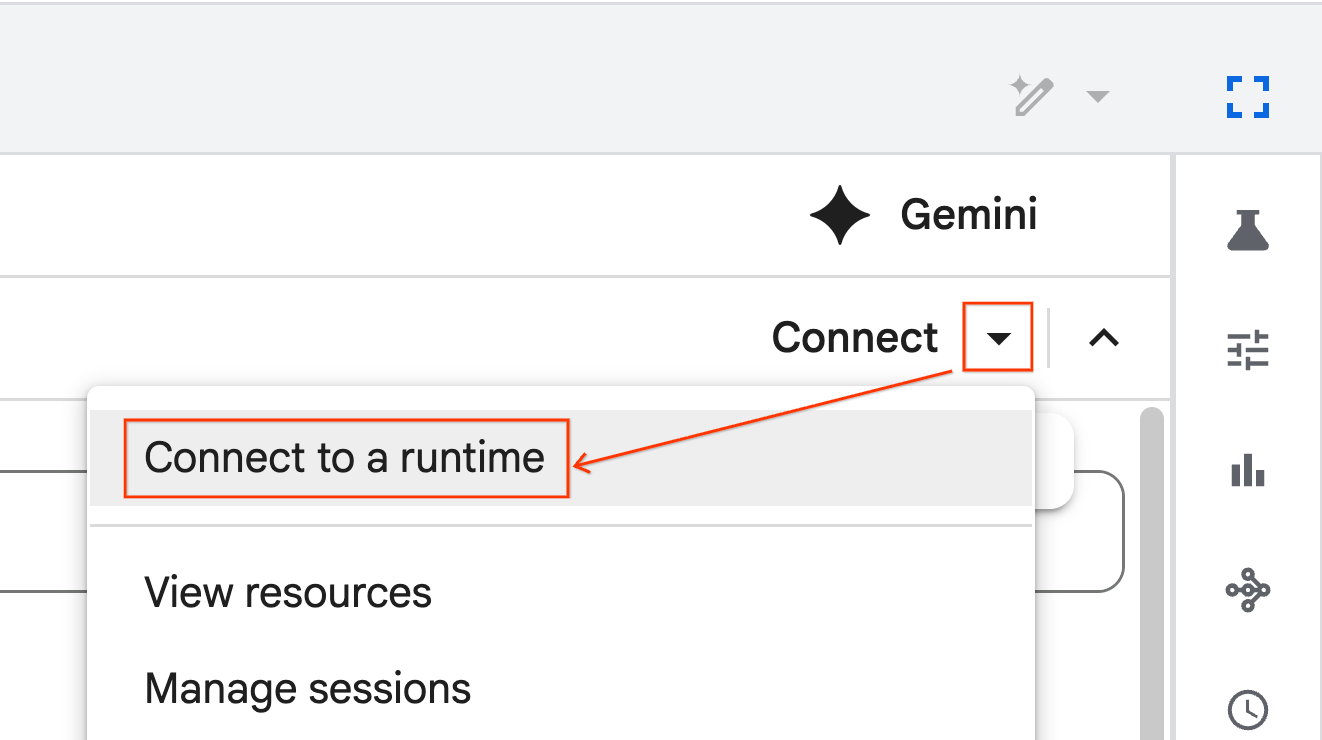
התחברות לסביבת זמן ריצה
- פותחים את ה-notebook החדש שיובא.
- לוחצים על החץ למטה לצד קישור.
- בוחרים באפשרות התחברות לסביבת זמן ריצה.
- משתמשים בתפריט הנפתח ובוחרים את זמן הריצה שיצרתם קודם.
- לוחצים על חיבור.
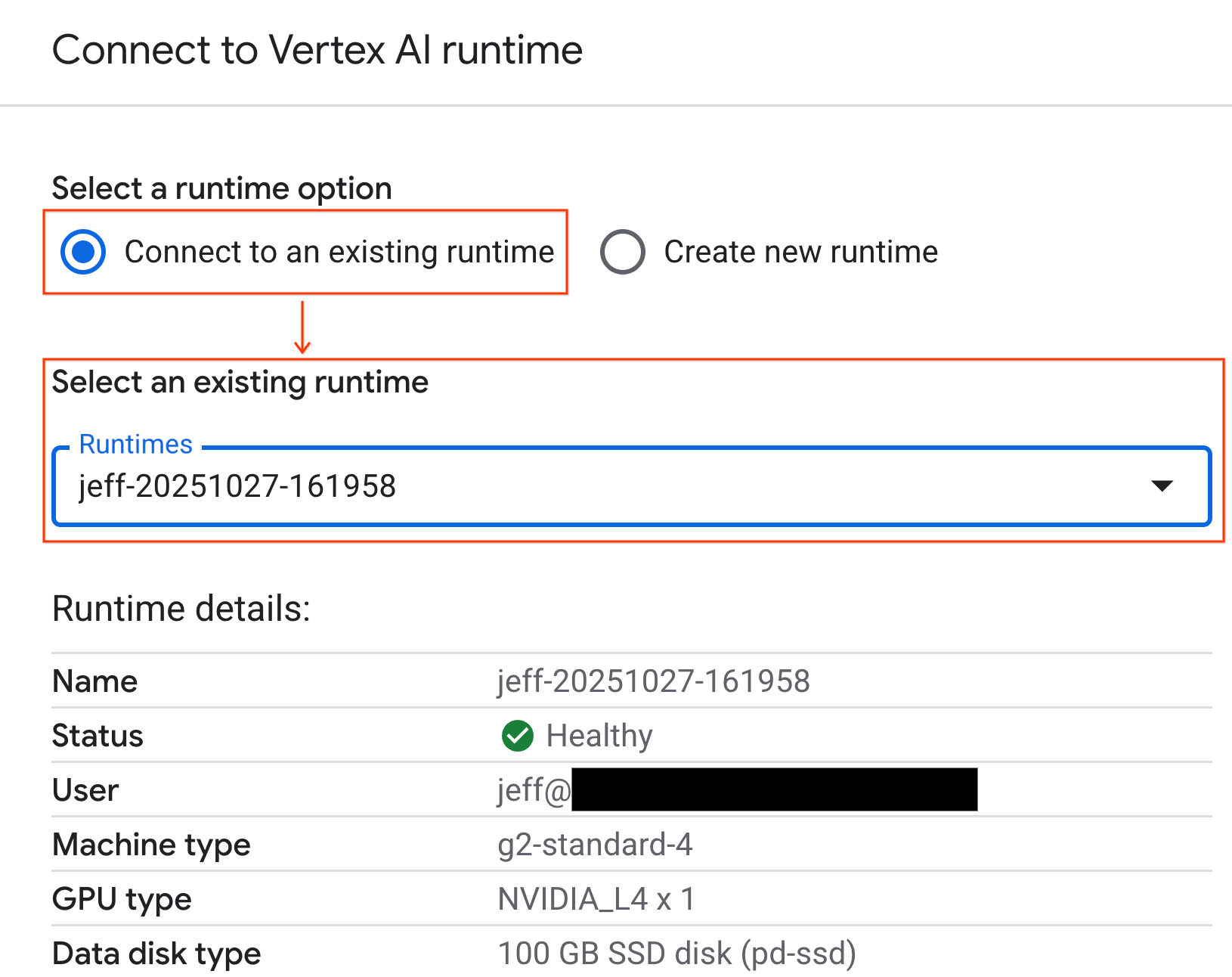
ה-notebook שלכם מחובר עכשיו לסביבת זמן ריצה עם GPU.
יחסי תלות מובנים
אחד היתרונות של שימוש ב-Colab Enterprise הוא שהספריות שאתם צריכים מותקנות מראש. אין צורך להתקין או לנהל באופן ידני תלויות כמו cuDF, cuML או XGBoost בשביל המעבדה הזו.
8. הכנת מערך הנתונים של מוניות בניו יורק
ב-Codelab הזה נשתמש בנתוני רשומות נסיעה של NYC Taxi & Limousine Commission (ועדת המוניות והלימוזינות של ניו יורק, TLC). מערך הנתונים מכיל רשומות של נסיעות במוניות צהובות בניו יורק, כולל:
- תאריכים, שעות ומיקומים של איסוף והורדה
- מרחקי נסיעה
- סכומי התעריפים המפורטים
- מספר הנוסעים
- סכומי הטיפים (זה מה שנחזה!)
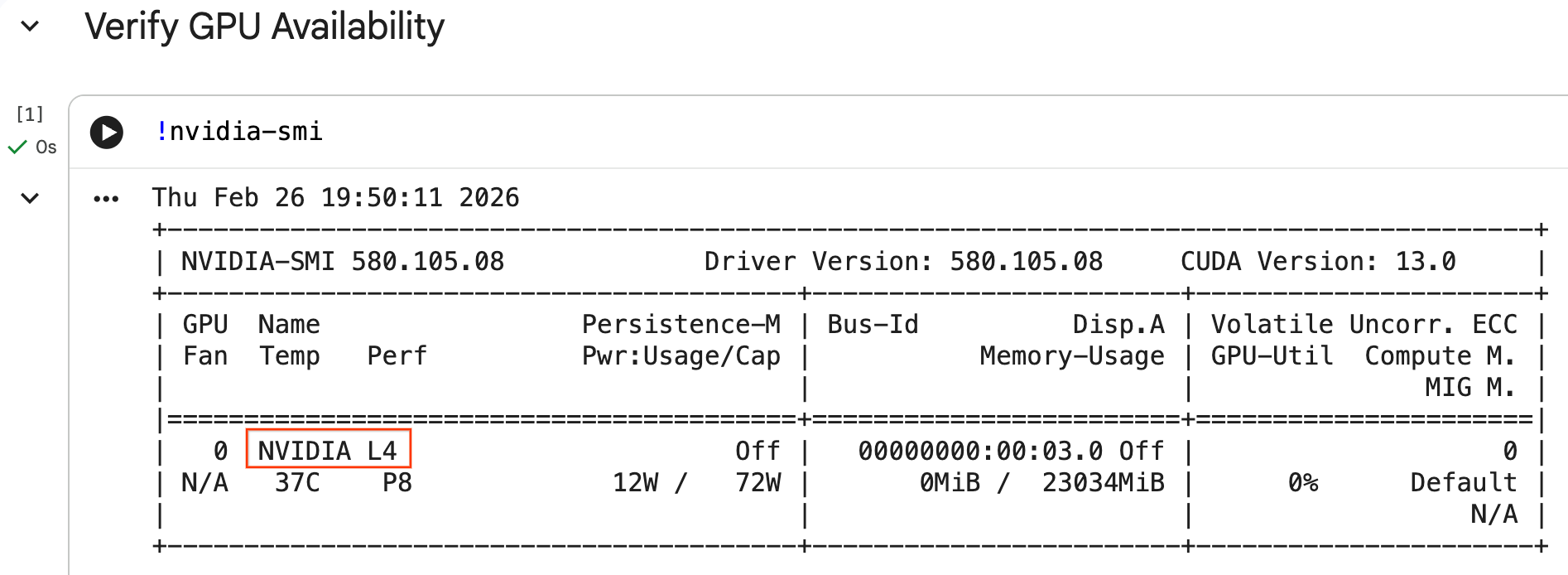
הגדרת GPU ואימות הזמינות
כדי לוודא שה-GPU מזוהה, מריצים את הפקודה nvidia-smi. מוצגת גרסת הדרייבר ופרטי ה-GPU (כמו NVIDIA L4).
nvidia-smi
התא צריך להחזיר את ה-GPU שמצורף לזמן הריצה, בדומה לתוצאה הבאה:
הורדת הנתונים
הורדת נתוני הנסיעה לשנת 2024.
from tqdm import tqdm
import requests
import time
import os
YEAR = 2024
DATA_DIR = "nyc_taxi_data"
os.makedirs(DATA_DIR, exist_ok=True)
print(f"Checking/Downloading files for {YEAR}...")
for month in tqdm(range(1, 13), unit="file"):
file_name = f"yellow_tripdata_{YEAR}-{month:02d}.parquet"
local_path = os.path.join(DATA_DIR, file_name)
url = f"https://d37ci6vzurychx.cloudfront.net/trip-data/{file_name}"
if not os.path.exists(local_path):
try:
with requests.get(url, stream=True) as response:
response.raise_for_status()
with open(local_path, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
time.sleep(1)
except requests.exceptions.HTTPError as e:
print(f"\nSkipping {file_name}: {e}")
if os.path.exists(local_path):
os.remove(local_path)
print("\nDownload complete.")
האצה של pandas באמצעות NVIDIA cuDF
הספרייה pandas פועלת במעבד (CPU) ויכולה להיות איטית כשמדובר במערכי נתונים גדולים. פקודת ה-magic של NVIDIA %load_ext cudf.pandas מבצעת תיקון דינמי של pandas כדי להשתמש בהאצת GPU, וחוזרת לשימוש במעבד אם צריך.
אנחנו משתמשים בפקודה הקסומה הזו במקום בייבוא רגיל כי היא מספקת האצה של 'אפס שינויים בקוד'. לא צריך לכתוב מחדש את הקוד הקיים. פקודה דומה, %load_ext cuml.accel, עושה בדיוק את אותו הדבר עבור scikit-learn models! השיטה הזו פועלת בכל סביבת Jupyter עם GPU תואם של NVIDIA, לא רק ב-Colab Enterprise.
%load_ext cudf.pandas
כדי לוודא שהיא פעילה, מייבאים את pandas ובודקים את הסוג שלה:
import pandas as pd
pd
הפלט יאשר שאתם משתמשים עכשיו במודול cudf.pandas.
טעינה וניקוי של נתונים
כשהאפשרות cudf.pandas פעילה, טוענים את קובצי Parquet ומבצעים ניקוי נתונים. התהליך הזה מופעל אוטומטית ב-GPU.
import glob
# Load data into memory
df = pd.concat(
[pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")],
ignore_index=True
)
# Filter for valid trips. We filter for payment_type=1 (credit card)
# because tip amounts are only reliably recorded for credit card transactions.
df = df[
(df['fare_amount'] > 0) & (df['fare_amount'] < 500) &
(df['trip_distance'] > 0) & (df['trip_distance'] < 100) &
(df['tip_amount'] >= 0) & (df['tip_amount'] < 100) &
(df['payment_type'] == 1)
].copy()
# Downcast numeric columns to save memory
float_cols = df.select_dtypes(include=['float64']).columns
df[float_cols] = df[float_cols].astype('float32')
int_cols = df.select_dtypes(include=['int64']).columns
df[int_cols] = df[int_cols].astype('int32')
Feature Engineering
יצירת מאפיינים נגזרים מתאריך ושעת האיסוף. מחברת ה-Notebook מכילה תכונות נוספות שמשמשות בשלבים הבאים.
import numpy as np
# Time Features
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['dow'] = df['tpep_pickup_datetime'].dt.dayofweek
df['is_weekend'] = (df['dow'] >= 5).astype(int)
df['is_rush_hour'] = (
((df['hour'] >= 7) & (df['hour'] <= 9)) |
((df['hour'] >= 17) & (df['hour'] <= 19))
).astype(int)
...
# Other features
...
9. אימון מודלים נפרדים באמצעות אימות צולב
כדי להראות איך ה-GPU יכול להאיץ למידת מכונה, תאמנו שלושה סוגים שונים של מודלים של רגרסיה כדי לחזות את tip_amount של נסיעה במונית.
האצה של scikit-learn באמצעות NVIDIA cuML
הפעלת אלגוריתמים של scikit-learn ב-GPU באמצעות cuML של NVIDIA בלי לשנות קריאות ל-API. קודם כול, טוענים את התוסף cuml.accel.
%load_ext cuml.accel
הגדרת תכונות ויעדים
מזהים את התכונות שמהן רוצים שהמודל ילמד ומפצלים את עמודת היעד (tip_amount).
feature_cols = [
'trip_distance', 'fare_amount', 'passenger_count',
'hour', 'dow', 'is_weekend', 'is_rush_hour',
'fare_log', 'fare_decimal', 'is_round_fare',
'route_frequency', 'pu_tip_mean', 'pu_tip_std',
'PULocationID', 'DOLocationID'
]
X = df[feature_cols].fillna(df[feature_cols].median())
y = df['tip_amount'].copy()
כדי להעריך את ביצועי המודל בצורה מהימנה, צריך להגדיר פיצולים של אימות צולב.
from sklearn.model_selection import KFold
import numpy as np
import time
from sklearn.metrics import mean_squared_error
from tqdm.notebook import tqdm
n_splits = 3
kf = KFold(n_splits=n_splits, shuffle=True, random_state=42)
1. XGBoost
XGBoost מואץ באופן טבעי על ידי GPU. מעבירים את tree_method='hist' ואת device='cuda' כדי להשתמש ב-GPU במהלך האימון.
import xgboost as xgb
start_time = time.perf_counter()
def train_xgb_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# XGBoost handles GPU natively when tree_method='hist' and device='cuda'
model = xgb.XGBRegressor(
objective='reg:squarederror',
max_depth=5,
learning_rate=0.1,
n_estimators=100,
tree_method='hist',
device='cuda',
random_state=42
)
model.fit(X_train, y_train)
preds = model.predict(X_val)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
xgb_rmse, xgb_preds = train_xgb_cv(X, y)
print(f"\n{'XGBoost RMSE:':<20} ${xgb_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
2. רגרסיה לינארית
מאמנים מודל רגרסיה ליניארית. כש-%load_ext cuml.accel פעיל, הוא ממופה אוטומטית למקבילה שלו ב-GPU.LinearRegression
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
start_time = time.perf_counter()
def train_linreg_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# Scale features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_val_scaled = scaler.transform(X_val)
# Automatically accelerated by cuML
model = LinearRegression()
model.fit(X_train_scaled, y_train)
preds = model.predict(X_val_scaled)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
linreg_rmse, linreg_preds = train_linreg_cv(X, y)
print(f"\n{'Linear Reg RMSE:':<20} ${linreg_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
3. Random Forest
אימון מודל משולב באמצעות RandomForestRegressor. בדרך כלל, אימון של מודלים מבוססי-עץ במעבד (CPU) הוא איטי, אבל האצת GPU מאפשרת לעבד מיליוני שורות מהר יותר.
from sklearn.ensemble import RandomForestRegressor
start_time = time.perf_counter()
def train_rf_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# Automatically accelerated by cuML
model = RandomForestRegressor(
n_estimators=100,
max_depth=10,
n_jobs=-1,
max_features='sqrt',
random_state=42
)
model.fit(X_train, y_train)
preds = model.predict(X_val)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
rf_rmse, rf_preds = train_rf_cv(X, y)
print(f"\n{'Random Forest RMSE:':<20} ${rf_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
10. הערכת פייפליין מקצה לקצה
משלבים את התחזיות משלושת המודלים באמצעות שילוב ליניארי פשוט. בדרך כלל, השימוש במודל הזה מספק שיפור קל ברמת הדיוק בהשוואה למודלים נפרדים.
מבצעים התאמה של רגרסיה ליניארית לתחזיות כדי למצוא את המשקלים האופטימליים:
ensemble_weights = LinearRegression(positive=True, fit_intercept=False).fit(
np.c_[xgb_preds, rf_preds, linreg_preds], y
).coef_
# Normalize weights
ensemble_weights = ensemble_weights / ensemble_weights.sum()
ensemble_preds = np.c_[xgb_preds, rf_preds, linreg_preds] @ ensemble_weights
ensemble_rmse = np.sqrt(mean_squared_error(y, ensemble_preds))
משווים את התוצאות כדי לראות את העלייה המשולבת:
print(f"\n{'Model':<20} {'RMSE':>10}")
print("-" * 32)
print(f"{'Linear Regression':<20} ${linreg_rmse:>9.4f}")
print(f"{'Random Forest':<20} ${rf_rmse:>9.4f}")
print(f"{'XGBoost':<20} ${xgb_rmse:>9.4f}")
print("-" * 32)
print(f"{'Ensemble':<20} ${ensemble_rmse:>9.4f}")
print(f"\nEnsemble lift: ${xgb_rmse - ensemble_rmse:.4f}")
11. השוואה בין ביצועי המעבד (CPU) לבין ביצועי המעבד הגרפי (GPU)
כדי להשוות את ההבדלים בביצועים בצורה נכונה, תצטרכו להפעיל מחדש את ליבת המערכת כדי להבטיח מצב ביצוע נקי, להריץ את כל צינור הנתונים של מדע הנתונים במעבד (CPU) ואז להפעיל פתרונות חכמים שוב במעבד הגרפי (GPU).
הפעלה מחדש של הליבה
מריצים את הפקודה IPython.Application.instance().kernel.do_shutdown(True) כדי להפעיל מחדש את הליבה ולפנות זיכרון.
import IPython
IPython.Application.instance().kernel.do_shutdown(True)
הגדרת צינור מדע הנתונים
עוטפים את תהליך העבודה המרכזי (טעינת נתונים, ניקוי, הנדסת תכונות ואימון מודל) בפונקציה אחת. הפונקציה הזו מקבלת מודול pandas pd_module וארגומנט use_gpu כדי לעבור בין סביבות.
def run_ml_pipeline(pd_module, use_gpu=False):
import time
import glob
import numpy as np
from sklearn.ensemble import RandomForestRegressor
import xgboost as xgb
timings = {}
# 1. Load Data
t0 = time.perf_counter()
df = pd_module.concat(
[pd_module.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")],
ignore_index=True
)
timings['Load Data'] = time.perf_counter() - t0
# 2. Clean Data
t0 = time.perf_counter()
# Filter for payment_type=1 (credit card) because tip amounts
# are only reliably recorded for credit card transactions.
df = df[
(df['fare_amount'] > 0) & (df['fare_amount'] < 500) &
(df['trip_distance'] > 0) & (df['trip_distance'] < 100) &
(df['tip_amount'] >= 0) & (df['tip_amount'] < 100) &
(df['payment_type'] == 1)
].copy()
# Downcast numeric columns to save memory
float_cols = df.select_dtypes(include=['float64']).columns
df[float_cols] = df[float_cols].astype('float32')
int_cols = df.select_dtypes(include=['int64']).columns
df[int_cols] = df[int_cols].astype('int32')
timings['Clean Data'] = time.perf_counter() - t0
# 3. Feature Engineering
t0 = time.perf_counter()
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['dow'] = df['tpep_pickup_datetime'].dt.dayofweek
df['is_weekend'] = (df['dow'] >= 5).astype(int)
df['fare_log'] = np.log1p(df['fare_amount'])
timings['Feature Engineering'] = time.perf_counter() - t0
# 4. Modeling Prep
feature_cols = ['trip_distance', 'fare_amount', 'passenger_count', 'hour', 'dow', 'is_weekend', 'fare_log']
X = df[feature_cols].fillna(df[feature_cols].median())
y = df['tip_amount'].copy()
# Free memory
del df
import gc
gc.collect()
# 5. Train Random Forest
t0 = time.perf_counter()
rf_model = RandomForestRegressor(
n_estimators=100,
max_depth=10,
n_jobs=-1,
max_features='sqrt',
random_state=42
).fit(X, y)
timings['Train Random Forest'] = time.perf_counter() - t0
# 6. Train XGBoost
t0 = time.perf_counter()
params = {
'objective': 'reg:squarederror',
'max_depth': 5,
'n_estimators': 100,
'random_state': 42
}
if use_gpu:
params['device'] = 'cuda'
params['tree_method'] = 'hist'
xgb_model = xgb.XGBRegressor(**params).fit(X, y)
timings['Train XGBoost'] = time.perf_counter() - t0
del X
del y
gc.collect()
return timings
הרצה במעבד (CPU)
מפעילים את צינור עיבוד הנתונים באמצעות מעבד רגיל pandas.
import pandas as pd
print("Running pipeline on CPU...")
cpu_times = run_ml_pipeline(pd, use_gpu=False)
print("CPU Execution Finished.")
הפעלה ב-GPU
טוענים את תוספי הספרייה של NVIDIA, מעבירים את מודול cudf.pandas המואץ לפייפליין ומגדירים את מכשיר XGBoost ל-cuda באופן פנימי.
import IPython.core.magic
if not hasattr(IPython.core.magic, 'output_can_be_silenced'):
IPython.core.magic.output_can_be_silenced = lambda x: x
%load_ext cudf.pandas
%load_ext cuml.accel
import pandas as pd
print("Running pipeline on GPU...")
gpu_times = run_ml_pipeline(pd, use_gpu=True)
print("GPU Execution Finished.")
הדמיה של שיפור המהירות
אפשר להמחיש את התזמונים באמצעות matplotlib. התוצאות מראות את הזמן שנחסך במהלך עיבוד הנתונים ואימון המודלים כשמשתמשים במעבדי GPU.
import matplotlib.pyplot as plt
import numpy as np
labels = list(cpu_times.keys())
cpu_values = list(cpu_times.values())
gpu_values = list(gpu_times.values())
x = np.arange(len(labels))
width = 0.35
fig, ax = plt.subplots(figsize=(10, 6))
rects1 = ax.bar(x - width/2, cpu_values, width, label='CPU', color='#4285F4')
rects2 = ax.bar(x + width/2, gpu_values, width, label='GPU', color='#76B900')
ax.set_ylabel('Execution Time (seconds)')
ax.set_title('NYC Taxi ML Pipeline: CPU vs. GPU Performance')
ax.set_xticks(x)
ax.set_xticklabels(labels, rotation=45, ha="right")
ax.legend()
# Add data labels
def autolabel(rects):
for rect in rects:
height = rect.get_height()
ax.annotate(f'{height:.2f}s',
xy=(rect.get_x() + rect.get_width() / 2, height),
xytext=(0, 3), # 3 points vertical offset
textcoords="offset points",
ha='center', va='bottom', fontsize=9)
autolabel(rects1)
autolabel(rects2)
plt.tight_layout()
plt.show()
# Calculate overall speedup
total_cpu_time = sum(cpu_values)
total_gpu_time = sum(gpu_values)
overall_speedup = total_cpu_time / total_gpu_time
print(f"\nOverall Pipeline Speedup: {overall_speedup:.2f}x faster on GPU!")
אמורה להופיע הודעה שדומה להודעה הבאה:
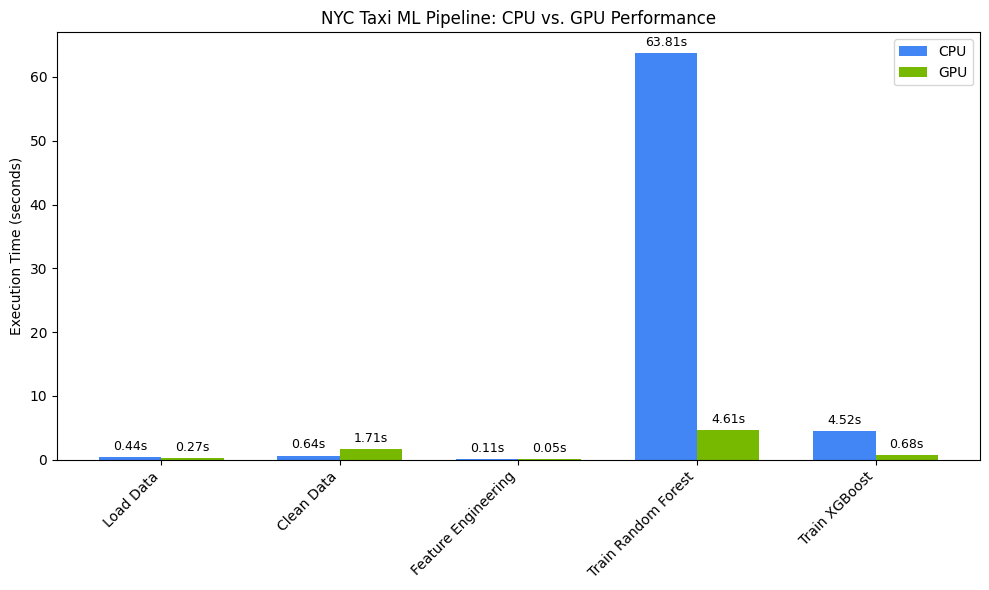
בתרשים הזה אפשר לראות את היתרון המשמעותי של ה-GPU בביצועים לאורך כל תהליך העבודה של מדע הנתונים. החיסכון המשמעותי ביותר בזמן צפוי בשלבי אימון המודל שדורשים הרבה חישובים, כמו אלגוריתמים של Random Forest ו-XGBoost.
12. יצירת פרופיל של הקוד כדי למצוא אילוצים שמשפיעים על הביצועים
כשמשתמשים ב-cudf.pandas, רוב הפונקציות פועלות ב-GPU. אם פעולה מסוימת עדיין לא נתמכת על ידי cuDF, הביצוע עובר באופן זמני ל-CPU. NVIDIA מספקת שתי פקודות magic מובנות של Jupyter כדי לזהות את חלופות הגיבוי האלה.
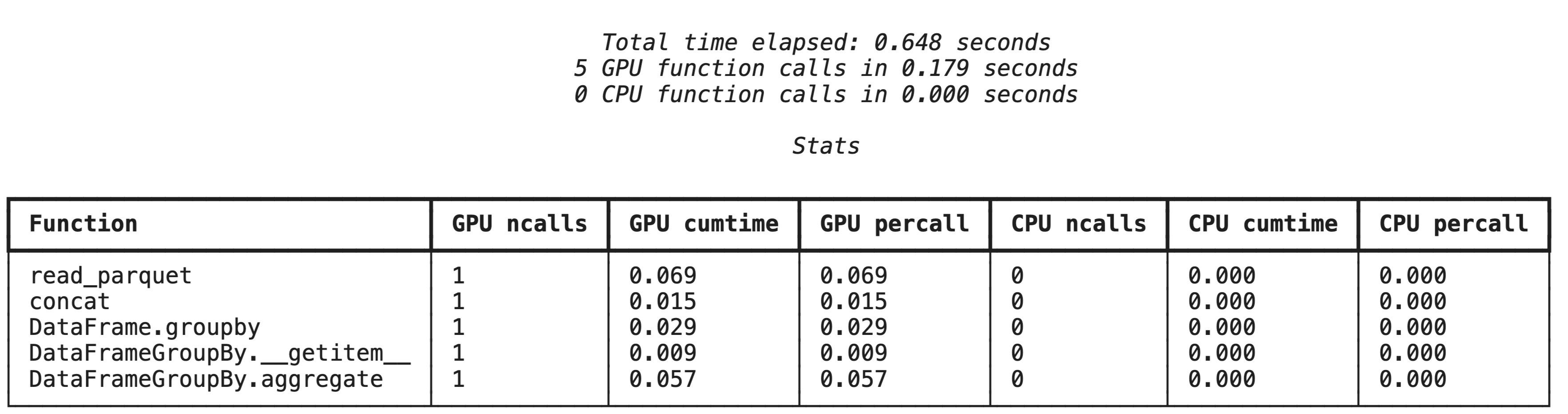
יצירת פרופיל ברמה גבוהה באמצעות %%cudf.pandas.profile
פקודת ה-magic %%cudf.pandas.profile מספקת סיכום של הפונקציות שהופעלו במעבד הגרפי או במעבד.
%%cudf.pandas.profile
import glob
import pandas as pd
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")], ignore_index=True)
summary = (
df
.groupby(['PULocationID', 'payment_type'])
[['passenger_count', 'fare_amount', 'tip_amount']]
.agg(['min', 'mean', 'max'])
)
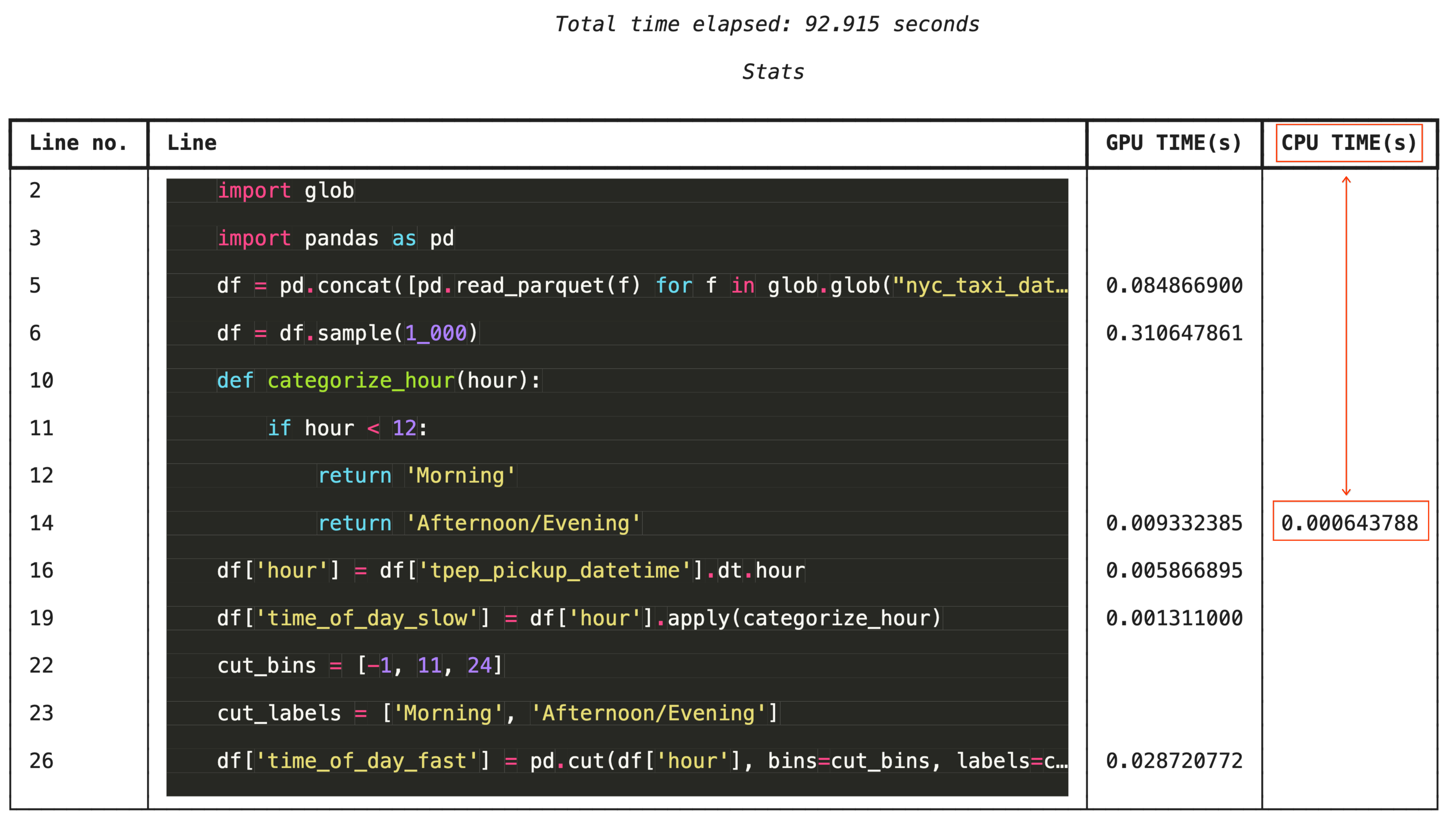
יצירת פרופיל שורה אחר שורה באמצעות %%cudf.pandas.line_profile
לפתרון בעיות ברמת הפירוט, %%cudf.pandas.line_profile מוסיף הערה לכל שורת קוד עם מספר הפעמים שהיא בוצעה ב-GPU לעומת ב-CPU.
%%cudf.pandas.line_profile
import glob
import pandas as pd
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")], ignore_index=True)
df = df.sample(1_000)
# Iterating row-by-row or using custom python apply functions often falls back to the CPU
def categorize_hour(hour):
if hour < 12:
return 'Morning'
else:
return 'Afternoon/Evening'
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['time_of_day_slow'] = df['hour'].apply(categorize_hour)
# Using vectorized pandas operations (like pd.cut) stays entirely on the GPU
cut_bins = [-1, 11, 24]
cut_labels = ['Morning', 'Afternoon/Evening']
df['time_of_day_fast'] = pd.cut(df['hour'], bins=cut_bins, labels=cut_labels)
13. הסרת המשאבים
כדי למנוע חיובים לא צפויים בחשבון Google Cloud, מוחקים את המשאבים שיצרתם במהלך ה-codelab הזה.
מחיקת משאבים
כדי למחוק את מערך הנתונים המקומי בסביבת זמן הריצה, משתמשים בפקודה !rm -rf בתא של notebook.
print("Deleting local 'nyc_taxi_data' directory...")
!rm -rf nyc_taxi_data
print("Local files deleted.")
כיבוי של סביבת זמן הריצה ב-Colab
- במסוף Google Cloud, עוברים לדף Runtimes של Colab Enterprise.
- בתפריט Region (אזור), בוחרים את האזור שבו נמצא זמן הריצה.
- בוחרים את זמן הריצה שרוצים למחוק.
- לוחצים על מחיקה.
- לוחצים על אישור.
מחיקת ה-Notebook
- במסוף Google Cloud, נכנסים לדף My Notebooks של Colab Enterprise.
- בתפריט Region (אזור), בוחרים את האזור שבו נמצא ה-Notebook.
- בוחרים את המחברת שרוצים למחוק.
- לוחצים על מחיקה.
- לוחצים על אישור.
14. מזל טוב
מעולה! הצלחתם להאיץ תהליך עבודה של למידת מכונה ב-Colab Enterprise באמצעות ספריות NVIDIA cuDF ו-cuML.pandasscikit-learn פשוט מוסיפים כמה פקודות קסם (%load_ext cudf.pandas ו-%load_ext cuml.accel), והקוד הרגיל יפעל במעבד הגרפי, יעבד רשומות ויתאים מודלים מורכבים באופן מקומי תוך חלק קטן מהזמן.
מידע נוסף על האצת ניתוח נתונים באמצעות GPU זמין ב-codelab בנושא ניתוח נתונים מואץ באמצעות GPU.
מה נכלל
- הסבר על Colab Enterprise ב-Google Cloud.
- התאמה אישית של סביבת זמן ריצה ב-Colab עם הגדרות ספציפיות של GPU וזיכרון.
- החלת האצת GPU כדי לחזות את סכומי הטיפים באמצעות מיליוני רשומות ממערך נתונים של מוניות בניו יורק.
- האצת
pandasללא שינויים בקוד באמצעות ספרייתcuDFשל NVIDIA. - האצת
scikit-learnללא שינויים בקוד באמצעות ספרייתcuMLומעבדי GPU של NVIDIA. - יצירת פרופיל של הקוד כדי לזהות אילוצים שמשפיעים על הביצועים ולבצע אופטימיזציה שלהם.