
1. परिचय
इस कोडलैब में, आपको Google Cloud पर NVIDIA GPU और ओपन-सोर्स लाइब्रेरी का इस्तेमाल करके, बड़े डेटासेट पर डेटा साइंस और मशीन लर्निंग के वर्कफ़्लो को तेज़ करने का तरीका बताया जाएगा. सबसे पहले, आपको अपना इन्फ़्रास्ट्रक्चर सेट अप करना होगा. इसके बाद, आपको यह पता चलेगा कि जीपीयू ऐक्सेलरेटेड कंप्यूटिंग को कैसे लागू किया जाता है.
इस कोर्स में, डेटा साइंस के लाइफ़साइकल पर फ़ोकस किया जाएगा. इसमें pandas की मदद से डेटा तैयार करने से लेकर, scikit-learn और XGBoost की मदद से मॉडल को ट्रेन करने तक की प्रोसेस शामिल है. आपको NVIDIA की cuDF और cuML लाइब्रेरी का इस्तेमाल करके, इन टास्क को तेज़ी से पूरा करने का तरीका बताया जाएगा. सबसे अच्छी बात यह है कि आपको मौजूदा pandas या scikit-learn कोड में बदलाव किए बिना, जीपीयू ऐक्सेलरेटर की सुविधा मिल सकती है.
आपको क्या सीखने को मिलेगा
- Google Cloud पर Colab Enterprise के बारे में जानें.
- किसी खास जीपीयू और मेमोरी कॉन्फ़िगरेशन के साथ, Colab के रनटाइम एनवायरमेंट को पसंद के मुताबिक बनाएं.
- न्यूयॉर्क सिटी टैक्सी के डेटासेट के लाखों रिकॉर्ड का इस्तेमाल करके, टिप की रकम का अनुमान लगाने के लिए, जीपीयू ऐक्सलरेशन लागू करें.
- NVIDIA की
cuDFलाइब्रेरी का इस्तेमाल करके, कोड में कोई बदलाव किए बिनाpandasको तेज़ करें. - NVIDIA की
cuMLलाइब्रेरी और जीपीयू का इस्तेमाल करके,scikit-learnको तेज़ करें. इसके लिए, कोड में कोई बदलाव करने की ज़रूरत नहीं है. - अपने कोड की परफ़ॉर्मेंस को बेहतर बनाने के लिए, उसकी प्रोफ़ाइल बनाएं.
अगले पेज में, लैब को पूरा करने के लिए इस्तेमाल किए जा सकने वाले क्रेडिट शामिल हैं.
2. मशीन लर्निंग को तेज़ क्यों करना चाहिए?
मशीन लर्निंग में तेज़ी से बदलाव करने की ज़रूरत
डेटा तैयार करने में समय लगता है. साथ ही, डेटासेट के बढ़ने पर मॉडल की ट्रेनिंग या आकलन में और भी ज़्यादा समय लग सकता है. सीपीयू की मदद से लाखों लाइनों वाले डेटा पर, रैंडम फ़ॉरेस्ट या XGBoost जैसे मॉडल को ट्रेन करने में कई घंटे या दिन लग सकते हैं.
जीपीयू का इस्तेमाल करने से, cuML और जीपीयू ऐक्सेलरेटेड XGBoost जैसी लाइब्रेरी की मदद से, ट्रेनिंग को तेज़ी से पूरा किया जा सकता है. इस सुविधा की मदद से, ये काम किए जा सकते हैं:
- तेज़ी से टेस्ट को दोहरा पाना: नई सुविधाओं और हाइपरपैरामीटर को तेज़ी से टेस्ट करें.
- पूरे डेटासेट पर ट्रेनिंग दें: बेहतर सटीक नतीजे पाने के लिए, डाउनसैंपलिंग के बजाय पूरे डेटा का इस्तेमाल करें.
- लागत कम करें: ज़्यादा काम वाले टास्क को कम समय में पूरा करें, ताकि कंप्यूटिंग की लागत कम हो.
3. सेटअप और ज़रूरी शर्तें
संभावित लागतें
इस कोडलैब में, Google Cloud के संसाधनों का इस्तेमाल किया जाता है. इनमें NVIDIA L4 GPU के साथ Colab Enterprise रनटाइम शामिल हैं. कृपया संभावित शुल्कों के बारे में जान लें. साथ ही, संसाधनों को बंद करने और बिलिंग को रोकने के लिए, कोडलैब के आखिर में दिए गए साफ़ करें सेक्शन में दिए गए निर्देशों का पालन करें. शुल्क के बारे में ज़्यादा जानकारी के लिए, Colab Enterprise का शुल्क और GPU का शुल्क लेख पढ़ें.
शुरू करने से पहले
यह मान लिया गया है कि आपको Python, pandas, scikit-learn, और मशीन लर्निंग की स्टैंडर्ड प्रक्रियाओं (जैसे, क्रॉस-वैलिडेशन/एनसेंबलिंग) के बारे में सामान्य जानकारी है.
- Google Cloud Console में, प्रोजेक्ट चुनने वाले पेज पर जाकर, कोई Google Cloud प्रोजेक्ट चुनें या बनाएं.
- पक्का करें कि आपके Google Cloud प्रोजेक्ट के लिए बिलिंग चालू हो.
एपीआई चालू करना
Colab Enterprise का इस्तेमाल करने के लिए, आपको सबसे पहले ज़रूरी एपीआई चालू करने होंगे.
- Google Cloud Console में सबसे ऊपर दाईं ओर मौजूद, Cloud Shell आइकॉन पर क्लिक करके Google Cloud Shell खोलें.

- Cloud Shell में,
PROJECT_IDकी जगह अपना प्रोजेक्ट आईडी डालकर, प्रोजेक्ट आईडी सेट करें:
gcloud config set project <PROJECT_ID>
- ज़रूरी एपीआई चालू करने के लिए, यह कमांड चलाएं:
gcloud services enable \
compute.googleapis.com \
dataform.googleapis.com \
notebooks.googleapis.com \
aiplatform.googleapis.com
टैग को सही तरीके से लागू करने के बाद, आपको यहां दिखाए गए मैसेज जैसा मैसेज दिखेगा:
Operation "operations/..." finished successfully.
4. नोटबुक एनवायरमेंट चुनना
कई डेटा साइंटिस्ट, निजी प्रोजेक्ट के लिए Colab का इस्तेमाल करते हैं. हालांकि, Colab Enterprise को कारोबारों के लिए डिज़ाइन किया गया है. यह सुरक्षित, सहयोगी, और इंटिग्रेटेड नोटबुक का अनुभव देता है.
Google Cloud पर, मैनेज किए गए नोटबुक एनवायरमेंट के लिए आपके पास दो मुख्य विकल्प हैं: Colab Enterprise और Gemini Enterprise Agent Platform Workbench. सही विकल्प चुनने के लिए, यह देखना ज़रूरी है कि आपके प्रोजेक्ट की प्राथमिकताएं क्या हैं.
Agent Platform Workbench का इस्तेमाल कब करना चाहिए
अगर आपकी प्राथमिकता कंट्रोल और बेहतर तरीके से पसंद के मुताबिक बनाना है, तो Agent Platform Workbench चुनें. अगर आपको ये काम करने हैं, तो यह विकल्प आपके लिए सबसे सही है:
- बुनियादी इंफ़्रास्ट्रक्चर और मशीन के लाइफ़साइकल को मैनेज करना.
- कस्टम कंटेनर और नेटवर्क कॉन्फ़िगरेशन का इस्तेमाल करें.
- MLOps पाइपलाइन और कस्टम लाइफ़साइकल टूलिंग के साथ इंटिग्रेट करें.
Colab Enterprise का इस्तेमाल कब करना चाहिए
अगर आपकी प्राथमिकता तेज़ी से सेटअप करना, इस्तेमाल में आसानी, और सुरक्षित तरीके से साथ मिलकर काम करना है, तो Colab Enterprise चुनें. यह पूरी तरह से मैनेज किया गया समाधान है. इससे आपकी टीम, इन्फ़्रास्ट्रक्चर के बजाय विश्लेषण पर ध्यान दे पाती है.
Colab Enterprise से आपको इन कामों में मदद मिलती है:
- डेटा साइंस के ऐसे वर्कफ़्लो बनाएं जो आपके डेटा वेयरहाउस से जुड़े हों. BigQuery Studio में जाकर, सीधे तौर पर अपनी नोटबुक खोली और मैनेज की जा सकती हैं.
- मशीन लर्निंग मॉडल को ट्रेन करें और उन्हें Agent Platform में MLOps टूल के साथ इंटिग्रेट करें.
- एक जैसा और बेहतर अनुभव पाएं. BigQuery में बनाया गया Colab Enterprise नोटबुक, Agent Platform में खोला और चलाया जा सकता है. इसके उलट, Agent Platform में बनाया गया Colab Enterprise नोटबुक, BigQuery में खोला और चलाया जा सकता है.
आज की लैब
इस कोडलैब में, मशीन लर्निंग को तेज़ी से प्रोसेस करने के लिए Colab Enterprise का इस्तेमाल किया गया है.
इनके बीच के अंतर के बारे में ज़्यादा जानने के लिए, सही नोटबुक समाधान चुनने से जुड़ा आधिकारिक दस्तावेज़ देखें.
5. रनटाइम टेंप्लेट को कॉन्फ़िगर करना
Colab Enterprise में, पहले से कॉन्फ़िगर किए गए रनटाइम टेंप्लेट के आधार पर, रनटाइम से कनेक्ट करें.
रनटाइम टेंप्लेट, फिर से इस्तेमाल किया जा सकने वाला कॉन्फ़िगरेशन होता है. यह आपकी नोटबुक के लिए एनवायरमेंट तय करता है. इसमें ये शामिल हैं:
- मशीन टाइप (सीपीयू, मेमोरी)
- ऐक्सेलरेटर (जीपीयू का टाइप और संख्या)
- डिस्क का साइज़ और टाइप
- नेटवर्क सेटिंग और सुरक्षा नीतियां
- निष्क्रियता की वजह से अपने-आप बंद होने के नियम
रनटाइम टेंप्लेट क्यों काम के होते हैं
- एक जैसा माहौल: आपको और आपकी टीम को एक जैसा माहौल मिलता है, ताकि काम को दोहराया जा सके.
- सुरक्षा: टेंप्लेट, संगठन की सुरक्षा नीतियों को लागू करते हैं.
- लागत मैनेजमेंट: टेंप्लेट में संसाधनों का साइज़ पहले से तय होता है, ताकि गलती से होने वाले खर्च से बचा जा सके.
रनटाइम टेंप्लेट बनाना
लैब के लिए, रीयूज़ किया जा सकने वाला रनटाइम टेंप्लेट सेट अप करें.
- Google Cloud Console में, नेविगेशन मेन्यू > एजेंट प्लैटफ़ॉर्म > नोटबुक पर जाएं.
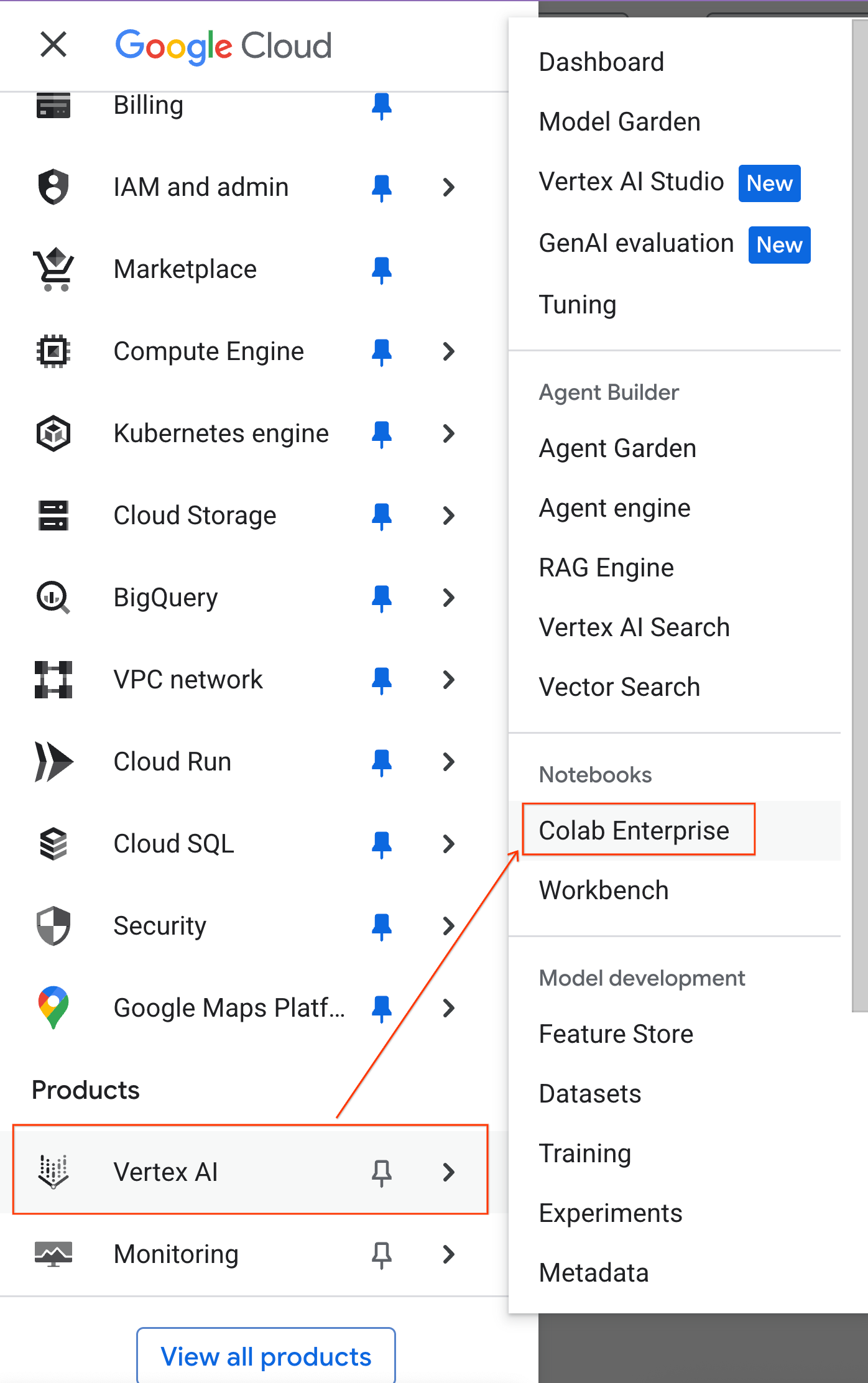
- Colab Enterprise में, रनटाइम टेंप्लेट पर क्लिक करें. इसके बाद, नया टेंप्लेट चुनें.
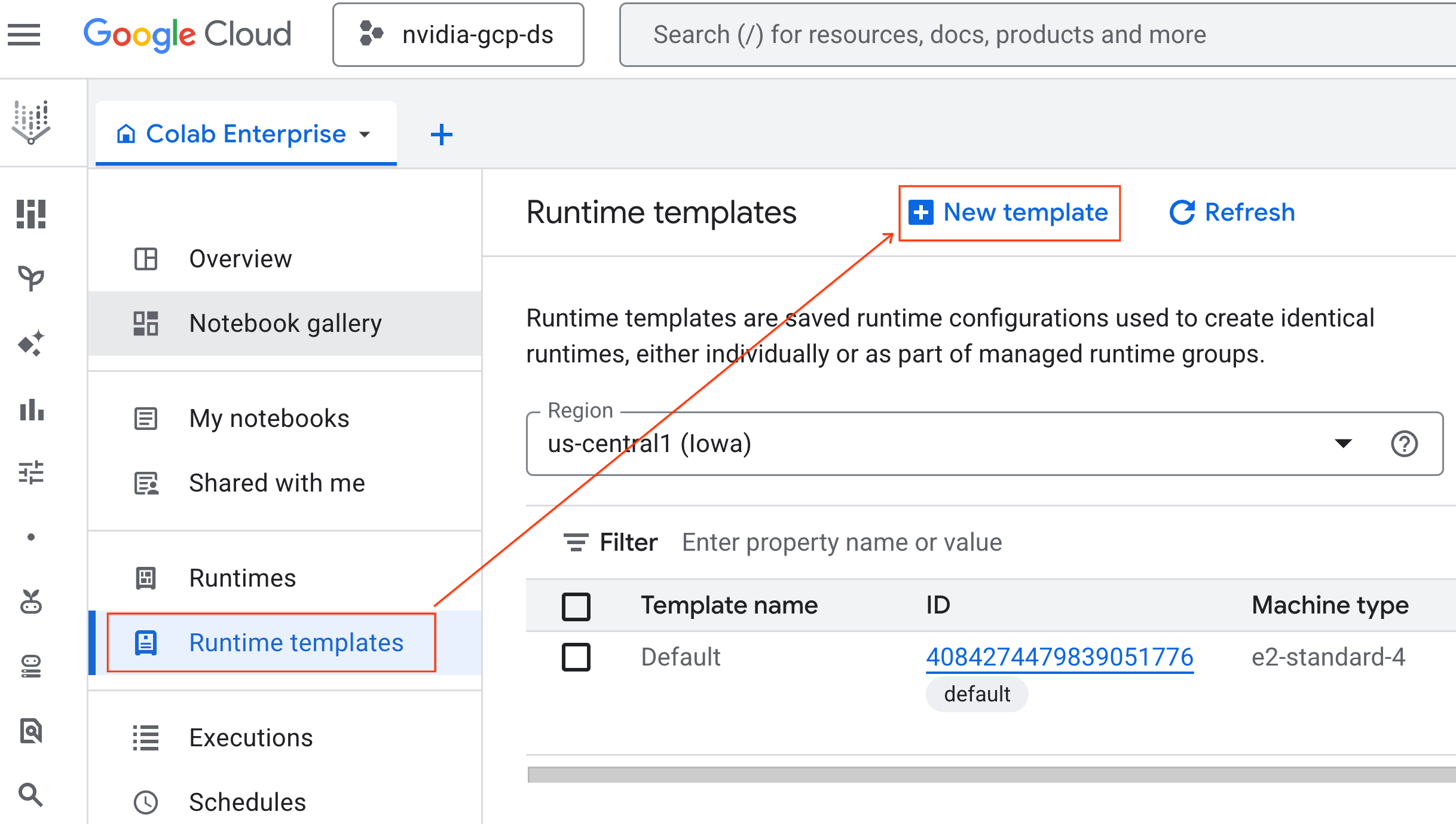
- रनटाइम की बुनियादी बातें में जाकर:
- डिसप्ले नेम को
gpu-templateके तौर पर सेट करें. - अपनी पसंद का देश/इलाका चुनें.
- डिसप्ले नेम को
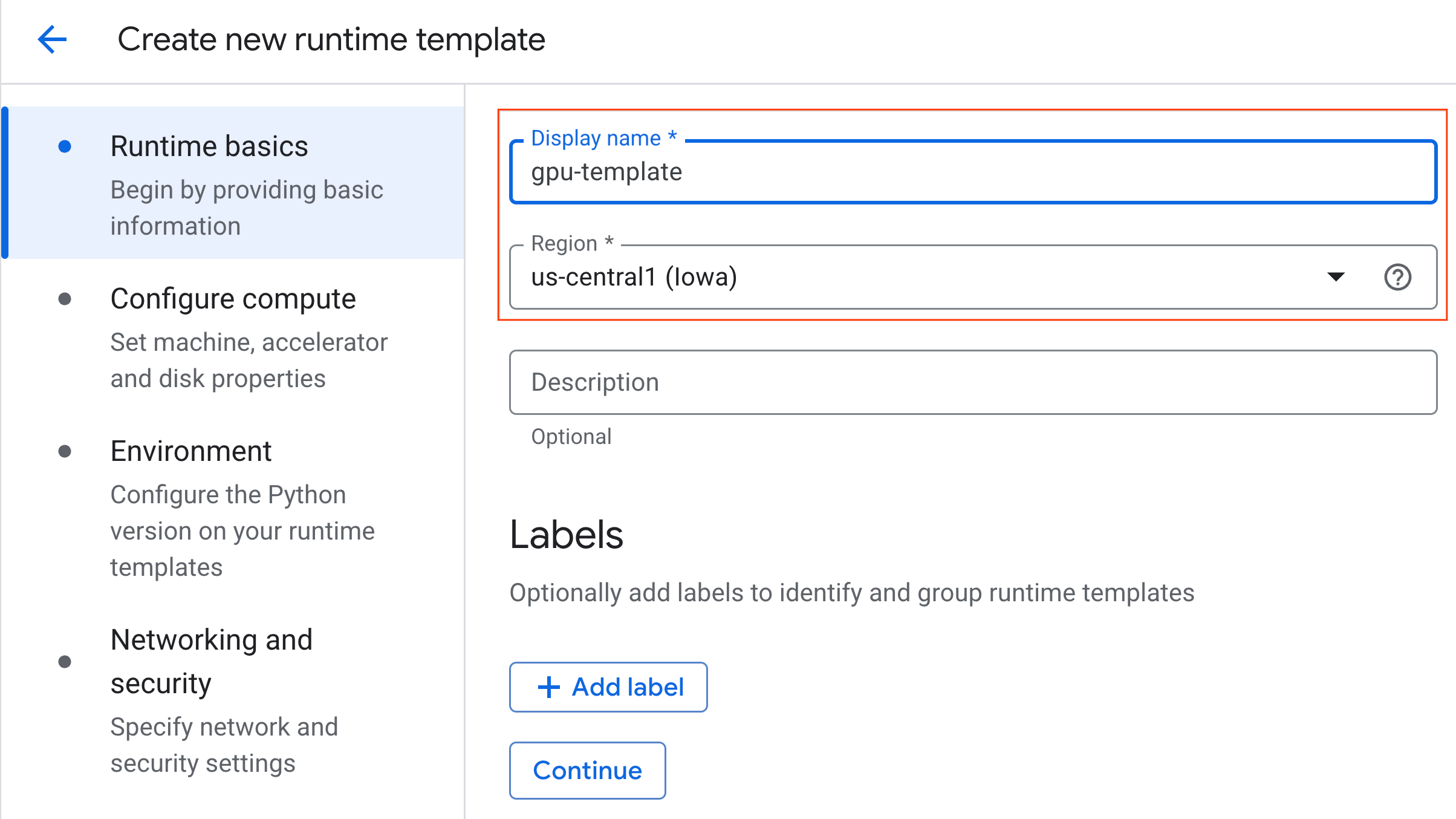
- कंप्यूट कॉन्फ़िगर करें में जाकर:
- मशीन टाइप को
g2-standard-4पर सेट करें. - डिफ़ॉल्ट ऐक्सलरेटर टाइप को
NVIDIA L4पर सेट रखें. साथ ही, ऐक्सलरेटर की संख्या को 1 पर सेट रखें. - निष्क्रिय होने पर बंद होने की सुविधा को 60 मिनट पर सेट करें.
- जारी रखें पर क्लिक करें.
- मशीन टाइप को
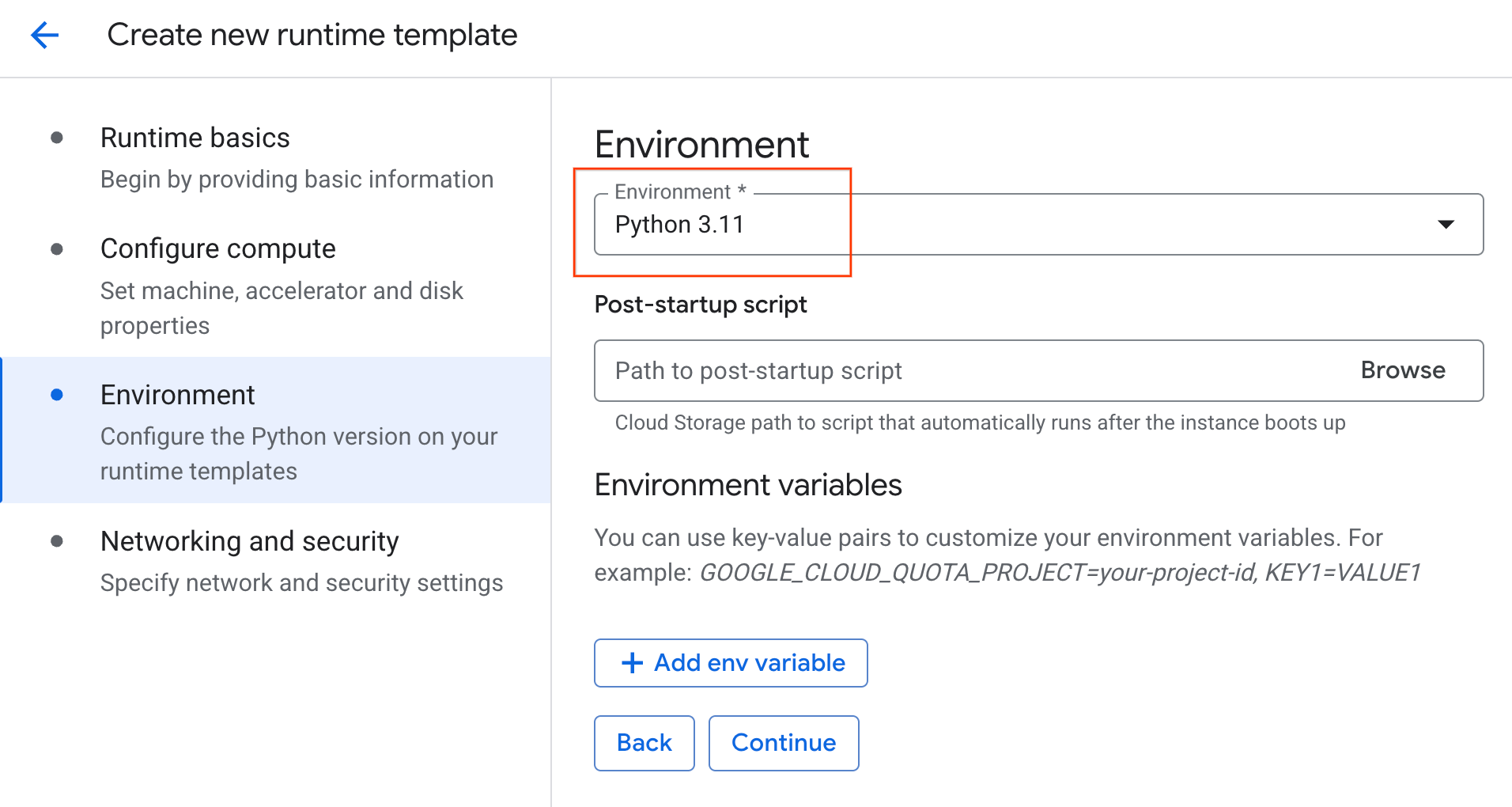
- परिवेश में जाकर:
- Environment को
Python 3.11पर सेट करें
- Environment को
- रनटाइम टेंप्लेट को सेव करने के लिए, बनाएं पर क्लिक करें. अब आपको रनटाइम टेंप्लेट वाले पेज पर नया टेंप्लेट दिखेगा.
6. रनटाइम शुरू करना
टेंप्लेट तैयार होने के बाद, नया रनटाइम बनाया जा सकता है.
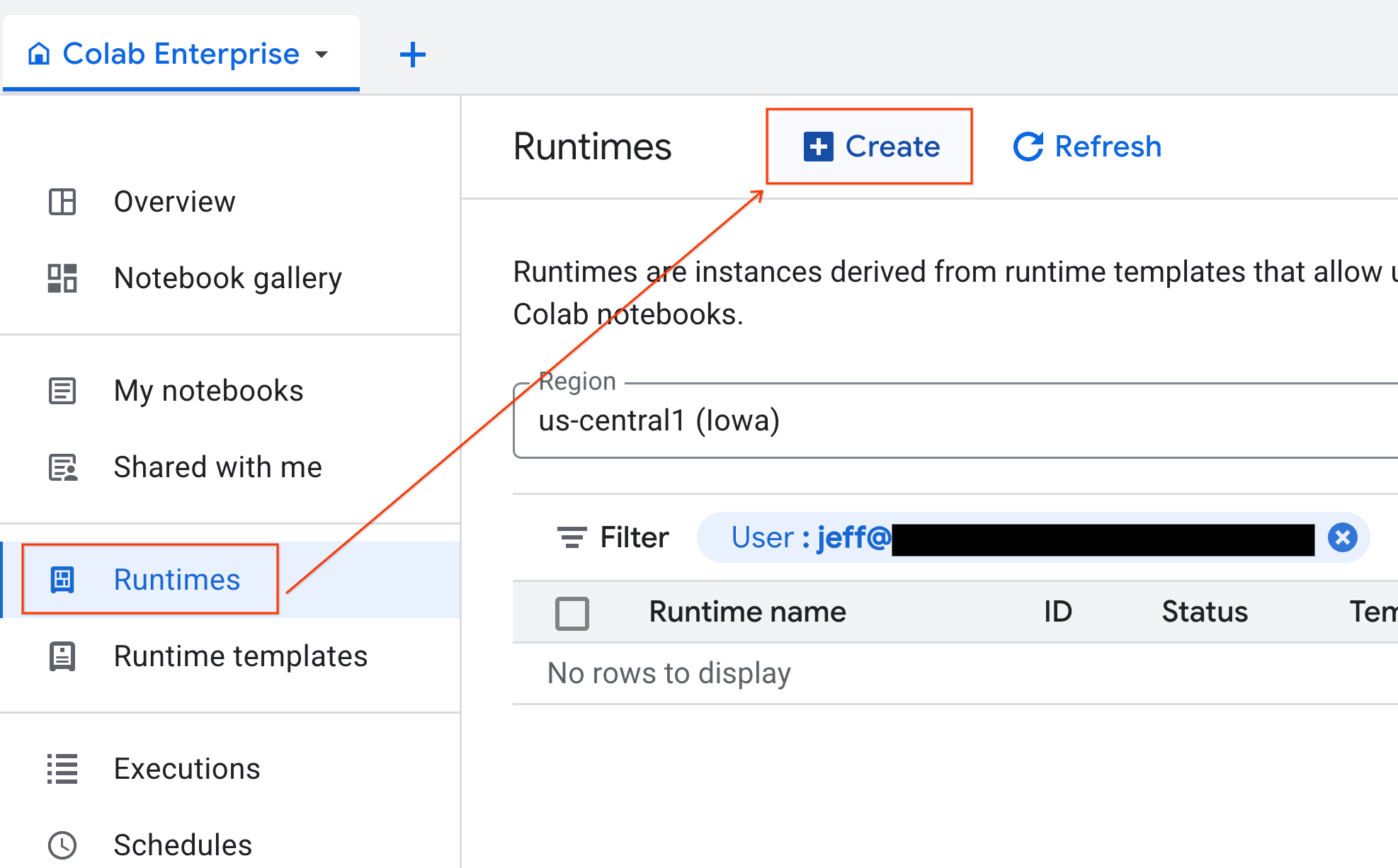
- Colab Enterprise में, Runtimes पर क्लिक करें. इसके बाद, Create को चुनें.
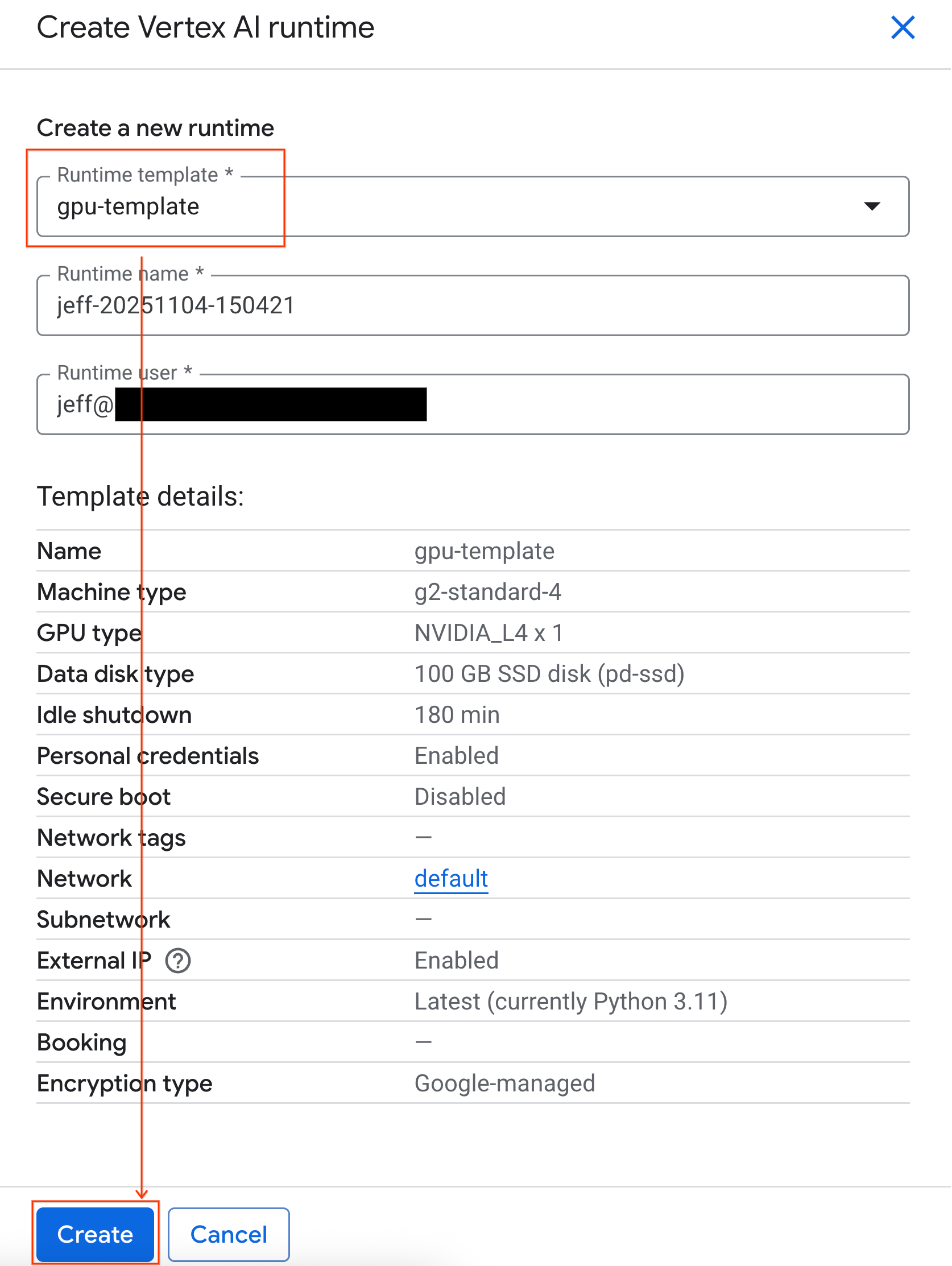
- रनटाइम टेंप्लेट में जाकर,
gpu-templateविकल्प चुनें. बनाएं पर क्लिक करें और रनटाइम के बूट अप होने का इंतज़ार करें.
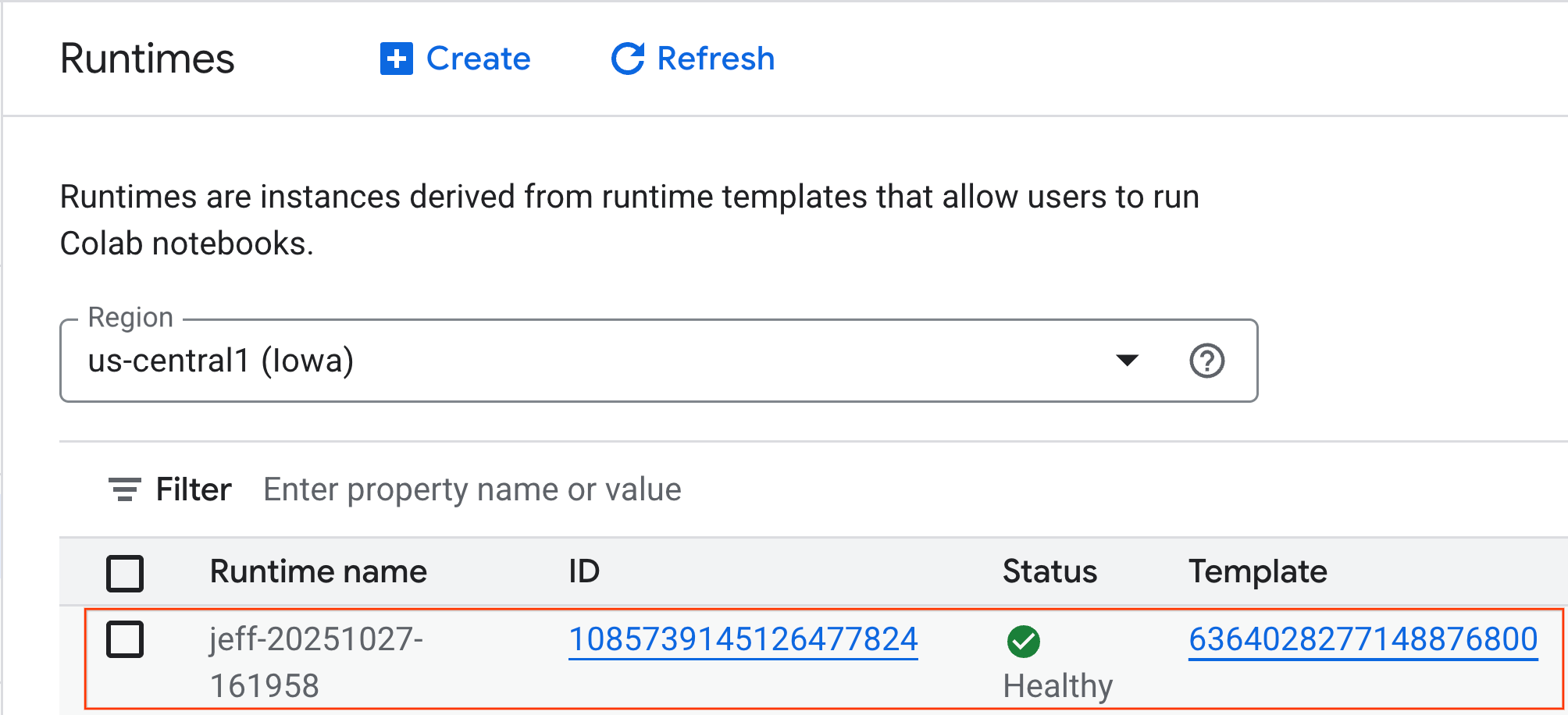
- कुछ मिनट बाद, आपको रनटाइम दिखेगा.
7. नोटबुक सेट अप करना
अब आपका इन्फ़्रास्ट्रक्चर चालू हो गया है. आपको लैब नोटबुक इंपोर्ट करनी होगी और उसे अपने रनटाइम से कनेक्ट करना होगा.
नोटबुक इंपोर्ट करना
- Colab Enterprise में, मेरी नोटबुक पर क्लिक करें. इसके बाद, इंपोर्ट करें पर क्लिक करें.
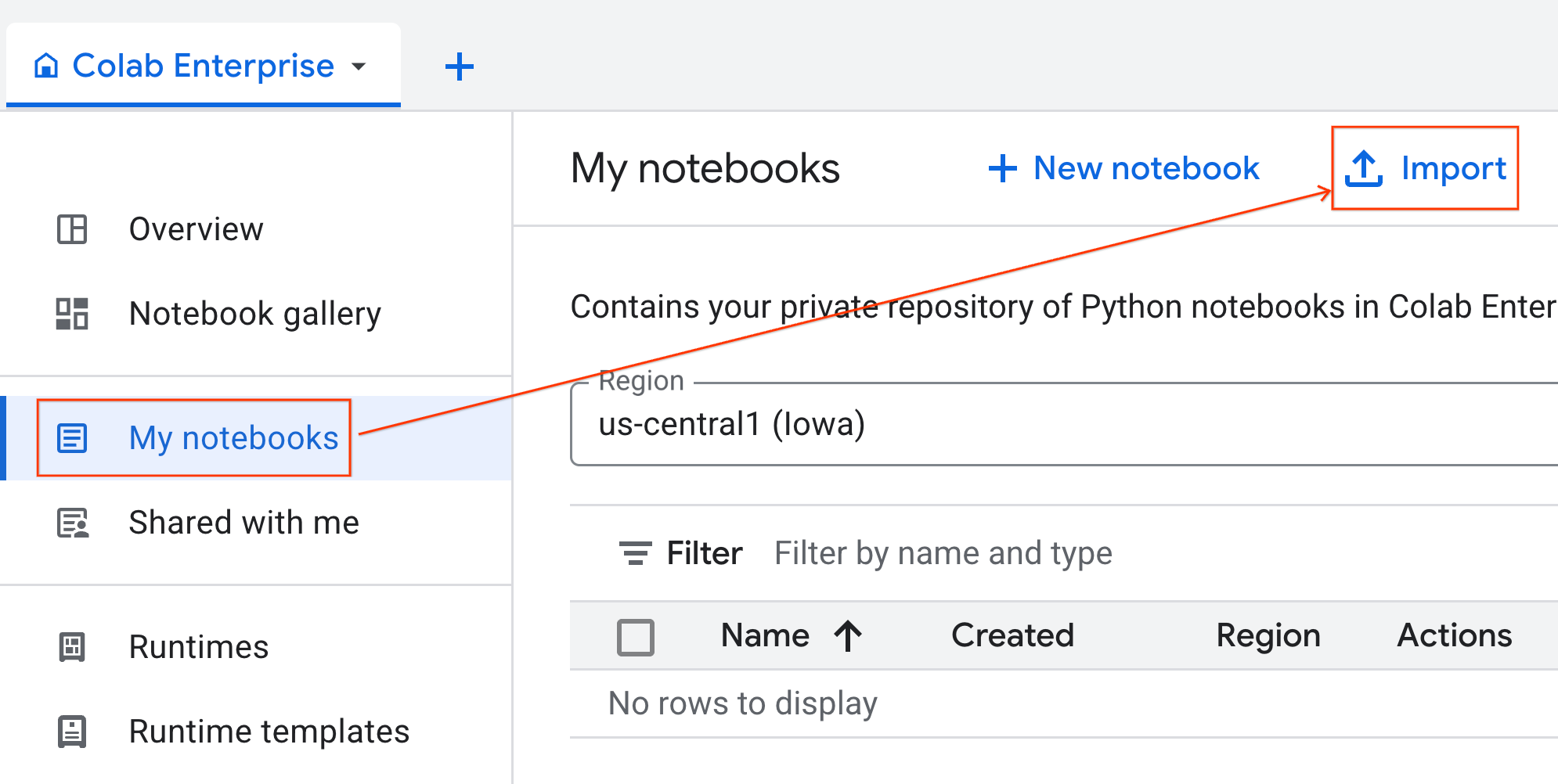
- यूआरएल रेडियो बटन चुनें और यह यूआरएल डालें:
https://github.com/GoogleCloudPlatform/ai-ml-recipes/blob/main/notebooks/regression/gpu_accelerated_regression/gpu_accelerated_regression.ipynb
- इंपोर्ट करें पर क्लिक करें. Colab Enterprise, GitHub से notebook को आपके एनवायरमेंट में कॉपी कर देगा.
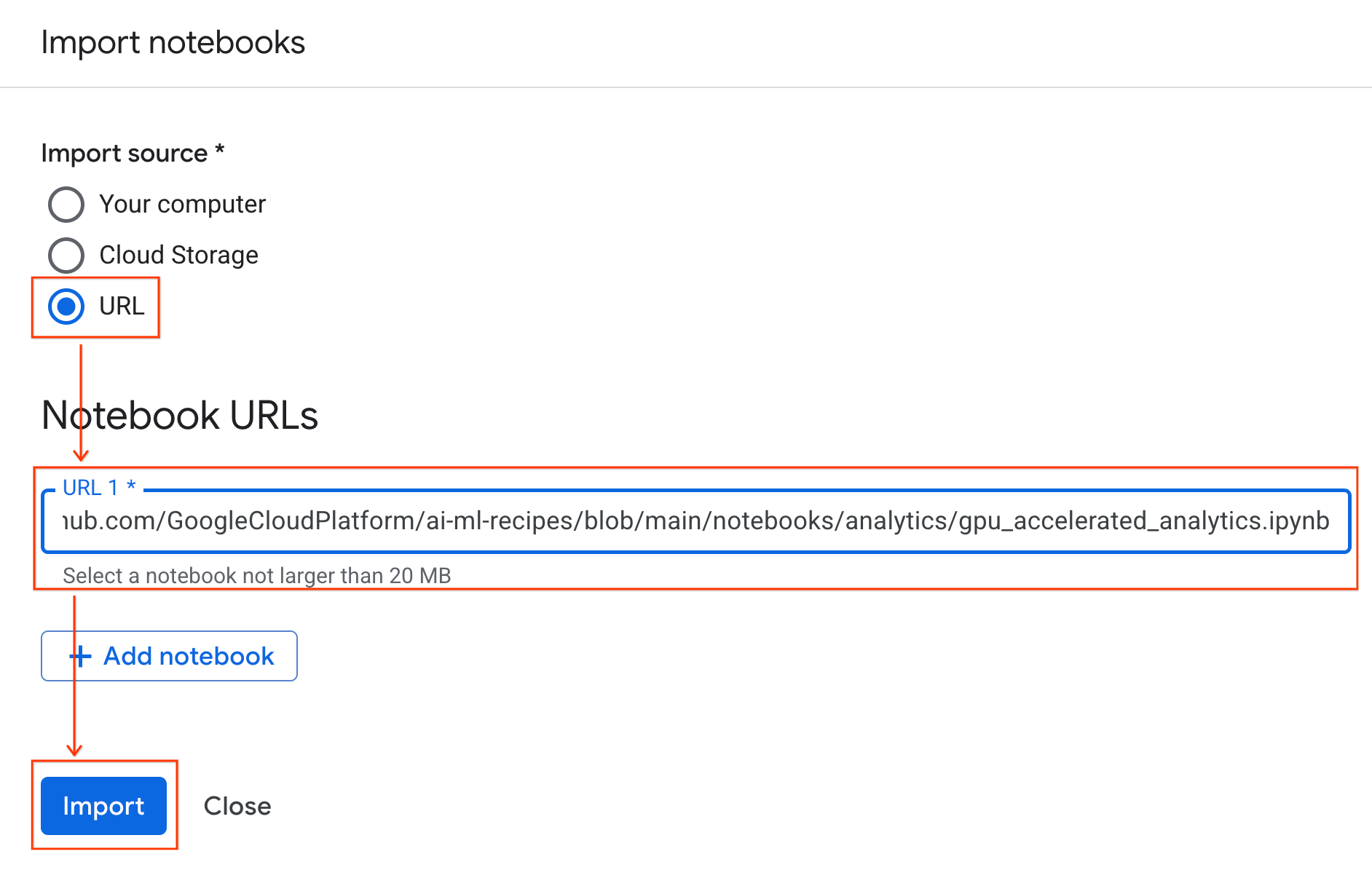
रनटाइम से कनेक्ट करना
- अभी इंपोर्ट की गई नोटबुक खोलें.
- कनेक्ट करें के बगल में मौजूद, डाउन ऐरो पर क्लिक करें.
- किसी रनटाइम से कनेक्ट करें को चुनें.
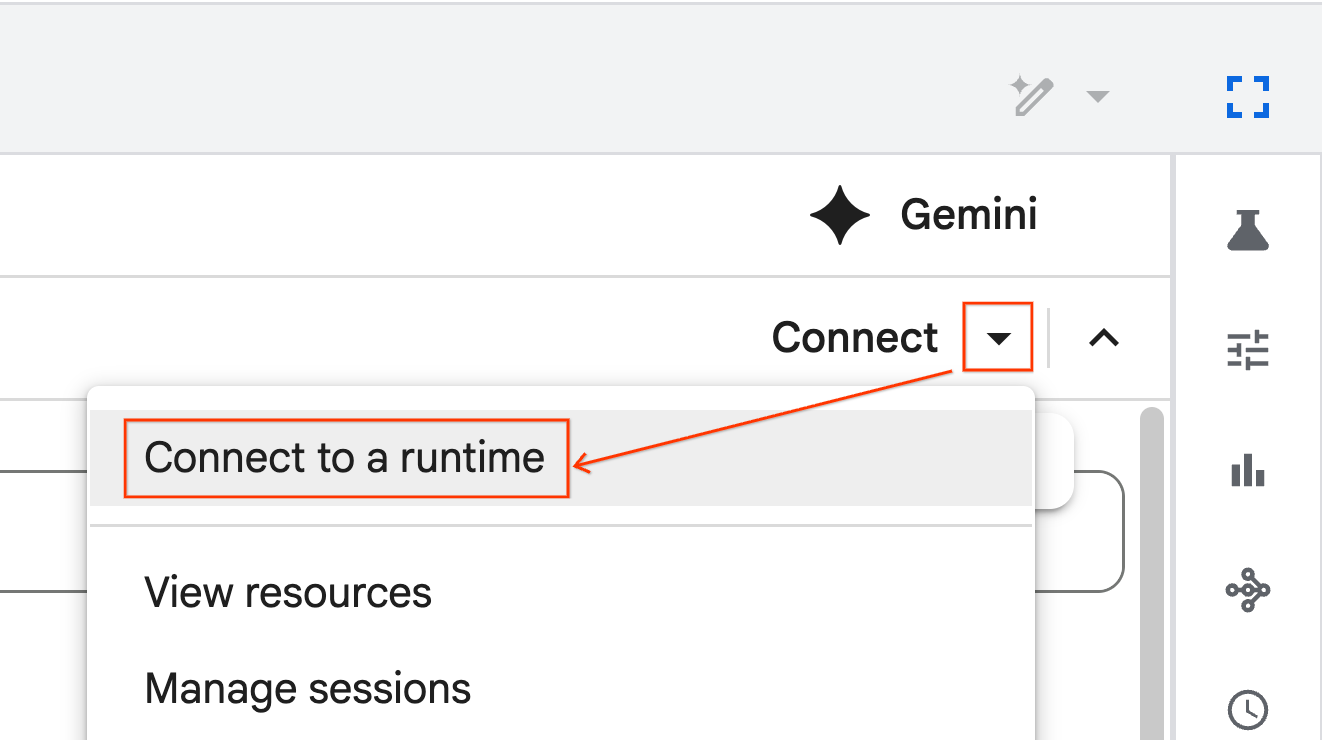
- ड्रॉपडाउन का इस्तेमाल करें और पहले से बनाया गया रनटाइम चुनें.
- कनेक्ट करें पर क्लिक करें.
आपकी नोटबुक अब GPU की सुविधा वाले रनटाइम से कनेक्ट हो गई है.
पहले से मौजूद डिपेंडेंसी
Colab Enterprise का इस्तेमाल करने का एक फ़ायदा यह है कि इसमें आपकी ज़रूरत की लाइब्रेरी पहले से इंस्टॉल होती हैं. इस लैब के लिए, आपको cuDF, cuML या XGBoost जैसी डिपेंडेंसी को मैन्युअल तरीके से इंस्टॉल या मैनेज करने की ज़रूरत नहीं है.
8. NYC टैक्सी का डेटासेट तैयार करना
इस कोडलैब में, NYC Taxi & Limousine Commission (TLC) के ट्रिप रिकॉर्ड डेटा का इस्तेमाल किया गया है. इस डेटासेट में, न्यूयॉर्क शहर में चलने वाली येलो टैक्सी की यात्राओं के रिकॉर्ड शामिल हैं. इनमें यह जानकारी शामिल है:
- पिक-अप और ड्रॉप-ऑफ़ की तारीखें, समय, और जगहें
- यात्रा की दूरी
- किराये की रकम की जानकारी
- यात्रियों की संख्या
- टिप की रकम (हम इसका अनुमान लगाएंगे!)
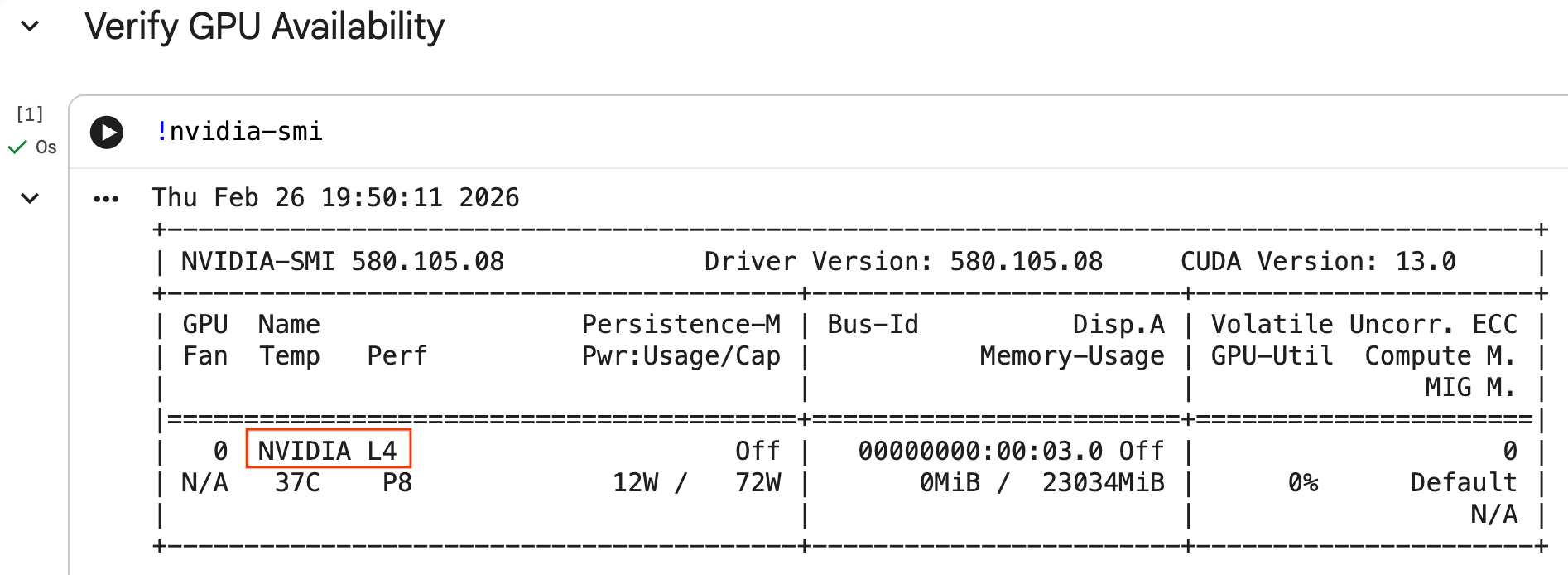
जीपीयू कॉन्फ़िगर करना और उपलब्धता की पुष्टि करना
nvidia-smi कमांड चलाकर, यह पुष्टि की जा सकती है कि GPU को पहचाना गया है या नहीं. इसमें ड्राइवर का वर्शन और जीपीयू की जानकारी दिखती है. जैसे, NVIDIA L4.
nvidia-smi
सेल में, आपके रनटाइम से जुड़ा जीपीयू दिखना चाहिए. यह कुछ ऐसा दिखना चाहिए:
डेटा डाउनलोड करें
साल 2024 की यात्रा का डेटा डाउनलोड करें.
from tqdm import tqdm
import requests
import time
import os
YEAR = 2024
DATA_DIR = "nyc_taxi_data"
os.makedirs(DATA_DIR, exist_ok=True)
print(f"Checking/Downloading files for {YEAR}...")
for month in tqdm(range(1, 13), unit="file"):
file_name = f"yellow_tripdata_{YEAR}-{month:02d}.parquet"
local_path = os.path.join(DATA_DIR, file_name)
url = f"https://d37ci6vzurychx.cloudfront.net/trip-data/{file_name}"
if not os.path.exists(local_path):
try:
with requests.get(url, stream=True) as response:
response.raise_for_status()
with open(local_path, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
time.sleep(1)
except requests.exceptions.HTTPError as e:
print(f"\nSkipping {file_name}: {e}")
if os.path.exists(local_path):
os.remove(local_path)
print("\nDownload complete.")
NVIDIA cuDF की मदद से pandas को बेहतर बनाएं
pandas लाइब्रेरी, सीपीयू पर काम करती है. बड़े डेटासेट के साथ इसका इस्तेमाल करने पर, यह धीमी हो सकती है. NVIDIA %load_ext cudf.pandas मैजिक कमांड, pandas को डाइनैमिक तरीके से पैच करती है, ताकि जीपीयू ऐक्सलरेशन का इस्तेमाल किया जा सके. अगर ज़रूरत हो, तो सीपीयू पर वापस आ जाती है.
हम स्टैंडर्ड इंपोर्ट के बजाय इस मैजिक कमांड का इस्तेमाल करते हैं, क्योंकि इससे ‘ज़ीरो कोड चेंज' ऐक्सेलरेट होता है. आपको अपने किसी भी मौजूदा कोड को फिर से लिखने की ज़रूरत नहीं है. इसी तरह का एक और निर्देश, %load_ext cuml.accel, scikit-learn models के लिए ठीक यही काम करता है! यह सुविधा, Colab Enterprise के साथ-साथ NVIDIA के साथ काम करने वाले जीपीयू वाले किसी भी Jupyter एनवायरमेंट में काम करती है.
%load_ext cudf.pandas
इसके चालू होने की पुष्टि करने के लिए, pandas इंपोर्ट करें और इसका टाइप देखें:
import pandas as pd
pd
आउटपुट से पुष्टि होगी कि अब cudf.pandas मॉड्यूल का इस्तेमाल किया जा रहा है.
डेटा लोड करना और उसे साफ़ करना
cudf.pandas चालू होने पर, Parquet फ़ाइलें लोड करें और डेटा को साफ़ करें. यह प्रोसेस, जीपीयू पर अपने-आप चलती है.
import glob
# Load data into memory
df = pd.concat(
[pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")],
ignore_index=True
)
# Filter for valid trips. We filter for payment_type=1 (credit card)
# because tip amounts are only reliably recorded for credit card transactions.
df = df[
(df['fare_amount'] > 0) & (df['fare_amount'] < 500) &
(df['trip_distance'] > 0) & (df['trip_distance'] < 100) &
(df['tip_amount'] >= 0) & (df['tip_amount'] < 100) &
(df['payment_type'] == 1)
].copy()
# Downcast numeric columns to save memory
float_cols = df.select_dtypes(include=['float64']).columns
df[float_cols] = df[float_cols].astype('float32')
int_cols = df.select_dtypes(include=['int64']).columns
df[int_cols] = df[int_cols].astype('int32')
फ़ीचर इंजीनियरिंग
पिकअप की तारीख और समय से, डिराइव की गई सुविधाएं बनाएं. नोटबुक में ऐसी अन्य सुविधाएं शामिल हैं जिनका इस्तेमाल बाद के चरणों में किया जाता है.
import numpy as np
# Time Features
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['dow'] = df['tpep_pickup_datetime'].dt.dayofweek
df['is_weekend'] = (df['dow'] >= 5).astype(int)
df['is_rush_hour'] = (
((df['hour'] >= 7) & (df['hour'] <= 9)) |
((df['hour'] >= 17) & (df['hour'] <= 19))
).astype(int)
...
# Other features
...
9. क्रॉस-वैलिडेशन की मदद से अलग-अलग मॉडल को ट्रेनिंग देना
इस नोटबुक में, यह दिखाया गया है कि जीपीयू, मशीन लर्निंग की प्रोसेस को कैसे तेज़ कर सकता है. इसके लिए, तीन अलग-अलग तरह के रिग्रेशन मॉडल को ट्रेन किया जाएगा, ताकि टैक्सी यात्रा के tip_amount का अनुमान लगाया जा सके.
NVIDIA cuML की मदद से scikit-learn को बेहतर बनाएं
एपीआई कॉल में बदलाव किए बिना, NVIDIA cuML का इस्तेमाल करके, जीपीयू पर scikit-learn एल्गोरिदम चलाएं. सबसे पहले, cuml.accel एक्सटेंशन लोड करें.
%load_ext cuml.accel
सेटअप की सुविधाएं और टारगेट
उन सुविधाओं की पहचान करें जिनसे आपको मॉडल को सीखना है. इसके बाद, टारगेट कॉलम (tip_amount) को अलग करें.
feature_cols = [
'trip_distance', 'fare_amount', 'passenger_count',
'hour', 'dow', 'is_weekend', 'is_rush_hour',
'fare_log', 'fare_decimal', 'is_round_fare',
'route_frequency', 'pu_tip_mean', 'pu_tip_std',
'PULocationID', 'DOLocationID'
]
X = df[feature_cols].fillna(df[feature_cols].median())
y = df['tip_amount'].copy()
मॉडल की परफ़ॉर्मेंस का बेहतर तरीके से आकलन करने के लिए, क्रॉस-वैलिडेशन स्प्लिट सेट अप करें.
from sklearn.model_selection import KFold
import numpy as np
import time
from sklearn.metrics import mean_squared_error
from tqdm.notebook import tqdm
n_splits = 3
kf = KFold(n_splits=n_splits, shuffle=True, random_state=42)
1. XGBoost
XGBoost में, जीपीयू ऐक्सेलरेटेड की सुविधा पहले से मौजूद होती है. ट्रेनिंग के दौरान GPU का इस्तेमाल करने के लिए, tree_method='hist' और device='cuda' पास करें.
import xgboost as xgb
start_time = time.perf_counter()
def train_xgb_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# XGBoost handles GPU natively when tree_method='hist' and device='cuda'
model = xgb.XGBRegressor(
objective='reg:squarederror',
max_depth=5,
learning_rate=0.1,
n_estimators=100,
tree_method='hist',
device='cuda',
random_state=42
)
model.fit(X_train, y_train)
preds = model.predict(X_val)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
xgb_rmse, xgb_preds = train_xgb_cv(X, y)
print(f"\n{'XGBoost RMSE:':<20} ${xgb_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
2. लीनियर रिग्रेशन
लीनियर रिग्रेशन मॉडल को ट्रेन करें. %load_ext cuml.accel चालू होने पर, LinearRegression अपने-आप GPU के बराबर मैप हो जाता है.
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
start_time = time.perf_counter()
def train_linreg_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# Scale features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_val_scaled = scaler.transform(X_val)
# Automatically accelerated by cuML
model = LinearRegression()
model.fit(X_train_scaled, y_train)
preds = model.predict(X_val_scaled)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
linreg_rmse, linreg_preds = train_linreg_cv(X, y)
print(f"\n{'Linear Reg RMSE:':<20} ${linreg_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
3. रैंडम फ़ॉरेस्ट
RandomForestRegressor का इस्तेमाल करके, एक एनसेंबल मॉडल को ट्रेन करें. ट्री-आधारित मॉडल को सीपीयू पर ट्रेन करने में अक्सर समय लगता है. हालांकि, जीपीयू की मदद से लाखों लाइनों को तेज़ी से प्रोसेस किया जा सकता है.
from sklearn.ensemble import RandomForestRegressor
start_time = time.perf_counter()
def train_rf_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# Automatically accelerated by cuML
model = RandomForestRegressor(
n_estimators=100,
max_depth=10,
n_jobs=-1,
max_features='sqrt',
random_state=42
)
model.fit(X_train, y_train)
preds = model.predict(X_val)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
rf_rmse, rf_preds = train_rf_cv(X, y)
print(f"\n{'Random Forest RMSE:':<20} ${rf_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
10. एंड-टू-एंड पाइपलाइन का आकलन करना
सिंपल लीनियर एन्सेम्बल का इस्तेमाल करके, तीनों मॉडल के अनुमानों को मिलाएं. आम तौर पर, इससे अलग-अलग मॉडल की तुलना में थोड़ी ज़्यादा सटीक जानकारी मिलती है.
सबसे सही वेट का पता लगाने के लिए, अनुमानों पर लीनियर रिग्रेशन लागू करें:
ensemble_weights = LinearRegression(positive=True, fit_intercept=False).fit(
np.c_[xgb_preds, rf_preds, linreg_preds], y
).coef_
# Normalize weights
ensemble_weights = ensemble_weights / ensemble_weights.sum()
ensemble_preds = np.c_[xgb_preds, rf_preds, linreg_preds] @ ensemble_weights
ensemble_rmse = np.sqrt(mean_squared_error(y, ensemble_preds))
ग्रुप लिफ़्ट देखने के लिए, नतीजों की तुलना करें:
print(f"\n{'Model':<20} {'RMSE':>10}")
print("-" * 32)
print(f"{'Linear Regression':<20} ${linreg_rmse:>9.4f}")
print(f"{'Random Forest':<20} ${rf_rmse:>9.4f}")
print(f"{'XGBoost':<20} ${xgb_rmse:>9.4f}")
print("-" * 32)
print(f"{'Ensemble':<20} ${ensemble_rmse:>9.4f}")
print(f"\nEnsemble lift: ${xgb_rmse - ensemble_rmse:.4f}")
11. सीपीयू और जीपीयू की परफ़ॉर्मेंस की तुलना करना
परफ़ॉर्मेंस में अंतर का सही तरीके से बेंचमार्क करने के लिए, आपको कर्नल को फिर से शुरू करना होगा. इससे यह पक्का किया जा सकेगा कि एक्ज़ीक्यूशन की स्थिति सही है. इसके बाद, सीपीयू पर पूरी डेटा साइंस पाइपलाइन चलाएं. इसके बाद, इसे फिर से जीपीयू पर चलाएं.
कर्नेल को रीस्टार्ट करें
कर्नल को रीस्टार्ट करने और मेमोरी खाली करने के लिए, IPython.Application.instance().kernel.do_shutdown(True) कमांड चलाएं.
import IPython
IPython.Application.instance().kernel.do_shutdown(True)
डेटा साइंस पाइपलाइन को परिभाषित करना
कोर वर्कफ़्लो (डेटा लोड करना, डेटा को साफ़ करना, फ़ीचर इंजीनियरिंग, और मॉडल ट्रेनिंग) को एक फ़ंक्शन में रैप करें. यह फ़ंक्शन, एनवायरमेंट के बीच स्विच करने के लिए, pandas मॉड्यूल pd_module और use_gpu आर्ग्युमेंट स्वीकार करता है.
def run_ml_pipeline(pd_module, use_gpu=False):
import time
import glob
import numpy as np
from sklearn.ensemble import RandomForestRegressor
import xgboost as xgb
timings = {}
# 1. Load Data
t0 = time.perf_counter()
df = pd_module.concat(
[pd_module.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")],
ignore_index=True
)
timings['Load Data'] = time.perf_counter() - t0
# 2. Clean Data
t0 = time.perf_counter()
# Filter for payment_type=1 (credit card) because tip amounts
# are only reliably recorded for credit card transactions.
df = df[
(df['fare_amount'] > 0) & (df['fare_amount'] < 500) &
(df['trip_distance'] > 0) & (df['trip_distance'] < 100) &
(df['tip_amount'] >= 0) & (df['tip_amount'] < 100) &
(df['payment_type'] == 1)
].copy()
# Downcast numeric columns to save memory
float_cols = df.select_dtypes(include=['float64']).columns
df[float_cols] = df[float_cols].astype('float32')
int_cols = df.select_dtypes(include=['int64']).columns
df[int_cols] = df[int_cols].astype('int32')
timings['Clean Data'] = time.perf_counter() - t0
# 3. Feature Engineering
t0 = time.perf_counter()
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['dow'] = df['tpep_pickup_datetime'].dt.dayofweek
df['is_weekend'] = (df['dow'] >= 5).astype(int)
df['fare_log'] = np.log1p(df['fare_amount'])
timings['Feature Engineering'] = time.perf_counter() - t0
# 4. Modeling Prep
feature_cols = ['trip_distance', 'fare_amount', 'passenger_count', 'hour', 'dow', 'is_weekend', 'fare_log']
X = df[feature_cols].fillna(df[feature_cols].median())
y = df['tip_amount'].copy()
# Free memory
del df
import gc
gc.collect()
# 5. Train Random Forest
t0 = time.perf_counter()
rf_model = RandomForestRegressor(
n_estimators=100,
max_depth=10,
n_jobs=-1,
max_features='sqrt',
random_state=42
).fit(X, y)
timings['Train Random Forest'] = time.perf_counter() - t0
# 6. Train XGBoost
t0 = time.perf_counter()
params = {
'objective': 'reg:squarederror',
'max_depth': 5,
'n_estimators': 100,
'random_state': 42
}
if use_gpu:
params['device'] = 'cuda'
params['tree_method'] = 'hist'
xgb_model = xgb.XGBRegressor(**params).fit(X, y)
timings['Train XGBoost'] = time.perf_counter() - t0
del X
del y
gc.collect()
return timings
सीपीयू पर चलता है
स्टैंडर्ड सीपीयू pandas का इस्तेमाल करके पाइपलाइन को कॉल करें.
import pandas as pd
print("Running pipeline on CPU...")
cpu_times = run_ml_pipeline(pd, use_gpu=False)
print("CPU Execution Finished.")
अपने जीपीयू पर चलाएं
NVIDIA लाइब्रेरी एक्सटेंशन लोड करें, ऐक्सेलरेटेड cudf.pandas मॉड्यूल को पाइपलाइन में पास करें, और अपने XGBoost डिवाइस को इंटरनल तौर पर cuda पर सेट करें.
import IPython.core.magic
if not hasattr(IPython.core.magic, 'output_can_be_silenced'):
IPython.core.magic.output_can_be_silenced = lambda x: x
%load_ext cudf.pandas
%load_ext cuml.accel
import pandas as pd
print("Running pipeline on GPU...")
gpu_times = run_ml_pipeline(pd, use_gpu=True)
print("GPU Execution Finished.")
परफ़ॉर्मेंस में हुई बढ़ोतरी को विज़ुअलाइज़ करना
matplotlib का इस्तेमाल करके, समय को विज़ुअलाइज़ करें. नतीजों में, जीपीयू का इस्तेमाल करने पर डेटा प्रोसेसिंग और मॉडल ट्रेनिंग के दौरान लगने वाले समय के बारे में बताया गया है.
import matplotlib.pyplot as plt
import numpy as np
labels = list(cpu_times.keys())
cpu_values = list(cpu_times.values())
gpu_values = list(gpu_times.values())
x = np.arange(len(labels))
width = 0.35
fig, ax = plt.subplots(figsize=(10, 6))
rects1 = ax.bar(x - width/2, cpu_values, width, label='CPU', color='#4285F4')
rects2 = ax.bar(x + width/2, gpu_values, width, label='GPU', color='#76B900')
ax.set_ylabel('Execution Time (seconds)')
ax.set_title('NYC Taxi ML Pipeline: CPU vs. GPU Performance')
ax.set_xticks(x)
ax.set_xticklabels(labels, rotation=45, ha="right")
ax.legend()
# Add data labels
def autolabel(rects):
for rect in rects:
height = rect.get_height()
ax.annotate(f'{height:.2f}s',
xy=(rect.get_x() + rect.get_width() / 2, height),
xytext=(0, 3), # 3 points vertical offset
textcoords="offset points",
ha='center', va='bottom', fontsize=9)
autolabel(rects1)
autolabel(rects2)
plt.tight_layout()
plt.show()
# Calculate overall speedup
total_cpu_time = sum(cpu_values)
total_gpu_time = sum(gpu_values)
overall_speedup = total_cpu_time / total_gpu_time
print(f"\nOverall Pipeline Speedup: {overall_speedup:.2f}x faster on GPU!")
आपको इस तरह की विंडो दिखेगी:
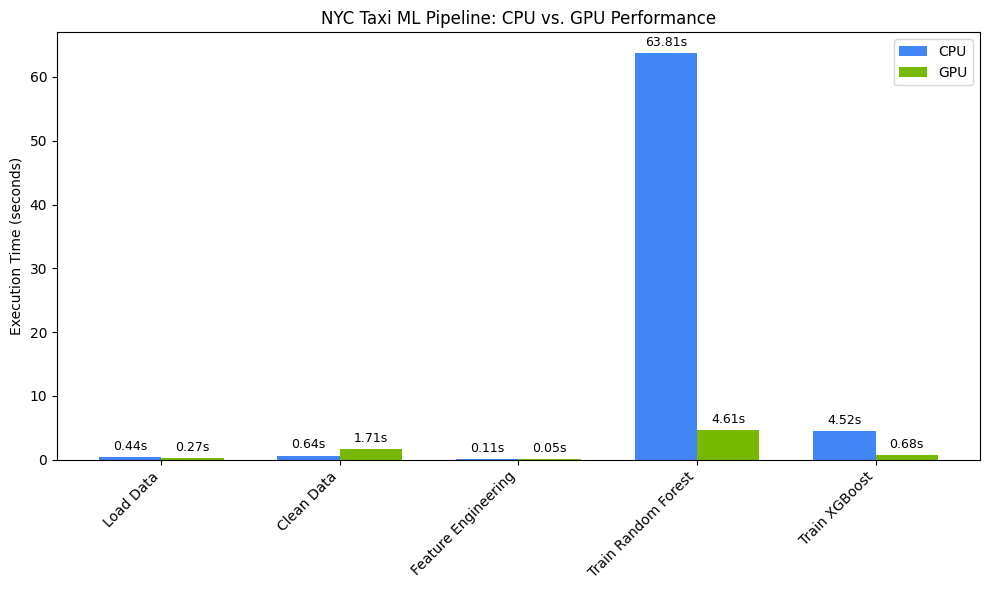
इस चार्ट में, पूरे डेटा साइंस वर्कफ़्लो में जीपीयू की बेहतर परफ़ॉर्मेंस के बारे में बताया गया है. आपको रैंडम फ़ॉरेस्ट और XGBoost जैसे एल्गोरिदम के लिए, कंप्यूटेशनल इंटेंसिव मॉडल ट्रेनिंग फ़ेज़ के दौरान, समय की सबसे ज़्यादा बचत देखने को मिल सकती है.
12. परफ़ॉर्मेंस से जुड़ी सीमाओं का पता लगाने के लिए, अपने कोड की प्रोफ़ाइल बनाएं
cudf.pandas का इस्तेमाल करते समय, ज़्यादातर फ़ंक्शन GPU पर चलते हैं. अगर कोई खास ऑपरेशन cuDF पर काम नहीं करता है, तो उसे कुछ समय के लिए सीपीयू पर किया जाता है. NVIDIA, इन फ़ॉलबैक की पहचान करने के लिए, Jupyter की दो इन-बिल्ट मैजिक कमांड उपलब्ध कराता है.
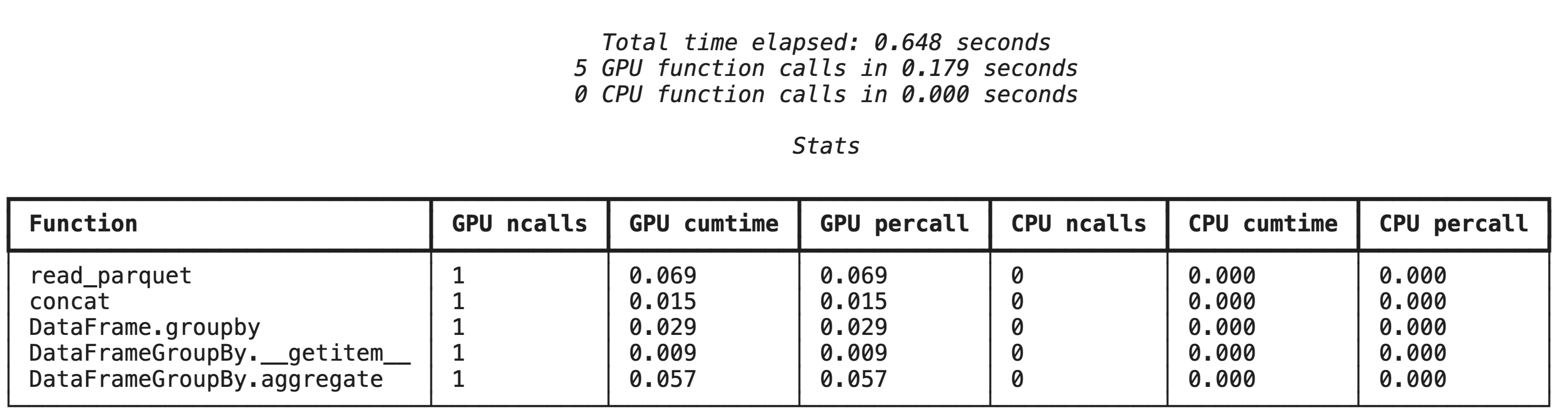
%%cudf.pandas.profile की मदद से बेहतर प्रोफ़ाइलिंग
%%cudf.pandas.profile मैजिक कमांड से, इस बात की खास जानकारी मिलती है कि कौनसे फ़ंक्शन GPU या सीपीयू पर चले.
%%cudf.pandas.profile
import glob
import pandas as pd
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")], ignore_index=True)
summary = (
df
.groupby(['PULocationID', 'payment_type'])
[['passenger_count', 'fare_amount', 'tip_amount']]
.agg(['min', 'mean', 'max'])
)
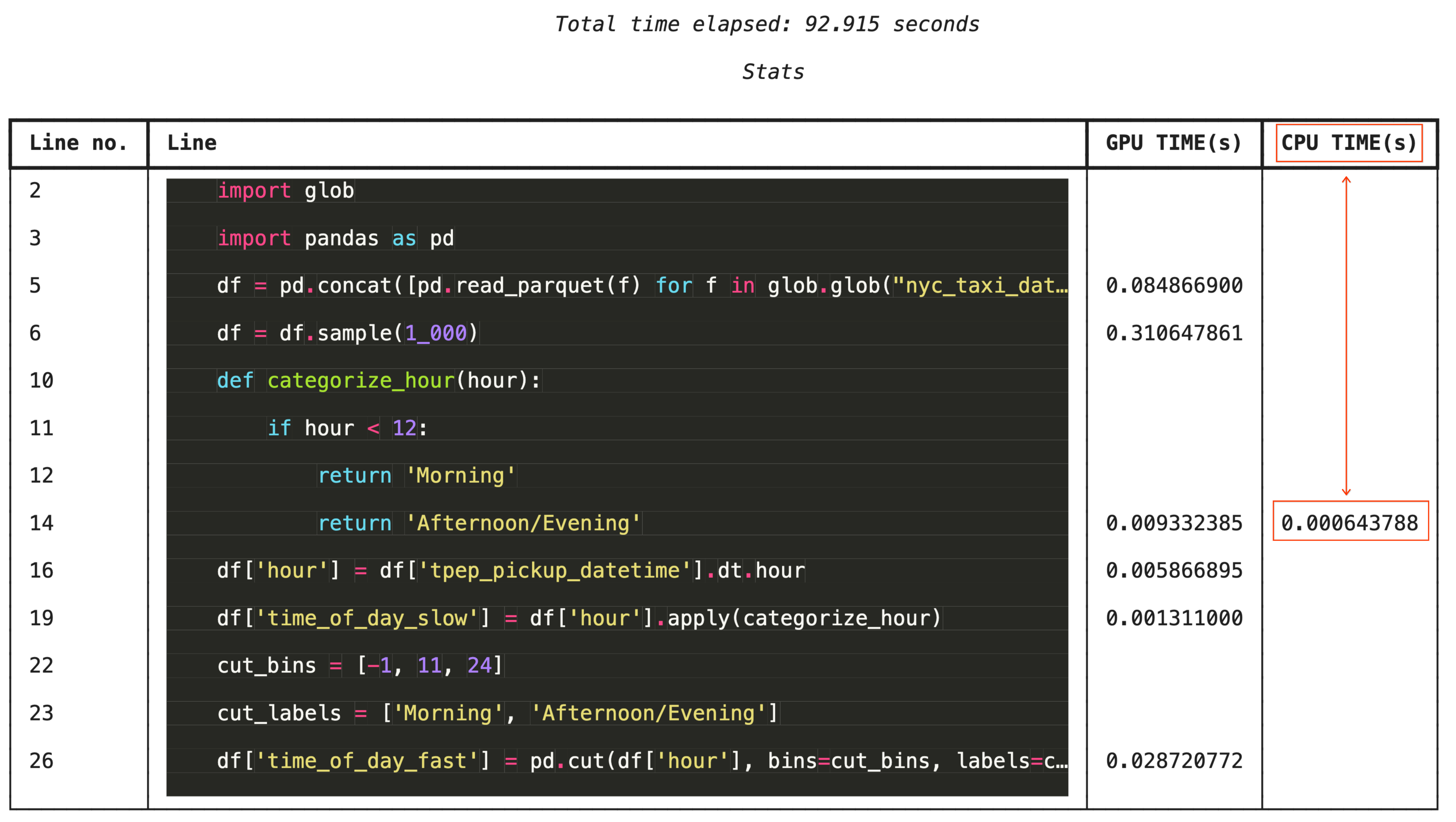
%%cudf.pandas.line_profile की मदद से, लाइन-बाय-लाइन प्रोफ़ाइलिंग
ज़्यादा बारीकी से समस्या हल करने के लिए, %%cudf.pandas.line_profile कोड की हर लाइन को इस जानकारी के साथ एनोटेट करता है कि उसे जीपीयू पर कितनी बार और सीपीयू पर कितनी बार एक्ज़ीक्यूट किया गया.
%%cudf.pandas.line_profile
import glob
import pandas as pd
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")], ignore_index=True)
df = df.sample(1_000)
# Iterating row-by-row or using custom python apply functions often falls back to the CPU
def categorize_hour(hour):
if hour < 12:
return 'Morning'
else:
return 'Afternoon/Evening'
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['time_of_day_slow'] = df['hour'].apply(categorize_hour)
# Using vectorized pandas operations (like pd.cut) stays entirely on the GPU
cut_bins = [-1, 11, 24]
cut_labels = ['Morning', 'Afternoon/Evening']
df['time_of_day_fast'] = pd.cut(df['hour'], bins=cut_bins, labels=cut_labels)
13. क्लीन अप करें
अपने Google Cloud खाते पर अनचाहे शुल्क से बचने के लिए, इस कोडलैब के दौरान बनाए गए संसाधनों को हटा दें.
संसाधन मिटाना
नोटबुक सेल में !rm -rf कमांड का इस्तेमाल करके, रनटाइम पर मौजूद लोकल डेटासेट मिटाएं.
print("Deleting local 'nyc_taxi_data' directory...")
!rm -rf nyc_taxi_data
print("Local files deleted.")
Colab रनटाइम बंद करना
- Google Cloud Console में, Colab Enterprise के रंटाइम पेज पर जाएं.
- रीजन मेन्यू में जाकर, वह रीजन चुनें जिसमें आपका रनटाइम मौजूद है.
- वह रनटाइम चुनें जिसे आपको मिटाना है.
- मिटाएं पर क्लिक करें.
- पुष्टि करें पर क्लिक करें.
अपनी नोटबुक मिटाना
- Google Cloud Console में, Colab Enterprise के My Notebooks पेज पर जाएं.
- रीजन मेन्यू में जाकर, वह रीजन चुनें जिसमें आपकी नोटबुक मौजूद है.
- वह नोटबुक चुनें जिसे मिटाना है.
- मिटाएं पर क्लिक करें.
- पुष्टि करें पर क्लिक करें.
14. बधाई हो
बधाई हो! आपने Colab Enterprise पर NVIDIA cuDF और cuML लाइब्रेरी का इस्तेमाल करके, pandas और scikit-learn मशीन लर्निंग वर्कफ़्लो को तेज़ी से पूरा किया है. सिर्फ़ कुछ मैजिक कमांड (%load_ext cudf.pandas और %load_ext cuml.accel) जोड़कर, आपके स्टैंडर्ड कोड को जीपीयू पर चलाया जा सकता है. इससे रिकॉर्ड प्रोसेस किए जा सकते हैं और जटिल मॉडल को कम समय में स्थानीय तौर पर फ़िट किया जा सकता है.
डेटा विश्लेषण के लिए जीपीयू की मदद से तेज़ी से काम करने की सुविधा के बारे में ज़्यादा जानने के लिए, जीपीयू की मदद से डेटा विश्लेषण को तेज़ करना कोडलैब देखें.
हमने क्या-क्या कवर किया है
- Google Cloud पर Colab Enterprise के बारे में जानकारी.
- किसी खास जीपीयू और मेमोरी कॉन्फ़िगरेशन के साथ, Colab के रनटाइम एनवायरमेंट को पसंद के मुताबिक बनाना.
- न्यूयॉर्क सिटी टैक्सी के डेटासेट से मिले लाखों रिकॉर्ड का इस्तेमाल करके, टिप की रकम का अनुमान लगाने के लिए, जीपीयू ऐक्सेलरेटेड कंप्यूटिंग का इस्तेमाल करना.
- NVIDIA की
cuDFलाइब्रेरी का इस्तेमाल करके, कोड में कोई बदलाव किए बिनाpandasको तेज़ करना. - NVIDIA की
cuMLलाइब्रेरी और जीपीयू का इस्तेमाल करके,scikit-learnको तेज़ किया जा सकता है. इसके लिए, कोड में कोई बदलाव करने की ज़रूरत नहीं होती. - परफ़ॉर्मेंस से जुड़ी समस्याओं का पता लगाने और उन्हें ऑप्टिमाइज़ करने के लिए, अपने कोड की प्रोफ़ाइलिंग करें.