
1. Pengantar
Dalam codelab ini, Anda akan mempelajari cara mempercepat alur kerja data science dan machine learning pada set data besar menggunakan GPU NVIDIA dan library open source di Google Cloud. Anda akan memulai dengan menyiapkan infrastruktur, lalu mempelajari cara menerapkan akselerasi GPU.
Anda akan berfokus pada siklus proses ilmu data, mulai dari persiapan data dengan pandas hingga pelatihan model dengan scikit-learn dan XGBoost. Anda akan mempelajari cara mempercepat tugas ini menggunakan library cuDF dan cuML NVIDIA. Yang terbaik adalah Anda bisa mendapatkan akselerasi GPU ini tanpa mengubah kode pandas atau scikit-learn yang ada.
Yang akan Anda pelajari
- Memahami Colab Enterprise di Google Cloud.
- Sesuaikan lingkungan runtime Colab dengan konfigurasi GPU dan memori tertentu.
- Terapkan akselerasi GPU untuk memprediksi jumlah tip menggunakan jutaan data dari set data NYC Taxi.
- Percepat
pandastanpa perubahan kode menggunakan librarycuDFNVIDIA. - Percepat
scikit-learntanpa perubahan kode menggunakan librarycuMLdan GPU NVIDIA. - Buat profil kode Anda untuk mengidentifikasi dan mengoptimalkan batasan performa.
Halaman berikutnya berisi kredit yang dapat Anda gunakan untuk menyelesaikan lab.
2. Mengapa perlu mempercepat machine learning?
Kebutuhan akan iterasi yang lebih cepat dalam ML
Persiapan data membutuhkan waktu yang lama, dan pelatihan atau evaluasi model dapat memakan waktu lebih lama lagi seiring bertambahnya set data. Melatih model seperti random forest atau XGBoost pada jutaan baris dengan CPU dapat memakan waktu berjam-jam atau berhari-hari.
Penggunaan GPU mempercepat proses pelatihan ini dengan library seperti cuML dan XGBoost yang dipercepat GPU. Dengan akselerasi ini, Anda dapat:
- Melakukan iterasi lebih cepat: Uji fitur dan hyperparameter baru dengan cepat.
- Latih pada set data lengkap: Gunakan data lengkap, bukan data yang di-downsampling, untuk akurasi yang lebih baik.
- Mengurangi biaya: Selesaikan workload berat dalam waktu yang lebih singkat untuk menurunkan biaya komputasi.
3. Penyiapan dan persyaratan
Potensi biaya
Codelab ini menggunakan resource Google Cloud, termasuk runtime Colab Enterprise dengan GPU NVIDIA L4. Perhatikan potensi biaya dan ikuti bagian Pembersihan di akhir codelab untuk menonaktifkan resource dan menghindari penagihan berkelanjutan. Untuk mengetahui informasi harga selengkapnya, lihat harga Colab Enterprise dan harga GPU.
Sebelum memulai
Diasumsikan Anda memiliki pemahaman tingkat menengah tentang Python, pandas, scikit-learn, dan praktik machine learning standar (seperti validasi silang/penggabungan).
- Di Konsol Google Cloud, pada halaman pemilih project, pilih atau buat project Google Cloud.
- Pastikan penagihan diaktifkan untuk project Google Cloud Anda.
Mengaktifkan API
Untuk menggunakan Colab Enterprise, Anda harus mengaktifkan API yang diperlukan terlebih dahulu.
- Buka Google Cloud Shell dengan mengklik ikon Cloud Shell di kanan atas Konsol Google Cloud.

- Di Cloud Shell, tetapkan project ID Anda dengan mengganti
PROJECT_IDdengan project ID Anda:
gcloud config set project <PROJECT_ID>
- Jalankan perintah berikut untuk mengaktifkan API yang diperlukan:
gcloud services enable \
compute.googleapis.com \
dataform.googleapis.com \
notebooks.googleapis.com \
aiplatform.googleapis.com
Setelah berhasil dieksekusi, Anda akan melihat pesan yang mirip dengan yang ditampilkan di bawah:
Operation "operations/..." finished successfully.
4. Memilih lingkungan notebook
Meskipun banyak ilmuwan data sudah familiar dengan Colab untuk project pribadi, Colab Enterprise memberikan pengalaman notebook yang aman, kolaboratif, dan terintegrasi yang dirancang untuk bisnis.
Di Google Cloud, Anda memiliki dua pilihan utama untuk lingkungan notebook terkelola: Colab Enterprise dan Gemini Enterprise Agent Platform Workbench. Pilihan yang tepat bergantung pada prioritas proyek Anda.
Kapan harus menggunakan Workbench Platform Agen
Pilih Agent Platform Workbench jika prioritas Anda adalah kontrol dan penyesuaian mendalam. Opsi ini adalah pilihan ideal jika Anda perlu:
- Mengelola infrastruktur dan siklus proses mesin yang mendasarinya.
- Menggunakan konfigurasi jaringan dan container kustom.
- Terintegrasi dengan pipeline MLOps dan alat siklus proses kustom.
Kapan harus menggunakan Colab Enterprise
Pilih Colab Enterprise jika prioritas Anda adalah penyiapan cepat, kemudahan penggunaan, dan kolaborasi yang aman. Layanan ini adalah solusi terkelola sepenuhnya yang memungkinkan tim Anda berfokus pada analisis, bukan infrastruktur.
Colab Enterprise membantu Anda:
- Kembangkan alur kerja data science yang terkait erat dengan data warehouse Anda. Anda dapat membuka dan mengelola notebook secara langsung di BigQuery Studio.
- Latih model machine learning dan integrasikan dengan alat MLOps di Agent Platform.
- Nikmati pengalaman yang fleksibel dan terpadu. Notebook Colab Enterprise yang dibuat di BigQuery dapat dibuka dan dijalankan di Agent Platform, dan sebaliknya.
Lab hari ini
Codelab ini menggunakan Colab Enterprise untuk machine learning yang dipercepat.
Untuk mempelajari lebih lanjut perbedaannya, lihat dokumentasi resmi tentang memilih solusi notebook yang tepat.
5. Mengonfigurasi template runtime
Di Colab Enterprise, hubungkan ke runtime berdasarkan template runtime yang telah dikonfigurasi sebelumnya.
Template runtime adalah konfigurasi yang dapat digunakan kembali yang menentukan lingkungan untuk notebook Anda, termasuk:
- Jenis mesin (CPU, memori)
- Akselerator (jenis dan jumlah GPU)
- Ukuran dan jenis disk
- Setelan jaringan dan kebijakan keamanan
- Aturan penonaktifan otomatis saat tidak ada aktivitas
Alasan pentingnya template runtime
- Konsistensi: Anda dan tim Anda mendapatkan lingkungan yang sama untuk memastikan pekerjaan dapat diulang.
- Keamanan: Template menerapkan kebijakan keamanan organisasi.
- Pengelolaan biaya: Resource telah ditentukan ukurannya dalam template untuk membantu mencegah biaya yang tidak disengaja.
Membuat template runtime
Siapkan template runtime yang dapat digunakan kembali untuk lab.
- Di Konsol Google Cloud, buka Navigation Menu > Agent Platform > Notebooks.
- Dari Colab Enterprise, klik Runtime templates, lalu pilih New Template.
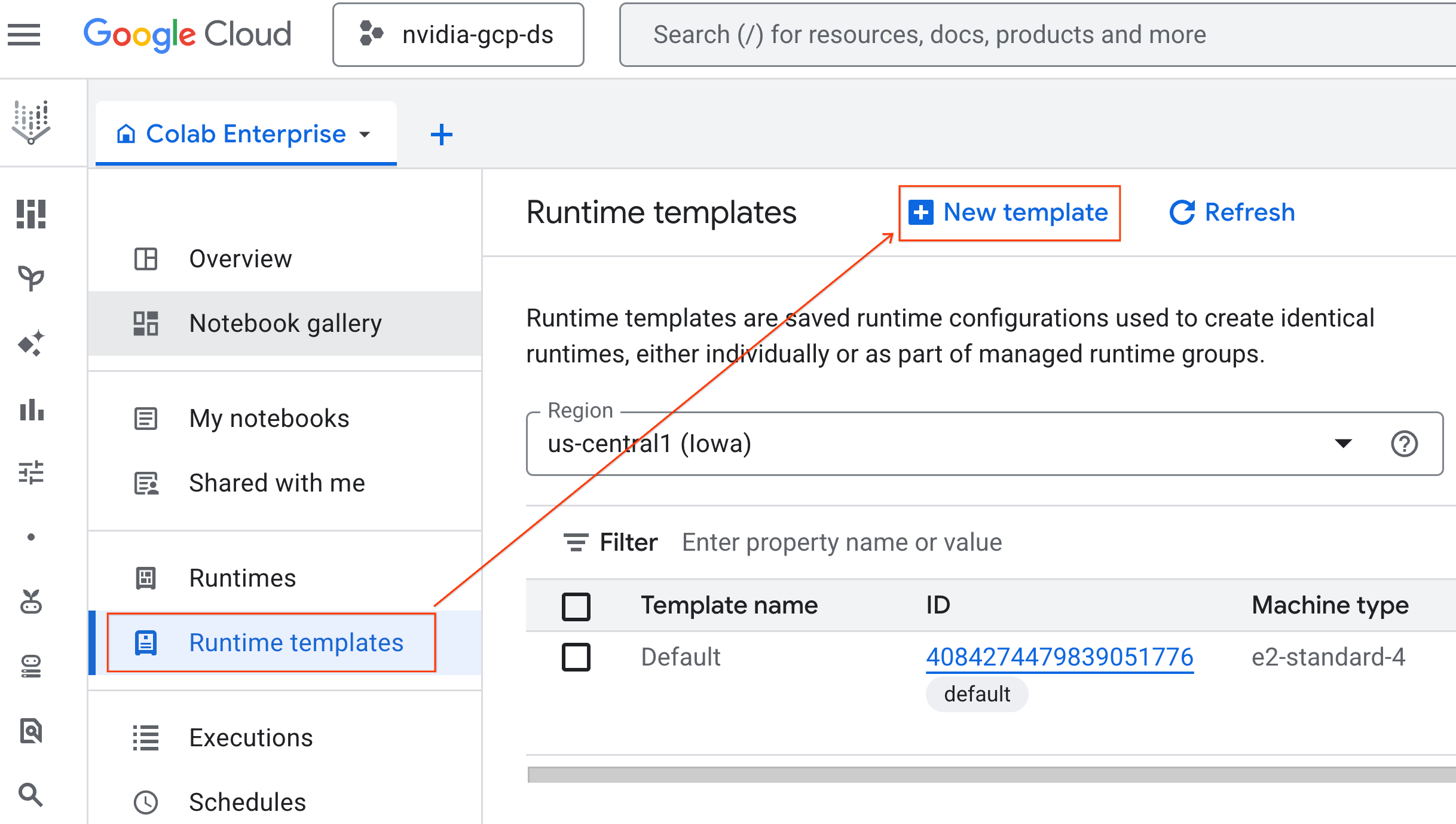
- Di bagian Dasar-dasar runtime:
- Tetapkan Display name sebagai
gpu-template. - Tetapkan Wilayah pilihan Anda.
- Tetapkan Display name sebagai
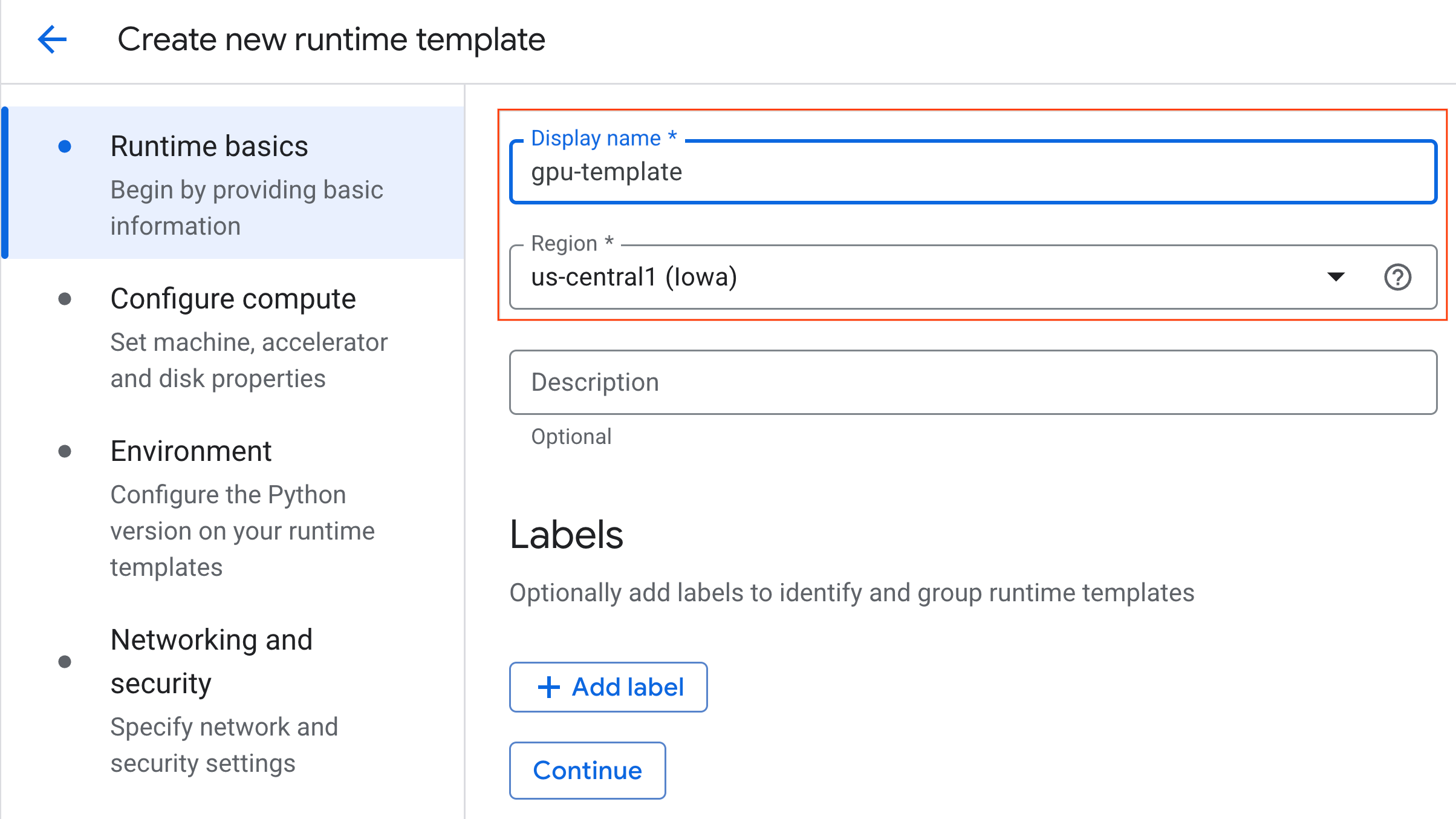
- Di bagian Konfigurasi komputasi:
- Tetapkan Jenis mesin ke
g2-standard-4. - Biarkan Jenis Akselerator default sebagai
NVIDIA L4dengan Jumlah akselerator 1. - Ubah Penonaktifan tidak ada aktivitas menjadi 60 menit.
- Klik Lanjutkan.
- Tetapkan Jenis mesin ke
- Di bagian Lingkungan:
- Tetapkan Environment ke
Python 3.11
- Tetapkan Environment ke
- Klik Buat untuk menyimpan template runtime. Halaman Template runtime Anda kini akan menampilkan template baru.
6. Mulai runtime
Setelah template siap, Anda dapat membuat runtime baru.
- Dari Colab Enterprise, klik Runtimes, lalu pilih Create.
- Di bagian Runtime template, pilih opsi
gpu-template. Klik Create dan tunggu hingga runtime di-boot.
- Setelah beberapa menit, Anda akan melihat runtime tersedia.
7. Menyiapkan notebook
Setelah infrastruktur Anda berjalan, Anda perlu mengimpor notebook lab dan menghubungkannya ke runtime Anda.
Mengimpor notebook
- Dari Colab Enterprise, klik Notebook saya, lalu klik Impor.
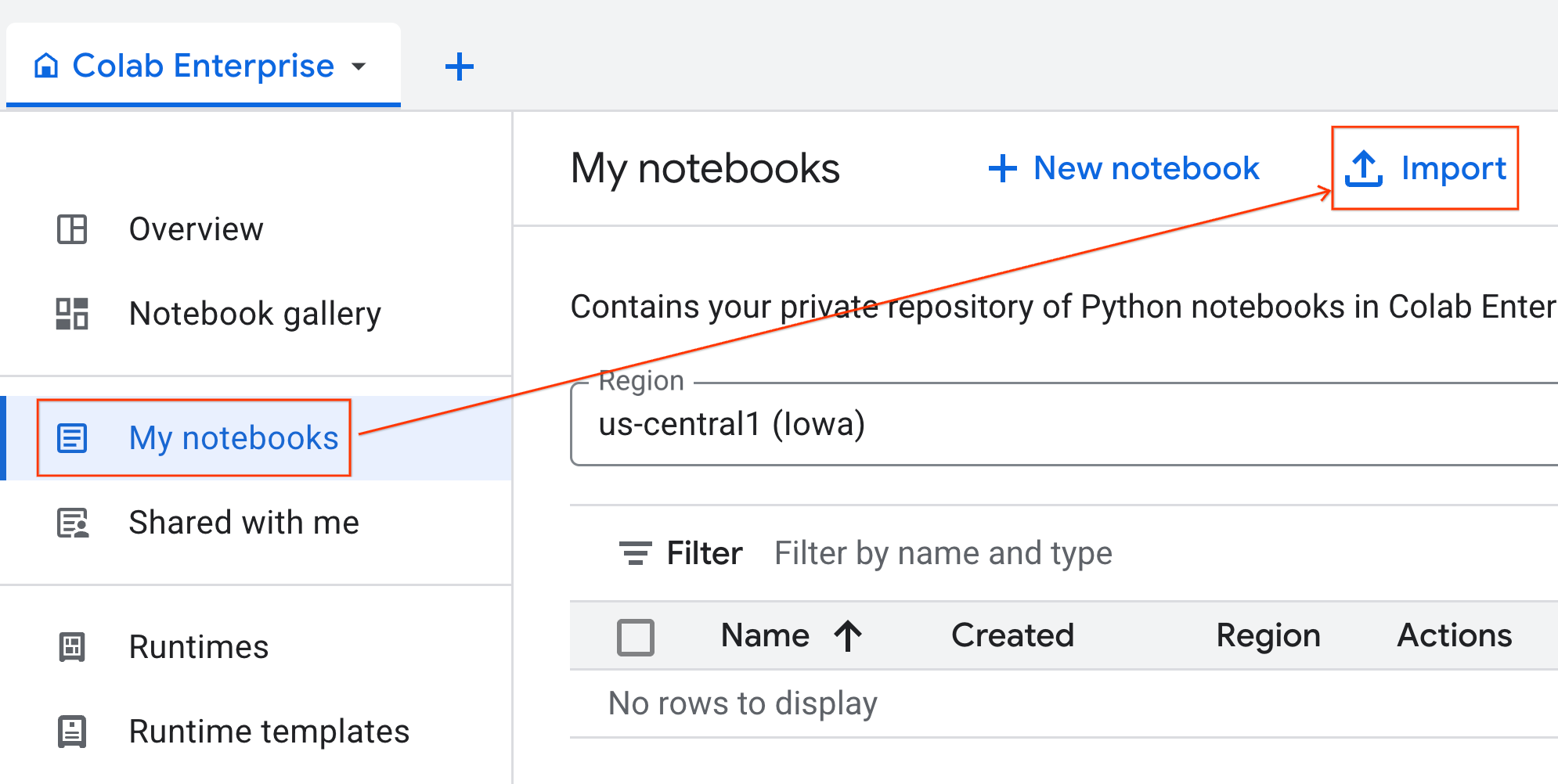
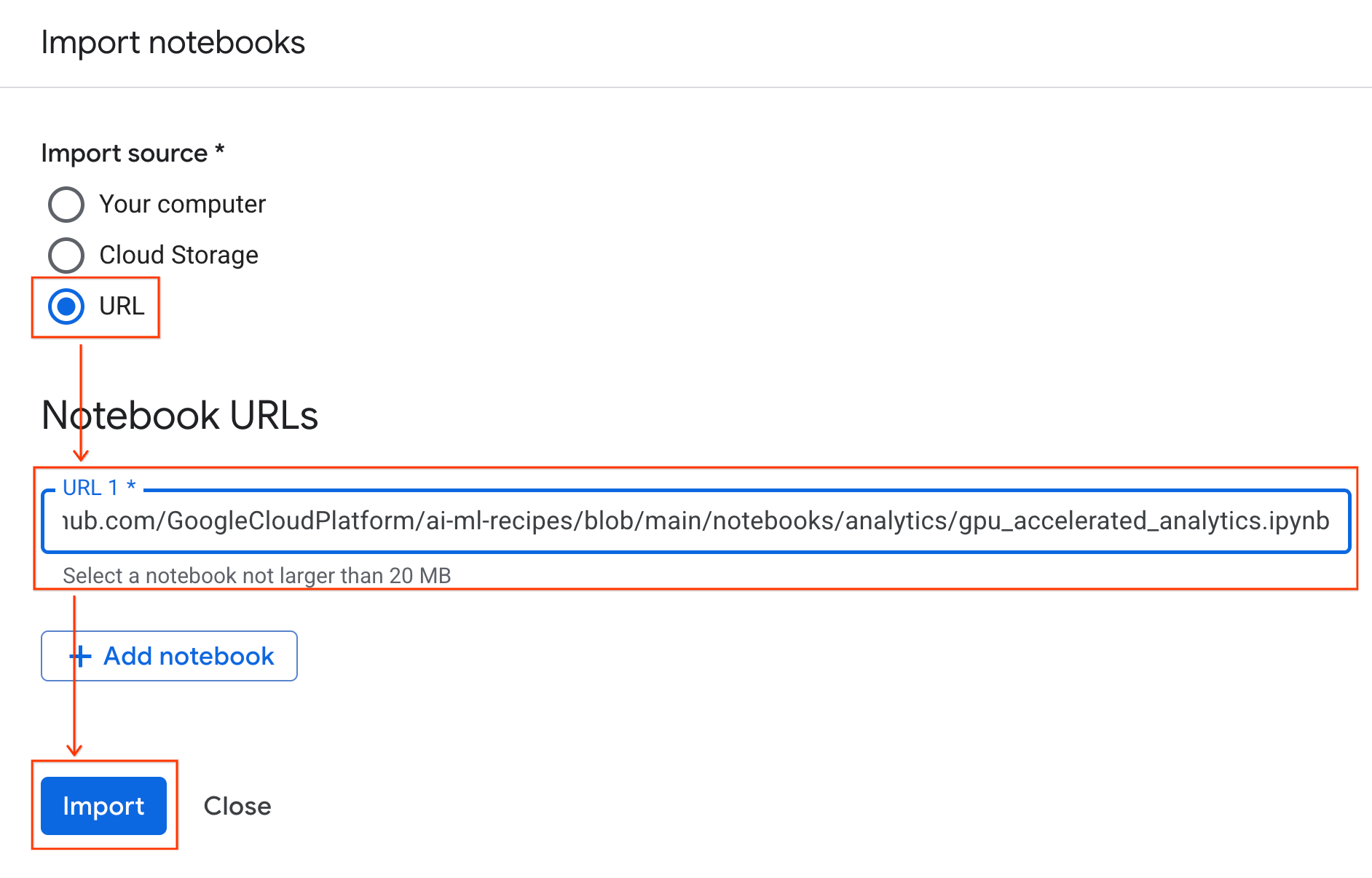
- Pilih tombol pilihan URL, lalu masukkan URL berikut:
https://github.com/GoogleCloudPlatform/ai-ml-recipes/blob/main/notebooks/regression/gpu_accelerated_regression/gpu_accelerated_regression.ipynb
- Klik Impor. Colab Enterprise akan menyalin notebook dari GitHub ke lingkungan Anda.
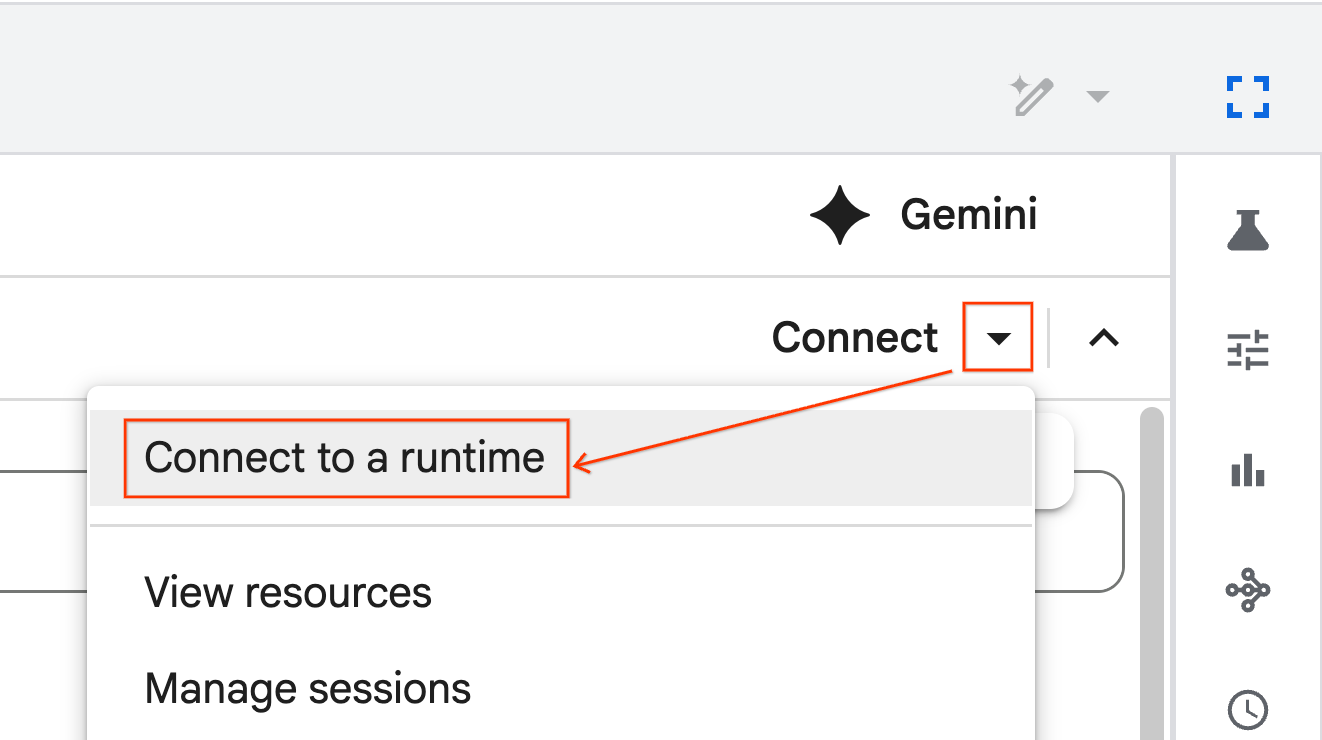
Menghubungkan notebook ke runtime
- Buka notebook yang baru diimpor.
- Klik panah drop-down di samping Connect.
- Pilih Connect to a runtime.
- Gunakan dropdown dan pilih runtime yang Anda buat sebelumnya.
- Klik Hubungkan.
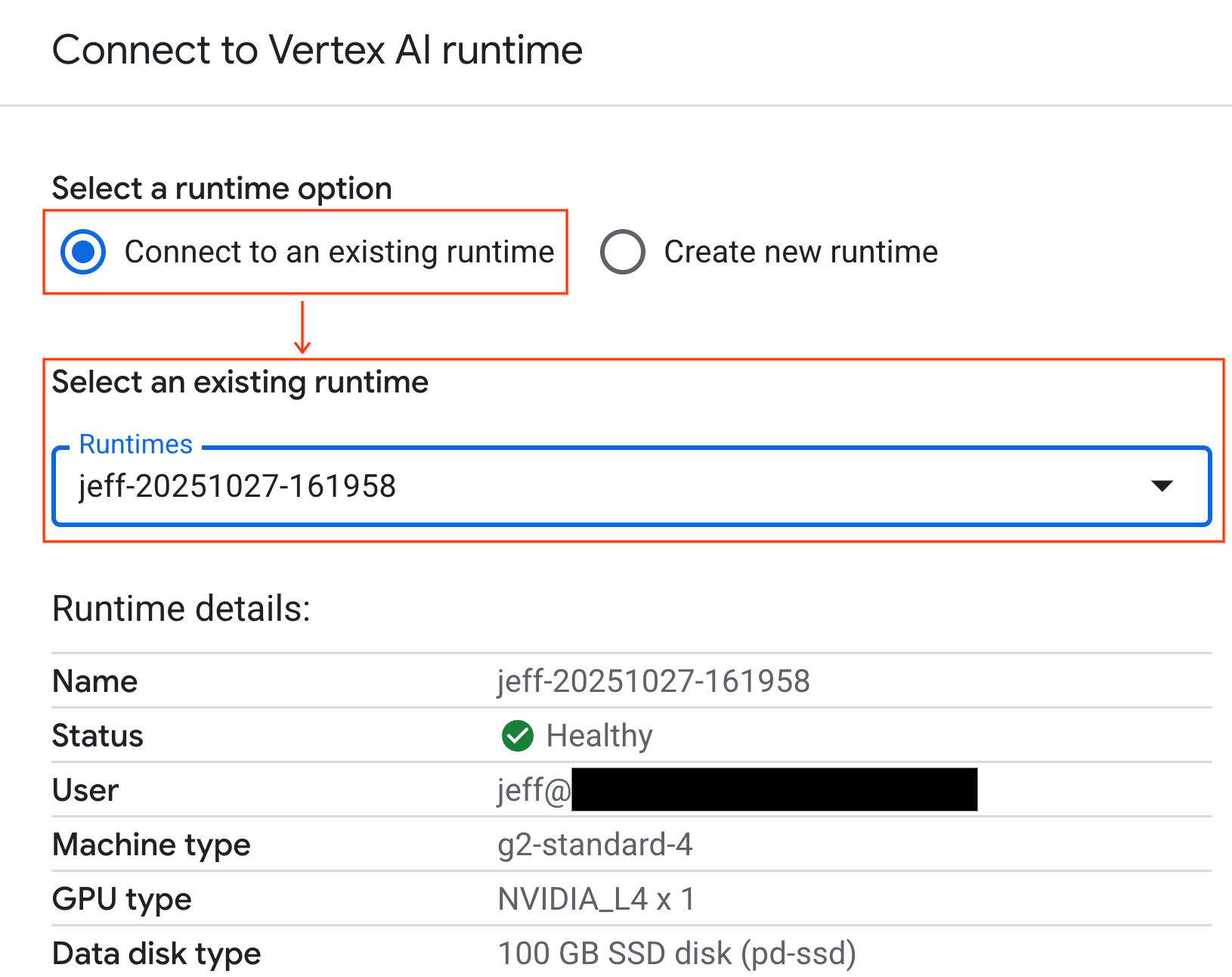
Notebook Anda kini terhubung ke runtime yang mendukung GPU.
Dependensi bawaan
Salah satu manfaat menggunakan Colab Enterprise adalah sudah diinstal sebelumnya dengan library yang Anda butuhkan. Anda tidak perlu menginstal atau mengelola dependensi seperti cuDF, cuML, atau XGBoost secara manual untuk lab ini.
8. Menyiapkan set data taksi NYC
Codelab ini menggunakan Data Catatan Perjalanan NYC Taxi & Limousine Commission (TLC). Set data ini berisi data perjalanan dari taksi kuning di New York City, termasuk:
- Tanggal, waktu, dan lokasi penjemputan dan pengantaran
- Jarak perjalanan
- Jumlah tarif yang dikelompokkan per item
- Jumlah penumpang
- Jumlah tips (ini yang akan kita prediksi!)
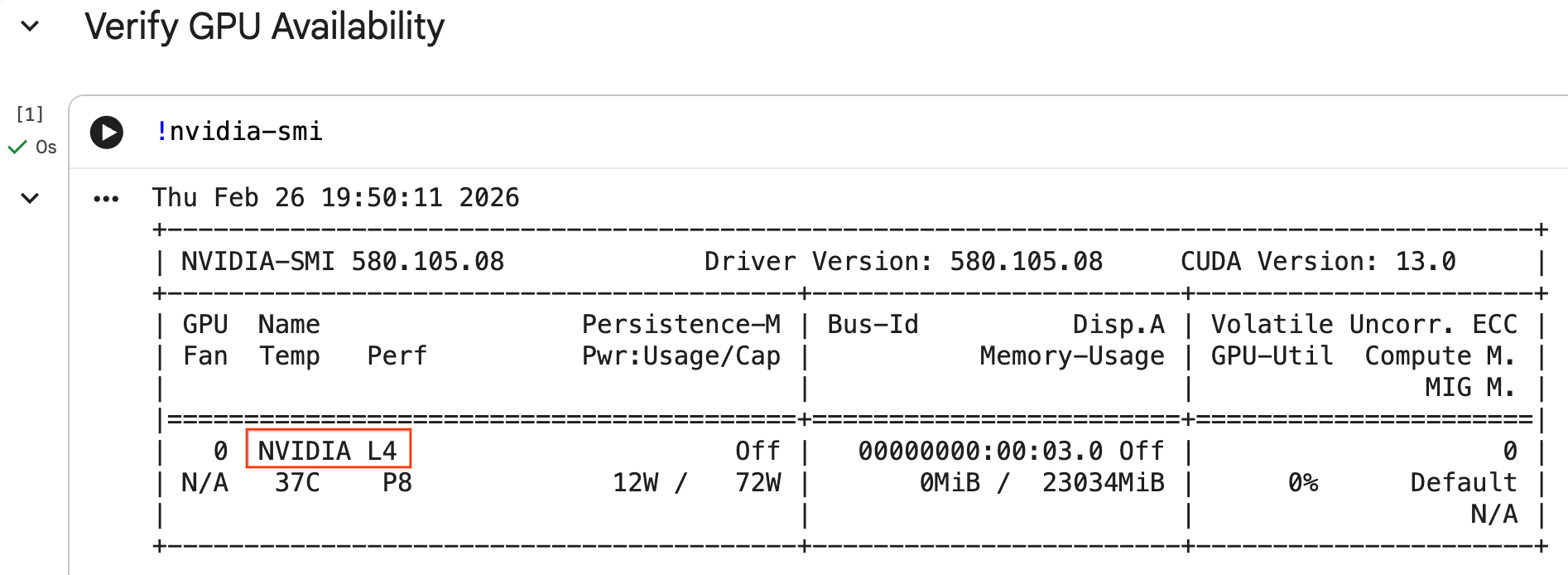
Mengonfigurasi GPU dan mengonfirmasi ketersediaan
Anda dapat mengonfirmasi bahwa GPU dikenali dengan menjalankan perintah nvidia-smi. Halaman ini menampilkan versi driver dan detail GPU (seperti NVIDIA L4).
nvidia-smi
Sel akan menampilkan GPU yang terpasang ke runtime Anda, mirip dengan berikut ini:
Mendownload data
Download data perjalanan untuk tahun 2024.
from tqdm import tqdm
import requests
import time
import os
YEAR = 2024
DATA_DIR = "nyc_taxi_data"
os.makedirs(DATA_DIR, exist_ok=True)
print(f"Checking/Downloading files for {YEAR}...")
for month in tqdm(range(1, 13), unit="file"):
file_name = f"yellow_tripdata_{YEAR}-{month:02d}.parquet"
local_path = os.path.join(DATA_DIR, file_name)
url = f"https://d37ci6vzurychx.cloudfront.net/trip-data/{file_name}"
if not os.path.exists(local_path):
try:
with requests.get(url, stream=True) as response:
response.raise_for_status()
with open(local_path, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
time.sleep(1)
except requests.exceptions.HTTPError as e:
print(f"\nSkipping {file_name}: {e}")
if os.path.exists(local_path):
os.remove(local_path)
print("\nDownload complete.")
Percepat pandas dengan cuDF NVIDIA
Library pandas berjalan di CPU dan dapat berjalan lambat dengan set data besar. Perintah ajaib %load_ext cudf.pandas NVIDIA secara dinamis mem-patch pandas untuk menggunakan akselerasi GPU, dan kembali ke CPU jika diperlukan.
Kita menggunakan perintah ajaib ini, bukan impor standar, karena perintah ini memberikan akselerasi 'tanpa perubahan kode'. Anda tidak perlu menulis ulang kode yang ada. Perintah serupa, %load_ext cuml.accel, melakukan hal yang sama persis untuk scikit-learn models. Hal ini berfungsi di lingkungan Jupyter mana pun dengan GPU NVIDIA yang kompatibel, bukan hanya Colab Enterprise.
%load_ext cudf.pandas
Untuk memverifikasi apakah sudah aktif, impor pandas dan periksa jenisnya:
import pandas as pd
pd
Output akan mengonfirmasi bahwa Anda sekarang menggunakan modul cudf.pandas.
Memuat dan membersihkan data
Dengan cudf.pandas aktif, muat file Parquet dan jalankan pembersihan data. Proses ini otomatis berjalan di GPU.
import glob
# Load data into memory
df = pd.concat(
[pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")],
ignore_index=True
)
# Filter for valid trips. We filter for payment_type=1 (credit card)
# because tip amounts are only reliably recorded for credit card transactions.
df = df[
(df['fare_amount'] > 0) & (df['fare_amount'] < 500) &
(df['trip_distance'] > 0) & (df['trip_distance'] < 100) &
(df['tip_amount'] >= 0) & (df['tip_amount'] < 100) &
(df['payment_type'] == 1)
].copy()
# Downcast numeric columns to save memory
float_cols = df.select_dtypes(include=['float64']).columns
df[float_cols] = df[float_cols].astype('float32')
int_cols = df.select_dtypes(include=['int64']).columns
df[int_cols] = df[int_cols].astype('int32')
Rekayasa Fitur
Buat fitur turunan dari tanggal dan waktu penjemputan. Notebook ini berisi fitur lain yang digunakan pada langkah-langkah selanjutnya.
import numpy as np
# Time Features
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['dow'] = df['tpep_pickup_datetime'].dt.dayofweek
df['is_weekend'] = (df['dow'] >= 5).astype(int)
df['is_rush_hour'] = (
((df['hour'] >= 7) & (df['hour'] <= 9)) |
((df['hour'] >= 17) & (df['hour'] <= 19))
).astype(int)
...
# Other features
...
9. Melatih Model Individual dengan Validasi Silang
Untuk menunjukkan cara GPU dapat mempercepat machine learning, Anda akan melatih tiga jenis model regresi yang berbeda untuk memprediksi tip_amount perjalanan taksi.
Percepat scikit-learn dengan cuML NVIDIA
Jalankan algoritma scikit-learn di GPU menggunakan cuML NVIDIA tanpa mengubah panggilan API. Pertama, muat ekstensi cuml.accel.
%load_ext cuml.accel
Menyiapkan fitur dan target
Identifikasi fitur yang ingin Anda pelajari dari model dan pisahkan kolom target (tip_amount).
feature_cols = [
'trip_distance', 'fare_amount', 'passenger_count',
'hour', 'dow', 'is_weekend', 'is_rush_hour',
'fare_log', 'fare_decimal', 'is_round_fare',
'route_frequency', 'pu_tip_mean', 'pu_tip_std',
'PULocationID', 'DOLocationID'
]
X = df[feature_cols].fillna(df[feature_cols].median())
y = df['tip_amount'].copy()
Siapkan pemisahan validasi silang untuk mengevaluasi performa model secara andal.
from sklearn.model_selection import KFold
import numpy as np
import time
from sklearn.metrics import mean_squared_error
from tqdm.notebook import tqdm
n_splits = 3
kf = KFold(n_splits=n_splits, shuffle=True, random_state=42)
1. XGBoost
XGBoost dipercepat secara native oleh GPU. Teruskan tree_method='hist' dan device='cuda' untuk menggunakan GPU selama pelatihan.
import xgboost as xgb
start_time = time.perf_counter()
def train_xgb_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# XGBoost handles GPU natively when tree_method='hist' and device='cuda'
model = xgb.XGBRegressor(
objective='reg:squarederror',
max_depth=5,
learning_rate=0.1,
n_estimators=100,
tree_method='hist',
device='cuda',
random_state=42
)
model.fit(X_train, y_train)
preds = model.predict(X_val)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
xgb_rmse, xgb_preds = train_xgb_cv(X, y)
print(f"\n{'XGBoost RMSE:':<20} ${xgb_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
2. Regresi Linear
Latih model regresi linear. Dengan %load_ext cuml.accel aktif, LinearRegression dipetakan ke GPU yang setara secara otomatis.
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
start_time = time.perf_counter()
def train_linreg_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# Scale features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_val_scaled = scaler.transform(X_val)
# Automatically accelerated by cuML
model = LinearRegression()
model.fit(X_train_scaled, y_train)
preds = model.predict(X_val_scaled)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
linreg_rmse, linreg_preds = train_linreg_cv(X, y)
print(f"\n{'Linear Reg RMSE:':<20} ${linreg_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
3. {i>Random Forest<i}
Latih model ansambel menggunakan RandomForestRegressor. Model berbasis pohon sering kali lambat untuk dilatih di CPU, tetapi akselerasi GPU memproses jutaan baris lebih cepat.
from sklearn.ensemble import RandomForestRegressor
start_time = time.perf_counter()
def train_rf_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# Automatically accelerated by cuML
model = RandomForestRegressor(
n_estimators=100,
max_depth=10,
n_jobs=-1,
max_features='sqrt',
random_state=42
)
model.fit(X_train, y_train)
preds = model.predict(X_val)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
rf_rmse, rf_preds = train_rf_cv(X, y)
print(f"\n{'Random Forest RMSE:':<20} ${rf_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
10. Mengevaluasi Pipeline End-to-End
Gabungkan prediksi dari ketiga model menggunakan ansambel linear sederhana. Biasanya memberikan peningkatan akurasi kecil dibandingkan model individual.
Sesuaikan regresi linear pada prediksi untuk menemukan bobot yang optimal:
ensemble_weights = LinearRegression(positive=True, fit_intercept=False).fit(
np.c_[xgb_preds, rf_preds, linreg_preds], y
).coef_
# Normalize weights
ensemble_weights = ensemble_weights / ensemble_weights.sum()
ensemble_preds = np.c_[xgb_preds, rf_preds, linreg_preds] @ ensemble_weights
ensemble_rmse = np.sqrt(mean_squared_error(y, ensemble_preds))
Bandingkan hasilnya untuk melihat peningkatan ansambel:
print(f"\n{'Model':<20} {'RMSE':>10}")
print("-" * 32)
print(f"{'Linear Regression':<20} ${linreg_rmse:>9.4f}")
print(f"{'Random Forest':<20} ${rf_rmse:>9.4f}")
print(f"{'XGBoost':<20} ${xgb_rmse:>9.4f}")
print("-" * 32)
print(f"{'Ensemble':<20} ${ensemble_rmse:>9.4f}")
print(f"\nEnsemble lift: ${xgb_rmse - ensemble_rmse:.4f}")
11. Membandingkan performa CPU vs. GPU
Untuk mengukur perbedaan performa dengan benar, Anda akan memulai ulang kernel untuk memastikan status eksekusi yang bersih, menjalankan seluruh pipeline ilmu data di CPU, lalu menjalankannya lagi di GPU.
Mulai ulang kernel
Jalankan perintah IPython.Application.instance().kernel.do_shutdown(True) untuk memulai ulang kernel dan melepaskan memori.
import IPython
IPython.Application.instance().kernel.do_shutdown(True)
Menentukan pipeline ilmu data
Gabungkan alur kerja inti (memuat data, pembersihan, rekayasa fitur, dan pelatihan model) ke dalam satu fungsi. Fungsi ini menerima pd_module modul pandas dan argumen use_gpu untuk beralih antar-lingkungan.
def run_ml_pipeline(pd_module, use_gpu=False):
import time
import glob
import numpy as np
from sklearn.ensemble import RandomForestRegressor
import xgboost as xgb
timings = {}
# 1. Load Data
t0 = time.perf_counter()
df = pd_module.concat(
[pd_module.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")],
ignore_index=True
)
timings['Load Data'] = time.perf_counter() - t0
# 2. Clean Data
t0 = time.perf_counter()
# Filter for payment_type=1 (credit card) because tip amounts
# are only reliably recorded for credit card transactions.
df = df[
(df['fare_amount'] > 0) & (df['fare_amount'] < 500) &
(df['trip_distance'] > 0) & (df['trip_distance'] < 100) &
(df['tip_amount'] >= 0) & (df['tip_amount'] < 100) &
(df['payment_type'] == 1)
].copy()
# Downcast numeric columns to save memory
float_cols = df.select_dtypes(include=['float64']).columns
df[float_cols] = df[float_cols].astype('float32')
int_cols = df.select_dtypes(include=['int64']).columns
df[int_cols] = df[int_cols].astype('int32')
timings['Clean Data'] = time.perf_counter() - t0
# 3. Feature Engineering
t0 = time.perf_counter()
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['dow'] = df['tpep_pickup_datetime'].dt.dayofweek
df['is_weekend'] = (df['dow'] >= 5).astype(int)
df['fare_log'] = np.log1p(df['fare_amount'])
timings['Feature Engineering'] = time.perf_counter() - t0
# 4. Modeling Prep
feature_cols = ['trip_distance', 'fare_amount', 'passenger_count', 'hour', 'dow', 'is_weekend', 'fare_log']
X = df[feature_cols].fillna(df[feature_cols].median())
y = df['tip_amount'].copy()
# Free memory
del df
import gc
gc.collect()
# 5. Train Random Forest
t0 = time.perf_counter()
rf_model = RandomForestRegressor(
n_estimators=100,
max_depth=10,
n_jobs=-1,
max_features='sqrt',
random_state=42
).fit(X, y)
timings['Train Random Forest'] = time.perf_counter() - t0
# 6. Train XGBoost
t0 = time.perf_counter()
params = {
'objective': 'reg:squarederror',
'max_depth': 5,
'n_estimators': 100,
'random_state': 42
}
if use_gpu:
params['device'] = 'cuda'
params['tree_method'] = 'hist'
xgb_model = xgb.XGBRegressor(**params).fit(X, y)
timings['Train XGBoost'] = time.perf_counter() - t0
del X
del y
gc.collect()
return timings
Menjalankan di CPU Anda
Panggil pipeline menggunakan pandas CPU standar.
import pandas as pd
print("Running pipeline on CPU...")
cpu_times = run_ml_pipeline(pd, use_gpu=False)
print("CPU Execution Finished.")
Menjalankan di GPU Anda
Muat ekstensi library NVIDIA, teruskan modul cudf.pandas yang dipercepat ke pipeline, dan tetapkan perangkat XGBoost Anda ke cuda secara internal.
import IPython.core.magic
if not hasattr(IPython.core.magic, 'output_can_be_silenced'):
IPython.core.magic.output_can_be_silenced = lambda x: x
%load_ext cudf.pandas
%load_ext cuml.accel
import pandas as pd
print("Running pipeline on GPU...")
gpu_times = run_ml_pipeline(pd, use_gpu=True)
print("GPU Execution Finished.")
Memvisualisasikan peningkatan kecepatan performa
Visualisasikan waktu menggunakan matplotlib. Hasilnya menunjukkan waktu yang dihemat selama pemrosesan data dan pelatihan model saat menggunakan GPU.
import matplotlib.pyplot as plt
import numpy as np
labels = list(cpu_times.keys())
cpu_values = list(cpu_times.values())
gpu_values = list(gpu_times.values())
x = np.arange(len(labels))
width = 0.35
fig, ax = plt.subplots(figsize=(10, 6))
rects1 = ax.bar(x - width/2, cpu_values, width, label='CPU', color='#4285F4')
rects2 = ax.bar(x + width/2, gpu_values, width, label='GPU', color='#76B900')
ax.set_ylabel('Execution Time (seconds)')
ax.set_title('NYC Taxi ML Pipeline: CPU vs. GPU Performance')
ax.set_xticks(x)
ax.set_xticklabels(labels, rotation=45, ha="right")
ax.legend()
# Add data labels
def autolabel(rects):
for rect in rects:
height = rect.get_height()
ax.annotate(f'{height:.2f}s',
xy=(rect.get_x() + rect.get_width() / 2, height),
xytext=(0, 3), # 3 points vertical offset
textcoords="offset points",
ha='center', va='bottom', fontsize=9)
autolabel(rects1)
autolabel(rects2)
plt.tight_layout()
plt.show()
# Calculate overall speedup
total_cpu_time = sum(cpu_values)
total_gpu_time = sum(gpu_values)
overall_speedup = total_cpu_time / total_gpu_time
print(f"\nOverall Pipeline Speedup: {overall_speedup:.2f}x faster on GPU!")
Anda akan melihat yang seperti:
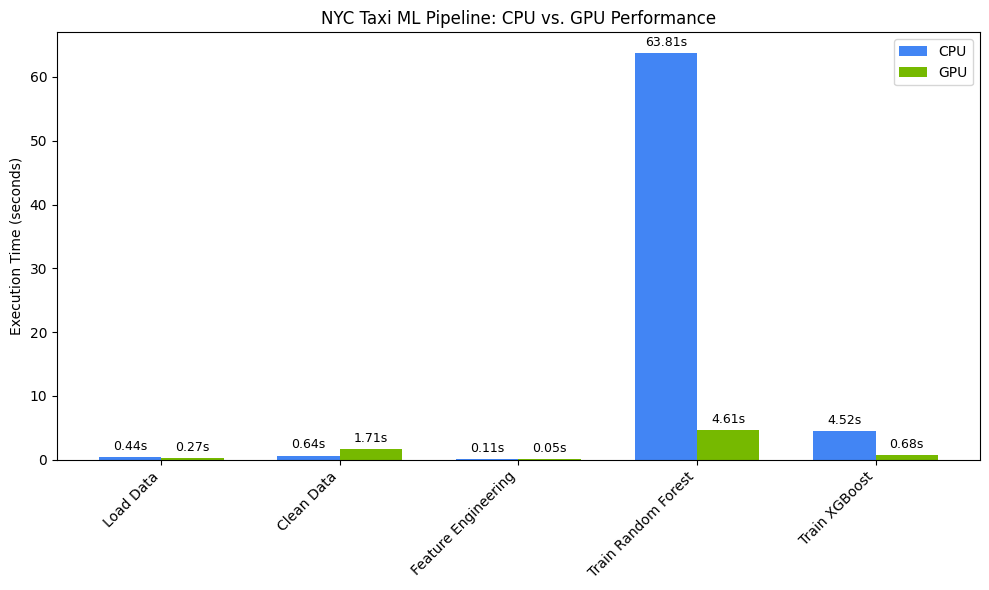
Diagram ini menggambarkan keunggulan performa GPU yang signifikan di seluruh alur kerja ilmu data. Anda akan melihat penghematan waktu yang paling signifikan selama fase pelatihan model yang intensif secara komputasi untuk algoritma seperti Random Forest dan XGBoost.
12. Membuat profil kode untuk menemukan batasan performa
Saat menggunakan cudf.pandas, sebagian besar fungsi berjalan di GPU. Jika operasi tertentu belum didukung oleh cuDF, eksekusi akan beralih kembali ke CPU untuk sementara. NVIDIA menyediakan dua perintah magic Jupyter bawaan untuk mengidentifikasi penggantian ini.
Pembuatan profil tingkat tinggi dengan %%cudf.pandas.profile
Perintah ajaib %%cudf.pandas.profile memberikan ringkasan fungsi mana yang berjalan di GPU atau CPU.
%%cudf.pandas.profile
import glob
import pandas as pd
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")], ignore_index=True)
summary = (
df
.groupby(['PULocationID', 'payment_type'])
[['passenger_count', 'fare_amount', 'tip_amount']]
.agg(['min', 'mean', 'max'])
)
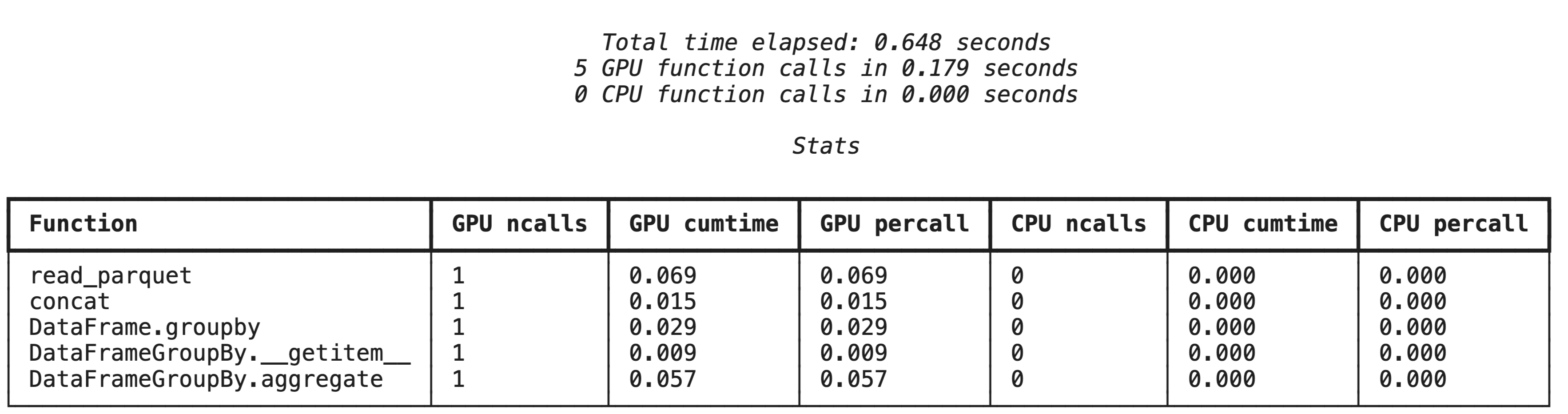
Pembuatan profil baris demi baris dengan %%cudf.pandas.line_profile
Untuk pemecahan masalah terperinci, %%cudf.pandas.line_profile menganotasi setiap baris kode dengan jumlah eksekusi di GPU versus CPU.
%%cudf.pandas.line_profile
import glob
import pandas as pd
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")], ignore_index=True)
df = df.sample(1_000)
# Iterating row-by-row or using custom python apply functions often falls back to the CPU
def categorize_hour(hour):
if hour < 12:
return 'Morning'
else:
return 'Afternoon/Evening'
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['time_of_day_slow'] = df['hour'].apply(categorize_hour)
# Using vectorized pandas operations (like pd.cut) stays entirely on the GPU
cut_bins = [-1, 11, 24]
cut_labels = ['Morning', 'Afternoon/Evening']
df['time_of_day_fast'] = pd.cut(df['hour'], bins=cut_bins, labels=cut_labels)
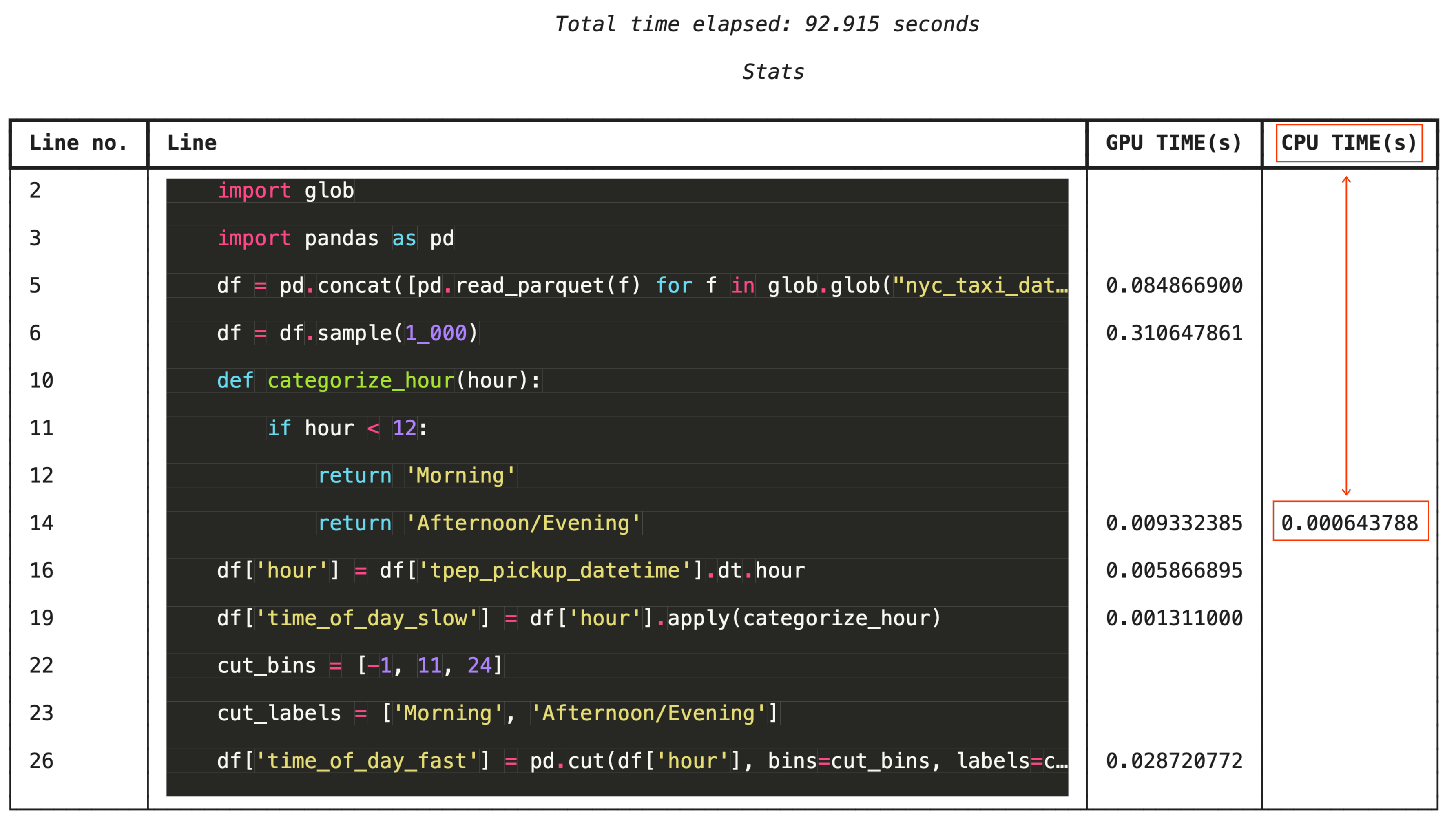
13. Pembersihan
Untuk menghindari timbulnya biaya yang tidak terduga di akun Google Cloud Anda, bersihkan resource yang Anda buat selama codelab ini.
Menghapus resource
Hapus set data lokal di runtime menggunakan perintah !rm -rf di sel notebook.
print("Deleting local 'nyc_taxi_data' directory...")
!rm -rf nyc_taxi_data
print("Local files deleted.")
Menutup runtime Colab
- Di konsol Google Cloud, buka halaman Runtimes Colab Enterprise.
- Di menu Region, pilih region yang berisi runtime Anda.
- Pilih runtime yang ingin Anda hapus.
- Klik Hapus.
- Klik Konfirmasi.
Menghapus Notebook Anda
- Di konsol Google Cloud, buka halaman Notebook Saya Colab Enterprise.
- Di menu Region, pilih region yang berisi notebook Anda.
- Pilih notebook yang ingin Anda hapus.
- Klik Hapus.
- Klik Konfirmasi.
14. Selamat
Selamat! Anda telah berhasil mempercepat alur kerja machine learning pandas dan scikit-learn menggunakan library cuDF dan cuML NVIDIA di Colab Enterprise. Hanya dengan menambahkan beberapa perintah ajaib (%load_ext cudf.pandas dan %load_ext cuml.accel), kode standar Anda akan berjalan di GPU, memproses data dan menyesuaikan model yang kompleks secara lokal dalam waktu yang lebih singkat.
Untuk mengetahui informasi selengkapnya tentang akselerasi GPU untuk analisis data, lihat codelab Accelerated Data Analytics with GPUs.
Yang telah kita bahas
- Memahami Colab Enterprise di Google Cloud.
- Menyesuaikan lingkungan runtime Colab dengan konfigurasi GPU dan memori tertentu.
- Menerapkan akselerasi GPU untuk memprediksi jumlah tip menggunakan jutaan data dari set data NYC Taxi.
- Mempercepat
pandastanpa perubahan kode menggunakan librarycuDFNVIDIA. - Mempercepat
scikit-learntanpa perubahan kode menggunakan librarycuMLdan GPU NVIDIA. - Membuat profil kode untuk mengidentifikasi dan mengoptimalkan batasan performa.