
1. 소개
이 Codelab에서는 Google Cloud에서 NVIDIA GPU와 오픈소스 라이브러리를 사용하여 대규모 데이터 세트에서 데이터 과학 및 머신러닝 워크플로를 가속화하는 방법을 알아봅니다. 먼저 인프라를 설정한 다음 GPU 가속을 적용하는 방법을 살펴봅니다.
pandas를 사용한 데이터 준비부터 scikit-learn 및 XGBoost를 사용한 모델 학습에 이르기까지 데이터 과학 수명 주기에 중점을 둡니다. NVIDIA의 cuDF 및 cuML 라이브러리를 사용하여 이러한 작업을 가속화하는 방법을 알아봅니다. 가장 좋은 점은 기존 pandas 또는 scikit-learn 코드를 변경하지 않고도 이 GPU 가속을 사용할 수 있다는 것입니다.
학습할 내용
- Google Cloud의 Colab Enterprise를 이해합니다.
- 특정 GPU 및 메모리 구성으로 Colab 런타임 환경을 맞춤설정합니다.
- GPU 가속을 적용하여 NYC 택시 데이터 세트의 수백만 개의 레코드를 사용하여 팁 금액을 예측합니다.
- NVIDIA의
cuDF라이브러리를 사용하여 코드 변경 없이pandas를 가속화하세요. - NVIDIA의
cuML라이브러리 및 GPU를 사용하여 코드 변경 없이scikit-learn를 가속화하세요. - 코드를 프로파일링하여 성능 제약 조건을 식별하고 최적화합니다.
다음 페이지에는 실습을 완료하는 데 사용할 수 있는 크레딧이 포함되어 있습니다.
2. 머신러닝을 가속화해야 하는 이유
ML에서 더 빠른 반복의 필요성
데이터 준비는 시간이 많이 걸리며 데이터 세트가 커지면 모델 학습 또는 평가에 더 많은 시간이 걸릴 수 있습니다. CPU를 사용하여 수백만 개의 행에 대해 랜덤 포레스트 또는 XGBoost와 같은 모델을 학습하는 데 몇 시간 또는 며칠이 걸릴 수 있습니다.
GPU를 사용하면 cuML 및 GPU 가속 XGBoost과 같은 라이브러리를 사용하여 이러한 학습 실행을 가속화할 수 있습니다. 이 가속화를 통해 다음 작업을 할 수 있습니다.
- 더 빠른 반복: 새로운 기능과 초매개변수를 빠르게 테스트합니다.
- 전체 데이터 세트로 학습: 정확도를 높이려면 다운샘플링 대신 전체 데이터를 사용하세요.
- 비용 절감: 짧은 시간 내에 대규모 워크로드를 완료하여 컴퓨팅 비용을 절감합니다.
3. 설정 및 요건
예상 비용
이 Codelab에서는 NVIDIA L4 GPU가 포함된 Colab Enterprise 런타임을 비롯한 Google Cloud 리소스를 사용합니다. 잠재적인 요금을 고려하고 Codelab 끝부분의 삭제 섹션에 따라 리소스를 종료하여 지속적인 요금이 청구되지 않도록 하세요. 자세한 가격 정보는 Colab Enterprise 가격 책정 및 GPU 가격 책정을 참고하세요.
시작하기 전에
Python, pandas, scikit-learn, 표준 머신러닝 관행 (교차 검증/앙상블 등)에 대한 중급 수준의 숙련도가 있다고 가정합니다.
- Google Cloud Console의 프로젝트 선택기 페이지에서 Google Cloud 프로젝트를 선택하거나 만듭니다.
- Google Cloud 프로젝트에 결제가 사용 설정되어 있는지 확인합니다.
API 사용 설정
Colab Enterprise를 사용하려면 먼저 필요한 API를 사용 설정해야 합니다.
- Google Cloud 콘솔의 오른쪽 상단에 있는 Cloud Shell 아이콘을 클릭하여 Google Cloud Shell을 엽니다.

- Cloud Shell에서
PROJECT_ID를 프로젝트 ID로 바꿔 프로젝트 ID를 설정합니다.
gcloud config set project <PROJECT_ID>
- 다음 명령어를 실행하여 필요한 API를 사용 설정합니다.
gcloud services enable \
compute.googleapis.com \
dataform.googleapis.com \
notebooks.googleapis.com \
aiplatform.googleapis.com
성공적으로 실행되면 아래와 비슷한 메시지가 표시됩니다.
Operation "operations/..." finished successfully.
4. 노트북 환경 선택
많은 데이터 과학자가 개인 프로젝트에 Colab을 잘 알고 있지만 Colab Enterprise는 비즈니스용으로 설계된 안전하고 협업적이며 통합된 노트북 환경을 제공합니다.
Google Cloud에는 Colab Enterprise와 Gemini Enterprise Agent Platform Workbench라는 두 가지 기본 관리형 노트북 환경이 있습니다. 적절한 선택은 프로젝트의 우선순위에 따라 달라집니다.
Agent Platform Workbench를 사용해야 하는 경우
제어 및 심층 맞춤설정이 우선인 경우 Agent Platform Workbench를 선택하세요. 다음과 같은 경우에 적합합니다.
- 기본 인프라 및 머신 수명 주기 관리
- 커스텀 컨테이너 및 네트워크 구성을 사용합니다.
- MLOps 파이프라인 및 맞춤 수명 주기 도구와 통합
Colab Enterprise를 사용해야 하는 경우
빠른 설정, 사용 편의성, 안전한 공동작업이 우선이라면 Colab Enterprise를 선택하세요. 팀이 인프라 대신 분석에 집중할 수 있는 완전 관리형 솔루션입니다.
Colab Enterprise를 사용하면 다음과 같은 이점이 있습니다.
- 데이터 웨어하우스와 밀접하게 연결된 데이터 과학 워크플로를 개발합니다. BigQuery Studio에서 직접 노트북을 열고 관리할 수 있습니다.
- Agent Platform에서 머신러닝 모델을 학습시키고 MLOps 도구와 통합합니다.
- 유연하고 통합된 환경을 즐기세요. BigQuery에서 만든 Colab Enterprise 노트북은 Agent Platform에서 열고 실행할 수 있으며 그 반대도 가능합니다.
오늘의 실습
이 Codelab에서는 머신러닝을 가속화하기 위해 Colab Enterprise를 사용합니다.
차이점에 대해 자세히 알아보려면 올바른 노트북 솔루션 선택에 관한 공식 문서를 참고하세요.
5. 런타임 템플릿 구성
Colab Enterprise에서 사전 구성된 런타임 템플릿을 기반으로 런타임에 연결합니다.
런타임 템플릿은 다음을 비롯한 노트북의 환경을 지정하는 재사용 가능한 구성입니다.
- 머신 유형 (CPU, 메모리)
- 가속기 (GPU 유형 및 수량)
- 디스크 크기 및 유형
- 네트워크 설정 및 보안 정책
- 유휴 상태 자동 종료 규칙
런타임 템플릿이 유용한 이유
- 일관성: 팀원 모두가 동일한 환경에서 작업하여 작업의 반복성을 보장합니다.
- 보안: 템플릿은 조직 보안 정책을 적용합니다.
- 비용 관리: 템플릿에서 리소스의 크기가 미리 조정되어 실수로 비용이 발생하지 않도록 합니다.
런타임 템플릿 만들기
실습을 위한 재사용 가능한 런타임 템플릿을 설정합니다.
- Google Cloud 콘솔에서 탐색 메뉴 > Agent Platform > Notebooks로 이동합니다.
- Colab Enterprise에서 런타임 템플릿을 클릭한 다음 새 템플릿을 선택합니다.
- 런타임 기본사항에서 다음을 수행합니다.
- 표시 이름을
gpu-template로 설정합니다. - 원하는 리전을 설정합니다.
- 표시 이름을
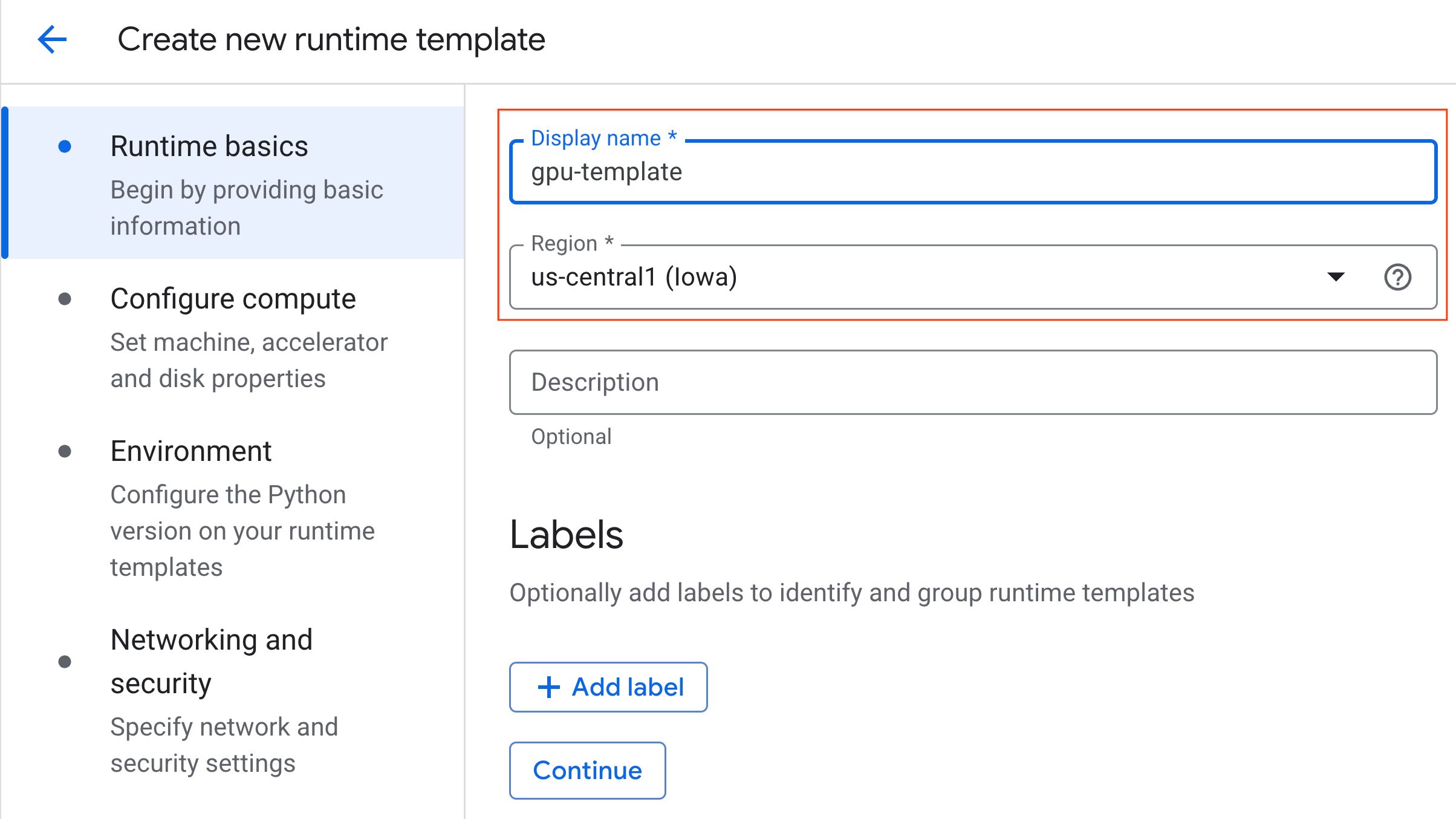
- 컴퓨팅 구성에서 다음을 수행합니다.
- 머신 유형을
g2-standard-4로 설정합니다. - 기본 가속기 유형을
NVIDIA L4로 유지하고 가속기 수를 1로 설정합니다. - 유휴 상태 종료를 60분으로 변경합니다.
- 계속을 클릭합니다.
- 머신 유형을
- 환경에서 다음을 수행합니다.
- 환경을
Python 3.11로 설정합니다.
- 환경을
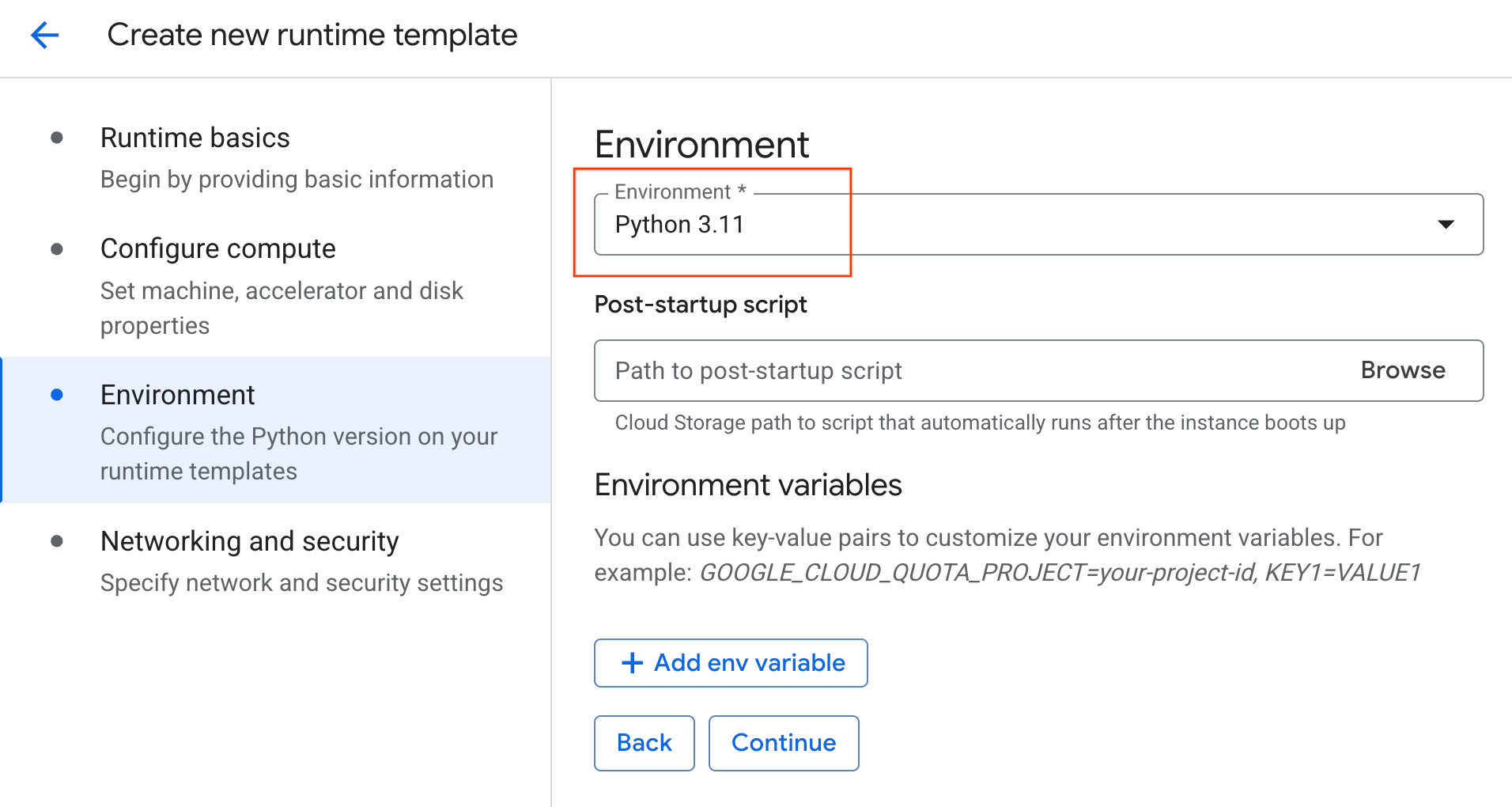
- 만들기를 클릭하여 런타임 템플릿을 저장합니다. 이제 런타임 템플릿 페이지에 새 템플릿이 표시됩니다.
6. 런타임 시작
템플릿이 준비되면 새 런타임을 만들 수 있습니다.
- Colab Enterprise에서 런타임을 클릭한 다음 만들기를 선택합니다.
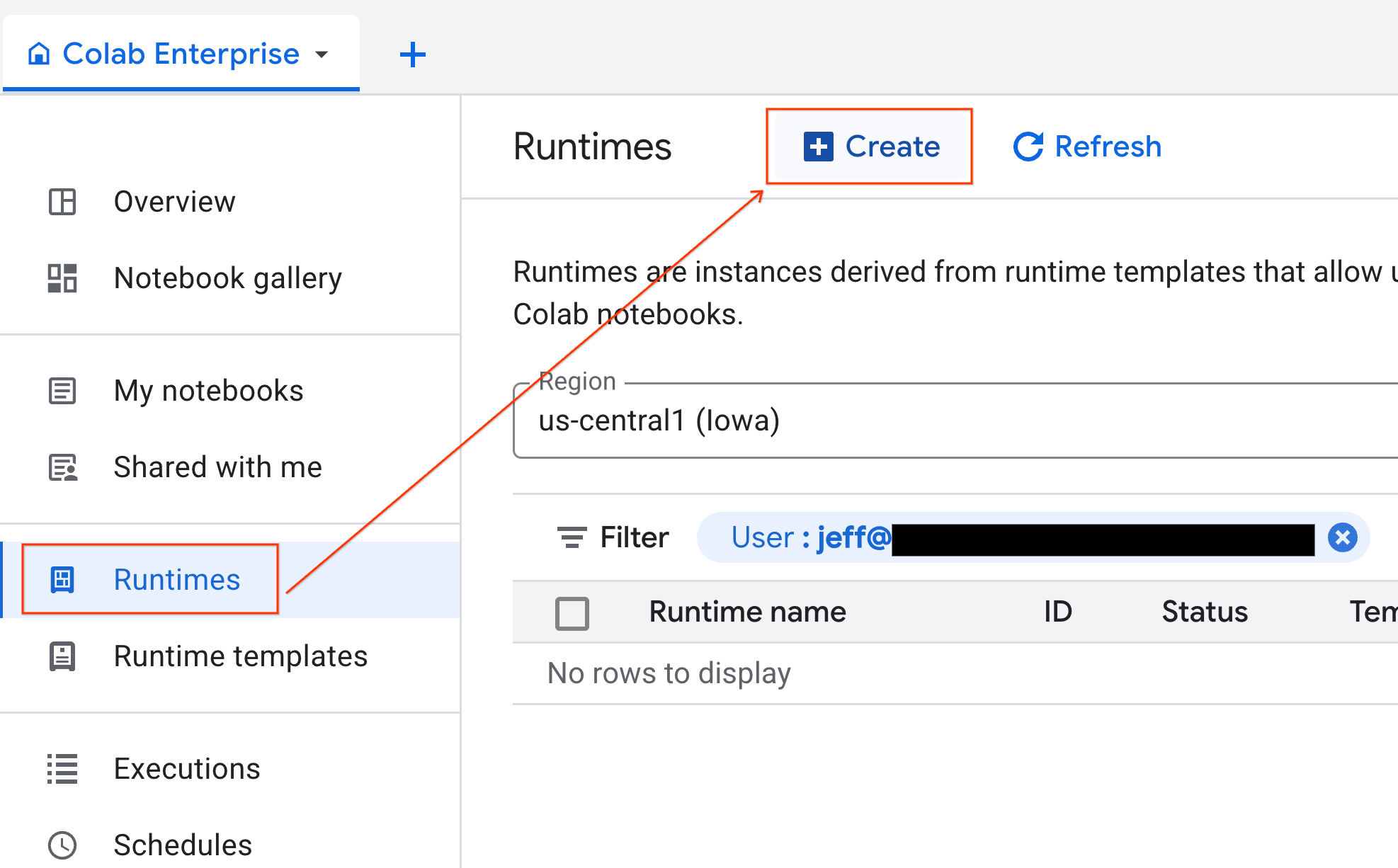
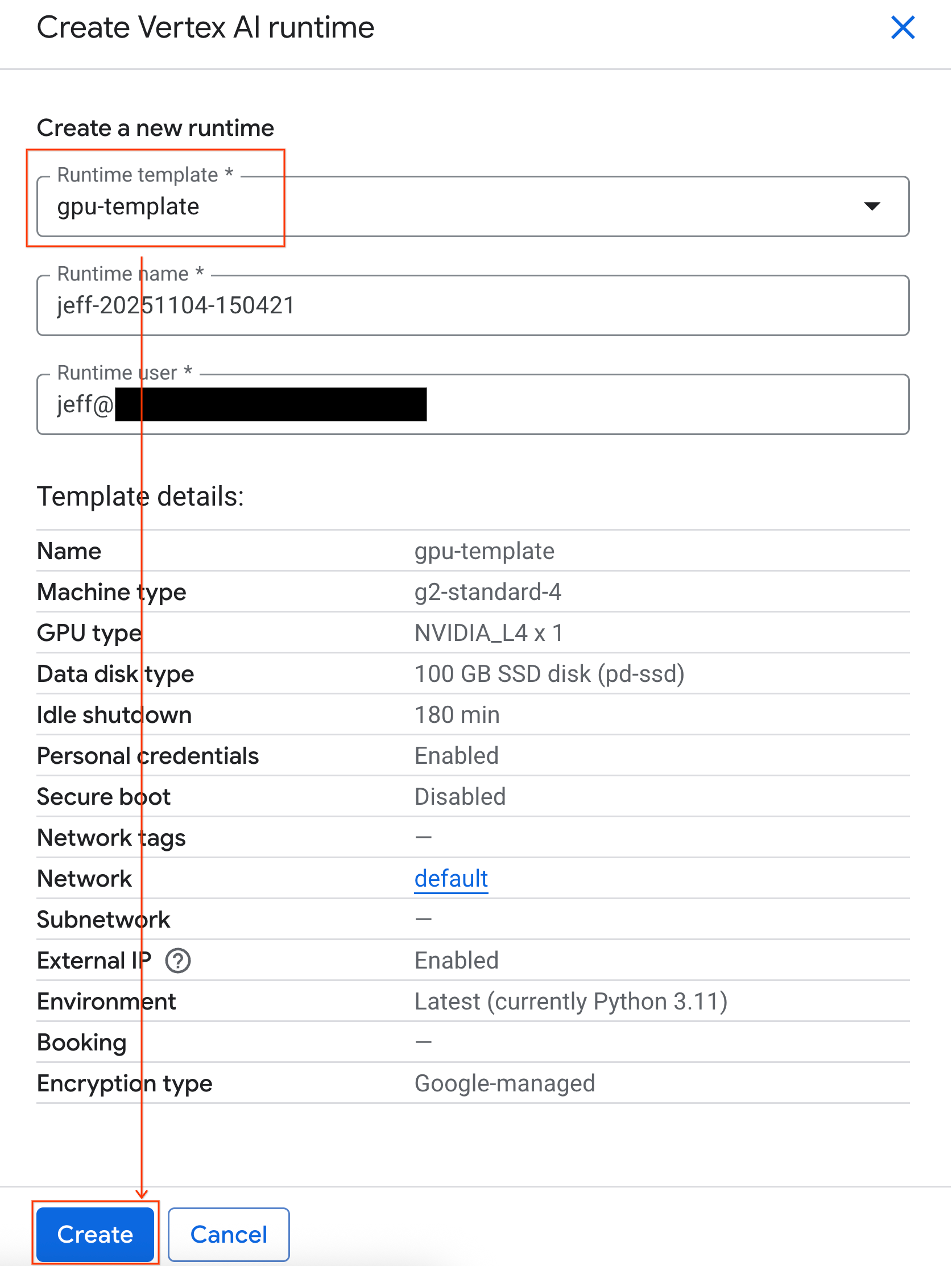
- 런타임 템플릿에서
gpu-template옵션을 선택합니다. 만들기를 클릭하고 런타임이 부팅될 때까지 기다립니다.
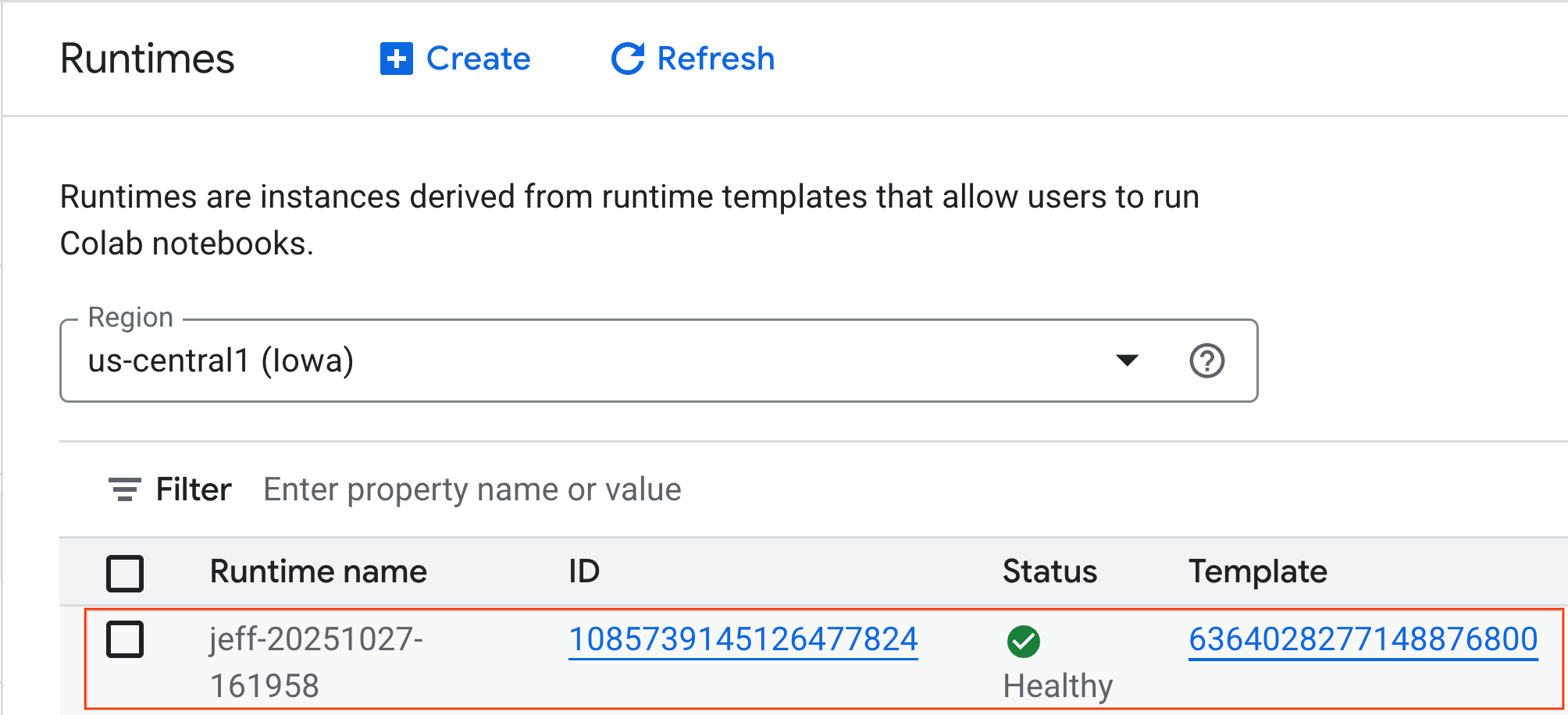
- 몇 분 후 런타임이 사용 가능해집니다.
7. 노트북 설정하기
이제 인프라가 실행 중이므로 실습 노트북을 가져와 런타임에 연결해야 합니다.
노트북 가져오기
- Colab Enterprise에서 내 노트북을 클릭한 다음 가져오기를 클릭합니다.
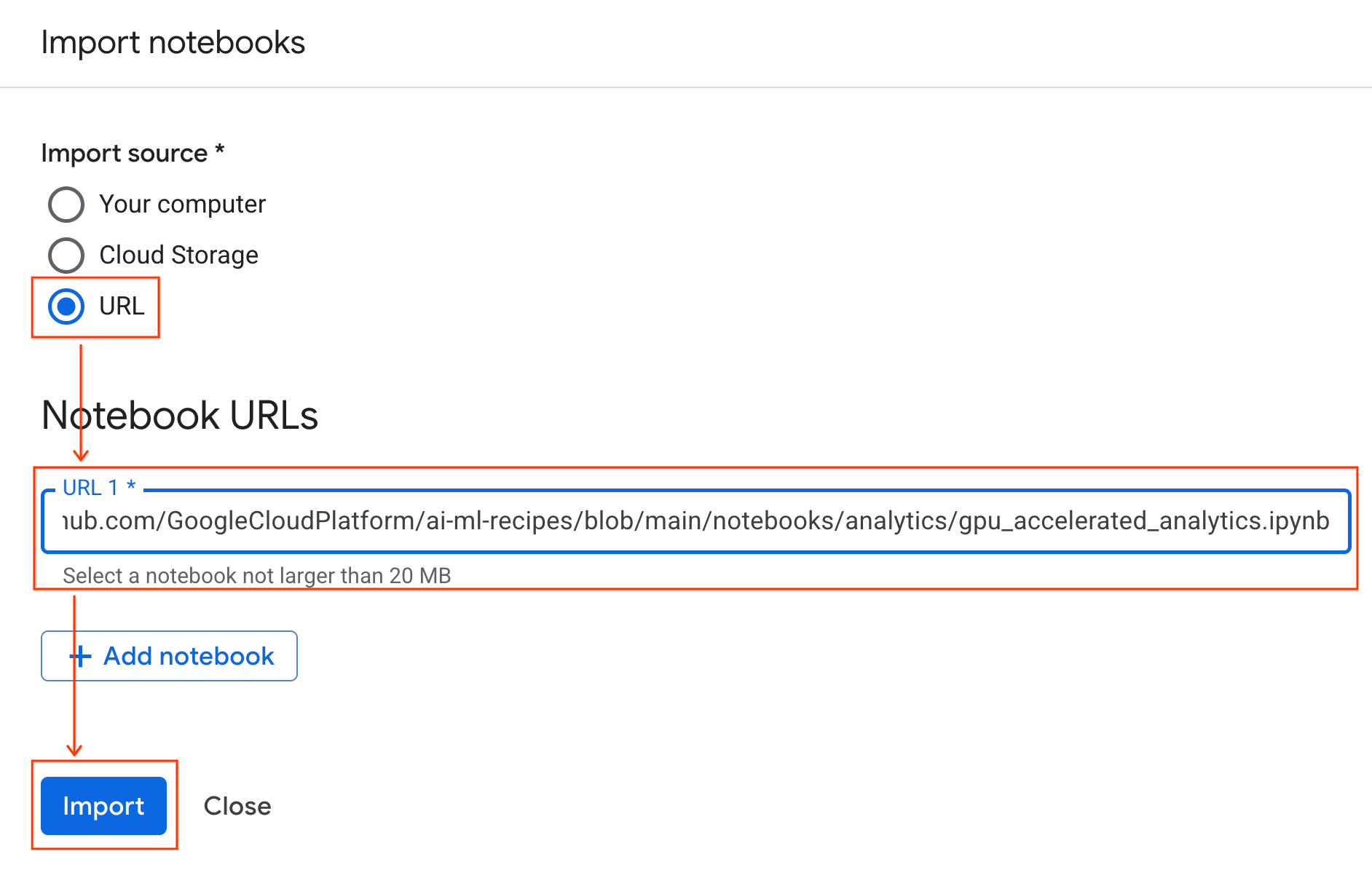
- URL 라디오 버튼을 선택하고 다음 URL을 입력합니다.
https://github.com/GoogleCloudPlatform/ai-ml-recipes/blob/main/notebooks/regression/gpu_accelerated_regression/gpu_accelerated_regression.ipynb
- 가져오기를 클릭합니다. Colab Enterprise에서 GitHub의 노트북을 환경에 복사합니다.
런타임에 연결하기
- 새로 가져온 노트북을 엽니다.
- 연결 옆에 있는 아래쪽 화살표를 클릭합니다.
- 런타임에 연결을 선택합니다.
- 드롭다운을 사용하여 이전에 만든 런타임을 선택합니다.
- 연결을 클릭합니다.
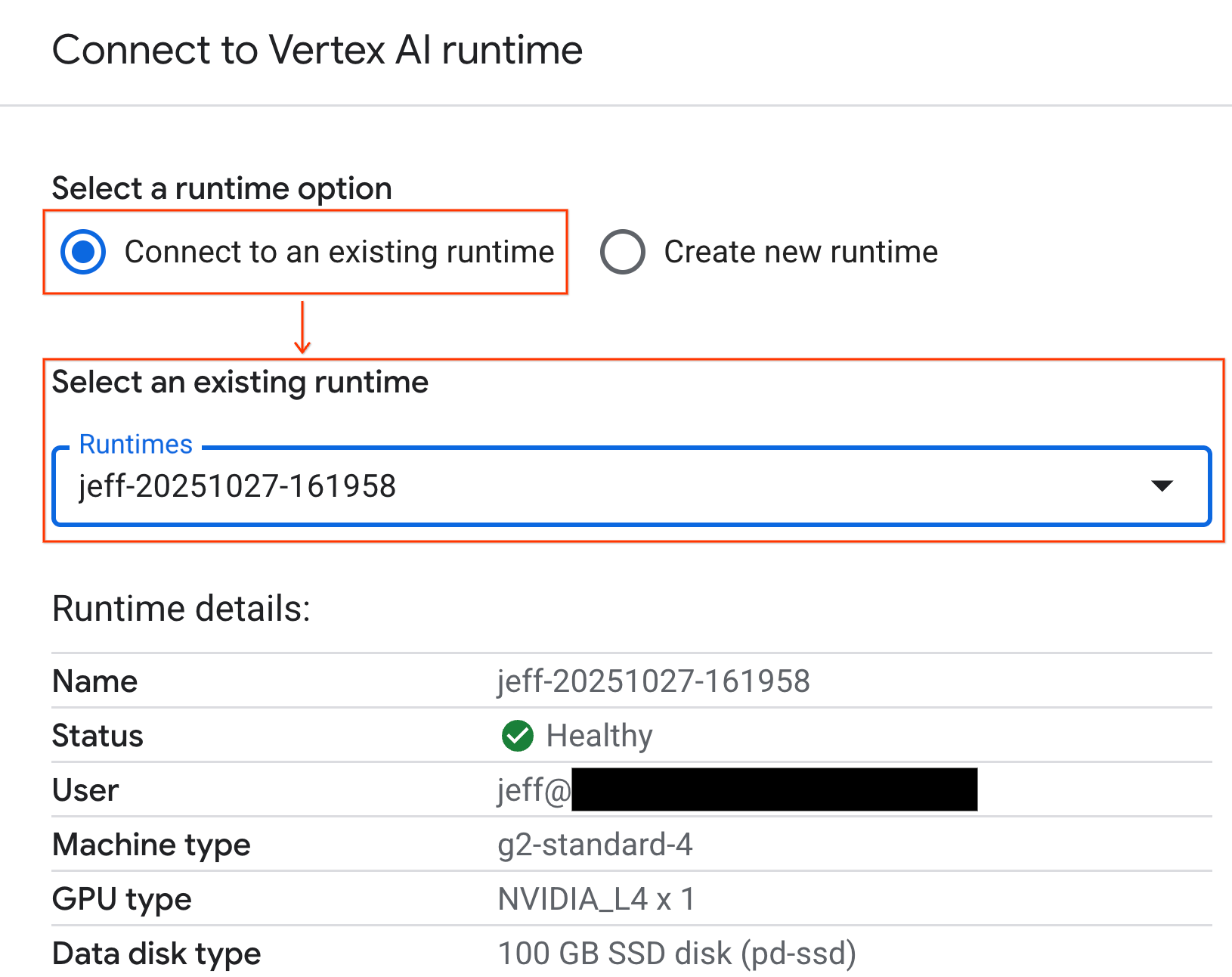
이제 노트북이 GPU 지원 런타임에 연결되었습니다.
기본 제공 종속 항목
Colab Enterprise를 사용하면 필요한 라이브러리가 사전 설치되어 있다는 장점이 있습니다. 이 실습에서는 cuDF, cuML, XGBoost와 같은 종속 항목을 수동으로 설치하거나 관리할 필요가 없습니다.
8. NYC 택시 데이터 세트 준비
이 Codelab에서는 NYC 택시 및 리무진 조합 (TLC) 운행 기록 데이터를 사용합니다. 데이터 세트에는 다음을 비롯한 뉴욕시의 노란색 택시 운행 기록이 포함되어 있습니다.
- 승차 및 하차 날짜, 시간, 위치
- 이동 거리
- 항목별 요금 금액
- 승객 수
- 팁 금액 (예측할 값)
GPU 구성 및 가용성 확인
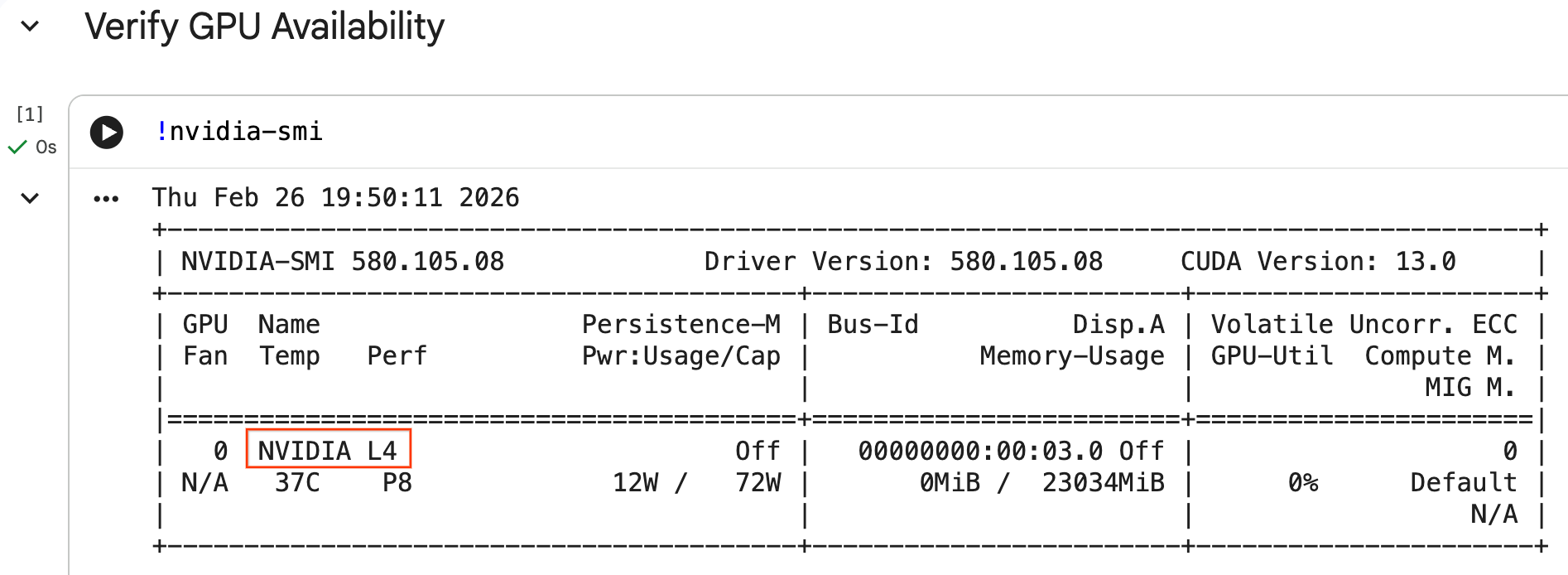
nvidia-smi 명령어를 실행하여 GPU가 인식되는지 확인할 수 있습니다. 드라이버 버전과 GPU 세부정보 (예: NVIDIA L4)가 표시됩니다.
nvidia-smi
셀에 런타임에 연결된 GPU가 다음과 같이 반환됩니다.
데이터 다운로드
2024년의 이동 데이터를 다운로드합니다.
from tqdm import tqdm
import requests
import time
import os
YEAR = 2024
DATA_DIR = "nyc_taxi_data"
os.makedirs(DATA_DIR, exist_ok=True)
print(f"Checking/Downloading files for {YEAR}...")
for month in tqdm(range(1, 13), unit="file"):
file_name = f"yellow_tripdata_{YEAR}-{month:02d}.parquet"
local_path = os.path.join(DATA_DIR, file_name)
url = f"https://d37ci6vzurychx.cloudfront.net/trip-data/{file_name}"
if not os.path.exists(local_path):
try:
with requests.get(url, stream=True) as response:
response.raise_for_status()
with open(local_path, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
time.sleep(1)
except requests.exceptions.HTTPError as e:
print(f"\nSkipping {file_name}: {e}")
if os.path.exists(local_path):
os.remove(local_path)
print("\nDownload complete.")
NVIDIA cuDF로 pandas 가속화
pandas 라이브러리는 CPU에서 실행되며 대규모 데이터 세트에서는 속도가 느릴 수 있습니다. NVIDIA %load_ext cudf.pandas 매직 명령어는 GPU 가속을 사용하도록 pandas를 동적으로 패치하고 필요한 경우 CPU로 대체합니다.
표준 가져오기 대신 이 매직 명령어를 사용하는 이유는 '코드 변경 없음' 가속을 제공하기 때문입니다. 기존 코드를 다시 작성할 필요가 없습니다. %load_ext cuml.accel와 비슷한 명령어인 %load_ext cuml.accel는 scikit-learn models에 대해 똑같은 작업을 실행합니다. 이는 Colab Enterprise뿐만 아니라 호환되는 NVIDIA GPU가 있는 모든 Jupyter 환경에서 작동합니다.
%load_ext cudf.pandas
활성 상태인지 확인하려면 pandas를 가져와서 유형을 확인합니다.
import pandas as pd
pd
출력을 통해 이제 cudf.pandas 모듈을 사용하고 있음을 확인할 수 있습니다.
데이터 로드 및 정리
cudf.pandas가 활성 상태인 상태에서 Parquet 파일을 로드하고 데이터 정리 작업을 실행합니다. 이 프로세스는 GPU에서 자동으로 실행됩니다.
import glob
# Load data into memory
df = pd.concat(
[pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")],
ignore_index=True
)
# Filter for valid trips. We filter for payment_type=1 (credit card)
# because tip amounts are only reliably recorded for credit card transactions.
df = df[
(df['fare_amount'] > 0) & (df['fare_amount'] < 500) &
(df['trip_distance'] > 0) & (df['trip_distance'] < 100) &
(df['tip_amount'] >= 0) & (df['tip_amount'] < 100) &
(df['payment_type'] == 1)
].copy()
# Downcast numeric columns to save memory
float_cols = df.select_dtypes(include=['float64']).columns
df[float_cols] = df[float_cols].astype('float32')
int_cols = df.select_dtypes(include=['int64']).columns
df[int_cols] = df[int_cols].astype('int32')
특성 추출
픽업 날짜 및 시간에서 파생된 특성을 만듭니다. 노트북에는 이후 단계에서 사용되는 다른 기능이 포함되어 있습니다.
import numpy as np
# Time Features
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['dow'] = df['tpep_pickup_datetime'].dt.dayofweek
df['is_weekend'] = (df['dow'] >= 5).astype(int)
df['is_rush_hour'] = (
((df['hour'] >= 7) & (df['hour'] <= 9)) |
((df['hour'] >= 17) & (df['hour'] <= 19))
).astype(int)
...
# Other features
...
9. 교차 검증으로 개별 모델 학습
GPU가 머신러닝을 가속화하는 방법을 보여주기 위해 택시 이동의 tip_amount을 예측하는 세 가지 유형의 회귀 모델을 학습시킵니다.
NVIDIA cuML로 scikit-learn 가속화
API 호출을 변경하지 않고 NVIDIA cuML을 사용하여 GPU에서 scikit-learn 알고리즘을 실행합니다. 먼저 cuml.accel 확장 프로그램을 로드합니다.
%load_ext cuml.accel
기능 및 타겟 설정
모델이 학습할 특성을 식별하고 타겟 열 (tip_amount)을 분할합니다.
feature_cols = [
'trip_distance', 'fare_amount', 'passenger_count',
'hour', 'dow', 'is_weekend', 'is_rush_hour',
'fare_log', 'fare_decimal', 'is_round_fare',
'route_frequency', 'pu_tip_mean', 'pu_tip_std',
'PULocationID', 'DOLocationID'
]
X = df[feature_cols].fillna(df[feature_cols].median())
y = df['tip_amount'].copy()
교차 검증 분할을 설정하여 모델 성능을 강력하게 평가합니다.
from sklearn.model_selection import KFold
import numpy as np
import time
from sklearn.metrics import mean_squared_error
from tqdm.notebook import tqdm
n_splits = 3
kf = KFold(n_splits=n_splits, shuffle=True, random_state=42)
1. XGBoost
XGBoost는 기본적으로 GPU 가속화됩니다. 학습 중에 GPU를 사용하려면 tree_method='hist' 및 device='cuda'를 전달하세요.
import xgboost as xgb
start_time = time.perf_counter()
def train_xgb_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# XGBoost handles GPU natively when tree_method='hist' and device='cuda'
model = xgb.XGBRegressor(
objective='reg:squarederror',
max_depth=5,
learning_rate=0.1,
n_estimators=100,
tree_method='hist',
device='cuda',
random_state=42
)
model.fit(X_train, y_train)
preds = model.predict(X_val)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
xgb_rmse, xgb_preds = train_xgb_cv(X, y)
print(f"\n{'XGBoost RMSE:':<20} ${xgb_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
2. 선형 회귀
선형 회귀 모델을 학습시킵니다. %load_ext cuml.accel가 활성화되면 LinearRegression가 GPU에 자동으로 매핑됩니다.
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
start_time = time.perf_counter()
def train_linreg_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# Scale features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_val_scaled = scaler.transform(X_val)
# Automatically accelerated by cuML
model = LinearRegression()
model.fit(X_train_scaled, y_train)
preds = model.predict(X_val_scaled)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
linreg_rmse, linreg_preds = train_linreg_cv(X, y)
print(f"\n{'Linear Reg RMSE:':<20} ${linreg_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
3. 랜덤 포레스트
RandomForestRegressor를 사용하여 앙상블 모델을 학습시킵니다. 트리 기반 모델은 CPU에서 학습하는 데 시간이 오래 걸리는 경우가 많지만 GPU 가속을 사용하면 수백만 개의 행을 더 빠르게 처리할 수 있습니다.
from sklearn.ensemble import RandomForestRegressor
start_time = time.perf_counter()
def train_rf_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# Automatically accelerated by cuML
model = RandomForestRegressor(
n_estimators=100,
max_depth=10,
n_jobs=-1,
max_features='sqrt',
random_state=42
)
model.fit(X_train, y_train)
preds = model.predict(X_val)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
rf_rmse, rf_preds = train_rf_cv(X, y)
print(f"\n{'Random Forest RMSE:':<20} ${rf_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
10. 엔드 투 엔드 파이프라인 평가
간단한 선형 앙상블을 사용하여 세 모델의 예측을 결합합니다. 일반적으로 개별 모델보다 정확도가 약간 향상됩니다.
예측에 선형 회귀를 적용하여 최적의 가중치를 찾습니다.
ensemble_weights = LinearRegression(positive=True, fit_intercept=False).fit(
np.c_[xgb_preds, rf_preds, linreg_preds], y
).coef_
# Normalize weights
ensemble_weights = ensemble_weights / ensemble_weights.sum()
ensemble_preds = np.c_[xgb_preds, rf_preds, linreg_preds] @ ensemble_weights
ensemble_rmse = np.sqrt(mean_squared_error(y, ensemble_preds))
결과를 비교하여 앙상블 광고 효과를 확인합니다.
print(f"\n{'Model':<20} {'RMSE':>10}")
print("-" * 32)
print(f"{'Linear Regression':<20} ${linreg_rmse:>9.4f}")
print(f"{'Random Forest':<20} ${rf_rmse:>9.4f}")
print(f"{'XGBoost':<20} ${xgb_rmse:>9.4f}")
print("-" * 32)
print(f"{'Ensemble':<20} ${ensemble_rmse:>9.4f}")
print(f"\nEnsemble lift: ${xgb_rmse - ensemble_rmse:.4f}")
11. CPU와 GPU 성능 비교
성능 차이를 적절하게 벤치마킹하려면 커널을 다시 시작하여 깨끗한 실행 상태를 보장하고, CPU에서 전체 데이터 과학 파이프라인을 실행한 다음 GPU에서 다시 실행합니다.
커널 다시 시작
IPython.Application.instance().kernel.do_shutdown(True) 명령어를 실행하여 커널을 다시 시작하고 메모리를 해제합니다.
import IPython
IPython.Application.instance().kernel.do_shutdown(True)
데이터 과학 파이프라인 정의
핵심 워크플로 (데이터 로드, 정리, 특성 추출, 모델 학습)를 단일 함수로 래핑합니다. 이 함수는 환경 간에 전환하기 위해 pandas 모듈 pd_module와 use_gpu 인수를 허용합니다.
def run_ml_pipeline(pd_module, use_gpu=False):
import time
import glob
import numpy as np
from sklearn.ensemble import RandomForestRegressor
import xgboost as xgb
timings = {}
# 1. Load Data
t0 = time.perf_counter()
df = pd_module.concat(
[pd_module.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")],
ignore_index=True
)
timings['Load Data'] = time.perf_counter() - t0
# 2. Clean Data
t0 = time.perf_counter()
# Filter for payment_type=1 (credit card) because tip amounts
# are only reliably recorded for credit card transactions.
df = df[
(df['fare_amount'] > 0) & (df['fare_amount'] < 500) &
(df['trip_distance'] > 0) & (df['trip_distance'] < 100) &
(df['tip_amount'] >= 0) & (df['tip_amount'] < 100) &
(df['payment_type'] == 1)
].copy()
# Downcast numeric columns to save memory
float_cols = df.select_dtypes(include=['float64']).columns
df[float_cols] = df[float_cols].astype('float32')
int_cols = df.select_dtypes(include=['int64']).columns
df[int_cols] = df[int_cols].astype('int32')
timings['Clean Data'] = time.perf_counter() - t0
# 3. Feature Engineering
t0 = time.perf_counter()
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['dow'] = df['tpep_pickup_datetime'].dt.dayofweek
df['is_weekend'] = (df['dow'] >= 5).astype(int)
df['fare_log'] = np.log1p(df['fare_amount'])
timings['Feature Engineering'] = time.perf_counter() - t0
# 4. Modeling Prep
feature_cols = ['trip_distance', 'fare_amount', 'passenger_count', 'hour', 'dow', 'is_weekend', 'fare_log']
X = df[feature_cols].fillna(df[feature_cols].median())
y = df['tip_amount'].copy()
# Free memory
del df
import gc
gc.collect()
# 5. Train Random Forest
t0 = time.perf_counter()
rf_model = RandomForestRegressor(
n_estimators=100,
max_depth=10,
n_jobs=-1,
max_features='sqrt',
random_state=42
).fit(X, y)
timings['Train Random Forest'] = time.perf_counter() - t0
# 6. Train XGBoost
t0 = time.perf_counter()
params = {
'objective': 'reg:squarederror',
'max_depth': 5,
'n_estimators': 100,
'random_state': 42
}
if use_gpu:
params['device'] = 'cuda'
params['tree_method'] = 'hist'
xgb_model = xgb.XGBRegressor(**params).fit(X, y)
timings['Train XGBoost'] = time.perf_counter() - t0
del X
del y
gc.collect()
return timings
CPU에서 실행
표준 CPU pandas를 사용하여 파이프라인을 호출합니다.
import pandas as pd
print("Running pipeline on CPU...")
cpu_times = run_ml_pipeline(pd, use_gpu=False)
print("CPU Execution Finished.")
GPU에서 실행
NVIDIA 라이브러리 확장 프로그램을 로드하고, 가속화된 cudf.pandas 모듈을 파이프라인에 전달하고, XGBoost 기기를 내부적으로 cuda로 설정합니다.
import IPython.core.magic
if not hasattr(IPython.core.magic, 'output_can_be_silenced'):
IPython.core.magic.output_can_be_silenced = lambda x: x
%load_ext cudf.pandas
%load_ext cuml.accel
import pandas as pd
print("Running pipeline on GPU...")
gpu_times = run_ml_pipeline(pd, use_gpu=True)
print("GPU Execution Finished.")
성능 향상 시각화
matplotlib을 사용하여 타이밍을 시각화합니다. 결과에는 GPU를 사용할 때 데이터 처리 및 모델 학습 중에 절약된 시간이 표시됩니다.
import matplotlib.pyplot as plt
import numpy as np
labels = list(cpu_times.keys())
cpu_values = list(cpu_times.values())
gpu_values = list(gpu_times.values())
x = np.arange(len(labels))
width = 0.35
fig, ax = plt.subplots(figsize=(10, 6))
rects1 = ax.bar(x - width/2, cpu_values, width, label='CPU', color='#4285F4')
rects2 = ax.bar(x + width/2, gpu_values, width, label='GPU', color='#76B900')
ax.set_ylabel('Execution Time (seconds)')
ax.set_title('NYC Taxi ML Pipeline: CPU vs. GPU Performance')
ax.set_xticks(x)
ax.set_xticklabels(labels, rotation=45, ha="right")
ax.legend()
# Add data labels
def autolabel(rects):
for rect in rects:
height = rect.get_height()
ax.annotate(f'{height:.2f}s',
xy=(rect.get_x() + rect.get_width() / 2, height),
xytext=(0, 3), # 3 points vertical offset
textcoords="offset points",
ha='center', va='bottom', fontsize=9)
autolabel(rects1)
autolabel(rects2)
plt.tight_layout()
plt.show()
# Calculate overall speedup
total_cpu_time = sum(cpu_values)
total_gpu_time = sum(gpu_values)
overall_speedup = total_cpu_time / total_gpu_time
print(f"\nOverall Pipeline Speedup: {overall_speedup:.2f}x faster on GPU!")
다음과 같이 표시됩니다.
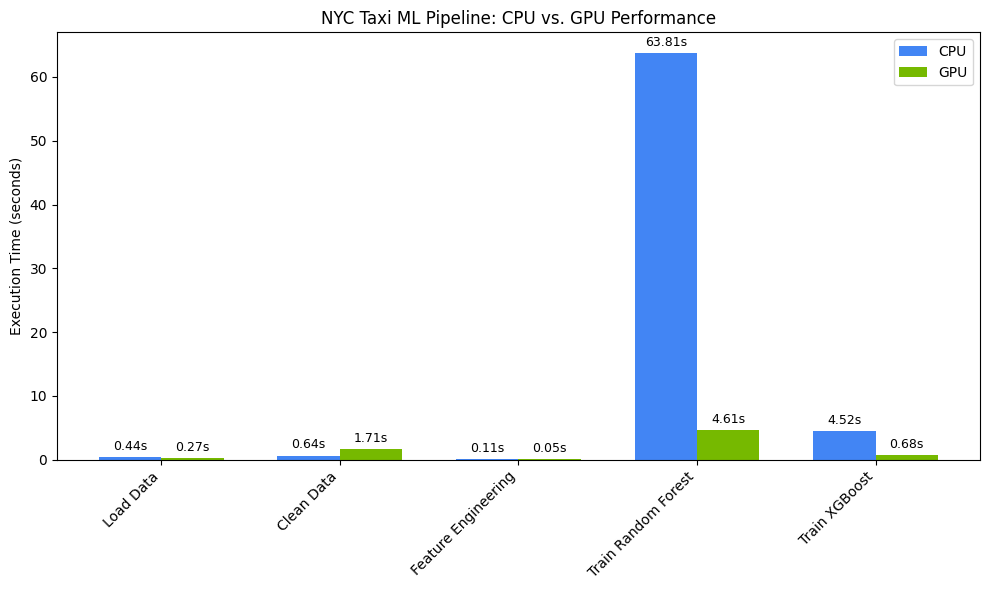
이 차트는 전체 데이터 과학 워크플로에서 GPU의 상당한 성능 이점을 보여줍니다. 계산 집약적인 모델 학습 단계에서 랜덤 포레스트 및 XGBoost와 같은 알고리즘의 경우 가장 큰 시간 절약 효과를 볼 수 있습니다.
12. 코드를 프로파일링하여 성능 제약 조건 찾기
cudf.pandas를 사용하면 대부분의 함수가 GPU에서 실행됩니다. cuDF에서 아직 특정 작업을 지원하지 않는 경우 실행이 일시적으로 CPU로 대체됩니다. NVIDIA는 이러한 대체를 식별하기 위해 두 개의 기본 제공 Jupyter 매직 명령어를 제공합니다.
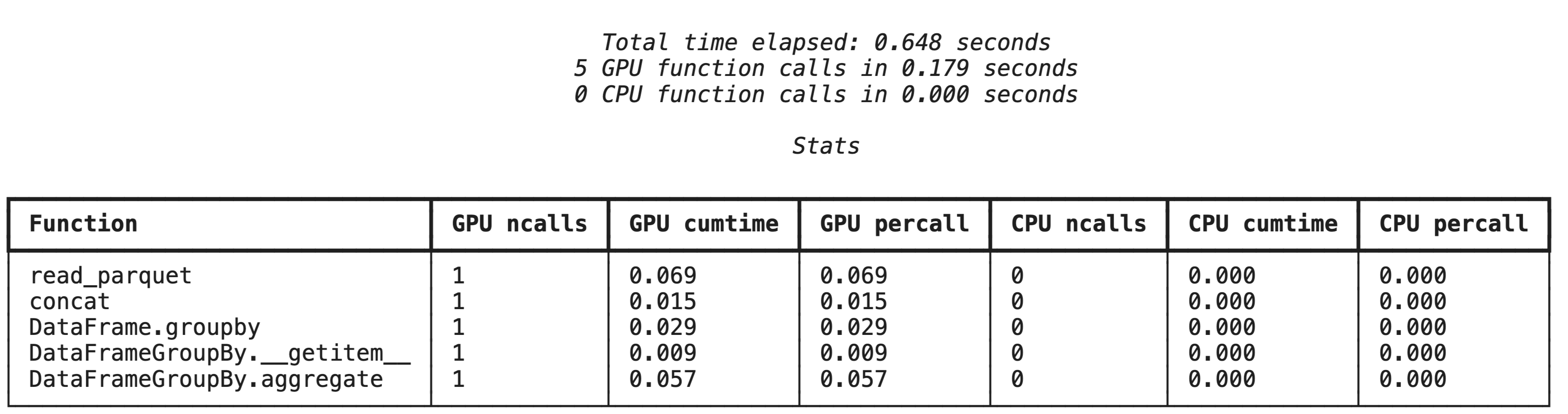
%%cudf.pandas.profile를 사용한 상위 수준 프로파일링
%%cudf.pandas.profile 매직 명령어는 GPU 또는 CPU에서 실행된 함수에 관한 요약을 제공합니다.
%%cudf.pandas.profile
import glob
import pandas as pd
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")], ignore_index=True)
summary = (
df
.groupby(['PULocationID', 'payment_type'])
[['passenger_count', 'fare_amount', 'tip_amount']]
.agg(['min', 'mean', 'max'])
)
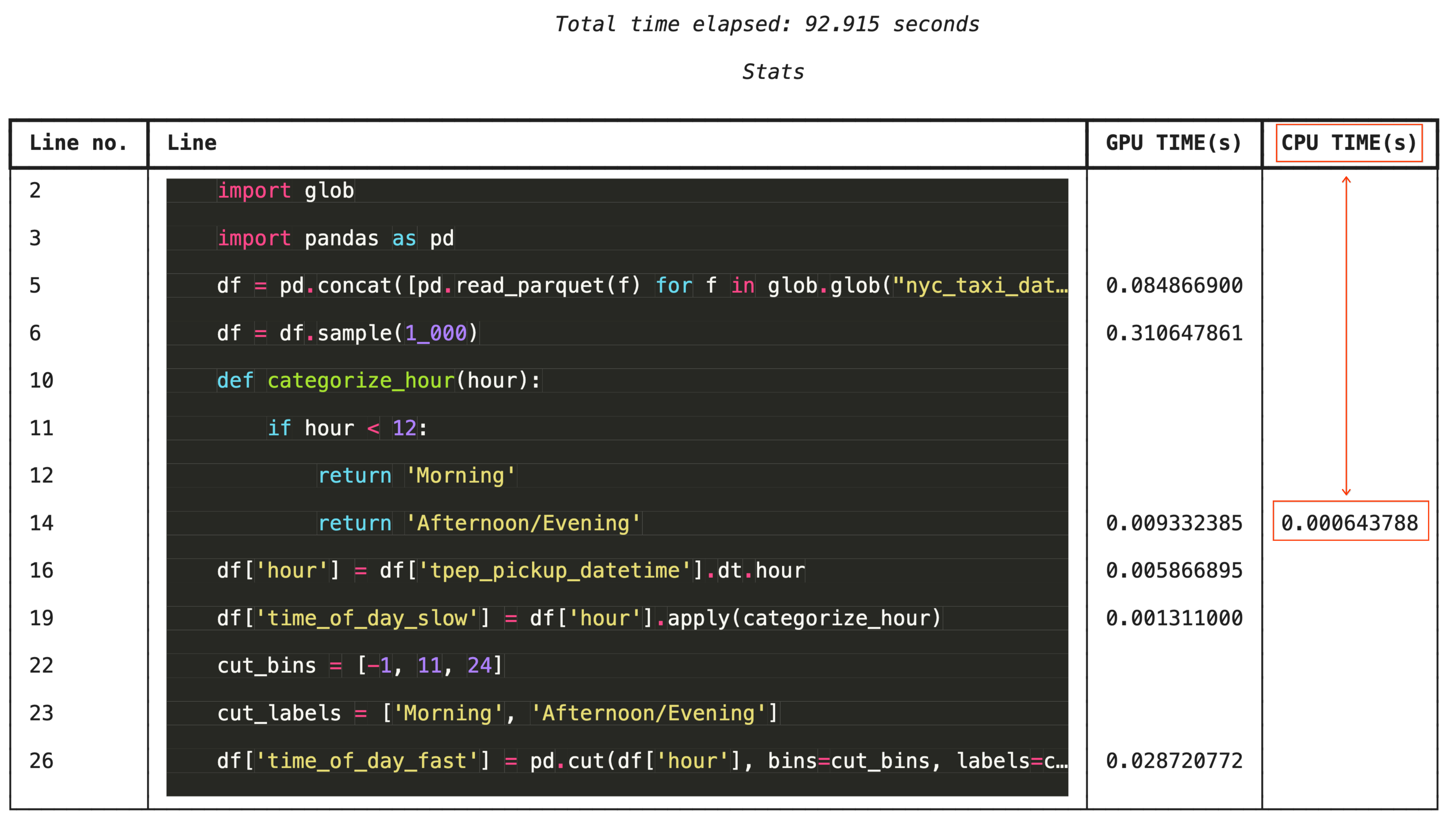
%%cudf.pandas.line_profile를 사용한 라인별 프로파일링
세부적인 문제 해결을 위해 %%cudf.pandas.line_profile는 각 코드 줄에 GPU에서 실행된 횟수와 CPU에서 실행된 횟수를 주석으로 표시합니다.
%%cudf.pandas.line_profile
import glob
import pandas as pd
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")], ignore_index=True)
df = df.sample(1_000)
# Iterating row-by-row or using custom python apply functions often falls back to the CPU
def categorize_hour(hour):
if hour < 12:
return 'Morning'
else:
return 'Afternoon/Evening'
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['time_of_day_slow'] = df['hour'].apply(categorize_hour)
# Using vectorized pandas operations (like pd.cut) stays entirely on the GPU
cut_bins = [-1, 11, 24]
cut_labels = ['Morning', 'Afternoon/Evening']
df['time_of_day_fast'] = pd.cut(df['hour'], bins=cut_bins, labels=cut_labels)
13. 삭제
Google Cloud 계정에 예기치 않은 요금이 청구되지 않도록 이 Codelab에서 만든 리소스를 정리합니다.
리소스 삭제
노트북 셀에서 !rm -rf 명령어를 사용하여 런타임의 로컬 데이터 세트를 삭제합니다.
print("Deleting local 'nyc_taxi_data' directory...")
!rm -rf nyc_taxi_data
print("Local files deleted.")
Colab 런타임 종료
- Google Cloud 콘솔에서 Colab Enterprise Runtimes 페이지로 이동합니다.
- 리전 메뉴에서 런타임이 포함된 리전을 선택합니다.
- 삭제하려는 런타임을 선택합니다.
- 삭제를 클릭합니다.
- 확인을 클릭합니다.
노트북 삭제
- Google Cloud 콘솔에서 Colab Enterprise 내 노트북 페이지로 이동합니다.
- 리전 메뉴에서 노트북이 포함된 리전을 선택합니다.
- 삭제하려는 노트북을 선택합니다.
- 삭제를 클릭합니다.
- 확인을 클릭합니다.
14. 축하합니다
축하합니다. Colab Enterprise에서 NVIDIA cuDF 및 cuML 라이브러리를 사용하여 pandas 및 scikit-learn 머신러닝 워크플로를 가속화했습니다. 몇 가지 매직 명령어 (%load_ext cudf.pandas 및 %load_ext cuml.accel)를 추가하기만 하면 표준 코드가 GPU에서 실행되어 레코드를 처리하고 복잡한 모델을 로컬에서 훨씬 짧은 시간에 적합시킵니다.
데이터 분석을 위한 GPU 가속에 대한 자세한 내용은 GPU를 사용한 데이터 분석 가속화 Codelab을 참고하세요.
학습한 내용
- Google Cloud의 Colab Enterprise 이해하기
- 특정 GPU 및 메모리 구성으로 Colab 런타임 환경 맞춤설정
- GPU 가속을 적용하여 NYC 택시 데이터 세트의 수백만 개의 레코드를 사용하여 팁 금액을 예측합니다.
- NVIDIA의
cuDF라이브러리를 사용하여 코드 변경 없이pandas가속화 - NVIDIA의
cuML라이브러리 및 GPU를 사용하여 코드 변경 없이scikit-learn가속화 - 성능 제약 조건을 식별하고 최적화하기 위해 코드를 프로파일링합니다.