
1. Wprowadzenie
Z tego ćwiczenia dowiesz się, jak przyspieszyć procesy związane z nauką o danych i uczeniem maszynowym w przypadku dużych zbiorów danych za pomocą procesorów graficznych NVIDIA i bibliotek open source w Google Cloud. Najpierw skonfigurujesz infrastrukturę, a potem dowiesz się, jak zastosować akcelerację GPU.
Skupisz się na cyklu życia nauki o danych, od przygotowania danych za pomocą pandas po trenowanie modelu za pomocą scikit-learn i XGBoost. Dowiesz się, jak przyspieszyć te zadania za pomocą bibliotek cuDF i cuML firmy NVIDIA. Najlepsze jest to, że możesz uzyskać to przyspieszenie GPU bez zmiany dotychczasowego kodu pandas lub scikit-learn.
Czego się nauczysz
- Poznaj Colab Enterprise w Google Cloud.
- Dostosowywanie środowiska wykonawczego Colab za pomocą określonych konfiguracji procesora graficznego i pamięci.
- Zastosuj akcelerację GPU, aby prognozować kwoty napiwków na podstawie milionów rekordów ze zbioru danych NYC Taxi.
- Przyspiesz
pandasbez wprowadzania zmian w kodzie za pomocą bibliotekicuDFfirmy NVIDIA. - Przyspiesz
scikit-learnbez wprowadzania zmian w kodzie, korzystając z bibliotekicuMLi procesorów graficznych NVIDIA. - Profiluj kod, aby identyfikować i optymalizować ograniczenia wydajności.
Na następnej stronie znajdziesz środki, których możesz użyć do ukończenia ćwiczenia.
2. Dlaczego warto przyspieszyć uczenie maszynowe?
Potrzeba szybszego iterowania w ML
Przygotowanie danych jest czasochłonne, a trenowanie lub ocenianie modelu może zająć jeszcze więcej czasu, gdy zbiory danych się powiększają. Trenowanie modeli, takich jak lasy losowe czy XGBoost, na milionach wierszy za pomocą procesora może zająć wiele godzin lub dni.
Używanie procesorów graficznych przyspiesza te procesy trenowania dzięki bibliotekom takim jak cuML i akcelerowane przez GPU XGBoost. Dzięki temu przyspieszeniu możesz:
- Szybsze iteracje: szybkie testowanie nowych funkcji i hiperparametrów.
- Trenuj na pełnych zbiorach danych: aby zwiększyć dokładność, używaj pełnych danych zamiast próbkowania w dół.
- Obniż koszty: wykonuj duże obciążenia w krótszym czasie, aby obniżyć koszty obliczeniowe.
3. Konfiguracja i wymagania
Potencjalne koszty
To ćwiczenie wykorzystuje zasoby Google Cloud, w tym środowiska wykonawcze Colab Enterprise z procesorami graficznymi NVIDIA L4. Pamiętaj o potencjalnych opłatach i postępuj zgodnie z instrukcjami w sekcji Czyszczenie na końcu ćwiczenia, aby wyłączyć zasoby i uniknąć dalszych opłat. Szczegółowe informacje o cenach znajdziesz w cenniku Colab Enterprise i cenniku GPU.
Zanim zaczniesz
Wymagana jest średnio zaawansowana znajomość języka Python, pandas, scikit-learn i standardowych praktyk uczenia maszynowego (takich jak walidacja krzyżowa czy łączenie modeli).
- W konsoli Google Cloud na stronie selektora projektów wybierz lub utwórz projekt w chmurze Google Cloud.
- Sprawdź, czy w projekcie Google Cloud włączone są płatności.
Włączanie interfejsów API
Aby korzystać z Colab Enterprise, musisz najpierw włączyć niezbędne interfejsy API.
- Otwórz Google Cloud Shell, klikając ikonę Cloud Shell w prawym górnym rogu konsoli Google Cloud.

- W Cloud Shell ustaw identyfikator projektu, zastępując
PROJECT_IDidentyfikatorem projektu:
gcloud config set project <PROJECT_ID>
- Aby włączyć niezbędne interfejsy API, uruchom to polecenie:
gcloud services enable \
compute.googleapis.com \
dataform.googleapis.com \
notebooks.googleapis.com \
aiplatform.googleapis.com
Po pomyślnym wykonaniu polecenia powinien wyświetlić się komunikat podobny do tego poniżej:
Operation "operations/..." finished successfully.
4. Wybór środowiska notatnika
Wielu specjalistów ds. danych zna Colab z projektów osobistych, ale Colab Enterprise zapewnia bezpieczne, oparte na współpracy i zintegrowane środowisko notatników zaprojektowane z myślą o firmach.
W Google Cloud masz 2 główne opcje zarządzanych środowisk notatników: Colab Enterprise i Gemini Enterprise Agent Platform Workbench. Wybór zależy od priorytetów projektu.
Kiedy używać Agent Platform Workbench
Wybierz Agent Platform Workbench, jeśli priorytetem jest kontrola i zaawansowane dostosowywanie. Jest to idealne rozwiązanie, jeśli chcesz:
- zarządzać bazową infrastrukturą i cyklem życia maszyny;
- używać kontenerów niestandardowych i konfiguracji sieci;
- Integracja z potokami MLOps i niestandardowymi narzędziami do zarządzania cyklem życia.
Kiedy używać Colab Enterprise
Wybierz Colab Enterprise, jeśli zależy Ci na szybkiej konfiguracji, łatwości obsługi i bezpiecznej współpracy. Jest to usługa w pełni zarządzana, która pozwala zespołowi skupić się na analizie zamiast na infrastrukturze.
Colab Enterprise ułatwia:
- Tworzenie przepływów pracy związanych z badaniem danych, które są ściśle powiązane z hurtownią danych. Notatniki możesz otwierać i nimi zarządzać bezpośrednio w BigQuery Studio.
- Trenuj modele uczenia maszynowego i integruj je z narzędziami MLOps na platformie Agent Platform.
- Korzystaj z elastycznego i ujednoliconego środowiska. Notatnik Colab Enterprise utworzony w BigQuery można otworzyć i uruchomić na platformie Agent Platform i odwrotnie.
Dzisiejsze laboratorium
To ćwiczenie wykorzystuje Colab Enterprise do przyspieszonego uczenia maszynowego.
Więcej informacji o różnicach między nimi znajdziesz w oficjalnej dokumentacji na temat wybierania odpowiedniego rozwiązania do obsługi notatników.
5. Konfigurowanie szablonu środowiska wykonawczego
W Colab Enterprise połącz się ze środowiskiem wykonawczym na podstawie wstępnie skonfigurowanego szablonu środowiska wykonawczego.
Szablon środowiska wykonawczego to konfiguracja wielokrotnego użytku, która określa środowisko notatnika, w tym:
- Typ maszyny (procesor, pamięć)
- Akcelerator (typ i liczba GPU)
- Rozmiar i typ dysku
- Ustawienia sieci i zasady zabezpieczeń
- Reguły automatycznego wyłączania w przypadku braku aktywności
Dlaczego szablony środowiska wykonawczego są przydatne
- Spójność: Ty i Twój zespół macie to samo środowisko, co zapewnia powtarzalność pracy.
- Bezpieczeństwo: szablony egzekwują zasady zabezpieczeń organizacji.
- Zarządzanie kosztami: zasoby są wstępnie dopasowane w szablonie, aby zapobiec przypadkowym kosztom.
Tworzenie szablonu środowiska wykonawczego
Skonfiguruj szablon środowiska wykonawczego do wielokrotnego użytku na potrzeby laboratorium.
- W konsoli Google Cloud otwórz Menu nawigacyjne > Platforma agentów > Notatniki.
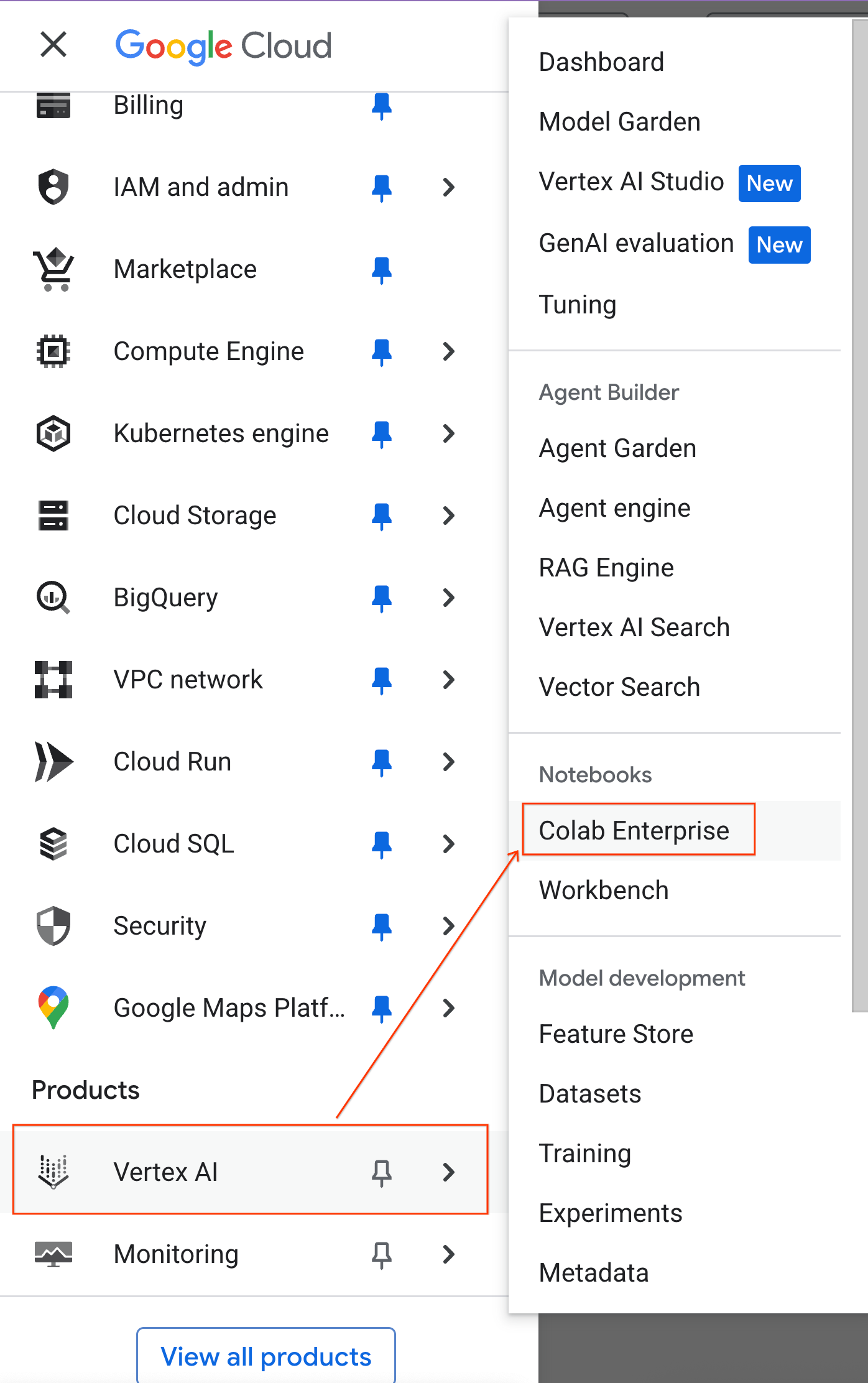
- W Colab Enterprise kliknij Szablony środowiska wykonawczego, a następnie wybierz Nowy szablon.
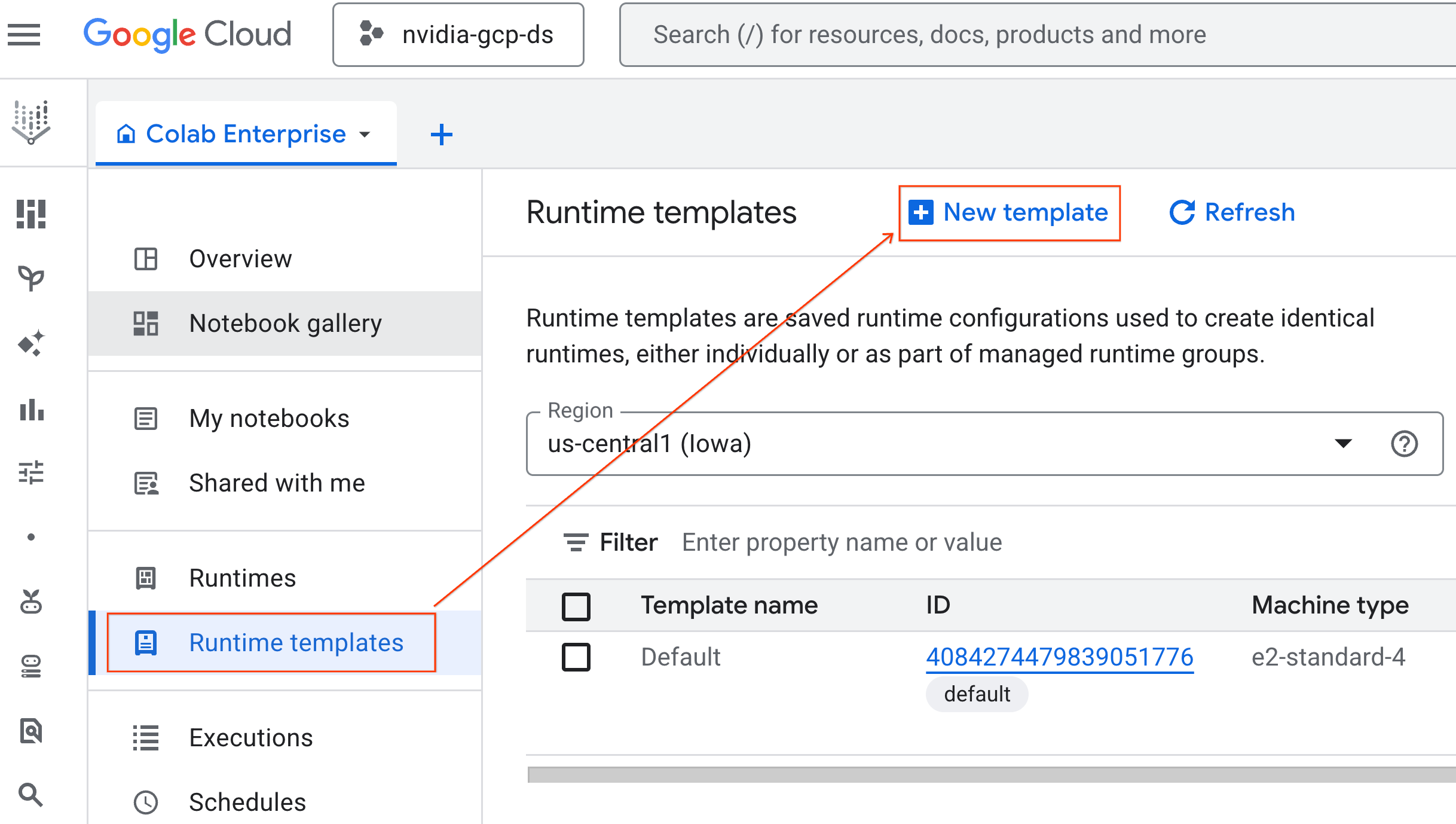
- W sekcji Podstawy środowiska wykonawczego:
- Ustaw wyświetlaną nazwę na
gpu-template. - Ustaw preferowany Region.
- Ustaw wyświetlaną nazwę na
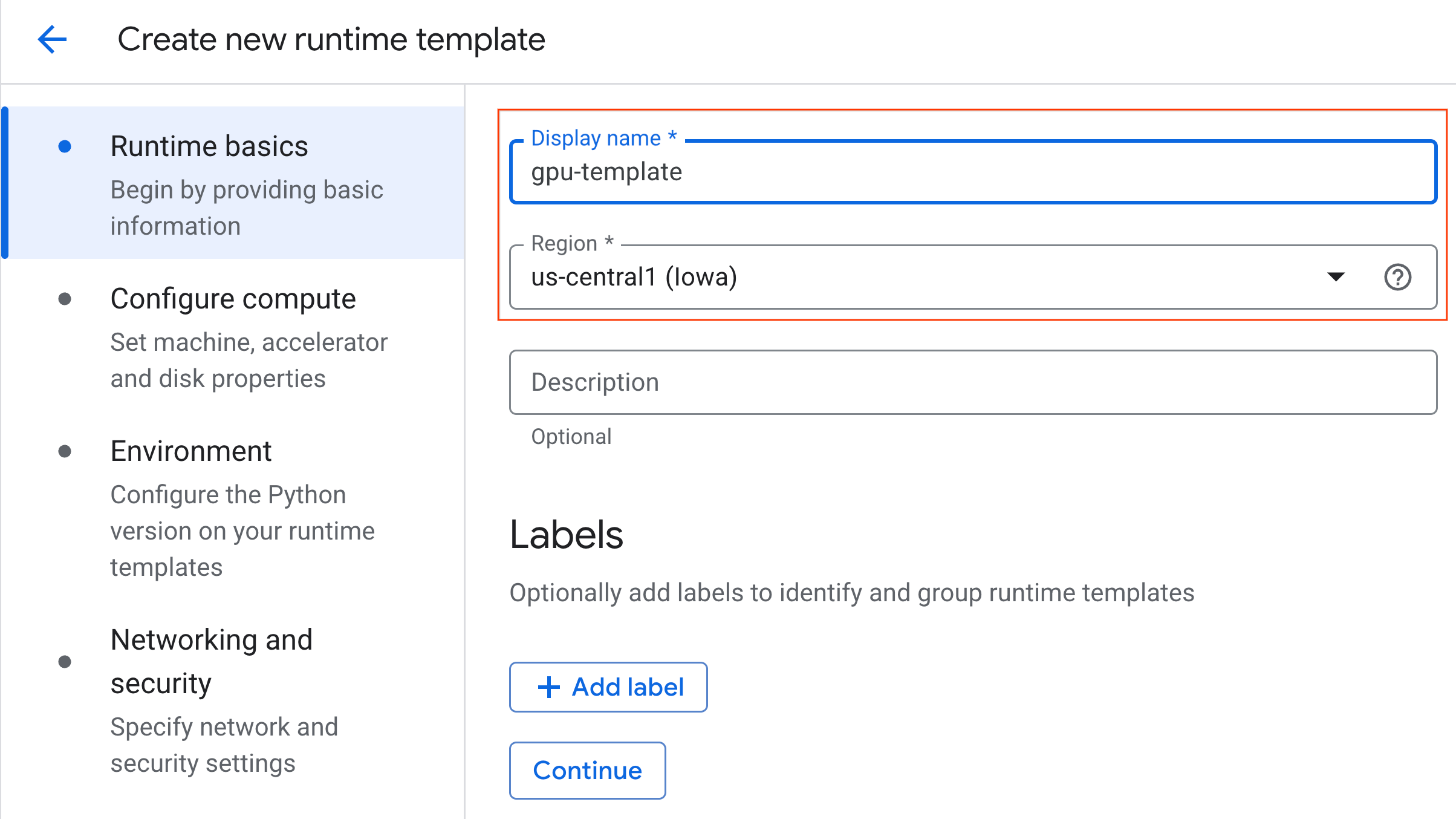
- W sekcji Skonfiguruj zasoby obliczeniowe:
- Ustaw Typ maszyny na
g2-standard-4. - Pozostaw domyślny typ akceleratora jako
NVIDIA L4z liczbą akceleratorów równą 1. - Zmień ustawienie Wyłączanie w przypadku braku aktywności na 60 minut.
- Kliknij Dalej.
- Ustaw Typ maszyny na
- W sekcji Środowisko:
- Ustaw Środowisko na
Python 3.11.
- Ustaw Środowisko na
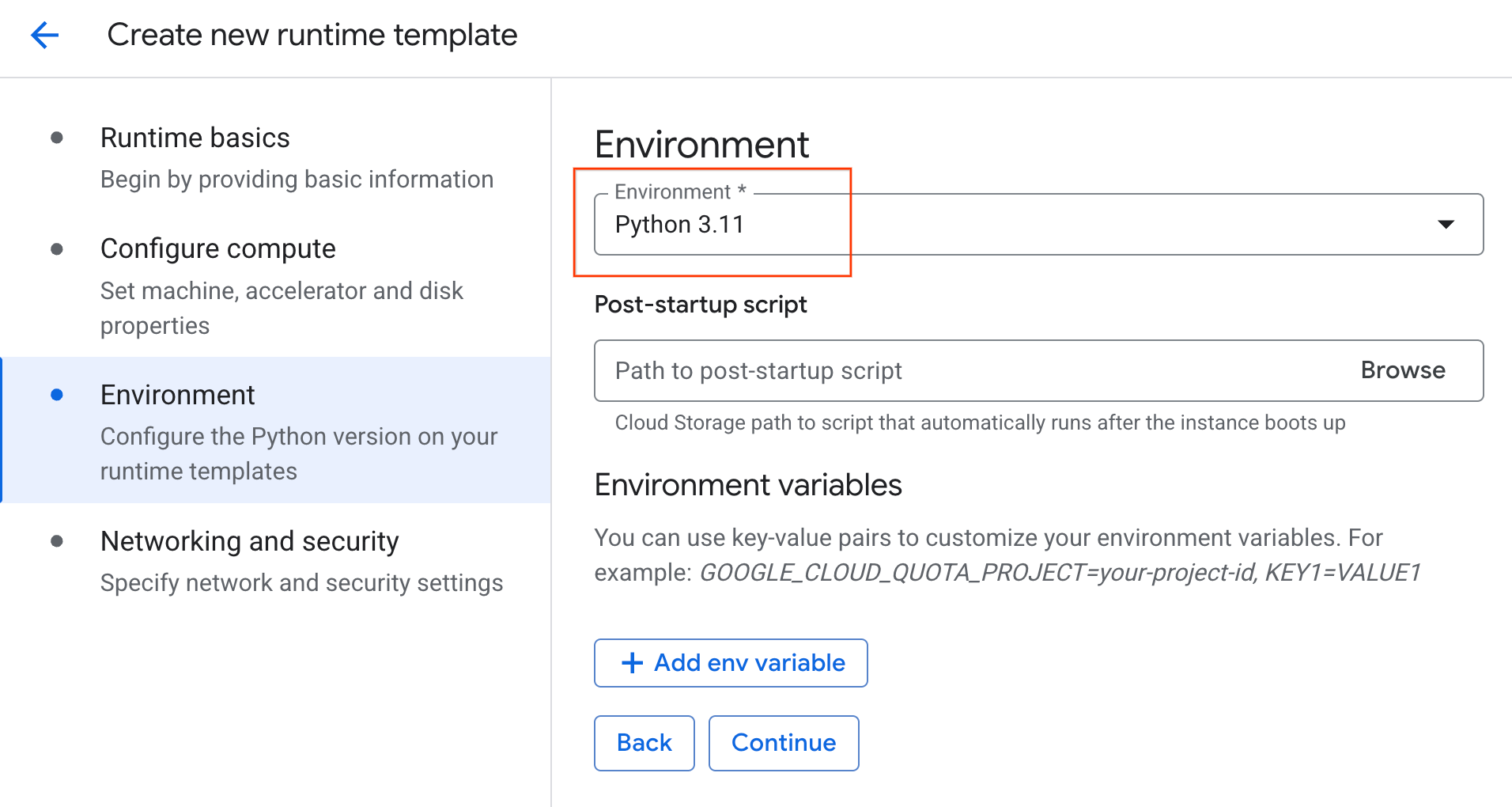
- Kliknij Utwórz, aby zapisać szablon środowiska wykonawczego. Na stronie Szablony środowiska wykonawczego powinien być teraz widoczny nowy szablon.
6. Uruchamianie środowiska wykonawczego
Gdy szablon będzie gotowy, możesz utworzyć nowe środowisko wykonawcze.
- W Colab Enterprise kliknij Środowiska wykonawcze, a następnie wybierz Utwórz.
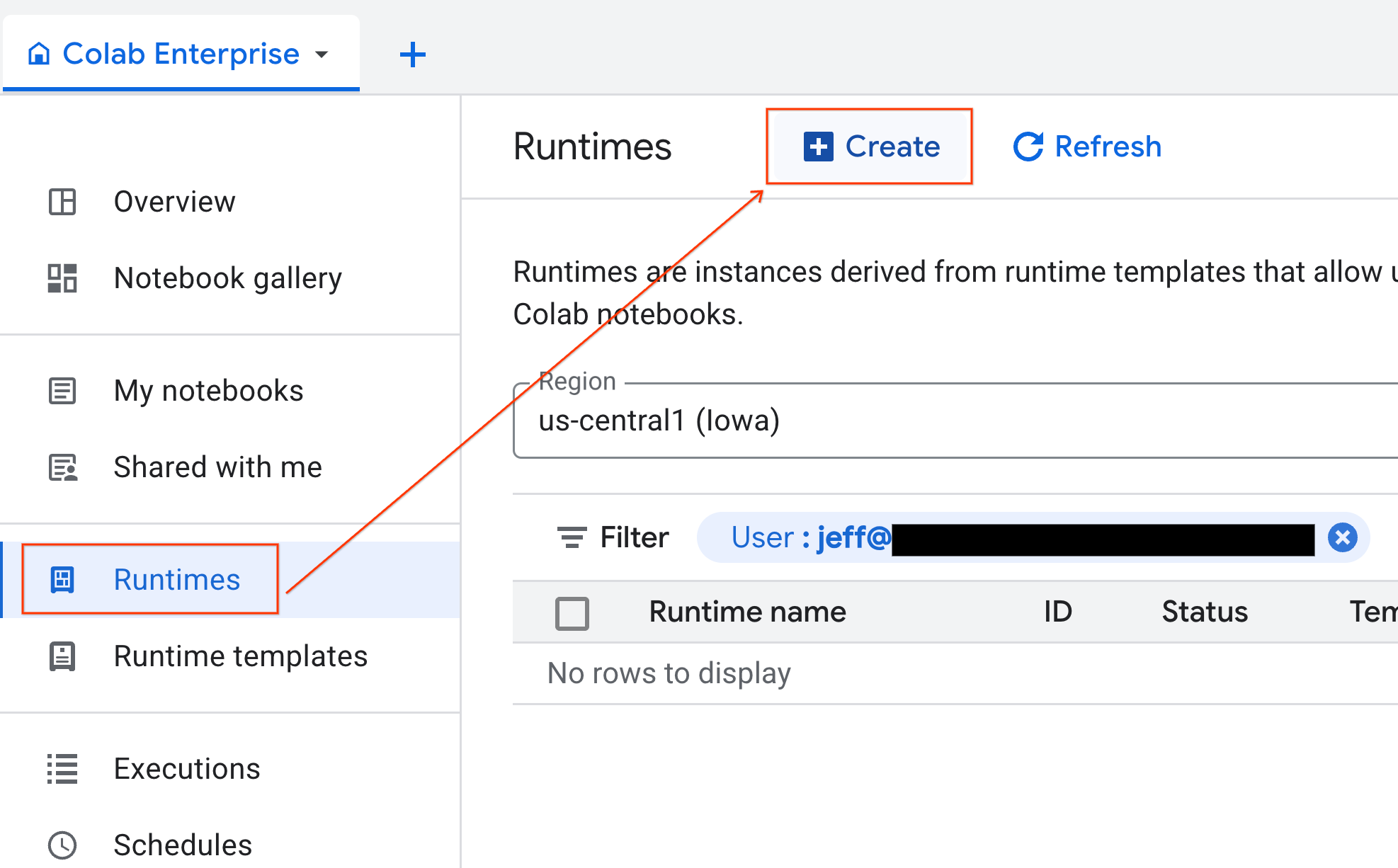
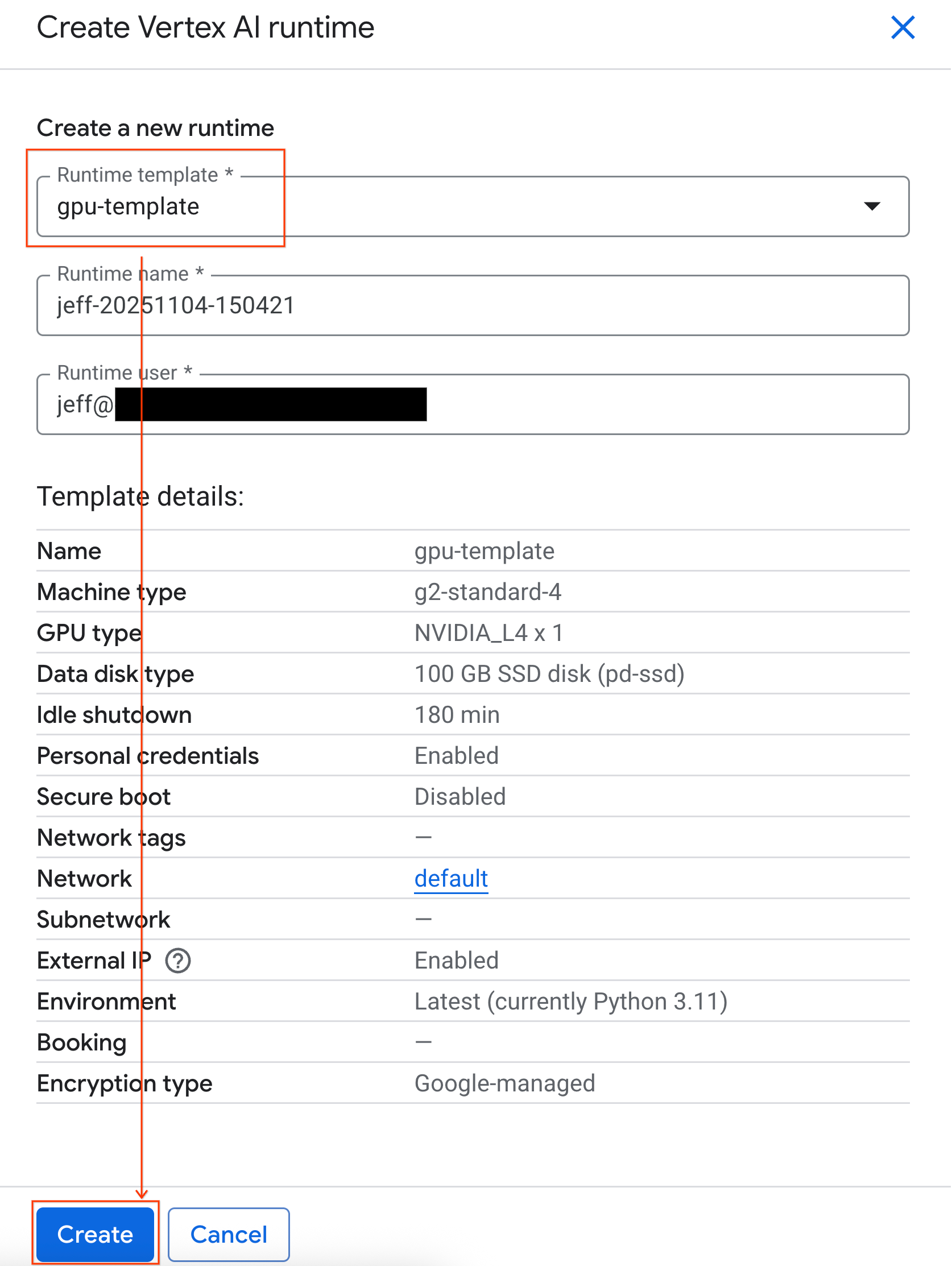
- W sekcji Szablon środowiska wykonawczego wybierz opcję
gpu-template. Kliknij Utwórz i poczekaj na uruchomienie środowiska wykonawczego.
- Po kilku minutach zobaczysz dostępny czas działania.
7. Konfigurowanie notatnika
Infrastruktura już działa, więc musisz zaimportować notatnik modułu i połączyć go ze środowiskiem wykonawczym.
Importowanie notatnika
- W Colab Enterprise kliknij Moje notatniki, a następnie Importuj.
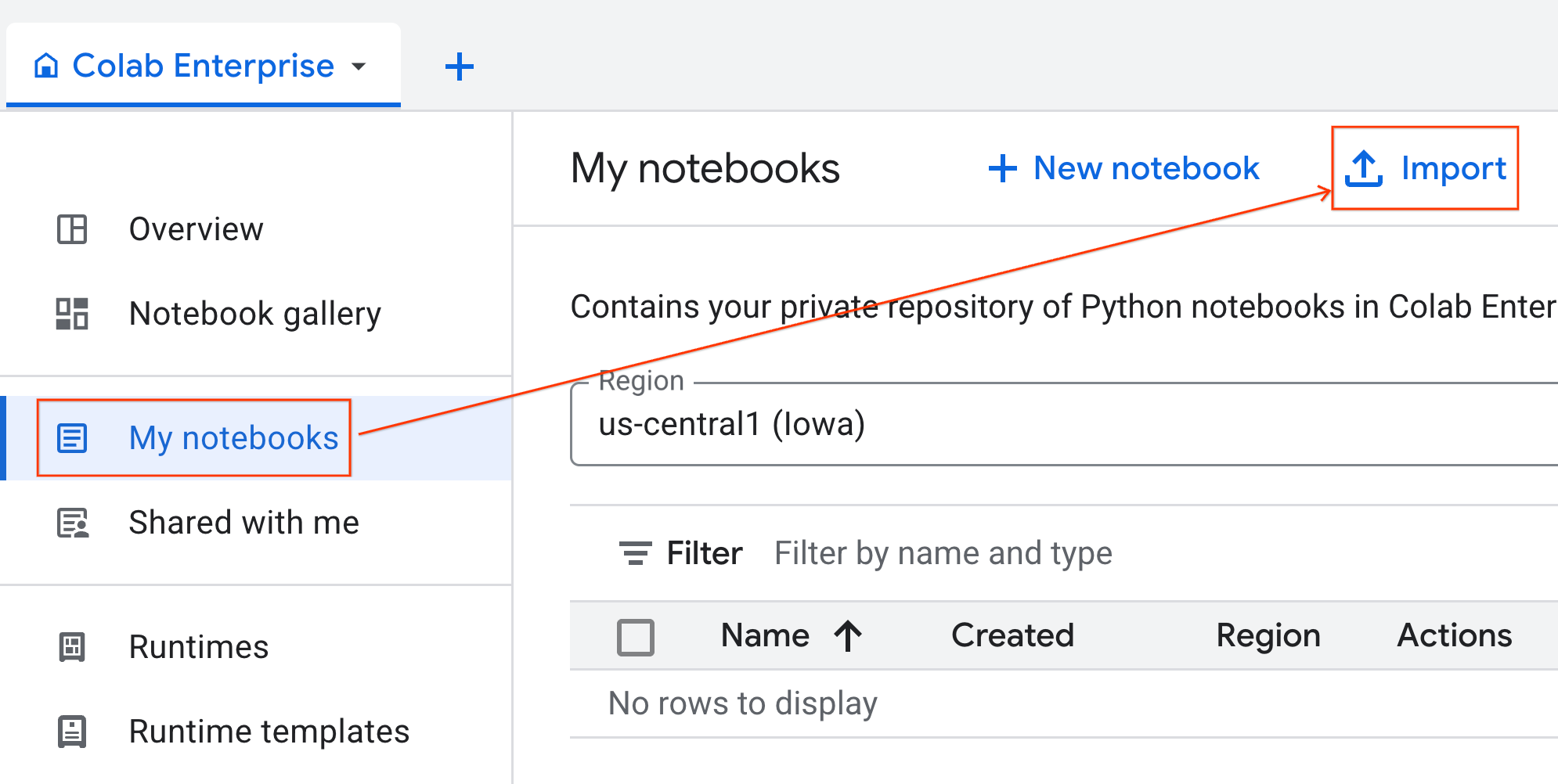
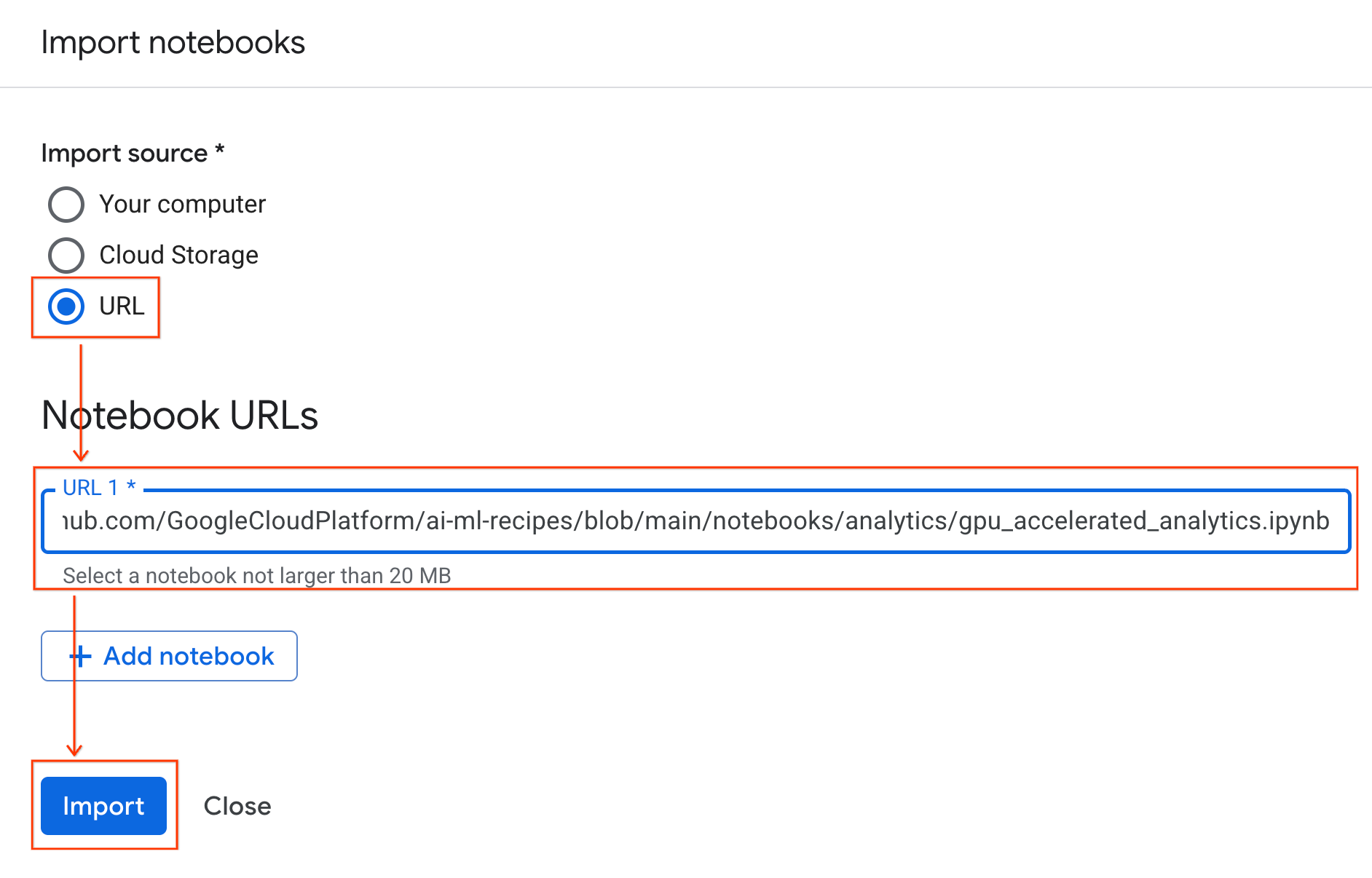
- Zaznacz opcję URL i wpisz ten adres URL:
https://github.com/GoogleCloudPlatform/ai-ml-recipes/blob/main/notebooks/regression/gpu_accelerated_regression/gpu_accelerated_regression.ipynb
- Kliknij Importuj. Colab Enterprise skopiuje notatnik z GitHuba do Twojego środowiska.
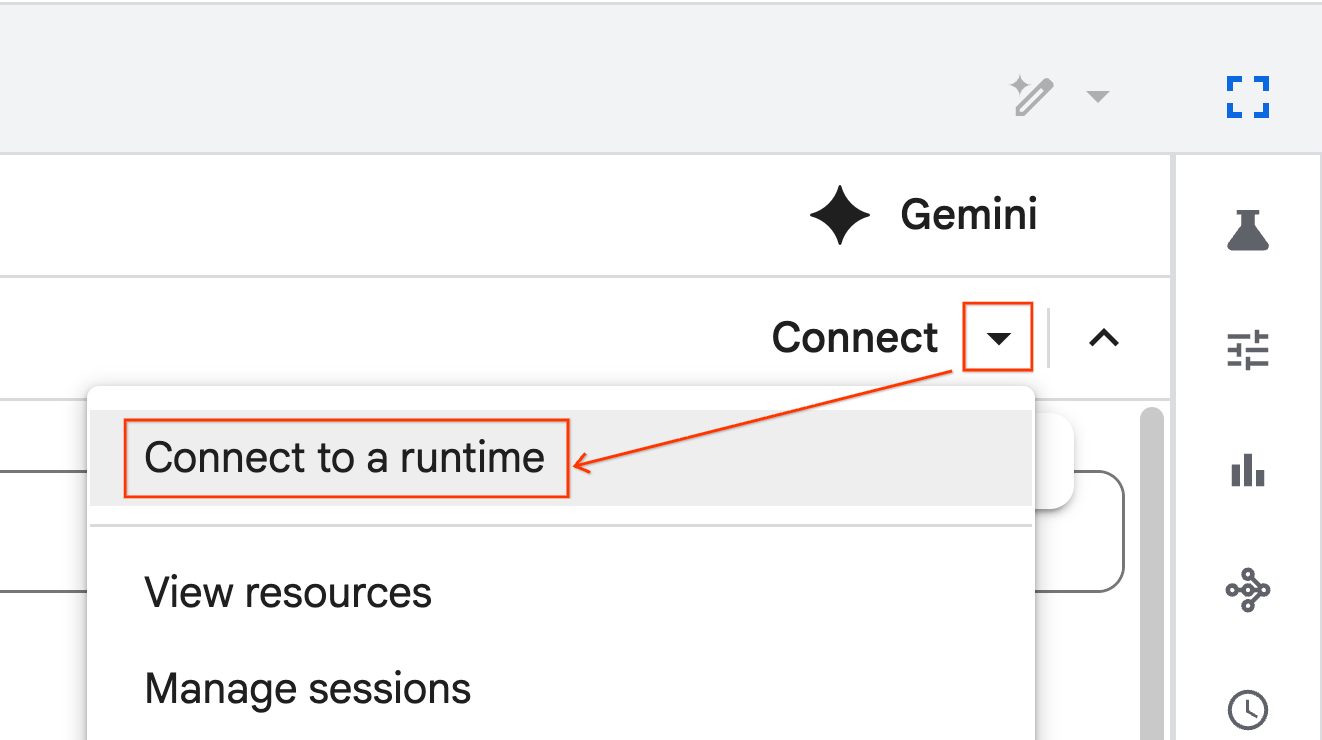
Połącz się ze środowiskiem wykonawczym
- Otwórz nowo zaimportowany notatnik.
- Kliknij strzałkę w dół obok opcji Połącz.
- Kliknij Połącz się ze środowiskiem wykonawczym.
- Użyj menu i wybierz utworzone wcześniej środowisko wykonawcze.
- Kliknij Połącz.
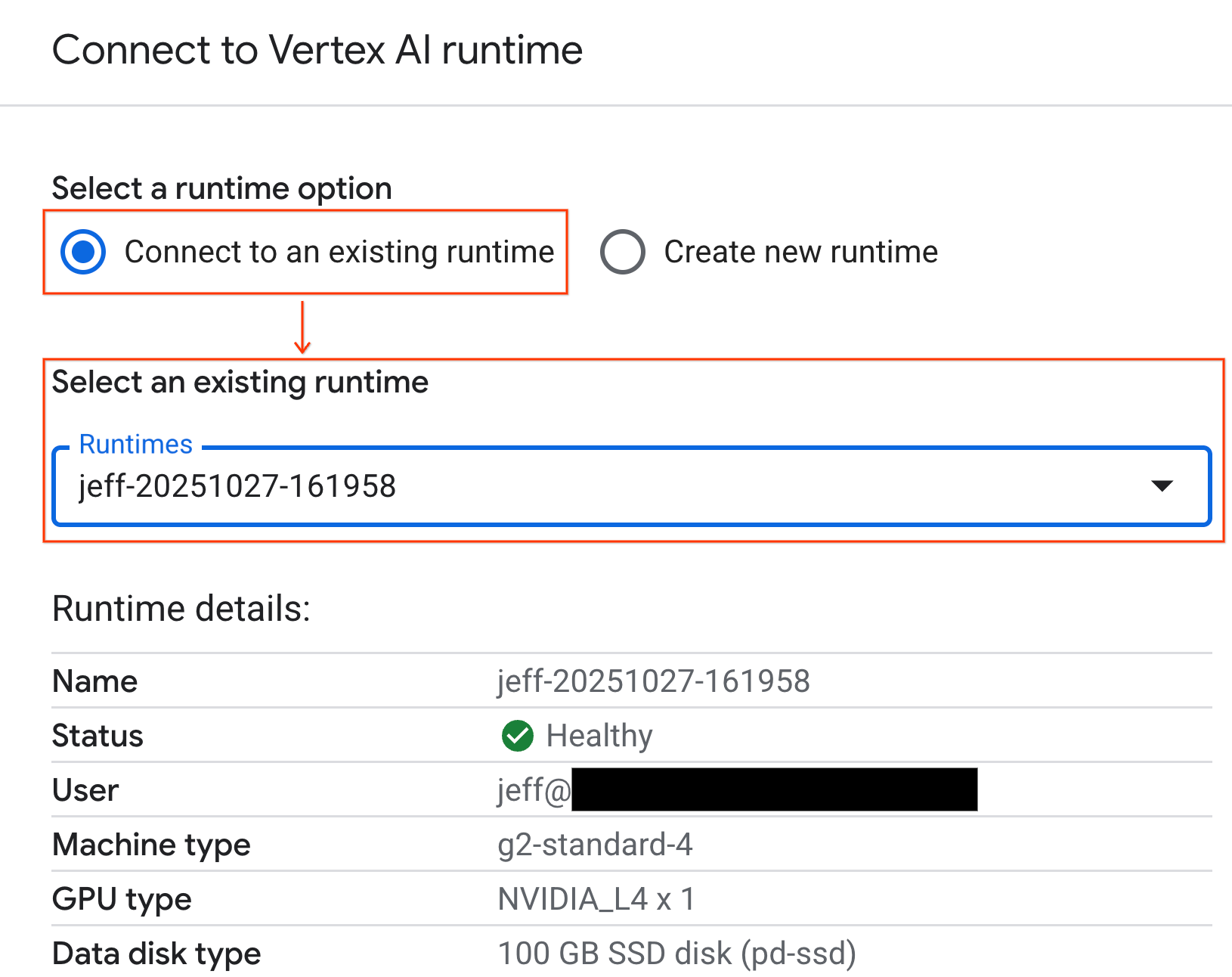
Notatnik jest teraz połączony ze środowiskiem wykonawczym z obsługą GPU.
Wbudowane zależności
Jedną z zalet korzystania z Colab Enterprise jest to, że zawiera ona wstępnie zainstalowane biblioteki, których potrzebujesz. W tym module nie musisz ręcznie instalować zależności ani nimi zarządzać, np. cuDF, cuML czy XGBoost.
8. Przygotowywanie zbioru danych o taksówkach w Nowym Jorku
W tym ćwiczeniu użyjemy danych o przejazdach taksówkami i limuzynami z komisji NYC Taxi & Limousine Commission (TLC). Zbiór danych zawiera rekordy przejazdów żółtymi taksówkami w Nowym Jorku, w tym:
- daty, godziny i miejsca odbioru i zwrotu;
- Dystans podróży
- Szczegółowe kwoty opłat
- Liczba pasażerów
- kwoty napiwków (to właśnie będziemy prognozować);
Konfigurowanie procesora GPU i potwierdzanie dostępności
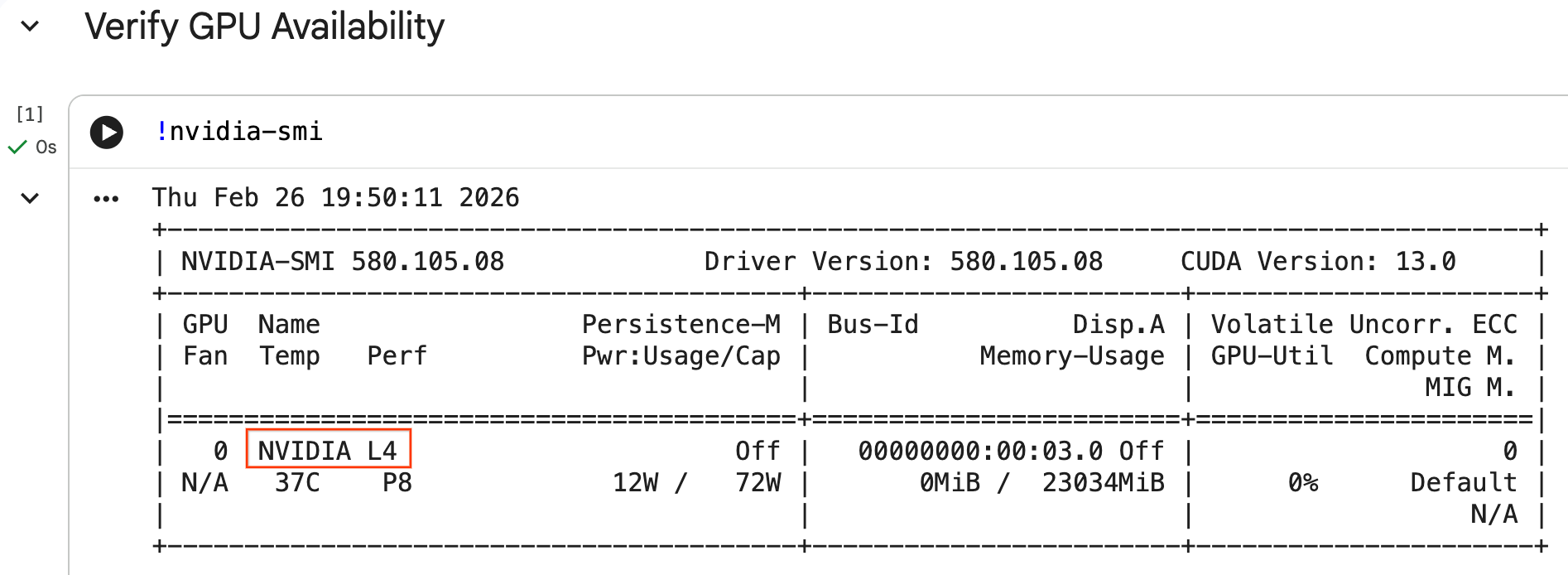
Aby sprawdzić, czy procesor graficzny jest rozpoznawany, uruchom polecenie nvidia-smi. Wyświetla wersję sterownika i szczegóły GPU (np. NVIDIA L4).
nvidia-smi
Komórka powinna zwrócić GPU dołączony do środowiska wykonawczego, podobnie jak w tym przykładzie:
Pobierz dane
Pobierz dane o podróżach za 2024 r.
from tqdm import tqdm
import requests
import time
import os
YEAR = 2024
DATA_DIR = "nyc_taxi_data"
os.makedirs(DATA_DIR, exist_ok=True)
print(f"Checking/Downloading files for {YEAR}...")
for month in tqdm(range(1, 13), unit="file"):
file_name = f"yellow_tripdata_{YEAR}-{month:02d}.parquet"
local_path = os.path.join(DATA_DIR, file_name)
url = f"https://d37ci6vzurychx.cloudfront.net/trip-data/{file_name}"
if not os.path.exists(local_path):
try:
with requests.get(url, stream=True) as response:
response.raise_for_status()
with open(local_path, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
time.sleep(1)
except requests.exceptions.HTTPError as e:
print(f"\nSkipping {file_name}: {e}")
if os.path.exists(local_path):
os.remove(local_path)
print("\nDownload complete.")
Przyspiesz pandas dzięki NVIDIA cuDF
Biblioteka pandas działa na procesorze i może być wolna w przypadku dużych zbiorów danych. Polecenie magiczne NVIDIA %load_ext cudf.pandas dynamicznie poprawia bibliotekę pandas, aby korzystać z akceleracji GPU, a w razie potrzeby wraca do procesora.
Używamy tego magicznego polecenia zamiast standardowego importu, ponieważ zapewnia ono przyspieszenie „bez zmiany kodu”. Nie musisz przepisywać żadnego z dotychczasowych kodów. Podobne polecenie %load_ext cuml.accel robi dokładnie to samo w przypadku scikit-learn models. Działa to w każdym środowisku Jupyter z kompatybilnym procesorem graficznym NVIDIA, nie tylko w Colab Enterprise.
%load_ext cudf.pandas
Aby sprawdzić, czy jest aktywny, zaimportuj pandas i sprawdź jego typ:
import pandas as pd
pd
Dane wyjściowe potwierdzą, że używasz teraz modułu cudf.pandas.
Wczytywanie i czyszczenie danych
Gdy cudf.pandas jest aktywne, wczytaj pliki Parquet i wykonaj czyszczenie danych. Ten proces jest automatycznie uruchamiany na procesorze graficznym.
import glob
# Load data into memory
df = pd.concat(
[pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")],
ignore_index=True
)
# Filter for valid trips. We filter for payment_type=1 (credit card)
# because tip amounts are only reliably recorded for credit card transactions.
df = df[
(df['fare_amount'] > 0) & (df['fare_amount'] < 500) &
(df['trip_distance'] > 0) & (df['trip_distance'] < 100) &
(df['tip_amount'] >= 0) & (df['tip_amount'] < 100) &
(df['payment_type'] == 1)
].copy()
# Downcast numeric columns to save memory
float_cols = df.select_dtypes(include=['float64']).columns
df[float_cols] = df[float_cols].astype('float32')
int_cols = df.select_dtypes(include=['int64']).columns
df[int_cols] = df[int_cols].astype('int32')
Inżynieria cech
Utwórz cechy pochodne na podstawie daty i godziny odbioru. Notatnik zawiera inne funkcje, które będą używane w dalszych krokach.
import numpy as np
# Time Features
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['dow'] = df['tpep_pickup_datetime'].dt.dayofweek
df['is_weekend'] = (df['dow'] >= 5).astype(int)
df['is_rush_hour'] = (
((df['hour'] >= 7) & (df['hour'] <= 9)) |
((df['hour'] >= 17) & (df['hour'] <= 19))
).astype(int)
...
# Other features
...
9. Trenowanie poszczególnych modeli z walidacją krzyżową
Aby pokazać, jak procesor GPU może przyspieszyć uczenie maszynowe, wytrenujesz 3 różne typy modeli regresji, aby przewidzieć tip_amount przejazdu taksówką.
Przyspiesz scikit-learn dzięki NVIDIA cuML
Uruchamiaj algorytmy scikit-learn na GPU za pomocą biblioteki NVIDIA cuML bez zmiany wywołań interfejsu API. Najpierw wczytaj rozszerzenie cuml.accel.
%load_ext cuml.accel
Ustawianie funkcji i celów
Wskaż funkcje, na podstawie których model ma się uczyć, i wydziel kolumnę docelową (tip_amount).
feature_cols = [
'trip_distance', 'fare_amount', 'passenger_count',
'hour', 'dow', 'is_weekend', 'is_rush_hour',
'fare_log', 'fare_decimal', 'is_round_fare',
'route_frequency', 'pu_tip_mean', 'pu_tip_std',
'PULocationID', 'DOLocationID'
]
X = df[feature_cols].fillna(df[feature_cols].median())
y = df['tip_amount'].copy()
Skonfiguruj podziały w ramach walidacji krzyżowej, aby dokładnie ocenić skuteczność modelu.
from sklearn.model_selection import KFold
import numpy as np
import time
from sklearn.metrics import mean_squared_error
from tqdm.notebook import tqdm
n_splits = 3
kf = KFold(n_splits=n_splits, shuffle=True, random_state=42)
1. XGBoost
XGBoost ma natywną akcelerację GPU. Przekaż tree_method='hist' i device='cuda', aby używać GPU podczas trenowania.
import xgboost as xgb
start_time = time.perf_counter()
def train_xgb_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# XGBoost handles GPU natively when tree_method='hist' and device='cuda'
model = xgb.XGBRegressor(
objective='reg:squarederror',
max_depth=5,
learning_rate=0.1,
n_estimators=100,
tree_method='hist',
device='cuda',
random_state=42
)
model.fit(X_train, y_train)
preds = model.predict(X_val)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
xgb_rmse, xgb_preds = train_xgb_cv(X, y)
print(f"\n{'XGBoost RMSE:':<20} ${xgb_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
2. Regresja liniowa
Wytrenuj model regresji liniowej. Gdy %load_ext cuml.accel jest aktywny, LinearRegression jest automatycznie mapowany na odpowiednik GPU.
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
start_time = time.perf_counter()
def train_linreg_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# Scale features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_val_scaled = scaler.transform(X_val)
# Automatically accelerated by cuML
model = LinearRegression()
model.fit(X_train_scaled, y_train)
preds = model.predict(X_val_scaled)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
linreg_rmse, linreg_preds = train_linreg_cv(X, y)
print(f"\n{'Linear Reg RMSE:':<20} ${linreg_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
3. Random Forest
Wytrenuj model zespołu za pomocą RandomForestRegressor. Trenowanie modeli opartych na drzewach na procesorze CPU jest często powolne, ale przyspieszenie za pomocą GPU umożliwia szybsze przetwarzanie milionów wierszy.
from sklearn.ensemble import RandomForestRegressor
start_time = time.perf_counter()
def train_rf_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# Automatically accelerated by cuML
model = RandomForestRegressor(
n_estimators=100,
max_depth=10,
n_jobs=-1,
max_features='sqrt',
random_state=42
)
model.fit(X_train, y_train)
preds = model.predict(X_val)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
rf_rmse, rf_preds = train_rf_cv(X, y)
print(f"\n{'Random Forest RMSE:':<20} ${rf_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
10. Ocena całego procesu
Połącz prognozy z 3 modeli za pomocą prostego zespołu liniowego. Zwykle zapewnia to niewielki wzrost dokładności w porównaniu z poszczególnymi modelami.
Dopasuj regresję liniową do prognoz, aby znaleźć optymalne wagi:
ensemble_weights = LinearRegression(positive=True, fit_intercept=False).fit(
np.c_[xgb_preds, rf_preds, linreg_preds], y
).coef_
# Normalize weights
ensemble_weights = ensemble_weights / ensemble_weights.sum()
ensemble_preds = np.c_[xgb_preds, rf_preds, linreg_preds] @ ensemble_weights
ensemble_rmse = np.sqrt(mean_squared_error(y, ensemble_preds))
Porównaj wyniki, aby zobaczyć wzrost zespołu:
print(f"\n{'Model':<20} {'RMSE':>10}")
print("-" * 32)
print(f"{'Linear Regression':<20} ${linreg_rmse:>9.4f}")
print(f"{'Random Forest':<20} ${rf_rmse:>9.4f}")
print(f"{'XGBoost':<20} ${xgb_rmse:>9.4f}")
print("-" * 32)
print(f"{'Ensemble':<20} ${ensemble_rmse:>9.4f}")
print(f"\nEnsemble lift: ${xgb_rmse - ensemble_rmse:.4f}")
11. Porównywanie wydajności procesora i procesora graficznego
Aby prawidłowo porównać różnice w wydajności, musisz ponownie uruchomić jądro systemu (operacyjnego), aby zapewnić czysty stan wykonania, uruchomić cały potok nauki o danych na procesorze, a następnie stosować go ponownie na GPU.
Ponowne uruchamianie jądra
Uruchom polecenie IPython.Application.instance().kernel.do_shutdown(True), aby ponownie uruchomić jądro i zwolnić pamięć.
import IPython
IPython.Application.instance().kernel.do_shutdown(True)
Określanie potoku nauki o danych
Zapakuj podstawowy przepływ pracy (wczytywanie danych, oczyszczanie, inżynieria cech i trenowanie modelu) w jedną funkcję. Ta funkcja przyjmuje moduł pandas pd_module i argument use_gpu, aby przełączać się między środowiskami.
def run_ml_pipeline(pd_module, use_gpu=False):
import time
import glob
import numpy as np
from sklearn.ensemble import RandomForestRegressor
import xgboost as xgb
timings = {}
# 1. Load Data
t0 = time.perf_counter()
df = pd_module.concat(
[pd_module.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")],
ignore_index=True
)
timings['Load Data'] = time.perf_counter() - t0
# 2. Clean Data
t0 = time.perf_counter()
# Filter for payment_type=1 (credit card) because tip amounts
# are only reliably recorded for credit card transactions.
df = df[
(df['fare_amount'] > 0) & (df['fare_amount'] < 500) &
(df['trip_distance'] > 0) & (df['trip_distance'] < 100) &
(df['tip_amount'] >= 0) & (df['tip_amount'] < 100) &
(df['payment_type'] == 1)
].copy()
# Downcast numeric columns to save memory
float_cols = df.select_dtypes(include=['float64']).columns
df[float_cols] = df[float_cols].astype('float32')
int_cols = df.select_dtypes(include=['int64']).columns
df[int_cols] = df[int_cols].astype('int32')
timings['Clean Data'] = time.perf_counter() - t0
# 3. Feature Engineering
t0 = time.perf_counter()
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['dow'] = df['tpep_pickup_datetime'].dt.dayofweek
df['is_weekend'] = (df['dow'] >= 5).astype(int)
df['fare_log'] = np.log1p(df['fare_amount'])
timings['Feature Engineering'] = time.perf_counter() - t0
# 4. Modeling Prep
feature_cols = ['trip_distance', 'fare_amount', 'passenger_count', 'hour', 'dow', 'is_weekend', 'fare_log']
X = df[feature_cols].fillna(df[feature_cols].median())
y = df['tip_amount'].copy()
# Free memory
del df
import gc
gc.collect()
# 5. Train Random Forest
t0 = time.perf_counter()
rf_model = RandomForestRegressor(
n_estimators=100,
max_depth=10,
n_jobs=-1,
max_features='sqrt',
random_state=42
).fit(X, y)
timings['Train Random Forest'] = time.perf_counter() - t0
# 6. Train XGBoost
t0 = time.perf_counter()
params = {
'objective': 'reg:squarederror',
'max_depth': 5,
'n_estimators': 100,
'random_state': 42
}
if use_gpu:
params['device'] = 'cuda'
params['tree_method'] = 'hist'
xgb_model = xgb.XGBRegressor(**params).fit(X, y)
timings['Train XGBoost'] = time.perf_counter() - t0
del X
del y
gc.collect()
return timings
Uruchamianie na procesorze
Wywołaj potok za pomocą standardowego procesora pandas.
import pandas as pd
print("Running pipeline on CPU...")
cpu_times = run_ml_pipeline(pd, use_gpu=False)
print("CPU Execution Finished.")
Uruchamianie na GPU
Załaduj rozszerzenia biblioteki NVIDIA, przekaż do potoku przyspieszony moduł cudf.pandas i ustaw wewnętrznie urządzenie XGBoost na cuda.
import IPython.core.magic
if not hasattr(IPython.core.magic, 'output_can_be_silenced'):
IPython.core.magic.output_can_be_silenced = lambda x: x
%load_ext cudf.pandas
%load_ext cuml.accel
import pandas as pd
print("Running pipeline on GPU...")
gpu_times = run_ml_pipeline(pd, use_gpu=True)
print("GPU Execution Finished.")
Wizualizacja przyspieszenia wydajności
Wizualizuj terminy za pomocą ikony matplotlib. Wyniki pokazują czas zaoszczędzony podczas przetwarzania danych i trenowania modeli przy użyciu procesorów GPU.
import matplotlib.pyplot as plt
import numpy as np
labels = list(cpu_times.keys())
cpu_values = list(cpu_times.values())
gpu_values = list(gpu_times.values())
x = np.arange(len(labels))
width = 0.35
fig, ax = plt.subplots(figsize=(10, 6))
rects1 = ax.bar(x - width/2, cpu_values, width, label='CPU', color='#4285F4')
rects2 = ax.bar(x + width/2, gpu_values, width, label='GPU', color='#76B900')
ax.set_ylabel('Execution Time (seconds)')
ax.set_title('NYC Taxi ML Pipeline: CPU vs. GPU Performance')
ax.set_xticks(x)
ax.set_xticklabels(labels, rotation=45, ha="right")
ax.legend()
# Add data labels
def autolabel(rects):
for rect in rects:
height = rect.get_height()
ax.annotate(f'{height:.2f}s',
xy=(rect.get_x() + rect.get_width() / 2, height),
xytext=(0, 3), # 3 points vertical offset
textcoords="offset points",
ha='center', va='bottom', fontsize=9)
autolabel(rects1)
autolabel(rects2)
plt.tight_layout()
plt.show()
# Calculate overall speedup
total_cpu_time = sum(cpu_values)
total_gpu_time = sum(gpu_values)
overall_speedup = total_cpu_time / total_gpu_time
print(f"\nOverall Pipeline Speedup: {overall_speedup:.2f}x faster on GPU!")
Powinien pojawić się ekran podobny do tego:
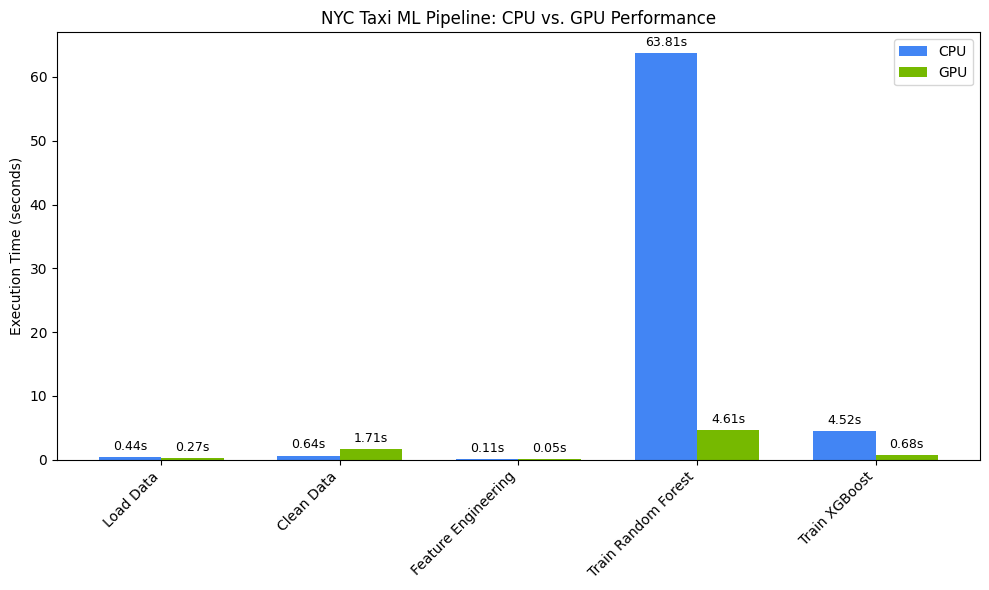
Ten wykres pokazuje znaczną przewagę wydajnościową GPU w całym przepływie pracy związanym z badaniem danych. Największe oszczędności czasu powinny być widoczne podczas wymagających obliczeniowo faz trenowania modeli w przypadku algorytmów takich jak Random Forest i XGBoost.
12. Profilowanie kodu w celu znalezienia ograniczeń wydajności
W przypadku korzystania z cudf.pandas większość funkcji jest uruchamiana na procesorze graficznym. Jeśli określona operacja nie jest jeszcze obsługiwana przez cuDF, wykonanie tymczasowo wraca do procesora. NVIDIA udostępnia 2 wbudowane polecenia magiczne Jupyter, które pomagają identyfikować te rezerwowe opcje.
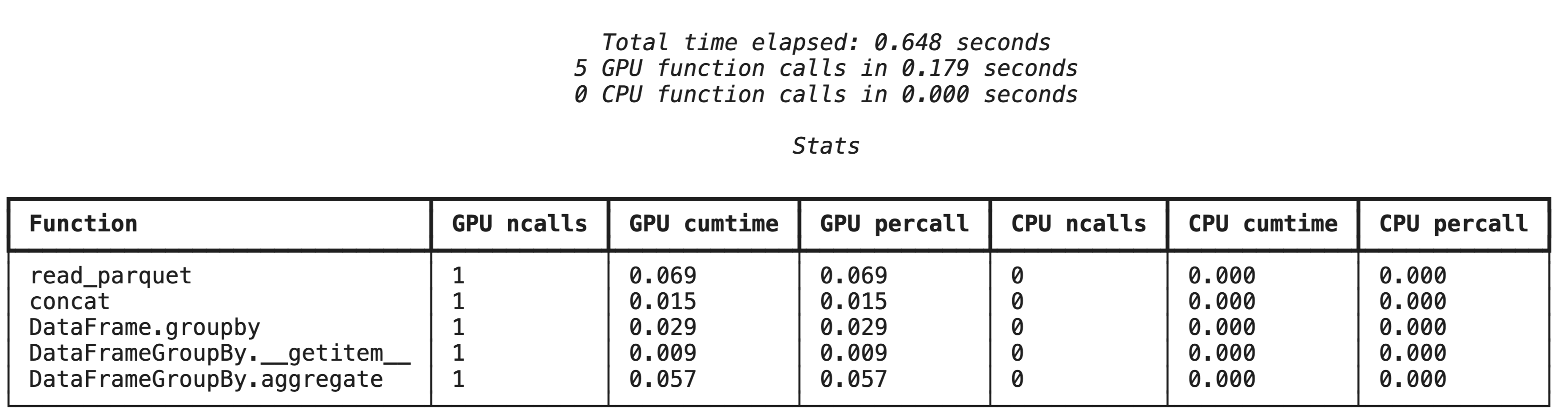
Profilowanie wysokiego poziomu za pomocą %%cudf.pandas.profile
Polecenie magiczne %%cudf.pandas.profile zawiera podsumowanie funkcji, które zostały uruchomione na procesorze lub karcie graficznej.
%%cudf.pandas.profile
import glob
import pandas as pd
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")], ignore_index=True)
summary = (
df
.groupby(['PULocationID', 'payment_type'])
[['passenger_count', 'fare_amount', 'tip_amount']]
.agg(['min', 'mean', 'max'])
)
Profilowanie wiersz po wierszu za pomocą %%cudf.pandas.line_profile
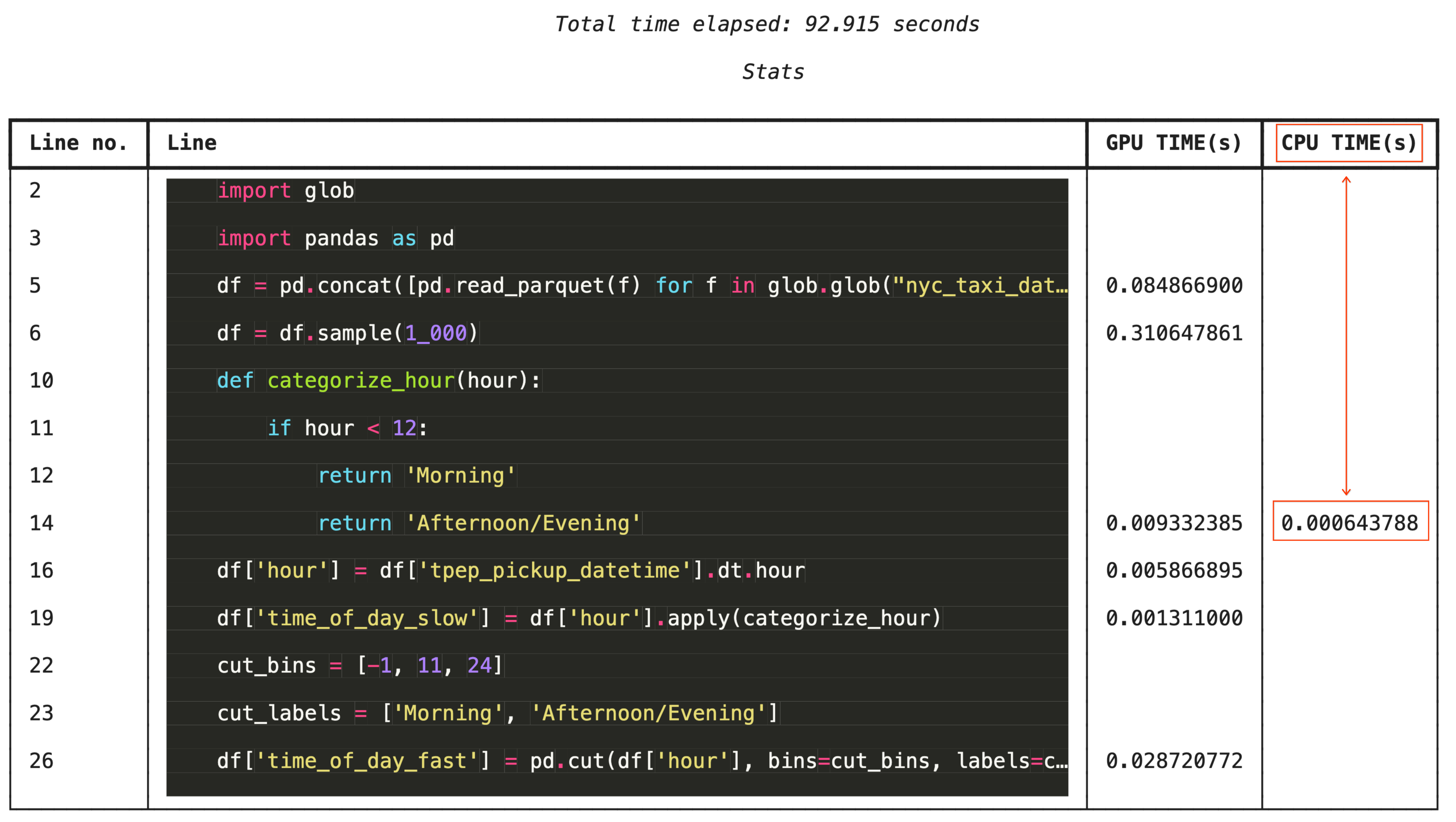
Aby ułatwić szczegółowe rozwiązywanie problemów, %%cudf.pandas.line_profile dodaje do każdego wiersza kodu adnotację z liczbą wykonań na GPU i CPU.
%%cudf.pandas.line_profile
import glob
import pandas as pd
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")], ignore_index=True)
df = df.sample(1_000)
# Iterating row-by-row or using custom python apply functions often falls back to the CPU
def categorize_hour(hour):
if hour < 12:
return 'Morning'
else:
return 'Afternoon/Evening'
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['time_of_day_slow'] = df['hour'].apply(categorize_hour)
# Using vectorized pandas operations (like pd.cut) stays entirely on the GPU
cut_bins = [-1, 11, 24]
cut_labels = ['Morning', 'Afternoon/Evening']
df['time_of_day_fast'] = pd.cut(df['hour'], bins=cut_bins, labels=cut_labels)
13. Czyszczenie
Aby uniknąć nieoczekiwanych opłat na koncie Google Cloud, zwalniaj miejsce, usuwając zasoby utworzone podczas tego ćwiczenia.
Usuwanie zasobów
Usuń lokalny zbiór danych w środowisku wykonawczym za pomocą polecenia !rm -rf w komórce notatnika.
print("Deleting local 'nyc_taxi_data' directory...")
!rm -rf nyc_taxi_data
print("Local files deleted.")
Wyłączanie środowiska wykonawczego Colab
- W konsoli Google Cloud otwórz stronę Colab Enterprise Runtimes (Środowiska wykonawcze).
- W menu Region wybierz region, w którym znajduje się środowisko wykonawcze.
- Wybierz czas działania, który chcesz usunąć.
- Kliknij Usuń.
- Kliknij Potwierdź.
Usuwanie notatnika
- W konsoli Google Cloud otwórz stronę Colab Enterprise Moje notatniki.
- W menu Region wybierz region, w którym znajduje się Twój notatnik.
- Wybierz notatnik, który chcesz usunąć.
- Kliknij Usuń.
- Kliknij Potwierdź.
14. Gratulacje
Gratulacje! Udało Ci się przyspieszyć przepływ pracy związany z uczeniem maszynowym pandas i scikit-learn za pomocą bibliotek NVIDIA cuDF i cuML w Colab Enterprise. Wystarczy dodać kilka magicznych poleceń (%load_ext cudf.pandas i %load_ext cuml.accel), aby standardowy kod działał na procesorze graficznym, przetwarzając rekordy i dopasowując złożone modele lokalnie w ułamku czasu.
Więcej informacji o przyspieszaniu analizy danych za pomocą procesorów graficznych znajdziesz w samouczku Accelerated Data Analytics with GPUs (Przyspieszona analiza danych za pomocą procesorów graficznych).
Omówione zagadnienia
- Informacje o Colab Enterprise w Google Cloud.
- Dostosowywanie środowiska wykonawczego Colab za pomocą określonych konfiguracji procesora graficznego i pamięci.
- Zastosowanie akceleracji GPU do prognozowania kwot napiwków na podstawie milionów rekordów ze zbioru danych NYC Taxi.
- Przyspieszanie
pandasbez wprowadzania zmian w kodzie za pomocą bibliotekicuDFfirmy NVIDIA. - Przyspieszanie
scikit-learnbez wprowadzania zmian w kodzie za pomocą bibliotekicuMLfirmy NVIDIA i procesorów graficznych. - profilowanie kodu w celu identyfikowania i optymalizowania ograniczeń wydajności;