
1. Introdução
Neste codelab, você vai aprender a acelerar seus fluxos de trabalho de ciência de dados e machine learning em grandes conjuntos de dados usando GPUs NVIDIA e bibliotecas de código aberto no Google Cloud. Você vai começar configurando sua infraestrutura e depois vai aprender a aplicar a aceleração de GPU.
Você vai se concentrar no ciclo de vida da ciência de dados, desde a preparação de dados com pandas até o treinamento de modelos com scikit-learn e XGBoost. Você vai aprender a acelerar essas tarefas usando as bibliotecas cuDF e cuML da NVIDIA. A melhor parte é que você pode aproveitar essa aceleração de GPU sem mudar o código pandas ou scikit-learn atual.
O que você vai aprender
- Entenda o Colab Enterprise no Google Cloud.
- Personalize um ambiente de execução do Colab com configurações específicas de GPU e memória.
- Aplique a aceleração de GPU para prever valores de gorjetas usando milhões de registros de um conjunto de dados de táxis de Nova York.
- Acelere o
pandassem fazer mudanças no código usando a bibliotecacuDFda NVIDIA. - Acelere o
scikit-learnsem mudar o código usando a bibliotecacuMLe as GPUs da NVIDIA. - Crie um perfil do seu código para identificar e otimizar restrições de desempenho.
A próxima página inclui créditos que você pode usar para concluir o laboratório.
2. Por que acelerar o machine learning?
A necessidade de iteração mais rápida em ML
A preparação de dados é demorada, e o treinamento de modelo ou a avaliação podem levar ainda mais tempo à medida que os conjuntos de dados crescem. O treinamento de modelos como florestas aleatórias ou XGBoost em milhões de linhas com uma CPU pode levar horas ou dias.
O uso de GPUs acelera essas execuções de treinamento com bibliotecas como cuML e XGBoost acelerado por GPU. Com essa aceleração, você pode:
- Iteração mais rápida:teste novos recursos e hiperparâmetros rapidamente.
- Treine com conjuntos de dados completos:use seus dados completos em vez de fazer subamostragem para aumentar a acurácia.
- Reduzir custos:conclua cargas de trabalho pesadas em menos tempo para diminuir os custos de computação.
3. Configuração e requisitos
Custos potenciais
Este codelab usa recursos do Google Cloud, incluindo tempos de execução do Colab Enterprise com GPUs NVIDIA L4. Esteja ciente de possíveis cobranças e siga a seção Limpeza no final do codelab para desligar recursos e evitar cobranças contínuas. Para informações detalhadas sobre preços, consulte Preços do Colab Enterprise e Preços de GPU.
Antes de começar
É necessário ter familiaridade intermediária com Python, pandas, scikit-learn e práticas padrão de machine learning, como validação cruzada/combinação.
- No Console do Google Cloud, na página de seletor de projetos, selecione ou crie um projeto do Google Cloud.
- Verifique se a cobrança está ativada para o seu projeto do Google Cloud.
Ative as APIs
Para usar o Colab Enterprise, primeiro ative as APIs necessárias.
- Abra o Google Cloud Shell clicando no ícone do Cloud Shell no canto superior direito do console do Google Cloud.

- No Cloud Shell, defina o ID do projeto substituindo
PROJECT_IDpelo ID do projeto:
gcloud config set project <PROJECT_ID>
- Execute o comando a seguir para ativar as APIs necessárias:
gcloud services enable \
compute.googleapis.com \
dataform.googleapis.com \
notebooks.googleapis.com \
aiplatform.googleapis.com
Se a execução for bem-sucedida, você vai receber uma mensagem semelhante a esta:
Operation "operations/..." finished successfully.
4. Como escolher um ambiente de notebook
Embora muitos cientistas de dados estejam familiarizados com o Colab para projetos pessoais, o Colab Enterprise oferece uma experiência de notebook segura, colaborativa e integrada projetada para empresas.
No Google Cloud, você tem duas opções principais de ambientes de notebook gerenciados: o Colab Enterprise e o Gemini Enterprise Agent Platform Workbench. A escolha certa depende das prioridades do seu projeto.
Quando usar o Workbench da plataforma de agentes
Escolha o Agent Platform Workbench quando sua prioridade for controle e personalização avançada. É a opção ideal se você precisa:
- Gerenciar a infraestrutura e o ciclo de vida da máquina.
- Usar contêineres personalizados e configurações de rede.
- Integração com pipelines de MLOps e ferramentas personalizadas de ciclo de vida.
Quando usar o Colab Enterprise
Escolha o Colab Enterprise quando sua prioridade for configuração rápida, facilidade de uso e colaboração segura. É uma solução totalmente gerenciada que permite que sua equipe se concentre na análise em vez da infraestrutura.
O Colab Enterprise ajuda você a:
- Desenvolva fluxos de trabalho de ciência de dados que estejam intimamente ligados ao seu data warehouse. É possível abrir e gerenciar seus notebooks diretamente no BigQuery Studio.
- Treine modelos de machine learning e faça a integração com ferramentas de MLOps na plataforma de agentes.
- Aproveite uma experiência flexível e unificada. Um notebook do Colab Enterprise criado no BigQuery pode ser aberto e executado na plataforma de agentes e vice-versa.
Laboratório de hoje
Este codelab usa o Colab Enterprise para machine learning acelerado.
Para saber mais sobre as diferenças, consulte a documentação oficial sobre como escolher a solução de notebook certa.
5. Configurar um modelo de ambiente de execução
No Colab Enterprise, conecte-se a um ambiente de execução com base em um modelo de ambiente de execução pré-configurado.
Um modelo de ambiente de execução é uma configuração reutilizável que especifica o ambiente do notebook, incluindo:
- Tipo de máquina (CPU, memória)
- Acelerador (tipo e contagem de GPU)
- Tamanho e tipo do disco
- Configurações de rede e políticas de segurança
- Regras de encerramento automático por inatividade
Por que os modelos de ambiente de execução são úteis
- Consistência:você e sua equipe têm o mesmo ambiente para garantir que o trabalho seja repetível.
- Segurança:os modelos aplicam as políticas de segurança da organização.
- Gerenciamento de custos:os recursos são pré-dimensionados no modelo para evitar custos acidentais.
Criar um modelo de ambiente de execução
Configure um modelo de ambiente de execução reutilizável para o laboratório.
- No console do Google Cloud, acesse o Menu de navegação > Plataforma de agentes > Notebooks.
- No Colab Enterprise, clique em Modelos de ambiente de execução e selecione Novo modelo.
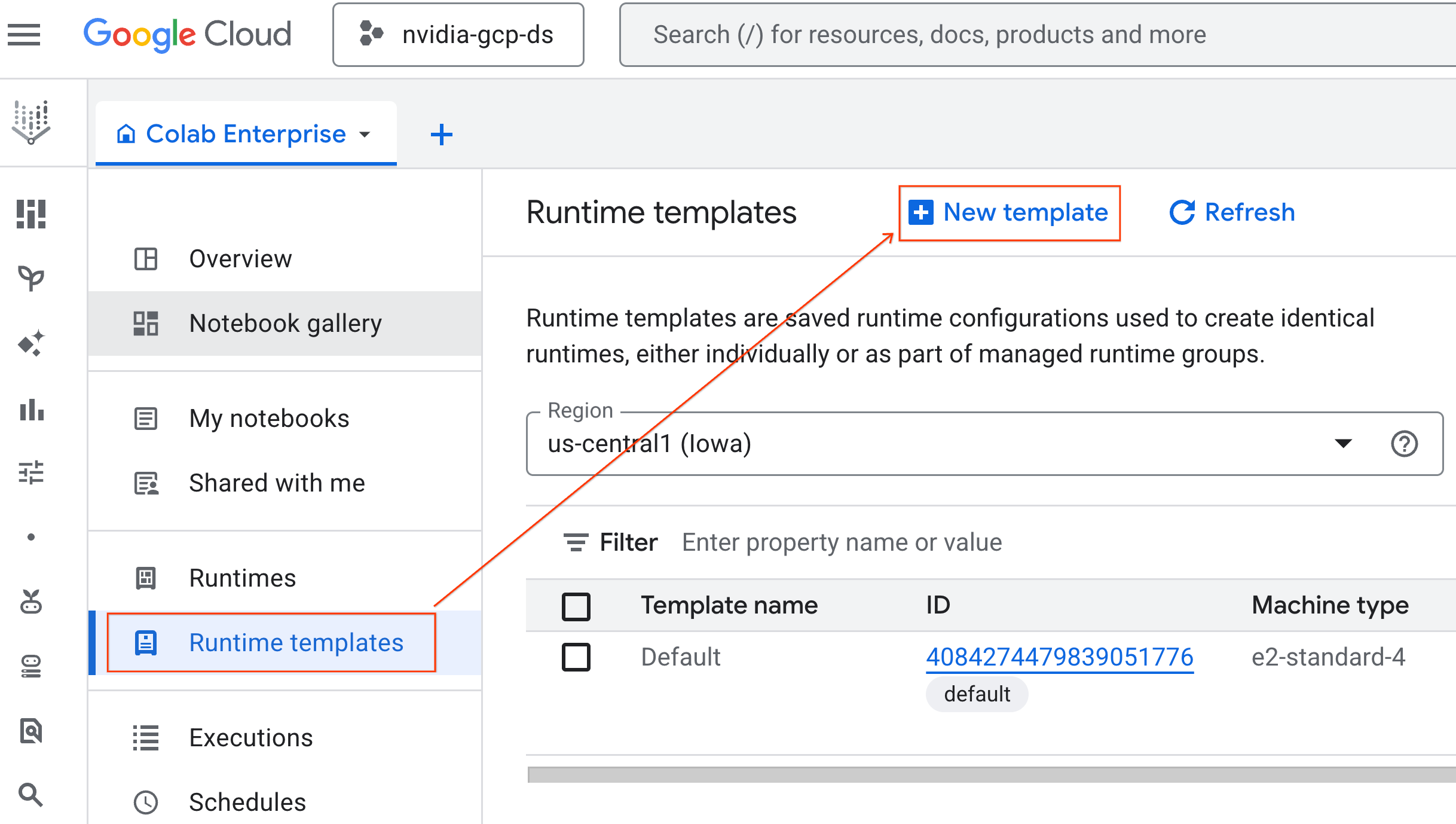
- Em Fundamentos do ambiente de execução:
- Defina o Nome de exibição como
gpu-template. - Defina a região de sua preferência.
- Defina o Nome de exibição como
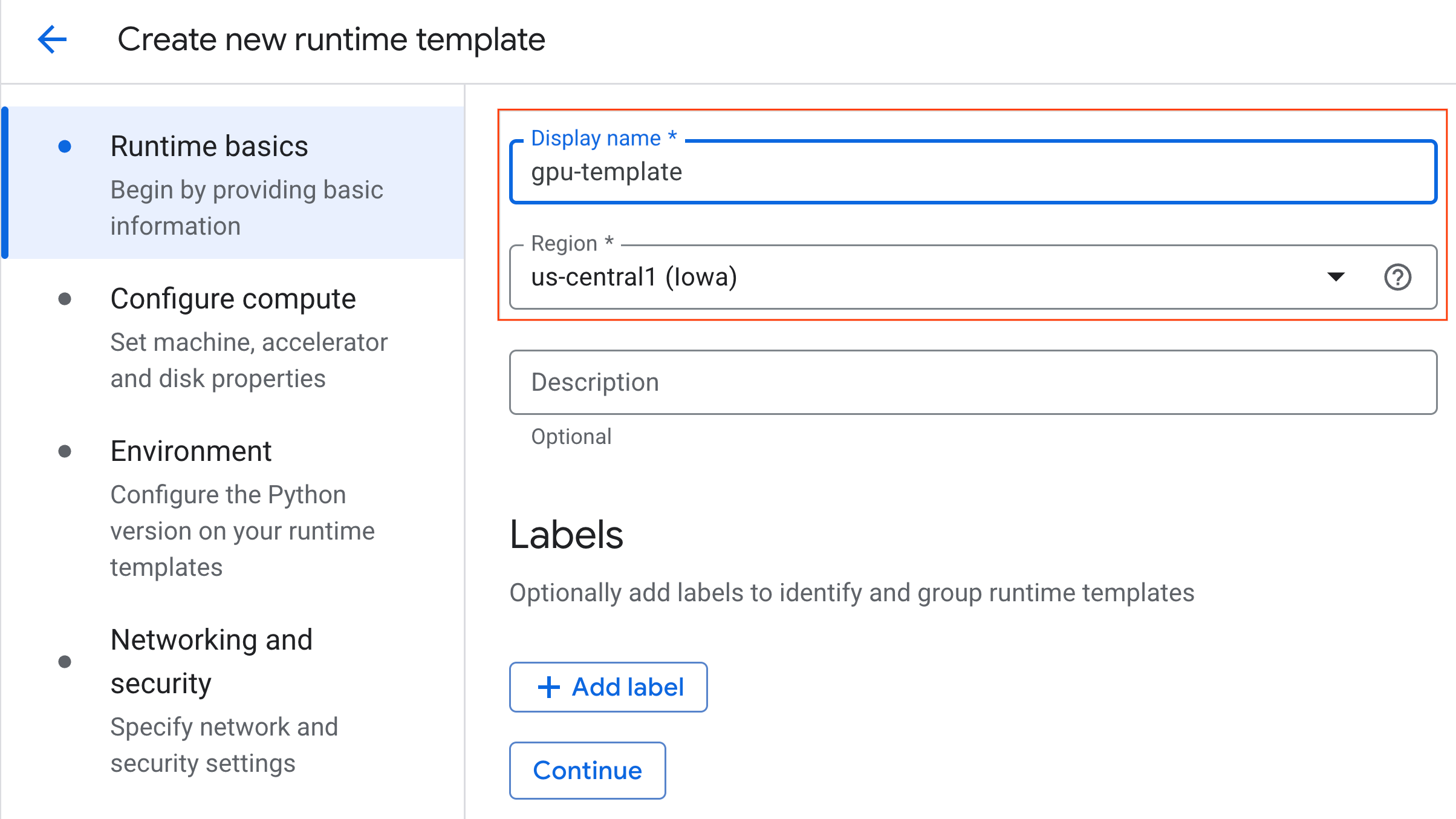
- Em Configurar computação:
- Defina o Tipo de máquina como
g2-standard-4. - Mantenha o Tipo de acelerador padrão como
NVIDIA L4com uma Contagem de aceleradores de 1. - Mude o Encerramento inativo para 60 minutos.
- Clique em Continuar.
- Defina o Tipo de máquina como
- Em Ambiente:
- Defina o ambiente como
Python 3.11
- Defina o ambiente como
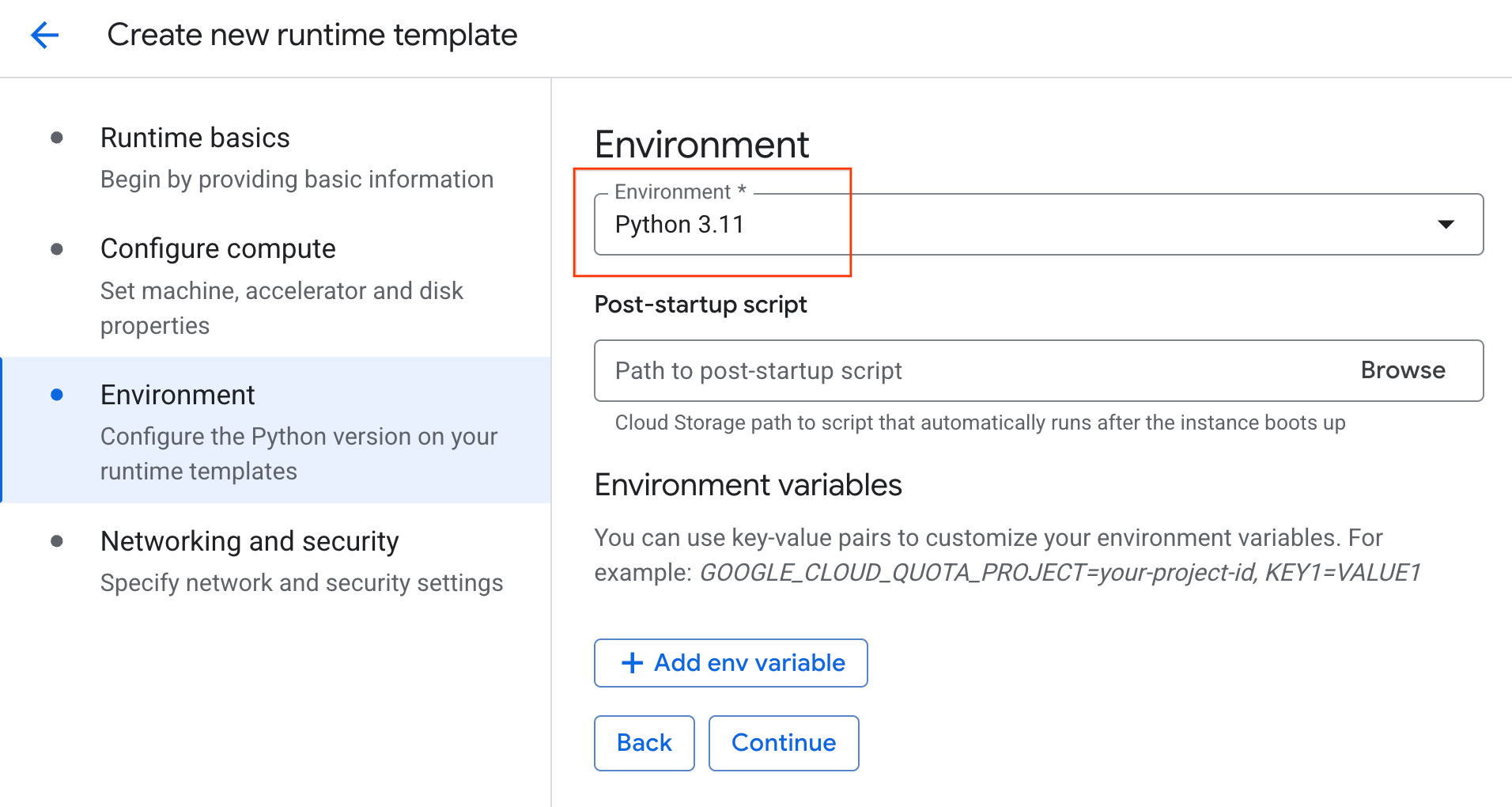
- Clique em Criar para salvar o modelo de ambiente de execução. A página "Modelos de ambiente de execução" agora vai mostrar o novo modelo.
6. Iniciar um ambiente de execução
Com o modelo pronto, você pode criar um novo ambiente de execução.
- No Colab Enterprise, clique em Tempos de execução e selecione Criar.
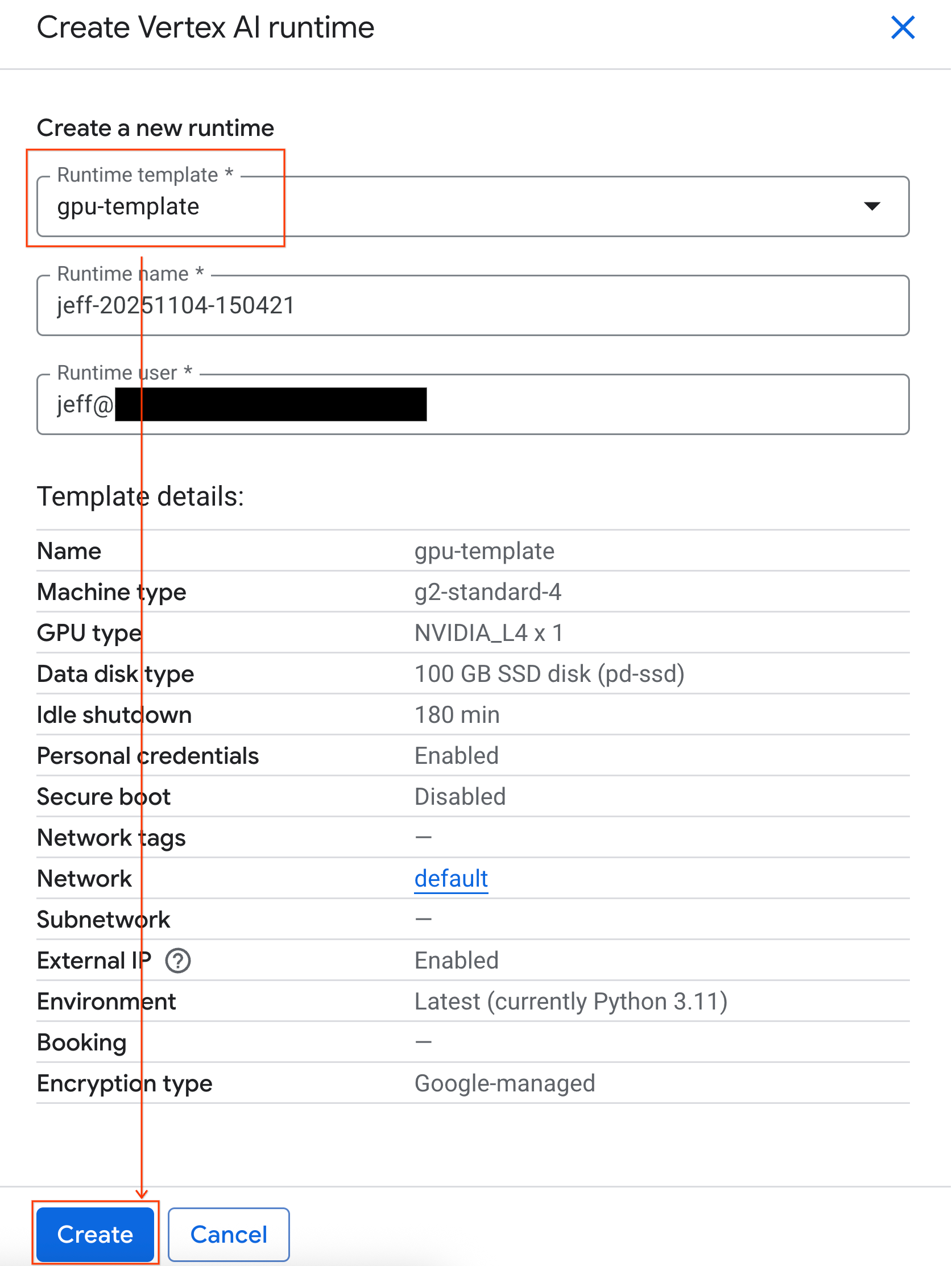
- Em Modelo de execução, selecione a opção
gpu-template. Clique em Criar e aguarde a inicialização do ambiente de execução.
- Depois de alguns minutos, o tempo de execução vai aparecer.
7. configurar o notebook
Agora que sua infraestrutura está em execução, importe o notebook do laboratório e conecte-o ao ambiente de execução.
Importar o notebook
- No Colab Enterprise, clique em Meus notebooks e em Importar.
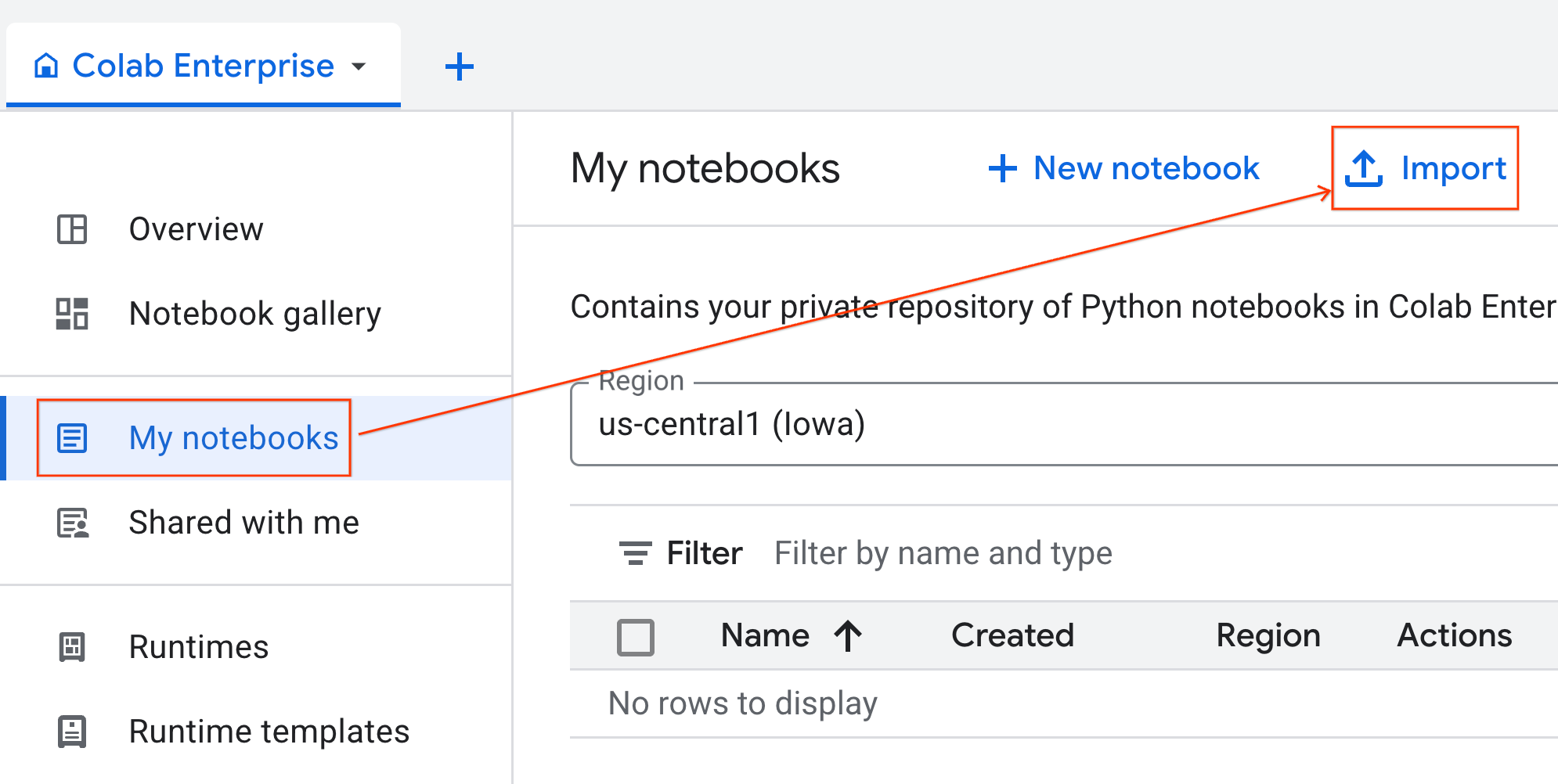
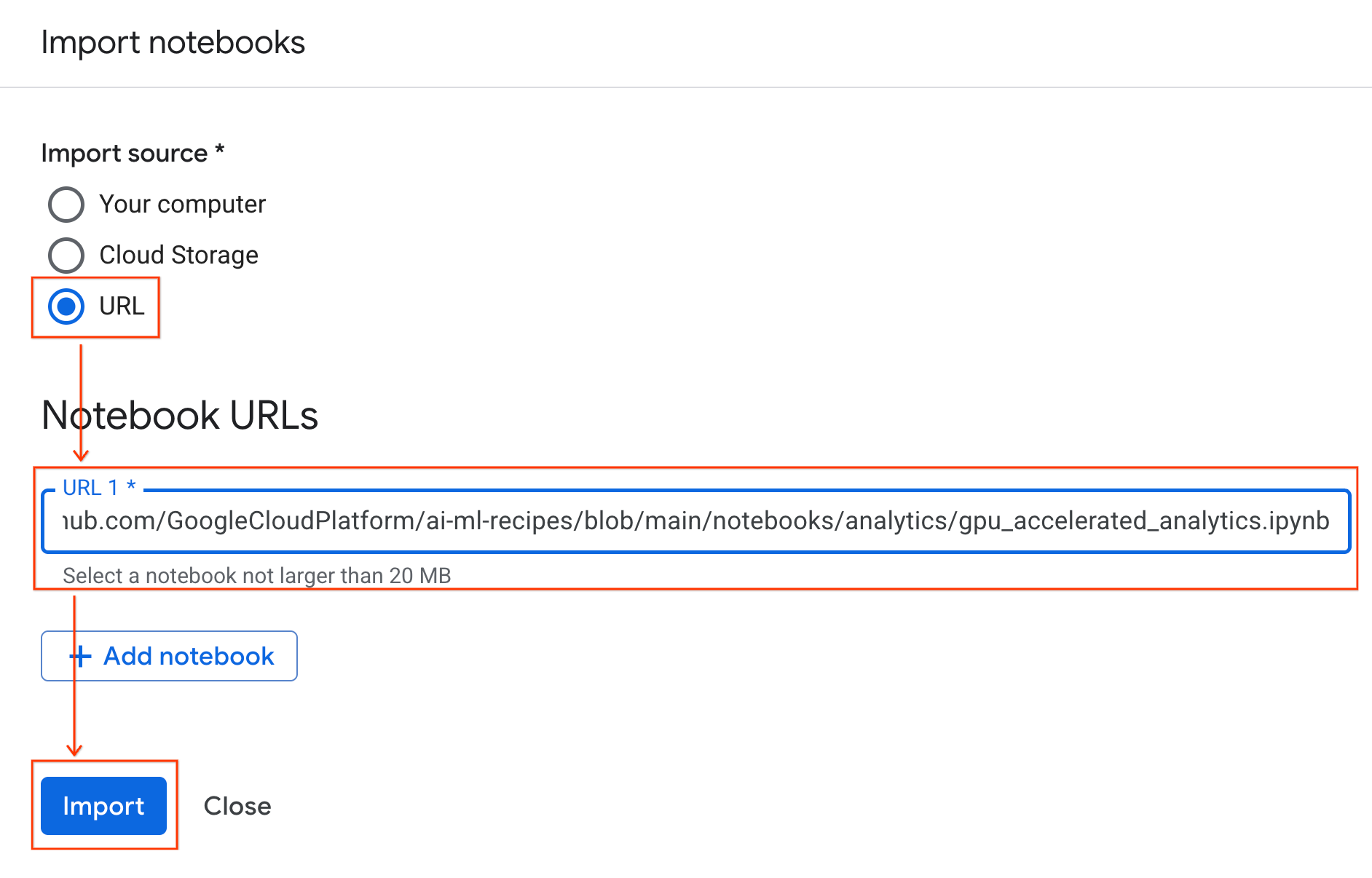
- Selecione o botão de opção URL e insira o seguinte URL:
https://github.com/GoogleCloudPlatform/ai-ml-recipes/blob/main/notebooks/regression/gpu_accelerated_regression/gpu_accelerated_regression.ipynb
- Clique em Importar. O Colab Enterprise vai copiar o notebook do GitHub para seu ambiente.
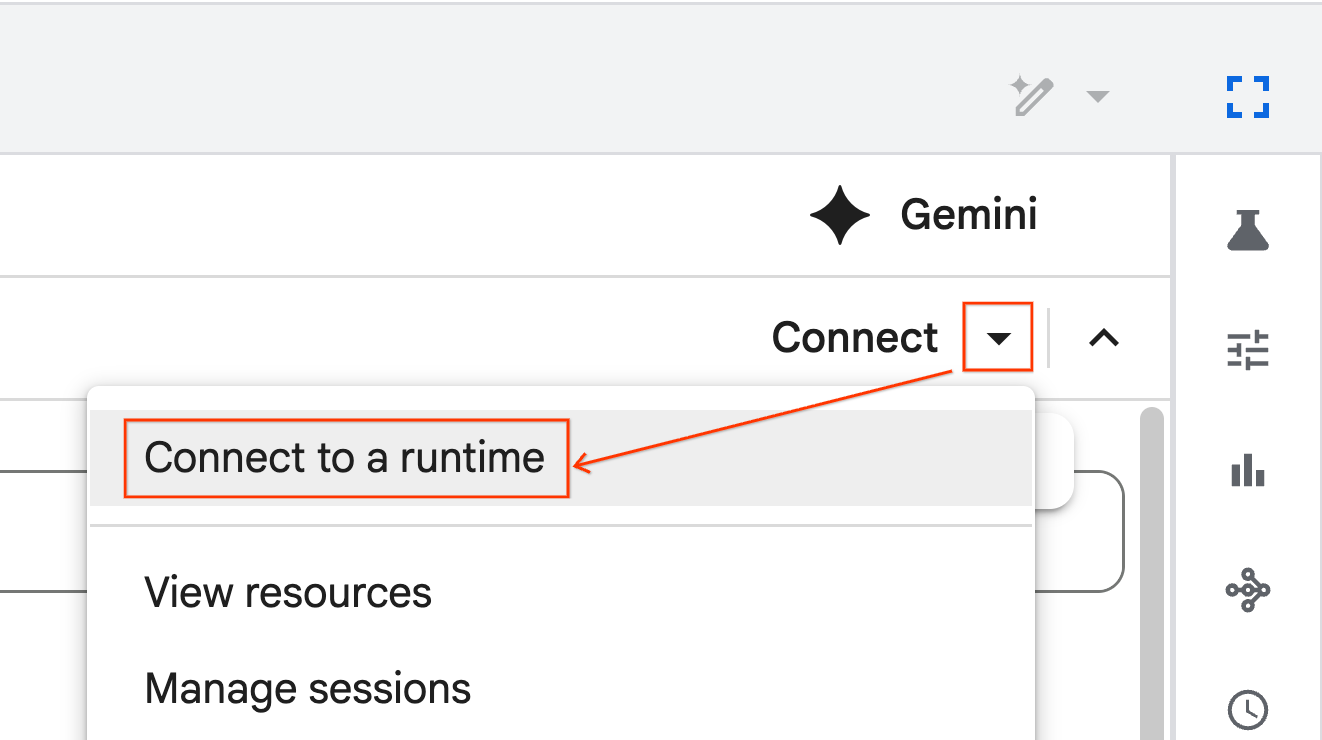
Conectar ao ambiente de execução
- Abra o notebook recém-importado.
- Clique na seta para baixo ao lado de Conectar.
- Selecione Conectar a um ambiente de execução.
- Use o menu suspenso e selecione o ambiente de execução que você criou anteriormente.
- Clique em Conectar.
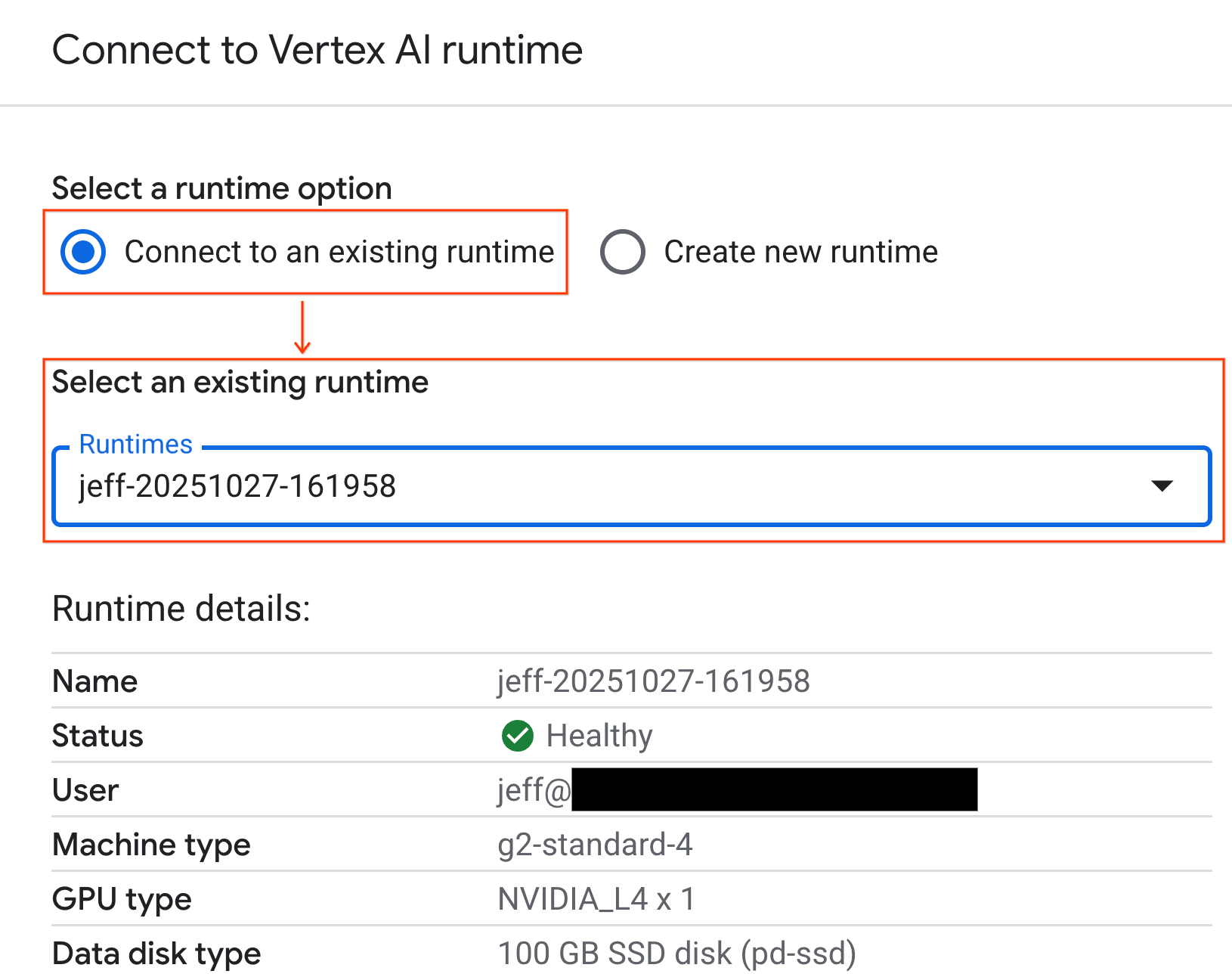
Seu notebook agora está conectado a um ambiente de execução ativado para GPU.
Dependências integradas
Um dos benefícios de usar o Colab Enterprise é que ele já vem com as bibliotecas necessárias pré-instaladas. Não é necessário instalar ou gerenciar manualmente dependências como cuDF, cuML ou XGBoost para este laboratório.
8. Preparar o conjunto de dados de táxis de Nova York
Este codelab usa os dados de registro de viagens da Comissão de Táxis e Limusines (TLC) de Nova York. O conjunto de dados contém registros de viagens de táxis amarelos em Nova York, incluindo:
- Datas, horários e locais de embarque e desembarque
- Distâncias da viagem
- Valores detalhados da tarifa
- Número de passageiros
- Valores de gorjeta (é isso que vamos prever!)
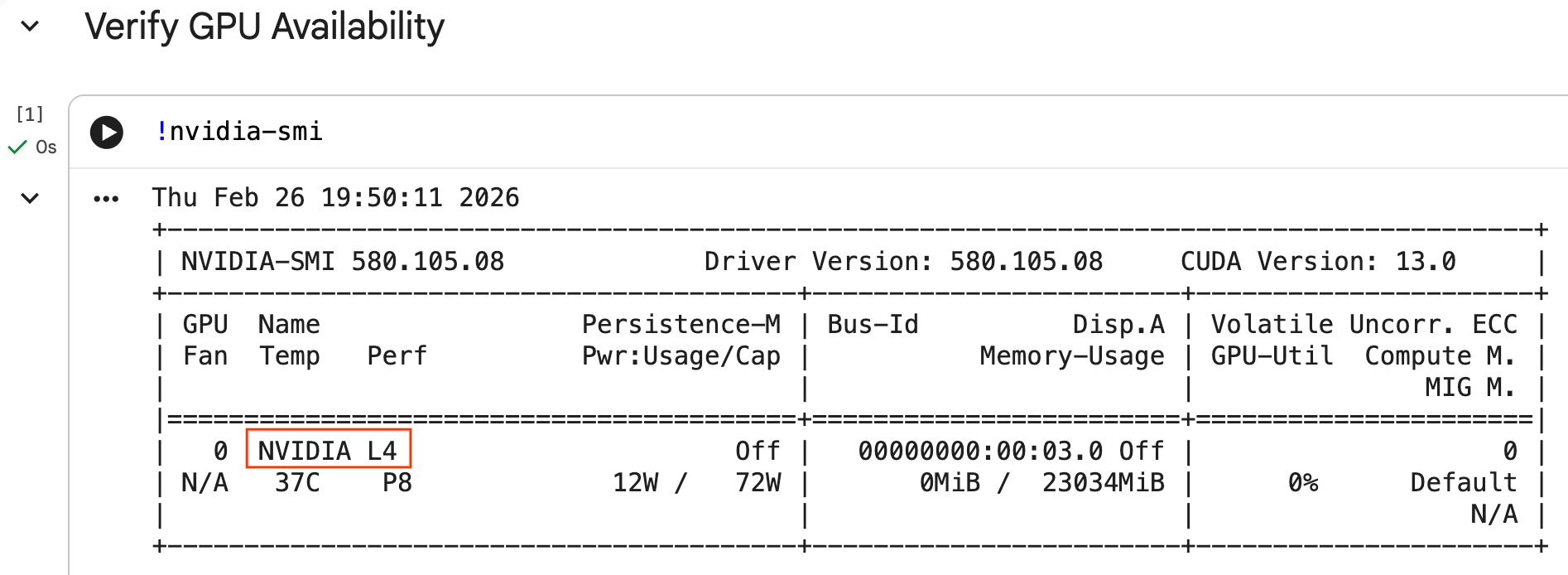
Configurar a GPU e confirmar a disponibilidade
Para confirmar se a GPU foi reconhecida, execute o comando nvidia-smi. Ela mostra a versão do driver e os detalhes da GPU, como a NVIDIA L4.
nvidia-smi
A célula vai retornar a GPU anexada ao seu ambiente de execução, semelhante a esta:
Fazer download dos dados
Baixe os dados da viagem de 2024.
from tqdm import tqdm
import requests
import time
import os
YEAR = 2024
DATA_DIR = "nyc_taxi_data"
os.makedirs(DATA_DIR, exist_ok=True)
print(f"Checking/Downloading files for {YEAR}...")
for month in tqdm(range(1, 13), unit="file"):
file_name = f"yellow_tripdata_{YEAR}-{month:02d}.parquet"
local_path = os.path.join(DATA_DIR, file_name)
url = f"https://d37ci6vzurychx.cloudfront.net/trip-data/{file_name}"
if not os.path.exists(local_path):
try:
with requests.get(url, stream=True) as response:
response.raise_for_status()
with open(local_path, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
time.sleep(1)
except requests.exceptions.HTTPError as e:
print(f"\nSkipping {file_name}: {e}")
if os.path.exists(local_path):
os.remove(local_path)
print("\nDownload complete.")
Acelere pandas com a NVIDIA cuDF
A biblioteca pandas é executada na CPU e pode ser lenta com grandes conjuntos de dados. O comando mágico %load_ext cudf.pandas da NVIDIA corrige dinamicamente o pandas para usar a aceleração da GPU, voltando à CPU se necessário.
Usamos esse comando mágico em vez de uma importação padrão porque ele oferece aceleração de "mudança de código zero". Não é necessário reescrever nenhum código atual. Um comando semelhante, %load_ext cuml.accel, faz exatamente a mesma coisa para scikit-learn models. Isso funciona em qualquer ambiente do Jupyter com uma GPU NVIDIA compatível, não apenas no Colab Enterprise.
%load_ext cudf.pandas
Para verificar se ele está ativo, importe pandas e confira o tipo:
import pandas as pd
pd
A saída vai confirmar que você está usando o módulo cudf.pandas.
Carregar e limpar dados
Com o cudf.pandas ativo, carregue os arquivos Parquet e execute a limpeza de dados. Esse processo é executado automaticamente na GPU.
import glob
# Load data into memory
df = pd.concat(
[pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")],
ignore_index=True
)
# Filter for valid trips. We filter for payment_type=1 (credit card)
# because tip amounts are only reliably recorded for credit card transactions.
df = df[
(df['fare_amount'] > 0) & (df['fare_amount'] < 500) &
(df['trip_distance'] > 0) & (df['trip_distance'] < 100) &
(df['tip_amount'] >= 0) & (df['tip_amount'] < 100) &
(df['payment_type'] == 1)
].copy()
# Downcast numeric columns to save memory
float_cols = df.select_dtypes(include=['float64']).columns
df[float_cols] = df[float_cols].astype('float32')
int_cols = df.select_dtypes(include=['int64']).columns
df[int_cols] = df[int_cols].astype('int32')
Engenharia de atributos
Crie atributos derivados do carimbo de data/hora de retirada. O notebook contém outros recursos usados nas etapas posteriores.
import numpy as np
# Time Features
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['dow'] = df['tpep_pickup_datetime'].dt.dayofweek
df['is_weekend'] = (df['dow'] >= 5).astype(int)
df['is_rush_hour'] = (
((df['hour'] >= 7) & (df['hour'] <= 9)) |
((df['hour'] >= 17) & (df['hour'] <= 19))
).astype(int)
...
# Other features
...
9. Treinar modelos individuais com validação cruzada
Para mostrar como a GPU pode acelerar o aprendizado de máquina, você vai treinar três tipos diferentes de modelos de regressão para prever o tip_amount de uma corrida de táxi.
Acelere scikit-learn com a NVIDIA cuML
Execute algoritmos scikit-learn na GPU usando o cuML da NVIDIA sem mudar as chamadas de API. Primeiro, carregue a extensão cuml.accel.
%load_ext cuml.accel
Configurar recursos e metas
Identifique os recursos que você quer que o modelo aprenda e divida a coluna de destino (tip_amount).
feature_cols = [
'trip_distance', 'fare_amount', 'passenger_count',
'hour', 'dow', 'is_weekend', 'is_rush_hour',
'fare_log', 'fare_decimal', 'is_round_fare',
'route_frequency', 'pu_tip_mean', 'pu_tip_std',
'PULocationID', 'DOLocationID'
]
X = df[feature_cols].fillna(df[feature_cols].median())
y = df['tip_amount'].copy()
Configure divisões de validação cruzada para avaliar o desempenho do modelo de maneira robusta.
from sklearn.model_selection import KFold
import numpy as np
import time
from sklearn.metrics import mean_squared_error
from tqdm.notebook import tqdm
n_splits = 3
kf = KFold(n_splits=n_splits, shuffle=True, random_state=42)
1. XGBoost
O XGBoost é acelerado por GPU de forma nativa. Transmita tree_method='hist' e device='cuda' para usar a GPU durante o treinamento.
import xgboost as xgb
start_time = time.perf_counter()
def train_xgb_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# XGBoost handles GPU natively when tree_method='hist' and device='cuda'
model = xgb.XGBRegressor(
objective='reg:squarederror',
max_depth=5,
learning_rate=0.1,
n_estimators=100,
tree_method='hist',
device='cuda',
random_state=42
)
model.fit(X_train, y_train)
preds = model.predict(X_val)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
xgb_rmse, xgb_preds = train_xgb_cv(X, y)
print(f"\n{'XGBoost RMSE:':<20} ${xgb_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
2. Regressão linear
Treine um modelo de regressão linear. Com o %load_ext cuml.accel ativo, o LinearRegression é mapeado automaticamente para o equivalente de GPU.
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
start_time = time.perf_counter()
def train_linreg_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# Scale features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_val_scaled = scaler.transform(X_val)
# Automatically accelerated by cuML
model = LinearRegression()
model.fit(X_train_scaled, y_train)
preds = model.predict(X_val_scaled)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
linreg_rmse, linreg_preds = train_linreg_cv(X, y)
print(f"\n{'Linear Reg RMSE:':<20} ${linreg_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
3. Floresta aleatória
Treine um modelo de ensemble usando RandomForestRegressor. Os modelos baseados em árvores geralmente são lentos para treinar na CPU, mas a aceleração da GPU processa milhões de linhas mais rápido.
from sklearn.ensemble import RandomForestRegressor
start_time = time.perf_counter()
def train_rf_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# Automatically accelerated by cuML
model = RandomForestRegressor(
n_estimators=100,
max_depth=10,
n_jobs=-1,
max_features='sqrt',
random_state=42
)
model.fit(X_train, y_train)
preds = model.predict(X_val)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
rf_rmse, rf_preds = train_rf_cv(X, y)
print(f"\n{'Random Forest RMSE:':<20} ${rf_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
10. Avaliar o pipeline completo
Combine as previsões dos três modelos usando um conjunto linear simples. Isso geralmente oferece um pequeno aumento na acurácia em relação aos modelos individuais.
Ajuste uma regressão linear nas previsões para encontrar os pesos ideais:
ensemble_weights = LinearRegression(positive=True, fit_intercept=False).fit(
np.c_[xgb_preds, rf_preds, linreg_preds], y
).coef_
# Normalize weights
ensemble_weights = ensemble_weights / ensemble_weights.sum()
ensemble_preds = np.c_[xgb_preds, rf_preds, linreg_preds] @ ensemble_weights
ensemble_rmse = np.sqrt(mean_squared_error(y, ensemble_preds))
Compare os resultados para conferir o Lift do conjunto:
print(f"\n{'Model':<20} {'RMSE':>10}")
print("-" * 32)
print(f"{'Linear Regression':<20} ${linreg_rmse:>9.4f}")
print(f"{'Random Forest':<20} ${rf_rmse:>9.4f}")
print(f"{'XGBoost':<20} ${xgb_rmse:>9.4f}")
print("-" * 32)
print(f"{'Ensemble':<20} ${ensemble_rmse:>9.4f}")
print(f"\nEnsemble lift: ${xgb_rmse - ensemble_rmse:.4f}")
11. Comparar o desempenho da CPU e da GPU
Para comparar a diferença de desempenho corretamente, reinicie o kernel para garantir um estado de execução limpo, execute todo o pipeline de ciência de dados na CPU e depois execute novamente na GPU.
Reiniciar o kernel
Execute o comando IPython.Application.instance().kernel.do_shutdown(True) para reiniciar o kernel e liberar memória.
import IPython
IPython.Application.instance().kernel.do_shutdown(True)
Definir o pipeline de ciência de dados
Encapsule o fluxo de trabalho principal (carregamento de dados, limpeza, engenharia de atributos e treinamento de modelo) em uma única função. Essa função aceita um módulo pd_module do pandas e um argumento use_gpu para alternar entre ambientes.
def run_ml_pipeline(pd_module, use_gpu=False):
import time
import glob
import numpy as np
from sklearn.ensemble import RandomForestRegressor
import xgboost as xgb
timings = {}
# 1. Load Data
t0 = time.perf_counter()
df = pd_module.concat(
[pd_module.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")],
ignore_index=True
)
timings['Load Data'] = time.perf_counter() - t0
# 2. Clean Data
t0 = time.perf_counter()
# Filter for payment_type=1 (credit card) because tip amounts
# are only reliably recorded for credit card transactions.
df = df[
(df['fare_amount'] > 0) & (df['fare_amount'] < 500) &
(df['trip_distance'] > 0) & (df['trip_distance'] < 100) &
(df['tip_amount'] >= 0) & (df['tip_amount'] < 100) &
(df['payment_type'] == 1)
].copy()
# Downcast numeric columns to save memory
float_cols = df.select_dtypes(include=['float64']).columns
df[float_cols] = df[float_cols].astype('float32')
int_cols = df.select_dtypes(include=['int64']).columns
df[int_cols] = df[int_cols].astype('int32')
timings['Clean Data'] = time.perf_counter() - t0
# 3. Feature Engineering
t0 = time.perf_counter()
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['dow'] = df['tpep_pickup_datetime'].dt.dayofweek
df['is_weekend'] = (df['dow'] >= 5).astype(int)
df['fare_log'] = np.log1p(df['fare_amount'])
timings['Feature Engineering'] = time.perf_counter() - t0
# 4. Modeling Prep
feature_cols = ['trip_distance', 'fare_amount', 'passenger_count', 'hour', 'dow', 'is_weekend', 'fare_log']
X = df[feature_cols].fillna(df[feature_cols].median())
y = df['tip_amount'].copy()
# Free memory
del df
import gc
gc.collect()
# 5. Train Random Forest
t0 = time.perf_counter()
rf_model = RandomForestRegressor(
n_estimators=100,
max_depth=10,
n_jobs=-1,
max_features='sqrt',
random_state=42
).fit(X, y)
timings['Train Random Forest'] = time.perf_counter() - t0
# 6. Train XGBoost
t0 = time.perf_counter()
params = {
'objective': 'reg:squarederror',
'max_depth': 5,
'n_estimators': 100,
'random_state': 42
}
if use_gpu:
params['device'] = 'cuda'
params['tree_method'] = 'hist'
xgb_model = xgb.XGBRegressor(**params).fit(X, y)
timings['Train XGBoost'] = time.perf_counter() - t0
del X
del y
gc.collect()
return timings
Executar na sua CPU
Chame o pipeline usando a CPU padrão pandas.
import pandas as pd
print("Running pipeline on CPU...")
cpu_times = run_ml_pipeline(pd, use_gpu=False)
print("CPU Execution Finished.")
Executar na sua GPU
Carregue as extensões da biblioteca NVIDIA, transmita o módulo cudf.pandas acelerado para o pipeline e defina o dispositivo XGBoost como cuda internamente.
import IPython.core.magic
if not hasattr(IPython.core.magic, 'output_can_be_silenced'):
IPython.core.magic.output_can_be_silenced = lambda x: x
%load_ext cudf.pandas
%load_ext cuml.accel
import pandas as pd
print("Running pipeline on GPU...")
gpu_times = run_ml_pipeline(pd, use_gpu=True)
print("GPU Execution Finished.")
Visualizar a melhoria de desempenho
Visualize os tempos usando matplotlib. Os resultados mostram o tempo economizado durante o processamento de dados e o treinamento de modelos ao usar GPUs.
import matplotlib.pyplot as plt
import numpy as np
labels = list(cpu_times.keys())
cpu_values = list(cpu_times.values())
gpu_values = list(gpu_times.values())
x = np.arange(len(labels))
width = 0.35
fig, ax = plt.subplots(figsize=(10, 6))
rects1 = ax.bar(x - width/2, cpu_values, width, label='CPU', color='#4285F4')
rects2 = ax.bar(x + width/2, gpu_values, width, label='GPU', color='#76B900')
ax.set_ylabel('Execution Time (seconds)')
ax.set_title('NYC Taxi ML Pipeline: CPU vs. GPU Performance')
ax.set_xticks(x)
ax.set_xticklabels(labels, rotation=45, ha="right")
ax.legend()
# Add data labels
def autolabel(rects):
for rect in rects:
height = rect.get_height()
ax.annotate(f'{height:.2f}s',
xy=(rect.get_x() + rect.get_width() / 2, height),
xytext=(0, 3), # 3 points vertical offset
textcoords="offset points",
ha='center', va='bottom', fontsize=9)
autolabel(rects1)
autolabel(rects2)
plt.tight_layout()
plt.show()
# Calculate overall speedup
total_cpu_time = sum(cpu_values)
total_gpu_time = sum(gpu_values)
overall_speedup = total_cpu_time / total_gpu_time
print(f"\nOverall Pipeline Speedup: {overall_speedup:.2f}x faster on GPU!")
Você verá um código como este:
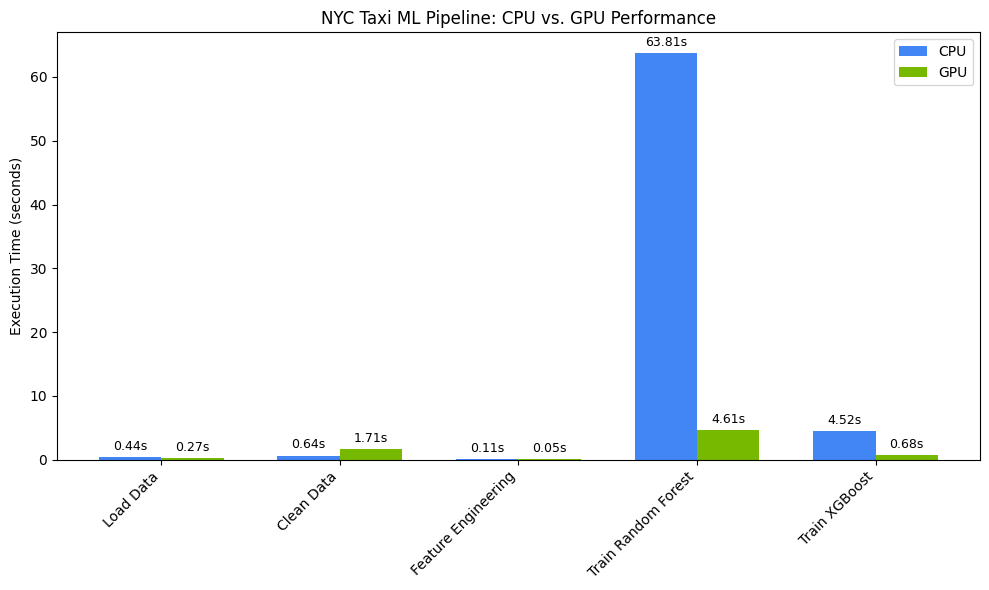
Este gráfico ilustra a vantagem significativa de desempenho da GPU em todo o fluxo de trabalho de ciência de dados. Você vai notar as maiores economias de tempo durante as fases de treinamento de modelos computacionalmente intensivas para algoritmos como Random Forest e XGBoost.
12. Crie um perfil do seu código para encontrar restrições de desempenho
Ao usar cudf.pandas, a maioria das funções é executada na GPU. Se uma operação específica ainda não for compatível com cuDF, a execução vai voltar temporariamente para a CPU. A NVIDIA oferece dois comandos mágicos integrados do Jupyter para identificar esses substitutos.
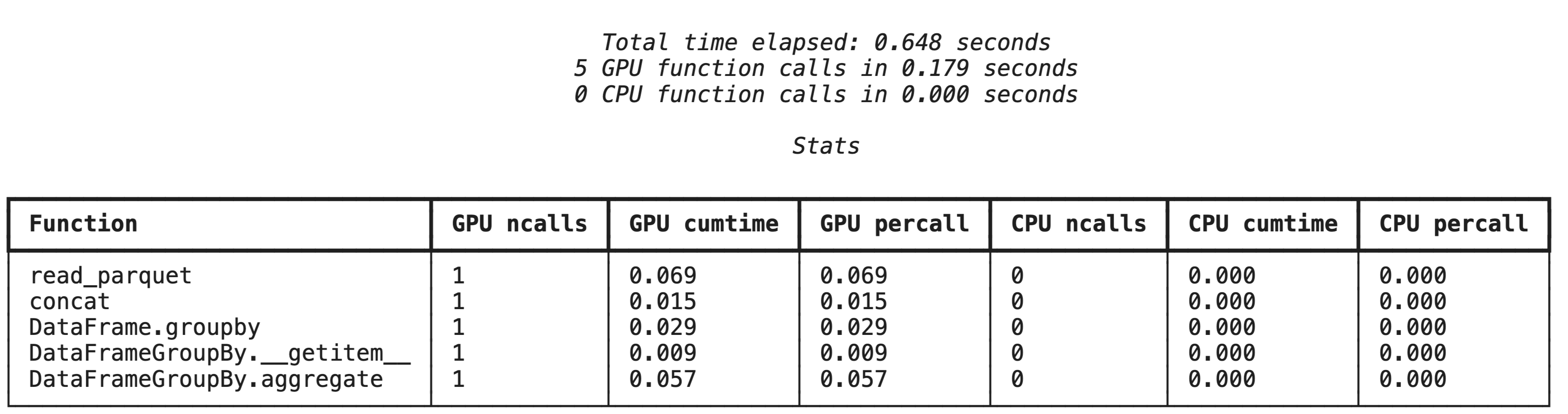
Criação de perfil de alto nível com %%cudf.pandas.profile
O comando mágico %%cudf.pandas.profile fornece um resumo de quais funções foram executadas na GPU ou na CPU.
%%cudf.pandas.profile
import glob
import pandas as pd
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")], ignore_index=True)
summary = (
df
.groupby(['PULocationID', 'payment_type'])
[['passenger_count', 'fare_amount', 'tip_amount']]
.agg(['min', 'mean', 'max'])
)
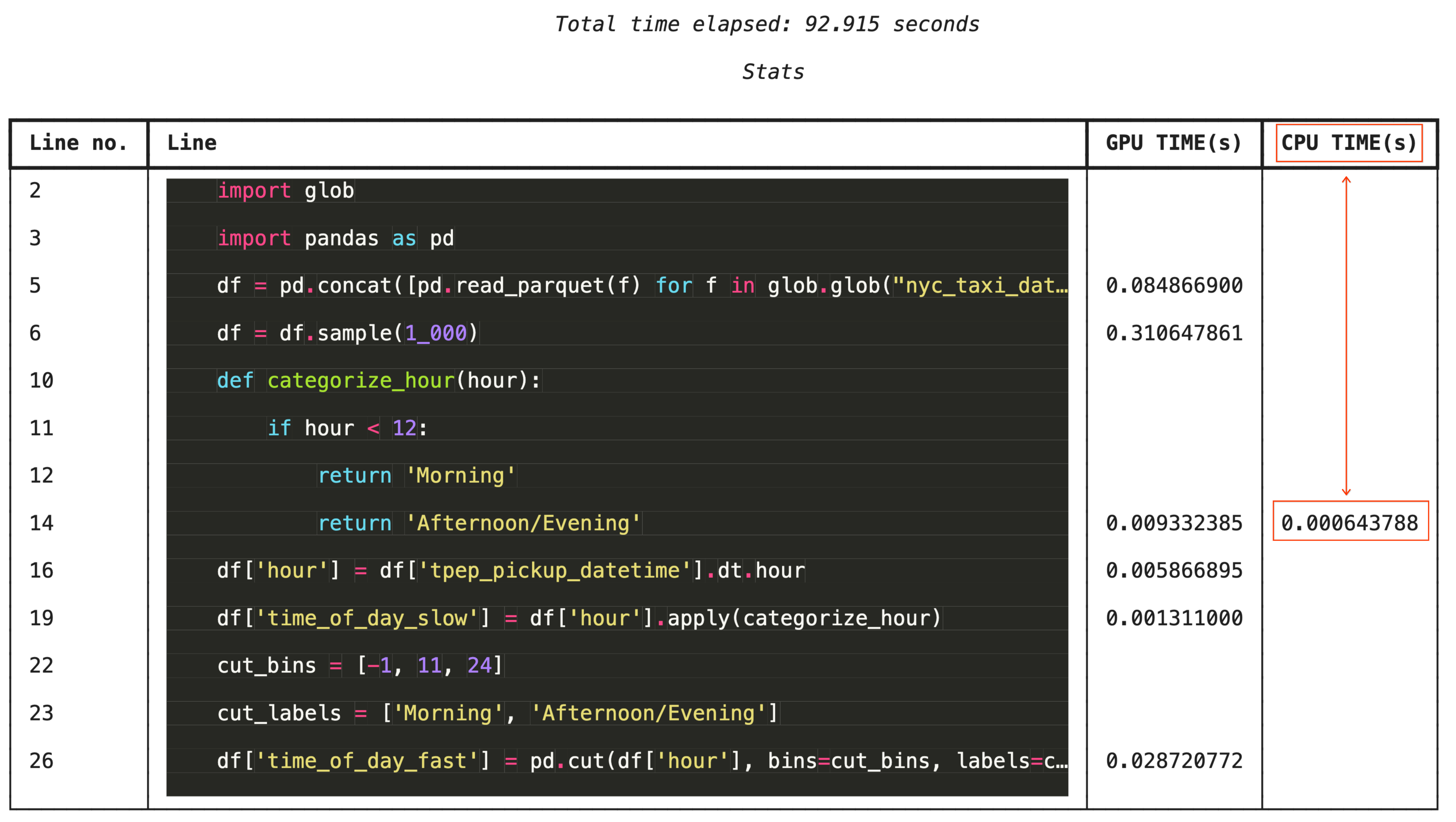
Perfil linha por linha com %%cudf.pandas.line_profile
Para uma solução de problemas granular, o %%cudf.pandas.line_profile anota cada linha de código com o número de vezes que ela foi executada na GPU em comparação com a CPU.
%%cudf.pandas.line_profile
import glob
import pandas as pd
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")], ignore_index=True)
df = df.sample(1_000)
# Iterating row-by-row or using custom python apply functions often falls back to the CPU
def categorize_hour(hour):
if hour < 12:
return 'Morning'
else:
return 'Afternoon/Evening'
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['time_of_day_slow'] = df['hour'].apply(categorize_hour)
# Using vectorized pandas operations (like pd.cut) stays entirely on the GPU
cut_bins = [-1, 11, 24]
cut_labels = ['Morning', 'Afternoon/Evening']
df['time_of_day_fast'] = pd.cut(df['hour'], bins=cut_bins, labels=cut_labels)
13. Limpeza
Para evitar cobranças inesperadas na sua conta do Google Cloud, limpe os recursos criados durante este codelab.
Excluir recursos
Exclua o conjunto de dados local no ambiente de execução usando o comando !rm -rf em uma célula do notebook.
print("Deleting local 'nyc_taxi_data' directory...")
!rm -rf nyc_taxi_data
print("Local files deleted.")
Desligar o ambiente de execução do Colab
- No console do Google Cloud, acesse a página Ambientes de execução do Colab Enterprise.
- No menu Região, selecione a região que contém o ambiente de execução.
- Selecione o tempo de execução que você quer excluir.
- Clique em Excluir.
- Clique em Confirmar.
Excluir o notebook
- No console do Google Cloud, acesse a página Meus notebooks do Colab Enterprise.
- No menu Região, selecione a região que contém o notebook.
- Selecione o notebook que você quer excluir.
- Clique em Excluir.
- Clique em Confirmar.
14. Parabéns
Parabéns! Você acelerou um fluxo de trabalho de machine learning pandas e scikit-learn usando as bibliotecas NVIDIA cuDF e cuML no Colab Enterprise. Basta adicionar alguns comandos mágicos (%load_ext cudf.pandas e %load_ext cuml.accel) para que seu código padrão seja executado na GPU, processando registros e ajustando modelos complexos localmente em uma fração do tempo.
Para mais informações sobre a aceleração de GPU para análise de dados, consulte o codelab Análise de dados acelerada com GPUs.
O que aprendemos
- Entenda o Colab Enterprise no Google Cloud.
- Personalizar um ambiente de execução do Colab com configurações específicas de GPU e memória.
- Aplicar a aceleração de GPU para prever valores de gorjetas usando milhões de registros de um conjunto de dados de táxi de Nova York.
- Acelerar o
pandassem mudanças no código usando a bibliotecacuDFda NVIDIA. - Acelere o
scikit-learnsem mudar o código usando a bibliotecacuMLe as GPUs da NVIDIA. - Criação de perfil do código para identificar e otimizar restrições de desempenho.