
1. บทนำ
ใน Codelab นี้ คุณจะได้เรียนรู้วิธีเร่งเวิร์กโฟลว์วิทยาศาสตร์ข้อมูลและแมชชีนเลิร์นนิงในชุดข้อมูลขนาดใหญ่โดยใช้ GPU ของ NVIDIA และไลบรารีโอเพนซอร์สใน Google Cloud คุณจะเริ่มต้นด้วยการตั้งค่าโครงสร้างพื้นฐาน จากนั้นจะดูวิธีใช้การเร่งความเร็วด้วย GPU
คุณจะมุ่งเน้นที่วงจรการทำงานของวิทยาศาสตร์ข้อมูล ตั้งแต่การเตรียมข้อมูลด้วย pandas ไปจนถึงการฝึกโมเดลด้วย scikit-learn และ XGBoost คุณจะได้เรียนรู้วิธีเร่งความเร็วงานเหล่านี้โดยใช้ไลบรารี cuDF และ cuML ของ NVIDIA และที่สำคัญที่สุดคือคุณสามารถใช้การเร่งความเร็ว GPU นี้ได้โดยไม่ต้องเปลี่ยนโค้ด pandas หรือ scikit-learn ที่มีอยู่
สิ่งที่คุณจะได้เรียนรู้
- ทำความเข้าใจ Colab Enterprise ใน Google Cloud
- ปรับแต่งสภาพแวดล้อมรันไทม์ของ Colab ด้วยการกำหนดค่า GPU และหน่วยความจำที่เฉพาะเจาะจง
- ใช้การเร่งความเร็วด้วย GPU เพื่อคาดการณ์จำนวนทิปโดยใช้บันทึกหลายล้านรายการจากชุดข้อมูลแท็กซี่ในนิวยอร์ก
- เร่งความเร็ว
pandasโดยไม่ต้องเปลี่ยนแปลงโค้ดด้วยไลบรารีcuDFของ NVIDIA - เร่งความเร็ว
scikit-learnโดยไม่ต้องเปลี่ยนแปลงโค้ดโดยใช้ไลบรารีcuMLและ GPU ของ NVIDIA - สร้างโปรไฟล์โค้ดเพื่อระบุและเพิ่มประสิทธิภาพข้อจำกัดด้านประสิทธิภาพ
หน้าถัดไปจะมีเครดิตที่คุณใช้เพื่อทำ Lab ให้เสร็จสมบูรณ์
2. เหตุผลที่ต้องเร่งแมชชีนเลิร์นนิง
ความจำเป็นในการทำซ้ำที่เร็วขึ้นใน ML
การเตรียมข้อมูลใช้เวลานาน และการฝึกหรือการประเมินโมเดลอาจใช้เวลานานยิ่งขึ้นเมื่อชุดข้อมูลมีขนาดใหญ่ขึ้น การฝึกโมเดล เช่น Random Forest หรือ XGBoost ในแถวหลายล้านแถวด้วย CPU อาจใช้เวลาหลายชั่วโมงหรือหลายวัน
การใช้ GPU จะช่วยเร่งการฝึกโมเดลเหล่านี้ด้วยไลบรารีอย่าง cuML และ XGBoost ที่เร่งด้วย GPU โปรแกรมเร่งนี้ช่วยให้คุณทำสิ่งต่อไปนี้ได้
- ทำซ้ำได้เร็วขึ้น: ทดสอบฟีเจอร์ใหม่และไฮเปอร์พารามิเตอร์ได้อย่างรวดเร็ว
- ฝึกโมเดลในชุดข้อมูลแบบเต็ม: ใช้ข้อมูลที่สมบูรณ์แทนการสุ่มตัวอย่างลงเพื่อให้มีความแม่นยำมากขึ้น
- ลดค่าใช้จ่าย: ทำงานที่มีภาระหนักให้เสร็จในเวลาที่น้อยลงเพื่อลดค่าใช้จ่ายในการคำนวณ
3. การตั้งค่าและข้อกำหนด
ค่าใช้จ่ายที่อาจเกิดขึ้น
Codelab นี้ใช้ทรัพยากร Google Cloud ซึ่งรวมถึงรันไทม์ Colab Enterprise ที่มี GPU NVIDIA L4 โปรดทราบว่าอาจมีการเรียกเก็บเงิน และทำตามส่วนล้างข้อมูลที่ท้าย Codelab เพื่อปิดทรัพยากรและหลีกเลี่ยงการเรียกเก็บเงินอย่างต่อเนื่อง ดูข้อมูลการกำหนดราคาโดยละเอียดได้ที่การกำหนดราคา Colab Enterprise และการกำหนดราคา GPU
ก่อนเริ่มต้น
เราถือว่าคุณมีความคุ้นเคยระดับปานกลางกับ Python, pandas, scikit-learn และแนวทางปฏิบัติมาตรฐานของแมชชีนเลิร์นนิง (เช่น การตรวจสอบแบบไขว้/การรวมโมเดล)
- ในคอนโซล Google Cloud ในหน้าตัวเลือกโปรเจ็กต์ ให้เลือกหรือสร้างโปรเจ็กต์ Google Cloud
- ตรวจสอบว่าได้เปิดใช้การเรียกเก็บเงินสำหรับโปรเจ็กต์ Google Cloud แล้ว
เปิดใช้ API
คุณต้องเปิดใช้ API ที่จำเป็นก่อนจึงจะใช้ Colab Enterprise ได้
- เปิด Google Cloud Shell โดยคลิกไอคอน Cloud Shell ที่ด้านขวาบนของ คอนโซล Google Cloud

- ใน Cloud Shell ให้ตั้งค่ารหัสโปรเจ็กต์โดยแทนที่
PROJECT_IDด้วยรหัสโปรเจ็กต์ของคุณ
gcloud config set project <PROJECT_ID>
- เรียกใช้คำสั่งต่อไปนี้เพื่อเปิดใช้ API ที่จำเป็น
gcloud services enable \
compute.googleapis.com \
dataform.googleapis.com \
notebooks.googleapis.com \
aiplatform.googleapis.com
เมื่อดำเนินการสำเร็จ คุณควรเห็นข้อความคล้ายกับข้อความที่แสดงด้านล่าง
Operation "operations/..." finished successfully.
4. การเลือกสภาพแวดล้อม Notebook
แม้ว่านักวิทยาศาสตร์ข้อมูลหลายคนจะคุ้นเคยกับ Colab สำหรับโปรเจ็กต์ส่วนตัว แต่ Colab Enterprise มอบประสบการณ์การใช้งาน Notebook ที่ปลอดภัย ทำงานร่วมกันได้ และผสานรวม ซึ่งออกแบบมาสำหรับธุรกิจ
ใน Google Cloud คุณมีตัวเลือกหลัก 2 อย่างสำหรับสภาพแวดล้อม Notebook ที่มีการจัดการ ได้แก่ Colab Enterprise และ Gemini Enterprise Agent Platform Workbench ตัวเลือกที่เหมาะสมจะขึ้นอยู่กับลำดับความสำคัญของโปรเจ็กต์
กรณีที่ควรใช้ Agent Platform Workbench
เลือก Agent Platform Workbench เมื่อคุณให้ความสำคัญกับการควบคุมและการปรับแต่งอย่างละเอียด ตัวเลือกนี้เหมาะสำหรับคุณในกรณีต่อไปนี้
- จัดการโครงสร้างพื้นฐานและวงจรของเครื่อง
- ใช้คอนเทนเนอร์และการกำหนดค่าเครือข่ายที่กำหนดเอง
- ผสานรวมกับไปป์ไลน์ MLOps และเครื่องมือวงจรที่กำหนดเอง
กรณีที่ควรใช้ Colab Enterprise
เลือก Colab Enterprise เมื่อคุณให้ความสำคัญกับการตั้งค่าที่รวดเร็ว ความสะดวกในการใช้งาน และการทำงานร่วมกันที่ปลอดภัย ซึ่งเป็นโซลูชันที่มีการจัดการครบวงจรที่ช่วยให้ทีมของคุณมุ่งเน้นที่การวิเคราะห์แทนที่จะเป็นโครงสร้างพื้นฐาน
Colab Enterprise ช่วยให้คุณทำสิ่งต่อไปนี้ได้
- พัฒนาเวิร์กโฟลว์วิทยาศาสตร์ข้อมูลที่เชื่อมโยงกับคลังข้อมูลอย่างใกล้ชิด คุณสามารถเปิดและจัดการ Notebook ได้โดยตรงใน BigQuery Studio
- ฝึกโมเดลแมชชีนเลิร์นนิงและผสานรวมกับเครื่องมือ MLOps ใน Agent Platform
- เพลิดเพลินกับประสบการณ์การใช้งานที่ยืดหยุ่นและเป็นหนึ่งเดียว สมุดบันทึก Colab Enterprise ที่สร้างใน BigQuery สามารถเปิดและเรียกใช้ใน Agent Platform ได้ และในทางกลับกัน
ห้องทดลองวันนี้
Codelab นี้ใช้ Colab Enterprise เพื่อเร่งความเร็วแมชชีนเลิร์นนิง
ดูข้อมูลเพิ่มเติมเกี่ยวกับความแตกต่างได้ในเอกสารอย่างเป็นทางการเกี่ยวกับการเลือกโซลูชัน Notebook ที่เหมาะสม
5. กำหนดค่าเทมเพลตรันไทม์
ใน Colab Enterprise ให้เชื่อมต่อกับรันไทม์ตามเทมเพลตรันไทม์ที่กำหนดค่าไว้ล่วงหน้า
เทมเพลตรันไทม์เป็นการกำหนดค่าที่นำมาใช้ใหม่ได้ซึ่งระบุสภาพแวดล้อมสำหรับ Notebook รวมถึง
- ประเภทเครื่อง (CPU, หน่วยความจำ)
- Accelerator (ประเภทและจำนวน GPU)
- ขนาดและประเภทดิสก์
- การตั้งค่าเครือข่ายและนโยบายความปลอดภัย
- กฎการปิดเครื่องอัตโนมัติเมื่อไม่มีการใช้งาน
เหตุผลที่เทมเพลตรันไทม์มีประโยชน์
- ความสอดคล้องกัน: คุณและทีมจะได้รับสภาพแวดล้อมเดียวกันเพื่อให้มั่นใจว่างานจะทำซ้ำได้
- ความปลอดภัย: เทมเพลตจะบังคับใช้นโยบายความปลอดภัยขององค์กร
- การจัดการค่าใช้จ่าย: ทรัพยากรได้รับการปรับขนาดล่วงหน้าในเทมเพลตเพื่อช่วยป้องกันค่าใช้จ่ายที่เกิดขึ้นโดยไม่ตั้งใจ
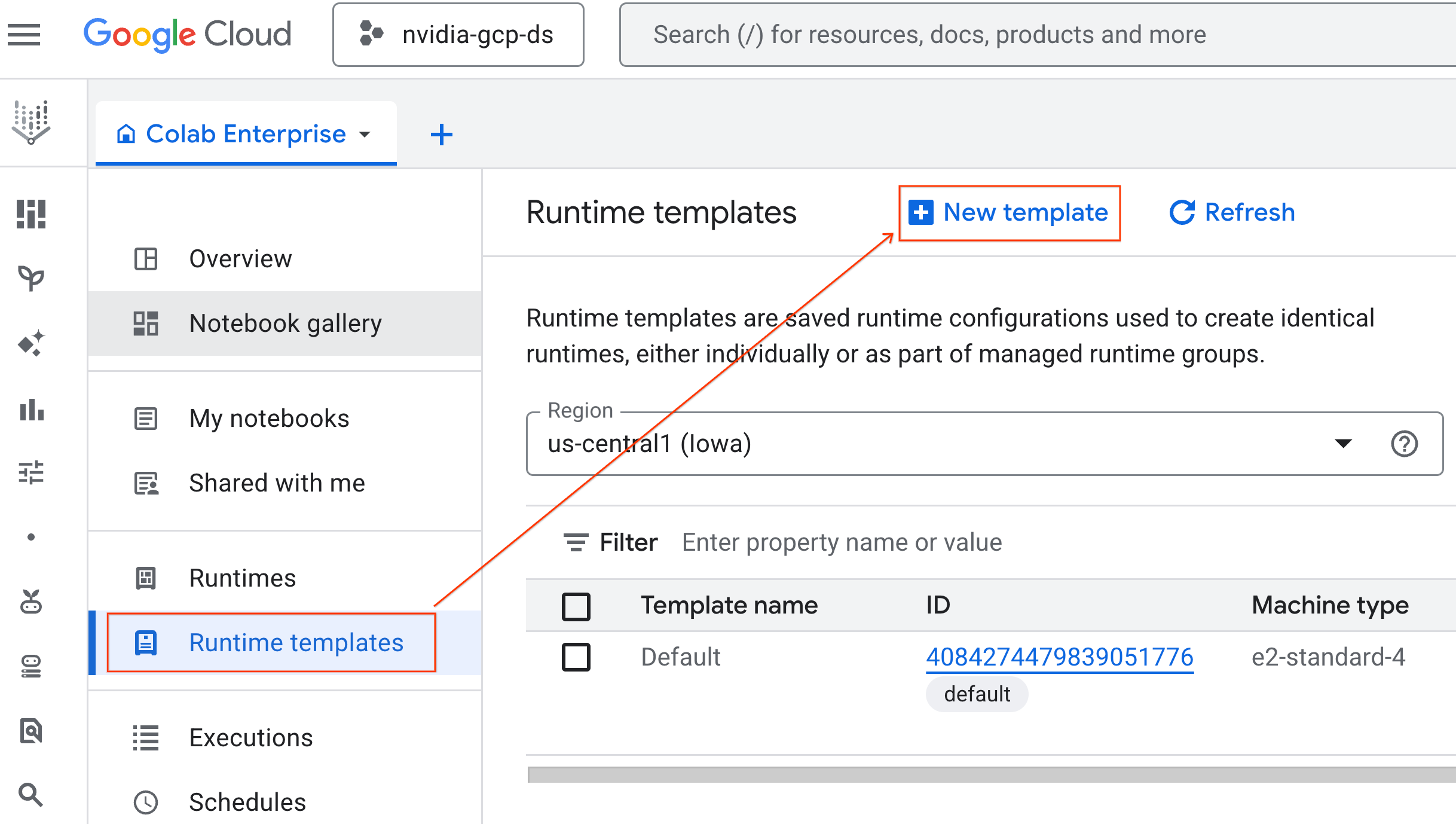
สร้างเทมเพลตรันไทม์
ตั้งค่าเทมเพลตรันไทม์ที่นำกลับมาใช้ใหม่ได้สำหรับแล็บ
- ในคอนโซล Google Cloud ให้ไปที่เมนูการนำทาง > แพลตฟอร์มเอเจนต์ > Notebook
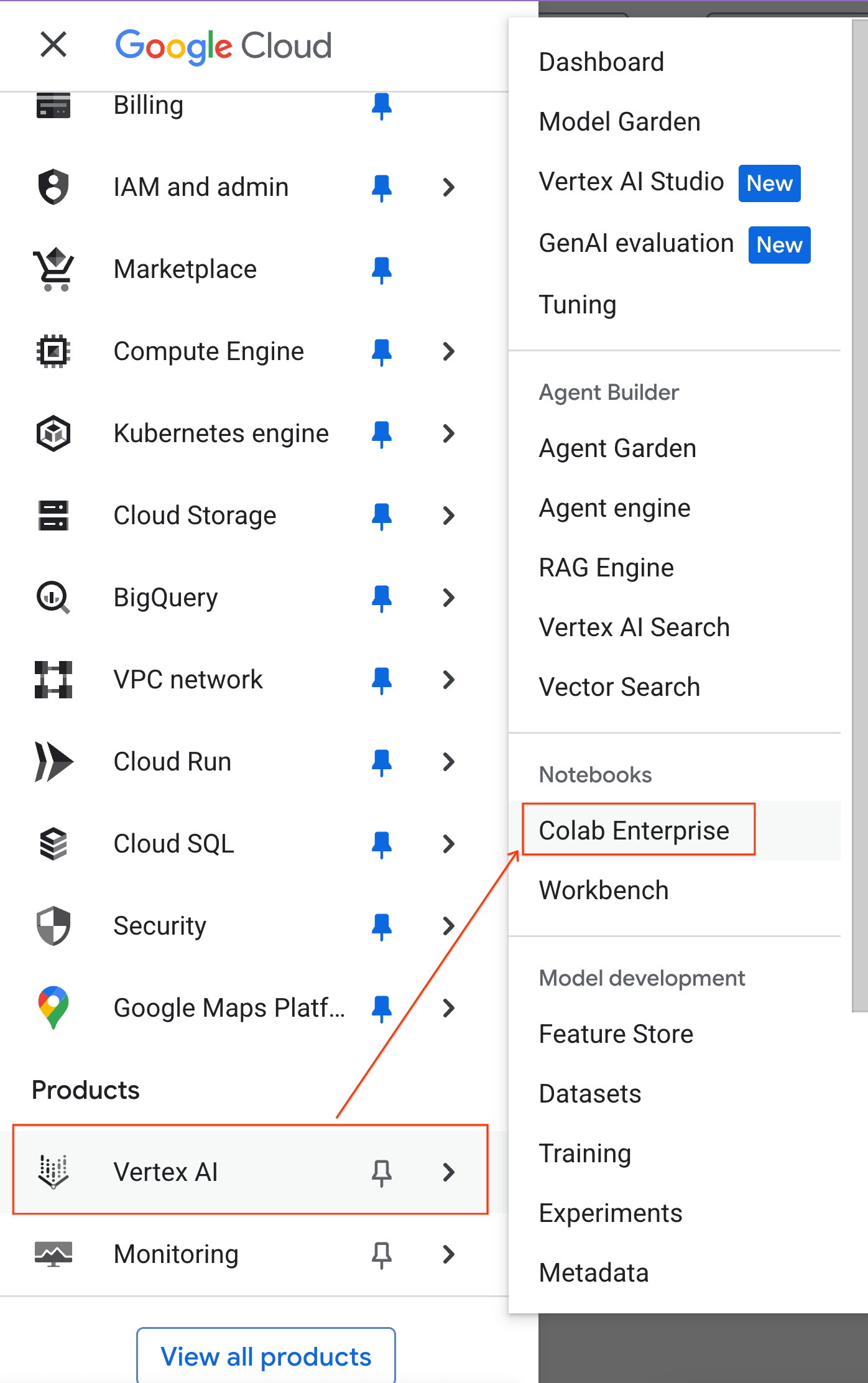
- จาก Colab Enterprise ให้คลิกเทมเพลตรันไทม์ แล้วเลือกเทมเพลตใหม่
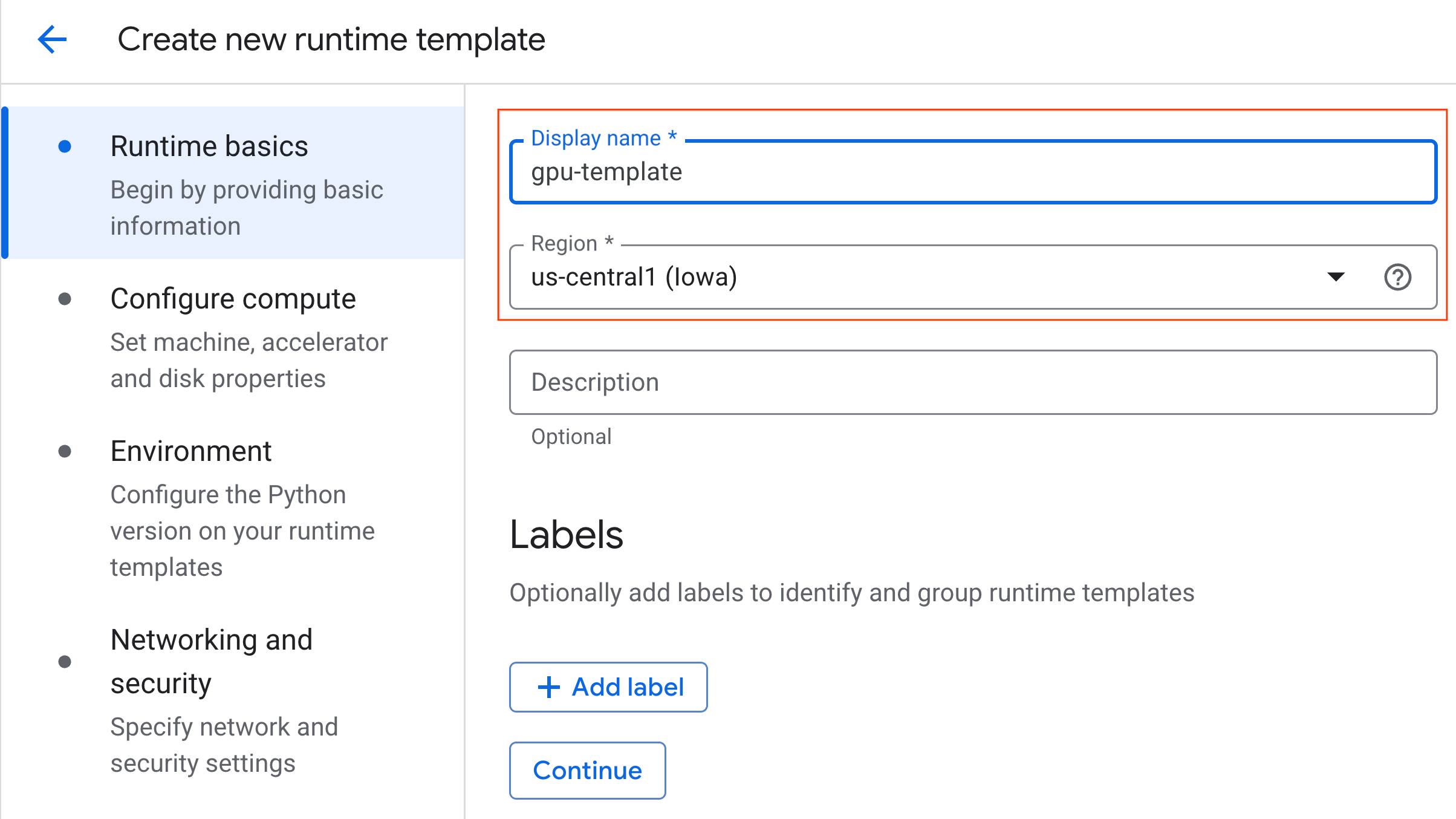
- ในส่วนข้อมูลพื้นฐานเกี่ยวกับรันไทม์ ให้ทำดังนี้
- ตั้งค่าชื่อที่แสดงเป็น
gpu-template - ตั้งค่าภูมิภาคที่ต้องการ
- ตั้งค่าชื่อที่แสดงเป็น
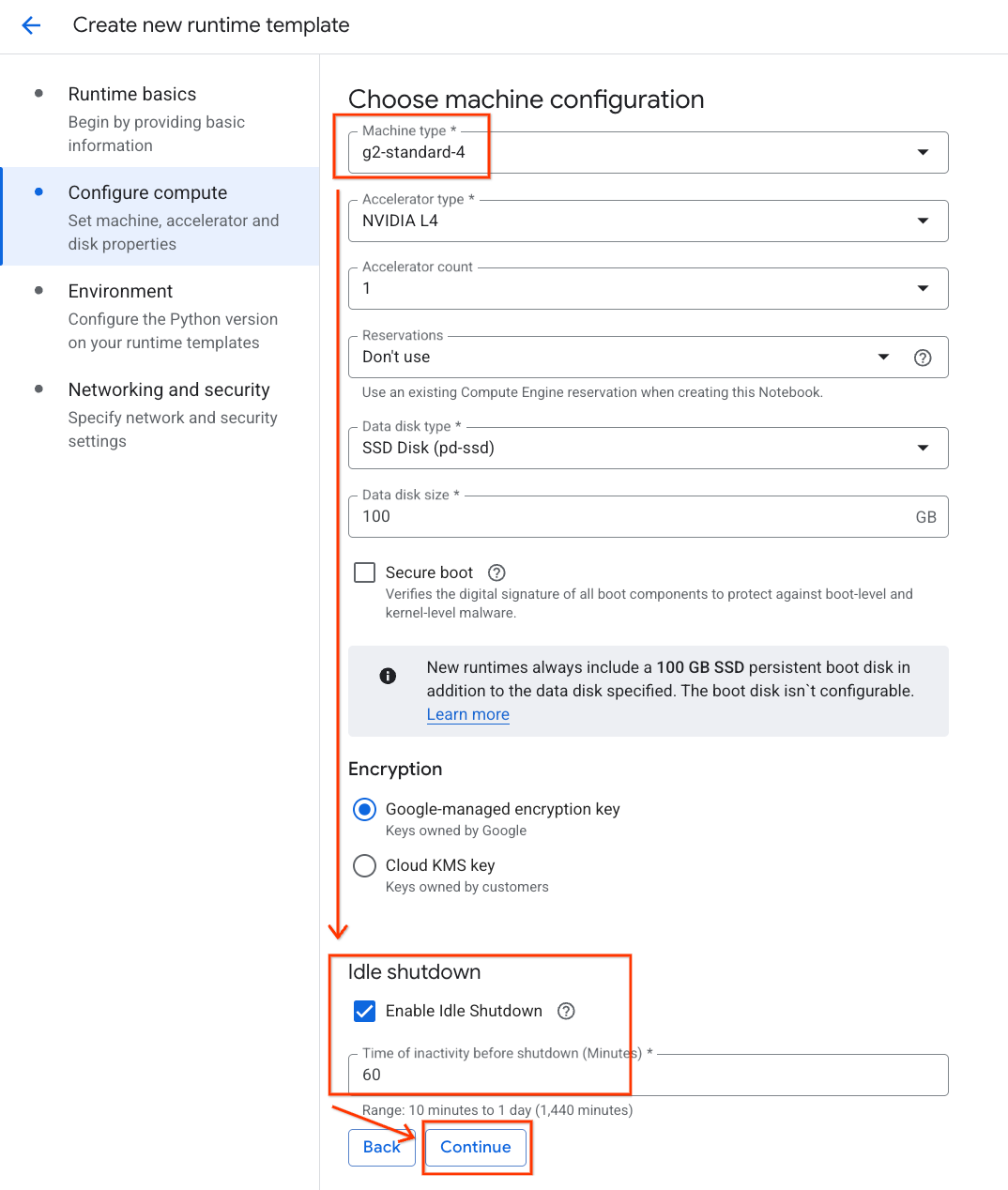
- ในส่วนกำหนดค่าการประมวลผล ให้ทำดังนี้
- ตั้งค่าประเภทเครื่องเป็น
g2-standard-4 - ใช้ประเภท Accelerator เป็น
NVIDIA L4ที่มีจำนวน Accelerator เป็น 1 ตามค่าเริ่มต้น - เปลี่ยนการปิดเครื่องเมื่อไม่มีการใช้งานเป็น 60 นาที
- คลิกต่อไป
- ตั้งค่าประเภทเครื่องเป็น
- ในส่วนสภาพแวดล้อม ให้ทำดังนี้
- ตั้งค่าสภาพแวดล้อมเป็น
Python 3.11
- ตั้งค่าสภาพแวดล้อมเป็น
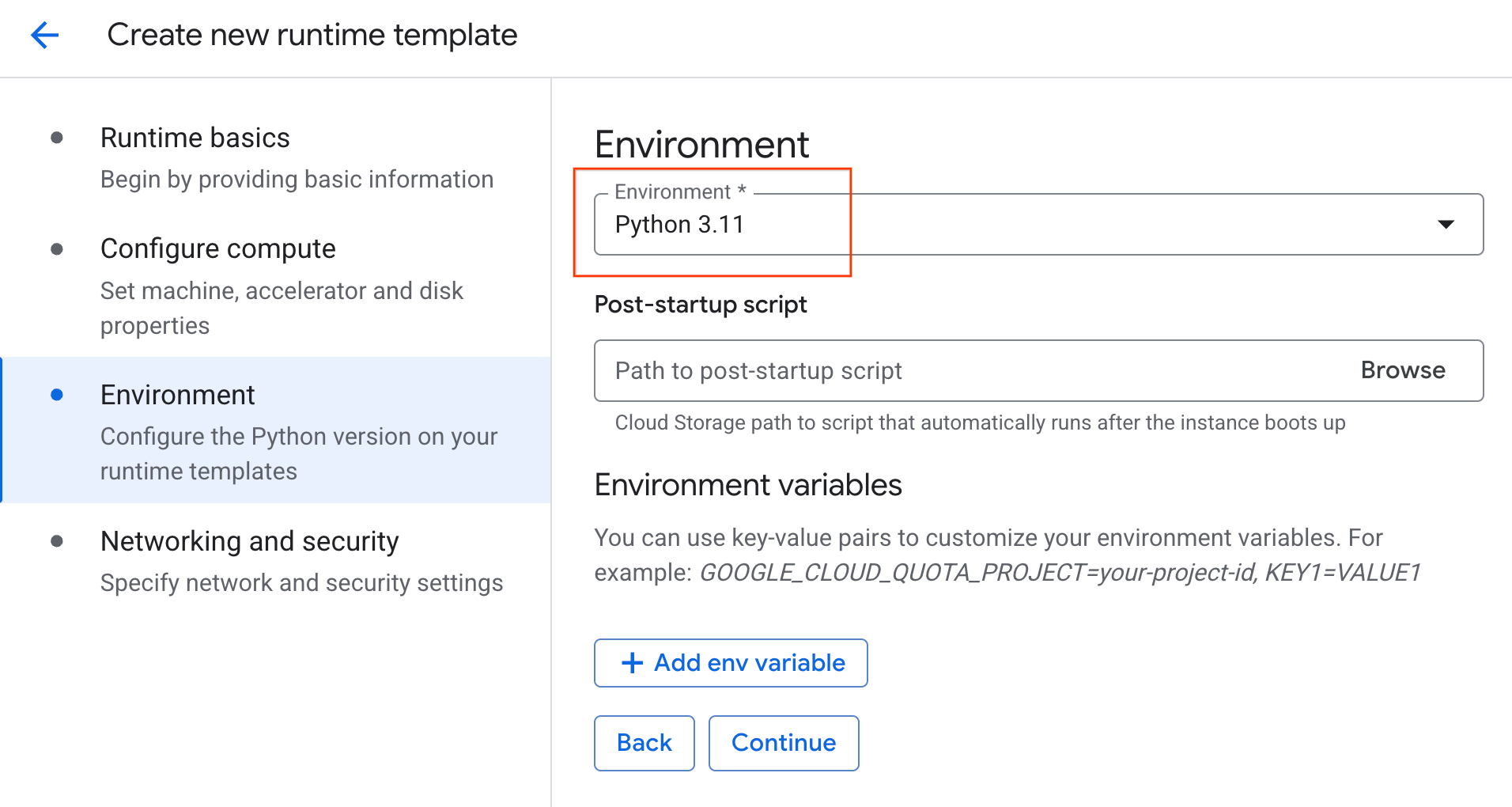
- คลิกสร้างเพื่อบันทึกเทมเพลตรันไทม์ ตอนนี้หน้าเทมเพลตรันไทม์ควรแสดงเทมเพลตใหม่แล้ว
6. เริ่มรันไทม์
เมื่อเทมเพลตพร้อมแล้ว คุณจะสร้างรันไทม์ใหม่ได้
- จาก Colab Enterprise ให้คลิกรันไทม์ แล้วเลือกสร้าง
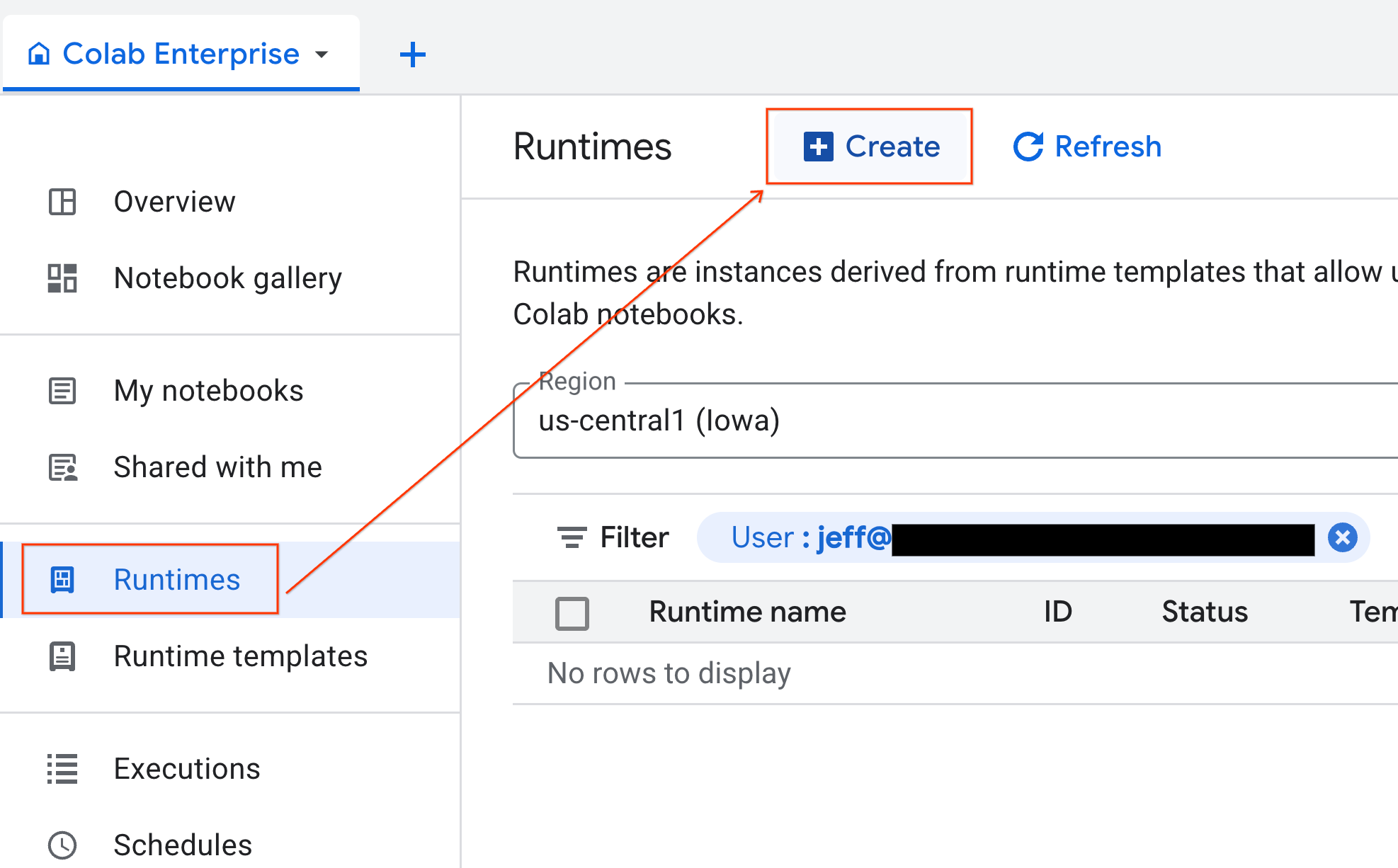
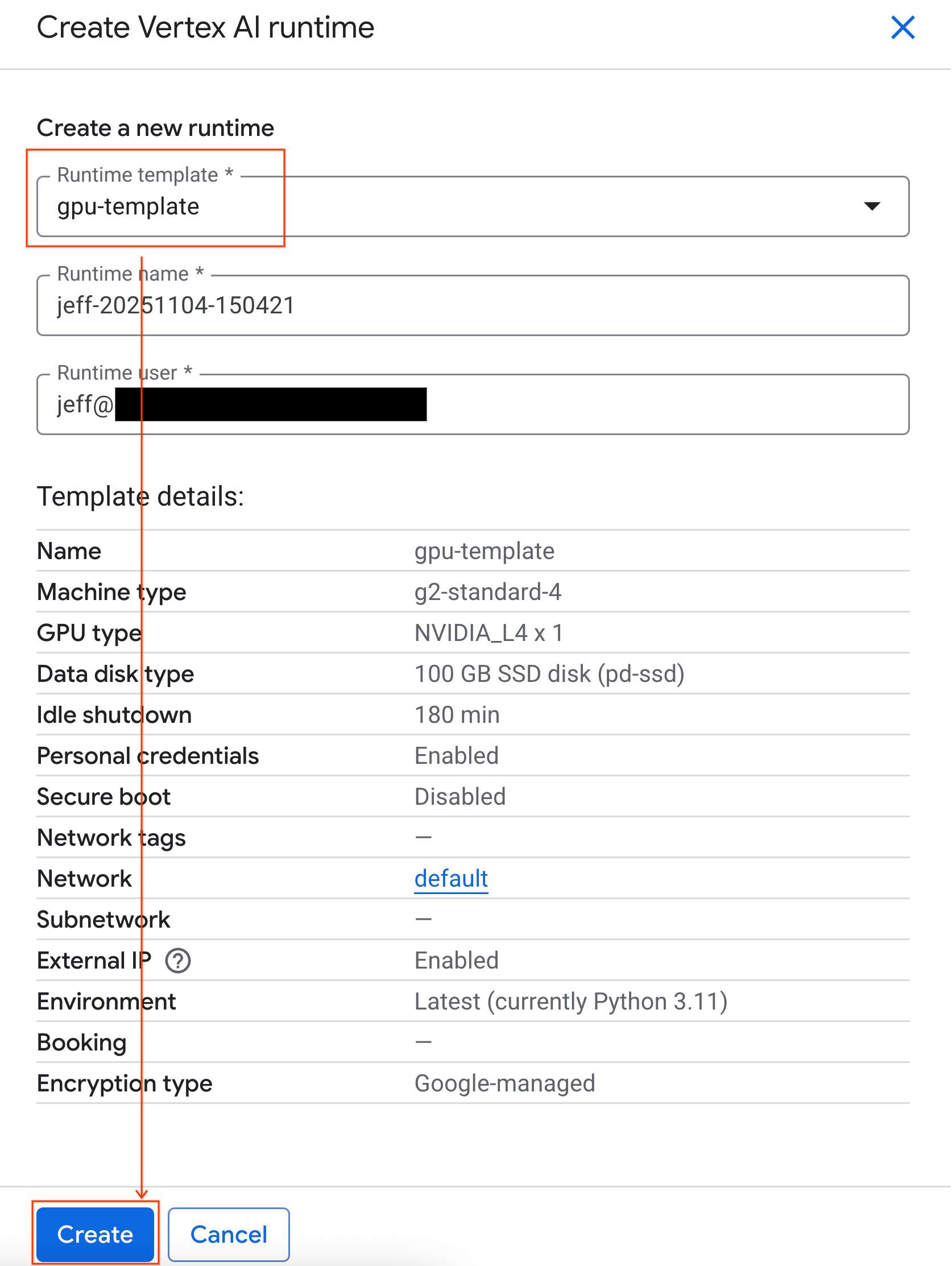
- ในส่วนเทมเพลตรันไทม์ ให้เลือกตัวเลือก
gpu-templateคลิกสร้าง แล้วรอให้รันไทม์บูตขึ้น
- หลังจากนั้นไม่กี่นาที คุณจะเห็นรันไทม์ที่พร้อมใช้งาน
7. ตั้งค่า Notebook
เมื่อโครงสร้างพื้นฐานทำงานแล้ว คุณต้องนำเข้า Notebook ของ Lab และเชื่อมต่อกับรันไทม์
นำเข้า Notebook
- จาก Colab Enterprise ให้คลิกสมุดบันทึกของฉัน แล้วคลิกนำเข้า
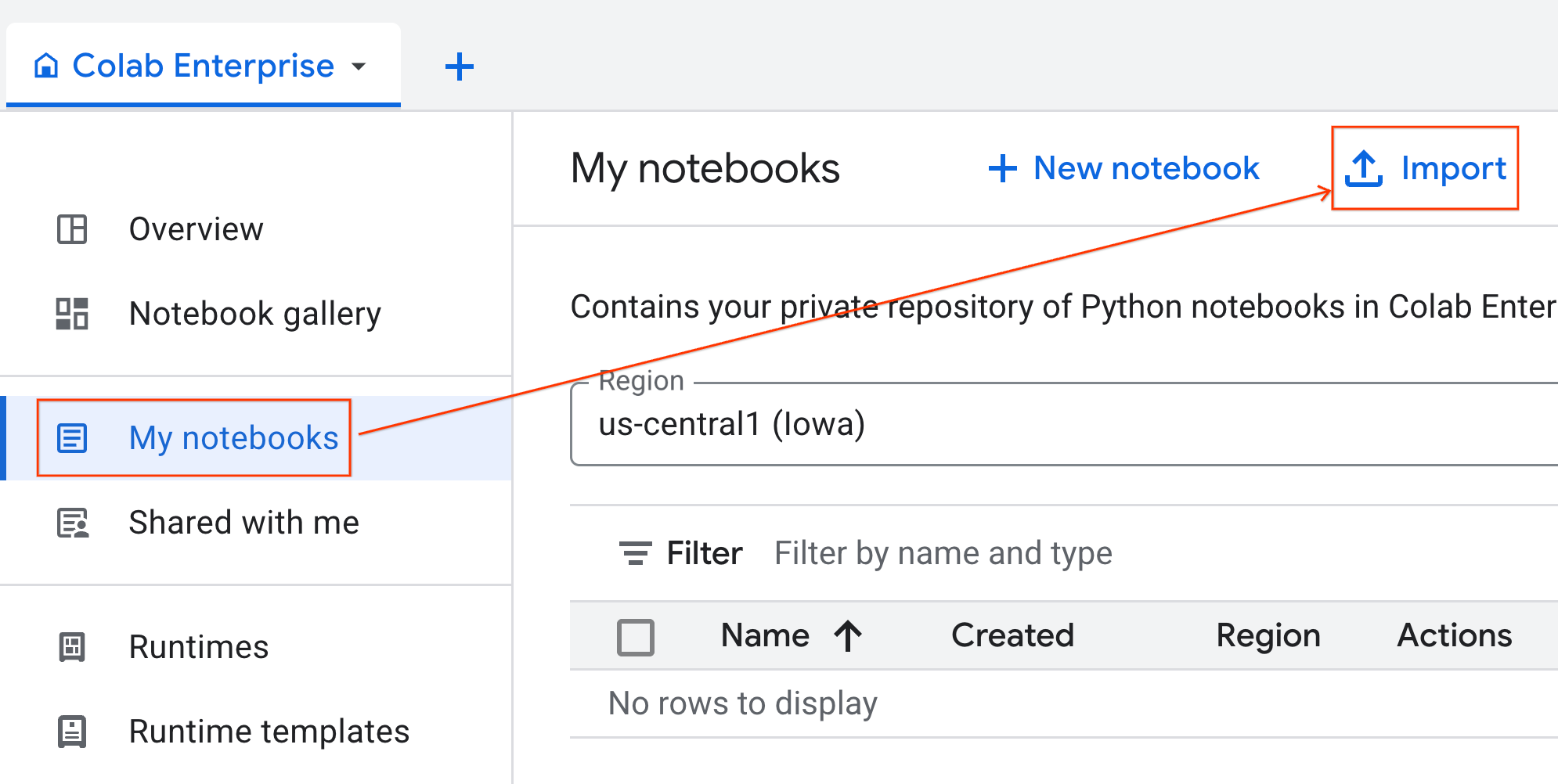
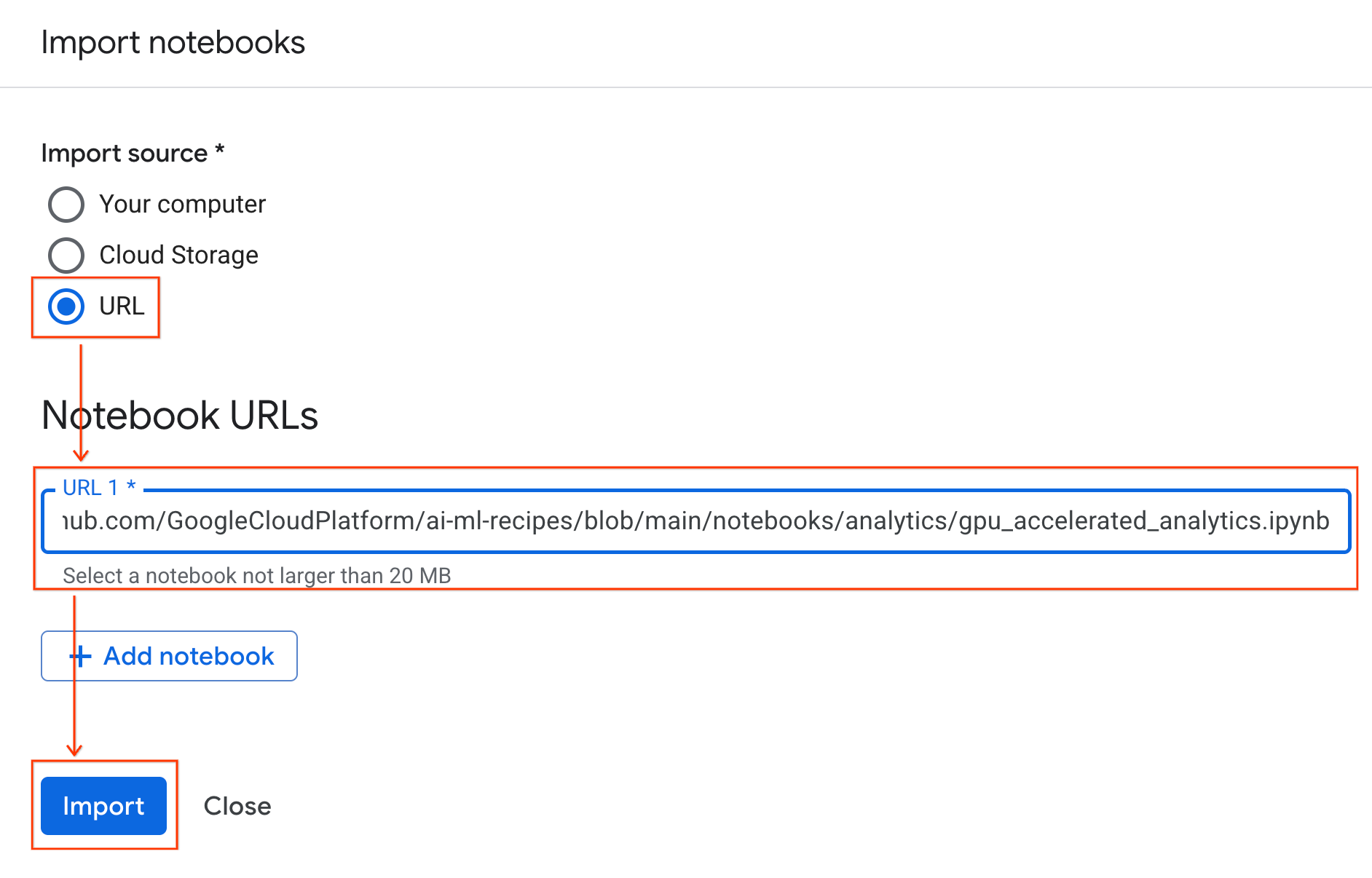
- เลือกปุ่มตัวเลือก URL แล้วป้อน URL ต่อไปนี้
https://github.com/GoogleCloudPlatform/ai-ml-recipes/blob/main/notebooks/regression/gpu_accelerated_regression/gpu_accelerated_regression.ipynb
- คลิกนำเข้า Colab Enterprise จะคัดลอกสมุดบันทึกจาก GitHub ไปยังสภาพแวดล้อมของคุณ
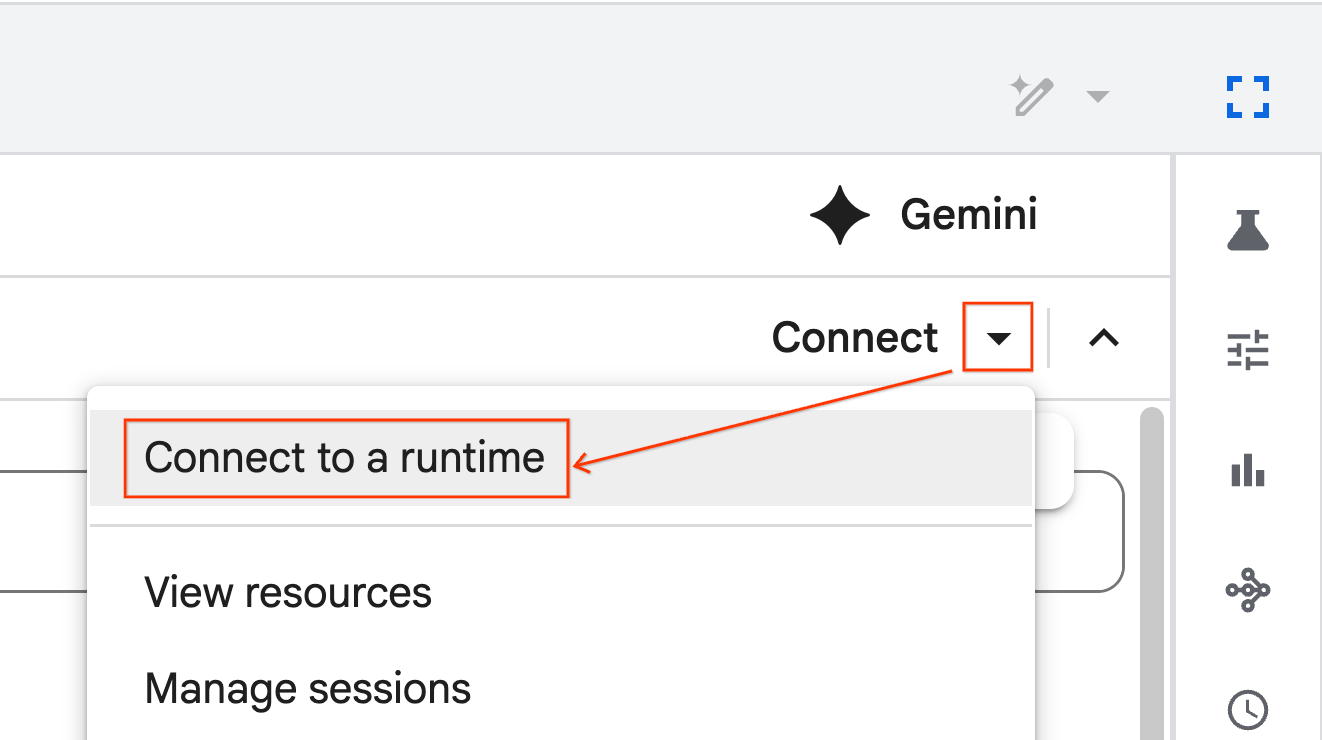
เชื่อมต่อกับรันไทม์
- เปิด Notebook ที่เพิ่งนำเข้า
- คลิกลูกศรลงข้างเชื่อมต่อ
- เลือกเชื่อมต่อกับรันไทม์
- ใช้เมนูแบบเลื่อนลงแล้วเลือกรุ่นรันไทม์ที่คุณสร้างไว้ก่อนหน้านี้
- คลิกเชื่อมต่อ
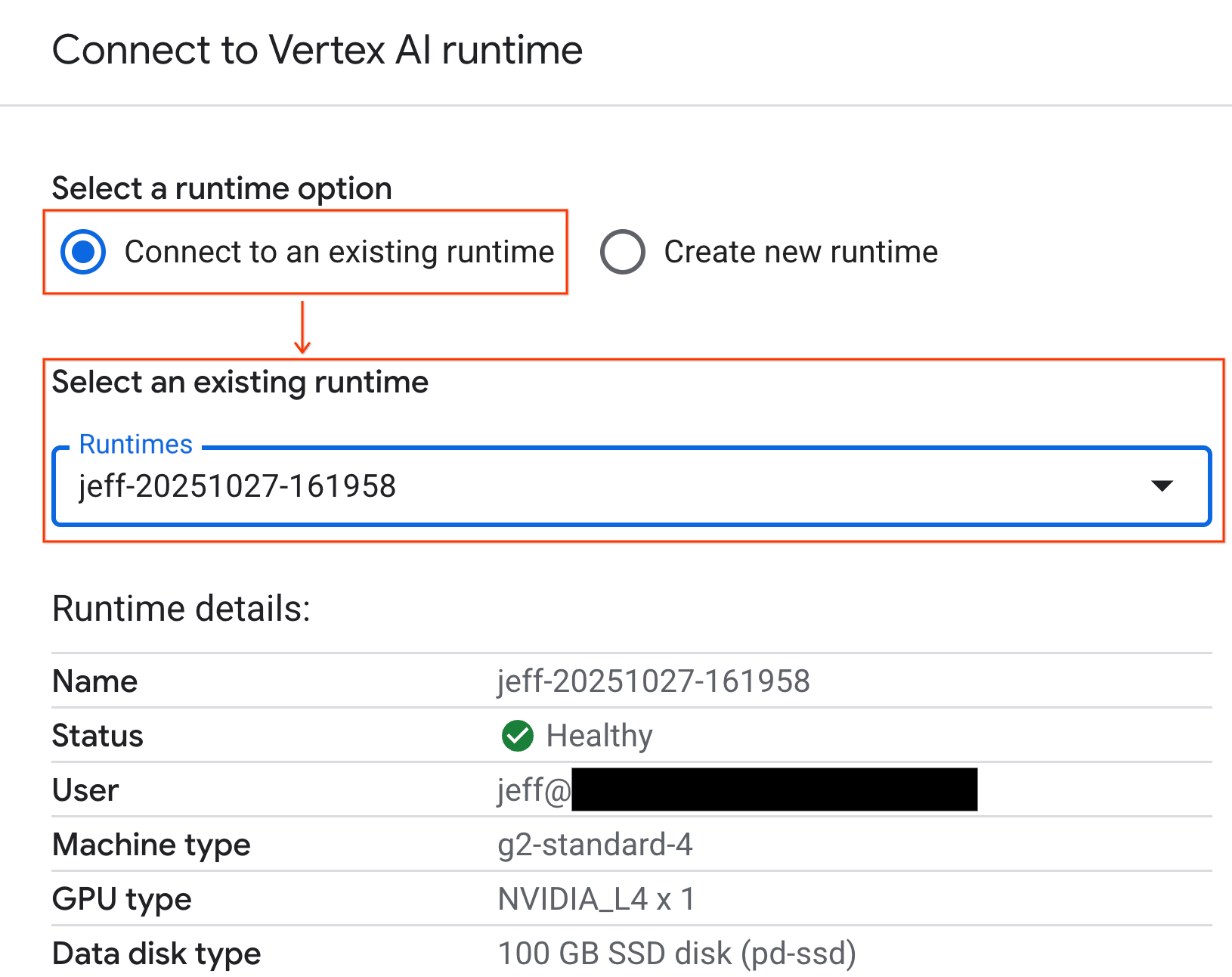
ตอนนี้สมุดบันทึกของคุณเชื่อมต่อกับรันไทม์ที่เปิดใช้ GPU แล้ว
ทรัพยากร Dependency ในตัว
ข้อดีอย่างหนึ่งของการใช้ Colab Enterprise คือมีการติดตั้งไลบรารีที่คุณต้องการไว้ล่วงหน้า คุณไม่จำเป็นต้องติดตั้งหรือจัดการการขึ้นต่อกัน เช่น cuDF, cuML หรือ XGBoost สำหรับแล็บนี้ด้วยตนเอง
8. เตรียมชุดข้อมูลแท็กซี่ในนิวยอร์ก
Codelab นี้ใช้ข้อมูลบันทึกการเดินทางของคณะกรรมการแท็กซี่และรถลีมูซีน (TLC) ของนิวยอร์ก ชุดข้อมูลประกอบด้วยบันทึกการเดินทางจากแท็กซี่สีเหลืองในนิวยอร์กซิตี้ ซึ่งรวมถึงข้อมูลต่อไปนี้
- วันที่ เวลา และสถานที่รับและส่ง
- ระยะทางการเดินทาง
- จำนวนค่าโดยสารแบบแยกรายการ
- จำนวนผู้โดยสาร
- จำนวนทิป (นี่คือสิ่งที่เราจะคาดการณ์)
กำหนดค่า GPU และยืนยันความพร้อมใช้งาน
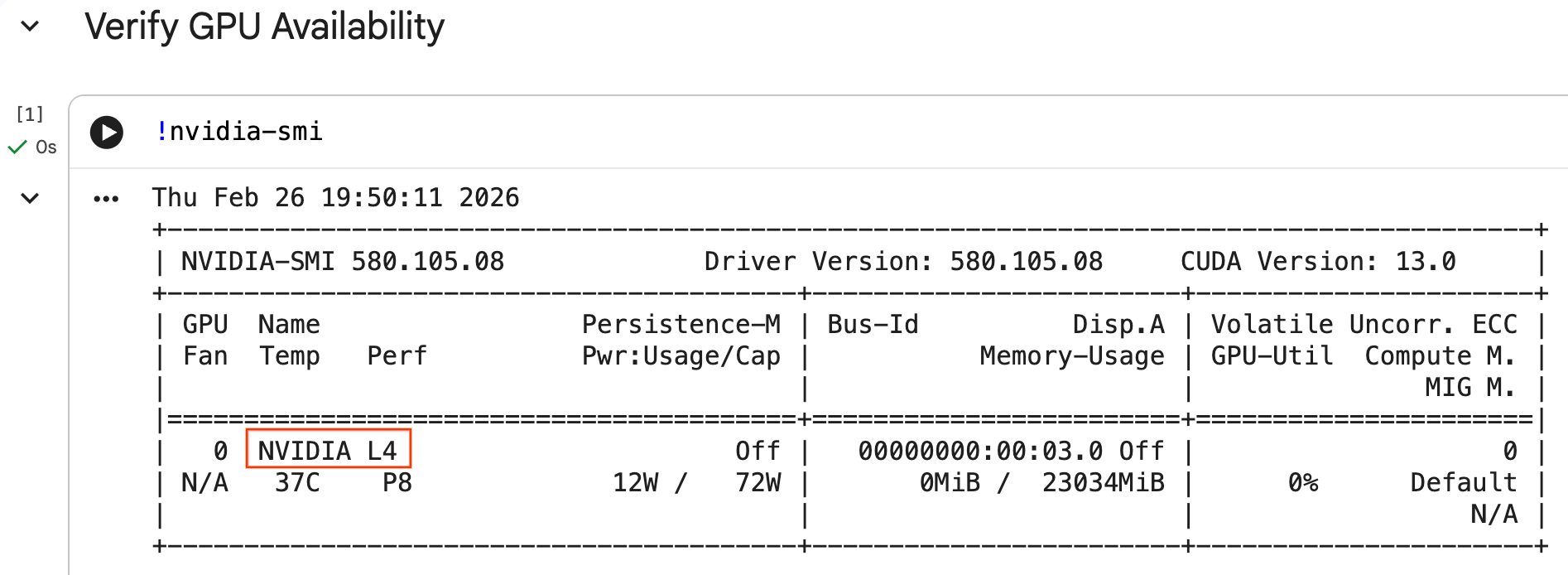
คุณยืนยันได้ว่าระบบรู้จัก GPU โดยเรียกใช้คำสั่ง nvidia-smi โดยจะแสดงเวอร์ชันไดรเวอร์และรายละเอียด GPU (เช่น NVIDIA L4)
nvidia-smi
เซลล์ควรแสดง GPU ที่แนบมากับรันไทม์ของคุณ ซึ่งคล้ายกับตัวอย่างต่อไปนี้
ดาวน์โหลดข้อมูล
ดาวน์โหลดข้อมูลการเดินทางสำหรับปี 2024
from tqdm import tqdm
import requests
import time
import os
YEAR = 2024
DATA_DIR = "nyc_taxi_data"
os.makedirs(DATA_DIR, exist_ok=True)
print(f"Checking/Downloading files for {YEAR}...")
for month in tqdm(range(1, 13), unit="file"):
file_name = f"yellow_tripdata_{YEAR}-{month:02d}.parquet"
local_path = os.path.join(DATA_DIR, file_name)
url = f"https://d37ci6vzurychx.cloudfront.net/trip-data/{file_name}"
if not os.path.exists(local_path):
try:
with requests.get(url, stream=True) as response:
response.raise_for_status()
with open(local_path, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
time.sleep(1)
except requests.exceptions.HTTPError as e:
print(f"\nSkipping {file_name}: {e}")
if os.path.exists(local_path):
os.remove(local_path)
print("\nDownload complete.")
เร่งความเร็ว pandas ด้วย NVIDIA cuDF
pandas ไลบรารีจะทำงานบน CPU และอาจช้าเมื่อใช้กับชุดข้อมูลขนาดใหญ่ คำสั่ง Magic ของ NVIDIA %load_ext cudf.pandas จะแก้ไขแพตช์ pandas แบบไดนามิกเพื่อใช้การเร่งความเร็ว GPU และจะกลับไปใช้ CPU หากจำเป็น
เราใช้คำสั่ง Magic นี้แทนการนำเข้ามาตรฐานเนื่องจากช่วยให้เร่งความเร็วได้โดย "ไม่ต้องเปลี่ยนแปลงโค้ด" คุณไม่จำเป็นต้องเขียนโค้ดที่มีอยู่ใหม่ คำสั่งที่คล้ายกันอย่าง %load_ext cuml.accel จะทำสิ่งเดียวกันนี้กับ scikit-learn models ซึ่งใช้ได้ในสภาพแวดล้อม Jupyter ที่มี NVIDIA GPU ที่เข้ากันได้ ไม่ใช่แค่ Colab Enterprise
%load_ext cudf.pandas
หากต้องการยืนยันว่าใช้งานได้ ให้นำเข้า pandas แล้วตรวจสอบประเภทของ pandas ดังนี้
import pandas as pd
pd
เอาต์พุตจะยืนยันว่าตอนนี้คุณใช้โมดูล cudf.pandas แล้ว
โหลดและล้างข้อมูล
เมื่อ cudf.pandas ทำงานอยู่ ให้โหลดไฟล์ Parquet และดำเนินการทำความสะอาดข้อมูล กระบวนการนี้จะทำงานบน GPU โดยอัตโนมัติ
import glob
# Load data into memory
df = pd.concat(
[pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")],
ignore_index=True
)
# Filter for valid trips. We filter for payment_type=1 (credit card)
# because tip amounts are only reliably recorded for credit card transactions.
df = df[
(df['fare_amount'] > 0) & (df['fare_amount'] < 500) &
(df['trip_distance'] > 0) & (df['trip_distance'] < 100) &
(df['tip_amount'] >= 0) & (df['tip_amount'] < 100) &
(df['payment_type'] == 1)
].copy()
# Downcast numeric columns to save memory
float_cols = df.select_dtypes(include=['float64']).columns
df[float_cols] = df[float_cols].astype('float32')
int_cols = df.select_dtypes(include=['int64']).columns
df[int_cols] = df[int_cols].astype('int32')
Feature Engineering
สร้างฟีเจอร์ที่ได้มาจากวันที่และเวลาที่รับ สมุดบันทึกมีฟีเจอร์อื่นๆ ที่ใช้ในขั้นตอนต่อๆ ไป
import numpy as np
# Time Features
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['dow'] = df['tpep_pickup_datetime'].dt.dayofweek
df['is_weekend'] = (df['dow'] >= 5).astype(int)
df['is_rush_hour'] = (
((df['hour'] >= 7) & (df['hour'] <= 9)) |
((df['hour'] >= 17) & (df['hour'] <= 19))
).astype(int)
...
# Other features
...
9. ฝึกโมเดลแต่ละรายการด้วยการตรวจสอบแบบไขว้
เพื่อแสดงให้เห็นว่า GPU เร่งแมชชีนเลิร์นนิงได้อย่างไร คุณจะฝึกโมเดลการถดถอย 3 ประเภทที่แตกต่างกันเพื่อคาดการณ์tip_amountของการเดินทางด้วยแท็กซี่
เร่งความเร็ว scikit-learn ด้วย NVIDIA cuML
เรียกใช้อัลกอริทึม scikit-learn ใน GPU โดยใช้ cuML ของ NVIDIA โดยไม่ต้องเปลี่ยนการเรียก API ก่อนอื่น ให้โหลดส่วนขยาย cuml.accel
%load_ext cuml.accel
ตั้งค่าฟีเจอร์และเป้าหมาย
ระบุฟีเจอร์ที่คุณต้องการให้โมเดลเรียนรู้และแยกคอลัมน์เป้าหมาย (tip_amount)
feature_cols = [
'trip_distance', 'fare_amount', 'passenger_count',
'hour', 'dow', 'is_weekend', 'is_rush_hour',
'fare_log', 'fare_decimal', 'is_round_fare',
'route_frequency', 'pu_tip_mean', 'pu_tip_std',
'PULocationID', 'DOLocationID'
]
X = df[feature_cols].fillna(df[feature_cols].median())
y = df['tip_amount'].copy()
ตั้งค่าการแยกการตรวจสอบแบบไขว้เพื่อประเมินประสิทธิภาพของโมเดลอย่างมีประสิทธิภาพ
from sklearn.model_selection import KFold
import numpy as np
import time
from sklearn.metrics import mean_squared_error
from tqdm.notebook import tqdm
n_splits = 3
kf = KFold(n_splits=n_splits, shuffle=True, random_state=42)
1. XGBoost
XGBoost เร่งด้วย GPU โดยกำเนิด ส่ง tree_method='hist' และ device='cuda' เพื่อใช้ GPU ระหว่างการฝึก
import xgboost as xgb
start_time = time.perf_counter()
def train_xgb_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# XGBoost handles GPU natively when tree_method='hist' and device='cuda'
model = xgb.XGBRegressor(
objective='reg:squarederror',
max_depth=5,
learning_rate=0.1,
n_estimators=100,
tree_method='hist',
device='cuda',
random_state=42
)
model.fit(X_train, y_train)
preds = model.predict(X_val)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
xgb_rmse, xgb_preds = train_xgb_cv(X, y)
print(f"\n{'XGBoost RMSE:':<20} ${xgb_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
2. การถดถอยเชิงเส้น
ฝึกโมเดลการถดถอยเชิงเส้น เมื่อ %load_ext cuml.accel ทำงานอยู่ LinearRegression จะแมปกับ GPU ที่เทียบเท่าโดยอัตโนมัติ
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
start_time = time.perf_counter()
def train_linreg_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# Scale features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_val_scaled = scaler.transform(X_val)
# Automatically accelerated by cuML
model = LinearRegression()
model.fit(X_train_scaled, y_train)
preds = model.predict(X_val_scaled)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
linreg_rmse, linreg_preds = train_linreg_cv(X, y)
print(f"\n{'Linear Reg RMSE:':<20} ${linreg_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
3. Random Forest
ฝึกโมเดล Ensemble โดยใช้ RandomForestRegressor โมเดลแบบอิงตามโครงสร้างต้นไม้มักจะฝึกบน CPU ได้ช้า แต่การเร่งความเร็วด้วย GPU จะประมวลผลแถวหลายล้านแถวได้เร็วกว่า
from sklearn.ensemble import RandomForestRegressor
start_time = time.perf_counter()
def train_rf_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# Automatically accelerated by cuML
model = RandomForestRegressor(
n_estimators=100,
max_depth=10,
n_jobs=-1,
max_features='sqrt',
random_state=42
)
model.fit(X_train, y_train)
preds = model.predict(X_val)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
rf_rmse, rf_preds = train_rf_cv(X, y)
print(f"\n{'Random Forest RMSE:':<20} ${rf_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
10. ประเมินไปป์ไลน์ตั้งแต่ต้นจนจบ
รวมการคาดการณ์จากโมเดลทั้ง 3 โดยใช้การรวมเชิงเส้นอย่างง่าย ซึ่งโดยปกติแล้วจะช่วยเพิ่มความแม่นยำเล็กน้อยเมื่อเทียบกับโมเดลแต่ละรายการ
ปรับการถดถอยเชิงเส้นกับการคาดการณ์เพื่อหาน้ำหนักที่เหมาะสมที่สุด
ensemble_weights = LinearRegression(positive=True, fit_intercept=False).fit(
np.c_[xgb_preds, rf_preds, linreg_preds], y
).coef_
# Normalize weights
ensemble_weights = ensemble_weights / ensemble_weights.sum()
ensemble_preds = np.c_[xgb_preds, rf_preds, linreg_preds] @ ensemble_weights
ensemble_rmse = np.sqrt(mean_squared_error(y, ensemble_preds))
เปรียบเทียบผลลัพธ์เพื่อดู Ensemble Lift โดยทำดังนี้
print(f"\n{'Model':<20} {'RMSE':>10}")
print("-" * 32)
print(f"{'Linear Regression':<20} ${linreg_rmse:>9.4f}")
print(f"{'Random Forest':<20} ${rf_rmse:>9.4f}")
print(f"{'XGBoost':<20} ${xgb_rmse:>9.4f}")
print("-" * 32)
print(f"{'Ensemble':<20} ${ensemble_rmse:>9.4f}")
print(f"\nEnsemble lift: ${xgb_rmse - ensemble_rmse:.4f}")
11. เปรียบเทียบประสิทธิภาพของ CPU กับ GPU
หากต้องการเปรียบเทียบความแตกต่างของประสิทธิภาพอย่างถูกต้อง คุณจะต้องรีสตาร์ทเคอร์เนลเพื่อให้แน่ใจว่าสถานะการดำเนินการสะอาด จากนั้นเรียกใช้ไปป์ไลน์วิทยาศาสตร์ข้อมูลทั้งหมดใน CPU แล้วเรียกใช้อีกครั้งใน GPU
รีสตาร์ทเคอร์เนล
เรียกใช้คำสั่ง IPython.Application.instance().kernel.do_shutdown(True) เพื่อรีสตาร์ทเคอร์เนลและปล่อยหน่วยความจำ
import IPython
IPython.Application.instance().kernel.do_shutdown(True)
กำหนด Data Pipeline ทางวิทยาศาสตร์
รวมเวิร์กโฟลว์หลัก (การโหลดข้อมูล การทำความสะอาดข้อมูล Feature Engineering และการฝึกโมเดล) ไว้ในฟังก์ชันเดียว ฟังก์ชันนี้ยอมรับโมดูล pandas pd_module และอาร์กิวเมนต์ use_gpu เพื่อสลับระหว่างสภาพแวดล้อม
def run_ml_pipeline(pd_module, use_gpu=False):
import time
import glob
import numpy as np
from sklearn.ensemble import RandomForestRegressor
import xgboost as xgb
timings = {}
# 1. Load Data
t0 = time.perf_counter()
df = pd_module.concat(
[pd_module.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")],
ignore_index=True
)
timings['Load Data'] = time.perf_counter() - t0
# 2. Clean Data
t0 = time.perf_counter()
# Filter for payment_type=1 (credit card) because tip amounts
# are only reliably recorded for credit card transactions.
df = df[
(df['fare_amount'] > 0) & (df['fare_amount'] < 500) &
(df['trip_distance'] > 0) & (df['trip_distance'] < 100) &
(df['tip_amount'] >= 0) & (df['tip_amount'] < 100) &
(df['payment_type'] == 1)
].copy()
# Downcast numeric columns to save memory
float_cols = df.select_dtypes(include=['float64']).columns
df[float_cols] = df[float_cols].astype('float32')
int_cols = df.select_dtypes(include=['int64']).columns
df[int_cols] = df[int_cols].astype('int32')
timings['Clean Data'] = time.perf_counter() - t0
# 3. Feature Engineering
t0 = time.perf_counter()
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['dow'] = df['tpep_pickup_datetime'].dt.dayofweek
df['is_weekend'] = (df['dow'] >= 5).astype(int)
df['fare_log'] = np.log1p(df['fare_amount'])
timings['Feature Engineering'] = time.perf_counter() - t0
# 4. Modeling Prep
feature_cols = ['trip_distance', 'fare_amount', 'passenger_count', 'hour', 'dow', 'is_weekend', 'fare_log']
X = df[feature_cols].fillna(df[feature_cols].median())
y = df['tip_amount'].copy()
# Free memory
del df
import gc
gc.collect()
# 5. Train Random Forest
t0 = time.perf_counter()
rf_model = RandomForestRegressor(
n_estimators=100,
max_depth=10,
n_jobs=-1,
max_features='sqrt',
random_state=42
).fit(X, y)
timings['Train Random Forest'] = time.perf_counter() - t0
# 6. Train XGBoost
t0 = time.perf_counter()
params = {
'objective': 'reg:squarederror',
'max_depth': 5,
'n_estimators': 100,
'random_state': 42
}
if use_gpu:
params['device'] = 'cuda'
params['tree_method'] = 'hist'
xgb_model = xgb.XGBRegressor(**params).fit(X, y)
timings['Train XGBoost'] = time.perf_counter() - t0
del X
del y
gc.collect()
return timings
เรียกใช้ใน CPU
เรียกใช้ไปป์ไลน์โดยใช้ CPU มาตรฐาน pandas
import pandas as pd
print("Running pipeline on CPU...")
cpu_times = run_ml_pipeline(pd, use_gpu=False)
print("CPU Execution Finished.")
เรียกใช้บน GPU
โหลดส่วนขยายไลบรารี NVIDIA ส่งโมดูล cudf.pandas ที่เร่งความเร็วไปยังไปป์ไลน์ และตั้งค่าอุปกรณ์ XGBoost เป็น cuda ภายใน
import IPython.core.magic
if not hasattr(IPython.core.magic, 'output_can_be_silenced'):
IPython.core.magic.output_can_be_silenced = lambda x: x
%load_ext cudf.pandas
%load_ext cuml.accel
import pandas as pd
print("Running pipeline on GPU...")
gpu_times = run_ml_pipeline(pd, use_gpu=True)
print("GPU Execution Finished.")
แสดงภาพการเพิ่มความเร็วของประสิทธิภาพ
แสดงภาพระยะเวลาโดยใช้ matplotlib ผลลัพธ์จะแสดงเวลาที่ประหยัดได้ระหว่างการประมวลผลข้อมูลและการฝึกโมเดลเมื่อใช้ GPU
import matplotlib.pyplot as plt
import numpy as np
labels = list(cpu_times.keys())
cpu_values = list(cpu_times.values())
gpu_values = list(gpu_times.values())
x = np.arange(len(labels))
width = 0.35
fig, ax = plt.subplots(figsize=(10, 6))
rects1 = ax.bar(x - width/2, cpu_values, width, label='CPU', color='#4285F4')
rects2 = ax.bar(x + width/2, gpu_values, width, label='GPU', color='#76B900')
ax.set_ylabel('Execution Time (seconds)')
ax.set_title('NYC Taxi ML Pipeline: CPU vs. GPU Performance')
ax.set_xticks(x)
ax.set_xticklabels(labels, rotation=45, ha="right")
ax.legend()
# Add data labels
def autolabel(rects):
for rect in rects:
height = rect.get_height()
ax.annotate(f'{height:.2f}s',
xy=(rect.get_x() + rect.get_width() / 2, height),
xytext=(0, 3), # 3 points vertical offset
textcoords="offset points",
ha='center', va='bottom', fontsize=9)
autolabel(rects1)
autolabel(rects2)
plt.tight_layout()
plt.show()
# Calculate overall speedup
total_cpu_time = sum(cpu_values)
total_gpu_time = sum(gpu_values)
overall_speedup = total_cpu_time / total_gpu_time
print(f"\nOverall Pipeline Speedup: {overall_speedup:.2f}x faster on GPU!")
คุณควรเห็นข้อความต่อไปนี้
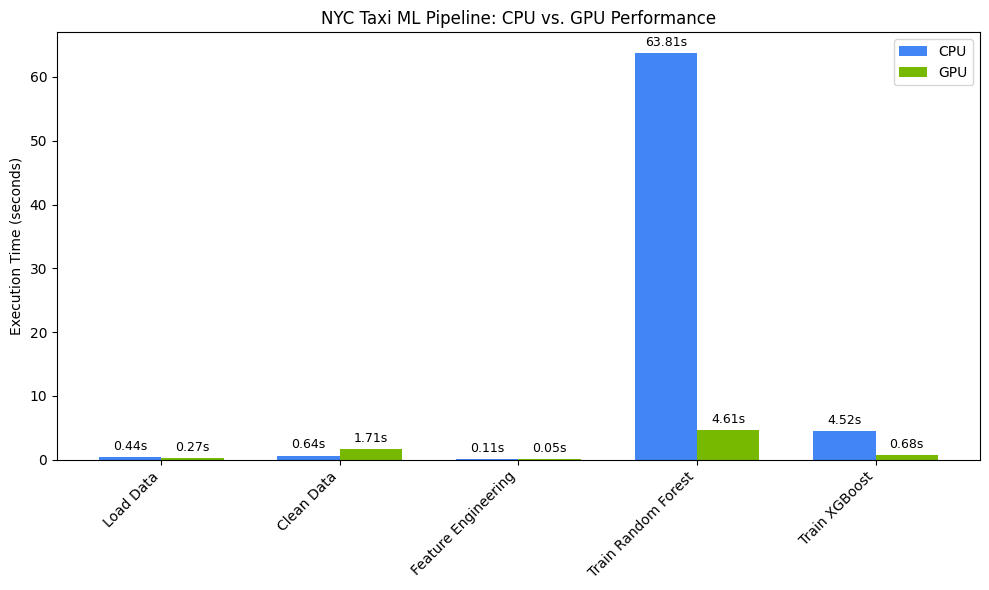
แผนภูมินี้แสดงให้เห็นถึงข้อได้เปรียบด้านประสิทธิภาพที่สำคัญของ GPU ในเวิร์กโฟลว์วิทยาศาสตร์ข้อมูลทั้งหมด คุณควรคาดหวังว่าจะประหยัดเวลาได้มากที่สุดในช่วงการฝึกโมเดลที่ต้องใช้การคำนวณอย่างเข้มข้นสำหรับอัลกอริทึม เช่น Random Forest และ XGBoost
12. สร้างโปรไฟล์โค้ดเพื่อหาข้อจำกัดด้านประสิทธิภาพ
เมื่อใช้ cudf.pandas ฟังก์ชันส่วนใหญ่จะทำงานบน GPU หาก cuDF ยังไม่รองรับการดำเนินการใดๆ ระบบจะเปลี่ยนไปใช้ CPU ชั่วคราว NVIDIA มีคำสั่ง Magic ของ Jupyter 2 คำสั่งในตัวเพื่อระบุการสำรองข้อมูลเหล่านี้
การทำโปรไฟล์ระดับสูงด้วย %%cudf.pandas.profile
%%cudf.pandas.profile คำสั่ง Magic จะแสดงสรุปของฟังก์ชันที่ทำงานบน GPU หรือ CPU
%%cudf.pandas.profile
import glob
import pandas as pd
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")], ignore_index=True)
summary = (
df
.groupby(['PULocationID', 'payment_type'])
[['passenger_count', 'fare_amount', 'tip_amount']]
.agg(['min', 'mean', 'max'])
)
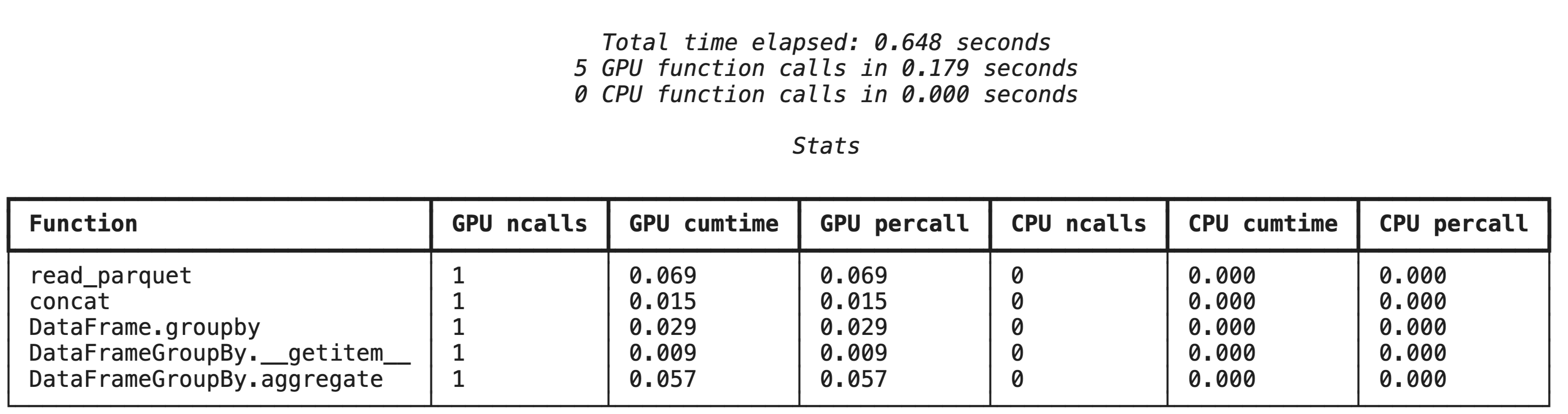
การสร้างโปรไฟล์ทีละบรรทัดด้วย %%cudf.pandas.line_profile
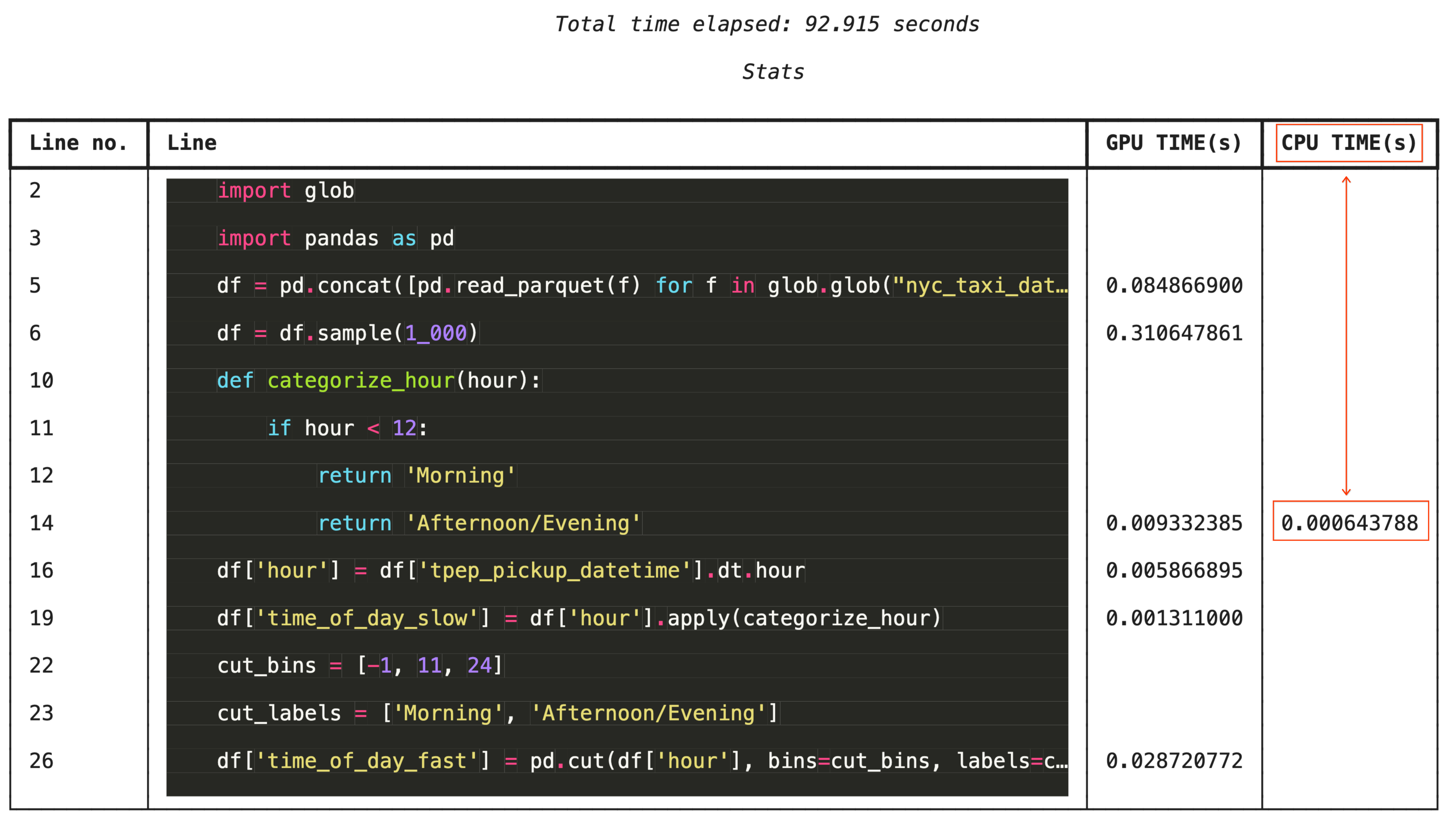
%%cudf.pandas.line_profile จะใส่คำอธิบายประกอบในโค้ดแต่ละบรรทัดพร้อมระบุจำนวนครั้งที่โค้ดนั้นทำงานบน GPU เทียบกับ CPU เพื่อการแก้ปัญหาแบบละเอียด
%%cudf.pandas.line_profile
import glob
import pandas as pd
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")], ignore_index=True)
df = df.sample(1_000)
# Iterating row-by-row or using custom python apply functions often falls back to the CPU
def categorize_hour(hour):
if hour < 12:
return 'Morning'
else:
return 'Afternoon/Evening'
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['time_of_day_slow'] = df['hour'].apply(categorize_hour)
# Using vectorized pandas operations (like pd.cut) stays entirely on the GPU
cut_bins = [-1, 11, 24]
cut_labels = ['Morning', 'Afternoon/Evening']
df['time_of_day_fast'] = pd.cut(df['hour'], bins=cut_bins, labels=cut_labels)
13. ล้าง
โปรดล้างข้อมูลทรัพยากรที่คุณสร้างขึ้นในระหว่าง Codelab นี้เพื่อหลีกเลี่ยงการเรียกเก็บเงินที่ไม่คาดคิดในบัญชี Google Cloud
ลบทรัพยากร
ลบชุดข้อมูลในเครื่องในรันไทม์โดยใช้คำสั่ง !rm -rf ในเซลล์สมุดบันทึก
print("Deleting local 'nyc_taxi_data' directory...")
!rm -rf nyc_taxi_data
print("Local files deleted.")
ปิดรันไทม์ Colab
- ในคอนโซล Google Cloud ให้ไปที่หน้ารันไทม์ของ Colab Enterprise
- ในเมนูภูมิภาค ให้เลือกภูมิภาคที่มีรันไทม์
- เลือกรันไทม์ที่ต้องการลบ
- คลิกลบ
- คลิกยืนยัน
ลบ Notebook
- ในคอนโซล Google Cloud ให้ไปที่หน้าสมุดบันทึกของฉันใน Colab Enterprise
- ในเมนูภูมิภาค ให้เลือกภูมิภาคที่มี Notebook
- เลือกสมุดบันทึกที่ต้องการลบ
- คลิกลบ
- คลิกยืนยัน
14. ขอแสดงความยินดี
ยินดีด้วย คุณเร่งเวิร์กโฟลว์แมชชีนเลิร์นนิงของ pandas และ scikit-learn โดยใช้ไลบรารี cuDF และ cuML ของ NVIDIA ใน Colab Enterprise ได้สำเร็จแล้ว เพียงเพิ่มคำสั่งวิเศษ 2-3 คำสั่ง (%load_ext cudf.pandas และ %load_ext cuml.accel) โค้ดมาตรฐานของคุณก็จะทำงานบน GPU ประมวลผลระเบียน และปรับโมเดลที่ซับซ้อนในเครื่องได้ในเวลาเพียงเสี้ยววินาที
ดูข้อมูลเพิ่มเติมเกี่ยวกับการเร่งความเร็วด้วย GPU สำหรับการวิเคราะห์ข้อมูลได้ที่ Codelab Accelerated Data Analytics with GPUs
สิ่งที่เราได้พูดถึงไปแล้ว
- ทำความเข้าใจ Colab Enterprise ใน Google Cloud
- การปรับแต่งสภาพแวดล้อมรันไทม์ของ Colab ด้วยการกำหนดค่า GPU และหน่วยความจำที่เฉพาะเจาะจง
- การใช้การเร่งความเร็วด้วย GPU เพื่อคาดการณ์จำนวนทิปโดยใช้บันทึกหลายล้านรายการจากชุดข้อมูลแท็กซี่ในนิวยอร์ก
- เร่งความเร็ว
pandasโดยไม่ต้องเปลี่ยนแปลงโค้ดโดยใช้ไลบรารีcuDFของ NVIDIA - เร่งความเร็ว
scikit-learnโดยไม่ต้องเปลี่ยนแปลงโค้ดโดยใช้ไลบรารีcuMLและ GPU ของ NVIDIA - การทำโปรไฟล์โค้ดเพื่อระบุและเพิ่มประสิทธิภาพข้อจำกัดด้านประสิทธิภาพ