
1. Giriş
Bu codelab'de, Google Cloud'da NVIDIA GPU'ları ve açık kaynaklı kitaplıkları kullanarak büyük veri kümelerindeki veri bilimi ve makine öğrenimi iş akışlarınızı nasıl hızlandıracağınızı öğreneceksiniz. Öncelikle altyapınızı kuracak, ardından GPU hızlandırmayı nasıl uygulayacağınızı öğreneceksiniz.
pandas ile veri hazırlamadan scikit-learn ve XGBoost ile model eğitimine kadar veri bilimi yaşam döngüsüne odaklanacaksınız. NVIDIA'nın cuDF ve cuML kitaplıklarını kullanarak bu görevleri nasıl hızlandıracağınızı öğreneceksiniz. En iyi yanı, mevcut pandas veya scikit-learn kodunuzu değiştirmeden bu GPU hızlandırmasını elde edebilmenizdir.
Neler öğreneceksiniz?
- Google Cloud'da Colab Enterprise'ı anlama
- Belirli GPU ve bellek yapılandırmalarıyla Colab çalışma zamanı ortamını özelleştirin.
- GPU hızlandırmayı kullanarak NYC Taxi veri kümesindeki milyonlarca kaydı kullanarak bahşiş tutarlarını tahmin edin.
- NVIDIA'nın
cuDFkitaplığını kullanarak kodda değişiklik yapmadanpandashızlandırın. - NVIDIA'nın
cuMLkitaplığını ve GPU'larını kullanarak kodda değişiklik yapmadanscikit-learnhızlandırın. - Performans kısıtlamalarını belirlemek ve optimize etmek için kodunuzun profilini oluşturun.
Bir sonraki sayfada, laboratuvarı tamamlamak için kullanabileceğiniz krediler yer alır.
2. Neden makine öğrenimini hızlandırmalısınız?
Makine öğreniminde daha hızlı yineleme yapma ihtiyacı
Veri hazırlama zaman alıcı bir işlemdir ve veri kümeleri büyüdükçe model eğitimi veya değerlendirmesi daha da uzun sürebilir. Rastgele ormanlar veya XGBoost gibi modelleri CPU ile milyonlarca satır üzerinde eğitmek saatler veya günler sürebilir.
GPU'ları kullanmak, cuML ve GPU hızlandırmalı XGBoost gibi kitaplıklarla bu eğitim çalıştırmalarını hızlandırır. Bu hızlandırma sayesinde:
- Daha hızlı yineleme: Yeni özellikleri ve hiperparametreleri hızlıca test edin.
- Tam veri kümeleriyle eğitme: Daha iyi doğruluk için alt örnekleme yerine tam verilerinizi kullanın.
- Maliyetleri azaltın: İşlem maliyetlerini düşürmek için ağır iş yüklerini daha kısa sürede tamamlayın.
3. Kurulum ve şartlar
Potansiyel maliyetler
Bu codelab'de, NVIDIA L4 GPU'ları içeren Colab Enterprise çalışma zamanları da dahil olmak üzere Google Cloud kaynakları kullanılır. Olası ücretler konusunda lütfen dikkatli olun ve kaynakları kapatıp devam eden faturalandırmayı önlemek için codelab'in sonundaki Temizleme bölümünü uygulayın. Ayrıntılı fiyatlandırma bilgileri için Colab Enterprise fiyatlandırması ve GPU fiyatlandırması sayfalarını inceleyin.
Başlamadan önce
Python, pandas, scikit-learn ve standart makine öğrenimi uygulamaları (ör. çapraz doğrulama/topluluk oluşturma) hakkında orta düzeyde bilgi sahibi olduğunuz varsayılır.
- Google Cloud Console'daki proje seçici sayfasında bir Google Cloud projesi seçin veya oluşturun.
- Google Cloud projeniz için faturalandırmanın etkinleştirildiğinden emin olun.
API'leri etkinleştirme
Colab Enterprise'ı kullanmak için önce gerekli API'leri etkinleştirmeniz gerekir.
- Google Cloud Console'un sağ üst kısmındaki Cloud Shell simgesini tıklayarak Google Cloud Shell'i açın.

- Cloud Shell'de
PROJECT_IDkısmını proje kimliğinizle değiştirerek proje kimliğinizi ayarlayın:
gcloud config set project <PROJECT_ID>
- Gerekli API'leri etkinleştirmek için aşağıdaki komutu çalıştırın:
gcloud services enable \
compute.googleapis.com \
dataform.googleapis.com \
notebooks.googleapis.com \
aiplatform.googleapis.com
Başarılı bir yürütme işleminden sonra aşağıda gösterilene benzer bir mesaj görmeniz gerekir:
Operation "operations/..." finished successfully.
4. Not defteri ortamı seçme
Birçok veri bilimci kişisel projeler için Colab'i kullanır. Colab Enterprise ise işletmeler için tasarlanmış güvenli, ortak çalışmaya uygun ve entegre bir not defteri deneyimi sunar.
Google Cloud'da yönetilen not defteri ortamları için iki temel seçeneğiniz vardır: Colab Enterprise ve Gemini Enterprise Agent Platform Workbench. Doğru seçim, projenizin önceliklerine bağlıdır.
Agent Platform Workbench ne zaman kullanılır?
Önceliğiniz kontrol ve derin özelleştirme ise Agent Platform Workbench'i seçin. Aşağıdaki durumlarda bu seçeneği kullanabilirsiniz:
- Temel altyapıyı ve makine yaşam döngüsünü yönetin.
- Özel container'lar ve ağ yapılandırmaları kullanın.
- MLOps işlem hatları ve özel yaşam döngüsü araçlarıyla entegrasyon.
Colab Enterprise'ı ne zaman kullanmalısınız?
Önceliğiniz hızlı kurulum, kullanım kolaylığı ve güvenli ortak çalışma olduğunda Colab Enterprise'ı seçin. Bu çözüm, ekibinizin altyapı yerine analize odaklanmasını sağlayan, tümüyle yönetilen bir çözümdür.
Colab Enterprise ile şunları yapabilirsiniz:
- Veri ambarınızla yakından ilişkili veri bilimi iş akışları geliştirin. Not defterlerinizi doğrudan BigQuery Studio'da açıp yönetebilirsiniz.
- Makine öğrenimi modellerini eğitin ve Agent Platform'daki MLOps araçlarıyla entegre edin.
- Esnek ve birleşik bir deneyimin keyfini çıkarın. BigQuery'de oluşturulan bir Colab Enterprise not defteri, Agent Platform'da açılıp çalıştırılabilir ve bunun tersi de geçerlidir.
Bugünün laboratuvarı
Bu Codelab'de hızlandırılmış makine öğrenimi için Colab Enterprise kullanılır.
Farklılıklar hakkında daha fazla bilgi edinmek için doğru not defteri çözümünü seçme ile ilgili resmi belgelere bakın.
5. Çalışma zamanı şablonunu yapılandırma
Colab Enterprise'da, önceden yapılandırılmış bir çalışma zamanı şablonuna dayalı bir çalışma zamanına bağlanın.
Çalışma zamanı şablonu, not defterinizin ortamını belirten tekrar kullanılabilir bir yapılandırmadır. Bu ortam şunları içerir:
- Makine türü (CPU, bellek)
- Hızlandırıcı (GPU türü ve sayısı)
- Disk boyutu ve türü
- Ağ ayarları ve güvenlik politikaları
- Otomatik boşta kalma kapatma kuralları
Çalışma zamanı şablonları neden yararlıdır?
- Tutarlılık: Siz ve ekibiniz, işin tekrarlanabilir olmasını sağlamak için aynı ortamı elde edersiniz.
- Güvenlik: Şablonlar, kuruluşun güvenlik politikalarını uygular.
- Maliyet yönetimi: Kaynaklar, yanlışlıkla maliyet oluşmasını önlemek için şablonda önceden boyutlandırılır.
Çalışma zamanı şablonu oluşturma
Laboratuvar için yeniden kullanılabilir bir çalışma zamanı şablonu oluşturun.
- Google Cloud Console'da Gezinme Menüsü > Agent Platform > Notebooks'a (Not Defterleri) gidin.
- Colab Enterprise'da Çalışma zamanı şablonları'nı tıklayın ve Yeni Şablon'u seçin.
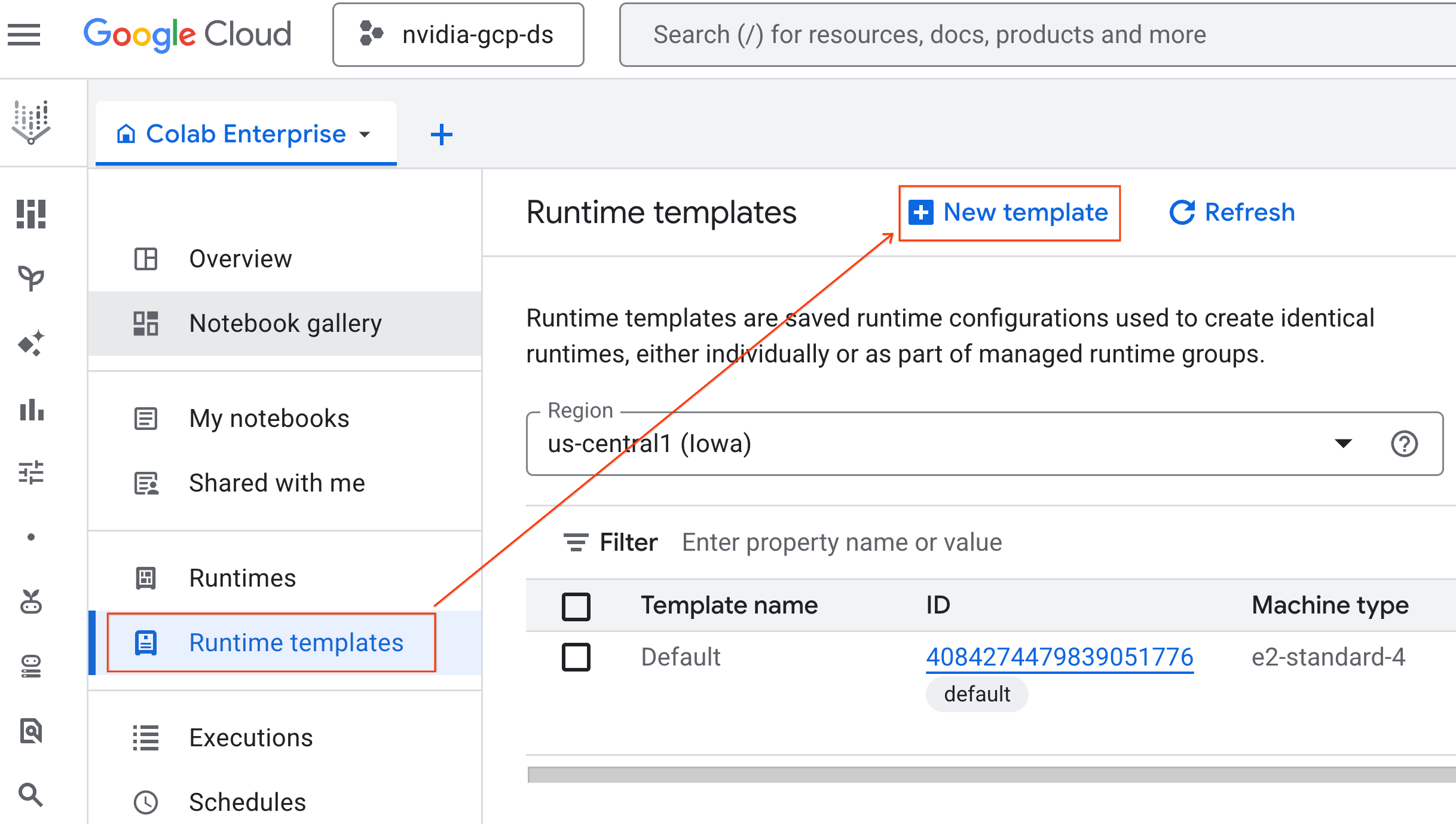
- Çalışma zamanıyla ilgili temel bilgiler bölümünde:
- Görünen adı
gpu-templateolarak ayarlayın. - Tercih ettiğiniz bölgeyi ayarlayın.
- Görünen adı
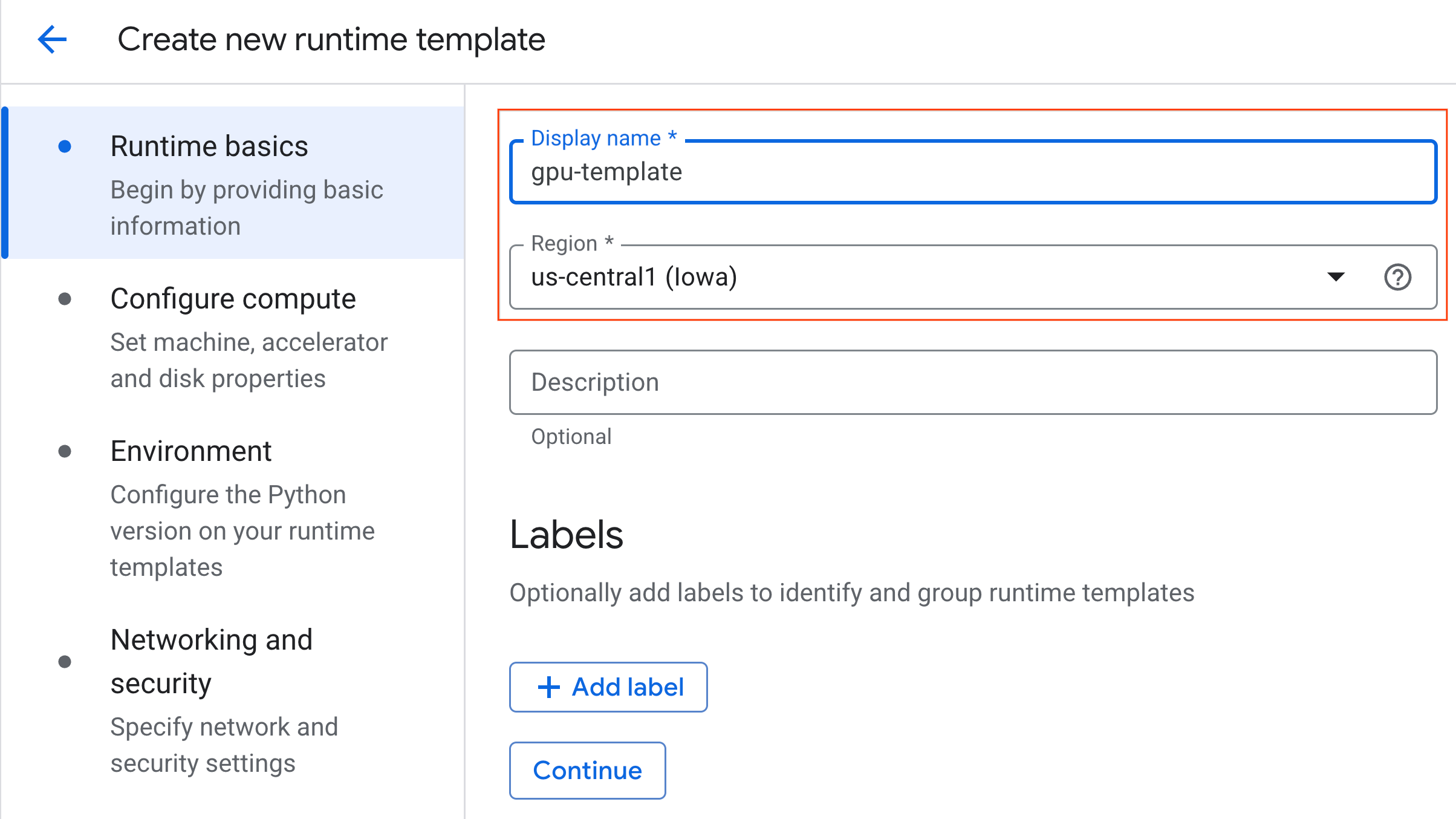
- Bilgi işlem yapılandırma bölümünde:
- Makine türü'nü
g2-standard-4olarak ayarlayın. - Varsayılan Hızlandırıcı Türü'nü
NVIDIA L4olarak ve Hızlandırıcı sayısı'nı 1 olarak bırakın. - Boşta kalma nedeniyle kapatma süresini 60 dakika olarak değiştirin.
- Devam'ı tıklayın.
- Makine türü'nü
- Ortam bölümünde:
- Ortam'ı
Python 3.11olarak ayarlayın.
- Ortam'ı
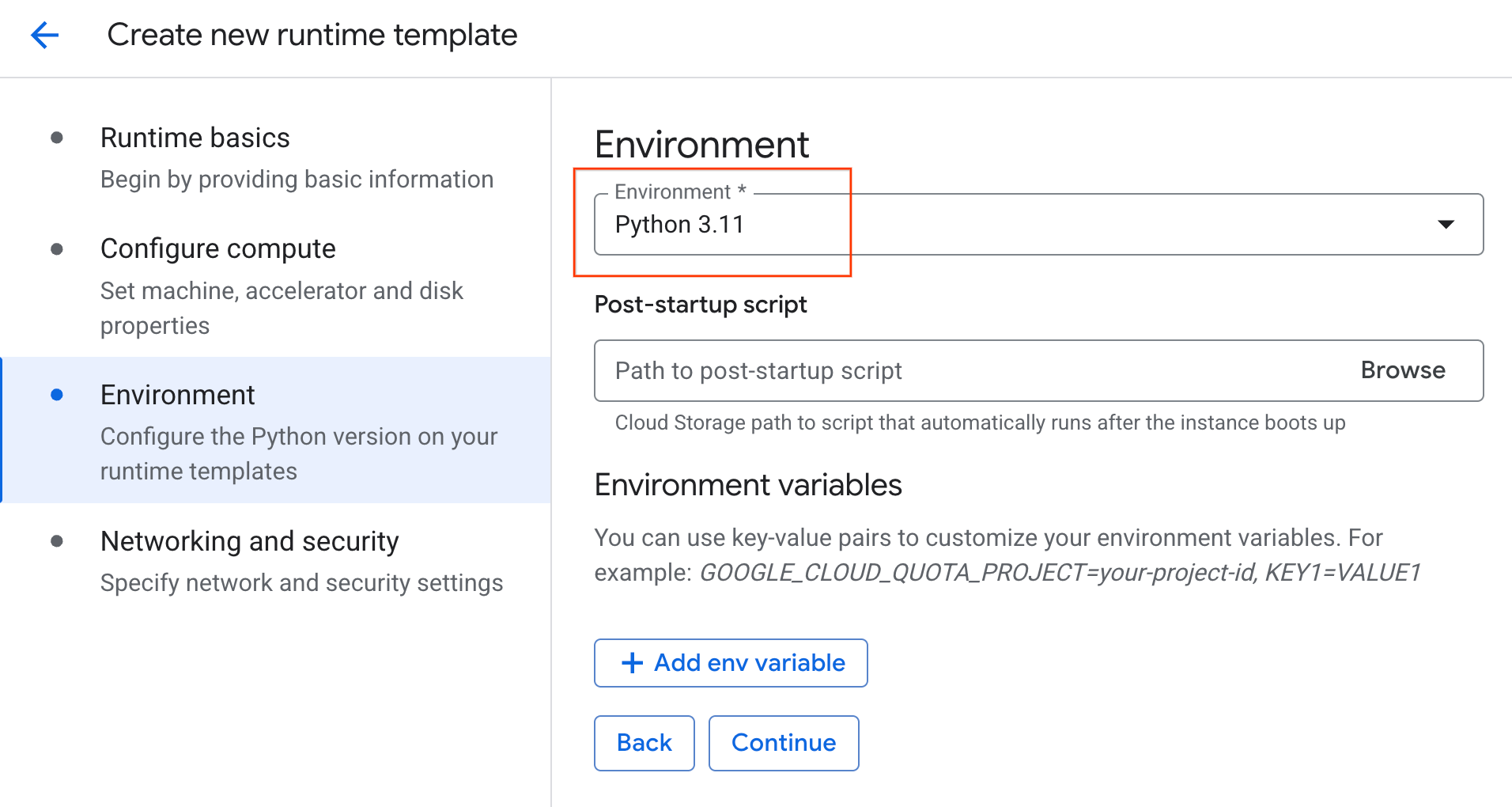
- Çalışma zamanı şablonunu kaydetmek için Oluştur'u tıklayın. Çalışma zamanı şablonları sayfanızda artık yeni şablon gösteriliyor olmalıdır.
6. Çalışma zamanı başlatma
Şablonunuz hazır olduğunda yeni bir çalışma zamanı oluşturabilirsiniz.
- Colab Enterprise'da Çalışma zamanları'nı tıklayın ve Oluştur'u seçin.
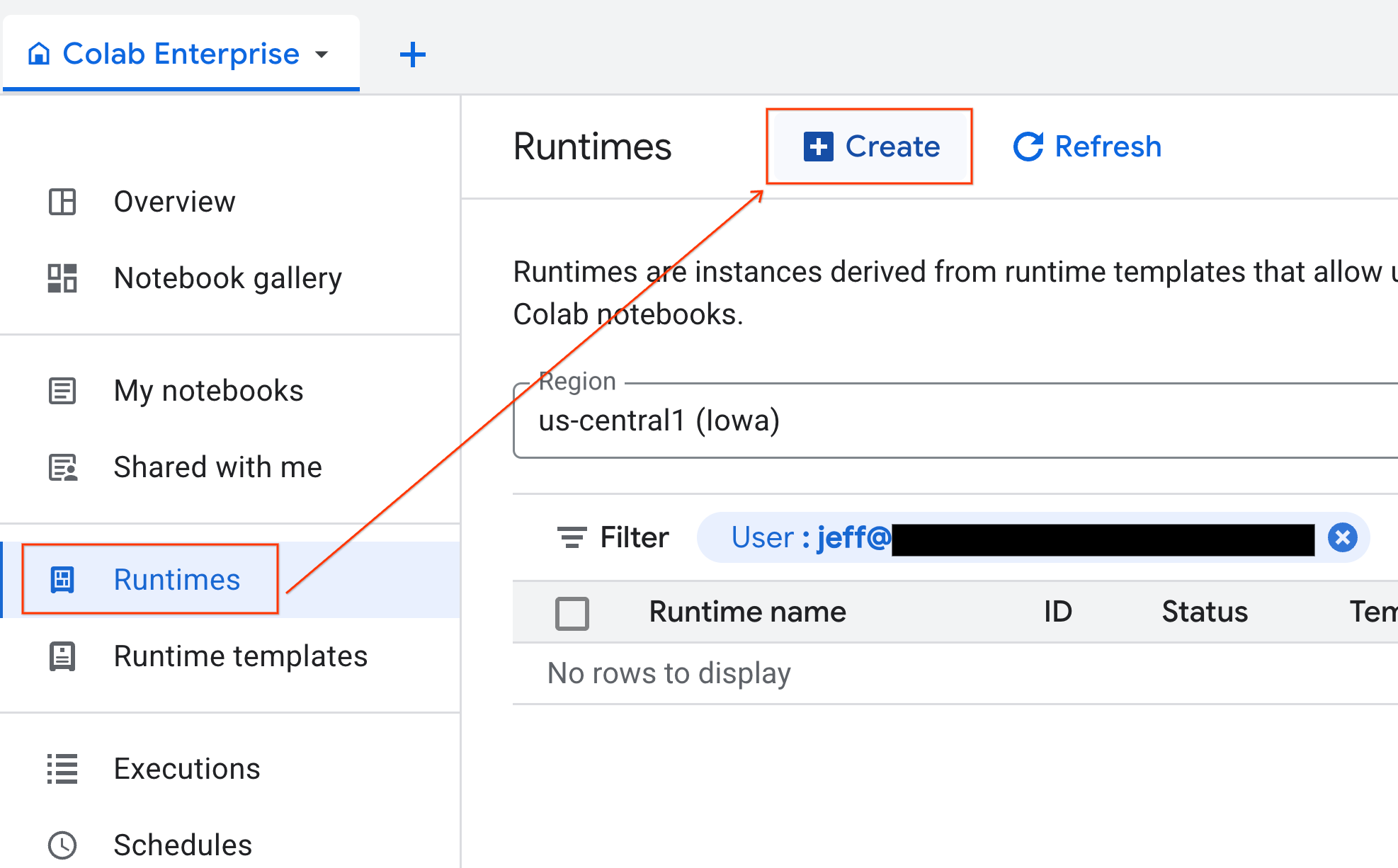
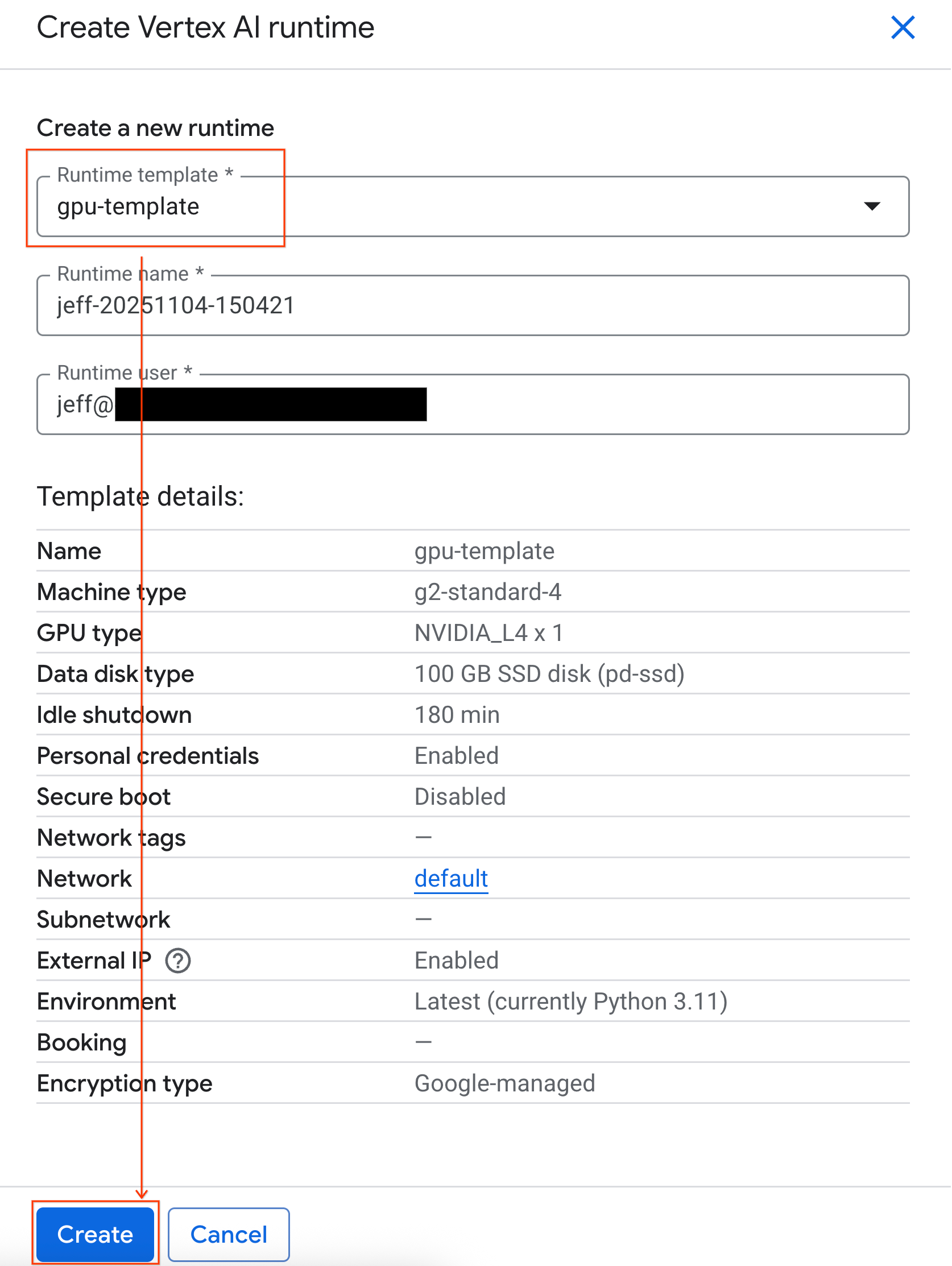
- Çalışma zamanı şablonu bölümünde
gpu-templateseçeneğini belirleyin. Oluştur'u tıklayın ve çalışma zamanının başlatılmasını bekleyin.
- Birkaç dakika sonra çalışma süresini görebilirsiniz.
7. Not defterini ayarlayın
Altyapınız çalışır duruma geldiğine göre artık laboratuvar not defterini içe aktarmanız ve çalışma zamanınıza bağlamanız gerekir.
Not defterini içe aktarma
- Colab Enterprise'da Not defterlerim'i ve ardından İçe aktar'ı tıklayın.
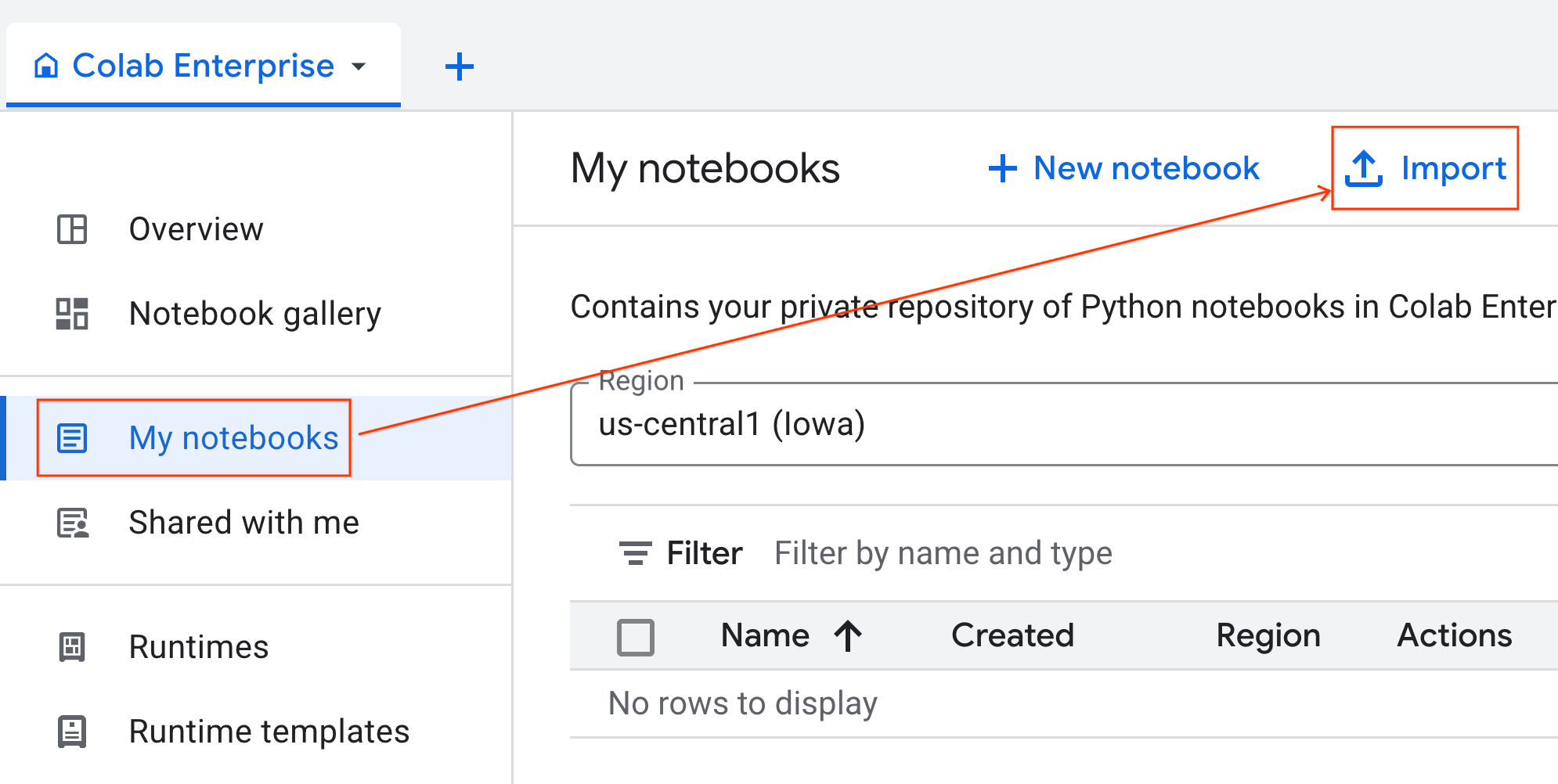
- URL radyo düğmesini seçin ve aşağıdaki URL'yi girin:
https://github.com/GoogleCloudPlatform/ai-ml-recipes/blob/main/notebooks/regression/gpu_accelerated_regression/gpu_accelerated_regression.ipynb
- İçe Aktar'ı tıklayın. Colab Enterprise, not defterini GitHub'dan ortamınıza kopyalar.
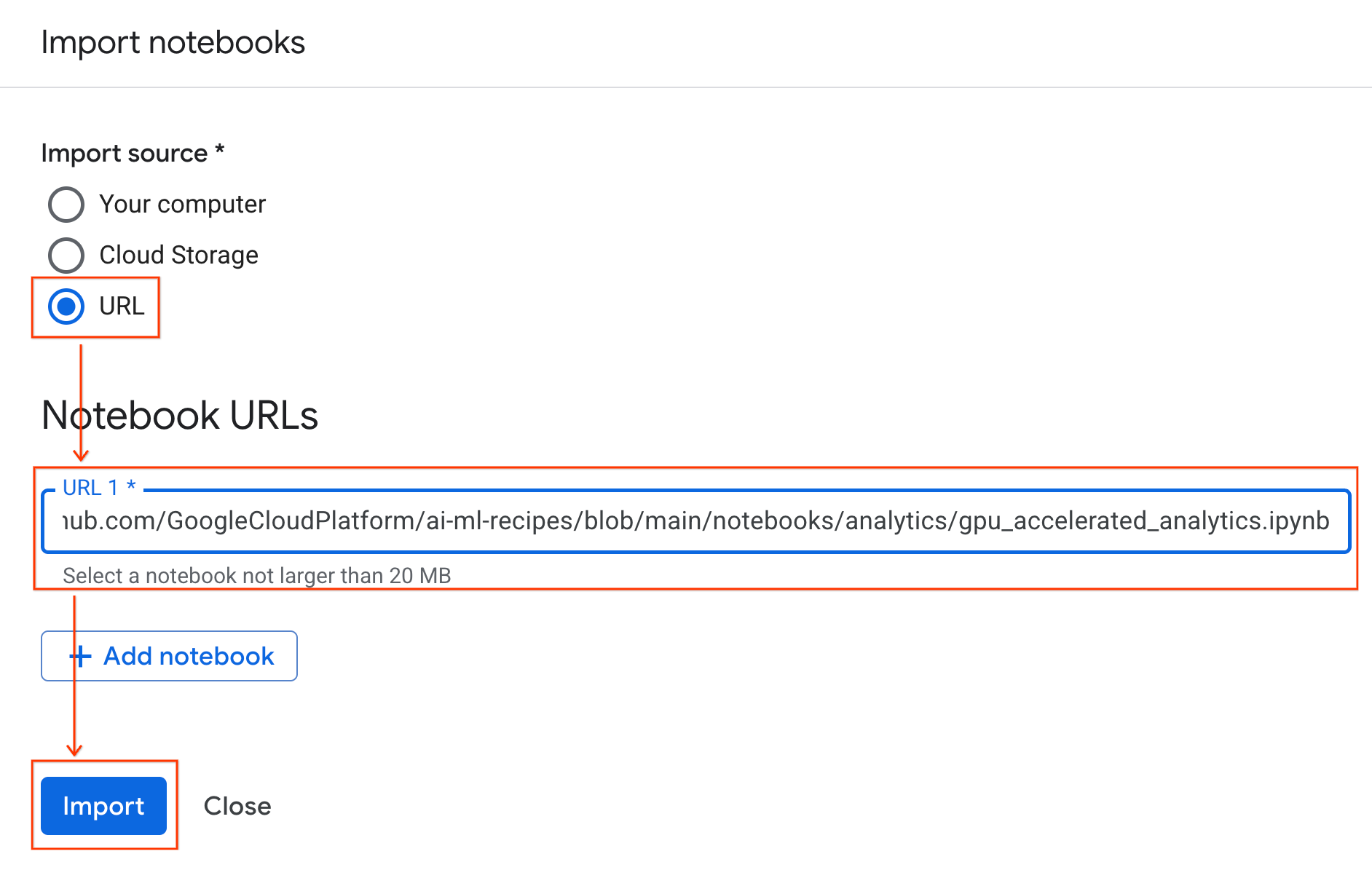
Çalışma zamanına bağlanma
- Yeni içe aktarılan not defterini açın.
- Bağlan'ın yanındaki aşağı oku tıklayın.
- Çalışma zamanına bağlan'ı seçin.
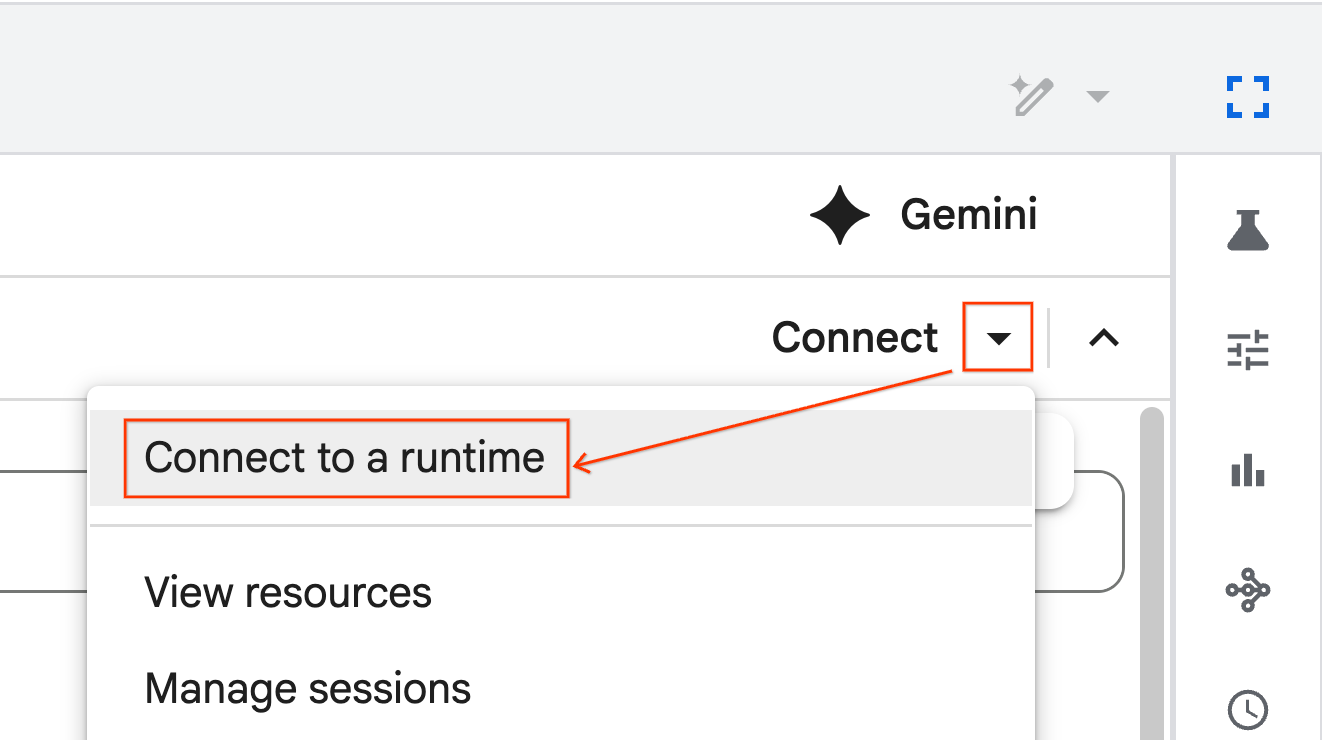
- Açılır listeyi kullanarak daha önce oluşturduğunuz çalışma zamanını seçin.
- Bağlan'ı tıklayın.
Not defteriniz artık GPU özellikli bir çalışma zamanına bağlı.
Yerleşik bağımlılıklar
Colab Enterprise'ı kullanmanın avantajlarından biri, ihtiyacınız olan kitaplıkların önceden yüklenmiş olarak gelmesidir. Bu laboratuvar için cuDF, cuML veya XGBoost gibi bağımlılıkları manuel olarak yüklemeniz ya da yönetmeniz gerekmez.
8. NYC taksi veri kümesini hazırlama
Bu codelab'de NYC Taxi & Limousine Commission (TLC) Trip Record Data kullanılır. Veri kümesi, New York City'deki sarı taksilerin yolculuk kayıtlarını içerir. Bu kayıtlar arasında şunlar yer alır:
- Teslim alma ve teslim etme tarihleri, saatleri ve konumları
- Gezi mesafeleri
- Ayrıntılı ücret tutarları
- Yolcu sayıları
- Bahşiş miktarları (tahmin edeceğimiz değer budur!)
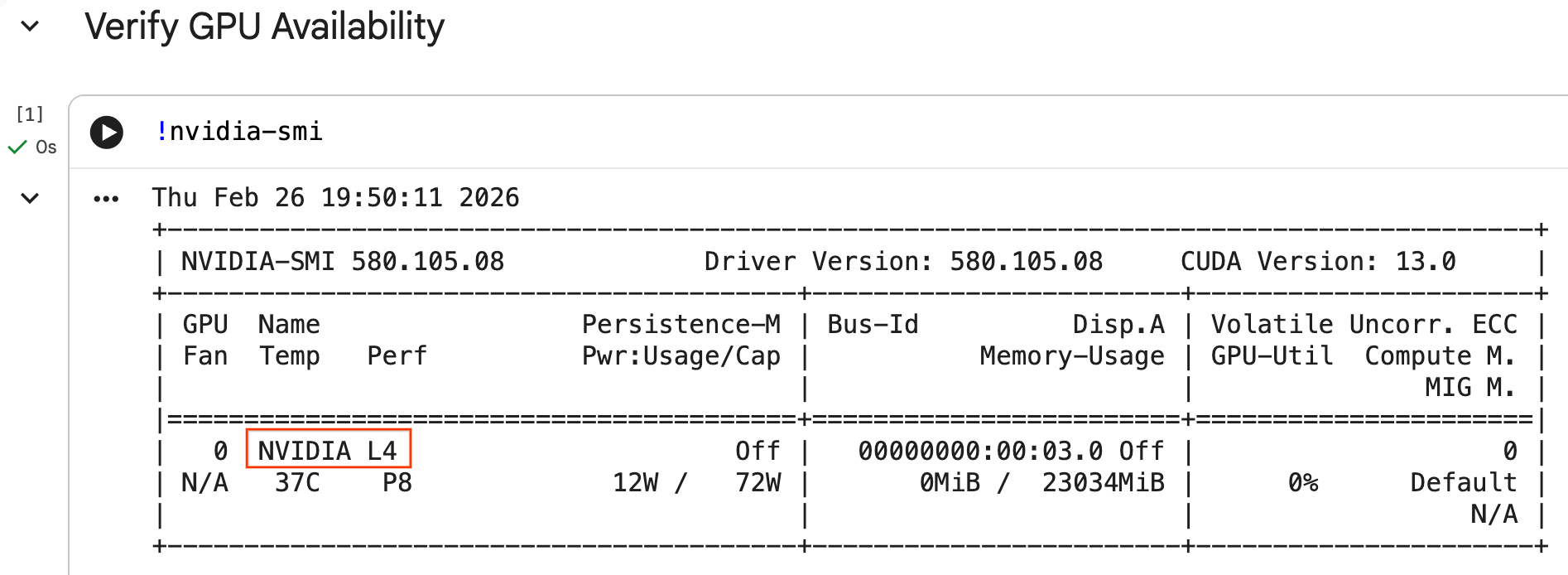
GPU'yu yapılandırma ve stok durumunu onaylama
GPU'nun tanındığını doğrulamak için nvidia-smi komutunu çalıştırabilirsiniz. Sürücü sürümünü ve GPU ayrıntılarını (ör. NVIDIA L4) gösterir.
nvidia-smi
Hücre, çalışma zamanınıza bağlı GPU'yu aşağıdaki gibi döndürmelidir:
Verileri indirin
2024'e ait gezi verilerini indirin.
from tqdm import tqdm
import requests
import time
import os
YEAR = 2024
DATA_DIR = "nyc_taxi_data"
os.makedirs(DATA_DIR, exist_ok=True)
print(f"Checking/Downloading files for {YEAR}...")
for month in tqdm(range(1, 13), unit="file"):
file_name = f"yellow_tripdata_{YEAR}-{month:02d}.parquet"
local_path = os.path.join(DATA_DIR, file_name)
url = f"https://d37ci6vzurychx.cloudfront.net/trip-data/{file_name}"
if not os.path.exists(local_path):
try:
with requests.get(url, stream=True) as response:
response.raise_for_status()
with open(local_path, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
time.sleep(1)
except requests.exceptions.HTTPError as e:
print(f"\nSkipping {file_name}: {e}")
if os.path.exists(local_path):
os.remove(local_path)
print("\nDownload complete.")
NVIDIA cuDF ile pandas hızlandırın
pandas kitaplığı CPU'da çalışır ve büyük veri kümelerinde yavaş olabilir. NVIDIA %load_ext cudf.pandas sihirli komutu, gerektiğinde CPU'ya geri dönerek GPU hızlandırmayı kullanmak için pandas'i dinamik olarak yamalar.
Bu sihirli komutu standart bir içe aktarma yerine kullanmamızın nedeni, "sıfır kod değişikliği" hızlandırması sağlamasıdır. Mevcut kodlarınızın hiçbirini yeniden yazmanız gerekmez. Benzer bir komut olan %load_ext cuml.accel, scikit-learn models için de aynı işlemi yapar. Bu özellik yalnızca Colab Enterprise'da değil, uyumlu bir NVIDIA GPU'ya sahip tüm Jupyter ortamlarında çalışır.
%load_ext cudf.pandas
Etkin olduğunu doğrulamak için pandas öğesini içe aktarın ve türünü kontrol edin:
import pandas as pd
pd
Çıktı, artık cudf.pandas modülünü kullandığınızı onaylar.
Verileri yükleme ve temizleme
cudf.pandas etkin durumdayken Parquet dosyalarını yükleyin ve veri temizleme işlemini gerçekleştirin. Bu işlem GPU'da otomatik olarak çalışır.
import glob
# Load data into memory
df = pd.concat(
[pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")],
ignore_index=True
)
# Filter for valid trips. We filter for payment_type=1 (credit card)
# because tip amounts are only reliably recorded for credit card transactions.
df = df[
(df['fare_amount'] > 0) & (df['fare_amount'] < 500) &
(df['trip_distance'] > 0) & (df['trip_distance'] < 100) &
(df['tip_amount'] >= 0) & (df['tip_amount'] < 100) &
(df['payment_type'] == 1)
].copy()
# Downcast numeric columns to save memory
float_cols = df.select_dtypes(include=['float64']).columns
df[float_cols] = df[float_cols].astype('float32')
int_cols = df.select_dtypes(include=['int64']).columns
df[int_cols] = df[int_cols].astype('int32')
Özellik Mühendisliği
Teslim alma tarihi ve saatinden türetilmiş özellikler oluşturun. Not defterinde, sonraki adımlarda kullanılan başka özellikler de bulunur.
import numpy as np
# Time Features
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['dow'] = df['tpep_pickup_datetime'].dt.dayofweek
df['is_weekend'] = (df['dow'] >= 5).astype(int)
df['is_rush_hour'] = (
((df['hour'] >= 7) & (df['hour'] <= 9)) |
((df['hour'] >= 17) & (df['hour'] <= 19))
).astype(int)
...
# Other features
...
9. Çapraz doğrulama ile ayrı modelleri eğitme
GPU'nun makine öğrenimini nasıl hızlandırabileceğini göstermek için taksi yolculuğunun tip_amount değerini tahmin etmek üzere üç farklı regresyon modeli türünü eğiteceksiniz.
NVIDIA cuML ile scikit-learn hızlandırın
API çağrılarını değiştirmeden NVIDIA cuML kullanarak GPU'da scikit-learn algoritmalarını çalıştırın. Öncelikle cuml.accel uzantısını yükleyin.
%load_ext cuml.accel
Kurulum özellikleri ve hedefleri
Modelin öğrenmesini istediğiniz özellikleri belirleyin ve hedef sütunu ayırın (tip_amount).
feature_cols = [
'trip_distance', 'fare_amount', 'passenger_count',
'hour', 'dow', 'is_weekend', 'is_rush_hour',
'fare_log', 'fare_decimal', 'is_round_fare',
'route_frequency', 'pu_tip_mean', 'pu_tip_std',
'PULocationID', 'DOLocationID'
]
X = df[feature_cols].fillna(df[feature_cols].median())
y = df['tip_amount'].copy()
Model performansını sağlam bir şekilde değerlendirmek için çapraz doğrulama bölümleri ayarlayın.
from sklearn.model_selection import KFold
import numpy as np
import time
from sklearn.metrics import mean_squared_error
from tqdm.notebook import tqdm
n_splits = 3
kf = KFold(n_splits=n_splits, shuffle=True, random_state=42)
1. XGBoost
XGBoost, yerel olarak GPU hızlandırmalıdır. Eğitim sırasında GPU'yu kullanmak için tree_method='hist' ve device='cuda' parametrelerini iletin.
import xgboost as xgb
start_time = time.perf_counter()
def train_xgb_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# XGBoost handles GPU natively when tree_method='hist' and device='cuda'
model = xgb.XGBRegressor(
objective='reg:squarederror',
max_depth=5,
learning_rate=0.1,
n_estimators=100,
tree_method='hist',
device='cuda',
random_state=42
)
model.fit(X_train, y_train)
preds = model.predict(X_val)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
xgb_rmse, xgb_preds = train_xgb_cv(X, y)
print(f"\n{'XGBoost RMSE:':<20} ${xgb_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
2. Doğrusal Regresyon
Doğrusal regresyon modeli eğitin. %load_ext cuml.accel etkin olduğunda, LinearRegression otomatik olarak GPU eşdeğerine eşlenir.
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
start_time = time.perf_counter()
def train_linreg_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# Scale features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_val_scaled = scaler.transform(X_val)
# Automatically accelerated by cuML
model = LinearRegression()
model.fit(X_train_scaled, y_train)
preds = model.predict(X_val_scaled)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
linreg_rmse, linreg_preds = train_linreg_cv(X, y)
print(f"\n{'Linear Reg RMSE:':<20} ${linreg_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
3. Rastgele Orman
RandomForestRegressor kullanarak bir topluluk modeli eğitin. Ağaç tabanlı modellerin CPU'da eğitilmesi genellikle yavaştır ancak GPU hızlandırma, milyonlarca satırı daha hızlı işler.
from sklearn.ensemble import RandomForestRegressor
start_time = time.perf_counter()
def train_rf_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# Automatically accelerated by cuML
model = RandomForestRegressor(
n_estimators=100,
max_depth=10,
n_jobs=-1,
max_features='sqrt',
random_state=42
)
model.fit(X_train, y_train)
preds = model.predict(X_val)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
rf_rmse, rf_preds = train_rf_cv(X, y)
print(f"\n{'Random Forest RMSE:':<20} ${rf_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
10. Uçtan uca ardışık düzeni değerlendirme
Üç modelin tahminlerini basit bir doğrusal topluluk kullanarak birleştirin. Bu yöntem genellikle tek tek modellere kıyasla biraz daha yüksek doğruluk sağlar.
En uygun ağırlıkları bulmak için tahminlere doğrusal regresyon uygulayın:
ensemble_weights = LinearRegression(positive=True, fit_intercept=False).fit(
np.c_[xgb_preds, rf_preds, linreg_preds], y
).coef_
# Normalize weights
ensemble_weights = ensemble_weights / ensemble_weights.sum()
ensemble_preds = np.c_[xgb_preds, rf_preds, linreg_preds] @ ensemble_weights
ensemble_rmse = np.sqrt(mean_squared_error(y, ensemble_preds))
Topluluk artışını görmek için sonuçları karşılaştırın:
print(f"\n{'Model':<20} {'RMSE':>10}")
print("-" * 32)
print(f"{'Linear Regression':<20} ${linreg_rmse:>9.4f}")
print(f"{'Random Forest':<20} ${rf_rmse:>9.4f}")
print(f"{'XGBoost':<20} ${xgb_rmse:>9.4f}")
print("-" * 32)
print(f"{'Ensemble':<20} ${ensemble_rmse:>9.4f}")
print(f"\nEnsemble lift: ${xgb_rmse - ensemble_rmse:.4f}")
11. CPU ve GPU performansını karşılaştırma
Performans farkını doğru şekilde karşılaştırmak için çekirdeği yeniden başlatarak temiz bir yürütme durumu elde edecek, tüm veri bilimi ardışık düzenini CPU'da uygulayacak ve ardından GPU'da tekrar uygulayacaksınız.
Çekirdeği yeniden başlatma
Çekirdeği yeniden başlatmak ve belleği serbest bırakmak için IPython.Application.instance().kernel.do_shutdown(True) komutunu çalıştırın.
import IPython
IPython.Application.instance().kernel.do_shutdown(True)
Veri bilimi ardışık düzenini tanımlama
Temel iş akışını (veri yükleme, temizleme, özellik mühendisliği ve model eğitimi) tek bir işlevde sarmalayın. Bu işlev, ortamlar arasında geçiş yapmak için bir pandas modülü pd_module ve bir use_gpu bağımsız değişkeni kabul eder.
def run_ml_pipeline(pd_module, use_gpu=False):
import time
import glob
import numpy as np
from sklearn.ensemble import RandomForestRegressor
import xgboost as xgb
timings = {}
# 1. Load Data
t0 = time.perf_counter()
df = pd_module.concat(
[pd_module.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")],
ignore_index=True
)
timings['Load Data'] = time.perf_counter() - t0
# 2. Clean Data
t0 = time.perf_counter()
# Filter for payment_type=1 (credit card) because tip amounts
# are only reliably recorded for credit card transactions.
df = df[
(df['fare_amount'] > 0) & (df['fare_amount'] < 500) &
(df['trip_distance'] > 0) & (df['trip_distance'] < 100) &
(df['tip_amount'] >= 0) & (df['tip_amount'] < 100) &
(df['payment_type'] == 1)
].copy()
# Downcast numeric columns to save memory
float_cols = df.select_dtypes(include=['float64']).columns
df[float_cols] = df[float_cols].astype('float32')
int_cols = df.select_dtypes(include=['int64']).columns
df[int_cols] = df[int_cols].astype('int32')
timings['Clean Data'] = time.perf_counter() - t0
# 3. Feature Engineering
t0 = time.perf_counter()
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['dow'] = df['tpep_pickup_datetime'].dt.dayofweek
df['is_weekend'] = (df['dow'] >= 5).astype(int)
df['fare_log'] = np.log1p(df['fare_amount'])
timings['Feature Engineering'] = time.perf_counter() - t0
# 4. Modeling Prep
feature_cols = ['trip_distance', 'fare_amount', 'passenger_count', 'hour', 'dow', 'is_weekend', 'fare_log']
X = df[feature_cols].fillna(df[feature_cols].median())
y = df['tip_amount'].copy()
# Free memory
del df
import gc
gc.collect()
# 5. Train Random Forest
t0 = time.perf_counter()
rf_model = RandomForestRegressor(
n_estimators=100,
max_depth=10,
n_jobs=-1,
max_features='sqrt',
random_state=42
).fit(X, y)
timings['Train Random Forest'] = time.perf_counter() - t0
# 6. Train XGBoost
t0 = time.perf_counter()
params = {
'objective': 'reg:squarederror',
'max_depth': 5,
'n_estimators': 100,
'random_state': 42
}
if use_gpu:
params['device'] = 'cuda'
params['tree_method'] = 'hist'
xgb_model = xgb.XGBRegressor(**params).fit(X, y)
timings['Train XGBoost'] = time.perf_counter() - t0
del X
del y
gc.collect()
return timings
CPU'nuzda çalıştırma
Standart CPU pandas kullanarak işlem hattını çağırın.
import pandas as pd
print("Running pipeline on CPU...")
cpu_times = run_ml_pipeline(pd, use_gpu=False)
print("CPU Execution Finished.")
GPU'nuzda çalıştırma
NVIDIA kitaplık uzantılarını yükleyin, hızlandırılmış cudf.pandas modülünü işlem hattına iletin ve XGBoost cihazınızı dahili olarak cuda olarak ayarlayın.
import IPython.core.magic
if not hasattr(IPython.core.magic, 'output_can_be_silenced'):
IPython.core.magic.output_can_be_silenced = lambda x: x
%load_ext cudf.pandas
%load_ext cuml.accel
import pandas as pd
print("Running pipeline on GPU...")
gpu_times = run_ml_pipeline(pd, use_gpu=True)
print("GPU Execution Finished.")
Performans hızlanmasını görselleştirme
matplotlib simgesini kullanarak zamanlamaları görselleştirin. Sonuçlar, GPU'lar kullanılırken veri işleme ve model eğitimi sırasında kazanılan zamanı gösterir.
import matplotlib.pyplot as plt
import numpy as np
labels = list(cpu_times.keys())
cpu_values = list(cpu_times.values())
gpu_values = list(gpu_times.values())
x = np.arange(len(labels))
width = 0.35
fig, ax = plt.subplots(figsize=(10, 6))
rects1 = ax.bar(x - width/2, cpu_values, width, label='CPU', color='#4285F4')
rects2 = ax.bar(x + width/2, gpu_values, width, label='GPU', color='#76B900')
ax.set_ylabel('Execution Time (seconds)')
ax.set_title('NYC Taxi ML Pipeline: CPU vs. GPU Performance')
ax.set_xticks(x)
ax.set_xticklabels(labels, rotation=45, ha="right")
ax.legend()
# Add data labels
def autolabel(rects):
for rect in rects:
height = rect.get_height()
ax.annotate(f'{height:.2f}s',
xy=(rect.get_x() + rect.get_width() / 2, height),
xytext=(0, 3), # 3 points vertical offset
textcoords="offset points",
ha='center', va='bottom', fontsize=9)
autolabel(rects1)
autolabel(rects2)
plt.tight_layout()
plt.show()
# Calculate overall speedup
total_cpu_time = sum(cpu_values)
total_gpu_time = sum(gpu_values)
overall_speedup = total_cpu_time / total_gpu_time
print(f"\nOverall Pipeline Speedup: {overall_speedup:.2f}x faster on GPU!")
Aşağıdakine benzer bir ifade görürsünüz:
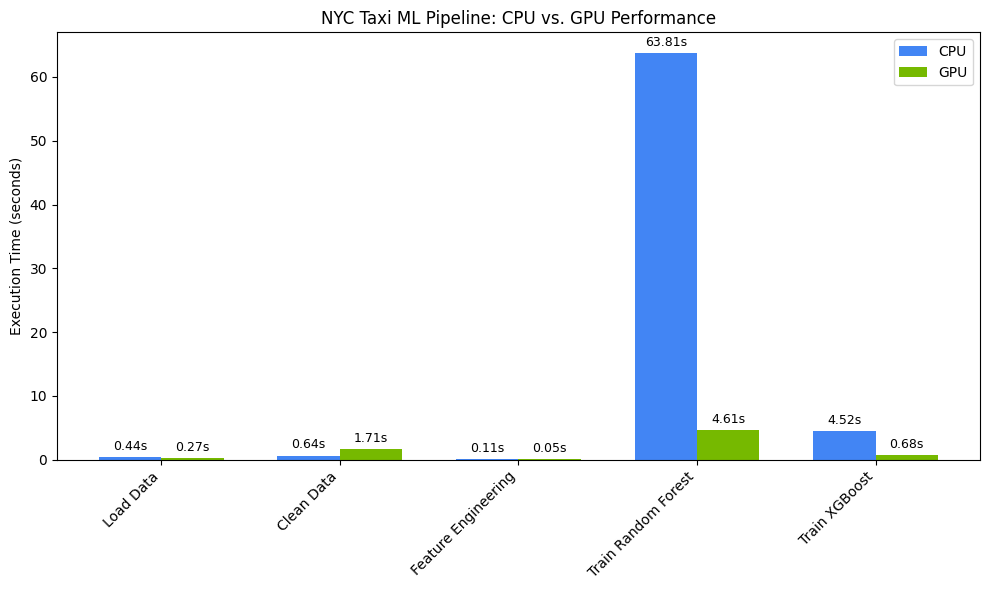
Bu grafik, GPU'nun tüm veri bilimi iş akışındaki önemli performans avantajını gösterir. En büyük zaman tasarrufunun, Random Forest ve XGBoost gibi algoritmaların hesaplama açısından yoğun model eğitimi aşamalarında elde edileceğini unutmayın.
12. Performans kısıtlamalarını bulmak için kodunuzun profilini oluşturma
cudf.pandas kullanılırken çoğu işlev GPU'da çalışır. Belirli bir işlem henüz cuDF tarafından desteklenmiyorsa yürütme işlemi geçici olarak CPU'ya geri döner. NVIDIA, bu yedekleri tanımlamak için iki yerleşik Jupyter sihirli komutu sağlar.
%%cudf.pandas.profile ile üst düzey profil oluşturma
%%cudf.pandas.profile sihirli komutu, GPU veya CPU'da hangi işlevlerin çalıştığına dair bir özet sağlar.
%%cudf.pandas.profile
import glob
import pandas as pd
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")], ignore_index=True)
summary = (
df
.groupby(['PULocationID', 'payment_type'])
[['passenger_count', 'fare_amount', 'tip_amount']]
.agg(['min', 'mean', 'max'])
)
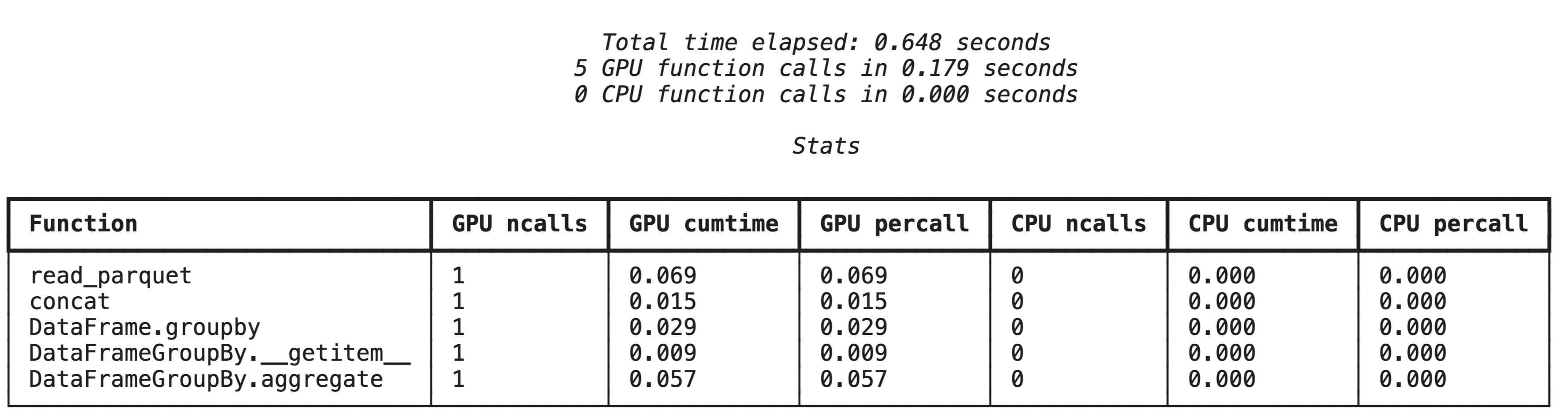
%%cudf.pandas.line_profile ile satır satır profilleme
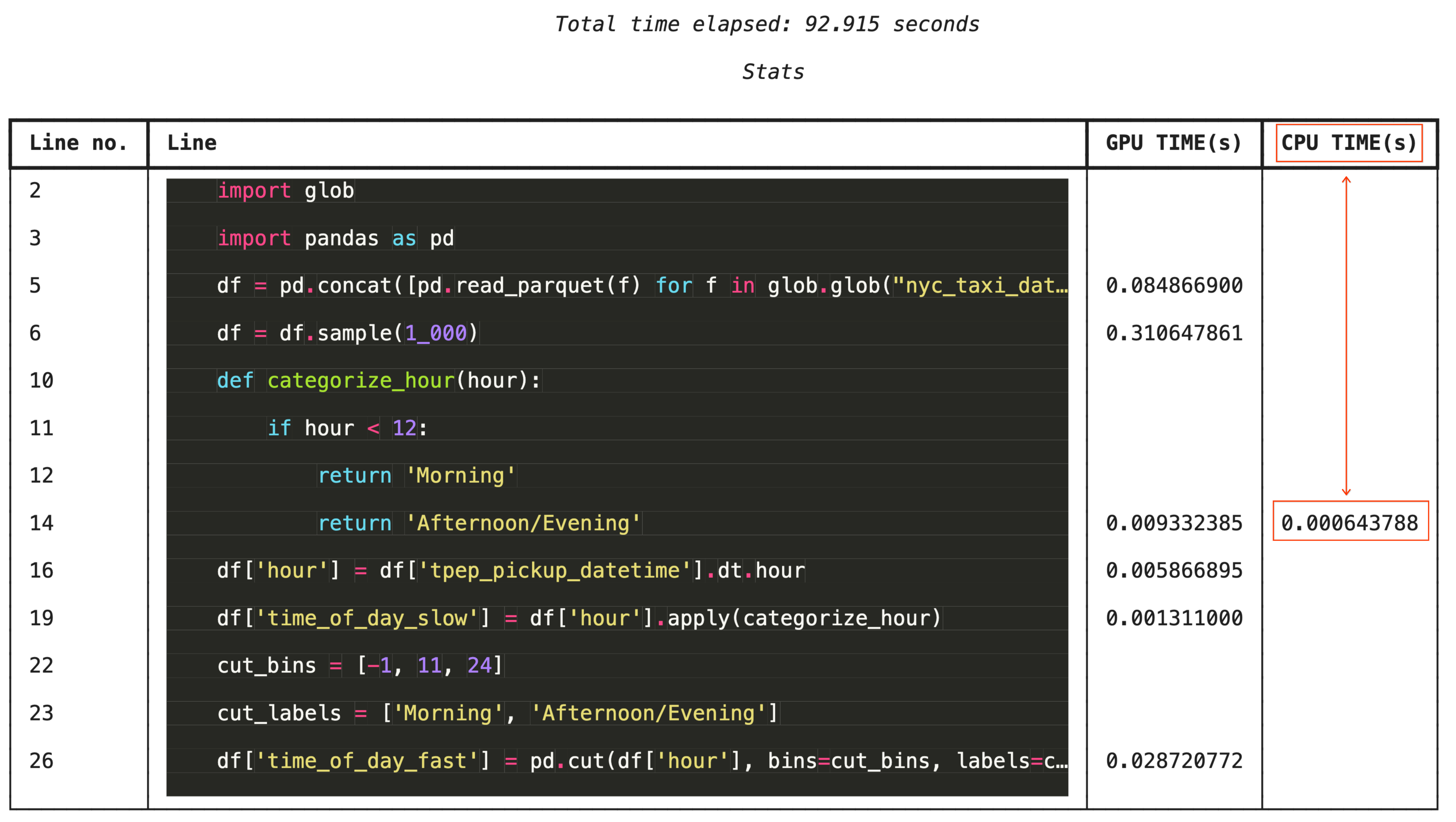
Ayrıntılı sorun giderme için %%cudf.pandas.line_profile, her bir kod satırına GPU'da ve CPU'da kaç kez yürütüldüğünü belirten bir not ekler.
%%cudf.pandas.line_profile
import glob
import pandas as pd
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")], ignore_index=True)
df = df.sample(1_000)
# Iterating row-by-row or using custom python apply functions often falls back to the CPU
def categorize_hour(hour):
if hour < 12:
return 'Morning'
else:
return 'Afternoon/Evening'
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['time_of_day_slow'] = df['hour'].apply(categorize_hour)
# Using vectorized pandas operations (like pd.cut) stays entirely on the GPU
cut_bins = [-1, 11, 24]
cut_labels = ['Morning', 'Afternoon/Evening']
df['time_of_day_fast'] = pd.cut(df['hour'], bins=cut_bins, labels=cut_labels)
13. Temizleme
Google Cloud hesabınızda beklenmedik ücretler alınmasını önlemek için bu codelab sırasında oluşturduğunuz kaynakları temizleyin.
Kaynakları silin
Not defteri hücresinde !rm -rf komutunu kullanarak çalışma zamanındaki yerel veri kümesini silin.
print("Deleting local 'nyc_taxi_data' directory...")
!rm -rf nyc_taxi_data
print("Local files deleted.")
Colab çalışma zamanınızı kapatma
- Google Cloud Console'da Colab Enterprise Çalışma Zamanları sayfasına gidin.
- Bölge menüsünde, çalışma zamanınızı içeren bölgeyi seçin.
- Silmek istediğiniz çalışma zamanını seçin.
- Sil'i tıklayın.
- Onayla'yı tıklayın.
Not defterinizi silme
- Google Cloud Console'da Colab Enterprise Not Defterlerim sayfasına gidin.
- Bölge menüsünde, not defterinizin bulunduğu bölgeyi seçin.
- Silmek istediğiniz not defterini seçin.
- Sil'i tıklayın.
- Onayla'yı tıklayın.
14. Tebrikler
Tebrikler! Colab Enterprise'da NVIDIA cuDF ve cuML kitaplıklarını kullanarak pandas ve scikit-learn makine öğrenimi iş akışını başarıyla hızlandırdınız. Birkaç sihirli komut (%load_ext cudf.pandas ve %load_ext cuml.accel) ekleyerek standart kodunuzu GPU'da çalıştırabilir, kayıtları işleyebilir ve karmaşık modelleri yerel olarak çok kısa bir sürede oluşturabilirsiniz.
Veri analizinde GPU hızlandırması hakkında daha fazla bilgi için Accelerated Data Analytics with GPUs (GPU'larla Hızlandırılmış Veri Analizi) adlı codelab'i inceleyin.
İşlediğimiz konular
- Google Cloud'da Colab Enterprise'ı anlama.
- Colab çalışma zamanı ortamını belirli GPU ve bellek yapılandırmalarıyla özelleştirme.
- GPU hızlandırmayı kullanarak New York'taki taksi veri kümesinden alınan milyonlarca kaydı kullanarak bahşiş tutarlarını tahmin etme.
- NVIDIA'nın
cuDFkitaplığı kullanılarak kodda değişiklik yapılmadanpandashızlandırılıyor. - NVIDIA'nın
cuMLkitaplığı ve GPU'ları kullanılarak kodda değişiklik yapılmadanscikit-learnhızlandırılıyor. - Performans kısıtlamalarını belirlemek ve optimize etmek için kodunuzun profilini oluşturma.