
1. The Late Night Code Review
الساعة 2 صباحًا
لقد استغرقت عملية تصحيح الأخطاء ساعات. تبدو الدالة صحيحة، ولكن هناك خطأ ما. لا شكّ أنّك تعرف هذا الشعور، عندما يفترض أن يعمل الرمز ولكنّه لا يعمل، ولا يمكنك معرفة السبب لأنّك أمعنت النظر فيه لفترة طويلة جدًا.
def dfs_search_v1(graph, start, target):
"""Find if target is reachable from start."""
visited = set()
stack = start # Looks innocent enough...
while stack:
current = stack.pop()
if current == target:
return True
if current not in visited:
visited.add(current)
for neighbor in graph[current]:
if neighbor not in visited:
stack.append(neighbor)
return False
رحلة المطوّر في مجال الذكاء الاصطناعي
إذا كنت تقرأ هذا المقال، من المرجّح أنّك اختبرت التحوّل الذي أحدثه الذكاء الاصطناعي في مجال الترميز. غيّرت أدوات مثل Gemini Code Assist وClaude Code وCursor طريقة كتابة الرموز البرمجية. وهي رائعة لإنشاء نماذج جاهزة واقتراح عمليات التنفيذ وتسريع عملية التطوير.
لكنّك هنا لأنّك تريد التعرّف على المزيد من التفاصيل. تريد معرفة كيفية إنشاء أنظمة الذكاء الاصطناعي هذه، وليس مجرد استخدامها. يجب أن يكون المحتوى الذي تريد إنشاءه:
- يتضمّن سلوكًا يمكن توقّعه وتتبُّعه
- يمكن نشرها في مرحلة الإنتاج بثقة
- تقدّم نتائج متّسقة يمكنك الاعتماد عليها
- توضيح طريقة اتخاذ القرارات
من مستهلك إلى صانع محتوى
اليوم، ستنتقل من استخدام أدوات الذكاء الاصطناعي إلى إنشائها. ستنشئ نظامًا متعدد الوكلاء يتضمّن ما يلي:
- تحليل بنية الرمز بشكل حتمي
- تنفيذ اختبارات فعلية للتحقّق من السلوك
- التحقّق من صحة توافق الأنماط مع أدوات التدقيق اللغوي الحقيقية
- تجميع النتائج في ملاحظات قابلة للتنفيذ
- عمليات النشر على Google Cloud مع إمكانية تتبُّع البيانات بالكامل
2. نشر الوكيل لأول مرة
سؤال المطوّر
"أفهم النماذج اللغوية الكبيرة، وقد استخدمت واجهات برمجة التطبيقات، ولكن كيف يمكنني الانتقال من نص Python البرمجي إلى وكيل ذكاء اصطناعي جاهز للإنتاج وقابل للتوسّع؟"
دعونا نجيب عن هذا السؤال من خلال إعداد بيئتك بشكل صحيح، ثم إنشاء وكيل بسيط لفهم الأساسيات قبل الانتقال إلى أنماط الإنتاج.
إجراء عملية الإعداد الأساسية أولاً
قبل إنشاء أي وكلاء، يجب التأكّد من أنّ بيئة Google Cloud جاهزة.
انقر على تفعيل Cloud Shell في أعلى "وحدة تحكّم Google Cloud" (رمز على شكل نافذة طرفية في أعلى لوحة Cloud Shell).
ابحث عن رقم تعريف مشروعك على Google Cloud:
- افتح Google Cloud Console: https://console.cloud.google.com
- اختَر المشروع الذي تريد استخدامه في ورشة العمل هذه من القائمة المنسدلة للمشاريع في أعلى الصفحة.
- يظهر رقم تعريف مشروعك في بطاقة "معلومات المشروع" على "لوحة البيانات"
الخطوة 1: ضبط رقم تعريف مشروعك
في Cloud Shell، تمّ إعداد أداة سطر الأوامر gcloud مسبقًا. نفِّذ الأمر التالي لضبط مشروعك النشط. يستخدِم هذا الأمر متغيّر البيئة $GOOGLE_CLOUD_PROJECT الذي يتم ضبطه تلقائيًا في جلسة Cloud Shell.
gcloud config set project $GOOGLE_CLOUD_PROJECT
الخطوة 2: التحقّق من عملية الإعداد
بعد ذلك، نفِّذ الأوامر التالية للتأكّد من ضبط مشروعك بشكلٍ صحيح ومن إثبات هويتك.
# Confirm project is set
echo "Current project: $(gcloud config get-value project)"
# Check authentication status
gcloud auth list
من المفترض أن يظهر رقم تعريف مشروعك مطبوعًا، وأن يظهر حساب المستخدم الخاص بك مع (ACTIVE) بجانبه.
إذا لم يكن حسابك مُدرَجًا على أنّه نشط، أو إذا ظهر لك خطأ في المصادقة، نفِّذ الأمر التالي لتسجيل الدخول:
gcloud auth application-default login
الخطوة 3: تفعيل واجهات برمجة التطبيقات الأساسية
نحتاج إلى واجهات برمجة التطبيقات التالية على الأقل لتوفير الوكيل الأساسي:
gcloud services enable \
aiplatform.googleapis.com \
compute.googleapis.com
قد يستغرق الأمر دقيقة أو اثنتين. وسترى ما يلي:
Operation "operations/..." finished successfully.
الخطوة 4: تثبيت حزمة ADK
# Install the ADK CLI
pip install google-adk --upgrade
# Verify installation
adk --version
من المفترض أن يظهر لك رقم إصدار مثل 1.15.0 أو إصدار أحدث.
الآن، أنشئ وكيلك الأساسي
بعد إعداد البيئة، لننشئ هذا الوكيل البسيط.
الخطوة 5: استخدام ADK Create
adk create my_first_agent
اتّبِع التعليمات التفاعلية:
Choose a model for the root agent:
1. gemini-2.5-flash
2. Other models (fill later)
Choose model (1, 2): 1
1. Google AI
2. Vertex AI
Choose a backend (1, 2): 2
Enter Google Cloud project ID [auto-detected-from-gcloud]:
Enter Google Cloud region [us-central1]:
الخطوة 6: فحص ما تم إنشاؤه
cd my_first_agent
ls -la
ستجد ثلاثة ملفات:
.env # Configuration (auto-populated with your project)
__init__.py # Package marker
agent.py # Your agent definition
الخطوة 7: التحقّق من الإعداد السريع
# Verify the .env was created correctly
cat .env
# Should show something like:
# GOOGLE_CLOUD_PROJECT=your-project-id
# GOOGLE_CLOUD_LOCATION=us-central1
# GOOGLE_GENAI_USE_VERTEXAI=1
إذا كان رقم تعريف المشروع مفقودًا أو غير صحيح، عدِّل الملف .env باتّباع الخطوات التالية:
nano .env # or use your preferred editor
الخطوة 8: الاطّلاع على رمز الوكيل
cat agent.py
from google.adk.agents.llm_agent import Agent
root_agent = Agent(
model='gemini-2.5-flash',
name='root_agent',
description='A helpful assistant for user questions.',
instruction='Answer user questions to the best of your knowledge',
)
بسيط ونظيف وبأقل قدر من التفاصيل هذا هو "مرحبًا بالعالم" الخاص بالوكلاء.
اختبار الوكيل الأساسي
الخطوة 9: تشغيل البرنامج
cd ..
adk run my_first_agent
من المفترض أن يظهر لك محتوى مثل:
Log setup complete: /tmp/agents_log/agent.20250930_162430.log
To access latest log: tail -F /tmp/agents_log/agent.latest.log
[user]:
الخطوة 10: تجربة بعض طلبات البحث
في الوحدة الطرفية التي يتم فيها تشغيل adk run، سيظهر لك طلب. اكتب طلبات البحث:
[user]: Hey, what can you do?
[root_agent]: I can help answer questions, generate text, explain concepts, assist with problem-solving, and provide information on a wide range of topics. What would you like to know or discuss?
[user]: What's the current weather in Mountain View?
[root_agent]: I'm sorry, but I cannot provide real-time weather information as I don't have access to current data or weather services. To get the current weather in Mountain View, I recommend checking a weather website or app like weather.com or using a search engine.
لاحظ القيد، وهو أنّه لا يمكن الوصول إلى البيانات الحالية. لنستعرض المزيد من التفاصيل:
[user]: Review this Python code: def add(a, b): return a + b
[root_agent]: This is a simple Python function that adds two numbers. Here's my review:
**Strengths:**
- Clean and concise implementation
- Follows Python conventions for simple operations
- Clear function name that describes its purpose
**Suggestions for improvement:**
- Add a docstring to document the function
- Consider adding type hints for better code clarity
- You might want to handle edge cases
Here's an enhanced version:
def add(a: float, b: float) -> float:
"""Add two numbers and return their sum."""
return a + b
يمكن للوكيل مناقشة التعليمات البرمجية، ولكن هل يمكنه إجراء ما يلي:
- هل يتم تحليل شجرة بناء الجملة المجردة لفهم البنية؟
- هل يمكن إجراء اختبارات للتحقّق من عملها؟
- التحقّق من التوافق مع النمط؟
- هل تتذكر مراجعاتك السابقة؟
لا، هذا هو المكان الذي نحتاج فيه إلى البنية.
🏃🚪 الخروج باستخدام
Ctrl+C
عند الانتهاء من الاستكشاف
3- إعداد مساحة عمل الإصدار العلني
الحلّ: بنية جاهزة للإنتاج
قدّم هذا الوكيل البسيط نقطة البداية، ولكنّ النظام الإنتاجي يتطلّب بنية قوية. سنعمل الآن على إعداد مشروع كامل يجسّد مبادئ الإنتاج.
إعداد الأساسيات
لقد سبق لك إعداد مشروعك على السحابة الإلكترونية على Google Cloud للوكيل الأساسي. لنجهّز الآن مساحة عمل الإنتاج الكامل بجميع الأدوات والأنماط والبنية الأساسية اللازمة لنظام حقيقي.
الخطوة 1: الحصول على "المشروع المنظَّم"
أولاً، اخرج من أي adk run قيد التشغيل باستخدام Ctrl+C ونفِّذ الخطوات التالية:
# Clean up the basic agent
cd ~ # Make sure you're not inside my_first_agent
rm -rf my_first_agent
# Get the production scaffold
git clone https://github.com/ayoisio/adk-code-review-assistant.git
cd adk-code-review-assistant
git checkout codelab
الخطوة 2: إنشاء بيئة افتراضية وتفعيلها
# Create the virtual environment
python -m venv .venv
# Activate it
# On macOS/Linux:
source .venv/bin/activate
# On Windows:
# .venv\Scripts\activate
التأكيد: من المفترض أن يظهر الآن (.venv) في بداية طلبك.
الخطوة 3: تثبيت التبعيات
pip install -r code_review_assistant/requirements.txt
# Install the package in editable mode (enables imports)
pip install -e .
يتم تثبيت ما يلي:
google-adk- إطار عمل ADK-
pycodestyle- للتحقّق من PEP 8 vertexai- للتفعيل في السحابة الإلكترونية- المهام التابعة الأخرى المتعلقة بالإنتاج
تتيح لك العلامة -e استيراد وحدات code_review_assistant من أي مكان.
الخطوة 4: ضبط بيئتك
# Copy the example environment file
cp .env.example .env
# Edit .env and replace the placeholders:
# - GOOGLE_CLOUD_PROJECT=your-project-id → your actual project ID
# - Keep other defaults as-is
التحقّق: تحقَّق من الإعدادات:
cat .env
يجب أن يظهر ما يلي:
GOOGLE_CLOUD_PROJECT=your-actual-project-id
GOOGLE_CLOUD_LOCATION=us-central1
GOOGLE_GENAI_USE_VERTEXAI=TRUE
الخطوة 5: التأكّد من المصادقة
بما أنّك سبق أن نفّذت gcloud auth، لننتقل إلى عملية التحقّق:
# Check current authentication
gcloud auth list
# Should show your account with (ACTIVE)
# If not, run:
gcloud auth application-default login
الخطوة 6: تفعيل واجهات برمجة التطبيقات الإضافية الخاصة بالإنتاج
لقد فعّلنا واجهات برمجة التطبيقات الأساسية. الآن، أضِف تلك المخصّصة للإنتاج:
gcloud services enable \
sqladmin.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
storage.googleapis.com \
cloudtrace.googleapis.com
يتيح ذلك ما يلي:
- مشرف SQL: بالنسبة إلى Cloud SQL في حال استخدام Cloud Run
- Cloud Run: للنشر بدون خادم
- Cloud Build: عمليات النشر المبرمَجة
- Artifact Registry: لصور الحاويات
- Cloud Storage: للقطع الأثرية والتحضير
- Cloud Trace: للمراقبة
الخطوة 7: إنشاء مستودع Artifact Registry
ستنشئ عملية النشر صور حاويات تحتاج إلى مكان:
gcloud artifacts repositories create code-review-assistant-repo \
--repository-format=docker \
--location=us-central1 \
--description="Docker repository for Code Review Assistant"
سيظهر لك ما يلي:
Created repository [code-review-assistant-repo].
إذا كان الملف موجودًا من قبل (ربما من محاولة سابقة)، لا بأس في ذلك، ستظهر لك رسالة خطأ يمكنك تجاهلها.
الخطوة 8: منح أذونات "إدارة الهوية وإمكانية الوصول"
# Get your project number
PROJECT_NUMBER=$(gcloud projects describe $GOOGLE_CLOUD_PROJECT \
--format="value(projectNumber)")
# Define the service account
SERVICE_ACCOUNT="${PROJECT_NUMBER}@cloudbuild.gserviceaccount.com"
# Grant necessary roles
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SERVICE_ACCOUNT}" \
--role="roles/run.admin"
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SERVICE_ACCOUNT}" \
--role="roles/iam.serviceAccountUser"
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SERVICE_ACCOUNT}" \
--role="roles/cloudsql.admin"
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SERVICE_ACCOUNT}" \
--role="roles/storage.admin"
سيؤدي كل أمر إلى عرض ما يلي:
Updated IAM policy for project [your-project-id].
إنجازاتك
تم الآن إعداد مساحة العمل الخاصة بالإصدار العلني بالكامل:
✅ تم إعداد مشروع Google Cloud والمصادقة عليه
✅ تم اختبار الوكيل الأساسي للتعرّف على القيود
✅ رمز المشروع مع العناصر النائبة الاستراتيجية جاهز
✅ تم عزل التبعيات في بيئة افتراضية
✅ تم تفعيل جميع واجهات برمجة التطبيقات اللازمة
✅ سجلّ الحاويات جاهز لعمليات النشر
✅ تم إعداد أذونات "إدارة الهوية وإمكانية الوصول" بشكلٍ صحيح
✅ تم ضبط متغيرات البيئة بشكلٍ صحيح
أنت الآن جاهز لإنشاء نظام ذكاء اصطناعي حقيقي باستخدام أدوات حتمية وإدارة الحالة وبنية مناسبة.
4. إنشاء أول وكيل لك
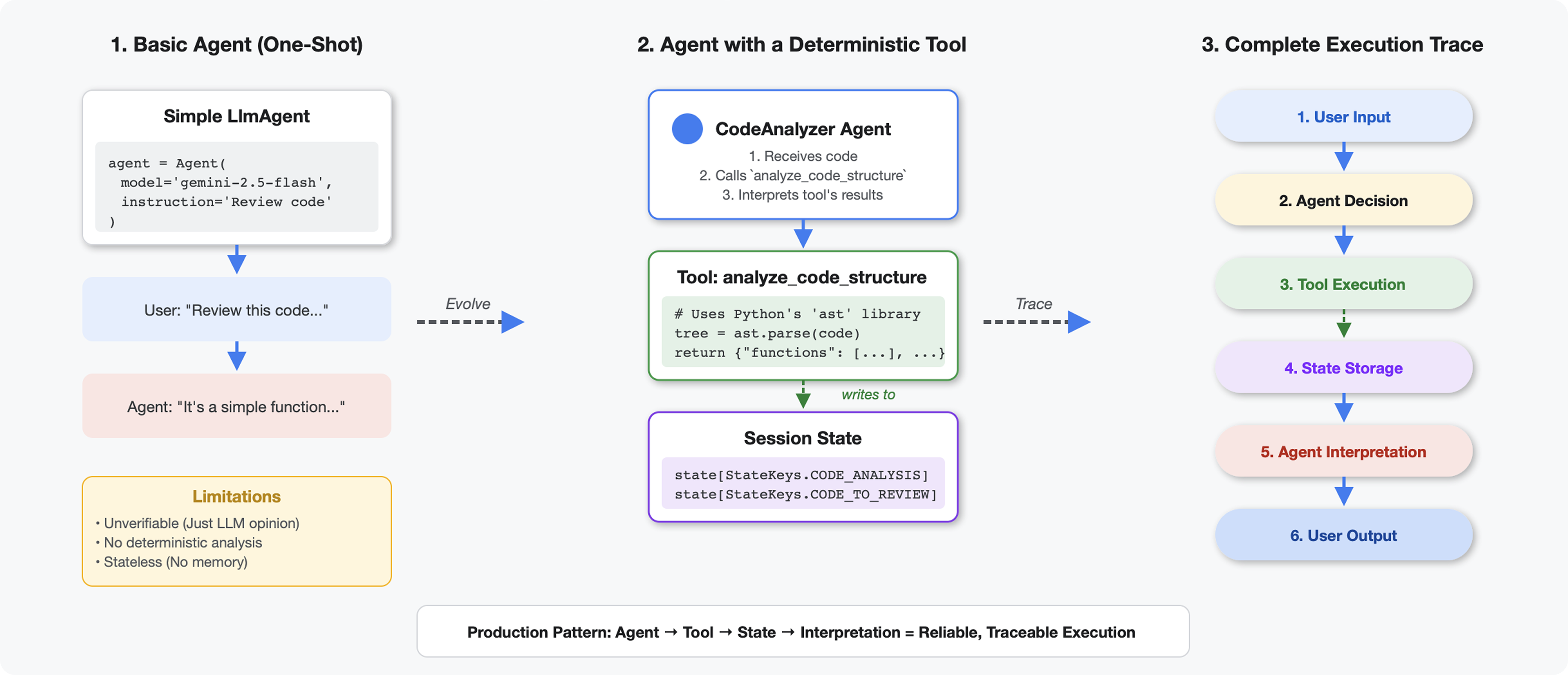
ما يميّز الأدوات عن النماذج اللغوية الكبيرة
عندما تطرح على نموذج لغوي كبير سؤالاً مثل "كم عدد الدوال في هذا الرمز؟"، يستخدم النموذج مطابقة الأنماط والتقدير. عند استخدام أداة تستدعي ast.parse() في Python، يتم تحليل شجرة البنية الفعلية، بدون أي تخمين، وستحصل على النتيجة نفسها في كل مرة.
ينشئ هذا القسم أداة تحلّل بنية الرمز البرمجي بشكل حتمي، ثم يربطها بعميل يعرف متى يتم استدعاؤها.
الخطوة 1: فهم Scaffold
لنلقِ نظرة على البنية التي ستملأها.
👉 فتح
code_review_assistant/tools.py
ستظهر لك الدالة analyze_code_structure مع تعليقات عنصر نائب تحدّد المكان الذي ستضيف فيه الرمز البرمجي. تتضمّن الدالة البنية الأساسية، وستعمل على تحسينها خطوة بخطوة.
الخطوة 2: إضافة State Storage
تتيح ميزة "تخزين الحالة" للوكلاء الآخرين في مسار البيانات الوصول إلى نتائج أداتك بدون إعادة تشغيل التحليل.
👉 البحث:
# MODULE_4_STEP_2_ADD_STATE_STORAGE
👉 استبدِل هذا السطر الواحد بما يلي:
# Store code and analysis for other agents to access
tool_context.state[StateKeys.CODE_TO_REVIEW] = code
tool_context.state[StateKeys.CODE_ANALYSIS] = analysis
tool_context.state[StateKeys.CODE_LINE_COUNT] = len(code.splitlines())
الخطوة 3: إضافة تحليل غير متزامن باستخدام مجموعات سلاسل المحادثات
يجب أن تحلّل أداتنا شجرة بناء الجملة المجردة بدون حظر العمليات الأخرى. لنضِف التنفيذ غير المتزامن باستخدام مجموعات سلاسل المحادثات.
👉 البحث:
# MODULE_4_STEP_3_ADD_ASYNC
👉 استبدِل هذا السطر الواحد بما يلي:
# Parse in thread pool to avoid blocking the event loop
loop = asyncio.get_event_loop()
with ThreadPoolExecutor() as executor:
tree = await loop.run_in_executor(executor, ast.parse, code)
الخطوة 4: استخراج معلومات شاملة
لنستخرِج الآن الفئات وعمليات الاستيراد والمقاييس التفصيلية، أي كل ما نحتاج إليه لإجراء مراجعة كاملة للتعليمات البرمجية.
👉 البحث:
# MODULE_4_STEP_4_EXTRACT_DETAILS
👉 استبدِل هذا السطر الواحد بما يلي:
# Extract comprehensive structural information
analysis = await loop.run_in_executor(
executor, _extract_code_structure, tree, code
)
👉 التحقّق: الدالة
analyze_code_structure
في
tools.py
لها جسم مركزي يظهر بالشكل التالي:
# Parse in thread pool to avoid blocking the event loop
loop = asyncio.get_event_loop()
with ThreadPoolExecutor() as executor:
tree = await loop.run_in_executor(executor, ast.parse, code)
# Extract comprehensive structural information
analysis = await loop.run_in_executor(
executor, _extract_code_structure, tree, code
)
# Store code and analysis for other agents to access
tool_context.state[StateKeys.CODE_TO_REVIEW] = code
tool_context.state[StateKeys.CODE_ANALYSIS] = analysis
tool_context.state[StateKeys.CODE_LINE_COUNT] = len(code.splitlines())
👉 انتقِل الآن إلى أسفل
tools.py
والعثور على:
# MODULE_4_STEP_4_HELPER_FUNCTION
👉 استبدِل هذا السطر الواحد بدالة المساعد الكاملة:
def _extract_code_structure(tree: ast.AST, code: str) -> Dict[str, Any]:
"""
Helper function to extract structural information from AST.
Runs in thread pool for CPU-bound work.
"""
functions = []
classes = []
imports = []
docstrings = []
for node in ast.walk(tree):
if isinstance(node, ast.FunctionDef):
func_info = {
'name': node.name,
'args': [arg.arg for arg in node.args.args],
'lineno': node.lineno,
'has_docstring': ast.get_docstring(node) is not None,
'is_async': isinstance(node, ast.AsyncFunctionDef),
'decorators': [d.id for d in node.decorator_list
if isinstance(d, ast.Name)]
}
functions.append(func_info)
if func_info['has_docstring']:
docstrings.append(f"{node.name}: {ast.get_docstring(node)[:50]}...")
elif isinstance(node, ast.ClassDef):
methods = []
for item in node.body:
if isinstance(item, ast.FunctionDef):
methods.append(item.name)
class_info = {
'name': node.name,
'lineno': node.lineno,
'methods': methods,
'has_docstring': ast.get_docstring(node) is not None,
'base_classes': [base.id for base in node.bases
if isinstance(base, ast.Name)]
}
classes.append(class_info)
elif isinstance(node, ast.Import):
for alias in node.names:
imports.append({
'module': alias.name,
'alias': alias.asname,
'type': 'import'
})
elif isinstance(node, ast.ImportFrom):
imports.append({
'module': node.module or '',
'names': [alias.name for alias in node.names],
'type': 'from_import',
'level': node.level
})
return {
'functions': functions,
'classes': classes,
'imports': imports,
'docstrings': docstrings,
'metrics': {
'line_count': len(code.splitlines()),
'function_count': len(functions),
'class_count': len(classes),
'import_count': len(imports),
'has_main': any(f['name'] == 'main' for f in functions),
'has_if_main': '__main__' in code,
'avg_function_length': _calculate_avg_function_length(tree)
}
}
def _calculate_avg_function_length(tree: ast.AST) -> float:
"""Calculate average function length in lines."""
function_lengths = []
for node in ast.walk(tree):
if isinstance(node, ast.FunctionDef):
if hasattr(node, 'end_lineno') and hasattr(node, 'lineno'):
length = node.end_lineno - node.lineno + 1
function_lengths.append(length)
if function_lengths:
return sum(function_lengths) / len(function_lengths)
return 0.0
الخطوة 5: التواصل مع موظّف الدعم
الآن، نربط الأداة بوكيل يعرف متى يجب استخدامها وكيفية تفسير نتائجها.
👉 فتح
code_review_assistant/sub_agents/review_pipeline/code_analyzer.py
👉 البحث:
# MODULE_4_STEP_5_CREATE_AGENT
👉 استبدِل هذا السطر الفردي بوكيل الإنتاج الكامل:
code_analyzer_agent = Agent(
name="CodeAnalyzer",
model=config.worker_model,
description="Analyzes Python code structure and identifies components",
instruction="""You are a code analysis specialist responsible for understanding code structure.
Your task:
1. Take the code submitted by the user (it will be provided in the user message)
2. Use the analyze_code_structure tool to parse and analyze it
3. Pass the EXACT code to your tool - do not modify, fix, or "improve" it
4. Identify all functions, classes, imports, and structural patterns
5. Note any syntax errors or structural issues
6. Store the analysis in state for other agents to use
CRITICAL:
- Pass the code EXACTLY as provided to the analyze_code_structure tool
- Do not fix syntax errors, even if obvious
- Do not add missing imports or fix indentation
- The goal is to analyze what IS there, not what SHOULD be there
When calling the tool, pass the code as a string to the 'code' parameter.
If the analysis fails due to syntax errors, clearly report the error location and type.
Provide a clear summary including:
- Number of functions and classes found
- Key structural observations
- Any syntax errors or issues detected
- Overall code organization assessment""",
tools=[FunctionTool(func=analyze_code_structure)],
output_key="structure_analysis_summary"
)
تجربة "أداة تحليل الرموز البرمجية"
الآن، تحقَّق من أنّ أداة التحليل تعمل بشكل صحيح.
👉 تشغيل النص البرمجي للاختبار:
python tests/test_code_analyzer.py
يحمّل نص الاختبار البرمجي الإعدادات تلقائيًا من ملف .env باستخدام python-dotenv، لذا لا حاجة إلى إعداد متغيرات البيئة يدويًا.
الناتج المتوقّع:
INFO:code_review_assistant.config:Code Review Assistant Configuration Loaded:
INFO:code_review_assistant.config: - GCP Project: your-project-id
INFO:code_review_assistant.config: - Artifact Bucket: gs://your-project-artifacts
INFO:code_review_assistant.config: - Models: worker=gemini-2.5-flash, critic=gemini-2.5-pro
Testing code analyzer...
INFO:code_review_assistant.tools:Tool: Analysis complete - 2 functions, 1 classes
=== Analyzer Response ===
The analysis of the provided code shows the following:
* **Functions Found:** 2
* `add(a, b)`: A global function at line 2.
* `multiply(self, x, y)`: A method within the `Calculator` class.
* **Classes Found:** 1
* `Calculator`: A class defined at line 5. Contains one method, `multiply`.
* **Imports:** 0
* **Structural Patterns:** The code defines one global function and one class
with a single method. Both are simple, each with a single return statement.
* **Syntax Errors/Issues:** No syntax errors detected.
* **Overall Code Organization:** The code is well-organized for its small size,
clearly defining a function and a class with a method.
آخر الأخبار:
- حمّل نص الاختبار البرمجي إعدادات
.envتلقائيًا - حلّلت أداة
analyze_code_structure()الرمز باستخدام شجرة بناء الجملة المجردة (AST) في Python - استخرجت الأداة المساعِدة
_extract_code_structure()الدوال والفئات والمقاييس - تم تخزين النتائج في حالة الجلسة باستخدام الثوابت
StateKeys - فسّر وكيل "محلّل الرموز" النتائج وقدّم ملخّصًا
تحديد المشاكل وحلّها:
- "No module named ‘code_review_assistant'": شغِّل
pip install -e .من الدليل الجذر للمشروع - "وسيطة إدخالات المفتاح غير متوفّرة": تأكَّد من أنّ
.envيتضمّنGOOGLE_CLOUD_PROJECTوGOOGLE_CLOUD_LOCATIONوGOOGLE_GENAI_USE_VERTEXAI=true
الميزات التي أنشأتها
يتوفّر لديك الآن محلّل رموز برمجية جاهز للاستخدام في مرحلة الإنتاج، ويوفّر الميزات التالية:
✅ تحليل شجرة بناء الجملة المجردة (AST) الفعلية في Python: تحديد النتائج وليس مطابقة الأنماط
✅ تخزين النتائج في الحالة: يمكن للوكلاء الآخرين الوصول إلى التحليل
✅ التشغيل بشكل غير متزامن: لا يحظر الأدوات الأخرى
✅ استخراج معلومات شاملة: الدوال والفئات وعمليات الاستيراد والمقاييس
✅ التعامل مع الأخطاء بشكل سليم: الإبلاغ عن أخطاء في بناء الجملة مع أرقام الأسطر
✅ التواصل مع وكيل: تعرف النماذج اللغوية الكبيرة متى وكيف يتم استخدامها
المفاهيم الرئيسية التي تم إتقانها
الأدوات في مقابل الموظفين:
- تنفّذ الأدوات مهامًا حتمية (تحليل بنية الشجرة المجردة)
- تحدّد البرامج الآلية متى تستخدم الأدوات وتفسّر النتائج
القيمة المرجَعة مقابل الحالة:
- النتيجة: ما يراه النموذج اللغوي الكبير على الفور
- الحالة: ما يبقى متاحًا للوكلاء الآخرين
ثوابت مفاتيح الحالة:
- منع الأخطاء الإملائية في الأنظمة المتعدّدة الوكلاء
- العمل كعقود بين العملاء
- أهمية مشاركة البيانات بين الوكلاء
العمليات غير المتزامنة ومجموعات سلاسل العمليات:
- تسمح
async defللأدوات بإيقاف التنفيذ مؤقتًا - تنفّذ مجموعات سلاسل العمل مهامًا مرتبطة بوحدة المعالجة المركزية في الخلفية
- وتعمل هذه العمليات معًا للحفاظ على استجابة حلقة معالجة الأحداث.
الدوال المساعِدة:
- فصل أدوات المزامنة عن أدوات عدم المزامنة
- يجعل الرمز قابلاً للاختبار وإعادة الاستخدام
تعليمات لموظفي الدعم:
- تجنُّب الأخطاء الشائعة في النماذج اللغوية الكبيرة من خلال التعليمات المفصّلة
- توضيح الإجراءات التي يجب تجنُّبها (عدم إصلاح الرمز البرمجي)
- محو خطوات سير العمل لضمان الاتساق
الخطوات التالية
في الوحدة 5، ستضيف ما يلي:
- مدقّق الأسلوب الذي يقرأ الرمز من الحالة
- برنامج تشغيل الاختبار الذي ينفّذ الاختبارات فعليًا
- أداة تجميع الملاحظات التي تجمع كل التحليلات
ستتعرّف على كيفية انتقال الحالة عبر مسار متسلسل، ولماذا يكون نمط الثوابت مهمًا عندما تقرأ عدة عناصر وتكتب البيانات نفسها.
5- إنشاء مسار: عمل عدّة وكلاء معًا
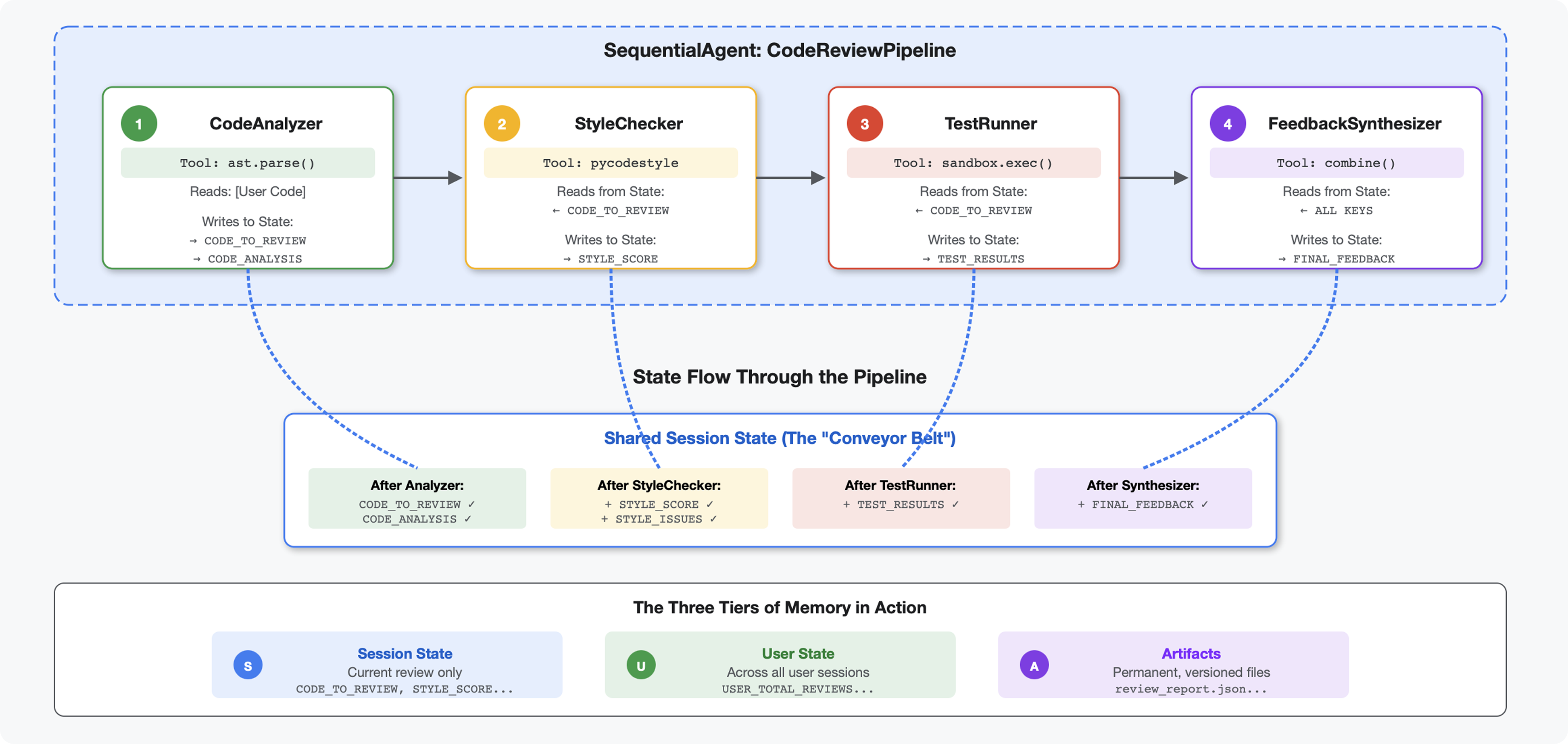
مقدمة
في الوحدة 4، أنشأتَ وكيلاً واحدًا يحلّل بنية الرمز البرمجي. لكنّ مراجعة الرمز البرمجي الشاملة تتطلّب أكثر من مجرد التحليل، إذ تحتاج إلى التحقّق من الأسلوب وتنفيذ الاختبار وتركيب الملاحظات الذكية.
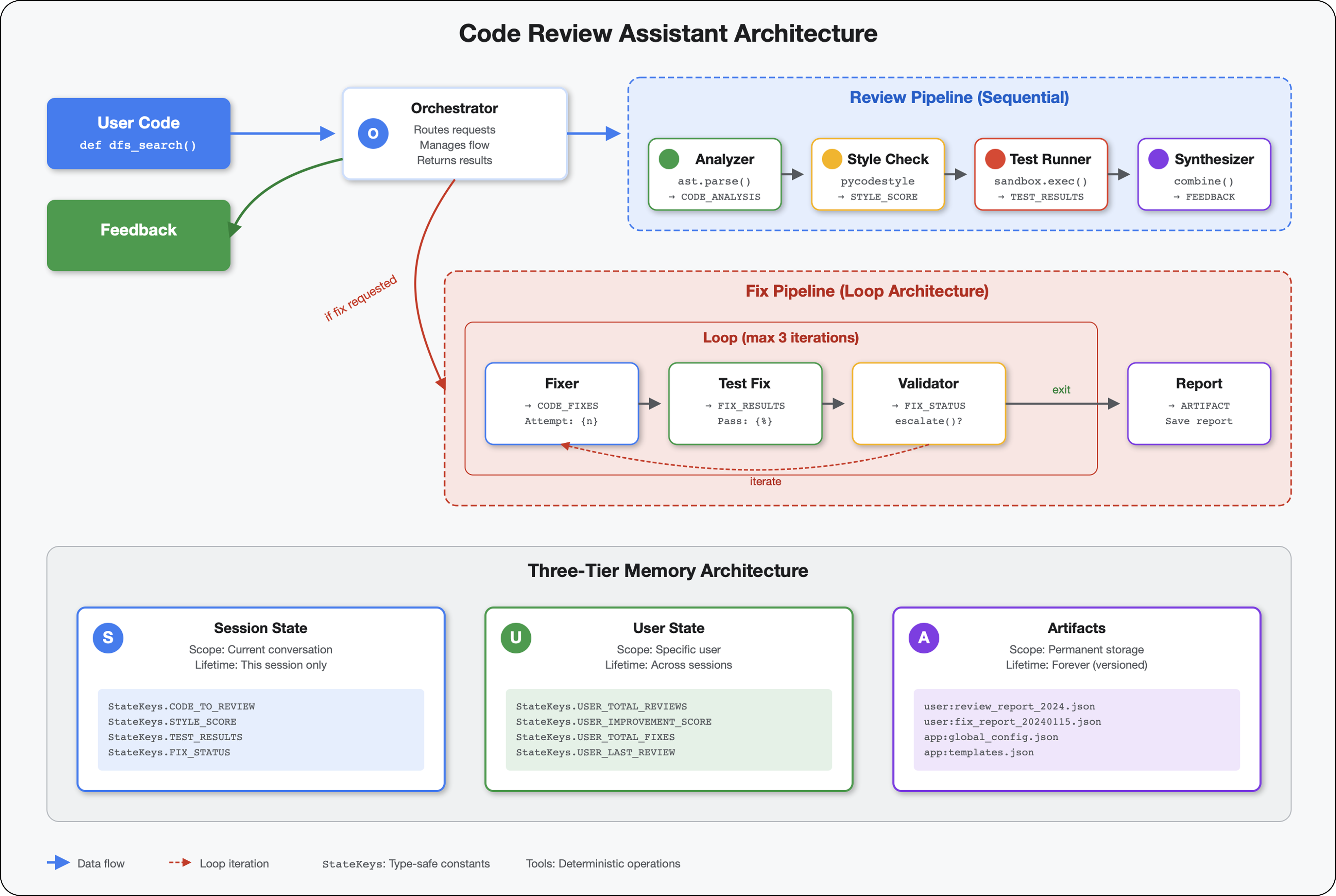
تنشئ هذه الوحدة سلسلة من 4 وكلاء يعملون معًا بالتسلسل، ويساهم كل منهم بتحليل متخصص:
- أداة تحليل الرموز (من الوحدة 4): تحلّل البنية
- مدقّق الأسلوب: يحدّد مخالفات الأسلوب
- Test Runner: لتنفيذ الاختبارات والتحقّق من صحتها
- أداة تجميع الملاحظات: تجمع كل الملاحظات في ملاحظات يمكن اتّخاذ إجراء بشأنها
المفهوم الأساسي: الحالة كقناة اتصال يقرأ كل وكيل ما كتبه الوكلاء السابقون لإضافة حالته، ويضيف تحليله الخاص، ثم يمرّر الحالة المحسّنة إلى الوكيل التالي. يصبح نمط الثوابت من الوحدة 4 مهمًا عندما تتشارك عدة برامج وكيل البيانات.
معاينة لما ستنشئه: إرسال رمز برمجي غير منظَّم → مشاهدة تدفّق الحالة من خلال 4 وكلاء → تلقّي تقرير شامل يتضمّن ملاحظات مخصّصة استنادًا إلى الأنماط السابقة
الخطوة 1: إضافة أداة "مدقّق الأسلوب" + وكيل
تحدّد أداة فحص الأسلوب انتهاكات PEP 8 باستخدام pycodestyle، وهي أداة تدقيق ثابتة وليست تفسيرًا مستندًا إلى نموذج لغوي كبير.
إضافة أداة التحقّق من الأسلوب
👉 فتح
code_review_assistant/tools.py
👉 البحث:
# MODULE_5_STEP_1_STYLE_CHECKER_TOOL
👉 استبدِل هذا السطر الواحد بما يلي:
async def check_code_style(code: str, tool_context: ToolContext) -> Dict[str, Any]:
"""
Checks code style compliance using pycodestyle (PEP 8).
Args:
code: Python source code to check (or will retrieve from state)
tool_context: ADK tool context
Returns:
Dictionary containing style score and issues
"""
logger.info("Tool: Checking code style...")
try:
# Retrieve code from state if not provided
if not code:
code = tool_context.state.get(StateKeys.CODE_TO_REVIEW, '')
if not code:
return {
"status": "error",
"message": "No code provided or found in state"
}
# Run style check in thread pool
loop = asyncio.get_event_loop()
with ThreadPoolExecutor() as executor:
result = await loop.run_in_executor(
executor, _perform_style_check, code
)
# Store results in state
tool_context.state[StateKeys.STYLE_SCORE] = result['score']
tool_context.state[StateKeys.STYLE_ISSUES] = result['issues']
tool_context.state[StateKeys.STYLE_ISSUE_COUNT] = result['issue_count']
logger.info(f"Tool: Style check complete - Score: {result['score']}/100, "
f"Issues: {result['issue_count']}")
return result
except Exception as e:
error_msg = f"Style check failed: {str(e)}"
logger.error(f"Tool: {error_msg}", exc_info=True)
# Set default values on error
tool_context.state[StateKeys.STYLE_SCORE] = 0
tool_context.state[StateKeys.STYLE_ISSUES] = []
return {
"status": "error",
"message": error_msg,
"score": 0
}
👉 انتقِل الآن إلى نهاية الملف وابحث عن:
# MODULE_5_STEP_1_STYLE_HELPERS
👉 استبدِل هذا السطر الفردي بالدوال المساعِدة:
def _perform_style_check(code: str) -> Dict[str, Any]:
"""Helper to perform style check in thread pool."""
import io
import sys
with tempfile.NamedTemporaryFile(mode='w', suffix='.py', delete=False) as tmp:
tmp.write(code)
tmp_path = tmp.name
try:
# Capture stdout to get pycodestyle output
old_stdout = sys.stdout
sys.stdout = captured_output = io.StringIO()
style_guide = pycodestyle.StyleGuide(
quiet=False, # We want output
max_line_length=100,
ignore=['E501', 'W503']
)
result = style_guide.check_files([tmp_path])
# Restore stdout
sys.stdout = old_stdout
# Parse captured output
output = captured_output.getvalue()
issues = []
for line in output.strip().split('\n'):
if line and ':' in line:
parts = line.split(':', 4)
if len(parts) >= 4:
try:
issues.append({
'line': int(parts[1]),
'column': int(parts[2]),
'code': parts[3].split()[0] if len(parts) > 3 else 'E000',
'message': parts[3].strip() if len(parts) > 3 else 'Unknown error'
})
except (ValueError, IndexError):
pass
# Add naming convention checks
try:
tree = ast.parse(code)
naming_issues = _check_naming_conventions(tree)
issues.extend(naming_issues)
except SyntaxError:
pass # Syntax errors will be caught elsewhere
# Calculate weighted score
score = _calculate_style_score(issues)
return {
"status": "success",
"score": score,
"issue_count": len(issues),
"issues": issues[:10], # First 10 issues
"summary": f"Style score: {score}/100 with {len(issues)} violations"
}
finally:
if os.path.exists(tmp_path):
os.unlink(tmp_path)
def _check_naming_conventions(tree: ast.AST) -> List[Dict[str, Any]]:
"""Check PEP 8 naming conventions."""
naming_issues = []
for node in ast.walk(tree):
if isinstance(node, ast.FunctionDef):
# Skip private/protected methods and __main__
if not node.name.startswith('_') and node.name != node.name.lower():
naming_issues.append({
'line': node.lineno,
'column': node.col_offset,
'code': 'N802',
'message': f"N802 function name '{node.name}' should be lowercase"
})
elif isinstance(node, ast.ClassDef):
# Check if class name follows CapWords convention
if not node.name[0].isupper() or '_' in node.name:
naming_issues.append({
'line': node.lineno,
'column': node.col_offset,
'code': 'N801',
'message': f"N801 class name '{node.name}' should use CapWords convention"
})
return naming_issues
def _calculate_style_score(issues: List[Dict[str, Any]]) -> int:
"""Calculate weighted style score based on violation severity."""
if not issues:
return 100
# Define weights by error type
weights = {
'E1': 10, # Indentation errors
'E2': 3, # Whitespace errors
'E3': 5, # Blank line errors
'E4': 8, # Import errors
'E5': 5, # Line length
'E7': 7, # Statement errors
'E9': 10, # Syntax errors
'W2': 2, # Whitespace warnings
'W3': 2, # Blank line warnings
'W5': 3, # Line break warnings
'N8': 7, # Naming conventions
}
total_deduction = 0
for issue in issues:
code_prefix = issue['code'][:2] if len(issue['code']) >= 2 else 'E2'
weight = weights.get(code_prefix, 3)
total_deduction += weight
# Cap at 100 points deduction
return max(0, 100 - min(total_deduction, 100))
إضافة وكيل "مدقّق الأسلوب"
👉 فتح
code_review_assistant/sub_agents/review_pipeline/style_checker.py
👉 البحث:
# MODULE_5_STEP_1_INSTRUCTION_PROVIDER
👉 استبدِل هذا السطر الواحد بما يلي:
async def style_checker_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are a code style expert focused on PEP 8 compliance.
Your task:
1. Use the check_code_style tool to validate PEP 8 compliance
2. The tool will retrieve the ORIGINAL code from state automatically
3. Report violations exactly as found
4. Present the results clearly and confidently
CRITICAL:
- The tool checks the code EXACTLY as provided by the user
- Do not suggest the code was modified or fixed
- Report actual violations found in the original code
- If there are style issues, they should be reported honestly
Call the check_code_style tool with an empty string for the code parameter,
as the tool will retrieve the code from state automatically.
When presenting results based on what the tool returns:
- State the exact score from the tool results
- If score >= 90: "Excellent style compliance!"
- If score 70-89: "Good style with minor improvements needed"
- If score 50-69: "Style needs attention"
- If score < 50: "Significant style improvements needed"
List the specific violations found (the tool will provide these):
- Show line numbers, error codes, and messages
- Focus on the top 10 most important issues
Previous analysis: {structure_analysis_summary}
Format your response as:
## Style Analysis Results
- Style Score: [exact score]/100
- Total Issues: [count]
- Assessment: [your assessment based on score]
## Top Style Issues
[List issues with line numbers and descriptions]
## Recommendations
[Specific fixes for the most critical issues]"""
return await instructions_utils.inject_session_state(template, context)
👉 البحث:
# MODULE_5_STEP_1_STYLE_CHECKER_AGENT
👉 استبدِل هذا السطر الواحد بما يلي:
style_checker_agent = Agent(
name="StyleChecker",
model=config.worker_model,
description="Checks Python code style against PEP 8 guidelines",
instruction=style_checker_instruction_provider,
tools=[FunctionTool(func=check_code_style)],
output_key="style_check_summary"
)
الخطوة 2: إضافة Test Runner Agent
تنشئ أداة تنفيذ الاختبارات اختبارات شاملة وتنفّذها باستخدام أداة تنفيذ الرموز البرمجية المضمّنة.
👉 فتح
code_review_assistant/sub_agents/review_pipeline/test_runner.py
👉 البحث:
# MODULE_5_STEP_2_INSTRUCTION_PROVIDER
👉 استبدِل هذا السطر الواحد بما يلي:
async def test_runner_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects the code_to_review directly."""
template = """You are a testing specialist who creates and runs tests for Python code.
THE CODE TO TEST IS:
{code_to_review}
YOUR TASK:
1. Understand what the function appears to do based on its name and structure
2. Generate comprehensive tests (15-20 test cases)
3. Execute the tests using your code executor
4. Analyze results to identify bugs vs expected behavior
5. Output a detailed JSON analysis
TESTING METHODOLOGY:
- Test with the most natural interpretation first
- When something fails, determine if it's a bug or unusual design
- Test edge cases, boundaries, and error scenarios
- Document any surprising behavior
Execute your tests and output ONLY valid JSON with this structure:
- "test_summary": object with "total_tests_run", "tests_passed", "tests_failed", "tests_with_errors", "critical_issues_found"
- "critical_issues": array of objects, each with "type", "description", "example_input", "expected_behavior", "actual_behavior", "severity"
- "test_categories": object with "basic_functionality", "edge_cases", "error_handling" (each containing "passed", "failed", "errors" counts)
- "function_behavior": object with "apparent_purpose", "actual_interface", "unexpected_requirements"
- "verdict": object with "status" (WORKING/BUGGY/BROKEN), "confidence" (high/medium/low), "recommendation"
Do NOT output the test code itself, only the JSON analysis."""
return await instructions_utils.inject_session_state(template, context)
👉 البحث:
# MODULE_5_STEP_2_TEST_RUNNER_AGENT
👉 استبدِل هذا السطر الواحد بما يلي:
test_runner_agent = Agent(
name="TestRunner",
model=config.critic_model,
description="Generates and runs tests for Python code using safe code execution",
instruction=test_runner_instruction_provider,
code_executor=BuiltInCodeExecutor(),
output_key="test_execution_summary"
)
الخطوة 3: فهم ميزة "الذاكرة" للتعلم على مستوى الجلسات
قبل إنشاء أداة تركيب الملاحظات، عليك فهم الفرق بين الحالة والذاكرة، وهما آليتان مختلفتان للتخزين لأغراض مختلفة.
الحالة مقابل الذاكرة: الفرق الأساسي
لنوضّح ذلك بمثال ملموس من مراجعة الرمز البرمجي:
الولاية (الجلسة الحالية فقط):
# Data from THIS review session
tool_context.state[StateKeys.STYLE_ISSUES] = [
{"line": 5, "code": "E231", "message": "missing whitespace"},
{"line": 12, "code": "E701", "message": "multiple statements"}
]
- النطاق: هذه المحادثة فقط
- الغرض: تمرير البيانات بين العملاء في مسار التعلّم الحالي
- مكان المعيشة حاليًا:
Session - مدة البقاء: يتم تجاهلها عند انتهاء الجلسة
الذاكرة (جميع الجلسات السابقة):
# Learned from 50 previous reviews
"User frequently forgets docstrings on helper functions"
"User tends to write long functions (avg 45 lines)"
"User improved error handling after feedback in session #23"
- النطاق: جميع الجلسات السابقة لهذا المستخدم
- الغرض: التعرّف على الأنماط وتقديم ملاحظات مخصّصة
- مكان المعيشة حاليًا:
MemoryService - المدة منذ الإنشاء: تستمرّ على مستوى الجلسات، ويمكن البحث فيها
سبب الحاجة إلى كليهما:
تخيَّل أداة التجميع تنشئ ملاحظات:
استخدام "الولاية" فقط (المراجعة الحالية):
"Function `calculate_total` has no docstring."
ملاحظات آلية عامة
استخدام الحالة والذاكرة (الأنماط الحالية والسابقة):
"Function `calculate_total` has no docstring. This is the 4th review
where helper functions lacked documentation. Consider adding docstrings
as you write functions, not afterwards - you mentioned in our last
session that you find it easier that way."
تحسين المراجع المخصّصة والسياقية بمرور الوقت
بالنسبة إلى عمليات النشر في مرحلة الإنتاج، تتوفّر لك خيارات:
الخيار 1: VertexAiMemoryBankService (متقدّم)
- الوظيفة: استخراج حقائق مفيدة من المحادثات باستخدام نموذج لغوي كبير
- البحث: البحث الدلالي (يفهم المعنى، وليس فقط الكلمات الرئيسية)
- إدارة الذكريات: يتم تلقائيًا دمج الذكريات وتعديلها بمرور الوقت
- المتطلبات: مشروع Google Cloud + إعداد Agent Engine
- يجب استخدامها في الحالات التالية: عندما تريد ذكريات متطورة ومتجددة ومخصّصة
- مثال: "يفضّل المستخدم البرمجة الوظيفية" (تم استخراجه من 10 محادثات حول نمط الرمز البرمجي)
الخيار 2: مواصلة استخدام InMemoryMemoryService + الجلسات الدائمة
- الدور الذي يؤديه: تخزين سجلّ المحادثات الكامل للبحث عن الكلمات الرئيسية
- البحث: مطابقة الكلمات الرئيسية الأساسية في الجلسات السابقة
- إدارة الذاكرة: يمكنك التحكّم في المحتوى الذي يتم تخزينه (من خلال
add_session_to_memory) - المتطلبات: يجب توفّر
SessionServiceدائم فقط (مثلVertexAiSessionServiceأوDatabaseSessionService) - يجب استخدام هذه الطريقة في الحالات التالية: عندما تحتاج إلى إجراء بحث بسيط في المحادثات السابقة بدون معالجة النموذج اللغوي الكبير
- مثال: يؤدي البحث عن "docstring" إلى عرض جميع الجلسات التي تتضمّن هذه الكلمة.
طريقة ملء الذاكرة
بعد اكتمال كل مراجعة للرمز البرمجي:
# At the end of a session (typically in your application code)
await memory_service.add_session_to_memory(session)
ما يحدث:
- InMemoryMemoryService: تخزِّن أحداث الجلسة الكاملة للبحث عن الكلمات الرئيسية
- VertexAiMemoryBankService: يستخرج النموذج اللغوي الكبير الحقائق الرئيسية ويدمجها مع الذكريات الحالية
يمكن للجلسات المستقبلية بعد ذلك طلب البحث عن:
# In a tool, search for relevant past feedback
results = tool_context.search_memory("feedback about docstrings")
الخطوة 4: إضافة "أدوات توليف الملاحظات" و"الوكيل"
مُركِّب الملاحظات هو الوكيل الأكثر تطورًا في سلسلة المعالجة. تنسّق هذه الأداة ثلاث أدوات، وتستخدم تعليمات ديناميكية، وتجمع بين الحالة والذاكرة والنتائج.
إضافة أدوات تركيب الأصوات الثلاث
👉 فتح
code_review_assistant/tools.py
👉 البحث:
# MODULE_5_STEP_4_SEARCH_PAST_FEEDBACK
👉 استبدِل النص التالي بـ "الأداة 1 - البحث في الذاكرة" (إصدار الإنتاج):
async def search_past_feedback(developer_id: str, tool_context: ToolContext) -> Dict[str, Any]:
"""
Search for past feedback in memory service.
Args:
developer_id: ID of the developer (defaults to "default_user")
tool_context: ADK tool context with potential memory service access
Returns:
Dictionary containing feedback search results
"""
logger.info(f"Tool: Searching for past feedback for developer {developer_id}...")
try:
# Default developer ID if not provided
if not developer_id:
developer_id = tool_context.state.get(StateKeys.USER_ID, 'default_user')
# Check if memory service is available
if hasattr(tool_context, 'search_memory'):
try:
# Perform structured searches
queries = [
f"developer:{developer_id} code review feedback",
f"developer:{developer_id} common issues",
f"developer:{developer_id} improvements"
]
all_feedback = []
patterns = {
'common_issues': [],
'improvements': [],
'strengths': []
}
for query in queries:
search_result = await tool_context.search_memory(query)
if search_result and hasattr(search_result, 'memories'):
for memory in search_result.memories[:5]:
memory_text = memory.text if hasattr(memory, 'text') else str(memory)
all_feedback.append(memory_text)
# Extract patterns
if 'style' in memory_text.lower():
patterns['common_issues'].append('style compliance')
if 'improved' in memory_text.lower():
patterns['improvements'].append('showing improvement')
if 'excellent' in memory_text.lower():
patterns['strengths'].append('consistent quality')
# Store in state
tool_context.state[StateKeys.PAST_FEEDBACK] = all_feedback
tool_context.state[StateKeys.FEEDBACK_PATTERNS] = patterns
logger.info(f"Tool: Found {len(all_feedback)} past feedback items")
return {
"status": "success",
"feedback_found": True,
"count": len(all_feedback),
"summary": " | ".join(all_feedback[:3]) if all_feedback else "No feedback",
"patterns": patterns
}
except Exception as e:
logger.warning(f"Tool: Memory search error: {e}")
# Fallback: Check state for cached feedback
cached_feedback = tool_context.state.get(StateKeys.USER_PAST_FEEDBACK_CACHE, [])
if cached_feedback:
tool_context.state[StateKeys.PAST_FEEDBACK] = cached_feedback
return {
"status": "success",
"feedback_found": True,
"count": len(cached_feedback),
"summary": "Using cached feedback",
"patterns": {}
}
# No feedback found
tool_context.state[StateKeys.PAST_FEEDBACK] = []
logger.info("Tool: No past feedback found")
return {
"status": "success",
"feedback_found": False,
"message": "No past feedback available - this appears to be a first submission",
"patterns": {}
}
except Exception as e:
error_msg = f"Feedback search error: {str(e)}"
logger.error(f"Tool: {error_msg}", exc_info=True)
tool_context.state[StateKeys.PAST_FEEDBACK] = []
return {
"status": "error",
"message": error_msg,
"feedback_found": False
}
👉 البحث:
# MODULE_5_STEP_4_UPDATE_GRADING_PROGRESS
👉 الاستبدال بالأداة 2 - أداة تتبُّع التقييم (إصدار الإنتاج):
async def update_grading_progress(tool_context: ToolContext) -> Dict[str, Any]:
"""
Updates grading progress counters and metrics in state.
"""
logger.info("Tool: Updating grading progress...")
try:
current_time = datetime.now().isoformat()
# Build all state changes
state_updates = {}
# Temporary (invocation-level) state
state_updates[StateKeys.TEMP_PROCESSING_TIMESTAMP] = current_time
# Session-level state
attempts = tool_context.state.get(StateKeys.GRADING_ATTEMPTS, 0) + 1
state_updates[StateKeys.GRADING_ATTEMPTS] = attempts
state_updates[StateKeys.LAST_GRADING_TIME] = current_time
# User-level persistent state
lifetime_submissions = tool_context.state.get(StateKeys.USER_TOTAL_SUBMISSIONS, 0) + 1
state_updates[StateKeys.USER_TOTAL_SUBMISSIONS] = lifetime_submissions
state_updates[StateKeys.USER_LAST_SUBMISSION_TIME] = current_time
# Calculate improvement metrics
current_style_score = tool_context.state.get(StateKeys.STYLE_SCORE, 0)
last_style_score = tool_context.state.get(StateKeys.USER_LAST_STYLE_SCORE, 0)
score_improvement = current_style_score - last_style_score
state_updates[StateKeys.USER_LAST_STYLE_SCORE] = current_style_score
state_updates[StateKeys.SCORE_IMPROVEMENT] = score_improvement
# Track test results if available
test_results = tool_context.state.get(StateKeys.TEST_EXECUTION_SUMMARY, {})
# Parse if it's a string
if isinstance(test_results, str):
try:
test_results = json.loads(test_results)
except:
test_results = {}
if test_results and test_results.get('test_summary', {}).get('total_tests_run', 0) > 0:
summary = test_results['test_summary']
total = summary.get('total_tests_run', 0)
passed = summary.get('tests_passed', 0)
if total > 0:
pass_rate = (passed / total) * 100
state_updates[StateKeys.USER_LAST_TEST_PASS_RATE] = pass_rate
# Apply all updates atomically
for key, value in state_updates.items():
tool_context.state[key] = value
logger.info(f"Tool: Progress updated - Attempt #{attempts}, "
f"Lifetime: {lifetime_submissions}")
return {
"status": "success",
"session_attempts": attempts,
"lifetime_submissions": lifetime_submissions,
"timestamp": current_time,
"improvement": {
"style_score_change": score_improvement,
"direction": "improved" if score_improvement > 0 else "declined"
},
"summary": f"Attempt #{attempts} recorded, {lifetime_submissions} total submissions"
}
except Exception as e:
error_msg = f"Progress update error: {str(e)}"
logger.error(f"Tool: {error_msg}", exc_info=True)
return {
"status": "error",
"message": error_msg
}
👉 البحث:
# MODULE_5_STEP_4_SAVE_GRADING_REPORT
👉 الاستبدال بالأداة 3 - أداة حفظ العناصر (إصدار الإنتاج):
async def save_grading_report(feedback_text: str, tool_context: ToolContext) -> Dict[str, Any]:
"""
Saves a detailed grading report as an artifact.
Args:
feedback_text: The feedback text to include in the report
tool_context: ADK tool context for state management
Returns:
Dictionary containing save status and details
"""
logger.info("Tool: Saving grading report...")
try:
# Gather all relevant data from state
code = tool_context.state.get(StateKeys.CODE_TO_REVIEW, '')
analysis = tool_context.state.get(StateKeys.CODE_ANALYSIS, {})
style_score = tool_context.state.get(StateKeys.STYLE_SCORE, 0)
style_issues = tool_context.state.get(StateKeys.STYLE_ISSUES, [])
# Get test results
test_results = tool_context.state.get(StateKeys.TEST_EXECUTION_SUMMARY, {})
# Parse if it's a string
if isinstance(test_results, str):
try:
test_results = json.loads(test_results)
except:
test_results = {}
timestamp = datetime.now().isoformat()
# Create comprehensive report dictionary
report = {
'timestamp': timestamp,
'grading_attempt': tool_context.state.get(StateKeys.GRADING_ATTEMPTS, 1),
'code': {
'content': code,
'line_count': len(code.splitlines()),
'hash': hashlib.md5(code.encode()).hexdigest()
},
'analysis': analysis,
'style': {
'score': style_score,
'issues': style_issues[:5] # First 5 issues
},
'tests': test_results,
'feedback': feedback_text,
'improvements': {
'score_change': tool_context.state.get(StateKeys.SCORE_IMPROVEMENT, 0),
'from_last_score': tool_context.state.get(StateKeys.USER_LAST_STYLE_SCORE, 0)
}
}
# Convert report to JSON string
report_json = json.dumps(report, indent=2)
report_part = types.Part.from_text(text=report_json)
# Try to save as artifact if the service is available
if hasattr(tool_context, 'save_artifact'):
try:
# Generate filename with timestamp (replace colons for filesystem compatibility)
filename = f"grading_report_{timestamp.replace(':', '-')}.json"
# Save the main report
version = await tool_context.save_artifact(filename, report_part)
# Also save a "latest" version for easy access
await tool_context.save_artifact("latest_grading_report.json", report_part)
logger.info(f"Tool: Report saved as {filename} (version {version})")
# Store report in state as well for redundancy
tool_context.state[StateKeys.USER_LAST_GRADING_REPORT] = report
return {
"status": "success",
"artifact_saved": True,
"filename": filename,
"version": str(version),
"size": len(report_json),
"summary": f"Report saved as {filename}"
}
except Exception as artifact_error:
logger.warning(f"Artifact service error: {artifact_error}, falling back to state storage")
# Continue to fallback below
# Fallback: Store in state if artifact service is not available or failed
tool_context.state[StateKeys.USER_LAST_GRADING_REPORT] = report
logger.info("Tool: Report saved to state (artifact service not available)")
return {
"status": "success",
"artifact_saved": False,
"message": "Report saved to state only",
"size": len(report_json),
"summary": "Report saved to session state"
}
except Exception as e:
error_msg = f"Report save error: {str(e)}"
logger.error(f"Tool: {error_msg}", exc_info=True)
# Still try to save minimal data to state
try:
tool_context.state[StateKeys.USER_LAST_GRADING_REPORT] = {
'error': error_msg,
'feedback': feedback_text,
'timestamp': datetime.now().isoformat()
}
except:
pass
return {
"status": "error",
"message": error_msg,
"artifact_saved": False,
"summary": f"Failed to save report: {error_msg}"
}
إنشاء وكيل التجميع
👉 فتح
code_review_assistant/sub_agents/review_pipeline/feedback_synthesizer.py
👉 البحث:
# MODULE_5_STEP_4_INSTRUCTION_PROVIDER
👉 استبدِل بما يلي:
async def feedback_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are an expert code reviewer and mentor providing constructive, educational feedback.
CONTEXT FROM PREVIOUS AGENTS:
- Structure analysis summary: {structure_analysis_summary}
- Style check summary: {style_check_summary}
- Test execution summary: {test_execution_summary}
YOUR TASK requires these steps IN ORDER:
1. Call search_past_feedback tool with developer_id="default_user"
2. Call update_grading_progress tool with no parameters
3. Carefully analyze the test results to understand what really happened
4. Generate comprehensive feedback following the structure below
5. Call save_grading_report tool with the feedback_text parameter
6. Return the feedback as your final output
CRITICAL - Understanding Test Results:
The test_execution_summary contains structured JSON. Parse it carefully:
- tests_passed = Code worked correctly
- tests_failed = Code produced wrong output
- tests_with_errors = Code crashed
- critical_issues = Fundamental problems with the code
If critical_issues array contains items, these are serious bugs that need fixing.
Do NOT count discovering bugs as test successes.
FEEDBACK STRUCTURE TO FOLLOW:
## 📊 Summary
Provide an honest assessment. Be encouraging but truthful about problems found.
## ✅ Strengths
List 2-3 things done well, referencing specific code elements.
## 📈 Code Quality Analysis
### Structure & Organization
Comment on code organization, readability, and documentation.
### Style Compliance
Report the actual style score and any specific issues.
### Test Results
Report the actual test results accurately:
- If critical_issues exist, report them as bugs to fix
- Be clear: "X tests passed, Y critical issues were found"
- List each critical issue
- Don't hide or minimize problems
## 💡 Recommendations for Improvement
Based on the analysis, provide specific actionable fixes.
If critical issues exist, fixing them is top priority.
## 🎯 Next Steps
Prioritized action list based on severity of issues.
## 💬 Encouragement
End with encouragement while being honest about what needs fixing.
Remember: Complete ALL steps including calling save_grading_report."""
return await instructions_utils.inject_session_state(template, context)
👉 البحث:
# MODULE_5_STEP_4_SYNTHESIZER_AGENT
👉 الاستبدال بـ:
feedback_synthesizer_agent = Agent(
name="FeedbackSynthesizer",
model=config.critic_model,
description="Synthesizes all analysis into constructive, personalized feedback",
instruction=feedback_instruction_provider,
tools=[
FunctionTool(func=search_past_feedback),
FunctionTool(func=update_grading_progress),
FunctionTool(func=save_grading_report)
],
output_key="final_feedback"
)
الخطوة 5: ربط Pipeline
الآن، اربط جميع الوكلاء الأربعة في مسار متسلسل وأنشئ الوكيل الجذر.
👉 فتح
code_review_assistant/agent.py
👉 أضِف عمليات الاستيراد اللازمة في أعلى الملف (بعد عمليات الاستيراد الحالية):
from google.adk.agents import Agent, SequentialAgent
from code_review_assistant.sub_agents.review_pipeline.code_analyzer import code_analyzer_agent
from code_review_assistant.sub_agents.review_pipeline.style_checker import style_checker_agent
from code_review_assistant.sub_agents.review_pipeline.test_runner import test_runner_agent
from code_review_assistant.sub_agents.review_pipeline.feedback_synthesizer import feedback_synthesizer_agent
يجب أن يظهر ملفك الآن على النحو التالي:
"""
Main agent orchestration for the Code Review Assistant.
"""
from google.adk.agents import Agent, SequentialAgent
from .config import config
from code_review_assistant.sub_agents.review_pipeline.code_analyzer import code_analyzer_agent
from code_review_assistant.sub_agents.review_pipeline.style_checker import style_checker_agent
from code_review_assistant.sub_agents.review_pipeline.test_runner import test_runner_agent
from code_review_assistant.sub_agents.review_pipeline.feedback_synthesizer import feedback_synthesizer_agent
# MODULE_5_STEP_5_CREATE_PIPELINE
# MODULE_6_STEP_5_CREATE_FIX_LOOP
# MODULE_6_STEP_5_UPDATE_ROOT_AGENT
👉 البحث عن:
# MODULE_5_STEP_5_CREATE_PIPELINE
👉 استبدِل هذا السطر الواحد بما يلي:
# Create sequential pipeline
code_review_pipeline = SequentialAgent(
name="CodeReviewPipeline",
description="Complete code review pipeline with analysis, testing, and feedback",
sub_agents=[
code_analyzer_agent,
style_checker_agent,
test_runner_agent,
feedback_synthesizer_agent
]
)
# Root agent - coordinates the review pipeline
root_agent = Agent(
name="CodeReviewAssistant",
model=config.worker_model,
description="An intelligent code review assistant that analyzes Python code and provides educational feedback",
instruction="""You are a specialized Python code review assistant focused on helping developers improve their code quality.
When a user provides Python code for review:
1. Immediately delegate to CodeReviewPipeline and pass the code EXACTLY as it was provided by the user.
2. The pipeline will handle all analysis and feedback
3. Return ONLY the final feedback from the pipeline - do not add any commentary
When a user asks what you can do or asks general questions:
- Explain your capabilities for code review
- Do NOT trigger the pipeline for non-code messages
The pipeline handles everything for code review - just pass through its final output.""",
sub_agents=[code_review_pipeline],
output_key="assistant_response"
)
الخطوة 6: اختبار Complete Pipeline
حان الوقت لمشاهدة العملاء الأربعة يعملون معًا.
👉 بدء النظام:
adk web code_review_assistant
بعد تنفيذ الأمر adk web، من المفترض أن تظهر لك في نافذة الأوامر نتيجة تشير إلى بدء تشغيل خادم الويب الخاص بـ ADK، على النحو التالي:
+-----------------------------------------------------------------------------+
| ADK Web Server started |
| |
| For local testing, access at http://localhost:8000. |
+-----------------------------------------------------------------------------+
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
👉 بعد ذلك، للوصول إلى واجهة مستخدم "حزمة تطوير التطبيقات" من المتصفّح، اتّبِع الخطوات التالية:
من رمز "معاينة الويب" (غالبًا ما يبدو كعين أو مربّع مع سهم) في شريط أدوات Cloud Shell (عادةً في أعلى يسار الصفحة)، اختَر "تغيير المنفذ". في النافذة المنبثقة، اضبط المنفذ على 8000 وانقر على "تغيير ومعاينة". سيفتح Cloud Shell بعد ذلك علامة تبويب أو نافذة متصفّح جديدة تعرض واجهة مستخدم ADK Dev.
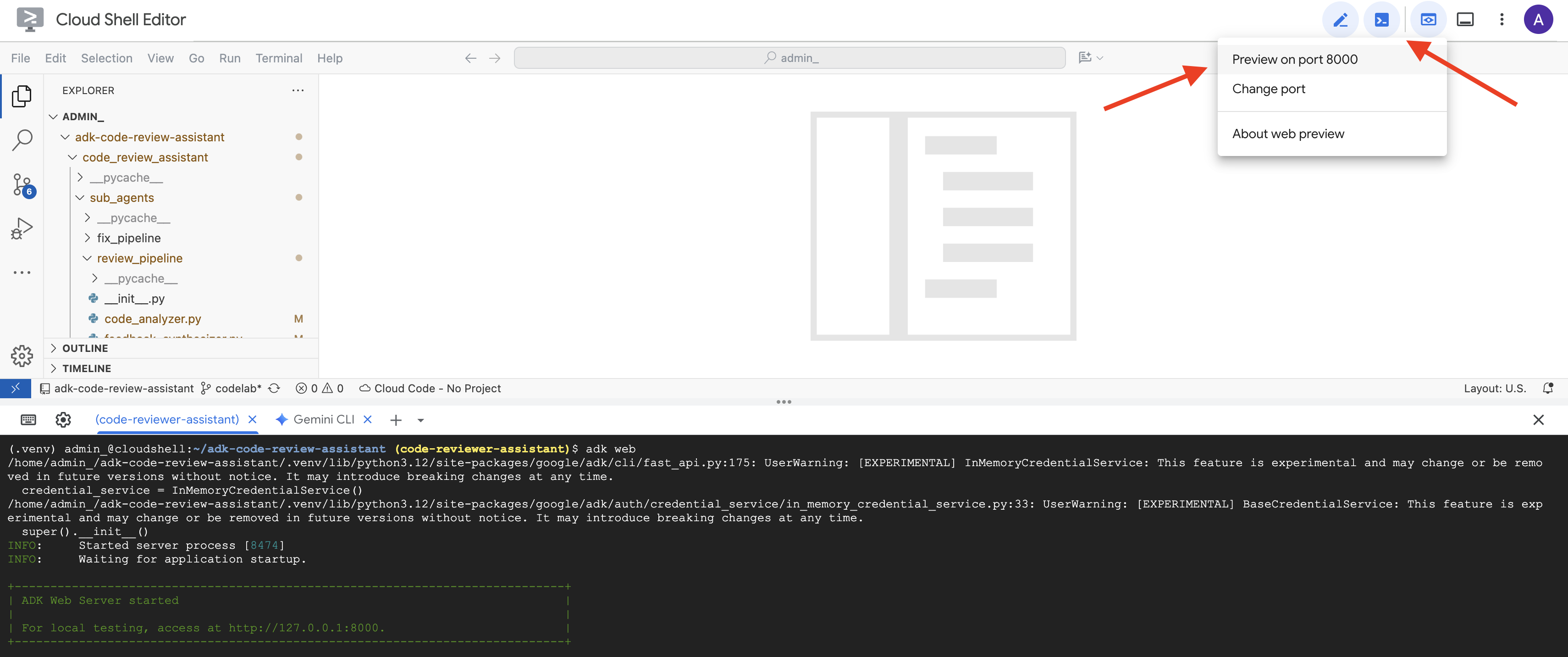
👉 الوكيل قيد التشغيل الآن. واجهة مستخدم مطوّري ADK في المتصفّح هي وسيلة التواصل المباشر مع الوكيل.
- اختيار الهدف: في القائمة المنسدلة أعلى واجهة المستخدم، اختَر وكيل
code_review_assistant.
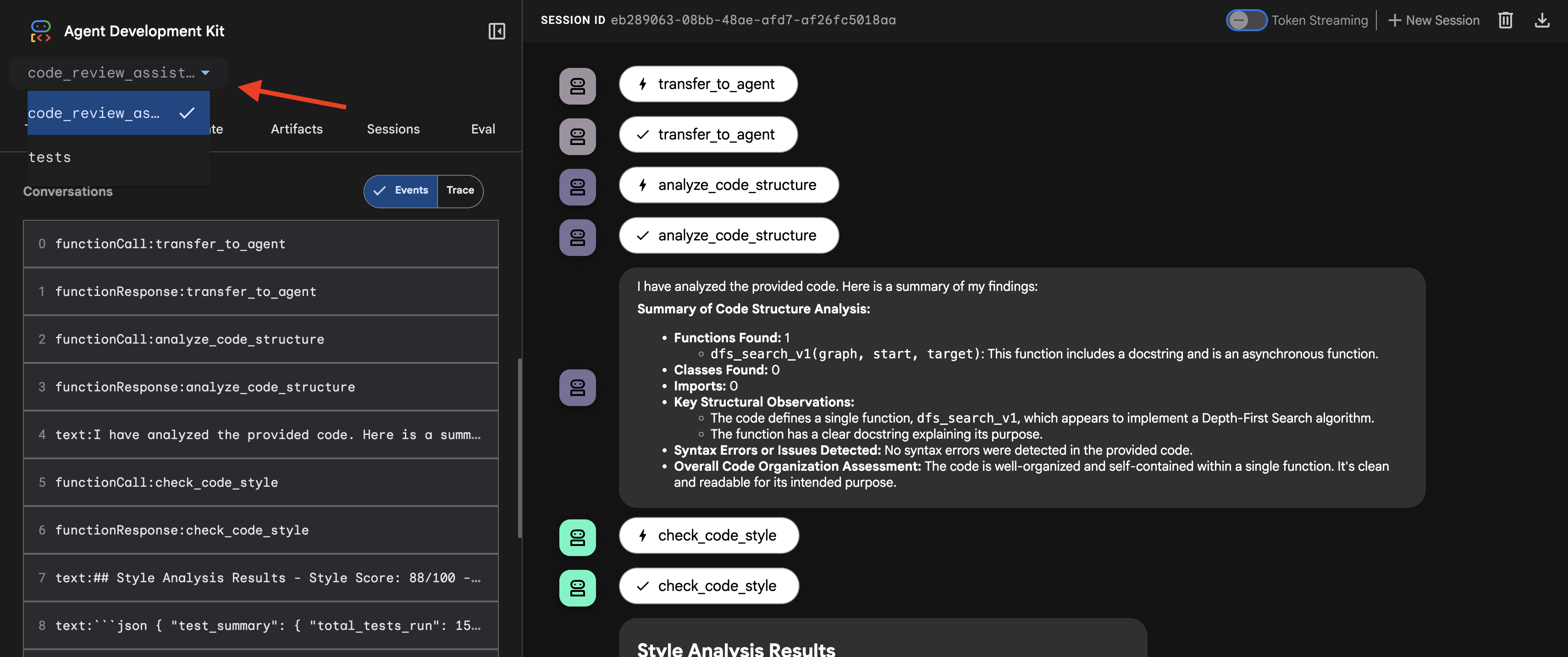
👉 طلب الاختبار:
Please analyze the following:
def dfs_search_v1(graph, start, target):
"""Find if target is reachable from start."""
visited = set()
stack = start
while stack:
current = stack.pop()
if current == target:
return True
if current not in visited:
visited.add(current)
for neighbor in graph[current]:
if neighbor not in visited:
stack.append(neighbor)
return False
👉 الاطّلاع على مسار مراجعة الرمز البرمجي أثناء التنفيذ:
عند إرسال الدالة dfs_search_v1 التي تتضمّن خطأ، لن تحصل على إجابة واحدة فقط. أنت تشاهد مسار العمل المتعدّد الوكلاء أثناء التنفيذ. إنّ ناتج البث الذي تراه هو نتيجة لأربعة وكلاء متخصصين يعملون بالتسلسل، حيث يعتمد كل وكيل على الوكيل السابق.
في ما يلي توضيح لما يساهم به كل عامل في المراجعة النهائية الشاملة، ما يؤدي إلى تحويل البيانات الأولية إلى معلومات قابلة للتنفيذ.
1. التقرير البنيوي في "أداة تحليل الرموز البرمجية"
أولاً، يتلقّى وكيل CodeAnalyzer الرمز البرمجي الأولي. لا تخمّن الأداة ما يفعله الرمز، بل تستخدم أداة analyze_code_structure لتنفيذ تحليل حتمي لشجرة بناء الجملة المجردة (AST).
يكون الناتج بيانات خالصة وواقعية حول بنية الرمز:
The analysis of the provided code reveals the following:
Summary:
- Functions Found: 1
- Classes Found: 0
Key Structural Observations:
- A single function, dfs_search_v1, is defined.
- It includes a docstring: "Find if target is reachable from start."
- No syntax errors were detected.
Overall Code Organization Assessment:
- The code snippet is a well-defined, self-contained function.
⭐ القيمة: توفّر هذه الخطوة الأولية أساسًا واضحًا وموثوقًا للعوامل الأخرى. تؤكّد هذه الأداة أنّ الرمز البرمجي صالح للاستخدام في Python وتحدّد المكوّنات التي يجب مراجعتها.
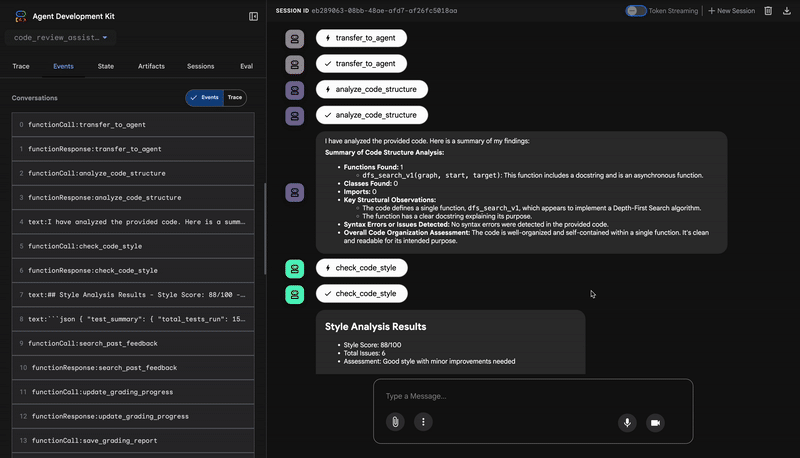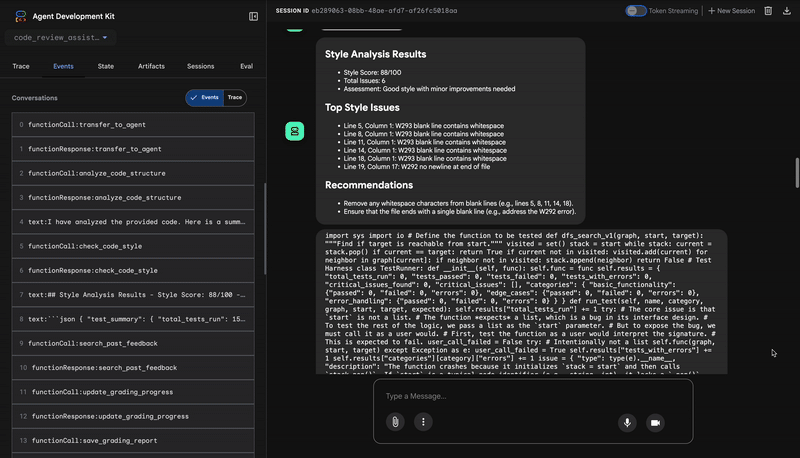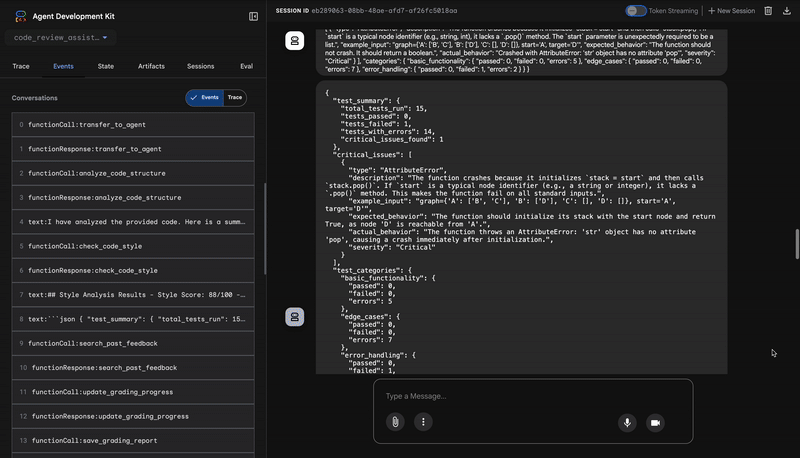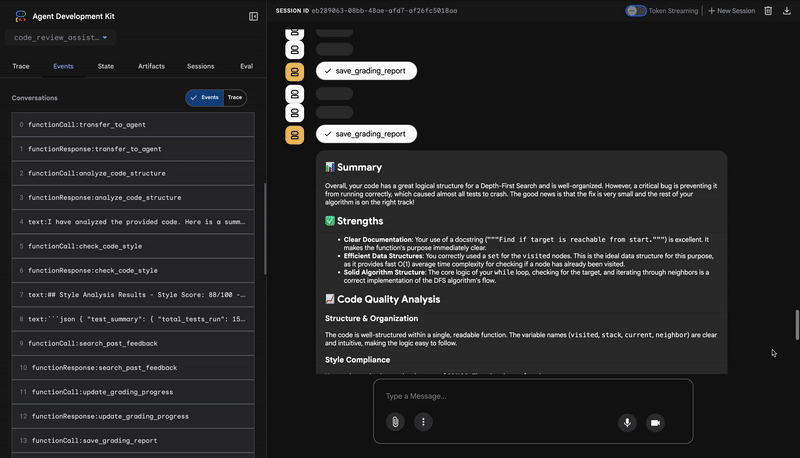
2. مراجعة PEP 8 في "مدقّق الأسلوب"
بعد ذلك، يتولّى وكيل StyleChecker المهمة. يقرأ الرمز من الحالة المشترَكة ويستخدم أداة check_code_style التي تستفيد من أداة pycodestyle.
تكون النتيجة عبارة عن تقييم جودة قابل للقياس الكمي ومخالفات محدّدة:
Style Analysis Results
- Style Score: 88/100
- Total Issues: 6
- Assessment: Good style with minor improvements needed
Top Style Issues
- Line 5, W293: blank line contains whitespace
- Line 19, W292: no newline at end of file
⭐ القيمة: يقدّم هذا الوكيل ملاحظات موضوعية غير قابلة للتفاوض استنادًا إلى معايير المنتدى المعمول بها (PEP 8). يُطلع نظام تسجيل النقاط المرجّح المستخدم على الفور على مدى خطورة المشاكل.
3- اكتشاف Test Runner لخطأ حرج
هذا هو المكان الذي يتجاوز فيه النظام التحليل السطحي. ينشئ TestRunner الوكيل مجموعة شاملة من الاختبارات وينفّذها للتحقّق من سلوك الرمز البرمجي.
يكون الناتج عبارة عن عنصر JSON منظَّم يحتوي على حكم قاطع:
{
"critical_issues": [
{
"type": "Critical Bug",
"description": "The function's initialization `stack = start` is incorrect... When a common input like a string... is provided... the function crashes with an AttributeError.",
"severity": "Critical"
}
],
"verdict": {
"status": "BROKEN",
"confidence": "high",
"recommendation": "The function is fundamentally broken... the stack initialization line `stack = start` must be changed to `stack = [start]`."
}
}
⭐ القيمة: هذه هي أهمّ الإحصاءات. لم يخمن الوكيل فحسب، بل أثبت أنّ الرمز البرمجي معطّل من خلال تشغيله. وقد رصدت هذه الأداة خطأً دقيقًا ولكنّه بالغ الأهمية في وقت التشغيل، وهو خطأ قد لا يرصده بسهولة أي مدقّق بشري، كما حدّدت الأداة السبب الدقيق للمشكلة والإصلاح المطلوب.
4. التقرير النهائي لـ "أداة تجميع الملاحظات"
أخيرًا، يعمل وكيل FeedbackSynthesizer كقائد الأوركسترا. يأخذ هذا الوكيل البيانات المنظَّمة من الوكلاء الثلاثة السابقين ويصمّم تقريرًا واحدًا سهل الاستخدام يتضمّن تحليلات ويشجّع المستخدم.
والنتيجة هي المراجعة النهائية والمحسّنة التي تظهر لك:
📊 Summary
Great effort on implementing the Depth-First Search algorithm! ... However, a critical bug in the initialization of the stack prevents the function from working correctly...
✅ Strengths
- Good Algorithm Structure
- Correct Use of `visited` Set
📈 Code Quality Analysis
...
### Style Compliance
The style analysis returned a good score of 88/100.
...
### Test Results
The automated testing revealed a critical issue... The line `stack = start` directly assigns the input... which results in an `AttributeError`.
💡 Recommendations for Improvement
**Fix the Critical Stack Initialization Bug:**
- Incorrect Code: `stack = start`
- Correct Code: `stack = [start]`
💬 Encouragement
You are very close to a perfect implementation! The core logic of your DFS algorithm is sound, which is the hardest part.
⭐ القيمة: يحوّل هذا الوكيل البيانات الفنية إلى تجربة مفيدة وتعليمية. تعطي الأولوية للمشكلة الأكثر أهمية (الخطأ)، وتشرحها بوضوح، وتقدّم الحلّ الدقيق، وتفعل ذلك بأسلوب مشجّع. وهي تدمج بنجاح النتائج من جميع المراحل السابقة في كلّ متماسك وقيم.
توضّح هذه العملية المتعدّدة المراحل فعالية مسار العمل المستند إلى الذكاء الاصطناعي الوكيل. بدلاً من الحصول على ردّ واحد شامل، ستحصل على تحليل متعدد الطبقات حيث يؤدي كل وكيل مهمة متخصصة يمكن التحقّق منها. يؤدي ذلك إلى مراجعة ليست مفيدة فحسب، بل أيضًا حتمية وموثوقة وتعليمية بشكل كبير.
👉💻 بعد الانتهاء من الاختبار، ارجع إلى نافذة Cloud Shell Editor واضغط على Ctrl+C لإيقاف واجهة مستخدم ADK Dev.
الميزات التي أنشأتها
أصبح لديك الآن مسار كامل لمراجعة الرموز البرمجية يتضمّن ما يلي:
✅ تحليل بنية الرمز: تحليل AST حتمي باستخدام دوال مساعدة
✅ التحقّق من الأسلوب: تسجيل مرجّح باستخدام اصطلاحات التسمية
✅ تنفيذ الاختبارات: إنشاء اختبار شامل مع إخراج JSON منظَّم
✅ إنشاء الملاحظات: دمج الحالة والذاكرة والنتائج
✅ تتبُّع مستوى التقدّم: حالة متعددة المستويات على مستوى عمليات الاستدعاء والجلسات والمستخدمين
✅ التعلم بمرور الوقت: خدمة الذاكرة للأنماط المتكررة في الجلسات
✅ توفير النتائج: تقارير JSON قابلة للتنزيل تتضمّن سجلّ تدقيق كاملاً
المفاهيم الرئيسية التي تم إتقانها
عمليات التسلسل:
- أربعة وكلاء ينفّذون المهام بترتيب صارم
- يُحسّن كلّ منها حالة العنصر التالي
- تحدّد التبعيات تسلسل التنفيذ
أنماط الإنتاج:
- فصل الدوال المساعدة (المزامنة في مجموعات سلاسل المحادثات)
- التكيّف مع الإصدارات الأقدم (استراتيجيات احتياطية)
- إدارة الحالة المتعددة المستويات (مؤقتة/جلسة/مستخدم)
- مقدّمو التعليمات الديناميكية (المدركون للسياق)
- مساحة تخزين مزدوجة (النتائج الاصطناعية + التكرار الاحتياطي للحالة)
الدولة ككيان تواصلي:
- تمنع الثوابت حدوث أخطاء إملائية في جميع الوكلاء
output_keyيكتب ملخّصات الوكلاء إلى الحالة- قراءة الوكلاء اللاحقين من خلال StateKeys
- تتدفّق الحالة بشكل خطي عبر مسار المعالجة
الذاكرة مقابل الحالة:
- الحالة: بيانات الجلسة الحالية
- الذاكرة: الأنماط في جميع الجلسات
- أغراض مختلفة، ومدة صلاحية مختلفة
تنظيم الأدوات:
- الوكلاء الذين يستخدمون أداة واحدة (analyzer وstyle_checker)
- برامج التنفيذ المضمّنة (test_runner)
- تنسيق أدوات متعددة (جهاز مزج موسيقي)
استراتيجية اختيار النموذج:
- نموذج المنفِّذ: المهام الميكانيكية (التحليل، والتحليل باستخدام أداة lint، وتحديد أفضل مسار)
- نموذج الناقد: مهام الاستدلال (الاختبار، التجميع)
- تحسين التكلفة من خلال الاختيار المناسب
الخطوات التالية
في الوحدة التدريبية 6، ستنشئ مسار الإصلاح:
- بنية LoopAgent لإصلاح الأخطاء بشكل متكرّر
- شروط الخروج من خلال التصعيد
- تراكم الحالة على مستوى التكرارات
- التحقّق من الصحة ومنطق إعادة المحاولة
- التكامل مع مسار المراجعة لاقتراح حلول
ستتعرّف على كيفية توسيع نطاق أنماط الحالة نفسها لتشمل سير عمل تكراريًا معقّدًا يحاول فيه الوكلاء تنفيذ المهام عدة مرات إلى أن تنجح، وكيفية تنسيق قنوات معالجة متعدّدة في تطبيق واحد.
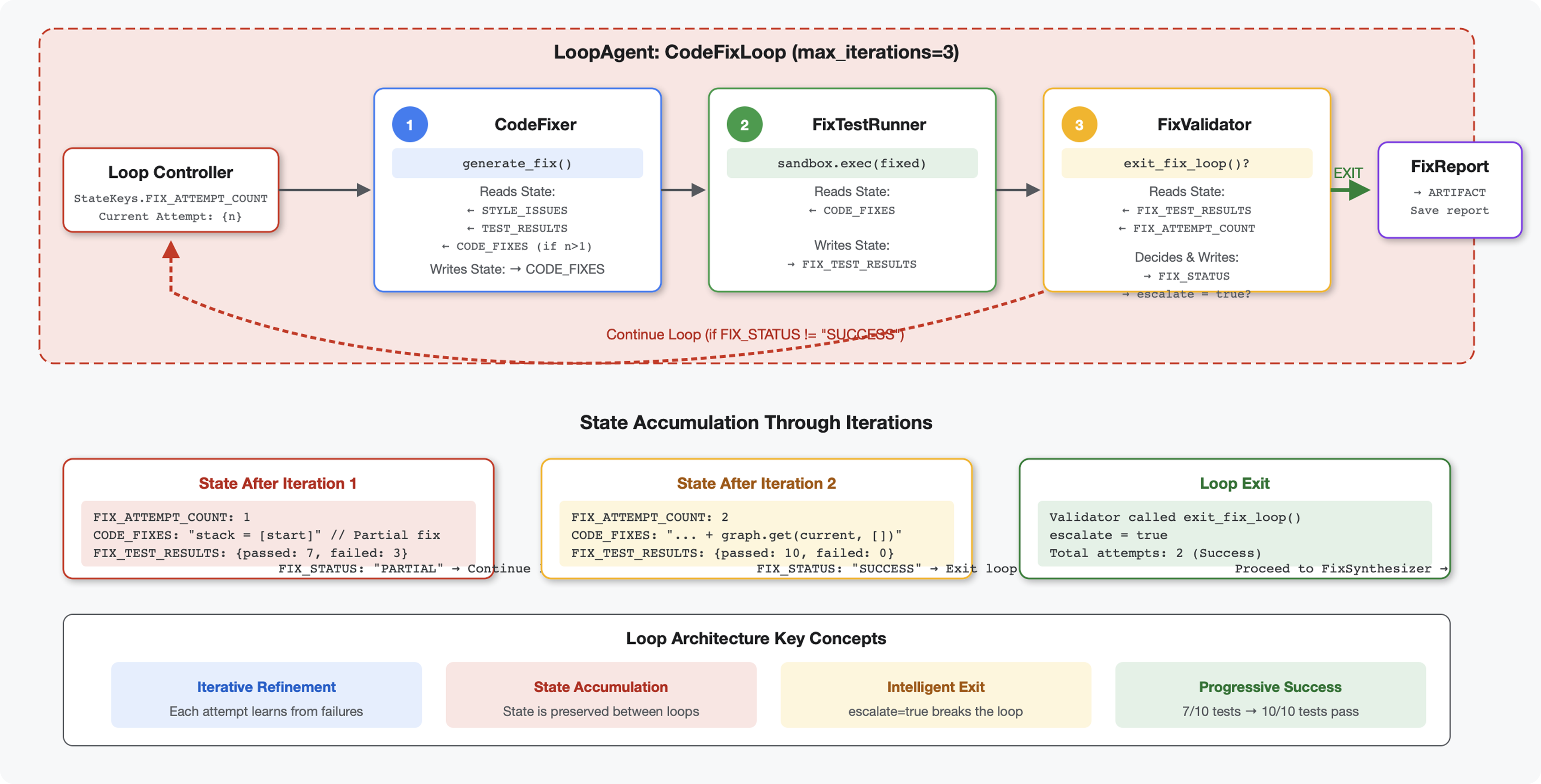
6. إضافة Fix Pipeline: بنية الحلقة
مقدمة
في الوحدة التدريبية 5، أنشأت مسار مراجعة تسلسليًا يحلّل الرمز البرمجي ويقدّم ملاحظات. لكن تحديد المشاكل ليس سوى نصف الحل، فالمطوّرون يحتاجون إلى المساعدة في إصلاحها.
تنشئ هذه الوحدة مسار حلّ آلي يعمل على:
- إنشاء إصلاحات استنادًا إلى نتائج المراجعة
- التحقّق من صحة الإصلاحات من خلال إجراء اختبارات شاملة
- إعادة المحاولة تلقائيًا في حال عدم نجاح الإصلاحات (حتى 3 محاولات)
- نتائج التقارير مع مقارنات قبل/بعد
المفهوم الأساسي: LoopAgent لإعادة المحاولة تلقائيًا على عكس الوكلاء التسلسليين الذين يتم تشغيلهم مرة واحدة، يكرّر الوكيل LoopAgent عمل الوكلاء الفرعيين إلى أن يتم استيفاء شرط الخروج أو الوصول إلى الحد الأقصى للتكرارات. تشير إشارة الأدوات إلى النجاح من خلال ضبط tool_context.actions.escalate = True.
معاينة لما ستنشئه: إرسال رمز برمجي يتضمّن أخطاء → مراجعة تحدّد المشاكل → إصلاح الحلقة ينشئ تصحيحات → اختبارات تتحقّق من صحة الرمز → إعادة المحاولة إذا لزم الأمر → تقرير نهائي شامل.
المفاهيم الأساسية: LoopAgent مقابل Sequential
المسار التسلسلي (الوحدة التدريبية 5):
SequentialAgent(agents=[A, B, C])
# Executes: A → B → C → Done
- التدفّق باتجاه واحد
- يتم تشغيل كل وكيل مرة واحدة بالضبط
- عدم إعادة المحاولة
Loop Pipeline (Module 6):
LoopAgent(agents=[A, B, C], max_iterations=3)
# Executes: A → B → C → (check exit) → A → B → C → (check exit) → ...
- التدفق الدوري
- يمكن تشغيل الوكلاء عدة مرات
- الخروج عند:
- تضبط إحدى الأدوات القيمة
tool_context.actions.escalate = True(نجاح) - تم بلوغ
max_iterations(حد الأمان) - حدوث استثناء لم تتم معالجته (خطأ)
- تضبط إحدى الأدوات القيمة
أسباب استخدام الحلقات لتصحيح الرموز:
غالبًا ما تحتاج إصلاحات الرموز البرمجية إلى محاولات متعددة:
- المحاولة الأولى: إصلاح الأخطاء الواضحة (أنواع المتغيرات غير الصحيحة)
- المحاولة الثانية: إصلاح المشاكل الثانوية التي كشفت عنها الاختبارات (حالات حدودية)
- المحاولة الثالثة: تحسين جميع الاختبارات والتحقّق من اجتيازها
بدون حلقة، ستحتاج إلى منطق شرطي معقّد في تعليمات الوكيل. باستخدام LoopAgent، تتم إعادة المحاولة تلقائيًا.
مقارنة البنية الهندسية:
Sequential (Module 5):
User → Review Pipeline → Feedback → Done
Loop (Module 6):
User → Review Pipeline → Feedback → Fix Pipeline
↓
┌──────────────┴──────────────┐
│ Fix Attempt Loop (1-3x) │
│ ┌─────────────────────┐ │
│ │ 1. Generate Fixes │ │
│ │ 2. Test Fixes │ │
│ │ 3. Validate & Exit? │────┼─→ If escalate=True
│ └─────────────────────┘ │ exit loop
│ ↓ If not │
│ Try Again (max 3) │
└─────────────────────────────┘
↓
4. Synthesize Final Report → Done
الخطوة 1: إضافة Code Fixer Agent
ينشئ مصحّح الرموز رمز Python البرمجي المعدَّل استنادًا إلى نتائج المراجعة.
👉 فتح
code_review_assistant/sub_agents/fix_pipeline/code_fixer.py
👉 البحث:
# MODULE_6_STEP_1_CODE_FIXER_INSTRUCTION_PROVIDER
👉 استبدِل هذا السطر الواحد بما يلي:
async def code_fixer_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are an expert code fixing specialist.
Original Code:
{code_to_review}
Analysis Results:
- Style Score: {style_score}/100
- Style Issues: {style_issues}
- Test Results: {test_execution_summary}
Based on the test results, identify and fix ALL issues including:
- Interface bugs (e.g., if start parameter expects wrong type)
- Logic errors (e.g., KeyError when accessing graph nodes)
- Style violations
- Missing documentation
YOUR TASK:
Generate the complete fixed Python code that addresses all identified issues.
CRITICAL INSTRUCTIONS:
- Output ONLY the corrected Python code
- Do NOT include markdown code blocks (```python)
- Do NOT include any explanations or commentary
- The output should be valid, executable Python code and nothing else
Common fixes to apply based on test results:
- If tests show AttributeError with 'pop', fix: stack = [start] instead of stack = start
- If tests show KeyError accessing graph, fix: use graph.get(current, [])
- Add docstrings if missing
- Fix any style violations identified
Output the complete fixed code now:"""
return await instructions_utils.inject_session_state(template, context)
👉 البحث:
# MODULE_6_STEP_1_CODE_FIXER_AGENT
👉 استبدِل هذا السطر الواحد بما يلي:
code_fixer_agent = Agent(
name="CodeFixer",
model=config.worker_model,
description="Generates comprehensive fixes for all identified code issues",
instruction=code_fixer_instruction_provider,
code_executor=BuiltInCodeExecutor(),
output_key="code_fixes"
)
الخطوة 2: إضافة Fix Test Runner Agent
يتحقّق برنامج تشغيل اختبارات الإصلاح من صحة التصحيحات من خلال تنفيذ اختبارات شاملة على الرمز البرمجي الذي تم إصلاحه.
👉 فتح
code_review_assistant/sub_agents/fix_pipeline/fix_test_runner.py
👉 البحث:
# MODULE_6_STEP_2_FIX_TEST_RUNNER_INSTRUCTION_PROVIDER
👉 استبدِل هذا السطر الواحد بما يلي:
async def fix_test_runner_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that uses the clean code from the previous step."""
template = """You are responsible for validating the fixed code by running tests.
THE FIXED CODE TO TEST:
{code_fixes}
ORIGINAL TEST RESULTS: {test_execution_summary}
YOUR TASK:
1. Understand the fixes that were applied
2. Generate the same comprehensive tests (15-20 test cases)
3. Execute the tests on the FIXED code using your code executor
4. Compare results with original test results
5. Output a detailed JSON analysis
TESTING METHODOLOGY:
- Run the same tests that revealed issues in the original code
- Verify that previously failing tests now pass
- Ensure no regressions were introduced
- Document the improvement
Execute your tests and output ONLY valid JSON with this structure:
- "passed": number of tests that passed
- "failed": number of tests that failed
- "total": total number of tests
- "pass_rate": percentage as a number
- "comparison": object with "original_pass_rate", "new_pass_rate", "improvement"
- "newly_passing_tests": array of test names that now pass
- "still_failing_tests": array of test names still failing
Do NOT output the test code itself, only the JSON analysis."""
return await instructions_utils.inject_session_state(template, context)
👉 البحث:
# MODULE_6_STEP_2_FIX_TEST_RUNNER_AGENT
👉 استبدِل هذا السطر الواحد بما يلي:
fix_test_runner_agent = Agent(
name="FixTestRunner",
model=config.critic_model,
description="Runs comprehensive tests on fixed code to verify all issues are resolved",
instruction=fix_test_runner_instruction_provider,
code_executor=BuiltInCodeExecutor(),
output_key="fix_test_execution_summary"
)
الخطوة 3: إضافة Fix Validator Agent
يتحقّق المدقّق ممّا إذا كانت عمليات الإصلاح ناجحة ويقرّر ما إذا كان سيتم الخروج من الحلقة.
التعرّف على الأدوات
أولاً، أضِف الأدوات الثلاث التي تحتاج إليها أداة التحقّق من الصحة.
👉 فتح
code_review_assistant/tools.py
👉 البحث:
# MODULE_6_STEP_3_VALIDATE_FIXED_STYLE
👉 الاستبدال بالأداة 1 - مدقّق الأنماط:
async def validate_fixed_style(tool_context: ToolContext) -> Dict[str, Any]:
"""
Validates style compliance of the fixed code.
Args:
tool_context: ADK tool context containing fixed code in state
Returns:
Dictionary with style validation results
"""
logger.info("Tool: Validating style of fixed code...")
try:
# Get the fixed code from state
code_fixes = tool_context.state.get(StateKeys.CODE_FIXES, '')
# Try to extract from markdown if present
if '```python' in code_fixes:
start = code_fixes.rfind('```python') + 9
end = code_fixes.rfind('```')
if start < end:
code_fixes = code_fixes[start:end].strip()
if not code_fixes:
return {
"status": "error",
"message": "No fixed code found in state"
}
# Store the extracted fixed code
tool_context.state[StateKeys.CODE_FIXES] = code_fixes
# Run style check on fixed code
loop = asyncio.get_event_loop()
with ThreadPoolExecutor() as executor:
style_result = await loop.run_in_executor(
executor, _perform_style_check, code_fixes
)
# Compare with original
original_score = tool_context.state.get(StateKeys.STYLE_SCORE, 0)
improvement = style_result['score'] - original_score
# Store results
tool_context.state[StateKeys.FIXED_STYLE_SCORE] = style_result['score']
tool_context.state[StateKeys.FIXED_STYLE_ISSUES] = style_result['issues']
logger.info(f"Tool: Fixed code style score: {style_result['score']}/100 "
f"(improvement: +{improvement})")
return {
"status": "success",
"fixed_style_score": style_result['score'],
"original_style_score": original_score,
"improvement": improvement,
"remaining_issues": style_result['issues'],
"perfect_style": style_result['score'] == 100
}
except Exception as e:
logger.error(f"Tool: Style validation failed: {e}", exc_info=True)
return {
"status": "error",
"message": str(e)
}
👉 البحث:
# MODULE_6_STEP_3_COMPILE_FIX_REPORT
👉 الاستبدال بالأداة 2 - أداة تجميع التقارير:
async def compile_fix_report(tool_context: ToolContext) -> Dict[str, Any]:
"""
Compiles comprehensive report of the fix process.
Args:
tool_context: ADK tool context with all fix pipeline data
Returns:
Comprehensive fix report
"""
logger.info("Tool: Compiling comprehensive fix report...")
try:
# Gather all data
original_code = tool_context.state.get(StateKeys.CODE_TO_REVIEW, '')
code_fixes = tool_context.state.get(StateKeys.CODE_FIXES, '')
# Test results
original_tests = tool_context.state.get(StateKeys.TEST_EXECUTION_SUMMARY, {})
fixed_tests = tool_context.state.get(StateKeys.FIX_TEST_EXECUTION_SUMMARY, {})
# Parse if strings
if isinstance(original_tests, str):
try:
original_tests = json.loads(original_tests)
except:
original_tests = {}
if isinstance(fixed_tests, str):
try:
fixed_tests = json.loads(fixed_tests)
except:
fixed_tests = {}
# Extract pass rates
original_pass_rate = 0
if original_tests:
if 'pass_rate' in original_tests:
original_pass_rate = original_tests['pass_rate']
elif 'test_summary' in original_tests:
# Handle test_runner_agent's JSON structure
summary = original_tests['test_summary']
total = summary.get('total_tests_run', 0)
passed = summary.get('tests_passed', 0)
if total > 0:
original_pass_rate = (passed / total) * 100
elif 'passed' in original_tests and 'total' in original_tests:
if original_tests['total'] > 0:
original_pass_rate = (original_tests['passed'] / original_tests['total']) * 100
fixed_pass_rate = 0
all_tests_pass = False
if fixed_tests:
if 'pass_rate' in fixed_tests:
fixed_pass_rate = fixed_tests['pass_rate']
all_tests_pass = fixed_tests.get('failed', 1) == 0
elif 'passed' in fixed_tests and 'total' in fixed_tests:
if fixed_tests['total'] > 0:
fixed_pass_rate = (fixed_tests['passed'] / fixed_tests['total']) * 100
all_tests_pass = fixed_tests.get('failed', 0) == 0
# Style scores
original_style = tool_context.state.get(StateKeys.STYLE_SCORE, 0)
fixed_style = tool_context.state.get(StateKeys.FIXED_STYLE_SCORE, 0)
# Calculate improvements
test_improvement = {
'original_pass_rate': original_pass_rate,
'fixed_pass_rate': fixed_pass_rate,
'improvement': fixed_pass_rate - original_pass_rate,
'all_tests_pass': all_tests_pass
}
style_improvement = {
'original_score': original_style,
'fixed_score': fixed_style,
'improvement': fixed_style - original_style,
'perfect_style': fixed_style == 100
}
# Determine overall status
if all_tests_pass and style_improvement['perfect_style']:
fix_status = 'SUCCESSFUL'
status_emoji = '✅'
elif test_improvement['improvement'] > 0 or style_improvement['improvement'] > 0:
fix_status = 'PARTIAL'
status_emoji = '⚠️'
else:
fix_status = 'FAILED'
status_emoji = '❌'
# Build comprehensive report
report = {
'status': fix_status,
'status_emoji': status_emoji,
'timestamp': datetime.now().isoformat(),
'original_code': original_code,
'code_fixes': code_fixes,
'improvements': {
'tests': test_improvement,
'style': style_improvement
},
'summary': f"{status_emoji} Fix Status: {fix_status}\n"
f"Tests: {original_pass_rate:.1f}% → {fixed_pass_rate:.1f}%\n"
f"Style: {original_style}/100 → {fixed_style}/100"
}
# Store report in state
tool_context.state[StateKeys.FIX_REPORT] = report
tool_context.state[StateKeys.FIX_STATUS] = fix_status
logger.info(f"Tool: Fix report compiled - Status: {fix_status}")
logger.info(f"Tool: Test improvement: {original_pass_rate:.1f}% → {fixed_pass_rate:.1f}%")
logger.info(f"Tool: Style improvement: {original_style} → {fixed_style}")
return {
"status": "success",
"fix_status": fix_status,
"report": report
}
except Exception as e:
logger.error(f"Tool: Failed to compile fix report: {e}", exc_info=True)
return {
"status": "error",
"message": str(e)
}
👉 البحث:
# MODULE_6_STEP_3_EXIT_FIX_LOOP
👉 الاستبدال بالأداة 3 - إشارة الخروج من الحلقة:
def exit_fix_loop(tool_context: ToolContext) -> Dict[str, Any]:
"""
Signal that fixing is complete and should exit the loop.
Args:
tool_context: ADK tool context
Returns:
Confirmation message
"""
logger.info("Tool: Setting escalate flag to exit fix loop")
# This is the critical line that exits the LoopAgent
tool_context.actions.escalate = True
return {
"status": "success",
"message": "Fix complete, exiting loop"
}
إنشاء وكيل التحقّق
👉 فتح
code_review_assistant/sub_agents/fix_pipeline/fix_validator.py
👉 البحث:
# MODULE_6_STEP_3_FIX_VALIDATOR_INSTRUCTION_PROVIDER
👉 استبدِل هذا السطر الواحد بما يلي:
async def fix_validator_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are the final validation specialist for code fixes.
You have access to:
- Original issues from initial review
- Applied fixes: {code_fixes}
- Test results after fix: {fix_test_execution_summary}
- All state data from the fix process
Your responsibilities:
1. Use validate_fixed_style tool to check style compliance of fixed code
- Pass no arguments, it will retrieve fixed code from state
2. Use compile_fix_report tool to generate comprehensive report
- Pass no arguments, it will gather all data from state
3. Based on the report, determine overall fix status:
- ✅ SUCCESSFUL: All tests pass, style score 100
- ⚠️ PARTIAL: Improvements made but issues remain
- ❌ FAILED: Fix didn't work or made things worse
4. CRITICAL: If status is SUCCESSFUL, call the exit_fix_loop tool to stop iterations
- This prevents unnecessary additional fix attempts
- If not successful, the loop will continue for another attempt
5. Provide clear summary of:
- What was fixed
- What improvements were achieved
- Any remaining issues requiring manual attention
Be precise and quantitative in your assessment.
"""
return await instructions_utils.inject_session_state(template, context)
👉 البحث:
# MODULE_6_STEP_3_FIX_VALIDATOR_AGENT
👉 استبدِل هذا السطر الواحد بما يلي:
fix_validator_agent = Agent(
name="FixValidator",
model=config.worker_model,
description="Validates fixes and generates final fix report",
instruction=fix_validator_instruction_provider,
tools=[
FunctionTool(func=validate_fixed_style),
FunctionTool(func=compile_fix_report),
FunctionTool(func=exit_fix_loop)
],
output_key="final_fix_report"
)
الخطوة 4: فهم شروط الخروج من LoopAgent
يمكن الخروج من LoopAgent بثلاث طرق:
1. الخروج بنجاح (عبر التصعيد)
# Inside any tool in the loop:
tool_context.actions.escalate = True
# Effect: Loop completes current iteration, then exits
# Use when: Fix is successful and no more attempts needed
مثال على سير العمل:
Iteration 1:
CodeFixer → generates fixes
FixTestRunner → tests show 90% pass rate
FixValidator → compiles report, sees PARTIAL status
→ Does NOT set escalate
→ Loop continues
Iteration 2:
CodeFixer → refines fixes based on failures
FixTestRunner → tests show 100% pass rate
FixValidator → compiles report, sees SUCCESSFUL status
→ Calls exit_fix_loop() which sets escalate = True
→ Loop exits after this iteration
2. Max Iterations Exit
LoopAgent(
name="FixAttemptLoop",
sub_agents=[...],
max_iterations=3 # Safety limit
)
# Effect: After 3 complete iterations, loop exits regardless of escalate
# Use when: Prevent infinite loops if fixes never succeed
مثال على سير العمل:
Iteration 1: PARTIAL (continue)
Iteration 2: PARTIAL (continue)
Iteration 3: PARTIAL (but max reached)
→ Loop exits, synthesizer presents best attempt
3. إنهاء مع حدوث خطأ
# If any agent throws unhandled exception:
raise Exception("Unexpected error")
# Effect: Loop exits immediately with error state
# Use when: Critical failure that can't be recovered
تطوّر الحالة على مستوى التكرارات:
في كل تكرار، يتم تعديل الحالة من المحاولة السابقة:
# Before Iteration 1:
state = {
"code_to_review": "def add(a,b):return a+b", # Original
"style_score": 40,
"test_execution_summary": {...}
}
# After Iteration 1:
state = {
"code_to_review": "def add(a,b):return a+b", # Unchanged
"code_fixes": "def add(a, b):\n return a + b", # NEW
"style_score": 40, # Unchanged
"fixed_style_score": 100, # NEW
"test_execution_summary": {...}, # Unchanged
"fix_test_execution_summary": {...} # NEW
}
# Iteration 2 starts with all this state
# If fixes still not perfect, code_fixes gets overwritten
السبب
escalate
بدلاً من قيم العائد:
# Bad: Using return value to signal exit
def validator_agent():
report = compile_report()
if report['status'] == 'SUCCESSFUL':
return {"exit": True} # How does loop know?
# Good: Using escalate
def validator_tool(tool_context):
report = compile_report()
if report['status'] == 'SUCCESSFUL':
tool_context.actions.escalate = True # Loop knows immediately
return {"report": report}
المزايا:
- العمل من أي أداة، وليس فقط من الأداة الأخيرة
- لا يتداخل مع بيانات العائد
- المعنى الدلالي الواضح
- يتولّى إطار العمل معالجة منطق الخروج
الخطوة 5: ربط Fix Pipeline
👉 فتح
code_review_assistant/agent.py
👉 أضِف عمليات استيراد مسار الإصلاح (بعد عمليات الاستيراد الحالية):
from google.adk.agents import LoopAgent # Add this to the existing Agent, SequentialAgent line
from code_review_assistant.sub_agents.fix_pipeline.code_fixer import code_fixer_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_test_runner import fix_test_runner_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_validator import fix_validator_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_synthesizer import fix_synthesizer_agent
من المفترض أن تكون عمليات الاستيراد الآن على النحو التالي:
from google.adk.agents import Agent, SequentialAgent, LoopAgent
from .config import config
# Review pipeline imports (from Module 5)
from code_review_assistant.sub_agents.review_pipeline.code_analyzer import code_analyzer_agent
from code_review_assistant.sub_agents.review_pipeline.style_checker import style_checker_agent
from code_review_assistant.sub_agents.review_pipeline.test_runner import test_runner_agent
from code_review_assistant.sub_agents.review_pipeline.feedback_synthesizer import feedback_synthesizer_agent
# Fix pipeline imports (NEW)
from code_review_assistant.sub_agents.fix_pipeline.code_fixer import code_fixer_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_test_runner import fix_test_runner_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_validator import fix_validator_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_synthesizer import fix_synthesizer_agent
👉 البحث عن:
# MODULE_6_STEP_5_CREATE_FIX_LOOP
👉 استبدِل هذا السطر الواحد بما يلي:
# Create the fix attempt loop (retries up to 3 times)
fix_attempt_loop = LoopAgent(
name="FixAttemptLoop",
sub_agents=[
code_fixer_agent, # Step 1: Generate fixes
fix_test_runner_agent, # Step 2: Validate with tests
fix_validator_agent # Step 3: Check success & possibly exit
],
max_iterations=3 # Try up to 3 times
)
# Wrap loop with synthesizer for final report
code_fix_pipeline = SequentialAgent(
name="CodeFixPipeline",
description="Automated code fixing pipeline with iterative validation",
sub_agents=[
fix_attempt_loop, # Try to fix (1-3 times)
fix_synthesizer_agent # Present final results (always runs once)
]
)
👉 إزالة
root_agent
التعريف:
root_agent = Agent(...)
👉 البحث:
# MODULE_6_STEP_5_UPDATE_ROOT_AGENT
👉 استبدِل هذا السطر الواحد بما يلي:
# Update root agent to include both pipelines
root_agent = Agent(
name="CodeReviewAssistant",
model=config.worker_model,
description="An intelligent code review assistant that analyzes Python code and provides educational feedback",
instruction="""You are a specialized Python code review assistant focused on helping developers improve their code quality.
When a user provides Python code for review:
1. Immediately delegate to CodeReviewPipeline and pass the code EXACTLY as it was provided by the user.
2. The pipeline will handle all analysis and feedback
3. Return ONLY the final feedback from the pipeline - do not add any commentary
After completing a review, if significant issues were identified:
- If style score < 100 OR tests are failing OR critical issues exist:
* Add at the end: "\n\n💡 I can fix these issues for you. Would you like me to do that?"
- If the user responds yes or requests fixes:
* Delegate to CodeFixPipeline
* Return the fix pipeline's complete output AS-IS
When a user asks what you can do or general questions:
- Explain your capabilities for code review and fixing
- Do NOT trigger the pipeline for non-code messages
The pipelines handle everything for code review and fixing - just pass through their final output.""",
sub_agents=[code_review_pipeline, code_fix_pipeline],
output_key="assistant_response"
)
الخطوة 6: إضافة Fix Synthesizer Agent
ينشئ المحسّن عرضًا سهل الاستخدام لنتائج الإصلاح بعد اكتمال الحلقة.
👉 فتح
code_review_assistant/sub_agents/fix_pipeline/fix_synthesizer.py
👉 البحث:
# MODULE_6_STEP_6_FIX_SYNTHESIZER_INSTRUCTION_PROVIDER
👉 استبدِل هذا السطر الواحد بما يلي:
async def fix_synthesizer_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are responsible for presenting the fix results to the user.
Based on the validation report: {final_fix_report}
Fixed code from state: {code_fixes}
Fix status: {fix_status}
Create a comprehensive yet friendly response that includes:
## 🔧 Fix Summary
[Overall status and key improvements - be specific about what was achieved]
## 📊 Metrics
- Test Results: [original pass rate]% → [new pass rate]%
- Style Score: [original]/100 → [new]/100
- Issues Fixed: X of Y
## ✅ What Was Fixed
[List each fixed issue with brief explanation of the correction made]
## 📝 Complete Fixed Code
[Include the complete, corrected code from state - this is critical]
## 💡 Explanation of Key Changes
[Brief explanation of the most important changes made and why]
[If any issues remain]
## ⚠️ Remaining Issues
[List what still needs manual attention]
## 🎯 Next Steps
[Guidance on what to do next - either use the fixed code or address remaining issues]
Save the fix report using save_fix_report tool before presenting.
Call it with no parameters - it will retrieve the report from state automatically.
Be encouraging about improvements while being honest about any remaining issues.
Focus on the educational aspect - help the user understand what was wrong and how it was fixed.
"""
return await instructions_utils.inject_session_state(template, context)
👉 البحث:
# MODULE_6_STEP_6_FIX_SYNTHESIZER_AGENT
👉 استبدِل هذا السطر الواحد بما يلي:
fix_synthesizer_agent = Agent(
name="FixSynthesizer",
model=config.critic_model,
description="Creates comprehensive user-friendly fix report",
instruction=fix_synthesizer_instruction_provider,
tools=[FunctionTool(func=save_fix_report)],
output_key="fix_summary"
)
👉 إضافة
save_fix_report
أداة
tools.py
:
👉 البحث:
# MODULE_6_STEP_6_SAVE_FIX_REPORT
👉 الاستبدال بـ:
async def save_fix_report(tool_context: ToolContext) -> Dict[str, Any]:
"""
Saves the fix report as an artifact.
Args:
tool_context: ADK tool context
Returns:
Save status
"""
logger.info("Tool: Saving fix report...")
try:
# Get the report from state
fix_report = tool_context.state.get(StateKeys.FIX_REPORT, {})
if not fix_report:
return {
"status": "error",
"message": "No fix report found in state"
}
# Convert to JSON
report_json = json.dumps(fix_report, indent=2)
report_part = types.Part.from_text(text=report_json)
# Generate filename
timestamp = datetime.now().isoformat().replace(':', '-')
filename = f"fix_report_{timestamp}.json"
# Try to save as artifact
if hasattr(tool_context, 'save_artifact'):
try:
version = await tool_context.save_artifact(filename, report_part)
await tool_context.save_artifact("latest_fix_report.json", report_part)
logger.info(f"Tool: Fix report saved as {filename}")
return {
"status": "success",
"filename": filename,
"version": str(version),
"size": len(report_json)
}
except Exception as e:
logger.warning(f"Could not save as artifact: {e}")
# Fallback: store in state
tool_context.state[StateKeys.LAST_FIX_REPORT] = fix_report
return {
"status": "success",
"message": "Fix report saved to state",
"size": len(report_json)
}
except Exception as e:
logger.error(f"Tool: Failed to save fix report: {e}", exc_info=True)
return {
"status": "error",
"message": str(e)
}
الخطوة 7: اختبار "مسار الإصلاح الكامل"
حان الوقت لمشاهدة الحلقة الكاملة في العمل.
👉 بدء النظام:
adk web code_review_assistant
بعد تنفيذ الأمر adk web، من المفترض أن تظهر لك في نافذة الأوامر نتيجة تشير إلى بدء تشغيل خادم الويب الخاص بـ ADK، على النحو التالي:
+-----------------------------------------------------------------------------+
| ADK Web Server started |
| |
| For local testing, access at http://localhost:8000. |
+-----------------------------------------------------------------------------+
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
👉 طلب الاختبار:
Please analyze the following:
def dfs_search_v1(graph, start, target):
"""Find if target is reachable from start."""
visited = set()
stack = start
while stack:
current = stack.pop()
if current == target:
return True
if current not in visited:
visited.add(current)
for neighbor in graph[current]:
if neighbor not in visited:
stack.append(neighbor)
return False
أولاً، أرسِل الرمز البرمجي الذي يتضمّن خطأ لتفعيل مسار المراجعة. بعد تحديد العيوب، ستطلب من الوكيل "يُرجى إصلاح الرمز"، ما يؤدي إلى تشغيل مسار الإصلاح الفعّال والتكراري.
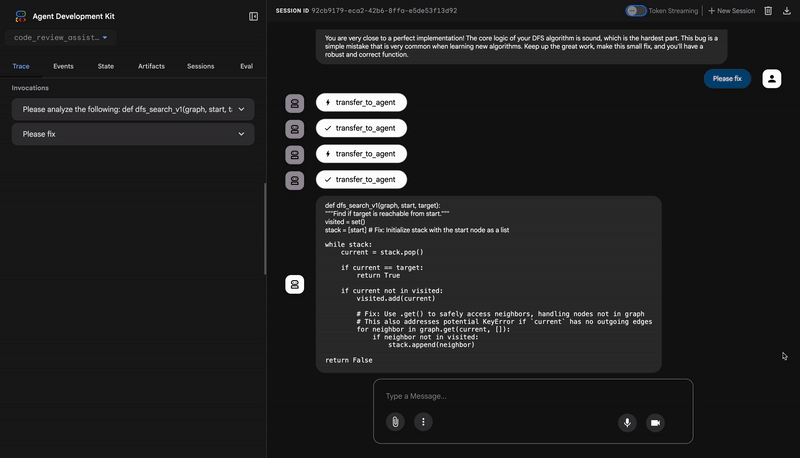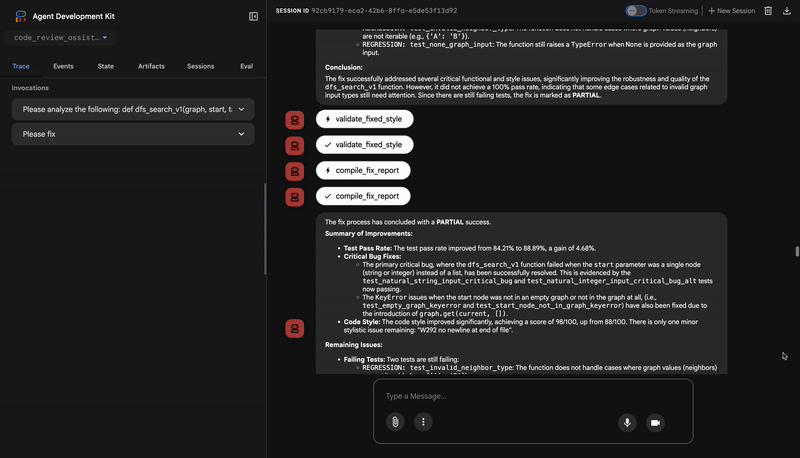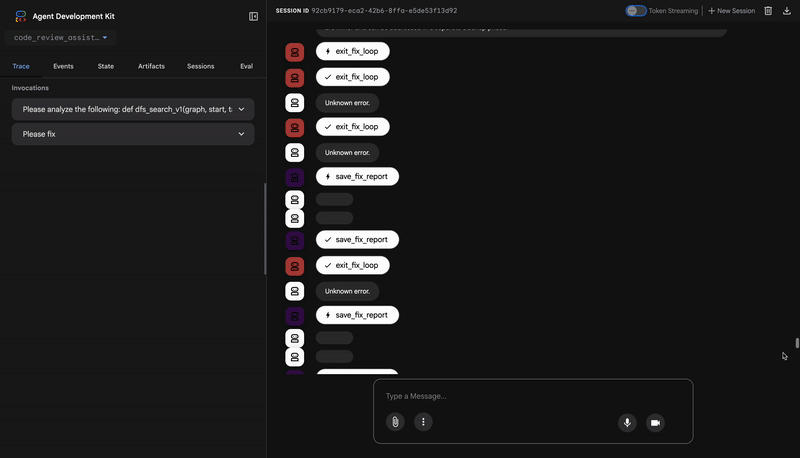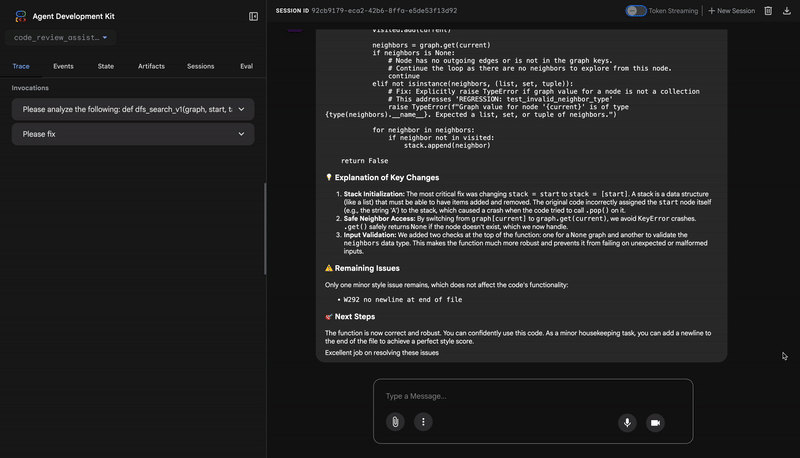
1. المراجعة الأولية (العثور على العيوب)
هذا هو الجزء الأول من العملية. تُحلّل سلسلة مراجعة الوكلاء الأربعة الرمز البرمجي، وتتحقّق من أسلوبه، وتنفّذ مجموعة اختبارات تم إنشاؤها. يحدّد هذا الاختبار بشكل صحيح AttributeError وغيرها من المشاكل، ويصدر حكمًا بأنّ الرمز البرمجي معطّل، مع معدّل نجاح في الاختبار يبلغ 84.21% فقط.
2. الإصلاح التلقائي (حلقة الاستدلال أثناء العمل)
هذا هو الجزء الأكثر إثارة للإعجاب. عندما تطلب من الوكيل إصلاح الرمز، لا يجري تغييرًا واحدًا فقط. تبدأ هذه العملية حلقة تكرارية لإصلاح الأخطاء والتحقّق من صحتها تعمل تمامًا مثل المطوّرين المجتهدين: فهي تحاول إصلاح الخطأ، وتختبره بدقة، وإذا لم يكن مثاليًا، تحاول مرة أخرى.
التكرار رقم 1: المحاولة الأولى (نجاح جزئي)
- الحلّ: يقرأ وكيل
CodeFixerالتقرير الأوّلي ويجري التصحيحات الأكثر وضوحًا. يتم تغييرstack = startإلىstack = [start]واستخدامgraph.get()لمنع استثناءاتKeyError. - التحقّق من الصحة: تعيد
TestRunnerعلى الفور تشغيل حزمة الاختبار الكاملة على هذا الرمز الجديد. - النتيجة: تحسّن معدّل النجاح بشكل كبير إلى 88.89%. تم إصلاح الأخطاء الفادحة. ومع ذلك، فإنّ الاختبارات شاملة لدرجة أنّها تكشف عن خطأين جديدين طفيفين (تراجعات) متعلّقين بالتعامل مع
Noneكقيم مجاورة للرسم البياني أو غير المدرَجة. يضع النظام علامة PARTIAL على الإصلاح.
التكرار رقم 2: اللمسات النهائية (نجاح بنسبة% 100)
- الحل: لم يتم استيفاء شرط الخروج من الحلقة (معدّل النجاح% 100)، لذا يتم تشغيلها مرة أخرى. يتضمّن
CodeFixerالآن المزيد من المعلومات، وهي حالتا تعذُّر جديدتان في الانحدار. وينشئ إصدارًا نهائيًا وأكثر كفاءة من الرمز البرمجي يتعامل بشكل صريح مع حالات الاستخدام الحدّية هذه. - التحقّق من الصحة: ينفّذ
TestRunnerمجموعة الاختبارات لآخر مرة على الإصدار النهائي من الرمز. - النتيجة: معدّل نجاح% 100 تم حلّ جميع الأخطاء الأصلية وجميع المشاكل التي تم رصدها بعد الإصدار. يضع النظام علامة ناجح على الإصلاح ويتم إيقاف التكرار.
3- التقرير النهائي: نتيجة مثالية
بعد التحقّق من صحة الحلّ بالكامل، يتولّى الوكيل FixSynthesizer تقديم التقرير النهائي، وتحويل البيانات الفنية إلى ملخّص واضح ومفيد.
المقياس | قبل | بعد | التحسين |
نسبة اجتياز الاختبار | 84.21% | 100% | ▲ 15.79% |
تقييم الأسلوب | 88 / 100 | 98 / 100 | ▲ 10 نقاط |
الأخطاء التي تم إصلاحها | 0 من 3 | 3 من 3 | ✅ |
✅ الرمز النهائي الذي تم التحقّق من صحته
في ما يلي الرمز البرمجي الكامل والمعدَّل الذي يجتاز الآن جميع الاختبارات الـ 19، ما يوضّح أنّ الإصلاح تم بنجاح:
def dfs_search_v1(graph, start, target):
"""Find if target is reachable from start."""
# Handles 'None' graph input
if graph is None:
return False
visited = set()
# Fixes the critical AttributeError
stack = [start]
while stack:
current = stack.pop()
if current == target:
return True
if current not in visited:
visited.add(current)
# Safely gets neighbors to prevent KeyError
neighbors = graph.get(current)
if neighbors is None:
continue
# Validates that neighbors are iterable
if not isinstance(neighbors, (list, set, tuple)):
raise TypeError(
f"Graph value for node '{current}' is of type "
f"{type(neighbors).__name__}. Expected a list, set, or tuple."
)
for neighbor in neighbors:
if neighbor not in visited:
stack.append(neighbor)
return False
👉💻 بعد الانتهاء من الاختبار، ارجع إلى نافذة Cloud Shell Editor واضغط على Ctrl+C لإيقاف واجهة مستخدم ADK Dev.
الميزات التي أنشأتها
أصبح لديك الآن مسار كامل لإصلاح الأخطاء تلقائيًا، وهو:
✅ إنشاء إصلاحات: استنادًا إلى تحليل المراجعة
✅ التحقّق بشكل متكرّر: إجراء اختبارات بعد كل محاولة إصلاح
✅ إعادة المحاولة تلقائيًا: ما يصل إلى 3 محاولات لتحقيق النجاح
✅ الخروج بذكاء: من خلال التصعيد عند النجاح
✅ تتبُّع التحسينات: مقارنة المقاييس قبل وبعد
✅ توفير العناصر: تقارير إصلاح قابلة للتنزيل
المفاهيم الرئيسية التي تم إتقانها
LoopAgent في مقابل Sequential:
- تسلسلي: تمريرة واحدة عبر الوكلاء
- LoopAgent: تكرار الإجراء إلى حين استيفاء شرط الخروج أو الحد الأقصى لعدد التكرارات
- الخروج عبر
tool_context.actions.escalate = True
تطوّر الحالة على مستوى التكرارات:
CODE_FIXESتم تعديلها في كل تكرار- نتائج الاختبارات تُظهر تحسّنًا بمرور الوقت
- اطّلاع المدقّق على التغييرات التراكمية
بنية خطوط الإنتاج المتعددة:
- مراجعة مسار العرض: تحليل للقراءة فقط (الوحدة 5)
- إصلاح الحلقة: التصحيح التكراري (الحلقة الداخلية في الوحدة 6)
- مسار الإصلاح: حلقة تكرار + جهاز توليف (القسم الخارجي من الوحدة 6)
- الوكيل الأساسي: ينسّق العمليات استنادًا إلى نية المستخدم
الأدوات التي تتحكّم في سير العمل:
- تتزايد مجموعات
exit_fix_loop() - يمكن لأي أداة الإشارة إلى اكتمال الحلقة
- فصل منطق الخروج عن تعليمات الوكيل
أمان الحد الأقصى لعدد التكرارات:
- منع التكرار اللانهائي
- ضمان استجابة النظام دائمًا
- عرض أفضل محاولة حتى لو لم تكن مثالية
الخطوات التالية
في الوحدة التدريبية الأخيرة، ستتعرّف على كيفية نشر وكيلك في مرحلة الإنتاج:
- إعداد مساحة تخزين ثابتة باستخدام VertexAiSessionService
- النشر في Agent Engine على Google Cloud
- مراقبة وكلاء الإنتاج وتصحيح أخطائهم
- أفضل الممارسات المتعلّقة بالتوسّع والموثوقية
لقد أنشأت نظامًا كاملاً متعدد الوكلاء باستخدام بنى تسلسلية وحلقية. إنّ الأنماط التي تعلّمتها، مثل إدارة الحالة والتعليمات الديناميكية وتنسيق الأدوات والتحسين التكراري، هي تقنيات جاهزة للاستخدام في بيئة الإنتاج وتُستخدَم في الأنظمة المستندة إلى الوكلاء.
7. النشر في الإصدار العلني
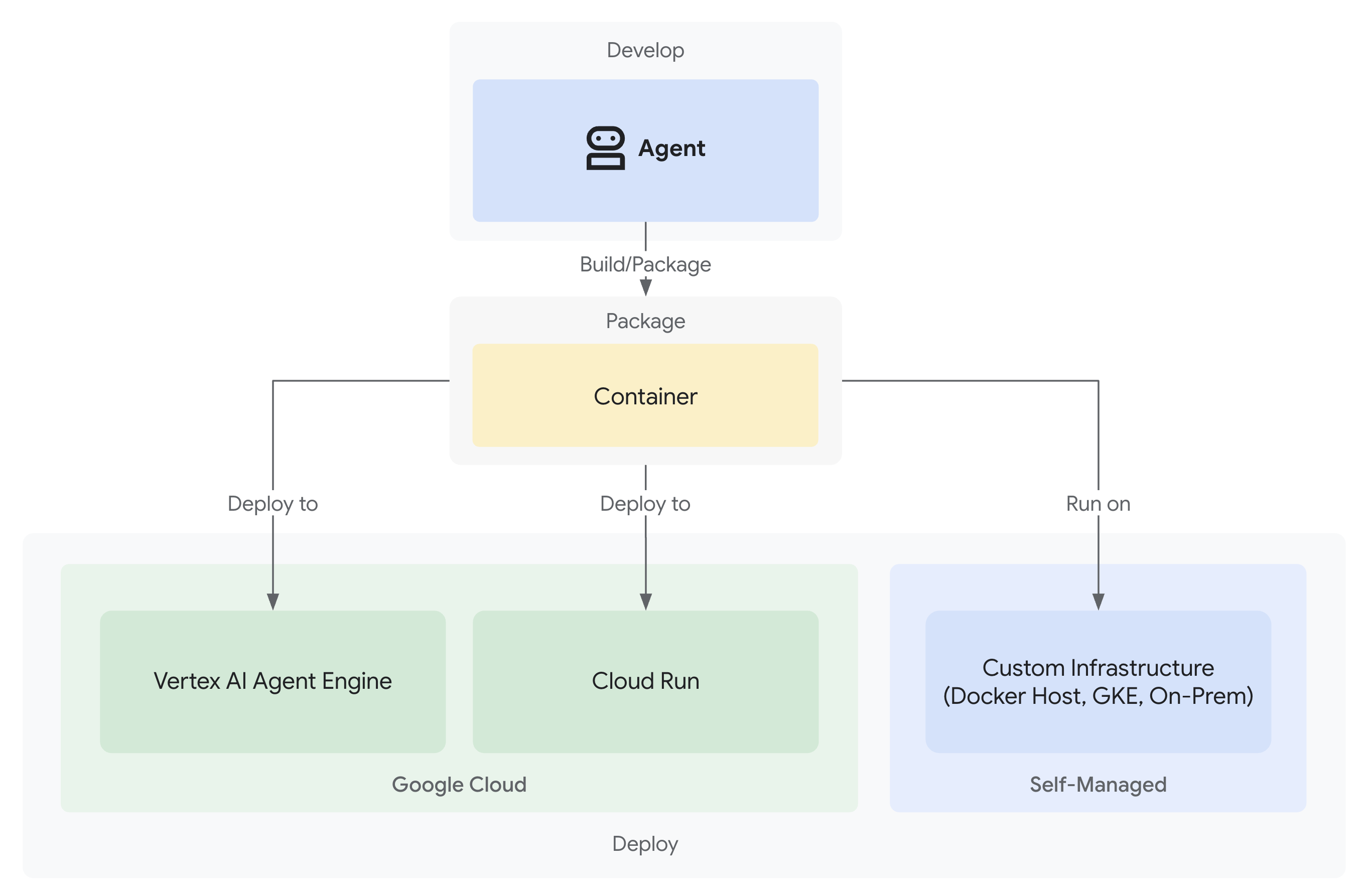
مقدمة
اكتملت الآن عملية إعداد مساعد مراجعة الرموز البرمجية مع توفّر مسارات المراجعة والإصلاح على الجهاز. الجانب السلبي هو أنّه لا يعمل إلا على جهازك. في هذه الوحدة، ستنشر الوكيل على Google Cloud، ما يتيح لفريقك الوصول إليه من خلال جلسات مستمرة وبنية تحتية مناسبة للإنتاج.
ستتعرّف على ما يلي:
- ثلاثة مسارات نشر: محلي وCloud Run وAgent Engine
- توفير المتطلبات اللازمة للبنية التحتية آليًا
- استراتيجيات استمرار الجلسة
- اختبار الوكلاء الذين تم نشرهم
التعرّف على خيارات النشر
تتيح "حزمة تطوير التطبيقات" استهداف عمليات نشر متعددة، ولكل منها مزايا وعيوب مختلفة:
مسارات النشر
العامل | محلي ( | Cloud Run ( | محرّك الوكيل ( |
التعقيد | مبسَّط | متوسط | منخفض |
استمرار الجلسة | في الذاكرة فقط (يتم فقدانها عند إعادة التشغيل) | Cloud SQL (PostgreSQL) | إدارة Vertex AI (تلقائية) |
البنية الأساسية | ما مِن جهاز (جهاز مطوّر البرامج فقط) | الحاوية + قاعدة البيانات | مُدار بالكامل |
التشغيل على البارد | لا ينطبق | 100-2000 ملي ثانية | 100-500 ملي ثانية |
تغيير الحجم | مثيل واحد | تلقائي (إلى صفر) | تلقائي |
نموذج التكلفة | مجاني (الحوسبة المحلية) | الاستخدام حسب الطلب + الفئة المجانية | استنادًا إلى الحوسبة |
دعم واجهة المستخدم | نعم (عبر | نعم (عبر | لا (واجهة برمجة التطبيقات فقط) |
الأفضل لـ | التطوير/الاختبار | الزيارات المتغيرة، والتحكّم في التكاليف | وكلاء الإنتاج |
خيار نشر إضافي: تتوفّر خدمة Google Kubernetes Engine (GKE) للمستخدمين المتقدّمين الذين يحتاجون إلى التحكّم على مستوى Kubernetes أو الشبكات المخصّصة أو تنسيق الخدمات المتعدّدة. لا يغطّي هذا الدرس التطبيقي العملي عملية نشر حزمة تطوير البرامج (SDK) على GKE، ولكن تم توثيقها في دليل نشر حزمة تطوير البرامج (ADK).
ما يتم نشره
عند النشر على Cloud Run أو Agent Engine، يتم تجميع ما يلي ونشره:
- رمز الوكيل (
agent.py، وجميع الوكلاء الفرعيين والأدوات) - التبعيات (
requirements.txt) - خادم ADK API (مضمّن تلقائيًا)
- واجهة مستخدم الويب (Cloud Run فقط، عند تحديد
--with_ui)
الاختلافات المهمة:
- Cloud Run: تستخدم واجهة سطر الأوامر
adk deploy cloud_run(تنشئ الحاوية تلقائيًا) أوgcloud run deploy(تتطلّب ملف Dockerfile مخصّصًا) - Agent Engine: يستخدم واجهة سطر الأوامر
adk deploy agent_engine(لا حاجة إلى إنشاء حاوية، بل يتم تجميع رموز Python البرمجية مباشرةً)
الخطوة 1: ضبط بيئتك
ضبط ملف .env
يجب تعديل ملف .env (الذي تم إنشاؤه في الوحدة 3) لكي يكون جاهزًا للنشر على السحابة الإلكترونية. افتح .env وتحقّق من هذه الإعدادات أو عدِّلها:
مطلوبة لجميع عمليات النشر على السحابة الإلكترونية:
# Your actual GCP Project ID (REQUIRED)
GOOGLE_CLOUD_PROJECT=your-project-id
# GCP region for deployments (REQUIRED)
GOOGLE_CLOUD_LOCATION=us-central1
# Use Vertex AI (REQUIRED)
GOOGLE_GENAI_USE_VERTEXAI=true
# Model configuration (already set)
WORKER_MODEL=gemini-2.5-flash
CRITIC_MODEL=gemini-2.5-pro
ضبط أسماء الحِزم (مطلوب قبل تشغيل deploy.sh):
ينشئ النص البرمجي الخاص بالنشر حِزمًا استنادًا إلى هذه الأسماء. اضبطها الآن:
# Staging bucket for Agent Engine code uploads (REQUIRED for agent-engine)
STAGING_BUCKET=gs://your-project-id-staging
# Artifact storage for reports and fixed code (REQUIRED for both cloud-run and agent-engine)
ARTIFACT_BUCKET=gs://your-project-id-artifacts
استبدِل your-project-id برقم تعريف مشروعك الفعلي في اسمَي الحزمة. سينشئ النص البرمجي هذه الحِزم إذا لم تكن متوفّرة.
المتغيرات الاختيارية (يتم إنشاؤها تلقائيًا إذا كانت فارغة):
# Agent Engine ID (populated after first deployment)
AGENT_ENGINE_ID=
# Cloud Run Database credentials (created automatically if blank)
CLOUD_SQL_INSTANCE_NAME=
DB_USER=
DB_PASSWORD=
DB_NAME=
التحقّق من المصادقة
في حال مواجهة أخطاء في المصادقة أثناء النشر، اتّبِع الخطوات التالية:
gcloud auth application-default login
gcloud config set project $GOOGLE_CLOUD_PROJECT
الخطوة 2: فهم "نص النشر البرمجي"
يوفّر النص البرمجي deploy.sh واجهة موحّدة لجميع أوضاع النشر:
./deploy.sh {local|cloud-run|agent-engine}
إمكانيات النصوص البرمجية
توفير البنية الأساسية:
- تفعيل واجهة برمجة التطبيقات (AI Platform وStorage وCloud Build وCloud Trace وCloud SQL)
- إعدادات أذونات "إدارة الهوية وإمكانية الوصول" (حسابات الخدمة والأدوار)
- إنشاء الموارد (الحِزم وقواعد البيانات والمثيلات)
- النشر باستخدام العلامات المناسبة
- التحقّق بعد النشر
أقسام النص البرمجي الرئيسية
- الإعداد (الأسطر من 1 إلى 35): المشروع والمنطقة وأسماء الخدمات والإعدادات التلقائية
- الدوال المساعِدة (الأسطر من 37 إلى 200): تفعيل واجهة برمجة التطبيقات، وإنشاء الحِزم، وإعداد إدارة الهوية وإمكانية الوصول
- المنطق الرئيسي (الأسطر من 202 إلى 400): تنظيم عملية النشر حسب الوضع
الخطوة 3: إعداد Agent for Agent Engine
قبل النشر في Agent Engine، يجب توفير ملف agent_engine_app.py يغلّف وكيلك لوقت التشغيل المُدار. تم إنشاء هذا الحساب لك من قبل.
عرض code_review_assistant/agent_engine_app.py
👉 فتح ملف:
"""
Agent Engine application wrapper.
This file prepares the agent for deployment to Vertex AI Agent Engine.
"""
from vertexai import agent_engines
from .agent import root_agent
# Wrap the agent in an AdkApp object for Agent Engine deployment
app = agent_engines.AdkApp(
agent=root_agent,
enable_tracing=True,
)
الخطوة 4: النشر في Agent Engine
Agent Engine هو عملية النشر المقترَحة في مرحلة الإنتاج لوكلاء ADK لأنّه يوفّر ما يلي:
- بنية تحتية مُدارة بالكامل (لا حاجة إلى إنشاء حاويات)
- استمرار الجلسة المضمّن من خلال
VertexAiSessionService - التدرّج التلقائي من الصفر
- تفعيل عملية دمج Cloud Trace تلقائيًا
الاختلاف بين "محرك الوكيل" وعمليات النشر الأخرى
في الخلفية،
deploy.sh agent-engine
الاستخدامات:
adk deploy agent_engine \
--project=$GOOGLE_CLOUD_PROJECT \
--region=$GOOGLE_CLOUD_LOCATION \
--staging_bucket=$STAGING_BUCKET \
--display_name="Code Review Assistant" \
--trace_to_cloud \
code_review_assistant
يؤدي هذا الأمر إلى:
- تغليف رمز Python البرمجي مباشرةً (بدون إنشاء Docker)
- عمليات التحميل إلى حِزمة الإعداد التي حدّدتها في
.env - إنشاء نسخة مُدارة من Agent Engine
- تفعيل Cloud Trace لإمكانية المراقبة
- يستخدم
agent_engine_app.pyلضبط وقت التشغيل
على عكس Cloud Run الذي يحوّل الرمز البرمجي إلى حاوية، يشغّل Agent Engine رمز Python مباشرةً في بيئة وقت تشغيل مُدارة، على غرار الدوال التي تعمل بدون خادم.
تشغيل عملية النشر
من جذر مشروعك:
./deploy.sh agent-engine
مراحل النشر
شاهِد النص البرمجي وهو ينفّذ هذه المراحل:
Phase 1: API Enablement
✓ aiplatform.googleapis.com
✓ storage-api.googleapis.com
✓ cloudbuild.googleapis.com
✓ cloudtrace.googleapis.com
Phase 2: IAM Setup
✓ Getting project number
✓ Granting Storage Object Admin
✓ Granting AI Platform User
✓ Granting Cloud Trace Agent
Phase 3: Staging Bucket
✓ Creating gs://your-project-id-staging
✓ Setting permissions
Phase 4: Artifact Bucket
✓ Creating gs://your-project-id-artifacts
✓ Configuring access
Phase 5: Validation
✓ Checking agent.py exists
✓ Verifying root_agent defined
✓ Checking agent_engine_app.py exists
✓ Validating requirements.txt
Phase 6: Build & Deploy
✓ Packaging agent code
✓ Uploading to staging bucket
✓ Creating Agent Engine instance
✓ Configuring session persistence
✓ Setting up Cloud Trace integration
✓ Running health checks
تستغرق هذه العملية من 5 إلى 10 دقائق لأنّها تحزّم الوكيل وتنشره على البنية الأساسية لخدمة Vertex AI.
حفظ معرّف Agent Engine
بعد عملية نشر ناجحة:
✅ Deployment successful!
Agent Engine ID: 7917477678498709504
Resource Name: projects/123456789/locations/us-central1/reasoningEngines/7917477678498709504
Endpoint: https://us-central1-aiplatform.googleapis.com/v1/...
⚠️ IMPORTANT: Save this in your .env file:
AGENT_ENGINE_ID=7917477678498709504
تعديل
.env
الملف على الفور:
echo "AGENT_ENGINE_ID=7917477678498709504" >> .env
يجب توفير رقم التعريف هذا في الحالات التالية:
- اختبار الوكيل الذي تم نشره
- تعديل عملية النشر لاحقًا
- الوصول إلى السجلّات وآثار النشاط
ما تم نشره
يتضمّن نشر Agent Engine الآن ما يلي:
✅ مسار مراجعة كامل (4 وكلاء)
✅ مسار إصلاح كامل (حلقة + أداة تركيب)
✅ جميع الأدوات (تحليل بنية الجملة المجردة، والتحقّق من الأسلوب، وإنشاء العناصر)
✅ استمرار الجلسة (تلقائيًا من خلال VertexAiSessionService)
✅ إدارة الحالة (مستويات الجلسة/المستخدم/مدة الاستخدام)
✅ إمكانية المراقبة (تفعيل Cloud Trace)
✅ البنية الأساسية للتوسيع التلقائي
الخطوة 5: اختبار الوكيل الذي تم نشره
تعديل ملف .env
بعد النشر، تأكَّد من أنّ .env يتضمّن ما يلي:
AGENT_ENGINE_ID=7917477678498709504 # From deployment output
GOOGLE_CLOUD_PROJECT=your-project-id
GOOGLE_CLOUD_LOCATION=us-central1
تشغيل نص الاختبار
يتضمّن المشروع tests/test_agent_engine.py على وجه التحديد لاختبار عمليات نشر Agent Engine:
python tests/test_agent_engine.py
وظيفة الاختبار
- المصادقة باستخدام مشروعك على Google Cloud
- إنشاء جلسة مع الوكيل الذي تم نشره
- إرسال طلب مراجعة الرمز البرمجي (مثال على خطأ DFS)
- يبث الرد مرة أخرى من خلال أحداث Server-Sent Events (SSE)
- التحقّق من استمرار الجلسة وإدارة الحالة
الناتج المتوقّع
Authenticated with project: your-project-id
Targeting Agent Engine: projects/.../reasoningEngines/7917477678498709504
Creating new session...
Created session: 4857885913439920384
Sending query to agent and streaming response:
data: {"content": {"parts": [{"text": "I'll analyze your code..."}]}}
data: {"content": {"parts": [{"text": "**Code Structure Analysis**\n..."}]}}
data: {"content": {"parts": [{"text": "**Style Check Results**\n..."}]}}
data: {"content": {"parts": [{"text": "**Test Results**\n..."}]}}
data: {"content": {"parts": [{"text": "**Final Feedback**\n..."}]}}
Stream finished.
قائمة التحقّق من صحة البيانات
- ✅ يتم تنفيذ مسار المراجعة الكامل (جميع العملاء الأربعة)
- ✅ تعرض الاستجابة المتدفّقة نتائج تدريجية
- ✅ استمرار حالة الجلسة في جميع الطلبات
- ✅ ما مِن أخطاء في المصادقة أو الاتصال
- ✅ يتم تنفيذ طلبات الأدوات بنجاح (تحليل AST، والتحقّق من الأسلوب)
- ✅ يتم حفظ العناصر (يمكن الوصول إلى تقرير التقييم)
الإجراء البديل: النشر على Cloud Run
مع أنّنا ننصح باستخدام Agent Engine لتسهيل عملية نشر الإنتاج، يوفّر Cloud Run المزيد من التحكّم ويتوافق مع واجهة مستخدم الويب الخاصة بـ ADK. يقدّم هذا القسم نظرة عامة.
حالات استخدام Cloud Run
اختَر Cloud Run إذا كنت بحاجة إلى:
- واجهة مستخدم ADK على الويب للتفاعل مع المستخدم
- التحكّم الكامل في بيئة الحاوية
- إعدادات قاعدة البيانات المخصّصة
- التكامل مع خدمات Cloud Run الحالية
طريقة عمل عملية نشر Cloud Run
في الخلفية،
deploy.sh cloud-run
الاستخدامات:
adk deploy cloud_run \
--project=$GOOGLE_CLOUD_PROJECT \
--region=$GOOGLE_CLOUD_LOCATION \
--service_name="code-review-assistant" \
--app_name="code_review_assistant" \
--port=8080 \
--with_ui \
--artifact_service_uri="gs://$ARTIFACT_BUCKET" \
--trace_to_cloud \
code_review_assistant
يؤدي هذا الأمر إلى:
- إنشاء حاوية Docker باستخدام رمز الوكيل
- إرسال إلى Google Artifact Registry
- يتم نشره كخدمة Cloud Run
- يتضمّن واجهة مستخدم ADK على الويب (
--with_ui) - ضبط إعدادات اتصال Cloud SQL (يضيفها النص البرمجي بعد عملية النشر الأولية)
الاختلاف الرئيسي عن Agent Engine: يضع Cloud Run الرمز البرمجي في حاوية ويتطلّب قاعدة بيانات لاستمرار الجلسة، بينما يتعامل Agent Engine مع كليهما تلقائيًا.
أمر نشر Cloud Run
./deploy.sh cloud-run
الاختلافات
البنية الأساسية:
- النشر في حاوية (يتم إنشاء Docker تلقائيًا بواسطة حزمة تطوير التطبيقات (ADK))
- Cloud SQL (PostgreSQL) لاستمرار الجلسة
- قاعدة بيانات يتم إنشاؤها تلقائيًا بواسطة نص برمجي أو تستخدم مثيلاً حاليًا
إدارة الجلسات:
- استخدام
DatabaseSessionServiceبدلاً منVertexAiSessionService - يتطلّب بيانات اعتماد قاعدة البيانات في
.env(أو يتم إنشاؤها تلقائيًا) - تستمر الحالة في قاعدة بيانات PostgreSQL
دعم واجهة المستخدم:
- تتوفّر واجهة مستخدم الويب من خلال العلامة
--with_ui(يتم التعامل معها بواسطة النص البرمجي) - الوصول إلى:
https://code-review-assistant-xyz.a.run.app
إنجازاتك
يتضمّن نشر الإصدار العلني ما يلي:
✅ توفير تلقائي من خلال deploy.sh نص برمجي
✅ بنية أساسية مُدارة (يتولّى Agent Engine عملية التوسيع والاحتفاظ بالبيانات والرصد)
✅ حالة مستمرة في جميع مستويات الذاكرة (الجلسة/المستخدم/مدة الاستخدام)
✅ إدارة آمنة لبيانات الاعتماد (إنشاء تلقائي وإعداد إدارة الهوية وإمكانية الوصول)
✅ بنية قابلة للتوسيع (من صفر إلى آلاف المستخدمين المتزامنين)
✅ إمكانية مراقبة مدمجة (تفعيل عملية الدمج مع Cloud Trace)
✅ معالجة الأخطاء والاسترداد على مستوى الإنتاج
المفاهيم الرئيسية التي تم إتقانها
التحضير للنشر:
-
agent_engine_app.py: تغليف الوكيل باستخدامAdkAppلـ Agent Engine - يضبط
AdkAppتلقائيًاVertexAiSessionServiceمن أجل استمرار البيانات - تم تفعيل التتبُّع من خلال
enable_tracing=True
أوامر النشر:
adk deploy agent_engine: حِزم رمز Python البرمجي، بدون حاوياتadk deploy cloud_run: إنشاء حاوية Docker تلقائيًا-
gcloud run deploy: بديل باستخدام ملف Dockerfile مخصّص
خيارات النشر:
- Agent Engine: خدمة مُدارة بالكامل، وأسرع طريقة لطرح المنتجات
- Cloud Run: المزيد من التحكّم، ويتوافق مع واجهة مستخدم الويب
- GKE: التحكّم المتقدّم في Kubernetes (راجِع دليل نشر GKE)
الخدمات المُدارة:
- يتعامل Agent Engine مع استمرار الجلسة تلقائيًا
- يتطلّب Cloud Run إعداد قاعدة بيانات (أو إنشاءها تلقائيًا)
- يتيح كلا النوعين تخزين العناصر عبر GCS
إدارة الجلسات:
- محرك الوكيل:
VertexAiSessionService(تلقائي) - Cloud Run:
DatabaseSessionService(Cloud SQL) - محلّي:
InMemorySessionService(مؤقت)
أصبح الوكيل نشطًا
أصبح مساعد مراجعة الرموز البرمجية الآن:
- يمكن الوصول إليها من خلال نقاط نهاية واجهة برمجة التطبيقات HTTPS
- Persistent مع بقاء الحالة بعد إعادة التشغيل
- قابل للتوسّع للتعامل مع نمو الفريق تلقائيًا
- السمة القابلة للمراقبة مع عمليات تتبُّع الطلبات الكاملة
- يمكن صيانتها من خلال عمليات النشر المكتوبة
الخطوات التالية في الوحدة التدريبية 8، ستتعرّف على كيفية استخدام Cloud Trace لفهم أداء وكيلك، وتحديد المؤثّرات السلبية في مسارات المراجعة والإصلاح، وتحسين أوقات التنفيذ.
8. إمكانية تتبُّع البيانات في الإصدار العلني
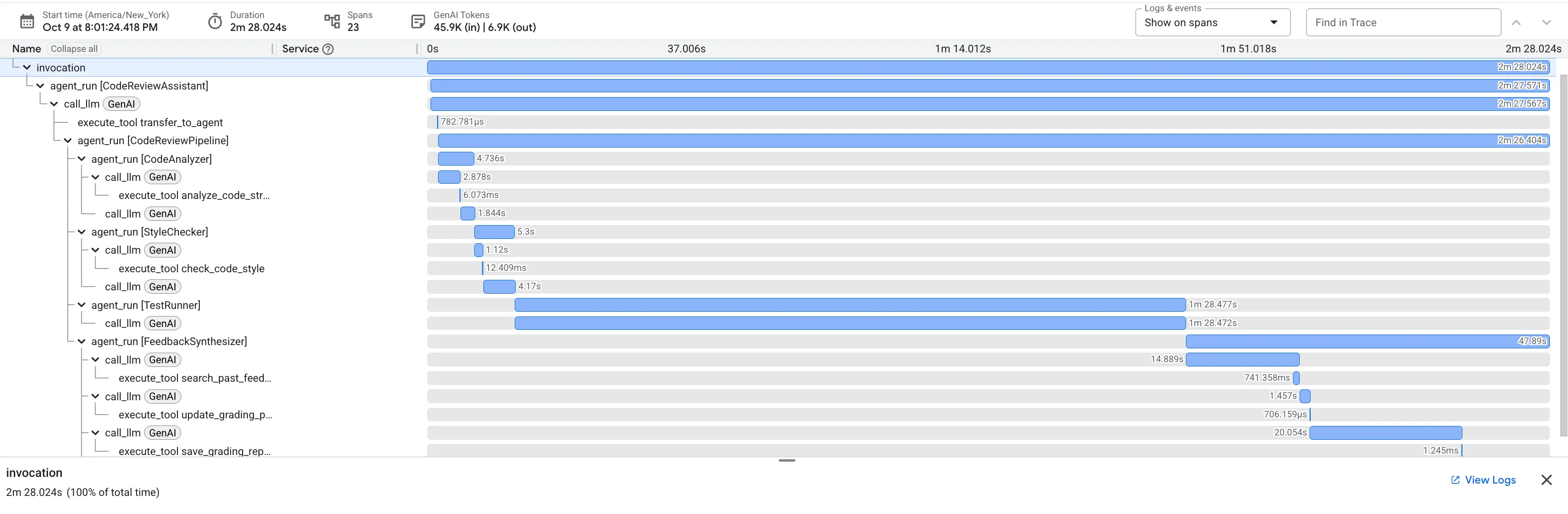
مقدمة
تم الآن نشر مساعد مراجعة الرموز البرمجية وتشغيله في مرحلة الإنتاج على Agent Engine. ولكن كيف تعرف ما إذا كان يعمل بشكل جيد؟ هل يمكنك الإجابة عن الأسئلة المهمة التالية:
- هل يستجيب الوكيل بسرعة كافية؟
- ما هي العمليات الأبطأ؟
- هل تكتمل حلقات الإصلاح بكفاءة؟
- أين تقع المؤثِّرات السلبية على الأداء؟
بدون إمكانية تتبّع البيانات، ستعمل بشكل غير مدرك للمشاكل. أدّى الخيار --trace-to-cloud الذي استخدمته أثناء عملية النشر إلى تفعيل Cloud Trace تلقائيًا، ما يتيح لك إمكانية الاطّلاع الكامل على كل طلب يعالجه وكيلك. ويحوّل ذلك عملية تصحيح الأخطاء من التخمين إلى التحليل الجنائي.
في هذه الوحدة، ستتعلّم كيفية قراءة عمليات التتبُّع وفهم خصائص أداء وكيلك وتحديد مجالات التحسين استنادًا إلى أدلة قاطعة.
فهم عمليات التتبُّع والنطاقات
ما هي "مسارات التطوير"؟
التتبُّع هو المخطط الزمني الكامل لوكيلك الذي يعالج طلبًا واحدًا. تسجّل هذه السمة كل شيء بدءًا من وقت إرسال المستخدم لطلب البحث وحتى تسليم الرد النهائي. يعرض كل تتبُّع ما يلي:
- إجمالي مدة الطلب
- جميع العمليات التي تم تنفيذها
- كيفية ارتباط العمليات ببعضها البعض (علاقات الأصل والفرع)
- وقت بدء كل عملية وانتهائها
ما هو Span؟
يمثّل النطاق وحدة عمل واحدة ضمن عملية تتبُّع. أنواع الفترات الزمنية الشائعة في أداة مساعدة مراجعة الرموز البرمجية:
-
agent_run: تنفيذ وكيل (وكيل رئيسي أو وكيل فرعي) -
call_llm: طلب إلى نموذج لغوي -
execute_tool: تنفيذ وظيفة الأداة -
state_read/state_write: عمليات إدارة الحالة -
code_executor: تشغيل الرمز مع الاختبارات
تحتوي الفترات على ما يلي:
- الاسم: العملية التي يمثّلها هذا الاسم
- المدة: المدة التي استغرقتها
- السمات: البيانات الوصفية، مثل اسم النموذج وعدد الرموز المميزة والمدخلات/المخرجات
- الحالة: نجاح أو تعذّر
- العلاقات الرئيسية/الثانوية: العمليات التي أدّت إلى تشغيل عمليات أخرى
قياس حالة التطبيق تلقائيًا
عند النشر باستخدام --trace-to-cloud، تعمل حزمة ADK تلقائيًا على قياس ما يلي:
- كل عملية استدعاء لوكيل وكل مكالمة وكيل فرعي
- جميع طلبات النماذج اللغوية الكبيرة مع عدد الرموز المميزة
- عمليات تنفيذ الأدوات مع المدخلات/المخرجات
- عمليات الحالة (قراءة/كتابة)
- تكرار الحلقات في مسار الإصلاح
- حالات الخطأ وعمليات إعادة المحاولة
لا يلزم إجراء أي تغييرات على الرموز البرمجية: ميزة التتبُّع مضمّنة في وقت تشغيل حزمة تطوير التطبيقات.
الخطوة 1: الوصول إلى Cloud Trace Explorer
افتح Cloud Trace في Google Cloud Console:
- انتقِل إلى مستكشف Cloud Trace.
- اختَر مشروعك من القائمة المنسدلة (يجب أن يكون محدّدًا مسبقًا).
- من المفترض أن تظهر لك آثار من اختبارك في الوحدة 7
إذا لم تظهر لك آثار بعد:
من المفترض أنّ الاختبار الذي أجريته في الوحدة التدريبية 7 قد أنشأ عمليات تتبُّع. إذا كانت القائمة فارغة، أنشئ بعض بيانات التتبُّع:
python tests/test_agent_engine.py
انتظِر من دقيقة إلى دقيقتين حتى تظهر عمليات التتبُّع في وحدة التحكّم.
ما الذي تنظر إليه؟
يعرض "مستكشف عمليات التتبُّع" ما يلي:
- قائمة عمليات التتبُّع: يمثّل كل صف طلبًا واحدًا كاملاً
- المخطط الزمني: الوقت الذي حدثت فيه الطلبات
- المدة: المدة التي استغرقها كل طلب
- تفاصيل الطلب: الطابع الزمني، ووقت الاستجابة، وعدد الفترات
هذا هو سجلّ زيارات الإنتاج، فكل تفاعل مع وكيلك ينشئ عملية تتبُّع.
الخطوة 2: فحص تتبُّع مسار المراجعة
انقر على أي تتبُّع في القائمة لفتح عرض الرسم البياني الشلالي.
سيظهر لك مخطط Gantt يعرض المخطط الزمني الكامل للتنفيذ. يمثّل النطاق الجذر invocation الطلب بأكمله. وتتضمّن هذه السمة فترات زمنية لكل وكيل فرعي وأداة وطلب LLM.
قراءة الرسم البياني الشلالي: تحديد الاختناقات
يمثّل كل شريط فترة زمنية. ويشير موضعها الأفقي إلى وقت بدئها، بينما يشير طولها إلى المدة التي استغرقتها. ويكشف هذا الإجراء على الفور عن الأماكن التي يقضي فيها الوكيل وقته.
الإحصاءات الرئيسية من التتبُّع أعلاه:
- إجمالي وقت الاستجابة: استغرق الطلب بأكمله دقيقتَين و28 ثانية.
- تفاصيل الوكيل الفرعي:
-
Code Analyzer: 4.7 ثانية -
Style Checker: 5.3 ثانية Test Runner: دقيقة واحدة و28 ثانية-
Feedback Synthesizer: 47.9 ثانية
-
- تحليل المسار الحرج: يمثّل وكيل
Test Runnerعنق الزجاجة الواضح للأداء، حيث يمثّل حوالي % 59 من إجمالي وقت الطلب.
هذه الإمكانية مفيدة جدًا. بدلاً من تخمين الوقت المستغرَق، يتوفّر لديك دليل ملموس على أنّ Test Runner هو الهدف الواضح إذا كنت بحاجة إلى تحسين وقت الاستجابة.
فحص استخدام الرموز المميزة لتحسين التكلفة
لا تعرض Cloud Trace الوقت فحسب، بل تكشف أيضًا عن التكاليف من خلال تسجيل استخدام الرموز المميزة لكل طلب يتم إرساله إلى نموذج لغوي كبير.
انقر على
call_llm
span ضمن التتبُّع في لوحة التفاصيل، ستجد سمات llm.usage.prompt_tokens وllm.usage.completion_tokens.

ويتيح لك ذلك ما يلي:
- تتبُّع التكاليف على مستوى تفصيلي: يمكنك الاطّلاع على عدد الرموز المميزة التي يستهلكها كل وكيل وأداة.
- تحديد فرص التحسين: إذا كان أحد العملاء يستخدم عددًا كبيرًا بشكل مفاجئ من الرموز المميزة، قد تكون هذه فرصة لتحسين طلبه أو التبديل إلى نموذج أصغر وأكثر فعالية من حيث التكلفة لهذه المهمة المحددة.
الخطوة 3: تحليل تتبُّع Fix Pipeline
تكون عملية إصلاح الأخطاء أكثر تعقيدًا لأنّها تتضمّن LoopAgent. تسهّل Cloud Trace فهم هذا السلوك التكراري.
ابحث عن عملية تتبُّع تتضمّن "FixAttemptLoop" في أسماء النطاقات.
إذا لم يكن لديك واحد، شغِّل نص الاختبار البرمجي وأجب بنعم عندما يُطلب منك تحديد ما إذا كنت تريد إصلاح الرمز.
فحص بنية Loop
يعرض عرض التتبُّع تنفيذ الحلقة بوضوح. إذا تم تشغيل حلقة الإصلاح مرتين قبل أن تنجح، سيظهر لك نطاقا loop_iteration متداخلان ضمن النطاق FixAttemptLoop، ويحتوي كل منهما على دورة كاملة من وكلاء CodeFixer وFixTestRunner وFixValidator.

الملاحظات الرئيسية من تتبُّع حلقة التكرار:
- التحسين التكراري مرئي: يمكنك رؤية النظام وهو يحاول إجراء إصلاح في
loop_iteration: 1، ثم التحقّق منه، ثم إعادة المحاولة فيloop_iteration: 2لأنّه لم يكن مثاليًا. - يمكن قياس التقارب: يمكنك مقارنة مدة كل تكرار ونتائجه لمعرفة كيف تقارب النظام للوصول إلى حلّ صحيح.
- تبسيط عملية تصحيح الأخطاء: إذا تم تنفيذ حلقة لأقصى عدد من التكرارات وظلّت غير ناجحة، يمكنك فحص حالة وسلوك الوكيل ضمن نطاق كل تكرار لتشخيص سبب عدم توافق الإصلاحات.
هذا المستوى من التفاصيل لا يقدّر بثمن لفهم سلوك الحلقات المعقّدة التي تتضمّن حالات وتصحيح أخطائها في مرحلة الإنتاج.
الخطوة 4: الإحصاءات التي حصلت عليها
أنماط الأداء
بعد فحص عمليات التتبُّع، أصبح لديك الآن إحصاءات مستندة إلى البيانات:
مسار المراجعة:
- مؤثِّر سلبي أساسي: إنّ وكيل
Test Runner، وتحديدًا تطبيق الرموز البرمجية وإنشاء الاختبارات المستندة إلى النماذج اللغوية الكبيرة، هو الجزء الأكثر استهلاكًا للوقت في عملية المراجعة. - العمليات السريعة: الأدوات الحتمية (
analyze_code_structure) وعمليات إدارة الحالة سريعة للغاية ولا تشكّل مصدر قلق بشأن الأداء.
إصلاح مسار العرض:
- معدّل التقارب: يمكنك ملاحظة أنّ معظم عمليات الإصلاح تكتمل في تكرار واحد أو تكرارَين، ما يؤكّد أنّ بنية التكرار فعّالة.
- التكلفة التدريجية: قد تستغرق التكرارات اللاحقة وقتًا أطول لأنّ سياق النموذج اللغوي الكبير يزداد مع المعلومات الواردة من المحاولات السابقة غير الناجحة.
العوامل المؤثرة في التكلفة:
- استهلاك الرموز المميزة: يمكنك تحديد العملاء (مثل أدوات التجميع) الذين يحتاجون إلى أكبر عدد من الرموز المميزة وتحديد ما إذا كان استخدام نموذج أكثر قوة ولكن أكثر تكلفة مبررًا لهذه المهمة.
مواضع البحث عن المشاكل
عند مراجعة عمليات التتبُّع في بيئة الإنتاج، ابحث عن ما يلي:
- عمليات تتبُّع طويلة بشكل غير معتاد: تشير إلى انخفاض في الأداء أو سلوك غير متوقّع في التكرار الحلقي.
- المدد الزمنية التي تعذّر تنفيذها (المميّزة باللون الأحمر): تحدّد العملية التي تعذّر تنفيذها بالضبط.
- عدد كبير جدًا من تكرارات الحلقة (>2): قد يشير إلى مشكلة في منطق إنشاء الإصلاح.
- عدد الرموز المميزة المرتفع: يسلّط الضوء على فرص تحسين الطلبات أو تغييرات اختيار النماذج.
ما تعلّمته
من خلال Cloud Trace، يمكنك الآن معرفة كيفية تنفيذ ما يلي:
✅ تصوُّر مسار الطلب: يمكنك الاطّلاع على مسار التنفيذ الكامل من خلال عملياتك المتسلسلة والمستندة إلى الحلقات.
✅ تحديد المؤثّرات السلبية في الأداء: استخدِم المخطط الانحداري للعثور على أبطأ العمليات باستخدام بيانات دقيقة.
✅ تحليل سلوك التكرار: راقِب كيف تتلاقى الوكلاء التكراريون للوصول إلى حلّ على مدار محاولات متعدّدة.
✅ تتبُّع تكاليف الرموز المميزة: يمكنك فحص نطاقات LLM لمراقبة استهلاك الرموز المميزة وتحسينه على مستوى دقيق.
المفاهيم الرئيسية التي تم إتقانها
- عمليات التتبُّع والنطاقات: الوحدات الأساسية لإمكانية تتبّع البيانات، وتمثّل الطلبات والعمليات ضِمنها.
- تحليل المخطط الشلالي: قراءة مخططات غانت لفهم وقت التنفيذ والتبعيات
- تحديد المسار الحرج: العثور على تسلسل العمليات التي تحدّد وقت الاستجابة الإجمالي
- إمكانية المراقبة الدقيقة: إمكانية الاطّلاع ليس فقط على الوقت، بل أيضًا على البيانات الوصفية، مثل عدد الرموز المميزة لكل عملية، ويتم ذلك تلقائيًا من خلال حزمة تطوير التطبيقات (ADK).
الخطوات التالية
مواصلة استكشاف Cloud Trace:
- مراقبة عمليات التتبُّع بانتظام لرصد المشاكل مبكرًا
- مقارنة عمليات التتبُّع لتحديد حالات تراجع الأداء
- استخدام بيانات التتبُّع لاتّخاذ قرارات التحسين
- الفلترة حسب المدة للعثور على الطلبات البطيئة
المراقبة المتقدّمة (اختيارية):
- تصدير عمليات التتبُّع إلى BigQuery لإجراء تحليل معقّد (المستندات)
- إنشاء لوحات بيانات مخصّصة في Cloud Monitoring
- إعداد تنبيهات بشأن تدهور الأداء
- ربط عمليات التتبُّع بسجلّات التطبيقات
9. الخلاصة: من النموذج الأوّلي إلى مرحلة الإصدار
الميزات التي أنشأتها
لقد بدأت بسبعة أسطر فقط من الرموز البرمجية وأنشأت نظام وكيل ذكاء اصطناعي يمكن استخدامه في بيئة إنتاج:
# Where we started (7 lines)
agent = Agent(
model="gemini-2.5-flash",
instruction="Review Python code for issues"
)
# Where we ended (production system)
- Two distinct multi-agent pipelines (review and fix) built from 8 specialized agents.
- An iterative fix loop architecture for automated validation and retries.
- Real AST-based code analysis tools for deterministic, accurate feedback.
- Robust state management using the "constants pattern" for type-safe communication.
- Fully automated deployment to a managed, scalable cloud infrastructure.
- Complete, built-in observability with Cloud Trace for production monitoring.
أنماط التصميم المعماري الرئيسية التي تم إتقانها
نمط | التنفيذ | التأثير على الإنتاج |
دمج الأدوات | تحليل بنية الشجرة المجردة، والتحقّق من الأسلوب | التحقّق من صحة المعلومات، وليس مجرد آراء النماذج اللغوية الكبيرة |
عمليات التسلسل | مراجعة → إصلاح سير العمل | تنفيذ يمكن توقّعه وتصحيح أخطائه |
بنية Loop | إصلاح الأخطاء بشكل متكرّر مع شروط الخروج | التحسين الذاتي حتى تحقيق النجاح |
إدارة الحالة | نمط الثوابت، الذاكرة ذات الطبقات الثلاث | التعامل مع الحالة بطريقة آمنة من حيث النوع وقابلة للصيانة |
نشر الإصدار العلني | Agent Engine من خلال deploy.sh | بنية تحتية مُدارة وقابلة للتوسّع |
إمكانية تتبُّع البيانات | دمج Cloud Trace | إمكانية الاطّلاع الكامل على سلوك الإنتاج |
إحصاءات الإنتاج من عمليات التتبُّع
كشفت بيانات Cloud Trace عن إحصاءات مهمة:
✅ تم تحديد مؤثِّر سلبي: تستغرق طلبات النموذج اللغوي الكبير في TestRunner معظم وقت الاستجابة
✅ أداء الأداة: يتم تنفيذ تحليل AST في 100 ملي ثانية (أداء ممتاز)
✅ معدّل النجاح: يتم دمج عمليات الإصلاح في غضون 2 إلى 3 تكرارات
✅ استخدام الرموز المميزة: حوالي 600 رمز مميز لكل مراجعة، وحوالي 1800 رمز مميز لكل عملية إصلاح
وتساعد هذه الإحصاءات في التحسين المستمر.
تنظيف الموارد (اختياري)
إذا انتهيت من إجراء التجارب وأردت تجنُّب تحمّل رسوم، اتّبِع الخطوات التالية:
حذف عملية نشر Agent Engine:
import vertexai
client = vertexai.Client( # For service interactions via client.agent_engines
project="PROJECT_ID",
location="LOCATION",
)
RESOURCE_NAME = "projects/{PROJECT_ID}/locations/{LOCATION}/reasoningEngines/{RESOURCE_ID}"
client.agent_engines.delete(
name=RESOURCE_NAME,
force=True, # Optional, if the agent has resources (e.g. sessions, memory)
)
حذف خدمة Cloud Run (في حال إنشائها):
gcloud run services delete code-review-assistant \
--region=$GOOGLE_CLOUD_LOCATION \
--quiet
احذف مثيل Cloud SQL (إذا تم إنشاؤه):
gcloud sql instances delete your-project-db \
--quiet
إخلاء مساحة في حِزم التخزين:
gsutil -m rm -r gs://your-project-staging
gsutil -m rm -r gs://your-project-artifacts
الخطوات التالية
بعد إكمال الأساسيات، ننصحك بإجراء التحسينات التالية:
- إضافة المزيد من اللغات: توسيع نطاق الأدوات لتشمل JavaScript وGo وJava
- التكامل مع GitHub: مراجعات تلقائية لطلبات السحب
- تنفيذ التخزين المؤقت: تقليل وقت الاستجابة للأنماط الشائعة
- إضافة وكلاء متخصصين: فحص الأمان، وتحليل الأداء
- تفعيل اختبار A/B: مقارنة النماذج والمطالبات المختلفة
- تصدير المقاييس: إرسال عمليات التتبُّع إلى منصات مراقبة متخصّصة
الخلاصات الرئيسية
- البدء بشكل بسيط والتكرار بسرعة: سبعة أسطر للإنتاج في خطوات يمكن إدارتها
- الأدوات أفضل من الطلبات: التحليل الفعلي لـ AST أفضل من "يُرجى التحقّق من الأخطاء"
- أهمية إدارة الحالة: يمنع نمط الثوابت أخطاء الكتابة
- يجب أن تتضمّن الحلقات شروط الخروج: يجب دائمًا ضبط الحد الأقصى للتكرارات والتصعيد
- النشر باستخدام التشغيل الآلي: يتعامل deploy.sh مع جميع التفاصيل المعقّدة
- إمكانية تتبّع البيانات أمر لا غنى عنه: لا يمكنك تحسين ما لا يمكنك قياسه
مراجع لمواصلة التعلّم
رحلتك مستمرة
لقد أنشأت أكثر من مجرد مساعد لمراجعة الرموز البرمجية، فقد أتقنت أنماط إنشاء أي وكيل ذكاء اصطناعي في بيئة إنتاج:
✅ سير عمل معقّد مع العديد من الوكلاء المتخصّصين
✅ دمج أدوات حقيقية للحصول على إمكانات حقيقية
✅ نشر في بيئة إنتاج مع إمكانية تتبُّع البيانات بشكل سليم
✅ إدارة الحالة للأنظمة التي يمكن صيانتها
تتراوح هذه الأنماط من المساعدين البسيطين إلى الأنظمة المستقلة المعقّدة. ستساعدك الأسس التي وضعتها هنا في التعامل مع بنى الوكلاء الأكثر تعقيدًا.
مرحبًا بك في مرحلة تطوير وكيل الذكاء الاصطناعي الجاهز للنشر. مساعد مراجعة الرموز البرمجية هو مجرد بداية.