
1. The Late Night Code Review
Es ist 2 Uhr morgens
Sie haben stundenlang nach Fehlern gesucht. Die Funktion sieht richtig aus, aber es ist ein Fehler aufgetreten. Sie kennen das sicher: Code sollte funktionieren, tut es aber nicht. Sie haben sich den Code schon so lange angesehen, dass Sie nicht mehr erkennen, warum.
def dfs_search_v1(graph, start, target):
"""Find if target is reachable from start."""
visited = set()
stack = start # Looks innocent enough...
while stack:
current = stack.pop()
if current == target:
return True
if current not in visited:
visited.add(current)
for neighbor in graph[current]:
if neighbor not in visited:
stack.append(neighbor)
return False
Der Weg zum KI-Entwickler
Wenn Sie das hier lesen, haben Sie wahrscheinlich schon selbst erlebt, wie KI das Programmieren verändert. Tools wie Gemini Code Assist, Claude Code und Cursor haben die Art und Weise, wie wir Code schreiben, verändert. Sie sind ideal, um Boilerplate-Code zu generieren, Implementierungen vorzuschlagen und die Entwicklung zu beschleunigen.
Aber Sie sind hier, weil Sie mehr wissen möchten. Sie möchten wissen, wie Sie diese KI-Systeme erstellen, nicht nur wie Sie sie verwenden. Sie möchten etwas erstellen, das
- Verhält sich vorhersehbar und nachvollziehbar
- Kann zuverlässig in der Produktion bereitgestellt werden
- Konsistente Ergebnisse, auf die Sie sich verlassen können
- Sie sehen genau, wie Entscheidungen getroffen werden.
Vom Konsumenten zum Creator
Heute werden Sie den Sprung von der Nutzung von KI‑Tools zur Entwicklung von KI‑Tools machen. Sie erstellen ein Multi-Agenten-System, das Folgendes kann:
- Analysiert die Codestruktur deterministisch
- Führt tatsächliche Tests aus, um das Verhalten zu überprüfen
- Validiert die Einhaltung von Stilrichtlinien mit echten Lintern
- Fasst die Ergebnisse zu umsetzbarem Feedback zusammen
- Bereitstellungen in Google Cloud mit vollständiger Beobachtbarkeit
2. Erste Bereitstellung eines KI-Agenten
Die Frage des Entwicklers
„Ich kenne mich mit LLMs aus und habe die APIs verwendet, aber wie entwickle ich aus einem Python-Script einen KI-Agenten für die Produktion, der skaliert?“
Wir beantworten diese Frage, indem wir Ihre Umgebung richtig einrichten und dann einen einfachen Agenten erstellen, um die Grundlagen zu verstehen, bevor wir uns mit Produktionsmustern befassen.
Wichtige Einrichtungsschritte zuerst
Bevor wir Agenten erstellen, müssen wir sicherstellen, dass Ihre Google Cloud-Umgebung bereit ist.
Klicken Sie oben in der Google Cloud Console auf Cloud Shell aktivieren (das Symbol mit der Terminalform oben im Cloud Shell-Bereich).
So finden Sie Ihre Google Cloud-Projekt-ID:
- Öffnen Sie die Google Cloud Console: https://console.cloud.google.com.
- Wählen Sie oben auf der Seite im Drop-down-Menü das Projekt aus, das Sie für diesen Workshop verwenden möchten.
- Ihre Projekt-ID wird auf der Karte „Projektinformationen“ im Dashboard
 angezeigt.
angezeigt.
Schritt 1: Projekt-ID festlegen
In Cloud Shell ist das gcloud-Befehlszeilentool bereits konfiguriert. Führen Sie den folgenden Befehl aus, um Ihr aktives Projekt festzulegen. Dabei wird die Umgebungsvariable $GOOGLE_CLOUD_PROJECT verwendet, die automatisch für Sie in Ihrer Cloud Shell-Sitzung festgelegt wird.
gcloud config set project $GOOGLE_CLOUD_PROJECT
Schritt 2: Einrichtung überprüfen
Führen Sie als Nächstes die folgenden Befehle aus, um zu bestätigen, dass Ihr Projekt richtig festgelegt ist und Sie authentifiziert sind.
# Confirm project is set
echo "Current project: $(gcloud config get-value project)"
# Check authentication status
gcloud auth list
Ihre Projekt-ID sollte angezeigt werden und Ihr Nutzerkonto mit (ACTIVE) daneben.
Wenn Ihr Konto nicht als aktiv aufgeführt wird oder Sie einen Authentifizierungsfehler erhalten, führen Sie den folgenden Befehl aus, um sich anzumelden:
gcloud auth application-default login
Schritt 3: Wichtige APIs aktivieren
Für den Basis-Agenten sind mindestens diese APIs erforderlich:
gcloud services enable \
aiplatform.googleapis.com \
compute.googleapis.com
Dies kann ein oder zwei Minuten dauern. Sie sehen hier Folgendes:
Operation "operations/..." finished successfully.
Schritt 4: ADK installieren
# Install the ADK CLI
pip install google-adk --upgrade
# Verify installation
adk --version
Sie sollten eine Versionsnummer wie 1.15.0 oder höher sehen.
Basis-Agent erstellen
Nachdem die Umgebung eingerichtet ist, erstellen wir den einfachen Agenten.
Schritt 5: ADK Create verwenden
adk create my_first_agent
Folgen Sie den interaktiven Aufforderungen:
Choose a model for the root agent:
1. gemini-2.5-flash
2. Other models (fill later)
Choose model (1, 2): 1
1. Google AI
2. Vertex AI
Choose a backend (1, 2): 2
Enter Google Cloud project ID [auto-detected-from-gcloud]:
Enter Google Cloud region [us-central1]:
Schritt 6: Erstellte Elemente prüfen
cd my_first_agent
ls -la
Sie finden drei Dateien:
.env # Configuration (auto-populated with your project)
__init__.py # Package marker
agent.py # Your agent definition
Schritt 7: Konfiguration schnell prüfen
# Verify the .env was created correctly
cat .env
# Should show something like:
# GOOGLE_CLOUD_PROJECT=your-project-id
# GOOGLE_CLOUD_LOCATION=us-central1
# GOOGLE_GENAI_USE_VERTEXAI=1
Wenn die Projekt-ID fehlt oder falsch ist, bearbeiten Sie die Datei .env:
nano .env # or use your preferred editor
Schritt 8: Agent-Code ansehen
cat agent.py
from google.adk.agents.llm_agent import Agent
root_agent = Agent(
model='gemini-2.5-flash',
name='root_agent',
description='A helpful assistant for user questions.',
instruction='Answer user questions to the best of your knowledge',
)
Einfach, klar, minimalistisch. Das ist Ihr „Hallo Welt“ für Agents.
Basis-Agent testen
Schritt 9: Agent ausführen
cd ..
adk run my_first_agent
Sie sollte etwa so aussehen:
Log setup complete: /tmp/agents_log/agent.20250930_162430.log
To access latest log: tail -F /tmp/agents_log/agent.latest.log
[user]:
Schritt 10: Suchanfragen ausprobieren
Im Terminal, in dem adk run ausgeführt wird, wird ein Prompt angezeigt. Geben Sie Ihre Anfragen ein:
[user]: Hey, what can you do?
[root_agent]: I can help answer questions, generate text, explain concepts, assist with problem-solving, and provide information on a wide range of topics. What would you like to know or discuss?
[user]: What's the current weather in Mountain View?
[root_agent]: I'm sorry, but I cannot provide real-time weather information as I don't have access to current data or weather services. To get the current weather in Mountain View, I recommend checking a weather website or app like weather.com or using a search engine.
Beachten Sie die Einschränkung: Auf aktuelle Daten kann nicht zugegriffen werden. Wir gehen noch einen Schritt weiter:
[user]: Review this Python code: def add(a, b): return a + b
[root_agent]: This is a simple Python function that adds two numbers. Here's my review:
**Strengths:**
- Clean and concise implementation
- Follows Python conventions for simple operations
- Clear function name that describes its purpose
**Suggestions for improvement:**
- Add a docstring to document the function
- Consider adding type hints for better code clarity
- You might want to handle edge cases
Here's an enhanced version:
def add(a: float, b: float) -> float:
"""Add two numbers and return their sum."""
return a + b
Der Agent kann Code diskutieren, aber kann er:
- AST tatsächlich parsen, um die Struktur zu verstehen?
- Tests ausführen, um zu prüfen, ob es funktioniert?
- Stilkonformität prüfen?
- Erinnern Sie sich an Ihre bisherigen Rezensionen?
Nein. Hier benötigen wir Architektur.
🏃🚪 Beenden mit
Ctrl+C
wenn Sie mit dem Erkunden fertig sind.
3. Produktionsarbeitsbereich vorbereiten
Die Lösung: Eine produktionsreife Architektur
Dieser einfache KI-Agent hat den Ausgangspunkt gezeigt, aber ein Produktionssystem erfordert eine robuste Struktur. Wir richten jetzt ein vollständiges Projekt ein, das Produktionsprinzipien verkörpert.
Grundlage schaffen
Sie haben Ihr Google Cloud-Projekt bereits für den einfachen Agenten konfiguriert. Jetzt bereiten wir den vollständigen Produktionsarbeitsbereich mit allen Tools, Mustern und der Infrastruktur vor, die für ein echtes System erforderlich sind.
Schritt 1: Strukturiertes Projekt abrufen
Beenden Sie zuerst alle laufenden adk run mit Ctrl+C und bereinigen Sie:
# Clean up the basic agent
cd ~ # Make sure you're not inside my_first_agent
rm -rf my_first_agent
# Get the production scaffold
git clone https://github.com/ayoisio/adk-code-review-assistant.git
cd adk-code-review-assistant
git checkout codelab
Schritt 2: Virtuelle Umgebung erstellen und aktivieren
# Create the virtual environment
python -m venv .venv
# Activate it
# On macOS/Linux:
source .venv/bin/activate
# On Windows:
# .venv\Scripts\activate
Bestätigung: Ihr Prompt sollte jetzt mit (.venv) beginnen.
Schritt 3: Abhängigkeiten installieren
pip install -r code_review_assistant/requirements.txt
# Install the package in editable mode (enables imports)
pip install -e .
Damit wird Folgendes installiert:
google-adk– Das ADK-Frameworkpycodestyle– Für PEP 8-Prüfungvertexai– Für die Cloud-Bereitstellung- Weitere Produktionsabhängigkeiten
Mit dem Flag -e können Sie code_review_assistant-Module von überall aus importieren.
Schritt 4: Umgebung konfigurieren
# Copy the example environment file
cp .env.example .env
# Edit .env and replace the placeholders:
# - GOOGLE_CLOUD_PROJECT=your-project-id → your actual project ID
# - Keep other defaults as-is
Bestätigung: Konfiguration prüfen:
cat .env
Es sollte Folgendes angezeigt werden:
GOOGLE_CLOUD_PROJECT=your-actual-project-id
GOOGLE_CLOUD_LOCATION=us-central1
GOOGLE_GENAI_USE_VERTEXAI=TRUE
Schritt 5: Authentifizierung sicherstellen
Da Sie gcloud auth bereits ausgeführt haben, prüfen wir Folgendes:
# Check current authentication
gcloud auth list
# Should show your account with (ACTIVE)
# If not, run:
gcloud auth application-default login
Schritt 6: Zusätzliche Produktions-APIs aktivieren
Wir haben bereits grundlegende APIs aktiviert. Fügen Sie nun die Produktions-IDs hinzu:
gcloud services enable \
sqladmin.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
storage.googleapis.com \
cloudtrace.googleapis.com
Dies ermöglicht Ihnen Folgendes:
- SQL-Administrator: Für Cloud SQL bei Verwendung von Cloud Run
- Cloud Run: Für die serverlose Bereitstellung
- Cloud Build: Für automatisierte Bereitstellungen
- Artifact Registry: Für Container-Images
- Cloud Storage: Für Artefakte und Staging
- Cloud Trace: Für die Beobachtbarkeit
Schritt 7: Artifact Registry-Repository erstellen
Bei der Bereitstellung werden Container-Images erstellt, die einen Speicherort benötigen:
gcloud artifacts repositories create code-review-assistant-repo \
--repository-format=docker \
--location=us-central1 \
--description="Docker repository for Code Review Assistant"
Hier sollten Sie dies sehen:
Created repository [code-review-assistant-repo].
Wenn sie bereits vorhanden ist (vielleicht aus einem früheren Versuch), ist das in Ordnung. Sie sehen dann eine Fehlermeldung, die Sie ignorieren können.
Schritt 8: IAM-Berechtigungen erteilen
# Get your project number
PROJECT_NUMBER=$(gcloud projects describe $GOOGLE_CLOUD_PROJECT \
--format="value(projectNumber)")
# Define the service account
SERVICE_ACCOUNT="${PROJECT_NUMBER}@cloudbuild.gserviceaccount.com"
# Grant necessary roles
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SERVICE_ACCOUNT}" \
--role="roles/run.admin"
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SERVICE_ACCOUNT}" \
--role="roles/iam.serviceAccountUser"
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SERVICE_ACCOUNT}" \
--role="roles/cloudsql.admin"
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SERVICE_ACCOUNT}" \
--role="roles/storage.admin"
Jeder Befehl gibt Folgendes aus:
Updated IAM policy for project [your-project-id].
Ihr Lernerfolg
Ihr Produktionsarbeitsbereich ist jetzt vollständig vorbereitet:
✅ Google Cloud-Projekt konfiguriert und authentifiziert
✅ Einfacher Agent getestet, um Einschränkungen zu verstehen
✅ Projektcode mit strategischen Platzhaltern bereit
✅ Abhängigkeiten in virtueller Umgebung isoliert
✅ Alle erforderlichen APIs aktiviert
✅ Container Registry für Bereitstellungen bereit
✅ IAM-Berechtigungen richtig konfiguriert
✅ Umgebungsvariablen richtig festgelegt
Jetzt können Sie ein echtes KI-System mit deterministischen Tools, Statusverwaltung und einer geeigneten Architektur erstellen.
4. Ersten KI-Agenten erstellen
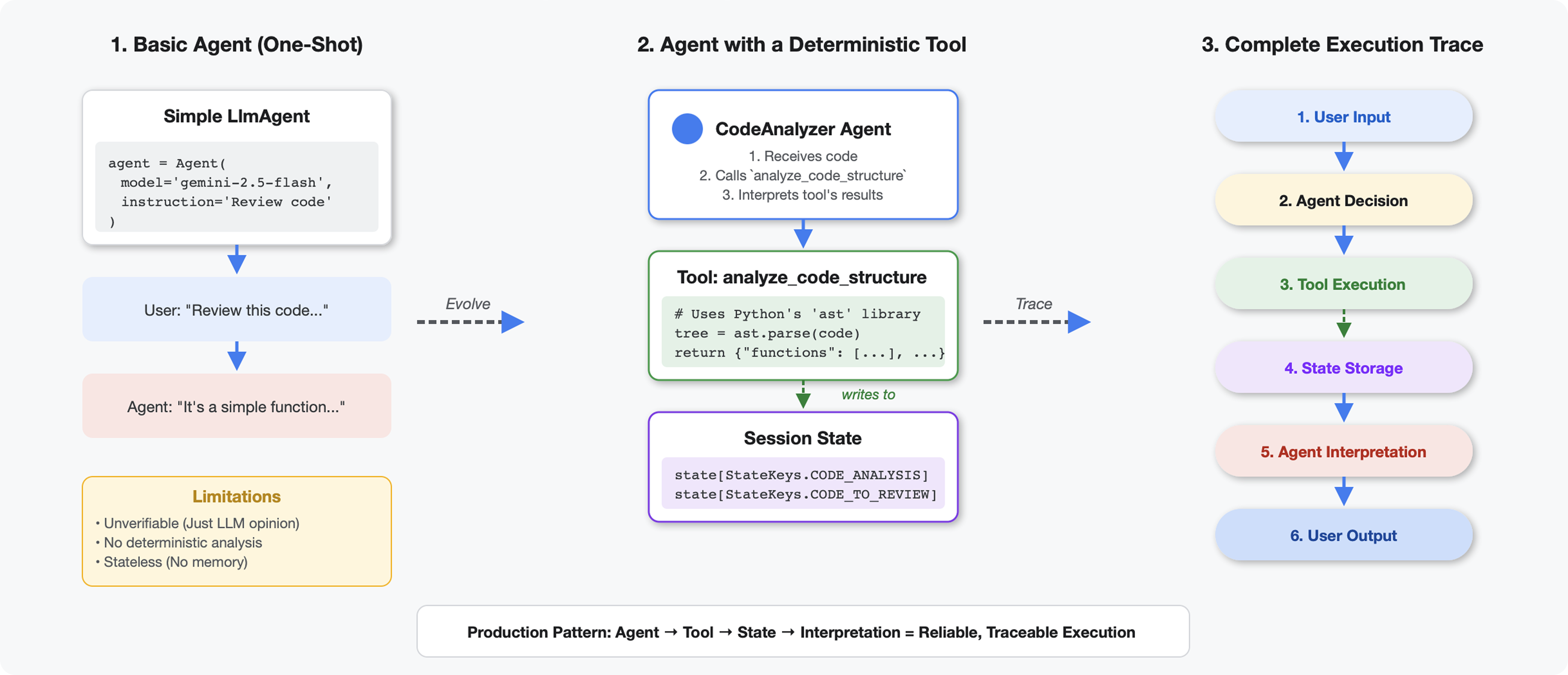
Was unterscheidet Tools von LLMs?
Wenn Sie ein LLM fragen, wie viele Funktionen in diesem Code enthalten sind, verwendet es Mustervergleich und Schätzung. Wenn Sie ein Tool verwenden, das ast.parse() von Python aufruft, wird der tatsächliche Syntaxbaum analysiert. Es wird nicht geraten und das Ergebnis ist jedes Mal dasselbe.
In diesem Abschnitt wird ein Tool erstellt, das die Codestruktur deterministisch analysiert und dann mit einem Agent verbunden wird, der weiß, wann es aufgerufen werden muss.
Schritt 1: Das Gerüst verstehen
Sehen wir uns die Struktur an, die Sie ausfüllen müssen.
👉 Offen
code_review_assistant/tools.py
Die analyze_code_structure-Funktion wird mit Platzhalterkommentaren angezeigt, die angeben, wo Sie Code hinzufügen müssen. Die Funktion hat bereits die grundlegende Struktur – Sie werden sie Schritt für Schritt erweitern.
Schritt 2: Status-Speicher hinzufügen
Durch die Speicherung des Status können andere Agents in der Pipeline auf die Ergebnisse Ihres Tools zugreifen, ohne dass die Analyse noch einmal ausgeführt werden muss.
👉 Finden:
# MODULE_4_STEP_2_ADD_STATE_STORAGE
👉 Ersetzen Sie diese einzelne Zeile durch:
# Store code and analysis for other agents to access
tool_context.state[StateKeys.CODE_TO_REVIEW] = code
tool_context.state[StateKeys.CODE_ANALYSIS] = analysis
tool_context.state[StateKeys.CODE_LINE_COUNT] = len(code.splitlines())
Schritt 3: Asynchrone Analyse mit Thread-Pools hinzufügen
Unser Tool muss den AST parsen, ohne andere Vorgänge zu blockieren. Fügen wir die asynchrone Ausführung mit Thread-Pools hinzu.
👉 Finden:
# MODULE_4_STEP_3_ADD_ASYNC
👉 Ersetzen Sie diese einzelne Zeile durch:
# Parse in thread pool to avoid blocking the event loop
loop = asyncio.get_event_loop()
with ThreadPoolExecutor() as executor:
tree = await loop.run_in_executor(executor, ast.parse, code)
Schritt 4: Umfassende Informationen extrahieren
Jetzt extrahieren wir Klassen, Importe und detaillierte Messwerte – alles, was wir für eine vollständige Codeüberprüfung benötigen.
👉 Finden:
# MODULE_4_STEP_4_EXTRACT_DETAILS
👉 Ersetzen Sie diese einzelne Zeile durch:
# Extract comprehensive structural information
analysis = await loop.run_in_executor(
executor, _extract_code_structure, tree, code
)
👉 Funktion bestätigen
analyze_code_structure
in
tools.py
hat einen zentralen Textkörper, der so aussieht:
# Parse in thread pool to avoid blocking the event loop
loop = asyncio.get_event_loop()
with ThreadPoolExecutor() as executor:
tree = await loop.run_in_executor(executor, ast.parse, code)
# Extract comprehensive structural information
analysis = await loop.run_in_executor(
executor, _extract_code_structure, tree, code
)
# Store code and analysis for other agents to access
tool_context.state[StateKeys.CODE_TO_REVIEW] = code
tool_context.state[StateKeys.CODE_ANALYSIS] = analysis
tool_context.state[StateKeys.CODE_LINE_COUNT] = len(code.splitlines())
👉 Scrollen Sie nun ganz nach unten.
tools.py
und finden:
# MODULE_4_STEP_4_HELPER_FUNCTION
👉 Ersetzen Sie diese einzelne Zeile durch die vollständige Hilfsfunktion:
def _extract_code_structure(tree: ast.AST, code: str) -> Dict[str, Any]:
"""
Helper function to extract structural information from AST.
Runs in thread pool for CPU-bound work.
"""
functions = []
classes = []
imports = []
docstrings = []
for node in ast.walk(tree):
if isinstance(node, ast.FunctionDef):
func_info = {
'name': node.name,
'args': [arg.arg for arg in node.args.args],
'lineno': node.lineno,
'has_docstring': ast.get_docstring(node) is not None,
'is_async': isinstance(node, ast.AsyncFunctionDef),
'decorators': [d.id for d in node.decorator_list
if isinstance(d, ast.Name)]
}
functions.append(func_info)
if func_info['has_docstring']:
docstrings.append(f"{node.name}: {ast.get_docstring(node)[:50]}...")
elif isinstance(node, ast.ClassDef):
methods = []
for item in node.body:
if isinstance(item, ast.FunctionDef):
methods.append(item.name)
class_info = {
'name': node.name,
'lineno': node.lineno,
'methods': methods,
'has_docstring': ast.get_docstring(node) is not None,
'base_classes': [base.id for base in node.bases
if isinstance(base, ast.Name)]
}
classes.append(class_info)
elif isinstance(node, ast.Import):
for alias in node.names:
imports.append({
'module': alias.name,
'alias': alias.asname,
'type': 'import'
})
elif isinstance(node, ast.ImportFrom):
imports.append({
'module': node.module or '',
'names': [alias.name for alias in node.names],
'type': 'from_import',
'level': node.level
})
return {
'functions': functions,
'classes': classes,
'imports': imports,
'docstrings': docstrings,
'metrics': {
'line_count': len(code.splitlines()),
'function_count': len(functions),
'class_count': len(classes),
'import_count': len(imports),
'has_main': any(f['name'] == 'main' for f in functions),
'has_if_main': '__main__' in code,
'avg_function_length': _calculate_avg_function_length(tree)
}
}
def _calculate_avg_function_length(tree: ast.AST) -> float:
"""Calculate average function length in lines."""
function_lengths = []
for node in ast.walk(tree):
if isinstance(node, ast.FunctionDef):
if hasattr(node, 'end_lineno') and hasattr(node, 'lineno'):
length = node.end_lineno - node.lineno + 1
function_lengths.append(length)
if function_lengths:
return sum(function_lengths) / len(function_lengths)
return 0.0
Schritt 5: Mit einem Kundenservicemitarbeiter verbinden
Jetzt verbinden wir das Tool mit einem Agent, der weiß, wann es verwendet werden muss und wie die Ergebnisse zu interpretieren sind.
👉 Offen
code_review_assistant/sub_agents/review_pipeline/code_analyzer.py
👉 Finden:
# MODULE_4_STEP_5_CREATE_AGENT
👉 Ersetzen Sie diese einzelne Zeile durch den vollständigen Produktions-Agenten:
code_analyzer_agent = Agent(
name="CodeAnalyzer",
model=config.worker_model,
description="Analyzes Python code structure and identifies components",
instruction="""You are a code analysis specialist responsible for understanding code structure.
Your task:
1. Take the code submitted by the user (it will be provided in the user message)
2. Use the analyze_code_structure tool to parse and analyze it
3. Pass the EXACT code to your tool - do not modify, fix, or "improve" it
4. Identify all functions, classes, imports, and structural patterns
5. Note any syntax errors or structural issues
6. Store the analysis in state for other agents to use
CRITICAL:
- Pass the code EXACTLY as provided to the analyze_code_structure tool
- Do not fix syntax errors, even if obvious
- Do not add missing imports or fix indentation
- The goal is to analyze what IS there, not what SHOULD be there
When calling the tool, pass the code as a string to the 'code' parameter.
If the analysis fails due to syntax errors, clearly report the error location and type.
Provide a clear summary including:
- Number of functions and classes found
- Key structural observations
- Any syntax errors or issues detected
- Overall code organization assessment""",
tools=[FunctionTool(func=analyze_code_structure)],
output_key="structure_analysis_summary"
)
Code Analyzer testen
Prüfen Sie nun, ob der Analyzer ordnungsgemäß funktioniert.
👉 Testskript ausführen:
python tests/test_code_analyzer.py
Das Testskript lädt die Konfiguration automatisch aus Ihrer .env-Datei mit python-dotenv. Eine manuelle Einrichtung von Umgebungsvariablen ist also nicht erforderlich.
Erwartete Ausgabe:
INFO:code_review_assistant.config:Code Review Assistant Configuration Loaded:
INFO:code_review_assistant.config: - GCP Project: your-project-id
INFO:code_review_assistant.config: - Artifact Bucket: gs://your-project-artifacts
INFO:code_review_assistant.config: - Models: worker=gemini-2.5-flash, critic=gemini-2.5-pro
Testing code analyzer...
INFO:code_review_assistant.tools:Tool: Analysis complete - 2 functions, 1 classes
=== Analyzer Response ===
The analysis of the provided code shows the following:
* **Functions Found:** 2
* `add(a, b)`: A global function at line 2.
* `multiply(self, x, y)`: A method within the `Calculator` class.
* **Classes Found:** 1
* `Calculator`: A class defined at line 5. Contains one method, `multiply`.
* **Imports:** 0
* **Structural Patterns:** The code defines one global function and one class
with a single method. Both are simple, each with a single return statement.
* **Syntax Errors/Issues:** No syntax errors detected.
* **Overall Code Organization:** The code is well-organized for its small size,
clearly defining a function and a class with a method.
Was ist gerade passiert?
- Das Testskript hat Ihre
.env-Konfiguration automatisch geladen. - Ihr
analyze_code_structure()-Tool hat den Code mit dem AST von Python geparst. - Der
_extract_code_structure()-Helfer hat Funktionen, Klassen und Messwerte extrahiert. - Die Ergebnisse wurden mithilfe von
StateKeys-Konstanten im Sitzungsstatus gespeichert. - Der Code Analyzer-Agent hat die Ergebnisse interpretiert und eine Zusammenfassung erstellt.
Fehlerbehebung:
- „No module named ‘code_review_assistant'“: Führen Sie
pip install -e .über das Projektstammverzeichnis aus. - „Missing key inputs argument“: Prüfen Sie, ob Ihr
.envdie ParameterGOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_LOCATIONundGOOGLE_GENAI_USE_VERTEXAI=trueenthält.
Was Sie erstellt haben
Sie haben jetzt einen produktionsreifen Code-Analyzer, der:
✅ Analysiert den tatsächlichen Python-AST – deterministisch, kein Musterabgleich
✅ Speichert Ergebnisse im Status – andere Agents können auf die Analyse zugreifen
✅ Wird asynchron ausgeführt – blockiert keine anderen Tools
✅ Extrahiert umfassende Informationen – Funktionen, Klassen, Importe, Messwerte
✅ Verarbeitet Fehler ordnungsgemäß – meldet Syntaxfehler mit Zeilennummern
✅ Stellt eine Verbindung zu einem Agent her – das LLM weiß, wann und wie es verwendet werden muss
Kennengelernte zentrale Konzepte
Tools im Vergleich zu Agents:
- Tools führen deterministische Aufgaben aus (AST-Parsing).
- Agents entscheiden, wann Tools verwendet werden, und interpretieren Ergebnisse.
Rückgabewert im Vergleich zum Status:
- Rückgabe: Was das LLM sofort sieht
- Zustand: Was für andere KI-Agenten erhalten bleibt
Konstanten für Status-Schlüssel:
- Tippfehler in Multi-Agenten-Systemen vermeiden
- Als Verträge zwischen Agenten fungieren
- Wichtig, wenn KI-Agenten Daten weitergeben
Async + Thread-Pools:
async defermöglicht es Tools, die Ausführung zu pausieren.- Threadpools führen CPU-intensive Aufgaben im Hintergrund aus
- Zusammen sorgen sie dafür, dass die Ereignisschleife reaktionsfähig bleibt.
Hilfsfunktionen:
- Synchronisierungshilfen von asynchronen Tools trennen
- Code wird testbar und wiederverwendbar
Anweisungen für Kundenservicemitarbeiter:
- Detaillierte Anweisungen verhindern häufige LLM-Fehler
- Explizit angeben, was NICHT zu tun ist (keinen Code korrigieren)
- Workflow-Schritte für Konsistenz löschen
Weitere Informationen
In Modul 5 fügen Sie Folgendes hinzu:
- Stilprüfung, die den Code aus dem Status liest
- Test-Runner, der Tests tatsächlich ausführt
- Feedback-Synthesizer, der alle Analysen kombiniert
Sie sehen, wie der Status durch eine sequenzielle Pipeline fließt und warum das Konstantenmuster wichtig ist, wenn mehrere Agents dieselben Daten lesen und schreiben.
5. Pipeline erstellen: Mehrere Agents arbeiten zusammen
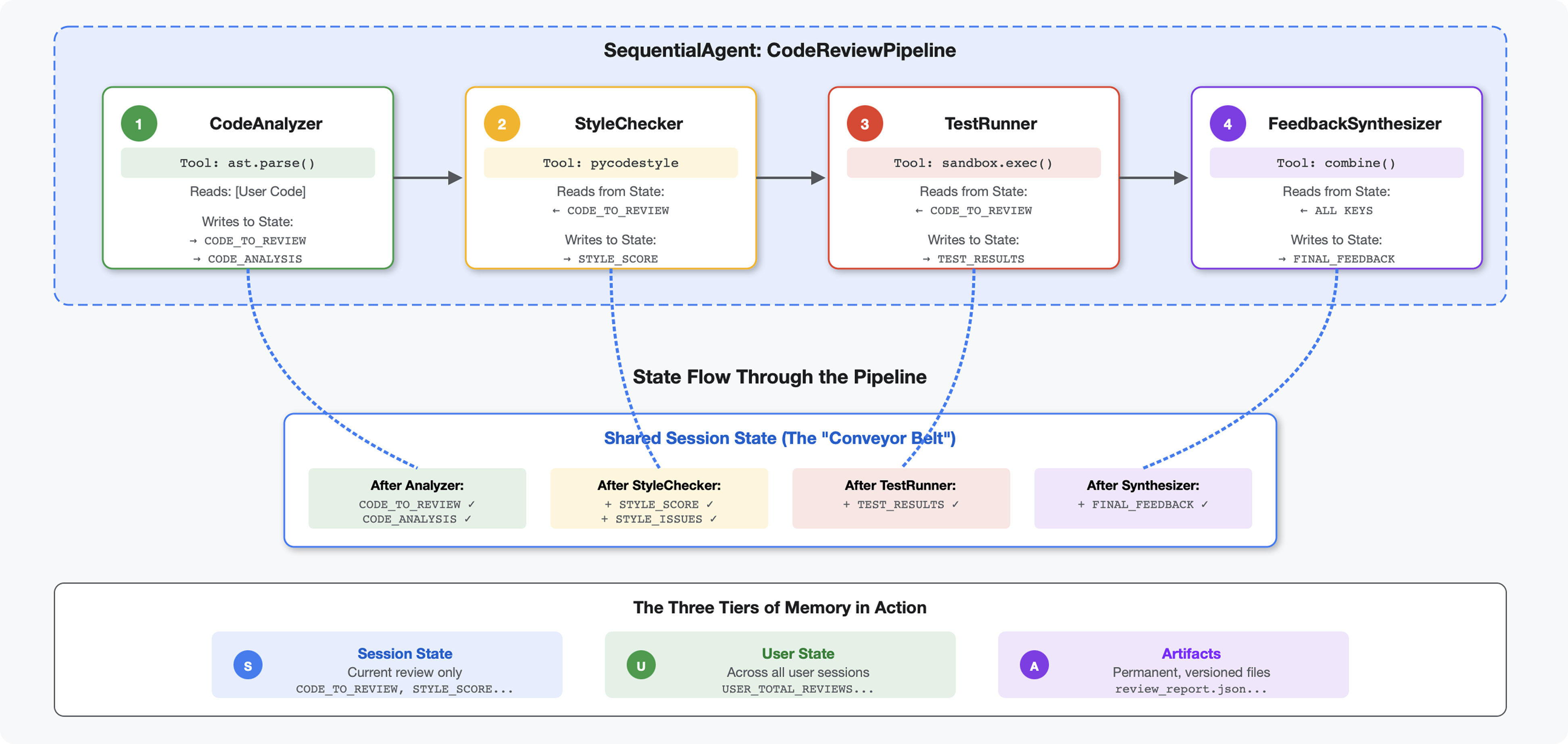
Einführung
In Modul 4 haben Sie einen einzelnen Agenten erstellt, der die Codestruktur analysiert. Für eine umfassende Codeüberprüfung ist jedoch mehr als nur das Parsen erforderlich. Sie benötigen Stilprüfungen, die Ausführung von Tests und eine intelligente Synthese von Feedback.
In diesem Modul wird eine Pipeline mit vier Agenten erstellt, die sequenziell zusammenarbeiten und jeweils eine spezielle Analyse durchführen:
- Code Analyzer (aus Modul 4): Analysiert die Struktur
- Stilprüfung: Identifiziert Stilverstöße
- Test Runner: Führt Tests aus und validiert sie.
- Feedback Synthesizer: Kombiniert alles zu umsetzbarem Feedback
Schlüsselkonzept: Status als Kommunikationskanal Jeder Agent liest, was vorherige Agents geschrieben haben, fügt seine eigene Analyse hinzu und übergibt den angereicherten Status an den nächsten Agent. Das Konstantenmuster aus Modul 4 ist entscheidend, wenn mehrere Agents Daten gemeinsam nutzen.
Vorschau auf das, was Sie erstellen werden:Sie senden unsauberen Code → der Status wird durch 4 Agents geleitet → Sie erhalten einen umfassenden Bericht mit personalisiertem Feedback basierend auf früheren Mustern.
Schritt 1: Style Checker-Tool und -Agent hinzufügen
Der Style-Checker erkennt PEP 8-Verstöße mithilfe von pycodestyle, einem deterministischen Linter, der nicht auf LLM-basierter Interpretation beruht.
Tool zur Stilprüfung hinzufügen
👉 Offen
code_review_assistant/tools.py
👉 Finden:
# MODULE_5_STEP_1_STYLE_CHECKER_TOOL
👉 Ersetzen Sie diese einzelne Zeile durch:
async def check_code_style(code: str, tool_context: ToolContext) -> Dict[str, Any]:
"""
Checks code style compliance using pycodestyle (PEP 8).
Args:
code: Python source code to check (or will retrieve from state)
tool_context: ADK tool context
Returns:
Dictionary containing style score and issues
"""
logger.info("Tool: Checking code style...")
try:
# Retrieve code from state if not provided
if not code:
code = tool_context.state.get(StateKeys.CODE_TO_REVIEW, '')
if not code:
return {
"status": "error",
"message": "No code provided or found in state"
}
# Run style check in thread pool
loop = asyncio.get_event_loop()
with ThreadPoolExecutor() as executor:
result = await loop.run_in_executor(
executor, _perform_style_check, code
)
# Store results in state
tool_context.state[StateKeys.STYLE_SCORE] = result['score']
tool_context.state[StateKeys.STYLE_ISSUES] = result['issues']
tool_context.state[StateKeys.STYLE_ISSUE_COUNT] = result['issue_count']
logger.info(f"Tool: Style check complete - Score: {result['score']}/100, "
f"Issues: {result['issue_count']}")
return result
except Exception as e:
error_msg = f"Style check failed: {str(e)}"
logger.error(f"Tool: {error_msg}", exc_info=True)
# Set default values on error
tool_context.state[StateKeys.STYLE_SCORE] = 0
tool_context.state[StateKeys.STYLE_ISSUES] = []
return {
"status": "error",
"message": error_msg,
"score": 0
}
👉 Scrollen Sie nun zum Ende der Datei und suchen Sie nach:
# MODULE_5_STEP_1_STYLE_HELPERS
👉 Ersetzen Sie diese einzelne Zeile durch die Hilfsfunktionen:
def _perform_style_check(code: str) -> Dict[str, Any]:
"""Helper to perform style check in thread pool."""
import io
import sys
with tempfile.NamedTemporaryFile(mode='w', suffix='.py', delete=False) as tmp:
tmp.write(code)
tmp_path = tmp.name
try:
# Capture stdout to get pycodestyle output
old_stdout = sys.stdout
sys.stdout = captured_output = io.StringIO()
style_guide = pycodestyle.StyleGuide(
quiet=False, # We want output
max_line_length=100,
ignore=['E501', 'W503']
)
result = style_guide.check_files([tmp_path])
# Restore stdout
sys.stdout = old_stdout
# Parse captured output
output = captured_output.getvalue()
issues = []
for line in output.strip().split('\n'):
if line and ':' in line:
parts = line.split(':', 4)
if len(parts) >= 4:
try:
issues.append({
'line': int(parts[1]),
'column': int(parts[2]),
'code': parts[3].split()[0] if len(parts) > 3 else 'E000',
'message': parts[3].strip() if len(parts) > 3 else 'Unknown error'
})
except (ValueError, IndexError):
pass
# Add naming convention checks
try:
tree = ast.parse(code)
naming_issues = _check_naming_conventions(tree)
issues.extend(naming_issues)
except SyntaxError:
pass # Syntax errors will be caught elsewhere
# Calculate weighted score
score = _calculate_style_score(issues)
return {
"status": "success",
"score": score,
"issue_count": len(issues),
"issues": issues[:10], # First 10 issues
"summary": f"Style score: {score}/100 with {len(issues)} violations"
}
finally:
if os.path.exists(tmp_path):
os.unlink(tmp_path)
def _check_naming_conventions(tree: ast.AST) -> List[Dict[str, Any]]:
"""Check PEP 8 naming conventions."""
naming_issues = []
for node in ast.walk(tree):
if isinstance(node, ast.FunctionDef):
# Skip private/protected methods and __main__
if not node.name.startswith('_') and node.name != node.name.lower():
naming_issues.append({
'line': node.lineno,
'column': node.col_offset,
'code': 'N802',
'message': f"N802 function name '{node.name}' should be lowercase"
})
elif isinstance(node, ast.ClassDef):
# Check if class name follows CapWords convention
if not node.name[0].isupper() or '_' in node.name:
naming_issues.append({
'line': node.lineno,
'column': node.col_offset,
'code': 'N801',
'message': f"N801 class name '{node.name}' should use CapWords convention"
})
return naming_issues
def _calculate_style_score(issues: List[Dict[str, Any]]) -> int:
"""Calculate weighted style score based on violation severity."""
if not issues:
return 100
# Define weights by error type
weights = {
'E1': 10, # Indentation errors
'E2': 3, # Whitespace errors
'E3': 5, # Blank line errors
'E4': 8, # Import errors
'E5': 5, # Line length
'E7': 7, # Statement errors
'E9': 10, # Syntax errors
'W2': 2, # Whitespace warnings
'W3': 2, # Blank line warnings
'W5': 3, # Line break warnings
'N8': 7, # Naming conventions
}
total_deduction = 0
for issue in issues:
code_prefix = issue['code'][:2] if len(issue['code']) >= 2 else 'E2'
weight = weights.get(code_prefix, 3)
total_deduction += weight
# Cap at 100 points deduction
return max(0, 100 - min(total_deduction, 100))
Style Checker-Agent hinzufügen
👉 Offen
code_review_assistant/sub_agents/review_pipeline/style_checker.py
👉 Finden:
# MODULE_5_STEP_1_INSTRUCTION_PROVIDER
👉 Ersetzen Sie diese einzelne Zeile durch:
async def style_checker_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are a code style expert focused on PEP 8 compliance.
Your task:
1. Use the check_code_style tool to validate PEP 8 compliance
2. The tool will retrieve the ORIGINAL code from state automatically
3. Report violations exactly as found
4. Present the results clearly and confidently
CRITICAL:
- The tool checks the code EXACTLY as provided by the user
- Do not suggest the code was modified or fixed
- Report actual violations found in the original code
- If there are style issues, they should be reported honestly
Call the check_code_style tool with an empty string for the code parameter,
as the tool will retrieve the code from state automatically.
When presenting results based on what the tool returns:
- State the exact score from the tool results
- If score >= 90: "Excellent style compliance!"
- If score 70-89: "Good style with minor improvements needed"
- If score 50-69: "Style needs attention"
- If score < 50: "Significant style improvements needed"
List the specific violations found (the tool will provide these):
- Show line numbers, error codes, and messages
- Focus on the top 10 most important issues
Previous analysis: {structure_analysis_summary}
Format your response as:
## Style Analysis Results
- Style Score: [exact score]/100
- Total Issues: [count]
- Assessment: [your assessment based on score]
## Top Style Issues
[List issues with line numbers and descriptions]
## Recommendations
[Specific fixes for the most critical issues]"""
return await instructions_utils.inject_session_state(template, context)
👉 Finden:
# MODULE_5_STEP_1_STYLE_CHECKER_AGENT
👉 Ersetzen Sie diese einzelne Zeile durch:
style_checker_agent = Agent(
name="StyleChecker",
model=config.worker_model,
description="Checks Python code style against PEP 8 guidelines",
instruction=style_checker_instruction_provider,
tools=[FunctionTool(func=check_code_style)],
output_key="style_check_summary"
)
Schritt 2: Test Runner-Agent hinzufügen
Der Test-Runner generiert umfassende Tests und führt sie mit dem integrierten Code-Executor aus.
👉 Offen
code_review_assistant/sub_agents/review_pipeline/test_runner.py
👉 Finden:
# MODULE_5_STEP_2_INSTRUCTION_PROVIDER
👉 Ersetzen Sie diese einzelne Zeile durch:
async def test_runner_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects the code_to_review directly."""
template = """You are a testing specialist who creates and runs tests for Python code.
THE CODE TO TEST IS:
{code_to_review}
YOUR TASK:
1. Understand what the function appears to do based on its name and structure
2. Generate comprehensive tests (15-20 test cases)
3. Execute the tests using your code executor
4. Analyze results to identify bugs vs expected behavior
5. Output a detailed JSON analysis
TESTING METHODOLOGY:
- Test with the most natural interpretation first
- When something fails, determine if it's a bug or unusual design
- Test edge cases, boundaries, and error scenarios
- Document any surprising behavior
Execute your tests and output ONLY valid JSON with this structure:
- "test_summary": object with "total_tests_run", "tests_passed", "tests_failed", "tests_with_errors", "critical_issues_found"
- "critical_issues": array of objects, each with "type", "description", "example_input", "expected_behavior", "actual_behavior", "severity"
- "test_categories": object with "basic_functionality", "edge_cases", "error_handling" (each containing "passed", "failed", "errors" counts)
- "function_behavior": object with "apparent_purpose", "actual_interface", "unexpected_requirements"
- "verdict": object with "status" (WORKING/BUGGY/BROKEN), "confidence" (high/medium/low), "recommendation"
Do NOT output the test code itself, only the JSON analysis."""
return await instructions_utils.inject_session_state(template, context)
👉 Finden:
# MODULE_5_STEP_2_TEST_RUNNER_AGENT
👉 Ersetzen Sie diese einzelne Zeile durch:
test_runner_agent = Agent(
name="TestRunner",
model=config.critic_model,
description="Generates and runs tests for Python code using safe code execution",
instruction=test_runner_instruction_provider,
code_executor=BuiltInCodeExecutor(),
output_key="test_execution_summary"
)
Schritt 3: Speicher für sitzungsübergreifendes Lernen
Bevor Sie den Feedback-Synthesizer erstellen, müssen Sie den Unterschied zwischen Status und Speicher verstehen. Das sind zwei verschiedene Speichermechanismen für zwei verschiedene Zwecke.
Zustand und Arbeitsspeicher: Der entscheidende Unterschied
Hier ein konkretes Beispiel aus einem Code-Review:
Status (nur aktuelle Sitzung):
# Data from THIS review session
tool_context.state[StateKeys.STYLE_ISSUES] = [
{"line": 5, "code": "E231", "message": "missing whitespace"},
{"line": 12, "code": "E701", "message": "multiple statements"}
]
- Umfang: Nur diese Unterhaltung
- Zweck: Daten zwischen KI-Agenten in der aktuellen Pipeline übergeben
- Wohnt in:
Session-Objekt - Lifetime: Wird nach Ende der Sitzung verworfen
Arbeitsspeicher (alle bisherigen Sitzungen):
# Learned from 50 previous reviews
"User frequently forgets docstrings on helper functions"
"User tends to write long functions (avg 45 lines)"
"User improved error handling after feedback in session #23"
- Gültigkeitsbereich: Alle bisherigen Sitzungen für diesen Nutzer
- Zweck: Muster erkennen, personalisiertes Feedback geben
- Wohnt in:
MemoryService - Lifetime: Bleibt über Sitzungen hinweg erhalten, durchsuchbar
Warum Feedback beides benötigt:
Stellen Sie sich vor, der Synthesizer gibt Feedback:
Nur „State“ verwenden (aktuelle Überprüfung):
"Function `calculate_total` has no docstring."
Allgemeines, mechanisches Feedback.
Zustand und Arbeitsspeicher verwenden (aktuelle und vergangene Muster):
"Function `calculate_total` has no docstring. This is the 4th review
where helper functions lacked documentation. Consider adding docstrings
as you write functions, not afterwards - you mentioned in our last
session that you find it easier that way."
Personalisierte, kontextbezogene Referenzen, die sich im Laufe der Zeit verbessern.
Für die Bereitstellung in der Produktion haben Sie folgende Optionen:
Option 1: VertexAiMemoryBankService (erweitert)
- Funktionsweise:LLM-basierte Extraktion aussagekräftiger Fakten aus Unterhaltungen
- Suche:Semantische Suche (versteht die Bedeutung, nicht nur Suchbegriffe)
- Speicherverwaltung:Erinnerungen werden im Laufe der Zeit automatisch zusammengeführt und aktualisiert.
- Erforderlich:Google Cloud-Projekt + Einrichtung der Agent Engine
- Verwenden, wenn:Sie anspruchsvolle, sich entwickelnde, personalisierte Erinnerungen wünschen.
- Beispiel: „Nutzer bevorzugt funktionale Programmierung“ (aus 10 Unterhaltungen zum Codestil extrahiert)
Option 2: Mit InMemoryMemoryService + persistenten Sitzungen fortfahren
- Funktionen:Speichert den vollständigen Unterhaltungsverlauf für die Keyword-Suche.
- Suche:Einfacher Keyword-Abgleich über vergangene Sitzungen hinweg
- Speicherverwaltung:Sie legen fest, was gespeichert wird (über
add_session_to_memory). - Erforderlich:Nur ein persistenter
SessionService(z. B.VertexAiSessionServiceoderDatabaseSessionService) - Verwendung: Sie benötigen eine einfache Suche in früheren Unterhaltungen ohne LLM-Verarbeitung.
- Beispiel:Wenn Sie nach „Docstring“ suchen, werden alle Sitzungen zurückgegeben, in denen dieses Wort erwähnt wird.
So wird der Arbeitsspeicher gefüllt
Nach Abschluss jeder Codeüberprüfung:
# At the end of a session (typically in your application code)
await memory_service.add_session_to_memory(session)
Was passiert?
- InMemoryMemoryService:Speichert die vollständigen Sitzungsereignisse für die Keyword-Suche.
- VertexAiMemoryBankService:LLM extrahiert wichtige Fakten und konsolidiert sie mit vorhandenen Erinnerungen.
In zukünftigen Sitzungen kann dann Folgendes abgefragt werden:
# In a tool, search for relevant past feedback
results = tool_context.search_memory("feedback about docstrings")
Schritt 4: Feedback-Synthesizer-Tools und -Agent hinzufügen
Der Feedback-Synthesizer ist der anspruchsvollste Agent in der Pipeline. Es werden drei Tools orchestriert, dynamische Anweisungen verwendet und Status, Speicher und Artefakte kombiniert.
Die drei Synthesizer-Tools hinzufügen
👉 Offen
code_review_assistant/tools.py
👉 Finden:
# MODULE_5_STEP_4_SEARCH_PAST_FEEDBACK
👉 Durch Tool 1 – Memory Search (Produktionsversion) ersetzen:
async def search_past_feedback(developer_id: str, tool_context: ToolContext) -> Dict[str, Any]:
"""
Search for past feedback in memory service.
Args:
developer_id: ID of the developer (defaults to "default_user")
tool_context: ADK tool context with potential memory service access
Returns:
Dictionary containing feedback search results
"""
logger.info(f"Tool: Searching for past feedback for developer {developer_id}...")
try:
# Default developer ID if not provided
if not developer_id:
developer_id = tool_context.state.get(StateKeys.USER_ID, 'default_user')
# Check if memory service is available
if hasattr(tool_context, 'search_memory'):
try:
# Perform structured searches
queries = [
f"developer:{developer_id} code review feedback",
f"developer:{developer_id} common issues",
f"developer:{developer_id} improvements"
]
all_feedback = []
patterns = {
'common_issues': [],
'improvements': [],
'strengths': []
}
for query in queries:
search_result = await tool_context.search_memory(query)
if search_result and hasattr(search_result, 'memories'):
for memory in search_result.memories[:5]:
memory_text = memory.text if hasattr(memory, 'text') else str(memory)
all_feedback.append(memory_text)
# Extract patterns
if 'style' in memory_text.lower():
patterns['common_issues'].append('style compliance')
if 'improved' in memory_text.lower():
patterns['improvements'].append('showing improvement')
if 'excellent' in memory_text.lower():
patterns['strengths'].append('consistent quality')
# Store in state
tool_context.state[StateKeys.PAST_FEEDBACK] = all_feedback
tool_context.state[StateKeys.FEEDBACK_PATTERNS] = patterns
logger.info(f"Tool: Found {len(all_feedback)} past feedback items")
return {
"status": "success",
"feedback_found": True,
"count": len(all_feedback),
"summary": " | ".join(all_feedback[:3]) if all_feedback else "No feedback",
"patterns": patterns
}
except Exception as e:
logger.warning(f"Tool: Memory search error: {e}")
# Fallback: Check state for cached feedback
cached_feedback = tool_context.state.get(StateKeys.USER_PAST_FEEDBACK_CACHE, [])
if cached_feedback:
tool_context.state[StateKeys.PAST_FEEDBACK] = cached_feedback
return {
"status": "success",
"feedback_found": True,
"count": len(cached_feedback),
"summary": "Using cached feedback",
"patterns": {}
}
# No feedback found
tool_context.state[StateKeys.PAST_FEEDBACK] = []
logger.info("Tool: No past feedback found")
return {
"status": "success",
"feedback_found": False,
"message": "No past feedback available - this appears to be a first submission",
"patterns": {}
}
except Exception as e:
error_msg = f"Feedback search error: {str(e)}"
logger.error(f"Tool: {error_msg}", exc_info=True)
tool_context.state[StateKeys.PAST_FEEDBACK] = []
return {
"status": "error",
"message": error_msg,
"feedback_found": False
}
👉 Finden:
# MODULE_5_STEP_4_UPDATE_GRADING_PROGRESS
👉 Mit Tool 2 ersetzen – Grading Tracker (Produktionsversion):
async def update_grading_progress(tool_context: ToolContext) -> Dict[str, Any]:
"""
Updates grading progress counters and metrics in state.
"""
logger.info("Tool: Updating grading progress...")
try:
current_time = datetime.now().isoformat()
# Build all state changes
state_updates = {}
# Temporary (invocation-level) state
state_updates[StateKeys.TEMP_PROCESSING_TIMESTAMP] = current_time
# Session-level state
attempts = tool_context.state.get(StateKeys.GRADING_ATTEMPTS, 0) + 1
state_updates[StateKeys.GRADING_ATTEMPTS] = attempts
state_updates[StateKeys.LAST_GRADING_TIME] = current_time
# User-level persistent state
lifetime_submissions = tool_context.state.get(StateKeys.USER_TOTAL_SUBMISSIONS, 0) + 1
state_updates[StateKeys.USER_TOTAL_SUBMISSIONS] = lifetime_submissions
state_updates[StateKeys.USER_LAST_SUBMISSION_TIME] = current_time
# Calculate improvement metrics
current_style_score = tool_context.state.get(StateKeys.STYLE_SCORE, 0)
last_style_score = tool_context.state.get(StateKeys.USER_LAST_STYLE_SCORE, 0)
score_improvement = current_style_score - last_style_score
state_updates[StateKeys.USER_LAST_STYLE_SCORE] = current_style_score
state_updates[StateKeys.SCORE_IMPROVEMENT] = score_improvement
# Track test results if available
test_results = tool_context.state.get(StateKeys.TEST_EXECUTION_SUMMARY, {})
# Parse if it's a string
if isinstance(test_results, str):
try:
test_results = json.loads(test_results)
except:
test_results = {}
if test_results and test_results.get('test_summary', {}).get('total_tests_run', 0) > 0:
summary = test_results['test_summary']
total = summary.get('total_tests_run', 0)
passed = summary.get('tests_passed', 0)
if total > 0:
pass_rate = (passed / total) * 100
state_updates[StateKeys.USER_LAST_TEST_PASS_RATE] = pass_rate
# Apply all updates atomically
for key, value in state_updates.items():
tool_context.state[key] = value
logger.info(f"Tool: Progress updated - Attempt #{attempts}, "
f"Lifetime: {lifetime_submissions}")
return {
"status": "success",
"session_attempts": attempts,
"lifetime_submissions": lifetime_submissions,
"timestamp": current_time,
"improvement": {
"style_score_change": score_improvement,
"direction": "improved" if score_improvement > 0 else "declined"
},
"summary": f"Attempt #{attempts} recorded, {lifetime_submissions} total submissions"
}
except Exception as e:
error_msg = f"Progress update error: {str(e)}"
logger.error(f"Tool: {error_msg}", exc_info=True)
return {
"status": "error",
"message": error_msg
}
👉 Finden:
# MODULE_5_STEP_4_SAVE_GRADING_REPORT
👉 Mit Tool 3 – Artifact Saver (Produktionsversion) ersetzen:
async def save_grading_report(feedback_text: str, tool_context: ToolContext) -> Dict[str, Any]:
"""
Saves a detailed grading report as an artifact.
Args:
feedback_text: The feedback text to include in the report
tool_context: ADK tool context for state management
Returns:
Dictionary containing save status and details
"""
logger.info("Tool: Saving grading report...")
try:
# Gather all relevant data from state
code = tool_context.state.get(StateKeys.CODE_TO_REVIEW, '')
analysis = tool_context.state.get(StateKeys.CODE_ANALYSIS, {})
style_score = tool_context.state.get(StateKeys.STYLE_SCORE, 0)
style_issues = tool_context.state.get(StateKeys.STYLE_ISSUES, [])
# Get test results
test_results = tool_context.state.get(StateKeys.TEST_EXECUTION_SUMMARY, {})
# Parse if it's a string
if isinstance(test_results, str):
try:
test_results = json.loads(test_results)
except:
test_results = {}
timestamp = datetime.now().isoformat()
# Create comprehensive report dictionary
report = {
'timestamp': timestamp,
'grading_attempt': tool_context.state.get(StateKeys.GRADING_ATTEMPTS, 1),
'code': {
'content': code,
'line_count': len(code.splitlines()),
'hash': hashlib.md5(code.encode()).hexdigest()
},
'analysis': analysis,
'style': {
'score': style_score,
'issues': style_issues[:5] # First 5 issues
},
'tests': test_results,
'feedback': feedback_text,
'improvements': {
'score_change': tool_context.state.get(StateKeys.SCORE_IMPROVEMENT, 0),
'from_last_score': tool_context.state.get(StateKeys.USER_LAST_STYLE_SCORE, 0)
}
}
# Convert report to JSON string
report_json = json.dumps(report, indent=2)
report_part = types.Part.from_text(text=report_json)
# Try to save as artifact if the service is available
if hasattr(tool_context, 'save_artifact'):
try:
# Generate filename with timestamp (replace colons for filesystem compatibility)
filename = f"grading_report_{timestamp.replace(':', '-')}.json"
# Save the main report
version = await tool_context.save_artifact(filename, report_part)
# Also save a "latest" version for easy access
await tool_context.save_artifact("latest_grading_report.json", report_part)
logger.info(f"Tool: Report saved as {filename} (version {version})")
# Store report in state as well for redundancy
tool_context.state[StateKeys.USER_LAST_GRADING_REPORT] = report
return {
"status": "success",
"artifact_saved": True,
"filename": filename,
"version": str(version),
"size": len(report_json),
"summary": f"Report saved as {filename}"
}
except Exception as artifact_error:
logger.warning(f"Artifact service error: {artifact_error}, falling back to state storage")
# Continue to fallback below
# Fallback: Store in state if artifact service is not available or failed
tool_context.state[StateKeys.USER_LAST_GRADING_REPORT] = report
logger.info("Tool: Report saved to state (artifact service not available)")
return {
"status": "success",
"artifact_saved": False,
"message": "Report saved to state only",
"size": len(report_json),
"summary": "Report saved to session state"
}
except Exception as e:
error_msg = f"Report save error: {str(e)}"
logger.error(f"Tool: {error_msg}", exc_info=True)
# Still try to save minimal data to state
try:
tool_context.state[StateKeys.USER_LAST_GRADING_REPORT] = {
'error': error_msg,
'feedback': feedback_text,
'timestamp': datetime.now().isoformat()
}
except:
pass
return {
"status": "error",
"message": error_msg,
"artifact_saved": False,
"summary": f"Failed to save report: {error_msg}"
}
Synthesizer-Agent erstellen
👉 Offen
code_review_assistant/sub_agents/review_pipeline/feedback_synthesizer.py
👉 Finden:
# MODULE_5_STEP_4_INSTRUCTION_PROVIDER
👉 Mit dem Anbieter der Produktionsanleitung ersetzen:
async def feedback_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are an expert code reviewer and mentor providing constructive, educational feedback.
CONTEXT FROM PREVIOUS AGENTS:
- Structure analysis summary: {structure_analysis_summary}
- Style check summary: {style_check_summary}
- Test execution summary: {test_execution_summary}
YOUR TASK requires these steps IN ORDER:
1. Call search_past_feedback tool with developer_id="default_user"
2. Call update_grading_progress tool with no parameters
3. Carefully analyze the test results to understand what really happened
4. Generate comprehensive feedback following the structure below
5. Call save_grading_report tool with the feedback_text parameter
6. Return the feedback as your final output
CRITICAL - Understanding Test Results:
The test_execution_summary contains structured JSON. Parse it carefully:
- tests_passed = Code worked correctly
- tests_failed = Code produced wrong output
- tests_with_errors = Code crashed
- critical_issues = Fundamental problems with the code
If critical_issues array contains items, these are serious bugs that need fixing.
Do NOT count discovering bugs as test successes.
FEEDBACK STRUCTURE TO FOLLOW:
## 📊 Summary
Provide an honest assessment. Be encouraging but truthful about problems found.
## ✅ Strengths
List 2-3 things done well, referencing specific code elements.
## 📈 Code Quality Analysis
### Structure & Organization
Comment on code organization, readability, and documentation.
### Style Compliance
Report the actual style score and any specific issues.
### Test Results
Report the actual test results accurately:
- If critical_issues exist, report them as bugs to fix
- Be clear: "X tests passed, Y critical issues were found"
- List each critical issue
- Don't hide or minimize problems
## 💡 Recommendations for Improvement
Based on the analysis, provide specific actionable fixes.
If critical issues exist, fixing them is top priority.
## 🎯 Next Steps
Prioritized action list based on severity of issues.
## 💬 Encouragement
End with encouragement while being honest about what needs fixing.
Remember: Complete ALL steps including calling save_grading_report."""
return await instructions_utils.inject_session_state(template, context)
👉 Finden:
# MODULE_5_STEP_4_SYNTHESIZER_AGENT
👉 Ersetzen durch:
feedback_synthesizer_agent = Agent(
name="FeedbackSynthesizer",
model=config.critic_model,
description="Synthesizes all analysis into constructive, personalized feedback",
instruction=feedback_instruction_provider,
tools=[
FunctionTool(func=search_past_feedback),
FunctionTool(func=update_grading_progress),
FunctionTool(func=save_grading_report)
],
output_key="final_feedback"
)
Schritt 5: Pipeline verkabeln
Verbinden Sie nun alle vier Agents in einer sequenziellen Pipeline und erstellen Sie den Root-Agent.
👉 Öffnen
code_review_assistant/agent.py
👉 Fügen Sie oben in der Datei (nach den vorhandenen Importen) die erforderlichen Importe hinzu:
from google.adk.agents import Agent, SequentialAgent
from code_review_assistant.sub_agents.review_pipeline.code_analyzer import code_analyzer_agent
from code_review_assistant.sub_agents.review_pipeline.style_checker import style_checker_agent
from code_review_assistant.sub_agents.review_pipeline.test_runner import test_runner_agent
from code_review_assistant.sub_agents.review_pipeline.feedback_synthesizer import feedback_synthesizer_agent
Ihre Datei sollte nun so aussehen:
"""
Main agent orchestration for the Code Review Assistant.
"""
from google.adk.agents import Agent, SequentialAgent
from .config import config
from code_review_assistant.sub_agents.review_pipeline.code_analyzer import code_analyzer_agent
from code_review_assistant.sub_agents.review_pipeline.style_checker import style_checker_agent
from code_review_assistant.sub_agents.review_pipeline.test_runner import test_runner_agent
from code_review_assistant.sub_agents.review_pipeline.feedback_synthesizer import feedback_synthesizer_agent
# MODULE_5_STEP_5_CREATE_PIPELINE
# MODULE_6_STEP_5_CREATE_FIX_LOOP
# MODULE_6_STEP_5_UPDATE_ROOT_AGENT
👉 Suchen:
# MODULE_5_STEP_5_CREATE_PIPELINE
👉 Ersetzen Sie diese einzelne Zeile durch:
# Create sequential pipeline
code_review_pipeline = SequentialAgent(
name="CodeReviewPipeline",
description="Complete code review pipeline with analysis, testing, and feedback",
sub_agents=[
code_analyzer_agent,
style_checker_agent,
test_runner_agent,
feedback_synthesizer_agent
]
)
# Root agent - coordinates the review pipeline
root_agent = Agent(
name="CodeReviewAssistant",
model=config.worker_model,
description="An intelligent code review assistant that analyzes Python code and provides educational feedback",
instruction="""You are a specialized Python code review assistant focused on helping developers improve their code quality.
When a user provides Python code for review:
1. Immediately delegate to CodeReviewPipeline and pass the code EXACTLY as it was provided by the user.
2. The pipeline will handle all analysis and feedback
3. Return ONLY the final feedback from the pipeline - do not add any commentary
When a user asks what you can do or asks general questions:
- Explain your capabilities for code review
- Do NOT trigger the pipeline for non-code messages
The pipeline handles everything for code review - just pass through its final output.""",
sub_agents=[code_review_pipeline],
output_key="assistant_response"
)
Schritt 6: Vollständige Pipeline testen
Zeit, alle vier Agents in Aktion zu sehen.
👉 System starten:
adk web code_review_assistant
Nachdem Sie den Befehl adk web ausgeführt haben, sollte in Ihrem Terminal eine Ausgabe angezeigt werden, die angibt, dass der ADK-Webserver gestartet wurde. Sie sollte in etwa so aussehen:
+-----------------------------------------------------------------------------+
| ADK Web Server started |
| |
| For local testing, access at http://localhost:8000. |
+-----------------------------------------------------------------------------+
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
👉 So greifen Sie über Ihren Browser auf die ADK-Entwicklungsoberfläche zu:
Wählen Sie in der Cloud Shell-Symbolleiste (normalerweise oben rechts) das Symbol „Webvorschau“ aus (oft ein Auge oder ein Quadrat mit einem Pfeil) und klicken Sie auf „Port ändern“. Legen Sie im Pop-up-Fenster den Port auf 8000 fest und klicken Sie auf „Ändern und Vorschau“. In Cloud Shell wird dann ein neuer Browsertab oder ein neues Browserfenster mit der ADK-Entwicklungsoberfläche geöffnet.
👉 Der KI‑Agent wird jetzt ausgeführt. Die ADK-Entwicklungsoberfläche in Ihrem Browser ist Ihre direkte Verbindung zum Agenten.
- Wählen Sie Ihr Ziel aus: Wählen Sie im Drop-down-Menü oben in der Benutzeroberfläche den
code_review_assistant-Agent aus.
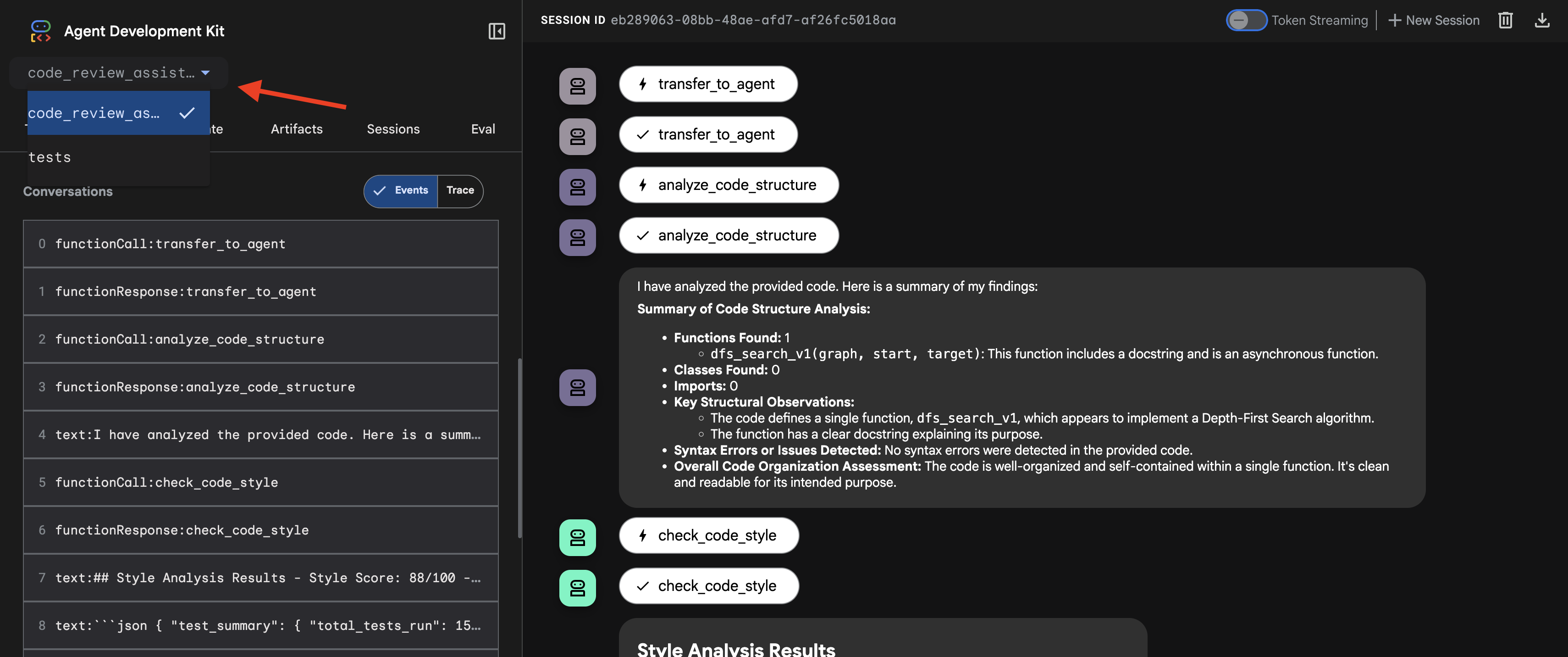
👉 Test-Prompt:
Please analyze the following:
def dfs_search_v1(graph, start, target):
"""Find if target is reachable from start."""
visited = set()
stack = start
while stack:
current = stack.pop()
if current == target:
return True
if current not in visited:
visited.add(current)
for neighbor in graph[current]:
if neighbor not in visited:
stack.append(neighbor)
return False
👉 Code-Review-Pipeline in Aktion ansehen
Wenn Sie die fehlerhafte Funktion dfs_search_v1 einreichen, erhalten Sie nicht nur eine Antwort. Sie sehen, wie Ihre Multi-Agent-Pipeline funktioniert. Die Streamingausgabe, die Sie sehen, ist das Ergebnis von vier spezialisierten KI-Agenten, die nacheinander ausgeführt werden und jeweils auf dem vorherigen aufbauen.
Hier sehen Sie, was die einzelnen Agents zur endgültigen, umfassenden Überprüfung beitragen und wie Rohdaten in umsetzbare Informationen umgewandelt werden.
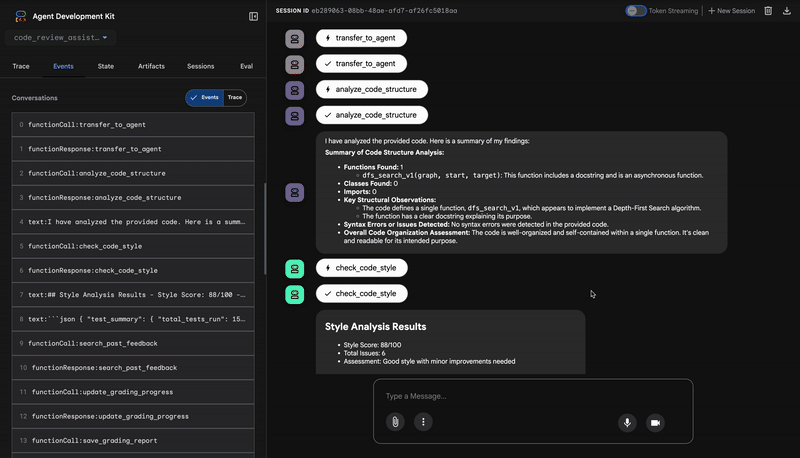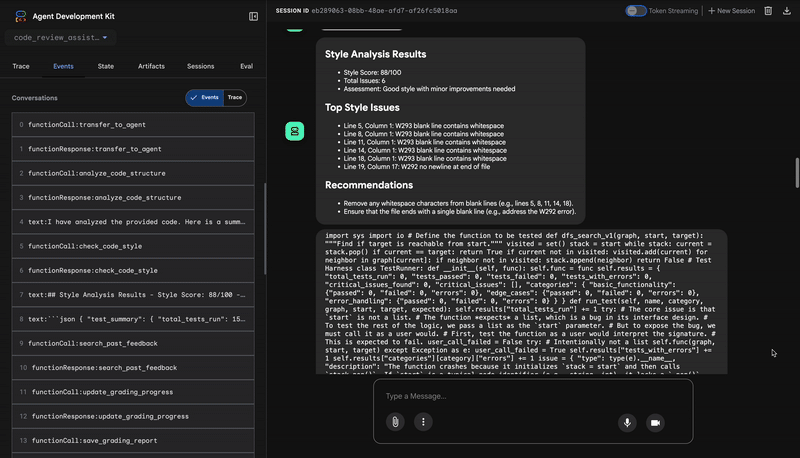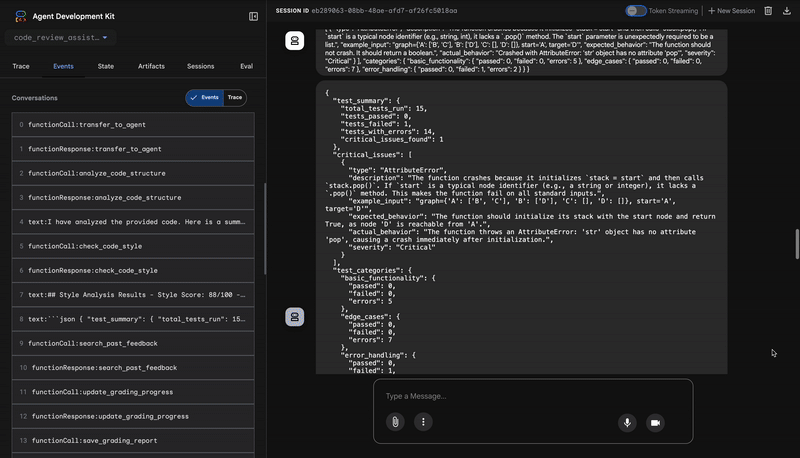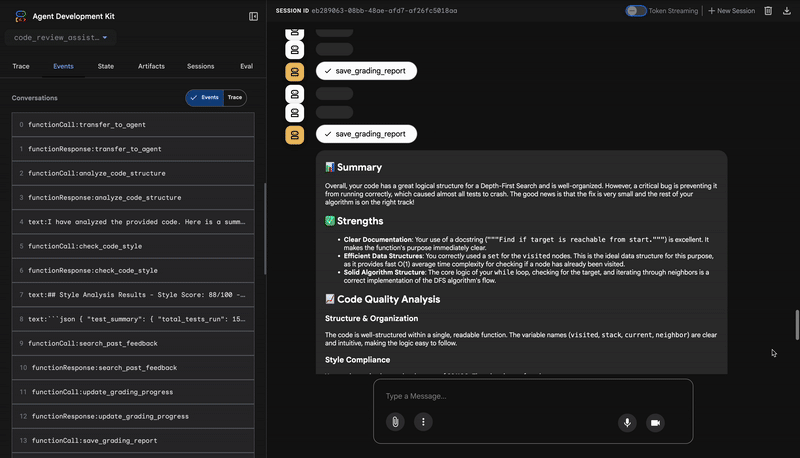
1. Strukturbericht des Code-Analyzers
Zuerst empfängt der CodeAnalyzer-Agent den Rohcode. Es wird nicht geraten, was der Code tut, sondern das analyze_code_structure-Tool wird verwendet, um eine deterministische Analyse des abstrakten Syntaxbaums (Abstract Syntax Tree, AST) durchzuführen.
Die Ausgabe besteht aus reinen, sachlichen Daten zur Struktur des Codes:
The analysis of the provided code reveals the following:
Summary:
- Functions Found: 1
- Classes Found: 0
Key Structural Observations:
- A single function, dfs_search_v1, is defined.
- It includes a docstring: "Find if target is reachable from start."
- No syntax errors were detected.
Overall Code Organization Assessment:
- The code snippet is a well-defined, self-contained function.
⭐ Wert:Dieser erste Schritt bietet eine saubere, zuverlässige Grundlage für die anderen Agents. Es wird bestätigt, dass der Code gültiger Python-Code ist, und die genauen Komponenten werden identifiziert, die überprüft werden müssen.
2. PEP 8-Prüfung des Style Checkers
Als Nächstes übernimmt der StyleChecker-Agent. Der Code wird aus dem freigegebenen Status gelesen und das check_code_style-Tool verwendet, das den pycodestyle-Linter nutzt.
Die Ausgabe besteht aus einem quantifizierbaren Qualitätsfaktor und spezifischen Verstößen:
Style Analysis Results
- Style Score: 88/100
- Total Issues: 6
- Assessment: Good style with minor improvements needed
Top Style Issues
- Line 5, W293: blank line contains whitespace
- Line 19, W292: no newline at end of file
⭐ Wert:Dieser Agent gibt objektives, nicht verhandelbares Feedback basierend auf etablierten Community-Standards (PEP 8). Das gewichtete Punktesystem informiert den Nutzer sofort über den Schweregrad der Probleme.
3. Kritische Fehlererkennung des Test-Ausführers
Hier geht das System über die oberflächliche Analyse hinaus. Der Agent TestRunner generiert und führt eine umfassende Reihe von Tests aus, um das Verhalten des Codes zu validieren.
Die Ausgabe ist ein strukturiertes JSON-Objekt, das ein vernichtendes Urteil enthält:
{
"critical_issues": [
{
"type": "Critical Bug",
"description": "The function's initialization `stack = start` is incorrect... When a common input like a string... is provided... the function crashes with an AttributeError.",
"severity": "Critical"
}
],
"verdict": {
"status": "BROKEN",
"confidence": "high",
"recommendation": "The function is fundamentally broken... the stack initialization line `stack = start` must be changed to `stack = [start]`."
}
}
⭐ Wert:Das ist die wichtigste Erkenntnis. Der Agent hat nicht nur geraten, sondern bewiesen, dass der Code fehlerhaft ist, indem er ihn ausgeführt hat. Es wurde ein subtiler, aber kritischer Laufzeitfehler aufgedeckt, den ein menschlicher Prüfer leicht übersehen könnte. Außerdem wurde die genaue Ursache und die erforderliche Korrektur ermittelt.
4. Abschlussbericht des Feedback-Synthesizers
Schließlich fungiert der FeedbackSynthesizer-Agent als Dirigent. Die strukturierte Daten der drei vorherigen Agents werden in einem einzigen, nutzerfreundlichen Bericht zusammengefasst, der sowohl analytisch als auch motivierend ist.
Die Ausgabe ist die endgültige, überarbeitete Rezension, die Sie sehen:
📊 Summary
Great effort on implementing the Depth-First Search algorithm! ... However, a critical bug in the initialization of the stack prevents the function from working correctly...
✅ Strengths
- Good Algorithm Structure
- Correct Use of `visited` Set
📈 Code Quality Analysis
...
### Style Compliance
The style analysis returned a good score of 88/100.
...
### Test Results
The automated testing revealed a critical issue... The line `stack = start` directly assigns the input... which results in an `AttributeError`.
💡 Recommendations for Improvement
**Fix the Critical Stack Initialization Bug:**
- Incorrect Code: `stack = start`
- Correct Code: `stack = [start]`
💬 Encouragement
You are very close to a perfect implementation! The core logic of your DFS algorithm is sound, which is the hardest part.
⭐ Wert:Dieser Agent wandelt technische Daten in eine hilfreiche, informative Erfahrung um. Die E‑Mail priorisiert das wichtigste Problem (den Fehler), erklärt es klar, liefert die genaue Lösung und ist dabei ermutigend. Hier werden die Ergebnisse aus allen vorherigen Phasen in ein kohäsives und wertvolles Ganzes integriert.
Dieser mehrstufige Prozess zeigt die Leistungsfähigkeit einer agentischen Pipeline. Statt einer einzelnen, monolithischen Antwort erhalten Sie eine mehrschichtige Analyse, bei der jeder Agent eine spezialisierte, überprüfbare Aufgabe ausführt. So entsteht eine Rezension, die nicht nur aufschlussreich, sondern auch deterministisch, zuverlässig und sehr lehrreich ist.
👉💻 Wenn Sie mit dem Testen fertig sind, kehren Sie zum Cloud Shell Editor-Terminal zurück und drücken Sie Ctrl+C, um die ADK-Entwicklungsoberfläche zu beenden.
Was Sie erstellt haben
Sie haben jetzt eine vollständige Pipeline für die Codeüberprüfung, die:
✅ Parses code structure (Code-Struktur analysieren) – deterministische AST-Analyse mit Hilfsfunktionen
✅ Checks style (Stil prüfen) – gewichtete Bewertung mit Namenskonventionen
✅ Runs tests (Tests ausführen) – umfassende Testgenerierung mit strukturierter JSON-Ausgabe
✅ Synthesizes feedback (Feedback zusammenfassen) – Integration von Status, Speicher und Artefakten
✅ Tracks progress (Fortschritt verfolgen) – mehrstufiger Status über Aufrufe/Sitzungen/Nutzer hinweg
✅ Learns over time (Im Laufe der Zeit lernen) – Speicherdienst für sitzungsübergreifende Muster
✅ Provides artifacts (Artefakte bereitstellen) – herunterladbare JSON-Berichte mit vollständigem Prüfpfad
Kennengelernte zentrale Konzepte
Sequenzielle Pipelines:
- Vier Agenten, die in strenger Reihenfolge ausgeführt werden
- Jeder Zustand bereichert den nächsten.
- Abhängigkeiten bestimmen die Ausführungsreihenfolge
Produktionsmuster:
- Trennung von Hilfsfunktionen (Synchronisierung in Threadpools)
- Graduelle Fehlertoleranz (Fallback-Strategien)
- Zustandsverwaltung mit mehreren Ebenen (temporär/Sitzung/Nutzer)
- Dynamische Instruction-Provider (kontextbezogen)
- Duale Speicherung (Artefakte + Statusredundanz)
Als Mitteilung angeben:
- Konstanten verhindern Tippfehler in allen KI-Agenten.
output_keyschreibt Agentenzusammenfassungen in den Status- Spätere Agenten lesen über StateKeys
- Status fließt linear durch die Pipeline
Arbeitsspeicher im Vergleich zu Status:
- Status: Daten der aktuellen Sitzung
- Speicher: Muster über Sitzungen hinweg
- Unterschiedliche Zwecke, unterschiedliche Lebensdauer
Tool-Orchestrierung:
- KI-Agenten mit einem Tool (analyzer, style_checker)
- Integrierte Executors (test_runner)
- Koordination mehrerer Tools (Synthesizer)
Strategie zur Modellauswahl:
- Worker-Modell: Mechanische Aufgaben (Parsing, Linting, Routing)
- Kritikermodell: Aufgaben zur Argumentation (Testen, Synthese)
- Kostenoptimierung durch geeignete Auswahl
Weitere Informationen
In Modul 6 erstellen Sie die fix pipeline:
- LoopAgent-Architektur für iterative Korrekturen
- Kündigungsbedingungen über Eskalierung
- Statusakkumulierung über Iterationen hinweg
- Validierungs- und Wiederholungslogik
- Einbindung in die Überprüfungspipeline, um Korrekturen anzubieten
Sie sehen, wie sich dieselben Statusmuster auf komplexe iterative Workflows skalieren lassen, in denen Agents mehrere Versuche unternehmen, bis sie erfolgreich sind, und wie Sie mehrere Pipelines in einer einzigen Anwendung koordinieren können.
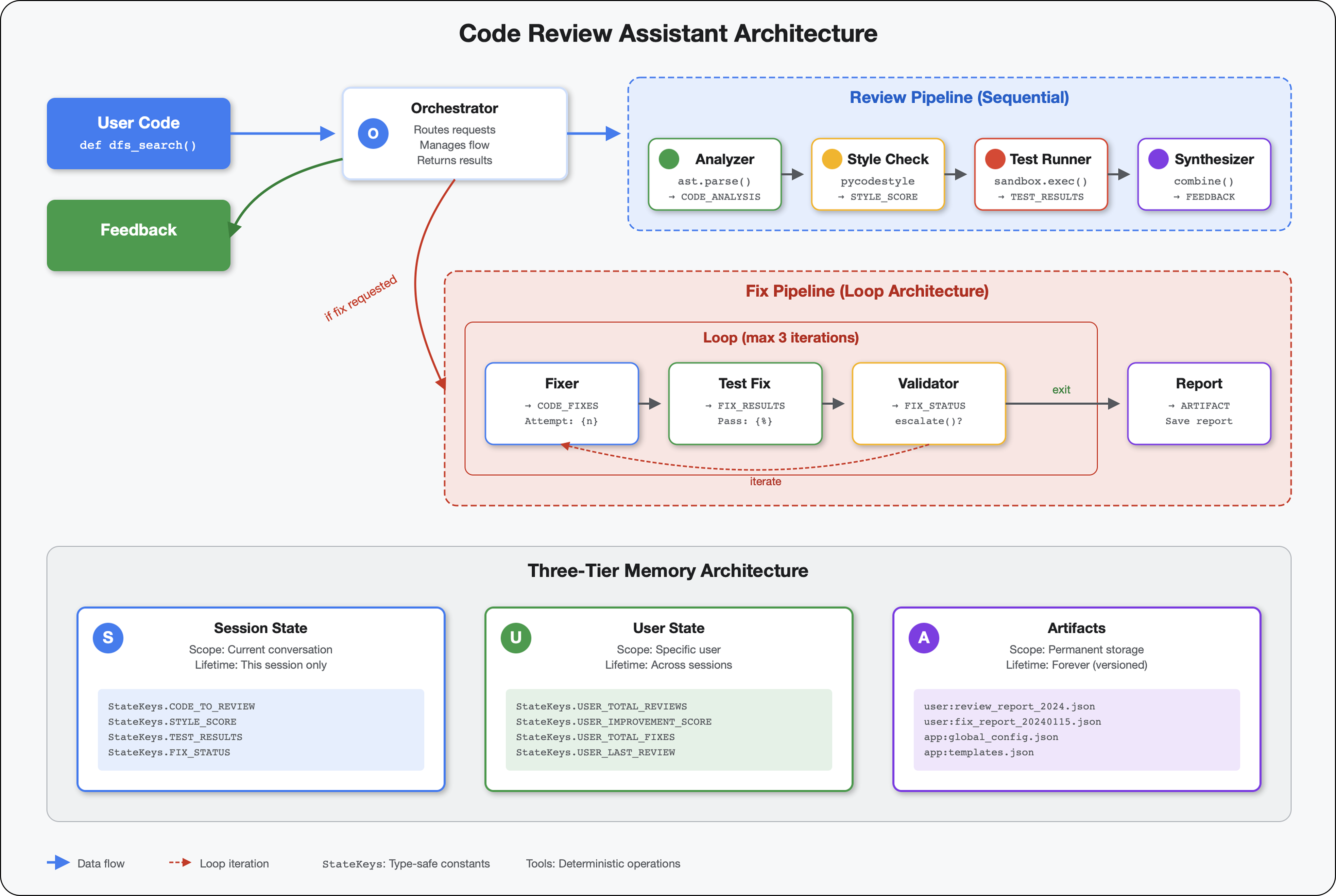
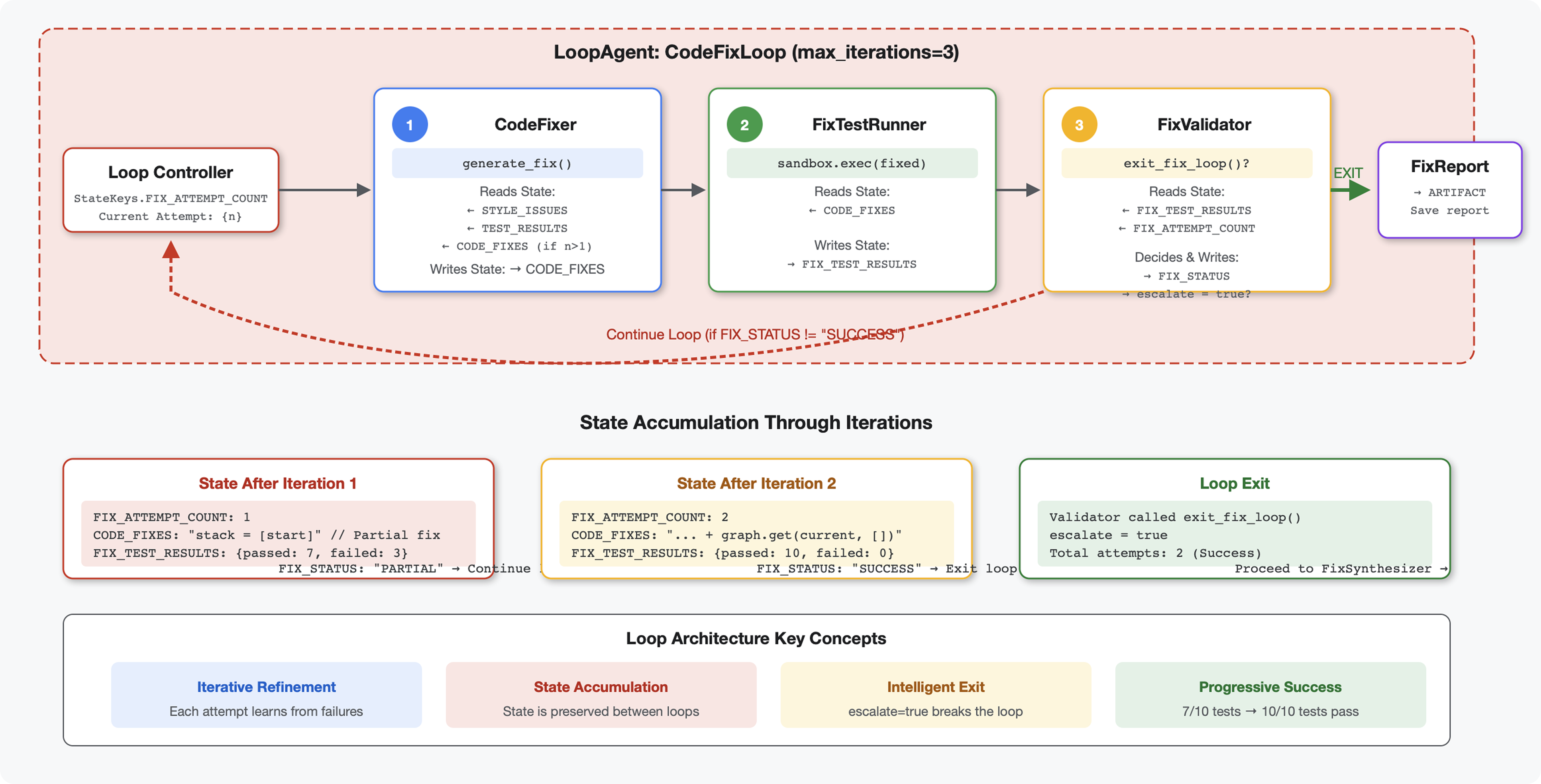
6. Fix-Pipeline hinzufügen: Loop-Architektur
Einführung
In Modul 5 haben Sie eine Pipeline für die sequenzielle Überprüfung erstellt, die Code analysiert und Feedback gibt. Das Erkennen von Problemen ist jedoch nur die halbe Lösung – Entwickler benötigen Hilfe bei der Behebung.
In diesem Modul wird eine Pipeline für automatische Korrekturen erstellt, die:
- Korrekturen werden basierend auf den Überprüfungsergebnissen generiert
- Fehlerbehebungen werden durch umfassende Tests validiert.
- Automatische Wiederholungen, wenn Korrekturen nicht funktionieren (bis zu 3 Versuche)
- Berichtsergebnisse mit Vorher-Nachher-Vergleichen
Schlüsselkonzept: LoopAgent für automatische Wiederholungen. Im Gegensatz zu sequenziellen Agents, die einmal ausgeführt werden, wiederholt ein LoopAgent seine Sub-Agents, bis eine Abbruchbedingung erfüllt oder die maximale Anzahl von Iterationen erreicht ist. Tools signalisieren Erfolg, indem sie tool_context.actions.escalate = True festlegen.
Vorschau auf das, was Sie erstellen werden:Sie reichen fehlerhaften Code ein → bei der Überprüfung werden Probleme erkannt → durch die Korrekturschleife werden Korrekturen generiert → Tests werden durchgeführt → bei Bedarf werden Wiederholungen durchgeführt → es wird ein umfassender Abschlussbericht erstellt.
Wichtige Konzepte: LoopAgent und Sequential
Sequenzielle Pipeline (Modul 5):
SequentialAgent(agents=[A, B, C])
# Executes: A → B → C → Done
- Unidirektionaler Fluss
- Jeder Agent wird genau einmal ausgeführt.
- Keine Wiederholungslogik
Loop-Pipeline (Modul 6):
LoopAgent(agents=[A, B, C], max_iterations=3)
# Executes: A → B → C → (check exit) → A → B → C → (check exit) → ...
- Zyklischer Fluss
- Agenten können mehrmals ausgeführt werden
- Wird beendet, wenn:
- Ein Tool setzt
tool_context.actions.escalate = True(Erfolg) max_iterationserreicht (Sicherheitsgrenzwert)- Es tritt eine unbehandelte Ausnahme auf (Fehler)
- Ein Tool setzt
Warum Schleifen zum Beheben von Code verwendet werden:
Für Codekorrekturen sind oft mehrere Versuche erforderlich:
- Erster Versuch: Offensichtliche Fehler beheben (falsche Variablentypen)
- Zweiter Versuch: Beheben Sie sekundäre Probleme, die durch Tests aufgedeckt wurden (Grenzfälle).
- Dritter Versuch: Alle Tests optimieren und validieren
Ohne Schleife wäre eine komplexe bedingte Logik in den Agentenanweisungen erforderlich. Bei LoopAgent erfolgt der Wiederholungsversuch automatisch.
Architekturvergleich:
Sequential (Module 5):
User → Review Pipeline → Feedback → Done
Loop (Module 6):
User → Review Pipeline → Feedback → Fix Pipeline
↓
┌──────────────┴──────────────┐
│ Fix Attempt Loop (1-3x) │
│ ┌─────────────────────┐ │
│ │ 1. Generate Fixes │ │
│ │ 2. Test Fixes │ │
│ │ 3. Validate & Exit? │────┼─→ If escalate=True
│ └─────────────────────┘ │ exit loop
│ ↓ If not │
│ Try Again (max 3) │
└─────────────────────────────┘
↓
4. Synthesize Final Report → Done
Schritt 1: Code Fixer-Agent hinzufügen
Der Code-Fixer generiert korrigierten Python-Code basierend auf den Überprüfungsergebnissen.
👉 Offen
code_review_assistant/sub_agents/fix_pipeline/code_fixer.py
👉 Finden:
# MODULE_6_STEP_1_CODE_FIXER_INSTRUCTION_PROVIDER
👉 Ersetzen Sie diese einzelne Zeile durch:
async def code_fixer_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are an expert code fixing specialist.
Original Code:
{code_to_review}
Analysis Results:
- Style Score: {style_score}/100
- Style Issues: {style_issues}
- Test Results: {test_execution_summary}
Based on the test results, identify and fix ALL issues including:
- Interface bugs (e.g., if start parameter expects wrong type)
- Logic errors (e.g., KeyError when accessing graph nodes)
- Style violations
- Missing documentation
YOUR TASK:
Generate the complete fixed Python code that addresses all identified issues.
CRITICAL INSTRUCTIONS:
- Output ONLY the corrected Python code
- Do NOT include markdown code blocks (```python)
- Do NOT include any explanations or commentary
- The output should be valid, executable Python code and nothing else
Common fixes to apply based on test results:
- If tests show AttributeError with 'pop', fix: stack = [start] instead of stack = start
- If tests show KeyError accessing graph, fix: use graph.get(current, [])
- Add docstrings if missing
- Fix any style violations identified
Output the complete fixed code now:"""
return await instructions_utils.inject_session_state(template, context)
👉 Finden:
# MODULE_6_STEP_1_CODE_FIXER_AGENT
👉 Ersetzen Sie diese einzelne Zeile durch:
code_fixer_agent = Agent(
name="CodeFixer",
model=config.worker_model,
description="Generates comprehensive fixes for all identified code issues",
instruction=code_fixer_instruction_provider,
code_executor=BuiltInCodeExecutor(),
output_key="code_fixes"
)
Schritt 2: „Fix Test Runner Agent“ hinzufügen
Der Fix-Test-Runner validiert Korrekturen, indem er umfassende Tests für den korrigierten Code ausführt.
👉 Offen
code_review_assistant/sub_agents/fix_pipeline/fix_test_runner.py
👉 Finden:
# MODULE_6_STEP_2_FIX_TEST_RUNNER_INSTRUCTION_PROVIDER
👉 Ersetzen Sie diese einzelne Zeile durch:
async def fix_test_runner_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that uses the clean code from the previous step."""
template = """You are responsible for validating the fixed code by running tests.
THE FIXED CODE TO TEST:
{code_fixes}
ORIGINAL TEST RESULTS: {test_execution_summary}
YOUR TASK:
1. Understand the fixes that were applied
2. Generate the same comprehensive tests (15-20 test cases)
3. Execute the tests on the FIXED code using your code executor
4. Compare results with original test results
5. Output a detailed JSON analysis
TESTING METHODOLOGY:
- Run the same tests that revealed issues in the original code
- Verify that previously failing tests now pass
- Ensure no regressions were introduced
- Document the improvement
Execute your tests and output ONLY valid JSON with this structure:
- "passed": number of tests that passed
- "failed": number of tests that failed
- "total": total number of tests
- "pass_rate": percentage as a number
- "comparison": object with "original_pass_rate", "new_pass_rate", "improvement"
- "newly_passing_tests": array of test names that now pass
- "still_failing_tests": array of test names still failing
Do NOT output the test code itself, only the JSON analysis."""
return await instructions_utils.inject_session_state(template, context)
👉 Finden:
# MODULE_6_STEP_2_FIX_TEST_RUNNER_AGENT
👉 Ersetzen Sie diese einzelne Zeile durch:
fix_test_runner_agent = Agent(
name="FixTestRunner",
model=config.critic_model,
description="Runs comprehensive tests on fixed code to verify all issues are resolved",
instruction=fix_test_runner_instruction_provider,
code_executor=BuiltInCodeExecutor(),
output_key="fix_test_execution_summary"
)
Schritt 3: Fix Validator Agent hinzufügen
Der Validator prüft, ob die Korrekturen erfolgreich waren, und entscheidet, ob die Schleife beendet werden soll.
Informationen zu den Tools
Fügen Sie zuerst die drei Tools hinzu, die für die Validierung erforderlich sind.
👉 Offen
code_review_assistant/tools.py
👉 Finden:
# MODULE_6_STEP_3_VALIDATE_FIXED_STYLE
👉 Mit Tool 1 ersetzen – Stilvalidator:
async def validate_fixed_style(tool_context: ToolContext) -> Dict[str, Any]:
"""
Validates style compliance of the fixed code.
Args:
tool_context: ADK tool context containing fixed code in state
Returns:
Dictionary with style validation results
"""
logger.info("Tool: Validating style of fixed code...")
try:
# Get the fixed code from state
code_fixes = tool_context.state.get(StateKeys.CODE_FIXES, '')
# Try to extract from markdown if present
if '```python' in code_fixes:
start = code_fixes.rfind('```python') + 9
end = code_fixes.rfind('```')
if start < end:
code_fixes = code_fixes[start:end].strip()
if not code_fixes:
return {
"status": "error",
"message": "No fixed code found in state"
}
# Store the extracted fixed code
tool_context.state[StateKeys.CODE_FIXES] = code_fixes
# Run style check on fixed code
loop = asyncio.get_event_loop()
with ThreadPoolExecutor() as executor:
style_result = await loop.run_in_executor(
executor, _perform_style_check, code_fixes
)
# Compare with original
original_score = tool_context.state.get(StateKeys.STYLE_SCORE, 0)
improvement = style_result['score'] - original_score
# Store results
tool_context.state[StateKeys.FIXED_STYLE_SCORE] = style_result['score']
tool_context.state[StateKeys.FIXED_STYLE_ISSUES] = style_result['issues']
logger.info(f"Tool: Fixed code style score: {style_result['score']}/100 "
f"(improvement: +{improvement})")
return {
"status": "success",
"fixed_style_score": style_result['score'],
"original_style_score": original_score,
"improvement": improvement,
"remaining_issues": style_result['issues'],
"perfect_style": style_result['score'] == 100
}
except Exception as e:
logger.error(f"Tool: Style validation failed: {e}", exc_info=True)
return {
"status": "error",
"message": str(e)
}
👉 Finden:
# MODULE_6_STEP_3_COMPILE_FIX_REPORT
👉 Durch Tool 2 – Report Compiler ersetzen:
async def compile_fix_report(tool_context: ToolContext) -> Dict[str, Any]:
"""
Compiles comprehensive report of the fix process.
Args:
tool_context: ADK tool context with all fix pipeline data
Returns:
Comprehensive fix report
"""
logger.info("Tool: Compiling comprehensive fix report...")
try:
# Gather all data
original_code = tool_context.state.get(StateKeys.CODE_TO_REVIEW, '')
code_fixes = tool_context.state.get(StateKeys.CODE_FIXES, '')
# Test results
original_tests = tool_context.state.get(StateKeys.TEST_EXECUTION_SUMMARY, {})
fixed_tests = tool_context.state.get(StateKeys.FIX_TEST_EXECUTION_SUMMARY, {})
# Parse if strings
if isinstance(original_tests, str):
try:
original_tests = json.loads(original_tests)
except:
original_tests = {}
if isinstance(fixed_tests, str):
try:
fixed_tests = json.loads(fixed_tests)
except:
fixed_tests = {}
# Extract pass rates
original_pass_rate = 0
if original_tests:
if 'pass_rate' in original_tests:
original_pass_rate = original_tests['pass_rate']
elif 'test_summary' in original_tests:
# Handle test_runner_agent's JSON structure
summary = original_tests['test_summary']
total = summary.get('total_tests_run', 0)
passed = summary.get('tests_passed', 0)
if total > 0:
original_pass_rate = (passed / total) * 100
elif 'passed' in original_tests and 'total' in original_tests:
if original_tests['total'] > 0:
original_pass_rate = (original_tests['passed'] / original_tests['total']) * 100
fixed_pass_rate = 0
all_tests_pass = False
if fixed_tests:
if 'pass_rate' in fixed_tests:
fixed_pass_rate = fixed_tests['pass_rate']
all_tests_pass = fixed_tests.get('failed', 1) == 0
elif 'passed' in fixed_tests and 'total' in fixed_tests:
if fixed_tests['total'] > 0:
fixed_pass_rate = (fixed_tests['passed'] / fixed_tests['total']) * 100
all_tests_pass = fixed_tests.get('failed', 0) == 0
# Style scores
original_style = tool_context.state.get(StateKeys.STYLE_SCORE, 0)
fixed_style = tool_context.state.get(StateKeys.FIXED_STYLE_SCORE, 0)
# Calculate improvements
test_improvement = {
'original_pass_rate': original_pass_rate,
'fixed_pass_rate': fixed_pass_rate,
'improvement': fixed_pass_rate - original_pass_rate,
'all_tests_pass': all_tests_pass
}
style_improvement = {
'original_score': original_style,
'fixed_score': fixed_style,
'improvement': fixed_style - original_style,
'perfect_style': fixed_style == 100
}
# Determine overall status
if all_tests_pass and style_improvement['perfect_style']:
fix_status = 'SUCCESSFUL'
status_emoji = '✅'
elif test_improvement['improvement'] > 0 or style_improvement['improvement'] > 0:
fix_status = 'PARTIAL'
status_emoji = '⚠️'
else:
fix_status = 'FAILED'
status_emoji = '❌'
# Build comprehensive report
report = {
'status': fix_status,
'status_emoji': status_emoji,
'timestamp': datetime.now().isoformat(),
'original_code': original_code,
'code_fixes': code_fixes,
'improvements': {
'tests': test_improvement,
'style': style_improvement
},
'summary': f"{status_emoji} Fix Status: {fix_status}\n"
f"Tests: {original_pass_rate:.1f}% → {fixed_pass_rate:.1f}%\n"
f"Style: {original_style}/100 → {fixed_style}/100"
}
# Store report in state
tool_context.state[StateKeys.FIX_REPORT] = report
tool_context.state[StateKeys.FIX_STATUS] = fix_status
logger.info(f"Tool: Fix report compiled - Status: {fix_status}")
logger.info(f"Tool: Test improvement: {original_pass_rate:.1f}% → {fixed_pass_rate:.1f}%")
logger.info(f"Tool: Style improvement: {original_style} → {fixed_style}")
return {
"status": "success",
"fix_status": fix_status,
"report": report
}
except Exception as e:
logger.error(f"Tool: Failed to compile fix report: {e}", exc_info=True)
return {
"status": "error",
"message": str(e)
}
👉 Finden:
# MODULE_6_STEP_3_EXIT_FIX_LOOP
👉 Mit Tool 3 ersetzen – Signal für Schleifenausstieg:
def exit_fix_loop(tool_context: ToolContext) -> Dict[str, Any]:
"""
Signal that fixing is complete and should exit the loop.
Args:
tool_context: ADK tool context
Returns:
Confirmation message
"""
logger.info("Tool: Setting escalate flag to exit fix loop")
# This is the critical line that exits the LoopAgent
tool_context.actions.escalate = True
return {
"status": "success",
"message": "Fix complete, exiting loop"
}
Validator-Agent erstellen
👉 Offen
code_review_assistant/sub_agents/fix_pipeline/fix_validator.py
👉 Finden:
# MODULE_6_STEP_3_FIX_VALIDATOR_INSTRUCTION_PROVIDER
👉 Ersetzen Sie diese einzelne Zeile durch:
async def fix_validator_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are the final validation specialist for code fixes.
You have access to:
- Original issues from initial review
- Applied fixes: {code_fixes}
- Test results after fix: {fix_test_execution_summary}
- All state data from the fix process
Your responsibilities:
1. Use validate_fixed_style tool to check style compliance of fixed code
- Pass no arguments, it will retrieve fixed code from state
2. Use compile_fix_report tool to generate comprehensive report
- Pass no arguments, it will gather all data from state
3. Based on the report, determine overall fix status:
- ✅ SUCCESSFUL: All tests pass, style score 100
- ⚠️ PARTIAL: Improvements made but issues remain
- ❌ FAILED: Fix didn't work or made things worse
4. CRITICAL: If status is SUCCESSFUL, call the exit_fix_loop tool to stop iterations
- This prevents unnecessary additional fix attempts
- If not successful, the loop will continue for another attempt
5. Provide clear summary of:
- What was fixed
- What improvements were achieved
- Any remaining issues requiring manual attention
Be precise and quantitative in your assessment.
"""
return await instructions_utils.inject_session_state(template, context)
👉 Finden:
# MODULE_6_STEP_3_FIX_VALIDATOR_AGENT
👉 Ersetzen Sie diese einzelne Zeile durch:
fix_validator_agent = Agent(
name="FixValidator",
model=config.worker_model,
description="Validates fixes and generates final fix report",
instruction=fix_validator_instruction_provider,
tools=[
FunctionTool(func=validate_fixed_style),
FunctionTool(func=compile_fix_report),
FunctionTool(func=exit_fix_loop)
],
output_key="final_fix_report"
)
Schritt 4: LoopAgent-Beendigungsbedingungen verstehen
Es gibt drei Möglichkeiten, die LoopAgent zu beenden:
1. Erfolgreicher Abschluss (über Eskalierung)
# Inside any tool in the loop:
tool_context.actions.escalate = True
# Effect: Loop completes current iteration, then exits
# Use when: Fix is successful and no more attempts needed
Beispielablauf:
Iteration 1:
CodeFixer → generates fixes
FixTestRunner → tests show 90% pass rate
FixValidator → compiles report, sees PARTIAL status
→ Does NOT set escalate
→ Loop continues
Iteration 2:
CodeFixer → refines fixes based on failures
FixTestRunner → tests show 100% pass rate
FixValidator → compiles report, sees SUCCESSFUL status
→ Calls exit_fix_loop() which sets escalate = True
→ Loop exits after this iteration
2. Max. Iterationen beenden
LoopAgent(
name="FixAttemptLoop",
sub_agents=[...],
max_iterations=3 # Safety limit
)
# Effect: After 3 complete iterations, loop exits regardless of escalate
# Use when: Prevent infinite loops if fixes never succeed
Beispielablauf:
Iteration 1: PARTIAL (continue)
Iteration 2: PARTIAL (continue)
Iteration 3: PARTIAL (but max reached)
→ Loop exits, synthesizer presents best attempt
3. Error Exit
# If any agent throws unhandled exception:
raise Exception("Unexpected error")
# Effect: Loop exits immediately with error state
# Use when: Critical failure that can't be recovered
Entwicklung des Status über Iterationen hinweg:
Bei jedem Durchlauf wird der Status aus dem vorherigen Versuch aktualisiert:
# Before Iteration 1:
state = {
"code_to_review": "def add(a,b):return a+b", # Original
"style_score": 40,
"test_execution_summary": {...}
}
# After Iteration 1:
state = {
"code_to_review": "def add(a,b):return a+b", # Unchanged
"code_fixes": "def add(a, b):\n return a + b", # NEW
"style_score": 40, # Unchanged
"fixed_style_score": 100, # NEW
"test_execution_summary": {...}, # Unchanged
"fix_test_execution_summary": {...} # NEW
}
# Iteration 2 starts with all this state
# If fixes still not perfect, code_fixes gets overwritten
Warum?
escalate
Anstelle von Rückgabewerten:
# Bad: Using return value to signal exit
def validator_agent():
report = compile_report()
if report['status'] == 'SUCCESSFUL':
return {"exit": True} # How does loop know?
# Good: Using escalate
def validator_tool(tool_context):
report = compile_report()
if report['status'] == 'SUCCESSFUL':
tool_context.actions.escalate = True # Loop knows immediately
return {"report": report}
Vorteile:
- Funktioniert mit jedem Tool, nicht nur mit dem letzten
- Beeinträchtigt keine Rückgabedaten
- Eindeutige semantische Bedeutung
- Framework übernimmt die Beendigungslogik
Schritt 5: Fix-Pipeline verbinden
👉 Öffnen
code_review_assistant/agent.py
👉 Importe für die Korrekturpipeline hinzufügen (nach den vorhandenen Importen):
from google.adk.agents import LoopAgent # Add this to the existing Agent, SequentialAgent line
from code_review_assistant.sub_agents.fix_pipeline.code_fixer import code_fixer_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_test_runner import fix_test_runner_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_validator import fix_validator_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_synthesizer import fix_synthesizer_agent
Ihre Importe sollten jetzt so aussehen:
from google.adk.agents import Agent, SequentialAgent, LoopAgent
from .config import config
# Review pipeline imports (from Module 5)
from code_review_assistant.sub_agents.review_pipeline.code_analyzer import code_analyzer_agent
from code_review_assistant.sub_agents.review_pipeline.style_checker import style_checker_agent
from code_review_assistant.sub_agents.review_pipeline.test_runner import test_runner_agent
from code_review_assistant.sub_agents.review_pipeline.feedback_synthesizer import feedback_synthesizer_agent
# Fix pipeline imports (NEW)
from code_review_assistant.sub_agents.fix_pipeline.code_fixer import code_fixer_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_test_runner import fix_test_runner_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_validator import fix_validator_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_synthesizer import fix_synthesizer_agent
👉 Suchen:
# MODULE_6_STEP_5_CREATE_FIX_LOOP
👉 Ersetzen Sie diese einzelne Zeile durch:
# Create the fix attempt loop (retries up to 3 times)
fix_attempt_loop = LoopAgent(
name="FixAttemptLoop",
sub_agents=[
code_fixer_agent, # Step 1: Generate fixes
fix_test_runner_agent, # Step 2: Validate with tests
fix_validator_agent # Step 3: Check success & possibly exit
],
max_iterations=3 # Try up to 3 times
)
# Wrap loop with synthesizer for final report
code_fix_pipeline = SequentialAgent(
name="CodeFixPipeline",
description="Automated code fixing pipeline with iterative validation",
sub_agents=[
fix_attempt_loop, # Try to fix (1-3 times)
fix_synthesizer_agent # Present final results (always runs once)
]
)
👉 Vorhandene entfernen
root_agent
Definition:
root_agent = Agent(...)
👉 Finden:
# MODULE_6_STEP_5_UPDATE_ROOT_AGENT
👉 Ersetzen Sie diese einzelne Zeile durch:
# Update root agent to include both pipelines
root_agent = Agent(
name="CodeReviewAssistant",
model=config.worker_model,
description="An intelligent code review assistant that analyzes Python code and provides educational feedback",
instruction="""You are a specialized Python code review assistant focused on helping developers improve their code quality.
When a user provides Python code for review:
1. Immediately delegate to CodeReviewPipeline and pass the code EXACTLY as it was provided by the user.
2. The pipeline will handle all analysis and feedback
3. Return ONLY the final feedback from the pipeline - do not add any commentary
After completing a review, if significant issues were identified:
- If style score < 100 OR tests are failing OR critical issues exist:
* Add at the end: "\n\n💡 I can fix these issues for you. Would you like me to do that?"
- If the user responds yes or requests fixes:
* Delegate to CodeFixPipeline
* Return the fix pipeline's complete output AS-IS
When a user asks what you can do or general questions:
- Explain your capabilities for code review and fixing
- Do NOT trigger the pipeline for non-code messages
The pipelines handle everything for code review and fixing - just pass through their final output.""",
sub_agents=[code_review_pipeline, code_fix_pipeline],
output_key="assistant_response"
)
Schritt 6: „Fix Synthesizer“-Agent hinzufügen
Der Synthesizer erstellt nach Abschluss des Loops eine benutzerfreundliche Darstellung der Korrekturergebnisse.
👉 Offen
code_review_assistant/sub_agents/fix_pipeline/fix_synthesizer.py
👉 Finden:
# MODULE_6_STEP_6_FIX_SYNTHESIZER_INSTRUCTION_PROVIDER
👉 Ersetzen Sie diese einzelne Zeile durch:
async def fix_synthesizer_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are responsible for presenting the fix results to the user.
Based on the validation report: {final_fix_report}
Fixed code from state: {code_fixes}
Fix status: {fix_status}
Create a comprehensive yet friendly response that includes:
## 🔧 Fix Summary
[Overall status and key improvements - be specific about what was achieved]
## 📊 Metrics
- Test Results: [original pass rate]% → [new pass rate]%
- Style Score: [original]/100 → [new]/100
- Issues Fixed: X of Y
## ✅ What Was Fixed
[List each fixed issue with brief explanation of the correction made]
## 📝 Complete Fixed Code
[Include the complete, corrected code from state - this is critical]
## 💡 Explanation of Key Changes
[Brief explanation of the most important changes made and why]
[If any issues remain]
## ⚠️ Remaining Issues
[List what still needs manual attention]
## 🎯 Next Steps
[Guidance on what to do next - either use the fixed code or address remaining issues]
Save the fix report using save_fix_report tool before presenting.
Call it with no parameters - it will retrieve the report from state automatically.
Be encouraging about improvements while being honest about any remaining issues.
Focus on the educational aspect - help the user understand what was wrong and how it was fixed.
"""
return await instructions_utils.inject_session_state(template, context)
👉 Finden:
# MODULE_6_STEP_6_FIX_SYNTHESIZER_AGENT
👉 Ersetzen Sie diese einzelne Zeile durch:
fix_synthesizer_agent = Agent(
name="FixSynthesizer",
model=config.critic_model,
description="Creates comprehensive user-friendly fix report",
instruction=fix_synthesizer_instruction_provider,
tools=[FunctionTool(func=save_fix_report)],
output_key="fix_summary"
)
👉 Hinzufügen
save_fix_report
Tool für
tools.py
:
👉 Finden:
# MODULE_6_STEP_6_SAVE_FIX_REPORT
👉 Ersetzen durch:
async def save_fix_report(tool_context: ToolContext) -> Dict[str, Any]:
"""
Saves the fix report as an artifact.
Args:
tool_context: ADK tool context
Returns:
Save status
"""
logger.info("Tool: Saving fix report...")
try:
# Get the report from state
fix_report = tool_context.state.get(StateKeys.FIX_REPORT, {})
if not fix_report:
return {
"status": "error",
"message": "No fix report found in state"
}
# Convert to JSON
report_json = json.dumps(fix_report, indent=2)
report_part = types.Part.from_text(text=report_json)
# Generate filename
timestamp = datetime.now().isoformat().replace(':', '-')
filename = f"fix_report_{timestamp}.json"
# Try to save as artifact
if hasattr(tool_context, 'save_artifact'):
try:
version = await tool_context.save_artifact(filename, report_part)
await tool_context.save_artifact("latest_fix_report.json", report_part)
logger.info(f"Tool: Fix report saved as {filename}")
return {
"status": "success",
"filename": filename,
"version": str(version),
"size": len(report_json)
}
except Exception as e:
logger.warning(f"Could not save as artifact: {e}")
# Fallback: store in state
tool_context.state[StateKeys.LAST_FIX_REPORT] = fix_report
return {
"status": "success",
"message": "Fix report saved to state",
"size": len(report_json)
}
except Exception as e:
logger.error(f"Tool: Failed to save fix report: {e}", exc_info=True)
return {
"status": "error",
"message": str(e)
}
Schritt 7: Pipeline für vollständige Korrekturen testen
Sehen wir uns den gesamten Loop in Aktion an.
👉 System starten:
adk web code_review_assistant
Nachdem Sie den Befehl adk web ausgeführt haben, sollte in Ihrem Terminal eine Ausgabe angezeigt werden, die angibt, dass der ADK-Webserver gestartet wurde. Sie sollte in etwa so aussehen:
+-----------------------------------------------------------------------------+
| ADK Web Server started |
| |
| For local testing, access at http://localhost:8000. |
+-----------------------------------------------------------------------------+
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
👉 Test-Prompt:
Please analyze the following:
def dfs_search_v1(graph, start, target):
"""Find if target is reachable from start."""
visited = set()
stack = start
while stack:
current = stack.pop()
if current == target:
return True
if current not in visited:
visited.add(current)
for neighbor in graph[current]:
if neighbor not in visited:
stack.append(neighbor)
return False
Reichen Sie zuerst den fehlerhaften Code ein, um die Prüfpipeline auszulösen. Nachdem die Fehler identifiziert wurden, bitten Sie den Agenten, den Code zu korrigieren. Dadurch wird die leistungsstarke, iterative Fix-Pipeline ausgelöst.
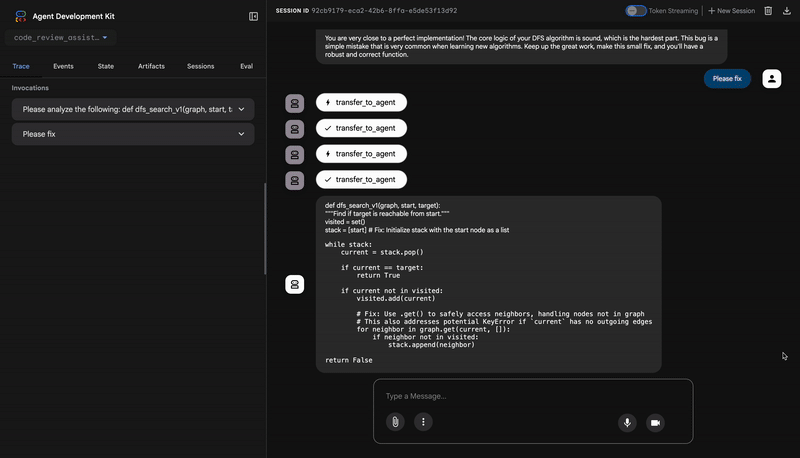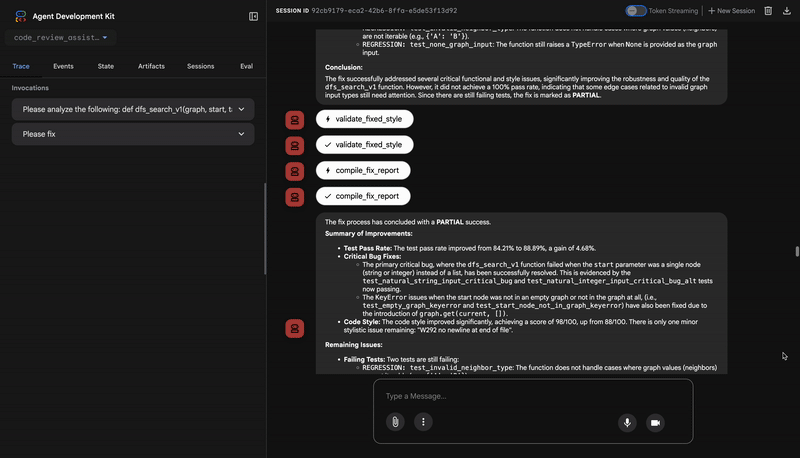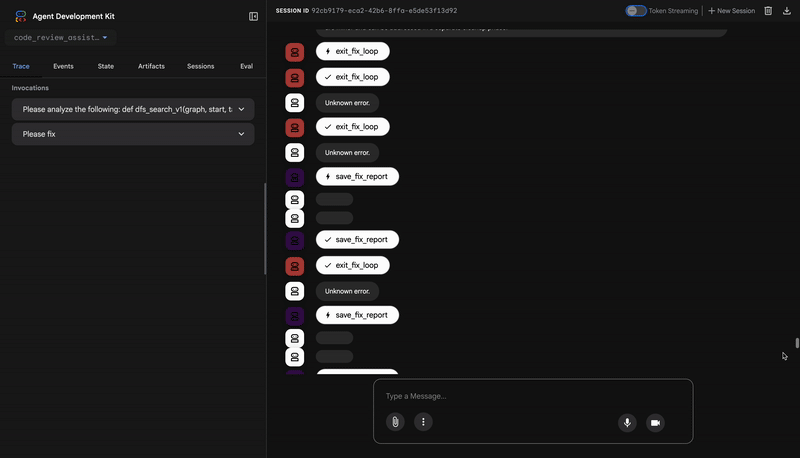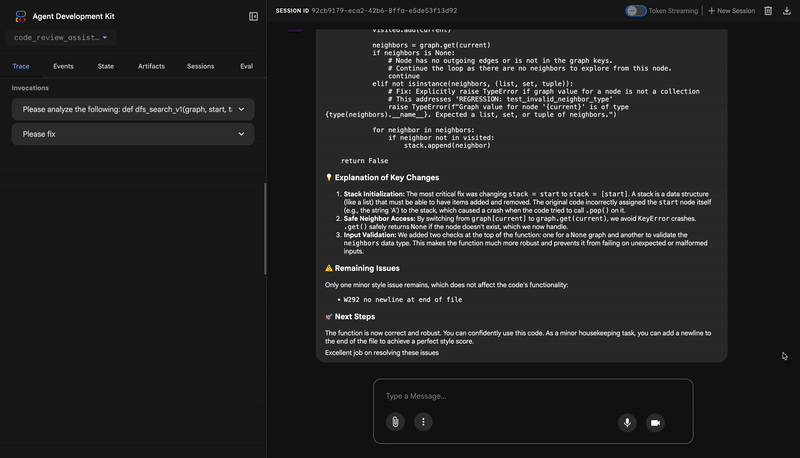
1. Erste Überprüfung (Fehler finden)
Das ist die erste Hälfte des Prozesses. Die Review-Pipeline mit vier Agents analysiert den Code, prüft seinen Stil und führt eine generierte Testsuite aus. Es wird ein kritischer AttributeError und andere Probleme korrekt erkannt und ein Ergebnis geliefert: Der Code ist DEFEKT, mit einer Testdurchlaufrate von nur 84, 21%.
2. Die automatische Korrektur (die Schleife in Aktion)
Das ist der beeindruckendste Teil. Wenn Sie den Agenten bitten, den Code zu korrigieren, nimmt er nicht nur eine Änderung vor. Dadurch wird ein iterativer Fix-and-Validate-Loop (Schleife zum Beheben und Validieren) gestartet, der genau wie ein sorgfältiger Entwickler funktioniert: Er versucht, einen Fehler zu beheben, testet die Lösung gründlich und versucht es noch einmal, wenn sie nicht perfekt ist.
Iteration 1: Der erste Versuch (teilweiser Erfolg)
- Die Korrektur:Der
CodeFixer-Agent liest den ursprünglichen Bericht und nimmt die offensichtlichsten Korrekturen vor. Dabei wirdstack = startinstack = [start]geändert undgraph.get()verwendet, umKeyError-Ausnahmen zu verhindern. - Die Validierung:Die
TestRunnerführt die gesamte Testsuite sofort noch einmal für diesen neuen Code aus. - Das Ergebnis:Die Bestehensrate verbessert sich deutlich auf 88,89%. Die kritischen Programmfehler sind behoben. Die Tests sind jedoch so umfassend, dass sie zwei neue, subtile Fehler (Regressionen) im Zusammenhang mit der Verarbeitung von
Noneals Graph oder als Nachbarwerte, die keine Liste sind, aufdecken. Das System markiert die Korrektur als PARTIAL (TEILWEISE).
Iteration 2: Der letzte Schliff (100% Erfolg)
- Die Korrektur:Da die Beendigungsbedingung der Schleife (100% bestandene Tests) nicht erfüllt wurde, wird sie noch einmal ausgeführt. Die
CodeFixerenthält jetzt mehr Informationen – die beiden neuen Regressionsfehler. Es wird eine endgültige, robustere Version des Codes generiert, in der diese Grenzfälle explizit behandelt werden. - Die Validierung:Der
TestRunnerführt die Testsuite ein letztes Mal für die endgültige Version des Codes aus. - Das Ergebnis:Eine perfekte Erfolgsquote von 100% . Alle ursprünglichen Fehler und alle Regressionen wurden behoben. Das System markiert die Korrektur als ERFOLGREICH und die Schleife wird beendet.
3. Der Abschlussbericht: Eine perfekte Punktzahl
Nachdem die Korrektur vollständig validiert wurde, übernimmt der FixSynthesizer-Agent, um den Abschlussbericht zu präsentieren. Er wandelt die technischen Daten in eine klare, informative Zusammenfassung um.
Messwert | Vorher | Nach | Verbesserung |
Bestandene Tests in Prozent | 84,21% | 100 % | ▲ 15,79% |
Stilbewertung | 88 / 100 | 98 / 100 | ▲ 10 Punkte |
Behobene Fehler | 0 von 3 | 3 von 3 | ✅ |
✅ Der endgültige, validierte Code
Hier ist der vollständige, korrigierte Code, der jetzt alle 19 Tests besteht und die erfolgreiche Korrektur demonstriert:
def dfs_search_v1(graph, start, target):
"""Find if target is reachable from start."""
# Handles 'None' graph input
if graph is None:
return False
visited = set()
# Fixes the critical AttributeError
stack = [start]
while stack:
current = stack.pop()
if current == target:
return True
if current not in visited:
visited.add(current)
# Safely gets neighbors to prevent KeyError
neighbors = graph.get(current)
if neighbors is None:
continue
# Validates that neighbors are iterable
if not isinstance(neighbors, (list, set, tuple)):
raise TypeError(
f"Graph value for node '{current}' is of type "
f"{type(neighbors).__name__}. Expected a list, set, or tuple."
)
for neighbor in neighbors:
if neighbor not in visited:
stack.append(neighbor)
return False
👉💻 Wenn Sie mit dem Testen fertig sind, kehren Sie zum Cloud Shell Editor-Terminal zurück und drücken Sie Ctrl+C, um die ADK-Entwicklungsoberfläche zu beenden.
Was Sie erstellt haben
Sie haben jetzt eine vollständige automatisierte Korrekturpipeline, die Folgendes leistet:
✅ Generiert Korrekturen: Basierend auf der Analyse der Rezensionen
✅ Iterative Validierung: Tests nach jedem Korrekturversuch
✅ Automatische Wiederholungen: Bis zu 3 Versuche
✅ Intelligenter Abschluss: Eskalierung bei Erfolg
✅ Nachverfolgung von Verbesserungen: Vergleich von Messwerten vor und nach der Korrektur
✅ Bereitstellung von Artefakten: Herunterladbare Korrekturberichte
Kennengelernte zentrale Konzepte
LoopAgent im Vergleich zu Sequential:
- Sequenziell: Ein Durchlauf durch Agenten
- LoopAgent: Wiederholt, bis die Beendigungsbedingung oder die maximale Anzahl von Iterationen erreicht ist
- Ausgang
tool_context.actions.escalate = Truenehmen
Entwicklung des Status über Iterationen hinweg:
CODE_FIXESwird bei jedem Durchlauf aktualisiert- Testergebnisse verbessern sich im Laufe der Zeit
- Prüfer sieht kumulative Änderungen
Multi-Pipeline-Architektur:
- Pipeline überprüfen: Analyse mit Lesezugriff (Modul 5)
- Schleife korrigieren: Iterative Korrektur (innere Schleife von Modul 6)
- Pipeline korrigieren: Loop + Synthesizer (Modul 6, außen)
- Root-Agent: Orchestriert basierend auf der Nutzerabsicht
Tools zur Steuerung des Ablaufs:
exit_fix_loop()Eskalierungen festlegen- Jedes Tool kann das Ende des Loops signalisieren
- Entkoppelt die Beendigungslogik von den Agent-Anweisungen
Sicherheit bei maximalen Iterationen:
- Verhindert Endlosschleifen
- Das System antwortet immer.
- Präsentiert den besten Versuch, auch wenn er nicht perfekt ist
Weitere Informationen
Im letzten Modul erfahren Sie, wie Sie Ihren Agenten in der Produktion bereitstellen:
- Nichtflüchtigen Speicher mit VertexAiSessionService einrichten
- In Agent Engine in Google Cloud bereitstellen
- Monitoring und Fehlerbehebung von Produktions-Agents
- Best Practices für Skalierung und Zuverlässigkeit
Sie haben ein vollständiges Multi-Agenten-System mit sequenziellen und Schleifenarchitekturen erstellt. Die Muster, die Sie kennengelernt haben – Statusverwaltung, dynamische Anweisungen, Tool-Orchestrierung und iterative Optimierung – sind produktionsreife Techniken, die in echten Agentensystemen verwendet werden.
7. In der Produktion bereitstellen
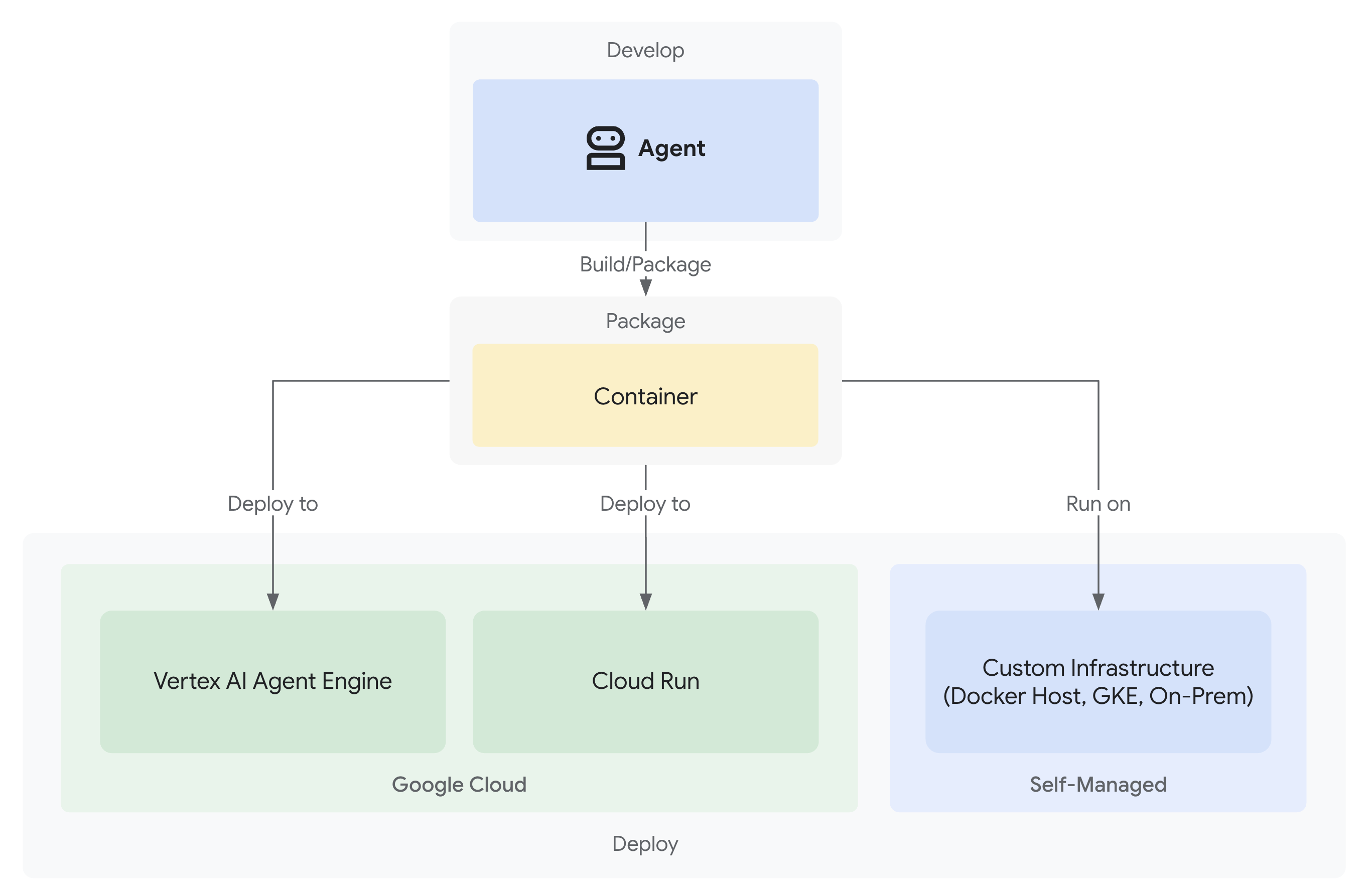
Einführung
Ihr Code-Review-Assistent ist jetzt vollständig und die Pipelines für die Überprüfung und Fehlerbehebung funktionieren lokal. Der Haken: Die Funktion läuft nur auf Ihrem Computer. In diesem Modul stellen Sie Ihren Agenten in Google Cloud bereit, damit Ihr Team mit persistenten Sitzungen und einer produktionsreifen Infrastruktur darauf zugreifen kann.
Lerninhalte:
- Drei Bereitstellungspfade: lokal, Cloud Run und Agent Engine
- Automatisierte Infrastrukturbereitstellung
- Strategien für die Sitzungspersistenz
- Bereitgestellte KI-Agenten testen
Bereitstellungsoptionen
Das ADK unterstützt mehrere Bereitstellungsziele, die jeweils unterschiedliche Vor- und Nachteile haben:
Bereitstellungspfade
Faktor | Lokal ( | Cloud Run ( | Agent Engine ( |
Komplexität | Minimal | Mittel | Niedrig |
Sitzungspersistenz | Nur im Arbeitsspeicher (geht beim Neustart verloren) | Cloud SQL (PostgreSQL) | Von Vertex AI verwaltet (automatisch) |
Infrastruktur | Keine (nur Entwicklercomputer) | Container + Datenbank | Vollständig verwaltet |
Kaltstart | – | 100–2.000 ms | 100–500 ms |
Skalieren | Einzelne Instanz | Automatisch (auf null) | Automatisch |
Kostenmodell | Kostenlos (lokale Verarbeitung) | Anfragebasiert + kostenlose Stufe | Compute-basiert |
UI-Support | Ja (über | Ja (über | Nein (nur API) |
Optimal für | Entwicklung/Tests | Variabler Traffic, Kostenkontrolle | Produktions-Agents |
Zusätzliche Bereitstellungsoption:Google Kubernetes Engine (GKE) ist für fortgeschrittene Nutzer verfügbar, die Kubernetes-Kontrolle, benutzerdefinierte Netzwerke oder die Orchestrierung mehrerer Dienste benötigen. Die GKE-Bereitstellung wird in diesem Codelab nicht behandelt, ist aber im ADK-Bereitstellungsleitfaden dokumentiert.
Was wird bereitgestellt?
Bei der Bereitstellung in Cloud Run oder Agent Engine wird Folgendes verpackt und bereitgestellt:
- Ihr Agentencode (
agent.py, alle untergeordneten Agents, Tools) - Abhängigkeiten (
requirements.txt) - ADK-API-Server (automatisch enthalten)
- Web-UI (nur Cloud Run, wenn
--with_uiangegeben ist)
Wichtige Unterschiede:
- Cloud Run: Verwendet die
adk deploy cloud_run-Befehlszeile (Container werden automatisch erstellt) odergcloud run deploy(benutzerdefiniertes Dockerfile erforderlich) - Agent Engine: Verwendet die
adk deploy agent_engine-Befehlszeile (kein Container erforderlich, Python-Code wird direkt verpackt)
Schritt 1: Umgebung konfigurieren
.env-Datei konfigurieren
Ihre .env-Datei (aus Modul 3) muss für die Cloud-Bereitstellung aktualisiert werden. Öffnen Sie .env und prüfen bzw. aktualisieren Sie die folgenden Einstellungen:
Für alle Cloud-Bereitstellungen erforderlich:
# Your actual GCP Project ID (REQUIRED)
GOOGLE_CLOUD_PROJECT=your-project-id
# GCP region for deployments (REQUIRED)
GOOGLE_CLOUD_LOCATION=us-central1
# Use Vertex AI (REQUIRED)
GOOGLE_GENAI_USE_VERTEXAI=true
# Model configuration (already set)
WORKER_MODEL=gemini-2.5-flash
CRITIC_MODEL=gemini-2.5-pro
Bucket-Namen festlegen (ERFORDERLICH, bevor „deploy.sh“ ausgeführt wird):
Das Bereitstellungsskript erstellt Buckets basierend auf diesen Namen. Jetzt festlegen:
# Staging bucket for Agent Engine code uploads (REQUIRED for agent-engine)
STAGING_BUCKET=gs://your-project-id-staging
# Artifact storage for reports and fixed code (REQUIRED for both cloud-run and agent-engine)
ARTIFACT_BUCKET=gs://your-project-id-artifacts
Ersetzen Sie your-project-id in beiden Bucket-Namen durch Ihre tatsächliche Projekt-ID. Das Skript erstellt diese Buckets, falls sie noch nicht vorhanden sind.
Optionale Variablen (werden automatisch erstellt, wenn sie leer sind):
# Agent Engine ID (populated after first deployment)
AGENT_ENGINE_ID=
# Cloud Run Database credentials (created automatically if blank)
CLOUD_SQL_INSTANCE_NAME=
DB_USER=
DB_PASSWORD=
DB_NAME=
Authentifizierungsprüfung
Wenn bei der Bereitstellung Authentifizierungsfehler auftreten:
gcloud auth application-default login
gcloud config set project $GOOGLE_CLOUD_PROJECT
Schritt 2: Bereitstellungsskript verstehen
Das Skript deploy.sh bietet eine einheitliche Schnittstelle für alle Bereitstellungsmodi:
./deploy.sh {local|cloud-run|agent-engine}
Scriptfunktionen
Infrastrukturbereitstellung:
- API-Aktivierung (AI Platform, Storage, Cloud Build, Cloud Trace, Cloud SQL)
- Konfiguration von IAM-Berechtigungen (Dienstkonten, Rollen)
- Ressourcenerstellung (Buckets, Datenbanken, Instanzen)
- Bereitstellung mit den richtigen Flags
- Überprüfung nach der Bereitstellung
Wichtige Scriptabschnitte
- Konfiguration (Zeilen 1–35): Projekt, Region, Dienstnamen, Standardeinstellungen
- Hilfsfunktionen (Zeilen 37–200): API-Aktivierung, Bucket-Erstellung, IAM-Einrichtung
- Hauptlogik (Zeilen 202–400): Modusspezifische Bereitstellungs-Orchestrierung
Schritt 3: Agent für die Agent Engine vorbereiten
Bevor Sie den Agent in Agent Engine bereitstellen können, benötigen Sie eine agent_engine_app.py-Datei, die den Agent für die verwaltete Laufzeitumgebung umschließt. Das wurde bereits für Sie erstellt.
code_review_assistant/agent_engine_app.py ansehen
👉 Datei öffnen:
"""
Agent Engine application wrapper.
This file prepares the agent for deployment to Vertex AI Agent Engine.
"""
from vertexai import agent_engines
from .agent import root_agent
# Wrap the agent in an AdkApp object for Agent Engine deployment
app = agent_engines.AdkApp(
agent=root_agent,
enable_tracing=True,
)
Schritt 4: In Agent Engine bereitstellen
Agent Engine ist die empfohlene Produktionsbereitstellung für ADK-Agenten, da sie Folgendes bietet:
- Vollständig verwaltete Infrastruktur (keine Container erforderlich)
- Integrierte Sitzungspersistenz über
VertexAiSessionService - Autoscaling ab null
- Cloud Trace-Einbindung standardmäßig aktiviert
Unterschiede zwischen Agent Engine und anderen Bereitstellungen
Im Detail:
deploy.sh agent-engine
Verwendungen:
adk deploy agent_engine \
--project=$GOOGLE_CLOUD_PROJECT \
--region=$GOOGLE_CLOUD_LOCATION \
--staging_bucket=$STAGING_BUCKET \
--display_name="Code Review Assistant" \
--trace_to_cloud \
code_review_assistant
Dieser Befehl:
- Ihr Python-Code wird direkt verpackt (kein Docker-Build).
- Lädt die Dateien in den Staging-Bucket hoch, den Sie in
.envangegeben haben. - Verwaltete Agent Engine-Instanz erstellen
- Cloud Trace für die Beobachtbarkeit aktivieren
- Verwendet
agent_engine_app.py, um die Laufzeit zu konfigurieren
Im Gegensatz zu Cloud Run, wo Ihr Code in Containern ausgeführt wird, wird Ihr Python-Code in Agent Engine direkt in einer verwalteten Laufzeitumgebung ausgeführt, ähnlich wie bei serverlosen Funktionen.
Deployment ausführen
Über das Stammverzeichnis Ihres Projekts:
./deploy.sh agent-engine
Bereitstellungsphasen
Sehen Sie sich an, wie das Skript diese Phasen durchläuft:
Phase 1: API Enablement
✓ aiplatform.googleapis.com
✓ storage-api.googleapis.com
✓ cloudbuild.googleapis.com
✓ cloudtrace.googleapis.com
Phase 2: IAM Setup
✓ Getting project number
✓ Granting Storage Object Admin
✓ Granting AI Platform User
✓ Granting Cloud Trace Agent
Phase 3: Staging Bucket
✓ Creating gs://your-project-id-staging
✓ Setting permissions
Phase 4: Artifact Bucket
✓ Creating gs://your-project-id-artifacts
✓ Configuring access
Phase 5: Validation
✓ Checking agent.py exists
✓ Verifying root_agent defined
✓ Checking agent_engine_app.py exists
✓ Validating requirements.txt
Phase 6: Build & Deploy
✓ Packaging agent code
✓ Uploading to staging bucket
✓ Creating Agent Engine instance
✓ Configuring session persistence
✓ Setting up Cloud Trace integration
✓ Running health checks
Dieser Vorgang dauert 5 bis 10 Minuten, da der Agent verpackt und in der Vertex AI-Infrastruktur bereitgestellt wird.
Agent Engine-ID speichern
Nach erfolgreicher Bereitstellung:
✅ Deployment successful!
Agent Engine ID: 7917477678498709504
Resource Name: projects/123456789/locations/us-central1/reasoningEngines/7917477678498709504
Endpoint: https://us-central1-aiplatform.googleapis.com/v1/...
⚠️ IMPORTANT: Save this in your .env file:
AGENT_ENGINE_ID=7917477678498709504
aktualisieren
.env
Datei sofort einreichen:
echo "AGENT_ENGINE_ID=7917477678498709504" >> .env
Diese ID ist für Folgendes erforderlich:
- Bereitgestellten KI-Agenten testen
- Deployment später aktualisieren
- Auf Logs und Traces zugreifen
Was wurde bereitgestellt?
Ihre Agent Engine-Bereitstellung umfasst jetzt Folgendes:
✅ Vollständiger Prüfprozess (4 Agents)
✅ Vollständiger Korrekturprozess (Loop + Synthesizer)
✅ Alle Tools (AST-Analyse, Stilprüfung, Artefaktgenerierung)
✅ Sitzungspersistenz (automatisch über VertexAiSessionService)
✅ Zustandsverwaltung (Sitzungs-, Nutzer- und Lebensdauerstufen)
✅ Beobachtbarkeit (Cloud Trace aktiviert)
✅ Automatisch skalierende Infrastruktur
Schritt 5: Bereitgestellten Agenten testen
.env-Datei aktualisieren
Prüfen Sie nach der Bereitstellung, ob .env Folgendes enthält:
AGENT_ENGINE_ID=7917477678498709504 # From deployment output
GOOGLE_CLOUD_PROJECT=your-project-id
GOOGLE_CLOUD_LOCATION=us-central1
Testskript ausführen
Das Projekt enthält tests/test_agent_engine.py speziell zum Testen von Agent Engine-Bereitstellungen:
python tests/test_agent_engine.py
Was der Test macht
- Authentifizierung mit Ihrem Google Cloud-Projekt
- Erstellt eine Sitzung mit dem bereitgestellten Agenten
- Senden einer Anfrage zur Codeüberprüfung (das DFS-Fehlerbeispiel)
- Streamt die Antwort über Server-Sent Events (SSE) zurück
- Überprüft die Sitzungspersistenz und die Statusverwaltung
Erwartete Ausgabe
Authenticated with project: your-project-id
Targeting Agent Engine: projects/.../reasoningEngines/7917477678498709504
Creating new session...
Created session: 4857885913439920384
Sending query to agent and streaming response:
data: {"content": {"parts": [{"text": "I'll analyze your code..."}]}}
data: {"content": {"parts": [{"text": "**Code Structure Analysis**\n..."}]}}
data: {"content": {"parts": [{"text": "**Style Check Results**\n..."}]}}
data: {"content": {"parts": [{"text": "**Test Results**\n..."}]}}
data: {"content": {"parts": [{"text": "**Final Feedback**\n..."}]}}
Stream finished.
Checkliste für die Bestätigung
- ✅ Die vollständige Überprüfungspipeline wird ausgeführt (alle 4 Agents).
- ✅ Streamingantwort zeigt progressive Ausgabe
- ✅ Der Sitzungsstatus bleibt über Anfragen hinweg erhalten.
- ✅ Keine Authentifizierungs- oder Verbindungsfehler
- ✅ Tool-Aufrufe werden erfolgreich ausgeführt (AST-Analyse, Stilprüfung)
- ✅ Artefakte werden gespeichert (Bewertungsbericht verfügbar)
Alternative: In Cloud Run bereitstellen
Die Agent Engine wird für eine optimierte Produktionsbereitstellung empfohlen. Cloud Run bietet jedoch mehr Kontrolle und unterstützt die ADK-Web-UI. Dieser Abschnitt bietet einen Überblick.
Wann sollte Cloud Run verwendet werden?
Wählen Sie Cloud Run, wenn Sie Folgendes benötigen:
- Die ADK-Web-UI für die Nutzerinteraktion
- Volle Kontrolle über die Containerumgebung
- Benutzerdefinierte Datenbankkonfigurationen
- Einbindung in bestehende Cloud Run-Dienste
Funktionsweise der Cloud Run-Bereitstellung
Im Detail:
deploy.sh cloud-run
Verwendungen:
adk deploy cloud_run \
--project=$GOOGLE_CLOUD_PROJECT \
--region=$GOOGLE_CLOUD_LOCATION \
--service_name="code-review-assistant" \
--app_name="code_review_assistant" \
--port=8080 \
--with_ui \
--artifact_service_uri="gs://$ARTIFACT_BUCKET" \
--trace_to_cloud \
code_review_assistant
Dieser Befehl:
- Erstellt einen Docker-Container mit Ihrem Agent-Code
- Pushes an Google Artifact Registry
- Bereitstellung als Cloud Run-Dienst
- Enthält die ADK-Web-UI (
--with_ui) - Konfiguriert die Cloud SQL-Verbindung (wird nach der ersten Bereitstellung vom Skript hinzugefügt)
Der Hauptunterschied zu Agent Engine besteht darin, dass Cloud Run Ihren Code in Containern ausführt und eine Datenbank für die Sitzungspersistenz erfordert, während Agent Engine beides automatisch übernimmt.
Cloud Run-Bereitstellungsbefehl
./deploy.sh cloud-run
Unterschiede
Infrastruktur:
- Containerisierte Bereitstellung (Docker wird automatisch vom ADK erstellt)
- Cloud SQL (PostgreSQL) für die Sitzungspersistenz
- Datenbank wird automatisch durch Skript erstellt oder verwendet vorhandene Instanz
Sitzungsverwaltung:
- Verwendet
DatabaseSessionServiceanstelle vonVertexAiSessionService - Erfordert Datenbankanmeldedaten in
.env(oder automatisch generiert) - Status wird in der PostgreSQL-Datenbank beibehalten
Unterstützung der Benutzeroberfläche:
- Web-UI über das Flag
--with_uiverfügbar (wird vom Skript verarbeitet) - Zugriff unter:
https://code-review-assistant-xyz.a.run.app
Ihr Lernerfolg
Ihre Produktionsbereitstellung umfasst:
✅ Automatisierte Bereitstellung über deploy.sh-Script
✅ Verwaltete Infrastruktur (Agent Engine übernimmt Skalierung, Persistenz und Monitoring)
✅ Persistenter Status über alle Speicherebenen (Sitzung/Nutzer/Lebensdauer)
✅ Sichere Verwaltung von Anmeldedaten (automatische Generierung und IAM-Einrichtung)
✅ Skalierbare Architektur (0 bis Tausende von gleichzeitigen Nutzern)
✅ Integrierte Observability (Cloud Trace-Integration aktiviert)
✅ Fehlerbehandlung und ‑behebung in Produktionsqualität
Kennengelernte zentrale Konzepte
Vorbereitung der Bereitstellung:
agent_engine_app.py: Umschließt den Agent mitAdkAppfür Agent Engine.AdkAppkonfiguriertVertexAiSessionServiceautomatisch für die Persistenz- Tracing über
enable_tracing=Trueaktiviert
Bereitstellungsbefehle:
adk deploy agent_engine: Pakete mit Python-Code, keine Containeradk deploy cloud_run: Erstellt automatisch Docker-Containergcloud run deploy: Alternative mit benutzerdefiniertem Dockerfile
Bereitstellungsoptionen:
- Agent Engine: Vollständig verwaltet, schnellste Produktionsbereitschaft
- Cloud Run: Mehr Kontrolle, unterstützt Web-UI
- GKE: Erweiterte Kubernetes-Steuerung (siehe GKE-Bereitstellungsleitfaden)
Verwaltete Dienste:
- Die Agent Engine übernimmt die Sitzungspersistenz automatisch.
- Für Cloud Run ist eine Datenbankeinrichtung (oder automatische Erstellung) erforderlich
- Beide unterstützen die Artefaktspeicherung über GCS.
Sitzungsverwaltung:
- Agent Engine:
VertexAiSessionService(automatisch) - Cloud Run:
DatabaseSessionService(Cloud SQL) - Lokal:
InMemorySessionService(ephemeral)
Ihr Agent ist aktiv
Ihr Code-Review-Assistent ist jetzt:
- Über HTTPS-API-Endpunkte zugänglich
- Persistent: Der Status bleibt auch nach Neustarts erhalten.
- Skalierbar, um das Wachstum des Teams automatisch zu bewältigen
- Observable mit vollständigen Anfragetraces
- Wartungsfreundlich durch skriptbasierte Bereitstellungen
Wie geht es weiter? In Modul 8 erfahren Sie, wie Sie mit Cloud Trace die Leistung Ihres Agents analysieren, Engpässe in den Pipelines für Überprüfung und Korrektur identifizieren und die Ausführungszeiten optimieren können.
8. Beobachtbarkeit in der Produktion
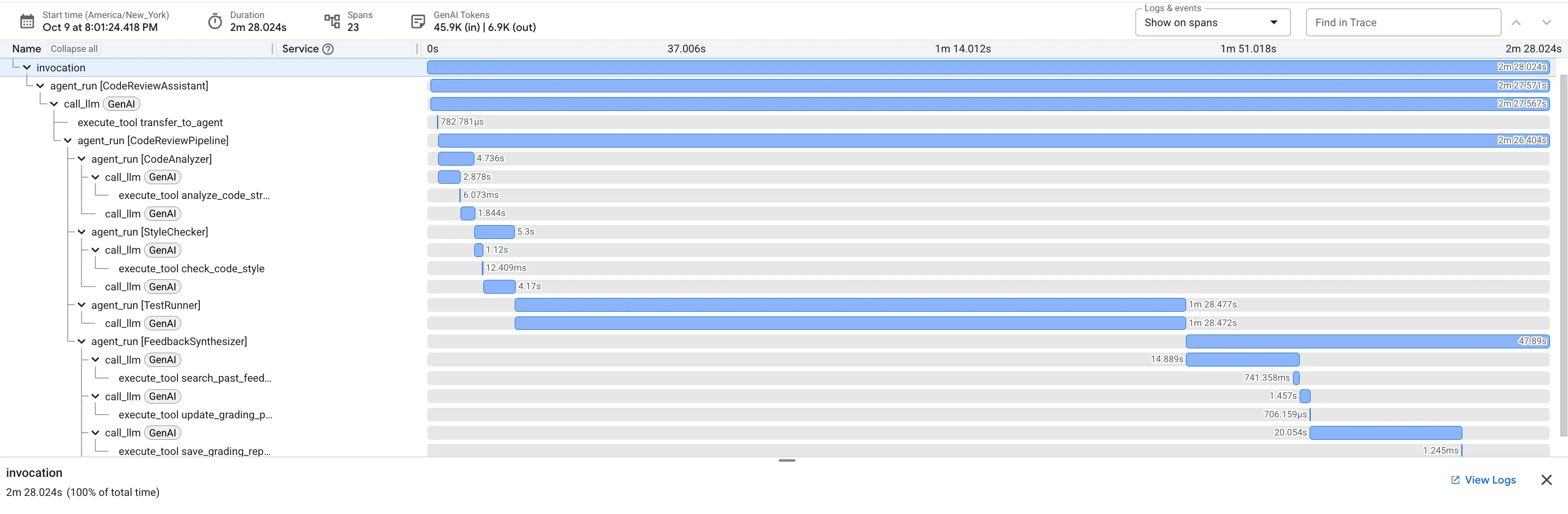
Einführung
Ihr Code-Review-Assistent wird jetzt in der Produktionsumgebung in Agent Engine bereitgestellt und ausgeführt. Aber woher wissen Sie, dass es gut funktioniert? Können Sie diese wichtigen Fragen beantworten:
- Reagiert der Agent schnell genug?
- Welche Vorgänge sind am langsamsten?
- Werden die Korrekturschleifen effizient abgeschlossen?
- Wo gibt es Leistungsengpässe?
Ohne Beobachtbarkeit können Sie nicht nachvollziehen, was in Ihrer Umgebung passiert. Das Flag --trace-to-cloud, das Sie während der Bereitstellung verwendet haben, hat Cloud Trace automatisch aktiviert. So haben Sie vollständigen Einblick in jede Anfrage, die Ihr Agent verarbeitet. Dadurch wird die Fehlersuche von einem Ratespiel zu einer forensischen Analyse.
In diesem Modul erfahren Sie, wie Sie Traces lesen, die Leistungsmerkmale Ihres Agenten verstehen und anhand von Fakten Optimierungsbereiche identifizieren.
Traces und Spans
Was ist ein Trace?
Ein Trace ist der vollständige Zeitablauf der Bearbeitung einer einzelnen Anfrage durch Ihren Agent. Sie umfasst alles vom Senden einer Anfrage durch einen Nutzer bis zur endgültigen Antwort. Jeder Trace zeigt Folgendes:
- Gesamtdauer der Anfrage
- Alle ausgeführten Vorgänge
- Wie Vorgänge zueinander in Beziehung stehen (über- und untergeordnete Beziehungen)
- Wann die einzelnen Vorgänge begonnen und beendet wurden
Was ist ein Span?
Ein Span stellt eine einzelne Arbeitseinheit in einem Trace dar. Häufige Spannenarten in Ihrem Code-Review-Assistenten:
agent_run: Ausführung eines Agenten (Root-Agent oder Sub-Agent)call_llm: Anfrage an ein Sprachmodellexecute_tool: Ausführung der Tool-Funktionstate_read/state_write: Vorgänge zur Statusverwaltungcode_executor: Code mit Tests ausführen
Spans haben:
- Name: Für welchen Vorgang steht diese Zeile?
- Dauer: Wie lange es gedauert hat
- Attribute: Metadaten wie Modellname, Anzahl der Tokens, Ein-/Ausgaben
- Status: Erfolg oder Fehler
- Über-/Untergeordnet-Beziehungen: Welche Vorgänge haben welche ausgelöst?
Automatische Instrumentierung
Wenn Sie die Bereitstellung mit --trace-to-cloud vorgenommen haben, instrumentiert das ADK automatisch Folgendes:
- Jeder Agentenaufruf und Sub-Agent-Aufruf
- Alle LLM-Anfragen mit Tokenanzahl
- Tool-Ausführungen mit Ein-/Ausgaben
- Statusvorgänge (Lesen/Schreiben)
- Schleifeniterationen in der Korrekturpipeline
- Fehlerbedingungen und Wiederholungsversuche
Keine Codeänderungen erforderlich: Tracing ist in die Laufzeit des ADK integriert.
Schritt 1: Auf Cloud Trace Explorer zugreifen
Cloud Trace in der Google Cloud Console öffnen:
- Rufen Sie den Cloud Trace Explorer auf.
- Wählen Sie Ihr Projekt im Drop-down-Menü aus (sollte bereits ausgewählt sein).
- In Modul 7 sollten Sie Traces aus Ihrem Test sehen.
Wenn noch keine Spuren angezeigt werden:
Beim Test, den Sie in Modul 7 ausgeführt haben, sollten Traces generiert worden sein. Wenn die Liste leer ist, generieren Sie einige Tracedaten:
python tests/test_agent_engine.py
Es kann 1 bis 2 Minuten dauern, bis Traces in der Console angezeigt werden.
Was Sie sehen
Der Trace Explorer enthält folgende Informationen:
- Liste der Traces: Jede Zeile steht für eine vollständige Anfrage.
- Zeitachse: Zeitpunkt der Anfragen
- Dauer: Wie lange jede Anfrage gedauert hat
- Anfragedetails: Zeitstempel, Latenz, Anzahl der Spannen
Dies ist Ihr Produktions-Traffic-Log. Jede Interaktion mit Ihrem Agent erstellt einen Trace.
Schritt 2: Review-Pipeline-Trace untersuchen
Klicken Sie in der Liste auf einen beliebigen Trace, um die Wasserfalldarstellung zu öffnen.
Es wird ein Gantt-Diagramm mit der vollständigen Ausführungszeitachse angezeigt. Der Stamm-invocation-Span stellt die gesamte Anfrage dar. Darunter befinden sich Spans für jeden Sub-Agenten, jedes Tool und jeden LLM-Aufruf.
Wasserfall lesen: Engpässe identifizieren
Jeder Balken steht für einen Bereich. Die horizontale Position gibt an, wann die Aktivität begonnen hat, und die Länge zeigt, wie lange sie gedauert hat. So sehen Sie sofort, womit Ihr Agent seine Zeit verbringt.
Wichtige Erkenntnisse aus dem obigen Trace:
- Gesamtlatenz: Die gesamte Anfrage hat 2 Minuten und 28 Sekunden gedauert.
- Aufschlüsselung nach Sub-Agenten:
Code Analyzer: 4,7 SekundenStyle Checker: 5,3 SekundenTest Runner: 1 Minute und 28 SekundenFeedback Synthesizer: 47,9 Sekunden
- Analyse des kritischen Pfads: Der
Test Runner-Agent ist der klare Leistungsengpass und macht etwa 59% der gesamten Anfragezeit aus.
Diese Sichtbarkeit ist sehr hilfreich. Anstatt zu raten, wo die Zeit verbracht wird, haben Sie konkrete Beweise dafür, dass Test Runner das offensichtliche Ziel ist, wenn Sie die Latenz optimieren müssen.
Tokennutzung zur Kostenoptimierung prüfen
Cloud Trace zeigt nicht nur die Zeit an, sondern auch die Kosten, indem die Tokennutzung für jeden LLM-Aufruf erfasst wird.
Klicken Sie auf ein
call_llm
Span innerhalb des Trace. Im Detailbereich finden Sie Attribute für llm.usage.prompt_tokens und llm.usage.completion_tokens.

Dadurch haben Sie diese Möglichkeiten:
- Kosten auf granularer Ebene nachverfolgen: Sie können genau sehen, wie viele Tokens von jedem Agent und Tool verbraucht werden.
- Optimierungsmöglichkeiten identifizieren: Wenn ein Agent eine überraschend hohe Anzahl von Tokens verwendet, kann es sinnvoll sein, den Prompt zu optimieren oder für diese spezielle Aufgabe zu einem kleineren, kostengünstigeren Modell zu wechseln.
Schritt 3: Fix-Pipeline-Trace analysieren
Die Fix-Pipeline ist komplexer, da sie ein LoopAgent enthält. Mit Cloud Trace lässt sich dieses iterative Verhalten leicht nachvollziehen.
Suchen Sie nach einem Trace, der „FixAttemptLoop“ in den Spannen-Namen enthält.
Wenn Sie keine haben, führen Sie das Testskript aus und antworten Sie mit „Ja“, wenn Sie gefragt werden, ob Sie den Code korrigieren möchten.
Schleifenstruktur untersuchen
In der Trace-Ansicht wird die Ausführung der Schleife deutlich visualisiert. Wenn der Korrekturschleife zwei Durchläufe benötigt hat, bevor sie erfolgreich war, sehen Sie zwei loop_iteration-Spannen, die in der FixAttemptLoop-Spanne verschachtelt sind. Jede enthält einen vollständigen Zyklus der CodeFixer-, FixTestRunner- und FixValidator-Agents.

Wichtige Beobachtungen aus dem Loop-Trace:
- Iterative Optimierung ist sichtbar: Sie können sehen, wie das System in
loop_iteration: 1versucht, das Problem zu beheben, die Korrektur validiert und dann, weil sie nicht perfekt war, inloop_iteration: 2noch einmal versucht. - Konvergenz ist messbar: Sie können die Dauer und die Ergebnisse der einzelnen Iterationen vergleichen, um nachzuvollziehen, wie das System zu einer korrekten Lösung konvergiert ist.
- Einfacheres Debugging: Wenn eine Schleife die maximale Anzahl von Iterationen durchläuft und trotzdem fehlschlägt, können Sie den Status und das Agent-Verhalten in jeder Iteration untersuchen, um herauszufinden, warum die Korrekturen nicht konvergiert sind.
Diese Detailtiefe ist von unschätzbarem Wert, um das Verhalten komplexer, zustandsbehafteter Schleifen in der Produktion zu verstehen und zu debuggen.
Schritt 4: Ergebnisse
Leistungsmuster
Durch die Analyse von Traces haben Sie jetzt datengestützte Informationen:
Überprüfungspipeline:
- Primärer Engpass: Der
Test Runner-Agent, insbesondere die Codeausführung und die LLM-basierte Testgenerierung, ist der zeitaufwendigste Teil der Überprüfung. - Schnelle Vorgänge: Deterministische Tools (
analyze_code_structure) und Vorgänge zur Statusverwaltung sind extrem schnell und stellen kein Leistungsproblem dar.
Pipeline korrigieren:
- Konvergenzrate: Die meisten Korrekturen werden in 1–2 Iterationen abgeschlossen. Das bestätigt, dass die Schleifenarchitektur effektiv ist.
- Progressive Kosten: Spätere Iterationen können länger dauern, da der LLM-Kontext mit Informationen aus früheren fehlgeschlagenen Versuchen wächst.
Kostentreiber:
- Tokenverbrauch: Sie können genau feststellen, welche Agents (z. B. die Synthesizer) die meisten Tokens benötigen, und entscheiden, ob die Verwendung eines leistungsstärkeren, aber teureren Modells für diese Aufgabe gerechtfertigt ist.
Wo finde ich Probleme?
Achten Sie beim Überprüfen von Traces in der Produktion auf Folgendes:
- Ungewöhnlich lange Traces: Ein Zeichen für eine Leistungsregression oder ein unerwartetes Schleifenverhalten.
- Fehlerhafte Spannen (rot markiert): Hier wird der genaue Vorgang angegeben, bei dem ein Fehler aufgetreten ist.
- Zu viele Schleifendurchläufe (> 2): Dies kann auf ein Problem mit der Logik zur Generierung von Korrekturen hinweisen.
- Hohe Anzahl von Tokens: Hier werden Möglichkeiten zur Optimierung von Prompts oder zur Änderung der Modellauswahl hervorgehoben.
Lerninhalte
Mit Cloud Trace können Sie jetzt:
✅ Anfragefluss visualisieren: Sie können den vollständigen Ausführungspfad durch Ihre sequenziellen und schleifenbasierten Pipelines sehen.
✅ Leistungsengpässe ermitteln: Verwenden Sie das Wasserfalldiagramm, um die langsamsten Vorgänge anhand von harten Daten zu ermitteln.
✅ Schleifenverhalten analysieren: Beobachten Sie, wie iterative Agents in mehreren Versuchen eine Lösung finden.
✅ Tokenkosten im Blick behalten: LLM-Spans untersuchen, um den Tokenverbrauch auf granularer Ebene zu überwachen und zu optimieren.
Kennengelernte zentrale Konzepte
- Traces und Spans:Die Grundeinheiten der Beobachtbarkeit, die Anfragen und die darin enthaltenen Vorgänge darstellen.
- Wasserfallanalyse:Gantt-Diagramme lesen, um die Ausführungszeit und Abhängigkeiten zu verstehen.
- Identifizierung des kritischen Pfads:Ermitteln der Abfolge von Vorgängen, die die Gesamtlatenz bestimmt.
- Granulare Beobachtbarkeit:Sie haben nicht nur Einblick in die Zeit, sondern auch in Metadaten wie die Anzahl der Tokens für jeden Vorgang, die automatisch vom ADK instrumentiert werden.
Weitere Informationen
Weitere Informationen zu Cloud Trace:
- Traces regelmäßig prüfen, um Probleme frühzeitig zu erkennen
- Traces vergleichen, um Leistungsabfälle zu erkennen
- Trace-Daten für Optimierungsentscheidungen nutzen
- Nach Dauer filtern, um langsame Anfragen zu finden
Erweiterte Observability (optional):
- Traces für komplexe Analysen in BigQuery exportieren (Dokumentation)
- Benutzerdefinierte Dashboards in Cloud Monitoring erstellen
- Benachrichtigungen für Leistungseinbußen einrichten
- Traces mit Anwendungslogs korrelieren
9. Fazit: Vom Prototyp zur Produktion
Was Sie erstellt haben
Sie haben mit nur sieben Codezeilen begonnen und ein KI-Agentensystem in Produktionsqualität erstellt:
# Where we started (7 lines)
agent = Agent(
model="gemini-2.5-flash",
instruction="Review Python code for issues"
)
# Where we ended (production system)
- Two distinct multi-agent pipelines (review and fix) built from 8 specialized agents.
- An iterative fix loop architecture for automated validation and retries.
- Real AST-based code analysis tools for deterministic, accurate feedback.
- Robust state management using the "constants pattern" for type-safe communication.
- Fully automated deployment to a managed, scalable cloud infrastructure.
- Complete, built-in observability with Cloud Trace for production monitoring.
Wichtige Architekturmuster
Muster | Implementierung | Auswirkungen auf die Produktion |
Tool-Integration | AST-Analyse, Stilprüfung | Echte Validierung, nicht nur LLM-Meinungen |
Sequenzielle Pipelines | Workflows prüfen → Workflows korrigieren | Vorhersagbare, debugfähige Ausführung |
Loop-Architektur | Iterative Korrektur mit Endbedingungen | Selbstoptimierung bis zum Erfolg |
Statusverwaltung | Konstantenmuster, dreistufiger Speicher | Typsichere, wartungsfreundliche Statusverwaltung |
Produktionsbereitstellung | Agent Engine über deploy.sh | Verwaltete, skalierbare Infrastruktur |
Beobachtbarkeit | Cloud Trace-Einbindung | Vollständige Transparenz des Produktionsverhaltens |
Produktionsstatistiken aus Traces
Ihre Cloud Trace-Daten haben wichtige Erkenntnisse geliefert:
✅ Engpass identifiziert: LLM-Aufrufe von TestRunner dominieren die Latenz.
✅ Tool-Leistung: Die AST-Analyse wird in 100 ms ausgeführt (ausgezeichnet).
✅ Erfolgsrate: Fix-Schleifen werden innerhalb von 2–3 Wiederholungen abgeschlossen.
✅ Token-Nutzung: ~600 Tokens pro Überprüfung, ~1.800 Tokens für Korrekturen
Diese Statistiken ermöglichen kontinuierliche Verbesserungen.
Ressourcen bereinigen (optional)
Wenn Sie mit den Tests fertig sind und Gebühren vermeiden möchten, gehen Sie so vor:
Agent Engine-Bereitstellung löschen:
import vertexai
client = vertexai.Client( # For service interactions via client.agent_engines
project="PROJECT_ID",
location="LOCATION",
)
RESOURCE_NAME = "projects/{PROJECT_ID}/locations/{LOCATION}/reasoningEngines/{RESOURCE_ID}"
client.agent_engines.delete(
name=RESOURCE_NAME,
force=True, # Optional, if the agent has resources (e.g. sessions, memory)
)
Cloud Run-Dienst löschen (falls erstellt):
gcloud run services delete code-review-assistant \
--region=$GOOGLE_CLOUD_LOCATION \
--quiet
Cloud SQL-Instanz löschen (falls erstellt):
gcloud sql instances delete your-project-db \
--quiet
Storage-Buckets bereinigen:
gsutil -m rm -r gs://your-project-staging
gsutil -m rm -r gs://your-project-artifacts
Nächste Schritte
Nachdem Sie die Grundlagen geschaffen haben, können Sie die folgenden Verbesserungen in Betracht ziehen:
- Weitere Sprachen hinzufügen: Tools für JavaScript, Go und Java erweitern
- In GitHub einbinden: Automatische PR-Überprüfungen
- Caching implementieren: Latenz für häufige Muster reduzieren
- Spezialisierte Agents hinzufügen: Sicherheitsprüfung, Leistungsanalyse
- A/B-Tests aktivieren: Vergleichen Sie verschiedene Modelle und Prompts.
- Messwerte exportieren: Traces an spezielle Observability-Plattformen senden
Zusammenfassung
- Einfach anfangen, schnell iterieren: Sieben Zeilen bis zur Produktion in überschaubaren Schritten
- Tools statt Prompts: Eine echte AST-Analyse ist besser als „Bitte auf Fehler prüfen“.
- Zustandsverwaltung ist wichtig: Das Konstantenmuster verhindert Tippfehler
- Schleifen benötigen Endbedingungen: Legen Sie immer die maximale Anzahl von Iterationen und die Eskalierung fest.
- Automatisch bereitstellen: deploy.sh übernimmt die gesamte Komplexität
- Observability ist nicht verhandelbar: Was man nicht messen kann, kann man nicht verbessern.
Ressourcen für das kontinuierliche Lernen
- ADK-Dokumentation
- Erweiterte ADK-Muster
- Agent Engine-Leitfaden
- Cloud Run-Dokumentation
- Cloud Trace-Dokumentation
Es geht weiter
Sie haben mehr als nur einen Assistenten für Code-Reviews erstellt. Sie haben die Muster für die Entwicklung eines beliebigen produktionsreifen KI-Agents gemeistert:
✅ Komplexe Workflows mit mehreren spezialisierten Agents
✅ Echte Tool-Integration für echte Funktionen
✅ Produktionsbereitstellung mit angemessener Beobachtbarkeit
✅ Statusverwaltung für wartungsfähige Systeme
Diese Muster reichen von einfachen Assistenten bis hin zu komplexen autonomen Systemen. Die hier geschaffene Grundlage wird Ihnen bei der Entwicklung immer komplexerer Agentenarchitekturen zugutekommen.
Willkommen bei der Entwicklung von KI-Agenten für die Produktion. Ihr Code-Review-Assistent ist erst der Anfang.