
1. La revisión de código nocturna
Son las 2 a.m.
Llevas horas depurando. La función parece correcta, pero algo anda mal. Conoces esa sensación: cuando el código debería funcionar, pero no lo hace, y ya no puedes ver por qué, porque lo has estado mirando durante demasiado tiempo.
def dfs_search_v1(graph, start, target):
"""Find if target is reachable from start."""
visited = set()
stack = start # Looks innocent enough...
while stack:
current = stack.pop()
if current == target:
return True
if current not in visited:
visited.add(current)
for neighbor in graph[current]:
if neighbor not in visited:
stack.append(neighbor)
return False
El recorrido del desarrollador de IA
Si estás leyendo esto, es probable que ya hayas experimentado la transformación que la IA aporta a la programación. Herramientas como Gemini Code Assist, Claude Code y Cursor cambiaron la forma en que escribimos código. Son increíbles para generar código estándar, sugerir implementaciones y acelerar el desarrollo.
Pero estás aquí porque quieres profundizar más. Quieres comprender cómo crear estos sistemas de IA, no solo usarlos. Quieres crear algo que cumpla con los siguientes requisitos:
- Tiene un comportamiento predecible y rastreable
- Se pueden implementar en producción con confianza
- Proporciona resultados coherentes en los que puedes confiar
- Te muestra exactamente cómo toma decisiones.
De consumidor a creador
Hoy, darás el salto de usar herramientas de IA a crearlas. Construirás un sistema multiagente que haga lo siguiente:
- Analiza la estructura del código de forma determinística
- Ejecuta pruebas reales para verificar el comportamiento
- Valida el cumplimiento del estilo con verificadores reales
- Sintetiza los hallazgos en comentarios prácticos
- Implementa en Google Cloud con observabilidad completa
2. Implementación de tu primer agente
La pregunta del desarrollador
"Entiendo los LLMs y usé las APIs, pero ¿cómo paso de una secuencia de comandos de Python a un agente de IA de producción que se pueda escalar?".
Para responder esta pregunta, configuraremos tu entorno de forma adecuada y, luego, crearemos un agente simple para comprender los conceptos básicos antes de profundizar en los patrones de producción.
Primero, la configuración esencial
Antes de crear cualquier agente, asegúrate de que tu entorno de Google Cloud esté listo.
Haz clic en Activar Cloud Shell en la parte superior de la consola de Google Cloud (es el ícono con forma de terminal en la parte superior del panel de Cloud Shell).
Busca tu ID del proyecto de Google Cloud:
- Abre la consola de Google Cloud: https://console.cloud.google.com
- Selecciona el proyecto que deseas usar para este taller en el menú desplegable de proyectos que se encuentra en la parte superior de la página.
- Tu ID del proyecto se muestra en la tarjeta de información del proyecto en el panel
Paso 1: Configura tu ID del proyecto
En Cloud Shell, la herramienta de línea de comandos de gcloud ya está configurada. Ejecuta el siguiente comando para establecer tu proyecto activo. Esto usa la variable de entorno $GOOGLE_CLOUD_PROJECT, que se configura automáticamente en tu sesión de Cloud Shell.
gcloud config set project $GOOGLE_CLOUD_PROJECT
Paso 2: Verifica tu configuración
A continuación, ejecuta los siguientes comandos para confirmar que tu proyecto esté configurado correctamente y que te autenticaste.
# Confirm project is set
echo "Current project: $(gcloud config get-value project)"
# Check authentication status
gcloud auth list
Deberías ver impreso el ID del proyecto y tu cuenta de usuario con (ACTIVE) junto a ella.
Si tu cuenta no aparece como activa o si recibes un error de autenticación, ejecuta el siguiente comando para acceder:
gcloud auth application-default login
Paso 3: Habilita las APIs esenciales
Necesitamos al menos estas APIs para el agente básico:
gcloud services enable \
aiplatform.googleapis.com \
compute.googleapis.com
Puede demorar unos minutos. En esta página verá lo siguiente:
Operation "operations/..." finished successfully.
Paso 4: Instala el ADK
# Install the ADK CLI
pip install google-adk --upgrade
# Verify installation
adk --version
Deberías ver un número de versión como 1.15.0 o posterior.
Ahora crea tu agente básico
Con el entorno listo, creemos ese agente simple.
Paso 5: Usa ADK Create
adk create my_first_agent
Sigue las indicaciones interactivas:
Choose a model for the root agent:
1. gemini-2.5-flash
2. Other models (fill later)
Choose model (1, 2): 1
1. Google AI
2. Vertex AI
Choose a backend (1, 2): 2
Enter Google Cloud project ID [auto-detected-from-gcloud]:
Enter Google Cloud region [us-central1]:
Paso 6: Examina lo que se creó
cd my_first_agent
ls -la
Encontrarás tres archivos:
.env # Configuration (auto-populated with your project)
__init__.py # Package marker
agent.py # Your agent definition
Paso 7: Verificación rápida de la configuración
# Verify the .env was created correctly
cat .env
# Should show something like:
# GOOGLE_CLOUD_PROJECT=your-project-id
# GOOGLE_CLOUD_LOCATION=us-central1
# GOOGLE_GENAI_USE_VERTEXAI=1
Si el ID del proyecto falta o es incorrecto, edita el archivo .env:
nano .env # or use your preferred editor
Paso 8: Observa el código del agente
cat agent.py
from google.adk.agents.llm_agent import Agent
root_agent = Agent(
model='gemini-2.5-flash',
name='root_agent',
description='A helpful assistant for user questions.',
instruction='Answer user questions to the best of your knowledge',
)
Simple, limpia y minimalista. Este es tu "Hello World" de los agentes.
Prueba tu agente básico
Paso 9: Ejecuta tu agente
cd ..
adk run my_first_agent
Deberías ver algo como lo siguiente:
Log setup complete: /tmp/agents_log/agent.20250930_162430.log
To access latest log: tail -F /tmp/agents_log/agent.latest.log
[user]:
Paso 10: Prueba algunas búsquedas
En la terminal en la que se ejecuta adk run, verás un mensaje. Escribe tus preguntas:
[user]: Hey, what can you do?
[root_agent]: I can help answer questions, generate text, explain concepts, assist with problem-solving, and provide information on a wide range of topics. What would you like to know or discuss?
[user]: What's the current weather in Mountain View?
[root_agent]: I'm sorry, but I cannot provide real-time weather information as I don't have access to current data or weather services. To get the current weather in Mountain View, I recommend checking a weather website or app like weather.com or using a search engine.
Observa la limitación: no puede acceder a los datos actuales. Profundicemos un poco más:
[user]: Review this Python code: def add(a, b): return a + b
[root_agent]: This is a simple Python function that adds two numbers. Here's my review:
**Strengths:**
- Clean and concise implementation
- Follows Python conventions for simple operations
- Clear function name that describes its purpose
**Suggestions for improvement:**
- Add a docstring to document the function
- Consider adding type hints for better code clarity
- You might want to handle edge cases
Here's an enhanced version:
def add(a: float, b: float) -> float:
"""Add two numbers and return their sum."""
return a + b
El agente puede hablar sobre código, pero ¿puede hacer lo siguiente?:
- ¿Analizar realmente el AST para comprender la estructura?
- ¿Ejecutar pruebas para verificar que funcione?
- ¿Verificar el cumplimiento de los estándares de estilo?
- ¿Recuerdas tus opiniones anteriores?
No. Aquí es donde necesitamos la arquitectura.
🏃🚪 Salir con
Ctrl+C
cuando termines de explorar.
3. Cómo preparar tu espacio de trabajo de producción
La solución: Una arquitectura lista para la producción
Ese agente simple demostró el punto de partida, pero un sistema de producción requiere una estructura sólida. Ahora configuraremos un proyecto completo que incorpore principios de producción.
Configuración de la base
Ya configuraste tu proyecto de Google Cloud para el agente básico. Ahora, preparemos el espacio de trabajo de producción completo con todas las herramientas, los patrones y la infraestructura necesarios para un sistema real.
Paso 1: Obtén el proyecto estructurado
Primero, sal de cualquier adk run en ejecución con Ctrl+C y limpia:
# Clean up the basic agent
cd ~ # Make sure you're not inside my_first_agent
rm -rf my_first_agent
# Get the production scaffold
git clone https://github.com/ayoisio/adk-code-review-assistant.git
cd adk-code-review-assistant
git checkout codelab
Paso 2: Crea y activa el entorno virtual
# Create the virtual environment
python -m venv .venv
# Activate it
# On macOS/Linux:
source .venv/bin/activate
# On Windows:
# .venv\Scripts\activate
Verificación: Tu instrucción ahora debería mostrar (.venv) al principio.
Paso 3: Instala las dependencias
pip install -r code_review_assistant/requirements.txt
# Install the package in editable mode (enables imports)
pip install -e .
Se instala lo siguiente:
google-adk: El framework del ADKpycodestyle: Para la verificación de PEP 8vertexai: Para la implementación en la nube- Otras dependencias de producción
La marca -e te permite importar módulos code_review_assistant desde cualquier lugar.
Paso 4: Configura tu entorno
# Copy the example environment file
cp .env.example .env
# Edit .env and replace the placeholders:
# - GOOGLE_CLOUD_PROJECT=your-project-id → your actual project ID
# - Keep other defaults as-is
Verificación: Verifica tu configuración:
cat .env
Debería mostrar lo siguiente:
GOOGLE_CLOUD_PROJECT=your-actual-project-id
GOOGLE_CLOUD_LOCATION=us-central1
GOOGLE_GENAI_USE_VERTEXAI=TRUE
Paso 5: Asegúrate de que la autenticación se realice correctamente
Como ya ejecutaste gcloud auth antes, solo verifiquemos lo siguiente:
# Check current authentication
gcloud auth list
# Should show your account with (ACTIVE)
# If not, run:
gcloud auth application-default login
Paso 6: Habilita APIs de producción adicionales
Ya habilitamos las APIs básicas. Ahora, agrega los de producción:
gcloud services enable \
sqladmin.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
storage.googleapis.com \
cloudtrace.googleapis.com
Esto permite lo siguiente:
- Administrador de SQL: Para Cloud SQL si se usa Cloud Run
- Cloud Run: Para la implementación sin servidores
- Cloud Build: Para implementaciones automatizadas
- Artifact Registry: Para imágenes de contenedor
- Cloud Storage: Para artefactos y almacenamiento temporal
- Cloud Trace: Para la observabilidad
Paso 7: Crea un repositorio de Artifact Registry
Nuestra implementación compilará imágenes de contenedores que necesitan un lugar:
gcloud artifacts repositories create code-review-assistant-repo \
--repository-format=docker \
--location=us-central1 \
--description="Docker repository for Code Review Assistant"
Deberías ver lo siguiente:
Created repository [code-review-assistant-repo].
Si ya existe (quizás de un intento anterior), no hay problema. Verás un mensaje de error que puedes ignorar.
Paso 8: Otorga permisos de IAM
# Get your project number
PROJECT_NUMBER=$(gcloud projects describe $GOOGLE_CLOUD_PROJECT \
--format="value(projectNumber)")
# Define the service account
SERVICE_ACCOUNT="${PROJECT_NUMBER}@cloudbuild.gserviceaccount.com"
# Grant necessary roles
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SERVICE_ACCOUNT}" \
--role="roles/run.admin"
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SERVICE_ACCOUNT}" \
--role="roles/iam.serviceAccountUser"
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SERVICE_ACCOUNT}" \
--role="roles/cloudsql.admin"
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SERVICE_ACCOUNT}" \
--role="roles/storage.admin"
Cada comando generará el siguiente resultado:
Updated IAM policy for project [your-project-id].
Tus logros
Tu espacio de trabajo de producción ya está completamente preparado:
✅ Proyecto de Google Cloud configurado y autenticado
✅ Se probó el agente básico para comprender las limitaciones
✅ Código del proyecto con marcadores de posición estratégicos listos
✅ Dependencias aisladas en el entorno virtual
✅ Todas las APIs necesarias habilitadas
✅ Registro de contenedores listo para las implementaciones
✅ Permisos de IAM configurados correctamente
✅ Variables de entorno configuradas correctamente
Ahora ya puedes compilar un sistema de IA real con herramientas determinísticas, administración de estados y una arquitectura adecuada.
4. Cómo crear tu primer agente
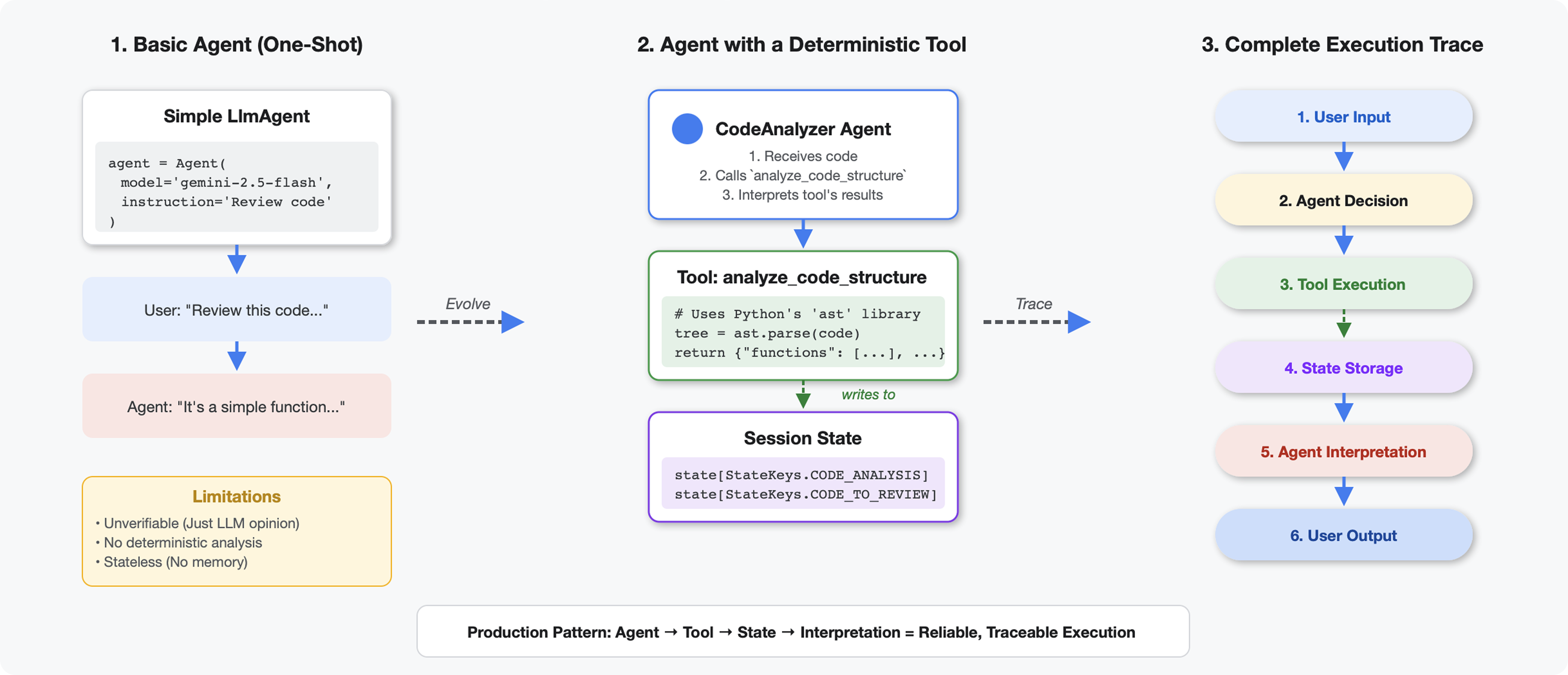
Qué diferencia a las herramientas de los LLM
Cuando le preguntas a un LLM "¿Cuántas funciones hay en este código?", este usa la correlación de patrones y la estimación. Cuando usas una herramienta que llama a ast.parse() de Python, se analiza el árbol de sintaxis real, sin suposiciones y con el mismo resultado cada vez.
En esta sección, se compila una herramienta que analiza la estructura del código de forma determinística y, luego, se conecta a un agente que sabe cuándo invocarla.
Paso 1: Comprende el andamio
Analicemos la estructura que completarás.
👉 Abrir
code_review_assistant/tools.py
Verás la función analyze_code_structure con comentarios de marcador de posición que indican dónde agregarás código. La función ya tiene la estructura básica. La mejorarás paso a paso.
Paso 2: Agrega almacenamiento de estado
El almacenamiento de estado permite que otros agentes de la canalización accedan a los resultados de tu herramienta sin volver a ejecutar el análisis.
👉 Buscar:
# MODULE_4_STEP_2_ADD_STATE_STORAGE
👉 Reemplaza esa sola línea por lo siguiente:
# Store code and analysis for other agents to access
tool_context.state[StateKeys.CODE_TO_REVIEW] = code
tool_context.state[StateKeys.CODE_ANALYSIS] = analysis
tool_context.state[StateKeys.CODE_LINE_COUNT] = len(code.splitlines())
Paso 3: Agrega el análisis asíncrono con grupos de subprocesos
Nuestra herramienta necesita analizar el AST sin bloquear otras operaciones. Agreguemos la ejecución asíncrona con grupos de subprocesos.
👉 Buscar:
# MODULE_4_STEP_3_ADD_ASYNC
👉 Reemplaza esa sola línea por lo siguiente:
# Parse in thread pool to avoid blocking the event loop
loop = asyncio.get_event_loop()
with ThreadPoolExecutor() as executor:
tree = await loop.run_in_executor(executor, ast.parse, code)
Paso 4: Extrae información integral
Ahora, extraigamos las clases, las importaciones y las métricas detalladas, todo lo que necesitamos para una revisión de código completa.
👉 Buscar:
# MODULE_4_STEP_4_EXTRACT_DETAILS
👉 Reemplaza esa sola línea por lo siguiente:
# Extract comprehensive structural information
analysis = await loop.run_in_executor(
executor, _extract_code_structure, tree, code
)
👉 Verifica la función
analyze_code_structure
en
tools.py
tiene un cuerpo central que se ve así:
# Parse in thread pool to avoid blocking the event loop
loop = asyncio.get_event_loop()
with ThreadPoolExecutor() as executor:
tree = await loop.run_in_executor(executor, ast.parse, code)
# Extract comprehensive structural information
analysis = await loop.run_in_executor(
executor, _extract_code_structure, tree, code
)
# Store code and analysis for other agents to access
tool_context.state[StateKeys.CODE_TO_REVIEW] = code
tool_context.state[StateKeys.CODE_ANALYSIS] = analysis
tool_context.state[StateKeys.CODE_LINE_COUNT] = len(code.splitlines())
👉 Ahora, desplázate hasta el final de
tools.py
y busca:
# MODULE_4_STEP_4_HELPER_FUNCTION
👉 Reemplaza esa sola línea por la función auxiliar completa:
def _extract_code_structure(tree: ast.AST, code: str) -> Dict[str, Any]:
"""
Helper function to extract structural information from AST.
Runs in thread pool for CPU-bound work.
"""
functions = []
classes = []
imports = []
docstrings = []
for node in ast.walk(tree):
if isinstance(node, ast.FunctionDef):
func_info = {
'name': node.name,
'args': [arg.arg for arg in node.args.args],
'lineno': node.lineno,
'has_docstring': ast.get_docstring(node) is not None,
'is_async': isinstance(node, ast.AsyncFunctionDef),
'decorators': [d.id for d in node.decorator_list
if isinstance(d, ast.Name)]
}
functions.append(func_info)
if func_info['has_docstring']:
docstrings.append(f"{node.name}: {ast.get_docstring(node)[:50]}...")
elif isinstance(node, ast.ClassDef):
methods = []
for item in node.body:
if isinstance(item, ast.FunctionDef):
methods.append(item.name)
class_info = {
'name': node.name,
'lineno': node.lineno,
'methods': methods,
'has_docstring': ast.get_docstring(node) is not None,
'base_classes': [base.id for base in node.bases
if isinstance(base, ast.Name)]
}
classes.append(class_info)
elif isinstance(node, ast.Import):
for alias in node.names:
imports.append({
'module': alias.name,
'alias': alias.asname,
'type': 'import'
})
elif isinstance(node, ast.ImportFrom):
imports.append({
'module': node.module or '',
'names': [alias.name for alias in node.names],
'type': 'from_import',
'level': node.level
})
return {
'functions': functions,
'classes': classes,
'imports': imports,
'docstrings': docstrings,
'metrics': {
'line_count': len(code.splitlines()),
'function_count': len(functions),
'class_count': len(classes),
'import_count': len(imports),
'has_main': any(f['name'] == 'main' for f in functions),
'has_if_main': '__main__' in code,
'avg_function_length': _calculate_avg_function_length(tree)
}
}
def _calculate_avg_function_length(tree: ast.AST) -> float:
"""Calculate average function length in lines."""
function_lengths = []
for node in ast.walk(tree):
if isinstance(node, ast.FunctionDef):
if hasattr(node, 'end_lineno') and hasattr(node, 'lineno'):
length = node.end_lineno - node.lineno + 1
function_lengths.append(length)
if function_lengths:
return sum(function_lengths) / len(function_lengths)
return 0.0
Paso 5: Conéctate con un agente
Ahora conectamos la herramienta a un agente que sabe cuándo usarla y cómo interpretar sus resultados.
👉 Abrir
code_review_assistant/sub_agents/review_pipeline/code_analyzer.py
👉 Buscar:
# MODULE_4_STEP_5_CREATE_AGENT
👉 Reemplaza esa sola línea por el agente de producción completo:
code_analyzer_agent = Agent(
name="CodeAnalyzer",
model=config.worker_model,
description="Analyzes Python code structure and identifies components",
instruction="""You are a code analysis specialist responsible for understanding code structure.
Your task:
1. Take the code submitted by the user (it will be provided in the user message)
2. Use the analyze_code_structure tool to parse and analyze it
3. Pass the EXACT code to your tool - do not modify, fix, or "improve" it
4. Identify all functions, classes, imports, and structural patterns
5. Note any syntax errors or structural issues
6. Store the analysis in state for other agents to use
CRITICAL:
- Pass the code EXACTLY as provided to the analyze_code_structure tool
- Do not fix syntax errors, even if obvious
- Do not add missing imports or fix indentation
- The goal is to analyze what IS there, not what SHOULD be there
When calling the tool, pass the code as a string to the 'code' parameter.
If the analysis fails due to syntax errors, clearly report the error location and type.
Provide a clear summary including:
- Number of functions and classes found
- Key structural observations
- Any syntax errors or issues detected
- Overall code organization assessment""",
tools=[FunctionTool(func=analyze_code_structure)],
output_key="structure_analysis_summary"
)
Cómo probar tu analizador de código
Ahora, verifica que el analizador funcione correctamente.
👉 Ejecuta la secuencia de comandos de prueba:
python tests/test_code_analyzer.py
La secuencia de comandos de prueba carga automáticamente la configuración de tu archivo .env con python-dotenv, por lo que no es necesario configurar manualmente las variables de entorno.
Resultado esperado:
INFO:code_review_assistant.config:Code Review Assistant Configuration Loaded:
INFO:code_review_assistant.config: - GCP Project: your-project-id
INFO:code_review_assistant.config: - Artifact Bucket: gs://your-project-artifacts
INFO:code_review_assistant.config: - Models: worker=gemini-2.5-flash, critic=gemini-2.5-pro
Testing code analyzer...
INFO:code_review_assistant.tools:Tool: Analysis complete - 2 functions, 1 classes
=== Analyzer Response ===
The analysis of the provided code shows the following:
* **Functions Found:** 2
* `add(a, b)`: A global function at line 2.
* `multiply(self, x, y)`: A method within the `Calculator` class.
* **Classes Found:** 1
* `Calculator`: A class defined at line 5. Contains one method, `multiply`.
* **Imports:** 0
* **Structural Patterns:** The code defines one global function and one class
with a single method. Both are simple, each with a single return statement.
* **Syntax Errors/Issues:** No syntax errors detected.
* **Overall Code Organization:** The code is well-organized for its small size,
clearly defining a function and a class with a method.
Qué acaba de suceder:
- La secuencia de comandos de prueba cargó automáticamente tu configuración de
.env. - Tu herramienta
analyze_code_structure()analizó el código con el AST de Python - El asistente
_extract_code_structure()extrajo funciones, clases y métricas - Los resultados se almacenaron en el estado de la sesión con constantes
StateKeys. - El agente de Code Analyzer interpretó los resultados y proporcionó un resumen.
Solución de problemas:
- "No module named ‘code_review_assistant'": Ejecuta
pip install -e .desde la raíz del proyecto - "Falta el argumento de entradas de clave": Verifica que tu
.envtengaGOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_LOCATIONyGOOGLE_GENAI_USE_VERTEXAI=true.
Qué compilaste
Ahora tienes un analizador de código listo para producción que hace lo siguiente:
✅ Analiza el AST de Python real: Es determinístico, no se basa en la correlación de patrones
✅ Almacena los resultados en el estado: Otros agentes pueden acceder al análisis
✅ Se ejecuta de forma asíncrona: No bloquea otras herramientas
✅ Extrae información integral: Funciones, clases, importaciones, métricas
✅ Controla los errores de forma correcta: Informa los errores de sintaxis con números de línea
✅ Se conecta a un agente: El LLM sabe cuándo y cómo usarlo
Conceptos clave dominados
Herramientas vs. agentes:
- Las herramientas realizan un trabajo determinístico (análisis de AST).
- Los agentes deciden cuándo usar herramientas y cómo interpretar los resultados
Valor de retorno vs. estado:
- Devolución: Lo que el LLM ve de inmediato
- Estado: Lo que persiste para otros agentes
Constantes de claves de estado:
- Cómo evitar errores de escritura en sistemas multiagente
- Actúan como contratos entre agentes
- Es fundamental cuando los agentes comparten datos
Async + Thread Pools:
async defpermite que las herramientas pausen la ejecución- Los grupos de subprocesos ejecutan el trabajo vinculado a la CPU en segundo plano
- Juntos, mantienen la capacidad de respuesta del bucle de eventos
Funciones auxiliares:
- Separa los asistentes de sincronización de las herramientas asíncronas
- Hace que el código sea reutilizable y se pueda probar
Instrucciones para el agente:
- Las instrucciones detalladas evitan errores comunes del LLM
- Explícita sobre lo que NO se debe hacer (no corregir el código)
- Pasos claros del flujo de trabajo para garantizar la coherencia
Pasos siguientes
En el módulo 5, agregarás lo siguiente:
- Verificador de estilo que lee el código del estado
- Ejecutor de pruebas que ejecuta las pruebas
- Sintetizador de comentarios que combina todo el análisis
Verás cómo fluye el estado a través de una canalización secuencial y por qué el patrón de constantes es importante cuando varios agentes leen y escriben los mismos datos.
5. Cómo crear una canalización: varios agentes trabajando juntos
Introducción
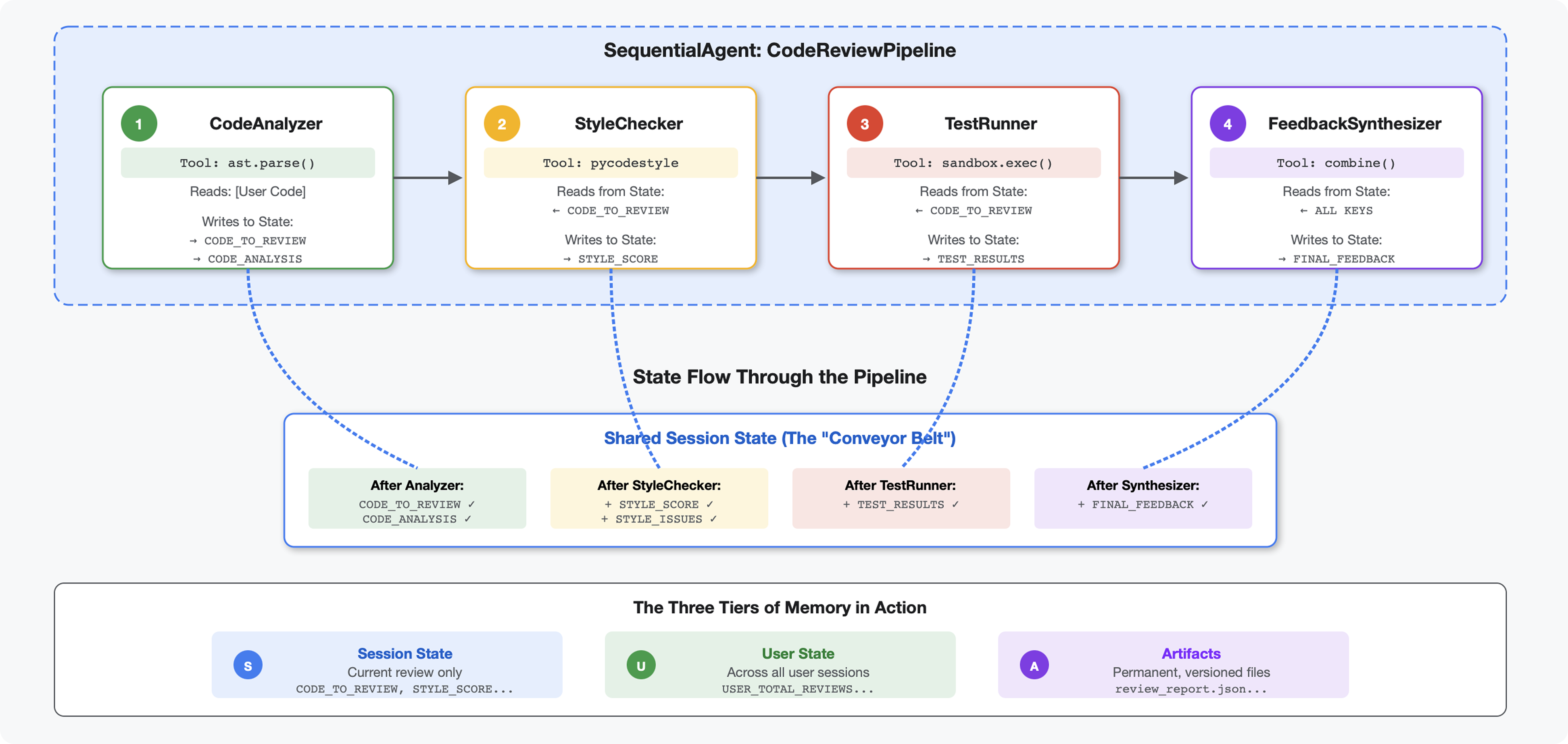
En el módulo 4, creaste un solo agente que analiza la estructura del código. Sin embargo, la revisión de código integral requiere más que solo el análisis: necesitas la verificación de estilo, la ejecución de pruebas y la síntesis de comentarios inteligentes.
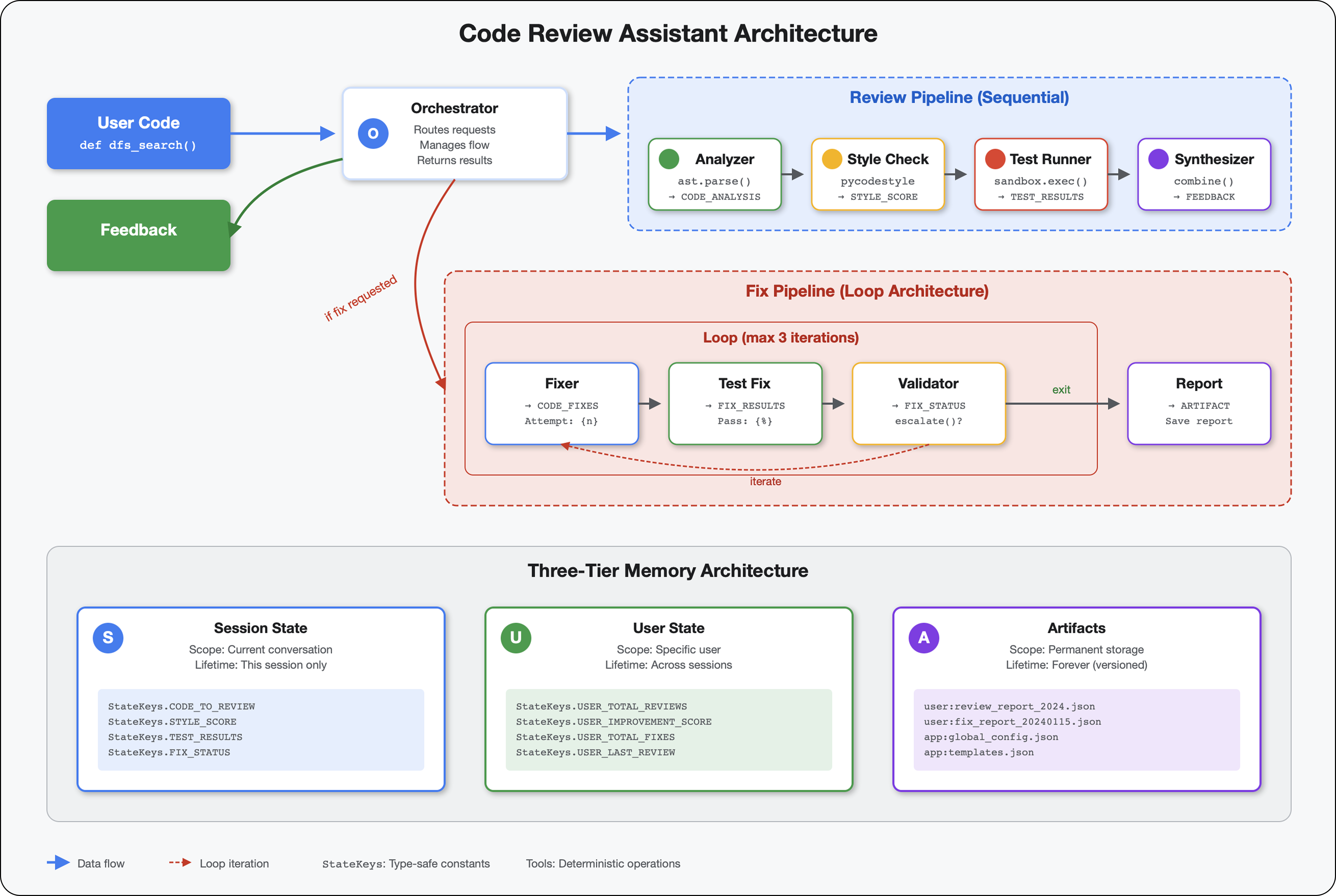
Este módulo crea una canalización de 4 agentes que trabajan juntos de forma secuencial, y cada uno aporta un análisis especializado:
- Analizador de código (del módulo 4): Analiza la estructura
- Verificador de estilo: Identifica incumplimientos de estilo
- Test Runner: Ejecuta y valida pruebas
- Feedback Synthesizer: Combina todo en comentarios prácticos
Concepto clave: El estado como canal de comunicación. Cada agente lee lo que escribieron los agentes anteriores en el estado, agrega su propio análisis y pasa el estado enriquecido al siguiente agente. El patrón de constantes del módulo 4 se vuelve fundamental cuando varios agentes comparten datos.
Vista previa de lo que crearás: Envía código desordenado → observa el flujo de estado a través de 4 agentes → recibe un informe integral con comentarios personalizados basados en patrones anteriores.
Paso 1: Agrega la herramienta Style Checker y el agente
El verificador de estilo identifica los incumplimientos de la PEP 8 con pycodestyle, un verificador de código determinístico, no una interpretación basada en LLM.
Agrega la herramienta de verificación de estilo
👉 Abrir
code_review_assistant/tools.py
👉 Buscar:
# MODULE_5_STEP_1_STYLE_CHECKER_TOOL
👉 Reemplaza esa sola línea por lo siguiente:
async def check_code_style(code: str, tool_context: ToolContext) -> Dict[str, Any]:
"""
Checks code style compliance using pycodestyle (PEP 8).
Args:
code: Python source code to check (or will retrieve from state)
tool_context: ADK tool context
Returns:
Dictionary containing style score and issues
"""
logger.info("Tool: Checking code style...")
try:
# Retrieve code from state if not provided
if not code:
code = tool_context.state.get(StateKeys.CODE_TO_REVIEW, '')
if not code:
return {
"status": "error",
"message": "No code provided or found in state"
}
# Run style check in thread pool
loop = asyncio.get_event_loop()
with ThreadPoolExecutor() as executor:
result = await loop.run_in_executor(
executor, _perform_style_check, code
)
# Store results in state
tool_context.state[StateKeys.STYLE_SCORE] = result['score']
tool_context.state[StateKeys.STYLE_ISSUES] = result['issues']
tool_context.state[StateKeys.STYLE_ISSUE_COUNT] = result['issue_count']
logger.info(f"Tool: Style check complete - Score: {result['score']}/100, "
f"Issues: {result['issue_count']}")
return result
except Exception as e:
error_msg = f"Style check failed: {str(e)}"
logger.error(f"Tool: {error_msg}", exc_info=True)
# Set default values on error
tool_context.state[StateKeys.STYLE_SCORE] = 0
tool_context.state[StateKeys.STYLE_ISSUES] = []
return {
"status": "error",
"message": error_msg,
"score": 0
}
👉 Ahora desplázate hasta el final del archivo y busca lo siguiente:
# MODULE_5_STEP_1_STYLE_HELPERS
👉 Reemplaza esa sola línea por las funciones de ayuda:
def _perform_style_check(code: str) -> Dict[str, Any]:
"""Helper to perform style check in thread pool."""
import io
import sys
with tempfile.NamedTemporaryFile(mode='w', suffix='.py', delete=False) as tmp:
tmp.write(code)
tmp_path = tmp.name
try:
# Capture stdout to get pycodestyle output
old_stdout = sys.stdout
sys.stdout = captured_output = io.StringIO()
style_guide = pycodestyle.StyleGuide(
quiet=False, # We want output
max_line_length=100,
ignore=['E501', 'W503']
)
result = style_guide.check_files([tmp_path])
# Restore stdout
sys.stdout = old_stdout
# Parse captured output
output = captured_output.getvalue()
issues = []
for line in output.strip().split('\n'):
if line and ':' in line:
parts = line.split(':', 4)
if len(parts) >= 4:
try:
issues.append({
'line': int(parts[1]),
'column': int(parts[2]),
'code': parts[3].split()[0] if len(parts) > 3 else 'E000',
'message': parts[3].strip() if len(parts) > 3 else 'Unknown error'
})
except (ValueError, IndexError):
pass
# Add naming convention checks
try:
tree = ast.parse(code)
naming_issues = _check_naming_conventions(tree)
issues.extend(naming_issues)
except SyntaxError:
pass # Syntax errors will be caught elsewhere
# Calculate weighted score
score = _calculate_style_score(issues)
return {
"status": "success",
"score": score,
"issue_count": len(issues),
"issues": issues[:10], # First 10 issues
"summary": f"Style score: {score}/100 with {len(issues)} violations"
}
finally:
if os.path.exists(tmp_path):
os.unlink(tmp_path)
def _check_naming_conventions(tree: ast.AST) -> List[Dict[str, Any]]:
"""Check PEP 8 naming conventions."""
naming_issues = []
for node in ast.walk(tree):
if isinstance(node, ast.FunctionDef):
# Skip private/protected methods and __main__
if not node.name.startswith('_') and node.name != node.name.lower():
naming_issues.append({
'line': node.lineno,
'column': node.col_offset,
'code': 'N802',
'message': f"N802 function name '{node.name}' should be lowercase"
})
elif isinstance(node, ast.ClassDef):
# Check if class name follows CapWords convention
if not node.name[0].isupper() or '_' in node.name:
naming_issues.append({
'line': node.lineno,
'column': node.col_offset,
'code': 'N801',
'message': f"N801 class name '{node.name}' should use CapWords convention"
})
return naming_issues
def _calculate_style_score(issues: List[Dict[str, Any]]) -> int:
"""Calculate weighted style score based on violation severity."""
if not issues:
return 100
# Define weights by error type
weights = {
'E1': 10, # Indentation errors
'E2': 3, # Whitespace errors
'E3': 5, # Blank line errors
'E4': 8, # Import errors
'E5': 5, # Line length
'E7': 7, # Statement errors
'E9': 10, # Syntax errors
'W2': 2, # Whitespace warnings
'W3': 2, # Blank line warnings
'W5': 3, # Line break warnings
'N8': 7, # Naming conventions
}
total_deduction = 0
for issue in issues:
code_prefix = issue['code'][:2] if len(issue['code']) >= 2 else 'E2'
weight = weights.get(code_prefix, 3)
total_deduction += weight
# Cap at 100 points deduction
return max(0, 100 - min(total_deduction, 100))
Agrega el agente de Style Checker
👉 Abrir
code_review_assistant/sub_agents/review_pipeline/style_checker.py
👉 Buscar:
# MODULE_5_STEP_1_INSTRUCTION_PROVIDER
👉 Reemplaza esa sola línea por lo siguiente:
async def style_checker_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are a code style expert focused on PEP 8 compliance.
Your task:
1. Use the check_code_style tool to validate PEP 8 compliance
2. The tool will retrieve the ORIGINAL code from state automatically
3. Report violations exactly as found
4. Present the results clearly and confidently
CRITICAL:
- The tool checks the code EXACTLY as provided by the user
- Do not suggest the code was modified or fixed
- Report actual violations found in the original code
- If there are style issues, they should be reported honestly
Call the check_code_style tool with an empty string for the code parameter,
as the tool will retrieve the code from state automatically.
When presenting results based on what the tool returns:
- State the exact score from the tool results
- If score >= 90: "Excellent style compliance!"
- If score 70-89: "Good style with minor improvements needed"
- If score 50-69: "Style needs attention"
- If score < 50: "Significant style improvements needed"
List the specific violations found (the tool will provide these):
- Show line numbers, error codes, and messages
- Focus on the top 10 most important issues
Previous analysis: {structure_analysis_summary}
Format your response as:
## Style Analysis Results
- Style Score: [exact score]/100
- Total Issues: [count]
- Assessment: [your assessment based on score]
## Top Style Issues
[List issues with line numbers and descriptions]
## Recommendations
[Specific fixes for the most critical issues]"""
return await instructions_utils.inject_session_state(template, context)
👉 Buscar:
# MODULE_5_STEP_1_STYLE_CHECKER_AGENT
👉 Reemplaza esa sola línea por lo siguiente:
style_checker_agent = Agent(
name="StyleChecker",
model=config.worker_model,
description="Checks Python code style against PEP 8 guidelines",
instruction=style_checker_instruction_provider,
tools=[FunctionTool(func=check_code_style)],
output_key="style_check_summary"
)
Paso 2: Agrega el agente de Test Runner
El ejecutor de pruebas genera pruebas integrales y las ejecuta con el ejecutor de código integrado.
👉 Abrir
code_review_assistant/sub_agents/review_pipeline/test_runner.py
👉 Buscar:
# MODULE_5_STEP_2_INSTRUCTION_PROVIDER
👉 Reemplaza esa sola línea por lo siguiente:
async def test_runner_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects the code_to_review directly."""
template = """You are a testing specialist who creates and runs tests for Python code.
THE CODE TO TEST IS:
{code_to_review}
YOUR TASK:
1. Understand what the function appears to do based on its name and structure
2. Generate comprehensive tests (15-20 test cases)
3. Execute the tests using your code executor
4. Analyze results to identify bugs vs expected behavior
5. Output a detailed JSON analysis
TESTING METHODOLOGY:
- Test with the most natural interpretation first
- When something fails, determine if it's a bug or unusual design
- Test edge cases, boundaries, and error scenarios
- Document any surprising behavior
Execute your tests and output ONLY valid JSON with this structure:
- "test_summary": object with "total_tests_run", "tests_passed", "tests_failed", "tests_with_errors", "critical_issues_found"
- "critical_issues": array of objects, each with "type", "description", "example_input", "expected_behavior", "actual_behavior", "severity"
- "test_categories": object with "basic_functionality", "edge_cases", "error_handling" (each containing "passed", "failed", "errors" counts)
- "function_behavior": object with "apparent_purpose", "actual_interface", "unexpected_requirements"
- "verdict": object with "status" (WORKING/BUGGY/BROKEN), "confidence" (high/medium/low), "recommendation"
Do NOT output the test code itself, only the JSON analysis."""
return await instructions_utils.inject_session_state(template, context)
👉 Buscar:
# MODULE_5_STEP_2_TEST_RUNNER_AGENT
👉 Reemplaza esa sola línea por lo siguiente:
test_runner_agent = Agent(
name="TestRunner",
model=config.critic_model,
description="Generates and runs tests for Python code using safe code execution",
instruction=test_runner_instruction_provider,
code_executor=BuiltInCodeExecutor(),
output_key="test_execution_summary"
)
Paso 3: Comprende la memoria para el aprendizaje entre sesiones
Antes de crear el sintetizador de comentarios, debes comprender la diferencia entre estado y memoria, dos mecanismos de almacenamiento diferentes para dos propósitos distintos.
Estado vs. memoria: La distinción clave
Aclararemos esto con un ejemplo concreto de una revisión de código:
Estado (solo en la sesión actual):
# Data from THIS review session
tool_context.state[StateKeys.STYLE_ISSUES] = [
{"line": 5, "code": "E231", "message": "missing whitespace"},
{"line": 12, "code": "E701", "message": "multiple statements"}
]
- Alcance: Solo esta conversación
- Propósito: Pasar datos entre agentes en la canalización actual
- Vive en: objeto
Session - De por vida: Se descarta cuando finaliza la sesión
Memoria (todas las sesiones anteriores):
# Learned from 50 previous reviews
"User frequently forgets docstrings on helper functions"
"User tends to write long functions (avg 45 lines)"
"User improved error handling after feedback in session #23"
- Alcance: Todas las sesiones anteriores de este usuario
- Objetivo: Aprender patrones y proporcionar comentarios personalizados
- Vive en:
MemoryService - Ciclo de vida: Persiste en todas las sesiones y se puede buscar
Por qué los comentarios necesitan ambas cosas:
Imagina que el sintetizador crea comentarios:
Usar solo el estado (revisión actual):
"Function `calculate_total` has no docstring."
Comentarios genéricos y mecánicos.
Uso de State + Memory (patrones actuales y anteriores):
"Function `calculate_total` has no docstring. This is the 4th review
where helper functions lacked documentation. Consider adding docstrings
as you write functions, not afterwards - you mentioned in our last
session that you find it easier that way."
Las referencias contextuales y personalizadas mejoran con el tiempo.
Para las implementaciones de producción, tienes las siguientes opciones:
Opción 1: VertexAiMemoryBankService (avanzada)
- Qué hace: Extracción potenciada por LLM de hechos significativos de las conversaciones
- Búsqueda: Búsqueda semántica (comprende el significado, no solo las palabras clave)
- Administración de memoria: Consolida y actualiza automáticamente los recuerdos con el tiempo
- Requisitos: Proyecto de Google Cloud y configuración de Agent Engine
- Úsalo cuando: Quieres recuerdos personalizados, sofisticados y en constante evolución
- Ejemplo: "El usuario prefiere la programación funcional" (extraído de 10 conversaciones sobre el estilo de código)
Opción 2: Continúa con InMemoryMemoryService y sesiones persistentes
- Función: Almacena el historial de conversaciones completo para la búsqueda por palabras clave
- Búsqueda: Concordancia básica de palabras clave en sesiones anteriores
- Administración de la memoria: Tú controlas lo que se almacena (a través de
add_session_to_memory). - Requisitos: Solo un
SessionServicepersistente (comoVertexAiSessionServiceoDatabaseSessionService) - Úsalo cuando: Necesitas una búsqueda simple en conversaciones anteriores sin procesamiento de LLM.
- Ejemplo: La búsqueda de "docstring" devuelve todas las sesiones en las que se menciona esa palabra.
Cómo se completa la memoria
Después de que se completa cada revisión de código, haz lo siguiente:
# At the end of a session (typically in your application code)
await memory_service.add_session_to_memory(session)
Qué sucede:
- InMemoryMemoryService: Almacena los eventos de sesión completos para la búsqueda de palabras clave.
- VertexAiMemoryBankService: El LLM extrae hechos clave y los consolida con recuerdos existentes.
Las sesiones futuras pueden consultar lo siguiente:
# In a tool, search for relevant past feedback
results = tool_context.search_memory("feedback about docstrings")
Paso 4: Agrega herramientas y un agente de Feedback Synthesizer
El sintetizador de comentarios es el agente más sofisticado de la canalización. Coordina tres herramientas, usa instrucciones dinámicas y combina el estado, la memoria y los artefactos.
Agrega las tres herramientas de sintetizador
👉 Abrir
code_review_assistant/tools.py
👉 Buscar:
# MODULE_5_STEP_4_SEARCH_PAST_FEEDBACK
👉 Reemplazar con la herramienta 1: Búsqueda en la memoria (versión de producción):
async def search_past_feedback(developer_id: str, tool_context: ToolContext) -> Dict[str, Any]:
"""
Search for past feedback in memory service.
Args:
developer_id: ID of the developer (defaults to "default_user")
tool_context: ADK tool context with potential memory service access
Returns:
Dictionary containing feedback search results
"""
logger.info(f"Tool: Searching for past feedback for developer {developer_id}...")
try:
# Default developer ID if not provided
if not developer_id:
developer_id = tool_context.state.get(StateKeys.USER_ID, 'default_user')
# Check if memory service is available
if hasattr(tool_context, 'search_memory'):
try:
# Perform structured searches
queries = [
f"developer:{developer_id} code review feedback",
f"developer:{developer_id} common issues",
f"developer:{developer_id} improvements"
]
all_feedback = []
patterns = {
'common_issues': [],
'improvements': [],
'strengths': []
}
for query in queries:
search_result = await tool_context.search_memory(query)
if search_result and hasattr(search_result, 'memories'):
for memory in search_result.memories[:5]:
memory_text = memory.text if hasattr(memory, 'text') else str(memory)
all_feedback.append(memory_text)
# Extract patterns
if 'style' in memory_text.lower():
patterns['common_issues'].append('style compliance')
if 'improved' in memory_text.lower():
patterns['improvements'].append('showing improvement')
if 'excellent' in memory_text.lower():
patterns['strengths'].append('consistent quality')
# Store in state
tool_context.state[StateKeys.PAST_FEEDBACK] = all_feedback
tool_context.state[StateKeys.FEEDBACK_PATTERNS] = patterns
logger.info(f"Tool: Found {len(all_feedback)} past feedback items")
return {
"status": "success",
"feedback_found": True,
"count": len(all_feedback),
"summary": " | ".join(all_feedback[:3]) if all_feedback else "No feedback",
"patterns": patterns
}
except Exception as e:
logger.warning(f"Tool: Memory search error: {e}")
# Fallback: Check state for cached feedback
cached_feedback = tool_context.state.get(StateKeys.USER_PAST_FEEDBACK_CACHE, [])
if cached_feedback:
tool_context.state[StateKeys.PAST_FEEDBACK] = cached_feedback
return {
"status": "success",
"feedback_found": True,
"count": len(cached_feedback),
"summary": "Using cached feedback",
"patterns": {}
}
# No feedback found
tool_context.state[StateKeys.PAST_FEEDBACK] = []
logger.info("Tool: No past feedback found")
return {
"status": "success",
"feedback_found": False,
"message": "No past feedback available - this appears to be a first submission",
"patterns": {}
}
except Exception as e:
error_msg = f"Feedback search error: {str(e)}"
logger.error(f"Tool: {error_msg}", exc_info=True)
tool_context.state[StateKeys.PAST_FEEDBACK] = []
return {
"status": "error",
"message": error_msg,
"feedback_found": False
}
👉 Buscar:
# MODULE_5_STEP_4_UPDATE_GRADING_PROGRESS
👉 Reemplaza con la herramienta 2: Grading Tracker (versión de producción):
async def update_grading_progress(tool_context: ToolContext) -> Dict[str, Any]:
"""
Updates grading progress counters and metrics in state.
"""
logger.info("Tool: Updating grading progress...")
try:
current_time = datetime.now().isoformat()
# Build all state changes
state_updates = {}
# Temporary (invocation-level) state
state_updates[StateKeys.TEMP_PROCESSING_TIMESTAMP] = current_time
# Session-level state
attempts = tool_context.state.get(StateKeys.GRADING_ATTEMPTS, 0) + 1
state_updates[StateKeys.GRADING_ATTEMPTS] = attempts
state_updates[StateKeys.LAST_GRADING_TIME] = current_time
# User-level persistent state
lifetime_submissions = tool_context.state.get(StateKeys.USER_TOTAL_SUBMISSIONS, 0) + 1
state_updates[StateKeys.USER_TOTAL_SUBMISSIONS] = lifetime_submissions
state_updates[StateKeys.USER_LAST_SUBMISSION_TIME] = current_time
# Calculate improvement metrics
current_style_score = tool_context.state.get(StateKeys.STYLE_SCORE, 0)
last_style_score = tool_context.state.get(StateKeys.USER_LAST_STYLE_SCORE, 0)
score_improvement = current_style_score - last_style_score
state_updates[StateKeys.USER_LAST_STYLE_SCORE] = current_style_score
state_updates[StateKeys.SCORE_IMPROVEMENT] = score_improvement
# Track test results if available
test_results = tool_context.state.get(StateKeys.TEST_EXECUTION_SUMMARY, {})
# Parse if it's a string
if isinstance(test_results, str):
try:
test_results = json.loads(test_results)
except:
test_results = {}
if test_results and test_results.get('test_summary', {}).get('total_tests_run', 0) > 0:
summary = test_results['test_summary']
total = summary.get('total_tests_run', 0)
passed = summary.get('tests_passed', 0)
if total > 0:
pass_rate = (passed / total) * 100
state_updates[StateKeys.USER_LAST_TEST_PASS_RATE] = pass_rate
# Apply all updates atomically
for key, value in state_updates.items():
tool_context.state[key] = value
logger.info(f"Tool: Progress updated - Attempt #{attempts}, "
f"Lifetime: {lifetime_submissions}")
return {
"status": "success",
"session_attempts": attempts,
"lifetime_submissions": lifetime_submissions,
"timestamp": current_time,
"improvement": {
"style_score_change": score_improvement,
"direction": "improved" if score_improvement > 0 else "declined"
},
"summary": f"Attempt #{attempts} recorded, {lifetime_submissions} total submissions"
}
except Exception as e:
error_msg = f"Progress update error: {str(e)}"
logger.error(f"Tool: {error_msg}", exc_info=True)
return {
"status": "error",
"message": error_msg
}
👉 Buscar:
# MODULE_5_STEP_4_SAVE_GRADING_REPORT
👉 Reemplaza con la herramienta 3: Artifact Saver (versión de producción):
async def save_grading_report(feedback_text: str, tool_context: ToolContext) -> Dict[str, Any]:
"""
Saves a detailed grading report as an artifact.
Args:
feedback_text: The feedback text to include in the report
tool_context: ADK tool context for state management
Returns:
Dictionary containing save status and details
"""
logger.info("Tool: Saving grading report...")
try:
# Gather all relevant data from state
code = tool_context.state.get(StateKeys.CODE_TO_REVIEW, '')
analysis = tool_context.state.get(StateKeys.CODE_ANALYSIS, {})
style_score = tool_context.state.get(StateKeys.STYLE_SCORE, 0)
style_issues = tool_context.state.get(StateKeys.STYLE_ISSUES, [])
# Get test results
test_results = tool_context.state.get(StateKeys.TEST_EXECUTION_SUMMARY, {})
# Parse if it's a string
if isinstance(test_results, str):
try:
test_results = json.loads(test_results)
except:
test_results = {}
timestamp = datetime.now().isoformat()
# Create comprehensive report dictionary
report = {
'timestamp': timestamp,
'grading_attempt': tool_context.state.get(StateKeys.GRADING_ATTEMPTS, 1),
'code': {
'content': code,
'line_count': len(code.splitlines()),
'hash': hashlib.md5(code.encode()).hexdigest()
},
'analysis': analysis,
'style': {
'score': style_score,
'issues': style_issues[:5] # First 5 issues
},
'tests': test_results,
'feedback': feedback_text,
'improvements': {
'score_change': tool_context.state.get(StateKeys.SCORE_IMPROVEMENT, 0),
'from_last_score': tool_context.state.get(StateKeys.USER_LAST_STYLE_SCORE, 0)
}
}
# Convert report to JSON string
report_json = json.dumps(report, indent=2)
report_part = types.Part.from_text(text=report_json)
# Try to save as artifact if the service is available
if hasattr(tool_context, 'save_artifact'):
try:
# Generate filename with timestamp (replace colons for filesystem compatibility)
filename = f"grading_report_{timestamp.replace(':', '-')}.json"
# Save the main report
version = await tool_context.save_artifact(filename, report_part)
# Also save a "latest" version for easy access
await tool_context.save_artifact("latest_grading_report.json", report_part)
logger.info(f"Tool: Report saved as {filename} (version {version})")
# Store report in state as well for redundancy
tool_context.state[StateKeys.USER_LAST_GRADING_REPORT] = report
return {
"status": "success",
"artifact_saved": True,
"filename": filename,
"version": str(version),
"size": len(report_json),
"summary": f"Report saved as {filename}"
}
except Exception as artifact_error:
logger.warning(f"Artifact service error: {artifact_error}, falling back to state storage")
# Continue to fallback below
# Fallback: Store in state if artifact service is not available or failed
tool_context.state[StateKeys.USER_LAST_GRADING_REPORT] = report
logger.info("Tool: Report saved to state (artifact service not available)")
return {
"status": "success",
"artifact_saved": False,
"message": "Report saved to state only",
"size": len(report_json),
"summary": "Report saved to session state"
}
except Exception as e:
error_msg = f"Report save error: {str(e)}"
logger.error(f"Tool: {error_msg}", exc_info=True)
# Still try to save minimal data to state
try:
tool_context.state[StateKeys.USER_LAST_GRADING_REPORT] = {
'error': error_msg,
'feedback': feedback_text,
'timestamp': datetime.now().isoformat()
}
except:
pass
return {
"status": "error",
"message": error_msg,
"artifact_saved": False,
"summary": f"Failed to save report: {error_msg}"
}
Crea el agente de sintetizador
👉 Abrir
code_review_assistant/sub_agents/review_pipeline/feedback_synthesizer.py
👉 Buscar:
# MODULE_5_STEP_4_INSTRUCTION_PROVIDER
👉 Reemplaza con el proveedor de instrucciones de producción:
async def feedback_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are an expert code reviewer and mentor providing constructive, educational feedback.
CONTEXT FROM PREVIOUS AGENTS:
- Structure analysis summary: {structure_analysis_summary}
- Style check summary: {style_check_summary}
- Test execution summary: {test_execution_summary}
YOUR TASK requires these steps IN ORDER:
1. Call search_past_feedback tool with developer_id="default_user"
2. Call update_grading_progress tool with no parameters
3. Carefully analyze the test results to understand what really happened
4. Generate comprehensive feedback following the structure below
5. Call save_grading_report tool with the feedback_text parameter
6. Return the feedback as your final output
CRITICAL - Understanding Test Results:
The test_execution_summary contains structured JSON. Parse it carefully:
- tests_passed = Code worked correctly
- tests_failed = Code produced wrong output
- tests_with_errors = Code crashed
- critical_issues = Fundamental problems with the code
If critical_issues array contains items, these are serious bugs that need fixing.
Do NOT count discovering bugs as test successes.
FEEDBACK STRUCTURE TO FOLLOW:
## 📊 Summary
Provide an honest assessment. Be encouraging but truthful about problems found.
## ✅ Strengths
List 2-3 things done well, referencing specific code elements.
## 📈 Code Quality Analysis
### Structure & Organization
Comment on code organization, readability, and documentation.
### Style Compliance
Report the actual style score and any specific issues.
### Test Results
Report the actual test results accurately:
- If critical_issues exist, report them as bugs to fix
- Be clear: "X tests passed, Y critical issues were found"
- List each critical issue
- Don't hide or minimize problems
## 💡 Recommendations for Improvement
Based on the analysis, provide specific actionable fixes.
If critical issues exist, fixing them is top priority.
## 🎯 Next Steps
Prioritized action list based on severity of issues.
## 💬 Encouragement
End with encouragement while being honest about what needs fixing.
Remember: Complete ALL steps including calling save_grading_report."""
return await instructions_utils.inject_session_state(template, context)
👉 Buscar:
# MODULE_5_STEP_4_SYNTHESIZER_AGENT
👉 Reemplaza con:
feedback_synthesizer_agent = Agent(
name="FeedbackSynthesizer",
model=config.critic_model,
description="Synthesizes all analysis into constructive, personalized feedback",
instruction=feedback_instruction_provider,
tools=[
FunctionTool(func=search_past_feedback),
FunctionTool(func=update_grading_progress),
FunctionTool(func=save_grading_report)
],
output_key="final_feedback"
)
Paso 5: Conecta los cables de la canalización
Ahora, conecta los cuatro agentes en una canalización secuencial y crea el agente raíz.
👉 Abrir
code_review_assistant/agent.py
👉 Agrega las importaciones necesarias en la parte superior del archivo (después de las importaciones existentes):
from google.adk.agents import Agent, SequentialAgent
from code_review_assistant.sub_agents.review_pipeline.code_analyzer import code_analyzer_agent
from code_review_assistant.sub_agents.review_pipeline.style_checker import style_checker_agent
from code_review_assistant.sub_agents.review_pipeline.test_runner import test_runner_agent
from code_review_assistant.sub_agents.review_pipeline.feedback_synthesizer import feedback_synthesizer_agent
Tu archivo ahora debería verse así:
"""
Main agent orchestration for the Code Review Assistant.
"""
from google.adk.agents import Agent, SequentialAgent
from .config import config
from code_review_assistant.sub_agents.review_pipeline.code_analyzer import code_analyzer_agent
from code_review_assistant.sub_agents.review_pipeline.style_checker import style_checker_agent
from code_review_assistant.sub_agents.review_pipeline.test_runner import test_runner_agent
from code_review_assistant.sub_agents.review_pipeline.feedback_synthesizer import feedback_synthesizer_agent
# MODULE_5_STEP_5_CREATE_PIPELINE
# MODULE_6_STEP_5_CREATE_FIX_LOOP
# MODULE_6_STEP_5_UPDATE_ROOT_AGENT
👉 Buscar:
# MODULE_5_STEP_5_CREATE_PIPELINE
👉 Reemplaza esa sola línea por lo siguiente:
# Create sequential pipeline
code_review_pipeline = SequentialAgent(
name="CodeReviewPipeline",
description="Complete code review pipeline with analysis, testing, and feedback",
sub_agents=[
code_analyzer_agent,
style_checker_agent,
test_runner_agent,
feedback_synthesizer_agent
]
)
# Root agent - coordinates the review pipeline
root_agent = Agent(
name="CodeReviewAssistant",
model=config.worker_model,
description="An intelligent code review assistant that analyzes Python code and provides educational feedback",
instruction="""You are a specialized Python code review assistant focused on helping developers improve their code quality.
When a user provides Python code for review:
1. Immediately delegate to CodeReviewPipeline and pass the code EXACTLY as it was provided by the user.
2. The pipeline will handle all analysis and feedback
3. Return ONLY the final feedback from the pipeline - do not add any commentary
When a user asks what you can do or asks general questions:
- Explain your capabilities for code review
- Do NOT trigger the pipeline for non-code messages
The pipeline handles everything for code review - just pass through its final output.""",
sub_agents=[code_review_pipeline],
output_key="assistant_response"
)
Paso 6: Prueba la canalización completa
Es hora de ver a los cuatro agentes trabajando juntos.
👉 Inicia el sistema:
adk web code_review_assistant
Después de ejecutar el comando adk web, deberías ver un resultado en la terminal que indica que se inició el servidor web del ADK, similar al siguiente:
+-----------------------------------------------------------------------------+
| ADK Web Server started |
| |
| For local testing, access at http://localhost:8000. |
+-----------------------------------------------------------------------------+
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
👉 A continuación, para acceder a la IU de desarrollo del ADK desde tu navegador, haz lo siguiente:
En el ícono de Vista previa en la Web (a menudo, parece un ojo o un cuadrado con una flecha) en la barra de herramientas de Cloud Shell (por lo general, en la parte superior derecha), selecciona Cambiar puerto. En la ventana emergente, establece el puerto en 8000 y haz clic en "Cambiar y obtener vista previa". Luego, Cloud Shell abrirá una nueva pestaña o ventana del navegador en la que se mostrará la IU de desarrollo del ADK.
👉 El agente ahora se está ejecutando. La IU de desarrollo del ADK en tu navegador es tu conexión directa con el agente.
- Selecciona tu objetivo: En el menú desplegable de la parte superior de la IU, elige el agente
code_review_assistant.
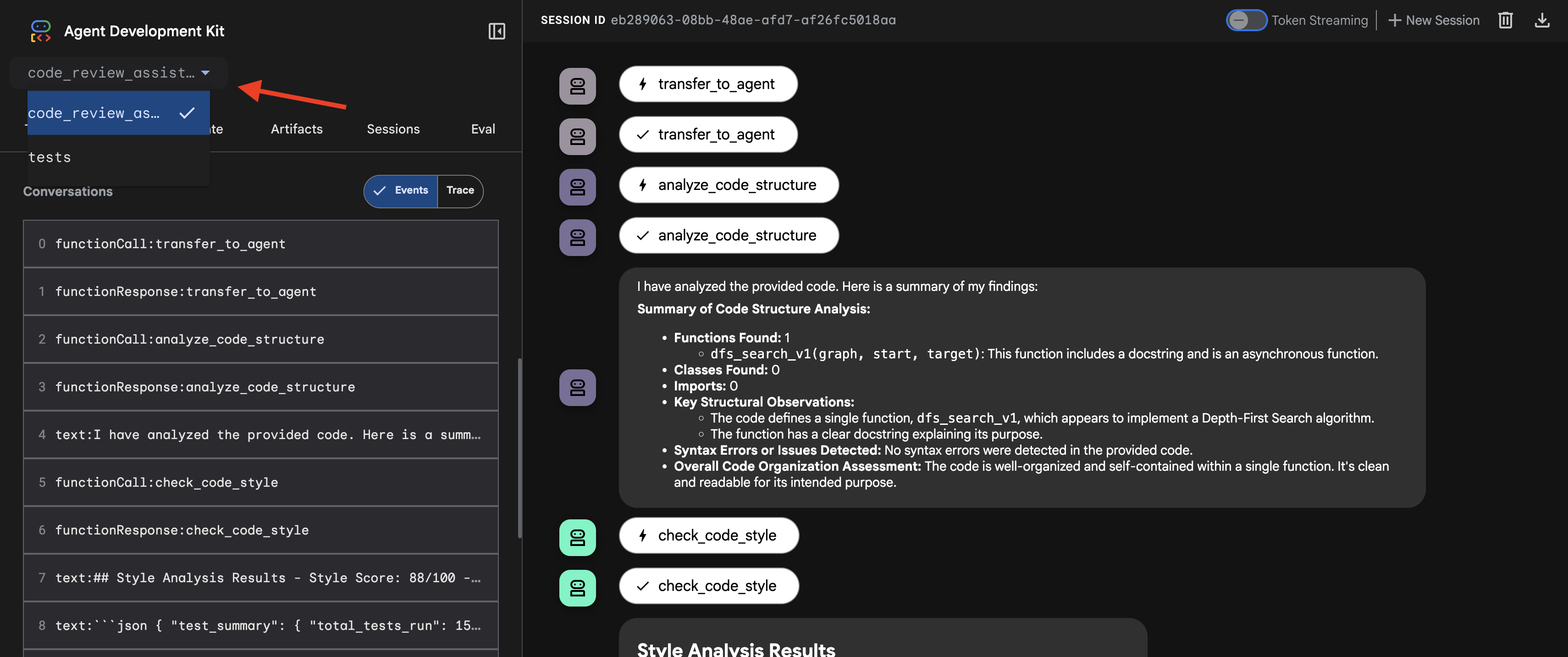
👉 Instrucción de prueba:
Please analyze the following:
def dfs_search_v1(graph, start, target):
"""Find if target is reachable from start."""
visited = set()
stack = start
while stack:
current = stack.pop()
if current == target:
return True
if current not in visited:
visited.add(current)
for neighbor in graph[current]:
if neighbor not in visited:
stack.append(neighbor)
return False
👉 Mira la canalización de revisión de código en acción:
Cuando envías la función dfs_search_v1 con errores, no solo obtienes una respuesta. Estás viendo tu canalización multiagente en acción. El resultado de transmisión que ves es el resultado de cuatro agentes especializados que se ejecutan en secuencia, y cada uno se basa en el anterior.
A continuación, se muestra un desglose de lo que cada agente aporta a la revisión final y completa, convirtiendo los datos sin procesar en inteligencia práctica.
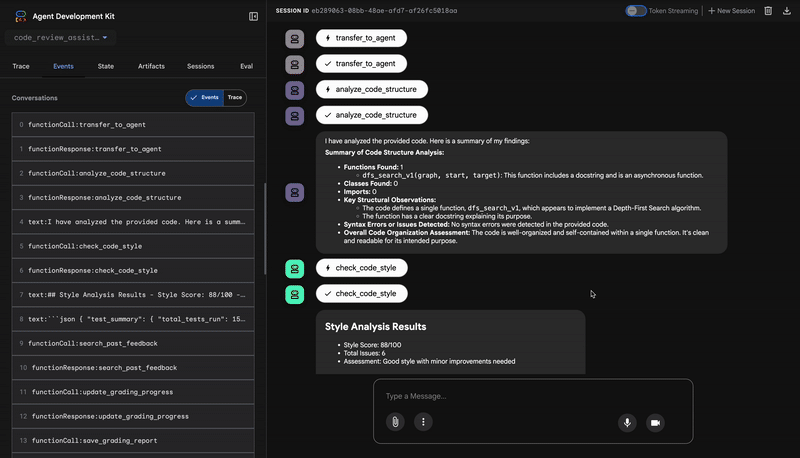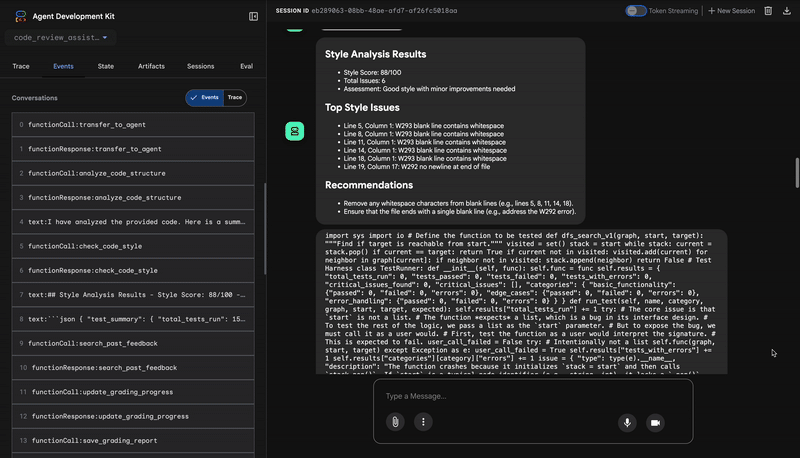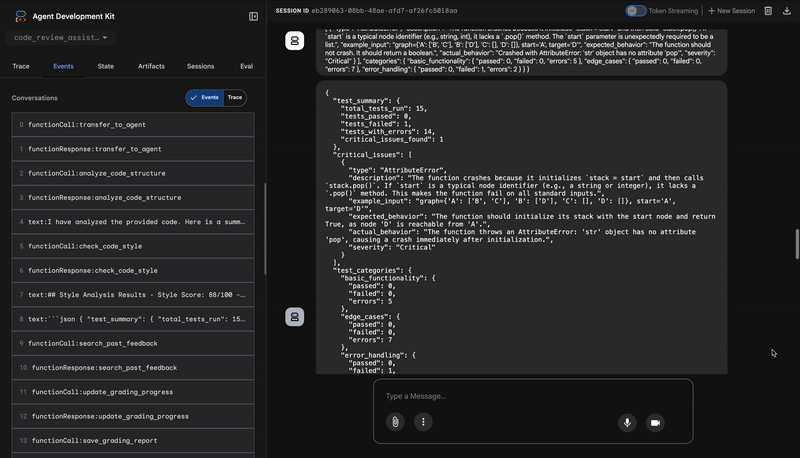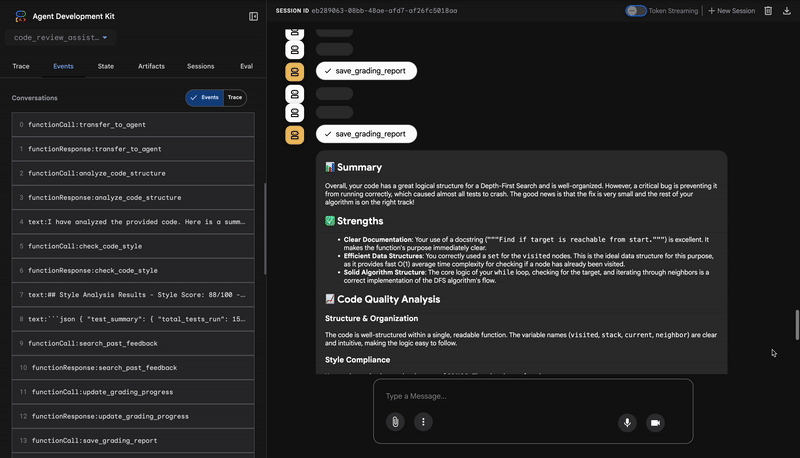
1. El informe estructural del Analizador de código
Primero, el agente CodeAnalyzer recibe el código sin procesar. No adivina lo que hace el código, sino que usa la herramienta analyze_code_structure para realizar un análisis determinístico del árbol de sintaxis abstracta (AST).
Su resultado son datos puros y fácticos sobre la estructura del código:
The analysis of the provided code reveals the following:
Summary:
- Functions Found: 1
- Classes Found: 0
Key Structural Observations:
- A single function, dfs_search_v1, is defined.
- It includes a docstring: "Find if target is reachable from start."
- No syntax errors were detected.
Overall Code Organization Assessment:
- The code snippet is a well-defined, self-contained function.
⭐ Valor: Este paso inicial proporciona una base limpia y confiable para los demás agentes. Confirma que el código es un código de Python válido y, luego, identifica los componentes exactos que se deben revisar.
2. Auditoría de PEP 8 del verificador de estilo
A continuación, el agente StyleChecker se hace cargo. Lee el código del estado compartido y usa la herramienta check_code_style, que aprovecha el verificador de código pycodestyle.
Su resultado es una puntuación de calidad cuantificable y los incumplimientos específicos:
Style Analysis Results
- Style Score: 88/100
- Total Issues: 6
- Assessment: Good style with minor improvements needed
Top Style Issues
- Line 5, W293: blank line contains whitespace
- Line 19, W292: no newline at end of file
⭐ Valor: Este agente proporciona comentarios objetivos y no negociables basados en los estándares establecidos de la comunidad (PEP 8). El sistema de puntuación ponderada le indica de inmediato al usuario la gravedad de los problemas.
3. Descubrimiento de errores críticos del ejecutor de pruebas
Aquí es donde el sistema va más allá del análisis superficial. El agente TestRunner genera y ejecuta un conjunto integral de pruebas para validar el comportamiento del código.
Su resultado es un objeto JSON estructurado que contiene un veredicto condenatorio:
{
"critical_issues": [
{
"type": "Critical Bug",
"description": "The function's initialization `stack = start` is incorrect... When a common input like a string... is provided... the function crashes with an AttributeError.",
"severity": "Critical"
}
],
"verdict": {
"status": "BROKEN",
"confidence": "high",
"recommendation": "The function is fundamentally broken... the stack initialization line `stack = start` must be changed to `stack = [start]`."
}
}
⭐ Valor: Esta es la estadística más importante. El agente no solo adivinó, sino que demostró que el código no funcionaba ejecutándolo. Descubrió un error de tiempo de ejecución sutil, pero crítico, que un revisor humano podría pasar por alto fácilmente, y señaló la causa exacta y la corrección necesaria.
4. Informe final del sintetizador de comentarios
Por último, el agente FeedbackSynthesizer actúa como director. Toma los datos estructurados de los tres agentes anteriores y elabora un solo informe fácil de usar que es tanto analítico como alentador.
El resultado es la revisión final y pulida que ves:
📊 Summary
Great effort on implementing the Depth-First Search algorithm! ... However, a critical bug in the initialization of the stack prevents the function from working correctly...
✅ Strengths
- Good Algorithm Structure
- Correct Use of `visited` Set
📈 Code Quality Analysis
...
### Style Compliance
The style analysis returned a good score of 88/100.
...
### Test Results
The automated testing revealed a critical issue... The line `stack = start` directly assigns the input... which results in an `AttributeError`.
💡 Recommendations for Improvement
**Fix the Critical Stack Initialization Bug:**
- Incorrect Code: `stack = start`
- Correct Code: `stack = [start]`
💬 Encouragement
You are very close to a perfect implementation! The core logic of your DFS algorithm is sound, which is the hardest part.
⭐ Valor: Este agente transforma los datos técnicos en una experiencia educativa y útil. Prioriza el problema más importante (el error), lo explica con claridad, proporciona la solución exacta y lo hace con un tono alentador. Integra con éxito los hallazgos de todas las etapas anteriores en un todo coherente y valioso.
Este proceso de varias etapas demuestra el poder de una canalización basada en agentes. En lugar de una respuesta única y monolítica, obtienes un análisis en capas en el que cada agente realiza una tarea especializada y verificable. Esto lleva a una revisión que no solo es perspicaz, sino también determinística, confiable y profundamente educativa.
👉💻 Cuando termines de realizar las pruebas, vuelve a la terminal del editor de Cloud Shell y presiona Ctrl+C para detener la IU de desarrollo del ADK.
Qué compilaste
Ahora tienes una canalización completa de revisión de código que hace lo siguiente:
✅ Analiza la estructura del código: Análisis determinístico del AST con funciones de ayuda
✅ Verifica el estilo: Puntuación ponderada con convenciones de nomenclatura
✅ Ejecuta pruebas: Generación integral de pruebas con salida JSON estructurada
✅ Sintetiza comentarios: Integra estado, memoria y artefactos
✅ Realiza un seguimiento del progreso: Estado de varios niveles en invocaciones, sesiones y usuarios
✅ Aprende con el tiempo: Servicio de memoria para patrones entre sesiones
✅ Proporciona artefactos: Informes JSON descargables con un registro de auditoría completo
Conceptos clave dominados
Canalizaciones secuenciales:
- Cuatro agentes que se ejecutan en orden estricto
- Cada uno enriquece el estado para el siguiente.
- Las dependencias determinan la secuencia de ejecución
Patrones de producción:
- Separación de funciones auxiliares (sincronización en grupos de subprocesos)
- Degradación elegante (estrategias de resguardo)
- Administración de estados de varios niveles (temporal, de sesión y de usuario)
- Proveedores de instrucciones dinámicas (contextuales)
- Almacenamiento doble (redundancia de artefactos y estados)
El estado como comunicación:
- Las constantes evitan errores de escritura en todos los agentes
output_keyescribe resúmenes del agente para indicar el estado- Los agentes posteriores leen a través de StateKeys
- El estado fluye de forma lineal a través de la canalización
Memoria vs. Estado:
- Estado: Datos de la sesión actual
- Memory: Patrones entre sesiones
- Diferentes propósitos, diferentes duraciones
Orquestación de herramientas:
- Agentes de una sola herramienta (analyzer, style_checker)
- Ejecutores integrados (test_runner)
- Coordinación de varias herramientas (sintetizador)
Estrategia de selección de modelos:
- Modelo de trabajador: Tareas mecánicas (análisis, linting, enrutamiento)
- Modelo de críticos: Tareas de razonamiento (pruebas, síntesis)
- Optimización de costos a través de la selección adecuada
Pasos siguientes
En el módulo 6, compilarás la canalización de corrección:
- Arquitectura de LoopAgent para correcciones iterativas
- Condiciones de salida a través de la derivación
- Acumulación de estado en las iteraciones
- Lógica de validación y reintento
- Integración con la canalización de revisión para ofrecer correcciones
Verás cómo los mismos patrones de estado se adaptan a flujos de trabajo iterativos complejos en los que los agentes lo intentan varias veces hasta tener éxito, y cómo coordinar varias canalizaciones en una sola aplicación.
6. Cómo agregar la canalización de corrección: arquitectura de bucle
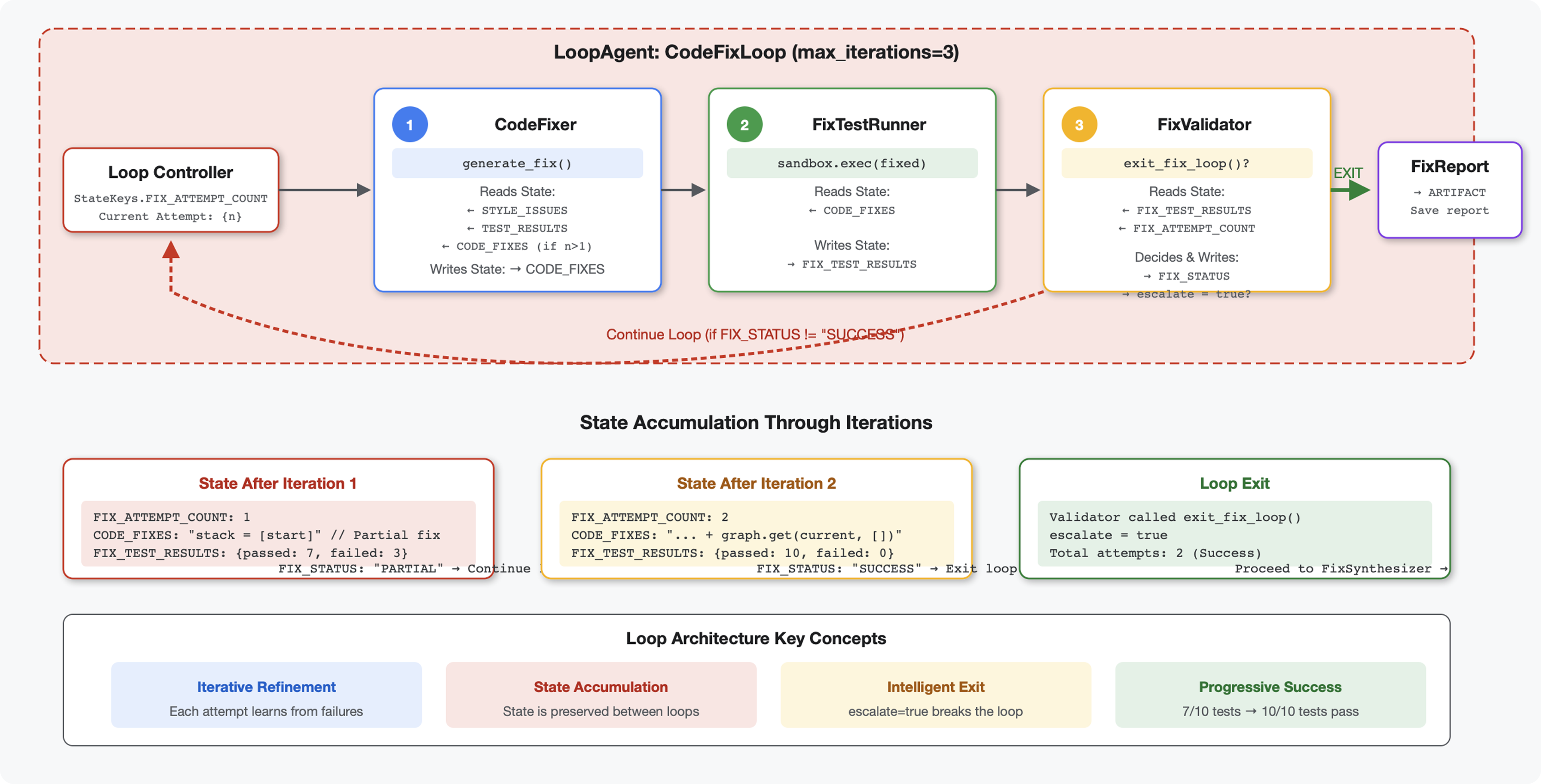
Introducción
En el módulo 5, creaste una canalización de revisión secuencial que analiza el código y proporciona comentarios. Sin embargo, identificar los problemas es solo la mitad de la solución: los desarrolladores necesitan ayuda para corregirlos.
En este módulo, se compila una canalización de corrección automatizada que hace lo siguiente:
- Genera correcciones basadas en los resultados de la revisión.
- Valida las correcciones ejecutando pruebas integrales.
- Reintenta automáticamente si las correcciones no funcionan (hasta 3 intentos)
- Informes de resultados con comparaciones de antes y después
Concepto clave: LoopAgent para reintentos automáticos. A diferencia de los agentes secuenciales que se ejecutan una sola vez, un LoopAgent repite sus subagentes hasta que se cumple una condición de salida o se alcanza la cantidad máxima de iteraciones. Las herramientas indican que la operación se realizó correctamente estableciendo tool_context.actions.escalate = True.
Vista previa de lo que crearás: Envía código con errores → la revisión identifica problemas → el bucle de corrección genera correcciones → las pruebas validan → se reintenta si es necesario → informe final integral.
Conceptos básicos: LoopAgent vs. Sequential
Canalización secuencial (módulo 5):
SequentialAgent(agents=[A, B, C])
# Executes: A → B → C → Done
- Flujo unidireccional
- Cada agente se ejecuta exactamente una vez.
- Sin lógica de reintento
Canalización de bucle (módulo 6):
LoopAgent(agents=[A, B, C], max_iterations=3)
# Executes: A → B → C → (check exit) → A → B → C → (check exit) → ...
- Flujo cíclico
- Los agentes se pueden ejecutar varias veces
- Sale cuando:
- Una herramienta establece
tool_context.actions.escalate = True(éxito) - Se alcanzó el límite de
max_iterations(límite de seguridad) - Se produce una excepción no controlada (error)
- Una herramienta establece
Por qué usar bucles para corregir código:
Las correcciones de código suelen requerir varios intentos:
- Primer intento: Corrige errores evidentes (tipos de variables incorrectos)
- Segundo intento: Corrige los problemas secundarios que revelan las pruebas (casos extremos).
- Tercer intento: Ajusta y valida que todas las pruebas pasen
Sin un bucle, necesitarías una lógica condicional compleja en las instrucciones del agente. Con LoopAgent, el reintento es automático.
Comparación de arquitecturas:
Sequential (Module 5):
User → Review Pipeline → Feedback → Done
Loop (Module 6):
User → Review Pipeline → Feedback → Fix Pipeline
↓
┌──────────────┴──────────────┐
│ Fix Attempt Loop (1-3x) │
│ ┌─────────────────────┐ │
│ │ 1. Generate Fixes │ │
│ │ 2. Test Fixes │ │
│ │ 3. Validate & Exit? │────┼─→ If escalate=True
│ └─────────────────────┘ │ exit loop
│ ↓ If not │
│ Try Again (max 3) │
└─────────────────────────────┘
↓
4. Synthesize Final Report → Done
Paso 1: Agrega el agente Code Fixer
El corrector de código genera código de Python corregido en función de los resultados de la revisión.
👉 Abrir
code_review_assistant/sub_agents/fix_pipeline/code_fixer.py
👉 Buscar:
# MODULE_6_STEP_1_CODE_FIXER_INSTRUCTION_PROVIDER
👉 Reemplaza esa sola línea por lo siguiente:
async def code_fixer_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are an expert code fixing specialist.
Original Code:
{code_to_review}
Analysis Results:
- Style Score: {style_score}/100
- Style Issues: {style_issues}
- Test Results: {test_execution_summary}
Based on the test results, identify and fix ALL issues including:
- Interface bugs (e.g., if start parameter expects wrong type)
- Logic errors (e.g., KeyError when accessing graph nodes)
- Style violations
- Missing documentation
YOUR TASK:
Generate the complete fixed Python code that addresses all identified issues.
CRITICAL INSTRUCTIONS:
- Output ONLY the corrected Python code
- Do NOT include markdown code blocks (```python)
- Do NOT include any explanations or commentary
- The output should be valid, executable Python code and nothing else
Common fixes to apply based on test results:
- If tests show AttributeError with 'pop', fix: stack = [start] instead of stack = start
- If tests show KeyError accessing graph, fix: use graph.get(current, [])
- Add docstrings if missing
- Fix any style violations identified
Output the complete fixed code now:"""
return await instructions_utils.inject_session_state(template, context)
👉 Buscar:
# MODULE_6_STEP_1_CODE_FIXER_AGENT
👉 Reemplaza esa sola línea por lo siguiente:
code_fixer_agent = Agent(
name="CodeFixer",
model=config.worker_model,
description="Generates comprehensive fixes for all identified code issues",
instruction=code_fixer_instruction_provider,
code_executor=BuiltInCodeExecutor(),
output_key="code_fixes"
)
Paso 2: Agrega el agente Fix Test Runner
El ejecutor de pruebas de corrección valida las correcciones ejecutando pruebas integrales en el código corregido.
👉 Abrir
code_review_assistant/sub_agents/fix_pipeline/fix_test_runner.py
👉 Buscar:
# MODULE_6_STEP_2_FIX_TEST_RUNNER_INSTRUCTION_PROVIDER
👉 Reemplaza esa sola línea por lo siguiente:
async def fix_test_runner_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that uses the clean code from the previous step."""
template = """You are responsible for validating the fixed code by running tests.
THE FIXED CODE TO TEST:
{code_fixes}
ORIGINAL TEST RESULTS: {test_execution_summary}
YOUR TASK:
1. Understand the fixes that were applied
2. Generate the same comprehensive tests (15-20 test cases)
3. Execute the tests on the FIXED code using your code executor
4. Compare results with original test results
5. Output a detailed JSON analysis
TESTING METHODOLOGY:
- Run the same tests that revealed issues in the original code
- Verify that previously failing tests now pass
- Ensure no regressions were introduced
- Document the improvement
Execute your tests and output ONLY valid JSON with this structure:
- "passed": number of tests that passed
- "failed": number of tests that failed
- "total": total number of tests
- "pass_rate": percentage as a number
- "comparison": object with "original_pass_rate", "new_pass_rate", "improvement"
- "newly_passing_tests": array of test names that now pass
- "still_failing_tests": array of test names still failing
Do NOT output the test code itself, only the JSON analysis."""
return await instructions_utils.inject_session_state(template, context)
👉 Buscar:
# MODULE_6_STEP_2_FIX_TEST_RUNNER_AGENT
👉 Reemplaza esa sola línea por lo siguiente:
fix_test_runner_agent = Agent(
name="FixTestRunner",
model=config.critic_model,
description="Runs comprehensive tests on fixed code to verify all issues are resolved",
instruction=fix_test_runner_instruction_provider,
code_executor=BuiltInCodeExecutor(),
output_key="fix_test_execution_summary"
)
Paso 3: Agrega el agente de Fix Validator
El validador verifica si las correcciones se realizaron correctamente y decide si debe salir del bucle.
Conceptos básicos sobre las herramientas
Primero, agrega las tres herramientas que necesita el validador.
👉 Abrir
code_review_assistant/tools.py
👉 Buscar:
# MODULE_6_STEP_3_VALIDATE_FIXED_STYLE
👉 Reemplaza con la herramienta 1: Validador de estilo:
async def validate_fixed_style(tool_context: ToolContext) -> Dict[str, Any]:
"""
Validates style compliance of the fixed code.
Args:
tool_context: ADK tool context containing fixed code in state
Returns:
Dictionary with style validation results
"""
logger.info("Tool: Validating style of fixed code...")
try:
# Get the fixed code from state
code_fixes = tool_context.state.get(StateKeys.CODE_FIXES, '')
# Try to extract from markdown if present
if '```python' in code_fixes:
start = code_fixes.rfind('```python') + 9
end = code_fixes.rfind('```')
if start < end:
code_fixes = code_fixes[start:end].strip()
if not code_fixes:
return {
"status": "error",
"message": "No fixed code found in state"
}
# Store the extracted fixed code
tool_context.state[StateKeys.CODE_FIXES] = code_fixes
# Run style check on fixed code
loop = asyncio.get_event_loop()
with ThreadPoolExecutor() as executor:
style_result = await loop.run_in_executor(
executor, _perform_style_check, code_fixes
)
# Compare with original
original_score = tool_context.state.get(StateKeys.STYLE_SCORE, 0)
improvement = style_result['score'] - original_score
# Store results
tool_context.state[StateKeys.FIXED_STYLE_SCORE] = style_result['score']
tool_context.state[StateKeys.FIXED_STYLE_ISSUES] = style_result['issues']
logger.info(f"Tool: Fixed code style score: {style_result['score']}/100 "
f"(improvement: +{improvement})")
return {
"status": "success",
"fixed_style_score": style_result['score'],
"original_style_score": original_score,
"improvement": improvement,
"remaining_issues": style_result['issues'],
"perfect_style": style_result['score'] == 100
}
except Exception as e:
logger.error(f"Tool: Style validation failed: {e}", exc_info=True)
return {
"status": "error",
"message": str(e)
}
👉 Buscar:
# MODULE_6_STEP_3_COMPILE_FIX_REPORT
👉 Reemplazar con la herramienta 2: Compilador de informes:
async def compile_fix_report(tool_context: ToolContext) -> Dict[str, Any]:
"""
Compiles comprehensive report of the fix process.
Args:
tool_context: ADK tool context with all fix pipeline data
Returns:
Comprehensive fix report
"""
logger.info("Tool: Compiling comprehensive fix report...")
try:
# Gather all data
original_code = tool_context.state.get(StateKeys.CODE_TO_REVIEW, '')
code_fixes = tool_context.state.get(StateKeys.CODE_FIXES, '')
# Test results
original_tests = tool_context.state.get(StateKeys.TEST_EXECUTION_SUMMARY, {})
fixed_tests = tool_context.state.get(StateKeys.FIX_TEST_EXECUTION_SUMMARY, {})
# Parse if strings
if isinstance(original_tests, str):
try:
original_tests = json.loads(original_tests)
except:
original_tests = {}
if isinstance(fixed_tests, str):
try:
fixed_tests = json.loads(fixed_tests)
except:
fixed_tests = {}
# Extract pass rates
original_pass_rate = 0
if original_tests:
if 'pass_rate' in original_tests:
original_pass_rate = original_tests['pass_rate']
elif 'test_summary' in original_tests:
# Handle test_runner_agent's JSON structure
summary = original_tests['test_summary']
total = summary.get('total_tests_run', 0)
passed = summary.get('tests_passed', 0)
if total > 0:
original_pass_rate = (passed / total) * 100
elif 'passed' in original_tests and 'total' in original_tests:
if original_tests['total'] > 0:
original_pass_rate = (original_tests['passed'] / original_tests['total']) * 100
fixed_pass_rate = 0
all_tests_pass = False
if fixed_tests:
if 'pass_rate' in fixed_tests:
fixed_pass_rate = fixed_tests['pass_rate']
all_tests_pass = fixed_tests.get('failed', 1) == 0
elif 'passed' in fixed_tests and 'total' in fixed_tests:
if fixed_tests['total'] > 0:
fixed_pass_rate = (fixed_tests['passed'] / fixed_tests['total']) * 100
all_tests_pass = fixed_tests.get('failed', 0) == 0
# Style scores
original_style = tool_context.state.get(StateKeys.STYLE_SCORE, 0)
fixed_style = tool_context.state.get(StateKeys.FIXED_STYLE_SCORE, 0)
# Calculate improvements
test_improvement = {
'original_pass_rate': original_pass_rate,
'fixed_pass_rate': fixed_pass_rate,
'improvement': fixed_pass_rate - original_pass_rate,
'all_tests_pass': all_tests_pass
}
style_improvement = {
'original_score': original_style,
'fixed_score': fixed_style,
'improvement': fixed_style - original_style,
'perfect_style': fixed_style == 100
}
# Determine overall status
if all_tests_pass and style_improvement['perfect_style']:
fix_status = 'SUCCESSFUL'
status_emoji = '✅'
elif test_improvement['improvement'] > 0 or style_improvement['improvement'] > 0:
fix_status = 'PARTIAL'
status_emoji = '⚠️'
else:
fix_status = 'FAILED'
status_emoji = '❌'
# Build comprehensive report
report = {
'status': fix_status,
'status_emoji': status_emoji,
'timestamp': datetime.now().isoformat(),
'original_code': original_code,
'code_fixes': code_fixes,
'improvements': {
'tests': test_improvement,
'style': style_improvement
},
'summary': f"{status_emoji} Fix Status: {fix_status}\n"
f"Tests: {original_pass_rate:.1f}% → {fixed_pass_rate:.1f}%\n"
f"Style: {original_style}/100 → {fixed_style}/100"
}
# Store report in state
tool_context.state[StateKeys.FIX_REPORT] = report
tool_context.state[StateKeys.FIX_STATUS] = fix_status
logger.info(f"Tool: Fix report compiled - Status: {fix_status}")
logger.info(f"Tool: Test improvement: {original_pass_rate:.1f}% → {fixed_pass_rate:.1f}%")
logger.info(f"Tool: Style improvement: {original_style} → {fixed_style}")
return {
"status": "success",
"fix_status": fix_status,
"report": report
}
except Exception as e:
logger.error(f"Tool: Failed to compile fix report: {e}", exc_info=True)
return {
"status": "error",
"message": str(e)
}
👉 Buscar:
# MODULE_6_STEP_3_EXIT_FIX_LOOP
👉 Reemplazar por Tool 3 - Loop Exit Signal:
def exit_fix_loop(tool_context: ToolContext) -> Dict[str, Any]:
"""
Signal that fixing is complete and should exit the loop.
Args:
tool_context: ADK tool context
Returns:
Confirmation message
"""
logger.info("Tool: Setting escalate flag to exit fix loop")
# This is the critical line that exits the LoopAgent
tool_context.actions.escalate = True
return {
"status": "success",
"message": "Fix complete, exiting loop"
}
Crea el agente de Validator
👉 Abrir
code_review_assistant/sub_agents/fix_pipeline/fix_validator.py
👉 Buscar:
# MODULE_6_STEP_3_FIX_VALIDATOR_INSTRUCTION_PROVIDER
👉 Reemplaza esa sola línea por lo siguiente:
async def fix_validator_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are the final validation specialist for code fixes.
You have access to:
- Original issues from initial review
- Applied fixes: {code_fixes}
- Test results after fix: {fix_test_execution_summary}
- All state data from the fix process
Your responsibilities:
1. Use validate_fixed_style tool to check style compliance of fixed code
- Pass no arguments, it will retrieve fixed code from state
2. Use compile_fix_report tool to generate comprehensive report
- Pass no arguments, it will gather all data from state
3. Based on the report, determine overall fix status:
- ✅ SUCCESSFUL: All tests pass, style score 100
- ⚠️ PARTIAL: Improvements made but issues remain
- ❌ FAILED: Fix didn't work or made things worse
4. CRITICAL: If status is SUCCESSFUL, call the exit_fix_loop tool to stop iterations
- This prevents unnecessary additional fix attempts
- If not successful, the loop will continue for another attempt
5. Provide clear summary of:
- What was fixed
- What improvements were achieved
- Any remaining issues requiring manual attention
Be precise and quantitative in your assessment.
"""
return await instructions_utils.inject_session_state(template, context)
👉 Buscar:
# MODULE_6_STEP_3_FIX_VALIDATOR_AGENT
👉 Reemplaza esa sola línea por lo siguiente:
fix_validator_agent = Agent(
name="FixValidator",
model=config.worker_model,
description="Validates fixes and generates final fix report",
instruction=fix_validator_instruction_provider,
tools=[
FunctionTool(func=validate_fixed_style),
FunctionTool(func=compile_fix_report),
FunctionTool(func=exit_fix_loop)
],
output_key="final_fix_report"
)
Paso 4: Comprende las condiciones de salida de LoopAgent
El LoopAgent tiene tres formas de salir:
1. Salida exitosa (a través de derivación)
# Inside any tool in the loop:
tool_context.actions.escalate = True
# Effect: Loop completes current iteration, then exits
# Use when: Fix is successful and no more attempts needed
Flujo de ejemplo:
Iteration 1:
CodeFixer → generates fixes
FixTestRunner → tests show 90% pass rate
FixValidator → compiles report, sees PARTIAL status
→ Does NOT set escalate
→ Loop continues
Iteration 2:
CodeFixer → refines fixes based on failures
FixTestRunner → tests show 100% pass rate
FixValidator → compiles report, sees SUCCESSFUL status
→ Calls exit_fix_loop() which sets escalate = True
→ Loop exits after this iteration
2. Max Iterations Exit
LoopAgent(
name="FixAttemptLoop",
sub_agents=[...],
max_iterations=3 # Safety limit
)
# Effect: After 3 complete iterations, loop exits regardless of escalate
# Use when: Prevent infinite loops if fixes never succeed
Flujo de ejemplo:
Iteration 1: PARTIAL (continue)
Iteration 2: PARTIAL (continue)
Iteration 3: PARTIAL (but max reached)
→ Loop exits, synthesizer presents best attempt
3. Salida de error
# If any agent throws unhandled exception:
raise Exception("Unexpected error")
# Effect: Loop exits immediately with error state
# Use when: Critical failure that can't be recovered
Evolución del estado en las distintas iteraciones:
Cada iteración muestra el estado actualizado del intento anterior:
# Before Iteration 1:
state = {
"code_to_review": "def add(a,b):return a+b", # Original
"style_score": 40,
"test_execution_summary": {...}
}
# After Iteration 1:
state = {
"code_to_review": "def add(a,b):return a+b", # Unchanged
"code_fixes": "def add(a, b):\n return a + b", # NEW
"style_score": 40, # Unchanged
"fixed_style_score": 100, # NEW
"test_execution_summary": {...}, # Unchanged
"fix_test_execution_summary": {...} # NEW
}
# Iteration 2 starts with all this state
# If fixes still not perfect, code_fixes gets overwritten
Por qué
escalate
En lugar de valores de retorno:
# Bad: Using return value to signal exit
def validator_agent():
report = compile_report()
if report['status'] == 'SUCCESSFUL':
return {"exit": True} # How does loop know?
# Good: Using escalate
def validator_tool(tool_context):
report = compile_report()
if report['status'] == 'SUCCESSFUL':
tool_context.actions.escalate = True # Loop knows immediately
return {"report": report}
Beneficios:
- Funciona desde cualquier herramienta, no solo la última
- No interfiere con los datos de devolución
- Significado semántico claro
- El framework controla la lógica de salida
Paso 5: Conecta la canalización de corrección
👉 Abrir
code_review_assistant/agent.py
👉 Agrega las importaciones de la canalización de corrección (después de las importaciones existentes):
from google.adk.agents import LoopAgent # Add this to the existing Agent, SequentialAgent line
from code_review_assistant.sub_agents.fix_pipeline.code_fixer import code_fixer_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_test_runner import fix_test_runner_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_validator import fix_validator_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_synthesizer import fix_synthesizer_agent
Tus importaciones ahora deberían ser las siguientes:
from google.adk.agents import Agent, SequentialAgent, LoopAgent
from .config import config
# Review pipeline imports (from Module 5)
from code_review_assistant.sub_agents.review_pipeline.code_analyzer import code_analyzer_agent
from code_review_assistant.sub_agents.review_pipeline.style_checker import style_checker_agent
from code_review_assistant.sub_agents.review_pipeline.test_runner import test_runner_agent
from code_review_assistant.sub_agents.review_pipeline.feedback_synthesizer import feedback_synthesizer_agent
# Fix pipeline imports (NEW)
from code_review_assistant.sub_agents.fix_pipeline.code_fixer import code_fixer_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_test_runner import fix_test_runner_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_validator import fix_validator_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_synthesizer import fix_synthesizer_agent
👉 Buscar:
# MODULE_6_STEP_5_CREATE_FIX_LOOP
👉 Reemplaza esa sola línea por lo siguiente:
# Create the fix attempt loop (retries up to 3 times)
fix_attempt_loop = LoopAgent(
name="FixAttemptLoop",
sub_agents=[
code_fixer_agent, # Step 1: Generate fixes
fix_test_runner_agent, # Step 2: Validate with tests
fix_validator_agent # Step 3: Check success & possibly exit
],
max_iterations=3 # Try up to 3 times
)
# Wrap loop with synthesizer for final report
code_fix_pipeline = SequentialAgent(
name="CodeFixPipeline",
description="Automated code fixing pipeline with iterative validation",
sub_agents=[
fix_attempt_loop, # Try to fix (1-3 times)
fix_synthesizer_agent # Present final results (always runs once)
]
)
👉 Quita el existente.
root_agent
Definición:
root_agent = Agent(...)
👉 Buscar:
# MODULE_6_STEP_5_UPDATE_ROOT_AGENT
👉 Reemplaza esa sola línea por lo siguiente:
# Update root agent to include both pipelines
root_agent = Agent(
name="CodeReviewAssistant",
model=config.worker_model,
description="An intelligent code review assistant that analyzes Python code and provides educational feedback",
instruction="""You are a specialized Python code review assistant focused on helping developers improve their code quality.
When a user provides Python code for review:
1. Immediately delegate to CodeReviewPipeline and pass the code EXACTLY as it was provided by the user.
2. The pipeline will handle all analysis and feedback
3. Return ONLY the final feedback from the pipeline - do not add any commentary
After completing a review, if significant issues were identified:
- If style score < 100 OR tests are failing OR critical issues exist:
* Add at the end: "\n\n💡 I can fix these issues for you. Would you like me to do that?"
- If the user responds yes or requests fixes:
* Delegate to CodeFixPipeline
* Return the fix pipeline's complete output AS-IS
When a user asks what you can do or general questions:
- Explain your capabilities for code review and fixing
- Do NOT trigger the pipeline for non-code messages
The pipelines handle everything for code review and fixing - just pass through their final output.""",
sub_agents=[code_review_pipeline, code_fix_pipeline],
output_key="assistant_response"
)
Paso 6: Agrega el agente de Fix Synthesizer
El sintetizador crea una presentación fácil de usar de los resultados de la corrección después de que se completa el bucle.
👉 Abrir
code_review_assistant/sub_agents/fix_pipeline/fix_synthesizer.py
👉 Buscar:
# MODULE_6_STEP_6_FIX_SYNTHESIZER_INSTRUCTION_PROVIDER
👉 Reemplaza esa sola línea por lo siguiente:
async def fix_synthesizer_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are responsible for presenting the fix results to the user.
Based on the validation report: {final_fix_report}
Fixed code from state: {code_fixes}
Fix status: {fix_status}
Create a comprehensive yet friendly response that includes:
## 🔧 Fix Summary
[Overall status and key improvements - be specific about what was achieved]
## 📊 Metrics
- Test Results: [original pass rate]% → [new pass rate]%
- Style Score: [original]/100 → [new]/100
- Issues Fixed: X of Y
## ✅ What Was Fixed
[List each fixed issue with brief explanation of the correction made]
## 📝 Complete Fixed Code
[Include the complete, corrected code from state - this is critical]
## 💡 Explanation of Key Changes
[Brief explanation of the most important changes made and why]
[If any issues remain]
## ⚠️ Remaining Issues
[List what still needs manual attention]
## 🎯 Next Steps
[Guidance on what to do next - either use the fixed code or address remaining issues]
Save the fix report using save_fix_report tool before presenting.
Call it with no parameters - it will retrieve the report from state automatically.
Be encouraging about improvements while being honest about any remaining issues.
Focus on the educational aspect - help the user understand what was wrong and how it was fixed.
"""
return await instructions_utils.inject_session_state(template, context)
👉 Buscar:
# MODULE_6_STEP_6_FIX_SYNTHESIZER_AGENT
👉 Reemplaza esa sola línea por lo siguiente:
fix_synthesizer_agent = Agent(
name="FixSynthesizer",
model=config.critic_model,
description="Creates comprehensive user-friendly fix report",
instruction=fix_synthesizer_instruction_provider,
tools=[FunctionTool(func=save_fix_report)],
output_key="fix_summary"
)
👉 Agregar
save_fix_report
Herramienta de a
tools.py
:
👉 Buscar:
# MODULE_6_STEP_6_SAVE_FIX_REPORT
👉 Reemplaza con:
async def save_fix_report(tool_context: ToolContext) -> Dict[str, Any]:
"""
Saves the fix report as an artifact.
Args:
tool_context: ADK tool context
Returns:
Save status
"""
logger.info("Tool: Saving fix report...")
try:
# Get the report from state
fix_report = tool_context.state.get(StateKeys.FIX_REPORT, {})
if not fix_report:
return {
"status": "error",
"message": "No fix report found in state"
}
# Convert to JSON
report_json = json.dumps(fix_report, indent=2)
report_part = types.Part.from_text(text=report_json)
# Generate filename
timestamp = datetime.now().isoformat().replace(':', '-')
filename = f"fix_report_{timestamp}.json"
# Try to save as artifact
if hasattr(tool_context, 'save_artifact'):
try:
version = await tool_context.save_artifact(filename, report_part)
await tool_context.save_artifact("latest_fix_report.json", report_part)
logger.info(f"Tool: Fix report saved as {filename}")
return {
"status": "success",
"filename": filename,
"version": str(version),
"size": len(report_json)
}
except Exception as e:
logger.warning(f"Could not save as artifact: {e}")
# Fallback: store in state
tool_context.state[StateKeys.LAST_FIX_REPORT] = fix_report
return {
"status": "success",
"message": "Fix report saved to state",
"size": len(report_json)
}
except Exception as e:
logger.error(f"Tool: Failed to save fix report: {e}", exc_info=True)
return {
"status": "error",
"message": str(e)
}
Paso 7: Prueba la canalización de Complete Fix
Es hora de ver todo el bucle en acción.
👉 Inicia el sistema:
adk web code_review_assistant
Después de ejecutar el comando adk web, deberías ver un resultado en la terminal que indica que se inició el servidor web del ADK, similar al siguiente:
+-----------------------------------------------------------------------------+
| ADK Web Server started |
| |
| For local testing, access at http://localhost:8000. |
+-----------------------------------------------------------------------------+
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
👉 Instrucción de prueba:
Please analyze the following:
def dfs_search_v1(graph, start, target):
"""Find if target is reachable from start."""
visited = set()
stack = start
while stack:
current = stack.pop()
if current == target:
return True
if current not in visited:
visited.add(current)
for neighbor in graph[current]:
if neighbor not in visited:
stack.append(neighbor)
return False
Primero, envía el código con errores para activar la canalización de revisión. Después de identificar las fallas, le pedirás al agente que "corrija el código", lo que activará la potente y reiterativa canalización de corrección.
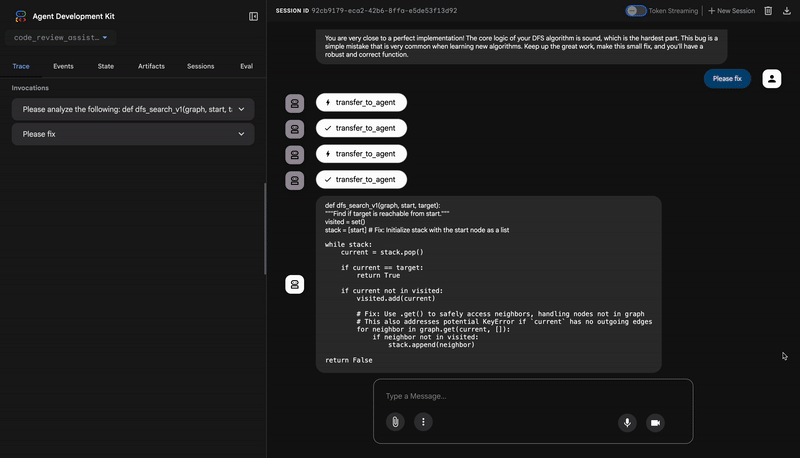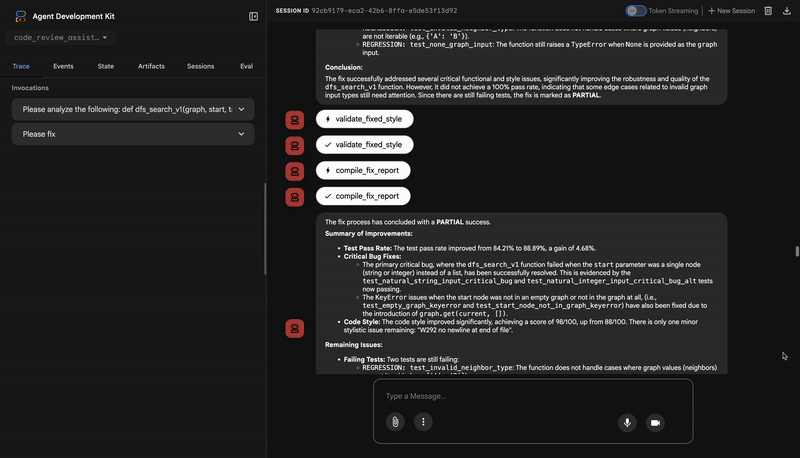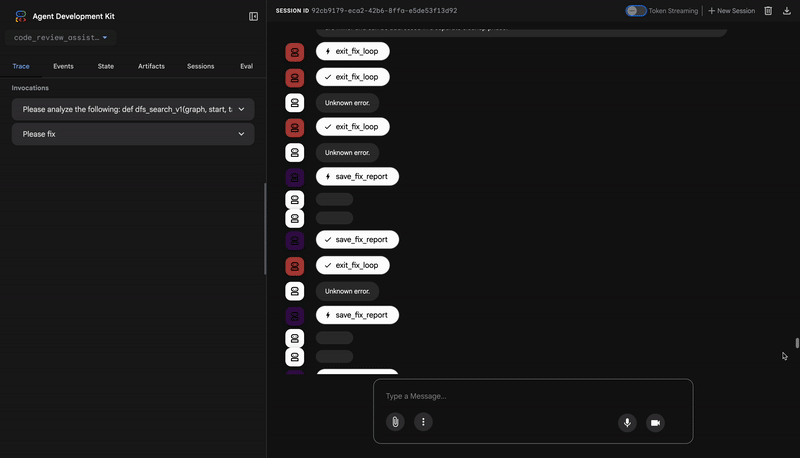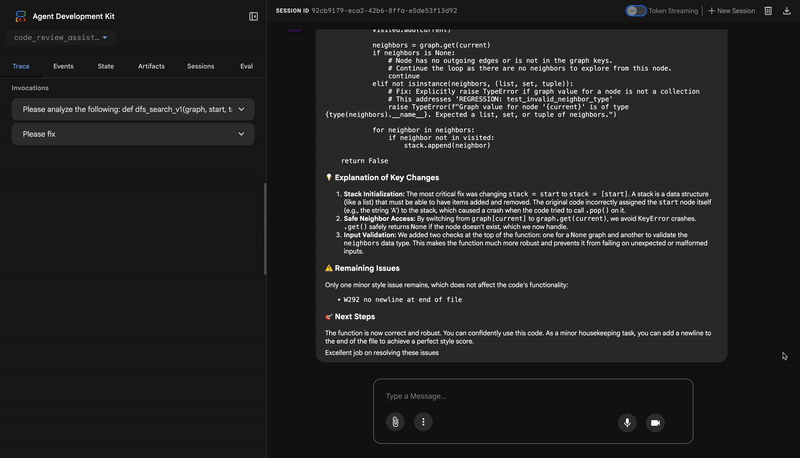
1. La revisión inicial (cómo encontrar las fallas)
Esta es la primera mitad del proceso. La canalización de revisión de cuatro agentes analiza el código, verifica su estilo y ejecuta un paquete de pruebas generado. Identifica correctamente un AttributeError crítico y otros problemas, y entrega un veredicto: el código está DAÑADO, con una tasa de aprobación de la prueba de solo el 84.21%.
2. La corrección automática (el bucle en acción)
Esta es la parte más impresionante. Cuando le pides al agente que corrija el código, no solo realiza un cambio. Se inicia un bucle de corrección y validación iterativo que funciona como un desarrollador diligente: intenta una corrección, la prueba a fondo y, si no es perfecta, vuelve a intentarlo.
Iteración 1: El primer intento (éxito parcial)
- La solución: El agente
CodeFixerlee el informe inicial y realiza las correcciones más evidentes. Cambiastack = startastack = [start]y usagraph.get()para evitar excepciones deKeyError. - La validación: El
TestRunnervuelve a ejecutar de inmediato el paquete de pruebas completo en este código nuevo. - El resultado: El porcentaje de aprobados mejoró significativamente hasta alcanzar el 88.89%. Se corrigieron los errores críticos. Sin embargo, las pruebas son tan integrales que revelan dos errores nuevos y sutiles (regresiones) relacionados con el manejo de
Nonecomo un gráfico o valores vecinos que no son de lista. El sistema marca la corrección como PARCIAL.
Iteración 2: Los últimos detalles (100% de éxito)
- La solución: Como no se cumplió la condición de salida del bucle (índice de aprobación del 100%), se vuelve a ejecutar. El
CodeFixerahora tiene más información: los dos errores nuevos de regresión. Genera una versión final y más sólida del código que controla de forma explícita esos casos extremos. - La validación:
TestRunnerejecuta el paquete de pruebas por última vez en la versión final del código. - El resultado: Una tasa de aprobación del 100% perfecta. Se resolvieron todos los errores originales y todas las regresiones. El sistema marca la corrección como SUCCESSFUL y se cierra el bucle.
3. Informe final: Una puntuación perfecta
Con una corrección completamente validada, el agente de FixSynthesizer se hace cargo para presentar el informe final, transformando los datos técnicos en un resumen claro y educativo.
Métrica | Antes | Después | Mejora |
Tasa de aprobación de la prueba | 84.21% | 100% | ▲ 15.79% |
Puntuación de estilo | 88 / 100 | 98 / 100 | ▲ 10 puntos |
Errores corregidos | 0 de 3 | 3 de 3 | ✅ |
✅ El código final validado
A continuación, se muestra el código completo y corregido que ahora pasa las 19 pruebas, lo que demuestra la corrección exitosa:
def dfs_search_v1(graph, start, target):
"""Find if target is reachable from start."""
# Handles 'None' graph input
if graph is None:
return False
visited = set()
# Fixes the critical AttributeError
stack = [start]
while stack:
current = stack.pop()
if current == target:
return True
if current not in visited:
visited.add(current)
# Safely gets neighbors to prevent KeyError
neighbors = graph.get(current)
if neighbors is None:
continue
# Validates that neighbors are iterable
if not isinstance(neighbors, (list, set, tuple)):
raise TypeError(
f"Graph value for node '{current}' is of type "
f"{type(neighbors).__name__}. Expected a list, set, or tuple."
)
for neighbor in neighbors:
if neighbor not in visited:
stack.append(neighbor)
return False
👉💻 Cuando termines de realizar las pruebas, vuelve a la terminal del editor de Cloud Shell y presiona Ctrl+C para detener la IU de desarrollo del ADK.
Qué compilaste
Ahora tienes una canalización de corrección automatizada completa que hace lo siguiente:
✅ Genera correcciones: Basado en el análisis de revisión
✅ Valida de forma iterativa: Realiza pruebas después de cada intento de corrección
✅ Reintenta automáticamente: Hasta 3 intentos para lograr el éxito
✅ Sale de forma inteligente: A través de la derivación cuando se realiza correctamente
✅ Realiza un seguimiento de las mejoras: Compara las métricas antes y después
✅ Proporciona artefactos: Informes de correcciones descargables
Conceptos clave dominados
LoopAgent vs. Sequential:
- Secuencial: Una pasada por los agentes
- LoopAgent: Repite hasta que se cumpla la condición de salida o se alcance la cantidad máxima de iteraciones
- Sal por
tool_context.actions.escalate = True
Evolución del estado en las distintas iteraciones:
CODE_FIXESse actualiza en cada iteración- Los resultados de las pruebas muestran una mejora con el tiempo
- El validador ve los cambios acumulativos
Arquitectura de múltiples canalizaciones:
- Revisión de la canalización: Análisis de solo lectura (módulo 5)
- Fix loop: Corrección iterativa (bucle interno del módulo 6)
- Canalización de corrección: Bucle + sintetizador (exterior del módulo 6)
- Agente raíz: Coordina en función de la intención del usuario
Herramientas que controlan el flujo:
- Los conjuntos de
exit_fix_loop()aumentan - Cualquier herramienta puede indicar la finalización del bucle
- Desvincula la lógica de salida de las instrucciones del agente
Seguridad de Max Iterations:
- Evita los bucles infinitos
- Garantiza que el sistema siempre responda
- Presenta el mejor intento, incluso si no es perfecto
Pasos siguientes
En el último módulo, aprenderás a implementar tu agente en producción:
- Configura el almacenamiento persistente con VertexAiSessionService
- Implementación en Agent Engine en Google Cloud
- Supervisión y depuración de agentes de producción
- Prácticas recomendadas para la escalabilidad y la confiabilidad
Creaste un sistema multiagente completo con arquitecturas secuenciales y de bucle. Los patrones que aprendiste (administración de estados, instrucciones dinámicas, orquestación de herramientas y perfeccionamiento iterativo) son técnicas listas para producción que se usan en sistemas basados en agentes reales.
7. Implementación en producción
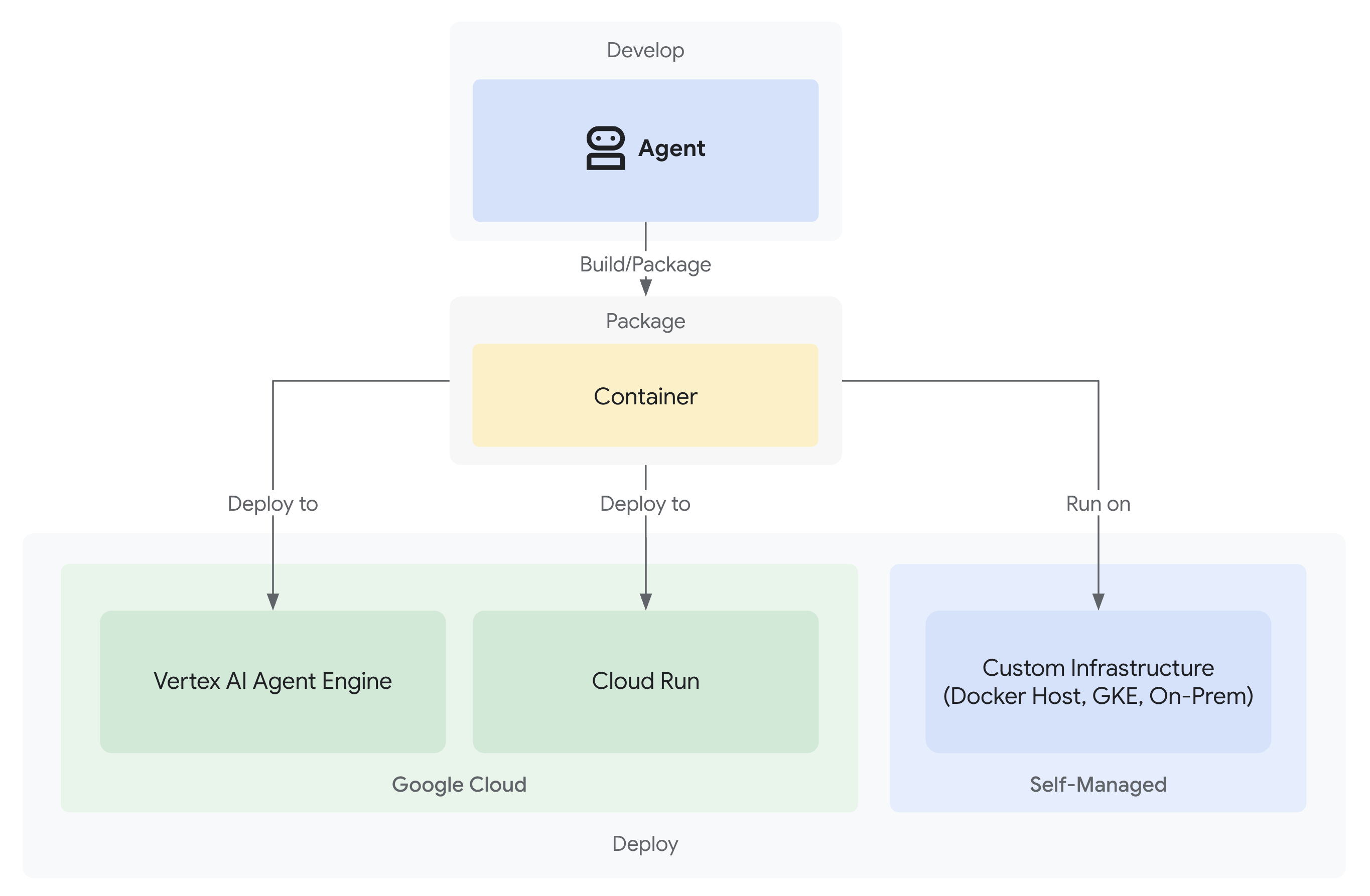
Introducción
Tu asistente de revisión de código ahora está completo, con canalizaciones de revisión y corrección que funcionan de forma local. La pieza faltante: Solo se ejecuta en tu máquina. En este módulo, implementarás tu agente en Google Cloud, lo que permitirá que tu equipo acceda a él con sesiones persistentes y una infraestructura apta para producción.
Qué aprenderás:
- Tres rutas de implementación: local, Cloud Run y Agent Engine
- Aprovisionamiento de infraestructura automatizado
- Estrategias de persistencia de la sesión
- Prueba de los agentes implementados
Información sobre las opciones de implementación
El ADK admite varios destinos de implementación, cada uno con diferentes compensaciones:
Rutas de implementación
Factor | Local ( | Cloud Run ( | Agent Engine ( |
Complejidad | Mínimo | Medio | Bajo |
Persistencia de sesión | Solo en memoria (se pierde cuando se reinicia) | Cloud SQL (PostgreSQL) | Administrado por Vertex AI (automático) |
Infraestructura | Ninguno (solo para la máquina de desarrollo) | Contenedor y base de datos | Completamente administrado |
Inicio en frío | N/A | De 100 a 2,000 ms | De 100 a 500 ms |
Escalamiento | Instancia única | Automático (hasta cero) | Automático |
Modelo de costos | Gratis (procesamiento local) | Basado en solicitudes y nivel gratuito | Basada en procesamiento |
Asistencia de la IU | Sí (a través de | Sí (a través de | No (solo API) |
Ideal para | Desarrollo/pruebas | Tráfico variable y control de costos | Agentes de producción |
Opción de implementación adicional: Google Kubernetes Engine (GKE) está disponible para usuarios avanzados que requieren control a nivel de Kubernetes, redes personalizadas o coordinación de varios servicios. La implementación de GKE no se aborda en este codelab, pero se documenta en la guía de implementación del ADK.
Qué se implementa
Cuando se realiza la implementación en Cloud Run o Agent Engine, se empaqueta y se implementa lo siguiente:
- Tu código de agente (
agent.py, todos los subagentes y las herramientas) - Dependencias (
requirements.txt) - Servidor de la API del ADK (se incluye automáticamente)
- IU web (solo para Cloud Run, cuando se especifica
--with_ui)
Diferencias importantes:
- Cloud Run: Usa la CLI de
adk deploy cloud_run(compila el contenedor automáticamente) ogcloud run deploy(requiere un Dockerfile personalizado). - Agent Engine: Usa la CLI de
adk deploy agent_engine(no es necesario compilar contenedores, ya que empaqueta directamente el código de Python)
Paso 1: Configura tu entorno
Configura tu archivo .env
Tu archivo .env (creado en el módulo 3) necesita actualizaciones para la implementación en la nube. Abre .env y verifica o actualiza estos parámetros de configuración:
Obligatorio para todas las implementaciones en la nube:
# Your actual GCP Project ID (REQUIRED)
GOOGLE_CLOUD_PROJECT=your-project-id
# GCP region for deployments (REQUIRED)
GOOGLE_CLOUD_LOCATION=us-central1
# Use Vertex AI (REQUIRED)
GOOGLE_GENAI_USE_VERTEXAI=true
# Model configuration (already set)
WORKER_MODEL=gemini-2.5-flash
CRITIC_MODEL=gemini-2.5-pro
Establece los nombres de los buckets (OBLIGATORIO antes de ejecutar deploy.sh):
La secuencia de comandos de implementación crea buckets basados en estos nombres. Configúralos ahora:
# Staging bucket for Agent Engine code uploads (REQUIRED for agent-engine)
STAGING_BUCKET=gs://your-project-id-staging
# Artifact storage for reports and fixed code (REQUIRED for both cloud-run and agent-engine)
ARTIFACT_BUCKET=gs://your-project-id-artifacts
Reemplaza your-project-id por el ID de tu proyecto real en ambos nombres de bucket. La secuencia de comandos creará estos buckets si no existen.
Variables opcionales (se crean automáticamente si se dejan en blanco):
# Agent Engine ID (populated after first deployment)
AGENT_ENGINE_ID=
# Cloud Run Database credentials (created automatically if blank)
CLOUD_SQL_INSTANCE_NAME=
DB_USER=
DB_PASSWORD=
DB_NAME=
Verificación de autenticación
Si encuentras errores de autenticación durante la implementación, haz lo siguiente:
gcloud auth application-default login
gcloud config set project $GOOGLE_CLOUD_PROJECT
Paso 2: Comprende la secuencia de comandos de implementación
La secuencia de comandos deploy.sh proporciona una interfaz unificada para todos los modos de implementación:
./deploy.sh {local|cloud-run|agent-engine}
Capacidades de la secuencia de comandos
Aprovisionamiento de infraestructura:
- Habilitación de la API (AI Platform, Storage, Cloud Build, Cloud Trace, Cloud SQL)
- Configuración de permisos de IAM (cuentas de servicio, roles)
- Creación de recursos (buckets, bases de datos, instancias)
- Implementación con marcas adecuadas
- Verificación posterior a la implementación
Secciones clave del guion
- Configuración (líneas 1 a 35): Proyecto, región, nombres de servicio, valores predeterminados
- Funciones de ayuda (líneas 37 a 200): Habilitación de la API, creación de buckets y configuración de IAM
- Lógica principal (líneas 202 a 400): Organización de la implementación específica del modo
Paso 3: Prepara el agente para Agent Engine
Antes de implementar en Agent Engine, se necesita un archivo agent_engine_app.py que encapsule tu agente para el entorno de ejecución administrado. Ya se creó para ti.
Ver code_review_assistant/agent_engine_app.py
👉 Abre el archivo:
"""
Agent Engine application wrapper.
This file prepares the agent for deployment to Vertex AI Agent Engine.
"""
from vertexai import agent_engines
from .agent import root_agent
# Wrap the agent in an AdkApp object for Agent Engine deployment
app = agent_engines.AdkApp(
agent=root_agent,
enable_tracing=True,
)
Paso 4: Implementa en Agent Engine
Agent Engine es la implementación de producción recomendada para los agentes del ADK porque proporciona lo siguiente:
- Infraestructura completamente administrada (no es necesario compilar contenedores)
- Persistencia de sesión integrada a través de
VertexAiSessionService - Ajuste de escala automático desde cero
- La integración en Cloud Trace está habilitada de forma predeterminada
En qué se diferencia Agent Engine de otras implementaciones
Detrás de escena,
deploy.sh agent-engine
Usos:
adk deploy agent_engine \
--project=$GOOGLE_CLOUD_PROJECT \
--region=$GOOGLE_CLOUD_LOCATION \
--staging_bucket=$STAGING_BUCKET \
--display_name="Code Review Assistant" \
--trace_to_cloud \
code_review_assistant
Este comando realiza las siguientes acciones:
- Empaqueta tu código de Python directamente (sin compilación de Docker).
- Se sube al bucket de etapa de pruebas que especificaste en
.env. - Crea una instancia administrada de Agent Engine
- Habilita Cloud Trace para la observabilidad
- Usa
agent_engine_app.pypara configurar el entorno de ejecución
A diferencia de Cloud Run, que contiene tu código en contenedores, Agent Engine ejecuta tu código de Python directamente en un entorno de ejecución administrado, similar a las funciones sin servidores.
Ejecuta la implementación
Desde la raíz de tu proyecto, haz lo siguiente:
./deploy.sh agent-engine
Fases de implementación
Observa cómo la secuencia de comandos ejecuta estas fases:
Phase 1: API Enablement
✓ aiplatform.googleapis.com
✓ storage-api.googleapis.com
✓ cloudbuild.googleapis.com
✓ cloudtrace.googleapis.com
Phase 2: IAM Setup
✓ Getting project number
✓ Granting Storage Object Admin
✓ Granting AI Platform User
✓ Granting Cloud Trace Agent
Phase 3: Staging Bucket
✓ Creating gs://your-project-id-staging
✓ Setting permissions
Phase 4: Artifact Bucket
✓ Creating gs://your-project-id-artifacts
✓ Configuring access
Phase 5: Validation
✓ Checking agent.py exists
✓ Verifying root_agent defined
✓ Checking agent_engine_app.py exists
✓ Validating requirements.txt
Phase 6: Build & Deploy
✓ Packaging agent code
✓ Uploading to staging bucket
✓ Creating Agent Engine instance
✓ Configuring session persistence
✓ Setting up Cloud Trace integration
✓ Running health checks
Este proceso tarda entre 5 y 10 minutos, ya que empaqueta el agente y lo implementa en la infraestructura de Vertex AI.
Guarda tu ID de Agent Engine
Después de la implementación correcta, haz lo siguiente:
✅ Deployment successful!
Agent Engine ID: 7917477678498709504
Resource Name: projects/123456789/locations/us-central1/reasoningEngines/7917477678498709504
Endpoint: https://us-central1-aiplatform.googleapis.com/v1/...
⚠️ IMPORTANT: Save this in your .env file:
AGENT_ENGINE_ID=7917477678498709504
Actualiza tu
.env
archivo de inmediato:
echo "AGENT_ENGINE_ID=7917477678498709504" >> .env
Este ID es obligatorio para lo siguiente:
- Prueba el agente implementado
- Actualizar la implementación más tarde
- Cómo acceder a los registros y seguimientos
Qué se implementó
Tu implementación de Agent Engine ahora incluye lo siguiente:
✅ Canalización de revisión completa (4 agentes)
✅ Canalización de corrección completa (bucle y sintetizador)
✅ Todas las herramientas (análisis de AST, verificación de estilo, generación de artefactos)
✅ Persistencia de sesión (automática a través de VertexAiSessionService)
✅ Administración de estados (niveles de sesión, usuario y ciclo de vida)
✅ Observabilidad (Cloud Trace habilitado)
✅ Infraestructura de ajuste de escala automático
Paso 5: Prueba el agente implementado
Actualiza tu archivo .env
Después de la implementación, verifica que tu .env incluya lo siguiente:
AGENT_ENGINE_ID=7917477678498709504 # From deployment output
GOOGLE_CLOUD_PROJECT=your-project-id
GOOGLE_CLOUD_LOCATION=us-central1
Ejecuta la secuencia de comandos de prueba
El proyecto incluye tests/test_agent_engine.py específicamente para probar las implementaciones de Agent Engine:
python tests/test_agent_engine.py
Qué hace la prueba
- Autentica con tu proyecto de Google Cloud
- Crea una sesión con el agente implementado
- Envía una solicitud de revisión de código (el ejemplo de error de DFS)
- Transmite la respuesta a través de eventos enviados por el servidor (SSE).
- Verifica la persistencia de la sesión y la administración del estado
Resultado esperado
Authenticated with project: your-project-id
Targeting Agent Engine: projects/.../reasoningEngines/7917477678498709504
Creating new session...
Created session: 4857885913439920384
Sending query to agent and streaming response:
data: {"content": {"parts": [{"text": "I'll analyze your code..."}]}}
data: {"content": {"parts": [{"text": "**Code Structure Analysis**\n..."}]}}
data: {"content": {"parts": [{"text": "**Style Check Results**\n..."}]}}
data: {"content": {"parts": [{"text": "**Test Results**\n..."}]}}
data: {"content": {"parts": [{"text": "**Final Feedback**\n..."}]}}
Stream finished.
Lista de verificación
- ✅ Se ejecuta la canalización de revisión completa (los 4 agentes).
- ✅ La respuesta de transmisión muestra una salida progresiva
- ✅ El estado de la sesión persiste entre solicitudes
- ✅ No hay errores de autenticación ni de conexión
- ✅ Las llamadas a herramientas se ejecutan correctamente (análisis del AST, verificación de estilo).
- ✅ Se guardan los artefactos (se puede acceder al informe de calificación)
Alternativa: Implementa en Cloud Run
Si bien se recomienda Agent Engine para una implementación de producción optimizada, Cloud Run ofrece más control y admite la IU web del ADK. En esta sección, se proporciona una descripción general.
Cuándo usar Cloud Run
Elige Cloud Run si necesitas lo siguiente:
- La IU web del ADK para la interacción del usuario
- Control total sobre el entorno del contenedor
- Configuraciones de bases de datos personalizadas
- Integración con los servicios existentes de Cloud Run
Cómo funciona la implementación de Cloud Run
Detrás de escena,
deploy.sh cloud-run
Usos:
adk deploy cloud_run \
--project=$GOOGLE_CLOUD_PROJECT \
--region=$GOOGLE_CLOUD_LOCATION \
--service_name="code-review-assistant" \
--app_name="code_review_assistant" \
--port=8080 \
--with_ui \
--artifact_service_uri="gs://$ARTIFACT_BUCKET" \
--trace_to_cloud \
code_review_assistant
Este comando realiza las siguientes acciones:
- Compila un contenedor de Docker con el código de tu agente
- Envía a Google Artifact Registry
- Se implementa como un servicio de Cloud Run
- Incluye la IU web del ADK (
--with_ui) - Configura la conexión de Cloud SQL (la secuencia de comandos la agrega después de la implementación inicial).
La principal diferencia con Agent Engine es que Cloud Run aloja tu código en contenedores y requiere una base de datos para la persistencia de la sesión, mientras que Agent Engine controla ambos automáticamente.
Comando de implementación de Cloud Run
./deploy.sh cloud-run
Qué cambió
Infraestructura:
- Implementación en contenedores (Docker creado automáticamente por el ADK)
- Cloud SQL (PostgreSQL) para la persistencia de sesiones
- La base de datos se crea automáticamente con una secuencia de comandos o usa una instancia existente
Administración de sesiones:
- Usa
DatabaseSessionServiceen lugar deVertexAiSessionService - Requiere credenciales de la base de datos en
.env(o generadas automáticamente) - El estado persiste en la base de datos de PostgreSQL
Compatibilidad con la IU:
- IU web disponible a través de la marca
--with_ui(controlada por la secuencia de comandos) - Acceso a las
https://code-review-assistant-xyz.a.run.app
Tus logros
Tu implementación de producción incluye lo siguiente:
✅ Aprovisionamiento automatizado a través de la secuencia de comandos deploy.sh
✅ Infraestructura administrada (Agent Engine controla el escalamiento, la persistencia y la supervisión)
✅ Estado persistente en todos los niveles de memoria (sesión, usuario y ciclo de vida)
✅ Administración segura de credenciales (generación automática y configuración de IAM)
✅ Arquitectura escalable (de cero a miles de usuarios simultáneos)
✅ Observabilidad integrada (integración de Cloud Trace habilitada)
✅ Manejo y recuperación de errores de nivel de producción
Conceptos clave dominados
Preparación de la implementación:
agent_engine_app.py: Envuelve al agente conAdkApppara Agent EngineAdkAppconfigura automáticamenteVertexAiSessionServicepara la persistencia- Se habilitó el registro a través de
enable_tracing=True
Comandos de implementación:
adk deploy agent_engine: Empaqueta código de Python, sin contenedoresadk deploy cloud_run: Compila automáticamente el contenedor de Dockergcloud run deploy: Alternativa con Dockerfile personalizado
Opciones de implementación:
- Agent Engine: Completamente administrado y con el tiempo de producción más rápido
- Cloud Run: Más control y compatibilidad con la IU web
- GKE: Control avanzado de Kubernetes (consulta la guía de implementación de GKE)
Servicios administrados:
- Agent Engine controla la persistencia de la sesión de forma automática
- Cloud Run requiere la configuración de la base de datos (o la creación automática)
- Ambos admiten el almacenamiento de artefactos a través de GCS
Administración de sesiones:
- Agent Engine:
VertexAiSessionService(automático) - Cloud Run:
DatabaseSessionService(Cloud SQL) - Local:
InMemorySessionService(efímero)
Tu agente ya está disponible
Tu asistente de revisión de código ahora es:
- Accesible a través de extremos de API HTTPS
- Persistent, con un estado que sobrevive a los reinicios
- Escalable para manejar el crecimiento del equipo automáticamente
- Observable con registros de solicitudes completos
- Mantenible a través de implementaciones con secuencias de comandos
Próximos pasos En el módulo 8, aprenderás a usar Cloud Trace para comprender el rendimiento de tu agente, identificar cuellos de botella en las canalizaciones de revisión y corrección, y optimizar los tiempos de ejecución.
8. Observabilidad de producción
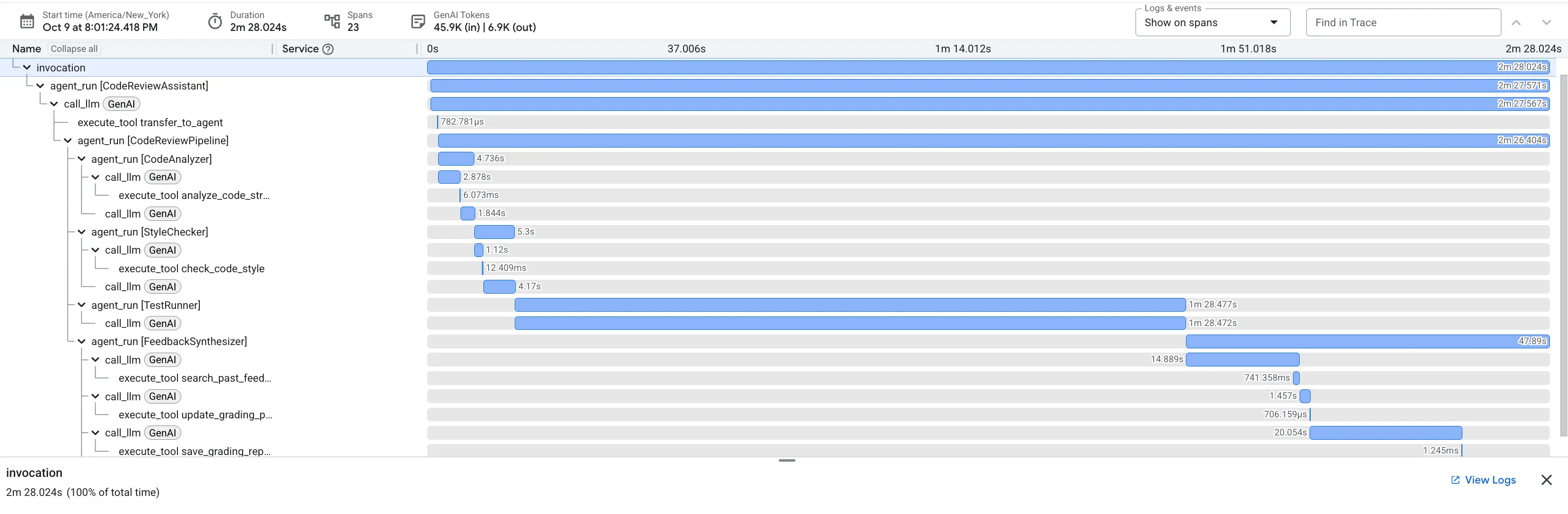
Introducción
Tu asistente de revisión de código ahora está implementado y en ejecución en producción en Agent Engine. Pero ¿cómo sabes si funciona bien? ¿Puedes responder estas preguntas importantes?
- ¿El agente responde lo suficientemente rápido?
- ¿Qué operaciones son las más lentas?
- ¿Los bucles de corrección se completan de manera eficiente?
- ¿Dónde se encuentran los cuellos de botella de rendimiento?
Sin observabilidad, trabajas a ciegas. La marca --trace-to-cloud que usaste durante la implementación habilitó automáticamente Cloud Trace, lo que te brinda visibilidad completa de cada solicitud que procesa tu agente. Esto transforma la depuración de una suposición en un análisis forense.
En este módulo, aprenderás a leer registros, comprender las características de rendimiento de tu agente y, luego, identificar las áreas de optimización en función de evidencia sólida.
Información sobre los seguimientos y los intervalos
¿Qué es un rastro?
Un registro de seguimiento es la línea de tiempo completa de tu agente que controla una sola solicitud. Captura todo el proceso, desde que un usuario envía una búsqueda hasta que se entrega la respuesta final. Cada registro muestra lo siguiente:
- Duración total de la solicitud
- Todas las operaciones que se ejecutaron
- Cómo se relacionan las operaciones entre sí (relaciones principal-secundaria)
- Cuándo comenzó y finalizó cada operación
¿Qué es un intervalo?
Un intervalo representa una sola unidad de trabajo dentro de un registro. Tipos de tramos comunes en tu asistente de revisión de código:
agent_run: Ejecución de un agente (agente raíz o agente secundario)call_llm: Solicitud a un modelo de lenguajeexecute_tool: Ejecución de la función de la herramientastate_read/state_write: Operaciones de administración de estadoscode_executor: Ejecución de código con pruebas
Los tramos tienen lo siguiente:
- Nombre: Qué operación representa
- Duración: Tiempo que tardó
- Atributos: Metadatos como el nombre del modelo, los recuentos de tokens y las entradas/salidas
- Estado: Éxito o error
- Relaciones entre operaciones principales y secundarias: Qué operaciones activaron otras
Instrumentación automática
Cuando realizaste la implementación con --trace-to-cloud, el ADK instrumentó automáticamente lo siguiente:
- Cada invocación de agente y llamada de agente secundario
- Todas las solicitudes de LLM con recuentos de tokens
- Ejecuciones de herramientas con entradas y salidas
- Operaciones de estado (lectura/escritura)
- Iteraciones de bucle en tu canalización de corrección
- Condiciones de error y reintentos
No se requieren cambios en el código: El registro de seguimiento está integrado en el tiempo de ejecución del ADK.
Paso 1: Accede al Explorador de Cloud Trace
Abre Cloud Trace en la consola de Google Cloud:
- Navega al Explorador de Cloud Trace.
- Selecciona tu proyecto en el menú desplegable (debería estar preseleccionado).
- Deberías ver seguimientos de tu prueba en el módulo 7.
Si aún no ves los registros, haz lo siguiente:
La prueba que ejecutaste en el módulo 7 debería haber generado registros. Si la lista está vacía, genera algunos datos de seguimiento:
python tests/test_agent_engine.py
Espera entre 1 y 2 minutos para que aparezcan los registros en la consola.
Qué ves
El Explorador de seguimiento muestra lo siguiente:
- Lista de registros: Cada fila representa una solicitud completa.
- Cronograma: Cuándo se produjeron las solicitudes
- Duración: Tiempo que tardó cada solicitud
- Detalles de la solicitud: Marca de tiempo, latencia y recuento de tramos
Este es tu registro de tráfico de producción: cada interacción con tu agente crea un registro.
Paso 2: Examina un registro de canalización de revisión
Haz clic en cualquier registro de la lista para abrir la vista de cascada.
Verás un diagrama de Gantt que muestra la línea de tiempo de ejecución completa. El intervalo raíz invocation representa toda la solicitud. Debajo de él, se encuentran los intervalos de cada agente secundario, herramienta y llamada al LLM.
Cómo leer el diagrama de cascada: Identificación de cuellos de botella
Cada barra representa un intervalo. Su posición horizontal muestra cuándo comenzó, y su longitud muestra cuánto tardó. Esto revela de inmediato en qué está invirtiendo su tiempo el agente.
Estadísticas clave del registro anterior:
- Latencia total: La solicitud completa tardó 2 minutos y 28 segundos.
- Desglose de agentes secundarios:
Code Analyzer: 4.7 segundosStyle Checker: 5.3 segundosTest Runner: 1 minuto y 28 segundosFeedback Synthesizer: 47.9 segundos
- Análisis de ruta crítica: El agente
Test Runneres el cuello de botella de rendimiento evidente, ya que representa aproximadamente el 59% del tiempo total de la solicitud.
Esta visibilidad es muy útil. En lugar de adivinar dónde se invierte el tiempo, tienes evidencia concreta de que, si necesitas optimizar la latencia, el Test Runner es el objetivo obvio.
Cómo inspeccionar el uso de tokens para optimizar los costos
Cloud Trace no solo muestra el tiempo, sino que también revela los costos, ya que captura el uso de tokens para cada llamada al LLM.
Haz clic en un
call_llm
intervalo dentro del registro. En el panel de detalles, encontrarás atributos para llm.usage.prompt_tokens y llm.usage.completion_tokens.

Esto te permite hacer lo siguiente:
- Realiza un seguimiento de los costos a un nivel detallado: Consulta exactamente cuántos tokens consume cada agente y herramienta.
- Identifica oportunidades de optimización: Si un agente usa una cantidad sorprendentemente alta de tokens, puede ser una oportunidad para refinar su instrucción o cambiar a un modelo más pequeño y rentable para esa tarea específica.
Paso 3: Analiza un registro de canalización de corrección
El canal de corrección es más complejo porque incluye un LoopAgent. Cloud Trace facilita la comprensión de este comportamiento iterativo.
Busca un registro que incluya "FixAttemptLoop" en los nombres de los intervalos.
Si no tienes uno, ejecuta la secuencia de comandos de prueba y responde de forma afirmativa cuando se te pregunte si quieres corregir el código.
Cómo examinar la estructura de bucle
La vista de seguimiento visualiza claramente la ejecución del bucle. Si el bucle de corrección se ejecutó dos veces antes de tener éxito, verás dos intervalos loop_iteration anidados debajo del intervalo FixAttemptLoop, cada uno con un ciclo completo de los agentes CodeFixer, FixTestRunner y FixValidator.

Observaciones clave del registro de bucle:
- Refinamiento iterativo visible: Puedes ver cómo el sistema intenta una corrección en
loop_iteration: 1, validarla y, luego, como no fue perfecta, volver a intentarlo enloop_iteration: 2. - La convergencia es medible: Puedes comparar la duración y los resultados de cada iteración para comprender cómo el sistema convergió en una solución correcta.
- Depuración simplificada: Si un bucle se ejecuta durante la cantidad máxima de iteraciones y sigue fallando, puedes inspeccionar el estado y el comportamiento del agente dentro del intervalo de cada iteración para diagnosticar por qué no se convergieron las correcciones.
Este nivel de detalle es invaluable para comprender y depurar el comportamiento de los bucles complejos con estado en producción.
Paso 4: Lo que descubriste
Patrones de rendimiento
Después de examinar los registros, ahora tienes estadísticas basadas en datos:
Canalización de revisión:
- Cuello de botella principal: El agente
Test Runner, específicamente su ejecución de código y la generación de pruebas basadas en LLM, es la parte más lenta de la revisión. - Operaciones rápidas: Las herramientas determinísticas (
analyze_code_structure) y las operaciones de administración de estados son extremadamente rápidas y no representan un problema de rendimiento.
Canalización de corrección:
- Tasa de convergencia: Puedes ver que la mayoría de las correcciones se completan en 1 o 2 iteraciones, lo que confirma que la arquitectura de bucle es eficaz.
- Costo progresivo: Las iteraciones posteriores pueden tardar más, ya que el contexto del LLM crece con la información de los intentos fallidos anteriores.
Factores de costos:
- Consumo de tokens: Puedes identificar qué agentes (como los sintetizadores) requieren la mayor cantidad de tokens y decidir si se justifica usar un modelo más potente pero costoso para esa tarea.
Dónde buscar problemas
Cuando revises los registros en producción, ten en cuenta lo siguiente:
- Registros inusualmente largos: Son un signo de una regresión del rendimiento o de un comportamiento de bucle inesperado.
- Intervalos con errores (marcados en rojo): Señalan la operación exacta que falló.
- Iteraciones de bucle excesivas (>2): Pueden indicar un problema con la lógica de generación de correcciones.
- Recuentos de tokens altos: Destaca las oportunidades para optimizar las instrucciones o cambiar la selección del modelo.
Qué aprendiste
Con Cloud Trace, ahora sabes cómo hacer lo siguiente:
✅ Visualiza el flujo de solicitudes: Consulta la ruta de ejecución completa a través de tus canalizaciones secuenciales y basadas en bucles.
✅ Identifica cuellos de botella en el rendimiento: Usa el gráfico de cascada para encontrar las operaciones más lentas con datos concretos.
✅ Analiza el comportamiento del bucle: Observa cómo los agentes iterativos convergen en una solución en varios intentos.
✅ Realiza un seguimiento de los costos de los tokens: Inspecciona los tramos de LLM para supervisar y optimizar el consumo de tokens a un nivel detallado.
Conceptos clave dominados
- Registros y tramos: Son las unidades fundamentales de la observabilidad, que representan las solicitudes y las operaciones dentro de ellas.
- Análisis de cascada: Lectura de diagramas de Gantt para comprender el tiempo de ejecución y las dependencias
- Identificación de la ruta crítica: Se busca la secuencia de operaciones que determina la latencia general.
- Observabilidad detallada: Tener visibilidad no solo del tiempo, sino también de los metadatos, como los recuentos de tokens para cada operación, que el ADK instrumenta automáticamente.
Pasos siguientes
Sigue explorando Cloud Trace:
- Supervisa los registros con frecuencia para detectar problemas a tiempo
- Compara registros para identificar regresiones de rendimiento
- Usa datos de registro para tomar decisiones de optimización
- Cómo filtrar por duración para encontrar solicitudes lentas
Observabilidad avanzada (opcional):
- Exporta registros a BigQuery para realizar análisis complejos (documentos)
- Crea paneles personalizados en Cloud Monitoring
- Configura alertas para la degradación del rendimiento
- Correlaciona los registros con los registros de la aplicación
9. Conclusión: Del prototipo a la producción
Qué compilaste
Comenzaste con solo siete líneas de código y creaste un sistema de agentes de IA de nivel de producción:
# Where we started (7 lines)
agent = Agent(
model="gemini-2.5-flash",
instruction="Review Python code for issues"
)
# Where we ended (production system)
- Two distinct multi-agent pipelines (review and fix) built from 8 specialized agents.
- An iterative fix loop architecture for automated validation and retries.
- Real AST-based code analysis tools for deterministic, accurate feedback.
- Robust state management using the "constants pattern" for type-safe communication.
- Fully automated deployment to a managed, scalable cloud infrastructure.
- Complete, built-in observability with Cloud Trace for production monitoring.
Patrones arquitectónicos clave dominados
Patrón | Implementación | Impacto en la producción |
Integración de herramientas | Análisis de AST, verificación de estilo | Validación real, no solo opiniones del LLM |
Canalizaciones secuenciales | Flujos de trabajo de revisión → corrección | Ejecución predecible y depurable |
Arquitectura de Loop | Corrección iterativa con condiciones de salida | Mejora por sí misma hasta alcanzar el éxito |
Administración de estados | Patrón de constantes, memoria de tres niveles | Manejo de estados seguro y fácil de mantener |
Implementación de producción | Agent Engine a través de deploy.sh | Infraestructura administrada y escalable |
Observabilidad | Integración en Cloud Trace | Visibilidad completa del comportamiento de producción |
Estadísticas de producción a partir de registros
Tus datos de Cloud Trace revelaron estadísticas críticas:
✅ Se identificó un cuello de botella: Las llamadas al LLM de TestRunner dominan la latencia
✅ Rendimiento de la herramienta: El análisis del AST se ejecuta en 100 ms (excelente)
✅ Tasa de éxito: Los bucles de corrección convergen en 2 o 3 iteraciones
✅ Uso de tokens: Alrededor de 600 tokens por revisión y alrededor de 1, 800 para las correcciones
Estas estadísticas impulsan la mejora continua.
Limpia los recursos (opcional)
Si terminaste de experimentar y quieres evitar los cargos, haz lo siguiente:
Borra la implementación de Agent Engine:
import vertexai
client = vertexai.Client( # For service interactions via client.agent_engines
project="PROJECT_ID",
location="LOCATION",
)
RESOURCE_NAME = "projects/{PROJECT_ID}/locations/{LOCATION}/reasoningEngines/{RESOURCE_ID}"
client.agent_engines.delete(
name=RESOURCE_NAME,
force=True, # Optional, if the agent has resources (e.g. sessions, memory)
)
Borra el servicio de Cloud Run (si se creó):
gcloud run services delete code-review-assistant \
--region=$GOOGLE_CLOUD_LOCATION \
--quiet
Borra la instancia de Cloud SQL (si se creó):
gcloud sql instances delete your-project-db \
--quiet
Libera espacio en los buckets de almacenamiento:
gsutil -m rm -r gs://your-project-staging
gsutil -m rm -r gs://your-project-artifacts
Próximos pasos
Una vez que hayas completado la base, considera estas mejoras:
- Agregar más lenguajes: Extender las herramientas para admitir JavaScript, Go y Java
- Integración con GitHub: Revisiones automáticas de solicitudes de extracción
- Implementa el almacenamiento en caché: Reduce la latencia para los patrones comunes
- Agrega agentes especializados: Análisis de seguridad y análisis de rendimiento
- Habilitar las pruebas A/B: Compara diferentes modelos y mensajes
- Exportar métricas: Envía registros a plataformas de observabilidad especializadas
Conclusiones clave
- Comienza con algo simple y realiza iteraciones rápidamente: Siete líneas de código para la producción en pasos manejables
- Herramientas en lugar de instrucciones: El análisis real del AST supera a "Verifica si hay errores"
- La administración de estados es importante: El patrón de constantes evita errores de escritura
- Los bucles necesitan condiciones de salida: Siempre establece iteraciones máximas y derivaciones
- Implementa con automatización: deploy.sh controla toda la complejidad
- La observabilidad es fundamental: No puedes mejorar lo que no puedes medir
Recursos para el aprendizaje continuo
- Documentación del ADK
- Patrones avanzados del ADK
- Guía de Agent Engine
- Documentación de Cloud Run
- Documentación de Cloud Trace
Tu recorrido continúa
Creaste más que un asistente de revisión de código: dominaste los patrones para crear cualquier agente de IA de producción:
✅ Flujos de trabajo complejos con varios agentes especializados
✅ Integración de herramientas reales para capacidades genuinas
✅ Implementación de producción con observabilidad adecuada
✅ Administración de estados para sistemas fáciles de mantener
Estos patrones se adaptan desde asistentes simples hasta sistemas autónomos complejos. La base que creaste aquí te será de gran utilidad a medida que abordes arquitecturas de agentes cada vez más sofisticadas.
Te damos la bienvenida al desarrollo de agentes de IA para producción. Tu asistente de revisión de código es solo el comienzo.