
1. Revue de code en fin de soirée
Il est 2h du matin
Vous déboguez depuis des heures. La fonction semble correcte, mais quelque chose ne va pas. Vous connaissez cette sensation : le code devrait fonctionner, mais il ne fonctionne pas, et vous ne comprenez plus pourquoi, car vous l'avez trop regardé.
def dfs_search_v1(graph, start, target):
"""Find if target is reachable from start."""
visited = set()
stack = start # Looks innocent enough...
while stack:
current = stack.pop()
if current == target:
return True
if current not in visited:
visited.add(current)
for neighbor in graph[current]:
if neighbor not in visited:
stack.append(neighbor)
return False
Parcours du développeur d'IA
Si vous lisez cet article, vous avez probablement déjà constaté la transformation que l'IA apporte au codage. Des outils comme Gemini Code Assist, Claude Code et Cursor ont changé notre façon d'écrire du code. Elles sont incroyables pour générer du code récurrent, suggérer des implémentations et accélérer le développement.
Mais vous êtes ici parce que vous souhaitez en savoir plus. Vous souhaitez comprendre comment créer ces systèmes d'IA, et pas seulement les utiliser. Vous souhaitez créer quelque chose qui :
- Comportement prévisible et traçable
- Déployez des agents en production en toute confiance
- Fournit des résultats cohérents et fiables
- Vous montre exactement comment il prend ses décisions
De consommateur à créateur
Aujourd'hui, vous allez passer de l'utilisation d'outils d'IA à leur création. Vous allez créer un système multi-agent qui :
- Analyse la structure du code de manière déterministe
- Exécute des tests réels pour vérifier le comportement
- Valide la conformité du style avec de vrais linters
- Synthétise les résultats en commentaires exploitables
- Déploiements sur Google Cloud avec une observabilité complète
2. Votre premier déploiement d'agent
Question du développeur
"Je comprends les LLM et j'ai utilisé les API, mais comment passer d'un script Python à un agent d'IA de production évolutif ?"
Pour répondre à cette question, nous allons configurer correctement votre environnement, puis créer un agent simple pour comprendre les bases avant de nous plonger dans les modèles de production.
Configuration essentielle d'abord
Avant de créer des agents, assurez-vous que votre environnement Google Cloud est prêt.
Cliquez sur Activer Cloud Shell en haut de la console Google Cloud (icône en forme de terminal en haut du volet Cloud Shell).
Trouvez votre ID de projet Google Cloud :
- Ouvrez la console Google Cloud : https://console.cloud.google.com.
- Sélectionnez le projet que vous souhaitez utiliser pour cet atelier dans le menu déroulant en haut de la page.
- L'ID de votre projet est affiché dans la fiche "Informations sur le projet" du tableau de bord
 .
.
Étape 1 : Définissez l'ID de votre projet
Dans Cloud Shell, l'outil de ligne de commande gcloud est déjà configuré. Exécutez la commande suivante pour définir votre projet actif. Cette commande utilise la variable d'environnement $GOOGLE_CLOUD_PROJECT, qui est automatiquement définie pour vous dans votre session Cloud Shell.
gcloud config set project $GOOGLE_CLOUD_PROJECT
Étape 2 : Vérifiez votre configuration
Exécutez ensuite les commandes suivantes pour vérifier que votre projet est correctement configuré et que vous êtes authentifié.
# Confirm project is set
echo "Current project: $(gcloud config get-value project)"
# Check authentication status
gcloud auth list
L'ID de votre projet devrait s'afficher, et votre compte utilisateur devrait être indiqué avec (ACTIVE) à côté.
Si votre compte n'est pas indiqué comme actif ou si vous recevez une erreur d'authentification, exécutez la commande suivante pour vous connecter :
gcloud auth application-default login
Étape 3 : Activez les API essentielles
Nous avons besoin au moins des API suivantes pour l'agent de base :
gcloud services enable \
aiplatform.googleapis.com \
compute.googleapis.com
L'opération peut prendre une ou deux minutes. Cette page vous indique les informations suivantes :
Operation "operations/..." finished successfully.
Étape 4 : Installer ADK
# Install the ADK CLI
pip install google-adk --upgrade
# Verify installation
adk --version
Vous devriez voir un numéro de version tel que 1.15.0 ou une version ultérieure.
Créer votre agent de base
Maintenant que l'environnement est prêt, créons cet agent simple.
Étape 5 : Utiliser ADK Create
adk create my_first_agent
Suivez les invites interactives :
Choose a model for the root agent:
1. gemini-2.5-flash
2. Other models (fill later)
Choose model (1, 2): 1
1. Google AI
2. Vertex AI
Choose a backend (1, 2): 2
Enter Google Cloud project ID [auto-detected-from-gcloud]:
Enter Google Cloud region [us-central1]:
Étape 6 : Examiner ce qui a été créé
cd my_first_agent
ls -la
Vous trouverez trois fichiers :
.env # Configuration (auto-populated with your project)
__init__.py # Package marker
agent.py # Your agent definition
Étape 7 : Vérification rapide de la configuration
# Verify the .env was created correctly
cat .env
# Should show something like:
# GOOGLE_CLOUD_PROJECT=your-project-id
# GOOGLE_CLOUD_LOCATION=us-central1
# GOOGLE_GENAI_USE_VERTEXAI=1
Si l'ID du projet est manquant ou incorrect, modifiez le fichier .env :
nano .env # or use your preferred editor
Étape 8 : Examiner le code de l'agent
cat agent.py
from google.adk.agents.llm_agent import Agent
root_agent = Agent(
model='gemini-2.5-flash',
name='root_agent',
description='A helpful assistant for user questions.',
instruction='Answer user questions to the best of your knowledge',
)
Simple, épuré, minimaliste. Il s'agit de votre "Hello World" d'agents.
Tester votre agent de base
Étape 9 : Exécuter votre agent
cd ..
adk run my_first_agent
Vous devez obtenir un résultat semblable au suivant :
Log setup complete: /tmp/agents_log/agent.20250930_162430.log
To access latest log: tail -F /tmp/agents_log/agent.latest.log
[user]:
Étape 10 : Tester quelques requêtes
Dans le terminal où adk run est en cours d'exécution, une invite s'affiche. Saisissez vos requêtes :
[user]: Hey, what can you do?
[root_agent]: I can help answer questions, generate text, explain concepts, assist with problem-solving, and provide information on a wide range of topics. What would you like to know or discuss?
[user]: What's the current weather in Mountain View?
[root_agent]: I'm sorry, but I cannot provide real-time weather information as I don't have access to current data or weather services. To get the current weather in Mountain View, I recommend checking a weather website or app like weather.com or using a search engine.
Notez la limite : il ne peut pas accéder aux données actuelles. Allons plus loin :
[user]: Review this Python code: def add(a, b): return a + b
[root_agent]: This is a simple Python function that adds two numbers. Here's my review:
**Strengths:**
- Clean and concise implementation
- Follows Python conventions for simple operations
- Clear function name that describes its purpose
**Suggestions for improvement:**
- Add a docstring to document the function
- Consider adding type hints for better code clarity
- You might want to handle edge cases
Here's an enhanced version:
def add(a: float, b: float) -> float:
"""Add two numbers and return their sum."""
return a + b
L'agent peut discuter du code, mais peut-il :
- Analyser réellement l'AST pour comprendre la structure ?
- Exécuter des tests pour vérifier que tout fonctionne ?
- Vérifier la conformité du style ?
- Vous vous souvenez de vos avis précédents ?
Non, c'est là que nous avons besoin d'une architecture.
🏃🚪 Quitter avec
Ctrl+C
lorsque vous avez terminé d'explorer la page.
3. Préparer votre espace de travail de production
La solution : une architecture prête pour la production
Cet agent simple a montré le point de départ, mais un système de production nécessite une structure robuste. Nous allons maintenant configurer un projet complet qui intègre les principes de production.
Configurer la base
Vous avez déjà configuré votre projet Google Cloud pour l'agent de base. Préparons maintenant l'espace de travail de production complet avec tous les outils, modèles et l'infrastructure nécessaires pour un système réel.
Étape 1 : Obtenez le projet structuré
Tout d'abord, quittez toute instance adk run en cours d'exécution avec Ctrl+C et nettoyez :
# Clean up the basic agent
cd ~ # Make sure you're not inside my_first_agent
rm -rf my_first_agent
# Get the production scaffold
git clone https://github.com/ayoisio/adk-code-review-assistant.git
cd adk-code-review-assistant
git checkout codelab
Étape 2 : Créer et activer un environnement virtuel
# Create the virtual environment
python -m venv .venv
# Activate it
# On macOS/Linux:
source .venv/bin/activate
# On Windows:
# .venv\Scripts\activate
Vérification : votre invite devrait maintenant afficher (.venv) au début.
Étape 3 : Installez les dépendances
pip install -r code_review_assistant/requirements.txt
# Install the package in editable mode (enables imports)
pip install -e .
Éléments installés :
google-adk: framework ADKpycodestyle: pour la vérification PEP 8vertexai: pour le déploiement dans le cloud- Autres dépendances de production
L'indicateur -e vous permet d'importer des modules code_review_assistant depuis n'importe où.
Étape 4 : Configurez votre environnement
# Copy the example environment file
cp .env.example .env
# Edit .env and replace the placeholders:
# - GOOGLE_CLOUD_PROJECT=your-project-id → your actual project ID
# - Keep other defaults as-is
Validation : vérifiez votre configuration :
cat .env
Voici ce qui devrait s'afficher :
GOOGLE_CLOUD_PROJECT=your-actual-project-id
GOOGLE_CLOUD_LOCATION=us-central1
GOOGLE_GENAI_USE_VERTEXAI=TRUE
Étape 5 : Assurer l'authentification
Étant donné que vous avez déjà exécuté gcloud auth plus tôt, vérifions simplement :
# Check current authentication
gcloud auth list
# Should show your account with (ACTIVE)
# If not, run:
gcloud auth application-default login
Étape 6 : Activer d'autres API de production
Nous avons déjà activé les API de base. Ajoutez maintenant les environnements de production :
gcloud services enable \
sqladmin.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
storage.googleapis.com \
cloudtrace.googleapis.com
De cette façon, vous disposez des avantages suivants :
- Administrateur SQL : pour Cloud SQL si vous utilisez Cloud Run
- Cloud Run : pour le déploiement sans serveur
- Cloud Build : pour les déploiements automatisés
- Artifact Registry : pour les images de conteneurs
- Cloud Storage : pour les artefacts et la préparation
- Cloud Trace : pour l'observabilité
Étape 7 : Créer un dépôt Artifact Registry
Notre déploiement créera des images de conteneur qui ont besoin d'un emplacement :
gcloud artifacts repositories create code-review-assistant-repo \
--repository-format=docker \
--location=us-central1 \
--description="Docker repository for Code Review Assistant"
Vous devriez obtenir le résultat suivant :
Created repository [code-review-assistant-repo].
Si elle existe déjà (peut-être à la suite d'une tentative précédente), ce n'est pas un problème. Un message d'erreur s'affichera, mais vous pourrez l'ignorer.
Étape 8 : Accorder des autorisations IAM
# Get your project number
PROJECT_NUMBER=$(gcloud projects describe $GOOGLE_CLOUD_PROJECT \
--format="value(projectNumber)")
# Define the service account
SERVICE_ACCOUNT="${PROJECT_NUMBER}@cloudbuild.gserviceaccount.com"
# Grant necessary roles
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SERVICE_ACCOUNT}" \
--role="roles/run.admin"
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SERVICE_ACCOUNT}" \
--role="roles/iam.serviceAccountUser"
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SERVICE_ACCOUNT}" \
--role="roles/cloudsql.admin"
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SERVICE_ACCOUNT}" \
--role="roles/storage.admin"
Chaque commande génère les informations suivantes :
Updated IAM policy for project [your-project-id].
Ce que vous avez accompli
Votre espace de travail de production est désormais entièrement préparé :
✅ Projet Google Cloud configuré et authentifié
✅ Agent de base testé pour comprendre les limites
✅ Code du projet avec des espaces réservés stratégiques prêt
✅ Dépendances isolées dans un environnement virtuel
✅ Toutes les API nécessaires activées
✅ Registre de conteneurs prêt pour les déploiements
✅ Autorisations IAM correctement configurées
✅ Variables d'environnement correctement définies
Vous êtes maintenant prêt à créer un véritable système d'IA avec des outils déterministes, une gestion de l'état et une architecture appropriée.
4. Créer votre premier agent
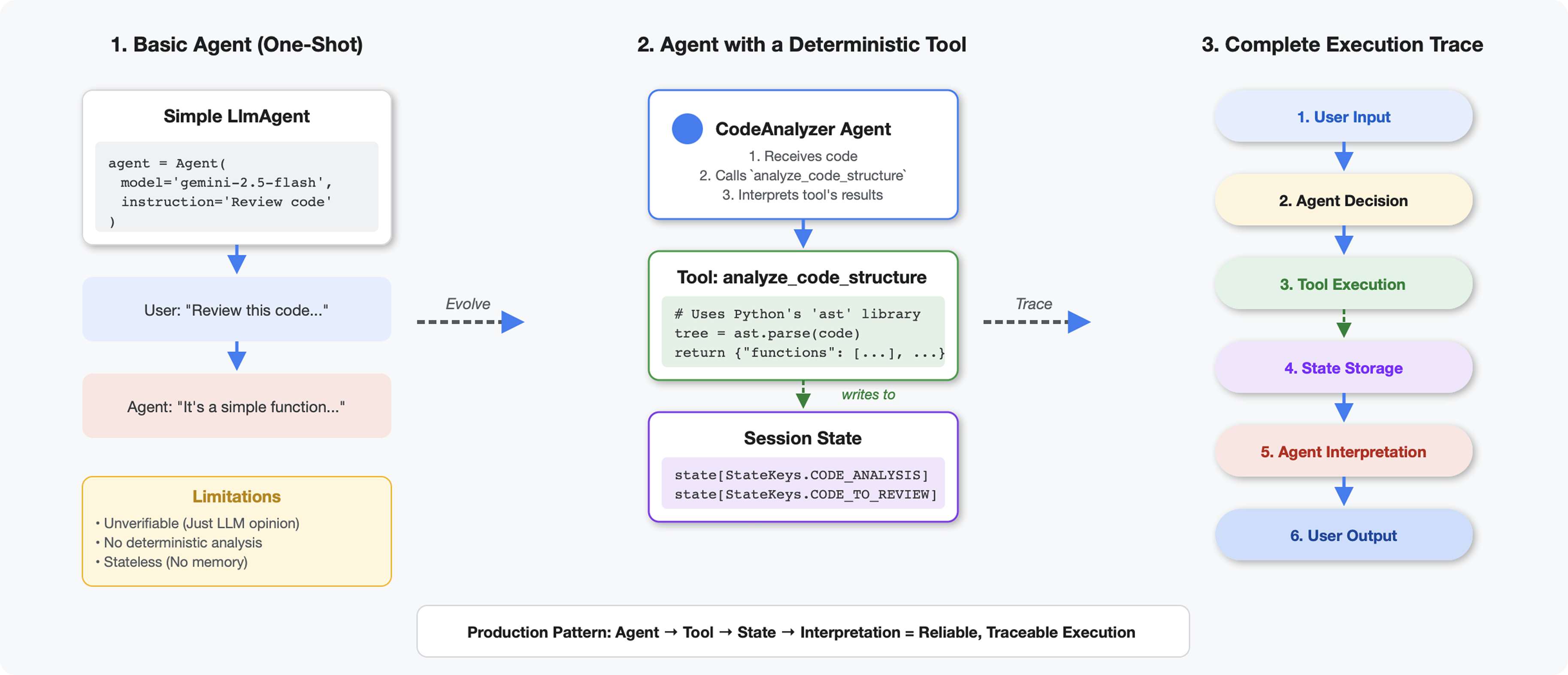
En quoi les outils sont-ils différents des LLM ?
Lorsque vous demandez à un LLM "combien de fonctions sont présentes dans ce code ?", il utilise la correspondance de motifs et l'estimation. Lorsque vous utilisez un outil qui appelle ast.parse() de Python, il analyse l'arborescence syntaxique réelle. Il n'y a pas de devinette, le résultat est le même à chaque fois.
Cette section explique comment créer un outil qui analyse la structure du code de manière déterministe, puis le connecte à un agent qui sait quand l'appeler.
Étape 1 : Comprendre le canevas
Examinons la structure que vous allez remplir.
👉 Ouvrir
code_review_assistant/tools.py
Vous verrez la fonction analyze_code_structure avec des commentaires de substitution indiquant où vous ajouterez du code. La fonction possède déjà la structure de base. Vous l'améliorerez étape par étape.
Étape 2 : Ajoutez State Storage
Le stockage de l'état permet aux autres agents du pipeline d'accéder aux résultats de votre outil sans relancer l'analyse.
👉 Trouver :
# MODULE_4_STEP_2_ADD_STATE_STORAGE
👉 Remplacez cette ligne par :
# Store code and analysis for other agents to access
tool_context.state[StateKeys.CODE_TO_REVIEW] = code
tool_context.state[StateKeys.CODE_ANALYSIS] = analysis
tool_context.state[StateKeys.CODE_LINE_COUNT] = len(code.splitlines())
Étape 3 : Ajouter l'analyse asynchrone avec des pools de threads
Notre outil doit analyser l'AST sans bloquer les autres opérations. Ajoutons l'exécution asynchrone avec des pools de threads.
👉 Trouver :
# MODULE_4_STEP_3_ADD_ASYNC
👉 Remplacez cette ligne par :
# Parse in thread pool to avoid blocking the event loop
loop = asyncio.get_event_loop()
with ThreadPoolExecutor() as executor:
tree = await loop.run_in_executor(executor, ast.parse, code)
Étape 4 : Extraire des informations complètes
Extrayons maintenant les classes, les importations et les métriques détaillées, c'est-à-dire tout ce dont nous avons besoin pour une revue de code complète.
👉 Trouver :
# MODULE_4_STEP_4_EXTRACT_DETAILS
👉 Remplacez cette ligne par :
# Extract comprehensive structural information
analysis = await loop.run_in_executor(
executor, _extract_code_structure, tree, code
)
👉 Vérifier la fonction
analyze_code_structure
dans
tools.py
comporte un corps central qui ressemble à ceci :
# Parse in thread pool to avoid blocking the event loop
loop = asyncio.get_event_loop()
with ThreadPoolExecutor() as executor:
tree = await loop.run_in_executor(executor, ast.parse, code)
# Extract comprehensive structural information
analysis = await loop.run_in_executor(
executor, _extract_code_structure, tree, code
)
# Store code and analysis for other agents to access
tool_context.state[StateKeys.CODE_TO_REVIEW] = code
tool_context.state[StateKeys.CODE_ANALYSIS] = analysis
tool_context.state[StateKeys.CODE_LINE_COUNT] = len(code.splitlines())
👉 Faites défiler la page jusqu'en bas.
tools.py
et recherchez :
# MODULE_4_STEP_4_HELPER_FUNCTION
👉 Remplacez cette ligne par la fonction d'assistance complète :
def _extract_code_structure(tree: ast.AST, code: str) -> Dict[str, Any]:
"""
Helper function to extract structural information from AST.
Runs in thread pool for CPU-bound work.
"""
functions = []
classes = []
imports = []
docstrings = []
for node in ast.walk(tree):
if isinstance(node, ast.FunctionDef):
func_info = {
'name': node.name,
'args': [arg.arg for arg in node.args.args],
'lineno': node.lineno,
'has_docstring': ast.get_docstring(node) is not None,
'is_async': isinstance(node, ast.AsyncFunctionDef),
'decorators': [d.id for d in node.decorator_list
if isinstance(d, ast.Name)]
}
functions.append(func_info)
if func_info['has_docstring']:
docstrings.append(f"{node.name}: {ast.get_docstring(node)[:50]}...")
elif isinstance(node, ast.ClassDef):
methods = []
for item in node.body:
if isinstance(item, ast.FunctionDef):
methods.append(item.name)
class_info = {
'name': node.name,
'lineno': node.lineno,
'methods': methods,
'has_docstring': ast.get_docstring(node) is not None,
'base_classes': [base.id for base in node.bases
if isinstance(base, ast.Name)]
}
classes.append(class_info)
elif isinstance(node, ast.Import):
for alias in node.names:
imports.append({
'module': alias.name,
'alias': alias.asname,
'type': 'import'
})
elif isinstance(node, ast.ImportFrom):
imports.append({
'module': node.module or '',
'names': [alias.name for alias in node.names],
'type': 'from_import',
'level': node.level
})
return {
'functions': functions,
'classes': classes,
'imports': imports,
'docstrings': docstrings,
'metrics': {
'line_count': len(code.splitlines()),
'function_count': len(functions),
'class_count': len(classes),
'import_count': len(imports),
'has_main': any(f['name'] == 'main' for f in functions),
'has_if_main': '__main__' in code,
'avg_function_length': _calculate_avg_function_length(tree)
}
}
def _calculate_avg_function_length(tree: ast.AST) -> float:
"""Calculate average function length in lines."""
function_lengths = []
for node in ast.walk(tree):
if isinstance(node, ast.FunctionDef):
if hasattr(node, 'end_lineno') and hasattr(node, 'lineno'):
length = node.end_lineno - node.lineno + 1
function_lengths.append(length)
if function_lengths:
return sum(function_lengths) / len(function_lengths)
return 0.0
Étape 5 : Se connecter à un agent
Nous allons maintenant connecter l'outil à un agent qui sait quand l'utiliser et comment interpréter ses résultats.
👉 Ouvrir
code_review_assistant/sub_agents/review_pipeline/code_analyzer.py
👉 Trouver :
# MODULE_4_STEP_5_CREATE_AGENT
👉 Remplacez cette ligne par l'agent de production complet :
code_analyzer_agent = Agent(
name="CodeAnalyzer",
model=config.worker_model,
description="Analyzes Python code structure and identifies components",
instruction="""You are a code analysis specialist responsible for understanding code structure.
Your task:
1. Take the code submitted by the user (it will be provided in the user message)
2. Use the analyze_code_structure tool to parse and analyze it
3. Pass the EXACT code to your tool - do not modify, fix, or "improve" it
4. Identify all functions, classes, imports, and structural patterns
5. Note any syntax errors or structural issues
6. Store the analysis in state for other agents to use
CRITICAL:
- Pass the code EXACTLY as provided to the analyze_code_structure tool
- Do not fix syntax errors, even if obvious
- Do not add missing imports or fix indentation
- The goal is to analyze what IS there, not what SHOULD be there
When calling the tool, pass the code as a string to the 'code' parameter.
If the analysis fails due to syntax errors, clearly report the error location and type.
Provide a clear summary including:
- Number of functions and classes found
- Key structural observations
- Any syntax errors or issues detected
- Overall code organization assessment""",
tools=[FunctionTool(func=analyze_code_structure)],
output_key="structure_analysis_summary"
)
Test Your Code Analyzer
Vérifiez maintenant que votre analyseur fonctionne correctement.
👉 Exécutez le script de test :
python tests/test_code_analyzer.py
Le script de test charge automatiquement la configuration à partir de votre fichier .env à l'aide de python-dotenv. Aucune configuration manuelle des variables d'environnement n'est donc nécessaire.
Résultat attendu :
INFO:code_review_assistant.config:Code Review Assistant Configuration Loaded:
INFO:code_review_assistant.config: - GCP Project: your-project-id
INFO:code_review_assistant.config: - Artifact Bucket: gs://your-project-artifacts
INFO:code_review_assistant.config: - Models: worker=gemini-2.5-flash, critic=gemini-2.5-pro
Testing code analyzer...
INFO:code_review_assistant.tools:Tool: Analysis complete - 2 functions, 1 classes
=== Analyzer Response ===
The analysis of the provided code shows the following:
* **Functions Found:** 2
* `add(a, b)`: A global function at line 2.
* `multiply(self, x, y)`: A method within the `Calculator` class.
* **Classes Found:** 1
* `Calculator`: A class defined at line 5. Contains one method, `multiply`.
* **Imports:** 0
* **Structural Patterns:** The code defines one global function and one class
with a single method. Both are simple, each with a single return statement.
* **Syntax Errors/Issues:** No syntax errors detected.
* **Overall Code Organization:** The code is well-organized for its small size,
clearly defining a function and a class with a method.
Que s'est-il passé ?
- Le script du test a chargé automatiquement votre configuration
.env. - Votre outil
analyze_code_structure()a analysé le code à l'aide de l'AST de Python. - L'assistant
_extract_code_structure()a extrait les fonctions, les classes et les métriques. - Les résultats ont été stockés dans l'état de la session à l'aide des constantes
StateKeys. - L'agent Code Analyzer a interprété les résultats et fourni un résumé.
Dépannage :
- "No module named ‘code_review_assistant'" : exécutez
pip install -e .à partir de la racine du projet. - "Argument d'entrée de clé manquant" : vérifiez que votre
.envcomporteGOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_LOCATIONetGOOGLE_GENAI_USE_VERTEXAI=true.
Ce que vous avez créé
Vous disposez désormais d'un analyseur de code prêt pour la production qui :
✅ Analyse l'AST Python réel : déterministe, pas de correspondance de modèle
✅ Stocke les résultats dans l'état : les autres agents peuvent accéder à l'analyse
✅ S'exécute de manière asynchrone : ne bloque pas les autres outils
✅ Extrait des informations complètes : fonctions, classes, importations, métriques
✅ Gère les erreurs de manière élégante : signale les erreurs de syntaxe avec les numéros de ligne
✅ Se connecte à un agent : le LLM sait quand et comment l'utiliser
Concepts clés maîtrisés
Outils et agents :
- Les outils effectuent un travail déterministe (analyse AST).
- Les agents décident quand utiliser les outils et interprètent les résultats.
Valeur renvoyée et état :
- Retour : ce que le LLM voit immédiatement
- État : ce qui persiste pour les autres agents
Constantes des clés d'état :
- Éviter les fautes de frappe dans les systèmes multi-agents
- Agir comme des contrats entre les agents
- Critique lorsque les agents partagent des données
Async + pools de threads :
async defpermet aux outils de suspendre l'exécution.- Les pools de threads exécutent le travail lié au processeur en arrière-plan
- Ensemble, ils permettent à la boucle d'événements de rester réactive.
Fonctions d'assistance :
- Séparer les assistants de synchronisation des outils asynchrones
- Rend le code testable et réutilisable
Instructions destinées aux agents :
- Des instructions détaillées permettent d'éviter les erreurs courantes des LLM
- Explicite sur ce qu'il NE FAUT PAS faire (ne corrige pas le code)
- Étapes de workflow claires pour assurer la cohérence
Étape suivante
Dans le module 5, vous allez ajouter :
- Vérificateur de style qui lit le code à partir de l'état
- Un lanceur de tests qui exécute réellement les tests
- Un synthétiseur de commentaires qui combine toutes les analyses
Vous verrez comment l'état circule dans un pipeline séquentiel et pourquoi le modèle de constantes est important lorsque plusieurs agents lisent et écrivent les mêmes données.
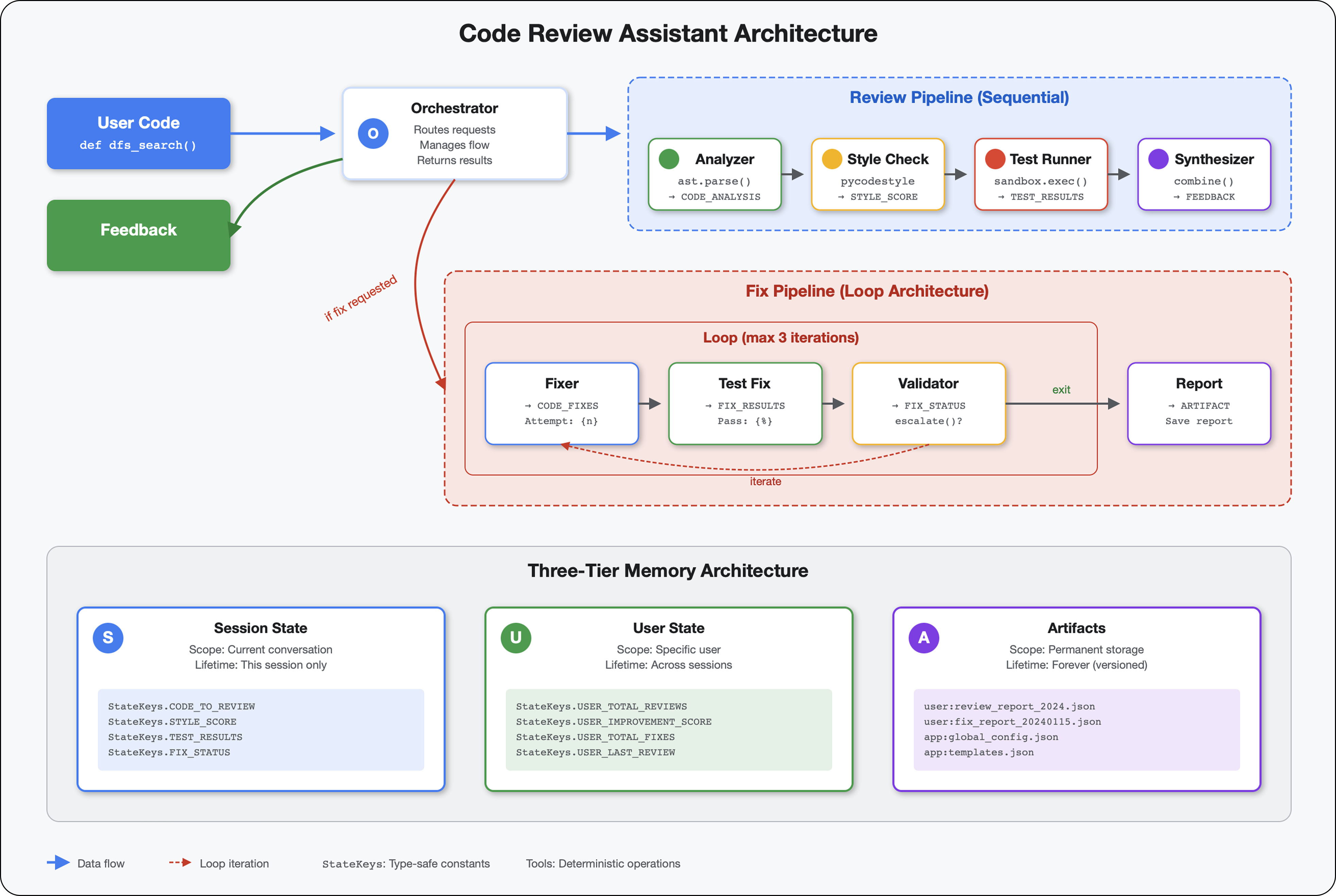
5. Créer un pipeline : plusieurs agents travaillent ensemble
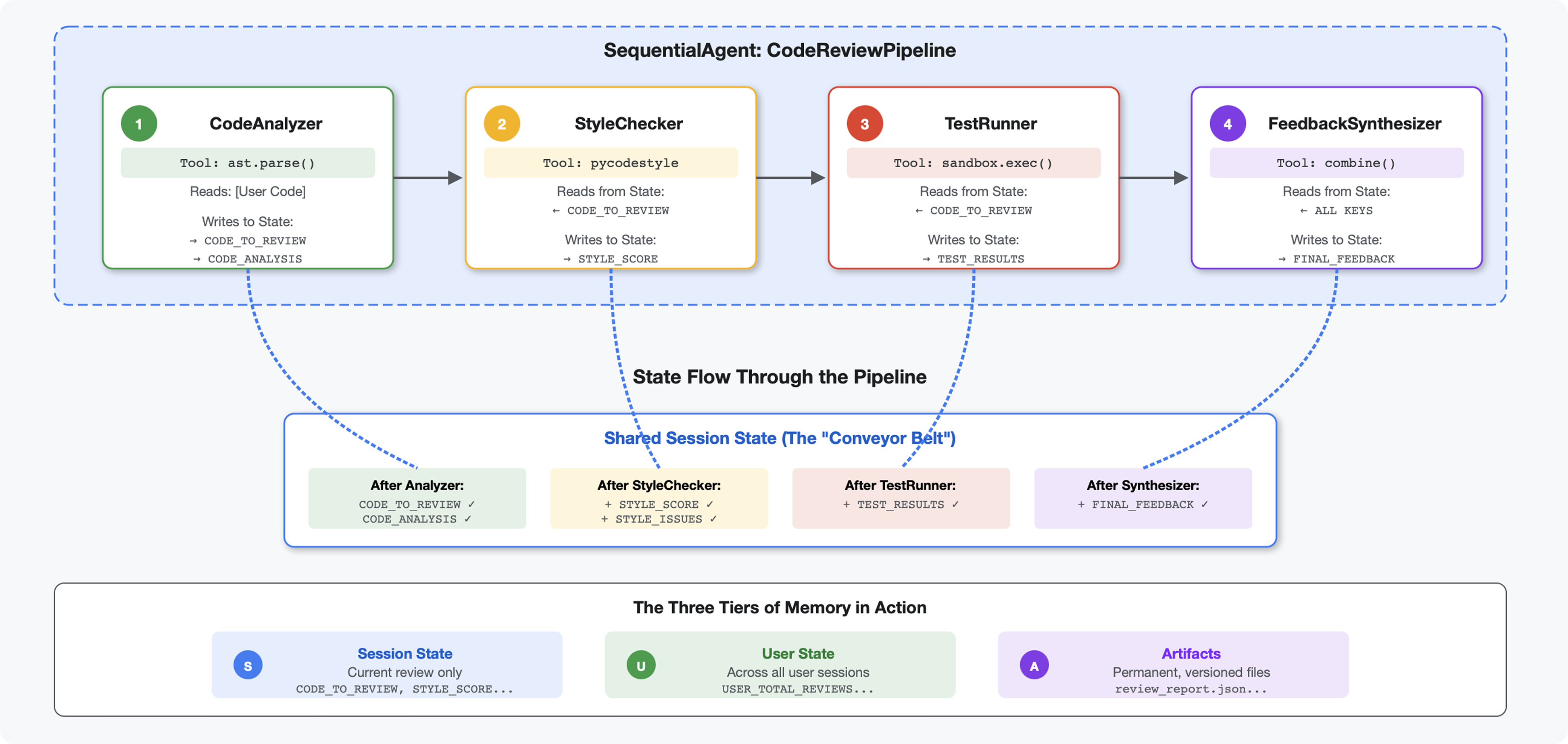
Introduction
Dans le module 4, vous avez créé un agent unique qui analyse la structure du code. Mais une revue de code complète nécessite plus qu'une simple analyse syntaxique : vous avez besoin d'une vérification du style, d'une exécution de test et d'une synthèse intelligente des commentaires.
Ce module crée un pipeline de quatre agents qui fonctionnent ensemble de manière séquentielle, chacun contribuant à une analyse spécialisée :
- Analyseur de code (du module 4) : analyse la structure
- Vérificateur de style : identifie les cas de non-respect du style
- Test Runner : exécute et valide les tests.
- Synthétiseur de commentaires : combine tous les éléments pour fournir des commentaires exploitables
Concept clé : l'état comme canal de communication. Chaque agent lit ce que les agents précédents ont écrit pour définir l'état, ajoute sa propre analyse et transmet l'état enrichi à l'agent suivant. Le modèle de constantes du module 4 devient essentiel lorsque plusieurs agents partagent des données.
Aperçu de ce que vous allez créer : envoyez du code désordonné → observez le flux d'état à travers quatre agents → recevez un rapport complet avec des commentaires personnalisés basés sur les modèles passés.
Étape 1 : Ajouter l'outil et l'agent Style Checker
Le vérificateur de style identifie les cas de non-respect de la norme PEP 8 à l'aide de pycodestyle, un linter déterministe et non basé sur l'interprétation LLM.
Ajouter l'outil de vérification du style
👉 Ouvrir
code_review_assistant/tools.py
👉 Trouver :
# MODULE_5_STEP_1_STYLE_CHECKER_TOOL
👉 Remplacez cette ligne par :
async def check_code_style(code: str, tool_context: ToolContext) -> Dict[str, Any]:
"""
Checks code style compliance using pycodestyle (PEP 8).
Args:
code: Python source code to check (or will retrieve from state)
tool_context: ADK tool context
Returns:
Dictionary containing style score and issues
"""
logger.info("Tool: Checking code style...")
try:
# Retrieve code from state if not provided
if not code:
code = tool_context.state.get(StateKeys.CODE_TO_REVIEW, '')
if not code:
return {
"status": "error",
"message": "No code provided or found in state"
}
# Run style check in thread pool
loop = asyncio.get_event_loop()
with ThreadPoolExecutor() as executor:
result = await loop.run_in_executor(
executor, _perform_style_check, code
)
# Store results in state
tool_context.state[StateKeys.STYLE_SCORE] = result['score']
tool_context.state[StateKeys.STYLE_ISSUES] = result['issues']
tool_context.state[StateKeys.STYLE_ISSUE_COUNT] = result['issue_count']
logger.info(f"Tool: Style check complete - Score: {result['score']}/100, "
f"Issues: {result['issue_count']}")
return result
except Exception as e:
error_msg = f"Style check failed: {str(e)}"
logger.error(f"Tool: {error_msg}", exc_info=True)
# Set default values on error
tool_context.state[StateKeys.STYLE_SCORE] = 0
tool_context.state[StateKeys.STYLE_ISSUES] = []
return {
"status": "error",
"message": error_msg,
"score": 0
}
👉 Faites défiler la page jusqu'à la fin du fichier et recherchez :
# MODULE_5_STEP_1_STYLE_HELPERS
👉 Remplacez cette ligne par les fonctions d'assistance :
def _perform_style_check(code: str) -> Dict[str, Any]:
"""Helper to perform style check in thread pool."""
import io
import sys
with tempfile.NamedTemporaryFile(mode='w', suffix='.py', delete=False) as tmp:
tmp.write(code)
tmp_path = tmp.name
try:
# Capture stdout to get pycodestyle output
old_stdout = sys.stdout
sys.stdout = captured_output = io.StringIO()
style_guide = pycodestyle.StyleGuide(
quiet=False, # We want output
max_line_length=100,
ignore=['E501', 'W503']
)
result = style_guide.check_files([tmp_path])
# Restore stdout
sys.stdout = old_stdout
# Parse captured output
output = captured_output.getvalue()
issues = []
for line in output.strip().split('\n'):
if line and ':' in line:
parts = line.split(':', 4)
if len(parts) >= 4:
try:
issues.append({
'line': int(parts[1]),
'column': int(parts[2]),
'code': parts[3].split()[0] if len(parts) > 3 else 'E000',
'message': parts[3].strip() if len(parts) > 3 else 'Unknown error'
})
except (ValueError, IndexError):
pass
# Add naming convention checks
try:
tree = ast.parse(code)
naming_issues = _check_naming_conventions(tree)
issues.extend(naming_issues)
except SyntaxError:
pass # Syntax errors will be caught elsewhere
# Calculate weighted score
score = _calculate_style_score(issues)
return {
"status": "success",
"score": score,
"issue_count": len(issues),
"issues": issues[:10], # First 10 issues
"summary": f"Style score: {score}/100 with {len(issues)} violations"
}
finally:
if os.path.exists(tmp_path):
os.unlink(tmp_path)
def _check_naming_conventions(tree: ast.AST) -> List[Dict[str, Any]]:
"""Check PEP 8 naming conventions."""
naming_issues = []
for node in ast.walk(tree):
if isinstance(node, ast.FunctionDef):
# Skip private/protected methods and __main__
if not node.name.startswith('_') and node.name != node.name.lower():
naming_issues.append({
'line': node.lineno,
'column': node.col_offset,
'code': 'N802',
'message': f"N802 function name '{node.name}' should be lowercase"
})
elif isinstance(node, ast.ClassDef):
# Check if class name follows CapWords convention
if not node.name[0].isupper() or '_' in node.name:
naming_issues.append({
'line': node.lineno,
'column': node.col_offset,
'code': 'N801',
'message': f"N801 class name '{node.name}' should use CapWords convention"
})
return naming_issues
def _calculate_style_score(issues: List[Dict[str, Any]]) -> int:
"""Calculate weighted style score based on violation severity."""
if not issues:
return 100
# Define weights by error type
weights = {
'E1': 10, # Indentation errors
'E2': 3, # Whitespace errors
'E3': 5, # Blank line errors
'E4': 8, # Import errors
'E5': 5, # Line length
'E7': 7, # Statement errors
'E9': 10, # Syntax errors
'W2': 2, # Whitespace warnings
'W3': 2, # Blank line warnings
'W5': 3, # Line break warnings
'N8': 7, # Naming conventions
}
total_deduction = 0
for issue in issues:
code_prefix = issue['code'][:2] if len(issue['code']) >= 2 else 'E2'
weight = weights.get(code_prefix, 3)
total_deduction += weight
# Cap at 100 points deduction
return max(0, 100 - min(total_deduction, 100))
Ajouter l'agent Style Checker
👉 Ouvrir
code_review_assistant/sub_agents/review_pipeline/style_checker.py
👉 Trouver :
# MODULE_5_STEP_1_INSTRUCTION_PROVIDER
👉 Remplacez cette ligne par :
async def style_checker_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are a code style expert focused on PEP 8 compliance.
Your task:
1. Use the check_code_style tool to validate PEP 8 compliance
2. The tool will retrieve the ORIGINAL code from state automatically
3. Report violations exactly as found
4. Present the results clearly and confidently
CRITICAL:
- The tool checks the code EXACTLY as provided by the user
- Do not suggest the code was modified or fixed
- Report actual violations found in the original code
- If there are style issues, they should be reported honestly
Call the check_code_style tool with an empty string for the code parameter,
as the tool will retrieve the code from state automatically.
When presenting results based on what the tool returns:
- State the exact score from the tool results
- If score >= 90: "Excellent style compliance!"
- If score 70-89: "Good style with minor improvements needed"
- If score 50-69: "Style needs attention"
- If score < 50: "Significant style improvements needed"
List the specific violations found (the tool will provide these):
- Show line numbers, error codes, and messages
- Focus on the top 10 most important issues
Previous analysis: {structure_analysis_summary}
Format your response as:
## Style Analysis Results
- Style Score: [exact score]/100
- Total Issues: [count]
- Assessment: [your assessment based on score]
## Top Style Issues
[List issues with line numbers and descriptions]
## Recommendations
[Specific fixes for the most critical issues]"""
return await instructions_utils.inject_session_state(template, context)
👉 Trouver :
# MODULE_5_STEP_1_STYLE_CHECKER_AGENT
👉 Remplacez cette ligne par :
style_checker_agent = Agent(
name="StyleChecker",
model=config.worker_model,
description="Checks Python code style against PEP 8 guidelines",
instruction=style_checker_instruction_provider,
tools=[FunctionTool(func=check_code_style)],
output_key="style_check_summary"
)
Étape 2 : Ajouter l'agent Test Runner
L'outil de test génère des tests complets et les exécute à l'aide de l'exécuteur de code intégré.
👉 Ouvrir
code_review_assistant/sub_agents/review_pipeline/test_runner.py
👉 Trouver :
# MODULE_5_STEP_2_INSTRUCTION_PROVIDER
👉 Remplacez cette ligne par :
async def test_runner_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects the code_to_review directly."""
template = """You are a testing specialist who creates and runs tests for Python code.
THE CODE TO TEST IS:
{code_to_review}
YOUR TASK:
1. Understand what the function appears to do based on its name and structure
2. Generate comprehensive tests (15-20 test cases)
3. Execute the tests using your code executor
4. Analyze results to identify bugs vs expected behavior
5. Output a detailed JSON analysis
TESTING METHODOLOGY:
- Test with the most natural interpretation first
- When something fails, determine if it's a bug or unusual design
- Test edge cases, boundaries, and error scenarios
- Document any surprising behavior
Execute your tests and output ONLY valid JSON with this structure:
- "test_summary": object with "total_tests_run", "tests_passed", "tests_failed", "tests_with_errors", "critical_issues_found"
- "critical_issues": array of objects, each with "type", "description", "example_input", "expected_behavior", "actual_behavior", "severity"
- "test_categories": object with "basic_functionality", "edge_cases", "error_handling" (each containing "passed", "failed", "errors" counts)
- "function_behavior": object with "apparent_purpose", "actual_interface", "unexpected_requirements"
- "verdict": object with "status" (WORKING/BUGGY/BROKEN), "confidence" (high/medium/low), "recommendation"
Do NOT output the test code itself, only the JSON analysis."""
return await instructions_utils.inject_session_state(template, context)
👉 Trouver :
# MODULE_5_STEP_2_TEST_RUNNER_AGENT
👉 Remplacez cette ligne par :
test_runner_agent = Agent(
name="TestRunner",
model=config.critic_model,
description="Generates and runs tests for Python code using safe code execution",
instruction=test_runner_instruction_provider,
code_executor=BuiltInCodeExecutor(),
output_key="test_execution_summary"
)
Étape 3 : Comprendre la mémoire pour l'apprentissage inter-session
Avant de créer le synthétiseur de commentaires, vous devez comprendre la différence entre état et mémoire, deux mécanismes de stockage différents pour deux objectifs différents.
État et mémoire : la distinction clé
Prenons un exemple concret de revue de code pour clarifier ce point :
État (session actuelle uniquement) :
# Data from THIS review session
tool_context.state[StateKeys.STYLE_ISSUES] = [
{"line": 5, "code": "E231", "message": "missing whitespace"},
{"line": 12, "code": "E701", "message": "multiple statements"}
]
- Périmètre : Cette conversation uniquement
- Objectif : transmettre des données entre les agents du pipeline actuel
- Vit à : objet
Session - Durée de vie : supprimé à la fin de la session
Mémoire (toutes les sessions précédentes) :
# Learned from 50 previous reviews
"User frequently forgets docstrings on helper functions"
"User tends to write long functions (avg 45 lines)"
"User improved error handling after feedback in session #23"
- Champ d'application : toutes les sessions passées de cet utilisateur
- Objectif : apprendre des schémas, fournir des commentaires personnalisés
- Lieu de résidence :
MemoryService - Durée de vie : persiste d'une session à l'autre, peut être recherché
Pourquoi les commentaires doivent-ils être à la fois positifs et négatifs ?
Imaginez que le synthétiseur crée un larsen :
Utiliser uniquement l'état (examen actuel) :
"Function `calculate_total` has no docstring."
Commentaires génériques et mécaniques.
Utilisation de l'état et de la mémoire (modèles actuels et passés) :
"Function `calculate_total` has no docstring. This is the 4th review
where helper functions lacked documentation. Consider adding docstrings
as you write functions, not afterwards - you mentioned in our last
session that you find it easier that way."
Personnalisée, contextuelle, les références s'améliorent au fil du temps.
Pour les déploiements en production, vous avez plusieurs options :
Option 1 : VertexAiMemoryBankService (avancé)
- Fonctionnement : extraction des faits importants des conversations grâce aux LLM
- Recherche : recherche sémantique (comprend la signification, et pas seulement les mots clés)
- Gestion de la mémoire : consolide et met à jour automatiquement les souvenirs au fil du temps
- Nécessite : un projet Google Cloud et la configuration d'Agent Engine
- À utiliser lorsque : vous souhaitez obtenir des souvenirs sophistiqués, évolutifs et personnalisés.
- Exemple : "L'utilisateur préfère la programmation fonctionnelle" (extrait de 10 conversations sur le style de code)
Option 2 : Continuer avec InMemoryMemoryService + sessions persistantes
- Fonctionnalité : stocke l'intégralité de l'historique des conversations pour la recherche par mots clés
- Recherche : correspondance de base des mots clés dans les sessions précédentes
- Gestion de la mémoire : vous contrôlez ce qui est stocké (via
add_session_to_memory). - Nécessite : uniquement un
SessionServicepersistant (commeVertexAiSessionServiceouDatabaseSessionService) - À utiliser lorsque vous avez besoin d'effectuer une recherche simple dans les conversations passées sans traitement par LLM.
- Exemple : La recherche "docstring" renvoie toutes les sessions mentionnant ce mot.
Comment la mémoire est-elle alimentée ?
Une fois chaque revue de code terminée :
# At the end of a session (typically in your application code)
await memory_service.add_session_to_memory(session)
Ce qui se passe :
- InMemoryMemoryService : stocke les événements de session complets pour la recherche par mot clé.
- VertexAiMemoryBankService : le LLM extrait les informations clés et les consolide avec les souvenirs existants.
Les sessions futures peuvent ensuite interroger :
# In a tool, search for relevant past feedback
results = tool_context.search_memory("feedback about docstrings")
Étape 4 : Ajouter des outils et un agent de synthèse des commentaires
Le synthétiseur de commentaires est l'agent le plus sophistiqué du pipeline. Il orchestre trois outils, utilise des instructions dynamiques et combine l'état, la mémoire et les artefacts.
Ajouter les trois outils de synthèse
👉 Ouvrir
code_review_assistant/tools.py
👉 Trouver :
# MODULE_5_STEP_4_SEARCH_PAST_FEEDBACK
👉 Remplacer par l'outil 1 : recherche dans la mémoire (version de production)
async def search_past_feedback(developer_id: str, tool_context: ToolContext) -> Dict[str, Any]:
"""
Search for past feedback in memory service.
Args:
developer_id: ID of the developer (defaults to "default_user")
tool_context: ADK tool context with potential memory service access
Returns:
Dictionary containing feedback search results
"""
logger.info(f"Tool: Searching for past feedback for developer {developer_id}...")
try:
# Default developer ID if not provided
if not developer_id:
developer_id = tool_context.state.get(StateKeys.USER_ID, 'default_user')
# Check if memory service is available
if hasattr(tool_context, 'search_memory'):
try:
# Perform structured searches
queries = [
f"developer:{developer_id} code review feedback",
f"developer:{developer_id} common issues",
f"developer:{developer_id} improvements"
]
all_feedback = []
patterns = {
'common_issues': [],
'improvements': [],
'strengths': []
}
for query in queries:
search_result = await tool_context.search_memory(query)
if search_result and hasattr(search_result, 'memories'):
for memory in search_result.memories[:5]:
memory_text = memory.text if hasattr(memory, 'text') else str(memory)
all_feedback.append(memory_text)
# Extract patterns
if 'style' in memory_text.lower():
patterns['common_issues'].append('style compliance')
if 'improved' in memory_text.lower():
patterns['improvements'].append('showing improvement')
if 'excellent' in memory_text.lower():
patterns['strengths'].append('consistent quality')
# Store in state
tool_context.state[StateKeys.PAST_FEEDBACK] = all_feedback
tool_context.state[StateKeys.FEEDBACK_PATTERNS] = patterns
logger.info(f"Tool: Found {len(all_feedback)} past feedback items")
return {
"status": "success",
"feedback_found": True,
"count": len(all_feedback),
"summary": " | ".join(all_feedback[:3]) if all_feedback else "No feedback",
"patterns": patterns
}
except Exception as e:
logger.warning(f"Tool: Memory search error: {e}")
# Fallback: Check state for cached feedback
cached_feedback = tool_context.state.get(StateKeys.USER_PAST_FEEDBACK_CACHE, [])
if cached_feedback:
tool_context.state[StateKeys.PAST_FEEDBACK] = cached_feedback
return {
"status": "success",
"feedback_found": True,
"count": len(cached_feedback),
"summary": "Using cached feedback",
"patterns": {}
}
# No feedback found
tool_context.state[StateKeys.PAST_FEEDBACK] = []
logger.info("Tool: No past feedback found")
return {
"status": "success",
"feedback_found": False,
"message": "No past feedback available - this appears to be a first submission",
"patterns": {}
}
except Exception as e:
error_msg = f"Feedback search error: {str(e)}"
logger.error(f"Tool: {error_msg}", exc_info=True)
tool_context.state[StateKeys.PAST_FEEDBACK] = []
return {
"status": "error",
"message": error_msg,
"feedback_found": False
}
👉 Trouver :
# MODULE_5_STEP_4_UPDATE_GRADING_PROGRESS
👉 Remplacer par l'outil 2 – Suivi des notes (version de production) :
async def update_grading_progress(tool_context: ToolContext) -> Dict[str, Any]:
"""
Updates grading progress counters and metrics in state.
"""
logger.info("Tool: Updating grading progress...")
try:
current_time = datetime.now().isoformat()
# Build all state changes
state_updates = {}
# Temporary (invocation-level) state
state_updates[StateKeys.TEMP_PROCESSING_TIMESTAMP] = current_time
# Session-level state
attempts = tool_context.state.get(StateKeys.GRADING_ATTEMPTS, 0) + 1
state_updates[StateKeys.GRADING_ATTEMPTS] = attempts
state_updates[StateKeys.LAST_GRADING_TIME] = current_time
# User-level persistent state
lifetime_submissions = tool_context.state.get(StateKeys.USER_TOTAL_SUBMISSIONS, 0) + 1
state_updates[StateKeys.USER_TOTAL_SUBMISSIONS] = lifetime_submissions
state_updates[StateKeys.USER_LAST_SUBMISSION_TIME] = current_time
# Calculate improvement metrics
current_style_score = tool_context.state.get(StateKeys.STYLE_SCORE, 0)
last_style_score = tool_context.state.get(StateKeys.USER_LAST_STYLE_SCORE, 0)
score_improvement = current_style_score - last_style_score
state_updates[StateKeys.USER_LAST_STYLE_SCORE] = current_style_score
state_updates[StateKeys.SCORE_IMPROVEMENT] = score_improvement
# Track test results if available
test_results = tool_context.state.get(StateKeys.TEST_EXECUTION_SUMMARY, {})
# Parse if it's a string
if isinstance(test_results, str):
try:
test_results = json.loads(test_results)
except:
test_results = {}
if test_results and test_results.get('test_summary', {}).get('total_tests_run', 0) > 0:
summary = test_results['test_summary']
total = summary.get('total_tests_run', 0)
passed = summary.get('tests_passed', 0)
if total > 0:
pass_rate = (passed / total) * 100
state_updates[StateKeys.USER_LAST_TEST_PASS_RATE] = pass_rate
# Apply all updates atomically
for key, value in state_updates.items():
tool_context.state[key] = value
logger.info(f"Tool: Progress updated - Attempt #{attempts}, "
f"Lifetime: {lifetime_submissions}")
return {
"status": "success",
"session_attempts": attempts,
"lifetime_submissions": lifetime_submissions,
"timestamp": current_time,
"improvement": {
"style_score_change": score_improvement,
"direction": "improved" if score_improvement > 0 else "declined"
},
"summary": f"Attempt #{attempts} recorded, {lifetime_submissions} total submissions"
}
except Exception as e:
error_msg = f"Progress update error: {str(e)}"
logger.error(f"Tool: {error_msg}", exc_info=True)
return {
"status": "error",
"message": error_msg
}
👉 Trouver :
# MODULE_5_STEP_4_SAVE_GRADING_REPORT
👉 Remplacer par l'outil 3 – Artifact Saver (version de production) :
async def save_grading_report(feedback_text: str, tool_context: ToolContext) -> Dict[str, Any]:
"""
Saves a detailed grading report as an artifact.
Args:
feedback_text: The feedback text to include in the report
tool_context: ADK tool context for state management
Returns:
Dictionary containing save status and details
"""
logger.info("Tool: Saving grading report...")
try:
# Gather all relevant data from state
code = tool_context.state.get(StateKeys.CODE_TO_REVIEW, '')
analysis = tool_context.state.get(StateKeys.CODE_ANALYSIS, {})
style_score = tool_context.state.get(StateKeys.STYLE_SCORE, 0)
style_issues = tool_context.state.get(StateKeys.STYLE_ISSUES, [])
# Get test results
test_results = tool_context.state.get(StateKeys.TEST_EXECUTION_SUMMARY, {})
# Parse if it's a string
if isinstance(test_results, str):
try:
test_results = json.loads(test_results)
except:
test_results = {}
timestamp = datetime.now().isoformat()
# Create comprehensive report dictionary
report = {
'timestamp': timestamp,
'grading_attempt': tool_context.state.get(StateKeys.GRADING_ATTEMPTS, 1),
'code': {
'content': code,
'line_count': len(code.splitlines()),
'hash': hashlib.md5(code.encode()).hexdigest()
},
'analysis': analysis,
'style': {
'score': style_score,
'issues': style_issues[:5] # First 5 issues
},
'tests': test_results,
'feedback': feedback_text,
'improvements': {
'score_change': tool_context.state.get(StateKeys.SCORE_IMPROVEMENT, 0),
'from_last_score': tool_context.state.get(StateKeys.USER_LAST_STYLE_SCORE, 0)
}
}
# Convert report to JSON string
report_json = json.dumps(report, indent=2)
report_part = types.Part.from_text(text=report_json)
# Try to save as artifact if the service is available
if hasattr(tool_context, 'save_artifact'):
try:
# Generate filename with timestamp (replace colons for filesystem compatibility)
filename = f"grading_report_{timestamp.replace(':', '-')}.json"
# Save the main report
version = await tool_context.save_artifact(filename, report_part)
# Also save a "latest" version for easy access
await tool_context.save_artifact("latest_grading_report.json", report_part)
logger.info(f"Tool: Report saved as {filename} (version {version})")
# Store report in state as well for redundancy
tool_context.state[StateKeys.USER_LAST_GRADING_REPORT] = report
return {
"status": "success",
"artifact_saved": True,
"filename": filename,
"version": str(version),
"size": len(report_json),
"summary": f"Report saved as {filename}"
}
except Exception as artifact_error:
logger.warning(f"Artifact service error: {artifact_error}, falling back to state storage")
# Continue to fallback below
# Fallback: Store in state if artifact service is not available or failed
tool_context.state[StateKeys.USER_LAST_GRADING_REPORT] = report
logger.info("Tool: Report saved to state (artifact service not available)")
return {
"status": "success",
"artifact_saved": False,
"message": "Report saved to state only",
"size": len(report_json),
"summary": "Report saved to session state"
}
except Exception as e:
error_msg = f"Report save error: {str(e)}"
logger.error(f"Tool: {error_msg}", exc_info=True)
# Still try to save minimal data to state
try:
tool_context.state[StateKeys.USER_LAST_GRADING_REPORT] = {
'error': error_msg,
'feedback': feedback_text,
'timestamp': datetime.now().isoformat()
}
except:
pass
return {
"status": "error",
"message": error_msg,
"artifact_saved": False,
"summary": f"Failed to save report: {error_msg}"
}
Créer l'agent de synthèse
👉 Ouvrir
code_review_assistant/sub_agents/review_pipeline/feedback_synthesizer.py
👉 Trouver :
# MODULE_5_STEP_4_INSTRUCTION_PROVIDER
👉 Remplacez par le fournisseur d'instructions de production :
async def feedback_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are an expert code reviewer and mentor providing constructive, educational feedback.
CONTEXT FROM PREVIOUS AGENTS:
- Structure analysis summary: {structure_analysis_summary}
- Style check summary: {style_check_summary}
- Test execution summary: {test_execution_summary}
YOUR TASK requires these steps IN ORDER:
1. Call search_past_feedback tool with developer_id="default_user"
2. Call update_grading_progress tool with no parameters
3. Carefully analyze the test results to understand what really happened
4. Generate comprehensive feedback following the structure below
5. Call save_grading_report tool with the feedback_text parameter
6. Return the feedback as your final output
CRITICAL - Understanding Test Results:
The test_execution_summary contains structured JSON. Parse it carefully:
- tests_passed = Code worked correctly
- tests_failed = Code produced wrong output
- tests_with_errors = Code crashed
- critical_issues = Fundamental problems with the code
If critical_issues array contains items, these are serious bugs that need fixing.
Do NOT count discovering bugs as test successes.
FEEDBACK STRUCTURE TO FOLLOW:
## 📊 Summary
Provide an honest assessment. Be encouraging but truthful about problems found.
## ✅ Strengths
List 2-3 things done well, referencing specific code elements.
## 📈 Code Quality Analysis
### Structure & Organization
Comment on code organization, readability, and documentation.
### Style Compliance
Report the actual style score and any specific issues.
### Test Results
Report the actual test results accurately:
- If critical_issues exist, report them as bugs to fix
- Be clear: "X tests passed, Y critical issues were found"
- List each critical issue
- Don't hide or minimize problems
## 💡 Recommendations for Improvement
Based on the analysis, provide specific actionable fixes.
If critical issues exist, fixing them is top priority.
## 🎯 Next Steps
Prioritized action list based on severity of issues.
## 💬 Encouragement
End with encouragement while being honest about what needs fixing.
Remember: Complete ALL steps including calling save_grading_report."""
return await instructions_utils.inject_session_state(template, context)
👉 Trouver :
# MODULE_5_STEP_4_SYNTHESIZER_AGENT
👉 Remplacez par :
feedback_synthesizer_agent = Agent(
name="FeedbackSynthesizer",
model=config.critic_model,
description="Synthesizes all analysis into constructive, personalized feedback",
instruction=feedback_instruction_provider,
tools=[
FunctionTool(func=search_past_feedback),
FunctionTool(func=update_grading_progress),
FunctionTool(func=save_grading_report)
],
output_key="final_feedback"
)
Étape 5 : Câblez le pipeline
Connectez maintenant les quatre agents dans un pipeline séquentiel et créez l'agent racine.
👉 Ouvrir
code_review_assistant/agent.py
👉 Ajoutez les importations nécessaires en haut du fichier (après les importations existantes) :
from google.adk.agents import Agent, SequentialAgent
from code_review_assistant.sub_agents.review_pipeline.code_analyzer import code_analyzer_agent
from code_review_assistant.sub_agents.review_pipeline.style_checker import style_checker_agent
from code_review_assistant.sub_agents.review_pipeline.test_runner import test_runner_agent
from code_review_assistant.sub_agents.review_pipeline.feedback_synthesizer import feedback_synthesizer_agent
Votre fichier devrait maintenant se présenter comme suit :
"""
Main agent orchestration for the Code Review Assistant.
"""
from google.adk.agents import Agent, SequentialAgent
from .config import config
from code_review_assistant.sub_agents.review_pipeline.code_analyzer import code_analyzer_agent
from code_review_assistant.sub_agents.review_pipeline.style_checker import style_checker_agent
from code_review_assistant.sub_agents.review_pipeline.test_runner import test_runner_agent
from code_review_assistant.sub_agents.review_pipeline.feedback_synthesizer import feedback_synthesizer_agent
# MODULE_5_STEP_5_CREATE_PIPELINE
# MODULE_6_STEP_5_CREATE_FIX_LOOP
# MODULE_6_STEP_5_UPDATE_ROOT_AGENT
👉 Trouver :
# MODULE_5_STEP_5_CREATE_PIPELINE
👉 Remplacez cette ligne par :
# Create sequential pipeline
code_review_pipeline = SequentialAgent(
name="CodeReviewPipeline",
description="Complete code review pipeline with analysis, testing, and feedback",
sub_agents=[
code_analyzer_agent,
style_checker_agent,
test_runner_agent,
feedback_synthesizer_agent
]
)
# Root agent - coordinates the review pipeline
root_agent = Agent(
name="CodeReviewAssistant",
model=config.worker_model,
description="An intelligent code review assistant that analyzes Python code and provides educational feedback",
instruction="""You are a specialized Python code review assistant focused on helping developers improve their code quality.
When a user provides Python code for review:
1. Immediately delegate to CodeReviewPipeline and pass the code EXACTLY as it was provided by the user.
2. The pipeline will handle all analysis and feedback
3. Return ONLY the final feedback from the pipeline - do not add any commentary
When a user asks what you can do or asks general questions:
- Explain your capabilities for code review
- Do NOT trigger the pipeline for non-code messages
The pipeline handles everything for code review - just pass through its final output.""",
sub_agents=[code_review_pipeline],
output_key="assistant_response"
)
Étape 6 : Tester le pipeline complet
Il est temps de voir les quatre agents travailler ensemble.
👉 Démarrez le système :
adk web code_review_assistant
Après avoir exécuté la commande adk web, vous devriez voir dans votre terminal un résultat indiquant que le serveur Web ADK a démarré, comme ceci :
+-----------------------------------------------------------------------------+
| ADK Web Server started |
| |
| For local testing, access at http://localhost:8000. |
+-----------------------------------------------------------------------------+
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
👉 Ensuite, pour accéder à l'UI de développement ADK depuis votre navigateur :
Dans la barre d'outils Cloud Shell (généralement en haut à droite), cliquez sur l'icône Aperçu sur le Web (qui ressemble souvent à un œil ou à un carré avec une flèche), puis sélectionnez "Modifier le port". Dans la fenêtre pop-up, définissez le port sur 8000, puis cliquez sur "Change and Preview" (Modifier et prévisualiser). Cloud Shell ouvre alors un nouvel onglet ou une nouvelle fenêtre de navigateur affichant l'UI de développement d'ADK.
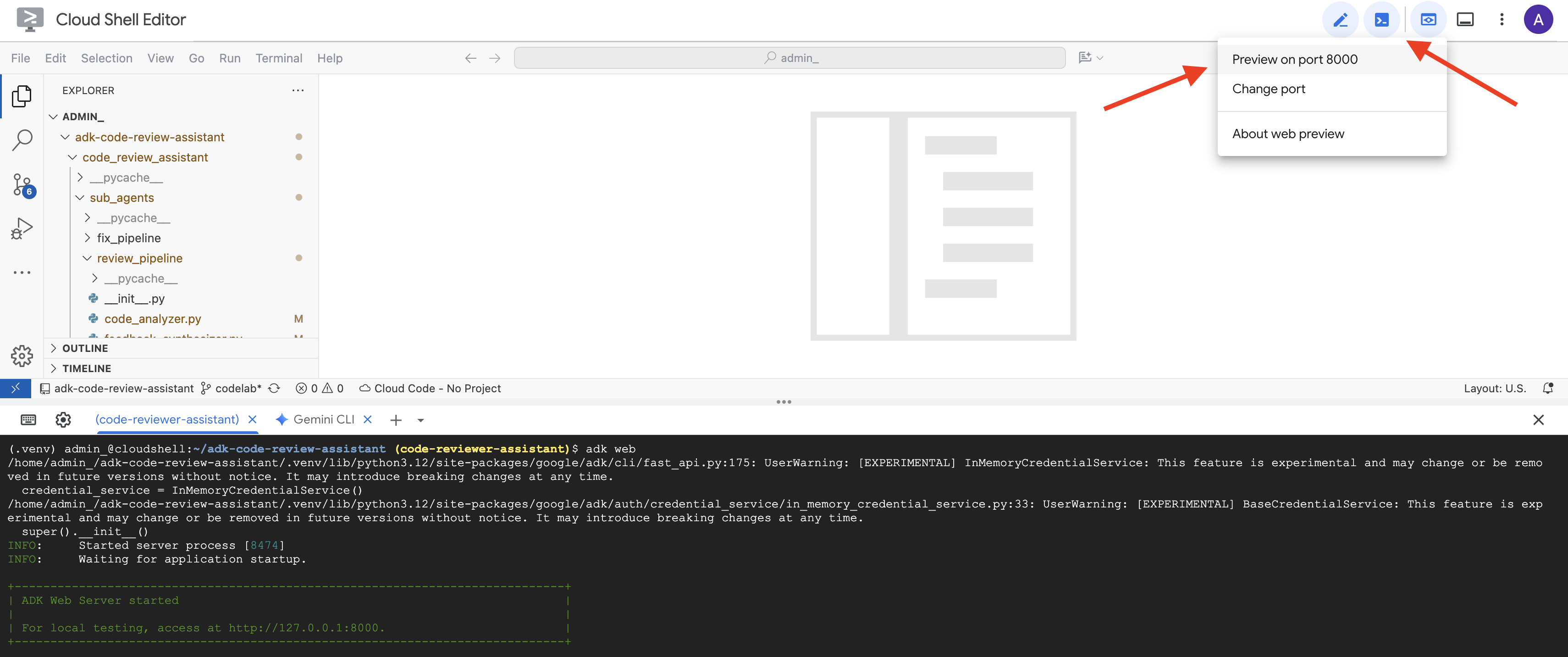
👉 L'agent est maintenant en cours d'exécution. L'UI de développement ADK dans votre navigateur est votre connexion directe à l'agent.
- Sélectionnez votre cible : dans le menu déroulant en haut de l'UI, choisissez l'agent
code_review_assistant.
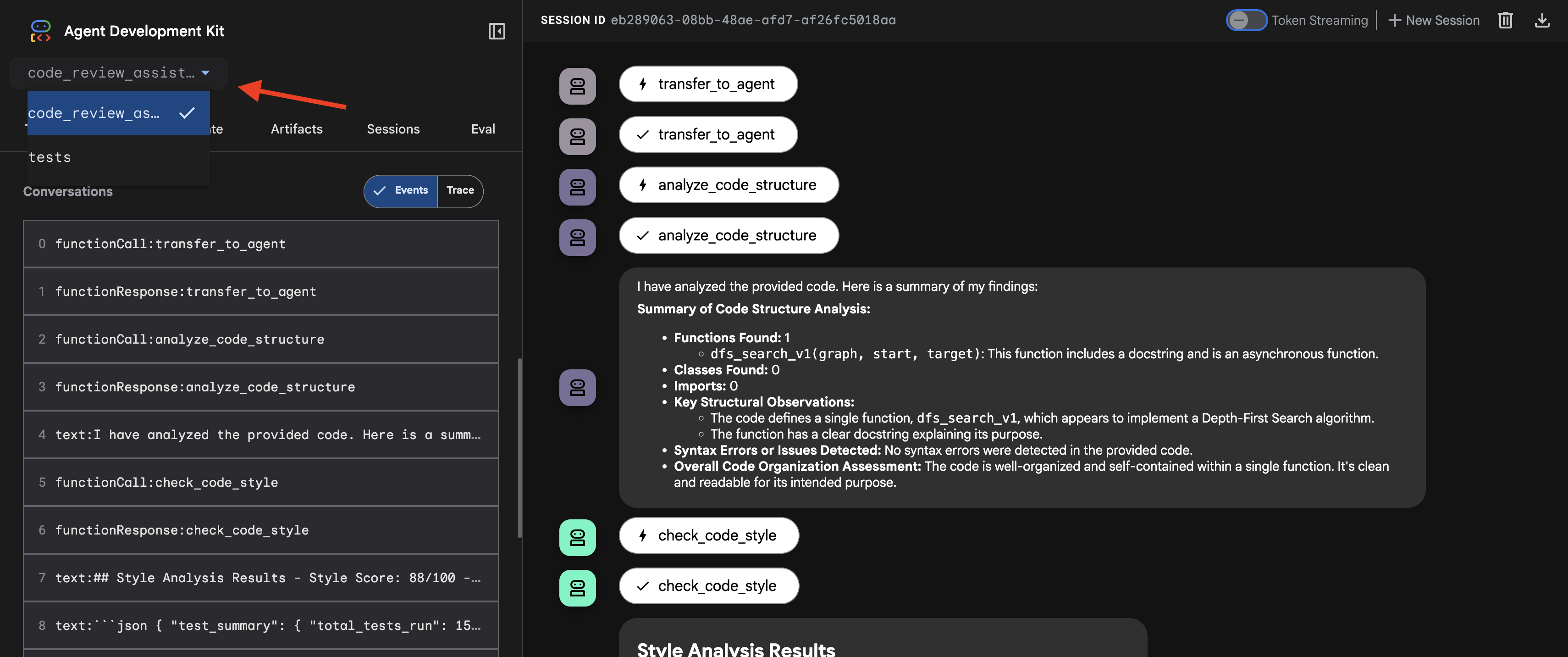
👉 Requête de test :
Please analyze the following:
def dfs_search_v1(graph, start, target):
"""Find if target is reachable from start."""
visited = set()
stack = start
while stack:
current = stack.pop()
if current == target:
return True
if current not in visited:
visited.add(current)
for neighbor in graph[current]:
if neighbor not in visited:
stack.append(neighbor)
return False
👉 Découvrez le pipeline d'examen du code en action :
Lorsque vous envoyez la fonction dfs_search_v1 boguée, vous n'obtenez pas une seule réponse. Vous voyez votre pipeline multi-agent à l'œuvre. Le flux de sortie que vous voyez est le résultat de quatre agents spécialisés qui s'exécutent séquentiellement, chacun s'appuyant sur le précédent.
Voici une présentation de la contribution de chaque agent à l'examen complet final, qui transforme les données brutes en informations exploitables.
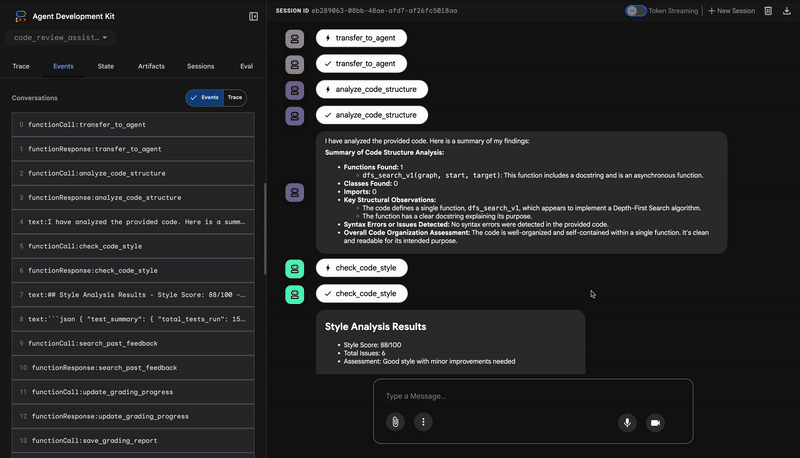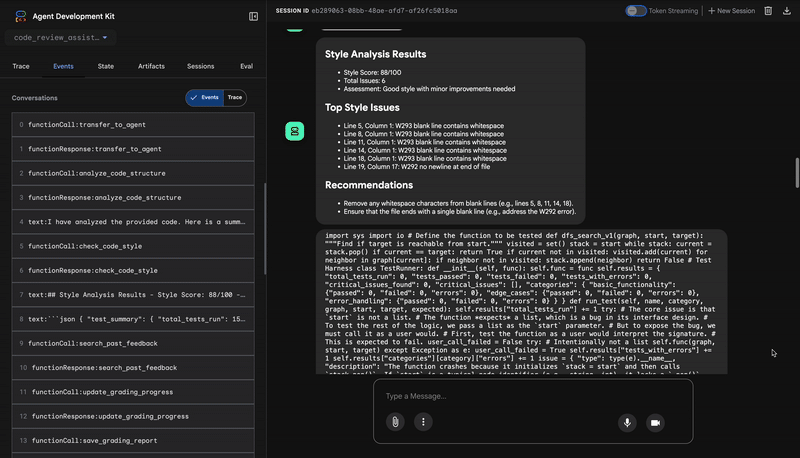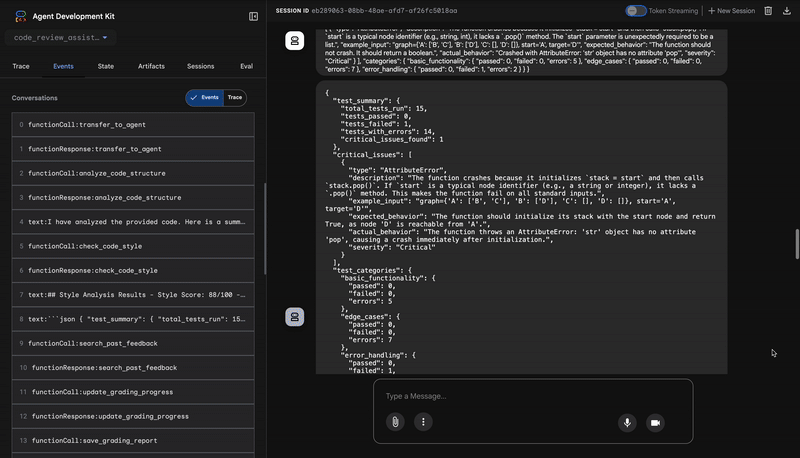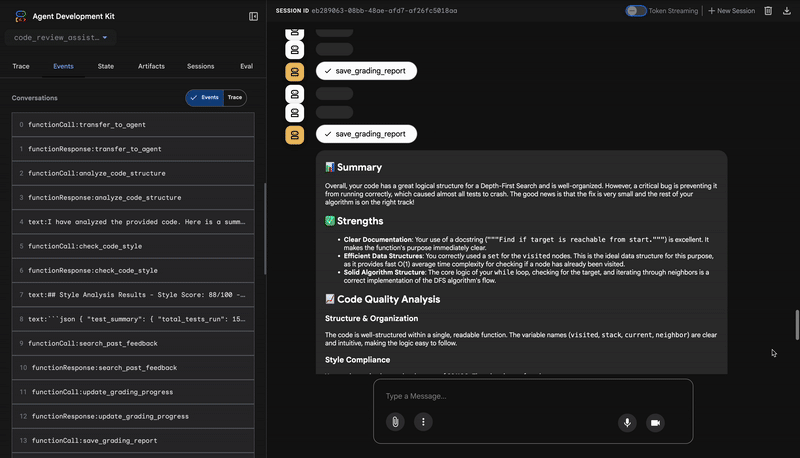
1. Rapport structurel de l'analyseur de code
Tout d'abord, l'agent CodeAnalyzer reçoit le code brut. Il ne devine pas ce que fait le code. Il utilise l'outil analyze_code_structure pour effectuer une analyse déterministe de l'arbre syntaxique abstrait (AST).
Son résultat est constitué de données pures et factuelles sur la structure du code :
The analysis of the provided code reveals the following:
Summary:
- Functions Found: 1
- Classes Found: 0
Key Structural Observations:
- A single function, dfs_search_v1, is defined.
- It includes a docstring: "Find if target is reachable from start."
- No syntax errors were detected.
Overall Code Organization Assessment:
- The code snippet is a well-defined, self-contained function.
⭐ Valeur : cette étape initiale fournit une base propre et fiable pour les autres agents. Il confirme que le code est un code Python valide et identifie les composants exacts qui doivent être examinés.
2. Audit PEP 8 du vérificateur de style
L'agent StyleChecker prend ensuite le relais. Il lit le code à partir de l'état partagé et utilise l'outil check_code_style, qui exploite le linter pycodestyle.
Le résultat est un score de qualité quantifiable et des cas spécifiques de non-respect :
Style Analysis Results
- Style Score: 88/100
- Total Issues: 6
- Assessment: Good style with minor improvements needed
Top Style Issues
- Line 5, W293: blank line contains whitespace
- Line 19, W292: no newline at end of file
⭐ Valeur : cet agent fournit des commentaires objectifs et non négociables basés sur les normes établies de la communauté (PEP 8). Le système de notation pondérée indique immédiatement à l'utilisateur la gravité des problèmes.
3. Découverte d'un bug critique par le Test Runner
C'est là que le système va au-delà de l'analyse superficielle. L'agent TestRunner génère et exécute une suite complète de tests pour valider le comportement du code.
Le résultat est un objet JSON structuré qui contient un verdict accablant :
{
"critical_issues": [
{
"type": "Critical Bug",
"description": "The function's initialization `stack = start` is incorrect... When a common input like a string... is provided... the function crashes with an AttributeError.",
"severity": "Critical"
}
],
"verdict": {
"status": "BROKEN",
"confidence": "high",
"recommendation": "The function is fundamentally broken... the stack initialization line `stack = start` must be changed to `stack = [start]`."
}
}
⭐ Valeur : il s'agit de l'insight le plus important. L'agent n'a pas simplement deviné ; il a prouvé que le code était cassé en l'exécutant. Il a détecté un bug d'exécution subtil, mais critique, qu'un réviseur humain aurait pu facilement manquer, et a identifié la cause exacte et la correction requise.
4. Rapport final du synthétiseur de commentaires
Enfin, l'agent FeedbackSynthesizer agit comme un chef d'orchestre. Il prend les données structurées des trois agents précédents et crée un rapport unique et convivial, à la fois analytique et encourageant.
Le résultat est l'avis final et soigné que vous voyez :
📊 Summary
Great effort on implementing the Depth-First Search algorithm! ... However, a critical bug in the initialization of the stack prevents the function from working correctly...
✅ Strengths
- Good Algorithm Structure
- Correct Use of `visited` Set
📈 Code Quality Analysis
...
### Style Compliance
The style analysis returned a good score of 88/100.
...
### Test Results
The automated testing revealed a critical issue... The line `stack = start` directly assigns the input... which results in an `AttributeError`.
💡 Recommendations for Improvement
**Fix the Critical Stack Initialization Bug:**
- Incorrect Code: `stack = start`
- Correct Code: `stack = [start]`
💬 Encouragement
You are very close to a perfect implementation! The core logic of your DFS algorithm is sound, which is the hardest part.
⭐ Valeur : cet agent transforme les données techniques en une expérience utile et pédagogique. Il donne la priorité au problème le plus important (le bug), l'explique clairement, fournit la solution exacte et le fait sur un ton encourageant. Il intègre avec succès les résultats de toutes les étapes précédentes dans un ensemble cohérent et utile.
Ce processus en plusieurs étapes illustre la puissance d'un pipeline agentique. Au lieu d'une réponse monolithique unique, vous obtenez une analyse par couches où chaque agent effectue une tâche spécialisée et vérifiable. Cela permet d'obtenir un examen non seulement perspicace, mais aussi déterministe, fiable et très instructif.
👉💻 Une fois les tests terminés, revenez au terminal de l'éditeur Cloud Shell et appuyez sur Ctrl+C pour arrêter l'UI de développement ADK.
Ce que vous avez créé
Vous disposez désormais d'un pipeline complet de revue de code qui :
✅ Analyse la structure du code : analyse AST déterministe avec fonctions d'assistance
✅ Vérifie le style : évaluation pondérée avec conventions de dénomination
✅ Exécute des tests : génération de tests complète avec sortie JSON structurée
✅ Synthétise les commentaires : intègre l'état, la mémoire et les artefacts
✅ Suit la progression : état à plusieurs niveaux pour les appels, les sessions et les utilisateurs
✅ Apprend au fil du temps : service de mémoire pour les modèles multisessions
✅ Fournit des artefacts : rapports JSON téléchargeables avec piste d'audit complète
Concepts clés maîtrisés
Pipelines séquentiels :
- Quatre agents s'exécutant dans un ordre strict
- Chacun enrichit l'état pour le suivant
- Les dépendances déterminent la séquence d'exécution
Modèles de production :
- Séparation des fonctions d'assistance (synchronisation dans les pools de threads)
- Dégradation élégante (stratégies de remplacement)
- Gestion de l'état à plusieurs niveaux (temporaire/session/utilisateur)
- Fournisseurs d'instructions dynamiques (contextuelles)
- Double stockage (artefacts + redondance de l'état)
État en tant que communication :
- Les constantes permettent d'éviter les fautes de frappe dans les agents.
output_keyrédige des résumés d'agent pour indiquer- Les agents ultérieurs lisent les StateKeys.
- L'état circule de manière linéaire dans le pipeline
Mémoire vs état :
- État : données de la session en cours
- Mémoire : schémas entre les sessions
- Différentes finalités, différentes durées de vie
Orchestration des outils :
- Agents à outil unique (analyzer, style_checker)
- Exécuteurs intégrés (test_runner)
- Coordination multi-outils (synthétiseur)
Stratégie de sélection du modèle :
- Modèle de worker : tâches mécaniques (analyse, linting, routage)
- Modèle critique : tâches de raisonnement (test, synthèse)
- Optimisation des coûts grâce à une sélection appropriée
Étape suivante
Dans le module 6, vous allez créer le pipeline de correction :
- Architecture LoopAgent pour la correction itérative
- Conditions de sortie via l'escalade
- Accumulation d'état au fil des itérations
- Validation et logique de nouvelle tentative
- Intégration au pipeline d'examen pour proposer des corrections
Vous verrez comment les mêmes modèles d'état s'adaptent aux workflows itératifs complexes où les agents tentent plusieurs fois jusqu'à ce qu'ils réussissent, et comment coordonner plusieurs pipelines dans une même application.
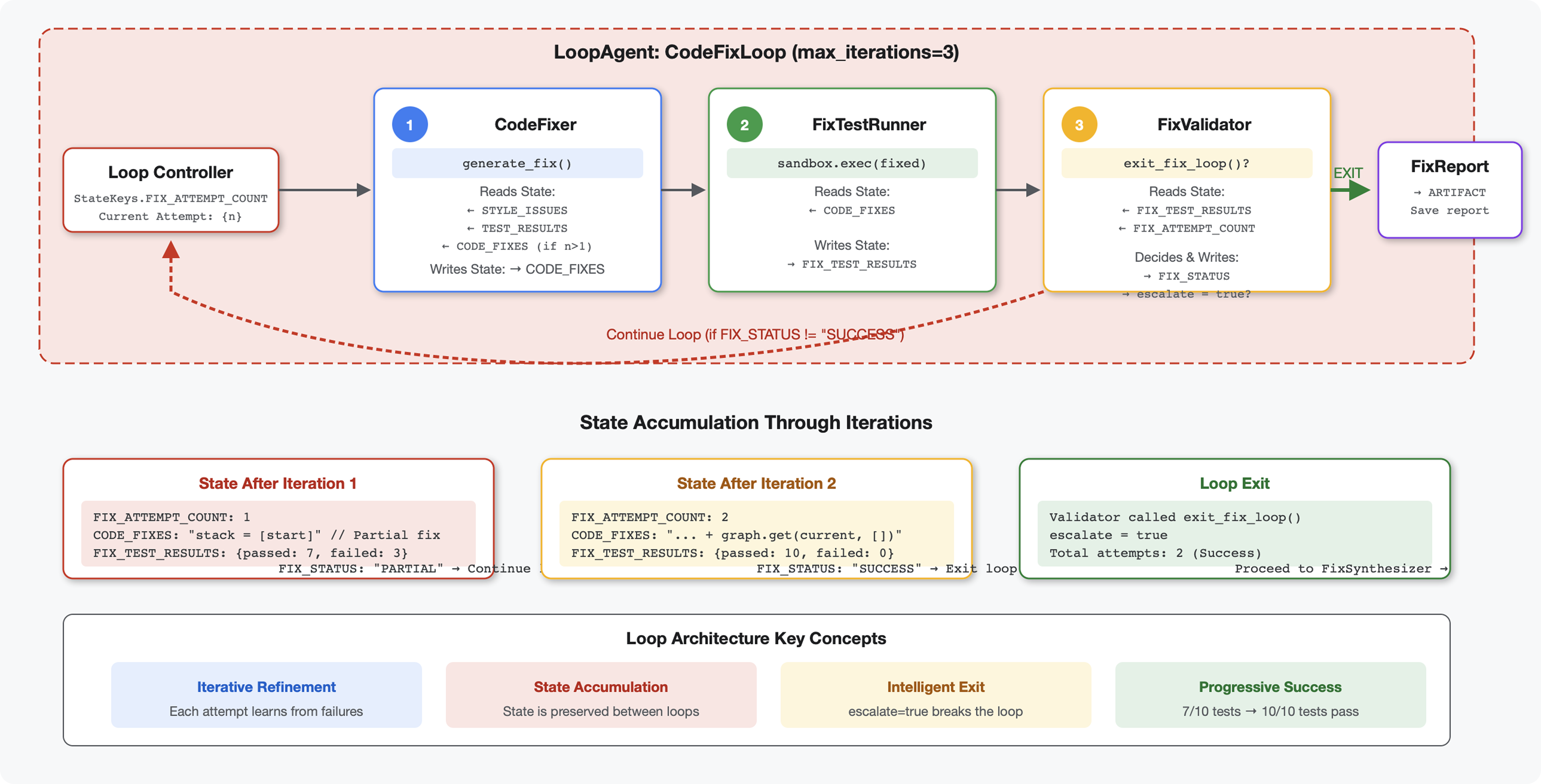
6. Ajouter le pipeline de correction : architecture de boucle
Introduction
Dans le module 5, vous avez créé un pipeline d'examen séquentiel qui analyse le code et fournit des commentaires. Mais identifier les problèmes ne suffit pas : les développeurs ont besoin d'aide pour les résoudre.
Ce module crée un pipeline de correction automatisé qui :
- Génère des corrections en fonction des résultats de l'examen
- Valide les corrections en exécutant des tests complets
- Réessaie automatiquement si les corrections ne fonctionnent pas (jusqu'à trois tentatives)
- Résultats des rapports avec des comparaisons avant/après
Concept clé : LoopAgent pour la réitération automatique. Contrairement aux agents séquentiels qui s'exécutent une seule fois, un LoopAgent répète ses sous-agents jusqu'à ce qu'une condition de sortie soit remplie ou que le nombre maximal d'itérations soit atteint. Les outils signalent la réussite en définissant tool_context.actions.escalate = True.
Aperçu de ce que vous allez créer : envoyer du code bugué → l'examen identifie les problèmes → la boucle de correction génère des corrections → les tests valident → nouvelles tentatives si nécessaire → rapport complet final.
Concepts fondamentaux : LoopAgent vs Sequential
Pipeline séquentiel (module 5) :
SequentialAgent(agents=[A, B, C])
# Executes: A → B → C → Done
- Flux unidirectionnel
- Chaque agent s'exécute une seule fois.
- Pas de logique de nouvelle tentative
Pipeline de boucle (module 6) :
LoopAgent(agents=[A, B, C], max_iterations=3)
# Executes: A → B → C → (check exit) → A → B → C → (check exit) → ...
- Flux cyclique
- Les agents peuvent s'exécuter plusieurs fois
- Sortie lorsque :
- Un ensemble d'outils
tool_context.actions.escalate = True(réussite) max_iterationsatteint (limite de sécurité)- Une exception non gérée se produit (erreur)
- Un ensemble d'outils
Pourquoi utiliser des boucles pour corriger le code ?
Les corrections de code nécessitent souvent plusieurs tentatives :
- Première tentative : corrigez les bugs évidents (types de variables incorrects).
- Deuxième tentative : corrigez les problèmes secondaires révélés par les tests (cas extrêmes).
- Troisième tentative : affiner et valider tous les tests réussis
Sans boucle, vous auriez besoin d'une logique conditionnelle complexe dans les instructions de l'agent. Avec LoopAgent, la réexécution est automatique.
Comparaison des architectures :
Sequential (Module 5):
User → Review Pipeline → Feedback → Done
Loop (Module 6):
User → Review Pipeline → Feedback → Fix Pipeline
↓
┌──────────────┴──────────────┐
│ Fix Attempt Loop (1-3x) │
│ ┌─────────────────────┐ │
│ │ 1. Generate Fixes │ │
│ │ 2. Test Fixes │ │
│ │ 3. Validate & Exit? │────┼─→ If escalate=True
│ └─────────────────────┘ │ exit loop
│ ↓ If not │
│ Try Again (max 3) │
└─────────────────────────────┘
↓
4. Synthesize Final Report → Done
Étape 1 : Ajouter l'agent Code Fixer
Le correcteur de code génère du code Python corrigé en fonction des résultats de l'examen.
👉 Ouvrir
code_review_assistant/sub_agents/fix_pipeline/code_fixer.py
👉 Trouver :
# MODULE_6_STEP_1_CODE_FIXER_INSTRUCTION_PROVIDER
👉 Remplacez cette ligne par :
async def code_fixer_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are an expert code fixing specialist.
Original Code:
{code_to_review}
Analysis Results:
- Style Score: {style_score}/100
- Style Issues: {style_issues}
- Test Results: {test_execution_summary}
Based on the test results, identify and fix ALL issues including:
- Interface bugs (e.g., if start parameter expects wrong type)
- Logic errors (e.g., KeyError when accessing graph nodes)
- Style violations
- Missing documentation
YOUR TASK:
Generate the complete fixed Python code that addresses all identified issues.
CRITICAL INSTRUCTIONS:
- Output ONLY the corrected Python code
- Do NOT include markdown code blocks (```python)
- Do NOT include any explanations or commentary
- The output should be valid, executable Python code and nothing else
Common fixes to apply based on test results:
- If tests show AttributeError with 'pop', fix: stack = [start] instead of stack = start
- If tests show KeyError accessing graph, fix: use graph.get(current, [])
- Add docstrings if missing
- Fix any style violations identified
Output the complete fixed code now:"""
return await instructions_utils.inject_session_state(template, context)
👉 Trouver :
# MODULE_6_STEP_1_CODE_FIXER_AGENT
👉 Remplacez cette ligne par :
code_fixer_agent = Agent(
name="CodeFixer",
model=config.worker_model,
description="Generates comprehensive fixes for all identified code issues",
instruction=code_fixer_instruction_provider,
code_executor=BuiltInCodeExecutor(),
output_key="code_fixes"
)
Étape 2 : Ajoutez l'agent Fix Test Runner
Le testeur de correctifs valide les corrections en exécutant des tests complets sur le code corrigé.
👉 Ouvrir
code_review_assistant/sub_agents/fix_pipeline/fix_test_runner.py
👉 Trouver :
# MODULE_6_STEP_2_FIX_TEST_RUNNER_INSTRUCTION_PROVIDER
👉 Remplacez cette ligne par :
async def fix_test_runner_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that uses the clean code from the previous step."""
template = """You are responsible for validating the fixed code by running tests.
THE FIXED CODE TO TEST:
{code_fixes}
ORIGINAL TEST RESULTS: {test_execution_summary}
YOUR TASK:
1. Understand the fixes that were applied
2. Generate the same comprehensive tests (15-20 test cases)
3. Execute the tests on the FIXED code using your code executor
4. Compare results with original test results
5. Output a detailed JSON analysis
TESTING METHODOLOGY:
- Run the same tests that revealed issues in the original code
- Verify that previously failing tests now pass
- Ensure no regressions were introduced
- Document the improvement
Execute your tests and output ONLY valid JSON with this structure:
- "passed": number of tests that passed
- "failed": number of tests that failed
- "total": total number of tests
- "pass_rate": percentage as a number
- "comparison": object with "original_pass_rate", "new_pass_rate", "improvement"
- "newly_passing_tests": array of test names that now pass
- "still_failing_tests": array of test names still failing
Do NOT output the test code itself, only the JSON analysis."""
return await instructions_utils.inject_session_state(template, context)
👉 Trouver :
# MODULE_6_STEP_2_FIX_TEST_RUNNER_AGENT
👉 Remplacez cette ligne par :
fix_test_runner_agent = Agent(
name="FixTestRunner",
model=config.critic_model,
description="Runs comprehensive tests on fixed code to verify all issues are resolved",
instruction=fix_test_runner_instruction_provider,
code_executor=BuiltInCodeExecutor(),
output_key="fix_test_execution_summary"
)
Étape 3 : Ajouter l'agent Fix Validator
Le validateur vérifie si les corrections ont réussi et décide s'il faut quitter la boucle.
Comprendre les outils
Commencez par ajouter les trois outils dont le validateur a besoin.
👉 Ouvrir
code_review_assistant/tools.py
👉 Trouver :
# MODULE_6_STEP_3_VALIDATE_FIXED_STYLE
👉 Remplacer par l'outil 1 : validateur de style :
async def validate_fixed_style(tool_context: ToolContext) -> Dict[str, Any]:
"""
Validates style compliance of the fixed code.
Args:
tool_context: ADK tool context containing fixed code in state
Returns:
Dictionary with style validation results
"""
logger.info("Tool: Validating style of fixed code...")
try:
# Get the fixed code from state
code_fixes = tool_context.state.get(StateKeys.CODE_FIXES, '')
# Try to extract from markdown if present
if '```python' in code_fixes:
start = code_fixes.rfind('```python') + 9
end = code_fixes.rfind('```')
if start < end:
code_fixes = code_fixes[start:end].strip()
if not code_fixes:
return {
"status": "error",
"message": "No fixed code found in state"
}
# Store the extracted fixed code
tool_context.state[StateKeys.CODE_FIXES] = code_fixes
# Run style check on fixed code
loop = asyncio.get_event_loop()
with ThreadPoolExecutor() as executor:
style_result = await loop.run_in_executor(
executor, _perform_style_check, code_fixes
)
# Compare with original
original_score = tool_context.state.get(StateKeys.STYLE_SCORE, 0)
improvement = style_result['score'] - original_score
# Store results
tool_context.state[StateKeys.FIXED_STYLE_SCORE] = style_result['score']
tool_context.state[StateKeys.FIXED_STYLE_ISSUES] = style_result['issues']
logger.info(f"Tool: Fixed code style score: {style_result['score']}/100 "
f"(improvement: +{improvement})")
return {
"status": "success",
"fixed_style_score": style_result['score'],
"original_style_score": original_score,
"improvement": improvement,
"remaining_issues": style_result['issues'],
"perfect_style": style_result['score'] == 100
}
except Exception as e:
logger.error(f"Tool: Style validation failed: {e}", exc_info=True)
return {
"status": "error",
"message": str(e)
}
👉 Trouver :
# MODULE_6_STEP_3_COMPILE_FIX_REPORT
👉 Remplacer par l'outil 2 : compilateur de rapports
async def compile_fix_report(tool_context: ToolContext) -> Dict[str, Any]:
"""
Compiles comprehensive report of the fix process.
Args:
tool_context: ADK tool context with all fix pipeline data
Returns:
Comprehensive fix report
"""
logger.info("Tool: Compiling comprehensive fix report...")
try:
# Gather all data
original_code = tool_context.state.get(StateKeys.CODE_TO_REVIEW, '')
code_fixes = tool_context.state.get(StateKeys.CODE_FIXES, '')
# Test results
original_tests = tool_context.state.get(StateKeys.TEST_EXECUTION_SUMMARY, {})
fixed_tests = tool_context.state.get(StateKeys.FIX_TEST_EXECUTION_SUMMARY, {})
# Parse if strings
if isinstance(original_tests, str):
try:
original_tests = json.loads(original_tests)
except:
original_tests = {}
if isinstance(fixed_tests, str):
try:
fixed_tests = json.loads(fixed_tests)
except:
fixed_tests = {}
# Extract pass rates
original_pass_rate = 0
if original_tests:
if 'pass_rate' in original_tests:
original_pass_rate = original_tests['pass_rate']
elif 'test_summary' in original_tests:
# Handle test_runner_agent's JSON structure
summary = original_tests['test_summary']
total = summary.get('total_tests_run', 0)
passed = summary.get('tests_passed', 0)
if total > 0:
original_pass_rate = (passed / total) * 100
elif 'passed' in original_tests and 'total' in original_tests:
if original_tests['total'] > 0:
original_pass_rate = (original_tests['passed'] / original_tests['total']) * 100
fixed_pass_rate = 0
all_tests_pass = False
if fixed_tests:
if 'pass_rate' in fixed_tests:
fixed_pass_rate = fixed_tests['pass_rate']
all_tests_pass = fixed_tests.get('failed', 1) == 0
elif 'passed' in fixed_tests and 'total' in fixed_tests:
if fixed_tests['total'] > 0:
fixed_pass_rate = (fixed_tests['passed'] / fixed_tests['total']) * 100
all_tests_pass = fixed_tests.get('failed', 0) == 0
# Style scores
original_style = tool_context.state.get(StateKeys.STYLE_SCORE, 0)
fixed_style = tool_context.state.get(StateKeys.FIXED_STYLE_SCORE, 0)
# Calculate improvements
test_improvement = {
'original_pass_rate': original_pass_rate,
'fixed_pass_rate': fixed_pass_rate,
'improvement': fixed_pass_rate - original_pass_rate,
'all_tests_pass': all_tests_pass
}
style_improvement = {
'original_score': original_style,
'fixed_score': fixed_style,
'improvement': fixed_style - original_style,
'perfect_style': fixed_style == 100
}
# Determine overall status
if all_tests_pass and style_improvement['perfect_style']:
fix_status = 'SUCCESSFUL'
status_emoji = '✅'
elif test_improvement['improvement'] > 0 or style_improvement['improvement'] > 0:
fix_status = 'PARTIAL'
status_emoji = '⚠️'
else:
fix_status = 'FAILED'
status_emoji = '❌'
# Build comprehensive report
report = {
'status': fix_status,
'status_emoji': status_emoji,
'timestamp': datetime.now().isoformat(),
'original_code': original_code,
'code_fixes': code_fixes,
'improvements': {
'tests': test_improvement,
'style': style_improvement
},
'summary': f"{status_emoji} Fix Status: {fix_status}\n"
f"Tests: {original_pass_rate:.1f}% → {fixed_pass_rate:.1f}%\n"
f"Style: {original_style}/100 → {fixed_style}/100"
}
# Store report in state
tool_context.state[StateKeys.FIX_REPORT] = report
tool_context.state[StateKeys.FIX_STATUS] = fix_status
logger.info(f"Tool: Fix report compiled - Status: {fix_status}")
logger.info(f"Tool: Test improvement: {original_pass_rate:.1f}% → {fixed_pass_rate:.1f}%")
logger.info(f"Tool: Style improvement: {original_style} → {fixed_style}")
return {
"status": "success",
"fix_status": fix_status,
"report": report
}
except Exception as e:
logger.error(f"Tool: Failed to compile fix report: {e}", exc_info=True)
return {
"status": "error",
"message": str(e)
}
👉 Trouver :
# MODULE_6_STEP_3_EXIT_FIX_LOOP
👉 Remplacer par l'outil 3 – Signal de sortie de boucle :
def exit_fix_loop(tool_context: ToolContext) -> Dict[str, Any]:
"""
Signal that fixing is complete and should exit the loop.
Args:
tool_context: ADK tool context
Returns:
Confirmation message
"""
logger.info("Tool: Setting escalate flag to exit fix loop")
# This is the critical line that exits the LoopAgent
tool_context.actions.escalate = True
return {
"status": "success",
"message": "Fix complete, exiting loop"
}
Créer l'agent de validation
👉 Ouvrir
code_review_assistant/sub_agents/fix_pipeline/fix_validator.py
👉 Trouver :
# MODULE_6_STEP_3_FIX_VALIDATOR_INSTRUCTION_PROVIDER
👉 Remplacez cette ligne par :
async def fix_validator_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are the final validation specialist for code fixes.
You have access to:
- Original issues from initial review
- Applied fixes: {code_fixes}
- Test results after fix: {fix_test_execution_summary}
- All state data from the fix process
Your responsibilities:
1. Use validate_fixed_style tool to check style compliance of fixed code
- Pass no arguments, it will retrieve fixed code from state
2. Use compile_fix_report tool to generate comprehensive report
- Pass no arguments, it will gather all data from state
3. Based on the report, determine overall fix status:
- ✅ SUCCESSFUL: All tests pass, style score 100
- ⚠️ PARTIAL: Improvements made but issues remain
- ❌ FAILED: Fix didn't work or made things worse
4. CRITICAL: If status is SUCCESSFUL, call the exit_fix_loop tool to stop iterations
- This prevents unnecessary additional fix attempts
- If not successful, the loop will continue for another attempt
5. Provide clear summary of:
- What was fixed
- What improvements were achieved
- Any remaining issues requiring manual attention
Be precise and quantitative in your assessment.
"""
return await instructions_utils.inject_session_state(template, context)
👉 Trouver :
# MODULE_6_STEP_3_FIX_VALIDATOR_AGENT
👉 Remplacez cette ligne par :
fix_validator_agent = Agent(
name="FixValidator",
model=config.worker_model,
description="Validates fixes and generates final fix report",
instruction=fix_validator_instruction_provider,
tools=[
FunctionTool(func=validate_fixed_style),
FunctionTool(func=compile_fix_report),
FunctionTool(func=exit_fix_loop)
],
output_key="final_fix_report"
)
Étape 4 : Comprendre les conditions de sortie de LoopAgent
Il existe trois façons de quitter LoopAgent :
1. Sortie réussie (via escalade)
# Inside any tool in the loop:
tool_context.actions.escalate = True
# Effect: Loop completes current iteration, then exits
# Use when: Fix is successful and no more attempts needed
Exemple de flux :
Iteration 1:
CodeFixer → generates fixes
FixTestRunner → tests show 90% pass rate
FixValidator → compiles report, sees PARTIAL status
→ Does NOT set escalate
→ Loop continues
Iteration 2:
CodeFixer → refines fixes based on failures
FixTestRunner → tests show 100% pass rate
FixValidator → compiles report, sees SUCCESSFUL status
→ Calls exit_fix_loop() which sets escalate = True
→ Loop exits after this iteration
2. Sortie "Nombre maximal d'itérations"
LoopAgent(
name="FixAttemptLoop",
sub_agents=[...],
max_iterations=3 # Safety limit
)
# Effect: After 3 complete iterations, loop exits regardless of escalate
# Use when: Prevent infinite loops if fixes never succeed
Exemple de flux :
Iteration 1: PARTIAL (continue)
Iteration 2: PARTIAL (continue)
Iteration 3: PARTIAL (but max reached)
→ Loop exits, synthesizer presents best attempt
3. Sortie d'erreur
# If any agent throws unhandled exception:
raise Exception("Unexpected error")
# Effect: Loop exits immediately with error state
# Use when: Critical failure that can't be recovered
Évolution de l'état au fil des itérations :
Chaque itération voit l'état mis à jour de la tentative précédente :
# Before Iteration 1:
state = {
"code_to_review": "def add(a,b):return a+b", # Original
"style_score": 40,
"test_execution_summary": {...}
}
# After Iteration 1:
state = {
"code_to_review": "def add(a,b):return a+b", # Unchanged
"code_fixes": "def add(a, b):\n return a + b", # NEW
"style_score": 40, # Unchanged
"fixed_style_score": 100, # NEW
"test_execution_summary": {...}, # Unchanged
"fix_test_execution_summary": {...} # NEW
}
# Iteration 2 starts with all this state
# If fixes still not perfect, code_fixes gets overwritten
Pourquoi ?
escalate
Au lieu des valeurs renvoyées :
# Bad: Using return value to signal exit
def validator_agent():
report = compile_report()
if report['status'] == 'SUCCESSFUL':
return {"exit": True} # How does loop know?
# Good: Using escalate
def validator_tool(tool_context):
report = compile_report()
if report['status'] == 'SUCCESSFUL':
tool_context.actions.escalate = True # Loop knows immediately
return {"report": report}
Avantages :
- Fonctionne à partir de n'importe quel outil, et pas seulement le dernier
- N'interfère pas avec les données de retour
- Signification sémantique claire
- Le framework gère la logique de sortie
Étape 5 : Câblez le pipeline de correction
👉 Ouvrir
code_review_assistant/agent.py
👉 Ajoutez les importations du pipeline de correction (après les importations existantes) :
from google.adk.agents import LoopAgent # Add this to the existing Agent, SequentialAgent line
from code_review_assistant.sub_agents.fix_pipeline.code_fixer import code_fixer_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_test_runner import fix_test_runner_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_validator import fix_validator_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_synthesizer import fix_synthesizer_agent
Vos importations doivent désormais être les suivantes :
from google.adk.agents import Agent, SequentialAgent, LoopAgent
from .config import config
# Review pipeline imports (from Module 5)
from code_review_assistant.sub_agents.review_pipeline.code_analyzer import code_analyzer_agent
from code_review_assistant.sub_agents.review_pipeline.style_checker import style_checker_agent
from code_review_assistant.sub_agents.review_pipeline.test_runner import test_runner_agent
from code_review_assistant.sub_agents.review_pipeline.feedback_synthesizer import feedback_synthesizer_agent
# Fix pipeline imports (NEW)
from code_review_assistant.sub_agents.fix_pipeline.code_fixer import code_fixer_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_test_runner import fix_test_runner_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_validator import fix_validator_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_synthesizer import fix_synthesizer_agent
👉 Trouver :
# MODULE_6_STEP_5_CREATE_FIX_LOOP
👉 Remplacez cette ligne par :
# Create the fix attempt loop (retries up to 3 times)
fix_attempt_loop = LoopAgent(
name="FixAttemptLoop",
sub_agents=[
code_fixer_agent, # Step 1: Generate fixes
fix_test_runner_agent, # Step 2: Validate with tests
fix_validator_agent # Step 3: Check success & possibly exit
],
max_iterations=3 # Try up to 3 times
)
# Wrap loop with synthesizer for final report
code_fix_pipeline = SequentialAgent(
name="CodeFixPipeline",
description="Automated code fixing pipeline with iterative validation",
sub_agents=[
fix_attempt_loop, # Try to fix (1-3 times)
fix_synthesizer_agent # Present final results (always runs once)
]
)
👉 Supprimez le
root_agent
définition :
root_agent = Agent(...)
👉 Trouver :
# MODULE_6_STEP_5_UPDATE_ROOT_AGENT
👉 Remplacez cette ligne par :
# Update root agent to include both pipelines
root_agent = Agent(
name="CodeReviewAssistant",
model=config.worker_model,
description="An intelligent code review assistant that analyzes Python code and provides educational feedback",
instruction="""You are a specialized Python code review assistant focused on helping developers improve their code quality.
When a user provides Python code for review:
1. Immediately delegate to CodeReviewPipeline and pass the code EXACTLY as it was provided by the user.
2. The pipeline will handle all analysis and feedback
3. Return ONLY the final feedback from the pipeline - do not add any commentary
After completing a review, if significant issues were identified:
- If style score < 100 OR tests are failing OR critical issues exist:
* Add at the end: "\n\n💡 I can fix these issues for you. Would you like me to do that?"
- If the user responds yes or requests fixes:
* Delegate to CodeFixPipeline
* Return the fix pipeline's complete output AS-IS
When a user asks what you can do or general questions:
- Explain your capabilities for code review and fixing
- Do NOT trigger the pipeline for non-code messages
The pipelines handle everything for code review and fixing - just pass through their final output.""",
sub_agents=[code_review_pipeline, code_fix_pipeline],
output_key="assistant_response"
)
Étape 6 : Ajouter l'agent Fix Synthesizer
Une fois la boucle terminée, le synthétiseur crée une présentation conviviale des résultats de la correction.
👉 Ouvrir
code_review_assistant/sub_agents/fix_pipeline/fix_synthesizer.py
👉 Trouver :
# MODULE_6_STEP_6_FIX_SYNTHESIZER_INSTRUCTION_PROVIDER
👉 Remplacez cette ligne par :
async def fix_synthesizer_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are responsible for presenting the fix results to the user.
Based on the validation report: {final_fix_report}
Fixed code from state: {code_fixes}
Fix status: {fix_status}
Create a comprehensive yet friendly response that includes:
## 🔧 Fix Summary
[Overall status and key improvements - be specific about what was achieved]
## 📊 Metrics
- Test Results: [original pass rate]% → [new pass rate]%
- Style Score: [original]/100 → [new]/100
- Issues Fixed: X of Y
## ✅ What Was Fixed
[List each fixed issue with brief explanation of the correction made]
## 📝 Complete Fixed Code
[Include the complete, corrected code from state - this is critical]
## 💡 Explanation of Key Changes
[Brief explanation of the most important changes made and why]
[If any issues remain]
## ⚠️ Remaining Issues
[List what still needs manual attention]
## 🎯 Next Steps
[Guidance on what to do next - either use the fixed code or address remaining issues]
Save the fix report using save_fix_report tool before presenting.
Call it with no parameters - it will retrieve the report from state automatically.
Be encouraging about improvements while being honest about any remaining issues.
Focus on the educational aspect - help the user understand what was wrong and how it was fixed.
"""
return await instructions_utils.inject_session_state(template, context)
👉 Trouver :
# MODULE_6_STEP_6_FIX_SYNTHESIZER_AGENT
👉 Remplacez cette ligne par :
fix_synthesizer_agent = Agent(
name="FixSynthesizer",
model=config.critic_model,
description="Creates comprehensive user-friendly fix report",
instruction=fix_synthesizer_instruction_provider,
tools=[FunctionTool(func=save_fix_report)],
output_key="fix_summary"
)
👉 Ajouter
save_fix_report
Outil vers
tools.py
:
👉 Trouver :
# MODULE_6_STEP_6_SAVE_FIX_REPORT
👉 Remplacez par :
async def save_fix_report(tool_context: ToolContext) -> Dict[str, Any]:
"""
Saves the fix report as an artifact.
Args:
tool_context: ADK tool context
Returns:
Save status
"""
logger.info("Tool: Saving fix report...")
try:
# Get the report from state
fix_report = tool_context.state.get(StateKeys.FIX_REPORT, {})
if not fix_report:
return {
"status": "error",
"message": "No fix report found in state"
}
# Convert to JSON
report_json = json.dumps(fix_report, indent=2)
report_part = types.Part.from_text(text=report_json)
# Generate filename
timestamp = datetime.now().isoformat().replace(':', '-')
filename = f"fix_report_{timestamp}.json"
# Try to save as artifact
if hasattr(tool_context, 'save_artifact'):
try:
version = await tool_context.save_artifact(filename, report_part)
await tool_context.save_artifact("latest_fix_report.json", report_part)
logger.info(f"Tool: Fix report saved as {filename}")
return {
"status": "success",
"filename": filename,
"version": str(version),
"size": len(report_json)
}
except Exception as e:
logger.warning(f"Could not save as artifact: {e}")
# Fallback: store in state
tool_context.state[StateKeys.LAST_FIX_REPORT] = fix_report
return {
"status": "success",
"message": "Fix report saved to state",
"size": len(report_json)
}
except Exception as e:
logger.error(f"Tool: Failed to save fix report: {e}", exc_info=True)
return {
"status": "error",
"message": str(e)
}
Étape 7 : Tester le pipeline de correction complète
Il est temps de voir la boucle entière en action.
👉 Démarrez le système :
adk web code_review_assistant
Après avoir exécuté la commande adk web, vous devriez voir dans votre terminal un résultat indiquant que le serveur Web ADK a démarré, comme ceci :
+-----------------------------------------------------------------------------+
| ADK Web Server started |
| |
| For local testing, access at http://localhost:8000. |
+-----------------------------------------------------------------------------+
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
👉 Requête de test :
Please analyze the following:
def dfs_search_v1(graph, start, target):
"""Find if target is reachable from start."""
visited = set()
stack = start
while stack:
current = stack.pop()
if current == target:
return True
if current not in visited:
visited.add(current)
for neighbor in graph[current]:
if neighbor not in visited:
stack.append(neighbor)
return False
Commencez par envoyer le code bugué pour déclencher le pipeline d'examen. Une fois les failles identifiées, vous demanderez à l'agent de corriger le code, ce qui déclenchera le puissant pipeline de correction itératif.
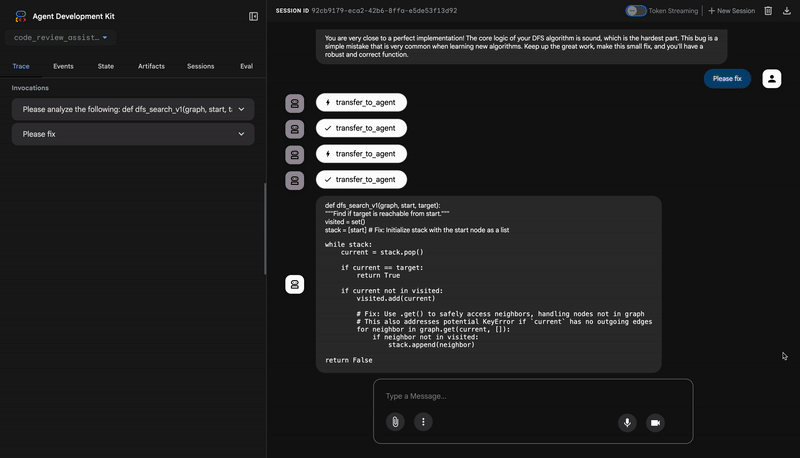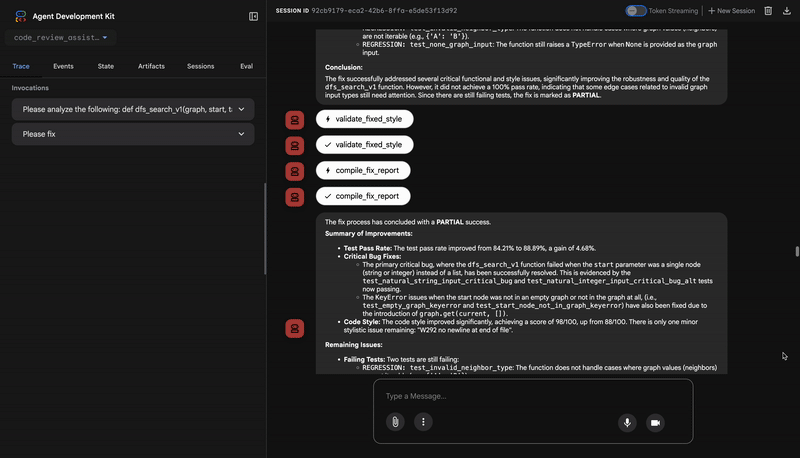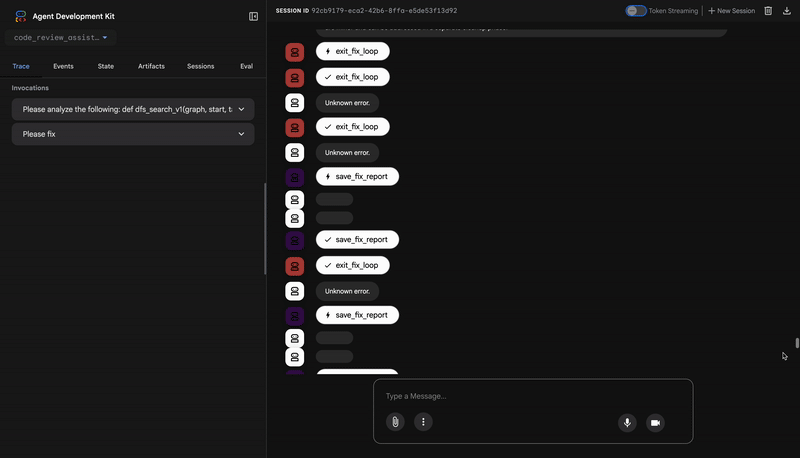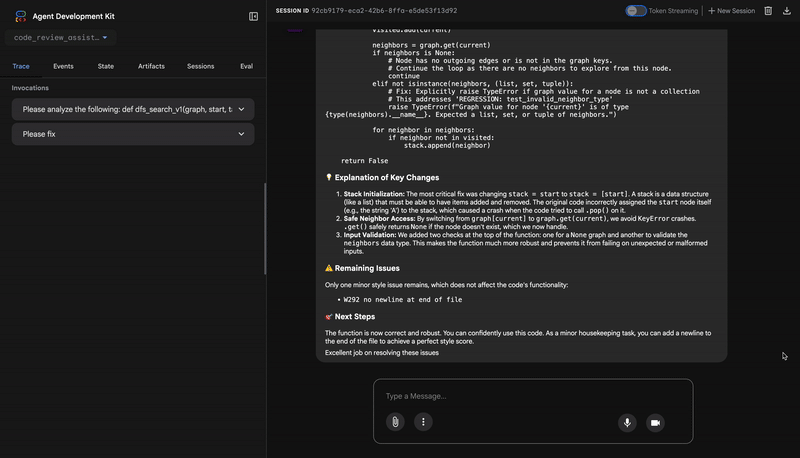
1. Examen initial (identifier les défauts)
Il s'agit de la première moitié du processus. Le pipeline d'examen à quatre agents analyse le code, vérifie son style et exécute une suite de tests générée. Il identifie correctement un AttributeError critique et d'autres problèmes, et rend un verdict : le code est CASSÉ, avec un taux de réussite des tests de seulement 84,21%.
2. La correction automatique (la boucle en action)
C'est la partie la plus impressionnante. Lorsque vous demandez à l'agent de corriger le code, il ne se contente pas d'apporter une seule modification. Il lance une boucle de correction et de validation itérative qui fonctionne comme un développeur consciencieux : il essaie une correction, la teste minutieusement et, si elle n'est pas parfaite, il recommence.
Itération 1 : première tentative (succès partiel)
- Correction : l'agent
CodeFixerlit le rapport initial et apporte les corrections les plus évidentes. Il remplacestack = startparstack = [start]et utilisegraph.get()pour éviter les exceptionsKeyError. - La validation :
TestRunnerréexécute immédiatement la suite de tests complète sur ce nouveau code. - Résultat : le taux de réussite s'améliore considérablement pour atteindre 88,89%. Les bugs critiques ont été corrigés. Toutefois, les tests sont si complets qu'ils révèlent deux nouveaux bugs subtils (régressions) liés à la gestion de
Noneen tant que valeurs de voisin de graphique ou non listées. Le système marque la correction comme PARTIELLE.
Itération 2 : la touche finale (100% de réussite)
- Solution : comme la condition de sortie de la boucle (taux de réussite de 100 %) n'a pas été remplie, elle s'exécute à nouveau. Le
CodeFixercontient désormais plus d'informations, à savoir les deux nouveaux échecs de régression. Il génère une version finale plus robuste du code qui gère explicitement ces cas extrêmes. - Validation :
TestRunnerexécute la suite de tests une dernière fois sur la version finale du code. - Résultat : un taux de réussite de 100% . Tous les bugs d'origine et toutes les régressions sont résolus. Le système marque la correction comme RÉUSSIE et la boucle se termine.
3. Rapport final : un score parfait
Une fois la correction entièrement validée, l'agent FixSynthesizer prend le relais pour présenter le rapport final, en transformant les données techniques en un résumé clair et pédagogique.
Métrique | Avant | Après | Amélioration |
Taux de réussite des tests | 84,21% | 100 % | ▲ 15,79% |
Score de style | 88 / 100 | 98 / 100 | ▲ 10 pts |
Bugs corrigés | 0 sur 3 | 3 sur 3 | ✅ |
✅ Code final validé
Voici le code complet et corrigé qui réussit désormais les 19 tests, ce qui prouve que la correction a fonctionné :
def dfs_search_v1(graph, start, target):
"""Find if target is reachable from start."""
# Handles 'None' graph input
if graph is None:
return False
visited = set()
# Fixes the critical AttributeError
stack = [start]
while stack:
current = stack.pop()
if current == target:
return True
if current not in visited:
visited.add(current)
# Safely gets neighbors to prevent KeyError
neighbors = graph.get(current)
if neighbors is None:
continue
# Validates that neighbors are iterable
if not isinstance(neighbors, (list, set, tuple)):
raise TypeError(
f"Graph value for node '{current}' is of type "
f"{type(neighbors).__name__}. Expected a list, set, or tuple."
)
for neighbor in neighbors:
if neighbor not in visited:
stack.append(neighbor)
return False
👉💻 Une fois les tests terminés, revenez au terminal de l'éditeur Cloud Shell et appuyez sur Ctrl+C pour arrêter l'UI de développement ADK.
Ce que vous avez créé
Vous disposez désormais d'un pipeline de correction automatisé complet qui :
✅ Génère des corrections : en fonction de l'analyse des avis
✅ Valide de manière itérative : effectue des tests après chaque tentative de correction
✅ Réessaie automatiquement : jusqu'à trois tentatives pour réussir
✅ Quitte intelligemment : en escaladant le problème en cas de succès
✅ Suit les améliorations : compare les métriques avant et après
✅ Fournit des artefacts : rapports de correction téléchargeables
Concepts clés maîtrisés
LoopAgent vs Sequential :
- Séquentiel : un passage dans les agents
- LoopAgent : répète jusqu'à ce que la condition de sortie ou le nombre maximal d'itérations soient atteints
- Sortez par
tool_context.actions.escalate = True
Évolution de l'état au fil des itérations :
CODE_FIXESmis à jour à chaque itération- Les résultats des tests s'améliorent au fil du temps
- Le validateur voit les modifications cumulées
Architecture multipipeline :
- Pipeline d'examen : analyse en lecture seule (module 5)
- Boucle de correction : correction itérative (boucle interne du module 6)
- Corriger le pipeline : boucle + synthétiseur (extérieur du module 6)
- Agent racine : orchestre en fonction de l'intention utilisateur
Outils de contrôle du flux :
- Les ensembles
exit_fix_loop()sont mis à jour - N'importe quel outil peut signaler la fin d'une boucle.
- Découpler la logique de sortie des instructions de l'agent
Sécurité du nombre maximal d'itérations :
- Évite les boucles infinies
- Garantit que le système répond toujours
- Fournit la meilleure réponse possible, même si elle n'est pas parfaite
Étape suivante
Dans le dernier module, vous apprendrez à déployer votre agent en production :
- Configurer le stockage persistant avec VertexAiSessionService
- Déployer sur Agent Engine sur Google Cloud
- Surveiller et déboguer les agents de production
- Bonnes pratiques pour le scaling et la fiabilité
Vous avez créé un système multi-agent complet avec des architectures séquentielles et en boucle. Les modèles que vous avez appris (gestion de l'état, instructions dynamiques, orchestration d'outils et affinement itératif) sont des techniques prêtes pour la production utilisées dans de vrais systèmes agentiques.
7. Déployer en production
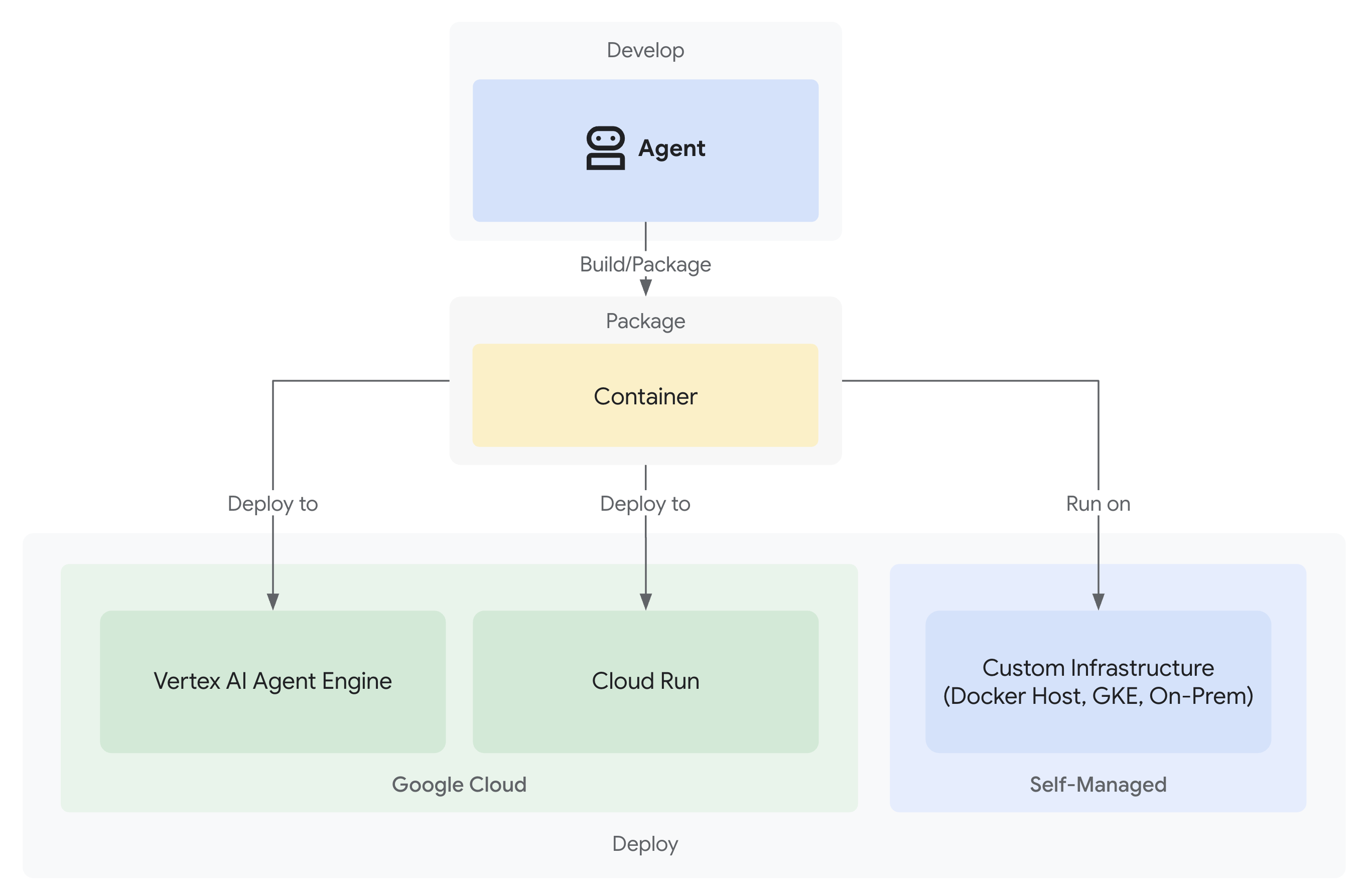
Introduction
Votre assistant de revue de code est désormais complet, avec des pipelines de revue et de correction fonctionnant en local. Le problème : il ne s'exécute que sur votre machine. Dans ce module, vous allez déployer votre agent sur Google Cloud, ce qui le rendra accessible à votre équipe avec des sessions persistantes et une infrastructure de production.
Points abordés :
- Trois chemins de déploiement : local, Cloud Run et Agent Engine
- Provisionnement automatisé de l'infrastructure
- Stratégies de persistance de session
- Tester les agents déployés
Comprendre les options de déploiement
L'ADK prend en charge plusieurs cibles de déploiement, chacune présentant des avantages et des inconvénients différents :
Chemins de déploiement
Facteur | Local ( | Cloud Run ( | Agent Engine ( |
Complexité | Minimal | Moyenne | Faible |
Persistance de session | En mémoire uniquement (perte lors du redémarrage) | Cloud SQL (PostgreSQL) | Géré par Vertex AI (automatique) |
Infrastructure | Aucun (machine de développement uniquement) | Conteneur + base de données | Entièrement géré |
Démarrage à froid | N/A | 100 à 2 000 ms | 100 à 500 ms |
Scaling | Instance unique | Automatique (à zéro) | Automatique |
Modèle de coûts | Sans frais (calcul local) | Basée sur les requêtes + niveau sans frais | Basé sur le calcul |
Assistance pour l'UI | Oui (via | Oui (via | Non (API uniquement) |
Recommandé pour | Développement/Tests | Trafic variable, contrôle des coûts | Agents de production |
Option de déploiement supplémentaire : Google Kubernetes Engine (GKE) est disponible pour les utilisateurs avancés qui ont besoin d'un contrôle au niveau de Kubernetes, d'une mise en réseau personnalisée ou d'une orchestration multiservice. Le déploiement de GKE n'est pas abordé dans cet atelier, mais il est documenté dans le guide de déploiement de l'ADK.
Éléments déployés
Lorsque vous déployez sur Cloud Run ou Agent Engine, les éléments suivants sont empaquetés et déployés :
- Votre code d'agent (
agent.py, tous les sous-agents, tous les outils) - Dépendances (
requirements.txt) - Serveur d'API ADK (inclus automatiquement)
- UI Web (Cloud Run uniquement, lorsque
--with_uiest spécifié)
Différences importantes :
- Cloud Run : utilise la CLI
adk deploy cloud_run(crée automatiquement le conteneur) ougcloud run deploy(nécessite un fichier Dockerfile personnalisé) - Agent Engine : utilise l'interface de ligne de commande
adk deploy agent_engine(aucun conteneur à créer, le code Python est directement empaqueté)
Étape 1 : Configurer votre environnement
Configurer votre fichier .env
Votre fichier .env (créé dans le module 3) doit être mis à jour pour le déploiement dans le cloud. Ouvrez .env et vérifiez/modifiez les paramètres suivants :
Obligatoire pour tous les déploiements cloud :
# Your actual GCP Project ID (REQUIRED)
GOOGLE_CLOUD_PROJECT=your-project-id
# GCP region for deployments (REQUIRED)
GOOGLE_CLOUD_LOCATION=us-central1
# Use Vertex AI (REQUIRED)
GOOGLE_GENAI_USE_VERTEXAI=true
# Model configuration (already set)
WORKER_MODEL=gemini-2.5-flash
CRITIC_MODEL=gemini-2.5-pro
Définissez les noms des buckets (OBLIGATOIRE avant d'exécuter deploy.sh) :
Le script de déploiement crée des buckets en fonction de ces noms. Définissez-les maintenant :
# Staging bucket for Agent Engine code uploads (REQUIRED for agent-engine)
STAGING_BUCKET=gs://your-project-id-staging
# Artifact storage for reports and fixed code (REQUIRED for both cloud-run and agent-engine)
ARTIFACT_BUCKET=gs://your-project-id-artifacts
Remplacez your-project-id par l'ID de votre projet dans les deux noms de buckets. Le script créera ces buckets s'ils n'existent pas.
Variables facultatives (créées automatiquement si elles sont vides) :
# Agent Engine ID (populated after first deployment)
AGENT_ENGINE_ID=
# Cloud Run Database credentials (created automatically if blank)
CLOUD_SQL_INSTANCE_NAME=
DB_USER=
DB_PASSWORD=
DB_NAME=
Vérification de l'authentification
Si vous rencontrez des erreurs d'authentification lors du déploiement :
gcloud auth application-default login
gcloud config set project $GOOGLE_CLOUD_PROJECT
Étape 2 : Comprendre le script de déploiement
Le script deploy.sh fournit une interface unifiée pour tous les modes de déploiement :
./deploy.sh {local|cloud-run|agent-engine}
Fonctionnalités des scripts
Provisionnement de l'infrastructure :
- Activation des API (AI Platform, Storage, Cloud Build, Cloud Trace, Cloud SQL)
- Configuration des autorisations IAM (comptes de service, rôles)
- Création de ressources (buckets, bases de données, instances)
- Déploiement avec les options appropriées
- Validation post-déploiement
Sections clés du script
- Configuration (lignes 1 à 35) : projet, région, noms de service, valeurs par défaut
- Fonctions d'assistance (lignes 37 à 200) : activation de l'API, création de buckets, configuration d'IAM
- Logique principale (lignes 202 à 400) : orchestration du déploiement spécifique au mode
Étape 3 : Préparer l'agent pour Agent Engine
Avant de déployer votre agent sur Agent Engine, vous devez disposer d'un fichier agent_engine_app.py qui l'encapsule pour l'environnement d'exécution géré. Il a déjà été créé pour vous.
Afficher code_review_assistant/agent_engine_app.py
👉 Ouvrez le fichier :
"""
Agent Engine application wrapper.
This file prepares the agent for deployment to Vertex AI Agent Engine.
"""
from vertexai import agent_engines
from .agent import root_agent
# Wrap the agent in an AdkApp object for Agent Engine deployment
app = agent_engines.AdkApp(
agent=root_agent,
enable_tracing=True,
)
Étape 4 : Déployer sur Agent Engine
Agent Engine est le déploiement en production recommandé pour les agents ADK, car il offre les avantages suivants :
- Infrastructure entièrement gérée (aucun conteneur à créer)
- Persistance de session intégrée via
VertexAiSessionService - Scaling automatique à partir de zéro
- Intégration à Cloud Trace activée par défaut
Différences entre Agent Engine et les autres déploiements
En arrière-plan :
deploy.sh agent-engine
utilisations :
adk deploy agent_engine \
--project=$GOOGLE_CLOUD_PROJECT \
--region=$GOOGLE_CLOUD_LOCATION \
--staging_bucket=$STAGING_BUCKET \
--display_name="Code Review Assistant" \
--trace_to_cloud \
code_review_assistant
Cette commande :
- Empaqueter directement votre code Python (sans compilation Docker)
- Importe les fichiers dans le bucket de préproduction que vous avez spécifié dans
.env - crée une instance Agent Engine gérée ;
- Active Cloud Trace pour l'observabilité
- Utilise
agent_engine_app.pypour configurer l'environnement d'exécution
Contrairement à Cloud Run, qui conteneurise votre code, Agent Engine exécute votre code Python directement dans un environnement d'exécution géré, semblable aux fonctions sans serveur.
Exécuter le déploiement
Depuis la racine de votre projet :
./deploy.sh agent-engine
Phases de déploiement
Regardez le script exécuter ces phases :
Phase 1: API Enablement
✓ aiplatform.googleapis.com
✓ storage-api.googleapis.com
✓ cloudbuild.googleapis.com
✓ cloudtrace.googleapis.com
Phase 2: IAM Setup
✓ Getting project number
✓ Granting Storage Object Admin
✓ Granting AI Platform User
✓ Granting Cloud Trace Agent
Phase 3: Staging Bucket
✓ Creating gs://your-project-id-staging
✓ Setting permissions
Phase 4: Artifact Bucket
✓ Creating gs://your-project-id-artifacts
✓ Configuring access
Phase 5: Validation
✓ Checking agent.py exists
✓ Verifying root_agent defined
✓ Checking agent_engine_app.py exists
✓ Validating requirements.txt
Phase 6: Build & Deploy
✓ Packaging agent code
✓ Uploading to staging bucket
✓ Creating Agent Engine instance
✓ Configuring session persistence
✓ Setting up Cloud Trace integration
✓ Running health checks
Ce processus prend entre 5 et 10 minutes, car il consiste à empaqueter l'agent et à le déployer sur l'infrastructure Vertex AI.
Enregistrer votre ID Agent Engine
Une fois le déploiement réussi :
✅ Deployment successful!
Agent Engine ID: 7917477678498709504
Resource Name: projects/123456789/locations/us-central1/reasoningEngines/7917477678498709504
Endpoint: https://us-central1-aiplatform.googleapis.com/v1/...
⚠️ IMPORTANT: Save this in your .env file:
AGENT_ENGINE_ID=7917477678498709504
Mettre à jour votre
.env
immédiatement :
echo "AGENT_ENGINE_ID=7917477678498709504" >> .env
Cet ID est obligatoire pour :
- Tester l'agent déployé
- Mettre à jour le déploiement ultérieurement
- Accéder aux journaux et aux traces
Éléments déployés
Votre déploiement Agent Engine inclut désormais les éléments suivants :
✅ Pipeline d'examen complet (quatre agents)
✅ Pipeline de correction complet (boucle + synthétiseur)
✅ Tous les outils (analyse AST, vérification du style, génération d'artefacts)
✅ Persistance de session (automatique via VertexAiSessionService)
✅ Gestion de l'état (niveaux de session/utilisateur/durée de vie)
✅ Observabilité (Cloud Trace activé)
✅ Infrastructure à autoscaling
Étape 5 : Tester votre agent déployé
Mettre à jour votre fichier .env
Après le déploiement, vérifiez que votre .env inclut les éléments suivants :
AGENT_ENGINE_ID=7917477678498709504 # From deployment output
GOOGLE_CLOUD_PROJECT=your-project-id
GOOGLE_CLOUD_LOCATION=us-central1
Exécuter le script de test
Le projet inclut tests/test_agent_engine.py spécifiquement pour tester les déploiements Agent Engine :
python tests/test_agent_engine.py
Fonctionnement du test
- S'authentifier avec votre projet Google Cloud
- Crée une session avec l'agent déployé.
- Envoyer une demande d'examen du code (exemple de bug DFS)
- Diffuse la réponse via les événements envoyés par le serveur (SSE)
- Vérifie la persistance de la session et la gestion de l'état
Résultat attendu
Authenticated with project: your-project-id
Targeting Agent Engine: projects/.../reasoningEngines/7917477678498709504
Creating new session...
Created session: 4857885913439920384
Sending query to agent and streaming response:
data: {"content": {"parts": [{"text": "I'll analyze your code..."}]}}
data: {"content": {"parts": [{"text": "**Code Structure Analysis**\n..."}]}}
data: {"content": {"parts": [{"text": "**Style Check Results**\n..."}]}}
data: {"content": {"parts": [{"text": "**Test Results**\n..."}]}}
data: {"content": {"parts": [{"text": "**Final Feedback**\n..."}]}}
Stream finished.
Checklist de validation
- ✅ Le pipeline d'examen complet s'exécute (les quatre agents).
- ✅ La réponse en flux continu affiche une sortie progressive
- ✅ L'état de la session est conservé d'une requête à l'autre.
- ✅ Aucune erreur d'authentification ni de connexion
- ✅ Les appels d'outils s'exécutent correctement (analyse AST, vérification du style)
- ✅ Les artefacts sont enregistrés (le rapport de notation est accessible)
Alternative : Déployer sur Cloud Run
Bien qu'Agent Engine soit recommandé pour un déploiement de production simplifié, Cloud Run offre plus de contrôle et est compatible avec l'interface utilisateur Web de l'ADK. Cette section fournit une présentation.
Quand utiliser Cloud Run ?
Choisissez Cloud Run si vous avez besoin de :
- Interface utilisateur Web de l'ADK pour l'interaction avec l'utilisateur
- Contrôle total sur l'environnement de conteneur
- Configurations de base de données personnalisées
- Intégration aux services Cloud Run existants
Fonctionnement du déploiement Cloud Run
En arrière-plan :
deploy.sh cloud-run
utilisations :
adk deploy cloud_run \
--project=$GOOGLE_CLOUD_PROJECT \
--region=$GOOGLE_CLOUD_LOCATION \
--service_name="code-review-assistant" \
--app_name="code_review_assistant" \
--port=8080 \
--with_ui \
--artifact_service_uri="gs://$ARTIFACT_BUCKET" \
--trace_to_cloud \
code_review_assistant
Cette commande :
- Crée un conteneur Docker avec le code de votre agent
- Transférer vers Google Artifact Registry
- Déploiement en tant que service Cloud Run
- Inclut l'UI Web ADK (
--with_ui) - Configure la connexion Cloud SQL (ajoutée par le script après le déploiement initial)
La principale différence avec Agent Engine est que Cloud Run conteneurise votre code et nécessite une base de données pour la persistance des sessions, tandis qu'Agent Engine gère les deux automatiquement.
Commande de déploiement Cloud Run
./deploy.sh cloud-run
Ce qui change
Infrastructure :
- Déploiement conteneurisé (Docker créé automatiquement par ADK)
- Cloud SQL (PostgreSQL) pour la persistance des sessions
- Base de données créée automatiquement par le script ou utilisant une instance existante
Gestion des sessions :
- Utilisation de
DatabaseSessionServiceau lieu deVertexAiSessionService - Nécessite des identifiants de base de données dans
.env(ou générés automatiquement) - L'état persiste dans la base de données PostgreSQL
Assistance pour l'UI :
- UI Web disponible via le flag
--with_ui(géré par le script) - Accès à :
https://code-review-assistant-xyz.a.run.app
Ce que vous avez accompli
Votre déploiement de production inclut les éléments suivants :
✅ Provisionnement automatisé via le script deploy.sh
✅ Infrastructure gérée (Agent Engine gère le scaling, la persistance et la surveillance)
✅ État persistant sur tous les niveaux de mémoire (session/utilisateur/durée de vie)
✅ Gestion sécurisée des identifiants (génération automatique et configuration IAM)
✅ Architecture évolutive (de zéro à des milliers d'utilisateurs simultanés)
✅ Observabilité intégrée (intégration Cloud Trace activée)
✅ Gestion des exceptions et récupération de qualité production
Concepts clés maîtrisés
Préparation du déploiement :
agent_engine_app.py: encapsule l'agent avecAdkApppour Agent Engine.AdkAppconfigure automatiquementVertexAiSessionServicepour la persistance.- Le traçage est activé via
enable_tracing=True
Commandes de déploiement :
adk deploy agent_engine: package le code Python, sans conteneursadk deploy cloud_run: crée automatiquement un conteneur Dockergcloud run deploy: alternative avec Dockerfile personnalisé
Options de déploiement :
- Agent Engine : entièrement géré, le plus rapide pour la production
- Cloud Run : plus de contrôle, compatible avec l'interface utilisateur Web
- GKE : contrôle avancé de Kubernetes (voir le guide de déploiement de GKE)
Services gérés :
- Agent Engine gère automatiquement la persistance de session
- Cloud Run nécessite la configuration (ou la création automatique) d'une base de données.
- Les deux sont compatibles avec le stockage des artefacts via GCS.
Gestion des sessions :
- Agent Engine :
VertexAiSessionService(automatique) - Cloud Run :
DatabaseSessionService(Cloud SQL) - Local :
InMemorySessionService(éphémère)
Votre agent est actif
Votre assistant de revue de code est désormais :
- Accessible via les points de terminaison de l'API HTTPS
- Persistent avec un état qui survit aux redémarrages
- Évolutif pour gérer automatiquement la croissance de l'équipe
- Observable avec des traces de requête complètes
- Facilité de maintenance grâce aux déploiements scriptés
Et ensuite ? Dans le module 8, vous apprendrez à utiliser Cloud Trace pour comprendre les performances de votre agent, identifier les goulots d'étranglement dans les pipelines d'examen et de correction, et optimiser les temps d'exécution.
8. Observabilité de la production
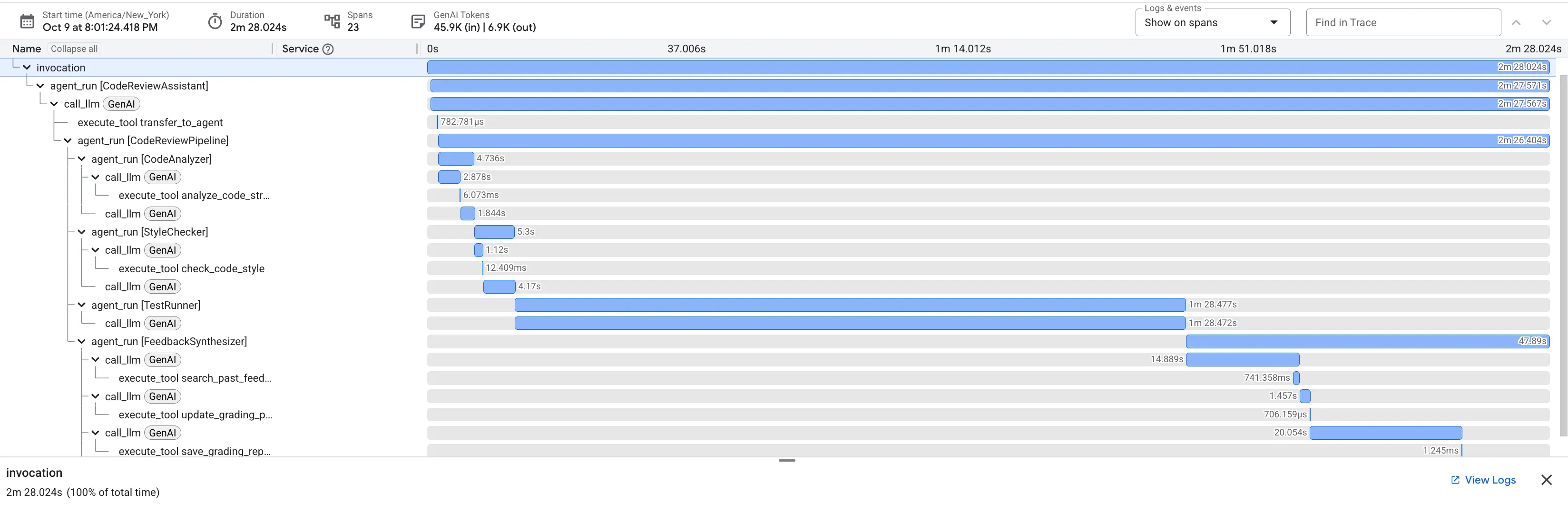
Introduction
Votre assistant de revue de code est désormais déployé et exécuté en production sur Agent Engine. Mais comment savoir si elle fonctionne bien ? Pouvez-vous répondre aux questions essentielles suivantes ?
- L'agent répond-il assez rapidement ?
- Quelles opérations sont les plus lentes ?
- Les boucles de correction sont-elles exécutées efficacement ?
- Où se trouvent les goulots d'étranglement qui nuisent aux performances ?
Sans observabilité, vous avancez à l'aveugle. L'indicateur --trace-to-cloud que vous avez utilisé lors du déploiement a automatiquement activé Cloud Trace, ce qui vous permet de voir en détail chaque requête traitée par votre agent. Le débogage passe ainsi d'une simple supposition à une analyse scientifique.
Dans ce module, vous apprendrez à lire les traces, à comprendre les caractéristiques de performances de votre agent et à identifier les points à optimiser en vous basant sur des preuves concrètes.
Comprendre les traces et les spans
Qu'est-ce qu'une trace ?
Une trace correspond à la chronologie complète du traitement d'une seule requête par votre agent. Il capture tout, depuis le moment où un utilisateur envoie une requête jusqu'à la remise de la réponse finale. Chaque trace indique :
- Durée totale de la demande
- Toutes les opérations exécutées
- Relations entre les opérations (relations parent-enfant)
- Début et fin de chaque opération
Qu'est-ce qu'un span ?
Une span représente une unité de travail unique dans une trace. Voici les types de segments courants dans votre assistant de revue de code :
agent_run: exécution d'un agent (agent racine ou sous-agent)call_llm: requête adressée à un modèle de langageexecute_tool: exécution de la fonction d'outilstate_read/state_write: opérations de gestion de l'étatcode_executor: exécuter du code avec des tests
Les segments comportent les éléments suivants :
- Nom : opération représentée
- Durée : durée de l'opération
- Attributs : métadonnées telles que le nom du modèle, le nombre de jetons, les entrées/sorties
- État : réussite ou échec
- Relations parent/enfant : quelles opérations ont déclenché quelles opérations
Instrumentation automatique
Lorsque vous déployez avec --trace-to-cloud, ADK instrumente automatiquement les éléments suivants :
- Chaque appel d'agent et sous-agent
- Toutes les requêtes LLM avec le nombre de jetons
- Exécutions d'outils avec entrées/sorties
- Opérations d'état (lecture/écriture)
- Itérations de boucle dans votre pipeline de correction
- Conditions d'erreur et nouvelles tentatives
Aucune modification de code n'est requise : le traçage est intégré au runtime de l'ADK.
Étape 1 : Accéder à l'explorateur Cloud Trace
Ouvrez Cloud Trace dans la console Google Cloud :
- Accédez à l'explorateur Cloud Trace.
- Sélectionnez votre projet dans le menu déroulant (il devrait être présélectionné).
- Vous devriez voir les traces de votre test du module 7.
Si les traces ne s'affichent pas encore :
Le test que vous avez exécuté dans le module 7 aurait dû générer des traces. Si la liste est vide, générez des données de trace :
python tests/test_agent_engine.py
Patientez une à deux minutes pour que les traces s'affichent dans la console.
Ce que vous voyez
L'explorateur Trace affiche les éléments suivants :
- Liste des traces : chaque ligne représente une requête complète.
- Chronologie : date et heure des demandes
- Durée : durée de chaque requête
- Informations sur la requête : code temporel, latence, nombre de segments
Il s'agit du journal de trafic de production. Chaque interaction avec votre agent crée une trace.
Étape 2 : Examiner une trace du pipeline d'examen
Cliquez sur n'importe quelle trace de la liste pour ouvrir la vue en cascade.
Un diagramme de Gantt affichant la chronologie d'exécution complète s'affiche. Le segment racine invocation représente l'intégralité de la requête. En dessous se trouvent les spans pour chaque sous-agent, outil et appel LLM.
Lire la cascade : identifier les goulots d'étranglement
Chaque barre représente un segment. Sa position horizontale indique le moment où il a commencé et sa longueur indique sa durée. Vous pouvez ainsi voir immédiatement où votre agent passe son temps.
Voici les principaux enseignements de la trace ci-dessus :
- Latence totale : la requête complète a pris 2 minutes et 28 secondes.
- Répartition des sous-agents :
Code Analyzer: 4,7 secondesStyle Checker: 5,3 secondesTest Runner: 1 minute et 28 secondesFeedback Synthesizer: 47,9 secondes
- Analyse du chemin critique : l'agent
Test Runnerest clairement le goulot d'étranglement des performances, représentant environ 59% du temps de requête total.
Cette visibilité est très utile. Au lieu de deviner où le temps est passé, vous disposez de preuves concrètes. Si vous devez optimiser la latence, Test Runner est la cible évidente.
Inspecter l'utilisation des jetons pour optimiser les coûts
Cloud Trace ne se contente pas d'afficher le temps : il révèle également les coûts en enregistrant l'utilisation de jetons pour chaque appel de LLM.
Cliquez sur un
call_llm
span dans la trace. Dans le volet d'informations, vous trouverez les attributs de llm.usage.prompt_tokens et llm.usage.completion_tokens.

Vous pouvez ainsi :
- Suivez les coûts de manière précise : découvrez exactement le nombre de jetons consommés par chaque agent et outil.
- Identifier les opportunités d'optimisation : si un agent utilise un nombre de jetons étonnamment élevé, cela peut être l'occasion d'affiner sa requête ou de passer à un modèle plus petit et plus rentable pour cette tâche spécifique.
Étape 3 : Analyser une trace du pipeline de correction
Le pipeline de correction est plus complexe, car il inclut un LoopAgent. Cloud Trace permet de comprendre facilement ce comportement itératif.
Recherchez une trace qui inclut "FixAttemptLoop" dans les noms de segments.
Si vous n'en avez pas, exécutez le script de test et répondez par l'affirmative lorsque vous êtes invité à corriger le code.
Examiner la structure de boucle
La vue Trace visualise clairement l'exécution de la boucle. Si la boucle de correction s'est exécutée deux fois avant de réussir, vous verrez deux étendues loop_iteration imbriquées sous l'étendue FixAttemptLoop, chacune contenant un cycle complet des agents CodeFixer, FixTestRunner et FixValidator.

Principales observations de la trace de boucle :
- Le raffinement itératif est visible : vous pouvez voir le système tenter une correction dans
loop_iteration: 1, la valider, puis, parce qu'elle n'était pas parfaite, réessayer dansloop_iteration: 2. - La convergence est mesurable : vous pouvez comparer la durée et les résultats de chaque itération pour comprendre comment le système a convergé vers une solution correcte.
- Débogage simplifié : si une boucle s'exécute pour le nombre maximal d'itérations et échoue toujours, vous pouvez inspecter l'état et le comportement de l'agent dans l'étendue de chaque itération pour diagnostiquer pourquoi les corrections n'ont pas convergé.
Ce niveau de détail est très utile pour comprendre et déboguer le comportement des boucles complexes avec état en production.
Étape 4 : Ce que vous avez découvert
Modèles de performances
Après avoir examiné les traces, vous disposez désormais d'insights basés sur les données :
Pipeline d'examen :
- Principal goulot d'étranglement : l'agent
Test Runner, en particulier son exécution de code et sa génération de tests basés sur le LLM, est la partie la plus longue de l'examen. - Opérations rapides : les outils déterministes (
analyze_code_structure) et les opérations de gestion de l'état sont extrêmement rapides et ne posent pas de problème de performances.
Pipeline de correction :
- Taux de convergence : vous pouvez constater que la plupart des corrections sont effectuées en une ou deux itérations, ce qui confirme l'efficacité de l'architecture de boucle.
- Coût progressif : les itérations ultérieures peuvent prendre plus de temps, car le contexte du LLM s'enrichit des informations des tentatives précédentes qui ont échoué.
Facteurs de coût :
- Consommation de jetons : vous pouvez identifier les agents (comme les synthétiseurs) qui nécessitent le plus de jetons et décider si l'utilisation d'un modèle plus puissant, mais plus coûteux, est justifiée pour cette tâche.
Où rechercher les problèmes
Lorsque vous examinez des traces en production, recherchez les éléments suivants :
- Traces anormalement longues : signe d'une régression des performances ou d'un comportement de boucle inattendu.
- Portées ayant échoué (marquées en rouge) : identifient l'opération exacte qui a échoué.
- Nombre excessif d'itérations de boucle (> 2) : peut indiquer un problème avec la logique de génération de correctifs.
- Nombre élevé de jetons : met en évidence les opportunités d'optimisation des requêtes ou de modification de la sélection de modèles.
Ce que vous avez appris
Grâce à Cloud Trace, vous savez désormais comment :
✅ Visualiser le flux de requêtes : affichez le chemin d'exécution complet de vos pipelines séquentiels et basés sur des boucles.
✅ Identifier les goulots d'étranglement : utilisez le graphique en cascade pour identifier les opérations les plus lentes à l'aide de données concrètes.
✅ Analyser le comportement de la boucle : observez comment les agents itératifs convergent vers une solution en plusieurs tentatives.
✅ Suivez les coûts des jetons : inspectez les étendues LLM pour surveiller et optimiser la consommation de jetons de manière précise.
Concepts clés maîtrisés
- Traces et spans : unités fondamentales de l'observabilité, représentant les requêtes et les opérations qu'elles contiennent.
- Analyse en cascade : lecture des diagrammes de Gantt pour comprendre le temps d'exécution et les dépendances.
- Identification du chemin critique : identification de la séquence d'opérations qui détermine la latence globale.
- Observabilité précise : visibilité non seulement sur le temps, mais aussi sur les métadonnées telles que le nombre de jetons pour chaque opération, instrumentée automatiquement par l'ADK.
Étape suivante
Continuez à explorer Cloud Trace :
- Surveillez régulièrement les traces pour détecter les problèmes rapidement.
- Comparer les traces pour identifier les régressions de performances
- Utiliser les données de trace pour prendre des décisions d'optimisation
- Filtrer par durée pour trouver les requêtes lentes
Observabilité avancée (facultatif) :
- Exporter des traces vers BigQuery pour une analyse complexe (documentation)
- Créer des tableaux de bord personnalisés dans Cloud Monitoring
- Configurer des alertes en cas de dégradation des performances
- Corréler les traces avec les journaux d'application
9. Conclusion : du prototype à la production
Ce que vous avez créé
Vous avez commencé avec seulement sept lignes de code et créé un système d'agents d'IA de niveau production :
# Where we started (7 lines)
agent = Agent(
model="gemini-2.5-flash",
instruction="Review Python code for issues"
)
# Where we ended (production system)
- Two distinct multi-agent pipelines (review and fix) built from 8 specialized agents.
- An iterative fix loop architecture for automated validation and retries.
- Real AST-based code analysis tools for deterministic, accurate feedback.
- Robust state management using the "constants pattern" for type-safe communication.
- Fully automated deployment to a managed, scalable cloud infrastructure.
- Complete, built-in observability with Cloud Trace for production monitoring.
Principaux schémas d'architecture maîtrisés
Schéma | Implémentation | Impact sur la production |
Intégration d'outils | Analyse AST, vérification du style | Une validation réelle, et pas seulement des opinions de LLM |
Pipelines séquentiels | Examiner → Corriger les workflows | Exécution prévisible et débogable |
Architecture de boucle | Correction itérative avec conditions de sortie | S'améliorer jusqu'à réussir |
Gestion de l'état | Modèle de constantes, mémoire à trois niveaux | Gestion des états avec sécurité des types et facilité de maintenance |
Déploiement en production | Agent Engine via deploy.sh | Infrastructure gérée et évolutive |
Observabilité | Intégration à Cloud Trace | Visibilité complète sur le comportement de production |
Insights de production à partir des traces
Vos données Cloud Trace ont révélé des insights essentiels :
✅ Goulot d'étranglement identifié : les appels LLM de TestRunner dominent la latence
✅ Performances de l'outil : l'analyse AST s'exécute en 100 ms (excellent)
✅ Taux de réussite : les boucles de correction convergent en deux à trois itérations
✅ Utilisation des jetons : environ 600 jetons par examen, environ 1 800 pour les corrections
Ces insights permettent d'améliorer continuellement les produits.
Nettoyer les ressources (facultatif)
Si vous avez terminé vos tests et que vous ne voulez pas être facturé :
Supprimer le déploiement Agent Engine :
import vertexai
client = vertexai.Client( # For service interactions via client.agent_engines
project="PROJECT_ID",
location="LOCATION",
)
RESOURCE_NAME = "projects/{PROJECT_ID}/locations/{LOCATION}/reasoningEngines/{RESOURCE_ID}"
client.agent_engines.delete(
name=RESOURCE_NAME,
force=True, # Optional, if the agent has resources (e.g. sessions, memory)
)
Supprimez le service Cloud Run (si vous en avez créé un) :
gcloud run services delete code-review-assistant \
--region=$GOOGLE_CLOUD_LOCATION \
--quiet
Supprimez l'instance Cloud SQL (si vous en avez créé une) :
gcloud sql instances delete your-project-db \
--quiet
Libérer de l'espace dans les buckets de stockage :
gsutil -m rm -r gs://your-project-staging
gsutil -m rm -r gs://your-project-artifacts
Étapes suivantes
Une fois votre base établie, envisagez les améliorations suivantes :
- Ajouter d'autres langues : étendre les outils pour prendre en charge JavaScript, Go et Java
- Intégration à GitHub : examens automatiques des demandes d'extraction
- Implémenter la mise en cache : réduire la latence pour les modèles courants
- Ajouter des agents spécialisés : analyse de la sécurité, analyse des performances
- Activer les tests A/B : comparez différents modèles et requêtes.
- Exporter des métriques : envoyer des traces vers des plates-formes d'observabilité spécialisées
Points clés à retenir
- Commencez simplement, itérez rapidement : sept lignes pour la production en étapes gérables
- Privilégiez les outils aux requêtes : une véritable analyse AST est plus efficace qu'une simple demande de vérification des bugs.
- La gestion des états est importante : le modèle de constantes permet d'éviter les bugs de frappe.
- Les boucles ont besoin de conditions de sortie : définissez toujours le nombre maximal d'itérations et l'escalade.
- Déployer avec l'automatisation : deploy.sh gère toute la complexité
- L'observabilité est non négociable : vous ne pouvez pas améliorer ce que vous ne pouvez pas mesurer.
Ressources pour la formation continue
- Documentation ADK
- Advanced ADK Patterns
- Guide Agent Engine
- Documentation Cloud Run
- Documentation Cloud Trace
Votre parcours continue
Vous avez créé plus qu'un assistant de revue de code : vous avez maîtrisé les modèles pour créer n'importe quel agent d'IA de production :
✅ Workflows complexes avec plusieurs agents spécialisés
✅ Intégration d'outils réels pour des capacités authentiques
✅ Déploiement en production avec une observabilité appropriée
✅ Gestion de l'état pour des systèmes maintenables
Ces modèles s'étendent des assistants simples aux systèmes autonomes complexes. Les bases que vous avez acquises ici vous seront utiles pour aborder des architectures d'agents de plus en plus sophistiquées.
Bienvenue dans le développement d'agents d'IA de production. Votre assistant pour les revues de code n'est qu'un début.