
1. The Late Night Code Review
השעה 2:00 לפנות בוקר
אתם מנסים לאתר באגים כבר שעות. הפונקציה נראית תקינה, אבל משהו לא בסדר. אתם מכירים את ההרגשה הזו – כשקוד אמור לעבוד אבל לא עובד, ואתם לא מצליחים להבין למה כי אתם בוהים בו כבר יותר מדי זמן.
def dfs_search_v1(graph, start, target):
"""Find if target is reachable from start."""
visited = set()
stack = start # Looks innocent enough...
while stack:
current = stack.pop()
if current == target:
return True
if current not in visited:
visited.add(current)
for neighbor in graph[current]:
if neighbor not in visited:
stack.append(neighbor)
return False
המסע של מפתחי AI
אם אתם קוראים את המאמר הזה, כנראה שחוויתם את השינוי ש-AI מביא לתכנות. כלים כמו Gemini Code Assist, Claude Code ו-Cursor שינו את האופן שבו אנחנו כותבים קוד. הם מצוינים ליצירת קוד boilerplate, להצעת הטמעות ולהאצת הפיתוח.
אבל אתם כאן כי אתם רוצים להעמיק. אתם רוצים להבין איך לבנות את מערכות ה-AI האלה, ולא רק להשתמש בהן. אתם רוצים ליצור משהו ש:
- התנהגות צפויה וניתנת למעקב
- אפשר לפרוס אותו בסביבת הייצור בראש שקט
- הוא מספק תוצאות עקביות שאפשר לסמוך עליהן
- הוא מראה לכם בדיוק איך הוא מקבל החלטות
מצרכן ליוצר
היום תעברו משימוש בכלי AI לבנייה שלהם. תבנו מערכת מרובת סוכנים שתעשה את הפעולות הבאות:
- מנתח את מבנה הקוד באופן דטרמיניסטי
- מריץ בדיקות בפועל כדי לאמת את ההתנהגות
- מאמת את התאימות לסגנון באמצעות כלי בדיקה אמיתיים
- מגבש ממצאים למשוב מעשי
- פריסה ב-Google Cloud עם ניראות מלאה
2. הפריסה הראשונה של הסוכן
השאלה של המפתח
"אני מבין מהם מודלים גדולים של שפה (LLM), השתמשתי בממשקי ה-API, אבל איך עוברים מסקריפט Python לסוכן AI בסביבת ייצור שאפשר להרחיב?"
כדי לענות על השאלה הזו, נגדיר את הסביבה שלכם בצורה נכונה, ואז ניצור סוכן פשוט כדי להבין את היסודות לפני שנעבור לדפוסי ייצור.
קודם מבצעים את ההגדרה הבסיסית
לפני שיוצרים סוכנים, צריך לוודא שהסביבה שלכם ב-Google Cloud מוכנה.
לוחצים על Activate Cloud Shell (הפעלת Cloud Shell) בחלק העליון של מסוף Google Cloud (זהו סמל בצורת מסוף בחלק העליון של חלונית Cloud Shell).
כדי למצוא את מזהה הפרויקט ב-Google Cloud:
- פותחים את מסוף Google Cloud: https://console.cloud.google.com
- בוחרים את הפרויקט שבו רוצים להשתמש בסדנה הזו מהתפריט הנפתח של הפרויקט בחלק העליון של הדף.
- מזהה הפרויקט מוצג בכרטיסיית מידע של הפרויקט בלוח הבקרה
שלב 1: הגדרת מזהה הפרויקט
ב-Cloud Shell, כלי שורת הפקודה gcloud כבר מוגדר. מריצים את הפקודה הבאה כדי להגדיר את הפרויקט הפעיל. בשלב הזה משתמשים במשתנה הסביבה $GOOGLE_CLOUD_PROJECT, שמוגדר אוטומטית בסשן שלכם ב-Cloud Shell.
gcloud config set project $GOOGLE_CLOUD_PROJECT
שלב 2: בדיקת ההגדרה
לאחר מכן, מריצים את הפקודות הבאות כדי לוודא שהפרויקט מוגדר בצורה נכונה ושהאימות בוצע.
# Confirm project is set
echo "Current project: $(gcloud config get-value project)"
# Check authentication status
gcloud auth list
מזהה הפרויקט שלכם אמור להופיע, וחשבון המשתמש שלכם יופיע עם (ACTIVE) לידו.
אם החשבון שלכם לא מופיע כפעיל, או אם מופיעה שגיאת אימות, מריצים את הפקודה הבאה כדי להיכנס:
gcloud auth application-default login
שלב 3: הפעלת ממשקי API חיוניים
אנחנו צריכים לפחות את ממשקי ה-API האלה לסוכן הבסיסי:
gcloud services enable \
aiplatform.googleapis.com \
compute.googleapis.com
העדכון יימשך דקה או שתיים. הפרטים שמוצגים הם:
Operation "operations/..." finished successfully.
שלב 4: התקנת ADK
# Install the ADK CLI
pip install google-adk --upgrade
# Verify installation
adk --version
אמור להופיע מספר גרסה כמו 1.15.0 ומעלה.
עכשיו יוצרים את הסוכן הבסיסי
אחרי שהסביבה מוכנה, אפשר ליצור את הסוכן הפשוט.
שלב 5: שימוש ב-ADK Create
adk create my_first_agent
פועלים לפי ההנחיות האינטראקטיביות:
Choose a model for the root agent:
1. gemini-2.5-flash
2. Other models (fill later)
Choose model (1, 2): 1
1. Google AI
2. Vertex AI
Choose a backend (1, 2): 2
Enter Google Cloud project ID [auto-detected-from-gcloud]:
Enter Google Cloud region [us-central1]:
שלב 6: בדיקה של מה שנוצר
cd my_first_agent
ls -la
יוצגו שלושה קבצים:
.env # Configuration (auto-populated with your project)
__init__.py # Package marker
agent.py # Your agent definition
שלב 7: בדיקה מהירה של ההגדרות
# Verify the .env was created correctly
cat .env
# Should show something like:
# GOOGLE_CLOUD_PROJECT=your-project-id
# GOOGLE_CLOUD_LOCATION=us-central1
# GOOGLE_GENAI_USE_VERTEXAI=1
אם מזהה הפרויקט חסר או שגוי, צריך לערוך את הקובץ .env:
nano .env # or use your preferred editor
שלב 8: בודקים את קוד הסוכן
cat agent.py
from google.adk.agents.llm_agent import Agent
root_agent = Agent(
model='gemini-2.5-flash',
name='root_agent',
description='A helpful assistant for user questions.',
instruction='Answer user questions to the best of your knowledge',
)
פשוט, נקי, מינימליסטי. זהו סוכן ה-Hello World שלכם.
בדיקת הסוכן הבסיסי
שלב 9: הפעלת הסוכן
cd ..
adk run my_first_agent
אמורה להופיע הודעה שדומה להודעה הבאה:
Log setup complete: /tmp/agents_log/agent.20250930_162430.log
To access latest log: tail -F /tmp/agents_log/agent.latest.log
[user]:
שלב 10: מנסים כמה שאילתות
במסוף שבו פועל adk run, תופיע הנחיה. מקלידים את השאילתות:
[user]: Hey, what can you do?
[root_agent]: I can help answer questions, generate text, explain concepts, assist with problem-solving, and provide information on a wide range of topics. What would you like to know or discuss?
[user]: What's the current weather in Mountain View?
[root_agent]: I'm sorry, but I cannot provide real-time weather information as I don't have access to current data or weather services. To get the current weather in Mountain View, I recommend checking a weather website or app like weather.com or using a search engine.
שימו לב למגבלה – אין לו גישה לנתונים עדכניים. בואו נמשיך:
[user]: Review this Python code: def add(a, b): return a + b
[root_agent]: This is a simple Python function that adds two numbers. Here's my review:
**Strengths:**
- Clean and concise implementation
- Follows Python conventions for simple operations
- Clear function name that describes its purpose
**Suggestions for improvement:**
- Add a docstring to document the function
- Consider adding type hints for better code clarity
- You might want to handle edge cases
Here's an enhanced version:
def add(a: float, b: float) -> float:
"""Add two numbers and return their sum."""
return a + b
הסוכן יכול לדון בקוד, אבל האם הוא יכול:
- לנתח את ה-AST כדי להבין את המבנה?
- להריץ בדיקות כדי לוודא שהיא פועלת?
- האם לבדוק את התאימות לסגנון?
- זוכר את הביקורות הקודמות שלך?
לא. כאן אנחנו צריכים ארכיטקטורה.
🏃🚪 יציאה עם
Ctrl+C
כשמסיימים את החיפוש.
3. הכנת סביבת הייצור שלכם ב-Workspace
הפתרון: ארכיטקטורה שמוכנה לייצור
הסוכן הפשוט הזה הדגים את נקודת ההתחלה, אבל מערכת ייצור דורשת מבנה חזק. עכשיו נגדיר פרויקט מלא שמגלם עקרונות של ייצור.
הגדרת הבסיס
כבר הגדרתם את פרויקט בענן של Google Cloud שלכם לסוכן הבסיסי. עכשיו נכין את סביבת העבודה המלאה לייצור עם כל הכלים, התבניות והתשתית שנדרשים למערכת אמיתית.
שלב 1: מקבלים את הפרויקט המובנה
קודם צריך לצאת מכל אפליקציה שפועלת adk run באמצעות Ctrl+C ולנקות:
# Clean up the basic agent
cd ~ # Make sure you're not inside my_first_agent
rm -rf my_first_agent
# Get the production scaffold
git clone https://github.com/ayoisio/adk-code-review-assistant.git
cd adk-code-review-assistant
git checkout codelab
שלב 2: יצירה והפעלה של סביבה וירטואלית
# Create the virtual environment
python -m venv .venv
# Activate it
# On macOS/Linux:
source .venv/bin/activate
# On Windows:
# .venv\Scripts\activate
אימות: ההנחיה שלכם צריכה להתחיל עכשיו ב-(.venv).
שלב 3: התקנת יחסי תלות
pip install -r code_review_assistant/requirements.txt
# Install the package in editable mode (enables imports)
pip install -e .
הפעולה הזו מתקינה:
-
google-adk– מסגרת ADK -
pycodestyle– לבדיקה של PEP 8 -
vertexai– לפריסה בענן - יחסי תלות אחרים של הפקה
הדגל -e מאפשר לייבא מודולים של code_review_assistant מכל מקום.
שלב 4: הגדרת הסביבה
# Copy the example environment file
cp .env.example .env
# Edit .env and replace the placeholders:
# - GOOGLE_CLOUD_PROJECT=your-project-id → your actual project ID
# - Keep other defaults as-is
אימות: בדיקת ההגדרה:
cat .env
צריך להופיע:
GOOGLE_CLOUD_PROJECT=your-actual-project-id
GOOGLE_CLOUD_LOCATION=us-central1
GOOGLE_GENAI_USE_VERTEXAI=TRUE
שלב 5: מוודאים שהאימות מתבצע
מכיוון שכבר הפעלת את gcloud auth קודם, נבדוק רק את הדברים הבאים:
# Check current authentication
gcloud auth list
# Should show your account with (ACTIVE)
# If not, run:
gcloud auth application-default login
שלב 6: הפעלת ממשקי API נוספים של סביבת הייצור
כבר הפעלנו ממשקי API בסיסיים. עכשיו מוסיפים את אלה של סביבת הייצור:
gcloud services enable \
sqladmin.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
storage.googleapis.com \
cloudtrace.googleapis.com
השינוי מאפשר:
- SQL Admin: ל-Cloud SQL אם משתמשים ב-Cloud Run
- Cloud Run: לפריסה ללא שרת
- Cloud Build: לפריסות אוטומטיות
- Artifact Registry: לתמונות של קונטיינרים
- Cloud Storage: לארטיפקטים ולסביבת ביניים
- Cloud Trace: לצורך יכולת תצפית
שלב 7: יוצרים Artifact Registry Repository
הפריסה שלנו תיצור קובצי אימג' של קונטיינרים שצריכים בית:
gcloud artifacts repositories create code-review-assistant-repo \
--repository-format=docker \
--location=us-central1 \
--description="Docker repository for Code Review Assistant"
הפרטים שמוצגים הם:
Created repository [code-review-assistant-repo].
אם הוא כבר קיים (אולי מניסיון קודם), זה בסדר – תוצג הודעת שגיאה שאפשר להתעלם ממנה.
שלב 8: מעניקים הרשאות IAM
# Get your project number
PROJECT_NUMBER=$(gcloud projects describe $GOOGLE_CLOUD_PROJECT \
--format="value(projectNumber)")
# Define the service account
SERVICE_ACCOUNT="${PROJECT_NUMBER}@cloudbuild.gserviceaccount.com"
# Grant necessary roles
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SERVICE_ACCOUNT}" \
--role="roles/run.admin"
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SERVICE_ACCOUNT}" \
--role="roles/iam.serviceAccountUser"
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SERVICE_ACCOUNT}" \
--role="roles/cloudsql.admin"
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SERVICE_ACCOUNT}" \
--role="roles/storage.admin"
הפלט של כל פקודה יהיה:
Updated IAM policy for project [your-project-id].
מה השגתם
סביבת הייצור שלכם מוכנה עכשיו באופן מלא:
✅ פרויקט בענן של Google מוגדר ומאומת
✅ סוכן בסיסי נבדק כדי להבין את המגבלות
✅ קוד הפרויקט עם פלייסהולדרים אסטרטגיים מוכן
✅ יחסי התלות מבודדים בסביבה וירטואלית
✅ כל ממשקי ה-API הנדרשים מופעלים
✅ מאגר התמונות של הקונטיינרים מוכן לפריסות
✅ הרשאות ה-IAM מוגדרות בצורה נכונה
✅ משתני הסביבה מוגדרים בצורה נכונה
עכשיו אתם מוכנים לבנות מערכת AI אמיתית עם כלים דטרמיניסטיים, ניהול מצב וארכיטקטורה מתאימה.
4. יצירת הסוכן הראשון
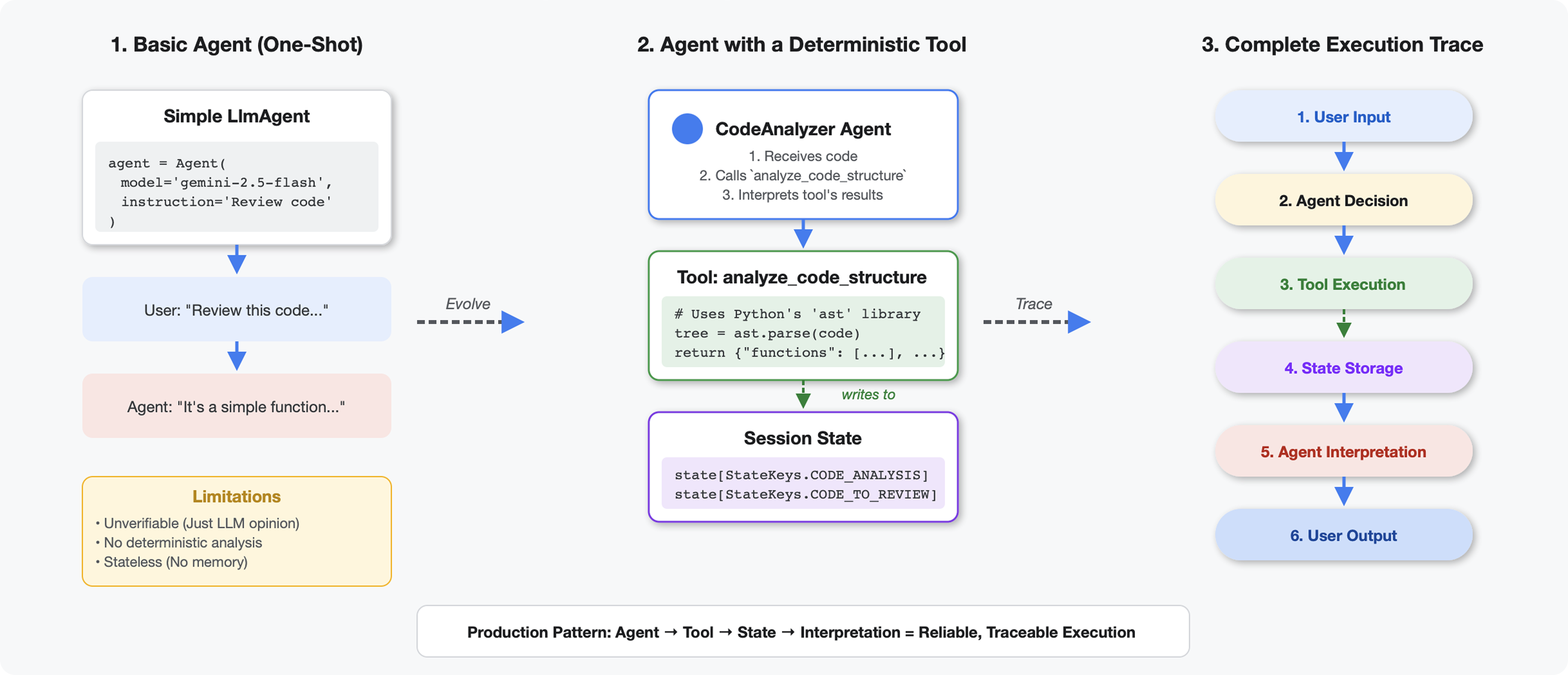
מה ההבדל בין כלים לבין LLM
כששואלים מודל שפה גדול (LLM) 'כמה פונקציות יש בקוד הזה?', הוא משתמש בהתאמת תבניות ובאומדן. כשמשתמשים בכלי שמפעיל את ast.parse() של Python, הכלי מנתח את עץ התחביר בפועל – אין ניחושים, והתוצאה תמיד זהה.
בקטע הזה נבנה כלי שמנתח את מבנה הקוד באופן דטרמיניסטי, ואז מקשר אותו לסוכן שיודע מתי להפעיל אותו.
שלב 1: הסבר על ה-Scaffold
בואו נבדוק את המבנה שתצטרכו למלא.
👈 פתיחה
code_review_assistant/tools.py
תופיע הפונקציה analyze_code_structure עם הערות placeholder שמציינות איפה צריך להוסיף קוד. לפונקציה כבר יש את המבנה הבסיסי – תשפרו אותה שלב אחרי שלב.
שלב 2: מוסיפים אחסון של מצב
אחסון המצב מאפשר לסוכנים אחרים בצינור הנתונים לגשת לתוצאות של הכלי בלי להריץ מחדש את הניתוח.
👉 Find:
# MODULE_4_STEP_2_ADD_STATE_STORAGE
👈 מחליפים את השורה היחידה הזו ב:
# Store code and analysis for other agents to access
tool_context.state[StateKeys.CODE_TO_REVIEW] = code
tool_context.state[StateKeys.CODE_ANALYSIS] = analysis
tool_context.state[StateKeys.CODE_LINE_COUNT] = len(code.splitlines())
שלב 3: הוספת ניתוח אסינכרוני באמצעות מאגרי שרשורים
הכלי שלנו צריך לנתח את ה-AST בלי לחסום פעולות אחרות. בואו נוסיף ביצוע אסינכרוני עם מאגרי שרשורים.
👉 Find:
# MODULE_4_STEP_3_ADD_ASYNC
👈 מחליפים את השורה היחידה הזו ב:
# Parse in thread pool to avoid blocking the event loop
loop = asyncio.get_event_loop()
with ThreadPoolExecutor() as executor:
tree = await loop.run_in_executor(executor, ast.parse, code)
שלב 4: חילוץ מידע מקיף
עכשיו נחלץ מחלקות, ייבוא ומדדים מפורטים – כל מה שצריך לביקורת קוד מלאה.
👉 Find:
# MODULE_4_STEP_4_EXTRACT_DETAILS
👈 מחליפים את השורה היחידה הזו ב:
# Extract comprehensive structural information
analysis = await loop.run_in_executor(
executor, _extract_code_structure, tree, code
)
👉 אימות: הפונקציה
analyze_code_structure
ב
tools.py
יש לו גוף מרכזי שנראה כך:
# Parse in thread pool to avoid blocking the event loop
loop = asyncio.get_event_loop()
with ThreadPoolExecutor() as executor:
tree = await loop.run_in_executor(executor, ast.parse, code)
# Extract comprehensive structural information
analysis = await loop.run_in_executor(
executor, _extract_code_structure, tree, code
)
# Store code and analysis for other agents to access
tool_context.state[StateKeys.CODE_TO_REVIEW] = code
tool_context.state[StateKeys.CODE_ANALYSIS] = analysis
tool_context.state[StateKeys.CODE_LINE_COUNT] = len(code.splitlines())
👈 עכשיו גוללים לתחתית הדף
tools.py
ולמצוא:
# MODULE_4_STEP_4_HELPER_FUNCTION
👉 מחליפים את השורה היחידה הזו בפונקציית העזר המלאה:
def _extract_code_structure(tree: ast.AST, code: str) -> Dict[str, Any]:
"""
Helper function to extract structural information from AST.
Runs in thread pool for CPU-bound work.
"""
functions = []
classes = []
imports = []
docstrings = []
for node in ast.walk(tree):
if isinstance(node, ast.FunctionDef):
func_info = {
'name': node.name,
'args': [arg.arg for arg in node.args.args],
'lineno': node.lineno,
'has_docstring': ast.get_docstring(node) is not None,
'is_async': isinstance(node, ast.AsyncFunctionDef),
'decorators': [d.id for d in node.decorator_list
if isinstance(d, ast.Name)]
}
functions.append(func_info)
if func_info['has_docstring']:
docstrings.append(f"{node.name}: {ast.get_docstring(node)[:50]}...")
elif isinstance(node, ast.ClassDef):
methods = []
for item in node.body:
if isinstance(item, ast.FunctionDef):
methods.append(item.name)
class_info = {
'name': node.name,
'lineno': node.lineno,
'methods': methods,
'has_docstring': ast.get_docstring(node) is not None,
'base_classes': [base.id for base in node.bases
if isinstance(base, ast.Name)]
}
classes.append(class_info)
elif isinstance(node, ast.Import):
for alias in node.names:
imports.append({
'module': alias.name,
'alias': alias.asname,
'type': 'import'
})
elif isinstance(node, ast.ImportFrom):
imports.append({
'module': node.module or '',
'names': [alias.name for alias in node.names],
'type': 'from_import',
'level': node.level
})
return {
'functions': functions,
'classes': classes,
'imports': imports,
'docstrings': docstrings,
'metrics': {
'line_count': len(code.splitlines()),
'function_count': len(functions),
'class_count': len(classes),
'import_count': len(imports),
'has_main': any(f['name'] == 'main' for f in functions),
'has_if_main': '__main__' in code,
'avg_function_length': _calculate_avg_function_length(tree)
}
}
def _calculate_avg_function_length(tree: ast.AST) -> float:
"""Calculate average function length in lines."""
function_lengths = []
for node in ast.walk(tree):
if isinstance(node, ast.FunctionDef):
if hasattr(node, 'end_lineno') and hasattr(node, 'lineno'):
length = node.end_lineno - node.lineno + 1
function_lengths.append(length)
if function_lengths:
return sum(function_lengths) / len(function_lengths)
return 0.0
שלב 5: התחברות לנציג
עכשיו נחבר את הכלי לסוכן שיודע מתי להשתמש בו ואיך לפרש את התוצאות שלו.
👈 פתיחה
code_review_assistant/sub_agents/review_pipeline/code_analyzer.py
👉 Find:
# MODULE_4_STEP_5_CREATE_AGENT
👈 מחליפים את השורה היחידה הזו בסוכן הייצור המלא:
code_analyzer_agent = Agent(
name="CodeAnalyzer",
model=config.worker_model,
description="Analyzes Python code structure and identifies components",
instruction="""You are a code analysis specialist responsible for understanding code structure.
Your task:
1. Take the code submitted by the user (it will be provided in the user message)
2. Use the analyze_code_structure tool to parse and analyze it
3. Pass the EXACT code to your tool - do not modify, fix, or "improve" it
4. Identify all functions, classes, imports, and structural patterns
5. Note any syntax errors or structural issues
6. Store the analysis in state for other agents to use
CRITICAL:
- Pass the code EXACTLY as provided to the analyze_code_structure tool
- Do not fix syntax errors, even if obvious
- Do not add missing imports or fix indentation
- The goal is to analyze what IS there, not what SHOULD be there
When calling the tool, pass the code as a string to the 'code' parameter.
If the analysis fails due to syntax errors, clearly report the error location and type.
Provide a clear summary including:
- Number of functions and classes found
- Key structural observations
- Any syntax errors or issues detected
- Overall code organization assessment""",
tools=[FunctionTool(func=analyze_code_structure)],
output_key="structure_analysis_summary"
)
בדיקת כלי ניתוח הקוד
עכשיו צריך לוודא שהכלי לניתוח פועל בצורה תקינה.
👈 מריצים את סקריפט הבדיקה:
python tests/test_code_analyzer.py
סקריפט הבדיקה טוען אוטומטית את ההגדרה מקובץ .env באמצעות python-dotenv, כך שלא צריך להגדיר משתני סביבה באופן ידני.
הפלט הצפוי:
INFO:code_review_assistant.config:Code Review Assistant Configuration Loaded:
INFO:code_review_assistant.config: - GCP Project: your-project-id
INFO:code_review_assistant.config: - Artifact Bucket: gs://your-project-artifacts
INFO:code_review_assistant.config: - Models: worker=gemini-2.5-flash, critic=gemini-2.5-pro
Testing code analyzer...
INFO:code_review_assistant.tools:Tool: Analysis complete - 2 functions, 1 classes
=== Analyzer Response ===
The analysis of the provided code shows the following:
* **Functions Found:** 2
* `add(a, b)`: A global function at line 2.
* `multiply(self, x, y)`: A method within the `Calculator` class.
* **Classes Found:** 1
* `Calculator`: A class defined at line 5. Contains one method, `multiply`.
* **Imports:** 0
* **Structural Patterns:** The code defines one global function and one class
with a single method. Both are simple, each with a single return statement.
* **Syntax Errors/Issues:** No syntax errors detected.
* **Overall Code Organization:** The code is well-organized for its small size,
clearly defining a function and a class with a method.
מה קרה עכשיו:
- סקריפט הבדיקה טען את ההגדרה
.envבאופן אוטומטי - כלי
analyze_code_structure()ניתח את הקוד באמצעות AST של Python - פונקציות העזר
_extract_code_structure()חילצו פונקציות, מחלקות ומדדים - התוצאות אוחסנו במצב הסשן באמצעות קבועי
StateKeys - הסוכן Code Analyzer פירש את התוצאות וסיפק סיכום
פתרון בעיות:
- 'No module named 'code_review_assistant'': מריצים את
pip install -e .מספריית השורש של הפרויקט - "חסר ארגומנט של קלט מפתח": מוודאים של-
.envישGOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_LOCATIONו-GOOGLE_GENAI_USE_VERTEXAI=true
מה יצרתם
עכשיו יש לכם כלי לניתוח קוד שמוכן לייצור, ש:
✅ מנתח Python AST בפועל – דטרמיניסטי, לא התאמת תבניות
✅ מאחסן את התוצאות במצב – סוכנים אחרים יכולים לגשת לניתוח
✅ פועל באופן אסינכרוני – לא חוסם כלים אחרים
✅ מחולל מידע מקיף – פונקציות, מחלקות, ייבוא, מדדים
✅ מטפל בשגיאות בצורה חלקה – מדווח על שגיאות תחביר עם מספרי שורות
✅ מתחבר לסוכן – מודל ה-LLM יודע מתי ואיך להשתמש בו
מושגים מרכזיים שנלמדו
כלים לעומת סוכנים:
- הכלים מבצעים עבודה דטרמיניסטית (ניתוח AST)
- סוכנים מחליטים מתי להשתמש בכלים ומפרשים את התוצאות
ערך ההחזרה לעומת מצב:
- החזרה: מה ש-LLM רואה באופן מיידי
- מצב: מה נשמר עבור סוכנים אחרים
קבועים של מקשי מצב:
- איך מונעים שגיאות הקלדה במערכות עם כמה סוכנים
- הסכמים בין סוכנים
- חשוב כשסוכנים משתפים נתונים
Async + Thread Pools:
async defמאפשרת לכלים להשהות את הביצוע- מאגרי Thread מריצים ברקע עבודות שקשורות ל-CPU
- ביחד הם שומרים על היענות של לולאת האירועים
פונקציות עזר:
- הפרדה בין כלי עזר לסנכרון לבין כלים אסינכרוניים
- הופך את הקוד לניתן לבדיקה ולשימוש חוזר
הוראות להתאמה אישית של הסוכן:
- הוראות מפורטות עוזרות למנוע שגיאות נפוצות של LLM
- הסבר ברור לגבי מה שאסור לעשות (לא לתקן את הקוד)
- ניקוי השלבים בתהליך העבודה כדי לשמור על עקביות
המאמרים הבאים
במודול 5, תוסיפו:
- בודק הסגנון שקורא את הקוד מהמצב
- כלי להרצת בדיקות שמבצע את הבדיקות בפועל
- כלי לסינתזת משוב שמשלב את כל הניתוחים
תראו איך הנתונים עוברים דרך צינורות עוקבים, ולמה דפוס הקבועים חשוב כשכמה סוכנים קוראים וכותבים את אותם נתונים.
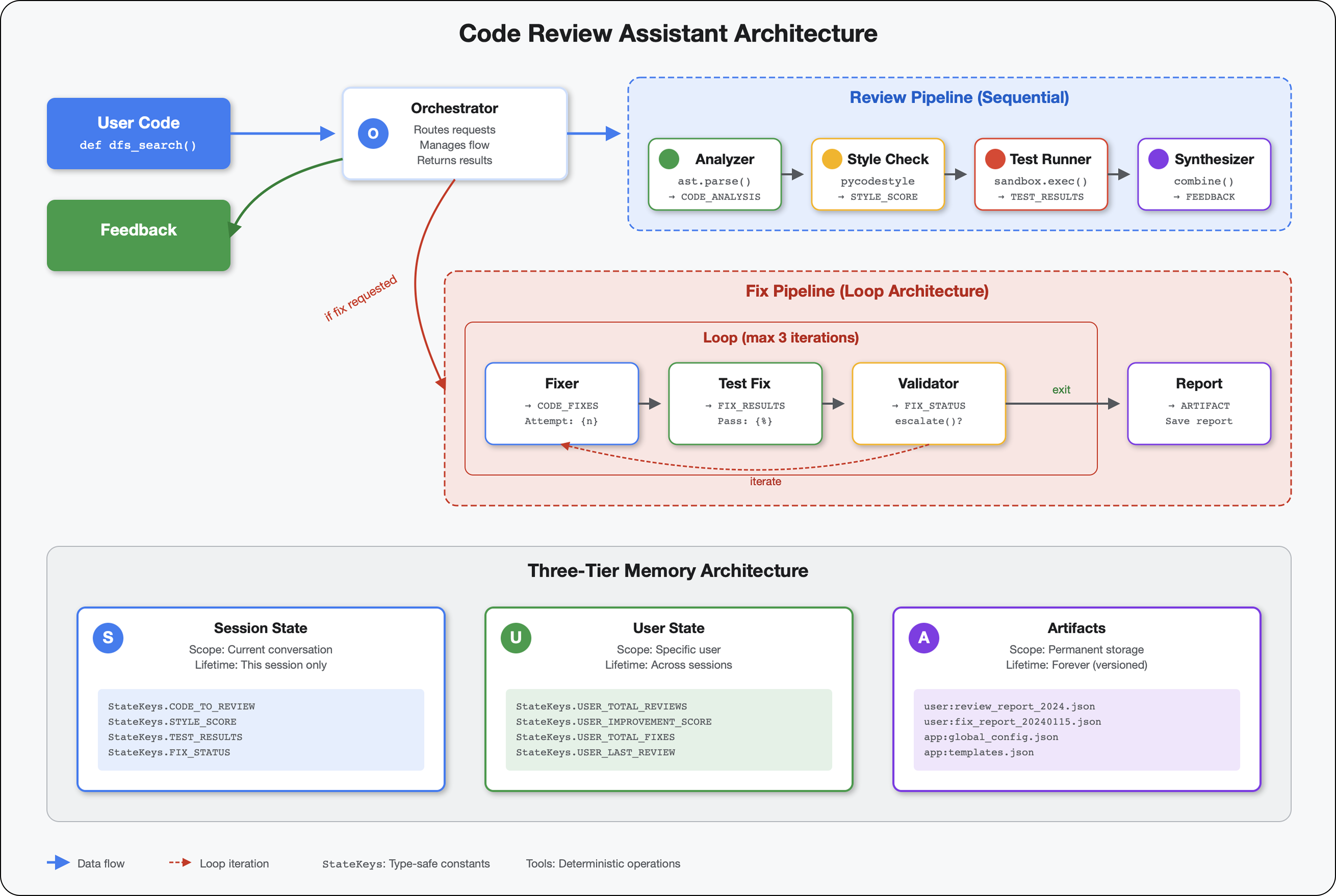
5. פיתוח צינור עיבוד נתונים: כמה סוכנים שעובדים יחד
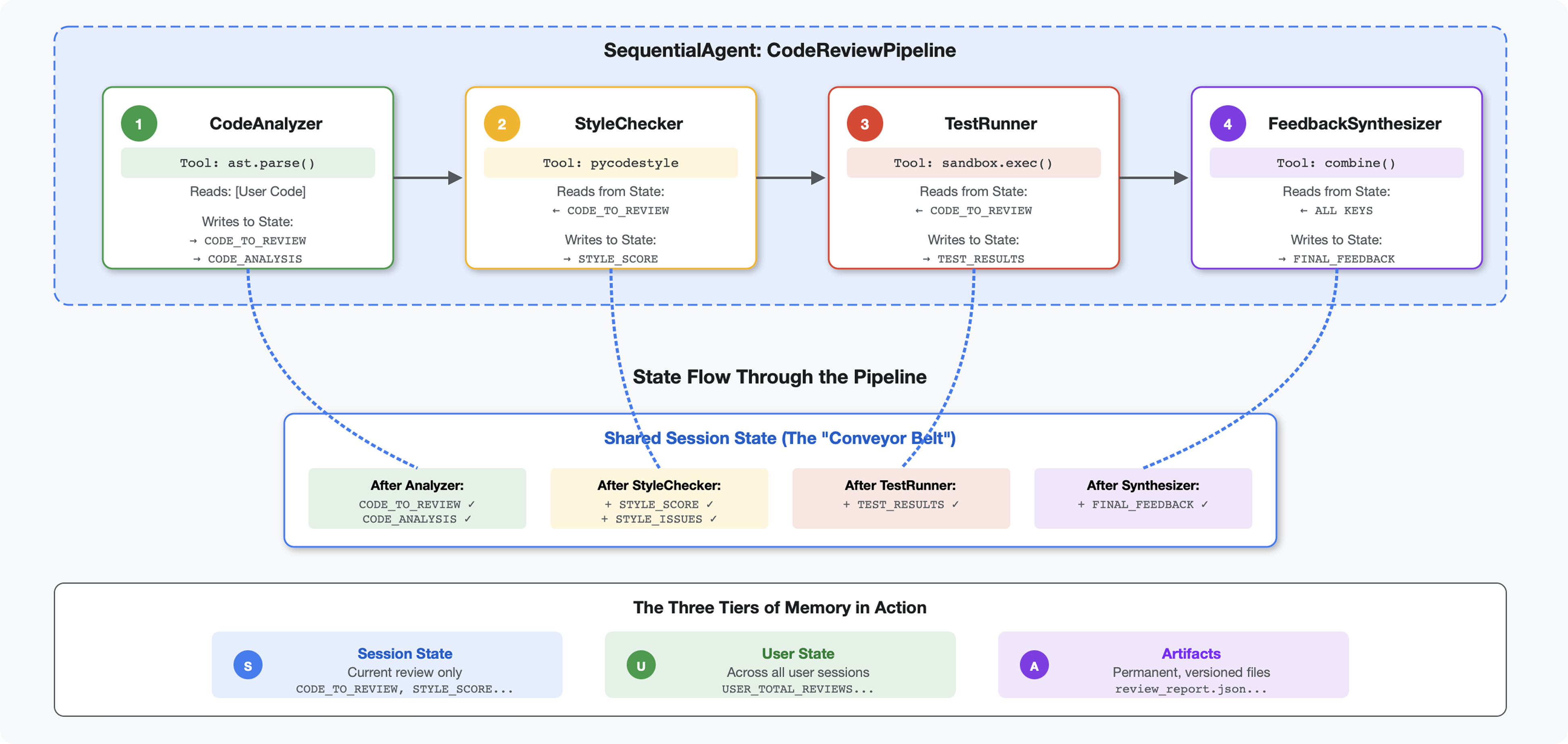
מבוא
במודול 4, יצרתם סוכן יחיד שמנתח את מבנה הקוד. אבל כדי לבצע בדיקת קוד מקיפה, צריך יותר מניתוח – צריך לבדוק את הסגנון, להריץ בדיקות ולסנתז משוב חכם.
במודול הזה נבנה צינור של 4 סוכנים שפועלים יחד באופן עקבי, וכל אחד מהם תורם ניתוח מיוחד:
- כלי לניתוח קוד (ממודול 4) – ניתוח מבנה
- כלי לבדיקת סגנון – מזהה הפרות של סגנון
- Test Runner – מריץ ומאמת בדיקות
- Feedback Synthesizer – משלב את כל הנתונים למשוב מעשי
מושג מרכזי: מצב כערוץ תקשורת. כל סוכן קורא את מה שסוכנים קודמים כתבו על המצב, מוסיף ניתוח משלו ומעביר את המצב המועשר לסוכן הבא. הדפוס של הקבועים ממודול 4 הופך לקריטי כשכמה סוכנים משתפים נתונים.
תצוגה מקדימה של מה שתבנו: שולחים קוד מבולגן → צופים בזרימת המצב דרך 4 סוכנים → מקבלים דוח מקיף עם משוב מותאם אישית על סמך דפוסים קודמים.
שלב 1: מוסיפים את הכלי לבדיקת סגנון ואת הסוכן
בודק הסגנון מזהה הפרות של PEP 8 באמצעות pycodestyle – כלי לינטר דטרמיניסטי, לא פרשנות מבוססת-LLM.
הוספת הכלי לבדיקת סגנון
👈 פתיחה
code_review_assistant/tools.py
👉 Find:
# MODULE_5_STEP_1_STYLE_CHECKER_TOOL
👈 מחליפים את השורה היחידה הזו ב:
async def check_code_style(code: str, tool_context: ToolContext) -> Dict[str, Any]:
"""
Checks code style compliance using pycodestyle (PEP 8).
Args:
code: Python source code to check (or will retrieve from state)
tool_context: ADK tool context
Returns:
Dictionary containing style score and issues
"""
logger.info("Tool: Checking code style...")
try:
# Retrieve code from state if not provided
if not code:
code = tool_context.state.get(StateKeys.CODE_TO_REVIEW, '')
if not code:
return {
"status": "error",
"message": "No code provided or found in state"
}
# Run style check in thread pool
loop = asyncio.get_event_loop()
with ThreadPoolExecutor() as executor:
result = await loop.run_in_executor(
executor, _perform_style_check, code
)
# Store results in state
tool_context.state[StateKeys.STYLE_SCORE] = result['score']
tool_context.state[StateKeys.STYLE_ISSUES] = result['issues']
tool_context.state[StateKeys.STYLE_ISSUE_COUNT] = result['issue_count']
logger.info(f"Tool: Style check complete - Score: {result['score']}/100, "
f"Issues: {result['issue_count']}")
return result
except Exception as e:
error_msg = f"Style check failed: {str(e)}"
logger.error(f"Tool: {error_msg}", exc_info=True)
# Set default values on error
tool_context.state[StateKeys.STYLE_SCORE] = 0
tool_context.state[StateKeys.STYLE_ISSUES] = []
return {
"status": "error",
"message": error_msg,
"score": 0
}
👉 עכשיו גוללים לסוף הקובץ ומחפשים את השורה:
# MODULE_5_STEP_1_STYLE_HELPERS
👈 מחליפים את השורה היחידה בפונקציות העזר:
def _perform_style_check(code: str) -> Dict[str, Any]:
"""Helper to perform style check in thread pool."""
import io
import sys
with tempfile.NamedTemporaryFile(mode='w', suffix='.py', delete=False) as tmp:
tmp.write(code)
tmp_path = tmp.name
try:
# Capture stdout to get pycodestyle output
old_stdout = sys.stdout
sys.stdout = captured_output = io.StringIO()
style_guide = pycodestyle.StyleGuide(
quiet=False, # We want output
max_line_length=100,
ignore=['E501', 'W503']
)
result = style_guide.check_files([tmp_path])
# Restore stdout
sys.stdout = old_stdout
# Parse captured output
output = captured_output.getvalue()
issues = []
for line in output.strip().split('\n'):
if line and ':' in line:
parts = line.split(':', 4)
if len(parts) >= 4:
try:
issues.append({
'line': int(parts[1]),
'column': int(parts[2]),
'code': parts[3].split()[0] if len(parts) > 3 else 'E000',
'message': parts[3].strip() if len(parts) > 3 else 'Unknown error'
})
except (ValueError, IndexError):
pass
# Add naming convention checks
try:
tree = ast.parse(code)
naming_issues = _check_naming_conventions(tree)
issues.extend(naming_issues)
except SyntaxError:
pass # Syntax errors will be caught elsewhere
# Calculate weighted score
score = _calculate_style_score(issues)
return {
"status": "success",
"score": score,
"issue_count": len(issues),
"issues": issues[:10], # First 10 issues
"summary": f"Style score: {score}/100 with {len(issues)} violations"
}
finally:
if os.path.exists(tmp_path):
os.unlink(tmp_path)
def _check_naming_conventions(tree: ast.AST) -> List[Dict[str, Any]]:
"""Check PEP 8 naming conventions."""
naming_issues = []
for node in ast.walk(tree):
if isinstance(node, ast.FunctionDef):
# Skip private/protected methods and __main__
if not node.name.startswith('_') and node.name != node.name.lower():
naming_issues.append({
'line': node.lineno,
'column': node.col_offset,
'code': 'N802',
'message': f"N802 function name '{node.name}' should be lowercase"
})
elif isinstance(node, ast.ClassDef):
# Check if class name follows CapWords convention
if not node.name[0].isupper() or '_' in node.name:
naming_issues.append({
'line': node.lineno,
'column': node.col_offset,
'code': 'N801',
'message': f"N801 class name '{node.name}' should use CapWords convention"
})
return naming_issues
def _calculate_style_score(issues: List[Dict[str, Any]]) -> int:
"""Calculate weighted style score based on violation severity."""
if not issues:
return 100
# Define weights by error type
weights = {
'E1': 10, # Indentation errors
'E2': 3, # Whitespace errors
'E3': 5, # Blank line errors
'E4': 8, # Import errors
'E5': 5, # Line length
'E7': 7, # Statement errors
'E9': 10, # Syntax errors
'W2': 2, # Whitespace warnings
'W3': 2, # Blank line warnings
'W5': 3, # Line break warnings
'N8': 7, # Naming conventions
}
total_deduction = 0
for issue in issues:
code_prefix = issue['code'][:2] if len(issue['code']) >= 2 else 'E2'
weight = weights.get(code_prefix, 3)
total_deduction += weight
# Cap at 100 points deduction
return max(0, 100 - min(total_deduction, 100))
הוספת הסוכן לבדיקת סגנון
👈 פתיחה
code_review_assistant/sub_agents/review_pipeline/style_checker.py
👉 Find:
# MODULE_5_STEP_1_INSTRUCTION_PROVIDER
👈 מחליפים את השורה היחידה הזו ב:
async def style_checker_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are a code style expert focused on PEP 8 compliance.
Your task:
1. Use the check_code_style tool to validate PEP 8 compliance
2. The tool will retrieve the ORIGINAL code from state automatically
3. Report violations exactly as found
4. Present the results clearly and confidently
CRITICAL:
- The tool checks the code EXACTLY as provided by the user
- Do not suggest the code was modified or fixed
- Report actual violations found in the original code
- If there are style issues, they should be reported honestly
Call the check_code_style tool with an empty string for the code parameter,
as the tool will retrieve the code from state automatically.
When presenting results based on what the tool returns:
- State the exact score from the tool results
- If score >= 90: "Excellent style compliance!"
- If score 70-89: "Good style with minor improvements needed"
- If score 50-69: "Style needs attention"
- If score < 50: "Significant style improvements needed"
List the specific violations found (the tool will provide these):
- Show line numbers, error codes, and messages
- Focus on the top 10 most important issues
Previous analysis: {structure_analysis_summary}
Format your response as:
## Style Analysis Results
- Style Score: [exact score]/100
- Total Issues: [count]
- Assessment: [your assessment based on score]
## Top Style Issues
[List issues with line numbers and descriptions]
## Recommendations
[Specific fixes for the most critical issues]"""
return await instructions_utils.inject_session_state(template, context)
👉 Find:
# MODULE_5_STEP_1_STYLE_CHECKER_AGENT
👈 מחליפים את השורה היחידה הזו ב:
style_checker_agent = Agent(
name="StyleChecker",
model=config.worker_model,
description="Checks Python code style against PEP 8 guidelines",
instruction=style_checker_instruction_provider,
tools=[FunctionTool(func=check_code_style)],
output_key="style_check_summary"
)
שלב 2: מוסיפים את סוכן Test Runner
כלי ההרצה של הבדיקות יוצר בדיקות מקיפות ומריץ אותן באמצעות כלי ההרצה המובנה של הקוד.
👈 פתיחה
code_review_assistant/sub_agents/review_pipeline/test_runner.py
👉 Find:
# MODULE_5_STEP_2_INSTRUCTION_PROVIDER
👈 מחליפים את השורה היחידה הזו ב:
async def test_runner_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects the code_to_review directly."""
template = """You are a testing specialist who creates and runs tests for Python code.
THE CODE TO TEST IS:
{code_to_review}
YOUR TASK:
1. Understand what the function appears to do based on its name and structure
2. Generate comprehensive tests (15-20 test cases)
3. Execute the tests using your code executor
4. Analyze results to identify bugs vs expected behavior
5. Output a detailed JSON analysis
TESTING METHODOLOGY:
- Test with the most natural interpretation first
- When something fails, determine if it's a bug or unusual design
- Test edge cases, boundaries, and error scenarios
- Document any surprising behavior
Execute your tests and output ONLY valid JSON with this structure:
- "test_summary": object with "total_tests_run", "tests_passed", "tests_failed", "tests_with_errors", "critical_issues_found"
- "critical_issues": array of objects, each with "type", "description", "example_input", "expected_behavior", "actual_behavior", "severity"
- "test_categories": object with "basic_functionality", "edge_cases", "error_handling" (each containing "passed", "failed", "errors" counts)
- "function_behavior": object with "apparent_purpose", "actual_interface", "unexpected_requirements"
- "verdict": object with "status" (WORKING/BUGGY/BROKEN), "confidence" (high/medium/low), "recommendation"
Do NOT output the test code itself, only the JSON analysis."""
return await instructions_utils.inject_session_state(template, context)
👉 Find:
# MODULE_5_STEP_2_TEST_RUNNER_AGENT
👈 מחליפים את השורה היחידה הזו ב:
test_runner_agent = Agent(
name="TestRunner",
model=config.critic_model,
description="Generates and runs tests for Python code using safe code execution",
instruction=test_runner_instruction_provider,
code_executor=BuiltInCodeExecutor(),
output_key="test_execution_summary"
)
שלב 3: הסבר על זיכרון ללמידה בין סשנים
לפני שיוצרים את כלי הסינתזה של המשוב, חשוב להבין את ההבדל בין מצב לבין זיכרון – שני מנגנוני אחסון שונים למטרות שונות.
מצב לעומת זיכרון: ההבדל העיקרי
כדי להבהיר את העניין, נשתמש בדוגמה קונקרטית מביקורת קוד:
מדינה (במהלך ההפעלה הנוכחית בלבד):
# Data from THIS review session
tool_context.state[StateKeys.STYLE_ISSUES] = [
{"line": 5, "code": "E231", "message": "missing whitespace"},
{"line": 12, "code": "E701", "message": "multiple statements"}
]
- היקף: השיחה הזו בלבד
- המטרה: העברת נתונים בין סוכנים בצינור הנוכחי
- מקום מגורים נוכחי: אובייקט
Session - משך החיים: נמחק בסיום הסשן
זיכרון (כל הסשנים הקודמים):
# Learned from 50 previous reviews
"User frequently forgets docstrings on helper functions"
"User tends to write long functions (avg 45 lines)"
"User improved error handling after feedback in session #23"
- היקף: כל הסשנים הקודמים של המשתמש הזה
- מטרה: ללמוד דפוסים, לספק משוב בהתאמה אישית
- מקום מגורים נוכחי:
MemoryService - במהלך כל משך החיים: נשמר בין סשנים, ניתן לחיפוש
למה חשוב לשלוח משוב משני המקומות:
תארו לעצמכם שהסינתיסייזר יוצר משוב:
שימוש רק בסטטוס (בדיקה נוכחית):
"Function `calculate_total` has no docstring."
משוב כללי ומכני.
שימוש במצב + זיכרון (דפוסים נוכחיים + קודמים):
"Function `calculate_total` has no docstring. This is the 4th review
where helper functions lacked documentation. Consider adding docstrings
as you write functions, not afterwards - you mentioned in our last
session that you find it easier that way."
שיפור הדרגתי של ההפניות בהתאמה אישית ובהקשר.
לפריסות בסביבת הייצור יש אפשרויות:
אפשרות 1: VertexAiMemoryBankService (מתקדם)
- מה זה עושה: חילוץ עובדות משמעותיות משיחות באמצעות LLM
- חיפוש: חיפוש סמנטי (מבין את המשמעות, לא רק מילות מפתח)
- ניהול זיכרון: איחוד ועדכון אוטומטי של הזיכרונות לאורך זמן
- נדרש: פרויקט ב-Google Cloud + הגדרה של Agent Engine
- כדאי להשתמש באפשרות הזו אם: אתם רוצים זיכרונות מותאמים אישית, מורכבים ומתפתחים
- דוגמה: "המשתמש מעדיף תכנות פונקציונלי" (חילוץ מ-10 שיחות על סגנון קוד)
אפשרות 2: המשך השימוש ב-InMemoryMemoryService + Persistent Sessions
- מה היא עושה: שומרת את היסטוריית השיחות המלאה לחיפוש מילות מפתח
- חיפוש: התאמה למילות מפתח בסיסית בסשנים קודמים
- ניהול הזיכרון: אתם קובעים מה יישמר (באמצעות
add_session_to_memory) - נדרש: רק
SessionServiceקבוע (כמוVertexAiSessionServiceאוDatabaseSessionService) - מתי כדאי להשתמש: כשצריך לבצע חיפוש פשוט בשיחות קודמות בלי עיבוד של LLM
- דוגמה: חיפוש של docstring יחזיר את כל הסשנים שבהם המילה הזו מוזכרת
איך הזיכרון מתמלא
אחרי שכל סקר קוד מסתיים:
# At the end of a session (typically in your application code)
await memory_service.add_session_to_memory(session)
מה קורה:
- InMemoryMemoryService: שומר את כל אירועי הסשן לחיפוש מילות מפתח
- VertexAiMemoryBankService: מודל LLM מחלץ עובדות מרכזיות ומאחד אותן עם זיכרונות קיימים
בסשנים עתידיים אפשר יהיה להריץ שאילתות:
# In a tool, search for relevant past feedback
results = tool_context.search_memory("feedback about docstrings")
שלב 4: הוספת כלי סינתזת משוב וסוכן
הסוכן לסינתזת משוב הוא הסוכן המתוחכם ביותר בצינור העיבוד. הוא מתזמן שלושה כלים, משתמש בהוראות דינמיות ומשלב מצב, זיכרון וארטיפקטים.
הוספת שלושת הכלים לסינתזה
👈 פתיחה
code_review_assistant/tools.py
👉 Find:
# MODULE_5_STEP_4_SEARCH_PAST_FEEDBACK
👈 Replace with Tool 1 - Memory Search (production version):
async def search_past_feedback(developer_id: str, tool_context: ToolContext) -> Dict[str, Any]:
"""
Search for past feedback in memory service.
Args:
developer_id: ID of the developer (defaults to "default_user")
tool_context: ADK tool context with potential memory service access
Returns:
Dictionary containing feedback search results
"""
logger.info(f"Tool: Searching for past feedback for developer {developer_id}...")
try:
# Default developer ID if not provided
if not developer_id:
developer_id = tool_context.state.get(StateKeys.USER_ID, 'default_user')
# Check if memory service is available
if hasattr(tool_context, 'search_memory'):
try:
# Perform structured searches
queries = [
f"developer:{developer_id} code review feedback",
f"developer:{developer_id} common issues",
f"developer:{developer_id} improvements"
]
all_feedback = []
patterns = {
'common_issues': [],
'improvements': [],
'strengths': []
}
for query in queries:
search_result = await tool_context.search_memory(query)
if search_result and hasattr(search_result, 'memories'):
for memory in search_result.memories[:5]:
memory_text = memory.text if hasattr(memory, 'text') else str(memory)
all_feedback.append(memory_text)
# Extract patterns
if 'style' in memory_text.lower():
patterns['common_issues'].append('style compliance')
if 'improved' in memory_text.lower():
patterns['improvements'].append('showing improvement')
if 'excellent' in memory_text.lower():
patterns['strengths'].append('consistent quality')
# Store in state
tool_context.state[StateKeys.PAST_FEEDBACK] = all_feedback
tool_context.state[StateKeys.FEEDBACK_PATTERNS] = patterns
logger.info(f"Tool: Found {len(all_feedback)} past feedback items")
return {
"status": "success",
"feedback_found": True,
"count": len(all_feedback),
"summary": " | ".join(all_feedback[:3]) if all_feedback else "No feedback",
"patterns": patterns
}
except Exception as e:
logger.warning(f"Tool: Memory search error: {e}")
# Fallback: Check state for cached feedback
cached_feedback = tool_context.state.get(StateKeys.USER_PAST_FEEDBACK_CACHE, [])
if cached_feedback:
tool_context.state[StateKeys.PAST_FEEDBACK] = cached_feedback
return {
"status": "success",
"feedback_found": True,
"count": len(cached_feedback),
"summary": "Using cached feedback",
"patterns": {}
}
# No feedback found
tool_context.state[StateKeys.PAST_FEEDBACK] = []
logger.info("Tool: No past feedback found")
return {
"status": "success",
"feedback_found": False,
"message": "No past feedback available - this appears to be a first submission",
"patterns": {}
}
except Exception as e:
error_msg = f"Feedback search error: {str(e)}"
logger.error(f"Tool: {error_msg}", exc_info=True)
tool_context.state[StateKeys.PAST_FEEDBACK] = []
return {
"status": "error",
"message": error_msg,
"feedback_found": False
}
👉 Find:
# MODULE_5_STEP_4_UPDATE_GRADING_PROGRESS
👈 החלפה בכלי 2 – כלי למעקב אחר ציונים (גרסת ייצור):
async def update_grading_progress(tool_context: ToolContext) -> Dict[str, Any]:
"""
Updates grading progress counters and metrics in state.
"""
logger.info("Tool: Updating grading progress...")
try:
current_time = datetime.now().isoformat()
# Build all state changes
state_updates = {}
# Temporary (invocation-level) state
state_updates[StateKeys.TEMP_PROCESSING_TIMESTAMP] = current_time
# Session-level state
attempts = tool_context.state.get(StateKeys.GRADING_ATTEMPTS, 0) + 1
state_updates[StateKeys.GRADING_ATTEMPTS] = attempts
state_updates[StateKeys.LAST_GRADING_TIME] = current_time
# User-level persistent state
lifetime_submissions = tool_context.state.get(StateKeys.USER_TOTAL_SUBMISSIONS, 0) + 1
state_updates[StateKeys.USER_TOTAL_SUBMISSIONS] = lifetime_submissions
state_updates[StateKeys.USER_LAST_SUBMISSION_TIME] = current_time
# Calculate improvement metrics
current_style_score = tool_context.state.get(StateKeys.STYLE_SCORE, 0)
last_style_score = tool_context.state.get(StateKeys.USER_LAST_STYLE_SCORE, 0)
score_improvement = current_style_score - last_style_score
state_updates[StateKeys.USER_LAST_STYLE_SCORE] = current_style_score
state_updates[StateKeys.SCORE_IMPROVEMENT] = score_improvement
# Track test results if available
test_results = tool_context.state.get(StateKeys.TEST_EXECUTION_SUMMARY, {})
# Parse if it's a string
if isinstance(test_results, str):
try:
test_results = json.loads(test_results)
except:
test_results = {}
if test_results and test_results.get('test_summary', {}).get('total_tests_run', 0) > 0:
summary = test_results['test_summary']
total = summary.get('total_tests_run', 0)
passed = summary.get('tests_passed', 0)
if total > 0:
pass_rate = (passed / total) * 100
state_updates[StateKeys.USER_LAST_TEST_PASS_RATE] = pass_rate
# Apply all updates atomically
for key, value in state_updates.items():
tool_context.state[key] = value
logger.info(f"Tool: Progress updated - Attempt #{attempts}, "
f"Lifetime: {lifetime_submissions}")
return {
"status": "success",
"session_attempts": attempts,
"lifetime_submissions": lifetime_submissions,
"timestamp": current_time,
"improvement": {
"style_score_change": score_improvement,
"direction": "improved" if score_improvement > 0 else "declined"
},
"summary": f"Attempt #{attempts} recorded, {lifetime_submissions} total submissions"
}
except Exception as e:
error_msg = f"Progress update error: {str(e)}"
logger.error(f"Tool: {error_msg}", exc_info=True)
return {
"status": "error",
"message": error_msg
}
👉 Find:
# MODULE_5_STEP_4_SAVE_GRADING_REPORT
👈 Replace with Tool 3 - Artifact Saver (production version):
async def save_grading_report(feedback_text: str, tool_context: ToolContext) -> Dict[str, Any]:
"""
Saves a detailed grading report as an artifact.
Args:
feedback_text: The feedback text to include in the report
tool_context: ADK tool context for state management
Returns:
Dictionary containing save status and details
"""
logger.info("Tool: Saving grading report...")
try:
# Gather all relevant data from state
code = tool_context.state.get(StateKeys.CODE_TO_REVIEW, '')
analysis = tool_context.state.get(StateKeys.CODE_ANALYSIS, {})
style_score = tool_context.state.get(StateKeys.STYLE_SCORE, 0)
style_issues = tool_context.state.get(StateKeys.STYLE_ISSUES, [])
# Get test results
test_results = tool_context.state.get(StateKeys.TEST_EXECUTION_SUMMARY, {})
# Parse if it's a string
if isinstance(test_results, str):
try:
test_results = json.loads(test_results)
except:
test_results = {}
timestamp = datetime.now().isoformat()
# Create comprehensive report dictionary
report = {
'timestamp': timestamp,
'grading_attempt': tool_context.state.get(StateKeys.GRADING_ATTEMPTS, 1),
'code': {
'content': code,
'line_count': len(code.splitlines()),
'hash': hashlib.md5(code.encode()).hexdigest()
},
'analysis': analysis,
'style': {
'score': style_score,
'issues': style_issues[:5] # First 5 issues
},
'tests': test_results,
'feedback': feedback_text,
'improvements': {
'score_change': tool_context.state.get(StateKeys.SCORE_IMPROVEMENT, 0),
'from_last_score': tool_context.state.get(StateKeys.USER_LAST_STYLE_SCORE, 0)
}
}
# Convert report to JSON string
report_json = json.dumps(report, indent=2)
report_part = types.Part.from_text(text=report_json)
# Try to save as artifact if the service is available
if hasattr(tool_context, 'save_artifact'):
try:
# Generate filename with timestamp (replace colons for filesystem compatibility)
filename = f"grading_report_{timestamp.replace(':', '-')}.json"
# Save the main report
version = await tool_context.save_artifact(filename, report_part)
# Also save a "latest" version for easy access
await tool_context.save_artifact("latest_grading_report.json", report_part)
logger.info(f"Tool: Report saved as {filename} (version {version})")
# Store report in state as well for redundancy
tool_context.state[StateKeys.USER_LAST_GRADING_REPORT] = report
return {
"status": "success",
"artifact_saved": True,
"filename": filename,
"version": str(version),
"size": len(report_json),
"summary": f"Report saved as {filename}"
}
except Exception as artifact_error:
logger.warning(f"Artifact service error: {artifact_error}, falling back to state storage")
# Continue to fallback below
# Fallback: Store in state if artifact service is not available or failed
tool_context.state[StateKeys.USER_LAST_GRADING_REPORT] = report
logger.info("Tool: Report saved to state (artifact service not available)")
return {
"status": "success",
"artifact_saved": False,
"message": "Report saved to state only",
"size": len(report_json),
"summary": "Report saved to session state"
}
except Exception as e:
error_msg = f"Report save error: {str(e)}"
logger.error(f"Tool: {error_msg}", exc_info=True)
# Still try to save minimal data to state
try:
tool_context.state[StateKeys.USER_LAST_GRADING_REPORT] = {
'error': error_msg,
'feedback': feedback_text,
'timestamp': datetime.now().isoformat()
}
except:
pass
return {
"status": "error",
"message": error_msg,
"artifact_saved": False,
"summary": f"Failed to save report: {error_msg}"
}
יצירת סוכן הסינתזה
👈 פתיחה
code_review_assistant/sub_agents/review_pipeline/feedback_synthesizer.py
👉 Find:
# MODULE_5_STEP_4_INSTRUCTION_PROVIDER
👉 Replace with the production instruction provider:
async def feedback_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are an expert code reviewer and mentor providing constructive, educational feedback.
CONTEXT FROM PREVIOUS AGENTS:
- Structure analysis summary: {structure_analysis_summary}
- Style check summary: {style_check_summary}
- Test execution summary: {test_execution_summary}
YOUR TASK requires these steps IN ORDER:
1. Call search_past_feedback tool with developer_id="default_user"
2. Call update_grading_progress tool with no parameters
3. Carefully analyze the test results to understand what really happened
4. Generate comprehensive feedback following the structure below
5. Call save_grading_report tool with the feedback_text parameter
6. Return the feedback as your final output
CRITICAL - Understanding Test Results:
The test_execution_summary contains structured JSON. Parse it carefully:
- tests_passed = Code worked correctly
- tests_failed = Code produced wrong output
- tests_with_errors = Code crashed
- critical_issues = Fundamental problems with the code
If critical_issues array contains items, these are serious bugs that need fixing.
Do NOT count discovering bugs as test successes.
FEEDBACK STRUCTURE TO FOLLOW:
## 📊 Summary
Provide an honest assessment. Be encouraging but truthful about problems found.
## ✅ Strengths
List 2-3 things done well, referencing specific code elements.
## 📈 Code Quality Analysis
### Structure & Organization
Comment on code organization, readability, and documentation.
### Style Compliance
Report the actual style score and any specific issues.
### Test Results
Report the actual test results accurately:
- If critical_issues exist, report them as bugs to fix
- Be clear: "X tests passed, Y critical issues were found"
- List each critical issue
- Don't hide or minimize problems
## 💡 Recommendations for Improvement
Based on the analysis, provide specific actionable fixes.
If critical issues exist, fixing them is top priority.
## 🎯 Next Steps
Prioritized action list based on severity of issues.
## 💬 Encouragement
End with encouragement while being honest about what needs fixing.
Remember: Complete ALL steps including calling save_grading_report."""
return await instructions_utils.inject_session_state(template, context)
👉 Find:
# MODULE_5_STEP_4_SYNTHESIZER_AGENT
👈 החלפה ב:
feedback_synthesizer_agent = Agent(
name="FeedbackSynthesizer",
model=config.critic_model,
description="Synthesizes all analysis into constructive, personalized feedback",
instruction=feedback_instruction_provider,
tools=[
FunctionTool(func=search_past_feedback),
FunctionTool(func=update_grading_progress),
FunctionTool(func=save_grading_report)
],
output_key="final_feedback"
)
שלב 5: חיבור הצינור
עכשיו מחברים את כל ארבעת הסוכנים לצינור עיבוד נתונים רציף ויוצרים את סוכן הבסיס.
👉 פתיחה
code_review_assistant/agent.py
👈 מוסיפים את הייבוא הנדרש בחלק העליון של הקובץ (אחרי הייבוא הקיים):
from google.adk.agents import Agent, SequentialAgent
from code_review_assistant.sub_agents.review_pipeline.code_analyzer import code_analyzer_agent
from code_review_assistant.sub_agents.review_pipeline.style_checker import style_checker_agent
from code_review_assistant.sub_agents.review_pipeline.test_runner import test_runner_agent
from code_review_assistant.sub_agents.review_pipeline.feedback_synthesizer import feedback_synthesizer_agent
הקובץ אמור להיראות כך:
"""
Main agent orchestration for the Code Review Assistant.
"""
from google.adk.agents import Agent, SequentialAgent
from .config import config
from code_review_assistant.sub_agents.review_pipeline.code_analyzer import code_analyzer_agent
from code_review_assistant.sub_agents.review_pipeline.style_checker import style_checker_agent
from code_review_assistant.sub_agents.review_pipeline.test_runner import test_runner_agent
from code_review_assistant.sub_agents.review_pipeline.feedback_synthesizer import feedback_synthesizer_agent
# MODULE_5_STEP_5_CREATE_PIPELINE
# MODULE_6_STEP_5_CREATE_FIX_LOOP
# MODULE_6_STEP_5_UPDATE_ROOT_AGENT
👉 חיפוש:
# MODULE_5_STEP_5_CREATE_PIPELINE
👈 מחליפים את השורה היחידה הזו בשורה הבאה:
# Create sequential pipeline
code_review_pipeline = SequentialAgent(
name="CodeReviewPipeline",
description="Complete code review pipeline with analysis, testing, and feedback",
sub_agents=[
code_analyzer_agent,
style_checker_agent,
test_runner_agent,
feedback_synthesizer_agent
]
)
# Root agent - coordinates the review pipeline
root_agent = Agent(
name="CodeReviewAssistant",
model=config.worker_model,
description="An intelligent code review assistant that analyzes Python code and provides educational feedback",
instruction="""You are a specialized Python code review assistant focused on helping developers improve their code quality.
When a user provides Python code for review:
1. Immediately delegate to CodeReviewPipeline and pass the code EXACTLY as it was provided by the user.
2. The pipeline will handle all analysis and feedback
3. Return ONLY the final feedback from the pipeline - do not add any commentary
When a user asks what you can do or asks general questions:
- Explain your capabilities for code review
- Do NOT trigger the pipeline for non-code messages
The pipeline handles everything for code review - just pass through its final output.""",
sub_agents=[code_review_pipeline],
output_key="assistant_response"
)
שלב 6: בדיקת צינור העברת הנתונים המלא
הגיע הזמן לראות את כל ארבעת הסוכנים עובדים יחד.
👈 הפעלת המערכת:
adk web code_review_assistant
אחרי שמריצים את הפקודה adk web, אמור להופיע פלט במסוף שמציין שהופעל שרת האינטרנט של ADK, בדומה לזה:
+-----------------------------------------------------------------------------+
| ADK Web Server started |
| |
| For local testing, access at http://localhost:8000. |
+-----------------------------------------------------------------------------+
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
👈 כדי לגשת לממשק המשתמש של ADK Dev מהדפדפן:
בסרגל הכלים של Cloud Shell (בדרך כלל בפינה השמאלית העליונה), לוחצים על סמל התצוגה המקדימה בדפדפן (שבדרך כלל נראה כמו עין או ריבוע עם חץ) ובוחרים באפשרות 'שינוי יציאה'. בחלון הקופץ, מגדירים את היציאה ל-8000 ולוחצים על 'שינוי ותצוגה מקדימה'. לאחר מכן ייפתחו ב-Cloud Shell כרטיסייה בדפדפן או חלון חדשים עם ממשק המשתמש של ADK Dev.
👈 הסוכן פועל עכשיו. ממשק המשתמש של ADK Dev בדפדפן הוא החיבור הישיר שלכם לסוכן.
- בוחרים את היעד: בתפריט הנפתח בחלק העליון של ממשק המשתמש, בוחרים את סוכן
code_review_assistant.
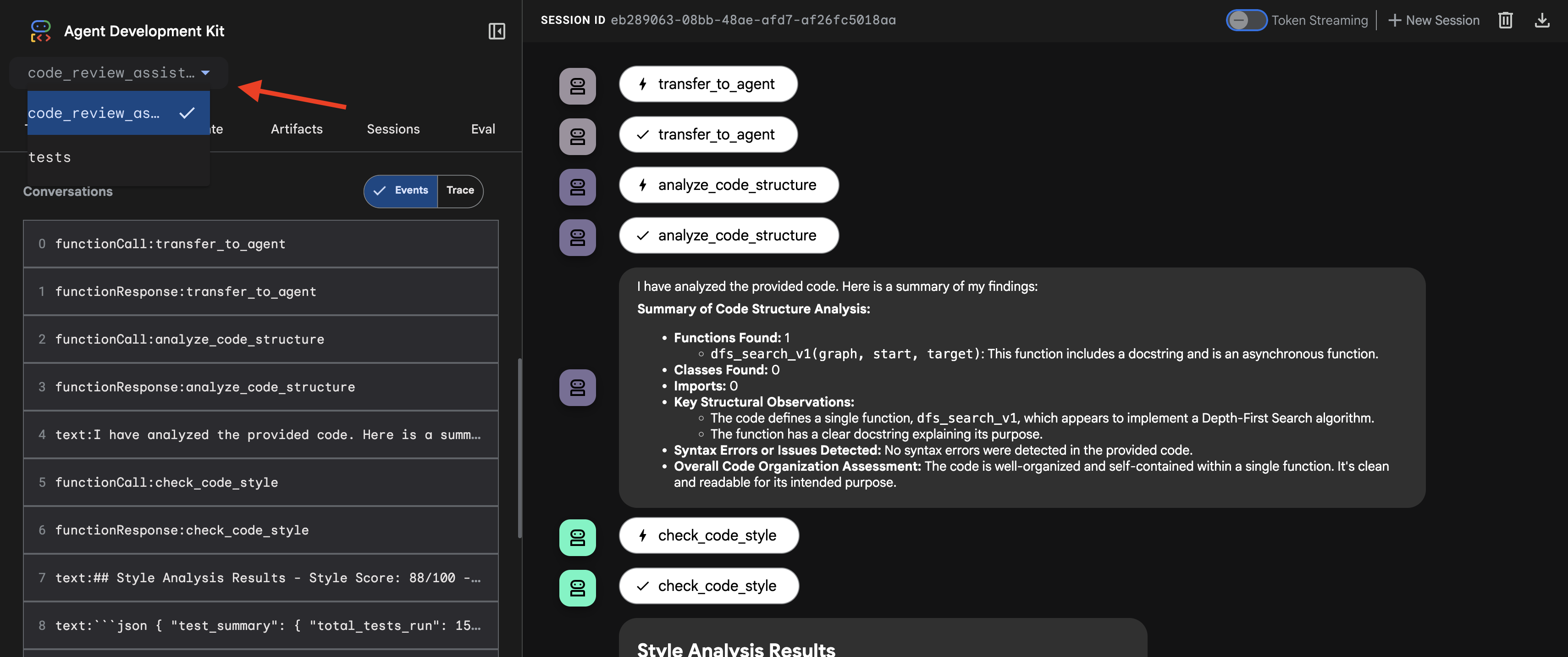
👉 בדיקת הפרומפט:
Please analyze the following:
def dfs_search_v1(graph, start, target):
"""Find if target is reachable from start."""
visited = set()
stack = start
while stack:
current = stack.pop()
if current == target:
return True
if current not in visited:
visited.add(current)
for neighbor in graph[current]:
if neighbor not in visited:
stack.append(neighbor)
return False
👈 כך נראה צינור עיבוד הנתונים של סקר הקוד בפעולה:
כששולחים את הפונקציה dfs_search_v1 עם הבאג, לא מקבלים רק תשובה אחת. אתם רואים את צינור הנתונים שלכם עם כמה סוכנים בפעולה. הפלט של הסטרימינג שאתם רואים הוא תוצאה של ארבעה סוכנים מומחים שפועלים ברצף, כשכל אחד מהם מתבסס על הקודם.
הנה פירוט של התרומה של כל סוכן לסקירה המקיפה הסופית, שבה הנתונים הגולמיים הופכים למידע שימושי.
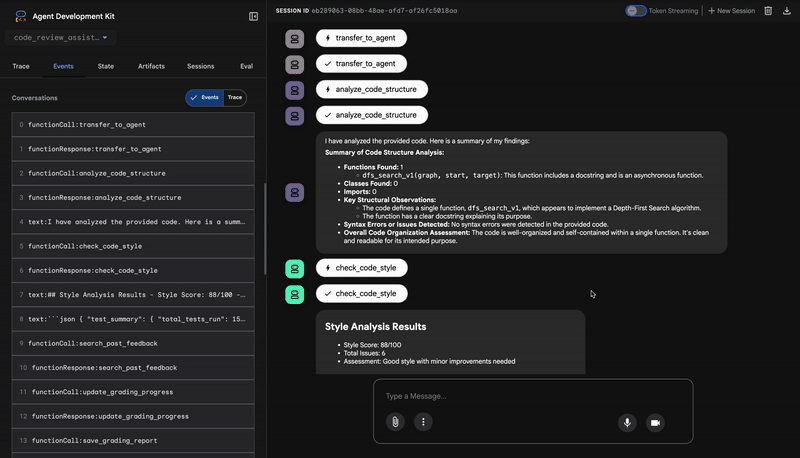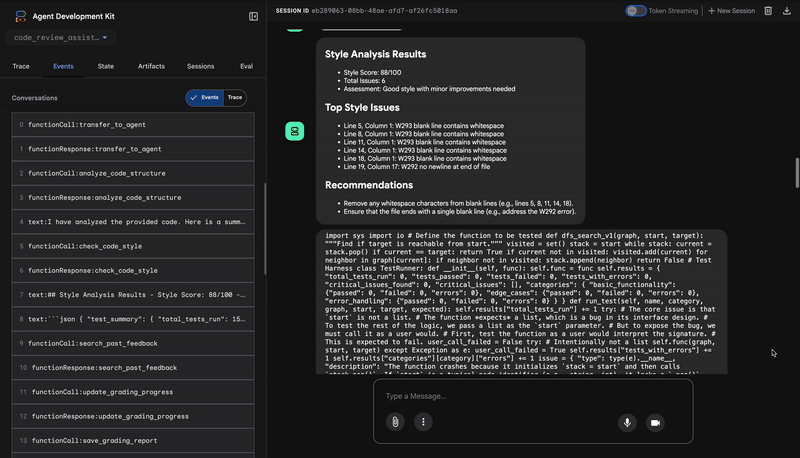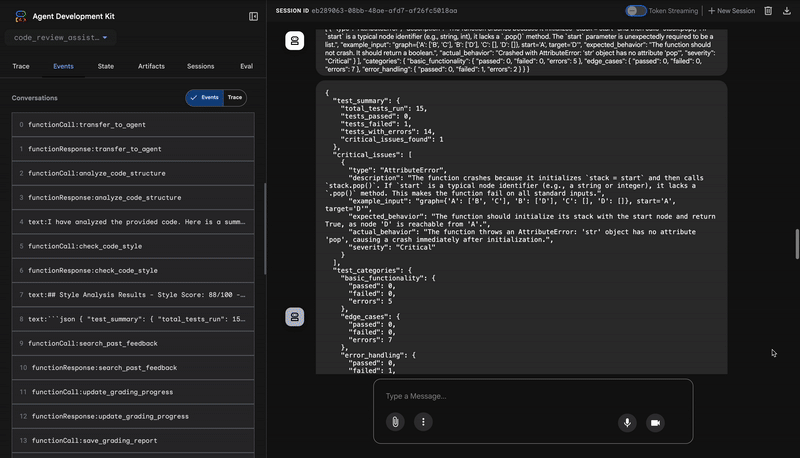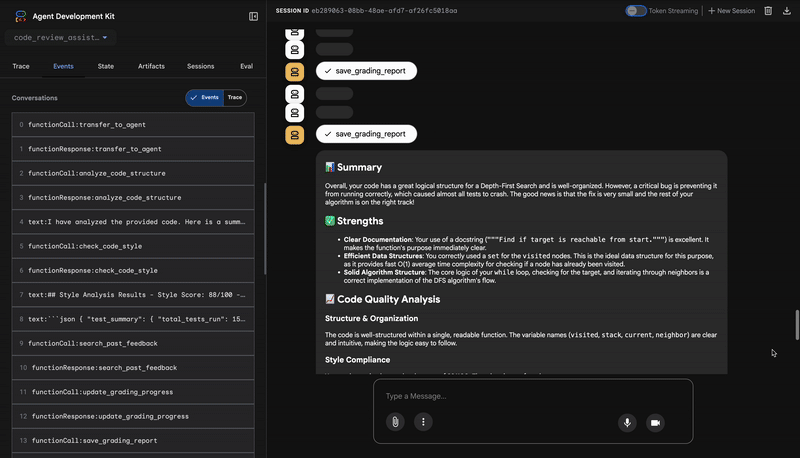
1. הדוח המבני של הכלי לניתוח קוד
קודם כל, CodeAnalyzer הסוכן מקבל את הקוד הגולמי. הוא לא מנחש מה הקוד עושה, אלא משתמש בכלי analyze_code_structure כדי לבצע ניתוח דטרמיניסטי של עץ תחביר מופשט (AST).
הפלט שלו הוא נתונים טהורים ועובדתיים על מבנה הקוד:
The analysis of the provided code reveals the following:
Summary:
- Functions Found: 1
- Classes Found: 0
Key Structural Observations:
- A single function, dfs_search_v1, is defined.
- It includes a docstring: "Find if target is reachable from start."
- No syntax errors were detected.
Overall Code Organization Assessment:
- The code snippet is a well-defined, self-contained function.
⭐ ערך: השלב הראשוני הזה מספק בסיס נקי ומהימן לסוכנים האחרים. הוא מאשר שהקוד הוא קוד Python תקין ומזהה את הרכיבים המדויקים שצריך לבדוק.
2. ביקורת PEP 8 של כלי בדיקת הסגנון
בשלב הבא, סוכן StyleChecker משתלט על השיחה. הוא קורא את הקוד מהמצב המשותף ומשתמש בכלי check_code_style, שמסתמך על pycodestyle linter.
הפלט של הכלי הוא ציון איכות כמותי והפרות ספציפיות:
Style Analysis Results
- Style Score: 88/100
- Total Issues: 6
- Assessment: Good style with minor improvements needed
Top Style Issues
- Line 5, W293: blank line contains whitespace
- Line 19, W292: no newline at end of file
⭐ ערך: הסוכן הזה מספק משוב אובייקטיבי שלא ניתן לשינוי, על סמך סטנדרטים קהילתיים מבוססים (PEP 8). מערכת הניקוד המשוקללת מציגה למשתמש באופן מיידי את חומרת הבעיות.
3. גילוי באגים קריטיים באמצעות Test Runner
כאן המערכת מבצעת ניתוח מעמיק יותר. הנציג TestRunner יוצר ומריץ חבילה מקיפה של בדיקות כדי לאמת את ההתנהגות של הקוד.
הפלט שלו הוא אובייקט JSON מובנה שמכיל פסק דין חמור:
{
"critical_issues": [
{
"type": "Critical Bug",
"description": "The function's initialization `stack = start` is incorrect... When a common input like a string... is provided... the function crashes with an AttributeError.",
"severity": "Critical"
}
],
"verdict": {
"status": "BROKEN",
"confidence": "high",
"recommendation": "The function is fundamentally broken... the stack initialization line `stack = start` must be changed to `stack = [start]`."
}
}
⭐ Value: התובנה הזו היא הכי חשובה. הסוכן לא ניחש את הקוד, אלא הוכיח שהקוד שבור על ידי הרצה שלו. הוא חשף באג קל אבל קריטי בזמן הריצה, שבודק אנושי עלול לפספס בקלות, וזיהה את הסיבה המדויקת ואת התיקון הנדרש.
4. הדוח הסופי של כלי סיכום המשוב
לבסוף, סוכן FeedbackSynthesizer פועל כמנצח. הוא לוקח את הנתונים המובנים משלושת הסוכנים הקודמים ויוצר דוח אחד ידידותי למשתמש, שהוא גם אנליטי וגם מעודד.
הפלט שלו הוא הביקורת הסופית והמלוטשת שאתם רואים:
📊 Summary
Great effort on implementing the Depth-First Search algorithm! ... However, a critical bug in the initialization of the stack prevents the function from working correctly...
✅ Strengths
- Good Algorithm Structure
- Correct Use of `visited` Set
📈 Code Quality Analysis
...
### Style Compliance
The style analysis returned a good score of 88/100.
...
### Test Results
The automated testing revealed a critical issue... The line `stack = start` directly assigns the input... which results in an `AttributeError`.
💡 Recommendations for Improvement
**Fix the Critical Stack Initialization Bug:**
- Incorrect Code: `stack = start`
- Correct Code: `stack = [start]`
💬 Encouragement
You are very close to a perfect implementation! The core logic of your DFS algorithm is sound, which is the hardest part.
⭐ ערך: הסוכן הזה הופך נתונים טכניים לחוויה מועילה וחינוכית. הוא מתעדף את הבעיה החשובה ביותר (הבאג), מסביר אותה בצורה ברורה, מספק את הפתרון המדויק ועושה זאת בנימה מעודדת. היא משלבת בהצלחה את הממצאים מכל השלבים הקודמים ליחידה מגובשת ובעלת ערך.
התהליך הרב-שלבי הזה מדגים את היכולות של צינור אג'נטי. במקום לקבל תשובה אחת גדולה, תקבלו ניתוח בשכבות שבו כל סוכן מבצע משימה מיוחדת שניתן לאמת. כך מתקבלת בדיקה שהיא לא רק מעמיקה, אלא גם דטרמיניסטית, מהימנה וחינוכית מאוד.
👈💻 אחרי שמסיימים את הבדיקה, חוזרים לטרמינל של Cloud Shell Editor ומקישים על Ctrl+C כדי להפסיק את ממשק המשתמש של ADK Dev.
מה יצרתם
עכשיו יש לכם צינור לסקר קוד מלא שכולל:
✅ ניתוח מבנה הקוד – ניתוח AST דטרמיניסטי עם פונקציות עזר
✅ בדיקת הסגנון – ניקוד משוקלל עם מוסכמות למתן שמות
✅ הרצת בדיקות – יצירת בדיקות מקיפה עם פלט JSON מובנה
✅ סינתוז משוב – שילוב של מצב + זיכרון + ארטיפקטים
✅ מעקב אחר ההתקדמות – מצב רב-שכבתי על פני הפעלות/סשנים/משתמשים
✅ למידה לאורך זמן – שירות זיכרון לדפוסים חוצי-סשנים
✅ אספקת ארטיפקטים – דוחות JSON להורדה עם נתיב ביקורת מלא
מושגים מרכזיים שנלמדו
צינורות עיבוד נתונים רציפים:
- ארבעה סוכנים שפועלים בסדר קפדני
- כל אחד משפר את המצב של הבא
- יחסי התלות קובעים את רצף הביצוע
דפוסי ייצור:
- הפרדה של פונקציות עזר (סנכרון במאגרי שרשורים)
- התדרדרות הדרגתית (אסטרטגיות חלופיות)
- ניהול מצב רב-שכבתי (זמני/סשן/משתמש)
- ספקי הוראות דינמיים (מודעים להקשר)
- אחסון כפול (ארטיפקטים + יתירות של מצב)
State as Communication:
- קבועים מונעים שגיאות הקלדה בכל הסוכנים
-
output_keyכתיבת סיכומים של סוכנים למצב - סוכנים מאוחרים יותר קוראים באמצעות StateKeys
- הסטטוס עובר באופן לינארי דרך הפייפליין
זיכרון לעומת מצב:
- מצב: נתוני הסשן הנוכחי
- זיכרון: דפוסים בסשנים
- מטרות שונות, משך חיים שונה
ארגון של כלים:
- סוכנים עם כלי אחד (analyzer, style_checker)
- מפעילים מובנים (test_runner)
- תיאום בין כמה כלים (סינתיסייזר)
שיטת בחירת המודל:
- מודל Worker: משימות מכניות (ניתוח, בדיקה, ניתוב)
- מודל ביקורת: משימות חשיבה רציונלית (בדיקה, סינתזה)
- אופטימיזציה של העלויות באמצעות בחירה מתאימה
המאמרים הבאים
במודול 6, תיצרו את צינור התיקון:
- ארכיטקטורת LoopAgent לתיקונים איטרטיביים
- תנאי יציאה באמצעות העברה לטיפול ברמה גבוהה יותר
- צבירת מצב בין איטרציות
- אימות ולוגיקה של ניסיון חוזר
- שילוב עם צינור העיבוד של הביקורות כדי להציע תיקונים
תוכלו לראות איך אותם דפוסי מצב משתנים בהתאם למורכבות של תהליכי עבודה איטרטיביים שבהם נציגים מנסים כמה פעמים עד שהם מצליחים, ואיך מתאמים בין כמה צינורות באפליקציה אחת.
6. הוספת צינור התיקון: ארכיטקטורת לולאה
מבוא
במודול 5 יצרתם צינור עיבוד נתונים לבדיקה רציפה שמנתח קוד ומספק משוב. אבל זיהוי בעיות הוא רק חצי מהפתרון – מפתחים צריכים עזרה בתיקון שלהן.
במודול הזה נבנה צינור אוטומטי לתיקון שכולל את הפעולות הבאות:
- יצירת תיקונים על סמך תוצאות הבדיקה
- אימות התיקונים על ידי הרצת בדיקות מקיפות
- מנסה שוב באופן אוטומטי אם התיקונים לא עובדים (עד 3 ניסיונות)
- תוצאות הדוחות עם השוואות לפני ואחרי
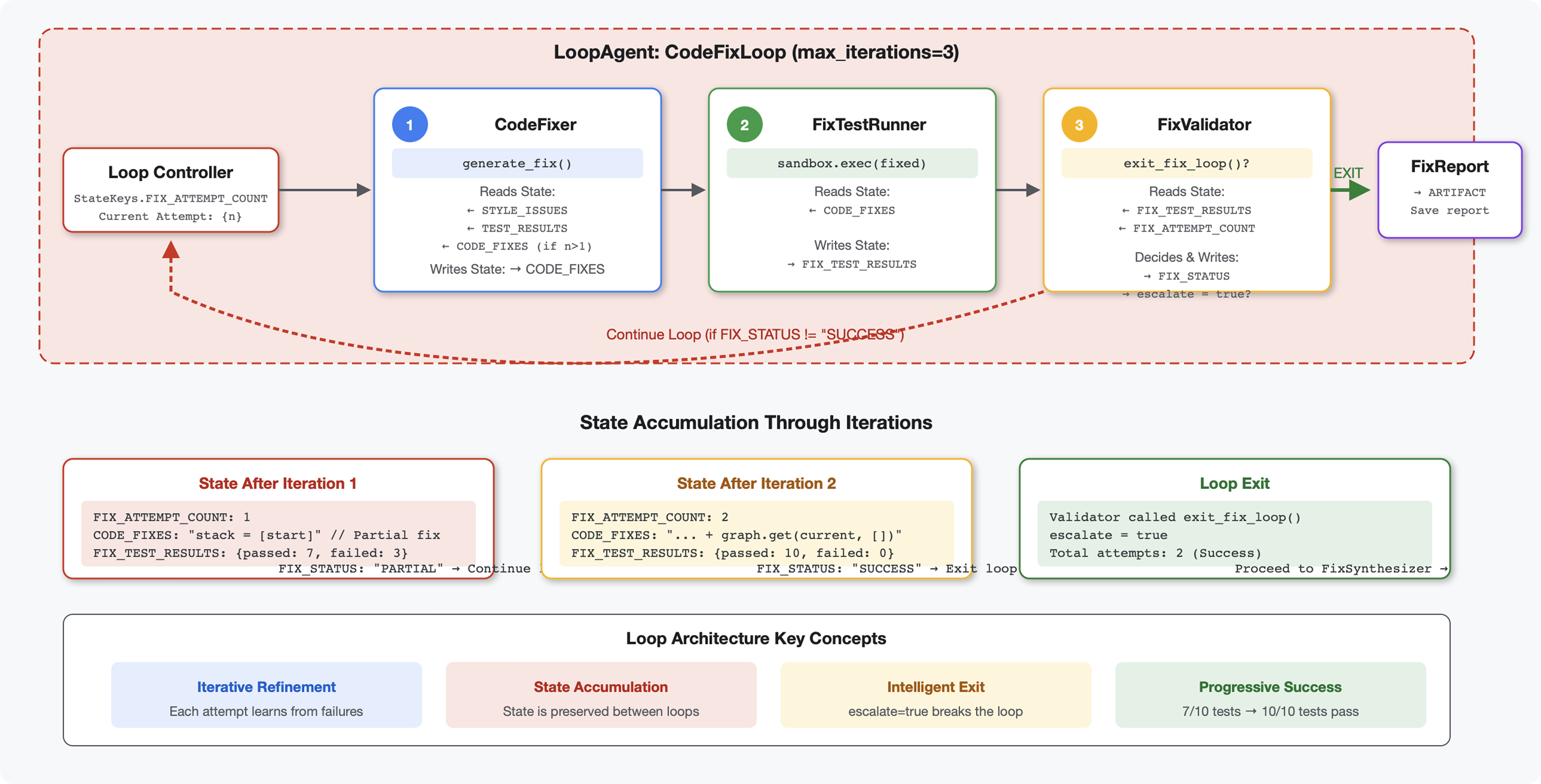
מושג מרכזי: LoopAgent לניסיון חוזר אוטומטי. בניגוד לסוכנים רציפים שפועלים פעם אחת, סוכן LoopAgent חוזר על פעולת הסוכנים המשניים שלו עד שמתקיים תנאי יציאה או עד שמגיעים למספר המקסימלי של איטרציות. הכלי מסמן הצלחה בהגדרת tool_context.actions.escalate = True.
תצוגה מקדימה של מה שתבנו: שליחת קוד עם באגים ← בדיקה מזהה בעיות ← תיקון בלולאה יוצר תיקונים ← בדיקות מאמתות ← ניסיונות חוזרים אם צריך ← דוח מקיף סופי.
מושגי ליבה: LoopAgent לעומת ברצף
Sequential Pipeline (Module 5):
SequentialAgent(agents=[A, B, C])
# Executes: A → B → C → Done
- זרימה חד-כיוונית
- כל סוכן מופעל בדיוק פעם אחת
- ללא לוגיקה לניסיון נוסף
Loop Pipeline (Module 6):
LoopAgent(agents=[A, B, C], max_iterations=3)
# Executes: A → B → C → (check exit) → A → B → C → (check exit) → ...
- תנועה מחזורית
- סוכנים יכולים לפעול כמה פעמים
- יציאה כשהתנאי הבא מתקיים:
- כלי מגדיר את
tool_context.actions.escalate = True(הצלחה) - הגעת למגבלה
max_iterations(מגבלת בטיחות) - מתרחשת חריגה לא מטופלת (שגיאה)
- כלי מגדיר את
למה כדאי להשתמש בלולאות לתיקון קוד:
לעתים קרובות צריך לנסות כמה פעמים לתקן את הקוד:
- ניסיון ראשון: תיקון באגים ברורים (סוגי משתנים שגויים)
- ניסיון שני: פתרון בעיות משניות שנחשפו בבדיקות (מקרים חריגים)
- ניסיון שלישי: מבצעים התאמות עדינות ומוודאים שכל הבדיקות עוברות
בלי לולאה, תצטרכו להשתמש בלוגיקה מורכבת של תנאים בהוראות לסוכן. ב-LoopAgent, הניסיון החוזר הוא אוטומטי.
השוואה בין ארכיטקטורות:
Sequential (Module 5):
User → Review Pipeline → Feedback → Done
Loop (Module 6):
User → Review Pipeline → Feedback → Fix Pipeline
↓
┌──────────────┴──────────────┐
│ Fix Attempt Loop (1-3x) │
│ ┌─────────────────────┐ │
│ │ 1. Generate Fixes │ │
│ │ 2. Test Fixes │ │
│ │ 3. Validate & Exit? │────┼─→ If escalate=True
│ └─────────────────────┘ │ exit loop
│ ↓ If not │
│ Try Again (max 3) │
└─────────────────────────────┘
↓
4. Synthesize Final Report → Done
שלב 1: מוסיפים את הסוכן Code Fixer
כלי לתיקון קוד יוצר קוד Python מתוקן על סמך תוצאות הבדיקה.
👈 פתיחה
code_review_assistant/sub_agents/fix_pipeline/code_fixer.py
👉 Find:
# MODULE_6_STEP_1_CODE_FIXER_INSTRUCTION_PROVIDER
👈 מחליפים את השורה היחידה הזו ב:
async def code_fixer_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are an expert code fixing specialist.
Original Code:
{code_to_review}
Analysis Results:
- Style Score: {style_score}/100
- Style Issues: {style_issues}
- Test Results: {test_execution_summary}
Based on the test results, identify and fix ALL issues including:
- Interface bugs (e.g., if start parameter expects wrong type)
- Logic errors (e.g., KeyError when accessing graph nodes)
- Style violations
- Missing documentation
YOUR TASK:
Generate the complete fixed Python code that addresses all identified issues.
CRITICAL INSTRUCTIONS:
- Output ONLY the corrected Python code
- Do NOT include markdown code blocks (```python)
- Do NOT include any explanations or commentary
- The output should be valid, executable Python code and nothing else
Common fixes to apply based on test results:
- If tests show AttributeError with 'pop', fix: stack = [start] instead of stack = start
- If tests show KeyError accessing graph, fix: use graph.get(current, [])
- Add docstrings if missing
- Fix any style violations identified
Output the complete fixed code now:"""
return await instructions_utils.inject_session_state(template, context)
👉 Find:
# MODULE_6_STEP_1_CODE_FIXER_AGENT
👈 מחליפים את השורה היחידה הזו ב:
code_fixer_agent = Agent(
name="CodeFixer",
model=config.worker_model,
description="Generates comprehensive fixes for all identified code issues",
instruction=code_fixer_instruction_provider,
code_executor=BuiltInCodeExecutor(),
output_key="code_fixes"
)
שלב 2: מוסיפים את Fix Test Runner Agent
כדי לוודא שהתיקונים תקינים, כלי הבדיקה מריץ בדיקות מקיפות על הקוד המתוקן.
👈 פתיחה
code_review_assistant/sub_agents/fix_pipeline/fix_test_runner.py
👉 Find:
# MODULE_6_STEP_2_FIX_TEST_RUNNER_INSTRUCTION_PROVIDER
👈 מחליפים את השורה היחידה הזו ב:
async def fix_test_runner_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that uses the clean code from the previous step."""
template = """You are responsible for validating the fixed code by running tests.
THE FIXED CODE TO TEST:
{code_fixes}
ORIGINAL TEST RESULTS: {test_execution_summary}
YOUR TASK:
1. Understand the fixes that were applied
2. Generate the same comprehensive tests (15-20 test cases)
3. Execute the tests on the FIXED code using your code executor
4. Compare results with original test results
5. Output a detailed JSON analysis
TESTING METHODOLOGY:
- Run the same tests that revealed issues in the original code
- Verify that previously failing tests now pass
- Ensure no regressions were introduced
- Document the improvement
Execute your tests and output ONLY valid JSON with this structure:
- "passed": number of tests that passed
- "failed": number of tests that failed
- "total": total number of tests
- "pass_rate": percentage as a number
- "comparison": object with "original_pass_rate", "new_pass_rate", "improvement"
- "newly_passing_tests": array of test names that now pass
- "still_failing_tests": array of test names still failing
Do NOT output the test code itself, only the JSON analysis."""
return await instructions_utils.inject_session_state(template, context)
👉 Find:
# MODULE_6_STEP_2_FIX_TEST_RUNNER_AGENT
👈 מחליפים את השורה היחידה הזו ב:
fix_test_runner_agent = Agent(
name="FixTestRunner",
model=config.critic_model,
description="Runs comprehensive tests on fixed code to verify all issues are resolved",
instruction=fix_test_runner_instruction_provider,
code_executor=BuiltInCodeExecutor(),
output_key="fix_test_execution_summary"
)
שלב 3: מוסיפים את Fix Validator Agent
הכלי לבדיקת תקינות בודק אם התיקונים הצליחו ומחליט אם לצאת מהלולאה.
הסבר על הכלים
קודם כול, מוסיפים את שלושת הכלים שנדרשים למאמת.
👈 פתיחה
code_review_assistant/tools.py
👉 Find:
# MODULE_6_STEP_3_VALIDATE_FIXED_STYLE
👈 החלפה בכלי 1 – כלי לתיקוף סגנונות:
async def validate_fixed_style(tool_context: ToolContext) -> Dict[str, Any]:
"""
Validates style compliance of the fixed code.
Args:
tool_context: ADK tool context containing fixed code in state
Returns:
Dictionary with style validation results
"""
logger.info("Tool: Validating style of fixed code...")
try:
# Get the fixed code from state
code_fixes = tool_context.state.get(StateKeys.CODE_FIXES, '')
# Try to extract from markdown if present
if '```python' in code_fixes:
start = code_fixes.rfind('```python') + 9
end = code_fixes.rfind('```')
if start < end:
code_fixes = code_fixes[start:end].strip()
if not code_fixes:
return {
"status": "error",
"message": "No fixed code found in state"
}
# Store the extracted fixed code
tool_context.state[StateKeys.CODE_FIXES] = code_fixes
# Run style check on fixed code
loop = asyncio.get_event_loop()
with ThreadPoolExecutor() as executor:
style_result = await loop.run_in_executor(
executor, _perform_style_check, code_fixes
)
# Compare with original
original_score = tool_context.state.get(StateKeys.STYLE_SCORE, 0)
improvement = style_result['score'] - original_score
# Store results
tool_context.state[StateKeys.FIXED_STYLE_SCORE] = style_result['score']
tool_context.state[StateKeys.FIXED_STYLE_ISSUES] = style_result['issues']
logger.info(f"Tool: Fixed code style score: {style_result['score']}/100 "
f"(improvement: +{improvement})")
return {
"status": "success",
"fixed_style_score": style_result['score'],
"original_style_score": original_score,
"improvement": improvement,
"remaining_issues": style_result['issues'],
"perfect_style": style_result['score'] == 100
}
except Exception as e:
logger.error(f"Tool: Style validation failed: {e}", exc_info=True)
return {
"status": "error",
"message": str(e)
}
👉 Find:
# MODULE_6_STEP_3_COMPILE_FIX_REPORT
👈 החלפה בכלי 2 – כלי ליצירת דוחות:
async def compile_fix_report(tool_context: ToolContext) -> Dict[str, Any]:
"""
Compiles comprehensive report of the fix process.
Args:
tool_context: ADK tool context with all fix pipeline data
Returns:
Comprehensive fix report
"""
logger.info("Tool: Compiling comprehensive fix report...")
try:
# Gather all data
original_code = tool_context.state.get(StateKeys.CODE_TO_REVIEW, '')
code_fixes = tool_context.state.get(StateKeys.CODE_FIXES, '')
# Test results
original_tests = tool_context.state.get(StateKeys.TEST_EXECUTION_SUMMARY, {})
fixed_tests = tool_context.state.get(StateKeys.FIX_TEST_EXECUTION_SUMMARY, {})
# Parse if strings
if isinstance(original_tests, str):
try:
original_tests = json.loads(original_tests)
except:
original_tests = {}
if isinstance(fixed_tests, str):
try:
fixed_tests = json.loads(fixed_tests)
except:
fixed_tests = {}
# Extract pass rates
original_pass_rate = 0
if original_tests:
if 'pass_rate' in original_tests:
original_pass_rate = original_tests['pass_rate']
elif 'test_summary' in original_tests:
# Handle test_runner_agent's JSON structure
summary = original_tests['test_summary']
total = summary.get('total_tests_run', 0)
passed = summary.get('tests_passed', 0)
if total > 0:
original_pass_rate = (passed / total) * 100
elif 'passed' in original_tests and 'total' in original_tests:
if original_tests['total'] > 0:
original_pass_rate = (original_tests['passed'] / original_tests['total']) * 100
fixed_pass_rate = 0
all_tests_pass = False
if fixed_tests:
if 'pass_rate' in fixed_tests:
fixed_pass_rate = fixed_tests['pass_rate']
all_tests_pass = fixed_tests.get('failed', 1) == 0
elif 'passed' in fixed_tests and 'total' in fixed_tests:
if fixed_tests['total'] > 0:
fixed_pass_rate = (fixed_tests['passed'] / fixed_tests['total']) * 100
all_tests_pass = fixed_tests.get('failed', 0) == 0
# Style scores
original_style = tool_context.state.get(StateKeys.STYLE_SCORE, 0)
fixed_style = tool_context.state.get(StateKeys.FIXED_STYLE_SCORE, 0)
# Calculate improvements
test_improvement = {
'original_pass_rate': original_pass_rate,
'fixed_pass_rate': fixed_pass_rate,
'improvement': fixed_pass_rate - original_pass_rate,
'all_tests_pass': all_tests_pass
}
style_improvement = {
'original_score': original_style,
'fixed_score': fixed_style,
'improvement': fixed_style - original_style,
'perfect_style': fixed_style == 100
}
# Determine overall status
if all_tests_pass and style_improvement['perfect_style']:
fix_status = 'SUCCESSFUL'
status_emoji = '✅'
elif test_improvement['improvement'] > 0 or style_improvement['improvement'] > 0:
fix_status = 'PARTIAL'
status_emoji = '⚠️'
else:
fix_status = 'FAILED'
status_emoji = '❌'
# Build comprehensive report
report = {
'status': fix_status,
'status_emoji': status_emoji,
'timestamp': datetime.now().isoformat(),
'original_code': original_code,
'code_fixes': code_fixes,
'improvements': {
'tests': test_improvement,
'style': style_improvement
},
'summary': f"{status_emoji} Fix Status: {fix_status}\n"
f"Tests: {original_pass_rate:.1f}% → {fixed_pass_rate:.1f}%\n"
f"Style: {original_style}/100 → {fixed_style}/100"
}
# Store report in state
tool_context.state[StateKeys.FIX_REPORT] = report
tool_context.state[StateKeys.FIX_STATUS] = fix_status
logger.info(f"Tool: Fix report compiled - Status: {fix_status}")
logger.info(f"Tool: Test improvement: {original_pass_rate:.1f}% → {fixed_pass_rate:.1f}%")
logger.info(f"Tool: Style improvement: {original_style} → {fixed_style}")
return {
"status": "success",
"fix_status": fix_status,
"report": report
}
except Exception as e:
logger.error(f"Tool: Failed to compile fix report: {e}", exc_info=True)
return {
"status": "error",
"message": str(e)
}
👉 Find:
# MODULE_6_STEP_3_EXIT_FIX_LOOP
👈 Replace with Tool 3 - Loop Exit Signal:
def exit_fix_loop(tool_context: ToolContext) -> Dict[str, Any]:
"""
Signal that fixing is complete and should exit the loop.
Args:
tool_context: ADK tool context
Returns:
Confirmation message
"""
logger.info("Tool: Setting escalate flag to exit fix loop")
# This is the critical line that exits the LoopAgent
tool_context.actions.escalate = True
return {
"status": "success",
"message": "Fix complete, exiting loop"
}
יצירת סוכן האימות
👈 פתיחה
code_review_assistant/sub_agents/fix_pipeline/fix_validator.py
👉 Find:
# MODULE_6_STEP_3_FIX_VALIDATOR_INSTRUCTION_PROVIDER
👈 מחליפים את השורה היחידה הזו ב:
async def fix_validator_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are the final validation specialist for code fixes.
You have access to:
- Original issues from initial review
- Applied fixes: {code_fixes}
- Test results after fix: {fix_test_execution_summary}
- All state data from the fix process
Your responsibilities:
1. Use validate_fixed_style tool to check style compliance of fixed code
- Pass no arguments, it will retrieve fixed code from state
2. Use compile_fix_report tool to generate comprehensive report
- Pass no arguments, it will gather all data from state
3. Based on the report, determine overall fix status:
- ✅ SUCCESSFUL: All tests pass, style score 100
- ⚠️ PARTIAL: Improvements made but issues remain
- ❌ FAILED: Fix didn't work or made things worse
4. CRITICAL: If status is SUCCESSFUL, call the exit_fix_loop tool to stop iterations
- This prevents unnecessary additional fix attempts
- If not successful, the loop will continue for another attempt
5. Provide clear summary of:
- What was fixed
- What improvements were achieved
- Any remaining issues requiring manual attention
Be precise and quantitative in your assessment.
"""
return await instructions_utils.inject_session_state(template, context)
👉 Find:
# MODULE_6_STEP_3_FIX_VALIDATOR_AGENT
👈 מחליפים את השורה היחידה הזו ב:
fix_validator_agent = Agent(
name="FixValidator",
model=config.worker_model,
description="Validates fixes and generates final fix report",
instruction=fix_validator_instruction_provider,
tools=[
FunctionTool(func=validate_fixed_style),
FunctionTool(func=compile_fix_report),
FunctionTool(func=exit_fix_loop)
],
output_key="final_fix_report"
)
שלב 4: הסבר על תנאי היציאה של LoopAgent
יש 3 דרכים לצאת מLoopAgent:
1. יציאה מוצלחת (דרך העברה לטיפול ברמה גבוהה יותר)
# Inside any tool in the loop:
tool_context.actions.escalate = True
# Effect: Loop completes current iteration, then exits
# Use when: Fix is successful and no more attempts needed
תרשים זרימה לדוגמה:
Iteration 1:
CodeFixer → generates fixes
FixTestRunner → tests show 90% pass rate
FixValidator → compiles report, sees PARTIAL status
→ Does NOT set escalate
→ Loop continues
Iteration 2:
CodeFixer → refines fixes based on failures
FixTestRunner → tests show 100% pass rate
FixValidator → compiles report, sees SUCCESSFUL status
→ Calls exit_fix_loop() which sets escalate = True
→ Loop exits after this iteration
2. יציאה אחרי מספר מקסימלי של איטרציות
LoopAgent(
name="FixAttemptLoop",
sub_agents=[...],
max_iterations=3 # Safety limit
)
# Effect: After 3 complete iterations, loop exits regardless of escalate
# Use when: Prevent infinite loops if fixes never succeed
תרשים זרימה לדוגמה:
Iteration 1: PARTIAL (continue)
Iteration 2: PARTIAL (continue)
Iteration 3: PARTIAL (but max reached)
→ Loop exits, synthesizer presents best attempt
3. יציאה עם שגיאה
# If any agent throws unhandled exception:
raise Exception("Unexpected error")
# Effect: Loop exits immediately with error state
# Use when: Critical failure that can't be recovered
התפתחות המצב לאורך האיטרציות:
בכל איטרציה מתעדכן המצב מהניסיון הקודם:
# Before Iteration 1:
state = {
"code_to_review": "def add(a,b):return a+b", # Original
"style_score": 40,
"test_execution_summary": {...}
}
# After Iteration 1:
state = {
"code_to_review": "def add(a,b):return a+b", # Unchanged
"code_fixes": "def add(a, b):\n return a + b", # NEW
"style_score": 40, # Unchanged
"fixed_style_score": 100, # NEW
"test_execution_summary": {...}, # Unchanged
"fix_test_execution_summary": {...} # NEW
}
# Iteration 2 starts with all this state
# If fixes still not perfect, code_fixes gets overwritten
למה
escalate
במקום ערכים מוחזרים:
# Bad: Using return value to signal exit
def validator_agent():
report = compile_report()
if report['status'] == 'SUCCESSFUL':
return {"exit": True} # How does loop know?
# Good: Using escalate
def validator_tool(tool_context):
report = compile_report()
if report['status'] == 'SUCCESSFUL':
tool_context.actions.escalate = True # Loop knows immediately
return {"report": report}
יתרונות:
- הוא פועל מכל כלי, לא רק מהכלי האחרון
- לא מפריע לנתוני ההחזרות
- משמעות סמנטית ברורה
- המסגרת מטפלת בלוגיקה של היציאה
שלב 5: חיבור צינור התיקון
👉 פתיחה
code_review_assistant/agent.py
👈 מוסיפים את הייבוא של צינור התיקון (אחרי הייבוא הקיים):
from google.adk.agents import LoopAgent # Add this to the existing Agent, SequentialAgent line
from code_review_assistant.sub_agents.fix_pipeline.code_fixer import code_fixer_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_test_runner import fix_test_runner_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_validator import fix_validator_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_synthesizer import fix_synthesizer_agent
עכשיו הייבוא אמור להיות:
from google.adk.agents import Agent, SequentialAgent, LoopAgent
from .config import config
# Review pipeline imports (from Module 5)
from code_review_assistant.sub_agents.review_pipeline.code_analyzer import code_analyzer_agent
from code_review_assistant.sub_agents.review_pipeline.style_checker import style_checker_agent
from code_review_assistant.sub_agents.review_pipeline.test_runner import test_runner_agent
from code_review_assistant.sub_agents.review_pipeline.feedback_synthesizer import feedback_synthesizer_agent
# Fix pipeline imports (NEW)
from code_review_assistant.sub_agents.fix_pipeline.code_fixer import code_fixer_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_test_runner import fix_test_runner_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_validator import fix_validator_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_synthesizer import fix_synthesizer_agent
👉 חיפוש:
# MODULE_6_STEP_5_CREATE_FIX_LOOP
👈 מחליפים את השורה היחידה הזו ב:
# Create the fix attempt loop (retries up to 3 times)
fix_attempt_loop = LoopAgent(
name="FixAttemptLoop",
sub_agents=[
code_fixer_agent, # Step 1: Generate fixes
fix_test_runner_agent, # Step 2: Validate with tests
fix_validator_agent # Step 3: Check success & possibly exit
],
max_iterations=3 # Try up to 3 times
)
# Wrap loop with synthesizer for final report
code_fix_pipeline = SequentialAgent(
name="CodeFixPipeline",
description="Automated code fixing pipeline with iterative validation",
sub_agents=[
fix_attempt_loop, # Try to fix (1-3 times)
fix_synthesizer_agent # Present final results (always runs once)
]
)
👈 הסרת הקיים
root_agent
הגדרה:
root_agent = Agent(...)
👉 Find:
# MODULE_6_STEP_5_UPDATE_ROOT_AGENT
👈 מחליפים את השורה היחידה הזו ב:
# Update root agent to include both pipelines
root_agent = Agent(
name="CodeReviewAssistant",
model=config.worker_model,
description="An intelligent code review assistant that analyzes Python code and provides educational feedback",
instruction="""You are a specialized Python code review assistant focused on helping developers improve their code quality.
When a user provides Python code for review:
1. Immediately delegate to CodeReviewPipeline and pass the code EXACTLY as it was provided by the user.
2. The pipeline will handle all analysis and feedback
3. Return ONLY the final feedback from the pipeline - do not add any commentary
After completing a review, if significant issues were identified:
- If style score < 100 OR tests are failing OR critical issues exist:
* Add at the end: "\n\n💡 I can fix these issues for you. Would you like me to do that?"
- If the user responds yes or requests fixes:
* Delegate to CodeFixPipeline
* Return the fix pipeline's complete output AS-IS
When a user asks what you can do or general questions:
- Explain your capabilities for code review and fixing
- Do NOT trigger the pipeline for non-code messages
The pipelines handle everything for code review and fixing - just pass through their final output.""",
sub_agents=[code_review_pipeline, code_fix_pipeline],
output_key="assistant_response"
)
שלב 6: מוסיפים את הסוכן Fix Synthesizer
אחרי שהלולאה מסתיימת, הכלי ליצירת סיכום יוצר סיכום של תוצאות התיקון שקל להבין.
👈 פתיחה
code_review_assistant/sub_agents/fix_pipeline/fix_synthesizer.py
👉 Find:
# MODULE_6_STEP_6_FIX_SYNTHESIZER_INSTRUCTION_PROVIDER
👈 מחליפים את השורה היחידה הזו ב:
async def fix_synthesizer_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are responsible for presenting the fix results to the user.
Based on the validation report: {final_fix_report}
Fixed code from state: {code_fixes}
Fix status: {fix_status}
Create a comprehensive yet friendly response that includes:
## 🔧 Fix Summary
[Overall status and key improvements - be specific about what was achieved]
## 📊 Metrics
- Test Results: [original pass rate]% → [new pass rate]%
- Style Score: [original]/100 → [new]/100
- Issues Fixed: X of Y
## ✅ What Was Fixed
[List each fixed issue with brief explanation of the correction made]
## 📝 Complete Fixed Code
[Include the complete, corrected code from state - this is critical]
## 💡 Explanation of Key Changes
[Brief explanation of the most important changes made and why]
[If any issues remain]
## ⚠️ Remaining Issues
[List what still needs manual attention]
## 🎯 Next Steps
[Guidance on what to do next - either use the fixed code or address remaining issues]
Save the fix report using save_fix_report tool before presenting.
Call it with no parameters - it will retrieve the report from state automatically.
Be encouraging about improvements while being honest about any remaining issues.
Focus on the educational aspect - help the user understand what was wrong and how it was fixed.
"""
return await instructions_utils.inject_session_state(template, context)
👉 Find:
# MODULE_6_STEP_6_FIX_SYNTHESIZER_AGENT
👈 מחליפים את השורה היחידה הזו ב:
fix_synthesizer_agent = Agent(
name="FixSynthesizer",
model=config.critic_model,
description="Creates comprehensive user-friendly fix report",
instruction=fix_synthesizer_instruction_provider,
tools=[FunctionTool(func=save_fix_report)],
output_key="fix_summary"
)
👉 הוספה
save_fix_report
הכלי ל
tools.py
:
👉 Find:
# MODULE_6_STEP_6_SAVE_FIX_REPORT
👈 החלפה ב:
async def save_fix_report(tool_context: ToolContext) -> Dict[str, Any]:
"""
Saves the fix report as an artifact.
Args:
tool_context: ADK tool context
Returns:
Save status
"""
logger.info("Tool: Saving fix report...")
try:
# Get the report from state
fix_report = tool_context.state.get(StateKeys.FIX_REPORT, {})
if not fix_report:
return {
"status": "error",
"message": "No fix report found in state"
}
# Convert to JSON
report_json = json.dumps(fix_report, indent=2)
report_part = types.Part.from_text(text=report_json)
# Generate filename
timestamp = datetime.now().isoformat().replace(':', '-')
filename = f"fix_report_{timestamp}.json"
# Try to save as artifact
if hasattr(tool_context, 'save_artifact'):
try:
version = await tool_context.save_artifact(filename, report_part)
await tool_context.save_artifact("latest_fix_report.json", report_part)
logger.info(f"Tool: Fix report saved as {filename}")
return {
"status": "success",
"filename": filename,
"version": str(version),
"size": len(report_json)
}
except Exception as e:
logger.warning(f"Could not save as artifact: {e}")
# Fallback: store in state
tool_context.state[StateKeys.LAST_FIX_REPORT] = fix_report
return {
"status": "success",
"message": "Fix report saved to state",
"size": len(report_json)
}
except Exception as e:
logger.error(f"Tool: Failed to save fix report: {e}", exc_info=True)
return {
"status": "error",
"message": str(e)
}
שלב 7: בדיקת צינור התיקון המלא
הגיע הזמן לראות את כל הלולאה בפעולה.
👈 הפעלת המערכת:
adk web code_review_assistant
אחרי שמריצים את הפקודה adk web, אמור להופיע פלט במסוף שמציין שהופעל שרת האינטרנט של ADK, בדומה לזה:
+-----------------------------------------------------------------------------+
| ADK Web Server started |
| |
| For local testing, access at http://localhost:8000. |
+-----------------------------------------------------------------------------+
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
👉 בדיקת הפרומפט:
Please analyze the following:
def dfs_search_v1(graph, start, target):
"""Find if target is reachable from start."""
visited = set()
stack = start
while stack:
current = stack.pop()
if current == target:
return True
if current not in visited:
visited.add(current)
for neighbor in graph[current]:
if neighbor not in visited:
stack.append(neighbor)
return False
קודם שולחים את הקוד עם הבאג כדי להפעיל את פייפליין הבדיקה. אחרי שהסוכן יזהה את הפגמים, תבקשו ממנו לתקן את הקוד, והפעולה הזו תפעיל את צינור התיקון החזק והאיטרטיבי.
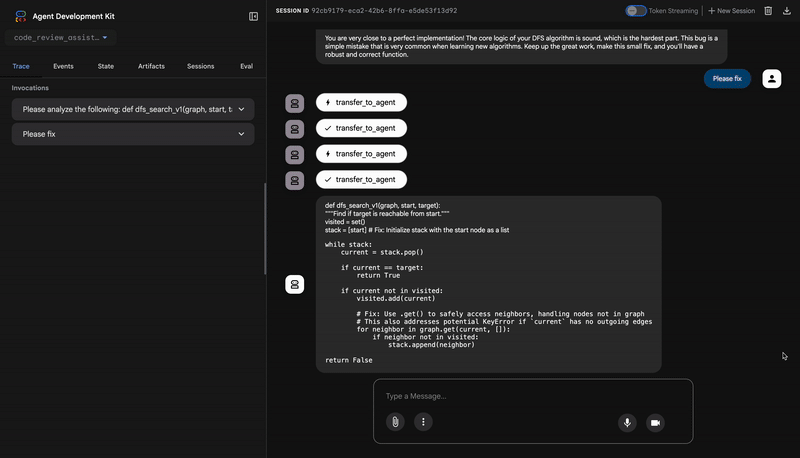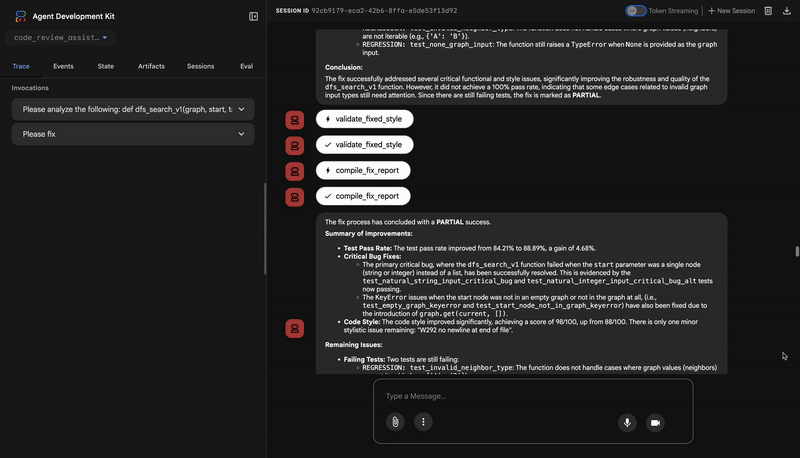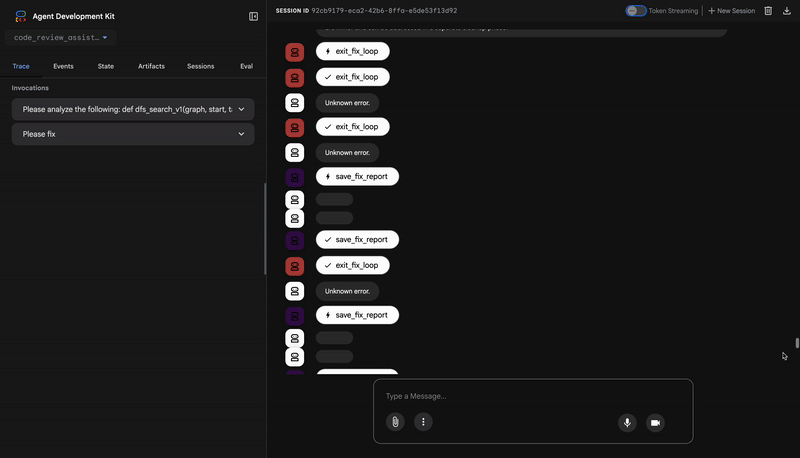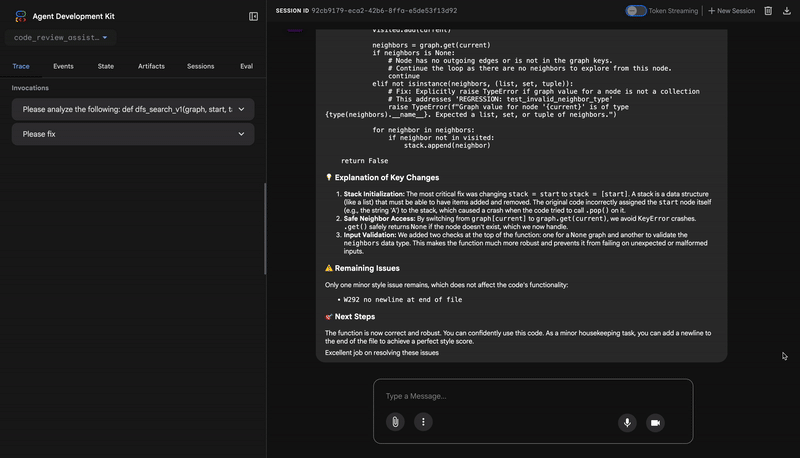
1. הבדיקה הראשונית (איתור הפגמים)
זה החלק הראשון בתהליך. פייפליין הבדיקה עם ארבעה סוכנים מנתח את הקוד, בודק את הסגנון שלו ומריץ חבילת מקרים לבדיקה שנוצרה. הוא מזהה נכון בעיה קריטית AttributeError ובעיות אחרות, ומספק פסיקה: הקוד BROKEN, עם שיעור הצלחה של הבדיקה של 84.21% בלבד.
2. התיקון האוטומטי (הלולאה בפעולה)
זה החלק הכי מרשים. כשמבקשים מהסוכן לתקן את הקוד, הוא לא מבצע רק שינוי אחד. הוא מפעיל לולאה איטרטיבית של תיקון ואימות שפועלת בדיוק כמו מפתח חרוץ: הוא מנסה לתקן, בודק את התיקון ביסודיות, ואם הוא לא מושלם, הוא מנסה שוב.
איטרציה מס' 1: הניסיון הראשון (הצלחה חלקית)
- התיקון: סוכן
CodeFixerקורא את הדוח הראשוני ומבצע את התיקונים הברורים ביותר. הוא משנה אתstack = startל-stack = [start]ומשתמש ב-graph.get()כדי למנוע חריגים שלKeyError. - האימות: המערכת של
TestRunnerמריצה מחדש באופן מיידי את חבילת מקרים לבדיקה המלאה על הקוד החדש. - התוצאה: שיעור ההצלחה השתפר באופן משמעותי ל-88.89%. הבאגים הקריטיים נעלמו. עם זאת, הבדיקות מקיפות כל כך שהן חושפות שני באגים חדשים ועדינים (רגרסיות) שקשורים לטיפול ב-
Noneכגרף או כערכים שכנים שאינם רשימה. המערכת מסמנת את התיקון כחלקי.
איטרציה מס' 2: ליטוש סופי (100% הצלחה)
- התיקון: התנאי ליציאה מהלולאה (שיעור הצלחה של 100%) לא מתקיים, ולכן הלולאה מופעלת שוב. עכשיו יש ב-
CodeFixerמידע נוסף – שני כשלים חדשים של רגרסיה. הוא יוצר גרסה סופית ויציבה יותר של הקוד, שמטפלת במקרים הקיצוניים האלה באופן מפורש. - האימות: התוסף
TestRunnerמריץ את חבילת הבדיקות בפעם האחרונה מול הגרסה הסופית של הקוד. - התוצאה: שיעור הצלחה של 100% . כל הבאגים המקוריים וכל הרגרסיות נפתרו. המערכת מסמנת את התיקון כהצלחה והלולאה מסתיימת.
3. הדוח הסופי: ציון מושלם
אחרי שהתיקון מאומת באופן מלא, FixSynthesizerהסוכן משתלט על השיחה ומציג את הדוח הסופי, תוך שהוא הופך את הנתונים הטכניים לסיכום ברור ומועיל.
מדד | לפני | אחרי | שיפור |
שיעור ההצלחה של הבדיקה | 84.21% | 100% | ▲ 15.79% |
ציון סגנון | 88 / 100 | 98 / 100 | ▲ 10 נקודות |
תיקוני באגים | 0 מתוך 3 | 3 מתוך 3 | ✅ |
✅ הקוד הסופי והמאומת
הנה הקוד המלא והמתוקן שעובר עכשיו את כל 19 הבדיקות, כהוכחה לתיקון המוצלח:
def dfs_search_v1(graph, start, target):
"""Find if target is reachable from start."""
# Handles 'None' graph input
if graph is None:
return False
visited = set()
# Fixes the critical AttributeError
stack = [start]
while stack:
current = stack.pop()
if current == target:
return True
if current not in visited:
visited.add(current)
# Safely gets neighbors to prevent KeyError
neighbors = graph.get(current)
if neighbors is None:
continue
# Validates that neighbors are iterable
if not isinstance(neighbors, (list, set, tuple)):
raise TypeError(
f"Graph value for node '{current}' is of type "
f"{type(neighbors).__name__}. Expected a list, set, or tuple."
)
for neighbor in neighbors:
if neighbor not in visited:
stack.append(neighbor)
return False
👈💻 אחרי שמסיימים את הבדיקה, חוזרים לטרמינל של Cloud Shell Editor ומקישים על Ctrl+C כדי להפסיק את ממשק המשתמש של ADK Dev.
מה יצרתם
עכשיו יש לכם צינור אוטומטי מלא לתיקון ש:
✅ יצירת תיקונים – על סמך ניתוח הבדיקה
✅ אימות איטרטיבי – בדיקות אחרי כל ניסיון תיקון
✅ ניסיון חוזר אוטומטי – עד 3 ניסיונות להצלחה
✅ יציאה חכמה – באמצעות העברה לטיפול ברמה גבוהה יותר כשהתיקון מצליח
✅ מעקב אחרי שיפורים – השוואה בין מדדים לפני ואחרי התיקון
✅ אספקת ארטיפקטים – דוחות תיקון שאפשר להוריד
מושגים מרכזיים שנלמדו
LoopAgent לעומת Sequential:
- רציף: מעבר אחד בין סוכנים
- LoopAgent: חוזר על עצמו עד לתנאי יציאה או למספר מקסימלי של איטרציות
- יציאה דרך
tool_context.actions.escalate = True
התפתחות המצב לאורך האיטרציות:
CODE_FIXESעודכן בכל איטרציה- תוצאות הבדיקה משתפרות לאורך זמן
- כלי התיקוף רואה את השינויים המצטברים
ארכיטקטורה של צינורות עיבוד נתונים מרובים:
- צינור לבדיקה: ניתוח לקריאה בלבד (מודול 5)
- תיקון חוזר: תיקון איטרטיבי (הלולאה הפנימית של מודול 6)
- תיקון צינור עיבוד נתונים: לולאה + סינתיסייזר (Module 6 outer)
- סוכן ראשי: מתזמן על סמך כוונת המשתמש
כלים לשליטה ב-Flow:
exit_fix_loop()sets escalate- כל כלי יכול לסמן השלמה של לולאה
- מפריד את לוגיקת היציאה מההוראות לסוכן
בטיחות של מספר האיטרציות המקסימלי:
- מונע לולאות אינסופיות
- המערכת תמיד תגיב
- מציג את הניסיון הכי טוב גם אם הוא לא מושלם
המאמרים הבאים
במודול האחרון נסביר איך פורסים את הסוכן בסביבת הייצור:
- הגדרת אחסון מתמיד באמצעות VertexAiSessionService
- פריסה ל-Agent Engine ב-Google Cloud
- מעקב אחרי סוכני ייצור וניפוי באגים שלהם
- שיטות מומלצות להרחבה ולמהימנות
יצרתם מערכת מרובת סוכנים (MAS) מלאה עם ארכיטקטורות של רצפים ולולאות. הדפוסים שלמדתם – ניהול מצב, הוראות דינמיות, תיאום כלים ושיפור איטרטיבי – הם טכניקות שמוכנות לייצור ומשמשות במערכות אמיתיות של סוכנים.
7. פריסה בסביבת הייצור
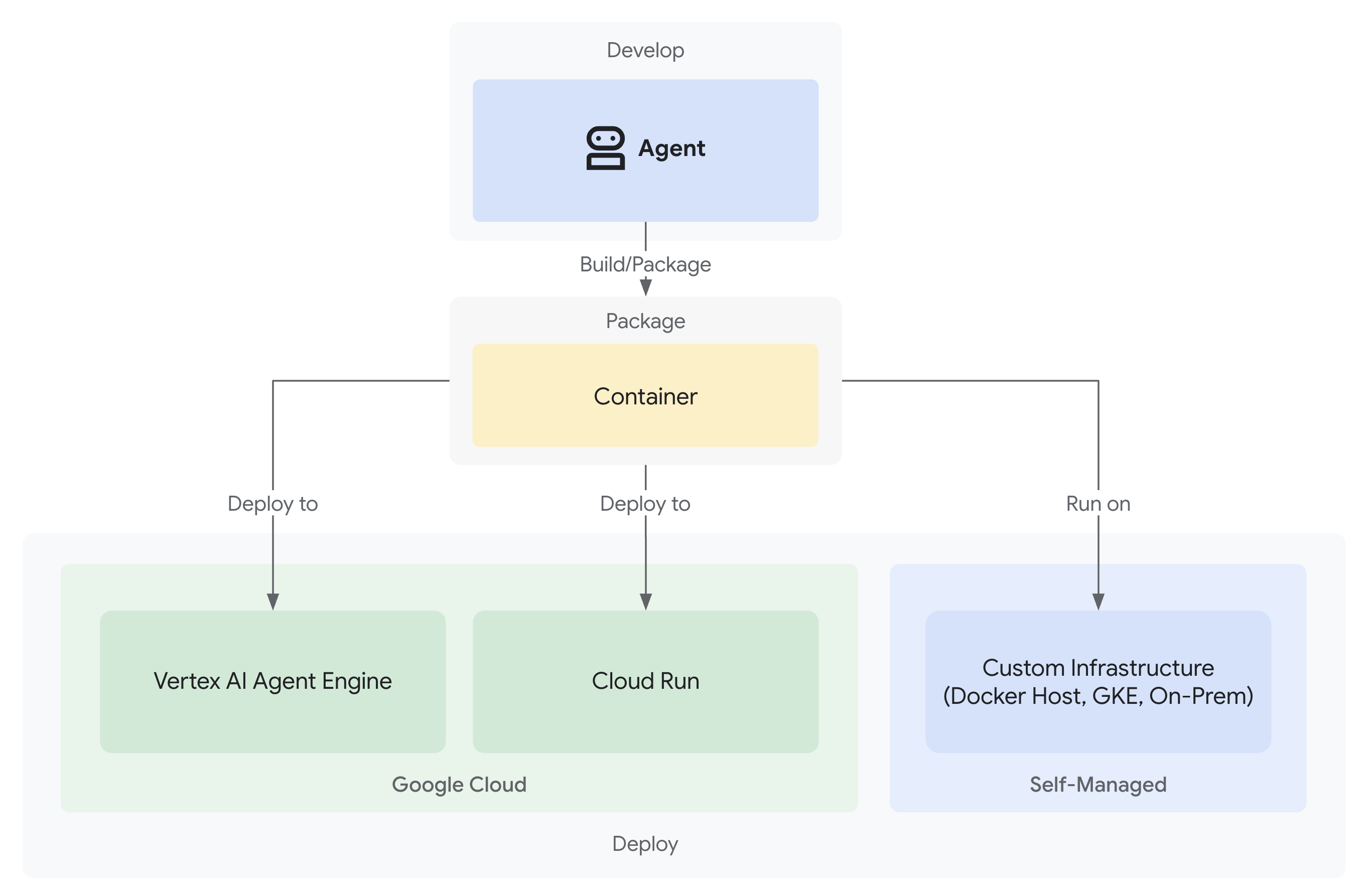
מבוא
עכשיו יש לכם עוזר ל<High Priority Term: סקר קוד> עם צינורות לבדיקה ולתיקון שפועלים באופן מקומי. החלק החסר: הוא פועל רק במחשב שלכם. במודול הזה תפרסו את הסוכן ב-Google Cloud, כך שהצוות שלכם יוכל לגשת אליו באמצעות סשנים מתמשכים ותשתית ברמת ייצור.
מה תלמדו:
- שלושה נתיבי פריסה: מקומי, Cloud Run ו-Agent Engine
- הקצאת הרשאות אוטומטית לתשתית
- אסטרטגיות של התמדה בסשן
- בדיקה של סוכנים שנפרסו
הסבר על אפשרויות הפריסה
ערכת ה-ADK תומכת בכמה יעדי פריסה, שלכל אחד מהם יש יתרונות וחסרונות שונים:
נתיבי פריסה
פירוק לגורמים | מקומי ( | Cloud Run ( | Agent Engine ( |
מורכבות | מינימלי | בינונית | נמוכה |
המשכיות של סשנים | בזיכרון בלבד (הנתונים אובדים בהפעלה מחדש) | Cloud SQL (PostgreSQL) | מנוהל (אוטומטי) על ידי Vertex AI |
תשתית | ללא (מכונת פיתוח בלבד) | מאגר + מסד נתונים | מנוהל במלואו |
הפעלה מההתחלה (cold startup) | לא רלוונטי | 100-2,000 אלפיות השנייה | 100-500 אלפיות השנייה |
שינוי גודל | מופע יחיד | אוטומטי (עד אפס) | אוטומטי |
מודל עלויות | בחינם (חישוב מקומי) | על בסיס בקשות + תוכנית בחינם | מבוסס-מחשוב |
תמיכה בממשק המשתמש | כן (דרך | כן (דרך | לא (API בלבד) |
מתאים במיוחד עבור | פיתוח/בדיקה | תנועה משתנה, בקרה על עלויות | סוכני הפקה |
אפשרות פריסה נוספת: Google Kubernetes Engine (GKE) זמין למשתמשים מתקדמים שזקוקים לשליטה ברמת Kubernetes, לרשת מותאמת אישית או לארגון של כמה שירותים. פריסת GKE לא נכללת ב-Codelab הזה, אבל היא מתועדת במדריך הפריסה של ADK.
מה נפרס
כשפורסים ב-Cloud Run או ב-Agent Engine, הפריטים הבאים נארזים ונפרסים:
- קוד הסוכן (
agent.py, כל הסוכנים המשניים, הכלים) - תלויות (
requirements.txt) - שרת ADK API (כלול אוטומטית)
- ממשק משתמש אינטרנטי (Cloud Run בלבד, כשמציינים
--with_ui)
הבדלים חשובים:
- Cloud Run: משתמש ב-CLI של
adk deploy cloud_run(יוצר קונטיינר באופן אוטומטי) או ב-gcloud run deploy(נדרש קובץ Dockerfile מותאם אישית) - Agent Engine: שימוש ב-
adk deploy agent_engineCLI (אין צורך ליצור קונטיינר, קוד Python נארז ישירות)
שלב 1: הגדרת הסביבה
הגדרת הקובץ .env
צריך לעדכן את הקובץ .env (שנוצר במודול 3) כדי לפרוס אותו בענן. פותחים את .env ומאמתים או מעדכנים את ההגדרות הבאות:
חובה לכל פריסות הענן:
# Your actual GCP Project ID (REQUIRED)
GOOGLE_CLOUD_PROJECT=your-project-id
# GCP region for deployments (REQUIRED)
GOOGLE_CLOUD_LOCATION=us-central1
# Use Vertex AI (REQUIRED)
GOOGLE_GENAI_USE_VERTEXAI=true
# Model configuration (already set)
WORKER_MODEL=gemini-2.5-flash
CRITIC_MODEL=gemini-2.5-pro
מגדירים שמות של קטגוריות (חובה לפני שמריצים את deploy.sh):
סקריפט הפריסה יוצר מאגרי מידע על סמך השמות האלה. להגדיר אותם עכשיו:
# Staging bucket for Agent Engine code uploads (REQUIRED for agent-engine)
STAGING_BUCKET=gs://your-project-id-staging
# Artifact storage for reports and fixed code (REQUIRED for both cloud-run and agent-engine)
ARTIFACT_BUCKET=gs://your-project-id-artifacts
מחליפים את your-project-id במזהה הפרויקט בפועל בשני שמות הקטגוריות. הסקריפט ייצור את הדליים האלה אם הם לא קיימים.
משתנים אופציונליים (נוצרים אוטומטית אם לא מציינים ערך):
# Agent Engine ID (populated after first deployment)
AGENT_ENGINE_ID=
# Cloud Run Database credentials (created automatically if blank)
CLOUD_SQL_INSTANCE_NAME=
DB_USER=
DB_PASSWORD=
DB_NAME=
בדיקת אימות
אם נתקלים בשגיאות אימות במהלך הפריסה:
gcloud auth application-default login
gcloud config set project $GOOGLE_CLOUD_PROJECT
שלב 2: הסבר על סקריפט הפריסה
הסקריפט deploy.sh מספק ממשק מאוחד לכל מצבי הפריסה:
./deploy.sh {local|cloud-run|agent-engine}
יכולות הסקריפט
הקצאת משאבים לתשתית:
- הפעלת API (AI Platform, Storage, Cloud Build, Cloud Trace, Cloud SQL)
- הגדרת הרשאות IAM (חשבונות שירות, תפקידים)
- יצירת משאבים (מאגרי מידע, מסדי נתונים, מופעים)
- פריסה עם דגלים מתאימים
- אימות אחרי הפריסה
קטעים עיקריים בסקריפט
- הגדרות (שורות 1-35): פרויקט, אזור, שמות שירותים, הגדרות ברירת מחדל
- פונקציות עזר (שורות 37-200): הפעלת API, יצירת קטגוריה, הגדרת IAM
- הלוגיקה הראשית (שורות 202-400): תזמור פריסה ספציפי למצב
שלב 3: הכנת הסוכן ל-Agent Engine
לפני שמבצעים פריסה ל-Agent Engine, צריך קובץ agent_engine_app.py שעוטף את הסוכן עבור זמן הריצה המנוהל. הוא כבר נוצר בשבילכם.
הצגת code_review_assistant/agent_engine_app.py
👉 פתיחת קובץ:
"""
Agent Engine application wrapper.
This file prepares the agent for deployment to Vertex AI Agent Engine.
"""
from vertexai import agent_engines
from .agent import root_agent
# Wrap the agent in an AdkApp object for Agent Engine deployment
app = agent_engines.AdkApp(
agent=root_agent,
enable_tracing=True,
)
שלב 4: פריסה ל-Agent Engine
Agent Engine הוא הפריסה המומלצת בסביבת ייצור לסוכני ADK כי הוא מספק:
- תשתית מנוהלת (אין צורך ליצור קונטיינרים)
- המשכיות מובנית של סשנים באמצעות
VertexAiSessionService - התאמה אוטומטית לעומס מאפס
- שילוב עם Cloud Trace מופעל כברירת מחדל
מה ההבדל בין Agent Engine לבין פריסות אחרות
הפרטים הטכניים
deploy.sh agent-engine
שימושים:
adk deploy agent_engine \
--project=$GOOGLE_CLOUD_PROJECT \
--region=$GOOGLE_CLOUD_LOCATION \
--staging_bucket=$STAGING_BUCKET \
--display_name="Code Review Assistant" \
--trace_to_cloud \
code_review_assistant
הפקודה הזו:
- אריזת קוד Python ישירות (ללא בניית Docker)
- העלאות לקטגוריית הביניים שציינתם ב-
.env - יצירת מופע מנוהל של Agent Engine
- הפעלת Cloud Trace לניראות (observability)
- הגדרת זמן הריצה באמצעות
agent_engine_app.py
בניגוד ל-Cloud Run שיוצר קונטיינר לקוד שלכם, Agent Engine מריץ את קוד ה-Python ישירות בסביבת זמן ריצה מנוהלת, בדומה לפונקציות ללא שרת.
הפעלת הפריסה
מתיקיית הבסיס של הפרויקט:
./deploy.sh agent-engine
שלבי הפריסה
צופים בהרצת הסקריפט בשלבים הבאים:
Phase 1: API Enablement
✓ aiplatform.googleapis.com
✓ storage-api.googleapis.com
✓ cloudbuild.googleapis.com
✓ cloudtrace.googleapis.com
Phase 2: IAM Setup
✓ Getting project number
✓ Granting Storage Object Admin
✓ Granting AI Platform User
✓ Granting Cloud Trace Agent
Phase 3: Staging Bucket
✓ Creating gs://your-project-id-staging
✓ Setting permissions
Phase 4: Artifact Bucket
✓ Creating gs://your-project-id-artifacts
✓ Configuring access
Phase 5: Validation
✓ Checking agent.py exists
✓ Verifying root_agent defined
✓ Checking agent_engine_app.py exists
✓ Validating requirements.txt
Phase 6: Build & Deploy
✓ Packaging agent code
✓ Uploading to staging bucket
✓ Creating Agent Engine instance
✓ Configuring session persistence
✓ Setting up Cloud Trace integration
✓ Running health checks
התהליך הזה נמשך 5-10 דקות כי הוא כולל אריזה של הסוכן ופריסה שלו בתשתית של Vertex AI.
שמירת המזהה של Agent Engine
לאחר פריסה מוצלחת:
✅ Deployment successful!
Agent Engine ID: 7917477678498709504
Resource Name: projects/123456789/locations/us-central1/reasoningEngines/7917477678498709504
Endpoint: https://us-central1-aiplatform.googleapis.com/v1/...
⚠️ IMPORTANT: Save this in your .env file:
AGENT_ENGINE_ID=7917477678498709504
עדכון של
.env
קובץ באופן מיידי:
echo "AGENT_ENGINE_ID=7917477678498709504" >> .env
המזהה הזה נדרש כדי:
- בדיקת הסוכן הפעיל
- עדכון הפריסה במועד מאוחר יותר
- גישה ליומנים ולעקבות
מה נפרס
הפריסה של Agent Engine כוללת עכשיו:
✅ פייפליין מלא של בדיקות (4 סוכנים)
✅ פייפליין מלא של תיקונים (loop + synthesizer)
✅ כל הכלים (ניתוח AST, בדיקת סגנון, יצירת ארטיפקטים)
✅ שמירת נתונים של סשן (אוטומטית דרך VertexAiSessionService)
✅ ניהול מצב (רמות סשן/משתמש/משך חיים)
✅ ניראות (Cloud Trace מופעל)
✅ תשתית של התאמה אוטומטית לעומס
שלב 5: בדיקת הסוכן שפרסתם
עדכון קובץ .env
אחרי הפריסה, מוודאים שהרכיב .env כולל:
AGENT_ENGINE_ID=7917477678498709504 # From deployment output
GOOGLE_CLOUD_PROJECT=your-project-id
GOOGLE_CLOUD_LOCATION=us-central1
הרצת סקריפט הבדיקה
הפרויקט כולל את tests/test_agent_engine.py במיוחד לבדיקת פריסות של Agent Engine:
python tests/test_agent_engine.py
מה עושים בבדיקה
- מאמת את הפרויקט שלכם ב-Google Cloud
- יצירת סשן עם הסוכן שנפרס
- שליחת בקשה לסקר קוד (הדוגמה של באג ב-DFS)
- התגובה מועברת בסטרימינג חזרה באמצעות אירועים שנשלחים מהשרת (SSE)
- אימות של שמירת הסשן וניהול המצב
הפלט הצפוי
Authenticated with project: your-project-id
Targeting Agent Engine: projects/.../reasoningEngines/7917477678498709504
Creating new session...
Created session: 4857885913439920384
Sending query to agent and streaming response:
data: {"content": {"parts": [{"text": "I'll analyze your code..."}]}}
data: {"content": {"parts": [{"text": "**Code Structure Analysis**\n..."}]}}
data: {"content": {"parts": [{"text": "**Style Check Results**\n..."}]}}
data: {"content": {"parts": [{"text": "**Test Results**\n..."}]}}
data: {"content": {"parts": [{"text": "**Final Feedback**\n..."}]}}
Stream finished.
רשימת משימות לאימות
- ✅ צינור הבדיקה המלא פועל (כל 4 הסוכנים)
- ✅ תגובת סטרימינג מציגה פלט מתקדם
- ✅ מצב ההפעלה נשמר בין בקשות
- ✅ אין שגיאות אימות או חיבור
- ✅ הפעלת הכלי מתבצעת בהצלחה (ניתוח AST, בדיקת סגנון)
- ✅ Artifacts נשמרים (אפשר לגשת לדוח הציונים)
אפשרות חלופית: פריסה ב-Cloud Run
מומלץ להשתמש ב-Agent Engine כדי לפרוס את הייצור בצורה יעילה, אבל Cloud Run מאפשר שליטה רבה יותר ותומך בממשק האינטרנט של ADK. בקטע הזה מופיעה סקירה כללית.
מתי כדאי להשתמש ב-Cloud Run
בוחרים ב-Cloud Run אם אתם צריכים:
- ממשק המשתמש באינטרנט של ADK לאינטראקציה עם המשתמש
- שליטה מלאה בסביבת הקונטיינר
- הגדרות בהתאמה אישית של מסד נתונים
- שילוב עם שירותי Cloud Run קיימים
איך פריסה ב-Cloud Run עובדת
הפרטים הטכניים
deploy.sh cloud-run
שימושים:
adk deploy cloud_run \
--project=$GOOGLE_CLOUD_PROJECT \
--region=$GOOGLE_CLOUD_LOCATION \
--service_name="code-review-assistant" \
--app_name="code_review_assistant" \
--port=8080 \
--with_ui \
--artifact_service_uri="gs://$ARTIFACT_BUCKET" \
--trace_to_cloud \
code_review_assistant
הפקודה הזו:
- יצירת קונטיינר Docker עם קוד הסוכן
- העלאות ל-Google Artifact Registry
- הפריסה מתבצעת כשירות Cloud Run
- כולל את ממשק האינטרנט של ADK (
--with_ui) - הגדרת חיבור ל-Cloud SQL (נוסף על ידי הסקריפט אחרי הפריסה הראשונית)
ההבדל העיקרי מ-Agent Engine: Cloud Run מכניס את הקוד שלכם לקונטיינר ודורש מסד נתונים כדי לשמור את הנתונים של הסשן, בעוד ש-Agent Engine מטפל בשני הדברים האלה באופן אוטומטי.
פקודת פריסה של Cloud Run
./deploy.sh cloud-run
מה ההבדל
תשתית:
- פריסה בקונטיינר (Docker נוצר אוטומטית על ידי ADK)
- Cloud SQL (PostgreSQL) לשימור נתונים של סשנים
- מסד נתונים שנוצר אוטומטית על ידי סקריפט או שמשתמש במופע קיים
ניהול סשנים:
- שימוש ב-
DatabaseSessionServiceבמקום ב-VertexAiSessionService - נדרשים פרטי כניסה למסד נתונים ב-
.env(או שנוצרו באופן אוטומטי) - המצב נשמר במסד הנתונים של PostgreSQL
תמיכה בממשק המשתמש:
- ממשק משתמש אינטרנטי זמין באמצעות התכונה הניסיונית
--with_ui(מטופל על ידי סקריפט) - גישה בתאריך:
https://code-review-assistant-xyz.a.run.app
מה השגתם
הפריסה בסביבת הייצור כוללת:
✅ הקצאת הרשאות אוטומטית באמצעות סקריפט deploy.sh
✅ תשתית מנוהלת (Agent Engine מטפל בהרחבה, בשימור ובניטור)
✅ מצב מתמשך בכל רמות הזיכרון (סשן, משתמש, משך החיים)
✅ ניהול מאובטח של פרטי כניסה (יצירה אוטומטית והגדרה של IAM)
✅ ארכיטקטורה ניתנת להרחבה (מאפס ועד אלפי משתמשים בו-זמנית)
✅ יכולת מובנית של מעקב אחר נתונים (שילוב של Cloud Trace מופעל)
✅ טיפול בשגיאות ושחזור ברמה של סביבת ייצור
מושגים מרכזיים שנלמדו
הכנות לפריסה:
-
agent_engine_app.py: עוטף את הסוכן ב-AdkAppעבור Agent Engine -
AdkAppמגדיר אוטומטית אתVertexAiSessionServiceלהתמדה - המעקב הופעל באמצעות
enable_tracing=True
פקודות פריסה:
-
adk deploy agent_engine: חבילות קוד Python, ללא קונטיינרים -
adk deploy cloud_run: יצירת קונטיינר Docker באופן אוטומטי -
gcloud run deploy: חלופה עם קובץ Dockerfile מותאם אישית
אפשרויות פריסה:
- Agent Engine: מנוהל באופן מלא, הכי מהיר להפקה
- Cloud Run: יותר שליטה, תמיכה בממשק משתמש בדפדפן
- GKE: שליטה מתקדמת ב-Kubernetes (ראו מדריך הפריסה של GKE)
שירותים מנוהלים:
- מנוע הנציגים מטפל באופן אוטומטי בשימור הסשן
- נדרשת הגדרה של מסד נתונים (או יצירה אוטומטית) ב-Cloud Run
- שניהם תומכים באחסון ארטיפקטים באמצעות GCS
ניהול סשנים:
- Agent Engine:
VertexAiSessionService(אוטומטי) - Cloud Run:
DatabaseSessionService(Cloud SQL) - מקומי:
InMemorySessionService(זמני)
הנציג שלך זמין
העוזר שלך לסקר קוד הוא עכשיו:
- נגיש דרך נקודות קצה של HTTPS API
- Persistent, עם מצב ששורד הפעלות מחדש
- ניתן להרחבה כדי לטפל באופן אוטומטי בגידול של הצוות
- Observable עם עקבות מלאות של בקשות
- ניתן לתחזוקה באמצעות פריסות מבוססות סקריפטים
מה השלב הבא? במודול 8 תלמדו איך להשתמש ב-Cloud Trace כדי להבין את הביצועים של הסוכן, לזהות צווארי בקבוק בצינורות של הבדיקה והתיקון ולבצע אופטימיזציה של זמני הביצוע.
8. ניראות (observability) בסביבת הייצור
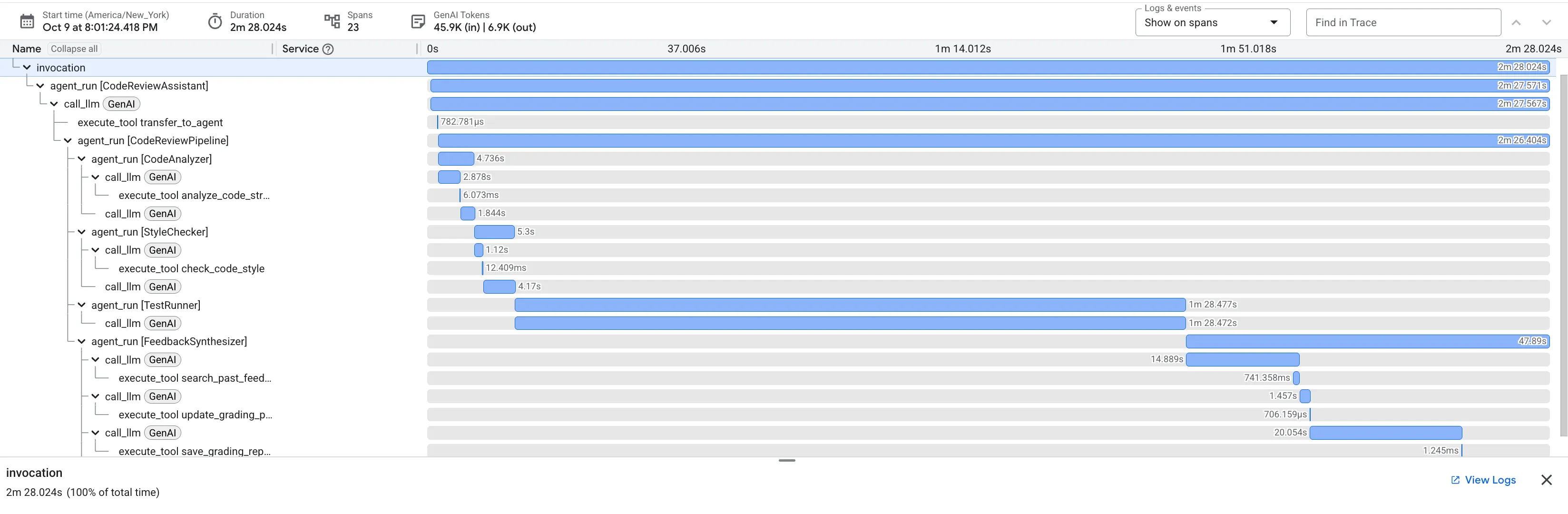
מבוא
עכשיו עוזר סקר הקוד פרוס ופועל בסביבת הייצור ב-Agent Engine. אבל איך יודעים שהיא פועלת בצורה טובה? האם תוכל לענות על השאלות החשובות הבאות:
- האם הנציג מגיב מספיק מהר?
- אילו פעולות הן האיטיות ביותר?
- האם לולאות התיקון מסתיימות ביעילות?
- איפה יש צווארי בקבוק בביצועים?
בלי יכולת צפייה, אתם פועלים בצורה עיוורת. הדגל --trace-to-cloud שבו השתמשתם במהלך הפריסה הפעיל באופן אוטומטי את Cloud Trace, כך שאתם מקבלים תצוגה מלאה של כל בקשה שהסוכן מעבד. השימוש בכלי הזה הופך את תהליך הניפוי באגים מניחוש לניתוח משפטי.
במודול הזה תלמדו איך לקרוא עקבות, להבין את מאפייני הביצועים של הסוכן ולזהות תחומים לאופטימיזציה על סמך ראיות מוצקות.
הסבר על Traces ו-Spans
מה זה Trace?
מעקב הוא ציר הזמן המלא של הטיפול של הסוכן בבקשה יחידה. הוא מתעד את כל מה שקורה מרגע שמשתמש שולח שאילתה ועד למסירת התשובה הסופית. בכל מעקב מוצגים הפרטים הבאים:
- משך הזמן הכולל של הבקשה
- כל הפעולות שהופעלו
- איך הפעולות קשורות זו לזו (קשרים של הורה-צאצא)
- מתי כל פעולה התחילה ומתי היא הסתיימה
מה זה Span?
span מייצג יחידת עבודה אחת בתוך trace. סוגים נפוצים של טווחים בעוזר לבדיקת קוד:
-
agent_run: הפעלה של סוכן (סוכן ראשי או סוכן משנה) -
call_llm: בקשה למודל שפה -
execute_tool: הפעלת פונקציית כלי -
state_read/state_write: פעולות לניהול מצב -
code_executor: הרצת קוד עם בדיקות
בטווחים יש:
- שם: הפעולה שהשורה מייצגת
- משך הזמן: כמה זמן זה לקח
- מאפיינים: מטא-נתונים כמו שם המודל, מספר הטוקנים, קלט/פלט
- סטטוס: הצלחה או כישלון
- קשרים של הורה/צאצא: אילו פעולות הפעילו אילו פעולות
אינסטרומנטציה אוטומטית
כשמבצעים פריסה באמצעות --trace-to-cloud, ADK מבצע אוטומטית את הפעולות הבאות:
- כל הפעלה של סוכן וכל שיחה עם סוכן משנה
- כל הבקשות ל-LLM עם ספירת טוקנים
- הפעלות של כלים עם קלט/פלט
- פעולות במצב (קריאה/כתיבה)
- חזרות של לולאות בצינור התיקון
- תנאי שגיאה וניסיונות חוזרים
אין צורך לשנות את הקוד – מעקב מוטמע בזמן הריצה של ADK.
שלב 1: גישה לכלי Cloud Trace Explorer
פותחים את Cloud Trace במסוף Google Cloud:
- עוברים אל Cloud Trace Explorer
- בוחרים את הפרויקט מהתפריט הנפתח (הוא אמור להיות מסומן מראש).
- אמורים לראות עקבות מהבדיקה במודול 7
אם עדיין לא רואים עקבות:
הבדיקה שהרצתם במודול 7 אמורה ליצור עקבות. אם הרשימה ריקה, צריך ליצור נתוני מעקב:
python tests/test_agent_engine.py
ממתינים דקה או שתיים עד שהעקבות יופיעו במסוף.
מה רואים
בכלי Trace Explorer מוצגות התוצאות הבאות:
- רשימת העקבות: כל שורה מייצגת בקשה אחת מלאה
- ציר הזמן: מתי התרחשו הבקשות
- משך הזמן: כמה זמן נמשכה כל בקשה
- פרטי הבקשה: חותמת זמן, זמן אחזור, מספר טווחים
זהו יומן תנועת הייצור שלכם – כל אינטראקציה עם הסוכן יוצרת מעקב.
שלב 2: בדיקת מעקב של צינור לבדיקת תוכן
לוחצים על אחד מהמעקבים ברשימה כדי לפתוח את תצוגת המפל.
יוצג תרשים גאנט שמציג את ציר הזמן המלא של ההפעלה. הטווח invocation root מייצג את הבקשה כולה. מתחתיו מוצגים טווחי זמן לכל סוכן משנה, כלי ושיחה עם מודל שפה גדול (LLM).
קריאת נתוני המפל: זיהוי צווארי בקבוק
כל עמודה מייצגת טווח. המיקום האופקי של כל פס מציין מתי הוא התחיל, והאורך שלו מציין כמה זמן הוא נמשך. כך אפשר לראות מיד איפה הסוכן מבלה את הזמן שלו.
תובנות מרכזיות מהמעקב שלמעלה:
- השהיה הכוללת: הבקשה כולה נמשכה 2 דקות ו-28 שניות.
- פירוט של סוכני משנה:
-
Code Analyzer: 4.7 שניות -
Style Checker: 5.3 שניות -
Test Runner: דקה ו-28 שניות -
Feedback Synthesizer: 47.9 שניות
-
- ניתוח הנתיב הקריטי: סוכן
Test Runnerהוא צוואר הבקבוק הברור בביצועים, והוא אחראי לכ-59% מזמן הבקשה הכולל.
היכולת הזו לראות את כל הנתונים היא עוצמתית. במקום לנחש איפה הזמן מנוצל, יש לכם הוכחות קונקרטיות שאם אתם צריכים לבצע אופטימיזציה של זמן האחזור, Test Runner הוא היעד הברור.
בדיקת השימוש בטוקנים לצורך אופטימיזציה של העלויות
ב-Cloud Trace לא מוצג רק הזמן, אלא גם העלויות, כי המערכת מתעדת את השימוש בטוקנים בכל קריאה למודל שפה גדול (LLM).
לוחצים על
call_llm
span within the trace. בחלונית הפרטים יופיעו מאפיינים של llm.usage.prompt_tokens ושל llm.usage.completion_tokens.

כך אתם יכולים:
- מעקב אחרי עלויות ברמה מפורטת: אתם יכולים לראות בדיוק כמה טוקנים כל סוכן וכלי צורכים.
- זיהוי הזדמנויות לאופטימיזציה: אם סוכן משתמש במספר גבוה באופן מפתיע של טוקנים, יכול להיות שזו הזדמנות לשפר את ההנחיה שלו או לעבור למודל קטן יותר וחסכוני יותר למשימה הספציפית הזו.
שלב 3: ניתוח של מעקב אחר צינור תיקון
תהליך התיקון מורכב יותר כי הוא כולל LoopAgent. בעזרת Cloud Trace קל להבין את ההתנהגות האיטרטיבית הזו.
חיפוש של מעקב שכולל את המחרוזת FixAttemptLoop בשמות של טווחים.
אם אין לכם כזה, מריצים את סקריפט הבדיקה ומשיבים בחיוב כשנשאלים אם רוצים לתקן את הקוד.
בדיקת המבנה של Loop
בתצוגת המעקב אפשר לראות בבירור את הביצוע של הלולאה. אם לולאת התיקון פעלה פעמיים לפני שהצליחה, יופיעו שני טווחי loop_iteration שמוטמעים בתוך טווח FixAttemptLoop, וכל אחד מהם מכיל מחזור מלא של סוכני CodeFixer, FixTestRunner ו-FixValidator.

תובנות מרכזיות ממעקב אחר לולאה:
- שיפור איטרטיבי גלוי: אפשר לראות את המערכת מנסה לתקן את הבעיה ב-
loop_iteration: 1, מאמתת את התיקון ואז – כי הוא לא היה מושלם – מנסה שוב ב-loop_iteration: 2. - אפשר למדוד את ההתכנסות: אפשר להשוות את משך הזמן והתוצאות של כל איטרציה כדי להבין איך המערכת התכנסה לפתרון נכון.
- ניפוי הבאגים פשוט יותר: אם לולאה פועלת למספר המקסימלי של איטרציות ועדיין נכשלת, אפשר לבדוק את המצב ואת התנהגות הסוכן בטווח של כל איטרציה כדי לאבחן למה התיקונים לא התכנסו.
רמת הפירוט הזו חשובה מאוד להבנה ולניפוי באגים של התנהגות לולאות מורכבות עם מצב בסביבת הייצור.
שלב 4: מה גיליתם
דפוסי ביצועים
מבדיקת העקבות, עכשיו יש לכם תובנות מבוססות-נתונים:
צינור עיבוד נתונים של ביקורות:
- צוואר הבקבוק העיקרי:
Test Runnerהסוכן, ובמיוחד ביצוע הקוד שלו ויצירת הבדיקות שמבוססות על LLM, הם החלקים שלוקחים הכי הרבה זמן בתהליך הבדיקה. - פעולות מהירות: כלים דטרמיניסטיים (
analyze_code_structure) ופעולות לניהול מצב הם מהירים מאוד ולא משפיעים על הביצועים.
תיקון צינור עיבוד הנתונים:
- שיעור ההתכנסות: אפשר לראות שרוב התיקונים הושלמו ב-1-2 איטרציות, מה שמאשר שהארכיטקטורה של הלולאה יעילה.
- עלות מתקדמת: יכול להיות שאיטרציות מאוחרות יותר יימשכו זמן רב יותר, כי ההקשר של מודל ה-LLM גדל עם מידע מניסיונות קודמים שנכשלו.
הגורמים לעלויות:
- צריכת טוקנים: אתם יכולים לזהות אילו סוכנים (כמו סינתיסייזרים) דורשים הכי הרבה טוקנים, ולהחליט אם השימוש במודל חזק יותר אבל יקר יותר מוצדק למשימה הזו.
איפה אפשר למצוא בעיות
כשבודקים עקבות בסביבת הייצור, חשוב לשים לב ל:
- עקבות ארוכים באופן חריג: סימן לנסיגה בביצועים או להתנהגות לא צפויה של לולאה.
- Failed spans (מסומן באדום): מציין את הפעולה המדויקת שנכשלה.
- חזרות מוגזמות על לולאה (>2): יכול להיות שיש בעיה בלוגיקה של יצירת התיקון.
- מספר גבוה של טוקנים: מדגיש הזדמנויות לאופטימיזציה של ההנחיה או לשינויים בבחירת המודל.
מה למדתם
בעזרת Cloud Trace, אתם יכולים להבין איך:
✅ Visualize request flow: See the complete execution path through your sequential and loop-based pipelines.
✅ זיהוי צווארי בקבוק בביצועים: אפשר להשתמש בתרשים Waterfall כדי למצוא את הפעולות הכי איטיות עם נתונים קונקרטיים.
✅ ניתוח התנהגות של לולאה: אפשר לראות איך סוכנים איטרטיביים מתכנסים לפתרון אחרי כמה ניסיונות.
✅ מעקב אחרי עלויות הטוקנים: בודקים את טווחי ה-LLM כדי לעקוב אחרי צריכת הטוקנים ולבצע אופטימיזציה שלה ברמה מפורטת.
מושגים מרכזיים שנלמדו
- עקבות וטווחים: היחידות הבסיסיות של ניראות (observability), שמייצגות בקשות והפעולות שמתבצעות בתוכן שלהן.
- ניתוח Waterfall: קריאת תרשימי גאנט כדי להבין את זמן הביצוע והתלות.
- זיהוי הנתיב הקריטי: מציאת רצף הפעולות שקובע את זמן האחזור הכולל.
- יכולת תצפית מפורטת: אפשר לראות לא רק את הזמן אלא גם מטא-נתונים כמו מספר האסימונים לכל פעולה, שמתועדים אוטומטית על ידי ADK.
המאמרים הבאים
המשך עיון ב-Cloud Trace:
- כדאי לעקוב אחרי העקבות באופן קבוע כדי לזהות בעיות בשלב מוקדם
- השוואת עקבות כדי לזהות ירידות בביצועים
- שימוש בנתוני מעקב כדי לקבל החלטות מושכלות לגבי אופטימיזציה
- סינון לפי משך הזמן כדי למצוא בקשות איטיות
יכולות מתקדמות של ניטור (אופציונלי):
- ייצוא עקבות ל-BigQuery לניתוח מורכב (מסמכים)
- יצירת מרכזי בקרה בהתאמה אישית ב-Cloud Monitoring
- הגדרת התראות על ירידה בביצועים
- התאמה בין עקבות לבין יומני אפליקציות
9. סיכום: מאב טיפוס לייצור
מה יצרתם
התחלתם עם שבע שורות קוד בלבד ובניתם מערכת סוכני AI ברמת ייצור:
# Where we started (7 lines)
agent = Agent(
model="gemini-2.5-flash",
instruction="Review Python code for issues"
)
# Where we ended (production system)
- Two distinct multi-agent pipelines (review and fix) built from 8 specialized agents.
- An iterative fix loop architecture for automated validation and retries.
- Real AST-based code analysis tools for deterministic, accurate feedback.
- Robust state management using the "constants pattern" for type-safe communication.
- Fully automated deployment to a managed, scalable cloud infrastructure.
- Complete, built-in observability with Cloud Trace for production monitoring.
דפוסי ארכיטקטורה מרכזיים
דוגמת קוד | הטמעה | השפעה על הייצור |
Tool Integration | ניתוח AST, בדיקת סגנון | אימות אמיתי, לא רק דעות של LLM |
צינורות עיבוד נתונים עוקבים | בדיקה → תיקון תהליכי עבודה | הרצה צפויה שניתן לנפות בה באגים |
ארכיטקטורת Loop | תיקון איטרטיבי עם תנאי יציאה | שיפור עצמי עד להצלחה |
State Management | דפוס קבועים, זיכרון תלת-שכבתי | טיפול במצב שניתן לתחזוקה ובטוח מבחינת סוגים |
פריסה בסביבת ייצור | Agent Engine באמצעות deploy.sh | תשתית מנוהלת עם יכולת התאמה |
ניראות (observability) | שילוב עם Cloud Trace | יכולת מלאה לראות את ההתנהגות בסביבת הייצור |
תובנות לגבי הפקה מנתוני מעקב
הנתונים של Cloud Trace חשפו תובנות חשובות:
✅ צוואר בקבוק זוהה: קריאות ה-LLM של TestRunner משפיעות על זמן האחזור
✅ ביצועי הכלי: ניתוח AST מתבצע ב-100ms (מצוין)
✅ שיעור ההצלחה: לולאות התיקון מתכנסות תוך 2-3 איטרציות
✅ שימוש בטוקנים: ~600 טוקנים לכל בדיקה, ~1,800 לתיקונים
התובנות האלה מאפשרות לנו לשפר את המוצרים שלנו באופן מתמשך.
הסרת המשאבים (אופציונלי)
אם סיימתם את הניסוי ואתם רוצים להימנע מחיובים:
מחיקת פריסה של Agent Engine:
import vertexai
client = vertexai.Client( # For service interactions via client.agent_engines
project="PROJECT_ID",
location="LOCATION",
)
RESOURCE_NAME = "projects/{PROJECT_ID}/locations/{LOCATION}/reasoningEngines/{RESOURCE_ID}"
client.agent_engines.delete(
name=RESOURCE_NAME,
force=True, # Optional, if the agent has resources (e.g. sessions, memory)
)
מחיקת שירות Cloud Run (אם נוצר):
gcloud run services delete code-review-assistant \
--region=$GOOGLE_CLOUD_LOCATION \
--quiet
מחיקת מכונה של Cloud SQL (אם נוצרה):
gcloud sql instances delete your-project-db \
--quiet
פינוי נפח אחסון בדלי אחסון:
gsutil -m rm -r gs://your-project-staging
gsutil -m rm -r gs://your-project-artifacts
השלבים הבאים
אחרי שסיימתם את ההגדרה הבסיסית, כדאי להשתמש בשיפורים הבאים:
- הוספת שפות נוספות: הרחבת הכלים כך שיכללו תמיכה ב-JavaScript, Go, Java
- שילוב עם GitHub: בדיקות אוטומטיות של בקשות למשיכת קוד
- הטמעת שמירה במטמון: קיצור זמן האחזור בדפוסים נפוצים
- הוספת סוכנים מיוחדים: סריקת אבטחה, ניתוח ביצועים
- הפעלת בדיקת A/B: השוואה בין מודלים והנחיות שונות
- ייצוא מדדים: שליחת נתונים למעקב לפלטפורמות ייעודיות לניתוח נתונים
נקודות עיקריות
- מתחילים בפשטות, חוזרים על הפעולה במהירות: שבע שורות עד לייצור בשלבים ניהוליים
- כלים עדיפים על הנחיות: ניתוח AST אמיתי עדיף על "בבקשה בדוק אם יש באגים"
- ניהול מצבים חשוב: דפוס הקבועים מונע באגים של שגיאות הקלדה
- ללולאות צריך להגדיר תנאי יציאה: תמיד מגדירים את מספר האיטרציות המקסימלי ואת ההסלמה
- פריסה באמצעות אוטומציה: deploy.sh מטפל בכל המורכבות
- יכולת התצפית היא חובה: אי אפשר לשפר את מה שלא ניתן למדוד
משאבים להמשך הלמידה
- מסמכי תיעוד של ADK
- דפוסי ADK מתקדמים
- מדריך Agent Engine
- מאמרי העזרה של Cloud Run
- חומרי עזר בנושא Cloud Trace
המסע שלך נמשך
יצרתם יותר מעוזר לסקר קוד – למדתם את הדפוסים ליצירת סוכן AI בסביבת ייצור:
✅ תהליכי עבודה מורכבים עם כמה סוכנים מיוחדים
✅ שילוב אמיתי של כלים ליכולות אמיתיות
✅ פריסה בסביבת ייצור עם ניראות מתאימה
✅ ניהול מצבים למערכות שניתנות לתחזוקה
הדפוסים האלה מתרחבים מעוזרים פשוטים למערכות אוטונומיות מורכבות. הידע שרכשתם כאן ישמש אתכם היטב כשתתמודדו עם ארכיטקטורות מתוחכמות יותר של סוכנים.
ברוכים הבאים לפיתוח סוכני AI לייצור. העוזר לסקר קוד הוא רק ההתחלה.