
1. Peninjauan Kode Tengah Malam
Sekarang pukul 02.00
Anda telah melakukan proses debug selama berjam-jam. Fungsinya terlihat benar, tetapi ada yang salah. Anda pasti pernah merasakan saat kode seharusnya berfungsi, tetapi tidak, dan Anda tidak tahu lagi alasannya karena sudah terlalu lama menatapnya.
def dfs_search_v1(graph, start, target):
"""Find if target is reachable from start."""
visited = set()
stack = start # Looks innocent enough...
while stack:
current = stack.pop()
if current == target:
return True
if current not in visited:
visited.add(current)
for neighbor in graph[current]:
if neighbor not in visited:
stack.append(neighbor)
return False
Perjalanan Developer AI
Jika Anda membaca artikel ini, kemungkinan Anda telah merasakan transformasi yang dibawa AI ke dalam coding. Alat seperti Gemini Code Assist, Claude Code, dan Cursor telah mengubah cara kita menulis kode. Fitur ini sangat berguna untuk membuat boilerplate, menyarankan penerapan, dan mempercepat pengembangan.
Namun, Anda berada di sini karena ingin mendalami lebih jauh. Anda ingin memahami cara membangun sistem AI ini, bukan hanya menggunakannya. Anda ingin membuat sesuatu yang:
- Memiliki perilaku yang dapat diprediksi dan dilacak
- Dapat di-deploy ke produksi dengan percaya diri
- Memberikan hasil yang konsisten dan dapat Anda andalkan
- Menunjukkan dengan tepat cara pengambilan keputusannya
Dari Konsumen menjadi Kreator
Hari ini, Anda akan beralih dari menggunakan alat AI ke membangunnya. Anda akan membuat sistem multi-agen yang:
- Menganalisis struktur kode secara deterministik
- Menjalankan pengujian sebenarnya untuk memverifikasi perilaku
- Memvalidasi kepatuhan gaya dengan linter sebenarnya
- Menyintesis temuan menjadi masukan yang dapat ditindaklanjuti
- Men-deploy ke Google Cloud dengan kemampuan observasi penuh
2. Deployment Agen Pertama Anda
Pertanyaan Developer
"Saya memahami LLM, saya telah menggunakan API, tetapi bagaimana cara beralih dari skrip Python ke agen AI produksi yang dapat diskalakan?"
Mari kita jawab pertanyaan ini dengan menyiapkan lingkungan Anda dengan benar, lalu membangun agen sederhana untuk memahami dasar-dasarnya sebelum mempelajari pola produksi.
Penyiapan Penting Terlebih Dahulu
Sebelum membuat agen, pastikan lingkungan Google Cloud Anda sudah siap.
Klik Activate Cloud Shell di bagian atas konsol Google Cloud (Ikon berbentuk terminal di bagian atas panel Cloud Shell),
Temukan ID Project Google Cloud Anda:
- Buka Konsol Google Cloud: https://console.cloud.google.com
- Pilih project yang ingin Anda gunakan untuk workshop ini dari dropdown project di bagian atas halaman.
- Project ID Anda ditampilkan di kartu Info project di Dasbor
Langkah 1: Tetapkan Project ID Anda
Di Cloud Shell, alat command line gcloud sudah dikonfigurasi. Jalankan perintah berikut untuk menetapkan project aktif Anda. Langkah ini menggunakan variabel lingkungan $GOOGLE_CLOUD_PROJECT, yang otomatis ditetapkan untuk Anda di sesi Cloud Shell.
gcloud config set project $GOOGLE_CLOUD_PROJECT
Langkah 2: Verifikasi Penyiapan Anda
Selanjutnya, jalankan perintah berikut untuk mengonfirmasi bahwa project Anda telah disetel dengan benar dan Anda telah diautentikasi.
# Confirm project is set
echo "Current project: $(gcloud config get-value project)"
# Check authentication status
gcloud auth list
Anda akan melihat ID project yang dicetak, dan akun pengguna Anda tercantum dengan (ACTIVE) di sampingnya.
Jika akun Anda tidak tercantum sebagai aktif, atau jika Anda mendapatkan error autentikasi, jalankan perintah berikut untuk login:
gcloud auth application-default login
Langkah 3: Aktifkan Essential API
Kita memerlukan setidaknya API berikut untuk agen dasar:
gcloud services enable \
aiplatform.googleapis.com \
compute.googleapis.com
Mungkin perlu waktu satu atau dua menit. Anda akan melihat:
Operation "operations/..." finished successfully.
Langkah 4: Instal ADK
# Install the ADK CLI
pip install google-adk --upgrade
# Verify installation
adk --version
Anda akan melihat nomor versi seperti 1.15.0 atau yang lebih tinggi.
Sekarang Buat Agen Dasar Anda
Setelah lingkungan siap, mari kita buat agen sederhana tersebut.
Langkah 5: Gunakan Pembuatan ADK
adk create my_first_agent
Ikuti perintah interaktif:
Choose a model for the root agent:
1. gemini-2.5-flash
2. Other models (fill later)
Choose model (1, 2): 1
1. Google AI
2. Vertex AI
Choose a backend (1, 2): 2
Enter Google Cloud project ID [auto-detected-from-gcloud]:
Enter Google Cloud region [us-central1]:
Langkah 6: Periksa Hasil Buatan
cd my_first_agent
ls -la
Anda akan menemukan tiga file:
.env # Configuration (auto-populated with your project)
__init__.py # Package marker
agent.py # Your agent definition
Langkah 7: Pemeriksaan Konfigurasi Cepat
# Verify the .env was created correctly
cat .env
# Should show something like:
# GOOGLE_CLOUD_PROJECT=your-project-id
# GOOGLE_CLOUD_LOCATION=us-central1
# GOOGLE_GENAI_USE_VERTEXAI=1
Jika project ID tidak ada atau salah, edit file .env:
nano .env # or use your preferred editor
Langkah 8: Lihat Kode Agen
cat agent.py
from google.adk.agents.llm_agent import Agent
root_agent = Agent(
model='gemini-2.5-flash',
name='root_agent',
description='A helpful assistant for user questions.',
instruction='Answer user questions to the best of your knowledge',
)
Sederhana, bersih, minimal. Ini adalah "Halo Dunia" agen Anda.
Menguji Agen Dasar Anda
Langkah 9: Jalankan Agen Anda
cd ..
adk run my_first_agent
Anda akan melihat yang seperti:
Log setup complete: /tmp/agents_log/agent.20250930_162430.log
To access latest log: tail -F /tmp/agents_log/agent.latest.log
[user]:
Langkah 10: Coba Beberapa Kueri
Di terminal tempat adk run berjalan, Anda akan melihat perintah. Ketik kueri Anda:
[user]: Hey, what can you do?
[root_agent]: I can help answer questions, generate text, explain concepts, assist with problem-solving, and provide information on a wide range of topics. What would you like to know or discuss?
[user]: What's the current weather in Mountain View?
[root_agent]: I'm sorry, but I cannot provide real-time weather information as I don't have access to current data or weather services. To get the current weather in Mountain View, I recommend checking a weather website or app like weather.com or using a search engine.
Perhatikan batasannya - tidak dapat mengakses data saat ini. Mari kita lanjutkan:
[user]: Review this Python code: def add(a, b): return a + b
[root_agent]: This is a simple Python function that adds two numbers. Here's my review:
**Strengths:**
- Clean and concise implementation
- Follows Python conventions for simple operations
- Clear function name that describes its purpose
**Suggestions for improvement:**
- Add a docstring to document the function
- Consider adding type hints for better code clarity
- You might want to handle edge cases
Here's an enhanced version:
def add(a: float, b: float) -> float:
"""Add two numbers and return their sum."""
return a + b
Agen dapat mendiskusikan kode, tetapi apakah agen dapat:
- Benar-benar mengurai AST untuk memahami struktur?
- Menjalankan pengujian untuk memverifikasi apakah fungsi ini berfungsi?
- Periksa kepatuhan gaya?
- Ingat ulasan Anda sebelumnya?
Tidak. Di sinilah kita membutuhkan arsitektur.
🏃🚪 Keluar dengan
Ctrl+C
setelah selesai menjelajah.
3. Menyiapkan Ruang Kerja Produksi Anda
Solusi: Arsitektur Siap Produksi
Agen sederhana tersebut menunjukkan titik awal, tetapi sistem produksi memerlukan struktur yang tangguh. Sekarang kita akan menyiapkan project lengkap yang menerapkan prinsip produksi.
Menyiapkan Fondasi
Anda telah mengonfigurasi project Google Cloud untuk agen dasar. Sekarang, mari kita siapkan ruang kerja produksi lengkap dengan semua alat, pola, dan infrastruktur yang diperlukan untuk sistem nyata.
Langkah 1: Dapatkan Project Terstruktur
Pertama, keluar dari adk run yang sedang berjalan dengan Ctrl+C dan bersihkan:
# Clean up the basic agent
cd ~ # Make sure you're not inside my_first_agent
rm -rf my_first_agent
# Get the production scaffold
git clone https://github.com/ayoisio/adk-code-review-assistant.git
cd adk-code-review-assistant
git checkout codelab
Langkah 2: Buat dan Aktifkan Lingkungan Virtual
# Create the virtual environment
python -m venv .venv
# Activate it
# On macOS/Linux:
source .venv/bin/activate
# On Windows:
# .venv\Scripts\activate
Verifikasi: Perintah Anda sekarang akan menampilkan (.venv) di bagian awal.
Langkah 3: Instal Dependensi
pip install -r code_review_assistant/requirements.txt
# Install the package in editable mode (enables imports)
pip install -e .
Tindakan ini akan menginstal:
google-adk- Framework ADKpycodestyle- Untuk pemeriksaan PEP 8vertexai- Untuk deployment cloud- Dependensi produksi lainnya
Dengan tanda -e, Anda dapat mengimpor modul code_review_assistant dari mana saja.
Langkah 4: Konfigurasi Lingkungan Anda
# Copy the example environment file
cp .env.example .env
# Edit .env and replace the placeholders:
# - GOOGLE_CLOUD_PROJECT=your-project-id → your actual project ID
# - Keep other defaults as-is
Verifikasi: Periksa konfigurasi Anda:
cat .env
Akan menampilkan:
GOOGLE_CLOUD_PROJECT=your-actual-project-id
GOOGLE_CLOUD_LOCATION=us-central1
GOOGLE_GENAI_USE_VERTEXAI=TRUE
Langkah 5: Pastikan Autentikasi
Karena Anda sudah menjalankan gcloud auth sebelumnya, mari kita verifikasi saja:
# Check current authentication
gcloud auth list
# Should show your account with (ACTIVE)
# If not, run:
gcloud auth application-default login
Langkah 6: Aktifkan API Produksi Tambahan
Kita sudah mengaktifkan API dasar. Sekarang tambahkan yang produksi:
gcloud services enable \
sqladmin.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
storage.googleapis.com \
cloudtrace.googleapis.com
Tindakan ini memungkinkan:
- SQL Admin: Untuk Cloud SQL jika menggunakan Cloud Run
- Cloud Run: Untuk deployment serverless
- Cloud Build: Untuk deployment otomatis
- Artifact Registry: Untuk image container
- Cloud Storage: Untuk artefak dan penyiapan
- Cloud Trace: Untuk kemampuan observasi
Langkah 7: Buat Repositori Artifact Registry
Deployment kita akan membuat image container yang memerlukan lokasi:
gcloud artifacts repositories create code-review-assistant-repo \
--repository-format=docker \
--location=us-central1 \
--description="Docker repository for Code Review Assistant"
Anda akan melihat:
Created repository [code-review-assistant-repo].
Jika sudah ada (mungkin dari upaya sebelumnya), tidak masalah - Anda akan melihat pesan error yang dapat diabaikan.
Langkah 8: Berikan Izin IAM
# Get your project number
PROJECT_NUMBER=$(gcloud projects describe $GOOGLE_CLOUD_PROJECT \
--format="value(projectNumber)")
# Define the service account
SERVICE_ACCOUNT="${PROJECT_NUMBER}@cloudbuild.gserviceaccount.com"
# Grant necessary roles
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SERVICE_ACCOUNT}" \
--role="roles/run.admin"
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SERVICE_ACCOUNT}" \
--role="roles/iam.serviceAccountUser"
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SERVICE_ACCOUNT}" \
--role="roles/cloudsql.admin"
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SERVICE_ACCOUNT}" \
--role="roles/storage.admin"
Setiap perintah akan menghasilkan output:
Updated IAM policy for project [your-project-id].
Yang Telah Anda Capai
Ruang kerja produksi Anda kini telah sepenuhnya disiapkan:
✅ Project Google Cloud dikonfigurasi dan diautentikasi
✅ Agen dasar diuji untuk memahami batasan
✅ Kode project dengan placeholder strategis siap
✅ Dependensi diisolasi di lingkungan virtual
✅ Semua API yang diperlukan diaktifkan
✅ Registry container siap untuk deployment
✅ Izin IAM dikonfigurasi dengan benar
✅ Variabel lingkungan ditetapkan dengan benar
Sekarang Anda siap membangun sistem AI nyata dengan alat deterministik, pengelolaan status, dan arsitektur yang tepat.
4. Membangun Agen Pertama Anda
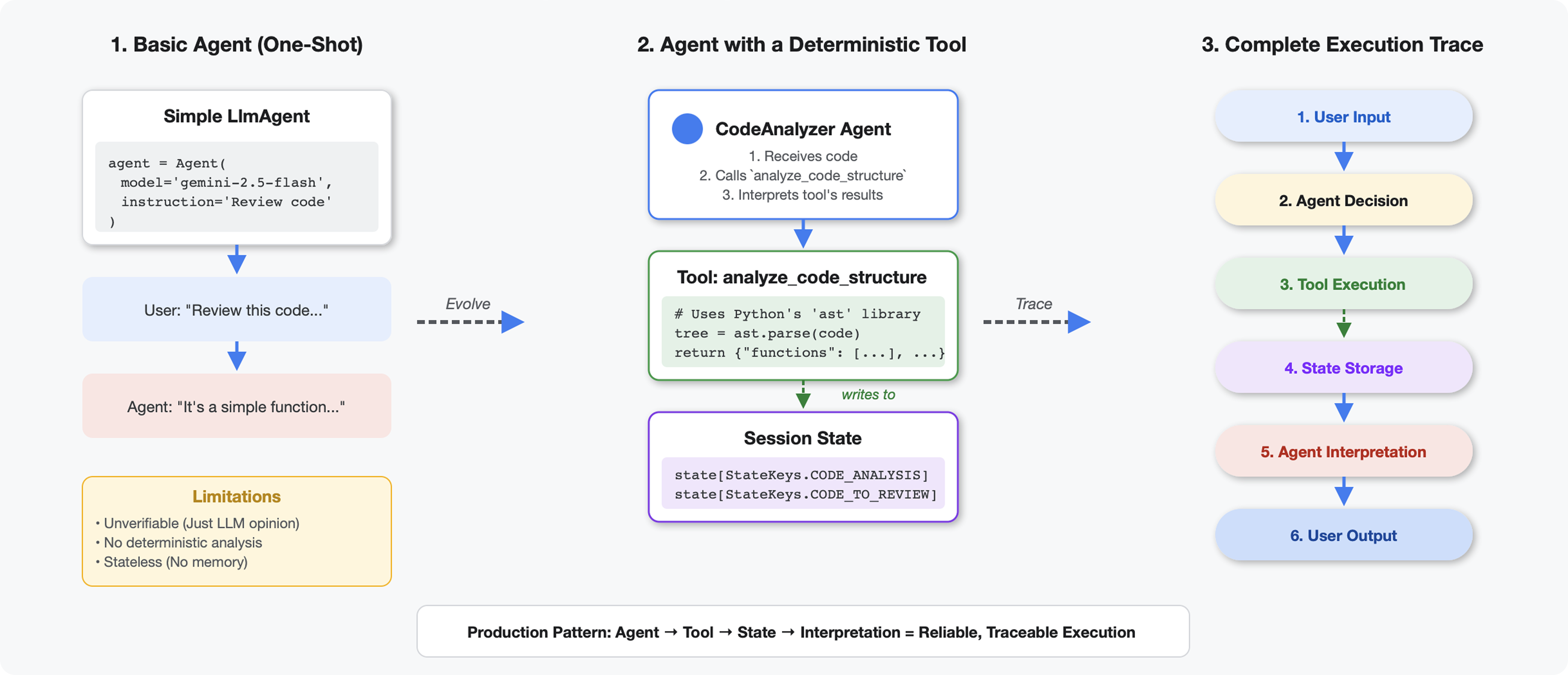
Yang Membedakan Alat dengan LLM
Saat Anda bertanya kepada LLM "berapa banyak fungsi dalam kode ini?", LLM akan menggunakan pencocokan pola dan estimasi. Saat Anda menggunakan alat yang memanggil ast.parse() Python, alat tersebut akan mem-parsing pohon sintaksis yang sebenarnya - tidak ada tebakan, hasil yang sama setiap saat.
Bagian ini membuat alat yang menganalisis struktur kode secara deterministik, lalu menghubungkannya ke agen yang tahu kapan harus memanggilnya.
Langkah 1: Memahami Scaffold
Mari kita periksa struktur yang akan Anda isi.
👉 Buka
code_review_assistant/tools.py
Anda akan melihat fungsi analyze_code_structure dengan komentar placeholder yang menandai tempat Anda akan menambahkan kode. Fungsi ini sudah memiliki struktur dasar - Anda akan menyempurnakannya langkah demi langkah.
Langkah 2: Tambahkan Penyimpanan Status
Penyimpanan status memungkinkan agen lain dalam pipeline mengakses hasil alat Anda tanpa menjalankan kembali analisis.
👉 Temukan:
# MODULE_4_STEP_2_ADD_STATE_STORAGE
👉 Ganti satu baris tersebut dengan:
# Store code and analysis for other agents to access
tool_context.state[StateKeys.CODE_TO_REVIEW] = code
tool_context.state[StateKeys.CODE_ANALYSIS] = analysis
tool_context.state[StateKeys.CODE_LINE_COUNT] = len(code.splitlines())
Langkah 3: Tambahkan Penguraian Asinkron dengan Thread Pool
Alat kami perlu mengurai AST tanpa memblokir operasi lain. Mari tambahkan eksekusi asinkron dengan thread pool.
👉 Temukan:
# MODULE_4_STEP_3_ADD_ASYNC
👉 Ganti satu baris tersebut dengan:
# Parse in thread pool to avoid blocking the event loop
loop = asyncio.get_event_loop()
with ThreadPoolExecutor() as executor:
tree = await loop.run_in_executor(executor, ast.parse, code)
Langkah 4: Ekstrak Informasi Komprehensif
Sekarang mari kita ekstrak class, impor, dan metrik mendetail - semua yang kita butuhkan untuk peninjauan kode yang lengkap.
👉 Temukan:
# MODULE_4_STEP_4_EXTRACT_DETAILS
👉 Ganti satu baris tersebut dengan:
# Extract comprehensive structural information
analysis = await loop.run_in_executor(
executor, _extract_code_structure, tree, code
)
👉 Verifikasi: fungsi
analyze_code_structure
di
tools.py
memiliki bagian tengah yang terlihat seperti ini:
# Parse in thread pool to avoid blocking the event loop
loop = asyncio.get_event_loop()
with ThreadPoolExecutor() as executor:
tree = await loop.run_in_executor(executor, ast.parse, code)
# Extract comprehensive structural information
analysis = await loop.run_in_executor(
executor, _extract_code_structure, tree, code
)
# Store code and analysis for other agents to access
tool_context.state[StateKeys.CODE_TO_REVIEW] = code
tool_context.state[StateKeys.CODE_ANALYSIS] = analysis
tool_context.state[StateKeys.CODE_LINE_COUNT] = len(code.splitlines())
👉 Sekarang scroll ke bagian bawah
tools.py
dan temukan:
# MODULE_4_STEP_4_HELPER_FUNCTION
👉 Ganti satu baris tersebut dengan fungsi bantuan lengkap:
def _extract_code_structure(tree: ast.AST, code: str) -> Dict[str, Any]:
"""
Helper function to extract structural information from AST.
Runs in thread pool for CPU-bound work.
"""
functions = []
classes = []
imports = []
docstrings = []
for node in ast.walk(tree):
if isinstance(node, ast.FunctionDef):
func_info = {
'name': node.name,
'args': [arg.arg for arg in node.args.args],
'lineno': node.lineno,
'has_docstring': ast.get_docstring(node) is not None,
'is_async': isinstance(node, ast.AsyncFunctionDef),
'decorators': [d.id for d in node.decorator_list
if isinstance(d, ast.Name)]
}
functions.append(func_info)
if func_info['has_docstring']:
docstrings.append(f"{node.name}: {ast.get_docstring(node)[:50]}...")
elif isinstance(node, ast.ClassDef):
methods = []
for item in node.body:
if isinstance(item, ast.FunctionDef):
methods.append(item.name)
class_info = {
'name': node.name,
'lineno': node.lineno,
'methods': methods,
'has_docstring': ast.get_docstring(node) is not None,
'base_classes': [base.id for base in node.bases
if isinstance(base, ast.Name)]
}
classes.append(class_info)
elif isinstance(node, ast.Import):
for alias in node.names:
imports.append({
'module': alias.name,
'alias': alias.asname,
'type': 'import'
})
elif isinstance(node, ast.ImportFrom):
imports.append({
'module': node.module or '',
'names': [alias.name for alias in node.names],
'type': 'from_import',
'level': node.level
})
return {
'functions': functions,
'classes': classes,
'imports': imports,
'docstrings': docstrings,
'metrics': {
'line_count': len(code.splitlines()),
'function_count': len(functions),
'class_count': len(classes),
'import_count': len(imports),
'has_main': any(f['name'] == 'main' for f in functions),
'has_if_main': '__main__' in code,
'avg_function_length': _calculate_avg_function_length(tree)
}
}
def _calculate_avg_function_length(tree: ast.AST) -> float:
"""Calculate average function length in lines."""
function_lengths = []
for node in ast.walk(tree):
if isinstance(node, ast.FunctionDef):
if hasattr(node, 'end_lineno') and hasattr(node, 'lineno'):
length = node.end_lineno - node.lineno + 1
function_lengths.append(length)
if function_lengths:
return sum(function_lengths) / len(function_lengths)
return 0.0
Langkah 5: Hubungkan ke Agen
Sekarang kita menghubungkan alat tersebut ke agen yang tahu kapan harus menggunakannya dan cara menafsirkan hasilnya.
👉 Buka
code_review_assistant/sub_agents/review_pipeline/code_analyzer.py
👉 Temukan:
# MODULE_4_STEP_5_CREATE_AGENT
👉 Ganti satu baris tersebut dengan agen produksi lengkap:
code_analyzer_agent = Agent(
name="CodeAnalyzer",
model=config.worker_model,
description="Analyzes Python code structure and identifies components",
instruction="""You are a code analysis specialist responsible for understanding code structure.
Your task:
1. Take the code submitted by the user (it will be provided in the user message)
2. Use the analyze_code_structure tool to parse and analyze it
3. Pass the EXACT code to your tool - do not modify, fix, or "improve" it
4. Identify all functions, classes, imports, and structural patterns
5. Note any syntax errors or structural issues
6. Store the analysis in state for other agents to use
CRITICAL:
- Pass the code EXACTLY as provided to the analyze_code_structure tool
- Do not fix syntax errors, even if obvious
- Do not add missing imports or fix indentation
- The goal is to analyze what IS there, not what SHOULD be there
When calling the tool, pass the code as a string to the 'code' parameter.
If the analysis fails due to syntax errors, clearly report the error location and type.
Provide a clear summary including:
- Number of functions and classes found
- Key structural observations
- Any syntax errors or issues detected
- Overall code organization assessment""",
tools=[FunctionTool(func=analyze_code_structure)],
output_key="structure_analysis_summary"
)
Menguji Penganalisis Kode Anda
Sekarang, verifikasi bahwa penganalisis Anda berfungsi dengan benar.
👉 Jalankan skrip pengujian:
python tests/test_code_analyzer.py
Skrip pengujian otomatis memuat konfigurasi dari file .env menggunakan python-dotenv, sehingga tidak perlu penyiapan variabel lingkungan secara manual.
Output yang diharapkan:
INFO:code_review_assistant.config:Code Review Assistant Configuration Loaded:
INFO:code_review_assistant.config: - GCP Project: your-project-id
INFO:code_review_assistant.config: - Artifact Bucket: gs://your-project-artifacts
INFO:code_review_assistant.config: - Models: worker=gemini-2.5-flash, critic=gemini-2.5-pro
Testing code analyzer...
INFO:code_review_assistant.tools:Tool: Analysis complete - 2 functions, 1 classes
=== Analyzer Response ===
The analysis of the provided code shows the following:
* **Functions Found:** 2
* `add(a, b)`: A global function at line 2.
* `multiply(self, x, y)`: A method within the `Calculator` class.
* **Classes Found:** 1
* `Calculator`: A class defined at line 5. Contains one method, `multiply`.
* **Imports:** 0
* **Structural Patterns:** The code defines one global function and one class
with a single method. Both are simple, each with a single return statement.
* **Syntax Errors/Issues:** No syntax errors detected.
* **Overall Code Organization:** The code is well-organized for its small size,
clearly defining a function and a class with a method.
Yang baru saja terjadi:
- Skrip pengujian memuat konfigurasi
.envAnda secara otomatis - Alat
analyze_code_structure()Anda mengurai kode menggunakan AST Python - Helper
_extract_code_structure()mengekstrak fungsi, class, dan metrik - Hasil disimpan dalam status sesi menggunakan konstanta
StateKeys - Agen Code Analyzer menafsirkan hasil dan memberikan ringkasan
Pemecahan masalah:
- "No module named ‘code_review_assistant'": Jalankan
pip install -e .dari root project - "Argumen input utama tidak ada": Pastikan
.envAnda memilikiGOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_LOCATION, danGOOGLE_GENAI_USE_VERTEXAI=true
Yang Telah Anda Bangun
Sekarang Anda memiliki penganalisis kode siap produksi yang:
✅ Mem-parsing AST Python sebenarnya - deterministik, bukan pencocokan pola
✅ Menyimpan hasil dalam status - agen lain dapat mengakses analisis
✅ Berjalan secara asinkron - tidak memblokir alat lain
✅ Mengekstrak informasi komprehensif - fungsi, class, impor, metrik
✅ Menangani error dengan baik - melaporkan error sintaksis dengan nomor baris
✅ Terhubung ke agen - LLM tahu kapan dan cara menggunakannya
Konsep Utama yang Dikuasai
Alat vs. Agen:
- Alat melakukan pekerjaan deterministik (parsing AST)
- Agen memutuskan kapan menggunakan alat dan menafsirkan hasilnya
Nilai Hasil vs. Status:
- Respons: apa yang langsung dilihat LLM
- Status: apa yang tetap ada untuk agen lain
Konstanta Kunci Status:
- Mencegah kesalahan ketik dalam sistem multi-agen
- Bertindak sebagai kontrak antar-agen
- Penting saat agen membagikan data
Async + Thread Pools:
async defmemungkinkan alat menjeda eksekusi- Kumpulan thread menjalankan pekerjaan yang terikat CPU di latar belakang
- Bersama-sama, mereka membuat loop peristiwa tetap responsif
Fungsi Bantuan:
- Memisahkan helper sinkronisasi dari alat asinkron
- Membuat kode dapat diuji dan digunakan kembali
Petunjuk Agen:
- Petunjuk mendetail mencegah kesalahan umum LLM
- Secara eksplisit menyatakan apa yang TIDAK boleh dilakukan (jangan perbaiki kode)
- Langkah-langkah alur kerja yang jelas untuk konsistensi
Langkah Berikutnya
Dalam Modul 5, Anda akan menambahkan:
- Pemeriksa gaya yang membaca kode dari status
- Test runner yang benar-benar menjalankan pengujian
- Penggabung masukan yang menggabungkan semua analisis
Anda akan melihat cara status mengalir melalui pipeline berurutan, dan alasan pola konstanta penting saat beberapa agen membaca dan menulis data yang sama.
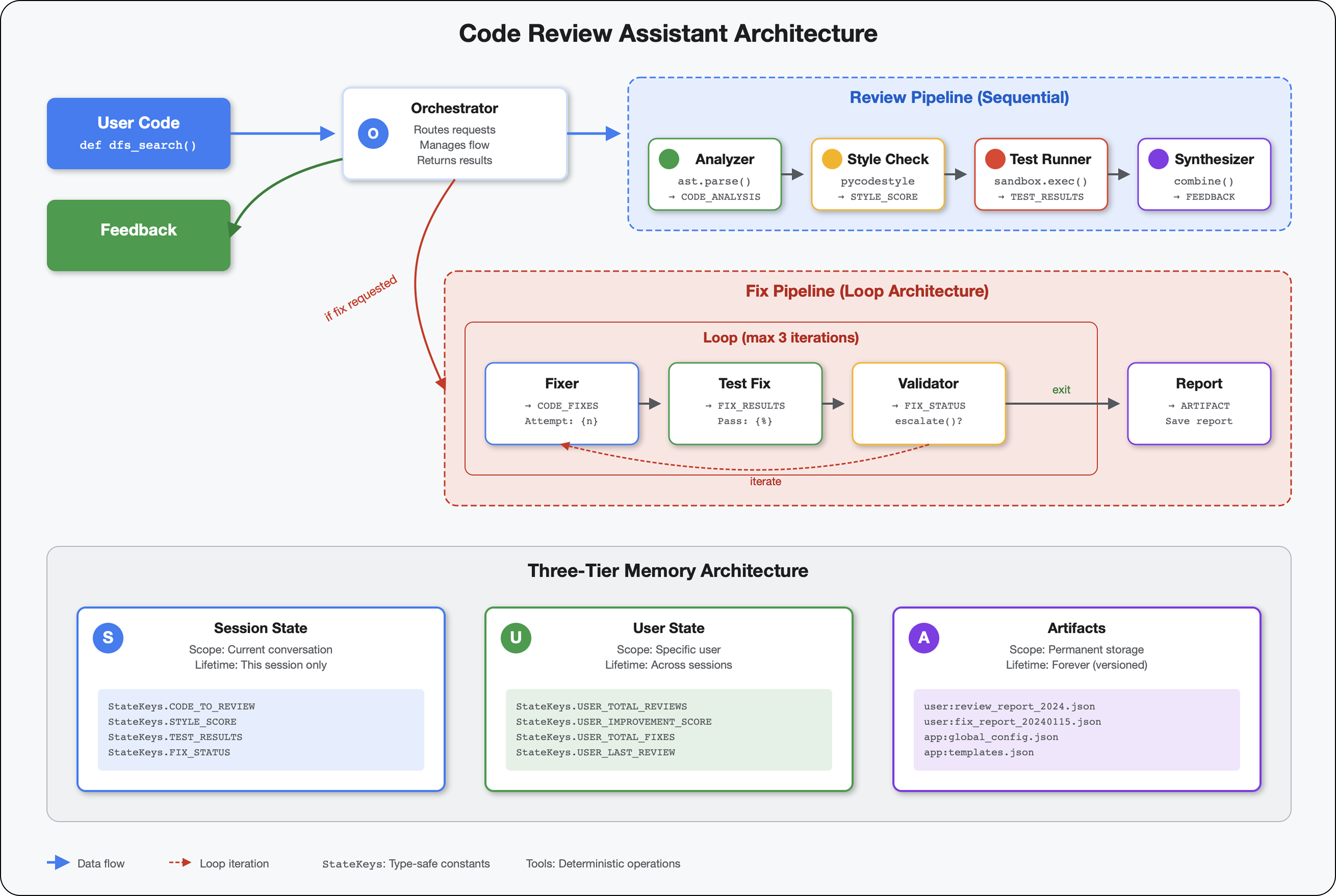
5. Membangun Pipeline: Beberapa Agen Bekerja Sama
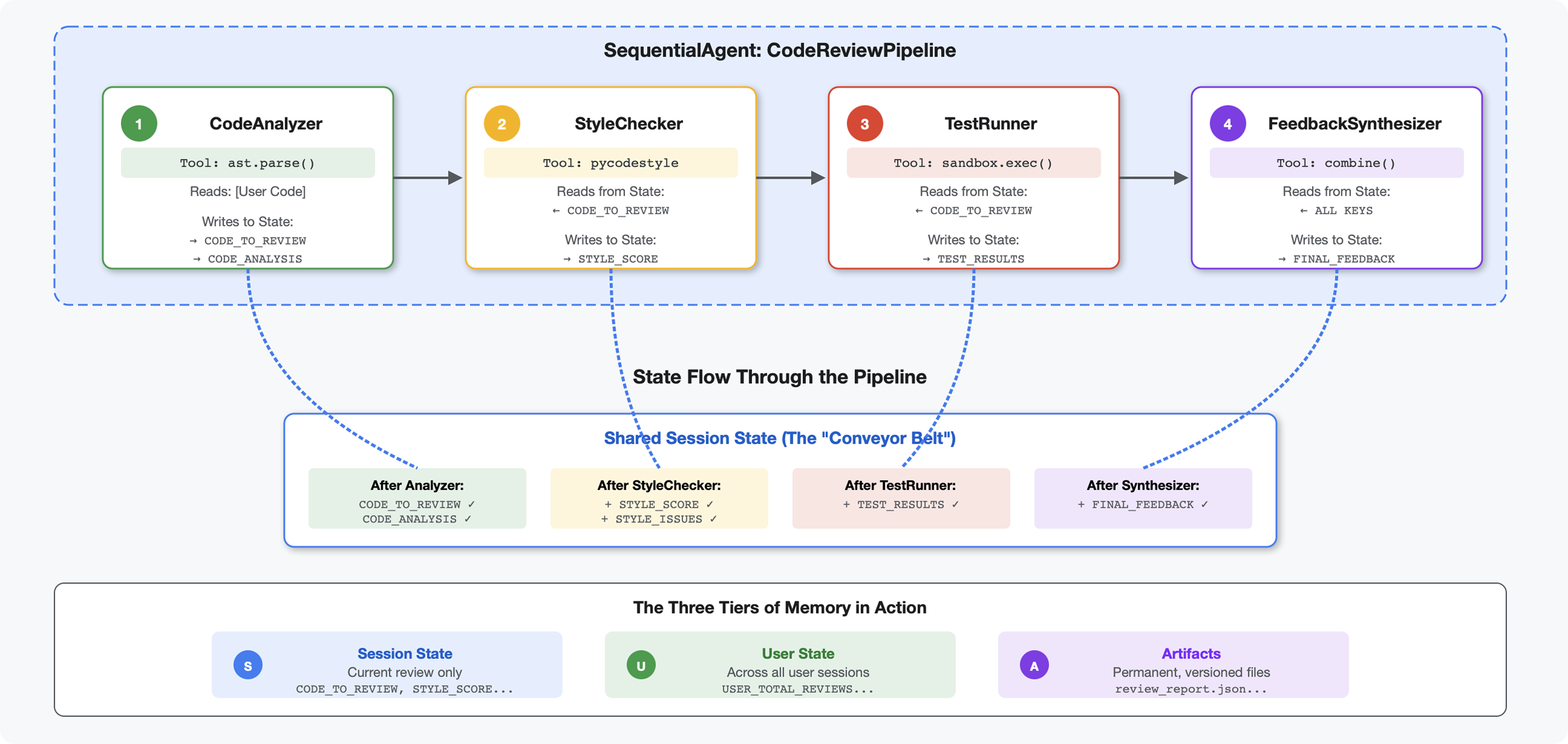
Pengantar
Dalam Modul 4, Anda telah membuat satu agen yang menganalisis struktur kode. Namun, peninjauan kode yang komprehensif memerlukan lebih dari sekadar parser - Anda memerlukan pemeriksaan gaya, eksekusi uji, dan sintesis masukan cerdas.
Modul ini membangun pipeline 4 agen yang bekerja sama secara berurutan, masing-masing memberikan analisis khusus:
- Code Analyzer (dari Modul 4) - Mengurai struktur
- Pemeriksa Gaya - Mengidentifikasi pelanggaran gaya
- Test Runner - Menjalankan dan memvalidasi pengujian
- Penggabung Masukan - Menggabungkan semuanya menjadi masukan yang dapat ditindaklanjuti
Konsep utama: Status sebagai saluran komunikasi. Setiap agen membaca apa yang ditulis agen sebelumnya ke status, menambahkan analisisnya sendiri, dan meneruskan status yang telah di-enrich ke agen berikutnya. Pola konstanta dari Modul 4 menjadi penting saat beberapa agen berbagi data.
Pratinjau yang akan Anda bangun: Kirimkan kode yang berantakan → amati alur status melalui 4 agen → terima laporan komprehensif dengan masukan yang dipersonalisasi berdasarkan pola sebelumnya.
Langkah 1: Tambahkan Alat + Agen Pemeriksa Gaya
Pemeriksa gaya mengidentifikasi pelanggaran PEP 8 menggunakan pycodestyle - linter deterministik, bukan interpretasi berbasis LLM.
Menambahkan Alat Pemeriksaan Gaya
👉 Buka
code_review_assistant/tools.py
👉 Temukan:
# MODULE_5_STEP_1_STYLE_CHECKER_TOOL
👉 Ganti satu baris tersebut dengan:
async def check_code_style(code: str, tool_context: ToolContext) -> Dict[str, Any]:
"""
Checks code style compliance using pycodestyle (PEP 8).
Args:
code: Python source code to check (or will retrieve from state)
tool_context: ADK tool context
Returns:
Dictionary containing style score and issues
"""
logger.info("Tool: Checking code style...")
try:
# Retrieve code from state if not provided
if not code:
code = tool_context.state.get(StateKeys.CODE_TO_REVIEW, '')
if not code:
return {
"status": "error",
"message": "No code provided or found in state"
}
# Run style check in thread pool
loop = asyncio.get_event_loop()
with ThreadPoolExecutor() as executor:
result = await loop.run_in_executor(
executor, _perform_style_check, code
)
# Store results in state
tool_context.state[StateKeys.STYLE_SCORE] = result['score']
tool_context.state[StateKeys.STYLE_ISSUES] = result['issues']
tool_context.state[StateKeys.STYLE_ISSUE_COUNT] = result['issue_count']
logger.info(f"Tool: Style check complete - Score: {result['score']}/100, "
f"Issues: {result['issue_count']}")
return result
except Exception as e:
error_msg = f"Style check failed: {str(e)}"
logger.error(f"Tool: {error_msg}", exc_info=True)
# Set default values on error
tool_context.state[StateKeys.STYLE_SCORE] = 0
tool_context.state[StateKeys.STYLE_ISSUES] = []
return {
"status": "error",
"message": error_msg,
"score": 0
}
👉 Sekarang scroll ke akhir file dan temukan:
# MODULE_5_STEP_1_STYLE_HELPERS
👉 Ganti satu baris tersebut dengan fungsi helper:
def _perform_style_check(code: str) -> Dict[str, Any]:
"""Helper to perform style check in thread pool."""
import io
import sys
with tempfile.NamedTemporaryFile(mode='w', suffix='.py', delete=False) as tmp:
tmp.write(code)
tmp_path = tmp.name
try:
# Capture stdout to get pycodestyle output
old_stdout = sys.stdout
sys.stdout = captured_output = io.StringIO()
style_guide = pycodestyle.StyleGuide(
quiet=False, # We want output
max_line_length=100,
ignore=['E501', 'W503']
)
result = style_guide.check_files([tmp_path])
# Restore stdout
sys.stdout = old_stdout
# Parse captured output
output = captured_output.getvalue()
issues = []
for line in output.strip().split('\n'):
if line and ':' in line:
parts = line.split(':', 4)
if len(parts) >= 4:
try:
issues.append({
'line': int(parts[1]),
'column': int(parts[2]),
'code': parts[3].split()[0] if len(parts) > 3 else 'E000',
'message': parts[3].strip() if len(parts) > 3 else 'Unknown error'
})
except (ValueError, IndexError):
pass
# Add naming convention checks
try:
tree = ast.parse(code)
naming_issues = _check_naming_conventions(tree)
issues.extend(naming_issues)
except SyntaxError:
pass # Syntax errors will be caught elsewhere
# Calculate weighted score
score = _calculate_style_score(issues)
return {
"status": "success",
"score": score,
"issue_count": len(issues),
"issues": issues[:10], # First 10 issues
"summary": f"Style score: {score}/100 with {len(issues)} violations"
}
finally:
if os.path.exists(tmp_path):
os.unlink(tmp_path)
def _check_naming_conventions(tree: ast.AST) -> List[Dict[str, Any]]:
"""Check PEP 8 naming conventions."""
naming_issues = []
for node in ast.walk(tree):
if isinstance(node, ast.FunctionDef):
# Skip private/protected methods and __main__
if not node.name.startswith('_') and node.name != node.name.lower():
naming_issues.append({
'line': node.lineno,
'column': node.col_offset,
'code': 'N802',
'message': f"N802 function name '{node.name}' should be lowercase"
})
elif isinstance(node, ast.ClassDef):
# Check if class name follows CapWords convention
if not node.name[0].isupper() or '_' in node.name:
naming_issues.append({
'line': node.lineno,
'column': node.col_offset,
'code': 'N801',
'message': f"N801 class name '{node.name}' should use CapWords convention"
})
return naming_issues
def _calculate_style_score(issues: List[Dict[str, Any]]) -> int:
"""Calculate weighted style score based on violation severity."""
if not issues:
return 100
# Define weights by error type
weights = {
'E1': 10, # Indentation errors
'E2': 3, # Whitespace errors
'E3': 5, # Blank line errors
'E4': 8, # Import errors
'E5': 5, # Line length
'E7': 7, # Statement errors
'E9': 10, # Syntax errors
'W2': 2, # Whitespace warnings
'W3': 2, # Blank line warnings
'W5': 3, # Line break warnings
'N8': 7, # Naming conventions
}
total_deduction = 0
for issue in issues:
code_prefix = issue['code'][:2] if len(issue['code']) >= 2 else 'E2'
weight = weights.get(code_prefix, 3)
total_deduction += weight
# Cap at 100 points deduction
return max(0, 100 - min(total_deduction, 100))
Menambahkan Agen Pemeriksa Gaya
👉 Buka
code_review_assistant/sub_agents/review_pipeline/style_checker.py
👉 Temukan:
# MODULE_5_STEP_1_INSTRUCTION_PROVIDER
👉 Ganti satu baris tersebut dengan:
async def style_checker_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are a code style expert focused on PEP 8 compliance.
Your task:
1. Use the check_code_style tool to validate PEP 8 compliance
2. The tool will retrieve the ORIGINAL code from state automatically
3. Report violations exactly as found
4. Present the results clearly and confidently
CRITICAL:
- The tool checks the code EXACTLY as provided by the user
- Do not suggest the code was modified or fixed
- Report actual violations found in the original code
- If there are style issues, they should be reported honestly
Call the check_code_style tool with an empty string for the code parameter,
as the tool will retrieve the code from state automatically.
When presenting results based on what the tool returns:
- State the exact score from the tool results
- If score >= 90: "Excellent style compliance!"
- If score 70-89: "Good style with minor improvements needed"
- If score 50-69: "Style needs attention"
- If score < 50: "Significant style improvements needed"
List the specific violations found (the tool will provide these):
- Show line numbers, error codes, and messages
- Focus on the top 10 most important issues
Previous analysis: {structure_analysis_summary}
Format your response as:
## Style Analysis Results
- Style Score: [exact score]/100
- Total Issues: [count]
- Assessment: [your assessment based on score]
## Top Style Issues
[List issues with line numbers and descriptions]
## Recommendations
[Specific fixes for the most critical issues]"""
return await instructions_utils.inject_session_state(template, context)
👉 Temukan:
# MODULE_5_STEP_1_STYLE_CHECKER_AGENT
👉 Ganti satu baris tersebut dengan:
style_checker_agent = Agent(
name="StyleChecker",
model=config.worker_model,
description="Checks Python code style against PEP 8 guidelines",
instruction=style_checker_instruction_provider,
tools=[FunctionTool(func=check_code_style)],
output_key="style_check_summary"
)
Langkah 2: Tambahkan Agen Test Runner
Runner pengujian membuat pengujian komprehensif dan mengeksekusinya menggunakan eksekutor kode bawaan.
👉 Buka
code_review_assistant/sub_agents/review_pipeline/test_runner.py
👉 Temukan:
# MODULE_5_STEP_2_INSTRUCTION_PROVIDER
👉 Ganti satu baris tersebut dengan:
async def test_runner_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects the code_to_review directly."""
template = """You are a testing specialist who creates and runs tests for Python code.
THE CODE TO TEST IS:
{code_to_review}
YOUR TASK:
1. Understand what the function appears to do based on its name and structure
2. Generate comprehensive tests (15-20 test cases)
3. Execute the tests using your code executor
4. Analyze results to identify bugs vs expected behavior
5. Output a detailed JSON analysis
TESTING METHODOLOGY:
- Test with the most natural interpretation first
- When something fails, determine if it's a bug or unusual design
- Test edge cases, boundaries, and error scenarios
- Document any surprising behavior
Execute your tests and output ONLY valid JSON with this structure:
- "test_summary": object with "total_tests_run", "tests_passed", "tests_failed", "tests_with_errors", "critical_issues_found"
- "critical_issues": array of objects, each with "type", "description", "example_input", "expected_behavior", "actual_behavior", "severity"
- "test_categories": object with "basic_functionality", "edge_cases", "error_handling" (each containing "passed", "failed", "errors" counts)
- "function_behavior": object with "apparent_purpose", "actual_interface", "unexpected_requirements"
- "verdict": object with "status" (WORKING/BUGGY/BROKEN), "confidence" (high/medium/low), "recommendation"
Do NOT output the test code itself, only the JSON analysis."""
return await instructions_utils.inject_session_state(template, context)
👉 Temukan:
# MODULE_5_STEP_2_TEST_RUNNER_AGENT
👉 Ganti satu baris tersebut dengan:
test_runner_agent = Agent(
name="TestRunner",
model=config.critic_model,
description="Generates and runs tests for Python code using safe code execution",
instruction=test_runner_instruction_provider,
code_executor=BuiltInCodeExecutor(),
output_key="test_execution_summary"
)
Langkah 3: Memahami Memori untuk Pembelajaran Lintas Sesi
Sebelum membuat synthesizer masukan, Anda harus memahami perbedaan antara status dan memori - dua mekanisme penyimpanan yang berbeda untuk dua tujuan yang berbeda.
Status vs. Memori: Perbedaan Utama
Mari kita perjelas dengan contoh konkret dari peninjauan kode:
Status (Khusus Sesi Saat Ini):
# Data from THIS review session
tool_context.state[StateKeys.STYLE_ISSUES] = [
{"line": 5, "code": "E231", "message": "missing whitespace"},
{"line": 12, "code": "E701", "message": "multiple statements"}
]
- Cakupan: Hanya percakapan ini
- Tujuan: Meneruskan data antar-agen dalam pipeline saat ini
- Tinggal di: Objek
Session - Seumur hidup: Dihapus saat sesi berakhir
Memori (Semua Sesi Sebelumnya):
# Learned from 50 previous reviews
"User frequently forgets docstrings on helper functions"
"User tends to write long functions (avg 45 lines)"
"User improved error handling after feedback in session #23"
- Cakupan: Semua sesi sebelumnya untuk pengguna ini
- Tujuan: Mempelajari pola, memberikan masukan yang dipersonalisasi
- Tinggal di:
MemoryService - Sepanjang waktu: Tetap ada di seluruh sesi, dapat ditelusuri
Alasan Masukan Memerlukan Keduanya:
Bayangkan synthesizer membuat masukan:
Hanya menggunakan Status (ulasan saat ini):
"Function `calculate_total` has no docstring."
Masukan umum dan mekanis.
Menggunakan Status + Memori (pola saat ini + sebelumnya):
"Function `calculate_total` has no docstring. This is the 4th review
where helper functions lacked documentation. Consider adding docstrings
as you write functions, not afterwards - you mentioned in our last
session that you find it easier that way."
Dipersonalisasi, kontekstual, peningkatan referensi dari waktu ke waktu.
Untuk deployment produksi, Anda memiliki opsi:
Opsi 1: VertexAiMemoryBankService (Lanjutan)
- Fungsinya: Ekstraksi fakta penting dari percakapan yang didukung LLM
- Penelusuran: Penelusuran semantik (memahami makna, bukan hanya kata kunci)
- Pengelolaan memori: Secara otomatis menggabungkan dan memperbarui kenangan dari waktu ke waktu
- Persyaratan: Penyiapan Project Google Cloud + Agent Engine
- Gunakan saat: Anda menginginkan memori yang canggih, berkembang, dan dipersonalisasi
- Contoh: "Pengguna lebih menyukai pemrograman fungsional" (diekstrak dari 10 percakapan tentang gaya kode)
Opsi 2: Lanjutkan dengan InMemoryMemoryService + Sesi Persisten
- Fungsi: Menyimpan histori percakapan lengkap untuk penelusuran kata kunci
- Penelusuran: Pencocokan kata kunci dasar di seluruh sesi sebelumnya
- Pengelolaan memori: Anda mengontrol jenis data yang disimpan (melalui
add_session_to_memory) - Persyaratan: Hanya
SessionServicepersisten (sepertiVertexAiSessionServiceatauDatabaseSessionService) - Gunakan saat: Anda memerlukan penelusuran sederhana di seluruh percakapan sebelumnya tanpa pemrosesan LLM
- Contoh: Penelusuran "docstring" akan menampilkan semua sesi yang menyebutkan kata tersebut
Cara Memori Diisi
Setelah setiap peninjauan kode selesai:
# At the end of a session (typically in your application code)
await memory_service.add_session_to_memory(session)
Yang terjadi:
- InMemoryMemoryService: Menyimpan peristiwa sesi lengkap untuk penelusuran kata kunci
- VertexAiMemoryBankService: LLM mengekstrak fakta penting, menggabungkan dengan memori yang ada
Sesi mendatang kemudian dapat membuat kueri:
# In a tool, search for relevant past feedback
results = tool_context.search_memory("feedback about docstrings")
Langkah 4: Tambahkan Alat dan Agen Feedback Synthesizer
Sintesis masukan adalah agen paling canggih dalam pipeline. Alat ini mengatur tiga alat, menggunakan petunjuk dinamis, dan menggabungkan status, memori, dan artefak.
Menambahkan Tiga Alat Synthesizer
👉 Buka
code_review_assistant/tools.py
👉 Temukan:
# MODULE_5_STEP_4_SEARCH_PAST_FEEDBACK
👉 Replace with Tool 1 - Memory Search (production version):
async def search_past_feedback(developer_id: str, tool_context: ToolContext) -> Dict[str, Any]:
"""
Search for past feedback in memory service.
Args:
developer_id: ID of the developer (defaults to "default_user")
tool_context: ADK tool context with potential memory service access
Returns:
Dictionary containing feedback search results
"""
logger.info(f"Tool: Searching for past feedback for developer {developer_id}...")
try:
# Default developer ID if not provided
if not developer_id:
developer_id = tool_context.state.get(StateKeys.USER_ID, 'default_user')
# Check if memory service is available
if hasattr(tool_context, 'search_memory'):
try:
# Perform structured searches
queries = [
f"developer:{developer_id} code review feedback",
f"developer:{developer_id} common issues",
f"developer:{developer_id} improvements"
]
all_feedback = []
patterns = {
'common_issues': [],
'improvements': [],
'strengths': []
}
for query in queries:
search_result = await tool_context.search_memory(query)
if search_result and hasattr(search_result, 'memories'):
for memory in search_result.memories[:5]:
memory_text = memory.text if hasattr(memory, 'text') else str(memory)
all_feedback.append(memory_text)
# Extract patterns
if 'style' in memory_text.lower():
patterns['common_issues'].append('style compliance')
if 'improved' in memory_text.lower():
patterns['improvements'].append('showing improvement')
if 'excellent' in memory_text.lower():
patterns['strengths'].append('consistent quality')
# Store in state
tool_context.state[StateKeys.PAST_FEEDBACK] = all_feedback
tool_context.state[StateKeys.FEEDBACK_PATTERNS] = patterns
logger.info(f"Tool: Found {len(all_feedback)} past feedback items")
return {
"status": "success",
"feedback_found": True,
"count": len(all_feedback),
"summary": " | ".join(all_feedback[:3]) if all_feedback else "No feedback",
"patterns": patterns
}
except Exception as e:
logger.warning(f"Tool: Memory search error: {e}")
# Fallback: Check state for cached feedback
cached_feedback = tool_context.state.get(StateKeys.USER_PAST_FEEDBACK_CACHE, [])
if cached_feedback:
tool_context.state[StateKeys.PAST_FEEDBACK] = cached_feedback
return {
"status": "success",
"feedback_found": True,
"count": len(cached_feedback),
"summary": "Using cached feedback",
"patterns": {}
}
# No feedback found
tool_context.state[StateKeys.PAST_FEEDBACK] = []
logger.info("Tool: No past feedback found")
return {
"status": "success",
"feedback_found": False,
"message": "No past feedback available - this appears to be a first submission",
"patterns": {}
}
except Exception as e:
error_msg = f"Feedback search error: {str(e)}"
logger.error(f"Tool: {error_msg}", exc_info=True)
tool_context.state[StateKeys.PAST_FEEDBACK] = []
return {
"status": "error",
"message": error_msg,
"feedback_found": False
}
👉 Temukan:
# MODULE_5_STEP_4_UPDATE_GRADING_PROGRESS
👉 Ganti dengan Alat 2 - Pelacak Penilaian (versi produksi):
async def update_grading_progress(tool_context: ToolContext) -> Dict[str, Any]:
"""
Updates grading progress counters and metrics in state.
"""
logger.info("Tool: Updating grading progress...")
try:
current_time = datetime.now().isoformat()
# Build all state changes
state_updates = {}
# Temporary (invocation-level) state
state_updates[StateKeys.TEMP_PROCESSING_TIMESTAMP] = current_time
# Session-level state
attempts = tool_context.state.get(StateKeys.GRADING_ATTEMPTS, 0) + 1
state_updates[StateKeys.GRADING_ATTEMPTS] = attempts
state_updates[StateKeys.LAST_GRADING_TIME] = current_time
# User-level persistent state
lifetime_submissions = tool_context.state.get(StateKeys.USER_TOTAL_SUBMISSIONS, 0) + 1
state_updates[StateKeys.USER_TOTAL_SUBMISSIONS] = lifetime_submissions
state_updates[StateKeys.USER_LAST_SUBMISSION_TIME] = current_time
# Calculate improvement metrics
current_style_score = tool_context.state.get(StateKeys.STYLE_SCORE, 0)
last_style_score = tool_context.state.get(StateKeys.USER_LAST_STYLE_SCORE, 0)
score_improvement = current_style_score - last_style_score
state_updates[StateKeys.USER_LAST_STYLE_SCORE] = current_style_score
state_updates[StateKeys.SCORE_IMPROVEMENT] = score_improvement
# Track test results if available
test_results = tool_context.state.get(StateKeys.TEST_EXECUTION_SUMMARY, {})
# Parse if it's a string
if isinstance(test_results, str):
try:
test_results = json.loads(test_results)
except:
test_results = {}
if test_results and test_results.get('test_summary', {}).get('total_tests_run', 0) > 0:
summary = test_results['test_summary']
total = summary.get('total_tests_run', 0)
passed = summary.get('tests_passed', 0)
if total > 0:
pass_rate = (passed / total) * 100
state_updates[StateKeys.USER_LAST_TEST_PASS_RATE] = pass_rate
# Apply all updates atomically
for key, value in state_updates.items():
tool_context.state[key] = value
logger.info(f"Tool: Progress updated - Attempt #{attempts}, "
f"Lifetime: {lifetime_submissions}")
return {
"status": "success",
"session_attempts": attempts,
"lifetime_submissions": lifetime_submissions,
"timestamp": current_time,
"improvement": {
"style_score_change": score_improvement,
"direction": "improved" if score_improvement > 0 else "declined"
},
"summary": f"Attempt #{attempts} recorded, {lifetime_submissions} total submissions"
}
except Exception as e:
error_msg = f"Progress update error: {str(e)}"
logger.error(f"Tool: {error_msg}", exc_info=True)
return {
"status": "error",
"message": error_msg
}
👉 Temukan:
# MODULE_5_STEP_4_SAVE_GRADING_REPORT
👉 Ganti dengan Alat 3 - Penyimpan Artefak (versi produksi):
async def save_grading_report(feedback_text: str, tool_context: ToolContext) -> Dict[str, Any]:
"""
Saves a detailed grading report as an artifact.
Args:
feedback_text: The feedback text to include in the report
tool_context: ADK tool context for state management
Returns:
Dictionary containing save status and details
"""
logger.info("Tool: Saving grading report...")
try:
# Gather all relevant data from state
code = tool_context.state.get(StateKeys.CODE_TO_REVIEW, '')
analysis = tool_context.state.get(StateKeys.CODE_ANALYSIS, {})
style_score = tool_context.state.get(StateKeys.STYLE_SCORE, 0)
style_issues = tool_context.state.get(StateKeys.STYLE_ISSUES, [])
# Get test results
test_results = tool_context.state.get(StateKeys.TEST_EXECUTION_SUMMARY, {})
# Parse if it's a string
if isinstance(test_results, str):
try:
test_results = json.loads(test_results)
except:
test_results = {}
timestamp = datetime.now().isoformat()
# Create comprehensive report dictionary
report = {
'timestamp': timestamp,
'grading_attempt': tool_context.state.get(StateKeys.GRADING_ATTEMPTS, 1),
'code': {
'content': code,
'line_count': len(code.splitlines()),
'hash': hashlib.md5(code.encode()).hexdigest()
},
'analysis': analysis,
'style': {
'score': style_score,
'issues': style_issues[:5] # First 5 issues
},
'tests': test_results,
'feedback': feedback_text,
'improvements': {
'score_change': tool_context.state.get(StateKeys.SCORE_IMPROVEMENT, 0),
'from_last_score': tool_context.state.get(StateKeys.USER_LAST_STYLE_SCORE, 0)
}
}
# Convert report to JSON string
report_json = json.dumps(report, indent=2)
report_part = types.Part.from_text(text=report_json)
# Try to save as artifact if the service is available
if hasattr(tool_context, 'save_artifact'):
try:
# Generate filename with timestamp (replace colons for filesystem compatibility)
filename = f"grading_report_{timestamp.replace(':', '-')}.json"
# Save the main report
version = await tool_context.save_artifact(filename, report_part)
# Also save a "latest" version for easy access
await tool_context.save_artifact("latest_grading_report.json", report_part)
logger.info(f"Tool: Report saved as {filename} (version {version})")
# Store report in state as well for redundancy
tool_context.state[StateKeys.USER_LAST_GRADING_REPORT] = report
return {
"status": "success",
"artifact_saved": True,
"filename": filename,
"version": str(version),
"size": len(report_json),
"summary": f"Report saved as {filename}"
}
except Exception as artifact_error:
logger.warning(f"Artifact service error: {artifact_error}, falling back to state storage")
# Continue to fallback below
# Fallback: Store in state if artifact service is not available or failed
tool_context.state[StateKeys.USER_LAST_GRADING_REPORT] = report
logger.info("Tool: Report saved to state (artifact service not available)")
return {
"status": "success",
"artifact_saved": False,
"message": "Report saved to state only",
"size": len(report_json),
"summary": "Report saved to session state"
}
except Exception as e:
error_msg = f"Report save error: {str(e)}"
logger.error(f"Tool: {error_msg}", exc_info=True)
# Still try to save minimal data to state
try:
tool_context.state[StateKeys.USER_LAST_GRADING_REPORT] = {
'error': error_msg,
'feedback': feedback_text,
'timestamp': datetime.now().isoformat()
}
except:
pass
return {
"status": "error",
"message": error_msg,
"artifact_saved": False,
"summary": f"Failed to save report: {error_msg}"
}
Membuat Agen Synthesizer
👉 Buka
code_review_assistant/sub_agents/review_pipeline/feedback_synthesizer.py
👉 Temukan:
# MODULE_5_STEP_4_INSTRUCTION_PROVIDER
👉 Ganti dengan penyedia petunjuk produksi:
async def feedback_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are an expert code reviewer and mentor providing constructive, educational feedback.
CONTEXT FROM PREVIOUS AGENTS:
- Structure analysis summary: {structure_analysis_summary}
- Style check summary: {style_check_summary}
- Test execution summary: {test_execution_summary}
YOUR TASK requires these steps IN ORDER:
1. Call search_past_feedback tool with developer_id="default_user"
2. Call update_grading_progress tool with no parameters
3. Carefully analyze the test results to understand what really happened
4. Generate comprehensive feedback following the structure below
5. Call save_grading_report tool with the feedback_text parameter
6. Return the feedback as your final output
CRITICAL - Understanding Test Results:
The test_execution_summary contains structured JSON. Parse it carefully:
- tests_passed = Code worked correctly
- tests_failed = Code produced wrong output
- tests_with_errors = Code crashed
- critical_issues = Fundamental problems with the code
If critical_issues array contains items, these are serious bugs that need fixing.
Do NOT count discovering bugs as test successes.
FEEDBACK STRUCTURE TO FOLLOW:
## 📊 Summary
Provide an honest assessment. Be encouraging but truthful about problems found.
## ✅ Strengths
List 2-3 things done well, referencing specific code elements.
## 📈 Code Quality Analysis
### Structure & Organization
Comment on code organization, readability, and documentation.
### Style Compliance
Report the actual style score and any specific issues.
### Test Results
Report the actual test results accurately:
- If critical_issues exist, report them as bugs to fix
- Be clear: "X tests passed, Y critical issues were found"
- List each critical issue
- Don't hide or minimize problems
## 💡 Recommendations for Improvement
Based on the analysis, provide specific actionable fixes.
If critical issues exist, fixing them is top priority.
## 🎯 Next Steps
Prioritized action list based on severity of issues.
## 💬 Encouragement
End with encouragement while being honest about what needs fixing.
Remember: Complete ALL steps including calling save_grading_report."""
return await instructions_utils.inject_session_state(template, context)
👉 Temukan:
# MODULE_5_STEP_4_SYNTHESIZER_AGENT
👉 Ganti dengan:
feedback_synthesizer_agent = Agent(
name="FeedbackSynthesizer",
model=config.critic_model,
description="Synthesizes all analysis into constructive, personalized feedback",
instruction=feedback_instruction_provider,
tools=[
FunctionTool(func=search_past_feedback),
FunctionTool(func=update_grading_progress),
FunctionTool(func=save_grading_report)
],
output_key="final_feedback"
)
Langkah 5: Hubungkan Pipeline
Sekarang, hubungkan keempat agen ke dalam pipeline berurutan dan buat agen root.
👉 Buka
code_review_assistant/agent.py
👉 Tambahkan impor yang diperlukan di bagian atas file (setelah impor yang ada):
from google.adk.agents import Agent, SequentialAgent
from code_review_assistant.sub_agents.review_pipeline.code_analyzer import code_analyzer_agent
from code_review_assistant.sub_agents.review_pipeline.style_checker import style_checker_agent
from code_review_assistant.sub_agents.review_pipeline.test_runner import test_runner_agent
from code_review_assistant.sub_agents.review_pipeline.feedback_synthesizer import feedback_synthesizer_agent
File Anda sekarang akan terlihat seperti:
"""
Main agent orchestration for the Code Review Assistant.
"""
from google.adk.agents import Agent, SequentialAgent
from .config import config
from code_review_assistant.sub_agents.review_pipeline.code_analyzer import code_analyzer_agent
from code_review_assistant.sub_agents.review_pipeline.style_checker import style_checker_agent
from code_review_assistant.sub_agents.review_pipeline.test_runner import test_runner_agent
from code_review_assistant.sub_agents.review_pipeline.feedback_synthesizer import feedback_synthesizer_agent
# MODULE_5_STEP_5_CREATE_PIPELINE
# MODULE_6_STEP_5_CREATE_FIX_LOOP
# MODULE_6_STEP_5_UPDATE_ROOT_AGENT
👉 Temukan:
# MODULE_5_STEP_5_CREATE_PIPELINE
👉 Ganti satu baris tersebut dengan:
# Create sequential pipeline
code_review_pipeline = SequentialAgent(
name="CodeReviewPipeline",
description="Complete code review pipeline with analysis, testing, and feedback",
sub_agents=[
code_analyzer_agent,
style_checker_agent,
test_runner_agent,
feedback_synthesizer_agent
]
)
# Root agent - coordinates the review pipeline
root_agent = Agent(
name="CodeReviewAssistant",
model=config.worker_model,
description="An intelligent code review assistant that analyzes Python code and provides educational feedback",
instruction="""You are a specialized Python code review assistant focused on helping developers improve their code quality.
When a user provides Python code for review:
1. Immediately delegate to CodeReviewPipeline and pass the code EXACTLY as it was provided by the user.
2. The pipeline will handle all analysis and feedback
3. Return ONLY the final feedback from the pipeline - do not add any commentary
When a user asks what you can do or asks general questions:
- Explain your capabilities for code review
- Do NOT trigger the pipeline for non-code messages
The pipeline handles everything for code review - just pass through its final output.""",
sub_agents=[code_review_pipeline],
output_key="assistant_response"
)
Langkah 6: Uji Pipeline Lengkap
Saatnya melihat keempat agen bekerja sama.
👉 Mulai sistem:
adk web code_review_assistant
Setelah menjalankan perintah adk web, Anda akan melihat output di terminal yang menunjukkan bahwa Server Web ADK telah dimulai, seperti ini:
+-----------------------------------------------------------------------------+
| ADK Web Server started |
| |
| For local testing, access at http://localhost:8000. |
+-----------------------------------------------------------------------------+
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
👉 Selanjutnya, untuk mengakses UI Dev ADK dari browser Anda:
Dari ikon Pratinjau web (sering kali terlihat seperti mata atau persegi dengan panah) di toolbar Cloud Shell (biasanya di kanan atas), pilih Ubah port. Di jendela pop-up, tetapkan port ke 8000, lalu klik "Ubah dan Pratinjau". Cloud Shell kemudian akan membuka tab browser atau jendela baru yang menampilkan UI Dev ADK.
👉 Agen kini berjalan. UI Dev ADK di browser Anda adalah koneksi langsung Anda ke agen.
- Pilih Target Anda: Di menu dropdown di bagian atas UI, pilih agen
code_review_assistant.
👉 Perintah Pengujian:
Please analyze the following:
def dfs_search_v1(graph, start, target):
"""Find if target is reachable from start."""
visited = set()
stack = start
while stack:
current = stack.pop()
if current == target:
return True
if current not in visited:
visited.add(current)
for neighbor in graph[current]:
if neighbor not in visited:
stack.append(neighbor)
return False
👉 Lihat cara kerja pipeline peninjauan kode:
Saat mengirimkan fungsi dfs_search_v1 yang penuh bug, Anda tidak hanya mendapatkan satu jawaban. Anda sedang menyaksikan pipeline multi-agen Anda bekerja. Output streaming yang Anda lihat adalah hasil dari empat agen khusus yang dieksekusi secara berurutan, yang masing-masing dibangun berdasarkan agen sebelumnya.
Berikut adalah pengelompokan kontribusi setiap agen terhadap ulasan akhir yang komprehensif, yang mengubah data mentah menjadi intelijen yang dapat ditindaklanjuti.
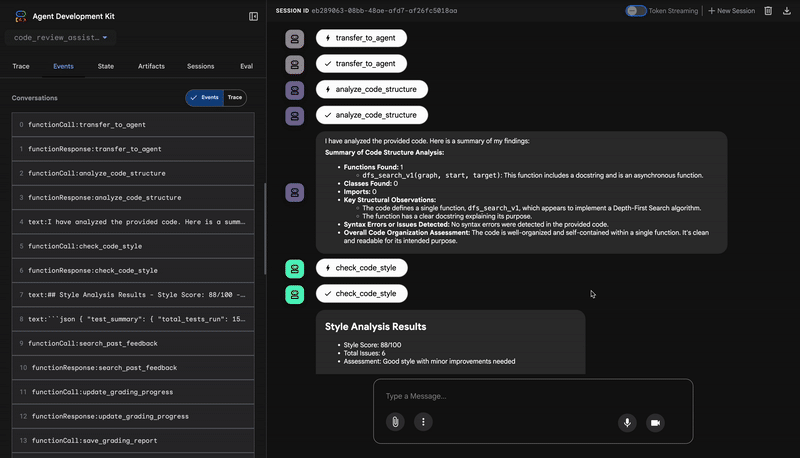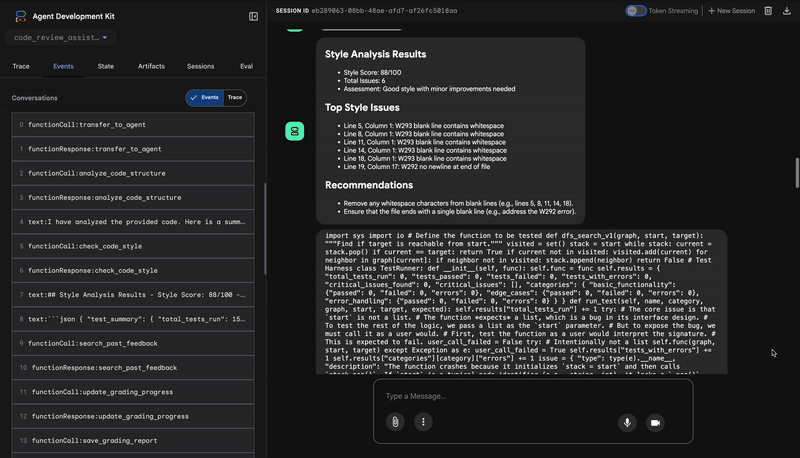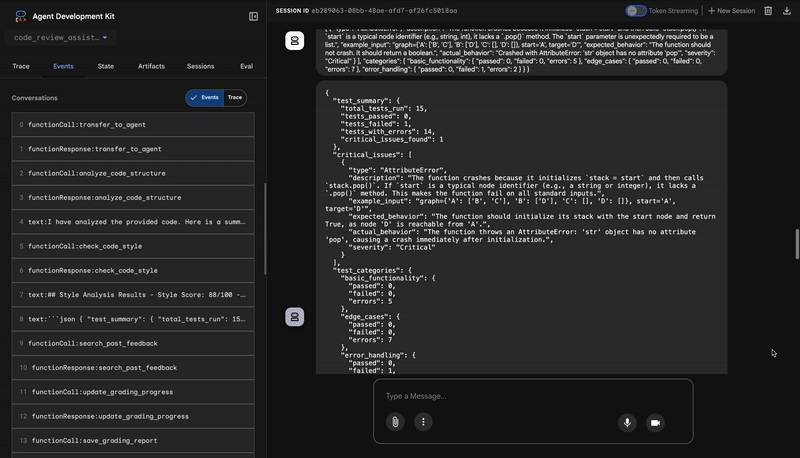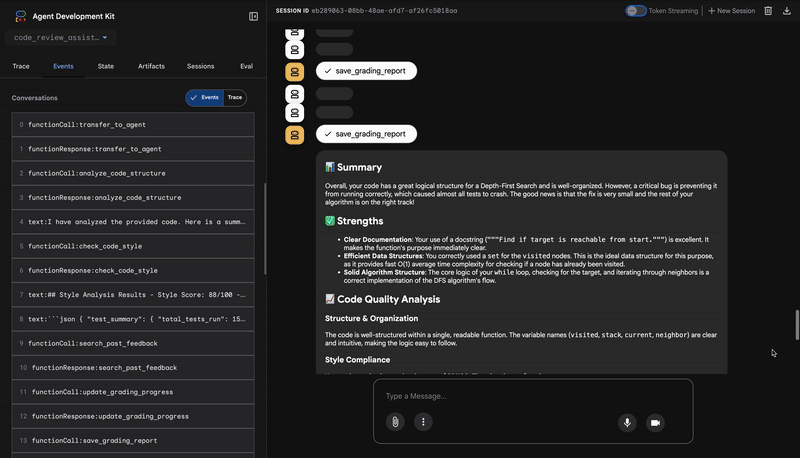
1. Laporan Struktural Penganalisis Kode
Pertama, agen CodeAnalyzer menerima kode mentah. Alat ini tidak menebak fungsi kode; alat ini menggunakan alat analyze_code_structure untuk melakukan penguraian Abstract Syntax Tree (AST) yang deterministik.
Outputnya adalah data faktual murni tentang struktur kode:
The analysis of the provided code reveals the following:
Summary:
- Functions Found: 1
- Classes Found: 0
Key Structural Observations:
- A single function, dfs_search_v1, is defined.
- It includes a docstring: "Find if target is reachable from start."
- No syntax errors were detected.
Overall Code Organization Assessment:
- The code snippet is a well-defined, self-contained function.
⭐ Nilai: Langkah awal ini memberikan fondasi yang bersih dan andal untuk agen lainnya. Alat ini mengonfirmasi bahwa kode adalah Python yang valid dan mengidentifikasi komponen persis yang perlu ditinjau.
2. Audit PEP 8 Pemeriksa Gaya
Selanjutnya, agen StyleChecker akan mengambil alih. Alat ini membaca kode dari status bersama dan menggunakan alat check_code_style, yang memanfaatkan linter pycodestyle.
Output-nya adalah skor kualitas yang dapat diukur dan pelanggaran tertentu:
Style Analysis Results
- Style Score: 88/100
- Total Issues: 6
- Assessment: Good style with minor improvements needed
Top Style Issues
- Line 5, W293: blank line contains whitespace
- Line 19, W292: no newline at end of file
⭐ Nilai: Agen ini memberikan masukan objektif yang tidak dapat dinegosiasikan berdasarkan standar komunitas yang telah ditetapkan (PEP 8). Sistem pemberian skor berbobot langsung memberi tahu pengguna tentang tingkat keparahan masalah.
3. Penemuan Bug Kritis Test Runner
Di sinilah sistem melampaui analisis tingkat permukaan. Agen TestRunner membuat dan menjalankan serangkaian pengujian komprehensif untuk memvalidasi perilaku kode.
Outputnya adalah objek JSON terstruktur yang berisi putusan yang memberatkan:
{
"critical_issues": [
{
"type": "Critical Bug",
"description": "The function's initialization `stack = start` is incorrect... When a common input like a string... is provided... the function crashes with an AttributeError.",
"severity": "Critical"
}
],
"verdict": {
"status": "BROKEN",
"confidence": "high",
"recommendation": "The function is fundamentally broken... the stack initialization line `stack = start` must be changed to `stack = [start]`."
}
}
⭐ Nilai: Ini adalah insight yang paling penting. Agen tidak hanya menebak; agen membuktikan bahwa kode rusak dengan menjalankannya. Alat ini menemukan bug runtime yang halus tetapi penting yang mungkin dengan mudah terlewatkan oleh peninjau manual dan menunjukkan penyebab pasti serta perbaikan yang diperlukan.
4. Laporan Akhir Feedback Synthesizer
Terakhir, agen FeedbackSynthesizer bertindak sebagai konduktor. Agent ini mengambil data terstruktur dari tiga agen sebelumnya dan membuat satu laporan yang mudah digunakan, bersifat analitis, dan memotivasi.
Outputnya adalah ulasan akhir yang sudah disempurnakan yang Anda lihat:
📊 Summary
Great effort on implementing the Depth-First Search algorithm! ... However, a critical bug in the initialization of the stack prevents the function from working correctly...
✅ Strengths
- Good Algorithm Structure
- Correct Use of `visited` Set
📈 Code Quality Analysis
...
### Style Compliance
The style analysis returned a good score of 88/100.
...
### Test Results
The automated testing revealed a critical issue... The line `stack = start` directly assigns the input... which results in an `AttributeError`.
💡 Recommendations for Improvement
**Fix the Critical Stack Initialization Bug:**
- Incorrect Code: `stack = start`
- Correct Code: `stack = [start]`
💬 Encouragement
You are very close to a perfect implementation! The core logic of your DFS algorithm is sound, which is the hardest part.
⭐ Nilai: Agen ini mengubah data teknis menjadi pengalaman yang bermanfaat dan mendidik. Bot memprioritaskan masalah yang paling penting (bug), menjelaskannya dengan jelas, memberikan solusi yang tepat, dan melakukannya dengan nada yang mendorong. Laporan ini berhasil mengintegrasikan temuan dari semua tahap sebelumnya menjadi satu kesatuan yang kohesif dan berharga.
Proses multi-tahap ini menunjukkan kemampuan pipeline agentic. Alih-alih respons monolitik tunggal, Anda akan mendapatkan analisis berlapis di mana setiap agen melakukan tugas khusus yang dapat diverifikasi. Hal ini menghasilkan ulasan yang tidak hanya berwawasan, tetapi juga deterministik, andal, dan sangat edukatif.
👉💻 Setelah selesai menguji, kembali ke terminal Cloud Shell Editor dan tekan Ctrl+C untuk menghentikan UI Dev ADK.
Yang Telah Anda Bangun
Sekarang Anda memiliki pipeline peninjauan kode lengkap yang:
✅ Mengurai struktur kode - analisis AST deterministik dengan fungsi bantuan
✅ Memeriksa gaya - pemberian skor berbobot dengan konvensi penamaan
✅ Menjalankan pengujian - pembuatan pengujian komprehensif dengan output JSON terstruktur
✅ Mensintesis masukan - mengintegrasikan status + memori + artefak
✅ Melacak progres - status multi-tingkat di seluruh pemanggilan/sesi/pengguna
✅ Belajar seiring waktu - layanan memori untuk pola lintas sesi
✅ Menyediakan artefak - laporan JSON yang dapat didownload dengan jejak audit lengkap
Konsep Utama yang Dikuasai
Pipeline Berurutan:
- Empat agen yang dieksekusi dalam urutan yang ketat
- Setiap status memperkaya status berikutnya
- Dependensi menentukan urutan eksekusi
Pola Produksi:
- Pemisahan fungsi helper (sinkronisasi di thread pool)
- Degradasi halus (strategi penggantian)
- Pengelolaan status multi-tingkat (sementara/sesi/pengguna)
- Penyedia petunjuk dinamis (dengan konteks)
- Penyimpanan ganda (artefak + redundansi status)
Negara Bagian sebagai Komunikasi:
- Konstanta mencegah kesalahan ketik di seluruh agen
output_keymenulis ringkasan agen ke status- Agen selanjutnya dibaca melalui StateKeys
- Status mengalir secara linear melalui pipeline
Memori vs. Status:
- Status: data sesi saat ini
- Memori: pola di semua sesi
- Tujuan berbeda, masa berlaku berbeda
Orkestrasi Alat:
- Agen alat tunggal (analyzer, style_checker)
- Eksekutor bawaan (test_runner)
- Koordinasi multi-alat (synthesizer)
Strategi Pemilihan Model:
- Model pekerja: tugas mekanis (parsing, linting, perutean)
- Model kritik: tugas penalaran (pengujian, sintesis)
- Pengoptimalan biaya melalui pemilihan yang tepat
Langkah Berikutnya
Dalam Modul 6, Anda akan membangun pipeline perbaikan:
- Arsitektur LoopAgent untuk perbaikan iteratif
- Kondisi keluar melalui eskalasi
- Akumulasi status di seluruh iterasi
- Validasi dan logika percobaan ulang
- Integrasi dengan pipeline ulasan untuk menawarkan perbaikan
Anda akan melihat cara pola status yang sama diskalakan ke alur kerja iteratif yang kompleks di mana agen mencoba beberapa kali hingga berhasil, dan cara mengoordinasikan beberapa pipeline dalam satu aplikasi.
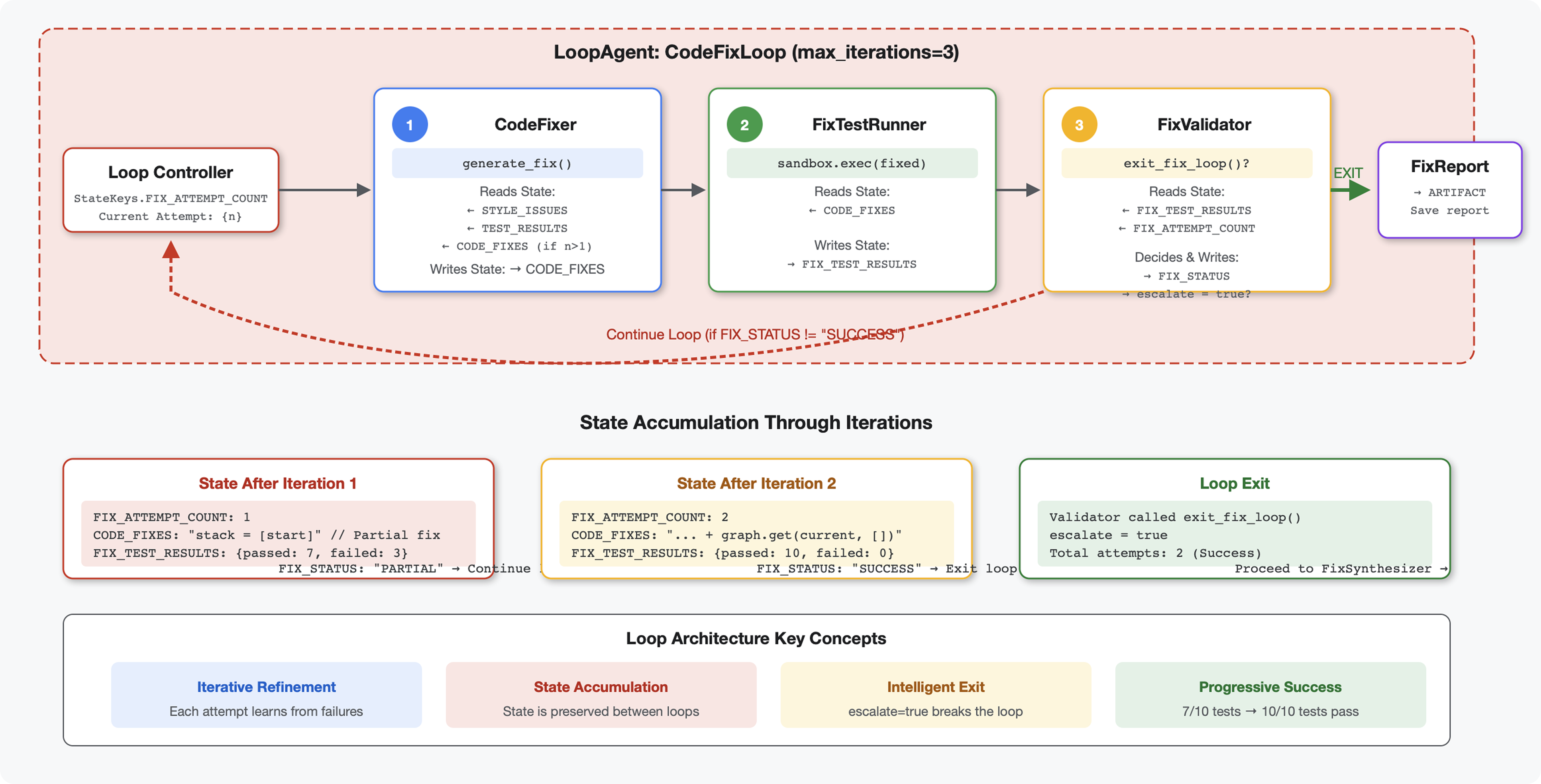
6. Menambahkan Pipeline Perbaikan: Arsitektur Loop
Pengantar
Di Modul 5, Anda membangun pipeline peninjauan berurutan yang menganalisis kode dan memberikan masukan. Namun, mengidentifikasi masalah hanyalah setengah dari solusi - developer memerlukan bantuan untuk memperbaikinya.
Modul ini membangun pipeline perbaikan otomatis yang:
- Membuat perbaikan berdasarkan hasil peninjauan
- Memvalidasi perbaikan dengan menjalankan pengujian komprehensif
- Mencoba lagi secara otomatis jika perbaikan tidak berhasil (hingga 3 kali percobaan)
- Hasil laporan dengan perbandingan sebelum/sesudah
Konsep utama: LoopAgent untuk percobaan ulang otomatis. Tidak seperti agen berurutan yang berjalan satu kali, LoopAgent mengulangi sub-agennya hingga kondisi keluar terpenuhi atau iterasi maksimum tercapai. Alat menandakan keberhasilan dengan menyetel tool_context.actions.escalate = True.
Pratinjau yang akan Anda bangun: Kirim kode yang penuh bug → peninjauan mengidentifikasi masalah → loop perbaikan menghasilkan koreksi → pengujian memvalidasi → coba lagi jika diperlukan → laporan komprehensif akhir.
Konsep Inti: LoopAgent vs. Berurutan
Pipeline Berurutan (Modul 5):
SequentialAgent(agents=[A, B, C])
# Executes: A → B → C → Done
- Alur satu arah
- Setiap agen berjalan tepat satu kali
- Tidak ada logika percobaan ulang
Pipeline Loop (Modul 6):
LoopAgent(agents=[A, B, C], max_iterations=3)
# Executes: A → B → C → (check exit) → A → B → C → (check exit) → ...
- Alur siklik
- Agen dapat dijalankan beberapa kali
- Keluar saat:
- Alat menetapkan
tool_context.actions.escalate = True(berhasil) max_iterationstercapai (batas keamanan)- Terjadi pengecualian yang tidak tertangani (error)
- Alat menetapkan
Alasan penggunaan loop untuk memperbaiki kode:
Perbaikan kode sering kali memerlukan beberapa upaya:
- Upaya pertama: Perbaiki bug yang jelas (jenis variabel yang salah)
- Upaya kedua: Memperbaiki masalah sekunder yang terungkap oleh pengujian (kasus ekstrem)
- Upaya ketiga: Sesuaikan dan validasi semua pengujian berhasil
Tanpa loop, Anda memerlukan logika bersyarat yang kompleks dalam petunjuk agen. Dengan LoopAgent, percobaan ulang dilakukan secara otomatis.
Perbandingan arsitektur:
Sequential (Module 5):
User → Review Pipeline → Feedback → Done
Loop (Module 6):
User → Review Pipeline → Feedback → Fix Pipeline
↓
┌──────────────┴──────────────┐
│ Fix Attempt Loop (1-3x) │
│ ┌─────────────────────┐ │
│ │ 1. Generate Fixes │ │
│ │ 2. Test Fixes │ │
│ │ 3. Validate & Exit? │────┼─→ If escalate=True
│ └─────────────────────┘ │ exit loop
│ ↓ If not │
│ Try Again (max 3) │
└─────────────────────────────┘
↓
4. Synthesize Final Report → Done
Langkah 1: Tambahkan Agen Perbaikan Kode
Perbaikan kode menghasilkan kode Python yang telah dikoreksi berdasarkan hasil peninjauan.
👉 Buka
code_review_assistant/sub_agents/fix_pipeline/code_fixer.py
👉 Temukan:
# MODULE_6_STEP_1_CODE_FIXER_INSTRUCTION_PROVIDER
👉 Ganti satu baris tersebut dengan:
async def code_fixer_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are an expert code fixing specialist.
Original Code:
{code_to_review}
Analysis Results:
- Style Score: {style_score}/100
- Style Issues: {style_issues}
- Test Results: {test_execution_summary}
Based on the test results, identify and fix ALL issues including:
- Interface bugs (e.g., if start parameter expects wrong type)
- Logic errors (e.g., KeyError when accessing graph nodes)
- Style violations
- Missing documentation
YOUR TASK:
Generate the complete fixed Python code that addresses all identified issues.
CRITICAL INSTRUCTIONS:
- Output ONLY the corrected Python code
- Do NOT include markdown code blocks (```python)
- Do NOT include any explanations or commentary
- The output should be valid, executable Python code and nothing else
Common fixes to apply based on test results:
- If tests show AttributeError with 'pop', fix: stack = [start] instead of stack = start
- If tests show KeyError accessing graph, fix: use graph.get(current, [])
- Add docstrings if missing
- Fix any style violations identified
Output the complete fixed code now:"""
return await instructions_utils.inject_session_state(template, context)
👉 Temukan:
# MODULE_6_STEP_1_CODE_FIXER_AGENT
👉 Ganti satu baris tersebut dengan:
code_fixer_agent = Agent(
name="CodeFixer",
model=config.worker_model,
description="Generates comprehensive fixes for all identified code issues",
instruction=code_fixer_instruction_provider,
code_executor=BuiltInCodeExecutor(),
output_key="code_fixes"
)
Langkah 2: Tambahkan Agen Fix Test Runner
Runner pengujian perbaikan memvalidasi koreksi dengan menjalankan pengujian komprehensif pada kode yang diperbaiki.
👉 Buka
code_review_assistant/sub_agents/fix_pipeline/fix_test_runner.py
👉 Temukan:
# MODULE_6_STEP_2_FIX_TEST_RUNNER_INSTRUCTION_PROVIDER
👉 Ganti satu baris tersebut dengan:
async def fix_test_runner_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that uses the clean code from the previous step."""
template = """You are responsible for validating the fixed code by running tests.
THE FIXED CODE TO TEST:
{code_fixes}
ORIGINAL TEST RESULTS: {test_execution_summary}
YOUR TASK:
1. Understand the fixes that were applied
2. Generate the same comprehensive tests (15-20 test cases)
3. Execute the tests on the FIXED code using your code executor
4. Compare results with original test results
5. Output a detailed JSON analysis
TESTING METHODOLOGY:
- Run the same tests that revealed issues in the original code
- Verify that previously failing tests now pass
- Ensure no regressions were introduced
- Document the improvement
Execute your tests and output ONLY valid JSON with this structure:
- "passed": number of tests that passed
- "failed": number of tests that failed
- "total": total number of tests
- "pass_rate": percentage as a number
- "comparison": object with "original_pass_rate", "new_pass_rate", "improvement"
- "newly_passing_tests": array of test names that now pass
- "still_failing_tests": array of test names still failing
Do NOT output the test code itself, only the JSON analysis."""
return await instructions_utils.inject_session_state(template, context)
👉 Temukan:
# MODULE_6_STEP_2_FIX_TEST_RUNNER_AGENT
👉 Ganti satu baris tersebut dengan:
fix_test_runner_agent = Agent(
name="FixTestRunner",
model=config.critic_model,
description="Runs comprehensive tests on fixed code to verify all issues are resolved",
instruction=fix_test_runner_instruction_provider,
code_executor=BuiltInCodeExecutor(),
output_key="fix_test_execution_summary"
)
Langkah 3: Tambahkan Agen Validator Perbaikan
Validator memeriksa apakah perbaikan berhasil dan memutuskan apakah akan keluar dari loop.
Memahami Alat
Pertama, tambahkan tiga alat yang dibutuhkan validator.
👉 Buka
code_review_assistant/tools.py
👉 Temukan:
# MODULE_6_STEP_3_VALIDATE_FIXED_STYLE
👉 Ganti dengan Alat 1 - Validator Gaya:
async def validate_fixed_style(tool_context: ToolContext) -> Dict[str, Any]:
"""
Validates style compliance of the fixed code.
Args:
tool_context: ADK tool context containing fixed code in state
Returns:
Dictionary with style validation results
"""
logger.info("Tool: Validating style of fixed code...")
try:
# Get the fixed code from state
code_fixes = tool_context.state.get(StateKeys.CODE_FIXES, '')
# Try to extract from markdown if present
if '```python' in code_fixes:
start = code_fixes.rfind('```python') + 9
end = code_fixes.rfind('```')
if start < end:
code_fixes = code_fixes[start:end].strip()
if not code_fixes:
return {
"status": "error",
"message": "No fixed code found in state"
}
# Store the extracted fixed code
tool_context.state[StateKeys.CODE_FIXES] = code_fixes
# Run style check on fixed code
loop = asyncio.get_event_loop()
with ThreadPoolExecutor() as executor:
style_result = await loop.run_in_executor(
executor, _perform_style_check, code_fixes
)
# Compare with original
original_score = tool_context.state.get(StateKeys.STYLE_SCORE, 0)
improvement = style_result['score'] - original_score
# Store results
tool_context.state[StateKeys.FIXED_STYLE_SCORE] = style_result['score']
tool_context.state[StateKeys.FIXED_STYLE_ISSUES] = style_result['issues']
logger.info(f"Tool: Fixed code style score: {style_result['score']}/100 "
f"(improvement: +{improvement})")
return {
"status": "success",
"fixed_style_score": style_result['score'],
"original_style_score": original_score,
"improvement": improvement,
"remaining_issues": style_result['issues'],
"perfect_style": style_result['score'] == 100
}
except Exception as e:
logger.error(f"Tool: Style validation failed: {e}", exc_info=True)
return {
"status": "error",
"message": str(e)
}
👉 Temukan:
# MODULE_6_STEP_3_COMPILE_FIX_REPORT
👉 Ganti dengan Alat 2 - Pengompilasi Laporan:
async def compile_fix_report(tool_context: ToolContext) -> Dict[str, Any]:
"""
Compiles comprehensive report of the fix process.
Args:
tool_context: ADK tool context with all fix pipeline data
Returns:
Comprehensive fix report
"""
logger.info("Tool: Compiling comprehensive fix report...")
try:
# Gather all data
original_code = tool_context.state.get(StateKeys.CODE_TO_REVIEW, '')
code_fixes = tool_context.state.get(StateKeys.CODE_FIXES, '')
# Test results
original_tests = tool_context.state.get(StateKeys.TEST_EXECUTION_SUMMARY, {})
fixed_tests = tool_context.state.get(StateKeys.FIX_TEST_EXECUTION_SUMMARY, {})
# Parse if strings
if isinstance(original_tests, str):
try:
original_tests = json.loads(original_tests)
except:
original_tests = {}
if isinstance(fixed_tests, str):
try:
fixed_tests = json.loads(fixed_tests)
except:
fixed_tests = {}
# Extract pass rates
original_pass_rate = 0
if original_tests:
if 'pass_rate' in original_tests:
original_pass_rate = original_tests['pass_rate']
elif 'test_summary' in original_tests:
# Handle test_runner_agent's JSON structure
summary = original_tests['test_summary']
total = summary.get('total_tests_run', 0)
passed = summary.get('tests_passed', 0)
if total > 0:
original_pass_rate = (passed / total) * 100
elif 'passed' in original_tests and 'total' in original_tests:
if original_tests['total'] > 0:
original_pass_rate = (original_tests['passed'] / original_tests['total']) * 100
fixed_pass_rate = 0
all_tests_pass = False
if fixed_tests:
if 'pass_rate' in fixed_tests:
fixed_pass_rate = fixed_tests['pass_rate']
all_tests_pass = fixed_tests.get('failed', 1) == 0
elif 'passed' in fixed_tests and 'total' in fixed_tests:
if fixed_tests['total'] > 0:
fixed_pass_rate = (fixed_tests['passed'] / fixed_tests['total']) * 100
all_tests_pass = fixed_tests.get('failed', 0) == 0
# Style scores
original_style = tool_context.state.get(StateKeys.STYLE_SCORE, 0)
fixed_style = tool_context.state.get(StateKeys.FIXED_STYLE_SCORE, 0)
# Calculate improvements
test_improvement = {
'original_pass_rate': original_pass_rate,
'fixed_pass_rate': fixed_pass_rate,
'improvement': fixed_pass_rate - original_pass_rate,
'all_tests_pass': all_tests_pass
}
style_improvement = {
'original_score': original_style,
'fixed_score': fixed_style,
'improvement': fixed_style - original_style,
'perfect_style': fixed_style == 100
}
# Determine overall status
if all_tests_pass and style_improvement['perfect_style']:
fix_status = 'SUCCESSFUL'
status_emoji = '✅'
elif test_improvement['improvement'] > 0 or style_improvement['improvement'] > 0:
fix_status = 'PARTIAL'
status_emoji = '⚠️'
else:
fix_status = 'FAILED'
status_emoji = '❌'
# Build comprehensive report
report = {
'status': fix_status,
'status_emoji': status_emoji,
'timestamp': datetime.now().isoformat(),
'original_code': original_code,
'code_fixes': code_fixes,
'improvements': {
'tests': test_improvement,
'style': style_improvement
},
'summary': f"{status_emoji} Fix Status: {fix_status}\n"
f"Tests: {original_pass_rate:.1f}% → {fixed_pass_rate:.1f}%\n"
f"Style: {original_style}/100 → {fixed_style}/100"
}
# Store report in state
tool_context.state[StateKeys.FIX_REPORT] = report
tool_context.state[StateKeys.FIX_STATUS] = fix_status
logger.info(f"Tool: Fix report compiled - Status: {fix_status}")
logger.info(f"Tool: Test improvement: {original_pass_rate:.1f}% → {fixed_pass_rate:.1f}%")
logger.info(f"Tool: Style improvement: {original_style} → {fixed_style}")
return {
"status": "success",
"fix_status": fix_status,
"report": report
}
except Exception as e:
logger.error(f"Tool: Failed to compile fix report: {e}", exc_info=True)
return {
"status": "error",
"message": str(e)
}
👉 Temukan:
# MODULE_6_STEP_3_EXIT_FIX_LOOP
👉 Ganti dengan Alat 3 - Sinyal Keluar Loop:
def exit_fix_loop(tool_context: ToolContext) -> Dict[str, Any]:
"""
Signal that fixing is complete and should exit the loop.
Args:
tool_context: ADK tool context
Returns:
Confirmation message
"""
logger.info("Tool: Setting escalate flag to exit fix loop")
# This is the critical line that exits the LoopAgent
tool_context.actions.escalate = True
return {
"status": "success",
"message": "Fix complete, exiting loop"
}
Buat Agen Validator
👉 Buka
code_review_assistant/sub_agents/fix_pipeline/fix_validator.py
👉 Temukan:
# MODULE_6_STEP_3_FIX_VALIDATOR_INSTRUCTION_PROVIDER
👉 Ganti satu baris tersebut dengan:
async def fix_validator_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are the final validation specialist for code fixes.
You have access to:
- Original issues from initial review
- Applied fixes: {code_fixes}
- Test results after fix: {fix_test_execution_summary}
- All state data from the fix process
Your responsibilities:
1. Use validate_fixed_style tool to check style compliance of fixed code
- Pass no arguments, it will retrieve fixed code from state
2. Use compile_fix_report tool to generate comprehensive report
- Pass no arguments, it will gather all data from state
3. Based on the report, determine overall fix status:
- ✅ SUCCESSFUL: All tests pass, style score 100
- ⚠️ PARTIAL: Improvements made but issues remain
- ❌ FAILED: Fix didn't work or made things worse
4. CRITICAL: If status is SUCCESSFUL, call the exit_fix_loop tool to stop iterations
- This prevents unnecessary additional fix attempts
- If not successful, the loop will continue for another attempt
5. Provide clear summary of:
- What was fixed
- What improvements were achieved
- Any remaining issues requiring manual attention
Be precise and quantitative in your assessment.
"""
return await instructions_utils.inject_session_state(template, context)
👉 Temukan:
# MODULE_6_STEP_3_FIX_VALIDATOR_AGENT
👉 Ganti satu baris tersebut dengan:
fix_validator_agent = Agent(
name="FixValidator",
model=config.worker_model,
description="Validates fixes and generates final fix report",
instruction=fix_validator_instruction_provider,
tools=[
FunctionTool(func=validate_fixed_style),
FunctionTool(func=compile_fix_report),
FunctionTool(func=exit_fix_loop)
],
output_key="final_fix_report"
)
Langkah 4: Memahami Kondisi Keluar LoopAgent
LoopAgent memiliki tiga cara untuk keluar:
1. Keluar Berhasil (melalui eskalasi)
# Inside any tool in the loop:
tool_context.actions.escalate = True
# Effect: Loop completes current iteration, then exits
# Use when: Fix is successful and no more attempts needed
Contoh alur:
Iteration 1:
CodeFixer → generates fixes
FixTestRunner → tests show 90% pass rate
FixValidator → compiles report, sees PARTIAL status
→ Does NOT set escalate
→ Loop continues
Iteration 2:
CodeFixer → refines fixes based on failures
FixTestRunner → tests show 100% pass rate
FixValidator → compiles report, sees SUCCESSFUL status
→ Calls exit_fix_loop() which sets escalate = True
→ Loop exits after this iteration
2. Keluar dari Iterasi Maksimum
LoopAgent(
name="FixAttemptLoop",
sub_agents=[...],
max_iterations=3 # Safety limit
)
# Effect: After 3 complete iterations, loop exits regardless of escalate
# Use when: Prevent infinite loops if fixes never succeed
Contoh alur:
Iteration 1: PARTIAL (continue)
Iteration 2: PARTIAL (continue)
Iteration 3: PARTIAL (but max reached)
→ Loop exits, synthesizer presents best attempt
3. Keluar karena Error
# If any agent throws unhandled exception:
raise Exception("Unexpected error")
# Effect: Loop exits immediately with error state
# Use when: Critical failure that can't be recovered
Evolusi Status di Seluruh Iterasi:
Setiap iterasi melihat status yang diperbarui dari percobaan sebelumnya:
# Before Iteration 1:
state = {
"code_to_review": "def add(a,b):return a+b", # Original
"style_score": 40,
"test_execution_summary": {...}
}
# After Iteration 1:
state = {
"code_to_review": "def add(a,b):return a+b", # Unchanged
"code_fixes": "def add(a, b):\n return a + b", # NEW
"style_score": 40, # Unchanged
"fixed_style_score": 100, # NEW
"test_execution_summary": {...}, # Unchanged
"fix_test_execution_summary": {...} # NEW
}
# Iteration 2 starts with all this state
# If fixes still not perfect, code_fixes gets overwritten
Mengapa
escalate
Sebagai ganti Nilai yang Ditampilkan:
# Bad: Using return value to signal exit
def validator_agent():
report = compile_report()
if report['status'] == 'SUCCESSFUL':
return {"exit": True} # How does loop know?
# Good: Using escalate
def validator_tool(tool_context):
report = compile_report()
if report['status'] == 'SUCCESSFUL':
tool_context.actions.escalate = True # Loop knows immediately
return {"report": report}
Manfaat:
- Berfungsi dari alat apa pun, bukan hanya alat terakhir
- Tidak mengganggu data yang ditampilkan
- Makna semantik yang jelas
- Framework menangani logika keluar
Langkah 5: Hubungkan Pipeline Perbaikan
👉 Buka
code_review_assistant/agent.py
👉 Tambahkan impor pipeline perbaikan (setelah impor yang ada):
from google.adk.agents import LoopAgent # Add this to the existing Agent, SequentialAgent line
from code_review_assistant.sub_agents.fix_pipeline.code_fixer import code_fixer_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_test_runner import fix_test_runner_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_validator import fix_validator_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_synthesizer import fix_synthesizer_agent
Impor Anda sekarang akan menjadi:
from google.adk.agents import Agent, SequentialAgent, LoopAgent
from .config import config
# Review pipeline imports (from Module 5)
from code_review_assistant.sub_agents.review_pipeline.code_analyzer import code_analyzer_agent
from code_review_assistant.sub_agents.review_pipeline.style_checker import style_checker_agent
from code_review_assistant.sub_agents.review_pipeline.test_runner import test_runner_agent
from code_review_assistant.sub_agents.review_pipeline.feedback_synthesizer import feedback_synthesizer_agent
# Fix pipeline imports (NEW)
from code_review_assistant.sub_agents.fix_pipeline.code_fixer import code_fixer_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_test_runner import fix_test_runner_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_validator import fix_validator_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_synthesizer import fix_synthesizer_agent
👉 Temukan:
# MODULE_6_STEP_5_CREATE_FIX_LOOP
👉 Ganti satu baris tersebut dengan:
# Create the fix attempt loop (retries up to 3 times)
fix_attempt_loop = LoopAgent(
name="FixAttemptLoop",
sub_agents=[
code_fixer_agent, # Step 1: Generate fixes
fix_test_runner_agent, # Step 2: Validate with tests
fix_validator_agent # Step 3: Check success & possibly exit
],
max_iterations=3 # Try up to 3 times
)
# Wrap loop with synthesizer for final report
code_fix_pipeline = SequentialAgent(
name="CodeFixPipeline",
description="Automated code fixing pipeline with iterative validation",
sub_agents=[
fix_attempt_loop, # Try to fix (1-3 times)
fix_synthesizer_agent # Present final results (always runs once)
]
)
👉 Hapus yang ada
root_agent
definisi:
root_agent = Agent(...)
👉 Temukan:
# MODULE_6_STEP_5_UPDATE_ROOT_AGENT
👉 Ganti satu baris tersebut dengan:
# Update root agent to include both pipelines
root_agent = Agent(
name="CodeReviewAssistant",
model=config.worker_model,
description="An intelligent code review assistant that analyzes Python code and provides educational feedback",
instruction="""You are a specialized Python code review assistant focused on helping developers improve their code quality.
When a user provides Python code for review:
1. Immediately delegate to CodeReviewPipeline and pass the code EXACTLY as it was provided by the user.
2. The pipeline will handle all analysis and feedback
3. Return ONLY the final feedback from the pipeline - do not add any commentary
After completing a review, if significant issues were identified:
- If style score < 100 OR tests are failing OR critical issues exist:
* Add at the end: "\n\n💡 I can fix these issues for you. Would you like me to do that?"
- If the user responds yes or requests fixes:
* Delegate to CodeFixPipeline
* Return the fix pipeline's complete output AS-IS
When a user asks what you can do or general questions:
- Explain your capabilities for code review and fixing
- Do NOT trigger the pipeline for non-code messages
The pipelines handle everything for code review and fixing - just pass through their final output.""",
sub_agents=[code_review_pipeline, code_fix_pipeline],
output_key="assistant_response"
)
Langkah 6: Tambahkan Agen Fix Synthesizer
Sintesis membuat presentasi hasil perbaikan yang mudah digunakan setelah loop selesai.
👉 Buka
code_review_assistant/sub_agents/fix_pipeline/fix_synthesizer.py
👉 Temukan:
# MODULE_6_STEP_6_FIX_SYNTHESIZER_INSTRUCTION_PROVIDER
👉 Ganti satu baris tersebut dengan:
async def fix_synthesizer_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are responsible for presenting the fix results to the user.
Based on the validation report: {final_fix_report}
Fixed code from state: {code_fixes}
Fix status: {fix_status}
Create a comprehensive yet friendly response that includes:
## 🔧 Fix Summary
[Overall status and key improvements - be specific about what was achieved]
## 📊 Metrics
- Test Results: [original pass rate]% → [new pass rate]%
- Style Score: [original]/100 → [new]/100
- Issues Fixed: X of Y
## ✅ What Was Fixed
[List each fixed issue with brief explanation of the correction made]
## 📝 Complete Fixed Code
[Include the complete, corrected code from state - this is critical]
## 💡 Explanation of Key Changes
[Brief explanation of the most important changes made and why]
[If any issues remain]
## ⚠️ Remaining Issues
[List what still needs manual attention]
## 🎯 Next Steps
[Guidance on what to do next - either use the fixed code or address remaining issues]
Save the fix report using save_fix_report tool before presenting.
Call it with no parameters - it will retrieve the report from state automatically.
Be encouraging about improvements while being honest about any remaining issues.
Focus on the educational aspect - help the user understand what was wrong and how it was fixed.
"""
return await instructions_utils.inject_session_state(template, context)
👉 Temukan:
# MODULE_6_STEP_6_FIX_SYNTHESIZER_AGENT
👉 Ganti satu baris tersebut dengan:
fix_synthesizer_agent = Agent(
name="FixSynthesizer",
model=config.critic_model,
description="Creates comprehensive user-friendly fix report",
instruction=fix_synthesizer_instruction_provider,
tools=[FunctionTool(func=save_fix_report)],
output_key="fix_summary"
)
👉 Tambahkan
save_fix_report
Alat ke
tools.py
:
👉 Temukan:
# MODULE_6_STEP_6_SAVE_FIX_REPORT
👉 Ganti dengan:
async def save_fix_report(tool_context: ToolContext) -> Dict[str, Any]:
"""
Saves the fix report as an artifact.
Args:
tool_context: ADK tool context
Returns:
Save status
"""
logger.info("Tool: Saving fix report...")
try:
# Get the report from state
fix_report = tool_context.state.get(StateKeys.FIX_REPORT, {})
if not fix_report:
return {
"status": "error",
"message": "No fix report found in state"
}
# Convert to JSON
report_json = json.dumps(fix_report, indent=2)
report_part = types.Part.from_text(text=report_json)
# Generate filename
timestamp = datetime.now().isoformat().replace(':', '-')
filename = f"fix_report_{timestamp}.json"
# Try to save as artifact
if hasattr(tool_context, 'save_artifact'):
try:
version = await tool_context.save_artifact(filename, report_part)
await tool_context.save_artifact("latest_fix_report.json", report_part)
logger.info(f"Tool: Fix report saved as {filename}")
return {
"status": "success",
"filename": filename,
"version": str(version),
"size": len(report_json)
}
except Exception as e:
logger.warning(f"Could not save as artifact: {e}")
# Fallback: store in state
tool_context.state[StateKeys.LAST_FIX_REPORT] = fix_report
return {
"status": "success",
"message": "Fix report saved to state",
"size": len(report_json)
}
except Exception as e:
logger.error(f"Tool: Failed to save fix report: {e}", exc_info=True)
return {
"status": "error",
"message": str(e)
}
Langkah 7: Uji Pipeline Perbaikan Lengkap
Saatnya melihat seluruh loop beraksi.
👉 Mulai sistem:
adk web code_review_assistant
Setelah menjalankan perintah adk web, Anda akan melihat output di terminal yang menunjukkan bahwa Server Web ADK telah dimulai, seperti ini:
+-----------------------------------------------------------------------------+
| ADK Web Server started |
| |
| For local testing, access at http://localhost:8000. |
+-----------------------------------------------------------------------------+
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
👉 Perintah Pengujian:
Please analyze the following:
def dfs_search_v1(graph, start, target):
"""Find if target is reachable from start."""
visited = set()
stack = start
while stack:
current = stack.pop()
if current == target:
return True
if current not in visited:
visited.add(current)
for neighbor in graph[current]:
if neighbor not in visited:
stack.append(neighbor)
return False
Pertama, kirimkan kode yang bermasalah untuk memicu pipeline peninjauan. Setelah mengidentifikasi kekurangan, Anda akan meminta agen untuk "Please fix the code" yang akan memicu pipeline perbaikan yang canggih dan iteratif.
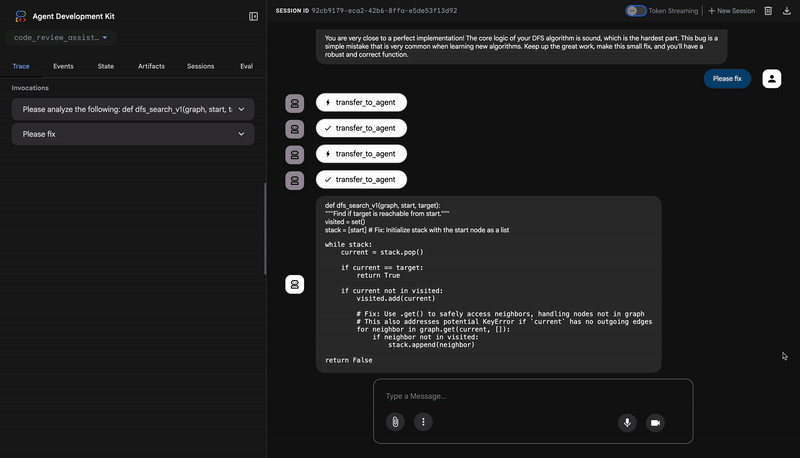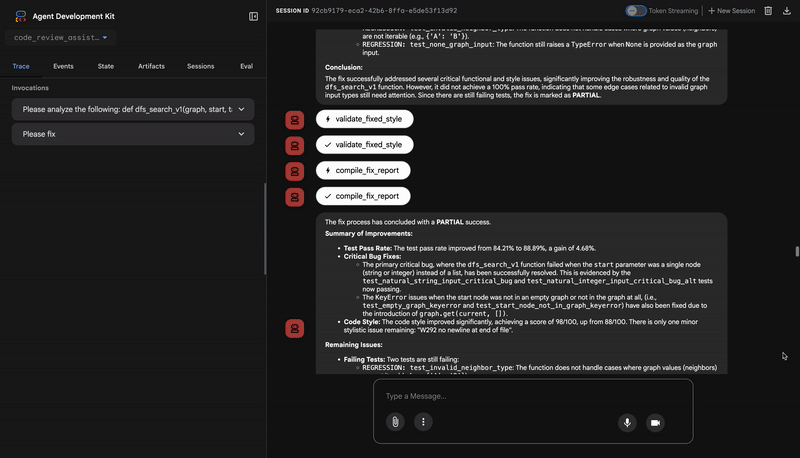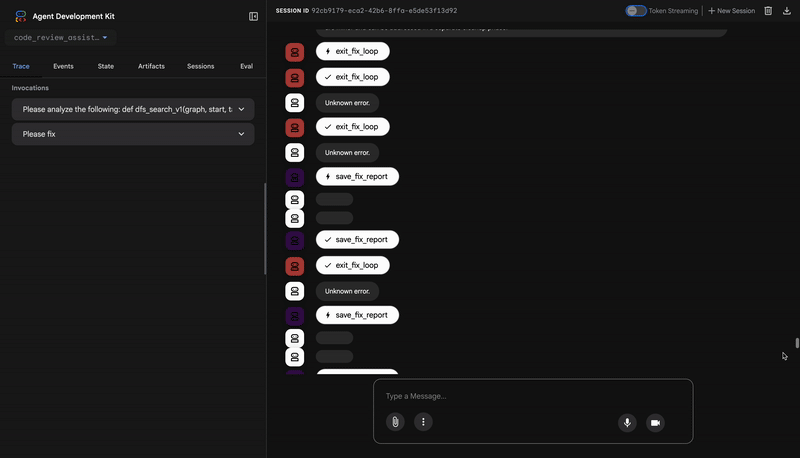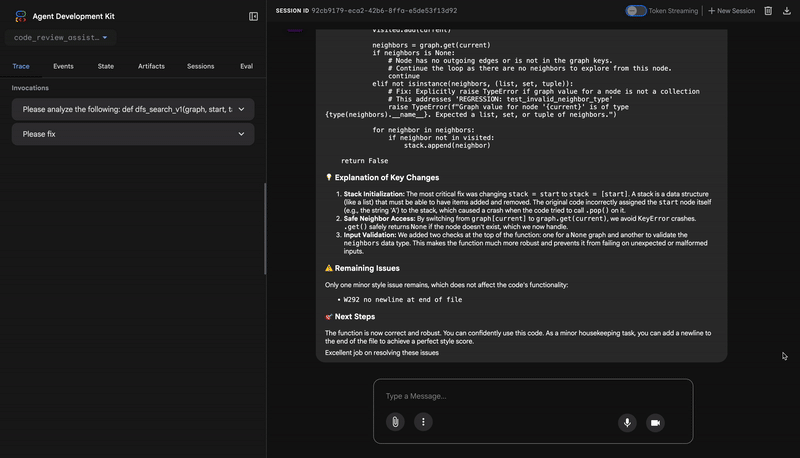
1. Peninjauan Awal (Menemukan Kekurangan)
Ini adalah paruh pertama proses. Pipeline peninjauan empat agen menganalisis kode, memeriksa gaya penulisannya, dan menjalankan rangkaian pengujian yang dihasilkan. Alat ini mengidentifikasi AttributeError kritis dan masalah lainnya dengan benar, serta memberikan putusan: kode tersebut RUSAK, dengan tingkat keberhasilan pengujian hanya 84,21%.
2. Perbaikan Otomatis (Loop dalam Tindakan)
Ini adalah bagian yang paling mengesankan. Saat Anda meminta agen untuk memperbaiki kode, agen tidak hanya membuat satu perubahan. Fitur ini memulai Loop Perbaikan dan Validasi iteratif yang berfungsi seperti developer yang rajin: mencoba perbaikan, mengujinya secara menyeluruh, dan jika tidak sempurna, fitur ini akan mencoba lagi.
Iterasi #1: Upaya Pertama (Berhasil Sebagian)
- Perbaikan: Agen
CodeFixermembaca laporan awal dan melakukan koreksi yang paling jelas. Perubahan ini mengubahstack = startmenjadistack = [start]dan menggunakangraph.get()untuk mencegah pengecualianKeyError. - Validasi:
TestRunnersegera menjalankan kembali rangkaian pengujian lengkap terhadap kode baru ini. - Hasilnya: Tingkat kelulusan meningkat secara signifikan menjadi 88,89%. Bug kritis sudah tidak ada. Namun, pengujiannya sangat komprehensif sehingga mengungkapkan dua bug baru yang tidak terlalu terlihat (regresi) terkait penanganan
Nonesebagai nilai tetangga grafik atau non-daftar. Sistem menandai perbaikan sebagai SEBAGIAN.
Iterasi #2: Sentuhan Akhir (Berhasil 100%)
- Perbaikan: Karena kondisi keluar loop (tingkat kelulusan 100%) tidak terpenuhi, loop akan berjalan lagi.
CodeFixerkini memiliki informasi lebih lanjut—dua kegagalan regresi baru. Hal ini menghasilkan versi akhir kode yang lebih efektif yang secara eksplisit menangani kasus ekstrem tersebut. - Validasi:
TestRunnermenjalankan suite pengujian untuk terakhir kalinya terhadap versi akhir kode. - Hasil: Tingkat kelulusan 100% yang sempurna. Semua bug asli dan semua regresi telah diselesaikan. Sistem menandai perbaikan sebagai BERHASIL dan loop keluar.
3. Laporan Akhir: Skor Sempurna
Dengan perbaikan yang divalidasi sepenuhnya, agen FixSynthesizer akan mengambil alih untuk menyajikan laporan akhir, yang mengubah data teknis menjadi ringkasan yang jelas dan edukatif.
Metrik | Sebelum | Setelah | Peningkatan |
Tingkat Kelulusan Ujian | 84,21% | 100% | ▲ 15,79% |
Skor Gaya (Style Score) | 88 / 100 | 98 / 100 | ▲ 10 poin |
Bug yang Diperbaiki | 0 dari 3 | 3 dari 3 | ✅ |
✅ Kode Akhir yang Divalidasi
Berikut adalah kode lengkap yang telah diperbaiki dan kini lulus semua 19 pengujian, yang menunjukkan keberhasilan perbaikan:
def dfs_search_v1(graph, start, target):
"""Find if target is reachable from start."""
# Handles 'None' graph input
if graph is None:
return False
visited = set()
# Fixes the critical AttributeError
stack = [start]
while stack:
current = stack.pop()
if current == target:
return True
if current not in visited:
visited.add(current)
# Safely gets neighbors to prevent KeyError
neighbors = graph.get(current)
if neighbors is None:
continue
# Validates that neighbors are iterable
if not isinstance(neighbors, (list, set, tuple)):
raise TypeError(
f"Graph value for node '{current}' is of type "
f"{type(neighbors).__name__}. Expected a list, set, or tuple."
)
for neighbor in neighbors:
if neighbor not in visited:
stack.append(neighbor)
return False
👉💻 Setelah selesai menguji, kembali ke terminal Cloud Shell Editor dan tekan Ctrl+C untuk menghentikan UI Dev ADK.
Yang Telah Anda Bangun
Sekarang Anda memiliki pipeline perbaikan otomatis lengkap yang:
✅ Membuat perbaikan - Berdasarkan analisis peninjauan
✅ Memvalidasi secara iteratif - Menguji setelah setiap upaya perbaikan
✅ Mencoba lagi secara otomatis - Hingga 3 upaya agar berhasil
✅ Keluar secara cerdas - Melalui eskalasi jika berhasil
✅ Melacak peningkatan - Membandingkan metrik sebelum/sesudah
✅ Menyediakan artefak - Laporan perbaikan yang dapat didownload
Konsep Utama yang Dikuasai
LoopAgent vs Sequential:
- Berurutan: Satu kali melewati agen
- LoopAgent: Berulang hingga kondisi keluar atau iterasi maksimum
- Keluar lewat
tool_context.actions.escalate = True
Evolusi Status di Seluruh Iterasi:
CODE_FIXESdiperbarui setiap iterasi- Hasil pengujian menunjukkan peningkatan seiring waktu
- Validator melihat perubahan kumulatif
Arsitektur Multi-Pipeline:
- Meninjau pipeline: Analisis hanya baca (Modul 5)
- Memperbaiki loop: Koreksi iteratif (Loop dalam Modul 6)
- Pipeline perbaikan: Loop + synthesizer (Luar Modul 6)
- Agen root: Mengorkestrasi berdasarkan niat pengguna
Alat Pengontrol Flow:
exit_fix_loop()setelan meningkat- Setiap alat dapat menandakan penyelesaian loop
- Memisahkan logika keluar dari petunjuk agen
Keamanan Iterasi Maksimal:
- Mencegah loop tanpa batas
- Memastikan sistem selalu merespons
- Menampilkan upaya terbaik meskipun tidak sempurna
Langkah Berikutnya
Dalam modul terakhir, Anda akan mempelajari cara men-deploy agen ke produksi:
- Menyiapkan penyimpanan persisten dengan VertexAiSessionService
- Men-deploy ke Agent Engine di Google Cloud
- Memantau dan men-debug agen produksi
- Praktik terbaik untuk penskalaan dan keandalan
Anda telah membangun sistem multi-agen yang lengkap dengan arsitektur berurutan dan loop. Pola yang telah Anda pelajari - pengelolaan status, petunjuk dinamis, orkestrasi alat, dan penyempurnaan iteratif - adalah teknik siap produksi yang digunakan dalam sistem agentik nyata.
7. Men-deploy ke Produksi
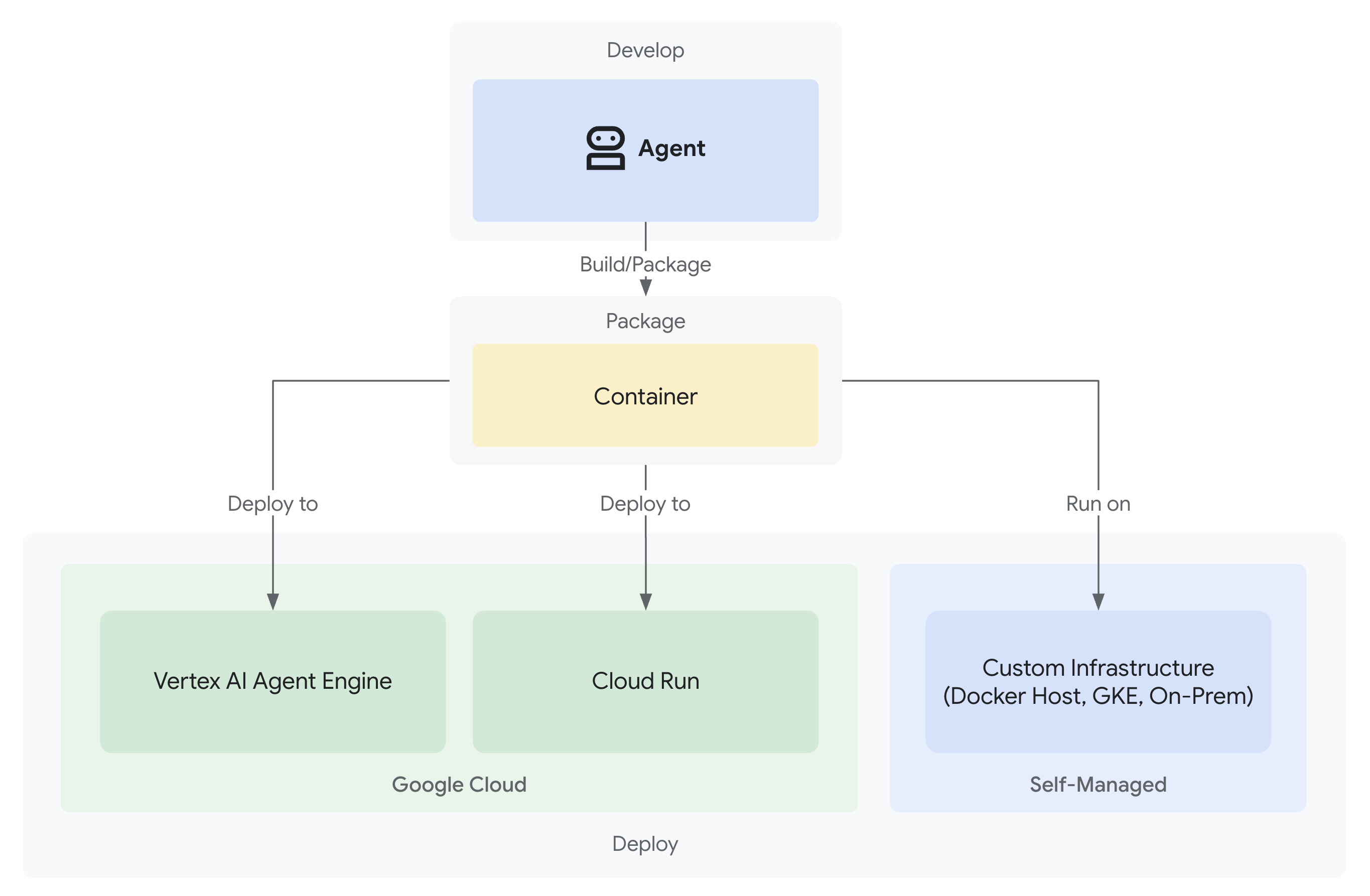
Pengantar
Asisten peninjauan kode Anda kini telah selesai dengan pipeline peninjauan dan perbaikan yang berfungsi secara lokal. Bagian yang hilang: hanya berjalan di komputer Anda. Dalam modul ini, Anda akan men-deploy agen ke Google Cloud, sehingga dapat diakses oleh tim Anda dengan sesi persisten dan infrastruktur tingkat produksi.
Yang akan Anda pelajari:
- Tiga jalur deployment: Lokal, Cloud Run, dan Agent Engine
- Penyediaan infrastruktur otomatis
- Strategi persistensi sesi
- Menguji agen yang di-deploy
Memahami Opsi Deployment
ADK mendukung beberapa target deployment, masing-masing dengan kelebihan dan kekurangan yang berbeda:
Jalur Deployment
Faktor | Lokal ( | Cloud Run ( | Agent Engine ( |
Kompleksitas | Minimal | Sedang | Rendah |
Persistensi Sesi | Khusus dalam memori (hilang saat dimulai ulang) | Cloud SQL (PostgreSQL) | Dikelola Vertex AI (otomatis) |
Infrastruktur | Tidak ada (khusus mesin dev) | Penampung + Database | Terkelola sepenuhnya |
Start Dingin | T/A | 100-2000 md | 100-500 md |
Penskalaan | Instance tunggal | Otomatis (ke nol) | Otomatis |
Model Biaya | Gratis (komputasi lokal) | Berbasis permintaan + paket gratis | Berbasis komputasi |
Dukungan UI | Ya (melalui | Ya (melalui | Tidak (khusus API) |
Paling Cocok untuk | Pengembangan/pengujian | Traffic bervariasi, kontrol biaya | Agen produksi |
Opsi deployment tambahan: Google Kubernetes Engine (GKE) tersedia untuk pengguna tingkat lanjut yang memerlukan kontrol tingkat Kubernetes, jaringan kustom, atau orkestrasi multi-layanan. Deployment GKE tidak dibahas dalam codelab ini, tetapi didokumentasikan dalam panduan deployment ADK.
Yang Di-deploy
Saat men-deploy ke Cloud Run atau Agent Engine, hal berikut akan dikemas dan di-deploy:
- Kode agen Anda (
agent.py, semua sub-agen, alat) - Dependensi (
requirements.txt) - Server API ADK (disertakan secara otomatis)
- UI Web (khusus Cloud Run, jika
--with_uiditentukan)
Perbedaan penting:
- Cloud Run: Menggunakan CLI
adk deploy cloud_run(mem-build container secara otomatis) ataugcloud run deploy(memerlukan Dockerfile kustom) - Agent Engine: Menggunakan CLI
adk deploy agent_engine(tidak perlu membangun container, langsung mengemas kode Python)
Langkah 1: Konfigurasi Lingkungan Anda
Mengonfigurasi File .env Anda
File .env Anda (dibuat di Modul 3) perlu diperbarui untuk deployment cloud. Buka .env dan verifikasi/perbarui setelan berikut:
Wajib untuk semua deployment cloud:
# Your actual GCP Project ID (REQUIRED)
GOOGLE_CLOUD_PROJECT=your-project-id
# GCP region for deployments (REQUIRED)
GOOGLE_CLOUD_LOCATION=us-central1
# Use Vertex AI (REQUIRED)
GOOGLE_GENAI_USE_VERTEXAI=true
# Model configuration (already set)
WORKER_MODEL=gemini-2.5-flash
CRITIC_MODEL=gemini-2.5-pro
Tetapkan nama bucket (WAJIB dilakukan sebelum menjalankan deploy.sh):
Skrip deployment membuat bucket berdasarkan nama ini. Tetapkan sekarang:
# Staging bucket for Agent Engine code uploads (REQUIRED for agent-engine)
STAGING_BUCKET=gs://your-project-id-staging
# Artifact storage for reports and fixed code (REQUIRED for both cloud-run and agent-engine)
ARTIFACT_BUCKET=gs://your-project-id-artifacts
Ganti your-project-id dengan project ID Anda yang sebenarnya di kedua nama bucket. Skrip akan membuat bucket ini jika belum ada.
Variabel opsional (dibuat otomatis jika kosong):
# Agent Engine ID (populated after first deployment)
AGENT_ENGINE_ID=
# Cloud Run Database credentials (created automatically if blank)
CLOUD_SQL_INSTANCE_NAME=
DB_USER=
DB_PASSWORD=
DB_NAME=
Pemeriksaan Autentikasi
Jika Anda mengalami error autentikasi selama deployment:
gcloud auth application-default login
gcloud config set project $GOOGLE_CLOUD_PROJECT
Langkah 2: Memahami Skrip Deployment
Skrip deploy.sh menyediakan antarmuka terpadu untuk semua mode deployment:
./deploy.sh {local|cloud-run|agent-engine}
Kemampuan Skrip
Penyediaan infrastruktur:
- Pengaktifan API (AI Platform, Storage, Cloud Build, Cloud Trace, Cloud SQL)
- Konfigurasi izin IAM (akun layanan, peran)
- Pembuatan resource (bucket, database, instance)
- Deployment dengan tanda yang tepat
- Verifikasi pasca-deployment
Bagian Skrip Utama
- Konfigurasi (baris 1-35): Project, region, nama layanan, default
- Fungsi Bantuan (baris 37-200): Pengaktifan API, pembuatan bucket, penyiapan IAM
- Logika Utama (baris 202-400): Orkestrasi deployment khusus mode
Langkah 3: Siapkan Agen untuk Agent Engine
Sebelum men-deploy ke Agent Engine, diperlukan file agent_engine_app.py yang membungkus agen Anda untuk runtime terkelola. Hal ini sudah dibuat untuk Anda.
Lihat code_review_assistant/agent_engine_app.py
👉 Buka file:
"""
Agent Engine application wrapper.
This file prepares the agent for deployment to Vertex AI Agent Engine.
"""
from vertexai import agent_engines
from .agent import root_agent
# Wrap the agent in an AdkApp object for Agent Engine deployment
app = agent_engines.AdkApp(
agent=root_agent,
enable_tracing=True,
)
Langkah 4: Deploy ke Agent Engine
Agent Engine adalah deployment produksi yang direkomendasikan untuk agen ADK karena menyediakan:
- Infrastruktur yang terkelola sepenuhnya (tidak ada container yang perlu dibuat)
- Persistensi sesi bawaan melalui
VertexAiSessionService - Penskalaan otomatis dari nol
- Integrasi Cloud Trace diaktifkan secara default
Perbedaan Agent Engine dengan Deployment Lainnya
Di balik layar,
deploy.sh agent-engine
Penggunaan:
adk deploy agent_engine \
--project=$GOOGLE_CLOUD_PROJECT \
--region=$GOOGLE_CLOUD_LOCATION \
--staging_bucket=$STAGING_BUCKET \
--display_name="Code Review Assistant" \
--trace_to_cloud \
code_review_assistant
Perintah ini:
- Mengemas kode Python Anda secara langsung (tanpa build Docker)
- Mengupload ke bucket staging yang Anda tentukan di
.env - Membuat instance Agent Engine terkelola
- Mengaktifkan Cloud Trace untuk kemampuan observasi
- Menggunakan
agent_engine_app.pyuntuk mengonfigurasi runtime
Tidak seperti Cloud Run yang membuat kode Anda dalam container, Agent Engine menjalankan kode Python Anda secara langsung di lingkungan runtime yang terkelola, mirip dengan fungsi serverless.
Menjalankan Deployment
Dari root project Anda:
./deploy.sh agent-engine
Tahap Deployment
Tonton skrip yang menjalankan fase ini:
Phase 1: API Enablement
✓ aiplatform.googleapis.com
✓ storage-api.googleapis.com
✓ cloudbuild.googleapis.com
✓ cloudtrace.googleapis.com
Phase 2: IAM Setup
✓ Getting project number
✓ Granting Storage Object Admin
✓ Granting AI Platform User
✓ Granting Cloud Trace Agent
Phase 3: Staging Bucket
✓ Creating gs://your-project-id-staging
✓ Setting permissions
Phase 4: Artifact Bucket
✓ Creating gs://your-project-id-artifacts
✓ Configuring access
Phase 5: Validation
✓ Checking agent.py exists
✓ Verifying root_agent defined
✓ Checking agent_engine_app.py exists
✓ Validating requirements.txt
Phase 6: Build & Deploy
✓ Packaging agent code
✓ Uploading to staging bucket
✓ Creating Agent Engine instance
✓ Configuring session persistence
✓ Setting up Cloud Trace integration
✓ Running health checks
Proses ini memerlukan waktu 5-10 menit karena mengemas agen dan men-deploy-nya ke infrastruktur Vertex AI.
Menyimpan ID Agent Engine Anda
Setelah deployment berhasil:
✅ Deployment successful!
Agent Engine ID: 7917477678498709504
Resource Name: projects/123456789/locations/us-central1/reasoningEngines/7917477678498709504
Endpoint: https://us-central1-aiplatform.googleapis.com/v1/...
⚠️ IMPORTANT: Save this in your .env file:
AGENT_ENGINE_ID=7917477678498709504
Perbarui Anda
.env
file segera:
echo "AGENT_ENGINE_ID=7917477678498709504" >> .env
ID ini diperlukan untuk:
- Menguji agen yang di-deploy
- Memperbarui deployment nanti
- Mengakses log dan rekaman aktivitas
Yang Di-deploy
Deployment Agent Engine Anda kini mencakup:
✅ Pipeline peninjauan lengkap (4 agen)
✅ Pipeline perbaikan lengkap (loop + synthesizer)
✅ Semua alat (analisis AST, pemeriksaan gaya, pembuatan artefak)
✅ Persistensi sesi (otomatis melalui VertexAiSessionService)
✅ Pengelolaan status (tingkatan sesi/pengguna/masa aktif)
✅ Kemampuan observasi (Cloud Trace diaktifkan)
✅ Infrastruktur penskalaan otomatis
Langkah 5: Uji Agen yang Di-deploy
Memperbarui File .env Anda
Setelah deployment, verifikasi bahwa .env Anda mencakup:
AGENT_ENGINE_ID=7917477678498709504 # From deployment output
GOOGLE_CLOUD_PROJECT=your-project-id
GOOGLE_CLOUD_LOCATION=us-central1
Jalankan Skrip Pengujian
Project ini menyertakan tests/test_agent_engine.py khusus untuk menguji deployment Agent Engine:
python tests/test_agent_engine.py
Fungsi Pengujian
- Melakukan autentikasi dengan project Google Cloud Anda
- Membuat sesi dengan agen yang di-deploy
- Mengirim permintaan peninjauan kode (contoh bug DFS)
- Mengalirkan respons kembali melalui Peristiwa yang Dikirim Server (SSE)
- Memverifikasi persistensi sesi dan pengelolaan status
Output yang Diinginkan
Authenticated with project: your-project-id
Targeting Agent Engine: projects/.../reasoningEngines/7917477678498709504
Creating new session...
Created session: 4857885913439920384
Sending query to agent and streaming response:
data: {"content": {"parts": [{"text": "I'll analyze your code..."}]}}
data: {"content": {"parts": [{"text": "**Code Structure Analysis**\n..."}]}}
data: {"content": {"parts": [{"text": "**Style Check Results**\n..."}]}}
data: {"content": {"parts": [{"text": "**Test Results**\n..."}]}}
data: {"content": {"parts": [{"text": "**Final Feedback**\n..."}]}}
Stream finished.
Checklist Verifikasi
- ✅ Pipeline peninjauan lengkap dijalankan (semua 4 agen)
- ✅ Respons streaming menampilkan output progresif
- ✅ Status sesi tetap ada di seluruh permintaan
- ✅ Tidak ada error autentikasi atau koneksi
- ✅ Panggilan alat berhasil dieksekusi (analisis AST, pemeriksaan gaya)
- ✅ Artefak disimpan (laporan penilaian dapat diakses)
Alternatif: Men-deploy ke Cloud Run
Meskipun Agent Engine direkomendasikan untuk deployment produksi yang disederhanakan, Cloud Run menawarkan lebih banyak kontrol dan mendukung UI web ADK. Bagian ini memberikan ringkasan.
Kapan Harus Menggunakan Cloud Run
Pilih Cloud Run jika Anda memerlukan:
- UI web ADK untuk interaksi pengguna
- Kontrol penuh atas lingkungan container
- Konfigurasi database kustom
- Integrasi dengan layanan Cloud Run yang ada
Cara Kerja Deployment Cloud Run
Di balik layar,
deploy.sh cloud-run
Penggunaan:
adk deploy cloud_run \
--project=$GOOGLE_CLOUD_PROJECT \
--region=$GOOGLE_CLOUD_LOCATION \
--service_name="code-review-assistant" \
--app_name="code_review_assistant" \
--port=8080 \
--with_ui \
--artifact_service_uri="gs://$ARTIFACT_BUCKET" \
--trace_to_cloud \
code_review_assistant
Perintah ini:
- Membangun container Docker dengan kode agen Anda
- Mengirim ke Google Artifact Registry
- Men-deploy sebagai layanan Cloud Run
- Mencakup UI web ADK (
--with_ui) - Mengonfigurasi koneksi Cloud SQL (ditambahkan oleh skrip setelah deployment awal)
Perbedaan utama dari Agent Engine: Cloud Run membuat container kode Anda dan memerlukan database untuk persistensi sesi, sedangkan Agent Engine menanganinya secara otomatis.
Perintah Deployment Cloud Run
./deploy.sh cloud-run
Apa yang Berbeda
Infrastruktur:
- Deployment dalam container (Docker dibuat otomatis oleh ADK)
- Cloud SQL (PostgreSQL) untuk persistensi sesi
- Database dibuat otomatis oleh skrip atau menggunakan instance yang ada
Pengelolaan Sesi:
- Menggunakan
DatabaseSessionService, bukanVertexAiSessionService - Memerlukan kredensial database di
.env(atau dibuat otomatis) - Status tetap ada di database PostgreSQL
Dukungan UI:
- UI Web tersedia melalui flag
--with_ui(ditangani oleh skrip) - Akses di:
https://code-review-assistant-xyz.a.run.app
Yang Telah Anda Capai
Deployment produksi Anda mencakup:
✅ Penyediaan otomatis melalui skrip deploy.sh
✅ Infrastruktur terkelola (Agent Engine menangani penskalaan, persistensi, pemantauan)
✅ Status persisten di semua tingkat memori (sesi/pengguna/masa aktif)
✅ Pengelolaan kredensial yang aman (pembuatan otomatis dan penyiapan IAM)
✅ Arsitektur yang dapat diskalakan (nol hingga ribuan pengguna serentak)
✅ Kemampuan pengamatan bawaan (integrasi Cloud Trace diaktifkan)
✅ Penanganan error dan pemulihan tingkat produksi
Konsep Utama yang Dikuasai
Persiapan Deployment:
agent_engine_app.py: Membungkus agen denganAdkAppuntuk Agent EngineAdkAppotomatis mengonfigurasiVertexAiSessionServiceuntuk persistensi- Perekaman aktivitas diaktifkan melalui
enable_tracing=True
Perintah Deployment:
adk deploy agent_engine: Mengemas kode Python, tanpa containeradk deploy cloud_run: Membangun container Docker secara otomatisgcloud run deploy: Alternatif dengan Dockerfile kustom
Opsi Deployment:
- Agent Engine: Terkelola sepenuhnya, tercepat untuk produksi
- Cloud Run: Kontrol lebih besar, mendukung UI web
- GKE: Kontrol Kubernetes tingkat lanjut (lihat panduan deployment GKE)
Layanan Terkelola:
- Agent Engine menangani persistensi sesi secara otomatis
- Cloud Run memerlukan penyiapan database (atau dibuat otomatis)
- Keduanya mendukung penyimpanan artefak melalui GCS
Pengelolaan Sesi:
- Agent Engine:
VertexAiSessionService(otomatis) - Cloud Run:
DatabaseSessionService(Cloud SQL) - Lokal:
InMemorySessionService(sementara)
Agen Anda Sudah Aktif
Asisten peninjauan kode Anda sekarang adalah:
- Dapat diakses melalui endpoint HTTPS API
- Persistent dengan status yang tetap ada setelah dimulai ulang
- Dapat diskalakan untuk menangani pertumbuhan tim secara otomatis
- Dapat diamati dengan rekaman aktivitas permintaan lengkap
- Dapat dipertahankan melalui deployment yang di-script
Apa Selanjutnya? Dalam Modul 8, Anda akan mempelajari cara menggunakan Cloud Trace untuk memahami performa agen, mengidentifikasi hambatan dalam pipeline peninjauan dan perbaikan, serta mengoptimalkan waktu eksekusi.
8. Kemampuan Observasi Produksi
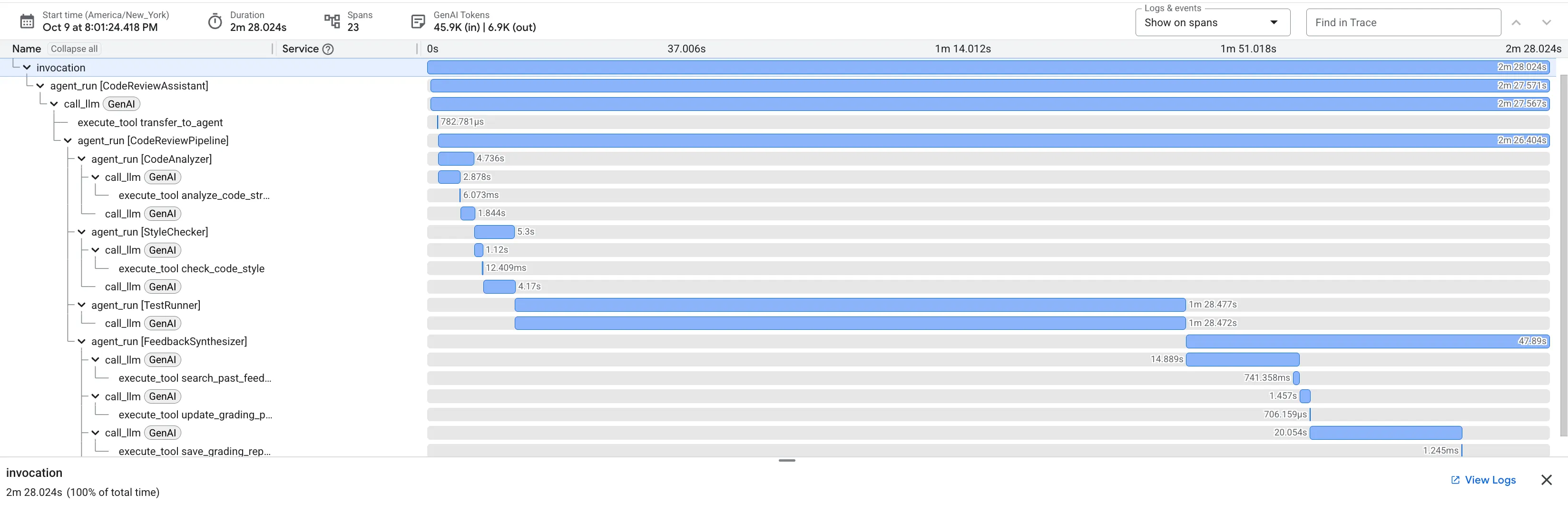
Pengantar
Asisten peninjauan kode Anda kini di-deploy dan berjalan dalam produksi di Agent Engine. Namun, bagaimana Anda tahu bahwa strategi tersebut berfungsi dengan baik? Dapatkah Anda menjawab pertanyaan penting berikut:
- Apakah agen merespons dengan cukup cepat?
- Operasi mana yang paling lambat?
- Apakah loop perbaikan selesai secara efisien?
- Di mana letak hambatan performa?
Tanpa kemampuan observasi, Anda beroperasi tanpa mengetahui apa pun. Flag --trace-to-cloud yang Anda gunakan selama deployment secara otomatis mengaktifkan Cloud Trace, sehingga memberi Anda visibilitas lengkap ke setiap permintaan yang diproses agen Anda. Hal ini mengubah proses debug dari tebakan menjadi analisis forensik.
Dalam modul ini, Anda akan mempelajari cara membaca rekaman aktivitas, memahami karakteristik performa agen, dan mengidentifikasi area yang perlu dioptimalkan berdasarkan bukti nyata.
Memahami Trace dan Span
Apa itu Trace?
Trace adalah linimasa lengkap agen Anda yang menangani satu permintaan. Proses ini mencakup semuanya, mulai dari saat pengguna mengirimkan kueri hingga respons akhir dikirimkan. Setiap rekaman aktivitas menampilkan:
- Total durasi permintaan
- Semua operasi yang dijalankan
- Bagaimana operasi saling terkait (hubungan induk-turunan)
- Saat setiap operasi dimulai dan berakhir
Apa yang dimaksud dengan Span?
Rentang mewakili satu unit kerja dalam rekaman aktivitas. Jenis rentang umum di asisten peninjauan kode Anda:
agent_run: Eksekusi agen (agen root atau sub-agen)call_llm: Permintaan ke model bahasaexecute_tool: Eksekusi fungsi alatstate_read/state_write: Operasi pengelolaan statuscode_executor: Menjalankan kode dengan pengujian
Rentang memiliki:
- Nama: Operasi yang diwakili
- Durasi: Berapa lama waktu yang diperlukan
- Atribut: Metadata seperti nama model, jumlah token, input/output
- Status: Berhasil atau gagal
- Hubungan induk/turunan: Operasi mana yang memicu operasi mana
Instrumentasi Otomatis
Saat Anda men-deploy dengan --trace-to-cloud, ADK akan otomatis menginstrumentasikan:
- Setiap pemanggilan agen dan panggilan sub-agen
- Semua permintaan LLM dengan jumlah token
- Eksekusi alat dengan input/output
- Operasi status (baca/tulis)
- Iterasi loop di pipeline perbaikan
- Kondisi error dan percobaan ulang
Tidak perlu mengubah kode - pelacakan sudah ada di runtime ADK.
Langkah 1: Akses Cloud Trace Explorer
Buka Cloud Trace di Konsol Google Cloud:
- Buka Cloud Trace Explorer
- Pilih project Anda dari menu dropdown (seharusnya sudah dipilih sebelumnya)
- Anda akan melihat rekaman aktivitas dari pengujian Anda di Modul 7
Jika Anda belum melihat jejak:
Pengujian yang Anda jalankan di Modul 7 seharusnya telah menghasilkan rekaman aktivitas. Jika daftar kosong, buat beberapa data rekaman aktivitas:
python tests/test_agent_engine.py
Tunggu 1-2 menit hingga rekaman aktivitas muncul di konsol.
Yang Anda Lihat
Trace Explorer menampilkan:
- Daftar rekaman aktivitas: Setiap baris mewakili satu permintaan lengkap
- Linimasa: Waktu terjadinya permintaan
- Durasi: Berapa lama setiap permintaan berlangsung
- Detail permintaan: Stempel waktu, latensi, jumlah rentang
Ini adalah log traffic produksi Anda - setiap interaksi dengan agen Anda akan membuat rekaman aktivitas.
Langkah 2: Periksa Rekaman Aktivitas Pipeline Peninjauan
Klik rekaman aktivitas mana pun dalam daftar untuk membuka tampilan waterfall.
Anda akan melihat diagram Gantt yang menampilkan linimasa eksekusi lengkap. Rentang invocation root mewakili seluruh permintaan. Di dalamnya terdapat rentang untuk setiap sub-agen, alat, dan panggilan LLM.
Membaca Waterfall: Mengidentifikasi Hambatan
Setiap batang mewakili rentang. Posisi horizontalnya menunjukkan kapan dimulai, dan panjangnya menunjukkan durasi yang diperlukan. Hal ini akan langsung menunjukkan tempat agen Anda menghabiskan waktunya.
Insight utama dari rekaman aktivitas di atas:
- Total latensi: Seluruh permintaan memerlukan waktu 2 menit dan 28 detik.
- Perincian sub-agen:
Code Analyzer: 4,7 detikStyle Checker: 5,3 detikTest Runner: 1 menit 28 detikFeedback Synthesizer: 47,9 detik
- Analisis Jalur Kritis: Agen
Test Runneradalah hambatan performa yang jelas, yang menyumbang sekitar 59% dari total waktu permintaan.
Visibilitas ini sangat efektif. Daripada menebak-nebak di mana waktu dihabiskan, Anda memiliki bukti konkret bahwa jika Anda perlu mengoptimalkan latensi, Test Runner adalah target yang jelas.
Memeriksa Penggunaan Token untuk Pengoptimalan Biaya
Cloud Trace tidak hanya menampilkan waktu; tetapi juga mengungkapkan biaya dengan mencatat penggunaan token untuk setiap panggilan LLM.
Klik
call_llm
dalam rentang aktivitas. Di panel detail, Anda akan menemukan atribut untuk llm.usage.prompt_tokens dan llm.usage.completion_tokens.

Hal ini memungkinkan Anda:
- Lacak biaya pada tingkat perincian: Lihat secara persis jumlah token yang digunakan oleh setiap agen dan alat.
- Mengidentifikasi peluang pengoptimalan: Jika agen menggunakan jumlah token yang sangat tinggi secara tidak terduga, Anda dapat menyempurnakan perintahnya atau beralih ke model yang lebih kecil dan hemat biaya untuk tugas tertentu tersebut.
Langkah 3: Analisis Rekaman Aktivitas Pipeline Perbaikan
Pipeline perbaikan lebih kompleks karena mencakup LoopAgent. Cloud Trace memudahkan pemahaman perilaku iteratif ini.
Temukan rekaman aktivitas yang menyertakan "FixAttemptLoop" dalam nama rentang.
Jika Anda tidak memilikinya, jalankan skrip pengujian dan jawab ya saat ditanya apakah Anda ingin memperbaiki kode.
Memeriksa Struktur Loop
Tampilan rekaman aktivitas memvisualisasikan eksekusi loop dengan jelas. Jika loop perbaikan berjalan dua kali sebelum berhasil, Anda akan melihat dua rentang loop_iteration yang disarangkan di bawah rentang FixAttemptLoop, yang masing-masing berisi siklus penuh agen CodeFixer, FixTestRunner, dan FixValidator.

Pengamatan Utama dari Rekaman Aktivitas Loop:
- Penyempurnaan Iteratif Terlihat: Anda dapat melihat sistem mencoba memperbaiki di
loop_iteration: 1, memvalidasinya, lalu—karena tidak sempurna—mencoba lagi diloop_iteration: 2. - Konvergensi Dapat Diukur: Anda dapat membandingkan durasi dan hasil setiap iterasi untuk memahami bagaimana sistem mencapai solusi yang benar.
- Proses Debugging yang Disederhanakan: Jika loop berjalan untuk jumlah iterasi maksimum dan masih gagal, Anda dapat memeriksa status dan perilaku agen dalam rentang setiap iterasi untuk mendiagnosis alasan perbaikan tidak konvergen.
Tingkat detail ini sangat berharga untuk memahami dan men-debug perilaku loop stateful yang kompleks dalam produksi.
Langkah 4: Yang Telah Anda Temukan
Pola Performa
Dari pemeriksaan rekaman aktivitas, Anda kini memiliki insight berbasis data:
Pipeline peninjauan:
- Hambatan Utama: Agen
Test Runner, khususnya eksekusi kode dan pembuatan pengujian berbasis LLM, adalah bagian yang paling memakan waktu dalam peninjauan. - Operasi Cepat: Alat deterministik (
analyze_code_structure) dan operasi pengelolaan status sangat cepat dan tidak menjadi masalah performa.
Pipeline perbaikan:
- Tingkat Konvergensi: Anda dapat melihat bahwa sebagian besar perbaikan selesai dalam 1-2 iterasi, yang mengonfirmasi bahwa arsitektur loop efektif.
- Biaya Progresif: Iterasi selanjutnya mungkin memerlukan waktu lebih lama karena konteks LLM bertambah dengan informasi dari upaya sebelumnya yang gagal.
Pendorong Biaya:
- Penggunaan Token: Anda dapat menentukan agen mana (seperti synthesizer) yang memerlukan token terbanyak dan memutuskan apakah penggunaan model yang lebih canggih tetapi mahal dapat dibenarkan untuk tugas tersebut.
Tempat Mencari Masalah
Saat meninjau rekaman aktivitas dalam produksi, perhatikan:
- Rekaman aktivitas yang sangat panjang: Tanda regresi performa atau perilaku loop yang tidak terduga.
- Rentang yang gagal (ditandai dengan warna merah): Menunjukkan operasi yang gagal.
- Iterasi loop yang berlebihan (>2): Dapat menunjukkan masalah pada logika pembuatan perbaikan.
- Jumlah token tinggi: Menyoroti peluang untuk pengoptimalan perintah atau perubahan pemilihan model.
Yang Telah Anda Pelajari
Melalui Cloud Trace, Anda kini memahami cara:
✅ Visualisasi alur permintaan: Lihat jalur eksekusi lengkap melalui pipeline berurutan dan berbasis loop.
✅ Mengidentifikasi hambatan performa: Gunakan diagram waterfall untuk menemukan operasi paling lambat dengan data yang akurat.
✅ Menganalisis perilaku loop: Amati bagaimana agen iteratif menyatu pada solusi dalam beberapa upaya.
✅ Melacak biaya token: Periksa rentang LLM untuk memantau dan mengoptimalkan penggunaan token pada tingkat perincian.
Konsep Utama yang Dikuasai
- Traces dan Span: Unit dasar kemampuan observasi, yang merepresentasikan permintaan dan operasi di dalamnya.
- Analisis Waterfall: Membaca diagram Gantt untuk memahami waktu eksekusi dan dependensi.
- Identifikasi Jalur Kritis: Menemukan urutan operasi yang menentukan latensi keseluruhan.
- Observabilitas Terperinci: Memiliki visibilitas tidak hanya ke waktu, tetapi juga metadata seperti jumlah token untuk setiap operasi, yang diinstrumentasikan secara otomatis oleh ADK.
Langkah Berikutnya
Terus jelajahi Cloud Trace:
- Pantau rekaman aktivitas secara rutin untuk mengidentifikasi masalah sejak dini
- Membandingkan rekaman aktivitas untuk mengidentifikasi regresi performa
- Menggunakan data rekaman aktivitas untuk menginformasikan keputusan pengoptimalan
- Memfilter menurut durasi untuk menemukan permintaan yang lambat
Observabilitas lanjutan (opsional):
- Mengekspor rekaman aktivitas ke BigQuery untuk analisis kompleks (dokumen)
- Membuat dasbor kustom di Cloud Monitoring
- Menyiapkan pemberitahuan untuk penurunan performa
- Menghubungkan rekaman aktivitas dengan log aplikasi
9. Kesimpulan: Dari Prototipe hingga Produksi
Yang Telah Anda Bangun
Anda memulai hanya dengan tujuh baris kode dan membangun sistem agen AI tingkat produksi:
# Where we started (7 lines)
agent = Agent(
model="gemini-2.5-flash",
instruction="Review Python code for issues"
)
# Where we ended (production system)
- Two distinct multi-agent pipelines (review and fix) built from 8 specialized agents.
- An iterative fix loop architecture for automated validation and retries.
- Real AST-based code analysis tools for deterministic, accurate feedback.
- Robust state management using the "constants pattern" for type-safe communication.
- Fully automated deployment to a managed, scalable cloud infrastructure.
- Complete, built-in observability with Cloud Trace for production monitoring.
Pola Arsitektur Utama yang Dikuasai
Pola | Penerapan | Dampak Produksi |
Integrasi Alat | Analisis AST, pemeriksaan gaya | Validasi nyata, bukan hanya pendapat LLM |
Pipeline Berurutan | Tinjau → Perbaiki alur kerja | Eksekusi yang dapat diprediksi dan di-debug |
Arsitektur Loop | Perbaikan iteratif dengan kondisi keluar | Meningkatkan diri hingga berhasil |
Pengelolaan Status | Pola konstanta, memori tiga tingkat | Penanganan status yang aman untuk jenis dan mudah dikelola |
Deployment Produksi | Agent Engine melalui deploy.sh | Infrastruktur terkelola dan skalabel |
Kemampuan observasi | Integrasi Cloud Trace | Visibilitas penuh terhadap perilaku produksi |
Insight Produksi dari Rekaman Aktivitas
Data Cloud Trace Anda mengungkapkan insight penting:
✅ Bottleneck teridentifikasi: Panggilan LLM TestRunner mendominasi latensi
✅ Performa alat: Analisis AST dieksekusi dalam 100 md (sangat baik)
✅ Tingkat keberhasilan: Loop perbaikan menyatu dalam 2-3 iterasi
✅ Penggunaan token: ~600 token per ulasan, ~1.800 untuk perbaikan
Insight ini mendorong peningkatan berkelanjutan.
Membersihkan Resource (Opsional)
Jika Anda telah selesai bereksperimen dan ingin menghindari biaya:
Menghapus deployment Agent Engine:
import vertexai
client = vertexai.Client( # For service interactions via client.agent_engines
project="PROJECT_ID",
location="LOCATION",
)
RESOURCE_NAME = "projects/{PROJECT_ID}/locations/{LOCATION}/reasoningEngines/{RESOURCE_ID}"
client.agent_engines.delete(
name=RESOURCE_NAME,
force=True, # Optional, if the agent has resources (e.g. sessions, memory)
)
Hapus layanan Cloud Run (jika dibuat):
gcloud run services delete code-review-assistant \
--region=$GOOGLE_CLOUD_LOCATION \
--quiet
Hapus instance Cloud SQL (jika dibuat):
gcloud sql instances delete your-project-db \
--quiet
Kosongkan bucket penyimpanan:
gsutil -m rm -r gs://your-project-staging
gsutil -m rm -r gs://your-project-artifacts
Langkah Berikutnya
Setelah fondasi Anda selesai, pertimbangkan peningkatan berikut:
- Menambahkan bahasa lainnya: Memperluas alat untuk mendukung JavaScript, Go, Java
- Integrasikan dengan GitHub: Peninjauan permintaan pull otomatis
- Menerapkan caching: Mengurangi latensi untuk pola umum
- Menambahkan agen khusus: Pemindaian keamanan, analisis performa
- Aktifkan pengujian A/B: Bandingkan berbagai model dan perintah
- Mengekspor metrik: Mengirim rekaman aktivitas ke platform observabilitas khusus
Poin-Poin Penting
- Mulai dari yang sederhana, lakukan iterasi dengan cepat: Tujuh baris menuju produksi dalam langkah-langkah yang mudah dikelola
- Alat daripada perintah: Analisis AST yang sebenarnya lebih baik daripada "periksa bug"
- Pengelolaan status penting: Pola konstanta mencegah bug akibat salah ketik
- Loop memerlukan kondisi keluar: Selalu tetapkan iterasi dan eskalasi maksimum
- Deploy dengan otomatisasi: deploy.sh menangani semua kompleksitas
- Kemampuan observasi tidak dapat dinegosiasikan: Anda tidak dapat meningkatkan sesuatu yang tidak dapat Anda ukur
Referensi untuk Pembelajaran Berkelanjutan
- Dokumentasi ADK
- Pola ADK Lanjutan
- Panduan Agent Engine
- Dokumentasi Cloud Run
- Dokumentasi Cloud Trace
Perjalanan Anda Berlanjut
Anda telah membangun lebih dari sekadar asisten peninjauan kode—Anda telah menguasai pola untuk membangun agen AI produksi apa pun:
✅ Alur kerja kompleks dengan beberapa agen khusus
✅ Integrasi alat nyata untuk kemampuan yang sebenarnya
✅ Deployment produksi dengan kemampuan pengamatan yang tepat
✅ Pengelolaan status untuk sistem yang mudah dikelola
Pola ini dapat diskalakan dari asisten sederhana hingga sistem otonom yang kompleks. Dasar yang telah Anda bangun di sini akan sangat berguna saat Anda menangani arsitektur agen yang semakin canggih.
Selamat datang di pengembangan agen AI produksi. Asisten peninjauan kode Anda baru permulaan.