
1. The Late Night Code Review
Sono le 2 del mattino
Hai eseguito il debug per ore. La funzione sembra corretta, ma qualcosa non va. Conosci quella sensazione: quando il codice dovrebbe funzionare, ma non funziona, e non riesci più a capire perché, perché lo stai fissando da troppo tempo.
def dfs_search_v1(graph, start, target):
"""Find if target is reachable from start."""
visited = set()
stack = start # Looks innocent enough...
while stack:
current = stack.pop()
if current == target:
return True
if current not in visited:
visited.add(current)
for neighbor in graph[current]:
if neighbor not in visited:
stack.append(neighbor)
return False
Il percorso dello sviluppatore di AI
Se stai leggendo questo articolo, probabilmente hai già sperimentato la trasformazione che l'AI porta alla programmazione. Strumenti come Gemini Code Assist, Claude Code e Cursor hanno cambiato il modo in cui scriviamo il codice. Sono incredibili per generare boilerplate, suggerire implementazioni e accelerare lo sviluppo.
Ma sei qui perché vuoi approfondire. Vuoi capire come creare questi sistemi di AI, non solo come utilizzarli. Vuoi creare qualcosa che:
- Ha un comportamento prevedibile e tracciabile
- Può essere implementato in produzione in tutta sicurezza
- Fornisce risultati coerenti su cui puoi fare affidamento
- Ti mostra esattamente come prende le decisioni
Da consumatore a creator
Oggi, passerai dall'utilizzo degli strumenti AI alla loro creazione. Creerai un sistema multi-agente che:
- Analizza la struttura del codice in modo deterministico
- Esegue test reali per verificare il comportamento
- Convalida la conformità dello stile con i linter reali
- Sintetizza i risultati in un feedback pratico
- Deployment su Google Cloud con osservabilità completa
2. Il primo deployment dell'agente
Domanda dello sviluppatore
"Conosco i modelli LLM, ho utilizzato le API, ma come faccio a passare da uno script Python a un agente AI di produzione scalabile?"
Rispondiamo a questa domanda configurando correttamente l'ambiente, quindi creando un semplice agente per comprendere le basi prima di passare ai pattern di produzione.
Eseguire prima la configurazione essenziale
Prima di creare agenti, assicuriamoci che l'ambiente Google Cloud sia pronto.
Fai clic su Attiva Cloud Shell nella parte superiore della console Google Cloud (l'icona a forma di terminale nella parte superiore del riquadro Cloud Shell),
Trova l'ID progetto Google Cloud:
- Apri la console Google Cloud: https://console.cloud.google.com
- Seleziona il progetto che vuoi utilizzare per questo workshop dal menu a discesa dei progetti nella parte superiore della pagina.
- Il tuo ID progetto viene visualizzato nella scheda Informazioni sul progetto della dashboard
Passaggio 1: imposta l'ID progetto
In Cloud Shell, lo strumento a riga di comando gcloud è già configurato. Esegui questo comando per impostare il progetto attivo. Viene utilizzata la variabile di ambiente $GOOGLE_CLOUD_PROJECT, che viene impostata automaticamente nella sessione Cloud Shell.
gcloud config set project $GOOGLE_CLOUD_PROJECT
Passaggio 2: verifica la configurazione
Successivamente, esegui questi comandi per verificare che il progetto sia impostato correttamente e che tu sia autenticato.
# Confirm project is set
echo "Current project: $(gcloud config get-value project)"
# Check authentication status
gcloud auth list
Dovresti vedere l'ID progetto stampato e il tuo account utente elencato con (ACTIVE) accanto.
Se il tuo account non è elencato come attivo o se ricevi un errore di autenticazione, esegui questo comando per accedere:
gcloud auth application-default login
Passaggio 3: attiva le API essenziali
Per l'agente di base sono necessarie almeno queste API:
gcloud services enable \
aiplatform.googleapis.com \
compute.googleapis.com
L'operazione può richiedere alcuni minuti. Visualizzerai:
Operation "operations/..." finished successfully.
Passaggio 4: installa ADK
# Install the ADK CLI
pip install google-adk --upgrade
# Verify installation
adk --version
Dovresti visualizzare un numero di versione pari o superiore a 1.15.0.
Ora crea il tuo agente di base
Con l'ambiente pronto, creiamo questo semplice agente.
Passaggio 5: utilizza ADK Create
adk create my_first_agent
Segui le istruzioni interattive:
Choose a model for the root agent:
1. gemini-2.5-flash
2. Other models (fill later)
Choose model (1, 2): 1
1. Google AI
2. Vertex AI
Choose a backend (1, 2): 2
Enter Google Cloud project ID [auto-detected-from-gcloud]:
Enter Google Cloud region [us-central1]:
Passaggio 6: esamina gli elementi creati
cd my_first_agent
ls -la
Troverai tre file:
.env # Configuration (auto-populated with your project)
__init__.py # Package marker
agent.py # Your agent definition
Passaggio 7: controllo rapido della configurazione
# Verify the .env was created correctly
cat .env
# Should show something like:
# GOOGLE_CLOUD_PROJECT=your-project-id
# GOOGLE_CLOUD_LOCATION=us-central1
# GOOGLE_GENAI_USE_VERTEXAI=1
Se l'ID progetto è mancante o errato, modifica il file .env:
nano .env # or use your preferred editor
Passaggio 8: esamina il codice agente
cat agent.py
from google.adk.agents.llm_agent import Agent
root_agent = Agent(
model='gemini-2.5-flash',
name='root_agent',
description='A helpful assistant for user questions.',
instruction='Answer user questions to the best of your knowledge',
)
Semplice, pulito, minimalista. Questo è il tuo "Hello World" degli agenti.
Testare l'agente di base
Passaggio 9: esegui l'agente
cd ..
adk run my_first_agent
Dovresti vedere qualcosa di simile a questo:
Log setup complete: /tmp/agents_log/agent.20250930_162430.log
To access latest log: tail -F /tmp/agents_log/agent.latest.log
[user]:
Passaggio 10: prova alcune query
Nel terminale in cui è in esecuzione adk run, vedrai un prompt. Digita le query:
[user]: Hey, what can you do?
[root_agent]: I can help answer questions, generate text, explain concepts, assist with problem-solving, and provide information on a wide range of topics. What would you like to know or discuss?
[user]: What's the current weather in Mountain View?
[root_agent]: I'm sorry, but I cannot provide real-time weather information as I don't have access to current data or weather services. To get the current weather in Mountain View, I recommend checking a weather website or app like weather.com or using a search engine.
Nota la limitazione: non può accedere ai dati attuali. Andiamo oltre:
[user]: Review this Python code: def add(a, b): return a + b
[root_agent]: This is a simple Python function that adds two numbers. Here's my review:
**Strengths:**
- Clean and concise implementation
- Follows Python conventions for simple operations
- Clear function name that describes its purpose
**Suggestions for improvement:**
- Add a docstring to document the function
- Consider adding type hints for better code clarity
- You might want to handle edge cases
Here's an enhanced version:
def add(a: float, b: float) -> float:
"""Add two numbers and return their sum."""
return a + b
L'agente può discutere del codice, ma può:
- Analizzare effettivamente l'AST per comprendere la struttura?
- Esegui test per verificare che funzioni.
- Controllare la conformità allo stile?
- Ricordi le tue recensioni precedenti?
No. È qui che abbiamo bisogno dell'architettura.
🏃🚪 Esci con
Ctrl+C
al termine dell'esplorazione.
3. Preparazione dello spazio di lavoro di produzione
La soluzione: un'architettura pronta per la produzione
Questo semplice agente ha dimostrato il punto di partenza, ma un sistema di produzione richiede una struttura solida. Ora configureremo un progetto completo che incarna i principi di produzione.
Configurazione della base
Hai già configurato il progetto Google Cloud per l'agente di base. Ora prepariamo lo spazio di lavoro di produzione completo con tutti gli strumenti, i pattern e l'infrastruttura necessari per un sistema reale.
Passaggio 1: recupera il progetto strutturato
Innanzitutto, esci da qualsiasi adk run in esecuzione con Ctrl+C e libera spazio:
# Clean up the basic agent
cd ~ # Make sure you're not inside my_first_agent
rm -rf my_first_agent
# Get the production scaffold
git clone https://github.com/ayoisio/adk-code-review-assistant.git
cd adk-code-review-assistant
git checkout codelab
Passaggio 2: crea e attiva l'ambiente virtuale
# Create the virtual environment
python -m venv .venv
# Activate it
# On macOS/Linux:
source .venv/bin/activate
# On Windows:
# .venv\Scripts\activate
Verifica: ora il prompt dovrebbe iniziare con (.venv).
Passaggio 3: installa le dipendenze
pip install -r code_review_assistant/requirements.txt
# Install the package in editable mode (enables imports)
pip install -e .
Viene installato:
google-adk- The ADK frameworkpycodestyle- Per il controllo PEP 8vertexai: per il deployment sul cloud- Altre dipendenze di produzione
Il flag -e ti consente di importare moduli code_review_assistant da qualsiasi posizione.
Passaggio 4: configura l'ambiente
# Copy the example environment file
cp .env.example .env
# Edit .env and replace the placeholders:
# - GOOGLE_CLOUD_PROJECT=your-project-id → your actual project ID
# - Keep other defaults as-is
Verifica: controlla la configurazione:
cat .env
Dovrebbe mostrare:
GOOGLE_CLOUD_PROJECT=your-actual-project-id
GOOGLE_CLOUD_LOCATION=us-central1
GOOGLE_GENAI_USE_VERTEXAI=TRUE
Passaggio 5: assicurati dell'autenticazione
Poiché hai già eseguito gcloud auth in precedenza, verifichiamo solo:
# Check current authentication
gcloud auth list
# Should show your account with (ACTIVE)
# If not, run:
gcloud auth application-default login
Passaggio 6: attiva le API di produzione aggiuntive
Abbiamo già abilitato le API di base. Ora aggiungi quelli di produzione:
gcloud services enable \
sqladmin.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
storage.googleapis.com \
cloudtrace.googleapis.com
Ciò consente:
- Amministratore SQL: per Cloud SQL se utilizzi Cloud Run
- Cloud Run: per il deployment serverless
- Cloud Build: per i deployment automatici
- Artifact Registry: per le immagini container
- Cloud Storage: per artefatti e staging
- Cloud Trace: per l'osservabilità
Passaggio 7: crea il repository Artifact Registry
Il nostro deployment creerà immagini container che necessitano di una casa:
gcloud artifacts repositories create code-review-assistant-repo \
--repository-format=docker \
--location=us-central1 \
--description="Docker repository for Code Review Assistant"
Dovresti vedere:
Created repository [code-review-assistant-repo].
Se esiste già (magari da un tentativo precedente), non preoccuparti: visualizzerai un messaggio di errore che puoi ignorare.
Passaggio 8: concedi autorizzazioni IAM
# Get your project number
PROJECT_NUMBER=$(gcloud projects describe $GOOGLE_CLOUD_PROJECT \
--format="value(projectNumber)")
# Define the service account
SERVICE_ACCOUNT="${PROJECT_NUMBER}@cloudbuild.gserviceaccount.com"
# Grant necessary roles
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SERVICE_ACCOUNT}" \
--role="roles/run.admin"
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SERVICE_ACCOUNT}" \
--role="roles/iam.serviceAccountUser"
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SERVICE_ACCOUNT}" \
--role="roles/cloudsql.admin"
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SERVICE_ACCOUNT}" \
--role="roles/storage.admin"
Ogni comando restituirà:
Updated IAM policy for project [your-project-id].
Cosa hai ottenuto
Il tuo workspace di produzione è ora completamente preparato:
✅ Progetto Google Cloud configurato e autenticato
✅ Agente di base testato per comprendere i limiti
✅ Codice del progetto con segnaposto strategici pronto
✅ Dipendenze isolate nell'ambiente virtuale
✅ Tutte le API necessarie abilitate
✅ Container Registry pronto per le implementazioni
✅ Autorizzazioni IAM configurate correttamente
✅ Variabili di ambiente impostate correttamente
Ora puoi creare un vero sistema di AI con strumenti deterministici, gestione dello stato e architettura adeguata.
4. Creazione del tuo primo agente
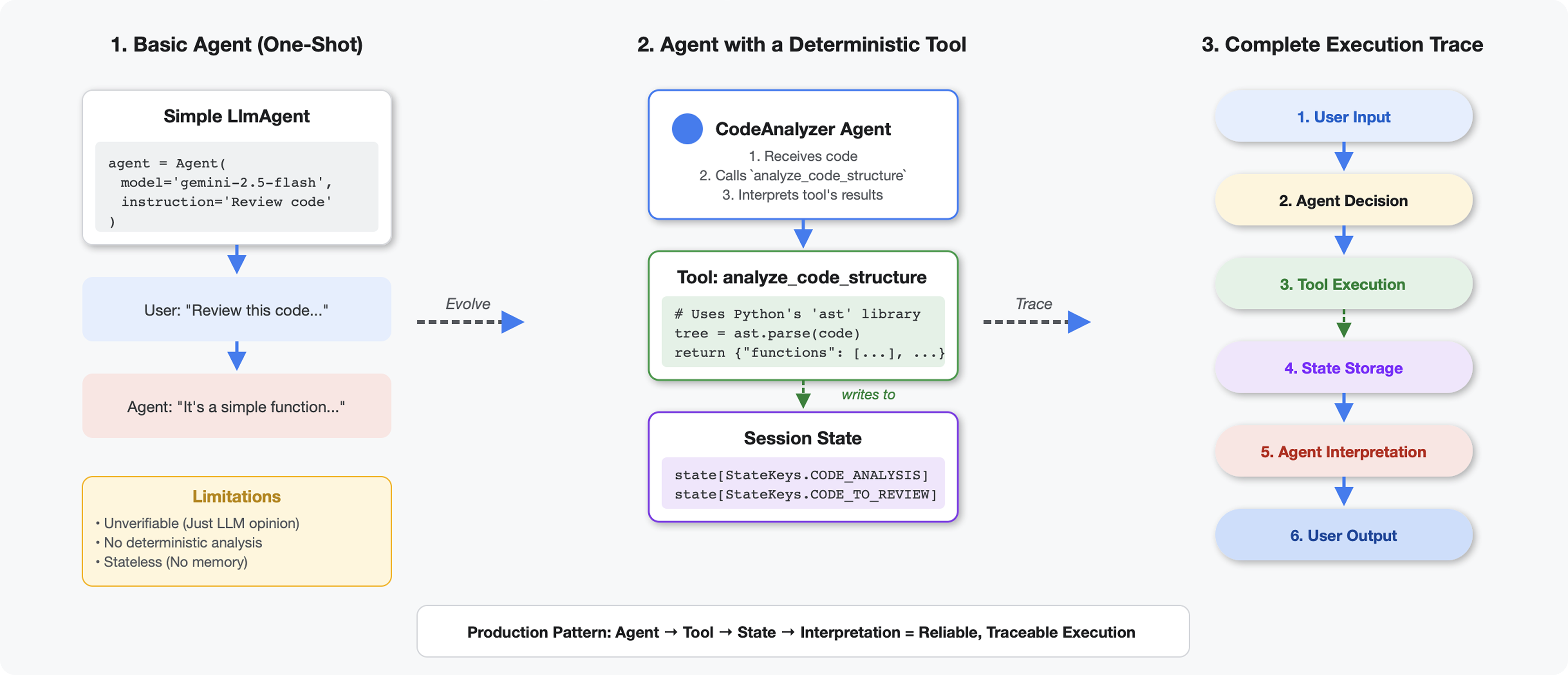
Cosa rende gli strumenti diversi dagli LLM
Quando chiedi a un LLM "quante funzioni ci sono in questo codice?", utilizza la corrispondenza di pattern e la stima. Quando utilizzi uno strumento che chiama ast.parse() di Python, analizza l'albero della sintassi effettivo, senza congetture, e restituisce lo stesso risultato ogni volta.
Questa sezione crea uno strumento che analizza la struttura del codice in modo deterministico, quindi lo collega a un agente che sa quando richiamarlo.
Passaggio 1: comprendi lo scaffold
Esaminiamo la struttura che dovrai compilare.
👉 Apri
code_review_assistant/tools.py
Visualizzerai la funzione analyze_code_structure con commenti segnaposto che indicano dove aggiungere il codice. La funzione ha già la struttura di base, che migliorerai passo dopo passo.
Passaggio 2: aggiungi State Storage
L'archiviazione dello stato consente ad altri agenti nella pipeline di accedere ai risultati dello strumento senza eseguire nuovamente l'analisi.
👉 Trova:
# MODULE_4_STEP_2_ADD_STATE_STORAGE
👉 Sostituisci quella singola riga con:
# Store code and analysis for other agents to access
tool_context.state[StateKeys.CODE_TO_REVIEW] = code
tool_context.state[StateKeys.CODE_ANALYSIS] = analysis
tool_context.state[StateKeys.CODE_LINE_COUNT] = len(code.splitlines())
Passaggio 3: aggiungi l'analisi asincrona con i pool di thread
Il nostro strumento deve analizzare l'AST senza bloccare altre operazioni. Aggiungiamo l'esecuzione asincrona con i pool di thread.
👉 Trova:
# MODULE_4_STEP_3_ADD_ASYNC
👉 Sostituisci quella singola riga con:
# Parse in thread pool to avoid blocking the event loop
loop = asyncio.get_event_loop()
with ThreadPoolExecutor() as executor:
tree = await loop.run_in_executor(executor, ast.parse, code)
Passaggio 4: estrai informazioni complete
Ora estraiamo classi, importazioni e metriche dettagliate, tutto ciò che ci serve per una revisione completa del codice.
👉 Trova:
# MODULE_4_STEP_4_EXTRACT_DETAILS
👉 Sostituisci quella singola riga con:
# Extract comprehensive structural information
analysis = await loop.run_in_executor(
executor, _extract_code_structure, tree, code
)
👉 Verifica: la funzione
analyze_code_structure
in
tools.py
ha un corpo centrale che ha questo aspetto:
# Parse in thread pool to avoid blocking the event loop
loop = asyncio.get_event_loop()
with ThreadPoolExecutor() as executor:
tree = await loop.run_in_executor(executor, ast.parse, code)
# Extract comprehensive structural information
analysis = await loop.run_in_executor(
executor, _extract_code_structure, tree, code
)
# Store code and analysis for other agents to access
tool_context.state[StateKeys.CODE_TO_REVIEW] = code
tool_context.state[StateKeys.CODE_ANALYSIS] = analysis
tool_context.state[StateKeys.CODE_LINE_COUNT] = len(code.splitlines())
👉 Ora scorri fino in fondo alla pagina
tools.py
e trova:
# MODULE_4_STEP_4_HELPER_FUNCTION
👉 Sostituisci quella singola riga con la funzione helper completa:
def _extract_code_structure(tree: ast.AST, code: str) -> Dict[str, Any]:
"""
Helper function to extract structural information from AST.
Runs in thread pool for CPU-bound work.
"""
functions = []
classes = []
imports = []
docstrings = []
for node in ast.walk(tree):
if isinstance(node, ast.FunctionDef):
func_info = {
'name': node.name,
'args': [arg.arg for arg in node.args.args],
'lineno': node.lineno,
'has_docstring': ast.get_docstring(node) is not None,
'is_async': isinstance(node, ast.AsyncFunctionDef),
'decorators': [d.id for d in node.decorator_list
if isinstance(d, ast.Name)]
}
functions.append(func_info)
if func_info['has_docstring']:
docstrings.append(f"{node.name}: {ast.get_docstring(node)[:50]}...")
elif isinstance(node, ast.ClassDef):
methods = []
for item in node.body:
if isinstance(item, ast.FunctionDef):
methods.append(item.name)
class_info = {
'name': node.name,
'lineno': node.lineno,
'methods': methods,
'has_docstring': ast.get_docstring(node) is not None,
'base_classes': [base.id for base in node.bases
if isinstance(base, ast.Name)]
}
classes.append(class_info)
elif isinstance(node, ast.Import):
for alias in node.names:
imports.append({
'module': alias.name,
'alias': alias.asname,
'type': 'import'
})
elif isinstance(node, ast.ImportFrom):
imports.append({
'module': node.module or '',
'names': [alias.name for alias in node.names],
'type': 'from_import',
'level': node.level
})
return {
'functions': functions,
'classes': classes,
'imports': imports,
'docstrings': docstrings,
'metrics': {
'line_count': len(code.splitlines()),
'function_count': len(functions),
'class_count': len(classes),
'import_count': len(imports),
'has_main': any(f['name'] == 'main' for f in functions),
'has_if_main': '__main__' in code,
'avg_function_length': _calculate_avg_function_length(tree)
}
}
def _calculate_avg_function_length(tree: ast.AST) -> float:
"""Calculate average function length in lines."""
function_lengths = []
for node in ast.walk(tree):
if isinstance(node, ast.FunctionDef):
if hasattr(node, 'end_lineno') and hasattr(node, 'lineno'):
length = node.end_lineno - node.lineno + 1
function_lengths.append(length)
if function_lengths:
return sum(function_lengths) / len(function_lengths)
return 0.0
Passaggio 5: contatta un agente
Ora colleghiamo lo strumento a un agente che sa quando utilizzarlo e come interpretarne i risultati.
👉 Apri
code_review_assistant/sub_agents/review_pipeline/code_analyzer.py
👉 Trova:
# MODULE_4_STEP_5_CREATE_AGENT
👉 Sostituisci quella singola riga con l'agente di produzione completo:
code_analyzer_agent = Agent(
name="CodeAnalyzer",
model=config.worker_model,
description="Analyzes Python code structure and identifies components",
instruction="""You are a code analysis specialist responsible for understanding code structure.
Your task:
1. Take the code submitted by the user (it will be provided in the user message)
2. Use the analyze_code_structure tool to parse and analyze it
3. Pass the EXACT code to your tool - do not modify, fix, or "improve" it
4. Identify all functions, classes, imports, and structural patterns
5. Note any syntax errors or structural issues
6. Store the analysis in state for other agents to use
CRITICAL:
- Pass the code EXACTLY as provided to the analyze_code_structure tool
- Do not fix syntax errors, even if obvious
- Do not add missing imports or fix indentation
- The goal is to analyze what IS there, not what SHOULD be there
When calling the tool, pass the code as a string to the 'code' parameter.
If the analysis fails due to syntax errors, clearly report the error location and type.
Provide a clear summary including:
- Number of functions and classes found
- Key structural observations
- Any syntax errors or issues detected
- Overall code organization assessment""",
tools=[FunctionTool(func=analyze_code_structure)],
output_key="structure_analysis_summary"
)
Testare lo strumento di analisi del codice
Ora verifica che l'analizzatore funzioni correttamente.
👉 Esegui lo script per il test:
python tests/test_code_analyzer.py
Lo script per il test carica automaticamente la configurazione dal file .env utilizzando python-dotenv, quindi non è necessaria alcuna configurazione manuale delle variabili di ambiente.
Output previsto:
INFO:code_review_assistant.config:Code Review Assistant Configuration Loaded:
INFO:code_review_assistant.config: - GCP Project: your-project-id
INFO:code_review_assistant.config: - Artifact Bucket: gs://your-project-artifacts
INFO:code_review_assistant.config: - Models: worker=gemini-2.5-flash, critic=gemini-2.5-pro
Testing code analyzer...
INFO:code_review_assistant.tools:Tool: Analysis complete - 2 functions, 1 classes
=== Analyzer Response ===
The analysis of the provided code shows the following:
* **Functions Found:** 2
* `add(a, b)`: A global function at line 2.
* `multiply(self, x, y)`: A method within the `Calculator` class.
* **Classes Found:** 1
* `Calculator`: A class defined at line 5. Contains one method, `multiply`.
* **Imports:** 0
* **Structural Patterns:** The code defines one global function and one class
with a single method. Both are simple, each with a single return statement.
* **Syntax Errors/Issues:** No syntax errors detected.
* **Overall Code Organization:** The code is well-organized for its small size,
clearly defining a function and a class with a method.
Cosa è appena successo:
- Lo script per il test ha caricato automaticamente la configurazione di
.env - Il tuo strumento
analyze_code_structure()ha analizzato il codice utilizzando l'AST di Python - L'helper
_extract_code_structure()ha estratto funzioni, classi e metriche - I risultati sono stati archiviati nello stato della sessione utilizzando le costanti
StateKeys - L'agente Code Analyzer ha interpretato i risultati e fornito un riepilogo
Risoluzione dei problemi:
- "No module named ‘code_review_assistant'": esegui
pip install -e .dalla radice del progetto - "Missing key inputs argument": verifica che
.envabbiaGOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_LOCATIONeGOOGLE_GENAI_USE_VERTEXAI=true
Cosa hai creato
Ora hai un analizzatore di codice pronto per la produzione che:
✅ Analizza l'AST Python effettivo: deterministico, non basato sulla corrispondenza di pattern
✅ Memorizza i risultati nello stato: altri agenti possono accedere all'analisi
✅ Viene eseguito in modo asincrono: non blocca altri strumenti
✅ Estrae informazioni complete: funzioni, classi, importazioni, metriche
✅ Gestisce gli errori in modo controllato: segnala gli errori di sintassi con i numeri di riga
✅ Si connette a un agente: il LLM sa quando e come utilizzarlo
Concetti fondamentali padroneggiati
Strumenti e agenti:
- Gli strumenti eseguono operazioni deterministiche (analisi AST)
- Gli agenti decidono quando utilizzare gli strumenti e interpretare i risultati
Valore di ritorno rispetto allo stato:
- Ritorno: ciò che l'LLM vede immediatamente
- Stato: ciò che persiste per gli altri agenti
Costanti delle chiavi di stato:
- Evitare errori di battitura nei sistemi multi-agente
- Fungono da contratti tra gli agenti
- Fondamentale quando gli agenti condividono i dati
Async + Thread Pools:
async defconsente agli strumenti di mettere in pausa l'esecuzione- I pool di thread eseguono in background il lavoro vincolato alla CPU
- Insieme, mantengono reattivo il ciclo degli eventi
Funzioni helper:
- Separare gli helper di sincronizzazione dagli strumenti asincroni
- Rende il codice testabile e riutilizzabile
Istruzioni per l'agente:
- Istruzioni dettagliate evitano errori comuni dell'LLM
- Spiega in modo esplicito cosa NON fare (non correggere il codice)
- Passaggi del workflow chiari per garantire la coerenza
Passaggi successivi
Nel modulo 5, aggiungerai:
- Controllo dello stile che legge il codice dallo stato
- Test runner che esegue effettivamente i test
- Sintetizzatore di feedback che combina tutte le analisi
Vedrai come lo stato scorre attraverso una pipeline sequenziale e perché il pattern delle costanti è importante quando più agenti leggono e scrivono gli stessi dati.
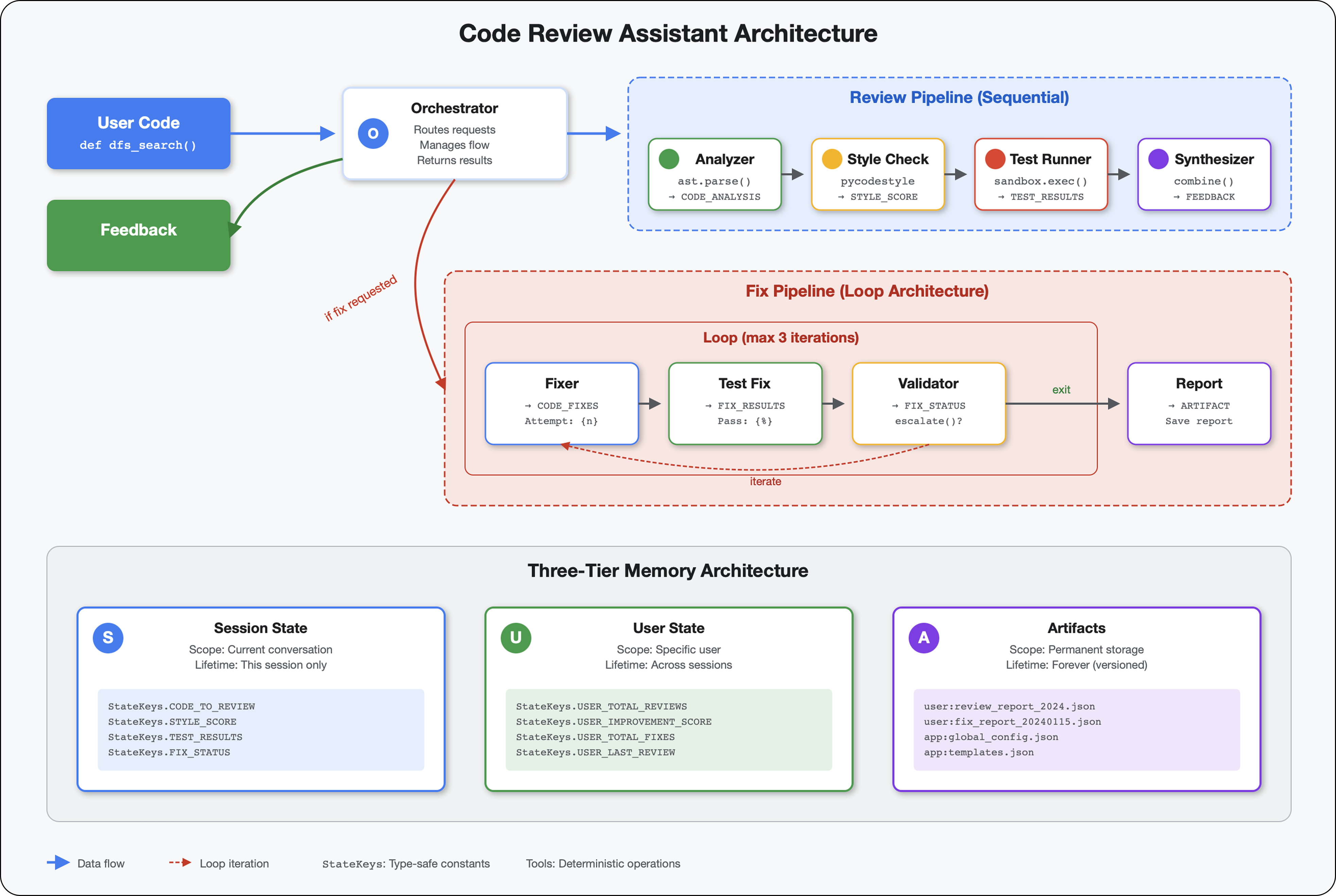
5. Creazione di una pipeline: più agenti che lavorano insieme
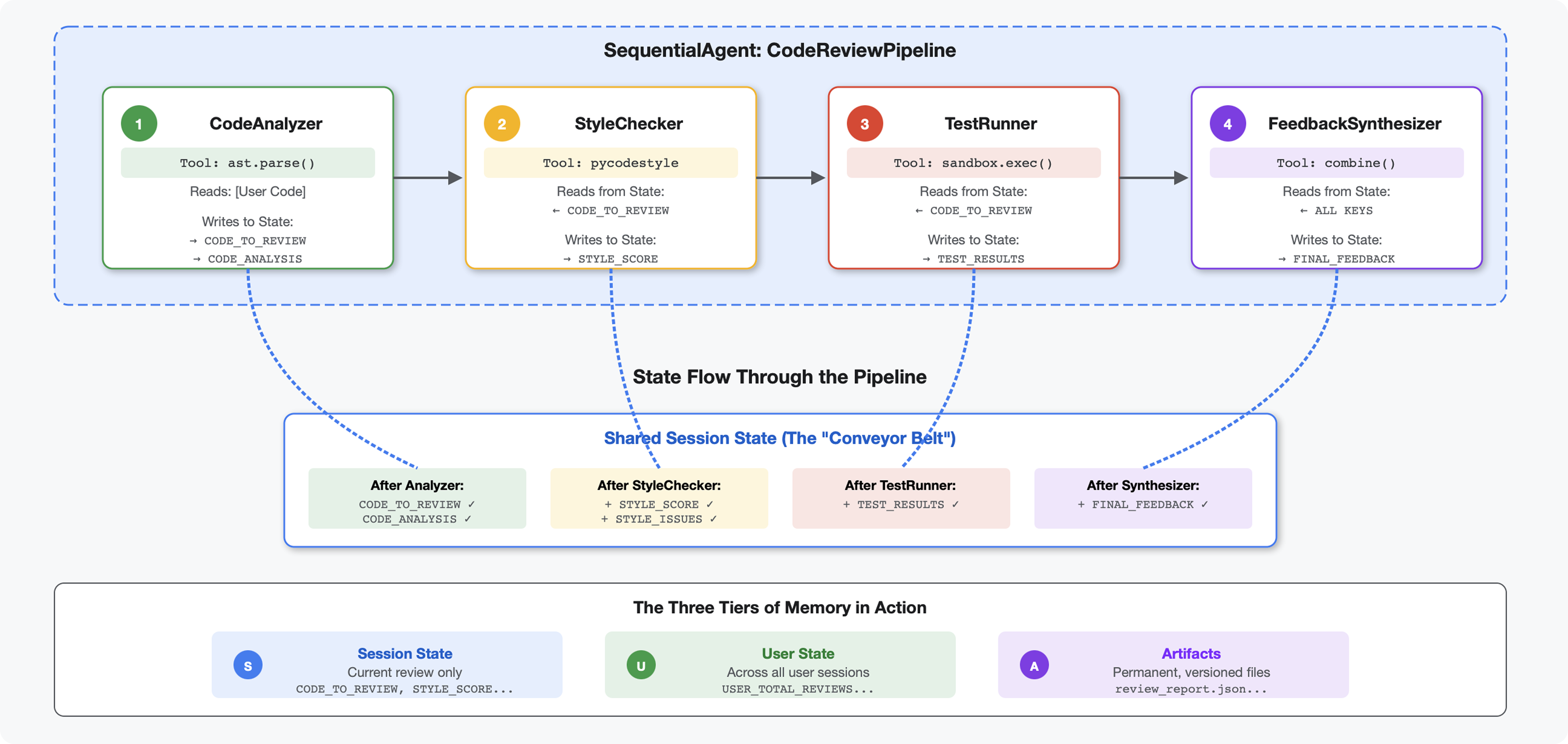
Introduzione
Nel modulo 4, hai creato un singolo agente che analizza la struttura del codice. Tuttavia, la revisione completa del codice richiede più della semplice analisi: è necessario il controllo dello stile, l'esecuzione dei test e la sintesi intelligente del feedback.
Questo modulo crea una pipeline di 4 agenti che lavorano insieme in sequenza, ognuno dei quali contribuisce con un'analisi specializzata:
- Analizzatore di codice (dal modulo 4) - Analizza la struttura
- Controllo dello stile: identifica le violazioni dello stile
- Test Runner: esegue e convalida i test
- Feedback Synthesizer: combina tutto in un feedback utile
Concetto chiave: lo stato come canale di comunicazione. Ogni agente legge ciò che hanno scritto gli agenti precedenti, aggiunge la propria analisi e passa lo stato arricchito all'agente successivo. Il pattern delle costanti del modulo 4 diventa fondamentale quando più agenti condividono i dati.
Anteprima di ciò che creerai: invia codice disordinato → osserva il flusso di stato attraverso 4 agenti → ricevi un report completo con feedback personalizzato basato su pattern passati.
Passaggio 1: aggiungi lo strumento di controllo dello stile + l'agente
Il controllo dello stile identifica le violazioni di PEP 8 utilizzando pycodestyle, un linter deterministico, non un'interpretazione basata su LLM.
Aggiungere lo strumento di controllo dello stile
👉 Apri
code_review_assistant/tools.py
👉 Trova:
# MODULE_5_STEP_1_STYLE_CHECKER_TOOL
👉 Sostituisci quella singola riga con:
async def check_code_style(code: str, tool_context: ToolContext) -> Dict[str, Any]:
"""
Checks code style compliance using pycodestyle (PEP 8).
Args:
code: Python source code to check (or will retrieve from state)
tool_context: ADK tool context
Returns:
Dictionary containing style score and issues
"""
logger.info("Tool: Checking code style...")
try:
# Retrieve code from state if not provided
if not code:
code = tool_context.state.get(StateKeys.CODE_TO_REVIEW, '')
if not code:
return {
"status": "error",
"message": "No code provided or found in state"
}
# Run style check in thread pool
loop = asyncio.get_event_loop()
with ThreadPoolExecutor() as executor:
result = await loop.run_in_executor(
executor, _perform_style_check, code
)
# Store results in state
tool_context.state[StateKeys.STYLE_SCORE] = result['score']
tool_context.state[StateKeys.STYLE_ISSUES] = result['issues']
tool_context.state[StateKeys.STYLE_ISSUE_COUNT] = result['issue_count']
logger.info(f"Tool: Style check complete - Score: {result['score']}/100, "
f"Issues: {result['issue_count']}")
return result
except Exception as e:
error_msg = f"Style check failed: {str(e)}"
logger.error(f"Tool: {error_msg}", exc_info=True)
# Set default values on error
tool_context.state[StateKeys.STYLE_SCORE] = 0
tool_context.state[StateKeys.STYLE_ISSUES] = []
return {
"status": "error",
"message": error_msg,
"score": 0
}
👉 Ora scorri fino alla fine del file e trova:
# MODULE_5_STEP_1_STYLE_HELPERS
👉 Sostituisci quella singola riga con le funzioni di assistenza:
def _perform_style_check(code: str) -> Dict[str, Any]:
"""Helper to perform style check in thread pool."""
import io
import sys
with tempfile.NamedTemporaryFile(mode='w', suffix='.py', delete=False) as tmp:
tmp.write(code)
tmp_path = tmp.name
try:
# Capture stdout to get pycodestyle output
old_stdout = sys.stdout
sys.stdout = captured_output = io.StringIO()
style_guide = pycodestyle.StyleGuide(
quiet=False, # We want output
max_line_length=100,
ignore=['E501', 'W503']
)
result = style_guide.check_files([tmp_path])
# Restore stdout
sys.stdout = old_stdout
# Parse captured output
output = captured_output.getvalue()
issues = []
for line in output.strip().split('\n'):
if line and ':' in line:
parts = line.split(':', 4)
if len(parts) >= 4:
try:
issues.append({
'line': int(parts[1]),
'column': int(parts[2]),
'code': parts[3].split()[0] if len(parts) > 3 else 'E000',
'message': parts[3].strip() if len(parts) > 3 else 'Unknown error'
})
except (ValueError, IndexError):
pass
# Add naming convention checks
try:
tree = ast.parse(code)
naming_issues = _check_naming_conventions(tree)
issues.extend(naming_issues)
except SyntaxError:
pass # Syntax errors will be caught elsewhere
# Calculate weighted score
score = _calculate_style_score(issues)
return {
"status": "success",
"score": score,
"issue_count": len(issues),
"issues": issues[:10], # First 10 issues
"summary": f"Style score: {score}/100 with {len(issues)} violations"
}
finally:
if os.path.exists(tmp_path):
os.unlink(tmp_path)
def _check_naming_conventions(tree: ast.AST) -> List[Dict[str, Any]]:
"""Check PEP 8 naming conventions."""
naming_issues = []
for node in ast.walk(tree):
if isinstance(node, ast.FunctionDef):
# Skip private/protected methods and __main__
if not node.name.startswith('_') and node.name != node.name.lower():
naming_issues.append({
'line': node.lineno,
'column': node.col_offset,
'code': 'N802',
'message': f"N802 function name '{node.name}' should be lowercase"
})
elif isinstance(node, ast.ClassDef):
# Check if class name follows CapWords convention
if not node.name[0].isupper() or '_' in node.name:
naming_issues.append({
'line': node.lineno,
'column': node.col_offset,
'code': 'N801',
'message': f"N801 class name '{node.name}' should use CapWords convention"
})
return naming_issues
def _calculate_style_score(issues: List[Dict[str, Any]]) -> int:
"""Calculate weighted style score based on violation severity."""
if not issues:
return 100
# Define weights by error type
weights = {
'E1': 10, # Indentation errors
'E2': 3, # Whitespace errors
'E3': 5, # Blank line errors
'E4': 8, # Import errors
'E5': 5, # Line length
'E7': 7, # Statement errors
'E9': 10, # Syntax errors
'W2': 2, # Whitespace warnings
'W3': 2, # Blank line warnings
'W5': 3, # Line break warnings
'N8': 7, # Naming conventions
}
total_deduction = 0
for issue in issues:
code_prefix = issue['code'][:2] if len(issue['code']) >= 2 else 'E2'
weight = weights.get(code_prefix, 3)
total_deduction += weight
# Cap at 100 points deduction
return max(0, 100 - min(total_deduction, 100))
Aggiungere l'agente di controllo dello stile
👉 Apri
code_review_assistant/sub_agents/review_pipeline/style_checker.py
👉 Trova:
# MODULE_5_STEP_1_INSTRUCTION_PROVIDER
👉 Sostituisci quella singola riga con:
async def style_checker_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are a code style expert focused on PEP 8 compliance.
Your task:
1. Use the check_code_style tool to validate PEP 8 compliance
2. The tool will retrieve the ORIGINAL code from state automatically
3. Report violations exactly as found
4. Present the results clearly and confidently
CRITICAL:
- The tool checks the code EXACTLY as provided by the user
- Do not suggest the code was modified or fixed
- Report actual violations found in the original code
- If there are style issues, they should be reported honestly
Call the check_code_style tool with an empty string for the code parameter,
as the tool will retrieve the code from state automatically.
When presenting results based on what the tool returns:
- State the exact score from the tool results
- If score >= 90: "Excellent style compliance!"
- If score 70-89: "Good style with minor improvements needed"
- If score 50-69: "Style needs attention"
- If score < 50: "Significant style improvements needed"
List the specific violations found (the tool will provide these):
- Show line numbers, error codes, and messages
- Focus on the top 10 most important issues
Previous analysis: {structure_analysis_summary}
Format your response as:
## Style Analysis Results
- Style Score: [exact score]/100
- Total Issues: [count]
- Assessment: [your assessment based on score]
## Top Style Issues
[List issues with line numbers and descriptions]
## Recommendations
[Specific fixes for the most critical issues]"""
return await instructions_utils.inject_session_state(template, context)
👉 Trova:
# MODULE_5_STEP_1_STYLE_CHECKER_AGENT
👉 Sostituisci quella singola riga con:
style_checker_agent = Agent(
name="StyleChecker",
model=config.worker_model,
description="Checks Python code style against PEP 8 guidelines",
instruction=style_checker_instruction_provider,
tools=[FunctionTool(func=check_code_style)],
output_key="style_check_summary"
)
Passaggio 2: aggiungi l'agente Test Runner
Il test runner genera test completi e li esegue utilizzando l'executor di codice integrato.
👉 Apri
code_review_assistant/sub_agents/review_pipeline/test_runner.py
👉 Trova:
# MODULE_5_STEP_2_INSTRUCTION_PROVIDER
👉 Sostituisci quella singola riga con:
async def test_runner_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects the code_to_review directly."""
template = """You are a testing specialist who creates and runs tests for Python code.
THE CODE TO TEST IS:
{code_to_review}
YOUR TASK:
1. Understand what the function appears to do based on its name and structure
2. Generate comprehensive tests (15-20 test cases)
3. Execute the tests using your code executor
4. Analyze results to identify bugs vs expected behavior
5. Output a detailed JSON analysis
TESTING METHODOLOGY:
- Test with the most natural interpretation first
- When something fails, determine if it's a bug or unusual design
- Test edge cases, boundaries, and error scenarios
- Document any surprising behavior
Execute your tests and output ONLY valid JSON with this structure:
- "test_summary": object with "total_tests_run", "tests_passed", "tests_failed", "tests_with_errors", "critical_issues_found"
- "critical_issues": array of objects, each with "type", "description", "example_input", "expected_behavior", "actual_behavior", "severity"
- "test_categories": object with "basic_functionality", "edge_cases", "error_handling" (each containing "passed", "failed", "errors" counts)
- "function_behavior": object with "apparent_purpose", "actual_interface", "unexpected_requirements"
- "verdict": object with "status" (WORKING/BUGGY/BROKEN), "confidence" (high/medium/low), "recommendation"
Do NOT output the test code itself, only the JSON analysis."""
return await instructions_utils.inject_session_state(template, context)
👉 Trova:
# MODULE_5_STEP_2_TEST_RUNNER_AGENT
👉 Sostituisci quella singola riga con:
test_runner_agent = Agent(
name="TestRunner",
model=config.critic_model,
description="Generates and runs tests for Python code using safe code execution",
instruction=test_runner_instruction_provider,
code_executor=BuiltInCodeExecutor(),
output_key="test_execution_summary"
)
Passaggio 3: comprendere la memoria per l'apprendimento cross-sessione
Prima di creare il sintetizzatore di feedback, devi comprendere la differenza tra stato e memoria, due meccanismi di archiviazione diversi per due scopi diversi.
Stato e memoria: la distinzione chiave
Vediamo un esempio concreto di revisione del codice:
Stato (solo sessione corrente):
# Data from THIS review session
tool_context.state[StateKeys.STYLE_ISSUES] = [
{"line": 5, "code": "E231", "message": "missing whitespace"},
{"line": 12, "code": "E701", "message": "multiple statements"}
]
- Ambito: Solo questa conversazione
- Scopo: passare i dati tra gli agenti nella pipeline corrente
- Vive a:
Sessionoggetto - Lifetime: eliminato al termine della sessione
Memoria (tutte le sessioni passate):
# Learned from 50 previous reviews
"User frequently forgets docstrings on helper functions"
"User tends to write long functions (avg 45 lines)"
"User improved error handling after feedback in session #23"
- Ambito: Tutte le sessioni passate per questo utente
- Scopo: apprendere i pattern, fornire feedback personalizzati
- Vive a:
MemoryService - Lifetime: persiste tra le sessioni, è possibile eseguire ricerche
Perché il feedback deve includere entrambi:
Immagina il sintetizzatore che crea un feedback:
Utilizzo solo dello stato (revisione attuale):
"Function `calculate_total` has no docstring."
Feedback generico e meccanico.
Utilizzo di Stato + Memoria (pattern attuali e passati):
"Function `calculate_total` has no docstring. This is the 4th review
where helper functions lacked documentation. Consider adding docstrings
as you write functions, not afterwards - you mentioned in our last
session that you find it easier that way."
Miglioramento personalizzato, contestuale e dei riferimenti nel tempo.
Per i deployment di produzione, hai opzioni:
Opzione 1: VertexAiMemoryBankService (avanzata)
- Come funziona: estrazione basata su LLM di fatti significativi dalle conversazioni
- Ricerca:ricerca semantica (comprende il significato, non solo le parole chiave)
- Gestione dei ricordi:consolida e aggiorna automaticamente i ricordi nel tempo
- Requisiti:progetto Google Cloud + configurazione di Agent Engine
- Utilizzo:vuoi ricordi sofisticati, in evoluzione e personalizzati
- Esempio: "L'utente preferisce la programmazione funzionale" (estratto da 10 conversazioni sullo stile di codice)
Opzione 2: continua con InMemoryMemoryService + sessioni persistenti
- Funzioni: memorizza la cronologia completa delle conversazioni per la ricerca di parole chiave
- Ricerca:corrispondenza di base delle parole chiave nelle sessioni precedenti
- Gestione della memoria:controlli cosa viene memorizzato (tramite
add_session_to_memory) - Richiede:solo un
SessionServicepersistente (ad esempioVertexAiSessionServiceoDatabaseSessionService) - Utilizzo: hai bisogno di una ricerca semplice nelle conversazioni passate senza l'elaborazione LLM
- Esempio: la ricerca "docstring" restituisce tutte le sessioni in cui viene menzionata questa parola
Come viene compilata la memoria
Al termine di ogni revisione del codice:
# At the end of a session (typically in your application code)
await memory_service.add_session_to_memory(session)
Che cosa succede:
- InMemoryMemoryService:memorizza gli eventi di sessione completi per la ricerca di parole chiave
- VertexAiMemoryBankService: l'LLM estrae i fatti chiave e li consolida con i ricordi esistenti
Le sessioni future possono quindi eseguire query:
# In a tool, search for relevant past feedback
results = tool_context.search_memory("feedback about docstrings")
Passaggio 4: aggiungi gli strumenti e l'agente di sintesi del feedback
Il sintetizzatore di feedback è l'agente più sofisticato della pipeline. Coordina tre strumenti, utilizza istruzioni dinamiche e combina stato, memoria e artefatti.
Aggiungere i tre strumenti di sintesi
👉 Apri
code_review_assistant/tools.py
👉 Trova:
# MODULE_5_STEP_4_SEARCH_PAST_FEEDBACK
👉 Sostituisci con Strumento 1 - Ricerca nella memoria (versione di produzione):
async def search_past_feedback(developer_id: str, tool_context: ToolContext) -> Dict[str, Any]:
"""
Search for past feedback in memory service.
Args:
developer_id: ID of the developer (defaults to "default_user")
tool_context: ADK tool context with potential memory service access
Returns:
Dictionary containing feedback search results
"""
logger.info(f"Tool: Searching for past feedback for developer {developer_id}...")
try:
# Default developer ID if not provided
if not developer_id:
developer_id = tool_context.state.get(StateKeys.USER_ID, 'default_user')
# Check if memory service is available
if hasattr(tool_context, 'search_memory'):
try:
# Perform structured searches
queries = [
f"developer:{developer_id} code review feedback",
f"developer:{developer_id} common issues",
f"developer:{developer_id} improvements"
]
all_feedback = []
patterns = {
'common_issues': [],
'improvements': [],
'strengths': []
}
for query in queries:
search_result = await tool_context.search_memory(query)
if search_result and hasattr(search_result, 'memories'):
for memory in search_result.memories[:5]:
memory_text = memory.text if hasattr(memory, 'text') else str(memory)
all_feedback.append(memory_text)
# Extract patterns
if 'style' in memory_text.lower():
patterns['common_issues'].append('style compliance')
if 'improved' in memory_text.lower():
patterns['improvements'].append('showing improvement')
if 'excellent' in memory_text.lower():
patterns['strengths'].append('consistent quality')
# Store in state
tool_context.state[StateKeys.PAST_FEEDBACK] = all_feedback
tool_context.state[StateKeys.FEEDBACK_PATTERNS] = patterns
logger.info(f"Tool: Found {len(all_feedback)} past feedback items")
return {
"status": "success",
"feedback_found": True,
"count": len(all_feedback),
"summary": " | ".join(all_feedback[:3]) if all_feedback else "No feedback",
"patterns": patterns
}
except Exception as e:
logger.warning(f"Tool: Memory search error: {e}")
# Fallback: Check state for cached feedback
cached_feedback = tool_context.state.get(StateKeys.USER_PAST_FEEDBACK_CACHE, [])
if cached_feedback:
tool_context.state[StateKeys.PAST_FEEDBACK] = cached_feedback
return {
"status": "success",
"feedback_found": True,
"count": len(cached_feedback),
"summary": "Using cached feedback",
"patterns": {}
}
# No feedback found
tool_context.state[StateKeys.PAST_FEEDBACK] = []
logger.info("Tool: No past feedback found")
return {
"status": "success",
"feedback_found": False,
"message": "No past feedback available - this appears to be a first submission",
"patterns": {}
}
except Exception as e:
error_msg = f"Feedback search error: {str(e)}"
logger.error(f"Tool: {error_msg}", exc_info=True)
tool_context.state[StateKeys.PAST_FEEDBACK] = []
return {
"status": "error",
"message": error_msg,
"feedback_found": False
}
👉 Trova:
# MODULE_5_STEP_4_UPDATE_GRADING_PROGRESS
👉 Sostituisci con lo strumento 2 - Grading Tracker (versione di produzione):
async def update_grading_progress(tool_context: ToolContext) -> Dict[str, Any]:
"""
Updates grading progress counters and metrics in state.
"""
logger.info("Tool: Updating grading progress...")
try:
current_time = datetime.now().isoformat()
# Build all state changes
state_updates = {}
# Temporary (invocation-level) state
state_updates[StateKeys.TEMP_PROCESSING_TIMESTAMP] = current_time
# Session-level state
attempts = tool_context.state.get(StateKeys.GRADING_ATTEMPTS, 0) + 1
state_updates[StateKeys.GRADING_ATTEMPTS] = attempts
state_updates[StateKeys.LAST_GRADING_TIME] = current_time
# User-level persistent state
lifetime_submissions = tool_context.state.get(StateKeys.USER_TOTAL_SUBMISSIONS, 0) + 1
state_updates[StateKeys.USER_TOTAL_SUBMISSIONS] = lifetime_submissions
state_updates[StateKeys.USER_LAST_SUBMISSION_TIME] = current_time
# Calculate improvement metrics
current_style_score = tool_context.state.get(StateKeys.STYLE_SCORE, 0)
last_style_score = tool_context.state.get(StateKeys.USER_LAST_STYLE_SCORE, 0)
score_improvement = current_style_score - last_style_score
state_updates[StateKeys.USER_LAST_STYLE_SCORE] = current_style_score
state_updates[StateKeys.SCORE_IMPROVEMENT] = score_improvement
# Track test results if available
test_results = tool_context.state.get(StateKeys.TEST_EXECUTION_SUMMARY, {})
# Parse if it's a string
if isinstance(test_results, str):
try:
test_results = json.loads(test_results)
except:
test_results = {}
if test_results and test_results.get('test_summary', {}).get('total_tests_run', 0) > 0:
summary = test_results['test_summary']
total = summary.get('total_tests_run', 0)
passed = summary.get('tests_passed', 0)
if total > 0:
pass_rate = (passed / total) * 100
state_updates[StateKeys.USER_LAST_TEST_PASS_RATE] = pass_rate
# Apply all updates atomically
for key, value in state_updates.items():
tool_context.state[key] = value
logger.info(f"Tool: Progress updated - Attempt #{attempts}, "
f"Lifetime: {lifetime_submissions}")
return {
"status": "success",
"session_attempts": attempts,
"lifetime_submissions": lifetime_submissions,
"timestamp": current_time,
"improvement": {
"style_score_change": score_improvement,
"direction": "improved" if score_improvement > 0 else "declined"
},
"summary": f"Attempt #{attempts} recorded, {lifetime_submissions} total submissions"
}
except Exception as e:
error_msg = f"Progress update error: {str(e)}"
logger.error(f"Tool: {error_msg}", exc_info=True)
return {
"status": "error",
"message": error_msg
}
👉 Trova:
# MODULE_5_STEP_4_SAVE_GRADING_REPORT
👉 Sostituisci con lo strumento 3 - Artifact Saver (versione di produzione):
async def save_grading_report(feedback_text: str, tool_context: ToolContext) -> Dict[str, Any]:
"""
Saves a detailed grading report as an artifact.
Args:
feedback_text: The feedback text to include in the report
tool_context: ADK tool context for state management
Returns:
Dictionary containing save status and details
"""
logger.info("Tool: Saving grading report...")
try:
# Gather all relevant data from state
code = tool_context.state.get(StateKeys.CODE_TO_REVIEW, '')
analysis = tool_context.state.get(StateKeys.CODE_ANALYSIS, {})
style_score = tool_context.state.get(StateKeys.STYLE_SCORE, 0)
style_issues = tool_context.state.get(StateKeys.STYLE_ISSUES, [])
# Get test results
test_results = tool_context.state.get(StateKeys.TEST_EXECUTION_SUMMARY, {})
# Parse if it's a string
if isinstance(test_results, str):
try:
test_results = json.loads(test_results)
except:
test_results = {}
timestamp = datetime.now().isoformat()
# Create comprehensive report dictionary
report = {
'timestamp': timestamp,
'grading_attempt': tool_context.state.get(StateKeys.GRADING_ATTEMPTS, 1),
'code': {
'content': code,
'line_count': len(code.splitlines()),
'hash': hashlib.md5(code.encode()).hexdigest()
},
'analysis': analysis,
'style': {
'score': style_score,
'issues': style_issues[:5] # First 5 issues
},
'tests': test_results,
'feedback': feedback_text,
'improvements': {
'score_change': tool_context.state.get(StateKeys.SCORE_IMPROVEMENT, 0),
'from_last_score': tool_context.state.get(StateKeys.USER_LAST_STYLE_SCORE, 0)
}
}
# Convert report to JSON string
report_json = json.dumps(report, indent=2)
report_part = types.Part.from_text(text=report_json)
# Try to save as artifact if the service is available
if hasattr(tool_context, 'save_artifact'):
try:
# Generate filename with timestamp (replace colons for filesystem compatibility)
filename = f"grading_report_{timestamp.replace(':', '-')}.json"
# Save the main report
version = await tool_context.save_artifact(filename, report_part)
# Also save a "latest" version for easy access
await tool_context.save_artifact("latest_grading_report.json", report_part)
logger.info(f"Tool: Report saved as {filename} (version {version})")
# Store report in state as well for redundancy
tool_context.state[StateKeys.USER_LAST_GRADING_REPORT] = report
return {
"status": "success",
"artifact_saved": True,
"filename": filename,
"version": str(version),
"size": len(report_json),
"summary": f"Report saved as {filename}"
}
except Exception as artifact_error:
logger.warning(f"Artifact service error: {artifact_error}, falling back to state storage")
# Continue to fallback below
# Fallback: Store in state if artifact service is not available or failed
tool_context.state[StateKeys.USER_LAST_GRADING_REPORT] = report
logger.info("Tool: Report saved to state (artifact service not available)")
return {
"status": "success",
"artifact_saved": False,
"message": "Report saved to state only",
"size": len(report_json),
"summary": "Report saved to session state"
}
except Exception as e:
error_msg = f"Report save error: {str(e)}"
logger.error(f"Tool: {error_msg}", exc_info=True)
# Still try to save minimal data to state
try:
tool_context.state[StateKeys.USER_LAST_GRADING_REPORT] = {
'error': error_msg,
'feedback': feedback_text,
'timestamp': datetime.now().isoformat()
}
except:
pass
return {
"status": "error",
"message": error_msg,
"artifact_saved": False,
"summary": f"Failed to save report: {error_msg}"
}
Crea l'agente di sintesi
👉 Apri
code_review_assistant/sub_agents/review_pipeline/feedback_synthesizer.py
👉 Trova:
# MODULE_5_STEP_4_INSTRUCTION_PROVIDER
👉 Sostituisci con il fornitore delle istruzioni di produzione:
async def feedback_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are an expert code reviewer and mentor providing constructive, educational feedback.
CONTEXT FROM PREVIOUS AGENTS:
- Structure analysis summary: {structure_analysis_summary}
- Style check summary: {style_check_summary}
- Test execution summary: {test_execution_summary}
YOUR TASK requires these steps IN ORDER:
1. Call search_past_feedback tool with developer_id="default_user"
2. Call update_grading_progress tool with no parameters
3. Carefully analyze the test results to understand what really happened
4. Generate comprehensive feedback following the structure below
5. Call save_grading_report tool with the feedback_text parameter
6. Return the feedback as your final output
CRITICAL - Understanding Test Results:
The test_execution_summary contains structured JSON. Parse it carefully:
- tests_passed = Code worked correctly
- tests_failed = Code produced wrong output
- tests_with_errors = Code crashed
- critical_issues = Fundamental problems with the code
If critical_issues array contains items, these are serious bugs that need fixing.
Do NOT count discovering bugs as test successes.
FEEDBACK STRUCTURE TO FOLLOW:
## 📊 Summary
Provide an honest assessment. Be encouraging but truthful about problems found.
## ✅ Strengths
List 2-3 things done well, referencing specific code elements.
## 📈 Code Quality Analysis
### Structure & Organization
Comment on code organization, readability, and documentation.
### Style Compliance
Report the actual style score and any specific issues.
### Test Results
Report the actual test results accurately:
- If critical_issues exist, report them as bugs to fix
- Be clear: "X tests passed, Y critical issues were found"
- List each critical issue
- Don't hide or minimize problems
## 💡 Recommendations for Improvement
Based on the analysis, provide specific actionable fixes.
If critical issues exist, fixing them is top priority.
## 🎯 Next Steps
Prioritized action list based on severity of issues.
## 💬 Encouragement
End with encouragement while being honest about what needs fixing.
Remember: Complete ALL steps including calling save_grading_report."""
return await instructions_utils.inject_session_state(template, context)
👉 Trova:
# MODULE_5_STEP_4_SYNTHESIZER_AGENT
👉 Sostituisci con:
feedback_synthesizer_agent = Agent(
name="FeedbackSynthesizer",
model=config.critic_model,
description="Synthesizes all analysis into constructive, personalized feedback",
instruction=feedback_instruction_provider,
tools=[
FunctionTool(func=search_past_feedback),
FunctionTool(func=update_grading_progress),
FunctionTool(func=save_grading_report)
],
output_key="final_feedback"
)
Passaggio 5: collega la pipeline
Ora collega tutti e quattro gli agenti in una pipeline sequenziale e crea l'agente principale.
👉 Apri
code_review_assistant/agent.py
👉 Aggiungi le importazioni necessarie all'inizio del file (dopo le importazioni esistenti):
from google.adk.agents import Agent, SequentialAgent
from code_review_assistant.sub_agents.review_pipeline.code_analyzer import code_analyzer_agent
from code_review_assistant.sub_agents.review_pipeline.style_checker import style_checker_agent
from code_review_assistant.sub_agents.review_pipeline.test_runner import test_runner_agent
from code_review_assistant.sub_agents.review_pipeline.feedback_synthesizer import feedback_synthesizer_agent
Il file ora dovrebbe avere il seguente aspetto:
"""
Main agent orchestration for the Code Review Assistant.
"""
from google.adk.agents import Agent, SequentialAgent
from .config import config
from code_review_assistant.sub_agents.review_pipeline.code_analyzer import code_analyzer_agent
from code_review_assistant.sub_agents.review_pipeline.style_checker import style_checker_agent
from code_review_assistant.sub_agents.review_pipeline.test_runner import test_runner_agent
from code_review_assistant.sub_agents.review_pipeline.feedback_synthesizer import feedback_synthesizer_agent
# MODULE_5_STEP_5_CREATE_PIPELINE
# MODULE_6_STEP_5_CREATE_FIX_LOOP
# MODULE_6_STEP_5_UPDATE_ROOT_AGENT
👉 Trova:
# MODULE_5_STEP_5_CREATE_PIPELINE
👉 Sostituisci quella singola riga con:
# Create sequential pipeline
code_review_pipeline = SequentialAgent(
name="CodeReviewPipeline",
description="Complete code review pipeline with analysis, testing, and feedback",
sub_agents=[
code_analyzer_agent,
style_checker_agent,
test_runner_agent,
feedback_synthesizer_agent
]
)
# Root agent - coordinates the review pipeline
root_agent = Agent(
name="CodeReviewAssistant",
model=config.worker_model,
description="An intelligent code review assistant that analyzes Python code and provides educational feedback",
instruction="""You are a specialized Python code review assistant focused on helping developers improve their code quality.
When a user provides Python code for review:
1. Immediately delegate to CodeReviewPipeline and pass the code EXACTLY as it was provided by the user.
2. The pipeline will handle all analysis and feedback
3. Return ONLY the final feedback from the pipeline - do not add any commentary
When a user asks what you can do or asks general questions:
- Explain your capabilities for code review
- Do NOT trigger the pipeline for non-code messages
The pipeline handles everything for code review - just pass through its final output.""",
sub_agents=[code_review_pipeline],
output_key="assistant_response"
)
Passaggio 6: testa la pipeline completa
È il momento di vedere tutti e quattro gli agenti collaborare.
👉 Avvia il sistema:
adk web code_review_assistant
Dopo aver eseguito il comando adk web, dovresti visualizzare un output nel terminale che indica che il server web ADK è stato avviato, simile a questo:
+-----------------------------------------------------------------------------+
| ADK Web Server started |
| |
| For local testing, access at http://localhost:8000. |
+-----------------------------------------------------------------------------+
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
👉 Successivamente, per accedere all'interfaccia utente per sviluppatori dell'ADK dal browser:
Dall'icona Anteprima web (spesso a forma di occhio o di quadrato con una freccia) nella barra degli strumenti di Cloud Shell (di solito in alto a destra), seleziona Cambia porta. Nella finestra popup, imposta la porta su 8000 e fai clic su "Cambia e visualizza anteprima". Cloud Shell aprirà quindi una nuova scheda o finestra del browser che mostra l'UI di ADK Dev.
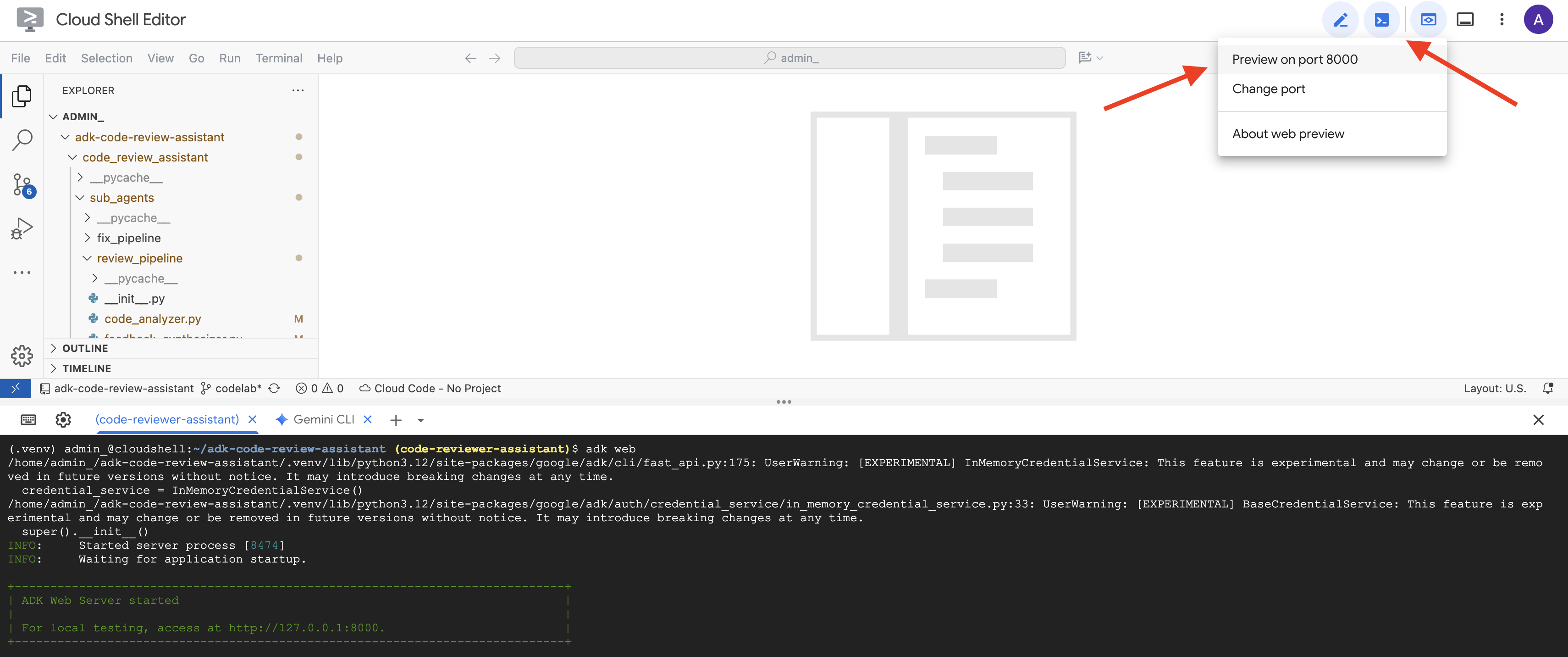
👉 L'agente è ora in esecuzione. La UI di sviluppo dell'ADK nel browser è la tua connessione diretta all'agente.
- Seleziona la destinazione: nel menu a discesa nella parte superiore della UI, scegli l'agente
code_review_assistant.
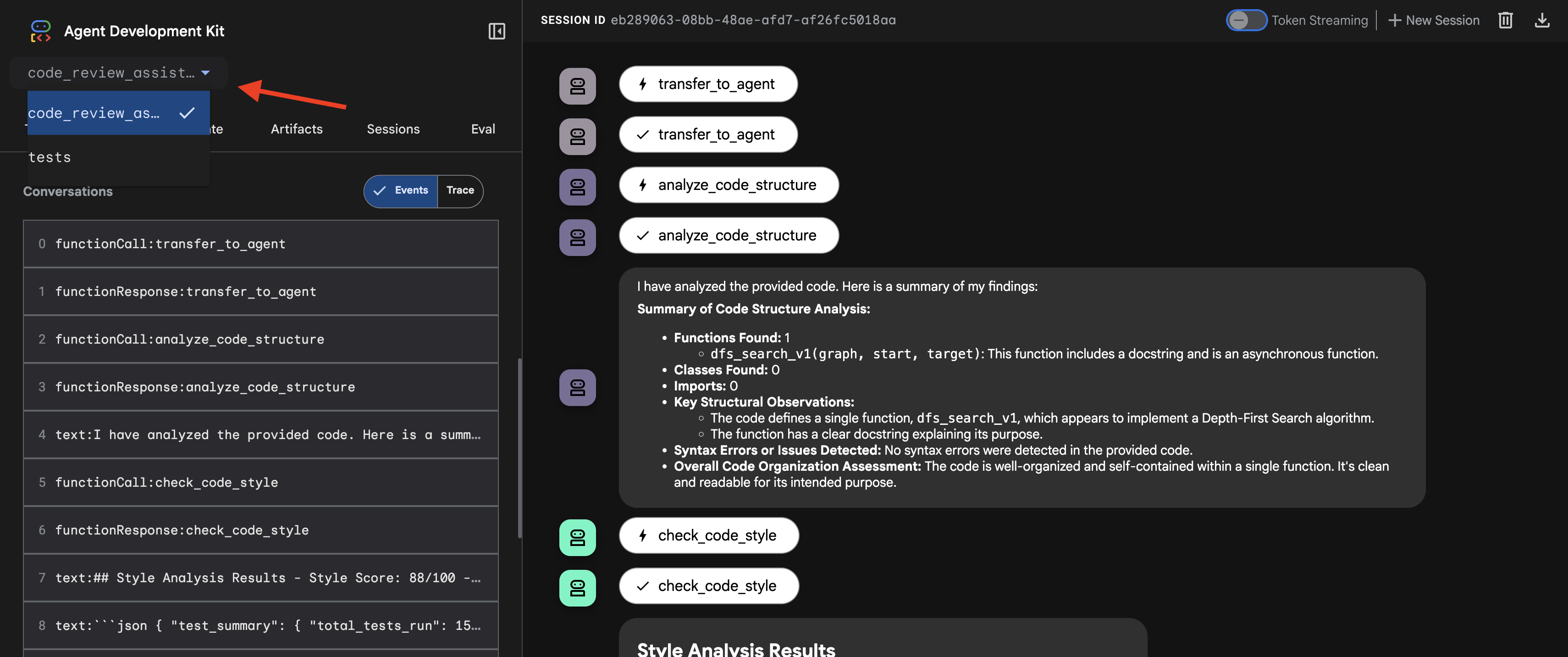
👉 Prompt di test:
Please analyze the following:
def dfs_search_v1(graph, start, target):
"""Find if target is reachable from start."""
visited = set()
stack = start
while stack:
current = stack.pop()
if current == target:
return True
if current not in visited:
visited.add(current)
for neighbor in graph[current]:
if neighbor not in visited:
stack.append(neighbor)
return False
👉 Guarda la pipeline di revisione del codice in azione:
Quando invii la funzione dfs_search_v1 con bug, non ricevi una sola risposta. Stai assistendo al funzionamento della tua pipeline multi-agente. L'output di streaming che vedi è il risultato dell'esecuzione in sequenza di quattro agenti specializzati, ognuno dei quali si basa sul precedente.
Ecco una suddivisione del contributo di ciascun agente alla revisione finale e completa, trasformando i dati non elaborati in informazioni fruibili.
1. Report strutturale di Code Analyzer
Innanzitutto, l'agente CodeAnalyzer riceve il codice non elaborato. Non indovina cosa fa il codice, ma utilizza lo strumento analyze_code_structure per eseguire un'analisi deterministica dell'albero della sintassi astratta (AST).
Il suo output sono dati puri e oggettivi sulla struttura del codice:
The analysis of the provided code reveals the following:
Summary:
- Functions Found: 1
- Classes Found: 0
Key Structural Observations:
- A single function, dfs_search_v1, is defined.
- It includes a docstring: "Find if target is reachable from start."
- No syntax errors were detected.
Overall Code Organization Assessment:
- The code snippet is a well-defined, self-contained function.
⭐ Valore:questo passaggio iniziale fornisce una base pulita e affidabile per gli altri agenti. Conferma che il codice è Python valido e identifica i componenti esatti che devono essere esaminati.
2. Controllo PEP 8 di Style Checker
A questo punto, interviene l'agente StyleChecker. Legge il codice dallo stato condiviso e utilizza lo strumento check_code_style, che sfrutta il linter pycodestyle.
Il suo output è un punteggio di qualità quantificabile e violazioni specifiche:
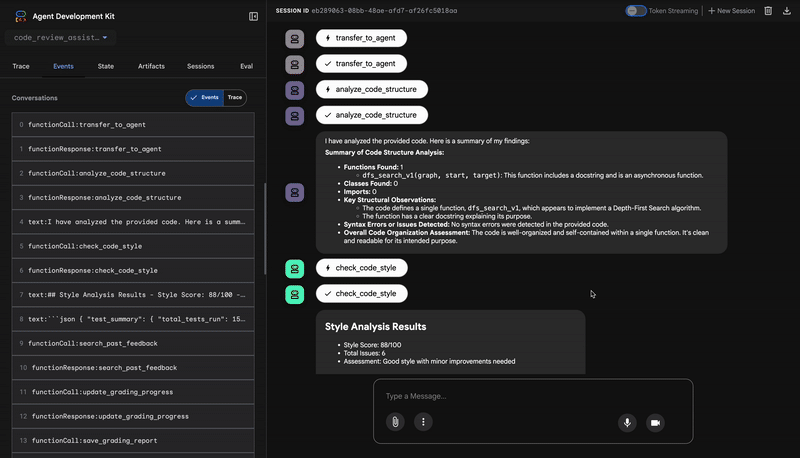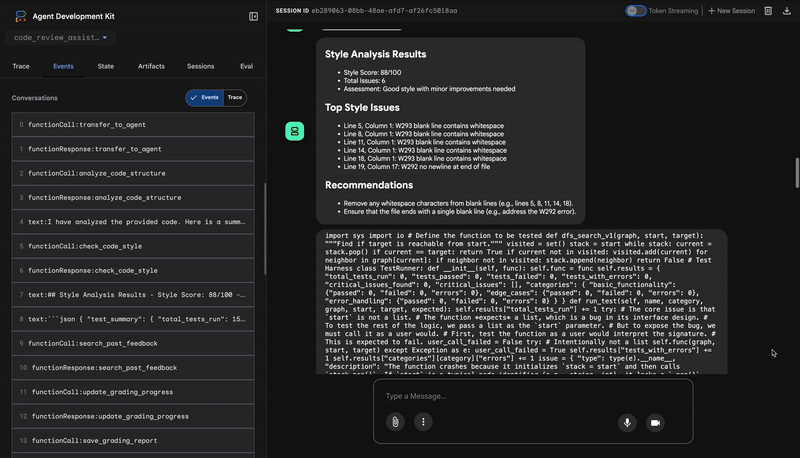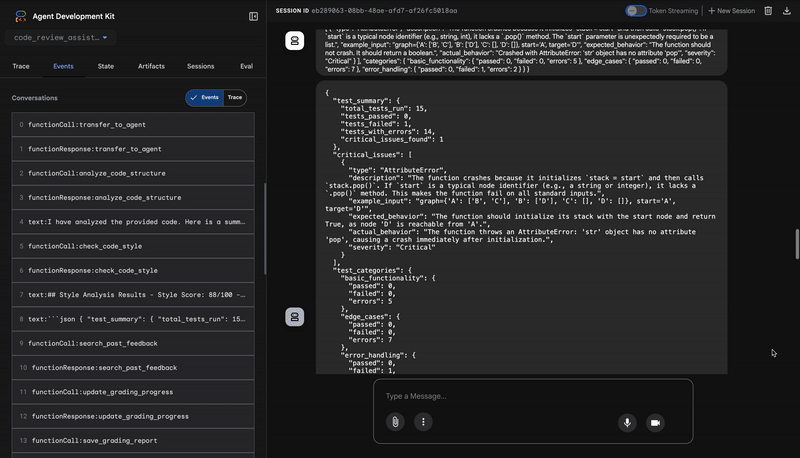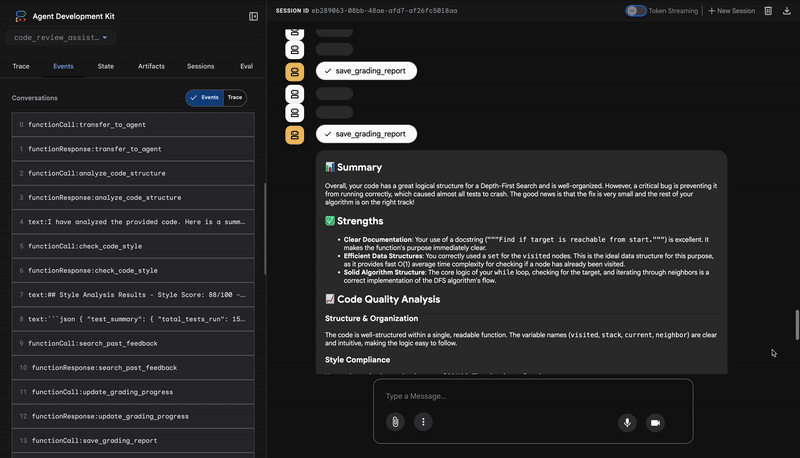
Style Analysis Results
- Style Score: 88/100
- Total Issues: 6
- Assessment: Good style with minor improvements needed
Top Style Issues
- Line 5, W293: blank line contains whitespace
- Line 19, W292: no newline at end of file
⭐ Valore:questo agente fornisce un feedback oggettivo e non negoziabile basato su standard della community consolidati (PEP 8). Il sistema di punteggio ponderato indica immediatamente all'utente la gravità dei problemi.
3. Rilevamento di bug critici di Test Runner
È qui che il sistema va oltre l'analisi superficiale. L'agente TestRunner genera ed esegue una suite completa di test per convalidare il comportamento del codice.
Il suo output è un oggetto JSON strutturato che contiene un verdetto condannatorio:
{
"critical_issues": [
{
"type": "Critical Bug",
"description": "The function's initialization `stack = start` is incorrect... When a common input like a string... is provided... the function crashes with an AttributeError.",
"severity": "Critical"
}
],
"verdict": {
"status": "BROKEN",
"confidence": "high",
"recommendation": "The function is fundamentally broken... the stack initialization line `stack = start` must be changed to `stack = [start]`."
}
}
⭐ Valore:questo è l'approfondimento più importante. L'agente non ha semplicemente indovinato, ma ha dimostrato che il codice non funzionava eseguendolo. Ha scoperto un bug di runtime sottile ma critico che un revisore umano potrebbe facilmente non notare e ha individuato la causa esatta e la correzione necessaria.
4. Report finale del sintetizzatore di feedback
Infine, l'agente FeedbackSynthesizer funge da direttore d'orchestra. Prende i dati strutturati dei tre agenti precedenti e crea un unico report intuitivo, analitico e incoraggiante.
Il suo output è la recensione finale e perfezionata che vedi:
📊 Summary
Great effort on implementing the Depth-First Search algorithm! ... However, a critical bug in the initialization of the stack prevents the function from working correctly...
✅ Strengths
- Good Algorithm Structure
- Correct Use of `visited` Set
📈 Code Quality Analysis
...
### Style Compliance
The style analysis returned a good score of 88/100.
...
### Test Results
The automated testing revealed a critical issue... The line `stack = start` directly assigns the input... which results in an `AttributeError`.
💡 Recommendations for Improvement
**Fix the Critical Stack Initialization Bug:**
- Incorrect Code: `stack = start`
- Correct Code: `stack = [start]`
💬 Encouragement
You are very close to a perfect implementation! The core logic of your DFS algorithm is sound, which is the hardest part.
⭐ Valore:questo agente trasforma i dati tecnici in un'esperienza utile e didattica. Dà la priorità al problema più importante (il bug), lo spiega chiaramente, fornisce la soluzione esatta e lo fa con un tono incoraggiante. Integra con successo i risultati di tutte le fasi precedenti in un insieme coeso e prezioso.
Questo processo multifase dimostra la potenza di una pipeline agentica. Anziché una singola risposta monolitica, ottieni un'analisi a più livelli in cui ogni agente esegue un'attività specializzata e verificabile. Ciò porta a una revisione non solo approfondita, ma anche deterministica, affidabile e profondamente educativa.
👉💻 Al termine del test, torna al terminale dell'editor di Cloud Shell e premi Ctrl+C per arrestare l'interfaccia utente di ADK Dev.
Cosa hai creato
Ora hai una pipeline completa di revisione del codice che:
✅ Analizza la struttura del codice: analisi AST deterministica con funzioni di supporto
✅ Controlla lo stile: punteggio ponderato con convenzioni di denominazione
✅ Esegue test: generazione completa di test con output JSON strutturato
✅ Sintetizza il feedback: integra stato, memoria e artefatti
✅ Monitora i progressi: stato a più livelli in invocazioni, sessioni e utenti
✅ Impara nel tempo: servizio di memoria per pattern tra sessioni
✅ Fornisce artefatti: report JSON scaricabili con audit trail completo
Concetti fondamentali padroneggiati
Pipeline sequenziali:
- Quattro agenti che vengono eseguiti in ordine rigoroso
- Ciascuno arricchisce lo stato per il successivo
- Le dipendenze determinano la sequenza di esecuzione
Modelli di produzione:
- Separazione delle funzioni helper (sincronizzazione nei pool di thread)
- Riduzione controllata (strategie di fallback)
- Gestione dello stato a più livelli (temporaneo/sessione/utente)
- Fornitori di istruzioni dinamiche (sensibili al contesto)
- Doppio spazio di archiviazione (ridondanza di artefatti e stato)
Stato come comunicazione:
- Le costanti evitano errori di battitura negli agenti
output_keyscrive i riepiloghi dell'agente nello stato- Gli agenti successivi leggono tramite StateKeys
- Lo stato scorre linearmente attraverso la pipeline
Memoria e stato:
- Stato: dati della sessione corrente
- Memoria: pattern tra le sessioni
- Scopi diversi, durate diverse
Orchestrazione degli strumenti:
- Agenti con un solo strumento (analyzer, style_checker)
- Esecutori integrati (test_runner)
- Coordinamento multi-strumento (sintetizzatore)
Strategia di selezione del modello:
- Modello di worker: attività meccaniche (analisi, linting, routing)
- Modello di critica: attività di ragionamento (test, sintesi)
- Ottimizzazione dei costi tramite una selezione appropriata
Passaggi successivi
Nel modulo 6, creerai la pipeline di correzione:
- Architettura LoopAgent per la correzione iterativa
- Condizioni di uscita tramite escalation
- Accumulo di stato nelle iterazioni
- Logica di convalida e riprova
- Integrazione con la pipeline di revisione per offrire correzioni
Vedrai come gli stessi pattern di stato vengono scalati a flussi di lavoro iterativi complessi in cui gli agenti tentano più volte fino a quando non riescono e come coordinare più pipeline in una singola applicazione.
6. Aggiunta della pipeline di correzione: architettura del ciclo
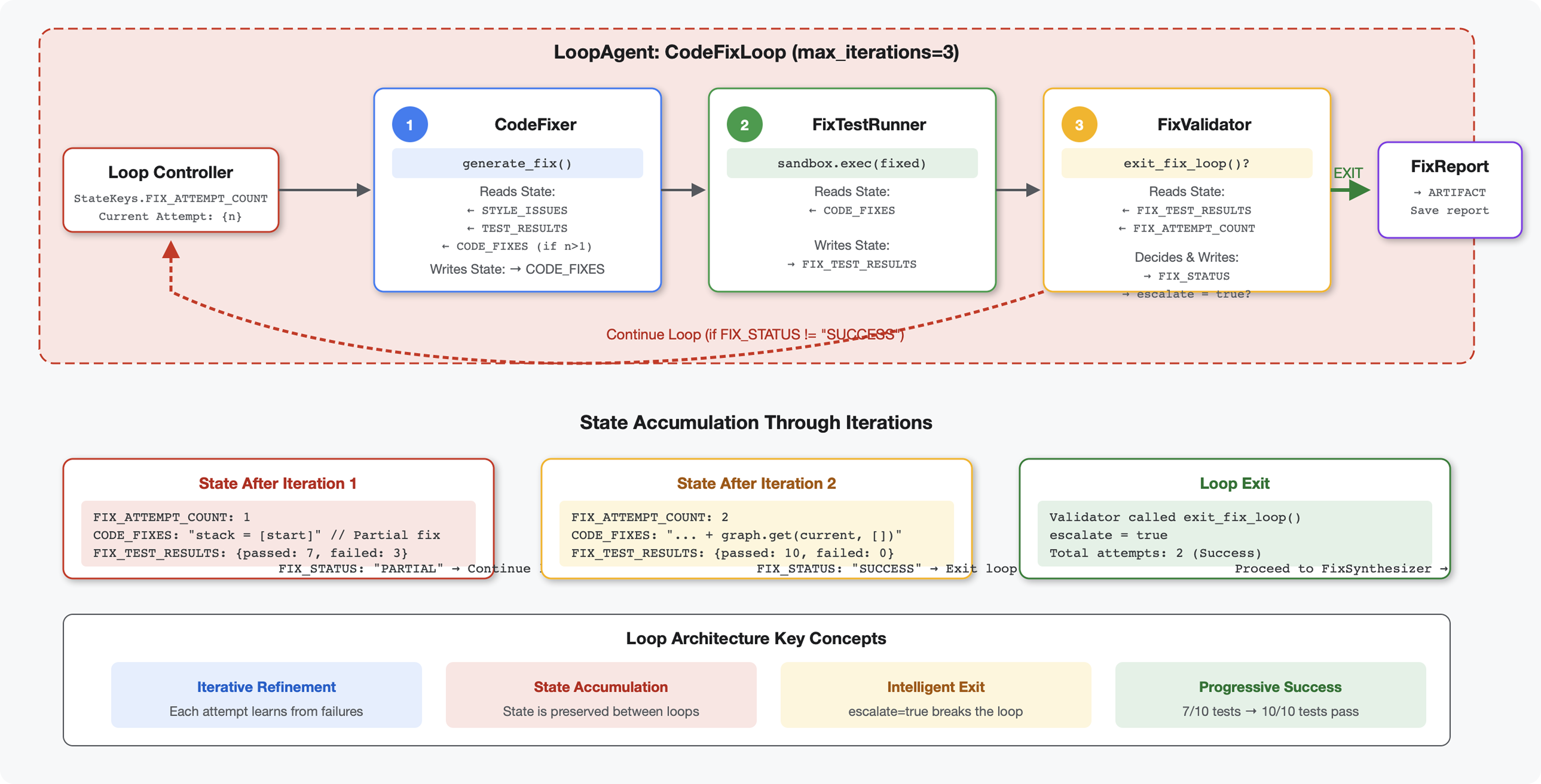
Introduzione
Nel modulo 5, hai creato una pipeline di revisione sequenziale che analizza il codice e fornisce feedback. Ma identificare i problemi è solo metà della soluzione: gli sviluppatori hanno bisogno di aiuto per risolverli.
Questo modulo crea una pipeline di correzione automatizzata che:
- Genera correzioni in base ai risultati della revisione
- Convalida le correzioni eseguendo test completi
- Riprova automaticamente se le correzioni non funzionano (fino a 3 tentativi)
- Risultati dei report con confronti prima/dopo
Concetto chiave: LoopAgent per il nuovo tentativo automatico. A differenza degli agenti sequenziali che vengono eseguiti una sola volta, un LoopAgent ripete i suoi subagenti finché non viene soddisfatta una condizione di uscita o non viene raggiunto il numero massimo di iterazioni. Gli strumenti segnalano la riuscita impostando tool_context.actions.escalate = True.
Anteprima di ciò che creerai:invio di codice con bug → revisione che identifica i problemi → ciclo di correzione che genera le correzioni → test che convalidano → tentativi se necessario → report finale completo.
Concetti principali: LoopAgent e Sequential
Sequential Pipeline (Module 5):
SequentialAgent(agents=[A, B, C])
# Executes: A → B → C → Done
- Flusso unidirezionale
- Ogni agente viene eseguito esattamente una volta
- Nessuna logica di nuovi tentativi
Loop Pipeline (Modulo 6):
LoopAgent(agents=[A, B, C], max_iterations=3)
# Executes: A → B → C → (check exit) → A → B → C → (check exit) → ...
- Flusso ciclico
- Gli agenti possono essere eseguiti più volte
- Termina quando:
- Un set di strumenti imposta
tool_context.actions.escalate = True(riuscito) max_iterationsraggiunto (limite di sicurezza)- Si verifica un'eccezione non gestita (errore)
- Un set di strumenti imposta
Perché i loop per la correzione del codice:
Le correzioni del codice spesso richiedono più tentativi:
- Primo tentativo: correggere i bug evidenti (tipi di variabili errati)
- Secondo tentativo: risolvi i problemi secondari rivelati dai test (casi limite)
- Terzo tentativo: perfeziona e verifica che tutti i test vengano superati
Senza un ciclo, avresti bisogno di una logica condizionale complessa nelle istruzioni dell'agente. Con LoopAgent, il nuovo tentativo è automatico.
Confronto tra le architetture:
Sequential (Module 5):
User → Review Pipeline → Feedback → Done
Loop (Module 6):
User → Review Pipeline → Feedback → Fix Pipeline
↓
┌──────────────┴──────────────┐
│ Fix Attempt Loop (1-3x) │
│ ┌─────────────────────┐ │
│ │ 1. Generate Fixes │ │
│ │ 2. Test Fixes │ │
│ │ 3. Validate & Exit? │────┼─→ If escalate=True
│ └─────────────────────┘ │ exit loop
│ ↓ If not │
│ Try Again (max 3) │
└─────────────────────────────┘
↓
4. Synthesize Final Report → Done
Passaggio 1: aggiungi l'agente Code Fixer
Lo strumento di correzione del codice genera codice Python corretto in base ai risultati della revisione.
👉 Apri
code_review_assistant/sub_agents/fix_pipeline/code_fixer.py
👉 Trova:
# MODULE_6_STEP_1_CODE_FIXER_INSTRUCTION_PROVIDER
👉 Sostituisci quella singola riga con:
async def code_fixer_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are an expert code fixing specialist.
Original Code:
{code_to_review}
Analysis Results:
- Style Score: {style_score}/100
- Style Issues: {style_issues}
- Test Results: {test_execution_summary}
Based on the test results, identify and fix ALL issues including:
- Interface bugs (e.g., if start parameter expects wrong type)
- Logic errors (e.g., KeyError when accessing graph nodes)
- Style violations
- Missing documentation
YOUR TASK:
Generate the complete fixed Python code that addresses all identified issues.
CRITICAL INSTRUCTIONS:
- Output ONLY the corrected Python code
- Do NOT include markdown code blocks (```python)
- Do NOT include any explanations or commentary
- The output should be valid, executable Python code and nothing else
Common fixes to apply based on test results:
- If tests show AttributeError with 'pop', fix: stack = [start] instead of stack = start
- If tests show KeyError accessing graph, fix: use graph.get(current, [])
- Add docstrings if missing
- Fix any style violations identified
Output the complete fixed code now:"""
return await instructions_utils.inject_session_state(template, context)
👉 Trova:
# MODULE_6_STEP_1_CODE_FIXER_AGENT
👉 Sostituisci quella singola riga con:
code_fixer_agent = Agent(
name="CodeFixer",
model=config.worker_model,
description="Generates comprehensive fixes for all identified code issues",
instruction=code_fixer_instruction_provider,
code_executor=BuiltInCodeExecutor(),
output_key="code_fixes"
)
Passaggio 2: aggiungi Fix Test Runner Agent
Il runner di test di correzione convalida le correzioni eseguendo test completi sul codice corretto.
👉 Apri
code_review_assistant/sub_agents/fix_pipeline/fix_test_runner.py
👉 Trova:
# MODULE_6_STEP_2_FIX_TEST_RUNNER_INSTRUCTION_PROVIDER
👉 Sostituisci quella singola riga con:
async def fix_test_runner_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that uses the clean code from the previous step."""
template = """You are responsible for validating the fixed code by running tests.
THE FIXED CODE TO TEST:
{code_fixes}
ORIGINAL TEST RESULTS: {test_execution_summary}
YOUR TASK:
1. Understand the fixes that were applied
2. Generate the same comprehensive tests (15-20 test cases)
3. Execute the tests on the FIXED code using your code executor
4. Compare results with original test results
5. Output a detailed JSON analysis
TESTING METHODOLOGY:
- Run the same tests that revealed issues in the original code
- Verify that previously failing tests now pass
- Ensure no regressions were introduced
- Document the improvement
Execute your tests and output ONLY valid JSON with this structure:
- "passed": number of tests that passed
- "failed": number of tests that failed
- "total": total number of tests
- "pass_rate": percentage as a number
- "comparison": object with "original_pass_rate", "new_pass_rate", "improvement"
- "newly_passing_tests": array of test names that now pass
- "still_failing_tests": array of test names still failing
Do NOT output the test code itself, only the JSON analysis."""
return await instructions_utils.inject_session_state(template, context)
👉 Trova:
# MODULE_6_STEP_2_FIX_TEST_RUNNER_AGENT
👉 Sostituisci quella singola riga con:
fix_test_runner_agent = Agent(
name="FixTestRunner",
model=config.critic_model,
description="Runs comprehensive tests on fixed code to verify all issues are resolved",
instruction=fix_test_runner_instruction_provider,
code_executor=BuiltInCodeExecutor(),
output_key="fix_test_execution_summary"
)
Passaggio 3: aggiungi l'agente di convalida delle correzioni
Lo strumento di convalida controlla se le correzioni sono andate a buon fine e decide se uscire dal loop.
Informazioni sugli strumenti
Innanzitutto, aggiungi i tre strumenti necessari allo strumento di convalida.
👉 Apri
code_review_assistant/tools.py
👉 Trova:
# MODULE_6_STEP_3_VALIDATE_FIXED_STYLE
👉 Sostituisci con lo strumento 1 - Strumento di convalida dello stile:
async def validate_fixed_style(tool_context: ToolContext) -> Dict[str, Any]:
"""
Validates style compliance of the fixed code.
Args:
tool_context: ADK tool context containing fixed code in state
Returns:
Dictionary with style validation results
"""
logger.info("Tool: Validating style of fixed code...")
try:
# Get the fixed code from state
code_fixes = tool_context.state.get(StateKeys.CODE_FIXES, '')
# Try to extract from markdown if present
if '```python' in code_fixes:
start = code_fixes.rfind('```python') + 9
end = code_fixes.rfind('```')
if start < end:
code_fixes = code_fixes[start:end].strip()
if not code_fixes:
return {
"status": "error",
"message": "No fixed code found in state"
}
# Store the extracted fixed code
tool_context.state[StateKeys.CODE_FIXES] = code_fixes
# Run style check on fixed code
loop = asyncio.get_event_loop()
with ThreadPoolExecutor() as executor:
style_result = await loop.run_in_executor(
executor, _perform_style_check, code_fixes
)
# Compare with original
original_score = tool_context.state.get(StateKeys.STYLE_SCORE, 0)
improvement = style_result['score'] - original_score
# Store results
tool_context.state[StateKeys.FIXED_STYLE_SCORE] = style_result['score']
tool_context.state[StateKeys.FIXED_STYLE_ISSUES] = style_result['issues']
logger.info(f"Tool: Fixed code style score: {style_result['score']}/100 "
f"(improvement: +{improvement})")
return {
"status": "success",
"fixed_style_score": style_result['score'],
"original_style_score": original_score,
"improvement": improvement,
"remaining_issues": style_result['issues'],
"perfect_style": style_result['score'] == 100
}
except Exception as e:
logger.error(f"Tool: Style validation failed: {e}", exc_info=True)
return {
"status": "error",
"message": str(e)
}
👉 Trova:
# MODULE_6_STEP_3_COMPILE_FIX_REPORT
👉 Sostituisci con lo strumento 2 - Compilatore di report:
async def compile_fix_report(tool_context: ToolContext) -> Dict[str, Any]:
"""
Compiles comprehensive report of the fix process.
Args:
tool_context: ADK tool context with all fix pipeline data
Returns:
Comprehensive fix report
"""
logger.info("Tool: Compiling comprehensive fix report...")
try:
# Gather all data
original_code = tool_context.state.get(StateKeys.CODE_TO_REVIEW, '')
code_fixes = tool_context.state.get(StateKeys.CODE_FIXES, '')
# Test results
original_tests = tool_context.state.get(StateKeys.TEST_EXECUTION_SUMMARY, {})
fixed_tests = tool_context.state.get(StateKeys.FIX_TEST_EXECUTION_SUMMARY, {})
# Parse if strings
if isinstance(original_tests, str):
try:
original_tests = json.loads(original_tests)
except:
original_tests = {}
if isinstance(fixed_tests, str):
try:
fixed_tests = json.loads(fixed_tests)
except:
fixed_tests = {}
# Extract pass rates
original_pass_rate = 0
if original_tests:
if 'pass_rate' in original_tests:
original_pass_rate = original_tests['pass_rate']
elif 'test_summary' in original_tests:
# Handle test_runner_agent's JSON structure
summary = original_tests['test_summary']
total = summary.get('total_tests_run', 0)
passed = summary.get('tests_passed', 0)
if total > 0:
original_pass_rate = (passed / total) * 100
elif 'passed' in original_tests and 'total' in original_tests:
if original_tests['total'] > 0:
original_pass_rate = (original_tests['passed'] / original_tests['total']) * 100
fixed_pass_rate = 0
all_tests_pass = False
if fixed_tests:
if 'pass_rate' in fixed_tests:
fixed_pass_rate = fixed_tests['pass_rate']
all_tests_pass = fixed_tests.get('failed', 1) == 0
elif 'passed' in fixed_tests and 'total' in fixed_tests:
if fixed_tests['total'] > 0:
fixed_pass_rate = (fixed_tests['passed'] / fixed_tests['total']) * 100
all_tests_pass = fixed_tests.get('failed', 0) == 0
# Style scores
original_style = tool_context.state.get(StateKeys.STYLE_SCORE, 0)
fixed_style = tool_context.state.get(StateKeys.FIXED_STYLE_SCORE, 0)
# Calculate improvements
test_improvement = {
'original_pass_rate': original_pass_rate,
'fixed_pass_rate': fixed_pass_rate,
'improvement': fixed_pass_rate - original_pass_rate,
'all_tests_pass': all_tests_pass
}
style_improvement = {
'original_score': original_style,
'fixed_score': fixed_style,
'improvement': fixed_style - original_style,
'perfect_style': fixed_style == 100
}
# Determine overall status
if all_tests_pass and style_improvement['perfect_style']:
fix_status = 'SUCCESSFUL'
status_emoji = '✅'
elif test_improvement['improvement'] > 0 or style_improvement['improvement'] > 0:
fix_status = 'PARTIAL'
status_emoji = '⚠️'
else:
fix_status = 'FAILED'
status_emoji = '❌'
# Build comprehensive report
report = {
'status': fix_status,
'status_emoji': status_emoji,
'timestamp': datetime.now().isoformat(),
'original_code': original_code,
'code_fixes': code_fixes,
'improvements': {
'tests': test_improvement,
'style': style_improvement
},
'summary': f"{status_emoji} Fix Status: {fix_status}\n"
f"Tests: {original_pass_rate:.1f}% → {fixed_pass_rate:.1f}%\n"
f"Style: {original_style}/100 → {fixed_style}/100"
}
# Store report in state
tool_context.state[StateKeys.FIX_REPORT] = report
tool_context.state[StateKeys.FIX_STATUS] = fix_status
logger.info(f"Tool: Fix report compiled - Status: {fix_status}")
logger.info(f"Tool: Test improvement: {original_pass_rate:.1f}% → {fixed_pass_rate:.1f}%")
logger.info(f"Tool: Style improvement: {original_style} → {fixed_style}")
return {
"status": "success",
"fix_status": fix_status,
"report": report
}
except Exception as e:
logger.error(f"Tool: Failed to compile fix report: {e}", exc_info=True)
return {
"status": "error",
"message": str(e)
}
👉 Trova:
# MODULE_6_STEP_3_EXIT_FIX_LOOP
👉 Sostituisci con lo strumento 3 - Segnale di uscita dal loop:
def exit_fix_loop(tool_context: ToolContext) -> Dict[str, Any]:
"""
Signal that fixing is complete and should exit the loop.
Args:
tool_context: ADK tool context
Returns:
Confirmation message
"""
logger.info("Tool: Setting escalate flag to exit fix loop")
# This is the critical line that exits the LoopAgent
tool_context.actions.escalate = True
return {
"status": "success",
"message": "Fix complete, exiting loop"
}
Crea l'agente di convalida
👉 Apri
code_review_assistant/sub_agents/fix_pipeline/fix_validator.py
👉 Trova:
# MODULE_6_STEP_3_FIX_VALIDATOR_INSTRUCTION_PROVIDER
👉 Sostituisci quella singola riga con:
async def fix_validator_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are the final validation specialist for code fixes.
You have access to:
- Original issues from initial review
- Applied fixes: {code_fixes}
- Test results after fix: {fix_test_execution_summary}
- All state data from the fix process
Your responsibilities:
1. Use validate_fixed_style tool to check style compliance of fixed code
- Pass no arguments, it will retrieve fixed code from state
2. Use compile_fix_report tool to generate comprehensive report
- Pass no arguments, it will gather all data from state
3. Based on the report, determine overall fix status:
- ✅ SUCCESSFUL: All tests pass, style score 100
- ⚠️ PARTIAL: Improvements made but issues remain
- ❌ FAILED: Fix didn't work or made things worse
4. CRITICAL: If status is SUCCESSFUL, call the exit_fix_loop tool to stop iterations
- This prevents unnecessary additional fix attempts
- If not successful, the loop will continue for another attempt
5. Provide clear summary of:
- What was fixed
- What improvements were achieved
- Any remaining issues requiring manual attention
Be precise and quantitative in your assessment.
"""
return await instructions_utils.inject_session_state(template, context)
👉 Trova:
# MODULE_6_STEP_3_FIX_VALIDATOR_AGENT
👉 Sostituisci quella singola riga con:
fix_validator_agent = Agent(
name="FixValidator",
model=config.worker_model,
description="Validates fixes and generates final fix report",
instruction=fix_validator_instruction_provider,
tools=[
FunctionTool(func=validate_fixed_style),
FunctionTool(func=compile_fix_report),
FunctionTool(func=exit_fix_loop)
],
output_key="final_fix_report"
)
Passaggio 4: comprendere le condizioni di uscita di LoopAgent
Il LoopAgent può essere chiuso in tre modi:
1. Uscita riuscita (tramite riassegnazione)
# Inside any tool in the loop:
tool_context.actions.escalate = True
# Effect: Loop completes current iteration, then exits
# Use when: Fix is successful and no more attempts needed
Flusso di esempio:
Iteration 1:
CodeFixer → generates fixes
FixTestRunner → tests show 90% pass rate
FixValidator → compiles report, sees PARTIAL status
→ Does NOT set escalate
→ Loop continues
Iteration 2:
CodeFixer → refines fixes based on failures
FixTestRunner → tests show 100% pass rate
FixValidator → compiles report, sees SUCCESSFUL status
→ Calls exit_fix_loop() which sets escalate = True
→ Loop exits after this iteration
2. Uscita per numero massimo di iterazioni
LoopAgent(
name="FixAttemptLoop",
sub_agents=[...],
max_iterations=3 # Safety limit
)
# Effect: After 3 complete iterations, loop exits regardless of escalate
# Use when: Prevent infinite loops if fixes never succeed
Flusso di esempio:
Iteration 1: PARTIAL (continue)
Iteration 2: PARTIAL (continue)
Iteration 3: PARTIAL (but max reached)
→ Loop exits, synthesizer presents best attempt
3. Error Exit
# If any agent throws unhandled exception:
raise Exception("Unexpected error")
# Effect: Loop exits immediately with error state
# Use when: Critical failure that can't be recovered
Evoluzione dello stato nelle varie iterazioni:
Ogni iterazione mostra lo stato aggiornato del tentativo precedente:
# Before Iteration 1:
state = {
"code_to_review": "def add(a,b):return a+b", # Original
"style_score": 40,
"test_execution_summary": {...}
}
# After Iteration 1:
state = {
"code_to_review": "def add(a,b):return a+b", # Unchanged
"code_fixes": "def add(a, b):\n return a + b", # NEW
"style_score": 40, # Unchanged
"fixed_style_score": 100, # NEW
"test_execution_summary": {...}, # Unchanged
"fix_test_execution_summary": {...} # NEW
}
# Iteration 2 starts with all this state
# If fixes still not perfect, code_fixes gets overwritten
Perché
escalate
Invece di Valori restituiti:
# Bad: Using return value to signal exit
def validator_agent():
report = compile_report()
if report['status'] == 'SUCCESSFUL':
return {"exit": True} # How does loop know?
# Good: Using escalate
def validator_tool(tool_context):
report = compile_report()
if report['status'] == 'SUCCESSFUL':
tool_context.actions.escalate = True # Loop knows immediately
return {"report": report}
Vantaggi:
- Funziona da qualsiasi strumento, non solo dall'ultimo
- Non interferisce con i dati di reso
- Significato semantico chiaro
- Il framework gestisce la logica di uscita
Passaggio 5: collega la pipeline di correzione
👉 Apri
code_review_assistant/agent.py
👉 Aggiungi le importazioni della pipeline di correzione (dopo le importazioni esistenti):
from google.adk.agents import LoopAgent # Add this to the existing Agent, SequentialAgent line
from code_review_assistant.sub_agents.fix_pipeline.code_fixer import code_fixer_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_test_runner import fix_test_runner_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_validator import fix_validator_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_synthesizer import fix_synthesizer_agent
I tuoi importazioni ora dovrebbero essere:
from google.adk.agents import Agent, SequentialAgent, LoopAgent
from .config import config
# Review pipeline imports (from Module 5)
from code_review_assistant.sub_agents.review_pipeline.code_analyzer import code_analyzer_agent
from code_review_assistant.sub_agents.review_pipeline.style_checker import style_checker_agent
from code_review_assistant.sub_agents.review_pipeline.test_runner import test_runner_agent
from code_review_assistant.sub_agents.review_pipeline.feedback_synthesizer import feedback_synthesizer_agent
# Fix pipeline imports (NEW)
from code_review_assistant.sub_agents.fix_pipeline.code_fixer import code_fixer_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_test_runner import fix_test_runner_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_validator import fix_validator_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_synthesizer import fix_synthesizer_agent
👉 Trova:
# MODULE_6_STEP_5_CREATE_FIX_LOOP
👉 Sostituisci quella singola riga con:
# Create the fix attempt loop (retries up to 3 times)
fix_attempt_loop = LoopAgent(
name="FixAttemptLoop",
sub_agents=[
code_fixer_agent, # Step 1: Generate fixes
fix_test_runner_agent, # Step 2: Validate with tests
fix_validator_agent # Step 3: Check success & possibly exit
],
max_iterations=3 # Try up to 3 times
)
# Wrap loop with synthesizer for final report
code_fix_pipeline = SequentialAgent(
name="CodeFixPipeline",
description="Automated code fixing pipeline with iterative validation",
sub_agents=[
fix_attempt_loop, # Try to fix (1-3 times)
fix_synthesizer_agent # Present final results (always runs once)
]
)
👉 Rimuovi l'account esistente
root_agent
definizione:
root_agent = Agent(...)
👉 Trova:
# MODULE_6_STEP_5_UPDATE_ROOT_AGENT
👉 Sostituisci quella singola riga con:
# Update root agent to include both pipelines
root_agent = Agent(
name="CodeReviewAssistant",
model=config.worker_model,
description="An intelligent code review assistant that analyzes Python code and provides educational feedback",
instruction="""You are a specialized Python code review assistant focused on helping developers improve their code quality.
When a user provides Python code for review:
1. Immediately delegate to CodeReviewPipeline and pass the code EXACTLY as it was provided by the user.
2. The pipeline will handle all analysis and feedback
3. Return ONLY the final feedback from the pipeline - do not add any commentary
After completing a review, if significant issues were identified:
- If style score < 100 OR tests are failing OR critical issues exist:
* Add at the end: "\n\n💡 I can fix these issues for you. Would you like me to do that?"
- If the user responds yes or requests fixes:
* Delegate to CodeFixPipeline
* Return the fix pipeline's complete output AS-IS
When a user asks what you can do or general questions:
- Explain your capabilities for code review and fixing
- Do NOT trigger the pipeline for non-code messages
The pipelines handle everything for code review and fixing - just pass through their final output.""",
sub_agents=[code_review_pipeline, code_fix_pipeline],
output_key="assistant_response"
)
Passaggio 6: aggiungi l'agente di correzione del sintetizzatore
Il sintetizzatore crea una presentazione intuitiva dei risultati della correzione al termine del ciclo.
👉 Apri
code_review_assistant/sub_agents/fix_pipeline/fix_synthesizer.py
👉 Trova:
# MODULE_6_STEP_6_FIX_SYNTHESIZER_INSTRUCTION_PROVIDER
👉 Sostituisci quella singola riga con:
async def fix_synthesizer_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are responsible for presenting the fix results to the user.
Based on the validation report: {final_fix_report}
Fixed code from state: {code_fixes}
Fix status: {fix_status}
Create a comprehensive yet friendly response that includes:
## 🔧 Fix Summary
[Overall status and key improvements - be specific about what was achieved]
## 📊 Metrics
- Test Results: [original pass rate]% → [new pass rate]%
- Style Score: [original]/100 → [new]/100
- Issues Fixed: X of Y
## ✅ What Was Fixed
[List each fixed issue with brief explanation of the correction made]
## 📝 Complete Fixed Code
[Include the complete, corrected code from state - this is critical]
## 💡 Explanation of Key Changes
[Brief explanation of the most important changes made and why]
[If any issues remain]
## ⚠️ Remaining Issues
[List what still needs manual attention]
## 🎯 Next Steps
[Guidance on what to do next - either use the fixed code or address remaining issues]
Save the fix report using save_fix_report tool before presenting.
Call it with no parameters - it will retrieve the report from state automatically.
Be encouraging about improvements while being honest about any remaining issues.
Focus on the educational aspect - help the user understand what was wrong and how it was fixed.
"""
return await instructions_utils.inject_session_state(template, context)
👉 Trova:
# MODULE_6_STEP_6_FIX_SYNTHESIZER_AGENT
👉 Sostituisci quella singola riga con:
fix_synthesizer_agent = Agent(
name="FixSynthesizer",
model=config.critic_model,
description="Creates comprehensive user-friendly fix report",
instruction=fix_synthesizer_instruction_provider,
tools=[FunctionTool(func=save_fix_report)],
output_key="fix_summary"
)
👉 Aggiungi
save_fix_report
tool to
tools.py
:
👉 Trova:
# MODULE_6_STEP_6_SAVE_FIX_REPORT
👉 Sostituisci con:
async def save_fix_report(tool_context: ToolContext) -> Dict[str, Any]:
"""
Saves the fix report as an artifact.
Args:
tool_context: ADK tool context
Returns:
Save status
"""
logger.info("Tool: Saving fix report...")
try:
# Get the report from state
fix_report = tool_context.state.get(StateKeys.FIX_REPORT, {})
if not fix_report:
return {
"status": "error",
"message": "No fix report found in state"
}
# Convert to JSON
report_json = json.dumps(fix_report, indent=2)
report_part = types.Part.from_text(text=report_json)
# Generate filename
timestamp = datetime.now().isoformat().replace(':', '-')
filename = f"fix_report_{timestamp}.json"
# Try to save as artifact
if hasattr(tool_context, 'save_artifact'):
try:
version = await tool_context.save_artifact(filename, report_part)
await tool_context.save_artifact("latest_fix_report.json", report_part)
logger.info(f"Tool: Fix report saved as {filename}")
return {
"status": "success",
"filename": filename,
"version": str(version),
"size": len(report_json)
}
except Exception as e:
logger.warning(f"Could not save as artifact: {e}")
# Fallback: store in state
tool_context.state[StateKeys.LAST_FIX_REPORT] = fix_report
return {
"status": "success",
"message": "Fix report saved to state",
"size": len(report_json)
}
except Exception as e:
logger.error(f"Tool: Failed to save fix report: {e}", exc_info=True)
return {
"status": "error",
"message": str(e)
}
Passaggio 7: testa la pipeline di correzione completa
È il momento di vedere l'intero loop in azione.
👉 Avvia il sistema:
adk web code_review_assistant
Dopo aver eseguito il comando adk web, dovresti visualizzare un output nel terminale che indica che il server web ADK è stato avviato, simile a questo:
+-----------------------------------------------------------------------------+
| ADK Web Server started |
| |
| For local testing, access at http://localhost:8000. |
+-----------------------------------------------------------------------------+
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
👉 Prompt di test:
Please analyze the following:
def dfs_search_v1(graph, start, target):
"""Find if target is reachable from start."""
visited = set()
stack = start
while stack:
current = stack.pop()
if current == target:
return True
if current not in visited:
visited.add(current)
for neighbor in graph[current]:
if neighbor not in visited:
stack.append(neighbor)
return False
Innanzitutto, invia il codice con bug per attivare la pipeline di revisione. Dopo aver identificato i difetti, chiedi all'agente di "Correggi il codice", il che attiva la potente pipeline di correzione iterativa.
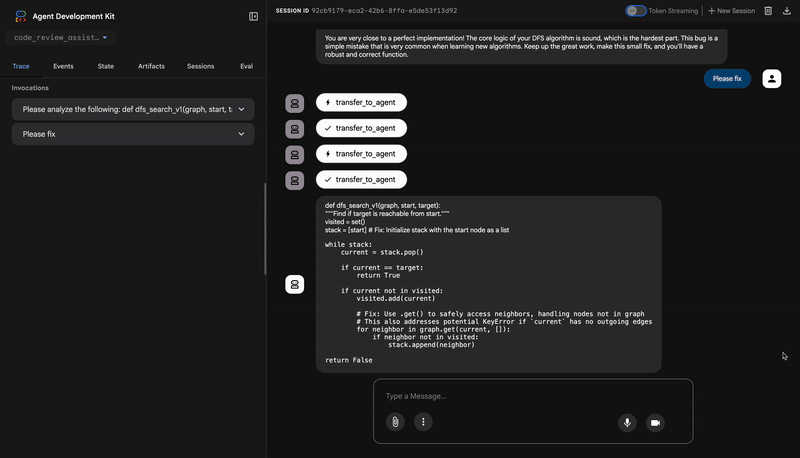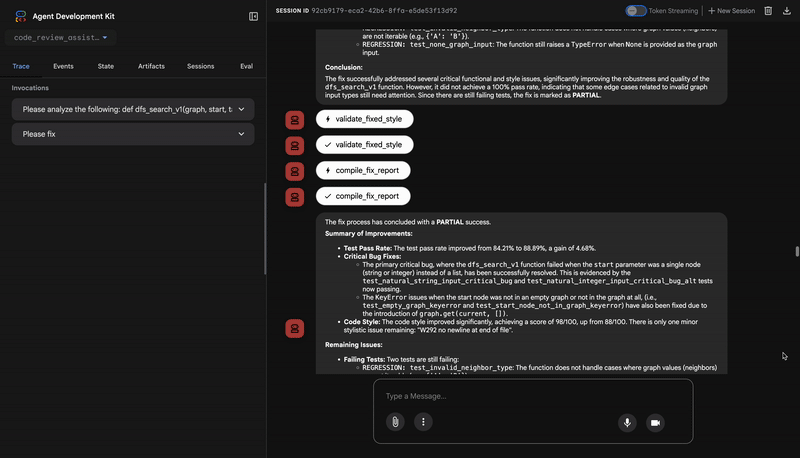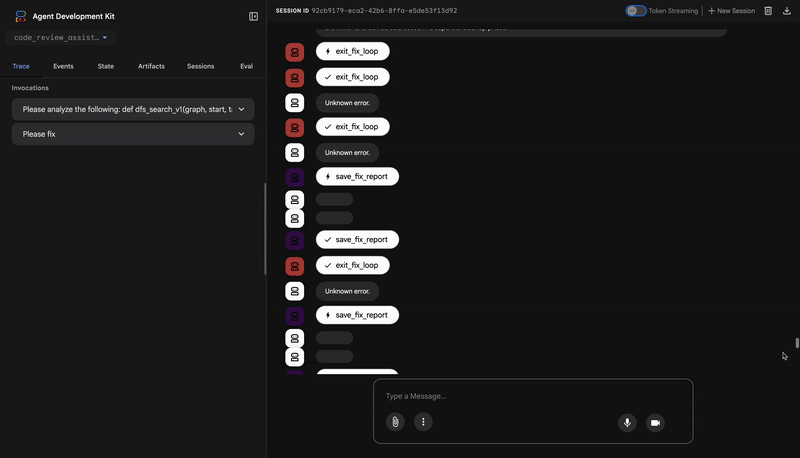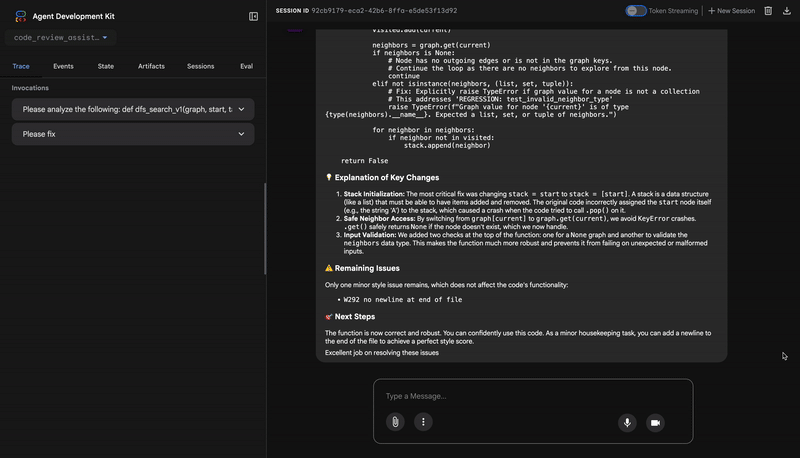
1. Revisione iniziale (individuazione dei difetti)
Questa è la prima metà della procedura. La pipeline di revisione a quattro agenti analizza il codice, ne controlla lo stile ed esegue una suite di test generata. Identifica correttamente un AttributeError critico e altri problemi, fornendo un verdetto: il codice è DANNEGGIATO, con un tasso di superamento del test di solo 84,21%.
2. La correzione automatica (il ciclo in azione)
Questa è la parte più impressionante. Quando chiedi all'agente di correggere il codice, non viene apportata una sola modifica. Avvia un ciclo di correzione e convalida iterativo che funziona proprio come uno sviluppatore diligente: prova una correzione, la testa a fondo e, se non è perfetta, riprova.
Iterazione n. 1: il primo tentativo (successo parziale)
- La soluzione:l'agente
CodeFixerlegge la segnalazione iniziale e apporta le correzioni più evidenti. Modificastack = startinstack = [start]e utilizzagraph.get()per evitare eccezioniKeyError. - La convalida:
TestRunneresegue nuovamente l'intera suite di test su questo nuovo codice. - Il risultato: il tasso di superamento migliora notevolmente fino all'88,89%. I bug critici sono stati risolti. Tuttavia, i test sono così completi che rivelano due nuovi bug sottili (regressioni) relativi alla gestione di
Nonecome valori vicini di grafici o non di elenchi. Il sistema contrassegna la correzione come PARZIALE.
Iterazione n. 2: la rifinitura finale (100% di successo)
- La correzione:poiché la condizione di uscita del ciclo (tasso di superamento del 100%) non è stata soddisfatta, il ciclo viene eseguito di nuovo. Il
CodeFixerora contiene più informazioni: i due nuovi errori di regressione. Genera una versione finale e più solida del codice che gestisce esplicitamente questi casi limite. - La convalida:
TestRunneresegue la suite di test un'ultima volta rispetto alla versione finale del codice. - Il risultato:un perfetto tasso di superamento del 100% . Tutti i bug originali e tutte le regressioni sono stati risolti. Il sistema contrassegna la correzione come RIUSCITA e il ciclo termina.
3. Il report finale: un punteggio perfetto
Con una correzione completamente convalidata, l'agente FixSynthesizer prende il controllo per presentare il report finale, trasformando i dati tecnici in un riepilogo chiaro ed esaustivo.
Metrica | Prima | Dopo | Miglioramento |
Tasso di superamento del test | 84,21% | 100% | ▲ 15,79% |
Punteggio di stile | 88 / 100 | 98 / 100 | ▲ 10 punti |
Bug corretti | 0 di 3 | 3 di 3 | ✅ |
✅ Il codice finale convalidato
Ecco il codice completo e corretto che ora supera tutti i 19 test, a dimostrazione della correzione riuscita:
def dfs_search_v1(graph, start, target):
"""Find if target is reachable from start."""
# Handles 'None' graph input
if graph is None:
return False
visited = set()
# Fixes the critical AttributeError
stack = [start]
while stack:
current = stack.pop()
if current == target:
return True
if current not in visited:
visited.add(current)
# Safely gets neighbors to prevent KeyError
neighbors = graph.get(current)
if neighbors is None:
continue
# Validates that neighbors are iterable
if not isinstance(neighbors, (list, set, tuple)):
raise TypeError(
f"Graph value for node '{current}' is of type "
f"{type(neighbors).__name__}. Expected a list, set, or tuple."
)
for neighbor in neighbors:
if neighbor not in visited:
stack.append(neighbor)
return False
👉💻 Al termine del test, torna al terminale dell'editor di Cloud Shell e premi Ctrl+C per arrestare l'interfaccia utente di ADK Dev.
Cosa hai creato
Ora hai una pipeline di correzione automatica completa che:
✅ Genera correzioni: in base all'analisi della revisione
✅ Esegue la convalida in modo iterativo: esegue test dopo ogni tentativo di correzione
✅ Esegue nuovi tentativi automaticamente: fino a tre tentativi per la riuscita
✅ Esce in modo intelligente: tramite escalation in caso di esito positivo
✅ Monitora i miglioramenti: confronta le metriche prima e dopo
✅ Fornisce artefatti: report sulle correzioni scaricabili
Concetti fondamentali padroneggiati
LoopAgent vs Sequential:
- Sequenziale: un passaggio tra gli agenti
- LoopAgent: si ripete fino alla condizione di uscita o al numero massimo di iterazioni
- Esci da
tool_context.actions.escalate = True
Evoluzione dello stato nelle varie iterazioni:
CODE_FIXESaggiornato a ogni iterazione- I risultati dei test mostrano un miglioramento nel tempo
- Il validatore vede le modifiche cumulative
Architettura multi-pipeline:
- Pipeline di revisione: analisi di sola lettura (modulo 5)
- Correzione del ciclo: correzione iterativa (ciclo interno del modulo 6)
- Fix pipeline: Loop + synthesizer (Module 6 outer)
- Agente principale: coordina in base all'intento dell'utente
Strumenti di controllo del flusso:
exit_fix_loop()set escalate- Qualsiasi strumento può segnalare il completamento del ciclo
- Disaccoppia la logica di uscita dalle istruzioni dell'agente
Sicurezza del numero massimo di iterazioni:
- Evita i loop infiniti
- Garantisce che il sistema risponda sempre
- Presenta il miglior tentativo anche se non è perfetto
Passaggi successivi
Nel modulo finale, imparerai a eseguire il deployment dell'agente in produzione:
- Configurazione dell'archiviazione permanente con VertexAiSessionService
- Deployment su Agent Engine su Google Cloud
- Monitoraggio e debug degli agenti di produzione
- Best practice per scalabilità e affidabilità
Hai creato un sistema multi-agente completo con architetture sequenziali e a ciclo. I pattern che hai appreso (gestione dello stato, istruzioni dinamiche, orchestrazione degli strumenti e perfezionamento iterativo) sono tecniche pronte per la produzione utilizzate in sistemi agentici reali.
7. Esegui il deployment in produzione
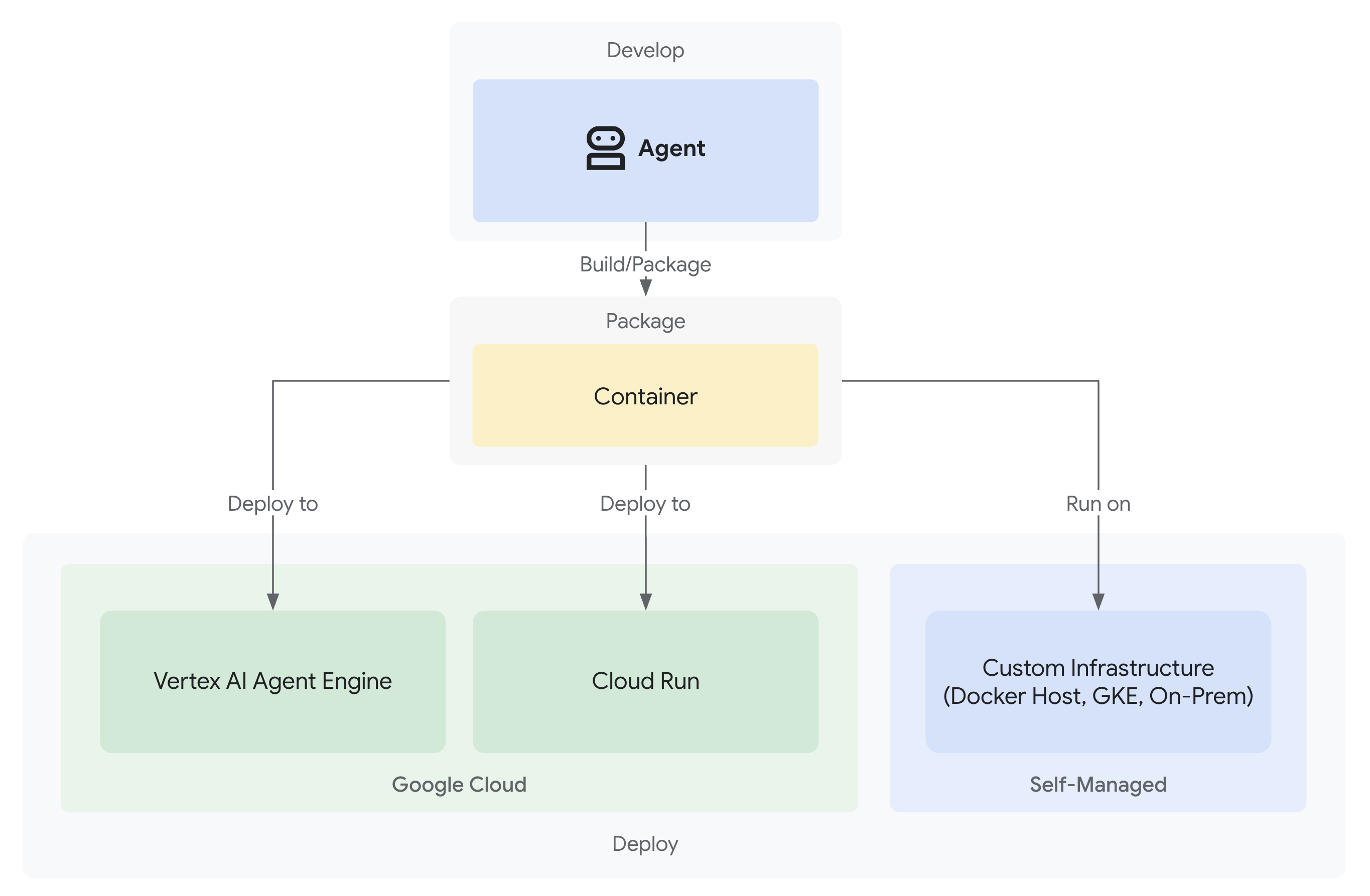
Introduzione
L'assistente per la revisione del codice è ora completo e le pipeline di revisione e correzione funzionano in locale. Il pezzo mancante: funziona solo sulla tua macchina. In questo modulo, eseguirai il deployment dell'agente su Google Cloud, rendendolo accessibile al tuo team con sessioni persistenti e un'infrastruttura di livello di produzione.
Obiettivi didattici:
- Tre percorsi di deployment: locale, Cloud Run e Agent Engine
- Provisioning automatizzato dell'infrastruttura
- Strategie di persistenza della sessione
- Test degli agenti di cui è stato eseguito il deployment
Informazioni sulle opzioni di deployment
L'ADK supporta più destinazioni di deployment, ognuna con compromessi diversi:
Percorsi di deployment
Fattore | Attività locali ( | Cloud Run ( | Motore agente ( |
complessità | Minimo | Media | Bassa |
Persistenza della sessione | Solo in memoria (perso al riavvio) | Cloud SQL (PostgreSQL) | Gestito da Vertex AI (automatico) |
Infrastruttura | Nessuno (solo macchina di sviluppo) | Container + Database | Completamente gestito |
Avvio a freddo | N/D | 100-2000ms | 100-500ms |
Scalabilità | Istanza singola | Automatico (a zero) | Automatico |
Modello di costo | Free (elaborazione locale) | Basata sulle richieste + livello senza costi | Basate su calcolo |
Supporto UI | Sì (tramite | Sì (tramite | No (solo API) |
Ideale per | Sviluppo/test | Traffico variabile, controllo dei costi | Agenti di produzione |
Opzione di deployment aggiuntiva:Google Kubernetes Engine (GKE) è disponibile per gli utenti avanzati che richiedono il controllo a livello di Kubernetes, il networking personalizzato o l'orchestrazione multiservizio. Il deployment di GKE non è trattato in questo codelab, ma è documentato nella guida al deployment dell'ADK.
Elementi di cui viene eseguito il deployment
Quando esegui il deployment in Cloud Run o Agent Engine, vengono pacchettizzati ed eseguiti i seguenti elementi:
- Il tuo codice agente (
agent.py, tutti i subagenti, strumenti) - Dipendenze (
requirements.txt) - Server API ADK (incluso automaticamente)
- UI web (solo Cloud Run, quando è specificato
--with_ui)
Differenze importanti:
- Cloud Run: utilizza l'interfaccia a riga di comando
adk deploy cloud_run(crea automaticamente il container) ogcloud run deploy(richiede Dockerfile personalizzato) - Agent Engine: utilizza la CLI
adk deploy agent_engine(non è necessaria la creazione di container, il codice Python viene pacchettizzato direttamente)
Passaggio 1: configura l'ambiente
Configura il file .env
Il file .env (creato nel modulo 3) deve essere aggiornato per il deployment sul cloud. Apri .env e verifica/aggiorna queste impostazioni:
Obbligatorio per tutti i deployment cloud:
# Your actual GCP Project ID (REQUIRED)
GOOGLE_CLOUD_PROJECT=your-project-id
# GCP region for deployments (REQUIRED)
GOOGLE_CLOUD_LOCATION=us-central1
# Use Vertex AI (REQUIRED)
GOOGLE_GENAI_USE_VERTEXAI=true
# Model configuration (already set)
WORKER_MODEL=gemini-2.5-flash
CRITIC_MODEL=gemini-2.5-pro
Imposta i nomi dei bucket (OBBLIGATORIO prima di eseguire deploy.sh):
Lo script di deployment crea bucket in base a questi nomi. Impostali ora:
# Staging bucket for Agent Engine code uploads (REQUIRED for agent-engine)
STAGING_BUCKET=gs://your-project-id-staging
# Artifact storage for reports and fixed code (REQUIRED for both cloud-run and agent-engine)
ARTIFACT_BUCKET=gs://your-project-id-artifacts
Sostituisci your-project-id con l'ID progetto effettivo in entrambi i nomi dei bucket. Lo script creerà questi bucket se non esistono.
Variabili facoltative (create automaticamente se vuote):
# Agent Engine ID (populated after first deployment)
AGENT_ENGINE_ID=
# Cloud Run Database credentials (created automatically if blank)
CLOUD_SQL_INSTANCE_NAME=
DB_USER=
DB_PASSWORD=
DB_NAME=
Controllo autenticazione
Se riscontri errori di autenticazione durante il deployment:
gcloud auth application-default login
gcloud config set project $GOOGLE_CLOUD_PROJECT
Passaggio 2: comprendi lo script di deployment
Lo script deploy.sh fornisce un'interfaccia unificata per tutte le modalità di deployment:
./deploy.sh {local|cloud-run|agent-engine}
Funzionalità degli script
Provisioning dell'infrastruttura:
- Abilitazione delle API (AI Platform, Storage, Cloud Build, Cloud Trace, Cloud SQL)
- Configurazione delle autorizzazioni IAM (service account, ruoli)
- Creazione di risorse (bucket, database, istanze)
- Deployment con flag appropriati
- Verifica post-deployment
Sezioni chiave del copione
- Configurazione (righe 1-35): progetto, regione, nomi dei servizi, valori predefiniti
- Funzioni helper (righe 37-200): attivazione dell'API, creazione di bucket, configurazione di IAM
- Main Logic (righe 202-400): orchestrazione del deployment specifica per la modalità
Passaggio 3: prepara l'agente per Agent Engine
Prima del deployment in Agent Engine, è necessario un file agent_engine_app.py che esegua il wrapping dell'agente per il runtime gestito. È già stato creato per te.
Visualizza code_review_assistant/agent_engine_app.py
👉 Apri file:
"""
Agent Engine application wrapper.
This file prepares the agent for deployment to Vertex AI Agent Engine.
"""
from vertexai import agent_engines
from .agent import root_agent
# Wrap the agent in an AdkApp object for Agent Engine deployment
app = agent_engines.AdkApp(
agent=root_agent,
enable_tracing=True,
)
Passaggio 4: esegui il deployment in Agent Engine
Agent Engine è il deployment di produzione consigliato per gli agenti ADK perché fornisce:
- Infrastruttura completamente gestita (nessun container da creare)
- Persistenza della sessione integrata tramite
VertexAiSessionService - Scalabilità automatica da zero
- Integrazione di Cloud Trace abilitata per impostazione predefinita
In che modo Agent Engine si differenzia dagli altri deployment
Dietro le quinte,
deploy.sh agent-engine
utilizzi:
adk deploy agent_engine \
--project=$GOOGLE_CLOUD_PROJECT \
--region=$GOOGLE_CLOUD_LOCATION \
--staging_bucket=$STAGING_BUCKET \
--display_name="Code Review Assistant" \
--trace_to_cloud \
code_review_assistant
Questo comando:
- Pacchettizza direttamente il codice Python (senza build Docker)
- Caricamenti nel bucket di staging specificato in
.env - Crea un'istanza di Agent Engine gestita
- Abilita Cloud Trace per l'osservabilità
- Utilizza
agent_engine_app.pyper configurare il runtime
A differenza di Cloud Run, che inserisce il codice in un container, Agent Engine esegue il codice Python direttamente in un ambiente di runtime gestito, in modo simile alle funzioni serverless.
Esegui il deployment
Dalla radice del progetto:
./deploy.sh agent-engine
Fasi di deployment
Guarda lo script eseguire queste fasi:
Phase 1: API Enablement
✓ aiplatform.googleapis.com
✓ storage-api.googleapis.com
✓ cloudbuild.googleapis.com
✓ cloudtrace.googleapis.com
Phase 2: IAM Setup
✓ Getting project number
✓ Granting Storage Object Admin
✓ Granting AI Platform User
✓ Granting Cloud Trace Agent
Phase 3: Staging Bucket
✓ Creating gs://your-project-id-staging
✓ Setting permissions
Phase 4: Artifact Bucket
✓ Creating gs://your-project-id-artifacts
✓ Configuring access
Phase 5: Validation
✓ Checking agent.py exists
✓ Verifying root_agent defined
✓ Checking agent_engine_app.py exists
✓ Validating requirements.txt
Phase 6: Build & Deploy
✓ Packaging agent code
✓ Uploading to staging bucket
✓ Creating Agent Engine instance
✓ Configuring session persistence
✓ Setting up Cloud Trace integration
✓ Running health checks
Questo processo richiede 5-10 minuti perché il pacchetto dell'agente viene creato e di cui viene eseguito il deployment nell'infrastruttura Vertex AI.
Salvare l'ID motore dell'agente
Al termine del deployment:
✅ Deployment successful!
Agent Engine ID: 7917477678498709504
Resource Name: projects/123456789/locations/us-central1/reasoningEngines/7917477678498709504
Endpoint: https://us-central1-aiplatform.googleapis.com/v1/...
⚠️ IMPORTANT: Save this in your .env file:
AGENT_ENGINE_ID=7917477678498709504
Aggiorna il tuo
.env
immediatamente:
echo "AGENT_ENGINE_ID=7917477678498709504" >> .env
Questo ID è obbligatorio per:
- Test dell'agente di cui è stato eseguito il deployment
- Aggiornamento del deployment in un secondo momento
- Accesso a log e tracce
Elementi di cui è stato eseguito il deployment
Il deployment di Agent Engine ora include:
✅ Pipeline di revisione completa (4 agenti)
✅ Pipeline di correzione completa (loop + sintetizzatore)
✅ Tutti gli strumenti (analisi AST, controllo dello stile, generazione di artefatti)
✅ Persistenza della sessione (automatica tramite VertexAiSessionService)
✅ Gestione dello stato (livelli di sessione/utente/durata)
✅ Osservabilità (Cloud Trace abilitato)
✅ Infrastruttura di scalabilità automatica
Passaggio 5: testa l'agente di cui è stato eseguito il deployment
Aggiorna il file .env
Dopo il deployment, verifica che .env includa:
AGENT_ENGINE_ID=7917477678498709504 # From deployment output
GOOGLE_CLOUD_PROJECT=your-project-id
GOOGLE_CLOUD_LOCATION=us-central1
Esegui lo script per il test
Il progetto include tests/test_agent_engine.py specificamente per testare le implementazioni di Agent Engine:
python tests/test_agent_engine.py
Cosa fa il test
- Esegue l'autenticazione con il tuo progetto Google Cloud
- Crea una sessione con l'agente di cui è stato eseguito il deployment
- Invia una richiesta di revisione del codice (l'esempio di bug DFS)
- Trasmette in streaming la risposta tramite Server-Sent Events (SSE)
- Verifica la persistenza della sessione e la gestione dello stato
Risultato previsto
Authenticated with project: your-project-id
Targeting Agent Engine: projects/.../reasoningEngines/7917477678498709504
Creating new session...
Created session: 4857885913439920384
Sending query to agent and streaming response:
data: {"content": {"parts": [{"text": "I'll analyze your code..."}]}}
data: {"content": {"parts": [{"text": "**Code Structure Analysis**\n..."}]}}
data: {"content": {"parts": [{"text": "**Style Check Results**\n..."}]}}
data: {"content": {"parts": [{"text": "**Test Results**\n..."}]}}
data: {"content": {"parts": [{"text": "**Final Feedback**\n..."}]}}
Stream finished.
Elenco di controllo per la verifica
- ✅ Viene eseguita la pipeline di revisione completa (tutti e 4 gli agenti)
- ✅ La risposta in streaming mostra l'output progressivo
- ✅ Lo stato della sessione viene mantenuto tra le richieste
- ✅ Nessun errore di autenticazione o connessione
- ✅ Le chiamate agli strumenti vengono eseguite correttamente (analisi AST, controllo dello stile)
- ✅ Gli artefatti vengono salvati (report di valutazione accessibile)
Alternativa: esegui il deployment in Cloud Run
Anche se Agent Engine è consigliato per un deployment di produzione semplificato, Cloud Run offre un maggiore controllo e supporta la GUI web dell'ADK. Questa sezione fornisce una panoramica.
Quando utilizzare Cloud Run
Scegli Cloud Run se hai bisogno di:
- L'interfaccia utente web dell'ADK per l'interazione utente
- Controllo completo sull'ambiente dei container
- Configurazioni personalizzate del database
- Integrazione con i servizi Cloud Run esistenti
Come funziona il deployment di Cloud Run
Dietro le quinte,
deploy.sh cloud-run
utilizzi:
adk deploy cloud_run \
--project=$GOOGLE_CLOUD_PROJECT \
--region=$GOOGLE_CLOUD_LOCATION \
--service_name="code-review-assistant" \
--app_name="code_review_assistant" \
--port=8080 \
--with_ui \
--artifact_service_uri="gs://$ARTIFACT_BUCKET" \
--trace_to_cloud \
code_review_assistant
Questo comando:
- Crea un container Docker con il codice dell'agente
- Push in Google Artifact Registry
- Esegue il deployment come servizio Cloud Run
- Include l'interfaccia utente web di ADK (
--with_ui) - Configura la connessione Cloud SQL (aggiunta dallo script dopo il deployment iniziale)
La differenza principale rispetto ad Agent Engine è che Cloud Run inserisce il codice in un container e richiede un database per la persistenza della sessione, mentre Agent Engine gestisce entrambi automaticamente.
Comando di deployment di Cloud Run
./deploy.sh cloud-run
Differenze
Infrastruttura:
- Deployment containerizzato (Docker creato automaticamente da ADK)
- Cloud SQL (PostgreSQL) per la persistenza della sessione
- Database creato automaticamente dallo script o che utilizza un'istanza esistente
Gestione delle sessioni:
- Utilizza
DatabaseSessionServiceinvece diVertexAiSessionService - Richiede le credenziali del database in
.env(o generate automaticamente) - Lo stato viene mantenuto nel database PostgreSQL
Supporto dell'interfaccia utente:
- Interfaccia utente web disponibile tramite il flag
--with_ui(gestito dallo script) - Accesso all'indirizzo:
https://code-review-assistant-xyz.a.run.app
Cosa hai ottenuto
Il deployment di produzione include:
✅ Provisioning automatizzato tramite deploy.shscript
✅ Infrastruttura gestita (Agent Engine gestisce scalabilità, persistenza e monitoraggio)
✅ Stato persistente in tutti i livelli di memoria (sessione/utente/durata)
✅ Gestione sicura delle credenziali (generazione automatica e configurazione IAM)
✅ Architettura scalabile (da zero a migliaia di utenti simultanei)
✅ Osservabilità integrata (integrazione di Cloud Trace attivata)
✅ Gestione degli errori e recupero di livello di produzione
Concetti fondamentali padroneggiati
Preparazione dell'implementazione:
agent_engine_app.py: esegue il wrapping dell'agente conAdkAppper il motore agenteAdkAppconfigura automaticamenteVertexAiSessionServiceper la persistenza- Tracciamento attivato tramite
enable_tracing=True
Comandi di deployment:
adk deploy agent_engine: pacchetti di codice Python, nessun containeradk deploy cloud_run: crea automaticamente il container Dockergcloud run deploy: alternativa con Dockerfile personalizzato
Opzioni di deployment:
- Agent Engine: completamente gestito, il più veloce per la produzione
- Cloud Run: maggiore controllo, supporta l'interfaccia utente web
- GKE: controllo avanzato di Kubernetes (consulta la guida al deployment di GKE)
Servizi gestiti:
- Agent Engine gestisce automaticamente la persistenza della sessione
- Cloud Run richiede la configurazione del database (o la creazione automatica)
- Entrambi supportano l'archiviazione degli artefatti tramite GCS
Gestione delle sessioni:
- Motore agente:
VertexAiSessionService(automatico) - Cloud Run:
DatabaseSessionService(Cloud SQL) - Locale:
InMemorySessionService(temporaneo)
Il tuo agente è attivo
Il tuo assistente per la revisione del codice ora è:
- Accessibile tramite endpoint API HTTPS
- Persistent, con lo stato che sopravvive ai riavvii
- Scalabile per gestire automaticamente la crescita del team
- Osservabile con tracce di richieste complete
- Gestibile tramite deployment basati su script
Passaggi successivi Nel modulo 8 imparerai a utilizzare Cloud Trace per comprendere il rendimento del tuo agente, identificare i colli di bottiglia nelle pipeline di revisione e correzione e ottimizzare i tempi di esecuzione.
8. Osservabilità della produzione
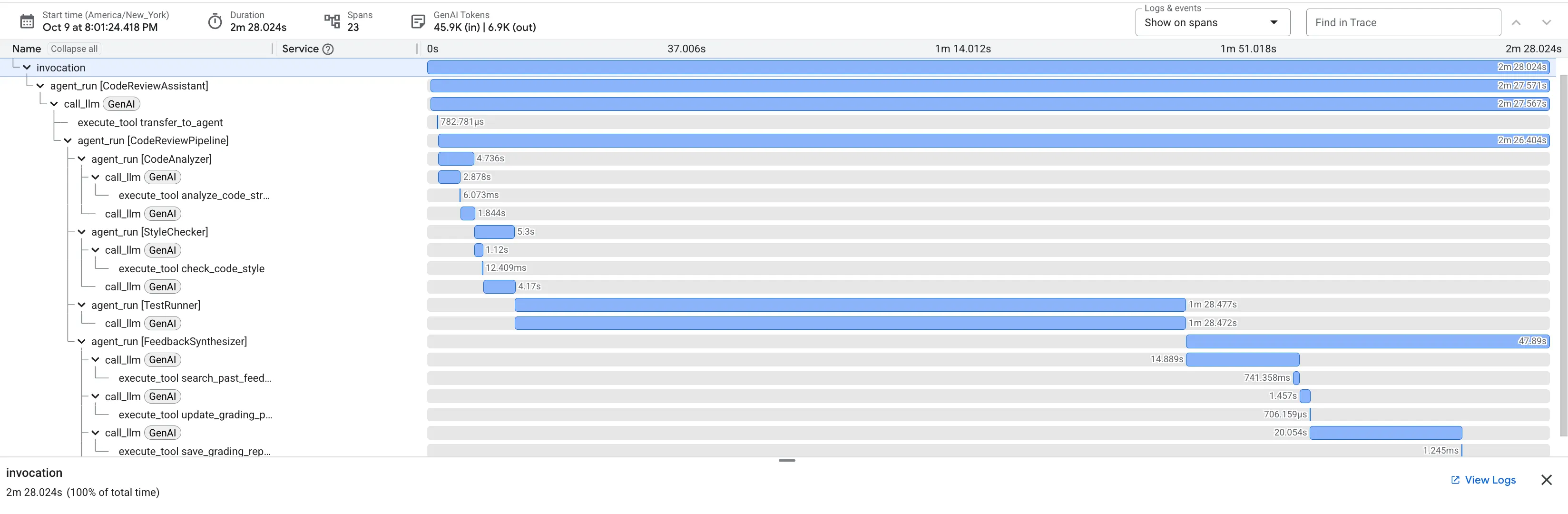
Introduzione
L'assistente per la revisione del codice è ora implementato e in esecuzione in produzione su Agent Engine. Ma come fai a sapere se funziona bene? Riesci a rispondere a queste domande fondamentali:
- L'agente risponde abbastanza rapidamente?
- Quali operazioni sono più lente?
- I cicli di correzione vengono completati in modo efficiente?
- Dove si trovano i colli di bottiglia delle prestazioni?
Senza l'osservabilità, non puoi fare nulla. Il flag --trace-to-cloud che hai utilizzato durante il deployment ha attivato automaticamente Cloud Trace, offrendoti una visibilità completa su ogni richiesta elaborata dal tuo agente. In questo modo, il debug passa da una procedura basata su ipotesi a un'analisi forense.
In questo modulo imparerai a leggere le tracce, a comprendere le caratteristiche di rendimento del tuo agente e a identificare le aree di ottimizzazione in base a prove concrete.
Informazioni su tracce e intervalli
Che cos'è una traccia?
Una traccia è la cronologia completa della gestione di una singola richiesta da parte dell'agente. Acquisisce tutto ciò che accade dall'invio di una query da parte di un utente fino alla ricezione della risposta finale. Ogni traccia mostra:
- Durata totale della richiesta
- Tutte le operazioni eseguite
- Come si relazionano tra loro le operazioni (relazioni padre-figlio)
- Quando è iniziata e terminata ogni operazione
Che cos'è uno span?
Uno span rappresenta una singola unità di lavoro all'interno di una traccia. Tipi di intervallo comuni nell'assistente per la revisione del codice:
agent_run: esecuzione di un agente (agente root o sub-agente)call_llm: Richiesta a un modello linguisticoexecute_tool: Esecuzione della funzione dello strumentostate_read/state_write: operazioni di gestione dello statocode_executor: Esecuzione del codice con i test
Gli intervalli hanno:
- Nome: l'operazione che rappresenta
- Durata: il tempo impiegato
- Attributi: metadati come nome del modello, conteggi dei token, input/output
- Stato: operazione riuscita o non riuscita
- Relazioni principale/secondario: quali operazioni hanno attivato quali
Strumentazione automatica
Quando esegui il deployment con --trace-to-cloud, ADK strumenta automaticamente:
- Ogni chiamata di un agente e di un subagente
- Tutte le richieste LLM con conteggi dei token
- Esecuzioni dello strumento con input/output
- Operazioni di stato (lettura/scrittura)
- Iterazioni del ciclo nella pipeline di correzione
- Condizioni di errore e tentativi
Non sono necessarie modifiche al codice: la tracciabilità è integrata nel runtime dell'ADK.
Passaggio 1: accedi a Cloud Trace Explorer
Apri Cloud Trace nella console Google Cloud:
- Vai a Cloud Trace Explorer.
- Seleziona il progetto dal menu a discesa (dovrebbe essere preselezionato).
- Dovresti vedere le tracce del test nel modulo 7.
Se non vedi ancora le tracce:
Il test eseguito nel modulo 7 dovrebbe aver generato tracce. Se l'elenco è vuoto, genera alcuni dati di traccia:
python tests/test_agent_engine.py
Attendi 1-2 minuti affinché le tracce vengano visualizzate nella console.
Cosa stai guardando
Esplora tracce mostra:
- Elenco delle tracce: ogni riga rappresenta una richiesta completa
- Cronologia: quando si sono verificate le richieste
- Durata: la durata di ogni richiesta
- Dettagli della richiesta: timestamp, latenza, numero di intervalli
Questo è il log del traffico di produzione: ogni interazione con l'agente crea una traccia.
Passaggio 2: esamina una traccia della pipeline di revisione
Fai clic su una traccia nell'elenco per aprire la visualizzazione a cascata.
Verrà visualizzato un grafico di Gantt che mostra la cronologia di esecuzione completa. Lo span principale invocation rappresenta l'intera richiesta. Sotto sono presenti gli intervalli per ogni chiamata di sub-agente, strumento e LLM.
Leggere la cascata: identificare i colli di bottiglia
Ogni barra rappresenta un intervallo. La sua posizione orizzontale indica quando è iniziato, mentre la sua lunghezza indica la durata. In questo modo, puoi capire immediatamente dove l'agente sta impiegando il suo tempo.
Approfondimenti chiave dalla traccia precedente:
- Latenza totale: l'intera richiesta ha richiesto 2 minuti e 28 secondi.
- Suddivisione dei subagenti:
Code Analyzer: 4,7 secondiStyle Checker: 5,3 secondiTest Runner: 1 minuto e 28 secondiFeedback Synthesizer: 47,9 secondi
- Analisi del percorso critico: l'agente
Test Runnerè il chiaro collo di bottiglia delle prestazioni, in quanto rappresenta circa il 59% del tempo totale della richiesta.
Questa visibilità è potente. Anziché fare ipotesi su dove viene impiegato il tempo, hai la prova concreta che, se devi ottimizzare la latenza, Test Runner è il target ovvio.
Esaminare l'utilizzo dei token per l'ottimizzazione dei costi
Cloud Trace non mostra solo il tempo, ma rivela anche i costi acquisendo l'utilizzo dei token per ogni chiamata LLM.
Fai clic su un
call_llm
intervallo all'interno della traccia. Nel riquadro dei dettagli, troverai gli attributi per llm.usage.prompt_tokens e llm.usage.completion_tokens.

In questo modo, puoi:
- Monitora i costi a un livello granulare: scopri esattamente quanti token consumano ogni agente e strumento.
- Identifica le opportunità di ottimizzazione: se un agente utilizza un numero sorprendentemente elevato di token, potrebbe essere l'occasione per perfezionare il prompt o passare a un modello più piccolo ed economico per quella specifica attività.
Passaggio 3: analizza una traccia della pipeline di correzione
La pipeline di correzione è più complessa perché include un LoopAgent. Cloud Trace semplifica la comprensione di questo comportamento iterativo.
Trova una traccia che includa "FixAttemptLoop" nei nomi degli intervalli.
Se non ne hai uno, esegui lo script per il test e rispondi in modo affermativo quando ti viene chiesto se vuoi correggere il codice.
Esaminare la struttura del ciclo
La visualizzazione della traccia mostra chiaramente l'esecuzione del ciclo. Se il ciclo di correzione è stato eseguito due volte prima di riuscire, vedrai due intervalli loop_iteration nidificati nell'intervallo FixAttemptLoop, ognuno contenente un ciclo completo degli agenti CodeFixer, FixTestRunner e FixValidator.

Osservazioni chiave della traccia del ciclo:
- Raffinamento iterativo visibile: puoi vedere il sistema tentare una correzione in
loop_iteration: 1, convalidarla e poi, poiché non era perfetta, riprovare inloop_iteration: 2. - La convergenza è misurabile: puoi confrontare la durata e i risultati di ogni iterazione per capire come il sistema è convergente verso una soluzione corretta.
- Debug semplificato: se un ciclo viene eseguito per il numero massimo di iterazioni e continua a non riuscire, puoi esaminare lo stato e il comportamento dell'agente all'interno dell'intervallo di ogni iterazione per diagnosticare il motivo per cui le correzioni non convergono.
Questo livello di dettaglio è prezioso per comprendere ed eseguire il debug del comportamento di loop complessi e stateful in produzione.
Passaggio 4: cosa hai scoperto
Modelli di rendimento
Dall'esame delle tracce, ora hai informazioni basate sui dati:
Pipeline di revisione:
- Collo di bottiglia principale: l'agente
Test Runner, in particolare l'esecuzione del codice e la generazione di test basati su LLM, è la parte più dispendiosa in termini di tempo della revisione. - Operazioni rapide: gli strumenti deterministici (
analyze_code_structure) e le operazioni di gestione dello stato sono estremamente veloci e non rappresentano un problema di prestazioni.
Pipeline di correzione:
- Tasso di convergenza: puoi notare che la maggior parte delle correzioni viene completata in 1-2 iterazioni, il che conferma l'efficacia dell'architettura del ciclo.
- Costo progressivo: le iterazioni successive potrebbero richiedere più tempo man mano che il contesto dell'LLM cresce con le informazioni dei tentativi precedenti non riusciti.
Fattori di costo:
- Consumo di token: puoi individuare gli agenti (come i sintetizzatori) che richiedono il maggior numero di token e decidere se l'utilizzo di un modello più potente ma costoso è giustificato per l'attività.
Dove cercare i problemi
Quando esamini le tracce in produzione, presta attenzione a:
- Tracce insolitamente lunghe: un segno di regressione delle prestazioni o di un comportamento di loop imprevisto.
- Span non riusciti (contrassegnati in rosso): indica l'operazione esatta non riuscita.
- Iterazioni eccessive del ciclo (> 2): potrebbe indicare un problema con la logica di generazione della correzione.
- Conteggi elevati di token: evidenzia le opportunità di ottimizzazione dei prompt o le modifiche alla selezione del modello.
Cosa hai imparato
Grazie a Cloud Trace, ora sai come:
✅ Visualizza il flusso delle richieste: visualizza il percorso di esecuzione completo attraverso le pipeline sequenziali e basate su loop.
✅ Identifica i colli di bottiglia delle prestazioni: utilizza il grafico a cascata per trovare le operazioni più lente con dati concreti.
✅ Analizza il comportamento del ciclo: osserva come gli agenti iterativi convergono su una soluzione in più tentativi.
✅ Monitora i costi dei token: esamina gli intervalli LLM per monitorare e ottimizzare il consumo di token a un livello granulare.
Concetti fondamentali padroneggiati
- Tracce e intervalli:le unità fondamentali di osservabilità, che rappresentano le richieste e le operazioni al loro interno.
- Analisi a cascata:lettura dei diagrammi di Gantt per comprendere il tempo di esecuzione e le dipendenze.
- Identificazione del percorso critico:individuazione della sequenza di operazioni che determina la latenza complessiva.
- Osservabilità granulare: visibilità non solo del tempo, ma anche dei metadati come i conteggi dei token per ogni operazione, strumentati automaticamente dall'ADK.
Passaggi successivi
Continua a esplorare Cloud Trace:
- Monitora regolarmente le tracce per individuare i problemi in anticipo
- Confrontare le tracce per identificare le regressioni delle prestazioni
- Utilizzare i dati di traccia per prendere decisioni di ottimizzazione
- Filtra per durata per trovare le richieste lente
Osservabilità avanzata (facoltativo):
- Esportare le tracce in BigQuery per analisi complesse (documenti)
- Creare dashboard personalizzate in Cloud Monitoring
- Configurare gli avvisi per il peggioramento delle prestazioni
- Correlare le tracce con i log delle applicazioni
9. Conclusione: dal prototipo alla produzione
Cosa hai creato
Hai iniziato con sole sette righe di codice e hai creato un sistema di agenti AI di livello di produzione:
# Where we started (7 lines)
agent = Agent(
model="gemini-2.5-flash",
instruction="Review Python code for issues"
)
# Where we ended (production system)
- Two distinct multi-agent pipelines (review and fix) built from 8 specialized agents.
- An iterative fix loop architecture for automated validation and retries.
- Real AST-based code analysis tools for deterministic, accurate feedback.
- Robust state management using the "constants pattern" for type-safe communication.
- Fully automated deployment to a managed, scalable cloud infrastructure.
- Complete, built-in observability with Cloud Trace for production monitoring.
Pattern architettonici chiave acquisiti
Pattern | Implementazione | Impatto sulla produzione |
Integrazione degli strumenti | Analisi AST, controllo dello stile | Convalida reale, non solo opinioni del modello LLM |
Pipeline sequenziali | Rivedi → Correggi i workflow | Esecuzione prevedibile e sottoponibile a debug |
Loop Architecture | Correzione iterativa con condizioni di uscita | Miglioramento automatico fino al successo |
Gestione dello stato | Pattern delle costanti, memoria a tre livelli | Gestione dello stato sicura e gestibile |
Deployment di produzione | Agent Engine tramite deploy.sh | Infrastruttura gestita e scalabile |
Osservabilità | Integrazione di Cloud Trace | Visibilità completa del comportamento di produzione |
Approfondimenti sulla produzione dalle tracce
I dati di Cloud Trace hanno rivelato informazioni fondamentali:
✅ Collo di bottiglia identificato: le chiamate LLM di TestRunner dominano la latenza
✅ Prestazioni dello strumento: l'analisi AST viene eseguita in 100 ms (ottimo)
✅ Tasso di successo: i loop di correzione convergono entro 2-3 iterazioni
✅ Utilizzo dei token: circa 600 token per revisione, circa 1800 per le correzioni
Questi approfondimenti favoriscono il miglioramento continuo.
Pulire le risorse (facoltativo)
Se hai terminato la sperimentazione e vuoi evitare addebiti:
Elimina il deployment di Agent Engine:
import vertexai
client = vertexai.Client( # For service interactions via client.agent_engines
project="PROJECT_ID",
location="LOCATION",
)
RESOURCE_NAME = "projects/{PROJECT_ID}/locations/{LOCATION}/reasoningEngines/{RESOURCE_ID}"
client.agent_engines.delete(
name=RESOURCE_NAME,
force=True, # Optional, if the agent has resources (e.g. sessions, memory)
)
Elimina il servizio Cloud Run (se creato):
gcloud run services delete code-review-assistant \
--region=$GOOGLE_CLOUD_LOCATION \
--quiet
Elimina l'istanza Cloud SQL (se creata):
gcloud sql instances delete your-project-db \
--quiet
Libera spazio nei bucket di archiviazione:
gsutil -m rm -r gs://your-project-staging
gsutil -m rm -r gs://your-project-artifacts
Passaggi successivi
Una volta completate le basi, valuta questi miglioramenti:
- Aggiungere altre lingue: estendere gli strumenti per supportare JavaScript, Go, Java
- Integrazione con GitHub: revisioni automatiche delle richieste di pull
- Implementa la memorizzazione nella cache: riduci la latenza per i pattern comuni
- Aggiungi agenti specializzati: scansione della sicurezza, analisi delle prestazioni
- Attiva i test A/B: confronta diversi modelli e prompt
- Esporta metriche: invia tracce a piattaforme di osservabilità specializzate
Concetti principali
- Inizia in modo semplice, itera rapidamente: sette righe per la produzione in passaggi gestibili
- Strumenti anziché prompt: l'analisi AST reale è meglio di "controlla la presenza di bug"
- La gestione dello stato è importante: il pattern delle costanti impedisce bug di battitura
- I loop richiedono condizioni di uscita: imposta sempre il numero massimo di iterazioni e il riassegnamento
- Esegui il deployment con l'automazione: deploy.sh gestisce tutta la complessità
- L'osservabilità è fondamentale: non puoi migliorare ciò che non puoi misurare
Risorse per l'apprendimento continuo
- Documentazione ADK
- Advanced ADK Patterns
- Guida al motore agente
- Documentazione di Cloud Run
- Documentazione di Cloud Trace
Il tuo percorso continua
Hai creato più di un assistente per la revisione del codice: hai acquisito le competenze per creare qualsiasi agente AI di produzione:
✅ Workflow complessi con più agenti specializzati
✅ Integrazione di strumenti reali per funzionalità autentiche
✅ Deployment di produzione con osservabilità adeguata
✅ Gestione dello stato per sistemi gestibili
Questi pattern vanno da semplici assistenti a complessi sistemi autonomi. Le basi che hai creato qui ti saranno utili man mano che affronterai architetture di agenti sempre più sofisticate.
Ti diamo il benvenuto nello sviluppo di agenti AI di produzione. L'assistente per la revisione del codice è solo l'inizio.