
1. The Late Night Code Review
Jest 2:00
Debugujesz od kilku godzin. Funkcja wygląda prawidłowo, ale coś jest nie tak. Znasz to uczucie, gdy kod powinien działać, ale nie działa, a Ty nie możesz już dostrzec przyczyny, bo za długo się w niego wpatrujesz.
def dfs_search_v1(graph, start, target):
"""Find if target is reachable from start."""
visited = set()
stack = start # Looks innocent enough...
while stack:
current = stack.pop()
if current == target:
return True
if current not in visited:
visited.add(current)
for neighbor in graph[current]:
if neighbor not in visited:
stack.append(neighbor)
return False
Ścieżka rozwoju programisty AI
Jeśli czytasz ten tekst, prawdopodobnie masz już za sobą transformację, jaką AI wprowadza w programowaniu. Narzędzia takie jak Gemini Code Assist, Claude Code i Cursor zmieniły sposób pisania kodu. Są świetne do generowania kodu standardowego, sugerowania implementacji i przyspieszania programowania.
Ale jesteś tu, bo chcesz dowiedzieć się więcej. Chcesz dowiedzieć się, jak tworzyć te systemy AI, a nie tylko z nich korzystać. Chcesz utworzyć coś, co:
- ma przewidywalne i możliwe do śledzenia działanie;
- Możesz je wdrożyć w środowisku produkcyjnym bez obaw.
- Zapewnia spójne wyniki, na których możesz polegać
- Pokazuje, jak dokładnie podejmuje decyzje
Od konsumenta do twórcy
Dziś przejdziesz od korzystania z narzędzi AI do ich tworzenia. Utworzysz system wieloagentowy, który:
- Analizuje strukturę kodu w sposób deterministyczny.
- Przeprowadza rzeczywiste testy w celu sprawdzenia działania.
- Sprawdza zgodność stylu za pomocą prawdziwych narzędzi do sprawdzania kodu
- Syntetyzuje wyniki w przydatne wskazówki
- Wdrażanie w Google Cloud z pełną widocznością
2. Pierwsze wdrożenie agenta
Pytanie dewelopera
„Rozumiem, jak działają duże modele językowe i korzystałem(-am) z interfejsów API, ale jak przekształcić skrypt w Pythonie w produkcyjnego agenta AI, który można skalować?”.
Aby odpowiedzieć na to pytanie, skonfigurujmy najpierw środowisko, a potem zbudujmy prostego agenta, aby poznać podstawy przed przejściem do wzorców produkcyjnych.
Najpierw skonfiguruj najważniejsze elementy
Zanim utworzymy agentów, upewnijmy się, że Twoje środowisko Google Cloud jest gotowe.
Kliknij Aktywuj Cloud Shell u góry konsoli Google Cloud (jest to ikona w kształcie terminala u góry panelu Cloud Shell).
Znajdź identyfikator projektu Google Cloud:
- Otwórz konsolę Google Cloud: https://console.cloud.google.com
- Wybierz projekt, którego chcesz użyć w tych warsztatach, z menu u góry strony.
- Identyfikator projektu jest wyświetlany na karcie Informacje o projekcie w panelu
 .
.
Krok 1. Ustaw identyfikator projektu
Narzędzie wiersza poleceń gcloud jest już skonfigurowane w Cloud Shell. Aby ustawić aktywny projekt, uruchom to polecenie. Używa to zmiennej środowiskowej $GOOGLE_CLOUD_PROJECT, która jest automatycznie ustawiana w sesji Cloud Shell.
gcloud config set project $GOOGLE_CLOUD_PROJECT
Krok 2. Sprawdź konfigurację
Następnie uruchom te polecenia, aby sprawdzić, czy projekt jest prawidłowo skonfigurowany i czy uwierzytelnianie zostało przeprowadzone.
# Confirm project is set
echo "Current project: $(gcloud config get-value project)"
# Check authentication status
gcloud auth list
Powinien wyświetlać się wydrukowany identyfikator projektu, a obok Twojego konta użytkownika powinien być widoczny symbol (ACTIVE).
Jeśli Twoje konto nie jest wymienione jako aktywne lub jeśli pojawi się błąd uwierzytelniania, uruchom to polecenie, aby się zalogować:
gcloud auth application-default login
Krok 3. Włącz podstawowe interfejsy API
W przypadku podstawowego agenta potrzebujemy co najmniej tych interfejsów API:
gcloud services enable \
aiplatform.googleapis.com \
compute.googleapis.com
Może to potrwać minutę lub dwie. Zobaczysz:
Operation "operations/..." finished successfully.
Krok 4. Zainstaluj ADK
# Install the ADK CLI
pip install google-adk --upgrade
# Verify installation
adk --version
Powinna pojawić się wersja 1.15.0 lub nowsza.
Teraz utwórz agenta podstawowego
Środowisko jest gotowe, więc utwórzmy prostego agenta.
Krok 5. Użyj ADK Create
adk create my_first_agent
Postępuj zgodnie z wyświetlanymi instrukcjami:
Choose a model for the root agent:
1. gemini-2.5-flash
2. Other models (fill later)
Choose model (1, 2): 1
1. Google AI
2. Vertex AI
Choose a backend (1, 2): 2
Enter Google Cloud project ID [auto-detected-from-gcloud]:
Enter Google Cloud region [us-central1]:
Krok 6. Sprawdź, co zostało utworzone
cd my_first_agent
ls -la
Znajdziesz tam 3 pliki:
.env # Configuration (auto-populated with your project)
__init__.py # Package marker
agent.py # Your agent definition
Krok 7. Szybkie sprawdzenie konfiguracji
# Verify the .env was created correctly
cat .env
# Should show something like:
# GOOGLE_CLOUD_PROJECT=your-project-id
# GOOGLE_CLOUD_LOCATION=us-central1
# GOOGLE_GENAI_USE_VERTEXAI=1
Jeśli identyfikator projektu jest nieprawidłowy lub go brakuje, edytuj plik .env:
nano .env # or use your preferred editor
Krok 8. Sprawdź kod agenta
cat agent.py
from google.adk.agents.llm_agent import Agent
root_agent = Agent(
model='gemini-2.5-flash',
name='root_agent',
description='A helpful assistant for user questions.',
instruction='Answer user questions to the best of your knowledge',
)
Prosty, przejrzysty, minimalistyczny. To jest Twój „Hello World” agentów.
Testowanie podstawowego agenta
Krok 9. Uruchom agenta
cd ..
adk run my_first_agent
Powinien pojawić się ekran podobny do tego:
Log setup complete: /tmp/agents_log/agent.20250930_162430.log
To access latest log: tail -F /tmp/agents_log/agent.latest.log
[user]:
Krok 10. Wypróbuj kilka zapytań
W terminalu, w którym działa adk run, zobaczysz prompt. Wpisz zapytania:
[user]: Hey, what can you do?
[root_agent]: I can help answer questions, generate text, explain concepts, assist with problem-solving, and provide information on a wide range of topics. What would you like to know or discuss?
[user]: What's the current weather in Mountain View?
[root_agent]: I'm sorry, but I cannot provide real-time weather information as I don't have access to current data or weather services. To get the current weather in Mountain View, I recommend checking a weather website or app like weather.com or using a search engine.
Zwróć uwagę na ograniczenie – nie ma dostępu do bieżących danych. Rozwińmy ten temat:
[user]: Review this Python code: def add(a, b): return a + b
[root_agent]: This is a simple Python function that adds two numbers. Here's my review:
**Strengths:**
- Clean and concise implementation
- Follows Python conventions for simple operations
- Clear function name that describes its purpose
**Suggestions for improvement:**
- Add a docstring to document the function
- Consider adding type hints for better code clarity
- You might want to handle edge cases
Here's an enhanced version:
def add(a: float, b: float) -> float:
"""Add two numbers and return their sum."""
return a + b
Agent może omówić kod, ale czy może:
- Czy faktycznie analizować AST, aby zrozumieć strukturę?
- Przeprowadzić testy, aby sprawdzić, czy działa?
- Sprawdzić zgodność ze stylem?
- Pamiętasz swoje poprzednie opinie?
Nie. W tym przypadku potrzebujemy architektury.
🏃🚪 Wyjdź z
Ctrl+C
gdy skończysz przeglądać tę stronę.
3. Przygotowywanie produkcyjnego obszaru roboczego
Rozwiązanie: architektura gotowa do użytku produkcyjnego
Ten prosty agent pokazał punkt początkowy, ale system produkcyjny wymaga solidnej struktury. Teraz skonfigurujemy kompletny projekt, który będzie zgodny z zasadami produkcji.
Konfigurowanie podstaw
Projekt Google Cloud został już skonfigurowany pod kątem podstawowego agenta. Teraz przygotujmy pełne środowisko produkcyjne ze wszystkimi narzędziami, wzorcami i infrastrukturą potrzebną do działania prawdziwego systemu.
Krok 1. Pobierz projekt strukturalny
Najpierw zamknij wszystkie uruchomione adk run za pomocą Ctrl+C i zwalniaj miejsce:
# Clean up the basic agent
cd ~ # Make sure you're not inside my_first_agent
rm -rf my_first_agent
# Get the production scaffold
git clone https://github.com/ayoisio/adk-code-review-assistant.git
cd adk-code-review-assistant
git checkout codelab
Krok 2. Utwórz i aktywuj środowisko wirtualne
# Create the virtual environment
python -m venv .venv
# Activate it
# On macOS/Linux:
source .venv/bin/activate
# On Windows:
# .venv\Scripts\activate
Weryfikacja: na początku promptu powinna się teraz pojawić ikona (.venv).
Krok 3. Zainstaluj zależności
pip install -r code_review_assistant/requirements.txt
# Install the package in editable mode (enables imports)
pip install -e .
Spowoduje to zainstalowanie:
google-adk– platforma ADKpycodestyle– do sprawdzania zgodności z PEP 8vertexai– w przypadku wdrożenia w chmurze.- Inne zależności produkcyjne
Flaga -e umożliwia importowanie modułów code_review_assistant z dowolnego miejsca.
Krok 4. Skonfiguruj środowisko
# Copy the example environment file
cp .env.example .env
# Edit .env and replace the placeholders:
# - GOOGLE_CLOUD_PROJECT=your-project-id → your actual project ID
# - Keep other defaults as-is
Weryfikacja: sprawdź konfigurację:
cat .env
Powinno się wyświetlić:
GOOGLE_CLOUD_PROJECT=your-actual-project-id
GOOGLE_CLOUD_LOCATION=us-central1
GOOGLE_GENAI_USE_VERTEXAI=TRUE
Krok 5. Zapewnij uwierzytelnianie
gcloud auth zostało już wcześniej uruchomione, więc sprawdźmy tylko:
# Check current authentication
gcloud auth list
# Should show your account with (ACTIVE)
# If not, run:
gcloud auth application-default login
Krok 6. Włącz dodatkowe interfejsy API wersji produkcyjnej
Podstawowe interfejsy API są już włączone. Teraz dodaj te produkcyjne:
gcloud services enable \
sqladmin.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
storage.googleapis.com \
cloudtrace.googleapis.com
Umożliwia to:
- Administrator SQL: w przypadku Cloud SQL, jeśli używasz Cloud Run.
- Cloud Run: do wdrażania bezserwerowego
- Cloud Build: do wdrożeń automatycznych.
- Artifact Registry: w przypadku obrazów kontenerów
- Cloud Storage: do przechowywania artefaktów i danych przejściowych.
- Cloud Trace: do obserwacji
Krok 7. Tworzenie repozytorium Artifact Registry
Wdrożenie utworzy obrazy kontenerów, które wymagają miejsca:
gcloud artifacts repositories create code-review-assistant-repo \
--repository-format=docker \
--location=us-central1 \
--description="Docker repository for Code Review Assistant"
Zobaczysz, że:
Created repository [code-review-assistant-repo].
Jeśli już istnieje (np. z poprzedniej próby), nie ma problemu – zobaczysz komunikat o błędzie, który możesz zignorować.
Krok 8. Przyznaj uprawnienia
# Get your project number
PROJECT_NUMBER=$(gcloud projects describe $GOOGLE_CLOUD_PROJECT \
--format="value(projectNumber)")
# Define the service account
SERVICE_ACCOUNT="${PROJECT_NUMBER}@cloudbuild.gserviceaccount.com"
# Grant necessary roles
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SERVICE_ACCOUNT}" \
--role="roles/run.admin"
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SERVICE_ACCOUNT}" \
--role="roles/iam.serviceAccountUser"
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SERVICE_ACCOUNT}" \
--role="roles/cloudsql.admin"
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SERVICE_ACCOUNT}" \
--role="roles/storage.admin"
Każde polecenie wygeneruje:
Updated IAM policy for project [your-project-id].
Co udało Ci się osiągnąć
Twój obszar roboczy w wersji produkcyjnej jest już w pełni przygotowany:
✅ Skonfigurowany i uwierzytelniony projekt Google Cloud
✅ Podstawowy agent przetestowany pod kątem ograniczeń
✅ Kod projektu z miejscami zastępczymi gotowy
✅ Zależności odizolowane w środowisku wirtualnym
✅ Włączone wszystkie niezbędne interfejsy API
✅ Rejestr kontenerów gotowy do wdrożeń
✅ Prawidłowo skonfigurowane uprawnienia IAM
✅ Prawidłowo ustawione zmienne środowiskowe
Teraz możesz zbudować prawdziwy system AI z użyciem deterministycznych narzędzi, zarządzania stanem i odpowiedniej architektury.
4. Tworzenie pierwszego agenta
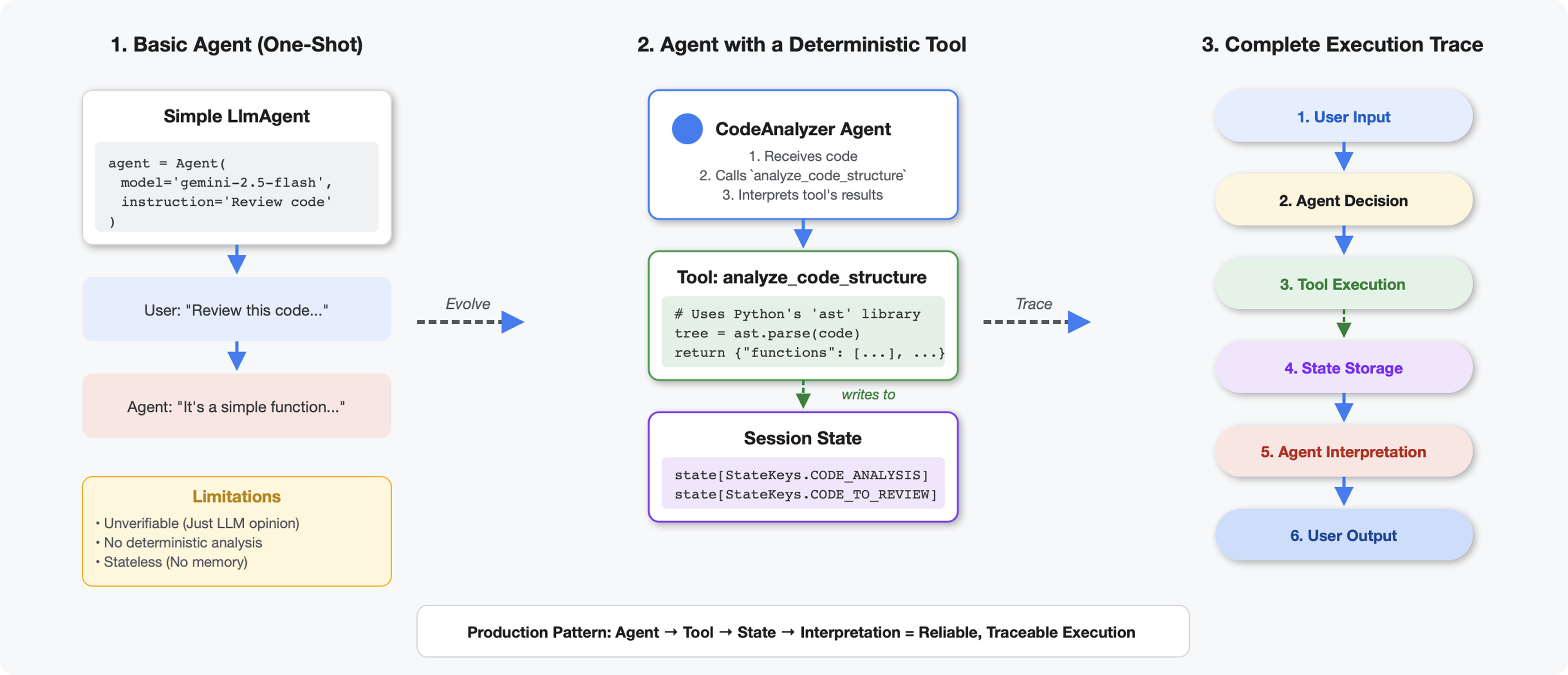
Czym narzędzia różnią się od dużych modeli językowych
Gdy zapytasz LLM-a „ile funkcji jest w tym kodzie?”, użyje on dopasowywania wzorców i szacowania. Gdy używasz narzędzia, które wywołuje funkcję ast.parse() w Pythonie, analizuje ono rzeczywiste drzewo składniowe – bez zgadywania, zawsze z tym samym wynikiem.
W tej sekcji utworzysz narzędzie, które deterministycznie analizuje strukturę kodu, a następnie połączysz je z agentem, który wie, kiedy je wywołać.
Krok 1. Zapoznaj się z platformą
Przyjrzyjmy się strukturze, którą będziesz wypełniać.
👉 Otwórz
code_review_assistant/tools.py
Zobaczysz funkcję analyze_code_structure z komentarzami zastępczymi, które wskazują miejsca, w których należy dodać kod. Funkcja ma już podstawową strukturę – będziesz ją ulepszać krok po kroku.
Krok 2. Dodaj State Storage
Przechowywanie stanu umożliwia innym agentom w potoku dostęp do wyników narzędzia bez ponownego uruchamiania analizy.
👉 Znajdź:
# MODULE_4_STEP_2_ADD_STATE_STORAGE
👉 Zastąp ten wiersz tym tekstem:
# Store code and analysis for other agents to access
tool_context.state[StateKeys.CODE_TO_REVIEW] = code
tool_context.state[StateKeys.CODE_ANALYSIS] = analysis
tool_context.state[StateKeys.CODE_LINE_COUNT] = len(code.splitlines())
Krok 3. Dodaj analizowanie asynchroniczne z pulami wątków
Nasze narzędzie musi analizować AST bez blokowania innych operacji. Dodajmy asynchroniczne wykonywanie za pomocą pul wątków.
👉 Znajdź:
# MODULE_4_STEP_3_ADD_ASYNC
👉 Zastąp ten wiersz tym tekstem:
# Parse in thread pool to avoid blocking the event loop
loop = asyncio.get_event_loop()
with ThreadPoolExecutor() as executor:
tree = await loop.run_in_executor(executor, ast.parse, code)
Krok 4. Wyodrębnij szczegółowe informacje
Teraz wyodrębnijmy klasy, importy i szczegółowe dane – wszystko, czego potrzebujemy do pełnej weryfikacji kodu.
👉 Znajdź:
# MODULE_4_STEP_4_EXTRACT_DETAILS
👉 Zastąp ten wiersz tym tekstem:
# Extract comprehensive structural information
analysis = await loop.run_in_executor(
executor, _extract_code_structure, tree, code
)
👉 Sprawdź: funkcja
analyze_code_structure
w
tools.py
ma centralną część, która wygląda tak:
# Parse in thread pool to avoid blocking the event loop
loop = asyncio.get_event_loop()
with ThreadPoolExecutor() as executor:
tree = await loop.run_in_executor(executor, ast.parse, code)
# Extract comprehensive structural information
analysis = await loop.run_in_executor(
executor, _extract_code_structure, tree, code
)
# Store code and analysis for other agents to access
tool_context.state[StateKeys.CODE_TO_REVIEW] = code
tool_context.state[StateKeys.CODE_ANALYSIS] = analysis
tool_context.state[StateKeys.CODE_LINE_COUNT] = len(code.splitlines())
👉 Przewiń na sam dół
tools.py
i znajdź:
# MODULE_4_STEP_4_HELPER_FUNCTION
👉 Zastąp ten wiersz kompletną funkcją pomocniczą:
def _extract_code_structure(tree: ast.AST, code: str) -> Dict[str, Any]:
"""
Helper function to extract structural information from AST.
Runs in thread pool for CPU-bound work.
"""
functions = []
classes = []
imports = []
docstrings = []
for node in ast.walk(tree):
if isinstance(node, ast.FunctionDef):
func_info = {
'name': node.name,
'args': [arg.arg for arg in node.args.args],
'lineno': node.lineno,
'has_docstring': ast.get_docstring(node) is not None,
'is_async': isinstance(node, ast.AsyncFunctionDef),
'decorators': [d.id for d in node.decorator_list
if isinstance(d, ast.Name)]
}
functions.append(func_info)
if func_info['has_docstring']:
docstrings.append(f"{node.name}: {ast.get_docstring(node)[:50]}...")
elif isinstance(node, ast.ClassDef):
methods = []
for item in node.body:
if isinstance(item, ast.FunctionDef):
methods.append(item.name)
class_info = {
'name': node.name,
'lineno': node.lineno,
'methods': methods,
'has_docstring': ast.get_docstring(node) is not None,
'base_classes': [base.id for base in node.bases
if isinstance(base, ast.Name)]
}
classes.append(class_info)
elif isinstance(node, ast.Import):
for alias in node.names:
imports.append({
'module': alias.name,
'alias': alias.asname,
'type': 'import'
})
elif isinstance(node, ast.ImportFrom):
imports.append({
'module': node.module or '',
'names': [alias.name for alias in node.names],
'type': 'from_import',
'level': node.level
})
return {
'functions': functions,
'classes': classes,
'imports': imports,
'docstrings': docstrings,
'metrics': {
'line_count': len(code.splitlines()),
'function_count': len(functions),
'class_count': len(classes),
'import_count': len(imports),
'has_main': any(f['name'] == 'main' for f in functions),
'has_if_main': '__main__' in code,
'avg_function_length': _calculate_avg_function_length(tree)
}
}
def _calculate_avg_function_length(tree: ast.AST) -> float:
"""Calculate average function length in lines."""
function_lengths = []
for node in ast.walk(tree):
if isinstance(node, ast.FunctionDef):
if hasattr(node, 'end_lineno') and hasattr(node, 'lineno'):
length = node.end_lineno - node.lineno + 1
function_lengths.append(length)
if function_lengths:
return sum(function_lengths) / len(function_lengths)
return 0.0
Krok 5. Połącz się z pracownikiem obsługi klienta
Teraz łączymy narzędzie z agentem, który wie, kiedy go używać i jak interpretować jego wyniki.
👉 Otwórz
code_review_assistant/sub_agents/review_pipeline/code_analyzer.py
👉 Znajdź:
# MODULE_4_STEP_5_CREATE_AGENT
👉 Zastąp tę jedną linię pełnym agentem produkcyjnym:
code_analyzer_agent = Agent(
name="CodeAnalyzer",
model=config.worker_model,
description="Analyzes Python code structure and identifies components",
instruction="""You are a code analysis specialist responsible for understanding code structure.
Your task:
1. Take the code submitted by the user (it will be provided in the user message)
2. Use the analyze_code_structure tool to parse and analyze it
3. Pass the EXACT code to your tool - do not modify, fix, or "improve" it
4. Identify all functions, classes, imports, and structural patterns
5. Note any syntax errors or structural issues
6. Store the analysis in state for other agents to use
CRITICAL:
- Pass the code EXACTLY as provided to the analyze_code_structure tool
- Do not fix syntax errors, even if obvious
- Do not add missing imports or fix indentation
- The goal is to analyze what IS there, not what SHOULD be there
When calling the tool, pass the code as a string to the 'code' parameter.
If the analysis fails due to syntax errors, clearly report the error location and type.
Provide a clear summary including:
- Number of functions and classes found
- Key structural observations
- Any syntax errors or issues detected
- Overall code organization assessment""",
tools=[FunctionTool(func=analyze_code_structure)],
output_key="structure_analysis_summary"
)
Testowanie analizatora kodu
Teraz sprawdź, czy analizator działa prawidłowo.
👉 Uruchom scenariusz testowania:
python tests/test_code_analyzer.py
Scenariusz testowania automatycznie wczytuje konfigurację z pliku .env za pomocą funkcji python-dotenv, więc nie musisz ręcznie konfigurować zmiennych środowiskowych.
Oczekiwane dane wyjściowe:
INFO:code_review_assistant.config:Code Review Assistant Configuration Loaded:
INFO:code_review_assistant.config: - GCP Project: your-project-id
INFO:code_review_assistant.config: - Artifact Bucket: gs://your-project-artifacts
INFO:code_review_assistant.config: - Models: worker=gemini-2.5-flash, critic=gemini-2.5-pro
Testing code analyzer...
INFO:code_review_assistant.tools:Tool: Analysis complete - 2 functions, 1 classes
=== Analyzer Response ===
The analysis of the provided code shows the following:
* **Functions Found:** 2
* `add(a, b)`: A global function at line 2.
* `multiply(self, x, y)`: A method within the `Calculator` class.
* **Classes Found:** 1
* `Calculator`: A class defined at line 5. Contains one method, `multiply`.
* **Imports:** 0
* **Structural Patterns:** The code defines one global function and one class
with a single method. Both are simple, each with a single return statement.
* **Syntax Errors/Issues:** No syntax errors detected.
* **Overall Code Organization:** The code is well-organized for its small size,
clearly defining a function and a class with a method.
Co się stało:
- Scenariusz testowania automatycznie wczytał konfigurację
.env. - Twoje
analyze_code_structure()narzędzie przeanalizowało kod za pomocą AST języka Python. - Funkcja pomocnicza
_extract_code_structure()wyodrębniła funkcje, klasy i dane. - Wyniki zostały zapisane w stanie sesji za pomocą stałych
StateKeys. - Agent Code Analyzer zinterpretował wyniki i przygotował podsumowanie.
Rozwiązywanie problemów:
- „No module named ‘code_review_assistant'”: uruchom
pip install -e .z katalogu głównego projektu. - „Missing key inputs argument”: sprawdź, czy urządzenie
.envmaGOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_LOCATIONiGOOGLE_GENAI_USE_VERTEXAI=true.
Co utworzysz
Masz teraz gotowy do wdrożenia analizator kodu, który:
✅ Analizuje rzeczywiste drzewo składniowe Pythona – deterministyczne, nie dopasowuje wzorców.
✅ Przechowuje wyniki w stanie – inne agenty mogą uzyskać dostęp do analizy.
✅ Działa asynchronicznie – nie blokuje innych narzędzi.
✅ Wyodrębnia kompleksowe informacje – funkcje, klasy, importy, dane.
✅ Elegancko obsługuje błędy – zgłasza błędy składni z numerami wierszy.
✅ Łączy się z agentem – LLM wie, kiedy i jak go używać.
Opanowane kluczowe pojęcia
Narzędzia a agenci:
- Narzędzia wykonują deterministyczną pracę (parsowanie AST)
- Agenci decydują, kiedy używać narzędzi, i interpretują wyniki
Zwracana wartość a stan:
- Odpowiedź: co model LLM widzi od razu
- Stan: co jest zachowywane dla innych agentów
Stałe wartości kluczy stanu:
- Zapobieganie literówkom w systemach wieloagentowych
- Działanie jako umowy między agentami
- Kluczowe, gdy agenty udostępniają dane
Asynchroniczność i pule wątków:
async defumożliwia narzędziom wstrzymywanie wykonywania,- Pule wątków wykonują w tle zadania wymagające dużej mocy obliczeniowej procesora
- Razem dbają o to, aby pętla zdarzeń była responsywna.
Funkcje pomocnicze:
- Oddzielanie pomocników synchronizacji od narzędzi asynchronicznych
- Umożliwia testowanie kodu i korzystanie z niego wielokrotnie
Instrukcje dla pracowników obsługi klienta:
- Szczegółowe instrukcje zapobiegają typowym błędom LLM
- Wyraźnie określ, czego NIE należy robić (nie poprawiaj kodu).
- Wyczyść kroki przepływu pracy, aby zachować spójność
Co dalej
W części 5 dodasz:
- Sprawdzanie stylu, które odczytuje kod ze stanu.
- program do uruchamiania testów, który faktycznie wykonuje testy;
- Syntetyzator opinii, który łączy wszystkie analizy.
Dowiesz się, jak stan przepływa przez sekwencyjny potok, i dlaczego wzorzec stałych ma znaczenie, gdy wielu agentów odczytuje i zapisuje te same dane.
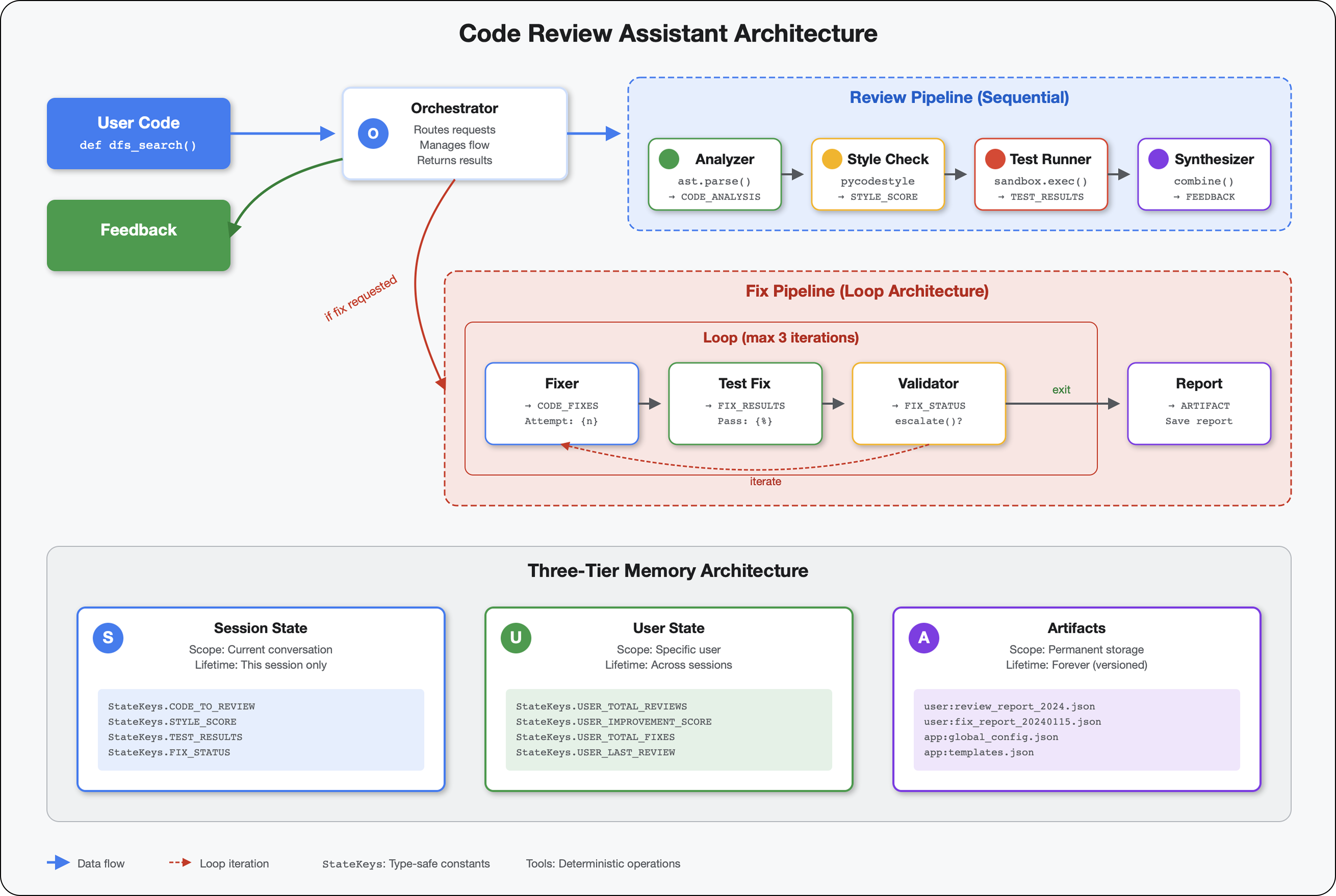
5. Tworzenie potoku: współpraca wielu agentów
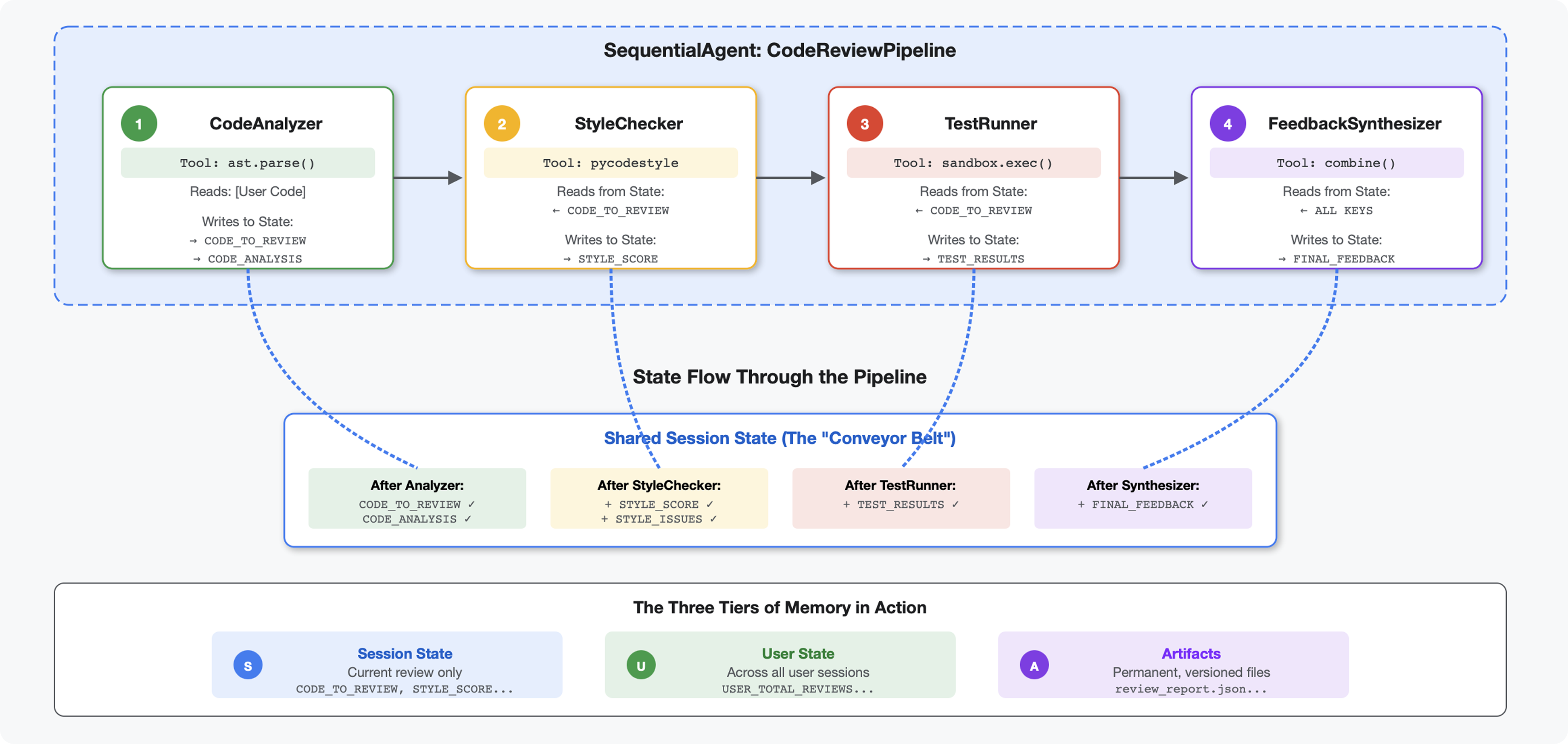
Wprowadzenie
W części 4 utworzyliśmy pojedynczego agenta, który analizuje strukturę kodu. Kompleksowa inspekcja kodu wymaga jednak czegoś więcej niż tylko analizowania – potrzebne jest sprawdzanie stylu, wykonywanie testów i inteligentna synteza opinii.
Ten moduł tworzy potok 4 agentów, którzy pracują razem sekwencyjnie, a każdy z nich wnosi specjalistyczną analizę:
- Analizator kodu (z modułu 4) – analizuje strukturę.
- Sprawdzanie stylu – wykrywa naruszenia stylu.
- Uruchamiający testy – przeprowadza i weryfikuje testy.
- Syntetyzator opinii – łączy wszystkie informacje w praktyczne wskazówki.
Kluczowe pojęcie: stan jako kanał komunikacji. Każdy agent odczytuje to, co napisali poprzedni agenci, dodaje własną analizę i przekazuje wzbogacony stan do następnego agenta. Wzorzec stałych z modułu 4 staje się kluczowy, gdy wielu agentów udostępnia dane.
Podgląd tego, co stworzysz: przesyłanie nieuporządkowanego kodu → obserwowanie przepływu stanu przez 4 agenty → otrzymywanie obszernego raportu ze spersonalizowanymi opiniami na podstawie wcześniejszych wzorców.
Krok 1. Dodaj narzędzie do sprawdzania stylu i agenta
Sprawdzanie stylu identyfikuje naruszenia PEP 8 za pomocą pycodestyle – deterministycznego narzędzia do sprawdzania kodu, a nie interpretacji opartej na LLM.
Dodawanie narzędzia do sprawdzania stylu
👉 Otwórz
code_review_assistant/tools.py
👉 Znajdź:
# MODULE_5_STEP_1_STYLE_CHECKER_TOOL
👉 Zastąp ten wiersz tym tekstem:
async def check_code_style(code: str, tool_context: ToolContext) -> Dict[str, Any]:
"""
Checks code style compliance using pycodestyle (PEP 8).
Args:
code: Python source code to check (or will retrieve from state)
tool_context: ADK tool context
Returns:
Dictionary containing style score and issues
"""
logger.info("Tool: Checking code style...")
try:
# Retrieve code from state if not provided
if not code:
code = tool_context.state.get(StateKeys.CODE_TO_REVIEW, '')
if not code:
return {
"status": "error",
"message": "No code provided or found in state"
}
# Run style check in thread pool
loop = asyncio.get_event_loop()
with ThreadPoolExecutor() as executor:
result = await loop.run_in_executor(
executor, _perform_style_check, code
)
# Store results in state
tool_context.state[StateKeys.STYLE_SCORE] = result['score']
tool_context.state[StateKeys.STYLE_ISSUES] = result['issues']
tool_context.state[StateKeys.STYLE_ISSUE_COUNT] = result['issue_count']
logger.info(f"Tool: Style check complete - Score: {result['score']}/100, "
f"Issues: {result['issue_count']}")
return result
except Exception as e:
error_msg = f"Style check failed: {str(e)}"
logger.error(f"Tool: {error_msg}", exc_info=True)
# Set default values on error
tool_context.state[StateKeys.STYLE_SCORE] = 0
tool_context.state[StateKeys.STYLE_ISSUES] = []
return {
"status": "error",
"message": error_msg,
"score": 0
}
👉 Przewiń teraz plik do końca i znajdź:
# MODULE_5_STEP_1_STYLE_HELPERS
👉 Zastąp tę pojedynczą linię funkcjami pomocniczymi:
def _perform_style_check(code: str) -> Dict[str, Any]:
"""Helper to perform style check in thread pool."""
import io
import sys
with tempfile.NamedTemporaryFile(mode='w', suffix='.py', delete=False) as tmp:
tmp.write(code)
tmp_path = tmp.name
try:
# Capture stdout to get pycodestyle output
old_stdout = sys.stdout
sys.stdout = captured_output = io.StringIO()
style_guide = pycodestyle.StyleGuide(
quiet=False, # We want output
max_line_length=100,
ignore=['E501', 'W503']
)
result = style_guide.check_files([tmp_path])
# Restore stdout
sys.stdout = old_stdout
# Parse captured output
output = captured_output.getvalue()
issues = []
for line in output.strip().split('\n'):
if line and ':' in line:
parts = line.split(':', 4)
if len(parts) >= 4:
try:
issues.append({
'line': int(parts[1]),
'column': int(parts[2]),
'code': parts[3].split()[0] if len(parts) > 3 else 'E000',
'message': parts[3].strip() if len(parts) > 3 else 'Unknown error'
})
except (ValueError, IndexError):
pass
# Add naming convention checks
try:
tree = ast.parse(code)
naming_issues = _check_naming_conventions(tree)
issues.extend(naming_issues)
except SyntaxError:
pass # Syntax errors will be caught elsewhere
# Calculate weighted score
score = _calculate_style_score(issues)
return {
"status": "success",
"score": score,
"issue_count": len(issues),
"issues": issues[:10], # First 10 issues
"summary": f"Style score: {score}/100 with {len(issues)} violations"
}
finally:
if os.path.exists(tmp_path):
os.unlink(tmp_path)
def _check_naming_conventions(tree: ast.AST) -> List[Dict[str, Any]]:
"""Check PEP 8 naming conventions."""
naming_issues = []
for node in ast.walk(tree):
if isinstance(node, ast.FunctionDef):
# Skip private/protected methods and __main__
if not node.name.startswith('_') and node.name != node.name.lower():
naming_issues.append({
'line': node.lineno,
'column': node.col_offset,
'code': 'N802',
'message': f"N802 function name '{node.name}' should be lowercase"
})
elif isinstance(node, ast.ClassDef):
# Check if class name follows CapWords convention
if not node.name[0].isupper() or '_' in node.name:
naming_issues.append({
'line': node.lineno,
'column': node.col_offset,
'code': 'N801',
'message': f"N801 class name '{node.name}' should use CapWords convention"
})
return naming_issues
def _calculate_style_score(issues: List[Dict[str, Any]]) -> int:
"""Calculate weighted style score based on violation severity."""
if not issues:
return 100
# Define weights by error type
weights = {
'E1': 10, # Indentation errors
'E2': 3, # Whitespace errors
'E3': 5, # Blank line errors
'E4': 8, # Import errors
'E5': 5, # Line length
'E7': 7, # Statement errors
'E9': 10, # Syntax errors
'W2': 2, # Whitespace warnings
'W3': 2, # Blank line warnings
'W5': 3, # Line break warnings
'N8': 7, # Naming conventions
}
total_deduction = 0
for issue in issues:
code_prefix = issue['code'][:2] if len(issue['code']) >= 2 else 'E2'
weight = weights.get(code_prefix, 3)
total_deduction += weight
# Cap at 100 points deduction
return max(0, 100 - min(total_deduction, 100))
Dodawanie agenta Style Checker
👉 Otwórz
code_review_assistant/sub_agents/review_pipeline/style_checker.py
👉 Znajdź:
# MODULE_5_STEP_1_INSTRUCTION_PROVIDER
👉 Zastąp ten wiersz tym tekstem:
async def style_checker_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are a code style expert focused on PEP 8 compliance.
Your task:
1. Use the check_code_style tool to validate PEP 8 compliance
2. The tool will retrieve the ORIGINAL code from state automatically
3. Report violations exactly as found
4. Present the results clearly and confidently
CRITICAL:
- The tool checks the code EXACTLY as provided by the user
- Do not suggest the code was modified or fixed
- Report actual violations found in the original code
- If there are style issues, they should be reported honestly
Call the check_code_style tool with an empty string for the code parameter,
as the tool will retrieve the code from state automatically.
When presenting results based on what the tool returns:
- State the exact score from the tool results
- If score >= 90: "Excellent style compliance!"
- If score 70-89: "Good style with minor improvements needed"
- If score 50-69: "Style needs attention"
- If score < 50: "Significant style improvements needed"
List the specific violations found (the tool will provide these):
- Show line numbers, error codes, and messages
- Focus on the top 10 most important issues
Previous analysis: {structure_analysis_summary}
Format your response as:
## Style Analysis Results
- Style Score: [exact score]/100
- Total Issues: [count]
- Assessment: [your assessment based on score]
## Top Style Issues
[List issues with line numbers and descriptions]
## Recommendations
[Specific fixes for the most critical issues]"""
return await instructions_utils.inject_session_state(template, context)
👉 Znajdź:
# MODULE_5_STEP_1_STYLE_CHECKER_AGENT
👉 Zastąp ten wiersz tym tekstem:
style_checker_agent = Agent(
name="StyleChecker",
model=config.worker_model,
description="Checks Python code style against PEP 8 guidelines",
instruction=style_checker_instruction_provider,
tools=[FunctionTool(func=check_code_style)],
output_key="style_check_summary"
)
Krok 2. Dodaj agenta Test Runner
Narzędzie do uruchamiania testów generuje kompleksowe testy i wykonuje je za pomocą wbudowanego narzędzia do wykonywania kodu.
👉 Otwórz
code_review_assistant/sub_agents/review_pipeline/test_runner.py
👉 Znajdź:
# MODULE_5_STEP_2_INSTRUCTION_PROVIDER
👉 Zastąp ten wiersz tym tekstem:
async def test_runner_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects the code_to_review directly."""
template = """You are a testing specialist who creates and runs tests for Python code.
THE CODE TO TEST IS:
{code_to_review}
YOUR TASK:
1. Understand what the function appears to do based on its name and structure
2. Generate comprehensive tests (15-20 test cases)
3. Execute the tests using your code executor
4. Analyze results to identify bugs vs expected behavior
5. Output a detailed JSON analysis
TESTING METHODOLOGY:
- Test with the most natural interpretation first
- When something fails, determine if it's a bug or unusual design
- Test edge cases, boundaries, and error scenarios
- Document any surprising behavior
Execute your tests and output ONLY valid JSON with this structure:
- "test_summary": object with "total_tests_run", "tests_passed", "tests_failed", "tests_with_errors", "critical_issues_found"
- "critical_issues": array of objects, each with "type", "description", "example_input", "expected_behavior", "actual_behavior", "severity"
- "test_categories": object with "basic_functionality", "edge_cases", "error_handling" (each containing "passed", "failed", "errors" counts)
- "function_behavior": object with "apparent_purpose", "actual_interface", "unexpected_requirements"
- "verdict": object with "status" (WORKING/BUGGY/BROKEN), "confidence" (high/medium/low), "recommendation"
Do NOT output the test code itself, only the JSON analysis."""
return await instructions_utils.inject_session_state(template, context)
👉 Znajdź:
# MODULE_5_STEP_2_TEST_RUNNER_AGENT
👉 Zastąp ten wiersz tym tekstem:
test_runner_agent = Agent(
name="TestRunner",
model=config.critic_model,
description="Generates and runs tests for Python code using safe code execution",
instruction=test_runner_instruction_provider,
code_executor=BuiltInCodeExecutor(),
output_key="test_execution_summary"
)
Krok 3. Zapoznaj się z funkcją Pamięć do uczenia się w ramach różnych sesji
Zanim zaczniesz tworzyć syntezator opinii, musisz poznać różnicę między stanem a pamięcią – dwoma różnymi mechanizmami przechowywania danych, które służą do różnych celów.
Stan a pamięć: kluczowa różnica
Wyjaśnijmy to na konkretnym przykładzie z procesu inspekcji kodu:
Stan (tylko bieżąca sesja):
# Data from THIS review session
tool_context.state[StateKeys.STYLE_ISSUES] = [
{"line": 5, "code": "E231", "message": "missing whitespace"},
{"line": 12, "code": "E701", "message": "multiple statements"}
]
- Zakres: tylko ta rozmowa
- Cel: przekazywanie danych między agentami w bieżącym potoku
- Mieszka w:
Session - Okres ważności: odrzucane po zakończeniu sesji
Pamięć (wszystkie poprzednie sesje):
# Learned from 50 previous reviews
"User frequently forgets docstrings on helper functions"
"User tends to write long functions (avg 45 lines)"
"User improved error handling after feedback in session #23"
- Zakres: wszystkie poprzednie sesje tego użytkownika
- Cel: uczenie się wzorców, przekazywanie spersonalizowanych opinii
- Mieszka w:
MemoryService - Od początku śledzenia: utrzymuje się w sesjach, można go wyszukiwać
Dlaczego opinia musi zawierać oba te elementy:
Wyobraź sobie, że syntezator generuje sprzężenie zwrotne:
Używanie tylko stanu (bieżąca weryfikacja):
"Function `calculate_total` has no docstring."
Ogólne, mechaniczne opinie.
Korzystanie ze stanu i pamięci (obecne i poprzednie wzorce):
"Function `calculate_total` has no docstring. This is the 4th review
where helper functions lacked documentation. Consider adding docstrings
as you write functions, not afterwards - you mentioned in our last
session that you find it easier that way."
Spersonalizowane, kontekstowe, z odniesieniami, z czasem ulepszane.
W przypadku wdrożeń produkcyjnych masz opcje:
Opcja 1. VertexAiMemoryBankService (zaawansowana)
- Działanie: wyodrębnianie istotnych faktów z rozmów za pomocą LLM.
- Wyszukiwanie: wyszukiwanie semantyczne (rozumie znaczenie, a nie tylko słowa kluczowe)
- Zarządzanie pamięcią: automatycznie konsoliduje i aktualizuje wspomnienia z biegiem czasu.
- Wymagania: projekt Google Cloud + konfiguracja Agent Engine
- Używaj, gdy: chcesz mieć zaawansowane, rozwijające się i spersonalizowane wspomnienia.
- Przykład: „Użytkownik preferuje programowanie funkcyjne” (wyodrębnione z 10 rozmów o stylu kodu)
Opcja 2. Kontynuuj korzystanie z usługi InMemoryMemoryService i sesji trwałych
- Do czego służy: przechowuje pełną historię rozmów na potrzeby wyszukiwania słów kluczowych.
- Wyszukiwanie: podstawowe dopasowywanie słów kluczowych w poprzednich sesjach
- Zarządzanie pamięcią: masz kontrolę nad tym, co jest przechowywane (za pomocą
add_session_to_memory). - Wymaga: tylko trwałego
SessionService(np.VertexAiSessionServicelubDatabaseSessionService). - Używaj, gdy: potrzebujesz prostego wyszukiwania w poprzednich rozmowach bez przetwarzania LLM.
- Przykład: wyszukiwanie „docstring” zwraca wszystkie sesje, w których pojawiło się to słowo.
Sposób wypełniania sekcji Pamięć
Po zakończeniu każdej weryfikacji kodu:
# At the end of a session (typically in your application code)
await memory_service.add_session_to_memory(session)
Co się stanie:
- InMemoryMemoryService: przechowuje pełne zdarzenia sesji na potrzeby wyszukiwania słów kluczowych.
- VertexAiMemoryBankService: LLM wyodrębnia kluczowe fakty i łączy je z istniejącymi wspomnieniami.
W przyszłości sesje mogą wysyłać zapytania:
# In a tool, search for relevant past feedback
results = tool_context.search_memory("feedback about docstrings")
Krok 4. Dodaj narzędzia i agenta do syntezy opinii
Syntezator opinii jest najbardziej zaawansowanym agentem w potoku. Orkiestruje 3 narzędzia, korzysta z dynamicznych instrukcji i łączy stan, pamięć oraz artefakty.
Dodawanie 3 narzędzi syntezatora
👉 Otwórz
code_review_assistant/tools.py
👉 Znajdź:
# MODULE_5_STEP_4_SEARCH_PAST_FEEDBACK
👉 Zastąp narzędziem 1 – wyszukiwanie w pamięci (wersja produkcyjna):
async def search_past_feedback(developer_id: str, tool_context: ToolContext) -> Dict[str, Any]:
"""
Search for past feedback in memory service.
Args:
developer_id: ID of the developer (defaults to "default_user")
tool_context: ADK tool context with potential memory service access
Returns:
Dictionary containing feedback search results
"""
logger.info(f"Tool: Searching for past feedback for developer {developer_id}...")
try:
# Default developer ID if not provided
if not developer_id:
developer_id = tool_context.state.get(StateKeys.USER_ID, 'default_user')
# Check if memory service is available
if hasattr(tool_context, 'search_memory'):
try:
# Perform structured searches
queries = [
f"developer:{developer_id} code review feedback",
f"developer:{developer_id} common issues",
f"developer:{developer_id} improvements"
]
all_feedback = []
patterns = {
'common_issues': [],
'improvements': [],
'strengths': []
}
for query in queries:
search_result = await tool_context.search_memory(query)
if search_result and hasattr(search_result, 'memories'):
for memory in search_result.memories[:5]:
memory_text = memory.text if hasattr(memory, 'text') else str(memory)
all_feedback.append(memory_text)
# Extract patterns
if 'style' in memory_text.lower():
patterns['common_issues'].append('style compliance')
if 'improved' in memory_text.lower():
patterns['improvements'].append('showing improvement')
if 'excellent' in memory_text.lower():
patterns['strengths'].append('consistent quality')
# Store in state
tool_context.state[StateKeys.PAST_FEEDBACK] = all_feedback
tool_context.state[StateKeys.FEEDBACK_PATTERNS] = patterns
logger.info(f"Tool: Found {len(all_feedback)} past feedback items")
return {
"status": "success",
"feedback_found": True,
"count": len(all_feedback),
"summary": " | ".join(all_feedback[:3]) if all_feedback else "No feedback",
"patterns": patterns
}
except Exception as e:
logger.warning(f"Tool: Memory search error: {e}")
# Fallback: Check state for cached feedback
cached_feedback = tool_context.state.get(StateKeys.USER_PAST_FEEDBACK_CACHE, [])
if cached_feedback:
tool_context.state[StateKeys.PAST_FEEDBACK] = cached_feedback
return {
"status": "success",
"feedback_found": True,
"count": len(cached_feedback),
"summary": "Using cached feedback",
"patterns": {}
}
# No feedback found
tool_context.state[StateKeys.PAST_FEEDBACK] = []
logger.info("Tool: No past feedback found")
return {
"status": "success",
"feedback_found": False,
"message": "No past feedback available - this appears to be a first submission",
"patterns": {}
}
except Exception as e:
error_msg = f"Feedback search error: {str(e)}"
logger.error(f"Tool: {error_msg}", exc_info=True)
tool_context.state[StateKeys.PAST_FEEDBACK] = []
return {
"status": "error",
"message": error_msg,
"feedback_found": False
}
👉 Znajdź:
# MODULE_5_STEP_4_UPDATE_GRADING_PROGRESS
👉 Zastąp narzędziem 2 – Grading Tracker (wersja produkcyjna):
async def update_grading_progress(tool_context: ToolContext) -> Dict[str, Any]:
"""
Updates grading progress counters and metrics in state.
"""
logger.info("Tool: Updating grading progress...")
try:
current_time = datetime.now().isoformat()
# Build all state changes
state_updates = {}
# Temporary (invocation-level) state
state_updates[StateKeys.TEMP_PROCESSING_TIMESTAMP] = current_time
# Session-level state
attempts = tool_context.state.get(StateKeys.GRADING_ATTEMPTS, 0) + 1
state_updates[StateKeys.GRADING_ATTEMPTS] = attempts
state_updates[StateKeys.LAST_GRADING_TIME] = current_time
# User-level persistent state
lifetime_submissions = tool_context.state.get(StateKeys.USER_TOTAL_SUBMISSIONS, 0) + 1
state_updates[StateKeys.USER_TOTAL_SUBMISSIONS] = lifetime_submissions
state_updates[StateKeys.USER_LAST_SUBMISSION_TIME] = current_time
# Calculate improvement metrics
current_style_score = tool_context.state.get(StateKeys.STYLE_SCORE, 0)
last_style_score = tool_context.state.get(StateKeys.USER_LAST_STYLE_SCORE, 0)
score_improvement = current_style_score - last_style_score
state_updates[StateKeys.USER_LAST_STYLE_SCORE] = current_style_score
state_updates[StateKeys.SCORE_IMPROVEMENT] = score_improvement
# Track test results if available
test_results = tool_context.state.get(StateKeys.TEST_EXECUTION_SUMMARY, {})
# Parse if it's a string
if isinstance(test_results, str):
try:
test_results = json.loads(test_results)
except:
test_results = {}
if test_results and test_results.get('test_summary', {}).get('total_tests_run', 0) > 0:
summary = test_results['test_summary']
total = summary.get('total_tests_run', 0)
passed = summary.get('tests_passed', 0)
if total > 0:
pass_rate = (passed / total) * 100
state_updates[StateKeys.USER_LAST_TEST_PASS_RATE] = pass_rate
# Apply all updates atomically
for key, value in state_updates.items():
tool_context.state[key] = value
logger.info(f"Tool: Progress updated - Attempt #{attempts}, "
f"Lifetime: {lifetime_submissions}")
return {
"status": "success",
"session_attempts": attempts,
"lifetime_submissions": lifetime_submissions,
"timestamp": current_time,
"improvement": {
"style_score_change": score_improvement,
"direction": "improved" if score_improvement > 0 else "declined"
},
"summary": f"Attempt #{attempts} recorded, {lifetime_submissions} total submissions"
}
except Exception as e:
error_msg = f"Progress update error: {str(e)}"
logger.error(f"Tool: {error_msg}", exc_info=True)
return {
"status": "error",
"message": error_msg
}
👉 Znajdź:
# MODULE_5_STEP_4_SAVE_GRADING_REPORT
👉 Zastąp narzędziem 3 – Artifact Saver (wersja produkcyjna):
async def save_grading_report(feedback_text: str, tool_context: ToolContext) -> Dict[str, Any]:
"""
Saves a detailed grading report as an artifact.
Args:
feedback_text: The feedback text to include in the report
tool_context: ADK tool context for state management
Returns:
Dictionary containing save status and details
"""
logger.info("Tool: Saving grading report...")
try:
# Gather all relevant data from state
code = tool_context.state.get(StateKeys.CODE_TO_REVIEW, '')
analysis = tool_context.state.get(StateKeys.CODE_ANALYSIS, {})
style_score = tool_context.state.get(StateKeys.STYLE_SCORE, 0)
style_issues = tool_context.state.get(StateKeys.STYLE_ISSUES, [])
# Get test results
test_results = tool_context.state.get(StateKeys.TEST_EXECUTION_SUMMARY, {})
# Parse if it's a string
if isinstance(test_results, str):
try:
test_results = json.loads(test_results)
except:
test_results = {}
timestamp = datetime.now().isoformat()
# Create comprehensive report dictionary
report = {
'timestamp': timestamp,
'grading_attempt': tool_context.state.get(StateKeys.GRADING_ATTEMPTS, 1),
'code': {
'content': code,
'line_count': len(code.splitlines()),
'hash': hashlib.md5(code.encode()).hexdigest()
},
'analysis': analysis,
'style': {
'score': style_score,
'issues': style_issues[:5] # First 5 issues
},
'tests': test_results,
'feedback': feedback_text,
'improvements': {
'score_change': tool_context.state.get(StateKeys.SCORE_IMPROVEMENT, 0),
'from_last_score': tool_context.state.get(StateKeys.USER_LAST_STYLE_SCORE, 0)
}
}
# Convert report to JSON string
report_json = json.dumps(report, indent=2)
report_part = types.Part.from_text(text=report_json)
# Try to save as artifact if the service is available
if hasattr(tool_context, 'save_artifact'):
try:
# Generate filename with timestamp (replace colons for filesystem compatibility)
filename = f"grading_report_{timestamp.replace(':', '-')}.json"
# Save the main report
version = await tool_context.save_artifact(filename, report_part)
# Also save a "latest" version for easy access
await tool_context.save_artifact("latest_grading_report.json", report_part)
logger.info(f"Tool: Report saved as {filename} (version {version})")
# Store report in state as well for redundancy
tool_context.state[StateKeys.USER_LAST_GRADING_REPORT] = report
return {
"status": "success",
"artifact_saved": True,
"filename": filename,
"version": str(version),
"size": len(report_json),
"summary": f"Report saved as {filename}"
}
except Exception as artifact_error:
logger.warning(f"Artifact service error: {artifact_error}, falling back to state storage")
# Continue to fallback below
# Fallback: Store in state if artifact service is not available or failed
tool_context.state[StateKeys.USER_LAST_GRADING_REPORT] = report
logger.info("Tool: Report saved to state (artifact service not available)")
return {
"status": "success",
"artifact_saved": False,
"message": "Report saved to state only",
"size": len(report_json),
"summary": "Report saved to session state"
}
except Exception as e:
error_msg = f"Report save error: {str(e)}"
logger.error(f"Tool: {error_msg}", exc_info=True)
# Still try to save minimal data to state
try:
tool_context.state[StateKeys.USER_LAST_GRADING_REPORT] = {
'error': error_msg,
'feedback': feedback_text,
'timestamp': datetime.now().isoformat()
}
except:
pass
return {
"status": "error",
"message": error_msg,
"artifact_saved": False,
"summary": f"Failed to save report: {error_msg}"
}
Tworzenie agenta syntezatora
👉 Otwórz
code_review_assistant/sub_agents/review_pipeline/feedback_synthesizer.py
👉 Znajdź:
# MODULE_5_STEP_4_INSTRUCTION_PROVIDER
👉 Zastąp nazwą dostawcy instrukcji produkcyjnych:
async def feedback_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are an expert code reviewer and mentor providing constructive, educational feedback.
CONTEXT FROM PREVIOUS AGENTS:
- Structure analysis summary: {structure_analysis_summary}
- Style check summary: {style_check_summary}
- Test execution summary: {test_execution_summary}
YOUR TASK requires these steps IN ORDER:
1. Call search_past_feedback tool with developer_id="default_user"
2. Call update_grading_progress tool with no parameters
3. Carefully analyze the test results to understand what really happened
4. Generate comprehensive feedback following the structure below
5. Call save_grading_report tool with the feedback_text parameter
6. Return the feedback as your final output
CRITICAL - Understanding Test Results:
The test_execution_summary contains structured JSON. Parse it carefully:
- tests_passed = Code worked correctly
- tests_failed = Code produced wrong output
- tests_with_errors = Code crashed
- critical_issues = Fundamental problems with the code
If critical_issues array contains items, these are serious bugs that need fixing.
Do NOT count discovering bugs as test successes.
FEEDBACK STRUCTURE TO FOLLOW:
## 📊 Summary
Provide an honest assessment. Be encouraging but truthful about problems found.
## ✅ Strengths
List 2-3 things done well, referencing specific code elements.
## 📈 Code Quality Analysis
### Structure & Organization
Comment on code organization, readability, and documentation.
### Style Compliance
Report the actual style score and any specific issues.
### Test Results
Report the actual test results accurately:
- If critical_issues exist, report them as bugs to fix
- Be clear: "X tests passed, Y critical issues were found"
- List each critical issue
- Don't hide or minimize problems
## 💡 Recommendations for Improvement
Based on the analysis, provide specific actionable fixes.
If critical issues exist, fixing them is top priority.
## 🎯 Next Steps
Prioritized action list based on severity of issues.
## 💬 Encouragement
End with encouragement while being honest about what needs fixing.
Remember: Complete ALL steps including calling save_grading_report."""
return await instructions_utils.inject_session_state(template, context)
👉 Znajdź:
# MODULE_5_STEP_4_SYNTHESIZER_AGENT
👉 Zastąp:
feedback_synthesizer_agent = Agent(
name="FeedbackSynthesizer",
model=config.critic_model,
description="Synthesizes all analysis into constructive, personalized feedback",
instruction=feedback_instruction_provider,
tools=[
FunctionTool(func=search_past_feedback),
FunctionTool(func=update_grading_progress),
FunctionTool(func=save_grading_report)
],
output_key="final_feedback"
)
Krok 5. Podłączanie potoku
Teraz połącz wszystkich 4 agentów w sekwencyjny potok i utwórz agenta głównego.
👉 Otwórz
code_review_assistant/agent.py
👉 Dodaj niezbędne instrukcje importu u góry pliku (po istniejących instrukcjach importu):
from google.adk.agents import Agent, SequentialAgent
from code_review_assistant.sub_agents.review_pipeline.code_analyzer import code_analyzer_agent
from code_review_assistant.sub_agents.review_pipeline.style_checker import style_checker_agent
from code_review_assistant.sub_agents.review_pipeline.test_runner import test_runner_agent
from code_review_assistant.sub_agents.review_pipeline.feedback_synthesizer import feedback_synthesizer_agent
Plik powinien teraz wyglądać tak:
"""
Main agent orchestration for the Code Review Assistant.
"""
from google.adk.agents import Agent, SequentialAgent
from .config import config
from code_review_assistant.sub_agents.review_pipeline.code_analyzer import code_analyzer_agent
from code_review_assistant.sub_agents.review_pipeline.style_checker import style_checker_agent
from code_review_assistant.sub_agents.review_pipeline.test_runner import test_runner_agent
from code_review_assistant.sub_agents.review_pipeline.feedback_synthesizer import feedback_synthesizer_agent
# MODULE_5_STEP_5_CREATE_PIPELINE
# MODULE_6_STEP_5_CREATE_FIX_LOOP
# MODULE_6_STEP_5_UPDATE_ROOT_AGENT
👉 Znajdź:
# MODULE_5_STEP_5_CREATE_PIPELINE
👉 Zastąp ten wiersz tym kodem:
# Create sequential pipeline
code_review_pipeline = SequentialAgent(
name="CodeReviewPipeline",
description="Complete code review pipeline with analysis, testing, and feedback",
sub_agents=[
code_analyzer_agent,
style_checker_agent,
test_runner_agent,
feedback_synthesizer_agent
]
)
# Root agent - coordinates the review pipeline
root_agent = Agent(
name="CodeReviewAssistant",
model=config.worker_model,
description="An intelligent code review assistant that analyzes Python code and provides educational feedback",
instruction="""You are a specialized Python code review assistant focused on helping developers improve their code quality.
When a user provides Python code for review:
1. Immediately delegate to CodeReviewPipeline and pass the code EXACTLY as it was provided by the user.
2. The pipeline will handle all analysis and feedback
3. Return ONLY the final feedback from the pipeline - do not add any commentary
When a user asks what you can do or asks general questions:
- Explain your capabilities for code review
- Do NOT trigger the pipeline for non-code messages
The pipeline handles everything for code review - just pass through its final output.""",
sub_agents=[code_review_pipeline],
output_key="assistant_response"
)
Krok 6. Testowanie pełnego potoku
Czas zobaczyć, jak wszyscy 4 agenci pracują razem.
👉 Uruchom system:
adk web code_review_assistant
Po uruchomieniu polecenia adk web w terminalu powinny pojawić się dane wyjściowe wskazujące, że serwer WWW ADK został uruchomiony. Będą one podobne do tych:
+-----------------------------------------------------------------------------+
| ADK Web Server started |
| |
| For local testing, access at http://localhost:8000. |
+-----------------------------------------------------------------------------+
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
👉 Następnie, aby uzyskać dostęp do interfejsu ADK Dev UI w przeglądarce:
Na pasku narzędzi Cloud Shell (zwykle w prawym górnym rogu) kliknij ikonę podglądu w przeglądarce (często wygląda jak oko lub kwadrat ze strzałką) i wybierz Zmień port. W wyskakującym okienku ustaw port na 8000 i kliknij „Zmień i wyświetl podgląd”. Cloud Shell otworzy nową kartę przeglądarki lub nowe okno przeglądarki z interfejsem ADK Dev.
👉 Agent jest teraz uruchomiony. Interfejs programisty ADK w przeglądarce to bezpośrednie połączenie z agentem.
- Wybierz cel: w menu u góry interfejsu wybierz agenta
code_review_assistant.
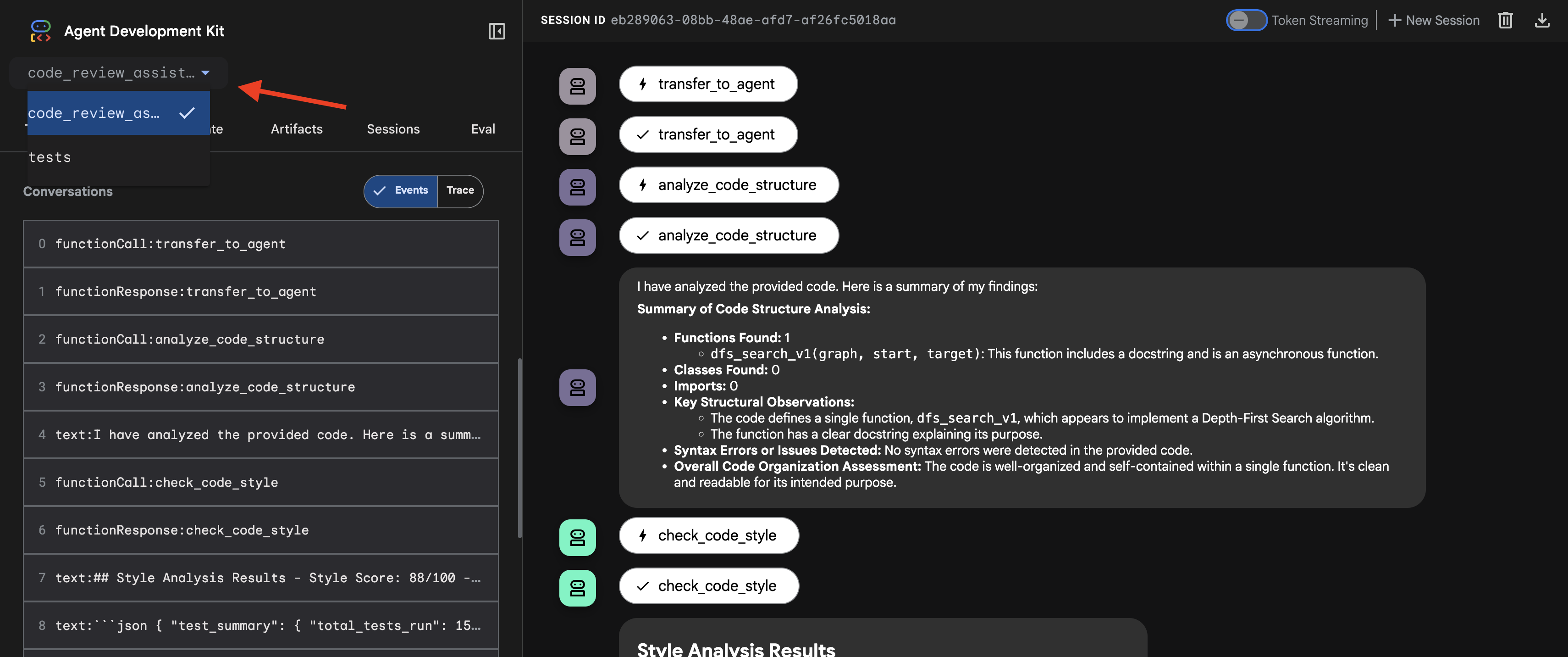
👉 Test Prompt:
Please analyze the following:
def dfs_search_v1(graph, start, target):
"""Find if target is reachable from start."""
visited = set()
stack = start
while stack:
current = stack.pop()
if current == target:
return True
if current not in visited:
visited.add(current)
for neighbor in graph[current]:
if neighbor not in visited:
stack.append(neighbor)
return False
👉 Zobacz, jak działa potok inspekcji kodu:
Gdy prześlesz funkcję dfs_search_v1 z błędem, otrzymasz nie tylko jedną odpowiedź. Obserwujesz działanie potoku z wieloma agentami. Wyświetlane dane wyjściowe przesyłania strumieniowego są wynikiem działania 4 specjalistycznych agentów, którzy wykonują zadania po kolei, a każdy z nich bazuje na wynikach poprzedniego.
Poniżej znajdziesz opis tego, w jaki sposób każdy agent przyczynia się do powstania ostatecznej, kompleksowej opinii, przekształcając surowe dane w praktyczne informacje.
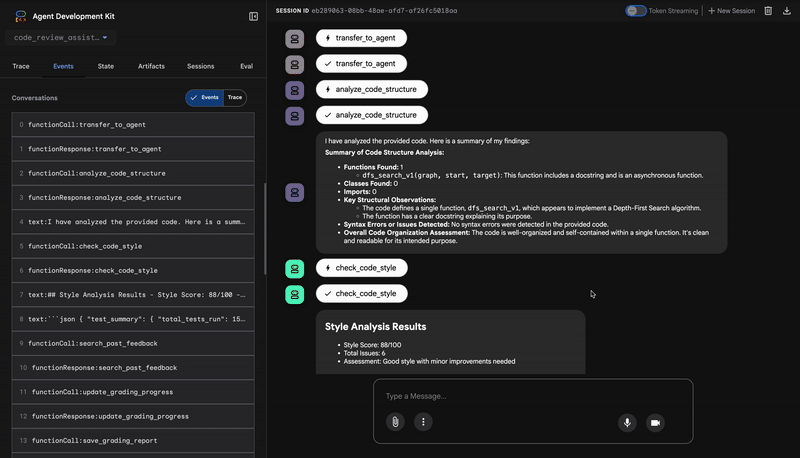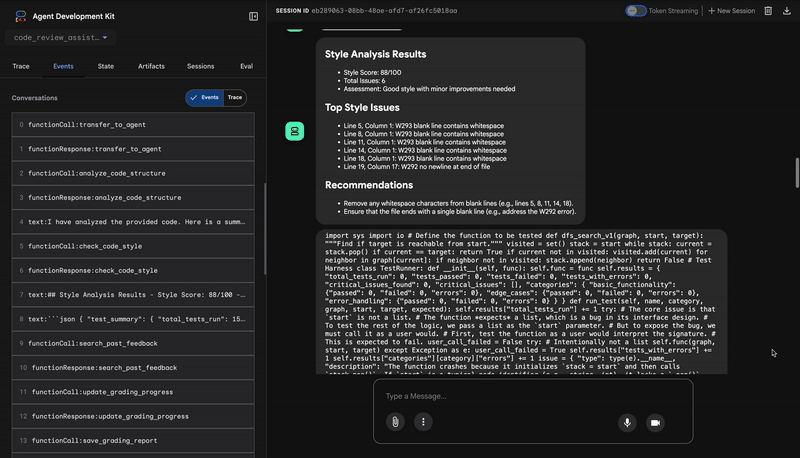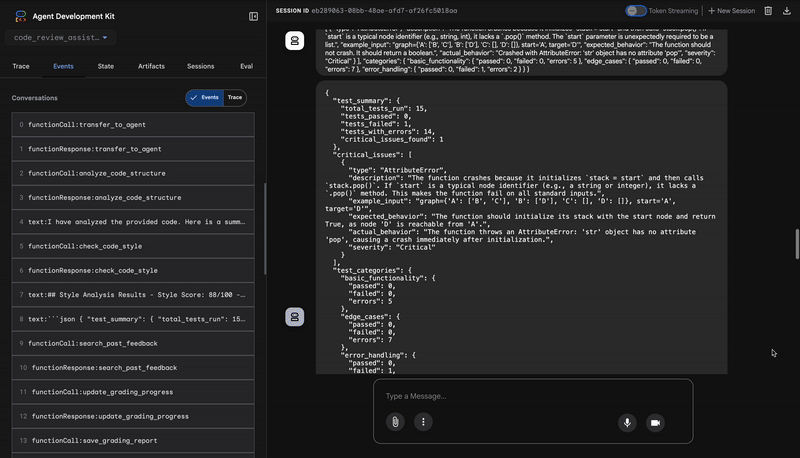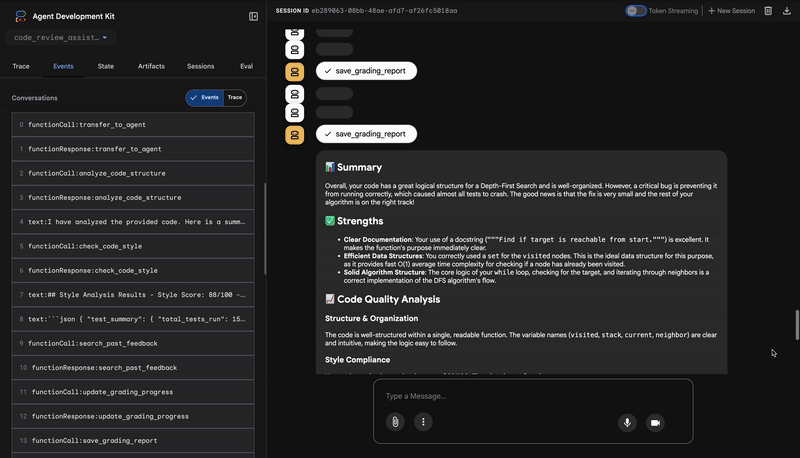
1. Raport strukturalny Analizatora kodu
Najpierw CodeAnalyzer otrzymuje surowy kod. Nie zgaduje, co robi kod, tylko używa narzędzia analyze_code_structure do deterministycznego parsowania drzewa składni abstrakcyjnej (AST).
Jego dane wyjściowe to czyste, oparte na faktach informacje o strukturze kodu:
The analysis of the provided code reveals the following:
Summary:
- Functions Found: 1
- Classes Found: 0
Key Structural Observations:
- A single function, dfs_search_v1, is defined.
- It includes a docstring: "Find if target is reachable from start."
- No syntax errors were detected.
Overall Code Organization Assessment:
- The code snippet is a well-defined, self-contained function.
⭐ Wartość: ten pierwszy krok zapewnia czystą i niezawodną podstawę dla pozostałych agentów. Potwierdza, że kod jest prawidłowym kodem w Pythonie, i wskazuje dokładne komponenty, które wymagają sprawdzenia.
2. Kontrola PEP 8 w narzędziu sprawdzającym styl
Następnie przejmuje kontrolę agent StyleChecker. Odczytuje kod ze stanu udostępnionego i używa narzędzia check_code_style, które korzysta z programu pycodestyle.
Dane wyjściowe to mierzalny wynik jakości i konkretne naruszenia:
Style Analysis Results
- Style Score: 88/100
- Total Issues: 6
- Assessment: Good style with minor improvements needed
Top Style Issues
- Line 5, W293: blank line contains whitespace
- Line 19, W292: no newline at end of file
⭐ Wartość: ten agent przekazuje obiektywne, niepodlegające negocjacjom opinie na podstawie ustalonych standardów społeczności (PEP 8). System ważonych wyników od razu informuje użytkownika o powadze problemów.
3. Wykrywanie krytycznych błędów przez uruchamiającego testy
W tym miejscu system wykracza poza analizę powierzchowną. Agent TestRunner generuje i uruchamia kompleksowy zestaw testów, aby sprawdzić zachowanie kodu.
Jego dane wyjściowe to strukturalny obiekt JSON, który zawiera druzgocący werdykt:
{
"critical_issues": [
{
"type": "Critical Bug",
"description": "The function's initialization `stack = start` is incorrect... When a common input like a string... is provided... the function crashes with an AttributeError.",
"severity": "Critical"
}
],
"verdict": {
"status": "BROKEN",
"confidence": "high",
"recommendation": "The function is fundamentally broken... the stack initialization line `stack = start` must be changed to `stack = [start]`."
}
}
⭐ Wartość: to najważniejsza informacja. Agent nie zgadywał, tylko udowodnił, że kod jest uszkodzony, uruchamiając go. Wykrył subtelny, ale krytyczny błąd czasu działania, który weryfikator mógłby łatwo przeoczyć, i wskazał jego dokładną przyczynę oraz wymaganą poprawkę.
4. Raport końcowy narzędzia Feedback Synthesizer
Na koniec FeedbackSynthesizer agent pełni rolę dyrygenta. Korzysta z danych strukturalnych z 3 poprzednich agentów i tworzy jeden, przyjazny dla użytkownika raport, który jest zarówno analityczny, jak i zachęcający.
Jego wynikiem jest ostateczna, dopracowana opinia, którą widzisz:
📊 Summary
Great effort on implementing the Depth-First Search algorithm! ... However, a critical bug in the initialization of the stack prevents the function from working correctly...
✅ Strengths
- Good Algorithm Structure
- Correct Use of `visited` Set
📈 Code Quality Analysis
...
### Style Compliance
The style analysis returned a good score of 88/100.
...
### Test Results
The automated testing revealed a critical issue... The line `stack = start` directly assigns the input... which results in an `AttributeError`.
💡 Recommendations for Improvement
**Fix the Critical Stack Initialization Bug:**
- Incorrect Code: `stack = start`
- Correct Code: `stack = [start]`
💬 Encouragement
You are very close to a perfect implementation! The core logic of your DFS algorithm is sound, which is the hardest part.
⭐ Wartość: ten agent przekształca dane techniczne w przydatne i edukacyjne informacje. Priorytetowo traktuje najważniejszy problem (błąd), jasno go wyjaśnia, podaje dokładne rozwiązanie i robi to w zachęcającym tonie. Skutecznie łączy on wyniki wszystkich poprzednich etapów w spójną i wartościową całość.
Ten wieloetapowy proces pokazuje możliwości potoku agentowego. Zamiast jednej, monolitycznej odpowiedzi otrzymujesz wielowarstwową analizę, w której każdy agent wykonuje specjalistyczne, weryfikowalne zadanie. Dzięki temu recenzja jest nie tylko wnikliwa, ale też deterministyczna, wiarygodna i bardzo pouczająca.
👉💻 Po zakończeniu testowania wróć do terminala edytora Cloud Shell i naciśnij Ctrl+C, aby zatrzymać interfejs ADK Dev.
Co utworzysz
Masz teraz kompletny potok weryfikacji kodu, który:
✅ Analizuje strukturę kodu – deterministyczna analiza AST z funkcjami pomocniczymi.
✅ Sprawdza styl – ważona ocena z konwencjami nazewnictwa.
✅ Przeprowadza testy – kompleksowe generowanie testów ze strukturalnymi danymi wyjściowymi JSON.
✅ Syntetyzuje opinie – integruje stan + pamięć + artefakty.
✅ Śledzi postępy – wielopoziomowy stan w ramach wywołań, sesji i użytkowników.
✅ Uczy się z czasem – usługa pamięci do wzorców między sesjami.
✅ Dostarcza artefakty – raporty JSON do pobrania z pełną ścieżką audytu.
Opanowane kluczowe pojęcia
Sekwencyjne potoki:
- 4 agenty wykonujące działania w ściśle określonej kolejności
- Każdy z nich wzbogaca stan dla następnego.
- Zależności określają kolejność wykonywania
Wzorce produkcji:
- Rozdzielenie funkcji pomocniczych (synchronizacja w pulach wątków)
- Łagodna degradacja (strategie rezerwowe)
- Wielopoziomowe zarządzanie stanem (tymczasowym, sesji i użytkownika)
- Dynamiczni dostawcy instrukcji (zależni od kontekstu)
- Podwójne miejsce na dane (artefakty + nadmiarowość stanu)
State as Communication:
- Stałe zapobiegają literówkom w przypadku agentów
output_keyzapisuje podsumowania agenta w stanie,- Późniejsze odczytywanie agentów za pomocą StateKeys
- Stan przepływa liniowo przez potok
Pamięć a stan:
- Stan: dane bieżącej sesji
- Pamięć: wzorce w sesjach
- Różne cele, różny okres użytkowania
Orkiestracja narzędzi:
- Agenty z jednym narzędziem (analyzer, style_checker)
- Wbudowane wykonawcy (test_runner)
- Koordynacja wielu narzędzi (syntezator)
Strategia wyboru modelu:
- Model procesu roboczego: zadania mechaniczne (parsowanie, lintowanie, routing)
- Model krytyka: zadania związane z rozumowaniem (testowanie, synteza)
- Optymalizacja kosztów dzięki odpowiedniemu wyborowi
Co dalej
W części 6 utworzysz potok poprawek:
- Architektura LoopAgent do iteracyjnego poprawiania
- Warunki wyjścia w przypadku przekazania
- Akumulacja stanu w kolejnych iteracjach
- Logika weryfikacji i ponawiania
- Integracja z potokiem sprawdzania, aby oferować poprawki
Dowiesz się, jak te same wzorce stanu skalują się do złożonych iteracyjnych przepływów pracy, w których agenci podejmują wiele prób, aż osiągną sukces, oraz jak koordynować wiele potoków w jednej aplikacji.
6. Dodawanie potoku Fix Pipeline: architektura pętli
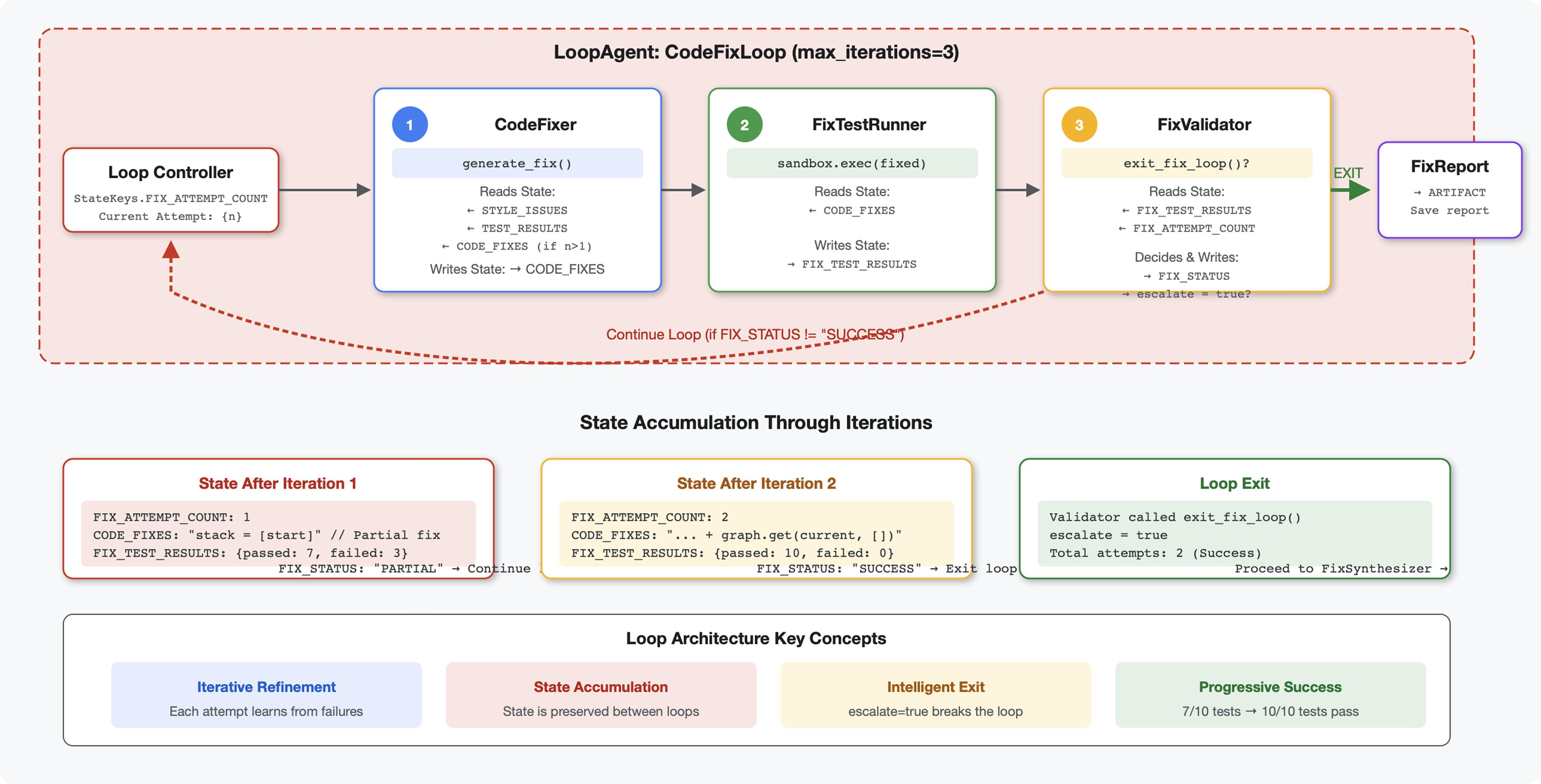
Wprowadzenie
W module 5 utworzyliśmy potok weryfikacji sekwencyjnej, który analizuje kod i przekazuje opinie. Wykrywanie problemów to jednak tylko połowa rozwiązania – deweloperzy potrzebują pomocy w ich naprawianiu.
Ten moduł tworzy automatyczny potok poprawek, który:
- Generuje poprawki na podstawie wyników sprawdzania.
- Weryfikuje poprawki, przeprowadzając kompleksowe testy.
- Automatycznie ponawia próbę, jeśli poprawki nie działają (do 3 razy).
- Wyniki raportów z porównaniami przed i po
Kluczowa koncepcja: LoopAgent do automatycznego ponawiania. W przeciwieństwie do agentów sekwencyjnych, którzy działają tylko raz, LoopAgent powtarza działanie swoich podagentów, dopóki nie zostanie spełniony warunek wyjścia lub nie zostanie osiągnięta maksymalna liczba iteracji. Narzędzia sygnalizują powodzenie, ustawiając wartość tool_context.actions.escalate = True.
Podgląd tego, co stworzysz: przesyłanie kodu z błędami → sprawdzanie identyfikuje problemy → pętla poprawek generuje korekty → testy weryfikują → w razie potrzeby ponawianie prób → końcowy raport kompleksowy.
Podstawowe pojęcia: LoopAgent a Sequential
Sequential Pipeline (Module 5):
SequentialAgent(agents=[A, B, C])
# Executes: A → B → C → Done
- Przepływ w jedną stronę
- Każdy agent jest uruchamiany dokładnie raz
- Brak logiki ponawiania
Loop Pipeline (moduł 6):
LoopAgent(agents=[A, B, C], max_iterations=3)
# Executes: A → B → C → (check exit) → A → B → C → (check exit) → ...
- Przepływ cykliczny
- Agenty mogą być uruchamiane wielokrotnie
- Zakończenie:
- Narzędzie ustawia wartość
tool_context.actions.escalate = True(sukces). - Osiągnięto limit
max_iterations(limit bezpieczeństwa) - Występuje nieobsługiwany wyjątek (błąd)
- Narzędzie ustawia wartość
Dlaczego pętle są przydatne do poprawiania kodu:
Poprawki kodu często wymagają wielu prób:
- Pierwsza próba: naprawienie oczywistych błędów (nieprawidłowe typy zmiennych).
- Druga próba: rozwiąż problemy dodatkowe wykryte przez testy (przypadki skrajne).
- Trzecia próba: dopracuj i sprawdź, czy wszystkie testy zostały zaliczone.
Bez pętli w instrukcjach agenta musiałaby się znaleźć skomplikowana logika warunkowa. W przypadku LoopAgent ponawianie jest automatyczne.
Porównanie architektury:
Sequential (Module 5):
User → Review Pipeline → Feedback → Done
Loop (Module 6):
User → Review Pipeline → Feedback → Fix Pipeline
↓
┌──────────────┴──────────────┐
│ Fix Attempt Loop (1-3x) │
│ ┌─────────────────────┐ │
│ │ 1. Generate Fixes │ │
│ │ 2. Test Fixes │ │
│ │ 3. Validate & Exit? │────┼─→ If escalate=True
│ └─────────────────────┘ │ exit loop
│ ↓ If not │
│ Try Again (max 3) │
└─────────────────────────────┘
↓
4. Synthesize Final Report → Done
Krok 1. Dodaj agenta Code Fixer
Narzędzie do poprawiania kodu generuje poprawiony kod w Pythonie na podstawie wyników sprawdzania.
👉 Otwórz
code_review_assistant/sub_agents/fix_pipeline/code_fixer.py
👉 Znajdź:
# MODULE_6_STEP_1_CODE_FIXER_INSTRUCTION_PROVIDER
👉 Zastąp ten wiersz tym tekstem:
async def code_fixer_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are an expert code fixing specialist.
Original Code:
{code_to_review}
Analysis Results:
- Style Score: {style_score}/100
- Style Issues: {style_issues}
- Test Results: {test_execution_summary}
Based on the test results, identify and fix ALL issues including:
- Interface bugs (e.g., if start parameter expects wrong type)
- Logic errors (e.g., KeyError when accessing graph nodes)
- Style violations
- Missing documentation
YOUR TASK:
Generate the complete fixed Python code that addresses all identified issues.
CRITICAL INSTRUCTIONS:
- Output ONLY the corrected Python code
- Do NOT include markdown code blocks (```python)
- Do NOT include any explanations or commentary
- The output should be valid, executable Python code and nothing else
Common fixes to apply based on test results:
- If tests show AttributeError with 'pop', fix: stack = [start] instead of stack = start
- If tests show KeyError accessing graph, fix: use graph.get(current, [])
- Add docstrings if missing
- Fix any style violations identified
Output the complete fixed code now:"""
return await instructions_utils.inject_session_state(template, context)
👉 Znajdź:
# MODULE_6_STEP_1_CODE_FIXER_AGENT
👉 Zastąp ten wiersz tym tekstem:
code_fixer_agent = Agent(
name="CodeFixer",
model=config.worker_model,
description="Generates comprehensive fixes for all identified code issues",
instruction=code_fixer_instruction_provider,
code_executor=BuiltInCodeExecutor(),
output_key="code_fixes"
)
Krok 2. Dodaj agenta Fix Test Runner
Program do uruchamiania testów poprawek weryfikuje poprawki, przeprowadzając kompleksowe testy poprawionego kodu.
👉 Otwórz
code_review_assistant/sub_agents/fix_pipeline/fix_test_runner.py
👉 Znajdź:
# MODULE_6_STEP_2_FIX_TEST_RUNNER_INSTRUCTION_PROVIDER
👉 Zastąp ten wiersz tym tekstem:
async def fix_test_runner_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that uses the clean code from the previous step."""
template = """You are responsible for validating the fixed code by running tests.
THE FIXED CODE TO TEST:
{code_fixes}
ORIGINAL TEST RESULTS: {test_execution_summary}
YOUR TASK:
1. Understand the fixes that were applied
2. Generate the same comprehensive tests (15-20 test cases)
3. Execute the tests on the FIXED code using your code executor
4. Compare results with original test results
5. Output a detailed JSON analysis
TESTING METHODOLOGY:
- Run the same tests that revealed issues in the original code
- Verify that previously failing tests now pass
- Ensure no regressions were introduced
- Document the improvement
Execute your tests and output ONLY valid JSON with this structure:
- "passed": number of tests that passed
- "failed": number of tests that failed
- "total": total number of tests
- "pass_rate": percentage as a number
- "comparison": object with "original_pass_rate", "new_pass_rate", "improvement"
- "newly_passing_tests": array of test names that now pass
- "still_failing_tests": array of test names still failing
Do NOT output the test code itself, only the JSON analysis."""
return await instructions_utils.inject_session_state(template, context)
👉 Znajdź:
# MODULE_6_STEP_2_FIX_TEST_RUNNER_AGENT
👉 Zastąp ten wiersz tym tekstem:
fix_test_runner_agent = Agent(
name="FixTestRunner",
model=config.critic_model,
description="Runs comprehensive tests on fixed code to verify all issues are resolved",
instruction=fix_test_runner_instruction_provider,
code_executor=BuiltInCodeExecutor(),
output_key="fix_test_execution_summary"
)
Krok 3. Dodaj agenta Fix Validator
Walidator sprawdza, czy poprawki zostały wprowadzone prawidłowo, i decyduje, czy zakończyć pętlę.
Omówienie narzędzi
Najpierw dodaj 3 narzędzia, których potrzebuje walidator.
👉 Otwórz
code_review_assistant/tools.py
👉 Znajdź:
# MODULE_6_STEP_3_VALIDATE_FIXED_STYLE
👉 Zastąp narzędziem Walidator stylu:
async def validate_fixed_style(tool_context: ToolContext) -> Dict[str, Any]:
"""
Validates style compliance of the fixed code.
Args:
tool_context: ADK tool context containing fixed code in state
Returns:
Dictionary with style validation results
"""
logger.info("Tool: Validating style of fixed code...")
try:
# Get the fixed code from state
code_fixes = tool_context.state.get(StateKeys.CODE_FIXES, '')
# Try to extract from markdown if present
if '```python' in code_fixes:
start = code_fixes.rfind('```python') + 9
end = code_fixes.rfind('```')
if start < end:
code_fixes = code_fixes[start:end].strip()
if not code_fixes:
return {
"status": "error",
"message": "No fixed code found in state"
}
# Store the extracted fixed code
tool_context.state[StateKeys.CODE_FIXES] = code_fixes
# Run style check on fixed code
loop = asyncio.get_event_loop()
with ThreadPoolExecutor() as executor:
style_result = await loop.run_in_executor(
executor, _perform_style_check, code_fixes
)
# Compare with original
original_score = tool_context.state.get(StateKeys.STYLE_SCORE, 0)
improvement = style_result['score'] - original_score
# Store results
tool_context.state[StateKeys.FIXED_STYLE_SCORE] = style_result['score']
tool_context.state[StateKeys.FIXED_STYLE_ISSUES] = style_result['issues']
logger.info(f"Tool: Fixed code style score: {style_result['score']}/100 "
f"(improvement: +{improvement})")
return {
"status": "success",
"fixed_style_score": style_result['score'],
"original_style_score": original_score,
"improvement": improvement,
"remaining_issues": style_result['issues'],
"perfect_style": style_result['score'] == 100
}
except Exception as e:
logger.error(f"Tool: Style validation failed: {e}", exc_info=True)
return {
"status": "error",
"message": str(e)
}
👉 Znajdź:
# MODULE_6_STEP_3_COMPILE_FIX_REPORT
👉 Zastąp narzędziem 2 – kompilatorem raportów:
async def compile_fix_report(tool_context: ToolContext) -> Dict[str, Any]:
"""
Compiles comprehensive report of the fix process.
Args:
tool_context: ADK tool context with all fix pipeline data
Returns:
Comprehensive fix report
"""
logger.info("Tool: Compiling comprehensive fix report...")
try:
# Gather all data
original_code = tool_context.state.get(StateKeys.CODE_TO_REVIEW, '')
code_fixes = tool_context.state.get(StateKeys.CODE_FIXES, '')
# Test results
original_tests = tool_context.state.get(StateKeys.TEST_EXECUTION_SUMMARY, {})
fixed_tests = tool_context.state.get(StateKeys.FIX_TEST_EXECUTION_SUMMARY, {})
# Parse if strings
if isinstance(original_tests, str):
try:
original_tests = json.loads(original_tests)
except:
original_tests = {}
if isinstance(fixed_tests, str):
try:
fixed_tests = json.loads(fixed_tests)
except:
fixed_tests = {}
# Extract pass rates
original_pass_rate = 0
if original_tests:
if 'pass_rate' in original_tests:
original_pass_rate = original_tests['pass_rate']
elif 'test_summary' in original_tests:
# Handle test_runner_agent's JSON structure
summary = original_tests['test_summary']
total = summary.get('total_tests_run', 0)
passed = summary.get('tests_passed', 0)
if total > 0:
original_pass_rate = (passed / total) * 100
elif 'passed' in original_tests and 'total' in original_tests:
if original_tests['total'] > 0:
original_pass_rate = (original_tests['passed'] / original_tests['total']) * 100
fixed_pass_rate = 0
all_tests_pass = False
if fixed_tests:
if 'pass_rate' in fixed_tests:
fixed_pass_rate = fixed_tests['pass_rate']
all_tests_pass = fixed_tests.get('failed', 1) == 0
elif 'passed' in fixed_tests and 'total' in fixed_tests:
if fixed_tests['total'] > 0:
fixed_pass_rate = (fixed_tests['passed'] / fixed_tests['total']) * 100
all_tests_pass = fixed_tests.get('failed', 0) == 0
# Style scores
original_style = tool_context.state.get(StateKeys.STYLE_SCORE, 0)
fixed_style = tool_context.state.get(StateKeys.FIXED_STYLE_SCORE, 0)
# Calculate improvements
test_improvement = {
'original_pass_rate': original_pass_rate,
'fixed_pass_rate': fixed_pass_rate,
'improvement': fixed_pass_rate - original_pass_rate,
'all_tests_pass': all_tests_pass
}
style_improvement = {
'original_score': original_style,
'fixed_score': fixed_style,
'improvement': fixed_style - original_style,
'perfect_style': fixed_style == 100
}
# Determine overall status
if all_tests_pass and style_improvement['perfect_style']:
fix_status = 'SUCCESSFUL'
status_emoji = '✅'
elif test_improvement['improvement'] > 0 or style_improvement['improvement'] > 0:
fix_status = 'PARTIAL'
status_emoji = '⚠️'
else:
fix_status = 'FAILED'
status_emoji = '❌'
# Build comprehensive report
report = {
'status': fix_status,
'status_emoji': status_emoji,
'timestamp': datetime.now().isoformat(),
'original_code': original_code,
'code_fixes': code_fixes,
'improvements': {
'tests': test_improvement,
'style': style_improvement
},
'summary': f"{status_emoji} Fix Status: {fix_status}\n"
f"Tests: {original_pass_rate:.1f}% → {fixed_pass_rate:.1f}%\n"
f"Style: {original_style}/100 → {fixed_style}/100"
}
# Store report in state
tool_context.state[StateKeys.FIX_REPORT] = report
tool_context.state[StateKeys.FIX_STATUS] = fix_status
logger.info(f"Tool: Fix report compiled - Status: {fix_status}")
logger.info(f"Tool: Test improvement: {original_pass_rate:.1f}% → {fixed_pass_rate:.1f}%")
logger.info(f"Tool: Style improvement: {original_style} → {fixed_style}")
return {
"status": "success",
"fix_status": fix_status,
"report": report
}
except Exception as e:
logger.error(f"Tool: Failed to compile fix report: {e}", exc_info=True)
return {
"status": "error",
"message": str(e)
}
👉 Znajdź:
# MODULE_6_STEP_3_EXIT_FIX_LOOP
👉 Zastąp narzędziem 3 – sygnał wyjścia z pętli:
def exit_fix_loop(tool_context: ToolContext) -> Dict[str, Any]:
"""
Signal that fixing is complete and should exit the loop.
Args:
tool_context: ADK tool context
Returns:
Confirmation message
"""
logger.info("Tool: Setting escalate flag to exit fix loop")
# This is the critical line that exits the LoopAgent
tool_context.actions.escalate = True
return {
"status": "success",
"message": "Fix complete, exiting loop"
}
Tworzenie agenta weryfikującego
👉 Otwórz
code_review_assistant/sub_agents/fix_pipeline/fix_validator.py
👉 Znajdź:
# MODULE_6_STEP_3_FIX_VALIDATOR_INSTRUCTION_PROVIDER
👉 Zastąp ten wiersz tym tekstem:
async def fix_validator_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are the final validation specialist for code fixes.
You have access to:
- Original issues from initial review
- Applied fixes: {code_fixes}
- Test results after fix: {fix_test_execution_summary}
- All state data from the fix process
Your responsibilities:
1. Use validate_fixed_style tool to check style compliance of fixed code
- Pass no arguments, it will retrieve fixed code from state
2. Use compile_fix_report tool to generate comprehensive report
- Pass no arguments, it will gather all data from state
3. Based on the report, determine overall fix status:
- ✅ SUCCESSFUL: All tests pass, style score 100
- ⚠️ PARTIAL: Improvements made but issues remain
- ❌ FAILED: Fix didn't work or made things worse
4. CRITICAL: If status is SUCCESSFUL, call the exit_fix_loop tool to stop iterations
- This prevents unnecessary additional fix attempts
- If not successful, the loop will continue for another attempt
5. Provide clear summary of:
- What was fixed
- What improvements were achieved
- Any remaining issues requiring manual attention
Be precise and quantitative in your assessment.
"""
return await instructions_utils.inject_session_state(template, context)
👉 Znajdź:
# MODULE_6_STEP_3_FIX_VALIDATOR_AGENT
👉 Zastąp ten wiersz tym tekstem:
fix_validator_agent = Agent(
name="FixValidator",
model=config.worker_model,
description="Validates fixes and generates final fix report",
instruction=fix_validator_instruction_provider,
tools=[
FunctionTool(func=validate_fixed_style),
FunctionTool(func=compile_fix_report),
FunctionTool(func=exit_fix_loop)
],
output_key="final_fix_report"
)
Krok 4. Zapoznaj się z warunkami zakończenia działania narzędzia LoopAgent
LoopAgent można zamknąć na 3 sposoby:
1. Zakończenie powodzeniem (przez przekazanie)
# Inside any tool in the loop:
tool_context.actions.escalate = True
# Effect: Loop completes current iteration, then exits
# Use when: Fix is successful and no more attempts needed
Przykładowy proces:
Iteration 1:
CodeFixer → generates fixes
FixTestRunner → tests show 90% pass rate
FixValidator → compiles report, sees PARTIAL status
→ Does NOT set escalate
→ Loop continues
Iteration 2:
CodeFixer → refines fixes based on failures
FixTestRunner → tests show 100% pass rate
FixValidator → compiles report, sees SUCCESSFUL status
→ Calls exit_fix_loop() which sets escalate = True
→ Loop exits after this iteration
2. Max Iterations Exit
LoopAgent(
name="FixAttemptLoop",
sub_agents=[...],
max_iterations=3 # Safety limit
)
# Effect: After 3 complete iterations, loop exits regardless of escalate
# Use when: Prevent infinite loops if fixes never succeed
Przykładowy proces:
Iteration 1: PARTIAL (continue)
Iteration 2: PARTIAL (continue)
Iteration 3: PARTIAL (but max reached)
→ Loop exits, synthesizer presents best attempt
3. Zakończenie z błędem
# If any agent throws unhandled exception:
raise Exception("Unexpected error")
# Effect: Loop exits immediately with error state
# Use when: Critical failure that can't be recovered
Ewolucja stanu w kolejnych iteracjach:
W każdej iteracji stan jest aktualizowany na podstawie poprzedniej próby:
# Before Iteration 1:
state = {
"code_to_review": "def add(a,b):return a+b", # Original
"style_score": 40,
"test_execution_summary": {...}
}
# After Iteration 1:
state = {
"code_to_review": "def add(a,b):return a+b", # Unchanged
"code_fixes": "def add(a, b):\n return a + b", # NEW
"style_score": 40, # Unchanged
"fixed_style_score": 100, # NEW
"test_execution_summary": {...}, # Unchanged
"fix_test_execution_summary": {...} # NEW
}
# Iteration 2 starts with all this state
# If fixes still not perfect, code_fixes gets overwritten
Dlaczego
escalate
Zamiast wartości zwracanych:
# Bad: Using return value to signal exit
def validator_agent():
report = compile_report()
if report['status'] == 'SUCCESSFUL':
return {"exit": True} # How does loop know?
# Good: Using escalate
def validator_tool(tool_context):
report = compile_report()
if report['status'] == 'SUCCESSFUL':
tool_context.actions.escalate = True # Loop knows immediately
return {"report": report}
Zalety:
- Działa w każdym narzędziu, nie tylko w ostatnim
- Nie wpływa na dane zwrotu
- jasne znaczenie semantyczne,
- Platforma obsługuje logikę zamykania
Krok 5. Połącz komponenty potoku Fix Pipeline
👉 Otwórz
code_review_assistant/agent.py
👉 Dodaj instrukcje importu potoku poprawek (po istniejących instrukcjach importu):
from google.adk.agents import LoopAgent # Add this to the existing Agent, SequentialAgent line
from code_review_assistant.sub_agents.fix_pipeline.code_fixer import code_fixer_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_test_runner import fix_test_runner_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_validator import fix_validator_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_synthesizer import fix_synthesizer_agent
Importy powinny teraz wyglądać tak:
from google.adk.agents import Agent, SequentialAgent, LoopAgent
from .config import config
# Review pipeline imports (from Module 5)
from code_review_assistant.sub_agents.review_pipeline.code_analyzer import code_analyzer_agent
from code_review_assistant.sub_agents.review_pipeline.style_checker import style_checker_agent
from code_review_assistant.sub_agents.review_pipeline.test_runner import test_runner_agent
from code_review_assistant.sub_agents.review_pipeline.feedback_synthesizer import feedback_synthesizer_agent
# Fix pipeline imports (NEW)
from code_review_assistant.sub_agents.fix_pipeline.code_fixer import code_fixer_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_test_runner import fix_test_runner_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_validator import fix_validator_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_synthesizer import fix_synthesizer_agent
👉 Znajdź:
# MODULE_6_STEP_5_CREATE_FIX_LOOP
👉 Zastąp ten wiersz tym tekstem:
# Create the fix attempt loop (retries up to 3 times)
fix_attempt_loop = LoopAgent(
name="FixAttemptLoop",
sub_agents=[
code_fixer_agent, # Step 1: Generate fixes
fix_test_runner_agent, # Step 2: Validate with tests
fix_validator_agent # Step 3: Check success & possibly exit
],
max_iterations=3 # Try up to 3 times
)
# Wrap loop with synthesizer for final report
code_fix_pipeline = SequentialAgent(
name="CodeFixPipeline",
description="Automated code fixing pipeline with iterative validation",
sub_agents=[
fix_attempt_loop, # Try to fix (1-3 times)
fix_synthesizer_agent # Present final results (always runs once)
]
)
👉 Usuń istniejący
root_agent
definicja:
root_agent = Agent(...)
👉 Znajdź:
# MODULE_6_STEP_5_UPDATE_ROOT_AGENT
👉 Zastąp ten wiersz tym tekstem:
# Update root agent to include both pipelines
root_agent = Agent(
name="CodeReviewAssistant",
model=config.worker_model,
description="An intelligent code review assistant that analyzes Python code and provides educational feedback",
instruction="""You are a specialized Python code review assistant focused on helping developers improve their code quality.
When a user provides Python code for review:
1. Immediately delegate to CodeReviewPipeline and pass the code EXACTLY as it was provided by the user.
2. The pipeline will handle all analysis and feedback
3. Return ONLY the final feedback from the pipeline - do not add any commentary
After completing a review, if significant issues were identified:
- If style score < 100 OR tests are failing OR critical issues exist:
* Add at the end: "\n\n💡 I can fix these issues for you. Would you like me to do that?"
- If the user responds yes or requests fixes:
* Delegate to CodeFixPipeline
* Return the fix pipeline's complete output AS-IS
When a user asks what you can do or general questions:
- Explain your capabilities for code review and fixing
- Do NOT trigger the pipeline for non-code messages
The pipelines handle everything for code review and fixing - just pass through their final output.""",
sub_agents=[code_review_pipeline, code_fix_pipeline],
output_key="assistant_response"
)
Krok 6. Dodaj agenta Fix Synthesizer
Po zakończeniu pętli syntezator tworzy przyjazną dla użytkownika prezentację wyników poprawki.
👉 Otwórz
code_review_assistant/sub_agents/fix_pipeline/fix_synthesizer.py
👉 Znajdź:
# MODULE_6_STEP_6_FIX_SYNTHESIZER_INSTRUCTION_PROVIDER
👉 Zastąp ten wiersz tym tekstem:
async def fix_synthesizer_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are responsible for presenting the fix results to the user.
Based on the validation report: {final_fix_report}
Fixed code from state: {code_fixes}
Fix status: {fix_status}
Create a comprehensive yet friendly response that includes:
## 🔧 Fix Summary
[Overall status and key improvements - be specific about what was achieved]
## 📊 Metrics
- Test Results: [original pass rate]% → [new pass rate]%
- Style Score: [original]/100 → [new]/100
- Issues Fixed: X of Y
## ✅ What Was Fixed
[List each fixed issue with brief explanation of the correction made]
## 📝 Complete Fixed Code
[Include the complete, corrected code from state - this is critical]
## 💡 Explanation of Key Changes
[Brief explanation of the most important changes made and why]
[If any issues remain]
## ⚠️ Remaining Issues
[List what still needs manual attention]
## 🎯 Next Steps
[Guidance on what to do next - either use the fixed code or address remaining issues]
Save the fix report using save_fix_report tool before presenting.
Call it with no parameters - it will retrieve the report from state automatically.
Be encouraging about improvements while being honest about any remaining issues.
Focus on the educational aspect - help the user understand what was wrong and how it was fixed.
"""
return await instructions_utils.inject_session_state(template, context)
👉 Znajdź:
# MODULE_6_STEP_6_FIX_SYNTHESIZER_AGENT
👉 Zastąp ten wiersz tym tekstem:
fix_synthesizer_agent = Agent(
name="FixSynthesizer",
model=config.critic_model,
description="Creates comprehensive user-friendly fix report",
instruction=fix_synthesizer_instruction_provider,
tools=[FunctionTool(func=save_fix_report)],
output_key="fix_summary"
)
👉 Dodaj
save_fix_report
narzędzie
tools.py
:
👉 Znajdź:
# MODULE_6_STEP_6_SAVE_FIX_REPORT
👉 Zastąp:
async def save_fix_report(tool_context: ToolContext) -> Dict[str, Any]:
"""
Saves the fix report as an artifact.
Args:
tool_context: ADK tool context
Returns:
Save status
"""
logger.info("Tool: Saving fix report...")
try:
# Get the report from state
fix_report = tool_context.state.get(StateKeys.FIX_REPORT, {})
if not fix_report:
return {
"status": "error",
"message": "No fix report found in state"
}
# Convert to JSON
report_json = json.dumps(fix_report, indent=2)
report_part = types.Part.from_text(text=report_json)
# Generate filename
timestamp = datetime.now().isoformat().replace(':', '-')
filename = f"fix_report_{timestamp}.json"
# Try to save as artifact
if hasattr(tool_context, 'save_artifact'):
try:
version = await tool_context.save_artifact(filename, report_part)
await tool_context.save_artifact("latest_fix_report.json", report_part)
logger.info(f"Tool: Fix report saved as {filename}")
return {
"status": "success",
"filename": filename,
"version": str(version),
"size": len(report_json)
}
except Exception as e:
logger.warning(f"Could not save as artifact: {e}")
# Fallback: store in state
tool_context.state[StateKeys.LAST_FIX_REPORT] = fix_report
return {
"status": "success",
"message": "Fix report saved to state",
"size": len(report_json)
}
except Exception as e:
logger.error(f"Tool: Failed to save fix report: {e}", exc_info=True)
return {
"status": "error",
"message": str(e)
}
Krok 7. Testowanie pełnego potoku poprawek
Czas zobaczyć całą pętlę w akcji.
👉 Uruchom system:
adk web code_review_assistant
Po uruchomieniu polecenia adk web w terminalu powinny pojawić się dane wyjściowe wskazujące, że serwer WWW ADK został uruchomiony. Będą one podobne do tych:
+-----------------------------------------------------------------------------+
| ADK Web Server started |
| |
| For local testing, access at http://localhost:8000. |
+-----------------------------------------------------------------------------+
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
👉 Test Prompt:
Please analyze the following:
def dfs_search_v1(graph, start, target):
"""Find if target is reachable from start."""
visited = set()
stack = start
while stack:
current = stack.pop()
if current == target:
return True
if current not in visited:
visited.add(current)
for neighbor in graph[current]:
if neighbor not in visited:
stack.append(neighbor)
return False
Najpierw prześlij wadliwy kod, aby uruchomić proces weryfikacji. Po wykryciu błędów poproś agenta, aby „poprawił kod”. Spowoduje to uruchomienie zaawansowanego, iteracyjnego potoku poprawek.
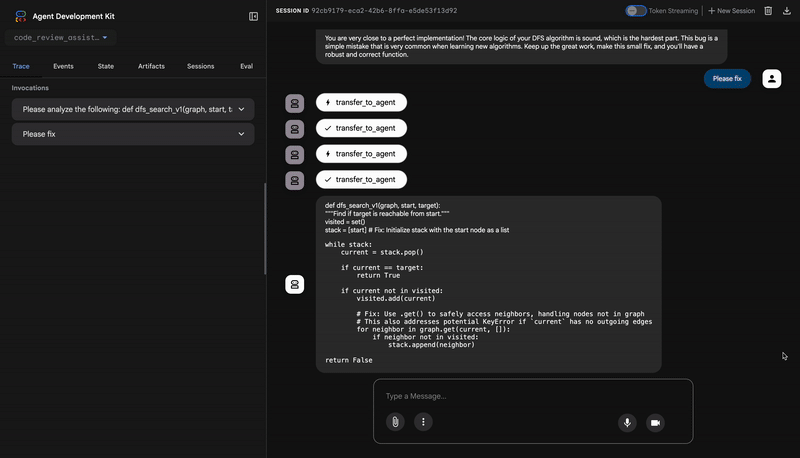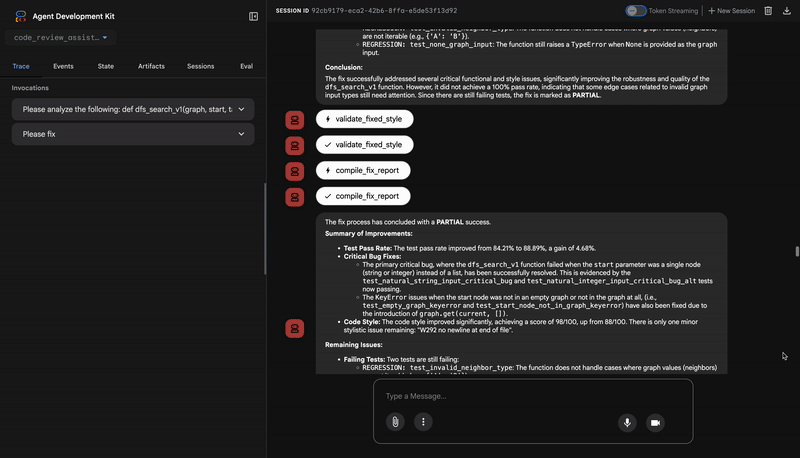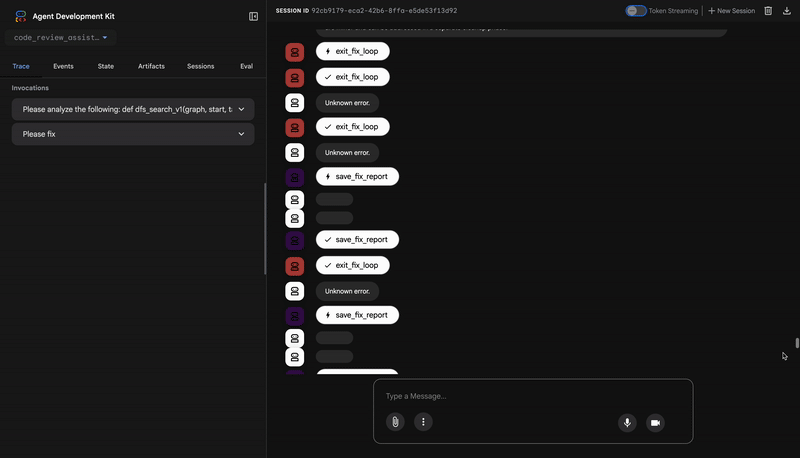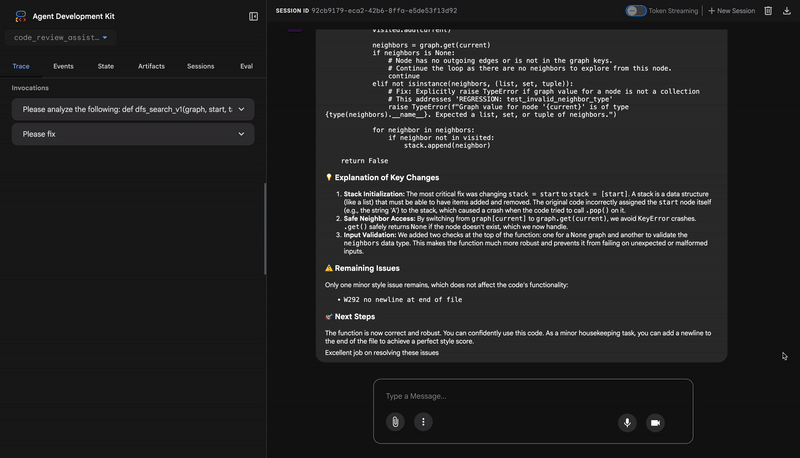
1. Wstępne sprawdzenie (znajdowanie błędów)
To pierwsza połowa procesu. Potok przeglądu z 4 agentami analizuje kod, sprawdza jego styl i uruchamia wygenerowany zestaw testów. Prawidłowo identyfikuje krytyczny AttributeError i inne problemy, wydając werdykt: kod jest USZKODZONY, a odsetek pozytywnych wyników testu wynosi tylko 84,21%.
2. Automatyczna poprawka (pętla w działaniu)
To jest najbardziej imponująca część. Gdy poprosisz agenta o naprawienie kodu, nie wprowadzi on tylko jednej zmiany. Uruchamia to iteracyjną pętlę naprawiania i weryfikowania, która działa jak sumienny deweloper: próbuje naprawić problem, dokładnie testuje rozwiązanie, a jeśli nie jest ono idealne, próbuje ponownie.
Iteracja 1. Pierwsza próba (częściowy sukces)
- Poprawka:
CodeFixeragent odczytuje początkowy raport i wprowadza najbardziej oczywiste poprawki. Zmieniastack = startnastack = [start]i używagraph.get(), aby zapobiec wyjątkomKeyError. - Weryfikacja:
TestRunnernatychmiast ponownie uruchamia pełny zestaw testów w odniesieniu do tego nowego kodu. - Wynik: odsetek zdanych egzaminów znacznie wzrósł do 88,89%. Krytyczne błędy zostały usunięte. Testy są jednak tak kompleksowe, że ujawniają 2 nowe, subtelne błędy (regresje) związane z traktowaniem znaku
Nonejako wartości sąsiednich w grafie lub poza listą. System oznacza poprawkę jako CZĘŚCIOWĄ.
Iteracja 2. Ostatnie szlify (100% skuteczności)
- Rozwiązanie: warunek wyjścia z pętli (100% odpowiedzi) nie został spełniony, więc pętla jest wykonywana ponownie.
CodeFixerzawiera teraz więcej informacji – 2 nowe błędy regresji. Generuje ona ostateczną, bardziej niezawodną wersję kodu, która wyraźnie obsługuje te przypadki brzegowe. - Weryfikacja:
TestRunnerwykonuje zestaw testów po raz ostatni na ostatecznej wersji kodu. - Wynik: 100% zdawalność. Wszystkie pierwotne błędy i wszystkie regresje zostały rozwiązane. System oznacza poprawkę jako SUCCESSFUL i pętla zostaje zakończona.
3. Raport końcowy: doskonały wynik
Po pełnej weryfikacji poprawki FixSynthesizer przejmuje kontrolę, aby przedstawić raport końcowy, przekształcając dane techniczne w jasne i edukacyjne podsumowanie.
Dane | Przed | Po | Poprawa |
Test Pass Rate | 84,21% | 100% | ▲ 15,79% |
Wynik stylu | 88 / 100 | 98 / 100 | ▲ 10 pkt |
Naprawione błędy | 0 z 3 | 3 z 3 | ✅ |
✅ Ostateczny, zweryfikowany kod
Oto pełny, poprawiony kod, który przechodzi wszystkie 19 testów, co pokazuje, że udało się go naprawić:
def dfs_search_v1(graph, start, target):
"""Find if target is reachable from start."""
# Handles 'None' graph input
if graph is None:
return False
visited = set()
# Fixes the critical AttributeError
stack = [start]
while stack:
current = stack.pop()
if current == target:
return True
if current not in visited:
visited.add(current)
# Safely gets neighbors to prevent KeyError
neighbors = graph.get(current)
if neighbors is None:
continue
# Validates that neighbors are iterable
if not isinstance(neighbors, (list, set, tuple)):
raise TypeError(
f"Graph value for node '{current}' is of type "
f"{type(neighbors).__name__}. Expected a list, set, or tuple."
)
for neighbor in neighbors:
if neighbor not in visited:
stack.append(neighbor)
return False
👉💻 Po zakończeniu testowania wróć do terminala edytora Cloud Shell i naciśnij Ctrl+C, aby zatrzymać interfejs ADK Dev.
Co utworzysz
Masz teraz kompletny zautomatyzowany potok poprawek, który:
✅ Generuje poprawki – na podstawie analizy opinii
✅ Przeprowadza iteracyjną weryfikację – testuje po każdej próbie wprowadzenia poprawki
✅ Automatycznie ponawia próby – do 3 razy
✅ Inteligentnie kończy działanie – w przypadku powodzenia przekazuje zgłoszenie do wyższej instancji
✅ Śledzi ulepszenia – porównuje dane przed i po wprowadzeniu zmian
✅ Dostarcza artefakty – raporty z poprawkami do pobrania
Opanowane kluczowe pojęcia
LoopAgent a Sequential
- Sekwencyjny: jeden przebieg przez agentów
- LoopAgent: powtarza działanie do momentu spełnienia warunku zakończenia lub osiągnięcia maksymalnej liczby iteracji.
- Skorzystaj z wyjścia
tool_context.actions.escalate = True
Ewolucja stanu w kolejnych iteracjach:
CODE_FIXESaktualizowany w każdej iteracji- Wyniki testów poprawiają się z czasem
- Weryfikator widzi skumulowane zmiany
Architektura wielu potoków:
- Sprawdzanie potoku: analiza tylko do odczytu (moduł 5)
- Pętla korekty: iteracyjne korygowanie (wewnętrzna pętla modułu 6)
- Poprawianie potoku: pętla + syntezator (moduł 6 zewnętrzny)
- Agent główny: koordynuje działania na podstawie intencji użytkownika
Narzędzia kontrolujące przepływ:
exit_fix_loop()zestawów rośnie- Każde narzędzie może sygnalizować zakończenie pętli
- Oddziela logikę wyjścia od instrukcji agenta
Bezpieczeństwo maksymalnej liczby iteracji:
- Zapobieganie nieskończonym pętlom
- Zapewnia, że system zawsze odpowiada
- Prezentuje najlepszą próbę, nawet jeśli nie jest idealna
Co dalej
W ostatnim module dowiesz się, jak wdrożyć agenta w środowisku produkcyjnym:
- Konfigurowanie pamięci trwałej za pomocą VertexAiSessionService
- Wdrażanie w Agent Engine w Google Cloud
- Monitorowanie i debugowanie agentów produkcyjnych
- Sprawdzone metody dotyczące skalowania i niezawodności
Udało Ci się utworzyć kompletny system wieloagentowy z architekturą sekwencyjną i pętlową. Poznane przez Ciebie wzorce – zarządzanie stanem, instrukcje dynamiczne, koordynacja narzędzi i iteracyjne udoskonalanie – to techniki gotowe do wdrożenia w systemach produkcyjnych, które są używane w rzeczywistych systemach opartych na agentach.
7. Wdrażanie w środowisku produkcyjnym
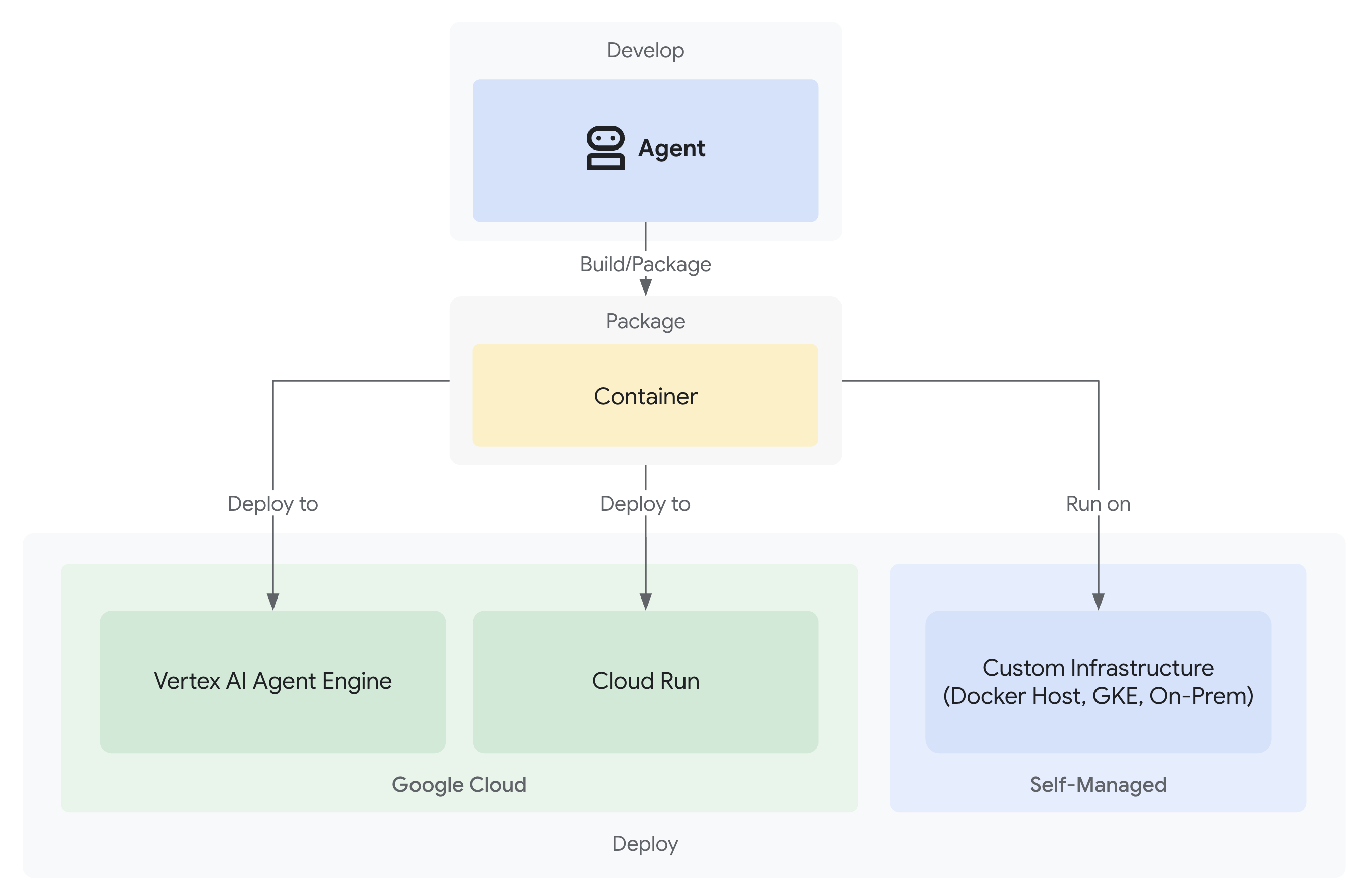
Wprowadzenie
Asystent inspekcji kodu jest już gotowy, a potoki inspekcji i poprawiania działają lokalnie. Brakujący element: działa tylko na Twoim urządzeniu. W tym module wdrożysz agenta w Google Cloud, dzięki czemu będzie on dostępny dla Twojego zespołu w ramach trwałych sesji i infrastruktury klasy produkcyjnej.
Czego się nauczysz:
- 3 ścieżki wdrażania: lokalna, Cloud Run i Agent Engine
- Automatyczne udostępnianie infrastruktury
- Strategie trwałości sesji
- Testowanie wdrożonych agentów
Omówienie opcji wdrażania
ADK obsługuje wiele miejsc docelowych wdrożenia, z których każde ma inne zalety i wady:
Ścieżki wdrożenia
Czynnik | Lokalne ( | Cloud Run ( | Silnik agenta ( |
Złożoność | Minimalny | Średni | Niski |
Trwałość sesji | Tylko w pamięci (utracone po ponownym uruchomieniu) | Cloud SQL (PostgreSQL) | Zarządzane przez Vertex AI (automatyczne) |
Infrastruktura | Brak (tylko na urządzeniu deweloperskim) | Kontener + baza danych | Usługa w pełni zarządzana |
Uruchomienie „na zimno” | Nie dotyczy | 100–2000 ms | 100–500 ms |
Skalowanie | Jedna instancja | Automatyczne (do zera) | Automatycznie |
Model kosztów | Bezpłatne (lokalne przetwarzanie) | Na podstawie żądań + poziom bezpłatny | Oparte na obliczeniach |
Pomoc dotycząca interfejsu | Tak (za pomocą | Tak (za pomocą | Nie (tylko interfejs API) |
Najlepsze zastosowania | Programowanie/testowanie | Zmienny ruch, kontrola kosztów | Agenci produkcji |
Dodatkowa opcja wdrażania: Google Kubernetes Engine (GKE) jest dostępny dla zaawansowanych użytkowników, którzy potrzebują kontroli na poziomie Kubernetes, niestandardowej sieci lub koordynacji wielu usług. Wdrożenie GKE nie jest objęte tymi instrukcjami, ale zostało opisane w przewodniku po wdrażaniu ADK.
Co jest wdrażane
Podczas wdrażania w Cloud Run lub Agent Engine pakowane i wdrażane są te elementy:
- Twój kod agenta (
agent.py, wszyscy subagenci, narzędzia) - Zależności (
requirements.txt) - Serwer API ADK (automatycznie uwzględniony)
- Interfejs internetowy (tylko Cloud Run, gdy określono
--with_ui)
Ważne różnice:
- Cloud Run: używa interfejsu wiersza poleceń
adk deploy cloud_run(automatycznie kompiluje kontener) lubgcloud run deploy(wymaga niestandardowego pliku Dockerfile). - Agent Engine: używa interfejsu
adk deploy agent_engineCLI (nie wymaga tworzenia kontenera, bezpośrednio pakuje kod w Pythonie).
Krok 1. Konfigurowanie środowiska
Konfigurowanie pliku .env
Twój plik .env (utworzony w module 3) wymaga aktualizacji na potrzeby wdrożenia w chmurze. Otwórz .env i sprawdź lub zaktualizuj te ustawienia:
Wymagane w przypadku wszystkich wdrożeń w chmurze:
# Your actual GCP Project ID (REQUIRED)
GOOGLE_CLOUD_PROJECT=your-project-id
# GCP region for deployments (REQUIRED)
GOOGLE_CLOUD_LOCATION=us-central1
# Use Vertex AI (REQUIRED)
GOOGLE_GENAI_USE_VERTEXAI=true
# Model configuration (already set)
WORKER_MODEL=gemini-2.5-flash
CRITIC_MODEL=gemini-2.5-pro
Ustaw nazwy zasobników (WYMAGANE przed uruchomieniem skryptu deploy.sh):
Skrypt wdrażania tworzy zasobniki na podstawie tych nazw. Ustaw je teraz:
# Staging bucket for Agent Engine code uploads (REQUIRED for agent-engine)
STAGING_BUCKET=gs://your-project-id-staging
# Artifact storage for reports and fixed code (REQUIRED for both cloud-run and agent-engine)
ARTIFACT_BUCKET=gs://your-project-id-artifacts
Zastąp your-project-id rzeczywistym identyfikatorem projektu w obu nazwach zasobników. Jeśli te zasobniki nie istnieją, skrypt je utworzy.
Zmienne opcjonalne (tworzone automatycznie, jeśli są puste):
# Agent Engine ID (populated after first deployment)
AGENT_ENGINE_ID=
# Cloud Run Database credentials (created automatically if blank)
CLOUD_SQL_INSTANCE_NAME=
DB_USER=
DB_PASSWORD=
DB_NAME=
Sprawdzanie uwierzytelniania
Jeśli podczas wdrażania wystąpią błędy uwierzytelniania:
gcloud auth application-default login
gcloud config set project $GOOGLE_CLOUD_PROJECT
Krok 2. Zapoznaj się ze skryptem wdrożenia
deploy.sh Skrypt udostępnia ujednolicony interfejs dla wszystkich trybów wdrażania:
./deploy.sh {local|cloud-run|agent-engine}
Możliwości skryptu
Udostępnianie infrastruktury:
- Włączanie interfejsów API (AI Platform, Storage, Cloud Build, Cloud Trace, Cloud SQL)
- Konfiguracja uprawnień IAM (konta usługi, role)
- Tworzenie zasobów (zasobników, baz danych, instancji)
- Wdrażanie z odpowiednimi flagami
- Weryfikacja po wdrożeniu
Kluczowe sekcje skryptu
- Konfiguracja (wiersze 1–35): projekt, region, nazwy usług, wartości domyślne
- Funkcje pomocnicze (wiersze 37–200): włączanie interfejsu API, tworzenie zasobnika, konfigurowanie IAM.
- Główna logika (wiersze 202–400): orkiestracja wdrażania w zależności od trybu
Krok 3. Przygotuj agenta do Agent Engine
Przed wdrożeniem w Agent Engine potrzebny jest plik agent_engine_app.py, który opakowuje agenta na potrzeby zarządzanego środowiska wykonawczego. Zostało ono już utworzone.
Wyświetl code_review_assistant/agent_engine_app.py
👉 Otwórz plik:
"""
Agent Engine application wrapper.
This file prepares the agent for deployment to Vertex AI Agent Engine.
"""
from vertexai import agent_engines
from .agent import root_agent
# Wrap the agent in an AdkApp object for Agent Engine deployment
app = agent_engines.AdkApp(
agent=root_agent,
enable_tracing=True,
)
Krok 4. Wdróż w Agent Engine
Agent Engine to zalecane wdrożenie produkcyjne agentów ADK, ponieważ zapewnia:
- W pełni zarządzana infrastruktura (bez konieczności tworzenia kontenerów)
- Wbudowana trwałość sesji za pomocą
VertexAiSessionService - Automatyczne skalowanie od zera
- Integracja z Cloud Trace włączona domyślnie
Różnice między Agent Engine a innymi wdrożeniami
W GA4
deploy.sh agent-engine
używa:
adk deploy agent_engine \
--project=$GOOGLE_CLOUD_PROJECT \
--region=$GOOGLE_CLOUD_LOCATION \
--staging_bucket=$STAGING_BUCKET \
--display_name="Code Review Assistant" \
--trace_to_cloud \
code_review_assistant
To polecenie:
- bezpośrednie pakowanie kodu Pythona (bez tworzenia Dockera);
- Przesyła do zasobnika tymczasowego określonego w
.env - Tworzy zarządzaną instancję Agent Engine.
- Włącza Cloud Trace na potrzeby obserwacji
- Używa
agent_engine_app.pydo konfigurowania środowiska wykonawczego
W przeciwieństwie do Cloud Run, która konteneryzuje Twój kod, Agent Engine uruchamia kod Pythona bezpośrednio w zarządzanym środowisku wykonawczym, podobnie jak funkcje bezserwerowe.
Uruchamianie wdrożenia
W katalogu głównym projektu:
./deploy.sh agent-engine
Etapy wdrażania
Obserwuj, jak skrypt wykonuje te fazy:
Phase 1: API Enablement
✓ aiplatform.googleapis.com
✓ storage-api.googleapis.com
✓ cloudbuild.googleapis.com
✓ cloudtrace.googleapis.com
Phase 2: IAM Setup
✓ Getting project number
✓ Granting Storage Object Admin
✓ Granting AI Platform User
✓ Granting Cloud Trace Agent
Phase 3: Staging Bucket
✓ Creating gs://your-project-id-staging
✓ Setting permissions
Phase 4: Artifact Bucket
✓ Creating gs://your-project-id-artifacts
✓ Configuring access
Phase 5: Validation
✓ Checking agent.py exists
✓ Verifying root_agent defined
✓ Checking agent_engine_app.py exists
✓ Validating requirements.txt
Phase 6: Build & Deploy
✓ Packaging agent code
✓ Uploading to staging bucket
✓ Creating Agent Engine instance
✓ Configuring session persistence
✓ Setting up Cloud Trace integration
✓ Running health checks
Ten proces trwa 5–10 minut, ponieważ obejmuje pakowanie agenta i wdrażanie go w infrastrukturze Vertex AI.
Zapisywanie identyfikatora silnika agenta
Po pomyślnym wdrożeniu:
✅ Deployment successful!
Agent Engine ID: 7917477678498709504
Resource Name: projects/123456789/locations/us-central1/reasoningEngines/7917477678498709504
Endpoint: https://us-central1-aiplatform.googleapis.com/v1/...
⚠️ IMPORTANT: Save this in your .env file:
AGENT_ENGINE_ID=7917477678498709504
Zaktualizuj
.env
plik od razu:
echo "AGENT_ENGINE_ID=7917477678498709504" >> .env
Ten identyfikator jest wymagany w przypadku:
- Testowanie wdrożonego agenta
- Późniejsze aktualizowanie wdrożenia
- Dostęp do logów i śladów
Co zostało wdrożone
Wdrożenie Agent Engine obejmuje teraz:
✅ Pełny potok weryfikacji (4 agenty)
✅ Pełny potok poprawek (pętla + syntezator)
✅ Wszystkie narzędzia (analiza AST, sprawdzanie stylu, generowanie artefaktów)
✅ Trwałość sesji (automatyczna za pomocą VertexAiSessionService)
✅ Zarządzanie stanem (poziomy sesji, użytkownika i całego okresu)
✅ Obserwacja (włączona usługa Cloud Trace)
✅ Infrastruktura automatycznego skalowania
Krok 5. Przetestuj wdrożonego agenta
Aktualizowanie pliku .env
Po wdrożeniu sprawdź, czy .env zawiera:
AGENT_ENGINE_ID=7917477678498709504 # From deployment output
GOOGLE_CLOUD_PROJECT=your-project-id
GOOGLE_CLOUD_LOCATION=us-central1
Uruchom scenariusz testowania
Projekt zawiera tests/test_agent_engine.py przeznaczone specjalnie do testowania wdrożeń Agent Engine:
python tests/test_agent_engine.py
Co sprawdza test
- Uwierzytelnia się w Twoim projekcie w chmurze Google Cloud.
- Tworzy sesję z wdrożonym agentem.
- Wysyła prośbę o weryfikację kodu (przykład błędu DFS)
- Przesyła strumieniowo odpowiedź za pomocą zdarzeń wysyłanych przez serwer (SSE).
- Weryfikuje trwałość sesji i zarządzanie stanem.
Oczekiwane dane wyjściowe
Authenticated with project: your-project-id
Targeting Agent Engine: projects/.../reasoningEngines/7917477678498709504
Creating new session...
Created session: 4857885913439920384
Sending query to agent and streaming response:
data: {"content": {"parts": [{"text": "I'll analyze your code..."}]}}
data: {"content": {"parts": [{"text": "**Code Structure Analysis**\n..."}]}}
data: {"content": {"parts": [{"text": "**Style Check Results**\n..."}]}}
data: {"content": {"parts": [{"text": "**Test Results**\n..."}]}}
data: {"content": {"parts": [{"text": "**Final Feedback**\n..."}]}}
Stream finished.
Lista kontrolna weryfikacji
- ✅ Wykonanie pełnego potoku weryfikacji (wszyscy 4 agenci)
- ✅ Strumieniowanie odpowiedzi pokazuje postępowe dane wyjściowe
- ✅ Stan sesji jest zachowywany w kolejnych żądaniach
- ✅ Brak błędów uwierzytelniania lub połączenia
- ✅ Wywołania narzędzi są wykonywane prawidłowo (analiza AST, sprawdzanie stylu).
- ✅ Artefakty są zapisywane (raport oceny jest dostępny).
Alternatywa: wdrażanie w Cloud Run
Agent Engine jest zalecany w przypadku uproszczonego wdrażania produkcyjnego, ale Cloud Run zapewnia większą kontrolę i obsługuje interfejs ADK. W tej sekcji znajdziesz ogólne informacje.
Kiedy używać Cloud Run
Wybierz Cloud Run, jeśli potrzebujesz:
- Interfejs internetowy ADK do interakcji z użytkownikiem
- Pełna kontrola nad środowiskiem kontenera
- Niestandardowe konfiguracje bazy danych
- Integracja z istniejącymi usługami Cloud Run
Jak działa wdrożenie Cloud Run
W GA4
deploy.sh cloud-run
używa:
adk deploy cloud_run \
--project=$GOOGLE_CLOUD_PROJECT \
--region=$GOOGLE_CLOUD_LOCATION \
--service_name="code-review-assistant" \
--app_name="code_review_assistant" \
--port=8080 \
--with_ui \
--artifact_service_uri="gs://$ARTIFACT_BUCKET" \
--trace_to_cloud \
code_review_assistant
To polecenie:
- tworzy kontener Dockera z kodem agenta;
- Wysyłanie do Google Artifact Registry
- Wdrażanie jako usługa Cloud Run
- Zawiera interfejs internetowy ADK (
--with_ui) - Konfiguruje połączenie z Cloud SQL (dodane przez skrypt po początkowym wdrożeniu)
Kluczowa różnica w porównaniu z Agent Engine: Cloud Run umieszcza kod w kontenerze i wymaga bazy danych do utrwalania sesji, podczas gdy Agent Engine automatycznie obsługuje obie te czynności.
Polecenie wdrożenia Cloud Run
./deploy.sh cloud-run
Co się zmieniło
Infrastruktura:
- Wdrożenie skonteneryzowane (Docker skompilowany automatycznie przez ADK)
- Cloud SQL (PostgreSQL) do utrwalania sesji
- Baza danych utworzona automatycznie przez skrypt lub korzystająca z istniejącej instancji
Zarządzanie sesjami:
- Używa
DatabaseSessionServicezamiastVertexAiSessionService - Wymaga danych logowania do bazy danych w
.env(lub wygenerowanych automatycznie) - Stan jest przechowywany w bazie danych PostgreSQL
Obsługa interfejsu:
- Interfejs internetowy dostępny za pomocą flagi
--with_ui(obsługiwany przez skrypt) - Dostęp:
https://code-review-assistant-xyz.a.run.app
Co udało Ci się osiągnąć
Wdrożenie w wersji produkcyjnej obejmuje:
✅ Automatyczne udostępnianie za pomocą deploy.shskryptu
✅ Zarządzana infrastruktura (Agent Engine obsługuje skalowanie, trwałość i monitorowanie)
✅ Trwały stan na wszystkich poziomach pamięci (sesja, użytkownik, czas życia)
✅ Bezpieczne zarządzanie danymi logowania (automatyczne generowanie i konfigurowanie IAM)
✅ Skalowalna architektura (od 0 do tysięcy użytkowników jednocześnie)
✅ Wbudowana widoczność (włączona integracja z Cloud Trace)
✅ Obsługa błędów i przywracanie na poziomie produkcyjnym
Opanowane kluczowe pojęcia
Przygotowanie do wdrożenia:
agent_engine_app.py: opakowuje agenta za pomocąAdkAppna potrzeby Agent EngineAdkAppautomatycznie konfigurujeVertexAiSessionServicepod kątem trwałości.- Śledzenie włączone przez
enable_tracing=True
Polecenia wdrażania:
adk deploy agent_engine: pakuje kod Pythona, bez kontenerów.adk deploy cloud_run: automatycznie tworzy kontener Dockera.gcloud run deploy: Alternatywa z niestandardowym plikiem Dockerfile
Opcje wdrażania:
- Agent Engine: w pełni zarządzana usługa, najszybsze wdrożenie w środowisku produkcyjnym
- Cloud Run: większa kontrola, obsługa interfejsu internetowego
- GKE: zaawansowane sterowanie Kubernetes (patrz przewodnik po wdrażaniu GKE)
Usługi zarządzane:
- Agent Engine automatycznie obsługuje trwałość sesji
- Cloud Run wymaga skonfigurowania bazy danych (lub automatycznego utworzenia)
- Obie usługi obsługują przechowywanie artefaktów w GCS.
Zarządzanie sesjami:
- Silnik agenta:
VertexAiSessionService(automatycznie) - Cloud Run:
DatabaseSessionService(Cloud SQL) - Lokalne:
InMemorySessionService(tymczasowe)
Twój agent jest aktywny
Twój asystent inspekcji kodu to teraz:
- Dostępne przez punkty końcowe interfejsu API HTTPS
- Persistent, w którym stan jest zachowywany po ponownym uruchomieniu.
- Skalowalność, która automatycznie dostosowuje się do wzrostu zespołu.
- Obserwowalna z pełnymi śladami żądań
- Łatwe w utrzymaniu dzięki wdrożeniom opartym na skryptach
Co dalej? W module 8 dowiesz się, jak używać Cloud Trace do analizowania skuteczności agenta, identyfikowania wąskich gardeł w potokach sprawdzania i poprawiania oraz optymalizowania czasu wykonania.
8. Dostrzegalność w środowisku produkcyjnym
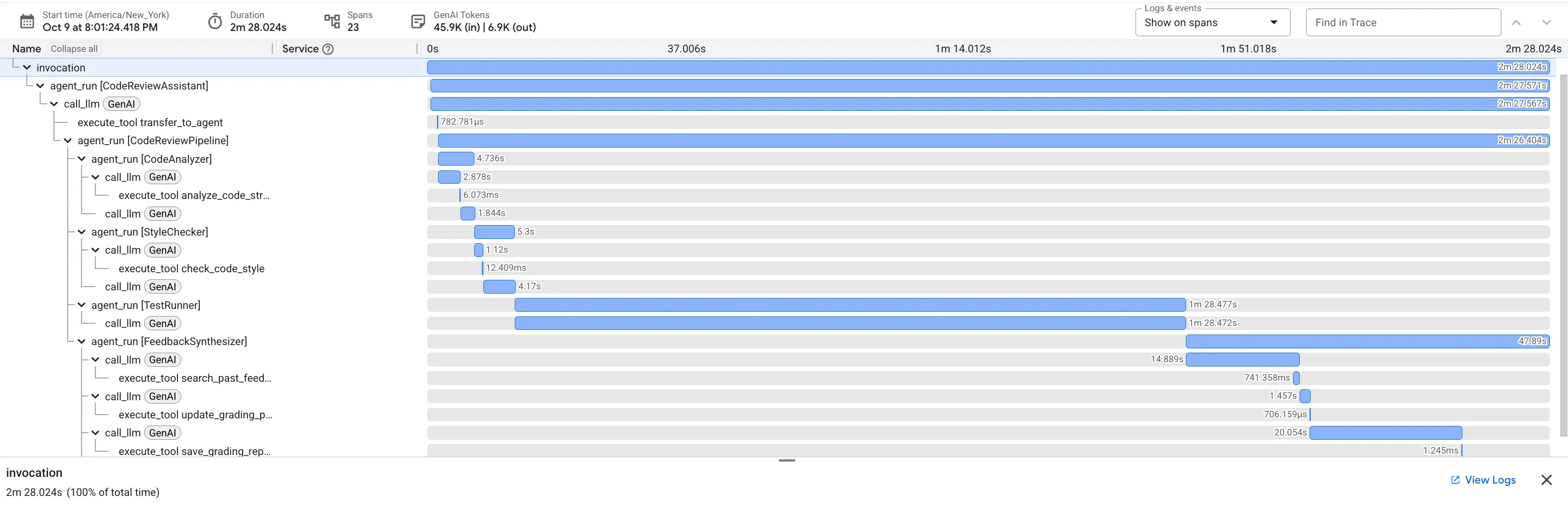
Wprowadzenie
Asystent inspekcji kodu został wdrożony i działa w środowisku produkcyjnym na platformie Agent Engine. Ale skąd wiesz, że działa dobrze? Czy potrafisz odpowiedzieć na te kluczowe pytania:
- Czy pracownik obsługi klienta odpowiada wystarczająco szybko?
- Które operacje są najwolniejsze?
- Czy pętle naprawcze działają wydajnie?
- Gdzie występują wąskie gardła wydajności?
Bez dostrzegalności działasz na ślepo. Flaga --trace-to-cloud użyta podczas wdrażania automatycznie włączyła Cloud Trace, co zapewnia pełną widoczność każdego żądania przetwarzanego przez agenta. Dzięki temu debugowanie przestaje być zgadywaniem, a staje się analizą kryminalistyczną.
Z tego modułu dowiesz się, jak odczytywać ślady, rozumieć charakterystykę działania agenta i na podstawie konkretnych dowodów określać obszary, które można zoptymalizować.
Omówienie śladów i zakresów
Czym jest ślad?
Log czasu to pełna oś czasu obsługi pojedynczego żądania przez agenta. Obejmuje wszystko od momentu wysłania zapytania przez użytkownika do momentu dostarczenia ostatecznej odpowiedzi. Każdy ślad zawiera:
- Łączny czas trwania żądania
- wszystkie operacje, które zostały wykonane;
- Jak operacje są ze sobą powiązane (relacje nadrzędne i podrzędne)
- Kiedy rozpoczęła się i zakończyła każda operacja
Co to jest zakres?
Zakres reprezentuje pojedynczą jednostkę pracy w śladzie. Typowe rodzaje zakresów w asystencie weryfikacji kodu:
agent_run: wykonanie agenta (głównego lub sub-agenta).call_llm: żądanie do modelu językowegoexecute_tool: wykonanie funkcji narzędziastate_read/state_write: operacje zarządzania stanemcode_executor: uruchamianie kodu z testami
Spany mają:
- Nazwa: jaką operację reprezentuje
- Czas trwania: ile czasu zajęło wykonanie zadania.
- Atrybuty: metadane takie jak nazwa modelu, liczba tokenów, dane wejściowe i wyjściowe.
- Stan: sukces lub niepowodzenie.
- Relacje nadrzędne i podrzędne: które operacje wywołały które.
Automatyczne instrumentowanie
Gdy wdrożysz pakiet ADK za pomocą --trace-to-cloud, automatycznie skonfiguruje on:
- Każde wywołanie agenta i wywołanie subagenta
- Wszystkie żądania LLM z liczbą tokenów
- Wykonania narzędzia z danymi wejściowymi i wyjściowymi
- Operacje stanu (odczyt/zapis)
- Iteracje pętli w potoku poprawek
- Warunki błędu i ponawianie
Nie wymaga to żadnych zmian w kodzie – śledzenie jest wbudowane w środowisko wykonawcze ADK.
Krok 1. Otwórz Eksplorator Cloud Trace
Otwórz Cloud Trace w konsoli Google Cloud:
- Otwórz Eksplorator Cloud Trace.
- Wybierz projekt z menu (powinien być już wybrany).
- W module 7 powinny być widoczne ślady testu.
Jeśli nie widzisz jeszcze śladów:
Test przeprowadzony w module 7 powinien wygenerować ślady. Jeśli lista jest pusta, wygeneruj dane logu czasu:
python tests/test_agent_engine.py
Poczekaj 1–2 minuty, aż ślady pojawią się w konsoli.
Na co patrzysz
Eksplorator logów czasu wyświetla:
- Lista śladów: każdy wiersz reprezentuje 1 pełne żądanie.
- Oś czasu: kiedy wystąpiły żądania.
- Czas trwania: czas trwania każdego żądania.
- Szczegóły żądania: sygnatura czasowa, czas oczekiwania, liczba zakresów
Jest to dziennik ruchu produkcyjnego – każda interakcja z agentem tworzy ślad.
Krok 2. Sprawdź ślad potoku sprawdzania
Kliknij dowolny ślad na liście, aby otworzyć widok kaskadowy.
Wyświetli się wykres Gantta przedstawiający pełną oś czasu wykonania. Główny span invocation reprezentuje całe żądanie. Pod nim znajdują się spany dla każdego sub-agenta, narzędzia i wywołania LLM.
Odczytywanie wykresu kaskadowego: identyfikowanie wąskich gardeł
Każdy pasek reprezentuje zakres. Pozycja pozioma pokazuje, kiedy się rozpoczęło, a długość – jak długo trwało. Od razu zobaczysz, na co agent poświęca czas.
Najważniejsze wnioski z powyższego śladu:
- Łączny czas oczekiwania: całe żądanie zajęło 2 minuty i 28 sekund.
- Podział na podmioty:
Code Analyzer: 4,7 sekundyStyle Checker: 5,3 sekundyTest Runner: 1 minuta i 28 sekundFeedback Synthesizer: 47,9 sekundy
- Analiza ścieżki krytycznej:
Test Runneragent jest wyraźnym wąskim gardłem wydajności, odpowiadającym za około 59% całkowitego czasu żądania.
Ta widoczność jest bardzo ważna. Zamiast zgadywać, gdzie jest spędzany czas, masz konkretne dowody na to, że jeśli chcesz zoptymalizować czas oczekiwania, oczywistym celem jest Test Runner.
Sprawdzanie wykorzystania tokenów pod kątem optymalizacji kosztów
Cloud Trace nie tylko pokazuje czas, ale też ujawnia koszty, rejestrując wykorzystanie tokenów w przypadku każdego wywołania LLM.
Kliknij
call_llm
przedział w śladzie. W panelu szczegółów znajdziesz atrybuty dla llm.usage.prompt_tokens i llm.usage.completion_tokens.

Dzięki temu możesz:
- Śledzenie kosztów na poziomie szczegółowym: możesz dokładnie sprawdzić, ile tokenów zużywa każdy agent i każde narzędzie.
- Wyszukiwanie możliwości optymalizacji: jeśli agent używa zaskakująco dużej liczby tokenów, może to być okazja do udoskonalenia promptu lub przejścia na mniejszy, bardziej opłacalny model do tego konkretnego zadania.
Krok 3. Analiza śladu potoku poprawek
Proces naprawy jest bardziej złożony, ponieważ obejmuje LoopAgent. Cloud Trace ułatwia zrozumienie tego iteracyjnego zachowania.
Znajdź ślad, który zawiera „FixAttemptLoop” w nazwach zakresów.
Jeśli nie masz takiego pliku, uruchom scenariusz testowania i odpowiedz twierdząco na pytanie, czy chcesz poprawić kod.
Badanie struktury pętli
Widok śledzenia wyraźnie pokazuje wykonanie pętli. Jeśli pętla naprawy została uruchomiona 2 razy, zanim udało się rozwiązać problem, zobaczysz 2 elementy loop_iteration zagnieżdżone w elemencie FixAttemptLoop. Każdy z nich będzie zawierać pełny cykl działania agentów CodeFixer, FixTestRunner i FixValidator.

Najważniejsze obserwacje dotyczące śledzenia pętli:
- Iteracyjne ulepszanie jest widoczne: możesz zobaczyć, jak system próbuje wprowadzić poprawkę w
loop_iteration: 1, zweryfikować ją, a potem – ponieważ nie była idealna – spróbować ponownie wloop_iteration: 2. - Konwergencja jest mierzalna: możesz porównać czas trwania i wyniki każdej iteracji, aby sprawdzić, jak system zbiega się do prawidłowego rozwiązania.
- Uproszczone debugowanie: jeśli pętla działa przez maksymalną liczbę iteracji i nadal nie działa, możesz sprawdzić stan i zachowanie agenta w zakresie każdej iteracji, aby zdiagnozować, dlaczego poprawki nie zbiegają się.
Ten poziom szczegółowości jest nieoceniony w przypadku zrozumienia i debugowania działania złożonych pętli stanowych w środowisku produkcyjnym.
Krok 4. Co udało Ci się odkryć
Wzorce wydajności
Po przeanalizowaniu śladów masz teraz wgląd w dane:
Potok sprawdzania:
- Główny wąskie gardło:
Test Runneragent, a zwłaszcza wykonywanie kodu i generowanie testów na podstawie LLM, to najbardziej czasochłonna część weryfikacji. - Szybkie operacje: narzędzia deterministyczne (
analyze_code_structure) i operacje zarządzania stanem są bardzo szybkie i nie wpływają na wydajność.
Popraw potok:
- Współczynnik zbieżności: większość poprawek jest wprowadzana w 1–2 iteracjach, co potwierdza skuteczność architektury pętli.
- Rosnący koszt: kolejne iteracje mogą trwać dłużej, ponieważ kontekst LLM rośnie wraz z informacjami z poprzednich nieudanych prób.
Czynniki kosztów:
- Zużycie tokenów: możesz określić, które agenty (np. syntezatory) wymagają najwięcej tokenów, i zdecydować, czy użycie wydajniejszego, ale droższego modelu jest uzasadnione w przypadku danego zadania.
Gdzie szukać problemów
Podczas sprawdzania śladów w wersji produkcyjnej zwróć uwagę na te kwestie:
- Nietypowo długie ślady: oznaka regresji wydajności lub nieoczekiwanego zachowania pętli.
- Nieudane zakresy (oznaczone na czerwono): wskazują dokładną operację, która się nie powiodła.
- Nadmierna liczba iteracji pętli (>2): może wskazywać na problem z logiką generowania poprawki.
- Duża liczba tokenów: wskazuje możliwości optymalizacji promptów lub zmiany wyboru modelu.
Czego się nauczysz
Dzięki Cloud Trace możesz teraz:
✅ Wizualizacja przepływu żądań: zobacz pełną ścieżkę wykonania w potokach sekwencyjnych i opartych na pętlach.
✅ Identyfikowanie wąskich gardeł wydajności: użyj wykresu kaskadowego, aby znaleźć najwolniejsze operacje na podstawie konkretnych danych.
✅ Analizowanie działania pętli: obserwuj, jak agenci iteracyjni dochodzą do rozwiązania w wielu próbach.
✅ Śledzenie kosztów tokenów: sprawdzaj zakresy LLM, aby monitorować i optymalizować zużycie tokenów na poziomie szczegółowym.
Opanowane kluczowe pojęcia
- Ślady i spany: podstawowe jednostki dostrzegalności, które reprezentują żądania i operacje w nich wykonywane.
- Analiza kaskadowa: odczytywanie wykresów Gantta w celu poznania czasu wykonania i zależności.
- Identyfikacja ścieżki krytycznej: znajdowanie sekwencji operacji, która określa ogólne opóźnienie.
- Szczegółowa dostrzegalność: wgląd nie tylko w czas, ale też w metadane, takie jak liczba tokenów dla każdej operacji, automatycznie instrumentowane przez pakiet ADK.
Co dalej
Dalsze informacje o Cloud Trace:
- Regularnie monitoruj ślady, aby wcześnie wykrywać problemy
- Porównywanie śladów w celu wykrywania regresji wydajności
- Wykorzystywanie danych śledzenia do podejmowania decyzji dotyczących optymalizacji
- Filtrowanie według czasu trwania w celu znalezienia wolnych żądań
Zaawansowana obserwacja (opcjonalnie):
- Eksportowanie śladów do BigQuery w celu przeprowadzenia złożonej analizy (dokumentacja)
- Tworzenie paneli niestandardowych w Cloud Monitoring
- Konfigurowanie alertów o pogorszeniu skuteczności
- Korelacja śladów z logami aplikacji
9. Podsumowanie: od prototypu do środowiska produkcyjnego
Co utworzysz
Zaczęliśmy od zaledwie 7 wierszy kodu, a stworzyliśmy system agentów AI, którego można używać w środowisku produkcyjnym:
# Where we started (7 lines)
agent = Agent(
model="gemini-2.5-flash",
instruction="Review Python code for issues"
)
# Where we ended (production system)
- Two distinct multi-agent pipelines (review and fix) built from 8 specialized agents.
- An iterative fix loop architecture for automated validation and retries.
- Real AST-based code analysis tools for deterministic, accurate feedback.
- Robust state management using the "constants pattern" for type-safe communication.
- Fully automated deployment to a managed, scalable cloud infrastructure.
- Complete, built-in observability with Cloud Trace for production monitoring.
Opanowanie kluczowych wzorców architektonicznych
Wzór | Implementacja | Wpływ na produkcję |
Integracja narzędzi | Analiza AST, sprawdzanie stylu | Prawdziwa weryfikacja, a nie tylko opinie LLM |
Potoki sekwencyjne | Sprawdzanie → naprawianie przepływów pracy | Przewidywalne i łatwe do debugowania wykonywanie |
Architektura Loop | Iteracyjne poprawianie z warunkami zakończenia | Samodzielne ulepszanie aż do osiągnięcia sukcesu |
Zarządzanie stanem | Wzorzec stałych, pamięć trójwarstwowa | Bezpieczna pod względem typów i łatwa w utrzymaniu obsługa stanu |
Wdrożenie produkcyjne | Agent Engine za pomocą skryptu deploy.sh | Zarządzana, skalowalna infrastruktura |
Dostrzegalność | Integracja z Cloud Trace | Pełna widoczność działania wersji produkcyjnej |
Statystyki produkcyjne z logów czasu
Dane Cloud Trace ujawniły kluczowe informacje:
✅ Zidentyfikowano wąskie gardło: wywołania LLM w TestRunnerze dominują w opóźnieniach
✅ Wydajność narzędzia: analiza AST jest wykonywana w 100 ms (doskonale)
✅ Odsetek sukcesów: pętle poprawek zbiegają się w 2–3 iteracjach
✅ Zużycie tokenów: ok. 600 tokenów na opinię, ok. 1800 tokenów na poprawki
Te informacje umożliwiają ciągłe doskonalenie.
Czyszczenie zasobów (opcjonalnie)
Jeśli zakończysz eksperymentowanie i chcesz uniknąć opłat:
Usuwanie wdrożenia Agent Engine:
import vertexai
client = vertexai.Client( # For service interactions via client.agent_engines
project="PROJECT_ID",
location="LOCATION",
)
RESOURCE_NAME = "projects/{PROJECT_ID}/locations/{LOCATION}/reasoningEngines/{RESOURCE_ID}"
client.agent_engines.delete(
name=RESOURCE_NAME,
force=True, # Optional, if the agent has resources (e.g. sessions, memory)
)
Usuń usługę Cloud Run (jeśli została utworzona):
gcloud run services delete code-review-assistant \
--region=$GOOGLE_CLOUD_LOCATION \
--quiet
Usuń instancję Cloud SQL (jeśli została utworzona):
gcloud sql instances delete your-project-db \
--quiet
Zwolnij miejsce w zasobnikach na dane:
gsutil -m rm -r gs://your-project-staging
gsutil -m rm -r gs://your-project-artifacts
Następne kroki
Po utworzeniu podstaw możesz wprowadzić te ulepszenia:
- Dodawanie kolejnych języków: rozszerzanie narzędzi o obsługę języków JavaScript, Go i Java.
- Integracja z GitHubem: automatyczne sprawdzanie żądań pull
- Wdrożenie buforowania: zmniejszanie czasu oczekiwania w przypadku typowych wzorców.
- Dodawanie wyspecjalizowanych agentów: skanowanie pod kątem bezpieczeństwa, analiza wydajności
- Włącz testy A/B: porównuj różne modele i prompty.
- Eksportowanie wskaźników: wysyłanie śladów do specjalistycznych platform dostrzegalności
Podsumowanie
- Zacznij od prostych rozwiązań i szybko je ulepszaj: 7 wierszy kodu w środowisku produkcyjnym w kilku prostych krokach
- Narzędzia zamiast promptów: analiza AST w czasie rzeczywistym jest lepsza niż prompt „sprawdź, czy nie ma błędów”.
- Zarządzanie stanem ma znaczenie: wzorzec stałych zapobiega błędom literowym
- Pętle wymagają warunków wyjścia: zawsze ustawiaj maksymalną liczbę iteracji i eskalację.
- Wdrażanie za pomocą automatyzacji: skrypt deploy.sh obsługuje wszystkie złożone operacje.
- Dostrzegalność jest niezbędna: nie możesz poprawić tego, czego nie możesz zmierzyć.
Materiały do dalszej nauki
- Dokumentacja pakietu ADK
- Zaawansowane wzorce ADK
- Przewodnik po Agent Engine
- Dokumentacja Cloud Run
- Dokumentacja Cloud Trace
Twoja podróż trwa dalej
Stworzyliśmy nie tylko asystenta do inspekcji kodu, ale też opanowaliśmy wzorce tworzenia dowolnego produkcyjnego agenta AI:
✅ złożone przepływy pracy z wieloma wyspecjalizowanymi agentami,
✅ integracja z prawdziwymi narzędziami zapewniająca rzeczywiste możliwości,
✅ wdrożenie produkcyjne z odpowiednią widocznością,
✅ zarządzanie stanem w celu utrzymania systemów.
Wzorce te obejmują zarówno proste asystenty, jak i złożone systemy autonomiczne. Podstawa, którą tu zbudujesz, przyda Ci się podczas pracy nad coraz bardziej zaawansowanymi architekturami agentów.
Witamy w części poświęconej tworzeniu produkcyjnych agentów AI. Asystent weryfikacji kodu to dopiero początek.