
1. The Late Night Code Review
São 2h.
Você está depurando há horas. A função parece estar certa, mas algo está errado. Você conhece aquela sensação: quando o código deveria funcionar, mas não funciona, e você não consegue mais entender por quê, porque já está olhando para ele há muito tempo.
def dfs_search_v1(graph, start, target):
"""Find if target is reachable from start."""
visited = set()
stack = start # Looks innocent enough...
while stack:
current = stack.pop()
if current == target:
return True
if current not in visited:
visited.add(current)
for neighbor in graph[current]:
if neighbor not in visited:
stack.append(neighbor)
return False
A jornada do desenvolvedor de IA
Se você está lendo isso, provavelmente já sentiu a transformação que a IA traz para a programação. Ferramentas como o Gemini Code Assist, o Claude Code e o Cursor mudaram a forma como escrevemos código. Elas são incríveis para gerar boilerplate, sugerir implementações e acelerar o desenvolvimento.
Mas você está aqui porque quer se aprofundar. Você quer entender como criar esses sistemas de IA, não apenas usá-los. Você quer criar algo que:
- Tem um comportamento previsível e rastreável
- Pode ser implantado na produção com confiança
- Oferece resultados consistentes e confiáveis
- Mostra exatamente como ele toma decisões
De consumidor a criador de conteúdo
Hoje, você vai passar de usar ferramentas de IA para criá-las. Você vai criar um sistema multiagente que:
- Analisa a estrutura do código de forma determinística
- Executa testes reais para verificar o comportamento
- Valida a conformidade do estilo com linters reais.
- Sintetiza descobertas em feedback prático
- Implantações no Google Cloud com observabilidade total
2. Sua primeira implantação de agente
A pergunta do desenvolvedor
"Entendo os LLMs e já usei as APIs, mas como faço para transformar um script Python em um agente de IA de produção que pode ser escalonado?"
Para responder a essa pergunta, vamos configurar seu ambiente corretamente e criar um agente simples para entender o básico antes de entrar nos padrões de produção.
Primeiro, a configuração essencial
Antes de criar agentes, vamos garantir que seu ambiente do Google Cloud esteja pronto.
Clique em Ativar o Cloud Shell na parte de cima do console do Google Cloud (é o ícone em forma de terminal na parte de cima do painel do Cloud Shell).
Encontre o ID do projeto do Google Cloud:
- Abra o console do Google Cloud: https://console.cloud.google.com
- Selecione o projeto que você quer usar neste workshop no menu suspenso na parte de cima da página.
- O ID do projeto é exibido no card de informação do projeto no painel
Etapa 1: definir o ID do projeto
No Cloud Shell, a ferramenta de linha de comando gcloud já está configurada. Execute o comando a seguir para definir seu projeto ativo. Isso usa a variável de ambiente $GOOGLE_CLOUD_PROJECT, que é definida automaticamente para você na sessão do Cloud Shell.
gcloud config set project $GOOGLE_CLOUD_PROJECT
Etapa 2: verificar sua configuração
Em seguida, execute os comandos abaixo para confirmar se o projeto está configurado corretamente e se você está autenticado.
# Confirm project is set
echo "Current project: $(gcloud config get-value project)"
# Check authentication status
gcloud auth list
O ID do projeto vai aparecer impresso, e sua conta de usuário vai estar listada com (ACTIVE) ao lado.
Se a sua conta não estiver listada como ativa ou se você receber um erro de autenticação, execute o seguinte comando para fazer login:
gcloud auth application-default login
Etapa 3: ativar as APIs essenciais
Precisamos pelo menos destas APIs para o agente básico:
gcloud services enable \
aiplatform.googleapis.com \
compute.googleapis.com
Isso pode demorar alguns minutos. Você vai ver:
Operation "operations/..." finished successfully.
Etapa 4: instalar o ADK
# Install the ADK CLI
pip install google-adk --upgrade
# Verify installation
adk --version
Você vai ver um número de versão como 1.15.0 ou mais recente.
Agora crie seu agente básico
Com o ambiente pronto, vamos criar esse agente simples.
Etapa 5: usar o ADK Create
adk create my_first_agent
Siga os comandos interativos:
Choose a model for the root agent:
1. gemini-2.5-flash
2. Other models (fill later)
Choose model (1, 2): 1
1. Google AI
2. Vertex AI
Choose a backend (1, 2): 2
Enter Google Cloud project ID [auto-detected-from-gcloud]:
Enter Google Cloud region [us-central1]:
Etapa 6: analisar o que foi criado
cd my_first_agent
ls -la
Você vai encontrar três arquivos:
.env # Configuration (auto-populated with your project)
__init__.py # Package marker
agent.py # Your agent definition
Etapa 7: verificação rápida da configuração
# Verify the .env was created correctly
cat .env
# Should show something like:
# GOOGLE_CLOUD_PROJECT=your-project-id
# GOOGLE_CLOUD_LOCATION=us-central1
# GOOGLE_GENAI_USE_VERTEXAI=1
Se o ID do projeto estiver ausente ou incorreto, edite o arquivo .env:
nano .env # or use your preferred editor
Etapa 8: analisar o código do agente
cat agent.py
from google.adk.agents.llm_agent import Agent
root_agent = Agent(
model='gemini-2.5-flash',
name='root_agent',
description='A helpful assistant for user questions.',
instruction='Answer user questions to the best of your knowledge',
)
Simples, limpo, minimalista. Este é o "Hello World" dos agentes.
Testar seu agente básico
Etapa 9: executar o agente
cd ..
adk run my_first_agent
Você verá um código como este:
Log setup complete: /tmp/agents_log/agent.20250930_162430.log
To access latest log: tail -F /tmp/agents_log/agent.latest.log
[user]:
Etapa 10: testar algumas consultas
No terminal em que adk run está sendo executado, uma solicitação vai aparecer. Digite suas consultas:
[user]: Hey, what can you do?
[root_agent]: I can help answer questions, generate text, explain concepts, assist with problem-solving, and provide information on a wide range of topics. What would you like to know or discuss?
[user]: What's the current weather in Mountain View?
[root_agent]: I'm sorry, but I cannot provide real-time weather information as I don't have access to current data or weather services. To get the current weather in Mountain View, I recommend checking a weather website or app like weather.com or using a search engine.
Observe a limitação: ela não pode acessar dados atuais. Vamos continuar:
[user]: Review this Python code: def add(a, b): return a + b
[root_agent]: This is a simple Python function that adds two numbers. Here's my review:
**Strengths:**
- Clean and concise implementation
- Follows Python conventions for simple operations
- Clear function name that describes its purpose
**Suggestions for improvement:**
- Add a docstring to document the function
- Consider adding type hints for better code clarity
- You might want to handle edge cases
Here's an enhanced version:
def add(a: float, b: float) -> float:
"""Add two numbers and return their sum."""
return a + b
O agente pode discutir código, mas ele consegue:
- Analisar o AST para entender a estrutura?
- Executar testes para verificar se ele funciona?
- Verificar a conformidade de estilo?
- Você se lembra das suas avaliações anteriores?
Não. É aqui que precisamos de arquitetura.
🏃🚪 Sair com
Ctrl+C
quando terminar de explorar.
3. Preparar seu espaço de trabalho de produção
A solução: uma arquitetura pronta para produção
Esse agente simples demonstrou o ponto de partida, mas um sistema de produção exige uma estrutura robusta. Agora vamos configurar um projeto completo que incorpora princípios de produção.
Como configurar a base
Você já configurou seu projeto na nuvem do Google Cloud para o agente básico. Agora vamos preparar o espaço de trabalho de produção completo com todas as ferramentas, padrões e infraestrutura necessários para um sistema real.
Etapa 1: extrair o projeto estruturado
Primeiro, saia de qualquer adk run em execução com Ctrl+C e faça uma limpeza:
# Clean up the basic agent
cd ~ # Make sure you're not inside my_first_agent
rm -rf my_first_agent
# Get the production scaffold
git clone https://github.com/ayoisio/adk-code-review-assistant.git
cd adk-code-review-assistant
git checkout codelab
Etapa 2: criar e ativar o ambiente virtual
# Create the virtual environment
python -m venv .venv
# Activate it
# On macOS/Linux:
source .venv/bin/activate
# On Windows:
# .venv\Scripts\activate
Verificação: seu prompt agora deve mostrar (.venv) no início.
Etapa 3: instalar dependências
pip install -r code_review_assistant/requirements.txt
# Install the package in editable mode (enables imports)
pip install -e .
Isso instala:
google-adk: o framework do ADKpycodestyle: para verificação da PEP 8.vertexai: para implantação na nuvem- Outras dependências de produção
A flag -e permite importar módulos code_review_assistant de qualquer lugar.
Etapa 4: configurar o ambiente
# Copy the example environment file
cp .env.example .env
# Edit .env and replace the placeholders:
# - GOOGLE_CLOUD_PROJECT=your-project-id → your actual project ID
# - Keep other defaults as-is
Verificação: confira sua configuração:
cat .env
Vai mostrar:
GOOGLE_CLOUD_PROJECT=your-actual-project-id
GOOGLE_CLOUD_LOCATION=us-central1
GOOGLE_GENAI_USE_VERTEXAI=TRUE
Etapa 5: garantir a autenticação
Como você já executou gcloud auth antes, vamos apenas verificar:
# Check current authentication
gcloud auth list
# Should show your account with (ACTIVE)
# If not, run:
gcloud auth application-default login
Etapa 6: ativar outras APIs de produção
Já ativamos as APIs básicas. Agora adicione os de produção:
gcloud services enable \
sqladmin.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
storage.googleapis.com \
cloudtrace.googleapis.com
Isso permite:
- Administrador do SQL: para o Cloud SQL se você estiver usando o Cloud Run
- Cloud Run: para implantação sem servidor
- Cloud Build: para implantações automatizadas
- Artifact Registry: para imagens de contêiner
- Cloud Storage: para artefatos e preparo
- Cloud Trace: para observabilidade
Etapa 7: criar o repositório do Artifact Registry
Nossa implantação vai criar imagens de contêiner que precisam de um local:
gcloud artifacts repositories create code-review-assistant-repo \
--repository-format=docker \
--location=us-central1 \
--description="Docker repository for Code Review Assistant"
Você verá:
Created repository [code-review-assistant-repo].
Se ele já existir (talvez de uma tentativa anterior), não tem problema. Você vai receber uma mensagem de erro que pode ignorar.
Etapa 8: conceder permissões do IAM
# Get your project number
PROJECT_NUMBER=$(gcloud projects describe $GOOGLE_CLOUD_PROJECT \
--format="value(projectNumber)")
# Define the service account
SERVICE_ACCOUNT="${PROJECT_NUMBER}@cloudbuild.gserviceaccount.com"
# Grant necessary roles
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SERVICE_ACCOUNT}" \
--role="roles/run.admin"
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SERVICE_ACCOUNT}" \
--role="roles/iam.serviceAccountUser"
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SERVICE_ACCOUNT}" \
--role="roles/cloudsql.admin"
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SERVICE_ACCOUNT}" \
--role="roles/storage.admin"
Cada comando vai gerar:
Updated IAM policy for project [your-project-id].
O que você realizou
Seu espaço de trabalho de produção está totalmente preparado:
✅ Projeto do Google Cloud configurado e autenticado
✅ Agente básico testado para entender as limitações
✅ Código do projeto com marcadores de posição estratégicos prontos
✅ Dependências isoladas em ambiente virtual
✅ Todas as APIs necessárias ativadas
✅ Registro de contêiner pronto para implantações
✅ Permissões do IAM configuradas corretamente
✅ Variáveis de ambiente definidas corretamente
Agora você está pronto para criar um sistema de IA real com ferramentas determinísticas, gerenciamento de estado e arquitetura adequada.
4. Como criar seu primeiro agente
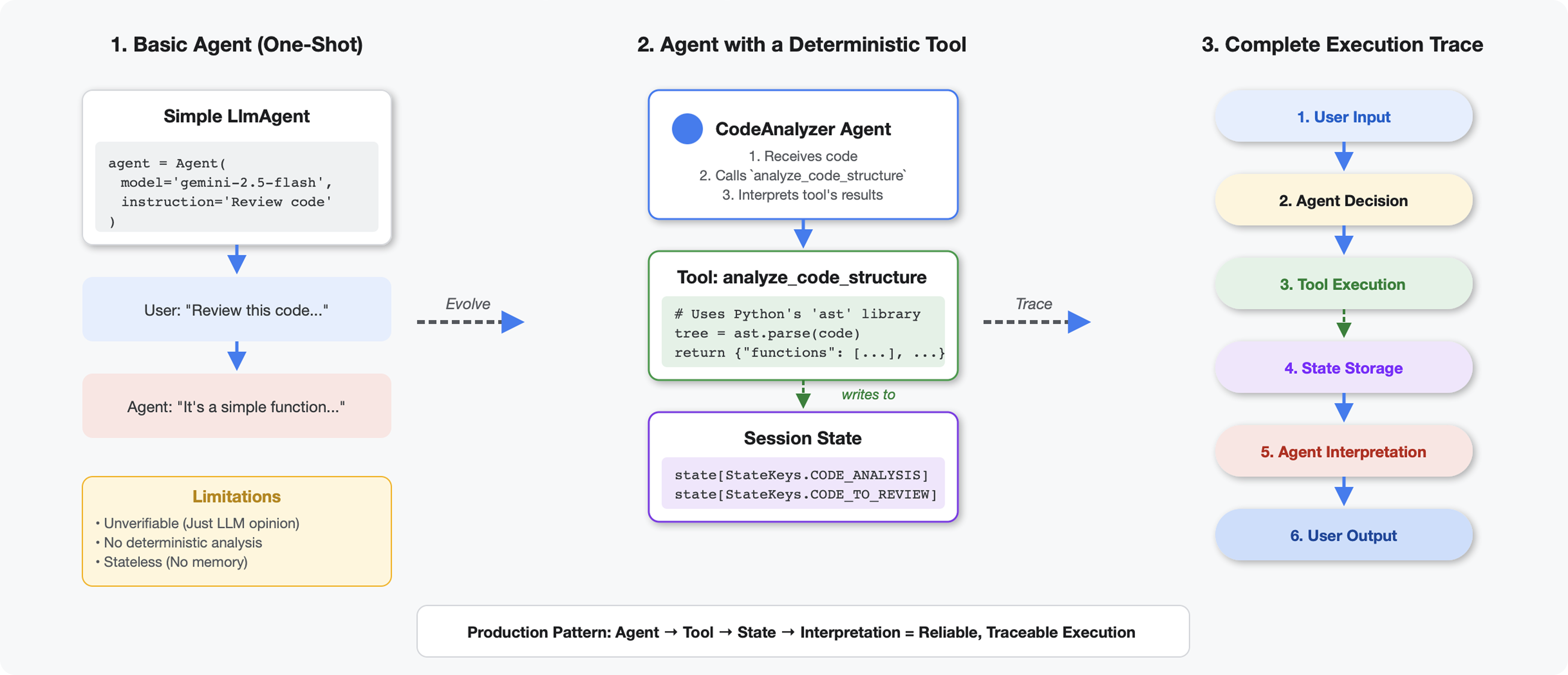
O que diferencia as ferramentas dos LLMs
Quando você pergunta a uma LLM "quantas funções há neste código?", ela usa correspondência de padrões e estimativa. Quando você usa uma ferramenta que chama ast.parse() do Python, ela analisa a árvore de sintaxe real. Não há adivinhação, e o resultado é sempre o mesmo.
Esta seção cria uma ferramenta que analisa a estrutura do código de forma determinística e a conecta a um agente que sabe quando invocar.
Etapa 1: entender o scaffold
Vamos analisar a estrutura que você vai preencher.
👉 Abrir
code_review_assistant/tools.py
Você vai ver a função analyze_code_structure com comentários de marcador de posição indicando onde adicionar o código. A função já tem a estrutura básica. Você vai aprimorá-la etapa por etapa.
Etapa 2: adicionar o armazenamento de estado
O armazenamento de estado permite que outros agentes no pipeline acessem os resultados da sua ferramenta sem executar a análise novamente.
👉 Encontre:
# MODULE_4_STEP_2_ADD_STATE_STORAGE
👉 Substitua essa linha única por:
# Store code and analysis for other agents to access
tool_context.state[StateKeys.CODE_TO_REVIEW] = code
tool_context.state[StateKeys.CODE_ANALYSIS] = analysis
tool_context.state[StateKeys.CODE_LINE_COUNT] = len(code.splitlines())
Etapa 3: adicionar análise assíncrona com pools de linhas de execução
Nossa ferramenta precisa analisar a AST sem bloquear outras operações. Vamos adicionar a execução assíncrona com pools de linhas de execução.
👉 Encontre:
# MODULE_4_STEP_3_ADD_ASYNC
👉 Substitua essa linha única por:
# Parse in thread pool to avoid blocking the event loop
loop = asyncio.get_event_loop()
with ThreadPoolExecutor() as executor:
tree = await loop.run_in_executor(executor, ast.parse, code)
Etapa 4: extrair informações abrangentes
Agora vamos extrair classes, importações e métricas detalhadas, tudo o que precisamos para uma revisão de código completa.
👉 Encontre:
# MODULE_4_STEP_4_EXTRACT_DETAILS
👉 Substitua essa linha única por:
# Extract comprehensive structural information
analysis = await loop.run_in_executor(
executor, _extract_code_structure, tree, code
)
👉 Verifique: a função
analyze_code_structure
em
tools.py
tem um corpo central assim:
# Parse in thread pool to avoid blocking the event loop
loop = asyncio.get_event_loop()
with ThreadPoolExecutor() as executor:
tree = await loop.run_in_executor(executor, ast.parse, code)
# Extract comprehensive structural information
analysis = await loop.run_in_executor(
executor, _extract_code_structure, tree, code
)
# Store code and analysis for other agents to access
tool_context.state[StateKeys.CODE_TO_REVIEW] = code
tool_context.state[StateKeys.CODE_ANALYSIS] = analysis
tool_context.state[StateKeys.CODE_LINE_COUNT] = len(code.splitlines())
👉 Role até a parte de baixo de
tools.py
e encontre:
# MODULE_4_STEP_4_HELPER_FUNCTION
👉 Substitua essa única linha pela função auxiliar completa:
def _extract_code_structure(tree: ast.AST, code: str) -> Dict[str, Any]:
"""
Helper function to extract structural information from AST.
Runs in thread pool for CPU-bound work.
"""
functions = []
classes = []
imports = []
docstrings = []
for node in ast.walk(tree):
if isinstance(node, ast.FunctionDef):
func_info = {
'name': node.name,
'args': [arg.arg for arg in node.args.args],
'lineno': node.lineno,
'has_docstring': ast.get_docstring(node) is not None,
'is_async': isinstance(node, ast.AsyncFunctionDef),
'decorators': [d.id for d in node.decorator_list
if isinstance(d, ast.Name)]
}
functions.append(func_info)
if func_info['has_docstring']:
docstrings.append(f"{node.name}: {ast.get_docstring(node)[:50]}...")
elif isinstance(node, ast.ClassDef):
methods = []
for item in node.body:
if isinstance(item, ast.FunctionDef):
methods.append(item.name)
class_info = {
'name': node.name,
'lineno': node.lineno,
'methods': methods,
'has_docstring': ast.get_docstring(node) is not None,
'base_classes': [base.id for base in node.bases
if isinstance(base, ast.Name)]
}
classes.append(class_info)
elif isinstance(node, ast.Import):
for alias in node.names:
imports.append({
'module': alias.name,
'alias': alias.asname,
'type': 'import'
})
elif isinstance(node, ast.ImportFrom):
imports.append({
'module': node.module or '',
'names': [alias.name for alias in node.names],
'type': 'from_import',
'level': node.level
})
return {
'functions': functions,
'classes': classes,
'imports': imports,
'docstrings': docstrings,
'metrics': {
'line_count': len(code.splitlines()),
'function_count': len(functions),
'class_count': len(classes),
'import_count': len(imports),
'has_main': any(f['name'] == 'main' for f in functions),
'has_if_main': '__main__' in code,
'avg_function_length': _calculate_avg_function_length(tree)
}
}
def _calculate_avg_function_length(tree: ast.AST) -> float:
"""Calculate average function length in lines."""
function_lengths = []
for node in ast.walk(tree):
if isinstance(node, ast.FunctionDef):
if hasattr(node, 'end_lineno') and hasattr(node, 'lineno'):
length = node.end_lineno - node.lineno + 1
function_lengths.append(length)
if function_lengths:
return sum(function_lengths) / len(function_lengths)
return 0.0
Etapa 5: falar com um agente
Agora vamos conectar a ferramenta a um agente que sabe quando usá-la e como interpretar os resultados.
👉 Abrir
code_review_assistant/sub_agents/review_pipeline/code_analyzer.py
👉 Encontre:
# MODULE_4_STEP_5_CREATE_AGENT
👉 Substitua essa linha única pelo agente de produção completo:
code_analyzer_agent = Agent(
name="CodeAnalyzer",
model=config.worker_model,
description="Analyzes Python code structure and identifies components",
instruction="""You are a code analysis specialist responsible for understanding code structure.
Your task:
1. Take the code submitted by the user (it will be provided in the user message)
2. Use the analyze_code_structure tool to parse and analyze it
3. Pass the EXACT code to your tool - do not modify, fix, or "improve" it
4. Identify all functions, classes, imports, and structural patterns
5. Note any syntax errors or structural issues
6. Store the analysis in state for other agents to use
CRITICAL:
- Pass the code EXACTLY as provided to the analyze_code_structure tool
- Do not fix syntax errors, even if obvious
- Do not add missing imports or fix indentation
- The goal is to analyze what IS there, not what SHOULD be there
When calling the tool, pass the code as a string to the 'code' parameter.
If the analysis fails due to syntax errors, clearly report the error location and type.
Provide a clear summary including:
- Number of functions and classes found
- Key structural observations
- Any syntax errors or issues detected
- Overall code organization assessment""",
tools=[FunctionTool(func=analyze_code_structure)],
output_key="structure_analysis_summary"
)
Teste seu analisador de código
Agora verifique se o analisador funciona corretamente.
👉 Execute o script de teste:
python tests/test_code_analyzer.py
O script de teste carrega automaticamente a configuração do arquivo .env usando python-dotenv. Portanto, não é necessário configurar variáveis de ambiente manualmente.
Resposta esperada:
INFO:code_review_assistant.config:Code Review Assistant Configuration Loaded:
INFO:code_review_assistant.config: - GCP Project: your-project-id
INFO:code_review_assistant.config: - Artifact Bucket: gs://your-project-artifacts
INFO:code_review_assistant.config: - Models: worker=gemini-2.5-flash, critic=gemini-2.5-pro
Testing code analyzer...
INFO:code_review_assistant.tools:Tool: Analysis complete - 2 functions, 1 classes
=== Analyzer Response ===
The analysis of the provided code shows the following:
* **Functions Found:** 2
* `add(a, b)`: A global function at line 2.
* `multiply(self, x, y)`: A method within the `Calculator` class.
* **Classes Found:** 1
* `Calculator`: A class defined at line 5. Contains one method, `multiply`.
* **Imports:** 0
* **Structural Patterns:** The code defines one global function and one class
with a single method. Both are simple, each with a single return statement.
* **Syntax Errors/Issues:** No syntax errors detected.
* **Overall Code Organization:** The code is well-organized for its small size,
clearly defining a function and a class with a method.
O que aconteceu:
- O script de teste carregou sua configuração do
.envautomaticamente. - Sua ferramenta
analyze_code_structure()analisou o código usando a AST do Python. - O auxiliar
_extract_code_structure()extraiu funções, classes e métricas. - Os resultados foram armazenados no estado da sessão usando constantes
StateKeys. - O agente do Code Analyzer interpretou os resultados e forneceu um resumo.
Solução de problemas:
- "No module named ‘code_review_assistant'": execute
pip install -e .na raiz do projeto - "Argumento de entradas de chave ausente": verifique se o
.envtemGOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_LOCATIONeGOOGLE_GENAI_USE_VERTEXAI=true.
O que você criou
Agora você tem um analisador de código pronto para produção que:
✅ Analisa a AST do Python real: determinista, não correspondência de padrões
✅ Armazena resultados no estado: outros agentes podem acessar a análise
✅ Executa de forma assíncrona: não bloqueia outras ferramentas
✅ Extrai informações abrangentes: funções, classes, importações, métricas
✅ Processa erros de maneira adequada: informa erros de sintaxe com números de linha
✅ Conecta-se a um agente: o LLM sabe quando e como usar
Conceitos principais dominados
Ferramentas x agentes:
- As ferramentas fazem um trabalho determinístico (análise de AST)
- Os agentes decidem quando usar ferramentas e interpretar resultados
Valor de retorno x estado:
- Retorno: o que o LLM vê imediatamente
- Estado: o que persiste para outros agentes
Constantes de chaves de estado:
- Evitar erros de digitação em sistemas multiagente
- Atuar como contratos entre agentes
- É fundamental quando os agentes compartilham dados
Assíncrono + pools de linhas de execução:
- O
async defpermite que as ferramentas pausem a execução. - Os pools de linhas de execução executam trabalhos vinculados à CPU em segundo plano
- Juntos, eles mantêm o loop de eventos responsivo
Funções auxiliares:
- Separar helpers de sincronização de ferramentas assíncronas
- Torna o código testável e reutilizável
Instruções para agentes:
- Instruções detalhadas evitam erros comuns de LLMs
- Explique o que NÃO fazer (não corrija o código)
- Limpar etapas do fluxo de trabalho para consistência
A seguir
No Módulo 5, você vai adicionar:
- Verificador de estilo que lê o código do estado
- Executor de testes que executa testes
- Sintetizador de feedback que combina todas as análises
Você vai entender como o estado flui por um pipeline sequencial e por que o padrão de constantes é importante quando vários agentes leem e gravam os mesmos dados.
5. Como criar um pipeline: vários agentes trabalhando juntos
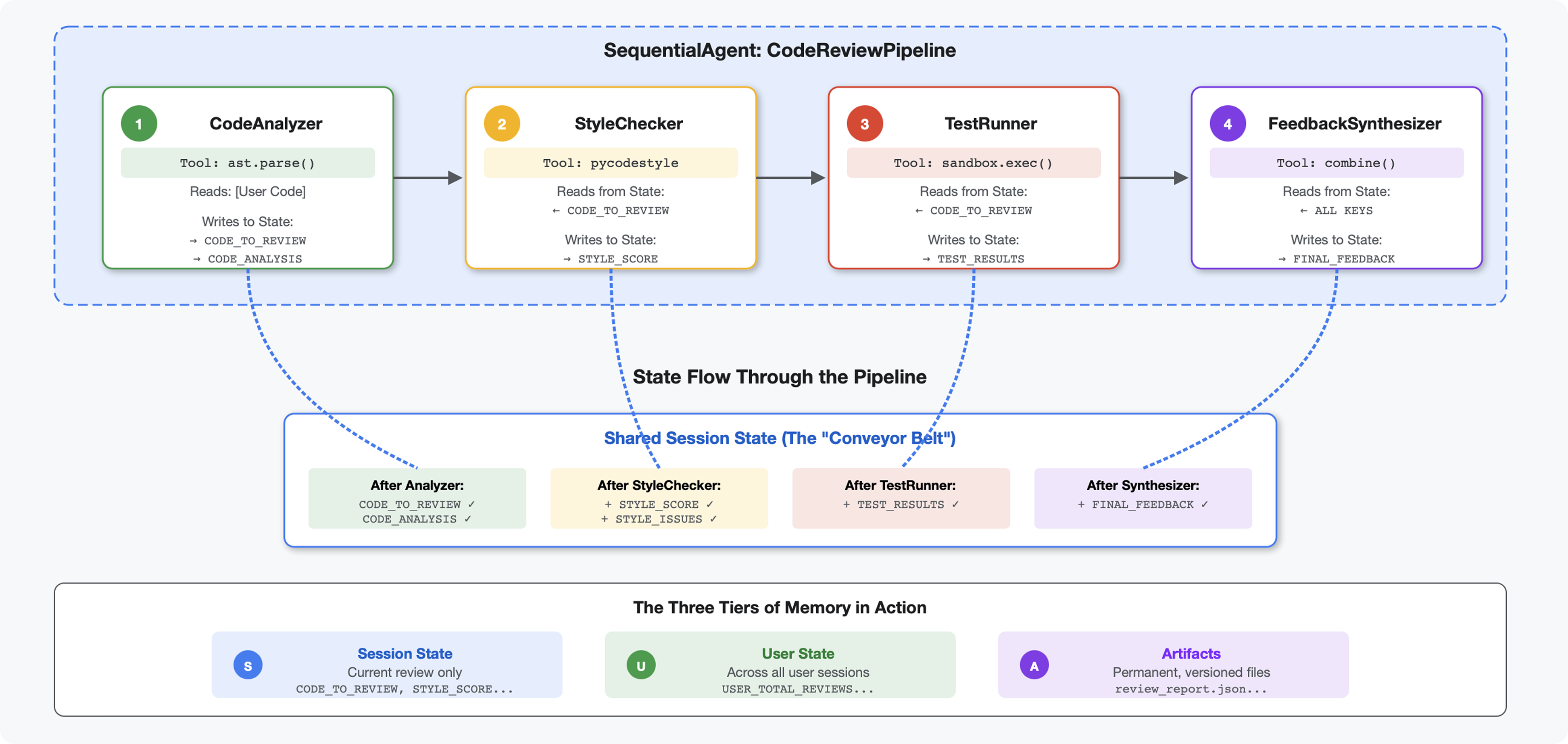
Introdução
No módulo 4, você criou um único agente que analisa a estrutura do código. Mas uma revisão de código abrangente exige mais do que apenas análise. É necessário verificar o estilo, executar a execução do teste e fazer uma síntese inteligente de feedback.
Este módulo cria um pipeline de quatro agentes que trabalham juntos em sequência, cada um contribuindo com uma análise especializada:
- Analisador de código (do módulo 4): analisa a estrutura.
- Verificador de estilo: identifica violações de estilo
- Test Runner: executa e valida testes.
- Sintetizador de feedback: combina tudo em um feedback útil
Conceito-chave: estado como canal de comunicação. Cada agente lê o que os agentes anteriores escreveram para declarar, adiciona a própria análise e passa o estado enriquecido para o próximo agente. O padrão de constantes do Módulo 4 se torna essencial quando vários agentes compartilham dados.
Prévia do que você vai criar:envie um código desorganizado → observe o fluxo de estado em quatro agentes → receba um relatório abrangente com feedback personalizado com base em padrões anteriores.
Etapa 1: adicionar a ferramenta e o agente do verificador de estilo
O verificador de estilo identifica violações da PEP 8 usando o pycodestyle, um linter determinista, não uma interpretação baseada em LLM.
Adicionar a ferramenta de verificação de estilo
👉 Abrir
code_review_assistant/tools.py
👉 Encontre:
# MODULE_5_STEP_1_STYLE_CHECKER_TOOL
👉 Substitua essa linha única por:
async def check_code_style(code: str, tool_context: ToolContext) -> Dict[str, Any]:
"""
Checks code style compliance using pycodestyle (PEP 8).
Args:
code: Python source code to check (or will retrieve from state)
tool_context: ADK tool context
Returns:
Dictionary containing style score and issues
"""
logger.info("Tool: Checking code style...")
try:
# Retrieve code from state if not provided
if not code:
code = tool_context.state.get(StateKeys.CODE_TO_REVIEW, '')
if not code:
return {
"status": "error",
"message": "No code provided or found in state"
}
# Run style check in thread pool
loop = asyncio.get_event_loop()
with ThreadPoolExecutor() as executor:
result = await loop.run_in_executor(
executor, _perform_style_check, code
)
# Store results in state
tool_context.state[StateKeys.STYLE_SCORE] = result['score']
tool_context.state[StateKeys.STYLE_ISSUES] = result['issues']
tool_context.state[StateKeys.STYLE_ISSUE_COUNT] = result['issue_count']
logger.info(f"Tool: Style check complete - Score: {result['score']}/100, "
f"Issues: {result['issue_count']}")
return result
except Exception as e:
error_msg = f"Style check failed: {str(e)}"
logger.error(f"Tool: {error_msg}", exc_info=True)
# Set default values on error
tool_context.state[StateKeys.STYLE_SCORE] = 0
tool_context.state[StateKeys.STYLE_ISSUES] = []
return {
"status": "error",
"message": error_msg,
"score": 0
}
👉 Role até o fim do arquivo e encontre:
# MODULE_5_STEP_1_STYLE_HELPERS
👉 Substitua essa única linha pelas funções auxiliares:
def _perform_style_check(code: str) -> Dict[str, Any]:
"""Helper to perform style check in thread pool."""
import io
import sys
with tempfile.NamedTemporaryFile(mode='w', suffix='.py', delete=False) as tmp:
tmp.write(code)
tmp_path = tmp.name
try:
# Capture stdout to get pycodestyle output
old_stdout = sys.stdout
sys.stdout = captured_output = io.StringIO()
style_guide = pycodestyle.StyleGuide(
quiet=False, # We want output
max_line_length=100,
ignore=['E501', 'W503']
)
result = style_guide.check_files([tmp_path])
# Restore stdout
sys.stdout = old_stdout
# Parse captured output
output = captured_output.getvalue()
issues = []
for line in output.strip().split('\n'):
if line and ':' in line:
parts = line.split(':', 4)
if len(parts) >= 4:
try:
issues.append({
'line': int(parts[1]),
'column': int(parts[2]),
'code': parts[3].split()[0] if len(parts) > 3 else 'E000',
'message': parts[3].strip() if len(parts) > 3 else 'Unknown error'
})
except (ValueError, IndexError):
pass
# Add naming convention checks
try:
tree = ast.parse(code)
naming_issues = _check_naming_conventions(tree)
issues.extend(naming_issues)
except SyntaxError:
pass # Syntax errors will be caught elsewhere
# Calculate weighted score
score = _calculate_style_score(issues)
return {
"status": "success",
"score": score,
"issue_count": len(issues),
"issues": issues[:10], # First 10 issues
"summary": f"Style score: {score}/100 with {len(issues)} violations"
}
finally:
if os.path.exists(tmp_path):
os.unlink(tmp_path)
def _check_naming_conventions(tree: ast.AST) -> List[Dict[str, Any]]:
"""Check PEP 8 naming conventions."""
naming_issues = []
for node in ast.walk(tree):
if isinstance(node, ast.FunctionDef):
# Skip private/protected methods and __main__
if not node.name.startswith('_') and node.name != node.name.lower():
naming_issues.append({
'line': node.lineno,
'column': node.col_offset,
'code': 'N802',
'message': f"N802 function name '{node.name}' should be lowercase"
})
elif isinstance(node, ast.ClassDef):
# Check if class name follows CapWords convention
if not node.name[0].isupper() or '_' in node.name:
naming_issues.append({
'line': node.lineno,
'column': node.col_offset,
'code': 'N801',
'message': f"N801 class name '{node.name}' should use CapWords convention"
})
return naming_issues
def _calculate_style_score(issues: List[Dict[str, Any]]) -> int:
"""Calculate weighted style score based on violation severity."""
if not issues:
return 100
# Define weights by error type
weights = {
'E1': 10, # Indentation errors
'E2': 3, # Whitespace errors
'E3': 5, # Blank line errors
'E4': 8, # Import errors
'E5': 5, # Line length
'E7': 7, # Statement errors
'E9': 10, # Syntax errors
'W2': 2, # Whitespace warnings
'W3': 2, # Blank line warnings
'W5': 3, # Line break warnings
'N8': 7, # Naming conventions
}
total_deduction = 0
for issue in issues:
code_prefix = issue['code'][:2] if len(issue['code']) >= 2 else 'E2'
weight = weights.get(code_prefix, 3)
total_deduction += weight
# Cap at 100 points deduction
return max(0, 100 - min(total_deduction, 100))
Adicionar o agente do verificador de estilo
👉 Abrir
code_review_assistant/sub_agents/review_pipeline/style_checker.py
👉 Encontre:
# MODULE_5_STEP_1_INSTRUCTION_PROVIDER
👉 Substitua essa linha única por:
async def style_checker_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are a code style expert focused on PEP 8 compliance.
Your task:
1. Use the check_code_style tool to validate PEP 8 compliance
2. The tool will retrieve the ORIGINAL code from state automatically
3. Report violations exactly as found
4. Present the results clearly and confidently
CRITICAL:
- The tool checks the code EXACTLY as provided by the user
- Do not suggest the code was modified or fixed
- Report actual violations found in the original code
- If there are style issues, they should be reported honestly
Call the check_code_style tool with an empty string for the code parameter,
as the tool will retrieve the code from state automatically.
When presenting results based on what the tool returns:
- State the exact score from the tool results
- If score >= 90: "Excellent style compliance!"
- If score 70-89: "Good style with minor improvements needed"
- If score 50-69: "Style needs attention"
- If score < 50: "Significant style improvements needed"
List the specific violations found (the tool will provide these):
- Show line numbers, error codes, and messages
- Focus on the top 10 most important issues
Previous analysis: {structure_analysis_summary}
Format your response as:
## Style Analysis Results
- Style Score: [exact score]/100
- Total Issues: [count]
- Assessment: [your assessment based on score]
## Top Style Issues
[List issues with line numbers and descriptions]
## Recommendations
[Specific fixes for the most critical issues]"""
return await instructions_utils.inject_session_state(template, context)
👉 Encontre:
# MODULE_5_STEP_1_STYLE_CHECKER_AGENT
👉 Substitua essa linha única por:
style_checker_agent = Agent(
name="StyleChecker",
model=config.worker_model,
description="Checks Python code style against PEP 8 guidelines",
instruction=style_checker_instruction_provider,
tools=[FunctionTool(func=check_code_style)],
output_key="style_check_summary"
)
Etapa 2: adicionar o agente do Test Runner
O executor de testes gera testes abrangentes e os executa usando o executor de código integrado.
👉 Abrir
code_review_assistant/sub_agents/review_pipeline/test_runner.py
👉 Encontre:
# MODULE_5_STEP_2_INSTRUCTION_PROVIDER
👉 Substitua essa linha única por:
async def test_runner_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects the code_to_review directly."""
template = """You are a testing specialist who creates and runs tests for Python code.
THE CODE TO TEST IS:
{code_to_review}
YOUR TASK:
1. Understand what the function appears to do based on its name and structure
2. Generate comprehensive tests (15-20 test cases)
3. Execute the tests using your code executor
4. Analyze results to identify bugs vs expected behavior
5. Output a detailed JSON analysis
TESTING METHODOLOGY:
- Test with the most natural interpretation first
- When something fails, determine if it's a bug or unusual design
- Test edge cases, boundaries, and error scenarios
- Document any surprising behavior
Execute your tests and output ONLY valid JSON with this structure:
- "test_summary": object with "total_tests_run", "tests_passed", "tests_failed", "tests_with_errors", "critical_issues_found"
- "critical_issues": array of objects, each with "type", "description", "example_input", "expected_behavior", "actual_behavior", "severity"
- "test_categories": object with "basic_functionality", "edge_cases", "error_handling" (each containing "passed", "failed", "errors" counts)
- "function_behavior": object with "apparent_purpose", "actual_interface", "unexpected_requirements"
- "verdict": object with "status" (WORKING/BUGGY/BROKEN), "confidence" (high/medium/low), "recommendation"
Do NOT output the test code itself, only the JSON analysis."""
return await instructions_utils.inject_session_state(template, context)
👉 Encontre:
# MODULE_5_STEP_2_TEST_RUNNER_AGENT
👉 Substitua essa linha única por:
test_runner_agent = Agent(
name="TestRunner",
model=config.critic_model,
description="Generates and runs tests for Python code using safe code execution",
instruction=test_runner_instruction_provider,
code_executor=BuiltInCodeExecutor(),
output_key="test_execution_summary"
)
Etapa 3: entender a memória para o aprendizado entre sessões
Antes de criar o sintetizador de feedback, é preciso entender a diferença entre estado e memória, dois mecanismos de armazenamento diferentes para duas finalidades diferentes.
Estado x memória: a principal distinção
Vamos esclarecer com um exemplo concreto de revisão de código:
Estado (somente sessão atual):
# Data from THIS review session
tool_context.state[StateKeys.STYLE_ISSUES] = [
{"line": 5, "code": "E231", "message": "missing whitespace"},
{"line": 12, "code": "E701", "message": "multiple statements"}
]
- Escopo: somente esta conversa
- Finalidade: transmitir dados entre agentes no pipeline atual
- Mora em: objeto
Session - Permanente: descartado quando a sessão termina
Memória (todas as sessões anteriores):
# Learned from 50 previous reviews
"User frequently forgets docstrings on helper functions"
"User tends to write long functions (avg 45 lines)"
"User improved error handling after feedback in session #23"
- Escopo: todas as sessões anteriores deste usuário
- Objetivo: aprender padrões e oferecer feedback personalizado
- Mora em:
MemoryService - Ciclo de vida: persiste entre sessões e pode ser pesquisado
Por que o feedback precisa dos dois:
Imagine o sintetizador criando feedback:
Usando apenas o estado (revisão atual):
"Function `calculate_total` has no docstring."
Feedback genérico e mecânico.
Usando estado + memória (padrões atuais e anteriores):
"Function `calculate_total` has no docstring. This is the 4th review
where helper functions lacked documentation. Consider adding docstrings
as you write functions, not afterwards - you mentioned in our last
session that you find it easier that way."
Personalizadas, contextuais e com melhoria das referências ao longo do tempo.
Para implantações de produção, você tem opções:
Opção 1: VertexAiMemoryBankService (avançado)
- O que ele faz:extração de fatos significativos de conversas com tecnologia de LLM
- Pesquisa:pesquisa semântica (entende o significado, não apenas palavras-chave)
- Gerenciamento de memória:consolida e atualiza automaticamente as recordações ao longo do tempo
- Requisitos:projeto do Google Cloud + configuração do Agent Engine
- Use quando:você quiser memórias sofisticadas, em evolução e personalizadas
- Exemplo: "O usuário prefere programação funcional" (extraído de 10 conversas sobre estilo de código)
Opção 2: continuar com InMemoryMemoryService + sessões persistentes
- O que faz:armazena o histórico completo de conversas para pesquisa por palavra-chave
- Pesquisa:correspondência básica de palavras-chave em sessões anteriores
- Gerenciamento de memória:você controla o que é armazenado (via
add_session_to_memory) - Requisitos:apenas um
SessionServicepersistente (comoVertexAiSessionServiceouDatabaseSessionService) - Use quando:você precisa de uma pesquisa simples em conversas anteriores sem o processamento do LLM.
- Exemplo:pesquisar "docstring" retorna todas as sessões que mencionam essa palavra.
Como a memória é preenchida
Depois que cada revisão de código for concluída:
# At the end of a session (typically in your application code)
await memory_service.add_session_to_memory(session)
O que acontece:
- InMemoryMemoryService:armazena os eventos de sessão completos para a pesquisa por palavra-chave.
- VertexAiMemoryBankService:o LLM extrai fatos importantes e consolida com memórias atuais
As sessões futuras podem consultar:
# In a tool, search for relevant past feedback
results = tool_context.search_memory("feedback about docstrings")
Etapa 4: adicionar ferramentas e agente do Feedback Synthesizer
O sintetizador de feedback é o agente mais sofisticado do pipeline. Ele orquestra três ferramentas, usa instruções dinâmicas e combina estado, memória e artefatos.
Adicionar as três ferramentas de sintetizador
👉 Abrir
code_review_assistant/tools.py
👉 Encontre:
# MODULE_5_STEP_4_SEARCH_PAST_FEEDBACK
👉 Substituir pela ferramenta 1: pesquisa na memória (versão de produção)
async def search_past_feedback(developer_id: str, tool_context: ToolContext) -> Dict[str, Any]:
"""
Search for past feedback in memory service.
Args:
developer_id: ID of the developer (defaults to "default_user")
tool_context: ADK tool context with potential memory service access
Returns:
Dictionary containing feedback search results
"""
logger.info(f"Tool: Searching for past feedback for developer {developer_id}...")
try:
# Default developer ID if not provided
if not developer_id:
developer_id = tool_context.state.get(StateKeys.USER_ID, 'default_user')
# Check if memory service is available
if hasattr(tool_context, 'search_memory'):
try:
# Perform structured searches
queries = [
f"developer:{developer_id} code review feedback",
f"developer:{developer_id} common issues",
f"developer:{developer_id} improvements"
]
all_feedback = []
patterns = {
'common_issues': [],
'improvements': [],
'strengths': []
}
for query in queries:
search_result = await tool_context.search_memory(query)
if search_result and hasattr(search_result, 'memories'):
for memory in search_result.memories[:5]:
memory_text = memory.text if hasattr(memory, 'text') else str(memory)
all_feedback.append(memory_text)
# Extract patterns
if 'style' in memory_text.lower():
patterns['common_issues'].append('style compliance')
if 'improved' in memory_text.lower():
patterns['improvements'].append('showing improvement')
if 'excellent' in memory_text.lower():
patterns['strengths'].append('consistent quality')
# Store in state
tool_context.state[StateKeys.PAST_FEEDBACK] = all_feedback
tool_context.state[StateKeys.FEEDBACK_PATTERNS] = patterns
logger.info(f"Tool: Found {len(all_feedback)} past feedback items")
return {
"status": "success",
"feedback_found": True,
"count": len(all_feedback),
"summary": " | ".join(all_feedback[:3]) if all_feedback else "No feedback",
"patterns": patterns
}
except Exception as e:
logger.warning(f"Tool: Memory search error: {e}")
# Fallback: Check state for cached feedback
cached_feedback = tool_context.state.get(StateKeys.USER_PAST_FEEDBACK_CACHE, [])
if cached_feedback:
tool_context.state[StateKeys.PAST_FEEDBACK] = cached_feedback
return {
"status": "success",
"feedback_found": True,
"count": len(cached_feedback),
"summary": "Using cached feedback",
"patterns": {}
}
# No feedback found
tool_context.state[StateKeys.PAST_FEEDBACK] = []
logger.info("Tool: No past feedback found")
return {
"status": "success",
"feedback_found": False,
"message": "No past feedback available - this appears to be a first submission",
"patterns": {}
}
except Exception as e:
error_msg = f"Feedback search error: {str(e)}"
logger.error(f"Tool: {error_msg}", exc_info=True)
tool_context.state[StateKeys.PAST_FEEDBACK] = []
return {
"status": "error",
"message": error_msg,
"feedback_found": False
}
👉 Encontre:
# MODULE_5_STEP_4_UPDATE_GRADING_PROGRESS
👉 Substitua pela Ferramenta 2: medidor de notas (versão de produção)
async def update_grading_progress(tool_context: ToolContext) -> Dict[str, Any]:
"""
Updates grading progress counters and metrics in state.
"""
logger.info("Tool: Updating grading progress...")
try:
current_time = datetime.now().isoformat()
# Build all state changes
state_updates = {}
# Temporary (invocation-level) state
state_updates[StateKeys.TEMP_PROCESSING_TIMESTAMP] = current_time
# Session-level state
attempts = tool_context.state.get(StateKeys.GRADING_ATTEMPTS, 0) + 1
state_updates[StateKeys.GRADING_ATTEMPTS] = attempts
state_updates[StateKeys.LAST_GRADING_TIME] = current_time
# User-level persistent state
lifetime_submissions = tool_context.state.get(StateKeys.USER_TOTAL_SUBMISSIONS, 0) + 1
state_updates[StateKeys.USER_TOTAL_SUBMISSIONS] = lifetime_submissions
state_updates[StateKeys.USER_LAST_SUBMISSION_TIME] = current_time
# Calculate improvement metrics
current_style_score = tool_context.state.get(StateKeys.STYLE_SCORE, 0)
last_style_score = tool_context.state.get(StateKeys.USER_LAST_STYLE_SCORE, 0)
score_improvement = current_style_score - last_style_score
state_updates[StateKeys.USER_LAST_STYLE_SCORE] = current_style_score
state_updates[StateKeys.SCORE_IMPROVEMENT] = score_improvement
# Track test results if available
test_results = tool_context.state.get(StateKeys.TEST_EXECUTION_SUMMARY, {})
# Parse if it's a string
if isinstance(test_results, str):
try:
test_results = json.loads(test_results)
except:
test_results = {}
if test_results and test_results.get('test_summary', {}).get('total_tests_run', 0) > 0:
summary = test_results['test_summary']
total = summary.get('total_tests_run', 0)
passed = summary.get('tests_passed', 0)
if total > 0:
pass_rate = (passed / total) * 100
state_updates[StateKeys.USER_LAST_TEST_PASS_RATE] = pass_rate
# Apply all updates atomically
for key, value in state_updates.items():
tool_context.state[key] = value
logger.info(f"Tool: Progress updated - Attempt #{attempts}, "
f"Lifetime: {lifetime_submissions}")
return {
"status": "success",
"session_attempts": attempts,
"lifetime_submissions": lifetime_submissions,
"timestamp": current_time,
"improvement": {
"style_score_change": score_improvement,
"direction": "improved" if score_improvement > 0 else "declined"
},
"summary": f"Attempt #{attempts} recorded, {lifetime_submissions} total submissions"
}
except Exception as e:
error_msg = f"Progress update error: {str(e)}"
logger.error(f"Tool: {error_msg}", exc_info=True)
return {
"status": "error",
"message": error_msg
}
👉 Encontre:
# MODULE_5_STEP_4_SAVE_GRADING_REPORT
👉 Substituir pela Ferramenta 3: Artifact Saver (versão de produção)
async def save_grading_report(feedback_text: str, tool_context: ToolContext) -> Dict[str, Any]:
"""
Saves a detailed grading report as an artifact.
Args:
feedback_text: The feedback text to include in the report
tool_context: ADK tool context for state management
Returns:
Dictionary containing save status and details
"""
logger.info("Tool: Saving grading report...")
try:
# Gather all relevant data from state
code = tool_context.state.get(StateKeys.CODE_TO_REVIEW, '')
analysis = tool_context.state.get(StateKeys.CODE_ANALYSIS, {})
style_score = tool_context.state.get(StateKeys.STYLE_SCORE, 0)
style_issues = tool_context.state.get(StateKeys.STYLE_ISSUES, [])
# Get test results
test_results = tool_context.state.get(StateKeys.TEST_EXECUTION_SUMMARY, {})
# Parse if it's a string
if isinstance(test_results, str):
try:
test_results = json.loads(test_results)
except:
test_results = {}
timestamp = datetime.now().isoformat()
# Create comprehensive report dictionary
report = {
'timestamp': timestamp,
'grading_attempt': tool_context.state.get(StateKeys.GRADING_ATTEMPTS, 1),
'code': {
'content': code,
'line_count': len(code.splitlines()),
'hash': hashlib.md5(code.encode()).hexdigest()
},
'analysis': analysis,
'style': {
'score': style_score,
'issues': style_issues[:5] # First 5 issues
},
'tests': test_results,
'feedback': feedback_text,
'improvements': {
'score_change': tool_context.state.get(StateKeys.SCORE_IMPROVEMENT, 0),
'from_last_score': tool_context.state.get(StateKeys.USER_LAST_STYLE_SCORE, 0)
}
}
# Convert report to JSON string
report_json = json.dumps(report, indent=2)
report_part = types.Part.from_text(text=report_json)
# Try to save as artifact if the service is available
if hasattr(tool_context, 'save_artifact'):
try:
# Generate filename with timestamp (replace colons for filesystem compatibility)
filename = f"grading_report_{timestamp.replace(':', '-')}.json"
# Save the main report
version = await tool_context.save_artifact(filename, report_part)
# Also save a "latest" version for easy access
await tool_context.save_artifact("latest_grading_report.json", report_part)
logger.info(f"Tool: Report saved as {filename} (version {version})")
# Store report in state as well for redundancy
tool_context.state[StateKeys.USER_LAST_GRADING_REPORT] = report
return {
"status": "success",
"artifact_saved": True,
"filename": filename,
"version": str(version),
"size": len(report_json),
"summary": f"Report saved as {filename}"
}
except Exception as artifact_error:
logger.warning(f"Artifact service error: {artifact_error}, falling back to state storage")
# Continue to fallback below
# Fallback: Store in state if artifact service is not available or failed
tool_context.state[StateKeys.USER_LAST_GRADING_REPORT] = report
logger.info("Tool: Report saved to state (artifact service not available)")
return {
"status": "success",
"artifact_saved": False,
"message": "Report saved to state only",
"size": len(report_json),
"summary": "Report saved to session state"
}
except Exception as e:
error_msg = f"Report save error: {str(e)}"
logger.error(f"Tool: {error_msg}", exc_info=True)
# Still try to save minimal data to state
try:
tool_context.state[StateKeys.USER_LAST_GRADING_REPORT] = {
'error': error_msg,
'feedback': feedback_text,
'timestamp': datetime.now().isoformat()
}
except:
pass
return {
"status": "error",
"message": error_msg,
"artifact_saved": False,
"summary": f"Failed to save report: {error_msg}"
}
Criar o agente sintetizador
👉 Abrir
code_review_assistant/sub_agents/review_pipeline/feedback_synthesizer.py
👉 Encontre:
# MODULE_5_STEP_4_INSTRUCTION_PROVIDER
👉 Substitua pelo provedor de instruções de produção:
async def feedback_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are an expert code reviewer and mentor providing constructive, educational feedback.
CONTEXT FROM PREVIOUS AGENTS:
- Structure analysis summary: {structure_analysis_summary}
- Style check summary: {style_check_summary}
- Test execution summary: {test_execution_summary}
YOUR TASK requires these steps IN ORDER:
1. Call search_past_feedback tool with developer_id="default_user"
2. Call update_grading_progress tool with no parameters
3. Carefully analyze the test results to understand what really happened
4. Generate comprehensive feedback following the structure below
5. Call save_grading_report tool with the feedback_text parameter
6. Return the feedback as your final output
CRITICAL - Understanding Test Results:
The test_execution_summary contains structured JSON. Parse it carefully:
- tests_passed = Code worked correctly
- tests_failed = Code produced wrong output
- tests_with_errors = Code crashed
- critical_issues = Fundamental problems with the code
If critical_issues array contains items, these are serious bugs that need fixing.
Do NOT count discovering bugs as test successes.
FEEDBACK STRUCTURE TO FOLLOW:
## 📊 Summary
Provide an honest assessment. Be encouraging but truthful about problems found.
## ✅ Strengths
List 2-3 things done well, referencing specific code elements.
## 📈 Code Quality Analysis
### Structure & Organization
Comment on code organization, readability, and documentation.
### Style Compliance
Report the actual style score and any specific issues.
### Test Results
Report the actual test results accurately:
- If critical_issues exist, report them as bugs to fix
- Be clear: "X tests passed, Y critical issues were found"
- List each critical issue
- Don't hide or minimize problems
## 💡 Recommendations for Improvement
Based on the analysis, provide specific actionable fixes.
If critical issues exist, fixing them is top priority.
## 🎯 Next Steps
Prioritized action list based on severity of issues.
## 💬 Encouragement
End with encouragement while being honest about what needs fixing.
Remember: Complete ALL steps including calling save_grading_report."""
return await instructions_utils.inject_session_state(template, context)
👉 Encontre:
# MODULE_5_STEP_4_SYNTHESIZER_AGENT
👉 Substitua por:
feedback_synthesizer_agent = Agent(
name="FeedbackSynthesizer",
model=config.critic_model,
description="Synthesizes all analysis into constructive, personalized feedback",
instruction=feedback_instruction_provider,
tools=[
FunctionTool(func=search_past_feedback),
FunctionTool(func=update_grading_progress),
FunctionTool(func=save_grading_report)
],
output_key="final_feedback"
)
Etapa 5: conectar o pipeline
Agora conecte todos os quatro agentes em um pipeline sequencial e crie o agente raiz.
👉 Abrir
code_review_assistant/agent.py
👉 Adicione as importações necessárias na parte de cima do arquivo (depois das importações atuais):
from google.adk.agents import Agent, SequentialAgent
from code_review_assistant.sub_agents.review_pipeline.code_analyzer import code_analyzer_agent
from code_review_assistant.sub_agents.review_pipeline.style_checker import style_checker_agent
from code_review_assistant.sub_agents.review_pipeline.test_runner import test_runner_agent
from code_review_assistant.sub_agents.review_pipeline.feedback_synthesizer import feedback_synthesizer_agent
O arquivo vai ficar assim:
"""
Main agent orchestration for the Code Review Assistant.
"""
from google.adk.agents import Agent, SequentialAgent
from .config import config
from code_review_assistant.sub_agents.review_pipeline.code_analyzer import code_analyzer_agent
from code_review_assistant.sub_agents.review_pipeline.style_checker import style_checker_agent
from code_review_assistant.sub_agents.review_pipeline.test_runner import test_runner_agent
from code_review_assistant.sub_agents.review_pipeline.feedback_synthesizer import feedback_synthesizer_agent
# MODULE_5_STEP_5_CREATE_PIPELINE
# MODULE_6_STEP_5_CREATE_FIX_LOOP
# MODULE_6_STEP_5_UPDATE_ROOT_AGENT
👉 Encontrar:
# MODULE_5_STEP_5_CREATE_PIPELINE
👉 Substitua essa linha única por:
# Create sequential pipeline
code_review_pipeline = SequentialAgent(
name="CodeReviewPipeline",
description="Complete code review pipeline with analysis, testing, and feedback",
sub_agents=[
code_analyzer_agent,
style_checker_agent,
test_runner_agent,
feedback_synthesizer_agent
]
)
# Root agent - coordinates the review pipeline
root_agent = Agent(
name="CodeReviewAssistant",
model=config.worker_model,
description="An intelligent code review assistant that analyzes Python code and provides educational feedback",
instruction="""You are a specialized Python code review assistant focused on helping developers improve their code quality.
When a user provides Python code for review:
1. Immediately delegate to CodeReviewPipeline and pass the code EXACTLY as it was provided by the user.
2. The pipeline will handle all analysis and feedback
3. Return ONLY the final feedback from the pipeline - do not add any commentary
When a user asks what you can do or asks general questions:
- Explain your capabilities for code review
- Do NOT trigger the pipeline for non-code messages
The pipeline handles everything for code review - just pass through its final output.""",
sub_agents=[code_review_pipeline],
output_key="assistant_response"
)
Etapa 6: testar o pipeline completo
Agora vamos ver os quatro agentes trabalhando juntos.
👉 Inicie o sistema:
adk web code_review_assistant
Depois de executar o comando adk web, você vai ver uma saída no terminal indicando que o servidor da Web do ADK foi iniciado, semelhante a esta:
+-----------------------------------------------------------------------------+
| ADK Web Server started |
| |
| For local testing, access at http://localhost:8000. |
+-----------------------------------------------------------------------------+
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
👉 Em seguida, para acessar a interface de desenvolvimento do ADK no navegador:
No ícone de visualização da Web (geralmente um olho ou um quadrado com uma seta) na barra de ferramentas do Cloud Shell (geralmente no canto superior direito), selecione "Alterar porta". Na janela pop-up, defina a porta como 8000 e clique em "Alterar e visualizar". O Cloud Shell vai abrir uma nova guia ou janela do navegador mostrando a interface de desenvolvimento do ADK.
👉 O agente está em execução. A interface de desenvolvimento do ADK no navegador é sua conexão direta com o agente.
- Selecione seu destino: no menu suspenso na parte de cima da interface, escolha o agente
code_review_assistant.
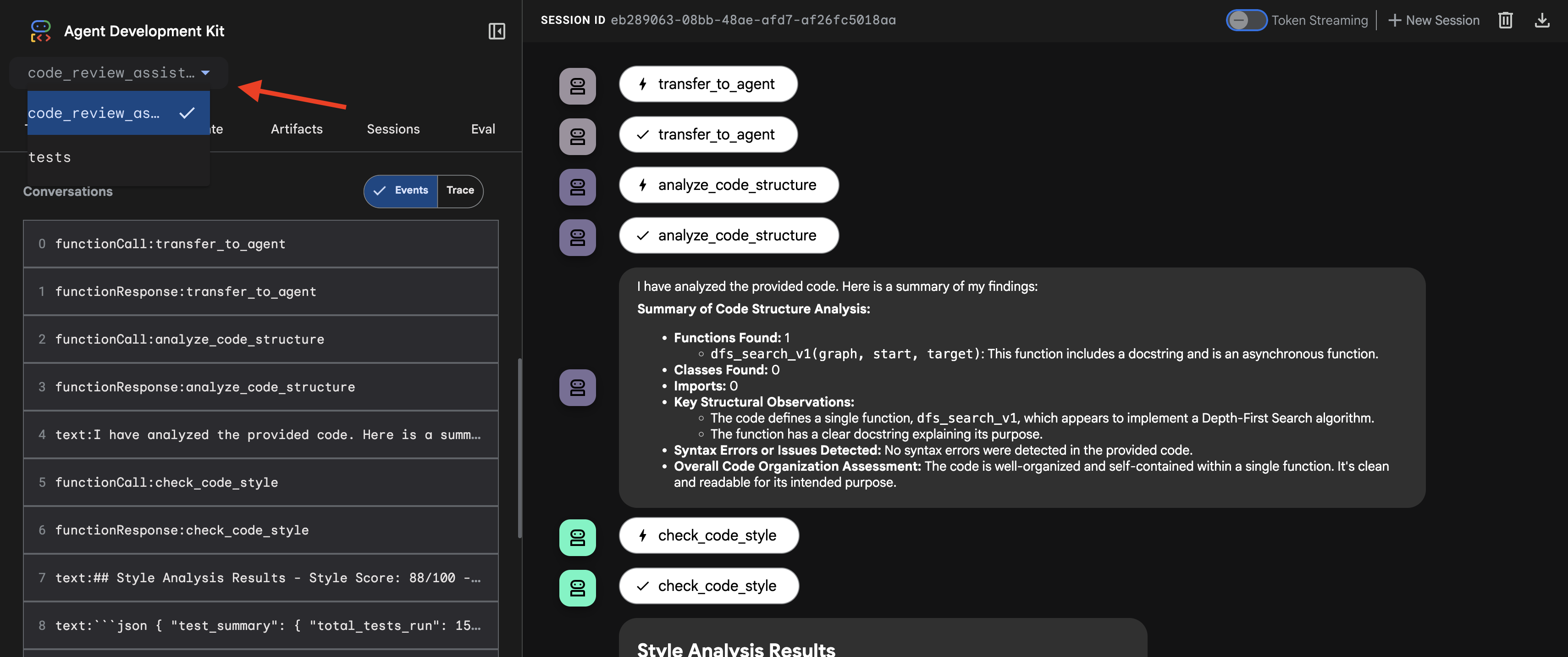
👉 Comando de teste:
Please analyze the following:
def dfs_search_v1(graph, start, target):
"""Find if target is reachable from start."""
visited = set()
stack = start
while stack:
current = stack.pop()
if current == target:
return True
if current not in visited:
visited.add(current)
for neighbor in graph[current]:
if neighbor not in visited:
stack.append(neighbor)
return False
👉 Confira o pipeline de revisão de código em ação
Ao enviar a função dfs_search_v1 com bugs, você não recebe apenas uma resposta. Você está vendo seu pipeline multiagente em ação. A saída de streaming que você vê é o resultado de quatro agentes especializados executados em sequência, cada um deles baseado no anterior.
Confira um detalhamento da contribuição de cada agente para a análise final e abrangente, transformando dados brutos em inteligência útil.
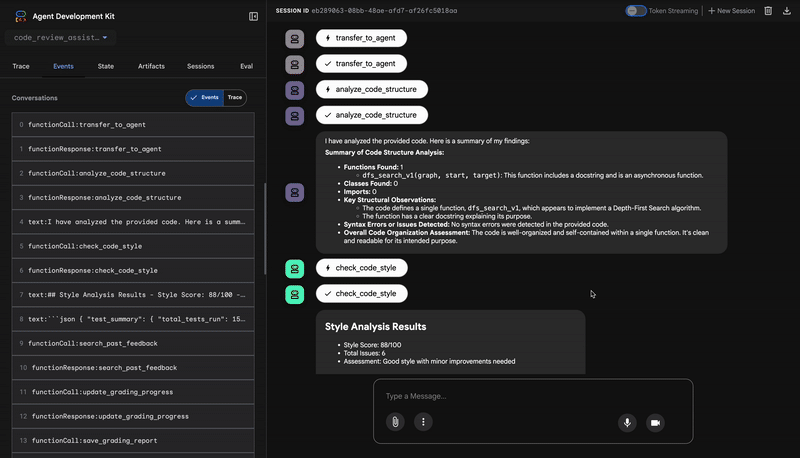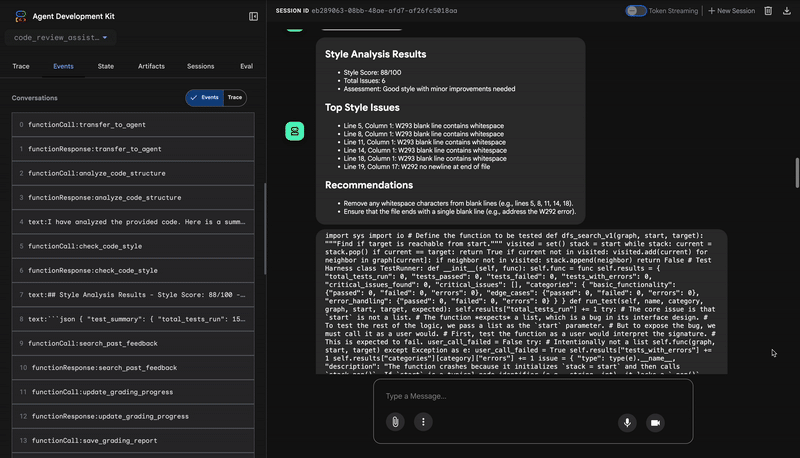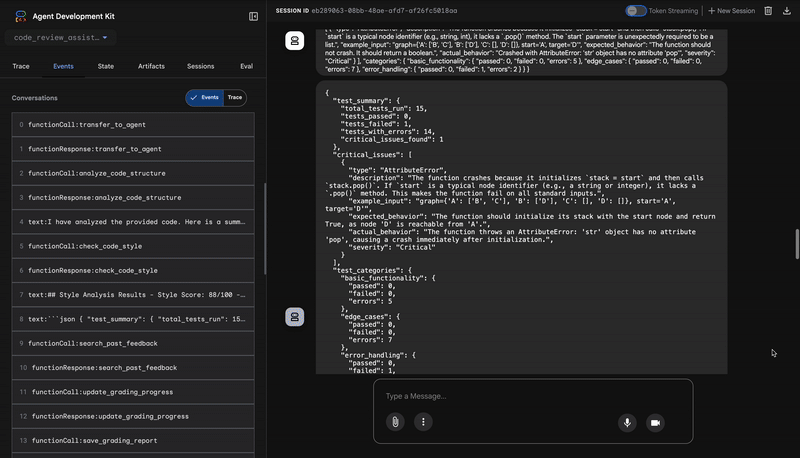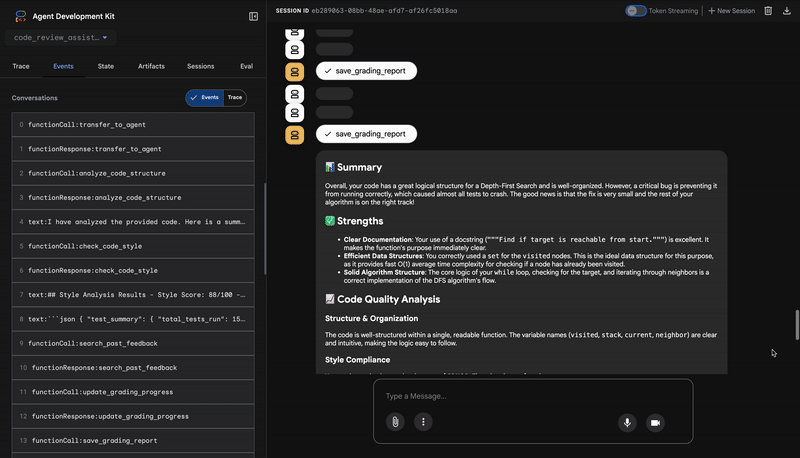
1. O relatório estrutural do Code Analyzer
Primeiro, o agente CodeAnalyzer recebe o código bruto. Ele não adivinha o que o código faz. Ele usa a ferramenta analyze_code_structure para realizar uma análise determinística da árvore de sintaxe abstrata (AST, na sigla em inglês).
A saída são dados puros e factuais sobre a estrutura do código:
The analysis of the provided code reveals the following:
Summary:
- Functions Found: 1
- Classes Found: 0
Key Structural Observations:
- A single function, dfs_search_v1, is defined.
- It includes a docstring: "Find if target is reachable from start."
- No syntax errors were detected.
Overall Code Organization Assessment:
- The code snippet is a well-defined, self-contained function.
⭐ Valor:essa etapa inicial fornece uma base limpa e confiável para os outros agentes. Ele confirma se o código é Python válido e identifica os componentes exatos que precisam ser revisados.
2. Auditoria PEP 8 do verificador de estilo
Em seguida, o agente StyleChecker assume. Ele lê o código do estado compartilhado e usa a ferramenta check_code_style, que aproveita o linter pycodestyle.
A saída é uma pontuação de qualidade quantificável e violações específicas:
Style Analysis Results
- Style Score: 88/100
- Total Issues: 6
- Assessment: Good style with minor improvements needed
Top Style Issues
- Line 5, W293: blank line contains whitespace
- Line 19, W292: no newline at end of file
⭐ Valor:esse agente fornece feedback objetivo e não negociável com base em padrões estabelecidos da comunidade (PEP 8). O sistema de pontuação ponderada informa imediatamente ao usuário a gravidade dos problemas.
3. Descoberta de bugs críticos do Test Runner
É aqui que o sistema vai além da análise superficial. O agente TestRunner gera e executa um pacote abrangente de testes para validar o comportamento do código.
A saída é um objeto JSON estruturado que contém um veredicto condenatório:
{
"critical_issues": [
{
"type": "Critical Bug",
"description": "The function's initialization `stack = start` is incorrect... When a common input like a string... is provided... the function crashes with an AttributeError.",
"severity": "Critical"
}
],
"verdict": {
"status": "BROKEN",
"confidence": "high",
"recommendation": "The function is fundamentally broken... the stack initialization line `stack = start` must be changed to `stack = [start]`."
}
}
⭐ Valor:este é o insight mais importante. O agente não apenas adivinhou, ele provou que o código estava corrompido ao executá-lo. Ele descobriu um bug de tempo de execução sutil, mas crítico, que um revisor humano poderia facilmente perder, e identificou a causa exata e a correção necessária.
4. Relatório final do Feedback Synthesizer
Por fim, o agente FeedbackSynthesizer atua como o condutor. Ele usa os dados estruturados dos três agentes anteriores e cria um único relatório fácil de usar, analítico e motivador.
A saída é a avaliação final e revisada que você vê:
📊 Summary
Great effort on implementing the Depth-First Search algorithm! ... However, a critical bug in the initialization of the stack prevents the function from working correctly...
✅ Strengths
- Good Algorithm Structure
- Correct Use of `visited` Set
📈 Code Quality Analysis
...
### Style Compliance
The style analysis returned a good score of 88/100.
...
### Test Results
The automated testing revealed a critical issue... The line `stack = start` directly assigns the input... which results in an `AttributeError`.
💡 Recommendations for Improvement
**Fix the Critical Stack Initialization Bug:**
- Incorrect Code: `stack = start`
- Correct Code: `stack = [start]`
💬 Encouragement
You are very close to a perfect implementation! The core logic of your DFS algorithm is sound, which is the hardest part.
⭐ Valor:esse agente transforma dados técnicos em uma experiência útil e educativa. Ele prioriza o problema mais importante (o bug), explica claramente, fornece a solução exata e faz isso em um tom encorajador. Ele integra com sucesso as descobertas de todas as etapas anteriores em um todo coeso e valioso.
Esse processo de vários estágios demonstra o poder de um pipeline agêntico. Em vez de uma única resposta monolítica, você recebe uma análise em camadas em que cada agente realiza uma tarefa especializada e verificável. Isso leva a uma análise que não é apenas perspicaz, mas também determinista, confiável e profundamente educativa.
👉💻 Quando terminar de testar, volte ao terminal do editor do Cloud Shell e pressione Ctrl+C para interromper a interface de desenvolvimento do ADK.
O que você criou
Agora você tem um pipeline completo de revisão de código que:
✅ Analisa a estrutura do código: análise determinística de AST com funções auxiliares
✅ Verifica o estilo: pontuação ponderada com convenções de nomenclatura
✅ Executa testes: geração abrangente de testes com saída JSON estruturada
✅ Sintetiza feedback: integra estado + memória + artefatos
✅ Acompanha o progresso: estado de vários níveis em invocações/sessões/usuários
✅ Aprende com o tempo: serviço de memória para padrões entre sessões
✅ Fornece artefatos: relatórios JSON para download com trilha de auditoria completa
Conceitos principais dominados
Pipelines sequenciais:
- Quatro agentes executando em ordem estrita
- Cada um enriquece o estado do próximo
- As dependências determinam a sequência de execução
Padrões de produção:
- Separação de funções auxiliares (sincronização em pools de linhas de execução)
- Degradação suave (estratégias de fallback)
- Gerenciamento de estado de vários níveis (temporário/sessão/usuário)
- Provedores de instruções dinâmicas (sensíveis ao contexto)
- Armazenamento duplo (artefatos + redundância de estado)
Estado como comunicação:
- As constantes evitam erros de digitação em todos os agentes
- O
output_keygrava resumos de agentes no estado - Agentes posteriores leem via StateKeys
- O estado flui linearmente pelo pipeline
Memória x estado:
- Estado: dados da sessão atual
- Memória: padrões entre sessões
- Finalidades e ciclos de vida diferentes
Orquestração de ferramentas:
- Agentes de ferramenta única (analyzer, style_checker)
- Executores integrados (test_runner)
- Coordenação de várias ferramentas (sintetizador)
Estratégia de seleção de modelo:
- Modelo de worker: tarefas mecânicas (análise, linting, roteamento)
- Modelo crítico: tarefas de raciocínio (teste, síntese)
- Otimização de custos com a seleção adequada
A seguir
No Módulo 6, você vai criar o pipeline de correção:
- Arquitetura do LoopAgent para correção iterativa
- Condições de saída por encaminhamento para um supervisor
- Acúmulo de estado em várias iterações
- Validação e lógica de repetição
- Integração com o pipeline de revisão para oferecer correções
Você vai aprender como os mesmos padrões de estado são dimensionados para fluxos de trabalho iterativos complexos em que os agentes tentam várias vezes até ter sucesso e como coordenar vários pipelines em um único aplicativo.
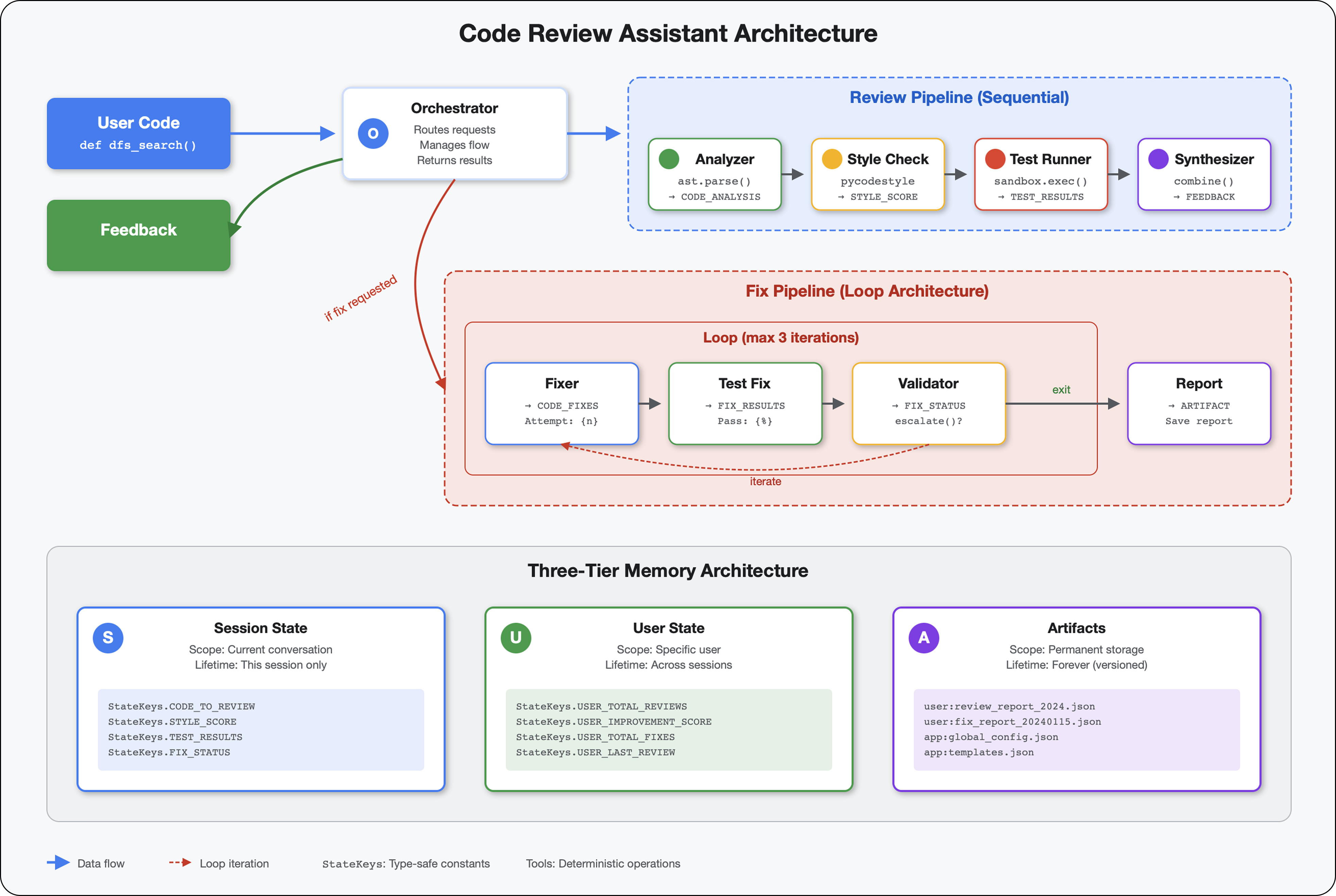
6. Adicionar o pipeline de correção: arquitetura de loop
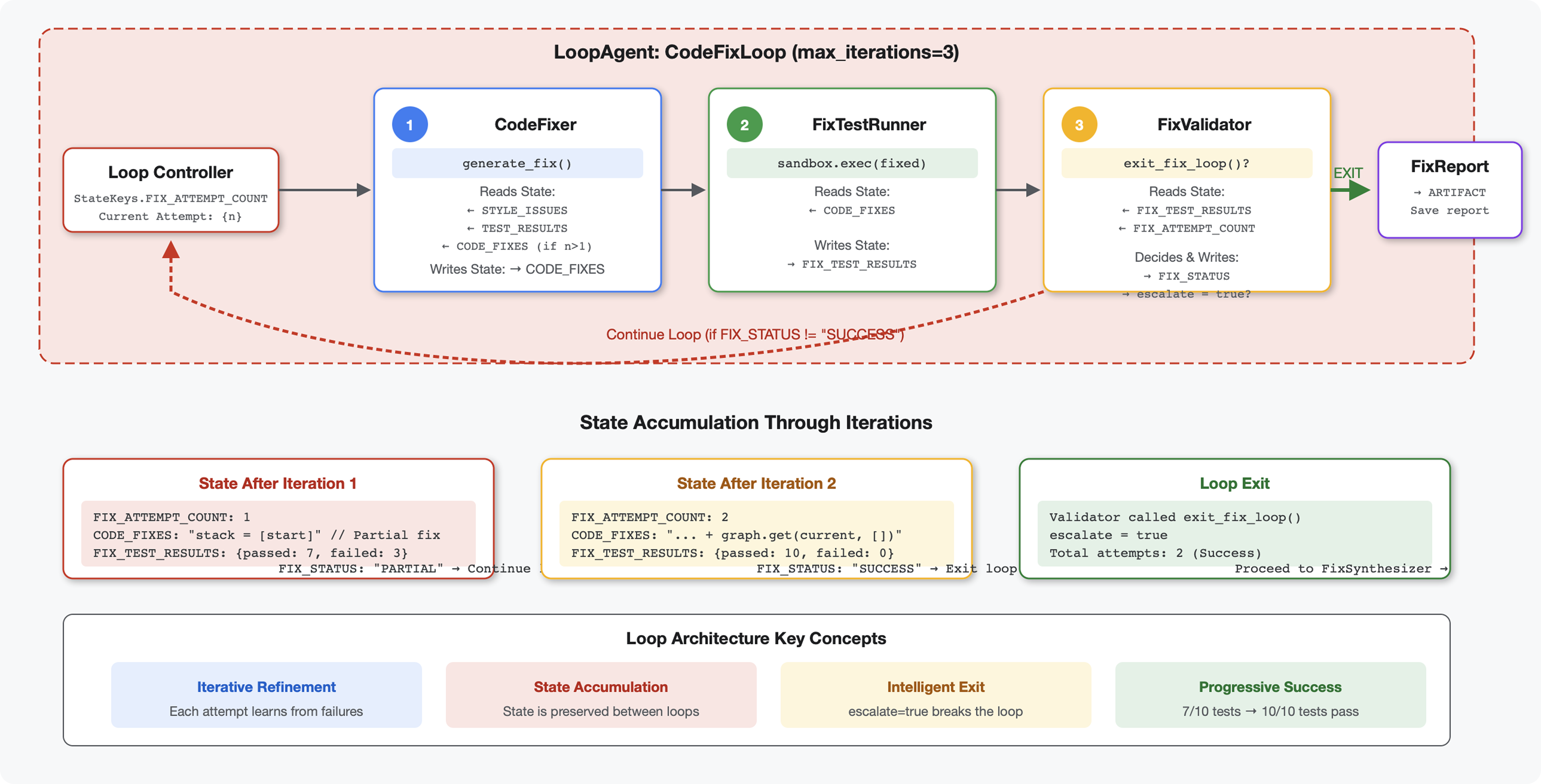
Introdução
No Módulo 5, você criou um pipeline de revisão sequencial que analisa o código e fornece feedback. Mas identificar problemas é apenas metade da solução. Os desenvolvedores precisam de ajuda para corrigi-los.
Este módulo cria um pipeline de correção automatizada que:
- Gera correções com base nos resultados da análise
- Valida correções executando testes abrangentes
- Tenta de novo automaticamente se as correções não funcionarem (até três tentativas)
- Resultados de relatórios com comparações de antes/depois
Conceito principal: LoopAgent para novas tentativas automáticas. Ao contrário dos agentes sequenciais que são executados uma vez, um LoopAgent repete os subagentes até que uma condição de saída seja atendida ou o número máximo de iterações seja alcançado. As ferramentas indicam sucesso definindo tool_context.actions.escalate = True.
Prévia do que você vai criar:envie um código com bugs → a revisão identifica problemas → o loop de correção gera correções → os testes validam → tenta novamente se necessário → relatório final abrangente.
Principais conceitos: LoopAgent x Sequential
Pipeline sequencial (módulo 5):
SequentialAgent(agents=[A, B, C])
# Executes: A → B → C → Done
- Fluxo unidirecional
- Cada agente é executado exatamente uma vez
- Sem lógica de novas tentativas
Pipeline de loop (módulo 6):
LoopAgent(agents=[A, B, C], max_iterations=3)
# Executes: A → B → C → (check exit) → A → B → C → (check exit) → ...
- Fluxo cíclico
- Os agentes podem ser executados várias vezes
- Sai quando:
- Uma ferramenta define
tool_context.actions.escalate = True(sucesso) max_iterationsatingido (limite de segurança)- Ocorreu uma exceção não tratada (erro)
- Uma ferramenta define
Por que usar loops para corrigir código:
As correções de código geralmente precisam de várias tentativas:
- Primeira tentativa: corrigir bugs óbvios (tipos de variáveis errados)
- Segunda tentativa: corrija problemas secundários revelados pelos testes (casos extremos).
- Terceira tentativa: ajuste e valide todos os testes aprovados
Sem um loop, você precisaria de uma lógica condicional complexa nas instruções do agente. Com o LoopAgent, a nova tentativa é automática.
Comparação de arquiteturas:
Sequential (Module 5):
User → Review Pipeline → Feedback → Done
Loop (Module 6):
User → Review Pipeline → Feedback → Fix Pipeline
↓
┌──────────────┴──────────────┐
│ Fix Attempt Loop (1-3x) │
│ ┌─────────────────────┐ │
│ │ 1. Generate Fixes │ │
│ │ 2. Test Fixes │ │
│ │ 3. Validate & Exit? │────┼─→ If escalate=True
│ └─────────────────────┘ │ exit loop
│ ↓ If not │
│ Try Again (max 3) │
└─────────────────────────────┘
↓
4. Synthesize Final Report → Done
Etapa 1: adicionar o agente do Code Fixer
O corretor de código gera código Python corrigido com base nos resultados da revisão.
👉 Abrir
code_review_assistant/sub_agents/fix_pipeline/code_fixer.py
👉 Encontre:
# MODULE_6_STEP_1_CODE_FIXER_INSTRUCTION_PROVIDER
👉 Substitua essa linha única por:
async def code_fixer_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are an expert code fixing specialist.
Original Code:
{code_to_review}
Analysis Results:
- Style Score: {style_score}/100
- Style Issues: {style_issues}
- Test Results: {test_execution_summary}
Based on the test results, identify and fix ALL issues including:
- Interface bugs (e.g., if start parameter expects wrong type)
- Logic errors (e.g., KeyError when accessing graph nodes)
- Style violations
- Missing documentation
YOUR TASK:
Generate the complete fixed Python code that addresses all identified issues.
CRITICAL INSTRUCTIONS:
- Output ONLY the corrected Python code
- Do NOT include markdown code blocks (```python)
- Do NOT include any explanations or commentary
- The output should be valid, executable Python code and nothing else
Common fixes to apply based on test results:
- If tests show AttributeError with 'pop', fix: stack = [start] instead of stack = start
- If tests show KeyError accessing graph, fix: use graph.get(current, [])
- Add docstrings if missing
- Fix any style violations identified
Output the complete fixed code now:"""
return await instructions_utils.inject_session_state(template, context)
👉 Encontre:
# MODULE_6_STEP_1_CODE_FIXER_AGENT
👉 Substitua essa linha única por:
code_fixer_agent = Agent(
name="CodeFixer",
model=config.worker_model,
description="Generates comprehensive fixes for all identified code issues",
instruction=code_fixer_instruction_provider,
code_executor=BuiltInCodeExecutor(),
output_key="code_fixes"
)
Etapa 2: adicionar o agente do Fix Test Runner
O executor de testes de correção valida as correções executando testes abrangentes no código corrigido.
👉 Abrir
code_review_assistant/sub_agents/fix_pipeline/fix_test_runner.py
👉 Encontre:
# MODULE_6_STEP_2_FIX_TEST_RUNNER_INSTRUCTION_PROVIDER
👉 Substitua essa linha única por:
async def fix_test_runner_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that uses the clean code from the previous step."""
template = """You are responsible for validating the fixed code by running tests.
THE FIXED CODE TO TEST:
{code_fixes}
ORIGINAL TEST RESULTS: {test_execution_summary}
YOUR TASK:
1. Understand the fixes that were applied
2. Generate the same comprehensive tests (15-20 test cases)
3. Execute the tests on the FIXED code using your code executor
4. Compare results with original test results
5. Output a detailed JSON analysis
TESTING METHODOLOGY:
- Run the same tests that revealed issues in the original code
- Verify that previously failing tests now pass
- Ensure no regressions were introduced
- Document the improvement
Execute your tests and output ONLY valid JSON with this structure:
- "passed": number of tests that passed
- "failed": number of tests that failed
- "total": total number of tests
- "pass_rate": percentage as a number
- "comparison": object with "original_pass_rate", "new_pass_rate", "improvement"
- "newly_passing_tests": array of test names that now pass
- "still_failing_tests": array of test names still failing
Do NOT output the test code itself, only the JSON analysis."""
return await instructions_utils.inject_session_state(template, context)
👉 Encontre:
# MODULE_6_STEP_2_FIX_TEST_RUNNER_AGENT
👉 Substitua essa linha única por:
fix_test_runner_agent = Agent(
name="FixTestRunner",
model=config.critic_model,
description="Runs comprehensive tests on fixed code to verify all issues are resolved",
instruction=fix_test_runner_instruction_provider,
code_executor=BuiltInCodeExecutor(),
output_key="fix_test_execution_summary"
)
Etapa 3: adicionar o agente do Fix Validator
O validador verifica se as correções foram bem-sucedidas e decide se deve sair do loop.
Como entender as ferramentas
Primeiro, adicione as três ferramentas necessárias ao validador.
👉 Abrir
code_review_assistant/tools.py
👉 Encontre:
# MODULE_6_STEP_3_VALIDATE_FIXED_STYLE
👉 Substituir pela ferramenta 1:validador de estilo
async def validate_fixed_style(tool_context: ToolContext) -> Dict[str, Any]:
"""
Validates style compliance of the fixed code.
Args:
tool_context: ADK tool context containing fixed code in state
Returns:
Dictionary with style validation results
"""
logger.info("Tool: Validating style of fixed code...")
try:
# Get the fixed code from state
code_fixes = tool_context.state.get(StateKeys.CODE_FIXES, '')
# Try to extract from markdown if present
if '```python' in code_fixes:
start = code_fixes.rfind('```python') + 9
end = code_fixes.rfind('```')
if start < end:
code_fixes = code_fixes[start:end].strip()
if not code_fixes:
return {
"status": "error",
"message": "No fixed code found in state"
}
# Store the extracted fixed code
tool_context.state[StateKeys.CODE_FIXES] = code_fixes
# Run style check on fixed code
loop = asyncio.get_event_loop()
with ThreadPoolExecutor() as executor:
style_result = await loop.run_in_executor(
executor, _perform_style_check, code_fixes
)
# Compare with original
original_score = tool_context.state.get(StateKeys.STYLE_SCORE, 0)
improvement = style_result['score'] - original_score
# Store results
tool_context.state[StateKeys.FIXED_STYLE_SCORE] = style_result['score']
tool_context.state[StateKeys.FIXED_STYLE_ISSUES] = style_result['issues']
logger.info(f"Tool: Fixed code style score: {style_result['score']}/100 "
f"(improvement: +{improvement})")
return {
"status": "success",
"fixed_style_score": style_result['score'],
"original_style_score": original_score,
"improvement": improvement,
"remaining_issues": style_result['issues'],
"perfect_style": style_result['score'] == 100
}
except Exception as e:
logger.error(f"Tool: Style validation failed: {e}", exc_info=True)
return {
"status": "error",
"message": str(e)
}
👉 Encontre:
# MODULE_6_STEP_3_COMPILE_FIX_REPORT
👉 Substituir pela Ferramenta 2:compilador de relatórios
async def compile_fix_report(tool_context: ToolContext) -> Dict[str, Any]:
"""
Compiles comprehensive report of the fix process.
Args:
tool_context: ADK tool context with all fix pipeline data
Returns:
Comprehensive fix report
"""
logger.info("Tool: Compiling comprehensive fix report...")
try:
# Gather all data
original_code = tool_context.state.get(StateKeys.CODE_TO_REVIEW, '')
code_fixes = tool_context.state.get(StateKeys.CODE_FIXES, '')
# Test results
original_tests = tool_context.state.get(StateKeys.TEST_EXECUTION_SUMMARY, {})
fixed_tests = tool_context.state.get(StateKeys.FIX_TEST_EXECUTION_SUMMARY, {})
# Parse if strings
if isinstance(original_tests, str):
try:
original_tests = json.loads(original_tests)
except:
original_tests = {}
if isinstance(fixed_tests, str):
try:
fixed_tests = json.loads(fixed_tests)
except:
fixed_tests = {}
# Extract pass rates
original_pass_rate = 0
if original_tests:
if 'pass_rate' in original_tests:
original_pass_rate = original_tests['pass_rate']
elif 'test_summary' in original_tests:
# Handle test_runner_agent's JSON structure
summary = original_tests['test_summary']
total = summary.get('total_tests_run', 0)
passed = summary.get('tests_passed', 0)
if total > 0:
original_pass_rate = (passed / total) * 100
elif 'passed' in original_tests and 'total' in original_tests:
if original_tests['total'] > 0:
original_pass_rate = (original_tests['passed'] / original_tests['total']) * 100
fixed_pass_rate = 0
all_tests_pass = False
if fixed_tests:
if 'pass_rate' in fixed_tests:
fixed_pass_rate = fixed_tests['pass_rate']
all_tests_pass = fixed_tests.get('failed', 1) == 0
elif 'passed' in fixed_tests and 'total' in fixed_tests:
if fixed_tests['total'] > 0:
fixed_pass_rate = (fixed_tests['passed'] / fixed_tests['total']) * 100
all_tests_pass = fixed_tests.get('failed', 0) == 0
# Style scores
original_style = tool_context.state.get(StateKeys.STYLE_SCORE, 0)
fixed_style = tool_context.state.get(StateKeys.FIXED_STYLE_SCORE, 0)
# Calculate improvements
test_improvement = {
'original_pass_rate': original_pass_rate,
'fixed_pass_rate': fixed_pass_rate,
'improvement': fixed_pass_rate - original_pass_rate,
'all_tests_pass': all_tests_pass
}
style_improvement = {
'original_score': original_style,
'fixed_score': fixed_style,
'improvement': fixed_style - original_style,
'perfect_style': fixed_style == 100
}
# Determine overall status
if all_tests_pass and style_improvement['perfect_style']:
fix_status = 'SUCCESSFUL'
status_emoji = '✅'
elif test_improvement['improvement'] > 0 or style_improvement['improvement'] > 0:
fix_status = 'PARTIAL'
status_emoji = '⚠️'
else:
fix_status = 'FAILED'
status_emoji = '❌'
# Build comprehensive report
report = {
'status': fix_status,
'status_emoji': status_emoji,
'timestamp': datetime.now().isoformat(),
'original_code': original_code,
'code_fixes': code_fixes,
'improvements': {
'tests': test_improvement,
'style': style_improvement
},
'summary': f"{status_emoji} Fix Status: {fix_status}\n"
f"Tests: {original_pass_rate:.1f}% → {fixed_pass_rate:.1f}%\n"
f"Style: {original_style}/100 → {fixed_style}/100"
}
# Store report in state
tool_context.state[StateKeys.FIX_REPORT] = report
tool_context.state[StateKeys.FIX_STATUS] = fix_status
logger.info(f"Tool: Fix report compiled - Status: {fix_status}")
logger.info(f"Tool: Test improvement: {original_pass_rate:.1f}% → {fixed_pass_rate:.1f}%")
logger.info(f"Tool: Style improvement: {original_style} → {fixed_style}")
return {
"status": "success",
"fix_status": fix_status,
"report": report
}
except Exception as e:
logger.error(f"Tool: Failed to compile fix report: {e}", exc_info=True)
return {
"status": "error",
"message": str(e)
}
👉 Encontre:
# MODULE_6_STEP_3_EXIT_FIX_LOOP
👉 Substitua por "Ferramenta 3: sinal de saída do loop":
def exit_fix_loop(tool_context: ToolContext) -> Dict[str, Any]:
"""
Signal that fixing is complete and should exit the loop.
Args:
tool_context: ADK tool context
Returns:
Confirmation message
"""
logger.info("Tool: Setting escalate flag to exit fix loop")
# This is the critical line that exits the LoopAgent
tool_context.actions.escalate = True
return {
"status": "success",
"message": "Fix complete, exiting loop"
}
Criar o agente de validação
👉 Abrir
code_review_assistant/sub_agents/fix_pipeline/fix_validator.py
👉 Encontre:
# MODULE_6_STEP_3_FIX_VALIDATOR_INSTRUCTION_PROVIDER
👉 Substitua essa linha única por:
async def fix_validator_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are the final validation specialist for code fixes.
You have access to:
- Original issues from initial review
- Applied fixes: {code_fixes}
- Test results after fix: {fix_test_execution_summary}
- All state data from the fix process
Your responsibilities:
1. Use validate_fixed_style tool to check style compliance of fixed code
- Pass no arguments, it will retrieve fixed code from state
2. Use compile_fix_report tool to generate comprehensive report
- Pass no arguments, it will gather all data from state
3. Based on the report, determine overall fix status:
- ✅ SUCCESSFUL: All tests pass, style score 100
- ⚠️ PARTIAL: Improvements made but issues remain
- ❌ FAILED: Fix didn't work or made things worse
4. CRITICAL: If status is SUCCESSFUL, call the exit_fix_loop tool to stop iterations
- This prevents unnecessary additional fix attempts
- If not successful, the loop will continue for another attempt
5. Provide clear summary of:
- What was fixed
- What improvements were achieved
- Any remaining issues requiring manual attention
Be precise and quantitative in your assessment.
"""
return await instructions_utils.inject_session_state(template, context)
👉 Encontre:
# MODULE_6_STEP_3_FIX_VALIDATOR_AGENT
👉 Substitua essa linha única por:
fix_validator_agent = Agent(
name="FixValidator",
model=config.worker_model,
description="Validates fixes and generates final fix report",
instruction=fix_validator_instruction_provider,
tools=[
FunctionTool(func=validate_fixed_style),
FunctionTool(func=compile_fix_report),
FunctionTool(func=exit_fix_loop)
],
output_key="final_fix_report"
)
Etapa 4: entender as condições de saída do LoopAgent
O LoopAgent pode ser encerrado de três maneiras:
1. Saída de sucesso (via encaminhamento)
# Inside any tool in the loop:
tool_context.actions.escalate = True
# Effect: Loop completes current iteration, then exits
# Use when: Fix is successful and no more attempts needed
Exemplo de fluxo:
Iteration 1:
CodeFixer → generates fixes
FixTestRunner → tests show 90% pass rate
FixValidator → compiles report, sees PARTIAL status
→ Does NOT set escalate
→ Loop continues
Iteration 2:
CodeFixer → refines fixes based on failures
FixTestRunner → tests show 100% pass rate
FixValidator → compiles report, sees SUCCESSFUL status
→ Calls exit_fix_loop() which sets escalate = True
→ Loop exits after this iteration
2. Max Iterations Exit
LoopAgent(
name="FixAttemptLoop",
sub_agents=[...],
max_iterations=3 # Safety limit
)
# Effect: After 3 complete iterations, loop exits regardless of escalate
# Use when: Prevent infinite loops if fixes never succeed
Exemplo de fluxo:
Iteration 1: PARTIAL (continue)
Iteration 2: PARTIAL (continue)
Iteration 3: PARTIAL (but max reached)
→ Loop exits, synthesizer presents best attempt
3. Saída de erro
# If any agent throws unhandled exception:
raise Exception("Unexpected error")
# Effect: Loop exits immediately with error state
# Use when: Critical failure that can't be recovered
Evolução do estado em várias iterações:
Cada iteração recebe o estado atualizado da tentativa anterior:
# Before Iteration 1:
state = {
"code_to_review": "def add(a,b):return a+b", # Original
"style_score": 40,
"test_execution_summary": {...}
}
# After Iteration 1:
state = {
"code_to_review": "def add(a,b):return a+b", # Unchanged
"code_fixes": "def add(a, b):\n return a + b", # NEW
"style_score": 40, # Unchanged
"fixed_style_score": 100, # NEW
"test_execution_summary": {...}, # Unchanged
"fix_test_execution_summary": {...} # NEW
}
# Iteration 2 starts with all this state
# If fixes still not perfect, code_fixes gets overwritten
Por que
escalate
Em vez de "Valores de retorno":
# Bad: Using return value to signal exit
def validator_agent():
report = compile_report()
if report['status'] == 'SUCCESSFUL':
return {"exit": True} # How does loop know?
# Good: Using escalate
def validator_tool(tool_context):
report = compile_report()
if report['status'] == 'SUCCESSFUL':
tool_context.actions.escalate = True # Loop knows immediately
return {"report": report}
Benefícios:
- Funciona com qualquer ferramenta, não apenas com a última
- Não interfere nos dados de retorno
- Significado semântico claro
- O framework processa a lógica de saída
Etapa 5: conectar o pipeline de correção
👉 Abrir
code_review_assistant/agent.py
👉 Adicione as importações do pipeline de correção (depois das importações atuais):
from google.adk.agents import LoopAgent # Add this to the existing Agent, SequentialAgent line
from code_review_assistant.sub_agents.fix_pipeline.code_fixer import code_fixer_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_test_runner import fix_test_runner_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_validator import fix_validator_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_synthesizer import fix_synthesizer_agent
Suas importações agora serão:
from google.adk.agents import Agent, SequentialAgent, LoopAgent
from .config import config
# Review pipeline imports (from Module 5)
from code_review_assistant.sub_agents.review_pipeline.code_analyzer import code_analyzer_agent
from code_review_assistant.sub_agents.review_pipeline.style_checker import style_checker_agent
from code_review_assistant.sub_agents.review_pipeline.test_runner import test_runner_agent
from code_review_assistant.sub_agents.review_pipeline.feedback_synthesizer import feedback_synthesizer_agent
# Fix pipeline imports (NEW)
from code_review_assistant.sub_agents.fix_pipeline.code_fixer import code_fixer_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_test_runner import fix_test_runner_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_validator import fix_validator_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_synthesizer import fix_synthesizer_agent
👉 Encontrar:
# MODULE_6_STEP_5_CREATE_FIX_LOOP
👉 Substitua essa linha única por:
# Create the fix attempt loop (retries up to 3 times)
fix_attempt_loop = LoopAgent(
name="FixAttemptLoop",
sub_agents=[
code_fixer_agent, # Step 1: Generate fixes
fix_test_runner_agent, # Step 2: Validate with tests
fix_validator_agent # Step 3: Check success & possibly exit
],
max_iterations=3 # Try up to 3 times
)
# Wrap loop with synthesizer for final report
code_fix_pipeline = SequentialAgent(
name="CodeFixPipeline",
description="Automated code fixing pipeline with iterative validation",
sub_agents=[
fix_attempt_loop, # Try to fix (1-3 times)
fix_synthesizer_agent # Present final results (always runs once)
]
)
👉 Remova o atual
root_agent
definition:
root_agent = Agent(...)
👉 Encontre:
# MODULE_6_STEP_5_UPDATE_ROOT_AGENT
👉 Substitua essa linha única por:
# Update root agent to include both pipelines
root_agent = Agent(
name="CodeReviewAssistant",
model=config.worker_model,
description="An intelligent code review assistant that analyzes Python code and provides educational feedback",
instruction="""You are a specialized Python code review assistant focused on helping developers improve their code quality.
When a user provides Python code for review:
1. Immediately delegate to CodeReviewPipeline and pass the code EXACTLY as it was provided by the user.
2. The pipeline will handle all analysis and feedback
3. Return ONLY the final feedback from the pipeline - do not add any commentary
After completing a review, if significant issues were identified:
- If style score < 100 OR tests are failing OR critical issues exist:
* Add at the end: "\n\n💡 I can fix these issues for you. Would you like me to do that?"
- If the user responds yes or requests fixes:
* Delegate to CodeFixPipeline
* Return the fix pipeline's complete output AS-IS
When a user asks what you can do or general questions:
- Explain your capabilities for code review and fixing
- Do NOT trigger the pipeline for non-code messages
The pipelines handle everything for code review and fixing - just pass through their final output.""",
sub_agents=[code_review_pipeline, code_fix_pipeline],
output_key="assistant_response"
)
Etapa 6: adicionar o agente do Fix Synthesizer
O sintetizador cria uma apresentação fácil de usar dos resultados da correção após a conclusão do loop.
👉 Abrir
code_review_assistant/sub_agents/fix_pipeline/fix_synthesizer.py
👉 Encontre:
# MODULE_6_STEP_6_FIX_SYNTHESIZER_INSTRUCTION_PROVIDER
👉 Substitua essa linha única por:
async def fix_synthesizer_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are responsible for presenting the fix results to the user.
Based on the validation report: {final_fix_report}
Fixed code from state: {code_fixes}
Fix status: {fix_status}
Create a comprehensive yet friendly response that includes:
## 🔧 Fix Summary
[Overall status and key improvements - be specific about what was achieved]
## 📊 Metrics
- Test Results: [original pass rate]% → [new pass rate]%
- Style Score: [original]/100 → [new]/100
- Issues Fixed: X of Y
## ✅ What Was Fixed
[List each fixed issue with brief explanation of the correction made]
## 📝 Complete Fixed Code
[Include the complete, corrected code from state - this is critical]
## 💡 Explanation of Key Changes
[Brief explanation of the most important changes made and why]
[If any issues remain]
## ⚠️ Remaining Issues
[List what still needs manual attention]
## 🎯 Next Steps
[Guidance on what to do next - either use the fixed code or address remaining issues]
Save the fix report using save_fix_report tool before presenting.
Call it with no parameters - it will retrieve the report from state automatically.
Be encouraging about improvements while being honest about any remaining issues.
Focus on the educational aspect - help the user understand what was wrong and how it was fixed.
"""
return await instructions_utils.inject_session_state(template, context)
👉 Encontre:
# MODULE_6_STEP_6_FIX_SYNTHESIZER_AGENT
👉 Substitua essa linha única por:
fix_synthesizer_agent = Agent(
name="FixSynthesizer",
model=config.critic_model,
description="Creates comprehensive user-friendly fix report",
instruction=fix_synthesizer_instruction_provider,
tools=[FunctionTool(func=save_fix_report)],
output_key="fix_summary"
)
👉 Adicionar
save_fix_report
ferramenta para
tools.py
:
👉 Encontre:
# MODULE_6_STEP_6_SAVE_FIX_REPORT
👉 Substitua por:
async def save_fix_report(tool_context: ToolContext) -> Dict[str, Any]:
"""
Saves the fix report as an artifact.
Args:
tool_context: ADK tool context
Returns:
Save status
"""
logger.info("Tool: Saving fix report...")
try:
# Get the report from state
fix_report = tool_context.state.get(StateKeys.FIX_REPORT, {})
if not fix_report:
return {
"status": "error",
"message": "No fix report found in state"
}
# Convert to JSON
report_json = json.dumps(fix_report, indent=2)
report_part = types.Part.from_text(text=report_json)
# Generate filename
timestamp = datetime.now().isoformat().replace(':', '-')
filename = f"fix_report_{timestamp}.json"
# Try to save as artifact
if hasattr(tool_context, 'save_artifact'):
try:
version = await tool_context.save_artifact(filename, report_part)
await tool_context.save_artifact("latest_fix_report.json", report_part)
logger.info(f"Tool: Fix report saved as {filename}")
return {
"status": "success",
"filename": filename,
"version": str(version),
"size": len(report_json)
}
except Exception as e:
logger.warning(f"Could not save as artifact: {e}")
# Fallback: store in state
tool_context.state[StateKeys.LAST_FIX_REPORT] = fix_report
return {
"status": "success",
"message": "Fix report saved to state",
"size": len(report_json)
}
except Exception as e:
logger.error(f"Tool: Failed to save fix report: {e}", exc_info=True)
return {
"status": "error",
"message": str(e)
}
Etapa 7: testar o pipeline de correção completa
Agora é hora de ver o loop inteiro em ação.
👉 Inicie o sistema:
adk web code_review_assistant
Depois de executar o comando adk web, você vai ver uma saída no terminal indicando que o servidor da Web do ADK foi iniciado, semelhante a esta:
+-----------------------------------------------------------------------------+
| ADK Web Server started |
| |
| For local testing, access at http://localhost:8000. |
+-----------------------------------------------------------------------------+
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
👉 Comando de teste:
Please analyze the following:
def dfs_search_v1(graph, start, target):
"""Find if target is reachable from start."""
visited = set()
stack = start
while stack:
current = stack.pop()
if current == target:
return True
if current not in visited:
visited.add(current)
for neighbor in graph[current]:
if neighbor not in visited:
stack.append(neighbor)
return False
Primeiro, envie o código com bugs para acionar o pipeline de revisão. Depois que ele identificar as falhas, peça ao agente para "Corrija o código", o que aciona o poderoso pipeline de correção iterativo.
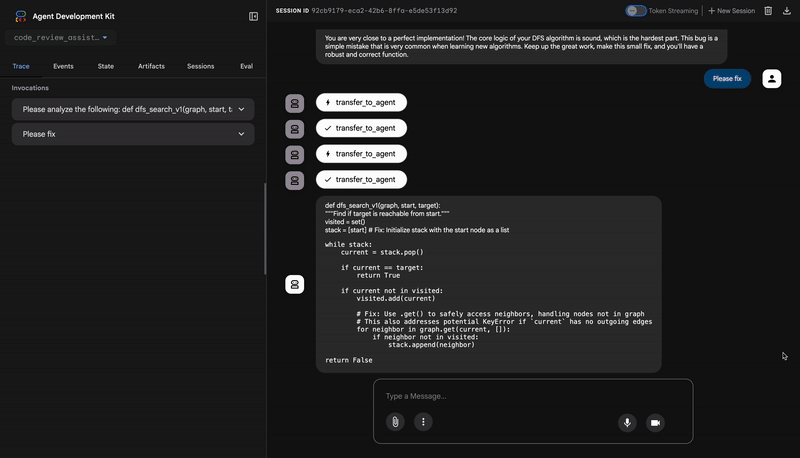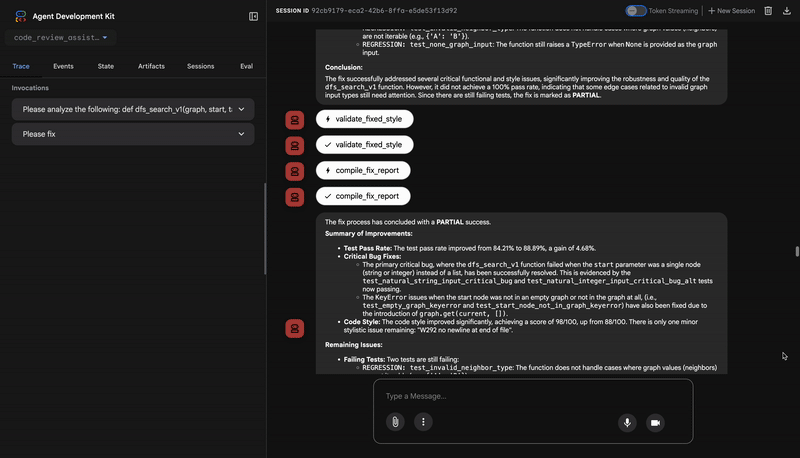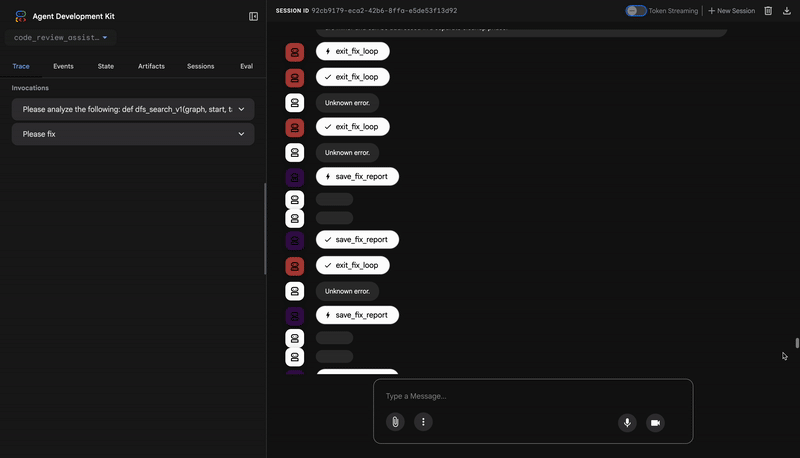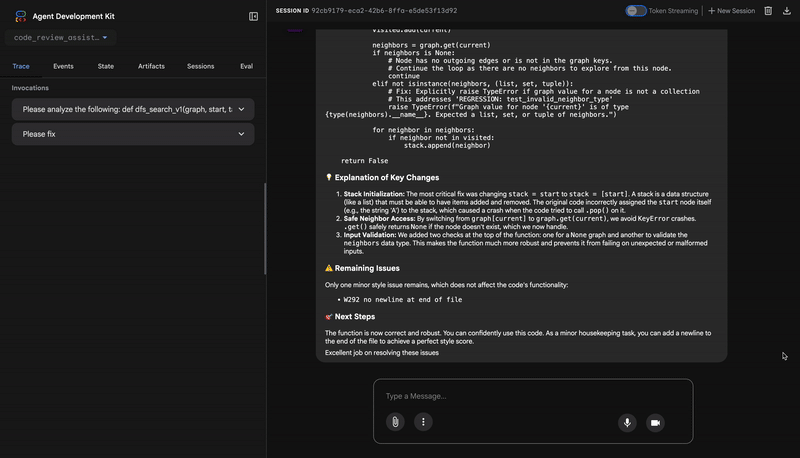
1. A análise inicial (encontrar as falhas)
Esta é a primeira metade do processo. O pipeline de revisão com quatro agentes analisa o código, verifica o estilo e executa um pacote de testes gerado. Ele identifica corretamente um problema crítico e outros problemas, emitindo um veredicto: o código está QUEBRADO, com uma taxa de aprovação no teste de apenas 84,21%.
2. A correção automática (o loop em ação)
Essa é a parte mais impressionante. Quando você pede ao agente para corrigir o código, ele não faz apenas uma mudança. Ele inicia um ciclo de correção e validação iterativo que funciona como um desenvolvedor diligente: tenta uma correção, testa completamente e, se não estiver perfeito, tenta de novo.
Iteração 1: a primeira tentativa (sucesso parcial)
- A correção:o agente
CodeFixerlê o relatório inicial e faz as correções mais óbvias. Ele mudastack = startparastack = [start]e usagraph.get()para evitar exceções deKeyError. - A validação:o
TestRunnerexecuta imediatamente o conjunto de testes completo no novo código. - O resultado:a taxa de aprovação melhora significativamente para 88,89%. Os bugs críticos foram corrigidos. No entanto, os testes são tão abrangentes que revelam dois novos bugs sutis (regressões) relacionados ao processamento de
Nonecomo um gráfico ou valores vizinhos não listados. O sistema marca a correção como PARCIAL.
Iteração 2: o toque final (100% de sucesso)
- A correção:como a condição de saída do loop (taxa de aprovação de 100%) não foi atendida, ele é executado novamente. O
CodeFixeragora tem mais informações: as duas novas falhas de regressão. Ele gera uma versão final e mais robusta do código que processa explicitamente esses casos extremos. - A validação:o
TestRunnerexecuta o conjunto de testes uma última vez na versão final do código. - O resultado:uma taxa de aprovação de 100% perfeita. Todos os bugs originais e todas as regressões foram resolvidos. O sistema marca a correção como SUCCESSFUL e o loop é encerrado.
3. O relatório final: uma pontuação perfeita
Com uma correção totalmente validada, o agente FixSynthesizer assume o controle para apresentar o relatório final, transformando os dados técnicos em um resumo claro e educativo.
Métrica | Antes | Depois | Melhoria |
Taxa de aprovação no teste | 84,21% | 100% | ▲ 15,79% |
Pontuação de estilo | 88 / 100 | 98 / 100 | ▲ 10 pts |
Bugs corrigidos | 0 de 3 | 3 de 3 | ✅ |
✅ O código final e validado
Este é o código completo e corrigido que agora passa em todos os 19 testes, demonstrando a correção bem-sucedida:
def dfs_search_v1(graph, start, target):
"""Find if target is reachable from start."""
# Handles 'None' graph input
if graph is None:
return False
visited = set()
# Fixes the critical AttributeError
stack = [start]
while stack:
current = stack.pop()
if current == target:
return True
if current not in visited:
visited.add(current)
# Safely gets neighbors to prevent KeyError
neighbors = graph.get(current)
if neighbors is None:
continue
# Validates that neighbors are iterable
if not isinstance(neighbors, (list, set, tuple)):
raise TypeError(
f"Graph value for node '{current}' is of type "
f"{type(neighbors).__name__}. Expected a list, set, or tuple."
)
for neighbor in neighbors:
if neighbor not in visited:
stack.append(neighbor)
return False
👉💻 Quando terminar de testar, volte ao terminal do editor do Cloud Shell e pressione Ctrl+C para interromper a interface de desenvolvimento do ADK.
O que você criou
Agora você tem um pipeline de correção automatizado completo que:
✅ Gera correções: com base na análise da revisão
✅ Valida de forma iterativa: testa após cada tentativa de correção
✅ Tenta novamente de forma automática: até três tentativas para ter sucesso
✅ Sai de forma inteligente: via escalonamento quando a correção é bem-sucedida
✅ Rastreia melhorias: compara métricas antes e depois
✅ Fornece artefatos: relatórios de correção para download
Conceitos principais dominados
LoopAgent vs. Sequential:
- Sequencial: uma passagem pelos agentes
- LoopAgent: repete até a condição de saída ou o número máximo de iterações
- Saia por
tool_context.actions.escalate = True
Evolução do estado em várias iterações:
CODE_FIXESatualizado em cada iteração- Os resultados do teste mostram melhoria com o tempo
- O validador vê as mudanças cumulativas
Arquitetura de vários pipelines:
- Revisão do pipeline: análise somente leitura (módulo 5)
- Correção iterativa (loop interno do módulo 6)
- Correção de pipeline: loop + sintetizador (externo do módulo 6)
- Agente raiz: coordena com base na intenção do usuário
Ferramentas que controlam o fluxo:
exit_fix_loop()conjuntos aumentam- Qualquer ferramenta pode sinalizar a conclusão do loop
- Desvincula a lógica de saída das instruções do agente
Segurança de iterações máximas:
- Evita loops infinitos
- Garante que o sistema sempre responda
- Apresenta a melhor tentativa, mesmo que não seja perfeita
A seguir
No último módulo, você vai aprender a implantar seu agente em produção:
- Como configurar o armazenamento permanente com o VertexAiSessionService
- Implantação no Agent Engine no Google Cloud
- Monitorar e depurar agentes de produção
- Práticas recomendadas para escalonamento e confiabilidade
Você criou um sistema multiagente completo com arquiteturas sequenciais e de loop. Os padrões que você aprendeu (gerenciamento de estado, instruções dinâmicas, orquestração de ferramentas e refinamento iterativo) são técnicas prontas para produção usadas em sistemas de agentes reais.
7. Como implantar a versão na produção
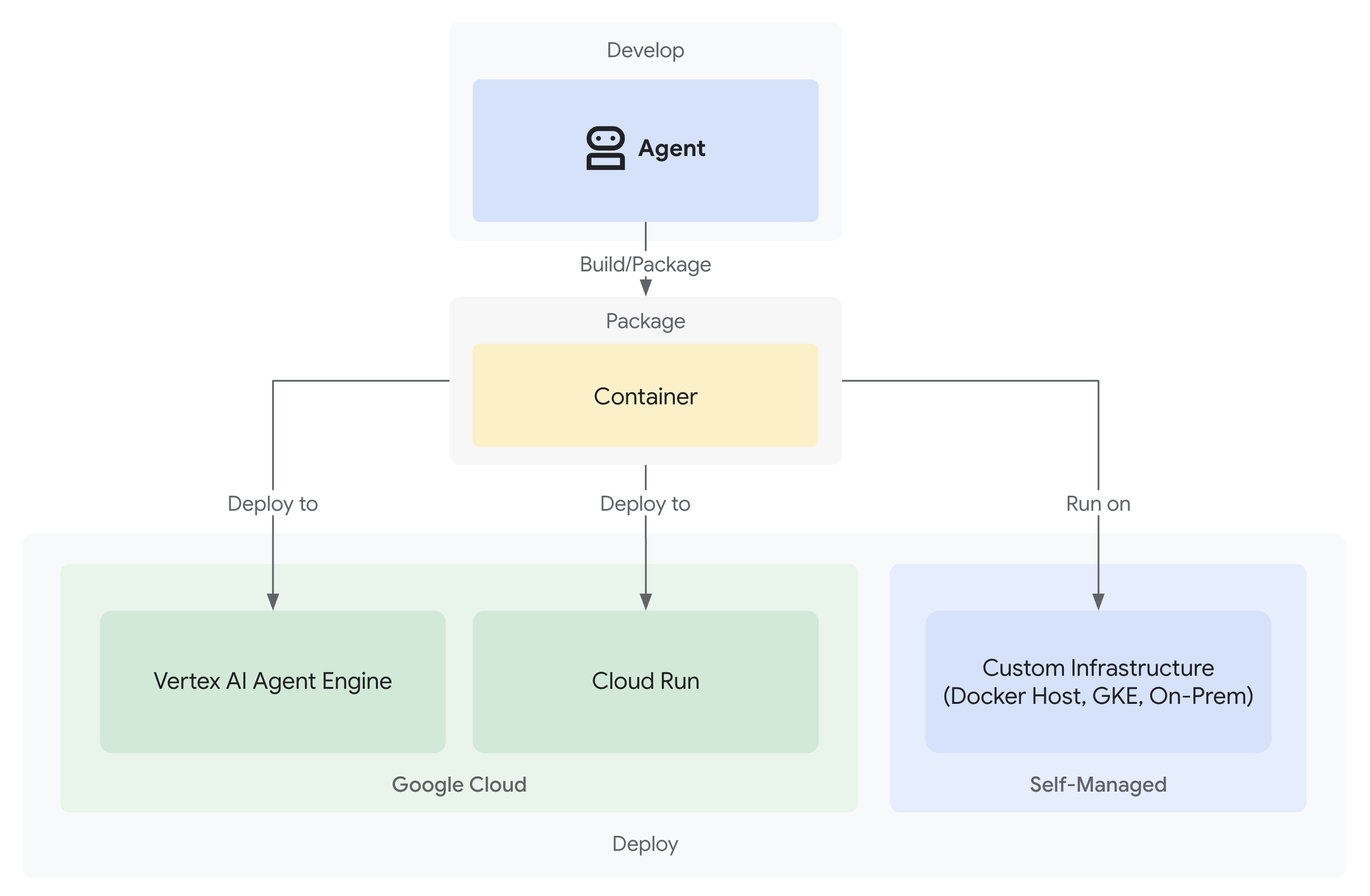
Introdução
Seu assistente de revisão de código agora está completo, com pipelines de revisão e correção funcionando localmente. A peça que falta: ele só é executado na sua máquina. Neste módulo, você vai implantar seu agente no Google Cloud, tornando-o acessível à sua equipe com sessões persistentes e infraestrutura de nível de produção.
Você vai aprender o seguinte:
- Três caminhos de implantação: local, Cloud Run e Agent Engine
- Provisionamento automatizado de infraestrutura
- Estratégias de persistência da sessão
- Testar agentes implantados
Noções básicas sobre opções de implantação
O ADK oferece suporte a vários destinos de implantação, cada um com diferentes compensações:
Caminhos de implantação
Fator | Local ( | Cloud Run ( | Agent Engine ( |
Complexidade | Mínimo | Médio | Baixo |
Persistência da sessão | Somente na memória (perdido na reinicialização) | Cloud SQL (PostgreSQL) | Gerenciado pela Vertex AI (automático) |
Infraestrutura | Nenhum (somente máquina de desenvolvimento) | Contêiner + banco de dados | Totalmente gerenciado |
Inicialização a frio | N/A | 100 a 2.000 ms | 100 a 500 ms |
Escalonamento | Instância única | Automático (para zero) | Automático |
Modelo de custo | Sem custos financeiros (computação local) | Baseada em solicitações + nível sem custo financeiro | Baseado em computação |
Suporte à interface | Sim (via | Sim (via | Não (somente API) |
Ideal para | Desenvolvimento/testes | Tráfego variável, controle de custos | Agentes de produção |
Outra opção de implantação:o Google Kubernetes Engine (GKE) está disponível para usuários avançados que precisam de controle no nível do Kubernetes, redes personalizadas ou orquestração de vários serviços. A implantação do GKE não é abordada neste codelab, mas está documentada no guia de implantação do ADK.
O que é implantado
Ao implantar no Cloud Run ou no Agent Engine, o seguinte é empacotado e implantado:
- Seu código de agente (
agent.py, todos os subagentes e ferramentas) - Dependências (
requirements.txt) - Servidor de API do ADK (incluído automaticamente)
- Interface da Web (somente no Cloud Run, quando
--with_uié especificado)
Principais diferenças:
- Cloud Run: usa a CLI
adk deploy cloud_run(cria o contêiner automaticamente) ougcloud run deploy(requer um Dockerfile personalizado) - Mecanismo de agente: usa a CLI
adk deploy agent_engine(não é necessário criar contêineres, empacota diretamente o código Python)
Etapa 1: configurar o ambiente
Configurar o arquivo .env
O arquivo .env (criado no módulo 3) precisa de atualizações para a implantação na nuvem. Abra o .env e verifique/atualize estas configurações:
Obrigatório para todas as implantações na nuvem:
# Your actual GCP Project ID (REQUIRED)
GOOGLE_CLOUD_PROJECT=your-project-id
# GCP region for deployments (REQUIRED)
GOOGLE_CLOUD_LOCATION=us-central1
# Use Vertex AI (REQUIRED)
GOOGLE_GENAI_USE_VERTEXAI=true
# Model configuration (already set)
WORKER_MODEL=gemini-2.5-flash
CRITIC_MODEL=gemini-2.5-pro
Defina os nomes dos buckets (OBRIGATÓRIO antes de executar deploy.sh):
O script de implantação cria buckets com base nesses nomes. Defina agora:
# Staging bucket for Agent Engine code uploads (REQUIRED for agent-engine)
STAGING_BUCKET=gs://your-project-id-staging
# Artifact storage for reports and fixed code (REQUIRED for both cloud-run and agent-engine)
ARTIFACT_BUCKET=gs://your-project-id-artifacts
Substitua your-project-id pelo ID do projeto real nos dois nomes de bucket. O script vai criar esses intervalos se eles não existirem.
Variáveis opcionais (criadas automaticamente se estiverem em branco):
# Agent Engine ID (populated after first deployment)
AGENT_ENGINE_ID=
# Cloud Run Database credentials (created automatically if blank)
CLOUD_SQL_INSTANCE_NAME=
DB_USER=
DB_PASSWORD=
DB_NAME=
Verificação de autenticação
Se você encontrar erros de autenticação durante a implantação:
gcloud auth application-default login
gcloud config set project $GOOGLE_CLOUD_PROJECT
Etapa 2: entender o script de implantação
O script deploy.sh oferece uma interface unificada para todos os modos de implantação:
./deploy.sh {local|cloud-run|agent-engine}
Capacidades de script
Provisionamento de infraestrutura:
- Ativação de API (AI Platform, Storage, Cloud Build, Cloud Trace, Cloud SQL)
- Configuração de permissões do IAM (contas de serviço, papéis)
- Criação de recursos (buckets, bancos de dados, instâncias)
- Implantação com flags adequadas
- Verificação pós-implantação
Principais seções do script
- Configuração (linhas 1 a 35): projeto, região, nomes de serviços, padrões
- Funções auxiliares (linhas 37 a 200): ativação da API, criação de bucket, configuração do IAM
- Lógica principal (linhas 202 a 400): orquestração de implantação específica do modo
Etapa 3: preparar o agente para o mecanismo de agente
Antes de fazer a implantação no Agent Engine, é necessário um arquivo agent_engine_app.py que encapsule seu agente para o ambiente de execução gerenciado. Isso já foi criado para você.
Ver code_review_assistant/agent_engine_app.py
👉 Abrir arquivo:
"""
Agent Engine application wrapper.
This file prepares the agent for deployment to Vertex AI Agent Engine.
"""
from vertexai import agent_engines
from .agent import root_agent
# Wrap the agent in an AdkApp object for Agent Engine deployment
app = agent_engines.AdkApp(
agent=root_agent,
enable_tracing=True,
)
Etapa 4: implantar no Agent Engine
O Agent Engine é a implantação de produção recomendada para agentes do ADK porque oferece:
- Infraestrutura totalmente gerenciada (sem contêineres para criar)
- Persistência de sessão integrada via
VertexAiSessionService - Escalonamento automático do zero
- Integração do Cloud Trace ativada por padrão
Como o Agent Engine é diferente de outras implantações
Em segundo plano,
deploy.sh agent-engine
usa:
adk deploy agent_engine \
--project=$GOOGLE_CLOUD_PROJECT \
--region=$GOOGLE_CLOUD_LOCATION \
--staging_bucket=$STAGING_BUCKET \
--display_name="Code Review Assistant" \
--trace_to_cloud \
code_review_assistant
Esse comando:
- Empacota seu código Python diretamente (sem build do Docker)
- Faz upload para o bucket de preparo especificado em
.env - Cria uma instância gerenciada do Agent Engine.
- Ativa o Cloud Trace para observabilidade.
- Usa
agent_engine_app.pypara configurar o ambiente de execução.
Ao contrário do Cloud Run, que coloca seu código em contêineres, o Agent Engine executa seu código Python diretamente em um ambiente de execução gerenciado, semelhante às funções sem servidor.
Executar a implantação
Na raiz do projeto:
./deploy.sh agent-engine
Fases de implantação
Assista o script executar estas fases:
Phase 1: API Enablement
✓ aiplatform.googleapis.com
✓ storage-api.googleapis.com
✓ cloudbuild.googleapis.com
✓ cloudtrace.googleapis.com
Phase 2: IAM Setup
✓ Getting project number
✓ Granting Storage Object Admin
✓ Granting AI Platform User
✓ Granting Cloud Trace Agent
Phase 3: Staging Bucket
✓ Creating gs://your-project-id-staging
✓ Setting permissions
Phase 4: Artifact Bucket
✓ Creating gs://your-project-id-artifacts
✓ Configuring access
Phase 5: Validation
✓ Checking agent.py exists
✓ Verifying root_agent defined
✓ Checking agent_engine_app.py exists
✓ Validating requirements.txt
Phase 6: Build & Deploy
✓ Packaging agent code
✓ Uploading to staging bucket
✓ Creating Agent Engine instance
✓ Configuring session persistence
✓ Setting up Cloud Trace integration
✓ Running health checks
Esse processo leva de 5 a 10 minutos, já que ele empacota o agente e o implanta na infraestrutura da Vertex AI.
Salvar o ID do Agent Engine
Após a implantação:
✅ Deployment successful!
Agent Engine ID: 7917477678498709504
Resource Name: projects/123456789/locations/us-central1/reasoningEngines/7917477678498709504
Endpoint: https://us-central1-aiplatform.googleapis.com/v1/...
⚠️ IMPORTANT: Save this in your .env file:
AGENT_ENGINE_ID=7917477678498709504
Atualizar seu
.env
arquivo imediatamente:
echo "AGENT_ENGINE_ID=7917477678498709504" >> .env
Esse ID é obrigatório para:
- Testar o agente implantado
- Atualizar a implantação mais tarde
- Como acessar registros e traces
O que foi implantado
Sua implantação do Agent Engine agora inclui:
✅ Pipeline de revisão completo (quatro agentes)
✅ Pipeline de correção completo (loop + sintetizador)
✅ Todas as ferramentas (análise AST, verificação de estilo, geração de artefatos)
✅ Persistência de sessão (automática via VertexAiSessionService)
✅ Gerenciamento de estado (níveis de sessão/usuário/tempo de vida)
✅ Observabilidade (Cloud Trace ativado)
✅ Infraestrutura de escalonamento automático
Etapa 5: testar o agente implantado
Atualizar o arquivo .env
Após a implantação, verifique se o .env inclui:
AGENT_ENGINE_ID=7917477678498709504 # From deployment output
GOOGLE_CLOUD_PROJECT=your-project-id
GOOGLE_CLOUD_LOCATION=us-central1
Executar o script de teste
O projeto inclui tests/test_agent_engine.py especificamente para testar implantações do Agent Engine:
python tests/test_agent_engine.py
O que o teste faz
- Autentica com seu projeto na nuvem do Google Cloud
- Cria uma sessão com o agente implantado
- Envia uma solicitação de revisão de código (o exemplo de bug do DFS)
- Transmite a resposta de volta usando eventos enviados pelo servidor (SSE)
- Verifica a persistência da sessão e o gerenciamento de estado.
Resposta esperada
Authenticated with project: your-project-id
Targeting Agent Engine: projects/.../reasoningEngines/7917477678498709504
Creating new session...
Created session: 4857885913439920384
Sending query to agent and streaming response:
data: {"content": {"parts": [{"text": "I'll analyze your code..."}]}}
data: {"content": {"parts": [{"text": "**Code Structure Analysis**\n..."}]}}
data: {"content": {"parts": [{"text": "**Style Check Results**\n..."}]}}
data: {"content": {"parts": [{"text": "**Test Results**\n..."}]}}
data: {"content": {"parts": [{"text": "**Final Feedback**\n..."}]}}
Stream finished.
Lista de verificação da confirmação
- ✅ O pipeline de revisão completa é executado (todos os quatro agentes)
- ✅ A resposta de streaming mostra a saída progressiva
- ✅ O estado da sessão persiste entre as solicitações.
- ✅ Sem erros de autenticação ou conexão
- ✅ As chamadas de ferramentas são executadas com sucesso (análise de AST, verificação de estilo)
- ✅ Os artefatos são salvos (relatório de avaliação acessível)
Alternativa: implantar no Cloud Run
Embora o Agent Engine seja recomendado para implantação de produção simplificada, o Cloud Run oferece mais controle e é compatível com a interface da Web do ADK. Esta seção fornece uma visão geral.
Quando usar o Cloud Run
Escolha o Cloud Run se você precisar:
- A interface da Web do ADK para interação do usuário
- Controle total sobre o ambiente de contêiner
- Configurações personalizadas de banco de dados
- Integração com serviços atuais do Cloud Run
Como funciona a implantação do Cloud Run
Em segundo plano,
deploy.sh cloud-run
usa:
adk deploy cloud_run \
--project=$GOOGLE_CLOUD_PROJECT \
--region=$GOOGLE_CLOUD_LOCATION \
--service_name="code-review-assistant" \
--app_name="code_review_assistant" \
--port=8080 \
--with_ui \
--artifact_service_uri="gs://$ARTIFACT_BUCKET" \
--trace_to_cloud \
code_review_assistant
Esse comando:
- Cria um contêiner do Docker com o código do seu agente
- Envia para o Google Artifact Registry
- Implanta como um serviço do Cloud Run
- Inclui a interface da web do ADK (
--with_ui) - Configura a conexão do Cloud SQL (adicionada pelo script após a implantação inicial).
A principal diferença do Agent Engine é que o Cloud Run conteineriza seu código e exige um banco de dados para persistência de sessão, enquanto o Agent Engine processa os dois automaticamente.
Comando de implantação do Cloud Run
./deploy.sh cloud-run
O que vai mudar
Infraestrutura:
- Implantação conteinerizada (o Docker é criado automaticamente pelo ADK)
- Cloud SQL (PostgreSQL) para persistência de sessão
- Banco de dados criado automaticamente por script ou que usa uma instância atual
Gerenciamento de sessão:
- Usa
DatabaseSessionServiceem vez deVertexAiSessionService - Requer credenciais de banco de dados em
.env(ou geradas automaticamente) - O estado persiste no banco de dados PostgreSQL
Suporte à interface:
- Interface da Web disponível pela flag
--with_ui(processada por script) - Acesso em:
https://code-review-assistant-xyz.a.run.app
O que você realizou
Sua implantação de produção inclui:
✅ Provisionamento automatizado via script deploy.sh
✅ Infraestrutura gerenciada (o Agent Engine lida com escalonamento, persistência e monitoramento)
✅ Estado persistente em todas as camadas de memória (sessão/usuário/tempo de vida)
✅ Gerenciamento seguro de credenciais (geração automática e configuração do IAM)
✅ Arquitetura escalonável (de zero a milhares de usuários simultâneos)
✅ Capacidade de observação integrada (integração do Cloud Trace ativada)
✅ Qualidade de produção: tratamento e recuperação de erros
Conceitos principais dominados
Preparação para a implantação:
agent_engine_app.py: encapsula o agente comAdkApppara o Agent Engine.- O
AdkAppconfigura automaticamente oVertexAiSessionServicepara persistência - Rastreamento ativado via
enable_tracing=True
Comandos de implantação:
adk deploy agent_engine: empacota código Python, sem contêineresadk deploy cloud_run: cria contêineres do Docker automaticamentegcloud run deploy: alternativa com Dockerfile personalizado
Opções de implantação:
- Agent Engine: totalmente gerenciado e mais rápido para produção
- Cloud Run: mais controle, compatível com a interface da Web
- GKE: controle avançado do Kubernetes (consulte o guia de implantação do GKE)
Serviços gerenciados:
- O Agent Engine processa a persistência de sessão automaticamente
- O Cloud Run exige configuração (ou criação automática) do banco de dados
- Ambos oferecem suporte ao armazenamento de artefatos via GCS
Gerenciamento de sessão:
- Agent Engine:
VertexAiSessionService(automático) - Cloud Run:
DatabaseSessionService(Cloud SQL) - Local:
InMemorySessionService(efêmero)
Seu agente está ativo
Seu assistente de revisão de código agora é:
- Acessível por endpoints de API HTTPS
- Persistent com estado que sobrevive a reinicializações
- Escalonável para lidar com o crescimento da equipe automaticamente
- Observable com rastreamentos de solicitação completos
- Fácil de manter com implantações programadas
A seguir No módulo 8, você vai aprender a usar o Cloud Trace para entender o desempenho do seu agente, identificar gargalos nos pipelines de revisão e correção e otimizar os tempos de execução.
8. Observabilidade da produção
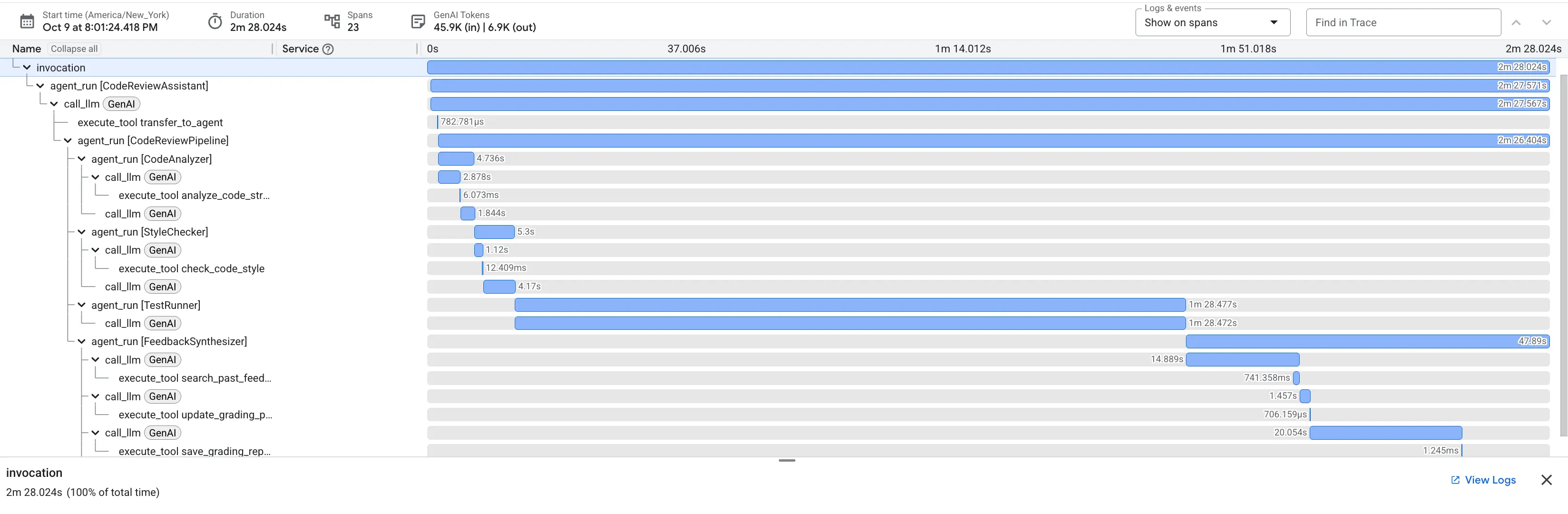
Introdução
Seu assistente de revisão de código agora está implantado e em execução na produção no Agent Engine. Mas como saber se ele está funcionando bem? Você consegue responder a estas perguntas importantes:
- O agente está respondendo rápido o suficiente?
- Quais operações são mais lentas?
- Os loops de correção estão sendo concluídos de maneira eficiente?
- Onde estão os gargalos de desempenho?
Sem observabilidade, você está operando às cegas. A flag --trace-to-cloud usada durante a implantação ativou automaticamente o Cloud Trace, oferecendo visibilidade completa de cada solicitação processada pelo agente. Isso transforma a depuração de uma adivinhação em uma análise forense.
Neste módulo, você vai aprender a ler rastreamentos, entender as características de desempenho do seu agente e identificar áreas de otimização com base em evidências concretas.
Noções básicas sobre traces e períodos
O que é um rastreamento?
Um trace é a linha do tempo completa do seu agente processando uma única solicitação. Ele captura tudo desde o momento em que um usuário envia uma consulta até a entrega da resposta final. Cada rastreamento mostra:
- Duração total da solicitação
- Todas as operações executadas
- Como as operações se relacionam (relações pai-filho)
- Quando cada operação começou e terminou
O que é um período?
Um span representa uma única unidade de trabalho em um trace. Tipos de extensão comuns no seu assistente de revisão de código:
agent_run: execução de um agente (agente raiz ou subagente)call_llm: solicitação a um modelo de linguagemexecute_tool: execução da função de ferramentastate_read/state_write: operações de gerenciamento de estadocode_executor: execução de código com testes
Os períodos têm:
- Nome: qual operação isso representa
- Duração: quanto tempo levou
- Atributos: metadados como nome do modelo, contagem de tokens, entradas/saídas
- Status: sucesso ou falha
- Relações pai/filho: quais operações acionaram quais
Instrumentação automática
Quando você implanta com --trace-to-cloud, o ADK instrumenta automaticamente:
- Cada invocação de agente e chamada de subagente
- Todas as solicitações de LLM com contagens de tokens
- Execuções de ferramentas com entradas/saídas
- Operações de estado (leitura/gravação)
- Iterações de loop no pipeline de correção
- Condições de erro e novas tentativas
Não é necessário mudar o código: o rastreamento é integrado ao tempo de execução do ADK.
Etapa 1: acessar o Explorador do Cloud Trace
Abra o Cloud Trace no console do Google Cloud:
- Navegue até o Explorador do Cloud Trace.
- Selecione seu projeto no menu suspenso (ele deve estar pré-selecionado).
- Você vai ver rastreamentos do seu teste no Módulo 7.
Se você ainda não encontrar rastreamentos:
O teste executado no Módulo 7 deve ter gerado rastreamentos. Se a lista estiver vazia, gere alguns dados de rastreamento:
python tests/test_agent_engine.py
Aguarde de um a dois minutos para que os rastreamentos apareçam no console.
O que você está vendo
O Explorador de traces mostra:
- Lista de traces: cada linha representa uma solicitação completa.
- Linha do tempo: quando as solicitações ocorreram
- Duração: quanto tempo cada solicitação levou
- Detalhes da solicitação: carimbo de data/hora, latência, contagem de intervalos
Esse é o registro de tráfego de produção. Cada interação com o agente cria um rastreamento.
Etapa 2: examinar um rastreamento do pipeline de revisão
Clique em qualquer rastreamento na lista para abrir a visualização em cascata.
Você vai ver um gráfico de Gantt mostrando a linha do tempo completa da execução. O período raiz invocation representa toda a solicitação. Aninhados abaixo dele estão os intervalos de cada subagente, ferramenta e chamada de LLM.
Leitura do diagrama de cascata: identificação de gargalos
Cada barra representa um período. A posição horizontal mostra quando ele começou, e o comprimento mostra quanto tempo levou. Isso revela imediatamente onde o agente está gastando o tempo.
Insights principais do rastreamento acima:
- Latência total: a solicitação inteira levou 2 minutos e 28 segundos.
- Detalhamento do subagente:
Code Analyzer: 4,7 segundosStyle Checker: 5,3 segundosTest Runner: 1 minuto e 28 segundosFeedback Synthesizer: 47,9 segundos
- Análise do caminho crítico: o agente
Test Runneré o gargalo de performance claro, representando aproximadamente 59% do tempo total da solicitação.
Essa visibilidade é muito útil. Em vez de adivinhar onde o tempo é gasto, você tem evidências concretas de que, se precisar otimizar a latência, o Test Runner é o destino óbvio.
Como inspecionar o uso de tokens para otimização de custos
O Cloud Trace não mostra apenas o tempo, mas também revela os custos ao capturar o uso de tokens em cada chamada de LLM.
Clique em um
call_llm
período no trace. No painel de detalhes, você encontra atributos para llm.usage.prompt_tokens e llm.usage.completion_tokens.

Assim, é possível:
- Acompanhe os custos em um nível granular: saiba exatamente quantos tokens cada agente e ferramenta estão consumindo.
- Identifique oportunidades de otimização: se um agente estiver usando um número surpreendentemente alto de tokens, talvez seja uma oportunidade de refinar o comando ou mudar para um modelo menor e mais econômico para essa tarefa específica.
Etapa 3: analisar um rastreamento de pipeline de correção
O pipeline de correção é mais complexo porque inclui um LoopAgent. O Cloud Trace facilita a compreensão desse comportamento iterativo.
Encontre um rastreamento que inclua "FixAttemptLoop" nos nomes dos períodos.
Se você não tiver um, execute o script de teste e responda afirmativamente quando perguntado se quer corrigir o código.
Como examinar a estrutura de loop
A visualização de rastreamento mostra claramente a execução do loop. Se o loop de correção foi executado duas vezes antes de ser concluído, você verá dois períodos loop_iteration aninhados no período FixAttemptLoop, cada um contendo um ciclo completo dos agentes CodeFixer, FixTestRunner e FixValidator.

Principais observações do rastreamento de loop:
- Refinamento iterativo visível: você pode ver o sistema tentar uma correção em
loop_iteration: 1, validar e, como não ficou perfeito, tentar de novo emloop_iteration: 2. - A convergência é mensurável: você pode comparar a duração e os resultados de cada iteração para entender como o sistema convergiu para uma solução correta.
- Depuração simplificada: se um loop for executado pelo número máximo de iterações e ainda falhar, você poderá inspecionar o estado e o comportamento do agente no intervalo de cada iteração para diagnosticar por que as correções não estavam convergindo.
Esse nível de detalhe é muito útil para entender e depurar o comportamento de loops complexos e com estado na produção.
Etapa 4: o que você descobriu
Padrões de performance
Ao examinar os traces, você agora tem insights baseados em dados:
Pipeline de revisão:
- Principal gargalo: o agente
Test Runner, especificamente a execução de código e a geração de testes com base em LLM, é a parte mais demorada da revisão. - Operações rápidas: ferramentas determinísticas (
analyze_code_structure) e operações de gerenciamento de estado são extremamente rápidas e não afetam a performance.
Pipeline de correção:
- Taxa de convergência: a maioria das correções é concluída em uma ou duas iterações, confirmando que a arquitetura de loop é eficaz.
- Custo progressivo: as iterações posteriores podem levar mais tempo à medida que o contexto do LLM aumenta com as informações das tentativas anteriores.
Fatores de custo:
- Consumo de tokens: você pode identificar quais agentes (como os sintetizadores) exigem mais tokens e decidir se o uso de um modelo mais potente, mas caro, é justificado para essa tarefa.
Onde encontrar problemas
Ao analisar rastreamentos em produção, observe:
- Rastreamentos muito longos: um sinal de regressão de performance ou um comportamento de loop inesperado.
- Intervalos com falha (marcados em vermelho): indicam a operação exata que falhou.
- Iterações de loop excessivas (>2): podem indicar um problema com a lógica de geração de correções.
- Contagens altas de tokens: destaca oportunidades de otimização de comandos ou mudanças na seleção de modelos.
O que você aprendeu
Com o Cloud Trace, agora você sabe como:
✅ Visualizar o fluxo de solicitações: confira o caminho de execução completo nos seus pipelines sequenciais e baseados em loop.
✅ Identifique gargalos de desempenho: use o gráfico de cascata para encontrar as operações mais lentas com dados concretos.
✅ Analisar o comportamento do loop: observe como os agentes iterativos convergem para uma solução em várias tentativas.
✅ Acompanhe os custos de token: inspecione intervalos de LLM para monitorar e otimizar o consumo de tokens em um nível granular.
Conceitos principais dominados
- Rastreamentos e períodos:as unidades fundamentais de observabilidade, que representam solicitações e as operações nelas.
- Análise em cascata:leitura de gráficos de Gantt para entender o tempo de execução e as dependências.
- Identificação do caminho crítico:encontrar a sequência de operações que determina a latência geral.
- Observabilidade granular:visibilidade não apenas do tempo, mas também de metadados, como contagens de tokens para cada operação, instrumentada automaticamente pelo ADK.
A seguir
Continue explorando o Cloud Trace:
- Monitore os rastreamentos regularmente para identificar problemas no início
- Comparar rastreamentos para identificar regressões de performance
- Usar dados de rastreamento para tomar decisões de otimização
- Filtrar por duração para encontrar solicitações lentas
Observabilidade avançada (opcional):
- Exportar rastreamentos para o BigQuery para análises complexas (documentos)
- Criar painéis personalizados no Cloud Monitoring
- Configurar alertas para degradação da performance
- Correlacionar traces com registros de aplicativos
9. Conclusão: do protótipo à produção
O que você criou
Você começou com apenas sete linhas de código e criou um sistema de agentes de IA de nível de produção:
# Where we started (7 lines)
agent = Agent(
model="gemini-2.5-flash",
instruction="Review Python code for issues"
)
# Where we ended (production system)
- Two distinct multi-agent pipelines (review and fix) built from 8 specialized agents.
- An iterative fix loop architecture for automated validation and retries.
- Real AST-based code analysis tools for deterministic, accurate feedback.
- Robust state management using the "constants pattern" for type-safe communication.
- Fully automated deployment to a managed, scalable cloud infrastructure.
- Complete, built-in observability with Cloud Trace for production monitoring.
Principais padrões de arquitetura dominados
Padrão | Implementação | Impacto na produção |
Integração de ferramentas | Análise de AST, verificação de estilo | Validação real, não apenas opiniões de LLMs |
Pipelines sequenciais | Revisar → Corrigir fluxos de trabalho | Execução previsível e depurável |
Arquitetura de loop | Correção iterativa com condições de saída | Melhoria contínua até o sucesso |
Gerenciamento de estado | Padrão de constantes, memória de três níveis | Processamento de estado seguro e fácil de manter |
Implantação de produção | Agent Engine via deploy.sh | Infraestrutura gerenciada e escalonável |
Observabilidade | Integração do Cloud Trace | Visibilidade total do comportamento de produção |
Insights de produção de traces
Os dados do Cloud Trace revelaram insights importantes:
✅ Gargalo identificado: as chamadas de LLM do TestRunner dominam a latência
✅ Desempenho da ferramenta: a análise de AST é executada em 100 ms (excelente)
✅ Taxa de sucesso: os loops de correção convergem em duas a três iterações
✅ Uso de tokens: ~600 tokens por revisão, ~1.800 para correções
Esses insights impulsionam a melhoria contínua.
Limpar recursos (opcional)
Se você já terminou de testar e quer evitar cobranças:
Excluir a implantação do Agent Engine:
import vertexai
client = vertexai.Client( # For service interactions via client.agent_engines
project="PROJECT_ID",
location="LOCATION",
)
RESOURCE_NAME = "projects/{PROJECT_ID}/locations/{LOCATION}/reasoningEngines/{RESOURCE_ID}"
client.agent_engines.delete(
name=RESOURCE_NAME,
force=True, # Optional, if the agent has resources (e.g. sessions, memory)
)
Exclua o serviço do Cloud Run (se ele tiver sido criado):
gcloud run services delete code-review-assistant \
--region=$GOOGLE_CLOUD_LOCATION \
--quiet
Exclua a instância do Cloud SQL (se ela tiver sido criada):
gcloud sql instances delete your-project-db \
--quiet
Limpe os buckets de armazenamento:
gsutil -m rm -r gs://your-project-staging
gsutil -m rm -r gs://your-project-artifacts
Próximas etapas
Com a base concluída, considere estas melhorias:
- Adicionar mais linguagens: estenda as ferramentas para oferecer suporte a JavaScript, Go e Java.
- Integração com o GitHub: revisões automáticas de pull requests
- Implementar o armazenamento em cache: reduzir a latência para padrões comuns
- Adicionar agentes especializados: verificação de segurança, análise de desempenho
- Ativar testes A/B: compare diferentes modelos e comandos
- Exportar métricas: envie rastreamentos para plataformas especializadas de observabilidade.
Pontos-chave
- Comece de forma simples, itere rápido: sete linhas para produção em etapas gerenciáveis
- Ferramentas em vez de comandos: a análise real de AST supera o "verifique se há bugs"
- O gerenciamento de estado é importante: o padrão de constantes evita bugs de erros de digitação
- Os loops precisam de condições de saída: sempre defina o número máximo de iterações e o escalonamento.
- Implantação com automação: o deploy.sh lida com toda a complexidade.
- A observabilidade é essencial: não é possível melhorar o que não pode ser medido.
Recursos para aprendizado contínuo
- Documentação do ADK
- Padrões avançados do ADK
- Guia do Agent Engine
- Documentação do Cloud Run
- Documentação do Cloud Trace
Sua jornada continua
Você criou mais do que um assistente de revisão de código. Você dominou os padrões para criar qualquer agente de IA de produção:
✅ Fluxos de trabalho complexos com vários agentes especializados
✅ Integração de ferramentas reais para recursos genuínos
✅ Implantação de produção com observabilidade adequada
✅ Gerenciamento de estado para sistemas fáceis de manter
Esses padrões variam de assistentes simples a sistemas autônomos complexos. A base que você criou aqui será muito útil ao lidar com arquiteturas de agentes cada vez mais sofisticadas.
Este é o desenvolvimento de agentes de IA de produção. Seu assistente de revisão de código é apenas o começo.