
1. The Late Night Code Review
Saat 02:00
Saatlerdir hata ayıklama yapıyorsunuz. İşlev doğru görünüyor ancak bir sorun var. Kodu çok uzun süre incelediğiniz için artık neden çalışmadığını göremediğiniz o sinir bozucu durumu bilirsiniz.
def dfs_search_v1(graph, start, target):
"""Find if target is reachable from start."""
visited = set()
stack = start # Looks innocent enough...
while stack:
current = stack.pop()
if current == target:
return True
if current not in visited:
visited.add(current)
for neighbor in graph[current]:
if neighbor not in visited:
stack.append(neighbor)
return False
Yapay Zeka Geliştiricilerinin Yolculuğu
Bu makaleyi okuyorsanız yapay zekanın kodlamaya getirdiği dönüşümü muhtemelen deneyimlemişsinizdir. Gemini Code Assist, Claude Code ve Cursor gibi araçlar, kod yazma şeklimizi değiştirdi. Standart metin oluşturma, uygulama önerisinde bulunma ve geliştirmeyi hızlandırma konusunda inanılmaz faydalıdırlar.
Ancak daha ayrıntılı bilgi edinmek için buradasınız. Bu yapay zeka sistemlerini yalnızca kullanmakla kalmayıp nasıl oluşturacağınızı da öğrenmek istiyorsunuz. Şunları yapabilen bir içerik oluşturmak istiyorsunuz:
- Tahmin edilebilir ve izlenebilir davranışlara sahip
- Üretimde güvenle dağıtılabilir.
- Güvenebileceğiniz tutarlı sonuçlar sunar.
- Kararlarını nasıl verdiğini tam olarak gösterir.
Tüketiciden İçerik Üreticiye
Bugün, yapay zeka araçlarını kullanmaktan bu araçları oluşturmaya geçiş yapacaksınız. Aşağıdaki özellikleri içeren bir çoklu temsilci sistemi oluşturacaksınız:
- Kod yapısını belirleyici bir şekilde analiz eder.
- Davranışı doğrulamak için gerçek testler yürütür.
- Gerçek linter'larla stil uygunluğunu doğrular.
- Bulguları sentezleyerek eyleme dönüştürülebilir geri bildirimler oluşturur.
- Tam gözlenebilirlik ile Google Cloud'a dağıtımlar
2. İlk aracı dağıtımınız
Geliştiricinin Sorusu
"LLM'leri anlıyorum, API'leri kullandım ancak Python komut dosyasından ölçeklenebilir bir üretim yapay zeka aracına nasıl geçebilirim?"
Öncelikle ortamınızı düzgün şekilde ayarlayarak bu soruyu yanıtlayalım. Ardından, üretim kalıplarına geçmeden önce temel bilgileri anlamak için basit bir aracı oluşturalım.
Öncelikle Temel Kurulum
Temsilci oluşturmadan önce Google Cloud ortamınızın hazır olduğundan emin olalım.
Google Cloud Console'un üst kısmında Activate Cloud Shell'i (Cloud Shell'i etkinleştir) tıklayın (Cloud Shell bölmesinin üst kısmındaki terminal şeklindeki simge).
Google Cloud proje kimliğinizi bulma:
- Google Cloud Console'u açın: https://console.cloud.google.com
- Sayfanın üst kısmındaki proje açılır listesinden bu atölye çalışması için kullanmak istediğiniz projeyi seçin.
- Proje kimliğiniz, kontrol panelindeki Proje bilgileri kartında gösterilir.
1. adım: Proje kimliğinizi ayarlayın
Cloud Shell'de gcloud komut satırı aracı zaten yapılandırılmıştır. Etkin projenizi ayarlamak için aşağıdaki komutu çalıştırın. Bu işlem, Cloud Shell oturumunuzda sizin için otomatik olarak ayarlanan $GOOGLE_CLOUD_PROJECT ortam değişkenini kullanır.
gcloud config set project $GOOGLE_CLOUD_PROJECT
2. adım: Kurulumunuzu doğrulayın
Ardından, projenizin doğru şekilde ayarlandığını ve kimliğinizin doğrulandığını onaylamak için aşağıdaki komutları çalıştırın.
# Confirm project is set
echo "Current project: $(gcloud config get-value project)"
# Check authentication status
gcloud auth list
Proje kimliğinizin yazdırıldığını ve kullanıcı hesabınızın yanında (ACTIVE) işaretiyle listelendiğini görürsünüz.
Hesabınız etkin olarak listelenmiyorsa veya kimlik doğrulama hatası alıyorsanız oturum açmak için aşağıdaki komutu çalıştırın:
gcloud auth application-default login
3. adım: Temel API'leri etkinleştirin
Temel temsilci için en az şu API'ler gereklidir:
gcloud services enable \
aiplatform.googleapis.com \
compute.googleapis.com
Bu işlem bir iki dakika sürebilir. Şunları görürsünüz:
Operation "operations/..." finished successfully.
4. adım: ADK'yı yükleyin
# Install the ADK CLI
pip install google-adk --upgrade
# Verify installation
adk --version
1.15.0 veya daha yüksek bir sürüm numarası görmelisiniz.
Şimdi Temel Ajanınızı Oluşturun
Ortam hazır olduğuna göre basit bir ajan oluşturalım.
5. adım: ADK Create'i kullanın
adk create my_first_agent
Etkileşimli istemleri uygulayın:
Choose a model for the root agent:
1. gemini-2.5-flash
2. Other models (fill later)
Choose model (1, 2): 1
1. Google AI
2. Vertex AI
Choose a backend (1, 2): 2
Enter Google Cloud project ID [auto-detected-from-gcloud]:
Enter Google Cloud region [us-central1]:
6. adım: Oluşturulanları inceleyin
cd my_first_agent
ls -la
Üç dosya görürsünüz:
.env # Configuration (auto-populated with your project)
__init__.py # Package marker
agent.py # Your agent definition
7. adım: Hızlı yapılandırma kontrolü
# Verify the .env was created correctly
cat .env
# Should show something like:
# GOOGLE_CLOUD_PROJECT=your-project-id
# GOOGLE_CLOUD_LOCATION=us-central1
# GOOGLE_GENAI_USE_VERTEXAI=1
Proje kimliği eksik veya yanlışsa .env dosyasını düzenleyin:
nano .env # or use your preferred editor
8. adım: Temsilci koduna bakın
cat agent.py
from google.adk.agents.llm_agent import Agent
root_agent = Agent(
model='gemini-2.5-flash',
name='root_agent',
description='A helpful assistant for user questions.',
instruction='Answer user questions to the best of your knowledge',
)
Sade, temiz, minimal. Bu, temsilcilerle ilgili "Hello World" örneğinizdir.
Temel Temsilcinizi Test Etme
9. adım: Aracınızı çalıştırın
cd ..
adk run my_first_agent
Aşağıdakine benzer bir ifade görürsünüz:
Log setup complete: /tmp/agents_log/agent.20250930_162430.log
To access latest log: tail -F /tmp/agents_log/agent.latest.log
[user]:
10. adım: Bazı sorguları deneyin
adk run komutunun çalıştığı terminalde bir istem görürsünüz. Sorgularınızı yazın:
[user]: Hey, what can you do?
[root_agent]: I can help answer questions, generate text, explain concepts, assist with problem-solving, and provide information on a wide range of topics. What would you like to know or discuss?
[user]: What's the current weather in Mountain View?
[root_agent]: I'm sorry, but I cannot provide real-time weather information as I don't have access to current data or weather services. To get the current weather in Mountain View, I recommend checking a weather website or app like weather.com or using a search engine.
Sınırlamaya dikkat edin. Bu araç, mevcut verilere erişemez. Daha da ileri gidelim:
[user]: Review this Python code: def add(a, b): return a + b
[root_agent]: This is a simple Python function that adds two numbers. Here's my review:
**Strengths:**
- Clean and concise implementation
- Follows Python conventions for simple operations
- Clear function name that describes its purpose
**Suggestions for improvement:**
- Add a docstring to document the function
- Consider adding type hints for better code clarity
- You might want to handle edge cases
Here's an enhanced version:
def add(a: float, b: float) -> float:
"""Add two numbers and return their sum."""
return a + b
Agent kod hakkında konuşabilir ancak şunları yapabilir mi?
- Yapıyı anlamak için AST'yi gerçekten ayrıştırıyor mu?
- Çalıştığını doğrulamak için testler yapın.
- Stil uygunluğu kontrol edilsin mi?
- Önceki yorumlarınızı hatırlıyor musunuz?
Hayır. Bu noktada mimariye ihtiyacımız var.
🏃🚪 Şununla çıkış yapın:
Ctrl+C
Keşfetme işlemi tamamlandığında
3. Üretim Workspace'inizi hazırlama
Çözüm: Üretime Hazır Bir Mimari
Bu basit aracı, başlangıç noktasını göstermek için kullandık ancak üretim sistemleri sağlam bir yapı gerektirir. Şimdi üretim ilkelerini içeren eksiksiz bir proje oluşturacağız.
Temeli Oluşturma
Google Cloud projenizi temel aracı için yapılandırmış olmanız gerekir. Şimdi de gerçek bir sistem için gereken tüm araçlar, desenler ve altyapıyla birlikte tam üretim çalışma alanını hazırlayalım.
1. adım: Yapılandırılmış projeyi alın
Öncelikle, adk run ile çalışan tüm Ctrl+C uygulamalarından çıkın ve temizleyin:
# Clean up the basic agent
cd ~ # Make sure you're not inside my_first_agent
rm -rf my_first_agent
# Get the production scaffold
git clone https://github.com/ayoisio/adk-code-review-assistant.git
cd adk-code-review-assistant
git checkout codelab
2. adım: Sanal ortam oluşturma ve etkinleştirme
# Create the virtual environment
python -m venv .venv
# Activate it
# On macOS/Linux:
source .venv/bin/activate
# On Windows:
# .venv\Scripts\activate
Doğrulama: İsteminizin başında artık (.venv) simgesi gösterilmelidir.
3. adım: Bağımlılıkları yükleyin
pip install -r code_review_assistant/requirements.txt
# Install the package in editable mode (enables imports)
pip install -e .
Bu işlemle şunlar yüklenir:
google-adk- ADK çerçevesipycodestyle- PEP 8 kontrolü içinvertexai- Bulut dağıtımı için- Diğer prodüksiyon bağımlılıkları
-e işareti, code_review_assistant modüllerini istediğiniz yerden içe aktarmanıza olanak tanır.
4. adım: Ortamınızı yapılandırın
# Copy the example environment file
cp .env.example .env
# Edit .env and replace the placeholders:
# - GOOGLE_CLOUD_PROJECT=your-project-id → your actual project ID
# - Keep other defaults as-is
Doğrulama: Yapılandırmanızı kontrol edin:
cat .env
Şunlar gösterilmelidir:
GOOGLE_CLOUD_PROJECT=your-actual-project-id
GOOGLE_CLOUD_LOCATION=us-central1
GOOGLE_GENAI_USE_VERTEXAI=TRUE
5. adım: Kimlik doğrulama
gcloud auth adresini daha önce çalıştırdığınız için yalnızca şunları doğrulayalım:
# Check current authentication
gcloud auth list
# Should show your account with (ACTIVE)
# If not, run:
gcloud auth application-default login
6. adım: Ek üretim API'lerini etkinleştirin
Temel API'leri zaten etkinleştirdik. Şimdi de üretimle ilgili olanları ekleyin:
gcloud services enable \
sqladmin.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
storage.googleapis.com \
cloudtrace.googleapis.com
Bu olanak aşağıdakileri sağlar:
- SQL Yöneticisi: Cloud Run kullanılıyorsa Cloud SQL için
- Cloud Run: Sunucusuz dağıtım için
- Cloud Build: Otomatik dağıtımlar için
- Artifact Registry: Container görüntüleri için
- Cloud Storage: Yapılar ve hazırlık için
- Cloud Trace: Gözlenebilirlik için
7. adım: Artifact Registry deposu oluşturun
Dağıtımımız, bir yere ihtiyaç duyan kapsayıcı görüntüleri oluşturacak:
gcloud artifacts repositories create code-review-assistant-repo \
--repository-format=docker \
--location=us-central1 \
--description="Docker repository for Code Review Assistant"
Aşağıdaki bilgileri görürsünüz:
Created repository [code-review-assistant-repo].
Dosya zaten varsa (örneğin, önceki bir denemeden kalmış olabilir) sorun yok. Yoksayabileceğiniz bir hata mesajı görürsünüz.
8. adım: IAM izinleri verin
# Get your project number
PROJECT_NUMBER=$(gcloud projects describe $GOOGLE_CLOUD_PROJECT \
--format="value(projectNumber)")
# Define the service account
SERVICE_ACCOUNT="${PROJECT_NUMBER}@cloudbuild.gserviceaccount.com"
# Grant necessary roles
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SERVICE_ACCOUNT}" \
--role="roles/run.admin"
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SERVICE_ACCOUNT}" \
--role="roles/iam.serviceAccountUser"
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SERVICE_ACCOUNT}" \
--role="roles/cloudsql.admin"
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SERVICE_ACCOUNT}" \
--role="roles/storage.admin"
Her komutun çıkışı:
Updated IAM policy for project [your-project-id].
Başarılarınız
Üretim çalışma alanınız artık tamamen hazır:
✅ Google Cloud projesi yapılandırılmış ve kimliği doğrulanmış olmalıdır.
✅ Temel aracı, sınırlamaları anlamak için test edilmiş olmalıdır.
✅ Stratejik yer tutucular içeren proje kodu hazır olmalıdır.
✅ Bağımlılıklar sanal ortamda izole edilmiş olmalıdır.
✅ Gerekli tüm API'ler etkinleştirilmiş olmalıdır.
✅ Kapsayıcı kayıt defteri dağıtımlara hazır olmalıdır.
✅ IAM izinleri düzgün şekilde yapılandırılmış olmalıdır.
✅ Ortam değişkenleri doğru şekilde ayarlanmış olmalıdır.
Artık deterministik araçlar, durum yönetimi ve uygun mimari ile gerçek bir yapay zeka sistemi oluşturmaya hazırsınız.
4. İlk Ajanınızı Oluşturma
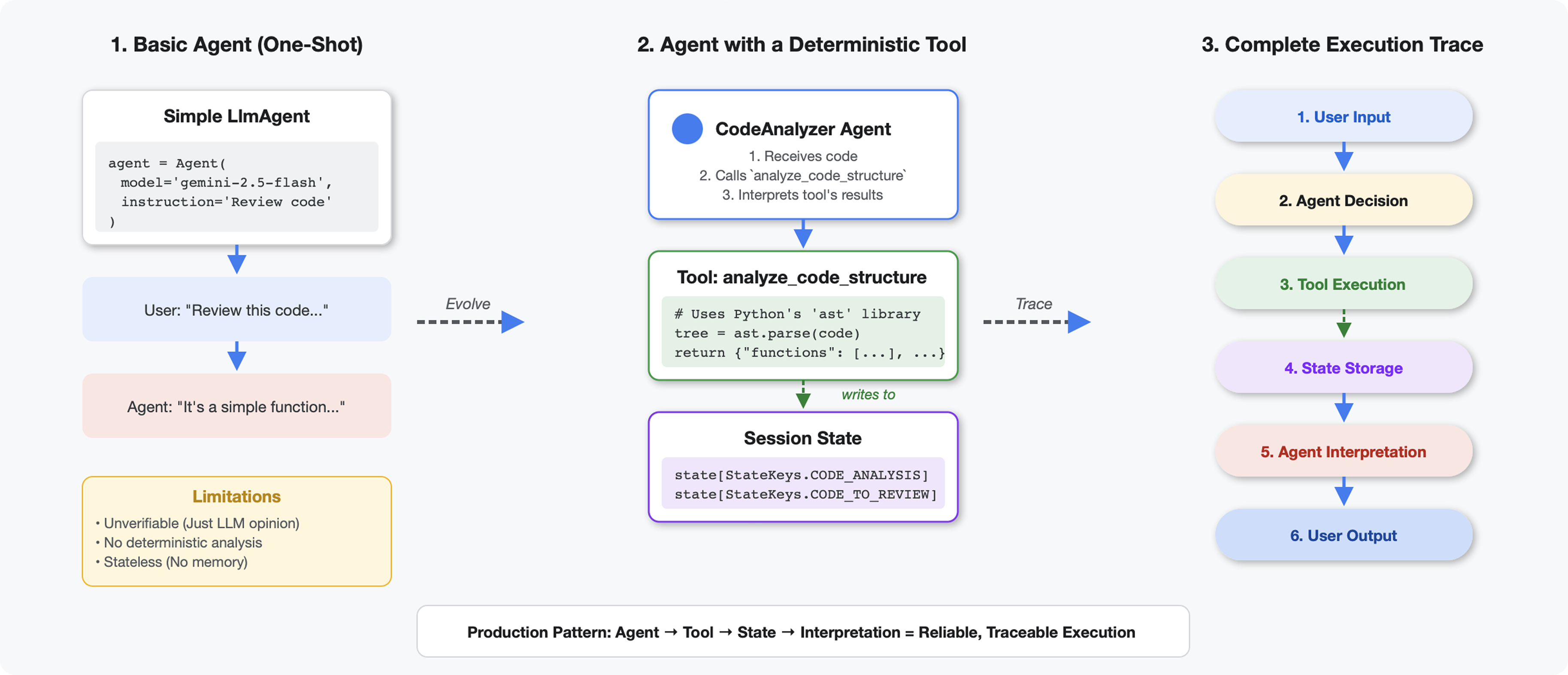
Araçları LLM'lerden Ayıran Özellikler
Bir LLM'ye "Bu kodda kaç işlev var?" diye sorduğunuzda, bu model kalıp eşleştirme ve tahmin yöntemini kullanır. Python'ın ast.parse() işlevini çağıran bir araç kullandığınızda, gerçek söz dizimi ağacı ayrıştırılır. Tahmin yapılmaz ve her seferinde aynı sonuç elde edilir.
Bu bölümde, kod yapısını deterministik olarak analiz eden ve ardından ne zaman çağrılacağını bilen bir aracıya bağlayan bir araç oluşturulur.
1. adım: İskeleyi anlama
Dolduracağınız yapıyı inceleyelim.
👉 Aç
code_review_assistant/tools.py
Kodu nereye ekleyeceğinizi belirten yer tutucu yorumlarla birlikte analyze_code_structure işlevini görürsünüz. İşlevin temel yapısı zaten var. Bunu adım adım geliştireceksiniz.
2. adım: State Storage'ı ekleyin
Durum depolama, ardışık düzendeki diğer aracıların analizi yeniden çalıştırmadan aracınızın sonuçlarına erişmesine olanak tanır.
👉 Bul:
# MODULE_4_STEP_2_ADD_STATE_STORAGE
👉 Tek satırı şununla değiştirin:
# Store code and analysis for other agents to access
tool_context.state[StateKeys.CODE_TO_REVIEW] = code
tool_context.state[StateKeys.CODE_ANALYSIS] = analysis
tool_context.state[StateKeys.CODE_LINE_COUNT] = len(code.splitlines())
3. adım: İş parçacığı havuzlarıyla eş zamansız ayrıştırma ekleyin
Aracımızın, diğer işlemleri engellemeden AST'yi ayrıştırması gerekiyor. İş parçacığı havuzlarıyla eşzamansız yürütme ekleyelim.
👉 Bul:
# MODULE_4_STEP_3_ADD_ASYNC
👉 Tek satırı şununla değiştirin:
# Parse in thread pool to avoid blocking the event loop
loop = asyncio.get_event_loop()
with ThreadPoolExecutor() as executor:
tree = await loop.run_in_executor(executor, ast.parse, code)
4. adım: Kapsamlı bilgileri ayıklayın
Şimdi de sınıfları, içe aktarmaları ve ayrıntılı metrikleri (tam bir kod incelemesi için ihtiyacımız olan her şeyi) çıkaralım.
👉 Bul:
# MODULE_4_STEP_4_EXTRACT_DETAILS
👉 Tek satırı şununla değiştirin:
# Extract comprehensive structural information
analysis = await loop.run_in_executor(
executor, _extract_code_structure, tree, code
)
👉 Doğrulama: İşlev
analyze_code_structure
içinde
tools.py
has a central body that looks like this:
# Parse in thread pool to avoid blocking the event loop
loop = asyncio.get_event_loop()
with ThreadPoolExecutor() as executor:
tree = await loop.run_in_executor(executor, ast.parse, code)
# Extract comprehensive structural information
analysis = await loop.run_in_executor(
executor, _extract_code_structure, tree, code
)
# Store code and analysis for other agents to access
tool_context.state[StateKeys.CODE_TO_REVIEW] = code
tool_context.state[StateKeys.CODE_ANALYSIS] = analysis
tool_context.state[StateKeys.CODE_LINE_COUNT] = len(code.splitlines())
👉 Şimdi ekranı en alta kaydırın.
tools.py
ve şunları bulun:
# MODULE_4_STEP_4_HELPER_FUNCTION
👉 Tek satırı yardımcı işlevin tamamıyla değiştirin:
def _extract_code_structure(tree: ast.AST, code: str) -> Dict[str, Any]:
"""
Helper function to extract structural information from AST.
Runs in thread pool for CPU-bound work.
"""
functions = []
classes = []
imports = []
docstrings = []
for node in ast.walk(tree):
if isinstance(node, ast.FunctionDef):
func_info = {
'name': node.name,
'args': [arg.arg for arg in node.args.args],
'lineno': node.lineno,
'has_docstring': ast.get_docstring(node) is not None,
'is_async': isinstance(node, ast.AsyncFunctionDef),
'decorators': [d.id for d in node.decorator_list
if isinstance(d, ast.Name)]
}
functions.append(func_info)
if func_info['has_docstring']:
docstrings.append(f"{node.name}: {ast.get_docstring(node)[:50]}...")
elif isinstance(node, ast.ClassDef):
methods = []
for item in node.body:
if isinstance(item, ast.FunctionDef):
methods.append(item.name)
class_info = {
'name': node.name,
'lineno': node.lineno,
'methods': methods,
'has_docstring': ast.get_docstring(node) is not None,
'base_classes': [base.id for base in node.bases
if isinstance(base, ast.Name)]
}
classes.append(class_info)
elif isinstance(node, ast.Import):
for alias in node.names:
imports.append({
'module': alias.name,
'alias': alias.asname,
'type': 'import'
})
elif isinstance(node, ast.ImportFrom):
imports.append({
'module': node.module or '',
'names': [alias.name for alias in node.names],
'type': 'from_import',
'level': node.level
})
return {
'functions': functions,
'classes': classes,
'imports': imports,
'docstrings': docstrings,
'metrics': {
'line_count': len(code.splitlines()),
'function_count': len(functions),
'class_count': len(classes),
'import_count': len(imports),
'has_main': any(f['name'] == 'main' for f in functions),
'has_if_main': '__main__' in code,
'avg_function_length': _calculate_avg_function_length(tree)
}
}
def _calculate_avg_function_length(tree: ast.AST) -> float:
"""Calculate average function length in lines."""
function_lengths = []
for node in ast.walk(tree):
if isinstance(node, ast.FunctionDef):
if hasattr(node, 'end_lineno') and hasattr(node, 'lineno'):
length = node.end_lineno - node.lineno + 1
function_lengths.append(length)
if function_lengths:
return sum(function_lengths) / len(function_lengths)
return 0.0
5. adım: Müşteri temsilcisine bağlanın
Şimdi aracı, ne zaman kullanacağını ve sonuçlarını nasıl yorumlayacağını bilen bir temsilciye bağlıyoruz.
👉 Aç
code_review_assistant/sub_agents/review_pipeline/code_analyzer.py
👉 Bul:
# MODULE_4_STEP_5_CREATE_AGENT
👉 Tek satırı eksiksiz üretim aracısıyla değiştirin:
code_analyzer_agent = Agent(
name="CodeAnalyzer",
model=config.worker_model,
description="Analyzes Python code structure and identifies components",
instruction="""You are a code analysis specialist responsible for understanding code structure.
Your task:
1. Take the code submitted by the user (it will be provided in the user message)
2. Use the analyze_code_structure tool to parse and analyze it
3. Pass the EXACT code to your tool - do not modify, fix, or "improve" it
4. Identify all functions, classes, imports, and structural patterns
5. Note any syntax errors or structural issues
6. Store the analysis in state for other agents to use
CRITICAL:
- Pass the code EXACTLY as provided to the analyze_code_structure tool
- Do not fix syntax errors, even if obvious
- Do not add missing imports or fix indentation
- The goal is to analyze what IS there, not what SHOULD be there
When calling the tool, pass the code as a string to the 'code' parameter.
If the analysis fails due to syntax errors, clearly report the error location and type.
Provide a clear summary including:
- Number of functions and classes found
- Key structural observations
- Any syntax errors or issues detected
- Overall code organization assessment""",
tools=[FunctionTool(func=analyze_code_structure)],
output_key="structure_analysis_summary"
)
Kod Analiz Aracınızı Test Etme
Şimdi analiz aracınızın doğru çalıştığını doğrulayın.
👉 Test komut dosyasını çalıştırın:
python tests/test_code_analyzer.py
Test komut dosyası, python-dotenv kullanarak yapılandırmayı .env dosyanızdan otomatik olarak yükler. Bu nedenle, manuel ortam değişkeni kurulumu gerekmez.
Beklenen çıkış:
INFO:code_review_assistant.config:Code Review Assistant Configuration Loaded:
INFO:code_review_assistant.config: - GCP Project: your-project-id
INFO:code_review_assistant.config: - Artifact Bucket: gs://your-project-artifacts
INFO:code_review_assistant.config: - Models: worker=gemini-2.5-flash, critic=gemini-2.5-pro
Testing code analyzer...
INFO:code_review_assistant.tools:Tool: Analysis complete - 2 functions, 1 classes
=== Analyzer Response ===
The analysis of the provided code shows the following:
* **Functions Found:** 2
* `add(a, b)`: A global function at line 2.
* `multiply(self, x, y)`: A method within the `Calculator` class.
* **Classes Found:** 1
* `Calculator`: A class defined at line 5. Contains one method, `multiply`.
* **Imports:** 0
* **Structural Patterns:** The code defines one global function and one class
with a single method. Both are simple, each with a single return statement.
* **Syntax Errors/Issues:** No syntax errors detected.
* **Overall Code Organization:** The code is well-organized for its small size,
clearly defining a function and a class with a method.
Ne oldu?
- Test komut dosyası,
.envyapılandırmanızı otomatik olarak yükledi. analyze_code_structure()aracınız, kodu Python'ın AST'sini kullanarak ayrıştırıyor._extract_code_structure()yardımcı programı, işlevleri, sınıfları ve metrikleri ayıkladı.- Sonuçlar,
StateKeyssabitleri kullanılarak oturum durumunda depolanıyordu. - Code Analyzer aracısı sonuçları yorumlayıp özetledi.
Sorun giderme:
- "No module named ‘code_review_assistant'":
pip install -e .komutunu proje kökünden çalıştırın. - "Missing key inputs argument":
.envcihazınızdaGOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_LOCATIONveGOOGLE_GENAI_USE_VERTEXAI=trueolup olmadığını doğrulayın.
Oluşturduklarınız
Artık aşağıdakileri yapabilen, üretime hazır bir kod analiz aracınız var:
✅ Gerçek Python AST'yi ayrıştırır: Belirleyicidir, kalıp eşleştirme yapmaz.
✅ Sonuçları durumda saklar: Diğer aracılar analize erişebilir.
✅ Asenkron olarak çalışır: Diğer araçları engellemez.
✅ Kapsamlı bilgiler çıkarır: İşlevler, sınıflar, içe aktarmalar, metrikler.
✅ Hataları düzgün şekilde işler: Söz dizimi hatalarını satır numaralarıyla bildirir.
✅ Bir aracıya bağlanır: LLM, aracıyı ne zaman ve nasıl kullanacağını bilir.
Uzmanlaşılan Temel Kavramlar
Araçlar ve Temsilciler:
- Araçlar deterministik çalışma yapar (AST ayrıştırma)
- Aracılar, araçları ne zaman kullanacaklarına karar verir ve sonuçları yorumlar.
Eyalete Göre İade Değeri:
- Döndürülen değer: LLM'nin anında gördüğü
- Durum: Diğer temsilciler için ne kalıcı olur?
State Keys Constants:
- Çoklu aracı sistemlerde yazım hatalarını önleme
- Temsilciler arasında sözleşme görevi görme
- Ajanlar veri paylaşırken kritik önem taşır.
Eşzamansız + İş Parçacığı Havuzları:
async defaraçların yürütmeyi duraklatmasına olanak tanır- İş parçacığı havuzları, CPU ile sınırlı işleri arka planda çalıştırır.
- Birlikte etkinlik döngüsünün yanıt vermesini sağlarlar.
Yardımcı İşlevler:
- Senkronizasyon yardımcılarını asenkron araçlardan ayırma
- Kodu test edilebilir ve yeniden kullanılabilir hale getirir.
Temsilci Talimatları:
- Ayrıntılı talimatlar, LLM'nin sık yaptığı hataları önler.
- NE YAPILMAMASI gerektiği konusunda net olun (kodu düzeltmeyin).
- Tutarlılık için iş akışı adımlarını temizleme
Sonraki Adımlar
5. modülde şunları ekleyeceksiniz:
- Durumdan kodu okuyan stil denetleyicisi
- Testleri gerçekten yürüten test çalıştırıcı
- Tüm analizleri birleştiren geri bildirim sentezleyici
Durumun sıralı bir işlem hattı boyunca nasıl aktığını ve birden fazla aracı aynı verileri okuyup yazdığında neden sabitler kalıbının önemli olduğunu göreceksiniz.
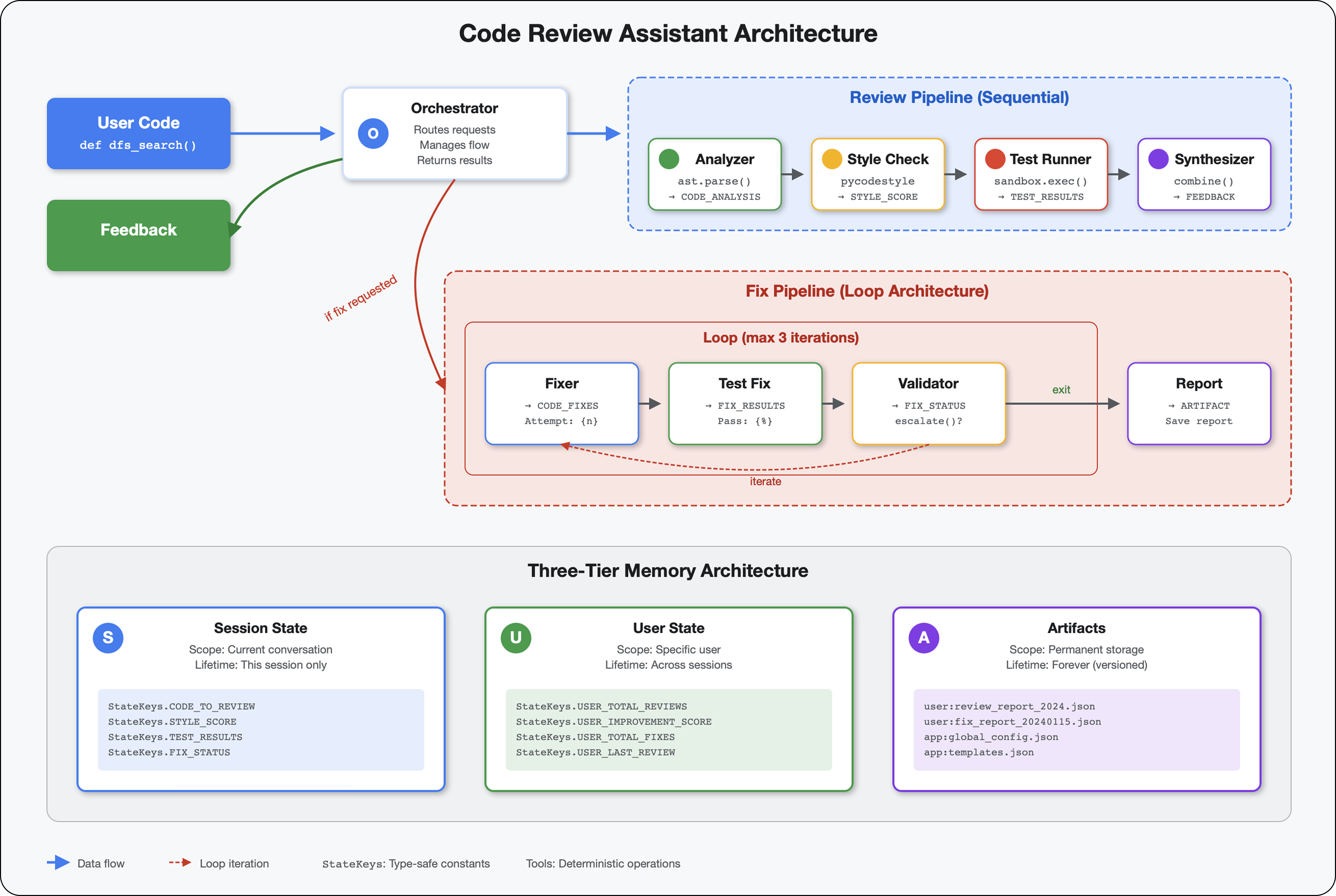
5. Ardışık Düzen Oluşturma: Birlikte Çalışan Birden Çok Temsilci
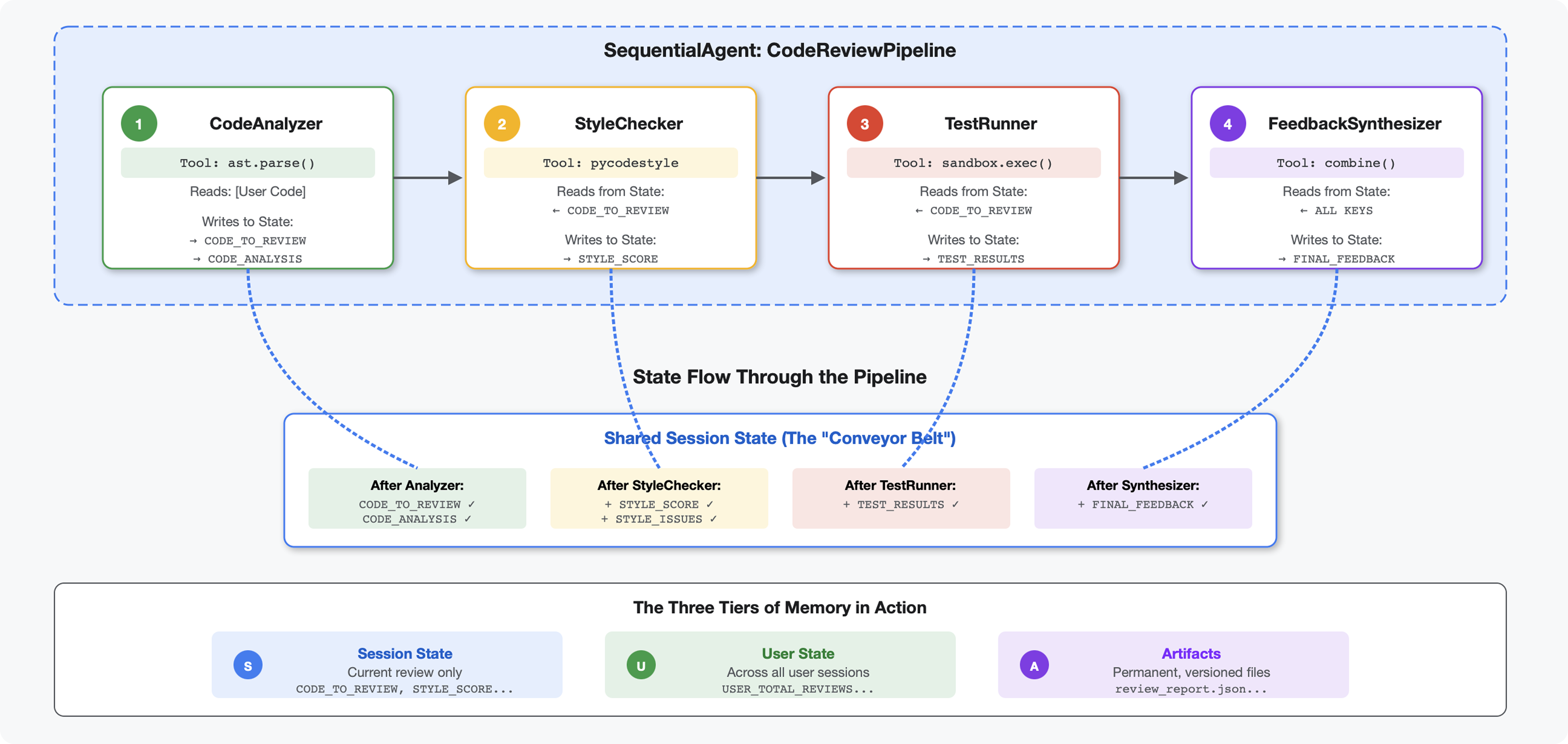
Giriş
4. modülde, kod yapısını analiz eden tek bir ajan oluşturmuştunuz. Ancak kapsamlı kod incelemesi için yalnızca ayrıştırma yeterli değildir. Stil kontrolü, test yürütme ve akıllı geri bildirim sentezi de gerekir.
Bu modülde, sırayla birlikte çalışan ve her biri özel bir analiz sunan 4 aracılık bir ardışık düzen oluşturulur:
- Kod Analiz Aracı (4. modülden): Yapıyı ayrıştırır.
- Stil Denetleyicisi: Stil ihlallerini belirler.
- Test Runner: Testleri yürütür ve doğrular.
- Geri Bildirim Sentezleyici: Her şeyi eyleme dönüştürülebilir geri bildirimler hâlinde birleştirir.
Temel kavram: İletişim kanalı olarak durum. Her aracı, önceki aracıların yazdıklarını okuyarak durumu belirtir, kendi analizini ekler ve zenginleştirilmiş durumu bir sonraki aracıya iletir. Birden fazla aracı verileri paylaştığında 4. modüldeki sabitler kalıbı kritik önem kazanır.
Oluşturacaklarınızın önizlemesi: Karışık kod gönderin → durumun 4 aracıdan geçmesini izleyin → geçmişteki kalıplara göre kişiselleştirilmiş geri bildirim içeren kapsamlı bir rapor alın.
1. adım: Stil Denetleyicisi Aracı + Aracısı'nı ekleyin
Stil denetleyici, PEP 8 ihlallerini pycodestyle (LLM tabanlı yorumlama değil, deterministik bir linter) kullanarak tanımlar.
Stil Denetleme Aracı'nı ekleme
👉 Aç
code_review_assistant/tools.py
👉 Bul:
# MODULE_5_STEP_1_STYLE_CHECKER_TOOL
👉 Tek satırı şununla değiştirin:
async def check_code_style(code: str, tool_context: ToolContext) -> Dict[str, Any]:
"""
Checks code style compliance using pycodestyle (PEP 8).
Args:
code: Python source code to check (or will retrieve from state)
tool_context: ADK tool context
Returns:
Dictionary containing style score and issues
"""
logger.info("Tool: Checking code style...")
try:
# Retrieve code from state if not provided
if not code:
code = tool_context.state.get(StateKeys.CODE_TO_REVIEW, '')
if not code:
return {
"status": "error",
"message": "No code provided or found in state"
}
# Run style check in thread pool
loop = asyncio.get_event_loop()
with ThreadPoolExecutor() as executor:
result = await loop.run_in_executor(
executor, _perform_style_check, code
)
# Store results in state
tool_context.state[StateKeys.STYLE_SCORE] = result['score']
tool_context.state[StateKeys.STYLE_ISSUES] = result['issues']
tool_context.state[StateKeys.STYLE_ISSUE_COUNT] = result['issue_count']
logger.info(f"Tool: Style check complete - Score: {result['score']}/100, "
f"Issues: {result['issue_count']}")
return result
except Exception as e:
error_msg = f"Style check failed: {str(e)}"
logger.error(f"Tool: {error_msg}", exc_info=True)
# Set default values on error
tool_context.state[StateKeys.STYLE_SCORE] = 0
tool_context.state[StateKeys.STYLE_ISSUES] = []
return {
"status": "error",
"message": error_msg,
"score": 0
}
👉 Şimdi dosyayı sonuna kadar kaydırın ve şunları bulun:
# MODULE_5_STEP_1_STYLE_HELPERS
👉 Tek satırı yardımcı işlevlerle değiştirin:
def _perform_style_check(code: str) -> Dict[str, Any]:
"""Helper to perform style check in thread pool."""
import io
import sys
with tempfile.NamedTemporaryFile(mode='w', suffix='.py', delete=False) as tmp:
tmp.write(code)
tmp_path = tmp.name
try:
# Capture stdout to get pycodestyle output
old_stdout = sys.stdout
sys.stdout = captured_output = io.StringIO()
style_guide = pycodestyle.StyleGuide(
quiet=False, # We want output
max_line_length=100,
ignore=['E501', 'W503']
)
result = style_guide.check_files([tmp_path])
# Restore stdout
sys.stdout = old_stdout
# Parse captured output
output = captured_output.getvalue()
issues = []
for line in output.strip().split('\n'):
if line and ':' in line:
parts = line.split(':', 4)
if len(parts) >= 4:
try:
issues.append({
'line': int(parts[1]),
'column': int(parts[2]),
'code': parts[3].split()[0] if len(parts) > 3 else 'E000',
'message': parts[3].strip() if len(parts) > 3 else 'Unknown error'
})
except (ValueError, IndexError):
pass
# Add naming convention checks
try:
tree = ast.parse(code)
naming_issues = _check_naming_conventions(tree)
issues.extend(naming_issues)
except SyntaxError:
pass # Syntax errors will be caught elsewhere
# Calculate weighted score
score = _calculate_style_score(issues)
return {
"status": "success",
"score": score,
"issue_count": len(issues),
"issues": issues[:10], # First 10 issues
"summary": f"Style score: {score}/100 with {len(issues)} violations"
}
finally:
if os.path.exists(tmp_path):
os.unlink(tmp_path)
def _check_naming_conventions(tree: ast.AST) -> List[Dict[str, Any]]:
"""Check PEP 8 naming conventions."""
naming_issues = []
for node in ast.walk(tree):
if isinstance(node, ast.FunctionDef):
# Skip private/protected methods and __main__
if not node.name.startswith('_') and node.name != node.name.lower():
naming_issues.append({
'line': node.lineno,
'column': node.col_offset,
'code': 'N802',
'message': f"N802 function name '{node.name}' should be lowercase"
})
elif isinstance(node, ast.ClassDef):
# Check if class name follows CapWords convention
if not node.name[0].isupper() or '_' in node.name:
naming_issues.append({
'line': node.lineno,
'column': node.col_offset,
'code': 'N801',
'message': f"N801 class name '{node.name}' should use CapWords convention"
})
return naming_issues
def _calculate_style_score(issues: List[Dict[str, Any]]) -> int:
"""Calculate weighted style score based on violation severity."""
if not issues:
return 100
# Define weights by error type
weights = {
'E1': 10, # Indentation errors
'E2': 3, # Whitespace errors
'E3': 5, # Blank line errors
'E4': 8, # Import errors
'E5': 5, # Line length
'E7': 7, # Statement errors
'E9': 10, # Syntax errors
'W2': 2, # Whitespace warnings
'W3': 2, # Blank line warnings
'W5': 3, # Line break warnings
'N8': 7, # Naming conventions
}
total_deduction = 0
for issue in issues:
code_prefix = issue['code'][:2] if len(issue['code']) >= 2 else 'E2'
weight = weights.get(code_prefix, 3)
total_deduction += weight
# Cap at 100 points deduction
return max(0, 100 - min(total_deduction, 100))
Stil Denetleyici Aracısı'nı ekleme
👉 Aç
code_review_assistant/sub_agents/review_pipeline/style_checker.py
👉 Bul:
# MODULE_5_STEP_1_INSTRUCTION_PROVIDER
👉 Tek satırı şununla değiştirin:
async def style_checker_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are a code style expert focused on PEP 8 compliance.
Your task:
1. Use the check_code_style tool to validate PEP 8 compliance
2. The tool will retrieve the ORIGINAL code from state automatically
3. Report violations exactly as found
4. Present the results clearly and confidently
CRITICAL:
- The tool checks the code EXACTLY as provided by the user
- Do not suggest the code was modified or fixed
- Report actual violations found in the original code
- If there are style issues, they should be reported honestly
Call the check_code_style tool with an empty string for the code parameter,
as the tool will retrieve the code from state automatically.
When presenting results based on what the tool returns:
- State the exact score from the tool results
- If score >= 90: "Excellent style compliance!"
- If score 70-89: "Good style with minor improvements needed"
- If score 50-69: "Style needs attention"
- If score < 50: "Significant style improvements needed"
List the specific violations found (the tool will provide these):
- Show line numbers, error codes, and messages
- Focus on the top 10 most important issues
Previous analysis: {structure_analysis_summary}
Format your response as:
## Style Analysis Results
- Style Score: [exact score]/100
- Total Issues: [count]
- Assessment: [your assessment based on score]
## Top Style Issues
[List issues with line numbers and descriptions]
## Recommendations
[Specific fixes for the most critical issues]"""
return await instructions_utils.inject_session_state(template, context)
👉 Bul:
# MODULE_5_STEP_1_STYLE_CHECKER_AGENT
👉 Tek satırı şununla değiştirin:
style_checker_agent = Agent(
name="StyleChecker",
model=config.worker_model,
description="Checks Python code style against PEP 8 guidelines",
instruction=style_checker_instruction_provider,
tools=[FunctionTool(func=check_code_style)],
output_key="style_check_summary"
)
2. adım: Test Runner Agent'ı ekleyin
Test çalıştırıcı, kapsamlı testler oluşturur ve bunları yerleşik kod yürütücüyü kullanarak yürütür.
👉 Aç
code_review_assistant/sub_agents/review_pipeline/test_runner.py
👉 Bul:
# MODULE_5_STEP_2_INSTRUCTION_PROVIDER
👉 Tek satırı şununla değiştirin:
async def test_runner_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects the code_to_review directly."""
template = """You are a testing specialist who creates and runs tests for Python code.
THE CODE TO TEST IS:
{code_to_review}
YOUR TASK:
1. Understand what the function appears to do based on its name and structure
2. Generate comprehensive tests (15-20 test cases)
3. Execute the tests using your code executor
4. Analyze results to identify bugs vs expected behavior
5. Output a detailed JSON analysis
TESTING METHODOLOGY:
- Test with the most natural interpretation first
- When something fails, determine if it's a bug or unusual design
- Test edge cases, boundaries, and error scenarios
- Document any surprising behavior
Execute your tests and output ONLY valid JSON with this structure:
- "test_summary": object with "total_tests_run", "tests_passed", "tests_failed", "tests_with_errors", "critical_issues_found"
- "critical_issues": array of objects, each with "type", "description", "example_input", "expected_behavior", "actual_behavior", "severity"
- "test_categories": object with "basic_functionality", "edge_cases", "error_handling" (each containing "passed", "failed", "errors" counts)
- "function_behavior": object with "apparent_purpose", "actual_interface", "unexpected_requirements"
- "verdict": object with "status" (WORKING/BUGGY/BROKEN), "confidence" (high/medium/low), "recommendation"
Do NOT output the test code itself, only the JSON analysis."""
return await instructions_utils.inject_session_state(template, context)
👉 Bul:
# MODULE_5_STEP_2_TEST_RUNNER_AGENT
👉 Tek satırı şununla değiştirin:
test_runner_agent = Agent(
name="TestRunner",
model=config.critic_model,
description="Generates and runs tests for Python code using safe code execution",
instruction=test_runner_instruction_provider,
code_executor=BuiltInCodeExecutor(),
output_key="test_execution_summary"
)
3. adım: Oturumlar Arası Öğrenme İçin Belleği Anlama
Geri bildirim sentezleyicisini oluşturmadan önce, iki farklı amaç için kullanılan iki farklı depolama mekanizması olan durum ve bellek arasındaki farkı anlamanız gerekir.
Durum ve Bellek: Temel Fark
Kod incelemesinden alınan somut bir örnekle durumu netleştirelim:
Durum (yalnızca mevcut oturum):
# Data from THIS review session
tool_context.state[StateKeys.STYLE_ISSUES] = [
{"line": 5, "code": "E231", "message": "missing whitespace"},
{"line": 12, "code": "E701", "message": "multiple statements"}
]
- Kapsam: Yalnızca bu görüşme
- Amaç: Geçerli ardışık düzendeki aracılar arasında veri geçirme
- Yaşadığı yer:
Sessionnesnesi - Yaşam boyu: Oturum sona erdiğinde atılır.
Hafıza (Tüm Geçmiş Oturumlar):
# Learned from 50 previous reviews
"User frequently forgets docstrings on helper functions"
"User tends to write long functions (avg 45 lines)"
"User improved error handling after feedback in session #23"
- Kapsam: Bu kullanıcının geçmişteki tüm oturumları
- Amaç: Kalıpları öğrenme, kişiselleştirilmiş geri bildirim sağlama
- Yaşadığı yer:
MemoryService - Yaşam boyu: Oturumlar arasında kalıcıdır, aranabilir.
Geri Bildirim Neden Her İkisini de İçermelidir?
Sentezleyicinin geri bildirim oluşturduğunu düşünün:
Yalnızca eyalet kullanma (mevcut inceleme):
"Function `calculate_total` has no docstring."
Genel, mekanik geri bildirim.
Durum + Bellek (mevcut ve geçmiş kalıplar) kullanma:
"Function `calculate_total` has no docstring. This is the 4th review
where helper functions lacked documentation. Consider adding docstrings
as you write functions, not afterwards - you mentioned in our last
session that you find it easier that way."
Kişiselleştirilmiş, bağlamsal, zaman içinde referansları iyileştirir.
Üretim dağıtımları için seçenekleriniz:
1. seçenek: VertexAiMemoryBankService (Gelişmiş)
- Ne yapar? Konuşmalardan anlamlı bilgileri LLM destekli olarak ayıklar.
- Arama: Semantik arama (yalnızca anahtar kelimeleri değil, anlamı da anlar)
- Bellek yönetimi: Anıları zaman içinde otomatik olarak birleştirir ve günceller.
- Gerekli: Google Cloud projesi + Agent Engine kurulumu
- Kullanım alanları: Gelişmiş, gelişen ve kişiselleştirilmiş anılar oluşturmak istediğinizde
- Örnek: "Kullanıcı, işlevsel programlamayı tercih ediyor" (kod stiliyle ilgili 10 sohbetten çıkarıldı)
2. seçenek: InMemoryMemoryService + Persistent Sessions ile devam edin
- Ne yapar? Anahtar kelime araması için tam sohbet geçmişini saklar.
- Arama: Geçmiş oturumlarda temel anahtar kelime eşleme
- Bellek yönetimi: Nelerin depolanacağını kontrol edebilirsiniz (
add_session_to_memoryaracılığıyla). - Gereklilikler: Yalnızca kalıcı bir
SessionService(ör.VertexAiSessionServiceveyaDatabaseSessionService) - Kullanım alanı: LLM işleme olmadan geçmiş görüşmelerde basit arama yapmanız gerektiğinde
- Örnek: "docstring" araması, bu kelimenin geçtiği tüm oturumları döndürür.
Anılar nasıl doldurulur?
Her kod incelemesi tamamlandıktan sonra:
# At the end of a session (typically in your application code)
await memory_service.add_session_to_memory(session)
Ne olur?
- InMemoryMemoryService: Anahtar kelime araması için tam oturum etkinliklerini depolar.
- VertexAiMemoryBankService: LLM, önemli bilgileri ayıklar ve mevcut anılarla birleştirir.
Gelecekteki oturumlar daha sonra şunları sorgulayabilir:
# In a tool, search for relevant past feedback
results = tool_context.search_memory("feedback about docstrings")
4. adım: Geri Bildirim Sentezleyici Araçları ve Aracı'yı ekleyin
Geri bildirim sentezleyici, işlem hattındaki en gelişmiş ajandır. Üç aracı yönetir, dinamik talimatlar kullanır ve durumu, belleği ve yapay nesneleri birleştirir.
Üç sentezleyici aracını ekleme
👉 Aç
code_review_assistant/tools.py
👉 Bul:
# MODULE_5_STEP_4_SEARCH_PAST_FEEDBACK
👉 Replace with Tool 1 - Memory Search (production version):
async def search_past_feedback(developer_id: str, tool_context: ToolContext) -> Dict[str, Any]:
"""
Search for past feedback in memory service.
Args:
developer_id: ID of the developer (defaults to "default_user")
tool_context: ADK tool context with potential memory service access
Returns:
Dictionary containing feedback search results
"""
logger.info(f"Tool: Searching for past feedback for developer {developer_id}...")
try:
# Default developer ID if not provided
if not developer_id:
developer_id = tool_context.state.get(StateKeys.USER_ID, 'default_user')
# Check if memory service is available
if hasattr(tool_context, 'search_memory'):
try:
# Perform structured searches
queries = [
f"developer:{developer_id} code review feedback",
f"developer:{developer_id} common issues",
f"developer:{developer_id} improvements"
]
all_feedback = []
patterns = {
'common_issues': [],
'improvements': [],
'strengths': []
}
for query in queries:
search_result = await tool_context.search_memory(query)
if search_result and hasattr(search_result, 'memories'):
for memory in search_result.memories[:5]:
memory_text = memory.text if hasattr(memory, 'text') else str(memory)
all_feedback.append(memory_text)
# Extract patterns
if 'style' in memory_text.lower():
patterns['common_issues'].append('style compliance')
if 'improved' in memory_text.lower():
patterns['improvements'].append('showing improvement')
if 'excellent' in memory_text.lower():
patterns['strengths'].append('consistent quality')
# Store in state
tool_context.state[StateKeys.PAST_FEEDBACK] = all_feedback
tool_context.state[StateKeys.FEEDBACK_PATTERNS] = patterns
logger.info(f"Tool: Found {len(all_feedback)} past feedback items")
return {
"status": "success",
"feedback_found": True,
"count": len(all_feedback),
"summary": " | ".join(all_feedback[:3]) if all_feedback else "No feedback",
"patterns": patterns
}
except Exception as e:
logger.warning(f"Tool: Memory search error: {e}")
# Fallback: Check state for cached feedback
cached_feedback = tool_context.state.get(StateKeys.USER_PAST_FEEDBACK_CACHE, [])
if cached_feedback:
tool_context.state[StateKeys.PAST_FEEDBACK] = cached_feedback
return {
"status": "success",
"feedback_found": True,
"count": len(cached_feedback),
"summary": "Using cached feedback",
"patterns": {}
}
# No feedback found
tool_context.state[StateKeys.PAST_FEEDBACK] = []
logger.info("Tool: No past feedback found")
return {
"status": "success",
"feedback_found": False,
"message": "No past feedback available - this appears to be a first submission",
"patterns": {}
}
except Exception as e:
error_msg = f"Feedback search error: {str(e)}"
logger.error(f"Tool: {error_msg}", exc_info=True)
tool_context.state[StateKeys.PAST_FEEDBACK] = []
return {
"status": "error",
"message": error_msg,
"feedback_found": False
}
👉 Bul:
# MODULE_5_STEP_4_UPDATE_GRADING_PROGRESS
👉 2. Araç - Not İzleyici (üretim sürümü) ile değiştirin:
async def update_grading_progress(tool_context: ToolContext) -> Dict[str, Any]:
"""
Updates grading progress counters and metrics in state.
"""
logger.info("Tool: Updating grading progress...")
try:
current_time = datetime.now().isoformat()
# Build all state changes
state_updates = {}
# Temporary (invocation-level) state
state_updates[StateKeys.TEMP_PROCESSING_TIMESTAMP] = current_time
# Session-level state
attempts = tool_context.state.get(StateKeys.GRADING_ATTEMPTS, 0) + 1
state_updates[StateKeys.GRADING_ATTEMPTS] = attempts
state_updates[StateKeys.LAST_GRADING_TIME] = current_time
# User-level persistent state
lifetime_submissions = tool_context.state.get(StateKeys.USER_TOTAL_SUBMISSIONS, 0) + 1
state_updates[StateKeys.USER_TOTAL_SUBMISSIONS] = lifetime_submissions
state_updates[StateKeys.USER_LAST_SUBMISSION_TIME] = current_time
# Calculate improvement metrics
current_style_score = tool_context.state.get(StateKeys.STYLE_SCORE, 0)
last_style_score = tool_context.state.get(StateKeys.USER_LAST_STYLE_SCORE, 0)
score_improvement = current_style_score - last_style_score
state_updates[StateKeys.USER_LAST_STYLE_SCORE] = current_style_score
state_updates[StateKeys.SCORE_IMPROVEMENT] = score_improvement
# Track test results if available
test_results = tool_context.state.get(StateKeys.TEST_EXECUTION_SUMMARY, {})
# Parse if it's a string
if isinstance(test_results, str):
try:
test_results = json.loads(test_results)
except:
test_results = {}
if test_results and test_results.get('test_summary', {}).get('total_tests_run', 0) > 0:
summary = test_results['test_summary']
total = summary.get('total_tests_run', 0)
passed = summary.get('tests_passed', 0)
if total > 0:
pass_rate = (passed / total) * 100
state_updates[StateKeys.USER_LAST_TEST_PASS_RATE] = pass_rate
# Apply all updates atomically
for key, value in state_updates.items():
tool_context.state[key] = value
logger.info(f"Tool: Progress updated - Attempt #{attempts}, "
f"Lifetime: {lifetime_submissions}")
return {
"status": "success",
"session_attempts": attempts,
"lifetime_submissions": lifetime_submissions,
"timestamp": current_time,
"improvement": {
"style_score_change": score_improvement,
"direction": "improved" if score_improvement > 0 else "declined"
},
"summary": f"Attempt #{attempts} recorded, {lifetime_submissions} total submissions"
}
except Exception as e:
error_msg = f"Progress update error: {str(e)}"
logger.error(f"Tool: {error_msg}", exc_info=True)
return {
"status": "error",
"message": error_msg
}
👉 Bul:
# MODULE_5_STEP_4_SAVE_GRADING_REPORT
👉 Replace with Tool 3 - Artifact Saver (production version):
async def save_grading_report(feedback_text: str, tool_context: ToolContext) -> Dict[str, Any]:
"""
Saves a detailed grading report as an artifact.
Args:
feedback_text: The feedback text to include in the report
tool_context: ADK tool context for state management
Returns:
Dictionary containing save status and details
"""
logger.info("Tool: Saving grading report...")
try:
# Gather all relevant data from state
code = tool_context.state.get(StateKeys.CODE_TO_REVIEW, '')
analysis = tool_context.state.get(StateKeys.CODE_ANALYSIS, {})
style_score = tool_context.state.get(StateKeys.STYLE_SCORE, 0)
style_issues = tool_context.state.get(StateKeys.STYLE_ISSUES, [])
# Get test results
test_results = tool_context.state.get(StateKeys.TEST_EXECUTION_SUMMARY, {})
# Parse if it's a string
if isinstance(test_results, str):
try:
test_results = json.loads(test_results)
except:
test_results = {}
timestamp = datetime.now().isoformat()
# Create comprehensive report dictionary
report = {
'timestamp': timestamp,
'grading_attempt': tool_context.state.get(StateKeys.GRADING_ATTEMPTS, 1),
'code': {
'content': code,
'line_count': len(code.splitlines()),
'hash': hashlib.md5(code.encode()).hexdigest()
},
'analysis': analysis,
'style': {
'score': style_score,
'issues': style_issues[:5] # First 5 issues
},
'tests': test_results,
'feedback': feedback_text,
'improvements': {
'score_change': tool_context.state.get(StateKeys.SCORE_IMPROVEMENT, 0),
'from_last_score': tool_context.state.get(StateKeys.USER_LAST_STYLE_SCORE, 0)
}
}
# Convert report to JSON string
report_json = json.dumps(report, indent=2)
report_part = types.Part.from_text(text=report_json)
# Try to save as artifact if the service is available
if hasattr(tool_context, 'save_artifact'):
try:
# Generate filename with timestamp (replace colons for filesystem compatibility)
filename = f"grading_report_{timestamp.replace(':', '-')}.json"
# Save the main report
version = await tool_context.save_artifact(filename, report_part)
# Also save a "latest" version for easy access
await tool_context.save_artifact("latest_grading_report.json", report_part)
logger.info(f"Tool: Report saved as {filename} (version {version})")
# Store report in state as well for redundancy
tool_context.state[StateKeys.USER_LAST_GRADING_REPORT] = report
return {
"status": "success",
"artifact_saved": True,
"filename": filename,
"version": str(version),
"size": len(report_json),
"summary": f"Report saved as {filename}"
}
except Exception as artifact_error:
logger.warning(f"Artifact service error: {artifact_error}, falling back to state storage")
# Continue to fallback below
# Fallback: Store in state if artifact service is not available or failed
tool_context.state[StateKeys.USER_LAST_GRADING_REPORT] = report
logger.info("Tool: Report saved to state (artifact service not available)")
return {
"status": "success",
"artifact_saved": False,
"message": "Report saved to state only",
"size": len(report_json),
"summary": "Report saved to session state"
}
except Exception as e:
error_msg = f"Report save error: {str(e)}"
logger.error(f"Tool: {error_msg}", exc_info=True)
# Still try to save minimal data to state
try:
tool_context.state[StateKeys.USER_LAST_GRADING_REPORT] = {
'error': error_msg,
'feedback': feedback_text,
'timestamp': datetime.now().isoformat()
}
except:
pass
return {
"status": "error",
"message": error_msg,
"artifact_saved": False,
"summary": f"Failed to save report: {error_msg}"
}
Sentezleyici aracısını oluşturma
👉 Aç
code_review_assistant/sub_agents/review_pipeline/feedback_synthesizer.py
👉 Bul:
# MODULE_5_STEP_4_INSTRUCTION_PROVIDER
👉 Üretim talimatı sağlayıcıyla değiştirin:
async def feedback_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are an expert code reviewer and mentor providing constructive, educational feedback.
CONTEXT FROM PREVIOUS AGENTS:
- Structure analysis summary: {structure_analysis_summary}
- Style check summary: {style_check_summary}
- Test execution summary: {test_execution_summary}
YOUR TASK requires these steps IN ORDER:
1. Call search_past_feedback tool with developer_id="default_user"
2. Call update_grading_progress tool with no parameters
3. Carefully analyze the test results to understand what really happened
4. Generate comprehensive feedback following the structure below
5. Call save_grading_report tool with the feedback_text parameter
6. Return the feedback as your final output
CRITICAL - Understanding Test Results:
The test_execution_summary contains structured JSON. Parse it carefully:
- tests_passed = Code worked correctly
- tests_failed = Code produced wrong output
- tests_with_errors = Code crashed
- critical_issues = Fundamental problems with the code
If critical_issues array contains items, these are serious bugs that need fixing.
Do NOT count discovering bugs as test successes.
FEEDBACK STRUCTURE TO FOLLOW:
## 📊 Summary
Provide an honest assessment. Be encouraging but truthful about problems found.
## ✅ Strengths
List 2-3 things done well, referencing specific code elements.
## 📈 Code Quality Analysis
### Structure & Organization
Comment on code organization, readability, and documentation.
### Style Compliance
Report the actual style score and any specific issues.
### Test Results
Report the actual test results accurately:
- If critical_issues exist, report them as bugs to fix
- Be clear: "X tests passed, Y critical issues were found"
- List each critical issue
- Don't hide or minimize problems
## 💡 Recommendations for Improvement
Based on the analysis, provide specific actionable fixes.
If critical issues exist, fixing them is top priority.
## 🎯 Next Steps
Prioritized action list based on severity of issues.
## 💬 Encouragement
End with encouragement while being honest about what needs fixing.
Remember: Complete ALL steps including calling save_grading_report."""
return await instructions_utils.inject_session_state(template, context)
👉 Bul:
# MODULE_5_STEP_4_SYNTHESIZER_AGENT
👉 Şununla değiştir:
feedback_synthesizer_agent = Agent(
name="FeedbackSynthesizer",
model=config.critic_model,
description="Synthesizes all analysis into constructive, personalized feedback",
instruction=feedback_instruction_provider,
tools=[
FunctionTool(func=search_past_feedback),
FunctionTool(func=update_grading_progress),
FunctionTool(func=save_grading_report)
],
output_key="final_feedback"
)
5. adım: Ardışık düzeni bağlayın
Şimdi dört ajanı da sıralı bir ardışık düzene bağlayın ve kök ajanı oluşturun.
👉 Aç
code_review_assistant/agent.py
👉 Gerekli içe aktarma işlemlerini dosyanın en üstüne (mevcut içe aktarma işlemlerinden sonra) ekleyin:
from google.adk.agents import Agent, SequentialAgent
from code_review_assistant.sub_agents.review_pipeline.code_analyzer import code_analyzer_agent
from code_review_assistant.sub_agents.review_pipeline.style_checker import style_checker_agent
from code_review_assistant.sub_agents.review_pipeline.test_runner import test_runner_agent
from code_review_assistant.sub_agents.review_pipeline.feedback_synthesizer import feedback_synthesizer_agent
Dosyanız artık şu şekilde görünmelidir:
"""
Main agent orchestration for the Code Review Assistant.
"""
from google.adk.agents import Agent, SequentialAgent
from .config import config
from code_review_assistant.sub_agents.review_pipeline.code_analyzer import code_analyzer_agent
from code_review_assistant.sub_agents.review_pipeline.style_checker import style_checker_agent
from code_review_assistant.sub_agents.review_pipeline.test_runner import test_runner_agent
from code_review_assistant.sub_agents.review_pipeline.feedback_synthesizer import feedback_synthesizer_agent
# MODULE_5_STEP_5_CREATE_PIPELINE
# MODULE_6_STEP_5_CREATE_FIX_LOOP
# MODULE_6_STEP_5_UPDATE_ROOT_AGENT
👉 Bul:
# MODULE_5_STEP_5_CREATE_PIPELINE
👉 Bu tek satırı şununla değiştirin:
# Create sequential pipeline
code_review_pipeline = SequentialAgent(
name="CodeReviewPipeline",
description="Complete code review pipeline with analysis, testing, and feedback",
sub_agents=[
code_analyzer_agent,
style_checker_agent,
test_runner_agent,
feedback_synthesizer_agent
]
)
# Root agent - coordinates the review pipeline
root_agent = Agent(
name="CodeReviewAssistant",
model=config.worker_model,
description="An intelligent code review assistant that analyzes Python code and provides educational feedback",
instruction="""You are a specialized Python code review assistant focused on helping developers improve their code quality.
When a user provides Python code for review:
1. Immediately delegate to CodeReviewPipeline and pass the code EXACTLY as it was provided by the user.
2. The pipeline will handle all analysis and feedback
3. Return ONLY the final feedback from the pipeline - do not add any commentary
When a user asks what you can do or asks general questions:
- Explain your capabilities for code review
- Do NOT trigger the pipeline for non-code messages
The pipeline handles everything for code review - just pass through its final output.""",
sub_agents=[code_review_pipeline],
output_key="assistant_response"
)
6. adım: Tam işlem hattını test edin
Dört temsilcinin birlikte çalıştığını görme zamanı.
👉 Sistemi başlatma:
adk web code_review_assistant
adk web komutunu çalıştırdıktan sonra terminalinizde ADK Web Sunucusu'nun başlatıldığını belirten bir çıkış görmelisiniz. Bu çıkış şuna benzer:
+-----------------------------------------------------------------------------+
| ADK Web Server started |
| |
| For local testing, access at http://localhost:8000. |
+-----------------------------------------------------------------------------+
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
👉 Ardından, tarayıcınızdan ADK Dev kullanıcı arayüzüne erişmek için:
Cloud Shell araç çubuğundaki (genellikle sağ üstte) web önizleme simgesinden (genellikle bir göz veya ok içeren bir kareye benzer) Bağlantı noktasını değiştir'i seçin. Pop-up pencerede bağlantı noktasını 8000 olarak ayarlayın ve "Değiştir ve Önizle"yi tıklayın. Cloud Shell, ADK Dev kullanıcı arayüzünü gösteren yeni bir tarayıcı sekmesi veya penceresi açar.
👉 Ajan artık çalışıyor. Tarayıcınızdaki ADK Dev UI, ajana doğrudan bağlanmanızı sağlar.
- Hedefinizi seçin: Kullanıcı arayüzünün üst kısmındaki açılır menüden
code_review_assistantaracısını seçin.
👉 Test istemi:
Please analyze the following:
def dfs_search_v1(graph, start, target):
"""Find if target is reachable from start."""
visited = set()
stack = start
while stack:
current = stack.pop()
if current == target:
return True
if current not in visited:
visited.add(current)
for neighbor in graph[current]:
if neighbor not in visited:
stack.append(neighbor)
return False
👉 Kod inceleme ardışık düzeninin nasıl çalıştığını görün:
Hatalı dfs_search_v1 işlevini gönderdiğinizde tek bir yanıt almazsınız. Çoklu aracı işlem hattınızın çalıştığını görüyorsunuz. Gördüğünüz yayın çıktısı, her biri bir öncekinin üzerine inşa edilen ve sırayla çalışan dört uzman aracının sonucudur.
Her bir aracının nihai ve kapsamlı incelemeye katkısı, ham verileri uygulanabilir analizlere dönüştürme açısından aşağıda açıklanmıştır.
1. Kod Analiz Aracı'nın Yapısal Raporu
Öncelikle CodeAnalyzer aracısı, ham kodu alır. Kodun ne yaptığını tahmin etmez. Belirleyici bir Soyut Sözdizimi Ağacı (AST) ayrıştırması yapmak için analyze_code_structure aracını kullanır.
Çıkışı, kodun yapısıyla ilgili saf ve gerçek verilerdir:
The analysis of the provided code reveals the following:
Summary:
- Functions Found: 1
- Classes Found: 0
Key Structural Observations:
- A single function, dfs_search_v1, is defined.
- It includes a docstring: "Find if target is reachable from start."
- No syntax errors were detected.
Overall Code Organization Assessment:
- The code snippet is a well-defined, self-contained function.
⭐ Değer: Bu ilk adım, diğer aracıların temiz ve güvenilir bir temelini oluşturur. Kodun geçerli Python kodu olduğunu onaylar ve incelenmesi gereken bileşenleri tam olarak belirler.
2. Stil denetleyicinin PEP 8 denetimi
Ardından StyleChecker aracısı devreye girer. Paylaşılan durumdaki kodu okur ve pycodestyle linter'dan yararlanan check_code_style aracını kullanır.
Çıkışı, ölçülebilir bir kalite puanı ve belirli ihlallerdir:
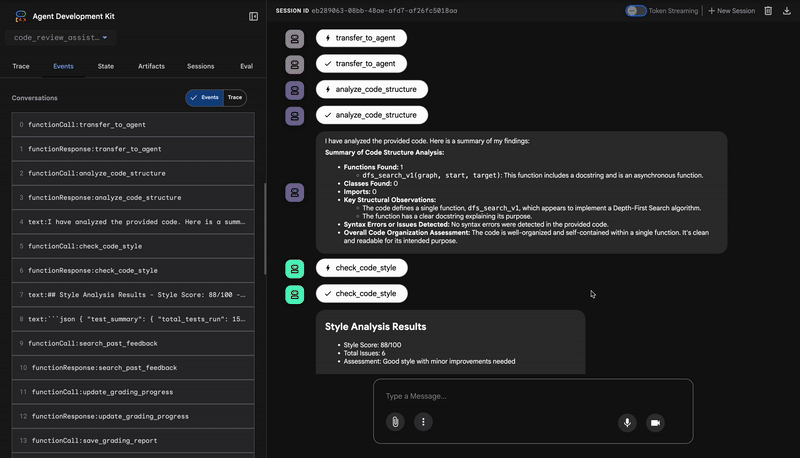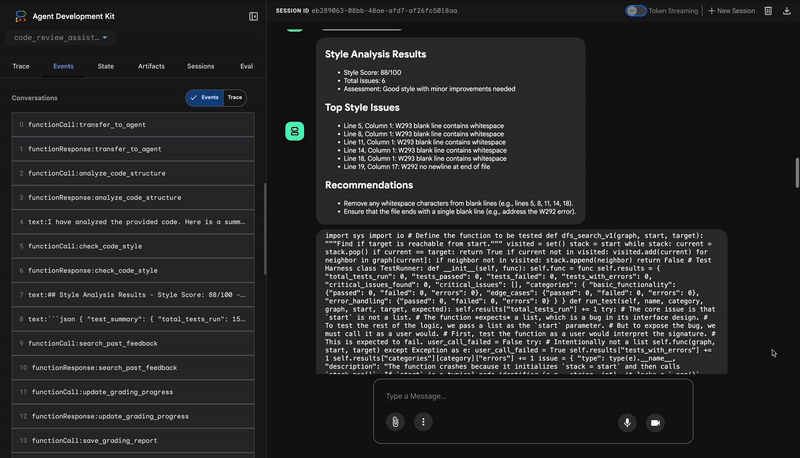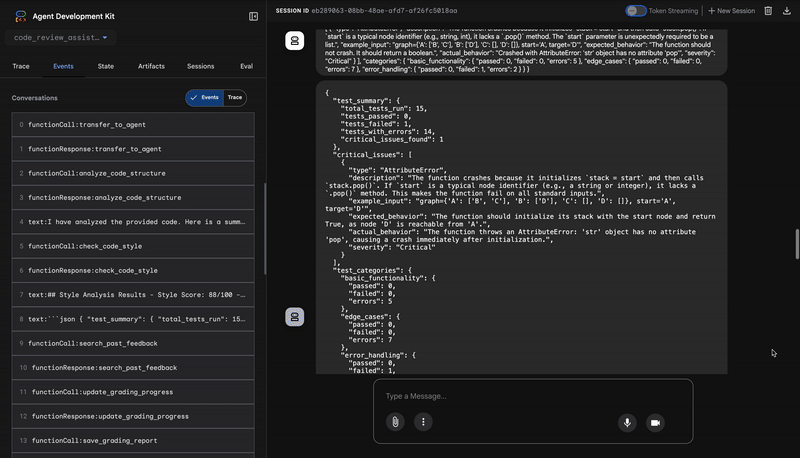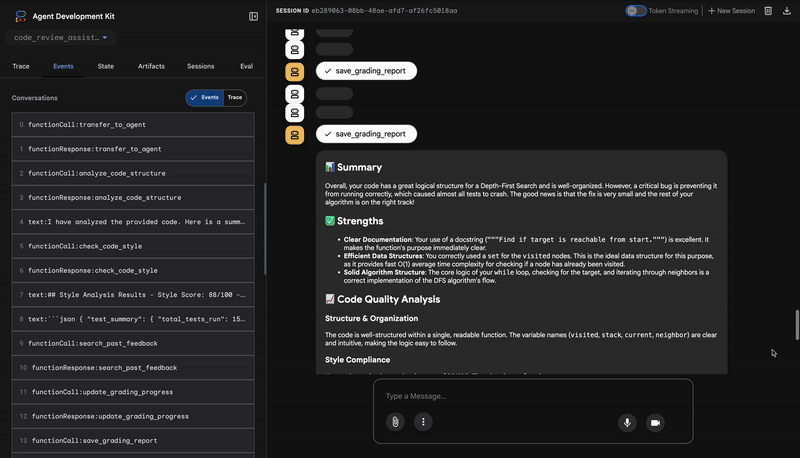
Style Analysis Results
- Style Score: 88/100
- Total Issues: 6
- Assessment: Good style with minor improvements needed
Top Style Issues
- Line 5, W293: blank line contains whitespace
- Line 19, W292: no newline at end of file
⭐ Değer: Bu aracı, belirlenmiş topluluk standartlarına (PEP 8) dayalı olarak nesnel ve pazarlığa açık olmayan geri bildirimler sağlar. Ağırlıklı puanlama sistemi, kullanıcılara sorunların ciddiyetini anında bildirir.
3. Test Runner'ın Kritik Hata Keşfi
Bu noktada sistem, yüzeysel analizlerin ötesine geçer. TestRunner aracısı, kodun davranışını doğrulamak için kapsamlı bir test paketi oluşturup yürütür.
Çıkışı, mahkum edici bir karar içeren yapılandırılmış bir JSON nesnesidir:
{
"critical_issues": [
{
"type": "Critical Bug",
"description": "The function's initialization `stack = start` is incorrect... When a common input like a string... is provided... the function crashes with an AttributeError.",
"severity": "Critical"
}
],
"verdict": {
"status": "BROKEN",
"confidence": "high",
"recommendation": "The function is fundamentally broken... the stack initialization line `stack = start` must be changed to `stack = [start]`."
}
}
⭐ Değer: Bu, en önemli analizdir. Ajan sadece tahmin etmedi, kodu çalıştırarak bozuk olduğunu kanıtladı. Bu sayede, gerçek bir incelemecinin kolayca gözden kaçırabileceği ince ancak kritik bir çalışma zamanı hatası ortaya çıkarıldı ve hatanın tam nedeni ile gerekli düzeltme belirlendi.
4. Geri Bildirim Sentezleyicinin Nihai Raporu
Son olarak, FeedbackSynthesizer temsilcisi orkestra şefi gibi davranır. Önceki üç ajandan gelen yapılandırılmış verileri alır ve hem analitik hem de teşvik edici olan tek bir kullanıcı dostu rapor oluşturur.
Çıkışı, gördüğünüz son ve düzenlenmiş incelemedir:
📊 Summary
Great effort on implementing the Depth-First Search algorithm! ... However, a critical bug in the initialization of the stack prevents the function from working correctly...
✅ Strengths
- Good Algorithm Structure
- Correct Use of `visited` Set
📈 Code Quality Analysis
...
### Style Compliance
The style analysis returned a good score of 88/100.
...
### Test Results
The automated testing revealed a critical issue... The line `stack = start` directly assigns the input... which results in an `AttributeError`.
💡 Recommendations for Improvement
**Fix the Critical Stack Initialization Bug:**
- Incorrect Code: `stack = start`
- Correct Code: `stack = [start]`
💬 Encouragement
You are very close to a perfect implementation! The core logic of your DFS algorithm is sound, which is the hardest part.
⭐ Değer: Bu aracı, teknik verileri faydalı ve eğitici bir deneyime dönüştürür. En önemli soruna (hata) öncelik veriyor, bunu net bir şekilde açıklıyor, tam çözümü sunuyor ve bunu teşvik edici bir üslupla yapıyor. Önceki tüm aşamalardaki bulguları başarılı bir şekilde tutarlı ve değerli bir bütün hâline getirir.
Bu çok kademeli süreç, üretken bir ardışık düzenin gücünü gösterir. Tek bir yanıt yerine, her aracının özel ve doğrulanabilir bir görev gerçekleştirdiği katmanlı bir analiz elde edersiniz. Bu sayede hem bilgilendirici hem de belirleyici, güvenilir ve eğitici bir inceleme elde edilir.
👉💻 Testi tamamladığınızda Cloud Shell Editor terminalinize dönün ve ADK Dev UI'yi durdurmak için Ctrl+C tuşuna basın.
Oluşturduklarınız
Artık aşağıdakileri yapabilen eksiksiz bir kod inceleme ardışık düzeniniz var:
✅ Kod yapısını ayrıştırır: Yardımcı işlevlerle deterministik AST analizi
✅ Stili kontrol eder: Adlandırma kurallarıyla ağırlıklı puanlama
✅ Testleri çalıştırır: Yapılandırılmış JSON çıkışıyla kapsamlı test oluşturma
✅ Geri bildirimi sentezler: Durum, bellek ve yapıtları entegre eder
✅ İlerlemeyi takip eder: Çağrılar/oturumlar/kullanıcılar arasında çok katmanlı durum
✅ Zaman içinde öğrenir: Oturumlar arası kalıplar için bellek hizmeti
✅ Yapıtlar sağlar: Tam denetim izi içeren indirilebilir JSON raporları
Uzmanlaşılan Temel Kavramlar
Sıralı ardışık düzenler:
- Dört temsilci kesin bir sırayla çalışıyor
- Her biri, bir sonraki için durumu zenginleştirir.
- Bağımlılıklar yürütme sırasını belirler
Üretim Desenleri:
- Yardımcı işlev ayrımı (iş parçacığı havuzlarında senkronizasyon)
- Kontrollü azalma (yedek stratejiler)
- Çok katmanlı durum yönetimi (geçici/oturum/kullanıcı)
- Dinamik talimat sağlayıcılar (bağlama duyarlı)
- Çift depolama (yapılar + durum yedekliliği)
İletişim Olarak Durum:
- Sabitler, ajanlar arasında yazım hatalarını önler
output_keydurumu belirtmek için aracı özetleri yazar- StateKey'ler aracılığıyla daha sonra okunan aracıları
- Durum, ardışık düzende doğrusal olarak akar.
Bellek ve Durum Karşılaştırması:
- Durum: Geçerli oturum verileri
- Bellek: Oturumlar genelindeki kalıplar
- Farklı amaçlar, farklı kullanım ömürleri
Araç Düzenleme:
- Tek araçlı ajanlar (analyzer, style_checker)
- Yerleşik yürütücüler (test_runner)
- Çoklu araç koordinasyonu (sentezleyici)
Model Seçim Stratejisi:
- Çalışan modeli: mekanik görevler (ayrıştırma, linting, yönlendirme)
- Eleştirmen modeli: Akıl yürütme görevleri (test etme, sentezleme)
- Uygun seçimle maliyet optimizasyonu
Sonraki Adımlar
6. modülde düzeltme kanalını oluşturacaksınız:
- Tekrarlı düzeltme için LoopAgent mimarisi
- Üst birime iletme yoluyla çıkış koşulları
- İterasyonlar arasında durum birikimi
- Doğrulama ve yeniden deneme mantığı
- Düzeltmeler sunmak için inceleme hattıyla entegrasyon
Aynı durum kalıplarının, aracıların başarıya ulaşana kadar birden çok kez denediği karmaşık yinelemeli iş akışlarına nasıl ölçeklendiğini ve tek bir uygulamada birden fazla işlem hattının nasıl koordine edileceğini göreceksiniz.
6. Fix Pipeline: Loop Architecture'ı ekleme
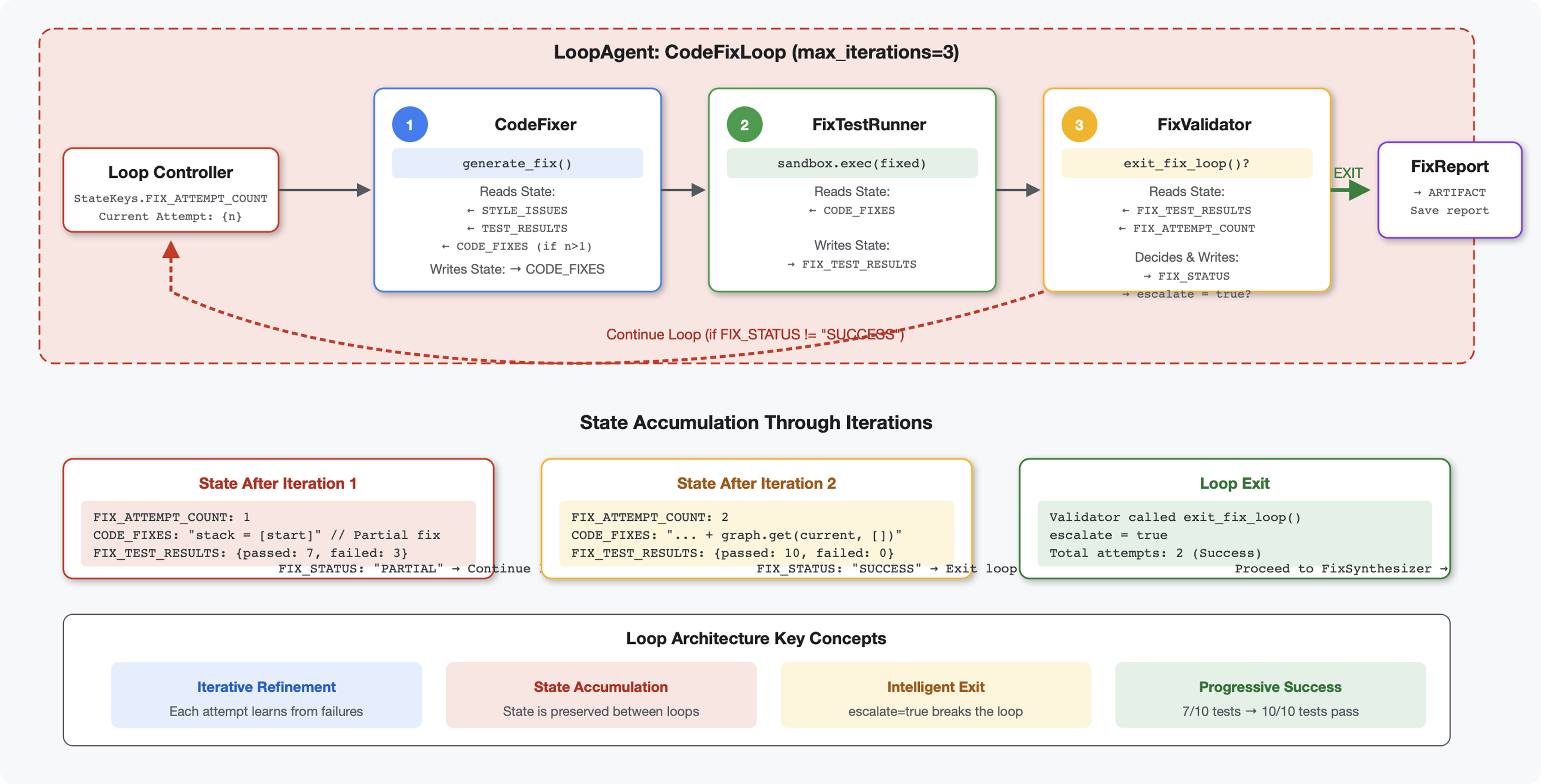
Giriş
5. modülde, kodu analiz eden ve geri bildirim sağlayan sıralı bir inceleme ardışık düzeni oluşturmuştunuz. Ancak sorunları belirlemek çözümün sadece yarısıdır. Geliştiricilerin sorunları düzeltmek için yardıma ihtiyacı vardır.
Bu modül, aşağıdakileri yapan bir otomatik düzeltme ardışık düzeni oluşturur:
- İnceleme sonuçlarına göre düzeltmeler oluşturur.
- Kapsamlı testler çalıştırarak düzeltmeleri doğrular.
- Düzeltmeler işe yaramazsa otomatik olarak yeniden dener (en fazla 3 deneme)
- Önce/sonra karşılaştırmaları içeren rapor sonuçları
Temel kavram: Otomatik yeniden deneme için LoopAgent. Bir kez çalışan sıralı ajanların aksine, LoopAgent, çıkış koşulu karşılanana veya maksimum yineleme sayısına ulaşılana kadar alt ajanlarını tekrarlar. Araçlar, tool_context.actions.escalate = True ayarını yaparak başarıyı gösterir.
Oluşturacaklarınızın önizlemesi: Hatalı kod gönderilir → inceleme sorunları tanımlar → düzeltme döngüsü düzeltmeler oluşturur → testler doğrular → gerekirse yeniden denenir → nihai kapsamlı rapor.
Temel Kavramlar: LoopAgent ve Sıralı
Sıralı İşlem Hattı (5. Modül):
SequentialAgent(agents=[A, B, C])
# Executes: A → B → C → Done
- Tek yönlü akış
- Her aracı tam olarak bir kez çalıştırılır.
- Yeniden deneme mantığı yok
Loop Pipeline (Module 6):
LoopAgent(agents=[A, B, C], max_iterations=3)
# Executes: A → B → C → (check exit) → A → B → C → (check exit) → ...
- Döngüsel akış
- Aracılar birden çok kez çalıştırılabilir
- Şu durumlarda çıkılır:
- Bir araç
tool_context.actions.escalate = True(başarılı) olarak ayarlanır. max_iterationsolan sınıra ulaşıldı (güvenlik sınırı)- İşlenmeyen istisna oluşuyor (hata)
- Bir araç
Kod düzeltme için neden döngüler kullanılır?
Kod düzeltmeleri genellikle birden fazla deneme gerektirir:
- İlk deneme: Bariz hataları (yanlış değişken türleri) düzeltme
- İkinci deneme: Testlerle ortaya çıkan ikincil sorunları (uç durumlar) düzeltin.
- Üçüncü deneme: Tüm testlerin başarılı olması için ince ayar yapın ve doğrulayın.
Döngü olmadan, aracı talimatlarında karmaşık koşullu mantık kullanmanız gerekir. LoopAgent ile yeniden deneme otomatik olarak yapılır.
Mimari karşılaştırması:
Sequential (Module 5):
User → Review Pipeline → Feedback → Done
Loop (Module 6):
User → Review Pipeline → Feedback → Fix Pipeline
↓
┌──────────────┴──────────────┐
│ Fix Attempt Loop (1-3x) │
│ ┌─────────────────────┐ │
│ │ 1. Generate Fixes │ │
│ │ 2. Test Fixes │ │
│ │ 3. Validate & Exit? │────┼─→ If escalate=True
│ └─────────────────────┘ │ exit loop
│ ↓ If not │
│ Try Again (max 3) │
└─────────────────────────────┘
↓
4. Synthesize Final Report → Done
1. adım: Code Fixer Agent'ı ekleyin
Kod düzeltici, inceleme sonuçlarına göre düzeltilmiş Python kodu oluşturur.
👉 Aç
code_review_assistant/sub_agents/fix_pipeline/code_fixer.py
👉 Bul:
# MODULE_6_STEP_1_CODE_FIXER_INSTRUCTION_PROVIDER
👉 Tek satırı şununla değiştirin:
async def code_fixer_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are an expert code fixing specialist.
Original Code:
{code_to_review}
Analysis Results:
- Style Score: {style_score}/100
- Style Issues: {style_issues}
- Test Results: {test_execution_summary}
Based on the test results, identify and fix ALL issues including:
- Interface bugs (e.g., if start parameter expects wrong type)
- Logic errors (e.g., KeyError when accessing graph nodes)
- Style violations
- Missing documentation
YOUR TASK:
Generate the complete fixed Python code that addresses all identified issues.
CRITICAL INSTRUCTIONS:
- Output ONLY the corrected Python code
- Do NOT include markdown code blocks (```python)
- Do NOT include any explanations or commentary
- The output should be valid, executable Python code and nothing else
Common fixes to apply based on test results:
- If tests show AttributeError with 'pop', fix: stack = [start] instead of stack = start
- If tests show KeyError accessing graph, fix: use graph.get(current, [])
- Add docstrings if missing
- Fix any style violations identified
Output the complete fixed code now:"""
return await instructions_utils.inject_session_state(template, context)
👉 Bul:
# MODULE_6_STEP_1_CODE_FIXER_AGENT
👉 Tek satırı şununla değiştirin:
code_fixer_agent = Agent(
name="CodeFixer",
model=config.worker_model,
description="Generates comprehensive fixes for all identified code issues",
instruction=code_fixer_instruction_provider,
code_executor=BuiltInCodeExecutor(),
output_key="code_fixes"
)
2. adım: Fix Test Runner Agent'ı ekleyin
Düzeltme test çalıştırıcısı, düzeltilmiş kod üzerinde kapsamlı testler yaparak düzeltmeleri doğrular.
👉 Aç
code_review_assistant/sub_agents/fix_pipeline/fix_test_runner.py
👉 Bul:
# MODULE_6_STEP_2_FIX_TEST_RUNNER_INSTRUCTION_PROVIDER
👉 Tek satırı şununla değiştirin:
async def fix_test_runner_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that uses the clean code from the previous step."""
template = """You are responsible for validating the fixed code by running tests.
THE FIXED CODE TO TEST:
{code_fixes}
ORIGINAL TEST RESULTS: {test_execution_summary}
YOUR TASK:
1. Understand the fixes that were applied
2. Generate the same comprehensive tests (15-20 test cases)
3. Execute the tests on the FIXED code using your code executor
4. Compare results with original test results
5. Output a detailed JSON analysis
TESTING METHODOLOGY:
- Run the same tests that revealed issues in the original code
- Verify that previously failing tests now pass
- Ensure no regressions were introduced
- Document the improvement
Execute your tests and output ONLY valid JSON with this structure:
- "passed": number of tests that passed
- "failed": number of tests that failed
- "total": total number of tests
- "pass_rate": percentage as a number
- "comparison": object with "original_pass_rate", "new_pass_rate", "improvement"
- "newly_passing_tests": array of test names that now pass
- "still_failing_tests": array of test names still failing
Do NOT output the test code itself, only the JSON analysis."""
return await instructions_utils.inject_session_state(template, context)
👉 Bul:
# MODULE_6_STEP_2_FIX_TEST_RUNNER_AGENT
👉 Tek satırı şununla değiştirin:
fix_test_runner_agent = Agent(
name="FixTestRunner",
model=config.critic_model,
description="Runs comprehensive tests on fixed code to verify all issues are resolved",
instruction=fix_test_runner_instruction_provider,
code_executor=BuiltInCodeExecutor(),
output_key="fix_test_execution_summary"
)
3. adım: Fix Validator Agent'ı ekleyin
Doğrulayıcı, düzeltmelerin başarılı olup olmadığını kontrol eder ve döngüden çıkıp çıkmayacağına karar verir.
Araçları Anlama
İlk olarak, doğrulayıcının ihtiyaç duyduğu üç aracı ekleyin.
👉 Aç
code_review_assistant/tools.py
👉 Bul:
# MODULE_6_STEP_3_VALIDATE_FIXED_STYLE
👉 1. Araç - Stil Doğrulayıcı ile değiştirme:
async def validate_fixed_style(tool_context: ToolContext) -> Dict[str, Any]:
"""
Validates style compliance of the fixed code.
Args:
tool_context: ADK tool context containing fixed code in state
Returns:
Dictionary with style validation results
"""
logger.info("Tool: Validating style of fixed code...")
try:
# Get the fixed code from state
code_fixes = tool_context.state.get(StateKeys.CODE_FIXES, '')
# Try to extract from markdown if present
if '```python' in code_fixes:
start = code_fixes.rfind('```python') + 9
end = code_fixes.rfind('```')
if start < end:
code_fixes = code_fixes[start:end].strip()
if not code_fixes:
return {
"status": "error",
"message": "No fixed code found in state"
}
# Store the extracted fixed code
tool_context.state[StateKeys.CODE_FIXES] = code_fixes
# Run style check on fixed code
loop = asyncio.get_event_loop()
with ThreadPoolExecutor() as executor:
style_result = await loop.run_in_executor(
executor, _perform_style_check, code_fixes
)
# Compare with original
original_score = tool_context.state.get(StateKeys.STYLE_SCORE, 0)
improvement = style_result['score'] - original_score
# Store results
tool_context.state[StateKeys.FIXED_STYLE_SCORE] = style_result['score']
tool_context.state[StateKeys.FIXED_STYLE_ISSUES] = style_result['issues']
logger.info(f"Tool: Fixed code style score: {style_result['score']}/100 "
f"(improvement: +{improvement})")
return {
"status": "success",
"fixed_style_score": style_result['score'],
"original_style_score": original_score,
"improvement": improvement,
"remaining_issues": style_result['issues'],
"perfect_style": style_result['score'] == 100
}
except Exception as e:
logger.error(f"Tool: Style validation failed: {e}", exc_info=True)
return {
"status": "error",
"message": str(e)
}
👉 Bul:
# MODULE_6_STEP_3_COMPILE_FIX_REPORT
👉 2. Araç - Rapor Derleyici ile değiştirme:
async def compile_fix_report(tool_context: ToolContext) -> Dict[str, Any]:
"""
Compiles comprehensive report of the fix process.
Args:
tool_context: ADK tool context with all fix pipeline data
Returns:
Comprehensive fix report
"""
logger.info("Tool: Compiling comprehensive fix report...")
try:
# Gather all data
original_code = tool_context.state.get(StateKeys.CODE_TO_REVIEW, '')
code_fixes = tool_context.state.get(StateKeys.CODE_FIXES, '')
# Test results
original_tests = tool_context.state.get(StateKeys.TEST_EXECUTION_SUMMARY, {})
fixed_tests = tool_context.state.get(StateKeys.FIX_TEST_EXECUTION_SUMMARY, {})
# Parse if strings
if isinstance(original_tests, str):
try:
original_tests = json.loads(original_tests)
except:
original_tests = {}
if isinstance(fixed_tests, str):
try:
fixed_tests = json.loads(fixed_tests)
except:
fixed_tests = {}
# Extract pass rates
original_pass_rate = 0
if original_tests:
if 'pass_rate' in original_tests:
original_pass_rate = original_tests['pass_rate']
elif 'test_summary' in original_tests:
# Handle test_runner_agent's JSON structure
summary = original_tests['test_summary']
total = summary.get('total_tests_run', 0)
passed = summary.get('tests_passed', 0)
if total > 0:
original_pass_rate = (passed / total) * 100
elif 'passed' in original_tests and 'total' in original_tests:
if original_tests['total'] > 0:
original_pass_rate = (original_tests['passed'] / original_tests['total']) * 100
fixed_pass_rate = 0
all_tests_pass = False
if fixed_tests:
if 'pass_rate' in fixed_tests:
fixed_pass_rate = fixed_tests['pass_rate']
all_tests_pass = fixed_tests.get('failed', 1) == 0
elif 'passed' in fixed_tests and 'total' in fixed_tests:
if fixed_tests['total'] > 0:
fixed_pass_rate = (fixed_tests['passed'] / fixed_tests['total']) * 100
all_tests_pass = fixed_tests.get('failed', 0) == 0
# Style scores
original_style = tool_context.state.get(StateKeys.STYLE_SCORE, 0)
fixed_style = tool_context.state.get(StateKeys.FIXED_STYLE_SCORE, 0)
# Calculate improvements
test_improvement = {
'original_pass_rate': original_pass_rate,
'fixed_pass_rate': fixed_pass_rate,
'improvement': fixed_pass_rate - original_pass_rate,
'all_tests_pass': all_tests_pass
}
style_improvement = {
'original_score': original_style,
'fixed_score': fixed_style,
'improvement': fixed_style - original_style,
'perfect_style': fixed_style == 100
}
# Determine overall status
if all_tests_pass and style_improvement['perfect_style']:
fix_status = 'SUCCESSFUL'
status_emoji = '✅'
elif test_improvement['improvement'] > 0 or style_improvement['improvement'] > 0:
fix_status = 'PARTIAL'
status_emoji = '⚠️'
else:
fix_status = 'FAILED'
status_emoji = '❌'
# Build comprehensive report
report = {
'status': fix_status,
'status_emoji': status_emoji,
'timestamp': datetime.now().isoformat(),
'original_code': original_code,
'code_fixes': code_fixes,
'improvements': {
'tests': test_improvement,
'style': style_improvement
},
'summary': f"{status_emoji} Fix Status: {fix_status}\n"
f"Tests: {original_pass_rate:.1f}% → {fixed_pass_rate:.1f}%\n"
f"Style: {original_style}/100 → {fixed_style}/100"
}
# Store report in state
tool_context.state[StateKeys.FIX_REPORT] = report
tool_context.state[StateKeys.FIX_STATUS] = fix_status
logger.info(f"Tool: Fix report compiled - Status: {fix_status}")
logger.info(f"Tool: Test improvement: {original_pass_rate:.1f}% → {fixed_pass_rate:.1f}%")
logger.info(f"Tool: Style improvement: {original_style} → {fixed_style}")
return {
"status": "success",
"fix_status": fix_status,
"report": report
}
except Exception as e:
logger.error(f"Tool: Failed to compile fix report: {e}", exc_info=True)
return {
"status": "error",
"message": str(e)
}
👉 Bul:
# MODULE_6_STEP_3_EXIT_FIX_LOOP
👉 3. Araç ile değiştirin - Döngüden Çıkış Sinyali:
def exit_fix_loop(tool_context: ToolContext) -> Dict[str, Any]:
"""
Signal that fixing is complete and should exit the loop.
Args:
tool_context: ADK tool context
Returns:
Confirmation message
"""
logger.info("Tool: Setting escalate flag to exit fix loop")
# This is the critical line that exits the LoopAgent
tool_context.actions.escalate = True
return {
"status": "success",
"message": "Fix complete, exiting loop"
}
Doğrulayıcı aracıyı oluşturma
👉 Aç
code_review_assistant/sub_agents/fix_pipeline/fix_validator.py
👉 Bul:
# MODULE_6_STEP_3_FIX_VALIDATOR_INSTRUCTION_PROVIDER
👉 Tek satırı şununla değiştirin:
async def fix_validator_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are the final validation specialist for code fixes.
You have access to:
- Original issues from initial review
- Applied fixes: {code_fixes}
- Test results after fix: {fix_test_execution_summary}
- All state data from the fix process
Your responsibilities:
1. Use validate_fixed_style tool to check style compliance of fixed code
- Pass no arguments, it will retrieve fixed code from state
2. Use compile_fix_report tool to generate comprehensive report
- Pass no arguments, it will gather all data from state
3. Based on the report, determine overall fix status:
- ✅ SUCCESSFUL: All tests pass, style score 100
- ⚠️ PARTIAL: Improvements made but issues remain
- ❌ FAILED: Fix didn't work or made things worse
4. CRITICAL: If status is SUCCESSFUL, call the exit_fix_loop tool to stop iterations
- This prevents unnecessary additional fix attempts
- If not successful, the loop will continue for another attempt
5. Provide clear summary of:
- What was fixed
- What improvements were achieved
- Any remaining issues requiring manual attention
Be precise and quantitative in your assessment.
"""
return await instructions_utils.inject_session_state(template, context)
👉 Bul:
# MODULE_6_STEP_3_FIX_VALIDATOR_AGENT
👉 Tek satırı şununla değiştirin:
fix_validator_agent = Agent(
name="FixValidator",
model=config.worker_model,
description="Validates fixes and generates final fix report",
instruction=fix_validator_instruction_provider,
tools=[
FunctionTool(func=validate_fixed_style),
FunctionTool(func=compile_fix_report),
FunctionTool(func=exit_fix_loop)
],
output_key="final_fix_report"
)
4. adım: LoopAgent çıkış koşullarını anlama
LoopAgent uygulamasından çıkmanın üç yolu vardır:
1. Başarılı çıkış (yükseltme yoluyla)
# Inside any tool in the loop:
tool_context.actions.escalate = True
# Effect: Loop completes current iteration, then exits
# Use when: Fix is successful and no more attempts needed
Örnek akış:
Iteration 1:
CodeFixer → generates fixes
FixTestRunner → tests show 90% pass rate
FixValidator → compiles report, sees PARTIAL status
→ Does NOT set escalate
→ Loop continues
Iteration 2:
CodeFixer → refines fixes based on failures
FixTestRunner → tests show 100% pass rate
FixValidator → compiles report, sees SUCCESSFUL status
→ Calls exit_fix_loop() which sets escalate = True
→ Loop exits after this iteration
2. Maksimum Yineleme Çıkışı
LoopAgent(
name="FixAttemptLoop",
sub_agents=[...],
max_iterations=3 # Safety limit
)
# Effect: After 3 complete iterations, loop exits regardless of escalate
# Use when: Prevent infinite loops if fixes never succeed
Örnek akış:
Iteration 1: PARTIAL (continue)
Iteration 2: PARTIAL (continue)
Iteration 3: PARTIAL (but max reached)
→ Loop exits, synthesizer presents best attempt
3. Hata Çıkışı
# If any agent throws unhandled exception:
raise Exception("Unexpected error")
# Effect: Loop exits immediately with error state
# Use when: Critical failure that can't be recovered
Yinelemeler Arasında Durum Gelişimi:
Her yinelemede önceki denemeden güncellenen durum görülür:
# Before Iteration 1:
state = {
"code_to_review": "def add(a,b):return a+b", # Original
"style_score": 40,
"test_execution_summary": {...}
}
# After Iteration 1:
state = {
"code_to_review": "def add(a,b):return a+b", # Unchanged
"code_fixes": "def add(a, b):\n return a + b", # NEW
"style_score": 40, # Unchanged
"fixed_style_score": 100, # NEW
"test_execution_summary": {...}, # Unchanged
"fix_test_execution_summary": {...} # NEW
}
# Iteration 2 starts with all this state
# If fixes still not perfect, code_fixes gets overwritten
Neden?
escalate
Döndürülen Değerler Yerine:
# Bad: Using return value to signal exit
def validator_agent():
report = compile_report()
if report['status'] == 'SUCCESSFUL':
return {"exit": True} # How does loop know?
# Good: Using escalate
def validator_tool(tool_context):
report = compile_report()
if report['status'] == 'SUCCESSFUL':
tool_context.actions.escalate = True # Loop knows immediately
return {"report": report}
Avantajları
- Yalnızca son araçta değil, tüm araçlarda çalışır.
- İade verilerine müdahale etmez.
- Net anlamsal anlam
- Çıkış mantığı çerçeve tarafından işlenir.
5. adım: Düzeltme işlem hattını bağlayın
👉 Aç
code_review_assistant/agent.py
👉 Düzeltme ardışık düzeni içe aktarma işlemlerini ekleyin (mevcut içe aktarma işlemlerinden sonra):
from google.adk.agents import LoopAgent # Add this to the existing Agent, SequentialAgent line
from code_review_assistant.sub_agents.fix_pipeline.code_fixer import code_fixer_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_test_runner import fix_test_runner_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_validator import fix_validator_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_synthesizer import fix_synthesizer_agent
İçe aktarma işlemleriniz artık şu şekilde olmalıdır:
from google.adk.agents import Agent, SequentialAgent, LoopAgent
from .config import config
# Review pipeline imports (from Module 5)
from code_review_assistant.sub_agents.review_pipeline.code_analyzer import code_analyzer_agent
from code_review_assistant.sub_agents.review_pipeline.style_checker import style_checker_agent
from code_review_assistant.sub_agents.review_pipeline.test_runner import test_runner_agent
from code_review_assistant.sub_agents.review_pipeline.feedback_synthesizer import feedback_synthesizer_agent
# Fix pipeline imports (NEW)
from code_review_assistant.sub_agents.fix_pipeline.code_fixer import code_fixer_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_test_runner import fix_test_runner_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_validator import fix_validator_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_synthesizer import fix_synthesizer_agent
👉 Bul:
# MODULE_6_STEP_5_CREATE_FIX_LOOP
👉 Tek satırı şununla değiştirin:
# Create the fix attempt loop (retries up to 3 times)
fix_attempt_loop = LoopAgent(
name="FixAttemptLoop",
sub_agents=[
code_fixer_agent, # Step 1: Generate fixes
fix_test_runner_agent, # Step 2: Validate with tests
fix_validator_agent # Step 3: Check success & possibly exit
],
max_iterations=3 # Try up to 3 times
)
# Wrap loop with synthesizer for final report
code_fix_pipeline = SequentialAgent(
name="CodeFixPipeline",
description="Automated code fixing pipeline with iterative validation",
sub_agents=[
fix_attempt_loop, # Try to fix (1-3 times)
fix_synthesizer_agent # Present final results (always runs once)
]
)
👉 Mevcut olanı kaldırın .
root_agent
tanımı:
root_agent = Agent(...)
👉 Bul:
# MODULE_6_STEP_5_UPDATE_ROOT_AGENT
👉 Tek satırı şununla değiştirin:
# Update root agent to include both pipelines
root_agent = Agent(
name="CodeReviewAssistant",
model=config.worker_model,
description="An intelligent code review assistant that analyzes Python code and provides educational feedback",
instruction="""You are a specialized Python code review assistant focused on helping developers improve their code quality.
When a user provides Python code for review:
1. Immediately delegate to CodeReviewPipeline and pass the code EXACTLY as it was provided by the user.
2. The pipeline will handle all analysis and feedback
3. Return ONLY the final feedback from the pipeline - do not add any commentary
After completing a review, if significant issues were identified:
- If style score < 100 OR tests are failing OR critical issues exist:
* Add at the end: "\n\n💡 I can fix these issues for you. Would you like me to do that?"
- If the user responds yes or requests fixes:
* Delegate to CodeFixPipeline
* Return the fix pipeline's complete output AS-IS
When a user asks what you can do or general questions:
- Explain your capabilities for code review and fixing
- Do NOT trigger the pipeline for non-code messages
The pipelines handle everything for code review and fixing - just pass through their final output.""",
sub_agents=[code_review_pipeline, code_fix_pipeline],
output_key="assistant_response"
)
6. adım: Fix Synthesizer Agent'ı ekleyin
Sentezleyici, döngü tamamlandıktan sonra düzeltme sonuçlarının kullanıcı dostu bir sunumunu oluşturur.
👉 Aç
code_review_assistant/sub_agents/fix_pipeline/fix_synthesizer.py
👉 Bul:
# MODULE_6_STEP_6_FIX_SYNTHESIZER_INSTRUCTION_PROVIDER
👉 Tek satırı şununla değiştirin:
async def fix_synthesizer_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are responsible for presenting the fix results to the user.
Based on the validation report: {final_fix_report}
Fixed code from state: {code_fixes}
Fix status: {fix_status}
Create a comprehensive yet friendly response that includes:
## 🔧 Fix Summary
[Overall status and key improvements - be specific about what was achieved]
## 📊 Metrics
- Test Results: [original pass rate]% → [new pass rate]%
- Style Score: [original]/100 → [new]/100
- Issues Fixed: X of Y
## ✅ What Was Fixed
[List each fixed issue with brief explanation of the correction made]
## 📝 Complete Fixed Code
[Include the complete, corrected code from state - this is critical]
## 💡 Explanation of Key Changes
[Brief explanation of the most important changes made and why]
[If any issues remain]
## ⚠️ Remaining Issues
[List what still needs manual attention]
## 🎯 Next Steps
[Guidance on what to do next - either use the fixed code or address remaining issues]
Save the fix report using save_fix_report tool before presenting.
Call it with no parameters - it will retrieve the report from state automatically.
Be encouraging about improvements while being honest about any remaining issues.
Focus on the educational aspect - help the user understand what was wrong and how it was fixed.
"""
return await instructions_utils.inject_session_state(template, context)
👉 Bul:
# MODULE_6_STEP_6_FIX_SYNTHESIZER_AGENT
👉 Tek satırı şununla değiştirin:
fix_synthesizer_agent = Agent(
name="FixSynthesizer",
model=config.critic_model,
description="Creates comprehensive user-friendly fix report",
instruction=fix_synthesizer_instruction_provider,
tools=[FunctionTool(func=save_fix_report)],
output_key="fix_summary"
)
👉 Ekle 'yi tıklayın.
save_fix_report
aracına
tools.py
:
👉 Bul:
# MODULE_6_STEP_6_SAVE_FIX_REPORT
👉 Şununla değiştir:
async def save_fix_report(tool_context: ToolContext) -> Dict[str, Any]:
"""
Saves the fix report as an artifact.
Args:
tool_context: ADK tool context
Returns:
Save status
"""
logger.info("Tool: Saving fix report...")
try:
# Get the report from state
fix_report = tool_context.state.get(StateKeys.FIX_REPORT, {})
if not fix_report:
return {
"status": "error",
"message": "No fix report found in state"
}
# Convert to JSON
report_json = json.dumps(fix_report, indent=2)
report_part = types.Part.from_text(text=report_json)
# Generate filename
timestamp = datetime.now().isoformat().replace(':', '-')
filename = f"fix_report_{timestamp}.json"
# Try to save as artifact
if hasattr(tool_context, 'save_artifact'):
try:
version = await tool_context.save_artifact(filename, report_part)
await tool_context.save_artifact("latest_fix_report.json", report_part)
logger.info(f"Tool: Fix report saved as {filename}")
return {
"status": "success",
"filename": filename,
"version": str(version),
"size": len(report_json)
}
except Exception as e:
logger.warning(f"Could not save as artifact: {e}")
# Fallback: store in state
tool_context.state[StateKeys.LAST_FIX_REPORT] = fix_report
return {
"status": "success",
"message": "Fix report saved to state",
"size": len(report_json)
}
except Exception as e:
logger.error(f"Tool: Failed to save fix report: {e}", exc_info=True)
return {
"status": "error",
"message": str(e)
}
7. adım: Testi tamamlayın ve düzeltme ardışık düzenini kullanın
Döngünün tamamını uygulamalı olarak görelim.
👉 Sistemi başlatma:
adk web code_review_assistant
adk web komutunu çalıştırdıktan sonra terminalinizde ADK Web Sunucusu'nun başlatıldığını belirten bir çıkış görmelisiniz. Bu çıkış şuna benzer:
+-----------------------------------------------------------------------------+
| ADK Web Server started |
| |
| For local testing, access at http://localhost:8000. |
+-----------------------------------------------------------------------------+
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
👉 Test istemi:
Please analyze the following:
def dfs_search_v1(graph, start, target):
"""Find if target is reachable from start."""
visited = set()
stack = start
while stack:
current = stack.pop()
if current == target:
return True
if current not in visited:
visited.add(current)
for neighbor in graph[current]:
if neighbor not in visited:
stack.append(neighbor)
return False
İlk olarak, inceleme ardışık düzenini tetiklemek için hatalı kodu gönderin. Kusurları belirledikten sonra, güçlü ve yinelemeli düzeltme işlem hattını tetikleyen "Lütfen kodu düzelt" istemini kullanarak aracıdan kodu düzeltmesini istersiniz.
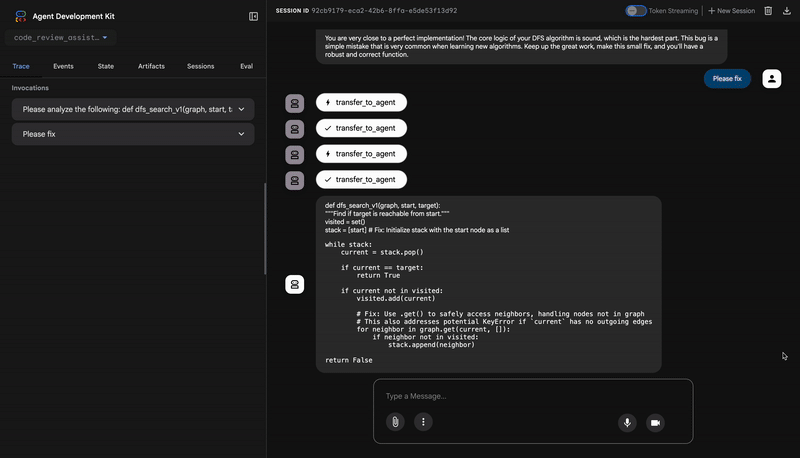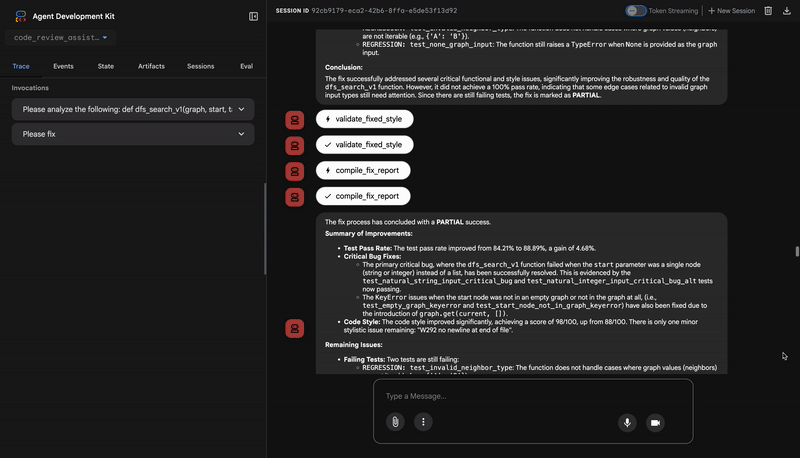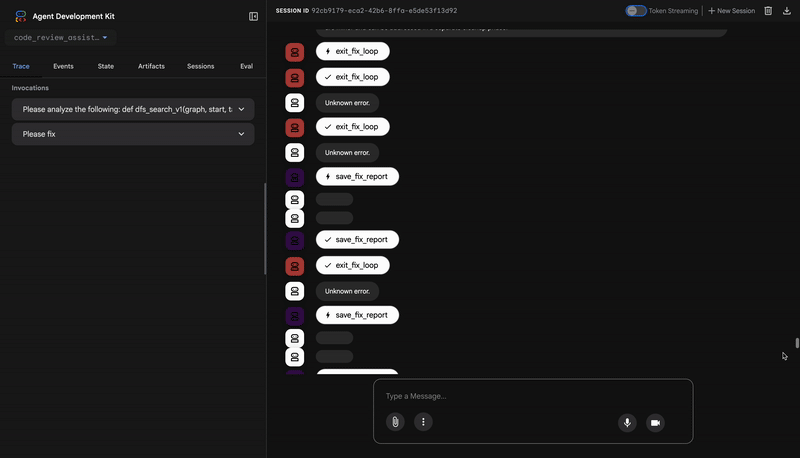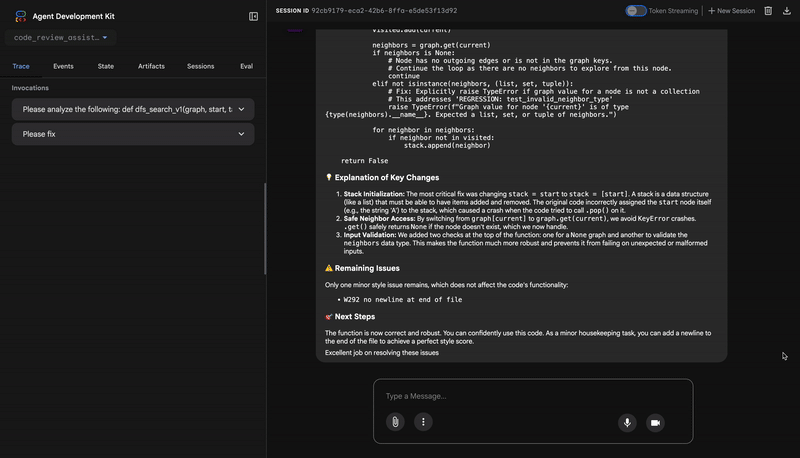
1. İlk İnceleme (Hataları Bulma)
Bu, sürecin ilk yarısıdır. Dört aracılı inceleme ardışık düzeni kodu analiz eder, stilini kontrol eder ve oluşturulan bir test paketini çalıştırır. AttributeError ile ilgili kritik sorunları ve diğer sorunları doğru şekilde tanımlayarak bir karar verir: Kod BOZUK ve test geçme oranı yalnızca %84,21'dir.
2. Otomatik Düzeltme (Döngü İşlemi)
En etkileyici kısım burası. Temsilciden kodu düzeltmesini istediğinizde yalnızca bir değişiklik yapılmaz. Bu işlem, tıpkı çalışkan bir geliştirici gibi çalışan yinelemeli bir Düzeltme ve Doğrulama Döngüsü başlatır: Bir düzeltme dener, bunu iyice test eder ve mükemmel değilse tekrar dener.
1. Yineleme: İlk Deneme (Kısmi Başarı)
- Düzeltme:
CodeFixerajanı, ilk raporu okur ve en belirgin düzeltmeleri yapar.stack = startdeğerinistack = [start]olarak değiştirir veKeyErroristisnalarını önlemek içingraph.get()değerini kullanır. - Doğrulama:
TestRunner, bu yeni koda karşı tam test paketini hemen yeniden çalıştırır. - Sonuç: Geçme oranı önemli ölçüde artarak %88,89'a yükseldi. Kritik hatalar giderildi. Ancak testler o kadar kapsamlıdır ki
Noneöğesinin grafik veya liste dışı komşu değerler olarak işlenmesiyle ilgili iki yeni ve küçük hata (gerileme) ortaya çıkar. Sistem, düzeltmeyi KISMI olarak işaretler.
2. Yineleme: Son Rötuş (Başarı Oranı: %100)
- Çözüm: Döngünün çıkış koşulu (%100 geçme oranı) karşılanmadığı için döngü tekrar çalışır.
CodeFixerartık daha fazla bilgi içeriyor: iki yeni regresyon hatası. Bu araç, uç durumları açıkça ele alan son ve daha sağlam bir kod sürümü oluşturur. - Doğrulama:
TestRunner, test paketini kodun son sürümüne karşı son bir kez daha çalıştırır. - Sonuç: Mükemmel bir % 100 geçme oranı. Tüm orijinal hatalar ve tüm gerilemeler çözülür. Sistem, düzeltmeyi BAŞARILI olarak işaretler ve döngüden çıkılır.
3. The Final Report: A Perfect Score
Tamamen doğrulanmış bir düzeltmeyle FixSynthesizer temsilcisi, son raporu sunmak için devreye girer ve teknik verileri net, eğitici bir özete dönüştürür.
Metrik | Önce | Sonra | İyileştirme |
Test Geçme Oranı | %84,21 | %100 | ▲ %15,79 |
Stil Puanı | 88 / 100 | 98 / 100 | ▲ 10 puan |
Düzeltilen Hatalar | 0/3 | 3/3 | ✅ |
✅ Son, Doğrulanmış Kod
İşte artık 19 testin tamamını geçen, düzeltilmiş ve eksiksiz kod. Bu kod, düzeltmenin başarılı olduğunu gösteriyor:
def dfs_search_v1(graph, start, target):
"""Find if target is reachable from start."""
# Handles 'None' graph input
if graph is None:
return False
visited = set()
# Fixes the critical AttributeError
stack = [start]
while stack:
current = stack.pop()
if current == target:
return True
if current not in visited:
visited.add(current)
# Safely gets neighbors to prevent KeyError
neighbors = graph.get(current)
if neighbors is None:
continue
# Validates that neighbors are iterable
if not isinstance(neighbors, (list, set, tuple)):
raise TypeError(
f"Graph value for node '{current}' is of type "
f"{type(neighbors).__name__}. Expected a list, set, or tuple."
)
for neighbor in neighbors:
if neighbor not in visited:
stack.append(neighbor)
return False
👉💻 Testi tamamladığınızda Cloud Shell Editor terminalinize dönün ve ADK Dev UI'yi durdurmak için Ctrl+C tuşuna basın.
Oluşturduklarınız
Artık aşağıdakileri yapan eksiksiz bir otomatik düzeltme ardışık düzeniniz var:
✅ Düzeltmeler oluşturur: İnceleme analizine göre
✅ Tekrarlı olarak doğrular: Her düzeltme denemesinden sonra test eder
✅ Otomatik olarak yeniden dener: Başarı için 3 denemeye kadar
✅ Akıllıca çıkar: Başarılı olduğunda yükseltme yoluyla
✅ İyileştirmeleri izler: Önceki ve sonraki metrikleri karşılaştırır
✅ Öğeler sağlar: İndirilebilir düzeltme raporları
Uzmanlaşılan Temel Kavramlar
LoopAgent ve Sequential karşılaştırması:
- Sıralı: Ajanlardan tek geçiş
- LoopAgent: Çıkış koşulu veya maksimum yineleme sayısı karşılanana kadar tekrarlanır.
tool_context.actions.escalate = Trueçıkışını kullanın
Yinelemeler Arasında Durum Gelişimi:
- Her yinelemede
CODE_FIXESgüncellendi - Test sonuçları zaman içinde iyileşme gösteriyor
- Doğrulayıcı, kümülatif değişiklikleri görür
Çoklu Ardışık Düzen Mimarisi:
- İnceleme ardışık düzeni: Salt okuma analizi (5. Modül)
- Düzeltme döngüsü: Yinelemeli düzeltme (6. modülün iç döngüsü)
- Düzeltme hattı: Döngü + sentezleyici (6. modül dış)
- Kök temsilci: Kullanıcı niyetine göre düzenleme yapar.
Akışı Kontrol Eden Araçlar:
exit_fix_loop()setler artar- Herhangi bir araç, döngü tamamlamayı işaret edebilir.
- Çıkış mantığını aracı talimatlarından ayırır.
Maksimum Yineleme Güvenliği:
- Sonsuz döngüleri önler
- Sistemin her zaman yanıt vermesini sağlar.
- Mükemmel olmasa bile en iyi denemeyi sunar
Sonraki Adımlar
Son modülde, aracınızı üretime nasıl dağıtacağınızı öğreneceksiniz:
- VertexAiSessionService ile kalıcı depolama ayarlama
- Google Cloud'da Agent Engine'e dağıtma
- Üretim aracılarını izleme ve hatalarını ayıklama
- Ölçeklendirme ve güvenilirlik için en iyi uygulamalar
Sıralı ve döngü mimarileriyle eksiksiz bir çoklu aracı sistemi oluşturdunuz. Öğrendiğiniz kalıplar (durum yönetimi, dinamik talimatlar, araç düzenleme ve yinelemeli iyileştirme), gerçek ajan sistemlerinde kullanılan üretime hazır tekniklerdir.
7. Üretime dağıtma
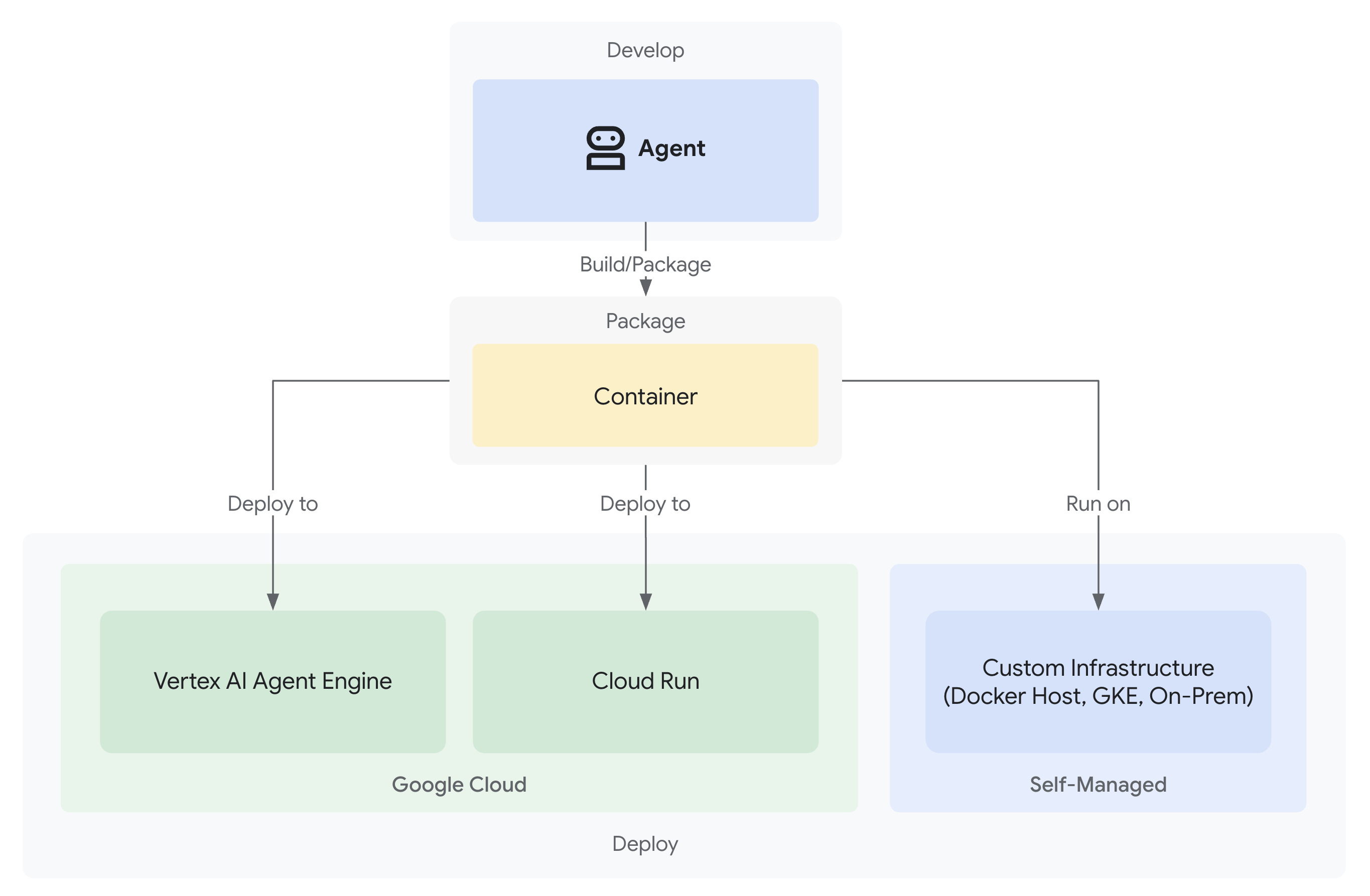
Giriş
Kod inceleme asistanınız artık yerel olarak çalışan inceleme ve düzeltme işlem hatlarıyla tamamlandı. Eksik parça: Yalnızca makinenizde çalışır. Bu modülde, Google Cloud'a aracınızı dağıtarak kalıcı oturumlar ve üretime hazır altyapı ile ekibinizin erişimine açacaksınız.
Öğrenecekleriniz:
- Üç dağıtım yolu: Yerel, Cloud Run ve Agent Engine
- Otomatik altyapı sağlama
- Oturum kalıcılığı stratejileri
- Dağıtılan aracıları test etme
Dağıtım Seçeneklerini Anlama
ADK, her biri farklı avantaj ve dezavantajlara sahip birden fazla dağıtım hedefini destekler:
Dağıtım Yolları
Faktör | Yerel ( | Cloud Run ( | Agent Engine ( |
Karmaşıklık | Minimal | Orta | Düşük |
Oturum Kalıcılığı | Yalnızca bellek içi (yeniden başlatıldığında kaybolur) | Cloud SQL (PostgreSQL) | Vertex AI tarafından yönetilen (otomatik) |
Altyapı | Yok (yalnızca geliştirme makinesi) | Kapsayıcı + Veritabanı | Tümüyle yönetilen |
Soğuk Başlatma (Cold Start) | Yok | 100-2000ms | 100-500ms |
Ölçeklendirme | Tek örnek | Otomatik (sıfıra) | Otomatik |
Maliyet modeli | Ücretsiz (yerel işlem) | İstek tabanlı + ücretsiz katman | İşleme dayalı |
UI Support | Evet ( | Evet ( | Hayır (yalnızca API) |
İdeal kullanım alanları | Geliştirme/test | Değişken trafik, maliyet kontrolü | Üretim aracıları |
Ek dağıtım seçeneği: Kubernetes düzeyinde kontrol, özel ağ veya çok hizmetli düzenleme gerektiren ileri düzey kullanıcılar için Google Kubernetes Engine (GKE) kullanılabilir. GKE dağıtımı bu codelab'de ele alınmamıştır ancak ADK dağıtım kılavuzunda belgelenmiştir.
Neler Dağıtılır?
Cloud Run veya Agent Engine'e dağıtım yaparken aşağıdakiler paketlenip dağıtılır:
- Temsilci kodunuz (
agent.py, tüm alt temsilciler, araçlar) - Bağımlılıklar (
requirements.txt) - ADK API sunucusu (otomatik olarak dahil edilir)
- Web kullanıcı arayüzü (yalnızca
--with_uibelirtildiğinde Cloud Run)
Önemli farklılıklar:
- Cloud Run:
adk deploy cloud_runCLI'yı (container'ı otomatik olarak oluşturur) veyagcloud run deploy'ı (özel Dockerfile gerektirir) kullanır. - Agent Engine:
adk deploy agent_engineCLI'yı kullanır (container oluşturmaya gerek yoktur, Python kodunu doğrudan paketler).
1. adım: Ortamınızı yapılandırın
.env Dosyanızı Yapılandırma
.env dosyanızın (3. modülde oluşturulmuştur) buluta dağıtım için güncellenmesi gerekir. .env simgesini açın ve aşağıdaki ayarları doğrulayın/güncelleyin:
Tüm bulut dağıtımları için gereklidir:
# Your actual GCP Project ID (REQUIRED)
GOOGLE_CLOUD_PROJECT=your-project-id
# GCP region for deployments (REQUIRED)
GOOGLE_CLOUD_LOCATION=us-central1
# Use Vertex AI (REQUIRED)
GOOGLE_GENAI_USE_VERTEXAI=true
# Model configuration (already set)
WORKER_MODEL=gemini-2.5-flash
CRITIC_MODEL=gemini-2.5-pro
Paket adlarını ayarlayın (deploy.sh çalıştırılmadan ÖNCE ZORUNLUDUR):
Dağıtım komut dosyası, bu adlara göre paketler oluşturur. Şimdi ayarlayın:
# Staging bucket for Agent Engine code uploads (REQUIRED for agent-engine)
STAGING_BUCKET=gs://your-project-id-staging
# Artifact storage for reports and fixed code (REQUIRED for both cloud-run and agent-engine)
ARTIFACT_BUCKET=gs://your-project-id-artifacts
your-project-id yerine her iki paket adında da gerçek proje kimliğinizi yazın. Komut dosyası, bu paketler mevcut değilse bunları oluşturur.
İsteğe bağlı değişkenler (boş bırakılırsa otomatik olarak oluşturulur):
# Agent Engine ID (populated after first deployment)
AGENT_ENGINE_ID=
# Cloud Run Database credentials (created automatically if blank)
CLOUD_SQL_INSTANCE_NAME=
DB_USER=
DB_PASSWORD=
DB_NAME=
Kimlik Doğrulama Kontrolü
Dağıtım sırasında kimlik doğrulama hatalarıyla karşılaşırsanız:
gcloud auth application-default login
gcloud config set project $GOOGLE_CLOUD_PROJECT
2. adım: Dağıtım komut dosyasını anlama
deploy.sh komut dosyası, tüm dağıtım modları için birleşik bir arayüz sağlar:
./deploy.sh {local|cloud-run|agent-engine}
Komut Dosyası Özellikleri
Altyapı sağlama:
- API etkinleştirme (AI Platform, Storage, Cloud Build, Cloud Trace, Cloud SQL)
- IAM izni yapılandırması (hizmet hesapları, roller)
- Kaynak oluşturma (paketler, veritabanları, örnekler)
- Uygun işaretlerle dağıtım
- Dağıtım sonrası doğrulama
Senaryonun önemli bölümleri
- Yapılandırma (1-35. satırlar): Proje, bölge, hizmet adları, varsayılanlar
- Yardımcı işlevler (37-200. satırlar): API etkinleştirme, paket oluşturma, IAM kurulumu
- Ana Mantık (202-400. satırlar): Moda özgü dağıtım düzenlemesi
3. adım: Temsilciyi Temsilci Motoru'na hazırlayın
Agent Engine'e dağıtım yapmadan önce, yönetilen çalışma zamanı için temsilcinizi sarmalayan bir agent_engine_app.py dosyası gerekir. Bu liste sizin için zaten oluşturulmuştur.
Göster: code_review_assistant/agent_engine_app.py
👉 Dosya açma:
"""
Agent Engine application wrapper.
This file prepares the agent for deployment to Vertex AI Agent Engine.
"""
from vertexai import agent_engines
from .agent import root_agent
# Wrap the agent in an AdkApp object for Agent Engine deployment
app = agent_engines.AdkApp(
agent=root_agent,
enable_tracing=True,
)
4. adım: Agent Engine'e dağıtın
Agent Engine, ADK aracıları için önerilen üretim dağıtımıdır. Bunun nedeni, Agent Engine'in aşağıdakileri sağlamasıdır:
- Tümüyle yönetilen altyapı (oluşturulacak container yok)
VertexAiSessionServiceüzerinden yerleşik oturum kalıcılığı- Sıfırdan otomatik ölçeklendirme
- Cloud Trace entegrasyonu varsayılan olarak etkindir.
Ajan Motoru'nun Diğer Dağıtımlardan Farkı
Perde arkasında
deploy.sh agent-engine
kullanır:
adk deploy agent_engine \
--project=$GOOGLE_CLOUD_PROJECT \
--region=$GOOGLE_CLOUD_LOCATION \
--staging_bucket=$STAGING_BUCKET \
--display_name="Code Review Assistant" \
--trace_to_cloud \
code_review_assistant
Bu komut:
- Python kodunuzu doğrudan paketler (Docker derlemesi gerekmez).
.enviçinde belirttiğiniz hazırlama paketine yüklemeler- Yönetilen bir Agent Engine örneği oluşturur.
- Gözlemlenebilirlik için Cloud Trace'i etkinleştirir.
- Çalışma zamanını yapılandırmak için
agent_engine_app.pykullanılır.
Cloud Run, kodunuzu kapsülleştirirken Agent Engine, Python kodunuzu sunucusuz işlevlere benzer şekilde doğrudan yönetilen bir çalışma zamanı ortamında çalıştırır.
Dağıtımı çalıştırma
Projenizin kökünden:
./deploy.sh agent-engine
Dağıtım Aşamaları
Komut dosyasının aşağıdaki aşamaları gerçekleştirmesini izleyin:
Phase 1: API Enablement
✓ aiplatform.googleapis.com
✓ storage-api.googleapis.com
✓ cloudbuild.googleapis.com
✓ cloudtrace.googleapis.com
Phase 2: IAM Setup
✓ Getting project number
✓ Granting Storage Object Admin
✓ Granting AI Platform User
✓ Granting Cloud Trace Agent
Phase 3: Staging Bucket
✓ Creating gs://your-project-id-staging
✓ Setting permissions
Phase 4: Artifact Bucket
✓ Creating gs://your-project-id-artifacts
✓ Configuring access
Phase 5: Validation
✓ Checking agent.py exists
✓ Verifying root_agent defined
✓ Checking agent_engine_app.py exists
✓ Validating requirements.txt
Phase 6: Build & Deploy
✓ Packaging agent code
✓ Uploading to staging bucket
✓ Creating Agent Engine instance
✓ Configuring session persistence
✓ Setting up Cloud Trace integration
✓ Running health checks
Bu işlem, aracı paketleyip Vertex AI altyapısına dağıttığı için 5-10 dakika sürer.
Ajan motoru kimliğinizi kaydetme
Dağıtım başarılı olduğunda:
✅ Deployment successful!
Agent Engine ID: 7917477678498709504
Resource Name: projects/123456789/locations/us-central1/reasoningEngines/7917477678498709504
Endpoint: https://us-central1-aiplatform.googleapis.com/v1/...
⚠️ IMPORTANT: Save this in your .env file:
AGENT_ENGINE_ID=7917477678498709504
.env
dosyasını hemen:
echo "AGENT_ENGINE_ID=7917477678498709504" >> .env
Bu kimlik şu işlemler için gereklidir:
- Dağıtılan aracı test etme
- Dağıtımı daha sonra güncelleme
- Günlüklere ve izlere erişme
Neler Dağıtıldı?
Agent Engine dağıtımınız artık şunları içeriyor:
✅ Tam inceleme ardışık düzeni (4 ajan)
✅ Tam düzeltme ardışık düzeni (döngü + sentezleyici)
✅ Tüm araçlar (AST analizi, stil kontrolü, yapı oluşturma)
✅ Oturum kalıcılığı (VertexAiSessionService aracılığıyla otomatik)
✅ Durum yönetimi (oturum/kullanıcı/ömür katmanları)
✅ Gözlemlenebilirlik (Cloud Trace etkin)
✅ Otomatik ölçeklendirme altyapısı
5. adım: Dağıtılan aracınızı test edin
.env Dosyanızı Güncelleme
Dağıtımdan sonra .env öğenizin aşağıdakileri içerdiğini doğrulayın:
AGENT_ENGINE_ID=7917477678498709504 # From deployment output
GOOGLE_CLOUD_PROJECT=your-project-id
GOOGLE_CLOUD_LOCATION=us-central1
Test komut dosyasını çalıştırma
Proje, tests/test_agent_engine.py için özel olarak Agent Engine dağıtımlarını test etme özelliğini içerir:
python tests/test_agent_engine.py
Testin İşlevi
- Google Cloud projenizle kimlik doğrulaması yapar.
- Dağıtılan temsilciyle oturum oluşturur.
- Kod inceleme isteği gönderir (DFS hatası örneği)
- Server-Sent Events (SSE) aracılığıyla yanıtı geri aktarır.
- Oturumun kalıcılığını ve durum yönetimini doğrular.
Beklenen Çıkış
Authenticated with project: your-project-id
Targeting Agent Engine: projects/.../reasoningEngines/7917477678498709504
Creating new session...
Created session: 4857885913439920384
Sending query to agent and streaming response:
data: {"content": {"parts": [{"text": "I'll analyze your code..."}]}}
data: {"content": {"parts": [{"text": "**Code Structure Analysis**\n..."}]}}
data: {"content": {"parts": [{"text": "**Style Check Results**\n..."}]}}
data: {"content": {"parts": [{"text": "**Test Results**\n..."}]}}
data: {"content": {"parts": [{"text": "**Final Feedback**\n..."}]}}
Stream finished.
Doğrulama Kontrol Listesi
- ✅ Tam inceleme ardışık düzeni yürütülür (4 aracının tamamı)
- ✅ Akış yanıtı, aşamalı çıkış gösteriyor
- ✅ Oturum durumu, istekler arasında kalıcı olur.
- ✅ Kimlik doğrulama veya bağlantı hatası yok
- ✅ Araç çağrıları başarıyla yürütülür (AST analizi, stil kontrolü).
- ✅ Yapay ürünler kaydedilir (puanlama raporuna erişilebilir)
Alternatif: Cloud Run'a dağıtma
Üretim dağıtımını kolaylaştırmak için Agent Engine önerilse de Cloud Run daha fazla kontrol olanağı sunar ve ADK web kullanıcı arayüzünü destekler. Bu bölümde genel bir bakış sunulmaktadır.
Cloud Run'ı Ne Zaman Kullanmalısınız?
Aşağıdaki durumlarda Cloud Run'ı seçin:
- Kullanıcı etkileşimi için ADK web kullanıcı arayüzü
- Container ortamı üzerinde tam kontrol
- Özel veritabanı yapılandırmaları
- Mevcut Cloud Run hizmetleriyle entegrasyon
Cloud Run dağıtımı nasıl çalışır?
Perde arkasında
deploy.sh cloud-run
kullanır:
adk deploy cloud_run \
--project=$GOOGLE_CLOUD_PROJECT \
--region=$GOOGLE_CLOUD_LOCATION \
--service_name="code-review-assistant" \
--app_name="code_review_assistant" \
--port=8080 \
--with_ui \
--artifact_service_uri="gs://$ARTIFACT_BUCKET" \
--trace_to_cloud \
code_review_assistant
Bu komut:
- Aracı kodunuzu içeren bir Docker container'ı oluşturur.
- Google Artifact Registry'ye göndermeler
- Cloud Run hizmeti olarak dağıtılır.
- ADK web kullanıcı arayüzünü içerir (
--with_ui) - Cloud SQL bağlantısını yapılandırır (ilk dağıtımdan sonra komut dosyası tarafından eklenir).
Agent Engine'den temel farkı: Cloud Run, kodunuzu kapsar ve oturum kalıcılığı için veritabanı gerektirirken Agent Engine her ikisini de otomatik olarak işler.
Cloud Run dağıtım komutu
./deploy.sh cloud-run
Farklılıklar
Altyapı:
- Container'a alınmış dağıtım (Docker, ADK tarafından otomatik olarak oluşturulur)
- Oturum kalıcılığı için Cloud SQL (PostgreSQL)
- Veritabanı, komut dosyası tarafından otomatik olarak oluşturulur veya mevcut örneği kullanır.
Oturum Yönetimi:
VertexAiSessionServiceyerineDatabaseSessionServicekullanılıyor..enviçinde veritabanı kimlik bilgileri (veya otomatik olarak oluşturulmuş kimlik bilgileri) gerekir.- Durum, PostgreSQL veritabanında kalıcı olur.
Kullanıcı arayüzü desteği:
- Web kullanıcı arayüzü,
--with_uiflag'i aracılığıyla kullanılabilir (komut dosyası tarafından işlenir). - Erişim tarihi:
https://code-review-assistant-xyz.a.run.app
Başarılarınız
Üretim dağıtımınızda şunlar bulunur:
✅ deploy.sh komut dosyası
aracılığıyla otomatik hazırlama ✅ Yönetilen altyapı (Agent Engine, ölçeklendirme, kalıcılık ve izleme işlemlerini gerçekleştirir)
✅ Tüm bellek katmanlarında (oturum/kullanıcı/ömür) kalıcı durum
✅ Güvenli kimlik bilgisi yönetimi (otomatik oluşturma ve IAM kurulumu)
✅ Ölçeklenebilir mimari (sıfırdan binlerce eşzamanlı kullanıcıya)
✅ Yerleşik gözlemlenebilirlik (Cloud Trace entegrasyonu etkin)
✅ Üretim düzeyinde hata işleme ve kurtarma
Uzmanlaşılan Temel Kavramlar
Dağıtıma Hazırlık:
agent_engine_app.py: Agent Engine içinAdkAppile aracı sarmalar.AdkApp,VertexAiSessionServiceiçin kalıcılığı otomatik olarak yapılandırır.enable_tracing=Trueüzerinden izleme etkinleştirildi
Dağıtım Komutları:
adk deploy agent_engine: Python kodunu paketler, kapsayıcı içermezadk deploy cloud_run: Docker container'ı otomatik olarak oluşturur.gcloud run deploy: Özel Dockerfile ile alternatif
Dağıtım Seçenekleri:
- Agent Engine: Tamamen yönetilen, en hızlı üretime geçiş
- Cloud Run: Daha fazla kontrol, web kullanıcı arayüzünü destekler
- GKE: Gelişmiş Kubernetes kontrolü (GKE dağıtım kılavuzuna bakın)
Yönetilen Hizmetler:
- Agent Engine, oturum kalıcılığını otomatik olarak yönetir.
- Cloud Run için veritabanı kurulumu (veya otomatik oluşturma) gerekir.
- Her ikisi de GCS üzerinden yapı depolamayı destekler.
Oturum Yönetimi:
- Agent Engine:
VertexAiSessionService(otomatik) - Cloud Run:
DatabaseSessionService(Cloud SQL) - Yerel:
InMemorySessionService(geçici)
Ajanınız Etkin
Kod inceleme yardımcınız artık:
- HTTPS API uç noktaları üzerinden erişilebilir
- Yeniden başlatma işlemlerinden sonra durumun korunması için Persistent olmalıdır.
- Ekip büyümesini otomatik olarak yönetmek için ölçeklenebilir
- İsteğin izlerinin tamamı gözlemlenebilir
- Komut dosyası oluşturulmuş dağıtımlar aracılığıyla bakımı yapılabilir
Sırada ne var? 8. modülde, aracı performansınızı anlamak, inceleme ve düzeltme işlem hatlarındaki darboğazları belirlemek ve yürütme sürelerini optimize etmek için Cloud Trace'i kullanmayı öğreneceksiniz.
8. Üretim Gözlemlenebilirliği
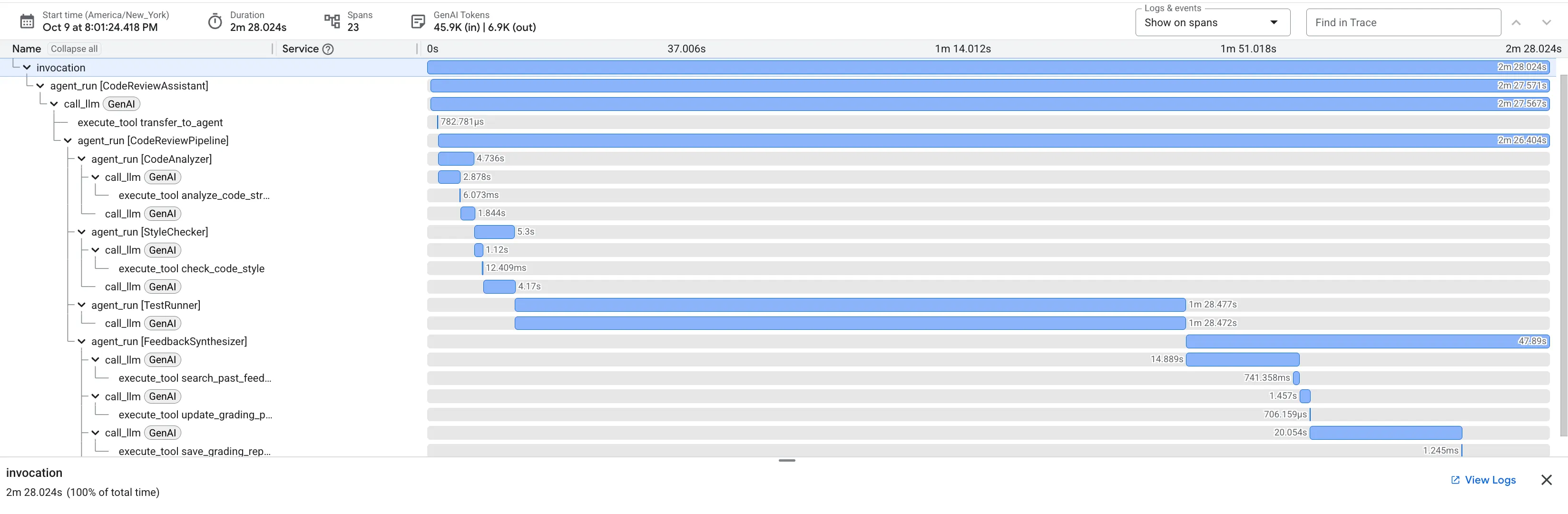
Giriş
Kod inceleme asistanınız artık Agent Engine'de üretimde dağıtılıyor ve çalışıyor. Peki, bu stratejinin iyi sonuç verdiğini nasıl anlarsınız? Aşağıdaki önemli soruları yanıtlayabilir misiniz?
- Aracı yeterince hızlı yanıt veriyor mu?
- En yavaş işlemler hangileri?
- Düzeltme döngüleri verimli bir şekilde tamamlanıyor mu?
- Performans sorunları nerede?
Gözlemlenebilirlik olmadan körü körüne hareket edersiniz. Dağıtım sırasında kullandığınız --trace-to-cloud işareti, Cloud Trace'i otomatik olarak etkinleştirerek aracınızın işlediği her istekle ilgili tam görünürlük sağlar. Bu sayede hata ayıklama, tahminden adli analize dönüşür.
Bu modülde, izlemeleri okumayı, aracınızın performans özelliklerini anlamayı ve kesin kanıtlara dayanarak optimizasyon alanlarını belirlemeyi öğreneceksiniz.
İzler ve Kapsamlar
İz nedir?
İzleme, aracınızın tek bir isteği işlediği zaman çizelgesinin tamamıdır. Kullanıcının sorgu göndermesinden nihai yanıtın teslim edilmesine kadar her şeyi yakalar. Her izlemede şunlar gösterilir:
- İsteğin toplam süresi
- Yürütülen tüm işlemler
- İşlemlerin birbirleriyle ilişkisi (üst-alt ilişkileri)
- Her işlemin başladığı ve bittiği zaman
Span nedir?
Aralık, izleme içindeki tek bir iş birimini temsil eder. Kod inceleme asistanınızdaki yaygın aralık türleri:
agent_run: Bir ajanın (kök ajan veya alt ajan) yürütülmesicall_llm: Dil modeline istekexecute_tool: Araç işlevinin yürütülmesistate_read/state_write: Durum yönetimi işlemlericode_executor: Testlerle kod çalıştırma
Aralıklar:
- Ad: Bu işlemin neyi temsil ettiği
- Süre: Ne kadar sürdüğü
- Özellikler: Model adı, jeton sayısı, girişler/çıkışlar gibi meta veriler
- Durum: Başarılı veya başarısız
- Üst/alt ilişkileri: Hangi işlemler hangilerini tetikledi?
Otomatik Araç Oluşturma
--trace-to-cloud ile dağıtım yaptığınızda ADK otomatik olarak şunları izler:
- Her aracı çağırma ve alt aracı çağrısı
- Jeton sayılarıyla birlikte tüm LLM istekleri
- Giriş/çıkış içeren araç yürütmeleri
- Durum işlemleri (okuma/yazma)
- Düzeltme ardışık düzeninizdeki döngü yinelemeleri
- Hata koşulları ve yeniden denemeler
Kod değişikliği gerekmez: İzleme, ADK'nın çalışma zamanına yerleştirilmiştir.
1. adım: Cloud Trace Explorer'a erişin
Google Cloud Console'unuzda Cloud Trace'i açın:
- Cloud Trace Gezgini'ne gidin.
- Açılır listeden projenizi seçin (önceden seçilmiş olmalıdır).
- 7. modülde testinizden gelen izleri görmeniz gerekir.
Henüz iz görmüyorsanız:
7. modülde çalıştırdığınız test izler oluşturmuş olmalıdır. Liste boşsa bazı izleme verileri oluşturun:
python tests/test_agent_engine.py
İzlerin konsolda görünmesi için 1-2 dakika bekleyin.
Ne Görüntülüyorsunuz?
Trace Explorer'da şunlar gösterilir:
- İzleme listesi: Her satır, tam bir isteği temsil eder.
- Zaman Çizelgesi: İsteklerin gerçekleştiği zaman
- Süre: Her isteğin ne kadar sürdüğü
- İstek ayrıntıları: Zaman damgası, gecikme, kapsam sayısı
Bu, üretim trafiği günlüğünüzdür. Temsilcinizle her etkileşimde bir izleme oluşturulur.
2. adım: İnceleme işlem hattı izini inceleyin
Şelale görünümünü açmak için listedeki herhangi bir izi tıklayın.
Tam uygulama zaman çizelgesini gösteren bir Gantt şeması görürsünüz. Kök invocation aralığı, isteğin tamamını temsil eder. Her alt aracı, araç ve LLM çağrısı için aralıklar bu aralığın altında yer alır.
Şelaleyi Okuma: Darboğazları Belirleme
Her çubuk bir aralığı temsil eder. Yatay konumu, ne zaman başladığını, uzunluğu ise ne kadar sürdüğünü gösterir. Bu sayede, temsilcinizin zamanını nerede geçirdiğini hemen öğrenebilirsiniz.
Yukarıdaki izlemeden elde edilen önemli analizler:
- Toplam gecikme: İsteğin tamamı 2 dakika 28 saniye sürdü.
- Alt acente dökümü:
Code Analyzer: 4,7 saniyeStyle Checker: 5,3 saniyeTest Runner: 1 dakika 28 saniyeFeedback Synthesizer: 47,9 saniye
- Kritik Yol Analizi:
Test Runneraracısı, toplam istek süresinin yaklaşık% 59'unu oluşturarak açık bir performans darboğazı oluşturuyor.
Bu görünürlük güçlü bir etki yaratır. Zamanın nerede harcandığını tahmin etmek yerine, gecikme için optimizasyon yapmanız gerekiyorsa Test Runner'nın açık hedef olduğunu gösteren somut kanıtlarınız olur.
Maliyet optimizasyonu için jeton kullanımını inceleme
Cloud Trace yalnızca süreyi göstermekle kalmaz, aynı zamanda her büyük dil modeli çağrısı için jeton kullanımını yakalayarak maliyetleri de ortaya çıkarır.
Bir
call_llm
İz içindeki aralık. Ayrıntılar bölmesinde llm.usage.prompt_tokens ve llm.usage.completion_tokens özelliklerini bulabilirsiniz.

Bu size şu imkanları tanır:
- Maliyetleri ayrıntılı düzeyde takip edin: Her bir aracının ve aracın tam olarak kaç jeton kullandığını görün.
- Optimizasyon fırsatlarını belirleme: Bir aracı şaşırtıcı derecede yüksek sayıda jeton kullanıyorsa istemini iyileştirme veya söz konusu görev için daha küçük ve daha uygun maliyetli bir modele geçme fırsatı olabilir.
3. adım: Düzeltme ardışık düzen izlemesini analiz edin
Düzeltme işlem hattı, LoopAgent içerdiğinden daha karmaşıktır. Cloud Trace, bu yinelemeli davranışı anlamayı kolaylaştırır.
Aralık adlarında "FixAttemptLoop" ifadesini içeren bir izleme bulun.
Yoksa test komut dosyasını çalıştırın ve kodu düzeltmek isteyip istemediğiniz sorulduğunda olumlu yanıt verin.
Döngü Yapısını İnceleme
İzleme görünümü, döngünün yürütülmesini net bir şekilde görselleştirir. Düzeltme döngüsü başarılı olmadan önce iki kez çalıştıysa loop_iteration aralığının altında iç içe yerleştirilmiş iki FixAttemptLoop aralığı görürsünüz. Bu aralıkların her birinde CodeFixer, FixTestRunner ve FixValidator aracıları tam bir döngü halinde yer alır.

Loop İzleme'den Elde Edilen Önemli Gözlemler:
- Tekrarlı İyileştirme Görünür: Sistem,
loop_iteration: 1içinde düzeltme yapmaya çalışır, bunu doğrular ve mükemmel olmadığı içinloop_iteration: 2içinde tekrar dener. - Yakınsama Ölçülebilir: Sistemin doğru bir çözüme nasıl yakınsadığını anlamak için her yinelemenin süresini ve sonuçlarını karşılaştırabilirsiniz.
- Hata ayıklama basitleştirildi: Bir döngü maksimum yineleme sayısı boyunca çalışmasına rağmen başarısız olursa düzeltmelerin neden birleşmediğini teşhis etmek için her yinelemenin kapsamındaki durumu ve aracı davranışını inceleyebilirsiniz.
Bu ayrıntı düzeyi, üretimdeki karmaşık ve durum bilgisi içeren döngülerin davranışını anlamak ve hatalarını ayıklamak için çok değerlidir.
4. adım: Keşfettikleriniz
Performans Kalıpları
İzleri inceleyerek artık veriye dayalı analizlere sahipsiniz:
İnceleme ardışık düzeni:
- Birincil performans sorunu:
Test Runneraracı, özellikle kod yürütme ve LLM tabanlı test üretimi, incelemenin en çok zaman alan kısmıdır. - Hızlı işlemler: Belirleyici araçlar (
analyze_code_structure) ve durum yönetimi işlemleri son derece hızlıdır ve performans açısından sorun teşkil etmez.
Ardışık düzeni düzeltme:
- Yakınsama oranı: Çoğu düzeltmenin 1-2 yinelemede tamamlandığını görebilirsiniz. Bu da döngü mimarisinin etkili olduğunu doğrular.
- Aşamalı Maliyet: Önceki başarısız denemelerden gelen bilgilerle LLM bağlamı büyüdükçe sonraki yinelemeler daha uzun sürebilir.
Maliyet faktörleri:
- Jeton Tüketimi: En çok jeton gerektiren aracıları (ör. sentezleyiciler) belirleyebilir ve bu görev için daha güçlü ancak daha pahalı bir model kullanmanın uygun olup olmadığına karar verebilirsiniz.
Sorunları Nerede Bulabilirsiniz?
Üretimde izlemeleri incelerken şunlara dikkat edin:
- Alışılmadık derecede uzun izler: Performansta gerileme veya beklenmedik bir döngü davranışının işareti.
- Başarısız olan kapsamlar (kırmızı renkle işaretlenir): Başarısız olan işlemi tam olarak gösterir.
- Aşırı döngü yinelemeleri (>2): Düzeltme oluşturma mantığıyla ilgili bir sorun olabilir.
- Yüksek jeton sayısı: İstem optimizasyonu veya model seçimi değişiklikleri için fırsatları vurgular.
Öğrendikleriniz
Cloud Trace ile artık şunları nasıl yapacağınızı biliyorsunuz:
✅ İstek akışını görselleştirme: Sıralı ve döngü tabanlı işlem hatlarınızdaki tam yürütme yolunu görün.
✅ Performans sorunlarını tespit etme: En yavaş işlemleri kesin verilerle bulmak için şelale grafiğini kullanın.
✅ Döngü davranışını analiz etme: Yinelemeli aracıların birden fazla denemede bir çözüm üzerinde nasıl birleştiğini gözlemleyin.
✅ Jeton maliyetlerini izleme: Jeton tüketimini ayrıntılı düzeyde izlemek ve optimize etmek için LLM aralıklarını inceleyin.
Uzmanlaşılan Temel Kavramlar
- İzler ve Kapsamlar: Gözlemlenebilirliğin temel birimleri olup istekleri ve bu isteklerdeki işlemleri temsil eder.
- Aşamalı analiz: Yürütme süresini ve bağımlılıkları anlamak için Gantt grafikleri okuma.
- Kritik Yol Tanımlama: Genel gecikmeyi belirleyen işlem sırasını bulma.
- Ayrıntılı Gözlemlenebilirlik: ADK tarafından otomatik olarak uygulanan her işlem için yalnızca zamana değil, aynı zamanda jeton sayısı gibi meta verilere de görünürlük sağlar.
Sonraki Adımlar
Cloud Trace'i keşfetmeye devam edin:
- Sorunları erkenden tespit etmek için izleri düzenli olarak izleyin
- Performans gerilemelerini belirlemek için izleri karşılaştırma
- Optimizasyon kararlarını bilgilendirmek için izleme verilerini kullanma
- Yavaş istekleri bulmak için süreye göre filtreleme
Gelişmiş gözlemlenebilirlik (isteğe bağlı):
- Karmaşık analiz için izlemeleri BigQuery'ye aktarma (dokümanlar)
- Cloud Monitoring'de özel kontrol panelleri oluşturma
- Performans düşüşü için uyarılar ayarlama
- İzlemeleri uygulama günlükleriyle ilişkilendirme
9. Sonuç: Prototipten Üretime
Oluşturduklarınız
Yalnızca yedi satırlık kodla başladınız ve üretim düzeyinde bir yapay zeka ajanı sistemi oluşturdunuz:
# Where we started (7 lines)
agent = Agent(
model="gemini-2.5-flash",
instruction="Review Python code for issues"
)
# Where we ended (production system)
- Two distinct multi-agent pipelines (review and fix) built from 8 specialized agents.
- An iterative fix loop architecture for automated validation and retries.
- Real AST-based code analysis tools for deterministic, accurate feedback.
- Robust state management using the "constants pattern" for type-safe communication.
- Fully automated deployment to a managed, scalable cloud infrastructure.
- Complete, built-in observability with Cloud Trace for production monitoring.
Ustalaşılan Temel Mimari Kalıplar
Kalıp | Uygulama | Üretim üzerindeki etki |
Araç Entegrasyonu | AST analizi, stil kontrolü | Yalnızca LLM görüşleri değil, gerçek doğrulama |
Sıralı Ardışık Düzenler | İnceleme → İş akışlarını düzeltme | Öngörülebilir ve hata ayıklanabilir yürütme |
Loop mimarisi | Çıkış koşullarıyla yinelemeli düzeltme | Başarıya ulaşana kadar kendini geliştirme |
Durum Yönetimi | Sabitler kalıbı, üç katmanlı bellek | Tür güvenli, sürdürülebilir durum yönetimi |
Üretim Dağıtımı | deploy.sh aracılığıyla Agent Engine | Yönetilen, ölçeklenebilir altyapı |
Gözlemlenebilirlik | Cloud Trace entegrasyonu | Üretim davranışına dair tam görünürlük |
İzlerden elde edilen üretim analizleri
Cloud Trace verileriniz önemli bilgiler ortaya çıkardı:
✅ Performans sorunu belirlendi: TestRunner'ın LLM çağrıları gecikmeye neden oluyor.
✅ Araç performansı: AST analizi 100 ms'de yürütülüyor (mükemmel).
✅ Başarı oranı: Düzeltme döngüleri 2-3 yinelemede tamamlanıyor.
✅ Jeton kullanımı: İnceleme başına ~600 jeton, düzeltmeler için ~1.800 jeton
Bu analizler sürekli iyileştirme yapılmasını sağlar.
Kaynakları Temizleme (İsteğe Bağlı)
Denemeyi tamamladıysanız ve ödeme alınmasını önlemek istiyorsanız:
Agent Engine dağıtımını silme:
import vertexai
client = vertexai.Client( # For service interactions via client.agent_engines
project="PROJECT_ID",
location="LOCATION",
)
RESOURCE_NAME = "projects/{PROJECT_ID}/locations/{LOCATION}/reasoningEngines/{RESOURCE_ID}"
client.agent_engines.delete(
name=RESOURCE_NAME,
force=True, # Optional, if the agent has resources (e.g. sessions, memory)
)
Cloud Run hizmetini silin (oluşturulduysa):
gcloud run services delete code-review-assistant \
--region=$GOOGLE_CLOUD_LOCATION \
--quiet
Cloud SQL örneğini silin (oluşturulduysa):
gcloud sql instances delete your-project-db \
--quiet
Depolama alanı gruplarını temizleme:
gsutil -m rm -r gs://your-project-staging
gsutil -m rm -r gs://your-project-artifacts
Sonraki Adımlar
Temel bilgileri edindikten sonra aşağıdaki geliştirmeleri yapabilirsiniz:
- Başka diller ekleme: Araçları JavaScript, Go ve Java'yı destekleyecek şekilde genişletme
- GitHub ile entegrasyon: Otomatik PR incelemeleri
- Önbelleğe alma işlemini uygulama: Sık kullanılan kalıplarda gecikmeyi azaltma
- Özel aracılar ekleme: Güvenlik taraması, performans analizi
- A/B testini etkinleştirme: Farklı modelleri ve istemleri karşılaştırma
- Metrikleri dışa aktarma: İzlemeleri özel gözlemlenebilirlik platformlarına gönderme
Temel çıkarımlar
- Basit başlayın, hızlı yineleyin: Yönetilebilir adımlarla yedi satırda üretime geçiş
- İstemler yerine araçlar: Gerçek AST analizi, "Lütfen hataları kontrol edin" isteminden daha iyidir.
- Durum yönetimi önemlidir: Sabitler kalıbı, yazım hatası kaynaklı hataları önler.
- Döngüler için çıkış koşulları gerekir: Maksimum yineleme ve artırma her zaman ayarlanmalıdır.
- Otomasyonla dağıtma: deploy.sh tüm karmaşıklığı yönetir.
- Gözlemlenebilirlik olmazsa olmazdır: Ölçemediğiniz şeyi geliştiremezsiniz.
Sürekli öğrenme kaynakları
- ADK Dokümanları
- Gelişmiş ADK Kalıpları
- Agent Engine Kılavuzu
- Cloud Run belgeleri
- Cloud Trace Belgeleri
Yolculuğunuz Devam Ediyor
Yalnızca bir kod inceleme asistanı oluşturmadınız. Üretim yapay zeka aracısı oluşturma kalıplarında uzmanlaştınız:
✅ Birden fazla uzmanlaşmış aracı içeren karmaşık iş akışları
✅ Gerçek yetenekler için gerçek araç entegrasyonu
✅ Uygun gözlemlenebilirlik ile üretim dağıtımı
✅ Sürdürülebilir sistemler için durum yönetimi
Bu kalıplar, basit asistanlardan karmaşık otonom sistemlere kadar ölçeklenebilir. Burada oluşturduğunuz temel, giderek daha karmaşık hale gelen aracı mimarileriyle uğraşırken size yardımcı olacaktır.
Üretim için yapay zeka aracısı geliştirmeye hoş geldiniz. Kod inceleme asistanınız sadece başlangıç.