
1. The Late Night Code Review
Bây giờ là 2 giờ sáng
Bạn đã gỡ lỗi trong nhiều giờ. Hàm có vẻ đúng, nhưng đã xảy ra lỗi. Bạn biết cảm giác đó – khi mã phải hoạt động nhưng không hoạt động, và bạn không thể biết lý do nữa vì bạn đã nhìn vào mã đó quá lâu.
def dfs_search_v1(graph, start, target):
"""Find if target is reachable from start."""
visited = set()
stack = start # Looks innocent enough...
while stack:
current = stack.pop()
if current == target:
return True
if current not in visited:
visited.add(current)
for neighbor in graph[current]:
if neighbor not in visited:
stack.append(neighbor)
return False
Hành trình của nhà phát triển AI
Nếu đang đọc bài viết này, có thể bạn đã trải nghiệm sự chuyển đổi mà AI mang lại cho hoạt động lập trình. Những công cụ như Gemini Code Assist, Claude Code và Cursor đã thay đổi cách chúng ta viết mã. Chúng rất hữu ích trong việc tạo mẫu, đề xuất cách triển khai và đẩy nhanh quá trình phát triển.
Nhưng bạn đang ở đây vì bạn muốn tìm hiểu sâu hơn. Bạn muốn tìm hiểu cách xây dựng các hệ thống AI này, chứ không chỉ sử dụng chúng. Bạn muốn tạo nội dung:
- Có hành vi có thể dự đoán và theo dõi
- Có thể triển khai cho quy trình phát hành công khai một cách tự tin
- Cung cấp kết quả nhất quán mà bạn có thể tin tưởng
- Cho bạn biết chính xác cách AI đưa ra quyết định
Từ người tiêu dùng đến nhà sáng tạo
Hôm nay, bạn sẽ chuyển từ việc sử dụng các công cụ AI sang xây dựng các công cụ này. Bạn sẽ xây dựng một hệ thống nhiều tác nhân có các đặc điểm sau:
- Phân tích cấu trúc mã một cách xác định
- Thực hiện các kiểm thử thực tế để xác minh hành vi
- Xác thực việc tuân thủ kiểu bằng các trình kiểm tra thực
- Tổng hợp kết quả thành thông tin phản hồi hữu ích
- Triển khai lên Google Cloud với khả năng quan sát đầy đủ
2. Triển khai nhân viên hỗ trợ đầu tiên
Câu hỏi của nhà phát triển
"Tôi hiểu về LLM, tôi đã sử dụng các API, nhưng làm cách nào để chuyển từ một tập lệnh Python sang một tác nhân AI có thể mở rộng trong môi trường sản xuất?"
Hãy trả lời câu hỏi này bằng cách thiết lập môi trường đúng cách, sau đó xây dựng một tác nhân đơn giản để hiểu những điều cơ bản trước khi đi sâu vào các mẫu sản xuất.
Thiết lập những thông tin thiết yếu trước
Trước khi tạo bất kỳ tác nhân nào, hãy đảm bảo môi trường Google Cloud của bạn đã sẵn sàng.
Nhấp vào Kích hoạt Cloud Shell ở đầu Cloud Console (Đây là biểu tượng có hình dạng thiết bị đầu cuối ở đầu ngăn Cloud Shell),
Tìm mã dự án trên Google Cloud:
- Mở Google Cloud Console: https://console.cloud.google.com
- Chọn dự án mà bạn muốn sử dụng cho hội thảo này trong trình đơn thả xuống dự án ở đầu trang.
- Mã dự án của bạn sẽ xuất hiện trong thẻ Thông tin dự án trên Trang tổng quan
Bước 1: Đặt mã dự án
Trong Cloud Shell, công cụ dòng lệnh gcloud đã được định cấu hình. Chạy lệnh sau để đặt dự án đang hoạt động. Lệnh này sử dụng biến môi trường $GOOGLE_CLOUD_PROJECT. Biến này sẽ tự động được thiết lập cho bạn trong phiên Cloud Shell.
gcloud config set project $GOOGLE_CLOUD_PROJECT
Bước 2: Xác minh chế độ thiết lập
Tiếp theo, hãy chạy các lệnh sau để xác nhận rằng dự án của bạn được thiết lập chính xác và bạn đã được xác thực.
# Confirm project is set
echo "Current project: $(gcloud config get-value project)"
# Check authentication status
gcloud auth list
Bạn sẽ thấy mã dự án được in và tài khoản người dùng của bạn xuất hiện cùng với biểu tượng (ACTIVE) bên cạnh.
Nếu tài khoản của bạn không được liệt kê là đang hoạt động hoặc nếu bạn gặp lỗi xác thực, hãy chạy lệnh sau để đăng nhập:
gcloud auth application-default login
Bước 3: Bật các API cần thiết
Chúng ta cần ít nhất những API sau cho nhân viên hỗ trợ cơ bản:
gcloud services enable \
aiplatform.googleapis.com \
compute.googleapis.com
Quá trình này có thể mất một hoặc hai phút. Bạn sẽ thấy:
Operation "operations/..." finished successfully.
Bước 4: Cài đặt ADK
# Install the ADK CLI
pip install google-adk --upgrade
# Verify installation
adk --version
Bạn sẽ thấy một số phiên bản như 1.15.0 trở lên.
Bây giờ, hãy tạo tác nhân cơ bản
Khi môi trường đã sẵn sàng, hãy tạo tác nhân đơn giản đó.
Bước 5: Sử dụng ADK Create
adk create my_first_agent
Làm theo lời nhắc tương tác:
Choose a model for the root agent:
1. gemini-2.5-flash
2. Other models (fill later)
Choose model (1, 2): 1
1. Google AI
2. Vertex AI
Choose a backend (1, 2): 2
Enter Google Cloud project ID [auto-detected-from-gcloud]:
Enter Google Cloud region [us-central1]:
Bước 6: Xem xét những gì đã được tạo
cd my_first_agent
ls -la
Bạn sẽ thấy 3 tệp:
.env # Configuration (auto-populated with your project)
__init__.py # Package marker
agent.py # Your agent definition
Bước 7: Kiểm tra nhanh cấu hình
# Verify the .env was created correctly
cat .env
# Should show something like:
# GOOGLE_CLOUD_PROJECT=your-project-id
# GOOGLE_CLOUD_LOCATION=us-central1
# GOOGLE_GENAI_USE_VERTEXAI=1
Nếu mã dự án bị thiếu hoặc không chính xác, hãy chỉnh sửa tệp .env:
nano .env # or use your preferred editor
Bước 8: Xem Mã đại lý
cat agent.py
from google.adk.agents.llm_agent import Agent
root_agent = Agent(
model='gemini-2.5-flash',
name='root_agent',
description='A helpful assistant for user questions.',
instruction='Answer user questions to the best of your knowledge',
)
Đơn giản, gọn gàng, tối giản. Đây là "Hello World" (Xin chào) của các tác nhân.
Kiểm thử nhân viên hỗ trợ cơ bản
Bước 9: Chạy tác nhân
cd ..
adk run my_first_agent
Bạn sẽ thấy một số dòng mã như:
Log setup complete: /tmp/agents_log/agent.20250930_162430.log
To access latest log: tail -F /tmp/agents_log/agent.latest.log
[user]:
Bước 10: Thử một số cụm từ tìm kiếm
Trong thiết bị đầu cuối đang chạy adk run, bạn sẽ thấy một lời nhắc. Nhập câu hỏi của bạn:
[user]: Hey, what can you do?
[root_agent]: I can help answer questions, generate text, explain concepts, assist with problem-solving, and provide information on a wide range of topics. What would you like to know or discuss?
[user]: What's the current weather in Mountain View?
[root_agent]: I'm sorry, but I cannot provide real-time weather information as I don't have access to current data or weather services. To get the current weather in Mountain View, I recommend checking a weather website or app like weather.com or using a search engine.
Lưu ý về hạn chế: không thể truy cập vào dữ liệu hiện tại. Hãy tìm hiểu thêm:
[user]: Review this Python code: def add(a, b): return a + b
[root_agent]: This is a simple Python function that adds two numbers. Here's my review:
**Strengths:**
- Clean and concise implementation
- Follows Python conventions for simple operations
- Clear function name that describes its purpose
**Suggestions for improvement:**
- Add a docstring to document the function
- Consider adding type hints for better code clarity
- You might want to handle edge cases
Here's an enhanced version:
def add(a: float, b: float) -> float:
"""Add two numbers and return their sum."""
return a + b
Tác nhân có thể thảo luận về mã, nhưng liệu tác nhân có thể:
- Có thực sự cần phân tích cú pháp AST để hiểu cấu trúc không?
- Chạy kiểm thử để xác minh xem có hoạt động không?
- Bạn có muốn kiểm tra tính tuân thủ về kiểu chữ không?
- Bạn có nhớ các bài đánh giá trước đây của mình không?
Không. Đây là lúc chúng ta cần cấu trúc.
🏃🚪 Thoát bằng
Ctrl+C
khi bạn khám phá xong.
3. Chuẩn bị không gian làm việc sản xuất
Giải pháp: Một cấu trúc sẵn sàng cho hoạt động sản xuất
Tác nhân đơn giản đó minh hoạ điểm xuất phát, nhưng một hệ thống sản xuất đòi hỏi phải có cấu trúc mạnh mẽ. Bây giờ, chúng ta sẽ thiết lập một dự án hoàn chỉnh thể hiện các nguyên tắc sản xuất.
Thiết lập nền tảng
Bạn đã định cấu hình dự án trên Google Cloud cho tác nhân cơ bản. Giờ thì hãy chuẩn bị không gian làm việc sản xuất đầy đủ với tất cả các công cụ, mẫu và cơ sở hạ tầng cần thiết cho một hệ thống thực.
Bước 1: Lấy dự án có cấu trúc
Trước tiên, hãy thoát mọi adk run đang chạy bằng Ctrl+C và dọn dẹp:
# Clean up the basic agent
cd ~ # Make sure you're not inside my_first_agent
rm -rf my_first_agent
# Get the production scaffold
git clone https://github.com/ayoisio/adk-code-review-assistant.git
cd adk-code-review-assistant
git checkout codelab
Bước 2: Tạo và kích hoạt môi trường ảo
# Create the virtual environment
python -m venv .venv
# Activate it
# On macOS/Linux:
source .venv/bin/activate
# On Windows:
# .venv\Scripts\activate
Xác minh: Giờ đây, câu lệnh của bạn sẽ có (.venv) ở đầu.
Bước 3: Cài đặt các phần phụ thuộc
pip install -r code_review_assistant/requirements.txt
# Install the package in editable mode (enables imports)
pip install -e .
Thao tác này sẽ cài đặt:
google-adk– Khung ADKpycodestyle– Để kiểm tra PEP 8vertexai– Để triển khai trên đám mây- Các phần phụ thuộc khác của quy trình sản xuất
Cờ -e cho phép bạn nhập các mô-đun code_review_assistant từ mọi nơi.
Bước 4: Định cấu hình môi trường
# Copy the example environment file
cp .env.example .env
# Edit .env and replace the placeholders:
# - GOOGLE_CLOUD_PROJECT=your-project-id → your actual project ID
# - Keep other defaults as-is
Xác minh: Kiểm tra cấu hình của bạn:
cat .env
Nên hiển thị:
GOOGLE_CLOUD_PROJECT=your-actual-project-id
GOOGLE_CLOUD_LOCATION=us-central1
GOOGLE_GENAI_USE_VERTEXAI=TRUE
Bước 5: Đảm bảo xác thực
Vì bạn đã chạy gcloud auth trước đó, nên hãy xác minh:
# Check current authentication
gcloud auth list
# Should show your account with (ACTIVE)
# If not, run:
gcloud auth application-default login
Bước 6: Bật các API bổ sung cho hoạt động sản xuất
Chúng tôi đã bật các API cơ bản. Bây giờ, hãy thêm các sản phẩm thực tế:
gcloud services enable \
sqladmin.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
storage.googleapis.com \
cloudtrace.googleapis.com
Điều này cho phép:
- Quản trị viên SQL: Đối với Cloud SQL nếu sử dụng Cloud Run
- Cloud Run: Để triển khai không cần máy chủ
- Cloud Build: Để triển khai tự động
- Artifact Registry: Đối với hình ảnh vùng chứa
- Cloud Storage: Dành cho các cấu phần phần mềm và giai đoạn dàn dựng
- Cloud Trace: Để có khả năng quan sát
Bước 7: Tạo kho lưu trữ Artifact Registry
Quy trình triển khai của chúng tôi sẽ tạo các hình ảnh vùng chứa cần có một vị trí:
gcloud artifacts repositories create code-review-assistant-repo \
--repository-format=docker \
--location=us-central1 \
--description="Docker repository for Code Review Assistant"
Bạn sẽ thấy:
Created repository [code-review-assistant-repo].
Nếu tệp này đã tồn tại (có thể là do một lần thử trước đó), thì không sao cả – bạn sẽ thấy một thông báo lỗi mà bạn có thể bỏ qua.
Bước 8: Cấp quyền IAM
# Get your project number
PROJECT_NUMBER=$(gcloud projects describe $GOOGLE_CLOUD_PROJECT \
--format="value(projectNumber)")
# Define the service account
SERVICE_ACCOUNT="${PROJECT_NUMBER}@cloudbuild.gserviceaccount.com"
# Grant necessary roles
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SERVICE_ACCOUNT}" \
--role="roles/run.admin"
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SERVICE_ACCOUNT}" \
--role="roles/iam.serviceAccountUser"
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SERVICE_ACCOUNT}" \
--role="roles/cloudsql.admin"
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member="serviceAccount:${SERVICE_ACCOUNT}" \
--role="roles/storage.admin"
Mỗi lệnh sẽ xuất ra:
Updated IAM policy for project [your-project-id].
Những thành tựu bạn đạt được
Không gian làm việc phát hành công khai của bạn hiện đã được chuẩn bị đầy đủ:
✅ Dự án trên đám mây của Google đã được định cấu hình và xác thực
✅ Đã kiểm thử tác nhân cơ bản để hiểu rõ các hạn chế
✅ Mã dự án có các phần giữ chỗ chiến lược đã sẵn sàng
✅ Các phần phụ thuộc được tách biệt trong môi trường ảo
✅ Đã bật tất cả API cần thiết
✅ Container Registry đã sẵn sàng cho việc triển khai
✅ Đã định cấu hình đúng các quyền IAM
✅ Đã đặt đúng các biến môi trường
Bây giờ, bạn có thể xây dựng một hệ thống AI thực sự bằng các công cụ xác định, tính năng quản lý trạng thái và cấu trúc phù hợp.
4. Xây dựng tác nhân đầu tiên
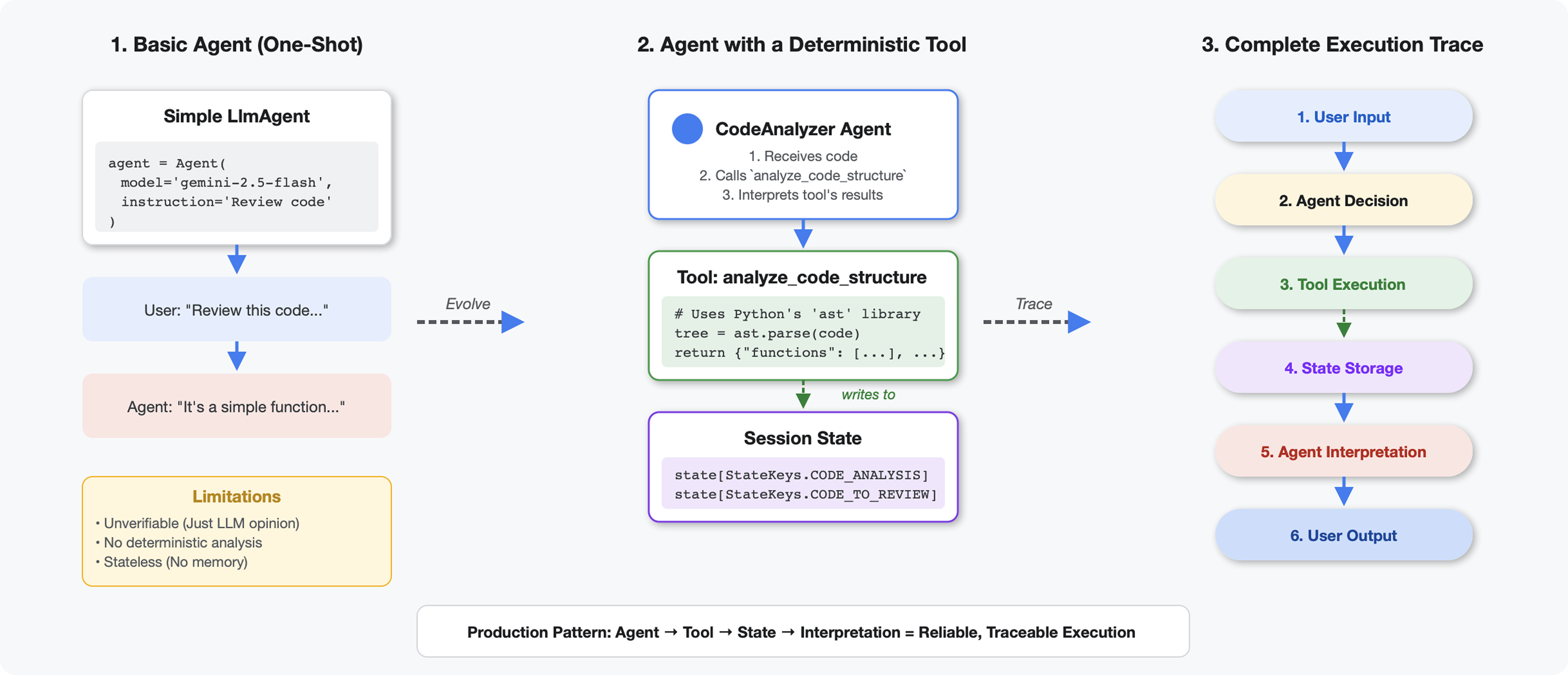
Điểm khác biệt giữa công cụ và LLM
Khi bạn hỏi một LLM "có bao nhiêu hàm trong mã này?", LLM sẽ sử dụng tính năng so khớp mẫu và ước tính. Khi bạn sử dụng một công cụ gọi ast.parse() của Python, công cụ đó sẽ phân tích cú pháp cây cú pháp thực tế – không đoán, kết quả luôn giống nhau.
Phần này tạo một công cụ phân tích cấu trúc mã một cách xác định, sau đó kết nối công cụ đó với một tác nhân biết thời điểm gọi công cụ.
Bước 1: Tìm hiểu về Scaffold
Hãy cùng xem xét cấu trúc mà bạn sẽ điền thông tin.
👉 Mở
code_review_assistant/tools.py
Bạn sẽ thấy hàm analyze_code_structure có các chú thích giữ chỗ đánh dấu vị trí mà bạn sẽ thêm mã. Hàm này đã có cấu trúc cơ bản – bạn sẽ cải thiện hàm này từng bước.
Bước 2: Thêm Bộ nhớ trạng thái
Tính năng lưu trữ trạng thái cho phép các tác nhân khác trong quy trình truy cập vào kết quả của công cụ mà không cần chạy lại quy trình phân tích.
👉 Tìm:
# MODULE_4_STEP_2_ADD_STATE_STORAGE
👉 Thay thế dòng đó bằng:
# Store code and analysis for other agents to access
tool_context.state[StateKeys.CODE_TO_REVIEW] = code
tool_context.state[StateKeys.CODE_ANALYSIS] = analysis
tool_context.state[StateKeys.CODE_LINE_COUNT] = len(code.splitlines())
Bước 3: Thêm Phân tích cú pháp không đồng bộ bằng Nhóm luồng
Công cụ của chúng tôi cần phân tích cú pháp AST mà không chặn các thao tác khác. Hãy thêm quá trình thực thi không đồng bộ bằng nhóm luồng.
👉 Tìm:
# MODULE_4_STEP_3_ADD_ASYNC
👉 Thay thế dòng đó bằng:
# Parse in thread pool to avoid blocking the event loop
loop = asyncio.get_event_loop()
with ThreadPoolExecutor() as executor:
tree = await loop.run_in_executor(executor, ast.parse, code)
Bước 4: Trích xuất thông tin toàn diện
Bây giờ, hãy trích xuất các lớp, lượt nhập và chỉ số chi tiết – mọi thứ chúng ta cần để xem xét mã hoàn chỉnh.
👉 Tìm:
# MODULE_4_STEP_4_EXTRACT_DETAILS
👉 Thay thế dòng đó bằng:
# Extract comprehensive structural information
analysis = await loop.run_in_executor(
executor, _extract_code_structure, tree, code
)
👉 Xác minh: hàm
analyze_code_structure
trong
tools.py
có phần thân chính như sau:
# Parse in thread pool to avoid blocking the event loop
loop = asyncio.get_event_loop()
with ThreadPoolExecutor() as executor:
tree = await loop.run_in_executor(executor, ast.parse, code)
# Extract comprehensive structural information
analysis = await loop.run_in_executor(
executor, _extract_code_structure, tree, code
)
# Store code and analysis for other agents to access
tool_context.state[StateKeys.CODE_TO_REVIEW] = code
tool_context.state[StateKeys.CODE_ANALYSIS] = analysis
tool_context.state[StateKeys.CODE_LINE_COUNT] = len(code.splitlines())
👉 Bây giờ, hãy di chuyển xuống cuối
tools.py
rồi tìm:
# MODULE_4_STEP_4_HELPER_FUNCTION
👉 Thay thế dòng đơn đó bằng hàm trợ giúp hoàn chỉnh:
def _extract_code_structure(tree: ast.AST, code: str) -> Dict[str, Any]:
"""
Helper function to extract structural information from AST.
Runs in thread pool for CPU-bound work.
"""
functions = []
classes = []
imports = []
docstrings = []
for node in ast.walk(tree):
if isinstance(node, ast.FunctionDef):
func_info = {
'name': node.name,
'args': [arg.arg for arg in node.args.args],
'lineno': node.lineno,
'has_docstring': ast.get_docstring(node) is not None,
'is_async': isinstance(node, ast.AsyncFunctionDef),
'decorators': [d.id for d in node.decorator_list
if isinstance(d, ast.Name)]
}
functions.append(func_info)
if func_info['has_docstring']:
docstrings.append(f"{node.name}: {ast.get_docstring(node)[:50]}...")
elif isinstance(node, ast.ClassDef):
methods = []
for item in node.body:
if isinstance(item, ast.FunctionDef):
methods.append(item.name)
class_info = {
'name': node.name,
'lineno': node.lineno,
'methods': methods,
'has_docstring': ast.get_docstring(node) is not None,
'base_classes': [base.id for base in node.bases
if isinstance(base, ast.Name)]
}
classes.append(class_info)
elif isinstance(node, ast.Import):
for alias in node.names:
imports.append({
'module': alias.name,
'alias': alias.asname,
'type': 'import'
})
elif isinstance(node, ast.ImportFrom):
imports.append({
'module': node.module or '',
'names': [alias.name for alias in node.names],
'type': 'from_import',
'level': node.level
})
return {
'functions': functions,
'classes': classes,
'imports': imports,
'docstrings': docstrings,
'metrics': {
'line_count': len(code.splitlines()),
'function_count': len(functions),
'class_count': len(classes),
'import_count': len(imports),
'has_main': any(f['name'] == 'main' for f in functions),
'has_if_main': '__main__' in code,
'avg_function_length': _calculate_avg_function_length(tree)
}
}
def _calculate_avg_function_length(tree: ast.AST) -> float:
"""Calculate average function length in lines."""
function_lengths = []
for node in ast.walk(tree):
if isinstance(node, ast.FunctionDef):
if hasattr(node, 'end_lineno') and hasattr(node, 'lineno'):
length = node.end_lineno - node.lineno + 1
function_lengths.append(length)
if function_lengths:
return sum(function_lengths) / len(function_lengths)
return 0.0
Bước 5: Kết nối với nhân viên hỗ trợ
Bây giờ, chúng ta sẽ kết nối công cụ này với một tác nhân biết thời điểm sử dụng và cách diễn giải kết quả của công cụ.
👉 Mở
code_review_assistant/sub_agents/review_pipeline/code_analyzer.py
👉 Tìm:
# MODULE_4_STEP_5_CREATE_AGENT
👉 Thay thế dòng đơn đó bằng tác nhân sản xuất hoàn chỉnh:
code_analyzer_agent = Agent(
name="CodeAnalyzer",
model=config.worker_model,
description="Analyzes Python code structure and identifies components",
instruction="""You are a code analysis specialist responsible for understanding code structure.
Your task:
1. Take the code submitted by the user (it will be provided in the user message)
2. Use the analyze_code_structure tool to parse and analyze it
3. Pass the EXACT code to your tool - do not modify, fix, or "improve" it
4. Identify all functions, classes, imports, and structural patterns
5. Note any syntax errors or structural issues
6. Store the analysis in state for other agents to use
CRITICAL:
- Pass the code EXACTLY as provided to the analyze_code_structure tool
- Do not fix syntax errors, even if obvious
- Do not add missing imports or fix indentation
- The goal is to analyze what IS there, not what SHOULD be there
When calling the tool, pass the code as a string to the 'code' parameter.
If the analysis fails due to syntax errors, clearly report the error location and type.
Provide a clear summary including:
- Number of functions and classes found
- Key structural observations
- Any syntax errors or issues detected
- Overall code organization assessment""",
tools=[FunctionTool(func=analyze_code_structure)],
output_key="structure_analysis_summary"
)
Kiểm thử trình phân tích mã
Bây giờ, hãy xác minh rằng trình phân tích của bạn hoạt động chính xác.
👉 Chạy kịch bản kiểm tra:
python tests/test_code_analyzer.py
Kịch bản kiểm tra sẽ tự động tải cấu hình từ tệp .env bằng cách sử dụng python-dotenv, nên bạn không cần thiết lập biến môi trường theo cách thủ công.
Kết quả đầu ra dự kiến:
INFO:code_review_assistant.config:Code Review Assistant Configuration Loaded:
INFO:code_review_assistant.config: - GCP Project: your-project-id
INFO:code_review_assistant.config: - Artifact Bucket: gs://your-project-artifacts
INFO:code_review_assistant.config: - Models: worker=gemini-2.5-flash, critic=gemini-2.5-pro
Testing code analyzer...
INFO:code_review_assistant.tools:Tool: Analysis complete - 2 functions, 1 classes
=== Analyzer Response ===
The analysis of the provided code shows the following:
* **Functions Found:** 2
* `add(a, b)`: A global function at line 2.
* `multiply(self, x, y)`: A method within the `Calculator` class.
* **Classes Found:** 1
* `Calculator`: A class defined at line 5. Contains one method, `multiply`.
* **Imports:** 0
* **Structural Patterns:** The code defines one global function and one class
with a single method. Both are simple, each with a single return statement.
* **Syntax Errors/Issues:** No syntax errors detected.
* **Overall Code Organization:** The code is well-organized for its small size,
clearly defining a function and a class with a method.
Điều gì vừa xảy ra:
- Kịch bản kiểm tra đã tự động tải cấu hình
.envcủa bạn - Công cụ
analyze_code_structure()của bạn đã phân tích cú pháp mã bằng AST của Python - Trợ lý
_extract_code_structure()đã trích xuất các hàm, lớp và chỉ số - Kết quả được lưu trữ trong trạng thái phiên bằng cách sử dụng các hằng số
StateKeys - Tác nhân Trình phân tích mã đã diễn giải kết quả và cung cấp bản tóm tắt
Khắc phục sự cố:
- "No module named ‘code_review_assistant'" (Không có mô-đun nào có tên là "code_review_assistant"): Chạy
pip install -e .từ thư mục gốc của dự án - "Thiếu đối số đầu vào khoá": Xác minh rằng
.envcủa bạn cóGOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_LOCATIONvàGOOGLE_GENAI_USE_VERTEXAI=true
Những gì bạn đã tạo
Giờ đây, bạn đã có một trình phân tích mã sẵn sàng cho bản phát hành chính thức:
✅ Phân tích cú pháp AST Python thực tế – xác định, không so khớp mẫu
✅ Lưu trữ kết quả trong trạng thái – các tác nhân khác có thể truy cập vào thông tin phân tích
✅ Chạy không đồng bộ – không chặn các công cụ khác
✅ Trích xuất thông tin toàn diện – hàm, lớp, lượt nhập, chỉ số
✅ Xử lý lỗi một cách hiệu quả – báo cáo lỗi cú pháp kèm theo số dòng
✅ Kết nối với một tác nhân – LLM biết thời điểm và cách sử dụng tác nhân này
Các khái niệm chính đã thành thạo
Công cụ so với Nhân viên hỗ trợ:
- Các công cụ thực hiện công việc xác định (phân tích cú pháp AST)
- Nhân viên quyết định thời điểm sử dụng công cụ và diễn giải kết quả
Giá trị trả về so với trạng thái:
- Trả về: nội dung mà LLM nhìn thấy ngay lập tức
- Trạng thái: những gì vẫn tồn tại đối với các tác nhân khác
Hằng số khoá trạng thái:
- Tránh lỗi chính tả trong hệ thống nhiều tác nhân
- Đóng vai trò là hợp đồng giữa các tác nhân
- Quan trọng khi nhân viên chia sẻ dữ liệu
Không đồng bộ + Nhóm luồng:
async defcho phép các công cụ tạm dừng quá trình thực thi- Các nhóm luồng chạy công việc liên kết với CPU ở chế độ nền
- Cùng nhau, chúng giúp vòng lặp sự kiện phản hồi
Hàm trợ giúp:
- Tách các trình trợ giúp đồng bộ hoá khỏi các công cụ không đồng bộ
- Giúp mã có thể kiểm thử và tái sử dụng
Hướng dẫn dành cho nhân viên hỗ trợ:
- Hướng dẫn chi tiết giúp ngăn chặn các lỗi thường gặp của LLM
- Nêu rõ những việc KHÔNG nên làm (không sửa mã)
- Xoá các bước trong quy trình công việc để đảm bảo tính nhất quán
Tiếp theo là gì?
Trong Mô-đun 5, bạn sẽ thêm:
- Trình kiểm tra kiểu đọc mã từ trạng thái
- Trình chạy kiểm thử thực sự thực thi các kiểm thử
- Công cụ tổng hợp ý kiến phản hồi kết hợp tất cả các bản phân tích
Bạn sẽ thấy cách trạng thái truyền qua một quy trình tuần tự và lý do mẫu hằng số có ý nghĩa khi nhiều tác nhân đọc và ghi cùng một dữ liệu.
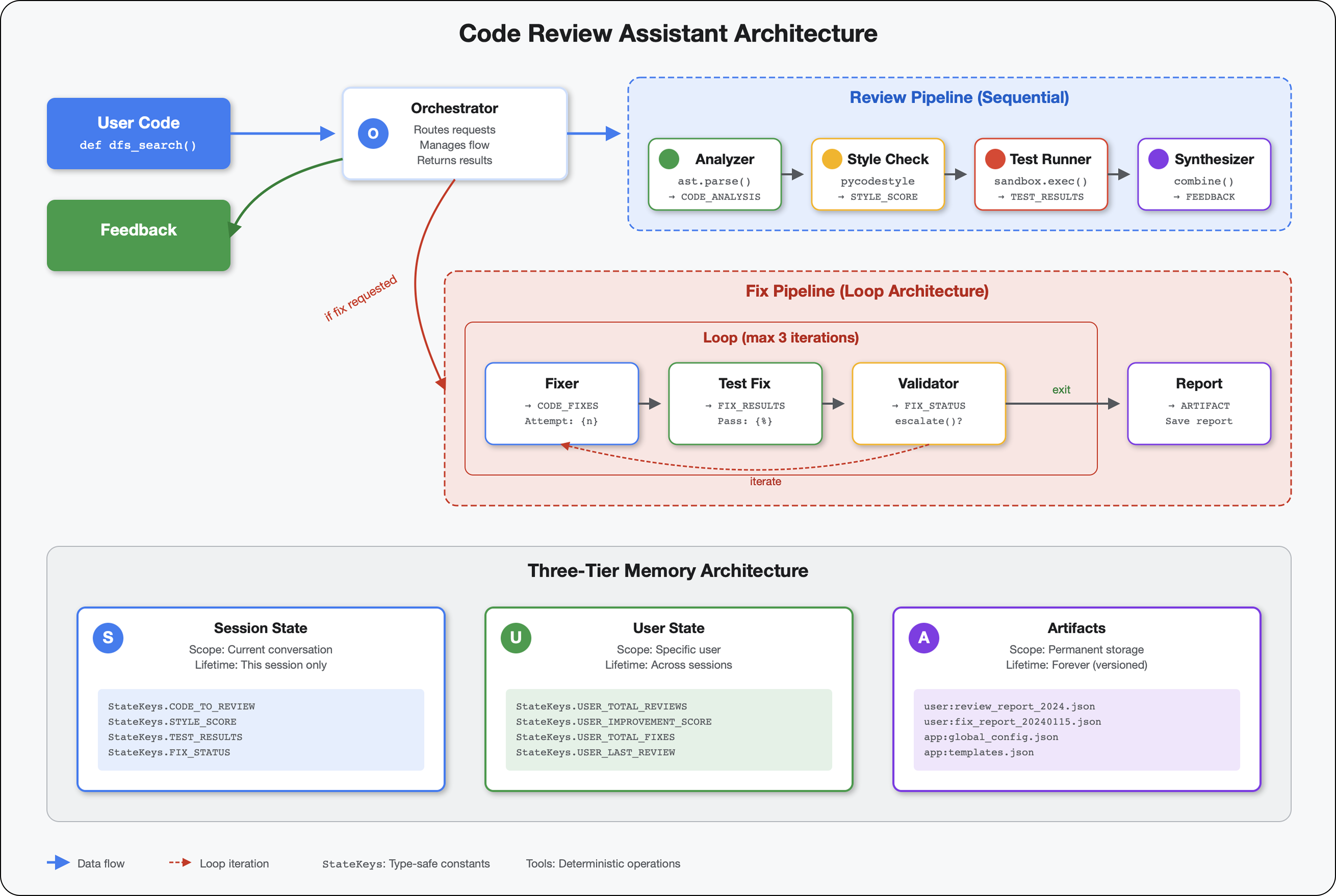
5. Xây dựng quy trình: Nhiều tác nhân cùng làm việc
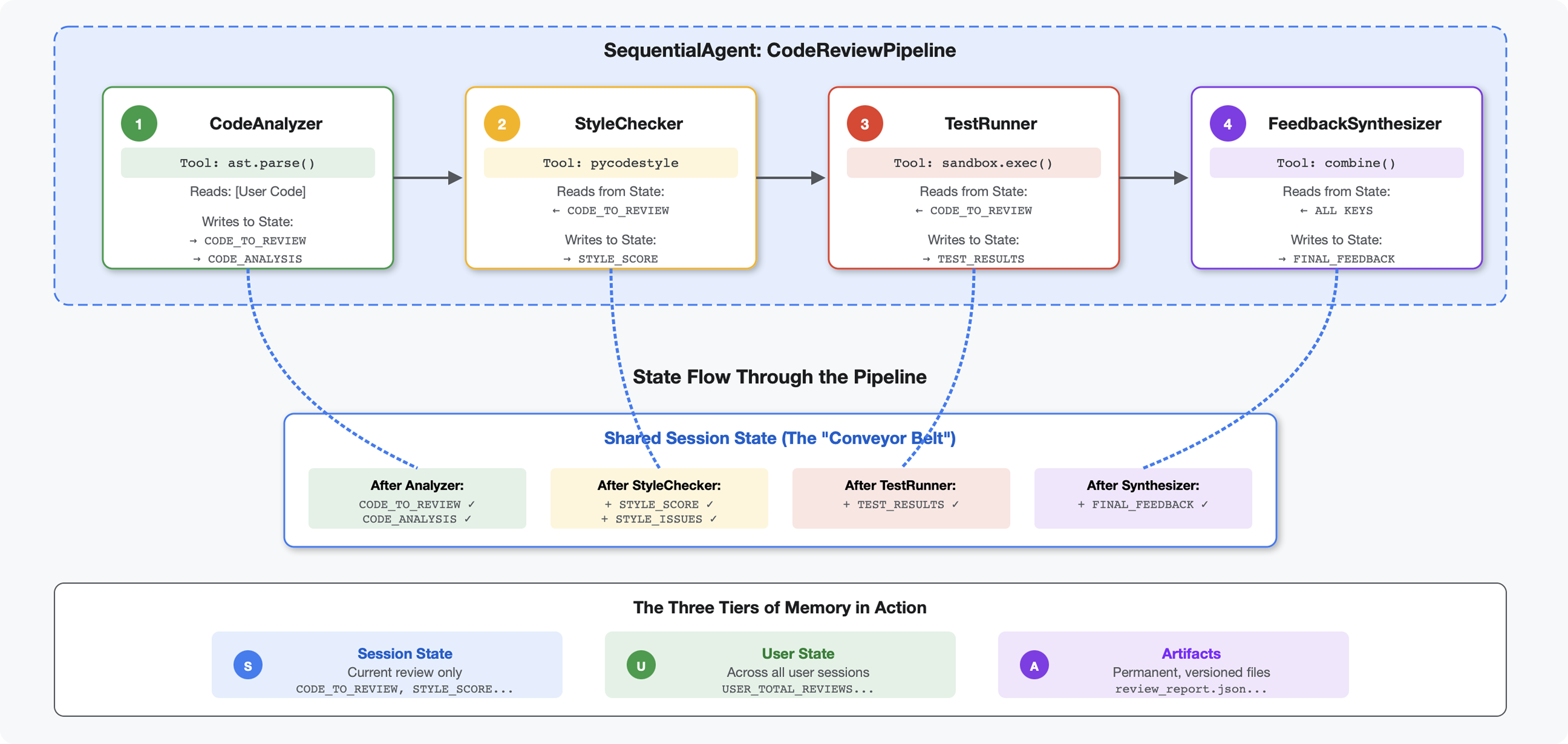
Giới thiệu
Trong Mô-đun 4, bạn đã tạo một tác nhân duy nhất để phân tích cấu trúc mã. Nhưng việc xem xét mã toàn diện không chỉ đơn thuần là phân tích cú pháp mà bạn cần kiểm tra kiểu, phiên chạy thử nghiệm và tổng hợp thông tin phản hồi thông minh.
Mô-đun này tạo ra một quy trình gồm 4 tác nhân hoạt động tuần tự với nhau, mỗi tác nhân đóng góp một phân tích chuyên biệt:
- Trình phân tích mã (từ Mô-đun 4) – Phân tích cú pháp cấu trúc
- Trình kiểm tra kiểu – Xác định các lỗi vi phạm kiểu
- Trình chạy kiểm thử – Thực thi và xác thực các kiểm thử
- Công cụ tổng hợp ý kiến phản hồi – Kết hợp mọi thứ thành ý kiến phản hồi hữu ích
Khái niệm chính: Trạng thái là kênh giao tiếp. Mỗi tác nhân sẽ đọc những gì các tác nhân trước đó đã viết để nêu trạng thái, thêm phân tích của riêng mình và chuyển trạng thái được làm phong phú cho tác nhân tiếp theo. Mẫu hằng số trong Mô-đun 4 trở nên quan trọng khi nhiều tác nhân chia sẻ dữ liệu.
Xem trước những gì bạn sẽ tạo: Gửi mã nguồn lộn xộn → xem trạng thái truyền qua 4 tác nhân → nhận báo cáo toàn diện kèm theo ý kiến phản hồi dành riêng cho bạn dựa trên các mẫu trước đây.
Bước 1: Thêm Công cụ kiểm tra kiểu + Tác nhân
Trình kiểm tra kiểu xác định các lỗi vi phạm PEP 8 bằng cách sử dụng pycodestyle – một trình kiểm tra cú pháp có tính xác định, không phải là cách diễn giải dựa trên LLM.
Thêm Công cụ kiểm tra phong cách
👉 Mở
code_review_assistant/tools.py
👉 Tìm:
# MODULE_5_STEP_1_STYLE_CHECKER_TOOL
👉 Thay thế dòng đó bằng:
async def check_code_style(code: str, tool_context: ToolContext) -> Dict[str, Any]:
"""
Checks code style compliance using pycodestyle (PEP 8).
Args:
code: Python source code to check (or will retrieve from state)
tool_context: ADK tool context
Returns:
Dictionary containing style score and issues
"""
logger.info("Tool: Checking code style...")
try:
# Retrieve code from state if not provided
if not code:
code = tool_context.state.get(StateKeys.CODE_TO_REVIEW, '')
if not code:
return {
"status": "error",
"message": "No code provided or found in state"
}
# Run style check in thread pool
loop = asyncio.get_event_loop()
with ThreadPoolExecutor() as executor:
result = await loop.run_in_executor(
executor, _perform_style_check, code
)
# Store results in state
tool_context.state[StateKeys.STYLE_SCORE] = result['score']
tool_context.state[StateKeys.STYLE_ISSUES] = result['issues']
tool_context.state[StateKeys.STYLE_ISSUE_COUNT] = result['issue_count']
logger.info(f"Tool: Style check complete - Score: {result['score']}/100, "
f"Issues: {result['issue_count']}")
return result
except Exception as e:
error_msg = f"Style check failed: {str(e)}"
logger.error(f"Tool: {error_msg}", exc_info=True)
# Set default values on error
tool_context.state[StateKeys.STYLE_SCORE] = 0
tool_context.state[StateKeys.STYLE_ISSUES] = []
return {
"status": "error",
"message": error_msg,
"score": 0
}
👉 Bây giờ, hãy di chuyển đến cuối tệp và tìm:
# MODULE_5_STEP_1_STYLE_HELPERS
👉 Thay thế dòng đơn đó bằng các hàm trợ giúp:
def _perform_style_check(code: str) -> Dict[str, Any]:
"""Helper to perform style check in thread pool."""
import io
import sys
with tempfile.NamedTemporaryFile(mode='w', suffix='.py', delete=False) as tmp:
tmp.write(code)
tmp_path = tmp.name
try:
# Capture stdout to get pycodestyle output
old_stdout = sys.stdout
sys.stdout = captured_output = io.StringIO()
style_guide = pycodestyle.StyleGuide(
quiet=False, # We want output
max_line_length=100,
ignore=['E501', 'W503']
)
result = style_guide.check_files([tmp_path])
# Restore stdout
sys.stdout = old_stdout
# Parse captured output
output = captured_output.getvalue()
issues = []
for line in output.strip().split('\n'):
if line and ':' in line:
parts = line.split(':', 4)
if len(parts) >= 4:
try:
issues.append({
'line': int(parts[1]),
'column': int(parts[2]),
'code': parts[3].split()[0] if len(parts) > 3 else 'E000',
'message': parts[3].strip() if len(parts) > 3 else 'Unknown error'
})
except (ValueError, IndexError):
pass
# Add naming convention checks
try:
tree = ast.parse(code)
naming_issues = _check_naming_conventions(tree)
issues.extend(naming_issues)
except SyntaxError:
pass # Syntax errors will be caught elsewhere
# Calculate weighted score
score = _calculate_style_score(issues)
return {
"status": "success",
"score": score,
"issue_count": len(issues),
"issues": issues[:10], # First 10 issues
"summary": f"Style score: {score}/100 with {len(issues)} violations"
}
finally:
if os.path.exists(tmp_path):
os.unlink(tmp_path)
def _check_naming_conventions(tree: ast.AST) -> List[Dict[str, Any]]:
"""Check PEP 8 naming conventions."""
naming_issues = []
for node in ast.walk(tree):
if isinstance(node, ast.FunctionDef):
# Skip private/protected methods and __main__
if not node.name.startswith('_') and node.name != node.name.lower():
naming_issues.append({
'line': node.lineno,
'column': node.col_offset,
'code': 'N802',
'message': f"N802 function name '{node.name}' should be lowercase"
})
elif isinstance(node, ast.ClassDef):
# Check if class name follows CapWords convention
if not node.name[0].isupper() or '_' in node.name:
naming_issues.append({
'line': node.lineno,
'column': node.col_offset,
'code': 'N801',
'message': f"N801 class name '{node.name}' should use CapWords convention"
})
return naming_issues
def _calculate_style_score(issues: List[Dict[str, Any]]) -> int:
"""Calculate weighted style score based on violation severity."""
if not issues:
return 100
# Define weights by error type
weights = {
'E1': 10, # Indentation errors
'E2': 3, # Whitespace errors
'E3': 5, # Blank line errors
'E4': 8, # Import errors
'E5': 5, # Line length
'E7': 7, # Statement errors
'E9': 10, # Syntax errors
'W2': 2, # Whitespace warnings
'W3': 2, # Blank line warnings
'W5': 3, # Line break warnings
'N8': 7, # Naming conventions
}
total_deduction = 0
for issue in issues:
code_prefix = issue['code'][:2] if len(issue['code']) >= 2 else 'E2'
weight = weights.get(code_prefix, 3)
total_deduction += weight
# Cap at 100 points deduction
return max(0, 100 - min(total_deduction, 100))
Thêm tác nhân kiểm tra kiểu
👉 Mở
code_review_assistant/sub_agents/review_pipeline/style_checker.py
👉 Tìm:
# MODULE_5_STEP_1_INSTRUCTION_PROVIDER
👉 Thay thế dòng đó bằng:
async def style_checker_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are a code style expert focused on PEP 8 compliance.
Your task:
1. Use the check_code_style tool to validate PEP 8 compliance
2. The tool will retrieve the ORIGINAL code from state automatically
3. Report violations exactly as found
4. Present the results clearly and confidently
CRITICAL:
- The tool checks the code EXACTLY as provided by the user
- Do not suggest the code was modified or fixed
- Report actual violations found in the original code
- If there are style issues, they should be reported honestly
Call the check_code_style tool with an empty string for the code parameter,
as the tool will retrieve the code from state automatically.
When presenting results based on what the tool returns:
- State the exact score from the tool results
- If score >= 90: "Excellent style compliance!"
- If score 70-89: "Good style with minor improvements needed"
- If score 50-69: "Style needs attention"
- If score < 50: "Significant style improvements needed"
List the specific violations found (the tool will provide these):
- Show line numbers, error codes, and messages
- Focus on the top 10 most important issues
Previous analysis: {structure_analysis_summary}
Format your response as:
## Style Analysis Results
- Style Score: [exact score]/100
- Total Issues: [count]
- Assessment: [your assessment based on score]
## Top Style Issues
[List issues with line numbers and descriptions]
## Recommendations
[Specific fixes for the most critical issues]"""
return await instructions_utils.inject_session_state(template, context)
👉 Tìm:
# MODULE_5_STEP_1_STYLE_CHECKER_AGENT
👉 Thay thế dòng đó bằng:
style_checker_agent = Agent(
name="StyleChecker",
model=config.worker_model,
description="Checks Python code style against PEP 8 guidelines",
instruction=style_checker_instruction_provider,
tools=[FunctionTool(func=check_code_style)],
output_key="style_check_summary"
)
Bước 2: Thêm Test Runner Agent
Trình chạy kiểm thử tạo các kiểm thử toàn diện và thực thi các kiểm thử đó bằng trình thực thi mã tích hợp.
👉 Mở
code_review_assistant/sub_agents/review_pipeline/test_runner.py
👉 Tìm:
# MODULE_5_STEP_2_INSTRUCTION_PROVIDER
👉 Thay thế dòng đó bằng:
async def test_runner_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects the code_to_review directly."""
template = """You are a testing specialist who creates and runs tests for Python code.
THE CODE TO TEST IS:
{code_to_review}
YOUR TASK:
1. Understand what the function appears to do based on its name and structure
2. Generate comprehensive tests (15-20 test cases)
3. Execute the tests using your code executor
4. Analyze results to identify bugs vs expected behavior
5. Output a detailed JSON analysis
TESTING METHODOLOGY:
- Test with the most natural interpretation first
- When something fails, determine if it's a bug or unusual design
- Test edge cases, boundaries, and error scenarios
- Document any surprising behavior
Execute your tests and output ONLY valid JSON with this structure:
- "test_summary": object with "total_tests_run", "tests_passed", "tests_failed", "tests_with_errors", "critical_issues_found"
- "critical_issues": array of objects, each with "type", "description", "example_input", "expected_behavior", "actual_behavior", "severity"
- "test_categories": object with "basic_functionality", "edge_cases", "error_handling" (each containing "passed", "failed", "errors" counts)
- "function_behavior": object with "apparent_purpose", "actual_interface", "unexpected_requirements"
- "verdict": object with "status" (WORKING/BUGGY/BROKEN), "confidence" (high/medium/low), "recommendation"
Do NOT output the test code itself, only the JSON analysis."""
return await instructions_utils.inject_session_state(template, context)
👉 Tìm:
# MODULE_5_STEP_2_TEST_RUNNER_AGENT
👉 Thay thế dòng đó bằng:
test_runner_agent = Agent(
name="TestRunner",
model=config.critic_model,
description="Generates and runs tests for Python code using safe code execution",
instruction=test_runner_instruction_provider,
code_executor=BuiltInCodeExecutor(),
output_key="test_execution_summary"
)
Bước 3: Tìm hiểu về Bộ nhớ để học tập trên nhiều phiên
Trước khi tạo bộ tổng hợp phản hồi, bạn cần hiểu rõ sự khác biệt giữa trạng thái và bộ nhớ – hai cơ chế lưu trữ khác nhau cho hai mục đích khác nhau.
Trạng thái so với bộ nhớ: Điểm khác biệt chính
Hãy làm rõ bằng một ví dụ cụ thể trong quy trình xem xét mã:
Trạng thái (Chỉ phiên hiện tại):
# Data from THIS review session
tool_context.state[StateKeys.STYLE_ISSUES] = [
{"line": 5, "code": "E231", "message": "missing whitespace"},
{"line": 12, "code": "E701", "message": "multiple statements"}
]
- Phạm vi: Chỉ cuộc trò chuyện này
- Mục đích: Truyền dữ liệu giữa các tác nhân trong quy trình hiện tại
- Sống tại: đối tượng
Session - Vòng đời: Bị loại bỏ khi phiên kết thúc
Bộ nhớ (Tất cả các phiên trước đây):
# Learned from 50 previous reviews
"User frequently forgets docstrings on helper functions"
"User tends to write long functions (avg 45 lines)"
"User improved error handling after feedback in session #23"
- Phạm vi: Tất cả các phiên trước đây của người dùng này
- Mục đích: Tìm hiểu các mẫu, cung cấp ý kiến phản hồi phù hợp với từng người dùng
- Sống tại:
MemoryService - Vòng đời: Duy trì trên các phiên, có thể tìm kiếm
Lý do cần cả hai loại ý kiến phản hồi:
Hãy tưởng tượng bộ tổng hợp tạo ra tiếng hú:
Chỉ sử dụng Tiểu bang (đánh giá hiện tại):
"Function `calculate_total` has no docstring."
Ý kiến phản hồi chung chung, mang tính cơ học.
Sử dụng State + Memory (các mẫu hiện tại và trước đây):
"Function `calculate_total` has no docstring. This is the 4th review
where helper functions lacked documentation. Consider adding docstrings
as you write functions, not afterwards - you mentioned in our last
session that you find it easier that way."
Cá nhân hoá, theo bối cảnh, cải thiện thông tin tham khảo theo thời gian.
Đối với việc triển khai cho kênh phát hành công khai, bạn có các lựa chọn:
Lựa chọn 1: VertexAiMemoryBankService (Nâng cao)
- Chức năng: Trích xuất các thông tin có ý nghĩa từ các cuộc trò chuyện bằng LLM
- Tìm kiếm: Tìm kiếm ngữ nghĩa (hiểu ý nghĩa, không chỉ từ khoá)
- Quản lý kỷ niệm: Tự động hợp nhất và cập nhật kỷ niệm theo thời gian
- Yêu cầu: Thiết lập Dự án trên Google Cloud + Agent Engine
- Sử dụng khi: Bạn muốn có những kỷ niệm tinh tế, luôn phát triển và dành riêng cho bạn
- Ví dụ: "Người dùng thích lập trình chức năng" (trích xuất từ 10 cuộc trò chuyện về kiểu mã)
Lựa chọn 2: Tiếp tục với InMemoryMemoryService + Persistent Sessions
- Chức năng: Lưu trữ toàn bộ nhật ký cuộc trò chuyện để tìm kiếm theo từ khoá
- Tìm kiếm: So khớp từ khoá cơ bản trong các phiên trước
- Quản lý bộ nhớ: Bạn kiểm soát những nội dung được lưu trữ (thông qua biểu tượng
add_session_to_memory) - Yêu cầu: Chỉ
SessionServiceliên tục (chẳng hạn nhưVertexAiSessionServicehoặcDatabaseSessionService) - Sử dụng khi: Bạn cần tìm kiếm đơn giản trong các cuộc trò chuyện trước đây mà không cần xử lý bằng LLM
- Ví dụ: Tìm kiếm "docstring" sẽ trả về tất cả các phiên có đề cập đến từ đó
Cách tính năng Bộ nhớ được điền sẵn
Sau khi mỗi quy trình xem xét mã hoàn tất:
# At the end of a session (typically in your application code)
await memory_service.add_session_to_memory(session)
Điều gì xảy ra:
- InMemoryMemoryService: Lưu trữ toàn bộ sự kiện trong phiên cho tìm kiếm từ khoá
- VertexAiMemoryBankService: LLM trích xuất các thông tin chính, hợp nhất với các thông tin đã lưu
Sau đó, các phiên trong tương lai có thể truy vấn:
# In a tool, search for relevant past feedback
results = tool_context.search_memory("feedback about docstrings")
Bước 4: Thêm Công cụ tổng hợp ý kiến phản hồi và Đặc vụ
Bộ tổng hợp ý kiến phản hồi là tác nhân tinh vi nhất trong quy trình. Nó điều phối 3 công cụ, sử dụng các chỉ dẫn linh hoạt và kết hợp trạng thái, bộ nhớ và các cấu phần phần mềm.
Thêm 3 công cụ tạo âm thanh
👉 Mở
code_review_assistant/tools.py
👉 Tìm:
# MODULE_5_STEP_4_SEARCH_PAST_FEEDBACK
👉 Thay thế bằng Công cụ 1 – Tìm kiếm thông tin trong bộ nhớ (phiên bản phát hành công khai):
async def search_past_feedback(developer_id: str, tool_context: ToolContext) -> Dict[str, Any]:
"""
Search for past feedback in memory service.
Args:
developer_id: ID of the developer (defaults to "default_user")
tool_context: ADK tool context with potential memory service access
Returns:
Dictionary containing feedback search results
"""
logger.info(f"Tool: Searching for past feedback for developer {developer_id}...")
try:
# Default developer ID if not provided
if not developer_id:
developer_id = tool_context.state.get(StateKeys.USER_ID, 'default_user')
# Check if memory service is available
if hasattr(tool_context, 'search_memory'):
try:
# Perform structured searches
queries = [
f"developer:{developer_id} code review feedback",
f"developer:{developer_id} common issues",
f"developer:{developer_id} improvements"
]
all_feedback = []
patterns = {
'common_issues': [],
'improvements': [],
'strengths': []
}
for query in queries:
search_result = await tool_context.search_memory(query)
if search_result and hasattr(search_result, 'memories'):
for memory in search_result.memories[:5]:
memory_text = memory.text if hasattr(memory, 'text') else str(memory)
all_feedback.append(memory_text)
# Extract patterns
if 'style' in memory_text.lower():
patterns['common_issues'].append('style compliance')
if 'improved' in memory_text.lower():
patterns['improvements'].append('showing improvement')
if 'excellent' in memory_text.lower():
patterns['strengths'].append('consistent quality')
# Store in state
tool_context.state[StateKeys.PAST_FEEDBACK] = all_feedback
tool_context.state[StateKeys.FEEDBACK_PATTERNS] = patterns
logger.info(f"Tool: Found {len(all_feedback)} past feedback items")
return {
"status": "success",
"feedback_found": True,
"count": len(all_feedback),
"summary": " | ".join(all_feedback[:3]) if all_feedback else "No feedback",
"patterns": patterns
}
except Exception as e:
logger.warning(f"Tool: Memory search error: {e}")
# Fallback: Check state for cached feedback
cached_feedback = tool_context.state.get(StateKeys.USER_PAST_FEEDBACK_CACHE, [])
if cached_feedback:
tool_context.state[StateKeys.PAST_FEEDBACK] = cached_feedback
return {
"status": "success",
"feedback_found": True,
"count": len(cached_feedback),
"summary": "Using cached feedback",
"patterns": {}
}
# No feedback found
tool_context.state[StateKeys.PAST_FEEDBACK] = []
logger.info("Tool: No past feedback found")
return {
"status": "success",
"feedback_found": False,
"message": "No past feedback available - this appears to be a first submission",
"patterns": {}
}
except Exception as e:
error_msg = f"Feedback search error: {str(e)}"
logger.error(f"Tool: {error_msg}", exc_info=True)
tool_context.state[StateKeys.PAST_FEEDBACK] = []
return {
"status": "error",
"message": error_msg,
"feedback_found": False
}
👉 Tìm:
# MODULE_5_STEP_4_UPDATE_GRADING_PROGRESS
👉 Thay thế bằng Công cụ 2 – Bảng theo dõi điểm (phiên bản chính thức):
async def update_grading_progress(tool_context: ToolContext) -> Dict[str, Any]:
"""
Updates grading progress counters and metrics in state.
"""
logger.info("Tool: Updating grading progress...")
try:
current_time = datetime.now().isoformat()
# Build all state changes
state_updates = {}
# Temporary (invocation-level) state
state_updates[StateKeys.TEMP_PROCESSING_TIMESTAMP] = current_time
# Session-level state
attempts = tool_context.state.get(StateKeys.GRADING_ATTEMPTS, 0) + 1
state_updates[StateKeys.GRADING_ATTEMPTS] = attempts
state_updates[StateKeys.LAST_GRADING_TIME] = current_time
# User-level persistent state
lifetime_submissions = tool_context.state.get(StateKeys.USER_TOTAL_SUBMISSIONS, 0) + 1
state_updates[StateKeys.USER_TOTAL_SUBMISSIONS] = lifetime_submissions
state_updates[StateKeys.USER_LAST_SUBMISSION_TIME] = current_time
# Calculate improvement metrics
current_style_score = tool_context.state.get(StateKeys.STYLE_SCORE, 0)
last_style_score = tool_context.state.get(StateKeys.USER_LAST_STYLE_SCORE, 0)
score_improvement = current_style_score - last_style_score
state_updates[StateKeys.USER_LAST_STYLE_SCORE] = current_style_score
state_updates[StateKeys.SCORE_IMPROVEMENT] = score_improvement
# Track test results if available
test_results = tool_context.state.get(StateKeys.TEST_EXECUTION_SUMMARY, {})
# Parse if it's a string
if isinstance(test_results, str):
try:
test_results = json.loads(test_results)
except:
test_results = {}
if test_results and test_results.get('test_summary', {}).get('total_tests_run', 0) > 0:
summary = test_results['test_summary']
total = summary.get('total_tests_run', 0)
passed = summary.get('tests_passed', 0)
if total > 0:
pass_rate = (passed / total) * 100
state_updates[StateKeys.USER_LAST_TEST_PASS_RATE] = pass_rate
# Apply all updates atomically
for key, value in state_updates.items():
tool_context.state[key] = value
logger.info(f"Tool: Progress updated - Attempt #{attempts}, "
f"Lifetime: {lifetime_submissions}")
return {
"status": "success",
"session_attempts": attempts,
"lifetime_submissions": lifetime_submissions,
"timestamp": current_time,
"improvement": {
"style_score_change": score_improvement,
"direction": "improved" if score_improvement > 0 else "declined"
},
"summary": f"Attempt #{attempts} recorded, {lifetime_submissions} total submissions"
}
except Exception as e:
error_msg = f"Progress update error: {str(e)}"
logger.error(f"Tool: {error_msg}", exc_info=True)
return {
"status": "error",
"message": error_msg
}
👉 Tìm:
# MODULE_5_STEP_4_SAVE_GRADING_REPORT
👉 Thay thế bằng Công cụ 3 – Trình lưu cấu phần phần mềm (phiên bản phát hành công khai):
async def save_grading_report(feedback_text: str, tool_context: ToolContext) -> Dict[str, Any]:
"""
Saves a detailed grading report as an artifact.
Args:
feedback_text: The feedback text to include in the report
tool_context: ADK tool context for state management
Returns:
Dictionary containing save status and details
"""
logger.info("Tool: Saving grading report...")
try:
# Gather all relevant data from state
code = tool_context.state.get(StateKeys.CODE_TO_REVIEW, '')
analysis = tool_context.state.get(StateKeys.CODE_ANALYSIS, {})
style_score = tool_context.state.get(StateKeys.STYLE_SCORE, 0)
style_issues = tool_context.state.get(StateKeys.STYLE_ISSUES, [])
# Get test results
test_results = tool_context.state.get(StateKeys.TEST_EXECUTION_SUMMARY, {})
# Parse if it's a string
if isinstance(test_results, str):
try:
test_results = json.loads(test_results)
except:
test_results = {}
timestamp = datetime.now().isoformat()
# Create comprehensive report dictionary
report = {
'timestamp': timestamp,
'grading_attempt': tool_context.state.get(StateKeys.GRADING_ATTEMPTS, 1),
'code': {
'content': code,
'line_count': len(code.splitlines()),
'hash': hashlib.md5(code.encode()).hexdigest()
},
'analysis': analysis,
'style': {
'score': style_score,
'issues': style_issues[:5] # First 5 issues
},
'tests': test_results,
'feedback': feedback_text,
'improvements': {
'score_change': tool_context.state.get(StateKeys.SCORE_IMPROVEMENT, 0),
'from_last_score': tool_context.state.get(StateKeys.USER_LAST_STYLE_SCORE, 0)
}
}
# Convert report to JSON string
report_json = json.dumps(report, indent=2)
report_part = types.Part.from_text(text=report_json)
# Try to save as artifact if the service is available
if hasattr(tool_context, 'save_artifact'):
try:
# Generate filename with timestamp (replace colons for filesystem compatibility)
filename = f"grading_report_{timestamp.replace(':', '-')}.json"
# Save the main report
version = await tool_context.save_artifact(filename, report_part)
# Also save a "latest" version for easy access
await tool_context.save_artifact("latest_grading_report.json", report_part)
logger.info(f"Tool: Report saved as {filename} (version {version})")
# Store report in state as well for redundancy
tool_context.state[StateKeys.USER_LAST_GRADING_REPORT] = report
return {
"status": "success",
"artifact_saved": True,
"filename": filename,
"version": str(version),
"size": len(report_json),
"summary": f"Report saved as {filename}"
}
except Exception as artifact_error:
logger.warning(f"Artifact service error: {artifact_error}, falling back to state storage")
# Continue to fallback below
# Fallback: Store in state if artifact service is not available or failed
tool_context.state[StateKeys.USER_LAST_GRADING_REPORT] = report
logger.info("Tool: Report saved to state (artifact service not available)")
return {
"status": "success",
"artifact_saved": False,
"message": "Report saved to state only",
"size": len(report_json),
"summary": "Report saved to session state"
}
except Exception as e:
error_msg = f"Report save error: {str(e)}"
logger.error(f"Tool: {error_msg}", exc_info=True)
# Still try to save minimal data to state
try:
tool_context.state[StateKeys.USER_LAST_GRADING_REPORT] = {
'error': error_msg,
'feedback': feedback_text,
'timestamp': datetime.now().isoformat()
}
except:
pass
return {
"status": "error",
"message": error_msg,
"artifact_saved": False,
"summary": f"Failed to save report: {error_msg}"
}
Tạo Synthesizer Agent
👉 Mở
code_review_assistant/sub_agents/review_pipeline/feedback_synthesizer.py
👉 Tìm:
# MODULE_5_STEP_4_INSTRUCTION_PROVIDER
👉 Thay thế bằng nhà cung cấp hướng dẫn sản xuất:
async def feedback_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are an expert code reviewer and mentor providing constructive, educational feedback.
CONTEXT FROM PREVIOUS AGENTS:
- Structure analysis summary: {structure_analysis_summary}
- Style check summary: {style_check_summary}
- Test execution summary: {test_execution_summary}
YOUR TASK requires these steps IN ORDER:
1. Call search_past_feedback tool with developer_id="default_user"
2. Call update_grading_progress tool with no parameters
3. Carefully analyze the test results to understand what really happened
4. Generate comprehensive feedback following the structure below
5. Call save_grading_report tool with the feedback_text parameter
6. Return the feedback as your final output
CRITICAL - Understanding Test Results:
The test_execution_summary contains structured JSON. Parse it carefully:
- tests_passed = Code worked correctly
- tests_failed = Code produced wrong output
- tests_with_errors = Code crashed
- critical_issues = Fundamental problems with the code
If critical_issues array contains items, these are serious bugs that need fixing.
Do NOT count discovering bugs as test successes.
FEEDBACK STRUCTURE TO FOLLOW:
## 📊 Summary
Provide an honest assessment. Be encouraging but truthful about problems found.
## ✅ Strengths
List 2-3 things done well, referencing specific code elements.
## 📈 Code Quality Analysis
### Structure & Organization
Comment on code organization, readability, and documentation.
### Style Compliance
Report the actual style score and any specific issues.
### Test Results
Report the actual test results accurately:
- If critical_issues exist, report them as bugs to fix
- Be clear: "X tests passed, Y critical issues were found"
- List each critical issue
- Don't hide or minimize problems
## 💡 Recommendations for Improvement
Based on the analysis, provide specific actionable fixes.
If critical issues exist, fixing them is top priority.
## 🎯 Next Steps
Prioritized action list based on severity of issues.
## 💬 Encouragement
End with encouragement while being honest about what needs fixing.
Remember: Complete ALL steps including calling save_grading_report."""
return await instructions_utils.inject_session_state(template, context)
👉 Tìm:
# MODULE_5_STEP_4_SYNTHESIZER_AGENT
👉 Thay thế bằng:
feedback_synthesizer_agent = Agent(
name="FeedbackSynthesizer",
model=config.critic_model,
description="Synthesizes all analysis into constructive, personalized feedback",
instruction=feedback_instruction_provider,
tools=[
FunctionTool(func=search_past_feedback),
FunctionTool(func=update_grading_progress),
FunctionTool(func=save_grading_report)
],
output_key="final_feedback"
)
Bước 5: Kết nối các thành phần trong quy trình
Giờ đây, hãy kết nối cả 4 tác nhân vào một quy trình tuần tự và tạo tác nhân gốc.
👉 Mở
code_review_assistant/agent.py
👉 Thêm các nội dung nhập cần thiết vào đầu tệp (sau các nội dung nhập hiện có):
from google.adk.agents import Agent, SequentialAgent
from code_review_assistant.sub_agents.review_pipeline.code_analyzer import code_analyzer_agent
from code_review_assistant.sub_agents.review_pipeline.style_checker import style_checker_agent
from code_review_assistant.sub_agents.review_pipeline.test_runner import test_runner_agent
from code_review_assistant.sub_agents.review_pipeline.feedback_synthesizer import feedback_synthesizer_agent
Bây giờ, tệp của bạn sẽ có dạng như sau:
"""
Main agent orchestration for the Code Review Assistant.
"""
from google.adk.agents import Agent, SequentialAgent
from .config import config
from code_review_assistant.sub_agents.review_pipeline.code_analyzer import code_analyzer_agent
from code_review_assistant.sub_agents.review_pipeline.style_checker import style_checker_agent
from code_review_assistant.sub_agents.review_pipeline.test_runner import test_runner_agent
from code_review_assistant.sub_agents.review_pipeline.feedback_synthesizer import feedback_synthesizer_agent
# MODULE_5_STEP_5_CREATE_PIPELINE
# MODULE_6_STEP_5_CREATE_FIX_LOOP
# MODULE_6_STEP_5_UPDATE_ROOT_AGENT
👉 Tìm:
# MODULE_5_STEP_5_CREATE_PIPELINE
👉 Thay thế dòng đó bằng:
# Create sequential pipeline
code_review_pipeline = SequentialAgent(
name="CodeReviewPipeline",
description="Complete code review pipeline with analysis, testing, and feedback",
sub_agents=[
code_analyzer_agent,
style_checker_agent,
test_runner_agent,
feedback_synthesizer_agent
]
)
# Root agent - coordinates the review pipeline
root_agent = Agent(
name="CodeReviewAssistant",
model=config.worker_model,
description="An intelligent code review assistant that analyzes Python code and provides educational feedback",
instruction="""You are a specialized Python code review assistant focused on helping developers improve their code quality.
When a user provides Python code for review:
1. Immediately delegate to CodeReviewPipeline and pass the code EXACTLY as it was provided by the user.
2. The pipeline will handle all analysis and feedback
3. Return ONLY the final feedback from the pipeline - do not add any commentary
When a user asks what you can do or asks general questions:
- Explain your capabilities for code review
- Do NOT trigger the pipeline for non-code messages
The pipeline handles everything for code review - just pass through its final output.""",
sub_agents=[code_review_pipeline],
output_key="assistant_response"
)
Bước 6: Kiểm thử toàn bộ quy trình
Đã đến lúc xem cả 4 tác nhân cùng hoạt động.
👉 Khởi động hệ thống:
adk web code_review_assistant
Sau khi chạy lệnh adk web, bạn sẽ thấy đầu ra trong thiết bị đầu cuối cho biết ADK Web Server đã khởi động, tương tự như sau:
+-----------------------------------------------------------------------------+
| ADK Web Server started |
| |
| For local testing, access at http://localhost:8000. |
+-----------------------------------------------------------------------------+
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
👉 Tiếp theo, để truy cập vào giao diện người dùng dành cho nhà phát triển ADK từ trình duyệt, hãy làm như sau:
Trong biểu tượng Xem trước trên web (thường có dạng con mắt hoặc hình vuông có mũi tên) trên thanh công cụ Cloud Shell (thường ở trên cùng bên phải), hãy chọn Thay đổi cổng. Trong cửa sổ bật lên, hãy đặt cổng thành 8000 rồi nhấp vào "Thay đổi và xem trước". Sau đó, Cloud Shell sẽ mở một thẻ trình duyệt hoặc cửa sổ mới hiển thị Giao diện người dùng dành cho nhà phát triển ADK.
👉 Tác nhân hiện đang chạy. Giao diện người dùng dành cho nhà phát triển ADK trong trình duyệt là kết nối trực tiếp của bạn với tác nhân.
- Chọn mục tiêu: Trong trình đơn thả xuống ở đầu giao diện người dùng, hãy chọn tác nhân
code_review_assistant.
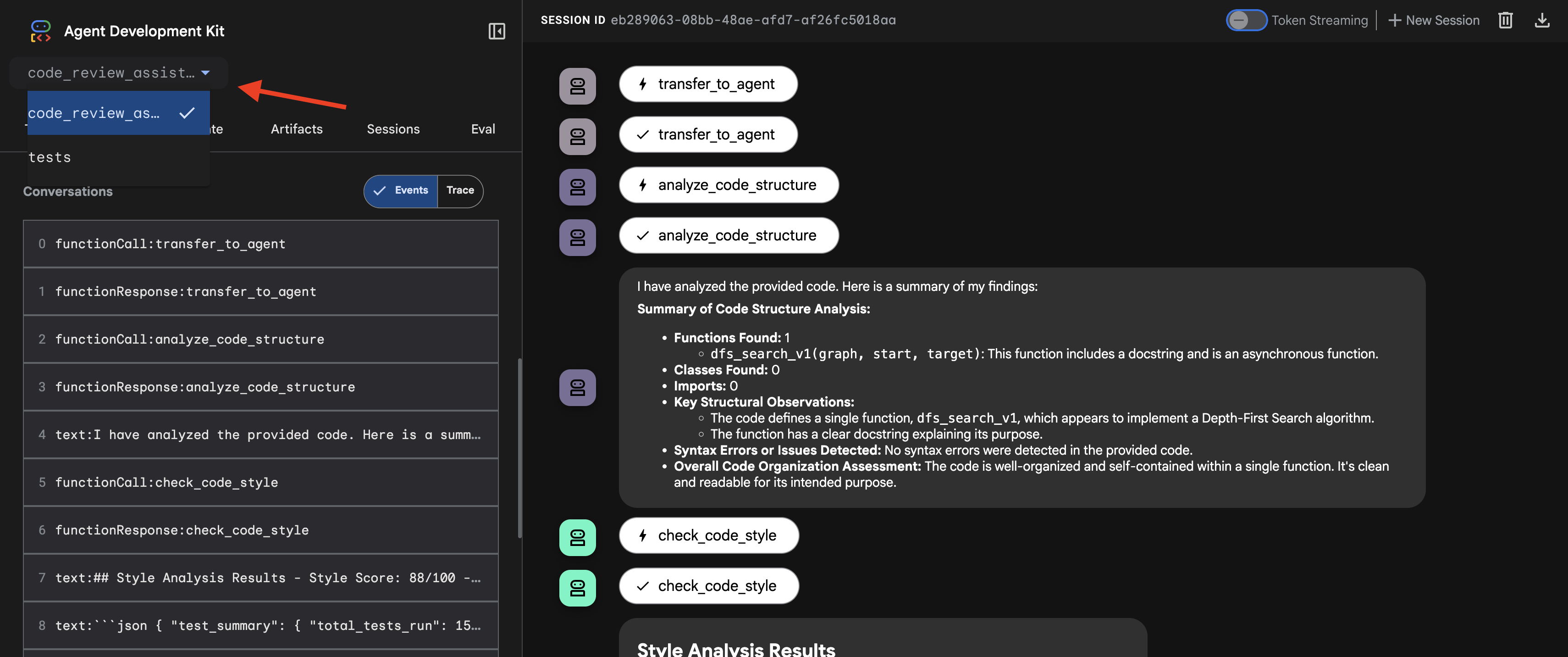
👉 Câu lệnh thử nghiệm:
Please analyze the following:
def dfs_search_v1(graph, start, target):
"""Find if target is reachable from start."""
visited = set()
stack = start
while stack:
current = stack.pop()
if current == target:
return True
if current not in visited:
visited.add(current)
for neighbor in graph[current]:
if neighbor not in visited:
stack.append(neighbor)
return False
👉 Xem quy trình xem xét mã đang hoạt động:
Khi gửi hàm dfs_search_v1 có lỗi, bạn không chỉ nhận được một câu trả lời. Bạn đang chứng kiến quy trình nhiều tác nhân hoạt động. Đầu ra phát trực tuyến mà bạn thấy là kết quả của 4 tác nhân chuyên biệt thực thi theo trình tự, mỗi tác nhân đều dựa trên tác nhân trước đó.
Sau đây là thông tin chi tiết về những gì mà mỗi tác nhân đóng góp vào quy trình đánh giá toàn diện cuối cùng, biến dữ liệu thô thành thông tin chi tiết hữu ích.
1. Báo cáo cấu trúc của Trình phân tích mã
Trước tiên, tác nhân CodeAnalyzer sẽ nhận được mã thô. Công cụ này không đoán chức năng của mã mà sử dụng công cụ analyze_code_structure để thực hiện một quy trình phân tích Cây cú pháp trừu tượng (AST) mang tính xác định.
Đầu ra của nó là dữ liệu thuần tuý, thực tế về cấu trúc của mã:
The analysis of the provided code reveals the following:
Summary:
- Functions Found: 1
- Classes Found: 0
Key Structural Observations:
- A single function, dfs_search_v1, is defined.
- It includes a docstring: "Find if target is reachable from start."
- No syntax errors were detected.
Overall Code Organization Assessment:
- The code snippet is a well-defined, self-contained function.
⭐ Giá trị: Bước ban đầu này cung cấp một nền tảng rõ ràng và đáng tin cậy cho các tác nhân khác. Công cụ này xác nhận rằng mã là Python hợp lệ và xác định chính xác những thành phần cần được xem xét.
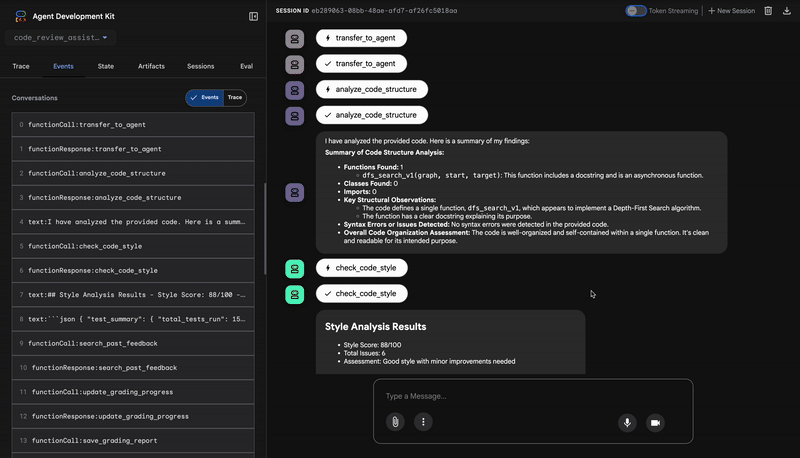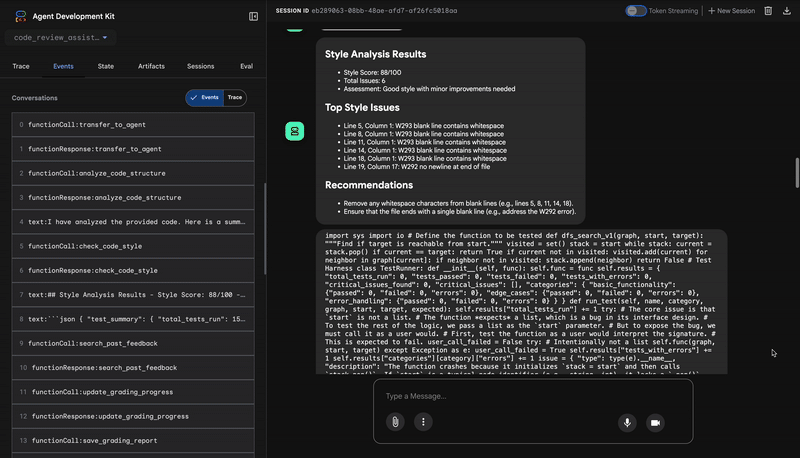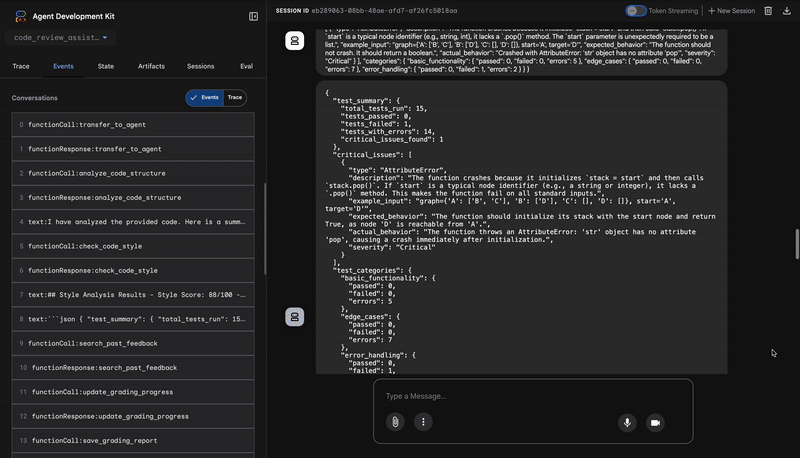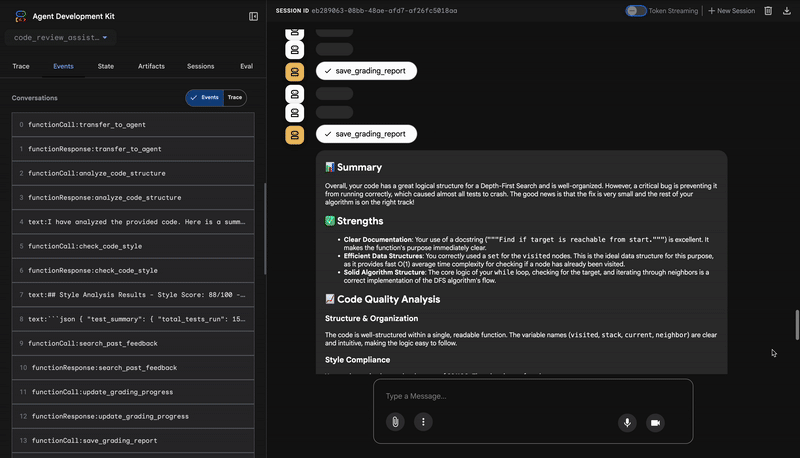
2. Kiểm tra PEP 8 của Trình kiểm tra kiểu
Tiếp theo, tác nhân StyleChecker sẽ tiếp quản. Nó đọc mã từ trạng thái dùng chung và sử dụng công cụ check_code_style, tận dụng trình kiểm tra pycodestyle.
Kết quả của công cụ này là điểm chất lượng có thể định lượng và các lỗi vi phạm cụ thể:
Style Analysis Results
- Style Score: 88/100
- Total Issues: 6
- Assessment: Good style with minor improvements needed
Top Style Issues
- Line 5, W293: blank line contains whitespace
- Line 19, W292: no newline at end of file
⭐ Giá trị: Đặc vụ này đưa ra ý kiến phản hồi khách quan, không thể thương lượng dựa trên các tiêu chuẩn cộng đồng đã được thiết lập (PEP 8). Hệ thống tính điểm có trọng số sẽ cho người dùng biết ngay mức độ nghiêm trọng của các vấn đề.
3. Phát hiện lỗi nghiêm trọng của Trình chạy kiểm thử
Đây là lúc hệ thống phân tích sâu hơn. Tác nhân TestRunner tạo và thực thi một bộ kiểm thử toàn diện để xác thực hành vi của mã.
Đầu ra của công cụ này là một đối tượng JSON có cấu trúc chứa một phán quyết bất lợi:
{
"critical_issues": [
{
"type": "Critical Bug",
"description": "The function's initialization `stack = start` is incorrect... When a common input like a string... is provided... the function crashes with an AttributeError.",
"severity": "Critical"
}
],
"verdict": {
"status": "BROKEN",
"confidence": "high",
"recommendation": "The function is fundamentally broken... the stack initialization line `stack = start` must be changed to `stack = [start]`."
}
}
⭐ Giá trị: Đây là thông tin chi tiết quan trọng nhất. Không chỉ đoán, tác nhân này còn chứng minh mã bị hỏng bằng cách chạy mã đó. Công cụ này đã phát hiện ra một lỗi thời gian chạy tinh vi nhưng nghiêm trọng mà người đánh giá thủ công có thể dễ dàng bỏ qua, đồng thời xác định chính xác nguyên nhân và bản sửa lỗi cần thiết.
4. Báo cáo cuối cùng của Trình tổng hợp ý kiến phản hồi
Cuối cùng, tác nhân FeedbackSynthesizer đóng vai trò là người điều phối. Công cụ này lấy dữ liệu có cấu trúc từ 3 tác nhân trước đó và tạo ra một báo cáo duy nhất, thân thiện với người dùng, vừa mang tính phân tích vừa mang tính khích lệ.
Kết quả đầu ra là bài đánh giá hoàn chỉnh và trau chuốt mà bạn thấy:
📊 Summary
Great effort on implementing the Depth-First Search algorithm! ... However, a critical bug in the initialization of the stack prevents the function from working correctly...
✅ Strengths
- Good Algorithm Structure
- Correct Use of `visited` Set
📈 Code Quality Analysis
...
### Style Compliance
The style analysis returned a good score of 88/100.
...
### Test Results
The automated testing revealed a critical issue... The line `stack = start` directly assigns the input... which results in an `AttributeError`.
💡 Recommendations for Improvement
**Fix the Critical Stack Initialization Bug:**
- Incorrect Code: `stack = start`
- Correct Code: `stack = [start]`
💬 Encouragement
You are very close to a perfect implementation! The core logic of your DFS algorithm is sound, which is the hardest part.
⭐ Giá trị: Đặc vụ này biến dữ liệu kỹ thuật thành một trải nghiệm hữu ích và mang tính giáo dục. Nó ưu tiên vấn đề quan trọng nhất (lỗi), giải thích rõ ràng, đưa ra giải pháp chính xác và làm như vậy với giọng điệu khích lệ. Giai đoạn này tích hợp thành công các phát hiện từ tất cả các giai đoạn trước đó thành một tổng thể gắn kết và có giá trị.
Quy trình nhiều giai đoạn này cho thấy sức mạnh của một quy trình dựa trên tác nhân. Thay vì một câu trả lời duy nhất, nguyên khối, bạn sẽ nhận được một bản phân tích theo lớp, trong đó mỗi tác nhân thực hiện một nhiệm vụ chuyên biệt, có thể xác minh. Điều này dẫn đến một bài đánh giá không chỉ sâu sắc mà còn mang tính quyết định, đáng tin cậy và có tính giáo dục cao.
👉💻 Sau khi kiểm thử xong, hãy quay lại thiết bị đầu cuối Cloud Shell Editor rồi nhấn Ctrl+C để dừng ADK Dev UI.
Những gì bạn đã tạo
Giờ đây, bạn đã có một quy trình xem xét mã hoàn chỉnh, bao gồm:
✅ Phân tích cú pháp cấu trúc mã – phân tích AST xác định bằng các hàm trợ giúp
✅ Kiểm tra kiểu – tính điểm có trọng số theo quy ước đặt tên
✅ Chạy kiểm thử – tạo kiểm thử toàn diện bằng đầu ra JSON có cấu trúc
✅ Tổng hợp ý kiến phản hồi – tích hợp trạng thái + bộ nhớ + cấu phần phần mềm
✅ Theo dõi tiến trình – trạng thái nhiều cấp trên các lệnh gọi/phiên/người dùng
✅ Học hỏi theo thời gian – dịch vụ bộ nhớ cho các mẫu trên nhiều phiên
✅ Cung cấp cấu phần phần mềm – báo cáo JSON có thể tải xuống với nhật ký kiểm tra đầy đủ
Các khái niệm chính đã thành thạo
Các quy trình tuần tự:
- Bốn tác nhân thực thi theo thứ tự nghiêm ngặt
- Mỗi trạng thái làm phong phú cho trạng thái tiếp theo
- Các phần phụ thuộc xác định trình tự thực thi
Mẫu sản xuất:
- Tách hàm trợ giúp (đồng bộ hoá trong nhóm luồng)
- Xuống cấp nhẹ (chiến lược dự phòng)
- Quản lý trạng thái nhiều tầng (tạm thời/phiên/người dùng)
- Nhà cung cấp hướng dẫn linh động (nhận biết bối cảnh)
- Bộ nhớ kép (hiện vật + dự phòng trạng thái)
Trạng thái dưới dạng Thông tin liên lạc:
- Hằng số giúp ngăn lỗi chính tả trên các tác nhân
output_keyghi nội dung tóm tắt của tác nhân vào trạng thái- Các tác nhân sau đó đọc thông qua StateKey
- Trạng thái chảy tuyến tính qua quy trình
Bộ nhớ so với Trạng thái:
- Trạng thái: dữ liệu phiên hiện tại
- Bộ nhớ: các mẫu trên các phiên
- Mục đích khác nhau, thời gian tồn tại khác nhau
Điều phối công cụ:
- Tác nhân một công cụ (analyzer, style_checker)
- Trình thực thi tích hợp (test_runner)
- Phối hợp nhiều công cụ (trình tạo nhạc)
Chiến lược lựa chọn mô hình:
- Mô hình worker: các tác vụ cơ học (phân tích cú pháp, kiểm tra lỗi, định tuyến)
- Mô hình đánh giá: các nhiệm vụ suy luận (kiểm thử, tổng hợp)
- Tối ưu hoá chi phí thông qua việc lựa chọn phù hợp
Tiếp theo là gì?
Trong Mô-đun 6, bạn sẽ tạo quy trình sửa lỗi:
- Cấu trúc LoopAgent để sửa lỗi lặp đi lặp lại
- Điều kiện thoát thông qua việc chuyển lên cấp trên
- Tích luỹ trạng thái qua các lần lặp
- Xác thực và logic thử lại
- Tích hợp với quy trình đánh giá để cung cấp các bản sửa lỗi
Bạn sẽ thấy cách các mẫu trạng thái tương tự mở rộng sang các quy trình lặp phức tạp, trong đó các tác nhân thử nhiều lần cho đến khi thành công, cũng như cách điều phối nhiều quy trình trong một ứng dụng duy nhất.
6. Thêm quy trình sửa lỗi: Cấu trúc vòng lặp
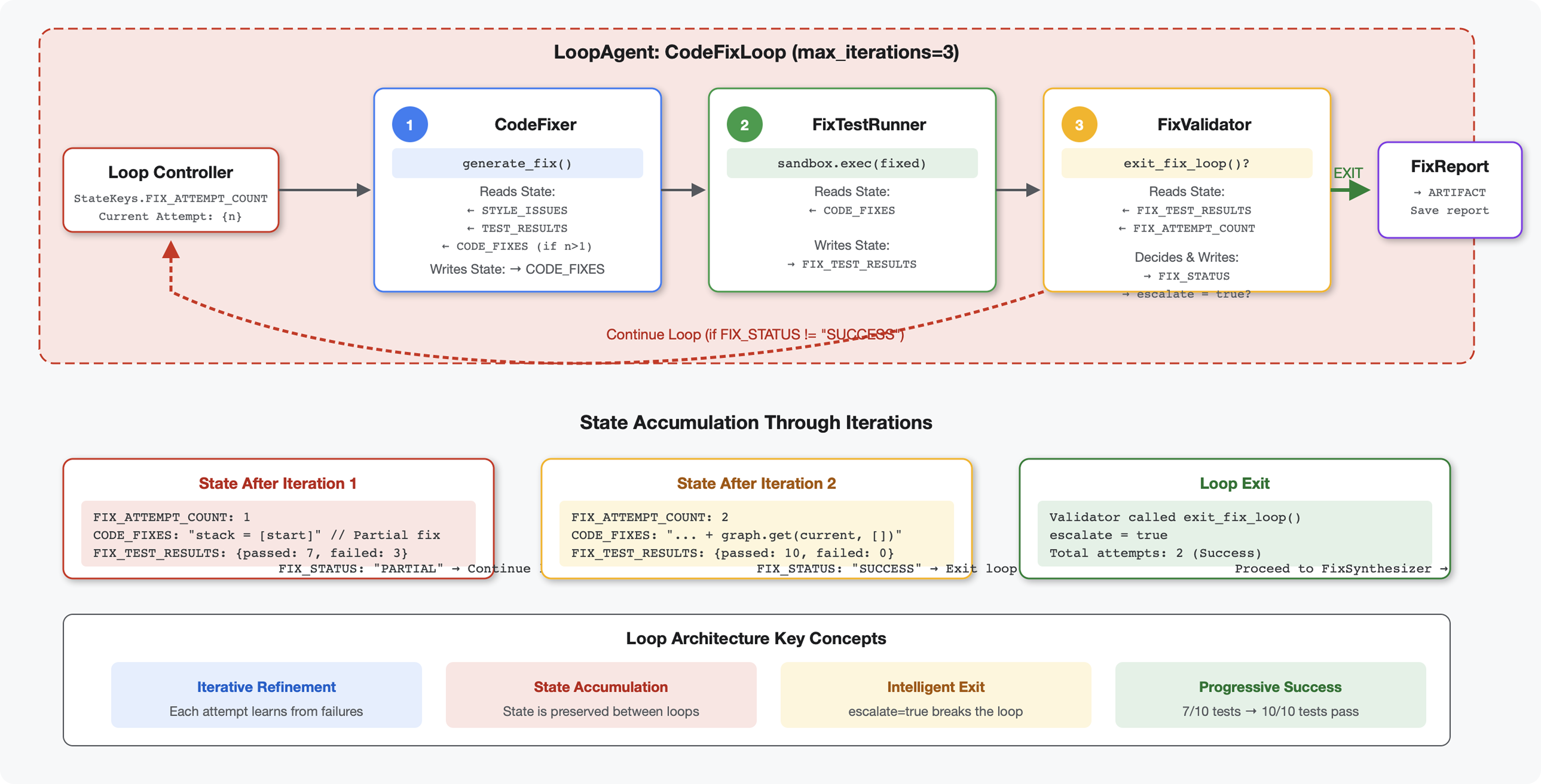
Giới thiệu
Trong Mô-đun 5, bạn đã tạo một quy trình đánh giá tuần tự để phân tích mã và cung cấp ý kiến phản hồi. Tuy nhiên, việc xác định vấn đề chỉ là một nửa giải pháp – nhà phát triển cần được trợ giúp để khắc phục vấn đề.
Mô-đun này tạo một quy trình khắc phục tự động để:
- Tạo bản sửa lỗi dựa trên kết quả xem xét
- Xác thực bản sửa lỗi bằng cách chạy các quy trình kiểm thử toàn diện
- Tự động thử lại nếu các biện pháp khắc phục không hiệu quả (tối đa 3 lần)
- Kết quả báo cáo có thông tin so sánh trước/sau
Khái niệm chính: LoopAgent để tự động thử lại. Không giống như các tác nhân tuần tự chỉ chạy một lần, LoopAgent sẽ lặp lại các tác nhân phụ cho đến khi đáp ứng điều kiện thoát hoặc đạt đến số lần lặp tối đa. Các công cụ báo hiệu trạng thái thành công bằng cách đặt tool_context.actions.escalate = True.
Xem trước những gì bạn sẽ tạo: Gửi mã có lỗi → xem xét để xác định vấn đề → vòng lặp sửa lỗi tạo ra các nội dung sửa lỗi → các bài kiểm thử xác thực → thử lại nếu cần → báo cáo toàn diện cuối cùng.
Các khái niệm cốt lõi: LoopAgent so với Sequential
Quy trình tuần tự (Mô-đun 5):
SequentialAgent(agents=[A, B, C])
# Executes: A → B → C → Done
- Luồng một chiều
- Mỗi tác nhân chạy chính xác một lần
- Không có logic thử lại
Loop Pipeline (Mô-đun 6):
LoopAgent(agents=[A, B, C], max_iterations=3)
# Executes: A → B → C → (check exit) → A → B → C → (check exit) → ...
- Dòng chảy tuần hoàn
- Các tác nhân có thể chạy nhiều lần
- Thoát khi:
- Một công cụ đặt
tool_context.actions.escalate = True(thành công) - Đã đạt đến
max_iterations(giới hạn an toàn) - Đã xảy ra ngoại lệ chưa được xử lý (lỗi)
- Một công cụ đặt
Lý do cần dùng vòng lặp để sửa mã:
Bạn thường phải thử nhiều lần để sửa mã:
- Lần thử đầu tiên: Sửa các lỗi rõ ràng (loại biến không chính xác)
- Lần thử thứ hai: Khắc phục các vấn đề thứ yếu được phát hiện qua các thử nghiệm (trường hợp đặc biệt)
- Lần thử thứ ba: Tinh chỉnh và xác thực tất cả các bài kiểm thử đều đạt
Nếu không có vòng lặp, bạn sẽ cần logic điều kiện phức tạp trong hướng dẫn cho nhân viên hỗ trợ. Với LoopAgent, quá trình thử lại sẽ diễn ra tự động.
So sánh cấu trúc:
Sequential (Module 5):
User → Review Pipeline → Feedback → Done
Loop (Module 6):
User → Review Pipeline → Feedback → Fix Pipeline
↓
┌──────────────┴──────────────┐
│ Fix Attempt Loop (1-3x) │
│ ┌─────────────────────┐ │
│ │ 1. Generate Fixes │ │
│ │ 2. Test Fixes │ │
│ │ 3. Validate & Exit? │────┼─→ If escalate=True
│ └─────────────────────┘ │ exit loop
│ ↓ If not │
│ Try Again (max 3) │
└─────────────────────────────┘
↓
4. Synthesize Final Report → Done
Bước 1: Thêm Code Fixer Agent
Trình sửa mã tạo mã Python đã sửa dựa trên kết quả đánh giá.
👉 Mở
code_review_assistant/sub_agents/fix_pipeline/code_fixer.py
👉 Tìm:
# MODULE_6_STEP_1_CODE_FIXER_INSTRUCTION_PROVIDER
👉 Thay thế dòng đó bằng:
async def code_fixer_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are an expert code fixing specialist.
Original Code:
{code_to_review}
Analysis Results:
- Style Score: {style_score}/100
- Style Issues: {style_issues}
- Test Results: {test_execution_summary}
Based on the test results, identify and fix ALL issues including:
- Interface bugs (e.g., if start parameter expects wrong type)
- Logic errors (e.g., KeyError when accessing graph nodes)
- Style violations
- Missing documentation
YOUR TASK:
Generate the complete fixed Python code that addresses all identified issues.
CRITICAL INSTRUCTIONS:
- Output ONLY the corrected Python code
- Do NOT include markdown code blocks (```python)
- Do NOT include any explanations or commentary
- The output should be valid, executable Python code and nothing else
Common fixes to apply based on test results:
- If tests show AttributeError with 'pop', fix: stack = [start] instead of stack = start
- If tests show KeyError accessing graph, fix: use graph.get(current, [])
- Add docstrings if missing
- Fix any style violations identified
Output the complete fixed code now:"""
return await instructions_utils.inject_session_state(template, context)
👉 Tìm:
# MODULE_6_STEP_1_CODE_FIXER_AGENT
👉 Thay thế dòng đó bằng:
code_fixer_agent = Agent(
name="CodeFixer",
model=config.worker_model,
description="Generates comprehensive fixes for all identified code issues",
instruction=code_fixer_instruction_provider,
code_executor=BuiltInCodeExecutor(),
output_key="code_fixes"
)
Bước 2: Thêm Fix Test Runner Agent
Trình chạy kiểm thử sửa lỗi sẽ xác thực các nội dung sửa lỗi bằng cách thực hiện các kiểm thử toàn diện trên mã đã sửa.
👉 Mở
code_review_assistant/sub_agents/fix_pipeline/fix_test_runner.py
👉 Tìm:
# MODULE_6_STEP_2_FIX_TEST_RUNNER_INSTRUCTION_PROVIDER
👉 Thay thế dòng đó bằng:
async def fix_test_runner_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that uses the clean code from the previous step."""
template = """You are responsible for validating the fixed code by running tests.
THE FIXED CODE TO TEST:
{code_fixes}
ORIGINAL TEST RESULTS: {test_execution_summary}
YOUR TASK:
1. Understand the fixes that were applied
2. Generate the same comprehensive tests (15-20 test cases)
3. Execute the tests on the FIXED code using your code executor
4. Compare results with original test results
5. Output a detailed JSON analysis
TESTING METHODOLOGY:
- Run the same tests that revealed issues in the original code
- Verify that previously failing tests now pass
- Ensure no regressions were introduced
- Document the improvement
Execute your tests and output ONLY valid JSON with this structure:
- "passed": number of tests that passed
- "failed": number of tests that failed
- "total": total number of tests
- "pass_rate": percentage as a number
- "comparison": object with "original_pass_rate", "new_pass_rate", "improvement"
- "newly_passing_tests": array of test names that now pass
- "still_failing_tests": array of test names still failing
Do NOT output the test code itself, only the JSON analysis."""
return await instructions_utils.inject_session_state(template, context)
👉 Tìm:
# MODULE_6_STEP_2_FIX_TEST_RUNNER_AGENT
👉 Thay thế dòng đó bằng:
fix_test_runner_agent = Agent(
name="FixTestRunner",
model=config.critic_model,
description="Runs comprehensive tests on fixed code to verify all issues are resolved",
instruction=fix_test_runner_instruction_provider,
code_executor=BuiltInCodeExecutor(),
output_key="fix_test_execution_summary"
)
Bước 3: Thêm Fix Validator Agent
Trình xác thực sẽ kiểm tra xem các bản sửa lỗi có thành công hay không và quyết định có thoát khỏi vòng lặp hay không.
Tìm hiểu về các công cụ
Trước tiên, hãy thêm 3 công cụ mà trình xác thực cần.
👉 Mở
code_review_assistant/tools.py
👉 Tìm:
# MODULE_6_STEP_3_VALIDATE_FIXED_STYLE
👉 Thay thế bằng Công cụ 1 – Trình xác thực kiểu:
async def validate_fixed_style(tool_context: ToolContext) -> Dict[str, Any]:
"""
Validates style compliance of the fixed code.
Args:
tool_context: ADK tool context containing fixed code in state
Returns:
Dictionary with style validation results
"""
logger.info("Tool: Validating style of fixed code...")
try:
# Get the fixed code from state
code_fixes = tool_context.state.get(StateKeys.CODE_FIXES, '')
# Try to extract from markdown if present
if '```python' in code_fixes:
start = code_fixes.rfind('```python') + 9
end = code_fixes.rfind('```')
if start < end:
code_fixes = code_fixes[start:end].strip()
if not code_fixes:
return {
"status": "error",
"message": "No fixed code found in state"
}
# Store the extracted fixed code
tool_context.state[StateKeys.CODE_FIXES] = code_fixes
# Run style check on fixed code
loop = asyncio.get_event_loop()
with ThreadPoolExecutor() as executor:
style_result = await loop.run_in_executor(
executor, _perform_style_check, code_fixes
)
# Compare with original
original_score = tool_context.state.get(StateKeys.STYLE_SCORE, 0)
improvement = style_result['score'] - original_score
# Store results
tool_context.state[StateKeys.FIXED_STYLE_SCORE] = style_result['score']
tool_context.state[StateKeys.FIXED_STYLE_ISSUES] = style_result['issues']
logger.info(f"Tool: Fixed code style score: {style_result['score']}/100 "
f"(improvement: +{improvement})")
return {
"status": "success",
"fixed_style_score": style_result['score'],
"original_style_score": original_score,
"improvement": improvement,
"remaining_issues": style_result['issues'],
"perfect_style": style_result['score'] == 100
}
except Exception as e:
logger.error(f"Tool: Style validation failed: {e}", exc_info=True)
return {
"status": "error",
"message": str(e)
}
👉 Tìm:
# MODULE_6_STEP_3_COMPILE_FIX_REPORT
👉 Thay thế bằng Công cụ 2 – Trình biên dịch báo cáo:
async def compile_fix_report(tool_context: ToolContext) -> Dict[str, Any]:
"""
Compiles comprehensive report of the fix process.
Args:
tool_context: ADK tool context with all fix pipeline data
Returns:
Comprehensive fix report
"""
logger.info("Tool: Compiling comprehensive fix report...")
try:
# Gather all data
original_code = tool_context.state.get(StateKeys.CODE_TO_REVIEW, '')
code_fixes = tool_context.state.get(StateKeys.CODE_FIXES, '')
# Test results
original_tests = tool_context.state.get(StateKeys.TEST_EXECUTION_SUMMARY, {})
fixed_tests = tool_context.state.get(StateKeys.FIX_TEST_EXECUTION_SUMMARY, {})
# Parse if strings
if isinstance(original_tests, str):
try:
original_tests = json.loads(original_tests)
except:
original_tests = {}
if isinstance(fixed_tests, str):
try:
fixed_tests = json.loads(fixed_tests)
except:
fixed_tests = {}
# Extract pass rates
original_pass_rate = 0
if original_tests:
if 'pass_rate' in original_tests:
original_pass_rate = original_tests['pass_rate']
elif 'test_summary' in original_tests:
# Handle test_runner_agent's JSON structure
summary = original_tests['test_summary']
total = summary.get('total_tests_run', 0)
passed = summary.get('tests_passed', 0)
if total > 0:
original_pass_rate = (passed / total) * 100
elif 'passed' in original_tests and 'total' in original_tests:
if original_tests['total'] > 0:
original_pass_rate = (original_tests['passed'] / original_tests['total']) * 100
fixed_pass_rate = 0
all_tests_pass = False
if fixed_tests:
if 'pass_rate' in fixed_tests:
fixed_pass_rate = fixed_tests['pass_rate']
all_tests_pass = fixed_tests.get('failed', 1) == 0
elif 'passed' in fixed_tests and 'total' in fixed_tests:
if fixed_tests['total'] > 0:
fixed_pass_rate = (fixed_tests['passed'] / fixed_tests['total']) * 100
all_tests_pass = fixed_tests.get('failed', 0) == 0
# Style scores
original_style = tool_context.state.get(StateKeys.STYLE_SCORE, 0)
fixed_style = tool_context.state.get(StateKeys.FIXED_STYLE_SCORE, 0)
# Calculate improvements
test_improvement = {
'original_pass_rate': original_pass_rate,
'fixed_pass_rate': fixed_pass_rate,
'improvement': fixed_pass_rate - original_pass_rate,
'all_tests_pass': all_tests_pass
}
style_improvement = {
'original_score': original_style,
'fixed_score': fixed_style,
'improvement': fixed_style - original_style,
'perfect_style': fixed_style == 100
}
# Determine overall status
if all_tests_pass and style_improvement['perfect_style']:
fix_status = 'SUCCESSFUL'
status_emoji = '✅'
elif test_improvement['improvement'] > 0 or style_improvement['improvement'] > 0:
fix_status = 'PARTIAL'
status_emoji = '⚠️'
else:
fix_status = 'FAILED'
status_emoji = '❌'
# Build comprehensive report
report = {
'status': fix_status,
'status_emoji': status_emoji,
'timestamp': datetime.now().isoformat(),
'original_code': original_code,
'code_fixes': code_fixes,
'improvements': {
'tests': test_improvement,
'style': style_improvement
},
'summary': f"{status_emoji} Fix Status: {fix_status}\n"
f"Tests: {original_pass_rate:.1f}% → {fixed_pass_rate:.1f}%\n"
f"Style: {original_style}/100 → {fixed_style}/100"
}
# Store report in state
tool_context.state[StateKeys.FIX_REPORT] = report
tool_context.state[StateKeys.FIX_STATUS] = fix_status
logger.info(f"Tool: Fix report compiled - Status: {fix_status}")
logger.info(f"Tool: Test improvement: {original_pass_rate:.1f}% → {fixed_pass_rate:.1f}%")
logger.info(f"Tool: Style improvement: {original_style} → {fixed_style}")
return {
"status": "success",
"fix_status": fix_status,
"report": report
}
except Exception as e:
logger.error(f"Tool: Failed to compile fix report: {e}", exc_info=True)
return {
"status": "error",
"message": str(e)
}
👉 Tìm:
# MODULE_6_STEP_3_EXIT_FIX_LOOP
👉 Thay thế bằng Công cụ 3 – Tín hiệu thoát vòng lặp:
def exit_fix_loop(tool_context: ToolContext) -> Dict[str, Any]:
"""
Signal that fixing is complete and should exit the loop.
Args:
tool_context: ADK tool context
Returns:
Confirmation message
"""
logger.info("Tool: Setting escalate flag to exit fix loop")
# This is the critical line that exits the LoopAgent
tool_context.actions.escalate = True
return {
"status": "success",
"message": "Fix complete, exiting loop"
}
Tạo Trình xác thực
👉 Mở
code_review_assistant/sub_agents/fix_pipeline/fix_validator.py
👉 Tìm:
# MODULE_6_STEP_3_FIX_VALIDATOR_INSTRUCTION_PROVIDER
👉 Thay thế dòng đó bằng:
async def fix_validator_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are the final validation specialist for code fixes.
You have access to:
- Original issues from initial review
- Applied fixes: {code_fixes}
- Test results after fix: {fix_test_execution_summary}
- All state data from the fix process
Your responsibilities:
1. Use validate_fixed_style tool to check style compliance of fixed code
- Pass no arguments, it will retrieve fixed code from state
2. Use compile_fix_report tool to generate comprehensive report
- Pass no arguments, it will gather all data from state
3. Based on the report, determine overall fix status:
- ✅ SUCCESSFUL: All tests pass, style score 100
- ⚠️ PARTIAL: Improvements made but issues remain
- ❌ FAILED: Fix didn't work or made things worse
4. CRITICAL: If status is SUCCESSFUL, call the exit_fix_loop tool to stop iterations
- This prevents unnecessary additional fix attempts
- If not successful, the loop will continue for another attempt
5. Provide clear summary of:
- What was fixed
- What improvements were achieved
- Any remaining issues requiring manual attention
Be precise and quantitative in your assessment.
"""
return await instructions_utils.inject_session_state(template, context)
👉 Tìm:
# MODULE_6_STEP_3_FIX_VALIDATOR_AGENT
👉 Thay thế dòng đó bằng:
fix_validator_agent = Agent(
name="FixValidator",
model=config.worker_model,
description="Validates fixes and generates final fix report",
instruction=fix_validator_instruction_provider,
tools=[
FunctionTool(func=validate_fixed_style),
FunctionTool(func=compile_fix_report),
FunctionTool(func=exit_fix_loop)
],
output_key="final_fix_report"
)
Bước 4: Tìm hiểu các điều kiện thoát LoopAgent
LoopAgent có 3 cách để thoát:
1. Thoát thành công (thông qua tính năng chuyển yêu cầu lên cấp)
# Inside any tool in the loop:
tool_context.actions.escalate = True
# Effect: Loop completes current iteration, then exits
# Use when: Fix is successful and no more attempts needed
Ví dụ về quy trình:
Iteration 1:
CodeFixer → generates fixes
FixTestRunner → tests show 90% pass rate
FixValidator → compiles report, sees PARTIAL status
→ Does NOT set escalate
→ Loop continues
Iteration 2:
CodeFixer → refines fixes based on failures
FixTestRunner → tests show 100% pass rate
FixValidator → compiles report, sees SUCCESSFUL status
→ Calls exit_fix_loop() which sets escalate = True
→ Loop exits after this iteration
2. Max Iterations Exit (Thoát sau số lần lặp tối đa)
LoopAgent(
name="FixAttemptLoop",
sub_agents=[...],
max_iterations=3 # Safety limit
)
# Effect: After 3 complete iterations, loop exits regardless of escalate
# Use when: Prevent infinite loops if fixes never succeed
Ví dụ về quy trình:
Iteration 1: PARTIAL (continue)
Iteration 2: PARTIAL (continue)
Iteration 3: PARTIAL (but max reached)
→ Loop exits, synthesizer presents best attempt
3. Lỗi thoát
# If any agent throws unhandled exception:
raise Exception("Unexpected error")
# Effect: Loop exits immediately with error state
# Use when: Critical failure that can't be recovered
Sự phát triển trạng thái qua các lần lặp:
Mỗi lần lặp lại sẽ thấy trạng thái được cập nhật từ lần thử trước:
# Before Iteration 1:
state = {
"code_to_review": "def add(a,b):return a+b", # Original
"style_score": 40,
"test_execution_summary": {...}
}
# After Iteration 1:
state = {
"code_to_review": "def add(a,b):return a+b", # Unchanged
"code_fixes": "def add(a, b):\n return a + b", # NEW
"style_score": 40, # Unchanged
"fixed_style_score": 100, # NEW
"test_execution_summary": {...}, # Unchanged
"fix_test_execution_summary": {...} # NEW
}
# Iteration 2 starts with all this state
# If fixes still not perfect, code_fixes gets overwritten
Lý do
escalate
Thay vì Giá trị trả về:
# Bad: Using return value to signal exit
def validator_agent():
report = compile_report()
if report['status'] == 'SUCCESSFUL':
return {"exit": True} # How does loop know?
# Good: Using escalate
def validator_tool(tool_context):
report = compile_report()
if report['status'] == 'SUCCESSFUL':
tool_context.actions.escalate = True # Loop knows immediately
return {"report": report}
Lợi ích:
- Hoạt động trên mọi công cụ, chứ không chỉ công cụ gần đây nhất
- Không ảnh hưởng đến dữ liệu trả về
- Ý nghĩa ngữ nghĩa rõ ràng
- Khung xử lý logic thoát
Bước 5: Kết nối Fix Pipeline
👉 Mở
code_review_assistant/agent.py
👉 Thêm các lệnh nhập quy trình sửa lỗi (sau các lệnh nhập hiện có):
from google.adk.agents import LoopAgent # Add this to the existing Agent, SequentialAgent line
from code_review_assistant.sub_agents.fix_pipeline.code_fixer import code_fixer_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_test_runner import fix_test_runner_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_validator import fix_validator_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_synthesizer import fix_synthesizer_agent
Các lệnh nhập của bạn bây giờ sẽ là:
from google.adk.agents import Agent, SequentialAgent, LoopAgent
from .config import config
# Review pipeline imports (from Module 5)
from code_review_assistant.sub_agents.review_pipeline.code_analyzer import code_analyzer_agent
from code_review_assistant.sub_agents.review_pipeline.style_checker import style_checker_agent
from code_review_assistant.sub_agents.review_pipeline.test_runner import test_runner_agent
from code_review_assistant.sub_agents.review_pipeline.feedback_synthesizer import feedback_synthesizer_agent
# Fix pipeline imports (NEW)
from code_review_assistant.sub_agents.fix_pipeline.code_fixer import code_fixer_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_test_runner import fix_test_runner_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_validator import fix_validator_agent
from code_review_assistant.sub_agents.fix_pipeline.fix_synthesizer import fix_synthesizer_agent
👉 Tìm:
# MODULE_6_STEP_5_CREATE_FIX_LOOP
👉 Thay thế dòng đó bằng:
# Create the fix attempt loop (retries up to 3 times)
fix_attempt_loop = LoopAgent(
name="FixAttemptLoop",
sub_agents=[
code_fixer_agent, # Step 1: Generate fixes
fix_test_runner_agent, # Step 2: Validate with tests
fix_validator_agent # Step 3: Check success & possibly exit
],
max_iterations=3 # Try up to 3 times
)
# Wrap loop with synthesizer for final report
code_fix_pipeline = SequentialAgent(
name="CodeFixPipeline",
description="Automated code fixing pipeline with iterative validation",
sub_agents=[
fix_attempt_loop, # Try to fix (1-3 times)
fix_synthesizer_agent # Present final results (always runs once)
]
)
👉 Xoá hiện có
root_agent
định nghĩa:
root_agent = Agent(...)
👉 Tìm:
# MODULE_6_STEP_5_UPDATE_ROOT_AGENT
👉 Thay thế dòng đó bằng:
# Update root agent to include both pipelines
root_agent = Agent(
name="CodeReviewAssistant",
model=config.worker_model,
description="An intelligent code review assistant that analyzes Python code and provides educational feedback",
instruction="""You are a specialized Python code review assistant focused on helping developers improve their code quality.
When a user provides Python code for review:
1. Immediately delegate to CodeReviewPipeline and pass the code EXACTLY as it was provided by the user.
2. The pipeline will handle all analysis and feedback
3. Return ONLY the final feedback from the pipeline - do not add any commentary
After completing a review, if significant issues were identified:
- If style score < 100 OR tests are failing OR critical issues exist:
* Add at the end: "\n\n💡 I can fix these issues for you. Would you like me to do that?"
- If the user responds yes or requests fixes:
* Delegate to CodeFixPipeline
* Return the fix pipeline's complete output AS-IS
When a user asks what you can do or general questions:
- Explain your capabilities for code review and fixing
- Do NOT trigger the pipeline for non-code messages
The pipelines handle everything for code review and fixing - just pass through their final output.""",
sub_agents=[code_review_pipeline, code_fix_pipeline],
output_key="assistant_response"
)
Bước 6: Thêm Fix Synthesizer Agent
Trình tổng hợp tạo ra một bản trình bày thân thiện với người dùng về kết quả sửa lỗi sau khi vòng lặp hoàn tất.
👉 Mở
code_review_assistant/sub_agents/fix_pipeline/fix_synthesizer.py
👉 Tìm:
# MODULE_6_STEP_6_FIX_SYNTHESIZER_INSTRUCTION_PROVIDER
👉 Thay thế dòng đó bằng:
async def fix_synthesizer_instruction_provider(context: ReadonlyContext) -> str:
"""Dynamic instruction provider that injects state variables."""
template = """You are responsible for presenting the fix results to the user.
Based on the validation report: {final_fix_report}
Fixed code from state: {code_fixes}
Fix status: {fix_status}
Create a comprehensive yet friendly response that includes:
## 🔧 Fix Summary
[Overall status and key improvements - be specific about what was achieved]
## 📊 Metrics
- Test Results: [original pass rate]% → [new pass rate]%
- Style Score: [original]/100 → [new]/100
- Issues Fixed: X of Y
## ✅ What Was Fixed
[List each fixed issue with brief explanation of the correction made]
## 📝 Complete Fixed Code
[Include the complete, corrected code from state - this is critical]
## 💡 Explanation of Key Changes
[Brief explanation of the most important changes made and why]
[If any issues remain]
## ⚠️ Remaining Issues
[List what still needs manual attention]
## 🎯 Next Steps
[Guidance on what to do next - either use the fixed code or address remaining issues]
Save the fix report using save_fix_report tool before presenting.
Call it with no parameters - it will retrieve the report from state automatically.
Be encouraging about improvements while being honest about any remaining issues.
Focus on the educational aspect - help the user understand what was wrong and how it was fixed.
"""
return await instructions_utils.inject_session_state(template, context)
👉 Tìm:
# MODULE_6_STEP_6_FIX_SYNTHESIZER_AGENT
👉 Thay thế dòng đó bằng:
fix_synthesizer_agent = Agent(
name="FixSynthesizer",
model=config.critic_model,
description="Creates comprehensive user-friendly fix report",
instruction=fix_synthesizer_instruction_provider,
tools=[FunctionTool(func=save_fix_report)],
output_key="fix_summary"
)
👉 Thêm
save_fix_report
Công cụ đến
tools.py
:
👉 Tìm:
# MODULE_6_STEP_6_SAVE_FIX_REPORT
👉 Thay thế bằng:
async def save_fix_report(tool_context: ToolContext) -> Dict[str, Any]:
"""
Saves the fix report as an artifact.
Args:
tool_context: ADK tool context
Returns:
Save status
"""
logger.info("Tool: Saving fix report...")
try:
# Get the report from state
fix_report = tool_context.state.get(StateKeys.FIX_REPORT, {})
if not fix_report:
return {
"status": "error",
"message": "No fix report found in state"
}
# Convert to JSON
report_json = json.dumps(fix_report, indent=2)
report_part = types.Part.from_text(text=report_json)
# Generate filename
timestamp = datetime.now().isoformat().replace(':', '-')
filename = f"fix_report_{timestamp}.json"
# Try to save as artifact
if hasattr(tool_context, 'save_artifact'):
try:
version = await tool_context.save_artifact(filename, report_part)
await tool_context.save_artifact("latest_fix_report.json", report_part)
logger.info(f"Tool: Fix report saved as {filename}")
return {
"status": "success",
"filename": filename,
"version": str(version),
"size": len(report_json)
}
except Exception as e:
logger.warning(f"Could not save as artifact: {e}")
# Fallback: store in state
tool_context.state[StateKeys.LAST_FIX_REPORT] = fix_report
return {
"status": "success",
"message": "Fix report saved to state",
"size": len(report_json)
}
except Exception as e:
logger.error(f"Tool: Failed to save fix report: {e}", exc_info=True)
return {
"status": "error",
"message": str(e)
}
Bước 7: Kiểm thử quy trình sửa lỗi hoàn chỉnh
Đã đến lúc xem toàn bộ vòng lặp hoạt động.
👉 Khởi động hệ thống:
adk web code_review_assistant
Sau khi chạy lệnh adk web, bạn sẽ thấy đầu ra trong thiết bị đầu cuối cho biết ADK Web Server đã khởi động, tương tự như sau:
+-----------------------------------------------------------------------------+
| ADK Web Server started |
| |
| For local testing, access at http://localhost:8000. |
+-----------------------------------------------------------------------------+
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
👉 Câu lệnh thử nghiệm:
Please analyze the following:
def dfs_search_v1(graph, start, target):
"""Find if target is reachable from start."""
visited = set()
stack = start
while stack:
current = stack.pop()
if current == target:
return True
if current not in visited:
visited.add(current)
for neighbor in graph[current]:
if neighbor not in visited:
stack.append(neighbor)
return False
Trước tiên, hãy gửi mã có lỗi để kích hoạt quy trình xem xét. Sau khi xác định được các điểm yếu, bạn sẽ yêu cầu tác nhân "Vui lòng sửa mã". Lệnh này sẽ kích hoạt quy trình sửa lỗi mạnh mẽ, lặp đi lặp lại.
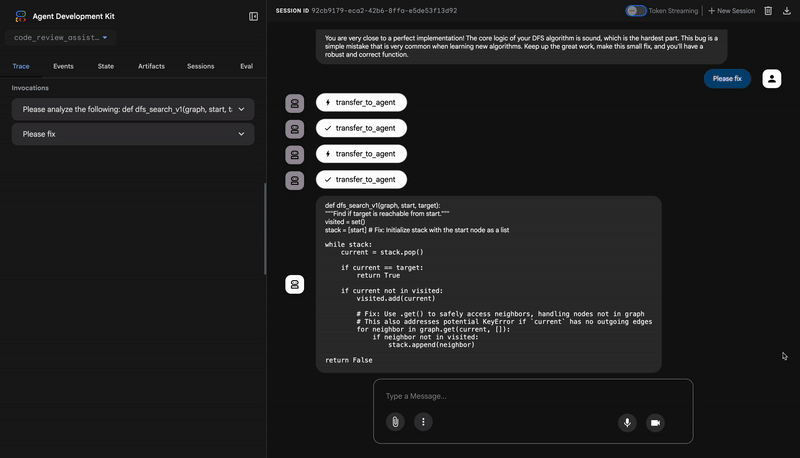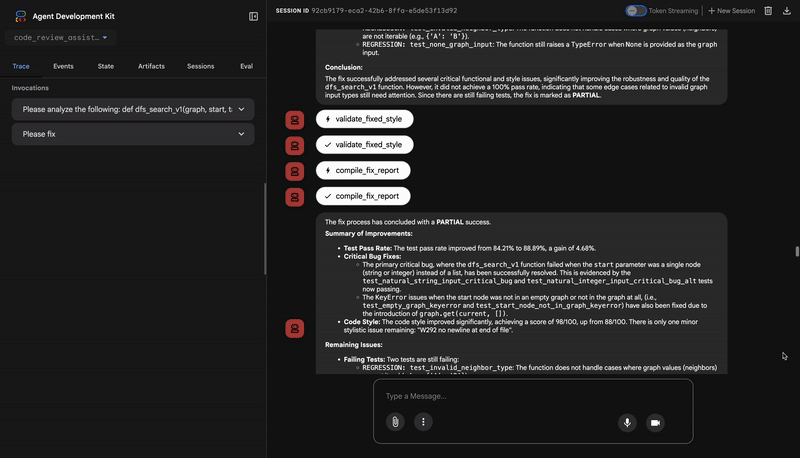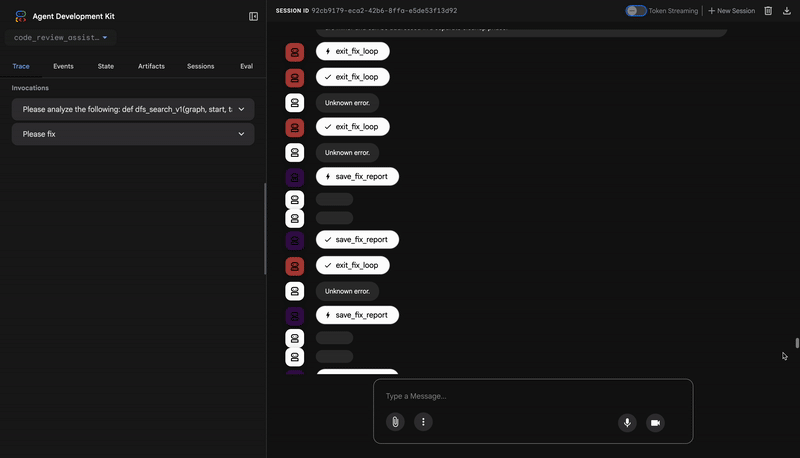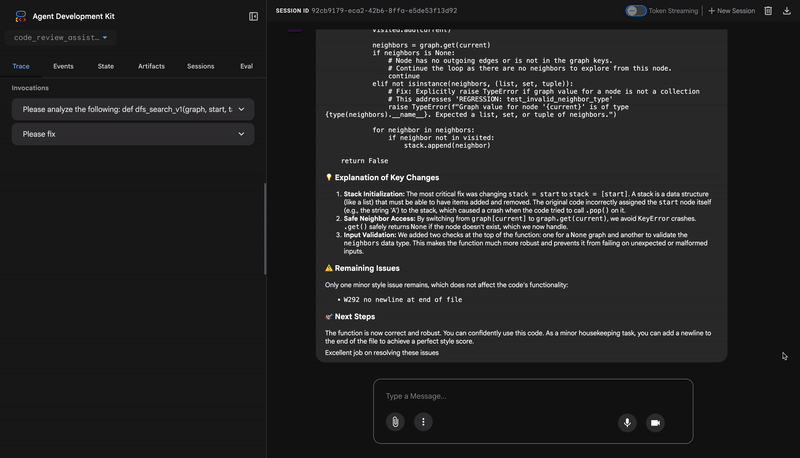
1. Xem xét sơ bộ (Tìm ra điểm yếu)
Đây là nửa đầu của quy trình. Quy trình đánh giá gồm 4 tác nhân sẽ phân tích mã, kiểm tra kiểu mã và chạy một bộ kiểm thử đã tạo. Công cụ này xác định chính xác một AttributeError quan trọng và các vấn đề khác, đưa ra kết quả: mã này BỊ LỖI, với tỷ lệ vượt qua kiểm thử chỉ là 84,21%.
2. Bản sửa lỗi tự động (Vòng lặp đang hoạt động)
Đây là phần ấn tượng nhất. Khi bạn yêu cầu tác nhân sửa mã, tác nhân này không chỉ thực hiện một thay đổi. Quá trình này bắt đầu một Vòng lặp sửa lỗi và xác thực lặp đi lặp lại, hoạt động giống như một nhà phát triển siêng năng: quá trình này sẽ thử sửa lỗi, kiểm tra kỹ lưỡng và nếu không hoàn hảo, quá trình này sẽ thử lại.
Lần lặp lại thứ nhất: Lần thử đầu tiên (Thành công một phần)
- Giải pháp:
CodeFixersẽ đọc báo cáo ban đầu và đưa ra những điểm chỉnh sửa rõ ràng nhất. Thao tác này sẽ thay đổistack = startthànhstack = [start]và sử dụnggraph.get()để ngăn các trường hợp ngoại lệKeyError. - Xác thực:
TestRunnerngay lập tức chạy lại bộ kiểm thử đầy đủ đối với mã mới này. - Kết quả: Tỷ lệ vượt qua đã tăng lên đáng kể, đạt 88,89%! Các lỗi nghiêm trọng đã được khắc phục. Tuy nhiên, các kiểm thử này toàn diện đến mức chúng cho thấy 2 lỗi mới, tinh vi (hồi quy) liên quan đến việc xử lý
Nonedưới dạng giá trị lân cận đồ thị hoặc không phải danh sách. Hệ thống đánh dấu bản sửa lỗi là PARTIAL.
Lần lặp lại thứ 2: Hoàn thiện lần cuối (Thành công 100%)
- Cách khắc phục: Vì điều kiện thoát của vòng lặp (tỷ lệ vượt qua là 100%) không được đáp ứng, nên vòng lặp sẽ chạy lại.
CodeFixerhiện có thêm thông tin – 2 lỗi hồi quy mới. Thao tác này sẽ tạo ra phiên bản mã cuối cùng, mạnh mẽ hơn và xử lý rõ ràng những trường hợp đặc biệt đó. - Xác thực:
TestRunnersẽ thực thi bộ kiểm thử lần cuối cùng đối với phiên bản cuối cùng của mã. - Kết quả: Tỷ lệ vượt qua 100% hoàn hảo. Đã giải quyết tất cả lỗi ban đầu và mọi lỗi hồi quy. Hệ thống đánh dấu bản sửa lỗi là THÀNH CÔNG và vòng lặp sẽ thoát.
3. Báo cáo cuối cùng: Điểm tuyệt đối
Sau khi xác thực hoàn toàn bản sửa lỗi, tác nhân FixSynthesizer sẽ tiếp quản để trình bày báo cáo cuối cùng, chuyển đổi dữ liệu kỹ thuật thành bản tóm tắt rõ ràng và mang tính giáo dục.
Chỉ số | Trước | Sau | Cải thiện |
Tỷ lệ đỗ bài kiểm tra | 84,21% | 100% | ▲ 15,79% |
Điểm phong cách | 88 / 100 | 98 / 100 | ▲ 10 điểm |
Các lỗi đã được khắc phục | 0/3 | 3/3 | ✅ |
✅ Mã cuối cùng, đã được xác thực
Sau đây là mã hoàn chỉnh và đã được sửa, hiện đã vượt qua cả 19 bài kiểm thử, cho thấy việc sửa lỗi đã thành công:
def dfs_search_v1(graph, start, target):
"""Find if target is reachable from start."""
# Handles 'None' graph input
if graph is None:
return False
visited = set()
# Fixes the critical AttributeError
stack = [start]
while stack:
current = stack.pop()
if current == target:
return True
if current not in visited:
visited.add(current)
# Safely gets neighbors to prevent KeyError
neighbors = graph.get(current)
if neighbors is None:
continue
# Validates that neighbors are iterable
if not isinstance(neighbors, (list, set, tuple)):
raise TypeError(
f"Graph value for node '{current}' is of type "
f"{type(neighbors).__name__}. Expected a list, set, or tuple."
)
for neighbor in neighbors:
if neighbor not in visited:
stack.append(neighbor)
return False
👉💻 Sau khi kiểm thử xong, hãy quay lại thiết bị đầu cuối Cloud Shell Editor rồi nhấn Ctrl+C để dừng ADK Dev UI.
Những gì bạn đã tạo
Giờ đây, bạn đã có một quy trình sửa lỗi tự động hoàn chỉnh:
✅ Tạo bản sửa lỗi – Dựa trên kết quả phân tích đánh giá
✅ Xác thực lặp lại – Kiểm thử sau mỗi lần sửa lỗi
✅ Tự động thử lại – Tối đa 3 lần thử để thành công
✅ Thoát một cách thông minh – Thông qua tính năng chuyển tiếp khi thành công
✅ Theo dõi các điểm cải thiện – So sánh các chỉ số trước và sau khi sửa lỗi
✅ Cung cấp các cấu phần phần mềm – Báo cáo sửa lỗi có thể tải xuống
Các khái niệm chính đã thành thạo
LoopAgent so với Sequential:
- Tuần tự: Một lần chuyển qua các tác nhân
- LoopAgent: Lặp lại cho đến khi điều kiện thoát hoặc số lần lặp tối đa
- Đi ra qua
tool_context.actions.escalate = True
Sự phát triển trạng thái qua các lần lặp:
CODE_FIXESđược cập nhật trong mỗi lần lặp- Kết quả kiểm thử cho thấy sự cải thiện theo thời gian
- Trình xác thực thấy các thay đổi tích luỹ
Cấu trúc nhiều quy trình:
- Quy trình đánh giá: Phân tích chỉ đọc (Mô-đun 5)
- Vòng lặp cố định: Điều chỉnh lặp lại (Vòng lặp bên trong của Mô-đun 6)
- Quy trình cố định: Vòng lặp + bộ tổng hợp (Module 6 outer)
- Tác nhân gốc: Điều phối dựa trên ý định của người dùng
Công cụ kiểm soát Flow:
exit_fix_loop()tập hợp tăng lên- Mọi công cụ đều có thể báo hiệu hoàn tất vòng lặp
- Tách rời logic thoát khỏi chỉ dẫn của nhân viên hỗ trợ
Độ an toàn của số lần lặp tối đa:
- Ngăn chặn vòng lặp vô hạn
- Đảm bảo hệ thống luôn phản hồi
- Đưa ra kết quả tốt nhất có thể ngay cả khi không hoàn hảo
Tiếp theo là gì?
Trong mô-đun cuối cùng, bạn sẽ tìm hiểu cách triển khai tác nhân cho hoạt động sản xuất:
- Thiết lập bộ nhớ liên tục bằng VertexAiSessionService
- Triển khai lên Agent Engine trên Google Cloud
- Giám sát và gỡ lỗi các tác nhân sản xuất
- Các phương pháp hay nhất để mở rộng quy mô và tăng độ tin cậy
Bạn đã xây dựng một hệ thống nhiều tác nhân hoàn chỉnh với cấu trúc tuần tự và vòng lặp. Các mẫu bạn đã học (quản lý trạng thái, hướng dẫn linh động, điều phối công cụ và tinh chỉnh lặp đi lặp lại) là những kỹ thuật sẵn sàng cho quá trình sản xuất được dùng trong các hệ thống dựa trên tác nhân thực tế.
7. Triển khai lên kênh phát hành công khai
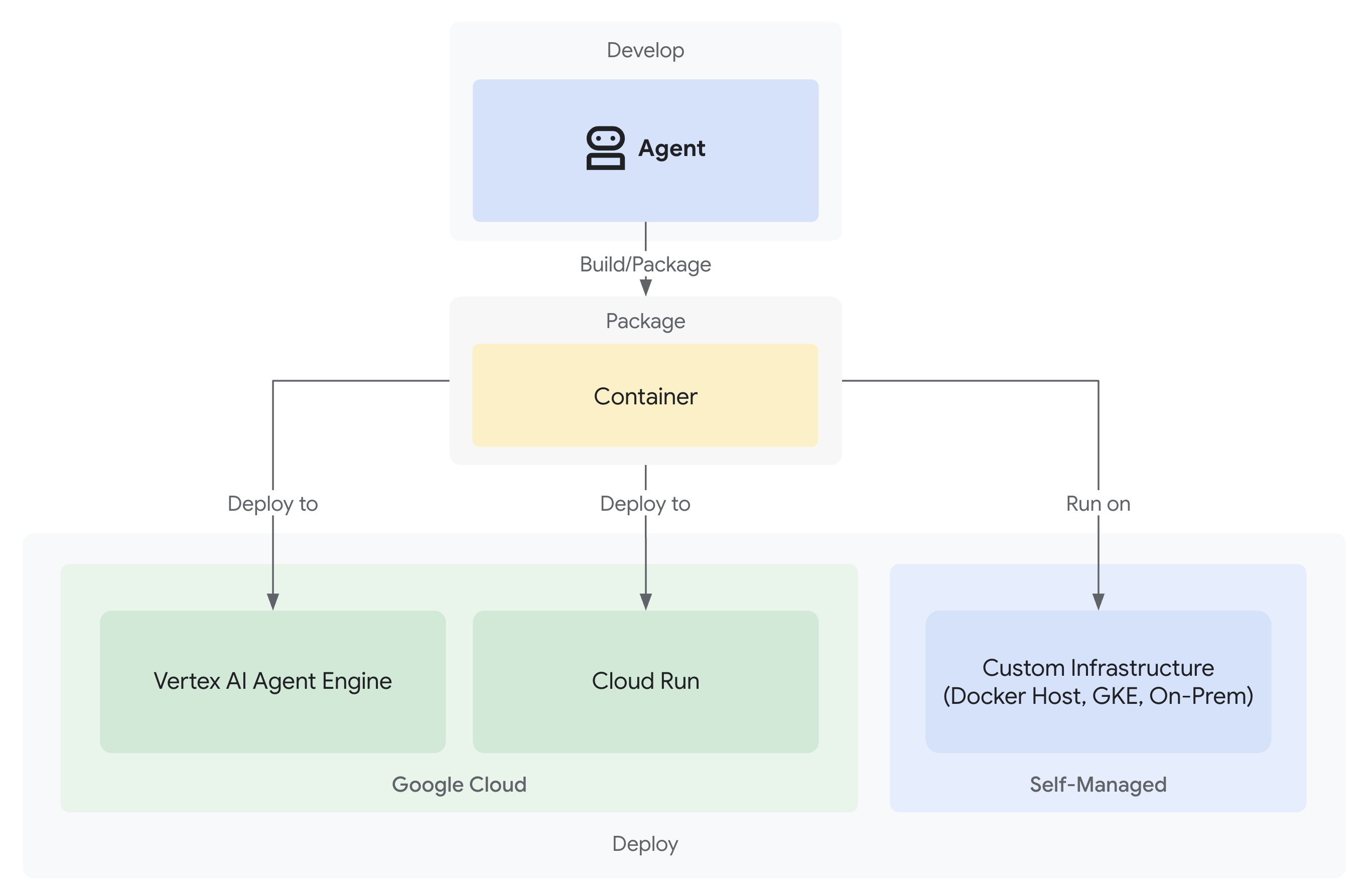
Giới thiệu
Trợ lý xem xét mã của bạn hiện đã hoàn tất với các pipeline xem xét và sửa lỗi hoạt động cục bộ. Phần còn thiếu: nó chỉ chạy trên máy của bạn. Trong mô-đun này, bạn sẽ triển khai tác nhân của mình lên Google Cloud, giúp nhóm của bạn có thể truy cập vào tác nhân này bằng các phiên liên tục và cơ sở hạ tầng cấp sản xuất.
Kiến thức bạn sẽ học được:
- 3 đường dẫn triển khai: Cục bộ, Cloud Run và Agent Engine
- Tự động cấp phép cơ sở hạ tầng
- Chiến lược duy trì phiên
- Kiểm thử tác nhân đã triển khai
Tìm hiểu về các lựa chọn triển khai
ADK hỗ trợ nhiều mục tiêu triển khai, mỗi mục tiêu có những điểm đánh đổi khác nhau:
Đường dẫn triển khai
Yếu tố | Địa phương ( | Cloud Run ( | Agent Engine ( |
Độ phức tạp | Tối giản | Trung bình | Thấp |
Tính năng duy trì phiên | Chỉ trong bộ nhớ (mất khi khởi động lại) | Cloud SQL (PostgreSQL) | Vertex AI được quản lý (tự động) |
Cơ sở hạ tầng | Không có (chỉ dành cho máy phát triển) | Vùng chứa + Cơ sở dữ liệu | Được quản lý đầy đủ |
Khởi động nguội | Không áp dụng | 100 – 2000 mili giây | 100 – 500 mili giây |
Điều chỉnh tỷ lệ | Một phiên bản | Tự động (về 0) | Tự động |
Mô hình chi phí | Miễn phí (tính toán cục bộ) | Dựa trên yêu cầu + bậc miễn phí | Dựa trên tài nguyên điện toán |
Hỗ trợ giao diện người dùng | Có (qua | Có (qua | Không (chỉ có API) |
Phù hợp nhất với | Phát triển/kiểm thử | Lưu lượng truy cập biến đổi, kiểm soát chi phí | Tác tử sản xuất |
Lựa chọn triển khai bổ sung: Google Kubernetes Engine (GKE) dành cho người dùng nâng cao cần có quyền kiểm soát ở cấp độ Kubernetes, mạng tuỳ chỉnh hoặc điều phối nhiều dịch vụ. Lớp học lập trình này không đề cập đến việc triển khai GKE nhưng có ghi lại trong hướng dẫn triển khai ADK.
Nội dung được triển khai
Khi triển khai lên Cloud Run hoặc Agent Engine, những nội dung sau sẽ được đóng gói và triển khai:
- Mã đại lý của bạn (
agent.py, tất cả các đại lý phụ, công cụ) - Phụ thuộc (
requirements.txt) - Máy chủ ADK API (tự động được đưa vào)
- Giao diện người dùng trên web (chỉ Cloud Run, khi
--with_uiđược chỉ định)
Những điểm khác biệt quan trọng:
- Cloud Run: Sử dụng
adk deploy cloud_runCLI (tự động tạo vùng chứa) hoặcgcloud run deploy(yêu cầu Dockerfile tuỳ chỉnh) - Agent Engine: Sử dụng
adk deploy agent_engineCLI (không cần tạo vùng chứa, đóng gói trực tiếp mã Python)
Bước 1: Định cấu hình môi trường
Định cấu hình tệp .env
Tệp .env của bạn (được tạo trong Mô-đun 3) cần được cập nhật để triển khai trên đám mây. Mở .env rồi xác minh/cập nhật các chế độ cài đặt sau:
Bắt buộc đối với tất cả các hoạt động triển khai trên đám mây:
# Your actual GCP Project ID (REQUIRED)
GOOGLE_CLOUD_PROJECT=your-project-id
# GCP region for deployments (REQUIRED)
GOOGLE_CLOUD_LOCATION=us-central1
# Use Vertex AI (REQUIRED)
GOOGLE_GENAI_USE_VERTEXAI=true
# Model configuration (already set)
WORKER_MODEL=gemini-2.5-flash
CRITIC_MODEL=gemini-2.5-pro
Đặt tên cho các vùng lưu trữ (BẮT BUỘC trước khi chạy deploy.sh):
Tập lệnh triển khai sẽ tạo các vùng chứa dựa trên những tên này. Thiết lập ngay:
# Staging bucket for Agent Engine code uploads (REQUIRED for agent-engine)
STAGING_BUCKET=gs://your-project-id-staging
# Artifact storage for reports and fixed code (REQUIRED for both cloud-run and agent-engine)
ARTIFACT_BUCKET=gs://your-project-id-artifacts
Thay thế your-project-id bằng mã dự án thực tế của bạn trong cả hai tên nhóm. Tập lệnh sẽ tạo các vùng chứa này nếu chưa có.
Các biến không bắt buộc (được tạo tự động nếu để trống):
# Agent Engine ID (populated after first deployment)
AGENT_ENGINE_ID=
# Cloud Run Database credentials (created automatically if blank)
CLOUD_SQL_INSTANCE_NAME=
DB_USER=
DB_PASSWORD=
DB_NAME=
Kiểm tra xác thực
Nếu bạn gặp lỗi xác thực trong quá trình triển khai:
gcloud auth application-default login
gcloud config set project $GOOGLE_CLOUD_PROJECT
Bước 2: Tìm hiểu về tập lệnh triển khai
Tập lệnh deploy.sh cung cấp một giao diện hợp nhất cho tất cả các chế độ triển khai:
./deploy.sh {local|cloud-run|agent-engine}
Các chức năng của tập lệnh
Cung cấp cơ sở hạ tầng:
- Bật API (AI Platform, Storage, Cloud Build, Cloud Trace, Cloud SQL)
- Cấu hình quyền IAM (tài khoản dịch vụ, vai trò)
- Tạo tài nguyên (thùng chứa, cơ sở dữ liệu, phiên bản)
- Triển khai bằng các cờ hiệu phù hợp
- Xác minh sau khi triển khai
Các phần chính của tập lệnh
- Cấu hình (dòng 1-35): Dự án, khu vực, tên dịch vụ, giá trị mặc định
- Hàm trợ giúp (dòng 37-200): Bật API, tạo vùng chứa, thiết lập IAM
- Logic chính (các dòng 202-400): Điều phối việc triển khai theo từng chế độ
Bước 3: Chuẩn bị Agent cho Agent Engine
Trước khi triển khai đến Agent Engine, bạn cần có một tệp agent_engine_app.py bao bọc tác nhân của bạn cho thời gian chạy được quản lý. Danh sách này đã được tạo cho bạn.
Xem code_review_assistant/agent_engine_app.py
👉 Mở tệp:
"""
Agent Engine application wrapper.
This file prepares the agent for deployment to Vertex AI Agent Engine.
"""
from vertexai import agent_engines
from .agent import root_agent
# Wrap the agent in an AdkApp object for Agent Engine deployment
app = agent_engines.AdkApp(
agent=root_agent,
enable_tracing=True,
)
Bước 4: Triển khai cho Agent Engine
Agent Engine là quy trình triển khai sản xuất được đề xuất cho các tác nhân ADK vì quy trình này cung cấp:
- Cơ sở hạ tầng được quản lý toàn diện (không cần tạo vùng chứa)
- Tính năng duy trì phiên tích hợp thông qua
VertexAiSessionService - Tự động cấp tài nguyên bổ sung từ 0
- Tích hợp Cloud Trace được bật theo mặc định
Điểm khác biệt giữa Agent Engine và các hoạt động triển khai khác
Về cơ bản,
deploy.sh agent-engine
sử dụng:
adk deploy agent_engine \
--project=$GOOGLE_CLOUD_PROJECT \
--region=$GOOGLE_CLOUD_LOCATION \
--staging_bucket=$STAGING_BUCKET \
--display_name="Code Review Assistant" \
--trace_to_cloud \
code_review_assistant
Lệnh này:
- Đóng gói mã Python trực tiếp (không cần bản dựng Docker)
- Tải lên bộ chứa dàn dựng mà bạn đã chỉ định trong
.env - Tạo một phiên bản Agent Engine được quản lý
- Bật Cloud Trace để có khả năng quan sát
- Sử dụng
agent_engine_app.pyđể định cấu hình thời gian chạy
Không giống như Cloud Run (nơi chứa mã của bạn), Agent Engine chạy mã Python của bạn trực tiếp trong một môi trường thời gian chạy được quản lý, tương tự như các hàm không máy chủ.
Chạy quy trình triển khai
Từ thư mục gốc của dự án:
./deploy.sh agent-engine
Giai đoạn triển khai
Xem tập lệnh thực thi các giai đoạn sau:
Phase 1: API Enablement
✓ aiplatform.googleapis.com
✓ storage-api.googleapis.com
✓ cloudbuild.googleapis.com
✓ cloudtrace.googleapis.com
Phase 2: IAM Setup
✓ Getting project number
✓ Granting Storage Object Admin
✓ Granting AI Platform User
✓ Granting Cloud Trace Agent
Phase 3: Staging Bucket
✓ Creating gs://your-project-id-staging
✓ Setting permissions
Phase 4: Artifact Bucket
✓ Creating gs://your-project-id-artifacts
✓ Configuring access
Phase 5: Validation
✓ Checking agent.py exists
✓ Verifying root_agent defined
✓ Checking agent_engine_app.py exists
✓ Validating requirements.txt
Phase 6: Build & Deploy
✓ Packaging agent code
✓ Uploading to staging bucket
✓ Creating Agent Engine instance
✓ Configuring session persistence
✓ Setting up Cloud Trace integration
✓ Running health checks
Quá trình này mất từ 5 đến 10 phút vì quá trình này đóng gói tác nhân và triển khai tác nhân đó vào cơ sở hạ tầng Vertex AI.
Lưu mã nhận dạng công cụ của đại lý
Sau khi triển khai thành công:
✅ Deployment successful!
Agent Engine ID: 7917477678498709504
Resource Name: projects/123456789/locations/us-central1/reasoningEngines/7917477678498709504
Endpoint: https://us-central1-aiplatform.googleapis.com/v1/...
⚠️ IMPORTANT: Save this in your .env file:
AGENT_ENGINE_ID=7917477678498709504
Cập nhật
.env
ngay lập tức:
echo "AGENT_ENGINE_ID=7917477678498709504" >> .env
Bạn phải nhập mã nhận dạng này cho:
- Kiểm thử tác nhân đã triển khai
- Cập nhật hoạt động triển khai sau
- Truy cập vào nhật ký và dấu vết
Nội dung đã được triển khai
Việc triển khai Agent Engine hiện bao gồm:
✅ Hoàn tất quy trình đánh giá (4 tác nhân)
✅ Hoàn tất quy trình sửa lỗi (vòng lặp + bộ tổng hợp)
✅ Tất cả công cụ (phân tích AST, kiểm tra kiểu, tạo cấu phần phần mềm)
✅ Duy trì phiên (tự động thông qua VertexAiSessionService)
✅ Quản lý trạng thái (các cấp phiên/người dùng/thời gian tồn tại)
✅ Khả năng quan sát (đã bật Cloud Trace)
✅ Cơ sở hạ tầng tự động mở rộng quy mô
Bước 5: Kiểm thử tác nhân đã triển khai
Cập nhật tệp .env
Sau khi triển khai, hãy xác minh rằng .env của bạn có:
AGENT_ENGINE_ID=7917477678498709504 # From deployment output
GOOGLE_CLOUD_PROJECT=your-project-id
GOOGLE_CLOUD_LOCATION=us-central1
Chạy tập lệnh kiểm thử
Dự án này có tests/test_agent_engine.py dành riêng cho việc kiểm thử quá trình triển khai Agent Engine:
python tests/test_agent_engine.py
Mục đích của bài kiểm tra
- Xác thực bằng dự án trên đám mây của Google Cloud
- Tạo một phiên với tác nhân đã triển khai
- Gửi yêu cầu xem xét mã (ví dụ về lỗi DFS)
- Truyền trực tuyến phản hồi trở lại thông qua Sự kiện được gửi bởi máy chủ (SSE)
- Xác minh khả năng duy trì phiên và quản lý trạng thái
Kết quả đầu ra dự kiến
Authenticated with project: your-project-id
Targeting Agent Engine: projects/.../reasoningEngines/7917477678498709504
Creating new session...
Created session: 4857885913439920384
Sending query to agent and streaming response:
data: {"content": {"parts": [{"text": "I'll analyze your code..."}]}}
data: {"content": {"parts": [{"text": "**Code Structure Analysis**\n..."}]}}
data: {"content": {"parts": [{"text": "**Style Check Results**\n..."}]}}
data: {"content": {"parts": [{"text": "**Test Results**\n..."}]}}
data: {"content": {"parts": [{"text": "**Final Feedback**\n..."}]}}
Stream finished.
Danh sách kiểm tra xác minh
- ✅ Quy trình xem xét đầy đủ được thực hiện (cả 4 nhân viên hỗ trợ)
- ✅ Phản hồi truyền trực tuyến cho thấy đầu ra tăng dần
- ✅ Trạng thái phiên vẫn duy trì trong các yêu cầu
- ✅ Không có lỗi xác thực hoặc kết nối
- ✅ Lệnh gọi công cụ thực thi thành công (phân tích AST, kiểm tra kiểu)
- ✅ Các hiện vật được lưu (có thể truy cập vào báo cáo chấm điểm)
Cách khác: Triển khai lên Cloud Run
Mặc dù Agent Engine được đề xuất để đơn giản hoá việc triển khai sản xuất, nhưng Cloud Run mang đến nhiều quyền kiểm soát hơn và hỗ trợ giao diện người dùng web ADK. Phần này cung cấp thông tin tổng quan.
Trường hợp nên dùng Cloud Run
Chọn Cloud Run nếu bạn cần:
- Giao diện người dùng web ADK để người dùng tương tác
- Toàn quyền kiểm soát môi trường vùng chứa
- Cấu hình cơ sở dữ liệu tuỳ chỉnh
- Tích hợp với các dịch vụ Cloud Run hiện có
Cách hoạt động của việc triển khai Cloud Run
Về cơ bản,
deploy.sh cloud-run
sử dụng:
adk deploy cloud_run \
--project=$GOOGLE_CLOUD_PROJECT \
--region=$GOOGLE_CLOUD_LOCATION \
--service_name="code-review-assistant" \
--app_name="code_review_assistant" \
--port=8080 \
--with_ui \
--artifact_service_uri="gs://$ARTIFACT_BUCKET" \
--trace_to_cloud \
code_review_assistant
Lệnh này:
- Tạo một vùng chứa Docker bằng mã tác nhân của bạn
- Đẩy lên Google Artifact Registry
- Triển khai dưới dạng một dịch vụ Cloud Run
- Bao gồm giao diện người dùng web ADK (
--with_ui) - Định cấu hình kết nối Cloud SQL (do tập lệnh thêm sau khi triển khai ban đầu)
Điểm khác biệt chính so với Agent Engine: Cloud Run chứa mã của bạn và yêu cầu phải có cơ sở dữ liệu để duy trì phiên, trong khi Agent Engine tự động xử lý cả hai.
Lệnh triển khai Cloud Run
./deploy.sh cloud-run
Điểm khác biệt
Cơ sở hạ tầng:
- Triển khai trong vùng chứa (Docker do ADK tự động tạo)
- Cloud SQL (PostgreSQL) để duy trì phiên
- Cơ sở dữ liệu do tập lệnh tạo tự động hoặc sử dụng phiên bản hiện có
Quản lý phiên:
- Sử dụng
DatabaseSessionServicethay vìVertexAiSessionService - Yêu cầu thông tin đăng nhập cơ sở dữ liệu trong
.env(hoặc được tạo tự động) - Trạng thái vẫn duy trì trong cơ sở dữ liệu PostgreSQL
Hỗ trợ giao diện người dùng:
- Giao diện người dùng web có sẵn thông qua cờ
--with_ui(do tập lệnh xử lý) - Truy cập vào:
https://code-review-assistant-xyz.a.run.app
Những thành tựu bạn đạt được
Việc triển khai bản phát hành công khai của bạn bao gồm:
✅ Cung cấp tự động thông qua tập lệnh deploy.sh
✅ Cơ sở hạ tầng được quản lý (Agent Engine xử lý việc mở rộng quy mô, tính liên tục, hoạt động giám sát)
✅ Trạng thái liên tục trên tất cả các cấp bộ nhớ (phiên/người dùng/thời gian tồn tại)
✅ Quản lý thông tin đăng nhập an toàn (tự động tạo và thiết lập IAM)
✅ Kiến trúc có thể mở rộng (từ 0 đến hàng nghìn người dùng đồng thời)
✅ Khả năng quan sát tích hợp (đã bật tính năng tích hợp Cloud Trace)
✅ Xử lý và khôi phục lỗi cấp sản xuất
Các khái niệm chính đã thành thạo
Chuẩn bị triển khai:
agent_engine_app.py: Gói tác nhân bằngAdkAppcho Agent EngineAdkApptự động định cấu hìnhVertexAiSessionServiceđể duy trì- Đã bật tính năng theo dõi qua
enable_tracing=True
Lệnh triển khai:
adk deploy agent_engine: Đóng gói mã Python, không có vùng chứaadk deploy cloud_run: Tự động tạo vùng chứa Dockergcloud run deploy: Lựa chọn thay thế bằng Dockerfile tuỳ chỉnh
Các lựa chọn triển khai:
- Agent Engine: Được quản lý hoàn toàn, nhanh nhất để sản xuất
- Cloud Run: Nhiều quyền kiểm soát hơn, hỗ trợ giao diện người dùng web
- GKE: Kiểm soát Kubernetes nâng cao (xem Hướng dẫn triển khai GKE)
Dịch vụ có quản lý:
- Agent Engine tự động xử lý việc duy trì phiên
- Cloud Run yêu cầu thiết lập cơ sở dữ liệu (hoặc tự động tạo)
- Cả hai đều hỗ trợ lưu trữ cấu phần phần mềm thông qua GCS
Quản lý phiên:
- Agent Engine:
VertexAiSessionService(tự động) - Cloud Run:
DatabaseSessionService(Cloud SQL) - Cục bộ:
InMemorySessionService(tạm thời)
Nhân viên hỗ trợ của bạn đang hoạt động
Trợ lý xem xét mã của bạn hiện là:
- Có thể truy cập thông qua các điểm cuối API HTTPS
- Persistent với trạng thái duy trì sau khi khởi động lại
- Có khả năng mở rộng để tự động xử lý sự tăng trưởng của nhóm
- Observable với dấu vết yêu cầu hoàn chỉnh
- Có thể duy trì thông qua các quy trình triển khai theo kịch bản
Các bước tiếp theo Trong Mô-đun 8, bạn sẽ tìm hiểu cách sử dụng Cloud Trace để nắm được hiệu suất của tác nhân, xác định các nút thắt cổ chai trong quy trình xem xét và sửa lỗi, đồng thời tối ưu hoá thời gian thực thi.
8. Khả năng ghi nhận trong quá trình phát hành công khai
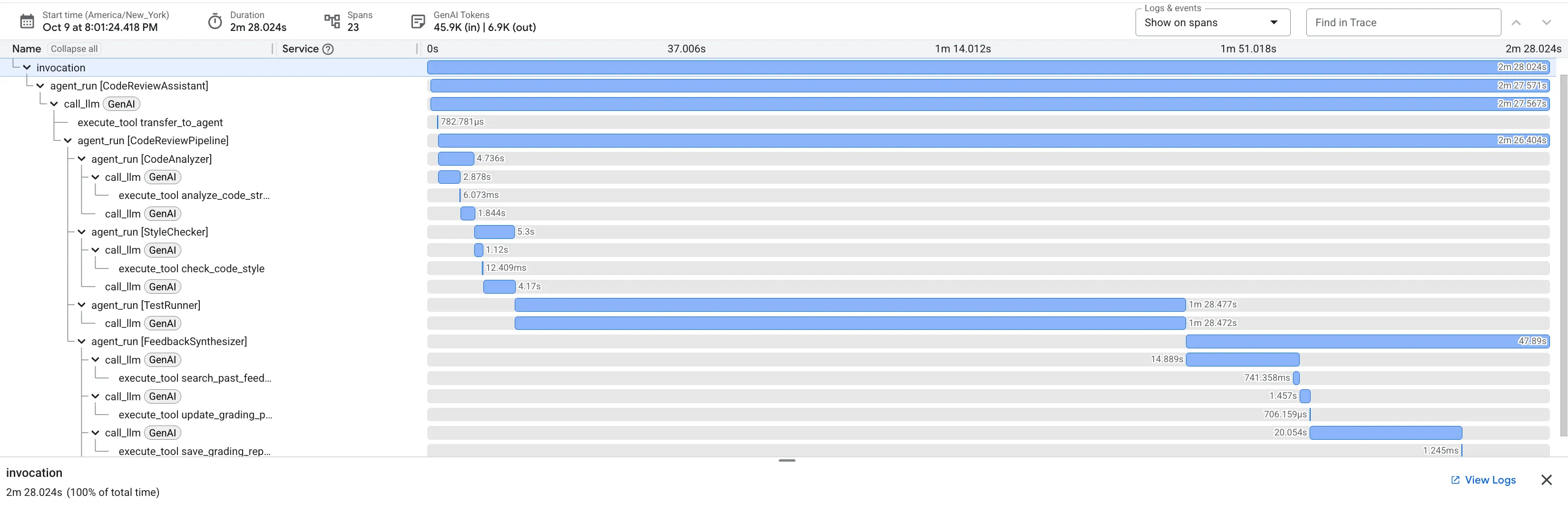
Giới thiệu
Trợ lý xem xét mã của bạn hiện đã được triển khai và đang chạy trong môi trường phát hành công khai trên Agent Engine. Nhưng làm sao bạn biết được rằng nó đang hoạt động hiệu quả? Bạn có thể trả lời những câu hỏi quan trọng sau đây không:
- Nhân viên hỗ trợ có phản hồi đủ nhanh không?
- Những thao tác nào chậm nhất?
- Các vòng lặp sửa lỗi có hoàn tất một cách hiệu quả không?
- Nút thắt cổ chai về hiệu suất nằm ở đâu?
Nếu không có khả năng quan sát, bạn sẽ hoạt động mà không biết gì. Cờ --trace-to-cloud mà bạn đã dùng trong quá trình triển khai sẽ tự động bật Cloud Trace, giúp bạn có được thông tin đầy đủ về mọi yêu cầu mà tác nhân của bạn xử lý. Điều này giúp quá trình gỡ lỗi chuyển từ phỏng đoán sang phân tích pháp y.
Trong mô-đun này, bạn sẽ tìm hiểu cách đọc dấu vết, hiểu các đặc điểm hiệu suất của tác nhân và xác định các lĩnh vực cần tối ưu hoá dựa trên bằng chứng xác thực.
Tìm hiểu về dấu vết và khoảng thời gian
Vết tích là gì?
Dấu vết là dòng thời gian hoàn chỉnh về cách mà tác nhân của bạn xử lý một yêu cầu duy nhất. Sự kiện này ghi lại mọi thứ, từ thời điểm người dùng gửi một truy vấn cho đến khi nhận được phản hồi cuối cùng. Mỗi dấu vết cho thấy:
- Tổng thời lượng của yêu cầu
- Tất cả các thao tác đã thực hiện
- Mối quan hệ giữa các thao tác (mối quan hệ mẹ con)
- Thời điểm bắt đầu và kết thúc của từng thao tác
Khoảng là gì?
Khoảng thời gian biểu thị một đơn vị công việc trong một dấu vết. Các loại khoảng phổ biến trong trợ lý xem xét mã của bạn:
agent_run: Thực thi một tác nhân (tác nhân gốc hoặc tác nhân phụ)call_llm: Yêu cầu đối với mô hình ngôn ngữexecute_tool: Thực thi chức năng của công cụstate_read/state_write: Các thao tác quản lý trạng tháicode_executor: Chạy mã có kiểm thử
Vùng có:
- Tên: Thao tác này đại diện cho thao tác nào
- Thời lượng: Khoảng thời gian
- Thuộc tính: Siêu dữ liệu như tên mô hình, số lượng mã thông báo, dữ liệu đầu vào/đầu ra
- Trạng thái: Thành công hoặc không thành công
- Mối quan hệ gốc/con: Thao tác nào kích hoạt thao tác nào
Đo lường tự động
Khi bạn triển khai bằng --trace-to-cloud, ADK sẽ tự động đo lường:
- Mọi lệnh gọi tác nhân và lệnh gọi tác nhân phụ
- Tất cả các yêu cầu LLM có số lượng mã thông báo
- Thực thi công cụ với đầu vào/đầu ra
- Các thao tác về trạng thái (đọc/ghi)
- Các lần lặp lại vòng lặp trong quy trình sửa lỗi
- Điều kiện lỗi và số lần thử lại
Không cần mã – tính năng theo dõi được tích hợp vào thời gian chạy của ADK.
Bước 1: Truy cập vào Cloud Trace Explorer
Mở Cloud Trace trong Google Cloud Console:
- Chuyển đến Cloud Trace Explorer
- Chọn dự án của bạn trong trình đơn thả xuống (phải được chọn trước)
- Bạn sẽ thấy dấu vết từ bài kiểm thử của mình trong Mô-đun 7
Nếu bạn chưa thấy dấu vết:
Bài kiểm thử mà bạn đã chạy trong Mô-đun 7 sẽ tạo ra các dấu vết. Nếu danh sách này còn trống, hãy tạo một số dữ liệu dấu vết:
python tests/test_agent_engine.py
Đợi 1 đến 2 phút để dấu vết xuất hiện trong bảng điều khiển.
Nội dung bạn đang xem
Trace Explorer cho thấy:
- Danh sách dấu vết: Mỗi hàng đại diện cho một yêu cầu hoàn chỉnh
- Dòng thời gian: Thời điểm yêu cầu xảy ra
- Thời lượng: Thời gian thực hiện mỗi yêu cầu
- Thông tin chi tiết về yêu cầu: Dấu thời gian, độ trễ, số lượng khoảng thời gian
Đây là nhật ký lưu lượng truy cập sản xuất của bạn – mọi hoạt động tương tác với tác nhân đều tạo ra một dấu vết.
Bước 2: Kiểm tra dấu vết của quy trình xem xét
Nhấp vào một dấu vết bất kỳ trong danh sách để mở chế độ xem thác nước.
Bạn sẽ thấy biểu đồ Gantt cho thấy toàn bộ tiến trình thực hiện. Khoảng thời gian invocation gốc đại diện cho toàn bộ yêu cầu. Nằm bên dưới là các khoảng thời gian cho mỗi lệnh gọi đến tác nhân phụ, công cụ và LLM.
Đọc thác nước: Xác định điểm tắc nghẽn
Mỗi thanh đại diện cho một khoảng thời gian. Vị trí ngang của chú thích cho biết thời điểm chú thích bắt đầu và độ dài của chú thích cho biết thời lượng chú thích. Điều này sẽ cho biết ngay lập tức nhân viên hỗ trợ của bạn đang dành thời gian ở đâu.
Thông tin chi tiết chính từ dấu vết ở trên:
- Tổng độ trễ: Toàn bộ yêu cầu mất 2 phút 28 giây.
- Bảng chi tiết theo tác nhân:
Code Analyzer: 4,7 giâyStyle Checker: 5,3 giâyTest Runner: 1 phút 28 giâyFeedback Synthesizer: 47,9 giây
- Phân tích đường dẫn quan trọng: Tác nhân
Test Runnerlà nút thắt hiệu suất rõ ràng, chiếm khoảng 59% tổng thời gian yêu cầu.
Khả năng hiển thị này rất hiệu quả. Thay vì đoán xem thời gian được dùng ở đâu, bạn có bằng chứng cụ thể rằng nếu cần tối ưu hoá độ trễ, thì Test Runner là mục tiêu rõ ràng.
Kiểm tra mức sử dụng mã thông báo để tối ưu hoá chi phí
Cloud Trace không chỉ cho biết thời gian mà còn cho thấy chi phí bằng cách ghi lại mức sử dụng mã thông báo cho mỗi lệnh gọi LLM.
Nhấp vào một
call_llm
trong dấu vết. Trong ngăn chi tiết, bạn sẽ thấy các thuộc tính cho llm.usage.prompt_tokens và llm.usage.completion_tokens.

Điều này cho phép bạn:
- Theo dõi chi phí ở mức độ chi tiết: Xem chính xác số lượng mã thông báo mà mỗi tác nhân và công cụ đang sử dụng.
- Xác định các cơ hội tối ưu hoá: Nếu một tác nhân đang sử dụng số lượng mã thông báo cao bất thường, thì đó có thể là cơ hội để tinh chỉnh câu lệnh hoặc chuyển sang một mô hình nhỏ hơn, tiết kiệm chi phí hơn cho tác vụ cụ thể đó.
Bước 3: Phân tích dấu vết của quy trình sửa lỗi
Quy trình sửa lỗi phức tạp hơn vì có chứa LoopAgent. Cloud Trace giúp bạn dễ dàng hiểu được hành vi lặp lại này.
Tìm dấu vết có chứa "FixAttemptLoop" trong tên khoảng thời gian.
Nếu bạn không có mã này, hãy chạy kịch bản kiểm tra và trả lời khẳng định khi được hỏi liệu bạn có muốn sửa mã hay không.
Kiểm tra cấu trúc vòng lặp
Chế độ xem dấu vết minh hoạ rõ ràng quá trình thực thi của vòng lặp. Nếu vòng lặp sửa lỗi chạy hai lần trước khi thành công, bạn sẽ thấy hai khoảng loop_iteration được lồng bên dưới khoảng FixAttemptLoop, mỗi khoảng chứa một chu kỳ đầy đủ của các tác nhân CodeFixer, FixTestRunner và FixValidator.

Các điểm quan sát chính từ Loop Trace:
- Có thể thấy quá trình tinh chỉnh lặp đi lặp lại: Bạn có thể thấy hệ thống cố gắng khắc phục trong
loop_iteration: 1, xác thực rồi thử lại trongloop_iteration: 2vì hệ thống chưa khắc phục hoàn toàn. - Sự hội tụ có thể đo lường được: Bạn có thể so sánh thời lượng và kết quả của từng lần lặp để hiểu cách hệ thống hội tụ đến một giải pháp chính xác.
- Gỡ lỗi đơn giản: Nếu một vòng lặp chạy với số lần lặp tối đa mà vẫn không thành công, bạn có thể kiểm tra trạng thái và hành vi của tác nhân trong khoảng thời gian của mỗi lần lặp để chẩn đoán lý do khiến các bản sửa lỗi không hội tụ.
Mức độ chi tiết này rất có giá trị để hiểu và gỡ lỗi hành vi của các vòng lặp phức tạp, có trạng thái trong giai đoạn phát hành chính thức.
Bước 4: Những điều bạn đã khám phá được
Mô hình hiệu suất
Từ việc kiểm tra dấu vết, giờ đây bạn đã có thông tin chi tiết dựa trên dữ liệu:
Quy trình đánh giá:
- Điểm tắc nghẽn chính: Tác nhân
Test Runner, cụ thể là quá trình thực thi mã và tạo kiểm thử dựa trên LLM, là phần tốn nhiều thời gian nhất trong quy trình đánh giá. - Thao tác nhanh: Các công cụ xác định (
analyze_code_structure) và các thao tác quản lý trạng thái cực kỳ nhanh và không ảnh hưởng đến hiệu suất.
Fix pipeline:
- Tỷ lệ hội tụ: Bạn có thể thấy rằng hầu hết các bản sửa lỗi đều hoàn tất trong 1-2 lần lặp lại, xác nhận rằng cấu trúc vòng lặp có hiệu quả.
- Chi phí tăng dần: Các lần lặp lại sau có thể mất nhiều thời gian hơn khi ngữ cảnh của LLM tăng lên cùng với thông tin từ những lần thử không thành công trước đó.
Yếu tố thúc đẩy chi phí:
- Mức tiêu thụ mã thông báo: Bạn có thể xác định chính xác những tác nhân (chẳng hạn như các trình tổng hợp) cần nhiều mã thông báo nhất và quyết định xem có nên sử dụng một mô hình mạnh mẽ nhưng tốn kém hơn cho tác vụ đó hay không.
Nơi tìm vấn đề
Khi xem xét các dấu vết trong quá trình sản xuất, hãy chú ý đến:
- Dấu vết dài bất thường: Dấu hiệu cho thấy hiệu suất giảm hoặc hành vi lặp lại ngoài dự kiến.
- Khoảng thời gian không thành công (được đánh dấu màu đỏ): Xác định chính xác thao tác không thành công.
- Số lần lặp vòng lặp quá mức (>2): Có thể cho thấy vấn đề với logic tạo bản sửa lỗi.
- Số lượng mã thông báo cao: Nhấn mạnh các cơ hội để tối ưu hoá câu lệnh hoặc thay đổi lựa chọn mô hình.
Kiến thức bạn học được
Thông qua Cloud Trace, giờ đây bạn đã hiểu cách:
✅ Trực quan hoá quy trình yêu cầu: Xem đường dẫn thực thi hoàn chỉnh thông qua các quy trình tuần tự và dựa trên vòng lặp.
✅ Xác định các điểm tắc nghẽn về hiệu suất: Sử dụng biểu đồ thác nước để tìm ra các thao tác chậm nhất bằng dữ liệu cụ thể.
✅ Phân tích hành vi lặp lại: Quan sát cách các tác nhân lặp lại hội tụ vào một giải pháp qua nhiều lần thử.
✅ Theo dõi chi phí mã thông báo: Kiểm tra các khoảng LLM để theo dõi và tối ưu hoá mức tiêu thụ mã thông báo ở cấp độ chi tiết.
Các khái niệm chính đã thành thạo
- Dấu vết và khoảng thời gian: Các đơn vị cơ bản của khả năng ghi nhận, thể hiện các yêu cầu và hoạt động trong đó.
- Phân tích theo kiểu thác nước: Đọc biểu đồ Gantt để nắm được thời gian thực thi và các phần phụ thuộc.
- Xác định đường dẫn quan trọng: Tìm chuỗi các thao tác xác định độ trễ tổng thể.
- Khả năng ghi nhận thật chi tiết: Có khả năng hiển thị không chỉ thời gian mà còn cả siêu dữ liệu như số token cho mọi thao tác, được ADK tự động gắn mã theo dõi.
Tiếp theo là gì?
Tiếp tục khám phá Cloud Trace:
- Thường xuyên theo dõi dấu vết để phát hiện sớm các vấn đề
- So sánh các dấu vết để xác định các trường hợp hồi quy hiệu suất
- Sử dụng dữ liệu theo dõi để đưa ra quyết định tối ưu hoá
- Lọc theo thời lượng để tìm các yêu cầu chậm
Khả năng quan sát nâng cao (không bắt buộc):
- Xuất dấu vết sang BigQuery để phân tích phức tạp (tài liệu)
- Tạo trang tổng quan tuỳ chỉnh trong Cloud Monitoring
- Thiết lập cảnh báo về hiệu suất giảm
- Tương quan các dấu vết với nhật ký ứng dụng
9. Kết luận: Từ nguyên mẫu đến sản phẩm thực tế
Những gì bạn đã tạo
Bạn chỉ bắt đầu với 7 dòng mã và đã xây dựng một hệ thống tác nhân AI cấp sản xuất:
# Where we started (7 lines)
agent = Agent(
model="gemini-2.5-flash",
instruction="Review Python code for issues"
)
# Where we ended (production system)
- Two distinct multi-agent pipelines (review and fix) built from 8 specialized agents.
- An iterative fix loop architecture for automated validation and retries.
- Real AST-based code analysis tools for deterministic, accurate feedback.
- Robust state management using the "constants pattern" for type-safe communication.
- Fully automated deployment to a managed, scalable cloud infrastructure.
- Complete, built-in observability with Cloud Trace for production monitoring.
Các mẫu kiến trúc chính đã thành thạo
Mẫu | Triển khai | Ảnh hưởng đến bản phát hành công khai |
Tích hợp công cụ | Phân tích AST, kiểm tra kiểu | Xác thực thực tế, không chỉ dựa trên ý kiến của LLM |
Sequential Pipelines (Các quy trình tuần tự) | Quy trình công việc Kiểm tra → Khắc phục | Thực thi có thể dự đoán và gỡ lỗi |
Cấu trúc vòng lặp | Sửa lỗi lặp đi lặp lại với các điều kiện thoát | Tự cải thiện cho đến khi thành công |
Quản lý trạng thái | Mẫu hằng số, bộ nhớ ba tầng | Xử lý trạng thái có thể duy trì và an toàn về kiểu |
Triển khai bản phát hành công khai | Agent Engine thông qua deploy.sh | Cơ sở hạ tầng có thể mở rộng và được quản lý |
Khả năng ghi nhận | Tích hợp Cloud Trace | Hiểu rõ hành vi trong giai đoạn phát hành chính thức |
Thông tin chi tiết về hoạt động sản xuất từ Traces
Dữ liệu Cloud Trace cho thấy những thông tin chi tiết quan trọng:
✅ Xác định điểm tắc nghẽn: Các lệnh gọi LLM của TestRunner chiếm phần lớn độ trễ
✅ Hiệu suất công cụ: Phân tích AST thực thi trong 100 mili giây (rất tốt)
✅ Tỷ lệ thành công: Các vòng lặp cố định hội tụ trong vòng 2-3 lần lặp
✅ Mức sử dụng mã thông báo: ~600 mã thông báo cho mỗi lượt đánh giá, ~1800 mã thông báo cho các bản sửa lỗi
Những thông tin chi tiết này giúp bạn liên tục cải thiện.
Dọn dẹp tài nguyên (Không bắt buộc)
Nếu bạn đã hoàn tất thử nghiệm và muốn tránh bị tính phí, hãy làm như sau:
Xoá việc triển khai Agent Engine:
import vertexai
client = vertexai.Client( # For service interactions via client.agent_engines
project="PROJECT_ID",
location="LOCATION",
)
RESOURCE_NAME = "projects/{PROJECT_ID}/locations/{LOCATION}/reasoningEngines/{RESOURCE_ID}"
client.agent_engines.delete(
name=RESOURCE_NAME,
force=True, # Optional, if the agent has resources (e.g. sessions, memory)
)
Xoá dịch vụ Cloud Run (nếu đã tạo):
gcloud run services delete code-review-assistant \
--region=$GOOGLE_CLOUD_LOCATION \
--quiet
Xoá phiên bản Cloud SQL (nếu đã tạo):
gcloud sql instances delete your-project-db \
--quiet
Dọn dẹp bộ chứa lưu trữ:
gsutil -m rm -r gs://your-project-staging
gsutil -m rm -r gs://your-project-artifacts
Các bước tiếp theo
Sau khi hoàn tất các bước cơ bản, hãy cân nhắc những điểm cải tiến sau:
- Thêm nhiều ngôn ngữ: Mở rộng các công cụ để hỗ trợ JavaScript, Go, Java
- Tích hợp với GitHub: Tự động đánh giá yêu cầu kéo
- Triển khai tính năng lưu vào bộ nhớ đệm: Giảm độ trễ cho các mẫu phổ biến
- Thêm các tác nhân chuyên biệt: Quét bảo mật, phân tích hiệu suất
- Bật thử nghiệm A/B: So sánh các mô hình và câu lệnh khác nhau
- Xuất chỉ số: Gửi dấu vết đến các nền tảng quan sát chuyên biệt
Những điểm chính cần ghi nhớ
- Bắt đầu đơn giản, lặp lại nhanh chóng: Bảy dòng để sản xuất theo các bước có thể quản lý
- Công cụ hơn câu lệnh: Phân tích AST thực tế hiệu quả hơn câu lệnh "vui lòng kiểm tra lỗi"
- Quản lý trạng thái là điều quan trọng: Mẫu hằng số giúp ngăn chặn lỗi chính tả
- Vòng lặp cần có điều kiện thoát: Luôn đặt số lần lặp tối đa và mức độ leo thang
- Triển khai bằng tính năng tự động hoá: deploy.sh xử lý mọi quy trình phức tạp
- Khả năng quan sát là điều kiện bắt buộc: Bạn không thể cải thiện những gì bạn không thể đo lường
Tài nguyên để tiếp tục học tập
- Tài liệu về ADK
- Các mẫu ADK nâng cao
- Hướng dẫn về Agent Engine
- Tài liệu về Cloud Run
- Tài liệu về Cloud Trace
Hành trình của bạn vẫn tiếp diễn
Bạn đã xây dựng được nhiều thứ hơn là một trợ lý xem xét mã – bạn đã nắm vững các mẫu để xây dựng mọi tác nhân AI cho môi trường phát hành công khai:
✅ Quy trình làm việc phức tạp với nhiều tác nhân chuyên biệt
✅ Tích hợp công cụ thực để có các khả năng thực
✅ Triển khai cho môi trường phát hành công khai với khả năng ghi nhận phù hợp
✅ Quản lý state cho các hệ thống có thể duy trì
Những mẫu này có quy mô từ trợ lý đơn giản đến hệ thống tự động phức tạp. Nền tảng mà bạn đã xây dựng ở đây sẽ giúp bạn giải quyết các cấu trúc tác nhân ngày càng tinh vi.
Chào mừng bạn đến với quá trình phát triển tác nhân AI sản xuất. Trợ lý xem xét mã chỉ là bước khởi đầu.