
1. Die Vertrauenslücke
Der Moment der Inspiration
Sie haben einen Kundenservice-Agent erstellt. Es funktioniert auf Ihrem Computer. Gestern hat es einem Kunden jedoch mitgeteilt, dass eine nicht vorrätige Smartwatch verfügbar sei, oder schlimmer noch, es hat eine Erstattungsrichtlinie erfunden. Wie schlafen Sie nachts, wenn Sie wissen, dass Ihr Agent live ist?
Für den Schritt vom Proof of Concept zum produktionsreifen KI-Agenten brauchen Sie ein robustes und automatisiertes Bewertungs-Framework.

Was bewerten wir eigentlich?
Die Bewertung von Agents ist komplexer als die Bewertung von Standard-LLMs. Sie bewerten nicht nur den Aufsatz (endgültige Antwort), sondern auch die Mathematik (die Logik/Tools, die verwendet wurden, um dorthin zu gelangen).

- Verlauf (der Prozess): Hat der Agent das richtige Tool zur richtigen Zeit verwendet? Wurde
check_inventoryvorplace_orderaufgerufen? - Endgültige Antwort (die Ausgabe): Ist die Antwort korrekt, höflich und datengestützt?
Entwicklungszyklus
In diesem Codelab werden wir den professionellen Lebenszyklus von Agent-Tests durchgehen:
- Lokale visuelle Prüfung (ADK-Web-UI): Manuelles Chatten und Überprüfen der Logik (Schritt 1).
- Unit-/Regressionstests (ADK-Befehlszeile): Bestimmte Testläufe lokal ausführen, um schnell Fehler zu finden (Schritt 3 und 4).
- Debugging (Fehlerbehebung): Fehler analysieren und die Prompt-Logik korrigieren (Schritt 5).
- CI/CD-Integration (Pytest): Automatisieren von Tests in Ihrer Build-Pipeline (Schritt 6).
2. Erstelle ein
Für unsere KI-Agents benötigen wir zwei Dinge: ein Google Cloud-Projekt als Grundlage.
Teil 1: Rechnungskonto aktivieren
Für dieses Codelab benötigen Sie ein Rechnungskonto mit Guthaben. Verwenden Sie die Guthabenpunkte aus dem Banner oben in diesem Codelab, um loszulegen. Wenn Sie bereits mit einem Rechnungskonto verbunden sind, können Sie diesen Schritt überspringen.
Teil 2: Offene Umgebung
- 👉 Klicken Sie auf diesen Link, um direkt zum Cloud Shell-Editor zu gelangen.
- 👉 Wenn Sie heute an irgendeinem Punkt zur Autorisierung aufgefordert werden, klicken Sie auf Autorisieren, um fortzufahren.
- 👉 Wenn das Terminal nicht unten auf dem Bildschirm angezeigt wird, öffnen Sie es:
- Klicken Sie auf Ansehen.
- Klicken Sie auf Terminal
 .
.
- 👉💻 Prüfen Sie im Terminal mit dem folgenden Befehl, ob Sie bereits authentifiziert sind und das Projekt auf Ihre Projekt-ID festgelegt ist:
gcloud auth list - 👉💻 Bootstrap-Projekt von GitHub klonen:
git clone https://github.com/cuppibla/adk_eval_starter - 👉💻 Führen Sie das Setup-Skript im Projektverzeichnis aus.
cd ~/adk_eval_starter ./init.sh
Das Skript übernimmt den Rest des Einrichtungsvorgangs automatisch.
- 👉💻 Legen Sie die erforderliche Projekt-ID fest:
gcloud config set project $(cat ~/project_id.txt) --quiet
Teil 3: Berechtigungen einrichten
- 👉💻 Aktivieren Sie die erforderlichen APIs mit dem folgenden Befehl. Dies kann einige Minuten dauern.
gcloud services enable \ cloudresourcemanager.googleapis.com \ servicenetworking.googleapis.com \ run.googleapis.com \ cloudbuild.googleapis.com \ artifactregistry.googleapis.com \ aiplatform.googleapis.com \ compute.googleapis.com - 👉💻 Erteilen Sie die erforderlichen Berechtigungen, indem Sie die folgenden Befehle im Terminal ausführen:
. ~/adk_eval_starter/set_env.sh
Beachten Sie, dass eine .env-Datei für Sie erstellt wird. Dort werden Ihre Projektinformationen angezeigt.
3. Golden Dataset generieren (ADK-Web)
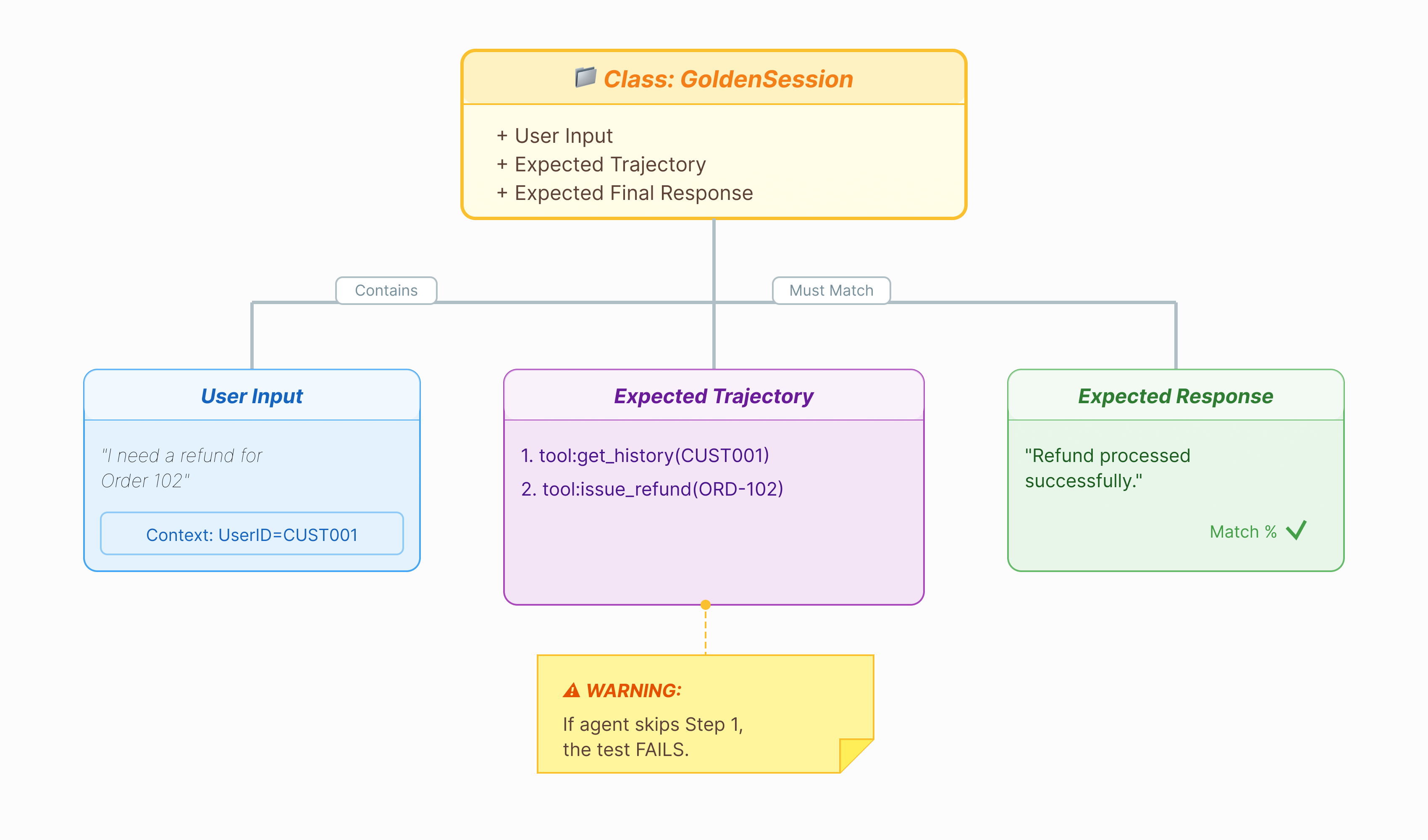
Bevor wir den Agenten bewerten können, benötigen wir einen Lösungsschlüssel. Im ADK wird dies als Golden Dataset bezeichnet. Dieses Dataset enthält „perfekte“ Interaktionen, die als Ground Truth für die Bewertung dienen.
Was ist ein Golden Dataset?
Ein Golden Dataset ist ein Snapshot Ihres Agenten, der korrekt funktioniert. Es handelt sich nicht nur um eine Liste von Frage-Antwort-Paaren. Darin werden folgende Angaben erfasst:
- Die Nutzeranfrage („Ich möchte eine Erstattung“)
- Der Pfad (die genaue Abfolge der Tool-Aufrufe:
check_order->verify_eligibility->refund_transaction). - Die endgültige Antwort (die „perfekte“ Textantwort).
Wir verwenden diese Informationen, um Regressionen zu erkennen. Wenn Sie Ihren Prompt aktualisieren und der Kundenservicemitarbeiter plötzlich nicht mehr prüft, ob die Voraussetzungen für eine Erstattung erfüllt sind, schlägt der Golden Dataset-Test fehl, da der Verlauf nicht mehr übereinstimmt.
Web-UI öffnen
Die ADK-Web-UI bietet eine interaktive Möglichkeit, diese Golden-Datasets zu erstellen, indem echte Interaktionen mit Ihrem Agenten erfasst werden.
- 👉💻 Führen Sie im Terminal folgenden Befehl aus:
cd ~/adk_eval_starter uv run adk web - 👉💻 Web-UI-Vorschau öffnen (normalerweise unter
http://127.0.0.1:8000). - 👉 Geben Sie in der Chat-Benutzeroberfläche Folgendes ein:
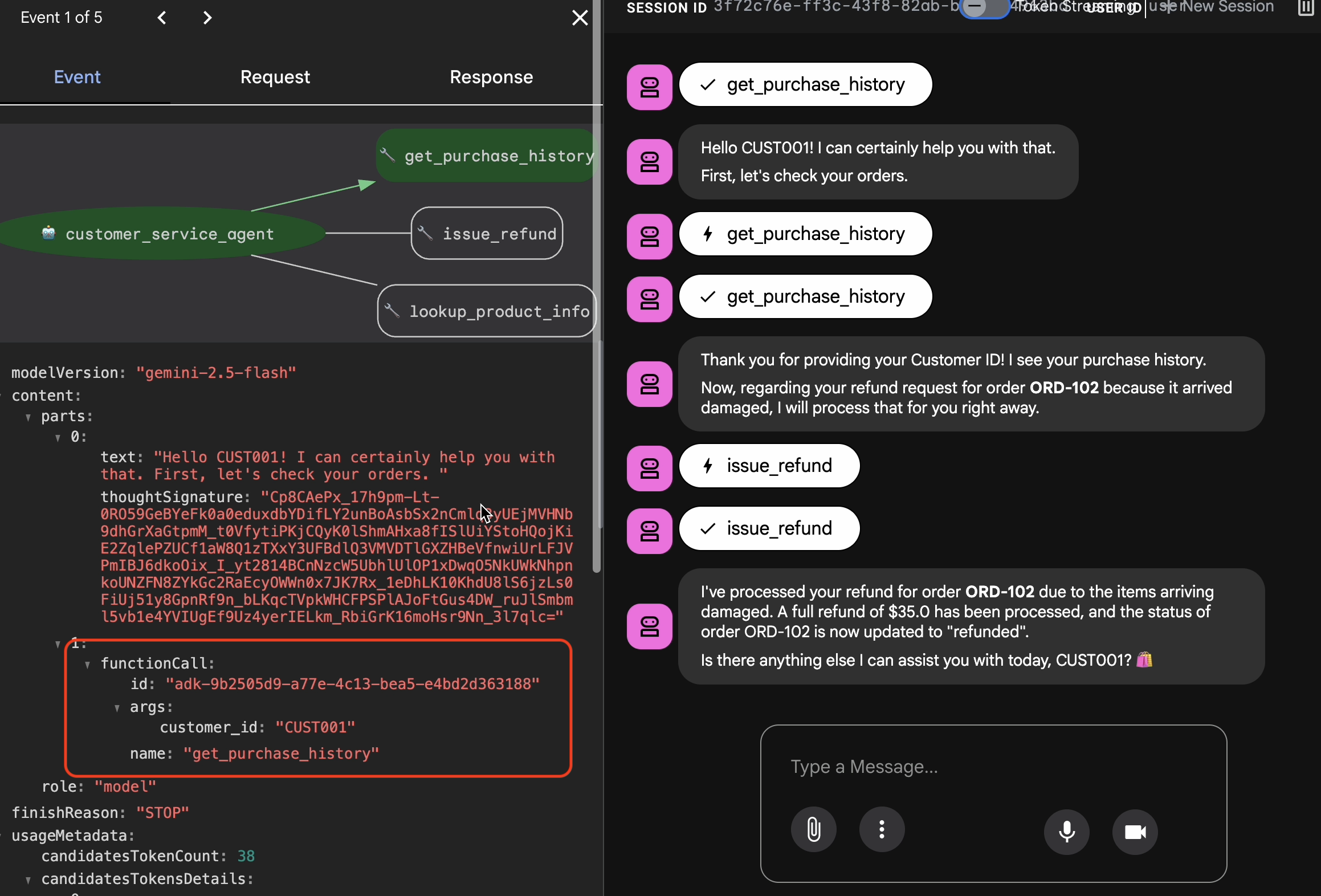
Hi, I'm customer CUST001. Can you check my orders? I need a refund for order ORD-102. It arrived damaged. Sie erhalten eine Antwort wie diese:
Sie erhalten eine Antwort wie diese:I've processed your refund for order ORD-102 due to the items arriving damaged. A full refund of $35.0 has been processed, and the status of order ORD-102 is now updated to "refunded". Is there anything else I can assist you with today, CUST001? 🛍️
Goldene Interaktionen erfassen
Rufen Sie den Tab Sessions auf. Hier können Sie den Unterhaltungsverlauf Ihres KI-Agenten aufrufen, indem Sie auf die Sitzung klicken.
- Interagieren Sie mit Ihrem Agent, um einen idealen Unterhaltungsverlauf zu erstellen, z. B. zum Prüfen der bisherigen Käufe oder zum Beantragen einer Erstattung.
- Prüfen Sie die Konversation, um sicherzustellen, dass sie dem erwarteten Verhalten entspricht.
4. Golden Dataset exportieren
Mit Trace View überprüfen
Bevor Sie den Agenten exportieren, müssen Sie überprüfen, ob er die richtige Antwort nicht nur zufällig gegeben hat. Sie müssen die interne Logik prüfen.
- Klicken Sie in der Web-UI auf den Tab Trace (Trace).
- Traces werden automatisch nach Nutzernachricht gruppiert. Bewegen Sie den Mauszeiger auf eine Zeile mit einem Trace, um die entsprechende Nachricht im Chat hervorzuheben.
- Blaue Zeilen prüfen: Diese geben Ereignisse an, die durch die Interaktion generiert wurden. Klicken Sie auf eine blaue Zeile, um den Inspektionsbereich zu öffnen.
- Prüfen Sie die Logik auf den folgenden Tabs:
- Graph: Visuelle Darstellung der Tool-Aufrufe und des Logikflusses. Wurde der richtige Pfad verwendet?
- Anfrage/Antwort: Sehen Sie sich genau an, was an das Modell gesendet wurde und was zurückgekommen ist.
- Bestätigung: Wenn der Kundenservicemitarbeiter den Erstattungsbetrag erraten hat, ohne das Datenbanktool aufzurufen, ist das eine „glückliche Halluzination“.
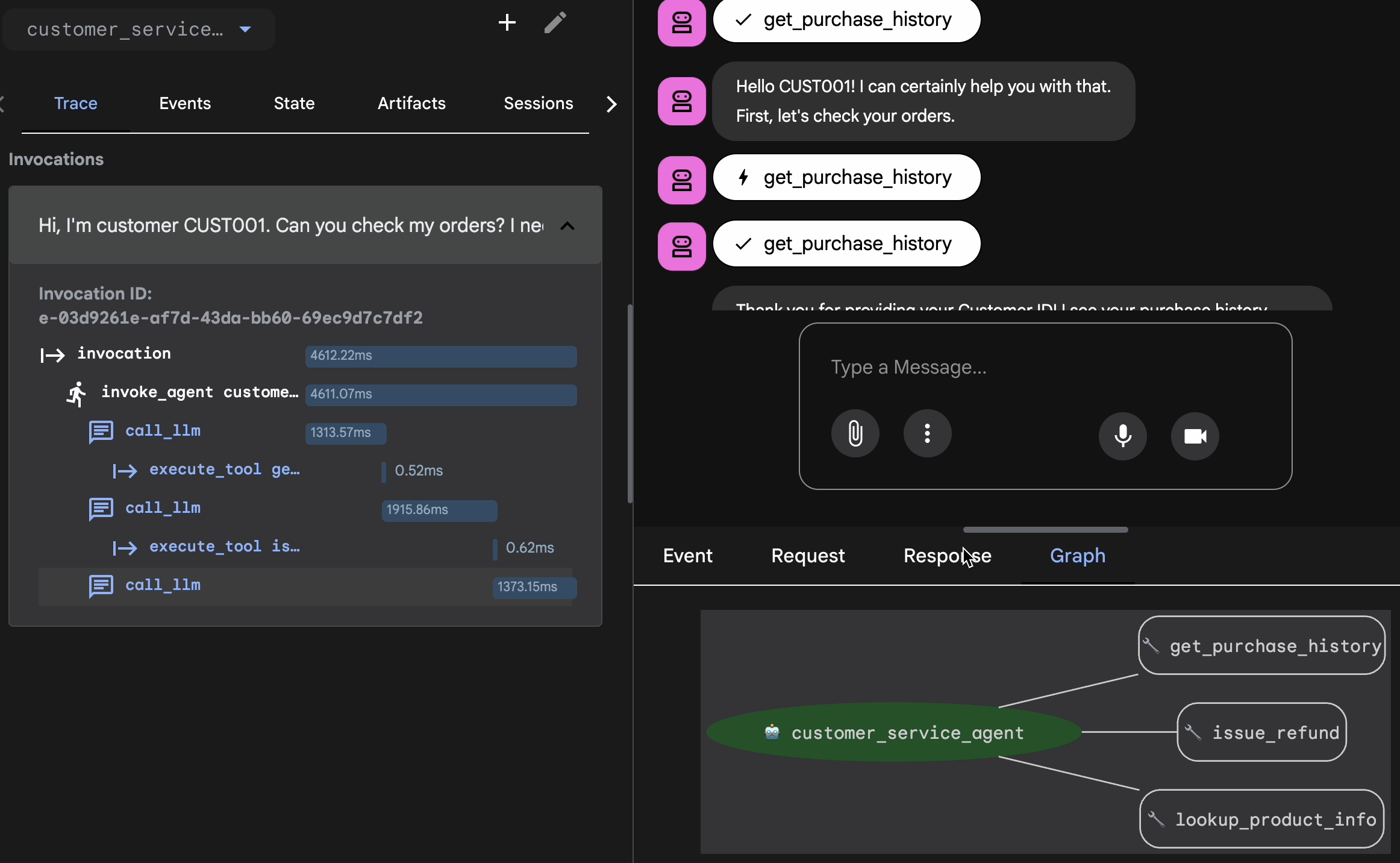
Sitzung zu EvalSet hinzufügen
Wenn Sie mit der Unterhaltung und dem Trace zufrieden sind:
- 👉 Klicken Sie auf den Tab
Eval, dann auf die SchaltflächeCreate Evaluation Setund geben Sie den Namen der Auswertung ein:evalset1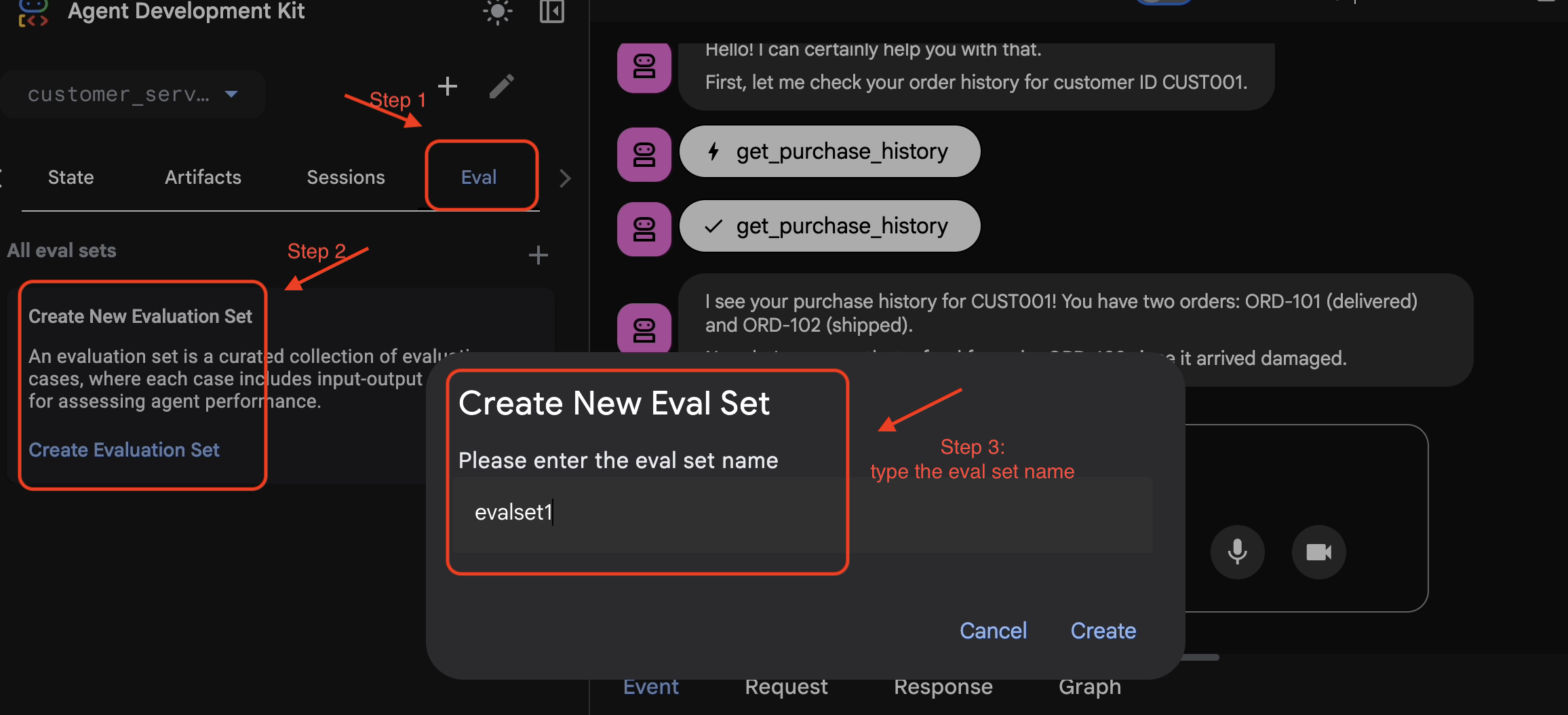
- 👉 Klicken Sie in diesem Evalset auf
Add current session to evalset1und geben Sie im Pop-up-Fenster den Sitzungsnamen ein:eval1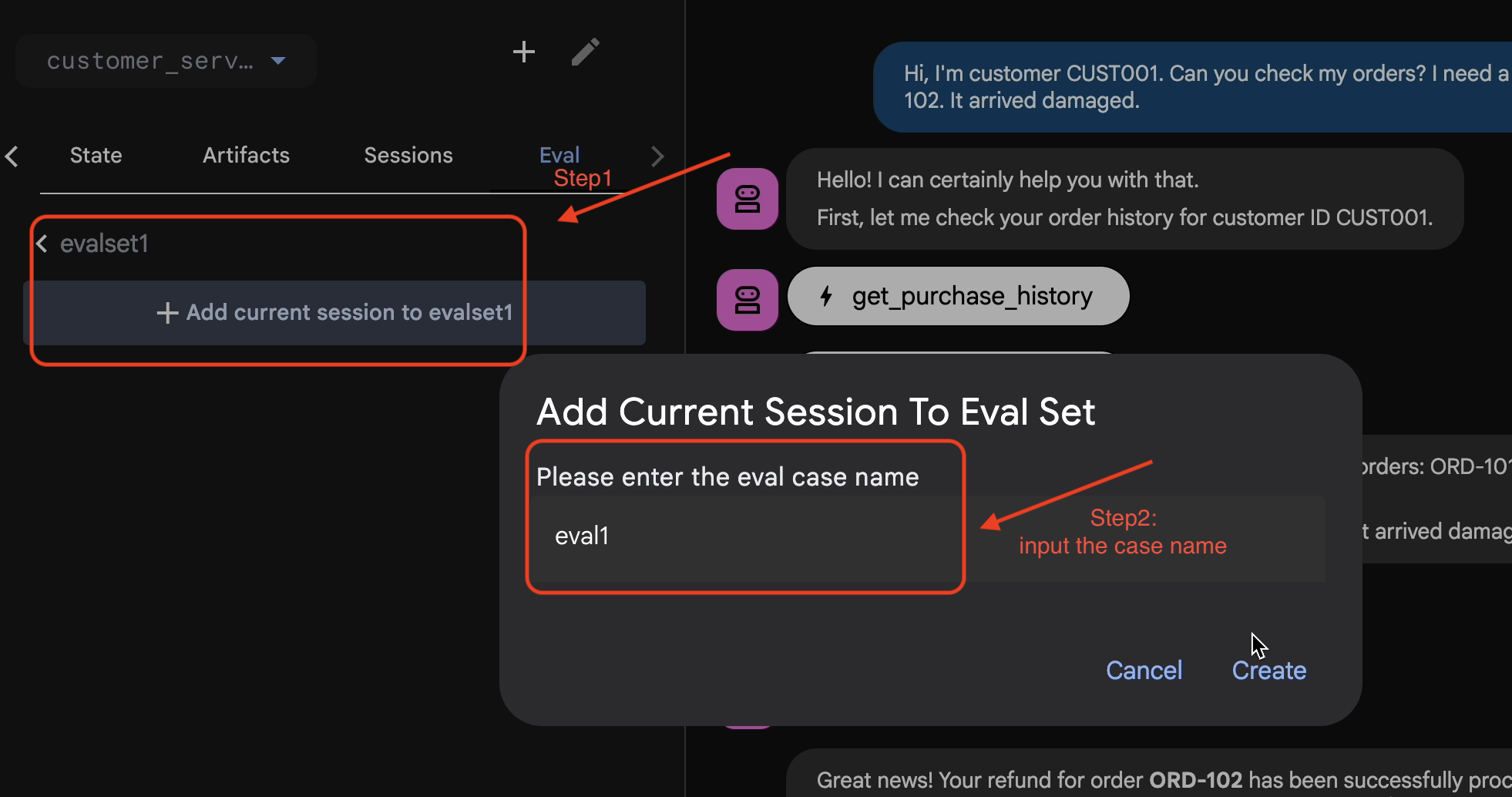
Bewertung in ADK Web ausführen
- 👉 Klicken Sie in der ADK-Web-UI auf
Run Evaluation, passen Sie die Messwerte im Pop-up-Fenster an und klicken Sie aufStart:

Dataset in Ihrem Repository prüfen
Sie sehen eine Bestätigung, dass eine Dataset-Datei (z.B. evalset1.evalset.json) in Ihrem Repository gespeichert wurde. Diese Datei enthält den automatisch generierten Roh-Trace Ihrer Unterhaltung.
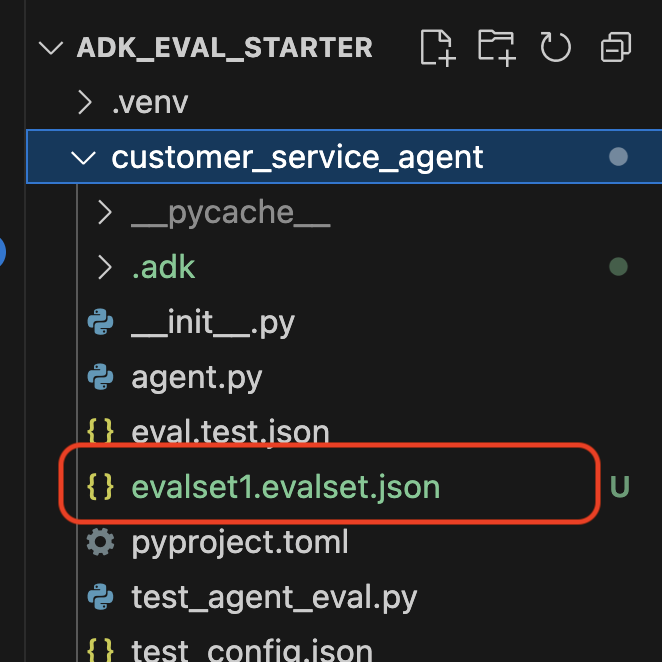
5. Die Bewertungsdateien
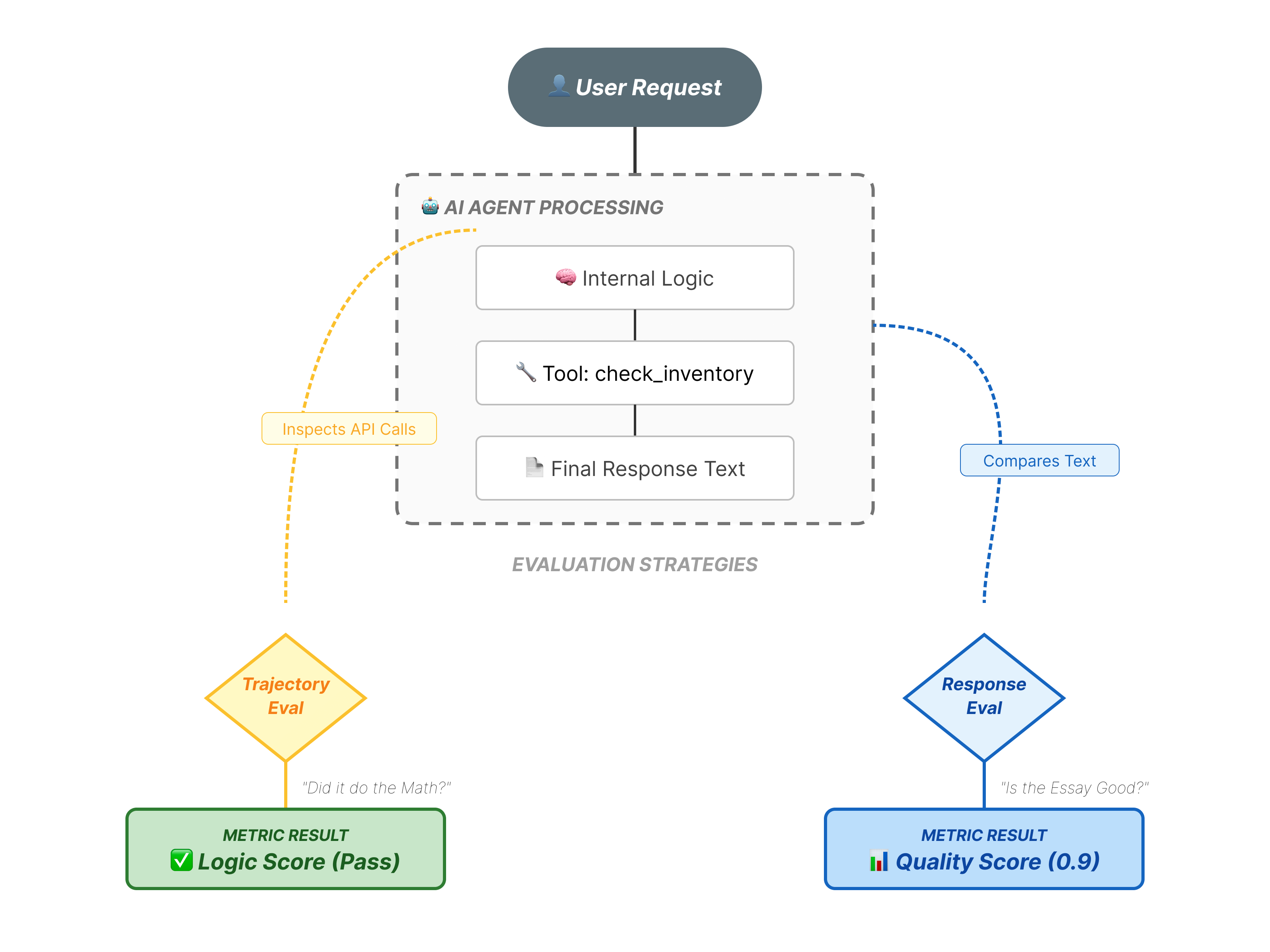
Während in der Web-UI eine komplexe .evalset.json-Datei generiert wird, möchten wir für automatisierte Tests oft eine übersichtlichere, strukturiertere Testdatei erstellen.
ADK Eval verwendet zwei Hauptkomponenten:
- Testdateien: Das kann das automatisch generierte Golden Dataset (z.B.
customer_service_agent/evalset1.evalset.json) oder ein manuell zusammengestelltes Set (z.B.customer_service_agent/eval.test.json) sein. - Konfigurationsdateien (z.B.
customer_service_agent/test_config.json): Hier werden die Messwerte und Schwellenwerte für das Bestehen definiert.
Testkonfigurationsdatei einrichten
- 👉💻 Geben Sie im Terminal des Cloud Shell-Editors Folgendes ein:
cloudshell edit customer_service_agent/test_config.json - 👉 Geben Sie den folgenden Code in das
customer_service_agent/test_config.jsonin Ihrem Editor ein.{ "criteria": { "tool_trajectory_avg_score": 0.8, "response_match_score": 0.5 } }
Messwerte entschlüsseln
tool_trajectory_avg_score(Der Prozess): Hier wird gemessen, ob der Agent die Tools richtig verwendet hat.
- 0,8: Wir fordern eine Übereinstimmung von 80 %.
response_match_score(Die Ausgabe): Hier wird ROUGE-1 (Wortübereinstimmung) verwendet, um die Antwort mit der goldenen Referenz zu vergleichen.
- Vorteile: Schnell, deterministisch, kostenlos.
- Nachteile: Der Test schlägt fehl, wenn der KI-Agent dieselbe Idee unterschiedlich formuliert (z.B. „Erstattet“ im Vergleich zu „Geld zurückgegeben“).
Erweiterte Messwerte (wenn Sie mehr Leistung benötigen)
6. Bewertung für Golden Dataset ausführen (adk eval)
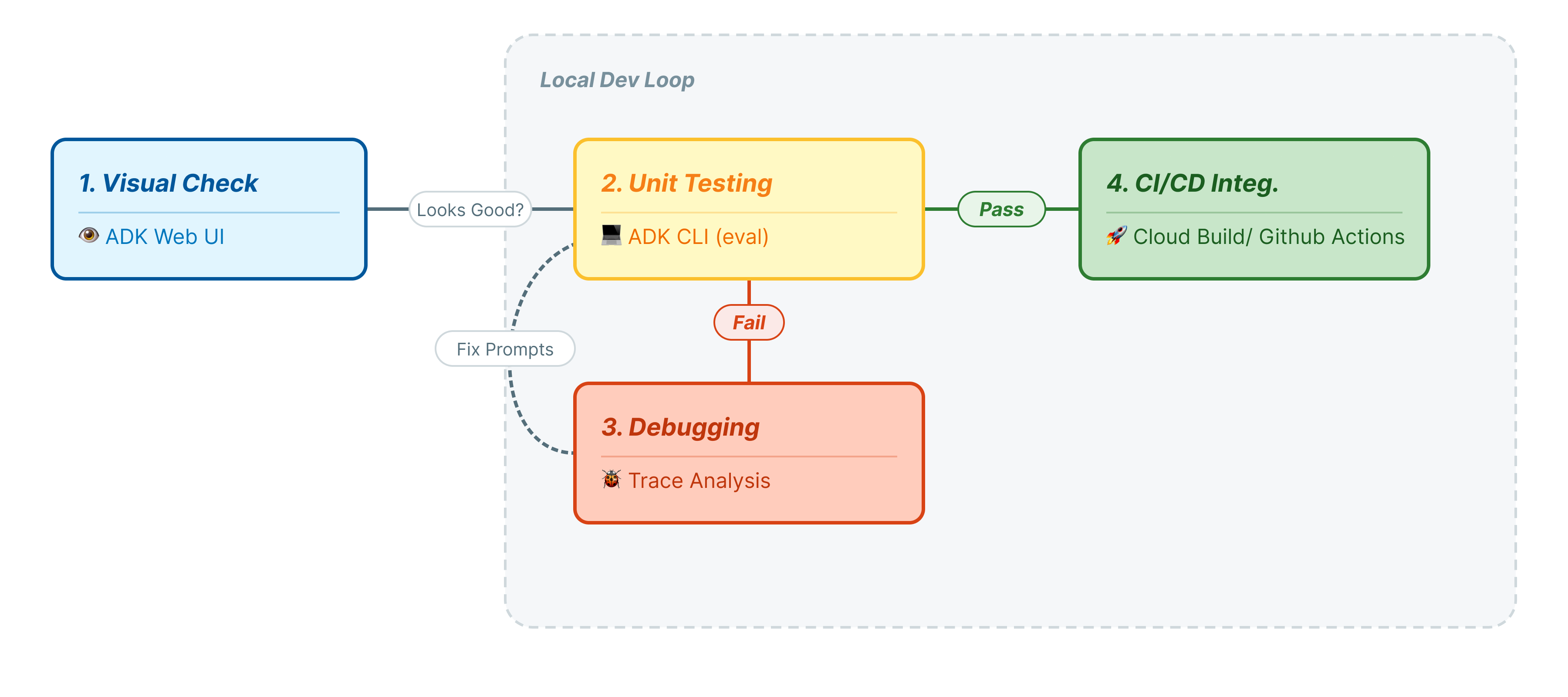
Dieser Schritt stellt den „Inner Loop“ der Entwicklung dar. Sie sind Entwickler und möchten Änderungen vornehmen und die Ergebnisse schnell überprüfen.
Golden Dataset ausführen
Führen wir den Datensatz aus, den Sie in Schritt 1 generiert haben. So wird sichergestellt, dass Ihre Baseline solide ist.
- 👉💻 Führen Sie im Terminal folgenden Befehl aus:
cd ~/adk_eval_starter uv run adk eval customer_service_agent customer_service_agent/evalset1.evalset.json --config_file_path=customer_service_agent/test_config.json --print_detailed_results
Was gibt's Neues?
Das ADK ist jetzt:
- Ihr KI-Agent wird aus
customer_service_agentgeladen. - Eingabeabfragen aus
evalset1.evalset.jsonausführen. - Vergleich des tatsächlichen Ablaufs und der Antworten des Agenten mit den erwarteten.
- Bewertung der Ergebnisse anhand der Kriterien in
test_config.json.
Ergebnisse analysieren
Sehen Sie sich die Terminalausgabe an. Sie sehen eine Zusammenfassung der bestandenen und fehlgeschlagenen Tests.
Eval Run Summary
evalset1:
Tests passed: 1
Tests failed: 0
********************************************************************
Eval Set Id: evalset1
Eval Id: eval1
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.5581395348837208, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+---------------------------+---------------------------+--------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+===========================+===========================+==========================+===========================+===========================+=============================+========================+
| 0 | Hi, I'm customer CUST001. | Great news! Your refund | Great news, CUST001! 🎉 | id='adk-051409fe-c230-43f | id='adk-4e9aa570-1cc6-4c3 | Status: PASSED, Score: | Status: PASSED, Score: |
| | Can you check my orders? | for order **ORD-102** has | I've successfully | 4-a7f1- 5747280fd878' | c-aa3e- 91dbe113dd4b' | 1.0 | 0.5581395348837208 |
| | I need a refund for order | been successfully | processed a full refund | args={'customer_id': | args={'customer_id': | | |
| | ORD-102. It arrived | processed due to the item | of $35.0 for your order | 'CUST001'} name='get_purc | 'CUST001'} name='get_purc | | |
| | damaged. | arriving damaged. You | ORD-102 because it | hase_history' | hase_history' | | |
| | | should see a full refund | arrived damaged. The | partial_args=None | partial_args=None | | |
| | | of $35.0 back to your | status of that order has | will_continue=None id= 'a | will_continue=None | | |
| | | original payment method | been updated to | dk-8a194cb8-5a82-47ce-a3a | id='adk- dad1b376-9bcc-48 | | |
| | | shortly. The status of | "refunded." Is there | 7- 3d24551f8c90' | bb-996f-a30f6ef5b70b' | | |
| | | this order has been | anything else I can | args={'reason': | args={'reason': | | |
| | | updated to "refunded". | assist you with today? | 'damaged', 'order_id': | 'damaged', 'order_id': | | |
| | | Here's your updated | | 'ORD-102'} | 'ORD-102'} | | |
| | | purchase history for | | name='issue_refund' | name='issue_refund' | | |
| | | CUST001: * **ORD-101**: | | partial_args=None | partial_args=None | | |
| | | Wireless Headphones, | | will_continue=None | will_continue=None | | |
| | | delivered on 2023-10-15 | | | | | |
| | | (Total: $120) * | | | | | |
| | | **ORD-102**: USB-C Cable, | | | | | |
| | | Phone Case, refunded on | | | | | |
| | | 2023-11-01 (Total: $35) | | | | | |
| | | Is there anything else I | | | | | |
| | | can help you with today? | | | | | |
| | | 😊 | | | | | |
+----+---------------------------+---------------------------+--------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
Hinweis: Da Sie dies gerade im Agent generiert haben, sollte es zu 100 % bestehen. Wenn der Test fehlschlägt, ist Ihr Agent nicht deterministisch (zufällig).
7. Benutzerdefinierten Test erstellen
Automatisch generierte Datasets sind zwar sehr nützlich, aber manchmal müssen Sie Grenzfälle manuell erstellen, z.B. für feindselige Angriffe oder die spezifische Fehlerbehandlung. Sehen wir uns an, wie Sie mit eval.test.json „Richtigkeit“ definieren können.
Wir erstellen eine umfassende Testsuite.
Das Test-Framework
Wenn Sie einen Testlauf im ADK schreiben, folgen Sie dieser dreiteiligen Formel:
- Die Einrichtung (
session_input): Wer ist der Nutzer? (z.B.user_id,state). Dadurch wird der Test isoliert. - Der Prompt (
user_content): Was ist der Trigger?
Mit Die Behauptungen (Erwartungen):
- Trajektorie (
tool_uses): Wurde richtig gerechnet? (Logik) - Antwort (
final_response): War die Antwort richtig? (Qualität) - Mittelstufe (
intermediate_responses): Haben sich die untergeordneten Agents richtig unterhalten? (Orchestrierung)
Test-Suite schreiben
- 👉💻 Geben Sie im Terminal des Cloud Shell-Editors Folgendes ein:
cloudshell edit customer_service_agent/eval.test.json - 👉 Geben Sie den folgenden Code in die Datei
customer_service_agent/eval.test.jsonein.{ "eval_set_id": "customer_service_eval", "name": "Customer Service Agent Evaluation", "description": "Evaluation suite for the customer service agent covering product info, purchase history, and refunds.", "eval_cases": [ { "eval_id": "product_info_check", "session_input": { "app_name": "customer_service_agent", "user_id": "eval_user_1", "state": {} }, "conversation": [ { "invocation_id": "turn_1_product_info", "user_content": { "role": "user", "parts": [ { "text": "Do you have wireless headphones in stock?" } ] }, "final_response": { "role": "model", "parts": [ { "text": "Yes, we have wireless headphones in stock! They are priced at $120.00 and feature noise-canceling with a 20-hour battery life. 🎧" } ] }, "intermediate_data": { "tool_uses": [ { "name": "lookup_product_info", "args": { "product_name": "wireless headphones" } } ], "intermediate_responses": [] } } ] }, { "eval_id": "purchase_history_check", "session_input": { "app_name": "customer_service_agent", "user_id": "eval_user_2", "state": {} }, "conversation": [ { "invocation_id": "turn_1_purchase_history", "user_content": { "role": "user", "parts": [ { "text": "What did I buy recently? My customer ID is CUST001." } ] }, "final_response": { "role": "model", "parts": [ { "text": "Here's your recent purchase history for Customer ID CUST001:\n\n* **Order ORD-101** (October 15, 2023): Wireless Headphones, Status: delivered, Total: $120\n* **Order ORD-102** (November 1, 2023): USB-C Cable, Phone Case, Status: refunded, Total: $35\n\nLet me know if you have any other questions or need further assistance! 🛍️" } ] }, "intermediate_data": { "tool_uses": [ { "name": "get_purchase_history", "args": { "customer_id": "CUST001" } } ], "intermediate_responses": [] } } ] }, { "eval_id": "refund_request", "session_input": { "app_name": "customer_service_agent", "user_id": "eval_user_3", "state": {} }, "conversation": [ { "invocation_id": "turn_1_refund", "user_content": { "role": "user", "parts": [ { "text": "I want a refund for order ORD-102 because it was damaged." } ] }, "final_response": { "role": "model", "parts": [ { "text": "Your refund for order **ORD-102** due to \"damaged\" has been successfully processed! Refund amount: **$35.0**. Your order status has been updated to **refunded**. \nIs there anything else I can help you with today? 🛍️" } ] }, "intermediate_data": { "tool_uses": [ { "name": "issue_refund", "args": { "order_id": "ORD-102", "reason": "damaged" } } ], "intermediate_responses": [] } } ] } ] }
Testtypen aufschlüsseln
Wir haben hier drei verschiedene Arten von Tests erstellt. Sehen wir uns an, was bei den einzelnen Tests bewertet wird und warum.
- Der Single Tool Test (
product_info_check)
- Ziel: Abrufen grundlegender Informationen überprüfen.
- Wichtige Behauptung: Wir prüfen
intermediate_data.tool_uses. Wir bestätigen, dasslookup_product_infoaufgerufen wird. Wir behaupten, dass das Argumentproduct_namegenau „kabellose Kopfhörer“ ist. - Grund: Wenn das Modell einen Preis halluziniert, ohne das Tool aufzurufen, schlägt dieser Test fehl. Dadurch wird die Fundierung sichergestellt.
- Kontext-Extraktionstest (
purchase_history_check)
- Ziel: Prüfen, ob der Agent Entitäten (CUST001) aus dem Nutzer-Prompt extrahieren und an das Tool übergeben kann.
- Wichtige Behauptung: Wir prüfen, ob
get_purchase_historymitcustomer_id: "CUST001"aufgerufen wird. - Grund: Ein häufiger Fehler ist, dass der Agent das richtige Tool aufruft, aber mit einer Null-ID. So wird die Genauigkeit der Parameter gewährleistet.
- Der Test für Aktionen/Trajektorien (
refund_request)
- Ziel: Einen kritischen Schreibvorgang überprüfen.
- Wichtige Behauptung: Der Pfad. In einem komplexeren Szenario würde diese Liste mehrere Schritte enthalten:
[verify_order, calculate_refund, issue_refund]. Das ADK prüft diese Liste in der angegebenen Reihenfolge. - Grund: Bei Aktionen, bei denen Geld bewegt oder Daten geändert werden, ist die Reihenfolge genauso wichtig wie das Ergebnis. Sie möchten keine Erstattung vor der Bestätigung vornehmen.
8. Bewertung für benutzerdefinierte Tests ausführen ( adk eval)
- 👉💻 Führen Sie im Terminal folgenden Befehl aus:
cd ~/adk_eval_starter uv run adk eval customer_service_agent customer_service_agent/eval.test.json --config_file_path=customer_service_agent/test_config.json --print_detailed_results
Ausgabe verstehen
Das Ergebnis sollte so aussehen:
Eval Run Summary
customer_service_eval:
Tests passed: 3
Tests failed: 0
********************************************************************
Eval Set Id: customer_service_eval
Eval Id: purchase_history_check
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.5473684210526315, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+--------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+==========================+===========================+===========================+===========================+===========================+=============================+========================+
| 0 | What did I buy recently? | Here's your recent | Looks like your recent | id=None | id='adk-8960eb53-2933-459 | Status: PASSED, Score: | Status: PASSED, Score: |
| | My customer ID is | purchase history for | orders include: * | args={'customer_id': | f-b306- 71e3c069e77e' | 1.0 | 0.5473684210526315 |
| | CUST001. | Customer ID CUST001: * | **ORD-101 (2023-10-15):** | 'CUST001'} name='get_purc | args={'customer_id': | | |
| | | **Order ORD-101** | Wireless Headphones for | hase_history' | 'CUST001'} name='get_purc | | |
| | | (October 15, 2023): | $120.00 - Status: | partial_args=None | hase_history' | | |
| | | Wireless Headphones, | Delivered 🎧 * **ORD-102 | will_continue=None | partial_args=None | | |
| | | Status: delivered, Total: | (2023-11-01):** USB-C | | will_continue=None | | |
| | | $120 * **Order | Cable, Phone Case for | | | | |
| | | ORD-102** (November 1, | $35.00 - Status: Refunded | | | | |
| | | 2023): USB-C Cable, Phone | 📱 Is there anything else | | | | |
| | | Case, Status: refunded, | I can help you with | | | | |
| | | Total: $35 Let me know | regarding these orders? | | | | |
| | | if you have any other | | | | | |
| | | questions or need further | | | | | |
| | | assistance! 🛍️ | | | | | |
+----+--------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
********************************************************************
Eval Set Id: customer_service_eval
Eval Id: product_info_check
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.6829268292682927, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+----------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+======================+===========================+===========================+===========================+===========================+=============================+========================+
| 0 | Do you have wireless | Yes, we have wireless | Yes, we do! 🎧 We have | id=None | id='adk-4571d660-a92b-412 | Status: PASSED, Score: | Status: PASSED, Score: |
| | headphones in stock? | headphones in stock! They | noise-canceling wireless | args={'product_name': | a-a79e- 5c54f8b8af2d' | 1.0 | 0.6829268292682927 |
| | | are priced at $120.00 and | headphones with a 20-hour | 'wireless headphones'} na | args={'product_name': | | |
| | | feature noise-canceling | battery life available | me='lookup_product_info' | 'wireless headphones'} na | | |
| | | with a 20-hour battery | for $120. | partial_args=None | me='lookup_product_info' | | |
| | | life. 🎧 | | will_continue=None | partial_args=None | | |
| | | | | | will_continue=None | | |
+----+----------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
********************************************************************
Eval Set Id: customer_service_eval
Eval Id: refund_request
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.6216216216216216, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+---------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+===========================+===========================+===========================+===========================+===========================+=============================+========================+
| 0 | I want a refund for order | Your refund for order | Your refund for order | id=None args={'order_id': | id='adk-fb8ff1cc- cf87-41 | Status: PASSED, Score: | Status: PASSED, Score: |
| | ORD-102 because it was | **ORD-102** due to | **ORD-102** has been | 'ORD-102', 'reason': | f2-9b11-d4571b14287f' | 1.0 | 0.6216216216216216 |
| | damaged. | "damaged" has been | successfully processed! | 'damaged'} | args={'order_id': | | |
| | | successfully processed! | You should see a full | name='issue_refund' | 'ORD-102', 'reason': | | |
| | | Refund amount: **$35.0**. | refund of $35.0 appear in | partial_args=None | 'damaged'} | | |
| | | Your order status has | your account shortly. We | will_continue=None | name='issue_refund' | | |
| | | been updated to | apologize for the | | partial_args=None | | |
| | | **refunded**. Is there | inconvenience! Is there | | will_continue=None | | |
| | | anything else I can help | anything else I can | | | | |
| | | you with today? 🛍️ | assist you with today? 😊 | | | | |
+----+---------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
Das bedeutet, dass Ihr Agent die richtigen Tools verwendet und eine Antwort gegeben hat, die Ihren Erwartungen entspricht.
9. (Optional: Nur lesen) – Fehlerbehebung und Debugging
Die Tests schlagen fehl. Das ist ihre Aufgabe. Aber wie beheben Sie sie? Sehen wir uns einige häufige Fehlerszenarien und die zugehörigen Debugging-Methoden an.
Szenario A: Fehler bei der Trajektorie
Der Fehler:
Result: FAILED
Reason: Criteria 'tool_trajectory_avg_score' failed. Score 0.0 < Threshold 1.0
Details:
EXPECTED: tool: lookup_order, then tool: issue_refund
ACTUAL: tool: issue_refund
Diagnose: Der Agent hat den Bestätigungsschritt (lookup_order) übersprungen. Dies ist ein Logikfehler.
Fehlerbehebung:
- Nicht raten: Gehen Sie zurück zur ADK-Web-UI (adk web).
- Reproduzieren: Geben Sie den genauen Prompt aus dem fehlgeschlagenen Test in den Chat ein.
- Trace: Öffnet die Trace-Ansicht. Sehen Sie sich den Tab „Diagramm“ an.
- Prompt korrigieren: In der Regel müssen Sie den System-Prompt aktualisieren. Änderung: „You are a helpful agent.“ An: „Du bist ein hilfsbereiter Kundenservicemitarbeiter. WICHTIG: Sie MÜSSEN lookup_order aufrufen, um die Details zu bestätigen, bevor Sie issue_refund aufrufen."
- Test anpassen: Wenn sich die Geschäftslogik geändert hat (z.B. ist die Bestätigung nicht mehr erforderlich), ist der Test falsch. Aktualisieren Sie „eval.test.json“, damit sie der neuen Realität entspricht.
Szenario B: Der „ROUGE“-Fehler
Der Fehler:
Result: FAILED
Reason: Criteria 'response_match_score' failed. Score 0.45 < Threshold 0.8
Expected: "The refund has been processed successfully."
Actual: "I've gone ahead and returned the money to your card."
Diagnose: Der Kundenservicemitarbeiter hat richtig gehandelt, aber andere Formulierungen verwendet. ROUGE (Wortüberschneidung) hat die Antwort negativ beeinflusst.
Lösung:
- Ist das falsch? Wenn die Bedeutung korrekt ist, ändern Sie den Prompt nicht.
- Grenzwert anpassen: Senken Sie den Grenzwert in
test_config.json(z.B. von0.8auf0.5). - Messwert aktualisieren: Wechseln Sie in der Konfiguration zu
final_response_match_v2. Dabei wird ein LLM verwendet, um beide Sätze zu lesen und zu beurteilen, ob sie dasselbe bedeuten.
10. CI/CD mit Pytest (pytest)
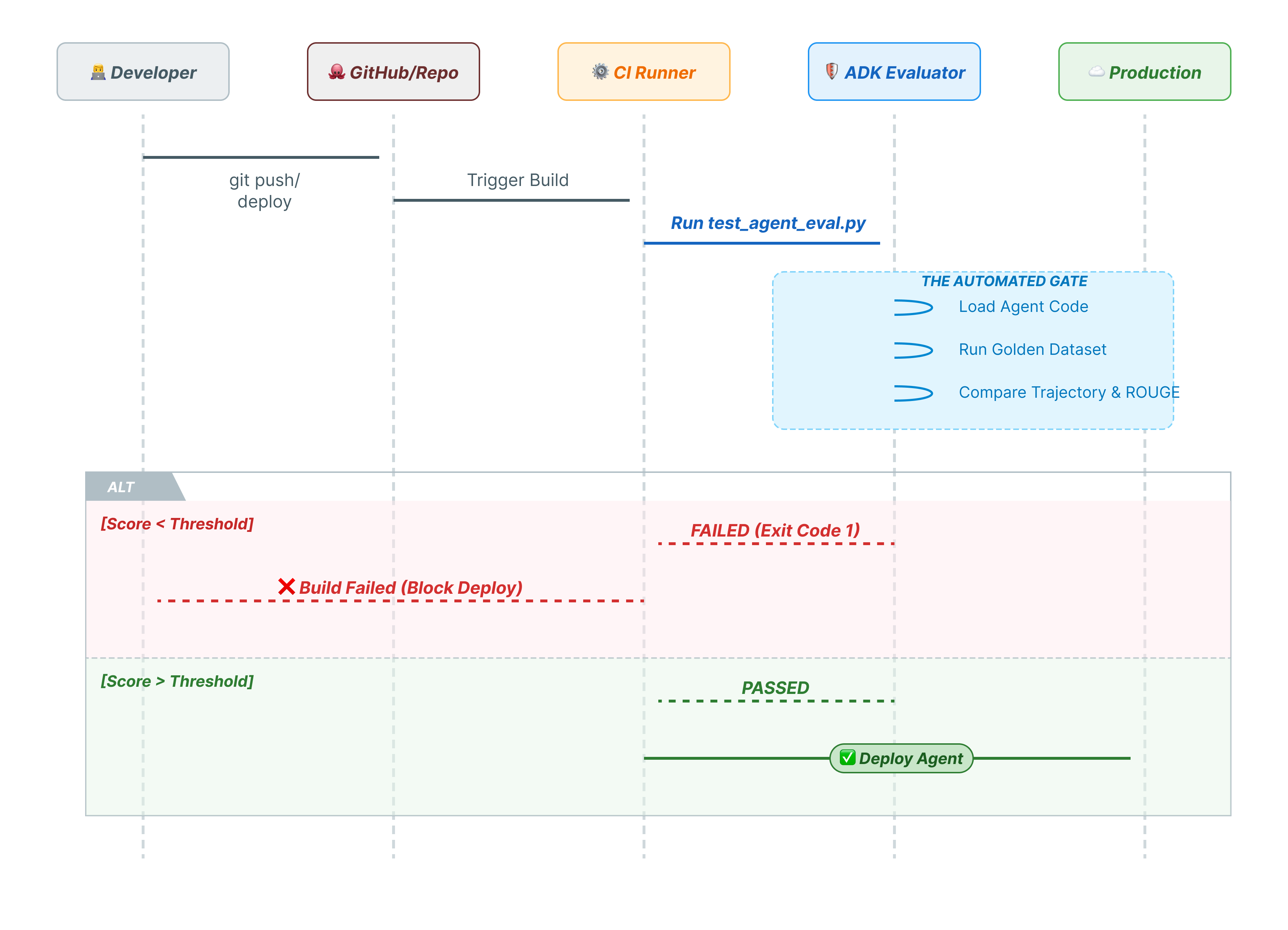
Befehlszeilenbefehle sind für Menschen gedacht. pytest ist für Maschinen. Um die Zuverlässigkeit in der Produktion zu gewährleisten, fassen wir unsere Auswertungen in einer Python-Test-Suite zusammen. So kann Ihre CI/CD-Pipeline (GitHub Actions, Jenkins) eine Bereitstellung blockieren, wenn die Leistung des KI-Agenten nachlässt.
Was gehört in diese Datei?
Diese Python-Datei fungiert als Brücke zwischen Ihrem CI/CD-Runner und dem ADK-Evaluator. Es muss:
- KI‑Agenten laden: Importieren Sie Ihren KI‑Agenten-Code dynamisch.
- Status zurücksetzen: Achten Sie darauf, dass der Agentspeicher sauber ist, damit Tests nicht ineinander übergehen.
- Bewertung ausführen: Rufen Sie
AgentEvaluator.evaluate()programmatisch auf. - Erfolg bestätigen: Wenn das Testergebnis niedrig ist, schlägt der Build fehl.
Der Integrationstestcode
- 👉 Öffnen Sie
customer_service_agent/test_agent_eval.py. Dieses Skript verwendetAgentEvaluator.evaluate, um die ineval.test.jsondefinierten Tests auszuführen. - 👉 Geben Sie den folgenden Code in das
customer_service_agent/test_agent_eval.pyin Ihrem Editor ein.from google.adk.evaluation.agent_evaluator import AgentEvaluator import pytest import importlib import sys import os @pytest.mark.asyncio async def test_with_single_test_file(): """Test the agent's basic ability via a session file.""" # Load the agent module robustly module_name = "customer_service_agent.agent" try: agent_module = importlib.import_module(module_name) # Reset the mock data to ensure a fresh state for the test if hasattr(agent_module, 'reset_mock_data'): agent_module.reset_mock_data() except ImportError: # Fallback if running from a different context sys.path.append(os.getcwd()) agent_module = importlib.import_module(module_name) if hasattr(agent_module, 'reset_mock_data'): agent_module.reset_mock_data() # Use absolute path to the eval file to be robust to where pytest is run script_dir = os.path.dirname(os.path.abspath(__file__)) eval_file = os.path.join(script_dir, "eval.test.json") await AgentEvaluator.evaluate( agent_module=module_name, eval_dataset_file_path_or_dir=eval_file, num_runs=1, )
Pytest ausführen
- 👉💻 Führen Sie im Terminal folgenden Befehl aus:
cd ~/adk_eval_starter uv pip install pytest uv run pytest customer_service_agent/test_agent_eval.py``` -- Docs: https://docs.pytest.org/en/stable/how-to/capture-warnings.html =============== 1 passed, 15 warnings in 12.84s =============== ```
11. Fazit
Glückwunsch! Sie haben Ihren Kundenservice-Agenten mit ADK Eval bewertet.
Das haben Sie gelernt
In diesem Codelab haben Sie Folgendes gelernt:
- ✅ Golden Dataset erstellen, um eine Referenz für Ihren Agenten zu erstellen.
- ✅ Evaluierungskonfiguration verstehen, um Erfolgskriterien zu definieren.
- ✅ Automatisierte Tests ausführen, um Regressionen frühzeitig zu erkennen.
Wenn Sie ADK Eval in Ihren Entwicklungs-Workflow einbinden, können Sie Agents mit Zuversicht erstellen, da Sie wissen, dass jede Verhaltensänderung durch Ihre automatisierten Tests erkannt wird.
Dieses Lab ist Teil des Lernpfads „Produktionsreife KI mit Google Cloud“.
- Gesamten Lehrplan ansehen
- Teile deinen Fortschritt mit dem Hashtag
ProductionReadyAI.
Weitere Informationen: