
1. La brecha de confianza
El momento de inspiración
Creaste un agente de atención al cliente. Funciona en tu máquina. Pero ayer le dijo a un cliente que un reloj inteligente agotado estaba disponible o, peor aún, alucinó una política de reembolsos. ¿Cómo duermes por la noche sabiendo que tu agente está en vivo?
Para cerrar la brecha entre un agente de IA de prueba de concepto y uno listo para producción, es fundamental contar con un marco de evaluación sólido y automatizado.

¿Qué evaluamos en realidad?
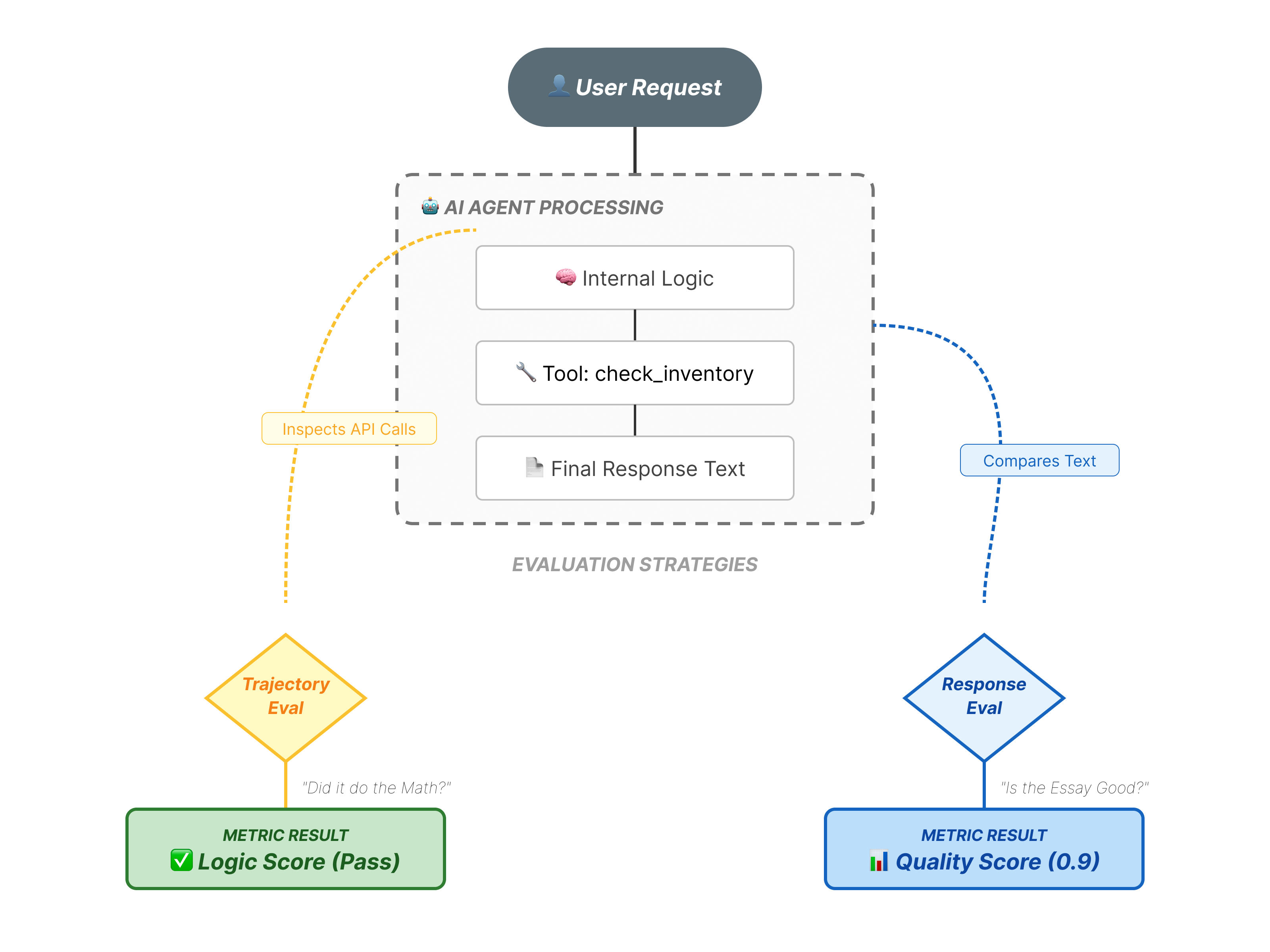
La evaluación de agentes es más compleja que la evaluación estándar de LLM. No solo calificas el Ensayo (respuesta final), sino también la Matemática (la lógica o las herramientas que se usaron para llegar a la respuesta).
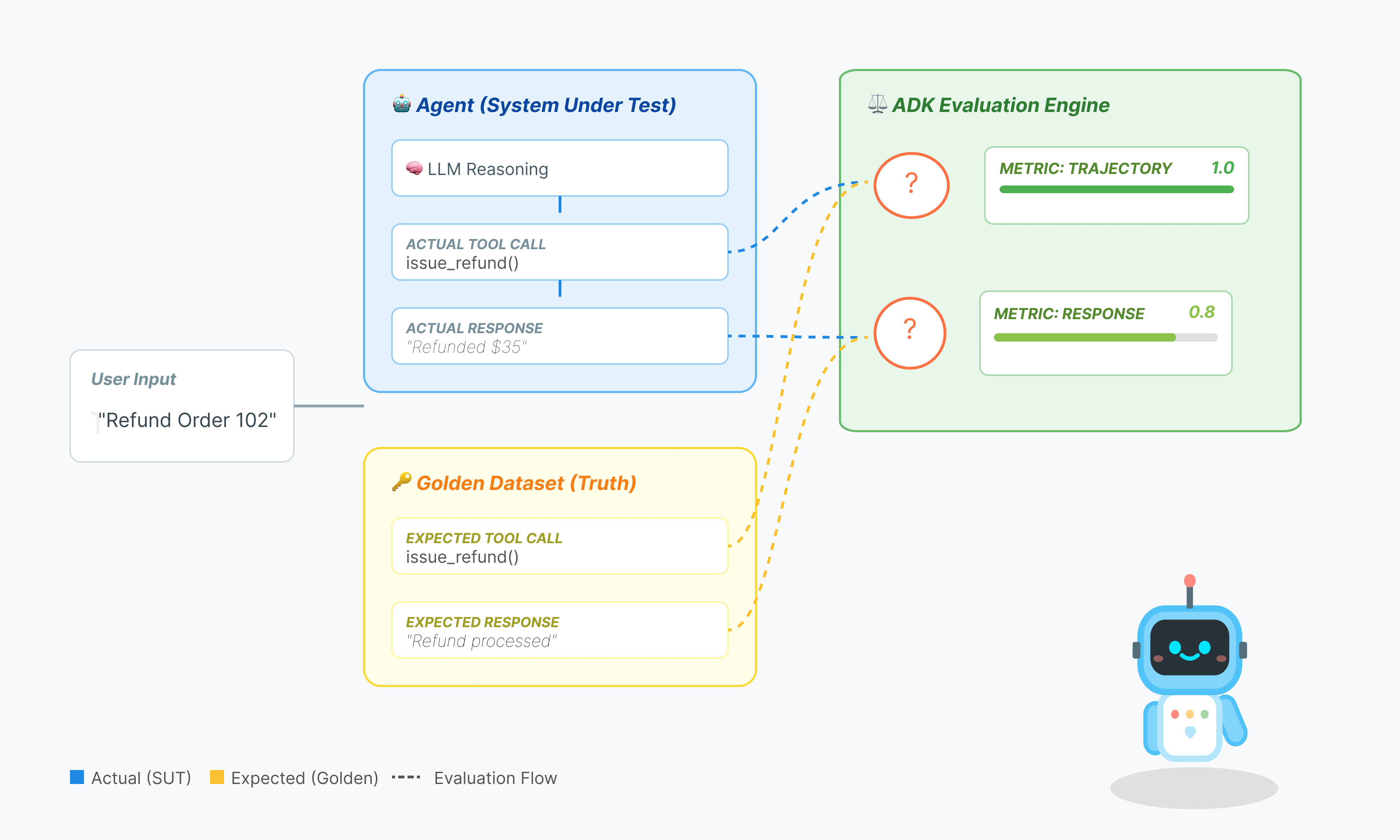
- Trayectoria (el proceso): ¿El agente usó la herramienta correcta en el momento adecuado? ¿Llamó a
check_inventoryantes deplace_order? - Respuesta final (la salida): ¿La respuesta es correcta, cortés y se basa en los datos?
El ciclo de vida del desarrollo
En este codelab, analizaremos el ciclo de vida profesional de las pruebas de agentes:
- Inspección visual local (IU web del ADK): Chatear y verificar la lógica de forma manual (paso 1)
- Pruebas de regresión y de unidades (CLI del ADK): Ejecuta casos de prueba específicos de forma local para detectar errores rápidamente (pasos 3 y 4).
- Depuración (solución de problemas): Analiza las fallas y corrige la lógica de las instrucciones (paso 5).
- Integración de CI/CD (Pytest): Automatiza las pruebas en tu canalización de compilación (paso 6).
2. Configurar
Para potenciar nuestros agentes de IA, necesitamos dos cosas: un proyecto de Google Cloud que proporcione la base.
Parte uno: Habilita la cuenta de facturación
Para ejecutar este codelab, necesitas una cuenta de facturación con algo de crédito. Usa los créditos del banner que se encuentra en la parte superior de este codelab para comenzar. Si ya te conectaste a una cuenta de facturación, puedes omitir este paso.
Parte dos: Entorno abierto
- 👉 Haz clic en este vínculo para navegar directamente al editor de Cloud Shell.
- 👉 Si se te solicita autorización en algún momento, haz clic en Autorizar para continuar.
- 👉 Si la terminal no aparece en la parte inferior de la pantalla, ábrela:
- Haz clic en Ver.
- Haz clic en Terminal.
- 👉💻 En la terminal, verifica que ya te autenticaste y que el proyecto esté configurado con tu ID del proyecto usando el siguiente comando:
gcloud auth list - 👉💻 Clona el proyecto de arranque desde GitHub:
git clone https://github.com/cuppibla/adk_eval_starter - 👉💻 Ejecuta la secuencia de comandos de configuración desde el directorio del proyecto.
cd ~/adk_eval_starter ./init.sh
La secuencia de comandos se encargará del resto del proceso de configuración automáticamente.
- 👉💻 Establece el ID del proyecto necesario:
gcloud config set project $(cat ~/project_id.txt) --quiet
Parte tres: Cómo configurar el permiso
- 👉💻 Habilita las APIs requeridas con el siguiente comando. Esto puede tardar algunos minutos.
gcloud services enable \ cloudresourcemanager.googleapis.com \ servicenetworking.googleapis.com \ run.googleapis.com \ cloudbuild.googleapis.com \ artifactregistry.googleapis.com \ aiplatform.googleapis.com \ compute.googleapis.com - 👉💻 Ejecuta los siguientes comandos en la terminal para otorgar los permisos necesarios:
. ~/adk_eval_starter/set_env.sh
Observa que se creó un archivo .env para ti. En ella, se muestra la información de tu proyecto.
3. Genera el conjunto de datos de referencia (ADK web)
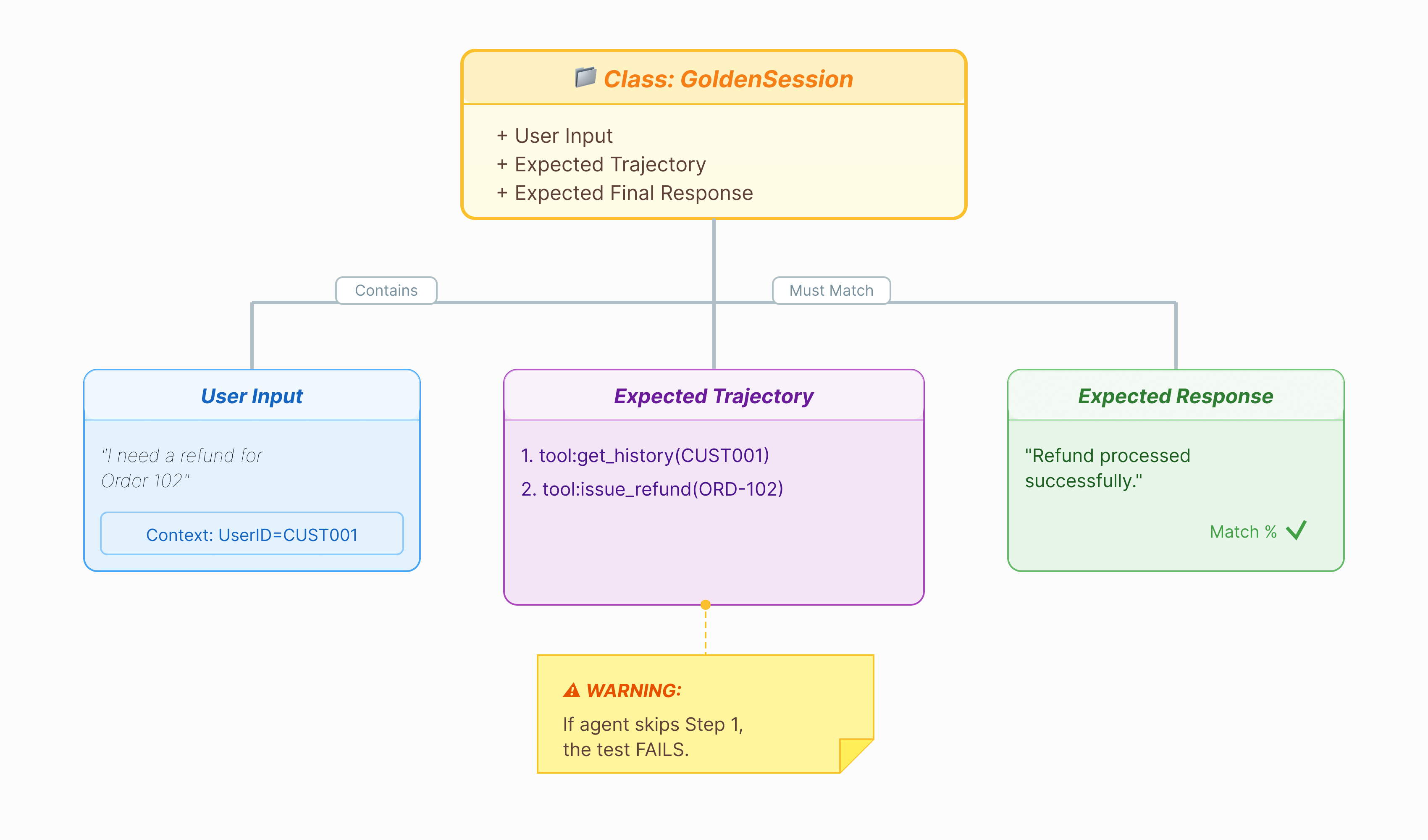
Antes de calificar al agente, necesitamos una clave de respuestas. En el ADK, lo llamamos conjunto de datos de referencia. Este conjunto de datos contiene interacciones "perfectas" que sirven como verdad fundamental para la evaluación.
¿Qué es un conjunto de datos de referencia?
Un conjunto de datos de referencia es una instantánea de tu agente que funciona correctamente. No es solo una lista de pares de preguntas y respuestas. Captura lo siguiente:
- La búsqueda del usuario ("Quiero un reembolso")
- La trayectoria (la secuencia exacta de llamadas a herramientas:
check_order->verify_eligibility->refund_transaction). - La respuesta final (la respuesta de texto "perfecta").
Usamos este valor para detectar regresiones. Si actualizas tu instrucción y el agente deja de verificar la elegibilidad antes de emitir el reembolso, la prueba del conjunto de datos de referencia fallará porque la trayectoria ya no coincide.
Abre la IU web
La IU web del ADK proporciona una forma interactiva de crear estos conjuntos de datos de referencia capturando interacciones reales con tu agente.
- 👉💻 En tu terminal, ejecuta lo siguiente:
cd ~/adk_eval_starter uv run adk web - 👉💻 Abre la vista previa de la IU web (por lo general, en
http://127.0.0.1:8000). - 👉 En la IU del chat, escribe
Hi, I'm customer CUST001. Can you check my orders? I need a refund for order ORD-102. It arrived damaged. Verás una respuesta como la siguiente:
Verás una respuesta como la siguiente:I've processed your refund for order ORD-102 due to the items arriving damaged. A full refund of $35.0 has been processed, and the status of order ORD-102 is now updated to "refunded". Is there anything else I can assist you with today, CUST001? 🛍️
Captura interacciones doradas
Navega a la pestaña Sessions. Aquí puedes ver el historial de conversaciones de tu agente haciendo clic en la sesión.
- Interactúa con tu agente para crear un flujo de conversación ideal, como consultar el historial de compras o solicitar un reembolso.
- Revisa la conversación para asegurarte de que represente el comportamiento esperado.
4. Exporta el conjunto de datos de referencia
Cómo realizar la verificación con Trace View
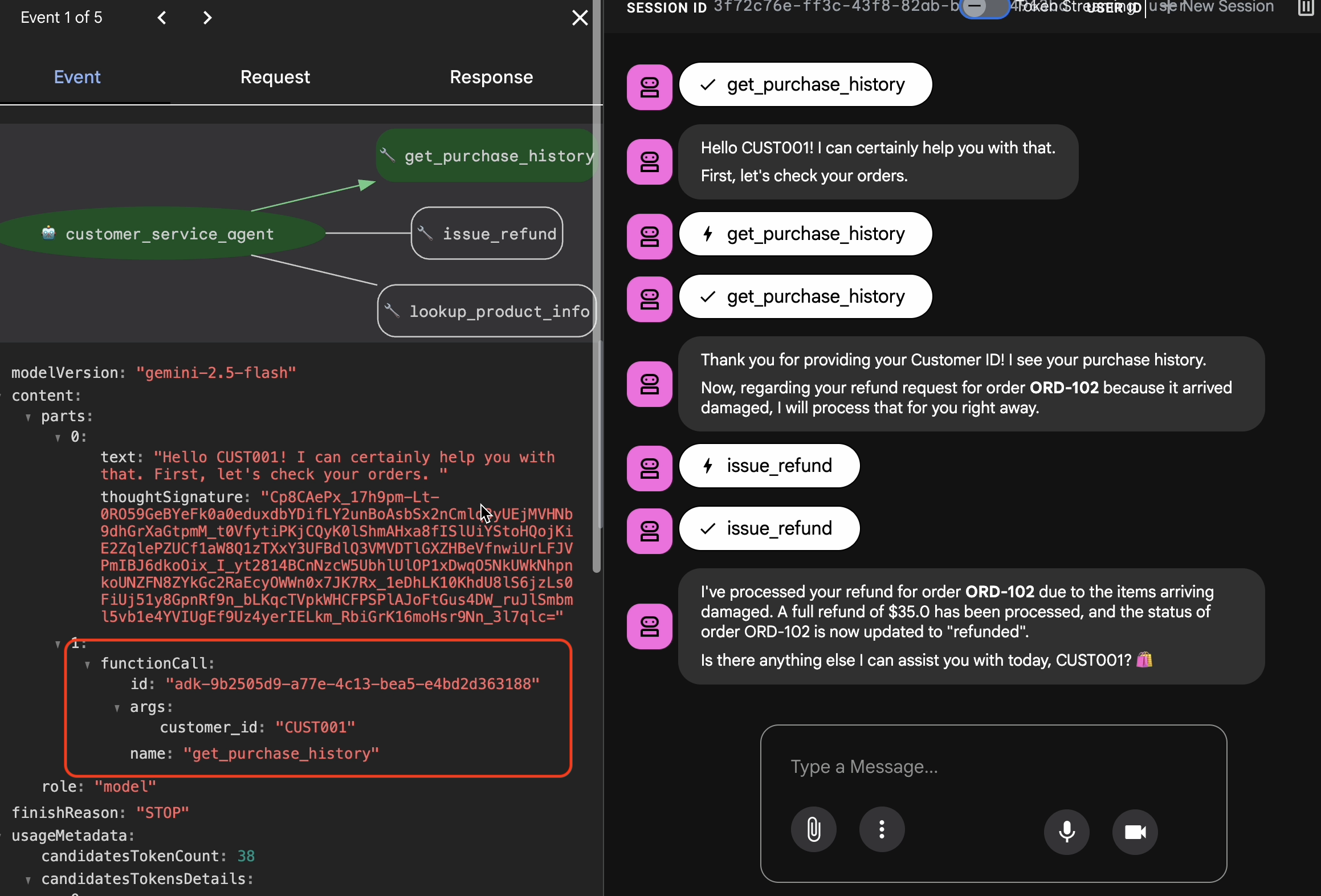
Antes de exportar, debes verificar que el agente no haya obtenido la respuesta correcta por casualidad. Debes inspeccionar la lógica interna.
- Haz clic en la pestaña Trace en la IU web.
- Los registros se agrupan automáticamente por mensaje del usuario. Coloca el cursor sobre una fila de registro para destacar el mensaje correspondiente en el chat.
- Inspecciona las filas azules: Indican eventos generados a partir de la interacción. Haz clic en una fila azul para abrir el panel de inspección.
- Consulta las siguientes pestañas para validar la lógica:
- Gráfico: Representación visual de las llamadas a herramientas y el flujo de lógica. ¿Tomó la ruta correcta?
- Solicitud/Respuesta: Revisa exactamente lo que se envió al modelo y lo que se devolvió.
- Verificación: Si el agente adivinó el importe del reembolso sin llamar a la herramienta de base de datos, se trata de una "alucinación afortunada".
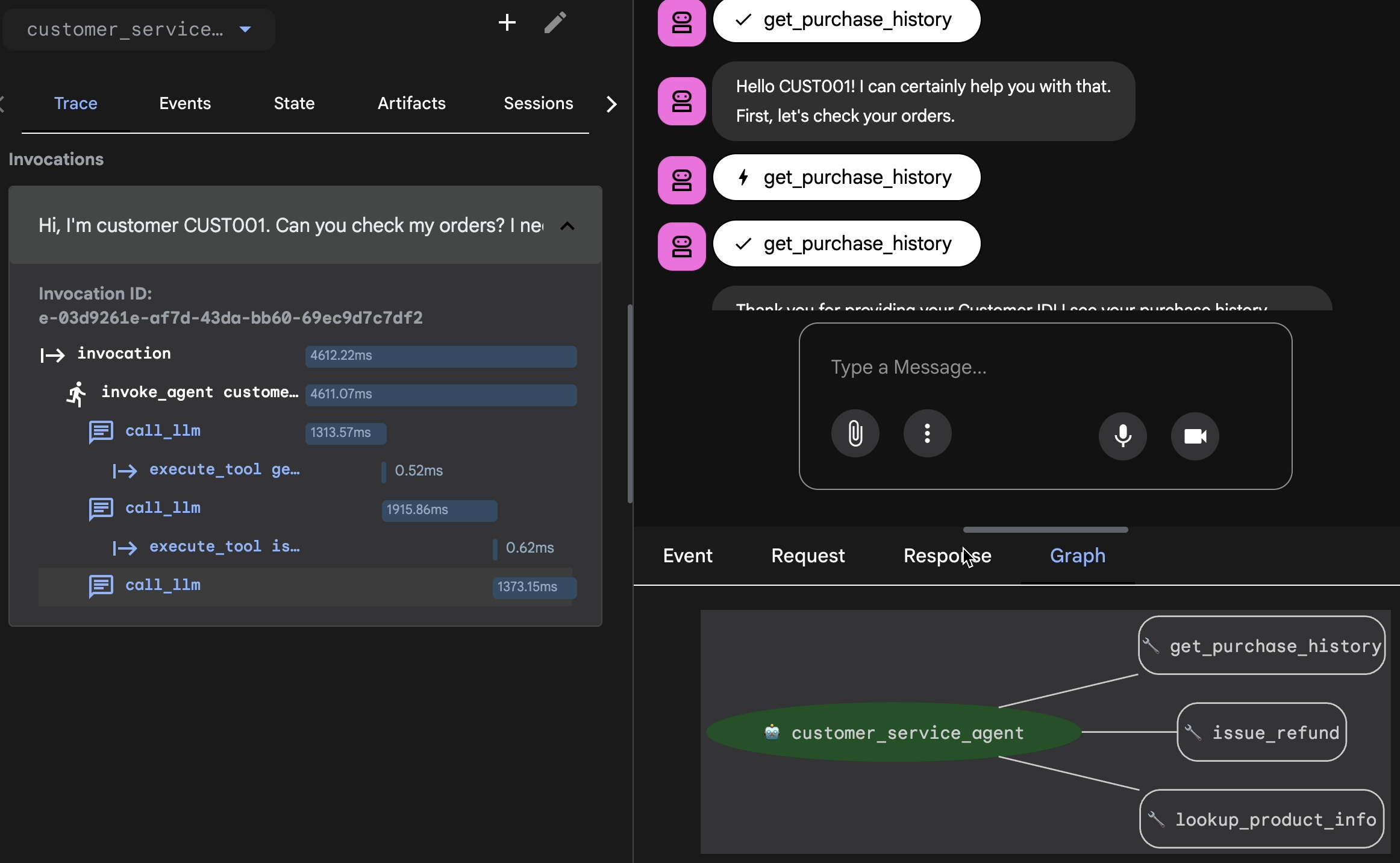
Agrega la sesión al conjunto de evaluación.
Una vez que estés conforme con la conversación y el registro, haz lo siguiente:
- 👉 Haz clic en la pestaña
Eval, luego en el botónCreate Evaluation Sety, luego, ingresa el nombre de la evaluación como:evalset1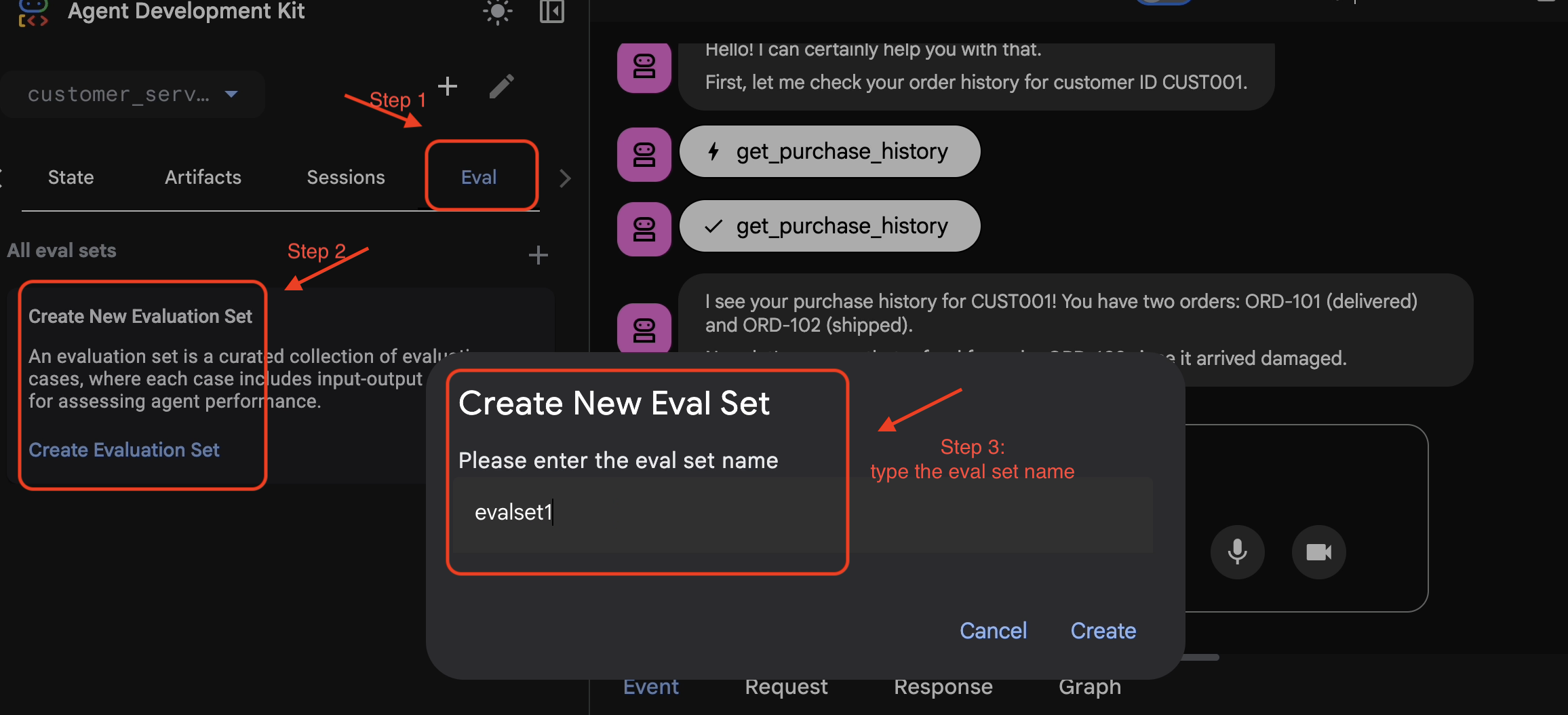
- 👉 En este conjunto de evaluación, haz clic en
Add current session to evalset1y, en la ventana emergente, ingresa el nombre de la sesión:eval1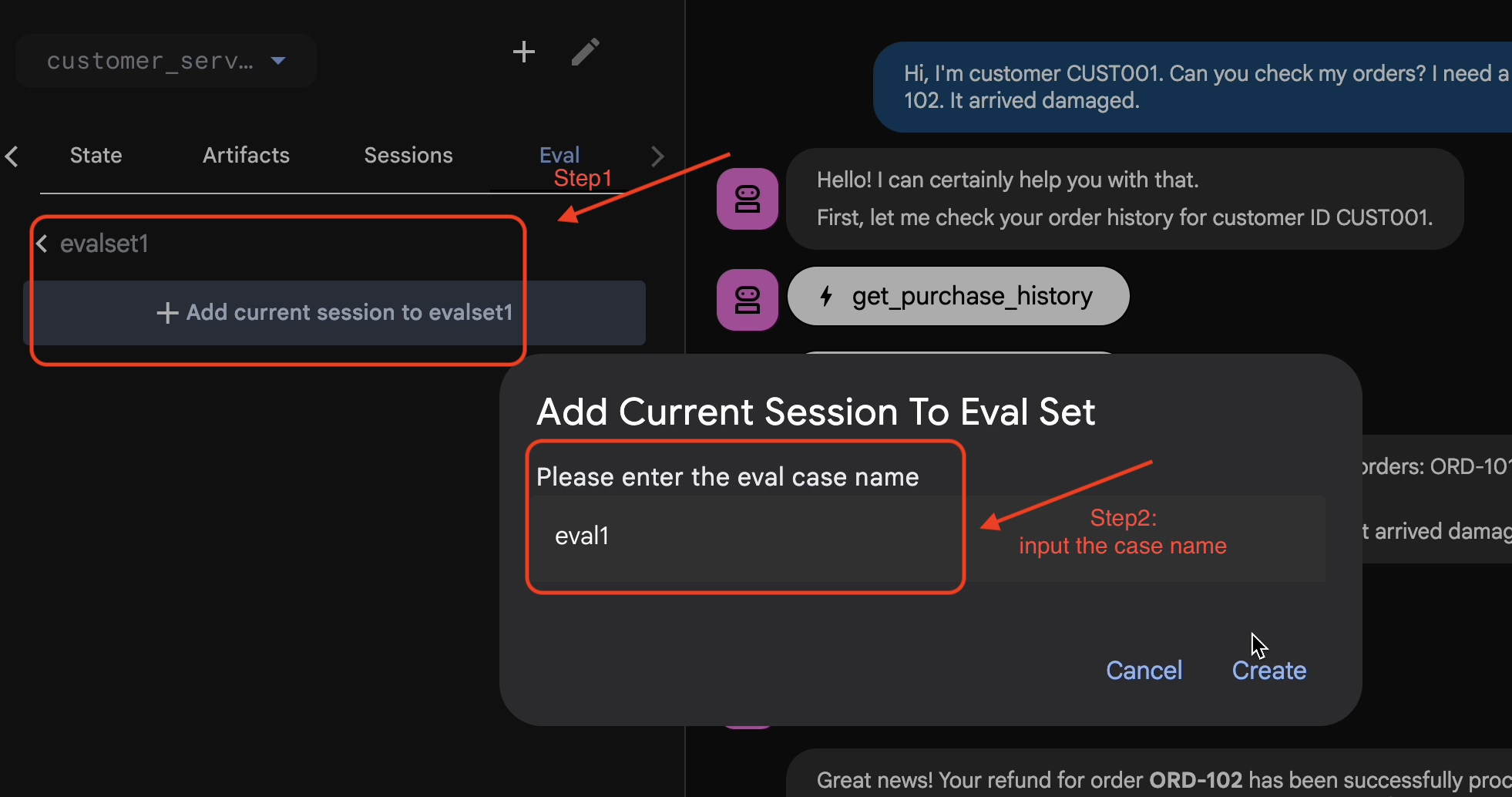
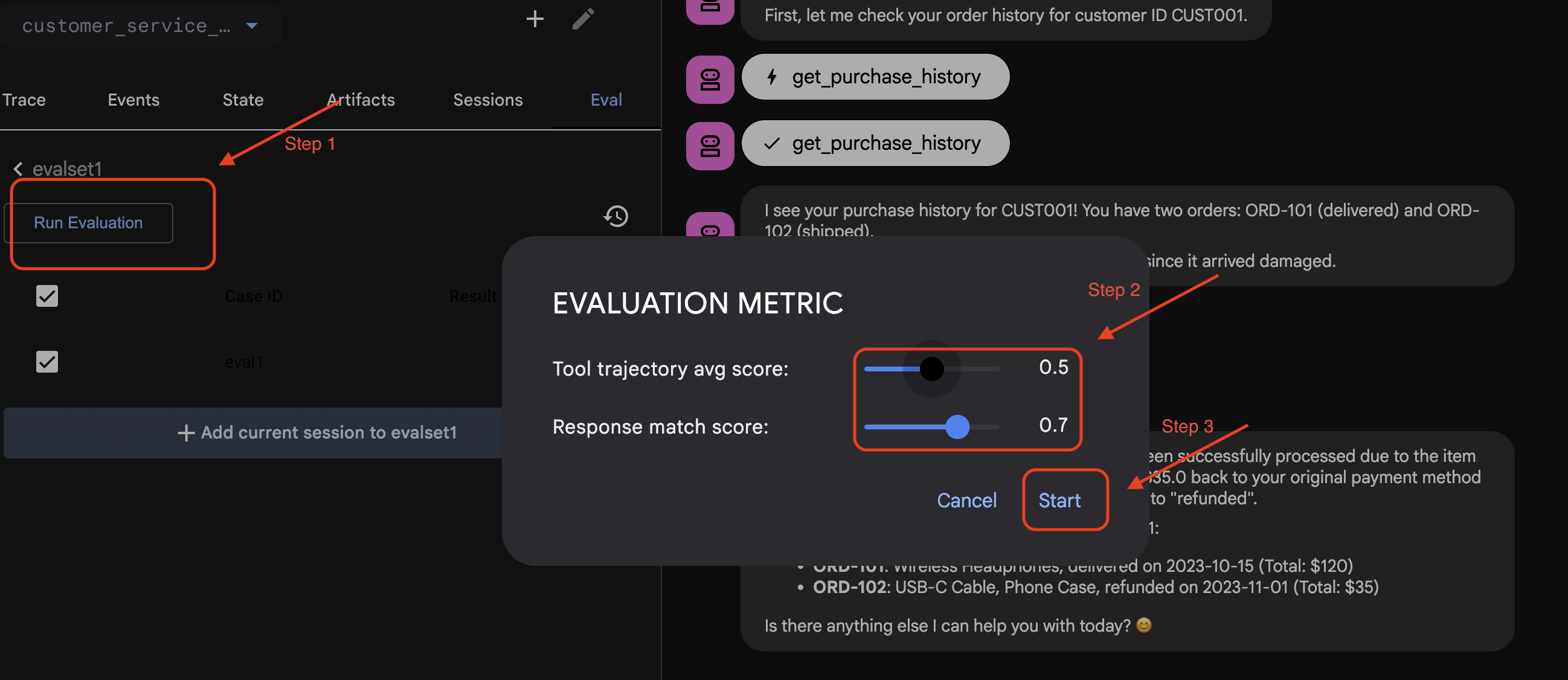
Ejecuta Eval en ADK Web
- 👉 En la IU web del ADK, haz clic en
Run Evaluation, ajusta las métricas en la ventana emergente y haz clic enStart:
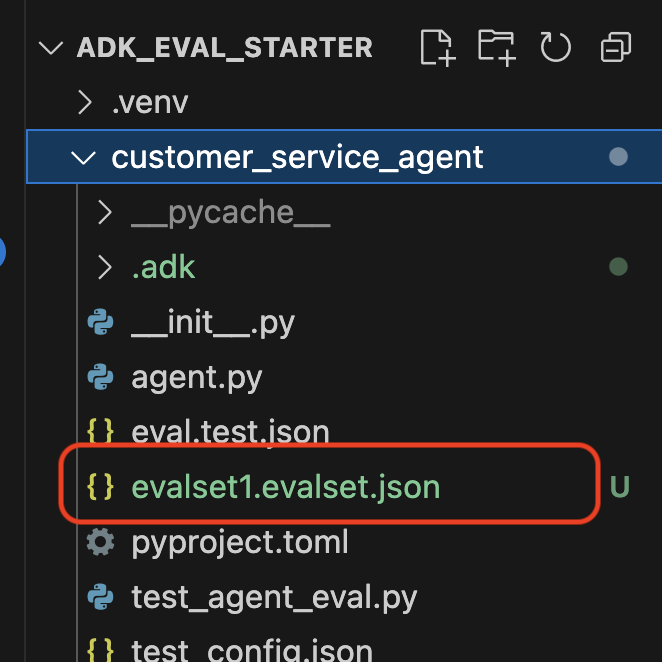
Verifica el conjunto de datos en tu repo
Verás una confirmación de que se guardó un archivo de conjunto de datos (p.ej., evalset1.evalset.json) en tu repositorio. Este archivo contiene el registro sin procesar y generado automáticamente de tu conversación.
5. Los archivos de evaluación
Si bien la IU web genera un archivo .evalset.json complejo, a menudo queremos crear un archivo de prueba más limpio y estructurado para las pruebas automatizadas.
ADK Eval usa dos componentes principales:
- Archivos de prueba: Pueden ser el conjunto de datos de referencia generado automáticamente (p.ej.,
customer_service_agent/evalset1.evalset.json) o un conjunto seleccionado de forma manual (p.ej.,customer_service_agent/eval.test.json). - Archivos de configuración (p.ej.,
customer_service_agent/test_config.json): Definen las métricas y los umbrales para aprobar.
Configura el archivo de configuración de la prueba
- 👉💻 En la terminal del Editor de Cloud Shell, ingresa
cloudshell edit customer_service_agent/test_config.json - 👉 Ingresa el siguiente código en
customer_service_agent/test_config.jsonen tu editor.{ "criteria": { "tool_trajectory_avg_score": 0.8, "response_match_score": 0.5 } }
Cómo decodificar las métricas
tool_trajectory_avg_score(El proceso) Mide si el agente usó las herramientas correctamente.
- 0.8: Exigimos una coincidencia del 80%.
response_match_score(El resultado) Usa ROUGE-1 (superposición de palabras) para comparar la respuesta con la referencia ideal.
- Ventajas: Es rápido, determinístico y gratuito.
- Desventajas: Falla si el agente expresa la misma idea de manera diferente (p.ej., "Se reembolsó" en lugar de "Se devolvió el dinero").
Métricas avanzadas (para cuando necesitas más potencia)
6. Ejecuta la evaluación para el conjunto de datos de referencia (adk eval)

Este paso representa el "bucle interno" del desarrollo. Eres desarrollador y quieres verificar los resultados rápidamente.
Ejecuta el conjunto de datos de referencia
Ejecutemos el conjunto de datos que generaste en el paso 1. Esto garantiza que tu referencia sea sólida.
- 👉💻 En tu terminal, ejecuta lo siguiente:
cd ~/adk_eval_starter uv run adk eval customer_service_agent customer_service_agent/evalset1.evalset.json --config_file_path=customer_service_agent/test_config.json --print_detailed_results
¿Qué sucede?
El ADK ahora es lo siguiente:
- Se está cargando tu agente desde
customer_service_agent. - Ejecuta las consultas de entrada desde
evalset1.evalset.json. - Comparar la trayectoria y las respuestas reales del agente con las esperadas
- Calificar los resultados según los criterios de
test_config.json
Analiza los resultados
Observa el resultado de la terminal. Verás un resumen de las pruebas aprobadas y con errores.
Eval Run Summary
evalset1:
Tests passed: 1
Tests failed: 0
********************************************************************
Eval Set Id: evalset1
Eval Id: eval1
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.5581395348837208, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+---------------------------+---------------------------+--------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+===========================+===========================+==========================+===========================+===========================+=============================+========================+
| 0 | Hi, I'm customer CUST001. | Great news! Your refund | Great news, CUST001! 🎉 | id='adk-051409fe-c230-43f | id='adk-4e9aa570-1cc6-4c3 | Status: PASSED, Score: | Status: PASSED, Score: |
| | Can you check my orders? | for order **ORD-102** has | I've successfully | 4-a7f1- 5747280fd878' | c-aa3e- 91dbe113dd4b' | 1.0 | 0.5581395348837208 |
| | I need a refund for order | been successfully | processed a full refund | args={'customer_id': | args={'customer_id': | | |
| | ORD-102. It arrived | processed due to the item | of $35.0 for your order | 'CUST001'} name='get_purc | 'CUST001'} name='get_purc | | |
| | damaged. | arriving damaged. You | ORD-102 because it | hase_history' | hase_history' | | |
| | | should see a full refund | arrived damaged. The | partial_args=None | partial_args=None | | |
| | | of $35.0 back to your | status of that order has | will_continue=None id= 'a | will_continue=None | | |
| | | original payment method | been updated to | dk-8a194cb8-5a82-47ce-a3a | id='adk- dad1b376-9bcc-48 | | |
| | | shortly. The status of | "refunded." Is there | 7- 3d24551f8c90' | bb-996f-a30f6ef5b70b' | | |
| | | this order has been | anything else I can | args={'reason': | args={'reason': | | |
| | | updated to "refunded". | assist you with today? | 'damaged', 'order_id': | 'damaged', 'order_id': | | |
| | | Here's your updated | | 'ORD-102'} | 'ORD-102'} | | |
| | | purchase history for | | name='issue_refund' | name='issue_refund' | | |
| | | CUST001: * **ORD-101**: | | partial_args=None | partial_args=None | | |
| | | Wireless Headphones, | | will_continue=None | will_continue=None | | |
| | | delivered on 2023-10-15 | | | | | |
| | | (Total: $120) * | | | | | |
| | | **ORD-102**: USB-C Cable, | | | | | |
| | | Phone Case, refunded on | | | | | |
| | | 2023-11-01 (Total: $35) | | | | | |
| | | Is there anything else I | | | | | |
| | | can help you with today? | | | | | |
| | | 😊 | | | | | |
+----+---------------------------+---------------------------+--------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
Nota: Como acabas de generar esto desde el propio agente, debería aprobarse en un 100%. Si falla, tu agente no es determinista (es aleatorio).
7. Crea tu propia prueba personalizada
Si bien los conjuntos de datos generados automáticamente son excelentes, a veces necesitas crear manualmente casos extremos (p.ej., ataques adversariales o manejo de errores específicos). Veamos cómo eval.test.json te permite definir la "Corrección".
Creemos un paquete de pruebas integral.
El marco de trabajo de pruebas
Cuando escribas un caso de prueba en el ADK, sigue esta fórmula de 3 partes:
- La configuración (
session_input): ¿Quién es el usuario? (p.ej.,user_id,state). Esto aísla la prueba. - La instrucción (
user_content): ¿Cuál es el activador?
Con Las aserciones (expectativas):
- Trayectoria (
tool_uses): ¿Hizo bien los cálculos? (Lógica) - Respuesta (
final_response): ¿Dijo la respuesta correcta? (Calidad) - Intermedio (
intermediate_responses): ¿Los subagentes hablaron correctamente? (Organización)
Escribe el paquete de pruebas
- 👉💻 En la terminal del Editor de Cloud Shell, ingresa
cloudshell edit customer_service_agent/eval.test.json - 👉 Ingresa el siguiente código en el archivo
customer_service_agent/eval.test.json.{ "eval_set_id": "customer_service_eval", "name": "Customer Service Agent Evaluation", "description": "Evaluation suite for the customer service agent covering product info, purchase history, and refunds.", "eval_cases": [ { "eval_id": "product_info_check", "session_input": { "app_name": "customer_service_agent", "user_id": "eval_user_1", "state": {} }, "conversation": [ { "invocation_id": "turn_1_product_info", "user_content": { "role": "user", "parts": [ { "text": "Do you have wireless headphones in stock?" } ] }, "final_response": { "role": "model", "parts": [ { "text": "Yes, we have wireless headphones in stock! They are priced at $120.00 and feature noise-canceling with a 20-hour battery life. 🎧" } ] }, "intermediate_data": { "tool_uses": [ { "name": "lookup_product_info", "args": { "product_name": "wireless headphones" } } ], "intermediate_responses": [] } } ] }, { "eval_id": "purchase_history_check", "session_input": { "app_name": "customer_service_agent", "user_id": "eval_user_2", "state": {} }, "conversation": [ { "invocation_id": "turn_1_purchase_history", "user_content": { "role": "user", "parts": [ { "text": "What did I buy recently? My customer ID is CUST001." } ] }, "final_response": { "role": "model", "parts": [ { "text": "Here's your recent purchase history for Customer ID CUST001:\n\n* **Order ORD-101** (October 15, 2023): Wireless Headphones, Status: delivered, Total: $120\n* **Order ORD-102** (November 1, 2023): USB-C Cable, Phone Case, Status: refunded, Total: $35\n\nLet me know if you have any other questions or need further assistance! 🛍️" } ] }, "intermediate_data": { "tool_uses": [ { "name": "get_purchase_history", "args": { "customer_id": "CUST001" } } ], "intermediate_responses": [] } } ] }, { "eval_id": "refund_request", "session_input": { "app_name": "customer_service_agent", "user_id": "eval_user_3", "state": {} }, "conversation": [ { "invocation_id": "turn_1_refund", "user_content": { "role": "user", "parts": [ { "text": "I want a refund for order ORD-102 because it was damaged." } ] }, "final_response": { "role": "model", "parts": [ { "text": "Your refund for order **ORD-102** due to \"damaged\" has been successfully processed! Refund amount: **$35.0**. Your order status has been updated to **refunded**. \nIs there anything else I can help you with today? 🛍️" } ] }, "intermediate_data": { "tool_uses": [ { "name": "issue_refund", "args": { "order_id": "ORD-102", "reason": "damaged" } } ], "intermediate_responses": [] } } ] } ] }
Desglosando los tipos de pruebas
Aquí creamos tres tipos de pruebas distintos. Desglosemos qué evalúa cada una y por qué.
- La prueba de una sola herramienta (
product_info_check)
- Objetivo: Verificar la recuperación de información básica.
- Aserción clave: Verificamos
intermediate_data.tool_uses. Afirmamos que se llama alookup_product_info. Afirmamos que el argumentoproduct_namees exactamente "auriculares inalámbricos". - Por qué: Si el modelo alucina un precio sin llamar a la herramienta, esta prueba falla. Esto garantiza la fundamentación.
- La prueba de extracción de contexto (
purchase_history_check)
- Objetivo: Verificar que el agente pueda extraer entidades (CUST001) de la instrucción del usuario y pasarlas a la herramienta.
- Aserción de clave: Verificamos que se llame a
get_purchase_historyconcustomer_id: "CUST001". - Motivo: Un modo de falla común es que el agente llame a la herramienta correcta, pero con un ID nulo. Esto garantiza la precisión de los parámetros.
- La prueba de acción o trayectoria (
refund_request)
- Objetivo: Verificar una operación de escritura crítica.
- Aserción clave: Es la trayectoria. En una situación más compleja, esta lista contendría varios pasos:
[verify_order, calculate_refund, issue_refund]. El ADK verifica esta lista en orden. - Por qué: Para las acciones que mueven dinero o cambian datos, la secuencia es tan importante como el resultado. No quieres emitir el reembolso antes de verificar.
8. Ejecuta la evaluación para pruebas personalizadas (adk eval)
- 👉💻 En tu terminal, ejecuta lo siguiente:
cd ~/adk_eval_starter uv run adk eval customer_service_agent customer_service_agent/eval.test.json --config_file_path=customer_service_agent/test_config.json --print_detailed_results
Cómo comprender el resultado
Deberías ver un resultado de APROBACIÓN como el siguiente:
Eval Run Summary
customer_service_eval:
Tests passed: 3
Tests failed: 0
********************************************************************
Eval Set Id: customer_service_eval
Eval Id: purchase_history_check
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.5473684210526315, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+--------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+==========================+===========================+===========================+===========================+===========================+=============================+========================+
| 0 | What did I buy recently? | Here's your recent | Looks like your recent | id=None | id='adk-8960eb53-2933-459 | Status: PASSED, Score: | Status: PASSED, Score: |
| | My customer ID is | purchase history for | orders include: * | args={'customer_id': | f-b306- 71e3c069e77e' | 1.0 | 0.5473684210526315 |
| | CUST001. | Customer ID CUST001: * | **ORD-101 (2023-10-15):** | 'CUST001'} name='get_purc | args={'customer_id': | | |
| | | **Order ORD-101** | Wireless Headphones for | hase_history' | 'CUST001'} name='get_purc | | |
| | | (October 15, 2023): | $120.00 - Status: | partial_args=None | hase_history' | | |
| | | Wireless Headphones, | Delivered 🎧 * **ORD-102 | will_continue=None | partial_args=None | | |
| | | Status: delivered, Total: | (2023-11-01):** USB-C | | will_continue=None | | |
| | | $120 * **Order | Cable, Phone Case for | | | | |
| | | ORD-102** (November 1, | $35.00 - Status: Refunded | | | | |
| | | 2023): USB-C Cable, Phone | 📱 Is there anything else | | | | |
| | | Case, Status: refunded, | I can help you with | | | | |
| | | Total: $35 Let me know | regarding these orders? | | | | |
| | | if you have any other | | | | | |
| | | questions or need further | | | | | |
| | | assistance! 🛍️ | | | | | |
+----+--------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
********************************************************************
Eval Set Id: customer_service_eval
Eval Id: product_info_check
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.6829268292682927, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+----------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+======================+===========================+===========================+===========================+===========================+=============================+========================+
| 0 | Do you have wireless | Yes, we have wireless | Yes, we do! 🎧 We have | id=None | id='adk-4571d660-a92b-412 | Status: PASSED, Score: | Status: PASSED, Score: |
| | headphones in stock? | headphones in stock! They | noise-canceling wireless | args={'product_name': | a-a79e- 5c54f8b8af2d' | 1.0 | 0.6829268292682927 |
| | | are priced at $120.00 and | headphones with a 20-hour | 'wireless headphones'} na | args={'product_name': | | |
| | | feature noise-canceling | battery life available | me='lookup_product_info' | 'wireless headphones'} na | | |
| | | with a 20-hour battery | for $120. | partial_args=None | me='lookup_product_info' | | |
| | | life. 🎧 | | will_continue=None | partial_args=None | | |
| | | | | | will_continue=None | | |
+----+----------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
********************************************************************
Eval Set Id: customer_service_eval
Eval Id: refund_request
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.6216216216216216, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+---------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+===========================+===========================+===========================+===========================+===========================+=============================+========================+
| 0 | I want a refund for order | Your refund for order | Your refund for order | id=None args={'order_id': | id='adk-fb8ff1cc- cf87-41 | Status: PASSED, Score: | Status: PASSED, Score: |
| | ORD-102 because it was | **ORD-102** due to | **ORD-102** has been | 'ORD-102', 'reason': | f2-9b11-d4571b14287f' | 1.0 | 0.6216216216216216 |
| | damaged. | "damaged" has been | successfully processed! | 'damaged'} | args={'order_id': | | |
| | | successfully processed! | You should see a full | name='issue_refund' | 'ORD-102', 'reason': | | |
| | | Refund amount: **$35.0**. | refund of $35.0 appear in | partial_args=None | 'damaged'} | | |
| | | Your order status has | your account shortly. We | will_continue=None | name='issue_refund' | | |
| | | been updated to | apologize for the | | partial_args=None | | |
| | | **refunded**. Is there | inconvenience! Is there | | will_continue=None | | |
| | | anything else I can help | anything else I can | | | | |
| | | you with today? 🛍️ | assist you with today? 😊 | | | | |
+----+---------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
Esto significa que tu agente usó las herramientas correctas y proporcionó una respuesta lo suficientemente similar a tus expectativas.
9. (Opcional: Solo lectura) - Solución de problemas y depuración
Las pruebas fallarán. Ese es su trabajo. Pero ¿cómo se solucionan? Analicemos situaciones de falla comunes y cómo depurarlas.
Situación A: La falla de "Trayectoria"
El error:
Result: FAILED
Reason: Criteria 'tool_trajectory_avg_score' failed. Score 0.0 < Threshold 1.0
Details:
EXPECTED: tool: lookup_order, then tool: issue_refund
ACTUAL: tool: issue_refund
Diagnóstico: El agente omitió el paso de verificación (lookup_order). Este es un error de lógica.
Cómo solucionar el problema:
- No adivines: Regresa a la IU web del ADK (adk web).
- Reproduce: Escribe la instrucción exacta de la prueba fallida en el chat.
- Trace: Abre la vista de Trace. Consulta la pestaña "Gráfico".
- Corrige la instrucción: Por lo general, debes actualizar la instrucción del sistema. Cambio: "Eres un agente útil". Para: "Eres un agente útil. CRÍTICO: DEBES llamar a lookup_order para verificar los detalles antes de llamar a issue_refund."
- Adapta la prueba: Si la lógica empresarial cambió (p.ej., ya no es necesaria la verificación), la prueba es incorrecta. Actualiza eval.test.json para que coincida con la nueva realidad.
Situación B: La falla de "ROUGE"
El error:
Result: FAILED
Reason: Criteria 'response_match_score' failed. Score 0.45 < Threshold 0.8
Expected: "The refund has been processed successfully."
Actual: "I've gone ahead and returned the money to your card."
Diagnóstico: El agente hizo lo correcto, pero usó palabras diferentes. ROUGE (superposición de palabras) lo penalizó.
Cómo corregir el problema:
- ¿Es incorrecto? Si el significado es correcto, no cambies la instrucción.
- Ajustar umbral: Reduce el umbral en
test_config.json(p.ej., de0.8a0.5). - Actualiza la métrica: Cambia a
final_response_match_v2en tu configuración. Esto usa un LLM para leer ambas oraciones y juzgar si significan lo mismo.
10. CI/CD con Pytest (pytest)
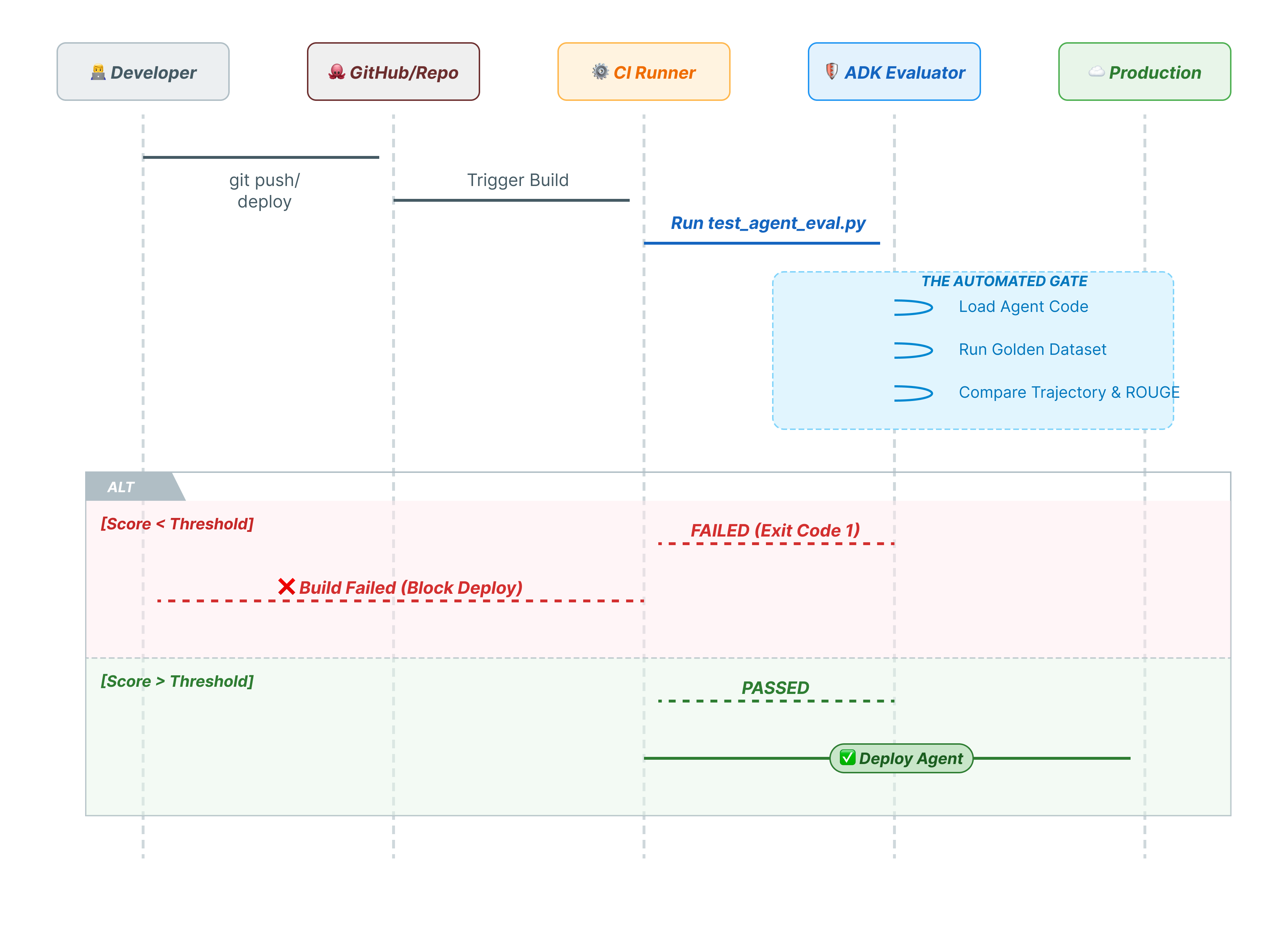
Los comandos de la CLI son para personas reales. pytest es para máquinas. Para garantizar la confiabilidad de la producción, incluimos nuestras evaluaciones en un paquete de pruebas de Python. Esto permite que tu canalización de CI/CD (GitHub Actions, Jenkins) bloquee una implementación si el agente se degrada.
¿Qué se incluye en este archivo?
Este archivo de Python actúa como puente entre el ejecutor de CI/CD y el evaluador del ADK. Debe cumplir con los siguientes requisitos:
- Carga tu agente: Importa de forma dinámica el código de tu agente.
- Reset State: Asegúrate de que la memoria del agente esté limpia para que las pruebas no se filtren entre sí.
- Run Evaluation: Llama a
AgentEvaluator.evaluate()de forma programática. - Assert Success: Si la puntuación de evaluación es baja, la compilación falla.
El código de prueba de integración
- 👉 Abre
customer_service_agent/test_agent_eval.py. Esta secuencia de comandos usaAgentEvaluator.evaluatepara ejecutar las pruebas definidas eneval.test.json. - 👉 Ingresa el siguiente código en
customer_service_agent/test_agent_eval.pyen tu editor.from google.adk.evaluation.agent_evaluator import AgentEvaluator import pytest import importlib import sys import os @pytest.mark.asyncio async def test_with_single_test_file(): """Test the agent's basic ability via a session file.""" # Load the agent module robustly module_name = "customer_service_agent.agent" try: agent_module = importlib.import_module(module_name) # Reset the mock data to ensure a fresh state for the test if hasattr(agent_module, 'reset_mock_data'): agent_module.reset_mock_data() except ImportError: # Fallback if running from a different context sys.path.append(os.getcwd()) agent_module = importlib.import_module(module_name) if hasattr(agent_module, 'reset_mock_data'): agent_module.reset_mock_data() # Use absolute path to the eval file to be robust to where pytest is run script_dir = os.path.dirname(os.path.abspath(__file__)) eval_file = os.path.join(script_dir, "eval.test.json") await AgentEvaluator.evaluate( agent_module=module_name, eval_dataset_file_path_or_dir=eval_file, num_runs=1, )
Ejecuta Pytest
- 👉💻 En tu terminal, ejecuta lo siguiente:
cd ~/adk_eval_starter uv pip install pytest uv run pytest customer_service_agent/test_agent_eval.py``` -- Docs: https://docs.pytest.org/en/stable/how-to/capture-warnings.html =============== 1 passed, 15 warnings in 12.84s =============== ```
11. Conclusión
¡Felicitaciones! Evaluaste correctamente tu agente de atención al cliente con ADK Eval.
Qué aprendiste
En este codelab aprendiste a hacer lo siguiente:
- ✅ Genera un conjunto de datos de referencia para establecer una verdad fundamental para tu agente.
- ✅ Comprende la configuración de la evaluación para definir los criterios de éxito.
- ✅ Ejecuta evaluaciones automatizadas para detectar regresiones de forma anticipada.
Si incorporas ADK Eval en tu flujo de trabajo de desarrollo, podrás crear agentes con confianza, ya que sabrás que tus pruebas automatizadas detectarán cualquier cambio en el comportamiento.
Este lab forma parte de la ruta de aprendizaje de IA lista para producción con Google Cloud.
- Explora el plan de estudios completo para cerrar la brecha entre el prototipo y la producción.
- Comparte tu progreso con el hashtag
ProductionReadyAI.
Lecturas adicionales: