
۱. شکاف اعتماد
لحظه الهام
شما یک نماینده خدمات مشتری ایجاد کردهاید. این نماینده روی دستگاه شما کار میکند. اما دیروز، به یک مشتری گفت که یک ساعت هوشمند ناموجود موجود است، یا بدتر از آن، سیاست بازپرداخت را توهم زد. چطور شبها با دانستن اینکه نماینده شما فعال است، میخوابید؟
برای پر کردن شکاف بین یک عامل هوش مصنوعی آماده برای تولید و یک اثبات مفهوم، یک چارچوب ارزیابی قوی و خودکار ضروری است.

ما در واقع چه چیزی را ارزیابی میکنیم؟
ارزیابی نماینده پیچیدهتر از ارزیابی استاندارد LLM است. شما فقط به انشا (پاسخ نهایی) نمره نمیدهید؛ بلکه به ریاضی (منطق/ابزارهای مورد استفاده برای رسیدن به آن) نیز نمره میدهید.
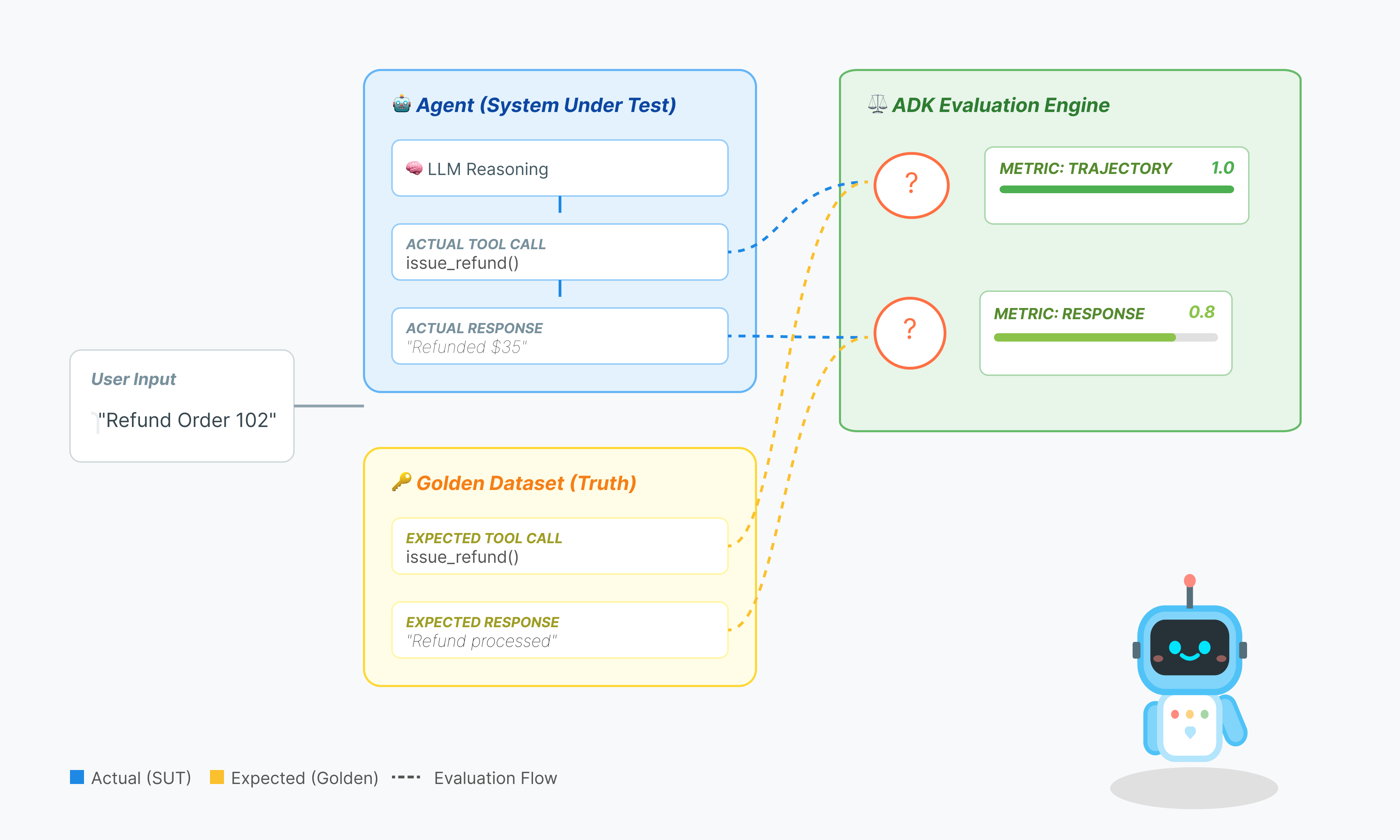
- مسیر (فرآیند): آیا عامل از ابزار مناسب در زمان مناسب استفاده کرد؟ آیا قبل از
place_orderتابعcheck_inventoryفراخوانی کرد؟ - پاسخ نهایی (خروجی): آیا پاسخ صحیح، مودبانه و مبتنی بر دادهها است؟
چرخه حیات توسعه
در این آزمایشگاه کد، چرخه حیات حرفهای تست عامل (ایجنت) را بررسی خواهیم کرد:
- بازرسی بصری محلی (رابط کاربری وب ADK): چت دستی و تأیید منطق (مرحله 1).
- تست واحد/رگرسیون (ADK CLI): اجرای موارد تست خاص به صورت محلی برای یافتن سریع خطاها (مرحله ۳ و ۴).
- اشکالزدایی (عیبیابی): تجزیه و تحلیل خرابیها و رفع منطق اعلان (مرحله ۵).
- یکپارچهسازی CI/CD (Pytest): خودکارسازی تستها در خط تولید (مرحله 6).
۲. راهاندازی
برای توانمندسازی عوامل هوش مصنوعی خود، به دو چیز نیاز داریم: یک پروژه ابری گوگل برای فراهم کردن پایه و اساس.
بخش اول: فعال کردن حساب صورتحساب
برای اجرای این codelab، به یک حساب کاربری billing با مقداری اعتبار نیاز دارید. برای شروع از اعتبارهای موجود در بنر بالای این codelab استفاده کنید. اگر از قبل به یک حساب کاربری billing متصل هستید، میتوانید از این مرحله صرف نظر کنید.
بخش دوم: محیط باز
- 👉 برای دسترسی مستقیم به ویرایشگر Cloud Shell ، روی این لینک کلیک کنید
- 👉 اگر امروز در هر مرحلهای از شما خواسته شد که مجوز دهید، برای ادامه روی «مجوز دادن» کلیک کنید.
- 👉 اگر ترمینال در پایین صفحه نمایش داده نشد، آن را باز کنید:
- روی مشاهده کلیک کنید
- روی ترمینال کلیک کنید
- 👉💻 در ترمینال، با استفاده از دستور زیر تأیید کنید که از قبل احراز هویت شدهاید و پروژه روی شناسه پروژه شما تنظیم شده است:
gcloud auth list - 👉💻 پروژه بوتاسترپ را از گیتهاب کپی کنید:
git clone https://github.com/cuppibla/adk_eval_starter - 👉💻 اسکریپت راهاندازی را از دایرکتوری پروژه اجرا کنید.
cd ~/adk_eval_starter ./init.sh
اسکریپت بقیه مراحل راهاندازی را بهطور خودکار انجام خواهد داد.
- 👉💻 شناسه پروژه مورد نیاز را تنظیم کنید:
gcloud config set project $(cat ~/project_id.txt) --quiet
بخش سوم: تنظیم مجوز
- 👉💻 با استفاده از دستور زیر، APIهای مورد نیاز را فعال کنید. این کار ممکن است چند دقیقه طول بکشد.
gcloud services enable \ cloudresourcemanager.googleapis.com \ servicenetworking.googleapis.com \ run.googleapis.com \ cloudbuild.googleapis.com \ artifactregistry.googleapis.com \ aiplatform.googleapis.com \ compute.googleapis.com - 👉💻 با اجرای دستورات زیر در ترمینال، مجوزهای لازم را اعطا کنید:
. ~/adk_eval_starter/set_env.sh
توجه داشته باشید که یک فایل .env برای شما ایجاد شده است که اطلاعات پروژه شما را نشان میدهد.
۳. تولید مجموعه داده طلایی (adk web)
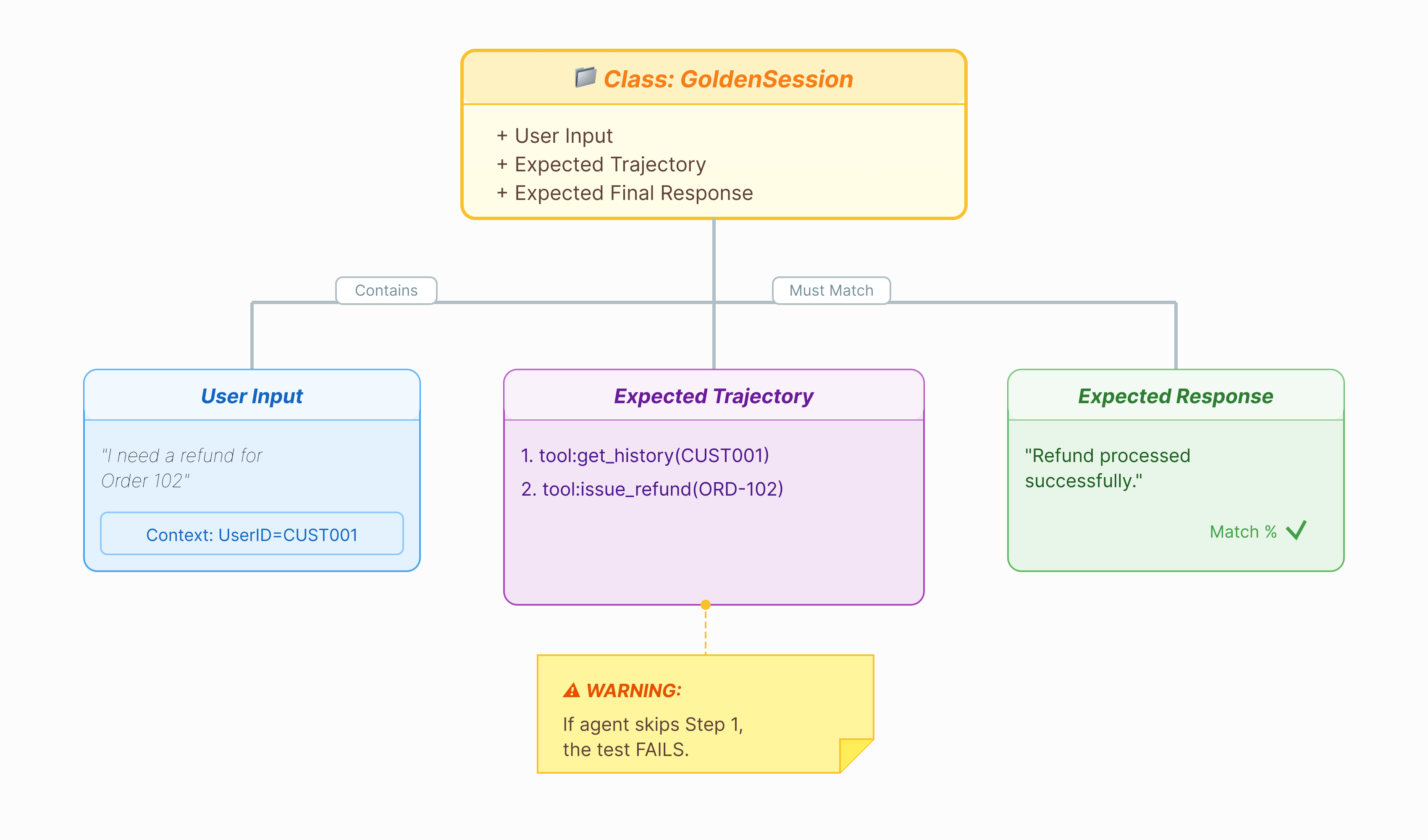
قبل از اینکه بتوانیم عامل را ارزیابی کنیم، به یک کلید پاسخ نیاز داریم. در ADK، ما این را مجموعه داده طلایی مینامیم. این مجموعه داده شامل تعاملات "کامل" است که به عنوان یک حقیقت پایه برای ارزیابی عمل میکنند.
مجموعه داده طلایی چیست؟
یک مجموعه داده طلایی، تصویری از عملکرد صحیح عامل شما است. این فقط لیستی از جفتهای پرسش و پاسخ نیست. این مجموعه شامل موارد زیر است:
- عبارت جستجوی کاربر ("من درخواست بازپرداخت دارم")
- مسیر (دنباله دقیق فراخوانیهای ابزار:
check_order->verify_eligibility->refund_transaction). - پاسخ نهایی (پاسخ متنی «کامل»).
ما از این برای تشخیص رگرسیونها استفاده میکنیم. اگر اعلان خود را بهروزرسانی کنید و نماینده ناگهان بررسی واجد شرایط بودن را قبل از بازپرداخت متوقف کند، آزمون مجموعه داده طلایی با شکست مواجه میشود زیرا مسیر دیگر مطابقت ندارد.
رابط کاربری وب را باز کنید
رابط کاربری وب ADK با ثبت تعاملات واقعی با نماینده شما، روشی تعاملی برای ایجاد این مجموعه دادههای طلایی ارائه میدهد.
- 👉💻 در ترمینال خود، دستور زیر را اجرا کنید:
cd ~/adk_eval_starter uv run adk web - 👉💻 پیشنمایش رابط کاربری وب (معمولاً در
http://127.0.0.1:8000) را باز کنید. - 👉 در رابط کاربری چت، تایپ کنید
Hi, I'm customer CUST001. Can you check my orders? I need a refund for order ORD-102. It arrived damaged. پاسخی مانند این خواهید دید:
پاسخی مانند این خواهید دید: I've processed your refund for order ORD-102 due to the items arriving damaged. A full refund of $35.0 has been processed, and the status of order ORD-102 is now updated to "refunded". Is there anything else I can assist you with today, CUST001? 🛍️
تعاملات طلایی را ثبت کنید
به برگه جلسات بروید. در اینجا میتوانید با کلیک روی جلسه، سابقه مکالمات نماینده خود را مشاهده کنید.
- با نماینده خود تعامل کنید تا یک جریان مکالمه ایدهآل ایجاد کنید، مانند بررسی سابقه خرید یا درخواست بازپرداخت.
- مکالمه را مرور کنید تا مطمئن شوید که نشاندهنده رفتار مورد انتظار است.

۴. خروجی گرفتن از مجموعه دادههای طلایی
با Trace View تأیید کنید
قبل از اینکه خروجی بگیرید، باید مطمئن شوید که عامل به طور اتفاقی پاسخ درست را پیدا نکرده است. باید منطق داخلی را بررسی کنید.
- روی تب Trace در رابط کاربری وب کلیک کنید.
- ردپاها به طور خودکار بر اساس پیام کاربر گروهبندی میشوند. برای هایلایت کردن پیام مربوطه در چت، نشانگر ماوس را روی ردیف ردپا نگه دارید .
- بررسی ردیفهای آبی : این ردیفها رویدادهای ایجاد شده از تعامل را نشان میدهند. برای باز کردن پنل بررسی، روی یک ردیف آبی کلیک کنید.
- برای اعتبارسنجی منطق، برگههای زیر را بررسی کنید:
- نمودار : نمایش بصری فراخوانیهای ابزار و جریان منطقی. آیا مسیر صحیح را طی کرده است؟
- درخواست/پاسخ : دقیقاً بررسی کنید که چه چیزی به مدل ارسال شده و چه چیزی برگردانده شده است.
- تأیید : اگر نماینده مبلغ بازپرداخت را بدون فراخوانی ابزار پایگاه داده حدس زده باشد، این یک «توهم خوششانسی» است.

افزودن جلسه به EvalSet
وقتی از مکالمه و ردیابی راضی شدید:
- 👉 روی برگه
Evalکلیک کنید و سپس روی دکمهCreate Evaluation Setکلیک کنید و نام eval مورد نظر را وارد کنید:evalset1
- 👉 در این مجموعه ارزیابی، روی
Add current session to evalset1کلیک کنید، در پنجره باز شده، نام جلسه را وارد کنید:eval1
اجرای Eval در ADK Web
- 👉 در رابط کاربری وب ADK، روی
Run Evaluationکلیک کنید، در پنجره بازشو، معیارها را تنظیم کنید وStartکلیک کنید:
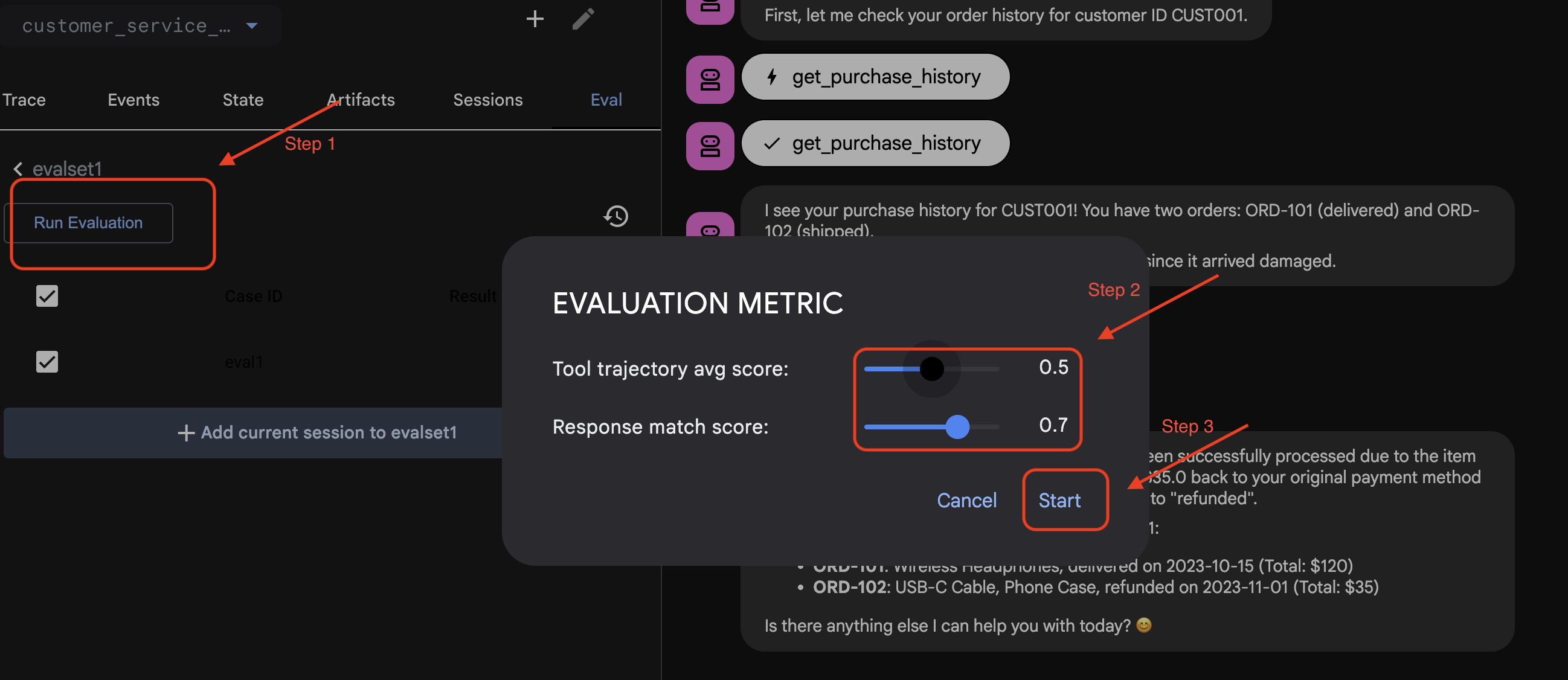
مجموعه داده را در مخزن خود تأیید کنید
تأییدیهای مبنی بر ذخیره شدن یک فایل مجموعه داده (مثلاً evalset1.evalset.json ) در مخزن شما مشاهده خواهید کرد. این فایل حاوی ردپای خام و خودکار ایجاد شده از مکالمه شما است.
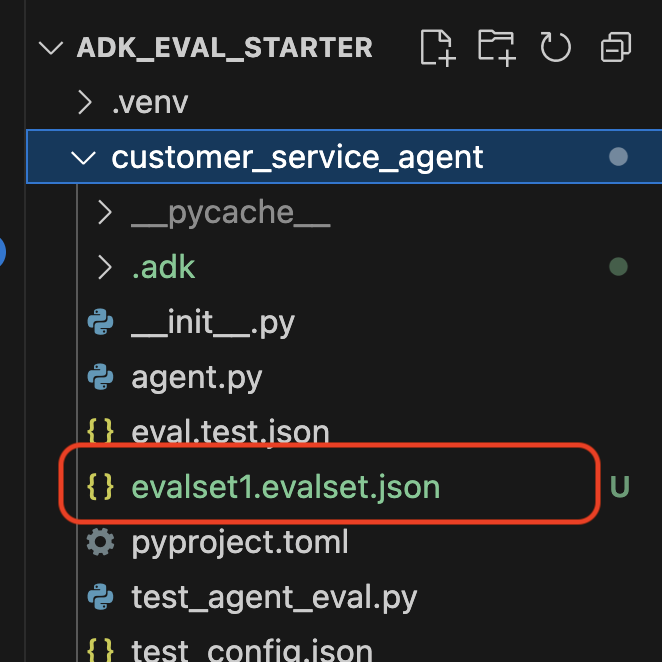
۵. پروندههای ارزیابی

در حالی که رابط کاربری وب یک فایل پیچیده .evalset.json تولید میکند، ما اغلب میخواهیم یک فایل تست تمیزتر و ساختاریافتهتر برای تست خودکار ایجاد کنیم.
ADK Eval از دو جزء اصلی استفاده میکند:
- فایلهای تست : میتوانند مجموعه دادههای طلایی تولید شده خودکار (مثلاً
customer_service_agent/evalset1.evalset.json) یا مجموعهای که به صورت دستی تنظیم شده است (مثلاًcustomer_service_agent/eval.test.json) باشند. - فایلهای پیکربندی (مثلاً
customer_service_agent/test_config.json): معیارها و آستانههای لازم برای قبولی را تعریف کنید.
فایل پیکربندی آزمایشی را تنظیم کنید
- 👉💻 در ترمینال ویرایشگر Cloud Shell، ورودی را وارد کنید
cloudshell edit customer_service_agent/test_config.json - 👉 کد زیر را در فایل
customer_service_agent/test_config.jsonدر ویرایشگر خود وارد کنید.{ "criteria": { "tool_trajectory_avg_score": 0.8, "response_match_score": 0.5 } }
رمزگشایی معیارها
-
tool_trajectory_avg_score(فرآیند) این معیار نشان میدهد که آیا عامل از ابزارها به درستی استفاده کرده است یا خیر.
- ۰.۸ : ما خواستار تطابق ۸۰٪ هستیم.
-
response_match_score(خروجی) این از ROUGE-1 (همپوشانی کلمات) برای مقایسه پاسخ با مرجع طلایی استفاده میکند.
- مزایا : سریع، قطعی، رایگان.
- معایب : اگر نماینده همان ایده را به صورت متفاوتی بیان کند (مثلاً "بازپرداخت شده" در مقابل "پول بازگردانده شده") ناموفق است.
معیارهای پیشرفته (برای زمانی که به قدرت بیشتری نیاز دارید)
۶. اجرای ارزیابی برای مجموعه دادههای طلایی (adk eval)
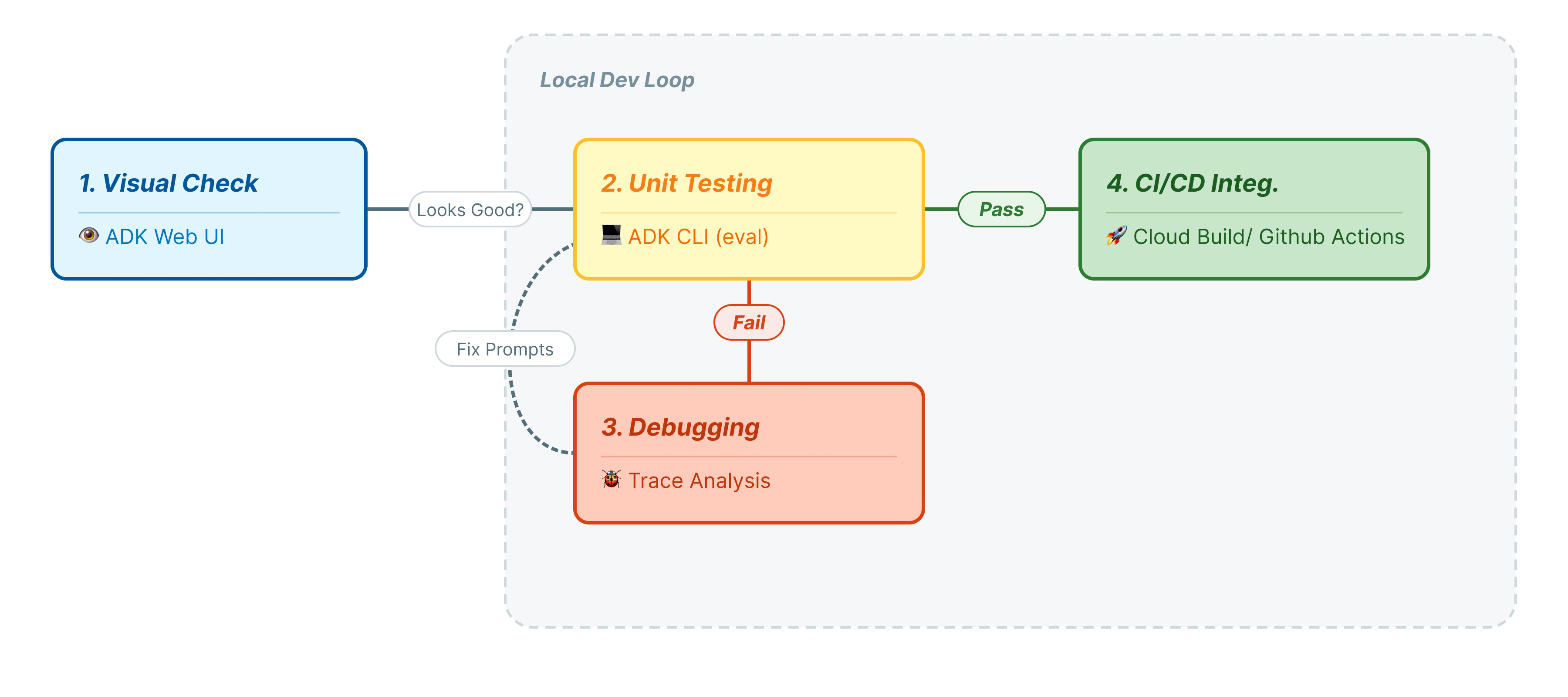
این مرحله نشاندهندهی «حلقهی داخلی» توسعه است. شما یک توسعهدهنده هستید که تغییراتی ایجاد میکنید و میخواهید به سرعت نتایج را تأیید کنید.
اجرای مجموعه داده طلایی
بیایید مجموعه دادهای را که در مرحله ۱ ایجاد کردید، اجرا کنیم. این کار تضمین میکند که خط پایه شما قابل اعتماد است.
- 👉💻 در ترمینال خود، دستور زیر را اجرا کنید:
cd ~/adk_eval_starter uv run adk eval customer_service_agent customer_service_agent/evalset1.evalset.json --config_file_path=customer_service_agent/test_config.json --print_detailed_results
چه اتفاقی دارد میافتد؟
ADK اکنون:
- بارگیری عامل شما از
customer_service_agent. - اجرای کوئریهای ورودی از
evalset1.evalset.json. - مقایسه مسیر و پاسخهای واقعی عامل با موارد مورد انتظار.
- امتیازدهی نتایج بر اساس معیارهای موجود در
test_config.json.
نتایج را تجزیه و تحلیل کنید
به خروجی ترمینال نگاه کنید. خلاصهای از تستهای موفق و ناموفق را مشاهده خواهید کرد.
Eval Run Summary
evalset1:
Tests passed: 1
Tests failed: 0
********************************************************************
Eval Set Id: evalset1
Eval Id: eval1
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.5581395348837208, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+---------------------------+---------------------------+--------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+===========================+===========================+==========================+===========================+===========================+=============================+========================+
| 0 | Hi, I'm customer CUST001. | Great news! Your refund | Great news, CUST001! 🎉 | id='adk-051409fe-c230-43f | id='adk-4e9aa570-1cc6-4c3 | Status: PASSED, Score: | Status: PASSED, Score: |
| | Can you check my orders? | for order **ORD-102** has | I've successfully | 4-a7f1- 5747280fd878' | c-aa3e- 91dbe113dd4b' | 1.0 | 0.5581395348837208 |
| | I need a refund for order | been successfully | processed a full refund | args={'customer_id': | args={'customer_id': | | |
| | ORD-102. It arrived | processed due to the item | of $35.0 for your order | 'CUST001'} name='get_purc | 'CUST001'} name='get_purc | | |
| | damaged. | arriving damaged. You | ORD-102 because it | hase_history' | hase_history' | | |
| | | should see a full refund | arrived damaged. The | partial_args=None | partial_args=None | | |
| | | of $35.0 back to your | status of that order has | will_continue=None id= 'a | will_continue=None | | |
| | | original payment method | been updated to | dk-8a194cb8-5a82-47ce-a3a | id='adk- dad1b376-9bcc-48 | | |
| | | shortly. The status of | "refunded." Is there | 7- 3d24551f8c90' | bb-996f-a30f6ef5b70b' | | |
| | | this order has been | anything else I can | args={'reason': | args={'reason': | | |
| | | updated to "refunded". | assist you with today? | 'damaged', 'order_id': | 'damaged', 'order_id': | | |
| | | Here's your updated | | 'ORD-102'} | 'ORD-102'} | | |
| | | purchase history for | | name='issue_refund' | name='issue_refund' | | |
| | | CUST001: * **ORD-101**: | | partial_args=None | partial_args=None | | |
| | | Wireless Headphones, | | will_continue=None | will_continue=None | | |
| | | delivered on 2023-10-15 | | | | | |
| | | (Total: $120) * | | | | | |
| | | **ORD-102**: USB-C Cable, | | | | | |
| | | Phone Case, refunded on | | | | | |
| | | 2023-11-01 (Total: $35) | | | | | |
| | | Is there anything else I | | | | | |
| | | can help you with today? | | | | | |
| | | 😊 | | | | | |
+----+---------------------------+---------------------------+--------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
نکته: از آنجایی که شما این را از خود عامل تولید کردهاید، باید ۱۰۰٪ قبول شود. اگر شکست بخورد، عامل شما غیرقطعی (تصادفی) است.
۷. آزمون سفارشی خودتان را بسازید
اگرچه مجموعه دادههای تولید شده خودکار عالی هستند، اما گاهی اوقات لازم است موارد مرزی را به صورت دستی ایجاد کنید (مثلاً حملات خصمانه یا مدیریت خطاهای خاص). بیایید ببینیم که eval.test.json چگونه به شما امکان تعریف «صحت» را میدهد.
بیایید یک مجموعه تست جامع بسازیم.
چارچوب آزمایش
هنگام نوشتن یک مورد آزمایشی در ADK، از این فرمول سه قسمتی پیروی کنید:
- تنظیمات (
session_input) : کاربر کیست؟ (مثلاًuser_id،state). این تست را ایزوله میکند. - اعلان (
user_content) : تریگر چیست؟
با ادعاها (انتظارات) :
- مسیر (
tool_uses) : آیا محاسبات را درست انجام داد؟ (منطق) - پاسخ (
final_response) : آیا پاسخ درست را گفت؟ (کیفیت) - سطح متوسط (
intermediate_responses) : آیا زیر-عاملها درست صحبت کردند؟ (ارکستراسیون)
مجموعه تست را بنویسید
- 👉💻 در ترمینال ویرایشگر Cloud Shell، ورودی را وارد کنید
cloudshell edit customer_service_agent/eval.test.json - 👉 کد زیر را در فایل
customer_service_agent/eval.test.jsonوارد کنید.{ "eval_set_id": "customer_service_eval", "name": "Customer Service Agent Evaluation", "description": "Evaluation suite for the customer service agent covering product info, purchase history, and refunds.", "eval_cases": [ { "eval_id": "product_info_check", "session_input": { "app_name": "customer_service_agent", "user_id": "eval_user_1", "state": {} }, "conversation": [ { "invocation_id": "turn_1_product_info", "user_content": { "role": "user", "parts": [ { "text": "Do you have wireless headphones in stock?" } ] }, "final_response": { "role": "model", "parts": [ { "text": "Yes, we have wireless headphones in stock! They are priced at $120.00 and feature noise-canceling with a 20-hour battery life. 🎧" } ] }, "intermediate_data": { "tool_uses": [ { "name": "lookup_product_info", "args": { "product_name": "wireless headphones" } } ], "intermediate_responses": [] } } ] }, { "eval_id": "purchase_history_check", "session_input": { "app_name": "customer_service_agent", "user_id": "eval_user_2", "state": {} }, "conversation": [ { "invocation_id": "turn_1_purchase_history", "user_content": { "role": "user", "parts": [ { "text": "What did I buy recently? My customer ID is CUST001." } ] }, "final_response": { "role": "model", "parts": [ { "text": "Here's your recent purchase history for Customer ID CUST001:\n\n* **Order ORD-101** (October 15, 2023): Wireless Headphones, Status: delivered, Total: $120\n* **Order ORD-102** (November 1, 2023): USB-C Cable, Phone Case, Status: refunded, Total: $35\n\nLet me know if you have any other questions or need further assistance! 🛍️" } ] }, "intermediate_data": { "tool_uses": [ { "name": "get_purchase_history", "args": { "customer_id": "CUST001" } } ], "intermediate_responses": [] } } ] }, { "eval_id": "refund_request", "session_input": { "app_name": "customer_service_agent", "user_id": "eval_user_3", "state": {} }, "conversation": [ { "invocation_id": "turn_1_refund", "user_content": { "role": "user", "parts": [ { "text": "I want a refund for order ORD-102 because it was damaged." } ] }, "final_response": { "role": "model", "parts": [ { "text": "Your refund for order **ORD-102** due to \"damaged\" has been successfully processed! Refund amount: **$35.0**. Your order status has been updated to **refunded**. \nIs there anything else I can help you with today? 🛍️" } ] }, "intermediate_data": { "tool_uses": [ { "name": "issue_refund", "args": { "order_id": "ORD-102", "reason": "damaged" } } ], "intermediate_responses": [] } } ] } ] }
تجزیه و تحلیل انواع آزمون
ما در اینجا سه نوع آزمون مجزا ایجاد کردهایم. بیایید بررسی کنیم که هر کدام چه چیزی را ارزیابی میکنند و چرا.
- تست تک ابزار (
product_info_check)
- هدف : تأیید بازیابی اطلاعات اولیه.
- ادعای کلید : ما
intermediate_data.tool_usesبررسی میکنیم. ما ادعا میکنیم کهlookup_product_infoفراخوانی شده است. ما ادعا میکنیم که آرگومانproduct_nameدقیقاً "هدفونهای بیسیم" است. - چرا : اگر مدل بدون فراخوانی ابزار، قیمت را توهم کند، این آزمایش با شکست مواجه میشود. این امر اتصال به زمین را تضمین میکند.
- آزمون استخراج متن (
purchase_history_check)
- هدف : تأیید کنید که عامل میتواند موجودیتها (CUST001) را از اعلان کاربر استخراج کرده و آنها را به ابزار منتقل کند.
- ادعای کلید : بررسی میکنیم که
get_purchase_historyباcustomer_id: "CUST001"فراخوانی شده باشد. - چرا : یک حالت خطای رایج، فراخوانی ابزار صحیح توسط عامل با شناسه تهی است. این امر دقت پارامتر را تضمین میکند.
- آزمون عمل/مسیر (
refund_request)
- هدف : تأیید یک عملیات نوشتن بحرانی.
- ادعای کلیدی : مسیر. در یک سناریوی پیچیدهتر، این لیست شامل چندین مرحله خواهد بود:
[verify_order, calculate_refund, issue_refund]. ADK این لیست را به ترتیب بررسی میکند. - چرا : برای اقداماتی که پول را جابجا میکنند یا دادهها را تغییر میدهند، ترتیب انجام کار به اندازه نتیجه مهم است. شما نمیخواهید قبل از تأیید، وجه را پس بدهید.
۸. اجرای ارزیابی برای تستهای سفارشی (adk eval)
- 👉💻 در ترمینال خود، دستور زیر را اجرا کنید:
cd ~/adk_eval_starter uv run adk eval customer_service_agent customer_service_agent/eval.test.json --config_file_path=customer_service_agent/test_config.json --print_detailed_results
درک خروجی
شما باید نتیجهی PASS مانند این را ببینید:
Eval Run Summary
customer_service_eval:
Tests passed: 3
Tests failed: 0
********************************************************************
Eval Set Id: customer_service_eval
Eval Id: purchase_history_check
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.5473684210526315, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+--------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+==========================+===========================+===========================+===========================+===========================+=============================+========================+
| 0 | What did I buy recently? | Here's your recent | Looks like your recent | id=None | id='adk-8960eb53-2933-459 | Status: PASSED, Score: | Status: PASSED, Score: |
| | My customer ID is | purchase history for | orders include: * | args={'customer_id': | f-b306- 71e3c069e77e' | 1.0 | 0.5473684210526315 |
| | CUST001. | Customer ID CUST001: * | **ORD-101 (2023-10-15):** | 'CUST001'} name='get_purc | args={'customer_id': | | |
| | | **Order ORD-101** | Wireless Headphones for | hase_history' | 'CUST001'} name='get_purc | | |
| | | (October 15, 2023): | $120.00 - Status: | partial_args=None | hase_history' | | |
| | | Wireless Headphones, | Delivered 🎧 * **ORD-102 | will_continue=None | partial_args=None | | |
| | | Status: delivered, Total: | (2023-11-01):** USB-C | | will_continue=None | | |
| | | $120 * **Order | Cable, Phone Case for | | | | |
| | | ORD-102** (November 1, | $35.00 - Status: Refunded | | | | |
| | | 2023): USB-C Cable, Phone | 📱 Is there anything else | | | | |
| | | Case, Status: refunded, | I can help you with | | | | |
| | | Total: $35 Let me know | regarding these orders? | | | | |
| | | if you have any other | | | | | |
| | | questions or need further | | | | | |
| | | assistance! 🛍️ | | | | | |
+----+--------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
********************************************************************
Eval Set Id: customer_service_eval
Eval Id: product_info_check
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.6829268292682927, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+----------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+======================+===========================+===========================+===========================+===========================+=============================+========================+
| 0 | Do you have wireless | Yes, we have wireless | Yes, we do! 🎧 We have | id=None | id='adk-4571d660-a92b-412 | Status: PASSED, Score: | Status: PASSED, Score: |
| | headphones in stock? | headphones in stock! They | noise-canceling wireless | args={'product_name': | a-a79e- 5c54f8b8af2d' | 1.0 | 0.6829268292682927 |
| | | are priced at $120.00 and | headphones with a 20-hour | 'wireless headphones'} na | args={'product_name': | | |
| | | feature noise-canceling | battery life available | me='lookup_product_info' | 'wireless headphones'} na | | |
| | | with a 20-hour battery | for $120. | partial_args=None | me='lookup_product_info' | | |
| | | life. 🎧 | | will_continue=None | partial_args=None | | |
| | | | | | will_continue=None | | |
+----+----------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
********************************************************************
Eval Set Id: customer_service_eval
Eval Id: refund_request
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.6216216216216216, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+---------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+===========================+===========================+===========================+===========================+===========================+=============================+========================+
| 0 | I want a refund for order | Your refund for order | Your refund for order | id=None args={'order_id': | id='adk-fb8ff1cc- cf87-41 | Status: PASSED, Score: | Status: PASSED, Score: |
| | ORD-102 because it was | **ORD-102** due to | **ORD-102** has been | 'ORD-102', 'reason': | f2-9b11-d4571b14287f' | 1.0 | 0.6216216216216216 |
| | damaged. | "damaged" has been | successfully processed! | 'damaged'} | args={'order_id': | | |
| | | successfully processed! | You should see a full | name='issue_refund' | 'ORD-102', 'reason': | | |
| | | Refund amount: **$35.0**. | refund of $35.0 appear in | partial_args=None | 'damaged'} | | |
| | | Your order status has | your account shortly. We | will_continue=None | name='issue_refund' | | |
| | | been updated to | apologize for the | | partial_args=None | | |
| | | **refunded**. Is there | inconvenience! Is there | | will_continue=None | | |
| | | anything else I can help | anything else I can | | | | |
| | | you with today? 🛍️ | assist you with today? 😊 | | | | |
+----+---------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
این یعنی نماینده شما از ابزارهای صحیح استفاده کرده و پاسخی ارائه داده که به اندازه کافی مشابه انتظارات شما بوده است.
۹. (اختیاری: فقط خواندنی) - عیبیابی و اشکالزدایی
تستها با شکست مواجه میشوند. این وظیفه آنهاست. اما چگونه آنها را برطرف میکنید؟ بیایید سناریوهای رایج شکست و نحوه اشکالزدایی آنها را تجزیه و تحلیل کنیم.
سناریوی الف: شکست «مسیر»
خطا:
Result: FAILED
Reason: Criteria 'tool_trajectory_avg_score' failed. Score 0.0 < Threshold 1.0
Details:
EXPECTED: tool: lookup_order, then tool: issue_refund
ACTUAL: tool: issue_refund
تشخیص : عامل مرحله تأیید (lookup_order) را نادیده گرفت. این یک خطای منطقی است.
نحوه عیب یابی :
- حدس نزن : به رابط کاربری وب ADK (adk web) برگردید.
- بازتولید : دقیقاً همان عبارت از آزمون ناموفق را در چت تایپ کنید.
- ردیابی : نمای ردیابی را باز کنید. به برگه «نمودار» نگاه کنید.
- رفع مشکل : معمولاً باید مشکل سیستم را بهروزرسانی کنید. عبارت "شما یک عامل مفید هستید" را به "شما یک عامل مفید هستید" تغییر دهید . نکته مهم: قبل از فراخوانی issue_refund، باید تابع lookup_order را برای تأیید جزئیات فراخوانی کنید.
- تطبیق تست : اگر منطق کسبوکار تغییر کرده است (مثلاً دیگر نیازی به تأیید نیست)، پس تست اشتباه است. eval.test.json را بهروزرسانی کنید تا با واقعیت جدید مطابقت داشته باشد.
سناریوی ب: شکست «سرخ»
خطا:
Result: FAILED
Reason: Criteria 'response_match_score' failed. Score 0.45 < Threshold 0.8
Expected: "The refund has been processed successfully."
Actual: "I've gone ahead and returned the money to your card."
تشخیص : مامور کار درست را انجام داد، اما از کلمات متفاوتی استفاده کرد. ROUGE (همپوشانی کلمات) آن را جریمه کرد.
نحوه رفع :
- آیا اشتباه است؟ اگر معنی درست است، سوال را تغییر ندهید.
- تنظیم آستانه : آستانه را در
test_config.jsonکاهش دهید (مثلاً از0.8به0.5). - معیار را ارتقا دهید : در پیکربندی خود به
final_response_match_v2تغییر دهید. این از یک LLM برای خواندن هر دو جمله و قضاوت در مورد اینکه آیا منظور آنها یکسان است یا خیر، استفاده میکند.
۱۰. CI/CD با Pytest (pytest)

دستورات CLI برای انسانها هستند. pytest برای ماشینها است. برای اطمینان از قابلیت اطمینان در محیط عملیاتی، ما ارزیابیهای خود را در یک مجموعه تست پایتون قرار میدهیم. این به خط لوله CI/CD شما (GitHub Actions، Jenkins) اجازه میدهد تا در صورت افت عملکرد عامل، استقرار را مسدود کند.
چه چیزهایی وارد این فایل میشود؟
این فایل پایتون به عنوان پلی بین CI/CD runner و ADK evaluator عمل میکند. این فایل باید:
- بارگذاری عامل شما : کد عامل خود را به صورت پویا وارد کنید.
- تنظیم مجدد وضعیت : اطمینان حاصل کنید که حافظه عامل پاک است تا تستها به یکدیگر نشت نکنند.
- اجرای ارزیابی : فراخوانی
AgentEvaluator.evaluate()به صورت برنامهنویسیشده. - موفقیت را اعلام کنید : اگر امتیاز ارزیابی پایین است، ساخت را با شکست مواجه کنید.
کد تست یکپارچهسازی
- 👉
customer_service_agent/test_agent_eval.pyرا باز کنید. این اسکریپتAgentEvaluator.evaluateبرای اجرای تستهای تعریف شده درeval.test.jsonاستفاده میکند. - 👉 کد زیر را در فایل
customer_service_agent/test_agent_eval.pyدر ویرایشگر خود وارد کنید.from google.adk.evaluation.agent_evaluator import AgentEvaluator import pytest import importlib import sys import os @pytest.mark.asyncio async def test_with_single_test_file(): """Test the agent's basic ability via a session file.""" # Load the agent module robustly module_name = "customer_service_agent.agent" try: agent_module = importlib.import_module(module_name) # Reset the mock data to ensure a fresh state for the test if hasattr(agent_module, 'reset_mock_data'): agent_module.reset_mock_data() except ImportError: # Fallback if running from a different context sys.path.append(os.getcwd()) agent_module = importlib.import_module(module_name) if hasattr(agent_module, 'reset_mock_data'): agent_module.reset_mock_data() # Use absolute path to the eval file to be robust to where pytest is run script_dir = os.path.dirname(os.path.abspath(__file__)) eval_file = os.path.join(script_dir, "eval.test.json") await AgentEvaluator.evaluate( agent_module=module_name, eval_dataset_file_path_or_dir=eval_file, num_runs=1, )
اجرای Pytest
- 👉💻 در ترمینال خود، دستور زیر را اجرا کنید:
cd ~/adk_eval_starter uv pip install pytest uv run pytest customer_service_agent/test_agent_eval.py``` -- Docs: https://docs.pytest.org/en/stable/how-to/capture-warnings.html =============== 1 passed, 15 warnings in 12.84s =============== ```
۱۱. نتیجهگیری
تبریک! شما با موفقیت کارشناس خدمات مشتری خود را با استفاده از ADK Eval ارزیابی کردید.
آنچه آموختید
در این آزمایشگاه کد، شما یاد گرفتید که چگونه:
- ✅ یک مجموعه داده طلایی ایجاد کنید تا یک حقیقت پایه برای عامل خود ایجاد کنید.
- ✅ درک پیکربندی ارزیابی برای تعریف معیارهای موفقیت.
- ✅ برای تشخیص زودهنگام رگرسیونها ، ارزیابیهای خودکار را اجرا کنید .
با گنجاندن ADK Eval در گردش کار توسعه خود، میتوانید با اطمینان خاطر، عاملهایی بسازید و بدانید که هرگونه تغییر در رفتار توسط تستهای خودکار شما ثبت خواهد شد.
این آزمایشگاه بخشی از پروژه «هوش مصنوعی آماده تولید با مسیر یادگیری ابری گوگل» است.
- برای پر کردن شکاف بین نمونه اولیه و تولید، برنامه درسی کامل را بررسی کنید .
- پیشرفت خود را با هشتگ
ProductionReadyAIبه اشتراک بگذارید.
مطالب خواندنی بیشتر: