
1. Le fossé de confiance
Le moment d'inspiration
Vous avez créé un agent du service client. Il fonctionne sur votre machine. Mais hier, il a indiqué à un client qu'une montre connectée en rupture de stock était disponible, ou pire, il a inventé une politique de remboursement. Comment dormez-vous la nuit en sachant que votre agent est en ligne ?
Pour passer d'une démonstration de faisabilité à un agent IA prêt pour la production, il est essentiel de disposer d'un framework d'évaluation automatisé et solide.

Qu'évaluons-nous exactement ?
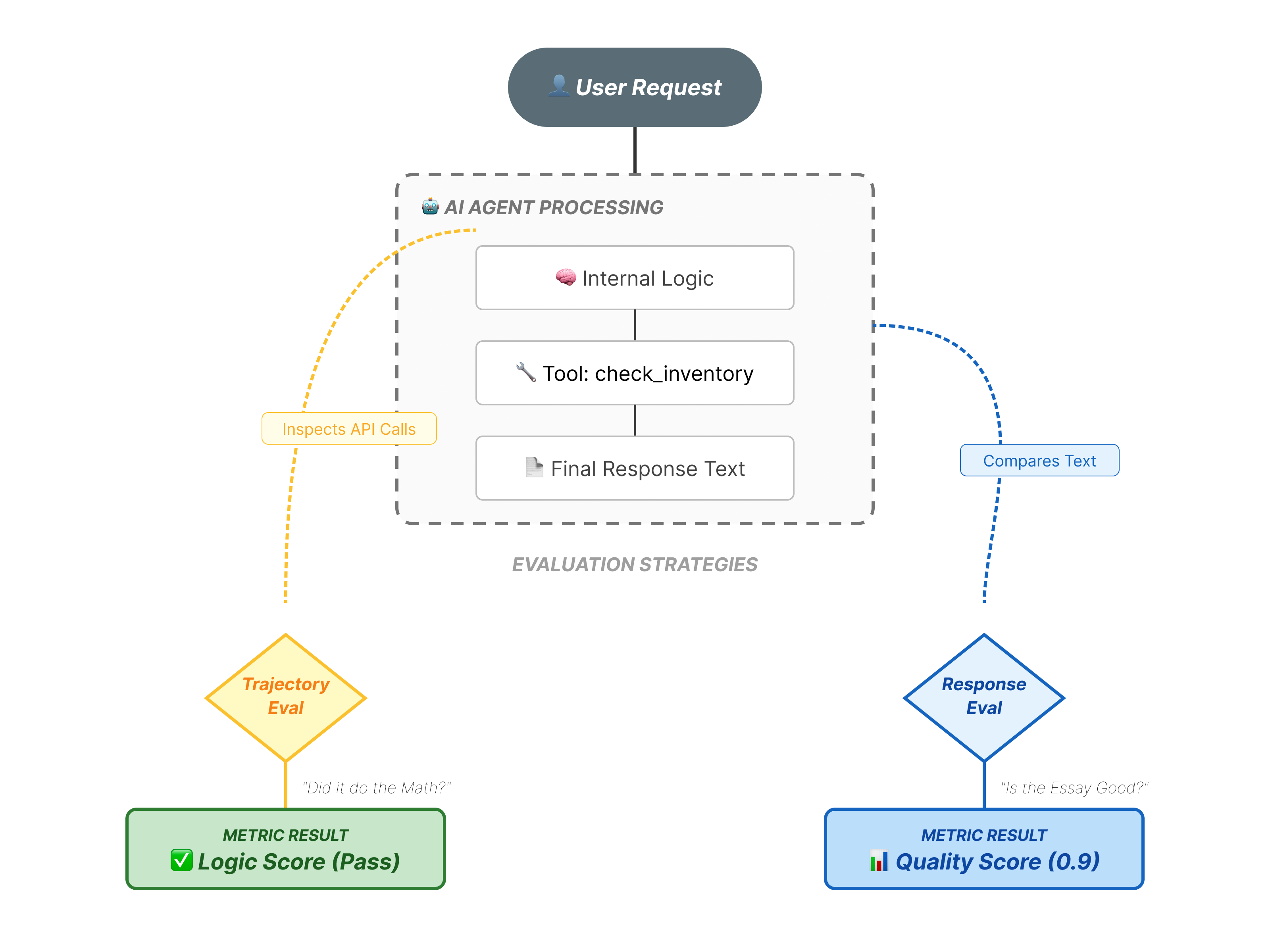
L'évaluation des agents est plus complexe que l'évaluation standard des LLM. Vous n'évaluez pas seulement l'essai (réponse finale), mais aussi les mathématiques (la logique/les outils utilisés pour y parvenir).

- Trajectoire (processus) : l'agent a-t-il utilisé le bon outil au bon moment ? A-t-il appelé
check_inventoryavantplace_order? - Réponse finale (sortie) : la réponse est-elle correcte, polie et ancrée dans les données ?
Cycle de vie du développement
Dans cet atelier de programmation, nous allons parcourir le cycle de vie professionnel des tests d'agents :
- Inspection visuelle locale (interface utilisateur Web ADK) : discuter manuellement et vérifier la logique (étape 1).
- Tests unitaires/de régression (CLI ADK) : exécutez des cas de test spécifiques en local pour détecter rapidement les erreurs (étapes 3 et 4).
- Débogage (dépannage) : analyse des échecs et correction de la logique des requêtes (étape 5).
- Intégration CI/CD (Pytest) : automatiser les tests dans votre pipeline de compilation (étape 6).
2. Configurer
Pour alimenter nos agents d'IA, nous avons besoin de deux éléments : un projet Google Cloud pour fournir les bases.
Première partie : Activer le compte de facturation
Pour effectuer cet atelier de programmation, vous avez besoin d'un compte de facturation avec un certain crédit. Utilisez les crédits de la bannière en haut de cet atelier de programmation pour commencer. Si vous êtes déjà associé à un compte de facturation, vous pouvez ignorer cette étape.
Deuxième partie : Environnement ouvert
- 👉 Cliquez sur ce lien pour accéder directement à l'éditeur Cloud Shell.
- 👉 Si vous êtes invité à autoriser l'accès à un moment donné aujourd'hui, cliquez sur Autoriser pour continuer.
- 👉 Si le terminal ne s'affiche pas en bas de l'écran, ouvrez-le :
- Cliquez sur Afficher.
- Cliquez sur Terminal
 .
.
- 👉💻 Dans le terminal, vérifiez que vous êtes déjà authentifié et que le projet est défini sur votre ID de projet à l'aide de la commande suivante :
gcloud auth list - 👉💻 Clonez le projet bootstrap depuis GitHub :
git clone https://github.com/cuppibla/adk_eval_starter - 👉💻 Exécutez le script de configuration à partir du répertoire du projet.
cd ~/adk_eval_starter ./init.sh
Le script gère automatiquement le reste du processus de configuration.
- 👉💻 Définissez l'ID de projet requis :
gcloud config set project $(cat ~/project_id.txt) --quiet
Troisième partie : Configurer les autorisations
- 👉💻 Activez les API requises à l'aide de la commande suivante. L'opération peut prendre quelques minutes.
gcloud services enable \ cloudresourcemanager.googleapis.com \ servicenetworking.googleapis.com \ run.googleapis.com \ cloudbuild.googleapis.com \ artifactregistry.googleapis.com \ aiplatform.googleapis.com \ compute.googleapis.com - 👉💻 Accordez les autorisations nécessaires en exécutant les commandes suivantes dans le terminal :
. ~/adk_eval_starter/set_env.sh
Notez qu'un fichier .env a été créé pour vous. Les informations sur votre projet s'affichent.
3. Générer l'ensemble de données de référence (adk web)
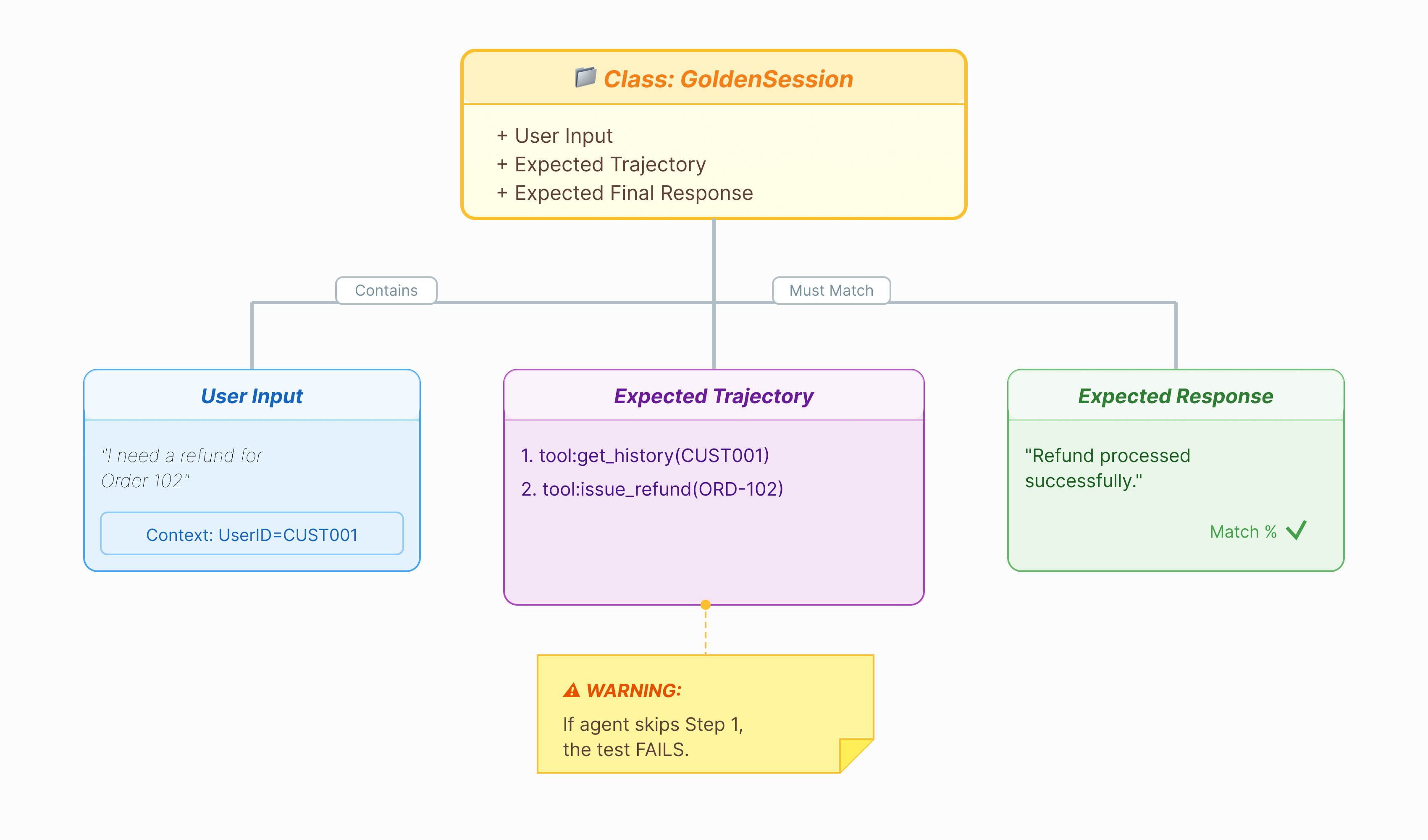
Avant de pouvoir évaluer l'agent, nous avons besoin d'un corrigé. Dans ADK, nous l'appelons ensemble de données de référence. Cet ensemble de données contient des interactions "parfaites" qui servent de vérité terrain pour l'évaluation.
Qu'est-ce qu'un ensemble de données de référence ?
Un ensemble de données de référence est un instantané de votre agent lorsqu'il fonctionne correctement. Il ne s'agit pas simplement d'une liste de paires de questions/réponses. Il permet de recueillir les informations suivantes :
- Requête de l'utilisateur ("Je souhaite être remboursé")
- La trajectoire (séquence exacte des appels d'outils :
check_order>verify_eligibility>refund_transaction). - La réponse finale (la réponse textuelle "parfaite").
Nous l'utilisons pour détecter les régressions. Si vous modifiez votre requête et que l'agent cesse soudainement de vérifier l'éligibilité avant de rembourser, le test du Golden Dataset échouera, car la trajectoire ne correspond plus.
Ouvrir l'interface utilisateur Web
L'interface utilisateur Web ADK offre un moyen interactif de créer ces ensembles de données de référence en capturant les interactions réelles avec votre agent.
- 👉💻 Dans votre terminal, exécutez :
cd ~/adk_eval_starter uv run adk web - 👉💻 Ouvrez l'aperçu de l'UI Web (généralement à l'adresse
http://127.0.0.1:8000). - 👉 Dans l'interface utilisateur du chat, saisissez
Hi, I'm customer CUST001. Can you check my orders? I need a refund for order ORD-102. It arrived damaged. Vous devriez obtenir une réponse semblable à celle-ci :
Vous devriez obtenir une réponse semblable à celle-ci :I've processed your refund for order ORD-102 due to the items arriving damaged. A full refund of $35.0 has been processed, and the status of order ORD-102 is now updated to "refunded". Is there anything else I can assist you with today, CUST001? 🛍️
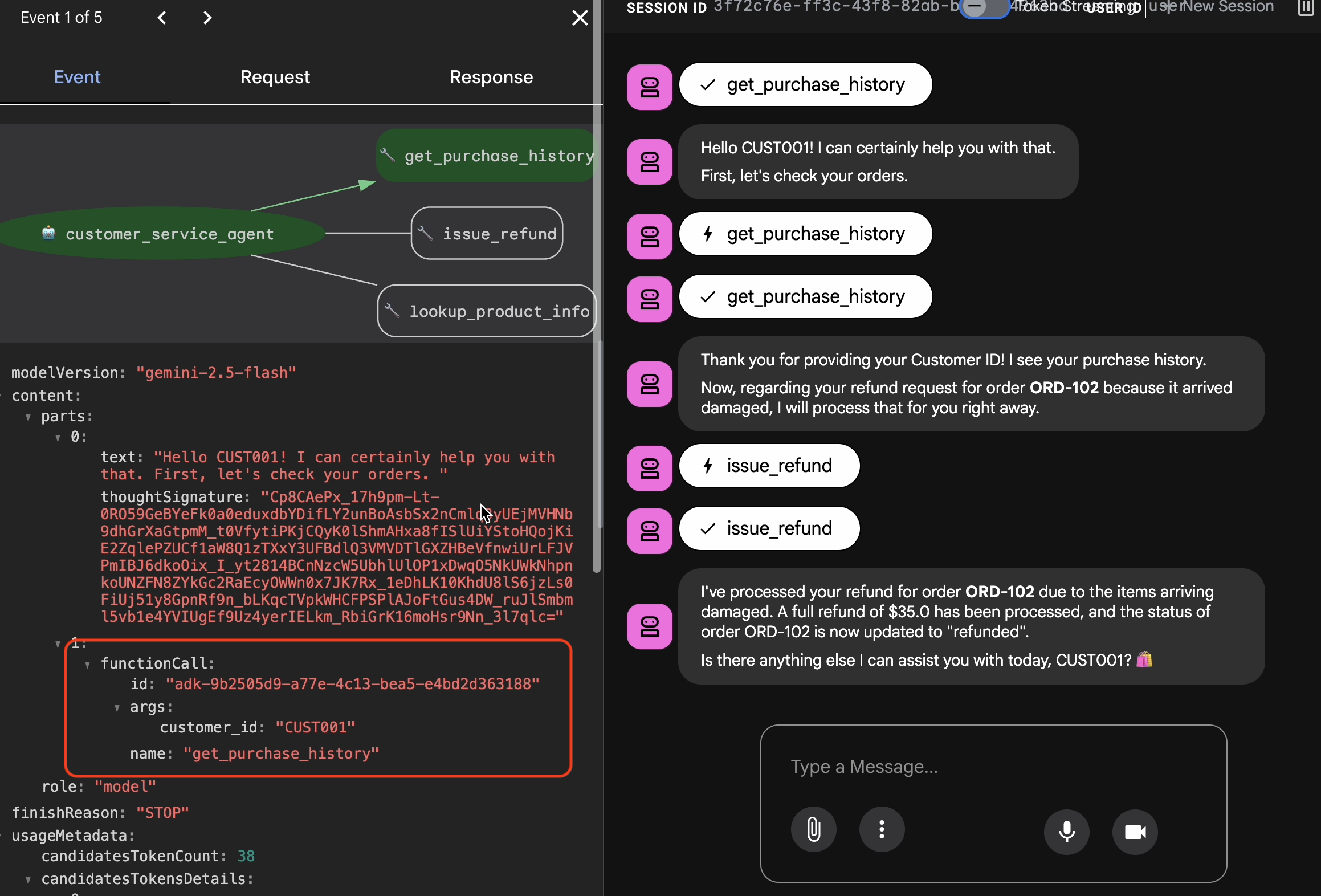
Capturer les interactions Golden
Accédez à l'onglet Sessions. Vous pouvez consulter l'historique des conversations de votre agent en cliquant sur la session.
- Interagissez avec votre agent pour créer un flux de conversation idéal, par exemple pour consulter l'historique des achats ou demander un remboursement.
- Examinez la conversation pour vous assurer qu'elle représente le comportement attendu.
4. Exporter l'ensemble de données de référence
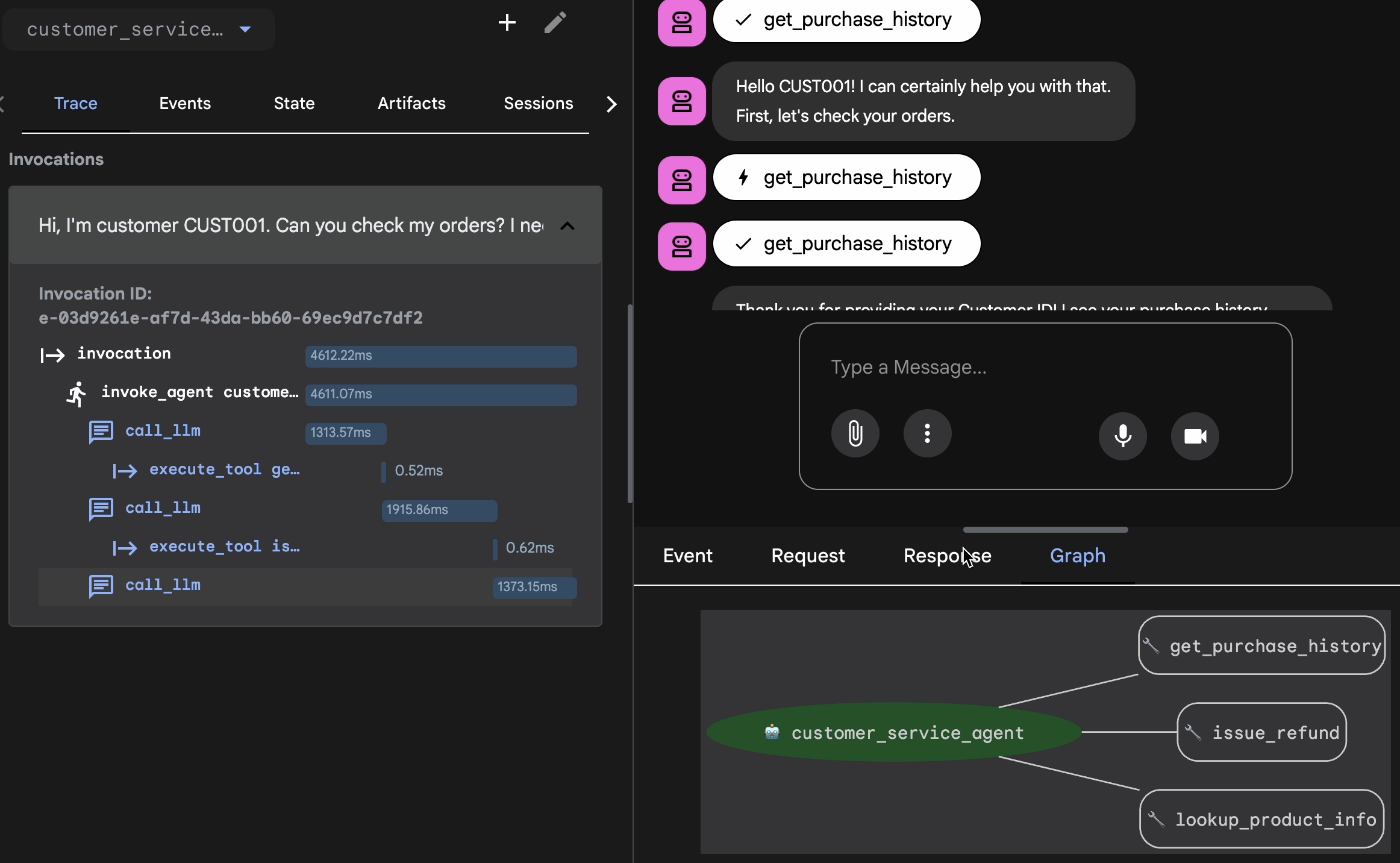
Valider avec la vue Trace
Avant d'exporter, vous devez vérifier que l'agent n'a pas trouvé la bonne réponse par hasard. Vous devez inspecter la logique interne.
- Cliquez sur l'onglet Trace dans l'interface utilisateur Web.
- Les traces sont automatiquement regroupées par message utilisateur. Pointez sur une ligne de trace pour mettre en évidence le message correspondant dans le chat.
- Inspectez les lignes bleues : elles indiquent les événements générés par l'interaction. Cliquez sur une ligne bleue pour ouvrir le panneau d'inspection.
- Consultez les onglets suivants pour valider la logique :
- Graphique : représentation visuelle des appels d'outils et du flux logique. A-t-il emprunté le bon chemin ?
- Requête/Réponse : examinez exactement ce qui a été envoyé au modèle et ce qui a été renvoyé.
- Validation : si l'agent a deviné le montant du remboursement sans appeler l'outil de base de données, il s'agit d'une "hallucination chanceuse".
Ajouter une session à EvalSet
Une fois que vous êtes satisfait de la conversation et de la trace :
- 👉 Cliquez sur l'onglet
Eval, puis sur le boutonCreate Evaluation Set, et saisissez le nom de l'évaluation :evalset1
- 👉 Dans cet ensemble d'évaluation, cliquez sur
Add current session to evalset1. Dans la fenêtre pop-up, saisissez le nom de la session :eval1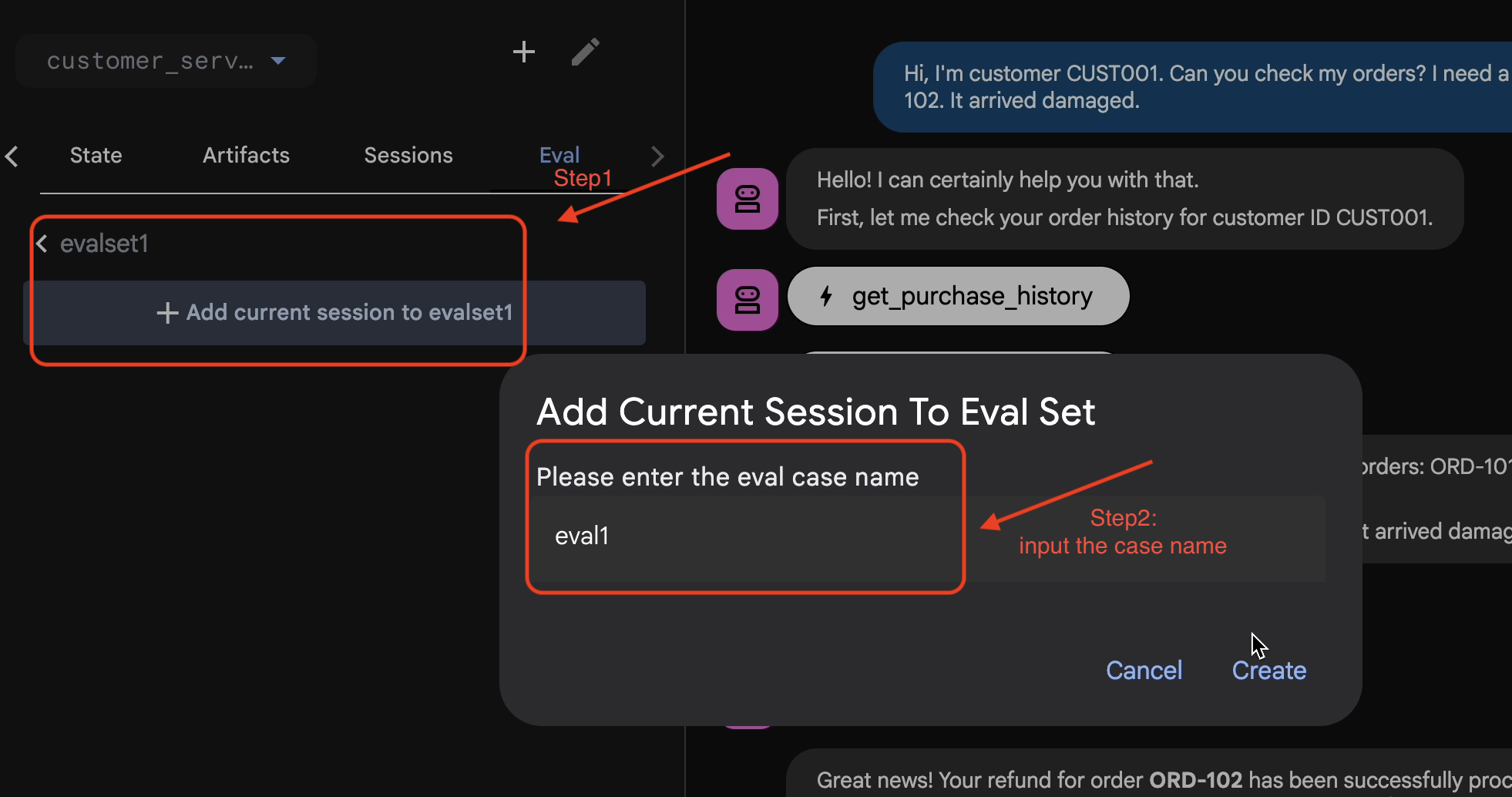
Exécuter une évaluation dans ADK Web
- 👉 Dans l'UI Web de l'ADK, cliquez sur
Run Evaluation. Dans la fenêtre pop-up, ajustez les métriques, puis cliquez surStart:

Vérifier l'ensemble de données dans votre dépôt
Vous verrez une confirmation indiquant qu'un fichier de données (par exemple, evalset1.evalset.json) a été enregistré dans votre dépôt. Ce fichier contient la trace brute et générée automatiquement de votre conversation.
5. Fichiers d'évaluation
Bien que l'interface utilisateur Web génère un fichier .evalset.json complexe, nous souhaitons souvent créer un fichier de test plus clair et plus structuré pour les tests automatisés.
ADK Eval utilise deux composants principaux :
- Fichiers de test : il peut s'agir de l'ensemble de données de référence généré automatiquement (par exemple,
customer_service_agent/evalset1.evalset.json) ou d'un ensemble organisé manuellement (par exemple,customer_service_agent/eval.test.json). - Fichiers de configuration (par exemple,
customer_service_agent/test_config.json) : définissez les métriques et les seuils à respecter.
Configurer le fichier de configuration du test
- 👉💻 Dans le terminal de l'éditeur Cloud Shell, saisissez
cloudshell edit customer_service_agent/test_config.json - 👉 Saisissez le code suivant dans
customer_service_agent/test_config.jsondans votre éditeur.{ "criteria": { "tool_trajectory_avg_score": 0.8, "response_match_score": 0.5 } }
Décoder les métriques
tool_trajectory_avg_score(Processus) : cette catégorie permet de déterminer si l'agent a utilisé les outils correctement.
- 0,8 : nous exigeons une correspondance de 80 %.
response_match_score(Résultat) : utilise ROUGE-1 (chevauchement de mots) pour comparer la réponse à la référence clé.
- Avantages : rapide, déterministe, sans frais.
- Inconvénients : échec si l'agent formule la même idée différemment (par exemple, "Remboursé" au lieu de "Argent restitué").
Métriques avancées (pour plus de précision)
6. Exécuter l'évaluation pour l'ensemble de données de référence (adk eval)
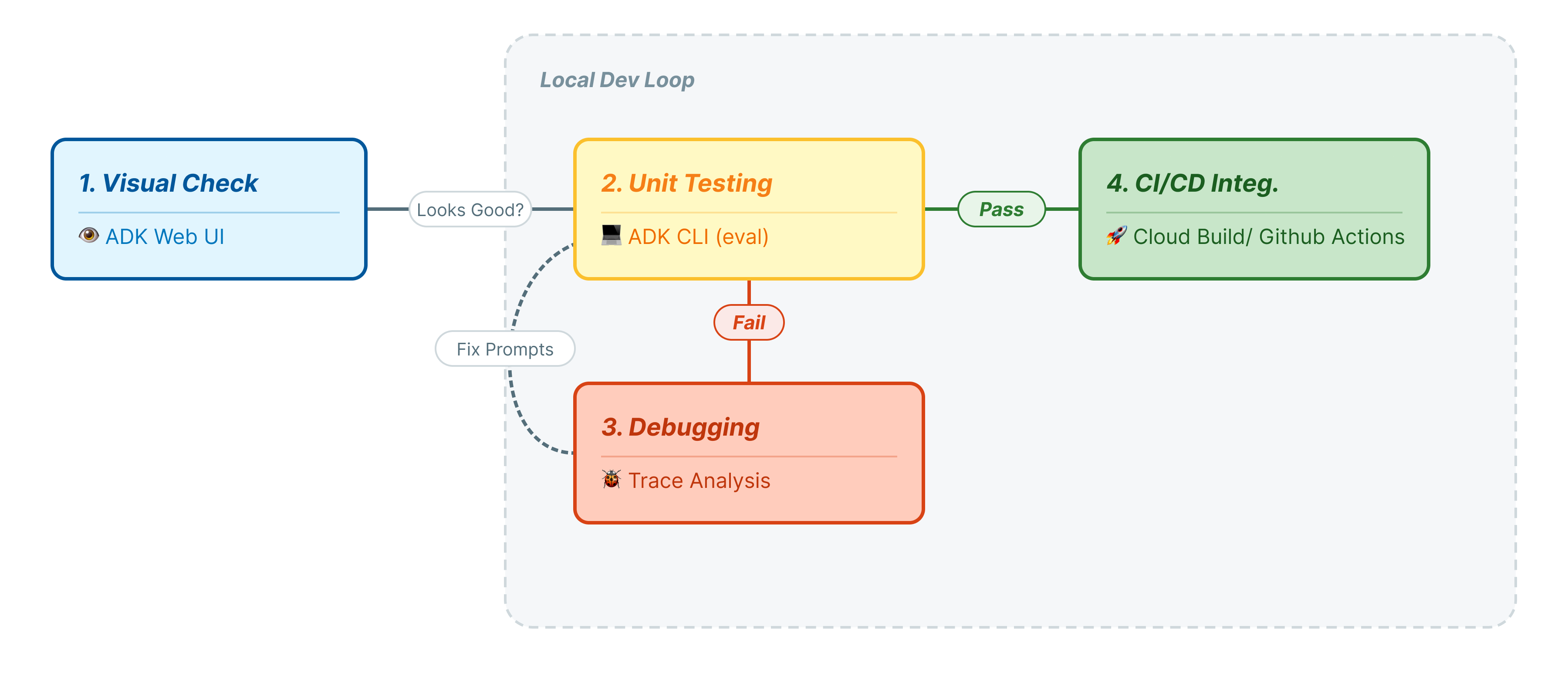
Cette étape représente la "boucle interne" du développement. Vous êtes un développeur qui apporte des modifications et vous souhaitez vérifier rapidement les résultats.
Exécuter l'ensemble de données de référence
Exécutons l'ensemble de données que vous avez généré à l'étape 1. Cela vous permettra de disposer d'une base solide.
- 👉💻 Dans votre terminal, exécutez :
cd ~/adk_eval_starter uv run adk eval customer_service_agent customer_service_agent/evalset1.evalset.json --config_file_path=customer_service_agent/test_config.json --print_detailed_results
Nouveautés
L'ADK est désormais :
- Chargement de votre agent à partir de
customer_service_agent. - Exécuter les requêtes d'entrée à partir de
evalset1.evalset.json. - Comparer la trajectoire et les réponses réelles de l'agent à celles attendues.
- Évaluez les résultats en fonction des critères définis dans
test_config.json.
Analyser les résultats
Observez la sortie du terminal. Un récapitulatif des tests réussis et échoués s'affiche.
Eval Run Summary
evalset1:
Tests passed: 1
Tests failed: 0
********************************************************************
Eval Set Id: evalset1
Eval Id: eval1
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.5581395348837208, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+---------------------------+---------------------------+--------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+===========================+===========================+==========================+===========================+===========================+=============================+========================+
| 0 | Hi, I'm customer CUST001. | Great news! Your refund | Great news, CUST001! 🎉 | id='adk-051409fe-c230-43f | id='adk-4e9aa570-1cc6-4c3 | Status: PASSED, Score: | Status: PASSED, Score: |
| | Can you check my orders? | for order **ORD-102** has | I've successfully | 4-a7f1- 5747280fd878' | c-aa3e- 91dbe113dd4b' | 1.0 | 0.5581395348837208 |
| | I need a refund for order | been successfully | processed a full refund | args={'customer_id': | args={'customer_id': | | |
| | ORD-102. It arrived | processed due to the item | of $35.0 for your order | 'CUST001'} name='get_purc | 'CUST001'} name='get_purc | | |
| | damaged. | arriving damaged. You | ORD-102 because it | hase_history' | hase_history' | | |
| | | should see a full refund | arrived damaged. The | partial_args=None | partial_args=None | | |
| | | of $35.0 back to your | status of that order has | will_continue=None id= 'a | will_continue=None | | |
| | | original payment method | been updated to | dk-8a194cb8-5a82-47ce-a3a | id='adk- dad1b376-9bcc-48 | | |
| | | shortly. The status of | "refunded." Is there | 7- 3d24551f8c90' | bb-996f-a30f6ef5b70b' | | |
| | | this order has been | anything else I can | args={'reason': | args={'reason': | | |
| | | updated to "refunded". | assist you with today? | 'damaged', 'order_id': | 'damaged', 'order_id': | | |
| | | Here's your updated | | 'ORD-102'} | 'ORD-102'} | | |
| | | purchase history for | | name='issue_refund' | name='issue_refund' | | |
| | | CUST001: * **ORD-101**: | | partial_args=None | partial_args=None | | |
| | | Wireless Headphones, | | will_continue=None | will_continue=None | | |
| | | delivered on 2023-10-15 | | | | | |
| | | (Total: $120) * | | | | | |
| | | **ORD-102**: USB-C Cable, | | | | | |
| | | Phone Case, refunded on | | | | | |
| | | 2023-11-01 (Total: $35) | | | | | |
| | | Is there anything else I | | | | | |
| | | can help you with today? | | | | | |
| | | 😊 | | | | | |
+----+---------------------------+---------------------------+--------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
Remarque : Étant donné que vous venez de générer cette réponse à partir de l'agent lui-même, elle devrait être validée à 100 %. Si elle échoue, votre agent est non déterministe (aléatoire).
7. Créer votre propre test personnalisé
Bien que les ensembles de données générés automatiquement soient très utiles, il est parfois nécessaire de créer manuellement des cas extrêmes (par exemple, des attaques adversariales ou une gestion spécifique des erreurs). Voyons comment eval.test.json vous permet de définir la "justesse".
Créons une suite de tests complète.
Framework de test
Lorsque vous rédigez un cas de test dans ADK, suivez cette formule en trois parties :
- Configuration (
session_input) : qui est l'utilisateur ? (par exemple,user_id,state). Cela permet d'isoler le test. - Requête (
user_content) : quel est le déclencheur ?
Avec The Assertions (Expectations) :
- Trajectoire (
tool_uses) : les calculs sont-ils corrects ? (Logique) - Réponse (
final_response) : la réponse était-elle correcte ? (Qualité) - Intermédiaire (
intermediate_responses) : les sous-agents ont-ils parlé correctement ? (Orchestration)
Écrire la suite de tests
- 👉💻 Dans le terminal de l'éditeur Cloud Shell, saisissez
cloudshell edit customer_service_agent/eval.test.json - 👉 Saisissez le code suivant dans le fichier
customer_service_agent/eval.test.json.{ "eval_set_id": "customer_service_eval", "name": "Customer Service Agent Evaluation", "description": "Evaluation suite for the customer service agent covering product info, purchase history, and refunds.", "eval_cases": [ { "eval_id": "product_info_check", "session_input": { "app_name": "customer_service_agent", "user_id": "eval_user_1", "state": {} }, "conversation": [ { "invocation_id": "turn_1_product_info", "user_content": { "role": "user", "parts": [ { "text": "Do you have wireless headphones in stock?" } ] }, "final_response": { "role": "model", "parts": [ { "text": "Yes, we have wireless headphones in stock! They are priced at $120.00 and feature noise-canceling with a 20-hour battery life. 🎧" } ] }, "intermediate_data": { "tool_uses": [ { "name": "lookup_product_info", "args": { "product_name": "wireless headphones" } } ], "intermediate_responses": [] } } ] }, { "eval_id": "purchase_history_check", "session_input": { "app_name": "customer_service_agent", "user_id": "eval_user_2", "state": {} }, "conversation": [ { "invocation_id": "turn_1_purchase_history", "user_content": { "role": "user", "parts": [ { "text": "What did I buy recently? My customer ID is CUST001." } ] }, "final_response": { "role": "model", "parts": [ { "text": "Here's your recent purchase history for Customer ID CUST001:\n\n* **Order ORD-101** (October 15, 2023): Wireless Headphones, Status: delivered, Total: $120\n* **Order ORD-102** (November 1, 2023): USB-C Cable, Phone Case, Status: refunded, Total: $35\n\nLet me know if you have any other questions or need further assistance! 🛍️" } ] }, "intermediate_data": { "tool_uses": [ { "name": "get_purchase_history", "args": { "customer_id": "CUST001" } } ], "intermediate_responses": [] } } ] }, { "eval_id": "refund_request", "session_input": { "app_name": "customer_service_agent", "user_id": "eval_user_3", "state": {} }, "conversation": [ { "invocation_id": "turn_1_refund", "user_content": { "role": "user", "parts": [ { "text": "I want a refund for order ORD-102 because it was damaged." } ] }, "final_response": { "role": "model", "parts": [ { "text": "Your refund for order **ORD-102** due to \"damaged\" has been successfully processed! Refund amount: **$35.0**. Your order status has been updated to **refunded**. \nIs there anything else I can help you with today? 🛍️" } ] }, "intermediate_data": { "tool_uses": [ { "name": "issue_refund", "args": { "order_id": "ORD-102", "reason": "damaged" } } ], "intermediate_responses": [] } } ] } ] }
Décomposer les types de tests
Nous avons créé trois types de tests distincts. Examinons ce que chacune de ces catégories évalue et pourquoi.
- Test de l'outil unique (
product_info_check)
- Objectif : vérifier la récupération d'informations de base.
- Assertion clé : nous vérifions
intermediate_data.tool_uses. Nous affirmons quelookup_product_infoest appelé. Nous affirmons que l'argumentproduct_nameest exactement "casque sans fil". - Pourquoi : ce test échoue si le modèle hallucine un prix sans appeler l'outil. Cela garantit l'ancrage.
- Test d'extraction du contexte (
purchase_history_check)
- Objectif : Vérifier que l'agent peut extraire des entités (CUST001) de la requête utilisateur et les transmettre à l'outil.
- Assertion clé : nous vérifions que
get_purchase_historyest appelé aveccustomer_id: "CUST001". - Pourquoi : un mode d'échec courant est l'appel de l'outil approprié par l'agent, mais avec un ID nul. Cela permet de garantir l'exactitude des paramètres.
- Test d'action/de trajectoire (
refund_request)
- Objectif : valider une opération d'écriture critique.
- Assertion clé : la trajectoire. Dans un scénario plus complexe, cette liste contiendrait plusieurs étapes :
[verify_order, calculate_refund, issue_refund]. L'ADK vérifie cette liste dans l'ordre. - Pourquoi : pour les actions qui déplacent de l'argent ou modifient des données, la séquence est aussi importante que le résultat. Vous ne souhaitez pas effectuer de remboursement avant d'avoir vérifié.
8. Exécuter l'évaluation pour les tests personnalisés ( adk eval)
- 👉💻 Dans votre terminal, exécutez :
cd ~/adk_eval_starter uv run adk eval customer_service_agent customer_service_agent/eval.test.json --config_file_path=customer_service_agent/test_config.json --print_detailed_results
Comprendre le résultat
Vous devriez obtenir un résultat PASS semblable à celui-ci :
Eval Run Summary
customer_service_eval:
Tests passed: 3
Tests failed: 0
********************************************************************
Eval Set Id: customer_service_eval
Eval Id: purchase_history_check
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.5473684210526315, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+--------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+==========================+===========================+===========================+===========================+===========================+=============================+========================+
| 0 | What did I buy recently? | Here's your recent | Looks like your recent | id=None | id='adk-8960eb53-2933-459 | Status: PASSED, Score: | Status: PASSED, Score: |
| | My customer ID is | purchase history for | orders include: * | args={'customer_id': | f-b306- 71e3c069e77e' | 1.0 | 0.5473684210526315 |
| | CUST001. | Customer ID CUST001: * | **ORD-101 (2023-10-15):** | 'CUST001'} name='get_purc | args={'customer_id': | | |
| | | **Order ORD-101** | Wireless Headphones for | hase_history' | 'CUST001'} name='get_purc | | |
| | | (October 15, 2023): | $120.00 - Status: | partial_args=None | hase_history' | | |
| | | Wireless Headphones, | Delivered 🎧 * **ORD-102 | will_continue=None | partial_args=None | | |
| | | Status: delivered, Total: | (2023-11-01):** USB-C | | will_continue=None | | |
| | | $120 * **Order | Cable, Phone Case for | | | | |
| | | ORD-102** (November 1, | $35.00 - Status: Refunded | | | | |
| | | 2023): USB-C Cable, Phone | 📱 Is there anything else | | | | |
| | | Case, Status: refunded, | I can help you with | | | | |
| | | Total: $35 Let me know | regarding these orders? | | | | |
| | | if you have any other | | | | | |
| | | questions or need further | | | | | |
| | | assistance! 🛍️ | | | | | |
+----+--------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
********************************************************************
Eval Set Id: customer_service_eval
Eval Id: product_info_check
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.6829268292682927, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+----------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+======================+===========================+===========================+===========================+===========================+=============================+========================+
| 0 | Do you have wireless | Yes, we have wireless | Yes, we do! 🎧 We have | id=None | id='adk-4571d660-a92b-412 | Status: PASSED, Score: | Status: PASSED, Score: |
| | headphones in stock? | headphones in stock! They | noise-canceling wireless | args={'product_name': | a-a79e- 5c54f8b8af2d' | 1.0 | 0.6829268292682927 |
| | | are priced at $120.00 and | headphones with a 20-hour | 'wireless headphones'} na | args={'product_name': | | |
| | | feature noise-canceling | battery life available | me='lookup_product_info' | 'wireless headphones'} na | | |
| | | with a 20-hour battery | for $120. | partial_args=None | me='lookup_product_info' | | |
| | | life. 🎧 | | will_continue=None | partial_args=None | | |
| | | | | | will_continue=None | | |
+----+----------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
********************************************************************
Eval Set Id: customer_service_eval
Eval Id: refund_request
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.6216216216216216, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+---------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+===========================+===========================+===========================+===========================+===========================+=============================+========================+
| 0 | I want a refund for order | Your refund for order | Your refund for order | id=None args={'order_id': | id='adk-fb8ff1cc- cf87-41 | Status: PASSED, Score: | Status: PASSED, Score: |
| | ORD-102 because it was | **ORD-102** due to | **ORD-102** has been | 'ORD-102', 'reason': | f2-9b11-d4571b14287f' | 1.0 | 0.6216216216216216 |
| | damaged. | "damaged" has been | successfully processed! | 'damaged'} | args={'order_id': | | |
| | | successfully processed! | You should see a full | name='issue_refund' | 'ORD-102', 'reason': | | |
| | | Refund amount: **$35.0**. | refund of $35.0 appear in | partial_args=None | 'damaged'} | | |
| | | Your order status has | your account shortly. We | will_continue=None | name='issue_refund' | | |
| | | been updated to | apologize for the | | partial_args=None | | |
| | | **refunded**. Is there | inconvenience! Is there | | will_continue=None | | |
| | | anything else I can help | anything else I can | | | | |
| | | you with today? 🛍️ | assist you with today? 😊 | | | | |
+----+---------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
Cela signifie que votre agent a utilisé les bons outils et fourni une réponse suffisamment proche de vos attentes.
9. (Facultatif : lecture seule) : dépannage et débogage
Les tests échoueront. C'est leur travail. Mais comment les corriger ? Analysons les scénarios d'échec courants et comment les déboguer.
Scénario A : Échec de la "trajectoire"
Erreur :
Result: FAILED
Reason: Criteria 'tool_trajectory_avg_score' failed. Score 0.0 < Threshold 1.0
Details:
EXPECTED: tool: lookup_order, then tool: issue_refund
ACTUAL: tool: issue_refund
Diagnostic : L'agent a ignoré l'étape de validation (lookup_order). Il s'agit d'une erreur de logique.
Procédure de dépannage :
- Ne devinez pas : revenez à l'UI Web ADK (adk web).
- Reproduire : saisissez le prompt exact du test ayant échoué dans le chat.
- Trace : ouvre la vue "Trace". Consultez l'onglet "Graphique".
- Corriger le prompt : vous devez généralement mettre à jour le prompt système. Modification : "Tu es un agent serviable." À : "Tu es un agent serviable. CRITIQUE : Vous DEVEZ appeler lookup_order pour vérifier les informations avant d'appeler issue_refund."
- Adapter le test : si la logique métier a changé (par exemple, la validation n'est plus nécessaire), le test est incorrect. Mettez à jour eval.test.json pour qu'il corresponde à la nouvelle réalité.
Scénario B : Échec de "ROUGE"
Erreur :
Result: FAILED
Reason: Criteria 'response_match_score' failed. Score 0.45 < Threshold 0.8
Expected: "The refund has been processed successfully."
Actual: "I've gone ahead and returned the money to your card."
Diagnostic : L'agent a fait ce qu'il fallait, mais a utilisé d'autres mots. ROUGE (chevauchement de mots) l'a pénalisé.
Solution :
- Est-ce une erreur ? Si le sens est correct, ne modifiez pas la requête.
- Ajuster le seuil : diminuez le seuil dans
test_config.json(par exemple, de0.8à0.5). - Mettre à niveau la métrique : passez à
final_response_match_v2dans votre configuration. Un LLM est utilisé pour lire les deux phrases et déterminer si elles ont la même signification.
10. CI/CD avec Pytest (pytest)
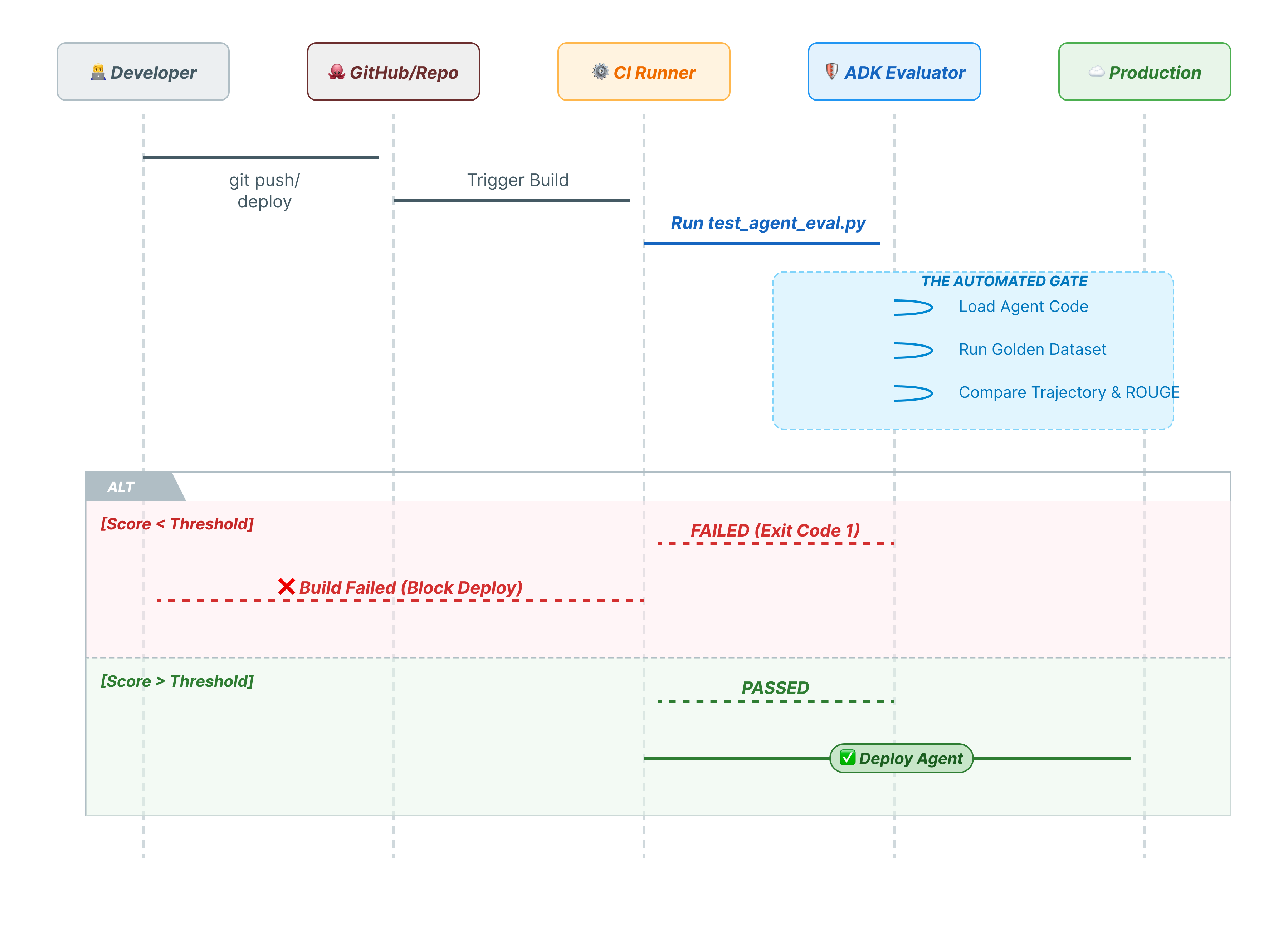
Les commandes CLI sont destinées aux humains. pytest est destiné aux machines. Pour garantir la fiabilité de la production, nous intégrons nos évaluations dans une suite de tests Python. Cela permet à votre pipeline CI/CD (GitHub Actions, Jenkins) de bloquer un déploiement si l'agent se dégrade.
Que contient ce fichier ?
Ce fichier Python sert de pont entre votre runner CI/CD et l'évaluateur ADK. Il doit :
- Chargez votre agent : importez dynamiquement le code de votre agent.
- Réinitialiser l'état : assurez-vous que la mémoire de l'agent est propre afin que les tests ne se chevauchent pas.
- Exécuter l'évaluation : appelez
AgentEvaluator.evaluate()de manière programmatique. - Assert Success (Affirmer le succès) : si le score d'évaluation est faible, la compilation échoue.
Code de test d'intégration
- 👉 Ouvrez
customer_service_agent/test_agent_eval.py. Ce script utiliseAgentEvaluator.evaluatepour exécuter les tests définis danseval.test.json. - 👉 Saisissez le code suivant dans
customer_service_agent/test_agent_eval.pydans votre éditeur.from google.adk.evaluation.agent_evaluator import AgentEvaluator import pytest import importlib import sys import os @pytest.mark.asyncio async def test_with_single_test_file(): """Test the agent's basic ability via a session file.""" # Load the agent module robustly module_name = "customer_service_agent.agent" try: agent_module = importlib.import_module(module_name) # Reset the mock data to ensure a fresh state for the test if hasattr(agent_module, 'reset_mock_data'): agent_module.reset_mock_data() except ImportError: # Fallback if running from a different context sys.path.append(os.getcwd()) agent_module = importlib.import_module(module_name) if hasattr(agent_module, 'reset_mock_data'): agent_module.reset_mock_data() # Use absolute path to the eval file to be robust to where pytest is run script_dir = os.path.dirname(os.path.abspath(__file__)) eval_file = os.path.join(script_dir, "eval.test.json") await AgentEvaluator.evaluate( agent_module=module_name, eval_dataset_file_path_or_dir=eval_file, num_runs=1, )
Exécuter Pytest
- 👉💻 Dans votre terminal, exécutez :
cd ~/adk_eval_starter uv pip install pytest uv run pytest customer_service_agent/test_agent_eval.py``` -- Docs: https://docs.pytest.org/en/stable/how-to/capture-warnings.html =============== 1 passed, 15 warnings in 12.84s =============== ```
11. Conclusion
Félicitations ! Vous avez réussi à évaluer votre agent de service client à l'aide d'ADK Eval.
Ce que vous avez appris
Dans cet atelier de programmation, vous avez appris à :
- ✅ Générez un ensemble de données de référence pour établir une vérité terrain pour votre agent.
- ✅ Comprendre la configuration de l'évaluation pour définir les critères de réussite.
- ✅ Exécutez des évaluations automatiques pour détecter les régressions de manière précoce.
En intégrant ADK Eval à votre workflow de développement, vous pouvez créer des agents en toute confiance, en sachant que tout changement de comportement sera détecté par vos tests automatisés.
Cet atelier fait partie du parcours de formation "L'IA prête pour la production avec Google Cloud".
- Découvrez le programme complet pour passer du prototype à la production.
- Partagez votre progression avec le hashtag
ProductionReadyAI.
Autres ressources :