
1. भरोसे का अंतर
नए वीडियो का आइडिया
आपने ग्राहक सेवा एजेंट बनाया है. यह आपके डिवाइस पर काम करता है. हालांकि, कल इसने एक खरीदार को बताया कि स्मार्ट वॉच उपलब्ध है, जबकि वह स्टॉक में नहीं थी. इसके अलावा, इसने रिफ़ंड की नीति के बारे में भी गलत जानकारी दी. आपको यह जानकर रात में कैसी नींद आती है कि आपका एजेंट लाइव है?
कॉन्सेप्ट के सबूत और प्रोडक्शन के लिए तैयार एआई एजेंट के बीच के अंतर को कम करने के लिए, बेहतर और अपने-आप काम करने वाले आकलन के फ़्रेमवर्क का होना ज़रूरी है.

हम असल में किस चीज़ का आकलन कर रहे हैं?
एजेंट का आकलन करना, स्टैंडर्ड एलएलएम के आकलन से ज़्यादा मुश्किल होता है. आपको सिर्फ़ निबंध (आखिरी जवाब) को ग्रेड नहीं करना है, बल्कि गणित (जवाब पाने के लिए इस्तेमाल किए गए लॉजिक/टूल) को भी ग्रेड करना है.

- ट्रैजेक्ट्री (प्रोसेस): क्या एजेंट ने सही समय पर सही टूल का इस्तेमाल किया? क्या इसने
place_orderसे पहलेcheck_inventoryको कॉल किया था? - फ़ाइनल जवाब (आउटपुट): क्या जवाब सही है, शालीनता से दिया गया है, और डेटा पर आधारित है?
डेवलपमेंट लाइफ़साइकल
इस कोडलैब में, हम एजेंट टेस्टिंग के पेशेवर लाइफ़साइकल के बारे में जानेंगे:
- लोकल विज़ुअल जांच (ADK Web UI): मैन्युअल तरीके से चैट करना और लॉजिक की पुष्टि करना (पहला चरण).
- यूनिट/रिग्रेशन टेस्टिंग (ADK CLI): गड़बड़ियों का पता लगाने के लिए, चुनिंदा टेस्ट केस को लोकल लेवल पर चलाना (तीसरा और चौथा चरण).
- डीबगिंग (समस्या हल करना): जवाब जनरेट न होने की वजहों का विश्लेषण करना और प्रॉम्प्ट लॉजिक को ठीक करना (पांचवां चरण).
- सीआई/सीडी इंटिग्रेशन (Pytest): अपनी बिल्ड पाइपलाइन में टेस्ट को ऑटोमेट करना (छठा चरण).
2. सेट करें
एआई एजेंट को बेहतर तरीके से काम करने के लिए, हमें दो चीज़ों की ज़रूरत होती है: पहला, Google Cloud प्रोजेक्ट.
पहला हिस्सा: बिलिंग खाता चालू करना
इस कोडलैब को चलाने के लिए, आपके पास कुछ क्रेडिट वाला बिलिंग खाता होना चाहिए. शुरू करने के लिए, इस कोडलैब के सबसे ऊपर मौजूद बैनर में दिए गए क्रेडिट का इस्तेमाल करें. अगर आपका खाता पहले से ही किसी बिलिंग खाते से कनेक्ट है, तो इस चरण को छोड़ा जा सकता है.
दूसरा हिस्सा: ओपन एनवायरमेंट
- 👉 सीधे Cloud Shell Editor पर जाने के लिए, इस लिंक पर क्लिक करें
- 👉 अगर आज किसी भी समय अनुमति देने के लिए कहा जाता है, तो जारी रखने के लिए अनुमति दें पर क्लिक करें.
- 👉 अगर टर्मिनल, स्क्रीन पर सबसे नीचे नहीं दिखता है, तो इसे खोलें:
- देखें पर क्लिक करें
- टर्मिनल
 पर क्लिक करें
पर क्लिक करें
- 👉💻 टर्मिनल में, पुष्टि करें कि आपने पहले ही पुष्टि कर ली है और प्रोजेक्ट को अपने प्रोजेक्ट आईडी पर सेट किया गया है. इसके लिए, यह कमांड इस्तेमाल करें:
gcloud auth list - 👉💻 GitHub से बूटस्ट्रैप प्रोजेक्ट का क्लोन बनाएं:
git clone https://github.com/cuppibla/adk_eval_starter - 👉💻 प्रोजेक्ट डायरेक्ट्री से सेटअप स्क्रिप्ट चलाएं.
cd ~/adk_eval_starter ./init.sh
स्क्रिप्ट, सेटअप की बाकी प्रोसेस को अपने-आप पूरा कर देगी.
- 👉💻 ज़रूरी प्रोजेक्ट आईडी सेट करें:
gcloud config set project $(cat ~/project_id.txt) --quiet
तीसरा पार्ट: अनुमति सेट अप करना
- 👉💻 यहां दी गई कमांड का इस्तेमाल करके, ज़रूरी एपीआई चालू करें. इसमें कुछ मिनट लग सकते हैं.
gcloud services enable \ cloudresourcemanager.googleapis.com \ servicenetworking.googleapis.com \ run.googleapis.com \ cloudbuild.googleapis.com \ artifactregistry.googleapis.com \ aiplatform.googleapis.com \ compute.googleapis.com - 👉💻 टर्मिनल में ये कमांड चलाकर, ज़रूरी अनुमतियां दें:
. ~/adk_eval_starter/set_env.sh
ध्यान दें कि आपके लिए एक .env फ़ाइल बनाई गई है. इससे आपके प्रोजेक्ट की जानकारी दिखती है.
3. गोल्डन डेटासेट (adk web) जनरेट किया जा रहा है

एजेंट को ग्रेड देने से पहले, हमें जवाबों की कुंजी की ज़रूरत होगी. ADK में, हम इसे गोल्डन डेटासेट कहते हैं. इस डेटासेट में "परफ़ेक्ट" इंटरैक्शन शामिल हैं. इनका इस्तेमाल, आकलन के लिए किया जाता है.
गोल्डन डेटासेट क्या होता है?
गोल्डन डेटासेट, आपके एजेंट के सही तरीके से काम करने का स्नैपशॉट होता है. यह सिर्फ़ सवाल और जवाब की सूची नहीं है. यह इन चीज़ों को कैप्चर करता है:
- उपयोगकर्ता की क्वेरी ("मुझे रिफ़ंड चाहिए")
- ट्रैजेक्ट्री (टूल कॉल का सटीक क्रम:
check_order->verify_eligibility->refund_transaction). - फ़ाइनल जवाब (टेक्स्ट के रूप में "परफ़ेक्ट" जवाब).
हम इसका इस्तेमाल, रिग्रेशन का पता लगाने के लिए करते हैं. अगर आपने अपने प्रॉम्प्ट को अपडेट किया है और एजेंट अचानक रिफ़ंड देने से पहले ज़रूरी शर्तें पूरी होने की जांच करना बंद कर देता है, तो गोल्डन डेटासेट टेस्ट पूरा नहीं होगा. ऐसा इसलिए, क्योंकि अब ट्रैजेक्ट्री मैच नहीं हो रही है.
वेब यूज़र इंटरफ़ेस (यूआई) खोलें
ADK के वेब यूज़र इंटरफ़ेस (यूआई) की मदद से, इन गोल्डन डेटासेट को इंटरैक्टिव तरीके से बनाया जा सकता है. इसके लिए, आपके एजेंट के साथ हुए असली इंटरैक्शन को कैप्चर किया जाता है.
- 👉💻 अपने टर्मिनल में, यह कमांड चलाएं:
cd ~/adk_eval_starter uv run adk web - 👉💻 वेब यूज़र इंटरफ़ेस की झलक खोलें (आम तौर पर
http://127.0.0.1:8000पर). - 👉 चैट यूज़र इंटरफ़ेस में, टाइप करें
Hi, I'm customer CUST001. Can you check my orders? I need a refund for order ORD-102. It arrived damaged. आपको इस तरह का जवाब दिखेगा:
आपको इस तरह का जवाब दिखेगा:I've processed your refund for order ORD-102 due to the items arriving damaged. A full refund of $35.0 has been processed, and the status of order ORD-102 is now updated to "refunded". Is there anything else I can assist you with today, CUST001? 🛍️
गोल्डन इंटरैक्शन कैप्चर करना
सेशन टैब पर जाएं. यहां आपको सेशन पर क्लिक करके, अपने एजेंट के साथ हुई बातचीत का इतिहास दिखेगा.
- खरीदारी का इतिहास देखने या रिफ़ंड का अनुरोध करने जैसे काम के लिए, अपने एजेंट से इंटरैक्ट करें.
- बातचीत की समीक्षा करें, ताकि यह पक्का किया जा सके कि यह उम्मीद के मुताबिक है.

4. गोल्डन डेटासेट एक्सपोर्ट करना
ट्रेस व्यू की मदद से पुष्टि करना
एक्सपोर्ट करने से पहले, आपको यह पुष्टि करनी होगी कि एजेंट को सही जवाब सिर्फ़ संयोग से नहीं मिला है. आपको इंटरनल लॉजिक की जांच करनी होगी.
- वेब यूज़र इंटरफ़ेस (यूआई) में, ट्रेस करें टैब पर क्लिक करें.
- ट्रेस को उपयोगकर्ता के मैसेज के हिसाब से अपने-आप ग्रुप किया जाता है. चैट में उससे जुड़ा मैसेज हाइलाइट करने के लिए, किसी ट्रेस लाइन पर कर्सर घुमाएं.
- नीली लाइनों की जांच करें: इनसे इंटरैक्शन से जनरेट हुए इवेंट के बारे में पता चलता है. नीले रंग की किसी लाइन पर क्लिक करके, जांच करने वाला पैनल खोलें.
- लॉजिक की पुष्टि करने के लिए, इन टैब को देखें:
- ग्राफ़: टूल कॉल और लॉजिक फ़्लो का विज़ुअल प्रज़ेंटेशन. क्या यह सही रास्ते पर गया?
- अनुरोध/जवाब: देखें कि मॉडल को क्या भेजा गया था और उससे क्या जवाब मिला.
- पुष्टि करना: अगर एजेंट ने डेटाबेस टूल का इस्तेमाल किए बिना रिफ़ंड की रकम का अनुमान लगाया है, तो यह "लकी हैलुसिनेशन" है.

Add Session to EvalSet
बातचीत और ट्रेस से संतुष्ट होने के बाद:
- 👉
Evalटैब पर क्लिक करें. इसके बाद,Create Evaluation Setबटन पर क्लिक करें. इसके बाद, आकलन का नाम डालें:evalset1
- 👉 इस evalset में,
Add current session to evalset1पर क्लिक करें. इसके बाद, पॉप-अप विंडो में सेशन का नाम डालें.eval1
ADK Web में Eval चलाना
- 👉 ADK के वेब यूज़र इंटरफ़ेस (यूआई) में,
Run Evaluationपर क्लिक करें. पॉप-अप विंडो में, मेट्रिक को अडजस्ट करें. इसके बाद,Startपर क्लिक करें:

अपने रेपो में डेटासेट की पुष्टि करना
आपको पुष्टि करने वाला एक मैसेज दिखेगा. इसमें बताया जाएगा कि डेटासेट फ़ाइल (जैसे, evalset1.evalset.json) आपकी रिपॉज़िटरी में सेव हो गई है. इस फ़ाइल में, आपकी बातचीत का अपने-आप जनरेट हुआ रॉ डेटा होता है.
5. इवैलुएशन फ़ाइलें

वेब यूज़र इंटरफ़ेस (यूआई) एक जटिल .evalset.json फ़ाइल जनरेट करता है. हालांकि, हमें अक्सर ऑटोमेटेड टेस्टिंग के लिए, ज़्यादा व्यवस्थित और आसान टेस्ट फ़ाइल बनानी होती है.
ADK Eval में दो मुख्य कॉम्पोनेंट होते हैं:
- जांच के लिए फ़ाइलें: ये अपने-आप जनरेट होने वाला गोल्डन डेटासेट (जैसे,
customer_service_agent/evalset1.evalset.json) या मैन्युअल तरीके से तैयार किया गया सेट (जैसे,customer_service_agent/eval.test.json) हो सकता है. - कॉन्फ़िगरेशन फ़ाइलें (जैसे,
customer_service_agent/test_config.json): पास होने के लिए मेट्रिक और थ्रेशोल्ड तय करें.
टेस्ट कॉन्फ़िगरेशन फ़ाइल सेट अप करना
- 👉💻 Cloud Shell Editor के टर्मिनल में, यह डालें
cloudshell edit customer_service_agent/test_config.json - 👉 अपने एडिटर में मौजूद
customer_service_agent/test_config.jsonमें यह कोड डालें.{ "criteria": { "tool_trajectory_avg_score": 0.8, "response_match_score": 0.5 } }
मेट्रिक को समझना
tool_trajectory_avg_score(प्रोसेस) इससे यह पता चलता है कि एजेंट ने टूल का सही तरीके से इस्तेमाल किया है या नहीं.
- 0.8: हम 80% मैच होने की मांग करते हैं.
response_match_score(आउटपुट) यह जवाब की तुलना, गोल्डन रेफ़रंस से करने के लिए ROUGE-1 (शब्दों का ओवरलैप) का इस्तेमाल करता है.
- फ़ायदे: तेज़, तय किया गया, और मुफ़्त.
- कमियां: अगर एजेंट एक ही आइडिया को अलग-अलग तरीके से बताता है, तो यह फ़ेल हो जाता है. उदाहरण के लिए, "रिफ़ंड कर दिया गया" बनाम "पैसे वापस कर दिए गए".
ऐडवांस मेट्रिक (जब आपको ज़्यादा कंट्रोल की ज़रूरत हो)
6. गोल्डन डेटासेट के लिए जांच करें (adk eval)
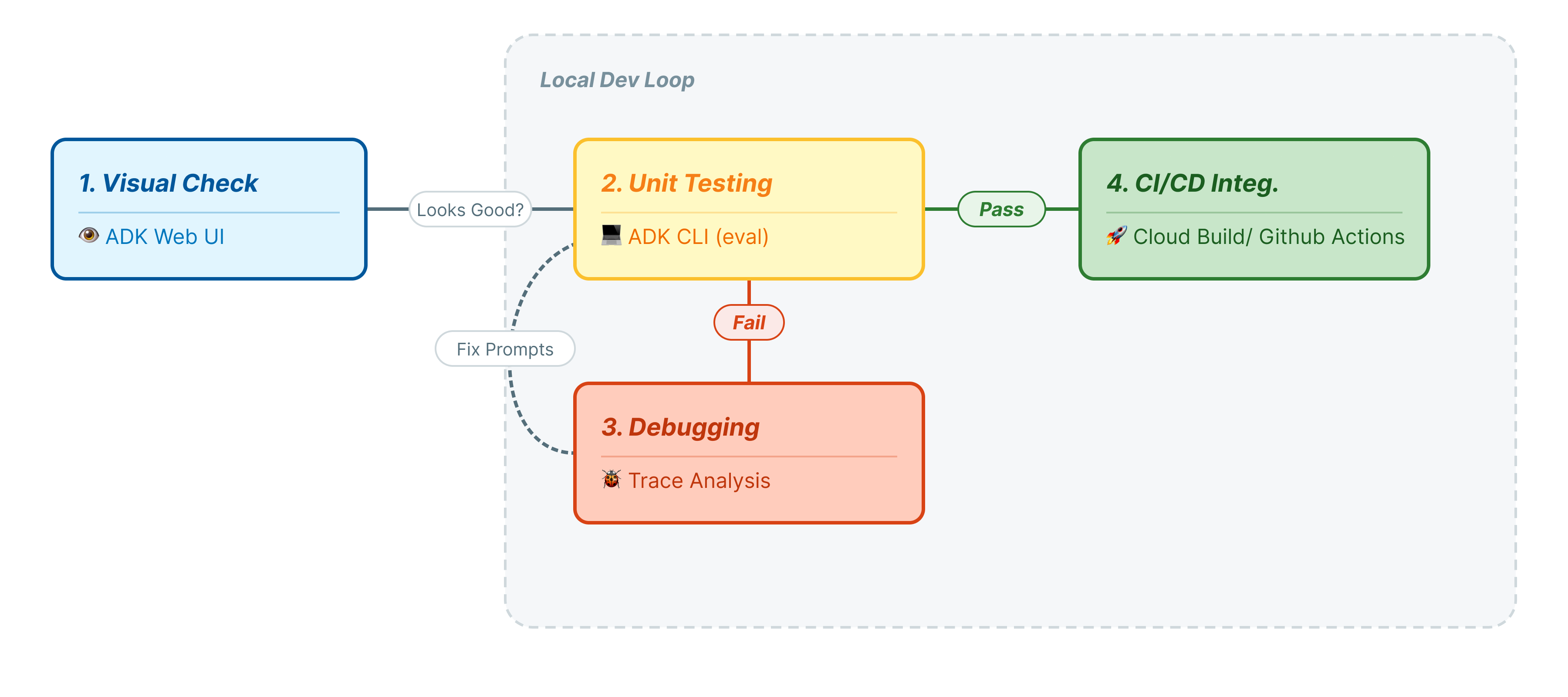
यह चरण, डेवलपमेंट के "इनर लूप" को दिखाता है. आप एक डेवलपर हैं और आपको बदलाव करने हैं. साथ ही, आपको नतीजों की पुष्टि तुरंत करनी है.
गोल्डन डेटासेट चलाना
आइए, पहले चरण में जनरेट किए गए डेटासेट को चलाएं. इससे यह पक्का होता है कि आपकी बेसलाइन सही है.
- 👉💻 अपने टर्मिनल में, यह कमांड चलाएं:
cd ~/adk_eval_starter uv run adk eval customer_service_agent customer_service_agent/evalset1.evalset.json --config_file_path=customer_service_agent/test_config.json --print_detailed_results
क्या हो रहा है?
ADK अब:
customer_service_agentसे एजेंट लोड हो रहा है.evalset1.evalset.jsonसे मिली इनपुट क्वेरी को प्रोसेस किया जा रहा है.- एजेंट की असल ट्रैजेक्ट्री और जवाबों की तुलना, अनुमानित ट्रैजेक्ट्री और जवाबों से करना.
test_config.jsonमें दी गई शर्तों के आधार पर नतीजों को स्कोर करना.
नतीजों का विश्लेषण करना
टर्मिनल आउटपुट देखें. आपको पास और फ़ेल हुए टेस्ट की खास जानकारी दिखेगी.
Eval Run Summary
evalset1:
Tests passed: 1
Tests failed: 0
********************************************************************
Eval Set Id: evalset1
Eval Id: eval1
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.5581395348837208, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+---------------------------+---------------------------+--------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+===========================+===========================+==========================+===========================+===========================+=============================+========================+
| 0 | Hi, I'm customer CUST001. | Great news! Your refund | Great news, CUST001! 🎉 | id='adk-051409fe-c230-43f | id='adk-4e9aa570-1cc6-4c3 | Status: PASSED, Score: | Status: PASSED, Score: |
| | Can you check my orders? | for order **ORD-102** has | I've successfully | 4-a7f1- 5747280fd878' | c-aa3e- 91dbe113dd4b' | 1.0 | 0.5581395348837208 |
| | I need a refund for order | been successfully | processed a full refund | args={'customer_id': | args={'customer_id': | | |
| | ORD-102. It arrived | processed due to the item | of $35.0 for your order | 'CUST001'} name='get_purc | 'CUST001'} name='get_purc | | |
| | damaged. | arriving damaged. You | ORD-102 because it | hase_history' | hase_history' | | |
| | | should see a full refund | arrived damaged. The | partial_args=None | partial_args=None | | |
| | | of $35.0 back to your | status of that order has | will_continue=None id= 'a | will_continue=None | | |
| | | original payment method | been updated to | dk-8a194cb8-5a82-47ce-a3a | id='adk- dad1b376-9bcc-48 | | |
| | | shortly. The status of | "refunded." Is there | 7- 3d24551f8c90' | bb-996f-a30f6ef5b70b' | | |
| | | this order has been | anything else I can | args={'reason': | args={'reason': | | |
| | | updated to "refunded". | assist you with today? | 'damaged', 'order_id': | 'damaged', 'order_id': | | |
| | | Here's your updated | | 'ORD-102'} | 'ORD-102'} | | |
| | | purchase history for | | name='issue_refund' | name='issue_refund' | | |
| | | CUST001: * **ORD-101**: | | partial_args=None | partial_args=None | | |
| | | Wireless Headphones, | | will_continue=None | will_continue=None | | |
| | | delivered on 2023-10-15 | | | | | |
| | | (Total: $120) * | | | | | |
| | | **ORD-102**: USB-C Cable, | | | | | |
| | | Phone Case, refunded on | | | | | |
| | | 2023-11-01 (Total: $35) | | | | | |
| | | Is there anything else I | | | | | |
| | | can help you with today? | | | | | |
| | | 😊 | | | | | |
+----+---------------------------+---------------------------+--------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
ध्यान दें: आपने इसे अभी-अभी एजेंट से जनरेट किया है. इसलिए, यह 100% पास होना चाहिए. अगर ऐसा नहीं होता है, तो आपका एजेंट नॉन-डिटरमिनिस्टिक (रैंडम) है.
7. अपनी पसंद के मुताबिक टेस्ट बनाना
अपने-आप जनरेट होने वाले डेटासेट बहुत काम के होते हैं.हालांकि, कभी-कभी आपको कुछ खास मामलों के लिए डेटासेट मैन्युअल तरीके से बनाने पड़ सकते हैं. जैसे, ऐडवर्सरियल अटैक या गड़बड़ी ठीक करने के लिए खास तरीके. आइए, देखते हैं कि eval.test.json की मदद से "सही जानकारी" को कैसे तय किया जा सकता है.
आइए, एक पूरी टेस्ट सुइट बनाते हैं.
टेस्टिंग फ़्रेमवर्क
ADK में टेस्ट केस लिखते समय, तीन हिस्सों वाले इस फ़ॉर्मूले का पालन करें:
- सेटअप (
session_input): उपयोगकर्ता कौन है? (जैसे,user_id,state). इससे टेस्ट अलग हो जाता है. - प्रॉम्प्ट (
user_content): ट्रिगर क्या है?
Assertions (उम्मीदें) के साथ:
- ट्रैजेक्ट्री (
tool_uses): क्या इसने सही हिसाब-किताब किया? (लॉजिक) - जवाब (
final_response): क्या इसमें सही जवाब दिया गया था? (क्वालिटी) - इंटरमीडिएट (
intermediate_responses): क्या सब-एजेंट ने सही तरीके से बातचीत की? (ऑर्केस्ट्रेशन)
टेस्ट सुइट लिखना
- 👉💻 Cloud Shell Editor के टर्मिनल में, यह डालें
cloudshell edit customer_service_agent/eval.test.json - 👉
customer_service_agent/eval.test.jsonफ़ाइल में यह कोड डालें.{ "eval_set_id": "customer_service_eval", "name": "Customer Service Agent Evaluation", "description": "Evaluation suite for the customer service agent covering product info, purchase history, and refunds.", "eval_cases": [ { "eval_id": "product_info_check", "session_input": { "app_name": "customer_service_agent", "user_id": "eval_user_1", "state": {} }, "conversation": [ { "invocation_id": "turn_1_product_info", "user_content": { "role": "user", "parts": [ { "text": "Do you have wireless headphones in stock?" } ] }, "final_response": { "role": "model", "parts": [ { "text": "Yes, we have wireless headphones in stock! They are priced at $120.00 and feature noise-canceling with a 20-hour battery life. 🎧" } ] }, "intermediate_data": { "tool_uses": [ { "name": "lookup_product_info", "args": { "product_name": "wireless headphones" } } ], "intermediate_responses": [] } } ] }, { "eval_id": "purchase_history_check", "session_input": { "app_name": "customer_service_agent", "user_id": "eval_user_2", "state": {} }, "conversation": [ { "invocation_id": "turn_1_purchase_history", "user_content": { "role": "user", "parts": [ { "text": "What did I buy recently? My customer ID is CUST001." } ] }, "final_response": { "role": "model", "parts": [ { "text": "Here's your recent purchase history for Customer ID CUST001:\n\n* **Order ORD-101** (October 15, 2023): Wireless Headphones, Status: delivered, Total: $120\n* **Order ORD-102** (November 1, 2023): USB-C Cable, Phone Case, Status: refunded, Total: $35\n\nLet me know if you have any other questions or need further assistance! 🛍️" } ] }, "intermediate_data": { "tool_uses": [ { "name": "get_purchase_history", "args": { "customer_id": "CUST001" } } ], "intermediate_responses": [] } } ] }, { "eval_id": "refund_request", "session_input": { "app_name": "customer_service_agent", "user_id": "eval_user_3", "state": {} }, "conversation": [ { "invocation_id": "turn_1_refund", "user_content": { "role": "user", "parts": [ { "text": "I want a refund for order ORD-102 because it was damaged." } ] }, "final_response": { "role": "model", "parts": [ { "text": "Your refund for order **ORD-102** due to \"damaged\" has been successfully processed! Refund amount: **$35.0**. Your order status has been updated to **refunded**. \nIs there anything else I can help you with today? 🛍️" } ] }, "intermediate_data": { "tool_uses": [ { "name": "issue_refund", "args": { "order_id": "ORD-102", "reason": "damaged" } } ], "intermediate_responses": [] } } ] } ] }
टेस्ट के टाइप को समझना
हमने यहां तीन अलग-अलग तरह के टेस्ट बनाए हैं. आइए, जानते हैं कि हर मेट्रिक से क्या पता चलता है और क्यों.
- सिंगल टूल टेस्ट (
product_info_check)
- लक्ष्य: बुनियादी जानकारी को वापस पाने की पुष्टि करना.
- मुख्य दावा: हम
intermediate_data.tool_usesकी जांच करते हैं. हम पुष्टि करते हैं किlookup_product_infoको कॉल किया गया है. हम यह दावा करते हैं किproduct_nameका मतलब "वायरलेस हेडफ़ोन" है. - क्यों: अगर मॉडल, टूल को कॉल किए बिना कीमत बताता है, तो यह टेस्ट पूरा नहीं होता. इससे यह पक्का होता है कि जवाब, सोर्स पर आधारित हो.
- कॉन्टेक्स्ट एक्सट्रैक्शन टेस्ट (
purchase_history_check)
- लक्ष्य: पुष्टि करें कि एजेंट, उपयोगकर्ता के प्रॉम्प्ट से इकाइयां (CUST001) निकाल सकता है और उन्हें टूल को पास कर सकता है.
- मुख्य पुष्टि: हम यह जांच करते हैं कि
get_purchase_historyकोcustomer_id: "CUST001"के साथ कॉल किया गया हो. - क्यों: आम तौर पर, एजेंट सही टूल को कॉल करता है, लेकिन आईडी की वैल्यू शून्य होती है. इससे पैरामीटर की वैल्यू सटीक होती है.
- ऐक्शन/ट्रैजेक्ट्री टेस्ट (
refund_request)
- लक्ष्य: राइट ऑपरेशन की पुष्टि करना.
- मुख्य दावा: ट्रैजेक्ट्री. ज़्यादा मुश्किल स्थिति में, इस सूची में कई चरण शामिल होंगे:
[verify_order, calculate_refund, issue_refund]. ADK, इस सूची की जांच क्रम से करता है. - क्यों: पैसे ट्रांसफ़र करने या डेटा में बदलाव करने जैसी कार्रवाइयों के लिए, नतीजे के साथ-साथ क्रम भी उतना ही ज़रूरी होता है. पुष्टि किए बिना रिफ़ंड नहीं करना है.
8. कस्टम टेस्ट के लिए जांच करें ( adk eval)
- 👉💻 अपने टर्मिनल में, यह कमांड चलाएं:
cd ~/adk_eval_starter uv run adk eval customer_service_agent customer_service_agent/eval.test.json --config_file_path=customer_service_agent/test_config.json --print_detailed_results
आउटपुट को समझना
आपको इस तरह का 'पास' नतीजा दिखेगा:
Eval Run Summary
customer_service_eval:
Tests passed: 3
Tests failed: 0
********************************************************************
Eval Set Id: customer_service_eval
Eval Id: purchase_history_check
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.5473684210526315, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+--------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+==========================+===========================+===========================+===========================+===========================+=============================+========================+
| 0 | What did I buy recently? | Here's your recent | Looks like your recent | id=None | id='adk-8960eb53-2933-459 | Status: PASSED, Score: | Status: PASSED, Score: |
| | My customer ID is | purchase history for | orders include: * | args={'customer_id': | f-b306- 71e3c069e77e' | 1.0 | 0.5473684210526315 |
| | CUST001. | Customer ID CUST001: * | **ORD-101 (2023-10-15):** | 'CUST001'} name='get_purc | args={'customer_id': | | |
| | | **Order ORD-101** | Wireless Headphones for | hase_history' | 'CUST001'} name='get_purc | | |
| | | (October 15, 2023): | $120.00 - Status: | partial_args=None | hase_history' | | |
| | | Wireless Headphones, | Delivered 🎧 * **ORD-102 | will_continue=None | partial_args=None | | |
| | | Status: delivered, Total: | (2023-11-01):** USB-C | | will_continue=None | | |
| | | $120 * **Order | Cable, Phone Case for | | | | |
| | | ORD-102** (November 1, | $35.00 - Status: Refunded | | | | |
| | | 2023): USB-C Cable, Phone | 📱 Is there anything else | | | | |
| | | Case, Status: refunded, | I can help you with | | | | |
| | | Total: $35 Let me know | regarding these orders? | | | | |
| | | if you have any other | | | | | |
| | | questions or need further | | | | | |
| | | assistance! 🛍️ | | | | | |
+----+--------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
********************************************************************
Eval Set Id: customer_service_eval
Eval Id: product_info_check
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.6829268292682927, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+----------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+======================+===========================+===========================+===========================+===========================+=============================+========================+
| 0 | Do you have wireless | Yes, we have wireless | Yes, we do! 🎧 We have | id=None | id='adk-4571d660-a92b-412 | Status: PASSED, Score: | Status: PASSED, Score: |
| | headphones in stock? | headphones in stock! They | noise-canceling wireless | args={'product_name': | a-a79e- 5c54f8b8af2d' | 1.0 | 0.6829268292682927 |
| | | are priced at $120.00 and | headphones with a 20-hour | 'wireless headphones'} na | args={'product_name': | | |
| | | feature noise-canceling | battery life available | me='lookup_product_info' | 'wireless headphones'} na | | |
| | | with a 20-hour battery | for $120. | partial_args=None | me='lookup_product_info' | | |
| | | life. 🎧 | | will_continue=None | partial_args=None | | |
| | | | | | will_continue=None | | |
+----+----------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
********************************************************************
Eval Set Id: customer_service_eval
Eval Id: refund_request
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.6216216216216216, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+---------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+===========================+===========================+===========================+===========================+===========================+=============================+========================+
| 0 | I want a refund for order | Your refund for order | Your refund for order | id=None args={'order_id': | id='adk-fb8ff1cc- cf87-41 | Status: PASSED, Score: | Status: PASSED, Score: |
| | ORD-102 because it was | **ORD-102** due to | **ORD-102** has been | 'ORD-102', 'reason': | f2-9b11-d4571b14287f' | 1.0 | 0.6216216216216216 |
| | damaged. | "damaged" has been | successfully processed! | 'damaged'} | args={'order_id': | | |
| | | successfully processed! | You should see a full | name='issue_refund' | 'ORD-102', 'reason': | | |
| | | Refund amount: **$35.0**. | refund of $35.0 appear in | partial_args=None | 'damaged'} | | |
| | | Your order status has | your account shortly. We | will_continue=None | name='issue_refund' | | |
| | | been updated to | apologize for the | | partial_args=None | | |
| | | **refunded**. Is there | inconvenience! Is there | | will_continue=None | | |
| | | anything else I can help | anything else I can | | | | |
| | | you with today? 🛍️ | assist you with today? 😊 | | | | |
+----+---------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
इसका मतलब है कि आपके एजेंट ने सही टूल इस्तेमाल किए हैं और आपकी उम्मीदों के मुताबिक जवाब दिया है.
9. (ज़रूरी नहीं: सिर्फ़ पढ़ने का अधिकार) - समस्या हल करना और डीबग करना
टेस्ट फ़ेल हो जाएंगे. यह उनका काम है. लेकिन इन्हें ठीक कैसे किया जाता है? आइए, आम तौर पर होने वाली गड़बड़ियों के बारे में जानें और उन्हें ठीक करने का तरीका जानें.
पहला परिदृश्य: "ट्रैजेक्ट्री" फ़ेल होना
गड़बड़ी:
Result: FAILED
Reason: Criteria 'tool_trajectory_avg_score' failed. Score 0.0 < Threshold 1.0
Details:
EXPECTED: tool: lookup_order, then tool: issue_refund
ACTUAL: tool: issue_refund
निदान: एजेंट ने पुष्टि करने का चरण (lookup_order) छोड़ दिया है. यह लॉजिक से जुड़ी गड़बड़ी है.
समस्या हल करने का तरीका:
- अंदाज़ा न लगाएं: ADK वेब यूज़र इंटरफ़ेस (यूआई) (adk web) पर वापस जाएं.
- दोबारा जनरेट करना: चैट में, टेस्ट के दौरान इस्तेमाल किया गया प्रॉम्प्ट टाइप करें.
- ट्रेस: ट्रेस व्यू खोलें. "ग्राफ़" टैब देखें.
- प्रॉम्प्ट ठीक करना: आम तौर पर, आपको सिस्टम प्रॉम्प्ट अपडेट करना होता है. बदलाव करें: "तुम एक मददगार एजेंट हो." निर्देश: "तुम एक मददगार एजेंट हो. अहम जानकारी: issue_refund को कॉल करने से पहले, आपको lookup_order को कॉल करके जानकारी की पुष्टि करनी होगी."
- टेस्ट में बदलाव करना: अगर कारोबार के लॉजिक में बदलाव हुआ है (जैसे, अब पुष्टि करने की ज़रूरत नहीं है), तो टेस्ट गलत है. eval.test.json फ़ाइल को नई जानकारी के हिसाब से अपडेट करें.
दूसरा उदाहरण: "ROUGE" का काम न करना
गड़बड़ी:
Result: FAILED
Reason: Criteria 'response_match_score' failed. Score 0.45 < Threshold 0.8
Expected: "The refund has been processed successfully."
Actual: "I've gone ahead and returned the money to your card."
विश्लेषण: एजेंट ने सही जवाब दिया है, लेकिन अलग शब्दों का इस्तेमाल किया है. ROUGE (शब्दों का ओवरलैप) ने इसे दंडित किया.
समस्या ठीक करने का तरीका:
- क्या यह गलत है? अगर मतलब सही है, तो प्रॉम्प्ट में बदलाव न करें.
- थ्रेशोल्ड में बदलाव करना:
test_config.jsonमें थ्रेशोल्ड को कम करें. उदाहरण के लिए,0.8से0.5तक. - मेट्रिक को अपग्रेड करना: अपने कॉन्फ़िगरेशन में
final_response_match_v2पर स्विच करें. इसमें एलएलएम का इस्तेमाल किया जाता है. यह दोनों वाक्यों को पढ़कर यह तय करता है कि क्या दोनों का मतलब एक ही है.
10. Pytest की मदद से सीआई/सीडी (pytest)
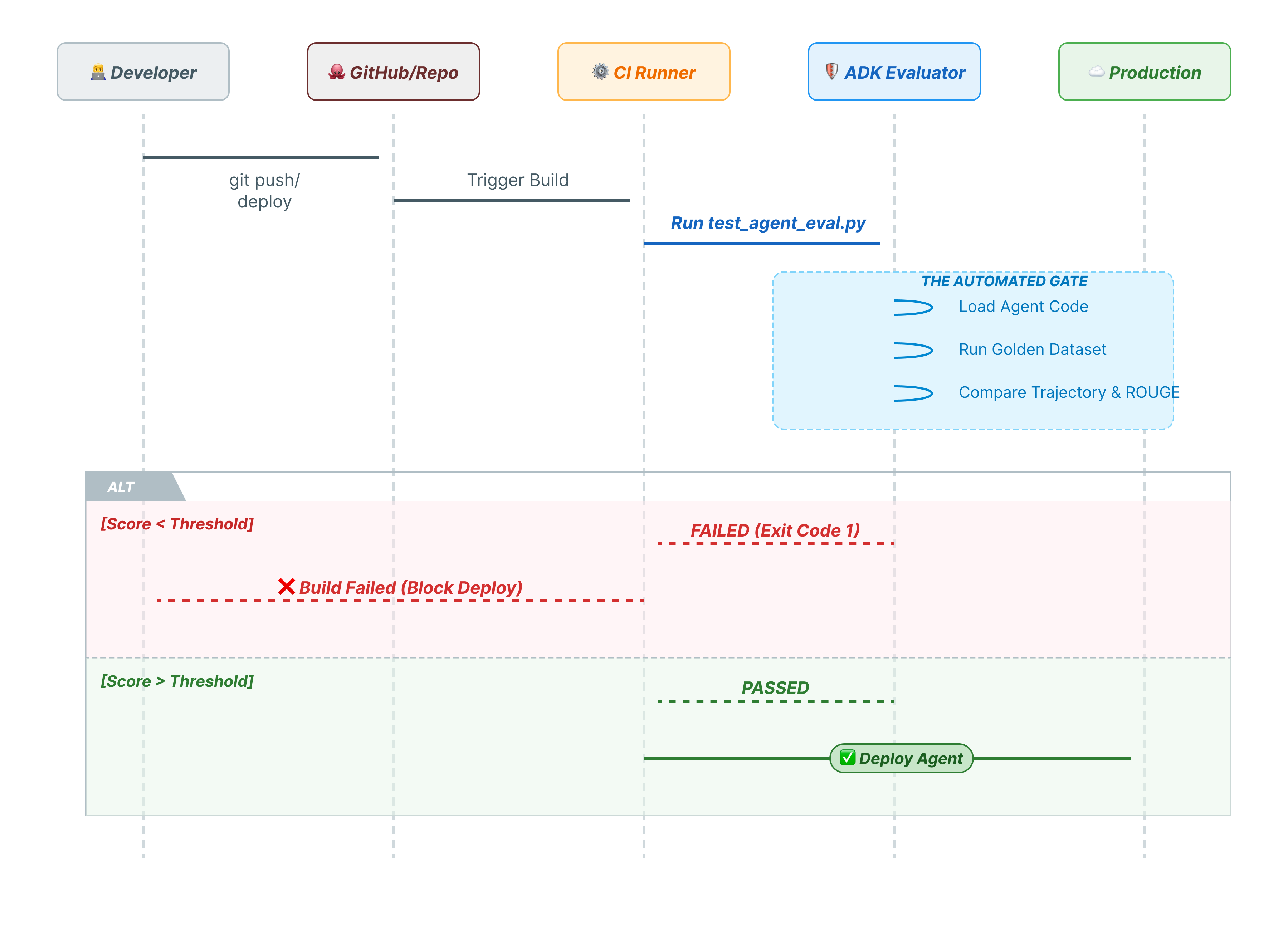
सीएलआई कमांड, इंसानों के लिए होती हैं. pytest, मशीनों के लिए होता है. प्रोडक्शन की विश्वसनीयता बनाए रखने के लिए, हम अपनी जांचों को Python टेस्ट सुइट में रैप करते हैं. इससे आपकी CI/CD पाइपलाइन (GitHub Actions, Jenkins) को यह अनुमति मिलती है कि अगर एजेंट की परफ़ॉर्मेंस खराब होती है, तो वह डिप्लॉयमेंट को ब्लॉक कर सके.
इस फ़ाइल में क्या-क्या शामिल होता है?
यह Python फ़ाइल, आपके CI/CD रनर और ADK के आकलन करने वाले टूल के बीच ब्रिज का काम करती है. इसके लिए यह ज़रूरी है कि:
- अपने एजेंट को लोड करें: अपने एजेंट कोड को डाइनैमिक रूप से इंपोर्ट करें.
- स्टेट रीसेट करें: पक्का करें कि एजेंट की मेमोरी साफ़ हो, ताकि टेस्ट एक-दूसरे में लीक न हों.
- Run Evaluation:
AgentEvaluator.evaluate()को प्रोग्राम के हिसाब से कॉल करें. - Assert Success: अगर आकलन का स्कोर कम है, तो बिल्ड को फ़ेल करें.
इंटिग्रेशन टेस्ट कोड
- 👉
customer_service_agent/test_agent_eval.pyखोलें. यह स्क्रिप्ट,eval.test.jsonमें तय की गई जांचों को चलाने के लिएAgentEvaluator.evaluateका इस्तेमाल करती है. - 👉 अपने एडिटर में मौजूद
customer_service_agent/test_agent_eval.pyमें यह कोड डालें.from google.adk.evaluation.agent_evaluator import AgentEvaluator import pytest import importlib import sys import os @pytest.mark.asyncio async def test_with_single_test_file(): """Test the agent's basic ability via a session file.""" # Load the agent module robustly module_name = "customer_service_agent.agent" try: agent_module = importlib.import_module(module_name) # Reset the mock data to ensure a fresh state for the test if hasattr(agent_module, 'reset_mock_data'): agent_module.reset_mock_data() except ImportError: # Fallback if running from a different context sys.path.append(os.getcwd()) agent_module = importlib.import_module(module_name) if hasattr(agent_module, 'reset_mock_data'): agent_module.reset_mock_data() # Use absolute path to the eval file to be robust to where pytest is run script_dir = os.path.dirname(os.path.abspath(__file__)) eval_file = os.path.join(script_dir, "eval.test.json") await AgentEvaluator.evaluate( agent_module=module_name, eval_dataset_file_path_or_dir=eval_file, num_runs=1, )
Pytest चलाना
- 👉💻 अपने टर्मिनल में, यह कमांड चलाएं:
cd ~/adk_eval_starter uv pip install pytest uv run pytest customer_service_agent/test_agent_eval.py``` -- Docs: https://docs.pytest.org/en/stable/how-to/capture-warnings.html =============== 1 passed, 15 warnings in 12.84s =============== ```
11. नतीजा
बधाई हो! आपने एडीके की जांच करने वाली सेवा का इस्तेमाल करके, ग्राहक सेवा एजेंट की जांच कर ली है.
आपने क्या सीखा
इस कोडलैब में, आपने ये सीखा:
- ✅ अपने एजेंट के लिए ग्राउंड ट्रूथ तय करने के लिए, गोल्डन डेटासेट जनरेट करें.
- ✅ सफलता के मानदंड तय करने के लिए, इवैलुएशन कॉन्फ़िगरेशन को समझें.
- ✅ रिग्रेशन का पता लगाने के लिए, अपने-आप होने वाले आकलन की सुविधा चालू करें.
ADK Eval को अपने डेवलपमेंट वर्कफ़्लो में शामिल करके, भरोसे के साथ एजेंट बनाए जा सकते हैं. ऐसा इसलिए, क्योंकि आपको पता होगा कि व्यवहार में होने वाले किसी भी बदलाव का पता, आपकी ऑटोमेटेड जांचों से चल जाएगा.
यह लैब, 'Google Cloud के साथ प्रोडक्शन-रेडी एआई' लर्निंग पाथ का हिस्सा है.
- प्रोटोटाइप से प्रोडक्शन तक के अंतर को कम करने के लिए, पूरा पाठ्यक्रम देखें.
- अपनी प्रोग्रेस को
ProductionReadyAIहैशटैग के साथ शेयर करें.
ज़्यादा रीडिंग: